
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_34867
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-3028
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NH: people scraper broken
State: NH (be sure to include in ticket title)
The NH people scraper is broken, because
http://www.gencourt.state.nh.us/downloads/Members.txt
no longer exists. Instead, there is a
http://www.gencourt.state.nh.us/downloads/Members.csv
I'll own this.
</issue>
<code>
[start of openstates/nh/people.py]
1 import re
2
3 from pupa.scrape import Person, Scraper
4 from openstates.utils import LXMLMixin
5
6
7 class NHPersonScraper(Scraper, LXMLMixin):
8 members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'
9 lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'
10 house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'
11 senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'
12
13 chamber_map = {'H': 'lower', 'S': 'upper'}
14 party_map = {
15 'D': 'Democratic',
16 'R': 'Republican',
17 'I': 'Independent',
18 'L': 'Libertarian',
19 }
20
21 def _get_photo(self, url, chamber):
22 """Attempts to find a portrait in the given legislator profile."""
23 try:
24 doc = self.lxmlize(url)
25 except Exception as e:
26 self.warning("skipping {}: {}".format(url, e))
27 return ""
28
29 if chamber == 'upper':
30 src = doc.xpath('//div[@id="page_content"]//img[contains(@src, '
31 '"images/senators") or contains(@src, "Senator")]/@src')
32 elif chamber == 'lower':
33 src = doc.xpath('//img[contains(@src, "images/memberpics")]/@src')
34
35 if src and 'nophoto' not in src[0]:
36 photo_url = src[0]
37 else:
38 photo_url = ''
39
40 return photo_url
41
42 def _parse_person(self, row, chamber, seat_map):
43 # Capture legislator vitals.
44 first_name = row['FirstName']
45 middle_name = row['MiddleName']
46 last_name = row['LastName']
47 full_name = '{} {} {}'.format(first_name, middle_name, last_name)
48 full_name = re.sub(r'[\s]{2,}', ' ', full_name)
49
50 if chamber == 'lower':
51 district = '{} {}'.format(row['County'], int(row['District'])).strip()
52 else:
53 district = str(int(row['District'])).strip()
54
55 party = self.party_map[row['party'].upper()]
56 email = row['WorkEmail']
57
58 if district == '0':
59 self.warning('Skipping {}, district is set to 0'.format(full_name))
60 return
61
62 # Temporary fix for Kari Lerner
63 if district == 'Rockingham 0' and last_name == 'Lerner':
64 district = 'Rockingham 4'
65
66 # Temporary fix for Casey Conley
67 if last_name == 'Conley':
68 if district == '13':
69 district = 'Strafford 13'
70 elif district == 'Strafford 13':
71 self.info('"Temporary fix for Casey Conley" can be removed')
72
73 person = Person(primary_org=chamber,
74 district=district,
75 name=full_name,
76 party=party)
77
78 extras = {
79 'first_name': first_name,
80 'middle_name': middle_name,
81 'last_name': last_name
82 }
83
84 person.extras = extras
85 if email:
86 office = 'Capitol' if email.endswith('@leg.state.nh.us') else 'District'
87 person.add_contact_detail(type='email', value=email, note=office + ' Office')
88
89 # Capture legislator office contact information.
90 district_address = '{}\n{}\n{}, {} {}'.format(row['Address'],
91 row['address2'],
92 row['city'], row['State'],
93 row['Zipcode']).strip()
94
95 phone = row['Phone'].strip()
96 if not phone:
97 phone = None
98
99 if district_address:
100 office = 'Capitol' if chamber == 'upper' else 'District'
101 person.add_contact_detail(type='address', value=district_address,
102 note=office + ' Office')
103 if phone:
104 office = 'Capitol' if '271-' in phone else 'District'
105 person.add_contact_detail(type='voice', value=phone, note=office + ' Office')
106
107 # Retrieve legislator portrait.
108 profile_url = None
109 if chamber == 'upper':
110 profile_url = self.senate_profile_url.format(row['District'])
111 elif chamber == 'lower':
112 try:
113 seat_number = seat_map[row['seatno']]
114 profile_url = self.house_profile_url.format(seat_number)
115 except KeyError:
116 pass
117
118 if profile_url:
119 person.image = self._get_photo(profile_url, chamber)
120 person.add_source(profile_url)
121
122 return person
123
124 def _parse_members_txt(self):
125 lines = self.get(self.members_url).text.splitlines()
126
127 header = lines[0].split('\t')
128
129 for line in lines[1:]:
130 yield dict(zip(header, line.split('\t')))
131
132 def _parse_seat_map(self):
133 """Get mapping between seat numbers and legislator identifiers."""
134 seat_map = {}
135 page = self.lxmlize(self.lookup_url)
136 options = page.xpath('//select[@id="member"]/option')
137 for option in options:
138 member_url = self.house_profile_url.format(option.attrib['value'])
139 member_page = self.lxmlize(member_url)
140 table = member_page.xpath('//table[@id="Table1"]')
141 if table:
142 res = re.search(r'seat #:(\d+)', table[0].text_content(), re.IGNORECASE)
143 if res:
144 seat_map[res.groups()[0]] = option.attrib['value']
145 return seat_map
146
147 def scrape(self, chamber=None):
148 chambers = [chamber] if chamber is not None else ['upper', 'lower']
149 seat_map = self._parse_seat_map()
150 for chamber in chambers:
151 for row in self._parse_members_txt():
152 print(row['electedStatus'])
153 if self.chamber_map[row['LegislativeBody']] == chamber:
154 person = self._parse_person(row, chamber, seat_map)
155
156 # allow for skipping
157 if not person:
158 continue
159
160 person.add_source(self.members_url)
161 person.add_link(self.members_url)
162 yield person
163
[end of openstates/nh/people.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/nh/people.py b/openstates/nh/people.py
--- a/openstates/nh/people.py
+++ b/openstates/nh/people.py
@@ -1,11 +1,12 @@
import re
-
+import csv
from pupa.scrape import Person, Scraper
from openstates.utils import LXMLMixin
+import requests
class NHPersonScraper(Scraper, LXMLMixin):
- members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'
+ members_url = 'http://www.gencourt.state.nh.us/downloads/Members.csv'
lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'
house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'
senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'
@@ -59,17 +60,6 @@
self.warning('Skipping {}, district is set to 0'.format(full_name))
return
- # Temporary fix for Kari Lerner
- if district == 'Rockingham 0' and last_name == 'Lerner':
- district = 'Rockingham 4'
-
- # Temporary fix for Casey Conley
- if last_name == 'Conley':
- if district == '13':
- district = 'Strafford 13'
- elif district == 'Strafford 13':
- self.info('"Temporary fix for Casey Conley" can be removed')
-
person = Person(primary_org=chamber,
district=district,
name=full_name,
@@ -122,12 +112,13 @@
return person
def _parse_members_txt(self):
- lines = self.get(self.members_url).text.splitlines()
+ response = requests.get(self.members_url)
+ lines = csv.reader(response.text.strip().split('\n'), delimiter=',')
- header = lines[0].split('\t')
+ header = next(lines)
- for line in lines[1:]:
- yield dict(zip(header, line.split('\t')))
+ for line in lines:
+ yield dict(zip(header, line))
def _parse_seat_map(self):
"""Get mapping between seat numbers and legislator identifiers."""
|
{"golden_diff": "diff --git a/openstates/nh/people.py b/openstates/nh/people.py\n--- a/openstates/nh/people.py\n+++ b/openstates/nh/people.py\n@@ -1,11 +1,12 @@\n import re\n-\n+import csv\n from pupa.scrape import Person, Scraper\n from openstates.utils import LXMLMixin\n+import requests\n \n \n class NHPersonScraper(Scraper, LXMLMixin):\n- members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'\n+ members_url = 'http://www.gencourt.state.nh.us/downloads/Members.csv'\n lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'\n house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'\n senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'\n@@ -59,17 +60,6 @@\n self.warning('Skipping {}, district is set to 0'.format(full_name))\n return\n \n- # Temporary fix for Kari Lerner\n- if district == 'Rockingham 0' and last_name == 'Lerner':\n- district = 'Rockingham 4'\n-\n- # Temporary fix for Casey Conley\n- if last_name == 'Conley':\n- if district == '13':\n- district = 'Strafford 13'\n- elif district == 'Strafford 13':\n- self.info('\"Temporary fix for Casey Conley\" can be removed')\n-\n person = Person(primary_org=chamber,\n district=district,\n name=full_name,\n@@ -122,12 +112,13 @@\n return person\n \n def _parse_members_txt(self):\n- lines = self.get(self.members_url).text.splitlines()\n+ response = requests.get(self.members_url)\n+ lines = csv.reader(response.text.strip().split('\\n'), delimiter=',')\n \n- header = lines[0].split('\\t')\n+ header = next(lines)\n \n- for line in lines[1:]:\n- yield dict(zip(header, line.split('\\t')))\n+ for line in lines:\n+ yield dict(zip(header, line))\n \n def _parse_seat_map(self):\n \"\"\"Get mapping between seat numbers and legislator identifiers.\"\"\"\n", "issue": "NH: people scraper broken\nState: NH (be sure to include in ticket title)\r\n\r\nThe NH people scraper is broken, because \r\n http://www.gencourt.state.nh.us/downloads/Members.txt\r\nno longer exists. Instead, there is a \r\n http://www.gencourt.state.nh.us/downloads/Members.csv\r\n\r\nI'll own this.\n", "before_files": [{"content": "import re\n\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin\n\n\nclass NHPersonScraper(Scraper, LXMLMixin):\n members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'\n lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'\n house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'\n senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'\n\n chamber_map = {'H': 'lower', 'S': 'upper'}\n party_map = {\n 'D': 'Democratic',\n 'R': 'Republican',\n 'I': 'Independent',\n 'L': 'Libertarian',\n }\n\n def _get_photo(self, url, chamber):\n \"\"\"Attempts to find a portrait in the given legislator profile.\"\"\"\n try:\n doc = self.lxmlize(url)\n except Exception as e:\n self.warning(\"skipping {}: {}\".format(url, e))\n return \"\"\n\n if chamber == 'upper':\n src = doc.xpath('//div[@id=\"page_content\"]//img[contains(@src, '\n '\"images/senators\") or contains(@src, \"Senator\")]/@src')\n elif chamber == 'lower':\n src = doc.xpath('//img[contains(@src, \"images/memberpics\")]/@src')\n\n if src and 'nophoto' not in src[0]:\n photo_url = src[0]\n else:\n photo_url = ''\n\n return photo_url\n\n def _parse_person(self, row, chamber, seat_map):\n # Capture legislator vitals.\n first_name = row['FirstName']\n middle_name = row['MiddleName']\n last_name = row['LastName']\n full_name = '{} {} {}'.format(first_name, middle_name, last_name)\n full_name = re.sub(r'[\\s]{2,}', ' ', full_name)\n\n if chamber == 'lower':\n district = '{} {}'.format(row['County'], int(row['District'])).strip()\n else:\n district = str(int(row['District'])).strip()\n\n party = self.party_map[row['party'].upper()]\n email = row['WorkEmail']\n\n if district == '0':\n self.warning('Skipping {}, district is set to 0'.format(full_name))\n return\n\n # Temporary fix for Kari Lerner\n if district == 'Rockingham 0' and last_name == 'Lerner':\n district = 'Rockingham 4'\n\n # Temporary fix for Casey Conley\n if last_name == 'Conley':\n if district == '13':\n district = 'Strafford 13'\n elif district == 'Strafford 13':\n self.info('\"Temporary fix for Casey Conley\" can be removed')\n\n person = Person(primary_org=chamber,\n district=district,\n name=full_name,\n party=party)\n\n extras = {\n 'first_name': first_name,\n 'middle_name': middle_name,\n 'last_name': last_name\n }\n\n person.extras = extras\n if email:\n office = 'Capitol' if email.endswith('@leg.state.nh.us') else 'District'\n person.add_contact_detail(type='email', value=email, note=office + ' Office')\n\n # Capture legislator office contact information.\n district_address = '{}\\n{}\\n{}, {} {}'.format(row['Address'],\n row['address2'],\n row['city'], row['State'],\n row['Zipcode']).strip()\n\n phone = row['Phone'].strip()\n if not phone:\n phone = None\n\n if district_address:\n office = 'Capitol' if chamber == 'upper' else 'District'\n person.add_contact_detail(type='address', value=district_address,\n note=office + ' Office')\n if phone:\n office = 'Capitol' if '271-' in phone else 'District'\n person.add_contact_detail(type='voice', value=phone, note=office + ' Office')\n\n # Retrieve legislator portrait.\n profile_url = None\n if chamber == 'upper':\n profile_url = self.senate_profile_url.format(row['District'])\n elif chamber == 'lower':\n try:\n seat_number = seat_map[row['seatno']]\n profile_url = self.house_profile_url.format(seat_number)\n except KeyError:\n pass\n\n if profile_url:\n person.image = self._get_photo(profile_url, chamber)\n person.add_source(profile_url)\n\n return person\n\n def _parse_members_txt(self):\n lines = self.get(self.members_url).text.splitlines()\n\n header = lines[0].split('\\t')\n\n for line in lines[1:]:\n yield dict(zip(header, line.split('\\t')))\n\n def _parse_seat_map(self):\n \"\"\"Get mapping between seat numbers and legislator identifiers.\"\"\"\n seat_map = {}\n page = self.lxmlize(self.lookup_url)\n options = page.xpath('//select[@id=\"member\"]/option')\n for option in options:\n member_url = self.house_profile_url.format(option.attrib['value'])\n member_page = self.lxmlize(member_url)\n table = member_page.xpath('//table[@id=\"Table1\"]')\n if table:\n res = re.search(r'seat #:(\\d+)', table[0].text_content(), re.IGNORECASE)\n if res:\n seat_map[res.groups()[0]] = option.attrib['value']\n return seat_map\n\n def scrape(self, chamber=None):\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n seat_map = self._parse_seat_map()\n for chamber in chambers:\n for row in self._parse_members_txt():\n print(row['electedStatus'])\n if self.chamber_map[row['LegislativeBody']] == chamber:\n person = self._parse_person(row, chamber, seat_map)\n\n # allow for skipping\n if not person:\n continue\n\n person.add_source(self.members_url)\n person.add_link(self.members_url)\n yield person\n", "path": "openstates/nh/people.py"}]}
| 2,338 | 528 |
gh_patches_debug_36742
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-2109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Search query got emphasized even in the middle of another, unrelated word
<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->
**Version of SearXNG**
2023.01.09-afd71a6c
**How did you install SearXNG?**
Installed using docker with clone, docker build and run.
**What happened?**
Query letters got emphasized even in the middle of another unrelated word.
**How To Reproduce**
Do some search using alphabetic, English words with all language flag, such as `the :all`, `java :all`, `master :all`.
**Expected behavior**
Emphasization should occur on queries found in standalone words only, such as `java` query only emphasize '**java**' instead of '**java**script', or `master` only in '**Master**' or '**master**' instead of 'grand**master**'.
**Screenshots & Logs**
|  |
| --- |
| In the word 'o**the**rwise' |
|  |
| --- |
| In the word '**The**saurus' and '**the**ir' |
|  |
| --- |
| In the word '**master**ful', '**master**s', 'grand**master**' |
**Additional context**
Likely happened because the regex being used does not isolate the query for occurrences in standalone words and instead it looks for all occurrences in the whole text without requiring the presence of spaces before or after it. This regex actually works well for the emphasization of queries in Chinese characters, for example:
|  |
| --- |
| Query used: ’村上春樹’ |
</issue>
<code>
[start of searx/webutils.py]
1 # -*- coding: utf-8 -*-
2 import os
3 import pathlib
4 import csv
5 import hashlib
6 import hmac
7 import re
8 import inspect
9 import itertools
10 from datetime import datetime, timedelta
11 from typing import Iterable, List, Tuple, Dict
12
13 from io import StringIO
14 from codecs import getincrementalencoder
15
16 from flask_babel import gettext, format_date
17
18 from searx import logger, settings
19 from searx.engines import Engine, OTHER_CATEGORY
20
21
22 VALID_LANGUAGE_CODE = re.compile(r'^[a-z]{2,3}(-[a-zA-Z]{2})?$')
23
24 logger = logger.getChild('webutils')
25
26
27 class UnicodeWriter:
28 """
29 A CSV writer which will write rows to CSV file "f",
30 which is encoded in the given encoding.
31 """
32
33 def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
34 # Redirect output to a queue
35 self.queue = StringIO()
36 self.writer = csv.writer(self.queue, dialect=dialect, **kwds)
37 self.stream = f
38 self.encoder = getincrementalencoder(encoding)()
39
40 def writerow(self, row):
41 self.writer.writerow(row)
42 # Fetch UTF-8 output from the queue ...
43 data = self.queue.getvalue()
44 data = data.strip('\x00')
45 # ... and re-encode it into the target encoding
46 data = self.encoder.encode(data)
47 # write to the target stream
48 self.stream.write(data.decode())
49 # empty queue
50 self.queue.truncate(0)
51
52 def writerows(self, rows):
53 for row in rows:
54 self.writerow(row)
55
56
57 def get_themes(templates_path):
58 """Returns available themes list."""
59 return os.listdir(templates_path)
60
61
62 def get_hash_for_file(file: pathlib.Path) -> str:
63 m = hashlib.sha1()
64 with file.open('rb') as f:
65 m.update(f.read())
66 return m.hexdigest()
67
68
69 def get_static_files(static_path: str) -> Dict[str, str]:
70 static_files: Dict[str, str] = {}
71 static_path_path = pathlib.Path(static_path)
72
73 def walk(path: pathlib.Path):
74 for file in path.iterdir():
75 if file.name.startswith('.'):
76 # ignore hidden file
77 continue
78 if file.is_file():
79 static_files[str(file.relative_to(static_path_path))] = get_hash_for_file(file)
80 if file.is_dir() and file.name not in ('node_modules', 'src'):
81 # ignore "src" and "node_modules" directories
82 walk(file)
83
84 walk(static_path_path)
85 return static_files
86
87
88 def get_result_templates(templates_path):
89 result_templates = set()
90 templates_path_length = len(templates_path) + 1
91 for directory, _, files in os.walk(templates_path):
92 if directory.endswith('result_templates'):
93 for filename in files:
94 f = os.path.join(directory[templates_path_length:], filename)
95 result_templates.add(f)
96 return result_templates
97
98
99 def new_hmac(secret_key, url):
100 return hmac.new(secret_key.encode(), url, hashlib.sha256).hexdigest()
101
102
103 def is_hmac_of(secret_key, value, hmac_to_check):
104 hmac_of_value = new_hmac(secret_key, value)
105 return len(hmac_of_value) == len(hmac_to_check) and hmac.compare_digest(hmac_of_value, hmac_to_check)
106
107
108 def prettify_url(url, max_length=74):
109 if len(url) > max_length:
110 chunk_len = int(max_length / 2 + 1)
111 return '{0}[...]{1}'.format(url[:chunk_len], url[-chunk_len:])
112 else:
113 return url
114
115
116 def highlight_content(content, query):
117
118 if not content:
119 return None
120 # ignoring html contents
121 # TODO better html content detection
122 if content.find('<') != -1:
123 return content
124
125 if content.lower().find(query.lower()) > -1:
126 query_regex = '({0})'.format(re.escape(query))
127 content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
128 else:
129 regex_parts = []
130 for chunk in query.split():
131 chunk = chunk.replace('"', '')
132 if len(chunk) == 0:
133 continue
134 elif len(chunk) == 1:
135 regex_parts.append('\\W+{0}\\W+'.format(re.escape(chunk)))
136 else:
137 regex_parts.append('{0}'.format(re.escape(chunk)))
138 query_regex = '({0})'.format('|'.join(regex_parts))
139 content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
140
141 return content
142
143
144 def searxng_l10n_timespan(dt: datetime) -> str: # pylint: disable=invalid-name
145 """Returns a human-readable and translated string indicating how long ago
146 a date was in the past / the time span of the date to the present.
147
148 On January 1st, midnight, the returned string only indicates how many years
149 ago the date was.
150 """
151 # TODO, check if timezone is calculated right # pylint: disable=fixme
152 d = dt.date()
153 t = dt.time()
154 if d.month == 1 and d.day == 1 and t.hour == 0 and t.minute == 0 and t.second == 0:
155 return str(d.year)
156 if dt.replace(tzinfo=None) >= datetime.now() - timedelta(days=1):
157 timedifference = datetime.now() - dt.replace(tzinfo=None)
158 minutes = int((timedifference.seconds / 60) % 60)
159 hours = int(timedifference.seconds / 60 / 60)
160 if hours == 0:
161 return gettext('{minutes} minute(s) ago').format(minutes=minutes)
162 return gettext('{hours} hour(s), {minutes} minute(s) ago').format(hours=hours, minutes=minutes)
163 return format_date(dt)
164
165
166 def is_flask_run_cmdline():
167 """Check if the application was started using "flask run" command line
168
169 Inspect the callstack.
170 See https://github.com/pallets/flask/blob/master/src/flask/__main__.py
171
172 Returns:
173 bool: True if the application was started using "flask run".
174 """
175 frames = inspect.stack()
176 if len(frames) < 2:
177 return False
178 return frames[-2].filename.endswith('flask/cli.py')
179
180
181 DEFAULT_GROUP_NAME = 'others'
182
183
184 def group_engines_in_tab(engines: Iterable[Engine]) -> List[Tuple[str, Iterable[Engine]]]:
185 """Groups an Iterable of engines by their first non tab category"""
186
187 def get_group(eng):
188 non_tab_categories = [
189 c for c in eng.categories if c not in list(settings['categories_as_tabs'].keys()) + [OTHER_CATEGORY]
190 ]
191 return non_tab_categories[0] if len(non_tab_categories) > 0 else DEFAULT_GROUP_NAME
192
193 groups = itertools.groupby(sorted(engines, key=get_group), get_group)
194
195 def group_sort_key(group):
196 return (group[0] == DEFAULT_GROUP_NAME, group[0].lower())
197
198 sorted_groups = sorted(((name, list(engines)) for name, engines in groups), key=group_sort_key)
199
200 def engine_sort_key(engine):
201 return (engine.about.get('language', ''), engine.name)
202
203 return [(groupname, sorted(engines, key=engine_sort_key)) for groupname, engines in sorted_groups]
204
[end of searx/webutils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/webutils.py b/searx/webutils.py
--- a/searx/webutils.py
+++ b/searx/webutils.py
@@ -113,31 +113,68 @@
return url
+def contains_cjko(s: str) -> bool:
+ """This function check whether or not a string contains Chinese, Japanese,
+ or Korean characters. It employs regex and uses the u escape sequence to
+ match any character in a set of Unicode ranges.
+
+ Args:
+ s (str): string to be checked.
+
+ Returns:
+ bool: True if the input s contains the characters and False otherwise.
+ """
+ unicode_ranges = (
+ '\u4e00-\u9fff' # Chinese characters
+ '\u3040-\u309f' # Japanese hiragana
+ '\u30a0-\u30ff' # Japanese katakana
+ '\u4e00-\u9faf' # Japanese kanji
+ '\uac00-\ud7af' # Korean hangul syllables
+ '\u1100-\u11ff' # Korean hangul jamo
+ )
+ return bool(re.search(fr'[{unicode_ranges}]', s))
+
+
+def regex_highlight_cjk(word: str) -> str:
+ """Generate the regex pattern to match for a given word according
+ to whether or not the word contains CJK characters or not.
+ If the word is and/or contains CJK character, the regex pattern
+ will match standalone word by taking into account the presence
+ of whitespace before and after it; if not, it will match any presence
+ of the word throughout the text, ignoring the whitespace.
+
+ Args:
+ word (str): the word to be matched with regex pattern.
+
+ Returns:
+ str: the regex pattern for the word.
+ """
+ rword = re.escape(word)
+ if contains_cjko(rword):
+ return fr'({rword})'
+ else:
+ return fr'\b({rword})(?!\w)'
+
+
def highlight_content(content, query):
if not content:
return None
+
# ignoring html contents
# TODO better html content detection
if content.find('<') != -1:
return content
- if content.lower().find(query.lower()) > -1:
- query_regex = '({0})'.format(re.escape(query))
- content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
- else:
- regex_parts = []
- for chunk in query.split():
- chunk = chunk.replace('"', '')
- if len(chunk) == 0:
- continue
- elif len(chunk) == 1:
- regex_parts.append('\\W+{0}\\W+'.format(re.escape(chunk)))
- else:
- regex_parts.append('{0}'.format(re.escape(chunk)))
- query_regex = '({0})'.format('|'.join(regex_parts))
- content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
-
+ querysplit = query.split()
+ queries = []
+ for qs in querysplit:
+ qs = qs.replace("'", "").replace('"', '').replace(" ", "")
+ if len(qs) > 0:
+ queries.extend(re.findall(regex_highlight_cjk(qs), content, flags=re.I | re.U))
+ if len(queries) > 0:
+ for q in set(queries):
+ content = re.sub(regex_highlight_cjk(q), f'<span class="highlight">{q}</span>', content)
return content
|
{"golden_diff": "diff --git a/searx/webutils.py b/searx/webutils.py\n--- a/searx/webutils.py\n+++ b/searx/webutils.py\n@@ -113,31 +113,68 @@\n return url\n \n \n+def contains_cjko(s: str) -> bool:\n+ \"\"\"This function check whether or not a string contains Chinese, Japanese,\n+ or Korean characters. It employs regex and uses the u escape sequence to\n+ match any character in a set of Unicode ranges.\n+\n+ Args:\n+ s (str): string to be checked.\n+\n+ Returns:\n+ bool: True if the input s contains the characters and False otherwise.\n+ \"\"\"\n+ unicode_ranges = (\n+ '\\u4e00-\\u9fff' # Chinese characters\n+ '\\u3040-\\u309f' # Japanese hiragana\n+ '\\u30a0-\\u30ff' # Japanese katakana\n+ '\\u4e00-\\u9faf' # Japanese kanji\n+ '\\uac00-\\ud7af' # Korean hangul syllables\n+ '\\u1100-\\u11ff' # Korean hangul jamo\n+ )\n+ return bool(re.search(fr'[{unicode_ranges}]', s))\n+\n+\n+def regex_highlight_cjk(word: str) -> str:\n+ \"\"\"Generate the regex pattern to match for a given word according\n+ to whether or not the word contains CJK characters or not.\n+ If the word is and/or contains CJK character, the regex pattern\n+ will match standalone word by taking into account the presence\n+ of whitespace before and after it; if not, it will match any presence\n+ of the word throughout the text, ignoring the whitespace.\n+\n+ Args:\n+ word (str): the word to be matched with regex pattern.\n+\n+ Returns:\n+ str: the regex pattern for the word.\n+ \"\"\"\n+ rword = re.escape(word)\n+ if contains_cjko(rword):\n+ return fr'({rword})'\n+ else:\n+ return fr'\\b({rword})(?!\\w)'\n+\n+\n def highlight_content(content, query):\n \n if not content:\n return None\n+\n # ignoring html contents\n # TODO better html content detection\n if content.find('<') != -1:\n return content\n \n- if content.lower().find(query.lower()) > -1:\n- query_regex = '({0})'.format(re.escape(query))\n- content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n- else:\n- regex_parts = []\n- for chunk in query.split():\n- chunk = chunk.replace('\"', '')\n- if len(chunk) == 0:\n- continue\n- elif len(chunk) == 1:\n- regex_parts.append('\\\\W+{0}\\\\W+'.format(re.escape(chunk)))\n- else:\n- regex_parts.append('{0}'.format(re.escape(chunk)))\n- query_regex = '({0})'.format('|'.join(regex_parts))\n- content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n-\n+ querysplit = query.split()\n+ queries = []\n+ for qs in querysplit:\n+ qs = qs.replace(\"'\", \"\").replace('\"', '').replace(\" \", \"\")\n+ if len(qs) > 0:\n+ queries.extend(re.findall(regex_highlight_cjk(qs), content, flags=re.I | re.U))\n+ if len(queries) > 0:\n+ for q in set(queries):\n+ content = re.sub(regex_highlight_cjk(q), f'<span class=\"highlight\">{q}</span>', content)\n return content\n", "issue": "Search query got emphasized even in the middle of another, unrelated word\n<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->\r\n\r\n**Version of SearXNG**\r\n\r\n2023.01.09-afd71a6c\r\n\r\n**How did you install SearXNG?**\r\n\r\nInstalled using docker with clone, docker build and run.\r\n\r\n**What happened?**\r\n\r\nQuery letters got emphasized even in the middle of another unrelated word.\r\n\r\n**How To Reproduce**\r\n\r\nDo some search using alphabetic, English words with all language flag, such as `the :all`, `java :all`, `master :all`. \r\n\r\n**Expected behavior**\r\n\r\nEmphasization should occur on queries found in standalone words only, such as `java` query only emphasize '**java**' instead of '**java**script', or `master` only in '**Master**' or '**master**' instead of 'grand**master**'.\r\n\r\n**Screenshots & Logs**\r\n\r\n|  |\r\n| --- |\r\n| In the word 'o**the**rwise' |\r\n \r\n|  |\r\n| --- |\r\n| In the word '**The**saurus' and '**the**ir' |\r\n\r\n|  |\r\n| --- |\r\n| In the word '**master**ful', '**master**s', 'grand**master**' |\r\n\r\n**Additional context**\r\n\r\nLikely happened because the regex being used does not isolate the query for occurrences in standalone words and instead it looks for all occurrences in the whole text without requiring the presence of spaces before or after it. This regex actually works well for the emphasization of queries in Chinese characters, for example:\r\n\r\n|  |\r\n| --- |\r\n| Query used: \u2019\u6751\u4e0a\u6625\u6a39\u2019 |\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nimport pathlib\nimport csv\nimport hashlib\nimport hmac\nimport re\nimport inspect\nimport itertools\nfrom datetime import datetime, timedelta\nfrom typing import Iterable, List, Tuple, Dict\n\nfrom io import StringIO\nfrom codecs import getincrementalencoder\n\nfrom flask_babel import gettext, format_date\n\nfrom searx import logger, settings\nfrom searx.engines import Engine, OTHER_CATEGORY\n\n\nVALID_LANGUAGE_CODE = re.compile(r'^[a-z]{2,3}(-[a-zA-Z]{2})?$')\n\nlogger = logger.getChild('webutils')\n\n\nclass UnicodeWriter:\n \"\"\"\n A CSV writer which will write rows to CSV file \"f\",\n which is encoded in the given encoding.\n \"\"\"\n\n def __init__(self, f, dialect=csv.excel, encoding=\"utf-8\", **kwds):\n # Redirect output to a queue\n self.queue = StringIO()\n self.writer = csv.writer(self.queue, dialect=dialect, **kwds)\n self.stream = f\n self.encoder = getincrementalencoder(encoding)()\n\n def writerow(self, row):\n self.writer.writerow(row)\n # Fetch UTF-8 output from the queue ...\n data = self.queue.getvalue()\n data = data.strip('\\x00')\n # ... and re-encode it into the target encoding\n data = self.encoder.encode(data)\n # write to the target stream\n self.stream.write(data.decode())\n # empty queue\n self.queue.truncate(0)\n\n def writerows(self, rows):\n for row in rows:\n self.writerow(row)\n\n\ndef get_themes(templates_path):\n \"\"\"Returns available themes list.\"\"\"\n return os.listdir(templates_path)\n\n\ndef get_hash_for_file(file: pathlib.Path) -> str:\n m = hashlib.sha1()\n with file.open('rb') as f:\n m.update(f.read())\n return m.hexdigest()\n\n\ndef get_static_files(static_path: str) -> Dict[str, str]:\n static_files: Dict[str, str] = {}\n static_path_path = pathlib.Path(static_path)\n\n def walk(path: pathlib.Path):\n for file in path.iterdir():\n if file.name.startswith('.'):\n # ignore hidden file\n continue\n if file.is_file():\n static_files[str(file.relative_to(static_path_path))] = get_hash_for_file(file)\n if file.is_dir() and file.name not in ('node_modules', 'src'):\n # ignore \"src\" and \"node_modules\" directories\n walk(file)\n\n walk(static_path_path)\n return static_files\n\n\ndef get_result_templates(templates_path):\n result_templates = set()\n templates_path_length = len(templates_path) + 1\n for directory, _, files in os.walk(templates_path):\n if directory.endswith('result_templates'):\n for filename in files:\n f = os.path.join(directory[templates_path_length:], filename)\n result_templates.add(f)\n return result_templates\n\n\ndef new_hmac(secret_key, url):\n return hmac.new(secret_key.encode(), url, hashlib.sha256).hexdigest()\n\n\ndef is_hmac_of(secret_key, value, hmac_to_check):\n hmac_of_value = new_hmac(secret_key, value)\n return len(hmac_of_value) == len(hmac_to_check) and hmac.compare_digest(hmac_of_value, hmac_to_check)\n\n\ndef prettify_url(url, max_length=74):\n if len(url) > max_length:\n chunk_len = int(max_length / 2 + 1)\n return '{0}[...]{1}'.format(url[:chunk_len], url[-chunk_len:])\n else:\n return url\n\n\ndef highlight_content(content, query):\n\n if not content:\n return None\n # ignoring html contents\n # TODO better html content detection\n if content.find('<') != -1:\n return content\n\n if content.lower().find(query.lower()) > -1:\n query_regex = '({0})'.format(re.escape(query))\n content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n else:\n regex_parts = []\n for chunk in query.split():\n chunk = chunk.replace('\"', '')\n if len(chunk) == 0:\n continue\n elif len(chunk) == 1:\n regex_parts.append('\\\\W+{0}\\\\W+'.format(re.escape(chunk)))\n else:\n regex_parts.append('{0}'.format(re.escape(chunk)))\n query_regex = '({0})'.format('|'.join(regex_parts))\n content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n\n return content\n\n\ndef searxng_l10n_timespan(dt: datetime) -> str: # pylint: disable=invalid-name\n \"\"\"Returns a human-readable and translated string indicating how long ago\n a date was in the past / the time span of the date to the present.\n\n On January 1st, midnight, the returned string only indicates how many years\n ago the date was.\n \"\"\"\n # TODO, check if timezone is calculated right # pylint: disable=fixme\n d = dt.date()\n t = dt.time()\n if d.month == 1 and d.day == 1 and t.hour == 0 and t.minute == 0 and t.second == 0:\n return str(d.year)\n if dt.replace(tzinfo=None) >= datetime.now() - timedelta(days=1):\n timedifference = datetime.now() - dt.replace(tzinfo=None)\n minutes = int((timedifference.seconds / 60) % 60)\n hours = int(timedifference.seconds / 60 / 60)\n if hours == 0:\n return gettext('{minutes} minute(s) ago').format(minutes=minutes)\n return gettext('{hours} hour(s), {minutes} minute(s) ago').format(hours=hours, minutes=minutes)\n return format_date(dt)\n\n\ndef is_flask_run_cmdline():\n \"\"\"Check if the application was started using \"flask run\" command line\n\n Inspect the callstack.\n See https://github.com/pallets/flask/blob/master/src/flask/__main__.py\n\n Returns:\n bool: True if the application was started using \"flask run\".\n \"\"\"\n frames = inspect.stack()\n if len(frames) < 2:\n return False\n return frames[-2].filename.endswith('flask/cli.py')\n\n\nDEFAULT_GROUP_NAME = 'others'\n\n\ndef group_engines_in_tab(engines: Iterable[Engine]) -> List[Tuple[str, Iterable[Engine]]]:\n \"\"\"Groups an Iterable of engines by their first non tab category\"\"\"\n\n def get_group(eng):\n non_tab_categories = [\n c for c in eng.categories if c not in list(settings['categories_as_tabs'].keys()) + [OTHER_CATEGORY]\n ]\n return non_tab_categories[0] if len(non_tab_categories) > 0 else DEFAULT_GROUP_NAME\n\n groups = itertools.groupby(sorted(engines, key=get_group), get_group)\n\n def group_sort_key(group):\n return (group[0] == DEFAULT_GROUP_NAME, group[0].lower())\n\n sorted_groups = sorted(((name, list(engines)) for name, engines in groups), key=group_sort_key)\n\n def engine_sort_key(engine):\n return (engine.about.get('language', ''), engine.name)\n\n return [(groupname, sorted(engines, key=engine_sort_key)) for groupname, engines in sorted_groups]\n", "path": "searx/webutils.py"}]}
| 3,414 | 852 |
gh_patches_debug_23663
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-17663
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`deploy_jar` attempts to build Java source files that do not exist in the package
Attempting to build a `deploy_jar` results in:
```
FileNotFoundError: [Errno 2] No such file or directory: '/Users/chrisjrn/src/pants/src/python/pants/jvm/jar_tool/src/java/org/pantsbuild/args4j'
```
Took a look through the unzipped pants wheel, and the relevant files are nowhere to be found.
</issue>
<code>
[start of src/python/pants/jvm/jar_tool/jar_tool.py]
1 # Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os
7 from dataclasses import dataclass
8 from enum import Enum, unique
9 from typing import Iterable, Mapping
10
11 import pkg_resources
12
13 from pants.base.glob_match_error_behavior import GlobMatchErrorBehavior
14 from pants.core.goals.generate_lockfiles import DEFAULT_TOOL_LOCKFILE, GenerateToolLockfileSentinel
15 from pants.engine.fs import (
16 CreateDigest,
17 Digest,
18 DigestEntries,
19 DigestSubset,
20 Directory,
21 FileContent,
22 FileEntry,
23 MergeDigests,
24 PathGlobs,
25 RemovePrefix,
26 )
27 from pants.engine.process import ProcessResult
28 from pants.engine.rules import Get, MultiGet, collect_rules, rule
29 from pants.engine.unions import UnionRule
30 from pants.jvm.jdk_rules import InternalJdk, JvmProcess
31 from pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest
32 from pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool
33 from pants.util.frozendict import FrozenDict
34 from pants.util.logging import LogLevel
35 from pants.util.meta import frozen_after_init
36 from pants.util.ordered_set import FrozenOrderedSet
37
38
39 @unique
40 class JarDuplicateAction(Enum):
41 SKIP = "skip"
42 REPLACE = "replace"
43 CONCAT = "concat"
44 CONCAT_TEXT = "concat_text"
45 THROW = "throw"
46
47
48 @dataclass(unsafe_hash=True)
49 @frozen_after_init
50 class JarToolRequest:
51 jar_name: str
52 digest: Digest
53 main_class: str | None
54 classpath_entries: tuple[str, ...]
55 manifest: str | None
56 jars: tuple[str, ...]
57 file_mappings: FrozenDict[str, str]
58 default_action: JarDuplicateAction | None
59 policies: tuple[tuple[str, JarDuplicateAction], ...]
60 skip: tuple[str, ...]
61 compress: bool
62 update: bool
63
64 def __init__(
65 self,
66 *,
67 jar_name: str,
68 digest: Digest,
69 main_class: str | None = None,
70 classpath_entries: Iterable[str] | None = None,
71 manifest: str | None = None,
72 jars: Iterable[str] | None = None,
73 file_mappings: Mapping[str, str] | None = None,
74 default_action: JarDuplicateAction | None = None,
75 policies: Iterable[tuple[str, str | JarDuplicateAction]] | None = None,
76 skip: Iterable[str] | None = None,
77 compress: bool = False,
78 update: bool = False,
79 ) -> None:
80 self.jar_name = jar_name
81 self.digest = digest
82 self.main_class = main_class
83 self.manifest = manifest
84 self.classpath_entries = tuple(classpath_entries or ())
85 self.jars = tuple(jars or ())
86 self.file_mappings = FrozenDict(file_mappings or {})
87 self.default_action = default_action
88 self.policies = tuple(JarToolRequest.__parse_policies(policies or ()))
89 self.skip = tuple(skip or ())
90 self.compress = compress
91 self.update = update
92
93 @staticmethod
94 def __parse_policies(
95 policies: Iterable[tuple[str, str | JarDuplicateAction]]
96 ) -> Iterable[tuple[str, JarDuplicateAction]]:
97 return [
98 (
99 pattern,
100 action
101 if isinstance(action, JarDuplicateAction)
102 else JarDuplicateAction(action.lower()),
103 )
104 for (pattern, action) in policies
105 ]
106
107
108 _JAR_TOOL_MAIN_CLASS = "org.pantsbuild.tools.jar.Main"
109
110
111 class JarToolGenerateLockfileSentinel(GenerateToolLockfileSentinel):
112 resolve_name = "jar_tool"
113
114
115 @dataclass(frozen=True)
116 class JarToolCompiledClassfiles:
117 digest: Digest
118
119
120 @rule
121 async def run_jar_tool(
122 request: JarToolRequest, jdk: InternalJdk, jar_tool: JarToolCompiledClassfiles
123 ) -> Digest:
124 output_prefix = "__out"
125 output_jarname = os.path.join(output_prefix, request.jar_name)
126
127 lockfile_request, empty_output_digest = await MultiGet(
128 Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),
129 Get(Digest, CreateDigest([Directory(output_prefix)])),
130 )
131
132 tool_classpath = await Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request))
133
134 toolcp_prefix = "__toolcp"
135 jartoolcp_prefix = "__jartoolcp"
136 input_prefix = "__in"
137 immutable_input_digests = {
138 toolcp_prefix: tool_classpath.digest,
139 jartoolcp_prefix: jar_tool.digest,
140 input_prefix: request.digest,
141 }
142
143 policies = ",".join(
144 f"{pattern}={action.value.upper()}" for (pattern, action) in request.policies
145 )
146 file_mappings = ",".join(
147 f"{os.path.join(input_prefix, fs_path)}={jar_path}"
148 for fs_path, jar_path in request.file_mappings.items()
149 )
150
151 tool_process = JvmProcess(
152 jdk=jdk,
153 argv=[
154 _JAR_TOOL_MAIN_CLASS,
155 output_jarname,
156 *((f"-main={request.main_class}",) if request.main_class else ()),
157 *(
158 (f"-classpath={','.join(request.classpath_entries)}",)
159 if request.classpath_entries
160 else ()
161 ),
162 *(
163 (f"-manifest={os.path.join(input_prefix, request.manifest)}",)
164 if request.manifest
165 else ()
166 ),
167 *(
168 (f"-jars={','.join([os.path.join(input_prefix, jar) for jar in request.jars])}",)
169 if request.jars
170 else ()
171 ),
172 *((f"-files={file_mappings}",) if file_mappings else ()),
173 *(
174 (f"-default_action={request.default_action.value.upper()}",)
175 if request.default_action
176 else ()
177 ),
178 *((f"-policies={policies}",) if policies else ()),
179 *((f"-skip={','.join(request.skip)}",) if request.skip else ()),
180 *(("-compress",) if request.compress else ()),
181 *(("-update",) if request.update else ()),
182 ],
183 classpath_entries=[*tool_classpath.classpath_entries(toolcp_prefix), jartoolcp_prefix],
184 input_digest=empty_output_digest,
185 extra_immutable_input_digests=immutable_input_digests,
186 extra_nailgun_keys=immutable_input_digests.keys(),
187 description=f"Building jar {request.jar_name}",
188 output_directories=(output_prefix,),
189 level=LogLevel.DEBUG,
190 )
191
192 result = await Get(ProcessResult, JvmProcess, tool_process)
193 return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))
194
195
196 _JAR_TOOL_SRC_PACKAGES = ["org.pantsbuild.args4j", "org.pantsbuild.tools.jar"]
197
198
199 def _load_jar_tool_sources() -> list[FileContent]:
200 result = []
201 for package in _JAR_TOOL_SRC_PACKAGES:
202 pkg_path = package.replace(".", os.path.sep)
203 relative_folder = os.path.join("src", pkg_path)
204 for basename in pkg_resources.resource_listdir(__name__, relative_folder):
205 result.append(
206 FileContent(
207 path=os.path.join(pkg_path, basename),
208 content=pkg_resources.resource_string(
209 __name__, os.path.join(relative_folder, basename)
210 ),
211 )
212 )
213 return result
214
215
216 # TODO(13879): Consolidate compilation of wrapper binaries to common rules.
217 @rule
218 async def build_jar_tool(jdk: InternalJdk) -> JarToolCompiledClassfiles:
219 lockfile_request, source_digest = await MultiGet(
220 Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),
221 Get(
222 Digest,
223 CreateDigest(_load_jar_tool_sources()),
224 ),
225 )
226
227 dest_dir = "classfiles"
228 materialized_classpath, java_subset_digest, empty_dest_dir = await MultiGet(
229 Get(ToolClasspath, ToolClasspathRequest(prefix="__toolcp", lockfile=lockfile_request)),
230 Get(
231 Digest,
232 DigestSubset(
233 source_digest,
234 PathGlobs(
235 ["**/*.java"],
236 glob_match_error_behavior=GlobMatchErrorBehavior.error,
237 description_of_origin="jar tool sources",
238 ),
239 ),
240 ),
241 Get(Digest, CreateDigest([Directory(path=dest_dir)])),
242 )
243
244 merged_digest, src_entries = await MultiGet(
245 Get(
246 Digest,
247 MergeDigests([materialized_classpath.digest, source_digest, empty_dest_dir]),
248 ),
249 Get(DigestEntries, Digest, java_subset_digest),
250 )
251
252 compile_result = await Get(
253 ProcessResult,
254 JvmProcess(
255 jdk=jdk,
256 classpath_entries=[f"{jdk.java_home}/lib/tools.jar"],
257 argv=[
258 "com.sun.tools.javac.Main",
259 "-cp",
260 ":".join(materialized_classpath.classpath_entries()),
261 "-d",
262 dest_dir,
263 *[entry.path for entry in src_entries if isinstance(entry, FileEntry)],
264 ],
265 input_digest=merged_digest,
266 output_directories=(dest_dir,),
267 description="Compile jar-tool sources using javac.",
268 level=LogLevel.DEBUG,
269 use_nailgun=False,
270 ),
271 )
272
273 stripped_classfiles_digest = await Get(
274 Digest, RemovePrefix(compile_result.output_digest, dest_dir)
275 )
276 return JarToolCompiledClassfiles(digest=stripped_classfiles_digest)
277
278
279 @rule
280 async def generate_jartool_lockfile_request(
281 _: JarToolGenerateLockfileSentinel,
282 ) -> GenerateJvmLockfileFromTool:
283 return GenerateJvmLockfileFromTool(
284 artifact_inputs=FrozenOrderedSet(
285 {
286 "args4j:args4j:2.33",
287 "com.google.code.findbugs:jsr305:3.0.2",
288 "com.google.guava:guava:18.0",
289 }
290 ),
291 artifact_option_name="n/a",
292 lockfile_option_name="n/a",
293 resolve_name=JarToolGenerateLockfileSentinel.resolve_name,
294 read_lockfile_dest=DEFAULT_TOOL_LOCKFILE,
295 write_lockfile_dest="src/python/pants/jvm/jar_tool/jar_tool.lock",
296 default_lockfile_resource=("pants.jvm.jar_tool", "jar_tool.lock"),
297 )
298
299
300 def rules():
301 return [
302 *collect_rules(),
303 UnionRule(GenerateToolLockfileSentinel, JarToolGenerateLockfileSentinel),
304 ]
305
[end of src/python/pants/jvm/jar_tool/jar_tool.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/jvm/jar_tool/jar_tool.py b/src/python/pants/jvm/jar_tool/jar_tool.py
--- a/src/python/pants/jvm/jar_tool/jar_tool.py
+++ b/src/python/pants/jvm/jar_tool/jar_tool.py
@@ -193,20 +193,20 @@
return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))
-_JAR_TOOL_SRC_PACKAGES = ["org.pantsbuild.args4j", "org.pantsbuild.tools.jar"]
+_JAR_TOOL_SRC_PACKAGES = ["args4j", "jar_tool_source"]
def _load_jar_tool_sources() -> list[FileContent]:
result = []
for package in _JAR_TOOL_SRC_PACKAGES:
- pkg_path = package.replace(".", os.path.sep)
- relative_folder = os.path.join("src", pkg_path)
- for basename in pkg_resources.resource_listdir(__name__, relative_folder):
+ # pkg_path = package.replace(".", os.path.sep)
+ # relative_folder = os.path.join("src", pkg_path)
+ for basename in pkg_resources.resource_listdir(__name__, package):
result.append(
FileContent(
- path=os.path.join(pkg_path, basename),
+ path=os.path.join(package, basename),
content=pkg_resources.resource_string(
- __name__, os.path.join(relative_folder, basename)
+ __name__, os.path.join(package, basename)
),
)
)
|
{"golden_diff": "diff --git a/src/python/pants/jvm/jar_tool/jar_tool.py b/src/python/pants/jvm/jar_tool/jar_tool.py\n--- a/src/python/pants/jvm/jar_tool/jar_tool.py\n+++ b/src/python/pants/jvm/jar_tool/jar_tool.py\n@@ -193,20 +193,20 @@\n return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))\n \n \n-_JAR_TOOL_SRC_PACKAGES = [\"org.pantsbuild.args4j\", \"org.pantsbuild.tools.jar\"]\n+_JAR_TOOL_SRC_PACKAGES = [\"args4j\", \"jar_tool_source\"]\n \n \n def _load_jar_tool_sources() -> list[FileContent]:\n result = []\n for package in _JAR_TOOL_SRC_PACKAGES:\n- pkg_path = package.replace(\".\", os.path.sep)\n- relative_folder = os.path.join(\"src\", pkg_path)\n- for basename in pkg_resources.resource_listdir(__name__, relative_folder):\n+ # pkg_path = package.replace(\".\", os.path.sep)\n+ # relative_folder = os.path.join(\"src\", pkg_path)\n+ for basename in pkg_resources.resource_listdir(__name__, package):\n result.append(\n FileContent(\n- path=os.path.join(pkg_path, basename),\n+ path=os.path.join(package, basename),\n content=pkg_resources.resource_string(\n- __name__, os.path.join(relative_folder, basename)\n+ __name__, os.path.join(package, basename)\n ),\n )\n )\n", "issue": "`deploy_jar` attempts to build Java source files that do not exist in the package\nAttempting to build a `deploy_jar` results in:\r\n\r\n```\r\nFileNotFoundError: [Errno 2] No such file or directory: '/Users/chrisjrn/src/pants/src/python/pants/jvm/jar_tool/src/java/org/pantsbuild/args4j'\r\n```\r\n\r\nTook a look through the unzipped pants wheel, and the relevant files are nowhere to be found.\n", "before_files": [{"content": "# Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nfrom dataclasses import dataclass\nfrom enum import Enum, unique\nfrom typing import Iterable, Mapping\n\nimport pkg_resources\n\nfrom pants.base.glob_match_error_behavior import GlobMatchErrorBehavior\nfrom pants.core.goals.generate_lockfiles import DEFAULT_TOOL_LOCKFILE, GenerateToolLockfileSentinel\nfrom pants.engine.fs import (\n CreateDigest,\n Digest,\n DigestEntries,\n DigestSubset,\n Directory,\n FileContent,\n FileEntry,\n MergeDigests,\n PathGlobs,\n RemovePrefix,\n)\nfrom pants.engine.process import ProcessResult\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.jdk_rules import InternalJdk, JvmProcess\nfrom pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\nfrom pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\nfrom pants.util.frozendict import FrozenDict\nfrom pants.util.logging import LogLevel\nfrom pants.util.meta import frozen_after_init\nfrom pants.util.ordered_set import FrozenOrderedSet\n\n\n@unique\nclass JarDuplicateAction(Enum):\n SKIP = \"skip\"\n REPLACE = \"replace\"\n CONCAT = \"concat\"\n CONCAT_TEXT = \"concat_text\"\n THROW = \"throw\"\n\n\n@dataclass(unsafe_hash=True)\n@frozen_after_init\nclass JarToolRequest:\n jar_name: str\n digest: Digest\n main_class: str | None\n classpath_entries: tuple[str, ...]\n manifest: str | None\n jars: tuple[str, ...]\n file_mappings: FrozenDict[str, str]\n default_action: JarDuplicateAction | None\n policies: tuple[tuple[str, JarDuplicateAction], ...]\n skip: tuple[str, ...]\n compress: bool\n update: bool\n\n def __init__(\n self,\n *,\n jar_name: str,\n digest: Digest,\n main_class: str | None = None,\n classpath_entries: Iterable[str] | None = None,\n manifest: str | None = None,\n jars: Iterable[str] | None = None,\n file_mappings: Mapping[str, str] | None = None,\n default_action: JarDuplicateAction | None = None,\n policies: Iterable[tuple[str, str | JarDuplicateAction]] | None = None,\n skip: Iterable[str] | None = None,\n compress: bool = False,\n update: bool = False,\n ) -> None:\n self.jar_name = jar_name\n self.digest = digest\n self.main_class = main_class\n self.manifest = manifest\n self.classpath_entries = tuple(classpath_entries or ())\n self.jars = tuple(jars or ())\n self.file_mappings = FrozenDict(file_mappings or {})\n self.default_action = default_action\n self.policies = tuple(JarToolRequest.__parse_policies(policies or ()))\n self.skip = tuple(skip or ())\n self.compress = compress\n self.update = update\n\n @staticmethod\n def __parse_policies(\n policies: Iterable[tuple[str, str | JarDuplicateAction]]\n ) -> Iterable[tuple[str, JarDuplicateAction]]:\n return [\n (\n pattern,\n action\n if isinstance(action, JarDuplicateAction)\n else JarDuplicateAction(action.lower()),\n )\n for (pattern, action) in policies\n ]\n\n\n_JAR_TOOL_MAIN_CLASS = \"org.pantsbuild.tools.jar.Main\"\n\n\nclass JarToolGenerateLockfileSentinel(GenerateToolLockfileSentinel):\n resolve_name = \"jar_tool\"\n\n\n@dataclass(frozen=True)\nclass JarToolCompiledClassfiles:\n digest: Digest\n\n\n@rule\nasync def run_jar_tool(\n request: JarToolRequest, jdk: InternalJdk, jar_tool: JarToolCompiledClassfiles\n) -> Digest:\n output_prefix = \"__out\"\n output_jarname = os.path.join(output_prefix, request.jar_name)\n\n lockfile_request, empty_output_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(Digest, CreateDigest([Directory(output_prefix)])),\n )\n\n tool_classpath = await Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request))\n\n toolcp_prefix = \"__toolcp\"\n jartoolcp_prefix = \"__jartoolcp\"\n input_prefix = \"__in\"\n immutable_input_digests = {\n toolcp_prefix: tool_classpath.digest,\n jartoolcp_prefix: jar_tool.digest,\n input_prefix: request.digest,\n }\n\n policies = \",\".join(\n f\"{pattern}={action.value.upper()}\" for (pattern, action) in request.policies\n )\n file_mappings = \",\".join(\n f\"{os.path.join(input_prefix, fs_path)}={jar_path}\"\n for fs_path, jar_path in request.file_mappings.items()\n )\n\n tool_process = JvmProcess(\n jdk=jdk,\n argv=[\n _JAR_TOOL_MAIN_CLASS,\n output_jarname,\n *((f\"-main={request.main_class}\",) if request.main_class else ()),\n *(\n (f\"-classpath={','.join(request.classpath_entries)}\",)\n if request.classpath_entries\n else ()\n ),\n *(\n (f\"-manifest={os.path.join(input_prefix, request.manifest)}\",)\n if request.manifest\n else ()\n ),\n *(\n (f\"-jars={','.join([os.path.join(input_prefix, jar) for jar in request.jars])}\",)\n if request.jars\n else ()\n ),\n *((f\"-files={file_mappings}\",) if file_mappings else ()),\n *(\n (f\"-default_action={request.default_action.value.upper()}\",)\n if request.default_action\n else ()\n ),\n *((f\"-policies={policies}\",) if policies else ()),\n *((f\"-skip={','.join(request.skip)}\",) if request.skip else ()),\n *((\"-compress\",) if request.compress else ()),\n *((\"-update\",) if request.update else ()),\n ],\n classpath_entries=[*tool_classpath.classpath_entries(toolcp_prefix), jartoolcp_prefix],\n input_digest=empty_output_digest,\n extra_immutable_input_digests=immutable_input_digests,\n extra_nailgun_keys=immutable_input_digests.keys(),\n description=f\"Building jar {request.jar_name}\",\n output_directories=(output_prefix,),\n level=LogLevel.DEBUG,\n )\n\n result = await Get(ProcessResult, JvmProcess, tool_process)\n return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))\n\n\n_JAR_TOOL_SRC_PACKAGES = [\"org.pantsbuild.args4j\", \"org.pantsbuild.tools.jar\"]\n\n\ndef _load_jar_tool_sources() -> list[FileContent]:\n result = []\n for package in _JAR_TOOL_SRC_PACKAGES:\n pkg_path = package.replace(\".\", os.path.sep)\n relative_folder = os.path.join(\"src\", pkg_path)\n for basename in pkg_resources.resource_listdir(__name__, relative_folder):\n result.append(\n FileContent(\n path=os.path.join(pkg_path, basename),\n content=pkg_resources.resource_string(\n __name__, os.path.join(relative_folder, basename)\n ),\n )\n )\n return result\n\n\n# TODO(13879): Consolidate compilation of wrapper binaries to common rules.\n@rule\nasync def build_jar_tool(jdk: InternalJdk) -> JarToolCompiledClassfiles:\n lockfile_request, source_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(\n Digest,\n CreateDigest(_load_jar_tool_sources()),\n ),\n )\n\n dest_dir = \"classfiles\"\n materialized_classpath, java_subset_digest, empty_dest_dir = await MultiGet(\n Get(ToolClasspath, ToolClasspathRequest(prefix=\"__toolcp\", lockfile=lockfile_request)),\n Get(\n Digest,\n DigestSubset(\n source_digest,\n PathGlobs(\n [\"**/*.java\"],\n glob_match_error_behavior=GlobMatchErrorBehavior.error,\n description_of_origin=\"jar tool sources\",\n ),\n ),\n ),\n Get(Digest, CreateDigest([Directory(path=dest_dir)])),\n )\n\n merged_digest, src_entries = await MultiGet(\n Get(\n Digest,\n MergeDigests([materialized_classpath.digest, source_digest, empty_dest_dir]),\n ),\n Get(DigestEntries, Digest, java_subset_digest),\n )\n\n compile_result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=[f\"{jdk.java_home}/lib/tools.jar\"],\n argv=[\n \"com.sun.tools.javac.Main\",\n \"-cp\",\n \":\".join(materialized_classpath.classpath_entries()),\n \"-d\",\n dest_dir,\n *[entry.path for entry in src_entries if isinstance(entry, FileEntry)],\n ],\n input_digest=merged_digest,\n output_directories=(dest_dir,),\n description=\"Compile jar-tool sources using javac.\",\n level=LogLevel.DEBUG,\n use_nailgun=False,\n ),\n )\n\n stripped_classfiles_digest = await Get(\n Digest, RemovePrefix(compile_result.output_digest, dest_dir)\n )\n return JarToolCompiledClassfiles(digest=stripped_classfiles_digest)\n\n\n@rule\nasync def generate_jartool_lockfile_request(\n _: JarToolGenerateLockfileSentinel,\n) -> GenerateJvmLockfileFromTool:\n return GenerateJvmLockfileFromTool(\n artifact_inputs=FrozenOrderedSet(\n {\n \"args4j:args4j:2.33\",\n \"com.google.code.findbugs:jsr305:3.0.2\",\n \"com.google.guava:guava:18.0\",\n }\n ),\n artifact_option_name=\"n/a\",\n lockfile_option_name=\"n/a\",\n resolve_name=JarToolGenerateLockfileSentinel.resolve_name,\n read_lockfile_dest=DEFAULT_TOOL_LOCKFILE,\n write_lockfile_dest=\"src/python/pants/jvm/jar_tool/jar_tool.lock\",\n default_lockfile_resource=(\"pants.jvm.jar_tool\", \"jar_tool.lock\"),\n )\n\n\ndef rules():\n return [\n *collect_rules(),\n UnionRule(GenerateToolLockfileSentinel, JarToolGenerateLockfileSentinel),\n ]\n", "path": "src/python/pants/jvm/jar_tool/jar_tool.py"}]}
| 3,741 | 324 |
gh_patches_debug_27381
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1985
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regression using mutable default values in arguments.
<!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
Prior to v0.115
```python
@strawberry.input
class Options:
flag: str = ''
@strawberry.type
class Query:
@strawberry.field
def field(self, x: list[str] = [], y: Options = {}) -> str:
return f'{x} {y}'
```
would correctly resolve to
```graphql
type Query {
field(x: [String!]! = [], y: Options! = {}): String!
}
```
As of v0.115 it raises
```python
File "lib/python3.10/site-packages/strawberry/types/fields/resolver.py", line 87, in find
resolver._resolved_annotations[parameter] = resolved_annotation
File "/lib/python3.10/inspect.py", line 2740, in __hash__
return hash((self.name, self.kind, self.annotation, self.default))
TypeError: unhashable type: 'list'
```
For lists, there is a workaround to use a tuple instead, but it's not ideal because GraphQL type coercion will correctly supply a list. For objects, there's no clean workaround; one would have to use the equivalent of a `frozendict`.
## System Information
- Strawberry version 0.115
</issue>
<code>
[start of strawberry/types/fields/resolver.py]
1 from __future__ import annotations as _
2
3 import builtins
4 import inspect
5 import sys
6 import warnings
7 from inspect import isasyncgenfunction, iscoroutinefunction
8 from typing import ( # type: ignore[attr-defined]
9 Any,
10 Callable,
11 Dict,
12 ForwardRef,
13 Generic,
14 List,
15 Mapping,
16 NamedTuple,
17 Optional,
18 Tuple,
19 Type,
20 TypeVar,
21 Union,
22 _eval_type,
23 )
24
25 from backports.cached_property import cached_property
26 from typing_extensions import Annotated, Protocol, get_args, get_origin
27
28 from strawberry.annotation import StrawberryAnnotation
29 from strawberry.arguments import StrawberryArgument
30 from strawberry.exceptions import MissingArgumentsAnnotationsError
31 from strawberry.type import StrawberryType
32 from strawberry.types.info import Info
33
34
35 class ReservedParameterSpecification(Protocol):
36 def find(
37 self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
38 ) -> Optional[inspect.Parameter]:
39 """Finds the reserved parameter from ``parameters``."""
40
41
42 class ReservedName(NamedTuple):
43 name: str
44
45 def find(
46 self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver
47 ) -> Optional[inspect.Parameter]:
48 return next((p for p in parameters if p.name == self.name), None)
49
50
51 class ReservedNameBoundParameter(NamedTuple):
52 name: str
53
54 def find(
55 self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver
56 ) -> Optional[inspect.Parameter]:
57 if parameters: # Add compatibility for resolvers with no arguments
58 first_parameter = parameters[0]
59 return first_parameter if first_parameter.name == self.name else None
60 else:
61 return None
62
63
64 class ReservedType(NamedTuple):
65 """Define a reserved type by name or by type.
66
67 To preserve backwards-comaptibility, if an annotation was defined but does not match
68 :attr:`type`, then the name is used as a fallback.
69 """
70
71 name: str
72 type: Type
73
74 def find(
75 self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
76 ) -> Optional[inspect.Parameter]:
77 for parameter in parameters:
78 annotation = parameter.annotation
79 try:
80 resolved_annotation = _eval_type(
81 ForwardRef(annotation)
82 if isinstance(annotation, str)
83 else annotation,
84 resolver._namespace,
85 None,
86 )
87 resolver._resolved_annotations[parameter] = resolved_annotation
88 except NameError:
89 # Type-annotation could not be resolved
90 resolved_annotation = annotation
91 if self.is_reserved_type(resolved_annotation):
92 return parameter
93
94 # Fallback to matching by name
95 reserved_name = ReservedName(name=self.name).find(parameters, resolver)
96 if reserved_name:
97 warning = DeprecationWarning(
98 f"Argument name-based matching of '{self.name}' is deprecated and will "
99 "be removed in v1.0. Ensure that reserved arguments are annotated "
100 "their respective types (i.e. use value: 'DirectiveValue[str]' instead "
101 "of 'value: str' and 'info: Info' instead of a plain 'info')."
102 )
103 warnings.warn(warning)
104 return reserved_name
105 else:
106 return None
107
108 def is_reserved_type(self, other: Type) -> bool:
109 if get_origin(other) is Annotated:
110 # Handle annotated arguments such as Private[str] and DirectiveValue[str]
111 return any(isinstance(argument, self.type) for argument in get_args(other))
112 else:
113 # Handle both concrete and generic types (i.e Info, and Info[Any, Any])
114 return other is self.type or get_origin(other) is self.type
115
116
117 SELF_PARAMSPEC = ReservedNameBoundParameter("self")
118 CLS_PARAMSPEC = ReservedNameBoundParameter("cls")
119 ROOT_PARAMSPEC = ReservedName("root")
120 INFO_PARAMSPEC = ReservedType("info", Info)
121
122 T = TypeVar("T")
123
124
125 class StrawberryResolver(Generic[T]):
126
127 RESERVED_PARAMSPEC: Tuple[ReservedParameterSpecification, ...] = (
128 SELF_PARAMSPEC,
129 CLS_PARAMSPEC,
130 ROOT_PARAMSPEC,
131 INFO_PARAMSPEC,
132 )
133
134 def __init__(
135 self,
136 func: Union[Callable[..., T], staticmethod, classmethod],
137 *,
138 description: Optional[str] = None,
139 type_override: Optional[Union[StrawberryType, type]] = None,
140 ):
141 self.wrapped_func = func
142 self._description = description
143 self._type_override = type_override
144 """Specify the type manually instead of calculating from wrapped func
145
146 This is used when creating copies of types w/ generics
147 """
148 self._resolved_annotations: Dict[inspect.Parameter, Any] = {}
149 """Populated during reserved parameter determination.
150
151 Caching resolved annotations this way prevents evaling them repeatedly.
152 """
153
154 # TODO: Use this when doing the actual resolving? How to deal with async resolvers?
155 def __call__(self, *args, **kwargs) -> T:
156 if not callable(self.wrapped_func):
157 raise UncallableResolverError(self)
158 return self.wrapped_func(*args, **kwargs)
159
160 @cached_property
161 def signature(self) -> inspect.Signature:
162 return inspect.signature(self._unbound_wrapped_func)
163
164 @cached_property
165 def reserved_parameters(
166 self,
167 ) -> Dict[ReservedParameterSpecification, Optional[inspect.Parameter]]:
168 """Mapping of reserved parameter specification to parameter."""
169 parameters = tuple(self.signature.parameters.values())
170 return {spec: spec.find(parameters, self) for spec in self.RESERVED_PARAMSPEC}
171
172 @cached_property
173 def arguments(self) -> List[StrawberryArgument]:
174 """Resolver arguments exposed in the GraphQL Schema."""
175 parameters = self.signature.parameters.values()
176 reserved_parameters = set(self.reserved_parameters.values())
177
178 missing_annotations = set()
179 arguments = []
180 user_parameters = (p for p in parameters if p not in reserved_parameters)
181 for param in user_parameters:
182 annotation = self._resolved_annotations.get(param, param.annotation)
183 if annotation is inspect.Signature.empty:
184 missing_annotations.add(param.name)
185 else:
186 argument = StrawberryArgument(
187 python_name=param.name,
188 graphql_name=None,
189 type_annotation=StrawberryAnnotation(
190 annotation=annotation, namespace=self._namespace
191 ),
192 default=param.default,
193 )
194 arguments.append(argument)
195 if missing_annotations:
196 raise MissingArgumentsAnnotationsError(self.name, missing_annotations)
197 return arguments
198
199 @cached_property
200 def info_parameter(self) -> Optional[inspect.Parameter]:
201 return self.reserved_parameters.get(INFO_PARAMSPEC)
202
203 @cached_property
204 def root_parameter(self) -> Optional[inspect.Parameter]:
205 return self.reserved_parameters.get(ROOT_PARAMSPEC)
206
207 @cached_property
208 def self_parameter(self) -> Optional[inspect.Parameter]:
209 return self.reserved_parameters.get(SELF_PARAMSPEC)
210
211 @cached_property
212 def name(self) -> str:
213 # TODO: What to do if resolver is a lambda?
214 return self._unbound_wrapped_func.__name__
215
216 @cached_property
217 def annotations(self) -> Dict[str, object]:
218 """Annotations for the resolver.
219
220 Does not include special args defined in `RESERVED_PARAMSPEC` (e.g. self, root,
221 info)
222 """
223 reserved_parameters = self.reserved_parameters
224 reserved_names = {p.name for p in reserved_parameters.values() if p is not None}
225
226 annotations = self._unbound_wrapped_func.__annotations__
227 annotations = {
228 name: annotation
229 for name, annotation in annotations.items()
230 if name not in reserved_names
231 }
232
233 return annotations
234
235 @cached_property
236 def type_annotation(self) -> Optional[StrawberryAnnotation]:
237 return_annotation = self.signature.return_annotation
238 if return_annotation is inspect.Signature.empty:
239 return None
240 else:
241 type_annotation = StrawberryAnnotation(
242 annotation=return_annotation, namespace=self._namespace
243 )
244 return type_annotation
245
246 @property
247 def type(self) -> Optional[Union[StrawberryType, type]]:
248 if self._type_override:
249 return self._type_override
250 if self.type_annotation is None:
251 return None
252 return self.type_annotation.resolve()
253
254 @cached_property
255 def is_async(self) -> bool:
256 return iscoroutinefunction(self._unbound_wrapped_func) or isasyncgenfunction(
257 self._unbound_wrapped_func
258 )
259
260 def copy_with(
261 self, type_var_map: Mapping[TypeVar, Union[StrawberryType, builtins.type]]
262 ) -> StrawberryResolver:
263 type_override = None
264
265 if self.type:
266 if isinstance(self.type, StrawberryType):
267 type_override = self.type.copy_with(type_var_map)
268 else:
269 type_override = self.type._type_definition.copy_with( # type: ignore
270 type_var_map,
271 )
272
273 return type(self)(
274 func=self.wrapped_func,
275 description=self._description,
276 type_override=type_override,
277 )
278
279 @cached_property
280 def _namespace(self) -> Dict[str, Any]:
281 return sys.modules[self._unbound_wrapped_func.__module__].__dict__
282
283 @cached_property
284 def _unbound_wrapped_func(self) -> Callable[..., T]:
285 if isinstance(self.wrapped_func, (staticmethod, classmethod)):
286 return self.wrapped_func.__func__
287
288 return self.wrapped_func
289
290
291 class UncallableResolverError(Exception):
292 def __init__(self, resolver: "StrawberryResolver"):
293 message = (
294 f"Attempted to call resolver {resolver} with uncallable function "
295 f"{resolver.wrapped_func}"
296 )
297 super().__init__(message)
298
299
300 __all__ = ["StrawberryResolver"]
301
[end of strawberry/types/fields/resolver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/types/fields/resolver.py b/strawberry/types/fields/resolver.py
--- a/strawberry/types/fields/resolver.py
+++ b/strawberry/types/fields/resolver.py
@@ -32,6 +32,29 @@
from strawberry.types.info import Info
+class Parameter(inspect.Parameter):
+ def __hash__(self):
+ """Override to exclude default value from hash.
+
+ This adds compatibility for using unhashable default values in resolvers such as
+ list and dict. The present use-case is limited to analyzing parameters from one
+ resolver. Therefore, the name, kind, and annotation combination are guaranteed
+ to be unique since two arguments cannot have the same name in a callable.
+
+ Furthermore, even though it is not currently a use-case to collect parameters
+ from different resolvers, the likelihood of collision from having the same hash
+ value but different defaults is mitigated by Python invoking the
+ :py:meth:`__eq__` method if two items have the same hash. See the verification
+ of this behavior in the `test_parameter_hash_collision` test.
+ """
+ return hash((self.name, self.kind, self.annotation))
+
+
+class Signature(inspect.Signature):
+
+ _parameter_cls = Parameter
+
+
class ReservedParameterSpecification(Protocol):
def find(
self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
@@ -159,7 +182,7 @@
@cached_property
def signature(self) -> inspect.Signature:
- return inspect.signature(self._unbound_wrapped_func)
+ return Signature.from_callable(self._unbound_wrapped_func, follow_wrapped=True)
@cached_property
def reserved_parameters(
|
{"golden_diff": "diff --git a/strawberry/types/fields/resolver.py b/strawberry/types/fields/resolver.py\n--- a/strawberry/types/fields/resolver.py\n+++ b/strawberry/types/fields/resolver.py\n@@ -32,6 +32,29 @@\n from strawberry.types.info import Info\n \n \n+class Parameter(inspect.Parameter):\n+ def __hash__(self):\n+ \"\"\"Override to exclude default value from hash.\n+\n+ This adds compatibility for using unhashable default values in resolvers such as\n+ list and dict. The present use-case is limited to analyzing parameters from one\n+ resolver. Therefore, the name, kind, and annotation combination are guaranteed\n+ to be unique since two arguments cannot have the same name in a callable.\n+\n+ Furthermore, even though it is not currently a use-case to collect parameters\n+ from different resolvers, the likelihood of collision from having the same hash\n+ value but different defaults is mitigated by Python invoking the\n+ :py:meth:`__eq__` method if two items have the same hash. See the verification\n+ of this behavior in the `test_parameter_hash_collision` test.\n+ \"\"\"\n+ return hash((self.name, self.kind, self.annotation))\n+\n+\n+class Signature(inspect.Signature):\n+\n+ _parameter_cls = Parameter\n+\n+\n class ReservedParameterSpecification(Protocol):\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n@@ -159,7 +182,7 @@\n \n @cached_property\n def signature(self) -> inspect.Signature:\n- return inspect.signature(self._unbound_wrapped_func)\n+ return Signature.from_callable(self._unbound_wrapped_func, follow_wrapped=True)\n \n @cached_property\n def reserved_parameters(\n", "issue": "Regression using mutable default values in arguments.\n<!-- Provide a general summary of the bug in the title above. -->\r\n\r\n<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->\r\n<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->\r\n\r\n## Describe the Bug\r\nPrior to v0.115\r\n```python\r\[email protected]\r\nclass Options:\r\n flag: str = ''\r\n\r\n\r\[email protected]\r\nclass Query:\r\n @strawberry.field\r\n def field(self, x: list[str] = [], y: Options = {}) -> str:\r\n return f'{x} {y}'\r\n```\r\nwould correctly resolve to\r\n```graphql\r\ntype Query {\r\n field(x: [String!]! = [], y: Options! = {}): String!\r\n}\r\n```\r\nAs of v0.115 it raises\r\n```python\r\n File \"lib/python3.10/site-packages/strawberry/types/fields/resolver.py\", line 87, in find\r\n resolver._resolved_annotations[parameter] = resolved_annotation\r\n File \"/lib/python3.10/inspect.py\", line 2740, in __hash__\r\n return hash((self.name, self.kind, self.annotation, self.default))\r\nTypeError: unhashable type: 'list'\r\n\r\n```\r\n\r\nFor lists, there is a workaround to use a tuple instead, but it's not ideal because GraphQL type coercion will correctly supply a list. For objects, there's no clean workaround; one would have to use the equivalent of a `frozendict`.\r\n\r\n## System Information\r\n - Strawberry version 0.115\r\n\n", "before_files": [{"content": "from __future__ import annotations as _\n\nimport builtins\nimport inspect\nimport sys\nimport warnings\nfrom inspect import isasyncgenfunction, iscoroutinefunction\nfrom typing import ( # type: ignore[attr-defined]\n Any,\n Callable,\n Dict,\n ForwardRef,\n Generic,\n List,\n Mapping,\n NamedTuple,\n Optional,\n Tuple,\n Type,\n TypeVar,\n Union,\n _eval_type,\n)\n\nfrom backports.cached_property import cached_property\nfrom typing_extensions import Annotated, Protocol, get_args, get_origin\n\nfrom strawberry.annotation import StrawberryAnnotation\nfrom strawberry.arguments import StrawberryArgument\nfrom strawberry.exceptions import MissingArgumentsAnnotationsError\nfrom strawberry.type import StrawberryType\nfrom strawberry.types.info import Info\n\n\nclass ReservedParameterSpecification(Protocol):\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n \"\"\"Finds the reserved parameter from ``parameters``.\"\"\"\n\n\nclass ReservedName(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n return next((p for p in parameters if p.name == self.name), None)\n\n\nclass ReservedNameBoundParameter(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n if parameters: # Add compatibility for resolvers with no arguments\n first_parameter = parameters[0]\n return first_parameter if first_parameter.name == self.name else None\n else:\n return None\n\n\nclass ReservedType(NamedTuple):\n \"\"\"Define a reserved type by name or by type.\n\n To preserve backwards-comaptibility, if an annotation was defined but does not match\n :attr:`type`, then the name is used as a fallback.\n \"\"\"\n\n name: str\n type: Type\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n for parameter in parameters:\n annotation = parameter.annotation\n try:\n resolved_annotation = _eval_type(\n ForwardRef(annotation)\n if isinstance(annotation, str)\n else annotation,\n resolver._namespace,\n None,\n )\n resolver._resolved_annotations[parameter] = resolved_annotation\n except NameError:\n # Type-annotation could not be resolved\n resolved_annotation = annotation\n if self.is_reserved_type(resolved_annotation):\n return parameter\n\n # Fallback to matching by name\n reserved_name = ReservedName(name=self.name).find(parameters, resolver)\n if reserved_name:\n warning = DeprecationWarning(\n f\"Argument name-based matching of '{self.name}' is deprecated and will \"\n \"be removed in v1.0. Ensure that reserved arguments are annotated \"\n \"their respective types (i.e. use value: 'DirectiveValue[str]' instead \"\n \"of 'value: str' and 'info: Info' instead of a plain 'info').\"\n )\n warnings.warn(warning)\n return reserved_name\n else:\n return None\n\n def is_reserved_type(self, other: Type) -> bool:\n if get_origin(other) is Annotated:\n # Handle annotated arguments such as Private[str] and DirectiveValue[str]\n return any(isinstance(argument, self.type) for argument in get_args(other))\n else:\n # Handle both concrete and generic types (i.e Info, and Info[Any, Any])\n return other is self.type or get_origin(other) is self.type\n\n\nSELF_PARAMSPEC = ReservedNameBoundParameter(\"self\")\nCLS_PARAMSPEC = ReservedNameBoundParameter(\"cls\")\nROOT_PARAMSPEC = ReservedName(\"root\")\nINFO_PARAMSPEC = ReservedType(\"info\", Info)\n\nT = TypeVar(\"T\")\n\n\nclass StrawberryResolver(Generic[T]):\n\n RESERVED_PARAMSPEC: Tuple[ReservedParameterSpecification, ...] = (\n SELF_PARAMSPEC,\n CLS_PARAMSPEC,\n ROOT_PARAMSPEC,\n INFO_PARAMSPEC,\n )\n\n def __init__(\n self,\n func: Union[Callable[..., T], staticmethod, classmethod],\n *,\n description: Optional[str] = None,\n type_override: Optional[Union[StrawberryType, type]] = None,\n ):\n self.wrapped_func = func\n self._description = description\n self._type_override = type_override\n \"\"\"Specify the type manually instead of calculating from wrapped func\n\n This is used when creating copies of types w/ generics\n \"\"\"\n self._resolved_annotations: Dict[inspect.Parameter, Any] = {}\n \"\"\"Populated during reserved parameter determination.\n\n Caching resolved annotations this way prevents evaling them repeatedly.\n \"\"\"\n\n # TODO: Use this when doing the actual resolving? How to deal with async resolvers?\n def __call__(self, *args, **kwargs) -> T:\n if not callable(self.wrapped_func):\n raise UncallableResolverError(self)\n return self.wrapped_func(*args, **kwargs)\n\n @cached_property\n def signature(self) -> inspect.Signature:\n return inspect.signature(self._unbound_wrapped_func)\n\n @cached_property\n def reserved_parameters(\n self,\n ) -> Dict[ReservedParameterSpecification, Optional[inspect.Parameter]]:\n \"\"\"Mapping of reserved parameter specification to parameter.\"\"\"\n parameters = tuple(self.signature.parameters.values())\n return {spec: spec.find(parameters, self) for spec in self.RESERVED_PARAMSPEC}\n\n @cached_property\n def arguments(self) -> List[StrawberryArgument]:\n \"\"\"Resolver arguments exposed in the GraphQL Schema.\"\"\"\n parameters = self.signature.parameters.values()\n reserved_parameters = set(self.reserved_parameters.values())\n\n missing_annotations = set()\n arguments = []\n user_parameters = (p for p in parameters if p not in reserved_parameters)\n for param in user_parameters:\n annotation = self._resolved_annotations.get(param, param.annotation)\n if annotation is inspect.Signature.empty:\n missing_annotations.add(param.name)\n else:\n argument = StrawberryArgument(\n python_name=param.name,\n graphql_name=None,\n type_annotation=StrawberryAnnotation(\n annotation=annotation, namespace=self._namespace\n ),\n default=param.default,\n )\n arguments.append(argument)\n if missing_annotations:\n raise MissingArgumentsAnnotationsError(self.name, missing_annotations)\n return arguments\n\n @cached_property\n def info_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(INFO_PARAMSPEC)\n\n @cached_property\n def root_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(ROOT_PARAMSPEC)\n\n @cached_property\n def self_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(SELF_PARAMSPEC)\n\n @cached_property\n def name(self) -> str:\n # TODO: What to do if resolver is a lambda?\n return self._unbound_wrapped_func.__name__\n\n @cached_property\n def annotations(self) -> Dict[str, object]:\n \"\"\"Annotations for the resolver.\n\n Does not include special args defined in `RESERVED_PARAMSPEC` (e.g. self, root,\n info)\n \"\"\"\n reserved_parameters = self.reserved_parameters\n reserved_names = {p.name for p in reserved_parameters.values() if p is not None}\n\n annotations = self._unbound_wrapped_func.__annotations__\n annotations = {\n name: annotation\n for name, annotation in annotations.items()\n if name not in reserved_names\n }\n\n return annotations\n\n @cached_property\n def type_annotation(self) -> Optional[StrawberryAnnotation]:\n return_annotation = self.signature.return_annotation\n if return_annotation is inspect.Signature.empty:\n return None\n else:\n type_annotation = StrawberryAnnotation(\n annotation=return_annotation, namespace=self._namespace\n )\n return type_annotation\n\n @property\n def type(self) -> Optional[Union[StrawberryType, type]]:\n if self._type_override:\n return self._type_override\n if self.type_annotation is None:\n return None\n return self.type_annotation.resolve()\n\n @cached_property\n def is_async(self) -> bool:\n return iscoroutinefunction(self._unbound_wrapped_func) or isasyncgenfunction(\n self._unbound_wrapped_func\n )\n\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, builtins.type]]\n ) -> StrawberryResolver:\n type_override = None\n\n if self.type:\n if isinstance(self.type, StrawberryType):\n type_override = self.type.copy_with(type_var_map)\n else:\n type_override = self.type._type_definition.copy_with( # type: ignore\n type_var_map,\n )\n\n return type(self)(\n func=self.wrapped_func,\n description=self._description,\n type_override=type_override,\n )\n\n @cached_property\n def _namespace(self) -> Dict[str, Any]:\n return sys.modules[self._unbound_wrapped_func.__module__].__dict__\n\n @cached_property\n def _unbound_wrapped_func(self) -> Callable[..., T]:\n if isinstance(self.wrapped_func, (staticmethod, classmethod)):\n return self.wrapped_func.__func__\n\n return self.wrapped_func\n\n\nclass UncallableResolverError(Exception):\n def __init__(self, resolver: \"StrawberryResolver\"):\n message = (\n f\"Attempted to call resolver {resolver} with uncallable function \"\n f\"{resolver.wrapped_func}\"\n )\n super().__init__(message)\n\n\n__all__ = [\"StrawberryResolver\"]\n", "path": "strawberry/types/fields/resolver.py"}]}
| 3,781 | 397 |
gh_patches_debug_13904
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-2930
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Changed exportDialog
This pull request fixes #2367. The code has been changed as it was suggested in the issue.
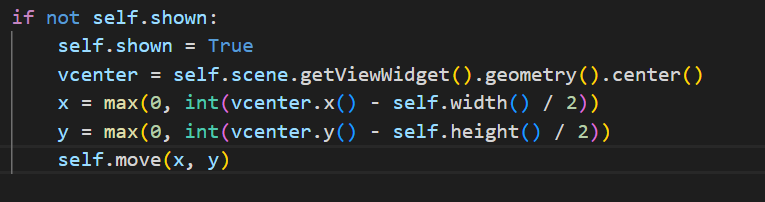
</issue>
<code>
[start of pyqtgraph/GraphicsScene/exportDialog.py]
1 from .. import exporters as exporters
2 from .. import functions as fn
3 from ..graphicsItems.PlotItem import PlotItem
4 from ..graphicsItems.ViewBox import ViewBox
5 from ..Qt import QtCore, QtWidgets
6
7 from . import exportDialogTemplate_generic as ui_template
8
9 class FormatExportListWidgetItem(QtWidgets.QListWidgetItem):
10 def __init__(self, expClass, *args, **kwargs):
11 QtWidgets.QListWidgetItem.__init__(self, *args, **kwargs)
12 self.expClass = expClass
13
14
15 class ExportDialog(QtWidgets.QWidget):
16 def __init__(self, scene):
17 QtWidgets.QWidget.__init__(self)
18 self.setVisible(False)
19 self.setWindowTitle("Export")
20 self.shown = False
21 self.currentExporter = None
22 self.scene = scene
23
24 self.selectBox = QtWidgets.QGraphicsRectItem()
25 self.selectBox.setPen(fn.mkPen('y', width=3, style=QtCore.Qt.PenStyle.DashLine))
26 self.selectBox.hide()
27 self.scene.addItem(self.selectBox)
28
29 self.ui = ui_template.Ui_Form()
30 self.ui.setupUi(self)
31
32 self.ui.closeBtn.clicked.connect(self.close)
33 self.ui.exportBtn.clicked.connect(self.exportClicked)
34 self.ui.copyBtn.clicked.connect(self.copyClicked)
35 self.ui.itemTree.currentItemChanged.connect(self.exportItemChanged)
36 self.ui.formatList.currentItemChanged.connect(self.exportFormatChanged)
37
38
39 def show(self, item=None):
40 if item is not None:
41 ## Select next exportable parent of the item originally clicked on
42 while not isinstance(item, ViewBox) and not isinstance(item, PlotItem) and item is not None:
43 item = item.parentItem()
44 ## if this is a ViewBox inside a PlotItem, select the parent instead.
45 if isinstance(item, ViewBox) and isinstance(item.parentItem(), PlotItem):
46 item = item.parentItem()
47 self.updateItemList(select=item)
48 self.setVisible(True)
49 self.activateWindow()
50 self.raise_()
51 self.selectBox.setVisible(True)
52 if not self.shown:
53 self.shown = True
54 vcenter = self.scene.getViewWidget().geometry().center()
55 x = max(0, int(vcenter.x() - self.width() / 2))
56 y = max(0, int(vcenter.y() - self.height() / 2))
57 self.move(x, y)
58
59 def updateItemList(self, select=None):
60 self.ui.itemTree.clear()
61 si = QtWidgets.QTreeWidgetItem(["Entire Scene"])
62 si.gitem = self.scene
63 self.ui.itemTree.addTopLevelItem(si)
64 self.ui.itemTree.setCurrentItem(si)
65 si.setExpanded(True)
66 for child in self.scene.items():
67 if child.parentItem() is None:
68 self.updateItemTree(child, si, select=select)
69
70 def updateItemTree(self, item, treeItem, select=None):
71 si = None
72 if isinstance(item, ViewBox):
73 si = QtWidgets.QTreeWidgetItem(['ViewBox'])
74 elif isinstance(item, PlotItem):
75 si = QtWidgets.QTreeWidgetItem(['Plot'])
76
77 if si is not None:
78 si.gitem = item
79 treeItem.addChild(si)
80 treeItem = si
81 if si.gitem is select:
82 self.ui.itemTree.setCurrentItem(si)
83
84 for ch in item.childItems():
85 self.updateItemTree(ch, treeItem, select=select)
86
87
88 def exportItemChanged(self, item, prev):
89 if item is None:
90 return
91 if item.gitem is self.scene:
92 newBounds = self.scene.views()[0].viewRect()
93 else:
94 newBounds = item.gitem.sceneBoundingRect()
95 self.selectBox.setRect(newBounds)
96 self.selectBox.show()
97 self.updateFormatList()
98
99 def updateFormatList(self):
100 current = self.ui.formatList.currentItem()
101
102 self.ui.formatList.clear()
103 gotCurrent = False
104 for exp in exporters.listExporters():
105 item = FormatExportListWidgetItem(exp, QtCore.QCoreApplication.translate('Exporter', exp.Name))
106 self.ui.formatList.addItem(item)
107 if item is current:
108 self.ui.formatList.setCurrentRow(self.ui.formatList.count() - 1)
109 gotCurrent = True
110
111 if not gotCurrent:
112 self.ui.formatList.setCurrentRow(0)
113
114 def exportFormatChanged(self, item, prev):
115 if item is None:
116 self.currentExporter = None
117 self.ui.paramTree.clear()
118 return
119 expClass = item.expClass
120 exp = expClass(item=self.ui.itemTree.currentItem().gitem)
121
122 params = exp.parameters()
123
124 if params is None:
125 self.ui.paramTree.clear()
126 else:
127 self.ui.paramTree.setParameters(params)
128 self.currentExporter = exp
129 self.ui.copyBtn.setEnabled(exp.allowCopy)
130
131 def exportClicked(self):
132 self.selectBox.hide()
133 self.currentExporter.export()
134
135 def copyClicked(self):
136 self.selectBox.hide()
137 self.currentExporter.export(copy=True)
138
139 def close(self):
140 self.selectBox.setVisible(False)
141 self.setVisible(False)
142
143 def closeEvent(self, event):
144 self.close()
145 super().closeEvent(event)
146
[end of pyqtgraph/GraphicsScene/exportDialog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyqtgraph/GraphicsScene/exportDialog.py b/pyqtgraph/GraphicsScene/exportDialog.py
--- a/pyqtgraph/GraphicsScene/exportDialog.py
+++ b/pyqtgraph/GraphicsScene/exportDialog.py
@@ -51,10 +51,11 @@
self.selectBox.setVisible(True)
if not self.shown:
self.shown = True
- vcenter = self.scene.getViewWidget().geometry().center()
- x = max(0, int(vcenter.x() - self.width() / 2))
- y = max(0, int(vcenter.y() - self.height() / 2))
- self.move(x, y)
+ screen = QtWidgets.QApplication.desktop().screenNumber(QtWidgets.QApplication.desktop().cursor().pos())
+ centre = QtWidgets.QDesktopWidget().availableGeometry(screen).center()
+ frame = self.frameGeometry()
+ frame.moveCenter(centre)
+ self.move(frame.topLeft())
def updateItemList(self, select=None):
self.ui.itemTree.clear()
|
{"golden_diff": "diff --git a/pyqtgraph/GraphicsScene/exportDialog.py b/pyqtgraph/GraphicsScene/exportDialog.py\n--- a/pyqtgraph/GraphicsScene/exportDialog.py\n+++ b/pyqtgraph/GraphicsScene/exportDialog.py\n@@ -51,10 +51,11 @@\n self.selectBox.setVisible(True)\n if not self.shown:\n self.shown = True\n- vcenter = self.scene.getViewWidget().geometry().center()\n- x = max(0, int(vcenter.x() - self.width() / 2))\n- y = max(0, int(vcenter.y() - self.height() / 2))\n- self.move(x, y)\n+ screen = QtWidgets.QApplication.desktop().screenNumber(QtWidgets.QApplication.desktop().cursor().pos())\n+ centre = QtWidgets.QDesktopWidget().availableGeometry(screen).center()\n+ frame = self.frameGeometry()\n+ frame.moveCenter(centre)\n+ self.move(frame.topLeft())\n \n def updateItemList(self, select=None):\n self.ui.itemTree.clear()\n", "issue": "Changed exportDialog\nThis pull request fixes #2367. The code has been changed as it was suggested in the issue.\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from .. import exporters as exporters\nfrom .. import functions as fn\nfrom ..graphicsItems.PlotItem import PlotItem\nfrom ..graphicsItems.ViewBox import ViewBox\nfrom ..Qt import QtCore, QtWidgets\n\nfrom . import exportDialogTemplate_generic as ui_template\n\nclass FormatExportListWidgetItem(QtWidgets.QListWidgetItem):\n def __init__(self, expClass, *args, **kwargs):\n QtWidgets.QListWidgetItem.__init__(self, *args, **kwargs)\n self.expClass = expClass\n\n\nclass ExportDialog(QtWidgets.QWidget):\n def __init__(self, scene):\n QtWidgets.QWidget.__init__(self)\n self.setVisible(False)\n self.setWindowTitle(\"Export\")\n self.shown = False\n self.currentExporter = None\n self.scene = scene\n\n self.selectBox = QtWidgets.QGraphicsRectItem()\n self.selectBox.setPen(fn.mkPen('y', width=3, style=QtCore.Qt.PenStyle.DashLine))\n self.selectBox.hide()\n self.scene.addItem(self.selectBox)\n \n self.ui = ui_template.Ui_Form()\n self.ui.setupUi(self)\n \n self.ui.closeBtn.clicked.connect(self.close)\n self.ui.exportBtn.clicked.connect(self.exportClicked)\n self.ui.copyBtn.clicked.connect(self.copyClicked)\n self.ui.itemTree.currentItemChanged.connect(self.exportItemChanged)\n self.ui.formatList.currentItemChanged.connect(self.exportFormatChanged)\n \n\n def show(self, item=None):\n if item is not None:\n ## Select next exportable parent of the item originally clicked on\n while not isinstance(item, ViewBox) and not isinstance(item, PlotItem) and item is not None:\n item = item.parentItem()\n ## if this is a ViewBox inside a PlotItem, select the parent instead.\n if isinstance(item, ViewBox) and isinstance(item.parentItem(), PlotItem):\n item = item.parentItem()\n self.updateItemList(select=item)\n self.setVisible(True)\n self.activateWindow()\n self.raise_()\n self.selectBox.setVisible(True)\n if not self.shown:\n self.shown = True\n vcenter = self.scene.getViewWidget().geometry().center()\n x = max(0, int(vcenter.x() - self.width() / 2))\n y = max(0, int(vcenter.y() - self.height() / 2))\n self.move(x, y)\n \n def updateItemList(self, select=None):\n self.ui.itemTree.clear()\n si = QtWidgets.QTreeWidgetItem([\"Entire Scene\"])\n si.gitem = self.scene\n self.ui.itemTree.addTopLevelItem(si)\n self.ui.itemTree.setCurrentItem(si)\n si.setExpanded(True)\n for child in self.scene.items():\n if child.parentItem() is None:\n self.updateItemTree(child, si, select=select)\n \n def updateItemTree(self, item, treeItem, select=None):\n si = None\n if isinstance(item, ViewBox):\n si = QtWidgets.QTreeWidgetItem(['ViewBox'])\n elif isinstance(item, PlotItem):\n si = QtWidgets.QTreeWidgetItem(['Plot'])\n \n if si is not None:\n si.gitem = item\n treeItem.addChild(si)\n treeItem = si\n if si.gitem is select:\n self.ui.itemTree.setCurrentItem(si)\n \n for ch in item.childItems():\n self.updateItemTree(ch, treeItem, select=select)\n \n \n def exportItemChanged(self, item, prev):\n if item is None:\n return\n if item.gitem is self.scene:\n newBounds = self.scene.views()[0].viewRect()\n else:\n newBounds = item.gitem.sceneBoundingRect()\n self.selectBox.setRect(newBounds)\n self.selectBox.show()\n self.updateFormatList()\n \n def updateFormatList(self):\n current = self.ui.formatList.currentItem()\n\n self.ui.formatList.clear()\n gotCurrent = False\n for exp in exporters.listExporters():\n item = FormatExportListWidgetItem(exp, QtCore.QCoreApplication.translate('Exporter', exp.Name))\n self.ui.formatList.addItem(item)\n if item is current:\n self.ui.formatList.setCurrentRow(self.ui.formatList.count() - 1)\n gotCurrent = True\n \n if not gotCurrent:\n self.ui.formatList.setCurrentRow(0)\n \n def exportFormatChanged(self, item, prev):\n if item is None:\n self.currentExporter = None\n self.ui.paramTree.clear()\n return\n expClass = item.expClass\n exp = expClass(item=self.ui.itemTree.currentItem().gitem)\n\n params = exp.parameters()\n\n if params is None:\n self.ui.paramTree.clear()\n else:\n self.ui.paramTree.setParameters(params)\n self.currentExporter = exp\n self.ui.copyBtn.setEnabled(exp.allowCopy)\n \n def exportClicked(self):\n self.selectBox.hide()\n self.currentExporter.export()\n \n def copyClicked(self):\n self.selectBox.hide()\n self.currentExporter.export(copy=True)\n \n def close(self):\n self.selectBox.setVisible(False)\n self.setVisible(False)\n\n def closeEvent(self, event):\n self.close()\n super().closeEvent(event)\n", "path": "pyqtgraph/GraphicsScene/exportDialog.py"}]}
| 2,060 | 220 |
gh_patches_debug_21441
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-197
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
In the DevDocNeeded model, consider bugs for which the dev-doc-needed keyword was removed as negative examples
See also #79.
</issue>
<code>
[start of bugbug/models/devdocneeded.py]
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import xgboost
7 from imblearn.under_sampling import RandomUnderSampler
8 from sklearn.compose import ColumnTransformer
9 from sklearn.feature_extraction import DictVectorizer
10 from sklearn.pipeline import Pipeline
11
12 from bugbug import bug_features
13 from bugbug import bugzilla
14 from bugbug.model import Model
15
16
17 class DevDocNeededModel(Model):
18 def __init__(self, lemmatization=False):
19 Model.__init__(self, lemmatization)
20
21 self.sampler = RandomUnderSampler(random_state=0)
22
23 feature_extractors = [
24 bug_features.has_str(),
25 bug_features.has_regression_range(),
26 bug_features.severity(),
27 bug_features.keywords({'dev-doc-needed', 'dev-doc-complete'}),
28 bug_features.is_coverity_issue(),
29 bug_features.has_crash_signature(),
30 bug_features.has_url(),
31 bug_features.has_w3c_url(),
32 bug_features.has_github_url(),
33 bug_features.whiteboard(),
34 bug_features.patches(),
35 bug_features.landings(),
36 bug_features.title(),
37 bug_features.product(),
38 bug_features.component(),
39
40 bug_features.commit_added(),
41 bug_features.commit_deleted(),
42 bug_features.commit_types(),
43 ]
44
45 cleanup_functions = [
46 bug_features.cleanup_fileref,
47 bug_features.cleanup_url,
48 bug_features.cleanup_synonyms,
49 ]
50
51 self.extraction_pipeline = Pipeline([
52 ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions, rollback=True, rollback_when=self.rollback, commit_data=True)),
53 ('union', ColumnTransformer([
54 ('data', DictVectorizer(), 'data'),
55
56 ('title', self.text_vectorizer(), 'title'),
57
58 ('comments', self.text_vectorizer(), 'comments'),
59 ])),
60 ])
61
62 self.clf = xgboost.XGBClassifier(n_jobs=16)
63 self.clf.set_params(predictor='cpu_predictor')
64
65 def rollback(self, change):
66 return change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete'])
67
68 def get_labels(self):
69 classes = {}
70
71 for bug_data in bugzilla.get_bugs():
72 bug_id = int(bug_data['id'])
73
74 for entry in bug_data['history']:
75 for change in entry['changes']:
76 if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
77 classes[bug_id] = 1
78
79 if bug_id not in classes:
80 classes[bug_id] = 0
81
82 return classes
83
84 def get_feature_names(self):
85 return self.extraction_pipeline.named_steps['union'].get_feature_names()
86
[end of bugbug/models/devdocneeded.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bugbug/models/devdocneeded.py b/bugbug/models/devdocneeded.py
--- a/bugbug/models/devdocneeded.py
+++ b/bugbug/models/devdocneeded.py
@@ -73,7 +73,14 @@
for entry in bug_data['history']:
for change in entry['changes']:
- if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
+ # Bugs that get dev-doc-needed removed from them at some point after it's been added (this suggests a false positive among human-analyzed bugs)
+ if change['field_name'] == 'keywords' and 'dev-doc-needed' in change['removed'] and 'dev-doc-complete' not in change['added']:
+ classes[bug_id] = 0
+ # Bugs that go from dev-doc-needed to dev-doc-complete are guaranteed to be good
+ # Bugs that go from not having dev-doc-needed to having dev-doc-complete are bugs
+ # that were missed by previous scans through content but someone realized it
+ # should have been flagged and updated the docs, found the docs already updated.
+ elif change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
classes[bug_id] = 1
if bug_id not in classes:
|
{"golden_diff": "diff --git a/bugbug/models/devdocneeded.py b/bugbug/models/devdocneeded.py\n--- a/bugbug/models/devdocneeded.py\n+++ b/bugbug/models/devdocneeded.py\n@@ -73,7 +73,14 @@\n \n for entry in bug_data['history']:\n for change in entry['changes']:\n- if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n+ # Bugs that get dev-doc-needed removed from them at some point after it's been added (this suggests a false positive among human-analyzed bugs)\n+ if change['field_name'] == 'keywords' and 'dev-doc-needed' in change['removed'] and 'dev-doc-complete' not in change['added']:\n+ classes[bug_id] = 0\n+ # Bugs that go from dev-doc-needed to dev-doc-complete are guaranteed to be good\n+ # Bugs that go from not having dev-doc-needed to having dev-doc-complete are bugs\n+ # that were missed by previous scans through content but someone realized it\n+ # should have been flagged and updated the docs, found the docs already updated.\n+ elif change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n classes[bug_id] = 1\n \n if bug_id not in classes:\n", "issue": "In the DevDocNeeded model, consider bugs for which the dev-doc-needed keyword was removed as negative examples\nSee also #79.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport xgboost\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features\nfrom bugbug import bugzilla\nfrom bugbug.model import Model\n\n\nclass DevDocNeededModel(Model):\n def __init__(self, lemmatization=False):\n Model.__init__(self, lemmatization)\n\n self.sampler = RandomUnderSampler(random_state=0)\n\n feature_extractors = [\n bug_features.has_str(),\n bug_features.has_regression_range(),\n bug_features.severity(),\n bug_features.keywords({'dev-doc-needed', 'dev-doc-complete'}),\n bug_features.is_coverity_issue(),\n bug_features.has_crash_signature(),\n bug_features.has_url(),\n bug_features.has_w3c_url(),\n bug_features.has_github_url(),\n bug_features.whiteboard(),\n bug_features.patches(),\n bug_features.landings(),\n bug_features.title(),\n bug_features.product(),\n bug_features.component(),\n\n bug_features.commit_added(),\n bug_features.commit_deleted(),\n bug_features.commit_types(),\n ]\n\n cleanup_functions = [\n bug_features.cleanup_fileref,\n bug_features.cleanup_url,\n bug_features.cleanup_synonyms,\n ]\n\n self.extraction_pipeline = Pipeline([\n ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions, rollback=True, rollback_when=self.rollback, commit_data=True)),\n ('union', ColumnTransformer([\n ('data', DictVectorizer(), 'data'),\n\n ('title', self.text_vectorizer(), 'title'),\n\n ('comments', self.text_vectorizer(), 'comments'),\n ])),\n ])\n\n self.clf = xgboost.XGBClassifier(n_jobs=16)\n self.clf.set_params(predictor='cpu_predictor')\n\n def rollback(self, change):\n return change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete'])\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n bug_id = int(bug_data['id'])\n\n for entry in bug_data['history']:\n for change in entry['changes']:\n if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n classes[bug_id] = 1\n\n if bug_id not in classes:\n classes[bug_id] = 0\n\n return classes\n\n def get_feature_names(self):\n return self.extraction_pipeline.named_steps['union'].get_feature_names()\n", "path": "bugbug/models/devdocneeded.py"}]}
| 1,358 | 311 |
gh_patches_debug_34208
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-353
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Grade preview
There must be an option for FSR members to see the grades for a course before publishing it.
This should be available in "in evaluation", "evaluated" and "reviewed".
</issue>
<code>
[start of evap/results/views.py]
1 from django.conf import settings
2 from django.http import HttpResponse
3 from django.shortcuts import get_object_or_404, render_to_response
4 from django.template import RequestContext
5 from django.utils.translation import get_language
6
7 from evap.evaluation.auth import login_required, fsr_required
8 from evap.evaluation.models import Semester
9 from evap.evaluation.tools import calculate_results, calculate_average_and_medium_grades, TextResult, can_publish_grades
10
11 from evap.results.exporters import ExcelExporter
12
13
14 @login_required
15 def index(request):
16 semesters = Semester.get_all_with_published_courses()
17
18 return render_to_response(
19 "results_index.html",
20 dict(semesters=semesters),
21 context_instance=RequestContext(request))
22
23
24 @login_required
25 def semester_detail(request, semester_id):
26 semester = get_object_or_404(Semester, id=semester_id)
27 courses = list(semester.course_set.filter(state="published"))
28
29 # annotate each course object with its grades
30 for course in courses:
31 # first, make sure that there are no preexisting grade attributes
32 course.avg_grade, course.med_grade = calculate_average_and_medium_grades(course)
33 course.can_publish_grades = can_publish_grades(course, request.user.is_staff)
34
35 return render_to_response(
36 "results_semester_detail.html",
37 dict(
38 semester=semester,
39 courses=courses
40 ),
41 context_instance=RequestContext(request))
42
43
44 @fsr_required
45 def semester_export(request, semester_id):
46 semester = get_object_or_404(Semester, id=semester_id)
47
48 filename = "Evaluation-%s-%s.xls" % (semester.name, get_language())
49
50 response = HttpResponse(mimetype="application/vnd.ms-excel")
51 response["Content-Disposition"] = "attachment; filename=\"%s\"" % filename
52
53 exporter = ExcelExporter(semester)
54
55 if 'all' in request.GET:
56 exporter.export(response, True)
57 else:
58 exporter.export(response)
59
60 return response
61
62
63 @login_required
64 def course_detail(request, semester_id, course_id):
65 semester = get_object_or_404(Semester, id=semester_id)
66 course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
67
68 sections = calculate_results(course, request.user.is_staff)
69
70 if (request.user.is_staff == False): # if user is not a student representative
71 # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)
72 for section in sections:
73 if not user_can_see_textresults(request.user, course, section):
74 for index, result in list(enumerate(section.results))[::-1]:
75 if isinstance(section.results[index], TextResult):
76 del section.results[index]
77
78 # remove empty sections
79 sections = [section for section in sections if section.results]
80
81 # check whether results are published
82 published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
83
84 # show a publishing warning to fsr members when the results are not publicly available
85 warning = (not published) and request.user.is_staff
86
87 return render_to_response(
88 "results_course_detail.html",
89 dict(
90 course=course,
91 sections=sections,
92 warning=warning
93 ),
94 context_instance=RequestContext(request))
95
96
97 def user_can_see_textresults(user, course, section):
98 if section.contributor == user:
99 return True
100 if course.is_user_responsible_or_delegate(user):
101 return True
102
103 represented_userprofiles = user.represented_users.all()
104 represented_users = [profile.user for profile in represented_userprofiles]
105 if section.contributor in represented_users:
106 return True
107
108 return False
109
[end of evap/results/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/results/views.py b/evap/results/views.py
--- a/evap/results/views.py
+++ b/evap/results/views.py
@@ -63,7 +63,13 @@
@login_required
def course_detail(request, semester_id, course_id):
semester = get_object_or_404(Semester, id=semester_id)
- course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
+
+ # staff can see preview of results even when course is not published
+ if request.user.is_staff:
+ course = get_object_or_404(semester.course_set.filter(state__in=['inEvaluation', 'evaluated', 'reviewed', 'published']), id=course_id)
+ # everyone else can only see published results
+ else:
+ course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
sections = calculate_results(course, request.user.is_staff)
@@ -78,18 +84,24 @@
# remove empty sections
sections = [section for section in sections if section.results]
- # check whether results are published
- published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
+ # show a warning if course is still in evaluation (for staff preview)
+ evaluation_warning = course.state != 'published'
+
+ # check whether course has a sufficient number of votes for publishing it
+ sufficient_votes = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
- # show a publishing warning to fsr members when the results are not publicly available
- warning = (not published) and request.user.is_staff
+ # results for a course might not be visible because there are not enough answers
+ # but it can still be "published" e.g. to show the comment results to lecturers
+ # the FSR can still see all results but gets a warning message
+ sufficient_votes_warning = (not sufficient_votes) and request.user.is_staff
return render_to_response(
"results_course_detail.html",
dict(
course=course,
sections=sections,
- warning=warning
+ evaluation_warning=evaluation_warning,
+ sufficient_votes_warning=sufficient_votes_warning
),
context_instance=RequestContext(request))
|
{"golden_diff": "diff --git a/evap/results/views.py b/evap/results/views.py\n--- a/evap/results/views.py\n+++ b/evap/results/views.py\n@@ -63,7 +63,13 @@\n @login_required\n def course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n- course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n+ \n+ # staff can see preview of results even when course is not published\n+ if request.user.is_staff:\n+ course = get_object_or_404(semester.course_set.filter(state__in=['inEvaluation', 'evaluated', 'reviewed', 'published']), id=course_id)\n+ # everyone else can only see published results\n+ else:\n+ course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n \n sections = calculate_results(course, request.user.is_staff)\n \n@@ -78,18 +84,24 @@\n # remove empty sections\n sections = [section for section in sections if section.results]\n \n- # check whether results are published\n- published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n+ # show a warning if course is still in evaluation (for staff preview)\n+ evaluation_warning = course.state != 'published'\n+\n+ # check whether course has a sufficient number of votes for publishing it\n+ sufficient_votes = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n \n- # show a publishing warning to fsr members when the results are not publicly available\n- warning = (not published) and request.user.is_staff\n+ # results for a course might not be visible because there are not enough answers\n+ # but it can still be \"published\" e.g. to show the comment results to lecturers\n+ # the FSR can still see all results but gets a warning message\n+ sufficient_votes_warning = (not sufficient_votes) and request.user.is_staff\n \n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n- warning=warning\n+ evaluation_warning=evaluation_warning,\n+ sufficient_votes_warning=sufficient_votes_warning\n ),\n context_instance=RequestContext(request))\n", "issue": "Grade preview\nThere must be an option for FSR members to see the grades for a course before publishing it.\nThis should be available in \"in evaluation\", \"evaluated\" and \"reviewed\".\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response\nfrom django.template import RequestContext\nfrom django.utils.translation import get_language\n\nfrom evap.evaluation.auth import login_required, fsr_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import calculate_results, calculate_average_and_medium_grades, TextResult, can_publish_grades\n\nfrom evap.results.exporters import ExcelExporter\n\n\n@login_required\ndef index(request):\n semesters = Semester.get_all_with_published_courses()\n\n return render_to_response(\n \"results_index.html\",\n dict(semesters=semesters),\n context_instance=RequestContext(request))\n\n\n@login_required\ndef semester_detail(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n courses = list(semester.course_set.filter(state=\"published\"))\n\n # annotate each course object with its grades\n for course in courses:\n # first, make sure that there are no preexisting grade attributes\n course.avg_grade, course.med_grade = calculate_average_and_medium_grades(course)\n course.can_publish_grades = can_publish_grades(course, request.user.is_staff)\n\n return render_to_response(\n \"results_semester_detail.html\",\n dict(\n semester=semester,\n courses=courses\n ),\n context_instance=RequestContext(request))\n\n\n@fsr_required\ndef semester_export(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n\n filename = \"Evaluation-%s-%s.xls\" % (semester.name, get_language())\n\n response = HttpResponse(mimetype=\"application/vnd.ms-excel\")\n response[\"Content-Disposition\"] = \"attachment; filename=\\\"%s\\\"\" % filename\n\n exporter = ExcelExporter(semester)\n\n if 'all' in request.GET:\n exporter.export(response, True)\n else:\n exporter.export(response)\n\n return response\n\n\n@login_required\ndef course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n\n sections = calculate_results(course, request.user.is_staff)\n\n if (request.user.is_staff == False): # if user is not a student representative\n # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)\n for section in sections:\n if not user_can_see_textresults(request.user, course, section):\n for index, result in list(enumerate(section.results))[::-1]:\n if isinstance(section.results[index], TextResult):\n del section.results[index]\n\n # remove empty sections\n sections = [section for section in sections if section.results]\n\n # check whether results are published\n published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n\n # show a publishing warning to fsr members when the results are not publicly available\n warning = (not published) and request.user.is_staff\n\n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n warning=warning\n ),\n context_instance=RequestContext(request))\n\n\ndef user_can_see_textresults(user, course, section):\n if section.contributor == user:\n return True\n if course.is_user_responsible_or_delegate(user):\n return True\n\n represented_userprofiles = user.represented_users.all()\n represented_users = [profile.user for profile in represented_userprofiles]\n if section.contributor in represented_users:\n return True\n\n return False\n", "path": "evap/results/views.py"}]}
| 1,619 | 552 |
gh_patches_debug_33395
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-4092
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Commands] `ctx.tick()` - add optional message to send when bot can't react
# Feature request
#### Select the type of feature you are requesting:
- [ ] Cog
- [ ] Command
- [x] API functionality
#### Describe your requested feature
Change function definition of `ctx.tick()` to:
```py
async def tick(self, message: Optional[str] = None) -> bool:
```
So that we can set an optional message that will be sent if bot is unable to send the reaction. We could also make it possible through `ctx.react_quietly()` as well
</issue>
<code>
[start of redbot/core/commands/context.py]
1 from __future__ import annotations
2
3 import asyncio
4 import contextlib
5 import os
6 import re
7 from typing import Iterable, List, Union, Optional, TYPE_CHECKING
8 import discord
9 from discord.ext.commands import Context as DPYContext
10
11 from .requires import PermState
12 from ..utils.chat_formatting import box
13 from ..utils.predicates import MessagePredicate
14 from ..utils import common_filters
15
16 if TYPE_CHECKING:
17 from .commands import Command
18 from ..bot import Red
19
20 TICK = "\N{WHITE HEAVY CHECK MARK}"
21
22 __all__ = ["Context", "GuildContext", "DMContext"]
23
24
25 class Context(DPYContext):
26 """Command invocation context for Red.
27
28 All context passed into commands will be of this type.
29
30 This class inherits from `discord.ext.commands.Context`.
31
32 Attributes
33 ----------
34 assume_yes: bool
35 Whether or not interactive checks should
36 be skipped and assumed to be confirmed.
37
38 This is intended for allowing automation of tasks.
39
40 An example of this would be scheduled commands
41 not requiring interaction if the cog developer
42 checks this value prior to confirming something interactively.
43
44 Depending on the potential impact of a command,
45 it may still be appropriate not to use this setting.
46 permission_state: PermState
47 The permission state the current context is in.
48 """
49
50 command: "Command"
51 invoked_subcommand: "Optional[Command]"
52 bot: "Red"
53
54 def __init__(self, **attrs):
55 self.assume_yes = attrs.pop("assume_yes", False)
56 super().__init__(**attrs)
57 self.permission_state: PermState = PermState.NORMAL
58
59 async def send(self, content=None, **kwargs):
60 """Sends a message to the destination with the content given.
61
62 This acts the same as `discord.ext.commands.Context.send`, with
63 one added keyword argument as detailed below in *Other Parameters*.
64
65 Parameters
66 ----------
67 content : str
68 The content of the message to send.
69
70 Other Parameters
71 ----------------
72 filter : callable (`str`) -> `str`, optional
73 A function which is used to filter the ``content`` before
74 it is sent.
75 This must take a single `str` as an argument, and return
76 the processed `str`. When `None` is passed, ``content`` won't be touched.
77 Defaults to `None`.
78 **kwargs
79 See `discord.ext.commands.Context.send`.
80
81 Returns
82 -------
83 discord.Message
84 The message that was sent.
85
86 """
87
88 _filter = kwargs.pop("filter", None)
89
90 if _filter and content:
91 content = _filter(str(content))
92
93 return await super().send(content=content, **kwargs)
94
95 async def send_help(self, command=None):
96 """ Send the command help message. """
97 # This allows people to manually use this similarly
98 # to the upstream d.py version, while retaining our use.
99 command = command or self.command
100 await self.bot.send_help_for(self, command)
101
102 async def tick(self) -> bool:
103 """Add a tick reaction to the command message.
104
105 Returns
106 -------
107 bool
108 :code:`True` if adding the reaction succeeded.
109
110 """
111 try:
112 await self.message.add_reaction(TICK)
113 except discord.HTTPException:
114 return False
115 else:
116 return True
117
118 async def react_quietly(
119 self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
120 ) -> bool:
121 """Adds a reaction to the command message.
122
123 Returns
124 -------
125 bool
126 :code:`True` if adding the reaction succeeded.
127 """
128 try:
129 await self.message.add_reaction(reaction)
130 except discord.HTTPException:
131 return False
132 else:
133 return True
134
135 async def send_interactive(
136 self, messages: Iterable[str], box_lang: str = None, timeout: int = 15
137 ) -> List[discord.Message]:
138 """Send multiple messages interactively.
139
140 The user will be prompted for whether or not they would like to view
141 the next message, one at a time. They will also be notified of how
142 many messages are remaining on each prompt.
143
144 Parameters
145 ----------
146 messages : `iterable` of `str`
147 The messages to send.
148 box_lang : str
149 If specified, each message will be contained within a codeblock of
150 this language.
151 timeout : int
152 How long the user has to respond to the prompt before it times out.
153 After timing out, the bot deletes its prompt message.
154
155 """
156 messages = tuple(messages)
157 ret = []
158
159 for idx, page in enumerate(messages, 1):
160 if box_lang is None:
161 msg = await self.send(page)
162 else:
163 msg = await self.send(box(page, lang=box_lang))
164 ret.append(msg)
165 n_remaining = len(messages) - idx
166 if n_remaining > 0:
167 if n_remaining == 1:
168 plural = ""
169 is_are = "is"
170 else:
171 plural = "s"
172 is_are = "are"
173 query = await self.send(
174 "There {} still {} message{} remaining. "
175 "Type `more` to continue."
176 "".format(is_are, n_remaining, plural)
177 )
178 try:
179 resp = await self.bot.wait_for(
180 "message",
181 check=MessagePredicate.lower_equal_to("more", self),
182 timeout=timeout,
183 )
184 except asyncio.TimeoutError:
185 with contextlib.suppress(discord.HTTPException):
186 await query.delete()
187 break
188 else:
189 try:
190 await self.channel.delete_messages((query, resp))
191 except (discord.HTTPException, AttributeError):
192 # In case the bot can't delete other users' messages,
193 # or is not a bot account
194 # or channel is a DM
195 with contextlib.suppress(discord.HTTPException):
196 await query.delete()
197 return ret
198
199 async def embed_colour(self):
200 """
201 Helper function to get the colour for an embed.
202
203 Returns
204 -------
205 discord.Colour:
206 The colour to be used
207 """
208 return await self.bot.get_embed_color(self)
209
210 @property
211 def embed_color(self):
212 # Rather than double awaiting.
213 return self.embed_colour
214
215 async def embed_requested(self):
216 """
217 Simple helper to call bot.embed_requested
218 with logic around if embed permissions are available
219
220 Returns
221 -------
222 bool:
223 :code:`True` if an embed is requested
224 """
225 if self.guild and not self.channel.permissions_for(self.guild.me).embed_links:
226 return False
227 return await self.bot.embed_requested(self.channel, self.author, command=self.command)
228
229 async def maybe_send_embed(self, message: str) -> discord.Message:
230 """
231 Simple helper to send a simple message to context
232 without manually checking ctx.embed_requested
233 This should only be used for simple messages.
234
235 Parameters
236 ----------
237 message: `str`
238 The string to send
239
240 Returns
241 -------
242 discord.Message:
243 the message which was sent
244
245 Raises
246 ------
247 discord.Forbidden
248 see `discord.abc.Messageable.send`
249 discord.HTTPException
250 see `discord.abc.Messageable.send`
251 ValueError
252 when the message's length is not between 1 and 2000 characters.
253 """
254 if not message or len(message) > 2000:
255 raise ValueError("Message length must be between 1 and 2000")
256 if await self.embed_requested():
257 return await self.send(
258 embed=discord.Embed(description=message, color=(await self.embed_colour()))
259 )
260 else:
261 return await self.send(
262 message,
263 allowed_mentions=discord.AllowedMentions(everyone=False, roles=False, users=False),
264 )
265
266 @property
267 def clean_prefix(self) -> str:
268 """
269 str: The command prefix, but with a sanitized version of the bot's mention if it was used as prefix.
270 This can be used in a context where discord user mentions might not render properly.
271 """
272 me = self.me
273 pattern = re.compile(rf"<@!?{me.id}>")
274 return pattern.sub(f"@{me.display_name}".replace("\\", r"\\"), self.prefix)
275
276 @property
277 def me(self) -> Union[discord.ClientUser, discord.Member]:
278 """
279 discord.abc.User: The bot member or user object.
280
281 If the context is DM, this will be a `discord.User` object.
282 """
283 if self.guild is not None:
284 return self.guild.me
285 else:
286 return self.bot.user
287
288
289 if TYPE_CHECKING or os.getenv("BUILDING_DOCS", False):
290
291 class DMContext(Context):
292 """
293 At runtime, this will still be a normal context object.
294
295 This lies about some type narrowing for type analysis in commands
296 using a dm_only decorator.
297
298 It is only correct to use when those types are already narrowed
299 """
300
301 @property
302 def author(self) -> discord.User:
303 ...
304
305 @property
306 def channel(self) -> discord.DMChannel:
307 ...
308
309 @property
310 def guild(self) -> None:
311 ...
312
313 @property
314 def me(self) -> discord.ClientUser:
315 ...
316
317 class GuildContext(Context):
318 """
319 At runtime, this will still be a normal context object.
320
321 This lies about some type narrowing for type analysis in commands
322 using a guild_only decorator.
323
324 It is only correct to use when those types are already narrowed
325 """
326
327 @property
328 def author(self) -> discord.Member:
329 ...
330
331 @property
332 def channel(self) -> discord.TextChannel:
333 ...
334
335 @property
336 def guild(self) -> discord.Guild:
337 ...
338
339 @property
340 def me(self) -> discord.Member:
341 ...
342
343
344 else:
345 GuildContext = Context
346 DMContext = Context
347
[end of redbot/core/commands/context.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redbot/core/commands/context.py b/redbot/core/commands/context.py
--- a/redbot/core/commands/context.py
+++ b/redbot/core/commands/context.py
@@ -99,35 +99,52 @@
command = command or self.command
await self.bot.send_help_for(self, command)
- async def tick(self) -> bool:
+ async def tick(self, *, message: Optional[str] = None) -> bool:
"""Add a tick reaction to the command message.
+ Keyword Arguments
+ -----------------
+ message : str, optional
+ The message to send if adding the reaction doesn't succeed.
+
Returns
-------
bool
:code:`True` if adding the reaction succeeded.
"""
- try:
- await self.message.add_reaction(TICK)
- except discord.HTTPException:
- return False
- else:
- return True
+ return await self.react_quietly(TICK, message=message)
async def react_quietly(
- self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
+ self,
+ reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str],
+ *,
+ message: Optional[str] = None,
) -> bool:
"""Adds a reaction to the command message.
+ Parameters
+ ----------
+ reaction : Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
+ The emoji to react with.
+
+ Keyword Arguments
+ -----------------
+ message : str, optional
+ The message to send if adding the reaction doesn't succeed.
+
Returns
-------
bool
:code:`True` if adding the reaction succeeded.
"""
try:
+ if not self.channel.permissions_for(self.me).add_reactions:
+ raise RuntimeError
await self.message.add_reaction(reaction)
- except discord.HTTPException:
+ except (RuntimeError, discord.HTTPException):
+ if message is not None:
+ await self.send(message)
return False
else:
return True
|
{"golden_diff": "diff --git a/redbot/core/commands/context.py b/redbot/core/commands/context.py\n--- a/redbot/core/commands/context.py\n+++ b/redbot/core/commands/context.py\n@@ -99,35 +99,52 @@\n command = command or self.command\n await self.bot.send_help_for(self, command)\n \n- async def tick(self) -> bool:\n+ async def tick(self, *, message: Optional[str] = None) -> bool:\n \"\"\"Add a tick reaction to the command message.\n \n+ Keyword Arguments\n+ -----------------\n+ message : str, optional\n+ The message to send if adding the reaction doesn't succeed.\n+\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \n \"\"\"\n- try:\n- await self.message.add_reaction(TICK)\n- except discord.HTTPException:\n- return False\n- else:\n- return True\n+ return await self.react_quietly(TICK, message=message)\n \n async def react_quietly(\n- self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n+ self,\n+ reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str],\n+ *,\n+ message: Optional[str] = None,\n ) -> bool:\n \"\"\"Adds a reaction to the command message.\n \n+ Parameters\n+ ----------\n+ reaction : Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n+ The emoji to react with.\n+\n+ Keyword Arguments\n+ -----------------\n+ message : str, optional\n+ The message to send if adding the reaction doesn't succeed.\n+\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \"\"\"\n try:\n+ if not self.channel.permissions_for(self.me).add_reactions:\n+ raise RuntimeError\n await self.message.add_reaction(reaction)\n- except discord.HTTPException:\n+ except (RuntimeError, discord.HTTPException):\n+ if message is not None:\n+ await self.send(message)\n return False\n else:\n return True\n", "issue": "[Commands] `ctx.tick()` - add optional message to send when bot can't react\n# Feature request\r\n\r\n#### Select the type of feature you are requesting:\r\n\r\n- [ ] Cog\r\n- [ ] Command\r\n- [x] API functionality\r\n\r\n#### Describe your requested feature\r\n\r\nChange function definition of `ctx.tick()` to:\r\n```py\r\nasync def tick(self, message: Optional[str] = None) -> bool:\r\n```\r\nSo that we can set an optional message that will be sent if bot is unable to send the reaction. We could also make it possible through `ctx.react_quietly()` as well\n", "before_files": [{"content": "from __future__ import annotations\n\nimport asyncio\nimport contextlib\nimport os\nimport re\nfrom typing import Iterable, List, Union, Optional, TYPE_CHECKING\nimport discord\nfrom discord.ext.commands import Context as DPYContext\n\nfrom .requires import PermState\nfrom ..utils.chat_formatting import box\nfrom ..utils.predicates import MessagePredicate\nfrom ..utils import common_filters\n\nif TYPE_CHECKING:\n from .commands import Command\n from ..bot import Red\n\nTICK = \"\\N{WHITE HEAVY CHECK MARK}\"\n\n__all__ = [\"Context\", \"GuildContext\", \"DMContext\"]\n\n\nclass Context(DPYContext):\n \"\"\"Command invocation context for Red.\n\n All context passed into commands will be of this type.\n\n This class inherits from `discord.ext.commands.Context`.\n\n Attributes\n ----------\n assume_yes: bool\n Whether or not interactive checks should\n be skipped and assumed to be confirmed.\n\n This is intended for allowing automation of tasks.\n\n An example of this would be scheduled commands\n not requiring interaction if the cog developer\n checks this value prior to confirming something interactively.\n\n Depending on the potential impact of a command,\n it may still be appropriate not to use this setting.\n permission_state: PermState\n The permission state the current context is in.\n \"\"\"\n\n command: \"Command\"\n invoked_subcommand: \"Optional[Command]\"\n bot: \"Red\"\n\n def __init__(self, **attrs):\n self.assume_yes = attrs.pop(\"assume_yes\", False)\n super().__init__(**attrs)\n self.permission_state: PermState = PermState.NORMAL\n\n async def send(self, content=None, **kwargs):\n \"\"\"Sends a message to the destination with the content given.\n\n This acts the same as `discord.ext.commands.Context.send`, with\n one added keyword argument as detailed below in *Other Parameters*.\n\n Parameters\n ----------\n content : str\n The content of the message to send.\n\n Other Parameters\n ----------------\n filter : callable (`str`) -> `str`, optional\n A function which is used to filter the ``content`` before\n it is sent.\n This must take a single `str` as an argument, and return\n the processed `str`. When `None` is passed, ``content`` won't be touched.\n Defaults to `None`.\n **kwargs\n See `discord.ext.commands.Context.send`.\n\n Returns\n -------\n discord.Message\n The message that was sent.\n\n \"\"\"\n\n _filter = kwargs.pop(\"filter\", None)\n\n if _filter and content:\n content = _filter(str(content))\n\n return await super().send(content=content, **kwargs)\n\n async def send_help(self, command=None):\n \"\"\" Send the command help message. \"\"\"\n # This allows people to manually use this similarly\n # to the upstream d.py version, while retaining our use.\n command = command or self.command\n await self.bot.send_help_for(self, command)\n\n async def tick(self) -> bool:\n \"\"\"Add a tick reaction to the command message.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n\n \"\"\"\n try:\n await self.message.add_reaction(TICK)\n except discord.HTTPException:\n return False\n else:\n return True\n\n async def react_quietly(\n self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n ) -> bool:\n \"\"\"Adds a reaction to the command message.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \"\"\"\n try:\n await self.message.add_reaction(reaction)\n except discord.HTTPException:\n return False\n else:\n return True\n\n async def send_interactive(\n self, messages: Iterable[str], box_lang: str = None, timeout: int = 15\n ) -> List[discord.Message]:\n \"\"\"Send multiple messages interactively.\n\n The user will be prompted for whether or not they would like to view\n the next message, one at a time. They will also be notified of how\n many messages are remaining on each prompt.\n\n Parameters\n ----------\n messages : `iterable` of `str`\n The messages to send.\n box_lang : str\n If specified, each message will be contained within a codeblock of\n this language.\n timeout : int\n How long the user has to respond to the prompt before it times out.\n After timing out, the bot deletes its prompt message.\n\n \"\"\"\n messages = tuple(messages)\n ret = []\n\n for idx, page in enumerate(messages, 1):\n if box_lang is None:\n msg = await self.send(page)\n else:\n msg = await self.send(box(page, lang=box_lang))\n ret.append(msg)\n n_remaining = len(messages) - idx\n if n_remaining > 0:\n if n_remaining == 1:\n plural = \"\"\n is_are = \"is\"\n else:\n plural = \"s\"\n is_are = \"are\"\n query = await self.send(\n \"There {} still {} message{} remaining. \"\n \"Type `more` to continue.\"\n \"\".format(is_are, n_remaining, plural)\n )\n try:\n resp = await self.bot.wait_for(\n \"message\",\n check=MessagePredicate.lower_equal_to(\"more\", self),\n timeout=timeout,\n )\n except asyncio.TimeoutError:\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n break\n else:\n try:\n await self.channel.delete_messages((query, resp))\n except (discord.HTTPException, AttributeError):\n # In case the bot can't delete other users' messages,\n # or is not a bot account\n # or channel is a DM\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n return ret\n\n async def embed_colour(self):\n \"\"\"\n Helper function to get the colour for an embed.\n\n Returns\n -------\n discord.Colour:\n The colour to be used\n \"\"\"\n return await self.bot.get_embed_color(self)\n\n @property\n def embed_color(self):\n # Rather than double awaiting.\n return self.embed_colour\n\n async def embed_requested(self):\n \"\"\"\n Simple helper to call bot.embed_requested\n with logic around if embed permissions are available\n\n Returns\n -------\n bool:\n :code:`True` if an embed is requested\n \"\"\"\n if self.guild and not self.channel.permissions_for(self.guild.me).embed_links:\n return False\n return await self.bot.embed_requested(self.channel, self.author, command=self.command)\n\n async def maybe_send_embed(self, message: str) -> discord.Message:\n \"\"\"\n Simple helper to send a simple message to context\n without manually checking ctx.embed_requested\n This should only be used for simple messages.\n\n Parameters\n ----------\n message: `str`\n The string to send\n\n Returns\n -------\n discord.Message:\n the message which was sent\n\n Raises\n ------\n discord.Forbidden\n see `discord.abc.Messageable.send`\n discord.HTTPException\n see `discord.abc.Messageable.send`\n ValueError\n when the message's length is not between 1 and 2000 characters.\n \"\"\"\n if not message or len(message) > 2000:\n raise ValueError(\"Message length must be between 1 and 2000\")\n if await self.embed_requested():\n return await self.send(\n embed=discord.Embed(description=message, color=(await self.embed_colour()))\n )\n else:\n return await self.send(\n message,\n allowed_mentions=discord.AllowedMentions(everyone=False, roles=False, users=False),\n )\n\n @property\n def clean_prefix(self) -> str:\n \"\"\"\n str: The command prefix, but with a sanitized version of the bot's mention if it was used as prefix.\n This can be used in a context where discord user mentions might not render properly.\n \"\"\"\n me = self.me\n pattern = re.compile(rf\"<@!?{me.id}>\")\n return pattern.sub(f\"@{me.display_name}\".replace(\"\\\\\", r\"\\\\\"), self.prefix)\n\n @property\n def me(self) -> Union[discord.ClientUser, discord.Member]:\n \"\"\"\n discord.abc.User: The bot member or user object.\n\n If the context is DM, this will be a `discord.User` object.\n \"\"\"\n if self.guild is not None:\n return self.guild.me\n else:\n return self.bot.user\n\n\nif TYPE_CHECKING or os.getenv(\"BUILDING_DOCS\", False):\n\n class DMContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a dm_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.User:\n ...\n\n @property\n def channel(self) -> discord.DMChannel:\n ...\n\n @property\n def guild(self) -> None:\n ...\n\n @property\n def me(self) -> discord.ClientUser:\n ...\n\n class GuildContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a guild_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.Member:\n ...\n\n @property\n def channel(self) -> discord.TextChannel:\n ...\n\n @property\n def guild(self) -> discord.Guild:\n ...\n\n @property\n def me(self) -> discord.Member:\n ...\n\n\nelse:\n GuildContext = Context\n DMContext = Context\n", "path": "redbot/core/commands/context.py"}]}
| 3,763 | 473 |
gh_patches_debug_58558
|
rasdani/github-patches
|
git_diff
|
roboflow__supervision-219
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Developement - version issue
### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
I have not installed `supervision` but running directly for developement purpose.
But I got an following error when I import supervision code:
```
raise PackageNotFoundError(name)
importlib.metadata.PackageNotFoundError: supervision
```
After a quick investigation, it is found that `__init__.py` of `supervision` where version information used. It is creating an issue. If I comment this line and the bug is gone.
@onuralpszr Can you take a look?
I think it should be ignorable, if valid version is not found then use `development` version. Though, I do not have concret idea, how to tackle it.
### Environment
_No response_
### Minimal Reproducible Example
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [X] Yes I'd like to help by submitting a PR!
</issue>
<code>
[start of supervision/__init__.py]
1 import importlib.metadata as importlib_metadata
2
3 __version__ = importlib_metadata.version(__package__)
4
5
6 from supervision.classification.core import Classifications
7 from supervision.dataset.core import (
8 BaseDataset,
9 ClassificationDataset,
10 DetectionDataset,
11 )
12 from supervision.detection.annotate import BoxAnnotator, MaskAnnotator
13 from supervision.detection.core import Detections
14 from supervision.detection.line_counter import LineZone, LineZoneAnnotator
15 from supervision.detection.tools.polygon_zone import PolygonZone, PolygonZoneAnnotator
16 from supervision.detection.utils import (
17 box_iou_batch,
18 filter_polygons_by_area,
19 mask_to_polygons,
20 mask_to_xyxy,
21 non_max_suppression,
22 polygon_to_mask,
23 polygon_to_xyxy,
24 )
25 from supervision.draw.color import Color, ColorPalette
26 from supervision.draw.utils import draw_filled_rectangle, draw_polygon, draw_text
27 from supervision.geometry.core import Point, Position, Rect
28 from supervision.geometry.utils import get_polygon_center
29 from supervision.metrics.detection import ConfusionMatrix
30 from supervision.utils.file import list_files_with_extensions
31 from supervision.utils.image import ImageSink, crop
32 from supervision.utils.notebook import plot_image, plot_images_grid
33 from supervision.utils.video import (
34 VideoInfo,
35 VideoSink,
36 get_video_frames_generator,
37 process_video,
38 )
39
[end of supervision/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/supervision/__init__.py b/supervision/__init__.py
--- a/supervision/__init__.py
+++ b/supervision/__init__.py
@@ -1,6 +1,10 @@
import importlib.metadata as importlib_metadata
-__version__ = importlib_metadata.version(__package__)
+try:
+ # This will read version from pyproject.toml
+ __version__ = importlib_metadata.version(__package__ or __name__)
+except importlib_metadata.PackageNotFoundError:
+ __version__ = "development"
from supervision.classification.core import Classifications
|
{"golden_diff": "diff --git a/supervision/__init__.py b/supervision/__init__.py\n--- a/supervision/__init__.py\n+++ b/supervision/__init__.py\n@@ -1,6 +1,10 @@\n import importlib.metadata as importlib_metadata\n \n-__version__ = importlib_metadata.version(__package__)\n+try:\n+ # This will read version from pyproject.toml\n+ __version__ = importlib_metadata.version(__package__ or __name__)\n+except importlib_metadata.PackageNotFoundError:\n+ __version__ = \"development\"\n \n \n from supervision.classification.core import Classifications\n", "issue": "Developement - version issue\n### Search before asking\n\n- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.\n\n\n### Bug\n\nI have not installed `supervision` but running directly for developement purpose.\r\n\r\nBut I got an following error when I import supervision code:\r\n\r\n```\r\n raise PackageNotFoundError(name)\r\nimportlib.metadata.PackageNotFoundError: supervision\r\n```\r\n\r\nAfter a quick investigation, it is found that `__init__.py` of `supervision` where version information used. It is creating an issue. If I comment this line and the bug is gone.\r\n\r\n@onuralpszr Can you take a look?\r\n\r\n\r\nI think it should be ignorable, if valid version is not found then use `development` version. Though, I do not have concret idea, how to tackle it.\r\n\r\n\r\n\r\n\n\n### Environment\n\n_No response_\n\n### Minimal Reproducible Example\n\n_No response_\n\n### Additional\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [X] Yes I'd like to help by submitting a PR!\n", "before_files": [{"content": "import importlib.metadata as importlib_metadata\n\n__version__ = importlib_metadata.version(__package__)\n\n\nfrom supervision.classification.core import Classifications\nfrom supervision.dataset.core import (\n BaseDataset,\n ClassificationDataset,\n DetectionDataset,\n)\nfrom supervision.detection.annotate import BoxAnnotator, MaskAnnotator\nfrom supervision.detection.core import Detections\nfrom supervision.detection.line_counter import LineZone, LineZoneAnnotator\nfrom supervision.detection.tools.polygon_zone import PolygonZone, PolygonZoneAnnotator\nfrom supervision.detection.utils import (\n box_iou_batch,\n filter_polygons_by_area,\n mask_to_polygons,\n mask_to_xyxy,\n non_max_suppression,\n polygon_to_mask,\n polygon_to_xyxy,\n)\nfrom supervision.draw.color import Color, ColorPalette\nfrom supervision.draw.utils import draw_filled_rectangle, draw_polygon, draw_text\nfrom supervision.geometry.core import Point, Position, Rect\nfrom supervision.geometry.utils import get_polygon_center\nfrom supervision.metrics.detection import ConfusionMatrix\nfrom supervision.utils.file import list_files_with_extensions\nfrom supervision.utils.image import ImageSink, crop\nfrom supervision.utils.notebook import plot_image, plot_images_grid\nfrom supervision.utils.video import (\n VideoInfo,\n VideoSink,\n get_video_frames_generator,\n process_video,\n)\n", "path": "supervision/__init__.py"}]}
| 1,113 | 136 |
gh_patches_debug_5710
|
rasdani/github-patches
|
git_diff
|
getredash__redash-2062
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
More flexible widgets grid (allow finer control over height/width)
## User should be able to control widget's placement, width and height
### Current implementation
Currently editing a dashboard works as follow:
1. When adding a widget you select its width: regular (half width) or double (full width). Height is set based on the content.
2. When opening the "Edit Dashboard" dialog, you can rearrange the order of the widgets.

Issues with the current approach:
* You can't change widget size after placing it.
* You can't change widget's height.
* You can't control widget's width beyond the current two options.
### Solution
To solve this we want to have a flexible (_but still responsive_) grid that the user can freely place and move widgets on.
* Each visualization will define minimum width and height sizes (derived from the visualization type). This will be the default sizes for the widget when placed on the grid, but the user will be able to resize it to be larger (but not smaller) afterwards.
* Once entering dashboard "edit mode", the user will be able to move around and resize the widgets in place instead of a dedicated UI.
* We should probably change other behaviors in the UI (move add widget to be part of the edit mode, change dashboard title editing to be in place, etc), but we will leave it to second iteration after the grid behavior is implemented.
### Technical Notes
* We currently use `angular-gridster` to allow moving around the widgets in the Edit Dashboard dialog. Maybe we can use it for the grid or a similar library.
* Currently the widget knows nothing about its placement, but only its size (width). The dashboard has a layout property, which is an array of arrays of widgets ids (each item in the array is a row/array of widgets). This is error prone and makes layout changes harder. If possible, it will be better if each widget retains its own placement information.
* The API to update a widget currently supports only updating a textbox widget. We will need to extend it to support all widget types.
</issue>
<code>
[start of redash/handlers/widgets.py]
1 import json
2
3 from flask import request
4 from redash import models
5 from redash.handlers.base import BaseResource
6 from redash.permissions import (require_access,
7 require_object_modify_permission,
8 require_permission, view_only)
9
10
11 class WidgetListResource(BaseResource):
12 @require_permission('edit_dashboard')
13 def post(self):
14 """
15 Add a widget to a dashboard.
16
17 :<json number dashboard_id: The ID for the dashboard being added to
18 :<json visualization_id: The ID of the visualization to put in this widget
19 :<json object options: Widget options
20 :<json string text: Text box contents
21 :<json number width: Width for widget display
22
23 :>json object widget: The created widget
24 :>json array layout: The new layout of the dashboard this widget was added to
25 :>json boolean new_row: Whether this widget was added on a new row or not
26 :>json number version: The revision number of the dashboard
27 """
28 widget_properties = request.get_json(force=True)
29 dashboard = models.Dashboard.get_by_id_and_org(widget_properties.pop('dashboard_id'), self.current_org)
30 require_object_modify_permission(dashboard, self.current_user)
31
32 widget_properties['options'] = json.dumps(widget_properties['options'])
33 widget_properties.pop('id', None)
34 widget_properties['dashboard'] = dashboard
35
36 visualization_id = widget_properties.pop('visualization_id')
37 if visualization_id:
38 visualization = models.Visualization.get_by_id_and_org(visualization_id, self.current_org)
39 require_access(visualization.query_rel.groups, self.current_user, view_only)
40 else:
41 visualization = None
42
43 widget_properties['visualization'] = visualization
44
45 widget = models.Widget(**widget_properties)
46 models.db.session.add(widget)
47 models.db.session.commit()
48
49 layout = json.loads(widget.dashboard.layout)
50 new_row = True
51
52 if len(layout) == 0 or widget.width == 2:
53 layout.append([widget.id])
54 elif len(layout[-1]) == 1:
55 neighbour_widget = models.Widget.query.get(layout[-1][0])
56 if neighbour_widget.width == 1:
57 layout[-1].append(widget.id)
58 new_row = False
59 else:
60 layout.append([widget.id])
61 else:
62 layout.append([widget.id])
63
64 widget.dashboard.layout = json.dumps(layout)
65 models.db.session.add(widget.dashboard)
66 models.db.session.commit()
67 return {'widget': widget.to_dict(), 'layout': layout, 'new_row': new_row, 'version': dashboard.version}
68
69
70 class WidgetResource(BaseResource):
71 @require_permission('edit_dashboard')
72 def post(self, widget_id):
73 """
74 Updates a widget in a dashboard.
75 This method currently handles Text Box widgets only.
76
77 :param number widget_id: The ID of the widget to modify
78
79 :<json string text: The new contents of the text box
80 """
81 widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)
82 require_object_modify_permission(widget.dashboard, self.current_user)
83 widget_properties = request.get_json(force=True)
84 widget.text = widget_properties['text']
85 models.db.session.commit()
86 return widget.to_dict()
87
88 @require_permission('edit_dashboard')
89 def delete(self, widget_id):
90 """
91 Remove a widget from a dashboard.
92
93 :param number widget_id: ID of widget to remove
94
95 :>json array layout: New layout of dashboard this widget was removed from
96 :>json number version: Revision number of dashboard
97 """
98 widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)
99 require_object_modify_permission(widget.dashboard, self.current_user)
100 widget.delete()
101 models.db.session.commit()
102 return {'layout': widget.dashboard.layout, 'version': widget.dashboard.version}
103
[end of redash/handlers/widgets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/handlers/widgets.py b/redash/handlers/widgets.py
--- a/redash/handlers/widgets.py
+++ b/redash/handlers/widgets.py
@@ -82,6 +82,7 @@
require_object_modify_permission(widget.dashboard, self.current_user)
widget_properties = request.get_json(force=True)
widget.text = widget_properties['text']
+ widget.options = json.dumps(widget_properties['options'])
models.db.session.commit()
return widget.to_dict()
|
{"golden_diff": "diff --git a/redash/handlers/widgets.py b/redash/handlers/widgets.py\n--- a/redash/handlers/widgets.py\n+++ b/redash/handlers/widgets.py\n@@ -82,6 +82,7 @@\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget_properties = request.get_json(force=True)\n widget.text = widget_properties['text']\n+ widget.options = json.dumps(widget_properties['options'])\n models.db.session.commit()\n return widget.to_dict()\n", "issue": "More flexible widgets grid (allow finer control over height/width)\n## User should be able to control widget's placement, width and height\r\n\r\n### Current implementation\r\n\r\nCurrently editing a dashboard works as follow:\r\n\r\n1. When adding a widget you select its width: regular (half width) or double (full width). Height is set based on the content.\r\n2. When opening the \"Edit Dashboard\" dialog, you can rearrange the order of the widgets.\r\n\r\n\r\n\r\nIssues with the current approach:\r\n\r\n* You can't change widget size after placing it.\r\n* You can't change widget's height.\r\n* You can't control widget's width beyond the current two options.\r\n\r\n### Solution\r\n\r\nTo solve this we want to have a flexible (_but still responsive_) grid that the user can freely place and move widgets on. \r\n\r\n* Each visualization will define minimum width and height sizes (derived from the visualization type). This will be the default sizes for the widget when placed on the grid, but the user will be able to resize it to be larger (but not smaller) afterwards.\r\n* Once entering dashboard \"edit mode\", the user will be able to move around and resize the widgets in place instead of a dedicated UI.\r\n* We should probably change other behaviors in the UI (move add widget to be part of the edit mode, change dashboard title editing to be in place, etc), but we will leave it to second iteration after the grid behavior is implemented.\r\n\r\n### Technical Notes\r\n\r\n* We currently use `angular-gridster` to allow moving around the widgets in the Edit Dashboard dialog. Maybe we can use it for the grid or a similar library.\r\n* Currently the widget knows nothing about its placement, but only its size (width). The dashboard has a layout property, which is an array of arrays of widgets ids (each item in the array is a row/array of widgets). This is error prone and makes layout changes harder. If possible, it will be better if each widget retains its own placement information.\r\n* The API to update a widget currently supports only updating a textbox widget. We will need to extend it to support all widget types.\n", "before_files": [{"content": "import json\n\nfrom flask import request\nfrom redash import models\nfrom redash.handlers.base import BaseResource\nfrom redash.permissions import (require_access,\n require_object_modify_permission,\n require_permission, view_only)\n\n\nclass WidgetListResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self):\n \"\"\"\n Add a widget to a dashboard.\n\n :<json number dashboard_id: The ID for the dashboard being added to\n :<json visualization_id: The ID of the visualization to put in this widget\n :<json object options: Widget options\n :<json string text: Text box contents\n :<json number width: Width for widget display\n\n :>json object widget: The created widget\n :>json array layout: The new layout of the dashboard this widget was added to\n :>json boolean new_row: Whether this widget was added on a new row or not\n :>json number version: The revision number of the dashboard\n \"\"\"\n widget_properties = request.get_json(force=True)\n dashboard = models.Dashboard.get_by_id_and_org(widget_properties.pop('dashboard_id'), self.current_org)\n require_object_modify_permission(dashboard, self.current_user)\n\n widget_properties['options'] = json.dumps(widget_properties['options'])\n widget_properties.pop('id', None)\n widget_properties['dashboard'] = dashboard\n\n visualization_id = widget_properties.pop('visualization_id')\n if visualization_id:\n visualization = models.Visualization.get_by_id_and_org(visualization_id, self.current_org)\n require_access(visualization.query_rel.groups, self.current_user, view_only)\n else:\n visualization = None\n\n widget_properties['visualization'] = visualization\n\n widget = models.Widget(**widget_properties)\n models.db.session.add(widget)\n models.db.session.commit()\n\n layout = json.loads(widget.dashboard.layout)\n new_row = True\n\n if len(layout) == 0 or widget.width == 2:\n layout.append([widget.id])\n elif len(layout[-1]) == 1:\n neighbour_widget = models.Widget.query.get(layout[-1][0])\n if neighbour_widget.width == 1:\n layout[-1].append(widget.id)\n new_row = False\n else:\n layout.append([widget.id])\n else:\n layout.append([widget.id])\n\n widget.dashboard.layout = json.dumps(layout)\n models.db.session.add(widget.dashboard)\n models.db.session.commit()\n return {'widget': widget.to_dict(), 'layout': layout, 'new_row': new_row, 'version': dashboard.version}\n\n\nclass WidgetResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self, widget_id):\n \"\"\"\n Updates a widget in a dashboard.\n This method currently handles Text Box widgets only.\n\n :param number widget_id: The ID of the widget to modify\n\n :<json string text: The new contents of the text box\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget_properties = request.get_json(force=True)\n widget.text = widget_properties['text']\n models.db.session.commit()\n return widget.to_dict()\n\n @require_permission('edit_dashboard')\n def delete(self, widget_id):\n \"\"\"\n Remove a widget from a dashboard.\n\n :param number widget_id: ID of widget to remove\n\n :>json array layout: New layout of dashboard this widget was removed from\n :>json number version: Revision number of dashboard\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget.delete()\n models.db.session.commit()\n return {'layout': widget.dashboard.layout, 'version': widget.dashboard.version}\n", "path": "redash/handlers/widgets.py"}]}
| 2,036 | 107 |
gh_patches_debug_33015
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1050
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bump minimum OpenTelemetry version to support type checks
See the following comment for details: https://github.com/googleapis/python-bigquery/pull/1036#discussion_r739787329
If confirmed, we should bump to at least `opentelemetry-*==1.1.0`, and adjust our OpenTelemetry logic to the changes in the library API.
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 pyarrow_dep = ["pyarrow >= 3.0.0, < 7.0dev"]
32 dependencies = [
33 "grpcio >= 1.38.1, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/695
34 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
35 # Until this issue is closed
36 # https://github.com/googleapis/google-cloud-python/issues/10566
37 "google-api-core[grpc] >= 1.29.0, <3.0.0dev",
38 "proto-plus >= 1.10.0",
39 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
40 # Until this issue is closed
41 # https://github.com/googleapis/google-cloud-python/issues/10566
42 "google-cloud-core >= 1.4.1, <3.0.0dev",
43 "google-resumable-media >= 0.6.0, < 3.0dev",
44 "packaging >= 14.3",
45 "protobuf >= 3.12.0",
46 "python-dateutil >= 2.7.2, <3.0dev",
47 "requests >= 2.18.0, < 3.0.0dev",
48 ]
49 extras = {
50 "bqstorage": [
51 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
52 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
53 # installed, even though `google-cloud-bigquery-storage` specifies it
54 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
55 # See: https://github.com/googleapis/python-bigquery/issues/83 The
56 # grpc.Channel.close() method isn't added until 1.32.0.
57 # https://github.com/grpc/grpc/pull/15254
58 "grpcio >= 1.38.1, < 2.0dev",
59 ]
60 + pyarrow_dep,
61 "geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.6.0, <2.0dev"],
62 "pandas": ["pandas>=0.24.2"] + pyarrow_dep,
63 "bignumeric_type": pyarrow_dep,
64 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
65 "opentelemetry": [
66 "opentelemetry-api >= 0.11b0",
67 "opentelemetry-sdk >= 0.11b0",
68 "opentelemetry-instrumentation >= 0.11b0",
69 ],
70 }
71
72 all_extras = []
73
74 for extra in extras:
75 # Exclude this extra from all to avoid overly strict dependencies on core
76 # libraries such as pyarrow.
77 # https://github.com/googleapis/python-bigquery/issues/563
78 if extra in {"bignumeric_type"}:
79 continue
80 all_extras.extend(extras[extra])
81
82 extras["all"] = all_extras
83
84 # Setup boilerplate below this line.
85
86 package_root = os.path.abspath(os.path.dirname(__file__))
87
88 readme_filename = os.path.join(package_root, "README.rst")
89 with io.open(readme_filename, encoding="utf-8") as readme_file:
90 readme = readme_file.read()
91
92 version = {}
93 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
94 exec(fp.read(), version)
95 version = version["__version__"]
96
97 # Only include packages under the 'google' namespace. Do not include tests,
98 # benchmarks, etc.
99 packages = [
100 package
101 for package in setuptools.PEP420PackageFinder.find()
102 if package.startswith("google")
103 ]
104
105 # Determine which namespaces are needed.
106 namespaces = ["google"]
107 if "google.cloud" in packages:
108 namespaces.append("google.cloud")
109
110
111 setuptools.setup(
112 name=name,
113 version=version,
114 description=description,
115 long_description=readme,
116 author="Google LLC",
117 author_email="[email protected]",
118 license="Apache 2.0",
119 url="https://github.com/googleapis/python-bigquery",
120 classifiers=[
121 release_status,
122 "Intended Audience :: Developers",
123 "License :: OSI Approved :: Apache Software License",
124 "Programming Language :: Python",
125 "Programming Language :: Python :: 3",
126 "Programming Language :: Python :: 3.6",
127 "Programming Language :: Python :: 3.7",
128 "Programming Language :: Python :: 3.8",
129 "Programming Language :: Python :: 3.9",
130 "Programming Language :: Python :: 3.10",
131 "Operating System :: OS Independent",
132 "Topic :: Internet",
133 ],
134 platforms="Posix; MacOS X; Windows",
135 packages=packages,
136 namespace_packages=namespaces,
137 install_requires=dependencies,
138 extras_require=extras,
139 python_requires=">=3.6, <3.11",
140 include_package_data=True,
141 zip_safe=False,
142 )
143
[end of setup.py]
[start of google/cloud/bigquery/opentelemetry_tracing.py]
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from contextlib import contextmanager
17 from google.api_core.exceptions import GoogleAPICallError
18
19 logger = logging.getLogger(__name__)
20 try:
21 from opentelemetry import trace
22 from opentelemetry.instrumentation.utils import http_status_to_canonical_code
23 from opentelemetry.trace.status import Status
24
25 HAS_OPENTELEMETRY = True
26 _warned_telemetry = True
27
28 except ImportError:
29 HAS_OPENTELEMETRY = False
30 _warned_telemetry = False
31
32 _default_attributes = {
33 "db.system": "BigQuery"
34 } # static, default values assigned to all spans
35
36
37 @contextmanager
38 def create_span(name, attributes=None, client=None, job_ref=None):
39 """Creates a ContextManager for a Span to be exported to the configured exporter.
40 If no configuration exists yields None.
41
42 Args:
43 name (str): Name that will be set for the span being created
44 attributes (Optional[dict]):
45 Additional attributes that pertain to
46 the specific API call (i.e. not a default attribute)
47 client (Optional[google.cloud.bigquery.client.Client]):
48 Pass in a Client object to extract any attributes that may be
49 relevant to it and add them to the created spans.
50 job_ref (Optional[google.cloud.bigquery.job._AsyncJob])
51 Pass in a _AsyncJob object to extract any attributes that may be
52 relevant to it and add them to the created spans.
53
54 Yields:
55 opentelemetry.trace.Span: Yields the newly created Span.
56
57 Raises:
58 google.api_core.exceptions.GoogleAPICallError:
59 Raised if a span could not be yielded or issue with call to
60 OpenTelemetry.
61 """
62 global _warned_telemetry
63 final_attributes = _get_final_span_attributes(attributes, client, job_ref)
64 if not HAS_OPENTELEMETRY:
65 if not _warned_telemetry:
66 logger.debug(
67 "This service is instrumented using OpenTelemetry. "
68 "OpenTelemetry could not be imported; please "
69 "add opentelemetry-api and opentelemetry-instrumentation "
70 "packages in order to get BigQuery Tracing data."
71 )
72 _warned_telemetry = True
73
74 yield None
75 return
76 tracer = trace.get_tracer(__name__)
77
78 # yield new span value
79 with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:
80 try:
81 yield span
82 except GoogleAPICallError as error:
83 if error.code is not None:
84 span.set_status(Status(http_status_to_canonical_code(error.code)))
85 raise
86
87
88 def _get_final_span_attributes(attributes=None, client=None, job_ref=None):
89 final_attributes = {}
90 final_attributes.update(_default_attributes.copy())
91 if client:
92 client_attributes = _set_client_attributes(client)
93 final_attributes.update(client_attributes)
94 if job_ref:
95 job_attributes = _set_job_attributes(job_ref)
96 final_attributes.update(job_attributes)
97 if attributes:
98 final_attributes.update(attributes)
99 return final_attributes
100
101
102 def _set_client_attributes(client):
103 return {"db.name": client.project, "location": client.location}
104
105
106 def _set_job_attributes(job_ref):
107 job_attributes = {
108 "db.name": job_ref.project,
109 "location": job_ref.location,
110 "num_child_jobs": job_ref.num_child_jobs,
111 "job_id": job_ref.job_id,
112 "parent_job_id": job_ref.parent_job_id,
113 "state": job_ref.state,
114 }
115
116 job_attributes["hasErrors"] = job_ref.error_result is not None
117
118 if job_ref.created is not None:
119 job_attributes["timeCreated"] = job_ref.created.isoformat()
120
121 if job_ref.started is not None:
122 job_attributes["timeStarted"] = job_ref.started.isoformat()
123
124 if job_ref.ended is not None:
125 job_attributes["timeEnded"] = job_ref.ended.isoformat()
126
127 return job_attributes
128
[end of google/cloud/bigquery/opentelemetry_tracing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py
--- a/google/cloud/bigquery/opentelemetry_tracing.py
+++ b/google/cloud/bigquery/opentelemetry_tracing.py
@@ -19,7 +19,7 @@
logger = logging.getLogger(__name__)
try:
from opentelemetry import trace
- from opentelemetry.instrumentation.utils import http_status_to_canonical_code
+ from opentelemetry.instrumentation.utils import http_status_to_status_code
from opentelemetry.trace.status import Status
HAS_OPENTELEMETRY = True
@@ -65,9 +65,10 @@
if not _warned_telemetry:
logger.debug(
"This service is instrumented using OpenTelemetry. "
- "OpenTelemetry could not be imported; please "
- "add opentelemetry-api and opentelemetry-instrumentation "
- "packages in order to get BigQuery Tracing data."
+ "OpenTelemetry or one of its components could not be imported; "
+ "please add compatible versions of opentelemetry-api and "
+ "opentelemetry-instrumentation packages in order to get BigQuery "
+ "Tracing data."
)
_warned_telemetry = True
@@ -81,7 +82,7 @@
yield span
except GoogleAPICallError as error:
if error.code is not None:
- span.set_status(Status(http_status_to_canonical_code(error.code)))
+ span.set_status(Status(http_status_to_status_code(error.code)))
raise
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -63,9 +63,9 @@
"bignumeric_type": pyarrow_dep,
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
"opentelemetry": [
- "opentelemetry-api >= 0.11b0",
- "opentelemetry-sdk >= 0.11b0",
- "opentelemetry-instrumentation >= 0.11b0",
+ "opentelemetry-api >= 1.1.0",
+ "opentelemetry-sdk >= 1.1.0",
+ "opentelemetry-instrumentation >= 0.20b0",
],
}
|
{"golden_diff": "diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py\n--- a/google/cloud/bigquery/opentelemetry_tracing.py\n+++ b/google/cloud/bigquery/opentelemetry_tracing.py\n@@ -19,7 +19,7 @@\n logger = logging.getLogger(__name__)\n try:\n from opentelemetry import trace\n- from opentelemetry.instrumentation.utils import http_status_to_canonical_code\n+ from opentelemetry.instrumentation.utils import http_status_to_status_code\n from opentelemetry.trace.status import Status\n \n HAS_OPENTELEMETRY = True\n@@ -65,9 +65,10 @@\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n- \"OpenTelemetry could not be imported; please \"\n- \"add opentelemetry-api and opentelemetry-instrumentation \"\n- \"packages in order to get BigQuery Tracing data.\"\n+ \"OpenTelemetry or one of its components could not be imported; \"\n+ \"please add compatible versions of opentelemetry-api and \"\n+ \"opentelemetry-instrumentation packages in order to get BigQuery \"\n+ \"Tracing data.\"\n )\n _warned_telemetry = True\n \n@@ -81,7 +82,7 @@\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n- span.set_status(Status(http_status_to_canonical_code(error.code)))\n+ span.set_status(Status(http_status_to_status_code(error.code)))\n raise\n \n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -63,9 +63,9 @@\n \"bignumeric_type\": pyarrow_dep,\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n- \"opentelemetry-api >= 0.11b0\",\n- \"opentelemetry-sdk >= 0.11b0\",\n- \"opentelemetry-instrumentation >= 0.11b0\",\n+ \"opentelemetry-api >= 1.1.0\",\n+ \"opentelemetry-sdk >= 1.1.0\",\n+ \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n }\n", "issue": "Bump minimum OpenTelemetry version to support type checks\nSee the following comment for details: https://github.com/googleapis/python-bigquery/pull/1036#discussion_r739787329\r\n\r\nIf confirmed, we should bump to at least `opentelemetry-*==1.1.0`, and adjust our OpenTelemetry logic to the changes in the library API.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\npyarrow_dep = [\"pyarrow >= 3.0.0, < 7.0dev\"]\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.29.0, <3.0.0dev\",\n \"proto-plus >= 1.10.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.38.1, < 2.0dev\",\n ]\n + pyarrow_dep,\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.6.0, <2.0dev\"],\n \"pandas\": [\"pandas>=0.24.2\"] + pyarrow_dep,\n \"bignumeric_type\": pyarrow_dep,\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 0.11b0\",\n \"opentelemetry-sdk >= 0.11b0\",\n \"opentelemetry-instrumentation >= 0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.11\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}, {"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom contextlib import contextmanager\nfrom google.api_core.exceptions import GoogleAPICallError\n\nlogger = logging.getLogger(__name__)\ntry:\n from opentelemetry import trace\n from opentelemetry.instrumentation.utils import http_status_to_canonical_code\n from opentelemetry.trace.status import Status\n\n HAS_OPENTELEMETRY = True\n _warned_telemetry = True\n\nexcept ImportError:\n HAS_OPENTELEMETRY = False\n _warned_telemetry = False\n\n_default_attributes = {\n \"db.system\": \"BigQuery\"\n} # static, default values assigned to all spans\n\n\n@contextmanager\ndef create_span(name, attributes=None, client=None, job_ref=None):\n \"\"\"Creates a ContextManager for a Span to be exported to the configured exporter.\n If no configuration exists yields None.\n\n Args:\n name (str): Name that will be set for the span being created\n attributes (Optional[dict]):\n Additional attributes that pertain to\n the specific API call (i.e. not a default attribute)\n client (Optional[google.cloud.bigquery.client.Client]):\n Pass in a Client object to extract any attributes that may be\n relevant to it and add them to the created spans.\n job_ref (Optional[google.cloud.bigquery.job._AsyncJob])\n Pass in a _AsyncJob object to extract any attributes that may be\n relevant to it and add them to the created spans.\n\n Yields:\n opentelemetry.trace.Span: Yields the newly created Span.\n\n Raises:\n google.api_core.exceptions.GoogleAPICallError:\n Raised if a span could not be yielded or issue with call to\n OpenTelemetry.\n \"\"\"\n global _warned_telemetry\n final_attributes = _get_final_span_attributes(attributes, client, job_ref)\n if not HAS_OPENTELEMETRY:\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n \"OpenTelemetry could not be imported; please \"\n \"add opentelemetry-api and opentelemetry-instrumentation \"\n \"packages in order to get BigQuery Tracing data.\"\n )\n _warned_telemetry = True\n\n yield None\n return\n tracer = trace.get_tracer(__name__)\n\n # yield new span value\n with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:\n try:\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n span.set_status(Status(http_status_to_canonical_code(error.code)))\n raise\n\n\ndef _get_final_span_attributes(attributes=None, client=None, job_ref=None):\n final_attributes = {}\n final_attributes.update(_default_attributes.copy())\n if client:\n client_attributes = _set_client_attributes(client)\n final_attributes.update(client_attributes)\n if job_ref:\n job_attributes = _set_job_attributes(job_ref)\n final_attributes.update(job_attributes)\n if attributes:\n final_attributes.update(attributes)\n return final_attributes\n\n\ndef _set_client_attributes(client):\n return {\"db.name\": client.project, \"location\": client.location}\n\n\ndef _set_job_attributes(job_ref):\n job_attributes = {\n \"db.name\": job_ref.project,\n \"location\": job_ref.location,\n \"num_child_jobs\": job_ref.num_child_jobs,\n \"job_id\": job_ref.job_id,\n \"parent_job_id\": job_ref.parent_job_id,\n \"state\": job_ref.state,\n }\n\n job_attributes[\"hasErrors\"] = job_ref.error_result is not None\n\n if job_ref.created is not None:\n job_attributes[\"timeCreated\"] = job_ref.created.isoformat()\n\n if job_ref.started is not None:\n job_attributes[\"timeStarted\"] = job_ref.started.isoformat()\n\n if job_ref.ended is not None:\n job_attributes[\"timeEnded\"] = job_ref.ended.isoformat()\n\n return job_attributes\n", "path": "google/cloud/bigquery/opentelemetry_tracing.py"}]}
| 3,580 | 528 |
gh_patches_debug_20122
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[cliquet] Split tests from kinto package
original : https://github.com/mozilla-services/cliquet/issues/267
Should we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.
Another related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.
[cliquet] Split tests from kinto package
original : https://github.com/mozilla-services/cliquet/issues/267
Should we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.
Another related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.
</issue>
<code>
[start of setup.py]
1 import platform
2 import codecs
3 import os
4 from setuptools import setup, find_packages
5
6 here = os.path.abspath(os.path.dirname(__file__))
7
8
9 def read_file(filename):
10 """Open a related file and return its content."""
11 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
12 content = f.read()
13 return content
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 installed_with_pypy = platform.python_implementation() == 'PyPy'
20
21 REQUIREMENTS = [
22 'colander',
23 'colorama',
24 'cornice >= 1.1', # Fix cache CORS
25 'jsonschema',
26 'python-dateutil',
27 'pyramid_multiauth >= 0.8', # User on policy selected event.
28 'pyramid_tm',
29 'requests',
30 'six',
31 'structlog >= 16.1.0',
32 'enum34',
33 'waitress',
34 ]
35
36 if installed_with_pypy:
37 # We install psycopg2cffi instead of psycopg2 when dealing with pypy
38 # Note: JSONB support landed after psycopg2cffi 2.7.0
39 POSTGRESQL_REQUIRES = [
40 'SQLAlchemy',
41 'psycopg2cffi>2.7.0',
42 'zope.sqlalchemy',
43 ]
44 else:
45 # ujson is not pypy compliant, as it uses the CPython C API
46 REQUIREMENTS.append('ujson >= 1.35')
47 POSTGRESQL_REQUIRES = [
48 'SQLAlchemy',
49 'psycopg2>2.5',
50 'zope.sqlalchemy',
51 ]
52
53 REDIS_REQUIRES = [
54 'kinto_redis'
55 ]
56
57 DEPENDENCY_LINKS = [
58 ]
59
60 MONITORING_REQUIRES = [
61 'raven',
62 'statsd',
63 'newrelic',
64 'werkzeug',
65 ]
66
67 ENTRY_POINTS = {
68 'paste.app_factory': [
69 'main = kinto:main',
70 ],
71 'console_scripts': [
72 'kinto = kinto.__main__:main'
73 ],
74 }
75
76
77 setup(name='kinto',
78 version='4.1.0.dev0',
79 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
80 long_description=README + "\n\n" + CHANGELOG + "\n\n" + CONTRIBUTORS,
81 license='Apache License (2.0)',
82 classifiers=[
83 "Programming Language :: Python",
84 "Programming Language :: Python :: 2",
85 "Programming Language :: Python :: 2.7",
86 "Programming Language :: Python :: 3",
87 "Programming Language :: Python :: 3.4",
88 "Programming Language :: Python :: 3.5",
89 "Programming Language :: Python :: Implementation :: CPython",
90 "Programming Language :: Python :: Implementation :: PyPy",
91 "Topic :: Internet :: WWW/HTTP",
92 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
93 "License :: OSI Approved :: Apache Software License"
94 ],
95 keywords="web sync json storage services",
96 author='Mozilla Services',
97 author_email='[email protected]',
98 url='https://github.com/Kinto/kinto',
99 packages=find_packages(),
100 package_data={'': ['*.rst', '*.py']},
101 include_package_data=True,
102 zip_safe=False,
103 install_requires=REQUIREMENTS,
104 extras_require={
105 'redis': REDIS_REQUIRES,
106 'postgresql': POSTGRESQL_REQUIRES,
107 'monitoring': MONITORING_REQUIRES,
108 ":python_version=='2.7'": ["functools32", "futures"],
109 },
110 test_suite="kinto.tests",
111 dependency_links=DEPENDENCY_LINKS,
112 entry_points=ENTRY_POINTS)
113
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,6 +54,15 @@
'kinto_redis'
]
+SETUP_REQUIRES = [
+ 'pytest-runner'
+]
+
+TEST_REQUIREMENTS = [
+ 'pytest',
+ 'WebTest'
+]
+
DEPENDENCY_LINKS = [
]
@@ -100,6 +109,8 @@
package_data={'': ['*.rst', '*.py']},
include_package_data=True,
zip_safe=False,
+ setup_requires=SETUP_REQUIRES,
+ tests_require=TEST_REQUIREMENTS,
install_requires=REQUIREMENTS,
extras_require={
'redis': REDIS_REQUIRES,
@@ -107,6 +118,6 @@
'monitoring': MONITORING_REQUIRES,
":python_version=='2.7'": ["functools32", "futures"],
},
- test_suite="kinto.tests",
+ test_suite="tests",
dependency_links=DEPENDENCY_LINKS,
entry_points=ENTRY_POINTS)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,6 +54,15 @@\n 'kinto_redis'\n ]\n \n+SETUP_REQUIRES = [\n+ 'pytest-runner'\n+]\n+\n+TEST_REQUIREMENTS = [\n+ 'pytest',\n+ 'WebTest'\n+]\n+\n DEPENDENCY_LINKS = [\n ]\n \n@@ -100,6 +109,8 @@\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n+ setup_requires=SETUP_REQUIRES,\n+ tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n@@ -107,6 +118,6 @@\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n- test_suite=\"kinto.tests\",\n+ test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "issue": "[cliquet] Split tests from kinto package\noriginal : https://github.com/mozilla-services/cliquet/issues/267\n\nShould we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.\n\nAnother related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.\n\n[cliquet] Split tests from kinto package\noriginal : https://github.com/mozilla-services/cliquet/issues/267\n\nShould we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.\n\nAnother related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.\n\n", "before_files": [{"content": "import platform\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\ninstalled_with_pypy = platform.python_implementation() == 'PyPy'\n\nREQUIREMENTS = [\n 'colander',\n 'colorama',\n 'cornice >= 1.1', # Fix cache CORS\n 'jsonschema',\n 'python-dateutil',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'pyramid_tm',\n 'requests',\n 'six',\n 'structlog >= 16.1.0',\n 'enum34',\n 'waitress',\n]\n\nif installed_with_pypy:\n # We install psycopg2cffi instead of psycopg2 when dealing with pypy\n # Note: JSONB support landed after psycopg2cffi 2.7.0\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2cffi>2.7.0',\n 'zope.sqlalchemy',\n ]\nelse:\n # ujson is not pypy compliant, as it uses the CPython C API\n REQUIREMENTS.append('ujson >= 1.35')\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2>2.5',\n 'zope.sqlalchemy',\n ]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='4.1.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=README + \"\\n\\n\" + CHANGELOG + \"\\n\\n\" + CONTRIBUTORS,\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n test_suite=\"kinto.tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 1,774 | 243 |
gh_patches_debug_22639
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-6608
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecated property "<AliasProperty name=filename>" of object "<kivy.core.audio(...)>" was accessed, it will be removed in a future version
### Versions
* Python: 3.7
* OS: independent
* Kivy: 1.11.1
* Kivy installation method: pip
### Description
The message displayed in title appears in the kivy logs when you load an audio using the default ```SoundLoader``` classes in ```kivy/core/audio``` files, excepting ```audio_ffpyplayer.py```. I was reading those files and realised that it happens because they are using ```self.filename``` instead of ```self.source```. As they belong to the kivy main files, the use of deprecated stuff should be replaced.
### Code and Logs
```python
from kivy.core.audio import SoundLoader
sound = SoundLoader.load('mytest.wav')
if sound:
print("Sound found at %s" % sound.source)
print("Sound is %.3f seconds" % sound.length)
sound.play()
```
Example, when using SDL2:
```python
[WARNING] Deprecated property "<AliasProperty name=filename>" of object "<kivy.core.audio.audio_sdl2.SoundSDL2>" was accessed, it will be removed in a future version
```
P.S: I don't know if the deprecation warnings in ```kivy/core/audio/__init__.py``` should be removed too.
</issue>
<code>
[start of kivy/core/audio/audio_gstplayer.py]
1 '''
2 Audio Gstplayer
3 ===============
4
5 .. versionadded:: 1.8.0
6
7 Implementation of a VideoBase with Kivy :class:`~kivy.lib.gstplayer.GstPlayer`
8 This player is the preferred player, using Gstreamer 1.0, working on both
9 Python 2 and 3.
10 '''
11
12 from kivy.lib.gstplayer import GstPlayer, get_gst_version
13 from kivy.core.audio import Sound, SoundLoader
14 from kivy.logger import Logger
15 from kivy.compat import PY2
16 from kivy.clock import Clock
17 from os.path import realpath
18
19 if PY2:
20 from urllib import pathname2url
21 else:
22 from urllib.request import pathname2url
23
24 Logger.info('AudioGstplayer: Using Gstreamer {}'.format(
25 '.'.join(map(str, get_gst_version()))))
26
27
28 def _on_gstplayer_message(mtype, message):
29 if mtype == 'error':
30 Logger.error('AudioGstplayer: {}'.format(message))
31 elif mtype == 'warning':
32 Logger.warning('AudioGstplayer: {}'.format(message))
33 elif mtype == 'info':
34 Logger.info('AudioGstplayer: {}'.format(message))
35
36
37 class SoundGstplayer(Sound):
38
39 @staticmethod
40 def extensions():
41 return ('wav', 'ogg', 'mp3', 'm4a', 'flac', 'mp4')
42
43 def __init__(self, **kwargs):
44 self.player = None
45 super(SoundGstplayer, self).__init__(**kwargs)
46
47 def _on_gst_eos_sync(self):
48 Clock.schedule_once(self._on_gst_eos, 0)
49
50 def _on_gst_eos(self, *dt):
51 if self.loop:
52 self.player.stop()
53 self.player.play()
54 else:
55 self.stop()
56
57 def load(self):
58 self.unload()
59 uri = self._get_uri()
60 self.player = GstPlayer(uri, None, self._on_gst_eos_sync,
61 _on_gstplayer_message)
62 self.player.load()
63
64 def play(self):
65 # we need to set the volume everytime, it seems that stopping + playing
66 # the sound reset the volume.
67 self.player.set_volume(self.volume)
68 self.player.play()
69 super(SoundGstplayer, self).play()
70
71 def stop(self):
72 self.player.stop()
73 super(SoundGstplayer, self).stop()
74
75 def unload(self):
76 if self.player:
77 self.player.unload()
78 self.player = None
79
80 def seek(self, position):
81 self.player.seek(position / self.length)
82
83 def get_pos(self):
84 return self.player.get_position()
85
86 def _get_length(self):
87 return self.player.get_duration()
88
89 def on_volume(self, instance, volume):
90 self.player.set_volume(volume)
91
92 def _get_uri(self):
93 uri = self.filename
94 if not uri:
95 return
96 if '://' not in uri:
97 uri = 'file:' + pathname2url(realpath(uri))
98 return uri
99
100
101 SoundLoader.register(SoundGstplayer)
102
[end of kivy/core/audio/audio_gstplayer.py]
[start of kivy/core/audio/audio_pygame.py]
1 '''
2 AudioPygame: implementation of Sound with Pygame
3
4 .. warning::
5
6 Pygame has been deprecated and will be removed in the release after Kivy
7 1.11.0.
8 '''
9
10 __all__ = ('SoundPygame', )
11
12 from kivy.clock import Clock
13 from kivy.utils import platform, deprecated
14 from kivy.core.audio import Sound, SoundLoader
15
16 _platform = platform
17 try:
18 if _platform == 'android':
19 try:
20 import android.mixer as mixer
21 except ImportError:
22 # old python-for-android version
23 import android_mixer as mixer
24 else:
25 from pygame import mixer
26 except:
27 raise
28
29 # init pygame sound
30 mixer.pre_init(44100, -16, 2, 1024)
31 mixer.init()
32 mixer.set_num_channels(32)
33
34
35 class SoundPygame(Sound):
36
37 # XXX we don't set __slots__ here, to automatically add
38 # a dictionary. We need that to be able to use weakref for
39 # SoundPygame object. Otherwise, it failed with:
40 # TypeError: cannot create weak reference to 'SoundPygame' object
41 # We use our clock in play() method.
42 # __slots__ = ('_data', '_channel')
43 _check_play_ev = None
44
45 @staticmethod
46 def extensions():
47 if _platform == 'android':
48 return ('wav', 'ogg', 'mp3', 'm4a')
49 return ('wav', 'ogg')
50
51 @deprecated(
52 msg='Pygame has been deprecated and will be removed after 1.11.0')
53 def __init__(self, **kwargs):
54 self._data = None
55 self._channel = None
56 super(SoundPygame, self).__init__(**kwargs)
57
58 def _check_play(self, dt):
59 if self._channel is None:
60 return False
61 if self._channel.get_busy():
62 return
63 if self.loop:
64 def do_loop(dt):
65 self.play()
66 Clock.schedule_once(do_loop)
67 else:
68 self.stop()
69 return False
70
71 def play(self):
72 if not self._data:
73 return
74 self._data.set_volume(self.volume)
75 self._channel = self._data.play()
76 self.start_time = Clock.time()
77 # schedule event to check if the sound is still playing or not
78 self._check_play_ev = Clock.schedule_interval(self._check_play, 0.1)
79 super(SoundPygame, self).play()
80
81 def stop(self):
82 if not self._data:
83 return
84 self._data.stop()
85 # ensure we don't have anymore the callback
86 if self._check_play_ev is not None:
87 self._check_play_ev.cancel()
88 self._check_play_ev = None
89 self._channel = None
90 super(SoundPygame, self).stop()
91
92 def load(self):
93 self.unload()
94 if self.filename is None:
95 return
96 self._data = mixer.Sound(self.filename)
97
98 def unload(self):
99 self.stop()
100 self._data = None
101
102 def seek(self, position):
103 if not self._data:
104 return
105 if _platform == 'android' and self._channel:
106 self._channel.seek(position)
107
108 def get_pos(self):
109 if self._data is not None and self._channel:
110 if _platform == 'android':
111 return self._channel.get_pos()
112 return Clock.time() - self.start_time
113 return 0
114
115 def on_volume(self, instance, volume):
116 if self._data is not None:
117 self._data.set_volume(volume)
118
119 def _get_length(self):
120 if _platform == 'android' and self._channel:
121 return self._channel.get_length()
122 if self._data is not None:
123 return self._data.get_length()
124 return super(SoundPygame, self)._get_length()
125
126
127 SoundLoader.register(SoundPygame)
128
[end of kivy/core/audio/audio_pygame.py]
[start of kivy/core/audio/audio_avplayer.py]
1 '''
2 AudioAvplayer: implementation of Sound using pyobjus / AVFoundation.
3 Works on iOS / OSX.
4 '''
5
6 __all__ = ('SoundAvplayer', )
7
8 from kivy.core.audio import Sound, SoundLoader
9 from pyobjus import autoclass
10 from pyobjus.dylib_manager import load_framework, INCLUDE
11
12 load_framework(INCLUDE.AVFoundation)
13 AVAudioPlayer = autoclass("AVAudioPlayer")
14 NSURL = autoclass("NSURL")
15 NSString = autoclass("NSString")
16
17
18 class SoundAvplayer(Sound):
19 @staticmethod
20 def extensions():
21 # taken from https://goo.gl/015kvU
22 return ("aac", "adts", "aif", "aiff", "aifc", "caf", "mp3", "mp4",
23 "m4a", "snd", "au", "sd2", "wav")
24
25 def __init__(self, **kwargs):
26 self._avplayer = None
27 super(SoundAvplayer, self).__init__(**kwargs)
28
29 def load(self):
30 self.unload()
31 fn = NSString.alloc().initWithUTF8String_(self.filename)
32 url = NSURL.alloc().initFileURLWithPath_(fn)
33 self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(
34 url, None)
35
36 def unload(self):
37 self.stop()
38 self._avplayer = None
39
40 def play(self):
41 if not self._avplayer:
42 return
43 self._avplayer.play()
44 super(SoundAvplayer, self).play()
45
46 def stop(self):
47 if not self._avplayer:
48 return
49 self._avplayer.stop()
50 super(SoundAvplayer, self).stop()
51
52 def seek(self, position):
53 if not self._avplayer:
54 return
55 self._avplayer.playAtTime_(float(position))
56
57 def get_pos(self):
58 if self._avplayer:
59 return self._avplayer.currentTime
60 return super(SoundAvplayer, self).get_pos()
61
62 def on_volume(self, instance, volume):
63 if self._avplayer:
64 self._avplayer.volume = float(volume)
65
66 def _get_length(self):
67 if self._avplayer:
68 return self._avplayer.duration
69 return super(SoundAvplayer, self)._get_length()
70
71
72 SoundLoader.register(SoundAvplayer)
73
[end of kivy/core/audio/audio_avplayer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kivy/core/audio/audio_avplayer.py b/kivy/core/audio/audio_avplayer.py
--- a/kivy/core/audio/audio_avplayer.py
+++ b/kivy/core/audio/audio_avplayer.py
@@ -28,7 +28,7 @@
def load(self):
self.unload()
- fn = NSString.alloc().initWithUTF8String_(self.filename)
+ fn = NSString.alloc().initWithUTF8String_(self.source)
url = NSURL.alloc().initFileURLWithPath_(fn)
self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(
url, None)
diff --git a/kivy/core/audio/audio_gstplayer.py b/kivy/core/audio/audio_gstplayer.py
--- a/kivy/core/audio/audio_gstplayer.py
+++ b/kivy/core/audio/audio_gstplayer.py
@@ -90,7 +90,7 @@
self.player.set_volume(volume)
def _get_uri(self):
- uri = self.filename
+ uri = self.source
if not uri:
return
if '://' not in uri:
diff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py
--- a/kivy/core/audio/audio_pygame.py
+++ b/kivy/core/audio/audio_pygame.py
@@ -91,9 +91,9 @@
def load(self):
self.unload()
- if self.filename is None:
+ if self.source is None:
return
- self._data = mixer.Sound(self.filename)
+ self._data = mixer.Sound(self.source)
def unload(self):
self.stop()
|
{"golden_diff": "diff --git a/kivy/core/audio/audio_avplayer.py b/kivy/core/audio/audio_avplayer.py\n--- a/kivy/core/audio/audio_avplayer.py\n+++ b/kivy/core/audio/audio_avplayer.py\n@@ -28,7 +28,7 @@\n \n def load(self):\n self.unload()\n- fn = NSString.alloc().initWithUTF8String_(self.filename)\n+ fn = NSString.alloc().initWithUTF8String_(self.source)\n url = NSURL.alloc().initFileURLWithPath_(fn)\n self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(\n url, None)\ndiff --git a/kivy/core/audio/audio_gstplayer.py b/kivy/core/audio/audio_gstplayer.py\n--- a/kivy/core/audio/audio_gstplayer.py\n+++ b/kivy/core/audio/audio_gstplayer.py\n@@ -90,7 +90,7 @@\n self.player.set_volume(volume)\n \n def _get_uri(self):\n- uri = self.filename\n+ uri = self.source\n if not uri:\n return\n if '://' not in uri:\ndiff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py\n--- a/kivy/core/audio/audio_pygame.py\n+++ b/kivy/core/audio/audio_pygame.py\n@@ -91,9 +91,9 @@\n \n def load(self):\n self.unload()\n- if self.filename is None:\n+ if self.source is None:\n return\n- self._data = mixer.Sound(self.filename)\n+ self._data = mixer.Sound(self.source)\n \n def unload(self):\n self.stop()\n", "issue": "Deprecated property \"<AliasProperty name=filename>\" of object \"<kivy.core.audio(...)>\" was accessed, it will be removed in a future version\n### Versions\r\n\r\n* Python: 3.7\r\n* OS: independent\r\n* Kivy: 1.11.1\r\n* Kivy installation method: pip\r\n\r\n### Description\r\n\r\nThe message displayed in title appears in the kivy logs when you load an audio using the default ```SoundLoader``` classes in ```kivy/core/audio``` files, excepting ```audio_ffpyplayer.py```. I was reading those files and realised that it happens because they are using ```self.filename``` instead of ```self.source```. As they belong to the kivy main files, the use of deprecated stuff should be replaced.\r\n\r\n### Code and Logs\r\n```python\r\nfrom kivy.core.audio import SoundLoader\r\n\r\nsound = SoundLoader.load('mytest.wav')\r\nif sound:\r\n print(\"Sound found at %s\" % sound.source)\r\n print(\"Sound is %.3f seconds\" % sound.length)\r\n sound.play()\r\n```\r\n\r\nExample, when using SDL2:\r\n```python\r\n[WARNING] Deprecated property \"<AliasProperty name=filename>\" of object \"<kivy.core.audio.audio_sdl2.SoundSDL2>\" was accessed, it will be removed in a future version\r\n```\r\n\r\nP.S: I don't know if the deprecation warnings in ```kivy/core/audio/__init__.py``` should be removed too.\n", "before_files": [{"content": "'''\nAudio Gstplayer\n===============\n\n.. versionadded:: 1.8.0\n\nImplementation of a VideoBase with Kivy :class:`~kivy.lib.gstplayer.GstPlayer`\nThis player is the preferred player, using Gstreamer 1.0, working on both\nPython 2 and 3.\n'''\n\nfrom kivy.lib.gstplayer import GstPlayer, get_gst_version\nfrom kivy.core.audio import Sound, SoundLoader\nfrom kivy.logger import Logger\nfrom kivy.compat import PY2\nfrom kivy.clock import Clock\nfrom os.path import realpath\n\nif PY2:\n from urllib import pathname2url\nelse:\n from urllib.request import pathname2url\n\nLogger.info('AudioGstplayer: Using Gstreamer {}'.format(\n '.'.join(map(str, get_gst_version()))))\n\n\ndef _on_gstplayer_message(mtype, message):\n if mtype == 'error':\n Logger.error('AudioGstplayer: {}'.format(message))\n elif mtype == 'warning':\n Logger.warning('AudioGstplayer: {}'.format(message))\n elif mtype == 'info':\n Logger.info('AudioGstplayer: {}'.format(message))\n\n\nclass SoundGstplayer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', 'm4a', 'flac', 'mp4')\n\n def __init__(self, **kwargs):\n self.player = None\n super(SoundGstplayer, self).__init__(**kwargs)\n\n def _on_gst_eos_sync(self):\n Clock.schedule_once(self._on_gst_eos, 0)\n\n def _on_gst_eos(self, *dt):\n if self.loop:\n self.player.stop()\n self.player.play()\n else:\n self.stop()\n\n def load(self):\n self.unload()\n uri = self._get_uri()\n self.player = GstPlayer(uri, None, self._on_gst_eos_sync,\n _on_gstplayer_message)\n self.player.load()\n\n def play(self):\n # we need to set the volume everytime, it seems that stopping + playing\n # the sound reset the volume.\n self.player.set_volume(self.volume)\n self.player.play()\n super(SoundGstplayer, self).play()\n\n def stop(self):\n self.player.stop()\n super(SoundGstplayer, self).stop()\n\n def unload(self):\n if self.player:\n self.player.unload()\n self.player = None\n\n def seek(self, position):\n self.player.seek(position / self.length)\n\n def get_pos(self):\n return self.player.get_position()\n\n def _get_length(self):\n return self.player.get_duration()\n\n def on_volume(self, instance, volume):\n self.player.set_volume(volume)\n\n def _get_uri(self):\n uri = self.filename\n if not uri:\n return\n if '://' not in uri:\n uri = 'file:' + pathname2url(realpath(uri))\n return uri\n\n\nSoundLoader.register(SoundGstplayer)\n", "path": "kivy/core/audio/audio_gstplayer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n\n.. warning::\n\n Pygame has been deprecated and will be removed in the release after Kivy\n 1.11.0.\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform, deprecated\nfrom kivy.core.audio import Sound, SoundLoader\n\n_platform = platform\ntry:\n if _platform == 'android':\n try:\n import android.mixer as mixer\n except ImportError:\n # old python-for-android version\n import android_mixer as mixer\n else:\n from pygame import mixer\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automatically add\n # a dictionary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n _check_play_ev = None\n\n @staticmethod\n def extensions():\n if _platform == 'android':\n return ('wav', 'ogg', 'mp3', 'm4a')\n return ('wav', 'ogg')\n\n @deprecated(\n msg='Pygame has been deprecated and will be removed after 1.11.0')\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n if self.loop:\n def do_loop(dt):\n self.play()\n Clock.schedule_once(do_loop)\n else:\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._data.set_volume(self.volume)\n self._channel = self._data.play()\n self.start_time = Clock.time()\n # schedule event to check if the sound is still playing or not\n self._check_play_ev = Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n if self._check_play_ev is not None:\n self._check_play_ev.cancel()\n self._check_play_ev = None\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.filename is None:\n return\n self._data = mixer.Sound(self.filename)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if not self._data:\n return\n if _platform == 'android' and self._channel:\n self._channel.seek(position)\n\n def get_pos(self):\n if self._data is not None and self._channel:\n if _platform == 'android':\n return self._channel.get_pos()\n return Clock.time() - self.start_time\n return 0\n\n def on_volume(self, instance, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n\n def _get_length(self):\n if _platform == 'android' and self._channel:\n return self._channel.get_length()\n if self._data is not None:\n return self._data.get_length()\n return super(SoundPygame, self)._get_length()\n\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}, {"content": "'''\nAudioAvplayer: implementation of Sound using pyobjus / AVFoundation.\nWorks on iOS / OSX.\n'''\n\n__all__ = ('SoundAvplayer', )\n\nfrom kivy.core.audio import Sound, SoundLoader\nfrom pyobjus import autoclass\nfrom pyobjus.dylib_manager import load_framework, INCLUDE\n\nload_framework(INCLUDE.AVFoundation)\nAVAudioPlayer = autoclass(\"AVAudioPlayer\")\nNSURL = autoclass(\"NSURL\")\nNSString = autoclass(\"NSString\")\n\n\nclass SoundAvplayer(Sound):\n @staticmethod\n def extensions():\n # taken from https://goo.gl/015kvU\n return (\"aac\", \"adts\", \"aif\", \"aiff\", \"aifc\", \"caf\", \"mp3\", \"mp4\",\n \"m4a\", \"snd\", \"au\", \"sd2\", \"wav\")\n\n def __init__(self, **kwargs):\n self._avplayer = None\n super(SoundAvplayer, self).__init__(**kwargs)\n\n def load(self):\n self.unload()\n fn = NSString.alloc().initWithUTF8String_(self.filename)\n url = NSURL.alloc().initFileURLWithPath_(fn)\n self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(\n url, None)\n\n def unload(self):\n self.stop()\n self._avplayer = None\n\n def play(self):\n if not self._avplayer:\n return\n self._avplayer.play()\n super(SoundAvplayer, self).play()\n\n def stop(self):\n if not self._avplayer:\n return\n self._avplayer.stop()\n super(SoundAvplayer, self).stop()\n\n def seek(self, position):\n if not self._avplayer:\n return\n self._avplayer.playAtTime_(float(position))\n\n def get_pos(self):\n if self._avplayer:\n return self._avplayer.currentTime\n return super(SoundAvplayer, self).get_pos()\n\n def on_volume(self, instance, volume):\n if self._avplayer:\n self._avplayer.volume = float(volume)\n\n def _get_length(self):\n if self._avplayer:\n return self._avplayer.duration\n return super(SoundAvplayer, self)._get_length()\n\n\nSoundLoader.register(SoundAvplayer)\n", "path": "kivy/core/audio/audio_avplayer.py"}]}
| 3,535 | 356 |
gh_patches_debug_32965
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-4197
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regression of #3305? Or new issue/same behavior
### Bug description
[This issue](https://github.com/lutris/lutris/issues/3305) appears to have returned in 5.10. Had 5.9 installed through manjaro pamac. Removed and installed 5.10 through AUR script. Launching Lutris shows all the new option of 5.10, but regardless of view (tree or icon), non of my games installed from 5.9 will bring up the context menu. Even games I add as manual after install of 5.10 won't call up the context menu. This even prevents removing/deleting from Lutris.
### How to Reproduce
Steps to reproduce the behavior:
Have 5.9 installed
Remove 5.9
Install 5.10 for AUR
Start Lutris
Click on any preinstalled game
Context menu does not appear
### Expected behavior
Context menu should appear.
### Log output
```shell
> INFO 2022-04-05 20:39:22,054 [startup.init_lutris:173]:Starting Lutris 0.5.10
> WARNING 2022-04-05 20:39:22,119 [libretro.get_libretro_cores:24]:No folder at /home/crono141/.local/share/lutris/runners/retroarch/
> DEBUG 2022-04-05 20:39:22,133 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR
> INFO 2022-04-05 20:39:22,177 [startup.check_driver:65]:Running AMD Mesa driver 21.3.7 on AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1) (0x699f)
> INFO 2022-04-05 20:39:22,177 [startup.check_driver:77]:GPU: 1002:699F 1028:1712 (amdgpu drivers)
> INFO 2022-04-05 20:39:22,242 [startup.update_runtime:213]:Startup complete
> DEBUG 2022-04-05 20:39:22,385 [lutriswindow.update_store:437]:Showing 8 games
> Traceback (most recent call last):
> File "/usr/lib/python3.10/site-packages/lutris/gui/lutriswindow.py", line 399, in update_revealer
> self.game_bar = GameBar(game, self.game_actions, self.application)
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 61, in __init__
> self.update_view()
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 86, in update_view
> self.play_button = self.get_play_button()
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 226, in get_play_button
> popover = self.get_popover(self.get_game_buttons(), popover_button)
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 233, in get_game_buttons
> displayed = self.game_actions.get_displayed_entries()
> File "/usr/lib/python3.10/site-packages/lutris/game_actions.py", line 141, in get_displayed_entries
> and not steam_shortcut.all_shortcuts_set(self.game)
> File "/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py", line 48, in all_shortcuts_set
> shortcut_found = [
> File "/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py", line 50, in <listcomp>
> if game.name in s['AppName']
> KeyError: 'AppName'
```
### System Information
```shell
> [System]
> OS: Manjaro Linux 21.2.5 Qonos
> Arch: x86_64
> Kernel: 5.15.28-1-MANJARO
> Desktop: KDE
> Display Server: x11
>
> [CPU]
> Vendor: GenuineIntel
> Model: Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz
> Physical cores: 2
> Logical cores: 4
>
> [Memory]
> RAM: 7.7 GB
> Swap: 0.5 GB
>
> [Graphics]
> Vendor: AMD
> OpenGL Renderer: AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1)
> OpenGL Version: 4.6 (Compatibility Profile) Mesa 21.3.7
> OpenGL Core: 4.6 (Core Profile) Mesa 21.3.7
> OpenGL ES: OpenGL ES 3.2 Mesa 21.3.7
> Vulkan: Supported
```
### Media (optional)
_No response_
### Checklist:
- [X] I'm not asking for support with a game or the wine runner.
- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.
- [X] I have checked for existing issues that describe my problem prior to opening this one.
- [X] I understand that improperly formatted bug reports may be closed without explanation.
</issue>
<code>
[start of lutris/util/steam/shortcut.py]
1 """Export lutris games to steam shortcuts"""
2 import binascii
3 import os
4 import shutil
5
6 from lutris.util import resources
7 from lutris.util.steam import vdf
8 from lutris.util.steam.config import search_recursive_in_steam_dirs
9
10
11 def get_shortcuts_vdf_paths():
12 path_suffix = "userdata/**/config/shortcuts.vdf"
13 shortcuts_vdf = search_recursive_in_steam_dirs(path_suffix)
14 return shortcuts_vdf
15
16
17 def get_artwork_target_paths():
18 path_suffix = "userdata/**/config/grid"
19 target_paths = search_recursive_in_steam_dirs(path_suffix)
20 return target_paths
21
22
23 def vdf_file_exists():
24 shortcuts_paths = get_shortcuts_vdf_paths()
25 if len(shortcuts_paths) > 0:
26 return True
27 return False
28
29
30 def shortcut_exists(game, shortcut_path):
31 with open(shortcut_path, "rb") as shortcut_file:
32 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
33 shortcut_found = [
34 s for s in shortcuts
35 if game.name in s['AppName']
36 ]
37 if not shortcut_found:
38 return False
39 return True
40
41
42 def all_shortcuts_set(game):
43 paths_shortcut = get_shortcuts_vdf_paths()
44 shortcuts_found = 0
45 for shortcut_path in paths_shortcut:
46 with open(shortcut_path, "rb") as shortcut_file:
47 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
48 shortcut_found = [
49 s for s in shortcuts
50 if game.name in s['AppName']
51 ]
52 shortcuts_found += len(shortcut_found)
53
54 if len(paths_shortcut) == shortcuts_found:
55 return True
56 return False
57
58
59 def has_steamtype_runner(game):
60 steamtype_runners = ['steam', 'winesteam']
61 for runner in steamtype_runners:
62 if runner == game.runner_name:
63 return True
64 return False
65
66
67 def update_shortcut(game):
68 if has_steamtype_runner(game):
69 return
70 for shortcut_path in get_shortcuts_vdf_paths():
71 if not shortcut_exists(game, shortcut_path):
72 create_shortcut(game, shortcut_path)
73
74
75 def remove_all_shortcuts(game):
76 for shortcut_path in get_shortcuts_vdf_paths():
77 remove_shortcut(game, shortcut_path)
78
79
80 def create_shortcut(game, shortcut_path):
81 with open(shortcut_path, "rb") as shortcut_file:
82 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
83 existing_shortcuts = list(shortcuts)
84 add_shortcut = [generate_shortcut(game)]
85 updated_shortcuts = {
86 'shortcuts': {
87 str(index): elem for index, elem in enumerate(existing_shortcuts + add_shortcut)
88 }
89 }
90 with open(shortcut_path, "wb") as shortcut_file:
91 shortcut_file.write(vdf.binary_dumps(updated_shortcuts))
92 set_artwork(game)
93
94
95 def remove_shortcut(game, shortcut_path):
96 with open(shortcut_path, "rb") as shortcut_file:
97 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
98 shortcut_found = [
99 s for s in shortcuts
100 if game.name in s['AppName']
101 ]
102
103 if not shortcut_found:
104 return
105
106 other_shortcuts = [
107 s for s in shortcuts
108 if game.name not in s['AppName']
109 ]
110 updated_shortcuts = {
111 'shortcuts': {
112 str(index): elem for index, elem in enumerate(other_shortcuts)
113 }
114 }
115 with open(shortcut_path, "wb") as shortcut_file:
116 shortcut_file.write(vdf.binary_dumps(updated_shortcuts))
117
118
119 def generate_shortcut(game):
120 name = game.name
121 slug = game.slug
122 gameId = game.id
123 icon = resources.get_icon_path(slug)
124 lutris_binary = shutil.which("lutris")
125 start_dir = os.path.dirname(lutris_binary)
126
127 return {
128 'appid': "lutris-{}".format(slug),
129 'AllowDesktopConfig': 1,
130 'AllowOverlay': 1,
131 'AppName': name,
132 'Devkit': 0,
133 'DevkitGameID': '',
134 'Exe': f'"{lutris_binary}"',
135 'IsHidden': 0,
136 'LastPlayTime': 0,
137 'LaunchOptions': f'lutris:rungameid/{gameId}',
138 'OpenVR': 0,
139 'ShortcutPath': '',
140 'StartDir': f'"{start_dir}"',
141 'icon': icon,
142 'tags': { # has been replaced by "collections" in steam. Tags are not visible in the UI anymore.
143 '0': "Lutris" # to identify generated shortcuts
144 }
145 }
146
147
148 def get_steam_shortcut_id(game):
149 lutris_binary = shutil.which("lutris")
150 exe = f'"{lutris_binary}"'
151 appname = "{} ({})".format(game.name, game.runner_name)
152 unique_id = ''.join([exe, appname])
153 return binascii.crc32(str.encode(unique_id)) | 0x80000000
154
155
156 def set_artwork(game):
157 shortcut_id = get_steam_shortcut_id(game)
158 source_cover = resources.get_cover_path(game.slug)
159 source_banner = resources.get_banner_path(game.slug)
160 target_cover = "{}p.jpg".format(shortcut_id)
161 target_banner = "{}_hero.jpg".format(shortcut_id)
162 for target_path in get_artwork_target_paths():
163 target_cover = os.path.join(target_path, target_cover)
164 target_banner = os.path.join(target_path, target_banner)
165 try:
166 shutil.copyfile(source_cover, target_cover)
167 shutil.copyfile(source_banner, target_banner)
168 except FileNotFoundError:
169 pass
170
[end of lutris/util/steam/shortcut.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/util/steam/shortcut.py b/lutris/util/steam/shortcut.py
--- a/lutris/util/steam/shortcut.py
+++ b/lutris/util/steam/shortcut.py
@@ -32,7 +32,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
if not shortcut_found:
return False
@@ -47,7 +47,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
shortcuts_found += len(shortcut_found)
@@ -97,7 +97,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
if not shortcut_found:
@@ -105,7 +105,7 @@
other_shortcuts = [
s for s in shortcuts
- if game.name not in s['AppName']
+ if not matches_appname(s, game)
]
updated_shortcuts = {
'shortcuts': {
@@ -145,6 +145,12 @@
}
+def matches_appname(shortcut, game):
+ """Test if the game seems to be the one a shortcut refers to."""
+ appname = shortcut.get('AppName') or shortcut.get('appname')
+ return appname and game.name in appname
+
+
def get_steam_shortcut_id(game):
lutris_binary = shutil.which("lutris")
exe = f'"{lutris_binary}"'
|
{"golden_diff": "diff --git a/lutris/util/steam/shortcut.py b/lutris/util/steam/shortcut.py\n--- a/lutris/util/steam/shortcut.py\n+++ b/lutris/util/steam/shortcut.py\n@@ -32,7 +32,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n if not shortcut_found:\n return False\n@@ -47,7 +47,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n shortcuts_found += len(shortcut_found)\n \n@@ -97,7 +97,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n \n if not shortcut_found:\n@@ -105,7 +105,7 @@\n \n other_shortcuts = [\n s for s in shortcuts\n- if game.name not in s['AppName']\n+ if not matches_appname(s, game)\n ]\n updated_shortcuts = {\n 'shortcuts': {\n@@ -145,6 +145,12 @@\n }\n \n \n+def matches_appname(shortcut, game):\n+ \"\"\"Test if the game seems to be the one a shortcut refers to.\"\"\"\n+ appname = shortcut.get('AppName') or shortcut.get('appname')\n+ return appname and game.name in appname\n+\n+\n def get_steam_shortcut_id(game):\n lutris_binary = shutil.which(\"lutris\")\n exe = f'\"{lutris_binary}\"'\n", "issue": "Regression of #3305? Or new issue/same behavior\n### Bug description\n\n[This issue](https://github.com/lutris/lutris/issues/3305) appears to have returned in 5.10. Had 5.9 installed through manjaro pamac. Removed and installed 5.10 through AUR script. Launching Lutris shows all the new option of 5.10, but regardless of view (tree or icon), non of my games installed from 5.9 will bring up the context menu. Even games I add as manual after install of 5.10 won't call up the context menu. This even prevents removing/deleting from Lutris.\r\n\r\n\r\n\r\n\n\n### How to Reproduce\n\nSteps to reproduce the behavior:\r\nHave 5.9 installed\r\nRemove 5.9\r\nInstall 5.10 for AUR\r\nStart Lutris\r\nClick on any preinstalled game\r\nContext menu does not appear\r\n\n\n### Expected behavior\n\nContext menu should appear.\n\n### Log output\n\n```shell\n> INFO 2022-04-05 20:39:22,054 [startup.init_lutris:173]:Starting Lutris 0.5.10\r\n> WARNING 2022-04-05 20:39:22,119 [libretro.get_libretro_cores:24]:No folder at /home/crono141/.local/share/lutris/runners/retroarch/\r\n> DEBUG 2022-04-05 20:39:22,133 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR\r\n> INFO 2022-04-05 20:39:22,177 [startup.check_driver:65]:Running AMD Mesa driver 21.3.7 on AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1) (0x699f)\r\n> INFO 2022-04-05 20:39:22,177 [startup.check_driver:77]:GPU: 1002:699F 1028:1712 (amdgpu drivers)\r\n> INFO 2022-04-05 20:39:22,242 [startup.update_runtime:213]:Startup complete\r\n> DEBUG 2022-04-05 20:39:22,385 [lutriswindow.update_store:437]:Showing 8 games\r\n> Traceback (most recent call last):\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/lutriswindow.py\", line 399, in update_revealer\r\n> self.game_bar = GameBar(game, self.game_actions, self.application)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 61, in __init__\r\n> self.update_view()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 86, in update_view\r\n> self.play_button = self.get_play_button()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 226, in get_play_button\r\n> popover = self.get_popover(self.get_game_buttons(), popover_button)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 233, in get_game_buttons\r\n> displayed = self.game_actions.get_displayed_entries()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/game_actions.py\", line 141, in get_displayed_entries\r\n> and not steam_shortcut.all_shortcuts_set(self.game)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py\", line 48, in all_shortcuts_set\r\n> shortcut_found = [\r\n> File \"/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py\", line 50, in <listcomp>\r\n> if game.name in s['AppName']\r\n> KeyError: 'AppName'\n```\n\n\n### System Information\n\n```shell\n> [System]\r\n> OS: Manjaro Linux 21.2.5 Qonos\r\n> Arch: x86_64\r\n> Kernel: 5.15.28-1-MANJARO\r\n> Desktop: KDE\r\n> Display Server: x11\r\n> \r\n> [CPU]\r\n> Vendor: GenuineIntel\r\n> Model: Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz\r\n> Physical cores: 2\r\n> Logical cores: 4\r\n> \r\n> [Memory]\r\n> RAM: 7.7 GB\r\n> Swap: 0.5 GB\r\n> \r\n> [Graphics]\r\n> Vendor: AMD\r\n> OpenGL Renderer: AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1)\r\n> OpenGL Version: 4.6 (Compatibility Profile) Mesa 21.3.7\r\n> OpenGL Core: 4.6 (Core Profile) Mesa 21.3.7\r\n> OpenGL ES: OpenGL ES 3.2 Mesa 21.3.7\r\n> Vulkan: Supported\n```\n\n\n### Media (optional)\n\n_No response_\n\n### Checklist:\n\n- [X] I'm not asking for support with a game or the wine runner.\n- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.\n- [X] I have checked for existing issues that describe my problem prior to opening this one.\n- [X] I understand that improperly formatted bug reports may be closed without explanation.\n", "before_files": [{"content": "\"\"\"Export lutris games to steam shortcuts\"\"\"\nimport binascii\nimport os\nimport shutil\n\nfrom lutris.util import resources\nfrom lutris.util.steam import vdf\nfrom lutris.util.steam.config import search_recursive_in_steam_dirs\n\n\ndef get_shortcuts_vdf_paths():\n path_suffix = \"userdata/**/config/shortcuts.vdf\"\n shortcuts_vdf = search_recursive_in_steam_dirs(path_suffix)\n return shortcuts_vdf\n\n\ndef get_artwork_target_paths():\n path_suffix = \"userdata/**/config/grid\"\n target_paths = search_recursive_in_steam_dirs(path_suffix)\n return target_paths\n\n\ndef vdf_file_exists():\n shortcuts_paths = get_shortcuts_vdf_paths()\n if len(shortcuts_paths) > 0:\n return True\n return False\n\n\ndef shortcut_exists(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n if not shortcut_found:\n return False\n return True\n\n\ndef all_shortcuts_set(game):\n paths_shortcut = get_shortcuts_vdf_paths()\n shortcuts_found = 0\n for shortcut_path in paths_shortcut:\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n shortcuts_found += len(shortcut_found)\n\n if len(paths_shortcut) == shortcuts_found:\n return True\n return False\n\n\ndef has_steamtype_runner(game):\n steamtype_runners = ['steam', 'winesteam']\n for runner in steamtype_runners:\n if runner == game.runner_name:\n return True\n return False\n\n\ndef update_shortcut(game):\n if has_steamtype_runner(game):\n return\n for shortcut_path in get_shortcuts_vdf_paths():\n if not shortcut_exists(game, shortcut_path):\n create_shortcut(game, shortcut_path)\n\n\ndef remove_all_shortcuts(game):\n for shortcut_path in get_shortcuts_vdf_paths():\n remove_shortcut(game, shortcut_path)\n\n\ndef create_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n existing_shortcuts = list(shortcuts)\n add_shortcut = [generate_shortcut(game)]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(existing_shortcuts + add_shortcut)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n set_artwork(game)\n\n\ndef remove_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n\n if not shortcut_found:\n return\n\n other_shortcuts = [\n s for s in shortcuts\n if game.name not in s['AppName']\n ]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(other_shortcuts)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n\n\ndef generate_shortcut(game):\n name = game.name\n slug = game.slug\n gameId = game.id\n icon = resources.get_icon_path(slug)\n lutris_binary = shutil.which(\"lutris\")\n start_dir = os.path.dirname(lutris_binary)\n\n return {\n 'appid': \"lutris-{}\".format(slug),\n 'AllowDesktopConfig': 1,\n 'AllowOverlay': 1,\n 'AppName': name,\n 'Devkit': 0,\n 'DevkitGameID': '',\n 'Exe': f'\"{lutris_binary}\"',\n 'IsHidden': 0,\n 'LastPlayTime': 0,\n 'LaunchOptions': f'lutris:rungameid/{gameId}',\n 'OpenVR': 0,\n 'ShortcutPath': '',\n 'StartDir': f'\"{start_dir}\"',\n 'icon': icon,\n 'tags': { # has been replaced by \"collections\" in steam. Tags are not visible in the UI anymore.\n '0': \"Lutris\" # to identify generated shortcuts\n }\n }\n\n\ndef get_steam_shortcut_id(game):\n lutris_binary = shutil.which(\"lutris\")\n exe = f'\"{lutris_binary}\"'\n appname = \"{} ({})\".format(game.name, game.runner_name)\n unique_id = ''.join([exe, appname])\n return binascii.crc32(str.encode(unique_id)) | 0x80000000\n\n\ndef set_artwork(game):\n shortcut_id = get_steam_shortcut_id(game)\n source_cover = resources.get_cover_path(game.slug)\n source_banner = resources.get_banner_path(game.slug)\n target_cover = \"{}p.jpg\".format(shortcut_id)\n target_banner = \"{}_hero.jpg\".format(shortcut_id)\n for target_path in get_artwork_target_paths():\n target_cover = os.path.join(target_path, target_cover)\n target_banner = os.path.join(target_path, target_banner)\n try:\n shutil.copyfile(source_cover, target_cover)\n shutil.copyfile(source_banner, target_banner)\n except FileNotFoundError:\n pass\n", "path": "lutris/util/steam/shortcut.py"}]}
| 3,606 | 441 |
gh_patches_debug_8204
|
rasdani/github-patches
|
git_diff
|
vas3k__vas3k.club-381
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Баг с пажинацией в разделе «Коммьюнити»
STR:
1. Открыть https://vas3k.club/people/
2. Отфильтровать по первым 4 фильтрам
3. Перейти на 2 страницу выдачи
ER: Фильтры сохранены
AR: Фильтры частично потеряны
Видео https://youtu.be/08cz2TOq60A
</issue>
<code>
[start of posts/templatetags/query_params.py]
1 from urllib.parse import urlencode
2
3 from django import template
4
5 register = template.Library()
6
7
8 @register.simple_tag(takes_context=True)
9 def append_query_param(context, **kwargs):
10 query_params = dict(context.request.GET.items())
11 query_params.update(kwargs)
12 return "?" + urlencode(query_params)
13
[end of posts/templatetags/query_params.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/posts/templatetags/query_params.py b/posts/templatetags/query_params.py
--- a/posts/templatetags/query_params.py
+++ b/posts/templatetags/query_params.py
@@ -1,4 +1,4 @@
-from urllib.parse import urlencode
+from copy import deepcopy
from django import template
@@ -7,6 +7,6 @@
@register.simple_tag(takes_context=True)
def append_query_param(context, **kwargs):
- query_params = dict(context.request.GET.items())
+ query_params = deepcopy(context.request.GET)
query_params.update(kwargs)
- return "?" + urlencode(query_params)
+ return "?" + query_params.urlencode()
|
{"golden_diff": "diff --git a/posts/templatetags/query_params.py b/posts/templatetags/query_params.py\n--- a/posts/templatetags/query_params.py\n+++ b/posts/templatetags/query_params.py\n@@ -1,4 +1,4 @@\n-from urllib.parse import urlencode\n+from copy import deepcopy\n \n from django import template\n \n@@ -7,6 +7,6 @@\n \n @register.simple_tag(takes_context=True)\n def append_query_param(context, **kwargs):\n- query_params = dict(context.request.GET.items())\n+ query_params = deepcopy(context.request.GET)\n query_params.update(kwargs)\n- return \"?\" + urlencode(query_params)\n+ return \"?\" + query_params.urlencode()\n", "issue": "\u0411\u0430\u0433 \u0441 \u043f\u0430\u0436\u0438\u043d\u0430\u0446\u0438\u0435\u0439 \u0432 \u0440\u0430\u0437\u0434\u0435\u043b\u0435 \u00ab\u041a\u043e\u043c\u043c\u044c\u044e\u043d\u0438\u0442\u0438\u00bb\nSTR:\r\n1. \u041e\u0442\u043a\u0440\u044b\u0442\u044c https://vas3k.club/people/\r\n2. \u041e\u0442\u0444\u0438\u043b\u044c\u0442\u0440\u043e\u0432\u0430\u0442\u044c\u00a0\u043f\u043e \u043f\u0435\u0440\u0432\u044b\u043c 4 \u0444\u0438\u043b\u044c\u0442\u0440\u0430\u043c\r\n3. \u041f\u0435\u0440\u0435\u0439\u0442\u0438 \u043d\u0430 2 \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432\u044b\u0434\u0430\u0447\u0438\r\n\r\nER: \u0424\u0438\u043b\u044c\u0442\u0440\u044b \u0441\u043e\u0445\u0440\u0430\u043d\u0435\u043d\u044b\r\nAR: \u0424\u0438\u043b\u044c\u0442\u0440\u044b \u0447\u0430\u0441\u0442\u0438\u0447\u043d\u043e \u043f\u043e\u0442\u0435\u0440\u044f\u043d\u044b\r\n\r\n\u0412\u0438\u0434\u0435\u043e\u00a0https://youtu.be/08cz2TOq60A\n", "before_files": [{"content": "from urllib.parse import urlencode\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=True)\ndef append_query_param(context, **kwargs):\n query_params = dict(context.request.GET.items())\n query_params.update(kwargs)\n return \"?\" + urlencode(query_params)\n", "path": "posts/templatetags/query_params.py"}]}
| 726 | 150 |
gh_patches_debug_10798
|
rasdani/github-patches
|
git_diff
|
spack__spack-14928
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Specifying more than one operating_system in the same compilers.yaml entry
For convenience, I'm using the same configuration files for two Macs that run a different MacOS version (one with Sierra, the other with High Sierra, but apart from that they are identical from spack's point of view: same compilers installed, same everything installed). Generated executables are exactly the same on both machines (exactly same compilers -custom build-, exactly same MacOS SDK, and exactly same ${MACOSX_DEPLOYMENT_TARGET} (ie: 10.12).
In fact, spack generates exactly the same `compilers.yaml` file on both machines, with the only difference that in one you see "sierra" for the `operating_system` entry, and in the other you see "highsierra".
Now, can I use the same `compilers.yaml` file for both machines? Apparently, `operating_system` will allow only one string, according to the schema. But is there any "dumb tag" that will allow both sierra and highsierra, or maybe even all MacOS versions? Or can I disable the `operating_system` entry in some way? If possible to disable, would it have any consequence on built packages?
</issue>
<code>
[start of lib/spack/spack/cmd/compiler.py]
1 # Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from __future__ import print_function
7
8 import argparse
9 import sys
10 from six import iteritems
11
12 import llnl.util.tty as tty
13 import spack.compilers
14 import spack.config
15 import spack.spec
16 from llnl.util.lang import index_by
17 from llnl.util.tty.colify import colify
18 from llnl.util.tty.color import colorize
19 from spack.spec import CompilerSpec, ArchSpec
20
21 description = "manage compilers"
22 section = "system"
23 level = "long"
24
25
26 def setup_parser(subparser):
27 sp = subparser.add_subparsers(
28 metavar='SUBCOMMAND', dest='compiler_command')
29
30 scopes = spack.config.scopes()
31 scopes_metavar = spack.config.scopes_metavar
32
33 # Find
34 find_parser = sp.add_parser(
35 'find', aliases=['add'],
36 help='search the system for compilers to add to Spack configuration')
37 find_parser.add_argument('add_paths', nargs=argparse.REMAINDER)
38 find_parser.add_argument(
39 '--scope', choices=scopes, metavar=scopes_metavar,
40 default=spack.config.default_modify_scope(),
41 help="configuration scope to modify")
42
43 # Remove
44 remove_parser = sp.add_parser(
45 'remove', aliases=['rm'], help='remove compiler by spec')
46 remove_parser.add_argument(
47 '-a', '--all', action='store_true',
48 help='remove ALL compilers that match spec')
49 remove_parser.add_argument('compiler_spec')
50 remove_parser.add_argument(
51 '--scope', choices=scopes, metavar=scopes_metavar,
52 default=spack.config.default_modify_scope(),
53 help="configuration scope to modify")
54
55 # List
56 list_parser = sp.add_parser('list', help='list available compilers')
57 list_parser.add_argument(
58 '--scope', choices=scopes, metavar=scopes_metavar,
59 default=spack.config.default_list_scope(),
60 help="configuration scope to read from")
61
62 # Info
63 info_parser = sp.add_parser('info', help='show compiler paths')
64 info_parser.add_argument('compiler_spec')
65 info_parser.add_argument(
66 '--scope', choices=scopes, metavar=scopes_metavar,
67 default=spack.config.default_list_scope(),
68 help="configuration scope to read from")
69
70
71 def compiler_find(args):
72 """Search either $PATH or a list of paths OR MODULES for compilers and
73 add them to Spack's configuration.
74
75 """
76 # None signals spack.compiler.find_compilers to use its default logic
77 paths = args.add_paths or None
78
79 # Don't initialize compilers config via compilers.get_compiler_config.
80 # Just let compiler_find do the
81 # entire process and return an empty config from all_compilers
82 # Default for any other process is init_config=True
83 compilers = [c for c in spack.compilers.find_compilers(paths)]
84 new_compilers = []
85 for c in compilers:
86 arch_spec = ArchSpec((None, c.operating_system, c.target))
87 same_specs = spack.compilers.compilers_for_spec(
88 c.spec, arch_spec, init_config=False)
89
90 if not same_specs:
91 new_compilers.append(c)
92
93 if new_compilers:
94 spack.compilers.add_compilers_to_config(new_compilers,
95 scope=args.scope,
96 init_config=False)
97 n = len(new_compilers)
98 s = 's' if n > 1 else ''
99
100 config = spack.config.config
101 filename = config.get_config_filename(args.scope, 'compilers')
102 tty.msg("Added %d new compiler%s to %s" % (n, s, filename))
103 colify(reversed(sorted(c.spec for c in new_compilers)), indent=4)
104 else:
105 tty.msg("Found no new compilers")
106 tty.msg("Compilers are defined in the following files:")
107 colify(spack.compilers.compiler_config_files(), indent=4)
108
109
110 def compiler_remove(args):
111 cspec = CompilerSpec(args.compiler_spec)
112 compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)
113 if not compilers:
114 tty.die("No compilers match spec %s" % cspec)
115 elif not args.all and len(compilers) > 1:
116 tty.error("Multiple compilers match spec %s. Choose one:" % cspec)
117 colify(reversed(sorted([c.spec for c in compilers])), indent=4)
118 tty.msg("Or, use `spack compiler remove -a` to remove all of them.")
119 sys.exit(1)
120
121 for compiler in compilers:
122 spack.compilers.remove_compiler_from_config(
123 compiler.spec, scope=args.scope)
124 tty.msg("Removed compiler %s" % compiler.spec)
125
126
127 def compiler_info(args):
128 """Print info about all compilers matching a spec."""
129 cspec = CompilerSpec(args.compiler_spec)
130 compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)
131
132 if not compilers:
133 tty.error("No compilers match spec %s" % cspec)
134 else:
135 for c in compilers:
136 print(str(c.spec) + ":")
137 print("\tpaths:")
138 for cpath in ['cc', 'cxx', 'f77', 'fc']:
139 print("\t\t%s = %s" % (cpath, getattr(c, cpath, None)))
140 if c.flags:
141 print("\tflags:")
142 for flag, flag_value in iteritems(c.flags):
143 print("\t\t%s = %s" % (flag, flag_value))
144 if len(c.environment) != 0:
145 if len(c.environment['set']) != 0:
146 print("\tenvironment:")
147 print("\t set:")
148 for key, value in iteritems(c.environment['set']):
149 print("\t %s = %s" % (key, value))
150 if c.extra_rpaths:
151 print("\tExtra rpaths:")
152 for extra_rpath in c.extra_rpaths:
153 print("\t\t%s" % extra_rpath)
154 print("\tmodules = %s" % c.modules)
155 print("\toperating system = %s" % c.operating_system)
156
157
158 def compiler_list(args):
159 tty.msg("Available compilers")
160 index = index_by(spack.compilers.all_compilers(scope=args.scope),
161 lambda c: (c.spec.name, c.operating_system, c.target))
162 ordered_sections = sorted(index.items(), key=lambda item: item[0])
163 for i, (key, compilers) in enumerate(ordered_sections):
164 if i >= 1:
165 print()
166 name, os, target = key
167 os_str = os
168 if target:
169 os_str += "-%s" % target
170 cname = "%s{%s} %s" % (spack.spec.compiler_color, name, os_str)
171 tty.hline(colorize(cname), char='-')
172 colify(reversed(sorted(c.spec for c in compilers)))
173
174
175 def compiler(parser, args):
176 action = {'add': compiler_find,
177 'find': compiler_find,
178 'remove': compiler_remove,
179 'rm': compiler_remove,
180 'info': compiler_info,
181 'list': compiler_list}
182 action[args.compiler_command](args)
183
[end of lib/spack/spack/cmd/compiler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/spack/spack/cmd/compiler.py b/lib/spack/spack/cmd/compiler.py
--- a/lib/spack/spack/cmd/compiler.py
+++ b/lib/spack/spack/cmd/compiler.py
@@ -142,7 +142,7 @@
for flag, flag_value in iteritems(c.flags):
print("\t\t%s = %s" % (flag, flag_value))
if len(c.environment) != 0:
- if len(c.environment['set']) != 0:
+ if len(c.environment.get('set', {})) != 0:
print("\tenvironment:")
print("\t set:")
for key, value in iteritems(c.environment['set']):
|
{"golden_diff": "diff --git a/lib/spack/spack/cmd/compiler.py b/lib/spack/spack/cmd/compiler.py\n--- a/lib/spack/spack/cmd/compiler.py\n+++ b/lib/spack/spack/cmd/compiler.py\n@@ -142,7 +142,7 @@\n for flag, flag_value in iteritems(c.flags):\n print(\"\\t\\t%s = %s\" % (flag, flag_value))\n if len(c.environment) != 0:\n- if len(c.environment['set']) != 0:\n+ if len(c.environment.get('set', {})) != 0:\n print(\"\\tenvironment:\")\n print(\"\\t set:\")\n for key, value in iteritems(c.environment['set']):\n", "issue": "Specifying more than one operating_system in the same compilers.yaml entry\nFor convenience, I'm using the same configuration files for two Macs that run a different MacOS version (one with Sierra, the other with High Sierra, but apart from that they are identical from spack's point of view: same compilers installed, same everything installed). Generated executables are exactly the same on both machines (exactly same compilers -custom build-, exactly same MacOS SDK, and exactly same ${MACOSX_DEPLOYMENT_TARGET} (ie: 10.12).\r\n\r\nIn fact, spack generates exactly the same `compilers.yaml` file on both machines, with the only difference that in one you see \"sierra\" for the `operating_system` entry, and in the other you see \"highsierra\".\r\n\r\nNow, can I use the same `compilers.yaml` file for both machines? Apparently, `operating_system` will allow only one string, according to the schema. But is there any \"dumb tag\" that will allow both sierra and highsierra, or maybe even all MacOS versions? Or can I disable the `operating_system` entry in some way? If possible to disable, would it have any consequence on built packages?\n", "before_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport argparse\nimport sys\nfrom six import iteritems\n\nimport llnl.util.tty as tty\nimport spack.compilers\nimport spack.config\nimport spack.spec\nfrom llnl.util.lang import index_by\nfrom llnl.util.tty.colify import colify\nfrom llnl.util.tty.color import colorize\nfrom spack.spec import CompilerSpec, ArchSpec\n\ndescription = \"manage compilers\"\nsection = \"system\"\nlevel = \"long\"\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(\n metavar='SUBCOMMAND', dest='compiler_command')\n\n scopes = spack.config.scopes()\n scopes_metavar = spack.config.scopes_metavar\n\n # Find\n find_parser = sp.add_parser(\n 'find', aliases=['add'],\n help='search the system for compilers to add to Spack configuration')\n find_parser.add_argument('add_paths', nargs=argparse.REMAINDER)\n find_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # Remove\n remove_parser = sp.add_parser(\n 'remove', aliases=['rm'], help='remove compiler by spec')\n remove_parser.add_argument(\n '-a', '--all', action='store_true',\n help='remove ALL compilers that match spec')\n remove_parser.add_argument('compiler_spec')\n remove_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # List\n list_parser = sp.add_parser('list', help='list available compilers')\n list_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n # Info\n info_parser = sp.add_parser('info', help='show compiler paths')\n info_parser.add_argument('compiler_spec')\n info_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n\ndef compiler_find(args):\n \"\"\"Search either $PATH or a list of paths OR MODULES for compilers and\n add them to Spack's configuration.\n\n \"\"\"\n # None signals spack.compiler.find_compilers to use its default logic\n paths = args.add_paths or None\n\n # Don't initialize compilers config via compilers.get_compiler_config.\n # Just let compiler_find do the\n # entire process and return an empty config from all_compilers\n # Default for any other process is init_config=True\n compilers = [c for c in spack.compilers.find_compilers(paths)]\n new_compilers = []\n for c in compilers:\n arch_spec = ArchSpec((None, c.operating_system, c.target))\n same_specs = spack.compilers.compilers_for_spec(\n c.spec, arch_spec, init_config=False)\n\n if not same_specs:\n new_compilers.append(c)\n\n if new_compilers:\n spack.compilers.add_compilers_to_config(new_compilers,\n scope=args.scope,\n init_config=False)\n n = len(new_compilers)\n s = 's' if n > 1 else ''\n\n config = spack.config.config\n filename = config.get_config_filename(args.scope, 'compilers')\n tty.msg(\"Added %d new compiler%s to %s\" % (n, s, filename))\n colify(reversed(sorted(c.spec for c in new_compilers)), indent=4)\n else:\n tty.msg(\"Found no new compilers\")\n tty.msg(\"Compilers are defined in the following files:\")\n colify(spack.compilers.compiler_config_files(), indent=4)\n\n\ndef compiler_remove(args):\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n if not compilers:\n tty.die(\"No compilers match spec %s\" % cspec)\n elif not args.all and len(compilers) > 1:\n tty.error(\"Multiple compilers match spec %s. Choose one:\" % cspec)\n colify(reversed(sorted([c.spec for c in compilers])), indent=4)\n tty.msg(\"Or, use `spack compiler remove -a` to remove all of them.\")\n sys.exit(1)\n\n for compiler in compilers:\n spack.compilers.remove_compiler_from_config(\n compiler.spec, scope=args.scope)\n tty.msg(\"Removed compiler %s\" % compiler.spec)\n\n\ndef compiler_info(args):\n \"\"\"Print info about all compilers matching a spec.\"\"\"\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n\n if not compilers:\n tty.error(\"No compilers match spec %s\" % cspec)\n else:\n for c in compilers:\n print(str(c.spec) + \":\")\n print(\"\\tpaths:\")\n for cpath in ['cc', 'cxx', 'f77', 'fc']:\n print(\"\\t\\t%s = %s\" % (cpath, getattr(c, cpath, None)))\n if c.flags:\n print(\"\\tflags:\")\n for flag, flag_value in iteritems(c.flags):\n print(\"\\t\\t%s = %s\" % (flag, flag_value))\n if len(c.environment) != 0:\n if len(c.environment['set']) != 0:\n print(\"\\tenvironment:\")\n print(\"\\t set:\")\n for key, value in iteritems(c.environment['set']):\n print(\"\\t %s = %s\" % (key, value))\n if c.extra_rpaths:\n print(\"\\tExtra rpaths:\")\n for extra_rpath in c.extra_rpaths:\n print(\"\\t\\t%s\" % extra_rpath)\n print(\"\\tmodules = %s\" % c.modules)\n print(\"\\toperating system = %s\" % c.operating_system)\n\n\ndef compiler_list(args):\n tty.msg(\"Available compilers\")\n index = index_by(spack.compilers.all_compilers(scope=args.scope),\n lambda c: (c.spec.name, c.operating_system, c.target))\n ordered_sections = sorted(index.items(), key=lambda item: item[0])\n for i, (key, compilers) in enumerate(ordered_sections):\n if i >= 1:\n print()\n name, os, target = key\n os_str = os\n if target:\n os_str += \"-%s\" % target\n cname = \"%s{%s} %s\" % (spack.spec.compiler_color, name, os_str)\n tty.hline(colorize(cname), char='-')\n colify(reversed(sorted(c.spec for c in compilers)))\n\n\ndef compiler(parser, args):\n action = {'add': compiler_find,\n 'find': compiler_find,\n 'remove': compiler_remove,\n 'rm': compiler_remove,\n 'info': compiler_info,\n 'list': compiler_list}\n action[args.compiler_command](args)\n", "path": "lib/spack/spack/cmd/compiler.py"}]}
| 2,836 | 152 |
gh_patches_debug_3083
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-462
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Device Support Request] Philips Hue Power Cycle Attribute
Hi
It would be great to have the Philips Hue Power Cycle attribute added. This allows for the bulb to remain powered on, off or set to previous settings when powered on.
The vendor attribute is `0x4003` and falls part of the `0x0006` (on_off) cluster. The possible values (enum8) are
```
Off = 0x00
On = 0x01
Previous = 0xff
```
The device signature for the ambient color bulb is as follows:
```
{
"node_descriptor": "<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>",
"endpoints": {
"11": {
"profile_id": 49246,
"device_type": "0x0210",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x0300",
"0x1000",
"0xfc01"
],
"out_clusters": [
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [
"0x0021"
],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "Philips",
"model": "LCT015",
"class": "zigpy.device.Device"
}
```
The device signature for the dimmable white bulb is as follows:
```
{
"node_descriptor": "<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>",
"endpoints": {
"11": {
"profile_id": 49246,
"device_type": "0x0100",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x1000"
],
"out_clusters": [
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [
"0x0021"
],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "Philips",
"model": "LWB010",
"class": "zigpy.device.Device"
}
```
I hope this is all that is needed to implement this. Please let me know if there anything you need.
Thanks.
Kurt
</issue>
<code>
[start of zhaquirks/philips/__init__.py]
1 """Module for Philips quirks implementations."""
2 import logging
3
4 from zigpy.quirks import CustomCluster
5 import zigpy.types as t
6 from zigpy.zcl.clusters.general import Basic, OnOff
7
8 from ..const import (
9 ARGS,
10 BUTTON,
11 COMMAND,
12 COMMAND_ID,
13 DIM_DOWN,
14 DIM_UP,
15 LONG_PRESS,
16 LONG_RELEASE,
17 PRESS_TYPE,
18 SHORT_PRESS,
19 SHORT_RELEASE,
20 TURN_OFF,
21 TURN_ON,
22 ZHA_SEND_EVENT,
23 )
24
25 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
26 PHILIPS = "Philips"
27 _LOGGER = logging.getLogger(__name__)
28
29 HUE_REMOTE_DEVICE_TRIGGERS = {
30 (SHORT_PRESS, TURN_ON): {COMMAND: "on_press"},
31 (SHORT_PRESS, TURN_OFF): {COMMAND: "off_press"},
32 (SHORT_PRESS, DIM_UP): {COMMAND: "up_press"},
33 (SHORT_PRESS, DIM_DOWN): {COMMAND: "down_press"},
34 (LONG_PRESS, TURN_ON): {COMMAND: "on_hold"},
35 (LONG_PRESS, TURN_OFF): {COMMAND: "off_hold"},
36 (LONG_PRESS, DIM_UP): {COMMAND: "up_hold"},
37 (LONG_PRESS, DIM_DOWN): {COMMAND: "down_hold"},
38 (SHORT_RELEASE, TURN_ON): {COMMAND: "on_short_release"},
39 (SHORT_RELEASE, TURN_OFF): {COMMAND: "off_short_release"},
40 (SHORT_RELEASE, DIM_UP): {COMMAND: "up_short_release"},
41 (SHORT_RELEASE, DIM_DOWN): {COMMAND: "down_short_release"},
42 (LONG_RELEASE, TURN_ON): {COMMAND: "on_long_release"},
43 (LONG_RELEASE, TURN_OFF): {COMMAND: "off_long_release"},
44 (LONG_RELEASE, DIM_UP): {COMMAND: "up_long_release"},
45 (LONG_RELEASE, DIM_DOWN): {COMMAND: "down_long_release"},
46 }
47
48
49 class PowerOnState(t.enum8):
50 """Philips power on state enum."""
51
52 Off = 0x00
53 On = 0x01
54 LastState = 0xFF
55
56
57 class PhilipsOnOffCluster(CustomCluster, OnOff):
58 """Philips OnOff cluster."""
59
60 manufacturer_attributes = {0x4003: ("power_on_state", PowerOnState)}
61
62
63 class PhilipsBasicCluster(CustomCluster, Basic):
64 """Philips Basic cluster."""
65
66 manufacturer_attributes = {0x0031: ("philips", t.bitmap16)}
67
68 attr_config = {0x0031: 0x000B}
69
70 async def bind(self):
71 """Bind cluster."""
72 result = await super().bind()
73 await self.write_attributes(self.attr_config, manufacturer=0x100B)
74 return result
75
76
77 class PhilipsRemoteCluster(CustomCluster):
78 """Philips remote cluster."""
79
80 cluster_id = 64512
81 name = "PhilipsRemoteCluster"
82 ep_attribute = "philips_remote_cluster"
83 manufacturer_client_commands = {
84 0x0000: (
85 "notification",
86 (t.uint8_t, t.uint24_t, t.uint8_t, t.uint8_t, t.uint8_t, t.uint8_t),
87 False,
88 )
89 }
90 BUTTONS = {1: "on", 2: "up", 3: "down", 4: "off"}
91 PRESS_TYPES = {0: "press", 1: "hold", 2: "short_release", 3: "long_release"}
92
93 def handle_cluster_request(self, tsn, command_id, args):
94 """Handle the cluster command."""
95 _LOGGER.debug(
96 "PhilipsRemoteCluster - handle_cluster_request tsn: [%s] command id: %s - args: [%s]",
97 tsn,
98 command_id,
99 args,
100 )
101 button = self.BUTTONS.get(args[0], args[0])
102 press_type = self.PRESS_TYPES.get(args[2], args[2])
103
104 event_args = {
105 BUTTON: button,
106 PRESS_TYPE: press_type,
107 COMMAND_ID: command_id,
108 ARGS: args,
109 }
110 action = "{}_{}".format(button, press_type)
111 self.listener_event(ZHA_SEND_EVENT, action, event_args)
112
[end of zhaquirks/philips/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zhaquirks/philips/__init__.py b/zhaquirks/philips/__init__.py
--- a/zhaquirks/philips/__init__.py
+++ b/zhaquirks/philips/__init__.py
@@ -57,7 +57,8 @@
class PhilipsOnOffCluster(CustomCluster, OnOff):
"""Philips OnOff cluster."""
- manufacturer_attributes = {0x4003: ("power_on_state", PowerOnState)}
+ attributes = OnOff.attributes.copy()
+ attributes.update({0x4003: ("power_on_state", PowerOnState)})
class PhilipsBasicCluster(CustomCluster, Basic):
|
{"golden_diff": "diff --git a/zhaquirks/philips/__init__.py b/zhaquirks/philips/__init__.py\n--- a/zhaquirks/philips/__init__.py\n+++ b/zhaquirks/philips/__init__.py\n@@ -57,7 +57,8 @@\n class PhilipsOnOffCluster(CustomCluster, OnOff):\n \"\"\"Philips OnOff cluster.\"\"\"\n \n- manufacturer_attributes = {0x4003: (\"power_on_state\", PowerOnState)}\n+ attributes = OnOff.attributes.copy()\n+ attributes.update({0x4003: (\"power_on_state\", PowerOnState)})\n \n \n class PhilipsBasicCluster(CustomCluster, Basic):\n", "issue": "[Device Support Request] Philips Hue Power Cycle Attribute\nHi \r\n\r\nIt would be great to have the Philips Hue Power Cycle attribute added. This allows for the bulb to remain powered on, off or set to previous settings when powered on.\r\n\r\nThe vendor attribute is `0x4003` and falls part of the `0x0006` (on_off) cluster. The possible values (enum8) are \r\n\r\n```\r\nOff = 0x00\r\nOn = 0x01\r\nPrevious = 0xff\r\n```\r\n\r\nThe device signature for the ambient color bulb is as follows:\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>\",\r\n \"endpoints\": {\r\n \"11\": {\r\n \"profile_id\": 49246,\r\n \"device_type\": \"0x0210\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x0300\",\r\n \"0x1000\",\r\n \"0xfc01\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [\r\n \"0x0021\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"Philips\",\r\n \"model\": \"LCT015\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\nThe device signature for the dimmable white bulb is as follows:\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>\",\r\n \"endpoints\": {\r\n \"11\": {\r\n \"profile_id\": 49246,\r\n \"device_type\": \"0x0100\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x1000\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [\r\n \"0x0021\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"Philips\",\r\n \"model\": \"LWB010\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\nI hope this is all that is needed to implement this. Please let me know if there anything you need.\r\n\r\nThanks.\r\n\r\nKurt \n", "before_files": [{"content": "\"\"\"Module for Philips quirks implementations.\"\"\"\nimport logging\n\nfrom zigpy.quirks import CustomCluster\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import Basic, OnOff\n\nfrom ..const import (\n ARGS,\n BUTTON,\n COMMAND,\n COMMAND_ID,\n DIM_DOWN,\n DIM_UP,\n LONG_PRESS,\n LONG_RELEASE,\n PRESS_TYPE,\n SHORT_PRESS,\n SHORT_RELEASE,\n TURN_OFF,\n TURN_ON,\n ZHA_SEND_EVENT,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nPHILIPS = \"Philips\"\n_LOGGER = logging.getLogger(__name__)\n\nHUE_REMOTE_DEVICE_TRIGGERS = {\n (SHORT_PRESS, TURN_ON): {COMMAND: \"on_press\"},\n (SHORT_PRESS, TURN_OFF): {COMMAND: \"off_press\"},\n (SHORT_PRESS, DIM_UP): {COMMAND: \"up_press\"},\n (SHORT_PRESS, DIM_DOWN): {COMMAND: \"down_press\"},\n (LONG_PRESS, TURN_ON): {COMMAND: \"on_hold\"},\n (LONG_PRESS, TURN_OFF): {COMMAND: \"off_hold\"},\n (LONG_PRESS, DIM_UP): {COMMAND: \"up_hold\"},\n (LONG_PRESS, DIM_DOWN): {COMMAND: \"down_hold\"},\n (SHORT_RELEASE, TURN_ON): {COMMAND: \"on_short_release\"},\n (SHORT_RELEASE, TURN_OFF): {COMMAND: \"off_short_release\"},\n (SHORT_RELEASE, DIM_UP): {COMMAND: \"up_short_release\"},\n (SHORT_RELEASE, DIM_DOWN): {COMMAND: \"down_short_release\"},\n (LONG_RELEASE, TURN_ON): {COMMAND: \"on_long_release\"},\n (LONG_RELEASE, TURN_OFF): {COMMAND: \"off_long_release\"},\n (LONG_RELEASE, DIM_UP): {COMMAND: \"up_long_release\"},\n (LONG_RELEASE, DIM_DOWN): {COMMAND: \"down_long_release\"},\n}\n\n\nclass PowerOnState(t.enum8):\n \"\"\"Philips power on state enum.\"\"\"\n\n Off = 0x00\n On = 0x01\n LastState = 0xFF\n\n\nclass PhilipsOnOffCluster(CustomCluster, OnOff):\n \"\"\"Philips OnOff cluster.\"\"\"\n\n manufacturer_attributes = {0x4003: (\"power_on_state\", PowerOnState)}\n\n\nclass PhilipsBasicCluster(CustomCluster, Basic):\n \"\"\"Philips Basic cluster.\"\"\"\n\n manufacturer_attributes = {0x0031: (\"philips\", t.bitmap16)}\n\n attr_config = {0x0031: 0x000B}\n\n async def bind(self):\n \"\"\"Bind cluster.\"\"\"\n result = await super().bind()\n await self.write_attributes(self.attr_config, manufacturer=0x100B)\n return result\n\n\nclass PhilipsRemoteCluster(CustomCluster):\n \"\"\"Philips remote cluster.\"\"\"\n\n cluster_id = 64512\n name = \"PhilipsRemoteCluster\"\n ep_attribute = \"philips_remote_cluster\"\n manufacturer_client_commands = {\n 0x0000: (\n \"notification\",\n (t.uint8_t, t.uint24_t, t.uint8_t, t.uint8_t, t.uint8_t, t.uint8_t),\n False,\n )\n }\n BUTTONS = {1: \"on\", 2: \"up\", 3: \"down\", 4: \"off\"}\n PRESS_TYPES = {0: \"press\", 1: \"hold\", 2: \"short_release\", 3: \"long_release\"}\n\n def handle_cluster_request(self, tsn, command_id, args):\n \"\"\"Handle the cluster command.\"\"\"\n _LOGGER.debug(\n \"PhilipsRemoteCluster - handle_cluster_request tsn: [%s] command id: %s - args: [%s]\",\n tsn,\n command_id,\n args,\n )\n button = self.BUTTONS.get(args[0], args[0])\n press_type = self.PRESS_TYPES.get(args[2], args[2])\n\n event_args = {\n BUTTON: button,\n PRESS_TYPE: press_type,\n COMMAND_ID: command_id,\n ARGS: args,\n }\n action = \"{}_{}\".format(button, press_type)\n self.listener_event(ZHA_SEND_EVENT, action, event_args)\n", "path": "zhaquirks/philips/__init__.py"}]}
| 2,473 | 152 |
gh_patches_debug_5500
|
rasdani/github-patches
|
git_diff
|
tensorflow__tfx-3813
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update tensorflow-hub requirement to allow 0.12.0?
If the feature is related to a specific library below, please raise an issue in
the respective repo directly:
[TensorFlow Data Validation Repo](https://github.com/tensorflow/data-validation/issues)
[TensorFlow Model Analysis Repo](https://github.com/tensorflow/model-analysis/issues)
[TensorFlow Transform Repo](https://github.com/tensorflow/transform/issues)
[TensorFlow Serving Repo](https://github.com/tensorflow/serving/issues)
**System information**
- TFX Version (you are using): 1.0.0-rc0
- Environment in which you plan to use the feature (e.g., Local
(Linux/MacOS/Windows), Interactive Notebook, Google Cloud, etc..): MacOS, AWS
- Are you willing to contribute it (Yes/No): Yes
**Describe the feature and the current behavior/state.**
tfx (1.0.0-rc0) currently depends on tensorflow-hub (>=0.9.0,<0.10)
I was wondering if we could update tensorflow-hub dependancy for tfx to allow tf-hub 0.12.0, so something like (>=0.9.0,<=0.12.0)?
I am not sure if that would break anything in tfx, but I am happy to investigate and contribute to this change
**Will this change the current API? How?**
No
**Who will benefit with this feature?**
tensorflow-hub has added some new features in 0.10.0 and beyond (specifically the one I'm interested in "`compute_output_shape` in `hub.KerasLayer`" which they added in 0.12.0). It would be cool to be able to take advantage of those while still being able to use tfx
**Do you have a workaround or are completely blocked by this?** :
Blocked
**Name of your Organization (Optional)**
**Any Other info.**
</issue>
<code>
[start of tfx/dependencies.py]
1 # Copyright 2019 Google LLC. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Package dependencies for TFX.
15
16 tfx and family libraries (such as tensorflow-model-analysis) adopts environment
17 variable (TFX_DEPENDENCY_SELECTOR) based dependency version selection. This
18 dependency will be baked in to the wheel, in other words you cannot change
19 dependency string once wheel is built.
20
21 - UNCONSTRAINED uses dependency without any version constraint string, which is
22 useful when you manually build wheels of parent library (e.g. tfx-bsl) of
23 arbitrary version, and install it without dependency constraints conflict.
24 - NIGHTLY uses x.(y+1).0.dev version as a lower version constraint. tfx nightly
25 will transitively depend on nightly versions of other TFX family libraries,
26 and this version constraint is required.
27 - GIT_MASTER uses github master branch URL of the dependency, which is useful
28 during development, or when depending on the github master HEAD version of
29 tfx. This is because tfx github master HEAD version is actually using github
30 master HEAD version of parent libraries.
31 Caveat: URL dependency is not upgraded with --upgrade flag, and you have to
32 specify --force-reinstall flag to fetch the latest change from each master
33 branch HEAD.
34 - For the release, we use a range of version, which is also used as a default.
35 """
36 import os
37
38
39 def select_constraint(default, nightly=None, git_master=None):
40 """Select dependency constraint based on TFX_DEPENDENCY_SELECTOR env var."""
41 selector = os.environ.get('TFX_DEPENDENCY_SELECTOR')
42 if selector == 'UNCONSTRAINED':
43 return ''
44 elif selector == 'NIGHTLY' and nightly is not None:
45 return nightly
46 elif selector == 'GIT_MASTER' and git_master is not None:
47 return git_master
48 else:
49 return default
50
51
52 def make_pipeline_sdk_required_install_packages():
53 return [
54 'absl-py>=0.9,<0.13',
55 'ml-metadata' + select_constraint(
56 # LINT.IfChange
57 default='>=0.30,<0.31',
58 # LINT.ThenChange(tfx/workspace.bzl)
59 nightly='>=0.31.0.dev',
60 git_master='@git+https://github.com/google/ml-metadata@master'),
61 'packaging>=20,<21',
62 'portpicker>=1.3.1,<2',
63 'protobuf>=3.12.2,<4',
64 'docker>=4.1,<5',
65 # TODO(b/176812386): Deprecate usage of jinja2 for placeholders.
66 'jinja2>=2.7.3,<3',
67 ]
68
69
70 def make_required_install_packages():
71 # Make sure to sync the versions of common dependencies (absl-py, numpy,
72 # and protobuf) with TF.
73 return make_pipeline_sdk_required_install_packages() + [
74 'apache-beam[gcp]>=2.29,<3',
75 'attrs>=19.3.0,<21',
76 'click>=7,<8',
77 'google-api-python-client>=1.7.8,<2',
78 'google-cloud-aiplatform>=0.5.0,<0.8',
79 'google-cloud-bigquery>=1.28.0,<3',
80 'grpcio>=1.28.1,<2',
81 # TODO(b/173976603): remove pinned keras-tuner upperbound when its
82 # dependency expecatation with TensorFlow is sorted out.
83 'keras-tuner>=1,<1.0.2',
84 'kubernetes>=10.0.1,<12',
85 # TODO(b/179195488): remove numpy dependency after 1.20 migration.
86 # This dependency was added only to limit numpy 1.20 installation.
87 'numpy>=1.16,<1.20',
88 'pyarrow>=1,<3',
89 'pyyaml>=3.12,<6',
90 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
91 'tensorflow-hub>=0.9.0,<0.10',
92 'tensorflow-data-validation' + select_constraint(
93 default='>=0.30,<0.31',
94 nightly='>=0.31.0.dev',
95 git_master='@git+https://github.com/tensorflow/data-validation@master'
96 ),
97 'tensorflow-model-analysis' + select_constraint(
98 default='>=0.30,<0.31',
99 nightly='>=0.31.0.dev',
100 git_master='@git+https://github.com/tensorflow/model-analysis@master'
101 ),
102 'tensorflow-serving-api>=1.15,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
103 'tensorflow-transform' + select_constraint(
104 default='>=0.30,<0.31',
105 nightly='>=0.31.0.dev',
106 git_master='@git+https://github.com/tensorflow/transform@master'),
107 'tfx-bsl' + select_constraint(
108 default='>=0.30,<0.31',
109 nightly='>=0.31.0.dev',
110 git_master='@git+https://github.com/tensorflow/tfx-bsl@master'),
111 ]
112
113
114 def make_extra_packages_airflow():
115 """Prepare extra packages needed for Apache Airflow orchestrator."""
116 return [
117 # TODO(b/188940096): update supported version.
118 'apache-airflow[mysql]>=1.10.14,!=2.1.*,<3',
119 # TODO(b/182848576): Delete pinned sqlalchemy after apache-airflow 2.0.2
120 # or later.(github.com/apache/airflow/issues/14811)
121 'sqlalchemy>=1.3,<1.4',
122 ]
123
124
125 def make_extra_packages_kfp():
126 """Prepare extra packages needed for Kubeflow Pipelines orchestrator."""
127 return [
128 'kfp>=1.1.0,<2',
129 'kfp-pipeline-spec>=0.1.7,<0.2',
130 ]
131
132
133 def make_extra_packages_test():
134 """Prepare extra packages needed for running unit tests."""
135 # Note: It is okay to pin packages to exact versions in this list to minimize
136 # conflicts.
137 return make_extra_packages_airflow() + make_extra_packages_kfp() + [
138 'pytest>=5,<6',
139 ]
140
141
142 def make_extra_packages_docker_image():
143 # Packages needed for tfx docker image.
144 return [
145 'kfp-pipeline-spec>=0.1.7,<0.2',
146 'mmh>=2.2,<3',
147 'python-snappy>=0.5,<0.6',
148 ]
149
150
151 def make_extra_packages_tfjs():
152 # Packages needed for tfjs.
153 return [
154 'tensorflowjs>=3.6.0,<4',
155 ]
156
157
158 def make_extra_packages_tf_ranking():
159 # Packages needed for tf-ranking which is used in tfx/examples/ranking.
160 return [
161 'tensorflow-ranking>=0.3.3,<0.4',
162 'struct2tensor' + select_constraint(
163 default='>=0.30,<0.31',
164 nightly='>=0.31.0.dev',
165 git_master='@git+https://github.com/google/struct2tensor@master'),
166 ]
167
168
169 def make_extra_packages_examples():
170 # Extra dependencies required for tfx/examples.
171 return [
172 # Required for presto ExampleGen custom component in
173 # tfx/examples/custom_components/presto_example_gen
174 'presto-python-client>=0.7,<0.8',
175 # Required for slack custom component in
176 # tfx/examples/custom_components/slack
177 'slackclient>=2.8.2,<3',
178 'websocket-client>=0.57,<1',
179 # Required for bert examples in tfx/examples/bert
180 'tensorflow-text>=1.15.1,<3',
181 # Required for tfx/examples/cifar10
182 'flatbuffers>=1.12,<2',
183 'tflite-support>=0.1.0a1,<0.1.1',
184 # Required for tfx/examples/penguin/experimental
185 # LINT.IfChange
186 'scikit-learn>=0.23,<0.24',
187 # LINT.ThenChange(
188 # examples/penguin/experimental/penguin_pipeline_sklearn_gcp.py)
189 # Required for the experimental tfx/examples using Flax, e.g.,
190 # tfx/examples/penguin.
191 'jax>=0.2.13,<0.3',
192 'jaxlib>=0.1.64,<0.2',
193 'flax>=0.3.3,<0.4',
194 # Required for tfx/examples/penguin/penguin_utils_cloud_tuner.py
195 'tensorflow-cloud>=0.1,<0.2',
196 ]
197
198
199 def make_extra_packages_all():
200 # All extra dependencies.
201 return [
202 *make_extra_packages_test(),
203 *make_extra_packages_tfjs(),
204 *make_extra_packages_tf_ranking(),
205 *make_extra_packages_examples(),
206 ]
207
[end of tfx/dependencies.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tfx/dependencies.py b/tfx/dependencies.py
--- a/tfx/dependencies.py
+++ b/tfx/dependencies.py
@@ -88,7 +88,7 @@
'pyarrow>=1,<3',
'pyyaml>=3.12,<6',
'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
- 'tensorflow-hub>=0.9.0,<0.10',
+ 'tensorflow-hub>=0.9.0,<=0.12.0',
'tensorflow-data-validation' + select_constraint(
default='>=0.30,<0.31',
nightly='>=0.31.0.dev',
|
{"golden_diff": "diff --git a/tfx/dependencies.py b/tfx/dependencies.py\n--- a/tfx/dependencies.py\n+++ b/tfx/dependencies.py\n@@ -88,7 +88,7 @@\n 'pyarrow>=1,<3',\n 'pyyaml>=3.12,<6',\n 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n- 'tensorflow-hub>=0.9.0,<0.10',\n+ 'tensorflow-hub>=0.9.0,<=0.12.0',\n 'tensorflow-data-validation' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n", "issue": "Update tensorflow-hub requirement to allow 0.12.0?\nIf the feature is related to a specific library below, please raise an issue in\r\nthe respective repo directly:\r\n\r\n[TensorFlow Data Validation Repo](https://github.com/tensorflow/data-validation/issues)\r\n\r\n[TensorFlow Model Analysis Repo](https://github.com/tensorflow/model-analysis/issues)\r\n\r\n[TensorFlow Transform Repo](https://github.com/tensorflow/transform/issues)\r\n\r\n[TensorFlow Serving Repo](https://github.com/tensorflow/serving/issues)\r\n\r\n**System information**\r\n\r\n- TFX Version (you are using): 1.0.0-rc0\r\n- Environment in which you plan to use the feature (e.g., Local\r\n (Linux/MacOS/Windows), Interactive Notebook, Google Cloud, etc..): MacOS, AWS\r\n- Are you willing to contribute it (Yes/No): Yes\r\n\r\n**Describe the feature and the current behavior/state.**\r\ntfx (1.0.0-rc0) currently depends on tensorflow-hub (>=0.9.0,<0.10)\r\n\r\nI was wondering if we could update tensorflow-hub dependancy for tfx to allow tf-hub 0.12.0, so something like (>=0.9.0,<=0.12.0)?\r\n\r\nI am not sure if that would break anything in tfx, but I am happy to investigate and contribute to this change\r\n\r\n**Will this change the current API? How?**\r\nNo\r\n\r\n**Who will benefit with this feature?**\r\ntensorflow-hub has added some new features in 0.10.0 and beyond (specifically the one I'm interested in \"`compute_output_shape` in `hub.KerasLayer`\" which they added in 0.12.0). It would be cool to be able to take advantage of those while still being able to use tfx\r\n\r\n**Do you have a workaround or are completely blocked by this?** :\r\nBlocked\r\n\r\n**Name of your Organization (Optional)**\r\n\r\n\r\n**Any Other info.**\r\n\n", "before_files": [{"content": "# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Package dependencies for TFX.\n\ntfx and family libraries (such as tensorflow-model-analysis) adopts environment\nvariable (TFX_DEPENDENCY_SELECTOR) based dependency version selection. This\ndependency will be baked in to the wheel, in other words you cannot change\ndependency string once wheel is built.\n\n- UNCONSTRAINED uses dependency without any version constraint string, which is\n useful when you manually build wheels of parent library (e.g. tfx-bsl) of\n arbitrary version, and install it without dependency constraints conflict.\n- NIGHTLY uses x.(y+1).0.dev version as a lower version constraint. tfx nightly\n will transitively depend on nightly versions of other TFX family libraries,\n and this version constraint is required.\n- GIT_MASTER uses github master branch URL of the dependency, which is useful\n during development, or when depending on the github master HEAD version of\n tfx. This is because tfx github master HEAD version is actually using github\n master HEAD version of parent libraries.\n Caveat: URL dependency is not upgraded with --upgrade flag, and you have to\n specify --force-reinstall flag to fetch the latest change from each master\n branch HEAD.\n- For the release, we use a range of version, which is also used as a default.\n\"\"\"\nimport os\n\n\ndef select_constraint(default, nightly=None, git_master=None):\n \"\"\"Select dependency constraint based on TFX_DEPENDENCY_SELECTOR env var.\"\"\"\n selector = os.environ.get('TFX_DEPENDENCY_SELECTOR')\n if selector == 'UNCONSTRAINED':\n return ''\n elif selector == 'NIGHTLY' and nightly is not None:\n return nightly\n elif selector == 'GIT_MASTER' and git_master is not None:\n return git_master\n else:\n return default\n\n\ndef make_pipeline_sdk_required_install_packages():\n return [\n 'absl-py>=0.9,<0.13',\n 'ml-metadata' + select_constraint(\n # LINT.IfChange\n default='>=0.30,<0.31',\n # LINT.ThenChange(tfx/workspace.bzl)\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/ml-metadata@master'),\n 'packaging>=20,<21',\n 'portpicker>=1.3.1,<2',\n 'protobuf>=3.12.2,<4',\n 'docker>=4.1,<5',\n # TODO(b/176812386): Deprecate usage of jinja2 for placeholders.\n 'jinja2>=2.7.3,<3',\n ]\n\n\ndef make_required_install_packages():\n # Make sure to sync the versions of common dependencies (absl-py, numpy,\n # and protobuf) with TF.\n return make_pipeline_sdk_required_install_packages() + [\n 'apache-beam[gcp]>=2.29,<3',\n 'attrs>=19.3.0,<21',\n 'click>=7,<8',\n 'google-api-python-client>=1.7.8,<2',\n 'google-cloud-aiplatform>=0.5.0,<0.8',\n 'google-cloud-bigquery>=1.28.0,<3',\n 'grpcio>=1.28.1,<2',\n # TODO(b/173976603): remove pinned keras-tuner upperbound when its\n # dependency expecatation with TensorFlow is sorted out.\n 'keras-tuner>=1,<1.0.2',\n 'kubernetes>=10.0.1,<12',\n # TODO(b/179195488): remove numpy dependency after 1.20 migration.\n # This dependency was added only to limit numpy 1.20 installation.\n 'numpy>=1.16,<1.20',\n 'pyarrow>=1,<3',\n 'pyyaml>=3.12,<6',\n 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-hub>=0.9.0,<0.10',\n 'tensorflow-data-validation' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/data-validation@master'\n ),\n 'tensorflow-model-analysis' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/model-analysis@master'\n ),\n 'tensorflow-serving-api>=1.15,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-transform' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/transform@master'),\n 'tfx-bsl' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/tfx-bsl@master'),\n ]\n\n\ndef make_extra_packages_airflow():\n \"\"\"Prepare extra packages needed for Apache Airflow orchestrator.\"\"\"\n return [\n # TODO(b/188940096): update supported version.\n 'apache-airflow[mysql]>=1.10.14,!=2.1.*,<3',\n # TODO(b/182848576): Delete pinned sqlalchemy after apache-airflow 2.0.2\n # or later.(github.com/apache/airflow/issues/14811)\n 'sqlalchemy>=1.3,<1.4',\n ]\n\n\ndef make_extra_packages_kfp():\n \"\"\"Prepare extra packages needed for Kubeflow Pipelines orchestrator.\"\"\"\n return [\n 'kfp>=1.1.0,<2',\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n ]\n\n\ndef make_extra_packages_test():\n \"\"\"Prepare extra packages needed for running unit tests.\"\"\"\n # Note: It is okay to pin packages to exact versions in this list to minimize\n # conflicts.\n return make_extra_packages_airflow() + make_extra_packages_kfp() + [\n 'pytest>=5,<6',\n ]\n\n\ndef make_extra_packages_docker_image():\n # Packages needed for tfx docker image.\n return [\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n 'mmh>=2.2,<3',\n 'python-snappy>=0.5,<0.6',\n ]\n\n\ndef make_extra_packages_tfjs():\n # Packages needed for tfjs.\n return [\n 'tensorflowjs>=3.6.0,<4',\n ]\n\n\ndef make_extra_packages_tf_ranking():\n # Packages needed for tf-ranking which is used in tfx/examples/ranking.\n return [\n 'tensorflow-ranking>=0.3.3,<0.4',\n 'struct2tensor' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/struct2tensor@master'),\n ]\n\n\ndef make_extra_packages_examples():\n # Extra dependencies required for tfx/examples.\n return [\n # Required for presto ExampleGen custom component in\n # tfx/examples/custom_components/presto_example_gen\n 'presto-python-client>=0.7,<0.8',\n # Required for slack custom component in\n # tfx/examples/custom_components/slack\n 'slackclient>=2.8.2,<3',\n 'websocket-client>=0.57,<1',\n # Required for bert examples in tfx/examples/bert\n 'tensorflow-text>=1.15.1,<3',\n # Required for tfx/examples/cifar10\n 'flatbuffers>=1.12,<2',\n 'tflite-support>=0.1.0a1,<0.1.1',\n # Required for tfx/examples/penguin/experimental\n # LINT.IfChange\n 'scikit-learn>=0.23,<0.24',\n # LINT.ThenChange(\n # examples/penguin/experimental/penguin_pipeline_sklearn_gcp.py)\n # Required for the experimental tfx/examples using Flax, e.g.,\n # tfx/examples/penguin.\n 'jax>=0.2.13,<0.3',\n 'jaxlib>=0.1.64,<0.2',\n 'flax>=0.3.3,<0.4',\n # Required for tfx/examples/penguin/penguin_utils_cloud_tuner.py\n 'tensorflow-cloud>=0.1,<0.2',\n ]\n\n\ndef make_extra_packages_all():\n # All extra dependencies.\n return [\n *make_extra_packages_test(),\n *make_extra_packages_tfjs(),\n *make_extra_packages_tf_ranking(),\n *make_extra_packages_examples(),\n ]\n", "path": "tfx/dependencies.py"}]}
| 3,645 | 179 |
gh_patches_debug_6040
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-2956
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ONNX error converting torch.mean
I've been working to convert some models using sentence embeddings via ONNX and have run into the following error while running `torch.onnx._export`:
`RuntimeError: PythonOp doesn't define symbolic Mean`
I also had this error when trying to implement my own "mean" operation using add and divide.
</issue>
<code>
[start of torch/autograd/_functions/reduce.py]
1 from functools import reduce
2
3 from ..function import Function
4 from ..variable import Variable
5 import torch
6
7
8 class Sum(Function):
9
10 @staticmethod
11 def forward(ctx, input, dim=None, keepdim=None):
12 ctx.dim = dim
13 ctx.keepdim = False if keepdim is None else keepdim
14 ctx.input_size = input.size()
15 if dim is None:
16 return input.new((input.sum(),))
17 else:
18 if keepdim is not None:
19 return input.sum(dim, keepdim=keepdim)
20 else:
21 return input.sum(dim)
22
23 @staticmethod
24 def backward(ctx, grad_output):
25 if ctx.dim is None:
26 return grad_output.expand(ctx.input_size), None, None
27 else:
28 if ctx.keepdim is False and len(ctx.input_size) != 1:
29 grad_output = grad_output.unsqueeze(ctx.dim)
30
31 repeats = [1 for _ in ctx.input_size]
32 repeats[ctx.dim] = ctx.input_size[ctx.dim]
33 return grad_output.repeat(*repeats), None, None
34
35
36 class Prod(Function):
37
38 @staticmethod
39 def forward(ctx, input, dim=None, keepdim=None):
40 ctx.dim = dim
41 ctx.keepdim = False if keepdim is None else keepdim
42 ctx.input_size = input.size()
43 if dim is None:
44 ctx.result = input.prod()
45 ctx.save_for_backward(input)
46 return input.new((ctx.result,))
47 else:
48 if keepdim is not None:
49 output = input.prod(dim, keepdim=keepdim)
50 else:
51 output = input.prod(dim)
52 ctx.save_for_backward(input, output)
53 return output
54
55 @staticmethod
56 def backward(ctx, grad_output):
57 def safe_zeros_backward(inp, dim):
58 # note that the gradient is equivalent to:
59 # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:
60 # input: [ a, b, c]
61 # cumprod(exclusive, normal): [1 , a, a * b]
62 # cumprod(exclusive, reverse): [b * c, c, 1]
63 # product: [b * c, a * c, a * b]
64 # and this is safe under input with 0s.
65 if inp.size(dim) == 1:
66 return grad_output
67
68 ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))
69 ones = Variable(grad_output.data.new(ones_size).fill_(1))
70 exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)
71 exclusive_normal = exclusive_normal_nocp.cumprod(dim)
72
73 def reverse_dim(var, dim):
74 index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))
75 return var.index_select(dim, index)
76
77 narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)
78 exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)
79 exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)
80
81 grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))
82 return grad_input
83
84 if ctx.dim is None:
85 input, = ctx.saved_variables
86 zero_idx = (input.data == 0).nonzero()
87 if zero_idx.dim() == 0:
88 return grad_output.mul(ctx.result).expand_as(input).div(input), None, None
89 elif zero_idx.size(0) > 1:
90 return (grad_output * 0).expand_as(input), None, None
91 else:
92 return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None
93
94 else:
95 input, output = ctx.saved_variables
96 dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()
97 if ctx.keepdim is False and len(ctx.input_size) != 1:
98 grad_output = grad_output.unsqueeze(dim)
99 output = output.unsqueeze(dim)
100
101 zero_mask = input == 0
102 slice_zero_count = zero_mask.sum(dim, True)
103 total_zeros = slice_zero_count.data.sum()
104 if total_zeros == 0:
105 grad_input = grad_output.mul(output).expand_as(input).div(input)
106 else:
107 grad_input = safe_zeros_backward(input, dim)
108
109 return grad_input, None, None
110
111
112 class Mean(Function):
113
114 @staticmethod
115 def forward(ctx, input, dim=None, keepdim=None):
116 ctx.dim = dim
117 ctx.keepdim = False if keepdim is None else keepdim
118 ctx.input_size = input.size()
119 if dim is None:
120 return input.new((input.mean(),))
121 else:
122 if keepdim is not None:
123 return input.mean(dim, keepdim=keepdim)
124 else:
125 return input.mean(dim)
126
127 @staticmethod
128 def backward(ctx, grad_output):
129 if ctx.dim is None:
130 grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)
131 return grad_input_val.expand(ctx.input_size), None, None
132 else:
133 if ctx.keepdim is False and len(ctx.input_size) != 1:
134 grad_output = grad_output.unsqueeze(ctx.dim)
135
136 repeats = [1 for _ in ctx.input_size]
137 dim_size = ctx.input_size[ctx.dim]
138 repeats[ctx.dim] = dim_size
139 return grad_output.repeat(*repeats).div_(dim_size), None, None
140
141
142 class _SelectionFunction(Function):
143 has_all_reduce = True
144 # additional_args is prepended before dim when calling the tensor
145 # function. It's a no-op for subclasses other than kthvalue.
146 # kthvalue not only requires us to pass a dim, but also precede it with k.
147
148 @classmethod
149 def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):
150 fn = getattr(input, cls.__name__.lower())
151 ctx.dim = dim
152 ctx.keepdim = False if keepdim is None else keepdim
153 ctx.additional_args = additional_args
154 ctx.input_size = input.size()
155 if ctx.dim is None and cls.has_all_reduce:
156 value = fn(*additional_args)
157 ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])
158 return input.new((value,))
159 else:
160 if ctx.dim is None:
161 dim = input.dim() - 1
162 else:
163 dim = ctx.dim
164 args = (dim,)
165 if additional_args:
166 args = additional_args + args
167 if keepdim is not None:
168 output, indices = fn(*args, keepdim=keepdim)
169 else:
170 output, indices = fn(*args)
171 ctx.save_for_backward(indices)
172 ctx.mark_non_differentiable(indices)
173 return output, indices
174
175 @classmethod
176 def backward(cls, ctx, grad_output, grad_indices=None):
177 grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())
178 if ctx.dim is None and cls.has_all_reduce:
179 grad_input[ctx.indices_tuple] = grad_output
180 else:
181 if ctx.dim is None:
182 dim = len(ctx.input_size) - 1
183 else:
184 dim = ctx.dim
185
186 indices, = ctx.saved_variables
187 if ctx.keepdim is False and len(ctx.input_size) != 1:
188 grad_output = grad_output.unsqueeze(dim)
189 grad_indices = grad_indices.unsqueeze(dim)
190 indices = indices.unsqueeze(dim)
191
192 grad_input.scatter_(dim, indices, grad_output)
193 return grad_input, None, None, None
194
195
196 class Max(_SelectionFunction):
197 pass
198
199
200 class Min(_SelectionFunction):
201 pass
202
203
204 class Mode(_SelectionFunction):
205 has_all_reduce = False
206
207
208 class Median(_SelectionFunction):
209 pass
210
211
212 class Kthvalue(_SelectionFunction):
213 has_all_reduce = False
214
215 @classmethod
216 def forward(cls, ctx, input, k, dim=None, keepdim=None):
217 return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))
218
219
220 class Norm(Function):
221
222 @staticmethod
223 def forward(ctx, input, p=2, dim=None, keepdim=None):
224 ctx.p = p
225 ctx.dim = dim
226 ctx.keepdim = False if keepdim is None else keepdim
227
228 if dim is None:
229 norm = input.norm(p)
230 output = input.new((norm,))
231 else:
232 if keepdim is not None:
233 output = input.norm(p, dim, keepdim=keepdim)
234 else:
235 output = input.norm(p, dim)
236 ctx.save_for_backward(input, output)
237 return output
238
239 @staticmethod
240 def backward(ctx, grad_output):
241 input, output = ctx.saved_variables
242 if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:
243 grad_output = grad_output.unsqueeze(ctx.dim)
244 output = output.unsqueeze(ctx.dim)
245
246 if ctx.p == 2:
247 grad_input = input.mul(grad_output).div(output)
248 else:
249 input_pow = input.abs().pow(ctx.p - 2)
250 output_pow = output.pow(ctx.p - 1)
251 grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)
252
253 # Special case at 0 where we return a subgradient containing 0
254 grad_input.masked_fill_(output == 0, 0)
255
256 return grad_input, None, None, None
257
258
259 # TODO: renorm
260 # TODO: std
261 # TODO: var
262
[end of torch/autograd/_functions/reduce.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py
--- a/torch/autograd/_functions/reduce.py
+++ b/torch/autograd/_functions/reduce.py
@@ -111,6 +111,15 @@
class Mean(Function):
+ @staticmethod
+ def symbolic(g, input, dim=None, keepdim=None):
+ output = g.create("ReduceMean", [input])
+ if dim is not None:
+ output = output.is_("axes", dim)
+ if keepdim is None or keepdim is False:
+ output = output.i_("keepdims", 0)
+ return g.appendNode(output)
+
@staticmethod
def forward(ctx, input, dim=None, keepdim=None):
ctx.dim = dim
|
{"golden_diff": "diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py\n--- a/torch/autograd/_functions/reduce.py\n+++ b/torch/autograd/_functions/reduce.py\n@@ -111,6 +111,15 @@\n \n class Mean(Function):\n \n+ @staticmethod\n+ def symbolic(g, input, dim=None, keepdim=None):\n+ output = g.create(\"ReduceMean\", [input])\n+ if dim is not None:\n+ output = output.is_(\"axes\", dim)\n+ if keepdim is None or keepdim is False:\n+ output = output.i_(\"keepdims\", 0)\n+ return g.appendNode(output)\n+\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n", "issue": "ONNX error converting torch.mean\nI've been working to convert some models using sentence embeddings via ONNX and have run into the following error while running `torch.onnx._export`: \r\n`RuntimeError: PythonOp doesn't define symbolic Mean`\r\n\r\nI also had this error when trying to implement my own \"mean\" operation using add and divide. \n", "before_files": [{"content": "from functools import reduce\n\nfrom ..function import Function\nfrom ..variable import Variable\nimport torch\n\n\nclass Sum(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.sum(),))\n else:\n if keepdim is not None:\n return input.sum(dim, keepdim=keepdim)\n else:\n return input.sum(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n return grad_output.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n repeats[ctx.dim] = ctx.input_size[ctx.dim]\n return grad_output.repeat(*repeats), None, None\n\n\nclass Prod(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n ctx.result = input.prod()\n ctx.save_for_backward(input)\n return input.new((ctx.result,))\n else:\n if keepdim is not None:\n output = input.prod(dim, keepdim=keepdim)\n else:\n output = input.prod(dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n def safe_zeros_backward(inp, dim):\n # note that the gradient is equivalent to:\n # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:\n # input: [ a, b, c]\n # cumprod(exclusive, normal): [1 , a, a * b]\n # cumprod(exclusive, reverse): [b * c, c, 1]\n # product: [b * c, a * c, a * b]\n # and this is safe under input with 0s.\n if inp.size(dim) == 1:\n return grad_output\n\n ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))\n ones = Variable(grad_output.data.new(ones_size).fill_(1))\n exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)\n exclusive_normal = exclusive_normal_nocp.cumprod(dim)\n\n def reverse_dim(var, dim):\n index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))\n return var.index_select(dim, index)\n\n narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)\n exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)\n exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)\n\n grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))\n return grad_input\n\n if ctx.dim is None:\n input, = ctx.saved_variables\n zero_idx = (input.data == 0).nonzero()\n if zero_idx.dim() == 0:\n return grad_output.mul(ctx.result).expand_as(input).div(input), None, None\n elif zero_idx.size(0) > 1:\n return (grad_output * 0).expand_as(input), None, None\n else:\n return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None\n\n else:\n input, output = ctx.saved_variables\n dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n output = output.unsqueeze(dim)\n\n zero_mask = input == 0\n slice_zero_count = zero_mask.sum(dim, True)\n total_zeros = slice_zero_count.data.sum()\n if total_zeros == 0:\n grad_input = grad_output.mul(output).expand_as(input).div(input)\n else:\n grad_input = safe_zeros_backward(input, dim)\n\n return grad_input, None, None\n\n\nclass Mean(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.mean(),))\n else:\n if keepdim is not None:\n return input.mean(dim, keepdim=keepdim)\n else:\n return input.mean(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)\n return grad_input_val.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n dim_size = ctx.input_size[ctx.dim]\n repeats[ctx.dim] = dim_size\n return grad_output.repeat(*repeats).div_(dim_size), None, None\n\n\nclass _SelectionFunction(Function):\n has_all_reduce = True\n # additional_args is prepended before dim when calling the tensor\n # function. It's a no-op for subclasses other than kthvalue.\n # kthvalue not only requires us to pass a dim, but also precede it with k.\n\n @classmethod\n def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):\n fn = getattr(input, cls.__name__.lower())\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.additional_args = additional_args\n ctx.input_size = input.size()\n if ctx.dim is None and cls.has_all_reduce:\n value = fn(*additional_args)\n ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])\n return input.new((value,))\n else:\n if ctx.dim is None:\n dim = input.dim() - 1\n else:\n dim = ctx.dim\n args = (dim,)\n if additional_args:\n args = additional_args + args\n if keepdim is not None:\n output, indices = fn(*args, keepdim=keepdim)\n else:\n output, indices = fn(*args)\n ctx.save_for_backward(indices)\n ctx.mark_non_differentiable(indices)\n return output, indices\n\n @classmethod\n def backward(cls, ctx, grad_output, grad_indices=None):\n grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())\n if ctx.dim is None and cls.has_all_reduce:\n grad_input[ctx.indices_tuple] = grad_output\n else:\n if ctx.dim is None:\n dim = len(ctx.input_size) - 1\n else:\n dim = ctx.dim\n\n indices, = ctx.saved_variables\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n grad_indices = grad_indices.unsqueeze(dim)\n indices = indices.unsqueeze(dim)\n\n grad_input.scatter_(dim, indices, grad_output)\n return grad_input, None, None, None\n\n\nclass Max(_SelectionFunction):\n pass\n\n\nclass Min(_SelectionFunction):\n pass\n\n\nclass Mode(_SelectionFunction):\n has_all_reduce = False\n\n\nclass Median(_SelectionFunction):\n pass\n\n\nclass Kthvalue(_SelectionFunction):\n has_all_reduce = False\n\n @classmethod\n def forward(cls, ctx, input, k, dim=None, keepdim=None):\n return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))\n\n\nclass Norm(Function):\n\n @staticmethod\n def forward(ctx, input, p=2, dim=None, keepdim=None):\n ctx.p = p\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n\n if dim is None:\n norm = input.norm(p)\n output = input.new((norm,))\n else:\n if keepdim is not None:\n output = input.norm(p, dim, keepdim=keepdim)\n else:\n output = input.norm(p, dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n input, output = ctx.saved_variables\n if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n output = output.unsqueeze(ctx.dim)\n\n if ctx.p == 2:\n grad_input = input.mul(grad_output).div(output)\n else:\n input_pow = input.abs().pow(ctx.p - 2)\n output_pow = output.pow(ctx.p - 1)\n grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)\n\n # Special case at 0 where we return a subgradient containing 0\n grad_input.masked_fill_(output == 0, 0)\n\n return grad_input, None, None, None\n\n\n# TODO: renorm\n# TODO: std\n# TODO: var\n", "path": "torch/autograd/_functions/reduce.py"}]}
| 3,410 | 184 |
gh_patches_debug_12565
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-2305
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
evolve_all "all" is not working
### Expected Behavior
Bot would try to evolve all eligible pokemon when "evolve_all": "all" is set
### Actual Behavior
Bot does not evolve anything when "evolve_all": "all" is set. If I set it to "evolve_all": "all,Weedle" I get the following output:
```
[19:11:08] Starting PokemonGo Bot....
[19:11:09] [x] Current egg hatches in 0.85 km
[19:11:10] [#] Successfully evolved Weedle with 180 CP and 0.4 IV!
[19:11:13] [#] Successfully evolved Weedle with 113 CP and 0.51 IV!
```
### Steps to Reproduce
Set "evolve_all" to all on this commit
### Other Information
OS: Ubuntu 14.04.4 LTS
Git Commit: eee7ba49c5c4e6bb1b3efefcf9f99a7c72a48671
Python Version: python 2.7.6
</issue>
<code>
[start of pokemongo_bot/cell_workers/evolve_all.py]
1 from pokemongo_bot import logger
2 from pokemongo_bot.human_behaviour import sleep
3 from pokemongo_bot.item_list import Item
4 from pokemongo_bot.cell_workers.base_task import BaseTask
5
6 class EvolveAll(BaseTask):
7 def initialize(self):
8 self.evolve_all = self.config.get('evolve_all', [])
9 self.evolve_speed = self.config.get('evolve_speed', 3.7)
10 self.evolve_cp_min = self.config.get('evolve_cp_min', 300)
11 self.use_lucky_egg = self.config.get('use_lucky_egg', False)
12
13 def _validate_config(self):
14 if isinstance(self.evolve_all, str):
15 self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]
16
17 def work(self):
18 if not self._should_run():
19 return
20
21 response_dict = self.bot.get_inventory()
22 cache = {}
23
24 try:
25 reduce(dict.__getitem__, [
26 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
27 except KeyError:
28 pass
29 else:
30 evolve_list = self._sort_by_cp_iv(
31 response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])
32 if self.evolve_all[0] != 'all':
33 # filter out non-listed pokemons
34 evolve_list = [x for x in evolve_list if str(x[1]) in self.evolve_all]
35
36 # enable to limit number of pokemons to evolve. Useful for testing.
37 # nn = 3
38 # if len(evolve_list) > nn:
39 # evolve_list = evolve_list[:nn]
40 #
41
42 id_list1 = self.count_pokemon_inventory()
43 for pokemon in evolve_list:
44 try:
45 self._execute_pokemon_evolve(pokemon, cache)
46 except Exception:
47 pass
48 id_list2 = self.count_pokemon_inventory()
49 release_cand_list_ids = list(set(id_list2) - set(id_list1))
50
51 if release_cand_list_ids:
52 logger.log('[#] Evolved {} pokemons! Checking if any of them needs to be released ...'.format(
53 len(release_cand_list_ids)
54 ))
55 self._release_evolved(release_cand_list_ids)
56
57 def _should_run(self):
58 # Will skip evolving if user wants to use an egg and there is none
59 if not self.evolve_all:
60 return False
61
62 # Evolve all is used - Don't run after the first tick or if the config flag is false
63 if self.bot.tick_count is not 1 or not self.use_lucky_egg:
64 return True
65
66 lucky_egg_count = self.bot.item_inventory_count(Item.ITEM_LUCKY_EGG.value)
67
68 # Lucky Egg should only be popped at the first tick
69 # Make sure the user has a lucky egg and skip if not
70 if lucky_egg_count > 0:
71 logger.log('Using lucky egg ... you have {}'.format(lucky_egg_count))
72 response_dict_lucky_egg = self.bot.use_lucky_egg()
73 if response_dict_lucky_egg and 'responses' in response_dict_lucky_egg and \
74 'USE_ITEM_XP_BOOST' in response_dict_lucky_egg['responses'] and \
75 'result' in response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']:
76 result = response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']['result']
77 if result is 1: # Request success
78 logger.log('Successfully used lucky egg... ({} left!)'.format(lucky_egg_count - 1), 'green')
79 return True
80 else:
81 logger.log('Failed to use lucky egg!', 'red')
82 return False
83 else:
84 # Skipping evolve so they aren't wasted
85 logger.log('No lucky eggs... skipping evolve!', 'yellow')
86 return False
87
88 def _release_evolved(self, release_cand_list_ids):
89 response_dict = self.bot.get_inventory()
90 cache = {}
91
92 try:
93 reduce(dict.__getitem__, [
94 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
95 except KeyError:
96 pass
97 else:
98 release_cand_list = self._sort_by_cp_iv(
99 response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])
100 release_cand_list = [x for x in release_cand_list if x[0] in release_cand_list_ids]
101
102 ## at this point release_cand_list contains evolved pokemons data
103 for cand in release_cand_list:
104 pokemon_id = cand[0]
105 pokemon_name = cand[1]
106 pokemon_cp = cand[2]
107 pokemon_potential = cand[3]
108
109 if self.should_release_pokemon(pokemon_name, pokemon_cp, pokemon_potential):
110 # Transfering Pokemon
111 self.transfer_pokemon(pokemon_id)
112 logger.log(
113 '[#] {} has been exchanged for candy!'.format(pokemon_name), 'red')
114
115 def _sort_by_cp_iv(self, inventory_items):
116 pokemons1 = []
117 pokemons2 = []
118 for item in inventory_items:
119 try:
120 reduce(dict.__getitem__, [
121 "inventory_item_data", "pokemon_data"], item)
122 except KeyError:
123 pass
124 else:
125 try:
126 pokemon = item['inventory_item_data']['pokemon_data']
127 pokemon_num = int(pokemon['pokemon_id']) - 1
128 pokemon_name = self.bot.pokemon_list[int(pokemon_num)]['Name']
129 v = [
130 pokemon['id'],
131 pokemon_name,
132 pokemon['cp'],
133 self._compute_iv(pokemon)
134 ]
135 if pokemon['cp'] > self.evolve_cp_min:
136 pokemons1.append(v)
137 else:
138 pokemons2.append(v)
139 except Exception:
140 pass
141
142 # Sort larger CP pokemons by IV, tie breaking by CP
143 pokemons1.sort(key=lambda x: (x[3], x[2]), reverse=True)
144
145 # Sort smaller CP pokemons by CP, tie breaking by IV
146 pokemons2.sort(key=lambda x: (x[2], x[3]), reverse=True)
147
148 return pokemons1 + pokemons2
149
150 def _execute_pokemon_evolve(self, pokemon, cache):
151 pokemon_id = pokemon[0]
152 pokemon_name = pokemon[1]
153 pokemon_cp = pokemon[2]
154 pokemon_iv = pokemon[3]
155
156 if pokemon_name in cache:
157 return
158
159 self.bot.api.evolve_pokemon(pokemon_id=pokemon_id)
160 response_dict = self.bot.api.call()
161 status = response_dict['responses']['EVOLVE_POKEMON']['result']
162 if status == 1:
163 logger.log('[#] Successfully evolved {} with {} CP and {} IV!'.format(
164 pokemon_name, pokemon_cp, pokemon_iv
165 ))
166
167 sleep(self.evolve_speed)
168
169 else:
170 # cache pokemons we can't evolve. Less server calls
171 cache[pokemon_name] = 1
172 sleep(0.7)
173
174 # TODO: move to utils. These methods are shared with other workers.
175 def transfer_pokemon(self, pid):
176 self.bot.api.release_pokemon(pokemon_id=pid)
177 response_dict = self.bot.api.call()
178
179 def count_pokemon_inventory(self):
180 response_dict = self.bot.get_inventory()
181 id_list = []
182 return self.counting_pokemon(response_dict, id_list)
183
184 def counting_pokemon(self, response_dict, id_list):
185 try:
186 reduce(dict.__getitem__, [
187 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
188 except KeyError:
189 pass
190 else:
191 for item in response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items']:
192 try:
193 reduce(dict.__getitem__, [
194 "inventory_item_data", "pokemon_data"], item)
195 except KeyError:
196 pass
197 else:
198 pokemon = item['inventory_item_data']['pokemon_data']
199 if pokemon.get('is_egg', False):
200 continue
201 id_list.append(pokemon['id'])
202
203 return id_list
204
205 def should_release_pokemon(self, pokemon_name, cp, iv):
206 if self._check_always_capture_exception_for(pokemon_name):
207 return False
208 else:
209 release_config = self._get_release_config_for(pokemon_name)
210 cp_iv_logic = release_config.get('logic')
211 if not cp_iv_logic:
212 cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')
213
214 release_results = {
215 'cp': False,
216 'iv': False,
217 }
218
219 if 'release_below_cp' in release_config:
220 min_cp = release_config['release_below_cp']
221 if cp < min_cp:
222 release_results['cp'] = True
223
224 if 'release_below_iv' in release_config:
225 min_iv = release_config['release_below_iv']
226 if iv < min_iv:
227 release_results['iv'] = True
228
229 if release_config.get('always_release'):
230 return True
231
232 logic_to_function = {
233 'or': lambda x, y: x or y,
234 'and': lambda x, y: x and y
235 }
236
237 # logger.log(
238 # "[x] Release config for {}: CP {} {} IV {}".format(
239 # pokemon_name,
240 # min_cp,
241 # cp_iv_logic,
242 # min_iv
243 # ), 'yellow'
244 # )
245
246 return logic_to_function[cp_iv_logic](*release_results.values())
247
248 def _get_release_config_for(self, pokemon):
249 release_config = self.bot.config.release.get(pokemon)
250 if not release_config:
251 release_config = self.bot.config.release['any']
252 return release_config
253
254 def _get_exceptions(self):
255 exceptions = self.bot.config.release.get('exceptions')
256 if not exceptions:
257 return None
258 return exceptions
259
260 def _get_always_capture_list(self):
261 exceptions = self._get_exceptions()
262 if not exceptions:
263 return []
264 always_capture_list = exceptions['always_capture']
265 if not always_capture_list:
266 return []
267 return always_capture_list
268
269 def _check_always_capture_exception_for(self, pokemon_name):
270 always_capture_list = self._get_always_capture_list()
271 if not always_capture_list:
272 return False
273 else:
274 for pokemon in always_capture_list:
275 if pokemon_name == str(pokemon):
276 return True
277 return False
278
279 # TODO: should also go to util and refactor in catch worker
280 def _compute_iv(self, pokemon):
281 total_IV = 0.0
282 iv_stats = ['individual_attack', 'individual_defense', 'individual_stamina']
283
284 for individual_stat in iv_stats:
285 try:
286 total_IV += pokemon[individual_stat]
287 except Exception:
288 pokemon[individual_stat] = 0
289 continue
290 pokemon_potential = round((total_IV / 45.0), 2)
291 return pokemon_potential
292
[end of pokemongo_bot/cell_workers/evolve_all.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pokemongo_bot/cell_workers/evolve_all.py b/pokemongo_bot/cell_workers/evolve_all.py
--- a/pokemongo_bot/cell_workers/evolve_all.py
+++ b/pokemongo_bot/cell_workers/evolve_all.py
@@ -9,9 +9,10 @@
self.evolve_speed = self.config.get('evolve_speed', 3.7)
self.evolve_cp_min = self.config.get('evolve_cp_min', 300)
self.use_lucky_egg = self.config.get('use_lucky_egg', False)
+ self._validate_config()
def _validate_config(self):
- if isinstance(self.evolve_all, str):
+ if isinstance(self.evolve_all, basestring):
self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]
def work(self):
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/evolve_all.py b/pokemongo_bot/cell_workers/evolve_all.py\n--- a/pokemongo_bot/cell_workers/evolve_all.py\n+++ b/pokemongo_bot/cell_workers/evolve_all.py\n@@ -9,9 +9,10 @@\n self.evolve_speed = self.config.get('evolve_speed', 3.7)\n self.evolve_cp_min = self.config.get('evolve_cp_min', 300)\n self.use_lucky_egg = self.config.get('use_lucky_egg', False)\n+ self._validate_config()\n \n def _validate_config(self):\n- if isinstance(self.evolve_all, str):\n+ if isinstance(self.evolve_all, basestring):\n self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]\n \n def work(self):\n", "issue": "evolve_all \"all\" is not working\n### Expected Behavior\n\nBot would try to evolve all eligible pokemon when \"evolve_all\": \"all\" is set\n### Actual Behavior\n\nBot does not evolve anything when \"evolve_all\": \"all\" is set. If I set it to \"evolve_all\": \"all,Weedle\" I get the following output: \n\n```\n[19:11:08] Starting PokemonGo Bot....\n[19:11:09] [x] Current egg hatches in 0.85 km\n[19:11:10] [#] Successfully evolved Weedle with 180 CP and 0.4 IV!\n[19:11:13] [#] Successfully evolved Weedle with 113 CP and 0.51 IV!\n```\n### Steps to Reproduce\n\nSet \"evolve_all\" to all on this commit\n### Other Information\n\nOS: Ubuntu 14.04.4 LTS\nGit Commit: eee7ba49c5c4e6bb1b3efefcf9f99a7c72a48671\nPython Version: python 2.7.6\n\n", "before_files": [{"content": "from pokemongo_bot import logger\nfrom pokemongo_bot.human_behaviour import sleep\nfrom pokemongo_bot.item_list import Item\nfrom pokemongo_bot.cell_workers.base_task import BaseTask\n\nclass EvolveAll(BaseTask):\n def initialize(self):\n self.evolve_all = self.config.get('evolve_all', [])\n self.evolve_speed = self.config.get('evolve_speed', 3.7)\n self.evolve_cp_min = self.config.get('evolve_cp_min', 300)\n self.use_lucky_egg = self.config.get('use_lucky_egg', False)\n\n def _validate_config(self):\n if isinstance(self.evolve_all, str):\n self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]\n\n def work(self):\n if not self._should_run():\n return\n\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n evolve_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n if self.evolve_all[0] != 'all':\n # filter out non-listed pokemons\n evolve_list = [x for x in evolve_list if str(x[1]) in self.evolve_all]\n\n # enable to limit number of pokemons to evolve. Useful for testing.\n # nn = 3\n # if len(evolve_list) > nn:\n # evolve_list = evolve_list[:nn]\n #\n\n id_list1 = self.count_pokemon_inventory()\n for pokemon in evolve_list:\n try:\n self._execute_pokemon_evolve(pokemon, cache)\n except Exception:\n pass\n id_list2 = self.count_pokemon_inventory()\n release_cand_list_ids = list(set(id_list2) - set(id_list1))\n\n if release_cand_list_ids:\n logger.log('[#] Evolved {} pokemons! Checking if any of them needs to be released ...'.format(\n len(release_cand_list_ids)\n ))\n self._release_evolved(release_cand_list_ids)\n\n def _should_run(self):\n # Will skip evolving if user wants to use an egg and there is none\n if not self.evolve_all:\n return False\n\n # Evolve all is used - Don't run after the first tick or if the config flag is false\n if self.bot.tick_count is not 1 or not self.use_lucky_egg:\n return True\n\n lucky_egg_count = self.bot.item_inventory_count(Item.ITEM_LUCKY_EGG.value)\n\n # Lucky Egg should only be popped at the first tick\n # Make sure the user has a lucky egg and skip if not\n if lucky_egg_count > 0:\n logger.log('Using lucky egg ... you have {}'.format(lucky_egg_count))\n response_dict_lucky_egg = self.bot.use_lucky_egg()\n if response_dict_lucky_egg and 'responses' in response_dict_lucky_egg and \\\n 'USE_ITEM_XP_BOOST' in response_dict_lucky_egg['responses'] and \\\n 'result' in response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']:\n result = response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']['result']\n if result is 1: # Request success\n logger.log('Successfully used lucky egg... ({} left!)'.format(lucky_egg_count - 1), 'green')\n return True\n else:\n logger.log('Failed to use lucky egg!', 'red')\n return False\n else:\n # Skipping evolve so they aren't wasted\n logger.log('No lucky eggs... skipping evolve!', 'yellow')\n return False\n\n def _release_evolved(self, release_cand_list_ids):\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n release_cand_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n release_cand_list = [x for x in release_cand_list if x[0] in release_cand_list_ids]\n\n ## at this point release_cand_list contains evolved pokemons data\n for cand in release_cand_list:\n pokemon_id = cand[0]\n pokemon_name = cand[1]\n pokemon_cp = cand[2]\n pokemon_potential = cand[3]\n\n if self.should_release_pokemon(pokemon_name, pokemon_cp, pokemon_potential):\n # Transfering Pokemon\n self.transfer_pokemon(pokemon_id)\n logger.log(\n '[#] {} has been exchanged for candy!'.format(pokemon_name), 'red')\n\n def _sort_by_cp_iv(self, inventory_items):\n pokemons1 = []\n pokemons2 = []\n for item in inventory_items:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n try:\n pokemon = item['inventory_item_data']['pokemon_data']\n pokemon_num = int(pokemon['pokemon_id']) - 1\n pokemon_name = self.bot.pokemon_list[int(pokemon_num)]['Name']\n v = [\n pokemon['id'],\n pokemon_name,\n pokemon['cp'],\n self._compute_iv(pokemon)\n ]\n if pokemon['cp'] > self.evolve_cp_min:\n pokemons1.append(v)\n else:\n pokemons2.append(v)\n except Exception:\n pass\n\n # Sort larger CP pokemons by IV, tie breaking by CP\n pokemons1.sort(key=lambda x: (x[3], x[2]), reverse=True)\n\n # Sort smaller CP pokemons by CP, tie breaking by IV\n pokemons2.sort(key=lambda x: (x[2], x[3]), reverse=True)\n\n return pokemons1 + pokemons2\n\n def _execute_pokemon_evolve(self, pokemon, cache):\n pokemon_id = pokemon[0]\n pokemon_name = pokemon[1]\n pokemon_cp = pokemon[2]\n pokemon_iv = pokemon[3]\n\n if pokemon_name in cache:\n return\n\n self.bot.api.evolve_pokemon(pokemon_id=pokemon_id)\n response_dict = self.bot.api.call()\n status = response_dict['responses']['EVOLVE_POKEMON']['result']\n if status == 1:\n logger.log('[#] Successfully evolved {} with {} CP and {} IV!'.format(\n pokemon_name, pokemon_cp, pokemon_iv\n ))\n\n sleep(self.evolve_speed)\n\n else:\n # cache pokemons we can't evolve. Less server calls\n cache[pokemon_name] = 1\n sleep(0.7)\n\n # TODO: move to utils. These methods are shared with other workers.\n def transfer_pokemon(self, pid):\n self.bot.api.release_pokemon(pokemon_id=pid)\n response_dict = self.bot.api.call()\n\n def count_pokemon_inventory(self):\n response_dict = self.bot.get_inventory()\n id_list = []\n return self.counting_pokemon(response_dict, id_list)\n\n def counting_pokemon(self, response_dict, id_list):\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n for item in response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items']:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n pokemon = item['inventory_item_data']['pokemon_data']\n if pokemon.get('is_egg', False):\n continue\n id_list.append(pokemon['id'])\n\n return id_list\n\n def should_release_pokemon(self, pokemon_name, cp, iv):\n if self._check_always_capture_exception_for(pokemon_name):\n return False\n else:\n release_config = self._get_release_config_for(pokemon_name)\n cp_iv_logic = release_config.get('logic')\n if not cp_iv_logic:\n cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')\n\n release_results = {\n 'cp': False,\n 'iv': False,\n }\n\n if 'release_below_cp' in release_config:\n min_cp = release_config['release_below_cp']\n if cp < min_cp:\n release_results['cp'] = True\n\n if 'release_below_iv' in release_config:\n min_iv = release_config['release_below_iv']\n if iv < min_iv:\n release_results['iv'] = True\n\n if release_config.get('always_release'):\n return True\n\n logic_to_function = {\n 'or': lambda x, y: x or y,\n 'and': lambda x, y: x and y\n }\n\n # logger.log(\n # \"[x] Release config for {}: CP {} {} IV {}\".format(\n # pokemon_name,\n # min_cp,\n # cp_iv_logic,\n # min_iv\n # ), 'yellow'\n # )\n\n return logic_to_function[cp_iv_logic](*release_results.values())\n\n def _get_release_config_for(self, pokemon):\n release_config = self.bot.config.release.get(pokemon)\n if not release_config:\n release_config = self.bot.config.release['any']\n return release_config\n\n def _get_exceptions(self):\n exceptions = self.bot.config.release.get('exceptions')\n if not exceptions:\n return None\n return exceptions\n\n def _get_always_capture_list(self):\n exceptions = self._get_exceptions()\n if not exceptions:\n return []\n always_capture_list = exceptions['always_capture']\n if not always_capture_list:\n return []\n return always_capture_list\n\n def _check_always_capture_exception_for(self, pokemon_name):\n always_capture_list = self._get_always_capture_list()\n if not always_capture_list:\n return False\n else:\n for pokemon in always_capture_list:\n if pokemon_name == str(pokemon):\n return True\n return False\n\n # TODO: should also go to util and refactor in catch worker\n def _compute_iv(self, pokemon):\n total_IV = 0.0\n iv_stats = ['individual_attack', 'individual_defense', 'individual_stamina']\n\n for individual_stat in iv_stats:\n try:\n total_IV += pokemon[individual_stat]\n except Exception:\n pokemon[individual_stat] = 0\n continue\n pokemon_potential = round((total_IV / 45.0), 2)\n return pokemon_potential\n", "path": "pokemongo_bot/cell_workers/evolve_all.py"}]}
| 3,973 | 202 |
gh_patches_debug_10785
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-916
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Show output of nvcc after stacktrace
In the current implementation, `nvcc` prints error messages in stdout/stderr before stack trace is printed. It is hard to read.
</issue>
<code>
[start of cupy/cuda/compiler.py]
1 import hashlib
2 import os
3 import re
4 import subprocess
5 import sys
6 import tempfile
7
8 import filelock
9 import six
10
11 from cupy.cuda import device
12 from cupy.cuda import function
13
14
15 def _get_arch():
16 cc = device.Device().compute_capability
17 return 'sm_%s' % cc
18
19
20 class TemporaryDirectory(object):
21
22 def __enter__(self):
23 self.path = tempfile.mkdtemp()
24 return self.path
25
26 def __exit__(self, exc_type, exc_value, traceback):
27 if exc_value is not None:
28 return
29
30 for name in os.listdir(self.path):
31 os.unlink(os.path.join(self.path, name))
32 os.rmdir(self.path)
33
34
35 def _run_nvcc(cmd, cwd):
36 try:
37 return subprocess.check_output(cmd, cwd=cwd)
38 except OSError as e:
39 msg = 'Failed to run `nvcc` command. ' \
40 'Check PATH environment variable: ' \
41 + str(e)
42 raise OSError(msg)
43
44
45 def nvcc(source, options=(), arch=None):
46 if not arch:
47 arch = _get_arch()
48 cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)
49
50 with TemporaryDirectory() as root_dir:
51 path = os.path.join(root_dir, 'kern')
52 cu_path = '%s.cu' % path
53 cubin_path = '%s.cubin' % path
54
55 with open(cu_path, 'w') as cu_file:
56 cu_file.write(source)
57
58 cmd.append(cu_path)
59 _run_nvcc(cmd, root_dir)
60
61 with open(cubin_path, 'rb') as bin_file:
62 return bin_file.read()
63
64
65 def preprocess(source, options=()):
66 cmd = ['nvcc', '--preprocess'] + list(options)
67 with TemporaryDirectory() as root_dir:
68 path = os.path.join(root_dir, 'kern')
69 cu_path = '%s.cu' % path
70
71 with open(cu_path, 'w') as cu_file:
72 cu_file.write(source)
73
74 cmd.append(cu_path)
75 pp_src = _run_nvcc(cmd, root_dir)
76
77 if isinstance(pp_src, six.binary_type):
78 pp_src = pp_src.decode('utf-8')
79 return re.sub('(?m)^#.*$', '', pp_src)
80
81
82 _default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')
83
84
85 def get_cache_dir():
86 return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)
87
88
89 _empty_file_preprocess_cache = {}
90
91
92 def compile_with_cache(source, options=(), arch=None, cache_dir=None):
93 global _empty_file_preprocess_cache
94 if cache_dir is None:
95 cache_dir = get_cache_dir()
96 if arch is None:
97 arch = _get_arch()
98
99 if 'win32' == sys.platform:
100 options += ('-Xcompiler', '/wd 4819')
101 if sys.maxsize == 9223372036854775807:
102 options += '-m64',
103 elif sys.maxsize == 2147483647:
104 options += '-m32',
105
106 env = (arch, options)
107 if '#include' in source:
108 pp_src = '%s %s' % (env, preprocess(source, options))
109 else:
110 base = _empty_file_preprocess_cache.get(env, None)
111 if base is None:
112 base = _empty_file_preprocess_cache[env] = preprocess('', options)
113 pp_src = '%s %s %s' % (env, base, source)
114
115 if isinstance(pp_src, six.text_type):
116 pp_src = pp_src.encode('utf-8')
117 name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()
118
119 mod = function.Module()
120
121 if not os.path.exists(cache_dir):
122 os.makedirs(cache_dir)
123
124 lock_path = os.path.join(cache_dir, 'lock_file.lock')
125
126 path = os.path.join(cache_dir, name)
127 with filelock.FileLock(lock_path) as lock:
128 if os.path.exists(path):
129 with open(path, 'rb') as file:
130 cubin = file.read()
131 mod.load(cubin)
132 else:
133 lock.release()
134 cubin = nvcc(source, options, arch)
135 mod.load(cubin)
136 lock.acquire()
137 with open(path, 'wb') as cubin_file:
138 cubin_file.write(cubin)
139
140 return mod
141
[end of cupy/cuda/compiler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py
--- a/cupy/cuda/compiler.py
+++ b/cupy/cuda/compiler.py
@@ -34,7 +34,14 @@
def _run_nvcc(cmd, cwd):
try:
- return subprocess.check_output(cmd, cwd=cwd)
+ return subprocess.check_output(cmd, cwd=cwd, stderr=subprocess.STDOUT)
+ except subprocess.CalledProcessError as e:
+ msg = ('`nvcc` command returns non-zero exit status. \n'
+ 'command: {0}\n'
+ 'return-code: {1}\n'
+ 'stdout/stderr: \n'
+ '{2}'.format(e.cmd, e.returncode, e.output))
+ raise RuntimeError(msg)
except OSError as e:
msg = 'Failed to run `nvcc` command. ' \
'Check PATH environment variable: ' \
|
{"golden_diff": "diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py\n--- a/cupy/cuda/compiler.py\n+++ b/cupy/cuda/compiler.py\n@@ -34,7 +34,14 @@\n \n def _run_nvcc(cmd, cwd):\n try:\n- return subprocess.check_output(cmd, cwd=cwd)\n+ return subprocess.check_output(cmd, cwd=cwd, stderr=subprocess.STDOUT)\n+ except subprocess.CalledProcessError as e:\n+ msg = ('`nvcc` command returns non-zero exit status. \\n'\n+ 'command: {0}\\n'\n+ 'return-code: {1}\\n'\n+ 'stdout/stderr: \\n'\n+ '{2}'.format(e.cmd, e.returncode, e.output))\n+ raise RuntimeError(msg)\n except OSError as e:\n msg = 'Failed to run `nvcc` command. ' \\\n 'Check PATH environment variable: ' \\\n", "issue": "Show output of nvcc after stacktrace\nIn the current implementation, `nvcc` prints error messages in stdout/stderr before stack trace is printed. It is hard to read.\n\n", "before_files": [{"content": "import hashlib\nimport os\nimport re\nimport subprocess\nimport sys\nimport tempfile\n\nimport filelock\nimport six\n\nfrom cupy.cuda import device\nfrom cupy.cuda import function\n\n\ndef _get_arch():\n cc = device.Device().compute_capability\n return 'sm_%s' % cc\n\n\nclass TemporaryDirectory(object):\n\n def __enter__(self):\n self.path = tempfile.mkdtemp()\n return self.path\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value is not None:\n return\n\n for name in os.listdir(self.path):\n os.unlink(os.path.join(self.path, name))\n os.rmdir(self.path)\n\n\ndef _run_nvcc(cmd, cwd):\n try:\n return subprocess.check_output(cmd, cwd=cwd)\n except OSError as e:\n msg = 'Failed to run `nvcc` command. ' \\\n 'Check PATH environment variable: ' \\\n + str(e)\n raise OSError(msg)\n\n\ndef nvcc(source, options=(), arch=None):\n if not arch:\n arch = _get_arch()\n cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)\n\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n cubin_path = '%s.cubin' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n _run_nvcc(cmd, root_dir)\n\n with open(cubin_path, 'rb') as bin_file:\n return bin_file.read()\n\n\ndef preprocess(source, options=()):\n cmd = ['nvcc', '--preprocess'] + list(options)\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n pp_src = _run_nvcc(cmd, root_dir)\n\n if isinstance(pp_src, six.binary_type):\n pp_src = pp_src.decode('utf-8')\n return re.sub('(?m)^#.*$', '', pp_src)\n\n\n_default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')\n\n\ndef get_cache_dir():\n return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)\n\n\n_empty_file_preprocess_cache = {}\n\n\ndef compile_with_cache(source, options=(), arch=None, cache_dir=None):\n global _empty_file_preprocess_cache\n if cache_dir is None:\n cache_dir = get_cache_dir()\n if arch is None:\n arch = _get_arch()\n\n if 'win32' == sys.platform:\n options += ('-Xcompiler', '/wd 4819')\n if sys.maxsize == 9223372036854775807:\n options += '-m64',\n elif sys.maxsize == 2147483647:\n options += '-m32',\n\n env = (arch, options)\n if '#include' in source:\n pp_src = '%s %s' % (env, preprocess(source, options))\n else:\n base = _empty_file_preprocess_cache.get(env, None)\n if base is None:\n base = _empty_file_preprocess_cache[env] = preprocess('', options)\n pp_src = '%s %s %s' % (env, base, source)\n\n if isinstance(pp_src, six.text_type):\n pp_src = pp_src.encode('utf-8')\n name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()\n\n mod = function.Module()\n\n if not os.path.exists(cache_dir):\n os.makedirs(cache_dir)\n\n lock_path = os.path.join(cache_dir, 'lock_file.lock')\n\n path = os.path.join(cache_dir, name)\n with filelock.FileLock(lock_path) as lock:\n if os.path.exists(path):\n with open(path, 'rb') as file:\n cubin = file.read()\n mod.load(cubin)\n else:\n lock.release()\n cubin = nvcc(source, options, arch)\n mod.load(cubin)\n lock.acquire()\n with open(path, 'wb') as cubin_file:\n cubin_file.write(cubin)\n\n return mod\n", "path": "cupy/cuda/compiler.py"}]}
| 1,882 | 205 |
gh_patches_debug_25333
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1246
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`nikola command --help` should work
Fix upcoming.
</issue>
<code>
[start of nikola/__main__.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 from __future__ import print_function, unicode_literals
28 from operator import attrgetter
29 import os
30 import shutil
31 try:
32 import readline # NOQA
33 except ImportError:
34 pass # This is only so raw_input/input does nicer things if it's available
35 import sys
36 import traceback
37
38 from doit.loader import generate_tasks
39 from doit.cmd_base import TaskLoader
40 from doit.reporter import ExecutedOnlyReporter
41 from doit.doit_cmd import DoitMain
42 from doit.cmd_help import Help as DoitHelp
43 from doit.cmd_run import Run as DoitRun
44 from doit.cmd_clean import Clean as DoitClean
45 from doit.cmd_auto import Auto as DoitAuto
46 from logbook import NullHandler
47
48 from . import __version__
49 from .nikola import Nikola
50 from .utils import _reload, sys_decode, get_root_dir, req_missing, LOGGER, STRICT_HANDLER
51
52
53 config = {}
54
55
56 def main(args=None):
57 if args is None:
58 args = sys.argv[1:]
59 quiet = False
60 if len(args) > 0 and args[0] == b'build' and b'--strict' in args:
61 LOGGER.notice('Running in strict mode')
62 STRICT_HANDLER.push_application()
63 if len(args) > 0 and args[0] == b'build' and b'-q' in args or b'--quiet' in args:
64 nullhandler = NullHandler()
65 nullhandler.push_application()
66 quiet = True
67 global config
68
69 colorful = False
70 if sys.stderr.isatty():
71 colorful = True
72 try:
73 import colorama
74 colorama.init()
75 except ImportError:
76 if os.name == 'nt':
77 colorful = False
78
79 # Those commands do not require a `conf.py`. (Issue #1132)
80 # Moreover, actually having one somewhere in the tree can be bad, putting
81 # the output of that command (the new site) in an unknown directory that is
82 # not the current working directory. (does not apply to `version`)
83 argname = args[0] if len(args) > 0 else None
84 # FIXME there are import plugins in the repo, so how do we handle this?
85 if argname not in ['init', 'import_wordpress', 'import_feed',
86 'import_blogger', 'version']:
87 root = get_root_dir()
88 if root:
89 os.chdir(root)
90
91 sys.path.append('')
92 try:
93 import conf
94 _reload(conf)
95 config = conf.__dict__
96 except Exception:
97 if os.path.exists('conf.py'):
98 msg = traceback.format_exc(0).splitlines()[1]
99 LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))
100 sys.exit(1)
101 config = {}
102
103 invariant = False
104
105 if len(args) > 0 and args[0] == b'build' and b'--invariant' in args:
106 try:
107 import freezegun
108 freeze = freezegun.freeze_time("2014-01-01")
109 freeze.start()
110 invariant = True
111 except ImportError:
112 req_missing(['freezegun'], 'perform invariant builds')
113
114 config['__colorful__'] = colorful
115 config['__invariant__'] = invariant
116
117 site = Nikola(**config)
118 _ = DoitNikola(site, quiet).run(args)
119
120 if site.invariant:
121 freeze.stop()
122 return _
123
124
125 class Help(DoitHelp):
126 """show Nikola usage instead of doit """
127
128 @staticmethod
129 def print_usage(cmds):
130 """print nikola "usage" (basic help) instructions"""
131 print("Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com/\n\n")
132 print("Available commands:")
133 for cmd in sorted(cmds.values(), key=attrgetter('name')):
134 print(" nikola %-*s %s" % (20, cmd.name, cmd.doc_purpose))
135 print("")
136 print(" nikola help show help / reference")
137 print(" nikola help <command> show command usage")
138 print(" nikola help <task-name> show task usage")
139
140
141 class Build(DoitRun):
142 """expose "run" command as "build" for backward compatibility"""
143 def __init__(self, *args, **kw):
144 opts = list(self.cmd_options)
145 opts.append(
146 {
147 'name': 'strict',
148 'long': 'strict',
149 'default': False,
150 'type': bool,
151 'help': "Fail on things that would normally be warnings.",
152 }
153 )
154 opts.append(
155 {
156 'name': 'invariant',
157 'long': 'invariant',
158 'default': False,
159 'type': bool,
160 'help': "Generate invariant output (for testing only!).",
161 }
162 )
163 opts.append(
164 {
165 'name': 'quiet',
166 'long': 'quiet',
167 'short': 'q',
168 'default': False,
169 'type': bool,
170 'help': "Run quietly.",
171 }
172 )
173 self.cmd_options = tuple(opts)
174 super(Build, self).__init__(*args, **kw)
175
176
177 class Clean(DoitClean):
178 """A clean that removes cache/"""
179
180 def clean_tasks(self, tasks, dryrun):
181 if not dryrun and config:
182 cache_folder = config.get('CACHE_FOLDER', 'cache')
183 if os.path.exists(cache_folder):
184 shutil.rmtree(cache_folder)
185 return super(Clean, self).clean_tasks(tasks, dryrun)
186
187 # Nikola has its own "auto" commands that uses livereload.
188 # Expose original doit "auto" command as "doit_auto".
189 DoitAuto.name = 'doit_auto'
190
191
192 class NikolaTaskLoader(TaskLoader):
193 """custom task loader to get tasks from Nikola instead of dodo.py file"""
194 def __init__(self, nikola, quiet=False):
195 self.nikola = nikola
196 self.quiet = quiet
197
198 def load_tasks(self, cmd, opt_values, pos_args):
199 if self.quiet:
200 DOIT_CONFIG = {
201 'verbosity': 0,
202 'reporter': 'zero',
203 }
204 else:
205 DOIT_CONFIG = {
206 'reporter': ExecutedOnlyReporter,
207 }
208 DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']
209 tasks = generate_tasks(
210 'render_site',
211 self.nikola.gen_tasks('render_site', "Task", 'Group of tasks to render the site.'))
212 latetasks = generate_tasks(
213 'post_render',
214 self.nikola.gen_tasks('post_render', "LateTask", 'Group of tasks to be executes after site is rendered.'))
215 return tasks + latetasks, DOIT_CONFIG
216
217
218 class DoitNikola(DoitMain):
219 # overwite help command
220 DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]
221 TASK_LOADER = NikolaTaskLoader
222
223 def __init__(self, nikola, quiet=False):
224 self.nikola = nikola
225 self.task_loader = self.TASK_LOADER(nikola, quiet)
226
227 def get_commands(self):
228 # core doit commands
229 cmds = DoitMain.get_commands(self)
230 # load nikola commands
231 for name, cmd in self.nikola.commands.items():
232 cmds[name] = cmd
233 return cmds
234
235 def run(self, cmd_args):
236 sub_cmds = self.get_commands()
237 args = self.process_args(cmd_args)
238 args = [sys_decode(arg) for arg in args]
239
240 if len(args) == 0 or any(arg in ["--help", '-h'] for arg in args):
241 cmd_args = ['help']
242 args = ['help']
243 # Hide run because Nikola uses build
244 sub_cmds.pop('run')
245 if len(args) == 0 or any(arg in ["--version", '-V'] for arg in args):
246 cmd_args = ['version']
247 args = ['version']
248 if len(args) == 0 or args[0] not in sub_cmds.keys() or \
249 args[0] in (
250 'build',
251 'list',
252 'clean',
253 'doit_auto',
254 'dumpdb',
255 'forget',
256 'ignore',
257 'run',
258 'strace'):
259 # Check for conf.py before launching run
260 if not self.nikola.configured:
261 LOGGER.error("This command needs to run inside an "
262 "existing Nikola site.")
263 return False
264 return super(DoitNikola, self).run(cmd_args)
265
266 @staticmethod
267 def print_version():
268 print("Nikola v" + __version__)
269
270 if __name__ == "__main__":
271 sys.exit(main(sys.argv[1:]))
272
[end of nikola/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/__main__.py b/nikola/__main__.py
--- a/nikola/__main__.py
+++ b/nikola/__main__.py
@@ -237,15 +237,32 @@
args = self.process_args(cmd_args)
args = [sys_decode(arg) for arg in args]
- if len(args) == 0 or any(arg in ["--help", '-h'] for arg in args):
+ if len(args) == 0:
cmd_args = ['help']
args = ['help']
# Hide run because Nikola uses build
sub_cmds.pop('run')
- if len(args) == 0 or any(arg in ["--version", '-V'] for arg in args):
+
+ if '--help' in args or '-h' in args:
+ new_cmd_args = ['help'] + cmd_args
+ new_args = ['help'] + args
+
+ cmd_args = []
+ args = []
+
+ for arg in new_cmd_args:
+ if arg not in ('--help', '-h'):
+ cmd_args.append(arg)
+ for arg in new_args:
+ if arg not in ('--help', '-h'):
+ args.append(arg)
+ # Hide run because Nikola uses build
+ sub_cmds.pop('run')
+
+ if any(arg in ("--version", '-V') for arg in args):
cmd_args = ['version']
args = ['version']
- if len(args) == 0 or args[0] not in sub_cmds.keys() or \
+ if args[0] not in sub_cmds.keys() or \
args[0] in (
'build',
'list',
|
{"golden_diff": "diff --git a/nikola/__main__.py b/nikola/__main__.py\n--- a/nikola/__main__.py\n+++ b/nikola/__main__.py\n@@ -237,15 +237,32 @@\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n \n- if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n+ if len(args) == 0:\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n- if len(args) == 0 or any(arg in [\"--version\", '-V'] for arg in args):\n+\n+ if '--help' in args or '-h' in args:\n+ new_cmd_args = ['help'] + cmd_args\n+ new_args = ['help'] + args\n+\n+ cmd_args = []\n+ args = []\n+\n+ for arg in new_cmd_args:\n+ if arg not in ('--help', '-h'):\n+ cmd_args.append(arg)\n+ for arg in new_args:\n+ if arg not in ('--help', '-h'):\n+ args.append(arg)\n+ # Hide run because Nikola uses build\n+ sub_cmds.pop('run')\n+\n+ if any(arg in (\"--version\", '-V') for arg in args):\n cmd_args = ['version']\n args = ['version']\n- if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n+ if args[0] not in sub_cmds.keys() or \\\n args[0] in (\n 'build',\n 'list',\n", "issue": "`nikola command --help` should work\nFix upcoming.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\nfrom operator import attrgetter\nimport os\nimport shutil\ntry:\n import readline # NOQA\nexcept ImportError:\n pass # This is only so raw_input/input does nicer things if it's available\nimport sys\nimport traceback\n\nfrom doit.loader import generate_tasks\nfrom doit.cmd_base import TaskLoader\nfrom doit.reporter import ExecutedOnlyReporter\nfrom doit.doit_cmd import DoitMain\nfrom doit.cmd_help import Help as DoitHelp\nfrom doit.cmd_run import Run as DoitRun\nfrom doit.cmd_clean import Clean as DoitClean\nfrom doit.cmd_auto import Auto as DoitAuto\nfrom logbook import NullHandler\n\nfrom . import __version__\nfrom .nikola import Nikola\nfrom .utils import _reload, sys_decode, get_root_dir, req_missing, LOGGER, STRICT_HANDLER\n\n\nconfig = {}\n\n\ndef main(args=None):\n if args is None:\n args = sys.argv[1:]\n quiet = False\n if len(args) > 0 and args[0] == b'build' and b'--strict' in args:\n LOGGER.notice('Running in strict mode')\n STRICT_HANDLER.push_application()\n if len(args) > 0 and args[0] == b'build' and b'-q' in args or b'--quiet' in args:\n nullhandler = NullHandler()\n nullhandler.push_application()\n quiet = True\n global config\n\n colorful = False\n if sys.stderr.isatty():\n colorful = True\n try:\n import colorama\n colorama.init()\n except ImportError:\n if os.name == 'nt':\n colorful = False\n\n # Those commands do not require a `conf.py`. (Issue #1132)\n # Moreover, actually having one somewhere in the tree can be bad, putting\n # the output of that command (the new site) in an unknown directory that is\n # not the current working directory. (does not apply to `version`)\n argname = args[0] if len(args) > 0 else None\n # FIXME there are import plugins in the repo, so how do we handle this?\n if argname not in ['init', 'import_wordpress', 'import_feed',\n 'import_blogger', 'version']:\n root = get_root_dir()\n if root:\n os.chdir(root)\n\n sys.path.append('')\n try:\n import conf\n _reload(conf)\n config = conf.__dict__\n except Exception:\n if os.path.exists('conf.py'):\n msg = traceback.format_exc(0).splitlines()[1]\n LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))\n sys.exit(1)\n config = {}\n\n invariant = False\n\n if len(args) > 0 and args[0] == b'build' and b'--invariant' in args:\n try:\n import freezegun\n freeze = freezegun.freeze_time(\"2014-01-01\")\n freeze.start()\n invariant = True\n except ImportError:\n req_missing(['freezegun'], 'perform invariant builds')\n\n config['__colorful__'] = colorful\n config['__invariant__'] = invariant\n\n site = Nikola(**config)\n _ = DoitNikola(site, quiet).run(args)\n\n if site.invariant:\n freeze.stop()\n return _\n\n\nclass Help(DoitHelp):\n \"\"\"show Nikola usage instead of doit \"\"\"\n\n @staticmethod\n def print_usage(cmds):\n \"\"\"print nikola \"usage\" (basic help) instructions\"\"\"\n print(\"Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com/\\n\\n\")\n print(\"Available commands:\")\n for cmd in sorted(cmds.values(), key=attrgetter('name')):\n print(\" nikola %-*s %s\" % (20, cmd.name, cmd.doc_purpose))\n print(\"\")\n print(\" nikola help show help / reference\")\n print(\" nikola help <command> show command usage\")\n print(\" nikola help <task-name> show task usage\")\n\n\nclass Build(DoitRun):\n \"\"\"expose \"run\" command as \"build\" for backward compatibility\"\"\"\n def __init__(self, *args, **kw):\n opts = list(self.cmd_options)\n opts.append(\n {\n 'name': 'strict',\n 'long': 'strict',\n 'default': False,\n 'type': bool,\n 'help': \"Fail on things that would normally be warnings.\",\n }\n )\n opts.append(\n {\n 'name': 'invariant',\n 'long': 'invariant',\n 'default': False,\n 'type': bool,\n 'help': \"Generate invariant output (for testing only!).\",\n }\n )\n opts.append(\n {\n 'name': 'quiet',\n 'long': 'quiet',\n 'short': 'q',\n 'default': False,\n 'type': bool,\n 'help': \"Run quietly.\",\n }\n )\n self.cmd_options = tuple(opts)\n super(Build, self).__init__(*args, **kw)\n\n\nclass Clean(DoitClean):\n \"\"\"A clean that removes cache/\"\"\"\n\n def clean_tasks(self, tasks, dryrun):\n if not dryrun and config:\n cache_folder = config.get('CACHE_FOLDER', 'cache')\n if os.path.exists(cache_folder):\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n\n# Nikola has its own \"auto\" commands that uses livereload.\n# Expose original doit \"auto\" command as \"doit_auto\".\nDoitAuto.name = 'doit_auto'\n\n\nclass NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.quiet = quiet\n\n def load_tasks(self, cmd, opt_values, pos_args):\n if self.quiet:\n DOIT_CONFIG = {\n 'verbosity': 0,\n 'reporter': 'zero',\n }\n else:\n DOIT_CONFIG = {\n 'reporter': ExecutedOnlyReporter,\n }\n DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']\n tasks = generate_tasks(\n 'render_site',\n self.nikola.gen_tasks('render_site', \"Task\", 'Group of tasks to render the site.'))\n latetasks = generate_tasks(\n 'post_render',\n self.nikola.gen_tasks('post_render', \"LateTask\", 'Group of tasks to be executes after site is rendered.'))\n return tasks + latetasks, DOIT_CONFIG\n\n\nclass DoitNikola(DoitMain):\n # overwite help command\n DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]\n TASK_LOADER = NikolaTaskLoader\n\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.task_loader = self.TASK_LOADER(nikola, quiet)\n\n def get_commands(self):\n # core doit commands\n cmds = DoitMain.get_commands(self)\n # load nikola commands\n for name, cmd in self.nikola.commands.items():\n cmds[name] = cmd\n return cmds\n\n def run(self, cmd_args):\n sub_cmds = self.get_commands()\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n\n if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n if len(args) == 0 or any(arg in [\"--version\", '-V'] for arg in args):\n cmd_args = ['version']\n args = ['version']\n if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n args[0] in (\n 'build',\n 'list',\n 'clean',\n 'doit_auto',\n 'dumpdb',\n 'forget',\n 'ignore',\n 'run',\n 'strace'):\n # Check for conf.py before launching run\n if not self.nikola.configured:\n LOGGER.error(\"This command needs to run inside an \"\n \"existing Nikola site.\")\n return False\n return super(DoitNikola, self).run(cmd_args)\n\n @staticmethod\n def print_version():\n print(\"Nikola v\" + __version__)\n\nif __name__ == \"__main__\":\n sys.exit(main(sys.argv[1:]))\n", "path": "nikola/__main__.py"}]}
| 3,456 | 379 |
gh_patches_debug_23660
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-3894
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tune Elasticsearch client for reindex separately from main search client
#3892 was necessary to alleviate the hard outage experienced due to ES cluster being down.
We were waiting 30s per request for Elasticsearch then retrying. This was added in #1471 to handle reindex issues.
</issue>
<code>
[start of warehouse/search/tasks.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import binascii
14 import os
15
16 from elasticsearch.helpers import parallel_bulk
17 from sqlalchemy import and_, func
18 from sqlalchemy.orm import aliased
19
20 from warehouse.packaging.models import (
21 Classifier, Project, Release, release_classifiers)
22 from warehouse.packaging.search import Project as ProjectDocType
23 from warehouse.search.utils import get_index
24 from warehouse import tasks
25 from warehouse.utils.db import windowed_query
26
27
28 def _project_docs(db):
29
30 releases_list = (
31 db.query(Release.name, Release.version)
32 .order_by(
33 Release.name,
34 Release.is_prerelease.nullslast(),
35 Release._pypi_ordering.desc(),
36 )
37 .distinct(Release.name)
38 .subquery("release_list")
39 )
40
41 r = aliased(Release, name="r")
42
43 all_versions = (
44 db.query(func.array_agg(r.version))
45 .filter(r.name == Release.name)
46 .correlate(Release)
47 .as_scalar()
48 .label("all_versions")
49 )
50
51 classifiers = (
52 db.query(func.array_agg(Classifier.classifier))
53 .select_from(release_classifiers)
54 .join(Classifier, Classifier.id == release_classifiers.c.trove_id)
55 .filter(Release.name == release_classifiers.c.name)
56 .filter(Release.version == release_classifiers.c.version)
57 .correlate(Release)
58 .as_scalar()
59 .label("classifiers")
60 )
61
62 release_data = (
63 db.query(
64 Release.description,
65 Release.name,
66 Release.version.label("latest_version"),
67 all_versions,
68 Release.author,
69 Release.author_email,
70 Release.maintainer,
71 Release.maintainer_email,
72 Release.home_page,
73 Release.summary,
74 Release.keywords,
75 Release.platform,
76 Release.download_url,
77 Release.created,
78 classifiers,
79 Project.normalized_name,
80 Project.name,
81 )
82 .select_from(releases_list)
83 .join(Release, and_(
84 Release.name == releases_list.c.name,
85 Release.version == releases_list.c.version))
86 .outerjoin(Release.project)
87 .order_by(Release.name)
88 )
89
90 for release in windowed_query(release_data, Release.name, 50000):
91 p = ProjectDocType.from_db(release)
92 p.full_clean()
93 yield p.to_dict(include_meta=True)
94
95
96 @tasks.task(ignore_result=True, acks_late=True)
97 def reindex(request):
98 """
99 Recreate the Search Index.
100 """
101 client = request.registry["elasticsearch.client"]
102 number_of_replicas = request.registry.get("elasticsearch.replicas", 0)
103 refresh_interval = request.registry.get("elasticsearch.interval", "1s")
104
105 # We use a randomly named index so that we can do a zero downtime reindex.
106 # Essentially we'll use a randomly named index which we will use until all
107 # of the data has been reindexed, at which point we'll point an alias at
108 # our randomly named index, and then delete the old randomly named index.
109
110 # Create the new index and associate all of our doc types with it.
111 index_base = request.registry["elasticsearch.index"]
112 random_token = binascii.hexlify(os.urandom(5)).decode("ascii")
113 new_index_name = "{}-{}".format(index_base, random_token)
114 doc_types = request.registry.get("search.doc_types", set())
115 shards = request.registry.get("elasticsearch.shards", 1)
116
117 # Create the new index with zero replicas and index refreshes disabled
118 # while we are bulk indexing.
119 new_index = get_index(
120 new_index_name,
121 doc_types,
122 using=client,
123 shards=shards,
124 replicas=0,
125 interval="-1",
126 )
127 new_index.create(wait_for_active_shards=shards)
128
129 # From this point on, if any error occurs, we want to be able to delete our
130 # in progress index.
131 try:
132 request.db.execute("SET statement_timeout = '600s'")
133
134 for _ in parallel_bulk(client, _project_docs(request.db)):
135 pass
136 except: # noqa
137 new_index.delete()
138 raise
139 finally:
140 request.db.rollback()
141 request.db.close()
142
143 # Now that we've finished indexing all of our data we can optimize it and
144 # update the replicas and refresh intervals.
145 client.indices.forcemerge(index=new_index_name)
146 client.indices.put_settings(
147 index=new_index_name,
148 body={
149 "index": {
150 "number_of_replicas": number_of_replicas,
151 "refresh_interval": refresh_interval,
152 }
153 }
154 )
155
156 # Point the alias at our new randomly named index and delete the old index.
157 if client.indices.exists_alias(name=index_base):
158 to_delete = set()
159 actions = []
160 for name in client.indices.get_alias(name=index_base):
161 to_delete.add(name)
162 actions.append({"remove": {"index": name, "alias": index_base}})
163 actions.append({"add": {"index": new_index_name, "alias": index_base}})
164 client.indices.update_aliases({"actions": actions})
165 client.indices.delete(",".join(to_delete))
166 else:
167 client.indices.put_alias(name=index_base, index=new_index_name)
168
[end of warehouse/search/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/search/tasks.py b/warehouse/search/tasks.py
--- a/warehouse/search/tasks.py
+++ b/warehouse/search/tasks.py
@@ -11,11 +11,15 @@
# limitations under the License.
import binascii
+import urllib
import os
from elasticsearch.helpers import parallel_bulk
+from elasticsearch_dsl import serializer
from sqlalchemy import and_, func
from sqlalchemy.orm import aliased
+import certifi
+import elasticsearch
from warehouse.packaging.models import (
Classifier, Project, Release, release_classifiers)
@@ -98,7 +102,15 @@
"""
Recreate the Search Index.
"""
- client = request.registry["elasticsearch.client"]
+ p = urllib.parse.urlparse(request.registry.settings["elasticsearch.url"])
+ client = elasticsearch.Elasticsearch(
+ [urllib.parse.urlunparse(p[:2] + ("",) * 4)],
+ verify_certs=True,
+ ca_certs=certifi.where(),
+ timeout=30,
+ retry_on_timeout=True,
+ serializer=serializer.serializer,
+ )
number_of_replicas = request.registry.get("elasticsearch.replicas", 0)
refresh_interval = request.registry.get("elasticsearch.interval", "1s")
|
{"golden_diff": "diff --git a/warehouse/search/tasks.py b/warehouse/search/tasks.py\n--- a/warehouse/search/tasks.py\n+++ b/warehouse/search/tasks.py\n@@ -11,11 +11,15 @@\n # limitations under the License.\n \n import binascii\n+import urllib\n import os\n \n from elasticsearch.helpers import parallel_bulk\n+from elasticsearch_dsl import serializer\n from sqlalchemy import and_, func\n from sqlalchemy.orm import aliased\n+import certifi\n+import elasticsearch\n \n from warehouse.packaging.models import (\n Classifier, Project, Release, release_classifiers)\n@@ -98,7 +102,15 @@\n \"\"\"\n Recreate the Search Index.\n \"\"\"\n- client = request.registry[\"elasticsearch.client\"]\n+ p = urllib.parse.urlparse(request.registry.settings[\"elasticsearch.url\"])\n+ client = elasticsearch.Elasticsearch(\n+ [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n+ verify_certs=True,\n+ ca_certs=certifi.where(),\n+ timeout=30,\n+ retry_on_timeout=True,\n+ serializer=serializer.serializer,\n+ )\n number_of_replicas = request.registry.get(\"elasticsearch.replicas\", 0)\n refresh_interval = request.registry.get(\"elasticsearch.interval\", \"1s\")\n", "issue": "Tune Elasticsearch client for reindex separately from main search client\n#3892 was necessary to alleviate the hard outage experienced due to ES cluster being down.\r\n\r\nWe were waiting 30s per request for Elasticsearch then retrying. This was added in #1471 to handle reindex issues.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport os\n\nfrom elasticsearch.helpers import parallel_bulk\nfrom sqlalchemy import and_, func\nfrom sqlalchemy.orm import aliased\n\nfrom warehouse.packaging.models import (\n Classifier, Project, Release, release_classifiers)\nfrom warehouse.packaging.search import Project as ProjectDocType\nfrom warehouse.search.utils import get_index\nfrom warehouse import tasks\nfrom warehouse.utils.db import windowed_query\n\n\ndef _project_docs(db):\n\n releases_list = (\n db.query(Release.name, Release.version)\n .order_by(\n Release.name,\n Release.is_prerelease.nullslast(),\n Release._pypi_ordering.desc(),\n )\n .distinct(Release.name)\n .subquery(\"release_list\")\n )\n\n r = aliased(Release, name=\"r\")\n\n all_versions = (\n db.query(func.array_agg(r.version))\n .filter(r.name == Release.name)\n .correlate(Release)\n .as_scalar()\n .label(\"all_versions\")\n )\n\n classifiers = (\n db.query(func.array_agg(Classifier.classifier))\n .select_from(release_classifiers)\n .join(Classifier, Classifier.id == release_classifiers.c.trove_id)\n .filter(Release.name == release_classifiers.c.name)\n .filter(Release.version == release_classifiers.c.version)\n .correlate(Release)\n .as_scalar()\n .label(\"classifiers\")\n )\n\n release_data = (\n db.query(\n Release.description,\n Release.name,\n Release.version.label(\"latest_version\"),\n all_versions,\n Release.author,\n Release.author_email,\n Release.maintainer,\n Release.maintainer_email,\n Release.home_page,\n Release.summary,\n Release.keywords,\n Release.platform,\n Release.download_url,\n Release.created,\n classifiers,\n Project.normalized_name,\n Project.name,\n )\n .select_from(releases_list)\n .join(Release, and_(\n Release.name == releases_list.c.name,\n Release.version == releases_list.c.version))\n .outerjoin(Release.project)\n .order_by(Release.name)\n )\n\n for release in windowed_query(release_data, Release.name, 50000):\n p = ProjectDocType.from_db(release)\n p.full_clean()\n yield p.to_dict(include_meta=True)\n\n\[email protected](ignore_result=True, acks_late=True)\ndef reindex(request):\n \"\"\"\n Recreate the Search Index.\n \"\"\"\n client = request.registry[\"elasticsearch.client\"]\n number_of_replicas = request.registry.get(\"elasticsearch.replicas\", 0)\n refresh_interval = request.registry.get(\"elasticsearch.interval\", \"1s\")\n\n # We use a randomly named index so that we can do a zero downtime reindex.\n # Essentially we'll use a randomly named index which we will use until all\n # of the data has been reindexed, at which point we'll point an alias at\n # our randomly named index, and then delete the old randomly named index.\n\n # Create the new index and associate all of our doc types with it.\n index_base = request.registry[\"elasticsearch.index\"]\n random_token = binascii.hexlify(os.urandom(5)).decode(\"ascii\")\n new_index_name = \"{}-{}\".format(index_base, random_token)\n doc_types = request.registry.get(\"search.doc_types\", set())\n shards = request.registry.get(\"elasticsearch.shards\", 1)\n\n # Create the new index with zero replicas and index refreshes disabled\n # while we are bulk indexing.\n new_index = get_index(\n new_index_name,\n doc_types,\n using=client,\n shards=shards,\n replicas=0,\n interval=\"-1\",\n )\n new_index.create(wait_for_active_shards=shards)\n\n # From this point on, if any error occurs, we want to be able to delete our\n # in progress index.\n try:\n request.db.execute(\"SET statement_timeout = '600s'\")\n\n for _ in parallel_bulk(client, _project_docs(request.db)):\n pass\n except: # noqa\n new_index.delete()\n raise\n finally:\n request.db.rollback()\n request.db.close()\n\n # Now that we've finished indexing all of our data we can optimize it and\n # update the replicas and refresh intervals.\n client.indices.forcemerge(index=new_index_name)\n client.indices.put_settings(\n index=new_index_name,\n body={\n \"index\": {\n \"number_of_replicas\": number_of_replicas,\n \"refresh_interval\": refresh_interval,\n }\n }\n )\n\n # Point the alias at our new randomly named index and delete the old index.\n if client.indices.exists_alias(name=index_base):\n to_delete = set()\n actions = []\n for name in client.indices.get_alias(name=index_base):\n to_delete.add(name)\n actions.append({\"remove\": {\"index\": name, \"alias\": index_base}})\n actions.append({\"add\": {\"index\": new_index_name, \"alias\": index_base}})\n client.indices.update_aliases({\"actions\": actions})\n client.indices.delete(\",\".join(to_delete))\n else:\n client.indices.put_alias(name=index_base, index=new_index_name)\n", "path": "warehouse/search/tasks.py"}]}
| 2,226 | 281 |
gh_patches_debug_5071
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1596
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Permission denied: '/tmp/logfile'
The submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:
```
(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI⟫ python scripts/workers/submission_worker.py settings.prod
Traceback (most recent call last):
File "scripts/workers/submission_worker.py", line 44, in <module>
django.setup()
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py", line 22, in setup
configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py", line 75, in configure_logging
logging_config_func(logging_settings)
File "/usr/lib/python2.7/logging/config.py", line 794, in dictConfig
dictConfigClass(config).configure()
File "/usr/lib/python2.7/logging/config.py", line 576, in configure
'%r: %s' % (name, e))
ValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'
```
Permission denied: '/tmp/logfile'
The submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:
```
(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI⟫ python scripts/workers/submission_worker.py settings.prod
Traceback (most recent call last):
File "scripts/workers/submission_worker.py", line 44, in <module>
django.setup()
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py", line 22, in setup
configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py", line 75, in configure_logging
logging_config_func(logging_settings)
File "/usr/lib/python2.7/logging/config.py", line 794, in dictConfig
dictConfigClass(config).configure()
File "/usr/lib/python2.7/logging/config.py", line 576, in configure
'%r: %s' % (name, e))
ValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'
```
</issue>
<code>
[start of settings/common.py]
1 """
2 Django settings for evalai project.
3
4 Generated by 'django-admin startproject' using Django 1.10.2.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.10/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.10/ref/settings/
11 """
12
13 import datetime
14 import os
15 import sys
16
17 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
18 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
19 APPS_DIR = os.path.join(BASE_DIR, 'apps')
20
21 sys.path.append(APPS_DIR)
22
23 # Quick-start development settings - unsuitable for production
24 # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
25
26 # SECURITY WARNING: keep the secret key used in production secret!
27 SECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')
28
29 # SECURITY WARNING: don't run with debug turned on in production!
30 DEBUG = True
31
32 ALLOWED_HOSTS = []
33
34
35 # Application definition
36
37 DEFAULT_APPS = [
38 'django.contrib.admin',
39 'django.contrib.auth',
40 'django.contrib.contenttypes',
41 'django.contrib.sessions',
42 'django.contrib.messages',
43 'django.contrib.staticfiles',
44 'django.contrib.sites',
45 ]
46
47 OUR_APPS = [
48 'accounts',
49 'analytics',
50 'base',
51 'challenges',
52 'hosts',
53 'jobs',
54 'participants',
55 'web',
56 ]
57
58 THIRD_PARTY_APPS = [
59 'allauth',
60 'allauth.account',
61 'corsheaders',
62 'import_export',
63 'rest_auth',
64 'rest_auth.registration',
65 'rest_framework.authtoken',
66 'rest_framework',
67 'rest_framework_docs',
68 'rest_framework_expiring_authtoken',
69 ]
70
71 INSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS
72
73 MIDDLEWARE = [
74 'corsheaders.middleware.CorsMiddleware',
75 'django.middleware.security.SecurityMiddleware',
76 'django.contrib.sessions.middleware.SessionMiddleware',
77 'django.middleware.common.CommonMiddleware',
78 'django.middleware.csrf.CsrfViewMiddleware',
79 'django.contrib.auth.middleware.AuthenticationMiddleware',
80 'django.contrib.messages.middleware.MessageMiddleware',
81 'django.middleware.clickjacking.XFrameOptionsMiddleware',
82 ]
83
84 ROOT_URLCONF = 'evalai.urls'
85
86
87 TEMPLATES = [
88 {
89 'BACKEND': 'django.template.backends.django.DjangoTemplates',
90 'DIRS': [],
91 'APP_DIRS': True,
92 'OPTIONS': {
93 'context_processors': [
94 'django.template.context_processors.debug',
95 'django.template.context_processors.request',
96 'django.contrib.auth.context_processors.auth',
97 'django.contrib.messages.context_processors.messages',
98 ],
99 },
100 },
101 ]
102
103 WSGI_APPLICATION = 'evalai.wsgi.application'
104
105
106 # Password validation
107 # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
108
109 AUTH_PASSWORD_VALIDATORS = [
110 {
111 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa
112 },
113 {
114 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa
115 },
116 {
117 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa
118 },
119 {
120 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa
121 },
122 ]
123
124
125 # Internationalization
126 # https://docs.djangoproject.com/en/1.10/topics/i18n/
127
128 LANGUAGE_CODE = 'en-us'
129
130 TIME_ZONE = 'UTC'
131
132 USE_I18N = True
133
134 USE_L10N = True
135
136 USE_TZ = True
137
138 # Static files (CSS, JavaScript, Images)
139 # https://docs.djangoproject.com/en/1.10/howto/static-files/
140
141 STATIC_URL = '/static/'
142 STATIC_ROOT = os.path.join(BASE_DIR, 'static')
143 MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
144 MEDIA_URL = "/media/"
145
146 SITE_ID = 1
147
148 REST_FRAMEWORK = {
149 'DEFAULT_PAGINATION_CLASS': (
150 'rest_framework.pagination.LimitOffsetPagination'),
151 'PAGE_SIZE': 10,
152 'DEFAULT_PERMISSION_CLASSES': [
153 'rest_framework.permissions.IsAuthenticatedOrReadOnly'
154 ],
155 'DEFAULT_AUTHENTICATION_CLASSES': [
156 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',
157 ],
158 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
159 'DEFAULT_THROTTLE_CLASSES': (
160 'rest_framework.throttling.AnonRateThrottle',
161 'rest_framework.throttling.UserRateThrottle'
162 ),
163 'DEFAULT_THROTTLE_RATES': {
164 'anon': '100/minute',
165 'user': '100/minute'
166 },
167 'DEFAULT_RENDERER_CLASSES': (
168 'rest_framework.renderers.JSONRenderer',
169 )
170 }
171
172 # ALLAUTH SETTINGS
173 ACCOUNT_EMAIL_REQUIRED = True
174 OLD_PASSWORD_FIELD_ENABLED = True
175 ACCOUNT_CONFIRM_EMAIL_ON_GET = True
176 ACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'
177 ACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'
178
179 AUTHENTICATION_BACKENDS = (
180 # Needed to login by username in Django admin, regardless of `allauth`
181 'django.contrib.auth.backends.ModelBackend',
182 # `allauth` specific authentication methods, such as login by e-mail
183 'allauth.account.auth_backends.AuthenticationBackend',
184 )
185
186 # CORS Settings
187 CORS_ORIGIN_ALLOW_ALL = True
188
189 # REST Framework Expiring Tokens Configuration
190 EXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)
191
192 # Logging
193 LOGGING = {
194 'version': 1,
195 'disable_existing_loggers': False,
196 'root': {
197 'level': 'INFO',
198 'handlers': ['console'],
199 },
200 'filters': {
201 'require_debug_false': {
202 '()': 'django.utils.log.RequireDebugFalse',
203 },
204 'require_debug_true': {
205 '()': 'django.utils.log.RequireDebugTrue',
206 }
207 },
208 'formatters': {
209 'simple': {
210 'format': '[%(asctime)s] %(levelname)s %(message)s',
211 'datefmt': '%Y-%m-%d %H:%M:%S'
212 },
213 'verbose': {
214 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',
215 'datefmt': '%Y-%m-%d %H:%M:%S'
216 }
217 },
218 'handlers': {
219 'console': {
220 'level': 'INFO',
221 'filters': ['require_debug_true'],
222 'class': 'logging.StreamHandler',
223 'formatter': 'simple'
224 },
225 'logfile': {
226 'level': 'DEBUG',
227 'class': 'logging.handlers.RotatingFileHandler',
228 'filename': "/tmp/logfile",
229 'maxBytes': 50000,
230 'backupCount': 10,
231 'formatter': 'verbose'
232 },
233 'mail_admins': {
234 'level': 'ERROR',
235 'class': 'django.utils.log.AdminEmailHandler',
236 'filters': ['require_debug_false'],
237 }
238 },
239 'loggers': {
240 'django': {
241 'handlers': ['console'],
242 'propagate': False,
243 },
244 'django.request': {
245 'handlers': ['mail_admins'],
246 'level': 'ERROR',
247 'propagate': False,
248 },
249 'django.security': {
250 'handlers': ['mail_admins'],
251 'level': 'ERROR',
252 'propagate': False,
253 },
254 'django.db.backends': {
255 'handlers': ['mail_admins'],
256 'level': 'ERROR',
257 'propagate': False,
258 }
259 }
260 }
261
262 CACHES = {
263 'default': {
264 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
265 }
266 }
267
268 RABBITMQ_PARAMETERS = {
269 'HOST': os.environ.get("RABBITMQ_HOST", 'localhost'),
270 'EVALAI_EXCHANGE': {
271 'NAME': 'evalai_submissions',
272 'TYPE': 'topic',
273 },
274 'SUBMISSION_QUEUE': 'submission_task_queue',
275 }
276
277 # The maximum size in bytes for request body
278 # https://docs.djangoproject.com/en/1.10/ref/settings/#data-upload-max-memory-size
279 FILE_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB
280 DATA_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB
281
282 # To make usermame field read-only, customized serializer is defined.
283 REST_AUTH_SERIALIZERS = {
284 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',
285 }
286
287 # For inviting users to participant and host teams.
288 ADMIN_EMAIL = "[email protected]"
289
[end of settings/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/settings/common.py b/settings/common.py
--- a/settings/common.py
+++ b/settings/common.py
@@ -225,7 +225,7 @@
'logfile': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
- 'filename': "/tmp/logfile",
+ 'filename': os.path.join(BASE_DIR, 'django.log'),
'maxBytes': 50000,
'backupCount': 10,
'formatter': 'verbose'
|
{"golden_diff": "diff --git a/settings/common.py b/settings/common.py\n--- a/settings/common.py\n+++ b/settings/common.py\n@@ -225,7 +225,7 @@\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n- 'filename': \"/tmp/logfile\",\n+ 'filename': os.path.join(BASE_DIR, 'django.log'),\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n", "issue": "Permission denied: '/tmp/logfile'\nThe submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:\r\n\r\n```\r\n(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI\u27eb python scripts/workers/submission_worker.py settings.prod\r\nTraceback (most recent call last):\r\n File \"scripts/workers/submission_worker.py\", line 44, in <module>\r\n django.setup()\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py\", line 22, in setup\r\n configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py\", line 75, in configure_logging\r\n logging_config_func(logging_settings)\r\n File \"/usr/lib/python2.7/logging/config.py\", line 794, in dictConfig\r\n dictConfigClass(config).configure()\r\n File \"/usr/lib/python2.7/logging/config.py\", line 576, in configure\r\n '%r: %s' % (name, e))\r\nValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'\r\n```\nPermission denied: '/tmp/logfile'\nThe submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:\r\n\r\n```\r\n(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI\u27eb python scripts/workers/submission_worker.py settings.prod\r\nTraceback (most recent call last):\r\n File \"scripts/workers/submission_worker.py\", line 44, in <module>\r\n django.setup()\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py\", line 22, in setup\r\n configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py\", line 75, in configure_logging\r\n logging_config_func(logging_settings)\r\n File \"/usr/lib/python2.7/logging/config.py\", line 794, in dictConfig\r\n dictConfigClass(config).configure()\r\n File \"/usr/lib/python2.7/logging/config.py\", line 576, in configure\r\n '%r: %s' % (name, e))\r\nValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'\r\n```\n", "before_files": [{"content": "\"\"\"\nDjango settings for evalai project.\n\nGenerated by 'django-admin startproject' using Django 1.10.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport datetime\nimport os\nimport sys\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nAPPS_DIR = os.path.join(BASE_DIR, 'apps')\n\nsys.path.append(APPS_DIR)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n\n# Application definition\n\nDEFAULT_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.sites',\n]\n\nOUR_APPS = [\n 'accounts',\n 'analytics',\n 'base',\n 'challenges',\n 'hosts',\n 'jobs',\n 'participants',\n 'web',\n]\n\nTHIRD_PARTY_APPS = [\n 'allauth',\n 'allauth.account',\n 'corsheaders',\n 'import_export',\n 'rest_auth',\n 'rest_auth.registration',\n 'rest_framework.authtoken',\n 'rest_framework',\n 'rest_framework_docs',\n 'rest_framework_expiring_authtoken',\n]\n\nINSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS\n\nMIDDLEWARE = [\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'evalai.urls'\n\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'evalai.wsgi.application'\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.10/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = \"/media/\"\n\nSITE_ID = 1\n\nREST_FRAMEWORK = {\n 'DEFAULT_PAGINATION_CLASS': (\n 'rest_framework.pagination.LimitOffsetPagination'),\n 'PAGE_SIZE': 10,\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticatedOrReadOnly'\n ],\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',\n ],\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'DEFAULT_THROTTLE_CLASSES': (\n 'rest_framework.throttling.AnonRateThrottle',\n 'rest_framework.throttling.UserRateThrottle'\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'anon': '100/minute',\n 'user': '100/minute'\n },\n 'DEFAULT_RENDERER_CLASSES': (\n 'rest_framework.renderers.JSONRenderer',\n )\n}\n\n# ALLAUTH SETTINGS\nACCOUNT_EMAIL_REQUIRED = True\nOLD_PASSWORD_FIELD_ENABLED = True\nACCOUNT_CONFIRM_EMAIL_ON_GET = True\nACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'\nACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# REST Framework Expiring Tokens Configuration\nEXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)\n\n# Logging\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'root': {\n 'level': 'INFO',\n 'handlers': ['console'],\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse',\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue',\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '[%(asctime)s] %(levelname)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'verbose': {\n 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'console': {\n 'level': 'INFO',\n 'filters': ['require_debug_true'],\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n },\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n 'filename': \"/tmp/logfile\",\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n },\n 'mail_admins': {\n 'level': 'ERROR',\n 'class': 'django.utils.log.AdminEmailHandler',\n 'filters': ['require_debug_false'],\n }\n },\n 'loggers': {\n 'django': {\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.security': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.db.backends': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n }\n }\n}\n\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n }\n}\n\nRABBITMQ_PARAMETERS = {\n 'HOST': os.environ.get(\"RABBITMQ_HOST\", 'localhost'),\n 'EVALAI_EXCHANGE': {\n 'NAME': 'evalai_submissions',\n 'TYPE': 'topic',\n },\n 'SUBMISSION_QUEUE': 'submission_task_queue',\n}\n\n# The maximum size in bytes for request body\n# https://docs.djangoproject.com/en/1.10/ref/settings/#data-upload-max-memory-size\nFILE_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\nDATA_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\n\n# To make usermame field read-only, customized serializer is defined.\nREST_AUTH_SERIALIZERS = {\n 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',\n}\n\n# For inviting users to participant and host teams.\nADMIN_EMAIL = \"[email protected]\"\n", "path": "settings/common.py"}]}
| 3,755 | 116 |
gh_patches_debug_14506
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-522
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Clean up test fixtures in Hydra and plugins
Should use conftest.py to simplify
</issue>
<code>
[start of noxfile.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 import copy
4 import os
5 import platform
6 from typing import List
7
8 import nox
9 from nox.logger import logger
10
11 BASE = os.path.abspath(os.path.dirname(__file__))
12
13 DEFAULT_PYTHON_VERSIONS = ["3.6", "3.7", "3.8"]
14 DEFAULT_OS_NAMES = ["Linux", "MacOS", "Windows"]
15
16 PYTHON_VERSIONS = os.environ.get(
17 "NOX_PYTHON_VERSIONS", ",".join(DEFAULT_PYTHON_VERSIONS)
18 ).split(",")
19
20 PLUGINS_INSTALL_COMMANDS = (["pip", "install"], ["pip", "install", "-e"])
21
22 # Allow limiting testing to specific plugins
23 # The list ['ALL'] indicates all plugins
24 PLUGINS = os.environ.get("PLUGINS", "ALL").split(",")
25
26 SKIP_CORE_TESTS = "0"
27 SKIP_CORE_TESTS = os.environ.get("SKIP_CORE_TESTS", SKIP_CORE_TESTS) != "0"
28
29 SILENT = os.environ.get("VERBOSE", "0") == "0"
30
31
32 def get_current_os() -> str:
33 current_os = platform.system()
34 if current_os == "Darwin":
35 current_os = "MacOS"
36 return current_os
37
38
39 print(f"Operating system\t:\t{get_current_os()}")
40 print(f"PYTHON_VERSIONS\t\t:\t{PYTHON_VERSIONS}")
41 print(f"PLUGINS\t\t\t:\t{PLUGINS}")
42 print(f"SKIP_CORE_TESTS\t\t:\t{SKIP_CORE_TESTS}")
43
44
45 def find_python_files(folder):
46 for root, folders, files in os.walk(folder):
47 for filename in folders + files:
48 if filename.endswith(".py"):
49 yield os.path.join(root, filename)
50
51
52 def install_hydra(session, cmd):
53 # clean install hydra
54 session.chdir(BASE)
55 session.run(*cmd, ".", silent=SILENT)
56
57
58 def pytest_args(session, *args):
59 ret = ["pytest"]
60 ret.extend(args)
61 if len(session.posargs) > 0:
62 ret.extend(session.posargs)
63 return ret
64
65
66 def run_pytest(session, directory="."):
67 pytest_cmd = pytest_args(session, directory)
68 session.run(*pytest_cmd, silent=SILENT)
69
70
71 def get_setup_python_versions(classifiers):
72 pythons = filter(lambda line: "Programming Language :: Python" in line, classifiers)
73 return [p[len("Programming Language :: Python :: ") :] for p in pythons]
74
75
76 def get_plugin_os_names(classifiers: List[str]) -> List[str]:
77 oses = list(filter(lambda line: "Operating System" in line, classifiers))
78 if len(oses) == 0:
79 # No Os is specified so all oses are supported
80 return DEFAULT_OS_NAMES
81 if len(oses) == 1 and oses[0] == "Operating System :: OS Independent":
82 # All oses are supported
83 return DEFAULT_OS_NAMES
84 else:
85 return [p.split("::")[-1].strip() for p in oses]
86
87
88 def select_plugins(session):
89 """
90 Select all plugins that should be tested in this session.
91 Considers the current Python version and operating systems against the supported ones,
92 as well as the user plugins selection (via the PLUGINS environment variable).
93 """
94
95 assert session.python is not None, "Session python version is not specified"
96
97 example_plugins = [
98 {"name": x, "path": "examples/{}".format(x)}
99 for x in sorted(os.listdir(os.path.join(BASE, "plugins/examples")))
100 ]
101 plugins = [
102 {"name": x, "path": x}
103 for x in sorted(os.listdir(os.path.join(BASE, "plugins")))
104 if x != "examples"
105 ]
106 available_plugins = plugins + example_plugins
107
108 ret = []
109 skipped = []
110 for plugin in available_plugins:
111 if not (plugin["name"] in PLUGINS or PLUGINS == ["ALL"]):
112 skipped.append(f"Deselecting {plugin['name']}: User request")
113 continue
114
115 setup_py = os.path.join(BASE, "plugins", plugin["path"], "setup.py")
116 classifiers = session.run(
117 "python", setup_py, "--classifiers", silent=True
118 ).splitlines()
119
120 plugin_python_versions = get_setup_python_versions(classifiers)
121 python_supported = session.python in plugin_python_versions
122
123 plugin_os_names = get_plugin_os_names(classifiers)
124 os_supported = get_current_os() in plugin_os_names
125
126 if not python_supported:
127 py_str = ", ".join(plugin_python_versions)
128 skipped.append(
129 f"Deselecting {plugin['name']} : Incompatible Python {session.python}. Supports [{py_str}]"
130 )
131 continue
132
133 # Verify this plugin supports the OS we are testing on, skip otherwise
134 if not os_supported:
135 os_str = ", ".join(plugin_os_names)
136 skipped.append(
137 f"Deselecting {plugin['name']}: Incompatible OS {get_current_os()}. Supports [{os_str}]"
138 )
139 continue
140
141 ret.append(
142 {
143 "name": plugin["name"],
144 "path": plugin["path"],
145 "module": "hydra_plugins." + plugin["name"],
146 }
147 )
148
149 for msg in skipped:
150 logger.warn(msg)
151
152 if len(ret) == 0:
153 logger.warn("No plugins selected")
154 return ret
155
156
157 @nox.session(python=PYTHON_VERSIONS)
158 def lint(session):
159 session.install("--upgrade", "setuptools", "pip", silent=SILENT)
160 session.run("pip", "install", "-r", "requirements/dev.txt", silent=SILENT)
161 session.run("pip", "install", "-e", ".", silent=SILENT)
162 session.run("flake8", "--config", ".circleci/flake8_py3.cfg")
163
164 session.install("black")
165 # if this fails you need to format your code with black
166 session.run("black", "--check", ".", silent=SILENT)
167
168 session.run("isort", "--check", ".", silent=SILENT)
169
170 # Mypy
171 session.run("mypy", ".", "--strict", silent=SILENT)
172
173 # Mypy for plugins
174 for plugin in select_plugins(session):
175 session.run(
176 "mypy", os.path.join("plugins", plugin["path"]), "--strict", silent=SILENT
177 )
178
179 # Mypy for examples
180 for pyfie in find_python_files("examples"):
181 session.run("mypy", pyfie, "--strict", silent=SILENT)
182
183
184 @nox.session(python=PYTHON_VERSIONS)
185 @nox.parametrize(
186 "install_cmd",
187 PLUGINS_INSTALL_COMMANDS,
188 ids=[" ".join(x) for x in PLUGINS_INSTALL_COMMANDS],
189 )
190 def test_core(session, install_cmd):
191 session.install("--upgrade", "setuptools", "pip")
192 install_hydra(session, install_cmd)
193 session.install("pytest")
194 run_pytest(session, "tests")
195
196 # test discovery_test_plugin
197 run_pytest(session, "tests/test_plugins/discovery_test_plugin")
198
199 # Install and test example app
200 session.run(*install_cmd, "examples/advanced/hydra_app_example", silent=SILENT)
201 run_pytest(session, "examples/advanced/hydra_app_example")
202
203
204 @nox.session(python=PYTHON_VERSIONS)
205 @nox.parametrize(
206 "install_cmd",
207 PLUGINS_INSTALL_COMMANDS,
208 ids=[" ".join(x) for x in PLUGINS_INSTALL_COMMANDS],
209 )
210 def test_plugins(session, install_cmd):
211 session.install("--upgrade", "setuptools", "pip")
212 session.install("pytest")
213 install_hydra(session, install_cmd)
214 selected_plugin = select_plugins(session)
215 # Install all supported plugins in session
216 for plugin in selected_plugin:
217 cmd = list(install_cmd) + [os.path.join("plugins", plugin["path"])]
218 session.run(*cmd, silent=SILENT)
219
220 # Test that we can import Hydra
221 session.run("python", "-c", "from hydra import main", silent=SILENT)
222
223 # Test that we can import all installed plugins
224 for plugin in selected_plugin:
225 session.run("python", "-c", "import {}".format(plugin["module"]))
226
227 # Run Hydra tests to verify installed plugins did not break anything
228 if not SKIP_CORE_TESTS:
229 run_pytest(session, "tests")
230 else:
231 session.log("Skipping Hydra core tests")
232
233 # Run tests for all installed plugins
234 for plugin in selected_plugin:
235 # install all other plugins that are compatible with the current Python version
236 session.chdir(os.path.join(BASE, "plugins", plugin["path"]))
237 run_pytest(session)
238
239
240 @nox.session(python="3.8")
241 def coverage(session):
242 coverage_env = {
243 "COVERAGE_HOME": BASE,
244 "COVERAGE_FILE": f"{BASE}/.coverage",
245 "COVERAGE_RCFILE": f"{BASE}/.coveragerc",
246 }
247
248 session.install("--upgrade", "setuptools", "pip")
249 session.install("coverage", "pytest")
250 session.run("pip", "install", "-e", ".", silent=SILENT)
251 session.run("coverage", "erase")
252
253 selected_plugins = select_plugins(session)
254 for plugin in selected_plugins:
255 session.run(
256 "pip",
257 "install",
258 "-e",
259 os.path.join("plugins", plugin["path"]),
260 silent=SILENT,
261 )
262
263 session.run("coverage", "erase", env=coverage_env)
264 # run plugin coverage
265 for plugin in selected_plugins:
266 session.chdir(os.path.join("plugins", plugin["path"]))
267 cov_args = ["coverage", "run", "--append", "-m"]
268 cov_args.extend(pytest_args(session))
269 session.run(*cov_args, silent=SILENT, env=coverage_env)
270 session.chdir(BASE)
271
272 # run hydra-core coverage
273 session.run(
274 "coverage",
275 "run",
276 "--append",
277 "-m",
278 silent=SILENT,
279 env=coverage_env,
280 *pytest_args(session),
281 )
282
283 # Increase the fail_under as coverage improves
284 session.run("coverage", "report", "--fail-under=80", env=coverage_env)
285 session.run("coverage", "erase", env=coverage_env)
286
287
288 @nox.session(python=PYTHON_VERSIONS)
289 def test_jupyter_notebook(session):
290 versions = copy.copy(DEFAULT_PYTHON_VERSIONS)
291 if session.python not in versions:
292 session.skip(
293 f"Not testing Jupyter notebook on Python {session.python}, supports [{','.join(versions)}]"
294 )
295 session.install("--upgrade", "setuptools", "pip")
296 session.install("jupyter", "nbval")
297 install_hydra(session, ["pip", "install", "-e"])
298 session.run(
299 *pytest_args(
300 session, "--nbval", "examples/notebook/hydra_notebook_example.ipynb"
301 ),
302 silent=SILENT,
303 )
304
[end of noxfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -63,8 +63,8 @@
return ret
-def run_pytest(session, directory="."):
- pytest_cmd = pytest_args(session, directory)
+def run_pytest(session, directory=".", *args):
+ pytest_cmd = pytest_args(session, directory, *args)
session.run(*pytest_cmd, silent=SILENT)
@@ -194,7 +194,7 @@
run_pytest(session, "tests")
# test discovery_test_plugin
- run_pytest(session, "tests/test_plugins/discovery_test_plugin")
+ run_pytest(session, "tests/test_plugins/discovery_test_plugin", "--noconftest")
# Install and test example app
session.run(*install_cmd, "examples/advanced/hydra_app_example", silent=SILENT)
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -63,8 +63,8 @@\n return ret\n \n \n-def run_pytest(session, directory=\".\"):\n- pytest_cmd = pytest_args(session, directory)\n+def run_pytest(session, directory=\".\", *args):\n+ pytest_cmd = pytest_args(session, directory, *args)\n session.run(*pytest_cmd, silent=SILENT)\n \n \n@@ -194,7 +194,7 @@\n run_pytest(session, \"tests\")\n \n # test discovery_test_plugin\n- run_pytest(session, \"tests/test_plugins/discovery_test_plugin\")\n+ run_pytest(session, \"tests/test_plugins/discovery_test_plugin\", \"--noconftest\")\n \n # Install and test example app\n session.run(*install_cmd, \"examples/advanced/hydra_app_example\", silent=SILENT)\n", "issue": "Clean up test fixtures in Hydra and plugins\nShould use conftest.py to simplify\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nimport copy\nimport os\nimport platform\nfrom typing import List\n\nimport nox\nfrom nox.logger import logger\n\nBASE = os.path.abspath(os.path.dirname(__file__))\n\nDEFAULT_PYTHON_VERSIONS = [\"3.6\", \"3.7\", \"3.8\"]\nDEFAULT_OS_NAMES = [\"Linux\", \"MacOS\", \"Windows\"]\n\nPYTHON_VERSIONS = os.environ.get(\n \"NOX_PYTHON_VERSIONS\", \",\".join(DEFAULT_PYTHON_VERSIONS)\n).split(\",\")\n\nPLUGINS_INSTALL_COMMANDS = ([\"pip\", \"install\"], [\"pip\", \"install\", \"-e\"])\n\n# Allow limiting testing to specific plugins\n# The list ['ALL'] indicates all plugins\nPLUGINS = os.environ.get(\"PLUGINS\", \"ALL\").split(\",\")\n\nSKIP_CORE_TESTS = \"0\"\nSKIP_CORE_TESTS = os.environ.get(\"SKIP_CORE_TESTS\", SKIP_CORE_TESTS) != \"0\"\n\nSILENT = os.environ.get(\"VERBOSE\", \"0\") == \"0\"\n\n\ndef get_current_os() -> str:\n current_os = platform.system()\n if current_os == \"Darwin\":\n current_os = \"MacOS\"\n return current_os\n\n\nprint(f\"Operating system\\t:\\t{get_current_os()}\")\nprint(f\"PYTHON_VERSIONS\\t\\t:\\t{PYTHON_VERSIONS}\")\nprint(f\"PLUGINS\\t\\t\\t:\\t{PLUGINS}\")\nprint(f\"SKIP_CORE_TESTS\\t\\t:\\t{SKIP_CORE_TESTS}\")\n\n\ndef find_python_files(folder):\n for root, folders, files in os.walk(folder):\n for filename in folders + files:\n if filename.endswith(\".py\"):\n yield os.path.join(root, filename)\n\n\ndef install_hydra(session, cmd):\n # clean install hydra\n session.chdir(BASE)\n session.run(*cmd, \".\", silent=SILENT)\n\n\ndef pytest_args(session, *args):\n ret = [\"pytest\"]\n ret.extend(args)\n if len(session.posargs) > 0:\n ret.extend(session.posargs)\n return ret\n\n\ndef run_pytest(session, directory=\".\"):\n pytest_cmd = pytest_args(session, directory)\n session.run(*pytest_cmd, silent=SILENT)\n\n\ndef get_setup_python_versions(classifiers):\n pythons = filter(lambda line: \"Programming Language :: Python\" in line, classifiers)\n return [p[len(\"Programming Language :: Python :: \") :] for p in pythons]\n\n\ndef get_plugin_os_names(classifiers: List[str]) -> List[str]:\n oses = list(filter(lambda line: \"Operating System\" in line, classifiers))\n if len(oses) == 0:\n # No Os is specified so all oses are supported\n return DEFAULT_OS_NAMES\n if len(oses) == 1 and oses[0] == \"Operating System :: OS Independent\":\n # All oses are supported\n return DEFAULT_OS_NAMES\n else:\n return [p.split(\"::\")[-1].strip() for p in oses]\n\n\ndef select_plugins(session):\n \"\"\"\n Select all plugins that should be tested in this session.\n Considers the current Python version and operating systems against the supported ones,\n as well as the user plugins selection (via the PLUGINS environment variable).\n \"\"\"\n\n assert session.python is not None, \"Session python version is not specified\"\n\n example_plugins = [\n {\"name\": x, \"path\": \"examples/{}\".format(x)}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins/examples\")))\n ]\n plugins = [\n {\"name\": x, \"path\": x}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins\")))\n if x != \"examples\"\n ]\n available_plugins = plugins + example_plugins\n\n ret = []\n skipped = []\n for plugin in available_plugins:\n if not (plugin[\"name\"] in PLUGINS or PLUGINS == [\"ALL\"]):\n skipped.append(f\"Deselecting {plugin['name']}: User request\")\n continue\n\n setup_py = os.path.join(BASE, \"plugins\", plugin[\"path\"], \"setup.py\")\n classifiers = session.run(\n \"python\", setup_py, \"--classifiers\", silent=True\n ).splitlines()\n\n plugin_python_versions = get_setup_python_versions(classifiers)\n python_supported = session.python in plugin_python_versions\n\n plugin_os_names = get_plugin_os_names(classifiers)\n os_supported = get_current_os() in plugin_os_names\n\n if not python_supported:\n py_str = \", \".join(plugin_python_versions)\n skipped.append(\n f\"Deselecting {plugin['name']} : Incompatible Python {session.python}. Supports [{py_str}]\"\n )\n continue\n\n # Verify this plugin supports the OS we are testing on, skip otherwise\n if not os_supported:\n os_str = \", \".join(plugin_os_names)\n skipped.append(\n f\"Deselecting {plugin['name']}: Incompatible OS {get_current_os()}. Supports [{os_str}]\"\n )\n continue\n\n ret.append(\n {\n \"name\": plugin[\"name\"],\n \"path\": plugin[\"path\"],\n \"module\": \"hydra_plugins.\" + plugin[\"name\"],\n }\n )\n\n for msg in skipped:\n logger.warn(msg)\n\n if len(ret) == 0:\n logger.warn(\"No plugins selected\")\n return ret\n\n\[email protected](python=PYTHON_VERSIONS)\ndef lint(session):\n session.install(\"--upgrade\", \"setuptools\", \"pip\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-r\", \"requirements/dev.txt\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"flake8\", \"--config\", \".circleci/flake8_py3.cfg\")\n\n session.install(\"black\")\n # if this fails you need to format your code with black\n session.run(\"black\", \"--check\", \".\", silent=SILENT)\n\n session.run(\"isort\", \"--check\", \".\", silent=SILENT)\n\n # Mypy\n session.run(\"mypy\", \".\", \"--strict\", silent=SILENT)\n\n # Mypy for plugins\n for plugin in select_plugins(session):\n session.run(\n \"mypy\", os.path.join(\"plugins\", plugin[\"path\"]), \"--strict\", silent=SILENT\n )\n\n # Mypy for examples\n for pyfie in find_python_files(\"examples\"):\n session.run(\"mypy\", pyfie, \"--strict\", silent=SILENT)\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_core(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n install_hydra(session, install_cmd)\n session.install(\"pytest\")\n run_pytest(session, \"tests\")\n\n # test discovery_test_plugin\n run_pytest(session, \"tests/test_plugins/discovery_test_plugin\")\n\n # Install and test example app\n session.run(*install_cmd, \"examples/advanced/hydra_app_example\", silent=SILENT)\n run_pytest(session, \"examples/advanced/hydra_app_example\")\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_plugins(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"pytest\")\n install_hydra(session, install_cmd)\n selected_plugin = select_plugins(session)\n # Install all supported plugins in session\n for plugin in selected_plugin:\n cmd = list(install_cmd) + [os.path.join(\"plugins\", plugin[\"path\"])]\n session.run(*cmd, silent=SILENT)\n\n # Test that we can import Hydra\n session.run(\"python\", \"-c\", \"from hydra import main\", silent=SILENT)\n\n # Test that we can import all installed plugins\n for plugin in selected_plugin:\n session.run(\"python\", \"-c\", \"import {}\".format(plugin[\"module\"]))\n\n # Run Hydra tests to verify installed plugins did not break anything\n if not SKIP_CORE_TESTS:\n run_pytest(session, \"tests\")\n else:\n session.log(\"Skipping Hydra core tests\")\n\n # Run tests for all installed plugins\n for plugin in selected_plugin:\n # install all other plugins that are compatible with the current Python version\n session.chdir(os.path.join(BASE, \"plugins\", plugin[\"path\"]))\n run_pytest(session)\n\n\[email protected](python=\"3.8\")\ndef coverage(session):\n coverage_env = {\n \"COVERAGE_HOME\": BASE,\n \"COVERAGE_FILE\": f\"{BASE}/.coverage\",\n \"COVERAGE_RCFILE\": f\"{BASE}/.coveragerc\",\n }\n\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"coverage\", \"pytest\")\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"coverage\", \"erase\")\n\n selected_plugins = select_plugins(session)\n for plugin in selected_plugins:\n session.run(\n \"pip\",\n \"install\",\n \"-e\",\n os.path.join(\"plugins\", plugin[\"path\"]),\n silent=SILENT,\n )\n\n session.run(\"coverage\", \"erase\", env=coverage_env)\n # run plugin coverage\n for plugin in selected_plugins:\n session.chdir(os.path.join(\"plugins\", plugin[\"path\"]))\n cov_args = [\"coverage\", \"run\", \"--append\", \"-m\"]\n cov_args.extend(pytest_args(session))\n session.run(*cov_args, silent=SILENT, env=coverage_env)\n session.chdir(BASE)\n\n # run hydra-core coverage\n session.run(\n \"coverage\",\n \"run\",\n \"--append\",\n \"-m\",\n silent=SILENT,\n env=coverage_env,\n *pytest_args(session),\n )\n\n # Increase the fail_under as coverage improves\n session.run(\"coverage\", \"report\", \"--fail-under=80\", env=coverage_env)\n session.run(\"coverage\", \"erase\", env=coverage_env)\n\n\[email protected](python=PYTHON_VERSIONS)\ndef test_jupyter_notebook(session):\n versions = copy.copy(DEFAULT_PYTHON_VERSIONS)\n if session.python not in versions:\n session.skip(\n f\"Not testing Jupyter notebook on Python {session.python}, supports [{','.join(versions)}]\"\n )\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"jupyter\", \"nbval\")\n install_hydra(session, [\"pip\", \"install\", \"-e\"])\n session.run(\n *pytest_args(\n session, \"--nbval\", \"examples/notebook/hydra_notebook_example.ipynb\"\n ),\n silent=SILENT,\n )\n", "path": "noxfile.py"}]}
| 3,721 | 205 |
gh_patches_debug_26736
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-446
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add axis labels to ITER parameters plot
The ITER parameters plot [here](http://docs.plasmapy.org/en/stable/auto_examples/plot_physics.html#sphx-glr-auto-examples-plot-physics-py) could use some labels and units in said labels.
</issue>
<code>
[start of plasmapy/__init__.py]
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2
3 # Packages may add whatever they like to this file, but
4 # should keep this content at the top.
5 # ----------------------------------------------------------------------------
6 from ._base_init import *
7 # ----------------------------------------------------------------------------
8
9 # Enforce Python version check during package import.
10 # This is the same check as the one at the top of setup.py
11 import sys
12
13 __name__ = "plasmapy"
14
15 __doc__ = ("A community-developed and community-driven open source "
16 "core Python package for plasma physics.")
17
18
19 class UnsupportedPythonError(Exception):
20 pass
21
22
23 if sys.version_info < tuple((int(val) for val in "3.6".split('.'))):
24 raise UnsupportedPythonError("plasmapy does not support Python < {}".format(3.6))
25
26 if not _ASTROPY_SETUP_:
27 # For egg_info test builds to pass, put package imports here.
28 from . import atomic
29 from . import classes
30 from . import constants
31 from . import diagnostics
32 from . import mathematics
33 from . import physics
34 from . import utils
35
36 __citation__ = """@misc{plasmapy_community_2018_1238132,
37 author = {PlasmaPy Community and
38 Murphy, Nicholas A. and
39 Leonard, Andrew J. and
40 Sta\'nczak, Dominik and
41 Kozlowski, Pawel M. and
42 Langendorf, Samuel J. and
43 Haggerty, Colby C. and
44 Beckers, Jasper P. and
45 Mumford, Stuart J. and
46 Parashar, Tulasi N. and
47 Huang, Yi-Min},
48 title = {{PlasmaPy: an open source community-developed
49 Python package for plasma physics}},
50 month = apr,
51 year = 2018,
52 doi = {10.5281/zenodo.1238132},
53 url = {https://doi.org/10.5281/zenodo.1238132}
54 }"""
55
[end of plasmapy/__init__.py]
[start of plasmapy/examples/plot_physics.py]
1 """
2 Analysing ITER parameters
3 =========================
4
5 Let's try to look at ITER plasma conditions using the `physics` subpackage.
6 """
7
8 from astropy import units as u
9 from plasmapy import physics
10 import matplotlib.pyplot as plt
11 import numpy as np
12 from mpl_toolkits.mplot3d import Axes3D
13
14 ######################################################
15 # The radius of electric field shielding clouds, also known as the Debye length,
16 # would be
17
18 electron_temperature = 8.8 * u.keV
19 electron_concentration = 10.1e19 / u.m**3
20 print(physics.Debye_length(electron_temperature, electron_concentration))
21
22 ############################################################
23 # Note that we can also neglect the unit for the concentration, as
24 # 1/m^3 is the a standard unit for this kind of Quantity:
25
26 print(physics.Debye_length(electron_temperature, 10.1e19))
27
28 ############################################################
29 # Assuming the magnetic field as 5.3 Teslas (which is the value at the major
30 # radius):
31
32 B = 5.3 * u.T
33
34 print(physics.gyrofrequency(B, particle='e'))
35
36 print(physics.gyroradius(B, T_i=electron_temperature, particle='e'))
37
38 ######################################################################
39 # The electron inertial length would be
40 print(physics.inertial_length(electron_concentration, particle='e'))
41
42 ######################################################################
43 # In these conditions, they should reach thermal velocities of about
44 print(physics.thermal_speed(T=electron_temperature, particle='e'))
45
46 ######################################################################
47 # And the Langmuir wave plasma frequency should be on the order of
48 print(physics.plasma_frequency(electron_concentration))
49
50 ############################################################
51 # Let's try to recreate some plots and get a feel for some of these quantities.
52
53 n_e = np.logspace(4, 30, 100) / u.m**3
54 plt.plot(n_e, physics.plasma_frequency(n_e))
55 plt.scatter(
56 electron_concentration,
57 physics.plasma_frequency(electron_concentration))
58
[end of plasmapy/examples/plot_physics.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py
--- a/plasmapy/__init__.py
+++ b/plasmapy/__init__.py
@@ -33,6 +33,29 @@
from . import physics
from . import utils
+def online_help(query):
+ """
+ Search the online PlasmaPy documentation for the given query from plasmapy.org
+ Opens the results in the default web browser.
+ Requires an active Internet connection.
+ Redirects to Astropy.units in case of query 'unit' or 'units'
+
+ Parameters
+ ----------
+ query : str
+ The search query.
+ """
+ from urllib.parse import urlencode
+ import webbrowser
+
+ url = 'http://docs.plasmapy.org/en/stable/search.html?\
+ {0}&check_keywords=yes&area=default'.format(urlencode({'q': query}))
+
+ if(query.lower() in ('unit', 'units')):
+ url = 'http://docs.astropy.org/en/stable/units/'
+
+ webbrowser.open(url)
+
__citation__ = """@misc{plasmapy_community_2018_1238132,
author = {PlasmaPy Community and
Murphy, Nicholas A. and
@@ -51,4 +74,4 @@
year = 2018,
doi = {10.5281/zenodo.1238132},
url = {https://doi.org/10.5281/zenodo.1238132}
-}"""
+}"""
\ No newline at end of file
diff --git a/plasmapy/examples/plot_physics.py b/plasmapy/examples/plot_physics.py
--- a/plasmapy/examples/plot_physics.py
+++ b/plasmapy/examples/plot_physics.py
@@ -55,3 +55,6 @@
plt.scatter(
electron_concentration,
physics.plasma_frequency(electron_concentration))
+plt.xlabel("Electron Concentration (m^-3)")
+plt.ylabel("Langmuir Wave Plasma Frequency (rad/s)")
+plt.show()
|
{"golden_diff": "diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py\n--- a/plasmapy/__init__.py\n+++ b/plasmapy/__init__.py\n@@ -33,6 +33,29 @@\n from . import physics\n from . import utils\n \n+def online_help(query):\n+ \"\"\"\n+ Search the online PlasmaPy documentation for the given query from plasmapy.org\n+ Opens the results in the default web browser.\n+ Requires an active Internet connection.\n+ Redirects to Astropy.units in case of query 'unit' or 'units'\n+\n+ Parameters\n+ ----------\n+ query : str\n+ The search query.\n+ \"\"\"\n+ from urllib.parse import urlencode\n+ import webbrowser\n+\n+ url = 'http://docs.plasmapy.org/en/stable/search.html?\\\n+ {0}&check_keywords=yes&area=default'.format(urlencode({'q': query}))\n+\n+ if(query.lower() in ('unit', 'units')):\n+ url = 'http://docs.astropy.org/en/stable/units/'\n+\n+ webbrowser.open(url)\n+\n __citation__ = \"\"\"@misc{plasmapy_community_2018_1238132,\n author = {PlasmaPy Community and\n Murphy, Nicholas A. and\n@@ -51,4 +74,4 @@\n year = 2018,\n doi = {10.5281/zenodo.1238132},\n url = {https://doi.org/10.5281/zenodo.1238132}\n-}\"\"\"\n+}\"\"\"\n\\ No newline at end of file\ndiff --git a/plasmapy/examples/plot_physics.py b/plasmapy/examples/plot_physics.py\n--- a/plasmapy/examples/plot_physics.py\n+++ b/plasmapy/examples/plot_physics.py\n@@ -55,3 +55,6 @@\n plt.scatter(\n electron_concentration,\n physics.plasma_frequency(electron_concentration))\n+plt.xlabel(\"Electron Concentration (m^-3)\")\n+plt.ylabel(\"Langmuir Wave Plasma Frequency (rad/s)\")\n+plt.show()\n", "issue": "add axis labels to ITER parameters plot\nThe ITER parameters plot [here](http://docs.plasmapy.org/en/stable/auto_examples/plot_physics.html#sphx-glr-auto-examples-plot-physics-py) could use some labels and units in said labels.\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\n# Packages may add whatever they like to this file, but\n# should keep this content at the top.\n# ----------------------------------------------------------------------------\nfrom ._base_init import *\n# ----------------------------------------------------------------------------\n\n# Enforce Python version check during package import.\n# This is the same check as the one at the top of setup.py\nimport sys\n\n__name__ = \"plasmapy\"\n\n__doc__ = (\"A community-developed and community-driven open source \"\n \"core Python package for plasma physics.\")\n\n\nclass UnsupportedPythonError(Exception):\n pass\n\n\nif sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n raise UnsupportedPythonError(\"plasmapy does not support Python < {}\".format(3.6))\n\nif not _ASTROPY_SETUP_:\n # For egg_info test builds to pass, put package imports here.\n from . import atomic\n from . import classes\n from . import constants\n from . import diagnostics\n from . import mathematics\n from . import physics\n from . import utils\n\n__citation__ = \"\"\"@misc{plasmapy_community_2018_1238132,\n author = {PlasmaPy Community and\n Murphy, Nicholas A. and\n Leonard, Andrew J. and\n Sta\\'nczak, Dominik and\n Kozlowski, Pawel M. and\n Langendorf, Samuel J. and\n Haggerty, Colby C. and\n Beckers, Jasper P. and\n Mumford, Stuart J. and\n Parashar, Tulasi N. and\n Huang, Yi-Min},\n title = {{PlasmaPy: an open source community-developed \n Python package for plasma physics}},\n month = apr,\n year = 2018,\n doi = {10.5281/zenodo.1238132},\n url = {https://doi.org/10.5281/zenodo.1238132}\n}\"\"\"\n", "path": "plasmapy/__init__.py"}, {"content": "\"\"\"\nAnalysing ITER parameters\n=========================\n\nLet's try to look at ITER plasma conditions using the `physics` subpackage.\n\"\"\"\n\nfrom astropy import units as u\nfrom plasmapy import physics\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom mpl_toolkits.mplot3d import Axes3D\n\n######################################################\n# The radius of electric field shielding clouds, also known as the Debye length,\n# would be\n\nelectron_temperature = 8.8 * u.keV\nelectron_concentration = 10.1e19 / u.m**3\nprint(physics.Debye_length(electron_temperature, electron_concentration))\n\n############################################################\n# Note that we can also neglect the unit for the concentration, as\n# 1/m^3 is the a standard unit for this kind of Quantity:\n\nprint(physics.Debye_length(electron_temperature, 10.1e19))\n\n############################################################\n# Assuming the magnetic field as 5.3 Teslas (which is the value at the major\n# radius):\n\nB = 5.3 * u.T\n\nprint(physics.gyrofrequency(B, particle='e'))\n\nprint(physics.gyroradius(B, T_i=electron_temperature, particle='e'))\n\n######################################################################\n# The electron inertial length would be\nprint(physics.inertial_length(electron_concentration, particle='e'))\n\n######################################################################\n# In these conditions, they should reach thermal velocities of about\nprint(physics.thermal_speed(T=electron_temperature, particle='e'))\n\n######################################################################\n# And the Langmuir wave plasma frequency should be on the order of\nprint(physics.plasma_frequency(electron_concentration))\n\n############################################################\n# Let's try to recreate some plots and get a feel for some of these quantities.\n\nn_e = np.logspace(4, 30, 100) / u.m**3\nplt.plot(n_e, physics.plasma_frequency(n_e))\nplt.scatter(\n electron_concentration,\n physics.plasma_frequency(electron_concentration))\n", "path": "plasmapy/examples/plot_physics.py"}]}
| 1,735 | 501 |
gh_patches_debug_17999
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-629
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unidecode dependency GPL license
In commit adc1b1b a dependency on the Unidecode python package was introduced.
Unidecode is released under the GPL license while Faker is using MIT. I'm concerned that this might not be permitted by the GPL license and that users of the Faker library might not realise they are introducing GPL code into their dependencies. It could be argued that any code using the Faker library now has to be licensed under the GPL too.
See here for some opinions on using GPL libraries:
https://opensource.stackexchange.com/questions/1640/if-im-using-a-gpl-3-library-in-my-project-can-i-license-my-project-under-mit-l
https://softwareengineering.stackexchange.com/questions/87446/using-a-gplv3-python-module-will-my-entire-project-have-to-be-gplv3-licensed
https://opensource.stackexchange.com/questions/2139/can-i-license-python-project-under-3-clause-bsd-while-it-has-gpl-based-dependenc
https://opensource.stackexchange.com/questions/6062/using-gpl-library-with-mit-licensed-code
I'm not an expert in this area at all, just a concerned user!
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # coding=utf-8
3
4 import os
5 import io
6
7 from setuptools import setup, find_packages
8
9 here = os.path.abspath(os.path.dirname(__file__))
10 README = io.open(os.path.join(here, 'README.rst'), encoding="utf8").read()
11
12
13 version = '0.8.5'
14
15 # this module can be zip-safe if the zipimporter implements iter_modules or if
16 # pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.
17 try:
18 import pkgutil
19 import zipimport
20 zip_safe = hasattr(zipimport.zipimporter, "iter_modules") or \
21 zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()
22 except (ImportError, AttributeError):
23 zip_safe = False
24
25 setup(
26 name='Faker',
27 version=version,
28 description="Faker is a Python package that generates fake data for you.",
29 long_description=README,
30 entry_points={
31 'console_scripts': ['faker=faker.cli:execute_from_command_line'],
32 },
33 classifiers=[
34 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
35 'Development Status :: 3 - Alpha',
36 'Environment :: Console',
37 'Intended Audience :: Developers',
38 'Programming Language :: Python',
39 'Programming Language :: Python :: 2',
40 'Programming Language :: Python :: 2.7',
41 'Programming Language :: Python :: 3',
42 'Programming Language :: Python :: 3.3',
43 'Programming Language :: Python :: 3.4',
44 'Programming Language :: Python :: 3.5',
45 'Programming Language :: Python :: 3.6',
46 'Programming Language :: Python :: Implementation :: CPython',
47 'Programming Language :: Python :: Implementation :: PyPy',
48 'Topic :: Software Development :: Libraries :: Python Modules',
49 'Topic :: Software Development :: Testing',
50 'Topic :: Utilities',
51 'License :: OSI Approved :: MIT License'
52 ],
53 keywords='faker fixtures data test mock generator',
54 author='joke2k',
55 author_email='[email protected]',
56 url='https://github.com/joke2k/faker',
57 license='MIT License',
58 packages=find_packages(exclude=["docs", "tests", "tests.*"]),
59 platforms=["any"],
60 test_suite='tests',
61 zip_safe=zip_safe,
62 install_requires=[
63 "python-dateutil>=2.4",
64 "six",
65 "unidecode",
66 ],
67 test_requires=[
68 "email_validator>=1.0.0,<1.1.0",
69 "ukpostcodeparser==1.1.1",
70 "mock",
71 ],
72 extras_require={
73 ':python_version=="2.7"': [
74 'ipaddress',
75 ],
76 ':python_version=="3.0"': [
77 'importlib',
78 ],
79 ':python_version=="3.2"': [
80 'ipaddress',
81 ],
82 }
83 )
84
[end of setup.py]
[start of faker/providers/internet/__init__.py]
1 # coding=utf-8
2 from __future__ import unicode_literals
3
4 import unidecode
5
6 from .. import BaseProvider
7
8 from ipaddress import ip_address, ip_network, IPV4LENGTH, IPV6LENGTH
9
10 # from faker.generator import random
11 # from faker.providers.lorem.la import Provider as Lorem
12 from faker.utils.decorators import lowercase, slugify, slugify_unicode
13
14
15 localized = True
16
17
18 class Provider(BaseProvider):
19 safe_email_tlds = ('org', 'com', 'net')
20 free_email_domains = ('gmail.com', 'yahoo.com', 'hotmail.com')
21 tlds = (
22 'com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org'
23 )
24
25 uri_pages = (
26 'index', 'home', 'search', 'main', 'post', 'homepage', 'category',
27 'register', 'login', 'faq', 'about', 'terms', 'privacy', 'author'
28 )
29 uri_paths = (
30 'app', 'main', 'wp-content', 'search', 'category', 'tag', 'categories',
31 'tags', 'blog', 'posts', 'list', 'explore'
32 )
33 uri_extensions = (
34 '.html', '.html', '.html', '.htm', '.htm', '.php', '.php', '.jsp',
35 '.asp'
36 )
37
38 user_name_formats = (
39 '{{last_name}}.{{first_name}}',
40 '{{first_name}}.{{last_name}}',
41 '{{first_name}}##',
42 '?{{last_name}}',
43 )
44 email_formats = (
45 '{{user_name}}@{{domain_name}}',
46 '{{user_name}}@{{free_email_domain}}',
47 )
48 url_formats = (
49 'http://www.{{domain_name}}/',
50 'http://{{domain_name}}/',
51 'https://www.{{domain_name}}/',
52 'https://{{domain_name}}/',
53 )
54 uri_formats = (
55 '{{url}}',
56 '{{url}}{{uri_page}}/',
57 '{{url}}{{uri_page}}{{uri_extension}}',
58 '{{url}}{{uri_path}}/{{uri_page}}/',
59 '{{url}}{{uri_path}}/{{uri_page}}{{uri_extension}}',
60 )
61 image_placeholder_services = (
62 'https://placeholdit.imgix.net/~text'
63 '?txtsize=55&txt={width}x{height}&w={width}&h={height}',
64 'https://www.lorempixel.com/{width}/{height}',
65 'https://dummyimage.com/{width}x{height}',
66 )
67
68 replacements = tuple()
69
70 def _to_ascii(self, string):
71 for search, replace in self.replacements:
72 string = string.replace(search, replace)
73
74 string = unidecode.unidecode(string)
75 return string
76
77 @lowercase
78 def email(self):
79 pattern = self.random_element(self.email_formats)
80 return "".join(self.generator.parse(pattern).split(" "))
81
82 @lowercase
83 def safe_email(self):
84 return '{}@example.{}'.format(
85 self.user_name(), self.random_element(self.safe_email_tlds)
86 )
87
88 @lowercase
89 def free_email(self):
90 return self.user_name() + '@' + self.free_email_domain()
91
92 @lowercase
93 def company_email(self):
94 return self.user_name() + '@' + self.domain_name()
95
96 @lowercase
97 def free_email_domain(self):
98 return self.random_element(self.free_email_domains)
99
100 @lowercase
101 def ascii_email(self):
102 pattern = self.random_element(self.email_formats)
103 return self._to_ascii(
104 "".join(self.generator.parse(pattern).split(" "))
105 )
106
107 @lowercase
108 def ascii_safe_email(self):
109 return self._to_ascii(
110 self.user_name() +
111 '@example.' +
112 self.random_element(self.safe_email_tlds)
113 )
114
115 @lowercase
116 def ascii_free_email(self):
117 return self._to_ascii(
118 self.user_name() + '@' + self.free_email_domain()
119 )
120
121 @lowercase
122 def ascii_company_email(self):
123 return self._to_ascii(
124 self.user_name() + '@' + self.domain_name()
125 )
126
127 @slugify_unicode
128 def user_name(self):
129 pattern = self.random_element(self.user_name_formats)
130 username = self._to_ascii(
131 self.bothify(self.generator.parse(pattern)).lower()
132 )
133 return username
134
135 @lowercase
136 def domain_name(self, levels=1):
137 """
138 Produce an Internet domain name with the specified number of
139 subdomain levels.
140
141 >>> domain_name()
142 nichols-phillips.com
143 >>> domain_name(2)
144 williamson-hopkins.jackson.com
145 """
146 if levels < 1:
147 raise ValueError("levels must be greater than or equal to 1")
148 if levels == 1:
149 return self.domain_word() + '.' + self.tld()
150 else:
151 return self.domain_word() + '.' + self.domain_name(levels - 1)
152
153 @lowercase
154 @slugify_unicode
155 def domain_word(self,):
156 company = self.generator.format('company')
157 company_elements = company.split(' ')
158 company = self._to_ascii(company_elements.pop(0))
159 return company
160
161 def tld(self):
162 return self.random_element(self.tlds)
163
164 def url(self):
165 pattern = self.random_element(self.url_formats)
166 return self.generator.parse(pattern)
167
168 def ipv4(self, network=False):
169 """Produce a random IPv4 address or network with a valid CIDR"""
170 address = str(ip_address(self.generator.random.randint(
171 0, (2 ** IPV4LENGTH) - 1)))
172 if network:
173 address += '/' + str(self.generator.random.randint(0, IPV4LENGTH))
174 address = str(ip_network(address, strict=False))
175 return address
176
177 def ipv6(self, network=False):
178 """Produce a random IPv6 address or network with a valid CIDR"""
179 address = str(ip_address(self.generator.random.randint(
180 2 ** IPV4LENGTH, (2 ** IPV6LENGTH) - 1)))
181 if network:
182 address += '/' + str(self.generator.random.randint(0, IPV6LENGTH))
183 address = str(ip_network(address, strict=False))
184 return address
185
186 def mac_address(self):
187 mac = [self.generator.random.randint(0x00, 0xff) for i in range(0, 6)]
188 return ":".join(map(lambda x: "%02x" % x, mac))
189
190 def uri_page(self):
191 return self.random_element(self.uri_pages)
192
193 def uri_path(self, deep=None):
194 deep = deep if deep else self.generator.random.randint(1, 3)
195 return "/".join(
196 [self.random_element(self.uri_paths) for _ in range(0, deep)]
197 )
198
199 def uri_extension(self):
200 return self.random_element(self.uri_extensions)
201
202 def uri(self):
203 pattern = self.random_element(self.uri_formats)
204 return self.generator.parse(pattern)
205
206 @slugify
207 def slug(self, value=None):
208 """Django algorithm"""
209 if value is None:
210 value = self.generator.text(20)
211 return value
212
213 def image_url(self, width=None, height=None):
214 """
215 Returns URL to placeholder image
216 Example: http://placehold.it/640x480
217 """
218 width_ = width or self.random_int(max=1024)
219 height_ = height or self.random_int(max=1024)
220 placeholder_url = self.random_element(self.image_placeholder_services)
221 return placeholder_url.format(width=width_, height=height_)
222
[end of faker/providers/internet/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/faker/providers/internet/__init__.py b/faker/providers/internet/__init__.py
--- a/faker/providers/internet/__init__.py
+++ b/faker/providers/internet/__init__.py
@@ -1,7 +1,7 @@
# coding=utf-8
from __future__ import unicode_literals
-import unidecode
+from text_unidecode import unidecode
from .. import BaseProvider
@@ -71,7 +71,7 @@
for search, replace in self.replacements:
string = string.replace(search, replace)
- string = unidecode.unidecode(string)
+ string = unidecode(string)
return string
@lowercase
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -62,7 +62,7 @@
install_requires=[
"python-dateutil>=2.4",
"six",
- "unidecode",
+ "text-unidecode",
],
test_requires=[
"email_validator>=1.0.0,<1.1.0",
|
{"golden_diff": "diff --git a/faker/providers/internet/__init__.py b/faker/providers/internet/__init__.py\n--- a/faker/providers/internet/__init__.py\n+++ b/faker/providers/internet/__init__.py\n@@ -1,7 +1,7 @@\n # coding=utf-8\n from __future__ import unicode_literals\n \n-import unidecode\n+from text_unidecode import unidecode\n \n from .. import BaseProvider\n \n@@ -71,7 +71,7 @@\n for search, replace in self.replacements:\n string = string.replace(search, replace)\n \n- string = unidecode.unidecode(string)\n+ string = unidecode(string)\n return string\n \n @lowercase\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -62,7 +62,7 @@\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n- \"unidecode\",\n+ \"text-unidecode\",\n ],\n test_requires=[\n \"email_validator>=1.0.0,<1.1.0\",\n", "issue": "Unidecode dependency GPL license\nIn commit adc1b1b a dependency on the Unidecode python package was introduced.\r\n\r\nUnidecode is released under the GPL license while Faker is using MIT. I'm concerned that this might not be permitted by the GPL license and that users of the Faker library might not realise they are introducing GPL code into their dependencies. It could be argued that any code using the Faker library now has to be licensed under the GPL too.\r\n\r\nSee here for some opinions on using GPL libraries:\r\n\r\nhttps://opensource.stackexchange.com/questions/1640/if-im-using-a-gpl-3-library-in-my-project-can-i-license-my-project-under-mit-l\r\nhttps://softwareengineering.stackexchange.com/questions/87446/using-a-gplv3-python-module-will-my-entire-project-have-to-be-gplv3-licensed\r\nhttps://opensource.stackexchange.com/questions/2139/can-i-license-python-project-under-3-clause-bsd-while-it-has-gpl-based-dependenc\r\nhttps://opensource.stackexchange.com/questions/6062/using-gpl-library-with-mit-licensed-code\r\n\r\nI'm not an expert in this area at all, just a concerned user!\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport os\nimport io\n\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = io.open(os.path.join(here, 'README.rst'), encoding=\"utf8\").read()\n\n\nversion = '0.8.5'\n\n# this module can be zip-safe if the zipimporter implements iter_modules or if\n# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\ntry:\n import pkgutil\n import zipimport\n zip_safe = hasattr(zipimport.zipimporter, \"iter_modules\") or \\\n zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()\nexcept (ImportError, AttributeError):\n zip_safe = False\n\nsetup(\n name='Faker',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README,\n entry_points={\n 'console_scripts': ['faker=faker.cli:execute_from_command_line'],\n },\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='https://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=[\"docs\", \"tests\", \"tests.*\"]),\n platforms=[\"any\"],\n test_suite='tests',\n zip_safe=zip_safe,\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n \"unidecode\",\n ],\n test_requires=[\n \"email_validator>=1.0.0,<1.1.0\",\n \"ukpostcodeparser==1.1.1\",\n \"mock\",\n ],\n extras_require={\n ':python_version==\"2.7\"': [\n 'ipaddress',\n ],\n ':python_version==\"3.0\"': [\n 'importlib',\n ],\n ':python_version==\"3.2\"': [\n 'ipaddress',\n ],\n }\n)\n", "path": "setup.py"}, {"content": "# coding=utf-8\nfrom __future__ import unicode_literals\n\nimport unidecode\n\nfrom .. import BaseProvider\n\nfrom ipaddress import ip_address, ip_network, IPV4LENGTH, IPV6LENGTH\n\n# from faker.generator import random\n# from faker.providers.lorem.la import Provider as Lorem\nfrom faker.utils.decorators import lowercase, slugify, slugify_unicode\n\n\nlocalized = True\n\n\nclass Provider(BaseProvider):\n safe_email_tlds = ('org', 'com', 'net')\n free_email_domains = ('gmail.com', 'yahoo.com', 'hotmail.com')\n tlds = (\n 'com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org'\n )\n\n uri_pages = (\n 'index', 'home', 'search', 'main', 'post', 'homepage', 'category',\n 'register', 'login', 'faq', 'about', 'terms', 'privacy', 'author'\n )\n uri_paths = (\n 'app', 'main', 'wp-content', 'search', 'category', 'tag', 'categories',\n 'tags', 'blog', 'posts', 'list', 'explore'\n )\n uri_extensions = (\n '.html', '.html', '.html', '.htm', '.htm', '.php', '.php', '.jsp',\n '.asp'\n )\n\n user_name_formats = (\n '{{last_name}}.{{first_name}}',\n '{{first_name}}.{{last_name}}',\n '{{first_name}}##',\n '?{{last_name}}',\n )\n email_formats = (\n '{{user_name}}@{{domain_name}}',\n '{{user_name}}@{{free_email_domain}}',\n )\n url_formats = (\n 'http://www.{{domain_name}}/',\n 'http://{{domain_name}}/',\n 'https://www.{{domain_name}}/',\n 'https://{{domain_name}}/',\n )\n uri_formats = (\n '{{url}}',\n '{{url}}{{uri_page}}/',\n '{{url}}{{uri_page}}{{uri_extension}}',\n '{{url}}{{uri_path}}/{{uri_page}}/',\n '{{url}}{{uri_path}}/{{uri_page}}{{uri_extension}}',\n )\n image_placeholder_services = (\n 'https://placeholdit.imgix.net/~text'\n '?txtsize=55&txt={width}x{height}&w={width}&h={height}',\n 'https://www.lorempixel.com/{width}/{height}',\n 'https://dummyimage.com/{width}x{height}',\n )\n\n replacements = tuple()\n\n def _to_ascii(self, string):\n for search, replace in self.replacements:\n string = string.replace(search, replace)\n\n string = unidecode.unidecode(string)\n return string\n\n @lowercase\n def email(self):\n pattern = self.random_element(self.email_formats)\n return \"\".join(self.generator.parse(pattern).split(\" \"))\n\n @lowercase\n def safe_email(self):\n return '{}@example.{}'.format(\n self.user_name(), self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def free_email(self):\n return self.user_name() + '@' + self.free_email_domain()\n\n @lowercase\n def company_email(self):\n return self.user_name() + '@' + self.domain_name()\n\n @lowercase\n def free_email_domain(self):\n return self.random_element(self.free_email_domains)\n\n @lowercase\n def ascii_email(self):\n pattern = self.random_element(self.email_formats)\n return self._to_ascii(\n \"\".join(self.generator.parse(pattern).split(\" \"))\n )\n\n @lowercase\n def ascii_safe_email(self):\n return self._to_ascii(\n self.user_name() +\n '@example.' +\n self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def ascii_free_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.free_email_domain()\n )\n\n @lowercase\n def ascii_company_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.domain_name()\n )\n\n @slugify_unicode\n def user_name(self):\n pattern = self.random_element(self.user_name_formats)\n username = self._to_ascii(\n self.bothify(self.generator.parse(pattern)).lower()\n )\n return username\n\n @lowercase\n def domain_name(self, levels=1):\n \"\"\"\n Produce an Internet domain name with the specified number of\n subdomain levels.\n\n >>> domain_name()\n nichols-phillips.com\n >>> domain_name(2)\n williamson-hopkins.jackson.com\n \"\"\"\n if levels < 1:\n raise ValueError(\"levels must be greater than or equal to 1\")\n if levels == 1:\n return self.domain_word() + '.' + self.tld()\n else:\n return self.domain_word() + '.' + self.domain_name(levels - 1)\n\n @lowercase\n @slugify_unicode\n def domain_word(self,):\n company = self.generator.format('company')\n company_elements = company.split(' ')\n company = self._to_ascii(company_elements.pop(0))\n return company\n\n def tld(self):\n return self.random_element(self.tlds)\n\n def url(self):\n pattern = self.random_element(self.url_formats)\n return self.generator.parse(pattern)\n\n def ipv4(self, network=False):\n \"\"\"Produce a random IPv4 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 0, (2 ** IPV4LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV4LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def ipv6(self, network=False):\n \"\"\"Produce a random IPv6 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 2 ** IPV4LENGTH, (2 ** IPV6LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV6LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def mac_address(self):\n mac = [self.generator.random.randint(0x00, 0xff) for i in range(0, 6)]\n return \":\".join(map(lambda x: \"%02x\" % x, mac))\n\n def uri_page(self):\n return self.random_element(self.uri_pages)\n\n def uri_path(self, deep=None):\n deep = deep if deep else self.generator.random.randint(1, 3)\n return \"/\".join(\n [self.random_element(self.uri_paths) for _ in range(0, deep)]\n )\n\n def uri_extension(self):\n return self.random_element(self.uri_extensions)\n\n def uri(self):\n pattern = self.random_element(self.uri_formats)\n return self.generator.parse(pattern)\n\n @slugify\n def slug(self, value=None):\n \"\"\"Django algorithm\"\"\"\n if value is None:\n value = self.generator.text(20)\n return value\n\n def image_url(self, width=None, height=None):\n \"\"\"\n Returns URL to placeholder image\n Example: http://placehold.it/640x480\n \"\"\"\n width_ = width or self.random_int(max=1024)\n height_ = height or self.random_int(max=1024)\n placeholder_url = self.random_element(self.image_placeholder_services)\n return placeholder_url.format(width=width_, height=height_)\n", "path": "faker/providers/internet/__init__.py"}]}
| 3,813 | 244 |
gh_patches_debug_1817
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-8318
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect docstrings in x25519 and x448 `.public_key()` methods
See:
https://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x25519.py#L60-L64
https://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x448.py#L60-L64
In both instances, the method does not return serialised bytes, but a public key object. The full [generated documentation](https://cryptography.io/en/latest/hazmat/primitives/asymmetric/x25519/#cryptography.hazmat.primitives.asymmetric.x25519.X25519PrivateKey.public_key) is correct, as are the Ed* docstrings.
</issue>
<code>
[start of src/cryptography/hazmat/primitives/asymmetric/x25519.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 import abc
7
8 from cryptography.exceptions import UnsupportedAlgorithm, _Reasons
9 from cryptography.hazmat.primitives import _serialization
10
11
12 class X25519PublicKey(metaclass=abc.ABCMeta):
13 @classmethod
14 def from_public_bytes(cls, data: bytes) -> "X25519PublicKey":
15 from cryptography.hazmat.backends.openssl.backend import backend
16
17 if not backend.x25519_supported():
18 raise UnsupportedAlgorithm(
19 "X25519 is not supported by this version of OpenSSL.",
20 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
21 )
22
23 return backend.x25519_load_public_bytes(data)
24
25 @abc.abstractmethod
26 def public_bytes(
27 self,
28 encoding: _serialization.Encoding,
29 format: _serialization.PublicFormat,
30 ) -> bytes:
31 """
32 The serialized bytes of the public key.
33 """
34
35
36 class X25519PrivateKey(metaclass=abc.ABCMeta):
37 @classmethod
38 def generate(cls) -> "X25519PrivateKey":
39 from cryptography.hazmat.backends.openssl.backend import backend
40
41 if not backend.x25519_supported():
42 raise UnsupportedAlgorithm(
43 "X25519 is not supported by this version of OpenSSL.",
44 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
45 )
46 return backend.x25519_generate_key()
47
48 @classmethod
49 def from_private_bytes(cls, data: bytes) -> "X25519PrivateKey":
50 from cryptography.hazmat.backends.openssl.backend import backend
51
52 if not backend.x25519_supported():
53 raise UnsupportedAlgorithm(
54 "X25519 is not supported by this version of OpenSSL.",
55 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
56 )
57
58 return backend.x25519_load_private_bytes(data)
59
60 @abc.abstractmethod
61 def public_key(self) -> X25519PublicKey:
62 """
63 The serialized bytes of the public key.
64 """
65
66 @abc.abstractmethod
67 def private_bytes(
68 self,
69 encoding: _serialization.Encoding,
70 format: _serialization.PrivateFormat,
71 encryption_algorithm: _serialization.KeySerializationEncryption,
72 ) -> bytes:
73 """
74 The serialized bytes of the private key.
75 """
76
77 @abc.abstractmethod
78 def exchange(self, peer_public_key: X25519PublicKey) -> bytes:
79 """
80 Performs a key exchange operation using the provided peer's public key.
81 """
82
[end of src/cryptography/hazmat/primitives/asymmetric/x25519.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/asymmetric/x25519.py b/src/cryptography/hazmat/primitives/asymmetric/x25519.py
--- a/src/cryptography/hazmat/primitives/asymmetric/x25519.py
+++ b/src/cryptography/hazmat/primitives/asymmetric/x25519.py
@@ -60,7 +60,7 @@
@abc.abstractmethod
def public_key(self) -> X25519PublicKey:
"""
- The serialized bytes of the public key.
+ Returns the public key assosciated with this private key
"""
@abc.abstractmethod
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/asymmetric/x25519.py b/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n--- a/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n+++ b/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n@@ -60,7 +60,7 @@\n @abc.abstractmethod\n def public_key(self) -> X25519PublicKey:\n \"\"\"\n- The serialized bytes of the public key.\n+ Returns the public key assosciated with this private key\n \"\"\"\n \n @abc.abstractmethod\n", "issue": "Incorrect docstrings in x25519 and x448 `.public_key()` methods\nSee:\r\n\r\nhttps://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x25519.py#L60-L64\r\n\r\nhttps://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x448.py#L60-L64\r\n\r\nIn both instances, the method does not return serialised bytes, but a public key object. The full [generated documentation](https://cryptography.io/en/latest/hazmat/primitives/asymmetric/x25519/#cryptography.hazmat.primitives.asymmetric.x25519.X25519PrivateKey.public_key) is correct, as are the Ed* docstrings.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nimport abc\n\nfrom cryptography.exceptions import UnsupportedAlgorithm, _Reasons\nfrom cryptography.hazmat.primitives import _serialization\n\n\nclass X25519PublicKey(metaclass=abc.ABCMeta):\n @classmethod\n def from_public_bytes(cls, data: bytes) -> \"X25519PublicKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_public_bytes(data)\n\n @abc.abstractmethod\n def public_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PublicFormat,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the public key.\n \"\"\"\n\n\nclass X25519PrivateKey(metaclass=abc.ABCMeta):\n @classmethod\n def generate(cls) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n return backend.x25519_generate_key()\n\n @classmethod\n def from_private_bytes(cls, data: bytes) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_private_bytes(data)\n\n @abc.abstractmethod\n def public_key(self) -> X25519PublicKey:\n \"\"\"\n The serialized bytes of the public key.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PrivateFormat,\n encryption_algorithm: _serialization.KeySerializationEncryption,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the private key.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, peer_public_key: X25519PublicKey) -> bytes:\n \"\"\"\n Performs a key exchange operation using the provided peer's public key.\n \"\"\"\n", "path": "src/cryptography/hazmat/primitives/asymmetric/x25519.py"}]}
| 1,558 | 148 |
gh_patches_debug_22657
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3674
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TD: IndexError: list index out of range
2018-01-25 20:40:04 ERROR FINDPROPERS :: [TorrentDay] :: [ad04c6b] Failed parsing provider.
Traceback (most recent call last):
File "/home/osmc/Medusa/medusa/providers/torrent/html/torrentday.py", line 158, in parse
name = cells[labels.index('name')]
IndexError: list index out of range
2018-01-25 20:40:03 INFO FINDPROPERS :: [TorrentDay] :: [ad04c6b] Searching for any new PROPER releases from TorrentDay
@p0psicles @OmgImAlexis
</issue>
<code>
[start of medusa/providers/torrent/html/torrentday.py]
1 # coding=utf-8
2
3 """Provider code for TorrentDay."""
4
5 from __future__ import unicode_literals
6
7 import logging
8
9 from medusa import tv
10 from medusa.bs4_parser import BS4Parser
11 from medusa.helper.common import convert_size, try_int
12 from medusa.logger.adapters.style import BraceAdapter
13 from medusa.providers.torrent.torrent_provider import TorrentProvider
14
15 from requests.compat import urljoin
16
17 log = BraceAdapter(logging.getLogger(__name__))
18 log.logger.addHandler(logging.NullHandler())
19
20
21 class TorrentDayProvider(TorrentProvider):
22 """TorrentDay Torrent provider."""
23
24 def __init__(self):
25 """Initialize the class."""
26 super(TorrentDayProvider, self).__init__('TorrentDay')
27
28 # URLs
29 self.url = 'https://www.torrentday.com'
30 self.urls = {
31 'search': urljoin(self.url, '/t'),
32 }
33
34 # Proper Strings
35
36 # Miscellaneous Options
37 self.freeleech = False
38 self.enable_cookies = True
39 self.cookies = ''
40 self.required_cookies = ('uid', 'pass')
41
42 # TV/480p - 24
43 # TV/Bluray - 32
44 # TV/DVD-R - 31
45 # TV/DVD-Rip - 33
46 # TV/Mobile - 46
47 # TV/Packs - 14
48 # TV/SD/x264 - 26
49 # TV/x264 - 7
50 # TV/x265 - 34
51 # TV/XviD - 2
52 # TV-all `-8`
53
54 self.categories = {
55 'Season': {'c14': 1},
56 'Episode': {'c2': 1, 'c7': 1, 'c24': 1, 'c26': 1, 'c31': 1, 'c32': 1, 'c33': 1, 'c34': 1, 'c46': 1},
57 'RSS': {'c2': 1, 'c26': 1, 'c7': 1, 'c24': 1, 'c14': 1}
58 }
59
60 # Torrent Stats
61 self.minseed = None
62 self.minleech = None
63
64 # Cache
65 self.cache = tv.Cache(self, min_time=10) # Only poll IPTorrents every 10 minutes max
66
67 def search(self, search_strings, age=0, ep_obj=None, **kwargs):
68 """
69 Search a provider and parse the results.
70
71 :param search_strings: A dict with mode (key) and the search value (value)
72 :param age: Not used
73 :param ep_obj: Not used
74 :returns: A list of search results (structure)
75 """
76 results = []
77 if not self.login():
78 return results
79
80 for mode in search_strings:
81 log.debug('Search mode: {0}', mode)
82
83 for search_string in search_strings[mode]:
84 if mode != 'RSS':
85 log.debug('Search string: {search}',
86 {'search': search_string})
87
88 search_string = '+'.join(search_string.split())
89
90 params = {
91 '24': '',
92 '32': '',
93 '31': '',
94 '33': '',
95 '46': '',
96 '26': '',
97 '7': '',
98 '34': '',
99 '2': ''
100 }
101
102 if self.freeleech:
103 params.update({'free': 'on'})
104
105 if search_string:
106 params.update({'q': search_string})
107
108 response = self.session.get(self.urls['search'], params=params)
109 if not response or not response.text:
110 log.debug('No data returned from provider')
111 continue
112
113 try:
114 data = response.text
115 except ValueError:
116 log.debug('No data returned from provider')
117 continue
118
119 try:
120 index = data.index('<form method="get"')
121 except ValueError:
122 log.debug('Could not find main torrent table')
123 continue
124
125 results += self.parse(data[index:], mode)
126
127 return results
128
129 def parse(self, data, mode):
130 """
131 Parse search results for items.
132
133 :param data: The raw response from a search
134 :param mode: The current mode used to search, e.g. RSS
135
136 :return: A list of items found
137 """
138 items = []
139
140 with BS4Parser(data, 'html5lib') as html:
141 torrent_table = html.find('table', {'id': 'torrentTable'})
142 torrent_rows = torrent_table('tr') if torrent_table else []
143
144 # Continue only if at least one release is found
145 if len(torrent_rows) < 2:
146 log.debug('Data returned from provider does not contain any torrents')
147 return items
148
149 # Adding the table column titles manually, as some are not titled. They can be used for easy referencing.
150 labels = ['category', 'name', 'download', 'bookmark', 'comments', 'size', 'seeders', 'leechers']
151
152 items = []
153 # Skip column headers
154 for row in torrent_rows[1:]:
155 cells = row('td')
156
157 try:
158 name = cells[labels.index('name')]
159 title = name.find('a').get_text(strip=True)
160 # details = name.find('a')['href']
161 download_url_raw = cells[labels.index('download')].find('a')['href']
162
163 if not all([title, download_url_raw]):
164 continue
165
166 download_url = urljoin(self.url, download_url_raw)
167
168 seeders = try_int(cells[labels.index('seeders')].get_text(strip=True))
169 leechers = try_int(cells[labels.index('leechers')].get_text(strip=True))
170
171 # Filter unseeded torrent
172 if seeders < min(self.minseed, 1):
173 if mode != 'RSS':
174 log.debug("Discarding torrent because it doesn't meet the"
175 " minimum seeders: {0}. Seeders: {1}",
176 title, seeders)
177 continue
178
179 torrent_size = cells[labels.index('size')].get_text()
180 size = convert_size(torrent_size) or -1
181
182 pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()
183 pubdate = self.parse_pubdate(pubdate_raw, human_time=True)
184
185 item = {
186 'title': title,
187 'link': download_url,
188 'size': size,
189 'seeders': seeders,
190 'leechers': leechers,
191 'pubdate': pubdate,
192 }
193 if mode != 'RSS':
194 log.debug('Found result: {0} with {1} seeders and {2} leechers',
195 title, seeders, leechers)
196
197 items.append(item)
198 except (AttributeError, TypeError, KeyError, ValueError, IndexError):
199 log.exception('Failed parsing provider.')
200
201 return items
202
203 def login(self):
204 """Login method used for logging in before doing search and torrent downloads."""
205 return self.cookie_login('sign In')
206
207
208 provider = TorrentDayProvider()
209
[end of medusa/providers/torrent/html/torrentday.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/providers/torrent/html/torrentday.py b/medusa/providers/torrent/html/torrentday.py
--- a/medusa/providers/torrent/html/torrentday.py
+++ b/medusa/providers/torrent/html/torrentday.py
@@ -142,7 +142,7 @@
torrent_rows = torrent_table('tr') if torrent_table else []
# Continue only if at least one release is found
- if len(torrent_rows) < 2:
+ if len(torrent_rows) < 3 and 'no torrents found' in torrent_rows[-1].find('td').get_text().lower():
log.debug('Data returned from provider does not contain any torrents')
return items
@@ -179,7 +179,7 @@
torrent_size = cells[labels.index('size')].get_text()
size = convert_size(torrent_size) or -1
- pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()
+ pubdate_raw = name.find('div').get_text(strip=True).split('|')[-1].strip()
pubdate = self.parse_pubdate(pubdate_raw, human_time=True)
item = {
|
{"golden_diff": "diff --git a/medusa/providers/torrent/html/torrentday.py b/medusa/providers/torrent/html/torrentday.py\n--- a/medusa/providers/torrent/html/torrentday.py\n+++ b/medusa/providers/torrent/html/torrentday.py\n@@ -142,7 +142,7 @@\n torrent_rows = torrent_table('tr') if torrent_table else []\n \n # Continue only if at least one release is found\n- if len(torrent_rows) < 2:\n+ if len(torrent_rows) < 3 and 'no torrents found' in torrent_rows[-1].find('td').get_text().lower():\n log.debug('Data returned from provider does not contain any torrents')\n return items\n \n@@ -179,7 +179,7 @@\n torrent_size = cells[labels.index('size')].get_text()\n size = convert_size(torrent_size) or -1\n \n- pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()\n+ pubdate_raw = name.find('div').get_text(strip=True).split('|')[-1].strip()\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n \n item = {\n", "issue": "TD: IndexError: list index out of range\n2018-01-25 20:40:04 ERROR FINDPROPERS :: [TorrentDay] :: [ad04c6b] Failed parsing provider.\r\nTraceback (most recent call last):\r\n File \"/home/osmc/Medusa/medusa/providers/torrent/html/torrentday.py\", line 158, in parse\r\n name = cells[labels.index('name')]\r\nIndexError: list index out of range\r\n2018-01-25 20:40:03 INFO FINDPROPERS :: [TorrentDay] :: [ad04c6b] Searching for any new PROPER releases from TorrentDay\r\n\r\n@p0psicles @OmgImAlexis \n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for TorrentDay.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import convert_size, try_int\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass TorrentDayProvider(TorrentProvider):\n \"\"\"TorrentDay Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(TorrentDayProvider, self).__init__('TorrentDay')\n\n # URLs\n self.url = 'https://www.torrentday.com'\n self.urls = {\n 'search': urljoin(self.url, '/t'),\n }\n\n # Proper Strings\n\n # Miscellaneous Options\n self.freeleech = False\n self.enable_cookies = True\n self.cookies = ''\n self.required_cookies = ('uid', 'pass')\n\n # TV/480p - 24\n # TV/Bluray - 32\n # TV/DVD-R - 31\n # TV/DVD-Rip - 33\n # TV/Mobile - 46\n # TV/Packs - 14\n # TV/SD/x264 - 26\n # TV/x264 - 7\n # TV/x265 - 34\n # TV/XviD - 2\n # TV-all `-8`\n\n self.categories = {\n 'Season': {'c14': 1},\n 'Episode': {'c2': 1, 'c7': 1, 'c24': 1, 'c26': 1, 'c31': 1, 'c32': 1, 'c33': 1, 'c34': 1, 'c46': 1},\n 'RSS': {'c2': 1, 'c26': 1, 'c7': 1, 'c24': 1, 'c14': 1}\n }\n\n # Torrent Stats\n self.minseed = None\n self.minleech = None\n\n # Cache\n self.cache = tv.Cache(self, min_time=10) # Only poll IPTorrents every 10 minutes max\n\n def search(self, search_strings, age=0, ep_obj=None, **kwargs):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n if not self.login():\n return results\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n\n search_string = '+'.join(search_string.split())\n\n params = {\n '24': '',\n '32': '',\n '31': '',\n '33': '',\n '46': '',\n '26': '',\n '7': '',\n '34': '',\n '2': ''\n }\n\n if self.freeleech:\n params.update({'free': 'on'})\n\n if search_string:\n params.update({'q': search_string})\n\n response = self.session.get(self.urls['search'], params=params)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n try:\n data = response.text\n except ValueError:\n log.debug('No data returned from provider')\n continue\n\n try:\n index = data.index('<form method=\"get\"')\n except ValueError:\n log.debug('Could not find main torrent table')\n continue\n\n results += self.parse(data[index:], mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', {'id': 'torrentTable'})\n torrent_rows = torrent_table('tr') if torrent_table else []\n\n # Continue only if at least one release is found\n if len(torrent_rows) < 2:\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n # Adding the table column titles manually, as some are not titled. They can be used for easy referencing.\n labels = ['category', 'name', 'download', 'bookmark', 'comments', 'size', 'seeders', 'leechers']\n\n items = []\n # Skip column headers\n for row in torrent_rows[1:]:\n cells = row('td')\n\n try:\n name = cells[labels.index('name')]\n title = name.find('a').get_text(strip=True)\n # details = name.find('a')['href']\n download_url_raw = cells[labels.index('download')].find('a')['href']\n\n if not all([title, download_url_raw]):\n continue\n\n download_url = urljoin(self.url, download_url_raw)\n\n seeders = try_int(cells[labels.index('seeders')].get_text(strip=True))\n leechers = try_int(cells[labels.index('leechers')].get_text(strip=True))\n\n # Filter unseeded torrent\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n torrent_size = cells[labels.index('size')].get_text()\n size = convert_size(torrent_size) or -1\n\n pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.exception('Failed parsing provider.')\n\n return items\n\n def login(self):\n \"\"\"Login method used for logging in before doing search and torrent downloads.\"\"\"\n return self.cookie_login('sign In')\n\n\nprovider = TorrentDayProvider()\n", "path": "medusa/providers/torrent/html/torrentday.py"}]}
| 2,809 | 269 |
gh_patches_debug_28810
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-5496
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make /random/ path works
Currently hitting https://readthedocs.org/random/ produces 502 and hitting https://readthedocs.org/random/pip/ may return a `.js` file or a non `.html` file which is not useful.
We need to fix it and return always return a HTML file. For this, we could use the model `HTMLFile`.
</issue>
<code>
[start of readthedocs/core/views/__init__.py]
1 # -*- coding: utf-8 -*-
2
3 """
4 Core views, including the main homepage,
5
6 documentation and header rendering, and server errors.
7 """
8
9 import os
10 import logging
11 from urllib.parse import urlparse
12
13 from django.conf import settings
14 from django.http import HttpResponseRedirect, Http404, JsonResponse
15 from django.shortcuts import render, get_object_or_404, redirect
16 from django.views.generic import TemplateView
17
18
19 from readthedocs.builds.models import Version
20 from readthedocs.core.utils.general import wipe_version_via_slugs
21 from readthedocs.core.resolver import resolve_path
22 from readthedocs.core.symlink import PrivateSymlink, PublicSymlink
23 from readthedocs.core.utils import broadcast
24 from readthedocs.core.views.serve import _serve_file
25 from readthedocs.projects.constants import PRIVATE
26 from readthedocs.projects.models import Project, ImportedFile
27 from readthedocs.projects.tasks import remove_dirs
28 from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path
29
30 log = logging.getLogger(__name__)
31
32
33 class NoProjectException(Exception):
34 pass
35
36
37 class HomepageView(TemplateView):
38
39 template_name = 'homepage.html'
40
41 def get_context_data(self, **kwargs):
42 """Add latest builds and featured projects."""
43 context = super().get_context_data(**kwargs)
44 context['featured_list'] = Project.objects.filter(featured=True)
45 context['projects_count'] = Project.objects.count()
46 return context
47
48
49 class SupportView(TemplateView):
50 template_name = 'support.html'
51
52 def get_context_data(self, **kwargs):
53 context = super().get_context_data(**kwargs)
54 support_email = getattr(settings, 'SUPPORT_EMAIL', None)
55 if not support_email:
56 support_email = 'support@{domain}'.format(
57 domain=getattr(
58 settings,
59 'PRODUCTION_DOMAIN',
60 'readthedocs.org',
61 ),
62 )
63
64 context['support_email'] = support_email
65 return context
66
67
68 def random_page(request, project_slug=None): # pylint: disable=unused-argument
69 imported_file = ImportedFile.objects.order_by('?')
70 if project_slug:
71 imported_file = imported_file.filter(project__slug=project_slug)
72 imported_file = imported_file.first()
73 if imported_file is None:
74 raise Http404
75 url = imported_file.get_absolute_url()
76 return HttpResponseRedirect(url)
77
78
79 def wipe_version(request, project_slug, version_slug):
80 version = get_object_or_404(
81 Version,
82 project__slug=project_slug,
83 slug=version_slug,
84 )
85 # We need to check by ``for_admin_user`` here to allow members of the
86 # ``Admin`` team (which doesn't own the project) under the corporate site.
87 if version.project not in Project.objects.for_admin_user(user=request.user):
88 raise Http404('You must own this project to wipe it.')
89
90 if request.method == 'POST':
91 wipe_version_via_slugs(
92 version_slug=version_slug,
93 project_slug=project_slug
94 )
95 return redirect('project_version_list', project_slug)
96 return render(
97 request,
98 'wipe_version.html',
99 {'version': version, 'project': version.project},
100 )
101
102
103 def server_error_500(request, template_name='500.html'):
104 """A simple 500 handler so we get media."""
105 r = render(request, template_name)
106 r.status_code = 500
107 return r
108
109
110 def server_error_404(request, exception=None, template_name='404.html'): # pylint: disable=unused-argument # noqa
111 """
112 A simple 404 handler so we get media.
113
114 .. note::
115
116 Marking exception as optional to make /404/ testing page to work.
117 """
118 response = get_redirect_response(request, full_path=request.get_full_path())
119
120 # Return a redirect response if there is one
121 if response:
122 if response.url == request.build_absolute_uri():
123 # check that we do have a response and avoid infinite redirect
124 log.warning(
125 'Infinite Redirect: FROM URL is the same than TO URL. url=%s',
126 response.url,
127 )
128 else:
129 return response
130
131 # Try to serve custom 404 pages if it's a subdomain/cname
132 if getattr(request, 'subdomain', False) or getattr(request, 'cname', False):
133 return server_error_404_subdomain(request, template_name)
134
135 # Return the default 404 page generated by Read the Docs
136 r = render(request, template_name)
137 r.status_code = 404
138 return r
139
140
141 def server_error_404_subdomain(request, template_name='404.html'):
142 """
143 Handler for 404 pages on subdomains.
144
145 Check if the project associated has a custom ``404.html`` and serve this
146 page. First search for a 404 page in the current version, then continues
147 with the default version and finally, if none of them are found, the Read
148 the Docs default page (Maze Found) is rendered by Django and served.
149 """
150
151 def resolve_404_path(project, version_slug=None, language=None):
152 """
153 Helper to resolve the path of ``404.html`` for project.
154
155 The resolution is based on ``project`` object, version slug and
156 language.
157
158 :returns: tuple containing the (basepath, filename)
159 :rtype: tuple
160 """
161 filename = resolve_path(
162 project,
163 version_slug=version_slug,
164 language=language,
165 filename='404.html',
166 subdomain=True, # subdomain will make it a "full" path without a URL prefix
167 )
168
169 # This breaks path joining, by ignoring the root when given an "absolute" path
170 if filename[0] == '/':
171 filename = filename[1:]
172
173 version = None
174 if version_slug:
175 version_qs = project.versions.filter(slug=version_slug)
176 if version_qs.exists():
177 version = version_qs.first()
178
179 private = any([
180 version and version.privacy_level == PRIVATE,
181 not version and project.privacy_level == PRIVATE,
182 ])
183 if private:
184 symlink = PrivateSymlink(project)
185 else:
186 symlink = PublicSymlink(project)
187 basepath = symlink.project_root
188 fullpath = os.path.join(basepath, filename)
189 return (basepath, filename, fullpath)
190
191 project, full_path = project_and_path_from_request(request, request.get_full_path())
192
193 if project:
194 language = None
195 version_slug = None
196 schema, netloc, path, params, query, fragments = urlparse(full_path)
197 if not project.single_version:
198 language, version_slug, path = language_and_version_from_path(path)
199
200 # Firstly, attempt to serve the 404 of the current version (version_slug)
201 # Secondly, try to serve the 404 page for the default version (project.get_default_version())
202 for slug in (version_slug, project.get_default_version()):
203 basepath, filename, fullpath = resolve_404_path(project, slug, language)
204 if os.path.exists(fullpath):
205 log.debug(
206 'serving 404.html page current version: [project: %s] [version: %s]',
207 project.slug,
208 slug,
209 )
210 r = _serve_file(request, filename, basepath)
211 r.status_code = 404
212 return r
213
214 # Finally, return the default 404 page generated by Read the Docs
215 r = render(request, template_name)
216 r.status_code = 404
217 return r
218
219
220 def do_not_track(request):
221 dnt_header = request.META.get('HTTP_DNT')
222
223 # https://w3c.github.io/dnt/drafts/tracking-dnt.html#status-representation
224 return JsonResponse( # pylint: disable=redundant-content-type-for-json-response
225 {
226 'policy': 'https://docs.readthedocs.io/en/latest/privacy-policy.html',
227 'same-party': [
228 'readthedocs.org',
229 'readthedocs.com',
230 'readthedocs.io', # .org Documentation Sites
231 'readthedocs-hosted.com', # .com Documentation Sites
232 ],
233 'tracking': 'N' if dnt_header == '1' else 'T',
234 }, content_type='application/tracking-status+json',
235 )
236
[end of readthedocs/core/views/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/core/views/__init__.py b/readthedocs/core/views/__init__.py
--- a/readthedocs/core/views/__init__.py
+++ b/readthedocs/core/views/__init__.py
@@ -20,12 +20,14 @@
from readthedocs.core.utils.general import wipe_version_via_slugs
from readthedocs.core.resolver import resolve_path
from readthedocs.core.symlink import PrivateSymlink, PublicSymlink
-from readthedocs.core.utils import broadcast
from readthedocs.core.views.serve import _serve_file
from readthedocs.projects.constants import PRIVATE
-from readthedocs.projects.models import Project, ImportedFile
-from readthedocs.projects.tasks import remove_dirs
-from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path
+from readthedocs.projects.models import HTMLFile, Project
+from readthedocs.redirects.utils import (
+ get_redirect_response,
+ project_and_path_from_request,
+ language_and_version_from_path
+)
log = logging.getLogger(__name__)
@@ -66,13 +68,13 @@
def random_page(request, project_slug=None): # pylint: disable=unused-argument
- imported_file = ImportedFile.objects.order_by('?')
+ html_file = HTMLFile.objects.order_by('?')
if project_slug:
- imported_file = imported_file.filter(project__slug=project_slug)
- imported_file = imported_file.first()
- if imported_file is None:
+ html_file = html_file.filter(project__slug=project_slug)
+ html_file = html_file.first()
+ if html_file is None:
raise Http404
- url = imported_file.get_absolute_url()
+ url = html_file.get_absolute_url()
return HttpResponseRedirect(url)
|
{"golden_diff": "diff --git a/readthedocs/core/views/__init__.py b/readthedocs/core/views/__init__.py\n--- a/readthedocs/core/views/__init__.py\n+++ b/readthedocs/core/views/__init__.py\n@@ -20,12 +20,14 @@\n from readthedocs.core.utils.general import wipe_version_via_slugs\n from readthedocs.core.resolver import resolve_path\n from readthedocs.core.symlink import PrivateSymlink, PublicSymlink\n-from readthedocs.core.utils import broadcast\n from readthedocs.core.views.serve import _serve_file\n from readthedocs.projects.constants import PRIVATE\n-from readthedocs.projects.models import Project, ImportedFile\n-from readthedocs.projects.tasks import remove_dirs\n-from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path\n+from readthedocs.projects.models import HTMLFile, Project\n+from readthedocs.redirects.utils import (\n+ get_redirect_response,\n+ project_and_path_from_request,\n+ language_and_version_from_path\n+)\n \n log = logging.getLogger(__name__)\n \n@@ -66,13 +68,13 @@\n \n \n def random_page(request, project_slug=None): # pylint: disable=unused-argument\n- imported_file = ImportedFile.objects.order_by('?')\n+ html_file = HTMLFile.objects.order_by('?')\n if project_slug:\n- imported_file = imported_file.filter(project__slug=project_slug)\n- imported_file = imported_file.first()\n- if imported_file is None:\n+ html_file = html_file.filter(project__slug=project_slug)\n+ html_file = html_file.first()\n+ if html_file is None:\n raise Http404\n- url = imported_file.get_absolute_url()\n+ url = html_file.get_absolute_url()\n return HttpResponseRedirect(url)\n", "issue": "Make /random/ path works\nCurrently hitting https://readthedocs.org/random/ produces 502 and hitting https://readthedocs.org/random/pip/ may return a `.js` file or a non `.html` file which is not useful.\r\n\r\nWe need to fix it and return always return a HTML file. For this, we could use the model `HTMLFile`.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nCore views, including the main homepage,\n\ndocumentation and header rendering, and server errors.\n\"\"\"\n\nimport os\nimport logging\nfrom urllib.parse import urlparse\n\nfrom django.conf import settings\nfrom django.http import HttpResponseRedirect, Http404, JsonResponse\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.views.generic import TemplateView\n\n\nfrom readthedocs.builds.models import Version\nfrom readthedocs.core.utils.general import wipe_version_via_slugs\nfrom readthedocs.core.resolver import resolve_path\nfrom readthedocs.core.symlink import PrivateSymlink, PublicSymlink\nfrom readthedocs.core.utils import broadcast\nfrom readthedocs.core.views.serve import _serve_file\nfrom readthedocs.projects.constants import PRIVATE\nfrom readthedocs.projects.models import Project, ImportedFile\nfrom readthedocs.projects.tasks import remove_dirs\nfrom readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path\n\nlog = logging.getLogger(__name__)\n\n\nclass NoProjectException(Exception):\n pass\n\n\nclass HomepageView(TemplateView):\n\n template_name = 'homepage.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Add latest builds and featured projects.\"\"\"\n context = super().get_context_data(**kwargs)\n context['featured_list'] = Project.objects.filter(featured=True)\n context['projects_count'] = Project.objects.count()\n return context\n\n\nclass SupportView(TemplateView):\n template_name = 'support.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n support_email = getattr(settings, 'SUPPORT_EMAIL', None)\n if not support_email:\n support_email = 'support@{domain}'.format(\n domain=getattr(\n settings,\n 'PRODUCTION_DOMAIN',\n 'readthedocs.org',\n ),\n )\n\n context['support_email'] = support_email\n return context\n\n\ndef random_page(request, project_slug=None): # pylint: disable=unused-argument\n imported_file = ImportedFile.objects.order_by('?')\n if project_slug:\n imported_file = imported_file.filter(project__slug=project_slug)\n imported_file = imported_file.first()\n if imported_file is None:\n raise Http404\n url = imported_file.get_absolute_url()\n return HttpResponseRedirect(url)\n\n\ndef wipe_version(request, project_slug, version_slug):\n version = get_object_or_404(\n Version,\n project__slug=project_slug,\n slug=version_slug,\n )\n # We need to check by ``for_admin_user`` here to allow members of the\n # ``Admin`` team (which doesn't own the project) under the corporate site.\n if version.project not in Project.objects.for_admin_user(user=request.user):\n raise Http404('You must own this project to wipe it.')\n\n if request.method == 'POST':\n wipe_version_via_slugs(\n version_slug=version_slug,\n project_slug=project_slug\n )\n return redirect('project_version_list', project_slug)\n return render(\n request,\n 'wipe_version.html',\n {'version': version, 'project': version.project},\n )\n\n\ndef server_error_500(request, template_name='500.html'):\n \"\"\"A simple 500 handler so we get media.\"\"\"\n r = render(request, template_name)\n r.status_code = 500\n return r\n\n\ndef server_error_404(request, exception=None, template_name='404.html'): # pylint: disable=unused-argument # noqa\n \"\"\"\n A simple 404 handler so we get media.\n\n .. note::\n\n Marking exception as optional to make /404/ testing page to work.\n \"\"\"\n response = get_redirect_response(request, full_path=request.get_full_path())\n\n # Return a redirect response if there is one\n if response:\n if response.url == request.build_absolute_uri():\n # check that we do have a response and avoid infinite redirect\n log.warning(\n 'Infinite Redirect: FROM URL is the same than TO URL. url=%s',\n response.url,\n )\n else:\n return response\n\n # Try to serve custom 404 pages if it's a subdomain/cname\n if getattr(request, 'subdomain', False) or getattr(request, 'cname', False):\n return server_error_404_subdomain(request, template_name)\n\n # Return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef server_error_404_subdomain(request, template_name='404.html'):\n \"\"\"\n Handler for 404 pages on subdomains.\n\n Check if the project associated has a custom ``404.html`` and serve this\n page. First search for a 404 page in the current version, then continues\n with the default version and finally, if none of them are found, the Read\n the Docs default page (Maze Found) is rendered by Django and served.\n \"\"\"\n\n def resolve_404_path(project, version_slug=None, language=None):\n \"\"\"\n Helper to resolve the path of ``404.html`` for project.\n\n The resolution is based on ``project`` object, version slug and\n language.\n\n :returns: tuple containing the (basepath, filename)\n :rtype: tuple\n \"\"\"\n filename = resolve_path(\n project,\n version_slug=version_slug,\n language=language,\n filename='404.html',\n subdomain=True, # subdomain will make it a \"full\" path without a URL prefix\n )\n\n # This breaks path joining, by ignoring the root when given an \"absolute\" path\n if filename[0] == '/':\n filename = filename[1:]\n\n version = None\n if version_slug:\n version_qs = project.versions.filter(slug=version_slug)\n if version_qs.exists():\n version = version_qs.first()\n\n private = any([\n version and version.privacy_level == PRIVATE,\n not version and project.privacy_level == PRIVATE,\n ])\n if private:\n symlink = PrivateSymlink(project)\n else:\n symlink = PublicSymlink(project)\n basepath = symlink.project_root\n fullpath = os.path.join(basepath, filename)\n return (basepath, filename, fullpath)\n\n project, full_path = project_and_path_from_request(request, request.get_full_path())\n\n if project:\n language = None\n version_slug = None\n schema, netloc, path, params, query, fragments = urlparse(full_path)\n if not project.single_version:\n language, version_slug, path = language_and_version_from_path(path)\n\n # Firstly, attempt to serve the 404 of the current version (version_slug)\n # Secondly, try to serve the 404 page for the default version (project.get_default_version())\n for slug in (version_slug, project.get_default_version()):\n basepath, filename, fullpath = resolve_404_path(project, slug, language)\n if os.path.exists(fullpath):\n log.debug(\n 'serving 404.html page current version: [project: %s] [version: %s]',\n project.slug,\n slug,\n )\n r = _serve_file(request, filename, basepath)\n r.status_code = 404\n return r\n\n # Finally, return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef do_not_track(request):\n dnt_header = request.META.get('HTTP_DNT')\n\n # https://w3c.github.io/dnt/drafts/tracking-dnt.html#status-representation\n return JsonResponse( # pylint: disable=redundant-content-type-for-json-response\n {\n 'policy': 'https://docs.readthedocs.io/en/latest/privacy-policy.html',\n 'same-party': [\n 'readthedocs.org',\n 'readthedocs.com',\n 'readthedocs.io', # .org Documentation Sites\n 'readthedocs-hosted.com', # .com Documentation Sites\n ],\n 'tracking': 'N' if dnt_header == '1' else 'T',\n }, content_type='application/tracking-status+json',\n )\n", "path": "readthedocs/core/views/__init__.py"}]}
| 3,071 | 395 |
gh_patches_debug_18999
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-1270
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update regex pattern for the envvar construtor
You can use envvars on your configuration, but they need to follow this pattern `$ENVVARNAME` the regex pattern should be updated to allow users to use either `$ENVVARNAME` or `${ENVVARNAME}`.
While we are at it we should allow users to use other characters as well like `_` or `-`.
This change needs to be done on [opsdroid.loader.load_config_file](https://github.com/opsdroid/opsdroid/blob/674013037eab826640174407a73f8fed1a29b290/opsdroid/loader.py#L347)
</issue>
<code>
[start of opsdroid/const.py]
1 """Constants used by OpsDroid."""
2 import os
3 from appdirs import user_log_dir, user_config_dir, user_data_dir
4 import opsdroid
5 from opsdroid import __version__ # noqa # pylint: disable=unused-import
6
7 NAME = "opsdroid"
8 MODULE_ROOT = os.path.dirname(os.path.abspath(opsdroid.__file__))
9 DEFAULT_GIT_URL = "https://github.com/opsdroid/"
10 MODULES_DIRECTORY = "opsdroid-modules"
11 DEFAULT_ROOT_PATH = user_data_dir(NAME)
12 DEFAULT_LOG_FILENAME = os.path.join(user_log_dir(NAME, appauthor=False), "output.log")
13 DEFAULT_MODULES_PATH = user_data_dir(NAME, MODULES_DIRECTORY)
14 DEFAULT_MODULE_DEPS_PATH = os.path.join(
15 user_data_dir(NAME, MODULES_DIRECTORY), "site-packages"
16 )
17 DEFAULT_CONFIG_PATH = os.path.join(
18 user_config_dir(NAME, appauthor=False), "configuration.yaml"
19 )
20 DEFAULT_MODULE_BRANCH = "master"
21 DEFAULT_LANGUAGE = "en"
22 LOCALE_DIR = os.path.join(MODULE_ROOT, "locale")
23 EXAMPLE_CONFIG_FILE = os.path.join(
24 os.path.dirname(os.path.abspath(__file__)),
25 "configuration/example_configuration.yaml",
26 )
27 REGEX_PARSE_SCORE_FACTOR = 0.6
28
29 RASANLU_DEFAULT_URL = "http://localhost:5000"
30 RASANLU_DEFAULT_PROJECT = "opsdroid"
31
32 LUISAI_DEFAULT_URL = "https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/"
33
34 DIALOGFLOW_API_ENDPOINT = "https://api.dialogflow.com/v1/query"
35 DIALOGFLOW_API_VERSION = "20150910"
36
37 WITAI_DEFAULT_VERSION = "20170307"
38 WITAI_API_ENDPOINT = "https://api.wit.ai/message?"
39
40 SAPCAI_API_ENDPOINT = "https://api.cai.tools.sap/v2/request"
41
42 WATSON_API_ENDPOINT = "https://{gateway}.watsonplatform.net/assistant/api"
43 WATSON_API_VERSION = "2019-02-28"
44
[end of opsdroid/const.py]
[start of opsdroid/configuration/__init__.py]
1 """Load configuration from yaml file."""
2
3 import os
4 import shutil
5 import sys
6 import re
7 import logging
8 import yaml
9
10 from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE
11 from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA
12 from opsdroid.helper import update_pre_0_17_config_format
13
14
15 _LOGGER = logging.getLogger(__name__)
16
17
18 def create_default_config(config_path):
19 """Create a default config file based on the example config file.
20
21 If we can't find any configuration.yaml, we will pull the whole
22 example_configuration.yaml and use this file as the configuration.
23
24 Args:
25 config_path: String containing the path to configuration.yaml
26 default install location
27
28 Returns:
29 str: path to configuration.yaml default install location
30
31 """
32 _LOGGER.info("Creating %s.", config_path)
33 config_dir, _ = os.path.split(config_path)
34 if not os.path.isdir(config_dir):
35 os.makedirs(config_dir)
36 shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)
37 return config_path
38
39
40 def get_config_path(config_paths):
41 """Get the path to configuration.yaml.
42
43 Opsdroid configuration.yaml can be located in different paths.
44 With this function, we will go through all of the possible paths and
45 return the correct path.
46
47 If we don't have any configuration.yaml we will just create one using
48 the example configuration file.
49
50 Args:
51 config_paths: List containing all the possible config paths.
52
53 Returns:
54 str: Path to the configuration file.
55
56 """
57 config_path = ""
58 for possible_path in config_paths:
59 if not os.path.isfile(possible_path):
60 _LOGGER.debug(_("Config file %s not found."), possible_path)
61 else:
62 config_path = possible_path
63 break
64
65 if not config_path:
66 _LOGGER.info(
67 _("No configuration files found. Creating %s"), DEFAULT_CONFIG_PATH
68 )
69 config_path = create_default_config(DEFAULT_CONFIG_PATH)
70
71 return config_path
72
73
74 env_var_pattern = re.compile(r"^\$([A-Z_]*)$")
75
76
77 def envvar_constructor(loader, node):
78 """Yaml parser for env vars."""
79 value = loader.construct_scalar(node)
80 [env_var] = env_var_pattern.match(value).groups()
81 return os.environ[env_var]
82
83
84 def load_config_file(config_paths):
85 """Load a yaml config file from path.
86
87 We get a path for the configuration file and then use the yaml
88 library to load this file - the configuration will be shown as a
89 dict. Here we also add constructors to our yaml loader and handle
90 different exceptions that could be raised when trying to load or
91 validate the file.
92
93 Args:
94 config_paths: List of paths to configuration.yaml files
95
96 Returns:
97 dict: Dict containing config fields
98
99 """
100
101 config_path = get_config_path(config_paths)
102
103 yaml.SafeLoader.add_implicit_resolver("!envvar", env_var_pattern, first="$")
104 yaml.SafeLoader.add_constructor("!envvar", envvar_constructor)
105
106 try:
107 with open(config_path, "r") as stream:
108 _LOGGER.info(_("Loaded config from %s."), config_path)
109
110 data = yaml.load(stream, Loader=yaml.SafeLoader)
111 configuration = update_pre_0_17_config_format(data)
112 validate_configuration(configuration, BASE_SCHEMA)
113
114 return configuration
115
116 except yaml.YAMLError as error:
117 _LOGGER.critical(error)
118 sys.exit(1)
119
120 except FileNotFoundError as error:
121 _LOGGER.critical(error)
122 sys.exit(1)
123
[end of opsdroid/configuration/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/configuration/__init__.py b/opsdroid/configuration/__init__.py
--- a/opsdroid/configuration/__init__.py
+++ b/opsdroid/configuration/__init__.py
@@ -7,7 +7,7 @@
import logging
import yaml
-from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE
+from opsdroid.const import DEFAULT_CONFIG_PATH, ENV_VAR_REGEX, EXAMPLE_CONFIG_FILE
from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA
from opsdroid.helper import update_pre_0_17_config_format
@@ -71,7 +71,7 @@
return config_path
-env_var_pattern = re.compile(r"^\$([A-Z_]*)$")
+env_var_pattern = re.compile(ENV_VAR_REGEX)
def envvar_constructor(loader, node):
diff --git a/opsdroid/const.py b/opsdroid/const.py
--- a/opsdroid/const.py
+++ b/opsdroid/const.py
@@ -41,3 +41,4 @@
WATSON_API_ENDPOINT = "https://{gateway}.watsonplatform.net/assistant/api"
WATSON_API_VERSION = "2019-02-28"
+ENV_VAR_REGEX = r"^\"?\${?(?=\_?[A-Z])([A-Z-_]+)}?\"?$"
|
{"golden_diff": "diff --git a/opsdroid/configuration/__init__.py b/opsdroid/configuration/__init__.py\n--- a/opsdroid/configuration/__init__.py\n+++ b/opsdroid/configuration/__init__.py\n@@ -7,7 +7,7 @@\n import logging\n import yaml\n \n-from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE\n+from opsdroid.const import DEFAULT_CONFIG_PATH, ENV_VAR_REGEX, EXAMPLE_CONFIG_FILE\n from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA\n from opsdroid.helper import update_pre_0_17_config_format\n \n@@ -71,7 +71,7 @@\n return config_path\n \n \n-env_var_pattern = re.compile(r\"^\\$([A-Z_]*)$\")\n+env_var_pattern = re.compile(ENV_VAR_REGEX)\n \n \n def envvar_constructor(loader, node):\ndiff --git a/opsdroid/const.py b/opsdroid/const.py\n--- a/opsdroid/const.py\n+++ b/opsdroid/const.py\n@@ -41,3 +41,4 @@\n \n WATSON_API_ENDPOINT = \"https://{gateway}.watsonplatform.net/assistant/api\"\n WATSON_API_VERSION = \"2019-02-28\"\n+ENV_VAR_REGEX = r\"^\\\"?\\${?(?=\\_?[A-Z])([A-Z-_]+)}?\\\"?$\"\n", "issue": "Update regex pattern for the envvar construtor\nYou can use envvars on your configuration, but they need to follow this pattern `$ENVVARNAME` the regex pattern should be updated to allow users to use either `$ENVVARNAME` or `${ENVVARNAME}`. \r\n\r\nWhile we are at it we should allow users to use other characters as well like `_` or `-`. \r\n\r\nThis change needs to be done on [opsdroid.loader.load_config_file](https://github.com/opsdroid/opsdroid/blob/674013037eab826640174407a73f8fed1a29b290/opsdroid/loader.py#L347)\n", "before_files": [{"content": "\"\"\"Constants used by OpsDroid.\"\"\"\nimport os\nfrom appdirs import user_log_dir, user_config_dir, user_data_dir\nimport opsdroid\nfrom opsdroid import __version__ # noqa # pylint: disable=unused-import\n\nNAME = \"opsdroid\"\nMODULE_ROOT = os.path.dirname(os.path.abspath(opsdroid.__file__))\nDEFAULT_GIT_URL = \"https://github.com/opsdroid/\"\nMODULES_DIRECTORY = \"opsdroid-modules\"\nDEFAULT_ROOT_PATH = user_data_dir(NAME)\nDEFAULT_LOG_FILENAME = os.path.join(user_log_dir(NAME, appauthor=False), \"output.log\")\nDEFAULT_MODULES_PATH = user_data_dir(NAME, MODULES_DIRECTORY)\nDEFAULT_MODULE_DEPS_PATH = os.path.join(\n user_data_dir(NAME, MODULES_DIRECTORY), \"site-packages\"\n)\nDEFAULT_CONFIG_PATH = os.path.join(\n user_config_dir(NAME, appauthor=False), \"configuration.yaml\"\n)\nDEFAULT_MODULE_BRANCH = \"master\"\nDEFAULT_LANGUAGE = \"en\"\nLOCALE_DIR = os.path.join(MODULE_ROOT, \"locale\")\nEXAMPLE_CONFIG_FILE = os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n \"configuration/example_configuration.yaml\",\n)\nREGEX_PARSE_SCORE_FACTOR = 0.6\n\nRASANLU_DEFAULT_URL = \"http://localhost:5000\"\nRASANLU_DEFAULT_PROJECT = \"opsdroid\"\n\nLUISAI_DEFAULT_URL = \"https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/\"\n\nDIALOGFLOW_API_ENDPOINT = \"https://api.dialogflow.com/v1/query\"\nDIALOGFLOW_API_VERSION = \"20150910\"\n\nWITAI_DEFAULT_VERSION = \"20170307\"\nWITAI_API_ENDPOINT = \"https://api.wit.ai/message?\"\n\nSAPCAI_API_ENDPOINT = \"https://api.cai.tools.sap/v2/request\"\n\nWATSON_API_ENDPOINT = \"https://{gateway}.watsonplatform.net/assistant/api\"\nWATSON_API_VERSION = \"2019-02-28\"\n", "path": "opsdroid/const.py"}, {"content": "\"\"\"Load configuration from yaml file.\"\"\"\n\nimport os\nimport shutil\nimport sys\nimport re\nimport logging\nimport yaml\n\nfrom opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE\nfrom opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA\nfrom opsdroid.helper import update_pre_0_17_config_format\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\ndef create_default_config(config_path):\n \"\"\"Create a default config file based on the example config file.\n\n If we can't find any configuration.yaml, we will pull the whole\n example_configuration.yaml and use this file as the configuration.\n\n Args:\n config_path: String containing the path to configuration.yaml\n default install location\n\n Returns:\n str: path to configuration.yaml default install location\n\n \"\"\"\n _LOGGER.info(\"Creating %s.\", config_path)\n config_dir, _ = os.path.split(config_path)\n if not os.path.isdir(config_dir):\n os.makedirs(config_dir)\n shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)\n return config_path\n\n\ndef get_config_path(config_paths):\n \"\"\"Get the path to configuration.yaml.\n\n Opsdroid configuration.yaml can be located in different paths.\n With this function, we will go through all of the possible paths and\n return the correct path.\n\n If we don't have any configuration.yaml we will just create one using\n the example configuration file.\n\n Args:\n config_paths: List containing all the possible config paths.\n\n Returns:\n str: Path to the configuration file.\n\n \"\"\"\n config_path = \"\"\n for possible_path in config_paths:\n if not os.path.isfile(possible_path):\n _LOGGER.debug(_(\"Config file %s not found.\"), possible_path)\n else:\n config_path = possible_path\n break\n\n if not config_path:\n _LOGGER.info(\n _(\"No configuration files found. Creating %s\"), DEFAULT_CONFIG_PATH\n )\n config_path = create_default_config(DEFAULT_CONFIG_PATH)\n\n return config_path\n\n\nenv_var_pattern = re.compile(r\"^\\$([A-Z_]*)$\")\n\n\ndef envvar_constructor(loader, node):\n \"\"\"Yaml parser for env vars.\"\"\"\n value = loader.construct_scalar(node)\n [env_var] = env_var_pattern.match(value).groups()\n return os.environ[env_var]\n\n\ndef load_config_file(config_paths):\n \"\"\"Load a yaml config file from path.\n\n We get a path for the configuration file and then use the yaml\n library to load this file - the configuration will be shown as a\n dict. Here we also add constructors to our yaml loader and handle\n different exceptions that could be raised when trying to load or\n validate the file.\n\n Args:\n config_paths: List of paths to configuration.yaml files\n\n Returns:\n dict: Dict containing config fields\n\n \"\"\"\n\n config_path = get_config_path(config_paths)\n\n yaml.SafeLoader.add_implicit_resolver(\"!envvar\", env_var_pattern, first=\"$\")\n yaml.SafeLoader.add_constructor(\"!envvar\", envvar_constructor)\n\n try:\n with open(config_path, \"r\") as stream:\n _LOGGER.info(_(\"Loaded config from %s.\"), config_path)\n\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n configuration = update_pre_0_17_config_format(data)\n validate_configuration(configuration, BASE_SCHEMA)\n\n return configuration\n\n except yaml.YAMLError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n\n except FileNotFoundError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n", "path": "opsdroid/configuration/__init__.py"}]}
| 2,264 | 299 |
gh_patches_debug_20188
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-2080
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Threading integration breaks OpenCensus' threading integration
### How do you use Sentry?
Sentry Saas (sentry.io)
### Version
1.21.1
### Steps to Reproduce
1. Enable threading Sentry integration (it seems to be enabled by default)
2. Enable [threading OpenCensus integration](https://pypi.org/project/opencensus-ext-threading/)
3. Start a thread
```python
import threading
import sentry_sdk.integrations.threading
import opencensus.trace.config_integration
sentry_sdk.init(integrations=[
sentry_sdk.integrations.threading.ThreadingIntegration(),
])
opencensus.trace.config_integration.trace_integrations(
integrations=["threading"],
)
thread = threading.Thread(target=print, args=("foo",))
thread.start()
thread.join()
```
### Expected Result
No error, output: `foo`
### Actual Result
Exceptions raised on every thread's startup
```python
Exception in thread Thread-1 (print):
Traceback (most recent call last):
File "/usr/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File ".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py", line 69, in run
reraise(*_capture_exception())
File ".venv/lib/python3.10/site-packages/sentry_sdk/_compat.py", line 60, in reraise
raise value
File ".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py", line 67, in run
return old_run_func(self, *a, **kw)
File ".venv/lib/python3.10/site-packages/opencensus/ext/threading/trace.py", line 80, in call
*self._opencensus_context
AttributeError: 'Thread' object has no attribute '_opencensus_context'
```
### Additional details
* Python: 3.10
* OpenCensus threading extension: 0.1.2
My suggestion is to use [`functools.update_wrapper`](https://docs.python.org/3/library/functools.html#functools.update_wrapper) (or the convenience decorator [`functools.wraps`](https://docs.python.org/3/library/functools.html#functools.wraps)) to set the name of [`sentry_start`](https://github.com/getsentry/sentry-python/blob/f763061ed9d9e99d85b3e95adc3ed63b623fc4a0/sentry_sdk/integrations/threading.py#L35-54) to `"start"` (and maybe the same for the result of `_wrap_run`, to `"run"`), so it "holds up to basic introspection".
PS: please include 'Additional details' block in issue template
</issue>
<code>
[start of sentry_sdk/integrations/threading.py]
1 from __future__ import absolute_import
2
3 import sys
4 from threading import Thread, current_thread
5
6 from sentry_sdk import Hub
7 from sentry_sdk._compat import reraise
8 from sentry_sdk._types import TYPE_CHECKING
9 from sentry_sdk.integrations import Integration
10 from sentry_sdk.utils import event_from_exception, capture_internal_exceptions
11
12 if TYPE_CHECKING:
13 from typing import Any
14 from typing import TypeVar
15 from typing import Callable
16 from typing import Optional
17
18 from sentry_sdk._types import ExcInfo
19
20 F = TypeVar("F", bound=Callable[..., Any])
21
22
23 class ThreadingIntegration(Integration):
24 identifier = "threading"
25
26 def __init__(self, propagate_hub=False):
27 # type: (bool) -> None
28 self.propagate_hub = propagate_hub
29
30 @staticmethod
31 def setup_once():
32 # type: () -> None
33 old_start = Thread.start
34
35 def sentry_start(self, *a, **kw):
36 # type: (Thread, *Any, **Any) -> Any
37 hub = Hub.current
38 integration = hub.get_integration(ThreadingIntegration)
39 if integration is not None:
40 if not integration.propagate_hub:
41 hub_ = None
42 else:
43 hub_ = Hub(hub)
44 # Patching instance methods in `start()` creates a reference cycle if
45 # done in a naive way. See
46 # https://github.com/getsentry/sentry-python/pull/434
47 #
48 # In threading module, using current_thread API will access current thread instance
49 # without holding it to avoid a reference cycle in an easier way.
50 with capture_internal_exceptions():
51 new_run = _wrap_run(hub_, getattr(self.run, "__func__", self.run))
52 self.run = new_run # type: ignore
53
54 return old_start(self, *a, **kw)
55
56 Thread.start = sentry_start # type: ignore
57
58
59 def _wrap_run(parent_hub, old_run_func):
60 # type: (Optional[Hub], F) -> F
61 def run(*a, **kw):
62 # type: (*Any, **Any) -> Any
63 hub = parent_hub or Hub.current
64 with hub:
65 try:
66 self = current_thread()
67 return old_run_func(self, *a, **kw)
68 except Exception:
69 reraise(*_capture_exception())
70
71 return run # type: ignore
72
73
74 def _capture_exception():
75 # type: () -> ExcInfo
76 hub = Hub.current
77 exc_info = sys.exc_info()
78
79 if hub.get_integration(ThreadingIntegration) is not None:
80 # If an integration is there, a client has to be there.
81 client = hub.client # type: Any
82
83 event, hint = event_from_exception(
84 exc_info,
85 client_options=client.options,
86 mechanism={"type": "threading", "handled": False},
87 )
88 hub.capture_event(event, hint=hint)
89
90 return exc_info
91
[end of sentry_sdk/integrations/threading.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/integrations/threading.py b/sentry_sdk/integrations/threading.py
--- a/sentry_sdk/integrations/threading.py
+++ b/sentry_sdk/integrations/threading.py
@@ -1,6 +1,7 @@
from __future__ import absolute_import
import sys
+from functools import wraps
from threading import Thread, current_thread
from sentry_sdk import Hub
@@ -32,6 +33,7 @@
# type: () -> None
old_start = Thread.start
+ @wraps(old_start)
def sentry_start(self, *a, **kw):
# type: (Thread, *Any, **Any) -> Any
hub = Hub.current
@@ -58,6 +60,7 @@
def _wrap_run(parent_hub, old_run_func):
# type: (Optional[Hub], F) -> F
+ @wraps(old_run_func)
def run(*a, **kw):
# type: (*Any, **Any) -> Any
hub = parent_hub or Hub.current
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/threading.py b/sentry_sdk/integrations/threading.py\n--- a/sentry_sdk/integrations/threading.py\n+++ b/sentry_sdk/integrations/threading.py\n@@ -1,6 +1,7 @@\n from __future__ import absolute_import\n \n import sys\n+from functools import wraps\n from threading import Thread, current_thread\n \n from sentry_sdk import Hub\n@@ -32,6 +33,7 @@\n # type: () -> None\n old_start = Thread.start\n \n+ @wraps(old_start)\n def sentry_start(self, *a, **kw):\n # type: (Thread, *Any, **Any) -> Any\n hub = Hub.current\n@@ -58,6 +60,7 @@\n \n def _wrap_run(parent_hub, old_run_func):\n # type: (Optional[Hub], F) -> F\n+ @wraps(old_run_func)\n def run(*a, **kw):\n # type: (*Any, **Any) -> Any\n hub = parent_hub or Hub.current\n", "issue": "Threading integration breaks OpenCensus' threading integration\n### How do you use Sentry?\r\n\r\nSentry Saas (sentry.io)\r\n\r\n### Version\r\n\r\n1.21.1\r\n\r\n### Steps to Reproduce\r\n\r\n1. Enable threading Sentry integration (it seems to be enabled by default)\r\n2. Enable [threading OpenCensus integration](https://pypi.org/project/opencensus-ext-threading/)\r\n3. Start a thread\r\n\r\n```python\r\nimport threading\r\n\r\nimport sentry_sdk.integrations.threading\r\nimport opencensus.trace.config_integration\r\n\r\nsentry_sdk.init(integrations=[\r\n sentry_sdk.integrations.threading.ThreadingIntegration(),\r\n])\r\n\r\nopencensus.trace.config_integration.trace_integrations(\r\n integrations=[\"threading\"],\r\n)\r\n\r\nthread = threading.Thread(target=print, args=(\"foo\",))\r\nthread.start()\r\nthread.join()\r\n```\r\n\r\n### Expected Result\r\n\r\nNo error, output: `foo`\r\n\r\n### Actual Result\r\n\r\nExceptions raised on every thread's startup\r\n\r\n```python\r\nException in thread Thread-1 (print):\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.10/threading.py\", line 1016, in _bootstrap_inner\r\n self.run()\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py\", line 69, in run\r\n reraise(*_capture_exception())\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/_compat.py\", line 60, in reraise\r\n raise value\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py\", line 67, in run\r\n return old_run_func(self, *a, **kw)\r\n File \".venv/lib/python3.10/site-packages/opencensus/ext/threading/trace.py\", line 80, in call\r\n *self._opencensus_context\r\nAttributeError: 'Thread' object has no attribute '_opencensus_context'\r\n```\r\n\r\n### Additional details\r\n\r\n* Python: 3.10\r\n* OpenCensus threading extension: 0.1.2\r\n\r\nMy suggestion is to use [`functools.update_wrapper`](https://docs.python.org/3/library/functools.html#functools.update_wrapper) (or the convenience decorator [`functools.wraps`](https://docs.python.org/3/library/functools.html#functools.wraps)) to set the name of [`sentry_start`](https://github.com/getsentry/sentry-python/blob/f763061ed9d9e99d85b3e95adc3ed63b623fc4a0/sentry_sdk/integrations/threading.py#L35-54) to `\"start\"` (and maybe the same for the result of `_wrap_run`, to `\"run\"`), so it \"holds up to basic introspection\".\r\n\r\nPS: please include 'Additional details' block in issue template\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport sys\nfrom threading import Thread, current_thread\n\nfrom sentry_sdk import Hub\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk._types import TYPE_CHECKING\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.utils import event_from_exception, capture_internal_exceptions\n\nif TYPE_CHECKING:\n from typing import Any\n from typing import TypeVar\n from typing import Callable\n from typing import Optional\n\n from sentry_sdk._types import ExcInfo\n\n F = TypeVar(\"F\", bound=Callable[..., Any])\n\n\nclass ThreadingIntegration(Integration):\n identifier = \"threading\"\n\n def __init__(self, propagate_hub=False):\n # type: (bool) -> None\n self.propagate_hub = propagate_hub\n\n @staticmethod\n def setup_once():\n # type: () -> None\n old_start = Thread.start\n\n def sentry_start(self, *a, **kw):\n # type: (Thread, *Any, **Any) -> Any\n hub = Hub.current\n integration = hub.get_integration(ThreadingIntegration)\n if integration is not None:\n if not integration.propagate_hub:\n hub_ = None\n else:\n hub_ = Hub(hub)\n # Patching instance methods in `start()` creates a reference cycle if\n # done in a naive way. See\n # https://github.com/getsentry/sentry-python/pull/434\n #\n # In threading module, using current_thread API will access current thread instance\n # without holding it to avoid a reference cycle in an easier way.\n with capture_internal_exceptions():\n new_run = _wrap_run(hub_, getattr(self.run, \"__func__\", self.run))\n self.run = new_run # type: ignore\n\n return old_start(self, *a, **kw)\n\n Thread.start = sentry_start # type: ignore\n\n\ndef _wrap_run(parent_hub, old_run_func):\n # type: (Optional[Hub], F) -> F\n def run(*a, **kw):\n # type: (*Any, **Any) -> Any\n hub = parent_hub or Hub.current\n with hub:\n try:\n self = current_thread()\n return old_run_func(self, *a, **kw)\n except Exception:\n reraise(*_capture_exception())\n\n return run # type: ignore\n\n\ndef _capture_exception():\n # type: () -> ExcInfo\n hub = Hub.current\n exc_info = sys.exc_info()\n\n if hub.get_integration(ThreadingIntegration) is not None:\n # If an integration is there, a client has to be there.\n client = hub.client # type: Any\n\n event, hint = event_from_exception(\n exc_info,\n client_options=client.options,\n mechanism={\"type\": \"threading\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n\n return exc_info\n", "path": "sentry_sdk/integrations/threading.py"}]}
| 2,009 | 238 |
gh_patches_debug_64193
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-1546
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ChrF score failing tests
ChrF score tests are failing with python 3.4 and python 3.5:
```
tox -e py34 nltk/nltk/translate/chrf_score.py
GLOB sdist-make: nltk/setup.py
py34 inst-nodeps: nltk/.tox/dist/nltk-3.2.1.zip
py34 installed: coverage==4.2,nltk==3.2.1,nose==1.3.7,numpy==1.11.2,oauthlib==2.0.0,pyparsing==2.1.10,python-crfsuite==0.8.4,requests==2.12.1,requests-oauthlib==0.7.0,scikit-learn==0.18.1,scipy==0.18.1,six==1.10.0,text-unidecode==1.0,twython==3.4.0
py34 runtests: PYTHONHASHSEED='300012027'
py34 runtests: commands[0] | pip install scipy scikit-learn
Requirement already satisfied: scipy in nltk/.tox/py34/lib/python3.4/site-packages
Requirement already satisfied: scikit-learn in nltk/.tox/py34/lib/python3.4/site-packages
py34 runtests: commands[1] | python runtests.py ../translate/chrf_score.py
.F
======================================================================
FAIL: Doctest: nltk.translate.chrf_score.sentence_chrf
----------------------------------------------------------------------
Traceback (most recent call last):
File "/usr/lib/python3.4/doctest.py", line 2187, in runTest
raise self.failureException(self.format_failure(new.getvalue()))
AssertionError: Failed doctest test for nltk.translate.chrf_score.sentence_chrf
File "nltk/nltk/translate/chrf_score.py", line 16, in sentence_chrf
----------------------------------------------------------------------
File "nltk/nltk/translate/chrf_score.py", line 58, in nltk.translate.chrf_score.sentence_chrf
Failed example:
type(ref1), type(hyp1)
Expected:
(<type 'str'>, <type 'str'>)
Got:
(<class 'str'>, <class 'str'>)
----------------------------------------------------------------------
Ran 2 tests in 0.013s
FAILED (failures=1)
```
@alvations could you please check?
</issue>
<code>
[start of nltk/translate/chrf_score.py]
1 # -*- coding: utf-8 -*-
2 # Natural Language Toolkit: ChrF score
3 #
4 # Copyright (C) 2001-2016 NLTK Project
5 # Authors: Maja Popovic
6 # Contributors: Liling Tan
7 # URL: <http://nltk.org/>
8 # For license information, see LICENSE.TXT
9
10 """ ChrF score implementation """
11 from __future__ import division
12 from collections import Counter
13
14 from nltk.util import ngrams, everygrams
15
16 def sentence_chrf(reference, hypothesis, min_len=1, max_len=6, beta=3.0):
17 """
18 Calculates the sentence level CHRF (Character n-gram F-score) described in
19 - Maja Popovic. 2015. CHRF: Character n-gram F-score for Automatic MT Evaluation.
20 In Proceedings of the 10th Workshop on Machine Translation.
21 http://www.statmt.org/wmt15/pdf/WMT49.pdf
22 - Maja Popovic. 2016. CHRF Deconstructed: β Parameters and n-gram Weights.
23 In Proceedings of the 1st Conference on Machine Translation.
24 http://www.statmt.org/wmt16/pdf/W16-2341.pdf
25
26 Unlike multi-reference BLEU, CHRF only supports a single reference.
27
28 An example from the original BLEU paper
29 http://www.aclweb.org/anthology/P02-1040.pdf
30
31 >>> ref1 = str('It is a guide to action that ensures that the military '
32 ... 'will forever heed Party commands').split()
33 >>> hyp1 = str('It is a guide to action which ensures that the military '
34 ... 'always obeys the commands of the party').split()
35 >>> hyp2 = str('It is to insure the troops forever hearing the activity '
36 ... 'guidebook that party direct').split()
37 >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
38 0.6768...
39 >>> sentence_chrf(ref1, hyp2) # doctest: +ELLIPSIS
40 0.4201...
41
42 The infamous "the the the ... " example
43
44 >>> ref = 'the cat is on the mat'.split()
45 >>> hyp = 'the the the the the the the'.split()
46 >>> sentence_chrf(ref, hyp) # doctest: +ELLIPSIS
47 0.2530...
48
49 An example to show that this function allows users to use strings instead of
50 tokens, i.e. list(str) as inputs.
51
52 >>> ref1 = str('It is a guide to action that ensures that the military '
53 ... 'will forever heed Party commands')
54 >>> hyp1 = str('It is a guide to action which ensures that the military '
55 ... 'always obeys the commands of the party')
56 >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
57 0.6768...
58 >>> type(ref1), type(hyp1)
59 (<type 'str'>, <type 'str'>)
60 >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS
61 0.6768...
62
63 To skip the unigrams and only use 2- to 3-grams:
64
65 >>> sentence_chrf(ref1, hyp1, min_len=2, max_len=3) # doctest: +ELLIPSIS
66 0.7018...
67
68 :param references: reference sentence
69 :type references: list(str) / str
70 :param hypothesis: a hypothesis sentence
71 :type hypothesis: list(str) / str
72 :param min_len: The minimum order of n-gram this function should extract.
73 :type min_len: int
74 :param max_len: The maximum order of n-gram this function should extract.
75 :type max_len: int
76 :param beta: the parameter to assign more importance to recall over precision
77 :type beta: float
78 :return: the sentence level CHRF score.
79 :rtype: float
80 """
81 return corpus_chrf([reference], [hypothesis], min_len, max_len, beta=beta)
82
83
84 def corpus_chrf(list_of_references, hypotheses, min_len=1, max_len=6, beta=3.0):
85 """
86 Calculates the corpus level CHRF (Character n-gram F-score), it is the
87 micro-averaged value of the sentence/segment level CHRF score.
88
89 CHRF only supports a single reference.
90
91 >>> ref1 = str('It is a guide to action that ensures that the military '
92 ... 'will forever heed Party commands').split()
93 >>> ref2 = str('It is the guiding principle which guarantees the military '
94 ... 'forces always being under the command of the Party').split()
95 >>>
96 >>> hyp1 = str('It is a guide to action which ensures that the military '
97 ... 'always obeys the commands of the party').split()
98 >>> hyp2 = str('It is to insure the troops forever hearing the activity '
99 ... 'guidebook that party direct')
100 >>> corpus_chrf([ref1, ref2, ref1, ref2], [hyp1, hyp2, hyp2, hyp1]) # doctest: +ELLIPSIS
101 0.4915...
102
103 :param references: a corpus of list of reference sentences, w.r.t. hypotheses
104 :type references: list(list(str)) / list(str)
105 :param hypotheses: a list of hypothesis sentences
106 :type hypotheses: list(list(str)) / list(str)
107 :param min_len: The minimum order of n-gram this function should extract.
108 :type min_len: int
109 :param max_len: The maximum order of n-gram this function should extract.
110 :type max_len: int
111 :param beta: the parameter to assign more importance to recall over precision
112 :type beta: float
113 :return: the sentence level CHRF score.
114 :rtype: float
115 """
116
117 assert len(list_of_references) == len(hypotheses), "The number of hypotheses and their references should be the same"
118
119 # Iterate through each hypothesis and their corresponding references.
120 for reference, hypothesis in zip(list_of_references, hypotheses):
121 # Cheating condition to allow users to input strings instead of tokens.
122 if type(reference) and type(hypothesis) != str:
123 reference, hypothesis = ' '.join(reference), ' '.join(hypothesis)
124 # For each order of ngram, calculate the no. of ngram matches and
125 # keep track of no. of ngram in references.
126 ref_ngrams = Counter(everygrams(reference, min_len, max_len))
127 hyp_ngrams = Counter(everygrams(hypothesis, min_len, max_len))
128 overlap_ngrams = ref_ngrams & hyp_ngrams
129 tp = sum(overlap_ngrams.values()) # True positives.
130 tpfp = sum(hyp_ngrams.values()) # True positives + False positives.
131 tffn = sum(ref_ngrams.values()) # True posities + False negatives.
132
133 precision = tp / tpfp
134 recall = tp / tffn
135 factor = beta**2
136 score = (1+ factor ) * (precision * recall) / ( factor * precision + recall)
137 return score
138
[end of nltk/translate/chrf_score.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nltk/translate/chrf_score.py b/nltk/translate/chrf_score.py
--- a/nltk/translate/chrf_score.py
+++ b/nltk/translate/chrf_score.py
@@ -55,8 +55,8 @@
... 'always obeys the commands of the party')
>>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
0.6768...
- >>> type(ref1), type(hyp1)
- (<type 'str'>, <type 'str'>)
+ >>> type(ref1) == type(hyp1) == str
+ True
>>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS
0.6768...
|
{"golden_diff": "diff --git a/nltk/translate/chrf_score.py b/nltk/translate/chrf_score.py\n--- a/nltk/translate/chrf_score.py\n+++ b/nltk/translate/chrf_score.py\n@@ -55,8 +55,8 @@\n ... 'always obeys the commands of the party')\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n- >>> type(ref1), type(hyp1)\n- (<type 'str'>, <type 'str'>)\n+ >>> type(ref1) == type(hyp1) == str\n+ True\n >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS\n 0.6768...\n", "issue": "ChrF score failing tests\nChrF score tests are failing with python 3.4 and python 3.5:\r\n\r\n```\r\ntox -e py34 nltk/nltk/translate/chrf_score.py\r\n\r\nGLOB sdist-make: nltk/setup.py\r\npy34 inst-nodeps: nltk/.tox/dist/nltk-3.2.1.zip\r\npy34 installed: coverage==4.2,nltk==3.2.1,nose==1.3.7,numpy==1.11.2,oauthlib==2.0.0,pyparsing==2.1.10,python-crfsuite==0.8.4,requests==2.12.1,requests-oauthlib==0.7.0,scikit-learn==0.18.1,scipy==0.18.1,six==1.10.0,text-unidecode==1.0,twython==3.4.0\r\npy34 runtests: PYTHONHASHSEED='300012027'\r\npy34 runtests: commands[0] | pip install scipy scikit-learn\r\nRequirement already satisfied: scipy in nltk/.tox/py34/lib/python3.4/site-packages\r\nRequirement already satisfied: scikit-learn in nltk/.tox/py34/lib/python3.4/site-packages\r\npy34 runtests: commands[1] | python runtests.py ../translate/chrf_score.py\r\n.F\r\n======================================================================\r\nFAIL: Doctest: nltk.translate.chrf_score.sentence_chrf\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.4/doctest.py\", line 2187, in runTest\r\n raise self.failureException(self.format_failure(new.getvalue()))\r\nAssertionError: Failed doctest test for nltk.translate.chrf_score.sentence_chrf\r\n File \"nltk/nltk/translate/chrf_score.py\", line 16, in sentence_chrf\r\n\r\n----------------------------------------------------------------------\r\nFile \"nltk/nltk/translate/chrf_score.py\", line 58, in nltk.translate.chrf_score.sentence_chrf\r\nFailed example:\r\n type(ref1), type(hyp1)\r\nExpected:\r\n (<type 'str'>, <type 'str'>)\r\nGot:\r\n (<class 'str'>, <class 'str'>)\r\n\r\n\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.013s\r\n\r\nFAILED (failures=1)\r\n```\r\n\r\n@alvations could you please check?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Natural Language Toolkit: ChrF score\n#\n# Copyright (C) 2001-2016 NLTK Project\n# Authors: Maja Popovic\n# Contributors: Liling Tan\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\" ChrF score implementation \"\"\"\nfrom __future__ import division\nfrom collections import Counter\n\nfrom nltk.util import ngrams, everygrams\n\ndef sentence_chrf(reference, hypothesis, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the sentence level CHRF (Character n-gram F-score) described in\n - Maja Popovic. 2015. CHRF: Character n-gram F-score for Automatic MT Evaluation.\n In Proceedings of the 10th Workshop on Machine Translation.\n http://www.statmt.org/wmt15/pdf/WMT49.pdf\n - Maja Popovic. 2016. CHRF Deconstructed: \u03b2 Parameters and n-gram Weights.\n In Proceedings of the 1st Conference on Machine Translation.\n http://www.statmt.org/wmt16/pdf/W16-2341.pdf\n\n Unlike multi-reference BLEU, CHRF only supports a single reference.\n\n An example from the original BLEU paper\n http://www.aclweb.org/anthology/P02-1040.pdf\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct').split()\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> sentence_chrf(ref1, hyp2) # doctest: +ELLIPSIS\n 0.4201...\n\n The infamous \"the the the ... \" example\n\n >>> ref = 'the cat is on the mat'.split()\n >>> hyp = 'the the the the the the the'.split()\n >>> sentence_chrf(ref, hyp) # doctest: +ELLIPSIS\n 0.2530...\n\n An example to show that this function allows users to use strings instead of\n tokens, i.e. list(str) as inputs.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands')\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party')\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> type(ref1), type(hyp1)\n (<type 'str'>, <type 'str'>)\n >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS\n 0.6768...\n\n To skip the unigrams and only use 2- to 3-grams:\n\n >>> sentence_chrf(ref1, hyp1, min_len=2, max_len=3) # doctest: +ELLIPSIS\n 0.7018...\n\n :param references: reference sentence\n :type references: list(str) / str\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str) / str\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n return corpus_chrf([reference], [hypothesis], min_len, max_len, beta=beta)\n\n\ndef corpus_chrf(list_of_references, hypotheses, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the corpus level CHRF (Character n-gram F-score), it is the\n micro-averaged value of the sentence/segment level CHRF score.\n\n CHRF only supports a single reference.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> ref2 = str('It is the guiding principle which guarantees the military '\n ... 'forces always being under the command of the Party').split()\n >>>\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct')\n >>> corpus_chrf([ref1, ref2, ref1, ref2], [hyp1, hyp2, hyp2, hyp1]) # doctest: +ELLIPSIS\n 0.4915...\n\n :param references: a corpus of list of reference sentences, w.r.t. hypotheses\n :type references: list(list(str)) / list(str)\n :param hypotheses: a list of hypothesis sentences\n :type hypotheses: list(list(str)) / list(str)\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n\n assert len(list_of_references) == len(hypotheses), \"The number of hypotheses and their references should be the same\"\n\n # Iterate through each hypothesis and their corresponding references.\n for reference, hypothesis in zip(list_of_references, hypotheses):\n # Cheating condition to allow users to input strings instead of tokens.\n if type(reference) and type(hypothesis) != str:\n reference, hypothesis = ' '.join(reference), ' '.join(hypothesis)\n # For each order of ngram, calculate the no. of ngram matches and\n # keep track of no. of ngram in references.\n ref_ngrams = Counter(everygrams(reference, min_len, max_len))\n hyp_ngrams = Counter(everygrams(hypothesis, min_len, max_len))\n overlap_ngrams = ref_ngrams & hyp_ngrams\n tp = sum(overlap_ngrams.values()) # True positives.\n tpfp = sum(hyp_ngrams.values()) # True positives + False positives.\n tffn = sum(ref_ngrams.values()) # True posities + False negatives.\n\n precision = tp / tpfp\n recall = tp / tffn\n factor = beta**2\n score = (1+ factor ) * (precision * recall) / ( factor * precision + recall)\n return score\n", "path": "nltk/translate/chrf_score.py"}]}
| 2,993 | 175 |
gh_patches_debug_4147
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1013
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Interoperability of logging with ignite logger
## 🐛 Bug description
This bug is related to logger from module logging. Actually, (logging) handlers are attached to loggers created by user. https://github.com/pytorch/ignite/blob/bef668c152dc86334a8ab09e9ce9368c48e48102/ignite/utils.py#L64-L137
From `logging` documentation (https://docs.python.org/3/howto/logging.html#loggers)
> Child loggers propagate messages up to the handlers associated with their ancestor loggers. Because of this, it is unnecessary to define and configure handlers for all the loggers an application uses. It is sufficient to configure handlers for a top-level logger and create child loggers as needed. (You can, however, turn off propagation by setting the propagate attribute of a logger to False.)
This code shows the problem of propagation to ancestor
```python
# no ancestor so print is ok
logger = setup_logger("logger")
logger.info("message 1 from test logger")
# logging creates root ancestor of all loggers including one above
logging.info("message from default logging, a root logger is defined !")
# root + logger dump...
logger.info("message 2 from test logger")
```
Result is
```
> 2020-05-05 09:24:27,583 logger INFO: message 1 from test logger
> 2020-05-05 09:24:27,583 logger INFO: message 2 from test logger
> INFO:logger:message 2 from test logger
```
## Environment
- PyTorch Version (e.g., 1.4): 1.5
- Ignite Version (e.g., 0.3.0): 0.4
- OS (e.g., Linux): Linux
- How you installed Ignite (`conda`, `pip`, source): conda
- Python version: 3.7
- Any other relevant information:
</issue>
<code>
[start of ignite/utils.py]
1 import random
2 import collections.abc as collections
3 import logging
4 from functools import wraps
5 from typing import Union, Optional, Callable, Any, Type, Tuple
6
7 import torch
8 import torch.distributed as dist
9
10 __all__ = ["convert_tensor", "apply_to_tensor", "apply_to_type", "to_onehot", "setup_logger", "one_rank_only"]
11
12
13 def convert_tensor(
14 input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes],
15 device: Optional[Union[str, torch.device]] = None,
16 non_blocking: bool = False,
17 ) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:
18 """Move tensors to relevant device."""
19
20 def _func(tensor: torch.Tensor) -> torch.Tensor:
21 return tensor.to(device=device, non_blocking=non_blocking) if device is not None else tensor
22
23 return apply_to_tensor(input_, _func)
24
25
26 def apply_to_tensor(
27 input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes], func: Callable
28 ) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:
29 """Apply a function on a tensor or mapping, or sequence of tensors.
30 """
31 return apply_to_type(input_, torch.Tensor, func)
32
33
34 def apply_to_type(
35 input_: Union[Any, collections.Sequence, collections.Mapping, str, bytes],
36 input_type: Union[Type, Tuple[Type[Any], Any]],
37 func: Callable,
38 ) -> Union[Any, collections.Sequence, collections.Mapping, str, bytes]:
39 """Apply a function on a object of `input_type` or mapping, or sequence of objects of `input_type`.
40 """
41 if isinstance(input_, input_type):
42 return func(input_)
43 elif isinstance(input_, (str, bytes)):
44 return input_
45 elif isinstance(input_, collections.Mapping):
46 return type(input_)({k: apply_to_type(sample, input_type, func) for k, sample in input_.items()})
47 elif isinstance(input_, tuple) and hasattr(input_, "_fields"): # namedtuple
48 return type(input_)(*(apply_to_type(sample, input_type, func) for sample in input_))
49 elif isinstance(input_, collections.Sequence):
50 return type(input_)([apply_to_type(sample, input_type, func) for sample in input_])
51 else:
52 raise TypeError(("input must contain {}, dicts or lists; found {}".format(input_type, type(input_))))
53
54
55 def to_onehot(indices: torch.Tensor, num_classes: int) -> torch.Tensor:
56 """Convert a tensor of indices of any shape `(N, ...)` to a
57 tensor of one-hot indicators of shape `(N, num_classes, ...) and of type uint8. Output's device is equal to the
58 input's device`.
59 """
60 onehot = torch.zeros(indices.shape[0], num_classes, *indices.shape[1:], dtype=torch.uint8, device=indices.device)
61 return onehot.scatter_(1, indices.unsqueeze(1), 1)
62
63
64 def setup_logger(
65 name: Optional[str] = None,
66 level: int = logging.INFO,
67 format: str = "%(asctime)s %(name)s %(levelname)s: %(message)s",
68 filepath: Optional[str] = None,
69 distributed_rank: Optional[int] = None,
70 ) -> logging.Logger:
71 """Setups logger: name, level, format etc.
72
73 Args:
74 name (str, optional): new name for the logger. If None, the standard logger is used.
75 level (int): logging level, e.g. CRITICAL, ERROR, WARNING, INFO, DEBUG
76 format (str): logging format. By default, `%(asctime)s %(name)s %(levelname)s: %(message)s`
77 filepath (str, optional): Optional logging file path. If not None, logs are written to the file.
78 distributed_rank (int, optional): Optional, rank in distributed configuration to avoid logger setup for workers.
79 If None, distributed_rank is initialized to the rank of process.
80
81 Returns:
82 logging.Logger
83
84 For example, to improve logs readability when training with a trainer and evaluator:
85
86 .. code-block:: python
87
88 from ignite.utils import setup_logger
89
90 trainer = ...
91 evaluator = ...
92
93 trainer.logger = setup_logger("trainer")
94 evaluator.logger = setup_logger("evaluator")
95
96 trainer.run(data, max_epochs=10)
97
98 # Logs will look like
99 # 2020-01-21 12:46:07,356 trainer INFO: Engine run starting with max_epochs=5.
100 # 2020-01-21 12:46:07,358 trainer INFO: Epoch[1] Complete. Time taken: 00:5:23
101 # 2020-01-21 12:46:07,358 evaluator INFO: Engine run starting with max_epochs=1.
102 # 2020-01-21 12:46:07,358 evaluator INFO: Epoch[1] Complete. Time taken: 00:01:02
103 # ...
104
105 """
106 logger = logging.getLogger(name)
107
108 # Remove previous handlers
109 if logger.hasHandlers():
110 for h in list(logger.handlers):
111 logger.removeHandler(h)
112
113 formatter = logging.Formatter(format)
114
115 if distributed_rank is None:
116 if dist.is_available() and dist.is_initialized():
117 distributed_rank = dist.get_rank()
118 else:
119 distributed_rank = 0
120
121 if distributed_rank > 0:
122 logger.addHandler(logging.NullHandler())
123 else:
124 logger.setLevel(level)
125
126 ch = logging.StreamHandler()
127 ch.setLevel(level)
128 ch.setFormatter(formatter)
129 logger.addHandler(ch)
130
131 if filepath is not None:
132 fh = logging.FileHandler(filepath)
133 fh.setLevel(level)
134 fh.setFormatter(formatter)
135 logger.addHandler(fh)
136
137 return logger
138
139
140 def manual_seed(seed: int) -> None:
141 """Setup random state from a seed for `torch`, `random` and optionally `numpy` (if can be imported).
142
143 Args:
144 seed (int): Random state seed
145
146 """
147 random.seed(seed)
148 torch.manual_seed(seed)
149 try:
150 import numpy as np
151
152 np.random.seed(seed)
153 except ImportError:
154 pass
155
156
157 def one_rank_only(rank: int = 0, barrier: bool = False):
158 """Decorator to filter handlers wrt a rank number
159
160 Args:
161 rank (int): rank number of the handler (default: 0).
162 barrier (bool): synchronisation with a barrier (default: False).
163
164 .. code-block:: python
165
166 engine = ...
167
168 @engine.on(...)
169 @one_rank_only() # means @one_rank_only(rank=0)
170 def some_handler(_):
171 ...
172
173 @engine.on(...)
174 @one_rank_only(rank=1)
175 def some_handler(_):
176 ...
177 """
178
179 def _one_rank_only(func):
180 @wraps(func)
181 def wrapper(*args, **kwargs):
182 ret = None
183 if dist.get_rank() == rank:
184 ret = func(*args, **kwargs)
185 if barrier:
186 dist.barrier()
187 return ret
188
189 return wrapper
190
191 return _one_rank_only
192
[end of ignite/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/utils.py b/ignite/utils.py
--- a/ignite/utils.py
+++ b/ignite/utils.py
@@ -105,6 +105,12 @@
"""
logger = logging.getLogger(name)
+ # don't propagate to ancestors
+ # the problem here is to attach handlers to loggers
+ # should we provide a default configuration less open ?
+ if name is not None:
+ logger.propagate = False
+
# Remove previous handlers
if logger.hasHandlers():
for h in list(logger.handlers):
|
{"golden_diff": "diff --git a/ignite/utils.py b/ignite/utils.py\n--- a/ignite/utils.py\n+++ b/ignite/utils.py\n@@ -105,6 +105,12 @@\n \"\"\"\n logger = logging.getLogger(name)\n \n+ # don't propagate to ancestors\n+ # the problem here is to attach handlers to loggers\n+ # should we provide a default configuration less open ?\n+ if name is not None:\n+ logger.propagate = False\n+\n # Remove previous handlers\n if logger.hasHandlers():\n for h in list(logger.handlers):\n", "issue": "Interoperability of logging with ignite logger\n## \ud83d\udc1b Bug description\r\n\r\nThis bug is related to logger from module logging. Actually, (logging) handlers are attached to loggers created by user. https://github.com/pytorch/ignite/blob/bef668c152dc86334a8ab09e9ce9368c48e48102/ignite/utils.py#L64-L137\r\n\r\nFrom `logging` documentation (https://docs.python.org/3/howto/logging.html#loggers)\r\n\r\n> Child loggers propagate messages up to the handlers associated with their ancestor loggers. Because of this, it is unnecessary to define and configure handlers for all the loggers an application uses. It is sufficient to configure handlers for a top-level logger and create child loggers as needed. (You can, however, turn off propagation by setting the propagate attribute of a logger to False.)\r\n\r\nThis code shows the problem of propagation to ancestor \r\n\r\n```python\r\n# no ancestor so print is ok\r\nlogger = setup_logger(\"logger\")\r\nlogger.info(\"message 1 from test logger\") \r\n\r\n# logging creates root ancestor of all loggers including one above \r\nlogging.info(\"message from default logging, a root logger is defined !\")\r\n\r\n# root + logger dump...\r\nlogger.info(\"message 2 from test logger\")\r\n```\r\n\r\nResult is\r\n```\r\n> 2020-05-05 09:24:27,583 logger INFO: message 1 from test logger\r\n> 2020-05-05 09:24:27,583 logger INFO: message 2 from test logger\r\n> INFO:logger:message 2 from test logger\r\n```\r\n\r\n## Environment\r\n\r\n - PyTorch Version (e.g., 1.4): 1.5\r\n - Ignite Version (e.g., 0.3.0): 0.4\r\n - OS (e.g., Linux): Linux\r\n - How you installed Ignite (`conda`, `pip`, source): conda\r\n - Python version: 3.7\r\n - Any other relevant information:\r\n\r\n\n", "before_files": [{"content": "import random\nimport collections.abc as collections\nimport logging\nfrom functools import wraps\nfrom typing import Union, Optional, Callable, Any, Type, Tuple\n\nimport torch\nimport torch.distributed as dist\n\n__all__ = [\"convert_tensor\", \"apply_to_tensor\", \"apply_to_type\", \"to_onehot\", \"setup_logger\", \"one_rank_only\"]\n\n\ndef convert_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes],\n device: Optional[Union[str, torch.device]] = None,\n non_blocking: bool = False,\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Move tensors to relevant device.\"\"\"\n\n def _func(tensor: torch.Tensor) -> torch.Tensor:\n return tensor.to(device=device, non_blocking=non_blocking) if device is not None else tensor\n\n return apply_to_tensor(input_, _func)\n\n\ndef apply_to_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes], func: Callable\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a tensor or mapping, or sequence of tensors.\n \"\"\"\n return apply_to_type(input_, torch.Tensor, func)\n\n\ndef apply_to_type(\n input_: Union[Any, collections.Sequence, collections.Mapping, str, bytes],\n input_type: Union[Type, Tuple[Type[Any], Any]],\n func: Callable,\n) -> Union[Any, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a object of `input_type` or mapping, or sequence of objects of `input_type`.\n \"\"\"\n if isinstance(input_, input_type):\n return func(input_)\n elif isinstance(input_, (str, bytes)):\n return input_\n elif isinstance(input_, collections.Mapping):\n return type(input_)({k: apply_to_type(sample, input_type, func) for k, sample in input_.items()})\n elif isinstance(input_, tuple) and hasattr(input_, \"_fields\"): # namedtuple\n return type(input_)(*(apply_to_type(sample, input_type, func) for sample in input_))\n elif isinstance(input_, collections.Sequence):\n return type(input_)([apply_to_type(sample, input_type, func) for sample in input_])\n else:\n raise TypeError((\"input must contain {}, dicts or lists; found {}\".format(input_type, type(input_))))\n\n\ndef to_onehot(indices: torch.Tensor, num_classes: int) -> torch.Tensor:\n \"\"\"Convert a tensor of indices of any shape `(N, ...)` to a\n tensor of one-hot indicators of shape `(N, num_classes, ...) and of type uint8. Output's device is equal to the\n input's device`.\n \"\"\"\n onehot = torch.zeros(indices.shape[0], num_classes, *indices.shape[1:], dtype=torch.uint8, device=indices.device)\n return onehot.scatter_(1, indices.unsqueeze(1), 1)\n\n\ndef setup_logger(\n name: Optional[str] = None,\n level: int = logging.INFO,\n format: str = \"%(asctime)s %(name)s %(levelname)s: %(message)s\",\n filepath: Optional[str] = None,\n distributed_rank: Optional[int] = None,\n) -> logging.Logger:\n \"\"\"Setups logger: name, level, format etc.\n\n Args:\n name (str, optional): new name for the logger. If None, the standard logger is used.\n level (int): logging level, e.g. CRITICAL, ERROR, WARNING, INFO, DEBUG\n format (str): logging format. By default, `%(asctime)s %(name)s %(levelname)s: %(message)s`\n filepath (str, optional): Optional logging file path. If not None, logs are written to the file.\n distributed_rank (int, optional): Optional, rank in distributed configuration to avoid logger setup for workers.\n If None, distributed_rank is initialized to the rank of process.\n\n Returns:\n logging.Logger\n\n For example, to improve logs readability when training with a trainer and evaluator:\n\n .. code-block:: python\n\n from ignite.utils import setup_logger\n\n trainer = ...\n evaluator = ...\n\n trainer.logger = setup_logger(\"trainer\")\n evaluator.logger = setup_logger(\"evaluator\")\n\n trainer.run(data, max_epochs=10)\n\n # Logs will look like\n # 2020-01-21 12:46:07,356 trainer INFO: Engine run starting with max_epochs=5.\n # 2020-01-21 12:46:07,358 trainer INFO: Epoch[1] Complete. Time taken: 00:5:23\n # 2020-01-21 12:46:07,358 evaluator INFO: Engine run starting with max_epochs=1.\n # 2020-01-21 12:46:07,358 evaluator INFO: Epoch[1] Complete. Time taken: 00:01:02\n # ...\n\n \"\"\"\n logger = logging.getLogger(name)\n\n # Remove previous handlers\n if logger.hasHandlers():\n for h in list(logger.handlers):\n logger.removeHandler(h)\n\n formatter = logging.Formatter(format)\n\n if distributed_rank is None:\n if dist.is_available() and dist.is_initialized():\n distributed_rank = dist.get_rank()\n else:\n distributed_rank = 0\n\n if distributed_rank > 0:\n logger.addHandler(logging.NullHandler())\n else:\n logger.setLevel(level)\n\n ch = logging.StreamHandler()\n ch.setLevel(level)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n\n if filepath is not None:\n fh = logging.FileHandler(filepath)\n fh.setLevel(level)\n fh.setFormatter(formatter)\n logger.addHandler(fh)\n\n return logger\n\n\ndef manual_seed(seed: int) -> None:\n \"\"\"Setup random state from a seed for `torch`, `random` and optionally `numpy` (if can be imported).\n\n Args:\n seed (int): Random state seed\n\n \"\"\"\n random.seed(seed)\n torch.manual_seed(seed)\n try:\n import numpy as np\n\n np.random.seed(seed)\n except ImportError:\n pass\n\n\ndef one_rank_only(rank: int = 0, barrier: bool = False):\n \"\"\"Decorator to filter handlers wrt a rank number\n\n Args:\n rank (int): rank number of the handler (default: 0).\n barrier (bool): synchronisation with a barrier (default: False).\n\n .. code-block:: python\n\n engine = ...\n\n @engine.on(...)\n @one_rank_only() # means @one_rank_only(rank=0)\n def some_handler(_):\n ...\n\n @engine.on(...)\n @one_rank_only(rank=1)\n def some_handler(_):\n ...\n \"\"\"\n\n def _one_rank_only(func):\n @wraps(func)\n def wrapper(*args, **kwargs):\n ret = None\n if dist.get_rank() == rank:\n ret = func(*args, **kwargs)\n if barrier:\n dist.barrier()\n return ret\n\n return wrapper\n\n return _one_rank_only\n", "path": "ignite/utils.py"}]}
| 3,030 | 125 |
gh_patches_debug_29915
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-398
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: confusion matrix chart displays wrong output
To reproduce: https://www.kaggle.com/itay94/notebook05f499eb19

</issue>
<code>
[start of deepchecks/checks/performance/confusion_matrix_report.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """The confusion_matrix_report check module."""
12 import numpy as np
13 import sklearn
14 from sklearn.base import BaseEstimator
15
16 import plotly.figure_factory as ff
17 from deepchecks import CheckResult, Dataset
18 from deepchecks.base.check import SingleDatasetBaseCheck
19 from deepchecks.utils.metrics import ModelType, task_type_validation
20
21
22 __all__ = ['ConfusionMatrixReport']
23
24
25 class ConfusionMatrixReport(SingleDatasetBaseCheck):
26 """Calculate the confusion matrix of the model on the given dataset."""
27
28 def run(self, dataset: Dataset, model: BaseEstimator) -> CheckResult:
29 """Run check.
30
31 Args:
32 model (BaseEstimator): A scikit-learn-compatible fitted estimator instance
33 dataset: a Dataset object
34
35 Returns:
36 CheckResult: value is numpy array of the confusion matrix, displays the confusion matrix
37
38 Raises:
39 DeepchecksValueError: If the object is not a Dataset instance with a label
40 """
41 return self._confusion_matrix_report(dataset, model)
42
43 def _confusion_matrix_report(self, dataset: Dataset, model):
44 Dataset.validate_dataset(dataset)
45 dataset.validate_label()
46 task_type_validation(model, dataset, [ModelType.MULTICLASS, ModelType.BINARY])
47
48 label = dataset.label_name
49 ds_x = dataset.data[dataset.features]
50 ds_y = dataset.data[label]
51 y_pred = model.predict(ds_x)
52
53 confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
54
55 labels = [str(val) for val in np.unique(ds_y)]
56 fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')
57 fig.update_layout(width=600, height=600)
58 fig.update_xaxes(title='Predicted Value')
59 fig.update_yaxes(title='True value', autorange='reversed')
60 fig['data'][0]['showscale'] = True
61 fig['layout']['xaxis']['side'] = 'bottom'
62
63 return CheckResult(confusion_matrix, display=fig)
64
[end of deepchecks/checks/performance/confusion_matrix_report.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/checks/performance/confusion_matrix_report.py b/deepchecks/checks/performance/confusion_matrix_report.py
--- a/deepchecks/checks/performance/confusion_matrix_report.py
+++ b/deepchecks/checks/performance/confusion_matrix_report.py
@@ -9,11 +9,10 @@
# ----------------------------------------------------------------------------
#
"""The confusion_matrix_report check module."""
-import numpy as np
import sklearn
from sklearn.base import BaseEstimator
-import plotly.figure_factory as ff
+import plotly.express as px
from deepchecks import CheckResult, Dataset
from deepchecks.base.check import SingleDatasetBaseCheck
from deepchecks.utils.metrics import ModelType, task_type_validation
@@ -49,15 +48,12 @@
ds_x = dataset.data[dataset.features]
ds_y = dataset.data[label]
y_pred = model.predict(ds_x)
-
confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
- labels = [str(val) for val in np.unique(ds_y)]
- fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')
+ # Figure
+ fig = px.imshow(confusion_matrix, x=dataset.classes, y=dataset.classes, text_auto=True)
fig.update_layout(width=600, height=600)
- fig.update_xaxes(title='Predicted Value')
- fig.update_yaxes(title='True value', autorange='reversed')
- fig['data'][0]['showscale'] = True
- fig['layout']['xaxis']['side'] = 'bottom'
+ fig.update_xaxes(title='Predicted Value', type='category')
+ fig.update_yaxes(title='True value', type='category')
return CheckResult(confusion_matrix, display=fig)
|
{"golden_diff": "diff --git a/deepchecks/checks/performance/confusion_matrix_report.py b/deepchecks/checks/performance/confusion_matrix_report.py\n--- a/deepchecks/checks/performance/confusion_matrix_report.py\n+++ b/deepchecks/checks/performance/confusion_matrix_report.py\n@@ -9,11 +9,10 @@\n # ----------------------------------------------------------------------------\n #\n \"\"\"The confusion_matrix_report check module.\"\"\"\n-import numpy as np\n import sklearn\n from sklearn.base import BaseEstimator\n \n-import plotly.figure_factory as ff\n+import plotly.express as px\n from deepchecks import CheckResult, Dataset\n from deepchecks.base.check import SingleDatasetBaseCheck\n from deepchecks.utils.metrics import ModelType, task_type_validation\n@@ -49,15 +48,12 @@\n ds_x = dataset.data[dataset.features]\n ds_y = dataset.data[label]\n y_pred = model.predict(ds_x)\n-\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n \n- labels = [str(val) for val in np.unique(ds_y)]\n- fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')\n+ # Figure\n+ fig = px.imshow(confusion_matrix, x=dataset.classes, y=dataset.classes, text_auto=True)\n fig.update_layout(width=600, height=600)\n- fig.update_xaxes(title='Predicted Value')\n- fig.update_yaxes(title='True value', autorange='reversed')\n- fig['data'][0]['showscale'] = True\n- fig['layout']['xaxis']['side'] = 'bottom'\n+ fig.update_xaxes(title='Predicted Value', type='category')\n+ fig.update_yaxes(title='True value', type='category')\n \n return CheckResult(confusion_matrix, display=fig)\n", "issue": "BUG: confusion matrix chart displays wrong output\nTo reproduce: https://www.kaggle.com/itay94/notebook05f499eb19\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The confusion_matrix_report check module.\"\"\"\nimport numpy as np\nimport sklearn\nfrom sklearn.base import BaseEstimator\n\nimport plotly.figure_factory as ff\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import SingleDatasetBaseCheck\nfrom deepchecks.utils.metrics import ModelType, task_type_validation\n\n\n__all__ = ['ConfusionMatrixReport']\n\n\nclass ConfusionMatrixReport(SingleDatasetBaseCheck):\n \"\"\"Calculate the confusion matrix of the model on the given dataset.\"\"\"\n\n def run(self, dataset: Dataset, model: BaseEstimator) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance\n dataset: a Dataset object\n\n Returns:\n CheckResult: value is numpy array of the confusion matrix, displays the confusion matrix\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance with a label\n \"\"\"\n return self._confusion_matrix_report(dataset, model)\n\n def _confusion_matrix_report(self, dataset: Dataset, model):\n Dataset.validate_dataset(dataset)\n dataset.validate_label()\n task_type_validation(model, dataset, [ModelType.MULTICLASS, ModelType.BINARY])\n\n label = dataset.label_name\n ds_x = dataset.data[dataset.features]\n ds_y = dataset.data[label]\n y_pred = model.predict(ds_x)\n\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n\n labels = [str(val) for val in np.unique(ds_y)]\n fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')\n fig.update_layout(width=600, height=600)\n fig.update_xaxes(title='Predicted Value')\n fig.update_yaxes(title='True value', autorange='reversed')\n fig['data'][0]['showscale'] = True\n fig['layout']['xaxis']['side'] = 'bottom'\n\n return CheckResult(confusion_matrix, display=fig)\n", "path": "deepchecks/checks/performance/confusion_matrix_report.py"}]}
| 1,302 | 399 |
gh_patches_debug_42763
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1002
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add events to track embeds usage
Add events to track embeds usage
</issue>
<code>
[start of redash/handlers/embed.py]
1 import json
2
3 from funcy import project
4 from flask import render_template, request
5 from flask_login import login_required, current_user
6 from flask_restful import abort
7
8 from redash import models, settings
9 from redash import serializers
10 from redash.utils import json_dumps
11 from redash.handlers import routes
12 from redash.handlers.base import org_scoped_rule
13 from redash.permissions import require_access, view_only
14 from authentication import current_org
15
16
17 @routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])
18 @login_required
19 def embed(query_id, visualization_id, org_slug=None):
20 # TODO: add event for embed access
21 query = models.Query.get_by_id_and_org(query_id, current_org)
22 require_access(query.groups, current_user, view_only)
23 vis = query.visualizations.where(models.Visualization.id == visualization_id).first()
24 qr = {}
25
26 if vis is not None:
27 vis = vis.to_dict()
28 qr = query.latest_query_data
29 if qr is None:
30 abort(400, message="No Results for this query")
31 else:
32 qr = qr.to_dict()
33 else:
34 abort(404, message="Visualization not found.")
35
36 client_config = {}
37 client_config.update(settings.COMMON_CLIENT_CONFIG)
38
39 qr = project(qr, ('data', 'id', 'retrieved_at'))
40 vis = project(vis, ('description', 'name', 'id', 'options', 'query', 'type', 'updated_at'))
41 vis['query'] = project(vis['query'], ('created_at', 'description', 'name', 'id', 'latest_query_data_id', 'name', 'updated_at'))
42
43 return render_template("embed.html",
44 client_config=json_dumps(client_config),
45 visualization=json_dumps(vis),
46 query_result=json_dumps(qr))
47
48
49 @routes.route(org_scoped_rule('/public/dashboards/<token>'), methods=['GET'])
50 @login_required
51 def public_dashboard(token, org_slug=None):
52 # TODO: verify object is a dashboard?
53 if not isinstance(current_user, models.ApiUser):
54 api_key = models.ApiKey.get_by_api_key(token)
55 dashboard = api_key.object
56 else:
57 dashboard = current_user.object
58
59 user = {
60 'permissions': [],
61 'apiKey': current_user.id
62 }
63
64 headers = {
65 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'
66 }
67
68 response = render_template("public.html",
69 headless='embed' in request.args,
70 user=json.dumps(user),
71 seed_data=json_dumps({
72 'dashboard': serializers.public_dashboard(dashboard)
73 }),
74 client_config=json.dumps(settings.COMMON_CLIENT_CONFIG))
75
76 return response, 200, headers
77
[end of redash/handlers/embed.py]
[start of redash/handlers/base.py]
1 import time
2 from flask import request, Blueprint
3 from flask_restful import Resource, abort
4 from flask_login import current_user, login_required
5 from peewee import DoesNotExist
6
7 from redash import settings
8 from redash.tasks import record_event
9 from redash.models import ApiUser
10 from redash.authentication import current_org
11
12 routes = Blueprint('redash', __name__, template_folder=settings.fix_assets_path('templates'))
13
14
15 class BaseResource(Resource):
16 decorators = [login_required]
17
18 def __init__(self, *args, **kwargs):
19 super(BaseResource, self).__init__(*args, **kwargs)
20 self._user = None
21
22 def dispatch_request(self, *args, **kwargs):
23 kwargs.pop('org_slug', None)
24
25 return super(BaseResource, self).dispatch_request(*args, **kwargs)
26
27 @property
28 def current_user(self):
29 return current_user._get_current_object()
30
31 @property
32 def current_org(self):
33 return current_org._get_current_object()
34
35 def record_event(self, options):
36 if isinstance(self.current_user, ApiUser):
37 options.update({
38 'api_key': self.current_user.name,
39 'org_id': self.current_org.id
40 })
41 else:
42 options.update({
43 'user_id': self.current_user.id,
44 'org_id': self.current_org.id
45 })
46
47 options.update({
48 'user_agent': request.user_agent.string,
49 'ip': request.remote_addr
50 })
51
52 if 'timestamp' not in options:
53 options['timestamp'] = int(time.time())
54
55 record_event.delay(options)
56
57
58 def require_fields(req, fields):
59 for f in fields:
60 if f not in req:
61 abort(400)
62
63
64 def get_object_or_404(fn, *args, **kwargs):
65 try:
66 return fn(*args, **kwargs)
67 except DoesNotExist:
68 abort(404)
69
70
71 def org_scoped_rule(rule):
72 if settings.MULTI_ORG:
73 return "/<org_slug:org_slug>{}".format(rule)
74
75 return rule
76
[end of redash/handlers/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/handlers/base.py b/redash/handlers/base.py
--- a/redash/handlers/base.py
+++ b/redash/handlers/base.py
@@ -5,7 +5,7 @@
from peewee import DoesNotExist
from redash import settings
-from redash.tasks import record_event
+from redash.tasks import record_event as record_event_task
from redash.models import ApiUser
from redash.authentication import current_org
@@ -33,26 +33,30 @@
return current_org._get_current_object()
def record_event(self, options):
- if isinstance(self.current_user, ApiUser):
- options.update({
- 'api_key': self.current_user.name,
- 'org_id': self.current_org.id
- })
- else:
- options.update({
- 'user_id': self.current_user.id,
- 'org_id': self.current_org.id
- })
+ record_event(self.current_org, self.current_user, options)
+
+def record_event(org, user, options):
+ if isinstance(user, ApiUser):
+ options.update({
+ 'api_key': user.name,
+ 'org_id': org.id
+ })
+ else:
options.update({
- 'user_agent': request.user_agent.string,
- 'ip': request.remote_addr
+ 'user_id': user.id,
+ 'org_id': org.id
})
- if 'timestamp' not in options:
- options['timestamp'] = int(time.time())
+ options.update({
+ 'user_agent': request.user_agent.string,
+ 'ip': request.remote_addr
+ })
+
+ if 'timestamp' not in options:
+ options['timestamp'] = int(time.time())
- record_event.delay(options)
+ record_event_task.delay(options)
def require_fields(req, fields):
diff --git a/redash/handlers/embed.py b/redash/handlers/embed.py
--- a/redash/handlers/embed.py
+++ b/redash/handlers/embed.py
@@ -9,7 +9,7 @@
from redash import serializers
from redash.utils import json_dumps
from redash.handlers import routes
-from redash.handlers.base import org_scoped_rule
+from redash.handlers.base import org_scoped_rule, record_event
from redash.permissions import require_access, view_only
from authentication import current_org
@@ -17,7 +17,6 @@
@routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])
@login_required
def embed(query_id, visualization_id, org_slug=None):
- # TODO: add event for embed access
query = models.Query.get_by_id_and_org(query_id, current_org)
require_access(query.groups, current_user, view_only)
vis = query.visualizations.where(models.Visualization.id == visualization_id).first()
@@ -33,6 +32,15 @@
else:
abort(404, message="Visualization not found.")
+ record_event(current_org, current_user, {
+ 'action': 'view',
+ 'object_id': visualization_id,
+ 'object_type': 'visualization',
+ 'query_id': query_id,
+ 'embed': True,
+ 'referer': request.headers.get('Referer')
+ })
+
client_config = {}
client_config.update(settings.COMMON_CLIENT_CONFIG)
@@ -65,6 +73,15 @@
'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'
}
+ record_event(current_org, current_user, {
+ 'action': 'view',
+ 'object_id': dashboard.id,
+ 'object_type': 'dashboard',
+ 'public': True,
+ 'headless': 'embed' in request.args,
+ 'referer': request.headers.get('Referer')
+ })
+
response = render_template("public.html",
headless='embed' in request.args,
user=json.dumps(user),
|
{"golden_diff": "diff --git a/redash/handlers/base.py b/redash/handlers/base.py\n--- a/redash/handlers/base.py\n+++ b/redash/handlers/base.py\n@@ -5,7 +5,7 @@\n from peewee import DoesNotExist\n \n from redash import settings\n-from redash.tasks import record_event\n+from redash.tasks import record_event as record_event_task\n from redash.models import ApiUser\n from redash.authentication import current_org\n \n@@ -33,26 +33,30 @@\n return current_org._get_current_object()\n \n def record_event(self, options):\n- if isinstance(self.current_user, ApiUser):\n- options.update({\n- 'api_key': self.current_user.name,\n- 'org_id': self.current_org.id\n- })\n- else:\n- options.update({\n- 'user_id': self.current_user.id,\n- 'org_id': self.current_org.id\n- })\n+ record_event(self.current_org, self.current_user, options)\n \n+\n+def record_event(org, user, options):\n+ if isinstance(user, ApiUser):\n+ options.update({\n+ 'api_key': user.name,\n+ 'org_id': org.id\n+ })\n+ else:\n options.update({\n- 'user_agent': request.user_agent.string,\n- 'ip': request.remote_addr\n+ 'user_id': user.id,\n+ 'org_id': org.id\n })\n \n- if 'timestamp' not in options:\n- options['timestamp'] = int(time.time())\n+ options.update({\n+ 'user_agent': request.user_agent.string,\n+ 'ip': request.remote_addr\n+ })\n+\n+ if 'timestamp' not in options:\n+ options['timestamp'] = int(time.time())\n \n- record_event.delay(options)\n+ record_event_task.delay(options)\n \n \n def require_fields(req, fields):\ndiff --git a/redash/handlers/embed.py b/redash/handlers/embed.py\n--- a/redash/handlers/embed.py\n+++ b/redash/handlers/embed.py\n@@ -9,7 +9,7 @@\n from redash import serializers\n from redash.utils import json_dumps\n from redash.handlers import routes\n-from redash.handlers.base import org_scoped_rule\n+from redash.handlers.base import org_scoped_rule, record_event\n from redash.permissions import require_access, view_only\n from authentication import current_org\n \n@@ -17,7 +17,6 @@\n @routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])\n @login_required\n def embed(query_id, visualization_id, org_slug=None):\n- # TODO: add event for embed access\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.groups, current_user, view_only)\n vis = query.visualizations.where(models.Visualization.id == visualization_id).first()\n@@ -33,6 +32,15 @@\n else:\n abort(404, message=\"Visualization not found.\")\n \n+ record_event(current_org, current_user, {\n+ 'action': 'view',\n+ 'object_id': visualization_id,\n+ 'object_type': 'visualization',\n+ 'query_id': query_id,\n+ 'embed': True,\n+ 'referer': request.headers.get('Referer')\n+ })\n+\n client_config = {}\n client_config.update(settings.COMMON_CLIENT_CONFIG)\n \n@@ -65,6 +73,15 @@\n 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'\n }\n \n+ record_event(current_org, current_user, {\n+ 'action': 'view',\n+ 'object_id': dashboard.id,\n+ 'object_type': 'dashboard',\n+ 'public': True,\n+ 'headless': 'embed' in request.args,\n+ 'referer': request.headers.get('Referer')\n+ })\n+\n response = render_template(\"public.html\",\n headless='embed' in request.args,\n user=json.dumps(user),\n", "issue": "Add events to track embeds usage\n\nAdd events to track embeds usage\n\n", "before_files": [{"content": "import json\n\nfrom funcy import project\nfrom flask import render_template, request\nfrom flask_login import login_required, current_user\nfrom flask_restful import abort\n\nfrom redash import models, settings\nfrom redash import serializers\nfrom redash.utils import json_dumps\nfrom redash.handlers import routes\nfrom redash.handlers.base import org_scoped_rule\nfrom redash.permissions import require_access, view_only\nfrom authentication import current_org\n\n\[email protected](org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])\n@login_required\ndef embed(query_id, visualization_id, org_slug=None):\n # TODO: add event for embed access\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.groups, current_user, view_only)\n vis = query.visualizations.where(models.Visualization.id == visualization_id).first()\n qr = {}\n\n if vis is not None:\n vis = vis.to_dict()\n qr = query.latest_query_data\n if qr is None:\n abort(400, message=\"No Results for this query\")\n else:\n qr = qr.to_dict()\n else:\n abort(404, message=\"Visualization not found.\")\n\n client_config = {}\n client_config.update(settings.COMMON_CLIENT_CONFIG)\n\n qr = project(qr, ('data', 'id', 'retrieved_at'))\n vis = project(vis, ('description', 'name', 'id', 'options', 'query', 'type', 'updated_at'))\n vis['query'] = project(vis['query'], ('created_at', 'description', 'name', 'id', 'latest_query_data_id', 'name', 'updated_at'))\n\n return render_template(\"embed.html\",\n client_config=json_dumps(client_config),\n visualization=json_dumps(vis),\n query_result=json_dumps(qr))\n\n\[email protected](org_scoped_rule('/public/dashboards/<token>'), methods=['GET'])\n@login_required\ndef public_dashboard(token, org_slug=None):\n # TODO: verify object is a dashboard?\n if not isinstance(current_user, models.ApiUser):\n api_key = models.ApiKey.get_by_api_key(token)\n dashboard = api_key.object\n else:\n dashboard = current_user.object\n\n user = {\n 'permissions': [],\n 'apiKey': current_user.id\n }\n\n headers = {\n 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'\n }\n\n response = render_template(\"public.html\",\n headless='embed' in request.args,\n user=json.dumps(user),\n seed_data=json_dumps({\n 'dashboard': serializers.public_dashboard(dashboard)\n }),\n client_config=json.dumps(settings.COMMON_CLIENT_CONFIG))\n\n return response, 200, headers\n", "path": "redash/handlers/embed.py"}, {"content": "import time\nfrom flask import request, Blueprint\nfrom flask_restful import Resource, abort\nfrom flask_login import current_user, login_required\nfrom peewee import DoesNotExist\n\nfrom redash import settings\nfrom redash.tasks import record_event\nfrom redash.models import ApiUser\nfrom redash.authentication import current_org\n\nroutes = Blueprint('redash', __name__, template_folder=settings.fix_assets_path('templates'))\n\n\nclass BaseResource(Resource):\n decorators = [login_required]\n\n def __init__(self, *args, **kwargs):\n super(BaseResource, self).__init__(*args, **kwargs)\n self._user = None\n\n def dispatch_request(self, *args, **kwargs):\n kwargs.pop('org_slug', None)\n\n return super(BaseResource, self).dispatch_request(*args, **kwargs)\n\n @property\n def current_user(self):\n return current_user._get_current_object()\n\n @property\n def current_org(self):\n return current_org._get_current_object()\n\n def record_event(self, options):\n if isinstance(self.current_user, ApiUser):\n options.update({\n 'api_key': self.current_user.name,\n 'org_id': self.current_org.id\n })\n else:\n options.update({\n 'user_id': self.current_user.id,\n 'org_id': self.current_org.id\n })\n\n options.update({\n 'user_agent': request.user_agent.string,\n 'ip': request.remote_addr\n })\n\n if 'timestamp' not in options:\n options['timestamp'] = int(time.time())\n\n record_event.delay(options)\n\n\ndef require_fields(req, fields):\n for f in fields:\n if f not in req:\n abort(400)\n\n\ndef get_object_or_404(fn, *args, **kwargs):\n try:\n return fn(*args, **kwargs)\n except DoesNotExist:\n abort(404)\n\n\ndef org_scoped_rule(rule):\n if settings.MULTI_ORG:\n return \"/<org_slug:org_slug>{}\".format(rule)\n\n return rule\n", "path": "redash/handlers/base.py"}]}
| 1,915 | 886 |
gh_patches_debug_23847
|
rasdani/github-patches
|
git_diff
|
AppDaemon__appdaemon-1661
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve packaging system
The `requirements.txt` file is used in a bit confusing way. It it usual practice for this file to contain all the dependencies present in the project virtualenv, created using `pip freeze > requirements.txt`, so that the virtualenv can be easily re-created by any developer locally using `pip install -r requirements.txt.`
But this file is also used as the `install_requires` inside `setup.py`, creating a bit of a conflict.
If one installs the appdaemon locally with `pip install .`, then run `pip freeze > requirements.txt`, the `requirements.txt` file is modified, since all the transitive dependencies are also loaded, as is expected. So the question is: shouldn't the declaration of the project dependencies be moved in a more appropriate place, separate from `requirements.txt`?
## Proposed solution
I propose to more crealry declare the project dependencies, by upgrading the way we use the Python packaging system.
At the moment the package is created from the `setup.py`, read by `setuptools` when building the package.
The way to package applications has changed a lot over the years. Nowadays if one were to follow the official [Python packaging guide](https://packaging.python.org/en/latest/tutorials/packaging-projects/), the recommended setup is to use a `pyproject.toml` to describe all the metadata of the project, including the build tool and the project dependencies.
I suggest we move from the current `setup.py` to a more modern and "standard" solution, by migrating to a `pyproject.toml` file to contain all the project dependencies.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 from setuptools import setup, find_packages
5
6 from appdaemon.version import __version__
7
8 # sudo apt-get install python3-aiohttp-dbg
9
10 with open("requirements.txt") as f:
11 install_requires = [x for x in f.read().split("\n") if x]
12
13 with open("README.md") as f:
14 long_description = f.read()
15
16 setup(
17 name="appdaemon",
18 version=__version__,
19 description="Apps for the Home Assistant home automation package.",
20 long_description=long_description,
21 long_description_content_type="text/markdown",
22 author="Andrew I Cockburn",
23 author_email="[email protected]",
24 url="https://github.com/home-assistant/appdaemon.git",
25 packages=find_packages(exclude=["contrib", "docs", "tests*"]),
26 include_package_data=True,
27 install_requires=install_requires,
28 license="Apache License 2.0",
29 python_requires=">=3.7",
30 zip_safe=False,
31 keywords=["appdaemon", "home", "automation"],
32 entry_points={"console_scripts": ["appdaemon = appdaemon.__main__:main"]},
33 classifiers=[
34 "Development Status :: 5 - Production/Stable",
35 "Intended Audience :: Developers",
36 "License :: OSI Approved :: Apache Software License",
37 "Natural Language :: English",
38 "Programming Language :: Python :: 3.7",
39 "Programming Language :: Python :: 3.8",
40 "Programming Language :: Python :: 3.9",
41 "Programming Language :: Python :: 3.10",
42 "Topic :: Home Automation",
43 ],
44 )
45
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
deleted file mode 100755
--- a/setup.py
+++ /dev/null
@@ -1,44 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-
-from setuptools import setup, find_packages
-
-from appdaemon.version import __version__
-
-# sudo apt-get install python3-aiohttp-dbg
-
-with open("requirements.txt") as f:
- install_requires = [x for x in f.read().split("\n") if x]
-
-with open("README.md") as f:
- long_description = f.read()
-
-setup(
- name="appdaemon",
- version=__version__,
- description="Apps for the Home Assistant home automation package.",
- long_description=long_description,
- long_description_content_type="text/markdown",
- author="Andrew I Cockburn",
- author_email="[email protected]",
- url="https://github.com/home-assistant/appdaemon.git",
- packages=find_packages(exclude=["contrib", "docs", "tests*"]),
- include_package_data=True,
- install_requires=install_requires,
- license="Apache License 2.0",
- python_requires=">=3.7",
- zip_safe=False,
- keywords=["appdaemon", "home", "automation"],
- entry_points={"console_scripts": ["appdaemon = appdaemon.__main__:main"]},
- classifiers=[
- "Development Status :: 5 - Production/Stable",
- "Intended Audience :: Developers",
- "License :: OSI Approved :: Apache Software License",
- "Natural Language :: English",
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
- "Programming Language :: Python :: 3.9",
- "Programming Language :: Python :: 3.10",
- "Topic :: Home Automation",
- ],
-)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\ndeleted file mode 100755\n--- a/setup.py\n+++ /dev/null\n@@ -1,44 +0,0 @@\n-#!/usr/bin/env python\n-# -*- coding: utf-8 -*-\n-\n-from setuptools import setup, find_packages\n-\n-from appdaemon.version import __version__\n-\n-# sudo apt-get install python3-aiohttp-dbg\n-\n-with open(\"requirements.txt\") as f:\n- install_requires = [x for x in f.read().split(\"\\n\") if x]\n-\n-with open(\"README.md\") as f:\n- long_description = f.read()\n-\n-setup(\n- name=\"appdaemon\",\n- version=__version__,\n- description=\"Apps for the Home Assistant home automation package.\",\n- long_description=long_description,\n- long_description_content_type=\"text/markdown\",\n- author=\"Andrew I Cockburn\",\n- author_email=\"[email protected]\",\n- url=\"https://github.com/home-assistant/appdaemon.git\",\n- packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests*\"]),\n- include_package_data=True,\n- install_requires=install_requires,\n- license=\"Apache License 2.0\",\n- python_requires=\">=3.7\",\n- zip_safe=False,\n- keywords=[\"appdaemon\", \"home\", \"automation\"],\n- entry_points={\"console_scripts\": [\"appdaemon = appdaemon.__main__:main\"]},\n- classifiers=[\n- \"Development Status :: 5 - Production/Stable\",\n- \"Intended Audience :: Developers\",\n- \"License :: OSI Approved :: Apache Software License\",\n- \"Natural Language :: English\",\n- \"Programming Language :: Python :: 3.7\",\n- \"Programming Language :: Python :: 3.8\",\n- \"Programming Language :: Python :: 3.9\",\n- \"Programming Language :: Python :: 3.10\",\n- \"Topic :: Home Automation\",\n- ],\n-)\n", "issue": "Improve packaging system\nThe `requirements.txt` file is used in a bit confusing way. It it usual practice for this file to contain all the dependencies present in the project virtualenv, created using `pip freeze > requirements.txt`, so that the virtualenv can be easily re-created by any developer locally using `pip install -r requirements.txt.`\r\nBut this file is also used as the `install_requires` inside `setup.py`, creating a bit of a conflict.\r\nIf one installs the appdaemon locally with `pip install .`, then run `pip freeze > requirements.txt`, the `requirements.txt` file is modified, since all the transitive dependencies are also loaded, as is expected. So the question is: shouldn't the declaration of the project dependencies be moved in a more appropriate place, separate from `requirements.txt`?\r\n\r\n## Proposed solution\r\nI propose to more crealry declare the project dependencies, by upgrading the way we use the Python packaging system.\r\nAt the moment the package is created from the `setup.py`, read by `setuptools` when building the package.\r\nThe way to package applications has changed a lot over the years. Nowadays if one were to follow the official [Python packaging guide](https://packaging.python.org/en/latest/tutorials/packaging-projects/), the recommended setup is to use a `pyproject.toml` to describe all the metadata of the project, including the build tool and the project dependencies.\r\nI suggest we move from the current `setup.py` to a more modern and \"standard\" solution, by migrating to a `pyproject.toml` file to contain all the project dependencies.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom setuptools import setup, find_packages\n\nfrom appdaemon.version import __version__\n\n# sudo apt-get install python3-aiohttp-dbg\n\nwith open(\"requirements.txt\") as f:\n install_requires = [x for x in f.read().split(\"\\n\") if x]\n\nwith open(\"README.md\") as f:\n long_description = f.read()\n\nsetup(\n name=\"appdaemon\",\n version=__version__,\n description=\"Apps for the Home Assistant home automation package.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"Andrew I Cockburn\",\n author_email=\"[email protected]\",\n url=\"https://github.com/home-assistant/appdaemon.git\",\n packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests*\"]),\n include_package_data=True,\n install_requires=install_requires,\n license=\"Apache License 2.0\",\n python_requires=\">=3.7\",\n zip_safe=False,\n keywords=[\"appdaemon\", \"home\", \"automation\"],\n entry_points={\"console_scripts\": [\"appdaemon = appdaemon.__main__:main\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Home Automation\",\n ],\n)\n", "path": "setup.py"}]}
| 1,298 | 427 |
gh_patches_debug_6209
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-3021
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
A suspicious user trying to log in results in a 500
https://app.getsentry.com/gratipay/gratipay-com/group/32039756/
<bountysource-plugin>
---
Want to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).
</bountysource-plugin>
A suspicious user trying to log in results in a 500
https://app.getsentry.com/gratipay/gratipay-com/group/32039756/
<bountysource-plugin>
---
Want to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).
</bountysource-plugin>
</issue>
<code>
[start of gratipay/security/user.py]
1
2 from datetime import timedelta
3 import uuid
4
5 from aspen.utils import utcnow
6 from gratipay.models.participant import Participant
7 from gratipay.utils import set_cookie
8
9
10 SESSION = b'session'
11 SESSION_REFRESH = timedelta(hours=1)
12 SESSION_TIMEOUT = timedelta(hours=6)
13
14
15 class User(object):
16 """Represent a user of our website.
17 """
18
19 participant = None
20
21
22 # Constructors
23 # ============
24
25 @classmethod
26 def from_session_token(cls, token):
27 """Find a participant based on token and return a User.
28 """
29 self = cls()
30 self.participant = Participant.from_session_token(token)
31 return self
32
33 @classmethod
34 def from_api_key(cls, api_key):
35 """Find a participant based on token and return a User.
36 """
37 self = cls()
38 self.participant = Participant.from_api_key(api_key)
39 return self
40
41 @classmethod
42 def from_username(cls, username):
43 """Find a participant based on username and return a User.
44 """
45 self = cls()
46 self.participant = Participant.from_username(username)
47 return self
48
49 def __str__(self):
50 if self.participant is None:
51 out = '<Anonymous>'
52 else:
53 out = '<User: %s>' % self.participant.username
54 return out
55 __repr__ = __str__
56
57
58 # Authentication Helpers
59 # ======================
60
61 def sign_in(self, cookies):
62 """Start a new session for the user.
63 """
64 token = uuid.uuid4().hex
65 expires = utcnow() + SESSION_TIMEOUT
66 self.participant.update_session(token, expires)
67 set_cookie(cookies, SESSION, token, expires)
68
69 def keep_signed_in(self, cookies):
70 """Extend the user's current session.
71 """
72 new_expires = utcnow() + SESSION_TIMEOUT
73 if new_expires - self.participant.session_expires > SESSION_REFRESH:
74 self.participant.set_session_expires(new_expires)
75 token = self.participant.session_token
76 set_cookie(cookies, SESSION, token, expires=new_expires)
77
78 def sign_out(self, cookies):
79 """End the user's current session.
80 """
81 self.participant.update_session(None, None)
82 self.participant = None
83 set_cookie(cookies, SESSION, '')
84
85
86 # Roles
87 # =====
88
89 @property
90 def ADMIN(self):
91 return not self.ANON and self.participant.is_admin
92
93 @property
94 def ANON(self):
95 return self.participant is None or self.participant.is_suspicious is True
96 # Append "is True" here because otherwise Python will return the result
97 # of evaluating the right side of the or expression, which can be None.
98
99 def get_highest_role(self, owner):
100 """Return a string representing the highest role this user has.
101
102 :param string owner: the username of the owner of the resource we're
103 concerned with, or None
104
105 """
106 def is_owner():
107 if self.participant is not None:
108 if owner is not None:
109 if self.participant.username == owner:
110 return True
111 return False
112
113 if self.ADMIN:
114 return 'admin'
115 elif is_owner():
116 return 'owner'
117 elif not self.ANON:
118 return 'authenticated'
119 else:
120 return 'anonymous'
121
[end of gratipay/security/user.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gratipay/security/user.py b/gratipay/security/user.py
--- a/gratipay/security/user.py
+++ b/gratipay/security/user.py
@@ -92,9 +92,7 @@
@property
def ANON(self):
- return self.participant is None or self.participant.is_suspicious is True
- # Append "is True" here because otherwise Python will return the result
- # of evaluating the right side of the or expression, which can be None.
+ return self.participant is None
def get_highest_role(self, owner):
"""Return a string representing the highest role this user has.
|
{"golden_diff": "diff --git a/gratipay/security/user.py b/gratipay/security/user.py\n--- a/gratipay/security/user.py\n+++ b/gratipay/security/user.py\n@@ -92,9 +92,7 @@\n \n @property\n def ANON(self):\n- return self.participant is None or self.participant.is_suspicious is True\n- # Append \"is True\" here because otherwise Python will return the result\n- # of evaluating the right side of the or expression, which can be None.\n+ return self.participant is None\n \n def get_highest_role(self, owner):\n \"\"\"Return a string representing the highest role this user has.\n", "issue": "A suspicious user trying to log in results in a 500\nhttps://app.getsentry.com/gratipay/gratipay-com/group/32039756/\n\n<bountysource-plugin>\n\n---\n\nWant to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).\n</bountysource-plugin>\n\nA suspicious user trying to log in results in a 500\nhttps://app.getsentry.com/gratipay/gratipay-com/group/32039756/\n\n<bountysource-plugin>\n\n---\n\nWant to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).\n</bountysource-plugin>\n\n", "before_files": [{"content": "\nfrom datetime import timedelta\nimport uuid\n\nfrom aspen.utils import utcnow\nfrom gratipay.models.participant import Participant\nfrom gratipay.utils import set_cookie\n\n\nSESSION = b'session'\nSESSION_REFRESH = timedelta(hours=1)\nSESSION_TIMEOUT = timedelta(hours=6)\n\n\nclass User(object):\n \"\"\"Represent a user of our website.\n \"\"\"\n\n participant = None\n\n\n # Constructors\n # ============\n\n @classmethod\n def from_session_token(cls, token):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_session_token(token)\n return self\n\n @classmethod\n def from_api_key(cls, api_key):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_api_key(api_key)\n return self\n\n @classmethod\n def from_username(cls, username):\n \"\"\"Find a participant based on username and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_username(username)\n return self\n\n def __str__(self):\n if self.participant is None:\n out = '<Anonymous>'\n else:\n out = '<User: %s>' % self.participant.username\n return out\n __repr__ = __str__\n\n\n # Authentication Helpers\n # ======================\n\n def sign_in(self, cookies):\n \"\"\"Start a new session for the user.\n \"\"\"\n token = uuid.uuid4().hex\n expires = utcnow() + SESSION_TIMEOUT\n self.participant.update_session(token, expires)\n set_cookie(cookies, SESSION, token, expires)\n\n def keep_signed_in(self, cookies):\n \"\"\"Extend the user's current session.\n \"\"\"\n new_expires = utcnow() + SESSION_TIMEOUT\n if new_expires - self.participant.session_expires > SESSION_REFRESH:\n self.participant.set_session_expires(new_expires)\n token = self.participant.session_token\n set_cookie(cookies, SESSION, token, expires=new_expires)\n\n def sign_out(self, cookies):\n \"\"\"End the user's current session.\n \"\"\"\n self.participant.update_session(None, None)\n self.participant = None\n set_cookie(cookies, SESSION, '')\n\n\n # Roles\n # =====\n\n @property\n def ADMIN(self):\n return not self.ANON and self.participant.is_admin\n\n @property\n def ANON(self):\n return self.participant is None or self.participant.is_suspicious is True\n # Append \"is True\" here because otherwise Python will return the result\n # of evaluating the right side of the or expression, which can be None.\n\n def get_highest_role(self, owner):\n \"\"\"Return a string representing the highest role this user has.\n\n :param string owner: the username of the owner of the resource we're\n concerned with, or None\n\n \"\"\"\n def is_owner():\n if self.participant is not None:\n if owner is not None:\n if self.participant.username == owner:\n return True\n return False\n\n if self.ADMIN:\n return 'admin'\n elif is_owner():\n return 'owner'\n elif not self.ANON:\n return 'authenticated'\n else:\n return 'anonymous'\n", "path": "gratipay/security/user.py"}]}
| 1,861 | 145 |
gh_patches_debug_31859
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-1142
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: dropdown menu on main no longer working
try selecting a version here: https://mne.tools/mne-bids/dev/index.html
</issue>
<code>
[start of doc/conf.py]
1 """Configure details for documentation with sphinx."""
2 import os
3 import sys
4 from datetime import date
5
6 import sphinx_gallery # noqa: F401
7 from sphinx_gallery.sorting import ExampleTitleSortKey
8
9 import mne_bids
10
11
12 # If extensions (or modules to document with autodoc) are in another directory,
13 # add these directories to sys.path here. If the directory is relative to the
14 # documentation root, use os.path.abspath to make it absolute, like shown here.
15 curdir = os.path.dirname(__file__)
16 sys.path.append(os.path.abspath(os.path.join(curdir, '..', 'mne_bids')))
17 sys.path.append(os.path.abspath(os.path.join(curdir, 'sphinxext')))
18
19
20 # -- General configuration ------------------------------------------------
21
22 # If your documentation needs a minimal Sphinx version, state it here.
23 #
24 # needs_sphinx = '1.0'
25
26 # Add any Sphinx extension module names here, as strings. They can be
27 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
28 # ones.
29 extensions = [
30 'sphinx.ext.githubpages',
31 'sphinx.ext.autodoc',
32 'sphinx.ext.mathjax',
33 'sphinx.ext.viewcode',
34 'sphinx.ext.autosummary',
35 'sphinx.ext.doctest',
36 'sphinx.ext.intersphinx',
37 'sphinx_gallery.gen_gallery',
38 'numpydoc',
39 'sphinx_copybutton',
40 'gen_cli', # custom extension, see ./sphinxext/gen_cli.py
41 'gh_substitutions', # custom extension, see ./sphinxext/gh_substitutions.py
42 ]
43
44 # configure sphinx-copybutton
45 copybutton_prompt_text = r">>> |\.\.\. |\$ "
46 copybutton_prompt_is_regexp = True
47
48 # configure numpydoc
49 numpydoc_xref_param_type = True
50 numpydoc_class_members_toctree = False
51 numpydoc_attributes_as_param_list = True
52 numpydoc_xref_aliases = {
53 'BIDSPath': ':class:`BIDSPath <mne_bids.BIDSPath>`',
54 'path-like': ':term:`path-like <mne:path-like>`',
55 'array-like': ':term:`array_like <numpy:array_like>`',
56 'int': ':class:`int <python:int>`',
57 'bool': ':class:`bool <python:bool>`',
58 'float': ':class:`float <python:float>`',
59 'list': ':class:`list <python:list>`',
60 'tuple': ':class:`tuple <python:tuple>`',
61 'NibabelImageObject': 'nibabel.spatialimages.SpatialImage',
62 }
63 numpydoc_xref_ignore = {
64 # words
65 'instance', 'instances', 'of'
66 }
67
68
69 # generate autosummary even if no references
70 autosummary_generate = True
71 autodoc_default_options = {'inherited-members': None}
72 default_role = 'autolink' # XXX silently allows bad syntax, someone should fix
73
74 # configure linkcheck
75 # https://sphinx-doc.org/en/master/usage/configuration.html?#options-for-the-linkcheck-builder
76 linkcheck_retries = 2
77 linkcheck_rate_limit_timeout = 15.0
78 linkcheck_ignore = [
79 r'https://www.researchgate.net/profile/.*',
80 ]
81
82 # The suffix(es) of source filenames.
83 # You can specify multiple suffix as a list of string:
84 #
85 # source_suffix = ['.rst', '.md']
86 source_suffix = '.rst'
87
88 # The master toctree document.
89 master_doc = 'index'
90
91 # General information about the project.
92 project = u'MNE-BIDS'
93 td = date.today()
94 copyright = u'2017-%s, MNE Developers. Last updated on %s' % (td.year,
95 td.isoformat())
96
97 author = u'MNE Developers'
98
99 # The version info for the project you're documenting, acts as replacement for
100 # |version| and |release|, also used in various other places throughout the
101 # built documents.
102 #
103 # The short X.Y version.
104 version = mne_bids.__version__
105 # The full version, including alpha/beta/rc tags.
106 release = version
107
108 # List of patterns, relative to source directory, that match files and
109 # directories to ignore when looking for source files.
110 # This patterns also effect to html_static_path and html_extra_path
111 exclude_patterns = ['auto_examples/index.rst', '_build', 'Thumbs.db',
112 '.DS_Store']
113
114 # HTML options (e.g., theme)
115 html_show_sourcelink = False
116 html_copy_source = False
117
118 html_theme = 'pydata_sphinx_theme'
119
120 # Add any paths that contain templates here, relative to this directory.
121 templates_path = ['_templates']
122 html_static_path = ['_static']
123 html_css_files = ['style.css']
124
125 # Theme options are theme-specific and customize the look and feel of a theme
126 # further. For a list of options available for each theme, see the
127 # documentation.
128 html_theme_options = {
129 'icon_links': [
130 dict(name='GitHub',
131 url='https://github.com/mne-tools/mne-bids',
132 icon='fab fa-github-square'),
133 dict(name='Discourse',
134 url='https://mne.discourse.group/tags/mne-bids',
135 icon='fab fa-discourse'),
136 ],
137 'icon_links_label': 'Quick Links', # for screen reader
138 'use_edit_page_button': False,
139 'navigation_with_keys': False,
140 'show_toc_level': 1,
141 'navbar_end': ['version-switcher', 'navbar-icon-links'],
142 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),
143 }
144
145 html_context = {
146 'versions_dropdown': {
147 'dev': 'v0.13 (devel)',
148 'stable': 'v0.12 (stable)',
149 'v0.11': 'v0.11',
150 'v0.10': 'v0.10',
151 'v0.9': 'v0.9',
152 'v0.8': 'v0.8',
153 'v0.7': 'v0.7',
154 'v0.6': 'v0.6',
155 'v0.5': 'v0.5',
156 'v0.4': 'v0.4',
157 'v0.3': 'v0.3',
158 'v0.2': 'v0.2',
159 'v0.1': 'v0.1',
160 },
161 }
162
163 html_sidebars = {}
164
165 # Example configuration for intersphinx: refer to the Python standard library.
166 intersphinx_mapping = {
167 'python': ('https://docs.python.org/3', None),
168 'mne': ('https://mne.tools/dev', None),
169 'mne-gui-addons': ('https://mne.tools/mne-gui-addons', None),
170 'numpy': ('https://numpy.org/devdocs', None),
171 'scipy': ('https://scipy.github.io/devdocs', None),
172 'matplotlib': ('https://matplotlib.org', None),
173 'nilearn': ('http://nilearn.github.io/stable', None),
174 'pandas': ('https://pandas.pydata.org/pandas-docs/dev', None),
175 'nibabel': ('https://nipy.org/nibabel', None),
176 }
177 intersphinx_timeout = 5
178
179 # Resolve binder filepath_prefix. From the docs:
180 # "A prefix to append to the filepath in the Binder links. You should use this
181 # if you will store your built documentation in a sub-folder of a repository,
182 # instead of in the root."
183 # we will store dev docs in a `dev` subdirectory and all other docs in a
184 # directory "v" + version_str. E.g., "v0.3"
185 if 'dev' in version:
186 filepath_prefix = 'dev'
187 else:
188 filepath_prefix = 'v{}'.format(version)
189
190 sphinx_gallery_conf = {
191 'doc_module': 'mne_bids',
192 'reference_url': {
193 'mne_bids': None,
194 },
195 'backreferences_dir': 'generated',
196 'examples_dirs': '../examples',
197 'within_subsection_order': ExampleTitleSortKey,
198 'gallery_dirs': 'auto_examples',
199 'filename_pattern': '^((?!sgskip).)*$',
200 'binder': {
201 # Required keys
202 'org': 'mne-tools',
203 'repo': 'mne-bids',
204 'branch': 'gh-pages', # noqa: E501 Can be any branch, tag, or commit hash. Use a branch that hosts your docs.
205 'binderhub_url': 'https://mybinder.org', # noqa: E501 Any URL of a binderhub deployment. Must be full URL (e.g. https://mybinder.org).
206 'filepath_prefix': filepath_prefix, # noqa: E501 A prefix to prepend to any filepaths in Binder links.
207 'dependencies': [
208 '../test_requirements.txt',
209 './requirements.txt',
210 ],
211 }
212 }
213
[end of doc/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -21,7 +21,7 @@
# If your documentation needs a minimal Sphinx version, state it here.
#
-# needs_sphinx = '1.0'
+needs_sphinx = '2.0'
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
@@ -125,6 +125,7 @@
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
+switcher_version_match = "dev" if "dev" in release else version
html_theme_options = {
'icon_links': [
dict(name='GitHub',
@@ -138,26 +139,17 @@
'use_edit_page_button': False,
'navigation_with_keys': False,
'show_toc_level': 1,
- 'navbar_end': ['version-switcher', 'navbar-icon-links'],
+ 'navbar_end': ['theme-switcher', 'version-switcher', 'navbar-icon-links'],
'analytics': dict(google_analytics_id='G-C8SH9E98QC'),
+ "switcher": {
+ "json_url": "https://raw.githubusercontent.com/mne-tools/mne-bids/main/doc/_static/versions.json", # noqa: E501
+ "version_match": switcher_version_match,
+ },
}
html_context = {
- 'versions_dropdown': {
- 'dev': 'v0.13 (devel)',
- 'stable': 'v0.12 (stable)',
- 'v0.11': 'v0.11',
- 'v0.10': 'v0.10',
- 'v0.9': 'v0.9',
- 'v0.8': 'v0.8',
- 'v0.7': 'v0.7',
- 'v0.6': 'v0.6',
- 'v0.5': 'v0.5',
- 'v0.4': 'v0.4',
- 'v0.3': 'v0.3',
- 'v0.2': 'v0.2',
- 'v0.1': 'v0.1',
- },
+ "default_mode": "auto",
+ "doc_path": "doc",
}
html_sidebars = {}
|
{"golden_diff": "diff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -21,7 +21,7 @@\n \n # If your documentation needs a minimal Sphinx version, state it here.\n #\n-# needs_sphinx = '1.0'\n+needs_sphinx = '2.0'\n \n # Add any Sphinx extension module names here, as strings. They can be\n # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n@@ -125,6 +125,7 @@\n # Theme options are theme-specific and customize the look and feel of a theme\n # further. For a list of options available for each theme, see the\n # documentation.\n+switcher_version_match = \"dev\" if \"dev\" in release else version\n html_theme_options = {\n 'icon_links': [\n dict(name='GitHub',\n@@ -138,26 +139,17 @@\n 'use_edit_page_button': False,\n 'navigation_with_keys': False,\n 'show_toc_level': 1,\n- 'navbar_end': ['version-switcher', 'navbar-icon-links'],\n+ 'navbar_end': ['theme-switcher', 'version-switcher', 'navbar-icon-links'],\n 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),\n+ \"switcher\": {\n+ \"json_url\": \"https://raw.githubusercontent.com/mne-tools/mne-bids/main/doc/_static/versions.json\", # noqa: E501\n+ \"version_match\": switcher_version_match,\n+ },\n }\n \n html_context = {\n- 'versions_dropdown': {\n- 'dev': 'v0.13 (devel)',\n- 'stable': 'v0.12 (stable)',\n- 'v0.11': 'v0.11',\n- 'v0.10': 'v0.10',\n- 'v0.9': 'v0.9',\n- 'v0.8': 'v0.8',\n- 'v0.7': 'v0.7',\n- 'v0.6': 'v0.6',\n- 'v0.5': 'v0.5',\n- 'v0.4': 'v0.4',\n- 'v0.3': 'v0.3',\n- 'v0.2': 'v0.2',\n- 'v0.1': 'v0.1',\n- },\n+ \"default_mode\": \"auto\",\n+ \"doc_path\": \"doc\",\n }\n \n html_sidebars = {}\n", "issue": "docs: dropdown menu on main no longer working\ntry selecting a version here: https://mne.tools/mne-bids/dev/index.html\n", "before_files": [{"content": "\"\"\"Configure details for documentation with sphinx.\"\"\"\nimport os\nimport sys\nfrom datetime import date\n\nimport sphinx_gallery # noqa: F401\nfrom sphinx_gallery.sorting import ExampleTitleSortKey\n\nimport mne_bids\n\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\ncurdir = os.path.dirname(__file__)\nsys.path.append(os.path.abspath(os.path.join(curdir, '..', 'mne_bids')))\nsys.path.append(os.path.abspath(os.path.join(curdir, 'sphinxext')))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.githubpages',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx_gallery.gen_gallery',\n 'numpydoc',\n 'sphinx_copybutton',\n 'gen_cli', # custom extension, see ./sphinxext/gen_cli.py\n 'gh_substitutions', # custom extension, see ./sphinxext/gh_substitutions.py\n]\n\n# configure sphinx-copybutton\ncopybutton_prompt_text = r\">>> |\\.\\.\\. |\\$ \"\ncopybutton_prompt_is_regexp = True\n\n# configure numpydoc\nnumpydoc_xref_param_type = True\nnumpydoc_class_members_toctree = False\nnumpydoc_attributes_as_param_list = True\nnumpydoc_xref_aliases = {\n 'BIDSPath': ':class:`BIDSPath <mne_bids.BIDSPath>`',\n 'path-like': ':term:`path-like <mne:path-like>`',\n 'array-like': ':term:`array_like <numpy:array_like>`',\n 'int': ':class:`int <python:int>`',\n 'bool': ':class:`bool <python:bool>`',\n 'float': ':class:`float <python:float>`',\n 'list': ':class:`list <python:list>`',\n 'tuple': ':class:`tuple <python:tuple>`',\n 'NibabelImageObject': 'nibabel.spatialimages.SpatialImage',\n}\nnumpydoc_xref_ignore = {\n # words\n 'instance', 'instances', 'of'\n}\n\n\n# generate autosummary even if no references\nautosummary_generate = True\nautodoc_default_options = {'inherited-members': None}\ndefault_role = 'autolink' # XXX silently allows bad syntax, someone should fix\n\n# configure linkcheck\n# https://sphinx-doc.org/en/master/usage/configuration.html?#options-for-the-linkcheck-builder\nlinkcheck_retries = 2\nlinkcheck_rate_limit_timeout = 15.0\nlinkcheck_ignore = [\n r'https://www.researchgate.net/profile/.*',\n]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'MNE-BIDS'\ntd = date.today()\ncopyright = u'2017-%s, MNE Developers. Last updated on %s' % (td.year,\n td.isoformat())\n\nauthor = u'MNE Developers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = mne_bids.__version__\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['auto_examples/index.rst', '_build', 'Thumbs.db',\n '.DS_Store']\n\n# HTML options (e.g., theme)\nhtml_show_sourcelink = False\nhtml_copy_source = False\n\nhtml_theme = 'pydata_sphinx_theme'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\nhtml_static_path = ['_static']\nhtml_css_files = ['style.css']\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n 'icon_links': [\n dict(name='GitHub',\n url='https://github.com/mne-tools/mne-bids',\n icon='fab fa-github-square'),\n dict(name='Discourse',\n url='https://mne.discourse.group/tags/mne-bids',\n icon='fab fa-discourse'),\n ],\n 'icon_links_label': 'Quick Links', # for screen reader\n 'use_edit_page_button': False,\n 'navigation_with_keys': False,\n 'show_toc_level': 1,\n 'navbar_end': ['version-switcher', 'navbar-icon-links'],\n 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),\n}\n\nhtml_context = {\n 'versions_dropdown': {\n 'dev': 'v0.13 (devel)',\n 'stable': 'v0.12 (stable)',\n 'v0.11': 'v0.11',\n 'v0.10': 'v0.10',\n 'v0.9': 'v0.9',\n 'v0.8': 'v0.8',\n 'v0.7': 'v0.7',\n 'v0.6': 'v0.6',\n 'v0.5': 'v0.5',\n 'v0.4': 'v0.4',\n 'v0.3': 'v0.3',\n 'v0.2': 'v0.2',\n 'v0.1': 'v0.1',\n },\n}\n\nhtml_sidebars = {}\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n 'mne': ('https://mne.tools/dev', None),\n 'mne-gui-addons': ('https://mne.tools/mne-gui-addons', None),\n 'numpy': ('https://numpy.org/devdocs', None),\n 'scipy': ('https://scipy.github.io/devdocs', None),\n 'matplotlib': ('https://matplotlib.org', None),\n 'nilearn': ('http://nilearn.github.io/stable', None),\n 'pandas': ('https://pandas.pydata.org/pandas-docs/dev', None),\n 'nibabel': ('https://nipy.org/nibabel', None),\n}\nintersphinx_timeout = 5\n\n# Resolve binder filepath_prefix. From the docs:\n# \"A prefix to append to the filepath in the Binder links. You should use this\n# if you will store your built documentation in a sub-folder of a repository,\n# instead of in the root.\"\n# we will store dev docs in a `dev` subdirectory and all other docs in a\n# directory \"v\" + version_str. E.g., \"v0.3\"\nif 'dev' in version:\n filepath_prefix = 'dev'\nelse:\n filepath_prefix = 'v{}'.format(version)\n\nsphinx_gallery_conf = {\n 'doc_module': 'mne_bids',\n 'reference_url': {\n 'mne_bids': None,\n },\n 'backreferences_dir': 'generated',\n 'examples_dirs': '../examples',\n 'within_subsection_order': ExampleTitleSortKey,\n 'gallery_dirs': 'auto_examples',\n 'filename_pattern': '^((?!sgskip).)*$',\n 'binder': {\n # Required keys\n 'org': 'mne-tools',\n 'repo': 'mne-bids',\n 'branch': 'gh-pages', # noqa: E501 Can be any branch, tag, or commit hash. Use a branch that hosts your docs.\n 'binderhub_url': 'https://mybinder.org', # noqa: E501 Any URL of a binderhub deployment. Must be full URL (e.g. https://mybinder.org).\n 'filepath_prefix': filepath_prefix, # noqa: E501 A prefix to prepend to any filepaths in Binder links.\n 'dependencies': [\n '../test_requirements.txt',\n './requirements.txt',\n ],\n }\n}\n", "path": "doc/conf.py"}]}
| 3,048 | 578 |
gh_patches_debug_2497
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1047
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Windows agent connection error
agent version: 4.4
OS: Windows 2008 Standard, SP2.
case: https://datadog.desk.com/agent/case/11902
- log snippet:
> 2014-06-24 13:45:04 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/intake?api_key=#################',error=gaierror(11001, 'getaddrinfo failed'),headers={},reason='Unknown',request=<tornado.httpclient.HTTPRequest object at 0x01212170>,request_time=0.018000125885009766,time_info={})
>
> 2014-06-24 13:45:04 Eastern Daylight Time | WARNING | transaction(transaction.pyc:213) | Transaction 4 in error (5 errors), it will be replayed after 2014-06-24 13:46:34
>
> 2014-06-24 13:45:05 Eastern Daylight Time | INFO | win32.agent(agent.pyc:91) | pup has died. Restarting...
>
> 2014-06-24 13:45:05 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/api/v1/series/?api_key=################',error=gaierror(11001, 'getaddrinfo failed`
- able to TCP connection (80 and 443) to app.datadoghq.com
EDIT:
> telnet app.datadoghq.com 80
> telnet app.datadoghq.com 443
- from agent python shell:
> print socket.getaddrinfo('app.datadoghq.com',443)
> Traceback (most recent call last):
> File "shell.py", line 13, in shell
> File "<string>", line 1, in <module>
> gaierror: [Errno 11001] getaddrinfo failed
</issue>
<code>
[start of setup.py]
1 import platform
2 import sys
3 from config import get_version
4 from jmxfetch import JMX_FETCH_JAR_NAME
5
6 try:
7 from setuptools import setup, find_packages
8
9 # required to build the cython extensions
10 from distutils.extension import Extension #pylint: disable=no-name-in-module
11
12 except ImportError:
13 from ez_setup import use_setuptools
14 use_setuptools()
15 from setuptools import setup, find_packages
16
17 # Extra arguments to pass to the setup function
18 extra_args = {}
19
20 # Prereqs of the build. Won't get installed when deploying the egg.
21 setup_requires = [
22 ]
23
24 # Prereqs of the install. Will install when deploying the egg.
25 install_requires=[
26 ]
27
28 if sys.platform == 'win32':
29 from glob import glob
30 import py2exe
31 install_requires.extend([
32 'tornado==3.0.1',
33 'pywin32==217',
34 'wmi==1.4.9',
35 'simplejson==2.6.1',
36 'mysql-python==1.2.3',
37 'pymongo==2.3',
38 'pg8000',
39 'python-memcached==1.48',
40 'adodbapi'
41 'elementtree',
42 'pycurl',
43 'pymysql',
44 'psutil',
45 'redis',
46 'requests',
47 'httplib2==0.9',
48 ])
49
50 # Modules to force-include in the exe
51 include_modules = [
52 # 3p
53 'win32service',
54 'win32serviceutil',
55 'win32event',
56 'simplejson',
57 'adodbapi',
58 'elementtree.ElementTree',
59 'pycurl',
60 'tornado.curl_httpclient',
61 'pymongo',
62 'pymysql',
63 'psutil',
64 'pg8000',
65 'redis',
66 'requests',
67
68 # agent
69 'checks.services_checks',
70 'httplib2',
71
72 # pup
73 'pup',
74 'pup.pup',
75 'tornado.websocket',
76 'tornado.web',
77 'tornado.ioloop',
78 ]
79
80 class Target(object):
81 def __init__(self, **kw):
82 self.__dict__.update(kw)
83 self.version = get_version()
84 self.company_name = 'Datadog, Inc.'
85 self.copyright = 'Copyright 2013 Datadog, Inc.'
86 self.cmdline_style = 'pywin32'
87
88 agent_svc = Target(name='Datadog Agent', modules='win32.agent', dest_base='ddagent')
89
90 extra_args = {
91 'options': {
92 'py2exe': {
93 'includes': ','.join(include_modules),
94 'optimize': 0,
95 'compressed': True,
96 'bundle_files': 3,
97 },
98 },
99 'console': ['win32\shell.py'],
100 'service': [agent_svc],
101 'windows': [{'script': 'win32\gui.py',
102 'dest_base': "agent-manager",
103 'uac_info': "requireAdministrator", # The manager needs to be administrator to stop/start the service
104 'icon_resources': [(1, r"packaging\datadog-agent\win32\install_files\dd_agent_win_256.ico")],
105 }],
106 'data_files': [
107 ("Microsoft.VC90.CRT", glob(r'C:\Python27\redist\*.*')),
108 ('pup', glob('pup/pup.html')),
109 ('pup', glob('pup/status.html')),
110 ('pup/static', glob('pup/static/*.*')),
111 ('jmxfetch', glob('checks/libs/%s' % JMX_FETCH_JAR_NAME)),
112 ],
113 }
114
115 setup(
116 name='datadog-agent',
117 version=get_version(),
118 description="DevOps' best friend",
119 author='DataDog',
120 author_email='[email protected]',
121 url='http://www.datadoghq.com',
122 install_requires=install_requires,
123 setup_requires=setup_requires,
124 packages=find_packages(exclude=['ez_setup']),
125 include_package_data=True,
126 test_suite='nose.collector',
127 zip_safe=False,
128 **extra_args
129 )
130
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -94,6 +94,7 @@
'optimize': 0,
'compressed': True,
'bundle_files': 3,
+ 'dll_excludes': [ "IPHLPAPI.DLL", "NSI.dll", "WINNSI.DLL", "WTSAPI32.dll"],
},
},
'console': ['win32\shell.py'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -94,6 +94,7 @@\n 'optimize': 0,\n 'compressed': True,\n 'bundle_files': 3,\n+ 'dll_excludes': [ \"IPHLPAPI.DLL\", \"NSI.dll\", \"WINNSI.DLL\", \"WTSAPI32.dll\"],\n },\n },\n 'console': ['win32\\shell.py'],\n", "issue": "Windows agent connection error\nagent version: 4.4\nOS: Windows 2008 Standard, SP2.\ncase: https://datadog.desk.com/agent/case/11902\n- log snippet:\n\n> 2014-06-24 13:45:04 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/intake?api_key=#################',error=gaierror(11001, 'getaddrinfo failed'),headers={},reason='Unknown',request=<tornado.httpclient.HTTPRequest object at 0x01212170>,request_time=0.018000125885009766,time_info={})\n> \n> 2014-06-24 13:45:04 Eastern Daylight Time | WARNING | transaction(transaction.pyc:213) | Transaction 4 in error (5 errors), it will be replayed after 2014-06-24 13:46:34\n> \n> 2014-06-24 13:45:05 Eastern Daylight Time | INFO | win32.agent(agent.pyc:91) | pup has died. Restarting...\n> \n> 2014-06-24 13:45:05 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/api/v1/series/?api_key=################',error=gaierror(11001, 'getaddrinfo failed`\n- able to TCP connection (80 and 443) to app.datadoghq.com\n EDIT:\n \n > telnet app.datadoghq.com 80\n > telnet app.datadoghq.com 443\n- from agent python shell:\n \n > print socket.getaddrinfo('app.datadoghq.com',443)\n > Traceback (most recent call last):\n > File \"shell.py\", line 13, in shell\n > File \"<string>\", line 1, in <module>\n > gaierror: [Errno 11001] getaddrinfo failed\n\n", "before_files": [{"content": "import platform\nimport sys\nfrom config import get_version\nfrom jmxfetch import JMX_FETCH_JAR_NAME\n\ntry:\n from setuptools import setup, find_packages\n\n # required to build the cython extensions\n from distutils.extension import Extension #pylint: disable=no-name-in-module\n\nexcept ImportError:\n from ez_setup import use_setuptools\n use_setuptools()\n from setuptools import setup, find_packages\n\n# Extra arguments to pass to the setup function\nextra_args = {}\n\n# Prereqs of the build. Won't get installed when deploying the egg.\nsetup_requires = [\n]\n\n# Prereqs of the install. Will install when deploying the egg.\ninstall_requires=[\n]\n\nif sys.platform == 'win32':\n from glob import glob\n import py2exe\n install_requires.extend([\n 'tornado==3.0.1',\n 'pywin32==217',\n 'wmi==1.4.9',\n 'simplejson==2.6.1',\n 'mysql-python==1.2.3',\n 'pymongo==2.3',\n 'pg8000',\n 'python-memcached==1.48',\n 'adodbapi'\n 'elementtree',\n 'pycurl',\n 'pymysql',\n 'psutil',\n 'redis',\n 'requests',\n 'httplib2==0.9',\n ])\n\n # Modules to force-include in the exe\n include_modules = [\n # 3p\n 'win32service',\n 'win32serviceutil',\n 'win32event',\n 'simplejson',\n 'adodbapi',\n 'elementtree.ElementTree',\n 'pycurl',\n 'tornado.curl_httpclient',\n 'pymongo',\n 'pymysql',\n 'psutil',\n 'pg8000',\n 'redis',\n 'requests',\n\n # agent\n 'checks.services_checks',\n 'httplib2',\n\n # pup\n 'pup',\n 'pup.pup',\n 'tornado.websocket',\n 'tornado.web',\n 'tornado.ioloop',\n ]\n\n class Target(object):\n def __init__(self, **kw):\n self.__dict__.update(kw) \n self.version = get_version()\n self.company_name = 'Datadog, Inc.'\n self.copyright = 'Copyright 2013 Datadog, Inc.'\n self.cmdline_style = 'pywin32'\n\n agent_svc = Target(name='Datadog Agent', modules='win32.agent', dest_base='ddagent')\n\n extra_args = {\n 'options': {\n 'py2exe': {\n 'includes': ','.join(include_modules),\n 'optimize': 0,\n 'compressed': True,\n 'bundle_files': 3,\n },\n },\n 'console': ['win32\\shell.py'],\n 'service': [agent_svc],\n 'windows': [{'script': 'win32\\gui.py',\n 'dest_base': \"agent-manager\",\n 'uac_info': \"requireAdministrator\", # The manager needs to be administrator to stop/start the service\n 'icon_resources': [(1, r\"packaging\\datadog-agent\\win32\\install_files\\dd_agent_win_256.ico\")],\n }],\n 'data_files': [\n (\"Microsoft.VC90.CRT\", glob(r'C:\\Python27\\redist\\*.*')),\n ('pup', glob('pup/pup.html')),\n ('pup', glob('pup/status.html')),\n ('pup/static', glob('pup/static/*.*')),\n ('jmxfetch', glob('checks/libs/%s' % JMX_FETCH_JAR_NAME)),\n ],\n }\n\nsetup(\n name='datadog-agent',\n version=get_version(),\n description=\"DevOps' best friend\",\n author='DataDog',\n author_email='[email protected]',\n url='http://www.datadoghq.com',\n install_requires=install_requires,\n setup_requires=setup_requires,\n packages=find_packages(exclude=['ez_setup']),\n include_package_data=True,\n test_suite='nose.collector',\n zip_safe=False,\n **extra_args\n)\n", "path": "setup.py"}]}
| 2,305 | 106 |
gh_patches_debug_14055
|
rasdani/github-patches
|
git_diff
|
spack__spack-12932
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Installation issue: py-adios
### Steps to reproduce the issue
```console
$ spack install -j 64 py-adios ^[email protected]:
```
The result is lots of errors like:
```adios_mpi.cpp:47080:21: error: 'PyThreadState' {aka 'struct _ts'} has no member named 'exc_type'; did you mean 'curexc_type'?```
And similar.
### Platform and user environment
```commandline
$ uname -a
Linux quokka1.ccs.ornl.gov 4.14.0-115.el7a.aarch64 #1 SMP Tue Sep 25 12:32:51 EDT 2018 aarch64 aarch64 aarch64 GNU/Linux
```
### Additional information
py-adios includes a file (adios_mpi.cpp) which was generated using Cython 0.28.2. This version of Cython generates code that won't compile against the Python 3.7 C API. (This was fixed in the 0.29 release.) The Adios developers have been notified (https://github.com/ornladios/ADIOS/issues/202).
I think the workaround is to add a ```depends_on()``` line for python <=3.6.x. If/when the issue is fixed in Adios, we can add a ```when``` clause to the dependency. I'll issue a pull request shortly.
</issue>
<code>
[start of var/spack/repos/builtin/packages/py-adios/package.py]
1 # Copyright 2013-2019 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class PyAdios(PythonPackage):
10 """NumPy bindings of ADIOS1"""
11
12 homepage = "https://www.olcf.ornl.gov/center-projects/adios/"
13 url = "https://github.com/ornladios/ADIOS/archive/v1.12.0.tar.gz"
14 git = "https://github.com/ornladios/ADIOS.git"
15
16 maintainers = ['ax3l']
17
18 version('develop', branch='master')
19 version('1.13.0', '68af36b821debbdf4748b20320a990ce')
20 version('1.12.0', '84a1c71b6698009224f6f748c5257fc9')
21 version('1.11.1', '5639bfc235e50bf17ba9dafb14ea4185')
22 version('1.11.0', '5eead5b2ccf962f5e6d5f254d29d5238')
23 version('1.10.0', 'eff450a4c0130479417cfd63186957f3')
24 version('1.9.0', '310ff02388bbaa2b1c1710ee970b5678')
25
26 variant('mpi', default=True,
27 description='Enable MPI support')
28
29 for v in ['1.9.0', '1.10.0', '1.11.0', '1.11.1', '1.12.0', '1.13.0',
30 'develop']:
31 depends_on('adios@{0} ~mpi'.format(v),
32 when='@{0} ~mpi'.format(v),
33 type=['build', 'link', 'run'])
34 depends_on('adios@{0} +mpi'.format(v),
35 when='@{0} +mpi'.format(v),
36 type=['build', 'link', 'run'])
37
38 depends_on('py-numpy', type=['build', 'run'])
39 depends_on('mpi', when='+mpi')
40 depends_on('py-mpi4py', type=['run'], when='+mpi')
41 depends_on('py-cython', type=['build'])
42
43 phases = ['build_clib', 'install']
44 build_directory = 'wrappers/numpy'
45
46 def setup_file(self):
47 """Returns the name of the setup file to use."""
48 if '+mpi' in self.spec:
49 return 'setup_mpi.py'
50 else:
51 return 'setup.py'
52
53 def build_clib(self, spec, prefix):
54 # calls: make [MPI=y] python
55 args = ''
56 if '+mpi' in self.spec:
57 args = 'MPI=y '
58 args += 'python'
59 with working_dir(self.build_directory):
60 make(args)
61
[end of var/spack/repos/builtin/packages/py-adios/package.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/var/spack/repos/builtin/packages/py-adios/package.py b/var/spack/repos/builtin/packages/py-adios/package.py
--- a/var/spack/repos/builtin/packages/py-adios/package.py
+++ b/var/spack/repos/builtin/packages/py-adios/package.py
@@ -35,6 +35,14 @@
when='@{0} +mpi'.format(v),
type=['build', 'link', 'run'])
+ # NOTE: this dependency is a work-around for a bug in Adios itself.
+ # Specifically, Adios uses code that was generated by Cython 0.28.2.
+ # This code won't compile against the Python 3.7 C API.
+ # See https://github.com/ornladios/ADIOS/issues/202 and
+ # the first entry under "Bug Fixes" at
+ # https://github.com/cython/cython/blob/0.29.x/CHANGES.rst
+ depends_on('python@:3.6')
+
depends_on('py-numpy', type=['build', 'run'])
depends_on('mpi', when='+mpi')
depends_on('py-mpi4py', type=['run'], when='+mpi')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/py-adios/package.py b/var/spack/repos/builtin/packages/py-adios/package.py\n--- a/var/spack/repos/builtin/packages/py-adios/package.py\n+++ b/var/spack/repos/builtin/packages/py-adios/package.py\n@@ -35,6 +35,14 @@\n when='@{0} +mpi'.format(v),\n type=['build', 'link', 'run'])\n \n+ # NOTE: this dependency is a work-around for a bug in Adios itself.\n+ # Specifically, Adios uses code that was generated by Cython 0.28.2.\n+ # This code won't compile against the Python 3.7 C API.\n+ # See https://github.com/ornladios/ADIOS/issues/202 and\n+ # the first entry under \"Bug Fixes\" at\n+ # https://github.com/cython/cython/blob/0.29.x/CHANGES.rst\n+ depends_on('python@:3.6')\n+\n depends_on('py-numpy', type=['build', 'run'])\n depends_on('mpi', when='+mpi')\n depends_on('py-mpi4py', type=['run'], when='+mpi')\n", "issue": "Installation issue: py-adios\n### Steps to reproduce the issue\r\n```console\r\n$ spack install -j 64 py-adios ^[email protected]:\r\n```\r\n\r\nThe result is lots of errors like:\r\n```adios_mpi.cpp:47080:21: error: 'PyThreadState' {aka 'struct _ts'} has no member named 'exc_type'; did you mean 'curexc_type'?```\r\n\r\nAnd similar.\r\n\r\n### Platform and user environment\r\n```commandline\r\n$ uname -a\r\nLinux quokka1.ccs.ornl.gov 4.14.0-115.el7a.aarch64 #1 SMP Tue Sep 25 12:32:51 EDT 2018 aarch64 aarch64 aarch64 GNU/Linux\r\n``` \r\n\r\n### Additional information\r\npy-adios includes a file (adios_mpi.cpp) which was generated using Cython 0.28.2. This version of Cython generates code that won't compile against the Python 3.7 C API. (This was fixed in the 0.29 release.) The Adios developers have been notified (https://github.com/ornladios/ADIOS/issues/202).\r\n\r\nI think the workaround is to add a ```depends_on()``` line for python <=3.6.x. If/when the issue is fixed in Adios, we can add a ```when``` clause to the dependency. I'll issue a pull request shortly.\r\n\n", "before_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass PyAdios(PythonPackage):\n \"\"\"NumPy bindings of ADIOS1\"\"\"\n\n homepage = \"https://www.olcf.ornl.gov/center-projects/adios/\"\n url = \"https://github.com/ornladios/ADIOS/archive/v1.12.0.tar.gz\"\n git = \"https://github.com/ornladios/ADIOS.git\"\n\n maintainers = ['ax3l']\n\n version('develop', branch='master')\n version('1.13.0', '68af36b821debbdf4748b20320a990ce')\n version('1.12.0', '84a1c71b6698009224f6f748c5257fc9')\n version('1.11.1', '5639bfc235e50bf17ba9dafb14ea4185')\n version('1.11.0', '5eead5b2ccf962f5e6d5f254d29d5238')\n version('1.10.0', 'eff450a4c0130479417cfd63186957f3')\n version('1.9.0', '310ff02388bbaa2b1c1710ee970b5678')\n\n variant('mpi', default=True,\n description='Enable MPI support')\n\n for v in ['1.9.0', '1.10.0', '1.11.0', '1.11.1', '1.12.0', '1.13.0',\n 'develop']:\n depends_on('adios@{0} ~mpi'.format(v),\n when='@{0} ~mpi'.format(v),\n type=['build', 'link', 'run'])\n depends_on('adios@{0} +mpi'.format(v),\n when='@{0} +mpi'.format(v),\n type=['build', 'link', 'run'])\n\n depends_on('py-numpy', type=['build', 'run'])\n depends_on('mpi', when='+mpi')\n depends_on('py-mpi4py', type=['run'], when='+mpi')\n depends_on('py-cython', type=['build'])\n\n phases = ['build_clib', 'install']\n build_directory = 'wrappers/numpy'\n\n def setup_file(self):\n \"\"\"Returns the name of the setup file to use.\"\"\"\n if '+mpi' in self.spec:\n return 'setup_mpi.py'\n else:\n return 'setup.py'\n\n def build_clib(self, spec, prefix):\n # calls: make [MPI=y] python\n args = ''\n if '+mpi' in self.spec:\n args = 'MPI=y '\n args += 'python'\n with working_dir(self.build_directory):\n make(args)\n", "path": "var/spack/repos/builtin/packages/py-adios/package.py"}]}
| 1,743 | 278 |
gh_patches_debug_24511
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sound.length always returns 0
The `sound.length` function is implemented to always return 0 on both `gstreamer` and `pygame` incarnations of the audio library. Yet it's documented to return the length of the sound...
</issue>
<code>
[start of kivy/core/audio/audio_gstreamer.py]
1 '''
2 AudioGstreamer: implementation of Sound with GStreamer
3 '''
4
5 try:
6 import pygst
7 if not hasattr(pygst, '_gst_already_checked'):
8 pygst.require('0.10')
9 pygst._gst_already_checked = True
10 import gst
11 except:
12 raise
13
14 from . import Sound, SoundLoader
15 import os
16 import sys
17 from kivy.logger import Logger
18
19 # install the gobject iteration
20 from kivy.support import install_gobject_iteration
21 install_gobject_iteration()
22
23
24 class SoundGstreamer(Sound):
25
26 @staticmethod
27 def extensions():
28 return ('wav', 'ogg', 'mp3', )
29
30 def __init__(self, **kwargs):
31 self._data = None
32 super(SoundGstreamer, self).__init__(**kwargs)
33
34 def __del__(self):
35 if self._data is not None:
36 self._data.set_state(gst.STATE_NULL)
37
38 def _on_gst_message(self, bus, message):
39 t = message.type
40 if t == gst.MESSAGE_EOS:
41 self._data.set_state(gst.STATE_NULL)
42 self.stop()
43 elif t == gst.MESSAGE_ERROR:
44 self._data.set_state(gst.STATE_NULL)
45 err, debug = message.parse_error()
46 Logger.error('AudioGstreamer: %s' % err)
47 Logger.debug(str(debug))
48 self.stop()
49
50 def play(self):
51 if not self._data:
52 return
53 self._data.set_state(gst.STATE_PLAYING)
54 super(SoundGstreamer, self).play()
55
56 def stop(self):
57 if not self._data:
58 return
59 self._data.set_state(gst.STATE_NULL)
60 super(SoundGstreamer, self).stop()
61
62 def load(self):
63 self.unload()
64 fn = self.filename
65 if fn is None:
66 return
67
68 slash = ''
69 if sys.platform in ('win32', 'cygwin'):
70 slash = '/'
71
72 if fn[0] == '/':
73 filepath = 'file://' + slash + fn
74 else:
75 filepath = 'file://' + slash + os.path.join(os.getcwd(), fn)
76
77 self._data = gst.element_factory_make('playbin2', 'player')
78 fakesink = gst.element_factory_make('fakesink', 'fakesink')
79 self._data.set_property('video-sink', fakesink)
80 bus = self._data.get_bus()
81 bus.add_signal_watch()
82 bus.connect('message', self._on_gst_message)
83
84 self._data.set_property('uri', filepath)
85 self._data.set_state(gst.STATE_READY)
86
87 def unload(self):
88 self.stop()
89 self._data = None
90
91 def seek(self, position):
92 if self._data is None:
93 return
94 self._data.seek_simple(gst.FORMAT_TIME, gst.SEEK_FLAG_SKIP,
95 position / 1000000000.)
96
97 def _get_volume(self):
98 if self._data is not None:
99 self._volume = self._data.get_property('volume')
100 return super(SoundGstreamer, self)._get_volume()
101
102 def _set_volume(self, volume):
103 if self._data is not None:
104 self._data.set_property('volume', volume)
105 return super(SoundGstreamer, self)._set_volume(volume)
106
107 SoundLoader.register(SoundGstreamer)
108
[end of kivy/core/audio/audio_gstreamer.py]
[start of kivy/core/audio/audio_pygame.py]
1 '''
2 AudioPygame: implementation of Sound with Pygame
3 '''
4
5 __all__ = ('SoundPygame', )
6
7 from kivy.clock import Clock
8 from kivy.utils import platform
9 from . import Sound, SoundLoader
10
11 try:
12 if platform() == 'android':
13 mixer = __import__('android_mixer')
14 else:
15 mixer = __import__('pygame.mixer', fromlist='.')
16 except:
17 raise
18
19 # init pygame sound
20 mixer.pre_init(44100, -16, 2, 1024)
21 mixer.init()
22 mixer.set_num_channels(32)
23
24
25 class SoundPygame(Sound):
26
27 # XXX we don't set __slots__ here, to automaticly add
28 # a dictionnary. We need that to be able to use weakref for
29 # SoundPygame object. Otherwise, it failed with:
30 # TypeError: cannot create weak reference to 'SoundPygame' object
31 # We use our clock in play() method.
32 # __slots__ = ('_data', '_channel')
33 @staticmethod
34 def extensions():
35 return ('wav', 'ogg', )
36
37 def __init__(self, **kwargs):
38 self._data = None
39 self._channel = None
40 super(SoundPygame, self).__init__(**kwargs)
41
42 def _check_play(self, dt):
43 if self._channel is None:
44 return False
45 if self._channel.get_busy():
46 return
47 self.stop()
48 return False
49
50 def play(self):
51 if not self._data:
52 return
53 self._channel = self._data.play()
54 # schedule event to check if the sound is still playing or not
55 Clock.schedule_interval(self._check_play, 0.1)
56 super(SoundPygame, self).play()
57
58 def stop(self):
59 if not self._data:
60 return
61 self._data.stop()
62 # ensure we don't have anymore the callback
63 Clock.unschedule(self._check_play)
64 self._channel = None
65 super(SoundPygame, self).stop()
66
67 def load(self):
68 self.unload()
69 if self.filename is None:
70 return
71 self._data = mixer.Sound(self.filename)
72
73 def unload(self):
74 self.stop()
75 self._data = None
76
77 def seek(self, position):
78 # Unable to seek in pygame...
79 pass
80
81 def _get_volume(self):
82 if self._data is not None:
83 self._volume = self._data.get_volume()
84 return super(SoundPygame, self)._get_volume()
85
86 def _set_volume(self, volume):
87 if self._data is not None:
88 self._data.set_volume(volume)
89 return super(SoundPygame, self)._set_volume(volume)
90
91 SoundLoader.register(SoundPygame)
92
[end of kivy/core/audio/audio_pygame.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kivy/core/audio/audio_gstreamer.py b/kivy/core/audio/audio_gstreamer.py
--- a/kivy/core/audio/audio_gstreamer.py
+++ b/kivy/core/audio/audio_gstreamer.py
@@ -104,4 +104,20 @@
self._data.set_property('volume', volume)
return super(SoundGstreamer, self)._set_volume(volume)
+ def _get_length(self):
+ if self._data is not None:
+ if self._data.get_state()[1] != gst.STATE_PLAYING:
+ volume_before = self._data.get_property('volume')
+ self._data.set_property('volume', 0)
+ self._data.set_state(gst.STATE_PLAYING)
+ try:
+ self._data.get_state()
+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.
+ finally:
+ self._data.set_state(gst.STATE_NULL)
+ self._data.set_property('volume', volume_before)
+ else:
+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.
+ return super(SoundGstreamer, self)._get_length()
+
SoundLoader.register(SoundGstreamer)
diff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py
--- a/kivy/core/audio/audio_pygame.py
+++ b/kivy/core/audio/audio_pygame.py
@@ -88,4 +88,9 @@
self._data.set_volume(volume)
return super(SoundPygame, self)._set_volume(volume)
+ def _get_length(self):
+ if self._data is not None:
+ return self._data.get_length()
+ return super(SoundPygame, self)._get_length()
+
SoundLoader.register(SoundPygame)
|
{"golden_diff": "diff --git a/kivy/core/audio/audio_gstreamer.py b/kivy/core/audio/audio_gstreamer.py\n--- a/kivy/core/audio/audio_gstreamer.py\n+++ b/kivy/core/audio/audio_gstreamer.py\n@@ -104,4 +104,20 @@\n self._data.set_property('volume', volume)\n return super(SoundGstreamer, self)._set_volume(volume)\n \n+ def _get_length(self):\n+ if self._data is not None:\n+ if self._data.get_state()[1] != gst.STATE_PLAYING:\n+ volume_before = self._data.get_property('volume')\n+ self._data.set_property('volume', 0)\n+ self._data.set_state(gst.STATE_PLAYING)\n+ try:\n+ self._data.get_state()\n+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n+ finally:\n+ self._data.set_state(gst.STATE_NULL)\n+ self._data.set_property('volume', volume_before)\n+ else:\n+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n+ return super(SoundGstreamer, self)._get_length()\n+\n SoundLoader.register(SoundGstreamer)\ndiff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py\n--- a/kivy/core/audio/audio_pygame.py\n+++ b/kivy/core/audio/audio_pygame.py\n@@ -88,4 +88,9 @@\n self._data.set_volume(volume)\n return super(SoundPygame, self)._set_volume(volume)\n \n+ def _get_length(self):\n+ if self._data is not None:\n+ return self._data.get_length()\n+ return super(SoundPygame, self)._get_length()\n+\n SoundLoader.register(SoundPygame)\n", "issue": "sound.length always returns 0\nThe `sound.length` function is implemented to always return 0 on both `gstreamer` and `pygame` incarnations of the audio library. Yet it's documented to return the length of the sound...\n\n", "before_files": [{"content": "'''\nAudioGstreamer: implementation of Sound with GStreamer\n'''\n\ntry:\n import pygst\n if not hasattr(pygst, '_gst_already_checked'):\n pygst.require('0.10')\n pygst._gst_already_checked = True\n import gst\nexcept:\n raise\n\nfrom . import Sound, SoundLoader\nimport os\nimport sys\nfrom kivy.logger import Logger\n\n# install the gobject iteration\nfrom kivy.support import install_gobject_iteration\ninstall_gobject_iteration()\n\n\nclass SoundGstreamer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', )\n\n def __init__(self, **kwargs):\n self._data = None\n super(SoundGstreamer, self).__init__(**kwargs)\n\n def __del__(self):\n if self._data is not None:\n self._data.set_state(gst.STATE_NULL)\n\n def _on_gst_message(self, bus, message):\n t = message.type\n if t == gst.MESSAGE_EOS:\n self._data.set_state(gst.STATE_NULL)\n self.stop()\n elif t == gst.MESSAGE_ERROR:\n self._data.set_state(gst.STATE_NULL)\n err, debug = message.parse_error()\n Logger.error('AudioGstreamer: %s' % err)\n Logger.debug(str(debug))\n self.stop()\n\n def play(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_PLAYING)\n super(SoundGstreamer, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_NULL)\n super(SoundGstreamer, self).stop()\n\n def load(self):\n self.unload()\n fn = self.filename\n if fn is None:\n return\n\n slash = ''\n if sys.platform in ('win32', 'cygwin'):\n slash = '/'\n\n if fn[0] == '/':\n filepath = 'file://' + slash + fn\n else:\n filepath = 'file://' + slash + os.path.join(os.getcwd(), fn)\n\n self._data = gst.element_factory_make('playbin2', 'player')\n fakesink = gst.element_factory_make('fakesink', 'fakesink')\n self._data.set_property('video-sink', fakesink)\n bus = self._data.get_bus()\n bus.add_signal_watch()\n bus.connect('message', self._on_gst_message)\n\n self._data.set_property('uri', filepath)\n self._data.set_state(gst.STATE_READY)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if self._data is None:\n return\n self._data.seek_simple(gst.FORMAT_TIME, gst.SEEK_FLAG_SKIP,\n position / 1000000000.)\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_property('volume')\n return super(SoundGstreamer, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_property('volume', volume)\n return super(SoundGstreamer, self)._set_volume(volume)\n\nSoundLoader.register(SoundGstreamer)\n", "path": "kivy/core/audio/audio_gstreamer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform\nfrom . import Sound, SoundLoader\n\ntry:\n if platform() == 'android':\n mixer = __import__('android_mixer')\n else:\n mixer = __import__('pygame.mixer', fromlist='.')\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automaticly add\n # a dictionnary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n @staticmethod\n def extensions():\n return ('wav', 'ogg', )\n\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._channel = self._data.play()\n # schedule event to check if the sound is still playing or not\n Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n Clock.unschedule(self._check_play)\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.filename is None:\n return\n self._data = mixer.Sound(self.filename)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n # Unable to seek in pygame...\n pass\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_volume()\n return super(SoundPygame, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n return super(SoundPygame, self)._set_volume(volume)\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}]}
| 2,356 | 427 |
gh_patches_debug_22564
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2064
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug with `geth_poa_middleware` in the case of non-existing blocks
* Version: 5.20.1
* Python: 3.7.2
* OS: linux
`pip freeze` output:
```
aiohttp==3.7.4.post0
async-timeout==3.0.1
attrs==20.3.0
base58==2.1.0
bitarray==1.2.2
certifi==2020.12.5
chardet==4.0.0
cytoolz==0.11.0
docutils==0.17.1
eth-abi==2.1.1
eth-account==0.5.4
eth-hash==0.3.1
eth-keyfile==0.5.1
eth-keys==0.3.3
eth-rlp==0.2.1
eth-typing==2.2.2
eth-utils==1.10.0
flock==0.1
hexbytes==0.2.1
idna==2.10
importlib-metadata==4.0.1
ipfshttpclient==0.7.0
jsonschema==3.2.0
lockfile==0.12.2
lru-dict==1.1.7
multiaddr==0.0.9
multidict==5.1.0
netaddr==0.8.0
parsimonious==0.8.1
protobuf==3.15.8
pycryptodome==3.10.1
pyrsistent==0.17.3
python-daemon==2.3.0
PyYAML==5.4.1
requests==2.25.1
rlp==2.0.1
six==1.15.0
toolz==0.11.1
typing-extensions==3.7.4.3
urllib3==1.26.4
varint==1.0.2
web3==5.20.1
websockets==9.1
yarl==1.6.3
zipp==3.4.1
```
### What was wrong?
The poa middleware formatters are applied to block contents even in the case when block is not found and `None` returned instead.
Reproducing:
```python
from eth_typing import URI
from web3 import Web3
from web3.middleware import geth_poa_middleware
from web3.providers.auto import load_provider_from_uri
w3 = Web3(load_provider_from_uri(URI('wss://rinkeby.infura.io/ws/v3/__project_id_here__'))) # please update the endpoint url
w3.middleware_onion.inject(geth_poa_middleware, layer=0)
print(w3.eth.get_block(200000000))
```
Expecting `web3.exceptions.BlockNotFound` to be risen.
Instead, got:
```
Traceback (most recent call last):
File "./bin/feed-query", line 85, in <module>
main()
File "./bin/feed-query", line 39, in main
print(w3.eth.get_block(200000000))
File "/venv/lib/python3.7/site-packages/web3/module.py", line 58, in caller
result = w3.manager.request_blocking(method_str, params, error_formatters)
File "/venv/lib/python3.7/site-packages/web3/manager.py", line 154, in request_blocking
response = self._make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/manager.py", line 133, in _make_request
return request_func(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/middleware/gas_price_strategy.py", line 34, in middleware
return make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/middleware/attrdict.py", line 33, in middleware
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 74, in apply_formatters
response = make_request(method, formatted_params)
File "/venv/lib/python3.7/site-packages/web3/middleware/normalize_errors.py", line 25, in middleware
result = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 83, in apply_formatters
formatter(response["result"]),
File "cytoolz/functoolz.pyx", line 503, in cytoolz.functoolz.Compose.__call__
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/eth_utils/functional.py", line 45, in inner
return callback(fn(*args, **kwargs))
File "/venv/lib/python3.7/site-packages/eth_utils/applicators.py", line 126, in apply_key_map
set(value.keys())
AttributeError: 'NoneType' object has no attribute 'keys'
```
### How can it be fixed?
A simple monkey-patch that works for me:
```
def _geth_poa_middleware():
from web3.middleware.geth_poa import geth_poa_cleanup
from web3.middleware import construct_formatting_middleware
from web3.types import RPCEndpoint
def m(value):
# eth_getBlock* may return None
return None if value is None else geth_poa_cleanup(value)
return construct_formatting_middleware(
result_formatters={
RPCEndpoint("eth_getBlockByHash"): m,
RPCEndpoint("eth_getBlockByNumber"): m,
},
)
```
Could be easily incorporated into `web3.middleware.geth_poa` IMO.
</issue>
<code>
[start of web3/middleware/geth_poa.py]
1 from eth_utils.curried import (
2 apply_formatters_to_dict,
3 apply_key_map,
4 )
5 from eth_utils.toolz import (
6 compose,
7 )
8 from hexbytes import (
9 HexBytes,
10 )
11
12 from web3.middleware.formatting import (
13 construct_formatting_middleware,
14 )
15 from web3.types import (
16 RPCEndpoint,
17 )
18
19 remap_geth_poa_fields = apply_key_map({
20 'extraData': 'proofOfAuthorityData',
21 })
22
23 pythonic_geth_poa = apply_formatters_to_dict({
24 'proofOfAuthorityData': HexBytes,
25 })
26
27 geth_poa_cleanup = compose(pythonic_geth_poa, remap_geth_poa_fields)
28
29 geth_poa_middleware = construct_formatting_middleware(
30 result_formatters={
31 RPCEndpoint("eth_getBlockByHash"): geth_poa_cleanup,
32 RPCEndpoint("eth_getBlockByNumber"): geth_poa_cleanup,
33 },
34 )
35
[end of web3/middleware/geth_poa.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web3/middleware/geth_poa.py b/web3/middleware/geth_poa.py
--- a/web3/middleware/geth_poa.py
+++ b/web3/middleware/geth_poa.py
@@ -1,20 +1,25 @@
from eth_utils.curried import (
+ apply_formatter_if,
apply_formatters_to_dict,
apply_key_map,
+ is_null,
)
from eth_utils.toolz import (
+ complement,
compose,
)
from hexbytes import (
HexBytes,
)
+from web3._utils.rpc_abi import (
+ RPC,
+)
from web3.middleware.formatting import (
construct_formatting_middleware,
)
-from web3.types import (
- RPCEndpoint,
-)
+
+is_not_null = complement(is_null)
remap_geth_poa_fields = apply_key_map({
'extraData': 'proofOfAuthorityData',
@@ -28,7 +33,7 @@
geth_poa_middleware = construct_formatting_middleware(
result_formatters={
- RPCEndpoint("eth_getBlockByHash"): geth_poa_cleanup,
- RPCEndpoint("eth_getBlockByNumber"): geth_poa_cleanup,
+ RPC.eth_getBlockByHash: apply_formatter_if(is_not_null, geth_poa_cleanup),
+ RPC.eth_getBlockByNumber: apply_formatter_if(is_not_null, geth_poa_cleanup),
},
)
|
{"golden_diff": "diff --git a/web3/middleware/geth_poa.py b/web3/middleware/geth_poa.py\n--- a/web3/middleware/geth_poa.py\n+++ b/web3/middleware/geth_poa.py\n@@ -1,20 +1,25 @@\n from eth_utils.curried import (\n+ apply_formatter_if,\n apply_formatters_to_dict,\n apply_key_map,\n+ is_null,\n )\n from eth_utils.toolz import (\n+ complement,\n compose,\n )\n from hexbytes import (\n HexBytes,\n )\n \n+from web3._utils.rpc_abi import (\n+ RPC,\n+)\n from web3.middleware.formatting import (\n construct_formatting_middleware,\n )\n-from web3.types import (\n- RPCEndpoint,\n-)\n+\n+is_not_null = complement(is_null)\n \n remap_geth_poa_fields = apply_key_map({\n 'extraData': 'proofOfAuthorityData',\n@@ -28,7 +33,7 @@\n \n geth_poa_middleware = construct_formatting_middleware(\n result_formatters={\n- RPCEndpoint(\"eth_getBlockByHash\"): geth_poa_cleanup,\n- RPCEndpoint(\"eth_getBlockByNumber\"): geth_poa_cleanup,\n+ RPC.eth_getBlockByHash: apply_formatter_if(is_not_null, geth_poa_cleanup),\n+ RPC.eth_getBlockByNumber: apply_formatter_if(is_not_null, geth_poa_cleanup),\n },\n )\n", "issue": "Bug with `geth_poa_middleware` in the case of non-existing blocks\n* Version: 5.20.1\r\n* Python: 3.7.2\r\n* OS: linux\r\n\r\n`pip freeze` output:\r\n\r\n```\r\naiohttp==3.7.4.post0\r\nasync-timeout==3.0.1\r\nattrs==20.3.0\r\nbase58==2.1.0\r\nbitarray==1.2.2\r\ncertifi==2020.12.5\r\nchardet==4.0.0\r\ncytoolz==0.11.0\r\ndocutils==0.17.1\r\neth-abi==2.1.1\r\neth-account==0.5.4\r\neth-hash==0.3.1\r\neth-keyfile==0.5.1\r\neth-keys==0.3.3\r\neth-rlp==0.2.1\r\neth-typing==2.2.2\r\neth-utils==1.10.0\r\nflock==0.1\r\nhexbytes==0.2.1\r\nidna==2.10\r\nimportlib-metadata==4.0.1\r\nipfshttpclient==0.7.0\r\njsonschema==3.2.0\r\nlockfile==0.12.2\r\nlru-dict==1.1.7\r\nmultiaddr==0.0.9\r\nmultidict==5.1.0\r\nnetaddr==0.8.0\r\nparsimonious==0.8.1\r\nprotobuf==3.15.8\r\npycryptodome==3.10.1\r\npyrsistent==0.17.3\r\npython-daemon==2.3.0\r\nPyYAML==5.4.1\r\nrequests==2.25.1\r\nrlp==2.0.1\r\nsix==1.15.0\r\ntoolz==0.11.1\r\ntyping-extensions==3.7.4.3\r\nurllib3==1.26.4\r\nvarint==1.0.2\r\nweb3==5.20.1\r\nwebsockets==9.1\r\nyarl==1.6.3\r\nzipp==3.4.1\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\nThe poa middleware formatters are applied to block contents even in the case when block is not found and `None` returned instead.\r\n\r\nReproducing:\r\n\r\n```python\r\nfrom eth_typing import URI\r\nfrom web3 import Web3\r\nfrom web3.middleware import geth_poa_middleware\r\nfrom web3.providers.auto import load_provider_from_uri\r\n\r\nw3 = Web3(load_provider_from_uri(URI('wss://rinkeby.infura.io/ws/v3/__project_id_here__'))) # please update the endpoint url\r\nw3.middleware_onion.inject(geth_poa_middleware, layer=0)\r\nprint(w3.eth.get_block(200000000))\r\n```\r\n\r\nExpecting `web3.exceptions.BlockNotFound` to be risen.\r\n\r\nInstead, got:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"./bin/feed-query\", line 85, in <module>\r\n main()\r\n File \"./bin/feed-query\", line 39, in main\r\n print(w3.eth.get_block(200000000))\r\n File \"/venv/lib/python3.7/site-packages/web3/module.py\", line 58, in caller\r\n result = w3.manager.request_blocking(method_str, params, error_formatters)\r\n File \"/venv/lib/python3.7/site-packages/web3/manager.py\", line 154, in request_blocking\r\n response = self._make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/manager.py\", line 133, in _make_request\r\n return request_func(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/gas_price_strategy.py\", line 34, in middleware\r\n return make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/attrdict.py\", line 33, in middleware\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 74, in apply_formatters\r\n response = make_request(method, formatted_params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/normalize_errors.py\", line 25, in middleware\r\n result = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 83, in apply_formatters\r\n formatter(response[\"result\"]),\r\n File \"cytoolz/functoolz.pyx\", line 503, in cytoolz.functoolz.Compose.__call__\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/eth_utils/functional.py\", line 45, in inner\r\n return callback(fn(*args, **kwargs))\r\n File \"/venv/lib/python3.7/site-packages/eth_utils/applicators.py\", line 126, in apply_key_map\r\n set(value.keys())\r\nAttributeError: 'NoneType' object has no attribute 'keys'\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nA simple monkey-patch that works for me:\r\n\r\n```\r\ndef _geth_poa_middleware():\r\n from web3.middleware.geth_poa import geth_poa_cleanup\r\n from web3.middleware import construct_formatting_middleware\r\n from web3.types import RPCEndpoint\r\n\r\n def m(value):\r\n # eth_getBlock* may return None\r\n return None if value is None else geth_poa_cleanup(value)\r\n\r\n return construct_formatting_middleware(\r\n result_formatters={\r\n RPCEndpoint(\"eth_getBlockByHash\"): m,\r\n RPCEndpoint(\"eth_getBlockByNumber\"): m,\r\n },\r\n )\r\n```\r\n\r\nCould be easily incorporated into `web3.middleware.geth_poa` IMO.\r\n\n", "before_files": [{"content": "from eth_utils.curried import (\n apply_formatters_to_dict,\n apply_key_map,\n)\nfrom eth_utils.toolz import (\n compose,\n)\nfrom hexbytes import (\n HexBytes,\n)\n\nfrom web3.middleware.formatting import (\n construct_formatting_middleware,\n)\nfrom web3.types import (\n RPCEndpoint,\n)\n\nremap_geth_poa_fields = apply_key_map({\n 'extraData': 'proofOfAuthorityData',\n})\n\npythonic_geth_poa = apply_formatters_to_dict({\n 'proofOfAuthorityData': HexBytes,\n})\n\ngeth_poa_cleanup = compose(pythonic_geth_poa, remap_geth_poa_fields)\n\ngeth_poa_middleware = construct_formatting_middleware(\n result_formatters={\n RPCEndpoint(\"eth_getBlockByHash\"): geth_poa_cleanup,\n RPCEndpoint(\"eth_getBlockByNumber\"): geth_poa_cleanup,\n },\n)\n", "path": "web3/middleware/geth_poa.py"}]}
| 2,505 | 315 |
gh_patches_debug_26161
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1984
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Setting workers more than 1
If I set `workers=2` when starting KFServer, it always kills the 2nd worker with the following error message
```
Traceback (most recent call last):
File "/usr/lib/python3.8/asyncio/selector_events.py", line 261, in _add_reader
key = self._selector.get_key(fd)
File "/usr/lib/python3.8/selectors.py", line 192, in get_key
raise KeyError("{!r} is not registered".format(fileobj)) from None
KeyError: '6 is not registered'
[I 210811 10:50:57 kfserver:151] Registering model: test
[I 210811 10:50:57 kfserver:121] Setting asyncio max_workers as 12
[I 210811 10:50:57 kfserver:128] Listening on port 8080
[I 210811 10:50:57 kfserver:130] Will fork 2 workers
[I 210811 10:50:57 process:123] Starting 2 processes
[E 210811 10:50:57 __main__:51] fail to load model test from dir /home/swapnesh/test/test_files/. exception type <class 'FileExistsError'>, exception msg: [Errno 17] File exists
[I 210811 10:50:58 process:163] child 1 (pid 5829) exited normally
```
Why can't I set more than 1 worker when max is 12?
</issue>
<code>
[start of python/kserve/kserve/model_server.py]
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import logging
17 from typing import List, Optional, Dict, Union
18 import tornado.ioloop
19 import tornado.web
20 import tornado.httpserver
21 import tornado.log
22 import asyncio
23 from tornado import concurrent
24
25 from .utils import utils
26
27 import kserve.handlers as handlers
28 from kserve import Model
29 from kserve.model_repository import ModelRepository
30 from ray.serve.api import Deployment, RayServeHandle
31 from ray import serve
32
33 DEFAULT_HTTP_PORT = 8080
34 DEFAULT_GRPC_PORT = 8081
35 DEFAULT_MAX_BUFFER_SIZE = 104857600
36
37 parser = argparse.ArgumentParser(add_help=False)
38 parser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,
39 help='The HTTP Port listened to by the model server.')
40 parser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,
41 help='The GRPC Port listened to by the model server.')
42 parser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,
43 help='The max buffer size for tornado.')
44 parser.add_argument('--workers', default=1, type=int,
45 help='The number of works to fork')
46 parser.add_argument('--max_asyncio_workers', default=None, type=int,
47 help='Max number of asyncio workers to spawn')
48
49 args, _ = parser.parse_known_args()
50
51 tornado.log.enable_pretty_logging()
52
53
54 class ModelServer:
55 def __init__(self, http_port: int = args.http_port,
56 grpc_port: int = args.grpc_port,
57 max_buffer_size: int = args.max_buffer_size,
58 workers: int = args.workers,
59 max_asyncio_workers: int = args.max_asyncio_workers,
60 registered_models: ModelRepository = ModelRepository()):
61 self.registered_models = registered_models
62 self.http_port = http_port
63 self.grpc_port = grpc_port
64 self.max_buffer_size = max_buffer_size
65 self.workers = workers
66 self.max_asyncio_workers = max_asyncio_workers
67 self._http_server: Optional[tornado.httpserver.HTTPServer] = None
68
69 def create_application(self):
70 return tornado.web.Application([
71 # Server Liveness API returns 200 if server is alive.
72 (r"/", handlers.LivenessHandler),
73 (r"/v2/health/live", handlers.LivenessHandler),
74 (r"/v1/models",
75 handlers.ListHandler, dict(models=self.registered_models)),
76 (r"/v2/models",
77 handlers.ListHandler, dict(models=self.registered_models)),
78 # Model Health API returns 200 if model is ready to serve.
79 (r"/v1/models/([a-zA-Z0-9_-]+)",
80 handlers.HealthHandler, dict(models=self.registered_models)),
81 (r"/v2/models/([a-zA-Z0-9_-]+)/status",
82 handlers.HealthHandler, dict(models=self.registered_models)),
83 (r"/v1/models/([a-zA-Z0-9_-]+):predict",
84 handlers.PredictHandler, dict(models=self.registered_models)),
85 (r"/v2/models/([a-zA-Z0-9_-]+)/infer",
86 handlers.PredictHandler, dict(models=self.registered_models)),
87 (r"/v1/models/([a-zA-Z0-9_-]+):explain",
88 handlers.ExplainHandler, dict(models=self.registered_models)),
89 (r"/v2/models/([a-zA-Z0-9_-]+)/explain",
90 handlers.ExplainHandler, dict(models=self.registered_models)),
91 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/load",
92 handlers.LoadHandler, dict(models=self.registered_models)),
93 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/unload",
94 handlers.UnloadHandler, dict(models=self.registered_models)),
95 ], default_handler_class=handlers.NotFoundHandler)
96
97 def start(self, models: Union[List[Model], Dict[str, Deployment]], nest_asyncio: bool = False):
98 if isinstance(models, list):
99 for model in models:
100 if isinstance(model, Model):
101 self.register_model(model)
102 else:
103 raise RuntimeError("Model type should be Model")
104 elif isinstance(models, dict):
105 if all([isinstance(v, Deployment) for v in models.values()]):
106 serve.start(detached=True, http_options={"host": "0.0.0.0", "port": 9071})
107 for key in models:
108 models[key].deploy()
109 handle = models[key].get_handle()
110 self.register_model_handle(key, handle)
111 else:
112 raise RuntimeError("Model type should be RayServe Deployment")
113 else:
114 raise RuntimeError("Unknown model collection types")
115
116 if self.max_asyncio_workers is None:
117 # formula as suggest in https://bugs.python.org/issue35279
118 self.max_asyncio_workers = min(32, utils.cpu_count()+4)
119
120 logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
121 asyncio.get_event_loop().set_default_executor(
122 concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
123
124 self._http_server = tornado.httpserver.HTTPServer(
125 self.create_application(), max_buffer_size=self.max_buffer_size)
126
127 logging.info("Listening on port %s", self.http_port)
128 self._http_server.bind(self.http_port)
129 logging.info("Will fork %d workers", self.workers)
130 self._http_server.start(self.workers)
131
132 # Need to start the IOLoop after workers have been started
133 # https://github.com/tornadoweb/tornado/issues/2426
134 # The nest_asyncio package needs to be installed by the downstream module
135 if nest_asyncio:
136 import nest_asyncio
137 nest_asyncio.apply()
138
139 tornado.ioloop.IOLoop.current().start()
140
141 def register_model_handle(self, name: str, model_handle: RayServeHandle):
142 self.registered_models.update_handle(name, model_handle)
143 logging.info("Registering model handle: %s", name)
144
145 def register_model(self, model: Model):
146 if not model.name:
147 raise Exception(
148 "Failed to register model, model.name must be provided.")
149 self.registered_models.update(model)
150 logging.info("Registering model: %s", model.name)
151
[end of python/kserve/kserve/model_server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/kserve/kserve/model_server.py b/python/kserve/kserve/model_server.py
--- a/python/kserve/kserve/model_server.py
+++ b/python/kserve/kserve/model_server.py
@@ -117,10 +117,6 @@
# formula as suggest in https://bugs.python.org/issue35279
self.max_asyncio_workers = min(32, utils.cpu_count()+4)
- logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
- asyncio.get_event_loop().set_default_executor(
- concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
-
self._http_server = tornado.httpserver.HTTPServer(
self.create_application(), max_buffer_size=self.max_buffer_size)
@@ -129,6 +125,10 @@
logging.info("Will fork %d workers", self.workers)
self._http_server.start(self.workers)
+ logging.info(f"Setting max asyncio worker threads as {self.max_asyncio_workers}")
+ asyncio.get_event_loop().set_default_executor(
+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
+
# Need to start the IOLoop after workers have been started
# https://github.com/tornadoweb/tornado/issues/2426
# The nest_asyncio package needs to be installed by the downstream module
|
{"golden_diff": "diff --git a/python/kserve/kserve/model_server.py b/python/kserve/kserve/model_server.py\n--- a/python/kserve/kserve/model_server.py\n+++ b/python/kserve/kserve/model_server.py\n@@ -117,10 +117,6 @@\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n \n- logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n- asyncio.get_event_loop().set_default_executor(\n- concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n-\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n \n@@ -129,6 +125,10 @@\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n \n+ logging.info(f\"Setting max asyncio worker threads as {self.max_asyncio_workers}\")\n+ asyncio.get_event_loop().set_default_executor(\n+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n+\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n", "issue": "Setting workers more than 1\nIf I set `workers=2` when starting KFServer, it always kills the 2nd worker with the following error message\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.8/asyncio/selector_events.py\", line 261, in _add_reader\r\n key = self._selector.get_key(fd)\r\n File \"/usr/lib/python3.8/selectors.py\", line 192, in get_key\r\n raise KeyError(\"{!r} is not registered\".format(fileobj)) from None\r\nKeyError: '6 is not registered'\r\n\r\n[I 210811 10:50:57 kfserver:151] Registering model: test\r\n[I 210811 10:50:57 kfserver:121] Setting asyncio max_workers as 12\r\n[I 210811 10:50:57 kfserver:128] Listening on port 8080\r\n[I 210811 10:50:57 kfserver:130] Will fork 2 workers\r\n[I 210811 10:50:57 process:123] Starting 2 processes\r\n[E 210811 10:50:57 __main__:51] fail to load model test from dir /home/swapnesh/test/test_files/. exception type <class 'FileExistsError'>, exception msg: [Errno 17] File exists\r\n[I 210811 10:50:58 process:163] child 1 (pid 5829) exited normally\r\n```\r\n\r\nWhy can't I set more than 1 worker when max is 12?\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nfrom typing import List, Optional, Dict, Union\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\nimport asyncio\nfrom tornado import concurrent\n\nfrom .utils import utils\n\nimport kserve.handlers as handlers\nfrom kserve import Model\nfrom kserve.model_repository import ModelRepository\nfrom ray.serve.api import Deployment, RayServeHandle\nfrom ray import serve\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nparser.add_argument('--max_asyncio_workers', default=None, type=int,\n help='Max number of asyncio workers to spawn')\n\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass ModelServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: ModelRepository = ModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", handlers.LivenessHandler),\n (r\"/v2/health/live\", handlers.LivenessHandler),\n (r\"/v1/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n handlers.LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n handlers.UnloadHandler, dict(models=self.registered_models)),\n ], default_handler_class=handlers.NotFoundHandler)\n\n def start(self, models: Union[List[Model], Dict[str, Deployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, Model):\n self.register_model(model)\n else:\n raise RuntimeError(\"Model type should be Model\")\n elif isinstance(models, dict):\n if all([isinstance(v, Deployment) for v in models.values()]):\n serve.start(detached=True, http_options={\"host\": \"0.0.0.0\", \"port\": 9071})\n for key in models:\n models[key].deploy()\n handle = models[key].get_handle()\n self.register_model_handle(key, handle)\n else:\n raise RuntimeError(\"Model type should be RayServe Deployment\")\n else:\n raise RuntimeError(\"Unknown model collection types\")\n\n if self.max_asyncio_workers is None:\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n\n logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n asyncio.get_event_loop().set_default_executor(\n concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model_handle(self, name: str, model_handle: RayServeHandle):\n self.registered_models.update_handle(name, model_handle)\n logging.info(\"Registering model handle: %s\", name)\n\n def register_model(self, model: Model):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n", "path": "python/kserve/kserve/model_server.py"}]}
| 2,768 | 306 |
gh_patches_debug_17029
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-3446
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
模型预测出错 TypeError: predict() got an unexpected keyword argument 'auc_roc'
### 问题确认 Search before asking
- [X] 我已经查询[历史issue](https://github.com/PaddlePaddle/PaddleSeg/issues)(包括open与closed),没有发现相似的bug。I have searched the [open and closed issues](https://github.com/PaddlePaddle/PaddleSeg/issues) and found no similar bug report.
### Bug描述 Describe the Bug
我在训练完unet之后,想用模型预测去查看输出的图片
python tools/predict.py \
--config configs/unet/unet_drive_128x128_40k.yml \
--model_path output/drive/best_model/model.pdparams \
--image_path data/DRIVE/images/training/21.png \
--save_dir output/drive/result
然后就报出这个错误。经过查阅,我发现auc_roc在drive.yml里的
test_config:
auc_roc: True
报错文本如下
W0728 08:50:13.112543 40846 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.4, Runtime API Version: 10.2
W0728 08:50:13.112588 40846 gpu_resources.cc:149] device: 0, cuDNN Version: 8.2.
2023-07-28 08:50:15 [INFO] The number of images: 1
Traceback (most recent call last):
File "/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py", line 145, in <module>
main(args)
File "/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py", line 140, in main
**test_config)
TypeError: predict() got an unexpected keyword argument 'auc_roc'
### 复现环境 Environment
platform: Linux-5.4.0-84-generic-x86_64-with-debian-buster-sid
Python: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.2.r11.2/compiler.29558016_0
cudnn: 8.2
GPUs used: 1
CUDA_VISIBLE_DEVICES: 7
GPU: ['GPU 0: Tesla T4', 'GPU 1: Tesla T4', 'GPU 2: Tesla T4', 'GPU 3: Tesla T4', 'GPU 4: Tesla T4', 'GPU 5: Tesla T4', 'GPU 6: Tesla T4', 'GPU 7: Tesla T4']
GCC: gcc (GCC) 8.2.0
PaddleSeg: 2.8.0
PaddlePaddle: 2.5.0
OpenCV: 4.5.5
### Bug描述确认 Bug description confirmation
- [X] 我确认已经提供了Bug复现步骤、代码改动说明、以及环境信息,确认问题是可以复现的。I confirm that the bug replication steps, code change instructions, and environment information have been provided, and the problem can be reproduced.
### 是否愿意提交PR? Are you willing to submit a PR?
- [X] 我愿意提交PR!I'd like to help by submitting a PR!
</issue>
<code>
[start of tools/predict.py]
1 # Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import os
17
18 import paddle
19
20 from paddleseg.cvlibs import manager, Config, SegBuilder
21 from paddleseg.utils import get_sys_env, logger, get_image_list, utils
22 from paddleseg.core import predict
23 from paddleseg.transforms import Compose
24
25
26 def parse_args():
27 parser = argparse.ArgumentParser(description='Model prediction')
28
29 # Common params
30 parser.add_argument("--config", help="The path of config file.", type=str)
31 parser.add_argument(
32 '--model_path',
33 help='The path of trained weights for prediction.',
34 type=str)
35 parser.add_argument(
36 '--image_path',
37 help='The image to predict, which can be a path of image, or a file list containing image paths, or a directory including images',
38 type=str)
39 parser.add_argument(
40 '--save_dir',
41 help='The directory for saving the predicted results.',
42 type=str,
43 default='./output/result')
44 parser.add_argument(
45 '--device',
46 help='Set the device place for predicting model.',
47 default='gpu',
48 choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],
49 type=str)
50 parser.add_argument(
51 '--device_id',
52 help='Set the device id for predicting model.',
53 default=0,
54 type=int)
55
56 # Data augment params
57 parser.add_argument(
58 '--aug_pred',
59 help='Whether to use mulit-scales and flip augment for prediction',
60 action='store_true')
61 parser.add_argument(
62 '--scales',
63 nargs='+',
64 help='Scales for augment, e.g., `--scales 0.75 1.0 1.25`.',
65 type=float,
66 default=1.0)
67 parser.add_argument(
68 '--flip_horizontal',
69 help='Whether to use flip horizontally augment',
70 action='store_true')
71 parser.add_argument(
72 '--flip_vertical',
73 help='Whether to use flip vertically augment',
74 action='store_true')
75
76 # Sliding window evaluation params
77 parser.add_argument(
78 '--is_slide',
79 help='Whether to predict images in sliding window method',
80 action='store_true')
81 parser.add_argument(
82 '--crop_size',
83 nargs=2,
84 help='The crop size of sliding window, the first is width and the second is height.'
85 'For example, `--crop_size 512 512`',
86 type=int)
87 parser.add_argument(
88 '--stride',
89 nargs=2,
90 help='The stride of sliding window, the first is width and the second is height.'
91 'For example, `--stride 512 512`',
92 type=int)
93
94 # Custom color map
95 parser.add_argument(
96 '--custom_color',
97 nargs='+',
98 help='Save images with a custom color map. Default: None, use paddleseg\'s default color map.',
99 type=int)
100
101 return parser.parse_args()
102
103
104 def merge_test_config(cfg, args):
105 test_config = cfg.test_config
106 if 'aug_eval' in test_config:
107 test_config.pop('aug_eval')
108 if args.aug_pred:
109 test_config['aug_pred'] = args.aug_pred
110 test_config['scales'] = args.scales
111 test_config['flip_horizontal'] = args.flip_horizontal
112 test_config['flip_vertical'] = args.flip_vertical
113 if args.is_slide:
114 test_config['is_slide'] = args.is_slide
115 test_config['crop_size'] = args.crop_size
116 test_config['stride'] = args.stride
117 if args.custom_color:
118 test_config['custom_color'] = args.custom_color
119 return test_config
120
121
122 def main(args):
123 assert args.config is not None, \
124 'No configuration file specified, please set --config'
125 cfg = Config(args.config)
126 builder = SegBuilder(cfg)
127 test_config = merge_test_config(cfg, args)
128
129 utils.show_env_info()
130 utils.show_cfg_info(cfg)
131 if args.device != 'cpu':
132 device = f"{args.device}:{args.device_id}"
133 else:
134 device = args.device
135 utils.set_device(device)
136
137 model = builder.model
138 transforms = Compose(builder.val_transforms)
139 image_list, image_dir = get_image_list(args.image_path)
140 logger.info('The number of images: {}'.format(len(image_list)))
141
142 predict(
143 model,
144 model_path=args.model_path,
145 transforms=transforms,
146 image_list=image_list,
147 image_dir=image_dir,
148 save_dir=args.save_dir,
149 **test_config)
150
151
152 if __name__ == '__main__':
153 args = parse_args()
154 main(args)
155
[end of tools/predict.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/predict.py b/tools/predict.py
--- a/tools/predict.py
+++ b/tools/predict.py
@@ -17,10 +17,10 @@
import paddle
-from paddleseg.cvlibs import manager, Config, SegBuilder
-from paddleseg.utils import get_sys_env, logger, get_image_list, utils
from paddleseg.core import predict
+from paddleseg.cvlibs import Config, SegBuilder, manager
from paddleseg.transforms import Compose
+from paddleseg.utils import get_image_list, get_sys_env, logger, utils
def parse_args():
@@ -105,6 +105,8 @@
test_config = cfg.test_config
if 'aug_eval' in test_config:
test_config.pop('aug_eval')
+ if 'auc_roc' in test_config:
+ test_config.pop('auc_roc')
if args.aug_pred:
test_config['aug_pred'] = args.aug_pred
test_config['scales'] = args.scales
|
{"golden_diff": "diff --git a/tools/predict.py b/tools/predict.py\n--- a/tools/predict.py\n+++ b/tools/predict.py\n@@ -17,10 +17,10 @@\n \n import paddle\n \n-from paddleseg.cvlibs import manager, Config, SegBuilder\n-from paddleseg.utils import get_sys_env, logger, get_image_list, utils\n from paddleseg.core import predict\n+from paddleseg.cvlibs import Config, SegBuilder, manager\n from paddleseg.transforms import Compose\n+from paddleseg.utils import get_image_list, get_sys_env, logger, utils\n \n \n def parse_args():\n@@ -105,6 +105,8 @@\n test_config = cfg.test_config\n if 'aug_eval' in test_config:\n test_config.pop('aug_eval')\n+ if 'auc_roc' in test_config:\n+ test_config.pop('auc_roc')\n if args.aug_pred:\n test_config['aug_pred'] = args.aug_pred\n test_config['scales'] = args.scales\n", "issue": "\u6a21\u578b\u9884\u6d4b\u51fa\u9519 TypeError: predict() got an unexpected keyword argument 'auc_roc'\n### \u95ee\u9898\u786e\u8ba4 Search before asking\n\n- [X] \u6211\u5df2\u7ecf\u67e5\u8be2[\u5386\u53f2issue](https://github.com/PaddlePaddle/PaddleSeg/issues)(\u5305\u62ecopen\u4e0eclosed)\uff0c\u6ca1\u6709\u53d1\u73b0\u76f8\u4f3c\u7684bug\u3002I have searched the [open and closed issues](https://github.com/PaddlePaddle/PaddleSeg/issues) and found no similar bug report.\n\n\n### Bug\u63cf\u8ff0 Describe the Bug\n\n\u6211\u5728\u8bad\u7ec3\u5b8cunet\u4e4b\u540e\uff0c\u60f3\u7528\u6a21\u578b\u9884\u6d4b\u53bb\u67e5\u770b\u8f93\u51fa\u7684\u56fe\u7247\r\npython tools/predict.py \\\r\n --config configs/unet/unet_drive_128x128_40k.yml \\\r\n --model_path output/drive/best_model/model.pdparams \\\r\n --image_path data/DRIVE/images/training/21.png \\\r\n --save_dir output/drive/result\r\n\u7136\u540e\u5c31\u62a5\u51fa\u8fd9\u4e2a\u9519\u8bef\u3002\u7ecf\u8fc7\u67e5\u9605\uff0c\u6211\u53d1\u73b0auc_roc\u5728drive.yml\u91cc\u7684\r\ntest_config:\r\n auc_roc: True\r\n\r\n\r\n\u62a5\u9519\u6587\u672c\u5982\u4e0b\r\nW0728 08:50:13.112543 40846 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.4, Runtime API Version: 10.2\r\nW0728 08:50:13.112588 40846 gpu_resources.cc:149] device: 0, cuDNN Version: 8.2.\r\n2023-07-28 08:50:15 [INFO]\tThe number of images: 1\r\nTraceback (most recent call last):\r\n File \"/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py\", line 145, in <module>\r\n main(args)\r\n File \"/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py\", line 140, in main\r\n **test_config)\r\nTypeError: predict() got an unexpected keyword argument 'auc_roc'\n\n### \u590d\u73b0\u73af\u5883 Environment\n\nplatform: Linux-5.4.0-84-generic-x86_64-with-debian-buster-sid\r\nPython: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0]\r\nPaddle compiled with cuda: True\r\nNVCC: Build cuda_11.2.r11.2/compiler.29558016_0\r\ncudnn: 8.2\r\nGPUs used: 1\r\nCUDA_VISIBLE_DEVICES: 7\r\nGPU: ['GPU 0: Tesla T4', 'GPU 1: Tesla T4', 'GPU 2: Tesla T4', 'GPU 3: Tesla T4', 'GPU 4: Tesla T4', 'GPU 5: Tesla T4', 'GPU 6: Tesla T4', 'GPU 7: Tesla T4']\r\nGCC: gcc (GCC) 8.2.0\r\nPaddleSeg: 2.8.0\r\nPaddlePaddle: 2.5.0\r\nOpenCV: 4.5.5\r\n\n\n### Bug\u63cf\u8ff0\u786e\u8ba4 Bug description confirmation\n\n- [X] \u6211\u786e\u8ba4\u5df2\u7ecf\u63d0\u4f9b\u4e86Bug\u590d\u73b0\u6b65\u9aa4\u3001\u4ee3\u7801\u6539\u52a8\u8bf4\u660e\u3001\u4ee5\u53ca\u73af\u5883\u4fe1\u606f\uff0c\u786e\u8ba4\u95ee\u9898\u662f\u53ef\u4ee5\u590d\u73b0\u7684\u3002I confirm that the bug replication steps, code change instructions, and environment information have been provided, and the problem can be reproduced.\n\n\n### \u662f\u5426\u613f\u610f\u63d0\u4ea4PR\uff1f Are you willing to submit a PR?\n\n- [X] \u6211\u613f\u610f\u63d0\u4ea4PR\uff01I'd like to help by submitting a PR!\n", "before_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport os\n\nimport paddle\n\nfrom paddleseg.cvlibs import manager, Config, SegBuilder\nfrom paddleseg.utils import get_sys_env, logger, get_image_list, utils\nfrom paddleseg.core import predict\nfrom paddleseg.transforms import Compose\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Model prediction')\n\n # Common params\n parser.add_argument(\"--config\", help=\"The path of config file.\", type=str)\n parser.add_argument(\n '--model_path',\n help='The path of trained weights for prediction.',\n type=str)\n parser.add_argument(\n '--image_path',\n help='The image to predict, which can be a path of image, or a file list containing image paths, or a directory including images',\n type=str)\n parser.add_argument(\n '--save_dir',\n help='The directory for saving the predicted results.',\n type=str,\n default='./output/result')\n parser.add_argument(\n '--device',\n help='Set the device place for predicting model.',\n default='gpu',\n choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],\n type=str)\n parser.add_argument(\n '--device_id',\n help='Set the device id for predicting model.',\n default=0,\n type=int)\n\n # Data augment params\n parser.add_argument(\n '--aug_pred',\n help='Whether to use mulit-scales and flip augment for prediction',\n action='store_true')\n parser.add_argument(\n '--scales',\n nargs='+',\n help='Scales for augment, e.g., `--scales 0.75 1.0 1.25`.',\n type=float,\n default=1.0)\n parser.add_argument(\n '--flip_horizontal',\n help='Whether to use flip horizontally augment',\n action='store_true')\n parser.add_argument(\n '--flip_vertical',\n help='Whether to use flip vertically augment',\n action='store_true')\n\n # Sliding window evaluation params\n parser.add_argument(\n '--is_slide',\n help='Whether to predict images in sliding window method',\n action='store_true')\n parser.add_argument(\n '--crop_size',\n nargs=2,\n help='The crop size of sliding window, the first is width and the second is height.'\n 'For example, `--crop_size 512 512`',\n type=int)\n parser.add_argument(\n '--stride',\n nargs=2,\n help='The stride of sliding window, the first is width and the second is height.'\n 'For example, `--stride 512 512`',\n type=int)\n\n # Custom color map\n parser.add_argument(\n '--custom_color',\n nargs='+',\n help='Save images with a custom color map. Default: None, use paddleseg\\'s default color map.',\n type=int)\n\n return parser.parse_args()\n\n\ndef merge_test_config(cfg, args):\n test_config = cfg.test_config\n if 'aug_eval' in test_config:\n test_config.pop('aug_eval')\n if args.aug_pred:\n test_config['aug_pred'] = args.aug_pred\n test_config['scales'] = args.scales\n test_config['flip_horizontal'] = args.flip_horizontal\n test_config['flip_vertical'] = args.flip_vertical\n if args.is_slide:\n test_config['is_slide'] = args.is_slide\n test_config['crop_size'] = args.crop_size\n test_config['stride'] = args.stride\n if args.custom_color:\n test_config['custom_color'] = args.custom_color\n return test_config\n\n\ndef main(args):\n assert args.config is not None, \\\n 'No configuration file specified, please set --config'\n cfg = Config(args.config)\n builder = SegBuilder(cfg)\n test_config = merge_test_config(cfg, args)\n\n utils.show_env_info()\n utils.show_cfg_info(cfg)\n if args.device != 'cpu':\n device = f\"{args.device}:{args.device_id}\"\n else:\n device = args.device\n utils.set_device(device)\n\n model = builder.model\n transforms = Compose(builder.val_transforms)\n image_list, image_dir = get_image_list(args.image_path)\n logger.info('The number of images: {}'.format(len(image_list)))\n\n predict(\n model,\n model_path=args.model_path,\n transforms=transforms,\n image_list=image_list,\n image_dir=image_dir,\n save_dir=args.save_dir,\n **test_config)\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "tools/predict.py"}]}
| 2,841 | 222 |
gh_patches_debug_11980
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1659
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update elasticsearch-dsl to 5.1.0
There's a new version of [elasticsearch-dsl](https://pypi.python.org/pypi/elasticsearch-dsl) available.
You are currently using **5.0.0**. I have updated it to **5.1.0**
These links might come in handy: <a href="http://pypi.python.org/pypi/elasticsearch-dsl">PyPI</a> | <a href="https://pyup.io/changelogs/elasticsearch-dsl/">Changelog</a> | <a href="https://github.com/elasticsearch/elasticsearch-dsl-py">Repo</a>
### Changelog
>
>### 5.1.0
>------------------
> * Renamed ``Result`` and ``ResultMeta`` to ``Hit`` and ``HitMeta`` respectively
> * ``Response`` now stores ``Search`` which it gets as first arg to ``__init__``
> * aggregation results are now wrapped in classes and properly deserialized
> * ``Date`` fields now allow for numerical timestamps in the java format (in millis)
> * Added API documentation
> * replaced generated classes with manually created
*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*
Happy merging! 🤖
</issue>
<code>
[start of warehouse/search.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import urllib.parse
14
15 import certifi
16 import elasticsearch
17 import venusian
18
19 from elasticsearch_dsl import Index
20
21
22 def doc_type(cls):
23 def callback(scanner, _name, item):
24 types_ = scanner.config.registry.setdefault("search.doc_types", set())
25 types_.add(item)
26
27 venusian.attach(cls, callback)
28
29 return cls
30
31
32 def get_index(name, doc_types, *, using, shards=1, replicas=0, interval="1s"):
33 index = Index(name, using=using)
34 for doc_type in doc_types:
35 index.doc_type(doc_type)
36 index.settings(
37 number_of_shards=shards,
38 number_of_replicas=replicas,
39 refresh_interval=interval,
40 )
41 return index
42
43
44 def es(request):
45 client = request.registry["elasticsearch.client"]
46 doc_types = request.registry.get("search.doc_types", set())
47 index_name = request.registry["elasticsearch.index"]
48 index = get_index(
49 index_name,
50 doc_types,
51 using=client,
52 shards=request.registry.get("elasticsearch.shards", 1),
53 replicas=request.registry.get("elasticsearch.replicas", 0),
54 )
55 return index.search()
56
57
58 def includeme(config):
59 p = urllib.parse.urlparse(config.registry.settings["elasticsearch.url"])
60 qs = urllib.parse.parse_qs(p.query)
61 config.registry["elasticsearch.client"] = elasticsearch.Elasticsearch(
62 [urllib.parse.urlunparse(p[:2] + ("",) * 4)],
63 verify_certs=True,
64 ca_certs=certifi.where(),
65 timeout=30,
66 retry_on_timeout=True,
67 )
68 config.registry["elasticsearch.index"] = p.path.strip("/")
69 config.registry["elasticsearch.shards"] = int(qs.get("shards", ["1"])[0])
70 config.registry["elasticsearch.replicas"] = \
71 int(qs.get("replicas", ["0"])[0])
72 config.add_request_method(es, name="es", reify=True)
73
[end of warehouse/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/search.py b/warehouse/search.py
--- a/warehouse/search.py
+++ b/warehouse/search.py
@@ -16,7 +16,7 @@
import elasticsearch
import venusian
-from elasticsearch_dsl import Index
+from elasticsearch_dsl import Index, serializer
def doc_type(cls):
@@ -64,6 +64,7 @@
ca_certs=certifi.where(),
timeout=30,
retry_on_timeout=True,
+ serializer=serializer.serializer,
)
config.registry["elasticsearch.index"] = p.path.strip("/")
config.registry["elasticsearch.shards"] = int(qs.get("shards", ["1"])[0])
|
{"golden_diff": "diff --git a/warehouse/search.py b/warehouse/search.py\n--- a/warehouse/search.py\n+++ b/warehouse/search.py\n@@ -16,7 +16,7 @@\n import elasticsearch\n import venusian\n \n-from elasticsearch_dsl import Index\n+from elasticsearch_dsl import Index, serializer\n \n \n def doc_type(cls):\n@@ -64,6 +64,7 @@\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n+ serializer=serializer.serializer,\n )\n config.registry[\"elasticsearch.index\"] = p.path.strip(\"/\")\n config.registry[\"elasticsearch.shards\"] = int(qs.get(\"shards\", [\"1\"])[0])\n", "issue": "Update elasticsearch-dsl to 5.1.0\n\nThere's a new version of [elasticsearch-dsl](https://pypi.python.org/pypi/elasticsearch-dsl) available.\nYou are currently using **5.0.0**. I have updated it to **5.1.0**\n\n\n\nThese links might come in handy: <a href=\"http://pypi.python.org/pypi/elasticsearch-dsl\">PyPI</a> | <a href=\"https://pyup.io/changelogs/elasticsearch-dsl/\">Changelog</a> | <a href=\"https://github.com/elasticsearch/elasticsearch-dsl-py\">Repo</a> \n\n\n\n### Changelog\n> \n>### 5.1.0\n\n>------------------\n> * Renamed ``Result`` and ``ResultMeta`` to ``Hit`` and ``HitMeta`` respectively\n> * ``Response`` now stores ``Search`` which it gets as first arg to ``__init__``\n> * aggregation results are now wrapped in classes and properly deserialized\n> * ``Date`` fields now allow for numerical timestamps in the java format (in millis)\n> * Added API documentation\n> * replaced generated classes with manually created\n\n\n\n\n\n\n\n*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*\n\nHappy merging! \ud83e\udd16\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.parse\n\nimport certifi\nimport elasticsearch\nimport venusian\n\nfrom elasticsearch_dsl import Index\n\n\ndef doc_type(cls):\n def callback(scanner, _name, item):\n types_ = scanner.config.registry.setdefault(\"search.doc_types\", set())\n types_.add(item)\n\n venusian.attach(cls, callback)\n\n return cls\n\n\ndef get_index(name, doc_types, *, using, shards=1, replicas=0, interval=\"1s\"):\n index = Index(name, using=using)\n for doc_type in doc_types:\n index.doc_type(doc_type)\n index.settings(\n number_of_shards=shards,\n number_of_replicas=replicas,\n refresh_interval=interval,\n )\n return index\n\n\ndef es(request):\n client = request.registry[\"elasticsearch.client\"]\n doc_types = request.registry.get(\"search.doc_types\", set())\n index_name = request.registry[\"elasticsearch.index\"]\n index = get_index(\n index_name,\n doc_types,\n using=client,\n shards=request.registry.get(\"elasticsearch.shards\", 1),\n replicas=request.registry.get(\"elasticsearch.replicas\", 0),\n )\n return index.search()\n\n\ndef includeme(config):\n p = urllib.parse.urlparse(config.registry.settings[\"elasticsearch.url\"])\n qs = urllib.parse.parse_qs(p.query)\n config.registry[\"elasticsearch.client\"] = elasticsearch.Elasticsearch(\n [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n verify_certs=True,\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n )\n config.registry[\"elasticsearch.index\"] = p.path.strip(\"/\")\n config.registry[\"elasticsearch.shards\"] = int(qs.get(\"shards\", [\"1\"])[0])\n config.registry[\"elasticsearch.replicas\"] = \\\n int(qs.get(\"replicas\", [\"0\"])[0])\n config.add_request_method(es, name=\"es\", reify=True)\n", "path": "warehouse/search.py"}]}
| 1,502 | 153 |
gh_patches_debug_38640
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-tf-545
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Possible error when training on a finite dataset with multiple GPU
When the total number of batches is not a multiple of the number of replicas (finite dataset), the training can stop with an error because some replicas receive an empty batch.
This error can happen on master, or on v2.2.0 when TensorFlow fails to use batch splitting approach to feed the replicas.
</issue>
<code>
[start of opennmt/training.py]
1 """Training related classes and functions."""
2
3 import collections
4 import os
5 import time
6 import six
7
8 import tensorflow as tf
9
10 from opennmt.data import dataset as dataset_util
11 from opennmt.optimizers import utils as optimizer_util
12 from opennmt.utils import misc
13
14
15 class Trainer(object):
16 """Model trainer."""
17
18 def __init__(self, checkpoint, devices=None, mixed_precision=False):
19 """Initializes the trainer.
20
21 Args:
22 checkpoint: A :class:`opennmt.utils.checkpoint.Checkpoint` instance.
23 devices: List of device strings to use for training.
24 mixed_precision: Whether mixed precision is enabled or not.
25 """
26 if checkpoint.optimizer is None:
27 raise ValueError("No optimizer is defined")
28 if not devices:
29 devices = misc.get_devices(count=1) # Train with 1 device by default.
30 self._checkpoint = checkpoint
31 self._mixed_precision = mixed_precision
32 self._model = checkpoint.model
33 self._optimizer = checkpoint.optimizer
34 self._strategy = tf.distribute.MirroredStrategy(devices=devices)
35 self._summary_writer = tf.summary.create_file_writer(checkpoint.model_dir)
36
37 def __call__(self,
38 dataset,
39 max_step=None,
40 accum_steps=1,
41 report_steps=100,
42 save_steps=5000,
43 evaluator=None,
44 eval_steps=5000,
45 export_on_best=None):
46 """Runs the training.
47
48 Args:
49 dataset: A training dataset.
50 max_step: The final training step.
51 accum_steps: The number of gradient accumulation steps.
52 report_steps: Report status every this many steps.
53 save_steps: Save a checkpoint every this many steps.
54 evaluator: A :class:`opennmt.evaluation.Evaluator` instance to call for
55 evaluation.
56 eval_steps: Evaluate every this many steps.
57 export_on_best: Export a SavedModel when this evaluation metric has the
58 best value so far.
59 """
60 if max_step is not None and self._optimizer.iterations.numpy() >= max_step:
61 tf.get_logger().warning("Model already reached max_step = %d. Exiting.", max_step)
62 return
63 if evaluator is not None and evaluator.should_stop():
64 tf.get_logger().warning("Early stopping conditions are already met. Exiting.")
65 return
66
67 with self._strategy.scope():
68 self._model.create_variables(optimizer=self._optimizer)
69 variables = self._model.trainable_variables
70 base_dataset = dataset
71 # We prefer not to use experimental_distribute_dataset here because it
72 # sometimes fails to split the batches (noticed with tokens batch type).
73 # We also assume for now that we are training with a single worker
74 # otherwise we would need to correctly shard the input dataset.
75 dataset = self._strategy.experimental_distribute_datasets_from_function(
76 lambda _: base_dataset)
77 gradient_accumulator = optimizer_util.GradientAccumulator()
78
79 if self._mixed_precision:
80 optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(
81 self._optimizer, "dynamic")
82 else:
83 optimizer = self._optimizer
84
85 def _accumulate_gradients(source, target):
86 outputs, _ = self._model(
87 source,
88 labels=target,
89 training=True,
90 step=self._optimizer.iterations)
91 loss = self._model.compute_loss(outputs, target, training=True)
92 if isinstance(loss, tuple):
93 training_loss = loss[0] / loss[1]
94 reported_loss = loss[0] / loss[2]
95 else:
96 training_loss, reported_loss = loss, loss
97 training_loss = self._model.regularize_loss(training_loss, variables=variables)
98 gradients = optimizer.get_gradients(training_loss, variables)
99 gradient_accumulator(gradients)
100 tf.summary.scalar("gradients/global_norm", tf.linalg.global_norm(gradients))
101 num_words = {}
102 if "length" in source:
103 num_words["source"] = tf.reduce_sum(source["length"])
104 if "length" in target:
105 num_words["target"] = tf.reduce_sum(target["length"])
106 return reported_loss, num_words
107
108 def _apply_gradients():
109 grads_and_vars = []
110 for gradient, variable in zip(gradient_accumulator.gradients, variables):
111 # optimizer.apply_gradients will sum the gradients accross replicas.
112 scaled_gradient = gradient / (self._strategy.num_replicas_in_sync * accum_steps)
113 grads_and_vars.append((scaled_gradient, variable))
114 optimizer.apply_gradients(grads_and_vars)
115 gradient_accumulator.reset()
116
117 @dataset_util.function_on_next(dataset)
118 def _forward(next_fn):
119 tf.summary.experimental.set_step(self._optimizer.iterations)
120 should_record_summaries = tf.logical_and(
121 tf.equal(self._optimizer.iterations % report_steps, 0),
122 tf.equal(gradient_accumulator.step, 0))
123 with tf.summary.record_if(should_record_summaries):
124 with self._strategy.scope():
125 per_replica_source, per_replica_target = next_fn()
126 per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
127 _accumulate_gradients, args=(per_replica_source, per_replica_target))
128
129 # TODO: these reductions could be delayed until _step is called.
130 loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
131 num_words = {
132 k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
133 for k, v in six.iteritems(per_replica_words)}
134 return loss, num_words
135
136 @tf.function
137 def _step():
138 with self._strategy.scope():
139 self._strategy.experimental_run_v2(_apply_gradients)
140
141 accum_num_words = collections.defaultdict(int)
142 last_report_time = time.time()
143 last_step = 0
144
145 with self._summary_writer.as_default():
146 if self._optimizer.iterations.numpy() == 0:
147 self._checkpoint.save(0)
148 self._model.visualize(self._checkpoint.model_dir)
149
150 for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
151 if tf.math.is_nan(loss):
152 raise RuntimeError("Model diverged with loss = NaN.")
153 if i == 0 or (i + 1) % accum_steps == 0:
154 _step()
155
156 for key, value in six.iteritems(num_words):
157 accum_num_words[key] += value.numpy()
158 step = self._optimizer.iterations.numpy()
159 if step == last_step:
160 continue # Do not process same step twice.
161 last_step = step
162 if step % report_steps == 0:
163 last_report_time = _report_training_status(
164 step,
165 loss,
166 self._optimizer.learning_rate,
167 accum_num_words,
168 last_report_time)
169 if save_steps is not None and step % save_steps == 0:
170 self._checkpoint.save(step)
171 if evaluator is not None and eval_steps is not None and step % eval_steps == 0:
172 self._evaluate(evaluator, step, export_on_best=export_on_best)
173 if evaluator.should_stop():
174 tf.get_logger().warning("Early stopping conditions are met. Exiting.")
175 break
176 if step == max_step:
177 break
178
179 if evaluator is not None and step != evaluator.last_evaluated_step:
180 self._evaluate(evaluator, step, export_on_best=export_on_best)
181 self._checkpoint.save(step)
182
183 def _evaluate(self, evaluator, step, export_on_best=None):
184 metrics = evaluator(step)
185 if export_on_best is not None and evaluator.is_best(export_on_best):
186 export_dir = os.path.join(self._checkpoint.model_dir, "export", str(step))
187 tf.get_logger().info("Exporting SavedModel to %s (best %s so far: %f)",
188 export_dir, export_on_best, metrics[export_on_best])
189 self._model.export(export_dir)
190
191
192 def _report_training_status(step, loss, learning_rate, accum_num_words, last_report_time):
193 tf.summary.experimental.set_step(step)
194 new_report_time = time.time()
195 words_per_sec_fmt = []
196 for key, value in six.iteritems(accum_num_words):
197 avg = int(value / (new_report_time - last_report_time))
198 accum_num_words[key] = 0
199 tf.summary.scalar(
200 "words_per_sec/%s" % key,
201 avg,
202 description="%s words per second" % key.capitalize())
203 fmt = "%s words/s = %d" % (key, avg)
204 words_per_sec_fmt.append(fmt)
205 words_per_sec_fmt = sorted(words_per_sec_fmt)
206 if isinstance(learning_rate, tf.optimizers.schedules.LearningRateSchedule):
207 learning_rate = learning_rate(step)
208 tf.get_logger().info(
209 "Step = %d ; %s ; Learning rate = %f ; Loss = %f",
210 step,
211 ", ".join(words_per_sec_fmt),
212 learning_rate,
213 loss)
214 tf.summary.scalar("loss", loss, description="Training loss")
215 tf.summary.scalar("optim/learning_rate", learning_rate, description="Learning rate")
216 return new_report_time
217
[end of opennmt/training.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opennmt/training.py b/opennmt/training.py
--- a/opennmt/training.py
+++ b/opennmt/training.py
@@ -123,15 +123,40 @@
with tf.summary.record_if(should_record_summaries):
with self._strategy.scope():
per_replica_source, per_replica_target = next_fn()
- per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
- _accumulate_gradients, args=(per_replica_source, per_replica_target))
- # TODO: these reductions could be delayed until _step is called.
- loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
- num_words = {
- k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
- for k, v in six.iteritems(per_replica_words)}
- return loss, num_words
+ def _run():
+ per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
+ _accumulate_gradients, args=(per_replica_source, per_replica_target))
+
+ # TODO: these reductions could be delayed until _step is called.
+ loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
+ num_words = {
+ k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
+ for k, v in six.iteritems(per_replica_words)}
+ return loss, num_words, False
+
+ def _skip():
+ loss = tf.constant(0, dtype=tf.float32)
+ num_words = {}
+ if "length" in per_replica_source:
+ num_words["source"] = tf.constant(0, dtype=tf.int32)
+ if "length" in per_replica_target:
+ num_words["target"] = tf.constant(0, dtype=tf.int32)
+ return loss, num_words, True
+
+ # We verify here that each replica receives a non empty batch. If not,
+ # we skip this iteration. This typically happens at the last iteration
+ # when training on a finite dataset.
+ # TODO: is there a simpler way to handle this case?
+ per_replica_non_empty_batch = self._strategy.experimental_run_v2(
+ lambda tensor: tf.math.count_nonzero(tf.shape(tensor)[0]),
+ args=(tf.nest.flatten(per_replica_source)[0],))
+ non_empty_batch_count = self._strategy.reduce(
+ tf.distribute.ReduceOp.SUM, per_replica_non_empty_batch, None)
+ return tf.cond(
+ tf.math.equal(non_empty_batch_count, self._strategy.num_replicas_in_sync),
+ true_fn=_run,
+ false_fn=_skip)
@tf.function
def _step():
@@ -147,7 +172,12 @@
self._checkpoint.save(0)
self._model.visualize(self._checkpoint.model_dir)
- for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
+ for i, (loss, num_words, skipped) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
+ if skipped:
+ # We assume only the last partial batch can possibly be skipped.
+ tf.get_logger().warning("Batch %d is partial, i.e. some training replicas "
+ "received an empty batch as input. Skipping.", i + 1)
+ break
if tf.math.is_nan(loss):
raise RuntimeError("Model diverged with loss = NaN.")
if i == 0 or (i + 1) % accum_steps == 0:
|
{"golden_diff": "diff --git a/opennmt/training.py b/opennmt/training.py\n--- a/opennmt/training.py\n+++ b/opennmt/training.py\n@@ -123,15 +123,40 @@\n with tf.summary.record_if(should_record_summaries):\n with self._strategy.scope():\n per_replica_source, per_replica_target = next_fn()\n- per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n- _accumulate_gradients, args=(per_replica_source, per_replica_target))\n \n- # TODO: these reductions could be delayed until _step is called.\n- loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n- num_words = {\n- k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n- for k, v in six.iteritems(per_replica_words)}\n- return loss, num_words\n+ def _run():\n+ per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n+ _accumulate_gradients, args=(per_replica_source, per_replica_target))\n+\n+ # TODO: these reductions could be delayed until _step is called.\n+ loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n+ num_words = {\n+ k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n+ for k, v in six.iteritems(per_replica_words)}\n+ return loss, num_words, False\n+\n+ def _skip():\n+ loss = tf.constant(0, dtype=tf.float32)\n+ num_words = {}\n+ if \"length\" in per_replica_source:\n+ num_words[\"source\"] = tf.constant(0, dtype=tf.int32)\n+ if \"length\" in per_replica_target:\n+ num_words[\"target\"] = tf.constant(0, dtype=tf.int32)\n+ return loss, num_words, True\n+\n+ # We verify here that each replica receives a non empty batch. If not,\n+ # we skip this iteration. This typically happens at the last iteration\n+ # when training on a finite dataset.\n+ # TODO: is there a simpler way to handle this case?\n+ per_replica_non_empty_batch = self._strategy.experimental_run_v2(\n+ lambda tensor: tf.math.count_nonzero(tf.shape(tensor)[0]),\n+ args=(tf.nest.flatten(per_replica_source)[0],))\n+ non_empty_batch_count = self._strategy.reduce(\n+ tf.distribute.ReduceOp.SUM, per_replica_non_empty_batch, None)\n+ return tf.cond(\n+ tf.math.equal(non_empty_batch_count, self._strategy.num_replicas_in_sync),\n+ true_fn=_run,\n+ false_fn=_skip)\n \n @tf.function\n def _step():\n@@ -147,7 +172,12 @@\n self._checkpoint.save(0)\n self._model.visualize(self._checkpoint.model_dir)\n \n- for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n+ for i, (loss, num_words, skipped) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n+ if skipped:\n+ # We assume only the last partial batch can possibly be skipped.\n+ tf.get_logger().warning(\"Batch %d is partial, i.e. some training replicas \"\n+ \"received an empty batch as input. Skipping.\", i + 1)\n+ break\n if tf.math.is_nan(loss):\n raise RuntimeError(\"Model diverged with loss = NaN.\")\n if i == 0 or (i + 1) % accum_steps == 0:\n", "issue": "Possible error when training on a finite dataset with multiple GPU\nWhen the total number of batches is not a multiple of the number of replicas (finite dataset), the training can stop with an error because some replicas receive an empty batch.\r\n\r\nThis error can happen on master, or on v2.2.0 when TensorFlow fails to use batch splitting approach to feed the replicas.\n", "before_files": [{"content": "\"\"\"Training related classes and functions.\"\"\"\n\nimport collections\nimport os\nimport time\nimport six\n\nimport tensorflow as tf\n\nfrom opennmt.data import dataset as dataset_util\nfrom opennmt.optimizers import utils as optimizer_util\nfrom opennmt.utils import misc\n\n\nclass Trainer(object):\n \"\"\"Model trainer.\"\"\"\n\n def __init__(self, checkpoint, devices=None, mixed_precision=False):\n \"\"\"Initializes the trainer.\n\n Args:\n checkpoint: A :class:`opennmt.utils.checkpoint.Checkpoint` instance.\n devices: List of device strings to use for training.\n mixed_precision: Whether mixed precision is enabled or not.\n \"\"\"\n if checkpoint.optimizer is None:\n raise ValueError(\"No optimizer is defined\")\n if not devices:\n devices = misc.get_devices(count=1) # Train with 1 device by default.\n self._checkpoint = checkpoint\n self._mixed_precision = mixed_precision\n self._model = checkpoint.model\n self._optimizer = checkpoint.optimizer\n self._strategy = tf.distribute.MirroredStrategy(devices=devices)\n self._summary_writer = tf.summary.create_file_writer(checkpoint.model_dir)\n\n def __call__(self,\n dataset,\n max_step=None,\n accum_steps=1,\n report_steps=100,\n save_steps=5000,\n evaluator=None,\n eval_steps=5000,\n export_on_best=None):\n \"\"\"Runs the training.\n\n Args:\n dataset: A training dataset.\n max_step: The final training step.\n accum_steps: The number of gradient accumulation steps.\n report_steps: Report status every this many steps.\n save_steps: Save a checkpoint every this many steps.\n evaluator: A :class:`opennmt.evaluation.Evaluator` instance to call for\n evaluation.\n eval_steps: Evaluate every this many steps.\n export_on_best: Export a SavedModel when this evaluation metric has the\n best value so far.\n \"\"\"\n if max_step is not None and self._optimizer.iterations.numpy() >= max_step:\n tf.get_logger().warning(\"Model already reached max_step = %d. Exiting.\", max_step)\n return\n if evaluator is not None and evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are already met. Exiting.\")\n return\n\n with self._strategy.scope():\n self._model.create_variables(optimizer=self._optimizer)\n variables = self._model.trainable_variables\n base_dataset = dataset\n # We prefer not to use experimental_distribute_dataset here because it\n # sometimes fails to split the batches (noticed with tokens batch type).\n # We also assume for now that we are training with a single worker\n # otherwise we would need to correctly shard the input dataset.\n dataset = self._strategy.experimental_distribute_datasets_from_function(\n lambda _: base_dataset)\n gradient_accumulator = optimizer_util.GradientAccumulator()\n\n if self._mixed_precision:\n optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(\n self._optimizer, \"dynamic\")\n else:\n optimizer = self._optimizer\n\n def _accumulate_gradients(source, target):\n outputs, _ = self._model(\n source,\n labels=target,\n training=True,\n step=self._optimizer.iterations)\n loss = self._model.compute_loss(outputs, target, training=True)\n if isinstance(loss, tuple):\n training_loss = loss[0] / loss[1]\n reported_loss = loss[0] / loss[2]\n else:\n training_loss, reported_loss = loss, loss\n training_loss = self._model.regularize_loss(training_loss, variables=variables)\n gradients = optimizer.get_gradients(training_loss, variables)\n gradient_accumulator(gradients)\n tf.summary.scalar(\"gradients/global_norm\", tf.linalg.global_norm(gradients))\n num_words = {}\n if \"length\" in source:\n num_words[\"source\"] = tf.reduce_sum(source[\"length\"])\n if \"length\" in target:\n num_words[\"target\"] = tf.reduce_sum(target[\"length\"])\n return reported_loss, num_words\n\n def _apply_gradients():\n grads_and_vars = []\n for gradient, variable in zip(gradient_accumulator.gradients, variables):\n # optimizer.apply_gradients will sum the gradients accross replicas.\n scaled_gradient = gradient / (self._strategy.num_replicas_in_sync * accum_steps)\n grads_and_vars.append((scaled_gradient, variable))\n optimizer.apply_gradients(grads_and_vars)\n gradient_accumulator.reset()\n\n @dataset_util.function_on_next(dataset)\n def _forward(next_fn):\n tf.summary.experimental.set_step(self._optimizer.iterations)\n should_record_summaries = tf.logical_and(\n tf.equal(self._optimizer.iterations % report_steps, 0),\n tf.equal(gradient_accumulator.step, 0))\n with tf.summary.record_if(should_record_summaries):\n with self._strategy.scope():\n per_replica_source, per_replica_target = next_fn()\n per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n _accumulate_gradients, args=(per_replica_source, per_replica_target))\n\n # TODO: these reductions could be delayed until _step is called.\n loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n num_words = {\n k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n for k, v in six.iteritems(per_replica_words)}\n return loss, num_words\n\n @tf.function\n def _step():\n with self._strategy.scope():\n self._strategy.experimental_run_v2(_apply_gradients)\n\n accum_num_words = collections.defaultdict(int)\n last_report_time = time.time()\n last_step = 0\n\n with self._summary_writer.as_default():\n if self._optimizer.iterations.numpy() == 0:\n self._checkpoint.save(0)\n self._model.visualize(self._checkpoint.model_dir)\n\n for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n if tf.math.is_nan(loss):\n raise RuntimeError(\"Model diverged with loss = NaN.\")\n if i == 0 or (i + 1) % accum_steps == 0:\n _step()\n\n for key, value in six.iteritems(num_words):\n accum_num_words[key] += value.numpy()\n step = self._optimizer.iterations.numpy()\n if step == last_step:\n continue # Do not process same step twice.\n last_step = step\n if step % report_steps == 0:\n last_report_time = _report_training_status(\n step,\n loss,\n self._optimizer.learning_rate,\n accum_num_words,\n last_report_time)\n if save_steps is not None and step % save_steps == 0:\n self._checkpoint.save(step)\n if evaluator is not None and eval_steps is not None and step % eval_steps == 0:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n if evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are met. Exiting.\")\n break\n if step == max_step:\n break\n\n if evaluator is not None and step != evaluator.last_evaluated_step:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n self._checkpoint.save(step)\n\n def _evaluate(self, evaluator, step, export_on_best=None):\n metrics = evaluator(step)\n if export_on_best is not None and evaluator.is_best(export_on_best):\n export_dir = os.path.join(self._checkpoint.model_dir, \"export\", str(step))\n tf.get_logger().info(\"Exporting SavedModel to %s (best %s so far: %f)\",\n export_dir, export_on_best, metrics[export_on_best])\n self._model.export(export_dir)\n\n\ndef _report_training_status(step, loss, learning_rate, accum_num_words, last_report_time):\n tf.summary.experimental.set_step(step)\n new_report_time = time.time()\n words_per_sec_fmt = []\n for key, value in six.iteritems(accum_num_words):\n avg = int(value / (new_report_time - last_report_time))\n accum_num_words[key] = 0\n tf.summary.scalar(\n \"words_per_sec/%s\" % key,\n avg,\n description=\"%s words per second\" % key.capitalize())\n fmt = \"%s words/s = %d\" % (key, avg)\n words_per_sec_fmt.append(fmt)\n words_per_sec_fmt = sorted(words_per_sec_fmt)\n if isinstance(learning_rate, tf.optimizers.schedules.LearningRateSchedule):\n learning_rate = learning_rate(step)\n tf.get_logger().info(\n \"Step = %d ; %s ; Learning rate = %f ; Loss = %f\",\n step,\n \", \".join(words_per_sec_fmt),\n learning_rate,\n loss)\n tf.summary.scalar(\"loss\", loss, description=\"Training loss\")\n tf.summary.scalar(\"optim/learning_rate\", learning_rate, description=\"Learning rate\")\n return new_report_time\n", "path": "opennmt/training.py"}]}
| 3,099 | 832 |
gh_patches_debug_638
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2278
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.150
On the docket:
+ [x] Add support for Pip 23.3.1. #2276
+ [x] Support .egg-info dist metadata. #2264
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.149"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.149"
+__version__ = "2.1.150"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.149\"\n+__version__ = \"2.1.150\"\n", "issue": "Release 2.1.150\nOn the docket:\r\n+ [x] Add support for Pip 23.3.1. #2276\r\n+ [x] Support .egg-info dist metadata. #2264\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.149\"\n", "path": "pex/version.py"}]}
| 637 | 98 |
gh_patches_debug_2529
|
rasdani/github-patches
|
git_diff
|
systemd__mkosi-1847
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tput smam breaks build
Using latest on Debian Sid.
```
‣ Running finalize script…
‣ Creating tar archive /home/ander/Desktop/mkosi/tools/mkosi.workspace/.mkosi-tmp9zitpbja/staging/image.tar…
‣ /home/ander/Desktop/mkosi/tools/mkosi.output/image size is 1016.1M, consumes 1016.1M.
‣ "tput smam" returned non-zero exit code 1.
make: *** [Makefile:13: build] Error 1
```
`tput` in Debian do not understand `smam`?
```
$ tput smam; echo $?
1
```
Introduced in e651b88.
Ugly workaround:
```
$ ln -s /usr/bin/true ~/.local/bin/tput
```
</issue>
<code>
[start of mkosi/__main__.py]
1 # SPDX-License-Identifier: LGPL-2.1+
2 # PYTHON_ARGCOMPLETE_OK
3
4 import contextlib
5 import logging
6 import shutil
7 import subprocess
8 import sys
9 from collections.abc import Iterator
10
11 from mkosi import run_verb
12 from mkosi.config import MkosiConfigParser
13 from mkosi.log import ARG_DEBUG, log_setup
14 from mkosi.run import ensure_exc_info, run
15
16
17 @contextlib.contextmanager
18 def propagate_failed_return() -> Iterator[None]:
19 try:
20 yield
21 except SystemExit as e:
22 if ARG_DEBUG.get():
23 sys.excepthook(*ensure_exc_info())
24
25 sys.exit(e.code)
26 except KeyboardInterrupt:
27 if ARG_DEBUG.get():
28 sys.excepthook(*ensure_exc_info())
29 else:
30 logging.error("Interrupted")
31
32 sys.exit(1)
33 except subprocess.CalledProcessError as e:
34 # Failures from qemu, ssh and systemd-nspawn are expected and we won't log stacktraces for those.
35 if ARG_DEBUG.get() and e.cmd and e.cmd[0] not in ("qemu", "ssh", "systemd-nspawn"):
36 sys.excepthook(*ensure_exc_info())
37
38 # We always log when subprocess.CalledProcessError is raised, so we don't log again here.
39 sys.exit(e.returncode)
40
41
42 @propagate_failed_return()
43 def main() -> None:
44 log_setup()
45 args, presets = MkosiConfigParser().parse()
46
47 if ARG_DEBUG.get():
48 logging.getLogger().setLevel(logging.DEBUG)
49
50 try:
51 run_verb(args, presets)
52 finally:
53 if sys.stderr.isatty() and shutil.which("tput"):
54 run(["tput", "cnorm"])
55 run(["tput", "smam"])
56
57
58 if __name__ == "__main__":
59 main()
60
[end of mkosi/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkosi/__main__.py b/mkosi/__main__.py
--- a/mkosi/__main__.py
+++ b/mkosi/__main__.py
@@ -51,8 +51,8 @@
run_verb(args, presets)
finally:
if sys.stderr.isatty() and shutil.which("tput"):
- run(["tput", "cnorm"])
- run(["tput", "smam"])
+ run(["tput", "cnorm"], check=False)
+ run(["tput", "smam"], check=False)
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/mkosi/__main__.py b/mkosi/__main__.py\n--- a/mkosi/__main__.py\n+++ b/mkosi/__main__.py\n@@ -51,8 +51,8 @@\n run_verb(args, presets)\n finally:\n if sys.stderr.isatty() and shutil.which(\"tput\"):\n- run([\"tput\", \"cnorm\"])\n- run([\"tput\", \"smam\"])\n+ run([\"tput\", \"cnorm\"], check=False)\n+ run([\"tput\", \"smam\"], check=False)\n \n \n if __name__ == \"__main__\":\n", "issue": "tput smam breaks build\nUsing latest on Debian Sid.\r\n\r\n```\r\n\u2023 Running finalize script\u2026\r\n\u2023 Creating tar archive /home/ander/Desktop/mkosi/tools/mkosi.workspace/.mkosi-tmp9zitpbja/staging/image.tar\u2026\r\n\u2023 /home/ander/Desktop/mkosi/tools/mkosi.output/image size is 1016.1M, consumes 1016.1M.\r\n\u2023 \"tput smam\" returned non-zero exit code 1.\r\nmake: *** [Makefile:13: build] Error 1\r\n```\r\n\r\n`tput` in Debian do not understand `smam`?\r\n\r\n```\r\n$ tput smam; echo $?\r\n1\r\n```\r\n\r\nIntroduced in e651b88.\r\n\r\nUgly workaround:\r\n```\r\n$ ln -s /usr/bin/true ~/.local/bin/tput\r\n```\n", "before_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\n# PYTHON_ARGCOMPLETE_OK\n\nimport contextlib\nimport logging\nimport shutil\nimport subprocess\nimport sys\nfrom collections.abc import Iterator\n\nfrom mkosi import run_verb\nfrom mkosi.config import MkosiConfigParser\nfrom mkosi.log import ARG_DEBUG, log_setup\nfrom mkosi.run import ensure_exc_info, run\n\n\[email protected]\ndef propagate_failed_return() -> Iterator[None]:\n try:\n yield\n except SystemExit as e:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n\n sys.exit(e.code)\n except KeyboardInterrupt:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n else:\n logging.error(\"Interrupted\")\n\n sys.exit(1)\n except subprocess.CalledProcessError as e:\n # Failures from qemu, ssh and systemd-nspawn are expected and we won't log stacktraces for those.\n if ARG_DEBUG.get() and e.cmd and e.cmd[0] not in (\"qemu\", \"ssh\", \"systemd-nspawn\"):\n sys.excepthook(*ensure_exc_info())\n\n # We always log when subprocess.CalledProcessError is raised, so we don't log again here.\n sys.exit(e.returncode)\n\n\n@propagate_failed_return()\ndef main() -> None:\n log_setup()\n args, presets = MkosiConfigParser().parse()\n\n if ARG_DEBUG.get():\n logging.getLogger().setLevel(logging.DEBUG)\n\n try:\n run_verb(args, presets)\n finally:\n if sys.stderr.isatty() and shutil.which(\"tput\"):\n run([\"tput\", \"cnorm\"])\n run([\"tput\", \"smam\"])\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mkosi/__main__.py"}]}
| 1,225 | 136 |
gh_patches_debug_24881
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-228
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug Report: six should be a required install for pyhf
# Description
While looking at Issue #223 I tried to reproduce it in the [python:3.6.6 Docker image](https://hub.docker.com/_/python/). However, after installing pyhf from PyPI and trying to run the example @lukasheinrich made in #223
```
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
# Expected Behavior
The example should work from any install of pyhf
# Actual Behavior
I came across a new error:
```python-traceback
Traceback (most recent call last):
File "/usr/local/bin/pyhf", line 7, in <module>
from pyhf.commandline import pyhf
File "/usr/local/lib/python3.6/site-packages/pyhf/__init__.py", line 55, in <module>
from .pdf import Model
File "/usr/local/lib/python3.6/site-packages/pyhf/pdf.py", line 7, in <module>
from . import modifiers
File "/usr/local/lib/python3.6/site-packages/pyhf/modifiers/__init__.py", line 1, in <module>
from six import string_types
ModuleNotFoundError: No module named 'six'
```
As the traceback tells us, `six` is not a [required installation library](https://github.com/diana-hep/pyhf/blob/master/setup.py#L11-L15) for pyhf at the moment, yet is [used in `modifiers`](https://github.com/diana-hep/pyhf/blob/master/pyhf/modifiers/__init__.py#L1).
# Steps to Reproduce
```
docker pull python:3.6.6
docker run --rm -it python:3.6.6 /bin/bash
cd root
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
If one then does
```
pip install six
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
then the error in Issue #223 is recovered.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
Bug Repot: basic functionality not working in non-develop pip installs
# Description
`jsonschema` is always imported in pdf.py so it must be a hard dependency unless we choose to make validation optional
# Expected Behavior
this should work for any install of `pyhf`
```
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
# Actual Behavior
```
ImportError: No module named jsonschema
```
# Steps to Reproduce
install pyhf without any extras -- run above example
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 setup(
3 name = 'pyhf',
4 version = '0.0.15',
5 description = '(partial) pure python histfactory implementation',
6 url = '',
7 author = 'Lukas Heinrich',
8 author_email = '[email protected]',
9 packages = find_packages(),
10 include_package_data = True,
11 install_requires = [
12 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us
13 'scipy',
14 'click>=6.0', # for console scripts,
15 'tqdm', # for readxml
16 ],
17 extras_require = {
18 'xmlimport': [
19 'uproot',
20 ],
21 'torch': [
22 'torch>=0.4.0'
23 ],
24 'mxnet':[
25 'mxnet>=1.0.0',
26 'requests<2.19.0,>=2.18.4',
27 'numpy<1.15.0,>=1.8.2',
28 'requests<2.19.0,>=2.18.4',
29 ],
30 'tensorflow':[
31 'tensorflow==1.10.0',
32 'numpy<=1.14.5,>=1.13.3',
33 'setuptools<=39.1.0',
34 ],
35 'develop': [
36 'pyflakes',
37 'pytest>=3.5.1',
38 'pytest-cov>=2.5.1',
39 'pytest-benchmark[histogram]',
40 'pytest-console-scripts',
41 'python-coveralls',
42 'coverage==4.0.3', # coveralls
43 'matplotlib',
44 'jupyter',
45 'uproot',
46 'papermill',
47 'graphviz',
48 'sphinx',
49 'sphinxcontrib-bibtex',
50 'sphinxcontrib-napoleon',
51 'sphinx_rtd_theme',
52 'nbsphinx',
53 'jsonpatch',
54 'jsonschema==v3.0.0a2' # alpha-release for draft 6
55 ]
56 },
57 entry_points = {
58 'console_scripts': ['pyhf=pyhf.commandline:pyhf']
59 },
60 dependency_links = [
61 ]
62 )
63
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -13,6 +13,8 @@
'scipy',
'click>=6.0', # for console scripts,
'tqdm', # for readxml
+ 'six', # for modifiers
+ 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
],
extras_require = {
'xmlimport': [
@@ -28,7 +30,7 @@
'requests<2.19.0,>=2.18.4',
],
'tensorflow':[
- 'tensorflow==1.10.0',
+ 'tensorflow>=1.10.0',
'numpy<=1.14.5,>=1.13.3',
'setuptools<=39.1.0',
],
@@ -39,7 +41,7 @@
'pytest-benchmark[histogram]',
'pytest-console-scripts',
'python-coveralls',
- 'coverage==4.0.3', # coveralls
+ 'coverage>=4.0', # coveralls
'matplotlib',
'jupyter',
'uproot',
@@ -50,8 +52,7 @@
'sphinxcontrib-napoleon',
'sphinx_rtd_theme',
'nbsphinx',
- 'jsonpatch',
- 'jsonschema==v3.0.0a2' # alpha-release for draft 6
+ 'jsonpatch'
]
},
entry_points = {
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -13,6 +13,8 @@\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n+ 'six', # for modifiers\n+ 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n ],\n extras_require = {\n 'xmlimport': [\n@@ -28,7 +30,7 @@\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n- 'tensorflow==1.10.0',\n+ 'tensorflow>=1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n@@ -39,7 +41,7 @@\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n- 'coverage==4.0.3', # coveralls\n+ 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n@@ -50,8 +52,7 @@\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n- 'jsonpatch',\n- 'jsonschema==v3.0.0a2' # alpha-release for draft 6\n+ 'jsonpatch'\n ]\n },\n entry_points = {\n", "issue": "Bug Report: six should be a required install for pyhf\n# Description\r\n\r\nWhile looking at Issue #223 I tried to reproduce it in the [python:3.6.6 Docker image](https://hub.docker.com/_/python/). However, after installing pyhf from PyPI and trying to run the example @lukasheinrich made in #223 \r\n```\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\n# Expected Behavior\r\n\r\nThe example should work from any install of pyhf\r\n\r\n# Actual Behavior\r\n\r\nI came across a new error:\r\n\r\n```python-traceback\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/pyhf\", line 7, in <module>\r\n from pyhf.commandline import pyhf\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/__init__.py\", line 55, in <module>\r\n from .pdf import Model\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/pdf.py\", line 7, in <module>\r\n from . import modifiers\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/modifiers/__init__.py\", line 1, in <module>\r\n from six import string_types\r\nModuleNotFoundError: No module named 'six'\r\n```\r\n\r\nAs the traceback tells us, `six` is not a [required installation library](https://github.com/diana-hep/pyhf/blob/master/setup.py#L11-L15) for pyhf at the moment, yet is [used in `modifiers`](https://github.com/diana-hep/pyhf/blob/master/pyhf/modifiers/__init__.py#L1).\r\n\r\n# Steps to Reproduce\r\n\r\n```\r\ndocker pull python:3.6.6\r\ndocker run --rm -it python:3.6.6 /bin/bash\r\ncd root\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\nIf one then does\r\n```\r\npip install six\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\nthen the error in Issue #223 is recovered.\r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\nBug Repot: basic functionality not working in non-develop pip installs \n# Description\r\n\r\n`jsonschema` is always imported in pdf.py so it must be a hard dependency unless we choose to make validation optional\r\n\r\n\r\n# Expected Behavior\r\n\r\nthis should work for any install of `pyhf`\r\n```\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n# Actual Behavior\r\n\r\n```\r\nImportError: No module named jsonschema\r\n```\r\n\r\n# Steps to Reproduce\r\n\r\ninstall pyhf without any extras -- run above example\r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nsetup(\n name = 'pyhf',\n version = '0.0.15',\n description = '(partial) pure python histfactory implementation',\n url = '',\n author = 'Lukas Heinrich',\n author_email = '[email protected]',\n packages = find_packages(),\n include_package_data = True,\n install_requires = [\n 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n ],\n extras_require = {\n 'xmlimport': [\n 'uproot',\n ],\n 'torch': [\n 'torch>=0.4.0'\n ],\n 'mxnet':[\n 'mxnet>=1.0.0',\n 'requests<2.19.0,>=2.18.4',\n 'numpy<1.15.0,>=1.8.2',\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n 'tensorflow==1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n 'develop': [\n 'pyflakes',\n 'pytest>=3.5.1',\n 'pytest-cov>=2.5.1',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage==4.0.3', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n 'papermill',\n 'graphviz',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'jsonpatch',\n 'jsonschema==v3.0.0a2' # alpha-release for draft 6\n ]\n },\n entry_points = {\n 'console_scripts': ['pyhf=pyhf.commandline:pyhf']\n },\n dependency_links = [\n ]\n)\n", "path": "setup.py"}]}
| 2,440 | 365 |
gh_patches_debug_9951
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-2574
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BootStrapper.reset() does not reset properly
## 🐛 Bug
Calling `BootStrapper.reset()` does not reset `self.metrics` properly.
### To Reproduce
```py
import torch
from torchmetrics.wrappers import BootStrapper
from torchmetrics.classification import MulticlassAccuracy
metric = BootStrapper(MulticlassAccuracy(num_classes=10))
for i in range(10):
output = torch.randn((2000, 10))
target = torch.randint(10, (2000,))
# output = 0.5 * (target + output)
metric.update(output, target)
print(metric.compute())
# {'mean': tensor(0.0990), 'std': tensor(0.0029)} <-- ok
print(metric.metrics[0].update_count)
# 10 <-- ok
metric.reset()
print(metric.compute())
# {'mean': tensor(0.0990), 'std': tensor(0.0029)} <-- ERROR, should be undefined after reset
print(metric.metrics[0].update_count)
# 10 <-- ERROR, should be 0 after reset
```
### Environment
- TorchMetrics version 1.4.0.post0
- Python version 3.11.9
- torch version 2.2.1+cu118
</issue>
<code>
[start of src/torchmetrics/wrappers/bootstrapping.py]
1 # Copyright The Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from copy import deepcopy
15 from typing import Any, Dict, Optional, Sequence, Union
16
17 import torch
18 from lightning_utilities import apply_to_collection
19 from torch import Tensor
20 from torch.nn import ModuleList
21
22 from torchmetrics.metric import Metric
23 from torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE
24 from torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE
25 from torchmetrics.wrappers.abstract import WrapperMetric
26
27 if not _MATPLOTLIB_AVAILABLE:
28 __doctest_skip__ = ["BootStrapper.plot"]
29
30
31 def _bootstrap_sampler(
32 size: int,
33 sampling_strategy: str = "poisson",
34 ) -> Tensor:
35 """Resample a tensor along its first dimension with replacement.
36
37 Args:
38 size: number of samples
39 sampling_strategy: the strategy to use for sampling, either ``'poisson'`` or ``'multinomial'``
40
41 Returns:
42 resampled tensor
43
44 """
45 if sampling_strategy == "poisson":
46 p = torch.distributions.Poisson(1)
47 n = p.sample((size,))
48 return torch.arange(size).repeat_interleave(n.long(), dim=0)
49 if sampling_strategy == "multinomial":
50 return torch.multinomial(torch.ones(size), num_samples=size, replacement=True)
51 raise ValueError("Unknown sampling strategy")
52
53
54 class BootStrapper(WrapperMetric):
55 r"""Using `Turn a Metric into a Bootstrapped`_.
56
57 That can automate the process of getting confidence intervals for metric values. This wrapper
58 class basically keeps multiple copies of the same base metric in memory and whenever ``update`` or
59 ``forward`` is called, all input tensors are resampled (with replacement) along the first dimension.
60
61 Args:
62 base_metric: base metric class to wrap
63 num_bootstraps: number of copies to make of the base metric for bootstrapping
64 mean: if ``True`` return the mean of the bootstraps
65 std: if ``True`` return the standard deviation of the bootstraps
66 quantile: if given, returns the quantile of the bootstraps. Can only be used with pytorch version 1.6 or higher
67 raw: if ``True``, return all bootstrapped values
68 sampling_strategy:
69 Determines how to produce bootstrapped samplings. Either ``'poisson'`` or ``multinomial``.
70 If ``'possion'`` is chosen, the number of times each sample will be included in the bootstrap
71 will be given by :math:`n\sim Poisson(\lambda=1)`, which approximates the true bootstrap distribution
72 when the number of samples is large. If ``'multinomial'`` is chosen, we will apply true bootstrapping
73 at the batch level to approximate bootstrapping over the hole dataset.
74 kwargs: Additional keyword arguments, see :ref:`Metric kwargs` for more info.
75
76 Example::
77 >>> from pprint import pprint
78 >>> from torchmetrics.wrappers import BootStrapper
79 >>> from torchmetrics.classification import MulticlassAccuracy
80 >>> _ = torch.manual_seed(123)
81 >>> base_metric = MulticlassAccuracy(num_classes=5, average='micro')
82 >>> bootstrap = BootStrapper(base_metric, num_bootstraps=20)
83 >>> bootstrap.update(torch.randint(5, (20,)), torch.randint(5, (20,)))
84 >>> output = bootstrap.compute()
85 >>> pprint(output)
86 {'mean': tensor(0.2205), 'std': tensor(0.0859)}
87
88 """
89
90 full_state_update: Optional[bool] = True
91
92 def __init__(
93 self,
94 base_metric: Metric,
95 num_bootstraps: int = 10,
96 mean: bool = True,
97 std: bool = True,
98 quantile: Optional[Union[float, Tensor]] = None,
99 raw: bool = False,
100 sampling_strategy: str = "poisson",
101 **kwargs: Any,
102 ) -> None:
103 super().__init__(**kwargs)
104 if not isinstance(base_metric, Metric):
105 raise ValueError(
106 f"Expected base metric to be an instance of torchmetrics.Metric but received {base_metric}"
107 )
108
109 self.metrics = ModuleList([deepcopy(base_metric) for _ in range(num_bootstraps)])
110 self.num_bootstraps = num_bootstraps
111
112 self.mean = mean
113 self.std = std
114 self.quantile = quantile
115 self.raw = raw
116
117 allowed_sampling = ("poisson", "multinomial")
118 if sampling_strategy not in allowed_sampling:
119 raise ValueError(
120 f"Expected argument ``sampling_strategy`` to be one of {allowed_sampling}"
121 f" but received {sampling_strategy}"
122 )
123 self.sampling_strategy = sampling_strategy
124
125 def update(self, *args: Any, **kwargs: Any) -> None:
126 """Update the state of the base metric.
127
128 Any tensor passed in will be bootstrapped along dimension 0.
129
130 """
131 args_sizes = apply_to_collection(args, Tensor, len)
132 kwargs_sizes = apply_to_collection(kwargs, Tensor, len)
133 if len(args_sizes) > 0:
134 size = args_sizes[0]
135 elif len(kwargs_sizes) > 0:
136 size = next(iter(kwargs_sizes.values()))
137 else:
138 raise ValueError("None of the input contained tensors, so could not determine the sampling size")
139
140 for idx in range(self.num_bootstraps):
141 sample_idx = _bootstrap_sampler(size, sampling_strategy=self.sampling_strategy).to(self.device)
142 if sample_idx.numel() == 0:
143 continue
144 new_args = apply_to_collection(args, Tensor, torch.index_select, dim=0, index=sample_idx)
145 new_kwargs = apply_to_collection(kwargs, Tensor, torch.index_select, dim=0, index=sample_idx)
146 self.metrics[idx].update(*new_args, **new_kwargs)
147
148 def compute(self) -> Dict[str, Tensor]:
149 """Compute the bootstrapped metric values.
150
151 Always returns a dict of tensors, which can contain the following keys: ``mean``, ``std``, ``quantile`` and
152 ``raw`` depending on how the class was initialized.
153
154 """
155 computed_vals = torch.stack([m.compute() for m in self.metrics], dim=0)
156 output_dict = {}
157 if self.mean:
158 output_dict["mean"] = computed_vals.mean(dim=0)
159 if self.std:
160 output_dict["std"] = computed_vals.std(dim=0)
161 if self.quantile is not None:
162 output_dict["quantile"] = torch.quantile(computed_vals, self.quantile)
163 if self.raw:
164 output_dict["raw"] = computed_vals
165 return output_dict
166
167 def forward(self, *args: Any, **kwargs: Any) -> Any:
168 """Use the original forward method of the base metric class."""
169 return super(WrapperMetric, self).forward(*args, **kwargs)
170
171 def plot(
172 self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None
173 ) -> _PLOT_OUT_TYPE:
174 """Plot a single or multiple values from the metric.
175
176 Args:
177 val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.
178 If no value is provided, will automatically call `metric.compute` and plot that result.
179 ax: An matplotlib axis object. If provided will add plot to that axis
180
181 Returns:
182 Figure and Axes object
183
184 Raises:
185 ModuleNotFoundError:
186 If `matplotlib` is not installed
187
188 .. plot::
189 :scale: 75
190
191 >>> # Example plotting a single value
192 >>> import torch
193 >>> from torchmetrics.wrappers import BootStrapper
194 >>> from torchmetrics.regression import MeanSquaredError
195 >>> metric = BootStrapper(MeanSquaredError(), num_bootstraps=20)
196 >>> metric.update(torch.randn(100,), torch.randn(100,))
197 >>> fig_, ax_ = metric.plot()
198
199 .. plot::
200 :scale: 75
201
202 >>> # Example plotting multiple values
203 >>> import torch
204 >>> from torchmetrics.wrappers import BootStrapper
205 >>> from torchmetrics.regression import MeanSquaredError
206 >>> metric = BootStrapper(MeanSquaredError(), num_bootstraps=20)
207 >>> values = [ ]
208 >>> for _ in range(3):
209 ... values.append(metric(torch.randn(100,), torch.randn(100,)))
210 >>> fig_, ax_ = metric.plot(values)
211
212 """
213 return self._plot(val, ax)
214
[end of src/torchmetrics/wrappers/bootstrapping.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/torchmetrics/wrappers/bootstrapping.py b/src/torchmetrics/wrappers/bootstrapping.py
--- a/src/torchmetrics/wrappers/bootstrapping.py
+++ b/src/torchmetrics/wrappers/bootstrapping.py
@@ -168,6 +168,12 @@
"""Use the original forward method of the base metric class."""
return super(WrapperMetric, self).forward(*args, **kwargs)
+ def reset(self) -> None:
+ """Reset the state of the base metric."""
+ for m in self.metrics:
+ m.reset()
+ super().reset()
+
def plot(
self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None
) -> _PLOT_OUT_TYPE:
|
{"golden_diff": "diff --git a/src/torchmetrics/wrappers/bootstrapping.py b/src/torchmetrics/wrappers/bootstrapping.py\n--- a/src/torchmetrics/wrappers/bootstrapping.py\n+++ b/src/torchmetrics/wrappers/bootstrapping.py\n@@ -168,6 +168,12 @@\n \"\"\"Use the original forward method of the base metric class.\"\"\"\n return super(WrapperMetric, self).forward(*args, **kwargs)\n \n+ def reset(self) -> None:\n+ \"\"\"Reset the state of the base metric.\"\"\"\n+ for m in self.metrics:\n+ m.reset()\n+ super().reset()\n+\n def plot(\n self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None\n ) -> _PLOT_OUT_TYPE:\n", "issue": "BootStrapper.reset() does not reset properly\n## \ud83d\udc1b Bug\r\n\r\nCalling `BootStrapper.reset()` does not reset `self.metrics` properly.\r\n\r\n### To Reproduce\r\n\r\n```py\r\nimport torch\r\nfrom torchmetrics.wrappers import BootStrapper\r\nfrom torchmetrics.classification import MulticlassAccuracy\r\n\r\nmetric = BootStrapper(MulticlassAccuracy(num_classes=10))\r\n\r\nfor i in range(10):\r\n output = torch.randn((2000, 10))\r\n target = torch.randint(10, (2000,))\r\n # output = 0.5 * (target + output)\r\n metric.update(output, target)\r\n\r\nprint(metric.compute())\r\n# {'mean': tensor(0.0990), 'std': tensor(0.0029)} <-- ok\r\nprint(metric.metrics[0].update_count)\r\n# 10 <-- ok\r\n\r\nmetric.reset()\r\n\r\nprint(metric.compute())\r\n# {'mean': tensor(0.0990), 'std': tensor(0.0029)} <-- ERROR, should be undefined after reset\r\nprint(metric.metrics[0].update_count)\r\n# 10 <-- ERROR, should be 0 after reset\r\n\r\n```\r\n\r\n### Environment\r\n\r\n- TorchMetrics version 1.4.0.post0\r\n- Python version 3.11.9\r\n- torch version 2.2.1+cu118\r\n\n", "before_files": [{"content": "# Copyright The Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom copy import deepcopy\nfrom typing import Any, Dict, Optional, Sequence, Union\n\nimport torch\nfrom lightning_utilities import apply_to_collection\nfrom torch import Tensor\nfrom torch.nn import ModuleList\n\nfrom torchmetrics.metric import Metric\nfrom torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE\nfrom torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE\nfrom torchmetrics.wrappers.abstract import WrapperMetric\n\nif not _MATPLOTLIB_AVAILABLE:\n __doctest_skip__ = [\"BootStrapper.plot\"]\n\n\ndef _bootstrap_sampler(\n size: int,\n sampling_strategy: str = \"poisson\",\n) -> Tensor:\n \"\"\"Resample a tensor along its first dimension with replacement.\n\n Args:\n size: number of samples\n sampling_strategy: the strategy to use for sampling, either ``'poisson'`` or ``'multinomial'``\n\n Returns:\n resampled tensor\n\n \"\"\"\n if sampling_strategy == \"poisson\":\n p = torch.distributions.Poisson(1)\n n = p.sample((size,))\n return torch.arange(size).repeat_interleave(n.long(), dim=0)\n if sampling_strategy == \"multinomial\":\n return torch.multinomial(torch.ones(size), num_samples=size, replacement=True)\n raise ValueError(\"Unknown sampling strategy\")\n\n\nclass BootStrapper(WrapperMetric):\n r\"\"\"Using `Turn a Metric into a Bootstrapped`_.\n\n That can automate the process of getting confidence intervals for metric values. This wrapper\n class basically keeps multiple copies of the same base metric in memory and whenever ``update`` or\n ``forward`` is called, all input tensors are resampled (with replacement) along the first dimension.\n\n Args:\n base_metric: base metric class to wrap\n num_bootstraps: number of copies to make of the base metric for bootstrapping\n mean: if ``True`` return the mean of the bootstraps\n std: if ``True`` return the standard deviation of the bootstraps\n quantile: if given, returns the quantile of the bootstraps. Can only be used with pytorch version 1.6 or higher\n raw: if ``True``, return all bootstrapped values\n sampling_strategy:\n Determines how to produce bootstrapped samplings. Either ``'poisson'`` or ``multinomial``.\n If ``'possion'`` is chosen, the number of times each sample will be included in the bootstrap\n will be given by :math:`n\\sim Poisson(\\lambda=1)`, which approximates the true bootstrap distribution\n when the number of samples is large. If ``'multinomial'`` is chosen, we will apply true bootstrapping\n at the batch level to approximate bootstrapping over the hole dataset.\n kwargs: Additional keyword arguments, see :ref:`Metric kwargs` for more info.\n\n Example::\n >>> from pprint import pprint\n >>> from torchmetrics.wrappers import BootStrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> _ = torch.manual_seed(123)\n >>> base_metric = MulticlassAccuracy(num_classes=5, average='micro')\n >>> bootstrap = BootStrapper(base_metric, num_bootstraps=20)\n >>> bootstrap.update(torch.randint(5, (20,)), torch.randint(5, (20,)))\n >>> output = bootstrap.compute()\n >>> pprint(output)\n {'mean': tensor(0.2205), 'std': tensor(0.0859)}\n\n \"\"\"\n\n full_state_update: Optional[bool] = True\n\n def __init__(\n self,\n base_metric: Metric,\n num_bootstraps: int = 10,\n mean: bool = True,\n std: bool = True,\n quantile: Optional[Union[float, Tensor]] = None,\n raw: bool = False,\n sampling_strategy: str = \"poisson\",\n **kwargs: Any,\n ) -> None:\n super().__init__(**kwargs)\n if not isinstance(base_metric, Metric):\n raise ValueError(\n f\"Expected base metric to be an instance of torchmetrics.Metric but received {base_metric}\"\n )\n\n self.metrics = ModuleList([deepcopy(base_metric) for _ in range(num_bootstraps)])\n self.num_bootstraps = num_bootstraps\n\n self.mean = mean\n self.std = std\n self.quantile = quantile\n self.raw = raw\n\n allowed_sampling = (\"poisson\", \"multinomial\")\n if sampling_strategy not in allowed_sampling:\n raise ValueError(\n f\"Expected argument ``sampling_strategy`` to be one of {allowed_sampling}\"\n f\" but received {sampling_strategy}\"\n )\n self.sampling_strategy = sampling_strategy\n\n def update(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Update the state of the base metric.\n\n Any tensor passed in will be bootstrapped along dimension 0.\n\n \"\"\"\n args_sizes = apply_to_collection(args, Tensor, len)\n kwargs_sizes = apply_to_collection(kwargs, Tensor, len)\n if len(args_sizes) > 0:\n size = args_sizes[0]\n elif len(kwargs_sizes) > 0:\n size = next(iter(kwargs_sizes.values()))\n else:\n raise ValueError(\"None of the input contained tensors, so could not determine the sampling size\")\n\n for idx in range(self.num_bootstraps):\n sample_idx = _bootstrap_sampler(size, sampling_strategy=self.sampling_strategy).to(self.device)\n if sample_idx.numel() == 0:\n continue\n new_args = apply_to_collection(args, Tensor, torch.index_select, dim=0, index=sample_idx)\n new_kwargs = apply_to_collection(kwargs, Tensor, torch.index_select, dim=0, index=sample_idx)\n self.metrics[idx].update(*new_args, **new_kwargs)\n\n def compute(self) -> Dict[str, Tensor]:\n \"\"\"Compute the bootstrapped metric values.\n\n Always returns a dict of tensors, which can contain the following keys: ``mean``, ``std``, ``quantile`` and\n ``raw`` depending on how the class was initialized.\n\n \"\"\"\n computed_vals = torch.stack([m.compute() for m in self.metrics], dim=0)\n output_dict = {}\n if self.mean:\n output_dict[\"mean\"] = computed_vals.mean(dim=0)\n if self.std:\n output_dict[\"std\"] = computed_vals.std(dim=0)\n if self.quantile is not None:\n output_dict[\"quantile\"] = torch.quantile(computed_vals, self.quantile)\n if self.raw:\n output_dict[\"raw\"] = computed_vals\n return output_dict\n\n def forward(self, *args: Any, **kwargs: Any) -> Any:\n \"\"\"Use the original forward method of the base metric class.\"\"\"\n return super(WrapperMetric, self).forward(*args, **kwargs)\n\n def plot(\n self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None\n ) -> _PLOT_OUT_TYPE:\n \"\"\"Plot a single or multiple values from the metric.\n\n Args:\n val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.\n If no value is provided, will automatically call `metric.compute` and plot that result.\n ax: An matplotlib axis object. If provided will add plot to that axis\n\n Returns:\n Figure and Axes object\n\n Raises:\n ModuleNotFoundError:\n If `matplotlib` is not installed\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting a single value\n >>> import torch\n >>> from torchmetrics.wrappers import BootStrapper\n >>> from torchmetrics.regression import MeanSquaredError\n >>> metric = BootStrapper(MeanSquaredError(), num_bootstraps=20)\n >>> metric.update(torch.randn(100,), torch.randn(100,))\n >>> fig_, ax_ = metric.plot()\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting multiple values\n >>> import torch\n >>> from torchmetrics.wrappers import BootStrapper\n >>> from torchmetrics.regression import MeanSquaredError\n >>> metric = BootStrapper(MeanSquaredError(), num_bootstraps=20)\n >>> values = [ ]\n >>> for _ in range(3):\n ... values.append(metric(torch.randn(100,), torch.randn(100,)))\n >>> fig_, ax_ = metric.plot(values)\n\n \"\"\"\n return self._plot(val, ax)\n", "path": "src/torchmetrics/wrappers/bootstrapping.py"}]}
| 3,380 | 183 |
gh_patches_debug_4127
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4074
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Latest docs specify an RC instead of a Release version
## Description
`update_version.sh` bumps version string in docs even when an RC is created. There might be a small period of time (e.g. during release QA) where that Tag exists (albeit not signed)
## Steps to Reproduce
https://docs.securedrop.org/en/latest/set_up_admin_tails.html?highlight=git%20checkout and observe instructions to check out 0.12.0~rc1 tag
## Expected Behavior
The tag should be the latest release (as of today, 0.11.1)
## Actual Behavior
The tag is 0.12.0~rc1
## Comments
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # SecureDrop documentation build configuration file, created by
4 # sphinx-quickstart on Tue Oct 13 12:08:52 2015.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import os
16
17 # Detect if we're being built by Read the Docs
18 # https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs
19 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
20
21 # If extensions (or modules to document with autodoc) are in another directory,
22 # add these directories to sys.path here. If the directory is relative to the
23 # documentation root, use os.path.abspath to make it absolute, like shown here.
24 # sys.path.insert(0, os.path.abspath('.'))
25
26 # -- General configuration ------------------------------------------------
27
28 # If your documentation needs a minimal Sphinx version, state it here.
29 # needs_sphinx = '1.0'
30
31 # Add any Sphinx extension module names here, as strings. They can be
32 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
33 # ones.
34 extensions = ['sphinx.ext.todo', ]
35
36 # Add any paths that contain templates here, relative to this directory.
37 templates_path = ['_templates']
38
39 # The suffix(es) of source filenames.
40 # You can specify multiple suffix as a list of string:
41 # source_suffix = ['.rst', '.md']
42 source_suffix = '.rst'
43
44 # The encoding of source files.
45 # source_encoding = 'utf-8-sig'
46
47 # The master toctree document.
48 master_doc = 'index'
49
50 # General information about the project.
51 project = u'SecureDrop'
52 copyright = u'2017, Freedom of the Press Foundation'
53 author = u'SecureDrop Team and Contributors'
54
55 # The version info for the project you're documenting, acts as replacement for
56 # |version| and |release|, also used in various other places throughout the
57 # built documents.
58 #
59 # The short X.Y version.
60 version = '0.13.0~rc1'
61 # The full version, including alpha/beta/rc tags.
62 release = '0.13.0~rc1'
63
64 # The language for content autogenerated by Sphinx. Refer to documentation
65 # for a list of supported languages.
66 #
67 # This is also used if you do content translation via gettext catalogs.
68 # Usually you set "language" from the command line for these cases.
69 language = None
70
71 # There are two options for replacing |today|: either, you set today to some
72 # non-false value, then it is used:
73 # today = ''
74 # Else, today_fmt is used as the format for a strftime call.
75 # today_fmt = '%B %d, %Y'
76
77 # List of patterns, relative to source directory, that match files and
78 # directories to ignore when looking for source files.
79 exclude_patterns = ['_build']
80
81 # The reST default role (used for this markup: `text`) to use for all
82 # documents.
83 # default_role = None
84
85 # If true, '()' will be appended to :func: etc. cross-reference text.
86 # add_function_parentheses = True
87
88 # If true, the current module name will be prepended to all description
89 # unit titles (such as .. function::).
90 # add_module_names = True
91
92 # If true, sectionauthor and moduleauthor directives will be shown in the
93 # output. They are ignored by default.
94 # show_authors = False
95
96 # The name of the Pygments (syntax highlighting) style to use.
97 pygments_style = 'sphinx'
98
99 # A list of ignored prefixes for module index sorting.
100 # modindex_common_prefix = []
101
102 # If true, keep warnings as "system message" paragraphs in the built documents.
103 # keep_warnings = False
104
105 # If true, `todo` and `todoList` produce output, else they produce nothing.
106 todo_include_todos = False
107
108
109 # -- Options for HTML output ----------------------------------------------
110
111 # The theme to use for HTML and HTML Help pages. See the documentation for
112 # a list of builtin themes.
113 if on_rtd:
114 html_theme = 'default'
115 else:
116 try:
117 # If you want to build the docs locally using the RTD theme,
118 # you may need to install it: ``pip install sphinx_rtd_theme``.
119 # https://github.com/snide/sphinx_rtd_theme#via-package
120 import sphinx_rtd_theme
121 html_theme = "sphinx_rtd_theme"
122 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
123 except ImportError:
124 # This theme is included with Sphinx and is quite nice (based
125 # on the Pocoo themes), but since we're using the RTD theme
126 # for the production docs, it's best to use that to avoid
127 # issues due to discrepancies between the themes.
128 html_theme = 'alabaster'
129
130 # Theme options are theme-specific and customize the look and feel of a theme
131 # further. For a list of options available for each theme, see the
132 # documentation.
133 # html_theme_options = {}
134
135 # Add any paths that contain custom themes here, relative to this directory.
136 # html_theme_path = []
137
138 # The name for this set of Sphinx documents. If None, it defaults to
139 # "<project> v<release> documentation".
140 # html_title = None
141
142 # A shorter title for the navigation bar. Default is the same as html_title.
143 # html_short_title = None
144
145 # The name of an image file (relative to this directory) to place at the top
146 # of the sidebar.
147 html_logo = '../securedrop/static/i/favicon.png'
148
149 # The name of an image file (within the static path) to use as favicon of the
150 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
151 # pixels large.
152 # html_favicon = None
153
154 # Add any paths that contain custom static files (such as style sheets) here,
155 # relative to this directory. They are copied after the builtin static files,
156 # so a file named "default.css" will overwrite the builtin "default.css".
157 # html_static_path = ['_static']
158
159 # Add any extra paths that contain custom files (such as robots.txt or
160 # .htaccess) here, relative to this directory. These files are copied
161 # directly to the root of the documentation.
162 # html_extra_path = []
163
164 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
165 # using the given strftime format.
166 # html_last_updated_fmt = '%b %d, %Y'
167
168 # If true, SmartyPants will be used to convert quotes and dashes to
169 # typographically correct entities.
170 # html_use_smartypants = True
171
172 # Custom sidebar templates, maps document names to template names.
173 # html_sidebars = {}
174
175 # Additional templates that should be rendered to pages, maps page names to
176 # template names.
177 # html_additional_pages = {}
178
179 # If false, no module index is generated.
180 # html_domain_indices = True
181
182 # If false, no index is generated.
183 # html_use_index = True
184
185 # If true, the index is split into individual pages for each letter.
186 # html_split_index = False
187
188 # If true, links to the reST sources are added to the pages.
189 # html_show_sourcelink = True
190
191 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
192 # html_show_sphinx = True
193
194 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
195 # html_show_copyright = True
196
197 # If true, an OpenSearch description file will be output, and all pages will
198 # contain a <link> tag referring to it. The value of this option must be the
199 # base URL from which the finished HTML is served.
200 # html_use_opensearch = ''
201
202 # This is the file name suffix for HTML files (e.g. ".xhtml").
203 # html_file_suffix = None
204
205 # Language to be used for generating the HTML full-text search index.
206 # Sphinx supports the following languages:
207 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
208 # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
209 # html_search_language = 'en'
210
211 # A dictionary with options for the search language support, empty by default.
212 # Now only 'ja' uses this config value
213 # html_search_options = {'type': 'default'}
214
215 # The name of a javascript file (relative to the configuration directory) that
216 # implements a search results scorer. If empty, the default will be used.
217 # html_search_scorer = 'scorer.js'
218
219 # Output file base name for HTML help builder.
220 htmlhelp_basename = 'SecureDropdoc'
221
222 # -- Options for LaTeX output ---------------------------------------------
223
224 latex_elements = {
225 # The paper size ('letterpaper' or 'a4paper').
226 # 'papersize': 'letterpaper',
227
228 # The font size ('10pt', '11pt' or '12pt').
229 # 'pointsize': '10pt',
230
231 # Additional stuff for the LaTeX preamble.
232 # 'preamble': '',
233
234 # Latex figure (float) alignment
235 # 'figure_align': 'htbp',
236 }
237
238 # Grouping the document tree into LaTeX files. List of tuples
239 # (source start file, target name, title,
240 # author, documentclass [howto, manual, or own class]).
241 latex_documents = [
242 (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',
243 author, 'manual'),
244 ]
245
246 # The name of an image file (relative to this directory) to place at the top of
247 # the title page.
248 # latex_logo = None
249
250 # For "manual" documents, if this is true, then toplevel headings are parts,
251 # not chapters.
252 # latex_use_parts = False
253
254 # If true, show page references after internal links.
255 # latex_show_pagerefs = False
256
257 # If true, show URL addresses after external links.
258 # latex_show_urls = False
259
260 # Documents to append as an appendix to all manuals.
261 # latex_appendices = []
262
263 # If false, no module index is generated.
264 # latex_domain_indices = True
265
266
267 # -- Options for manual page output ---------------------------------------
268
269 # One entry per manual page. List of tuples
270 # (source start file, name, description, authors, manual section).
271 man_pages = [
272 (master_doc, 'securedrop', u'SecureDrop Documentation',
273 [author], 1)
274 ]
275
276 # If true, show URL addresses after external links.
277 # man_show_urls = False
278
279
280 # -- Options for Texinfo output -------------------------------------------
281
282 # Grouping the document tree into Texinfo files. List of tuples
283 # (source start file, target name, title, author,
284 # dir menu entry, description, category)
285 texinfo_documents = [
286 (master_doc, 'SecureDrop', u'SecureDrop Documentation',
287 author, 'SecureDrop', 'One line description of project.',
288 'Miscellaneous'),
289 ]
290
291 # Documents to append as an appendix to all manuals.
292 # texinfo_appendices = []
293
294 # If false, no module index is generated.
295 # texinfo_domain_indices = True
296
297 # How to display URL addresses: 'footnote', 'no', or 'inline'.
298 # texinfo_show_urls = 'footnote'
299
300 # If true, do not generate a @detailmenu in the "Top" node's menu.
301 # texinfo_no_detailmenu = False
302
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -57,9 +57,9 @@
# built documents.
#
# The short X.Y version.
-version = '0.13.0~rc1'
+version = '0.12.1'
# The full version, including alpha/beta/rc tags.
-release = '0.13.0~rc1'
+release = '0.12.1'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -57,9 +57,9 @@\n # built documents.\n #\n # The short X.Y version.\n-version = '0.13.0~rc1'\n+version = '0.12.1'\n # The full version, including alpha/beta/rc tags.\n-release = '0.13.0~rc1'\n+release = '0.12.1'\n \n # The language for content autogenerated by Sphinx. Refer to documentation\n # for a list of supported languages.\n", "issue": "Latest docs specify an RC instead of a Release version\n## Description\r\n\r\n`update_version.sh` bumps version string in docs even when an RC is created. There might be a small period of time (e.g. during release QA) where that Tag exists (albeit not signed)\r\n\r\n## Steps to Reproduce\r\n\r\nhttps://docs.securedrop.org/en/latest/set_up_admin_tails.html?highlight=git%20checkout and observe instructions to check out 0.12.0~rc1 tag\r\n\r\n## Expected Behavior\r\n\r\nThe tag should be the latest release (as of today, 0.11.1)\r\n## Actual Behavior\r\n\r\nThe tag is 0.12.0~rc1\r\n\r\n## Comments\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# SecureDrop documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 13 12:08:52 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\n\n# Detect if we're being built by Read the Docs\n# https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n# sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.todo', ]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'SecureDrop'\ncopyright = u'2017, Freedom of the Press Foundation'\nauthor = u'SecureDrop Team and Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.13.0~rc1'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.13.0~rc1'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n# default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nif on_rtd:\n html_theme = 'default'\nelse:\n try:\n # If you want to build the docs locally using the RTD theme,\n # you may need to install it: ``pip install sphinx_rtd_theme``.\n # https://github.com/snide/sphinx_rtd_theme#via-package\n import sphinx_rtd_theme\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n # This theme is included with Sphinx and is quite nice (based\n # on the Pocoo themes), but since we're using the RTD theme\n # for the production docs, it's best to use that to avoid\n # issues due to discrepancies between the themes.\n html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n# html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n# html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n# html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = '../securedrop/static/i/favicon.png'\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n# html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n# html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n# html_domain_indices = True\n\n# If false, no index is generated.\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# Now only 'ja' uses this config value\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'SecureDropdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n # 'preamble': '',\n\n # Latex figure (float) alignment\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',\n author, 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n# latex_appendices = []\n\n# If false, no module index is generated.\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'securedrop', u'SecureDrop Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'SecureDrop', u'SecureDrop Documentation',\n author, 'SecureDrop', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}]}
| 4,052 | 130 |
gh_patches_debug_28259
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-302
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add option to pass additional dependencies to hooks
I am currently working on implementing this framework and one of the things I am trying to run is eslint. As part of that I have a number of plugins that are in my configuration file. I think that, rather than forcing anyone who is using plugins to create a new hook definition with a corresponding package.json it might be useful to add a global option to pass a list of dependencies in the configuration file.
For instance, something lilke this:
``` yaml
- repo: https://github.com/pre-commit/mirrors-eslint
sha: 135f285caf8e6e886b28c8e98fdff402b69c4490
hooks:
- id: eslint
language_version: '0.12.7'
dependencies: [eslint-plugin-react, eslint-plugin-html]
```
and have those dependencies installed into the generated environment for that language.
I am going to work on implementing this in my forked repo but would like feedback on whether this is a desired feature or any implementation advice on how best to facilitate this.
</issue>
<code>
[start of pre_commit/output.py]
1 from __future__ import unicode_literals
2
3 import os
4 import subprocess
5 import sys
6
7 from pre_commit import color
8 from pre_commit import five
9
10
11 # TODO: smell: import side-effects
12 try:
13 if not os.environ.get('TERM'): # pragma: no cover (dumb terminal)
14 raise OSError('Cannot determine width without TERM')
15 COLS = int(
16 subprocess.Popen(
17 ('tput', 'cols'), stdout=subprocess.PIPE,
18 ).communicate()[0] or
19 # Default in the case of no terminal
20 80
21 )
22 except OSError: # pragma: no cover (windows)
23 COLS = 80
24
25
26 def get_hook_message(
27 start,
28 postfix='',
29 end_msg=None,
30 end_len=0,
31 end_color=None,
32 use_color=None,
33 cols=COLS,
34 ):
35 """Prints a message for running a hook.
36
37 This currently supports three approaches:
38
39 # Print `start` followed by dots, leaving 6 characters at the end
40 >>> print_hook_message('start', end_len=6)
41 start...............................................................
42
43 # Print `start` followed by dots with the end message colored if coloring
44 # is specified and a newline afterwards
45 >>> print_hook_message(
46 'start',
47 end_msg='end',
48 end_color=color.RED,
49 use_color=True,
50 )
51 start...................................................................end
52
53 # Print `start` followed by dots, followed by the `postfix` message
54 # uncolored, followed by the `end_msg` colored if specified and a newline
55 # afterwards
56 >>> print_hook_message(
57 'start',
58 postfix='postfix ',
59 end_msg='end',
60 end_color=color.RED,
61 use_color=True,
62 )
63 start...........................................................postfix end
64 """
65 if bool(end_msg) == bool(end_len):
66 raise ValueError('Expected one of (`end_msg`, `end_len`)')
67 if end_msg is not None and (end_color is None or use_color is None):
68 raise ValueError(
69 '`end_color` and `use_color` are required with `end_msg`'
70 )
71
72 if end_len:
73 return start + '.' * (cols - len(start) - end_len - 1)
74 else:
75 return '{0}{1}{2}{3}\n'.format(
76 start,
77 '.' * (cols - len(start) - len(postfix) - len(end_msg) - 1),
78 postfix,
79 color.format_color(end_msg, end_color, use_color),
80 )
81
82
83 stdout_byte_stream = getattr(sys.stdout, 'buffer', sys.stdout)
84
85
86 def sys_stdout_write_wrapper(s, stream=stdout_byte_stream):
87 stream.write(five.to_bytes(s))
88
[end of pre_commit/output.py]
[start of pre_commit/languages/python.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import distutils.spawn
5 import os
6 import sys
7
8 import virtualenv
9
10 from pre_commit.languages import helpers
11 from pre_commit.util import clean_path_on_failure
12 from pre_commit.util import shell_escape
13
14
15 ENVIRONMENT_DIR = 'py_env'
16
17
18 class PythonEnv(helpers.Environment):
19 @property
20 def env_prefix(self):
21 return ". '{{prefix}}{0}activate' &&".format(
22 virtualenv.path_locations(
23 helpers.environment_dir(ENVIRONMENT_DIR, self.language_version)
24 )[-1].rstrip(os.sep) + os.sep,
25 )
26
27
28 @contextlib.contextmanager
29 def in_env(repo_cmd_runner, language_version):
30 yield PythonEnv(repo_cmd_runner, language_version)
31
32
33 def norm_version(version):
34 version = os.path.expanduser(version)
35 if os.name == 'nt': # pragma: no cover (windows)
36 if not distutils.spawn.find_executable(version):
37 # expanduser introduces a leading slash
38 version = version.strip('\\')
39 # The default place for python on windows is:
40 # C:\PythonXX\python.exe
41 version = r'C:\{0}\python.exe'.format(version.replace('.', ''))
42 return version
43
44
45 def install_environment(
46 repo_cmd_runner,
47 version='default',
48 additional_dependencies=None,
49 ):
50 assert repo_cmd_runner.exists('setup.py')
51 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
52
53 # Install a virtualenv
54 with clean_path_on_failure(repo_cmd_runner.path(directory)):
55 venv_cmd = [
56 sys.executable, '-m', 'virtualenv',
57 '{{prefix}}{0}'.format(directory)
58 ]
59 if version != 'default':
60 venv_cmd.extend(['-p', norm_version(version)])
61 repo_cmd_runner.run(venv_cmd)
62 with in_env(repo_cmd_runner, version) as env:
63 env.run("cd '{prefix}' && pip install .")
64 if additional_dependencies:
65 env.run(
66 "cd '{prefix}' && pip install " +
67 ' '.join(
68 shell_escape(dep) for dep in additional_dependencies
69 )
70 )
71
72
73 def run_hook(repo_cmd_runner, hook, file_args):
74 with in_env(repo_cmd_runner, hook['language_version']) as env:
75 return helpers.run_hook(env, hook, file_args)
76
[end of pre_commit/languages/python.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/python.py b/pre_commit/languages/python.py
--- a/pre_commit/languages/python.py
+++ b/pre_commit/languages/python.py
@@ -31,15 +31,18 @@
def norm_version(version):
- version = os.path.expanduser(version)
if os.name == 'nt': # pragma: no cover (windows)
- if not distutils.spawn.find_executable(version):
- # expanduser introduces a leading slash
- version = version.strip('\\')
- # The default place for python on windows is:
- # C:\PythonXX\python.exe
- version = r'C:\{0}\python.exe'.format(version.replace('.', ''))
- return version
+ # Try looking up by name
+ if distutils.spawn.find_executable(version):
+ return version
+
+ # If it is in the form pythonx.x search in the default
+ # place on windows
+ if version.startswith('python'):
+ return r'C:\{0}\python.exe'.format(version.replace('.', ''))
+
+ # Otherwise assume it is a path
+ return os.path.expanduser(version)
def install_environment(
diff --git a/pre_commit/output.py b/pre_commit/output.py
--- a/pre_commit/output.py
+++ b/pre_commit/output.py
@@ -12,13 +12,14 @@
try:
if not os.environ.get('TERM'): # pragma: no cover (dumb terminal)
raise OSError('Cannot determine width without TERM')
- COLS = int(
- subprocess.Popen(
- ('tput', 'cols'), stdout=subprocess.PIPE,
- ).communicate()[0] or
- # Default in the case of no terminal
- 80
- )
+ else: # pragma no cover (windows)
+ COLS = int(
+ subprocess.Popen(
+ ('tput', 'cols'), stdout=subprocess.PIPE,
+ ).communicate()[0] or
+ # Default in the case of no terminal
+ 80
+ )
except OSError: # pragma: no cover (windows)
COLS = 80
|
{"golden_diff": "diff --git a/pre_commit/languages/python.py b/pre_commit/languages/python.py\n--- a/pre_commit/languages/python.py\n+++ b/pre_commit/languages/python.py\n@@ -31,15 +31,18 @@\n \n \n def norm_version(version):\n- version = os.path.expanduser(version)\n if os.name == 'nt': # pragma: no cover (windows)\n- if not distutils.spawn.find_executable(version):\n- # expanduser introduces a leading slash\n- version = version.strip('\\\\')\n- # The default place for python on windows is:\n- # C:\\PythonXX\\python.exe\n- version = r'C:\\{0}\\python.exe'.format(version.replace('.', ''))\n- return version\n+ # Try looking up by name\n+ if distutils.spawn.find_executable(version):\n+ return version\n+\n+ # If it is in the form pythonx.x search in the default\n+ # place on windows\n+ if version.startswith('python'):\n+ return r'C:\\{0}\\python.exe'.format(version.replace('.', ''))\n+\n+ # Otherwise assume it is a path\n+ return os.path.expanduser(version)\n \n \n def install_environment(\ndiff --git a/pre_commit/output.py b/pre_commit/output.py\n--- a/pre_commit/output.py\n+++ b/pre_commit/output.py\n@@ -12,13 +12,14 @@\n try:\n if not os.environ.get('TERM'): # pragma: no cover (dumb terminal)\n raise OSError('Cannot determine width without TERM')\n- COLS = int(\n- subprocess.Popen(\n- ('tput', 'cols'), stdout=subprocess.PIPE,\n- ).communicate()[0] or\n- # Default in the case of no terminal\n- 80\n- )\n+ else: # pragma no cover (windows)\n+ COLS = int(\n+ subprocess.Popen(\n+ ('tput', 'cols'), stdout=subprocess.PIPE,\n+ ).communicate()[0] or\n+ # Default in the case of no terminal\n+ 80\n+ )\n except OSError: # pragma: no cover (windows)\n COLS = 80\n", "issue": "Add option to pass additional dependencies to hooks\nI am currently working on implementing this framework and one of the things I am trying to run is eslint. As part of that I have a number of plugins that are in my configuration file. I think that, rather than forcing anyone who is using plugins to create a new hook definition with a corresponding package.json it might be useful to add a global option to pass a list of dependencies in the configuration file.\n\nFor instance, something lilke this:\n\n``` yaml\n- repo: https://github.com/pre-commit/mirrors-eslint\n sha: 135f285caf8e6e886b28c8e98fdff402b69c4490\n hooks:\n - id: eslint\n language_version: '0.12.7'\n dependencies: [eslint-plugin-react, eslint-plugin-html]\n```\n\nand have those dependencies installed into the generated environment for that language.\n\nI am going to work on implementing this in my forked repo but would like feedback on whether this is a desired feature or any implementation advice on how best to facilitate this.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport os\nimport subprocess\nimport sys\n\nfrom pre_commit import color\nfrom pre_commit import five\n\n\n# TODO: smell: import side-effects\ntry:\n if not os.environ.get('TERM'): # pragma: no cover (dumb terminal)\n raise OSError('Cannot determine width without TERM')\n COLS = int(\n subprocess.Popen(\n ('tput', 'cols'), stdout=subprocess.PIPE,\n ).communicate()[0] or\n # Default in the case of no terminal\n 80\n )\nexcept OSError: # pragma: no cover (windows)\n COLS = 80\n\n\ndef get_hook_message(\n start,\n postfix='',\n end_msg=None,\n end_len=0,\n end_color=None,\n use_color=None,\n cols=COLS,\n):\n \"\"\"Prints a message for running a hook.\n\n This currently supports three approaches:\n\n # Print `start` followed by dots, leaving 6 characters at the end\n >>> print_hook_message('start', end_len=6)\n start...............................................................\n\n # Print `start` followed by dots with the end message colored if coloring\n # is specified and a newline afterwards\n >>> print_hook_message(\n 'start',\n end_msg='end',\n end_color=color.RED,\n use_color=True,\n )\n start...................................................................end\n\n # Print `start` followed by dots, followed by the `postfix` message\n # uncolored, followed by the `end_msg` colored if specified and a newline\n # afterwards\n >>> print_hook_message(\n 'start',\n postfix='postfix ',\n end_msg='end',\n end_color=color.RED,\n use_color=True,\n )\n start...........................................................postfix end\n \"\"\"\n if bool(end_msg) == bool(end_len):\n raise ValueError('Expected one of (`end_msg`, `end_len`)')\n if end_msg is not None and (end_color is None or use_color is None):\n raise ValueError(\n '`end_color` and `use_color` are required with `end_msg`'\n )\n\n if end_len:\n return start + '.' * (cols - len(start) - end_len - 1)\n else:\n return '{0}{1}{2}{3}\\n'.format(\n start,\n '.' * (cols - len(start) - len(postfix) - len(end_msg) - 1),\n postfix,\n color.format_color(end_msg, end_color, use_color),\n )\n\n\nstdout_byte_stream = getattr(sys.stdout, 'buffer', sys.stdout)\n\n\ndef sys_stdout_write_wrapper(s, stream=stdout_byte_stream):\n stream.write(five.to_bytes(s))\n", "path": "pre_commit/output.py"}, {"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport distutils.spawn\nimport os\nimport sys\n\nimport virtualenv\n\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import shell_escape\n\n\nENVIRONMENT_DIR = 'py_env'\n\n\nclass PythonEnv(helpers.Environment):\n @property\n def env_prefix(self):\n return \". '{{prefix}}{0}activate' &&\".format(\n virtualenv.path_locations(\n helpers.environment_dir(ENVIRONMENT_DIR, self.language_version)\n )[-1].rstrip(os.sep) + os.sep,\n )\n\n\[email protected]\ndef in_env(repo_cmd_runner, language_version):\n yield PythonEnv(repo_cmd_runner, language_version)\n\n\ndef norm_version(version):\n version = os.path.expanduser(version)\n if os.name == 'nt': # pragma: no cover (windows)\n if not distutils.spawn.find_executable(version):\n # expanduser introduces a leading slash\n version = version.strip('\\\\')\n # The default place for python on windows is:\n # C:\\PythonXX\\python.exe\n version = r'C:\\{0}\\python.exe'.format(version.replace('.', ''))\n return version\n\n\ndef install_environment(\n repo_cmd_runner,\n version='default',\n additional_dependencies=None,\n):\n assert repo_cmd_runner.exists('setup.py')\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n # Install a virtualenv\n with clean_path_on_failure(repo_cmd_runner.path(directory)):\n venv_cmd = [\n sys.executable, '-m', 'virtualenv',\n '{{prefix}}{0}'.format(directory)\n ]\n if version != 'default':\n venv_cmd.extend(['-p', norm_version(version)])\n repo_cmd_runner.run(venv_cmd)\n with in_env(repo_cmd_runner, version) as env:\n env.run(\"cd '{prefix}' && pip install .\")\n if additional_dependencies:\n env.run(\n \"cd '{prefix}' && pip install \" +\n ' '.join(\n shell_escape(dep) for dep in additional_dependencies\n )\n )\n\n\ndef run_hook(repo_cmd_runner, hook, file_args):\n with in_env(repo_cmd_runner, hook['language_version']) as env:\n return helpers.run_hook(env, hook, file_args)\n", "path": "pre_commit/languages/python.py"}]}
| 2,190 | 477 |
gh_patches_debug_18579
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-62
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove responder exception handling
Can hide problems, encourage bad coding practices.
</issue>
<code>
[start of falcon/api.py]
1 """Defines the API class.
2
3 Copyright 2013 by Rackspace Hosting, Inc.
4
5 Licensed under the Apache License, Version 2.0 (the "License");
6 you may not use this file except in compliance with the License.
7 You may obtain a copy of the License at
8
9 http://www.apache.org/licenses/LICENSE-2.0
10
11 Unless required by applicable law or agreed to in writing, software
12 distributed under the License is distributed on an "AS IS" BASIS,
13 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 See the License for the specific language governing permissions and
15 limitations under the License.
16
17 """
18
19 import traceback
20
21 from .request import Request
22 from .response import Response
23 from . import responders
24 from .status_codes import *
25 from .api_helpers import *
26
27 from .http_error import HTTPError
28
29
30 class API(object):
31 """Provides routing and such for building a web service application
32
33 This class is the main entry point into a Falcon-based app. It provides a
34 callable WSGI interface and a simple routing engine based on URI templates.
35
36 """
37
38 __slots__ = ('_routes')
39
40 def __init__(self):
41 """Initialize default values"""
42 self._routes = []
43
44 def __call__(self, env, start_response):
45 """WSGI "app" method
46
47 Makes instances of API callable by any WSGI server. See also PEP 333.
48
49 Args:
50 env: A WSGI environment dictionary
51 start_response: A WSGI helper method for setting status and headers
52 on a response.
53
54 """
55
56 req = Request(env)
57 resp = Response()
58
59 responder, params = self._get_responder(req.path, req.method)
60
61 try:
62 responder(req, resp, **params)
63
64 except HTTPError as ex:
65 resp.status = ex.status
66 if ex.headers is not None:
67 resp.set_headers(ex.headers)
68
69 if req.client_accepts_json():
70 resp.body = ex.json()
71
72 except Exception as ex:
73 # Reset to a known state and respond with a generic error
74 req = Request(env)
75 resp = Response()
76
77 message = ['Responder raised ', ex.__class__.__name__]
78
79 details = str(ex)
80 if details:
81 message.append(': ')
82 message.append(details)
83
84 stack = traceback.format_exc()
85 message.append('\n')
86 message.append(stack)
87
88 req.log_error(''.join(message))
89 responders.server_error(req, resp)
90
91 #
92 # Set status and headers
93 #
94 use_body = not should_ignore_body(resp.status, req.method)
95 if use_body:
96 set_content_length(resp)
97
98 start_response(resp.status, resp._wsgi_headers())
99
100 # Return an iterable for the body, per the WSGI spec
101 if use_body:
102 return prepare_wsgi_content(resp)
103
104 # Default: return an empty body
105 return []
106
107 def add_route(self, uri_template, resource):
108 """Associate a URI path with a resource
109
110 Args:
111 uri_template: Relative URI template. Currently only Level 1
112 templates are supported. See also RFC 6570.
113 resource: Object which represents an HTTP/REST "resource". Falcon
114 will pass "GET" requests to on_get, "PUT" requests to on_put,
115 etc. If any HTTP methods are not supported by your resource,
116 simply don't define the corresponding request handlers, and
117 Falcon will do the right thing.
118
119 """
120
121 if not uri_template:
122 uri_template = '/'
123
124 path_template = compile_uri_template(uri_template)
125 method_map = create_http_method_map(resource)
126
127 # Insert at the head of the list in case we get duplicate
128 # adds (will cause the last one to win).
129 self._routes.insert(0, (path_template, method_map))
130
131 def _get_responder(self, path, method):
132 """Searches routes for a matching responder
133
134 Args:
135 path: URI path to search (without query stirng)
136 method: HTTP method (uppercase) requested
137 Returns:
138 A 2-member tuple, containing a responder callable and a dict
139 containing parsed path fields, if any were specified in
140 the matching route's URI template
141
142 """
143
144 for path_template, method_map in self._routes:
145 m = path_template.match(path)
146 if m:
147 params = m.groupdict()
148
149 try:
150 responder = method_map[method]
151 except KeyError:
152 responder = responders.bad_request
153
154 break
155 else:
156 responder = responders.path_not_found
157 params = {}
158
159 return (responder, params)
160
[end of falcon/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/falcon/api.py b/falcon/api.py
--- a/falcon/api.py
+++ b/falcon/api.py
@@ -16,8 +16,6 @@
"""
-import traceback
-
from .request import Request
from .response import Response
from . import responders
@@ -69,25 +67,6 @@
if req.client_accepts_json():
resp.body = ex.json()
- except Exception as ex:
- # Reset to a known state and respond with a generic error
- req = Request(env)
- resp = Response()
-
- message = ['Responder raised ', ex.__class__.__name__]
-
- details = str(ex)
- if details:
- message.append(': ')
- message.append(details)
-
- stack = traceback.format_exc()
- message.append('\n')
- message.append(stack)
-
- req.log_error(''.join(message))
- responders.server_error(req, resp)
-
#
# Set status and headers
#
|
{"golden_diff": "diff --git a/falcon/api.py b/falcon/api.py\n--- a/falcon/api.py\n+++ b/falcon/api.py\n@@ -16,8 +16,6 @@\n \n \"\"\"\n \n-import traceback\n-\n from .request import Request\n from .response import Response\n from . import responders\n@@ -69,25 +67,6 @@\n if req.client_accepts_json():\n resp.body = ex.json()\n \n- except Exception as ex:\n- # Reset to a known state and respond with a generic error\n- req = Request(env)\n- resp = Response()\n-\n- message = ['Responder raised ', ex.__class__.__name__]\n-\n- details = str(ex)\n- if details:\n- message.append(': ')\n- message.append(details)\n-\n- stack = traceback.format_exc()\n- message.append('\\n')\n- message.append(stack)\n-\n- req.log_error(''.join(message))\n- responders.server_error(req, resp)\n-\n #\n # Set status and headers\n #\n", "issue": "Remove responder exception handling\nCan hide problems, encourage bad coding practices.\n\n", "before_files": [{"content": "\"\"\"Defines the API class.\n\nCopyright 2013 by Rackspace Hosting, Inc.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\n\"\"\"\n\nimport traceback\n\nfrom .request import Request\nfrom .response import Response\nfrom . import responders\nfrom .status_codes import *\nfrom .api_helpers import *\n\nfrom .http_error import HTTPError\n\n\nclass API(object):\n \"\"\"Provides routing and such for building a web service application\n\n This class is the main entry point into a Falcon-based app. It provides a\n callable WSGI interface and a simple routing engine based on URI templates.\n\n \"\"\"\n\n __slots__ = ('_routes')\n\n def __init__(self):\n \"\"\"Initialize default values\"\"\"\n self._routes = []\n\n def __call__(self, env, start_response):\n \"\"\"WSGI \"app\" method\n\n Makes instances of API callable by any WSGI server. See also PEP 333.\n\n Args:\n env: A WSGI environment dictionary\n start_response: A WSGI helper method for setting status and headers\n on a response.\n\n \"\"\"\n\n req = Request(env)\n resp = Response()\n\n responder, params = self._get_responder(req.path, req.method)\n\n try:\n responder(req, resp, **params)\n\n except HTTPError as ex:\n resp.status = ex.status\n if ex.headers is not None:\n resp.set_headers(ex.headers)\n\n if req.client_accepts_json():\n resp.body = ex.json()\n\n except Exception as ex:\n # Reset to a known state and respond with a generic error\n req = Request(env)\n resp = Response()\n\n message = ['Responder raised ', ex.__class__.__name__]\n\n details = str(ex)\n if details:\n message.append(': ')\n message.append(details)\n\n stack = traceback.format_exc()\n message.append('\\n')\n message.append(stack)\n\n req.log_error(''.join(message))\n responders.server_error(req, resp)\n\n #\n # Set status and headers\n #\n use_body = not should_ignore_body(resp.status, req.method)\n if use_body:\n set_content_length(resp)\n\n start_response(resp.status, resp._wsgi_headers())\n\n # Return an iterable for the body, per the WSGI spec\n if use_body:\n return prepare_wsgi_content(resp)\n\n # Default: return an empty body\n return []\n\n def add_route(self, uri_template, resource):\n \"\"\"Associate a URI path with a resource\n\n Args:\n uri_template: Relative URI template. Currently only Level 1\n templates are supported. See also RFC 6570.\n resource: Object which represents an HTTP/REST \"resource\". Falcon\n will pass \"GET\" requests to on_get, \"PUT\" requests to on_put,\n etc. If any HTTP methods are not supported by your resource,\n simply don't define the corresponding request handlers, and\n Falcon will do the right thing.\n\n \"\"\"\n\n if not uri_template:\n uri_template = '/'\n\n path_template = compile_uri_template(uri_template)\n method_map = create_http_method_map(resource)\n\n # Insert at the head of the list in case we get duplicate\n # adds (will cause the last one to win).\n self._routes.insert(0, (path_template, method_map))\n\n def _get_responder(self, path, method):\n \"\"\"Searches routes for a matching responder\n\n Args:\n path: URI path to search (without query stirng)\n method: HTTP method (uppercase) requested\n Returns:\n A 2-member tuple, containing a responder callable and a dict\n containing parsed path fields, if any were specified in\n the matching route's URI template\n\n \"\"\"\n\n for path_template, method_map in self._routes:\n m = path_template.match(path)\n if m:\n params = m.groupdict()\n\n try:\n responder = method_map[method]\n except KeyError:\n responder = responders.bad_request\n\n break\n else:\n responder = responders.path_not_found\n params = {}\n\n return (responder, params)\n", "path": "falcon/api.py"}]}
| 1,926 | 223 |
gh_patches_debug_31655
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__codeforlife-portal-686
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CMS upgrade
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 from setuptools import find_packages, setup
3 import versioneer
4
5
6 setup(name='codeforlife-portal',
7 cmdclass=versioneer.get_cmdclass(),
8 version=versioneer.get_version(),
9 packages=find_packages(),
10 include_package_data=True,
11 install_requires=[
12 'django==1.8.2',
13 'django-appconf==1.0.1',
14 'django-countries==3.4.1',
15 'djangorestframework==3.1.3',
16 'django-jquery==1.9.1',
17 'django-autoconfig==0.3.6',
18 'django-pipeline==1.5.4',
19 'django-recaptcha==1.3.1', # 1.4 dropped support for < 1.11
20
21 'pyyaml==3.10',
22 'rapid-router >= 1.0.0.post.dev1',
23 'six==1.9.0',
24 'docutils==0.12',
25 'reportlab==3.2.0',
26 'postcodes==0.1',
27 'django-formtools==1.0',
28 'django-two-factor-auth==1.2.0',
29 'urllib3==1.10.4',
30 'requests==2.7.0',
31
32 'django-cms==3.1.2',
33
34 'django-classy-tags==0.6.1',
35 'django-treebeard==3.0',
36 'django-sekizai==0.8.2',
37 'djangocms-admin-style==0.2.8',
38
39 'djangocms-text-ckeditor==2.6.0',
40 'djangocms-link==1.6.2',
41 'djangocms-snippet==1.5',
42 'djangocms-style==1.5',
43 'djangocms-column==1.5',
44 'djangocms-grid==1.2',
45 'djangocms-oembed==0.5',
46 'djangocms-table==1.2',
47 'djangocms-file==0.1',
48 'djangocms_flash==0.2.0',
49 'djangocms_googlemap==0.3',
50 'djangocms_inherit==0.1',
51 'djangocms_picture==0.1',
52 'djangocms_teaser==0.1',
53 'djangocms_video==0.1',
54 'django-online-status==0.1.0',
55
56
57 'Pillow==2.9.0',
58 'django-reversion==1.9.3',
59 'sqlparse',
60 'libsass',
61 ],
62 tests_require=[
63 'django-setuptest',
64 'django-selenium-clean==0.2.1',
65 'responses==0.4.0',
66 'selenium==2.48.0',
67 ],
68 test_suite='setuptest.setuptest.SetupTestSuite',
69 zip_safe=False,
70 )
71
[end of setup.py]
[start of portal/autoconfig.py]
1 # -*- coding: utf-8 -*-
2 # Code for Life
3 #
4 # Copyright (C) 2018, Ocado Innovation Limited
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as
8 # published by the Free Software Foundation, either version 3 of the
9 # License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 # ADDITIONAL TERMS – Section 7 GNU General Public Licence
20 #
21 # This licence does not grant any right, title or interest in any “Ocado” logos,
22 # trade names or the trademark “Ocado” or any other trademarks or domain names
23 # owned by Ocado Innovation Limited or the Ocado group of companies or any other
24 # distinctive brand features of “Ocado” as may be secured from time to time. You
25 # must not distribute any modification of this program using the trademark
26 # “Ocado” or claim any affiliation or association with Ocado or its employees.
27 #
28 # You are not authorised to use the name Ocado (or any of its trade names) or
29 # the names of any author or contributor in advertising or for publicity purposes
30 # pertaining to the distribution of this program, without the prior written
31 # authorisation of Ocado.
32 #
33 # Any propagation, distribution or conveyance of this program must include this
34 # copyright notice and these terms. You must not misrepresent the origins of this
35 # program; modified versions of the program must be marked as such and not
36 # identified as the original program.
37 '''Portal autoconfig'''
38 import os
39
40 from django_autoconfig.autoconfig import OrderingRelationship
41
42
43 DEFAULT_SETTINGS = {
44 'AUTOCONFIG_INDEX_VIEW': 'home',
45 'LANGUAGE_CODE': 'en-gb',
46 'SITE_ID': 1,
47 'MEDIA_ROOT': os.path.join(os.path.join(os.path.dirname(__file__), 'static'), 'email_media/')
48 }
49
50 SETTINGS = {
51 'AUTOCONFIG_DISABLED_APPS': [
52 'django_otp',
53 'django_otp.plugins.otp_static',
54 'django_otp.plugins.otp_totp',
55 ],
56 'PIPELINE_COMPILERS': (
57 'pipeline.compilers.sass.SASSCompiler',
58 ),
59 'PIPELINE_CSS': {
60 'css': {
61 'source_filenames': (
62 'portal/sass/bootstrap.scss',
63 'portal/sass/colorbox.scss',
64 'portal/sass/styles.scss',
65 ),
66 'output_filename': 'portal.css',
67 },
68 'base': {
69 'source_filenames': (
70 'portal/sass/old_styles.scss',
71 ),
72 'output_filename': 'base.css',
73 },
74 },
75 'PIPELINE_CSS_COMPRESSOR': None,
76 'INSTALLED_APPS': [
77 'cms',
78 'game',
79 'pipeline',
80 'portal',
81 'ratelimit',
82 'django.contrib.admin',
83 'django.contrib.admindocs',
84 'django.contrib.auth',
85 'django.contrib.contenttypes',
86 'django.contrib.sessions',
87 'django.contrib.messages',
88 'django.contrib.sites',
89 'django.contrib.staticfiles',
90 'rest_framework',
91 'jquery',
92 'django_otp',
93 'django_otp.plugins.otp_static',
94 'django_otp.plugins.otp_totp',
95 'sekizai', # for javascript and css management
96 'treebeard',
97 'two_factor',
98 ],
99 'LANGUAGES': [
100 ('en-gb', 'English'),
101 ],
102 'STATICFILES_FINDERS': [
103 'pipeline.finders.PipelineFinder',
104 ],
105 'STATICFILES_STORAGE': 'pipeline.storage.PipelineStorage',
106 'MESSAGE_STORAGE': 'django.contrib.messages.storage.session.SessionStorage',
107 'MIDDLEWARE_CLASSES': [
108 'django.contrib.sessions.middleware.SessionMiddleware',
109 'django.middleware.locale.LocaleMiddleware',
110 'django.middleware.common.CommonMiddleware',
111 'django.middleware.csrf.CsrfViewMiddleware',
112 'django.contrib.auth.middleware.AuthenticationMiddleware',
113 'online_status.middleware.OnlineStatusMiddleware',
114 'django.contrib.messages.middleware.MessageMiddleware',
115 'django.middleware.clickjacking.XFrameOptionsMiddleware',
116 'deploy.middleware.exceptionlogging.ExceptionLoggingMiddleware',
117 'cms.middleware.user.CurrentUserMiddleware',
118 'cms.middleware.page.CurrentPageMiddleware',
119 'cms.middleware.toolbar.ToolbarMiddleware',
120 'cms.middleware.language.LanguageCookieMiddleware',
121 'portal.middleware.ratelimit_login_attempts.RateLimitLoginAttemptsMiddleware',
122 'django_otp.middleware.OTPMiddleware',
123 ],
124
125 'TEMPLATES': [
126 {
127 'BACKEND': 'django.template.backends.django.DjangoTemplates',
128 'APP_DIRS': True,
129 'OPTIONS': {
130 'context_processors': [
131 'django.contrib.auth.context_processors.auth',
132 'django.template.context_processors.request',
133 'django.contrib.messages.context_processors.messages',
134 'sekizai.context_processors.sekizai',
135 ]
136 }
137 }
138 ],
139
140 'CODEFORLIFE_WEBSITE': 'www.codeforlife.education',
141
142 'CLOUD_STORAGE_PREFIX': '//storage.googleapis.com/codeforlife-assets/',
143
144 'LOGGING': {
145 'version': 1,
146 'disable_existing_loggers': False,
147 'handlers': {
148 'console': {
149 'level': 'DEBUG',
150 'class': 'logging.StreamHandler',
151 },
152 },
153 'loggers': {
154 'two_factor': {
155 'handlers': ['console'],
156 'level': 'INFO',
157 }
158 }
159 },
160
161 'RAPID_ROUTER_EARLY_ACCESS_FUNCTION_NAME': 'portal.beta.has_beta_access',
162 }
163
164 RELATIONSHIPS = [
165 OrderingRelationship(
166 'MIDDLEWARE_CLASSES',
167 'cms.middleware.toolbar.ToolbarMiddleware',
168 after=[
169 'django.contrib.auth.middleware.AuthenticationMiddleware',
170 ],
171 add_missing=False,
172 ),
173 OrderingRelationship(
174 'MIDDLEWARE_CLASSES',
175 'online_status.middleware.OnlineStatusMiddleware',
176 after=[
177 'django.contrib.auth.middleware.AuthenticationMiddleware',
178 ],
179 add_missing=False,
180 ),
181 OrderingRelationship(
182 'MIDDLEWARE_CLASSES',
183 'django_otp.middleware.OTPMiddleware',
184 after=[
185 'django.contrib.auth.middleware.AuthenticationMiddleware',
186 ],
187 add_missing=False,
188 ),
189 ]
190
191 try:
192 import django_pandasso
193 SETTINGS['INSTALLED_APPS'].append('django_pandasso')
194 SETTINGS['INSTALLED_APPS'].append('social.apps.django_app.default')
195 except ImportError:
196 pass
197
[end of portal/autoconfig.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/portal/autoconfig.py b/portal/autoconfig.py
--- a/portal/autoconfig.py
+++ b/portal/autoconfig.py
@@ -74,7 +74,6 @@
},
'PIPELINE_CSS_COMPRESSOR': None,
'INSTALLED_APPS': [
- 'cms',
'game',
'pipeline',
'portal',
@@ -114,10 +113,6 @@
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'deploy.middleware.exceptionlogging.ExceptionLoggingMiddleware',
- 'cms.middleware.user.CurrentUserMiddleware',
- 'cms.middleware.page.CurrentPageMiddleware',
- 'cms.middleware.toolbar.ToolbarMiddleware',
- 'cms.middleware.language.LanguageCookieMiddleware',
'portal.middleware.ratelimit_login_attempts.RateLimitLoginAttemptsMiddleware',
'django_otp.middleware.OTPMiddleware',
],
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,28 +29,10 @@
'urllib3==1.10.4',
'requests==2.7.0',
- 'django-cms==3.1.2',
-
'django-classy-tags==0.6.1',
'django-treebeard==3.0',
'django-sekizai==0.8.2',
- 'djangocms-admin-style==0.2.8',
- 'djangocms-text-ckeditor==2.6.0',
- 'djangocms-link==1.6.2',
- 'djangocms-snippet==1.5',
- 'djangocms-style==1.5',
- 'djangocms-column==1.5',
- 'djangocms-grid==1.2',
- 'djangocms-oembed==0.5',
- 'djangocms-table==1.2',
- 'djangocms-file==0.1',
- 'djangocms_flash==0.2.0',
- 'djangocms_googlemap==0.3',
- 'djangocms_inherit==0.1',
- 'djangocms_picture==0.1',
- 'djangocms_teaser==0.1',
- 'djangocms_video==0.1',
'django-online-status==0.1.0',
|
{"golden_diff": "diff --git a/portal/autoconfig.py b/portal/autoconfig.py\n--- a/portal/autoconfig.py\n+++ b/portal/autoconfig.py\n@@ -74,7 +74,6 @@\n },\n 'PIPELINE_CSS_COMPRESSOR': None,\n 'INSTALLED_APPS': [\n- 'cms',\n 'game',\n 'pipeline',\n 'portal',\n@@ -114,10 +113,6 @@\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'deploy.middleware.exceptionlogging.ExceptionLoggingMiddleware',\n- 'cms.middleware.user.CurrentUserMiddleware',\n- 'cms.middleware.page.CurrentPageMiddleware',\n- 'cms.middleware.toolbar.ToolbarMiddleware',\n- 'cms.middleware.language.LanguageCookieMiddleware',\n 'portal.middleware.ratelimit_login_attempts.RateLimitLoginAttemptsMiddleware',\n 'django_otp.middleware.OTPMiddleware',\n ],\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -29,28 +29,10 @@\n 'urllib3==1.10.4',\n 'requests==2.7.0',\n \n- 'django-cms==3.1.2',\n-\n 'django-classy-tags==0.6.1',\n 'django-treebeard==3.0',\n 'django-sekizai==0.8.2',\n- 'djangocms-admin-style==0.2.8',\n \n- 'djangocms-text-ckeditor==2.6.0',\n- 'djangocms-link==1.6.2',\n- 'djangocms-snippet==1.5',\n- 'djangocms-style==1.5',\n- 'djangocms-column==1.5',\n- 'djangocms-grid==1.2',\n- 'djangocms-oembed==0.5',\n- 'djangocms-table==1.2',\n- 'djangocms-file==0.1',\n- 'djangocms_flash==0.2.0',\n- 'djangocms_googlemap==0.3',\n- 'djangocms_inherit==0.1',\n- 'djangocms_picture==0.1',\n- 'djangocms_teaser==0.1',\n- 'djangocms_video==0.1',\n 'django-online-status==0.1.0',\n", "issue": "CMS upgrade\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom setuptools import find_packages, setup\nimport versioneer\n\n\nsetup(name='codeforlife-portal',\n cmdclass=versioneer.get_cmdclass(),\n version=versioneer.get_version(),\n packages=find_packages(),\n include_package_data=True,\n install_requires=[\n 'django==1.8.2',\n 'django-appconf==1.0.1',\n 'django-countries==3.4.1',\n 'djangorestframework==3.1.3',\n 'django-jquery==1.9.1',\n 'django-autoconfig==0.3.6',\n 'django-pipeline==1.5.4',\n 'django-recaptcha==1.3.1', # 1.4 dropped support for < 1.11\n\n 'pyyaml==3.10',\n 'rapid-router >= 1.0.0.post.dev1',\n 'six==1.9.0',\n 'docutils==0.12',\n 'reportlab==3.2.0',\n 'postcodes==0.1',\n 'django-formtools==1.0',\n 'django-two-factor-auth==1.2.0',\n 'urllib3==1.10.4',\n 'requests==2.7.0',\n\n 'django-cms==3.1.2',\n\n 'django-classy-tags==0.6.1',\n 'django-treebeard==3.0',\n 'django-sekizai==0.8.2',\n 'djangocms-admin-style==0.2.8',\n\n 'djangocms-text-ckeditor==2.6.0',\n 'djangocms-link==1.6.2',\n 'djangocms-snippet==1.5',\n 'djangocms-style==1.5',\n 'djangocms-column==1.5',\n 'djangocms-grid==1.2',\n 'djangocms-oembed==0.5',\n 'djangocms-table==1.2',\n 'djangocms-file==0.1',\n 'djangocms_flash==0.2.0',\n 'djangocms_googlemap==0.3',\n 'djangocms_inherit==0.1',\n 'djangocms_picture==0.1',\n 'djangocms_teaser==0.1',\n 'djangocms_video==0.1',\n 'django-online-status==0.1.0',\n\n\n 'Pillow==2.9.0',\n 'django-reversion==1.9.3',\n 'sqlparse',\n 'libsass',\n ],\n tests_require=[\n 'django-setuptest',\n 'django-selenium-clean==0.2.1',\n 'responses==0.4.0',\n 'selenium==2.48.0',\n ],\n test_suite='setuptest.setuptest.SetupTestSuite',\n zip_safe=False,\n )\n", "path": "setup.py"}, {"content": "# -*- coding: utf-8 -*-\n# Code for Life\n#\n# Copyright (C) 2018, Ocado Innovation Limited\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n# ADDITIONAL TERMS \u2013 Section 7 GNU General Public Licence\n#\n# This licence does not grant any right, title or interest in any \u201cOcado\u201d logos,\n# trade names or the trademark \u201cOcado\u201d or any other trademarks or domain names\n# owned by Ocado Innovation Limited or the Ocado group of companies or any other\n# distinctive brand features of \u201cOcado\u201d as may be secured from time to time. You\n# must not distribute any modification of this program using the trademark\n# \u201cOcado\u201d or claim any affiliation or association with Ocado or its employees.\n#\n# You are not authorised to use the name Ocado (or any of its trade names) or\n# the names of any author or contributor in advertising or for publicity purposes\n# pertaining to the distribution of this program, without the prior written\n# authorisation of Ocado.\n#\n# Any propagation, distribution or conveyance of this program must include this\n# copyright notice and these terms. You must not misrepresent the origins of this\n# program; modified versions of the program must be marked as such and not\n# identified as the original program.\n'''Portal autoconfig'''\nimport os\n\nfrom django_autoconfig.autoconfig import OrderingRelationship\n\n\nDEFAULT_SETTINGS = {\n 'AUTOCONFIG_INDEX_VIEW': 'home',\n 'LANGUAGE_CODE': 'en-gb',\n 'SITE_ID': 1,\n 'MEDIA_ROOT': os.path.join(os.path.join(os.path.dirname(__file__), 'static'), 'email_media/')\n}\n\nSETTINGS = {\n 'AUTOCONFIG_DISABLED_APPS': [\n 'django_otp',\n 'django_otp.plugins.otp_static',\n 'django_otp.plugins.otp_totp',\n ],\n 'PIPELINE_COMPILERS': (\n 'pipeline.compilers.sass.SASSCompiler',\n ),\n 'PIPELINE_CSS': {\n 'css': {\n 'source_filenames': (\n 'portal/sass/bootstrap.scss',\n 'portal/sass/colorbox.scss',\n 'portal/sass/styles.scss',\n ),\n 'output_filename': 'portal.css',\n },\n 'base': {\n 'source_filenames': (\n 'portal/sass/old_styles.scss',\n ),\n 'output_filename': 'base.css',\n },\n },\n 'PIPELINE_CSS_COMPRESSOR': None,\n 'INSTALLED_APPS': [\n 'cms',\n 'game',\n 'pipeline',\n 'portal',\n 'ratelimit',\n 'django.contrib.admin',\n 'django.contrib.admindocs',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.sites',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'jquery',\n 'django_otp',\n 'django_otp.plugins.otp_static',\n 'django_otp.plugins.otp_totp',\n 'sekizai', # for javascript and css management\n 'treebeard',\n 'two_factor',\n ],\n 'LANGUAGES': [\n ('en-gb', 'English'),\n ],\n 'STATICFILES_FINDERS': [\n 'pipeline.finders.PipelineFinder',\n ],\n 'STATICFILES_STORAGE': 'pipeline.storage.PipelineStorage',\n 'MESSAGE_STORAGE': 'django.contrib.messages.storage.session.SessionStorage',\n 'MIDDLEWARE_CLASSES': [\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.locale.LocaleMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'online_status.middleware.OnlineStatusMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'deploy.middleware.exceptionlogging.ExceptionLoggingMiddleware',\n 'cms.middleware.user.CurrentUserMiddleware',\n 'cms.middleware.page.CurrentPageMiddleware',\n 'cms.middleware.toolbar.ToolbarMiddleware',\n 'cms.middleware.language.LanguageCookieMiddleware',\n 'portal.middleware.ratelimit_login_attempts.RateLimitLoginAttemptsMiddleware',\n 'django_otp.middleware.OTPMiddleware',\n ],\n\n 'TEMPLATES': [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.contrib.auth.context_processors.auth',\n 'django.template.context_processors.request',\n 'django.contrib.messages.context_processors.messages',\n 'sekizai.context_processors.sekizai',\n ]\n }\n }\n ],\n\n 'CODEFORLIFE_WEBSITE': 'www.codeforlife.education',\n\n 'CLOUD_STORAGE_PREFIX': '//storage.googleapis.com/codeforlife-assets/',\n\n 'LOGGING': {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'handlers': {\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n },\n },\n 'loggers': {\n 'two_factor': {\n 'handlers': ['console'],\n 'level': 'INFO',\n }\n }\n },\n\n 'RAPID_ROUTER_EARLY_ACCESS_FUNCTION_NAME': 'portal.beta.has_beta_access',\n}\n\nRELATIONSHIPS = [\n OrderingRelationship(\n 'MIDDLEWARE_CLASSES',\n 'cms.middleware.toolbar.ToolbarMiddleware',\n after=[\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n ],\n add_missing=False,\n ),\n OrderingRelationship(\n 'MIDDLEWARE_CLASSES',\n 'online_status.middleware.OnlineStatusMiddleware',\n after=[\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n ],\n add_missing=False,\n ),\n OrderingRelationship(\n 'MIDDLEWARE_CLASSES',\n 'django_otp.middleware.OTPMiddleware',\n after=[\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n ],\n add_missing=False,\n ),\n]\n\ntry:\n import django_pandasso\n SETTINGS['INSTALLED_APPS'].append('django_pandasso')\n SETTINGS['INSTALLED_APPS'].append('social.apps.django_app.default')\nexcept ImportError:\n pass\n", "path": "portal/autoconfig.py"}]}
| 3,264 | 542 |
gh_patches_debug_29686
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-1842
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better error message when BLAS is expected in the Easyblock but the toolchain does not provide it
I tried to build SuperLU in GCCcore and got the following error:
```
$ eb SAIGE-0.35.8.8-foss-2019a-R-3.6.0.eb -Tr
== temporary log file in case of crash /scratch/branfosj-admin/eb-5y3HuT/easybuild-HPGR5T.log
== resolving dependencies ...
== processing EasyBuild easyconfig /rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-easyconfigs/easybuild/easyconfigs/s/SuperLU/SuperLU-5.2.1-GCCcore-8.2.0.eb
== building and installing SuperLU/5.2.1-GCCcore-8.2.0...
>> installation prefix: /rds/bear-apps/devel/2019a/branfosj-eb-4/EL7/EL7-cascadelake/software/SuperLU/5.2.1-GCCcore-8.2.0
== fetching files...
>> sources:
>> /rds/bear-sysadmin/configmgmt/easybuild/sources/s/SuperLU/superlu_5.2.1.tar.gz [SHA256: 28fb66d6107ee66248d5cf508c79de03d0621852a0ddeba7301801d3d859f463]
== creating build dir, resetting environment...
>> build dir: /dev/shm/build-branfosj-admin/branfosj-admin-4/SuperLU/5.2.1/GCCcore-8.2.0
== unpacking...
>> running command:
[started at: 2019-10-14 13:48:47]
[output logged in /scratch/branfosj-admin/eb-5y3HuT/easybuild-run_cmd-3y3GN5.log]
tar xzf /rds/bear-sysadmin/configmgmt/easybuild/sources/s/SuperLU/superlu_5.2.1.tar.gz
>> command completed: exit 0, ran in < 1s
== patching...
== preparing...
>> loading toolchain module: GCCcore/8.2.0
>> loading modules for build dependencies:
>> * CMake/3.13.3-GCCcore-8.2.0
>> (no (runtime) dependencies specified)
>> defining build environment for GCCcore/8.2.0 toolchain
== configuring...
ERROR: Traceback (most recent call last):
File "/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/main.py", line 112, in build_and_install_software
(ec_res['success'], app_log, err) = build_and_install_one(ec, init_env)
File "/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py", line 3046, in build_and_install_one
result = app.run_all_steps(run_test_cases=run_test_cases)
File "/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py", line 2956, in run_all_steps
self.run_step(step_name, step_methods)
File "/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py", line 2826, in run_step
step_method(self)()
File "/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-easyblocks/easybuild/easyblocks/s/superlu.py", line 80, in configure_step
toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]
TypeError: 'NoneType' object has no attribute '__getitem__
```
Moving SuperLU to foss fixed the issue (as per a suggestion from Boegel).
</issue>
<code>
[start of easybuild/easyblocks/s/superlu.py]
1 ##
2 # Copyright 2009-2019 Ghent University, University of Luxembourg
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing the SuperLU library, implemented as an easyblock
27
28 @author: Xavier Besseron (University of Luxembourg)
29 """
30
31 import os
32 from distutils.version import LooseVersion
33
34 from easybuild.easyblocks.generic.cmakemake import CMakeMake
35 from easybuild.framework.easyconfig import CUSTOM
36 from easybuild.tools.build_log import EasyBuildError
37 from easybuild.tools.systemtools import get_shared_lib_ext
38 from easybuild.tools.modules import get_software_root, get_software_version, get_software_libdir
39
40
41 class EB_SuperLU(CMakeMake):
42 """
43 Support for building the SuperLU library
44 """
45
46 @staticmethod
47 def extra_options():
48 """
49 Define custom easyconfig parameters for SuperLU.
50 """
51 extra_vars = {
52 'build_shared_libs': [False, "Build shared library (instead of static library)", CUSTOM],
53 }
54 return CMakeMake.extra_options(extra_vars)
55
56 def configure_step(self):
57 """
58 Set the CMake options for SuperLU
59 """
60 self.cfg['separate_build_dir'] = True
61
62 if self.cfg['build_shared_libs']:
63 self.cfg.update('configopts', '-DBUILD_SHARED_LIBS=ON')
64 self.lib_ext = get_shared_lib_ext()
65
66 else:
67 self.cfg.update('configopts', '-DBUILD_SHARED_LIBS=OFF')
68 self.lib_ext = 'a'
69
70 # Add -fPIC flag if necessary
71 pic_flag = ('OFF', 'ON')[self.toolchain.options['pic']]
72 self.cfg.update('configopts', '-DCMAKE_POSITION_INDEPENDENT_CODE=%s' % pic_flag)
73
74 # Make sure not to build the slow BLAS library included in the package
75 self.cfg.update('configopts', '-Denable_blaslib=OFF')
76
77 # Set the BLAS library to use
78 # For this, use the BLA_VENDOR option from the FindBLAS module of CMake
79 # Check for all possible values at https://cmake.org/cmake/help/latest/module/FindBLAS.html
80 toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]
81 if toolchain_blas == 'imkl':
82 imkl_version = get_software_version('imkl')
83 if LooseVersion(imkl_version) >= LooseVersion('10'):
84 # 'Intel10_64lp' -> For Intel mkl v10 64 bit,lp thread model, lp64 model
85 # It should work for Intel MKL 10 and above, as long as the library names stay the same
86 # SuperLU requires thread, 'Intel10_64lp_seq' will not work!
87 self.cfg.update('configopts', '-DBLA_VENDOR="Intel10_64lp"')
88
89 else:
90 # 'Intel' -> For older versions of mkl 32 and 64 bit
91 self.cfg.update('configopts', '-DBLA_VENDOR="Intel"')
92
93 elif toolchain_blas in ['ACML', 'ATLAS']:
94 self.cfg.update('configopts', '-DBLA_VENDOR="%s"' % toolchain_blas)
95
96 elif toolchain_blas == 'OpenBLAS':
97 # Unfortunately, OpenBLAS is not recognized by FindBLAS from CMake,
98 # we have to specify the OpenBLAS library manually
99 openblas_lib = os.path.join(get_software_root('OpenBLAS'), get_software_libdir('OpenBLAS'), "libopenblas.a")
100 self.cfg.update('configopts', '-DBLAS_LIBRARIES="%s;-pthread"' % openblas_lib)
101
102 elif toolchain_blas is None:
103 # This toolchain has no BLAS library
104 raise EasyBuildError("No BLAS library found in the toolchain")
105
106 else:
107 # This BLAS library is not supported yet
108 raise EasyBuildError("BLAS library '%s' is not supported yet", toolchain_blas)
109
110 super(EB_SuperLU, self).configure_step()
111
112 def test_step(self):
113 """
114 Run the testsuite of SuperLU
115 """
116 if self.cfg['runtest'] is None:
117 self.cfg['runtest'] = 'test'
118 super(EB_SuperLU, self).test_step()
119
120 def install_step(self):
121 """
122 Custom install procedure for SuperLU
123 """
124 super(EB_SuperLU, self).install_step()
125
126 self.libbits = 'lib'
127 if not os.path.exists(os.path.join(self.installdir, self.libbits)):
128 self.libbits = 'lib64'
129
130 if not os.path.exists(os.path.join(self.installdir, self.libbits)):
131 raise EasyBuildError("No lib or lib64 subdirectory exist in %s", self.installdir)
132
133 expected_libpath = os.path.join(self.installdir, self.libbits, "libsuperlu.%s" % self.lib_ext)
134 actual_libpath = os.path.join(self.installdir, self.libbits, "libsuperlu_%s.%s" %
135 (self.cfg['version'], self.lib_ext))
136
137 if not os.path.exists(expected_libpath):
138 try:
139 os.symlink(actual_libpath, expected_libpath)
140 except OSError as err:
141 raise EasyBuildError("Failed to create symlink '%s' -> '%s: %s", expected_libpath, actual_libpath, err)
142
143 def sanity_check_step(self):
144 """
145 Check for main library files for SuperLU
146 """
147 custom_paths = {
148 'files': ["include/supermatrix.h", os.path.join(self.libbits, "libsuperlu.%s" % self.lib_ext)],
149 'dirs': [],
150 }
151 super(EB_SuperLU, self).sanity_check_step(custom_paths=custom_paths)
152
[end of easybuild/easyblocks/s/superlu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/s/superlu.py b/easybuild/easyblocks/s/superlu.py
--- a/easybuild/easyblocks/s/superlu.py
+++ b/easybuild/easyblocks/s/superlu.py
@@ -77,7 +77,12 @@
# Set the BLAS library to use
# For this, use the BLA_VENDOR option from the FindBLAS module of CMake
# Check for all possible values at https://cmake.org/cmake/help/latest/module/FindBLAS.html
- toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]
+ toolchain_blas_list = self.toolchain.definition().get('BLAS', None)
+ if toolchain_blas_list is None:
+ # This toolchain has no BLAS library
+ raise EasyBuildError("No BLAS library found in the toolchain")
+
+ toolchain_blas = toolchain_blas_list[0]
if toolchain_blas == 'imkl':
imkl_version = get_software_version('imkl')
if LooseVersion(imkl_version) >= LooseVersion('10'):
@@ -99,10 +104,6 @@
openblas_lib = os.path.join(get_software_root('OpenBLAS'), get_software_libdir('OpenBLAS'), "libopenblas.a")
self.cfg.update('configopts', '-DBLAS_LIBRARIES="%s;-pthread"' % openblas_lib)
- elif toolchain_blas is None:
- # This toolchain has no BLAS library
- raise EasyBuildError("No BLAS library found in the toolchain")
-
else:
# This BLAS library is not supported yet
raise EasyBuildError("BLAS library '%s' is not supported yet", toolchain_blas)
|
{"golden_diff": "diff --git a/easybuild/easyblocks/s/superlu.py b/easybuild/easyblocks/s/superlu.py\n--- a/easybuild/easyblocks/s/superlu.py\n+++ b/easybuild/easyblocks/s/superlu.py\n@@ -77,7 +77,12 @@\n # Set the BLAS library to use\n # For this, use the BLA_VENDOR option from the FindBLAS module of CMake\n # Check for all possible values at https://cmake.org/cmake/help/latest/module/FindBLAS.html\n- toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]\n+ toolchain_blas_list = self.toolchain.definition().get('BLAS', None)\n+ if toolchain_blas_list is None:\n+ # This toolchain has no BLAS library\n+ raise EasyBuildError(\"No BLAS library found in the toolchain\")\n+\n+ toolchain_blas = toolchain_blas_list[0]\n if toolchain_blas == 'imkl':\n imkl_version = get_software_version('imkl')\n if LooseVersion(imkl_version) >= LooseVersion('10'):\n@@ -99,10 +104,6 @@\n openblas_lib = os.path.join(get_software_root('OpenBLAS'), get_software_libdir('OpenBLAS'), \"libopenblas.a\")\n self.cfg.update('configopts', '-DBLAS_LIBRARIES=\"%s;-pthread\"' % openblas_lib)\n \n- elif toolchain_blas is None:\n- # This toolchain has no BLAS library\n- raise EasyBuildError(\"No BLAS library found in the toolchain\")\n-\n else:\n # This BLAS library is not supported yet\n raise EasyBuildError(\"BLAS library '%s' is not supported yet\", toolchain_blas)\n", "issue": "Better error message when BLAS is expected in the Easyblock but the toolchain does not provide it\nI tried to build SuperLU in GCCcore and got the following error:\r\n```\r\n$ eb SAIGE-0.35.8.8-foss-2019a-R-3.6.0.eb -Tr\r\n== temporary log file in case of crash /scratch/branfosj-admin/eb-5y3HuT/easybuild-HPGR5T.log\r\n== resolving dependencies ...\r\n== processing EasyBuild easyconfig /rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-easyconfigs/easybuild/easyconfigs/s/SuperLU/SuperLU-5.2.1-GCCcore-8.2.0.eb\r\n== building and installing SuperLU/5.2.1-GCCcore-8.2.0...\r\n >> installation prefix: /rds/bear-apps/devel/2019a/branfosj-eb-4/EL7/EL7-cascadelake/software/SuperLU/5.2.1-GCCcore-8.2.0\r\n== fetching files...\r\n >> sources:\r\n >> /rds/bear-sysadmin/configmgmt/easybuild/sources/s/SuperLU/superlu_5.2.1.tar.gz [SHA256: 28fb66d6107ee66248d5cf508c79de03d0621852a0ddeba7301801d3d859f463]\r\n== creating build dir, resetting environment...\r\n >> build dir: /dev/shm/build-branfosj-admin/branfosj-admin-4/SuperLU/5.2.1/GCCcore-8.2.0\r\n== unpacking...\r\n >> running command:\r\n [started at: 2019-10-14 13:48:47]\r\n [output logged in /scratch/branfosj-admin/eb-5y3HuT/easybuild-run_cmd-3y3GN5.log]\r\n tar xzf /rds/bear-sysadmin/configmgmt/easybuild/sources/s/SuperLU/superlu_5.2.1.tar.gz\r\n >> command completed: exit 0, ran in < 1s\r\n== patching...\r\n== preparing...\r\n >> loading toolchain module: GCCcore/8.2.0\r\n >> loading modules for build dependencies:\r\n >> * CMake/3.13.3-GCCcore-8.2.0\r\n >> (no (runtime) dependencies specified)\r\n >> defining build environment for GCCcore/8.2.0 toolchain\r\n== configuring...\r\nERROR: Traceback (most recent call last):\r\n File \"/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/main.py\", line 112, in build_and_install_software\r\n (ec_res['success'], app_log, err) = build_and_install_one(ec, init_env)\r\n File \"/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py\", line 3046, in build_and_install_one\r\n result = app.run_all_steps(run_test_cases=run_test_cases)\r\n File \"/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py\", line 2956, in run_all_steps\r\n self.run_step(step_name, step_methods)\r\n File \"/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-framework/easybuild/framework/easyblock.py\", line 2826, in run_step\r\n step_method(self)()\r\n File \"/rds/bear-apps/devel/2019a/branfosj-eb-4/src/easybuild-easyblocks/easybuild/easyblocks/s/superlu.py\", line 80, in configure_step\r\n toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]\r\nTypeError: 'NoneType' object has no attribute '__getitem__\r\n```\r\n\r\nMoving SuperLU to foss fixed the issue (as per a suggestion from Boegel).\n", "before_files": [{"content": "##\n# Copyright 2009-2019 Ghent University, University of Luxembourg\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing the SuperLU library, implemented as an easyblock\n\n@author: Xavier Besseron (University of Luxembourg)\n\"\"\"\n\nimport os\nfrom distutils.version import LooseVersion\n\nfrom easybuild.easyblocks.generic.cmakemake import CMakeMake\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.systemtools import get_shared_lib_ext\nfrom easybuild.tools.modules import get_software_root, get_software_version, get_software_libdir\n\n\nclass EB_SuperLU(CMakeMake):\n \"\"\"\n Support for building the SuperLU library\n \"\"\"\n\n @staticmethod\n def extra_options():\n \"\"\"\n Define custom easyconfig parameters for SuperLU.\n \"\"\"\n extra_vars = {\n 'build_shared_libs': [False, \"Build shared library (instead of static library)\", CUSTOM],\n }\n return CMakeMake.extra_options(extra_vars)\n\n def configure_step(self):\n \"\"\"\n Set the CMake options for SuperLU\n \"\"\"\n self.cfg['separate_build_dir'] = True\n\n if self.cfg['build_shared_libs']:\n self.cfg.update('configopts', '-DBUILD_SHARED_LIBS=ON')\n self.lib_ext = get_shared_lib_ext()\n\n else:\n self.cfg.update('configopts', '-DBUILD_SHARED_LIBS=OFF')\n self.lib_ext = 'a'\n\n # Add -fPIC flag if necessary\n pic_flag = ('OFF', 'ON')[self.toolchain.options['pic']]\n self.cfg.update('configopts', '-DCMAKE_POSITION_INDEPENDENT_CODE=%s' % pic_flag)\n\n # Make sure not to build the slow BLAS library included in the package\n self.cfg.update('configopts', '-Denable_blaslib=OFF')\n\n # Set the BLAS library to use\n # For this, use the BLA_VENDOR option from the FindBLAS module of CMake\n # Check for all possible values at https://cmake.org/cmake/help/latest/module/FindBLAS.html\n toolchain_blas = self.toolchain.definition().get('BLAS', None)[0]\n if toolchain_blas == 'imkl':\n imkl_version = get_software_version('imkl')\n if LooseVersion(imkl_version) >= LooseVersion('10'):\n # 'Intel10_64lp' -> For Intel mkl v10 64 bit,lp thread model, lp64 model\n # It should work for Intel MKL 10 and above, as long as the library names stay the same\n # SuperLU requires thread, 'Intel10_64lp_seq' will not work!\n self.cfg.update('configopts', '-DBLA_VENDOR=\"Intel10_64lp\"')\n\n else:\n # 'Intel' -> For older versions of mkl 32 and 64 bit\n self.cfg.update('configopts', '-DBLA_VENDOR=\"Intel\"')\n\n elif toolchain_blas in ['ACML', 'ATLAS']:\n self.cfg.update('configopts', '-DBLA_VENDOR=\"%s\"' % toolchain_blas)\n\n elif toolchain_blas == 'OpenBLAS':\n # Unfortunately, OpenBLAS is not recognized by FindBLAS from CMake,\n # we have to specify the OpenBLAS library manually\n openblas_lib = os.path.join(get_software_root('OpenBLAS'), get_software_libdir('OpenBLAS'), \"libopenblas.a\")\n self.cfg.update('configopts', '-DBLAS_LIBRARIES=\"%s;-pthread\"' % openblas_lib)\n\n elif toolchain_blas is None:\n # This toolchain has no BLAS library\n raise EasyBuildError(\"No BLAS library found in the toolchain\")\n\n else:\n # This BLAS library is not supported yet\n raise EasyBuildError(\"BLAS library '%s' is not supported yet\", toolchain_blas)\n\n super(EB_SuperLU, self).configure_step()\n\n def test_step(self):\n \"\"\"\n Run the testsuite of SuperLU\n \"\"\"\n if self.cfg['runtest'] is None:\n self.cfg['runtest'] = 'test'\n super(EB_SuperLU, self).test_step()\n\n def install_step(self):\n \"\"\"\n Custom install procedure for SuperLU\n \"\"\"\n super(EB_SuperLU, self).install_step()\n\n self.libbits = 'lib'\n if not os.path.exists(os.path.join(self.installdir, self.libbits)):\n self.libbits = 'lib64'\n\n if not os.path.exists(os.path.join(self.installdir, self.libbits)):\n raise EasyBuildError(\"No lib or lib64 subdirectory exist in %s\", self.installdir)\n\n expected_libpath = os.path.join(self.installdir, self.libbits, \"libsuperlu.%s\" % self.lib_ext)\n actual_libpath = os.path.join(self.installdir, self.libbits, \"libsuperlu_%s.%s\" %\n (self.cfg['version'], self.lib_ext))\n\n if not os.path.exists(expected_libpath):\n try:\n os.symlink(actual_libpath, expected_libpath)\n except OSError as err:\n raise EasyBuildError(\"Failed to create symlink '%s' -> '%s: %s\", expected_libpath, actual_libpath, err)\n\n def sanity_check_step(self):\n \"\"\"\n Check for main library files for SuperLU\n \"\"\"\n custom_paths = {\n 'files': [\"include/supermatrix.h\", os.path.join(self.libbits, \"libsuperlu.%s\" % self.lib_ext)],\n 'dirs': [],\n }\n super(EB_SuperLU, self).sanity_check_step(custom_paths=custom_paths)\n", "path": "easybuild/easyblocks/s/superlu.py"}]}
| 3,416 | 408 |
gh_patches_debug_17836
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-1023
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Hide "Number of chants" and "Number of melodies" fields in Source admin
On the Source detail page in the admin area, we are currently displaying the number of melodies and number of chants for the source.

We only use this information behind the scenes, so we should not allow users to edit this field since they will be automatically updated as chants or melodies are added/removed from the Source.
Earlier, I found an issue where these fields weren't being updated correctly. I found this because the only place we can see the number of chants and melodies is in the admin area. For this reason and for future situations like this, I think we should make these fields `read_only` instead of hidden altogether.
</issue>
<code>
[start of django/cantusdb_project/main_app/admin.py]
1 from django.contrib import admin
2 from main_app.models import *
3 from main_app.forms import (
4 AdminCenturyForm,
5 AdminChantForm,
6 AdminFeastForm,
7 AdminGenreForm,
8 AdminNotationForm,
9 AdminOfficeForm,
10 AdminProvenanceForm,
11 AdminRismSiglumForm,
12 AdminSegmentForm,
13 AdminSequenceForm,
14 AdminSourceForm,
15 )
16
17 # these fields should not be editable by all classes
18 EXCLUDE = (
19 "created_by",
20 "last_updated_by",
21 "json_info",
22 )
23
24
25 class BaseModelAdmin(admin.ModelAdmin):
26 exclude = EXCLUDE
27
28 # if an object is created in the admin interface, assign the user to the created_by field
29 # else if an object is updated in the admin interface, assign the user to the last_updated_by field
30 def save_model(self, request, obj, form, change):
31 if change:
32 obj.last_updated_by = request.user
33 else:
34 obj.created_by = request.user
35 super().save_model(request, obj, form, change)
36
37
38 class CenturyAdmin(BaseModelAdmin):
39 search_fields = ("name",)
40 form = AdminCenturyForm
41
42
43 class ChantAdmin(BaseModelAdmin):
44 @admin.display(description="Source Siglum")
45 def get_source_siglum(self, obj):
46 if obj.source:
47 return obj.source.siglum
48
49 list_display = (
50 "incipit",
51 "get_source_siglum",
52 "genre",
53 )
54 search_fields = (
55 "title",
56 "incipit",
57 "cantus_id",
58 "id",
59 )
60 list_filter = (
61 "genre",
62 "office",
63 )
64 exclude = EXCLUDE + (
65 "col1",
66 "col2",
67 "col3",
68 "next_chant",
69 "s_sequence",
70 "is_last_chant_in_feast",
71 "visible_status",
72 "date",
73 )
74 form = AdminChantForm
75 raw_id_fields = (
76 "source",
77 "feast",
78 )
79 ordering = ("source__siglum",)
80
81
82 class FeastAdmin(BaseModelAdmin):
83 search_fields = (
84 "name",
85 "feast_code",
86 )
87 list_display = (
88 "name",
89 "month",
90 "day",
91 "feast_code",
92 )
93 form = AdminFeastForm
94
95
96 class GenreAdmin(BaseModelAdmin):
97 search_fields = ("name",)
98 form = AdminGenreForm
99
100
101 class NotationAdmin(BaseModelAdmin):
102 search_fields = ("name",)
103 form = AdminNotationForm
104
105
106 class OfficeAdmin(BaseModelAdmin):
107 search_fields = ("name",)
108 form = AdminOfficeForm
109
110
111 class ProvenanceAdmin(BaseModelAdmin):
112 search_fields = ("name",)
113 form = AdminProvenanceForm
114
115
116 class RismSiglumAdmin(BaseModelAdmin):
117 search_fields = ("name",)
118 form = AdminRismSiglumForm
119
120
121 class SegmentAdmin(BaseModelAdmin):
122 search_fields = ("name",)
123 form = AdminSegmentForm
124
125
126 class SequenceAdmin(BaseModelAdmin):
127 @admin.display(description="Source Siglum")
128 def get_source_siglum(self, obj):
129 if obj.source:
130 return obj.source.siglum
131
132 search_fields = (
133 "title",
134 "incipit",
135 "cantus_id",
136 "id",
137 )
138 exclude = EXCLUDE + (
139 "c_sequence",
140 "next_chant",
141 "is_last_chant_in_feast",
142 "visible_status",
143 )
144 list_display = ("incipit", "get_source_siglum", "genre")
145 list_filter = (
146 "genre",
147 "office",
148 )
149 raw_id_fields = (
150 "source",
151 "feast",
152 )
153 ordering = ("source__siglum",)
154 form = AdminSequenceForm
155
156
157 class SourceAdmin(BaseModelAdmin):
158 # These search fields are also available on the user-source inline relationship in the user admin page
159 search_fields = (
160 "siglum",
161 "title",
162 "id",
163 )
164 # from the Django docs:
165 # Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript “filter” interface
166 # that allows searching within the options. The unselected and selected options appear in two boxes side by side.
167 filter_horizontal = (
168 "century",
169 "notation",
170 "current_editors",
171 "inventoried_by",
172 "full_text_entered_by",
173 "melodies_entered_by",
174 "proofreaders",
175 "other_editors",
176 )
177
178 list_display = (
179 "title",
180 "siglum",
181 "id",
182 )
183
184 list_filter = (
185 "full_source",
186 "segment",
187 "source_status",
188 "published",
189 "century",
190 )
191
192 ordering = ("siglum",)
193
194 form = AdminSourceForm
195
196
197 admin.site.register(Century, CenturyAdmin)
198 admin.site.register(Chant, ChantAdmin)
199 admin.site.register(Feast, FeastAdmin)
200 admin.site.register(Genre, GenreAdmin)
201 admin.site.register(Notation, NotationAdmin)
202 admin.site.register(Office, OfficeAdmin)
203 admin.site.register(Provenance, ProvenanceAdmin)
204 admin.site.register(RismSiglum, RismSiglumAdmin)
205 admin.site.register(Segment, SegmentAdmin)
206 admin.site.register(Sequence, SequenceAdmin)
207 admin.site.register(Source, SourceAdmin)
208
[end of django/cantusdb_project/main_app/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/cantusdb_project/main_app/admin.py b/django/cantusdb_project/main_app/admin.py
--- a/django/cantusdb_project/main_app/admin.py
+++ b/django/cantusdb_project/main_app/admin.py
@@ -57,6 +57,12 @@
"cantus_id",
"id",
)
+
+ readonly_fields = (
+ "date_created",
+ "date_updated",
+ )
+
list_filter = (
"genre",
"office",
@@ -161,6 +167,12 @@
"title",
"id",
)
+ readonly_fields = (
+ "number_of_chants",
+ "number_of_melodies",
+ "date_created",
+ "date_updated",
+ )
# from the Django docs:
# Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript “filter” interface
# that allows searching within the options. The unselected and selected options appear in two boxes side by side.
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/admin.py b/django/cantusdb_project/main_app/admin.py\n--- a/django/cantusdb_project/main_app/admin.py\n+++ b/django/cantusdb_project/main_app/admin.py\n@@ -57,6 +57,12 @@\n \"cantus_id\",\n \"id\",\n )\n+\n+ readonly_fields = (\n+ \"date_created\",\n+ \"date_updated\",\n+ )\n+\n list_filter = (\n \"genre\",\n \"office\",\n@@ -161,6 +167,12 @@\n \"title\",\n \"id\",\n )\n+ readonly_fields = (\n+ \"number_of_chants\",\n+ \"number_of_melodies\",\n+ \"date_created\",\n+ \"date_updated\",\n+ )\n # from the Django docs:\n # Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript \u201cfilter\u201d interface\n # that allows searching within the options. The unselected and selected options appear in two boxes side by side.\n", "issue": "Hide \"Number of chants\" and \"Number of melodies\" fields in Source admin\nOn the Source detail page in the admin area, we are currently displaying the number of melodies and number of chants for the source.\r\n\r\n\r\nWe only use this information behind the scenes, so we should not allow users to edit this field since they will be automatically updated as chants or melodies are added/removed from the Source.\r\n\r\nEarlier, I found an issue where these fields weren't being updated correctly. I found this because the only place we can see the number of chants and melodies is in the admin area. For this reason and for future situations like this, I think we should make these fields `read_only` instead of hidden altogether.\n", "before_files": [{"content": "from django.contrib import admin\nfrom main_app.models import *\nfrom main_app.forms import (\n AdminCenturyForm,\n AdminChantForm,\n AdminFeastForm,\n AdminGenreForm,\n AdminNotationForm,\n AdminOfficeForm,\n AdminProvenanceForm,\n AdminRismSiglumForm,\n AdminSegmentForm,\n AdminSequenceForm,\n AdminSourceForm,\n)\n\n# these fields should not be editable by all classes\nEXCLUDE = (\n \"created_by\",\n \"last_updated_by\",\n \"json_info\",\n)\n\n\nclass BaseModelAdmin(admin.ModelAdmin):\n exclude = EXCLUDE\n\n # if an object is created in the admin interface, assign the user to the created_by field\n # else if an object is updated in the admin interface, assign the user to the last_updated_by field\n def save_model(self, request, obj, form, change):\n if change:\n obj.last_updated_by = request.user\n else:\n obj.created_by = request.user\n super().save_model(request, obj, form, change)\n\n\nclass CenturyAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminCenturyForm\n\n\nclass ChantAdmin(BaseModelAdmin):\n @admin.display(description=\"Source Siglum\")\n def get_source_siglum(self, obj):\n if obj.source:\n return obj.source.siglum\n\n list_display = (\n \"incipit\",\n \"get_source_siglum\",\n \"genre\",\n )\n search_fields = (\n \"title\",\n \"incipit\",\n \"cantus_id\",\n \"id\",\n )\n list_filter = (\n \"genre\",\n \"office\",\n )\n exclude = EXCLUDE + (\n \"col1\",\n \"col2\",\n \"col3\",\n \"next_chant\",\n \"s_sequence\",\n \"is_last_chant_in_feast\",\n \"visible_status\",\n \"date\",\n )\n form = AdminChantForm\n raw_id_fields = (\n \"source\",\n \"feast\",\n )\n ordering = (\"source__siglum\",)\n\n\nclass FeastAdmin(BaseModelAdmin):\n search_fields = (\n \"name\",\n \"feast_code\",\n )\n list_display = (\n \"name\",\n \"month\",\n \"day\",\n \"feast_code\",\n )\n form = AdminFeastForm\n\n\nclass GenreAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminGenreForm\n\n\nclass NotationAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminNotationForm\n\n\nclass OfficeAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminOfficeForm\n\n\nclass ProvenanceAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminProvenanceForm\n\n\nclass RismSiglumAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminRismSiglumForm\n\n\nclass SegmentAdmin(BaseModelAdmin):\n search_fields = (\"name\",)\n form = AdminSegmentForm\n\n\nclass SequenceAdmin(BaseModelAdmin):\n @admin.display(description=\"Source Siglum\")\n def get_source_siglum(self, obj):\n if obj.source:\n return obj.source.siglum\n\n search_fields = (\n \"title\",\n \"incipit\",\n \"cantus_id\",\n \"id\",\n )\n exclude = EXCLUDE + (\n \"c_sequence\",\n \"next_chant\",\n \"is_last_chant_in_feast\",\n \"visible_status\",\n )\n list_display = (\"incipit\", \"get_source_siglum\", \"genre\")\n list_filter = (\n \"genre\",\n \"office\",\n )\n raw_id_fields = (\n \"source\",\n \"feast\",\n )\n ordering = (\"source__siglum\",)\n form = AdminSequenceForm\n\n\nclass SourceAdmin(BaseModelAdmin):\n # These search fields are also available on the user-source inline relationship in the user admin page\n search_fields = (\n \"siglum\",\n \"title\",\n \"id\",\n )\n # from the Django docs:\n # Adding a ManyToManyField to this list will instead use a nifty unobtrusive JavaScript \u201cfilter\u201d interface\n # that allows searching within the options. The unselected and selected options appear in two boxes side by side.\n filter_horizontal = (\n \"century\",\n \"notation\",\n \"current_editors\",\n \"inventoried_by\",\n \"full_text_entered_by\",\n \"melodies_entered_by\",\n \"proofreaders\",\n \"other_editors\",\n )\n\n list_display = (\n \"title\",\n \"siglum\",\n \"id\",\n )\n\n list_filter = (\n \"full_source\",\n \"segment\",\n \"source_status\",\n \"published\",\n \"century\",\n )\n\n ordering = (\"siglum\",)\n\n form = AdminSourceForm\n\n\nadmin.site.register(Century, CenturyAdmin)\nadmin.site.register(Chant, ChantAdmin)\nadmin.site.register(Feast, FeastAdmin)\nadmin.site.register(Genre, GenreAdmin)\nadmin.site.register(Notation, NotationAdmin)\nadmin.site.register(Office, OfficeAdmin)\nadmin.site.register(Provenance, ProvenanceAdmin)\nadmin.site.register(RismSiglum, RismSiglumAdmin)\nadmin.site.register(Segment, SegmentAdmin)\nadmin.site.register(Sequence, SequenceAdmin)\nadmin.site.register(Source, SourceAdmin)\n", "path": "django/cantusdb_project/main_app/admin.py"}]}
| 2,456 | 236 |
gh_patches_debug_8483
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSpeech-2171
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
切换英文语音合成报错 get_input_ids() got an unexpected keyword argument 'get_tone_ids'
要切换成英文语音合成时,更改了/paddlespeech/server/conf/application.yaml这个配置文件中的tts_python里面的声学模型和声码器,声学模型用的是fastspeech2_ljspeech,声码器用的pwgan_ljspeech,并且lang改为en,但是报错 get_input_ids() got an unexpected keyword argument 'get_tone_ids'
</issue>
<code>
[start of paddlespeech/server/engine/engine_warmup.py]
1 # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import time
15
16 from paddlespeech.cli.log import logger
17 from paddlespeech.server.engine.engine_pool import get_engine_pool
18
19
20 def warm_up(engine_and_type: str, warm_up_time: int=3) -> bool:
21 engine_pool = get_engine_pool()
22
23 if "tts" in engine_and_type:
24 tts_engine = engine_pool['tts']
25 flag_online = False
26 if tts_engine.lang == 'zh':
27 sentence = "您好,欢迎使用语音合成服务。"
28 elif tts_engine.lang == 'en':
29 sentence = "Hello and welcome to the speech synthesis service."
30 else:
31 logger.error("tts engine only support lang: zh or en.")
32 sys.exit(-1)
33
34 if engine_and_type == "tts_python":
35 from paddlespeech.server.engine.tts.python.tts_engine import PaddleTTSConnectionHandler
36 elif engine_and_type == "tts_inference":
37 from paddlespeech.server.engine.tts.paddleinference.tts_engine import PaddleTTSConnectionHandler
38 elif engine_and_type == "tts_online":
39 from paddlespeech.server.engine.tts.online.python.tts_engine import PaddleTTSConnectionHandler
40 flag_online = True
41 elif engine_and_type == "tts_online-onnx":
42 from paddlespeech.server.engine.tts.online.onnx.tts_engine import PaddleTTSConnectionHandler
43 flag_online = True
44 else:
45 logger.error("Please check tte engine type.")
46
47 try:
48 logger.debug("Start to warm up tts engine.")
49 for i in range(warm_up_time):
50 connection_handler = PaddleTTSConnectionHandler(tts_engine)
51 if flag_online:
52 for wav in connection_handler.infer(
53 text=sentence,
54 lang=tts_engine.lang,
55 am=tts_engine.config.am):
56 logger.debug(
57 f"The first response time of the {i} warm up: {connection_handler.first_response_time} s"
58 )
59 break
60
61 else:
62 st = time.time()
63 connection_handler.infer(text=sentence)
64 et = time.time()
65 logger.debug(
66 f"The response time of the {i} warm up: {et - st} s")
67 except Exception as e:
68 logger.error("Failed to warm up on tts engine.")
69 logger.error(e)
70 return False
71
72 else:
73 pass
74
75 return True
76
[end of paddlespeech/server/engine/engine_warmup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/paddlespeech/server/engine/engine_warmup.py b/paddlespeech/server/engine/engine_warmup.py
--- a/paddlespeech/server/engine/engine_warmup.py
+++ b/paddlespeech/server/engine/engine_warmup.py
@@ -60,7 +60,10 @@
else:
st = time.time()
- connection_handler.infer(text=sentence)
+ connection_handler.infer(
+ text=sentence,
+ lang=tts_engine.lang,
+ am=tts_engine.config.am)
et = time.time()
logger.debug(
f"The response time of the {i} warm up: {et - st} s")
|
{"golden_diff": "diff --git a/paddlespeech/server/engine/engine_warmup.py b/paddlespeech/server/engine/engine_warmup.py\n--- a/paddlespeech/server/engine/engine_warmup.py\n+++ b/paddlespeech/server/engine/engine_warmup.py\n@@ -60,7 +60,10 @@\n \n else:\n st = time.time()\n- connection_handler.infer(text=sentence)\n+ connection_handler.infer(\n+ text=sentence,\n+ lang=tts_engine.lang,\n+ am=tts_engine.config.am)\n et = time.time()\n logger.debug(\n f\"The response time of the {i} warm up: {et - st} s\")\n", "issue": "\u5207\u6362\u82f1\u6587\u8bed\u97f3\u5408\u6210\u62a5\u9519 get_input_ids() got an unexpected keyword argument 'get_tone_ids'\n\u8981\u5207\u6362\u6210\u82f1\u6587\u8bed\u97f3\u5408\u6210\u65f6\uff0c\u66f4\u6539\u4e86/paddlespeech/server/conf/application.yaml\u8fd9\u4e2a\u914d\u7f6e\u6587\u4ef6\u4e2d\u7684tts_python\u91cc\u9762\u7684\u58f0\u5b66\u6a21\u578b\u548c\u58f0\u7801\u5668\uff0c\u58f0\u5b66\u6a21\u578b\u7528\u7684\u662ffastspeech2_ljspeech\uff0c\u58f0\u7801\u5668\u7528\u7684pwgan_ljspeech\uff0c\u5e76\u4e14lang\u6539\u4e3aen\uff0c\u4f46\u662f\u62a5\u9519 get_input_ids() got an unexpected keyword argument 'get_tone_ids'\n", "before_files": [{"content": "# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport time\n\nfrom paddlespeech.cli.log import logger\nfrom paddlespeech.server.engine.engine_pool import get_engine_pool\n\n\ndef warm_up(engine_and_type: str, warm_up_time: int=3) -> bool:\n engine_pool = get_engine_pool()\n\n if \"tts\" in engine_and_type:\n tts_engine = engine_pool['tts']\n flag_online = False\n if tts_engine.lang == 'zh':\n sentence = \"\u60a8\u597d\uff0c\u6b22\u8fce\u4f7f\u7528\u8bed\u97f3\u5408\u6210\u670d\u52a1\u3002\"\n elif tts_engine.lang == 'en':\n sentence = \"Hello and welcome to the speech synthesis service.\"\n else:\n logger.error(\"tts engine only support lang: zh or en.\")\n sys.exit(-1)\n\n if engine_and_type == \"tts_python\":\n from paddlespeech.server.engine.tts.python.tts_engine import PaddleTTSConnectionHandler\n elif engine_and_type == \"tts_inference\":\n from paddlespeech.server.engine.tts.paddleinference.tts_engine import PaddleTTSConnectionHandler\n elif engine_and_type == \"tts_online\":\n from paddlespeech.server.engine.tts.online.python.tts_engine import PaddleTTSConnectionHandler\n flag_online = True\n elif engine_and_type == \"tts_online-onnx\":\n from paddlespeech.server.engine.tts.online.onnx.tts_engine import PaddleTTSConnectionHandler\n flag_online = True\n else:\n logger.error(\"Please check tte engine type.\")\n\n try:\n logger.debug(\"Start to warm up tts engine.\")\n for i in range(warm_up_time):\n connection_handler = PaddleTTSConnectionHandler(tts_engine)\n if flag_online:\n for wav in connection_handler.infer(\n text=sentence,\n lang=tts_engine.lang,\n am=tts_engine.config.am):\n logger.debug(\n f\"The first response time of the {i} warm up: {connection_handler.first_response_time} s\"\n )\n break\n\n else:\n st = time.time()\n connection_handler.infer(text=sentence)\n et = time.time()\n logger.debug(\n f\"The response time of the {i} warm up: {et - st} s\")\n except Exception as e:\n logger.error(\"Failed to warm up on tts engine.\")\n logger.error(e)\n return False\n\n else:\n pass\n\n return True\n", "path": "paddlespeech/server/engine/engine_warmup.py"}]}
| 1,438 | 149 |
gh_patches_debug_35491
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-4874
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Proposal: aws ecr get-login-password
This is a proposal for a new AWS CLI command for ECR
```
$ aws ecr get-login-password
cGFzc3dvcmQ=
```
This command can be used in the following ways:
```
$ aws ecr get-login-password | docker login --username AWS --password-stdin 111111111111.dkr.ecr.us-west-2.amazonaws.com
Login Succeeded
$ docker login --username AWS --password "$(aws ecr get-login-password)" 111111111111.dkr.ecr.us-west-2.amazonaws.com
Login Succeeded
```
This idea has been previously proposed by @theY4Kman https://github.com/aws/aws-cli/issues/2875#issuecomment-433565983 and @kojiromike https://github.com/aws/aws-cli/issues/3687#issue-374397564
</issue>
<code>
[start of awscli/customizations/ecr.py]
1 # Copyright 2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"). You
4 # may not use this file except in compliance with the License. A copy of
5 # the License is located at
6 #
7 # http://aws.amazon.com/apache2.0/
8 #
9 # or in the "license" file accompanying this file. This file is
10 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific
12 # language governing permissions and limitations under the License.
13 from awscli.customizations.commands import BasicCommand
14 from awscli.customizations.utils import create_client_from_parsed_globals
15
16 from base64 import b64decode
17 import sys
18
19
20 def register_ecr_commands(cli):
21 cli.register('building-command-table.ecr', _inject_get_login)
22
23
24 def _inject_get_login(command_table, session, **kwargs):
25 command_table['get-login'] = ECRLogin(session)
26
27
28 class ECRLogin(BasicCommand):
29 """Log in with docker login"""
30 NAME = 'get-login'
31
32 DESCRIPTION = BasicCommand.FROM_FILE('ecr/get-login_description.rst')
33
34 ARG_TABLE = [
35 {
36 'name': 'registry-ids',
37 'help_text': 'A list of AWS account IDs that correspond to the '
38 'Amazon ECR registries that you want to log in to.',
39 'required': False,
40 'nargs': '+'
41 },
42 {
43 'name': 'include-email',
44 'action': 'store_true',
45 'group_name': 'include-email',
46 'dest': 'include_email',
47 'default': True,
48 'required': False,
49 'help_text': (
50 "Specify if the '-e' flag should be included in the "
51 "'docker login' command. The '-e' option has been deprecated "
52 "and is removed in docker version 17.06 and later. You must "
53 "specify --no-include-email if you're using docker version "
54 "17.06 or later. The default behavior is to include the "
55 "'-e' flag in the 'docker login' output."),
56 },
57 {
58 'name': 'no-include-email',
59 'help_text': 'Include email arg',
60 'action': 'store_false',
61 'default': True,
62 'group_name': 'include-email',
63 'dest': 'include_email',
64 'required': False,
65 },
66 ]
67
68 def _run_main(self, parsed_args, parsed_globals):
69 ecr_client = create_client_from_parsed_globals(
70 self._session, 'ecr', parsed_globals)
71 if not parsed_args.registry_ids:
72 result = ecr_client.get_authorization_token()
73 else:
74 result = ecr_client.get_authorization_token(
75 registryIds=parsed_args.registry_ids)
76 for auth in result['authorizationData']:
77 auth_token = b64decode(auth['authorizationToken']).decode()
78 username, password = auth_token.split(':')
79 command = ['docker', 'login', '-u', username, '-p', password]
80 if parsed_args.include_email:
81 command.extend(['-e', 'none'])
82 command.append(auth['proxyEndpoint'])
83 sys.stdout.write(' '.join(command))
84 sys.stdout.write('\n')
85 return 0
86
[end of awscli/customizations/ecr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/awscli/customizations/ecr.py b/awscli/customizations/ecr.py
--- a/awscli/customizations/ecr.py
+++ b/awscli/customizations/ecr.py
@@ -18,15 +18,16 @@
def register_ecr_commands(cli):
- cli.register('building-command-table.ecr', _inject_get_login)
+ cli.register('building-command-table.ecr', _inject_commands)
-def _inject_get_login(command_table, session, **kwargs):
+def _inject_commands(command_table, session, **kwargs):
command_table['get-login'] = ECRLogin(session)
+ command_table['get-login-password'] = ECRGetLoginPassword(session)
class ECRLogin(BasicCommand):
- """Log in with docker login"""
+ """Log in with 'docker login'"""
NAME = 'get-login'
DESCRIPTION = BasicCommand.FROM_FILE('ecr/get-login_description.rst')
@@ -49,8 +50,8 @@
'help_text': (
"Specify if the '-e' flag should be included in the "
"'docker login' command. The '-e' option has been deprecated "
- "and is removed in docker version 17.06 and later. You must "
- "specify --no-include-email if you're using docker version "
+ "and is removed in Docker version 17.06 and later. You must "
+ "specify --no-include-email if you're using Docker version "
"17.06 or later. The default behavior is to include the "
"'-e' flag in the 'docker login' output."),
},
@@ -83,3 +84,24 @@
sys.stdout.write(' '.join(command))
sys.stdout.write('\n')
return 0
+
+
+class ECRGetLoginPassword(BasicCommand):
+ """Get a password to be used with container clients such as Docker"""
+ NAME = 'get-login-password'
+
+ DESCRIPTION = BasicCommand.FROM_FILE(
+ 'ecr/get-login-password_description.rst')
+
+ def _run_main(self, parsed_args, parsed_globals):
+ ecr_client = create_client_from_parsed_globals(
+ self._session,
+ 'ecr',
+ parsed_globals)
+ result = ecr_client.get_authorization_token()
+ auth = result['authorizationData'][0]
+ auth_token = b64decode(auth['authorizationToken']).decode()
+ _, password = auth_token.split(':')
+ sys.stdout.write(password)
+ sys.stdout.write('\n')
+ return 0
|
{"golden_diff": "diff --git a/awscli/customizations/ecr.py b/awscli/customizations/ecr.py\n--- a/awscli/customizations/ecr.py\n+++ b/awscli/customizations/ecr.py\n@@ -18,15 +18,16 @@\n \n \n def register_ecr_commands(cli):\n- cli.register('building-command-table.ecr', _inject_get_login)\n+ cli.register('building-command-table.ecr', _inject_commands)\n \n \n-def _inject_get_login(command_table, session, **kwargs):\n+def _inject_commands(command_table, session, **kwargs):\n command_table['get-login'] = ECRLogin(session)\n+ command_table['get-login-password'] = ECRGetLoginPassword(session)\n \n \n class ECRLogin(BasicCommand):\n- \"\"\"Log in with docker login\"\"\"\n+ \"\"\"Log in with 'docker login'\"\"\"\n NAME = 'get-login'\n \n DESCRIPTION = BasicCommand.FROM_FILE('ecr/get-login_description.rst')\n@@ -49,8 +50,8 @@\n 'help_text': (\n \"Specify if the '-e' flag should be included in the \"\n \"'docker login' command. The '-e' option has been deprecated \"\n- \"and is removed in docker version 17.06 and later. You must \"\n- \"specify --no-include-email if you're using docker version \"\n+ \"and is removed in Docker version 17.06 and later. You must \"\n+ \"specify --no-include-email if you're using Docker version \"\n \"17.06 or later. The default behavior is to include the \"\n \"'-e' flag in the 'docker login' output.\"),\n },\n@@ -83,3 +84,24 @@\n sys.stdout.write(' '.join(command))\n sys.stdout.write('\\n')\n return 0\n+\n+\n+class ECRGetLoginPassword(BasicCommand):\n+ \"\"\"Get a password to be used with container clients such as Docker\"\"\"\n+ NAME = 'get-login-password'\n+\n+ DESCRIPTION = BasicCommand.FROM_FILE(\n+ 'ecr/get-login-password_description.rst')\n+\n+ def _run_main(self, parsed_args, parsed_globals):\n+ ecr_client = create_client_from_parsed_globals(\n+ self._session,\n+ 'ecr',\n+ parsed_globals)\n+ result = ecr_client.get_authorization_token()\n+ auth = result['authorizationData'][0]\n+ auth_token = b64decode(auth['authorizationToken']).decode()\n+ _, password = auth_token.split(':')\n+ sys.stdout.write(password)\n+ sys.stdout.write('\\n')\n+ return 0\n", "issue": "Proposal: aws ecr get-login-password\nThis is a proposal for a new AWS CLI command for ECR\r\n\r\n```\r\n$ aws ecr get-login-password\r\ncGFzc3dvcmQ=\r\n```\r\n\r\nThis command can be used in the following ways:\r\n\r\n```\r\n$ aws ecr get-login-password | docker login --username AWS --password-stdin 111111111111.dkr.ecr.us-west-2.amazonaws.com\r\nLogin Succeeded\r\n\r\n$ docker login --username AWS --password \"$(aws ecr get-login-password)\" 111111111111.dkr.ecr.us-west-2.amazonaws.com\r\nLogin Succeeded\r\n```\r\n\r\nThis idea has been previously proposed by @theY4Kman https://github.com/aws/aws-cli/issues/2875#issuecomment-433565983 and @kojiromike https://github.com/aws/aws-cli/issues/3687#issue-374397564\n", "before_files": [{"content": "# Copyright 2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nfrom awscli.customizations.commands import BasicCommand\nfrom awscli.customizations.utils import create_client_from_parsed_globals\n\nfrom base64 import b64decode\nimport sys\n\n\ndef register_ecr_commands(cli):\n cli.register('building-command-table.ecr', _inject_get_login)\n\n\ndef _inject_get_login(command_table, session, **kwargs):\n command_table['get-login'] = ECRLogin(session)\n\n\nclass ECRLogin(BasicCommand):\n \"\"\"Log in with docker login\"\"\"\n NAME = 'get-login'\n\n DESCRIPTION = BasicCommand.FROM_FILE('ecr/get-login_description.rst')\n\n ARG_TABLE = [\n {\n 'name': 'registry-ids',\n 'help_text': 'A list of AWS account IDs that correspond to the '\n 'Amazon ECR registries that you want to log in to.',\n 'required': False,\n 'nargs': '+'\n },\n {\n 'name': 'include-email',\n 'action': 'store_true',\n 'group_name': 'include-email',\n 'dest': 'include_email',\n 'default': True,\n 'required': False,\n 'help_text': (\n \"Specify if the '-e' flag should be included in the \"\n \"'docker login' command. The '-e' option has been deprecated \"\n \"and is removed in docker version 17.06 and later. You must \"\n \"specify --no-include-email if you're using docker version \"\n \"17.06 or later. The default behavior is to include the \"\n \"'-e' flag in the 'docker login' output.\"),\n },\n {\n 'name': 'no-include-email',\n 'help_text': 'Include email arg',\n 'action': 'store_false',\n 'default': True,\n 'group_name': 'include-email',\n 'dest': 'include_email',\n 'required': False,\n },\n ]\n\n def _run_main(self, parsed_args, parsed_globals):\n ecr_client = create_client_from_parsed_globals(\n self._session, 'ecr', parsed_globals)\n if not parsed_args.registry_ids:\n result = ecr_client.get_authorization_token()\n else:\n result = ecr_client.get_authorization_token(\n registryIds=parsed_args.registry_ids)\n for auth in result['authorizationData']:\n auth_token = b64decode(auth['authorizationToken']).decode()\n username, password = auth_token.split(':')\n command = ['docker', 'login', '-u', username, '-p', password]\n if parsed_args.include_email:\n command.extend(['-e', 'none'])\n command.append(auth['proxyEndpoint'])\n sys.stdout.write(' '.join(command))\n sys.stdout.write('\\n')\n return 0\n", "path": "awscli/customizations/ecr.py"}]}
| 1,650 | 576 |
gh_patches_debug_24070
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1727
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pre-commit fails for git >=2.25 if repo is on a Windows subst drive
Cross reference for another issue with same apparent root cause: https://github.com/microsoft/vscode/issues/100274#issuecomment-646499795
Issue observed with pre-commit==2.7.1 and git 2.27.
Issue resolved with downgrading git to 2.21 (I only have access to certain versions on my work machine).
Steps to recreate for pre-commit (some taken from the above cross-reference):
- Install git >= 2.25 on Windows
- Create a subst drive (`mkdir C:\subst_dir && subst Z: C:\subst_dir`)
- Create a git repo in there (`mkdir Z:\repo && cd /d Z:\repo && git init`)
- Add some python code, configure pre-commit, and run pre-commit.
Failure observed: `An unexpected error has occurred: ValueError: path is on mount 'Z:', start on mount 'C:'`
Diagnosis - it appears that the use of `git rev-parse --show-toplevel` in `pre_commit.main.get_root()` is suffering the same issue as seen in cross-referenced ticket; git will "see through" the subst command and rather than return a path on the subst-defined Z: drive, it will return the path from the C: drive. With this, after `pre_commit.main._adjust_args_and_chdir()` calls `pre_commit.main.get_root()` and does a chdir to the returned location, the following call to `os.path.relpath(args.config)` then fails with the ValueError as above, because it sees the path to the config file being on `Z:` but the current location being on `C:`.
Afraid I don't have a suggested resolution but wanted to flag this up. I'm not too familiar with Windows systems and I'm a long way from Admin access on my work machine so opportunities for testing are limited; this was discovered as my scratch space for repos is a subst drive.
</issue>
<code>
[start of pre_commit/git.py]
1 import logging
2 import os.path
3 import sys
4 from typing import Dict
5 from typing import List
6 from typing import MutableMapping
7 from typing import Optional
8 from typing import Set
9
10 from pre_commit.errors import FatalError
11 from pre_commit.util import CalledProcessError
12 from pre_commit.util import cmd_output
13 from pre_commit.util import cmd_output_b
14
15
16 logger = logging.getLogger(__name__)
17
18
19 def zsplit(s: str) -> List[str]:
20 s = s.strip('\0')
21 if s:
22 return s.split('\0')
23 else:
24 return []
25
26
27 def no_git_env(
28 _env: Optional[MutableMapping[str, str]] = None,
29 ) -> Dict[str, str]:
30 # Too many bugs dealing with environment variables and GIT:
31 # https://github.com/pre-commit/pre-commit/issues/300
32 # In git 2.6.3 (maybe others), git exports GIT_WORK_TREE while running
33 # pre-commit hooks
34 # In git 1.9.1 (maybe others), git exports GIT_DIR and GIT_INDEX_FILE
35 # while running pre-commit hooks in submodules.
36 # GIT_DIR: Causes git clone to clone wrong thing
37 # GIT_INDEX_FILE: Causes 'error invalid object ...' during commit
38 _env = _env if _env is not None else os.environ
39 return {
40 k: v for k, v in _env.items()
41 if not k.startswith('GIT_') or
42 k in {
43 'GIT_EXEC_PATH', 'GIT_SSH', 'GIT_SSH_COMMAND', 'GIT_SSL_CAINFO',
44 'GIT_SSL_NO_VERIFY',
45 }
46 }
47
48
49 def get_root() -> str:
50 try:
51 root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()
52 except CalledProcessError:
53 raise FatalError(
54 'git failed. Is it installed, and are you in a Git repository '
55 'directory?',
56 )
57 else:
58 if root == '': # pragma: no cover (old git)
59 raise FatalError(
60 'git toplevel unexpectedly empty! make sure you are not '
61 'inside the `.git` directory of your repository.',
62 )
63 else:
64 return root
65
66
67 def get_git_dir(git_root: str = '.') -> str:
68 opts = ('--git-common-dir', '--git-dir')
69 _, out, _ = cmd_output('git', 'rev-parse', *opts, cwd=git_root)
70 for line, opt in zip(out.splitlines(), opts):
71 if line != opt: # pragma: no branch (git < 2.5)
72 return os.path.normpath(os.path.join(git_root, line))
73 else:
74 raise AssertionError('unreachable: no git dir')
75
76
77 def get_remote_url(git_root: str) -> str:
78 _, out, _ = cmd_output('git', 'config', 'remote.origin.url', cwd=git_root)
79 return out.strip()
80
81
82 def is_in_merge_conflict() -> bool:
83 git_dir = get_git_dir('.')
84 return (
85 os.path.exists(os.path.join(git_dir, 'MERGE_MSG')) and
86 os.path.exists(os.path.join(git_dir, 'MERGE_HEAD'))
87 )
88
89
90 def parse_merge_msg_for_conflicts(merge_msg: bytes) -> List[str]:
91 # Conflicted files start with tabs
92 return [
93 line.lstrip(b'#').strip().decode()
94 for line in merge_msg.splitlines()
95 # '#\t' for git 2.4.1
96 if line.startswith((b'\t', b'#\t'))
97 ]
98
99
100 def get_conflicted_files() -> Set[str]:
101 logger.info('Checking merge-conflict files only.')
102 # Need to get the conflicted files from the MERGE_MSG because they could
103 # have resolved the conflict by choosing one side or the other
104 with open(os.path.join(get_git_dir('.'), 'MERGE_MSG'), 'rb') as f:
105 merge_msg = f.read()
106 merge_conflict_filenames = parse_merge_msg_for_conflicts(merge_msg)
107
108 # This will get the rest of the changes made after the merge.
109 # If they resolved the merge conflict by choosing a mesh of both sides
110 # this will also include the conflicted files
111 tree_hash = cmd_output('git', 'write-tree')[1].strip()
112 merge_diff_filenames = zsplit(
113 cmd_output(
114 'git', 'diff', '--name-only', '--no-ext-diff', '-z',
115 '-m', tree_hash, 'HEAD', 'MERGE_HEAD',
116 )[1],
117 )
118 return set(merge_conflict_filenames) | set(merge_diff_filenames)
119
120
121 def get_staged_files(cwd: Optional[str] = None) -> List[str]:
122 return zsplit(
123 cmd_output(
124 'git', 'diff', '--staged', '--name-only', '--no-ext-diff', '-z',
125 # Everything except for D
126 '--diff-filter=ACMRTUXB',
127 cwd=cwd,
128 )[1],
129 )
130
131
132 def intent_to_add_files() -> List[str]:
133 _, stdout, _ = cmd_output(
134 'git', 'status', '--ignore-submodules', '--porcelain', '-z',
135 )
136 parts = list(reversed(zsplit(stdout)))
137 intent_to_add = []
138 while parts:
139 line = parts.pop()
140 status, filename = line[:3], line[3:]
141 if status[0] in {'C', 'R'}: # renames / moves have an additional arg
142 parts.pop()
143 if status[1] == 'A':
144 intent_to_add.append(filename)
145 return intent_to_add
146
147
148 def get_all_files() -> List[str]:
149 return zsplit(cmd_output('git', 'ls-files', '-z')[1])
150
151
152 def get_changed_files(old: str, new: str) -> List[str]:
153 return zsplit(
154 cmd_output(
155 'git', 'diff', '--name-only', '--no-ext-diff', '-z',
156 f'{old}...{new}',
157 )[1],
158 )
159
160
161 def head_rev(remote: str) -> str:
162 _, out, _ = cmd_output('git', 'ls-remote', '--exit-code', remote, 'HEAD')
163 return out.split()[0]
164
165
166 def has_diff(*args: str, repo: str = '.') -> bool:
167 cmd = ('git', 'diff', '--quiet', '--no-ext-diff', *args)
168 return cmd_output_b(*cmd, cwd=repo, retcode=None)[0] == 1
169
170
171 def has_core_hookpaths_set() -> bool:
172 _, out, _ = cmd_output_b('git', 'config', 'core.hooksPath', retcode=None)
173 return bool(out.strip())
174
175
176 def init_repo(path: str, remote: str) -> None:
177 if os.path.isdir(remote):
178 remote = os.path.abspath(remote)
179
180 env = no_git_env()
181 # avoid the user's template so that hooks do not recurse
182 cmd_output_b('git', 'init', '--template=', path, env=env)
183 cmd_output_b('git', 'remote', 'add', 'origin', remote, cwd=path, env=env)
184
185
186 def commit(repo: str = '.') -> None:
187 env = no_git_env()
188 name, email = 'pre-commit', '[email protected]'
189 env['GIT_AUTHOR_NAME'] = env['GIT_COMMITTER_NAME'] = name
190 env['GIT_AUTHOR_EMAIL'] = env['GIT_COMMITTER_EMAIL'] = email
191 cmd = ('git', 'commit', '--no-edit', '--no-gpg-sign', '-n', '-minit')
192 cmd_output_b(*cmd, cwd=repo, env=env)
193
194
195 def git_path(name: str, repo: str = '.') -> str:
196 _, out, _ = cmd_output('git', 'rev-parse', '--git-path', name, cwd=repo)
197 return os.path.join(repo, out.strip())
198
199
200 def check_for_cygwin_mismatch() -> None:
201 """See https://github.com/pre-commit/pre-commit/issues/354"""
202 if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)
203 is_cygwin_python = sys.platform == 'cygwin'
204 try:
205 toplevel = get_root()
206 except FatalError: # skip the check if we're not in a git repo
207 return
208 is_cygwin_git = toplevel.startswith('/')
209
210 if is_cygwin_python ^ is_cygwin_git:
211 exe_type = {True: '(cygwin)', False: '(windows)'}
212 logger.warn(
213 f'pre-commit has detected a mix of cygwin python / git\n'
214 f'This combination is not supported, it is likely you will '
215 f'receive an error later in the program.\n'
216 f'Make sure to use cygwin git+python while using cygwin\n'
217 f'These can be installed through the cygwin installer.\n'
218 f' - python {exe_type[is_cygwin_python]}\n'
219 f' - git {exe_type[is_cygwin_git]}\n',
220 )
221
[end of pre_commit/git.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/git.py b/pre_commit/git.py
--- a/pre_commit/git.py
+++ b/pre_commit/git.py
@@ -47,21 +47,26 @@
def get_root() -> str:
+ # Git 2.25 introduced a change to "rev-parse --show-toplevel" that exposed
+ # underlying volumes for Windows drives mapped with SUBST. We use
+ # "rev-parse --show-cdup" to get the appropriate path, but must perform
+ # an extra check to see if we are in the .git directory.
try:
- root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()
+ root = os.path.realpath(
+ cmd_output('git', 'rev-parse', '--show-cdup')[1].strip(),
+ )
+ git_dir = os.path.realpath(get_git_dir())
except CalledProcessError:
raise FatalError(
'git failed. Is it installed, and are you in a Git repository '
'directory?',
)
- else:
- if root == '': # pragma: no cover (old git)
- raise FatalError(
- 'git toplevel unexpectedly empty! make sure you are not '
- 'inside the `.git` directory of your repository.',
- )
- else:
- return root
+ if os.path.commonpath((root, git_dir)) == git_dir:
+ raise FatalError(
+ 'git toplevel unexpectedly empty! make sure you are not '
+ 'inside the `.git` directory of your repository.',
+ )
+ return root
def get_git_dir(git_root: str = '.') -> str:
|
{"golden_diff": "diff --git a/pre_commit/git.py b/pre_commit/git.py\n--- a/pre_commit/git.py\n+++ b/pre_commit/git.py\n@@ -47,21 +47,26 @@\n \n \n def get_root() -> str:\n+ # Git 2.25 introduced a change to \"rev-parse --show-toplevel\" that exposed\n+ # underlying volumes for Windows drives mapped with SUBST. We use\n+ # \"rev-parse --show-cdup\" to get the appropriate path, but must perform\n+ # an extra check to see if we are in the .git directory.\n try:\n- root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()\n+ root = os.path.realpath(\n+ cmd_output('git', 'rev-parse', '--show-cdup')[1].strip(),\n+ )\n+ git_dir = os.path.realpath(get_git_dir())\n except CalledProcessError:\n raise FatalError(\n 'git failed. Is it installed, and are you in a Git repository '\n 'directory?',\n )\n- else:\n- if root == '': # pragma: no cover (old git)\n- raise FatalError(\n- 'git toplevel unexpectedly empty! make sure you are not '\n- 'inside the `.git` directory of your repository.',\n- )\n- else:\n- return root\n+ if os.path.commonpath((root, git_dir)) == git_dir:\n+ raise FatalError(\n+ 'git toplevel unexpectedly empty! make sure you are not '\n+ 'inside the `.git` directory of your repository.',\n+ )\n+ return root\n \n \n def get_git_dir(git_root: str = '.') -> str:\n", "issue": "Pre-commit fails for git >=2.25 if repo is on a Windows subst drive\nCross reference for another issue with same apparent root cause: https://github.com/microsoft/vscode/issues/100274#issuecomment-646499795\r\n\r\nIssue observed with pre-commit==2.7.1 and git 2.27.\r\nIssue resolved with downgrading git to 2.21 (I only have access to certain versions on my work machine).\r\n\r\nSteps to recreate for pre-commit (some taken from the above cross-reference):\r\n\r\n- Install git >= 2.25 on Windows\r\n\r\n- Create a subst drive (`mkdir C:\\subst_dir && subst Z: C:\\subst_dir`)\r\n\r\n- Create a git repo in there (`mkdir Z:\\repo && cd /d Z:\\repo && git init`)\r\n\r\n- Add some python code, configure pre-commit, and run pre-commit.\r\n\r\nFailure observed: `An unexpected error has occurred: ValueError: path is on mount 'Z:', start on mount 'C:'`\r\n\r\nDiagnosis - it appears that the use of `git rev-parse --show-toplevel` in `pre_commit.main.get_root()` is suffering the same issue as seen in cross-referenced ticket; git will \"see through\" the subst command and rather than return a path on the subst-defined Z: drive, it will return the path from the C: drive. With this, after `pre_commit.main._adjust_args_and_chdir()` calls `pre_commit.main.get_root()` and does a chdir to the returned location, the following call to `os.path.relpath(args.config)` then fails with the ValueError as above, because it sees the path to the config file being on `Z:` but the current location being on `C:`.\r\n\r\nAfraid I don't have a suggested resolution but wanted to flag this up. I'm not too familiar with Windows systems and I'm a long way from Admin access on my work machine so opportunities for testing are limited; this was discovered as my scratch space for repos is a subst drive.\r\n\n", "before_files": [{"content": "import logging\nimport os.path\nimport sys\nfrom typing import Dict\nfrom typing import List\nfrom typing import MutableMapping\nfrom typing import Optional\nfrom typing import Set\n\nfrom pre_commit.errors import FatalError\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef zsplit(s: str) -> List[str]:\n s = s.strip('\\0')\n if s:\n return s.split('\\0')\n else:\n return []\n\n\ndef no_git_env(\n _env: Optional[MutableMapping[str, str]] = None,\n) -> Dict[str, str]:\n # Too many bugs dealing with environment variables and GIT:\n # https://github.com/pre-commit/pre-commit/issues/300\n # In git 2.6.3 (maybe others), git exports GIT_WORK_TREE while running\n # pre-commit hooks\n # In git 1.9.1 (maybe others), git exports GIT_DIR and GIT_INDEX_FILE\n # while running pre-commit hooks in submodules.\n # GIT_DIR: Causes git clone to clone wrong thing\n # GIT_INDEX_FILE: Causes 'error invalid object ...' during commit\n _env = _env if _env is not None else os.environ\n return {\n k: v for k, v in _env.items()\n if not k.startswith('GIT_') or\n k in {\n 'GIT_EXEC_PATH', 'GIT_SSH', 'GIT_SSH_COMMAND', 'GIT_SSL_CAINFO',\n 'GIT_SSL_NO_VERIFY',\n }\n }\n\n\ndef get_root() -> str:\n try:\n root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()\n except CalledProcessError:\n raise FatalError(\n 'git failed. Is it installed, and are you in a Git repository '\n 'directory?',\n )\n else:\n if root == '': # pragma: no cover (old git)\n raise FatalError(\n 'git toplevel unexpectedly empty! make sure you are not '\n 'inside the `.git` directory of your repository.',\n )\n else:\n return root\n\n\ndef get_git_dir(git_root: str = '.') -> str:\n opts = ('--git-common-dir', '--git-dir')\n _, out, _ = cmd_output('git', 'rev-parse', *opts, cwd=git_root)\n for line, opt in zip(out.splitlines(), opts):\n if line != opt: # pragma: no branch (git < 2.5)\n return os.path.normpath(os.path.join(git_root, line))\n else:\n raise AssertionError('unreachable: no git dir')\n\n\ndef get_remote_url(git_root: str) -> str:\n _, out, _ = cmd_output('git', 'config', 'remote.origin.url', cwd=git_root)\n return out.strip()\n\n\ndef is_in_merge_conflict() -> bool:\n git_dir = get_git_dir('.')\n return (\n os.path.exists(os.path.join(git_dir, 'MERGE_MSG')) and\n os.path.exists(os.path.join(git_dir, 'MERGE_HEAD'))\n )\n\n\ndef parse_merge_msg_for_conflicts(merge_msg: bytes) -> List[str]:\n # Conflicted files start with tabs\n return [\n line.lstrip(b'#').strip().decode()\n for line in merge_msg.splitlines()\n # '#\\t' for git 2.4.1\n if line.startswith((b'\\t', b'#\\t'))\n ]\n\n\ndef get_conflicted_files() -> Set[str]:\n logger.info('Checking merge-conflict files only.')\n # Need to get the conflicted files from the MERGE_MSG because they could\n # have resolved the conflict by choosing one side or the other\n with open(os.path.join(get_git_dir('.'), 'MERGE_MSG'), 'rb') as f:\n merge_msg = f.read()\n merge_conflict_filenames = parse_merge_msg_for_conflicts(merge_msg)\n\n # This will get the rest of the changes made after the merge.\n # If they resolved the merge conflict by choosing a mesh of both sides\n # this will also include the conflicted files\n tree_hash = cmd_output('git', 'write-tree')[1].strip()\n merge_diff_filenames = zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n '-m', tree_hash, 'HEAD', 'MERGE_HEAD',\n )[1],\n )\n return set(merge_conflict_filenames) | set(merge_diff_filenames)\n\n\ndef get_staged_files(cwd: Optional[str] = None) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--staged', '--name-only', '--no-ext-diff', '-z',\n # Everything except for D\n '--diff-filter=ACMRTUXB',\n cwd=cwd,\n )[1],\n )\n\n\ndef intent_to_add_files() -> List[str]:\n _, stdout, _ = cmd_output(\n 'git', 'status', '--ignore-submodules', '--porcelain', '-z',\n )\n parts = list(reversed(zsplit(stdout)))\n intent_to_add = []\n while parts:\n line = parts.pop()\n status, filename = line[:3], line[3:]\n if status[0] in {'C', 'R'}: # renames / moves have an additional arg\n parts.pop()\n if status[1] == 'A':\n intent_to_add.append(filename)\n return intent_to_add\n\n\ndef get_all_files() -> List[str]:\n return zsplit(cmd_output('git', 'ls-files', '-z')[1])\n\n\ndef get_changed_files(old: str, new: str) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n f'{old}...{new}',\n )[1],\n )\n\n\ndef head_rev(remote: str) -> str:\n _, out, _ = cmd_output('git', 'ls-remote', '--exit-code', remote, 'HEAD')\n return out.split()[0]\n\n\ndef has_diff(*args: str, repo: str = '.') -> bool:\n cmd = ('git', 'diff', '--quiet', '--no-ext-diff', *args)\n return cmd_output_b(*cmd, cwd=repo, retcode=None)[0] == 1\n\n\ndef has_core_hookpaths_set() -> bool:\n _, out, _ = cmd_output_b('git', 'config', 'core.hooksPath', retcode=None)\n return bool(out.strip())\n\n\ndef init_repo(path: str, remote: str) -> None:\n if os.path.isdir(remote):\n remote = os.path.abspath(remote)\n\n env = no_git_env()\n # avoid the user's template so that hooks do not recurse\n cmd_output_b('git', 'init', '--template=', path, env=env)\n cmd_output_b('git', 'remote', 'add', 'origin', remote, cwd=path, env=env)\n\n\ndef commit(repo: str = '.') -> None:\n env = no_git_env()\n name, email = 'pre-commit', '[email protected]'\n env['GIT_AUTHOR_NAME'] = env['GIT_COMMITTER_NAME'] = name\n env['GIT_AUTHOR_EMAIL'] = env['GIT_COMMITTER_EMAIL'] = email\n cmd = ('git', 'commit', '--no-edit', '--no-gpg-sign', '-n', '-minit')\n cmd_output_b(*cmd, cwd=repo, env=env)\n\n\ndef git_path(name: str, repo: str = '.') -> str:\n _, out, _ = cmd_output('git', 'rev-parse', '--git-path', name, cwd=repo)\n return os.path.join(repo, out.strip())\n\n\ndef check_for_cygwin_mismatch() -> None:\n \"\"\"See https://github.com/pre-commit/pre-commit/issues/354\"\"\"\n if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)\n is_cygwin_python = sys.platform == 'cygwin'\n try:\n toplevel = get_root()\n except FatalError: # skip the check if we're not in a git repo\n return\n is_cygwin_git = toplevel.startswith('/')\n\n if is_cygwin_python ^ is_cygwin_git:\n exe_type = {True: '(cygwin)', False: '(windows)'}\n logger.warn(\n f'pre-commit has detected a mix of cygwin python / git\\n'\n f'This combination is not supported, it is likely you will '\n f'receive an error later in the program.\\n'\n f'Make sure to use cygwin git+python while using cygwin\\n'\n f'These can be installed through the cygwin installer.\\n'\n f' - python {exe_type[is_cygwin_python]}\\n'\n f' - git {exe_type[is_cygwin_git]}\\n',\n )\n", "path": "pre_commit/git.py"}]}
| 3,511 | 372 |
gh_patches_debug_13272
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1133
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add `Matplotlib` framework classifier to `setup.py`
`Matplotlib` now has a [trove classifier on pypi](https://twitter.com/matplotlib/status/1235216347925286913). We can add:
```python
classifiers = [
'Framework :: Matplotlib',
]
```
to `arviz`'s `setup.py` to acknowledge that it is part of `Matplotlib` ecosystem.
I believe that `arviz` currently doesn't have any classifiers ([there are many!](https://pypi.org/classifiers/)). We could add something like the following to `setup.py`:
```python
classifiers = [
'Framework :: Matplotlib',
'Intended Audience :: Science/Research',
'License :: OSI Approved :: Apache Software License'
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Topic :: Scientific/Engineering :: Visualization',
]
```
I'm not sure if you would say if `arviz` is:
```
'Development Status :: 5 - Production/Stable',
```
or
```
'Development Status :: 4 - Beta',
```
There may be thoughts on other classifiers to add, but I can quickly put together a PR for this
</issue>
<code>
[start of setup.py]
1 import codecs
2 import os
3 import re
4
5 import setuptools
6 from setuptools import setup, find_packages
7 from setuptools.command.install import install
8 from setuptools.command.develop import develop
9
10
11 PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))
12 REQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, "requirements.txt")
13 REQUIREMENTS_OPTIONAL_FILE = os.path.join(PROJECT_ROOT, "requirements-optional.txt")
14 REQUIREMENTS_DEV_FILE = os.path.join(PROJECT_ROOT, "requirements-dev.txt")
15 README_FILE = os.path.join(PROJECT_ROOT, "README.md")
16 VERSION_FILE = os.path.join(PROJECT_ROOT, "arviz", "__init__.py")
17
18
19 def get_requirements():
20 with codecs.open(REQUIREMENTS_FILE) as buff:
21 return buff.read().splitlines()
22
23
24 def get_requirements_dev():
25 with codecs.open(REQUIREMENTS_DEV_FILE) as buff:
26 return buff.read().splitlines()
27
28
29 def get_requirements_optional():
30 with codecs.open(REQUIREMENTS_OPTIONAL_FILE) as buff:
31 return buff.read().splitlines()
32
33
34 def get_long_description():
35 with codecs.open(README_FILE, "rt") as buff:
36 return buff.read()
37
38
39 def get_version():
40 lines = open(VERSION_FILE, "rt").readlines()
41 version_regex = r"^__version__ = ['\"]([^'\"]*)['\"]"
42 for line in lines:
43 mo = re.search(version_regex, line, re.M)
44 if mo:
45 return mo.group(1)
46 raise RuntimeError("Unable to find version in %s." % (VERSION_FILE,))
47
48
49 setup(
50 name="arviz",
51 license="Apache-2.0",
52 version=get_version(),
53 description="Exploratory analysis of Bayesian models",
54 author="ArviZ Developers",
55 url="http://github.com/arviz-devs/arviz",
56 packages=find_packages(),
57 install_requires=get_requirements(),
58 extras_require=dict(all=get_requirements_optional()), # test=get_requirements_dev(),
59 long_description=get_long_description(),
60 long_description_content_type="text/markdown",
61 include_package_data=True,
62 )
63
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -59,4 +59,19 @@
long_description=get_long_description(),
long_description_content_type="text/markdown",
include_package_data=True,
+ classifiers=[
+ "Development Status :: 4 - Beta",
+ "Framework :: Matplotlib",
+ "Intended Audience :: Science/Research",
+ "Intended Audience :: Education",
+ "License :: OSI Approved :: Apache Software License",
+ "Programming Language :: Python",
+ "Programming Language :: Python :: 3",
+ "Programming Language :: Python :: 3.6",
+ "Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
+ "Topic :: Scientific/Engineering",
+ "Topic :: Scientific/Engineering :: Visualization",
+ "Topic :: Scientific/Engineering :: Mathematics",
+ ],
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -59,4 +59,19 @@\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n+ classifiers=[\n+ \"Development Status :: 4 - Beta\",\n+ \"Framework :: Matplotlib\",\n+ \"Intended Audience :: Science/Research\",\n+ \"Intended Audience :: Education\",\n+ \"License :: OSI Approved :: Apache Software License\",\n+ \"Programming Language :: Python\",\n+ \"Programming Language :: Python :: 3\",\n+ \"Programming Language :: Python :: 3.6\",\n+ \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n+ \"Topic :: Scientific/Engineering\",\n+ \"Topic :: Scientific/Engineering :: Visualization\",\n+ \"Topic :: Scientific/Engineering :: Mathematics\",\n+ ],\n )\n", "issue": "Add `Matplotlib` framework classifier to `setup.py`\n`Matplotlib` now has a [trove classifier on pypi](https://twitter.com/matplotlib/status/1235216347925286913). We can add:\r\n\r\n```python\r\nclassifiers = [\r\n 'Framework :: Matplotlib',\r\n ]\r\n```\r\nto `arviz`'s `setup.py` to acknowledge that it is part of `Matplotlib` ecosystem.\r\n\r\nI believe that `arviz` currently doesn't have any classifiers ([there are many!](https://pypi.org/classifiers/)). We could add something like the following to `setup.py`:\r\n\r\n```python\r\nclassifiers = [\r\n 'Framework :: Matplotlib',\r\n 'Intended Audience :: Science/Research',\r\n 'License :: OSI Approved :: Apache Software License'\r\n 'Programming Language :: Python',\r\n 'Programming Language :: Python :: 3',\r\n 'Programming Language :: Python :: 3.5',\r\n 'Programming Language :: Python :: 3.6',\r\n 'Programming Language :: Python :: 3.7',\r\n 'Topic :: Scientific/Engineering :: Visualization',\r\n ]\r\n```\r\n\r\nI'm not sure if you would say if `arviz` is:\r\n```\r\n'Development Status :: 5 - Production/Stable',\r\n```\r\nor\r\n```\r\n'Development Status :: 4 - Beta',\r\n```\r\n\r\nThere may be thoughts on other classifiers to add, but I can quickly put together a PR for this\n", "before_files": [{"content": "import codecs\nimport os\nimport re\n\nimport setuptools\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\n\n\nPROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))\nREQUIREMENTS_FILE = os.path.join(PROJECT_ROOT, \"requirements.txt\")\nREQUIREMENTS_OPTIONAL_FILE = os.path.join(PROJECT_ROOT, \"requirements-optional.txt\")\nREQUIREMENTS_DEV_FILE = os.path.join(PROJECT_ROOT, \"requirements-dev.txt\")\nREADME_FILE = os.path.join(PROJECT_ROOT, \"README.md\")\nVERSION_FILE = os.path.join(PROJECT_ROOT, \"arviz\", \"__init__.py\")\n\n\ndef get_requirements():\n with codecs.open(REQUIREMENTS_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_requirements_dev():\n with codecs.open(REQUIREMENTS_DEV_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_requirements_optional():\n with codecs.open(REQUIREMENTS_OPTIONAL_FILE) as buff:\n return buff.read().splitlines()\n\n\ndef get_long_description():\n with codecs.open(README_FILE, \"rt\") as buff:\n return buff.read()\n\n\ndef get_version():\n lines = open(VERSION_FILE, \"rt\").readlines()\n version_regex = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\n for line in lines:\n mo = re.search(version_regex, line, re.M)\n if mo:\n return mo.group(1)\n raise RuntimeError(\"Unable to find version in %s.\" % (VERSION_FILE,))\n\n\nsetup(\n name=\"arviz\",\n license=\"Apache-2.0\",\n version=get_version(),\n description=\"Exploratory analysis of Bayesian models\",\n author=\"ArviZ Developers\",\n url=\"http://github.com/arviz-devs/arviz\",\n packages=find_packages(),\n install_requires=get_requirements(),\n extras_require=dict(all=get_requirements_optional()), # test=get_requirements_dev(),\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n)\n", "path": "setup.py"}]}
| 1,395 | 204 |
gh_patches_debug_6966
|
rasdani/github-patches
|
git_diff
|
encode__starlette-706
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
WSGI mount error
When I mount a django application and try to access it
```
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\uvicorn\protocols\http\h11_impl.py", line 375, in run_asgi
result = await app(self.scope, self.receive, self.send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\applications.py", line 134, in __call__
await self.error_middleware(scope, receive, send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\errors.py", line 178, in __call__
raise exc from None
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\errors.py", line 156, in __call__
await self.app(scope, receive, _send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\exceptions.py", line 73, in __call__
raise exc from None
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\exceptions.py", line 62, in __call__
await self.app(scope, receive, sender)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\routing.py", line 590, in __call__
await route(scope, receive, send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\routing.py", line 352, in __call__
await self.app(scope, receive, send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\wsgi.py", line 62, in __call__
await responder(receive, send)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\wsgi.py", line 91, in __call__
await asyncio.wait_for(sender, None)
File "c:\users\abers\appdata\local\programs\python\python37\Lib\asyncio\tasks.py", line 414, in wait_for
return await fut
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\wsgi.py", line 106, in sender
await send(message)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\exceptions.py", line 59, in sender
await send(message)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\starlette\middleware\errors.py", line 153, in _send
await send(message)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\uvicorn\protocols\http\h11_impl.py", line 449, in send
status_code=status_code, headers=headers, reason=reason
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\h11\_events.py", line 47, in __init__
self.headers, _parsed=_parsed)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\h11\_headers.py", line 75, in normalize_and_validate
validate(_field_value_re, value, "Illegal header value {!r}", value)
File "C:\Users\AberS\Documents\Coding\lexiang\lebu\.venv\lib\site-packages\h11\_util.py", line 96, in validate
raise LocalProtocolError(msg)
h11._util.LocalProtocolError: Illegal header value b' sessionid=""; expires=Thu, 01 Jan 1970 00:00:00 GMT; Max-Age=0; Path=/'
```
This is my minimal implementation code, `lebu` is my django program
```python
from starlette.applications import Starlette
from starlette.middleware.wsgi import WSGIMiddleware
import uvicorn
from lebu.wsgi import application
app = Starlette(debug=True)
app.mount("/api", WSGIMiddleware(application))
if __name__ == "__main__":
uvicorn.run(app)
```
By the way, starlette version is 0.12.9
</issue>
<code>
[start of starlette/middleware/wsgi.py]
1 import asyncio
2 import io
3 import sys
4 import typing
5
6 from starlette.concurrency import run_in_threadpool
7 from starlette.types import Message, Receive, Scope, Send
8
9
10 def build_environ(scope: Scope, body: bytes) -> dict:
11 """
12 Builds a scope and request body into a WSGI environ object.
13 """
14 environ = {
15 "REQUEST_METHOD": scope["method"],
16 "SCRIPT_NAME": scope.get("root_path", ""),
17 "PATH_INFO": scope["path"],
18 "QUERY_STRING": scope["query_string"].decode("ascii"),
19 "SERVER_PROTOCOL": f"HTTP/{scope['http_version']}",
20 "wsgi.version": (1, 0),
21 "wsgi.url_scheme": scope.get("scheme", "http"),
22 "wsgi.input": io.BytesIO(body),
23 "wsgi.errors": sys.stdout,
24 "wsgi.multithread": True,
25 "wsgi.multiprocess": True,
26 "wsgi.run_once": False,
27 }
28
29 # Get server name and port - required in WSGI, not in ASGI
30 server = scope.get("server") or ("localhost", 80)
31 environ["SERVER_NAME"] = server[0]
32 environ["SERVER_PORT"] = server[1]
33
34 # Get client IP address
35 if scope.get("client"):
36 environ["REMOTE_ADDR"] = scope["client"][0]
37
38 # Go through headers and make them into environ entries
39 for name, value in scope.get("headers", []):
40 name = name.decode("latin1")
41 if name == "content-length":
42 corrected_name = "CONTENT_LENGTH"
43 elif name == "content-type":
44 corrected_name = "CONTENT_TYPE"
45 else:
46 corrected_name = f"HTTP_{name}".upper().replace("-", "_")
47 # HTTPbis say only ASCII chars are allowed in headers, but we latin1 just in case
48 value = value.decode("latin1")
49 if corrected_name in environ:
50 value = environ[corrected_name] + "," + value
51 environ[corrected_name] = value
52 return environ
53
54
55 class WSGIMiddleware:
56 def __init__(self, app: typing.Callable, workers: int = 10) -> None:
57 self.app = app
58
59 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
60 assert scope["type"] == "http"
61 responder = WSGIResponder(self.app, scope)
62 await responder(receive, send)
63
64
65 class WSGIResponder:
66 def __init__(self, app: typing.Callable, scope: Scope) -> None:
67 self.app = app
68 self.scope = scope
69 self.status = None
70 self.response_headers = None
71 self.send_event = asyncio.Event()
72 self.send_queue = [] # type: typing.List[typing.Optional[Message]]
73 self.loop = asyncio.get_event_loop()
74 self.response_started = False
75 self.exc_info = None # type: typing.Any
76
77 async def __call__(self, receive: Receive, send: Send) -> None:
78 body = b""
79 more_body = True
80 while more_body:
81 message = await receive()
82 body += message.get("body", b"")
83 more_body = message.get("more_body", False)
84 environ = build_environ(self.scope, body)
85 sender = None
86 try:
87 sender = self.loop.create_task(self.sender(send))
88 await run_in_threadpool(self.wsgi, environ, self.start_response)
89 self.send_queue.append(None)
90 self.send_event.set()
91 await asyncio.wait_for(sender, None)
92 if self.exc_info is not None:
93 raise self.exc_info[0].with_traceback(
94 self.exc_info[1], self.exc_info[2]
95 )
96 finally:
97 if sender and not sender.done():
98 sender.cancel() # pragma: no cover
99
100 async def sender(self, send: Send) -> None:
101 while True:
102 if self.send_queue:
103 message = self.send_queue.pop(0)
104 if message is None:
105 return
106 await send(message)
107 else:
108 await self.send_event.wait()
109 self.send_event.clear()
110
111 def start_response(
112 self,
113 status: str,
114 response_headers: typing.List[typing.Tuple[str, str]],
115 exc_info: typing.Any = None,
116 ) -> None:
117 self.exc_info = exc_info
118 if not self.response_started:
119 self.response_started = True
120 status_code_string, _ = status.split(" ", 1)
121 status_code = int(status_code_string)
122 headers = [
123 (name.encode("ascii"), value.encode("ascii"))
124 for name, value in response_headers
125 ]
126 self.send_queue.append(
127 {
128 "type": "http.response.start",
129 "status": status_code,
130 "headers": headers,
131 }
132 )
133 self.loop.call_soon_threadsafe(self.send_event.set)
134
135 def wsgi(self, environ: dict, start_response: typing.Callable) -> None:
136 for chunk in self.app(environ, start_response):
137 self.send_queue.append(
138 {"type": "http.response.body", "body": chunk, "more_body": True}
139 )
140 self.loop.call_soon_threadsafe(self.send_event.set)
141
142 self.send_queue.append({"type": "http.response.body", "body": b""})
143 self.loop.call_soon_threadsafe(self.send_event.set)
144
[end of starlette/middleware/wsgi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlette/middleware/wsgi.py b/starlette/middleware/wsgi.py
--- a/starlette/middleware/wsgi.py
+++ b/starlette/middleware/wsgi.py
@@ -120,7 +120,7 @@
status_code_string, _ = status.split(" ", 1)
status_code = int(status_code_string)
headers = [
- (name.encode("ascii"), value.encode("ascii"))
+ (name.strip().encode("ascii"), value.strip().encode("ascii"))
for name, value in response_headers
]
self.send_queue.append(
|
{"golden_diff": "diff --git a/starlette/middleware/wsgi.py b/starlette/middleware/wsgi.py\n--- a/starlette/middleware/wsgi.py\n+++ b/starlette/middleware/wsgi.py\n@@ -120,7 +120,7 @@\n status_code_string, _ = status.split(\" \", 1)\n status_code = int(status_code_string)\n headers = [\n- (name.encode(\"ascii\"), value.encode(\"ascii\"))\n+ (name.strip().encode(\"ascii\"), value.strip().encode(\"ascii\"))\n for name, value in response_headers\n ]\n self.send_queue.append(\n", "issue": "WSGI mount error\nWhen I mount a django application and try to access it\r\n\r\n```\r\nERROR: Exception in ASGI application\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\uvicorn\\protocols\\http\\h11_impl.py\", line 375, in run_asgi\r\n result = await app(self.scope, self.receive, self.send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\applications.py\", line 134, in __call__\r\n await self.error_middleware(scope, receive, send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\errors.py\", line 178, in __call__\r\n raise exc from None\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\errors.py\", line 156, in __call__\r\n await self.app(scope, receive, _send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\exceptions.py\", line 73, in __call__\r\n raise exc from None\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\exceptions.py\", line 62, in __call__\r\n await self.app(scope, receive, sender)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\routing.py\", line 590, in __call__\r\n await route(scope, receive, send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\routing.py\", line 352, in __call__\r\n await self.app(scope, receive, send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\wsgi.py\", line 62, in __call__\r\n await responder(receive, send)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\wsgi.py\", line 91, in __call__\r\n await asyncio.wait_for(sender, None)\r\n File \"c:\\users\\abers\\appdata\\local\\programs\\python\\python37\\Lib\\asyncio\\tasks.py\", line 414, in wait_for\r\n return await fut\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\wsgi.py\", line 106, in sender\r\n await send(message)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\exceptions.py\", line 59, in sender\r\n await send(message)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\starlette\\middleware\\errors.py\", line 153, in _send\r\n await send(message)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\uvicorn\\protocols\\http\\h11_impl.py\", line 449, in send\r\n status_code=status_code, headers=headers, reason=reason\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\h11\\_events.py\", line 47, in __init__\r\n self.headers, _parsed=_parsed)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\h11\\_headers.py\", line 75, in normalize_and_validate\r\n validate(_field_value_re, value, \"Illegal header value {!r}\", value)\r\n File \"C:\\Users\\AberS\\Documents\\Coding\\lexiang\\lebu\\.venv\\lib\\site-packages\\h11\\_util.py\", line 96, in validate\r\n raise LocalProtocolError(msg)\r\nh11._util.LocalProtocolError: Illegal header value b' sessionid=\"\"; expires=Thu, 01 Jan 1970 00:00:00 GMT; Max-Age=0; Path=/'\r\n```\r\n\r\nThis is my minimal implementation code, `lebu` is my django program\r\n\r\n```python\r\nfrom starlette.applications import Starlette\r\nfrom starlette.middleware.wsgi import WSGIMiddleware\r\nimport uvicorn\r\n\r\nfrom lebu.wsgi import application\r\n\r\napp = Starlette(debug=True)\r\napp.mount(\"/api\", WSGIMiddleware(application))\r\n\r\nif __name__ == \"__main__\":\r\n uvicorn.run(app)\r\n```\r\n\r\nBy the way, starlette version is 0.12.9\n", "before_files": [{"content": "import asyncio\nimport io\nimport sys\nimport typing\n\nfrom starlette.concurrency import run_in_threadpool\nfrom starlette.types import Message, Receive, Scope, Send\n\n\ndef build_environ(scope: Scope, body: bytes) -> dict:\n \"\"\"\n Builds a scope and request body into a WSGI environ object.\n \"\"\"\n environ = {\n \"REQUEST_METHOD\": scope[\"method\"],\n \"SCRIPT_NAME\": scope.get(\"root_path\", \"\"),\n \"PATH_INFO\": scope[\"path\"],\n \"QUERY_STRING\": scope[\"query_string\"].decode(\"ascii\"),\n \"SERVER_PROTOCOL\": f\"HTTP/{scope['http_version']}\",\n \"wsgi.version\": (1, 0),\n \"wsgi.url_scheme\": scope.get(\"scheme\", \"http\"),\n \"wsgi.input\": io.BytesIO(body),\n \"wsgi.errors\": sys.stdout,\n \"wsgi.multithread\": True,\n \"wsgi.multiprocess\": True,\n \"wsgi.run_once\": False,\n }\n\n # Get server name and port - required in WSGI, not in ASGI\n server = scope.get(\"server\") or (\"localhost\", 80)\n environ[\"SERVER_NAME\"] = server[0]\n environ[\"SERVER_PORT\"] = server[1]\n\n # Get client IP address\n if scope.get(\"client\"):\n environ[\"REMOTE_ADDR\"] = scope[\"client\"][0]\n\n # Go through headers and make them into environ entries\n for name, value in scope.get(\"headers\", []):\n name = name.decode(\"latin1\")\n if name == \"content-length\":\n corrected_name = \"CONTENT_LENGTH\"\n elif name == \"content-type\":\n corrected_name = \"CONTENT_TYPE\"\n else:\n corrected_name = f\"HTTP_{name}\".upper().replace(\"-\", \"_\")\n # HTTPbis say only ASCII chars are allowed in headers, but we latin1 just in case\n value = value.decode(\"latin1\")\n if corrected_name in environ:\n value = environ[corrected_name] + \",\" + value\n environ[corrected_name] = value\n return environ\n\n\nclass WSGIMiddleware:\n def __init__(self, app: typing.Callable, workers: int = 10) -> None:\n self.app = app\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n assert scope[\"type\"] == \"http\"\n responder = WSGIResponder(self.app, scope)\n await responder(receive, send)\n\n\nclass WSGIResponder:\n def __init__(self, app: typing.Callable, scope: Scope) -> None:\n self.app = app\n self.scope = scope\n self.status = None\n self.response_headers = None\n self.send_event = asyncio.Event()\n self.send_queue = [] # type: typing.List[typing.Optional[Message]]\n self.loop = asyncio.get_event_loop()\n self.response_started = False\n self.exc_info = None # type: typing.Any\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n body = b\"\"\n more_body = True\n while more_body:\n message = await receive()\n body += message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n environ = build_environ(self.scope, body)\n sender = None\n try:\n sender = self.loop.create_task(self.sender(send))\n await run_in_threadpool(self.wsgi, environ, self.start_response)\n self.send_queue.append(None)\n self.send_event.set()\n await asyncio.wait_for(sender, None)\n if self.exc_info is not None:\n raise self.exc_info[0].with_traceback(\n self.exc_info[1], self.exc_info[2]\n )\n finally:\n if sender and not sender.done():\n sender.cancel() # pragma: no cover\n\n async def sender(self, send: Send) -> None:\n while True:\n if self.send_queue:\n message = self.send_queue.pop(0)\n if message is None:\n return\n await send(message)\n else:\n await self.send_event.wait()\n self.send_event.clear()\n\n def start_response(\n self,\n status: str,\n response_headers: typing.List[typing.Tuple[str, str]],\n exc_info: typing.Any = None,\n ) -> None:\n self.exc_info = exc_info\n if not self.response_started:\n self.response_started = True\n status_code_string, _ = status.split(\" \", 1)\n status_code = int(status_code_string)\n headers = [\n (name.encode(\"ascii\"), value.encode(\"ascii\"))\n for name, value in response_headers\n ]\n self.send_queue.append(\n {\n \"type\": \"http.response.start\",\n \"status\": status_code,\n \"headers\": headers,\n }\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n def wsgi(self, environ: dict, start_response: typing.Callable) -> None:\n for chunk in self.app(environ, start_response):\n self.send_queue.append(\n {\"type\": \"http.response.body\", \"body\": chunk, \"more_body\": True}\n )\n self.loop.call_soon_threadsafe(self.send_event.set)\n\n self.send_queue.append({\"type\": \"http.response.body\", \"body\": b\"\"})\n self.loop.call_soon_threadsafe(self.send_event.set)\n", "path": "starlette/middleware/wsgi.py"}]}
| 3,217 | 128 |
gh_patches_debug_30956
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3602
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider superdrug is broken
During the global build at 2021-06-30-14-42-26, spider **superdrug** failed with **0 features** and **2 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/logs/superdrug.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/superdrug.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/superdrug.geojson))
</issue>
<code>
[start of locations/spiders/superdrug.py]
1 # -*- coding: utf-8 -*-
2 import json
3
4 import scrapy
5
6 from locations.items import GeojsonPointItem
7
8
9 class SuperdrugSpider(scrapy.Spider):
10 name = "superdrug"
11 item_attributes = {"brand": "Superdrug", "brand_wikidata": "Q7643261"}
12 allowed_domains = ["superdrug.com"]
13 download_delay = 0.5
14
15 start_urls = ["https://www.superdrug.com/stores/a-to-z"]
16
17 def parse(self, response):
18 urls = response.xpath('//a[@class="row store-link"]/@href').extract()
19
20 for url in urls:
21 yield scrapy.Request(response.urljoin(url), callback=self.parse_location)
22
23 def parse_location(self, response):
24 data = json.loads(
25 response.xpath(
26 '//script[@type="application/ld+json" and contains(text(), "streetAddress")]/text()'
27 ).extract_first()
28 )
29
30 properties = {
31 "name": data["name"],
32 "ref": data["name"],
33 "addr_full": data["address"]["streetAddress"],
34 "city": data["address"]["addressLocality"],
35 "state": data["address"]["addressRegion"],
36 "postcode": data["address"]["postalCode"],
37 "country": data["address"]["addressCountry"],
38 "phone": data.get("telephone"),
39 "website": response.url,
40 "lat": float(
41 response.xpath(
42 '//div[@class="store-locator store-locator__overview"]/@data-lat'
43 ).extract_first()
44 ),
45 "lon": float(
46 response.xpath(
47 '//div[@class="store-locator store-locator__overview"]/@data-lng'
48 ).extract_first()
49 ),
50 }
51 yield GeojsonPointItem(**properties)
52
[end of locations/spiders/superdrug.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/superdrug.py b/locations/spiders/superdrug.py
--- a/locations/spiders/superdrug.py
+++ b/locations/spiders/superdrug.py
@@ -4,6 +4,7 @@
import scrapy
from locations.items import GeojsonPointItem
+from locations.hours import OpeningHours
class SuperdrugSpider(scrapy.Spider):
@@ -14,6 +15,10 @@
start_urls = ["https://www.superdrug.com/stores/a-to-z"]
+ custom_settings = {
+ "USER_AGENT": "Mozilla/5.0 (X11; Linux x86_64; rv:99.0) Gecko/20100101 Firefox/99.0"
+ }
+
def parse(self, response):
urls = response.xpath('//a[@class="row store-link"]/@href').extract()
@@ -28,9 +33,11 @@
)
properties = {
- "name": data["name"],
- "ref": data["name"],
- "addr_full": data["address"]["streetAddress"],
+ "name": data["name"].replace("Superdrug", "").strip(),
+ "ref": data["@id"],
+ "street_address": data["address"]["streetAddress"]
+ .replace("Superdrug", "")
+ .strip(),
"city": data["address"]["addressLocality"],
"state": data["address"]["addressRegion"],
"postcode": data["address"]["postalCode"],
@@ -48,4 +55,15 @@
).extract_first()
),
}
+
+ oh = OpeningHours()
+
+ for rule in data["OpeningHoursSpecification"]:
+ oh.add_range(
+ day=rule["dayOfWeek"][0:2],
+ open_time=rule["opens"],
+ close_time=rule["closes"],
+ time_format="%I:%M %p",
+ )
+
yield GeojsonPointItem(**properties)
|
{"golden_diff": "diff --git a/locations/spiders/superdrug.py b/locations/spiders/superdrug.py\n--- a/locations/spiders/superdrug.py\n+++ b/locations/spiders/superdrug.py\n@@ -4,6 +4,7 @@\n import scrapy\n \n from locations.items import GeojsonPointItem\n+from locations.hours import OpeningHours\n \n \n class SuperdrugSpider(scrapy.Spider):\n@@ -14,6 +15,10 @@\n \n start_urls = [\"https://www.superdrug.com/stores/a-to-z\"]\n \n+ custom_settings = {\n+ \"USER_AGENT\": \"Mozilla/5.0 (X11; Linux x86_64; rv:99.0) Gecko/20100101 Firefox/99.0\"\n+ }\n+\n def parse(self, response):\n urls = response.xpath('//a[@class=\"row store-link\"]/@href').extract()\n \n@@ -28,9 +33,11 @@\n )\n \n properties = {\n- \"name\": data[\"name\"],\n- \"ref\": data[\"name\"],\n- \"addr_full\": data[\"address\"][\"streetAddress\"],\n+ \"name\": data[\"name\"].replace(\"Superdrug\", \"\").strip(),\n+ \"ref\": data[\"@id\"],\n+ \"street_address\": data[\"address\"][\"streetAddress\"]\n+ .replace(\"Superdrug\", \"\")\n+ .strip(),\n \"city\": data[\"address\"][\"addressLocality\"],\n \"state\": data[\"address\"][\"addressRegion\"],\n \"postcode\": data[\"address\"][\"postalCode\"],\n@@ -48,4 +55,15 @@\n ).extract_first()\n ),\n }\n+\n+ oh = OpeningHours()\n+\n+ for rule in data[\"OpeningHoursSpecification\"]:\n+ oh.add_range(\n+ day=rule[\"dayOfWeek\"][0:2],\n+ open_time=rule[\"opens\"],\n+ close_time=rule[\"closes\"],\n+ time_format=\"%I:%M %p\",\n+ )\n+\n yield GeojsonPointItem(**properties)\n", "issue": "Spider superdrug is broken\nDuring the global build at 2021-06-30-14-42-26, spider **superdrug** failed with **0 features** and **2 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/logs/superdrug.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/superdrug.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-30-14-42-26/output/superdrug.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport json\n\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\n\n\nclass SuperdrugSpider(scrapy.Spider):\n name = \"superdrug\"\n item_attributes = {\"brand\": \"Superdrug\", \"brand_wikidata\": \"Q7643261\"}\n allowed_domains = [\"superdrug.com\"]\n download_delay = 0.5\n\n start_urls = [\"https://www.superdrug.com/stores/a-to-z\"]\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"row store-link\"]/@href').extract()\n\n for url in urls:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n\n def parse_location(self, response):\n data = json.loads(\n response.xpath(\n '//script[@type=\"application/ld+json\" and contains(text(), \"streetAddress\")]/text()'\n ).extract_first()\n )\n\n properties = {\n \"name\": data[\"name\"],\n \"ref\": data[\"name\"],\n \"addr_full\": data[\"address\"][\"streetAddress\"],\n \"city\": data[\"address\"][\"addressLocality\"],\n \"state\": data[\"address\"][\"addressRegion\"],\n \"postcode\": data[\"address\"][\"postalCode\"],\n \"country\": data[\"address\"][\"addressCountry\"],\n \"phone\": data.get(\"telephone\"),\n \"website\": response.url,\n \"lat\": float(\n response.xpath(\n '//div[@class=\"store-locator store-locator__overview\"]/@data-lat'\n ).extract_first()\n ),\n \"lon\": float(\n response.xpath(\n '//div[@class=\"store-locator store-locator__overview\"]/@data-lng'\n ).extract_first()\n ),\n }\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/superdrug.py"}]}
| 1,199 | 444 |
gh_patches_debug_996
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-2522
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unpin pytest
revert https://github.com/pyca/cryptography/pull/2513
waiting on a pytest release with https://github.com/pytest-dev/pytest/issues/1238 landed
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 # This file is dual licensed under the terms of the Apache License, Version
4 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
5 # for complete details.
6
7 from __future__ import absolute_import, division, print_function
8
9 import os
10 import platform
11 import subprocess
12 import sys
13 from distutils.command.build import build
14
15 import pkg_resources
16
17 from setuptools import find_packages, setup
18 from setuptools.command.install import install
19 from setuptools.command.test import test
20
21
22 base_dir = os.path.dirname(__file__)
23 src_dir = os.path.join(base_dir, "src")
24
25 # When executing the setup.py, we need to be able to import ourselves, this
26 # means that we need to add the src/ directory to the sys.path.
27 sys.path.insert(0, src_dir)
28
29 about = {}
30 with open(os.path.join(src_dir, "cryptography", "__about__.py")) as f:
31 exec(f.read(), about)
32
33
34 VECTORS_DEPENDENCY = "cryptography_vectors=={0}".format(about['__version__'])
35
36 requirements = [
37 "idna>=2.0",
38 "pyasn1>=0.1.8",
39 "six>=1.4.1",
40 "setuptools",
41 ]
42 setup_requirements = []
43
44 if sys.version_info < (3, 4):
45 requirements.append("enum34")
46
47 if sys.version_info < (3, 3):
48 requirements.append("ipaddress")
49
50 if platform.python_implementation() == "PyPy":
51 if sys.pypy_version_info < (2, 6):
52 raise RuntimeError(
53 "cryptography 1.0 is not compatible with PyPy < 2.6. Please "
54 "upgrade PyPy to use this library."
55 )
56 else:
57 requirements.append("cffi>=1.1.0")
58 setup_requirements.append("cffi>=1.1.0")
59
60 # If you add a new dep here you probably need to add it in the tox.ini as well
61 test_requirements = [
62 "pytest!=2.8.4",
63 "pretend",
64 "iso8601",
65 "hypothesis",
66 "pyasn1_modules",
67 ]
68
69 # If there's no vectors locally that probably means we are in a tarball and
70 # need to go and get the matching vectors package from PyPi
71 if not os.path.exists(os.path.join(base_dir, "vectors/setup.py")):
72 test_requirements.append(VECTORS_DEPENDENCY)
73
74
75 def cc_is_available():
76 return sys.platform == "darwin" and list(map(
77 int, platform.mac_ver()[0].split("."))) >= [10, 8, 0]
78
79
80 backends = [
81 "openssl = cryptography.hazmat.backends.openssl:backend"
82 ]
83
84 if cc_is_available():
85 backends.append(
86 "commoncrypto = cryptography.hazmat.backends.commoncrypto:backend",
87 )
88
89
90 class PyTest(test):
91 def finalize_options(self):
92 test.finalize_options(self)
93 self.test_args = []
94 self.test_suite = True
95
96 # This means there's a vectors/ folder with the package in here.
97 # cd into it, install the vectors package and then refresh sys.path
98 if VECTORS_DEPENDENCY not in test_requirements:
99 subprocess.check_call(
100 [sys.executable, "setup.py", "install"], cwd="vectors"
101 )
102 pkg_resources.get_distribution("cryptography_vectors").activate()
103
104 def run_tests(self):
105 # Import here because in module scope the eggs are not loaded.
106 import pytest
107 test_args = [os.path.join(base_dir, "tests")]
108 errno = pytest.main(test_args)
109 sys.exit(errno)
110
111
112 def keywords_with_side_effects(argv):
113 """
114 Get a dictionary with setup keywords that (can) have side effects.
115
116 :param argv: A list of strings with command line arguments.
117 :returns: A dictionary with keyword arguments for the ``setup()`` function.
118
119 This setup.py script uses the setuptools 'setup_requires' feature because
120 this is required by the cffi package to compile extension modules. The
121 purpose of ``keywords_with_side_effects()`` is to avoid triggering the cffi
122 build process as a result of setup.py invocations that don't need the cffi
123 module to be built (setup.py serves the dual purpose of exposing package
124 metadata).
125
126 All of the options listed by ``python setup.py --help`` that print
127 information should be recognized here. The commands ``clean``,
128 ``egg_info``, ``register``, ``sdist`` and ``upload`` are also recognized.
129 Any combination of these options and commands is also supported.
130
131 This function was originally based on the `setup.py script`_ of SciPy (see
132 also the discussion in `pip issue #25`_).
133
134 .. _pip issue #25: https://github.com/pypa/pip/issues/25
135 .. _setup.py script: https://github.com/scipy/scipy/blob/master/setup.py
136 """
137 no_setup_requires_arguments = (
138 '-h', '--help',
139 '-n', '--dry-run',
140 '-q', '--quiet',
141 '-v', '--verbose',
142 '-V', '--version',
143 '--author',
144 '--author-email',
145 '--classifiers',
146 '--contact',
147 '--contact-email',
148 '--description',
149 '--egg-base',
150 '--fullname',
151 '--help-commands',
152 '--keywords',
153 '--licence',
154 '--license',
155 '--long-description',
156 '--maintainer',
157 '--maintainer-email',
158 '--name',
159 '--no-user-cfg',
160 '--obsoletes',
161 '--platforms',
162 '--provides',
163 '--requires',
164 '--url',
165 'clean',
166 'egg_info',
167 'register',
168 'sdist',
169 'upload',
170 )
171
172 def is_short_option(argument):
173 """Check whether a command line argument is a short option."""
174 return len(argument) >= 2 and argument[0] == '-' and argument[1] != '-'
175
176 def expand_short_options(argument):
177 """Expand combined short options into canonical short options."""
178 return ('-' + char for char in argument[1:])
179
180 def argument_without_setup_requirements(argv, i):
181 """Check whether a command line argument needs setup requirements."""
182 if argv[i] in no_setup_requires_arguments:
183 # Simple case: An argument which is either an option or a command
184 # which doesn't need setup requirements.
185 return True
186 elif (is_short_option(argv[i]) and
187 all(option in no_setup_requires_arguments
188 for option in expand_short_options(argv[i]))):
189 # Not so simple case: Combined short options none of which need
190 # setup requirements.
191 return True
192 elif argv[i - 1:i] == ['--egg-base']:
193 # Tricky case: --egg-info takes an argument which should not make
194 # us use setup_requires (defeating the purpose of this code).
195 return True
196 else:
197 return False
198
199 if all(argument_without_setup_requirements(argv, i)
200 for i in range(1, len(argv))):
201 return {
202 "cmdclass": {
203 "build": DummyBuild,
204 "install": DummyInstall,
205 "test": DummyPyTest,
206 }
207 }
208 else:
209 cffi_modules = [
210 "src/_cffi_src/build_openssl.py:ffi",
211 "src/_cffi_src/build_constant_time.py:ffi",
212 "src/_cffi_src/build_padding.py:ffi",
213 ]
214 if cc_is_available():
215 cffi_modules.append("src/_cffi_src/build_commoncrypto.py:ffi")
216
217 return {
218 "setup_requires": setup_requirements,
219 "cmdclass": {
220 "test": PyTest,
221 },
222 "cffi_modules": cffi_modules
223 }
224
225
226 setup_requires_error = ("Requested setup command that needs 'setup_requires' "
227 "while command line arguments implied a side effect "
228 "free command or option.")
229
230
231 class DummyBuild(build):
232 """
233 This class makes it very obvious when ``keywords_with_side_effects()`` has
234 incorrectly interpreted the command line arguments to ``setup.py build`` as
235 one of the 'side effect free' commands or options.
236 """
237
238 def run(self):
239 raise RuntimeError(setup_requires_error)
240
241
242 class DummyInstall(install):
243 """
244 This class makes it very obvious when ``keywords_with_side_effects()`` has
245 incorrectly interpreted the command line arguments to ``setup.py install``
246 as one of the 'side effect free' commands or options.
247 """
248
249 def run(self):
250 raise RuntimeError(setup_requires_error)
251
252
253 class DummyPyTest(test):
254 """
255 This class makes it very obvious when ``keywords_with_side_effects()`` has
256 incorrectly interpreted the command line arguments to ``setup.py test`` as
257 one of the 'side effect free' commands or options.
258 """
259
260 def run_tests(self):
261 raise RuntimeError(setup_requires_error)
262
263
264 with open(os.path.join(base_dir, "README.rst")) as f:
265 long_description = f.read()
266
267
268 setup(
269 name=about["__title__"],
270 version=about["__version__"],
271
272 description=about["__summary__"],
273 long_description=long_description,
274 license=about["__license__"],
275 url=about["__uri__"],
276
277 author=about["__author__"],
278 author_email=about["__email__"],
279
280 classifiers=[
281 "Intended Audience :: Developers",
282 "License :: OSI Approved :: Apache Software License",
283 "License :: OSI Approved :: BSD License",
284 "Natural Language :: English",
285 "Operating System :: MacOS :: MacOS X",
286 "Operating System :: POSIX",
287 "Operating System :: POSIX :: BSD",
288 "Operating System :: POSIX :: Linux",
289 "Operating System :: Microsoft :: Windows",
290 "Programming Language :: Python",
291 "Programming Language :: Python :: 2",
292 "Programming Language :: Python :: 2.6",
293 "Programming Language :: Python :: 2.7",
294 "Programming Language :: Python :: 3",
295 "Programming Language :: Python :: 3.3",
296 "Programming Language :: Python :: 3.4",
297 "Programming Language :: Python :: 3.5",
298 "Programming Language :: Python :: Implementation :: CPython",
299 "Programming Language :: Python :: Implementation :: PyPy",
300 "Topic :: Security :: Cryptography",
301 ],
302
303 package_dir={"": "src"},
304 packages=find_packages(
305 where="src", exclude=["_cffi_src", "_cffi_src.*", "tests", "tests.*"]
306 ),
307 include_package_data=True,
308
309 install_requires=requirements,
310 tests_require=test_requirements,
311
312 # for cffi
313 zip_safe=False,
314 ext_package="cryptography.hazmat.bindings",
315 entry_points={
316 "cryptography.backends": backends,
317 },
318 **keywords_with_side_effects(sys.argv)
319 )
320
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -59,7 +59,7 @@
# If you add a new dep here you probably need to add it in the tox.ini as well
test_requirements = [
- "pytest!=2.8.4",
+ "pytest",
"pretend",
"iso8601",
"hypothesis",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -59,7 +59,7 @@\n \n # If you add a new dep here you probably need to add it in the tox.ini as well\n test_requirements = [\n- \"pytest!=2.8.4\",\n+ \"pytest\",\n \"pretend\",\n \"iso8601\",\n \"hypothesis\",\n", "issue": "Unpin pytest\nrevert https://github.com/pyca/cryptography/pull/2513\n\nwaiting on a pytest release with https://github.com/pytest-dev/pytest/issues/1238 landed\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport os\nimport platform\nimport subprocess\nimport sys\nfrom distutils.command.build import build\n\nimport pkg_resources\n\nfrom setuptools import find_packages, setup\nfrom setuptools.command.install import install\nfrom setuptools.command.test import test\n\n\nbase_dir = os.path.dirname(__file__)\nsrc_dir = os.path.join(base_dir, \"src\")\n\n# When executing the setup.py, we need to be able to import ourselves, this\n# means that we need to add the src/ directory to the sys.path.\nsys.path.insert(0, src_dir)\n\nabout = {}\nwith open(os.path.join(src_dir, \"cryptography\", \"__about__.py\")) as f:\n exec(f.read(), about)\n\n\nVECTORS_DEPENDENCY = \"cryptography_vectors=={0}\".format(about['__version__'])\n\nrequirements = [\n \"idna>=2.0\",\n \"pyasn1>=0.1.8\",\n \"six>=1.4.1\",\n \"setuptools\",\n]\nsetup_requirements = []\n\nif sys.version_info < (3, 4):\n requirements.append(\"enum34\")\n\nif sys.version_info < (3, 3):\n requirements.append(\"ipaddress\")\n\nif platform.python_implementation() == \"PyPy\":\n if sys.pypy_version_info < (2, 6):\n raise RuntimeError(\n \"cryptography 1.0 is not compatible with PyPy < 2.6. Please \"\n \"upgrade PyPy to use this library.\"\n )\nelse:\n requirements.append(\"cffi>=1.1.0\")\n setup_requirements.append(\"cffi>=1.1.0\")\n\n# If you add a new dep here you probably need to add it in the tox.ini as well\ntest_requirements = [\n \"pytest!=2.8.4\",\n \"pretend\",\n \"iso8601\",\n \"hypothesis\",\n \"pyasn1_modules\",\n]\n\n# If there's no vectors locally that probably means we are in a tarball and\n# need to go and get the matching vectors package from PyPi\nif not os.path.exists(os.path.join(base_dir, \"vectors/setup.py\")):\n test_requirements.append(VECTORS_DEPENDENCY)\n\n\ndef cc_is_available():\n return sys.platform == \"darwin\" and list(map(\n int, platform.mac_ver()[0].split(\".\"))) >= [10, 8, 0]\n\n\nbackends = [\n \"openssl = cryptography.hazmat.backends.openssl:backend\"\n]\n\nif cc_is_available():\n backends.append(\n \"commoncrypto = cryptography.hazmat.backends.commoncrypto:backend\",\n )\n\n\nclass PyTest(test):\n def finalize_options(self):\n test.finalize_options(self)\n self.test_args = []\n self.test_suite = True\n\n # This means there's a vectors/ folder with the package in here.\n # cd into it, install the vectors package and then refresh sys.path\n if VECTORS_DEPENDENCY not in test_requirements:\n subprocess.check_call(\n [sys.executable, \"setup.py\", \"install\"], cwd=\"vectors\"\n )\n pkg_resources.get_distribution(\"cryptography_vectors\").activate()\n\n def run_tests(self):\n # Import here because in module scope the eggs are not loaded.\n import pytest\n test_args = [os.path.join(base_dir, \"tests\")]\n errno = pytest.main(test_args)\n sys.exit(errno)\n\n\ndef keywords_with_side_effects(argv):\n \"\"\"\n Get a dictionary with setup keywords that (can) have side effects.\n\n :param argv: A list of strings with command line arguments.\n :returns: A dictionary with keyword arguments for the ``setup()`` function.\n\n This setup.py script uses the setuptools 'setup_requires' feature because\n this is required by the cffi package to compile extension modules. The\n purpose of ``keywords_with_side_effects()`` is to avoid triggering the cffi\n build process as a result of setup.py invocations that don't need the cffi\n module to be built (setup.py serves the dual purpose of exposing package\n metadata).\n\n All of the options listed by ``python setup.py --help`` that print\n information should be recognized here. The commands ``clean``,\n ``egg_info``, ``register``, ``sdist`` and ``upload`` are also recognized.\n Any combination of these options and commands is also supported.\n\n This function was originally based on the `setup.py script`_ of SciPy (see\n also the discussion in `pip issue #25`_).\n\n .. _pip issue #25: https://github.com/pypa/pip/issues/25\n .. _setup.py script: https://github.com/scipy/scipy/blob/master/setup.py\n \"\"\"\n no_setup_requires_arguments = (\n '-h', '--help',\n '-n', '--dry-run',\n '-q', '--quiet',\n '-v', '--verbose',\n '-V', '--version',\n '--author',\n '--author-email',\n '--classifiers',\n '--contact',\n '--contact-email',\n '--description',\n '--egg-base',\n '--fullname',\n '--help-commands',\n '--keywords',\n '--licence',\n '--license',\n '--long-description',\n '--maintainer',\n '--maintainer-email',\n '--name',\n '--no-user-cfg',\n '--obsoletes',\n '--platforms',\n '--provides',\n '--requires',\n '--url',\n 'clean',\n 'egg_info',\n 'register',\n 'sdist',\n 'upload',\n )\n\n def is_short_option(argument):\n \"\"\"Check whether a command line argument is a short option.\"\"\"\n return len(argument) >= 2 and argument[0] == '-' and argument[1] != '-'\n\n def expand_short_options(argument):\n \"\"\"Expand combined short options into canonical short options.\"\"\"\n return ('-' + char for char in argument[1:])\n\n def argument_without_setup_requirements(argv, i):\n \"\"\"Check whether a command line argument needs setup requirements.\"\"\"\n if argv[i] in no_setup_requires_arguments:\n # Simple case: An argument which is either an option or a command\n # which doesn't need setup requirements.\n return True\n elif (is_short_option(argv[i]) and\n all(option in no_setup_requires_arguments\n for option in expand_short_options(argv[i]))):\n # Not so simple case: Combined short options none of which need\n # setup requirements.\n return True\n elif argv[i - 1:i] == ['--egg-base']:\n # Tricky case: --egg-info takes an argument which should not make\n # us use setup_requires (defeating the purpose of this code).\n return True\n else:\n return False\n\n if all(argument_without_setup_requirements(argv, i)\n for i in range(1, len(argv))):\n return {\n \"cmdclass\": {\n \"build\": DummyBuild,\n \"install\": DummyInstall,\n \"test\": DummyPyTest,\n }\n }\n else:\n cffi_modules = [\n \"src/_cffi_src/build_openssl.py:ffi\",\n \"src/_cffi_src/build_constant_time.py:ffi\",\n \"src/_cffi_src/build_padding.py:ffi\",\n ]\n if cc_is_available():\n cffi_modules.append(\"src/_cffi_src/build_commoncrypto.py:ffi\")\n\n return {\n \"setup_requires\": setup_requirements,\n \"cmdclass\": {\n \"test\": PyTest,\n },\n \"cffi_modules\": cffi_modules\n }\n\n\nsetup_requires_error = (\"Requested setup command that needs 'setup_requires' \"\n \"while command line arguments implied a side effect \"\n \"free command or option.\")\n\n\nclass DummyBuild(build):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py build`` as\n one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nclass DummyInstall(install):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py install``\n as one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nclass DummyPyTest(test):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py test`` as\n one of the 'side effect free' commands or options.\n \"\"\"\n\n def run_tests(self):\n raise RuntimeError(setup_requires_error)\n\n\nwith open(os.path.join(base_dir, \"README.rst\")) as f:\n long_description = f.read()\n\n\nsetup(\n name=about[\"__title__\"],\n version=about[\"__version__\"],\n\n description=about[\"__summary__\"],\n long_description=long_description,\n license=about[\"__license__\"],\n url=about[\"__uri__\"],\n\n author=about[\"__author__\"],\n author_email=about[\"__email__\"],\n\n classifiers=[\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"License :: OSI Approved :: BSD License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Security :: Cryptography\",\n ],\n\n package_dir={\"\": \"src\"},\n packages=find_packages(\n where=\"src\", exclude=[\"_cffi_src\", \"_cffi_src.*\", \"tests\", \"tests.*\"]\n ),\n include_package_data=True,\n\n install_requires=requirements,\n tests_require=test_requirements,\n\n # for cffi\n zip_safe=False,\n ext_package=\"cryptography.hazmat.bindings\",\n entry_points={\n \"cryptography.backends\": backends,\n },\n **keywords_with_side_effects(sys.argv)\n)\n", "path": "setup.py"}]}
| 3,773 | 93 |
gh_patches_debug_21214
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-893
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
notebooks_dir ~ expands incorrectly
**How to reproduce the issue**
Configure jupyterhub 0.7.0b1 with:
```
c.SudoSpawner.sudospawner_path = "/some/where/bin/sudospawner"
c.SudoSpawner.sudo_args = ['-nH']
c.Spawner.notebook_dir = '~/notebooks'
```
Try to login. Notebook server startup logs:
```
[C 2016-11-21 12:32:15.936 SingleUserNotebookApp application:91] No such notebook dir: '/home/pparente/~/notebooks'
```
**What you expected to happen**
Path should be expanded properly.
**What actually happens**
Path is expanded but also gets the ~ part tacked back on.
**Share what version of JupyterHub you are using**
0.7.0b1
I put a print in the jupyterhub-singleuser script and confirmed that it is receiving `--notebook-dir="~/notebooks"` as in `sys.argv`. So it appears the incorrect expansion is happening somewhere after that.
</issue>
<code>
[start of jupyterhub/singleuser.py]
1 #!/usr/bin/env python
2 """Extend regular notebook server to be aware of multiuser things."""
3
4 # Copyright (c) Jupyter Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 import os
8
9 from jinja2 import ChoiceLoader, FunctionLoader
10
11 from tornado import ioloop
12 from textwrap import dedent
13
14 try:
15 import notebook
16 except ImportError:
17 raise ImportError("JupyterHub single-user server requires notebook >= 4.0")
18
19 from traitlets import (
20 Bool,
21 Unicode,
22 CUnicode,
23 default,
24 validate,
25 )
26
27 from notebook.notebookapp import (
28 NotebookApp,
29 aliases as notebook_aliases,
30 flags as notebook_flags,
31 )
32 from notebook.auth.login import LoginHandler
33 from notebook.auth.logout import LogoutHandler
34
35 from jupyterhub import __version__
36 from .services.auth import HubAuth, HubAuthenticated
37 from .utils import url_path_join
38
39 # Authenticate requests with the Hub
40
41 class HubAuthenticatedHandler(HubAuthenticated):
42 """Class we are going to patch-in for authentication with the Hub"""
43 @property
44 def hub_auth(self):
45 return self.settings['hub_auth']
46 @property
47 def hub_users(self):
48 return { self.settings['user'] }
49
50
51 class JupyterHubLoginHandler(LoginHandler):
52 """LoginHandler that hooks up Hub authentication"""
53 @staticmethod
54 def login_available(settings):
55 return True
56
57 @staticmethod
58 def get_user(handler):
59 """alternative get_current_user to query the Hub"""
60 # patch in HubAuthenticated class for querying the Hub for cookie authentication
61 name = 'NowHubAuthenticated'
62 if handler.__class__.__name__ != name:
63 handler.__class__ = type(name, (HubAuthenticatedHandler, handler.__class__), {})
64 return handler.get_current_user()
65
66
67 class JupyterHubLogoutHandler(LogoutHandler):
68 def get(self):
69 self.redirect(
70 self.settings['hub_host'] +
71 url_path_join(self.settings['hub_prefix'], 'logout'))
72
73
74 # register new hub related command-line aliases
75 aliases = dict(notebook_aliases)
76 aliases.update({
77 'user' : 'SingleUserNotebookApp.user',
78 'cookie-name': 'HubAuth.cookie_name',
79 'hub-prefix': 'SingleUserNotebookApp.hub_prefix',
80 'hub-host': 'SingleUserNotebookApp.hub_host',
81 'hub-api-url': 'SingleUserNotebookApp.hub_api_url',
82 'base-url': 'SingleUserNotebookApp.base_url',
83 })
84 flags = dict(notebook_flags)
85 flags.update({
86 'disable-user-config': ({
87 'SingleUserNotebookApp': {
88 'disable_user_config': True
89 }
90 }, "Disable user-controlled configuration of the notebook server.")
91 })
92
93 page_template = """
94 {% extends "templates/page.html" %}
95
96 {% block header_buttons %}
97 {{super()}}
98
99 <a href='{{hub_control_panel_url}}'
100 class='btn btn-default btn-sm navbar-btn pull-right'
101 style='margin-right: 4px; margin-left: 2px;'
102 >
103 Control Panel</a>
104 {% endblock %}
105 {% block logo %}
106 <img src='{{logo_url}}' alt='Jupyter Notebook'/>
107 {% endblock logo %}
108 """
109
110 def _exclude_home(path_list):
111 """Filter out any entries in a path list that are in my home directory.
112
113 Used to disable per-user configuration.
114 """
115 home = os.path.expanduser('~')
116 for p in path_list:
117 if not p.startswith(home):
118 yield p
119
120 class SingleUserNotebookApp(NotebookApp):
121 """A Subclass of the regular NotebookApp that is aware of the parent multiuser context."""
122 description = dedent("""
123 Single-user server for JupyterHub. Extends the Jupyter Notebook server.
124
125 Meant to be invoked by JupyterHub Spawners, and not directly.
126 """)
127
128 examples = ""
129 subcommands = {}
130 version = __version__
131 classes = NotebookApp.classes + [HubAuth]
132
133 user = CUnicode(config=True)
134 def _user_changed(self, name, old, new):
135 self.log.name = new
136 hub_prefix = Unicode().tag(config=True)
137 hub_host = Unicode().tag(config=True)
138 hub_api_url = Unicode().tag(config=True)
139 aliases = aliases
140 flags = flags
141 open_browser = False
142 trust_xheaders = True
143 login_handler_class = JupyterHubLoginHandler
144 logout_handler_class = JupyterHubLogoutHandler
145 port_retries = 0 # disable port-retries, since the Spawner will tell us what port to use
146
147 disable_user_config = Bool(False,
148 help="""Disable user configuration of single-user server.
149
150 Prevents user-writable files that normally configure the single-user server
151 from being loaded, ensuring admins have full control of configuration.
152 """
153 ).tag(config=True)
154
155 @default('log_datefmt')
156 def _log_datefmt_default(self):
157 """Exclude date from default date format"""
158 return "%Y-%m-%d %H:%M:%S"
159
160 @default('log_format')
161 def _log_format_default(self):
162 """override default log format to include time"""
163 return "%(color)s[%(levelname)1.1s %(asctime)s.%(msecs).03d %(name)s %(module)s:%(lineno)d]%(end_color)s %(message)s"
164
165 def _confirm_exit(self):
166 # disable the exit confirmation for background notebook processes
167 ioloop.IOLoop.instance().stop()
168
169 def migrate_config(self):
170 if self.disable_user_config:
171 # disable config-migration when user config is disabled
172 return
173 else:
174 super(SingleUserNotebookApp, self).migrate_config()
175
176 @property
177 def config_file_paths(self):
178 path = super(SingleUserNotebookApp, self).config_file_paths
179
180 if self.disable_user_config:
181 # filter out user-writable config dirs if user config is disabled
182 path = list(_exclude_home(path))
183 return path
184
185 @property
186 def nbextensions_path(self):
187 path = super(SingleUserNotebookApp, self).nbextensions_path
188
189 if self.disable_user_config:
190 path = list(_exclude_home(path))
191 return path
192
193 @validate('static_custom_path')
194 def _validate_static_custom_path(self, proposal):
195 path = proposal['value']
196 if self.disable_user_config:
197 path = list(_exclude_home(path))
198 return path
199
200 def start(self):
201 super(SingleUserNotebookApp, self).start()
202
203 def init_hub_auth(self):
204 if not os.environ.get('JPY_API_TOKEN'):
205 self.exit("JPY_API_TOKEN env is required to run jupyterhub-singleuser. Did you launch it manually?")
206 self.hub_auth = HubAuth(
207 parent=self,
208 api_token=os.environ.pop('JPY_API_TOKEN'),
209 api_url=self.hub_api_url,
210 )
211
212 def init_webapp(self):
213 # load the hub related settings into the tornado settings dict
214 self.init_hub_auth()
215 s = self.tornado_settings
216 s['user'] = self.user
217 s['hub_prefix'] = self.hub_prefix
218 s['hub_host'] = self.hub_host
219 s['hub_auth'] = self.hub_auth
220 s['login_url'] = self.hub_host + self.hub_prefix
221 s['csp_report_uri'] = self.hub_host + url_path_join(self.hub_prefix, 'security/csp-report')
222 super(SingleUserNotebookApp, self).init_webapp()
223 self.patch_templates()
224
225 def patch_templates(self):
226 """Patch page templates to add Hub-related buttons"""
227
228 self.jinja_template_vars['logo_url'] = self.hub_host + url_path_join(self.hub_prefix, 'logo')
229 self.jinja_template_vars['hub_host'] = self.hub_host
230 self.jinja_template_vars['hub_prefix'] = self.hub_prefix
231 env = self.web_app.settings['jinja2_env']
232
233 env.globals['hub_control_panel_url'] = \
234 self.hub_host + url_path_join(self.hub_prefix, 'home')
235
236 # patch jinja env loading to modify page template
237 def get_page(name):
238 if name == 'page.html':
239 return page_template
240
241 orig_loader = env.loader
242 env.loader = ChoiceLoader([
243 FunctionLoader(get_page),
244 orig_loader,
245 ])
246
247
248 def main(argv=None):
249 return SingleUserNotebookApp.launch_instance(argv)
250
251
252 if __name__ == "__main__":
253 main()
254
[end of jupyterhub/singleuser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jupyterhub/singleuser.py b/jupyterhub/singleuser.py
--- a/jupyterhub/singleuser.py
+++ b/jupyterhub/singleuser.py
@@ -22,6 +22,7 @@
CUnicode,
default,
validate,
+ TraitError,
)
from notebook.notebookapp import (
@@ -151,7 +152,23 @@
from being loaded, ensuring admins have full control of configuration.
"""
).tag(config=True)
-
+
+ @validate('notebook_dir')
+ def _notebook_dir_validate(self, proposal):
+ value = os.path.expanduser(proposal['value'])
+ # Strip any trailing slashes
+ # *except* if it's root
+ _, path = os.path.splitdrive(value)
+ if path == os.sep:
+ return value
+ value = value.rstrip(os.sep)
+ if not os.path.isabs(value):
+ # If we receive a non-absolute path, make it absolute.
+ value = os.path.abspath(value)
+ if not os.path.isdir(value):
+ raise TraitError("No such notebook dir: %r" % value)
+ return value
+
@default('log_datefmt')
def _log_datefmt_default(self):
"""Exclude date from default date format"""
|
{"golden_diff": "diff --git a/jupyterhub/singleuser.py b/jupyterhub/singleuser.py\n--- a/jupyterhub/singleuser.py\n+++ b/jupyterhub/singleuser.py\n@@ -22,6 +22,7 @@\n CUnicode,\n default,\n validate,\n+ TraitError,\n )\n \n from notebook.notebookapp import (\n@@ -151,7 +152,23 @@\n from being loaded, ensuring admins have full control of configuration.\n \"\"\"\n ).tag(config=True)\n- \n+\n+ @validate('notebook_dir')\n+ def _notebook_dir_validate(self, proposal):\n+ value = os.path.expanduser(proposal['value'])\n+ # Strip any trailing slashes\n+ # *except* if it's root\n+ _, path = os.path.splitdrive(value)\n+ if path == os.sep:\n+ return value\n+ value = value.rstrip(os.sep)\n+ if not os.path.isabs(value):\n+ # If we receive a non-absolute path, make it absolute.\n+ value = os.path.abspath(value)\n+ if not os.path.isdir(value):\n+ raise TraitError(\"No such notebook dir: %r\" % value)\n+ return value\n+\n @default('log_datefmt')\n def _log_datefmt_default(self):\n \"\"\"Exclude date from default date format\"\"\"\n", "issue": "notebooks_dir ~ expands incorrectly\n**How to reproduce the issue**\r\n\r\nConfigure jupyterhub 0.7.0b1 with:\r\n\r\n```\r\nc.SudoSpawner.sudospawner_path = \"/some/where/bin/sudospawner\"\r\nc.SudoSpawner.sudo_args = ['-nH']\r\nc.Spawner.notebook_dir = '~/notebooks'\r\n```\r\n\r\nTry to login. Notebook server startup logs:\r\n\r\n```\r\n[C 2016-11-21 12:32:15.936 SingleUserNotebookApp application:91] No such notebook dir: '/home/pparente/~/notebooks'\r\n```\r\n\r\n**What you expected to happen**\r\n\r\nPath should be expanded properly.\r\n\r\n**What actually happens**\r\n\r\nPath is expanded but also gets the ~ part tacked back on.\r\n\r\n**Share what version of JupyterHub you are using**\r\n\r\n0.7.0b1\r\n\r\nI put a print in the jupyterhub-singleuser script and confirmed that it is receiving `--notebook-dir=\"~/notebooks\"` as in `sys.argv`. So it appears the incorrect expansion is happening somewhere after that.\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"Extend regular notebook server to be aware of multiuser things.\"\"\"\n\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\n\nfrom jinja2 import ChoiceLoader, FunctionLoader\n\nfrom tornado import ioloop\nfrom textwrap import dedent\n\ntry:\n import notebook\nexcept ImportError:\n raise ImportError(\"JupyterHub single-user server requires notebook >= 4.0\")\n\nfrom traitlets import (\n Bool,\n Unicode,\n CUnicode,\n default,\n validate,\n)\n\nfrom notebook.notebookapp import (\n NotebookApp,\n aliases as notebook_aliases,\n flags as notebook_flags,\n)\nfrom notebook.auth.login import LoginHandler\nfrom notebook.auth.logout import LogoutHandler\n\nfrom jupyterhub import __version__\nfrom .services.auth import HubAuth, HubAuthenticated\nfrom .utils import url_path_join\n\n# Authenticate requests with the Hub\n\nclass HubAuthenticatedHandler(HubAuthenticated):\n \"\"\"Class we are going to patch-in for authentication with the Hub\"\"\"\n @property\n def hub_auth(self):\n return self.settings['hub_auth']\n @property\n def hub_users(self):\n return { self.settings['user'] }\n\n\nclass JupyterHubLoginHandler(LoginHandler):\n \"\"\"LoginHandler that hooks up Hub authentication\"\"\"\n @staticmethod\n def login_available(settings):\n return True\n\n @staticmethod\n def get_user(handler):\n \"\"\"alternative get_current_user to query the Hub\"\"\"\n # patch in HubAuthenticated class for querying the Hub for cookie authentication\n name = 'NowHubAuthenticated'\n if handler.__class__.__name__ != name:\n handler.__class__ = type(name, (HubAuthenticatedHandler, handler.__class__), {})\n return handler.get_current_user()\n\n\nclass JupyterHubLogoutHandler(LogoutHandler):\n def get(self):\n self.redirect(\n self.settings['hub_host'] +\n url_path_join(self.settings['hub_prefix'], 'logout'))\n\n\n# register new hub related command-line aliases\naliases = dict(notebook_aliases)\naliases.update({\n 'user' : 'SingleUserNotebookApp.user',\n 'cookie-name': 'HubAuth.cookie_name',\n 'hub-prefix': 'SingleUserNotebookApp.hub_prefix',\n 'hub-host': 'SingleUserNotebookApp.hub_host',\n 'hub-api-url': 'SingleUserNotebookApp.hub_api_url',\n 'base-url': 'SingleUserNotebookApp.base_url',\n})\nflags = dict(notebook_flags)\nflags.update({\n 'disable-user-config': ({\n 'SingleUserNotebookApp': {\n 'disable_user_config': True\n }\n }, \"Disable user-controlled configuration of the notebook server.\")\n})\n\npage_template = \"\"\"\n{% extends \"templates/page.html\" %}\n\n{% block header_buttons %}\n{{super()}}\n\n<a href='{{hub_control_panel_url}}'\n class='btn btn-default btn-sm navbar-btn pull-right'\n style='margin-right: 4px; margin-left: 2px;'\n>\nControl Panel</a>\n{% endblock %}\n{% block logo %}\n<img src='{{logo_url}}' alt='Jupyter Notebook'/>\n{% endblock logo %}\n\"\"\"\n\ndef _exclude_home(path_list):\n \"\"\"Filter out any entries in a path list that are in my home directory.\n\n Used to disable per-user configuration.\n \"\"\"\n home = os.path.expanduser('~')\n for p in path_list:\n if not p.startswith(home):\n yield p\n\nclass SingleUserNotebookApp(NotebookApp):\n \"\"\"A Subclass of the regular NotebookApp that is aware of the parent multiuser context.\"\"\"\n description = dedent(\"\"\"\n Single-user server for JupyterHub. Extends the Jupyter Notebook server.\n \n Meant to be invoked by JupyterHub Spawners, and not directly.\n \"\"\")\n \n examples = \"\"\n subcommands = {}\n version = __version__\n classes = NotebookApp.classes + [HubAuth]\n\n user = CUnicode(config=True)\n def _user_changed(self, name, old, new):\n self.log.name = new\n hub_prefix = Unicode().tag(config=True)\n hub_host = Unicode().tag(config=True)\n hub_api_url = Unicode().tag(config=True)\n aliases = aliases\n flags = flags\n open_browser = False\n trust_xheaders = True\n login_handler_class = JupyterHubLoginHandler\n logout_handler_class = JupyterHubLogoutHandler\n port_retries = 0 # disable port-retries, since the Spawner will tell us what port to use\n\n disable_user_config = Bool(False,\n help=\"\"\"Disable user configuration of single-user server.\n\n Prevents user-writable files that normally configure the single-user server\n from being loaded, ensuring admins have full control of configuration.\n \"\"\"\n ).tag(config=True)\n \n @default('log_datefmt')\n def _log_datefmt_default(self):\n \"\"\"Exclude date from default date format\"\"\"\n return \"%Y-%m-%d %H:%M:%S\"\n\n @default('log_format')\n def _log_format_default(self):\n \"\"\"override default log format to include time\"\"\"\n return \"%(color)s[%(levelname)1.1s %(asctime)s.%(msecs).03d %(name)s %(module)s:%(lineno)d]%(end_color)s %(message)s\"\n\n def _confirm_exit(self):\n # disable the exit confirmation for background notebook processes\n ioloop.IOLoop.instance().stop()\n\n def migrate_config(self):\n if self.disable_user_config:\n # disable config-migration when user config is disabled\n return\n else:\n super(SingleUserNotebookApp, self).migrate_config()\n\n @property\n def config_file_paths(self):\n path = super(SingleUserNotebookApp, self).config_file_paths\n\n if self.disable_user_config:\n # filter out user-writable config dirs if user config is disabled\n path = list(_exclude_home(path))\n return path\n\n @property\n def nbextensions_path(self):\n path = super(SingleUserNotebookApp, self).nbextensions_path\n\n if self.disable_user_config:\n path = list(_exclude_home(path))\n return path\n\n @validate('static_custom_path')\n def _validate_static_custom_path(self, proposal):\n path = proposal['value']\n if self.disable_user_config:\n path = list(_exclude_home(path))\n return path\n\n def start(self):\n super(SingleUserNotebookApp, self).start()\n\n def init_hub_auth(self):\n if not os.environ.get('JPY_API_TOKEN'):\n self.exit(\"JPY_API_TOKEN env is required to run jupyterhub-singleuser. Did you launch it manually?\")\n self.hub_auth = HubAuth(\n parent=self,\n api_token=os.environ.pop('JPY_API_TOKEN'),\n api_url=self.hub_api_url,\n )\n\n def init_webapp(self):\n # load the hub related settings into the tornado settings dict\n self.init_hub_auth()\n s = self.tornado_settings\n s['user'] = self.user\n s['hub_prefix'] = self.hub_prefix\n s['hub_host'] = self.hub_host\n s['hub_auth'] = self.hub_auth\n s['login_url'] = self.hub_host + self.hub_prefix\n s['csp_report_uri'] = self.hub_host + url_path_join(self.hub_prefix, 'security/csp-report')\n super(SingleUserNotebookApp, self).init_webapp()\n self.patch_templates()\n\n def patch_templates(self):\n \"\"\"Patch page templates to add Hub-related buttons\"\"\"\n\n self.jinja_template_vars['logo_url'] = self.hub_host + url_path_join(self.hub_prefix, 'logo')\n self.jinja_template_vars['hub_host'] = self.hub_host\n self.jinja_template_vars['hub_prefix'] = self.hub_prefix\n env = self.web_app.settings['jinja2_env']\n\n env.globals['hub_control_panel_url'] = \\\n self.hub_host + url_path_join(self.hub_prefix, 'home')\n\n # patch jinja env loading to modify page template\n def get_page(name):\n if name == 'page.html':\n return page_template\n\n orig_loader = env.loader\n env.loader = ChoiceLoader([\n FunctionLoader(get_page),\n orig_loader,\n ])\n\n\ndef main(argv=None):\n return SingleUserNotebookApp.launch_instance(argv)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "jupyterhub/singleuser.py"}]}
| 3,270 | 290 |
gh_patches_debug_39330
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-546
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature: 对戳一戳事件的响应
**是否在使用中遇到某些问题而需要新的特性?请描述:**
虽然可以通过event.type来判断是否是戳一戳,但加一个对于戳一戳事件的完整支持我觉得还是更好一点
**描述你所需要的特性:**
支持对戳一戳事件的响应
Feature: 对戳一戳事件的响应
**是否在使用中遇到某些问题而需要新的特性?请描述:**
虽然可以通过event.type来判断是否是戳一戳,但加一个对于戳一戳事件的完整支持我觉得还是更好一点
**描述你所需要的特性:**
支持对戳一戳事件的响应
</issue>
<code>
[start of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py]
1 import json
2 from enum import Enum
3 from typing import Any, Dict, Optional, Type
4
5 from pydantic import BaseModel, Field, ValidationError
6 from typing_extensions import Literal
7
8 from nonebot.adapters import Event as BaseEvent
9 from nonebot.adapters import Message as BaseMessage
10 from nonebot.log import logger
11 from nonebot.typing import overrides
12 from nonebot.utils import escape_tag
13
14
15 class UserPermission(str, Enum):
16 """
17 :说明:
18
19 用户权限枚举类
20
21 * ``OWNER``: 群主
22 * ``ADMINISTRATOR``: 群管理
23 * ``MEMBER``: 普通群成员
24 """
25 OWNER = 'OWNER'
26 ADMINISTRATOR = 'ADMINISTRATOR'
27 MEMBER = 'MEMBER'
28
29
30 class GroupInfo(BaseModel):
31 id: int
32 name: str
33 permission: UserPermission
34
35
36 class GroupChatInfo(BaseModel):
37 id: int
38 name: str = Field(alias='memberName')
39 permission: UserPermission
40 group: GroupInfo
41
42
43 class PrivateChatInfo(BaseModel):
44 id: int
45 nickname: str
46 remark: str
47
48
49 class Event(BaseEvent):
50 """
51 mirai-api-http 协议事件,字段与 mirai-api-http 一致。各事件字段参考 `mirai-api-http 事件类型`_
52
53 .. _mirai-api-http 事件类型:
54 https://github.com/project-mirai/mirai-api-http/blob/master/docs/EventType.md
55 """
56 self_id: int
57 type: str
58
59 @classmethod
60 def new(cls, data: Dict[str, Any]) -> "Event":
61 """
62 此事件类的工厂函数, 能够通过事件数据选择合适的子类进行序列化
63 """
64 type = data['type']
65
66 def all_subclasses(cls: Type[Event]):
67 return set(cls.__subclasses__()).union(
68 [s for c in cls.__subclasses__() for s in all_subclasses(c)])
69
70 event_class: Optional[Type[Event]] = None
71 for subclass in all_subclasses(cls):
72 if subclass.__name__ != type:
73 continue
74 event_class = subclass
75
76 if event_class is None:
77 return Event.parse_obj(data)
78
79 while event_class and issubclass(event_class, Event):
80 try:
81 return event_class.parse_obj(data)
82 except ValidationError as e:
83 logger.info(
84 f'Failed to parse {data} to class {event_class.__name__}: '
85 f'{e.errors()!r}. Fallback to parent class.')
86 event_class = event_class.__base__ # type: ignore
87
88 raise ValueError(f'Failed to serialize {data}.')
89
90 @overrides(BaseEvent)
91 def get_type(self) -> Literal["message", "notice", "request", "meta_event"]:
92 from . import message, meta, notice, request
93 if isinstance(self, message.MessageEvent):
94 return 'message'
95 elif isinstance(self, notice.NoticeEvent):
96 return 'notice'
97 elif isinstance(self, request.RequestEvent):
98 return 'request'
99 else:
100 return 'meta_event'
101
102 @overrides(BaseEvent)
103 def get_event_name(self) -> str:
104 return self.type
105
106 @overrides(BaseEvent)
107 def get_event_description(self) -> str:
108 return escape_tag(str(self.normalize_dict()))
109
110 @overrides(BaseEvent)
111 def get_message(self) -> BaseMessage:
112 raise ValueError("Event has no message!")
113
114 @overrides(BaseEvent)
115 def get_plaintext(self) -> str:
116 raise ValueError("Event has no message!")
117
118 @overrides(BaseEvent)
119 def get_user_id(self) -> str:
120 raise ValueError("Event has no message!")
121
122 @overrides(BaseEvent)
123 def get_session_id(self) -> str:
124 raise ValueError("Event has no message!")
125
126 @overrides(BaseEvent)
127 def is_tome(self) -> bool:
128 return False
129
130 def normalize_dict(self, **kwargs) -> Dict[str, Any]:
131 """
132 返回可以被json正常反序列化的结构体
133 """
134 return json.loads(self.json(**kwargs))
135
[end of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py]
[start of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py]
1 from typing import Any, Optional
2
3 from pydantic import Field
4
5 from .base import Event, GroupChatInfo, GroupInfo, UserPermission
6
7
8 class NoticeEvent(Event):
9 """通知事件基类"""
10 pass
11
12
13 class MuteEvent(NoticeEvent):
14 """禁言类事件基类"""
15 operator: GroupChatInfo
16
17
18 class BotMuteEvent(MuteEvent):
19 """Bot被禁言"""
20 pass
21
22
23 class BotUnmuteEvent(MuteEvent):
24 """Bot被取消禁言"""
25 pass
26
27
28 class MemberMuteEvent(MuteEvent):
29 """群成员被禁言事件(该成员不是Bot)"""
30 duration_seconds: int = Field(alias='durationSeconds')
31 member: GroupChatInfo
32 operator: Optional[GroupChatInfo] = None
33
34
35 class MemberUnmuteEvent(MuteEvent):
36 """群成员被取消禁言事件(该成员不是Bot)"""
37 member: GroupChatInfo
38 operator: Optional[GroupChatInfo] = None
39
40
41 class BotJoinGroupEvent(NoticeEvent):
42 """Bot加入了一个新群"""
43 group: GroupInfo
44
45
46 class BotLeaveEventActive(BotJoinGroupEvent):
47 """Bot主动退出一个群"""
48 pass
49
50
51 class BotLeaveEventKick(BotJoinGroupEvent):
52 """Bot被踢出一个群"""
53 pass
54
55
56 class MemberJoinEvent(NoticeEvent):
57 """新人入群的事件"""
58 member: GroupChatInfo
59
60
61 class MemberLeaveEventKick(MemberJoinEvent):
62 """成员被踢出群(该成员不是Bot)"""
63 operator: Optional[GroupChatInfo] = None
64
65
66 class MemberLeaveEventQuit(MemberJoinEvent):
67 """成员主动离群(该成员不是Bot)"""
68 pass
69
70
71 class FriendRecallEvent(NoticeEvent):
72 """好友消息撤回"""
73 author_id: int = Field(alias='authorId')
74 message_id: int = Field(alias='messageId')
75 time: int
76 operator: int
77
78
79 class GroupRecallEvent(FriendRecallEvent):
80 """群消息撤回"""
81 group: GroupInfo
82 operator: Optional[GroupChatInfo] = None
83
84
85 class GroupStateChangeEvent(NoticeEvent):
86 """群变化事件基类"""
87 origin: Any
88 current: Any
89 group: GroupInfo
90 operator: Optional[GroupChatInfo] = None
91
92
93 class GroupNameChangeEvent(GroupStateChangeEvent):
94 """某个群名改变"""
95 origin: str
96 current: str
97
98
99 class GroupEntranceAnnouncementChangeEvent(GroupStateChangeEvent):
100 """某群入群公告改变"""
101 origin: str
102 current: str
103
104
105 class GroupMuteAllEvent(GroupStateChangeEvent):
106 """全员禁言"""
107 origin: bool
108 current: bool
109
110
111 class GroupAllowAnonymousChatEvent(GroupStateChangeEvent):
112 """匿名聊天"""
113 origin: bool
114 current: bool
115
116
117 class GroupAllowConfessTalkEvent(GroupStateChangeEvent):
118 """坦白说"""
119 origin: bool
120 current: bool
121
122
123 class GroupAllowMemberInviteEvent(GroupStateChangeEvent):
124 """允许群员邀请好友加群"""
125 origin: bool
126 current: bool
127
128
129 class MemberStateChangeEvent(NoticeEvent):
130 """群成员变化事件基类"""
131 member: GroupChatInfo
132 operator: Optional[GroupChatInfo] = None
133
134
135 class MemberCardChangeEvent(MemberStateChangeEvent):
136 """群名片改动"""
137 origin: str
138 current: str
139
140
141 class MemberSpecialTitleChangeEvent(MemberStateChangeEvent):
142 """群头衔改动(只有群主有操作限权)"""
143 origin: str
144 current: str
145
146
147 class BotGroupPermissionChangeEvent(MemberStateChangeEvent):
148 """Bot在群里的权限被改变"""
149 origin: UserPermission
150 current: UserPermission
151
152
153 class MemberPermissionChangeEvent(MemberStateChangeEvent):
154 """成员权限改变的事件(该成员不是Bot)"""
155 origin: UserPermission
156 current: UserPermission
157
[end of packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py
--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py
+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py
@@ -1,15 +1,15 @@
import json
from enum import Enum
-from typing import Any, Dict, Optional, Type
-
-from pydantic import BaseModel, Field, ValidationError
from typing_extensions import Literal
+from typing import Any, Dict, Type, Optional
+
+from pydantic import Field, BaseModel, ValidationError
-from nonebot.adapters import Event as BaseEvent
-from nonebot.adapters import Message as BaseMessage
from nonebot.log import logger
from nonebot.typing import overrides
from nonebot.utils import escape_tag
+from nonebot.adapters import Event as BaseEvent
+from nonebot.adapters import Message as BaseMessage
class UserPermission(str, Enum):
@@ -18,15 +18,28 @@
用户权限枚举类
- * ``OWNER``: 群主
- * ``ADMINISTRATOR``: 群管理
- * ``MEMBER``: 普通群成员
+ * ``OWNER``: 群主
+ * ``ADMINISTRATOR``: 群管理
+ * ``MEMBER``: 普通群成员
"""
OWNER = 'OWNER'
ADMINISTRATOR = 'ADMINISTRATOR'
MEMBER = 'MEMBER'
+class NudgeSubjectKind(str, Enum):
+ """
+ :说明:
+
+ 戳一戳类型枚举类
+
+ * ``Group``: 群
+ * ``Friend``: 好友
+ """
+ Group = 'Group'
+ Friend = 'Friend'
+
+
class GroupInfo(BaseModel):
id: int
name: str
@@ -46,6 +59,11 @@
remark: str
+class NudgeSubject(BaseModel):
+ id: int
+ kind: NudgeSubjectKind
+
+
class Event(BaseEvent):
"""
mirai-api-http 协议事件,字段与 mirai-api-http 一致。各事件字段参考 `mirai-api-http 事件类型`_
@@ -89,7 +107,7 @@
@overrides(BaseEvent)
def get_type(self) -> Literal["message", "notice", "request", "meta_event"]:
- from . import message, meta, notice, request
+ from . import meta, notice, message, request
if isinstance(self, message.MessageEvent):
return 'message'
elif isinstance(self, notice.NoticeEvent):
diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py
--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py
+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py
@@ -2,7 +2,7 @@
from pydantic import Field
-from .base import Event, GroupChatInfo, GroupInfo, UserPermission
+from .base import Event, GroupChatInfo, GroupInfo, NudgeSubject, UserPermission
class NoticeEvent(Event):
@@ -154,3 +154,12 @@
"""成员权限改变的事件(该成员不是Bot)"""
origin: UserPermission
current: UserPermission
+
+
+class NudgeEvent(NoticeEvent):
+ """戳一戳触发事件"""
+ from_id: int = Field(alias='fromId')
+ target: int
+ subject: NudgeSubject
+ action: str
+ suffix: str
|
{"golden_diff": "diff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py\n--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py\n+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py\n@@ -1,15 +1,15 @@\n import json\n from enum import Enum\n-from typing import Any, Dict, Optional, Type\n-\n-from pydantic import BaseModel, Field, ValidationError\n from typing_extensions import Literal\n+from typing import Any, Dict, Type, Optional\n+\n+from pydantic import Field, BaseModel, ValidationError\n \n-from nonebot.adapters import Event as BaseEvent\n-from nonebot.adapters import Message as BaseMessage\n from nonebot.log import logger\n from nonebot.typing import overrides\n from nonebot.utils import escape_tag\n+from nonebot.adapters import Event as BaseEvent\n+from nonebot.adapters import Message as BaseMessage\n \n \n class UserPermission(str, Enum):\n@@ -18,15 +18,28 @@\n \n \u7528\u6237\u6743\u9650\u679a\u4e3e\u7c7b\n \n- * ``OWNER``: \u7fa4\u4e3b\n- * ``ADMINISTRATOR``: \u7fa4\u7ba1\u7406\n- * ``MEMBER``: \u666e\u901a\u7fa4\u6210\u5458\n+ * ``OWNER``: \u7fa4\u4e3b\n+ * ``ADMINISTRATOR``: \u7fa4\u7ba1\u7406\n+ * ``MEMBER``: \u666e\u901a\u7fa4\u6210\u5458\n \"\"\"\n OWNER = 'OWNER'\n ADMINISTRATOR = 'ADMINISTRATOR'\n MEMBER = 'MEMBER'\n \n \n+class NudgeSubjectKind(str, Enum):\n+ \"\"\"\n+ :\u8bf4\u660e:\n+\n+ \u6233\u4e00\u6233\u7c7b\u578b\u679a\u4e3e\u7c7b\n+\n+ * ``Group``: \u7fa4\n+ * ``Friend``: \u597d\u53cb\n+ \"\"\"\n+ Group = 'Group'\n+ Friend = 'Friend'\n+\n+\n class GroupInfo(BaseModel):\n id: int\n name: str\n@@ -46,6 +59,11 @@\n remark: str\n \n \n+class NudgeSubject(BaseModel):\n+ id: int\n+ kind: NudgeSubjectKind\n+\n+\n class Event(BaseEvent):\n \"\"\"\n mirai-api-http \u534f\u8bae\u4e8b\u4ef6\uff0c\u5b57\u6bb5\u4e0e mirai-api-http \u4e00\u81f4\u3002\u5404\u4e8b\u4ef6\u5b57\u6bb5\u53c2\u8003 `mirai-api-http \u4e8b\u4ef6\u7c7b\u578b`_\n@@ -89,7 +107,7 @@\n \n @overrides(BaseEvent)\n def get_type(self) -> Literal[\"message\", \"notice\", \"request\", \"meta_event\"]:\n- from . import message, meta, notice, request\n+ from . import meta, notice, message, request\n if isinstance(self, message.MessageEvent):\n return 'message'\n elif isinstance(self, notice.NoticeEvent):\ndiff --git a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py\n--- a/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py\n+++ b/packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py\n@@ -2,7 +2,7 @@\n \n from pydantic import Field\n \n-from .base import Event, GroupChatInfo, GroupInfo, UserPermission\n+from .base import Event, GroupChatInfo, GroupInfo, NudgeSubject, UserPermission\n \n \n class NoticeEvent(Event):\n@@ -154,3 +154,12 @@\n \"\"\"\u6210\u5458\u6743\u9650\u6539\u53d8\u7684\u4e8b\u4ef6\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n origin: UserPermission\n current: UserPermission\n+\n+\n+class NudgeEvent(NoticeEvent):\n+ \"\"\"\u6233\u4e00\u6233\u89e6\u53d1\u4e8b\u4ef6\"\"\"\n+ from_id: int = Field(alias='fromId')\n+ target: int\n+ subject: NudgeSubject\n+ action: str\n+ suffix: str\n", "issue": "Feature: \u5bf9\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u54cd\u5e94\n**\u662f\u5426\u5728\u4f7f\u7528\u4e2d\u9047\u5230\u67d0\u4e9b\u95ee\u9898\u800c\u9700\u8981\u65b0\u7684\u7279\u6027\uff1f\u8bf7\u63cf\u8ff0\uff1a**\r\n\r\n\u867d\u7136\u53ef\u4ee5\u901a\u8fc7event.type\u6765\u5224\u65ad\u662f\u5426\u662f\u6233\u4e00\u6233\uff0c\u4f46\u52a0\u4e00\u4e2a\u5bf9\u4e8e\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u5b8c\u6574\u652f\u6301\u6211\u89c9\u5f97\u8fd8\u662f\u66f4\u597d\u4e00\u70b9\r\n\r\n**\u63cf\u8ff0\u4f60\u6240\u9700\u8981\u7684\u7279\u6027\uff1a**\r\n\r\n\u652f\u6301\u5bf9\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u54cd\u5e94\r\n\nFeature: \u5bf9\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u54cd\u5e94\n**\u662f\u5426\u5728\u4f7f\u7528\u4e2d\u9047\u5230\u67d0\u4e9b\u95ee\u9898\u800c\u9700\u8981\u65b0\u7684\u7279\u6027\uff1f\u8bf7\u63cf\u8ff0\uff1a**\r\n\r\n\u867d\u7136\u53ef\u4ee5\u901a\u8fc7event.type\u6765\u5224\u65ad\u662f\u5426\u662f\u6233\u4e00\u6233\uff0c\u4f46\u52a0\u4e00\u4e2a\u5bf9\u4e8e\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u5b8c\u6574\u652f\u6301\u6211\u89c9\u5f97\u8fd8\u662f\u66f4\u597d\u4e00\u70b9\r\n\r\n**\u63cf\u8ff0\u4f60\u6240\u9700\u8981\u7684\u7279\u6027\uff1a**\r\n\r\n\u652f\u6301\u5bf9\u6233\u4e00\u6233\u4e8b\u4ef6\u7684\u54cd\u5e94\r\n\n", "before_files": [{"content": "import json\nfrom enum import Enum\nfrom typing import Any, Dict, Optional, Type\n\nfrom pydantic import BaseModel, Field, ValidationError\nfrom typing_extensions import Literal\n\nfrom nonebot.adapters import Event as BaseEvent\nfrom nonebot.adapters import Message as BaseMessage\nfrom nonebot.log import logger\nfrom nonebot.typing import overrides\nfrom nonebot.utils import escape_tag\n\n\nclass UserPermission(str, Enum):\n \"\"\"\n :\u8bf4\u660e:\n\n \u7528\u6237\u6743\u9650\u679a\u4e3e\u7c7b\n\n * ``OWNER``: \u7fa4\u4e3b\n * ``ADMINISTRATOR``: \u7fa4\u7ba1\u7406\n * ``MEMBER``: \u666e\u901a\u7fa4\u6210\u5458\n \"\"\"\n OWNER = 'OWNER'\n ADMINISTRATOR = 'ADMINISTRATOR'\n MEMBER = 'MEMBER'\n\n\nclass GroupInfo(BaseModel):\n id: int\n name: str\n permission: UserPermission\n\n\nclass GroupChatInfo(BaseModel):\n id: int\n name: str = Field(alias='memberName')\n permission: UserPermission\n group: GroupInfo\n\n\nclass PrivateChatInfo(BaseModel):\n id: int\n nickname: str\n remark: str\n\n\nclass Event(BaseEvent):\n \"\"\"\n mirai-api-http \u534f\u8bae\u4e8b\u4ef6\uff0c\u5b57\u6bb5\u4e0e mirai-api-http \u4e00\u81f4\u3002\u5404\u4e8b\u4ef6\u5b57\u6bb5\u53c2\u8003 `mirai-api-http \u4e8b\u4ef6\u7c7b\u578b`_\n\n .. _mirai-api-http \u4e8b\u4ef6\u7c7b\u578b:\n https://github.com/project-mirai/mirai-api-http/blob/master/docs/EventType.md\n \"\"\"\n self_id: int\n type: str\n\n @classmethod\n def new(cls, data: Dict[str, Any]) -> \"Event\":\n \"\"\"\n \u6b64\u4e8b\u4ef6\u7c7b\u7684\u5de5\u5382\u51fd\u6570, \u80fd\u591f\u901a\u8fc7\u4e8b\u4ef6\u6570\u636e\u9009\u62e9\u5408\u9002\u7684\u5b50\u7c7b\u8fdb\u884c\u5e8f\u5217\u5316\n \"\"\"\n type = data['type']\n\n def all_subclasses(cls: Type[Event]):\n return set(cls.__subclasses__()).union(\n [s for c in cls.__subclasses__() for s in all_subclasses(c)])\n\n event_class: Optional[Type[Event]] = None\n for subclass in all_subclasses(cls):\n if subclass.__name__ != type:\n continue\n event_class = subclass\n\n if event_class is None:\n return Event.parse_obj(data)\n\n while event_class and issubclass(event_class, Event):\n try:\n return event_class.parse_obj(data)\n except ValidationError as e:\n logger.info(\n f'Failed to parse {data} to class {event_class.__name__}: '\n f'{e.errors()!r}. Fallback to parent class.')\n event_class = event_class.__base__ # type: ignore\n\n raise ValueError(f'Failed to serialize {data}.')\n\n @overrides(BaseEvent)\n def get_type(self) -> Literal[\"message\", \"notice\", \"request\", \"meta_event\"]:\n from . import message, meta, notice, request\n if isinstance(self, message.MessageEvent):\n return 'message'\n elif isinstance(self, notice.NoticeEvent):\n return 'notice'\n elif isinstance(self, request.RequestEvent):\n return 'request'\n else:\n return 'meta_event'\n\n @overrides(BaseEvent)\n def get_event_name(self) -> str:\n return self.type\n\n @overrides(BaseEvent)\n def get_event_description(self) -> str:\n return escape_tag(str(self.normalize_dict()))\n\n @overrides(BaseEvent)\n def get_message(self) -> BaseMessage:\n raise ValueError(\"Event has no message!\")\n\n @overrides(BaseEvent)\n def get_plaintext(self) -> str:\n raise ValueError(\"Event has no message!\")\n\n @overrides(BaseEvent)\n def get_user_id(self) -> str:\n raise ValueError(\"Event has no message!\")\n\n @overrides(BaseEvent)\n def get_session_id(self) -> str:\n raise ValueError(\"Event has no message!\")\n\n @overrides(BaseEvent)\n def is_tome(self) -> bool:\n return False\n\n def normalize_dict(self, **kwargs) -> Dict[str, Any]:\n \"\"\"\n \u8fd4\u56de\u53ef\u4ee5\u88abjson\u6b63\u5e38\u53cd\u5e8f\u5217\u5316\u7684\u7ed3\u6784\u4f53\n \"\"\"\n return json.loads(self.json(**kwargs))\n", "path": "packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/base.py"}, {"content": "from typing import Any, Optional\n\nfrom pydantic import Field\n\nfrom .base import Event, GroupChatInfo, GroupInfo, UserPermission\n\n\nclass NoticeEvent(Event):\n \"\"\"\u901a\u77e5\u4e8b\u4ef6\u57fa\u7c7b\"\"\"\n pass\n\n\nclass MuteEvent(NoticeEvent):\n \"\"\"\u7981\u8a00\u7c7b\u4e8b\u4ef6\u57fa\u7c7b\"\"\"\n operator: GroupChatInfo\n\n\nclass BotMuteEvent(MuteEvent):\n \"\"\"Bot\u88ab\u7981\u8a00\"\"\"\n pass\n\n\nclass BotUnmuteEvent(MuteEvent):\n \"\"\"Bot\u88ab\u53d6\u6d88\u7981\u8a00\"\"\"\n pass\n\n\nclass MemberMuteEvent(MuteEvent):\n \"\"\"\u7fa4\u6210\u5458\u88ab\u7981\u8a00\u4e8b\u4ef6\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n duration_seconds: int = Field(alias='durationSeconds')\n member: GroupChatInfo\n operator: Optional[GroupChatInfo] = None\n\n\nclass MemberUnmuteEvent(MuteEvent):\n \"\"\"\u7fa4\u6210\u5458\u88ab\u53d6\u6d88\u7981\u8a00\u4e8b\u4ef6\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n member: GroupChatInfo\n operator: Optional[GroupChatInfo] = None\n\n\nclass BotJoinGroupEvent(NoticeEvent):\n \"\"\"Bot\u52a0\u5165\u4e86\u4e00\u4e2a\u65b0\u7fa4\"\"\"\n group: GroupInfo\n\n\nclass BotLeaveEventActive(BotJoinGroupEvent):\n \"\"\"Bot\u4e3b\u52a8\u9000\u51fa\u4e00\u4e2a\u7fa4\"\"\"\n pass\n\n\nclass BotLeaveEventKick(BotJoinGroupEvent):\n \"\"\"Bot\u88ab\u8e22\u51fa\u4e00\u4e2a\u7fa4\"\"\"\n pass\n\n\nclass MemberJoinEvent(NoticeEvent):\n \"\"\"\u65b0\u4eba\u5165\u7fa4\u7684\u4e8b\u4ef6\"\"\"\n member: GroupChatInfo\n\n\nclass MemberLeaveEventKick(MemberJoinEvent):\n \"\"\"\u6210\u5458\u88ab\u8e22\u51fa\u7fa4\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n operator: Optional[GroupChatInfo] = None\n\n\nclass MemberLeaveEventQuit(MemberJoinEvent):\n \"\"\"\u6210\u5458\u4e3b\u52a8\u79bb\u7fa4\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n pass\n\n\nclass FriendRecallEvent(NoticeEvent):\n \"\"\"\u597d\u53cb\u6d88\u606f\u64a4\u56de\"\"\"\n author_id: int = Field(alias='authorId')\n message_id: int = Field(alias='messageId')\n time: int\n operator: int\n\n\nclass GroupRecallEvent(FriendRecallEvent):\n \"\"\"\u7fa4\u6d88\u606f\u64a4\u56de\"\"\"\n group: GroupInfo\n operator: Optional[GroupChatInfo] = None\n\n\nclass GroupStateChangeEvent(NoticeEvent):\n \"\"\"\u7fa4\u53d8\u5316\u4e8b\u4ef6\u57fa\u7c7b\"\"\"\n origin: Any\n current: Any\n group: GroupInfo\n operator: Optional[GroupChatInfo] = None\n\n\nclass GroupNameChangeEvent(GroupStateChangeEvent):\n \"\"\"\u67d0\u4e2a\u7fa4\u540d\u6539\u53d8\"\"\"\n origin: str\n current: str\n\n\nclass GroupEntranceAnnouncementChangeEvent(GroupStateChangeEvent):\n \"\"\"\u67d0\u7fa4\u5165\u7fa4\u516c\u544a\u6539\u53d8\"\"\"\n origin: str\n current: str\n\n\nclass GroupMuteAllEvent(GroupStateChangeEvent):\n \"\"\"\u5168\u5458\u7981\u8a00\"\"\"\n origin: bool\n current: bool\n\n\nclass GroupAllowAnonymousChatEvent(GroupStateChangeEvent):\n \"\"\"\u533f\u540d\u804a\u5929\"\"\"\n origin: bool\n current: bool\n\n\nclass GroupAllowConfessTalkEvent(GroupStateChangeEvent):\n \"\"\"\u5766\u767d\u8bf4\"\"\"\n origin: bool\n current: bool\n\n\nclass GroupAllowMemberInviteEvent(GroupStateChangeEvent):\n \"\"\"\u5141\u8bb8\u7fa4\u5458\u9080\u8bf7\u597d\u53cb\u52a0\u7fa4\"\"\"\n origin: bool\n current: bool\n\n\nclass MemberStateChangeEvent(NoticeEvent):\n \"\"\"\u7fa4\u6210\u5458\u53d8\u5316\u4e8b\u4ef6\u57fa\u7c7b\"\"\"\n member: GroupChatInfo\n operator: Optional[GroupChatInfo] = None\n\n\nclass MemberCardChangeEvent(MemberStateChangeEvent):\n \"\"\"\u7fa4\u540d\u7247\u6539\u52a8\"\"\"\n origin: str\n current: str\n\n\nclass MemberSpecialTitleChangeEvent(MemberStateChangeEvent):\n \"\"\"\u7fa4\u5934\u8854\u6539\u52a8\uff08\u53ea\u6709\u7fa4\u4e3b\u6709\u64cd\u4f5c\u9650\u6743\uff09\"\"\"\n origin: str\n current: str\n\n\nclass BotGroupPermissionChangeEvent(MemberStateChangeEvent):\n \"\"\"Bot\u5728\u7fa4\u91cc\u7684\u6743\u9650\u88ab\u6539\u53d8\"\"\"\n origin: UserPermission\n current: UserPermission\n\n\nclass MemberPermissionChangeEvent(MemberStateChangeEvent):\n \"\"\"\u6210\u5458\u6743\u9650\u6539\u53d8\u7684\u4e8b\u4ef6\uff08\u8be5\u6210\u5458\u4e0d\u662fBot\uff09\"\"\"\n origin: UserPermission\n current: UserPermission\n", "path": "packages/nonebot-adapter-mirai/nonebot/adapters/mirai/event/notice.py"}]}
| 3,182 | 890 |
gh_patches_debug_1104
|
rasdani/github-patches
|
git_diff
|
blaze__blaze-872
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Truncate column name is too verbose
Do we have to have a unique name for the result of such operations?
How about having it renamed to the unit, i.e. instead of `when_datetimetruncate` we use `when_day` or `when_week`, etc?
</issue>
<code>
[start of blaze/expr/datetime.py]
1 from __future__ import absolute_import, division, print_function
2
3 from .expressions import Expr, ElemWise
4 from datashape import dshape, Record, DataShape, Unit, Option, date_, datetime_
5 import datashape
6
7 __all__ = ['DateTime', 'Date', 'date', 'Year', 'year', 'Month', 'month', 'Day',
8 'day', 'Hour', 'hour', 'Second', 'second', 'Millisecond',
9 'millisecond', 'Microsecond', 'microsecond', 'Date', 'date', 'Time',
10 'time', 'UTCFromTimestamp', 'DateTimeTruncate']
11
12 class DateTime(ElemWise):
13 """ Superclass for datetime accessors """
14 __slots__ = '_hash', '_child',
15
16 def __str__(self):
17 return '%s.%s' % (str(self._child), type(self).__name__.lower())
18
19 @property
20 def schema(self):
21 return dshape(self._dtype)
22
23 @property
24 def _name(self):
25 return '%s_%s' % (self._child._name, self.attr)
26
27 @property
28 def attr(self):
29 return type(self).__name__.lower()
30
31
32 class Date(DateTime):
33 _dtype = datashape.date_
34
35 def date(expr):
36 return Date(expr)
37
38 class Year(DateTime):
39 _dtype = datashape.int32
40
41 def year(expr):
42 return Year(expr)
43
44 class Month(DateTime):
45 _dtype = datashape.int32
46
47 def month(expr):
48 return Month(expr)
49
50 class Day(DateTime):
51 _dtype = datashape.int32
52
53 def day(expr):
54 return Day(expr)
55
56 class Time(DateTime):
57 _dtype = datashape.time_
58
59 def time(expr):
60 return Time(Expr)
61
62 class Hour(DateTime):
63 _dtype = datashape.int32
64
65 def hour(expr):
66 return Hour(expr)
67
68 class Minute(DateTime):
69 _dtype = datashape.int32
70
71 def minute(expr):
72 return Minute(expr)
73
74 class Second(DateTime):
75 _dtype = datashape.int32
76
77 def second(expr):
78 return Second(expr)
79
80 class Millisecond(DateTime):
81 _dtype = datashape.int64
82
83 def millisecond(expr):
84 return Millisecond(expr)
85
86 class Microsecond(DateTime):
87 _dtype = datashape.int64
88
89 def microsecond(expr):
90 return Microsecond(expr)
91
92 class UTCFromTimestamp(DateTime):
93 _dtype = datashape.datetime_
94
95 def utcfromtimestamp(expr):
96 return UTCFromTimestamp(expr)
97
98 units = ['year', 'month', 'week', 'day', 'hour', 'minute', 'second',
99 'millisecond', 'microsecond', 'nanosecond']
100
101
102 _unit_aliases = {'y': 'year', 'w': 'week', 'd': 'day', 'date': 'day',
103 'h': 'hour', 's': 'second', 'ms': 'millisecond', 'us': 'microsecond',
104 'ns': 'nanosecond'}
105
106 def normalize_time_unit(s):
107 """ Normalize time input to one of 'year', 'second', 'millisecond', etc..
108
109 Example
110 -------
111
112 >>> normalize_time_unit('milliseconds')
113 'millisecond'
114 >>> normalize_time_unit('ms')
115 'millisecond'
116 """
117 s = s.lower().strip()
118 if s in units:
119 return s
120 if s in _unit_aliases:
121 return _unit_aliases[s]
122 if s[-1] == 's':
123 return normalize_time_unit(s.rstrip('s'))
124
125 raise ValueError("Do not understand time unit %s" % s)
126
127
128 class DateTimeTruncate(DateTime):
129 __slots__ = '_hash', '_child', 'measure', 'unit'
130
131 @property
132 def _dtype(self):
133 if units.index('day') >= units.index(self.unit):
134 return datashape.date_
135 else:
136 return datashape.datetime_
137
138
139 def truncate(expr, *args, **kwargs):
140 """ Truncate datetime expression
141
142 Example
143 -------
144
145 >>> from blaze import symbol, compute
146 >>> from datetime import datetime
147 >>> s = symbol('s', 'datetime')
148
149 >>> expr = s.truncate(10, 'minutes')
150 >>> compute(expr, datetime(2000, 6, 25, 12, 35, 10))
151 datetime.datetime(2000, 6, 25, 12, 30)
152
153 >>> expr = s.truncate(1, 'week')
154 >>> compute(expr, datetime(2000, 6, 25, 12, 35, 10))
155 datetime.date(2000, 6, 25)
156
157 Alternatively use keyword arguments to specify unit and measure
158
159 >>> # expr = s.truncate(2, 'weeks')
160 >>> expr = s.truncate(weeks=2)
161 """
162 if args:
163 assert not kwargs
164 measure, unit = args
165 if kwargs:
166 assert not args
167 [(unit, measure)] = kwargs.items()
168 return DateTimeTruncate(expr, measure, normalize_time_unit(unit))
169
170
171 from .expressions import schema_method_list, method_properties
172 from datashape.predicates import isdatelike, isnumeric
173
174 schema_method_list.extend([
175 (isdatelike, set([year, month, day, hour, minute, date, time, second,
176 millisecond, microsecond, truncate])),
177 (isnumeric, set([utcfromtimestamp]))
178 ])
179
180 method_properties |= set([year, month, day, hour, minute, second, millisecond,
181 microsecond, date, time, utcfromtimestamp])
182
[end of blaze/expr/datetime.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/blaze/expr/datetime.py b/blaze/expr/datetime.py
--- a/blaze/expr/datetime.py
+++ b/blaze/expr/datetime.py
@@ -135,6 +135,10 @@
else:
return datashape.datetime_
+ @property
+ def _name(self):
+ return self._child._name
+
def truncate(expr, *args, **kwargs):
""" Truncate datetime expression
|
{"golden_diff": "diff --git a/blaze/expr/datetime.py b/blaze/expr/datetime.py\n--- a/blaze/expr/datetime.py\n+++ b/blaze/expr/datetime.py\n@@ -135,6 +135,10 @@\n else:\n return datashape.datetime_\n \n+ @property\n+ def _name(self):\n+ return self._child._name\n+\n \n def truncate(expr, *args, **kwargs):\n \"\"\" Truncate datetime expression\n", "issue": "Truncate column name is too verbose\nDo we have to have a unique name for the result of such operations?\n\nHow about having it renamed to the unit, i.e. instead of `when_datetimetruncate` we use `when_day` or `when_week`, etc?\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nfrom .expressions import Expr, ElemWise\nfrom datashape import dshape, Record, DataShape, Unit, Option, date_, datetime_\nimport datashape\n\n__all__ = ['DateTime', 'Date', 'date', 'Year', 'year', 'Month', 'month', 'Day',\n 'day', 'Hour', 'hour', 'Second', 'second', 'Millisecond',\n 'millisecond', 'Microsecond', 'microsecond', 'Date', 'date', 'Time',\n 'time', 'UTCFromTimestamp', 'DateTimeTruncate']\n\nclass DateTime(ElemWise):\n \"\"\" Superclass for datetime accessors \"\"\"\n __slots__ = '_hash', '_child',\n\n def __str__(self):\n return '%s.%s' % (str(self._child), type(self).__name__.lower())\n\n @property\n def schema(self):\n return dshape(self._dtype)\n\n @property\n def _name(self):\n return '%s_%s' % (self._child._name, self.attr)\n\n @property\n def attr(self):\n return type(self).__name__.lower()\n\n\nclass Date(DateTime):\n _dtype = datashape.date_\n\ndef date(expr):\n return Date(expr)\n\nclass Year(DateTime):\n _dtype = datashape.int32\n\ndef year(expr):\n return Year(expr)\n\nclass Month(DateTime):\n _dtype = datashape.int32\n\ndef month(expr):\n return Month(expr)\n\nclass Day(DateTime):\n _dtype = datashape.int32\n\ndef day(expr):\n return Day(expr)\n\nclass Time(DateTime):\n _dtype = datashape.time_\n\ndef time(expr):\n return Time(Expr)\n\nclass Hour(DateTime):\n _dtype = datashape.int32\n\ndef hour(expr):\n return Hour(expr)\n\nclass Minute(DateTime):\n _dtype = datashape.int32\n\ndef minute(expr):\n return Minute(expr)\n\nclass Second(DateTime):\n _dtype = datashape.int32\n\ndef second(expr):\n return Second(expr)\n\nclass Millisecond(DateTime):\n _dtype = datashape.int64\n\ndef millisecond(expr):\n return Millisecond(expr)\n\nclass Microsecond(DateTime):\n _dtype = datashape.int64\n\ndef microsecond(expr):\n return Microsecond(expr)\n\nclass UTCFromTimestamp(DateTime):\n _dtype = datashape.datetime_\n\ndef utcfromtimestamp(expr):\n return UTCFromTimestamp(expr)\n\nunits = ['year', 'month', 'week', 'day', 'hour', 'minute', 'second',\n'millisecond', 'microsecond', 'nanosecond']\n\n\n_unit_aliases = {'y': 'year', 'w': 'week', 'd': 'day', 'date': 'day',\n 'h': 'hour', 's': 'second', 'ms': 'millisecond', 'us': 'microsecond',\n 'ns': 'nanosecond'}\n\ndef normalize_time_unit(s):\n \"\"\" Normalize time input to one of 'year', 'second', 'millisecond', etc..\n\n Example\n -------\n\n >>> normalize_time_unit('milliseconds')\n 'millisecond'\n >>> normalize_time_unit('ms')\n 'millisecond'\n \"\"\"\n s = s.lower().strip()\n if s in units:\n return s\n if s in _unit_aliases:\n return _unit_aliases[s]\n if s[-1] == 's':\n return normalize_time_unit(s.rstrip('s'))\n\n raise ValueError(\"Do not understand time unit %s\" % s)\n\n\nclass DateTimeTruncate(DateTime):\n __slots__ = '_hash', '_child', 'measure', 'unit'\n\n @property\n def _dtype(self):\n if units.index('day') >= units.index(self.unit):\n return datashape.date_\n else:\n return datashape.datetime_\n\n\ndef truncate(expr, *args, **kwargs):\n \"\"\" Truncate datetime expression\n\n Example\n -------\n\n >>> from blaze import symbol, compute\n >>> from datetime import datetime\n >>> s = symbol('s', 'datetime')\n\n >>> expr = s.truncate(10, 'minutes')\n >>> compute(expr, datetime(2000, 6, 25, 12, 35, 10))\n datetime.datetime(2000, 6, 25, 12, 30)\n\n >>> expr = s.truncate(1, 'week')\n >>> compute(expr, datetime(2000, 6, 25, 12, 35, 10))\n datetime.date(2000, 6, 25)\n\n Alternatively use keyword arguments to specify unit and measure\n\n >>> # expr = s.truncate(2, 'weeks')\n >>> expr = s.truncate(weeks=2)\n \"\"\"\n if args:\n assert not kwargs\n measure, unit = args\n if kwargs:\n assert not args\n [(unit, measure)] = kwargs.items()\n return DateTimeTruncate(expr, measure, normalize_time_unit(unit))\n\n\nfrom .expressions import schema_method_list, method_properties\nfrom datashape.predicates import isdatelike, isnumeric\n\nschema_method_list.extend([\n (isdatelike, set([year, month, day, hour, minute, date, time, second,\n millisecond, microsecond, truncate])),\n (isnumeric, set([utcfromtimestamp]))\n ])\n\nmethod_properties |= set([year, month, day, hour, minute, second, millisecond,\n microsecond, date, time, utcfromtimestamp])\n", "path": "blaze/expr/datetime.py"}]}
| 2,275 | 106 |
gh_patches_debug_59056
|
rasdani/github-patches
|
git_diff
|
google__jax-19166
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unexpected behavior of `jax.scipy.stats.binom.pmf`
### Description
pmf of a random variable should be zero outside of its range. While plotting the graph for `jax.scipy.stats.binom.pmf`, I notice that for $n>5$ and $p>0.5$, there are some oscillations in the values of the pmf, which should not be there. For evidence, I am attaching a plot too.
```python
import jax
from jax import numpy as jnp
from matplotlib import pyplot as plt
x = jnp.linspace(-1, 10, 1000)
xxf = jax.scipy.stats.binom.pmf(k=x, n=5, p=0.8)
plt.plot(x, xxf)
plt.tight_layout()
plt.show()
```

The side left to the zero is as expected.
### What jax/jaxlib version are you using?
jax v0.4.23
### Which accelerator(s) are you using?
CPU
</issue>
<code>
[start of jax/_src/scipy/stats/binom.py]
1 # Copyright 2023 The JAX Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License
14
15
16 import scipy.stats as osp_stats
17
18 from jax import lax
19 import jax.numpy as jnp
20 from jax._src.numpy.util import _wraps, promote_args_inexact
21 from jax._src.scipy.special import gammaln, xlogy, xlog1py
22 from jax._src.typing import Array, ArrayLike
23
24
25 @_wraps(osp_stats.nbinom.logpmf, update_doc=False)
26 def logpmf(k: ArrayLike, n: ArrayLike, p: ArrayLike, loc: ArrayLike = 0) -> Array:
27 """JAX implementation of scipy.stats.binom.logpmf."""
28 k, n, p, loc = promote_args_inexact("binom.logpmf", k, n, p, loc)
29 y = lax.sub(k, loc)
30 comb_term = lax.sub(
31 gammaln(n + 1),
32 lax.add(gammaln(y + 1), gammaln(n - y + 1))
33 )
34 log_linear_term = lax.add(xlogy(y, p), xlog1py(lax.sub(n, y), lax.neg(p)))
35 log_probs = lax.add(comb_term, log_linear_term)
36 return jnp.where(lax.lt(k, loc), -jnp.inf, log_probs)
37
38
39 @_wraps(osp_stats.nbinom.pmf, update_doc=False)
40 def pmf(k: ArrayLike, n: ArrayLike, p: ArrayLike, loc: ArrayLike = 0) -> Array:
41 """JAX implementation of scipy.stats.binom.pmf."""
42 return lax.exp(logpmf(k, n, p, loc))
43
[end of jax/_src/scipy/stats/binom.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jax/_src/scipy/stats/binom.py b/jax/_src/scipy/stats/binom.py
--- a/jax/_src/scipy/stats/binom.py
+++ b/jax/_src/scipy/stats/binom.py
@@ -33,7 +33,7 @@
)
log_linear_term = lax.add(xlogy(y, p), xlog1py(lax.sub(n, y), lax.neg(p)))
log_probs = lax.add(comb_term, log_linear_term)
- return jnp.where(lax.lt(k, loc), -jnp.inf, log_probs)
+ return jnp.where(lax.ge(k, loc) & lax.lt(k, loc + n + 1), log_probs, -jnp.inf)
@_wraps(osp_stats.nbinom.pmf, update_doc=False)
|
{"golden_diff": "diff --git a/jax/_src/scipy/stats/binom.py b/jax/_src/scipy/stats/binom.py\n--- a/jax/_src/scipy/stats/binom.py\n+++ b/jax/_src/scipy/stats/binom.py\n@@ -33,7 +33,7 @@\n )\n log_linear_term = lax.add(xlogy(y, p), xlog1py(lax.sub(n, y), lax.neg(p)))\n log_probs = lax.add(comb_term, log_linear_term)\n- return jnp.where(lax.lt(k, loc), -jnp.inf, log_probs)\n+ return jnp.where(lax.ge(k, loc) & lax.lt(k, loc + n + 1), log_probs, -jnp.inf)\n \n \n @_wraps(osp_stats.nbinom.pmf, update_doc=False)\n", "issue": "Unexpected behavior of `jax.scipy.stats.binom.pmf`\n### Description\r\n\r\npmf of a random variable should be zero outside of its range. While plotting the graph for `jax.scipy.stats.binom.pmf`, I notice that for $n>5$ and $p>0.5$, there are some oscillations in the values of the pmf, which should not be there. For evidence, I am attaching a plot too.\r\n\r\n```python\r\nimport jax\r\nfrom jax import numpy as jnp\r\nfrom matplotlib import pyplot as plt\r\n\r\nx = jnp.linspace(-1, 10, 1000)\r\nxxf = jax.scipy.stats.binom.pmf(k=x, n=5, p=0.8)\r\n\r\nplt.plot(x, xxf)\r\nplt.tight_layout()\r\nplt.show()\r\n```\r\n\r\nThe side left to the zero is as expected.\r\n\r\n### What jax/jaxlib version are you using?\r\n\r\njax v0.4.23\r\n\r\n### Which accelerator(s) are you using?\r\n\r\nCPU\n", "before_files": [{"content": "# Copyright 2023 The JAX Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License\n\n\nimport scipy.stats as osp_stats\n\nfrom jax import lax\nimport jax.numpy as jnp\nfrom jax._src.numpy.util import _wraps, promote_args_inexact\nfrom jax._src.scipy.special import gammaln, xlogy, xlog1py\nfrom jax._src.typing import Array, ArrayLike\n\n\n@_wraps(osp_stats.nbinom.logpmf, update_doc=False)\ndef logpmf(k: ArrayLike, n: ArrayLike, p: ArrayLike, loc: ArrayLike = 0) -> Array:\n \"\"\"JAX implementation of scipy.stats.binom.logpmf.\"\"\"\n k, n, p, loc = promote_args_inexact(\"binom.logpmf\", k, n, p, loc)\n y = lax.sub(k, loc)\n comb_term = lax.sub(\n gammaln(n + 1),\n lax.add(gammaln(y + 1), gammaln(n - y + 1))\n )\n log_linear_term = lax.add(xlogy(y, p), xlog1py(lax.sub(n, y), lax.neg(p)))\n log_probs = lax.add(comb_term, log_linear_term)\n return jnp.where(lax.lt(k, loc), -jnp.inf, log_probs)\n\n\n@_wraps(osp_stats.nbinom.pmf, update_doc=False)\ndef pmf(k: ArrayLike, n: ArrayLike, p: ArrayLike, loc: ArrayLike = 0) -> Array:\n \"\"\"JAX implementation of scipy.stats.binom.pmf.\"\"\"\n return lax.exp(logpmf(k, n, p, loc))\n", "path": "jax/_src/scipy/stats/binom.py"}]}
| 1,374 | 178 |
gh_patches_debug_43748
|
rasdani/github-patches
|
git_diff
|
twisted__twisted-11636
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`t.w.http_headers.Headers` methods `addRawHeader` and `setRawHeaders` are typed `AnyStr`
A call like `headers.addRawHeader(b'foo', 'bar')` is correct at runtime, but fails to typecheck because `AnyStr` is a type variable that constrains both parameters to be the same type.
Similar for `headers.setRawHeaders('foo', [b'ar'])`.
These calls are valid, so the constraint should be removed from `Headers`.
</issue>
<code>
[start of src/twisted/web/http_headers.py]
1 # -*- test-case-name: twisted.web.test.test_http_headers -*-
2 # Copyright (c) Twisted Matrix Laboratories.
3 # See LICENSE for details.
4
5 """
6 An API for storing HTTP header names and values.
7 """
8
9 from collections.abc import Sequence as _Sequence
10 from typing import (
11 AnyStr,
12 Dict,
13 Iterator,
14 List,
15 Mapping,
16 Optional,
17 Sequence,
18 Tuple,
19 TypeVar,
20 Union,
21 cast,
22 overload,
23 )
24
25 from twisted.python.compat import cmp, comparable
26
27 _T = TypeVar("_T")
28
29
30 def _dashCapitalize(name: bytes) -> bytes:
31 """
32 Return a byte string which is capitalized using '-' as a word separator.
33
34 @param name: The name of the header to capitalize.
35
36 @return: The given header capitalized using '-' as a word separator.
37 """
38 return b"-".join([word.capitalize() for word in name.split(b"-")])
39
40
41 def _sanitizeLinearWhitespace(headerComponent: bytes) -> bytes:
42 r"""
43 Replace linear whitespace (C{\n}, C{\r\n}, C{\r}) in a header key
44 or value with a single space.
45
46 @param headerComponent: The header key or value to sanitize.
47
48 @return: The sanitized header key or value.
49 """
50 return b" ".join(headerComponent.splitlines())
51
52
53 @comparable
54 class Headers:
55 """
56 Stores HTTP headers in a key and multiple value format.
57
58 When passed L{str}, header names (e.g. 'Content-Type')
59 are encoded using ISO-8859-1 and header values (e.g.
60 'text/html;charset=utf-8') are encoded using UTF-8. Some methods that return
61 values will return them in the same type as the name given.
62
63 If the header keys or values cannot be encoded or decoded using the rules
64 above, using just L{bytes} arguments to the methods of this class will
65 ensure no decoding or encoding is done, and L{Headers} will treat the keys
66 and values as opaque byte strings.
67
68 @cvar _caseMappings: A L{dict} that maps lowercase header names
69 to their canonicalized representation.
70
71 @ivar _rawHeaders: A L{dict} mapping header names as L{bytes} to L{list}s of
72 header values as L{bytes}.
73 """
74
75 _caseMappings = {
76 b"content-md5": b"Content-MD5",
77 b"dnt": b"DNT",
78 b"etag": b"ETag",
79 b"p3p": b"P3P",
80 b"te": b"TE",
81 b"www-authenticate": b"WWW-Authenticate",
82 b"x-xss-protection": b"X-XSS-Protection",
83 }
84
85 def __init__(
86 self,
87 rawHeaders: Optional[Mapping[AnyStr, Sequence[AnyStr]]] = None,
88 ):
89 self._rawHeaders: Dict[bytes, List[bytes]] = {}
90 if rawHeaders is not None:
91 for name, values in rawHeaders.items():
92 self.setRawHeaders(name, values)
93
94 def __repr__(self) -> str:
95 """
96 Return a string fully describing the headers set on this object.
97 """
98 return "{}({!r})".format(
99 self.__class__.__name__,
100 self._rawHeaders,
101 )
102
103 def __cmp__(self, other):
104 """
105 Define L{Headers} instances as being equal to each other if they have
106 the same raw headers.
107 """
108 if isinstance(other, Headers):
109 return cmp(
110 sorted(self._rawHeaders.items()), sorted(other._rawHeaders.items())
111 )
112 return NotImplemented
113
114 def _encodeName(self, name: AnyStr) -> bytes:
115 """
116 Encode the name of a header (eg 'Content-Type') to an ISO-8859-1 encoded
117 bytestring if required.
118
119 @param name: A HTTP header name
120
121 @return: C{name}, encoded if required, lowercased
122 """
123 if isinstance(name, str):
124 return name.lower().encode("iso-8859-1")
125 return name.lower()
126
127 def copy(self):
128 """
129 Return a copy of itself with the same headers set.
130
131 @return: A new L{Headers}
132 """
133 return self.__class__(self._rawHeaders)
134
135 def hasHeader(self, name: AnyStr) -> bool:
136 """
137 Check for the existence of a given header.
138
139 @param name: The name of the HTTP header to check for.
140
141 @return: C{True} if the header exists, otherwise C{False}.
142 """
143 return self._encodeName(name) in self._rawHeaders
144
145 def removeHeader(self, name: AnyStr) -> None:
146 """
147 Remove the named header from this header object.
148
149 @param name: The name of the HTTP header to remove.
150
151 @return: L{None}
152 """
153 self._rawHeaders.pop(self._encodeName(name), None)
154
155 def setRawHeaders(self, name: AnyStr, values: Sequence[AnyStr]) -> None:
156 """
157 Sets the raw representation of the given header.
158
159 @param name: The name of the HTTP header to set the values for.
160
161 @param values: A list of strings each one being a header value of
162 the given name.
163
164 @raise TypeError: Raised if C{values} is not a L{list} of L{bytes}
165 or L{str} strings, or if C{name} is not a L{bytes} or
166 L{str} string.
167
168 @return: L{None}
169 """
170 if not isinstance(values, _Sequence):
171 raise TypeError(
172 "Header entry %r should be sequence but found "
173 "instance of %r instead" % (name, type(values))
174 )
175
176 if not isinstance(name, (bytes, str)):
177 raise TypeError(
178 "Header name is an instance of %r, " "not bytes or str" % (type(name),)
179 )
180
181 for count, value in enumerate(values):
182 if not isinstance(value, (bytes, str)):
183 raise TypeError(
184 "Header value at position %s is an instance of %r, not "
185 "bytes or str"
186 % (
187 count,
188 type(value),
189 )
190 )
191
192 _name = _sanitizeLinearWhitespace(self._encodeName(name))
193 encodedValues: List[bytes] = []
194 for v in values:
195 if isinstance(v, str):
196 _v = v.encode("utf8")
197 else:
198 _v = v
199 encodedValues.append(_sanitizeLinearWhitespace(_v))
200
201 self._rawHeaders[_name] = encodedValues
202
203 def addRawHeader(self, name: AnyStr, value: AnyStr) -> None:
204 """
205 Add a new raw value for the given header.
206
207 @param name: The name of the header for which to set the value.
208
209 @param value: The value to set for the named header.
210 """
211 if not isinstance(name, (bytes, str)):
212 raise TypeError(
213 "Header name is an instance of %r, " "not bytes or str" % (type(name),)
214 )
215
216 if not isinstance(value, (bytes, str)):
217 raise TypeError(
218 "Header value is an instance of %r, not "
219 "bytes or str" % (type(value),)
220 )
221
222 # We secretly know getRawHeaders is really returning a list
223 values = cast(List[AnyStr], self.getRawHeaders(name, default=[]))
224 values.append(value)
225
226 self.setRawHeaders(name, values)
227
228 @overload
229 def getRawHeaders(self, name: AnyStr) -> Optional[Sequence[AnyStr]]:
230 ...
231
232 @overload
233 def getRawHeaders(self, name: AnyStr, default: _T) -> Union[Sequence[AnyStr], _T]:
234 ...
235
236 def getRawHeaders(
237 self, name: AnyStr, default: Optional[_T] = None
238 ) -> Union[Sequence[AnyStr], Optional[_T]]:
239 """
240 Returns a sequence of headers matching the given name as the raw string
241 given.
242
243 @param name: The name of the HTTP header to get the values of.
244
245 @param default: The value to return if no header with the given C{name}
246 exists.
247
248 @return: If the named header is present, a sequence of its
249 values. Otherwise, C{default}.
250 """
251 encodedName = self._encodeName(name)
252 values = self._rawHeaders.get(encodedName, [])
253 if not values:
254 return default
255
256 if isinstance(name, str):
257 return [v.decode("utf8") for v in values]
258 return values
259
260 def getAllRawHeaders(self) -> Iterator[Tuple[bytes, Sequence[bytes]]]:
261 """
262 Return an iterator of key, value pairs of all headers contained in this
263 object, as L{bytes}. The keys are capitalized in canonical
264 capitalization.
265 """
266 for k, v in self._rawHeaders.items():
267 yield self._canonicalNameCaps(k), v
268
269 def _canonicalNameCaps(self, name: bytes) -> bytes:
270 """
271 Return the canonical name for the given header.
272
273 @param name: The all-lowercase header name to capitalize in its
274 canonical form.
275
276 @return: The canonical name of the header.
277 """
278 return self._caseMappings.get(name, _dashCapitalize(name))
279
280
281 __all__ = ["Headers"]
282
[end of src/twisted/web/http_headers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/twisted/web/http_headers.py b/src/twisted/web/http_headers.py
--- a/src/twisted/web/http_headers.py
+++ b/src/twisted/web/http_headers.py
@@ -18,7 +18,6 @@
Tuple,
TypeVar,
Union,
- cast,
overload,
)
@@ -85,7 +84,7 @@
def __init__(
self,
rawHeaders: Optional[Mapping[AnyStr, Sequence[AnyStr]]] = None,
- ):
+ ) -> None:
self._rawHeaders: Dict[bytes, List[bytes]] = {}
if rawHeaders is not None:
for name, values in rawHeaders.items():
@@ -111,7 +110,7 @@
)
return NotImplemented
- def _encodeName(self, name: AnyStr) -> bytes:
+ def _encodeName(self, name: Union[str, bytes]) -> bytes:
"""
Encode the name of a header (eg 'Content-Type') to an ISO-8859-1 encoded
bytestring if required.
@@ -152,7 +151,21 @@
"""
self._rawHeaders.pop(self._encodeName(name), None)
- def setRawHeaders(self, name: AnyStr, values: Sequence[AnyStr]) -> None:
+ @overload
+ def setRawHeaders(self, name: Union[str, bytes], values: Sequence[bytes]) -> None:
+ ...
+
+ @overload
+ def setRawHeaders(self, name: Union[str, bytes], values: Sequence[str]) -> None:
+ ...
+
+ @overload
+ def setRawHeaders(
+ self, name: Union[str, bytes], values: Sequence[Union[str, bytes]]
+ ) -> None:
+ ...
+
+ def setRawHeaders(self, name: Union[str, bytes], values: object) -> None:
"""
Sets the raw representation of the given header.
@@ -161,9 +174,8 @@
@param values: A list of strings each one being a header value of
the given name.
- @raise TypeError: Raised if C{values} is not a L{list} of L{bytes}
- or L{str} strings, or if C{name} is not a L{bytes} or
- L{str} string.
+ @raise TypeError: Raised if C{values} is not a sequence of L{bytes}
+ or L{str}, or if C{name} is not L{bytes} or L{str}.
@return: L{None}
"""
@@ -175,7 +187,7 @@
if not isinstance(name, (bytes, str)):
raise TypeError(
- "Header name is an instance of %r, " "not bytes or str" % (type(name),)
+ f"Header name is an instance of {type(name)!r}, not bytes or str"
)
for count, value in enumerate(values):
@@ -200,7 +212,7 @@
self._rawHeaders[_name] = encodedValues
- def addRawHeader(self, name: AnyStr, value: AnyStr) -> None:
+ def addRawHeader(self, name: Union[str, bytes], value: Union[str, bytes]) -> None:
"""
Add a new raw value for the given header.
@@ -210,7 +222,7 @@
"""
if not isinstance(name, (bytes, str)):
raise TypeError(
- "Header name is an instance of %r, " "not bytes or str" % (type(name),)
+ f"Header name is an instance of {type(name)!r}, not bytes or str"
)
if not isinstance(value, (bytes, str)):
@@ -219,11 +231,13 @@
"bytes or str" % (type(value),)
)
- # We secretly know getRawHeaders is really returning a list
- values = cast(List[AnyStr], self.getRawHeaders(name, default=[]))
- values.append(value)
-
- self.setRawHeaders(name, values)
+ self._rawHeaders.setdefault(
+ _sanitizeLinearWhitespace(self._encodeName(name)), []
+ ).append(
+ _sanitizeLinearWhitespace(
+ value.encode("utf8") if isinstance(value, str) else value
+ )
+ )
@overload
def getRawHeaders(self, name: AnyStr) -> Optional[Sequence[AnyStr]]:
|
{"golden_diff": "diff --git a/src/twisted/web/http_headers.py b/src/twisted/web/http_headers.py\n--- a/src/twisted/web/http_headers.py\n+++ b/src/twisted/web/http_headers.py\n@@ -18,7 +18,6 @@\n Tuple,\n TypeVar,\n Union,\n- cast,\n overload,\n )\n \n@@ -85,7 +84,7 @@\n def __init__(\n self,\n rawHeaders: Optional[Mapping[AnyStr, Sequence[AnyStr]]] = None,\n- ):\n+ ) -> None:\n self._rawHeaders: Dict[bytes, List[bytes]] = {}\n if rawHeaders is not None:\n for name, values in rawHeaders.items():\n@@ -111,7 +110,7 @@\n )\n return NotImplemented\n \n- def _encodeName(self, name: AnyStr) -> bytes:\n+ def _encodeName(self, name: Union[str, bytes]) -> bytes:\n \"\"\"\n Encode the name of a header (eg 'Content-Type') to an ISO-8859-1 encoded\n bytestring if required.\n@@ -152,7 +151,21 @@\n \"\"\"\n self._rawHeaders.pop(self._encodeName(name), None)\n \n- def setRawHeaders(self, name: AnyStr, values: Sequence[AnyStr]) -> None:\n+ @overload\n+ def setRawHeaders(self, name: Union[str, bytes], values: Sequence[bytes]) -> None:\n+ ...\n+\n+ @overload\n+ def setRawHeaders(self, name: Union[str, bytes], values: Sequence[str]) -> None:\n+ ...\n+\n+ @overload\n+ def setRawHeaders(\n+ self, name: Union[str, bytes], values: Sequence[Union[str, bytes]]\n+ ) -> None:\n+ ...\n+\n+ def setRawHeaders(self, name: Union[str, bytes], values: object) -> None:\n \"\"\"\n Sets the raw representation of the given header.\n \n@@ -161,9 +174,8 @@\n @param values: A list of strings each one being a header value of\n the given name.\n \n- @raise TypeError: Raised if C{values} is not a L{list} of L{bytes}\n- or L{str} strings, or if C{name} is not a L{bytes} or\n- L{str} string.\n+ @raise TypeError: Raised if C{values} is not a sequence of L{bytes}\n+ or L{str}, or if C{name} is not L{bytes} or L{str}.\n \n @return: L{None}\n \"\"\"\n@@ -175,7 +187,7 @@\n \n if not isinstance(name, (bytes, str)):\n raise TypeError(\n- \"Header name is an instance of %r, \" \"not bytes or str\" % (type(name),)\n+ f\"Header name is an instance of {type(name)!r}, not bytes or str\"\n )\n \n for count, value in enumerate(values):\n@@ -200,7 +212,7 @@\n \n self._rawHeaders[_name] = encodedValues\n \n- def addRawHeader(self, name: AnyStr, value: AnyStr) -> None:\n+ def addRawHeader(self, name: Union[str, bytes], value: Union[str, bytes]) -> None:\n \"\"\"\n Add a new raw value for the given header.\n \n@@ -210,7 +222,7 @@\n \"\"\"\n if not isinstance(name, (bytes, str)):\n raise TypeError(\n- \"Header name is an instance of %r, \" \"not bytes or str\" % (type(name),)\n+ f\"Header name is an instance of {type(name)!r}, not bytes or str\"\n )\n \n if not isinstance(value, (bytes, str)):\n@@ -219,11 +231,13 @@\n \"bytes or str\" % (type(value),)\n )\n \n- # We secretly know getRawHeaders is really returning a list\n- values = cast(List[AnyStr], self.getRawHeaders(name, default=[]))\n- values.append(value)\n-\n- self.setRawHeaders(name, values)\n+ self._rawHeaders.setdefault(\n+ _sanitizeLinearWhitespace(self._encodeName(name)), []\n+ ).append(\n+ _sanitizeLinearWhitespace(\n+ value.encode(\"utf8\") if isinstance(value, str) else value\n+ )\n+ )\n \n @overload\n def getRawHeaders(self, name: AnyStr) -> Optional[Sequence[AnyStr]]:\n", "issue": "`t.w.http_headers.Headers` methods `addRawHeader` and `setRawHeaders` are typed `AnyStr`\nA call like `headers.addRawHeader(b'foo', 'bar')` is correct at runtime, but fails to typecheck because `AnyStr` is a type variable that constrains both parameters to be the same type.\r\n\r\nSimilar for `headers.setRawHeaders('foo', [b'ar'])`.\r\n\r\nThese calls are valid, so the constraint should be removed from `Headers`.\n", "before_files": [{"content": "# -*- test-case-name: twisted.web.test.test_http_headers -*-\n# Copyright (c) Twisted Matrix Laboratories.\n# See LICENSE for details.\n\n\"\"\"\nAn API for storing HTTP header names and values.\n\"\"\"\n\nfrom collections.abc import Sequence as _Sequence\nfrom typing import (\n AnyStr,\n Dict,\n Iterator,\n List,\n Mapping,\n Optional,\n Sequence,\n Tuple,\n TypeVar,\n Union,\n cast,\n overload,\n)\n\nfrom twisted.python.compat import cmp, comparable\n\n_T = TypeVar(\"_T\")\n\n\ndef _dashCapitalize(name: bytes) -> bytes:\n \"\"\"\n Return a byte string which is capitalized using '-' as a word separator.\n\n @param name: The name of the header to capitalize.\n\n @return: The given header capitalized using '-' as a word separator.\n \"\"\"\n return b\"-\".join([word.capitalize() for word in name.split(b\"-\")])\n\n\ndef _sanitizeLinearWhitespace(headerComponent: bytes) -> bytes:\n r\"\"\"\n Replace linear whitespace (C{\\n}, C{\\r\\n}, C{\\r}) in a header key\n or value with a single space.\n\n @param headerComponent: The header key or value to sanitize.\n\n @return: The sanitized header key or value.\n \"\"\"\n return b\" \".join(headerComponent.splitlines())\n\n\n@comparable\nclass Headers:\n \"\"\"\n Stores HTTP headers in a key and multiple value format.\n\n When passed L{str}, header names (e.g. 'Content-Type')\n are encoded using ISO-8859-1 and header values (e.g.\n 'text/html;charset=utf-8') are encoded using UTF-8. Some methods that return\n values will return them in the same type as the name given.\n\n If the header keys or values cannot be encoded or decoded using the rules\n above, using just L{bytes} arguments to the methods of this class will\n ensure no decoding or encoding is done, and L{Headers} will treat the keys\n and values as opaque byte strings.\n\n @cvar _caseMappings: A L{dict} that maps lowercase header names\n to their canonicalized representation.\n\n @ivar _rawHeaders: A L{dict} mapping header names as L{bytes} to L{list}s of\n header values as L{bytes}.\n \"\"\"\n\n _caseMappings = {\n b\"content-md5\": b\"Content-MD5\",\n b\"dnt\": b\"DNT\",\n b\"etag\": b\"ETag\",\n b\"p3p\": b\"P3P\",\n b\"te\": b\"TE\",\n b\"www-authenticate\": b\"WWW-Authenticate\",\n b\"x-xss-protection\": b\"X-XSS-Protection\",\n }\n\n def __init__(\n self,\n rawHeaders: Optional[Mapping[AnyStr, Sequence[AnyStr]]] = None,\n ):\n self._rawHeaders: Dict[bytes, List[bytes]] = {}\n if rawHeaders is not None:\n for name, values in rawHeaders.items():\n self.setRawHeaders(name, values)\n\n def __repr__(self) -> str:\n \"\"\"\n Return a string fully describing the headers set on this object.\n \"\"\"\n return \"{}({!r})\".format(\n self.__class__.__name__,\n self._rawHeaders,\n )\n\n def __cmp__(self, other):\n \"\"\"\n Define L{Headers} instances as being equal to each other if they have\n the same raw headers.\n \"\"\"\n if isinstance(other, Headers):\n return cmp(\n sorted(self._rawHeaders.items()), sorted(other._rawHeaders.items())\n )\n return NotImplemented\n\n def _encodeName(self, name: AnyStr) -> bytes:\n \"\"\"\n Encode the name of a header (eg 'Content-Type') to an ISO-8859-1 encoded\n bytestring if required.\n\n @param name: A HTTP header name\n\n @return: C{name}, encoded if required, lowercased\n \"\"\"\n if isinstance(name, str):\n return name.lower().encode(\"iso-8859-1\")\n return name.lower()\n\n def copy(self):\n \"\"\"\n Return a copy of itself with the same headers set.\n\n @return: A new L{Headers}\n \"\"\"\n return self.__class__(self._rawHeaders)\n\n def hasHeader(self, name: AnyStr) -> bool:\n \"\"\"\n Check for the existence of a given header.\n\n @param name: The name of the HTTP header to check for.\n\n @return: C{True} if the header exists, otherwise C{False}.\n \"\"\"\n return self._encodeName(name) in self._rawHeaders\n\n def removeHeader(self, name: AnyStr) -> None:\n \"\"\"\n Remove the named header from this header object.\n\n @param name: The name of the HTTP header to remove.\n\n @return: L{None}\n \"\"\"\n self._rawHeaders.pop(self._encodeName(name), None)\n\n def setRawHeaders(self, name: AnyStr, values: Sequence[AnyStr]) -> None:\n \"\"\"\n Sets the raw representation of the given header.\n\n @param name: The name of the HTTP header to set the values for.\n\n @param values: A list of strings each one being a header value of\n the given name.\n\n @raise TypeError: Raised if C{values} is not a L{list} of L{bytes}\n or L{str} strings, or if C{name} is not a L{bytes} or\n L{str} string.\n\n @return: L{None}\n \"\"\"\n if not isinstance(values, _Sequence):\n raise TypeError(\n \"Header entry %r should be sequence but found \"\n \"instance of %r instead\" % (name, type(values))\n )\n\n if not isinstance(name, (bytes, str)):\n raise TypeError(\n \"Header name is an instance of %r, \" \"not bytes or str\" % (type(name),)\n )\n\n for count, value in enumerate(values):\n if not isinstance(value, (bytes, str)):\n raise TypeError(\n \"Header value at position %s is an instance of %r, not \"\n \"bytes or str\"\n % (\n count,\n type(value),\n )\n )\n\n _name = _sanitizeLinearWhitespace(self._encodeName(name))\n encodedValues: List[bytes] = []\n for v in values:\n if isinstance(v, str):\n _v = v.encode(\"utf8\")\n else:\n _v = v\n encodedValues.append(_sanitizeLinearWhitespace(_v))\n\n self._rawHeaders[_name] = encodedValues\n\n def addRawHeader(self, name: AnyStr, value: AnyStr) -> None:\n \"\"\"\n Add a new raw value for the given header.\n\n @param name: The name of the header for which to set the value.\n\n @param value: The value to set for the named header.\n \"\"\"\n if not isinstance(name, (bytes, str)):\n raise TypeError(\n \"Header name is an instance of %r, \" \"not bytes or str\" % (type(name),)\n )\n\n if not isinstance(value, (bytes, str)):\n raise TypeError(\n \"Header value is an instance of %r, not \"\n \"bytes or str\" % (type(value),)\n )\n\n # We secretly know getRawHeaders is really returning a list\n values = cast(List[AnyStr], self.getRawHeaders(name, default=[]))\n values.append(value)\n\n self.setRawHeaders(name, values)\n\n @overload\n def getRawHeaders(self, name: AnyStr) -> Optional[Sequence[AnyStr]]:\n ...\n\n @overload\n def getRawHeaders(self, name: AnyStr, default: _T) -> Union[Sequence[AnyStr], _T]:\n ...\n\n def getRawHeaders(\n self, name: AnyStr, default: Optional[_T] = None\n ) -> Union[Sequence[AnyStr], Optional[_T]]:\n \"\"\"\n Returns a sequence of headers matching the given name as the raw string\n given.\n\n @param name: The name of the HTTP header to get the values of.\n\n @param default: The value to return if no header with the given C{name}\n exists.\n\n @return: If the named header is present, a sequence of its\n values. Otherwise, C{default}.\n \"\"\"\n encodedName = self._encodeName(name)\n values = self._rawHeaders.get(encodedName, [])\n if not values:\n return default\n\n if isinstance(name, str):\n return [v.decode(\"utf8\") for v in values]\n return values\n\n def getAllRawHeaders(self) -> Iterator[Tuple[bytes, Sequence[bytes]]]:\n \"\"\"\n Return an iterator of key, value pairs of all headers contained in this\n object, as L{bytes}. The keys are capitalized in canonical\n capitalization.\n \"\"\"\n for k, v in self._rawHeaders.items():\n yield self._canonicalNameCaps(k), v\n\n def _canonicalNameCaps(self, name: bytes) -> bytes:\n \"\"\"\n Return the canonical name for the given header.\n\n @param name: The all-lowercase header name to capitalize in its\n canonical form.\n\n @return: The canonical name of the header.\n \"\"\"\n return self._caseMappings.get(name, _dashCapitalize(name))\n\n\n__all__ = [\"Headers\"]\n", "path": "src/twisted/web/http_headers.py"}]}
| 3,451 | 1,017 |
gh_patches_debug_4030
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-1419
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Order of packages in requirements.txt -- pip-compile vs. pip freeze
The issue regards packages with names containing `-` character or a digit. This may cause an unexpected order of packages in the output file, different than with `pip freeze`. It seems that the output file is sorted by the whole lines, together with `==` and version name, instead of just by the package names.
#### Environment Versions
1. Windows 10
2. Python version: 3.7.6
3. pip version: 21.1.2
4. pip-tools version: 6.1.0
#### Steps to replicate
`pip-compile` with `requirements.in` file:
```
django
django-redis
django-sendfile
django-sendfile2
djangorestframework
```
#### Expected result
(without comments and additional libraries, for clarity)
```
django==3.2.4
django-redis==5.0.0
django-sendfile==0.3.11
django-sendfile2==0.6.0
djangorestframework==3.12.4
```
#### Actual result
```
django-redis==5.0.0
django-sendfile2==0.6.0
django-sendfile==0.3.11
django==3.2.4
djangorestframework==3.12.4
```
</issue>
<code>
[start of piptools/writer.py]
1 import os
2 import re
3 import sys
4 from itertools import chain
5 from typing import BinaryIO, Dict, Iterable, Iterator, List, Optional, Set, Tuple
6
7 from click import unstyle
8 from click.core import Context
9 from pip._internal.models.format_control import FormatControl
10 from pip._internal.req.req_install import InstallRequirement
11 from pip._vendor.packaging.markers import Marker
12
13 from .logging import log
14 from .utils import (
15 UNSAFE_PACKAGES,
16 comment,
17 dedup,
18 format_requirement,
19 get_compile_command,
20 key_from_ireq,
21 )
22
23 MESSAGE_UNHASHED_PACKAGE = comment(
24 "# WARNING: pip install will require the following package to be hashed."
25 "\n# Consider using a hashable URL like "
26 "https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip"
27 )
28
29 MESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(
30 "# WARNING: The following packages were not pinned, but pip requires them to be"
31 "\n# pinned when the requirements file includes hashes. "
32 "Consider using the --allow-unsafe flag."
33 )
34
35 MESSAGE_UNSAFE_PACKAGES = comment(
36 "# The following packages are considered to be unsafe in a requirements file:"
37 )
38
39 MESSAGE_UNINSTALLABLE = (
40 "The generated requirements file may be rejected by pip install. "
41 "See # WARNING lines for details."
42 )
43
44
45 strip_comes_from_line_re = re.compile(r" \(line \d+\)$")
46
47
48 def _comes_from_as_string(ireq: InstallRequirement) -> str:
49 if isinstance(ireq.comes_from, str):
50 return strip_comes_from_line_re.sub("", ireq.comes_from)
51 return key_from_ireq(ireq.comes_from)
52
53
54 class OutputWriter:
55 def __init__(
56 self,
57 dst_file: BinaryIO,
58 click_ctx: Context,
59 dry_run: bool,
60 emit_header: bool,
61 emit_index_url: bool,
62 emit_trusted_host: bool,
63 annotate: bool,
64 strip_extras: bool,
65 generate_hashes: bool,
66 default_index_url: str,
67 index_urls: Iterable[str],
68 trusted_hosts: Iterable[str],
69 format_control: FormatControl,
70 allow_unsafe: bool,
71 find_links: List[str],
72 emit_find_links: bool,
73 ) -> None:
74 self.dst_file = dst_file
75 self.click_ctx = click_ctx
76 self.dry_run = dry_run
77 self.emit_header = emit_header
78 self.emit_index_url = emit_index_url
79 self.emit_trusted_host = emit_trusted_host
80 self.annotate = annotate
81 self.strip_extras = strip_extras
82 self.generate_hashes = generate_hashes
83 self.default_index_url = default_index_url
84 self.index_urls = index_urls
85 self.trusted_hosts = trusted_hosts
86 self.format_control = format_control
87 self.allow_unsafe = allow_unsafe
88 self.find_links = find_links
89 self.emit_find_links = emit_find_links
90
91 def _sort_key(self, ireq: InstallRequirement) -> Tuple[bool, str]:
92 return (not ireq.editable, str(ireq.req).lower())
93
94 def write_header(self) -> Iterator[str]:
95 if self.emit_header:
96 yield comment("#")
97 yield comment(
98 "# This file is autogenerated by pip-compile with python "
99 f"{sys.version_info.major}.{sys.version_info.minor}"
100 )
101 yield comment("# To update, run:")
102 yield comment("#")
103 compile_command = os.environ.get(
104 "CUSTOM_COMPILE_COMMAND"
105 ) or get_compile_command(self.click_ctx)
106 yield comment(f"# {compile_command}")
107 yield comment("#")
108
109 def write_index_options(self) -> Iterator[str]:
110 if self.emit_index_url:
111 for index, index_url in enumerate(dedup(self.index_urls)):
112 if index == 0 and index_url.rstrip("/") == self.default_index_url:
113 continue
114 flag = "--index-url" if index == 0 else "--extra-index-url"
115 yield f"{flag} {index_url}"
116
117 def write_trusted_hosts(self) -> Iterator[str]:
118 if self.emit_trusted_host:
119 for trusted_host in dedup(self.trusted_hosts):
120 yield f"--trusted-host {trusted_host}"
121
122 def write_format_controls(self) -> Iterator[str]:
123 for nb in dedup(sorted(self.format_control.no_binary)):
124 yield f"--no-binary {nb}"
125 for ob in dedup(sorted(self.format_control.only_binary)):
126 yield f"--only-binary {ob}"
127
128 def write_find_links(self) -> Iterator[str]:
129 if self.emit_find_links:
130 for find_link in dedup(self.find_links):
131 yield f"--find-links {find_link}"
132
133 def write_flags(self) -> Iterator[str]:
134 emitted = False
135 for line in chain(
136 self.write_index_options(),
137 self.write_find_links(),
138 self.write_trusted_hosts(),
139 self.write_format_controls(),
140 ):
141 emitted = True
142 yield line
143 if emitted:
144 yield ""
145
146 def _iter_lines(
147 self,
148 results: Set[InstallRequirement],
149 unsafe_requirements: Optional[Set[InstallRequirement]] = None,
150 markers: Optional[Dict[str, Marker]] = None,
151 hashes: Optional[Dict[InstallRequirement, Set[str]]] = None,
152 ) -> Iterator[str]:
153 # default values
154 unsafe_requirements = unsafe_requirements or set()
155 markers = markers or {}
156 hashes = hashes or {}
157
158 # Check for unhashed or unpinned packages if at least one package does have
159 # hashes, which will trigger pip install's --require-hashes mode.
160 warn_uninstallable = False
161 has_hashes = hashes and any(hash for hash in hashes.values())
162
163 yielded = False
164
165 for line in self.write_header():
166 yield line
167 yielded = True
168 for line in self.write_flags():
169 yield line
170 yielded = True
171
172 unsafe_requirements = (
173 {r for r in results if r.name in UNSAFE_PACKAGES}
174 if not unsafe_requirements
175 else unsafe_requirements
176 )
177 packages = {r for r in results if r.name not in UNSAFE_PACKAGES}
178
179 if packages:
180 for ireq in sorted(packages, key=self._sort_key):
181 if has_hashes and not hashes.get(ireq):
182 yield MESSAGE_UNHASHED_PACKAGE
183 warn_uninstallable = True
184 line = self._format_requirement(
185 ireq, markers.get(key_from_ireq(ireq)), hashes=hashes
186 )
187 yield line
188 yielded = True
189
190 if unsafe_requirements:
191 yield ""
192 yielded = True
193 if has_hashes and not self.allow_unsafe:
194 yield MESSAGE_UNSAFE_PACKAGES_UNPINNED
195 warn_uninstallable = True
196 else:
197 yield MESSAGE_UNSAFE_PACKAGES
198
199 for ireq in sorted(unsafe_requirements, key=self._sort_key):
200 ireq_key = key_from_ireq(ireq)
201 if not self.allow_unsafe:
202 yield comment(f"# {ireq_key}")
203 else:
204 line = self._format_requirement(
205 ireq, marker=markers.get(ireq_key), hashes=hashes
206 )
207 yield line
208
209 # Yield even when there's no real content, so that blank files are written
210 if not yielded:
211 yield ""
212
213 if warn_uninstallable:
214 log.warning(MESSAGE_UNINSTALLABLE)
215
216 def write(
217 self,
218 results: Set[InstallRequirement],
219 unsafe_requirements: Set[InstallRequirement],
220 markers: Dict[str, Marker],
221 hashes: Optional[Dict[InstallRequirement, Set[str]]],
222 ) -> None:
223
224 for line in self._iter_lines(results, unsafe_requirements, markers, hashes):
225 log.info(line)
226 if not self.dry_run:
227 self.dst_file.write(unstyle(line).encode())
228 self.dst_file.write(os.linesep.encode())
229
230 def _format_requirement(
231 self,
232 ireq: InstallRequirement,
233 marker: Optional[Marker] = None,
234 hashes: Optional[Dict[InstallRequirement, Set[str]]] = None,
235 ) -> str:
236 ireq_hashes = (hashes if hashes is not None else {}).get(ireq)
237
238 line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)
239 if self.strip_extras:
240 line = re.sub(r"\[.+?\]", "", line)
241
242 if not self.annotate:
243 return line
244
245 # Annotate what packages or reqs-ins this package is required by
246 required_by = set()
247 if hasattr(ireq, "_source_ireqs"):
248 required_by |= {
249 _comes_from_as_string(src_ireq)
250 for src_ireq in ireq._source_ireqs
251 if src_ireq.comes_from
252 }
253 elif ireq.comes_from:
254 required_by.add(_comes_from_as_string(ireq))
255
256 if required_by:
257 sorted_required_by = sorted(required_by)
258 if len(sorted_required_by) == 1:
259 source = sorted_required_by[0]
260 annotation = " # via " + source
261 else:
262 annotation_lines = [" # via"]
263 for source in sorted_required_by:
264 annotation_lines.append(" # " + source)
265 annotation = "\n".join(annotation_lines)
266 line = f"{line}\n{comment(annotation)}"
267
268 return line
269
[end of piptools/writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/piptools/writer.py b/piptools/writer.py
--- a/piptools/writer.py
+++ b/piptools/writer.py
@@ -89,7 +89,7 @@
self.emit_find_links = emit_find_links
def _sort_key(self, ireq: InstallRequirement) -> Tuple[bool, str]:
- return (not ireq.editable, str(ireq.req).lower())
+ return (not ireq.editable, key_from_ireq(ireq))
def write_header(self) -> Iterator[str]:
if self.emit_header:
|
{"golden_diff": "diff --git a/piptools/writer.py b/piptools/writer.py\n--- a/piptools/writer.py\n+++ b/piptools/writer.py\n@@ -89,7 +89,7 @@\n self.emit_find_links = emit_find_links\n \n def _sort_key(self, ireq: InstallRequirement) -> Tuple[bool, str]:\n- return (not ireq.editable, str(ireq.req).lower())\n+ return (not ireq.editable, key_from_ireq(ireq))\n \n def write_header(self) -> Iterator[str]:\n if self.emit_header:\n", "issue": "Order of packages in requirements.txt -- pip-compile vs. pip freeze\nThe issue regards packages with names containing `-` character or a digit. This may cause an unexpected order of packages in the output file, different than with `pip freeze`. It seems that the output file is sorted by the whole lines, together with `==` and version name, instead of just by the package names.\r\n\r\n#### Environment Versions\r\n\r\n1. Windows 10\r\n2. Python version: 3.7.6\r\n3. pip version: 21.1.2\r\n4. pip-tools version: 6.1.0\r\n\r\n#### Steps to replicate\r\n\r\n`pip-compile` with `requirements.in` file:\r\n\r\n```\r\ndjango\r\ndjango-redis\r\ndjango-sendfile\r\ndjango-sendfile2\r\ndjangorestframework\r\n```\r\n\r\n#### Expected result\r\n\r\n(without comments and additional libraries, for clarity)\r\n\r\n```\r\ndjango==3.2.4\r\ndjango-redis==5.0.0\r\ndjango-sendfile==0.3.11\r\ndjango-sendfile2==0.6.0\r\ndjangorestframework==3.12.4\r\n```\r\n\r\n#### Actual result\r\n\r\n```\r\ndjango-redis==5.0.0\r\ndjango-sendfile2==0.6.0\r\ndjango-sendfile==0.3.11\r\ndjango==3.2.4\r\ndjangorestframework==3.12.4\r\n```\r\n\n", "before_files": [{"content": "import os\nimport re\nimport sys\nfrom itertools import chain\nfrom typing import BinaryIO, Dict, Iterable, Iterator, List, Optional, Set, Tuple\n\nfrom click import unstyle\nfrom click.core import Context\nfrom pip._internal.models.format_control import FormatControl\nfrom pip._internal.req.req_install import InstallRequirement\nfrom pip._vendor.packaging.markers import Marker\n\nfrom .logging import log\nfrom .utils import (\n UNSAFE_PACKAGES,\n comment,\n dedup,\n format_requirement,\n get_compile_command,\n key_from_ireq,\n)\n\nMESSAGE_UNHASHED_PACKAGE = comment(\n \"# WARNING: pip install will require the following package to be hashed.\"\n \"\\n# Consider using a hashable URL like \"\n \"https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip\"\n)\n\nMESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(\n \"# WARNING: The following packages were not pinned, but pip requires them to be\"\n \"\\n# pinned when the requirements file includes hashes. \"\n \"Consider using the --allow-unsafe flag.\"\n)\n\nMESSAGE_UNSAFE_PACKAGES = comment(\n \"# The following packages are considered to be unsafe in a requirements file:\"\n)\n\nMESSAGE_UNINSTALLABLE = (\n \"The generated requirements file may be rejected by pip install. \"\n \"See # WARNING lines for details.\"\n)\n\n\nstrip_comes_from_line_re = re.compile(r\" \\(line \\d+\\)$\")\n\n\ndef _comes_from_as_string(ireq: InstallRequirement) -> str:\n if isinstance(ireq.comes_from, str):\n return strip_comes_from_line_re.sub(\"\", ireq.comes_from)\n return key_from_ireq(ireq.comes_from)\n\n\nclass OutputWriter:\n def __init__(\n self,\n dst_file: BinaryIO,\n click_ctx: Context,\n dry_run: bool,\n emit_header: bool,\n emit_index_url: bool,\n emit_trusted_host: bool,\n annotate: bool,\n strip_extras: bool,\n generate_hashes: bool,\n default_index_url: str,\n index_urls: Iterable[str],\n trusted_hosts: Iterable[str],\n format_control: FormatControl,\n allow_unsafe: bool,\n find_links: List[str],\n emit_find_links: bool,\n ) -> None:\n self.dst_file = dst_file\n self.click_ctx = click_ctx\n self.dry_run = dry_run\n self.emit_header = emit_header\n self.emit_index_url = emit_index_url\n self.emit_trusted_host = emit_trusted_host\n self.annotate = annotate\n self.strip_extras = strip_extras\n self.generate_hashes = generate_hashes\n self.default_index_url = default_index_url\n self.index_urls = index_urls\n self.trusted_hosts = trusted_hosts\n self.format_control = format_control\n self.allow_unsafe = allow_unsafe\n self.find_links = find_links\n self.emit_find_links = emit_find_links\n\n def _sort_key(self, ireq: InstallRequirement) -> Tuple[bool, str]:\n return (not ireq.editable, str(ireq.req).lower())\n\n def write_header(self) -> Iterator[str]:\n if self.emit_header:\n yield comment(\"#\")\n yield comment(\n \"# This file is autogenerated by pip-compile with python \"\n f\"{sys.version_info.major}.{sys.version_info.minor}\"\n )\n yield comment(\"# To update, run:\")\n yield comment(\"#\")\n compile_command = os.environ.get(\n \"CUSTOM_COMPILE_COMMAND\"\n ) or get_compile_command(self.click_ctx)\n yield comment(f\"# {compile_command}\")\n yield comment(\"#\")\n\n def write_index_options(self) -> Iterator[str]:\n if self.emit_index_url:\n for index, index_url in enumerate(dedup(self.index_urls)):\n if index == 0 and index_url.rstrip(\"/\") == self.default_index_url:\n continue\n flag = \"--index-url\" if index == 0 else \"--extra-index-url\"\n yield f\"{flag} {index_url}\"\n\n def write_trusted_hosts(self) -> Iterator[str]:\n if self.emit_trusted_host:\n for trusted_host in dedup(self.trusted_hosts):\n yield f\"--trusted-host {trusted_host}\"\n\n def write_format_controls(self) -> Iterator[str]:\n for nb in dedup(sorted(self.format_control.no_binary)):\n yield f\"--no-binary {nb}\"\n for ob in dedup(sorted(self.format_control.only_binary)):\n yield f\"--only-binary {ob}\"\n\n def write_find_links(self) -> Iterator[str]:\n if self.emit_find_links:\n for find_link in dedup(self.find_links):\n yield f\"--find-links {find_link}\"\n\n def write_flags(self) -> Iterator[str]:\n emitted = False\n for line in chain(\n self.write_index_options(),\n self.write_find_links(),\n self.write_trusted_hosts(),\n self.write_format_controls(),\n ):\n emitted = True\n yield line\n if emitted:\n yield \"\"\n\n def _iter_lines(\n self,\n results: Set[InstallRequirement],\n unsafe_requirements: Optional[Set[InstallRequirement]] = None,\n markers: Optional[Dict[str, Marker]] = None,\n hashes: Optional[Dict[InstallRequirement, Set[str]]] = None,\n ) -> Iterator[str]:\n # default values\n unsafe_requirements = unsafe_requirements or set()\n markers = markers or {}\n hashes = hashes or {}\n\n # Check for unhashed or unpinned packages if at least one package does have\n # hashes, which will trigger pip install's --require-hashes mode.\n warn_uninstallable = False\n has_hashes = hashes and any(hash for hash in hashes.values())\n\n yielded = False\n\n for line in self.write_header():\n yield line\n yielded = True\n for line in self.write_flags():\n yield line\n yielded = True\n\n unsafe_requirements = (\n {r for r in results if r.name in UNSAFE_PACKAGES}\n if not unsafe_requirements\n else unsafe_requirements\n )\n packages = {r for r in results if r.name not in UNSAFE_PACKAGES}\n\n if packages:\n for ireq in sorted(packages, key=self._sort_key):\n if has_hashes and not hashes.get(ireq):\n yield MESSAGE_UNHASHED_PACKAGE\n warn_uninstallable = True\n line = self._format_requirement(\n ireq, markers.get(key_from_ireq(ireq)), hashes=hashes\n )\n yield line\n yielded = True\n\n if unsafe_requirements:\n yield \"\"\n yielded = True\n if has_hashes and not self.allow_unsafe:\n yield MESSAGE_UNSAFE_PACKAGES_UNPINNED\n warn_uninstallable = True\n else:\n yield MESSAGE_UNSAFE_PACKAGES\n\n for ireq in sorted(unsafe_requirements, key=self._sort_key):\n ireq_key = key_from_ireq(ireq)\n if not self.allow_unsafe:\n yield comment(f\"# {ireq_key}\")\n else:\n line = self._format_requirement(\n ireq, marker=markers.get(ireq_key), hashes=hashes\n )\n yield line\n\n # Yield even when there's no real content, so that blank files are written\n if not yielded:\n yield \"\"\n\n if warn_uninstallable:\n log.warning(MESSAGE_UNINSTALLABLE)\n\n def write(\n self,\n results: Set[InstallRequirement],\n unsafe_requirements: Set[InstallRequirement],\n markers: Dict[str, Marker],\n hashes: Optional[Dict[InstallRequirement, Set[str]]],\n ) -> None:\n\n for line in self._iter_lines(results, unsafe_requirements, markers, hashes):\n log.info(line)\n if not self.dry_run:\n self.dst_file.write(unstyle(line).encode())\n self.dst_file.write(os.linesep.encode())\n\n def _format_requirement(\n self,\n ireq: InstallRequirement,\n marker: Optional[Marker] = None,\n hashes: Optional[Dict[InstallRequirement, Set[str]]] = None,\n ) -> str:\n ireq_hashes = (hashes if hashes is not None else {}).get(ireq)\n\n line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)\n if self.strip_extras:\n line = re.sub(r\"\\[.+?\\]\", \"\", line)\n\n if not self.annotate:\n return line\n\n # Annotate what packages or reqs-ins this package is required by\n required_by = set()\n if hasattr(ireq, \"_source_ireqs\"):\n required_by |= {\n _comes_from_as_string(src_ireq)\n for src_ireq in ireq._source_ireqs\n if src_ireq.comes_from\n }\n elif ireq.comes_from:\n required_by.add(_comes_from_as_string(ireq))\n\n if required_by:\n sorted_required_by = sorted(required_by)\n if len(sorted_required_by) == 1:\n source = sorted_required_by[0]\n annotation = \" # via \" + source\n else:\n annotation_lines = [\" # via\"]\n for source in sorted_required_by:\n annotation_lines.append(\" # \" + source)\n annotation = \"\\n\".join(annotation_lines)\n line = f\"{line}\\n{comment(annotation)}\"\n\n return line\n", "path": "piptools/writer.py"}]}
| 3,560 | 132 |
gh_patches_debug_13311
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3367
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DX-Site-Root: ZMI Nav-Tree is no longer expandable
After migrating to dx-site-root, the navtree within the zmi is no longer expandable

https://github.com/plone/Products.CMFPlone/issues/2454 @jaroel @ale-rt
</issue>
<code>
[start of Products/CMFPlone/Portal.py]
1 from AccessControl import ClassSecurityInfo
2 from AccessControl import Unauthorized
3 from AccessControl.class_init import InitializeClass
4 from Acquisition import aq_base
5 from ComputedAttribute import ComputedAttribute
6 from five.localsitemanager.registry import PersistentComponents
7 from OFS.ObjectManager import REPLACEABLE
8 from plone.dexterity.content import Container
9 from Products.CMFCore import permissions
10 from Products.CMFCore.interfaces import IContentish
11 from Products.CMFCore.interfaces import ISiteRoot
12 from Products.CMFCore.permissions import AccessContentsInformation
13 from Products.CMFCore.permissions import AddPortalMember
14 from Products.CMFCore.permissions import MailForgottenPassword
15 from Products.CMFCore.permissions import RequestReview
16 from Products.CMFCore.permissions import ReviewPortalContent
17 from Products.CMFCore.permissions import SetOwnPassword
18 from Products.CMFCore.permissions import SetOwnProperties
19 from Products.CMFCore.PortalFolder import PortalFolderBase
20 from Products.CMFCore.PortalObject import PortalObjectBase
21 from Products.CMFCore.Skinnable import SkinnableObjectManager
22 from Products.CMFCore.utils import _checkPermission
23 from Products.CMFCore.utils import getToolByName
24 from Products.CMFCore.utils import UniqueObject
25 from Products.CMFPlone import bbb
26 from Products.CMFPlone import PloneMessageFactory as _
27 from Products.CMFPlone.interfaces.siteroot import IPloneSiteRoot
28 from Products.CMFPlone.interfaces.syndication import ISyndicatable
29 from Products.CMFPlone.permissions import AddPortalContent
30 from Products.CMFPlone.permissions import AddPortalFolders
31 from Products.CMFPlone.permissions import ListPortalMembers
32 from Products.CMFPlone.permissions import ModifyPortalContent
33 from Products.CMFPlone.permissions import ReplyToItem
34 from Products.CMFPlone.permissions import View
35 from Products.Five.component.interfaces import IObjectManagerSite
36 from zope.interface.interfaces import ComponentLookupError
37 from zope.event import notify
38 from zope.interface import classImplementsOnly
39 from zope.interface import implementedBy
40 from zope.interface import implementer
41 from zope.traversing.interfaces import BeforeTraverseEvent
42
43
44 if bbb.HAS_ZSERVER:
45 from webdav.NullResource import NullResource
46
47
48 @implementer(IPloneSiteRoot, ISiteRoot, ISyndicatable, IObjectManagerSite)
49 class PloneSite(Container, SkinnableObjectManager, UniqueObject):
50 """ The Plone site object. """
51
52 security = ClassSecurityInfo()
53 meta_type = portal_type = 'Plone Site'
54
55 # Ensure certain attributes come from the correct base class.
56 _checkId = SkinnableObjectManager._checkId
57 manage_main = PortalFolderBase.manage_main
58
59 def __getattr__(self, name):
60 try:
61 # Try DX
62 return super().__getattr__(name)
63 except AttributeError:
64 # Check portal_skins
65 return SkinnableObjectManager.__getattr__(self, name)
66
67 def __setattr__(self, name, obj):
68 # handle re setting an item as an attribute
69 if self._tree is not None and name in self:
70 del self[name]
71 self[name] = obj
72 else:
73 super().__setattr__(name, obj)
74
75 def __delattr__(self, name):
76 try:
77 return super().__delattr__(name)
78 except AttributeError:
79 return self.__delitem__(name)
80
81 # Removes the 'Components Folder'
82
83 manage_options = (
84 Container.manage_options[:2] +
85 Container.manage_options[3:])
86
87 __ac_permissions__ = (
88 (AccessContentsInformation, ()),
89 (AddPortalMember, ()),
90 (SetOwnPassword, ()),
91 (SetOwnProperties, ()),
92 (MailForgottenPassword, ()),
93 (RequestReview, ()),
94 (ReviewPortalContent, ()),
95 (AddPortalContent, ()),
96 (AddPortalFolders, ()),
97 (ListPortalMembers, ()),
98 (ReplyToItem, ()),
99 (View, ('isEffective',)),
100 (ModifyPortalContent, ('manage_cutObjects', 'manage_pasteObjects',
101 'manage_renameForm', 'manage_renameObject',
102 'manage_renameObjects')))
103
104 # Switch off ZMI ordering interface as it assumes a slightly
105 # different functionality
106 has_order_support = 0
107 management_page_charset = 'utf-8'
108 _default_sort_key = 'id'
109 _properties = (
110 {'id': 'title', 'type': 'string', 'mode': 'w'},
111 {'id': 'description', 'type': 'text', 'mode': 'w'},
112 )
113 title = ''
114 description = ''
115 icon = 'misc_/CMFPlone/tool.gif'
116
117 # From PortalObjectBase
118 def __init__(self, id, title=''):
119 super(PloneSite, self).__init__(id, title=title)
120 components = PersistentComponents('++etc++site')
121 components.__parent__ = self
122 self.setSiteManager(components)
123
124 # From PortalObjectBase
125 def __before_publishing_traverse__(self, arg1, arg2=None):
126 """ Pre-traversal hook.
127 """
128 # XXX hack around a bug(?) in BeforeTraverse.MultiHook
129 REQUEST = arg2 or arg1
130
131 try:
132 notify(BeforeTraverseEvent(self, REQUEST))
133 except ComponentLookupError:
134 # allow ZMI access, even if the portal's site manager is missing
135 pass
136 self.setupCurrentSkin(REQUEST)
137
138 super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)
139
140 def __browser_default__(self, request):
141 """ Set default so we can return whatever we want instead
142 of index_html """
143 return getToolByName(self, 'plone_utils').browserDefault(self)
144
145 def index_html(self):
146 """ Acquire if not present. """
147 request = getattr(self, 'REQUEST', None)
148 if (
149 request is not None
150 and 'REQUEST_METHOD' in request
151 and request.maybe_webdav_client
152 ):
153 method = request['REQUEST_METHOD']
154 if bbb.HAS_ZSERVER and method in ('PUT', ):
155 # Very likely a WebDAV client trying to create something
156 result = NullResource(self, 'index_html')
157 setattr(result, '__replaceable__', REPLACEABLE)
158 return result
159 elif method not in ('GET', 'HEAD', 'POST'):
160 raise AttributeError('index_html')
161 # Acquire from skin.
162 _target = self.__getattr__('index_html')
163 result = aq_base(_target).__of__(self)
164 setattr(result, '__replaceable__', REPLACEABLE)
165 return result
166
167 index_html = ComputedAttribute(index_html, 1)
168
169 def manage_beforeDelete(self, container, item):
170 # Should send out an Event before Site is being deleted.
171 self.removal_inprogress = 1
172 PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,
173 item)
174
175 @security.protected(permissions.DeleteObjects)
176 def manage_delObjects(self, ids=None, REQUEST=None):
177 """We need to enforce security."""
178 if ids is None:
179 ids = []
180 if isinstance(ids, str):
181 ids = [ids]
182 for id in ids:
183 item = self._getOb(id)
184 if not _checkPermission(permissions.DeleteObjects, item):
185 raise Unauthorized(
186 "Do not have permissions to remove this object")
187 return PortalObjectBase.manage_delObjects(self, ids, REQUEST=REQUEST)
188
189 def view(self):
190 """ Ensure that we get a plain view of the object, via a delegation to
191 __call__(), which is defined in BrowserDefaultMixin
192 """
193 return self()
194
195 @security.protected(permissions.AccessContentsInformation)
196 def folderlistingFolderContents(self, contentFilter=None):
197 """Calls listFolderContents in protected only by ACI so that
198 folder_listing can work without the List folder contents permission.
199
200 This is copied from Archetypes Basefolder and is needed by the
201 reference browser.
202 """
203 return self.listFolderContents(contentFilter)
204
205 def isEffective(self, date):
206 # Override DefaultDublinCoreImpl's test, since we are always viewable.
207 return 1
208
209
210 # Remove the IContentish interface so we don't listen to events that won't
211 # apply to the site root, ie handleUidAnnotationEvent
212 classImplementsOnly(PloneSite, implementedBy(PloneSite) - IContentish)
213
214 InitializeClass(PloneSite)
215
[end of Products/CMFPlone/Portal.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/Portal.py b/Products/CMFPlone/Portal.py
--- a/Products/CMFPlone/Portal.py
+++ b/Products/CMFPlone/Portal.py
@@ -137,6 +137,16 @@
super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)
+ # Concept from OFS.OrderSupport
+ @security.protected(permissions.AccessContentsInformation)
+ def tpValues(self):
+ # Return a list of subobjects, used by ZMI tree tag (and only there).
+ # see also https://github.com/plone/Products.CMFPlone/issues/3323
+ return sorted(
+ (obj for obj in self.objectValues() if getattr(aq_base(obj), 'isPrincipiaFolderish', False)),
+ key=lambda obj: obj.getId(),
+ )
+
def __browser_default__(self, request):
""" Set default so we can return whatever we want instead
of index_html """
|
{"golden_diff": "diff --git a/Products/CMFPlone/Portal.py b/Products/CMFPlone/Portal.py\n--- a/Products/CMFPlone/Portal.py\n+++ b/Products/CMFPlone/Portal.py\n@@ -137,6 +137,16 @@\n \n super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)\n \n+ # Concept from OFS.OrderSupport\n+ @security.protected(permissions.AccessContentsInformation)\n+ def tpValues(self):\n+ # Return a list of subobjects, used by ZMI tree tag (and only there).\n+ # see also https://github.com/plone/Products.CMFPlone/issues/3323\n+ return sorted(\n+ (obj for obj in self.objectValues() if getattr(aq_base(obj), 'isPrincipiaFolderish', False)),\n+ key=lambda obj: obj.getId(),\n+ )\n+\n def __browser_default__(self, request):\n \"\"\" Set default so we can return whatever we want instead\n of index_html \"\"\"\n", "issue": "DX-Site-Root: ZMI Nav-Tree is no longer expandable\nAfter migrating to dx-site-root, the navtree within the zmi is no longer expandable\r\n\r\n\r\n\r\nhttps://github.com/plone/Products.CMFPlone/issues/2454 @jaroel @ale-rt \n", "before_files": [{"content": "from AccessControl import ClassSecurityInfo\nfrom AccessControl import Unauthorized\nfrom AccessControl.class_init import InitializeClass\nfrom Acquisition import aq_base\nfrom ComputedAttribute import ComputedAttribute\nfrom five.localsitemanager.registry import PersistentComponents\nfrom OFS.ObjectManager import REPLACEABLE\nfrom plone.dexterity.content import Container\nfrom Products.CMFCore import permissions\nfrom Products.CMFCore.interfaces import IContentish\nfrom Products.CMFCore.interfaces import ISiteRoot\nfrom Products.CMFCore.permissions import AccessContentsInformation\nfrom Products.CMFCore.permissions import AddPortalMember\nfrom Products.CMFCore.permissions import MailForgottenPassword\nfrom Products.CMFCore.permissions import RequestReview\nfrom Products.CMFCore.permissions import ReviewPortalContent\nfrom Products.CMFCore.permissions import SetOwnPassword\nfrom Products.CMFCore.permissions import SetOwnProperties\nfrom Products.CMFCore.PortalFolder import PortalFolderBase\nfrom Products.CMFCore.PortalObject import PortalObjectBase\nfrom Products.CMFCore.Skinnable import SkinnableObjectManager\nfrom Products.CMFCore.utils import _checkPermission\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFCore.utils import UniqueObject\nfrom Products.CMFPlone import bbb\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.interfaces.siteroot import IPloneSiteRoot\nfrom Products.CMFPlone.interfaces.syndication import ISyndicatable\nfrom Products.CMFPlone.permissions import AddPortalContent\nfrom Products.CMFPlone.permissions import AddPortalFolders\nfrom Products.CMFPlone.permissions import ListPortalMembers\nfrom Products.CMFPlone.permissions import ModifyPortalContent\nfrom Products.CMFPlone.permissions import ReplyToItem\nfrom Products.CMFPlone.permissions import View\nfrom Products.Five.component.interfaces import IObjectManagerSite\nfrom zope.interface.interfaces import ComponentLookupError\nfrom zope.event import notify\nfrom zope.interface import classImplementsOnly\nfrom zope.interface import implementedBy\nfrom zope.interface import implementer\nfrom zope.traversing.interfaces import BeforeTraverseEvent\n\n\nif bbb.HAS_ZSERVER:\n from webdav.NullResource import NullResource\n\n\n@implementer(IPloneSiteRoot, ISiteRoot, ISyndicatable, IObjectManagerSite)\nclass PloneSite(Container, SkinnableObjectManager, UniqueObject):\n \"\"\" The Plone site object. \"\"\"\n\n security = ClassSecurityInfo()\n meta_type = portal_type = 'Plone Site'\n\n # Ensure certain attributes come from the correct base class.\n _checkId = SkinnableObjectManager._checkId\n manage_main = PortalFolderBase.manage_main\n\n def __getattr__(self, name):\n try:\n # Try DX\n return super().__getattr__(name)\n except AttributeError:\n # Check portal_skins\n return SkinnableObjectManager.__getattr__(self, name)\n\n def __setattr__(self, name, obj):\n # handle re setting an item as an attribute\n if self._tree is not None and name in self:\n del self[name]\n self[name] = obj\n else:\n super().__setattr__(name, obj)\n\n def __delattr__(self, name):\n try:\n return super().__delattr__(name)\n except AttributeError:\n return self.__delitem__(name)\n\n # Removes the 'Components Folder'\n\n manage_options = (\n Container.manage_options[:2] +\n Container.manage_options[3:])\n\n __ac_permissions__ = (\n (AccessContentsInformation, ()),\n (AddPortalMember, ()),\n (SetOwnPassword, ()),\n (SetOwnProperties, ()),\n (MailForgottenPassword, ()),\n (RequestReview, ()),\n (ReviewPortalContent, ()),\n (AddPortalContent, ()),\n (AddPortalFolders, ()),\n (ListPortalMembers, ()),\n (ReplyToItem, ()),\n (View, ('isEffective',)),\n (ModifyPortalContent, ('manage_cutObjects', 'manage_pasteObjects',\n 'manage_renameForm', 'manage_renameObject',\n 'manage_renameObjects')))\n\n # Switch off ZMI ordering interface as it assumes a slightly\n # different functionality\n has_order_support = 0\n management_page_charset = 'utf-8'\n _default_sort_key = 'id'\n _properties = (\n {'id': 'title', 'type': 'string', 'mode': 'w'},\n {'id': 'description', 'type': 'text', 'mode': 'w'},\n )\n title = ''\n description = ''\n icon = 'misc_/CMFPlone/tool.gif'\n\n # From PortalObjectBase\n def __init__(self, id, title=''):\n super(PloneSite, self).__init__(id, title=title)\n components = PersistentComponents('++etc++site')\n components.__parent__ = self\n self.setSiteManager(components)\n\n # From PortalObjectBase\n def __before_publishing_traverse__(self, arg1, arg2=None):\n \"\"\" Pre-traversal hook.\n \"\"\"\n # XXX hack around a bug(?) in BeforeTraverse.MultiHook\n REQUEST = arg2 or arg1\n\n try:\n notify(BeforeTraverseEvent(self, REQUEST))\n except ComponentLookupError:\n # allow ZMI access, even if the portal's site manager is missing\n pass\n self.setupCurrentSkin(REQUEST)\n\n super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)\n\n def __browser_default__(self, request):\n \"\"\" Set default so we can return whatever we want instead\n of index_html \"\"\"\n return getToolByName(self, 'plone_utils').browserDefault(self)\n\n def index_html(self):\n \"\"\" Acquire if not present. \"\"\"\n request = getattr(self, 'REQUEST', None)\n if (\n request is not None\n and 'REQUEST_METHOD' in request\n and request.maybe_webdav_client\n ):\n method = request['REQUEST_METHOD']\n if bbb.HAS_ZSERVER and method in ('PUT', ):\n # Very likely a WebDAV client trying to create something\n result = NullResource(self, 'index_html')\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n elif method not in ('GET', 'HEAD', 'POST'):\n raise AttributeError('index_html')\n # Acquire from skin.\n _target = self.__getattr__('index_html')\n result = aq_base(_target).__of__(self)\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n\n index_html = ComputedAttribute(index_html, 1)\n\n def manage_beforeDelete(self, container, item):\n # Should send out an Event before Site is being deleted.\n self.removal_inprogress = 1\n PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,\n item)\n\n @security.protected(permissions.DeleteObjects)\n def manage_delObjects(self, ids=None, REQUEST=None):\n \"\"\"We need to enforce security.\"\"\"\n if ids is None:\n ids = []\n if isinstance(ids, str):\n ids = [ids]\n for id in ids:\n item = self._getOb(id)\n if not _checkPermission(permissions.DeleteObjects, item):\n raise Unauthorized(\n \"Do not have permissions to remove this object\")\n return PortalObjectBase.manage_delObjects(self, ids, REQUEST=REQUEST)\n\n def view(self):\n \"\"\" Ensure that we get a plain view of the object, via a delegation to\n __call__(), which is defined in BrowserDefaultMixin\n \"\"\"\n return self()\n\n @security.protected(permissions.AccessContentsInformation)\n def folderlistingFolderContents(self, contentFilter=None):\n \"\"\"Calls listFolderContents in protected only by ACI so that\n folder_listing can work without the List folder contents permission.\n\n This is copied from Archetypes Basefolder and is needed by the\n reference browser.\n \"\"\"\n return self.listFolderContents(contentFilter)\n\n def isEffective(self, date):\n # Override DefaultDublinCoreImpl's test, since we are always viewable.\n return 1\n\n\n# Remove the IContentish interface so we don't listen to events that won't\n# apply to the site root, ie handleUidAnnotationEvent\nclassImplementsOnly(PloneSite, implementedBy(PloneSite) - IContentish)\n\nInitializeClass(PloneSite)\n", "path": "Products/CMFPlone/Portal.py"}]}
| 3,049 | 238 |
gh_patches_debug_9029
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1420
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sort evaluations in email lists by name
When sending emails which include lists of evaluations (when asking for preparation, reminding for preparation, publishing results), these lists should be sorted alphabetically by the name of the evaluation.
</issue>
<code>
[start of evap/evaluation/templatetags/evaluation_filters.py]
1 from collections import namedtuple
2
3 from django.forms import TypedChoiceField
4 from django.template import Library
5 from django.utils.translation import gettext_lazy as _
6
7 from evap.evaluation.models import BASE_UNIPOLAR_CHOICES
8 from evap.rewards.tools import can_reward_points_be_used_by
9 from evap.student.forms import HeadingField
10
11
12 # the names displayed for contributors
13 STATE_NAMES = {
14 'new': _('new'),
15 'prepared': _('prepared'),
16 'editor_approved': _('editor approved'),
17 'approved': _('approved'),
18 'in_evaluation': _('in evaluation'),
19 'evaluated': _('evaluated'),
20 'reviewed': _('reviewed'),
21 'published': _('published'),
22 }
23
24
25 # the descriptions used in tooltips for contributors
26 STATE_DESCRIPTIONS = {
27 'new': _('The evaluation was newly created and will be prepared by the evaluation team.'),
28 'prepared': _('The evaluation was prepared by the evaluation team and is now available for editors.'),
29 'editor_approved': _('The evaluation was approved by an editor and will now be checked by the evaluation team.'),
30 'approved': _('All preparations are finished. The evaluation will begin once the defined start date is reached.'),
31 'in_evaluation': _('The evaluation is currently running until the defined end date is reached.'),
32 'evaluated': _('The evaluation has finished and will now be reviewed by the evaluation team.'),
33 'reviewed': _('The evaluation has finished and was reviewed by the evaluation team. You will receive an email when its results are published.'),
34 'published': _('The results for this evaluation have been published.'),
35 }
36
37
38 # values for approval states shown to staff
39 StateValues = namedtuple('StateValues', ('order', 'icon', 'filter', 'description'))
40 APPROVAL_STATES = {
41 'new': StateValues(0, 'fas fa-circle icon-yellow', 'new', _('In preparation')),
42 'prepared': StateValues(2, 'far fa-square icon-gray', 'prepared', _('Awaiting editor review')),
43 'editor_approved': StateValues(1, 'far fa-check-square icon-yellow', 'editor_approved', _('Approved by editor, awaiting manager review')),
44 'approved': StateValues(3, 'far fa-check-square icon-green', 'approved', _('Approved by manager')),
45 }
46
47
48 register = Library()
49
50
51 @register.filter(name='zip')
52 def _zip(a, b):
53 return zip(a, b)
54
55
56 @register.filter()
57 def zip_choices(counts, choices):
58 return zip(counts, choices.names, choices.colors, choices.values)
59
60
61 @register.filter
62 def ordering_index(evaluation):
63 if evaluation.state in ['new', 'prepared', 'editor_approved', 'approved']:
64 return evaluation.days_until_evaluation
65 if evaluation.state == "in_evaluation":
66 return 100000 + evaluation.days_left_for_evaluation
67 return 200000 + evaluation.days_left_for_evaluation
68
69
70 # from http://www.jongales.com/blog/2009/10/19/percentage-django-template-tag/
71 @register.filter
72 def percentage(fraction, population):
73 try:
74 return "{0:.0f}%".format(int(float(fraction) / float(population) * 100))
75 except ValueError:
76 return None
77 except ZeroDivisionError:
78 return None
79
80
81 @register.filter
82 def percentage_one_decimal(fraction, population):
83 try:
84 return "{0:.1f}%".format((float(fraction) / float(population)) * 100)
85 except ValueError:
86 return None
87 except ZeroDivisionError:
88 return None
89
90
91 @register.filter
92 def to_colors(choices):
93 if not choices:
94 # When displaying the course distribution, there are no associated voting choices.
95 # In that case, we just use the colors of a unipolar scale.
96 return BASE_UNIPOLAR_CHOICES['colors']
97 return choices.colors
98
99
100 @register.filter
101 def weight_info(evaluation):
102 try:
103 course = evaluation.course
104 except AttributeError:
105 return None
106 if course.evaluation_weight_sum and course.evaluation_count > 1:
107 return percentage(evaluation.weight, course.evaluation_weight_sum)
108 return None
109
110
111 @register.filter
112 def statename(state):
113 return STATE_NAMES.get(state)
114
115
116 @register.filter
117 def statedescription(state):
118 return STATE_DESCRIPTIONS.get(state)
119
120
121 @register.filter
122 def approval_state_values(state):
123 if state in APPROVAL_STATES:
124 return APPROVAL_STATES[state]
125 if state in ['in_evaluation', 'evaluated', 'reviewed', 'published']:
126 return APPROVAL_STATES['approved']
127 return None
128
129
130 @register.filter
131 def approval_state_icon(state):
132 if state in APPROVAL_STATES:
133 return APPROVAL_STATES[state].icon
134 if state in ['in_evaluation', 'evaluated', 'reviewed', 'published']:
135 return APPROVAL_STATES['approved'].icon
136 return None
137
138
139 @register.filter
140 def can_results_page_be_seen_by(evaluation, user):
141 return evaluation.can_results_page_be_seen_by(user)
142
143
144 @register.filter(name='can_reward_points_be_used_by')
145 def _can_reward_points_be_used_by(user):
146 return can_reward_points_be_used_by(user)
147
148
149 @register.filter
150 def is_choice_field(field):
151 return isinstance(field.field, TypedChoiceField)
152
153
154 @register.filter
155 def is_heading_field(field):
156 return isinstance(field.field, HeadingField)
157
158
159 @register.filter
160 def is_user_editor_or_delegate(evaluation, user):
161 return evaluation.is_user_editor_or_delegate(user)
162
163
164 @register.filter
165 def is_user_responsible_or_contributor_or_delegate(evaluation, user):
166 return evaluation.is_user_responsible_or_contributor_or_delegate(user)
167
168
169 @register.filter
170 def message_class(level):
171 return {
172 'debug': 'info',
173 'info': 'info',
174 'success': 'success',
175 'warning': 'warning',
176 'error': 'danger',
177 }.get(level, 'info')
178
179
180 @register.filter
181 def hours_and_minutes(time_left_for_evaluation):
182 hours = time_left_for_evaluation.seconds // 3600
183 minutes = (time_left_for_evaluation.seconds // 60) % 60
184 return "{:02}:{:02}".format(hours, minutes)
185
186
187 @register.filter
188 def has_nonresponsible_editor(evaluation):
189 return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()
190
[end of evap/evaluation/templatetags/evaluation_filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/evaluation/templatetags/evaluation_filters.py b/evap/evaluation/templatetags/evaluation_filters.py
--- a/evap/evaluation/templatetags/evaluation_filters.py
+++ b/evap/evaluation/templatetags/evaluation_filters.py
@@ -187,3 +187,13 @@
@register.filter
def has_nonresponsible_editor(evaluation):
return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()
+
+
[email protected]
+def order_by(iterable, attribute):
+ return sorted(iterable, key=lambda item: getattr(item, attribute))
+
+
[email protected]
+def order_due_evaluations_by(due_evaluations, attribute):
+ return sorted(due_evaluations, key=lambda due_evaluation: getattr(due_evaluation[1], attribute))
|
{"golden_diff": "diff --git a/evap/evaluation/templatetags/evaluation_filters.py b/evap/evaluation/templatetags/evaluation_filters.py\n--- a/evap/evaluation/templatetags/evaluation_filters.py\n+++ b/evap/evaluation/templatetags/evaluation_filters.py\n@@ -187,3 +187,13 @@\n @register.filter\n def has_nonresponsible_editor(evaluation):\n return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()\n+\n+\[email protected]\n+def order_by(iterable, attribute):\n+ return sorted(iterable, key=lambda item: getattr(item, attribute))\n+\n+\[email protected]\n+def order_due_evaluations_by(due_evaluations, attribute):\n+ return sorted(due_evaluations, key=lambda due_evaluation: getattr(due_evaluation[1], attribute))\n", "issue": "Sort evaluations in email lists by name\nWhen sending emails which include lists of evaluations (when asking for preparation, reminding for preparation, publishing results), these lists should be sorted alphabetically by the name of the evaluation.\n", "before_files": [{"content": "from collections import namedtuple\n\nfrom django.forms import TypedChoiceField\nfrom django.template import Library\nfrom django.utils.translation import gettext_lazy as _\n\nfrom evap.evaluation.models import BASE_UNIPOLAR_CHOICES\nfrom evap.rewards.tools import can_reward_points_be_used_by\nfrom evap.student.forms import HeadingField\n\n\n# the names displayed for contributors\nSTATE_NAMES = {\n 'new': _('new'),\n 'prepared': _('prepared'),\n 'editor_approved': _('editor approved'),\n 'approved': _('approved'),\n 'in_evaluation': _('in evaluation'),\n 'evaluated': _('evaluated'),\n 'reviewed': _('reviewed'),\n 'published': _('published'),\n}\n\n\n# the descriptions used in tooltips for contributors\nSTATE_DESCRIPTIONS = {\n 'new': _('The evaluation was newly created and will be prepared by the evaluation team.'),\n 'prepared': _('The evaluation was prepared by the evaluation team and is now available for editors.'),\n 'editor_approved': _('The evaluation was approved by an editor and will now be checked by the evaluation team.'),\n 'approved': _('All preparations are finished. The evaluation will begin once the defined start date is reached.'),\n 'in_evaluation': _('The evaluation is currently running until the defined end date is reached.'),\n 'evaluated': _('The evaluation has finished and will now be reviewed by the evaluation team.'),\n 'reviewed': _('The evaluation has finished and was reviewed by the evaluation team. You will receive an email when its results are published.'),\n 'published': _('The results for this evaluation have been published.'),\n}\n\n\n# values for approval states shown to staff\nStateValues = namedtuple('StateValues', ('order', 'icon', 'filter', 'description'))\nAPPROVAL_STATES = {\n 'new': StateValues(0, 'fas fa-circle icon-yellow', 'new', _('In preparation')),\n 'prepared': StateValues(2, 'far fa-square icon-gray', 'prepared', _('Awaiting editor review')),\n 'editor_approved': StateValues(1, 'far fa-check-square icon-yellow', 'editor_approved', _('Approved by editor, awaiting manager review')),\n 'approved': StateValues(3, 'far fa-check-square icon-green', 'approved', _('Approved by manager')),\n}\n\n\nregister = Library()\n\n\[email protected](name='zip')\ndef _zip(a, b):\n return zip(a, b)\n\n\[email protected]()\ndef zip_choices(counts, choices):\n return zip(counts, choices.names, choices.colors, choices.values)\n\n\[email protected]\ndef ordering_index(evaluation):\n if evaluation.state in ['new', 'prepared', 'editor_approved', 'approved']:\n return evaluation.days_until_evaluation\n if evaluation.state == \"in_evaluation\":\n return 100000 + evaluation.days_left_for_evaluation\n return 200000 + evaluation.days_left_for_evaluation\n\n\n# from http://www.jongales.com/blog/2009/10/19/percentage-django-template-tag/\[email protected]\ndef percentage(fraction, population):\n try:\n return \"{0:.0f}%\".format(int(float(fraction) / float(population) * 100))\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef percentage_one_decimal(fraction, population):\n try:\n return \"{0:.1f}%\".format((float(fraction) / float(population)) * 100)\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef to_colors(choices):\n if not choices:\n # When displaying the course distribution, there are no associated voting choices.\n # In that case, we just use the colors of a unipolar scale.\n return BASE_UNIPOLAR_CHOICES['colors']\n return choices.colors\n\n\[email protected]\ndef weight_info(evaluation):\n try:\n course = evaluation.course\n except AttributeError:\n return None\n if course.evaluation_weight_sum and course.evaluation_count > 1:\n return percentage(evaluation.weight, course.evaluation_weight_sum)\n return None\n\n\[email protected]\ndef statename(state):\n return STATE_NAMES.get(state)\n\n\[email protected]\ndef statedescription(state):\n return STATE_DESCRIPTIONS.get(state)\n\n\[email protected]\ndef approval_state_values(state):\n if state in APPROVAL_STATES:\n return APPROVAL_STATES[state]\n if state in ['in_evaluation', 'evaluated', 'reviewed', 'published']:\n return APPROVAL_STATES['approved']\n return None\n\n\[email protected]\ndef approval_state_icon(state):\n if state in APPROVAL_STATES:\n return APPROVAL_STATES[state].icon\n if state in ['in_evaluation', 'evaluated', 'reviewed', 'published']:\n return APPROVAL_STATES['approved'].icon\n return None\n\n\[email protected]\ndef can_results_page_be_seen_by(evaluation, user):\n return evaluation.can_results_page_be_seen_by(user)\n\n\[email protected](name='can_reward_points_be_used_by')\ndef _can_reward_points_be_used_by(user):\n return can_reward_points_be_used_by(user)\n\n\[email protected]\ndef is_choice_field(field):\n return isinstance(field.field, TypedChoiceField)\n\n\[email protected]\ndef is_heading_field(field):\n return isinstance(field.field, HeadingField)\n\n\[email protected]\ndef is_user_editor_or_delegate(evaluation, user):\n return evaluation.is_user_editor_or_delegate(user)\n\n\[email protected]\ndef is_user_responsible_or_contributor_or_delegate(evaluation, user):\n return evaluation.is_user_responsible_or_contributor_or_delegate(user)\n\n\[email protected]\ndef message_class(level):\n return {\n 'debug': 'info',\n 'info': 'info',\n 'success': 'success',\n 'warning': 'warning',\n 'error': 'danger',\n }.get(level, 'info')\n\n\[email protected]\ndef hours_and_minutes(time_left_for_evaluation):\n hours = time_left_for_evaluation.seconds // 3600\n minutes = (time_left_for_evaluation.seconds // 60) % 60\n return \"{:02}:{:02}\".format(hours, minutes)\n\n\[email protected]\ndef has_nonresponsible_editor(evaluation):\n return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()\n", "path": "evap/evaluation/templatetags/evaluation_filters.py"}]}
| 2,426 | 198 |
gh_patches_debug_1261
|
rasdani/github-patches
|
git_diff
|
swcarpentry__python-novice-inflammation-736
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lesson 10 - numpy.mean(data) and data.mean
In lesson 10, when the lesson refers to readings_03.py, the code shows that to calculate the mean over 'data' across all days, numpy.mean is used: numpy.mean(data, axis=1). However when looking at the file readings_03.py (at least the version I downloaded recently) uses the instruction data.mean(axis=1). Both lead to the same result, but for consistency I would suggest to either modify the readings_*.py to use numpy.mean (as this is what it has been used throughout the entire lesson), or explain explicitly that both expressions lead to the same result (it would be a good time to remind students about object attributes).
</issue>
<code>
[start of code/readings_03.py]
1 import sys
2 import numpy
3
4
5 def main():
6 script = sys.argv[0]
7 for filename in sys.argv[1:]:
8 data = numpy.loadtxt(filename, delimiter=',')
9 for m in data.mean(axis=1):
10 print(m)
11
12
13 if __name__ == '__main__':
14 main()
15
[end of code/readings_03.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/code/readings_03.py b/code/readings_03.py
--- a/code/readings_03.py
+++ b/code/readings_03.py
@@ -6,7 +6,7 @@
script = sys.argv[0]
for filename in sys.argv[1:]:
data = numpy.loadtxt(filename, delimiter=',')
- for m in data.mean(axis=1):
+ for m in numpy.mean(data, axis=1):
print(m)
|
{"golden_diff": "diff --git a/code/readings_03.py b/code/readings_03.py\n--- a/code/readings_03.py\n+++ b/code/readings_03.py\n@@ -6,7 +6,7 @@\n script = sys.argv[0]\n for filename in sys.argv[1:]:\n data = numpy.loadtxt(filename, delimiter=',')\n- for m in data.mean(axis=1):\n+ for m in numpy.mean(data, axis=1):\n print(m)\n", "issue": "Lesson 10 - numpy.mean(data) and data.mean\nIn lesson 10, when the lesson refers to readings_03.py, the code shows that to calculate the mean over 'data' across all days, numpy.mean is used: numpy.mean(data, axis=1). However when looking at the file readings_03.py (at least the version I downloaded recently) uses the instruction data.mean(axis=1). Both lead to the same result, but for consistency I would suggest to either modify the readings_*.py to use numpy.mean (as this is what it has been used throughout the entire lesson), or explain explicitly that both expressions lead to the same result (it would be a good time to remind students about object attributes). \n", "before_files": [{"content": "import sys\nimport numpy\n\n\ndef main():\n script = sys.argv[0]\n for filename in sys.argv[1:]:\n data = numpy.loadtxt(filename, delimiter=',')\n for m in data.mean(axis=1):\n print(m)\n\n\nif __name__ == '__main__':\n main()\n", "path": "code/readings_03.py"}]}
| 780 | 105 |
gh_patches_debug_37853
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-9611
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
api: support config/credentials passing
dvcfs now supports config passing https://github.com/iterative/dvc/issues/9154 and we need to allow for the same with api methods.
Related https://github.com/iterative/dvc/issues/4336
</issue>
<code>
[start of dvc/api/data.py]
1 from contextlib import _GeneratorContextManager as GCM
2 from contextlib import contextmanager
3 from typing import Any, Dict, Optional
4
5 from funcy import reraise
6
7 from dvc.exceptions import FileMissingError, OutputNotFoundError, PathMissingError
8 from dvc.repo import Repo
9
10
11 @contextmanager
12 def _wrap_exceptions(repo, url):
13 from dvc.config import NoRemoteError
14 from dvc.exceptions import NoOutputInExternalRepoError, NoRemoteInExternalRepoError
15
16 try:
17 yield
18 except NoRemoteError as exc:
19 raise NoRemoteInExternalRepoError(url) from exc
20 except OutputNotFoundError as exc:
21 if exc.repo is repo:
22 raise NoOutputInExternalRepoError(exc.output, repo.root_dir, url) from exc
23 raise
24 except FileMissingError as exc:
25 raise PathMissingError(exc.path, url) from exc
26
27
28 def get_url(path, repo=None, rev=None, remote=None):
29 """
30 Returns the URL to the storage location of a data file or directory tracked
31 in a DVC repo. For Git repos, HEAD is used unless a rev argument is
32 supplied. The default remote is tried unless a remote argument is supplied.
33
34 Raises OutputNotFoundError if the file is not tracked by DVC.
35
36 NOTE: This function does not check for the actual existence of the file or
37 directory in the remote storage.
38 """
39 with Repo.open(repo, rev=rev, subrepos=True, uninitialized=True) as _repo:
40 with _wrap_exceptions(_repo, path):
41 fs_path = _repo.dvcfs.from_os_path(path)
42
43 with reraise(FileNotFoundError, PathMissingError(path, repo)):
44 info = _repo.dvcfs.info(fs_path)
45
46 dvc_info = info.get("dvc_info")
47 if not dvc_info:
48 raise OutputNotFoundError(path, repo)
49
50 dvc_repo = info["repo"] # pylint: disable=unsubscriptable-object
51 md5 = dvc_info["md5"]
52
53 return dvc_repo.cloud.get_url_for(remote, checksum=md5)
54
55
56 class _OpenContextManager(GCM):
57 def __init__(self, func, args, kwds): # pylint: disable=super-init-not-called
58 self.gen = func(*args, **kwds)
59 self.func, self.args, self.kwds = ( # type: ignore[assignment]
60 func,
61 args,
62 kwds,
63 )
64
65 def __getattr__(self, name):
66 raise AttributeError("dvc.api.open() should be used in a with statement.")
67
68
69 def open( # noqa, pylint: disable=redefined-builtin
70 path: str,
71 repo: Optional[str] = None,
72 rev: Optional[str] = None,
73 remote: Optional[str] = None,
74 mode: str = "r",
75 encoding: Optional[str] = None,
76 ):
77 """
78 Opens a file tracked in a DVC project.
79
80 This function may only be used as a context manager (using the `with`
81 keyword, as shown in the examples).
82
83 This function makes a direct connection to the remote storage, so the file
84 contents can be streamed. Your code can process the data buffer as it's
85 streamed, which optimizes memory usage.
86
87 Note:
88 Use dvc.api.read() to load the complete file contents
89 in a single function call, no context manager involved.
90 Neither function utilizes disc space.
91
92 Args:
93 path (str): location and file name of the target to open,
94 relative to the root of `repo`.
95 repo (str, optional): location of the DVC project or Git Repo.
96 Defaults to the current DVC project (found by walking up from the
97 current working directory tree).
98 It can be a URL or a file system path.
99 Both HTTP and SSH protocols are supported for online Git repos
100 (e.g. [user@]server:project.git).
101 rev (str, optional): Any `Git revision`_ such as a branch or tag name,
102 a commit hash or a dvc experiment name.
103 Defaults to HEAD.
104 If `repo` is not a Git repo, this option is ignored.
105 remote (str, optional): Name of the `DVC remote`_ used to form the
106 returned URL string.
107 Defaults to the `default remote`_ of `repo`.
108 For local projects, the cache is tried before the default remote.
109 mode (str, optional): Specifies the mode in which the file is opened.
110 Defaults to "r" (read).
111 Mirrors the namesake parameter in builtin `open()`_.
112 Only reading `mode` is supported.
113 encoding(str, optional): `Codec`_ used to decode the file contents.
114 Defaults to None.
115 This should only be used in text mode.
116 Mirrors the namesake parameter in builtin `open()`_.
117
118 Returns:
119 _OpenContextManager: A context manager that generatse a corresponding
120 `file object`_.
121 The exact type of file object depends on the mode used.
122 For more details, please refer to Python's `open()`_ built-in,
123 which is used under the hood.
124
125 Raises:
126 AttributeError: If this method is not used as a context manager.
127 ValueError: If non-read `mode` is used.
128
129 Examples:
130
131 - Use data or models from a DVC repository.
132
133 Any file tracked in a DVC project (and stored remotely) can be
134 processed directly in your Python code with this API.
135 For example, an XML file tracked in a public DVC repo on GitHub can be
136 processed like this:
137
138 >>> from xml.sax import parse
139 >>> import dvc.api
140 >>> from mymodule import mySAXHandler
141
142 >>> with dvc.api.open(
143 ... 'get-started/data.xml',
144 ... repo='https://github.com/iterative/dataset-registry'
145 ... ) as fd:
146 ... parse(fd, mySAXHandler)
147
148 We use a SAX XML parser here because dvc.api.open() is able to stream
149 the data from remote storage.
150 The mySAXHandler object should handle the event-driven parsing of the
151 document in this case.
152 This increases the performance of the code (minimizing memory usage),
153 and is typically faster than loading the whole data into memory.
154
155 - Accessing private repos
156
157 This is just a matter of using the right repo argument, for example an
158 SSH URL (requires that the credentials are configured locally):
159
160 >>> import dvc.api
161
162 >>> with dvc.api.open(
163 ... 'features.dat',
164 ... repo='[email protected]:path/to/repo.git'
165 ... ) as fd:
166 ... # ... Process 'features'
167 ... pass
168
169 - Use different versions of data
170
171 Any git revision (see `rev`) can be accessed programmatically.
172 For example, if your DVC repo has tagged releases of a CSV dataset:
173
174 >>> import csv
175 >>> import dvc.api
176 >>> with dvc.api.open(
177 ... 'clean.csv',
178 ... rev='v1.1.0'
179 ... ) as fd:
180 ... reader = csv.reader(fd)
181 ... # ... Process 'clean' data from version 1.1.0
182
183 .. _Git revision:
184 https://git-scm.com/docs/revisions
185
186 .. _DVC remote:
187 https://dvc.org/doc/command-reference/remote
188
189 .. _default remote:
190 https://dvc.org/doc/command-reference/remote/default
191
192 .. _open():
193 https://docs.python.org/3/library/functions.html#open
194
195 .. _Codec:
196 https://docs.python.org/3/library/codecs.html#standard-encodings
197
198 .. _file object:
199 https://docs.python.org/3/glossary.html#term-file-object
200
201 """
202 if "r" not in mode:
203 raise ValueError("Only reading `mode` is supported.")
204
205 args = (path,)
206 kwargs = {
207 "repo": repo,
208 "remote": remote,
209 "rev": rev,
210 "mode": mode,
211 "encoding": encoding,
212 }
213 return _OpenContextManager(_open, args, kwargs)
214
215
216 def _open(path, repo=None, rev=None, remote=None, mode="r", encoding=None):
217 repo_kwargs: Dict[str, Any] = {"subrepos": True, "uninitialized": True}
218 if remote:
219 repo_kwargs["config"] = {"core": {"remote": remote}}
220
221 with Repo.open(repo, rev=rev, **repo_kwargs) as _repo:
222 with _wrap_exceptions(_repo, path):
223 import os
224 from typing import TYPE_CHECKING, Union
225
226 from dvc.exceptions import IsADirectoryError as DvcIsADirectoryError
227 from dvc.fs.data import DataFileSystem
228 from dvc.fs.dvc import DVCFileSystem
229
230 if TYPE_CHECKING:
231 from dvc.fs import FileSystem
232
233 fs: Union["FileSystem", DataFileSystem, DVCFileSystem]
234 if os.path.isabs(path):
235 fs = DataFileSystem(index=_repo.index.data["local"])
236 fs_path = path
237 else:
238 fs = DVCFileSystem(repo=_repo, subrepos=True)
239 fs_path = fs.from_os_path(path)
240
241 try:
242 with fs.open(
243 fs_path,
244 mode=mode,
245 encoding=encoding,
246 ) as fobj:
247 yield fobj
248 except FileNotFoundError as exc:
249 raise FileMissingError(path) from exc
250 except IsADirectoryError as exc:
251 raise DvcIsADirectoryError(f"'{path}' is a directory") from exc
252
253
254 def read(path, repo=None, rev=None, remote=None, mode="r", encoding=None):
255 """
256 Returns the contents of a tracked file (by DVC or Git). For Git repos, HEAD
257 is used unless a rev argument is supplied. The default remote is tried
258 unless a remote argument is supplied.
259 """
260 with open(
261 path, repo=repo, rev=rev, remote=remote, mode=mode, encoding=encoding
262 ) as fd:
263 return fd.read()
264
[end of dvc/api/data.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/api/data.py b/dvc/api/data.py
--- a/dvc/api/data.py
+++ b/dvc/api/data.py
@@ -73,6 +73,7 @@
remote: Optional[str] = None,
mode: str = "r",
encoding: Optional[str] = None,
+ config: Optional[Dict[str, Any]] = None,
):
"""
Opens a file tracked in a DVC project.
@@ -114,6 +115,8 @@
Defaults to None.
This should only be used in text mode.
Mirrors the namesake parameter in builtin `open()`_.
+ config(dict, optional): config to be passed to the DVC repository.
+ Defaults to None.
Returns:
_OpenContextManager: A context manager that generatse a corresponding
@@ -209,14 +212,24 @@
"rev": rev,
"mode": mode,
"encoding": encoding,
+ "config": config,
}
return _OpenContextManager(_open, args, kwargs)
-def _open(path, repo=None, rev=None, remote=None, mode="r", encoding=None):
- repo_kwargs: Dict[str, Any] = {"subrepos": True, "uninitialized": True}
+def _open(path, repo=None, rev=None, remote=None, mode="r", encoding=None, config=None):
if remote:
- repo_kwargs["config"] = {"core": {"remote": remote}}
+ if config is not None:
+ raise ValueError(
+ "can't specify both `remote` and `config` at the same time"
+ )
+ config = {"core": {"remote": remote}}
+
+ repo_kwargs: Dict[str, Any] = {
+ "subrepos": True,
+ "uninitialized": True,
+ "config": config,
+ }
with Repo.open(repo, rev=rev, **repo_kwargs) as _repo:
with _wrap_exceptions(_repo, path):
@@ -251,13 +264,19 @@
raise DvcIsADirectoryError(f"'{path}' is a directory") from exc
-def read(path, repo=None, rev=None, remote=None, mode="r", encoding=None):
+def read(path, repo=None, rev=None, remote=None, mode="r", encoding=None, config=None):
"""
Returns the contents of a tracked file (by DVC or Git). For Git repos, HEAD
is used unless a rev argument is supplied. The default remote is tried
unless a remote argument is supplied.
"""
with open(
- path, repo=repo, rev=rev, remote=remote, mode=mode, encoding=encoding
+ path,
+ repo=repo,
+ rev=rev,
+ remote=remote,
+ mode=mode,
+ encoding=encoding,
+ config=config,
) as fd:
return fd.read()
|
{"golden_diff": "diff --git a/dvc/api/data.py b/dvc/api/data.py\n--- a/dvc/api/data.py\n+++ b/dvc/api/data.py\n@@ -73,6 +73,7 @@\n remote: Optional[str] = None,\n mode: str = \"r\",\n encoding: Optional[str] = None,\n+ config: Optional[Dict[str, Any]] = None,\n ):\n \"\"\"\n Opens a file tracked in a DVC project.\n@@ -114,6 +115,8 @@\n Defaults to None.\n This should only be used in text mode.\n Mirrors the namesake parameter in builtin `open()`_.\n+ config(dict, optional): config to be passed to the DVC repository.\n+ Defaults to None.\n \n Returns:\n _OpenContextManager: A context manager that generatse a corresponding\n@@ -209,14 +212,24 @@\n \"rev\": rev,\n \"mode\": mode,\n \"encoding\": encoding,\n+ \"config\": config,\n }\n return _OpenContextManager(_open, args, kwargs)\n \n \n-def _open(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None):\n- repo_kwargs: Dict[str, Any] = {\"subrepos\": True, \"uninitialized\": True}\n+def _open(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None, config=None):\n if remote:\n- repo_kwargs[\"config\"] = {\"core\": {\"remote\": remote}}\n+ if config is not None:\n+ raise ValueError(\n+ \"can't specify both `remote` and `config` at the same time\"\n+ )\n+ config = {\"core\": {\"remote\": remote}}\n+\n+ repo_kwargs: Dict[str, Any] = {\n+ \"subrepos\": True,\n+ \"uninitialized\": True,\n+ \"config\": config,\n+ }\n \n with Repo.open(repo, rev=rev, **repo_kwargs) as _repo:\n with _wrap_exceptions(_repo, path):\n@@ -251,13 +264,19 @@\n raise DvcIsADirectoryError(f\"'{path}' is a directory\") from exc\n \n \n-def read(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None):\n+def read(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None, config=None):\n \"\"\"\n Returns the contents of a tracked file (by DVC or Git). For Git repos, HEAD\n is used unless a rev argument is supplied. The default remote is tried\n unless a remote argument is supplied.\n \"\"\"\n with open(\n- path, repo=repo, rev=rev, remote=remote, mode=mode, encoding=encoding\n+ path,\n+ repo=repo,\n+ rev=rev,\n+ remote=remote,\n+ mode=mode,\n+ encoding=encoding,\n+ config=config,\n ) as fd:\n return fd.read()\n", "issue": "api: support config/credentials passing\ndvcfs now supports config passing https://github.com/iterative/dvc/issues/9154 and we need to allow for the same with api methods.\r\n\r\nRelated https://github.com/iterative/dvc/issues/4336\n", "before_files": [{"content": "from contextlib import _GeneratorContextManager as GCM\nfrom contextlib import contextmanager\nfrom typing import Any, Dict, Optional\n\nfrom funcy import reraise\n\nfrom dvc.exceptions import FileMissingError, OutputNotFoundError, PathMissingError\nfrom dvc.repo import Repo\n\n\n@contextmanager\ndef _wrap_exceptions(repo, url):\n from dvc.config import NoRemoteError\n from dvc.exceptions import NoOutputInExternalRepoError, NoRemoteInExternalRepoError\n\n try:\n yield\n except NoRemoteError as exc:\n raise NoRemoteInExternalRepoError(url) from exc\n except OutputNotFoundError as exc:\n if exc.repo is repo:\n raise NoOutputInExternalRepoError(exc.output, repo.root_dir, url) from exc\n raise\n except FileMissingError as exc:\n raise PathMissingError(exc.path, url) from exc\n\n\ndef get_url(path, repo=None, rev=None, remote=None):\n \"\"\"\n Returns the URL to the storage location of a data file or directory tracked\n in a DVC repo. For Git repos, HEAD is used unless a rev argument is\n supplied. The default remote is tried unless a remote argument is supplied.\n\n Raises OutputNotFoundError if the file is not tracked by DVC.\n\n NOTE: This function does not check for the actual existence of the file or\n directory in the remote storage.\n \"\"\"\n with Repo.open(repo, rev=rev, subrepos=True, uninitialized=True) as _repo:\n with _wrap_exceptions(_repo, path):\n fs_path = _repo.dvcfs.from_os_path(path)\n\n with reraise(FileNotFoundError, PathMissingError(path, repo)):\n info = _repo.dvcfs.info(fs_path)\n\n dvc_info = info.get(\"dvc_info\")\n if not dvc_info:\n raise OutputNotFoundError(path, repo)\n\n dvc_repo = info[\"repo\"] # pylint: disable=unsubscriptable-object\n md5 = dvc_info[\"md5\"]\n\n return dvc_repo.cloud.get_url_for(remote, checksum=md5)\n\n\nclass _OpenContextManager(GCM):\n def __init__(self, func, args, kwds): # pylint: disable=super-init-not-called\n self.gen = func(*args, **kwds)\n self.func, self.args, self.kwds = ( # type: ignore[assignment]\n func,\n args,\n kwds,\n )\n\n def __getattr__(self, name):\n raise AttributeError(\"dvc.api.open() should be used in a with statement.\")\n\n\ndef open( # noqa, pylint: disable=redefined-builtin\n path: str,\n repo: Optional[str] = None,\n rev: Optional[str] = None,\n remote: Optional[str] = None,\n mode: str = \"r\",\n encoding: Optional[str] = None,\n):\n \"\"\"\n Opens a file tracked in a DVC project.\n\n This function may only be used as a context manager (using the `with`\n keyword, as shown in the examples).\n\n This function makes a direct connection to the remote storage, so the file\n contents can be streamed. Your code can process the data buffer as it's\n streamed, which optimizes memory usage.\n\n Note:\n Use dvc.api.read() to load the complete file contents\n in a single function call, no context manager involved.\n Neither function utilizes disc space.\n\n Args:\n path (str): location and file name of the target to open,\n relative to the root of `repo`.\n repo (str, optional): location of the DVC project or Git Repo.\n Defaults to the current DVC project (found by walking up from the\n current working directory tree).\n It can be a URL or a file system path.\n Both HTTP and SSH protocols are supported for online Git repos\n (e.g. [user@]server:project.git).\n rev (str, optional): Any `Git revision`_ such as a branch or tag name,\n a commit hash or a dvc experiment name.\n Defaults to HEAD.\n If `repo` is not a Git repo, this option is ignored.\n remote (str, optional): Name of the `DVC remote`_ used to form the\n returned URL string.\n Defaults to the `default remote`_ of `repo`.\n For local projects, the cache is tried before the default remote.\n mode (str, optional): Specifies the mode in which the file is opened.\n Defaults to \"r\" (read).\n Mirrors the namesake parameter in builtin `open()`_.\n Only reading `mode` is supported.\n encoding(str, optional): `Codec`_ used to decode the file contents.\n Defaults to None.\n This should only be used in text mode.\n Mirrors the namesake parameter in builtin `open()`_.\n\n Returns:\n _OpenContextManager: A context manager that generatse a corresponding\n `file object`_.\n The exact type of file object depends on the mode used.\n For more details, please refer to Python's `open()`_ built-in,\n which is used under the hood.\n\n Raises:\n AttributeError: If this method is not used as a context manager.\n ValueError: If non-read `mode` is used.\n\n Examples:\n\n - Use data or models from a DVC repository.\n\n Any file tracked in a DVC project (and stored remotely) can be\n processed directly in your Python code with this API.\n For example, an XML file tracked in a public DVC repo on GitHub can be\n processed like this:\n\n >>> from xml.sax import parse\n >>> import dvc.api\n >>> from mymodule import mySAXHandler\n\n >>> with dvc.api.open(\n ... 'get-started/data.xml',\n ... repo='https://github.com/iterative/dataset-registry'\n ... ) as fd:\n ... parse(fd, mySAXHandler)\n\n We use a SAX XML parser here because dvc.api.open() is able to stream\n the data from remote storage.\n The mySAXHandler object should handle the event-driven parsing of the\n document in this case.\n This increases the performance of the code (minimizing memory usage),\n and is typically faster than loading the whole data into memory.\n\n - Accessing private repos\n\n This is just a matter of using the right repo argument, for example an\n SSH URL (requires that the credentials are configured locally):\n\n >>> import dvc.api\n\n >>> with dvc.api.open(\n ... 'features.dat',\n ... repo='[email protected]:path/to/repo.git'\n ... ) as fd:\n ... # ... Process 'features'\n ... pass\n\n - Use different versions of data\n\n Any git revision (see `rev`) can be accessed programmatically.\n For example, if your DVC repo has tagged releases of a CSV dataset:\n\n >>> import csv\n >>> import dvc.api\n >>> with dvc.api.open(\n ... 'clean.csv',\n ... rev='v1.1.0'\n ... ) as fd:\n ... reader = csv.reader(fd)\n ... # ... Process 'clean' data from version 1.1.0\n\n .. _Git revision:\n https://git-scm.com/docs/revisions\n\n .. _DVC remote:\n https://dvc.org/doc/command-reference/remote\n\n .. _default remote:\n https://dvc.org/doc/command-reference/remote/default\n\n .. _open():\n https://docs.python.org/3/library/functions.html#open\n\n .. _Codec:\n https://docs.python.org/3/library/codecs.html#standard-encodings\n\n .. _file object:\n https://docs.python.org/3/glossary.html#term-file-object\n\n \"\"\"\n if \"r\" not in mode:\n raise ValueError(\"Only reading `mode` is supported.\")\n\n args = (path,)\n kwargs = {\n \"repo\": repo,\n \"remote\": remote,\n \"rev\": rev,\n \"mode\": mode,\n \"encoding\": encoding,\n }\n return _OpenContextManager(_open, args, kwargs)\n\n\ndef _open(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None):\n repo_kwargs: Dict[str, Any] = {\"subrepos\": True, \"uninitialized\": True}\n if remote:\n repo_kwargs[\"config\"] = {\"core\": {\"remote\": remote}}\n\n with Repo.open(repo, rev=rev, **repo_kwargs) as _repo:\n with _wrap_exceptions(_repo, path):\n import os\n from typing import TYPE_CHECKING, Union\n\n from dvc.exceptions import IsADirectoryError as DvcIsADirectoryError\n from dvc.fs.data import DataFileSystem\n from dvc.fs.dvc import DVCFileSystem\n\n if TYPE_CHECKING:\n from dvc.fs import FileSystem\n\n fs: Union[\"FileSystem\", DataFileSystem, DVCFileSystem]\n if os.path.isabs(path):\n fs = DataFileSystem(index=_repo.index.data[\"local\"])\n fs_path = path\n else:\n fs = DVCFileSystem(repo=_repo, subrepos=True)\n fs_path = fs.from_os_path(path)\n\n try:\n with fs.open(\n fs_path,\n mode=mode,\n encoding=encoding,\n ) as fobj:\n yield fobj\n except FileNotFoundError as exc:\n raise FileMissingError(path) from exc\n except IsADirectoryError as exc:\n raise DvcIsADirectoryError(f\"'{path}' is a directory\") from exc\n\n\ndef read(path, repo=None, rev=None, remote=None, mode=\"r\", encoding=None):\n \"\"\"\n Returns the contents of a tracked file (by DVC or Git). For Git repos, HEAD\n is used unless a rev argument is supplied. The default remote is tried\n unless a remote argument is supplied.\n \"\"\"\n with open(\n path, repo=repo, rev=rev, remote=remote, mode=mode, encoding=encoding\n ) as fd:\n return fd.read()\n", "path": "dvc/api/data.py"}]}
| 3,492 | 652 |
gh_patches_debug_7288
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-1378
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Merge changes from 0.3.8 into develop
This is blocking on #1313 and #1345.
</issue>
<code>
[start of securedrop/version.py]
1 __version__ = '0.3.7'
2
[end of securedrop/version.py]
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # SecureDrop documentation build configuration file, created by
4 # sphinx-quickstart on Tue Oct 13 12:08:52 2015.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import sys
16 import os
17 import shlex
18
19 # Detect if we're being built by Read the Docs
20 # https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs
21 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
22
23 # If extensions (or modules to document with autodoc) are in another directory,
24 # add these directories to sys.path here. If the directory is relative to the
25 # documentation root, use os.path.abspath to make it absolute, like shown here.
26 #sys.path.insert(0, os.path.abspath('.'))
27
28 # -- General configuration ------------------------------------------------
29
30 # If your documentation needs a minimal Sphinx version, state it here.
31 #needs_sphinx = '1.0'
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = ['sphinx.ext.todo', ]
37
38 # Add any paths that contain templates here, relative to this directory.
39 templates_path = ['_templates']
40
41 # The suffix(es) of source filenames.
42 # You can specify multiple suffix as a list of string:
43 # source_suffix = ['.rst', '.md']
44 source_suffix = '.rst'
45
46 # The encoding of source files.
47 #source_encoding = 'utf-8-sig'
48
49 # The master toctree document.
50 master_doc = 'index'
51
52 # General information about the project.
53 project = u'SecureDrop'
54 copyright = u'2015, Freedom of the Press Foundation'
55 author = u'SecureDrop Team and Contributors'
56
57 # The version info for the project you're documenting, acts as replacement for
58 # |version| and |release|, also used in various other places throughout the
59 # built documents.
60 #
61 # The short X.Y version.
62 version = '0.3.7'
63 # The full version, including alpha/beta/rc tags.
64 release = '0.3.7'
65
66 # The language for content autogenerated by Sphinx. Refer to documentation
67 # for a list of supported languages.
68 #
69 # This is also used if you do content translation via gettext catalogs.
70 # Usually you set "language" from the command line for these cases.
71 language = None
72
73 # There are two options for replacing |today|: either, you set today to some
74 # non-false value, then it is used:
75 #today = ''
76 # Else, today_fmt is used as the format for a strftime call.
77 #today_fmt = '%B %d, %Y'
78
79 # List of patterns, relative to source directory, that match files and
80 # directories to ignore when looking for source files.
81 exclude_patterns = ['_build']
82
83 # The reST default role (used for this markup: `text`) to use for all
84 # documents.
85 #default_role = None
86
87 # If true, '()' will be appended to :func: etc. cross-reference text.
88 #add_function_parentheses = True
89
90 # If true, the current module name will be prepended to all description
91 # unit titles (such as .. function::).
92 #add_module_names = True
93
94 # If true, sectionauthor and moduleauthor directives will be shown in the
95 # output. They are ignored by default.
96 #show_authors = False
97
98 # The name of the Pygments (syntax highlighting) style to use.
99 pygments_style = 'sphinx'
100
101 # A list of ignored prefixes for module index sorting.
102 #modindex_common_prefix = []
103
104 # If true, keep warnings as "system message" paragraphs in the built documents.
105 #keep_warnings = False
106
107 # If true, `todo` and `todoList` produce output, else they produce nothing.
108 todo_include_todos = False
109
110
111 # -- Options for HTML output ----------------------------------------------
112
113 # The theme to use for HTML and HTML Help pages. See the documentation for
114 # a list of builtin themes.
115 if on_rtd:
116 html_theme = 'default'
117 else:
118 try:
119 # If you want to build the docs locally using the RTD theme,
120 # you may need to install it: ``pip install sphinx_rtd_theme``.
121 # https://github.com/snide/sphinx_rtd_theme#via-package
122 import sphinx_rtd_theme
123 html_theme = "sphinx_rtd_theme"
124 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
125 except ImportError:
126 # This theme is included with Sphinx and is quite nice (based
127 # on the Pocoo themes), but since we're using the RTD theme
128 # for the production docs, it's best to use that to avoid
129 # issues due to discrepancies between the themes.
130 html_theme = 'alabaster'
131
132 # Theme options are theme-specific and customize the look and feel of a theme
133 # further. For a list of options available for each theme, see the
134 # documentation.
135 #html_theme_options = {}
136
137 # Add any paths that contain custom themes here, relative to this directory.
138 #html_theme_path = []
139
140 # The name for this set of Sphinx documents. If None, it defaults to
141 # "<project> v<release> documentation".
142 #html_title = None
143
144 # A shorter title for the navigation bar. Default is the same as html_title.
145 #html_short_title = None
146
147 # The name of an image file (relative to this directory) to place at the top
148 # of the sidebar.
149 #html_logo = None
150
151 # The name of an image file (within the static path) to use as favicon of the
152 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
153 # pixels large.
154 #html_favicon = None
155
156 # Add any paths that contain custom static files (such as style sheets) here,
157 # relative to this directory. They are copied after the builtin static files,
158 # so a file named "default.css" will overwrite the builtin "default.css".
159 html_static_path = ['_static']
160
161 # Add any extra paths that contain custom files (such as robots.txt or
162 # .htaccess) here, relative to this directory. These files are copied
163 # directly to the root of the documentation.
164 #html_extra_path = []
165
166 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
167 # using the given strftime format.
168 #html_last_updated_fmt = '%b %d, %Y'
169
170 # If true, SmartyPants will be used to convert quotes and dashes to
171 # typographically correct entities.
172 #html_use_smartypants = True
173
174 # Custom sidebar templates, maps document names to template names.
175 #html_sidebars = {}
176
177 # Additional templates that should be rendered to pages, maps page names to
178 # template names.
179 #html_additional_pages = {}
180
181 # If false, no module index is generated.
182 #html_domain_indices = True
183
184 # If false, no index is generated.
185 #html_use_index = True
186
187 # If true, the index is split into individual pages for each letter.
188 #html_split_index = False
189
190 # If true, links to the reST sources are added to the pages.
191 #html_show_sourcelink = True
192
193 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
194 #html_show_sphinx = True
195
196 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
197 #html_show_copyright = True
198
199 # If true, an OpenSearch description file will be output, and all pages will
200 # contain a <link> tag referring to it. The value of this option must be the
201 # base URL from which the finished HTML is served.
202 #html_use_opensearch = ''
203
204 # This is the file name suffix for HTML files (e.g. ".xhtml").
205 #html_file_suffix = None
206
207 # Language to be used for generating the HTML full-text search index.
208 # Sphinx supports the following languages:
209 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
210 # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
211 #html_search_language = 'en'
212
213 # A dictionary with options for the search language support, empty by default.
214 # Now only 'ja' uses this config value
215 #html_search_options = {'type': 'default'}
216
217 # The name of a javascript file (relative to the configuration directory) that
218 # implements a search results scorer. If empty, the default will be used.
219 #html_search_scorer = 'scorer.js'
220
221 # Output file base name for HTML help builder.
222 htmlhelp_basename = 'SecureDropdoc'
223
224 # -- Options for LaTeX output ---------------------------------------------
225
226 latex_elements = {
227 # The paper size ('letterpaper' or 'a4paper').
228 #'papersize': 'letterpaper',
229
230 # The font size ('10pt', '11pt' or '12pt').
231 #'pointsize': '10pt',
232
233 # Additional stuff for the LaTeX preamble.
234 #'preamble': '',
235
236 # Latex figure (float) alignment
237 #'figure_align': 'htbp',
238 }
239
240 # Grouping the document tree into LaTeX files. List of tuples
241 # (source start file, target name, title,
242 # author, documentclass [howto, manual, or own class]).
243 latex_documents = [
244 (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',
245 author, 'manual'),
246 ]
247
248 # The name of an image file (relative to this directory) to place at the top of
249 # the title page.
250 #latex_logo = None
251
252 # For "manual" documents, if this is true, then toplevel headings are parts,
253 # not chapters.
254 #latex_use_parts = False
255
256 # If true, show page references after internal links.
257 #latex_show_pagerefs = False
258
259 # If true, show URL addresses after external links.
260 #latex_show_urls = False
261
262 # Documents to append as an appendix to all manuals.
263 #latex_appendices = []
264
265 # If false, no module index is generated.
266 #latex_domain_indices = True
267
268
269 # -- Options for manual page output ---------------------------------------
270
271 # One entry per manual page. List of tuples
272 # (source start file, name, description, authors, manual section).
273 man_pages = [
274 (master_doc, 'securedrop', u'SecureDrop Documentation',
275 [author], 1)
276 ]
277
278 # If true, show URL addresses after external links.
279 #man_show_urls = False
280
281
282 # -- Options for Texinfo output -------------------------------------------
283
284 # Grouping the document tree into Texinfo files. List of tuples
285 # (source start file, target name, title, author,
286 # dir menu entry, description, category)
287 texinfo_documents = [
288 (master_doc, 'SecureDrop', u'SecureDrop Documentation',
289 author, 'SecureDrop', 'One line description of project.',
290 'Miscellaneous'),
291 ]
292
293 # Documents to append as an appendix to all manuals.
294 #texinfo_appendices = []
295
296 # If false, no module index is generated.
297 #texinfo_domain_indices = True
298
299 # How to display URL addresses: 'footnote', 'no', or 'inline'.
300 #texinfo_show_urls = 'footnote'
301
302 # If true, do not generate a @detailmenu in the "Top" node's menu.
303 #texinfo_no_detailmenu = False
304
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -59,9 +59,9 @@
# built documents.
#
# The short X.Y version.
-version = '0.3.7'
+version = '0.3.8'
# The full version, including alpha/beta/rc tags.
-release = '0.3.7'
+release = '0.3.8'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
diff --git a/securedrop/version.py b/securedrop/version.py
--- a/securedrop/version.py
+++ b/securedrop/version.py
@@ -1 +1 @@
-__version__ = '0.3.7'
+__version__ = '0.3.8'
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -59,9 +59,9 @@\n # built documents.\n #\n # The short X.Y version.\n-version = '0.3.7'\n+version = '0.3.8'\n # The full version, including alpha/beta/rc tags.\n-release = '0.3.7'\n+release = '0.3.8'\n \n # The language for content autogenerated by Sphinx. Refer to documentation\n # for a list of supported languages.\ndiff --git a/securedrop/version.py b/securedrop/version.py\n--- a/securedrop/version.py\n+++ b/securedrop/version.py\n@@ -1 +1 @@\n-__version__ = '0.3.7'\n+__version__ = '0.3.8'\n", "issue": "Merge changes from 0.3.8 into develop\nThis is blocking on #1313 and #1345.\n\n", "before_files": [{"content": "__version__ = '0.3.7'\n", "path": "securedrop/version.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# SecureDrop documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 13 12:08:52 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport sys\nimport os\nimport shlex\n\n# Detect if we're being built by Read the Docs\n# https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.todo', ]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'SecureDrop'\ncopyright = u'2015, Freedom of the Press Foundation'\nauthor = u'SecureDrop Team and Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.3.7'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.3.7'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nif on_rtd:\n html_theme = 'default'\nelse:\n try:\n # If you want to build the docs locally using the RTD theme,\n # you may need to install it: ``pip install sphinx_rtd_theme``.\n # https://github.com/snide/sphinx_rtd_theme#via-package\n import sphinx_rtd_theme\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n # This theme is included with Sphinx and is quite nice (based\n # on the Pocoo themes), but since we're using the RTD theme\n # for the production docs, it's best to use that to avoid\n # issues due to discrepancies between the themes.\n html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'\n#html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# Now only 'ja' uses this config value\n#html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'SecureDropdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n\n# Latex figure (float) alignment\n#'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',\n author, 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'securedrop', u'SecureDrop Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'SecureDrop', u'SecureDrop Documentation',\n author, 'SecureDrop', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}]}
| 3,944 | 182 |
gh_patches_debug_954
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-2895
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Link to book in python documentation wrong
Not sure if this is a bug in the documentation or in the DNS/web server setup.
The python documentation for nltk says:
```
Steven Bird, Ewan Klein, and Edward Loper (2009).
Natural Language Processing with Python. O'Reilly Media Inc.
http://nltk.org/book
```
but this link does not work, `https://www.nltk.org/book/` does.
</issue>
<code>
[start of nltk/__init__.py]
1 # Natural Language Toolkit (NLTK)
2 #
3 # Copyright (C) 2001-2021 NLTK Project
4 # Authors: Steven Bird <[email protected]>
5 # Edward Loper <[email protected]>
6 # URL: <https://www.nltk.org/>
7 # For license information, see LICENSE.TXT
8
9 """
10 The Natural Language Toolkit (NLTK) is an open source Python library
11 for Natural Language Processing. A free online book is available.
12 (If you use the library for academic research, please cite the book.)
13
14 Steven Bird, Ewan Klein, and Edward Loper (2009).
15 Natural Language Processing with Python. O'Reilly Media Inc.
16 https://www.nltk.org/book
17
18 isort:skip_file
19 """
20
21 import os
22
23 # //////////////////////////////////////////////////////
24 # Metadata
25 # //////////////////////////////////////////////////////
26
27 # Version. For each new release, the version number should be updated
28 # in the file VERSION.
29 try:
30 # If a VERSION file exists, use it!
31 version_file = os.path.join(os.path.dirname(__file__), "VERSION")
32 with open(version_file) as infile:
33 __version__ = infile.read().strip()
34 except NameError:
35 __version__ = "unknown (running code interactively?)"
36 except OSError as ex:
37 __version__ = "unknown (%s)" % ex
38
39 if __doc__ is not None: # fix for the ``python -OO``
40 __doc__ += "\n@version: " + __version__
41
42
43 # Copyright notice
44 __copyright__ = """\
45 Copyright (C) 2001-2021 NLTK Project.
46
47 Distributed and Licensed under the Apache License, Version 2.0,
48 which is included by reference.
49 """
50
51 __license__ = "Apache License, Version 2.0"
52 # Description of the toolkit, keywords, and the project's primary URL.
53 __longdescr__ = """\
54 The Natural Language Toolkit (NLTK) is a Python package for
55 natural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9."""
56 __keywords__ = [
57 "NLP",
58 "CL",
59 "natural language processing",
60 "computational linguistics",
61 "parsing",
62 "tagging",
63 "tokenizing",
64 "syntax",
65 "linguistics",
66 "language",
67 "natural language",
68 "text analytics",
69 ]
70 __url__ = "https://www.nltk.org/"
71
72 # Maintainer, contributors, etc.
73 __maintainer__ = "NLTK Team"
74 __maintainer_email__ = "[email protected]"
75 __author__ = __maintainer__
76 __author_email__ = __maintainer_email__
77
78 # "Trove" classifiers for Python Package Index.
79 __classifiers__ = [
80 "Development Status :: 5 - Production/Stable",
81 "Intended Audience :: Developers",
82 "Intended Audience :: Education",
83 "Intended Audience :: Information Technology",
84 "Intended Audience :: Science/Research",
85 "License :: OSI Approved :: Apache Software License",
86 "Operating System :: OS Independent",
87 "Programming Language :: Python :: 3.6",
88 "Programming Language :: Python :: 3.7",
89 "Programming Language :: Python :: 3.8",
90 "Programming Language :: Python :: 3.9",
91 "Topic :: Scientific/Engineering",
92 "Topic :: Scientific/Engineering :: Artificial Intelligence",
93 "Topic :: Scientific/Engineering :: Human Machine Interfaces",
94 "Topic :: Scientific/Engineering :: Information Analysis",
95 "Topic :: Text Processing",
96 "Topic :: Text Processing :: Filters",
97 "Topic :: Text Processing :: General",
98 "Topic :: Text Processing :: Indexing",
99 "Topic :: Text Processing :: Linguistic",
100 ]
101
102 from nltk.internals import config_java
103
104 # support numpy from pypy
105 try:
106 import numpypy
107 except ImportError:
108 pass
109
110 # Override missing methods on environments where it cannot be used like GAE.
111 import subprocess
112
113 if not hasattr(subprocess, "PIPE"):
114
115 def _fake_PIPE(*args, **kwargs):
116 raise NotImplementedError("subprocess.PIPE is not supported.")
117
118 subprocess.PIPE = _fake_PIPE
119 if not hasattr(subprocess, "Popen"):
120
121 def _fake_Popen(*args, **kwargs):
122 raise NotImplementedError("subprocess.Popen is not supported.")
123
124 subprocess.Popen = _fake_Popen
125
126 ###########################################################
127 # TOP-LEVEL MODULES
128 ###########################################################
129
130 # Import top-level functionality into top-level namespace
131
132 from nltk.collocations import *
133 from nltk.decorators import decorator, memoize
134 from nltk.featstruct import *
135 from nltk.grammar import *
136 from nltk.probability import *
137 from nltk.text import *
138 from nltk.util import *
139 from nltk.jsontags import *
140
141 ###########################################################
142 # PACKAGES
143 ###########################################################
144
145 from nltk.chunk import *
146 from nltk.classify import *
147 from nltk.inference import *
148 from nltk.metrics import *
149 from nltk.parse import *
150 from nltk.tag import *
151 from nltk.tokenize import *
152 from nltk.translate import *
153 from nltk.tree import *
154 from nltk.sem import *
155 from nltk.stem import *
156
157 # Packages which can be lazily imported
158 # (a) we don't import *
159 # (b) they're slow to import or have run-time dependencies
160 # that can safely fail at run time
161
162 from nltk import lazyimport
163
164 app = lazyimport.LazyModule("nltk.app", locals(), globals())
165 chat = lazyimport.LazyModule("nltk.chat", locals(), globals())
166 corpus = lazyimport.LazyModule("nltk.corpus", locals(), globals())
167 draw = lazyimport.LazyModule("nltk.draw", locals(), globals())
168 toolbox = lazyimport.LazyModule("nltk.toolbox", locals(), globals())
169
170 # Optional loading
171
172 try:
173 import numpy
174 except ImportError:
175 pass
176 else:
177 from nltk import cluster
178
179 from nltk.downloader import download, download_shell
180
181 try:
182 import tkinter
183 except ImportError:
184 pass
185 else:
186 try:
187 from nltk.downloader import download_gui
188 except RuntimeError as e:
189 import warnings
190
191 warnings.warn(
192 "Corpus downloader GUI not loaded "
193 "(RuntimeError during import: %s)" % str(e)
194 )
195
196 # explicitly import all top-level modules (ensuring
197 # they override the same names inadvertently imported
198 # from a subpackage)
199
200 from nltk import ccg, chunk, classify, collocations
201 from nltk import data, featstruct, grammar, help, inference, metrics
202 from nltk import misc, parse, probability, sem, stem, wsd
203 from nltk import tag, tbl, text, tokenize, translate, tree, util
204
205
206 # FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116
207 def demo():
208 print("To run the demo code for a module, type nltk.module.demo()")
209
[end of nltk/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nltk/__init__.py b/nltk/__init__.py
--- a/nltk/__init__.py
+++ b/nltk/__init__.py
@@ -13,7 +13,7 @@
Steven Bird, Ewan Klein, and Edward Loper (2009).
Natural Language Processing with Python. O'Reilly Media Inc.
-https://www.nltk.org/book
+https://www.nltk.org/book/
isort:skip_file
"""
|
{"golden_diff": "diff --git a/nltk/__init__.py b/nltk/__init__.py\n--- a/nltk/__init__.py\n+++ b/nltk/__init__.py\n@@ -13,7 +13,7 @@\n \n Steven Bird, Ewan Klein, and Edward Loper (2009).\n Natural Language Processing with Python. O'Reilly Media Inc.\n-https://www.nltk.org/book\n+https://www.nltk.org/book/\n \n isort:skip_file\n \"\"\"\n", "issue": "Link to book in python documentation wrong\nNot sure if this is a bug in the documentation or in the DNS/web server setup.\r\nThe python documentation for nltk says:\r\n```\r\n Steven Bird, Ewan Klein, and Edward Loper (2009).\r\n Natural Language Processing with Python. O'Reilly Media Inc.\r\n http://nltk.org/book\r\n```\r\nbut this link does not work, `https://www.nltk.org/book/` does.\n", "before_files": [{"content": "# Natural Language Toolkit (NLTK)\n#\n# Copyright (C) 2001-2021 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <https://www.nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nThe Natural Language Toolkit (NLTK) is an open source Python library\nfor Natural Language Processing. A free online book is available.\n(If you use the library for academic research, please cite the book.)\n\nSteven Bird, Ewan Klein, and Edward Loper (2009).\nNatural Language Processing with Python. O'Reilly Media Inc.\nhttps://www.nltk.org/book\n\nisort:skip_file\n\"\"\"\n\nimport os\n\n# //////////////////////////////////////////////////////\n# Metadata\n# //////////////////////////////////////////////////////\n\n# Version. For each new release, the version number should be updated\n# in the file VERSION.\ntry:\n # If a VERSION file exists, use it!\n version_file = os.path.join(os.path.dirname(__file__), \"VERSION\")\n with open(version_file) as infile:\n __version__ = infile.read().strip()\nexcept NameError:\n __version__ = \"unknown (running code interactively?)\"\nexcept OSError as ex:\n __version__ = \"unknown (%s)\" % ex\n\nif __doc__ is not None: # fix for the ``python -OO``\n __doc__ += \"\\n@version: \" + __version__\n\n\n# Copyright notice\n__copyright__ = \"\"\"\\\nCopyright (C) 2001-2021 NLTK Project.\n\nDistributed and Licensed under the Apache License, Version 2.0,\nwhich is included by reference.\n\"\"\"\n\n__license__ = \"Apache License, Version 2.0\"\n# Description of the toolkit, keywords, and the project's primary URL.\n__longdescr__ = \"\"\"\\\nThe Natural Language Toolkit (NLTK) is a Python package for\nnatural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9.\"\"\"\n__keywords__ = [\n \"NLP\",\n \"CL\",\n \"natural language processing\",\n \"computational linguistics\",\n \"parsing\",\n \"tagging\",\n \"tokenizing\",\n \"syntax\",\n \"linguistics\",\n \"language\",\n \"natural language\",\n \"text analytics\",\n]\n__url__ = \"https://www.nltk.org/\"\n\n# Maintainer, contributors, etc.\n__maintainer__ = \"NLTK Team\"\n__maintainer_email__ = \"[email protected]\"\n__author__ = __maintainer__\n__author_email__ = __maintainer_email__\n\n# \"Trove\" classifiers for Python Package Index.\n__classifiers__ = [\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Text Processing\",\n \"Topic :: Text Processing :: Filters\",\n \"Topic :: Text Processing :: General\",\n \"Topic :: Text Processing :: Indexing\",\n \"Topic :: Text Processing :: Linguistic\",\n]\n\nfrom nltk.internals import config_java\n\n# support numpy from pypy\ntry:\n import numpypy\nexcept ImportError:\n pass\n\n# Override missing methods on environments where it cannot be used like GAE.\nimport subprocess\n\nif not hasattr(subprocess, \"PIPE\"):\n\n def _fake_PIPE(*args, **kwargs):\n raise NotImplementedError(\"subprocess.PIPE is not supported.\")\n\n subprocess.PIPE = _fake_PIPE\nif not hasattr(subprocess, \"Popen\"):\n\n def _fake_Popen(*args, **kwargs):\n raise NotImplementedError(\"subprocess.Popen is not supported.\")\n\n subprocess.Popen = _fake_Popen\n\n###########################################################\n# TOP-LEVEL MODULES\n###########################################################\n\n# Import top-level functionality into top-level namespace\n\nfrom nltk.collocations import *\nfrom nltk.decorators import decorator, memoize\nfrom nltk.featstruct import *\nfrom nltk.grammar import *\nfrom nltk.probability import *\nfrom nltk.text import *\nfrom nltk.util import *\nfrom nltk.jsontags import *\n\n###########################################################\n# PACKAGES\n###########################################################\n\nfrom nltk.chunk import *\nfrom nltk.classify import *\nfrom nltk.inference import *\nfrom nltk.metrics import *\nfrom nltk.parse import *\nfrom nltk.tag import *\nfrom nltk.tokenize import *\nfrom nltk.translate import *\nfrom nltk.tree import *\nfrom nltk.sem import *\nfrom nltk.stem import *\n\n# Packages which can be lazily imported\n# (a) we don't import *\n# (b) they're slow to import or have run-time dependencies\n# that can safely fail at run time\n\nfrom nltk import lazyimport\n\napp = lazyimport.LazyModule(\"nltk.app\", locals(), globals())\nchat = lazyimport.LazyModule(\"nltk.chat\", locals(), globals())\ncorpus = lazyimport.LazyModule(\"nltk.corpus\", locals(), globals())\ndraw = lazyimport.LazyModule(\"nltk.draw\", locals(), globals())\ntoolbox = lazyimport.LazyModule(\"nltk.toolbox\", locals(), globals())\n\n# Optional loading\n\ntry:\n import numpy\nexcept ImportError:\n pass\nelse:\n from nltk import cluster\n\nfrom nltk.downloader import download, download_shell\n\ntry:\n import tkinter\nexcept ImportError:\n pass\nelse:\n try:\n from nltk.downloader import download_gui\n except RuntimeError as e:\n import warnings\n\n warnings.warn(\n \"Corpus downloader GUI not loaded \"\n \"(RuntimeError during import: %s)\" % str(e)\n )\n\n# explicitly import all top-level modules (ensuring\n# they override the same names inadvertently imported\n# from a subpackage)\n\nfrom nltk import ccg, chunk, classify, collocations\nfrom nltk import data, featstruct, grammar, help, inference, metrics\nfrom nltk import misc, parse, probability, sem, stem, wsd\nfrom nltk import tag, tbl, text, tokenize, translate, tree, util\n\n\n# FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116\ndef demo():\n print(\"To run the demo code for a module, type nltk.module.demo()\")\n", "path": "nltk/__init__.py"}]}
| 2,611 | 105 |
gh_patches_debug_30884
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-3042
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sonority sequencing syllable tokenizer performs significantly slower on numbers than on words
The sonority sequencing syllable tokenizer (`nltk.SyllableTokenizer`) performs significantly slower on numbers than on words. It seems that the time complexity for words is O(n), which is okay, but O(n^2) for numbers, which is not so good.
```
>>> timeit.timeit('t.tokenize("99")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 100)
0.03364099999998871
>>> timeit.timeit('t.tokenize("thisisanextremelylongword")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 100)
0.002708099999949809
>>> timeit.timeit('t.tokenize("99")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 1000)
2.5833234000000402
>>> timeit.timeit('t.tokenize("thisisanextremelylongword")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 1000)
0.023796200000106182
>>> timeit.timeit('t.tokenize("99")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 10000)
264.43897390000006
>>> timeit.timeit('t.tokenize("thisisanextremelylongword")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 10000)
0.24109669999984362
```
OS: Windows 10 x64
Python: 3.8.10 x64
NLTK: 3.7
</issue>
<code>
[start of nltk/tokenize/sonority_sequencing.py]
1 # Natural Language Toolkit: Tokenizers
2 #
3 # Copyright (C) 2001-2022 NLTK Project
4 # Author: Christopher Hench <[email protected]>
5 # Alex Estes
6 # URL: <https://www.nltk.org>
7 # For license information, see LICENSE.TXT
8
9 """
10 The Sonority Sequencing Principle (SSP) is a language agnostic algorithm proposed
11 by Otto Jesperson in 1904. The sonorous quality of a phoneme is judged by the
12 openness of the lips. Syllable breaks occur before troughs in sonority. For more
13 on the SSP see Selkirk (1984).
14
15 The default implementation uses the English alphabet, but the `sonority_hiearchy`
16 can be modified to IPA or any other alphabet for the use-case. The SSP is a
17 universal syllabification algorithm, but that does not mean it performs equally
18 across languages. Bartlett et al. (2009) is a good benchmark for English accuracy
19 if utilizing IPA (pg. 311).
20
21 Importantly, if a custom hierarchy is supplied and vowels span across more than
22 one level, they should be given separately to the `vowels` class attribute.
23
24 References:
25
26 - Otto Jespersen. 1904. Lehrbuch der Phonetik.
27 Leipzig, Teubner. Chapter 13, Silbe, pp. 185-203.
28 - Elisabeth Selkirk. 1984. On the major class features and syllable theory.
29 In Aronoff & Oehrle (eds.) Language Sound Structure: Studies in Phonology.
30 Cambridge, MIT Press. pp. 107-136.
31 - Susan Bartlett, et al. 2009. On the Syllabification of Phonemes.
32 In HLT-NAACL. pp. 308-316.
33 """
34
35 import re
36 import warnings
37 from string import punctuation
38
39 from nltk.tokenize.api import TokenizerI
40 from nltk.util import ngrams
41
42
43 class SyllableTokenizer(TokenizerI):
44 """
45 Syllabifies words based on the Sonority Sequencing Principle (SSP).
46
47 >>> from nltk.tokenize import SyllableTokenizer
48 >>> from nltk import word_tokenize
49 >>> SSP = SyllableTokenizer()
50 >>> SSP.tokenize('justification')
51 ['jus', 'ti', 'fi', 'ca', 'tion']
52 >>> text = "This is a foobar-like sentence."
53 >>> [SSP.tokenize(token) for token in word_tokenize(text)]
54 [['This'], ['is'], ['a'], ['foo', 'bar', '-', 'li', 'ke'], ['sen', 'ten', 'ce'], ['.']]
55 """
56
57 def __init__(self, lang="en", sonority_hierarchy=False):
58 """
59 :param lang: Language parameter, default is English, 'en'
60 :type lang: str
61 :param sonority_hierarchy: Sonority hierarchy according to the
62 Sonority Sequencing Principle.
63 :type sonority_hierarchy: list(str)
64 """
65 # Sonority hierarchy should be provided in descending order.
66 # If vowels are spread across multiple levels, they should be
67 # passed assigned self.vowels var together, otherwise should be
68 # placed in first index of hierarchy.
69 if not sonority_hierarchy and lang == "en":
70 sonority_hierarchy = [
71 "aeiouy", # vowels.
72 "lmnrw", # nasals.
73 "zvsf", # fricatives.
74 "bcdgtkpqxhj", # stops.
75 ]
76
77 self.vowels = sonority_hierarchy[0]
78 self.phoneme_map = {}
79 for i, level in enumerate(sonority_hierarchy):
80 for c in level:
81 sonority_level = len(sonority_hierarchy) - i
82 self.phoneme_map[c] = sonority_level
83 self.phoneme_map[c.upper()] = sonority_level
84
85 def assign_values(self, token):
86 """
87 Assigns each phoneme its value from the sonority hierarchy.
88 Note: Sentence/text has to be tokenized first.
89
90 :param token: Single word or token
91 :type token: str
92 :return: List of tuples, first element is character/phoneme and
93 second is the soronity value.
94 :rtype: list(tuple(str, int))
95 """
96 syllables_values = []
97 for c in token:
98 try:
99 syllables_values.append((c, self.phoneme_map[c]))
100 except KeyError:
101 if c not in punctuation:
102 warnings.warn(
103 "Character not defined in sonority_hierarchy,"
104 " assigning as vowel: '{}'".format(c)
105 )
106 syllables_values.append((c, max(self.phoneme_map.values())))
107 self.vowels += c
108 else: # If it's a punctuation, assign -1.
109 syllables_values.append((c, -1))
110 return syllables_values
111
112 def validate_syllables(self, syllable_list):
113 """
114 Ensures each syllable has at least one vowel.
115 If the following syllable doesn't have vowel, add it to the current one.
116
117 :param syllable_list: Single word or token broken up into syllables.
118 :type syllable_list: list(str)
119 :return: Single word or token broken up into syllables
120 (with added syllables if necessary)
121 :rtype: list(str)
122 """
123 valid_syllables = []
124 front = ""
125 for i, syllable in enumerate(syllable_list):
126 if syllable in punctuation:
127 valid_syllables.append(syllable)
128 continue
129 if not re.search("|".join(self.vowels), syllable):
130 if len(valid_syllables) == 0:
131 front += syllable
132 else:
133 valid_syllables = valid_syllables[:-1] + [
134 valid_syllables[-1] + syllable
135 ]
136 else:
137 if len(valid_syllables) == 0:
138 valid_syllables.append(front + syllable)
139 else:
140 valid_syllables.append(syllable)
141
142 return valid_syllables
143
144 def tokenize(self, token):
145 """
146 Apply the SSP to return a list of syllables.
147 Note: Sentence/text has to be tokenized first.
148
149 :param token: Single word or token
150 :type token: str
151 :return syllable_list: Single word or token broken up into syllables.
152 :rtype: list(str)
153 """
154 # assign values from hierarchy
155 syllables_values = self.assign_values(token)
156
157 # if only one vowel return word
158 if sum(token.count(x) for x in self.vowels) <= 1:
159 return [token]
160
161 syllable_list = []
162 syllable = syllables_values[0][0] # start syllable with first phoneme
163 for trigram in ngrams(syllables_values, n=3):
164 phonemes, values = zip(*trigram)
165 # Sonority of previous, focal and following phoneme
166 prev_value, focal_value, next_value = values
167 # Focal phoneme.
168 focal_phoneme = phonemes[1]
169
170 # These cases trigger syllable break.
171 if focal_value == -1: # If it's a punctuation, just break.
172 syllable_list.append(syllable)
173 syllable_list.append(focal_phoneme)
174 syllable = ""
175 elif prev_value >= focal_value == next_value:
176 syllable += focal_phoneme
177 syllable_list.append(syllable)
178 syllable = ""
179
180 elif prev_value > focal_value < next_value:
181 syllable_list.append(syllable)
182 syllable = ""
183 syllable += focal_phoneme
184
185 # no syllable break
186 else:
187 syllable += focal_phoneme
188
189 syllable += syllables_values[-1][0] # append last phoneme
190 syllable_list.append(syllable)
191
192 return self.validate_syllables(syllable_list)
193
[end of nltk/tokenize/sonority_sequencing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nltk/tokenize/sonority_sequencing.py b/nltk/tokenize/sonority_sequencing.py
--- a/nltk/tokenize/sonority_sequencing.py
+++ b/nltk/tokenize/sonority_sequencing.py
@@ -98,14 +98,15 @@
try:
syllables_values.append((c, self.phoneme_map[c]))
except KeyError:
- if c not in punctuation:
+ if c not in "0123456789" and c not in punctuation:
warnings.warn(
"Character not defined in sonority_hierarchy,"
" assigning as vowel: '{}'".format(c)
)
syllables_values.append((c, max(self.phoneme_map.values())))
- self.vowels += c
- else: # If it's a punctuation, assign -1.
+ if c not in self.vowels:
+ self.vowels += c
+ else: # If it's a punctuation or numbers, assign -1.
syllables_values.append((c, -1))
return syllables_values
@@ -122,11 +123,12 @@
"""
valid_syllables = []
front = ""
+ vowel_pattern = re.compile("|".join(self.vowels))
for i, syllable in enumerate(syllable_list):
if syllable in punctuation:
valid_syllables.append(syllable)
continue
- if not re.search("|".join(self.vowels), syllable):
+ if not vowel_pattern.search(syllable):
if len(valid_syllables) == 0:
front += syllable
else:
|
{"golden_diff": "diff --git a/nltk/tokenize/sonority_sequencing.py b/nltk/tokenize/sonority_sequencing.py\n--- a/nltk/tokenize/sonority_sequencing.py\n+++ b/nltk/tokenize/sonority_sequencing.py\n@@ -98,14 +98,15 @@\n try:\n syllables_values.append((c, self.phoneme_map[c]))\n except KeyError:\n- if c not in punctuation:\n+ if c not in \"0123456789\" and c not in punctuation:\n warnings.warn(\n \"Character not defined in sonority_hierarchy,\"\n \" assigning as vowel: '{}'\".format(c)\n )\n syllables_values.append((c, max(self.phoneme_map.values())))\n- self.vowels += c\n- else: # If it's a punctuation, assign -1.\n+ if c not in self.vowels:\n+ self.vowels += c\n+ else: # If it's a punctuation or numbers, assign -1.\n syllables_values.append((c, -1))\n return syllables_values\n \n@@ -122,11 +123,12 @@\n \"\"\"\n valid_syllables = []\n front = \"\"\n+ vowel_pattern = re.compile(\"|\".join(self.vowels))\n for i, syllable in enumerate(syllable_list):\n if syllable in punctuation:\n valid_syllables.append(syllable)\n continue\n- if not re.search(\"|\".join(self.vowels), syllable):\n+ if not vowel_pattern.search(syllable):\n if len(valid_syllables) == 0:\n front += syllable\n else:\n", "issue": "Sonority sequencing syllable tokenizer performs significantly slower on numbers than on words\nThe sonority sequencing syllable tokenizer (`nltk.SyllableTokenizer`) performs significantly slower on numbers than on words. It seems that the time complexity for words is O(n), which is okay, but O(n^2) for numbers, which is not so good.\r\n\r\n```\r\n>>> timeit.timeit('t.tokenize(\"99\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 100)\r\n0.03364099999998871\r\n>>> timeit.timeit('t.tokenize(\"thisisanextremelylongword\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 100)\r\n0.002708099999949809\r\n>>> timeit.timeit('t.tokenize(\"99\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 1000)\r\n2.5833234000000402\r\n>>> timeit.timeit('t.tokenize(\"thisisanextremelylongword\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 1000)\r\n0.023796200000106182\r\n>>> timeit.timeit('t.tokenize(\"99\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 10000)\r\n264.43897390000006\r\n>>> timeit.timeit('t.tokenize(\"thisisanextremelylongword\")', setup='import nltk; t = nltk.SyllableTokenizer()', number = 10000)\r\n0.24109669999984362\r\n```\r\n\r\nOS: Windows 10 x64\r\nPython: 3.8.10 x64\r\nNLTK: 3.7\n", "before_files": [{"content": "# Natural Language Toolkit: Tokenizers\n#\n# Copyright (C) 2001-2022 NLTK Project\n# Author: Christopher Hench <[email protected]>\n# Alex Estes\n# URL: <https://www.nltk.org>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nThe Sonority Sequencing Principle (SSP) is a language agnostic algorithm proposed\nby Otto Jesperson in 1904. The sonorous quality of a phoneme is judged by the\nopenness of the lips. Syllable breaks occur before troughs in sonority. For more\non the SSP see Selkirk (1984).\n\nThe default implementation uses the English alphabet, but the `sonority_hiearchy`\ncan be modified to IPA or any other alphabet for the use-case. The SSP is a\nuniversal syllabification algorithm, but that does not mean it performs equally\nacross languages. Bartlett et al. (2009) is a good benchmark for English accuracy\nif utilizing IPA (pg. 311).\n\nImportantly, if a custom hierarchy is supplied and vowels span across more than\none level, they should be given separately to the `vowels` class attribute.\n\nReferences:\n\n- Otto Jespersen. 1904. Lehrbuch der Phonetik.\n Leipzig, Teubner. Chapter 13, Silbe, pp. 185-203.\n- Elisabeth Selkirk. 1984. On the major class features and syllable theory.\n In Aronoff & Oehrle (eds.) Language Sound Structure: Studies in Phonology.\n Cambridge, MIT Press. pp. 107-136.\n- Susan Bartlett, et al. 2009. On the Syllabification of Phonemes.\n In HLT-NAACL. pp. 308-316.\n\"\"\"\n\nimport re\nimport warnings\nfrom string import punctuation\n\nfrom nltk.tokenize.api import TokenizerI\nfrom nltk.util import ngrams\n\n\nclass SyllableTokenizer(TokenizerI):\n \"\"\"\n Syllabifies words based on the Sonority Sequencing Principle (SSP).\n\n >>> from nltk.tokenize import SyllableTokenizer\n >>> from nltk import word_tokenize\n >>> SSP = SyllableTokenizer()\n >>> SSP.tokenize('justification')\n ['jus', 'ti', 'fi', 'ca', 'tion']\n >>> text = \"This is a foobar-like sentence.\"\n >>> [SSP.tokenize(token) for token in word_tokenize(text)]\n [['This'], ['is'], ['a'], ['foo', 'bar', '-', 'li', 'ke'], ['sen', 'ten', 'ce'], ['.']]\n \"\"\"\n\n def __init__(self, lang=\"en\", sonority_hierarchy=False):\n \"\"\"\n :param lang: Language parameter, default is English, 'en'\n :type lang: str\n :param sonority_hierarchy: Sonority hierarchy according to the\n Sonority Sequencing Principle.\n :type sonority_hierarchy: list(str)\n \"\"\"\n # Sonority hierarchy should be provided in descending order.\n # If vowels are spread across multiple levels, they should be\n # passed assigned self.vowels var together, otherwise should be\n # placed in first index of hierarchy.\n if not sonority_hierarchy and lang == \"en\":\n sonority_hierarchy = [\n \"aeiouy\", # vowels.\n \"lmnrw\", # nasals.\n \"zvsf\", # fricatives.\n \"bcdgtkpqxhj\", # stops.\n ]\n\n self.vowels = sonority_hierarchy[0]\n self.phoneme_map = {}\n for i, level in enumerate(sonority_hierarchy):\n for c in level:\n sonority_level = len(sonority_hierarchy) - i\n self.phoneme_map[c] = sonority_level\n self.phoneme_map[c.upper()] = sonority_level\n\n def assign_values(self, token):\n \"\"\"\n Assigns each phoneme its value from the sonority hierarchy.\n Note: Sentence/text has to be tokenized first.\n\n :param token: Single word or token\n :type token: str\n :return: List of tuples, first element is character/phoneme and\n second is the soronity value.\n :rtype: list(tuple(str, int))\n \"\"\"\n syllables_values = []\n for c in token:\n try:\n syllables_values.append((c, self.phoneme_map[c]))\n except KeyError:\n if c not in punctuation:\n warnings.warn(\n \"Character not defined in sonority_hierarchy,\"\n \" assigning as vowel: '{}'\".format(c)\n )\n syllables_values.append((c, max(self.phoneme_map.values())))\n self.vowels += c\n else: # If it's a punctuation, assign -1.\n syllables_values.append((c, -1))\n return syllables_values\n\n def validate_syllables(self, syllable_list):\n \"\"\"\n Ensures each syllable has at least one vowel.\n If the following syllable doesn't have vowel, add it to the current one.\n\n :param syllable_list: Single word or token broken up into syllables.\n :type syllable_list: list(str)\n :return: Single word or token broken up into syllables\n (with added syllables if necessary)\n :rtype: list(str)\n \"\"\"\n valid_syllables = []\n front = \"\"\n for i, syllable in enumerate(syllable_list):\n if syllable in punctuation:\n valid_syllables.append(syllable)\n continue\n if not re.search(\"|\".join(self.vowels), syllable):\n if len(valid_syllables) == 0:\n front += syllable\n else:\n valid_syllables = valid_syllables[:-1] + [\n valid_syllables[-1] + syllable\n ]\n else:\n if len(valid_syllables) == 0:\n valid_syllables.append(front + syllable)\n else:\n valid_syllables.append(syllable)\n\n return valid_syllables\n\n def tokenize(self, token):\n \"\"\"\n Apply the SSP to return a list of syllables.\n Note: Sentence/text has to be tokenized first.\n\n :param token: Single word or token\n :type token: str\n :return syllable_list: Single word or token broken up into syllables.\n :rtype: list(str)\n \"\"\"\n # assign values from hierarchy\n syllables_values = self.assign_values(token)\n\n # if only one vowel return word\n if sum(token.count(x) for x in self.vowels) <= 1:\n return [token]\n\n syllable_list = []\n syllable = syllables_values[0][0] # start syllable with first phoneme\n for trigram in ngrams(syllables_values, n=3):\n phonemes, values = zip(*trigram)\n # Sonority of previous, focal and following phoneme\n prev_value, focal_value, next_value = values\n # Focal phoneme.\n focal_phoneme = phonemes[1]\n\n # These cases trigger syllable break.\n if focal_value == -1: # If it's a punctuation, just break.\n syllable_list.append(syllable)\n syllable_list.append(focal_phoneme)\n syllable = \"\"\n elif prev_value >= focal_value == next_value:\n syllable += focal_phoneme\n syllable_list.append(syllable)\n syllable = \"\"\n\n elif prev_value > focal_value < next_value:\n syllable_list.append(syllable)\n syllable = \"\"\n syllable += focal_phoneme\n\n # no syllable break\n else:\n syllable += focal_phoneme\n\n syllable += syllables_values[-1][0] # append last phoneme\n syllable_list.append(syllable)\n\n return self.validate_syllables(syllable_list)\n", "path": "nltk/tokenize/sonority_sequencing.py"}]}
| 3,242 | 378 |
gh_patches_debug_6547
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-376
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
I can't compile my project by pyinstaller
I have a script with code:
```
from mimesis import Personal
person = Personal('en')
person.full_name()
```
and it works well, but after compiling this code to .exe via pyinstaller I have an error **FileNotFoundError: [Errno 2] No such file or directory: 'B:\\_MEI131682\\mimesis\\data/es\\personal.json'
[20624] Failed to execute script myproject**
So, I think that problem in path (`data/es\\personal`). What ways of solving this problem can you recommend?
</issue>
<code>
[start of mimesis/utils.py]
1 """This module is provide internal util functions."""
2
3 import collections
4 import functools
5 import json
6 import ssl
7 from os import path
8 from typing import Mapping, Optional, Union
9 from urllib import request
10
11 from mimesis import config
12 from mimesis.exceptions import UnsupportedLocale
13 from mimesis.typing import JSON
14
15 __all__ = ['download_image', 'locale_info',
16 'luhn_checksum', 'setup_locale', 'pull']
17
18 DATA_DIR = path.abspath(path.join(path.dirname(__file__), 'data'))
19
20
21 def locale_info(locale: str) -> str:
22 """Check information about locale.
23
24 :param locale: Locale abbreviation.
25 :return: Locale name.
26 :raises UnsupportedLocale: if locale is not supported.
27 """
28 locale = locale.lower()
29 supported = config.SUPPORTED_LOCALES
30
31 if locale not in supported:
32 raise UnsupportedLocale(locale)
33
34 return supported[locale]['name']
35
36
37 def luhn_checksum(num: str) -> str:
38 """Calculate a checksum for num using the Luhn algorithm.
39
40 :param num: The number to calculate a checksum for as a string.
41 :return: Checksum for number.
42 """
43 check = 0
44 for i, s in enumerate(reversed(num)):
45 sx = int(s)
46 sx = sx * 2 if i % 2 == 0 else sx
47 sx = sx - 9 if sx > 9 else sx
48 check += sx
49 return str(check * 9 % 10)
50
51
52 def update_dict(initial: JSON, other: Mapping) -> JSON:
53 """Recursively update a dictionary.
54
55 :param initial: Dict to update.
56 :type initial: dict or list
57 :param other: Dict to update from.
58 :type other: Mapping
59 :return: Updated dict.
60 :rtype: dict
61 """
62 for key, value in other.items():
63 if isinstance(value, collections.Mapping):
64 r = update_dict(initial.get(key, {}), value)
65 initial[key] = r
66 else:
67 initial[key] = other[key]
68 return initial
69
70
71 @functools.lru_cache(maxsize=None)
72 def pull(file: str, locale: str = 'en') -> JSON:
73 """Pull the content from the JSON and memorize one.
74
75 Opens JSON file ``file`` in the folder ``data/locale``
76 and get content from the file and memorize ones using lru_cache.
77
78 :param file: The name of file.
79 :param locale: Locale.
80 :return: The content of the file.
81 :rtype: dict
82 :raises UnsupportedLocale: if locale is not supported.
83
84 :Example:
85
86 >>> from mimesis.utils import pull
87 >>> en = pull(file='datetime.json', locale='en')
88 >>> isinstance(en, dict)
89 True
90 >>> en['day']['abbr'][0]
91 'Mon.'
92 """
93 def get_data(locale_name: str) -> JSON:
94 """Pull JSON data from file.
95
96 :param locale_name: Locale name.
97 :return: Content of JSON file as dict.
98 """
99 file_path = path.join(DATA_DIR + '/' + locale_name, file)
100 # Needs explicit encoding for Windows
101 with open(file_path, 'r', encoding='utf8') as f:
102 return json.load(f)
103
104 locale = locale.lower()
105
106 if locale not in config.SUPPORTED_LOCALES:
107 raise UnsupportedLocale(locale)
108
109 master_locale = locale.split('-')[0]
110 data = get_data(master_locale)
111
112 # Handle sub-locales
113 if '-' in locale:
114 data = update_dict(data, get_data(locale))
115
116 return data
117
118
119 def download_image(url: str = '', save_path: str = '',
120 unverified_ctx: bool = False) -> Union[None, str]:
121 """Download image and save in current directory on local machine.
122
123 :param url: URL to image.
124 :param save_path: Saving path.
125 :param unverified_ctx: Create unverified context.
126 :return: Image name.
127 :rtype: str or None
128 """
129 if unverified_ctx:
130 ssl._create_default_https_context = ssl._create_unverified_context
131
132 if url is not None:
133 image_name = url.rsplit('/')[-1]
134 request.urlretrieve(url, save_path + image_name)
135 return image_name
136 return None
137
138
139 def setup_locale(locale: Optional[str] = None) -> str:
140 """Set up locale after pre-check.
141
142 :param str locale: Locale
143 :return: Locale in lowercase.
144 :raises UnsupportedLocale: if locales is not supported.
145 """
146 if not locale:
147 return config.DEFAULT_LOCALE
148
149 locale = locale.lower()
150 if locale not in config.SUPPORTED_LOCALES:
151 raise UnsupportedLocale(locale)
152
153 return locale
154
[end of mimesis/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mimesis/utils.py b/mimesis/utils.py
--- a/mimesis/utils.py
+++ b/mimesis/utils.py
@@ -96,7 +96,7 @@
:param locale_name: Locale name.
:return: Content of JSON file as dict.
"""
- file_path = path.join(DATA_DIR + '/' + locale_name, file)
+ file_path = path.join(DATA_DIR, locale_name, file)
# Needs explicit encoding for Windows
with open(file_path, 'r', encoding='utf8') as f:
return json.load(f)
|
{"golden_diff": "diff --git a/mimesis/utils.py b/mimesis/utils.py\n--- a/mimesis/utils.py\n+++ b/mimesis/utils.py\n@@ -96,7 +96,7 @@\n :param locale_name: Locale name.\n :return: Content of JSON file as dict.\n \"\"\"\n- file_path = path.join(DATA_DIR + '/' + locale_name, file)\n+ file_path = path.join(DATA_DIR, locale_name, file)\n # Needs explicit encoding for Windows\n with open(file_path, 'r', encoding='utf8') as f:\n return json.load(f)\n", "issue": "I can't compile my project by pyinstaller\nI have a script with code:\r\n```\r\nfrom mimesis import Personal\r\nperson = Personal('en')\r\nperson.full_name()\r\n```\r\nand it works well, but after compiling this code to .exe via pyinstaller I have an error **FileNotFoundError: [Errno 2] No such file or directory: 'B:\\\\_MEI131682\\\\mimesis\\\\data/es\\\\personal.json'\r\n[20624] Failed to execute script myproject**\r\nSo, I think that problem in path (`data/es\\\\personal`). What ways of solving this problem can you recommend?\n", "before_files": [{"content": "\"\"\"This module is provide internal util functions.\"\"\"\n\nimport collections\nimport functools\nimport json\nimport ssl\nfrom os import path\nfrom typing import Mapping, Optional, Union\nfrom urllib import request\n\nfrom mimesis import config\nfrom mimesis.exceptions import UnsupportedLocale\nfrom mimesis.typing import JSON\n\n__all__ = ['download_image', 'locale_info',\n 'luhn_checksum', 'setup_locale', 'pull']\n\nDATA_DIR = path.abspath(path.join(path.dirname(__file__), 'data'))\n\n\ndef locale_info(locale: str) -> str:\n \"\"\"Check information about locale.\n\n :param locale: Locale abbreviation.\n :return: Locale name.\n :raises UnsupportedLocale: if locale is not supported.\n \"\"\"\n locale = locale.lower()\n supported = config.SUPPORTED_LOCALES\n\n if locale not in supported:\n raise UnsupportedLocale(locale)\n\n return supported[locale]['name']\n\n\ndef luhn_checksum(num: str) -> str:\n \"\"\"Calculate a checksum for num using the Luhn algorithm.\n\n :param num: The number to calculate a checksum for as a string.\n :return: Checksum for number.\n \"\"\"\n check = 0\n for i, s in enumerate(reversed(num)):\n sx = int(s)\n sx = sx * 2 if i % 2 == 0 else sx\n sx = sx - 9 if sx > 9 else sx\n check += sx\n return str(check * 9 % 10)\n\n\ndef update_dict(initial: JSON, other: Mapping) -> JSON:\n \"\"\"Recursively update a dictionary.\n\n :param initial: Dict to update.\n :type initial: dict or list\n :param other: Dict to update from.\n :type other: Mapping\n :return: Updated dict.\n :rtype: dict\n \"\"\"\n for key, value in other.items():\n if isinstance(value, collections.Mapping):\n r = update_dict(initial.get(key, {}), value)\n initial[key] = r\n else:\n initial[key] = other[key]\n return initial\n\n\[email protected]_cache(maxsize=None)\ndef pull(file: str, locale: str = 'en') -> JSON:\n \"\"\"Pull the content from the JSON and memorize one.\n\n Opens JSON file ``file`` in the folder ``data/locale``\n and get content from the file and memorize ones using lru_cache.\n\n :param file: The name of file.\n :param locale: Locale.\n :return: The content of the file.\n :rtype: dict\n :raises UnsupportedLocale: if locale is not supported.\n\n :Example:\n\n >>> from mimesis.utils import pull\n >>> en = pull(file='datetime.json', locale='en')\n >>> isinstance(en, dict)\n True\n >>> en['day']['abbr'][0]\n 'Mon.'\n \"\"\"\n def get_data(locale_name: str) -> JSON:\n \"\"\"Pull JSON data from file.\n\n :param locale_name: Locale name.\n :return: Content of JSON file as dict.\n \"\"\"\n file_path = path.join(DATA_DIR + '/' + locale_name, file)\n # Needs explicit encoding for Windows\n with open(file_path, 'r', encoding='utf8') as f:\n return json.load(f)\n\n locale = locale.lower()\n\n if locale not in config.SUPPORTED_LOCALES:\n raise UnsupportedLocale(locale)\n\n master_locale = locale.split('-')[0]\n data = get_data(master_locale)\n\n # Handle sub-locales\n if '-' in locale:\n data = update_dict(data, get_data(locale))\n\n return data\n\n\ndef download_image(url: str = '', save_path: str = '',\n unverified_ctx: bool = False) -> Union[None, str]:\n \"\"\"Download image and save in current directory on local machine.\n\n :param url: URL to image.\n :param save_path: Saving path.\n :param unverified_ctx: Create unverified context.\n :return: Image name.\n :rtype: str or None\n \"\"\"\n if unverified_ctx:\n ssl._create_default_https_context = ssl._create_unverified_context\n\n if url is not None:\n image_name = url.rsplit('/')[-1]\n request.urlretrieve(url, save_path + image_name)\n return image_name\n return None\n\n\ndef setup_locale(locale: Optional[str] = None) -> str:\n \"\"\"Set up locale after pre-check.\n\n :param str locale: Locale\n :return: Locale in lowercase.\n :raises UnsupportedLocale: if locales is not supported.\n \"\"\"\n if not locale:\n return config.DEFAULT_LOCALE\n\n locale = locale.lower()\n if locale not in config.SUPPORTED_LOCALES:\n raise UnsupportedLocale(locale)\n\n return locale\n", "path": "mimesis/utils.py"}]}
| 2,066 | 129 |
gh_patches_debug_40879
|
rasdani/github-patches
|
git_diff
|
aimhubio__aim-2422
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GPU utilization is not tracked if querying power usage fails
## 🐛 Bug
I am running experiments on a machine with a GPU, yet no GPU metrics are tracked. It seems like this code is responsible:
https://github.com/aimhubio/aim/blob/480e063cde063897283bcd8adb221e9baa861637/aim/ext/resource/stat.py#L152-L186
When any part of the GPU stats collection fails, we just give up entirely and store no information. In my case querying the power usage seems not supported by nvml, it raises `nvml.NVMLError_NotSupported`. Querying utilization and memory usage works just fine though and it would be nice if we could track those stats anyway.
### To reproduce
I'm not sure how to reproduce this, since it depends on a setup where `nvml` fails to determine the GPU power usage.
### Expected behavior
Aim tracks all the information that it can query without exceptions.
### Environment
- Aim Version (e.g., 3.15.1)
- Python version 3.10.9
- pip version 22.0.3
- OS (e.g., Linux) Linux
- Any other relevant information
### Additional context
--
</issue>
<code>
[start of aim/ext/resource/stat.py]
1 import psutil
2 import json
3 from typing import List
4
5 from aim.ext.resource.utils import round10e5
6
7 try:
8 # Import python wrapper for the NVIDIA Management Library
9 # Initialize it or pass if NVIDIA ML is not initialized
10 from py3nvml import py3nvml as nvml
11 nvml.nvmlInit()
12 except Exception:
13 pass
14
15
16 class StatDict(object):
17 # Available aggregation functions
18 AGG_MODE_AVG = 'average'
19 AGG_MODE_MIN = 'min'
20 AGG_MODE_MAX = 'max'
21 AGG_MODE_DIFF = 'diff'
22 AGG_DEFAULT = AGG_MODE_AVG
23
24 @classmethod
25 def aggregate(cls, items: List, mode: str):
26 """
27 Aggregates array of numbers by a given 'mode'
28 """
29 if mode == cls.AGG_MODE_MAX:
30 return max(items)
31 elif mode == cls.AGG_MODE_MIN:
32 return min(items)
33 elif mode == cls.AGG_MODE_AVG:
34 return round10e5(sum(items) / len(items))
35 elif mode == cls.AGG_MODE_DIFF:
36 return round10e5(max(items) - min(items))
37 else:
38 raise ValueError('unknown aggregation mode: \'{}\''.format(mode))
39
40 @classmethod
41 def aggregate_items(cls,
42 items: 'List[StatDict]',
43 agg_mode: str = AGG_DEFAULT,
44 ):
45 """
46 Aggregates array of `StatDict` items by a given `mode`
47 """
48 aggregated_stat = cls()
49
50 # Return empty item if items array is empty
51 if not items or len(items) == 0:
52 return aggregated_stat
53
54 gpu_stats = []
55 for s in items:
56 # Collect system stats
57 for k in s.system.keys():
58 aggregated_stat.system.setdefault(k, [])
59 aggregated_stat.system[k].append(s.system[k])
60
61 # Collect GPU device stats
62 for stat_item_gpu_idx in range(len(s.gpus)):
63 stat_item_gpu_stat = s.gpus[stat_item_gpu_idx]
64 if len(gpu_stats) == stat_item_gpu_idx:
65 gpu_stats.append({})
66 for gpu_stat_key in stat_item_gpu_stat.keys():
67 gpu_stat = stat_item_gpu_stat[gpu_stat_key]
68 gpu_stats[stat_item_gpu_idx].setdefault(gpu_stat_key, [])
69 gpu_stats[stat_item_gpu_idx][gpu_stat_key].append(gpu_stat)
70
71 # Aggregate system stats
72 for k in aggregated_stat.system.keys():
73 aggregated_stat.system[k] = cls.aggregate(aggregated_stat.system[k],
74 agg_mode)
75
76 # Aggregate GPU device stats
77 for g in range(len(gpu_stats)):
78 for k in gpu_stats[g].keys():
79 gpu_stats[g][k] = cls.aggregate(gpu_stats[g][k], agg_mode)
80 aggregated_stat.gpu = gpu_stats
81
82 return aggregated_stat
83
84 def __init__(self, system: dict = None, gpus: List[dict] = None):
85 self.system = system or {}
86 self.gpus = gpus or []
87
88 def __str__(self):
89 return json.dumps(self.to_dict())
90
91 def to_dict(self):
92 """
93 Returns system and GPU device statistics
94 """
95 return {
96 'system': self.system,
97 'gpus': self.gpus,
98 }
99
100
101 class Stat(object):
102 def __init__(self, process):
103 # Set process
104 self._process = process
105
106 # Get statistics
107 system, gpus = self.get_stats()
108 self._stat = StatDict(system, gpus)
109
110 @property
111 def process(self):
112 return self._process
113
114 @property
115 def stat_item(self):
116 return self._stat
117
118 @property
119 def system(self):
120 return self._stat.system
121
122 @property
123 def gpus(self):
124 return self._stat.gpus
125
126 def get_stats(self):
127 """
128 Get system statistics and assign to `self`
129 """
130 memory_usage = psutil.virtual_memory()
131 disk_usage = psutil.disk_usage('/')
132 # net = psutil.net_io_counters()
133 system = {
134 # CPU utilization percent(can be over 100%)
135 'cpu': round10e5(self._process.cpu_percent(0.0)),
136
137 # Whole system memory usage
138 # 'memory_used': round10e5(memory_usage.used / 1024 / 1024),
139 'memory_percent': round10e5(memory_usage.used * 100 / memory_usage.total),
140
141 # Get the portion of memory occupied by a process
142 # 'p_memory_rss': round10e5(self._process.memory_info().rss
143 # / 1024 / 1024),
144 'p_memory_percent': round10e5(self._process.memory_percent()),
145
146 # Disk usage
147 # 'disk_used': round10e5(disk_usage.used / 1024 / 1024),
148 'disk_percent': round10e5(disk_usage.percent),
149 }
150
151 # Collect GPU statistics
152 gpus = []
153 try:
154 gpu_device_count = nvml.nvmlDeviceGetCount()
155 for i in range(gpu_device_count):
156 handle = nvml.nvmlDeviceGetHandleByIndex(i)
157 nvml_tmp = nvml.NVML_TEMPERATURE_GPU
158
159 # Get device memory and temperature
160 util = nvml.nvmlDeviceGetUtilizationRates(handle)
161 memory = nvml.nvmlDeviceGetMemoryInfo(handle)
162 temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)
163
164 # Compute power usage in watts and percent
165 power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000
166 power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)
167 power_cap_watts = power_cap / 1000
168 power_watts / power_cap_watts * 100
169
170 gpus.append({
171 # GPU utilization percent
172 'gpu': round10e5(util.gpu),
173
174 # Device memory usage
175 # 'memory_used': round10e5(memory.used / 1024 / 1024),
176 'gpu_memory_percent': round10e5(memory.used * 100 / memory.total),
177
178 # Power usage in watts and percent
179 'gpu_power_watts': round10e5(power_watts),
180 # 'power_percent': round10e5(power_usage),
181
182 # Device temperature
183 'gpu_temp': round10e5(temp),
184 })
185 except Exception:
186 pass
187
188 return system, gpus
189
[end of aim/ext/resource/stat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aim/ext/resource/stat.py b/aim/ext/resource/stat.py
--- a/aim/ext/resource/stat.py
+++ b/aim/ext/resource/stat.py
@@ -4,13 +4,7 @@
from aim.ext.resource.utils import round10e5
-try:
- # Import python wrapper for the NVIDIA Management Library
- # Initialize it or pass if NVIDIA ML is not initialized
- from py3nvml import py3nvml as nvml
- nvml.nvmlInit()
-except Exception:
- pass
+from py3nvml import py3nvml as nvml
class StatDict(object):
@@ -151,38 +145,49 @@
# Collect GPU statistics
gpus = []
try:
+ nvml.nvmlInit()
gpu_device_count = nvml.nvmlDeviceGetCount()
for i in range(gpu_device_count):
+ gpu_info = dict()
handle = nvml.nvmlDeviceGetHandleByIndex(i)
- nvml_tmp = nvml.NVML_TEMPERATURE_GPU
-
- # Get device memory and temperature
- util = nvml.nvmlDeviceGetUtilizationRates(handle)
- memory = nvml.nvmlDeviceGetMemoryInfo(handle)
- temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)
-
- # Compute power usage in watts and percent
- power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000
- power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)
- power_cap_watts = power_cap / 1000
- power_watts / power_cap_watts * 100
-
- gpus.append({
+ try:
+ util = nvml.nvmlDeviceGetUtilizationRates(handle)
# GPU utilization percent
- 'gpu': round10e5(util.gpu),
-
+ gpu_info["gpu"] = round10e5(util.gpu)
+ except nvml.NVMLError_NotSupported:
+ pass
+ try:
+ # Get device memory
+ memory = nvml.nvmlDeviceGetMemoryInfo(handle)
# Device memory usage
# 'memory_used': round10e5(memory.used / 1024 / 1024),
- 'gpu_memory_percent': round10e5(memory.used * 100 / memory.total),
-
- # Power usage in watts and percent
- 'gpu_power_watts': round10e5(power_watts),
- # 'power_percent': round10e5(power_usage),
-
+ gpu_info["gpu_memory_percent"] = (
+ round10e5(memory.used * 100 / memory.total),
+ )
+ except nvml.NVMLError_NotSupported:
+ pass
+ try:
+ # Get device temperature
+ nvml_tmp = nvml.NVML_TEMPERATURE_GPU
+ temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)
# Device temperature
- 'gpu_temp': round10e5(temp),
- })
- except Exception:
+ gpu_info["gpu_temp"] = round10e5(temp)
+ except nvml.NVMLError_NotSupported:
+ pass
+ try:
+ # Compute power usage in watts and percent
+ power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000
+ power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)
+ power_cap_watts = power_cap / 1000
+ power_watts / power_cap_watts * 100
+ # Power usage in watts and percent
+ gpu_info["gpu_power_watts"]: round10e5(power_watts)
+ # gpu_info["power_percent"] = round10e5(power_usage)
+ except nvml.NVMLError_NotSupported:
+ pass
+ gpus.append(gpu_info)
+ nvml.nvmlShutdown()
+ except (nvml.NVMLError_LibraryNotFound, nvml.NVMLError_NotSupported):
pass
return system, gpus
|
{"golden_diff": "diff --git a/aim/ext/resource/stat.py b/aim/ext/resource/stat.py\n--- a/aim/ext/resource/stat.py\n+++ b/aim/ext/resource/stat.py\n@@ -4,13 +4,7 @@\n \n from aim.ext.resource.utils import round10e5\n \n-try:\n- # Import python wrapper for the NVIDIA Management Library\n- # Initialize it or pass if NVIDIA ML is not initialized\n- from py3nvml import py3nvml as nvml\n- nvml.nvmlInit()\n-except Exception:\n- pass\n+from py3nvml import py3nvml as nvml\n \n \n class StatDict(object):\n@@ -151,38 +145,49 @@\n # Collect GPU statistics\n gpus = []\n try:\n+ nvml.nvmlInit()\n gpu_device_count = nvml.nvmlDeviceGetCount()\n for i in range(gpu_device_count):\n+ gpu_info = dict()\n handle = nvml.nvmlDeviceGetHandleByIndex(i)\n- nvml_tmp = nvml.NVML_TEMPERATURE_GPU\n-\n- # Get device memory and temperature\n- util = nvml.nvmlDeviceGetUtilizationRates(handle)\n- memory = nvml.nvmlDeviceGetMemoryInfo(handle)\n- temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)\n-\n- # Compute power usage in watts and percent\n- power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000\n- power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)\n- power_cap_watts = power_cap / 1000\n- power_watts / power_cap_watts * 100\n-\n- gpus.append({\n+ try:\n+ util = nvml.nvmlDeviceGetUtilizationRates(handle)\n # GPU utilization percent\n- 'gpu': round10e5(util.gpu),\n-\n+ gpu_info[\"gpu\"] = round10e5(util.gpu)\n+ except nvml.NVMLError_NotSupported:\n+ pass\n+ try:\n+ # Get device memory\n+ memory = nvml.nvmlDeviceGetMemoryInfo(handle)\n # Device memory usage\n # 'memory_used': round10e5(memory.used / 1024 / 1024),\n- 'gpu_memory_percent': round10e5(memory.used * 100 / memory.total),\n-\n- # Power usage in watts and percent\n- 'gpu_power_watts': round10e5(power_watts),\n- # 'power_percent': round10e5(power_usage),\n-\n+ gpu_info[\"gpu_memory_percent\"] = (\n+ round10e5(memory.used * 100 / memory.total),\n+ )\n+ except nvml.NVMLError_NotSupported:\n+ pass\n+ try:\n+ # Get device temperature\n+ nvml_tmp = nvml.NVML_TEMPERATURE_GPU\n+ temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)\n # Device temperature\n- 'gpu_temp': round10e5(temp),\n- })\n- except Exception:\n+ gpu_info[\"gpu_temp\"] = round10e5(temp)\n+ except nvml.NVMLError_NotSupported:\n+ pass\n+ try:\n+ # Compute power usage in watts and percent\n+ power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000\n+ power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)\n+ power_cap_watts = power_cap / 1000\n+ power_watts / power_cap_watts * 100\n+ # Power usage in watts and percent\n+ gpu_info[\"gpu_power_watts\"]: round10e5(power_watts)\n+ # gpu_info[\"power_percent\"] = round10e5(power_usage)\n+ except nvml.NVMLError_NotSupported:\n+ pass\n+ gpus.append(gpu_info)\n+ nvml.nvmlShutdown()\n+ except (nvml.NVMLError_LibraryNotFound, nvml.NVMLError_NotSupported):\n pass\n \n return system, gpus\n", "issue": "GPU utilization is not tracked if querying power usage fails\n## \ud83d\udc1b Bug\r\n\r\nI am running experiments on a machine with a GPU, yet no GPU metrics are tracked. It seems like this code is responsible:\r\n\r\nhttps://github.com/aimhubio/aim/blob/480e063cde063897283bcd8adb221e9baa861637/aim/ext/resource/stat.py#L152-L186\r\n\r\nWhen any part of the GPU stats collection fails, we just give up entirely and store no information. In my case querying the power usage seems not supported by nvml, it raises `nvml.NVMLError_NotSupported`. Querying utilization and memory usage works just fine though and it would be nice if we could track those stats anyway.\r\n\r\n### To reproduce\r\n\r\nI'm not sure how to reproduce this, since it depends on a setup where `nvml` fails to determine the GPU power usage.\r\n\r\n### Expected behavior\r\n\r\nAim tracks all the information that it can query without exceptions.\r\n\r\n### Environment\r\n\r\n- Aim Version (e.g., 3.15.1)\r\n- Python version 3.10.9\r\n- pip version 22.0.3\r\n- OS (e.g., Linux) Linux\r\n- Any other relevant information\r\n\r\n### Additional context\r\n\r\n--\r\n\n", "before_files": [{"content": "import psutil\nimport json\nfrom typing import List\n\nfrom aim.ext.resource.utils import round10e5\n\ntry:\n # Import python wrapper for the NVIDIA Management Library\n # Initialize it or pass if NVIDIA ML is not initialized\n from py3nvml import py3nvml as nvml\n nvml.nvmlInit()\nexcept Exception:\n pass\n\n\nclass StatDict(object):\n # Available aggregation functions\n AGG_MODE_AVG = 'average'\n AGG_MODE_MIN = 'min'\n AGG_MODE_MAX = 'max'\n AGG_MODE_DIFF = 'diff'\n AGG_DEFAULT = AGG_MODE_AVG\n\n @classmethod\n def aggregate(cls, items: List, mode: str):\n \"\"\"\n Aggregates array of numbers by a given 'mode'\n \"\"\"\n if mode == cls.AGG_MODE_MAX:\n return max(items)\n elif mode == cls.AGG_MODE_MIN:\n return min(items)\n elif mode == cls.AGG_MODE_AVG:\n return round10e5(sum(items) / len(items))\n elif mode == cls.AGG_MODE_DIFF:\n return round10e5(max(items) - min(items))\n else:\n raise ValueError('unknown aggregation mode: \\'{}\\''.format(mode))\n\n @classmethod\n def aggregate_items(cls,\n items: 'List[StatDict]',\n agg_mode: str = AGG_DEFAULT,\n ):\n \"\"\"\n Aggregates array of `StatDict` items by a given `mode`\n \"\"\"\n aggregated_stat = cls()\n\n # Return empty item if items array is empty\n if not items or len(items) == 0:\n return aggregated_stat\n\n gpu_stats = []\n for s in items:\n # Collect system stats\n for k in s.system.keys():\n aggregated_stat.system.setdefault(k, [])\n aggregated_stat.system[k].append(s.system[k])\n\n # Collect GPU device stats\n for stat_item_gpu_idx in range(len(s.gpus)):\n stat_item_gpu_stat = s.gpus[stat_item_gpu_idx]\n if len(gpu_stats) == stat_item_gpu_idx:\n gpu_stats.append({})\n for gpu_stat_key in stat_item_gpu_stat.keys():\n gpu_stat = stat_item_gpu_stat[gpu_stat_key]\n gpu_stats[stat_item_gpu_idx].setdefault(gpu_stat_key, [])\n gpu_stats[stat_item_gpu_idx][gpu_stat_key].append(gpu_stat)\n\n # Aggregate system stats\n for k in aggregated_stat.system.keys():\n aggregated_stat.system[k] = cls.aggregate(aggregated_stat.system[k],\n agg_mode)\n\n # Aggregate GPU device stats\n for g in range(len(gpu_stats)):\n for k in gpu_stats[g].keys():\n gpu_stats[g][k] = cls.aggregate(gpu_stats[g][k], agg_mode)\n aggregated_stat.gpu = gpu_stats\n\n return aggregated_stat\n\n def __init__(self, system: dict = None, gpus: List[dict] = None):\n self.system = system or {}\n self.gpus = gpus or []\n\n def __str__(self):\n return json.dumps(self.to_dict())\n\n def to_dict(self):\n \"\"\"\n Returns system and GPU device statistics\n \"\"\"\n return {\n 'system': self.system,\n 'gpus': self.gpus,\n }\n\n\nclass Stat(object):\n def __init__(self, process):\n # Set process\n self._process = process\n\n # Get statistics\n system, gpus = self.get_stats()\n self._stat = StatDict(system, gpus)\n\n @property\n def process(self):\n return self._process\n\n @property\n def stat_item(self):\n return self._stat\n\n @property\n def system(self):\n return self._stat.system\n\n @property\n def gpus(self):\n return self._stat.gpus\n\n def get_stats(self):\n \"\"\"\n Get system statistics and assign to `self`\n \"\"\"\n memory_usage = psutil.virtual_memory()\n disk_usage = psutil.disk_usage('/')\n # net = psutil.net_io_counters()\n system = {\n # CPU utilization percent(can be over 100%)\n 'cpu': round10e5(self._process.cpu_percent(0.0)),\n\n # Whole system memory usage\n # 'memory_used': round10e5(memory_usage.used / 1024 / 1024),\n 'memory_percent': round10e5(memory_usage.used * 100 / memory_usage.total),\n\n # Get the portion of memory occupied by a process\n # 'p_memory_rss': round10e5(self._process.memory_info().rss\n # / 1024 / 1024),\n 'p_memory_percent': round10e5(self._process.memory_percent()),\n\n # Disk usage\n # 'disk_used': round10e5(disk_usage.used / 1024 / 1024),\n 'disk_percent': round10e5(disk_usage.percent),\n }\n\n # Collect GPU statistics\n gpus = []\n try:\n gpu_device_count = nvml.nvmlDeviceGetCount()\n for i in range(gpu_device_count):\n handle = nvml.nvmlDeviceGetHandleByIndex(i)\n nvml_tmp = nvml.NVML_TEMPERATURE_GPU\n\n # Get device memory and temperature\n util = nvml.nvmlDeviceGetUtilizationRates(handle)\n memory = nvml.nvmlDeviceGetMemoryInfo(handle)\n temp = nvml.nvmlDeviceGetTemperature(handle, nvml_tmp)\n\n # Compute power usage in watts and percent\n power_watts = nvml.nvmlDeviceGetPowerUsage(handle) / 1000\n power_cap = nvml.nvmlDeviceGetEnforcedPowerLimit(handle)\n power_cap_watts = power_cap / 1000\n power_watts / power_cap_watts * 100\n\n gpus.append({\n # GPU utilization percent\n 'gpu': round10e5(util.gpu),\n\n # Device memory usage\n # 'memory_used': round10e5(memory.used / 1024 / 1024),\n 'gpu_memory_percent': round10e5(memory.used * 100 / memory.total),\n\n # Power usage in watts and percent\n 'gpu_power_watts': round10e5(power_watts),\n # 'power_percent': round10e5(power_usage),\n\n # Device temperature\n 'gpu_temp': round10e5(temp),\n })\n except Exception:\n pass\n\n return system, gpus\n", "path": "aim/ext/resource/stat.py"}]}
| 2,736 | 937 |
gh_patches_debug_13779
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-4877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.atresplayer: error: Unable to validate response text: ValidationError(NoneOrAllSchema)
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Using the latest app image with Tvheadend with command:
pipe:///usr/local/bin/streamlink -O https://www.atresplayer.com/directos/nova best
2022-10-09 23:21:29.885 mpegts: nova HD in Streams - tuning on IPTV #1
2022-10-09 23:21:29.927 subscription: 0121: "scan" subscribing to mux "nova HD", weight: 6, adapter: "IPTV #1", network: "Streams", service: "Raw PID Subscription"
2022-10-09 23:21:29.927 spawn: Executing "/usr/local/bin/streamlink"
2022-10-09 23:21:30.352 spawn: [cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/nova/
2022-10-09 23:21:30.621 spawn: [cli][info] Available streams: 360p (worst), 480p, 720p, 1080p (best)
2022-10-09 23:21:30.621 spawn: [cli][info] Opening stream: 1080p (hls)
2022-10-09 23:21:44.927 mpegts: nova HD in Streams - scan no data, failed
2022-10-09 23:21:44.927 subscription: 0121: "scan" unsubscribing
### Debug log
```text
nico@NUC:~/streamlink$ ./streamlink -l debug https://www.atresplayer.com/directos/nova
[cli][debug] OS: Linux-5.15.0-48-generic-x86_64-with-glibc2.31
[cli][debug] Python: 3.10.7
[cli][debug] Streamlink: 5.0.1
[cli][debug] Dependencies:
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.1
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.15.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.28.1
[cli][debug] websocket-client: 1.4.1
[cli][debug] Arguments:
[cli][debug] url=https://www.atresplayer.com/directos/nova
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/nova
error: Unable to validate response text: ValidationError(NoneOrAllSchema):
ValidationError(dict):
Unable to validate value of key 'links'
Context(dict):
Key '/directos/nova' not found in <{'/directos/nova/': {'url': '/directos/nova/', 'redirec...>
nuc@NUC:~/streamlink$ ./streamlink --version-check
[cli][info] Your Streamlink version (5.0.1) is up to date!
nuc@NUC:~/streamlink$ ./streamlink --version
streamlink 5.0.1
nuc@NUC:~/streamlink$ ./streamlink --plugins
Loaded plugins: abematv, adultswim, afreeca, albavision, aloula, app17, ard_live, ard_mediathek, artetv, atpchallenger, atresplayer, bbciplayer, bfmtv, bigo, bilibili, blazetv, bloomberg, booyah, brightcove, btv, cbsnews, cdnbg, ceskatelevize, cinergroup, clubbingtv, cmmedia, cnews, crunchyroll, dailymotion, dash, delfi, deutschewelle, dlive, dogan, dogus, drdk, earthcam, egame, euronews, facebook, filmon, foxtr, funimationnow, galatasaraytv, **goltelevision**, goodgame, googledrive, gulli, hiplayer, hls, http, htv, huajiao, huya, idf1, invintus, kugou, linelive, livestream, lnk, lrt, ltv_lsm_lv, mdstrm, mediaklikk, mediavitrina, mildom, mitele, mjunoon, mrtmk, n13tv, nbcnews, nhkworld, nicolive, nimotv, nos, nownews, nrk, ntv, okru, olympicchannel, oneplusone, onetv, openrectv, orf_tvthek, pandalive, picarto, piczel, pixiv, pluto, pluzz, qq, radiko, radionet, raiplay, reuters, rtbf, rtpa, rtpplay, rtve, rtvs, ruv, sbscokr, schoolism, showroom, sportal, sportschau, ssh101, stadium, steam, streamable, streann, stv, svtplay, swisstxt, telefe, tf1, trovo, turkuvaz, tv360, tv3cat, tv4play, tv5monde, tv8, tv999, tvibo, tviplayer, tvp, tvrby, tvrplus, tvtoya, twitcasting, twitch, useetv, ustreamtv, ustvnow, vidio, vimeo, vinhlongtv, vk, vlive, vtvgo, wasd, webtv, welt, wwenetwork, youtube, yupptv, zattoo, zdf_mediathek, zeenews, zengatv, zhanqi
```
</issue>
<code>
[start of src/streamlink/plugins/atresplayer.py]
1 """
2 $description Spanish live TV channels from Atresmedia Television, including Antena 3 and laSexta.
3 $url atresplayer.com
4 $type live
5 $region Spain
6 """
7
8 import logging
9 import re
10 from urllib.parse import urlparse
11
12 from streamlink.plugin import Plugin, pluginmatcher
13 from streamlink.plugin.api import validate
14 from streamlink.stream.dash import DASHStream
15 from streamlink.stream.hls import HLSStream
16 from streamlink.utils.url import update_scheme
17
18 log = logging.getLogger(__name__)
19
20
21 @pluginmatcher(re.compile(
22 r"https?://(?:www\.)?atresplayer\.com/"
23 ))
24 class AtresPlayer(Plugin):
25 def _get_streams(self):
26 self.url = update_scheme("https://", self.url)
27 path = urlparse(self.url).path
28
29 api_url = self.session.http.get(self.url, schema=validate.Schema(
30 re.compile(r"""window.__PRELOADED_STATE__\s*=\s*({.*?});""", re.DOTALL),
31 validate.none_or_all(
32 validate.get(1),
33 validate.parse_json(),
34 {"links": {path: {"href": validate.url()}}},
35 validate.get(("links", path, "href")),
36 ),
37 ))
38 if not api_url:
39 return
40 log.debug(f"API URL: {api_url}")
41
42 player_api_url = self.session.http.get(api_url, schema=validate.Schema(
43 validate.parse_json(),
44 {"urlVideo": validate.url()},
45 validate.get("urlVideo"),
46 ))
47
48 log.debug(f"Player API URL: {player_api_url}")
49 sources = self.session.http.get(player_api_url, acceptable_status=(200, 403), schema=validate.Schema(
50 validate.parse_json(),
51 validate.any(
52 {
53 "error": str,
54 "error_description": str,
55 },
56 {
57 "sources": [
58 validate.all(
59 {
60 "src": validate.url(),
61 validate.optional("type"): str,
62 },
63 validate.union_get("type", "src"),
64 ),
65 ],
66 },
67 ),
68 ))
69 if "error" in sources:
70 log.error(f"Player API error: {sources['error']} - {sources['error_description']}")
71 return
72
73 for streamtype, streamsrc in sources.get("sources"):
74 log.debug(f"Stream source: {streamsrc} ({streamtype or 'n/a'})")
75
76 if streamtype == "application/vnd.apple.mpegurl":
77 streams = HLSStream.parse_variant_playlist(self.session, streamsrc)
78 if not streams:
79 yield "live", HLSStream(self.session, streamsrc)
80 else:
81 yield from streams.items()
82 elif streamtype == "application/dash+xml":
83 yield from DASHStream.parse_manifest(self.session, streamsrc).items()
84
85
86 __plugin__ = AtresPlayer
87
[end of src/streamlink/plugins/atresplayer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/atresplayer.py b/src/streamlink/plugins/atresplayer.py
--- a/src/streamlink/plugins/atresplayer.py
+++ b/src/streamlink/plugins/atresplayer.py
@@ -22,10 +22,12 @@
r"https?://(?:www\.)?atresplayer\.com/"
))
class AtresPlayer(Plugin):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.url = update_scheme("https://", f"{self.url.rstrip('/')}/")
+
def _get_streams(self):
- self.url = update_scheme("https://", self.url)
path = urlparse(self.url).path
-
api_url = self.session.http.get(self.url, schema=validate.Schema(
re.compile(r"""window.__PRELOADED_STATE__\s*=\s*({.*?});""", re.DOTALL),
validate.none_or_all(
|
{"golden_diff": "diff --git a/src/streamlink/plugins/atresplayer.py b/src/streamlink/plugins/atresplayer.py\n--- a/src/streamlink/plugins/atresplayer.py\n+++ b/src/streamlink/plugins/atresplayer.py\n@@ -22,10 +22,12 @@\n r\"https?://(?:www\\.)?atresplayer\\.com/\"\n ))\n class AtresPlayer(Plugin):\n+ def __init__(self, *args, **kwargs):\n+ super().__init__(*args, **kwargs)\n+ self.url = update_scheme(\"https://\", f\"{self.url.rstrip('/')}/\")\n+\n def _get_streams(self):\n- self.url = update_scheme(\"https://\", self.url)\n path = urlparse(self.url).path\n-\n api_url = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"window.__PRELOADED_STATE__\\s*=\\s*({.*?});\"\"\", re.DOTALL),\n validate.none_or_all(\n", "issue": "plugins.atresplayer: error: Unable to validate response text: ValidationError(NoneOrAllSchema)\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nUsing the latest app image with Tvheadend with command:\r\n\r\npipe:///usr/local/bin/streamlink -O https://www.atresplayer.com/directos/nova best\r\n\r\n2022-10-09 23:21:29.885 mpegts: nova HD in Streams - tuning on IPTV #1\r\n2022-10-09 23:21:29.927 subscription: 0121: \"scan\" subscribing to mux \"nova HD\", weight: 6, adapter: \"IPTV #1\", network: \"Streams\", service: \"Raw PID Subscription\"\r\n2022-10-09 23:21:29.927 spawn: Executing \"/usr/local/bin/streamlink\"\r\n2022-10-09 23:21:30.352 spawn: [cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/nova/\r\n2022-10-09 23:21:30.621 spawn: [cli][info] Available streams: 360p (worst), 480p, 720p, 1080p (best)\r\n2022-10-09 23:21:30.621 spawn: [cli][info] Opening stream: 1080p (hls)\r\n2022-10-09 23:21:44.927 mpegts: nova HD in Streams - scan no data, failed\r\n2022-10-09 23:21:44.927 subscription: 0121: \"scan\" unsubscribing\n\n### Debug log\n\n```text\nnico@NUC:~/streamlink$ ./streamlink -l debug https://www.atresplayer.com/directos/nova\r\n[cli][debug] OS: Linux-5.15.0-48-generic-x86_64-with-glibc2.31\r\n[cli][debug] Python: 3.10.7\r\n[cli][debug] Streamlink: 5.0.1\r\n[cli][debug] Dependencies:\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.1\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.15.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.28.1\r\n[cli][debug] websocket-client: 1.4.1\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.atresplayer.com/directos/nova\r\n[cli][debug] --loglevel=debug\r\n[cli][info] Found matching plugin atresplayer for URL https://www.atresplayer.com/directos/nova\r\nerror: Unable to validate response text: ValidationError(NoneOrAllSchema):\r\n ValidationError(dict):\r\n Unable to validate value of key 'links'\r\n Context(dict):\r\n Key '/directos/nova' not found in <{'/directos/nova/': {'url': '/directos/nova/', 'redirec...>\r\n\r\nnuc@NUC:~/streamlink$ ./streamlink --version-check\r\n[cli][info] Your Streamlink version (5.0.1) is up to date!\r\n\r\nnuc@NUC:~/streamlink$ ./streamlink --version\r\nstreamlink 5.0.1\r\n\r\nnuc@NUC:~/streamlink$ ./streamlink --plugins\r\nLoaded plugins: abematv, adultswim, afreeca, albavision, aloula, app17, ard_live, ard_mediathek, artetv, atpchallenger, atresplayer, bbciplayer, bfmtv, bigo, bilibili, blazetv, bloomberg, booyah, brightcove, btv, cbsnews, cdnbg, ceskatelevize, cinergroup, clubbingtv, cmmedia, cnews, crunchyroll, dailymotion, dash, delfi, deutschewelle, dlive, dogan, dogus, drdk, earthcam, egame, euronews, facebook, filmon, foxtr, funimationnow, galatasaraytv, **goltelevision**, goodgame, googledrive, gulli, hiplayer, hls, http, htv, huajiao, huya, idf1, invintus, kugou, linelive, livestream, lnk, lrt, ltv_lsm_lv, mdstrm, mediaklikk, mediavitrina, mildom, mitele, mjunoon, mrtmk, n13tv, nbcnews, nhkworld, nicolive, nimotv, nos, nownews, nrk, ntv, okru, olympicchannel, oneplusone, onetv, openrectv, orf_tvthek, pandalive, picarto, piczel, pixiv, pluto, pluzz, qq, radiko, radionet, raiplay, reuters, rtbf, rtpa, rtpplay, rtve, rtvs, ruv, sbscokr, schoolism, showroom, sportal, sportschau, ssh101, stadium, steam, streamable, streann, stv, svtplay, swisstxt, telefe, tf1, trovo, turkuvaz, tv360, tv3cat, tv4play, tv5monde, tv8, tv999, tvibo, tviplayer, tvp, tvrby, tvrplus, tvtoya, twitcasting, twitch, useetv, ustreamtv, ustvnow, vidio, vimeo, vinhlongtv, vk, vlive, vtvgo, wasd, webtv, welt, wwenetwork, youtube, yupptv, zattoo, zdf_mediathek, zeenews, zengatv, zhanqi\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Spanish live TV channels from Atresmedia Television, including Antena 3 and laSexta.\n$url atresplayer.com\n$type live\n$region Spain\n\"\"\"\n\nimport logging\nimport re\nfrom urllib.parse import urlparse\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.url import update_scheme\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?atresplayer\\.com/\"\n))\nclass AtresPlayer(Plugin):\n def _get_streams(self):\n self.url = update_scheme(\"https://\", self.url)\n path = urlparse(self.url).path\n\n api_url = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"window.__PRELOADED_STATE__\\s*=\\s*({.*?});\"\"\", re.DOTALL),\n validate.none_or_all(\n validate.get(1),\n validate.parse_json(),\n {\"links\": {path: {\"href\": validate.url()}}},\n validate.get((\"links\", path, \"href\")),\n ),\n ))\n if not api_url:\n return\n log.debug(f\"API URL: {api_url}\")\n\n player_api_url = self.session.http.get(api_url, schema=validate.Schema(\n validate.parse_json(),\n {\"urlVideo\": validate.url()},\n validate.get(\"urlVideo\"),\n ))\n\n log.debug(f\"Player API URL: {player_api_url}\")\n sources = self.session.http.get(player_api_url, acceptable_status=(200, 403), schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"error\": str,\n \"error_description\": str,\n },\n {\n \"sources\": [\n validate.all(\n {\n \"src\": validate.url(),\n validate.optional(\"type\"): str,\n },\n validate.union_get(\"type\", \"src\"),\n ),\n ],\n },\n ),\n ))\n if \"error\" in sources:\n log.error(f\"Player API error: {sources['error']} - {sources['error_description']}\")\n return\n\n for streamtype, streamsrc in sources.get(\"sources\"):\n log.debug(f\"Stream source: {streamsrc} ({streamtype or 'n/a'})\")\n\n if streamtype == \"application/vnd.apple.mpegurl\":\n streams = HLSStream.parse_variant_playlist(self.session, streamsrc)\n if not streams:\n yield \"live\", HLSStream(self.session, streamsrc)\n else:\n yield from streams.items()\n elif streamtype == \"application/dash+xml\":\n yield from DASHStream.parse_manifest(self.session, streamsrc).items()\n\n\n__plugin__ = AtresPlayer\n", "path": "src/streamlink/plugins/atresplayer.py"}]}
| 2,881 | 209 |
gh_patches_debug_28856
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-1918
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`ClasswiseWrapper` double prefixes with `self.prefix` when enclosed in a `MetricCollection`
## 🐛 Bug
#1866 double prefixes with `self.prefix` when enclosed in a `MetricCollection`. This is because `MetricCollection` already handles prefixing, here:
https://github.com/Lightning-AI/torchmetrics/blob/a448ad3ff4329682a83fe1036ef21f35a2a8418a/src/torchmetrics/collections.py#L335-L339
but #1866 doesn't account for it.
### To Reproduce
Enclose a `ClasswiseWrapper` with a `prefix` within a `MetricCollection`.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
<details>
<summary>Finds a multiclass accuracy and a classwise f1 score.</summary>
```py
from torchmetrics import *
import torch
category_names = ['Tree', 'Bush']
num_classes = len(category_names)
input_ = torch.rand((5, num_classes, 3, 3))
target = torch.ones((5, num_classes, 3, 3)).long()
val_metrics = MetricCollection(
{
"accuracy": Accuracy(task="multiclass", num_classes=num_classes),
"f1": ClasswiseWrapper(
F1Score(
task="multiclass",
num_classes=num_classes,
average="none",
dist_sync_on_step=True,
),
category_names,
prefix="f_score_",
),
},
prefix="val/",
)
val_metrics["precision"](input_, target)
val_metrics(input_, target)
```
</details>
### Expected behavior
I should get `{'val/acc': tensor(0.), 'val/f1_Tree': tensor(0.), 'val/f1_Bush': tensor(0.)}`. I instead get `{'val/acc': tensor(0.), 'val/f1_f1_Tree': tensor(0.), 'val/f1_f1_Bush': tensor(0.)}`.
### Environment
- `torchmetrics` 1.0.0 via `pip`
- Python `3.10.6` & PyTorch `1.12`:
- OS: Linux
</issue>
<code>
[start of src/torchmetrics/wrappers/classwise.py]
1 # Copyright The Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, Callable, Dict, List, Optional, Sequence, Union
15
16 from torch import Tensor
17
18 from torchmetrics.metric import Metric
19 from torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE
20 from torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE
21 from torchmetrics.wrappers.abstract import WrapperMetric
22
23 if not _MATPLOTLIB_AVAILABLE:
24 __doctest_skip__ = ["ClasswiseWrapper.plot"]
25
26
27 class ClasswiseWrapper(WrapperMetric):
28 """Wrapper metric for altering the output of classification metrics.
29
30 This metric works together with classification metrics that returns multiple values (one value per class) such that
31 label information can be automatically included in the output.
32
33 Args:
34 metric: base metric that should be wrapped. It is assumed that the metric outputs a single
35 tensor that is split along the first dimension.
36 labels: list of strings indicating the different classes.
37 prefix: string that is prepended to the metric names.
38 postfix: string that is appended to the metric names.
39
40 Example::
41 Basic example where the ouput of a metric is unwrapped into a dictionary with the class index as keys:
42
43 >>> import torch
44 >>> _ = torch.manual_seed(42)
45 >>> from torchmetrics.wrappers import ClasswiseWrapper
46 >>> from torchmetrics.classification import MulticlassAccuracy
47 >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))
48 >>> preds = torch.randn(10, 3).softmax(dim=-1)
49 >>> target = torch.randint(3, (10,))
50 >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE
51 {'multiclassaccuracy_0': tensor(0.5000),
52 'multiclassaccuracy_1': tensor(0.7500),
53 'multiclassaccuracy_2': tensor(0.)}
54
55 Example::
56 Using custom name via prefix and postfix:
57
58 >>> import torch
59 >>> _ = torch.manual_seed(42)
60 >>> from torchmetrics.wrappers import ClasswiseWrapper
61 >>> from torchmetrics.classification import MulticlassAccuracy
62 >>> metric_pre = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), prefix="acc-")
63 >>> metric_post = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), postfix="-acc")
64 >>> preds = torch.randn(10, 3).softmax(dim=-1)
65 >>> target = torch.randint(3, (10,))
66 >>> metric_pre(preds, target) # doctest: +NORMALIZE_WHITESPACE
67 {'acc-0': tensor(0.5000),
68 'acc-1': tensor(0.7500),
69 'acc-2': tensor(0.)}
70 >>> metric_post(preds, target) # doctest: +NORMALIZE_WHITESPACE
71 {'0-acc': tensor(0.5000),
72 '1-acc': tensor(0.7500),
73 '2-acc': tensor(0.)}
74
75 Example::
76 Providing labels as a list of strings:
77
78 >>> from torchmetrics.wrappers import ClasswiseWrapper
79 >>> from torchmetrics.classification import MulticlassAccuracy
80 >>> metric = ClasswiseWrapper(
81 ... MulticlassAccuracy(num_classes=3, average=None),
82 ... labels=["horse", "fish", "dog"]
83 ... )
84 >>> preds = torch.randn(10, 3).softmax(dim=-1)
85 >>> target = torch.randint(3, (10,))
86 >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE
87 {'multiclassaccuracy_horse': tensor(0.3333),
88 'multiclassaccuracy_fish': tensor(0.6667),
89 'multiclassaccuracy_dog': tensor(0.)}
90
91 Example::
92 Classwise can also be used in combination with :class:`~torchmetrics.MetricCollection`. In this case, everything
93 will be flattened into a single dictionary:
94
95 >>> from torchmetrics import MetricCollection
96 >>> from torchmetrics.wrappers import ClasswiseWrapper
97 >>> from torchmetrics.classification import MulticlassAccuracy, MulticlassRecall
98 >>> labels = ["horse", "fish", "dog"]
99 >>> metric = MetricCollection(
100 ... {'multiclassaccuracy': ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), labels),
101 ... 'multiclassrecall': ClasswiseWrapper(MulticlassRecall(num_classes=3, average=None), labels)}
102 ... )
103 >>> preds = torch.randn(10, 3).softmax(dim=-1)
104 >>> target = torch.randint(3, (10,))
105 >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE
106 {'multiclassaccuracy_horse': tensor(0.),
107 'multiclassaccuracy_fish': tensor(0.3333),
108 'multiclassaccuracy_dog': tensor(0.4000),
109 'multiclassrecall_horse': tensor(0.),
110 'multiclassrecall_fish': tensor(0.3333),
111 'multiclassrecall_dog': tensor(0.4000)}
112
113 """
114
115 def __init__(
116 self,
117 metric: Metric,
118 labels: Optional[List[str]] = None,
119 prefix: Optional[str] = None,
120 postfix: Optional[str] = None,
121 ) -> None:
122 super().__init__()
123 if not isinstance(metric, Metric):
124 raise ValueError(f"Expected argument `metric` to be an instance of `torchmetrics.Metric` but got {metric}")
125 self.metric = metric
126
127 if labels is not None and not (isinstance(labels, list) and all(isinstance(lab, str) for lab in labels)):
128 raise ValueError(f"Expected argument `labels` to either be `None` or a list of strings but got {labels}")
129 self.labels = labels
130
131 if prefix is not None and not isinstance(prefix, str):
132 raise ValueError(f"Expected argument `prefix` to either be `None` or a string but got {prefix}")
133 self.prefix = prefix
134
135 if postfix is not None and not isinstance(postfix, str):
136 raise ValueError(f"Expected argument `postfix` to either be `None` or a string but got {postfix}")
137 self.postfix = postfix
138
139 self._update_count = 1
140
141 def _convert(self, x: Tensor) -> Dict[str, Any]:
142 # Will set the class name as prefix if neither prefix nor postfix is given
143 if not self.prefix and not self.postfix:
144 prefix = f"{self.metric.__class__.__name__.lower()}_"
145 postfix = ""
146 else:
147 prefix = self.prefix or ""
148 postfix = self.postfix or ""
149 if self.labels is None:
150 return {f"{prefix}{i}{postfix}": val for i, val in enumerate(x)}
151 return {f"{prefix}{lab}{postfix}": val for lab, val in zip(self.labels, x)}
152
153 def forward(self, *args: Any, **kwargs: Any) -> Any:
154 """Calculate on batch and accumulate to global state."""
155 return self._convert(self.metric(*args, **kwargs))
156
157 def update(self, *args: Any, **kwargs: Any) -> None:
158 """Update state."""
159 self.metric.update(*args, **kwargs)
160
161 def compute(self) -> Dict[str, Tensor]:
162 """Compute metric."""
163 return self._convert(self.metric.compute())
164
165 def reset(self) -> None:
166 """Reset metric."""
167 self.metric.reset()
168
169 def plot(
170 self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None
171 ) -> _PLOT_OUT_TYPE:
172 """Plot a single or multiple values from the metric.
173
174 Args:
175 val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.
176 If no value is provided, will automatically call `metric.compute` and plot that result.
177 ax: An matplotlib axis object. If provided will add plot to that axis
178
179 Returns:
180 Figure and Axes object
181
182 Raises:
183 ModuleNotFoundError:
184 If `matplotlib` is not installed
185
186 .. plot::
187 :scale: 75
188
189 >>> # Example plotting a single value
190 >>> import torch
191 >>> from torchmetrics.wrappers import ClasswiseWrapper
192 >>> from torchmetrics.classification import MulticlassAccuracy
193 >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))
194 >>> metric.update(torch.randint(3, (20,)), torch.randint(3, (20,)))
195 >>> fig_, ax_ = metric.plot()
196
197 .. plot::
198 :scale: 75
199
200 >>> # Example plotting multiple values
201 >>> import torch
202 >>> from torchmetrics.wrappers import ClasswiseWrapper
203 >>> from torchmetrics.classification import MulticlassAccuracy
204 >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))
205 >>> values = [ ]
206 >>> for _ in range(3):
207 ... values.append(metric(torch.randint(3, (20,)), torch.randint(3, (20,))))
208 >>> fig_, ax_ = metric.plot(values)
209
210 """
211 return self._plot(val, ax)
212
[end of src/torchmetrics/wrappers/classwise.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/torchmetrics/wrappers/classwise.py b/src/torchmetrics/wrappers/classwise.py
--- a/src/torchmetrics/wrappers/classwise.py
+++ b/src/torchmetrics/wrappers/classwise.py
@@ -130,22 +130,22 @@
if prefix is not None and not isinstance(prefix, str):
raise ValueError(f"Expected argument `prefix` to either be `None` or a string but got {prefix}")
- self.prefix = prefix
+ self._prefix = prefix
if postfix is not None and not isinstance(postfix, str):
raise ValueError(f"Expected argument `postfix` to either be `None` or a string but got {postfix}")
- self.postfix = postfix
+ self._postfix = postfix
self._update_count = 1
def _convert(self, x: Tensor) -> Dict[str, Any]:
# Will set the class name as prefix if neither prefix nor postfix is given
- if not self.prefix and not self.postfix:
+ if not self._prefix and not self._postfix:
prefix = f"{self.metric.__class__.__name__.lower()}_"
postfix = ""
else:
- prefix = self.prefix or ""
- postfix = self.postfix or ""
+ prefix = self._prefix or ""
+ postfix = self._postfix or ""
if self.labels is None:
return {f"{prefix}{i}{postfix}": val for i, val in enumerate(x)}
return {f"{prefix}{lab}{postfix}": val for lab, val in zip(self.labels, x)}
|
{"golden_diff": "diff --git a/src/torchmetrics/wrappers/classwise.py b/src/torchmetrics/wrappers/classwise.py\n--- a/src/torchmetrics/wrappers/classwise.py\n+++ b/src/torchmetrics/wrappers/classwise.py\n@@ -130,22 +130,22 @@\n \n if prefix is not None and not isinstance(prefix, str):\n raise ValueError(f\"Expected argument `prefix` to either be `None` or a string but got {prefix}\")\n- self.prefix = prefix\n+ self._prefix = prefix\n \n if postfix is not None and not isinstance(postfix, str):\n raise ValueError(f\"Expected argument `postfix` to either be `None` or a string but got {postfix}\")\n- self.postfix = postfix\n+ self._postfix = postfix\n \n self._update_count = 1\n \n def _convert(self, x: Tensor) -> Dict[str, Any]:\n # Will set the class name as prefix if neither prefix nor postfix is given\n- if not self.prefix and not self.postfix:\n+ if not self._prefix and not self._postfix:\n prefix = f\"{self.metric.__class__.__name__.lower()}_\"\n postfix = \"\"\n else:\n- prefix = self.prefix or \"\"\n- postfix = self.postfix or \"\"\n+ prefix = self._prefix or \"\"\n+ postfix = self._postfix or \"\"\n if self.labels is None:\n return {f\"{prefix}{i}{postfix}\": val for i, val in enumerate(x)}\n return {f\"{prefix}{lab}{postfix}\": val for lab, val in zip(self.labels, x)}\n", "issue": "`ClasswiseWrapper` double prefixes with `self.prefix` when enclosed in a `MetricCollection`\n## \ud83d\udc1b Bug\r\n\r\n#1866 double prefixes with `self.prefix` when enclosed in a `MetricCollection`. This is because `MetricCollection` already handles prefixing, here:\r\nhttps://github.com/Lightning-AI/torchmetrics/blob/a448ad3ff4329682a83fe1036ef21f35a2a8418a/src/torchmetrics/collections.py#L335-L339\r\nbut #1866 doesn't account for it.\r\n\r\n### To Reproduce\r\n\r\nEnclose a `ClasswiseWrapper` with a `prefix` within a `MetricCollection`.\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n<details>\r\n <summary>Finds a multiclass accuracy and a classwise f1 score.</summary>\r\n\r\n\r\n```py\r\nfrom torchmetrics import *\r\nimport torch\r\n\r\ncategory_names = ['Tree', 'Bush']\r\nnum_classes = len(category_names)\r\n\r\ninput_ = torch.rand((5, num_classes, 3, 3))\r\ntarget = torch.ones((5, num_classes, 3, 3)).long()\r\n\r\n\r\nval_metrics = MetricCollection(\r\n {\r\n \"accuracy\": Accuracy(task=\"multiclass\", num_classes=num_classes),\r\n \"f1\": ClasswiseWrapper(\r\n F1Score(\r\n task=\"multiclass\",\r\n num_classes=num_classes,\r\n average=\"none\",\r\n dist_sync_on_step=True,\r\n ),\r\n category_names,\r\n prefix=\"f_score_\",\r\n ),\r\n },\r\n prefix=\"val/\",\r\n)\r\n\r\nval_metrics[\"precision\"](input_, target)\r\nval_metrics(input_, target)\r\n```\r\n\r\n</details>\r\n\r\n### Expected behavior\r\n\r\nI should get `{'val/acc': tensor(0.), 'val/f1_Tree': tensor(0.), 'val/f1_Bush': tensor(0.)}`. I instead get `{'val/acc': tensor(0.), 'val/f1_f1_Tree': tensor(0.), 'val/f1_f1_Bush': tensor(0.)}`.\r\n\r\n### Environment\r\n\r\n- `torchmetrics` 1.0.0 via `pip`\r\n- Python `3.10.6` & PyTorch `1.12`:\r\n- OS: Linux\r\n\r\n\n", "before_files": [{"content": "# Copyright The Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Dict, List, Optional, Sequence, Union\n\nfrom torch import Tensor\n\nfrom torchmetrics.metric import Metric\nfrom torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE\nfrom torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE\nfrom torchmetrics.wrappers.abstract import WrapperMetric\n\nif not _MATPLOTLIB_AVAILABLE:\n __doctest_skip__ = [\"ClasswiseWrapper.plot\"]\n\n\nclass ClasswiseWrapper(WrapperMetric):\n \"\"\"Wrapper metric for altering the output of classification metrics.\n\n This metric works together with classification metrics that returns multiple values (one value per class) such that\n label information can be automatically included in the output.\n\n Args:\n metric: base metric that should be wrapped. It is assumed that the metric outputs a single\n tensor that is split along the first dimension.\n labels: list of strings indicating the different classes.\n prefix: string that is prepended to the metric names.\n postfix: string that is appended to the metric names.\n\n Example::\n Basic example where the ouput of a metric is unwrapped into a dictionary with the class index as keys:\n\n >>> import torch\n >>> _ = torch.manual_seed(42)\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))\n >>> preds = torch.randn(10, 3).softmax(dim=-1)\n >>> target = torch.randint(3, (10,))\n >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE\n {'multiclassaccuracy_0': tensor(0.5000),\n 'multiclassaccuracy_1': tensor(0.7500),\n 'multiclassaccuracy_2': tensor(0.)}\n\n Example::\n Using custom name via prefix and postfix:\n\n >>> import torch\n >>> _ = torch.manual_seed(42)\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> metric_pre = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), prefix=\"acc-\")\n >>> metric_post = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), postfix=\"-acc\")\n >>> preds = torch.randn(10, 3).softmax(dim=-1)\n >>> target = torch.randint(3, (10,))\n >>> metric_pre(preds, target) # doctest: +NORMALIZE_WHITESPACE\n {'acc-0': tensor(0.5000),\n 'acc-1': tensor(0.7500),\n 'acc-2': tensor(0.)}\n >>> metric_post(preds, target) # doctest: +NORMALIZE_WHITESPACE\n {'0-acc': tensor(0.5000),\n '1-acc': tensor(0.7500),\n '2-acc': tensor(0.)}\n\n Example::\n Providing labels as a list of strings:\n\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> metric = ClasswiseWrapper(\n ... MulticlassAccuracy(num_classes=3, average=None),\n ... labels=[\"horse\", \"fish\", \"dog\"]\n ... )\n >>> preds = torch.randn(10, 3).softmax(dim=-1)\n >>> target = torch.randint(3, (10,))\n >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE\n {'multiclassaccuracy_horse': tensor(0.3333),\n 'multiclassaccuracy_fish': tensor(0.6667),\n 'multiclassaccuracy_dog': tensor(0.)}\n\n Example::\n Classwise can also be used in combination with :class:`~torchmetrics.MetricCollection`. In this case, everything\n will be flattened into a single dictionary:\n\n >>> from torchmetrics import MetricCollection\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy, MulticlassRecall\n >>> labels = [\"horse\", \"fish\", \"dog\"]\n >>> metric = MetricCollection(\n ... {'multiclassaccuracy': ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None), labels),\n ... 'multiclassrecall': ClasswiseWrapper(MulticlassRecall(num_classes=3, average=None), labels)}\n ... )\n >>> preds = torch.randn(10, 3).softmax(dim=-1)\n >>> target = torch.randint(3, (10,))\n >>> metric(preds, target) # doctest: +NORMALIZE_WHITESPACE\n {'multiclassaccuracy_horse': tensor(0.),\n 'multiclassaccuracy_fish': tensor(0.3333),\n 'multiclassaccuracy_dog': tensor(0.4000),\n 'multiclassrecall_horse': tensor(0.),\n 'multiclassrecall_fish': tensor(0.3333),\n 'multiclassrecall_dog': tensor(0.4000)}\n\n \"\"\"\n\n def __init__(\n self,\n metric: Metric,\n labels: Optional[List[str]] = None,\n prefix: Optional[str] = None,\n postfix: Optional[str] = None,\n ) -> None:\n super().__init__()\n if not isinstance(metric, Metric):\n raise ValueError(f\"Expected argument `metric` to be an instance of `torchmetrics.Metric` but got {metric}\")\n self.metric = metric\n\n if labels is not None and not (isinstance(labels, list) and all(isinstance(lab, str) for lab in labels)):\n raise ValueError(f\"Expected argument `labels` to either be `None` or a list of strings but got {labels}\")\n self.labels = labels\n\n if prefix is not None and not isinstance(prefix, str):\n raise ValueError(f\"Expected argument `prefix` to either be `None` or a string but got {prefix}\")\n self.prefix = prefix\n\n if postfix is not None and not isinstance(postfix, str):\n raise ValueError(f\"Expected argument `postfix` to either be `None` or a string but got {postfix}\")\n self.postfix = postfix\n\n self._update_count = 1\n\n def _convert(self, x: Tensor) -> Dict[str, Any]:\n # Will set the class name as prefix if neither prefix nor postfix is given\n if not self.prefix and not self.postfix:\n prefix = f\"{self.metric.__class__.__name__.lower()}_\"\n postfix = \"\"\n else:\n prefix = self.prefix or \"\"\n postfix = self.postfix or \"\"\n if self.labels is None:\n return {f\"{prefix}{i}{postfix}\": val for i, val in enumerate(x)}\n return {f\"{prefix}{lab}{postfix}\": val for lab, val in zip(self.labels, x)}\n\n def forward(self, *args: Any, **kwargs: Any) -> Any:\n \"\"\"Calculate on batch and accumulate to global state.\"\"\"\n return self._convert(self.metric(*args, **kwargs))\n\n def update(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Update state.\"\"\"\n self.metric.update(*args, **kwargs)\n\n def compute(self) -> Dict[str, Tensor]:\n \"\"\"Compute metric.\"\"\"\n return self._convert(self.metric.compute())\n\n def reset(self) -> None:\n \"\"\"Reset metric.\"\"\"\n self.metric.reset()\n\n def plot(\n self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None\n ) -> _PLOT_OUT_TYPE:\n \"\"\"Plot a single or multiple values from the metric.\n\n Args:\n val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.\n If no value is provided, will automatically call `metric.compute` and plot that result.\n ax: An matplotlib axis object. If provided will add plot to that axis\n\n Returns:\n Figure and Axes object\n\n Raises:\n ModuleNotFoundError:\n If `matplotlib` is not installed\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting a single value\n >>> import torch\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))\n >>> metric.update(torch.randint(3, (20,)), torch.randint(3, (20,)))\n >>> fig_, ax_ = metric.plot()\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting multiple values\n >>> import torch\n >>> from torchmetrics.wrappers import ClasswiseWrapper\n >>> from torchmetrics.classification import MulticlassAccuracy\n >>> metric = ClasswiseWrapper(MulticlassAccuracy(num_classes=3, average=None))\n >>> values = [ ]\n >>> for _ in range(3):\n ... values.append(metric(torch.randint(3, (20,)), torch.randint(3, (20,))))\n >>> fig_, ax_ = metric.plot(values)\n\n \"\"\"\n return self._plot(val, ax)\n", "path": "src/torchmetrics/wrappers/classwise.py"}]}
| 3,735 | 359 |
gh_patches_debug_11035
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-821
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyPy performance on test_image_point is awful
Hoisted from #476, test_image_point.py takes ~ 2 minutes to run, vs < 1 sec for cpython.
</issue>
<code>
[start of profile-installed.py]
1 #!/usr/bin/env python
2 import nose
3 import os
4 import sys
5 import glob
6
7 import profile
8
9 # monkey with the path, removing the local directory but adding the Tests/
10 # directory for helper.py and the other local imports there.
11
12 del(sys.path[0])
13 sys.path.insert(0, os.path.abspath('./Tests'))
14
15 # if there's no test selected (mostly) choose a working default.
16 # Something is required, because if we import the tests from the local
17 # directory, once again, we've got the non-installed PIL in the way
18 if len(sys.argv) == 1:
19 sys.argv.extend(glob.glob('Tests/test*.py'))
20
21 # Make sure that nose doesn't muck with our paths.
22 if ('--no-path-adjustment' not in sys.argv) and ('-P' not in sys.argv):
23 sys.argv.insert(1, '--no-path-adjustment')
24
25 if 'NOSE_PROCESSES' not in os.environ:
26 for arg in sys.argv:
27 if '--processes' in arg:
28 break
29 else: # for
30 sys.argv.insert(1, '--processes=-1') # -1 == number of cores
31 sys.argv.insert(1, '--process-timeout=30')
32
33 if __name__ == '__main__':
34 profile.run("nose.main()", sort=2)
35
[end of profile-installed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/profile-installed.py b/profile-installed.py
--- a/profile-installed.py
+++ b/profile-installed.py
@@ -21,14 +21,6 @@
# Make sure that nose doesn't muck with our paths.
if ('--no-path-adjustment' not in sys.argv) and ('-P' not in sys.argv):
sys.argv.insert(1, '--no-path-adjustment')
-
-if 'NOSE_PROCESSES' not in os.environ:
- for arg in sys.argv:
- if '--processes' in arg:
- break
- else: # for
- sys.argv.insert(1, '--processes=-1') # -1 == number of cores
- sys.argv.insert(1, '--process-timeout=30')
if __name__ == '__main__':
profile.run("nose.main()", sort=2)
|
{"golden_diff": "diff --git a/profile-installed.py b/profile-installed.py\n--- a/profile-installed.py\n+++ b/profile-installed.py\n@@ -21,14 +21,6 @@\n # Make sure that nose doesn't muck with our paths.\n if ('--no-path-adjustment' not in sys.argv) and ('-P' not in sys.argv):\n sys.argv.insert(1, '--no-path-adjustment')\n-\n-if 'NOSE_PROCESSES' not in os.environ:\n- for arg in sys.argv:\n- if '--processes' in arg:\n- break\n- else: # for\n- sys.argv.insert(1, '--processes=-1') # -1 == number of cores\n- sys.argv.insert(1, '--process-timeout=30') \n \n if __name__ == '__main__':\n profile.run(\"nose.main()\", sort=2)\n", "issue": "PyPy performance on test_image_point is awful\nHoisted from #476, test_image_point.py takes ~ 2 minutes to run, vs < 1 sec for cpython.\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport nose\nimport os\nimport sys\nimport glob\n\nimport profile\n\n# monkey with the path, removing the local directory but adding the Tests/\n# directory for helper.py and the other local imports there.\n\ndel(sys.path[0])\nsys.path.insert(0, os.path.abspath('./Tests'))\n\n# if there's no test selected (mostly) choose a working default.\n# Something is required, because if we import the tests from the local\n# directory, once again, we've got the non-installed PIL in the way\nif len(sys.argv) == 1:\n sys.argv.extend(glob.glob('Tests/test*.py'))\n\n# Make sure that nose doesn't muck with our paths.\nif ('--no-path-adjustment' not in sys.argv) and ('-P' not in sys.argv):\n sys.argv.insert(1, '--no-path-adjustment')\n\nif 'NOSE_PROCESSES' not in os.environ:\n for arg in sys.argv:\n if '--processes' in arg:\n break\n else: # for\n sys.argv.insert(1, '--processes=-1') # -1 == number of cores\n sys.argv.insert(1, '--process-timeout=30') \n \nif __name__ == '__main__':\n profile.run(\"nose.main()\", sort=2)\n", "path": "profile-installed.py"}]}
| 922 | 194 |
gh_patches_debug_2448
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-3200
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't create config object
Much like https://github.com/docker/docker-py/issues/2025 the config model is failing to create a new object due to 'name' KeyError
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "docker\models\configs.py", line 10, in __repr__
return f"<{self.__class__.__name__}: '{self.name}'>"
File "docker\models\configs.py", line 14, in name
return self.attrs['Spec']['Name']
```
This https://github.com/docker/docker-py/pull/2793 appears to be the fix that was implemented and should likely be implements for configs as well (if not other models that might have this issue)
</issue>
<code>
[start of docker/models/configs.py]
1 from ..api import APIClient
2 from .resource import Model, Collection
3
4
5 class Config(Model):
6 """A config."""
7 id_attribute = 'ID'
8
9 def __repr__(self):
10 return f"<{self.__class__.__name__}: '{self.name}'>"
11
12 @property
13 def name(self):
14 return self.attrs['Spec']['Name']
15
16 def remove(self):
17 """
18 Remove this config.
19
20 Raises:
21 :py:class:`docker.errors.APIError`
22 If config failed to remove.
23 """
24 return self.client.api.remove_config(self.id)
25
26
27 class ConfigCollection(Collection):
28 """Configs on the Docker server."""
29 model = Config
30
31 def create(self, **kwargs):
32 obj = self.client.api.create_config(**kwargs)
33 return self.prepare_model(obj)
34 create.__doc__ = APIClient.create_config.__doc__
35
36 def get(self, config_id):
37 """
38 Get a config.
39
40 Args:
41 config_id (str): Config ID.
42
43 Returns:
44 (:py:class:`Config`): The config.
45
46 Raises:
47 :py:class:`docker.errors.NotFound`
48 If the config does not exist.
49 :py:class:`docker.errors.APIError`
50 If the server returns an error.
51 """
52 return self.prepare_model(self.client.api.inspect_config(config_id))
53
54 def list(self, **kwargs):
55 """
56 List configs. Similar to the ``docker config ls`` command.
57
58 Args:
59 filters (dict): Server-side list filtering options.
60
61 Returns:
62 (list of :py:class:`Config`): The configs.
63
64 Raises:
65 :py:class:`docker.errors.APIError`
66 If the server returns an error.
67 """
68 resp = self.client.api.configs(**kwargs)
69 return [self.prepare_model(obj) for obj in resp]
70
[end of docker/models/configs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docker/models/configs.py b/docker/models/configs.py
--- a/docker/models/configs.py
+++ b/docker/models/configs.py
@@ -30,6 +30,7 @@
def create(self, **kwargs):
obj = self.client.api.create_config(**kwargs)
+ obj.setdefault("Spec", {})["Name"] = kwargs.get("name")
return self.prepare_model(obj)
create.__doc__ = APIClient.create_config.__doc__
|
{"golden_diff": "diff --git a/docker/models/configs.py b/docker/models/configs.py\n--- a/docker/models/configs.py\n+++ b/docker/models/configs.py\n@@ -30,6 +30,7 @@\n \n def create(self, **kwargs):\n obj = self.client.api.create_config(**kwargs)\n+ obj.setdefault(\"Spec\", {})[\"Name\"] = kwargs.get(\"name\")\n return self.prepare_model(obj)\n create.__doc__ = APIClient.create_config.__doc__\n", "issue": "Can't create config object\nMuch like https://github.com/docker/docker-py/issues/2025 the config model is failing to create a new object due to 'name' KeyError\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"docker\\models\\configs.py\", line 10, in __repr__\r\n return f\"<{self.__class__.__name__}: '{self.name}'>\"\r\n File \"docker\\models\\configs.py\", line 14, in name\r\n return self.attrs['Spec']['Name']\r\n```\r\n\r\nThis https://github.com/docker/docker-py/pull/2793 appears to be the fix that was implemented and should likely be implements for configs as well (if not other models that might have this issue)\n", "before_files": [{"content": "from ..api import APIClient\nfrom .resource import Model, Collection\n\n\nclass Config(Model):\n \"\"\"A config.\"\"\"\n id_attribute = 'ID'\n\n def __repr__(self):\n return f\"<{self.__class__.__name__}: '{self.name}'>\"\n\n @property\n def name(self):\n return self.attrs['Spec']['Name']\n\n def remove(self):\n \"\"\"\n Remove this config.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If config failed to remove.\n \"\"\"\n return self.client.api.remove_config(self.id)\n\n\nclass ConfigCollection(Collection):\n \"\"\"Configs on the Docker server.\"\"\"\n model = Config\n\n def create(self, **kwargs):\n obj = self.client.api.create_config(**kwargs)\n return self.prepare_model(obj)\n create.__doc__ = APIClient.create_config.__doc__\n\n def get(self, config_id):\n \"\"\"\n Get a config.\n\n Args:\n config_id (str): Config ID.\n\n Returns:\n (:py:class:`Config`): The config.\n\n Raises:\n :py:class:`docker.errors.NotFound`\n If the config does not exist.\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.prepare_model(self.client.api.inspect_config(config_id))\n\n def list(self, **kwargs):\n \"\"\"\n List configs. Similar to the ``docker config ls`` command.\n\n Args:\n filters (dict): Server-side list filtering options.\n\n Returns:\n (list of :py:class:`Config`): The configs.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n resp = self.client.api.configs(**kwargs)\n return [self.prepare_model(obj) for obj in resp]\n", "path": "docker/models/configs.py"}]}
| 1,224 | 101 |
gh_patches_debug_16039
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-2342
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Kserve defaulting causing duplicates of environment variable
/kind bug
**What steps did you take and what happened:**
Create example xgboost isvc and enable gRPC
```
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "xgboost-iris"
spec:
predictor:
xgboost:
protocolVersion: "v2"
storageUri: "gs://kfserving-examples/models/xgboost/iris"
ports:
- containerPort: 9000
name: h2c
protocol: TCP
```
The pod spec has duplicated environment variable
```
Environment:
MLSERVER_MODEL_NAME: xgboost-iris
MLSERVER_MODEL_URI: /mnt/models
MLSERVER_MODEL_NAME: xgboost-iris
MLSERVER_MODEL_URI: /mnt/models
```
Additionally, attempt to override the defaults leads to duplicated environment variable with different values
```
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "xgboost-iris"
spec:
predictor:
xgboost:
protocolVersion: "v2"
storageUri: "gs://kfserving-examples/models/xgboost/iris"
ports:
- containerPort: 9000
name: h2c
protocol: TCP
env:
- name: MLSERVER_MODEL_NAME
value: my-model
```
The pod spec:
```
Environment:
MLSERVER_MODEL_NAME: my-model
MLSERVER_MODEL_NAME: xgboost-iris
MLSERVER_MODEL_URI: /mnt/models
```
**What did you expect to happen:**
- Defaulting should not duplicate environment variable and should prioritise user's defined environment variable
**Anything else you would like to add:**
I believe it's because the defaulter always append `.Env` without checking the presence of existing environment variable. (https://github.com/kserve/kserve/blob/a6ed8e4b006e27433de2336e0e8b7cec11137dc1/pkg/apis/serving/v1beta1/inference_service_defaults.go#L264)
**Environment:**
- Kserve: 0.8.0
</issue>
<code>
[start of python/custom_transformer/model_grpc.py]
1 # Copyright 2022 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import base64
17 from typing import Dict, Union
18
19 from kserve import Model, ModelServer, model_server
20 from kserve.grpc.grpc_predict_v2_pb2 import ModelInferRequest
21 from kserve.handlers.v2_datamodels import InferenceRequest
22
23
24 class ImageTransformer(Model):
25 def __init__(self, name: str, predictor_host: str, protocol: str):
26 super().__init__(name)
27 self.predictor_host = predictor_host
28 self.protocol = protocol
29 self.model_name = name
30
31 def preprocess(self, request: Union[Dict, ModelInferRequest, InferenceRequest], headers=None) -> ModelInferRequest:
32 if isinstance(request, ModelInferRequest):
33 return request
34 else:
35 payload = [
36 {
37 "name": "input-0",
38 "shape": [],
39 "datatype": "BYTES",
40 "contents": {
41 "bytes_contents": [base64.b64decode(request["inputs"][0]["data"][0])]
42 }
43 }
44 ]
45 return ModelInferRequest(model_name=self.model_name, inputs=payload)
46
47
48 parser = argparse.ArgumentParser(parents=[model_server.parser])
49 parser.add_argument(
50 "--predictor_host", help="The URL for the model predict function", required=True
51 )
52 parser.add_argument(
53 "--protocol", help="The protocol for the predictor", default="v1"
54 )
55 parser.add_argument(
56 "--model_name", help="The name that the model is served under."
57 )
58 args, _ = parser.parse_known_args()
59
60 if __name__ == "__main__":
61 model = ImageTransformer(args.model_name, predictor_host=args.predictor_host,
62 protocol=args.protocol)
63 ModelServer(workers=1).start([model])
64
[end of python/custom_transformer/model_grpc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/custom_transformer/model_grpc.py b/python/custom_transformer/model_grpc.py
--- a/python/custom_transformer/model_grpc.py
+++ b/python/custom_transformer/model_grpc.py
@@ -18,7 +18,6 @@
from kserve import Model, ModelServer, model_server
from kserve.grpc.grpc_predict_v2_pb2 import ModelInferRequest
-from kserve.handlers.v2_datamodels import InferenceRequest
class ImageTransformer(Model):
@@ -28,7 +27,7 @@
self.protocol = protocol
self.model_name = name
- def preprocess(self, request: Union[Dict, ModelInferRequest, InferenceRequest], headers=None) -> ModelInferRequest:
+ def preprocess(self, request: Union[Dict, ModelInferRequest], headers=None) -> ModelInferRequest:
if isinstance(request, ModelInferRequest):
return request
else:
|
{"golden_diff": "diff --git a/python/custom_transformer/model_grpc.py b/python/custom_transformer/model_grpc.py\n--- a/python/custom_transformer/model_grpc.py\n+++ b/python/custom_transformer/model_grpc.py\n@@ -18,7 +18,6 @@\n \n from kserve import Model, ModelServer, model_server\n from kserve.grpc.grpc_predict_v2_pb2 import ModelInferRequest\n-from kserve.handlers.v2_datamodels import InferenceRequest\n \n \n class ImageTransformer(Model):\n@@ -28,7 +27,7 @@\n self.protocol = protocol\n self.model_name = name\n \n- def preprocess(self, request: Union[Dict, ModelInferRequest, InferenceRequest], headers=None) -> ModelInferRequest:\n+ def preprocess(self, request: Union[Dict, ModelInferRequest], headers=None) -> ModelInferRequest:\n if isinstance(request, ModelInferRequest):\n return request\n else:\n", "issue": "Kserve defaulting causing duplicates of environment variable \n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\nCreate example xgboost isvc and enable gRPC\r\n```\r\napiVersion: \"serving.kserve.io/v1beta1\"\r\nkind: \"InferenceService\"\r\nmetadata:\r\n name: \"xgboost-iris\"\r\nspec:\r\n predictor:\r\n xgboost:\r\n protocolVersion: \"v2\"\r\n storageUri: \"gs://kfserving-examples/models/xgboost/iris\"\r\n ports:\r\n - containerPort: 9000\r\n name: h2c\r\n protocol: TCP\r\n```\r\n\r\nThe pod spec has duplicated environment variable\r\n```\r\n Environment:\r\n MLSERVER_MODEL_NAME: xgboost-iris\r\n MLSERVER_MODEL_URI: /mnt/models\r\n MLSERVER_MODEL_NAME: xgboost-iris\r\n MLSERVER_MODEL_URI: /mnt/models\r\n```\r\n\r\nAdditionally, attempt to override the defaults leads to duplicated environment variable with different values\r\n\r\n```\r\napiVersion: \"serving.kserve.io/v1beta1\"\r\nkind: \"InferenceService\"\r\nmetadata:\r\n name: \"xgboost-iris\"\r\nspec:\r\n predictor:\r\n xgboost:\r\n protocolVersion: \"v2\"\r\n storageUri: \"gs://kfserving-examples/models/xgboost/iris\"\r\n ports:\r\n - containerPort: 9000\r\n name: h2c\r\n protocol: TCP\r\n env:\r\n - name: MLSERVER_MODEL_NAME\r\n value: my-model\r\n```\r\n\r\nThe pod spec:\r\n```\r\n Environment:\r\n MLSERVER_MODEL_NAME: my-model\r\n MLSERVER_MODEL_NAME: xgboost-iris\r\n MLSERVER_MODEL_URI: /mnt/models\r\n```\r\n\r\n**What did you expect to happen:**\r\n- Defaulting should not duplicate environment variable and should prioritise user's defined environment variable\r\n\r\n**Anything else you would like to add:**\r\nI believe it's because the defaulter always append `.Env` without checking the presence of existing environment variable. (https://github.com/kserve/kserve/blob/a6ed8e4b006e27433de2336e0e8b7cec11137dc1/pkg/apis/serving/v1beta1/inference_service_defaults.go#L264)\r\n\r\n\r\n**Environment:**\r\n\r\n- Kserve: 0.8.0\n", "before_files": [{"content": "# Copyright 2022 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport base64\nfrom typing import Dict, Union\n\nfrom kserve import Model, ModelServer, model_server\nfrom kserve.grpc.grpc_predict_v2_pb2 import ModelInferRequest\nfrom kserve.handlers.v2_datamodels import InferenceRequest\n\n\nclass ImageTransformer(Model):\n def __init__(self, name: str, predictor_host: str, protocol: str):\n super().__init__(name)\n self.predictor_host = predictor_host\n self.protocol = protocol\n self.model_name = name\n\n def preprocess(self, request: Union[Dict, ModelInferRequest, InferenceRequest], headers=None) -> ModelInferRequest:\n if isinstance(request, ModelInferRequest):\n return request\n else:\n payload = [\n {\n \"name\": \"input-0\",\n \"shape\": [],\n \"datatype\": \"BYTES\",\n \"contents\": {\n \"bytes_contents\": [base64.b64decode(request[\"inputs\"][0][\"data\"][0])]\n }\n }\n ]\n return ModelInferRequest(model_name=self.model_name, inputs=payload)\n\n\nparser = argparse.ArgumentParser(parents=[model_server.parser])\nparser.add_argument(\n \"--predictor_host\", help=\"The URL for the model predict function\", required=True\n)\nparser.add_argument(\n \"--protocol\", help=\"The protocol for the predictor\", default=\"v1\"\n)\nparser.add_argument(\n \"--model_name\", help=\"The name that the model is served under.\"\n)\nargs, _ = parser.parse_known_args()\n\nif __name__ == \"__main__\":\n model = ImageTransformer(args.model_name, predictor_host=args.predictor_host,\n protocol=args.protocol)\n ModelServer(workers=1).start([model])\n", "path": "python/custom_transformer/model_grpc.py"}]}
| 1,680 | 203 |
gh_patches_debug_20425
|
rasdani/github-patches
|
git_diff
|
wenet-e2e__wenet-1221
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DLL load failed while importing _wenet: 找不到指定的模块。
我安装了wenet, pip install wenet.
安装提示成功了。
我用例子程序做识别。
程序如下:
import sys
import wenet
def get_text_from_wav(dir, wav):
model_dir = dir
wav_file = wav
decoder = wenet.Decoder(model_dir)
ans = decoder.decode_wav(wav_file)
print(ans)
if __name__ == '__main__':
dir = "./models"
wav = "./1.wav"
get_text_from_wav(dir,wav)
但是运行报错如下:
Traceback (most recent call last):
File "D:\codes\speech2word\main.py", line 2, in <module>
import wenet
File "D:\codes\speech2word\venv\lib\site-packages\wenet\__init__.py", line 1, in <module>
from .decoder import Decoder # noqa
File "D:\codes\speech2word\venv\lib\site-packages\wenet\decoder.py", line 17, in <module>
import _wenet
ImportError: DLL load failed while importing _wenet: 找不到指定的模块。
请问如何解决?
</issue>
<code>
[start of runtime/binding/python/setup.py]
1 #!/usr/bin/env python3
2 # Copyright (c) 2020 Xiaomi Corporation (author: Fangjun Kuang)
3 # 2022 Binbin Zhang([email protected])
4
5 import glob
6 import os
7 import platform
8 import shutil
9 import sys
10
11 import setuptools
12 from setuptools.command.build_ext import build_ext
13
14
15 def is_windows():
16 return platform.system() == "Windows"
17
18
19 def cmake_extension(name, *args, **kwargs) -> setuptools.Extension:
20 kwargs["language"] = "c++"
21 sources = []
22 return setuptools.Extension(name, sources, *args, **kwargs)
23
24
25 class BuildExtension(build_ext):
26 def build_extension(self, ext: setuptools.extension.Extension):
27 os.makedirs(self.build_temp, exist_ok=True)
28 os.makedirs(self.build_lib, exist_ok=True)
29
30 cmake_args = os.environ.get("WENET_CMAKE_ARGS",
31 "-DCMAKE_BUILD_TYPE=Release")
32 if "PYTHON_EXECUTABLE" not in cmake_args:
33 print(f"Setting PYTHON_EXECUTABLE to {sys.executable}")
34 cmake_args += f" -DPYTHON_EXECUTABLE={sys.executable}"
35
36 src_dir = os.path.dirname(os.path.abspath(__file__))
37 os.system(f"cmake {cmake_args} -B {self.build_temp} -S {src_dir}")
38 ret = os.system(f"""
39 cmake --build {self.build_temp} --target _wenet --config Release
40 """)
41 if ret != 0:
42 raise Exception(
43 "\nBuild wenet failed. Please check the error message.\n"
44 "You can ask for help by creating an issue on GitHub.\n"
45 "\nClick:\n https://github.com/wenet-e2e/wenet/issues/new\n"
46 )
47
48 libs = []
49 torch_lib = 'fc_base/libtorch-src/lib'
50 for ext in ['so', 'pyd']:
51 libs.extend(glob.glob(
52 f"{self.build_temp}/**/_wenet*.{ext}", recursive=True))
53 for ext in ['so', 'dylib', 'dll']:
54 libs.extend(glob.glob(
55 f"{self.build_temp}/**/*wenet_api.{ext}", recursive=True))
56 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/*c10.{ext}'))
57 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/*torch_cpu.{ext}'))
58
59 if not is_windows():
60 fst_lib = 'fc_base/openfst-build/src/lib/.libs'
61 for ext in ['so', 'dylib']:
62 libs.extend(glob.glob(f'{src_dir}/{fst_lib}/libfst.{ext}'))
63 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux
64 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp*')) # macos
65 else:
66 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/asmjit.dll'))
67 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/fbgemm.dll'))
68 libs.extend(glob.glob(f'{src_dir}/{torch_lib}/uv.dll'))
69
70 for lib in libs:
71 print(f"Copying {lib} to {self.build_lib}/")
72 shutil.copy(f"{lib}", f"{self.build_lib}/")
73
74
75 def read_long_description():
76 with open("README.md", encoding="utf8") as f:
77 readme = f.read()
78 return readme
79
80
81 package_name = "wenet"
82
83 setuptools.setup(
84 name=package_name,
85 version='1.0.4',
86 author="Binbin Zhang",
87 author_email="[email protected]",
88 package_dir={
89 package_name: "py",
90 },
91 packages=[package_name],
92 url="https://github.com/wenet-e2e/wenet",
93 long_description=read_long_description(),
94 long_description_content_type="text/markdown",
95 ext_modules=[cmake_extension("_wenet")],
96 cmdclass={"build_ext": BuildExtension},
97 zip_safe=False,
98 classifiers=[
99 "Programming Language :: C++",
100 "Programming Language :: Python",
101 "Topic :: Scientific/Engineering :: Artificial Intelligence",
102 ],
103 license="Apache licensed, as found in the LICENSE file",
104 python_requires=">=3.6",
105 )
106
[end of runtime/binding/python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/runtime/binding/python/setup.py b/runtime/binding/python/setup.py
--- a/runtime/binding/python/setup.py
+++ b/runtime/binding/python/setup.py
@@ -60,12 +60,12 @@
fst_lib = 'fc_base/openfst-build/src/lib/.libs'
for ext in ['so', 'dylib']:
libs.extend(glob.glob(f'{src_dir}/{fst_lib}/libfst.{ext}'))
- libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux
- libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp*')) # macos
else:
libs.extend(glob.glob(f'{src_dir}/{torch_lib}/asmjit.dll'))
libs.extend(glob.glob(f'{src_dir}/{torch_lib}/fbgemm.dll'))
libs.extend(glob.glob(f'{src_dir}/{torch_lib}/uv.dll'))
+ libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux
+ libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp5*')) # macos/win
for lib in libs:
print(f"Copying {lib} to {self.build_lib}/")
|
{"golden_diff": "diff --git a/runtime/binding/python/setup.py b/runtime/binding/python/setup.py\n--- a/runtime/binding/python/setup.py\n+++ b/runtime/binding/python/setup.py\n@@ -60,12 +60,12 @@\n fst_lib = 'fc_base/openfst-build/src/lib/.libs'\n for ext in ['so', 'dylib']:\n libs.extend(glob.glob(f'{src_dir}/{fst_lib}/libfst.{ext}'))\n- libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux\n- libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp*')) # macos\n else:\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/asmjit.dll'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/fbgemm.dll'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/uv.dll'))\n+ libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux\n+ libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp5*')) # macos/win\n \n for lib in libs:\n print(f\"Copying {lib} to {self.build_lib}/\")\n", "issue": "DLL load failed while importing _wenet: \u627e\u4e0d\u5230\u6307\u5b9a\u7684\u6a21\u5757\u3002\n\u6211\u5b89\u88c5\u4e86wenet, pip install wenet.\r\n\u5b89\u88c5\u63d0\u793a\u6210\u529f\u4e86\u3002\r\n\u6211\u7528\u4f8b\u5b50\u7a0b\u5e8f\u505a\u8bc6\u522b\u3002\r\n\u7a0b\u5e8f\u5982\u4e0b\uff1a\r\nimport sys\r\nimport wenet\r\n\r\ndef get_text_from_wav(dir, wav):\r\n model_dir = dir\r\n wav_file = wav\r\n decoder = wenet.Decoder(model_dir)\r\n ans = decoder.decode_wav(wav_file)\r\n print(ans)\r\n\r\nif __name__ == '__main__':\r\n dir = \"./models\"\r\n wav = \"./1.wav\"\r\n get_text_from_wav(dir,wav)\r\n\r\n\u4f46\u662f\u8fd0\u884c\u62a5\u9519\u5982\u4e0b\uff1a\r\nTraceback (most recent call last):\r\n File \"D:\\codes\\speech2word\\main.py\", line 2, in <module>\r\n import wenet\r\n File \"D:\\codes\\speech2word\\venv\\lib\\site-packages\\wenet\\__init__.py\", line 1, in <module>\r\n from .decoder import Decoder # noqa\r\n File \"D:\\codes\\speech2word\\venv\\lib\\site-packages\\wenet\\decoder.py\", line 17, in <module>\r\n import _wenet\r\nImportError: DLL load failed while importing _wenet: \u627e\u4e0d\u5230\u6307\u5b9a\u7684\u6a21\u5757\u3002\r\n\r\n\u8bf7\u95ee\u5982\u4f55\u89e3\u51b3\uff1f\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright (c) 2020 Xiaomi Corporation (author: Fangjun Kuang)\n# 2022 Binbin Zhang([email protected])\n\nimport glob\nimport os\nimport platform\nimport shutil\nimport sys\n\nimport setuptools\nfrom setuptools.command.build_ext import build_ext\n\n\ndef is_windows():\n return platform.system() == \"Windows\"\n\n\ndef cmake_extension(name, *args, **kwargs) -> setuptools.Extension:\n kwargs[\"language\"] = \"c++\"\n sources = []\n return setuptools.Extension(name, sources, *args, **kwargs)\n\n\nclass BuildExtension(build_ext):\n def build_extension(self, ext: setuptools.extension.Extension):\n os.makedirs(self.build_temp, exist_ok=True)\n os.makedirs(self.build_lib, exist_ok=True)\n\n cmake_args = os.environ.get(\"WENET_CMAKE_ARGS\",\n \"-DCMAKE_BUILD_TYPE=Release\")\n if \"PYTHON_EXECUTABLE\" not in cmake_args:\n print(f\"Setting PYTHON_EXECUTABLE to {sys.executable}\")\n cmake_args += f\" -DPYTHON_EXECUTABLE={sys.executable}\"\n\n src_dir = os.path.dirname(os.path.abspath(__file__))\n os.system(f\"cmake {cmake_args} -B {self.build_temp} -S {src_dir}\")\n ret = os.system(f\"\"\"\n cmake --build {self.build_temp} --target _wenet --config Release\n \"\"\")\n if ret != 0:\n raise Exception(\n \"\\nBuild wenet failed. Please check the error message.\\n\"\n \"You can ask for help by creating an issue on GitHub.\\n\"\n \"\\nClick:\\n https://github.com/wenet-e2e/wenet/issues/new\\n\"\n )\n\n libs = []\n torch_lib = 'fc_base/libtorch-src/lib'\n for ext in ['so', 'pyd']:\n libs.extend(glob.glob(\n f\"{self.build_temp}/**/_wenet*.{ext}\", recursive=True))\n for ext in ['so', 'dylib', 'dll']:\n libs.extend(glob.glob(\n f\"{self.build_temp}/**/*wenet_api.{ext}\", recursive=True))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/*c10.{ext}'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/*torch_cpu.{ext}'))\n\n if not is_windows():\n fst_lib = 'fc_base/openfst-build/src/lib/.libs'\n for ext in ['so', 'dylib']:\n libs.extend(glob.glob(f'{src_dir}/{fst_lib}/libfst.{ext}'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libgomp*')) # linux\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/libiomp*')) # macos\n else:\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/asmjit.dll'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/fbgemm.dll'))\n libs.extend(glob.glob(f'{src_dir}/{torch_lib}/uv.dll'))\n\n for lib in libs:\n print(f\"Copying {lib} to {self.build_lib}/\")\n shutil.copy(f\"{lib}\", f\"{self.build_lib}/\")\n\n\ndef read_long_description():\n with open(\"README.md\", encoding=\"utf8\") as f:\n readme = f.read()\n return readme\n\n\npackage_name = \"wenet\"\n\nsetuptools.setup(\n name=package_name,\n version='1.0.4',\n author=\"Binbin Zhang\",\n author_email=\"[email protected]\",\n package_dir={\n package_name: \"py\",\n },\n packages=[package_name],\n url=\"https://github.com/wenet-e2e/wenet\",\n long_description=read_long_description(),\n long_description_content_type=\"text/markdown\",\n ext_modules=[cmake_extension(\"_wenet\")],\n cmdclass={\"build_ext\": BuildExtension},\n zip_safe=False,\n classifiers=[\n \"Programming Language :: C++\",\n \"Programming Language :: Python\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n license=\"Apache licensed, as found in the LICENSE file\",\n python_requires=\">=3.6\",\n)\n", "path": "runtime/binding/python/setup.py"}]}
| 1,948 | 274 |
gh_patches_debug_42539
|
rasdani/github-patches
|
git_diff
|
translate__pootle-6705
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate update/sync stores
Wondering what is best with these commands.
on the one hand they are quite useful for grouping common operations
on the other, it would be better for users to learn the more powerful fs api, and grouping can be done in other ways
</issue>
<code>
[start of pootle/apps/pootle_app/management/commands/update_stores.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import logging
10 import os
11 os.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'
12
13 from pootle_app.management.commands import PootleCommand
14 from pootle_language.models import Language
15 from pootle_fs.utils import FSPlugin
16 from pootle_project.models import Project
17
18
19 logger = logging.getLogger(__name__)
20
21
22 class Command(PootleCommand):
23 help = "Update database stores from files."
24 process_disabled_projects = True
25 log_name = "update"
26
27 def add_arguments(self, parser):
28 super(Command, self).add_arguments(parser)
29 parser.add_argument(
30 '--overwrite',
31 action='store_true',
32 dest='overwrite',
33 default=False,
34 help="Don't just update untranslated units "
35 "and add new units, but overwrite database "
36 "translations to reflect state in files.",
37 )
38 parser.add_argument(
39 '--force',
40 action='store_true',
41 dest='force',
42 default=False,
43 help="Unconditionally process all files (even if they "
44 "appear unchanged).",
45 )
46
47 def handle_translation_project(self, translation_project, **options):
48 """
49 """
50 path_glob = "%s*" % translation_project.pootle_path
51 plugin = FSPlugin(translation_project.project)
52 plugin.add(pootle_path=path_glob, update="pootle")
53 plugin.rm(pootle_path=path_glob, update="pootle")
54 plugin.resolve(pootle_path=path_glob)
55 plugin.sync(pootle_path=path_glob, update="pootle")
56
57 def _parse_tps_to_create(self, project):
58 plugin = FSPlugin(project)
59 plugin.fetch()
60 untracked_languages = set(
61 fs.pootle_path.split("/")[1]
62 for fs
63 in plugin.state()["fs_untracked"])
64 new_langs = (
65 [lang for lang
66 in untracked_languages
67 if lang in self.languages]
68 if self.languages
69 else untracked_languages)
70 return Language.objects.filter(
71 code__in=new_langs).exclude(
72 code__in=project.translationproject_set.values_list(
73 "language__code", flat=True))
74
75 def _create_tps_for_project(self, project):
76 for language in self._parse_tps_to_create(project):
77 project.translationproject_set.create(
78 language=language,
79 project=project)
80
81 def handle_all(self, **options):
82 projects = (
83 Project.objects.filter(code__in=self.projects)
84 if self.projects
85 else Project.objects.all())
86 for project in projects.iterator():
87 self._create_tps_for_project(project)
88 super(Command, self).handle_all(**options)
89
[end of pootle/apps/pootle_app/management/commands/update_stores.py]
[start of pootle/apps/pootle_app/management/commands/sync_stores.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import logging
10 import os
11 os.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'
12
13 from pootle_app.management.commands import PootleCommand
14 from pootle_fs.utils import FSPlugin
15
16
17 logger = logging.getLogger(__name__)
18
19
20 class Command(PootleCommand):
21 help = "Save new translations to disk manually."
22 process_disabled_projects = True
23
24 def add_arguments(self, parser):
25 super(Command, self).add_arguments(parser)
26 parser.add_argument(
27 '--overwrite',
28 action='store_true',
29 dest='overwrite',
30 default=False,
31 help="Don't just save translations, but "
32 "overwrite files to reflect state in database",
33 )
34 parser.add_argument(
35 '--skip-missing',
36 action='store_true',
37 dest='skip_missing',
38 default=False,
39 help="Ignore missing files on disk",
40 )
41 parser.add_argument(
42 '--force',
43 action='store_true',
44 dest='force',
45 default=False,
46 help="Don't ignore stores synced after last change",
47 )
48
49 warn_on_conflict = []
50
51 def handle_all_stores(self, translation_project, **options):
52 path_glob = "%s*" % translation_project.pootle_path
53 plugin = FSPlugin(translation_project.project)
54 plugin.fetch()
55 if translation_project.project.pk not in self.warn_on_conflict:
56 state = plugin.state()
57 if any(k in state for k in ["conflict", "conflict_untracked"]):
58 logger.warn(
59 "The project '%s' has conflicting changes in the database "
60 "and translation files. Use `pootle fs resolve` to tell "
61 "pootle how to merge",
62 translation_project.project.code)
63 self.warn_on_conflict.append(
64 translation_project.project.pk)
65 if not options["skip_missing"]:
66 plugin.add(pootle_path=path_glob, update="fs")
67 if options["overwrite"]:
68 plugin.resolve(
69 pootle_path=path_glob,
70 pootle_wins=True)
71 plugin.sync(pootle_path=path_glob, update="fs")
72 if options["force"]:
73 # touch the timestamps on disk for files that
74 # werent updated
75 pass
76
[end of pootle/apps/pootle_app/management/commands/sync_stores.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/apps/pootle_app/management/commands/sync_stores.py b/pootle/apps/pootle_app/management/commands/sync_stores.py
--- a/pootle/apps/pootle_app/management/commands/sync_stores.py
+++ b/pootle/apps/pootle_app/management/commands/sync_stores.py
@@ -28,9 +28,7 @@
action='store_true',
dest='overwrite',
default=False,
- help="Don't just save translations, but "
- "overwrite files to reflect state in database",
- )
+ help="This option has been removed.")
parser.add_argument(
'--skip-missing',
action='store_true',
@@ -43,11 +41,21 @@
action='store_true',
dest='force',
default=False,
- help="Don't ignore stores synced after last change",
- )
+ help="This option has been removed.")
warn_on_conflict = []
+ def handle(self, **options):
+ logger.warn(
+ "The sync_stores command is deprecated, use pootle fs instead")
+ if options["force"]:
+ logger.warn(
+ "The force option no longer has any affect on this command")
+ if options["overwrite"]:
+ logger.warn(
+ "The overwrite option no longer has any affect on this command")
+ super(Command, self).handle(**options)
+
def handle_all_stores(self, translation_project, **options):
path_glob = "%s*" % translation_project.pootle_path
plugin = FSPlugin(translation_project.project)
@@ -64,12 +72,4 @@
translation_project.project.pk)
if not options["skip_missing"]:
plugin.add(pootle_path=path_glob, update="fs")
- if options["overwrite"]:
- plugin.resolve(
- pootle_path=path_glob,
- pootle_wins=True)
plugin.sync(pootle_path=path_glob, update="fs")
- if options["force"]:
- # touch the timestamps on disk for files that
- # werent updated
- pass
diff --git a/pootle/apps/pootle_app/management/commands/update_stores.py b/pootle/apps/pootle_app/management/commands/update_stores.py
--- a/pootle/apps/pootle_app/management/commands/update_stores.py
+++ b/pootle/apps/pootle_app/management/commands/update_stores.py
@@ -40,9 +40,7 @@
action='store_true',
dest='force',
default=False,
- help="Unconditionally process all files (even if they "
- "appear unchanged).",
- )
+ help="This option has been removed.")
def handle_translation_project(self, translation_project, **options):
"""
@@ -51,7 +49,9 @@
plugin = FSPlugin(translation_project.project)
plugin.add(pootle_path=path_glob, update="pootle")
plugin.rm(pootle_path=path_glob, update="pootle")
- plugin.resolve(pootle_path=path_glob)
+ plugin.resolve(
+ pootle_path=path_glob,
+ merge=not options["overwrite"])
plugin.sync(pootle_path=path_glob, update="pootle")
def _parse_tps_to_create(self, project):
@@ -79,6 +79,11 @@
project=project)
def handle_all(self, **options):
+ logger.warn(
+ "The update_stores command is deprecated, use pootle fs instead")
+ if options["force"]:
+ logger.warn(
+ "The force option no longer has any affect on this command")
projects = (
Project.objects.filter(code__in=self.projects)
if self.projects
|
{"golden_diff": "diff --git a/pootle/apps/pootle_app/management/commands/sync_stores.py b/pootle/apps/pootle_app/management/commands/sync_stores.py\n--- a/pootle/apps/pootle_app/management/commands/sync_stores.py\n+++ b/pootle/apps/pootle_app/management/commands/sync_stores.py\n@@ -28,9 +28,7 @@\n action='store_true',\n dest='overwrite',\n default=False,\n- help=\"Don't just save translations, but \"\n- \"overwrite files to reflect state in database\",\n- )\n+ help=\"This option has been removed.\")\n parser.add_argument(\n '--skip-missing',\n action='store_true',\n@@ -43,11 +41,21 @@\n action='store_true',\n dest='force',\n default=False,\n- help=\"Don't ignore stores synced after last change\",\n- )\n+ help=\"This option has been removed.\")\n \n warn_on_conflict = []\n \n+ def handle(self, **options):\n+ logger.warn(\n+ \"The sync_stores command is deprecated, use pootle fs instead\")\n+ if options[\"force\"]:\n+ logger.warn(\n+ \"The force option no longer has any affect on this command\")\n+ if options[\"overwrite\"]:\n+ logger.warn(\n+ \"The overwrite option no longer has any affect on this command\")\n+ super(Command, self).handle(**options)\n+\n def handle_all_stores(self, translation_project, **options):\n path_glob = \"%s*\" % translation_project.pootle_path\n plugin = FSPlugin(translation_project.project)\n@@ -64,12 +72,4 @@\n translation_project.project.pk)\n if not options[\"skip_missing\"]:\n plugin.add(pootle_path=path_glob, update=\"fs\")\n- if options[\"overwrite\"]:\n- plugin.resolve(\n- pootle_path=path_glob,\n- pootle_wins=True)\n plugin.sync(pootle_path=path_glob, update=\"fs\")\n- if options[\"force\"]:\n- # touch the timestamps on disk for files that\n- # werent updated\n- pass\ndiff --git a/pootle/apps/pootle_app/management/commands/update_stores.py b/pootle/apps/pootle_app/management/commands/update_stores.py\n--- a/pootle/apps/pootle_app/management/commands/update_stores.py\n+++ b/pootle/apps/pootle_app/management/commands/update_stores.py\n@@ -40,9 +40,7 @@\n action='store_true',\n dest='force',\n default=False,\n- help=\"Unconditionally process all files (even if they \"\n- \"appear unchanged).\",\n- )\n+ help=\"This option has been removed.\")\n \n def handle_translation_project(self, translation_project, **options):\n \"\"\"\n@@ -51,7 +49,9 @@\n plugin = FSPlugin(translation_project.project)\n plugin.add(pootle_path=path_glob, update=\"pootle\")\n plugin.rm(pootle_path=path_glob, update=\"pootle\")\n- plugin.resolve(pootle_path=path_glob)\n+ plugin.resolve(\n+ pootle_path=path_glob,\n+ merge=not options[\"overwrite\"])\n plugin.sync(pootle_path=path_glob, update=\"pootle\")\n \n def _parse_tps_to_create(self, project):\n@@ -79,6 +79,11 @@\n project=project)\n \n def handle_all(self, **options):\n+ logger.warn(\n+ \"The update_stores command is deprecated, use pootle fs instead\")\n+ if options[\"force\"]:\n+ logger.warn(\n+ \"The force option no longer has any affect on this command\")\n projects = (\n Project.objects.filter(code__in=self.projects)\n if self.projects\n", "issue": "Deprecate update/sync stores\nWondering what is best with these commands.\r\n\r\non the one hand they are quite useful for grouping common operations\r\n\r\non the other, it would be better for users to learn the more powerful fs api, and grouping can be done in other ways\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nos.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'\n\nfrom pootle_app.management.commands import PootleCommand\nfrom pootle_language.models import Language\nfrom pootle_fs.utils import FSPlugin\nfrom pootle_project.models import Project\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(PootleCommand):\n help = \"Update database stores from files.\"\n process_disabled_projects = True\n log_name = \"update\"\n\n def add_arguments(self, parser):\n super(Command, self).add_arguments(parser)\n parser.add_argument(\n '--overwrite',\n action='store_true',\n dest='overwrite',\n default=False,\n help=\"Don't just update untranslated units \"\n \"and add new units, but overwrite database \"\n \"translations to reflect state in files.\",\n )\n parser.add_argument(\n '--force',\n action='store_true',\n dest='force',\n default=False,\n help=\"Unconditionally process all files (even if they \"\n \"appear unchanged).\",\n )\n\n def handle_translation_project(self, translation_project, **options):\n \"\"\"\n \"\"\"\n path_glob = \"%s*\" % translation_project.pootle_path\n plugin = FSPlugin(translation_project.project)\n plugin.add(pootle_path=path_glob, update=\"pootle\")\n plugin.rm(pootle_path=path_glob, update=\"pootle\")\n plugin.resolve(pootle_path=path_glob)\n plugin.sync(pootle_path=path_glob, update=\"pootle\")\n\n def _parse_tps_to_create(self, project):\n plugin = FSPlugin(project)\n plugin.fetch()\n untracked_languages = set(\n fs.pootle_path.split(\"/\")[1]\n for fs\n in plugin.state()[\"fs_untracked\"])\n new_langs = (\n [lang for lang\n in untracked_languages\n if lang in self.languages]\n if self.languages\n else untracked_languages)\n return Language.objects.filter(\n code__in=new_langs).exclude(\n code__in=project.translationproject_set.values_list(\n \"language__code\", flat=True))\n\n def _create_tps_for_project(self, project):\n for language in self._parse_tps_to_create(project):\n project.translationproject_set.create(\n language=language,\n project=project)\n\n def handle_all(self, **options):\n projects = (\n Project.objects.filter(code__in=self.projects)\n if self.projects\n else Project.objects.all())\n for project in projects.iterator():\n self._create_tps_for_project(project)\n super(Command, self).handle_all(**options)\n", "path": "pootle/apps/pootle_app/management/commands/update_stores.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nos.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'\n\nfrom pootle_app.management.commands import PootleCommand\nfrom pootle_fs.utils import FSPlugin\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(PootleCommand):\n help = \"Save new translations to disk manually.\"\n process_disabled_projects = True\n\n def add_arguments(self, parser):\n super(Command, self).add_arguments(parser)\n parser.add_argument(\n '--overwrite',\n action='store_true',\n dest='overwrite',\n default=False,\n help=\"Don't just save translations, but \"\n \"overwrite files to reflect state in database\",\n )\n parser.add_argument(\n '--skip-missing',\n action='store_true',\n dest='skip_missing',\n default=False,\n help=\"Ignore missing files on disk\",\n )\n parser.add_argument(\n '--force',\n action='store_true',\n dest='force',\n default=False,\n help=\"Don't ignore stores synced after last change\",\n )\n\n warn_on_conflict = []\n\n def handle_all_stores(self, translation_project, **options):\n path_glob = \"%s*\" % translation_project.pootle_path\n plugin = FSPlugin(translation_project.project)\n plugin.fetch()\n if translation_project.project.pk not in self.warn_on_conflict:\n state = plugin.state()\n if any(k in state for k in [\"conflict\", \"conflict_untracked\"]):\n logger.warn(\n \"The project '%s' has conflicting changes in the database \"\n \"and translation files. Use `pootle fs resolve` to tell \"\n \"pootle how to merge\",\n translation_project.project.code)\n self.warn_on_conflict.append(\n translation_project.project.pk)\n if not options[\"skip_missing\"]:\n plugin.add(pootle_path=path_glob, update=\"fs\")\n if options[\"overwrite\"]:\n plugin.resolve(\n pootle_path=path_glob,\n pootle_wins=True)\n plugin.sync(pootle_path=path_glob, update=\"fs\")\n if options[\"force\"]:\n # touch the timestamps on disk for files that\n # werent updated\n pass\n", "path": "pootle/apps/pootle_app/management/commands/sync_stores.py"}]}
| 2,136 | 843 |
gh_patches_debug_58086
|
rasdani/github-patches
|
git_diff
|
secondmind-labs__trieste-730
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot install trieste from pypi on MacOS
**Describe the bug**
`pip install trieste` fails on MacOS
**To reproduce**
Steps to reproduce the behaviour:
```
$ pip install trieste
Collecting trieste
Downloading trieste-1.1.2-py3-none-any.whl (246 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 246.6/246.6 kB 3.4 MB/s eta 0:00:00
Downloading trieste-1.1.1-py3-none-any.whl (246 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 246.5/246.5 kB 10.5 MB/s eta 0:00:00
Downloading trieste-1.1.0-py3-none-any.whl (246 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 246.5/246.5 kB 10.5 MB/s eta 0:00:00
Downloading trieste-1.0.0-py3-none-any.whl (240 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 240.4/240.4 kB 16.6 MB/s eta 0:00:00
Using cached trieste-0.13.3-py3-none-any.whl (233 kB)
Using cached trieste-0.13.2-py3-none-any.whl (218 kB)
Using cached trieste-0.13.1-py3-none-any.whl (220 kB)
Collecting dill==0.3.4
Using cached dill-0.3.4-py2.py3-none-any.whl (86 kB)
Collecting gpflow==2.5.2
Using cached gpflow-2.5.2-py3-none-any.whl (383 kB)
Collecting trieste
Using cached trieste-0.13.0-py3-none-any.whl (215 kB)
Using cached trieste-0.12.0-py3-none-any.whl (208 kB)
Using cached trieste-0.11.3-py3-none-any.whl (196 kB)
Using cached trieste-0.11.2-py3-none-any.whl (196 kB)
Using cached trieste-0.11.1-py3-none-any.whl (195 kB)
Using cached trieste-0.11.0-py3-none-any.whl (195 kB)
Using cached trieste-0.10.0-py3-none-any.whl (168 kB)
Using cached trieste-0.9.1-py3-none-any.whl (139 kB)
Using cached trieste-0.9.0-py3-none-any.whl (136 kB)
Using cached trieste-0.8.0-py3-none-any.whl (150 kB)
Using cached trieste-0.7.0-py3-none-any.whl (110 kB)
Using cached trieste-0.6.1-py3-none-any.whl (77 kB)
Using cached trieste-0.6.0-py3-none-any.whl (77 kB)
Using cached trieste-0.5.1-py3-none-any.whl (63 kB)
Collecting gpflow==2.2.*
Using cached gpflow-2.2.1-py3-none-any.whl (271 kB)
Collecting numpy
Downloading numpy-1.24.3-cp39-cp39-macosx_11_0_arm64.whl (13.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.9/13.9 MB 16.5 MB/s eta 0:00:00
Collecting trieste
Using cached trieste-0.5.0-py3-none-any.whl (63 kB)
Collecting gpflow==2.1.*
Using cached gpflow-2.1.5-py3-none-any.whl (260 kB)
Collecting trieste
Using cached trieste-0.4.0-py3-none-any.whl (43 kB)
Using cached trieste-0.3.1-py3-none-any.whl (38 kB)
Using cached trieste-0.3.0-py3-none-any.whl (38 kB)
Using cached trieste-0.2.0-py3-none-any.whl (35 kB)
ERROR: Cannot install trieste==0.10.0, trieste==0.11.0, trieste==0.11.1, trieste==0.11.2, trieste==0.11.3, trieste==0.12.0, trieste==0.13.0, trieste==0.13.1, trieste==0.13.2, trieste==0.13.3, trieste==0.2.0, trieste==0.3.0, trieste==0.3.1, trieste==0.4.0, trieste==0.5.0, trieste==0.5.1, trieste==0.6.0, trieste==0.6.1, trieste==0.7.0, trieste==0.8.0, trieste==0.9.0, trieste==0.9.1, trieste==1.0.0, trieste==1.1.0, trieste==1.1.1 and trieste==1.1.2 because these package versions have conflicting dependencies.
The conflict is caused by:
trieste 1.1.2 depends on tensorflow>=2.5
trieste 1.1.1 depends on tensorflow>=2.5
trieste 1.1.0 depends on tensorflow>=2.5
trieste 1.0.0 depends on tensorflow>=2.5
trieste 0.13.3 depends on tensorflow>=2.5
trieste 0.13.2 depends on tensorflow>=2.4
trieste 0.13.1 depends on tensorflow>=2.4
trieste 0.13.0 depends on tensorflow>=2.4
trieste 0.12.0 depends on tensorflow>=2.4
trieste 0.11.3 depends on tensorflow>=2.4
trieste 0.11.2 depends on tensorflow>=2.4
trieste 0.11.1 depends on tensorflow>=2.4
trieste 0.11.0 depends on tensorflow>=2.4
trieste 0.10.0 depends on tensorflow>=2.4
trieste 0.9.1 depends on tensorflow>=2.4
trieste 0.9.0 depends on tensorflow>=2.4
trieste 0.8.0 depends on tensorflow>=2.4
trieste 0.7.0 depends on tensorflow>=2.4
trieste 0.6.1 depends on tensorflow>=2.4
trieste 0.6.0 depends on tensorflow>=2.4
trieste 0.5.1 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
trieste 0.5.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
trieste 0.4.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
trieste 0.3.1 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
trieste 0.3.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
trieste 0.2.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1
To fix this you could try to:
1. loosen the range of package versions you've specified
2. remove package versions to allow pip attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/topics/dependency-resolution/#dealing-with-dependency-conflicts
```
**Expected behaviour**
It should be possible to install trieste from pypi on MacOS
**System information**
- OS: MacOS Ventura 13.2
- Python version: 3.8.13
- Trieste version: 0.2.0 - 1.1.2
- TensorFlow version: 2.11.0
- GPflow version: 2.8.0
</issue>
<code>
[start of setup.py]
1 # Copyright 2020 The Trieste Contributors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from pathlib import Path
15
16 from setuptools import find_packages, setup
17
18 with open("README.md", "r") as file:
19 long_description = file.read()
20
21 setup(
22 name="trieste",
23 version=Path("trieste/VERSION").read_text().strip(),
24 author="The Trieste contributors",
25 author_email="[email protected]",
26 description="A Bayesian optimization research toolbox built on TensorFlow",
27 long_description=long_description,
28 long_description_content_type="text/markdown",
29 url="https://github.com/secondmind-labs/trieste",
30 packages=find_packages(include=("trieste*",)),
31 package_data={
32 "trieste": ["py.typed", "VERSION"],
33 },
34 classifiers=[
35 "Programming Language :: Python :: 3.7",
36 "License :: OSI Approved :: Apache Software License",
37 "Operating System :: OS Independent",
38 ],
39 python_requires="~=3.7",
40 install_requires=[
41 "absl-py",
42 "dill!=0.3.6",
43 "gpflow>=2.7.0",
44 "gpflux>=0.4.0",
45 "numpy",
46 "tensorflow>=2.5",
47 "tensorflow-probability>=0.13",
48 "greenlet>=1.1.0",
49 ],
50 extras_require={
51 "plotting": ["seaborn", "plotly"],
52 "qhsri": ["pymoo", "cvxpy"],
53 },
54 )
55
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -43,7 +43,8 @@
"gpflow>=2.7.0",
"gpflux>=0.4.0",
"numpy",
- "tensorflow>=2.5",
+ "tensorflow>=2.5; platform_system!='Darwin' or platform_machine!='arm64'",
+ "tensorflow-macos>=2.5; platform_system=='Darwin' and platform_machine=='arm64'",
"tensorflow-probability>=0.13",
"greenlet>=1.1.0",
],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -43,7 +43,8 @@\n \"gpflow>=2.7.0\",\n \"gpflux>=0.4.0\",\n \"numpy\",\n- \"tensorflow>=2.5\",\n+ \"tensorflow>=2.5; platform_system!='Darwin' or platform_machine!='arm64'\",\n+ \"tensorflow-macos>=2.5; platform_system=='Darwin' and platform_machine=='arm64'\",\n \"tensorflow-probability>=0.13\",\n \"greenlet>=1.1.0\",\n ],\n", "issue": "Cannot install trieste from pypi on MacOS\n**Describe the bug**\r\n`pip install trieste` fails on MacOS\r\n\r\n**To reproduce**\r\nSteps to reproduce the behaviour:\r\n```\r\n$ pip install trieste\r\nCollecting trieste\r\n Downloading trieste-1.1.2-py3-none-any.whl (246 kB)\r\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 246.6/246.6 kB 3.4 MB/s eta 0:00:00\r\n Downloading trieste-1.1.1-py3-none-any.whl (246 kB)\r\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 246.5/246.5 kB 10.5 MB/s eta 0:00:00\r\n Downloading trieste-1.1.0-py3-none-any.whl (246 kB)\r\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 246.5/246.5 kB 10.5 MB/s eta 0:00:00\r\n Downloading trieste-1.0.0-py3-none-any.whl (240 kB)\r\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 240.4/240.4 kB 16.6 MB/s eta 0:00:00\r\n Using cached trieste-0.13.3-py3-none-any.whl (233 kB)\r\n Using cached trieste-0.13.2-py3-none-any.whl (218 kB)\r\n Using cached trieste-0.13.1-py3-none-any.whl (220 kB)\r\nCollecting dill==0.3.4\r\n Using cached dill-0.3.4-py2.py3-none-any.whl (86 kB)\r\nCollecting gpflow==2.5.2\r\n Using cached gpflow-2.5.2-py3-none-any.whl (383 kB)\r\nCollecting trieste\r\n Using cached trieste-0.13.0-py3-none-any.whl (215 kB)\r\n Using cached trieste-0.12.0-py3-none-any.whl (208 kB)\r\n Using cached trieste-0.11.3-py3-none-any.whl (196 kB)\r\n Using cached trieste-0.11.2-py3-none-any.whl (196 kB)\r\n Using cached trieste-0.11.1-py3-none-any.whl (195 kB)\r\n Using cached trieste-0.11.0-py3-none-any.whl (195 kB)\r\n Using cached trieste-0.10.0-py3-none-any.whl (168 kB)\r\n Using cached trieste-0.9.1-py3-none-any.whl (139 kB)\r\n Using cached trieste-0.9.0-py3-none-any.whl (136 kB)\r\n Using cached trieste-0.8.0-py3-none-any.whl (150 kB)\r\n Using cached trieste-0.7.0-py3-none-any.whl (110 kB)\r\n Using cached trieste-0.6.1-py3-none-any.whl (77 kB)\r\n Using cached trieste-0.6.0-py3-none-any.whl (77 kB)\r\n Using cached trieste-0.5.1-py3-none-any.whl (63 kB)\r\nCollecting gpflow==2.2.*\r\n Using cached gpflow-2.2.1-py3-none-any.whl (271 kB)\r\nCollecting numpy\r\n Downloading numpy-1.24.3-cp39-cp39-macosx_11_0_arm64.whl (13.9 MB)\r\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 13.9/13.9 MB 16.5 MB/s eta 0:00:00\r\nCollecting trieste\r\n Using cached trieste-0.5.0-py3-none-any.whl (63 kB)\r\nCollecting gpflow==2.1.*\r\n Using cached gpflow-2.1.5-py3-none-any.whl (260 kB)\r\nCollecting trieste\r\n Using cached trieste-0.4.0-py3-none-any.whl (43 kB)\r\n Using cached trieste-0.3.1-py3-none-any.whl (38 kB)\r\n Using cached trieste-0.3.0-py3-none-any.whl (38 kB)\r\n Using cached trieste-0.2.0-py3-none-any.whl (35 kB)\r\nERROR: Cannot install trieste==0.10.0, trieste==0.11.0, trieste==0.11.1, trieste==0.11.2, trieste==0.11.3, trieste==0.12.0, trieste==0.13.0, trieste==0.13.1, trieste==0.13.2, trieste==0.13.3, trieste==0.2.0, trieste==0.3.0, trieste==0.3.1, trieste==0.4.0, trieste==0.5.0, trieste==0.5.1, trieste==0.6.0, trieste==0.6.1, trieste==0.7.0, trieste==0.8.0, trieste==0.9.0, trieste==0.9.1, trieste==1.0.0, trieste==1.1.0, trieste==1.1.1 and trieste==1.1.2 because these package versions have conflicting dependencies.\r\n\r\nThe conflict is caused by:\r\n trieste 1.1.2 depends on tensorflow>=2.5\r\n trieste 1.1.1 depends on tensorflow>=2.5\r\n trieste 1.1.0 depends on tensorflow>=2.5\r\n trieste 1.0.0 depends on tensorflow>=2.5\r\n trieste 0.13.3 depends on tensorflow>=2.5\r\n trieste 0.13.2 depends on tensorflow>=2.4\r\n trieste 0.13.1 depends on tensorflow>=2.4\r\n trieste 0.13.0 depends on tensorflow>=2.4\r\n trieste 0.12.0 depends on tensorflow>=2.4\r\n trieste 0.11.3 depends on tensorflow>=2.4\r\n trieste 0.11.2 depends on tensorflow>=2.4\r\n trieste 0.11.1 depends on tensorflow>=2.4\r\n trieste 0.11.0 depends on tensorflow>=2.4\r\n trieste 0.10.0 depends on tensorflow>=2.4\r\n trieste 0.9.1 depends on tensorflow>=2.4\r\n trieste 0.9.0 depends on tensorflow>=2.4\r\n trieste 0.8.0 depends on tensorflow>=2.4\r\n trieste 0.7.0 depends on tensorflow>=2.4\r\n trieste 0.6.1 depends on tensorflow>=2.4\r\n trieste 0.6.0 depends on tensorflow>=2.4\r\n trieste 0.5.1 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n trieste 0.5.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n trieste 0.4.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n trieste 0.3.1 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n trieste 0.3.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n trieste 0.2.0 depends on tensorflow!=2.2.0, !=2.3.0 and >=2.1\r\n\r\nTo fix this you could try to:\r\n1. loosen the range of package versions you've specified\r\n2. remove package versions to allow pip attempt to solve the dependency conflict\r\n\r\nERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/topics/dependency-resolution/#dealing-with-dependency-conflicts\r\n```\r\n\r\n**Expected behaviour**\r\nIt should be possible to install trieste from pypi on MacOS\r\n\r\n**System information**\r\n - OS: MacOS Ventura 13.2\r\n - Python version: 3.8.13\r\n - Trieste version: 0.2.0 - 1.1.2\r\n - TensorFlow version: 2.11.0\r\n - GPflow version: 2.8.0\r\n\r\n\n", "before_files": [{"content": "# Copyright 2020 The Trieste Contributors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom pathlib import Path\n\nfrom setuptools import find_packages, setup\n\nwith open(\"README.md\", \"r\") as file:\n long_description = file.read()\n\nsetup(\n name=\"trieste\",\n version=Path(\"trieste/VERSION\").read_text().strip(),\n author=\"The Trieste contributors\",\n author_email=\"[email protected]\",\n description=\"A Bayesian optimization research toolbox built on TensorFlow\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/secondmind-labs/trieste\",\n packages=find_packages(include=(\"trieste*\",)),\n package_data={\n \"trieste\": [\"py.typed\", \"VERSION\"],\n },\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n ],\n python_requires=\"~=3.7\",\n install_requires=[\n \"absl-py\",\n \"dill!=0.3.6\",\n \"gpflow>=2.7.0\",\n \"gpflux>=0.4.0\",\n \"numpy\",\n \"tensorflow>=2.5\",\n \"tensorflow-probability>=0.13\",\n \"greenlet>=1.1.0\",\n ],\n extras_require={\n \"plotting\": [\"seaborn\", \"plotly\"],\n \"qhsri\": [\"pymoo\", \"cvxpy\"],\n },\n)\n", "path": "setup.py"}]}
| 3,162 | 140 |
gh_patches_debug_63270
|
rasdani/github-patches
|
git_diff
|
google__turbinia-1086
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sphinx docs build broken
Getting an error when trying to build the docs:
```
$ sphinx-build -b html -d build/doctrees docs dist/docs
Running Sphinx v4.5.0
WARNING: html_static_path entry '_static' does not exist
building [mo]: targets for 0 po files that are out of date
building [html]: targets for 19 source files that are out of date
updating environment: [new config] 19 added, 0 changed, 0 removed
reading sources... [ 5%] developer/contributing
Extension error (sphinx_markdown_tables):
Handler <function process_tables at 0x7fb9b1b0a700> for event 'source-read' threw an exception (exception: __init__() missing 1 required positional argument: 'config')
```
Trying an earlier version of sphinx and an earlier version of the repo does not resolve the issue. It seems to be something in the sphinx-markdown-tables module, but that doesn't seem to have changed that recently either (more than a month ago: https://pypi.org/project/sphinx-markdown-tables/0.0.15/#history).
</issue>
<code>
[start of docs/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 # import os
14 # import sys
15 # sys.path.insert(0, os.path.abspath('.'))
16
17 from __future__ import unicode_literals
18 import re
19
20 from recommonmark.parser import CommonMarkParser
21 from recommonmark.transform import AutoStructify
22 from docutils import nodes, transforms
23
24 # -- Project information -----------------------------------------------------
25
26 project = 'Turbinia'
27 copyright = '2020, Google Inc'
28 author = 'Turbinia maintainers'
29
30 # -- General configuration ---------------------------------------------------
31
32 # Add any Sphinx extension module names here, as strings. They can be
33 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
34 # ones.
35 extensions = [
36 'sphinx.ext.autodoc', 'sphinx.ext.doctest', 'sphinx.ext.coverage',
37 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'sphinx_markdown_tables',
38 'recommonmark'
39 ]
40
41 # Add any paths that contain templates here, relative to this directory.
42 templates_path = ['_templates']
43
44 # List of patterns, relative to source directory, that match files and
45 # directories to ignore when looking for source files.
46 # This pattern also affects html_static_path and html_extra_path.
47 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'design/*']
48
49 # -- Options for HTML output -------------------------------------------------
50
51 # The theme to use for HTML and HTML Help pages. See the documentation for
52 # a list of builtin themes.
53 #
54 html_theme = 'sphinx_rtd_theme'
55
56 # The master toctree document.
57 master_doc = 'index'
58
59 # The name of the Pygments (syntax highlighting) style to use.
60 pygments_style = 'sphinx'
61
62 # Add any paths that contain custom static files (such as style sheets) here,
63 # relative to this directory. They are copied after the builtin static files,
64 # so a file named "default.css" will overwrite the builtin "default.css".
65 html_static_path = ['_static']
66
67 # The default sidebars (for documents that don't match any pattern) are
68 # defined by theme itself. Builtin themes are using these templates by
69 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
70 # 'searchbox.html']``.
71 #
72 html_sidebars = {
73 '**': [
74 'sidebar.html', 'localtoc.html', 'relations.html', 'sourcelink.html',
75 'searchbox.html'
76 ]
77 }
78
79 # Adding retries to linkchecks before declaring a link broken
80 linkcheck_retries = 3
81
82 # Output file base name for HTML help builder.
83 htmlhelp_basename = 'turbiniadoc'
84
85 html_logo = "images/turbinia-logo.jpg"
86
87
88 class ProcessLink(transforms.Transform):
89 """Transform definition to parse .md references to internal pages."""
90
91 default_priority = 1000
92
93 def find_replace(self, node):
94 """Parses URIs containing .md and replaces them with their HTML page."""
95 if isinstance(node, nodes.reference) and 'refuri' in node:
96 r = node['refuri']
97 if r.endswith('.md'):
98 r = r[:-3] + '.html'
99 node['refuri'] = r
100
101 return node
102
103 def traverse(self, node):
104 """Traverse the document tree rooted at node.
105 node : docutil node
106 current root node to traverse
107 """
108 self.find_replace(node)
109
110 for c in node.children:
111 self.traverse(c)
112
113 # pylint: disable=arguments-differ,attribute-defined-outside-init
114 # this was taken from GRR's config file for documentation
115 def apply(self):
116 self.current_level = 0
117 self.traverse(self.document)
118
119
120 def setup(app):
121 """Add custom parsers to Sphinx generation."""
122 app.add_config_value(
123 'recommonmark_config', {
124 'enable_auto_doc_ref': False,
125 }, True)
126 app.add_transform(AutoStructify)
127 app.add_transform(ProcessLink)
128
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -34,8 +34,7 @@
# ones.
extensions = [
'sphinx.ext.autodoc', 'sphinx.ext.doctest', 'sphinx.ext.coverage',
- 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'sphinx_markdown_tables',
- 'recommonmark'
+ 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'recommonmark'
]
# Add any paths that contain templates here, relative to this directory.
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -34,8 +34,7 @@\n # ones.\n extensions = [\n 'sphinx.ext.autodoc', 'sphinx.ext.doctest', 'sphinx.ext.coverage',\n- 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'sphinx_markdown_tables',\n- 'recommonmark'\n+ 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'recommonmark'\n ]\n \n # Add any paths that contain templates here, relative to this directory.\n", "issue": "sphinx docs build broken\nGetting an error when trying to build the docs:\r\n```\r\n$ sphinx-build -b html -d build/doctrees docs dist/docs\r\nRunning Sphinx v4.5.0\r\nWARNING: html_static_path entry '_static' does not exist\r\nbuilding [mo]: targets for 0 po files that are out of date\r\nbuilding [html]: targets for 19 source files that are out of date\r\nupdating environment: [new config] 19 added, 0 changed, 0 removed\r\nreading sources... [ 5%] developer/contributing \r\nExtension error (sphinx_markdown_tables):\r\nHandler <function process_tables at 0x7fb9b1b0a700> for event 'source-read' threw an exception (exception: __init__() missing 1 required positional argument: 'config')\r\n```\r\n\r\nTrying an earlier version of sphinx and an earlier version of the repo does not resolve the issue. It seems to be something in the sphinx-markdown-tables module, but that doesn't seem to have changed that recently either (more than a month ago: https://pypi.org/project/sphinx-markdown-tables/0.0.15/#history).\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nfrom __future__ import unicode_literals\nimport re\n\nfrom recommonmark.parser import CommonMarkParser\nfrom recommonmark.transform import AutoStructify\nfrom docutils import nodes, transforms\n\n# -- Project information -----------------------------------------------------\n\nproject = 'Turbinia'\ncopyright = '2020, Google Inc'\nauthor = 'Turbinia maintainers'\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc', 'sphinx.ext.doctest', 'sphinx.ext.coverage',\n 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', 'sphinx_markdown_tables',\n 'recommonmark'\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'design/*']\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\nhtml_sidebars = {\n '**': [\n 'sidebar.html', 'localtoc.html', 'relations.html', 'sourcelink.html',\n 'searchbox.html'\n ]\n}\n\n# Adding retries to linkchecks before declaring a link broken\nlinkcheck_retries = 3\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'turbiniadoc'\n\nhtml_logo = \"images/turbinia-logo.jpg\"\n\n\nclass ProcessLink(transforms.Transform):\n \"\"\"Transform definition to parse .md references to internal pages.\"\"\"\n\n default_priority = 1000\n\n def find_replace(self, node):\n \"\"\"Parses URIs containing .md and replaces them with their HTML page.\"\"\"\n if isinstance(node, nodes.reference) and 'refuri' in node:\n r = node['refuri']\n if r.endswith('.md'):\n r = r[:-3] + '.html'\n node['refuri'] = r\n\n return node\n\n def traverse(self, node):\n \"\"\"Traverse the document tree rooted at node.\n node : docutil node\n current root node to traverse\n \"\"\"\n self.find_replace(node)\n\n for c in node.children:\n self.traverse(c)\n\n # pylint: disable=arguments-differ,attribute-defined-outside-init\n # this was taken from GRR's config file for documentation\n def apply(self):\n self.current_level = 0\n self.traverse(self.document)\n\n\ndef setup(app):\n \"\"\"Add custom parsers to Sphinx generation.\"\"\"\n app.add_config_value(\n 'recommonmark_config', {\n 'enable_auto_doc_ref': False,\n }, True)\n app.add_transform(AutoStructify)\n app.add_transform(ProcessLink)\n", "path": "docs/conf.py"}]}
| 2,035 | 134 |
gh_patches_debug_3111
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-128
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lists being marked as Optional
When defining a list the resulting schema marks the list as optional (or nullable in GraphQL terms) even if it wasn't wrapped in `typing.Optional`, we should fix that :)
</issue>
<code>
[start of strawberry/type_converter.py]
1 from collections.abc import AsyncGenerator
2
3 from graphql import (
4 GraphQLBoolean,
5 GraphQLFloat,
6 GraphQLID,
7 GraphQLInt,
8 GraphQLList,
9 GraphQLNonNull,
10 GraphQLString,
11 GraphQLUnionType,
12 )
13
14 from .exceptions import UnallowedReturnTypeForUnion, WrongReturnTypeForUnion
15 from .scalars import ID
16 from .utils.typing import is_union
17
18
19 REGISTRY = {
20 str: GraphQLString,
21 int: GraphQLInt,
22 float: GraphQLFloat,
23 bool: GraphQLBoolean,
24 ID: GraphQLID,
25 }
26
27
28 # TODO: make so that we don't pass force optional
29 # we use that when trying to get the type for a
30 # option field (which can either be a scalar or an object type)
31 def get_graphql_type_for_annotation(
32 annotation, field_name: str, force_optional: bool = False
33 ):
34 # TODO: this might lead to issues with types that have a field value
35 is_field_optional = force_optional
36
37 if hasattr(annotation, "field"):
38 graphql_type = annotation.field
39 else:
40 annotation_name = getattr(annotation, "_name", None)
41
42 if annotation_name == "List":
43 list_of_type = get_graphql_type_for_annotation(
44 annotation.__args__[0], field_name
45 )
46
47 return GraphQLList(list_of_type)
48
49 annotation_origin = getattr(annotation, "__origin__", None)
50
51 if annotation_origin == AsyncGenerator:
52 # async generators are used in subscription, we only need the yield type
53 # https://docs.python.org/3/library/typing.html#typing.AsyncGenerator
54 return get_graphql_type_for_annotation(annotation.__args__[0], field_name)
55
56 elif is_union(annotation):
57 types = annotation.__args__
58 non_none_types = [x for x in types if x != None.__class__] # noqa:E721
59
60 # optionals are represented as Union[type, None]
61 if len(non_none_types) == 1:
62 is_field_optional = True
63 graphql_type = get_graphql_type_for_annotation(
64 non_none_types[0], field_name, force_optional=True
65 )
66 else:
67 is_field_optional = None.__class__ in types
68
69 def _resolve_type(self, value, _type):
70 if not hasattr(self, "field"):
71 raise WrongReturnTypeForUnion(value.field_name, str(type(self)))
72
73 if self.field not in _type.types:
74 raise UnallowedReturnTypeForUnion(
75 value.field_name, str(type(self)), _type.types
76 )
77
78 return self.field
79
80 # TODO: union types don't work with scalar types
81 # so we want to return a nice error
82 # also we want to make sure we have been passed
83 # strawberry types
84 graphql_type = GraphQLUnionType(
85 field_name, [type.field for type in types]
86 )
87 graphql_type.resolve_type = _resolve_type
88 else:
89 graphql_type = REGISTRY.get(annotation)
90
91 if not graphql_type:
92 raise ValueError(f"Unable to get GraphQL type for {annotation}")
93
94 if is_field_optional:
95 return graphql_type
96
97 return GraphQLNonNull(graphql_type)
98
[end of strawberry/type_converter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/type_converter.py b/strawberry/type_converter.py
--- a/strawberry/type_converter.py
+++ b/strawberry/type_converter.py
@@ -44,7 +44,9 @@
annotation.__args__[0], field_name
)
- return GraphQLList(list_of_type)
+ list_type = GraphQLList(list_of_type)
+
+ return list_type if is_field_optional else GraphQLNonNull(list_type)
annotation_origin = getattr(annotation, "__origin__", None)
|
{"golden_diff": "diff --git a/strawberry/type_converter.py b/strawberry/type_converter.py\n--- a/strawberry/type_converter.py\n+++ b/strawberry/type_converter.py\n@@ -44,7 +44,9 @@\n annotation.__args__[0], field_name\n )\n \n- return GraphQLList(list_of_type)\n+ list_type = GraphQLList(list_of_type)\n+\n+ return list_type if is_field_optional else GraphQLNonNull(list_type)\n \n annotation_origin = getattr(annotation, \"__origin__\", None)\n", "issue": "Lists being marked as Optional\nWhen defining a list the resulting schema marks the list as optional (or nullable in GraphQL terms) even if it wasn't wrapped in `typing.Optional`, we should fix that :)\n", "before_files": [{"content": "from collections.abc import AsyncGenerator\n\nfrom graphql import (\n GraphQLBoolean,\n GraphQLFloat,\n GraphQLID,\n GraphQLInt,\n GraphQLList,\n GraphQLNonNull,\n GraphQLString,\n GraphQLUnionType,\n)\n\nfrom .exceptions import UnallowedReturnTypeForUnion, WrongReturnTypeForUnion\nfrom .scalars import ID\nfrom .utils.typing import is_union\n\n\nREGISTRY = {\n str: GraphQLString,\n int: GraphQLInt,\n float: GraphQLFloat,\n bool: GraphQLBoolean,\n ID: GraphQLID,\n}\n\n\n# TODO: make so that we don't pass force optional\n# we use that when trying to get the type for a\n# option field (which can either be a scalar or an object type)\ndef get_graphql_type_for_annotation(\n annotation, field_name: str, force_optional: bool = False\n):\n # TODO: this might lead to issues with types that have a field value\n is_field_optional = force_optional\n\n if hasattr(annotation, \"field\"):\n graphql_type = annotation.field\n else:\n annotation_name = getattr(annotation, \"_name\", None)\n\n if annotation_name == \"List\":\n list_of_type = get_graphql_type_for_annotation(\n annotation.__args__[0], field_name\n )\n\n return GraphQLList(list_of_type)\n\n annotation_origin = getattr(annotation, \"__origin__\", None)\n\n if annotation_origin == AsyncGenerator:\n # async generators are used in subscription, we only need the yield type\n # https://docs.python.org/3/library/typing.html#typing.AsyncGenerator\n return get_graphql_type_for_annotation(annotation.__args__[0], field_name)\n\n elif is_union(annotation):\n types = annotation.__args__\n non_none_types = [x for x in types if x != None.__class__] # noqa:E721\n\n # optionals are represented as Union[type, None]\n if len(non_none_types) == 1:\n is_field_optional = True\n graphql_type = get_graphql_type_for_annotation(\n non_none_types[0], field_name, force_optional=True\n )\n else:\n is_field_optional = None.__class__ in types\n\n def _resolve_type(self, value, _type):\n if not hasattr(self, \"field\"):\n raise WrongReturnTypeForUnion(value.field_name, str(type(self)))\n\n if self.field not in _type.types:\n raise UnallowedReturnTypeForUnion(\n value.field_name, str(type(self)), _type.types\n )\n\n return self.field\n\n # TODO: union types don't work with scalar types\n # so we want to return a nice error\n # also we want to make sure we have been passed\n # strawberry types\n graphql_type = GraphQLUnionType(\n field_name, [type.field for type in types]\n )\n graphql_type.resolve_type = _resolve_type\n else:\n graphql_type = REGISTRY.get(annotation)\n\n if not graphql_type:\n raise ValueError(f\"Unable to get GraphQL type for {annotation}\")\n\n if is_field_optional:\n return graphql_type\n\n return GraphQLNonNull(graphql_type)\n", "path": "strawberry/type_converter.py"}]}
| 1,435 | 115 |
gh_patches_debug_847
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-3202
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`pc_pos_map` for small methods is empty
### Version Information
* vyper Version (output of `vyper --version`): 0.3.7
* OS: osx
* Python Version (output of `python --version`): 3.10.4
### Bug
```
(vyper) ~/vyper $ cat tmp/baz.vy
@external
def foo():
pass
(vyper) ~/vyper $ vyc -f source_map tmp/baz.vy
{"breakpoints": [], "error_map": {"51": "fallback function"}, "pc_breakpoints": [], "pc_jump_map": {"0": "-", "7": "-", "11": "-", "12": "-", "23": "-", "34": "-", "42": "-", "44": "-", "46": "-", "52": "-"}, "pc_pos_map": {}, "pc_pos_map_compressed": "-1:-1:0:-;;;;:::-;;:::-;:::-;;;;;;;:::-;;;;;:::-;;;;;:::-;;:::-;;:::-;;;;:::-;;;"}
```
pc_pos_map should not be empty.
</issue>
<code>
[start of vyper/codegen/function_definitions/external_function.py]
1 from typing import Any, List
2
3 import vyper.utils as util
4 from vyper.address_space import CALLDATA, DATA, MEMORY
5 from vyper.ast.signatures.function_signature import FunctionSignature, VariableRecord
6 from vyper.codegen.abi_encoder import abi_encoding_matches_vyper
7 from vyper.codegen.context import Context
8 from vyper.codegen.core import get_element_ptr, getpos, make_setter, needs_clamp
9 from vyper.codegen.expr import Expr
10 from vyper.codegen.function_definitions.utils import get_nonreentrant_lock
11 from vyper.codegen.ir_node import Encoding, IRnode
12 from vyper.codegen.stmt import parse_body
13 from vyper.codegen.types.types import TupleType
14
15
16 # register function args with the local calling context.
17 # also allocate the ones that live in memory (i.e. kwargs)
18 def _register_function_args(context: Context, sig: FunctionSignature) -> List[IRnode]:
19 ret = []
20
21 # the type of the calldata
22 base_args_t = TupleType([arg.typ for arg in sig.base_args])
23
24 # tuple with the abi_encoded args
25 if sig.is_init_func:
26 base_args_ofst = IRnode(0, location=DATA, typ=base_args_t, encoding=Encoding.ABI)
27 else:
28 base_args_ofst = IRnode(4, location=CALLDATA, typ=base_args_t, encoding=Encoding.ABI)
29
30 for i, arg in enumerate(sig.base_args):
31
32 arg_ir = get_element_ptr(base_args_ofst, i)
33
34 if needs_clamp(arg.typ, Encoding.ABI):
35 # allocate a memory slot for it and copy
36 p = context.new_variable(arg.name, arg.typ, is_mutable=False)
37 dst = IRnode(p, typ=arg.typ, location=MEMORY)
38
39 copy_arg = make_setter(dst, arg_ir)
40 copy_arg.source_pos = getpos(arg.ast_source)
41 ret.append(copy_arg)
42 else:
43 assert abi_encoding_matches_vyper(arg.typ)
44 # leave it in place
45 context.vars[arg.name] = VariableRecord(
46 name=arg.name,
47 pos=arg_ir,
48 typ=arg.typ,
49 mutable=False,
50 location=arg_ir.location,
51 encoding=Encoding.ABI,
52 )
53
54 return ret
55
56
57 def _annotated_method_id(abi_sig):
58 method_id = util.method_id_int(abi_sig)
59 annotation = f"{hex(method_id)}: {abi_sig}"
60 return IRnode(method_id, annotation=annotation)
61
62
63 def _generate_kwarg_handlers(context: Context, sig: FunctionSignature) -> List[Any]:
64 # generate kwarg handlers.
65 # since they might come in thru calldata or be default,
66 # allocate them in memory and then fill it in based on calldata or default,
67 # depending on the signature
68 # a kwarg handler looks like
69 # (if (eq _method_id <method_id>)
70 # copy calldata args to memory
71 # write default args to memory
72 # goto external_function_common_ir
73
74 def handler_for(calldata_kwargs, default_kwargs):
75 calldata_args = sig.base_args + calldata_kwargs
76 # create a fake type so that get_element_ptr works
77 calldata_args_t = TupleType(list(arg.typ for arg in calldata_args))
78
79 abi_sig = sig.abi_signature_for_kwargs(calldata_kwargs)
80 method_id = _annotated_method_id(abi_sig)
81
82 calldata_kwargs_ofst = IRnode(
83 4, location=CALLDATA, typ=calldata_args_t, encoding=Encoding.ABI
84 )
85
86 # a sequence of statements to strictify kwargs into memory
87 ret = ["seq"]
88
89 # ensure calldata is at least of minimum length
90 args_abi_t = calldata_args_t.abi_type
91 calldata_min_size = args_abi_t.min_size() + 4
92 ret.append(["assert", ["ge", "calldatasize", calldata_min_size]])
93
94 # TODO optimize make_setter by using
95 # TupleType(list(arg.typ for arg in calldata_kwargs + default_kwargs))
96 # (must ensure memory area is contiguous)
97
98 n_base_args = len(sig.base_args)
99
100 for i, arg_meta in enumerate(calldata_kwargs):
101 k = n_base_args + i
102
103 dst = context.lookup_var(arg_meta.name).pos
104
105 lhs = IRnode(dst, location=MEMORY, typ=arg_meta.typ)
106
107 rhs = get_element_ptr(calldata_kwargs_ofst, k, array_bounds_check=False)
108
109 copy_arg = make_setter(lhs, rhs)
110 copy_arg.source_pos = getpos(arg_meta.ast_source)
111 ret.append(copy_arg)
112
113 for x in default_kwargs:
114 dst = context.lookup_var(x.name).pos
115 lhs = IRnode(dst, location=MEMORY, typ=x.typ)
116 lhs.source_pos = getpos(x.ast_source)
117 kw_ast_val = sig.default_values[x.name] # e.g. `3` in x: int = 3
118 rhs = Expr(kw_ast_val, context).ir_node
119
120 copy_arg = make_setter(lhs, rhs)
121 copy_arg.source_pos = getpos(x.ast_source)
122 ret.append(copy_arg)
123
124 ret.append(["goto", sig.external_function_base_entry_label])
125
126 ret = ["if", ["eq", "_calldata_method_id", method_id], ret]
127 return ret
128
129 ret = ["seq"]
130
131 keyword_args = sig.default_args
132
133 # allocate variable slots in memory
134 for arg in keyword_args:
135 context.new_variable(arg.name, arg.typ, is_mutable=False)
136
137 for i, _ in enumerate(keyword_args):
138 calldata_kwargs = keyword_args[:i]
139 default_kwargs = keyword_args[i:]
140
141 ret.append(handler_for(calldata_kwargs, default_kwargs))
142
143 ret.append(handler_for(keyword_args, []))
144
145 return ret
146
147
148 # TODO it would be nice if this returned a data structure which were
149 # amenable to generating a jump table instead of the linear search for
150 # method_id we have now.
151 def generate_ir_for_external_function(code, sig, context, skip_nonpayable_check):
152 # TODO type hints:
153 # def generate_ir_for_external_function(
154 # code: vy_ast.FunctionDef, sig: FunctionSignature, context: Context, check_nonpayable: bool,
155 # ) -> IRnode:
156 """Return the IR for an external function. Includes code to inspect the method_id,
157 enter the function (nonpayable and reentrancy checks), handle kwargs and exit
158 the function (clean up reentrancy storage variables)
159 """
160 func_type = code._metadata["type"]
161
162 nonreentrant_pre, nonreentrant_post = get_nonreentrant_lock(func_type)
163
164 # generate handlers for base args and register the variable records
165 handle_base_args = _register_function_args(context, sig)
166
167 # generate handlers for kwargs and register the variable records
168 kwarg_handlers = _generate_kwarg_handlers(context, sig)
169
170 body = ["seq"]
171 # once optional args have been handled,
172 # generate the main body of the function
173 body += handle_base_args
174
175 if sig.mutability != "payable" and not skip_nonpayable_check:
176 # if the contract contains payable functions, but this is not one of them
177 # add an assertion that the value of the call is zero
178 body += [["assert", ["iszero", "callvalue"]]]
179
180 body += nonreentrant_pre
181
182 body += [parse_body(code.body, context, ensure_terminated=True)]
183
184 # wrap the body in labeled block
185 body = ["label", sig.external_function_base_entry_label, ["var_list"], body]
186
187 exit_sequence = ["seq"] + nonreentrant_post
188 if sig.is_init_func:
189 pass # init func has special exit sequence generated by module.py
190 elif context.return_type is None:
191 exit_sequence += [["stop"]]
192 else:
193 exit_sequence += [["return", "ret_ofst", "ret_len"]]
194
195 exit_sequence_args = ["var_list"]
196 if context.return_type is not None:
197 exit_sequence_args += ["ret_ofst", "ret_len"]
198 # wrap the exit in a labeled block
199 exit = ["label", sig.exit_sequence_label, exit_sequence_args, exit_sequence]
200
201 # the ir which comprises the main body of the function,
202 # besides any kwarg handling
203 func_common_ir = ["seq", body, exit]
204
205 if sig.is_default_func or sig.is_init_func:
206 ret = ["seq"]
207 # add a goto to make the function entry look like other functions
208 # (for zksync interpreter)
209 ret.append(["goto", sig.external_function_base_entry_label])
210 ret.append(func_common_ir)
211 else:
212 ret = kwarg_handlers
213 # sneak the base code into the kwarg handler
214 # TODO rethink this / make it clearer
215 ret[-1][-1].append(func_common_ir)
216
217 return IRnode.from_list(ret)
218
[end of vyper/codegen/function_definitions/external_function.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/codegen/function_definitions/external_function.py b/vyper/codegen/function_definitions/external_function.py
--- a/vyper/codegen/function_definitions/external_function.py
+++ b/vyper/codegen/function_definitions/external_function.py
@@ -214,4 +214,4 @@
# TODO rethink this / make it clearer
ret[-1][-1].append(func_common_ir)
- return IRnode.from_list(ret)
+ return IRnode.from_list(ret, source_pos=getpos(sig.func_ast_code))
|
{"golden_diff": "diff --git a/vyper/codegen/function_definitions/external_function.py b/vyper/codegen/function_definitions/external_function.py\n--- a/vyper/codegen/function_definitions/external_function.py\n+++ b/vyper/codegen/function_definitions/external_function.py\n@@ -214,4 +214,4 @@\n # TODO rethink this / make it clearer\n ret[-1][-1].append(func_common_ir)\n \n- return IRnode.from_list(ret)\n+ return IRnode.from_list(ret, source_pos=getpos(sig.func_ast_code))\n", "issue": "`pc_pos_map` for small methods is empty\n### Version Information\r\n\r\n* vyper Version (output of `vyper --version`): 0.3.7\r\n* OS: osx\r\n* Python Version (output of `python --version`): 3.10.4\r\n\r\n### Bug\r\n\r\n```\r\n(vyper) ~/vyper $ cat tmp/baz.vy \r\n\r\n@external\r\ndef foo():\r\n pass\r\n\r\n(vyper) ~/vyper $ vyc -f source_map tmp/baz.vy \r\n\r\n{\"breakpoints\": [], \"error_map\": {\"51\": \"fallback function\"}, \"pc_breakpoints\": [], \"pc_jump_map\": {\"0\": \"-\", \"7\": \"-\", \"11\": \"-\", \"12\": \"-\", \"23\": \"-\", \"34\": \"-\", \"42\": \"-\", \"44\": \"-\", \"46\": \"-\", \"52\": \"-\"}, \"pc_pos_map\": {}, \"pc_pos_map_compressed\": \"-1:-1:0:-;;;;:::-;;:::-;:::-;;;;;;;:::-;;;;;:::-;;;;;:::-;;:::-;;:::-;;;;:::-;;;\"}\r\n\r\n```\r\npc_pos_map should not be empty.\r\n\r\n\n", "before_files": [{"content": "from typing import Any, List\n\nimport vyper.utils as util\nfrom vyper.address_space import CALLDATA, DATA, MEMORY\nfrom vyper.ast.signatures.function_signature import FunctionSignature, VariableRecord\nfrom vyper.codegen.abi_encoder import abi_encoding_matches_vyper\nfrom vyper.codegen.context import Context\nfrom vyper.codegen.core import get_element_ptr, getpos, make_setter, needs_clamp\nfrom vyper.codegen.expr import Expr\nfrom vyper.codegen.function_definitions.utils import get_nonreentrant_lock\nfrom vyper.codegen.ir_node import Encoding, IRnode\nfrom vyper.codegen.stmt import parse_body\nfrom vyper.codegen.types.types import TupleType\n\n\n# register function args with the local calling context.\n# also allocate the ones that live in memory (i.e. kwargs)\ndef _register_function_args(context: Context, sig: FunctionSignature) -> List[IRnode]:\n ret = []\n\n # the type of the calldata\n base_args_t = TupleType([arg.typ for arg in sig.base_args])\n\n # tuple with the abi_encoded args\n if sig.is_init_func:\n base_args_ofst = IRnode(0, location=DATA, typ=base_args_t, encoding=Encoding.ABI)\n else:\n base_args_ofst = IRnode(4, location=CALLDATA, typ=base_args_t, encoding=Encoding.ABI)\n\n for i, arg in enumerate(sig.base_args):\n\n arg_ir = get_element_ptr(base_args_ofst, i)\n\n if needs_clamp(arg.typ, Encoding.ABI):\n # allocate a memory slot for it and copy\n p = context.new_variable(arg.name, arg.typ, is_mutable=False)\n dst = IRnode(p, typ=arg.typ, location=MEMORY)\n\n copy_arg = make_setter(dst, arg_ir)\n copy_arg.source_pos = getpos(arg.ast_source)\n ret.append(copy_arg)\n else:\n assert abi_encoding_matches_vyper(arg.typ)\n # leave it in place\n context.vars[arg.name] = VariableRecord(\n name=arg.name,\n pos=arg_ir,\n typ=arg.typ,\n mutable=False,\n location=arg_ir.location,\n encoding=Encoding.ABI,\n )\n\n return ret\n\n\ndef _annotated_method_id(abi_sig):\n method_id = util.method_id_int(abi_sig)\n annotation = f\"{hex(method_id)}: {abi_sig}\"\n return IRnode(method_id, annotation=annotation)\n\n\ndef _generate_kwarg_handlers(context: Context, sig: FunctionSignature) -> List[Any]:\n # generate kwarg handlers.\n # since they might come in thru calldata or be default,\n # allocate them in memory and then fill it in based on calldata or default,\n # depending on the signature\n # a kwarg handler looks like\n # (if (eq _method_id <method_id>)\n # copy calldata args to memory\n # write default args to memory\n # goto external_function_common_ir\n\n def handler_for(calldata_kwargs, default_kwargs):\n calldata_args = sig.base_args + calldata_kwargs\n # create a fake type so that get_element_ptr works\n calldata_args_t = TupleType(list(arg.typ for arg in calldata_args))\n\n abi_sig = sig.abi_signature_for_kwargs(calldata_kwargs)\n method_id = _annotated_method_id(abi_sig)\n\n calldata_kwargs_ofst = IRnode(\n 4, location=CALLDATA, typ=calldata_args_t, encoding=Encoding.ABI\n )\n\n # a sequence of statements to strictify kwargs into memory\n ret = [\"seq\"]\n\n # ensure calldata is at least of minimum length\n args_abi_t = calldata_args_t.abi_type\n calldata_min_size = args_abi_t.min_size() + 4\n ret.append([\"assert\", [\"ge\", \"calldatasize\", calldata_min_size]])\n\n # TODO optimize make_setter by using\n # TupleType(list(arg.typ for arg in calldata_kwargs + default_kwargs))\n # (must ensure memory area is contiguous)\n\n n_base_args = len(sig.base_args)\n\n for i, arg_meta in enumerate(calldata_kwargs):\n k = n_base_args + i\n\n dst = context.lookup_var(arg_meta.name).pos\n\n lhs = IRnode(dst, location=MEMORY, typ=arg_meta.typ)\n\n rhs = get_element_ptr(calldata_kwargs_ofst, k, array_bounds_check=False)\n\n copy_arg = make_setter(lhs, rhs)\n copy_arg.source_pos = getpos(arg_meta.ast_source)\n ret.append(copy_arg)\n\n for x in default_kwargs:\n dst = context.lookup_var(x.name).pos\n lhs = IRnode(dst, location=MEMORY, typ=x.typ)\n lhs.source_pos = getpos(x.ast_source)\n kw_ast_val = sig.default_values[x.name] # e.g. `3` in x: int = 3\n rhs = Expr(kw_ast_val, context).ir_node\n\n copy_arg = make_setter(lhs, rhs)\n copy_arg.source_pos = getpos(x.ast_source)\n ret.append(copy_arg)\n\n ret.append([\"goto\", sig.external_function_base_entry_label])\n\n ret = [\"if\", [\"eq\", \"_calldata_method_id\", method_id], ret]\n return ret\n\n ret = [\"seq\"]\n\n keyword_args = sig.default_args\n\n # allocate variable slots in memory\n for arg in keyword_args:\n context.new_variable(arg.name, arg.typ, is_mutable=False)\n\n for i, _ in enumerate(keyword_args):\n calldata_kwargs = keyword_args[:i]\n default_kwargs = keyword_args[i:]\n\n ret.append(handler_for(calldata_kwargs, default_kwargs))\n\n ret.append(handler_for(keyword_args, []))\n\n return ret\n\n\n# TODO it would be nice if this returned a data structure which were\n# amenable to generating a jump table instead of the linear search for\n# method_id we have now.\ndef generate_ir_for_external_function(code, sig, context, skip_nonpayable_check):\n # TODO type hints:\n # def generate_ir_for_external_function(\n # code: vy_ast.FunctionDef, sig: FunctionSignature, context: Context, check_nonpayable: bool,\n # ) -> IRnode:\n \"\"\"Return the IR for an external function. Includes code to inspect the method_id,\n enter the function (nonpayable and reentrancy checks), handle kwargs and exit\n the function (clean up reentrancy storage variables)\n \"\"\"\n func_type = code._metadata[\"type\"]\n\n nonreentrant_pre, nonreentrant_post = get_nonreentrant_lock(func_type)\n\n # generate handlers for base args and register the variable records\n handle_base_args = _register_function_args(context, sig)\n\n # generate handlers for kwargs and register the variable records\n kwarg_handlers = _generate_kwarg_handlers(context, sig)\n\n body = [\"seq\"]\n # once optional args have been handled,\n # generate the main body of the function\n body += handle_base_args\n\n if sig.mutability != \"payable\" and not skip_nonpayable_check:\n # if the contract contains payable functions, but this is not one of them\n # add an assertion that the value of the call is zero\n body += [[\"assert\", [\"iszero\", \"callvalue\"]]]\n\n body += nonreentrant_pre\n\n body += [parse_body(code.body, context, ensure_terminated=True)]\n\n # wrap the body in labeled block\n body = [\"label\", sig.external_function_base_entry_label, [\"var_list\"], body]\n\n exit_sequence = [\"seq\"] + nonreentrant_post\n if sig.is_init_func:\n pass # init func has special exit sequence generated by module.py\n elif context.return_type is None:\n exit_sequence += [[\"stop\"]]\n else:\n exit_sequence += [[\"return\", \"ret_ofst\", \"ret_len\"]]\n\n exit_sequence_args = [\"var_list\"]\n if context.return_type is not None:\n exit_sequence_args += [\"ret_ofst\", \"ret_len\"]\n # wrap the exit in a labeled block\n exit = [\"label\", sig.exit_sequence_label, exit_sequence_args, exit_sequence]\n\n # the ir which comprises the main body of the function,\n # besides any kwarg handling\n func_common_ir = [\"seq\", body, exit]\n\n if sig.is_default_func or sig.is_init_func:\n ret = [\"seq\"]\n # add a goto to make the function entry look like other functions\n # (for zksync interpreter)\n ret.append([\"goto\", sig.external_function_base_entry_label])\n ret.append(func_common_ir)\n else:\n ret = kwarg_handlers\n # sneak the base code into the kwarg handler\n # TODO rethink this / make it clearer\n ret[-1][-1].append(func_common_ir)\n\n return IRnode.from_list(ret)\n", "path": "vyper/codegen/function_definitions/external_function.py"}]}
| 3,288 | 116 |
gh_patches_debug_29154
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1036
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Setting value in cache should never fail
The cache is a key value store. The transaction isolation and integrity constraints are details of implementation. Setting a value in the cache should just never fail.
Setting value in cache should never fail
The cache is a key value store. The transaction isolation and integrity constraints are details of implementation. Setting a value in the cache should just never fail.
</issue>
<code>
[start of kinto/core/cache/postgresql/__init__.py]
1 from __future__ import absolute_import
2
3 import os
4
5 from kinto.core import logger
6 from kinto.core.cache import CacheBase
7 from kinto.core.storage.postgresql.client import create_from_config
8 from kinto.core.utils import json
9
10
11 class Cache(CacheBase):
12 """Cache backend using PostgreSQL.
13
14 Enable in configuration::
15
16 kinto.cache_backend = kinto.core.cache.postgresql
17
18 Database location URI can be customized::
19
20 kinto.cache_url = postgres://user:[email protected]:5432/dbname
21
22 Alternatively, username and password could also rely on system user ident
23 or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).
24
25 .. note::
26
27 Some tables and indices are created when ``kinto migrate`` is run.
28 This requires some privileges on the database, or some error will
29 be raised.
30
31 **Alternatively**, the schema can be initialized outside the
32 python application, using the SQL file located in
33 :file:`kinto/core/cache/postgresql/schema.sql`. This allows to
34 distinguish schema manipulation privileges from schema usage.
35
36
37 A connection pool is enabled by default::
38
39 kinto.cache_pool_size = 10
40 kinto.cache_maxoverflow = 10
41 kinto.cache_max_backlog = -1
42 kinto.cache_pool_recycle = -1
43 kinto.cache_pool_timeout = 30
44 kinto.cache_poolclass =
45 kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog
46
47 The ``max_backlog`` limits the number of threads that can be in the queue
48 waiting for a connection. Once this limit has been reached, any further
49 attempts to acquire a connection will be rejected immediately, instead of
50 locking up all threads by keeping them waiting in the queue.
51
52 See `dedicated section in SQLAlchemy documentation
53 <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_
54 for default values and behaviour.
55
56 .. note::
57
58 Using a `dedicated connection pool <http://pgpool.net>`_ is still
59 recommended to allow load balancing, replication or limit the number
60 of connections used in a multi-process deployment.
61
62 :noindex:
63 """ # NOQA
64 def __init__(self, client, *args, **kwargs):
65 super(Cache, self).__init__(*args, **kwargs)
66 self.client = client
67
68 def initialize_schema(self, dry_run=False):
69 # Check if cache table exists.
70 query = """
71 SELECT 1
72 FROM information_schema.tables
73 WHERE table_name = 'cache';
74 """
75 with self.client.connect(readonly=True) as conn:
76 result = conn.execute(query)
77 if result.rowcount > 0:
78 logger.info("PostgreSQL cache schema is up-to-date.")
79 return
80
81 # Create schema
82 here = os.path.abspath(os.path.dirname(__file__))
83 sql_file = os.path.join(here, 'schema.sql')
84
85 if dry_run:
86 logger.info("Create cache schema from %s" % sql_file)
87 return
88
89 # Since called outside request, force commit.
90 schema = open(sql_file).read()
91 with self.client.connect(force_commit=True) as conn:
92 conn.execute(schema)
93 logger.info('Created PostgreSQL cache tables')
94
95 def flush(self):
96 query = """
97 DELETE FROM cache;
98 """
99 # Since called outside request (e.g. tests), force commit.
100 with self.client.connect(force_commit=True) as conn:
101 conn.execute(query)
102 logger.debug('Flushed PostgreSQL cache tables')
103
104 def ttl(self, key):
105 query = """
106 SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl
107 FROM cache
108 WHERE key = :key
109 AND ttl IS NOT NULL;
110 """
111 with self.client.connect(readonly=True) as conn:
112 result = conn.execute(query, dict(key=self.prefix + key))
113 if result.rowcount > 0:
114 return result.fetchone()['ttl']
115 return -1
116
117 def expire(self, key, ttl):
118 query = """
119 UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;
120 """
121 with self.client.connect() as conn:
122 conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
123
124 def set(self, key, value, ttl=None):
125 if ttl is None:
126 logger.warning("No TTL for cache key %r" % key)
127 query = """
128 WITH upsert AS (
129 UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)
130 WHERE key=:key
131 RETURNING *)
132 INSERT INTO cache (key, value, ttl)
133 SELECT :key, :value, sec2ttl(:ttl)
134 WHERE NOT EXISTS (SELECT * FROM upsert)
135 """
136 value = json.dumps(value)
137 with self.client.connect() as conn:
138 conn.execute(query, dict(key=self.prefix + key,
139 value=value, ttl=ttl))
140
141 def get(self, key):
142 purge = "DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;"
143 query = "SELECT value FROM cache WHERE key = :key;"
144 with self.client.connect() as conn:
145 conn.execute(purge)
146 result = conn.execute(query, dict(key=self.prefix + key))
147 if result.rowcount > 0:
148 value = result.fetchone()['value']
149 return json.loads(value)
150
151 def delete(self, key):
152 query = "DELETE FROM cache WHERE key = :key"
153 with self.client.connect() as conn:
154 conn.execute(query, dict(key=self.prefix + key))
155
156
157 def load_from_config(config):
158 settings = config.get_settings()
159 client = create_from_config(config, prefix='cache_', with_transaction=False)
160 return Cache(client=client, cache_prefix=settings['cache_prefix'])
161
[end of kinto/core/cache/postgresql/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py
--- a/kinto/core/cache/postgresql/__init__.py
+++ b/kinto/core/cache/postgresql/__init__.py
@@ -1,13 +1,41 @@
from __future__ import absolute_import
+from functools import wraps
import os
+import time
from kinto.core import logger
from kinto.core.cache import CacheBase
from kinto.core.storage.postgresql.client import create_from_config
+from kinto.core.storage.exceptions import BackendError
from kinto.core.utils import json
+DELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005
+MAX_RETRIES = 10
+
+
+def retry_on_failure(func):
+ try:
+ import psycopg2
+ except ImportError: # pragma: no cover
+ pass # Do not break (but will fail nicely later anyway)
+
+ @wraps(func)
+ def wraps_func(self, *args, **kwargs):
+ tries = kwargs.pop('tries', 0)
+ try:
+ return func(self, *args, **kwargs)
+ except psycopg2.IntegrityError as e:
+ if tries < MAX_RETRIES:
+ # Skip delay the 2 first times.
+ delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS
+ time.sleep(delay)
+ return wraps_func(self, tries=(tries + 1), *args, **kwargs)
+ raise BackendError(original=e)
+ return wraps_func
+
+
class Cache(CacheBase):
"""Cache backend using PostgreSQL.
@@ -121,6 +149,7 @@
with self.client.connect() as conn:
conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
+ @retry_on_failure
def set(self, key, value, ttl=None):
if ttl is None:
logger.warning("No TTL for cache key %r" % key)
|
{"golden_diff": "diff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py\n--- a/kinto/core/cache/postgresql/__init__.py\n+++ b/kinto/core/cache/postgresql/__init__.py\n@@ -1,13 +1,41 @@\n from __future__ import absolute_import\n+from functools import wraps\n \n import os\n+import time\n \n from kinto.core import logger\n from kinto.core.cache import CacheBase\n from kinto.core.storage.postgresql.client import create_from_config\n+from kinto.core.storage.exceptions import BackendError\n from kinto.core.utils import json\n \n \n+DELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005\n+MAX_RETRIES = 10\n+\n+\n+def retry_on_failure(func):\n+ try:\n+ import psycopg2\n+ except ImportError: # pragma: no cover\n+ pass # Do not break (but will fail nicely later anyway)\n+\n+ @wraps(func)\n+ def wraps_func(self, *args, **kwargs):\n+ tries = kwargs.pop('tries', 0)\n+ try:\n+ return func(self, *args, **kwargs)\n+ except psycopg2.IntegrityError as e:\n+ if tries < MAX_RETRIES:\n+ # Skip delay the 2 first times.\n+ delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS\n+ time.sleep(delay)\n+ return wraps_func(self, tries=(tries + 1), *args, **kwargs)\n+ raise BackendError(original=e)\n+ return wraps_func\n+\n+\n class Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n \n@@ -121,6 +149,7 @@\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n \n+ @retry_on_failure\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key %r\" % key)\n", "issue": "Setting value in cache should never fail\nThe cache is a key value store. The transaction isolation and integrity constraints are details of implementation. Setting a value in the cache should just never fail.\nSetting value in cache should never fail\nThe cache is a key value store. The transaction isolation and integrity constraints are details of implementation. Setting a value in the cache should just never fail.\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport os\n\nfrom kinto.core import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.storage.postgresql.client import create_from_config\nfrom kinto.core.utils import json\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.postgresql\n\n Database location URI can be customized::\n\n kinto.cache_url = postgres://user:[email protected]:5432/dbname\n\n Alternatively, username and password could also rely on system user ident\n or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).\n\n .. note::\n\n Some tables and indices are created when ``kinto migrate`` is run.\n This requires some privileges on the database, or some error will\n be raised.\n\n **Alternatively**, the schema can be initialized outside the\n python application, using the SQL file located in\n :file:`kinto/core/cache/postgresql/schema.sql`. This allows to\n distinguish schema manipulation privileges from schema usage.\n\n\n A connection pool is enabled by default::\n\n kinto.cache_pool_size = 10\n kinto.cache_maxoverflow = 10\n kinto.cache_max_backlog = -1\n kinto.cache_pool_recycle = -1\n kinto.cache_pool_timeout = 30\n kinto.cache_poolclass =\n kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog\n\n The ``max_backlog`` limits the number of threads that can be in the queue\n waiting for a connection. Once this limit has been reached, any further\n attempts to acquire a connection will be rejected immediately, instead of\n locking up all threads by keeping them waiting in the queue.\n\n See `dedicated section in SQLAlchemy documentation\n <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_\n for default values and behaviour.\n\n .. note::\n\n Using a `dedicated connection pool <http://pgpool.net>`_ is still\n recommended to allow load balancing, replication or limit the number\n of connections used in a multi-process deployment.\n\n :noindex:\n \"\"\" # NOQA\n def __init__(self, client, *args, **kwargs):\n super(Cache, self).__init__(*args, **kwargs)\n self.client = client\n\n def initialize_schema(self, dry_run=False):\n # Check if cache table exists.\n query = \"\"\"\n SELECT 1\n FROM information_schema.tables\n WHERE table_name = 'cache';\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query)\n if result.rowcount > 0:\n logger.info(\"PostgreSQL cache schema is up-to-date.\")\n return\n\n # Create schema\n here = os.path.abspath(os.path.dirname(__file__))\n sql_file = os.path.join(here, 'schema.sql')\n\n if dry_run:\n logger.info(\"Create cache schema from %s\" % sql_file)\n return\n\n # Since called outside request, force commit.\n schema = open(sql_file).read()\n with self.client.connect(force_commit=True) as conn:\n conn.execute(schema)\n logger.info('Created PostgreSQL cache tables')\n\n def flush(self):\n query = \"\"\"\n DELETE FROM cache;\n \"\"\"\n # Since called outside request (e.g. tests), force commit.\n with self.client.connect(force_commit=True) as conn:\n conn.execute(query)\n logger.debug('Flushed PostgreSQL cache tables')\n\n def ttl(self, key):\n query = \"\"\"\n SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl\n FROM cache\n WHERE key = :key\n AND ttl IS NOT NULL;\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n return result.fetchone()['ttl']\n return -1\n\n def expire(self, key, ttl):\n query = \"\"\"\n UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;\n \"\"\"\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key %r\" % key)\n query = \"\"\"\n WITH upsert AS (\n UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)\n WHERE key=:key\n RETURNING *)\n INSERT INTO cache (key, value, ttl)\n SELECT :key, :value, sec2ttl(:ttl)\n WHERE NOT EXISTS (SELECT * FROM upsert)\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key,\n value=value, ttl=ttl))\n\n def get(self, key):\n purge = \"DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;\"\n query = \"SELECT value FROM cache WHERE key = :key;\"\n with self.client.connect() as conn:\n conn.execute(purge)\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n value = result.fetchone()['value']\n return json.loads(value)\n\n def delete(self, key):\n query = \"DELETE FROM cache WHERE key = :key\"\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key))\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n client = create_from_config(config, prefix='cache_', with_transaction=False)\n return Cache(client=client, cache_prefix=settings['cache_prefix'])\n", "path": "kinto/core/cache/postgresql/__init__.py"}]}
| 2,255 | 448 |
gh_patches_debug_1075
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-563
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
from_mpc failed to load the case generated by to_mpc
After checking the source code, I found the to_mpc function saves the fields in a loose format. According to the from_mpc function, all the fields should be under a variable called "mpc" (default), however the to_mpc function does not follow this, which leads to a situation that the from_mpc function cannot load the case generated by the to_mpc function.
</issue>
<code>
[start of pandapower/converter/matpower/to_mpc.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2019 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6
7 import copy
8
9 import numpy as np
10 from scipy.io import savemat
11
12 from pandapower.converter.pypower import to_ppc
13
14 try:
15 import pplog as logging
16 except ImportError:
17 import logging
18
19 logger = logging.getLogger(__name__)
20
21
22 def to_mpc(net, filename=None, **kwargs):
23 """
24 This function converts a pandapower net to a matpower case files (.mat) version 2.
25 Note: python is 0-based while Matlab is 1-based.
26
27 INPUT:
28 **net** - The pandapower net.
29
30 OPTIONAL:
31 **filename** (str, None) - File path + name of the mat file which will be created. If None
32 the mpc will only be returned
33
34 ****kwargs** - please look at to_ppc() documentation
35
36 EXAMPLE:
37 import pandapower.converter as pc
38 import pandapower.networks as pn
39 net = pn.case9()
40 pc.to_mpc(net, "case9.mat")
41
42 """
43 ppc = to_ppc(net, **kwargs)
44
45 mpc = _ppc2mpc(ppc)
46 if filename is not None:
47 # savemat
48 savemat(filename, mpc)
49
50 return mpc
51
52
53 def _ppc2mpc(ppc):
54 """
55 Convert network in Pypower/Matpower format
56 Convert 0-based python to 1-based Matlab
57
58 **INPUT**:
59 * net - The pandapower format network
60 * filename - File path + name of the mat file which is created
61 """
62
63 # convert to matpower
64 # Matlab is one-based, so all entries (buses, lines, gens) have to start with 1 instead of 0
65 mpc = copy.deepcopy(ppc)
66 if len(np.where(mpc["bus"][:, 0] == 0)[0]):
67 mpc["bus"][:, 0] = mpc["bus"][:, 0] + 1
68 mpc["gen"][:, 0] = mpc["gen"][:, 0] + 1
69 mpc["branch"][:, 0:2] = mpc["branch"][:, 0:2] + 1
70 # adjust for the matpower converter -> taps should be 0 when there is no transformer, but are 1
71 mpc["branch"][np.where(mpc["branch"][:, 8] == 1), 8] = 0
72 # version is a string
73 mpc["version"] = str(mpc["version"])
74 # baseMVA has to be a float instead of int
75 mpc["baseMVA"] = mpc["baseMVA"] * 1.0
76 return mpc
77
78
79 if "__main__" == __name__:
80 pass
81
[end of pandapower/converter/matpower/to_mpc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pandapower/converter/matpower/to_mpc.py b/pandapower/converter/matpower/to_mpc.py
--- a/pandapower/converter/matpower/to_mpc.py
+++ b/pandapower/converter/matpower/to_mpc.py
@@ -42,7 +42,8 @@
"""
ppc = to_ppc(net, **kwargs)
- mpc = _ppc2mpc(ppc)
+ mpc = dict()
+ mpc["mpc"] = _ppc2mpc(ppc)
if filename is not None:
# savemat
savemat(filename, mpc)
|
{"golden_diff": "diff --git a/pandapower/converter/matpower/to_mpc.py b/pandapower/converter/matpower/to_mpc.py\n--- a/pandapower/converter/matpower/to_mpc.py\n+++ b/pandapower/converter/matpower/to_mpc.py\n@@ -42,7 +42,8 @@\n \"\"\"\n ppc = to_ppc(net, **kwargs)\n \n- mpc = _ppc2mpc(ppc)\n+ mpc = dict()\n+ mpc[\"mpc\"] = _ppc2mpc(ppc)\n if filename is not None:\n # savemat\n savemat(filename, mpc)\n", "issue": "from_mpc failed to load the case generated by to_mpc\nAfter checking the source code, I found the to_mpc function saves the fields in a loose format. According to the from_mpc function, all the fields should be under a variable called \"mpc\" (default), however the to_mpc function does not follow this, which leads to a situation that the from_mpc function cannot load the case generated by the to_mpc function.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2019 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\n\nimport copy\n\nimport numpy as np\nfrom scipy.io import savemat\n\nfrom pandapower.converter.pypower import to_ppc\n\ntry:\n import pplog as logging\nexcept ImportError:\n import logging\n\nlogger = logging.getLogger(__name__)\n\n\ndef to_mpc(net, filename=None, **kwargs):\n \"\"\"\n This function converts a pandapower net to a matpower case files (.mat) version 2.\n Note: python is 0-based while Matlab is 1-based.\n\n INPUT:\n **net** - The pandapower net.\n\n OPTIONAL:\n **filename** (str, None) - File path + name of the mat file which will be created. If None\n the mpc will only be returned\n\n ****kwargs** - please look at to_ppc() documentation\n\n EXAMPLE:\n import pandapower.converter as pc\n import pandapower.networks as pn\n net = pn.case9()\n pc.to_mpc(net, \"case9.mat\")\n\n \"\"\"\n ppc = to_ppc(net, **kwargs)\n\n mpc = _ppc2mpc(ppc)\n if filename is not None:\n # savemat\n savemat(filename, mpc)\n\n return mpc\n\n\ndef _ppc2mpc(ppc):\n \"\"\"\n Convert network in Pypower/Matpower format\n Convert 0-based python to 1-based Matlab\n\n **INPUT**:\n * net - The pandapower format network\n * filename - File path + name of the mat file which is created\n \"\"\"\n\n # convert to matpower\n # Matlab is one-based, so all entries (buses, lines, gens) have to start with 1 instead of 0\n mpc = copy.deepcopy(ppc)\n if len(np.where(mpc[\"bus\"][:, 0] == 0)[0]):\n mpc[\"bus\"][:, 0] = mpc[\"bus\"][:, 0] + 1\n mpc[\"gen\"][:, 0] = mpc[\"gen\"][:, 0] + 1\n mpc[\"branch\"][:, 0:2] = mpc[\"branch\"][:, 0:2] + 1\n # adjust for the matpower converter -> taps should be 0 when there is no transformer, but are 1\n mpc[\"branch\"][np.where(mpc[\"branch\"][:, 8] == 1), 8] = 0\n # version is a string\n mpc[\"version\"] = str(mpc[\"version\"])\n # baseMVA has to be a float instead of int\n mpc[\"baseMVA\"] = mpc[\"baseMVA\"] * 1.0\n return mpc\n\n\nif \"__main__\" == __name__:\n pass\n", "path": "pandapower/converter/matpower/to_mpc.py"}]}
| 1,468 | 146 |
gh_patches_debug_22402
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-6607
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logger from get_logger does not log to backend - prefect 2.0.4
### First check
- [X] I added a descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the Prefect documentation for this issue.
- [X] I checked that this issue is related to Prefect and not one of its dependencies.
### Bug summary
The logger i get from get_logger does log in the local shell session but the logs do not show up in backend.
Logs with made by get_run_logger are captured as expected!
### Reproduction
```python
from prefect import flow, task
from prefect.logging import get_logger, get_run_logger
@flow
def world():
get_logger().info("get_logger World")
get_run_logger().info("get_run_logger World")
@task
def hello():
get_logger().info(" get_logger Hello")
get_run_logger().info("get_run_logger Hello")
@flow
def test_flow():
get_logger().info("get_logger test")
get_run_logger().info("get_run_logger test")
hello()
world()
test_flow()
```
### Error
Local logs
```
19:22:45.427 | INFO | prefect.engine - Created flow run 'unyielding-wolverine' for flow 'test-flow'
19:22:46.433 | INFO | prefect - get_logger test
19:22:46.433 | INFO | Flow run 'unyielding-wolverine' - get_run_logger test
19:22:46.604 | INFO | Flow run 'unyielding-wolverine' - Created task run 'hello-b3a437c7-0' for task 'hello'
19:22:46.605 | INFO | Flow run 'unyielding-wolverine' - Executing 'hello-b3a437c7-0' immediately...
19:22:46.902 | INFO | prefect - get_logger Hello
19:22:46.903 | INFO | Task run 'hello-b3a437c7-0' - get_run_logger Hello
19:22:47.170 | INFO | Task run 'hello-b3a437c7-0' - Finished in state Completed()
19:22:47.732 | INFO | Flow run 'unyielding-wolverine' - Created subflow run 'watchful-puffin' for flow 'world'
19:22:48.065 | INFO | prefect - get_logger World
19:22:48.065 | INFO | Flow run 'watchful-puffin' - get_run_logger World
19:22:48.273 | INFO | Flow run 'watchful-puffin' - Finished in state Completed()
19:22:48.456 | INFO | Flow run 'unyielding-wolverine' - Finished in state Completed('All states completed.')
```
Remote logs
<img width="943" alt="image" src="https://user-images.githubusercontent.com/24698503/187261871-9d89681e-03fe-4557-b942-b24fafb71be5.png">
Subflow logs
<img width="961" alt="image" src="https://user-images.githubusercontent.com/24698503/187261992-8d029968-434e-43f6-9d5b-cd405e250a9e.png">
### Versions
```
Version: 2.0.4
API version: 0.8.0
Python version: 3.8.10
Git commit: 39db6fb1
Built: Wed, Aug 10, 2022 1:19 PM
OS/Arch: linux/x86_64
Profile: ci
Server type: hosted
```
### Additional context
_No response_
</issue>
<code>
[start of src/prefect/logging/loggers.py]
1 import logging
2 from functools import lru_cache
3 from typing import TYPE_CHECKING
4
5 import prefect
6
7 if TYPE_CHECKING:
8 from prefect.context import RunContext
9 from prefect.flows import Flow
10 from prefect.orion.schemas.core import FlowRun, TaskRun
11 from prefect.tasks import Task
12
13
14 class PrefectLogAdapter(logging.LoggerAdapter):
15 """
16 Adapter that ensures extra kwargs are passed through correctly; without this
17 the `extra` fields set on the adapter would overshadow any provided on a
18 log-by-log basis.
19
20 See https://bugs.python.org/issue32732 — the Python team has declared that this is
21 not a bug in the LoggingAdapter and subclassing is the intended workaround.
22 """
23
24 def process(self, msg, kwargs):
25 kwargs["extra"] = {**self.extra, **(kwargs.get("extra") or {})}
26 return (msg, kwargs)
27
28
29 @lru_cache()
30 def get_logger(name: str = None) -> logging.Logger:
31 """
32 Get a `prefect` logger. For use within Prefect.
33 """
34
35 parent_logger = logging.getLogger("prefect")
36
37 if name:
38 # Append the name if given but allow explicit full names e.g. "prefect.test"
39 # should not become "prefect.prefect.test"
40 if not name.startswith(parent_logger.name + "."):
41 logger = parent_logger.getChild(name)
42 else:
43 logger = logging.getLogger(name)
44 else:
45 logger = parent_logger
46
47 return logger
48
49
50 def get_run_logger(context: "RunContext" = None, **kwargs: str) -> logging.Logger:
51 """
52 Get a Prefect logger for the current task run or flow run.
53
54 The logger will be named either `prefect.task_runs` or `prefect.flow_runs`.
55 Contextual data about the run will be attached to the log records.
56
57 Arguments:
58 context: A specific context may be provided as an override. By default, the
59 context is inferred from global state and this should not be needed.
60 **kwargs: Additional keyword arguments will be attached to the log records in
61 addition to the run metadata
62
63 Raises:
64 RuntimeError: If no context can be found
65 """
66 # Check for existing contexts
67 task_run_context = prefect.context.TaskRunContext.get()
68 flow_run_context = prefect.context.FlowRunContext.get()
69
70 # Apply the context override
71 if context:
72 if isinstance(context, prefect.context.FlowRunContext):
73 flow_run_context = context
74 elif isinstance(context, prefect.context.TaskRunContext):
75 task_run_context = context
76 else:
77 raise TypeError(
78 f"Received unexpected type {type(context).__name__!r} for context. "
79 "Expected one of 'None', 'FlowRunContext', or 'TaskRunContext'."
80 )
81
82 # Determine if this is a task or flow run logger
83 if task_run_context:
84 logger = task_run_logger(
85 task_run=task_run_context.task_run,
86 task=task_run_context.task,
87 flow_run=flow_run_context.flow_run if flow_run_context else None,
88 flow=flow_run_context.flow if flow_run_context else None,
89 **kwargs,
90 )
91 elif flow_run_context:
92 logger = flow_run_logger(
93 flow_run=flow_run_context.flow_run, flow=flow_run_context.flow, **kwargs
94 )
95 else:
96 raise RuntimeError("There is no active flow or task run context.")
97
98 return logger
99
100
101 def flow_run_logger(flow_run: "FlowRun", flow: "Flow" = None, **kwargs: str):
102 """
103 Create a flow run logger with the run's metadata attached.
104
105 Additional keyword arguments can be provided to attach custom data to the log
106 records.
107
108 If the context is available, see `run_logger` instead.
109 """
110 return PrefectLogAdapter(
111 get_logger("prefect.flow_runs"),
112 extra={
113 **{
114 "flow_run_name": flow_run.name,
115 "flow_run_id": str(flow_run.id),
116 "flow_name": flow.name if flow else "<unknown>",
117 },
118 **kwargs,
119 },
120 )
121
122
123 def task_run_logger(
124 task_run: "TaskRun",
125 task: "Task" = None,
126 flow_run: "FlowRun" = None,
127 flow: "Flow" = None,
128 **kwargs: str,
129 ):
130 """
131 Create a task run logger with the run's metadata attached.
132
133 Additional keyword arguments can be provided to attach custom data to the log
134 records.
135
136 If the context is available, see `run_logger` instead.
137 """
138 return PrefectLogAdapter(
139 get_logger("prefect.task_runs"),
140 extra={
141 **{
142 "task_run_id": str(task_run.id),
143 "flow_run_id": str(task_run.flow_run_id),
144 "task_run_name": task_run.name,
145 "task_name": task.name if task else "<unknown>",
146 "flow_run_name": flow_run.name if flow_run else "<unknown>",
147 "flow_name": flow.name if flow else "<unknown>",
148 },
149 **kwargs,
150 },
151 )
152
[end of src/prefect/logging/loggers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/logging/loggers.py b/src/prefect/logging/loggers.py
--- a/src/prefect/logging/loggers.py
+++ b/src/prefect/logging/loggers.py
@@ -29,7 +29,11 @@
@lru_cache()
def get_logger(name: str = None) -> logging.Logger:
"""
- Get a `prefect` logger. For use within Prefect.
+ Get a `prefect` logger. These loggers are intended for internal use within the
+ `prefect` package.
+
+ See `get_run_logger` for retrieving loggers for use within task or flow runs.
+ By default, only run-related loggers are connected to the `OrionHandler`.
"""
parent_logger = logging.getLogger("prefect")
@@ -54,6 +58,9 @@
The logger will be named either `prefect.task_runs` or `prefect.flow_runs`.
Contextual data about the run will be attached to the log records.
+ These loggers are connected to the `OrionHandler` by default to send log records to
+ the API.
+
Arguments:
context: A specific context may be provided as an override. By default, the
context is inferred from global state and this should not be needed.
|
{"golden_diff": "diff --git a/src/prefect/logging/loggers.py b/src/prefect/logging/loggers.py\n--- a/src/prefect/logging/loggers.py\n+++ b/src/prefect/logging/loggers.py\n@@ -29,7 +29,11 @@\n @lru_cache()\n def get_logger(name: str = None) -> logging.Logger:\n \"\"\"\n- Get a `prefect` logger. For use within Prefect.\n+ Get a `prefect` logger. These loggers are intended for internal use within the\n+ `prefect` package.\n+\n+ See `get_run_logger` for retrieving loggers for use within task or flow runs.\n+ By default, only run-related loggers are connected to the `OrionHandler`.\n \"\"\"\n \n parent_logger = logging.getLogger(\"prefect\")\n@@ -54,6 +58,9 @@\n The logger will be named either `prefect.task_runs` or `prefect.flow_runs`.\n Contextual data about the run will be attached to the log records.\n \n+ These loggers are connected to the `OrionHandler` by default to send log records to\n+ the API.\n+\n Arguments:\n context: A specific context may be provided as an override. By default, the\n context is inferred from global state and this should not be needed.\n", "issue": "Logger from get_logger does not log to backend - prefect 2.0.4\n### First check\n\n- [X] I added a descriptive title to this issue.\n- [X] I used the GitHub search to find a similar issue and didn't find it.\n- [X] I searched the Prefect documentation for this issue.\n- [X] I checked that this issue is related to Prefect and not one of its dependencies.\n\n### Bug summary\n\nThe logger i get from get_logger does log in the local shell session but the logs do not show up in backend.\r\n\r\nLogs with made by get_run_logger are captured as expected!\n\n### Reproduction\n\n```python\nfrom prefect import flow, task\r\nfrom prefect.logging import get_logger, get_run_logger\r\n\r\n\r\n@flow\r\ndef world():\r\n get_logger().info(\"get_logger World\")\r\n get_run_logger().info(\"get_run_logger World\")\r\n\r\n\r\n@task\r\ndef hello():\r\n get_logger().info(\" get_logger Hello\")\r\n get_run_logger().info(\"get_run_logger Hello\")\r\n\r\n\r\n@flow\r\ndef test_flow():\r\n get_logger().info(\"get_logger test\")\r\n get_run_logger().info(\"get_run_logger test\")\r\n hello()\r\n world()\r\n\r\n\r\ntest_flow()\n```\n\n\n### Error\n\nLocal logs\r\n```\r\n19:22:45.427 | INFO | prefect.engine - Created flow run 'unyielding-wolverine' for flow 'test-flow'\r\n19:22:46.433 | INFO | prefect - get_logger test\r\n19:22:46.433 | INFO | Flow run 'unyielding-wolverine' - get_run_logger test\r\n19:22:46.604 | INFO | Flow run 'unyielding-wolverine' - Created task run 'hello-b3a437c7-0' for task 'hello'\r\n19:22:46.605 | INFO | Flow run 'unyielding-wolverine' - Executing 'hello-b3a437c7-0' immediately...\r\n19:22:46.902 | INFO | prefect - get_logger Hello\r\n19:22:46.903 | INFO | Task run 'hello-b3a437c7-0' - get_run_logger Hello\r\n19:22:47.170 | INFO | Task run 'hello-b3a437c7-0' - Finished in state Completed()\r\n19:22:47.732 | INFO | Flow run 'unyielding-wolverine' - Created subflow run 'watchful-puffin' for flow 'world'\r\n19:22:48.065 | INFO | prefect - get_logger World\r\n19:22:48.065 | INFO | Flow run 'watchful-puffin' - get_run_logger World\r\n19:22:48.273 | INFO | Flow run 'watchful-puffin' - Finished in state Completed()\r\n19:22:48.456 | INFO | Flow run 'unyielding-wolverine' - Finished in state Completed('All states completed.')\r\n```\r\nRemote logs\r\n<img width=\"943\" alt=\"image\" src=\"https://user-images.githubusercontent.com/24698503/187261871-9d89681e-03fe-4557-b942-b24fafb71be5.png\">\r\n\r\nSubflow logs\r\n<img width=\"961\" alt=\"image\" src=\"https://user-images.githubusercontent.com/24698503/187261992-8d029968-434e-43f6-9d5b-cd405e250a9e.png\">\r\n\n\n### Versions\n\n```\r\n\r\nVersion: 2.0.4\r\nAPI version: 0.8.0\r\nPython version: 3.8.10\r\nGit commit: 39db6fb1\r\nBuilt: Wed, Aug 10, 2022 1:19 PM\r\nOS/Arch: linux/x86_64\r\nProfile: ci\r\nServer type: hosted\r\n\r\n```\r\n\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "import logging\nfrom functools import lru_cache\nfrom typing import TYPE_CHECKING\n\nimport prefect\n\nif TYPE_CHECKING:\n from prefect.context import RunContext\n from prefect.flows import Flow\n from prefect.orion.schemas.core import FlowRun, TaskRun\n from prefect.tasks import Task\n\n\nclass PrefectLogAdapter(logging.LoggerAdapter):\n \"\"\"\n Adapter that ensures extra kwargs are passed through correctly; without this\n the `extra` fields set on the adapter would overshadow any provided on a\n log-by-log basis.\n\n See https://bugs.python.org/issue32732 \u2014 the Python team has declared that this is\n not a bug in the LoggingAdapter and subclassing is the intended workaround.\n \"\"\"\n\n def process(self, msg, kwargs):\n kwargs[\"extra\"] = {**self.extra, **(kwargs.get(\"extra\") or {})}\n return (msg, kwargs)\n\n\n@lru_cache()\ndef get_logger(name: str = None) -> logging.Logger:\n \"\"\"\n Get a `prefect` logger. For use within Prefect.\n \"\"\"\n\n parent_logger = logging.getLogger(\"prefect\")\n\n if name:\n # Append the name if given but allow explicit full names e.g. \"prefect.test\"\n # should not become \"prefect.prefect.test\"\n if not name.startswith(parent_logger.name + \".\"):\n logger = parent_logger.getChild(name)\n else:\n logger = logging.getLogger(name)\n else:\n logger = parent_logger\n\n return logger\n\n\ndef get_run_logger(context: \"RunContext\" = None, **kwargs: str) -> logging.Logger:\n \"\"\"\n Get a Prefect logger for the current task run or flow run.\n\n The logger will be named either `prefect.task_runs` or `prefect.flow_runs`.\n Contextual data about the run will be attached to the log records.\n\n Arguments:\n context: A specific context may be provided as an override. By default, the\n context is inferred from global state and this should not be needed.\n **kwargs: Additional keyword arguments will be attached to the log records in\n addition to the run metadata\n\n Raises:\n RuntimeError: If no context can be found\n \"\"\"\n # Check for existing contexts\n task_run_context = prefect.context.TaskRunContext.get()\n flow_run_context = prefect.context.FlowRunContext.get()\n\n # Apply the context override\n if context:\n if isinstance(context, prefect.context.FlowRunContext):\n flow_run_context = context\n elif isinstance(context, prefect.context.TaskRunContext):\n task_run_context = context\n else:\n raise TypeError(\n f\"Received unexpected type {type(context).__name__!r} for context. \"\n \"Expected one of 'None', 'FlowRunContext', or 'TaskRunContext'.\"\n )\n\n # Determine if this is a task or flow run logger\n if task_run_context:\n logger = task_run_logger(\n task_run=task_run_context.task_run,\n task=task_run_context.task,\n flow_run=flow_run_context.flow_run if flow_run_context else None,\n flow=flow_run_context.flow if flow_run_context else None,\n **kwargs,\n )\n elif flow_run_context:\n logger = flow_run_logger(\n flow_run=flow_run_context.flow_run, flow=flow_run_context.flow, **kwargs\n )\n else:\n raise RuntimeError(\"There is no active flow or task run context.\")\n\n return logger\n\n\ndef flow_run_logger(flow_run: \"FlowRun\", flow: \"Flow\" = None, **kwargs: str):\n \"\"\"\n Create a flow run logger with the run's metadata attached.\n\n Additional keyword arguments can be provided to attach custom data to the log\n records.\n\n If the context is available, see `run_logger` instead.\n \"\"\"\n return PrefectLogAdapter(\n get_logger(\"prefect.flow_runs\"),\n extra={\n **{\n \"flow_run_name\": flow_run.name,\n \"flow_run_id\": str(flow_run.id),\n \"flow_name\": flow.name if flow else \"<unknown>\",\n },\n **kwargs,\n },\n )\n\n\ndef task_run_logger(\n task_run: \"TaskRun\",\n task: \"Task\" = None,\n flow_run: \"FlowRun\" = None,\n flow: \"Flow\" = None,\n **kwargs: str,\n):\n \"\"\"\n Create a task run logger with the run's metadata attached.\n\n Additional keyword arguments can be provided to attach custom data to the log\n records.\n\n If the context is available, see `run_logger` instead.\n \"\"\"\n return PrefectLogAdapter(\n get_logger(\"prefect.task_runs\"),\n extra={\n **{\n \"task_run_id\": str(task_run.id),\n \"flow_run_id\": str(task_run.flow_run_id),\n \"task_run_name\": task_run.name,\n \"task_name\": task.name if task else \"<unknown>\",\n \"flow_run_name\": flow_run.name if flow_run else \"<unknown>\",\n \"flow_name\": flow.name if flow else \"<unknown>\",\n },\n **kwargs,\n },\n )\n", "path": "src/prefect/logging/loggers.py"}]}
| 2,953 | 286 |
gh_patches_debug_43407
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-5083
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add FileClassifier media support
**Is your feature request related to a problem? Please describe.**
As a user I want to add WhisperTranscriber in my pipeline. I would like to use FileClassifier to classify my documents/media and direct to the correct node.
**Describe the solution you'd like**
- Add support to media files (that Whisper allows) into the FileClassifier
**Describe alternatives you've considered**
Keep as it's and don't integrate into the current pipelines
**Additional context**
This feature request is supposed to be considered after the merge of the current Whisper PR #4335.
</issue>
<code>
[start of haystack/nodes/file_classifier/file_type.py]
1 import mimetypes
2 from typing import Any, Dict, List, Union, Optional
3
4 import logging
5 from pathlib import Path
6
7 from haystack.nodes.base import BaseComponent
8 from haystack.lazy_imports import LazyImport
9
10
11 logger = logging.getLogger(__name__)
12
13 with LazyImport() as magic_import:
14 import magic
15
16
17 DEFAULT_TYPES = ["txt", "pdf", "md", "docx", "html"]
18
19
20 class FileTypeClassifier(BaseComponent):
21 """
22 Route files in an Indexing Pipeline to corresponding file converters.
23 """
24
25 outgoing_edges = len(DEFAULT_TYPES)
26
27 def __init__(self, supported_types: Optional[List[str]] = None):
28 """
29 Node that sends out files on a different output edge depending on their extension.
30
31 :param supported_types: The file types that this node can distinguish between.
32 If no value is provided, the value created by default comprises: `txt`, `pdf`, `md`, `docx`, and `html`.
33 Lists with duplicate elements are not allowed.
34 """
35 if supported_types is None:
36 supported_types = DEFAULT_TYPES
37 if len(set(supported_types)) != len(supported_types):
38 duplicates = supported_types
39 for item in set(supported_types):
40 duplicates.remove(item)
41 raise ValueError(f"supported_types can't contain duplicate values ({duplicates}).")
42
43 super().__init__()
44
45 self.supported_types = supported_types
46
47 @classmethod
48 def _calculate_outgoing_edges(cls, component_params: Dict[str, Any]) -> int:
49 supported_types = component_params.get("supported_types", DEFAULT_TYPES)
50 return len(supported_types)
51
52 def _estimate_extension(self, file_path: Path) -> str:
53 """
54 Return the extension found based on the contents of the given file
55
56 :param file_path: the path to extract the extension from
57 """
58 try:
59 magic_import.check()
60 extension = magic.from_file(str(file_path), mime=True)
61 return mimetypes.guess_extension(extension) or ""
62 except (NameError, ImportError):
63 logger.error(
64 "The type of '%s' could not be guessed, probably because 'python-magic' is not installed. Ignoring this error."
65 "Please make sure the necessary OS libraries are installed if you need this functionality ('python-magic' or 'python-magic-bin' on Windows).",
66 file_path,
67 )
68 return ""
69
70 def _get_extension(self, file_paths: List[Path]) -> str:
71 """
72 Return the extension found in the given list of files.
73 Also makes sure that all files have the same extension.
74 If this is not true, it throws an exception.
75
76 :param file_paths: the paths to extract the extension from
77 :return: a set of strings with all the extensions (without duplicates), the extension will be guessed if the file has none
78 """
79 extension = file_paths[0].suffix.lower()
80 if extension == "":
81 extension = self._estimate_extension(file_paths[0])
82
83 for path in file_paths:
84 path_suffix = path.suffix.lower()
85 if path_suffix == "":
86 path_suffix = self._estimate_extension(path)
87 if path_suffix != extension:
88 raise ValueError("Multiple file types are not allowed at once.")
89
90 return extension.lstrip(".")
91
92 def run(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore
93 """
94 Sends out files on a different output edge depending on their extension.
95
96 :param file_paths: paths to route on different edges.
97 """
98 if not isinstance(file_paths, list):
99 file_paths = [file_paths]
100
101 paths = [Path(path) for path in file_paths]
102
103 output = {"file_paths": paths}
104 extension = self._get_extension(paths)
105 try:
106 index = self.supported_types.index(extension) + 1
107 except ValueError:
108 raise ValueError(
109 f"Files of type '{extension}' ({paths[0]}) are not supported. "
110 f"The supported types are: {self.supported_types}. "
111 "Consider using the 'supported_types' parameter to "
112 "change the types accepted by this node."
113 )
114 return output, f"output_{index}"
115
116 def run_batch(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore
117 return self.run(file_paths=file_paths)
118
[end of haystack/nodes/file_classifier/file_type.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/haystack/nodes/file_classifier/file_type.py b/haystack/nodes/file_classifier/file_type.py
--- a/haystack/nodes/file_classifier/file_type.py
+++ b/haystack/nodes/file_classifier/file_type.py
@@ -14,7 +14,9 @@
import magic
-DEFAULT_TYPES = ["txt", "pdf", "md", "docx", "html"]
+DEFAULT_TYPES = ["txt", "pdf", "md", "docx", "html", "media"]
+
+DEFAULT_MEDIA_TYPES = ["mp3", "mp4", "mpeg", "m4a", "wav", "webm"]
class FileTypeClassifier(BaseComponent):
@@ -24,15 +26,20 @@
outgoing_edges = len(DEFAULT_TYPES)
- def __init__(self, supported_types: Optional[List[str]] = None):
+ def __init__(self, supported_types: Optional[List[str]] = None, full_analysis: bool = False):
"""
Node that sends out files on a different output edge depending on their extension.
- :param supported_types: The file types that this node can distinguish between.
- If no value is provided, the value created by default comprises: `txt`, `pdf`, `md`, `docx`, and `html`.
- Lists with duplicate elements are not allowed.
+ :param supported_types: The file types this node distinguishes. Optional.
+ If you don't provide any value, the default is: `txt`, `pdf`, `md`, `docx`, and `html`.
+ You can't use lists with duplicate elements.
+ :param full_analysis: If True, the whole file is analyzed to determine the file type.
+ If False, only the first 2049 bytes are analyzed.
"""
+ self.full_analysis = full_analysis
+ self._default_types = False
if supported_types is None:
+ self._default_types = True
supported_types = DEFAULT_TYPES
if len(set(supported_types)) != len(supported_types):
duplicates = supported_types
@@ -56,9 +63,17 @@
:param file_path: the path to extract the extension from
"""
try:
- magic_import.check()
- extension = magic.from_file(str(file_path), mime=True)
- return mimetypes.guess_extension(extension) or ""
+ with open(file_path, "rb") as f:
+ if self.full_analysis:
+ buffer = f.read()
+ else:
+ buffer = f.read(2049)
+ extension = magic.from_buffer(buffer, mime=True)
+ real_extension = mimetypes.guess_extension(extension) or ""
+ real_extension = real_extension.lstrip(".")
+ if self._default_types and real_extension in DEFAULT_MEDIA_TYPES:
+ return "media"
+ return real_extension or ""
except (NameError, ImportError):
logger.error(
"The type of '%s' could not be guessed, probably because 'python-magic' is not installed. Ignoring this error."
@@ -76,18 +91,19 @@
:param file_paths: the paths to extract the extension from
:return: a set of strings with all the extensions (without duplicates), the extension will be guessed if the file has none
"""
- extension = file_paths[0].suffix.lower()
- if extension == "":
+ extension = file_paths[0].suffix.lower().lstrip(".")
+
+ if extension == "" or (self._default_types and extension in DEFAULT_MEDIA_TYPES):
extension = self._estimate_extension(file_paths[0])
for path in file_paths:
- path_suffix = path.suffix.lower()
- if path_suffix == "":
+ path_suffix = path.suffix.lower().lstrip(".")
+ if path_suffix == "" or (self._default_types and path_suffix in DEFAULT_MEDIA_TYPES):
path_suffix = self._estimate_extension(path)
if path_suffix != extension:
- raise ValueError("Multiple file types are not allowed at once.")
+ raise ValueError("Multiple non-default file types are not allowed at once.")
- return extension.lstrip(".")
+ return extension
def run(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore
"""
|
{"golden_diff": "diff --git a/haystack/nodes/file_classifier/file_type.py b/haystack/nodes/file_classifier/file_type.py\n--- a/haystack/nodes/file_classifier/file_type.py\n+++ b/haystack/nodes/file_classifier/file_type.py\n@@ -14,7 +14,9 @@\n import magic\n \n \n-DEFAULT_TYPES = [\"txt\", \"pdf\", \"md\", \"docx\", \"html\"]\n+DEFAULT_TYPES = [\"txt\", \"pdf\", \"md\", \"docx\", \"html\", \"media\"]\n+\n+DEFAULT_MEDIA_TYPES = [\"mp3\", \"mp4\", \"mpeg\", \"m4a\", \"wav\", \"webm\"]\n \n \n class FileTypeClassifier(BaseComponent):\n@@ -24,15 +26,20 @@\n \n outgoing_edges = len(DEFAULT_TYPES)\n \n- def __init__(self, supported_types: Optional[List[str]] = None):\n+ def __init__(self, supported_types: Optional[List[str]] = None, full_analysis: bool = False):\n \"\"\"\n Node that sends out files on a different output edge depending on their extension.\n \n- :param supported_types: The file types that this node can distinguish between.\n- If no value is provided, the value created by default comprises: `txt`, `pdf`, `md`, `docx`, and `html`.\n- Lists with duplicate elements are not allowed.\n+ :param supported_types: The file types this node distinguishes. Optional.\n+ If you don't provide any value, the default is: `txt`, `pdf`, `md`, `docx`, and `html`.\n+ You can't use lists with duplicate elements.\n+ :param full_analysis: If True, the whole file is analyzed to determine the file type.\n+ If False, only the first 2049 bytes are analyzed.\n \"\"\"\n+ self.full_analysis = full_analysis\n+ self._default_types = False\n if supported_types is None:\n+ self._default_types = True\n supported_types = DEFAULT_TYPES\n if len(set(supported_types)) != len(supported_types):\n duplicates = supported_types\n@@ -56,9 +63,17 @@\n :param file_path: the path to extract the extension from\n \"\"\"\n try:\n- magic_import.check()\n- extension = magic.from_file(str(file_path), mime=True)\n- return mimetypes.guess_extension(extension) or \"\"\n+ with open(file_path, \"rb\") as f:\n+ if self.full_analysis:\n+ buffer = f.read()\n+ else:\n+ buffer = f.read(2049)\n+ extension = magic.from_buffer(buffer, mime=True)\n+ real_extension = mimetypes.guess_extension(extension) or \"\"\n+ real_extension = real_extension.lstrip(\".\")\n+ if self._default_types and real_extension in DEFAULT_MEDIA_TYPES:\n+ return \"media\"\n+ return real_extension or \"\"\n except (NameError, ImportError):\n logger.error(\n \"The type of '%s' could not be guessed, probably because 'python-magic' is not installed. Ignoring this error.\"\n@@ -76,18 +91,19 @@\n :param file_paths: the paths to extract the extension from\n :return: a set of strings with all the extensions (without duplicates), the extension will be guessed if the file has none\n \"\"\"\n- extension = file_paths[0].suffix.lower()\n- if extension == \"\":\n+ extension = file_paths[0].suffix.lower().lstrip(\".\")\n+\n+ if extension == \"\" or (self._default_types and extension in DEFAULT_MEDIA_TYPES):\n extension = self._estimate_extension(file_paths[0])\n \n for path in file_paths:\n- path_suffix = path.suffix.lower()\n- if path_suffix == \"\":\n+ path_suffix = path.suffix.lower().lstrip(\".\")\n+ if path_suffix == \"\" or (self._default_types and path_suffix in DEFAULT_MEDIA_TYPES):\n path_suffix = self._estimate_extension(path)\n if path_suffix != extension:\n- raise ValueError(\"Multiple file types are not allowed at once.\")\n+ raise ValueError(\"Multiple non-default file types are not allowed at once.\")\n \n- return extension.lstrip(\".\")\n+ return extension\n \n def run(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore\n \"\"\"\n", "issue": "Add FileClassifier media support\n**Is your feature request related to a problem? Please describe.**\r\nAs a user I want to add WhisperTranscriber in my pipeline. I would like to use FileClassifier to classify my documents/media and direct to the correct node. \r\n\r\n**Describe the solution you'd like**\r\n- Add support to media files (that Whisper allows) into the FileClassifier\r\n\r\n**Describe alternatives you've considered**\r\nKeep as it's and don't integrate into the current pipelines\r\n\r\n**Additional context**\r\nThis feature request is supposed to be considered after the merge of the current Whisper PR #4335.\r\n\n", "before_files": [{"content": "import mimetypes\nfrom typing import Any, Dict, List, Union, Optional\n\nimport logging\nfrom pathlib import Path\n\nfrom haystack.nodes.base import BaseComponent\nfrom haystack.lazy_imports import LazyImport\n\n\nlogger = logging.getLogger(__name__)\n\nwith LazyImport() as magic_import:\n import magic\n\n\nDEFAULT_TYPES = [\"txt\", \"pdf\", \"md\", \"docx\", \"html\"]\n\n\nclass FileTypeClassifier(BaseComponent):\n \"\"\"\n Route files in an Indexing Pipeline to corresponding file converters.\n \"\"\"\n\n outgoing_edges = len(DEFAULT_TYPES)\n\n def __init__(self, supported_types: Optional[List[str]] = None):\n \"\"\"\n Node that sends out files on a different output edge depending on their extension.\n\n :param supported_types: The file types that this node can distinguish between.\n If no value is provided, the value created by default comprises: `txt`, `pdf`, `md`, `docx`, and `html`.\n Lists with duplicate elements are not allowed.\n \"\"\"\n if supported_types is None:\n supported_types = DEFAULT_TYPES\n if len(set(supported_types)) != len(supported_types):\n duplicates = supported_types\n for item in set(supported_types):\n duplicates.remove(item)\n raise ValueError(f\"supported_types can't contain duplicate values ({duplicates}).\")\n\n super().__init__()\n\n self.supported_types = supported_types\n\n @classmethod\n def _calculate_outgoing_edges(cls, component_params: Dict[str, Any]) -> int:\n supported_types = component_params.get(\"supported_types\", DEFAULT_TYPES)\n return len(supported_types)\n\n def _estimate_extension(self, file_path: Path) -> str:\n \"\"\"\n Return the extension found based on the contents of the given file\n\n :param file_path: the path to extract the extension from\n \"\"\"\n try:\n magic_import.check()\n extension = magic.from_file(str(file_path), mime=True)\n return mimetypes.guess_extension(extension) or \"\"\n except (NameError, ImportError):\n logger.error(\n \"The type of '%s' could not be guessed, probably because 'python-magic' is not installed. Ignoring this error.\"\n \"Please make sure the necessary OS libraries are installed if you need this functionality ('python-magic' or 'python-magic-bin' on Windows).\",\n file_path,\n )\n return \"\"\n\n def _get_extension(self, file_paths: List[Path]) -> str:\n \"\"\"\n Return the extension found in the given list of files.\n Also makes sure that all files have the same extension.\n If this is not true, it throws an exception.\n\n :param file_paths: the paths to extract the extension from\n :return: a set of strings with all the extensions (without duplicates), the extension will be guessed if the file has none\n \"\"\"\n extension = file_paths[0].suffix.lower()\n if extension == \"\":\n extension = self._estimate_extension(file_paths[0])\n\n for path in file_paths:\n path_suffix = path.suffix.lower()\n if path_suffix == \"\":\n path_suffix = self._estimate_extension(path)\n if path_suffix != extension:\n raise ValueError(\"Multiple file types are not allowed at once.\")\n\n return extension.lstrip(\".\")\n\n def run(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore\n \"\"\"\n Sends out files on a different output edge depending on their extension.\n\n :param file_paths: paths to route on different edges.\n \"\"\"\n if not isinstance(file_paths, list):\n file_paths = [file_paths]\n\n paths = [Path(path) for path in file_paths]\n\n output = {\"file_paths\": paths}\n extension = self._get_extension(paths)\n try:\n index = self.supported_types.index(extension) + 1\n except ValueError:\n raise ValueError(\n f\"Files of type '{extension}' ({paths[0]}) are not supported. \"\n f\"The supported types are: {self.supported_types}. \"\n \"Consider using the 'supported_types' parameter to \"\n \"change the types accepted by this node.\"\n )\n return output, f\"output_{index}\"\n\n def run_batch(self, file_paths: Union[Path, List[Path], str, List[str], List[Union[Path, str]]]): # type: ignore\n return self.run(file_paths=file_paths)\n", "path": "haystack/nodes/file_classifier/file_type.py"}]}
| 1,868 | 948 |
gh_patches_debug_32538
|
rasdani/github-patches
|
git_diff
|
dask__distributed-3104
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wait on single connection or try multiple connections
When we connect to a remote connection we currently wait on for our full timeout, often ten seconds, something like this:
```python
comm = await connect(address, timeout="10s")
```
However, @jacobtomlinson and I just ran into a situation with Kubernetes where the address that we were connecting to was created at just about the same time, so when we first tried to connect we were sent somewhere that would never receive the connection, but if we try again a second later, things are fine.
```python
comm = await connect(address, timeout="10s") # this hangs for 10s
```
```python
for i in range(10): # this connects after 1s
with ignoring(TimeoutError):
comm = await comm(address, timeout="1s")
```
This seems to work because, presumably, after the first connection fails and we try reconnecting the network now routes us to the correct location.
In general this second approach seems more robust to networks that might be fiddled with on-the-fly, which is presumably more common in cloud and Kubernetes situations. However, it also means that we need to become better about cleaning up missed connections.
cc @jcrist @jacobtomlinson and @mmccarty
The actual code for this is here: https://github.com/dask/distributed/blob/549660e07c0c70fdb17e07c6a18ca438933bd8ba/distributed/comm/core.py#L205-L228
</issue>
<code>
[start of distributed/comm/core.py]
1 from abc import ABC, abstractmethod, abstractproperty
2 from datetime import timedelta
3 import logging
4 import weakref
5
6 import dask
7 from tornado import gen
8
9 from ..metrics import time
10 from ..utils import parse_timedelta
11 from . import registry
12 from .addressing import parse_address
13
14
15 logger = logging.getLogger(__name__)
16
17
18 class CommClosedError(IOError):
19 pass
20
21
22 class FatalCommClosedError(CommClosedError):
23 pass
24
25
26 class Comm(ABC):
27 """
28 A message-oriented communication object, representing an established
29 communication channel. There should be only one reader and one
30 writer at a time: to manage current communications, even with a
31 single peer, you must create distinct ``Comm`` objects.
32
33 Messages are arbitrary Python objects. Concrete implementations
34 of this class can implement different serialization mechanisms
35 depending on the underlying transport's characteristics.
36 """
37
38 _instances = weakref.WeakSet()
39
40 def __init__(self):
41 self._instances.add(self)
42 self.name = None
43
44 # XXX add set_close_callback()?
45
46 @abstractmethod
47 def read(self, deserializers=None):
48 """
49 Read and return a message (a Python object).
50
51 This method is a coroutine.
52
53 Parameters
54 ----------
55 deserializers : Optional[Dict[str, Tuple[Callable, Callable, bool]]]
56 An optional dict appropriate for distributed.protocol.deserialize.
57 See :ref:`serialization` for more.
58 """
59
60 @abstractmethod
61 def write(self, msg, on_error=None):
62 """
63 Write a message (a Python object).
64
65 This method is a coroutine.
66
67 Parameters
68 ----------
69 msg :
70 on_error : Optional[str]
71 The behavior when serialization fails. See
72 ``distributed.protocol.core.dumps`` for valid values.
73 """
74
75 @abstractmethod
76 def close(self):
77 """
78 Close the communication cleanly. This will attempt to flush
79 outgoing buffers before actually closing the underlying transport.
80
81 This method is a coroutine.
82 """
83
84 @abstractmethod
85 def abort(self):
86 """
87 Close the communication immediately and abruptly.
88 Useful in destructors or generators' ``finally`` blocks.
89 """
90
91 @abstractmethod
92 def closed(self):
93 """
94 Return whether the stream is closed.
95 """
96
97 @abstractproperty
98 def local_address(self):
99 """
100 The local address. For logging and debugging purposes only.
101 """
102
103 @abstractproperty
104 def peer_address(self):
105 """
106 The peer's address. For logging and debugging purposes only.
107 """
108
109 @property
110 def extra_info(self):
111 """
112 Return backend-specific information about the communication,
113 as a dict. Typically, this is information which is initialized
114 when the communication is established and doesn't vary afterwards.
115 """
116 return {}
117
118 def __repr__(self):
119 clsname = self.__class__.__name__
120 if self.closed():
121 return "<closed %s>" % (clsname,)
122 else:
123 return "<%s %s local=%s remote=%s>" % (
124 clsname,
125 self.name or "",
126 self.local_address,
127 self.peer_address,
128 )
129
130
131 class Listener(ABC):
132 @abstractmethod
133 def start(self):
134 """
135 Start listening for incoming connections.
136 """
137
138 @abstractmethod
139 def stop(self):
140 """
141 Stop listening. This does not shutdown already established
142 communications, but prevents accepting new ones.
143 """
144
145 @abstractproperty
146 def listen_address(self):
147 """
148 The listening address as a URI string.
149 """
150
151 @abstractproperty
152 def contact_address(self):
153 """
154 An address this listener can be contacted on. This can be
155 different from `listen_address` if the latter is some wildcard
156 address such as 'tcp://0.0.0.0:123'.
157 """
158
159 def __enter__(self):
160 self.start()
161 return self
162
163 def __exit__(self, *exc):
164 self.stop()
165
166
167 class Connector(ABC):
168 @abstractmethod
169 def connect(self, address, deserialize=True):
170 """
171 Connect to the given address and return a Comm object.
172 This function is a coroutine. It may raise EnvironmentError
173 if the other endpoint is unreachable or unavailable. It
174 may raise ValueError if the address is malformed.
175 """
176
177
178 async def connect(addr, timeout=None, deserialize=True, connection_args=None):
179 """
180 Connect to the given address (a URI such as ``tcp://127.0.0.1:1234``)
181 and yield a ``Comm`` object. If the connection attempt fails, it is
182 retried until the *timeout* is expired.
183 """
184 if timeout is None:
185 timeout = dask.config.get("distributed.comm.timeouts.connect")
186 timeout = parse_timedelta(timeout, default="seconds")
187
188 scheme, loc = parse_address(addr)
189 backend = registry.get_backend(scheme)
190 connector = backend.get_connector()
191
192 start = time()
193 deadline = start + timeout
194 error = None
195
196 def _raise(error):
197 error = error or "connect() didn't finish in time"
198 msg = "Timed out trying to connect to %r after %s s: %s" % (
199 addr,
200 timeout,
201 error,
202 )
203 raise IOError(msg)
204
205 # This starts a thread
206 while True:
207 try:
208 future = connector.connect(
209 loc, deserialize=deserialize, **(connection_args or {})
210 )
211 comm = await gen.with_timeout(
212 timedelta(seconds=deadline - time()),
213 future,
214 quiet_exceptions=EnvironmentError,
215 )
216 except FatalCommClosedError:
217 raise
218 except EnvironmentError as e:
219 error = str(e)
220 if time() < deadline:
221 await gen.sleep(0.01)
222 logger.debug("sleeping on connect")
223 else:
224 _raise(error)
225 except gen.TimeoutError:
226 _raise(error)
227 else:
228 break
229
230 return comm
231
232
233 def listen(addr, handle_comm, deserialize=True, connection_args=None):
234 """
235 Create a listener object with the given parameters. When its ``start()``
236 method is called, the listener will listen on the given address
237 (a URI such as ``tcp://0.0.0.0``) and call *handle_comm* with a
238 ``Comm`` object for each incoming connection.
239
240 *handle_comm* can be a regular function or a coroutine.
241 """
242 try:
243 scheme, loc = parse_address(addr, strict=True)
244 except ValueError:
245 if connection_args and connection_args.get("ssl_context"):
246 addr = "tls://" + addr
247 else:
248 addr = "tcp://" + addr
249 scheme, loc = parse_address(addr, strict=True)
250
251 backend = registry.get_backend(scheme)
252
253 return backend.get_listener(
254 loc, handle_comm, deserialize, **(connection_args or {})
255 )
256
[end of distributed/comm/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/distributed/comm/core.py b/distributed/comm/core.py
--- a/distributed/comm/core.py
+++ b/distributed/comm/core.py
@@ -7,7 +7,7 @@
from tornado import gen
from ..metrics import time
-from ..utils import parse_timedelta
+from ..utils import parse_timedelta, ignoring
from . import registry
from .addressing import parse_address
@@ -188,6 +188,7 @@
scheme, loc = parse_address(addr)
backend = registry.get_backend(scheme)
connector = backend.get_connector()
+ comm = None
start = time()
deadline = start + timeout
@@ -205,14 +206,19 @@
# This starts a thread
while True:
try:
- future = connector.connect(
- loc, deserialize=deserialize, **(connection_args or {})
- )
- comm = await gen.with_timeout(
- timedelta(seconds=deadline - time()),
- future,
- quiet_exceptions=EnvironmentError,
- )
+ while deadline - time() > 0:
+ future = connector.connect(
+ loc, deserialize=deserialize, **(connection_args or {})
+ )
+ with ignoring(gen.TimeoutError):
+ comm = await gen.with_timeout(
+ timedelta(seconds=min(deadline - time(), 1)),
+ future,
+ quiet_exceptions=EnvironmentError,
+ )
+ break
+ if not comm:
+ _raise(error)
except FatalCommClosedError:
raise
except EnvironmentError as e:
@@ -222,8 +228,6 @@
logger.debug("sleeping on connect")
else:
_raise(error)
- except gen.TimeoutError:
- _raise(error)
else:
break
|
{"golden_diff": "diff --git a/distributed/comm/core.py b/distributed/comm/core.py\n--- a/distributed/comm/core.py\n+++ b/distributed/comm/core.py\n@@ -7,7 +7,7 @@\n from tornado import gen\n \n from ..metrics import time\n-from ..utils import parse_timedelta\n+from ..utils import parse_timedelta, ignoring\n from . import registry\n from .addressing import parse_address\n \n@@ -188,6 +188,7 @@\n scheme, loc = parse_address(addr)\n backend = registry.get_backend(scheme)\n connector = backend.get_connector()\n+ comm = None\n \n start = time()\n deadline = start + timeout\n@@ -205,14 +206,19 @@\n # This starts a thread\n while True:\n try:\n- future = connector.connect(\n- loc, deserialize=deserialize, **(connection_args or {})\n- )\n- comm = await gen.with_timeout(\n- timedelta(seconds=deadline - time()),\n- future,\n- quiet_exceptions=EnvironmentError,\n- )\n+ while deadline - time() > 0:\n+ future = connector.connect(\n+ loc, deserialize=deserialize, **(connection_args or {})\n+ )\n+ with ignoring(gen.TimeoutError):\n+ comm = await gen.with_timeout(\n+ timedelta(seconds=min(deadline - time(), 1)),\n+ future,\n+ quiet_exceptions=EnvironmentError,\n+ )\n+ break\n+ if not comm:\n+ _raise(error)\n except FatalCommClosedError:\n raise\n except EnvironmentError as e:\n@@ -222,8 +228,6 @@\n logger.debug(\"sleeping on connect\")\n else:\n _raise(error)\n- except gen.TimeoutError:\n- _raise(error)\n else:\n break\n", "issue": "Wait on single connection or try multiple connections\nWhen we connect to a remote connection we currently wait on for our full timeout, often ten seconds, something like this:\r\n\r\n```python\r\ncomm = await connect(address, timeout=\"10s\")\r\n```\r\n\r\nHowever, @jacobtomlinson and I just ran into a situation with Kubernetes where the address that we were connecting to was created at just about the same time, so when we first tried to connect we were sent somewhere that would never receive the connection, but if we try again a second later, things are fine.\r\n\r\n```python\r\ncomm = await connect(address, timeout=\"10s\") # this hangs for 10s\r\n```\r\n```python\r\nfor i in range(10): # this connects after 1s\r\n with ignoring(TimeoutError):\r\n comm = await comm(address, timeout=\"1s\")\r\n```\r\n\r\nThis seems to work because, presumably, after the first connection fails and we try reconnecting the network now routes us to the correct location.\r\n\r\nIn general this second approach seems more robust to networks that might be fiddled with on-the-fly, which is presumably more common in cloud and Kubernetes situations. However, it also means that we need to become better about cleaning up missed connections.\r\n\r\ncc @jcrist @jacobtomlinson and @mmccarty \r\n\r\nThe actual code for this is here: https://github.com/dask/distributed/blob/549660e07c0c70fdb17e07c6a18ca438933bd8ba/distributed/comm/core.py#L205-L228\n", "before_files": [{"content": "from abc import ABC, abstractmethod, abstractproperty\nfrom datetime import timedelta\nimport logging\nimport weakref\n\nimport dask\nfrom tornado import gen\n\nfrom ..metrics import time\nfrom ..utils import parse_timedelta\nfrom . import registry\nfrom .addressing import parse_address\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass CommClosedError(IOError):\n pass\n\n\nclass FatalCommClosedError(CommClosedError):\n pass\n\n\nclass Comm(ABC):\n \"\"\"\n A message-oriented communication object, representing an established\n communication channel. There should be only one reader and one\n writer at a time: to manage current communications, even with a\n single peer, you must create distinct ``Comm`` objects.\n\n Messages are arbitrary Python objects. Concrete implementations\n of this class can implement different serialization mechanisms\n depending on the underlying transport's characteristics.\n \"\"\"\n\n _instances = weakref.WeakSet()\n\n def __init__(self):\n self._instances.add(self)\n self.name = None\n\n # XXX add set_close_callback()?\n\n @abstractmethod\n def read(self, deserializers=None):\n \"\"\"\n Read and return a message (a Python object).\n\n This method is a coroutine.\n\n Parameters\n ----------\n deserializers : Optional[Dict[str, Tuple[Callable, Callable, bool]]]\n An optional dict appropriate for distributed.protocol.deserialize.\n See :ref:`serialization` for more.\n \"\"\"\n\n @abstractmethod\n def write(self, msg, on_error=None):\n \"\"\"\n Write a message (a Python object).\n\n This method is a coroutine.\n\n Parameters\n ----------\n msg :\n on_error : Optional[str]\n The behavior when serialization fails. See\n ``distributed.protocol.core.dumps`` for valid values.\n \"\"\"\n\n @abstractmethod\n def close(self):\n \"\"\"\n Close the communication cleanly. This will attempt to flush\n outgoing buffers before actually closing the underlying transport.\n\n This method is a coroutine.\n \"\"\"\n\n @abstractmethod\n def abort(self):\n \"\"\"\n Close the communication immediately and abruptly.\n Useful in destructors or generators' ``finally`` blocks.\n \"\"\"\n\n @abstractmethod\n def closed(self):\n \"\"\"\n Return whether the stream is closed.\n \"\"\"\n\n @abstractproperty\n def local_address(self):\n \"\"\"\n The local address. For logging and debugging purposes only.\n \"\"\"\n\n @abstractproperty\n def peer_address(self):\n \"\"\"\n The peer's address. For logging and debugging purposes only.\n \"\"\"\n\n @property\n def extra_info(self):\n \"\"\"\n Return backend-specific information about the communication,\n as a dict. Typically, this is information which is initialized\n when the communication is established and doesn't vary afterwards.\n \"\"\"\n return {}\n\n def __repr__(self):\n clsname = self.__class__.__name__\n if self.closed():\n return \"<closed %s>\" % (clsname,)\n else:\n return \"<%s %s local=%s remote=%s>\" % (\n clsname,\n self.name or \"\",\n self.local_address,\n self.peer_address,\n )\n\n\nclass Listener(ABC):\n @abstractmethod\n def start(self):\n \"\"\"\n Start listening for incoming connections.\n \"\"\"\n\n @abstractmethod\n def stop(self):\n \"\"\"\n Stop listening. This does not shutdown already established\n communications, but prevents accepting new ones.\n \"\"\"\n\n @abstractproperty\n def listen_address(self):\n \"\"\"\n The listening address as a URI string.\n \"\"\"\n\n @abstractproperty\n def contact_address(self):\n \"\"\"\n An address this listener can be contacted on. This can be\n different from `listen_address` if the latter is some wildcard\n address such as 'tcp://0.0.0.0:123'.\n \"\"\"\n\n def __enter__(self):\n self.start()\n return self\n\n def __exit__(self, *exc):\n self.stop()\n\n\nclass Connector(ABC):\n @abstractmethod\n def connect(self, address, deserialize=True):\n \"\"\"\n Connect to the given address and return a Comm object.\n This function is a coroutine. It may raise EnvironmentError\n if the other endpoint is unreachable or unavailable. It\n may raise ValueError if the address is malformed.\n \"\"\"\n\n\nasync def connect(addr, timeout=None, deserialize=True, connection_args=None):\n \"\"\"\n Connect to the given address (a URI such as ``tcp://127.0.0.1:1234``)\n and yield a ``Comm`` object. If the connection attempt fails, it is\n retried until the *timeout* is expired.\n \"\"\"\n if timeout is None:\n timeout = dask.config.get(\"distributed.comm.timeouts.connect\")\n timeout = parse_timedelta(timeout, default=\"seconds\")\n\n scheme, loc = parse_address(addr)\n backend = registry.get_backend(scheme)\n connector = backend.get_connector()\n\n start = time()\n deadline = start + timeout\n error = None\n\n def _raise(error):\n error = error or \"connect() didn't finish in time\"\n msg = \"Timed out trying to connect to %r after %s s: %s\" % (\n addr,\n timeout,\n error,\n )\n raise IOError(msg)\n\n # This starts a thread\n while True:\n try:\n future = connector.connect(\n loc, deserialize=deserialize, **(connection_args or {})\n )\n comm = await gen.with_timeout(\n timedelta(seconds=deadline - time()),\n future,\n quiet_exceptions=EnvironmentError,\n )\n except FatalCommClosedError:\n raise\n except EnvironmentError as e:\n error = str(e)\n if time() < deadline:\n await gen.sleep(0.01)\n logger.debug(\"sleeping on connect\")\n else:\n _raise(error)\n except gen.TimeoutError:\n _raise(error)\n else:\n break\n\n return comm\n\n\ndef listen(addr, handle_comm, deserialize=True, connection_args=None):\n \"\"\"\n Create a listener object with the given parameters. When its ``start()``\n method is called, the listener will listen on the given address\n (a URI such as ``tcp://0.0.0.0``) and call *handle_comm* with a\n ``Comm`` object for each incoming connection.\n\n *handle_comm* can be a regular function or a coroutine.\n \"\"\"\n try:\n scheme, loc = parse_address(addr, strict=True)\n except ValueError:\n if connection_args and connection_args.get(\"ssl_context\"):\n addr = \"tls://\" + addr\n else:\n addr = \"tcp://\" + addr\n scheme, loc = parse_address(addr, strict=True)\n\n backend = registry.get_backend(scheme)\n\n return backend.get_listener(\n loc, handle_comm, deserialize, **(connection_args or {})\n )\n", "path": "distributed/comm/core.py"}]}
| 3,036 | 396 |
gh_patches_debug_64926
|
rasdani/github-patches
|
git_diff
|
biopython__biopython-3922
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
KEGG.Compound.parse not returning mass
### Setup
I am reporting a problem with Biopython version, Python version, and operating
system as follows:
1.78
3.9.12
Windows 10 Pro
### Expected behaviour
Calling KEGG.Compound.parse on a KEGG record should return a KEGG record object containing the mass. For example, compound C00120 should have a mass attribute containing 244.0882.
### Actual behaviour
However, no mass attribute is returned.
### Steps to reproduce
```
from Bio.KEGG.Compound import parse
from Bio.KEGG.REST import kegg_get
c00120 = next(parse(kegg_get('C00120')))
print(c00120.mass)
```
### Fix
This is because the KEGG record now uses separate EXACT_MASS and MOL_WEIGHT fields (can be seen by running kegg_get('C00120').read()). Fixed by replacing line 156 in KEGG.Compound.__init__.py with:
`elif keyword == "EXACT_MASS ":`
</issue>
<code>
[start of Bio/KEGG/Compound/__init__.py]
1 # Copyright 2001 by Tarjei Mikkelsen. All rights reserved.
2 # Copyright 2007 by Michiel de Hoon. All rights reserved.
3 #
4 # This file is part of the Biopython distribution and governed by your
5 # choice of the "Biopython License Agreement" or the "BSD 3-Clause License".
6 # Please see the LICENSE file that should have been included as part of this
7 # package.
8
9 """Code to work with the KEGG Ligand/Compound database.
10
11 Functions:
12 - parse - Returns an iterator giving Record objects.
13
14 Classes:
15 - Record - A representation of a KEGG Ligand/Compound.
16 """
17
18
19 from Bio.KEGG import _default_wrap, _struct_wrap, _wrap_kegg, _write_kegg
20
21
22 # Set up line wrapping rules (see Bio.KEGG._wrap_kegg)
23 name_wrap = [0, "", (" ", "$", 1, 1), ("-", "$", 1, 1)]
24 id_wrap = _default_wrap
25 struct_wrap = _struct_wrap
26
27
28 class Record:
29 """Holds info from a KEGG Ligand/Compound record.
30
31 Attributes:
32 - entry The entry identifier.
33 - name A list of the compound names.
34 - formula The chemical formula for the compound
35 - mass The molecular weight for the compound
36 - pathway A list of 3-tuples: ('PATH', pathway id, pathway)
37 - enzyme A list of the EC numbers.
38 - structures A list of 2-tuples: (database, list of struct ids)
39 - dblinks A list of 2-tuples: (database, list of link ids)
40
41 """
42
43 def __init__(self):
44 """Initialize as new record."""
45 self.entry = ""
46 self.name = []
47 self.formula = ""
48 self.mass = ""
49 self.pathway = []
50 self.enzyme = []
51 self.structures = []
52 self.dblinks = []
53
54 def __str__(self):
55 """Return a string representation of this Record."""
56 return (
57 self._entry()
58 + self._name()
59 + self._formula()
60 + self._mass()
61 + self._pathway()
62 + self._enzyme()
63 + self._structures()
64 + self._dblinks()
65 + "///"
66 )
67
68 def _entry(self):
69 return _write_kegg("ENTRY", [self.entry])
70
71 def _name(self):
72 return _write_kegg(
73 "NAME", [_wrap_kegg(l, wrap_rule=name_wrap) for l in self.name]
74 )
75
76 def _formula(self):
77 return _write_kegg("FORMULA", [self.formula])
78
79 def _mass(self):
80 return _write_kegg("MASS", [self.mass])
81
82 def _pathway(self):
83 s = []
84 for entry in self.pathway:
85 s.append(entry[0] + " " + entry[1])
86 return _write_kegg("PATHWAY", [_wrap_kegg(l, wrap_rule=id_wrap(16)) for l in s])
87
88 def _enzyme(self):
89 return _write_kegg(
90 "ENZYME", [_wrap_kegg(l, wrap_rule=name_wrap) for l in self.enzyme]
91 )
92
93 def _structures(self):
94 s = []
95 for entry in self.structures:
96 s.append(entry[0] + ": " + " ".join(entry[1]) + " ")
97 return _write_kegg(
98 "STRUCTURES", [_wrap_kegg(l, wrap_rule=struct_wrap(5)) for l in s]
99 )
100
101 def _dblinks(self):
102 s = []
103 for entry in self.dblinks:
104 s.append(entry[0] + ": " + " ".join(entry[1]))
105 return _write_kegg("DBLINKS", [_wrap_kegg(l, wrap_rule=id_wrap(9)) for l in s])
106
107
108 def parse(handle):
109 """Parse a KEGG Ligan/Compound file, returning Record objects.
110
111 This is an iterator function, typically used in a for loop. For
112 example, using one of the example KEGG files in the Biopython
113 test suite,
114
115 >>> with open("KEGG/compound.sample") as handle:
116 ... for record in parse(handle):
117 ... print("%s %s" % (record.entry, record.name[0]))
118 ...
119 C00023 Iron
120 C00017 Protein
121 C00099 beta-Alanine
122 C00294 Inosine
123 C00298 Trypsin
124 C00348 all-trans-Undecaprenyl phosphate
125 C00349 2-Methyl-3-oxopropanoate
126 C01386 NH2Mec
127
128 """
129 record = Record()
130 for line in handle:
131 if line[:3] == "///":
132 yield record
133 record = Record()
134 continue
135 if line[:12] != " ":
136 keyword = line[:12]
137 data = line[12:].strip()
138 if keyword == "ENTRY ":
139 words = data.split()
140 record.entry = words[0]
141 elif keyword == "NAME ":
142 data = data.strip(";")
143 record.name.append(data)
144 elif keyword == "ENZYME ":
145 while data:
146 column = data[:16]
147 data = data[16:]
148 enzyme = column.strip()
149 record.enzyme.append(enzyme)
150 elif keyword == "PATHWAY ":
151 map, name = data.split(" ")
152 pathway = ("PATH", map, name)
153 record.pathway.append(pathway)
154 elif keyword == "FORMULA ":
155 record.formula = data
156 elif keyword == "MASS ":
157 record.mass = data
158 elif keyword == "DBLINKS ":
159 if ":" in data:
160 key, values = data.split(":")
161 values = values.split()
162 row = (key, values)
163 record.dblinks.append(row)
164 else:
165 row = record.dblinks[-1]
166 key, values = row
167 values.extend(data.split())
168 row = key, values
169 record.dblinks[-1] = row
170
171
172 if __name__ == "__main__":
173 from Bio._utils import run_doctest
174
175 run_doctest()
176
[end of Bio/KEGG/Compound/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Bio/KEGG/Compound/__init__.py b/Bio/KEGG/Compound/__init__.py
--- a/Bio/KEGG/Compound/__init__.py
+++ b/Bio/KEGG/Compound/__init__.py
@@ -153,7 +153,7 @@
record.pathway.append(pathway)
elif keyword == "FORMULA ":
record.formula = data
- elif keyword == "MASS ":
+ elif keyword in ("MASS ", "EXACT_MASS "):
record.mass = data
elif keyword == "DBLINKS ":
if ":" in data:
|
{"golden_diff": "diff --git a/Bio/KEGG/Compound/__init__.py b/Bio/KEGG/Compound/__init__.py\n--- a/Bio/KEGG/Compound/__init__.py\n+++ b/Bio/KEGG/Compound/__init__.py\n@@ -153,7 +153,7 @@\n record.pathway.append(pathway)\n elif keyword == \"FORMULA \":\n record.formula = data\n- elif keyword == \"MASS \":\n+ elif keyword in (\"MASS \", \"EXACT_MASS \"):\n record.mass = data\n elif keyword == \"DBLINKS \":\n if \":\" in data:\n", "issue": "KEGG.Compound.parse not returning mass \n### Setup\r\n\r\nI am reporting a problem with Biopython version, Python version, and operating\r\nsystem as follows:\r\n\r\n1.78\r\n3.9.12\r\nWindows 10 Pro\r\n\r\n### Expected behaviour\r\n\r\nCalling KEGG.Compound.parse on a KEGG record should return a KEGG record object containing the mass. For example, compound C00120 should have a mass attribute containing 244.0882.\r\n\r\n### Actual behaviour\r\n\r\nHowever, no mass attribute is returned. \r\n\r\n### Steps to reproduce\r\n\r\n```\r\nfrom Bio.KEGG.Compound import parse\r\nfrom Bio.KEGG.REST import kegg_get\r\nc00120 = next(parse(kegg_get('C00120')))\r\nprint(c00120.mass)\r\n```\r\n### Fix\r\nThis is because the KEGG record now uses separate EXACT_MASS and MOL_WEIGHT fields (can be seen by running kegg_get('C00120').read()). Fixed by replacing line 156 in KEGG.Compound.__init__.py with:\r\n`elif keyword == \"EXACT_MASS \":`\r\n\r\n\n", "before_files": [{"content": "# Copyright 2001 by Tarjei Mikkelsen. All rights reserved.\n# Copyright 2007 by Michiel de Hoon. All rights reserved.\n#\n# This file is part of the Biopython distribution and governed by your\n# choice of the \"Biopython License Agreement\" or the \"BSD 3-Clause License\".\n# Please see the LICENSE file that should have been included as part of this\n# package.\n\n\"\"\"Code to work with the KEGG Ligand/Compound database.\n\nFunctions:\n - parse - Returns an iterator giving Record objects.\n\nClasses:\n - Record - A representation of a KEGG Ligand/Compound.\n\"\"\"\n\n\nfrom Bio.KEGG import _default_wrap, _struct_wrap, _wrap_kegg, _write_kegg\n\n\n# Set up line wrapping rules (see Bio.KEGG._wrap_kegg)\nname_wrap = [0, \"\", (\" \", \"$\", 1, 1), (\"-\", \"$\", 1, 1)]\nid_wrap = _default_wrap\nstruct_wrap = _struct_wrap\n\n\nclass Record:\n \"\"\"Holds info from a KEGG Ligand/Compound record.\n\n Attributes:\n - entry The entry identifier.\n - name A list of the compound names.\n - formula The chemical formula for the compound\n - mass The molecular weight for the compound\n - pathway A list of 3-tuples: ('PATH', pathway id, pathway)\n - enzyme A list of the EC numbers.\n - structures A list of 2-tuples: (database, list of struct ids)\n - dblinks A list of 2-tuples: (database, list of link ids)\n\n \"\"\"\n\n def __init__(self):\n \"\"\"Initialize as new record.\"\"\"\n self.entry = \"\"\n self.name = []\n self.formula = \"\"\n self.mass = \"\"\n self.pathway = []\n self.enzyme = []\n self.structures = []\n self.dblinks = []\n\n def __str__(self):\n \"\"\"Return a string representation of this Record.\"\"\"\n return (\n self._entry()\n + self._name()\n + self._formula()\n + self._mass()\n + self._pathway()\n + self._enzyme()\n + self._structures()\n + self._dblinks()\n + \"///\"\n )\n\n def _entry(self):\n return _write_kegg(\"ENTRY\", [self.entry])\n\n def _name(self):\n return _write_kegg(\n \"NAME\", [_wrap_kegg(l, wrap_rule=name_wrap) for l in self.name]\n )\n\n def _formula(self):\n return _write_kegg(\"FORMULA\", [self.formula])\n\n def _mass(self):\n return _write_kegg(\"MASS\", [self.mass])\n\n def _pathway(self):\n s = []\n for entry in self.pathway:\n s.append(entry[0] + \" \" + entry[1])\n return _write_kegg(\"PATHWAY\", [_wrap_kegg(l, wrap_rule=id_wrap(16)) for l in s])\n\n def _enzyme(self):\n return _write_kegg(\n \"ENZYME\", [_wrap_kegg(l, wrap_rule=name_wrap) for l in self.enzyme]\n )\n\n def _structures(self):\n s = []\n for entry in self.structures:\n s.append(entry[0] + \": \" + \" \".join(entry[1]) + \" \")\n return _write_kegg(\n \"STRUCTURES\", [_wrap_kegg(l, wrap_rule=struct_wrap(5)) for l in s]\n )\n\n def _dblinks(self):\n s = []\n for entry in self.dblinks:\n s.append(entry[0] + \": \" + \" \".join(entry[1]))\n return _write_kegg(\"DBLINKS\", [_wrap_kegg(l, wrap_rule=id_wrap(9)) for l in s])\n\n\ndef parse(handle):\n \"\"\"Parse a KEGG Ligan/Compound file, returning Record objects.\n\n This is an iterator function, typically used in a for loop. For\n example, using one of the example KEGG files in the Biopython\n test suite,\n\n >>> with open(\"KEGG/compound.sample\") as handle:\n ... for record in parse(handle):\n ... print(\"%s %s\" % (record.entry, record.name[0]))\n ...\n C00023 Iron\n C00017 Protein\n C00099 beta-Alanine\n C00294 Inosine\n C00298 Trypsin\n C00348 all-trans-Undecaprenyl phosphate\n C00349 2-Methyl-3-oxopropanoate\n C01386 NH2Mec\n\n \"\"\"\n record = Record()\n for line in handle:\n if line[:3] == \"///\":\n yield record\n record = Record()\n continue\n if line[:12] != \" \":\n keyword = line[:12]\n data = line[12:].strip()\n if keyword == \"ENTRY \":\n words = data.split()\n record.entry = words[0]\n elif keyword == \"NAME \":\n data = data.strip(\";\")\n record.name.append(data)\n elif keyword == \"ENZYME \":\n while data:\n column = data[:16]\n data = data[16:]\n enzyme = column.strip()\n record.enzyme.append(enzyme)\n elif keyword == \"PATHWAY \":\n map, name = data.split(\" \")\n pathway = (\"PATH\", map, name)\n record.pathway.append(pathway)\n elif keyword == \"FORMULA \":\n record.formula = data\n elif keyword == \"MASS \":\n record.mass = data\n elif keyword == \"DBLINKS \":\n if \":\" in data:\n key, values = data.split(\":\")\n values = values.split()\n row = (key, values)\n record.dblinks.append(row)\n else:\n row = record.dblinks[-1]\n key, values = row\n values.extend(data.split())\n row = key, values\n record.dblinks[-1] = row\n\n\nif __name__ == \"__main__\":\n from Bio._utils import run_doctest\n\n run_doctest()\n", "path": "Bio/KEGG/Compound/__init__.py"}]}
| 2,636 | 147 |
gh_patches_debug_47663
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-875
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tag cog crashes bot on systems with non utf8 default encoding.
The tag cog leaves out encoding when opening files, assuming the default is UTF8 but that is not the case on some OSs and fails with the `UnicodeDecodeError`.
The offending block of code can be found here:
https://github.com/python-discord/bot/blob/7571cabe65e39d231523e713923cd23b927225bc/bot/cogs/tags.py#L43-L48
paging @kmonteith25 here as they mentioned the issue in #dev-contrib
</issue>
<code>
[start of bot/cogs/tags.py]
1 import logging
2 import re
3 import time
4 from pathlib import Path
5 from typing import Callable, Dict, Iterable, List, Optional
6
7 from discord import Colour, Embed
8 from discord.ext.commands import Cog, Context, group
9
10 from bot import constants
11 from bot.bot import Bot
12 from bot.converters import TagNameConverter
13 from bot.pagination import LinePaginator
14 from bot.utils.messages import wait_for_deletion
15
16 log = logging.getLogger(__name__)
17
18 TEST_CHANNELS = (
19 constants.Channels.bot_commands,
20 constants.Channels.helpers
21 )
22
23 REGEX_NON_ALPHABET = re.compile(r"[^a-z]", re.MULTILINE & re.IGNORECASE)
24 FOOTER_TEXT = f"To show a tag, type {constants.Bot.prefix}tags <tagname>."
25
26
27 class Tags(Cog):
28 """Save new tags and fetch existing tags."""
29
30 def __init__(self, bot: Bot):
31 self.bot = bot
32 self.tag_cooldowns = {}
33 self._cache = self.get_tags()
34
35 @staticmethod
36 def get_tags() -> dict:
37 """Get all tags."""
38 # Save all tags in memory.
39 cache = {}
40 tag_files = Path("bot", "resources", "tags").iterdir()
41 for file in tag_files:
42 tag_title = file.stem
43 tag = {
44 "title": tag_title,
45 "embed": {
46 "description": file.read_text()
47 }
48 }
49 cache[tag_title] = tag
50 return cache
51
52 @staticmethod
53 def _fuzzy_search(search: str, target: str) -> float:
54 """A simple scoring algorithm based on how many letters are found / total, with order in mind."""
55 current, index = 0, 0
56 _search = REGEX_NON_ALPHABET.sub('', search.lower())
57 _targets = iter(REGEX_NON_ALPHABET.split(target.lower()))
58 _target = next(_targets)
59 try:
60 while True:
61 while index < len(_target) and _search[current] == _target[index]:
62 current += 1
63 index += 1
64 index, _target = 0, next(_targets)
65 except (StopIteration, IndexError):
66 pass
67 return current / len(_search) * 100
68
69 def _get_suggestions(self, tag_name: str, thresholds: Optional[List[int]] = None) -> List[str]:
70 """Return a list of suggested tags."""
71 scores: Dict[str, int] = {
72 tag_title: Tags._fuzzy_search(tag_name, tag['title'])
73 for tag_title, tag in self._cache.items()
74 }
75
76 thresholds = thresholds or [100, 90, 80, 70, 60]
77
78 for threshold in thresholds:
79 suggestions = [
80 self._cache[tag_title]
81 for tag_title, matching_score in scores.items()
82 if matching_score >= threshold
83 ]
84 if suggestions:
85 return suggestions
86
87 return []
88
89 def _get_tag(self, tag_name: str) -> list:
90 """Get a specific tag."""
91 found = [self._cache.get(tag_name.lower(), None)]
92 if not found[0]:
93 return self._get_suggestions(tag_name)
94 return found
95
96 def _get_tags_via_content(self, check: Callable[[Iterable], bool], keywords: str) -> list:
97 """
98 Search for tags via contents.
99
100 `predicate` will be the built-in any, all, or a custom callable. Must return a bool.
101 """
102 keywords_processed: List[str] = []
103 for keyword in keywords.split(','):
104 keyword_sanitized = keyword.strip().casefold()
105 if not keyword_sanitized:
106 # this happens when there are leading / trailing / consecutive comma.
107 continue
108 keywords_processed.append(keyword_sanitized)
109
110 if not keywords_processed:
111 # after sanitizing, we can end up with an empty list, for example when keywords is ','
112 # in that case, we simply want to search for such keywords directly instead.
113 keywords_processed = [keywords]
114
115 matching_tags = []
116 for tag in self._cache.values():
117 if check(query in tag['embed']['description'].casefold() for query in keywords_processed):
118 matching_tags.append(tag)
119
120 return matching_tags
121
122 async def _send_matching_tags(self, ctx: Context, keywords: str, matching_tags: list) -> None:
123 """Send the result of matching tags to user."""
124 if not matching_tags:
125 pass
126 elif len(matching_tags) == 1:
127 await ctx.send(embed=Embed().from_dict(matching_tags[0]['embed']))
128 else:
129 is_plural = keywords.strip().count(' ') > 0 or keywords.strip().count(',') > 0
130 embed = Embed(
131 title=f"Here are the tags containing the given keyword{'s' * is_plural}:",
132 description='\n'.join(tag['title'] for tag in matching_tags[:10])
133 )
134 await LinePaginator.paginate(
135 sorted(f"**»** {tag['title']}" for tag in matching_tags),
136 ctx,
137 embed,
138 footer_text=FOOTER_TEXT,
139 empty=False,
140 max_lines=15
141 )
142
143 @group(name='tags', aliases=('tag', 't'), invoke_without_command=True)
144 async def tags_group(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:
145 """Show all known tags, a single tag, or run a subcommand."""
146 await ctx.invoke(self.get_command, tag_name=tag_name)
147
148 @tags_group.group(name='search', invoke_without_command=True)
149 async def search_tag_content(self, ctx: Context, *, keywords: str) -> None:
150 """
151 Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.
152
153 Only search for tags that has ALL the keywords.
154 """
155 matching_tags = self._get_tags_via_content(all, keywords)
156 await self._send_matching_tags(ctx, keywords, matching_tags)
157
158 @search_tag_content.command(name='any')
159 async def search_tag_content_any_keyword(self, ctx: Context, *, keywords: Optional[str] = 'any') -> None:
160 """
161 Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.
162
163 Search for tags that has ANY of the keywords.
164 """
165 matching_tags = self._get_tags_via_content(any, keywords or 'any')
166 await self._send_matching_tags(ctx, keywords, matching_tags)
167
168 @tags_group.command(name='get', aliases=('show', 'g'))
169 async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:
170 """Get a specified tag, or a list of all tags if no tag is specified."""
171
172 def _command_on_cooldown(tag_name: str) -> bool:
173 """
174 Check if the command is currently on cooldown, on a per-tag, per-channel basis.
175
176 The cooldown duration is set in constants.py.
177 """
178 now = time.time()
179
180 cooldown_conditions = (
181 tag_name
182 and tag_name in self.tag_cooldowns
183 and (now - self.tag_cooldowns[tag_name]["time"]) < constants.Cooldowns.tags
184 and self.tag_cooldowns[tag_name]["channel"] == ctx.channel.id
185 )
186
187 if cooldown_conditions:
188 return True
189 return False
190
191 if _command_on_cooldown(tag_name):
192 time_elapsed = time.time() - self.tag_cooldowns[tag_name]["time"]
193 time_left = constants.Cooldowns.tags - time_elapsed
194 log.info(
195 f"{ctx.author} tried to get the '{tag_name}' tag, but the tag is on cooldown. "
196 f"Cooldown ends in {time_left:.1f} seconds."
197 )
198 return
199
200 if tag_name is not None:
201 founds = self._get_tag(tag_name)
202
203 if len(founds) == 1:
204 tag = founds[0]
205 if ctx.channel.id not in TEST_CHANNELS:
206 self.tag_cooldowns[tag_name] = {
207 "time": time.time(),
208 "channel": ctx.channel.id
209 }
210
211 self.bot.stats.incr(f"tags.usages.{tag['title'].replace('-', '_')}")
212
213 await wait_for_deletion(
214 await ctx.send(embed=Embed.from_dict(tag['embed'])),
215 [ctx.author.id],
216 client=self.bot
217 )
218 elif founds and len(tag_name) >= 3:
219 await wait_for_deletion(
220 await ctx.send(
221 embed=Embed(
222 title='Did you mean ...',
223 description='\n'.join(tag['title'] for tag in founds[:10])
224 )
225 ),
226 [ctx.author.id],
227 client=self.bot
228 )
229
230 else:
231 tags = self._cache.values()
232 if not tags:
233 await ctx.send(embed=Embed(
234 description="**There are no tags in the database!**",
235 colour=Colour.red()
236 ))
237 else:
238 embed: Embed = Embed(title="**Current tags**")
239 await LinePaginator.paginate(
240 sorted(f"**»** {tag['title']}" for tag in tags),
241 ctx,
242 embed,
243 footer_text=FOOTER_TEXT,
244 empty=False,
245 max_lines=15
246 )
247
248
249 def setup(bot: Bot) -> None:
250 """Load the Tags cog."""
251 bot.add_cog(Tags(bot))
252
[end of bot/cogs/tags.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/tags.py b/bot/cogs/tags.py
--- a/bot/cogs/tags.py
+++ b/bot/cogs/tags.py
@@ -43,7 +43,7 @@
tag = {
"title": tag_title,
"embed": {
- "description": file.read_text()
+ "description": file.read_text(encoding="utf-8")
}
}
cache[tag_title] = tag
|
{"golden_diff": "diff --git a/bot/cogs/tags.py b/bot/cogs/tags.py\n--- a/bot/cogs/tags.py\n+++ b/bot/cogs/tags.py\n@@ -43,7 +43,7 @@\n tag = {\n \"title\": tag_title,\n \"embed\": {\n- \"description\": file.read_text()\n+ \"description\": file.read_text(encoding=\"utf-8\")\n }\n }\n cache[tag_title] = tag\n", "issue": "Tag cog crashes bot on systems with non utf8 default encoding.\nThe tag cog leaves out encoding when opening files, assuming the default is UTF8 but that is not the case on some OSs and fails with the `UnicodeDecodeError`.\r\n\r\nThe offending block of code can be found here:\r\nhttps://github.com/python-discord/bot/blob/7571cabe65e39d231523e713923cd23b927225bc/bot/cogs/tags.py#L43-L48\r\n\r\npaging @kmonteith25 here as they mentioned the issue in #dev-contrib\n", "before_files": [{"content": "import logging\nimport re\nimport time\nfrom pathlib import Path\nfrom typing import Callable, Dict, Iterable, List, Optional\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import Cog, Context, group\n\nfrom bot import constants\nfrom bot.bot import Bot\nfrom bot.converters import TagNameConverter\nfrom bot.pagination import LinePaginator\nfrom bot.utils.messages import wait_for_deletion\n\nlog = logging.getLogger(__name__)\n\nTEST_CHANNELS = (\n constants.Channels.bot_commands,\n constants.Channels.helpers\n)\n\nREGEX_NON_ALPHABET = re.compile(r\"[^a-z]\", re.MULTILINE & re.IGNORECASE)\nFOOTER_TEXT = f\"To show a tag, type {constants.Bot.prefix}tags <tagname>.\"\n\n\nclass Tags(Cog):\n \"\"\"Save new tags and fetch existing tags.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.tag_cooldowns = {}\n self._cache = self.get_tags()\n\n @staticmethod\n def get_tags() -> dict:\n \"\"\"Get all tags.\"\"\"\n # Save all tags in memory.\n cache = {}\n tag_files = Path(\"bot\", \"resources\", \"tags\").iterdir()\n for file in tag_files:\n tag_title = file.stem\n tag = {\n \"title\": tag_title,\n \"embed\": {\n \"description\": file.read_text()\n }\n }\n cache[tag_title] = tag\n return cache\n\n @staticmethod\n def _fuzzy_search(search: str, target: str) -> float:\n \"\"\"A simple scoring algorithm based on how many letters are found / total, with order in mind.\"\"\"\n current, index = 0, 0\n _search = REGEX_NON_ALPHABET.sub('', search.lower())\n _targets = iter(REGEX_NON_ALPHABET.split(target.lower()))\n _target = next(_targets)\n try:\n while True:\n while index < len(_target) and _search[current] == _target[index]:\n current += 1\n index += 1\n index, _target = 0, next(_targets)\n except (StopIteration, IndexError):\n pass\n return current / len(_search) * 100\n\n def _get_suggestions(self, tag_name: str, thresholds: Optional[List[int]] = None) -> List[str]:\n \"\"\"Return a list of suggested tags.\"\"\"\n scores: Dict[str, int] = {\n tag_title: Tags._fuzzy_search(tag_name, tag['title'])\n for tag_title, tag in self._cache.items()\n }\n\n thresholds = thresholds or [100, 90, 80, 70, 60]\n\n for threshold in thresholds:\n suggestions = [\n self._cache[tag_title]\n for tag_title, matching_score in scores.items()\n if matching_score >= threshold\n ]\n if suggestions:\n return suggestions\n\n return []\n\n def _get_tag(self, tag_name: str) -> list:\n \"\"\"Get a specific tag.\"\"\"\n found = [self._cache.get(tag_name.lower(), None)]\n if not found[0]:\n return self._get_suggestions(tag_name)\n return found\n\n def _get_tags_via_content(self, check: Callable[[Iterable], bool], keywords: str) -> list:\n \"\"\"\n Search for tags via contents.\n\n `predicate` will be the built-in any, all, or a custom callable. Must return a bool.\n \"\"\"\n keywords_processed: List[str] = []\n for keyword in keywords.split(','):\n keyword_sanitized = keyword.strip().casefold()\n if not keyword_sanitized:\n # this happens when there are leading / trailing / consecutive comma.\n continue\n keywords_processed.append(keyword_sanitized)\n\n if not keywords_processed:\n # after sanitizing, we can end up with an empty list, for example when keywords is ','\n # in that case, we simply want to search for such keywords directly instead.\n keywords_processed = [keywords]\n\n matching_tags = []\n for tag in self._cache.values():\n if check(query in tag['embed']['description'].casefold() for query in keywords_processed):\n matching_tags.append(tag)\n\n return matching_tags\n\n async def _send_matching_tags(self, ctx: Context, keywords: str, matching_tags: list) -> None:\n \"\"\"Send the result of matching tags to user.\"\"\"\n if not matching_tags:\n pass\n elif len(matching_tags) == 1:\n await ctx.send(embed=Embed().from_dict(matching_tags[0]['embed']))\n else:\n is_plural = keywords.strip().count(' ') > 0 or keywords.strip().count(',') > 0\n embed = Embed(\n title=f\"Here are the tags containing the given keyword{'s' * is_plural}:\",\n description='\\n'.join(tag['title'] for tag in matching_tags[:10])\n )\n await LinePaginator.paginate(\n sorted(f\"**\u00bb** {tag['title']}\" for tag in matching_tags),\n ctx,\n embed,\n footer_text=FOOTER_TEXT,\n empty=False,\n max_lines=15\n )\n\n @group(name='tags', aliases=('tag', 't'), invoke_without_command=True)\n async def tags_group(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:\n \"\"\"Show all known tags, a single tag, or run a subcommand.\"\"\"\n await ctx.invoke(self.get_command, tag_name=tag_name)\n\n @tags_group.group(name='search', invoke_without_command=True)\n async def search_tag_content(self, ctx: Context, *, keywords: str) -> None:\n \"\"\"\n Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.\n\n Only search for tags that has ALL the keywords.\n \"\"\"\n matching_tags = self._get_tags_via_content(all, keywords)\n await self._send_matching_tags(ctx, keywords, matching_tags)\n\n @search_tag_content.command(name='any')\n async def search_tag_content_any_keyword(self, ctx: Context, *, keywords: Optional[str] = 'any') -> None:\n \"\"\"\n Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.\n\n Search for tags that has ANY of the keywords.\n \"\"\"\n matching_tags = self._get_tags_via_content(any, keywords or 'any')\n await self._send_matching_tags(ctx, keywords, matching_tags)\n\n @tags_group.command(name='get', aliases=('show', 'g'))\n async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:\n \"\"\"Get a specified tag, or a list of all tags if no tag is specified.\"\"\"\n\n def _command_on_cooldown(tag_name: str) -> bool:\n \"\"\"\n Check if the command is currently on cooldown, on a per-tag, per-channel basis.\n\n The cooldown duration is set in constants.py.\n \"\"\"\n now = time.time()\n\n cooldown_conditions = (\n tag_name\n and tag_name in self.tag_cooldowns\n and (now - self.tag_cooldowns[tag_name][\"time\"]) < constants.Cooldowns.tags\n and self.tag_cooldowns[tag_name][\"channel\"] == ctx.channel.id\n )\n\n if cooldown_conditions:\n return True\n return False\n\n if _command_on_cooldown(tag_name):\n time_elapsed = time.time() - self.tag_cooldowns[tag_name][\"time\"]\n time_left = constants.Cooldowns.tags - time_elapsed\n log.info(\n f\"{ctx.author} tried to get the '{tag_name}' tag, but the tag is on cooldown. \"\n f\"Cooldown ends in {time_left:.1f} seconds.\"\n )\n return\n\n if tag_name is not None:\n founds = self._get_tag(tag_name)\n\n if len(founds) == 1:\n tag = founds[0]\n if ctx.channel.id not in TEST_CHANNELS:\n self.tag_cooldowns[tag_name] = {\n \"time\": time.time(),\n \"channel\": ctx.channel.id\n }\n\n self.bot.stats.incr(f\"tags.usages.{tag['title'].replace('-', '_')}\")\n\n await wait_for_deletion(\n await ctx.send(embed=Embed.from_dict(tag['embed'])),\n [ctx.author.id],\n client=self.bot\n )\n elif founds and len(tag_name) >= 3:\n await wait_for_deletion(\n await ctx.send(\n embed=Embed(\n title='Did you mean ...',\n description='\\n'.join(tag['title'] for tag in founds[:10])\n )\n ),\n [ctx.author.id],\n client=self.bot\n )\n\n else:\n tags = self._cache.values()\n if not tags:\n await ctx.send(embed=Embed(\n description=\"**There are no tags in the database!**\",\n colour=Colour.red()\n ))\n else:\n embed: Embed = Embed(title=\"**Current tags**\")\n await LinePaginator.paginate(\n sorted(f\"**\u00bb** {tag['title']}\" for tag in tags),\n ctx,\n embed,\n footer_text=FOOTER_TEXT,\n empty=False,\n max_lines=15\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Tags cog.\"\"\"\n bot.add_cog(Tags(bot))\n", "path": "bot/cogs/tags.py"}]}
| 3,346 | 99 |
gh_patches_debug_27324
|
rasdani/github-patches
|
git_diff
|
pretalx__pretalx-217
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When redirecting to login view, urlquote path
Paths need to be urlquoted and get params need to be passed aswell.
</issue>
<code>
[start of src/pretalx/common/middleware.py]
1 from contextlib import suppress
2
3 import pytz
4 from django.conf import settings
5 from django.core.exceptions import PermissionDenied
6 from django.db.models import Q
7 from django.shortcuts import redirect, reverse
8 from django.urls import resolve
9 from django.utils import timezone, translation
10 from django.utils.translation.trans_real import (
11 get_supported_language_variant, language_code_re, parse_accept_lang_header,
12 )
13
14 from pretalx.event.models import Event
15 from pretalx.person.models import EventPermission
16
17
18 class EventPermissionMiddleware:
19 UNAUTHENTICATED_ORGA_URLS = (
20 'invitation.view',
21 'login',
22 )
23 REVIEWER_URLS = (
24 'submissions.list',
25 'submissions.content.view',
26 'submissions.questions.view'
27 )
28
29 def __init__(self, get_response):
30 self.get_response = get_response
31
32 def _set_orga_events(self, request):
33 if not request.user.is_anonymous:
34 if request.user.is_superuser:
35 request.orga_events = Event.objects.all()
36 else:
37 request.orga_events = Event.objects.filter(
38 Q(permissions__is_orga=True) | Q(permissions__is_reviewer=True),
39 permissions__user=request.user,
40 )
41
42 def _is_reviewer_url(self, url):
43 if url.url_name.startswith('reviews'):
44 return True
45 if url.url_name.endswith('dashboard'):
46 return True
47 if url.url_name in self.REVIEWER_URLS:
48 return True
49 return False
50
51 def _handle_orga_url(self, request, url):
52 if request.user.is_anonymous and url.url_name not in self.UNAUTHENTICATED_ORGA_URLS:
53 return reverse('orga:login') + f'?next={request.path}'
54 if hasattr(request, 'event') and request.event:
55 if not (request.is_orga or request.is_reviewer):
56 raise PermissionDenied()
57 if (request.is_orga and not request.user.is_superuser) and url.url_name.startswith('reviews'):
58 raise PermissionDenied()
59 if (request.is_reviewer and not request.user.is_superuser) and not self._is_reviewer_url(url):
60 raise PermissionDenied()
61 elif hasattr(request, 'event') and not request.user.is_superuser:
62 raise PermissionDenied()
63 self._select_locale(request)
64
65 def __call__(self, request):
66 url = resolve(request.path_info)
67
68 event_slug = url.kwargs.get('event')
69 if event_slug:
70 try:
71 request.event = Event.objects.get(slug__iexact=event_slug)
72 except Event.DoesNotExist:
73 request.event = None
74
75 if hasattr(request, 'event') and request.event:
76 if not request.user.is_anonymous:
77 request.is_orga = request.user.is_superuser or EventPermission.objects.filter(
78 user=request.user,
79 event=request.event,
80 is_orga=True
81 ).exists()
82 request.is_reviewer = request.user.is_superuser or EventPermission.objects.filter(
83 user=request.user,
84 event=request.event,
85 is_reviewer=True
86 ).exists()
87 else:
88 request.is_orga = False
89 request.is_reviewer = False
90 timezone.activate(pytz.timezone(request.event.timezone))
91
92 self._set_orga_events(request)
93
94 if 'orga' in url.namespaces:
95 url = self._handle_orga_url(request, url)
96 if url:
97 return redirect(url)
98 return self.get_response(request)
99
100 def _select_locale(self, request):
101 supported = request.event.locales if (hasattr(request, 'event') and request.event) else settings.LANGUAGES
102 language = (
103 self._language_from_user(request, supported)
104 or self._language_from_cookie(request, supported)
105 or self._language_from_browser(request, supported)
106 )
107 if hasattr(request, 'event') and request.event:
108 language = language or request.event.locale
109
110 translation.activate(language)
111 request.LANGUAGE_CODE = translation.get_language()
112
113 with suppress(pytz.UnknownTimeZoneError):
114 if request.user.is_authenticated:
115 tzname = request.user.timezone
116 elif hasattr(request, 'event') and request.event:
117 tzname = request.event.timezone
118 else:
119 tzname = settings.TIME_ZONE
120 timezone.activate(pytz.timezone(tzname))
121 request.timezone = tzname
122
123 def _language_from_browser(self, request, supported):
124 accept_value = request.META.get('HTTP_ACCEPT_LANGUAGE', '')
125 for accept_lang, unused in parse_accept_lang_header(accept_value):
126 if accept_lang == '*':
127 break
128
129 if not language_code_re.search(accept_lang):
130 continue
131
132 try:
133 val = get_supported_language_variant(accept_lang)
134 if val and val in supported:
135 return val
136 except LookupError:
137 continue
138
139 def _language_from_cookie(self, request, supported):
140 cookie_value = request.COOKIES.get(settings.LANGUAGE_COOKIE_NAME)
141 with suppress(LookupError):
142 cookie_value = get_supported_language_variant(cookie_value)
143 if cookie_value and cookie_value in supported:
144 return cookie_value
145
146 def _language_from_user(self, request, supported):
147 if request.user.is_authenticated:
148 with suppress(LookupError):
149 value = get_supported_language_variant(request.user.locale)
150 if value and value in supported:
151 return value
152
[end of src/pretalx/common/middleware.py]
[start of src/pretalx/orga/views/auth.py]
1 import random
2 import urllib
3
4 from django.contrib import messages
5 from django.contrib.auth import authenticate, login, logout
6 from django.http import HttpRequest, HttpResponseRedirect
7 from django.shortcuts import redirect
8 from django.urls import reverse
9 from django.utils.http import is_safe_url
10 from django.utils.translation import ugettext as _
11 from django.views.generic import TemplateView
12
13
14 class LoginView(TemplateView):
15 template_name = 'orga/auth/login.html'
16
17 def post(self, request: HttpRequest, *args, **kwargs) -> HttpResponseRedirect:
18 username = request.POST.get('username')
19 password = request.POST.get('password')
20 user = authenticate(username=username, password=password)
21
22 if user is None:
23 messages.error(request, _('No user account matches the entered credentials.'))
24 return redirect('orga:login')
25
26 if not user.is_active:
27 messages.error(request, _('User account is deactivated.'))
28 return redirect('orga:login')
29
30 login(request, user)
31 url = urllib.parse.unquote(request.GET.get('next', ''))
32 if url and is_safe_url(url, request.get_host()):
33 return redirect(url)
34
35 # check where to reasonably redirect:
36 # orga of a running event? go to that event.
37 # speaker of a running event? go to that event.
38 # neither? go to (a) current cfp
39 # no current cfp? dummy page
40
41 messages.success(request, random.choice([
42 _('Hi, nice to see you!'),
43 _('Welcome!'),
44 _('I hope you are having a good day :)'),
45 _('Remember: organizing events is lots of work, but it pays off.'),
46 _('If you are waiting for feedback from your speakers, try sending a mail to a subset of them.'),
47 _('Remember to provide your speakers with all information they need ahead of time.'),
48 _('Even the busiest event organizers should make time to see at least one talk ;)'),
49 ]))
50 return redirect(reverse('orga:dashboard'))
51
52
53 def logout_view(request: HttpRequest) -> HttpResponseRedirect:
54 logout(request)
55 return redirect(reverse('orga:login'))
56
[end of src/pretalx/orga/views/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretalx/common/middleware.py b/src/pretalx/common/middleware.py
--- a/src/pretalx/common/middleware.py
+++ b/src/pretalx/common/middleware.py
@@ -1,3 +1,4 @@
+import urllib
from contextlib import suppress
import pytz
@@ -50,7 +51,8 @@
def _handle_orga_url(self, request, url):
if request.user.is_anonymous and url.url_name not in self.UNAUTHENTICATED_ORGA_URLS:
- return reverse('orga:login') + f'?next={request.path}'
+ params = '&' + request.GET.urlencode() if request.GET else ''
+ return reverse('orga:login') + f'?next={urllib.parse.quote(request.path)}' + params
if hasattr(request, 'event') and request.event:
if not (request.is_orga or request.is_reviewer):
raise PermissionDenied()
diff --git a/src/pretalx/orga/views/auth.py b/src/pretalx/orga/views/auth.py
--- a/src/pretalx/orga/views/auth.py
+++ b/src/pretalx/orga/views/auth.py
@@ -28,9 +28,10 @@
return redirect('orga:login')
login(request, user)
- url = urllib.parse.unquote(request.GET.get('next', ''))
+ params = request.GET.copy()
+ url = urllib.parse.unquote(params.pop('next', [''])[0])
if url and is_safe_url(url, request.get_host()):
- return redirect(url)
+ return redirect(url + ('?' + params.urlencode() if params else ''))
# check where to reasonably redirect:
# orga of a running event? go to that event.
|
{"golden_diff": "diff --git a/src/pretalx/common/middleware.py b/src/pretalx/common/middleware.py\n--- a/src/pretalx/common/middleware.py\n+++ b/src/pretalx/common/middleware.py\n@@ -1,3 +1,4 @@\n+import urllib\n from contextlib import suppress\n \n import pytz\n@@ -50,7 +51,8 @@\n \n def _handle_orga_url(self, request, url):\n if request.user.is_anonymous and url.url_name not in self.UNAUTHENTICATED_ORGA_URLS:\n- return reverse('orga:login') + f'?next={request.path}'\n+ params = '&' + request.GET.urlencode() if request.GET else ''\n+ return reverse('orga:login') + f'?next={urllib.parse.quote(request.path)}' + params\n if hasattr(request, 'event') and request.event:\n if not (request.is_orga or request.is_reviewer):\n raise PermissionDenied()\ndiff --git a/src/pretalx/orga/views/auth.py b/src/pretalx/orga/views/auth.py\n--- a/src/pretalx/orga/views/auth.py\n+++ b/src/pretalx/orga/views/auth.py\n@@ -28,9 +28,10 @@\n return redirect('orga:login')\n \n login(request, user)\n- url = urllib.parse.unquote(request.GET.get('next', ''))\n+ params = request.GET.copy()\n+ url = urllib.parse.unquote(params.pop('next', [''])[0])\n if url and is_safe_url(url, request.get_host()):\n- return redirect(url)\n+ return redirect(url + ('?' + params.urlencode() if params else ''))\n \n # check where to reasonably redirect:\n # orga of a running event? go to that event.\n", "issue": "When redirecting to login view, urlquote path\nPaths need to be urlquoted and get params need to be passed aswell.\n", "before_files": [{"content": "from contextlib import suppress\n\nimport pytz\nfrom django.conf import settings\nfrom django.core.exceptions import PermissionDenied\nfrom django.db.models import Q\nfrom django.shortcuts import redirect, reverse\nfrom django.urls import resolve\nfrom django.utils import timezone, translation\nfrom django.utils.translation.trans_real import (\n get_supported_language_variant, language_code_re, parse_accept_lang_header,\n)\n\nfrom pretalx.event.models import Event\nfrom pretalx.person.models import EventPermission\n\n\nclass EventPermissionMiddleware:\n UNAUTHENTICATED_ORGA_URLS = (\n 'invitation.view',\n 'login',\n )\n REVIEWER_URLS = (\n 'submissions.list',\n 'submissions.content.view',\n 'submissions.questions.view'\n )\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def _set_orga_events(self, request):\n if not request.user.is_anonymous:\n if request.user.is_superuser:\n request.orga_events = Event.objects.all()\n else:\n request.orga_events = Event.objects.filter(\n Q(permissions__is_orga=True) | Q(permissions__is_reviewer=True),\n permissions__user=request.user,\n )\n\n def _is_reviewer_url(self, url):\n if url.url_name.startswith('reviews'):\n return True\n if url.url_name.endswith('dashboard'):\n return True\n if url.url_name in self.REVIEWER_URLS:\n return True\n return False\n\n def _handle_orga_url(self, request, url):\n if request.user.is_anonymous and url.url_name not in self.UNAUTHENTICATED_ORGA_URLS:\n return reverse('orga:login') + f'?next={request.path}'\n if hasattr(request, 'event') and request.event:\n if not (request.is_orga or request.is_reviewer):\n raise PermissionDenied()\n if (request.is_orga and not request.user.is_superuser) and url.url_name.startswith('reviews'):\n raise PermissionDenied()\n if (request.is_reviewer and not request.user.is_superuser) and not self._is_reviewer_url(url):\n raise PermissionDenied()\n elif hasattr(request, 'event') and not request.user.is_superuser:\n raise PermissionDenied()\n self._select_locale(request)\n\n def __call__(self, request):\n url = resolve(request.path_info)\n\n event_slug = url.kwargs.get('event')\n if event_slug:\n try:\n request.event = Event.objects.get(slug__iexact=event_slug)\n except Event.DoesNotExist:\n request.event = None\n\n if hasattr(request, 'event') and request.event:\n if not request.user.is_anonymous:\n request.is_orga = request.user.is_superuser or EventPermission.objects.filter(\n user=request.user,\n event=request.event,\n is_orga=True\n ).exists()\n request.is_reviewer = request.user.is_superuser or EventPermission.objects.filter(\n user=request.user,\n event=request.event,\n is_reviewer=True\n ).exists()\n else:\n request.is_orga = False\n request.is_reviewer = False\n timezone.activate(pytz.timezone(request.event.timezone))\n\n self._set_orga_events(request)\n\n if 'orga' in url.namespaces:\n url = self._handle_orga_url(request, url)\n if url:\n return redirect(url)\n return self.get_response(request)\n\n def _select_locale(self, request):\n supported = request.event.locales if (hasattr(request, 'event') and request.event) else settings.LANGUAGES\n language = (\n self._language_from_user(request, supported)\n or self._language_from_cookie(request, supported)\n or self._language_from_browser(request, supported)\n )\n if hasattr(request, 'event') and request.event:\n language = language or request.event.locale\n\n translation.activate(language)\n request.LANGUAGE_CODE = translation.get_language()\n\n with suppress(pytz.UnknownTimeZoneError):\n if request.user.is_authenticated:\n tzname = request.user.timezone\n elif hasattr(request, 'event') and request.event:\n tzname = request.event.timezone\n else:\n tzname = settings.TIME_ZONE\n timezone.activate(pytz.timezone(tzname))\n request.timezone = tzname\n\n def _language_from_browser(self, request, supported):\n accept_value = request.META.get('HTTP_ACCEPT_LANGUAGE', '')\n for accept_lang, unused in parse_accept_lang_header(accept_value):\n if accept_lang == '*':\n break\n\n if not language_code_re.search(accept_lang):\n continue\n\n try:\n val = get_supported_language_variant(accept_lang)\n if val and val in supported:\n return val\n except LookupError:\n continue\n\n def _language_from_cookie(self, request, supported):\n cookie_value = request.COOKIES.get(settings.LANGUAGE_COOKIE_NAME)\n with suppress(LookupError):\n cookie_value = get_supported_language_variant(cookie_value)\n if cookie_value and cookie_value in supported:\n return cookie_value\n\n def _language_from_user(self, request, supported):\n if request.user.is_authenticated:\n with suppress(LookupError):\n value = get_supported_language_variant(request.user.locale)\n if value and value in supported:\n return value\n", "path": "src/pretalx/common/middleware.py"}, {"content": "import random\nimport urllib\n\nfrom django.contrib import messages\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.http import HttpRequest, HttpResponseRedirect\nfrom django.shortcuts import redirect\nfrom django.urls import reverse\nfrom django.utils.http import is_safe_url\nfrom django.utils.translation import ugettext as _\nfrom django.views.generic import TemplateView\n\n\nclass LoginView(TemplateView):\n template_name = 'orga/auth/login.html'\n\n def post(self, request: HttpRequest, *args, **kwargs) -> HttpResponseRedirect:\n username = request.POST.get('username')\n password = request.POST.get('password')\n user = authenticate(username=username, password=password)\n\n if user is None:\n messages.error(request, _('No user account matches the entered credentials.'))\n return redirect('orga:login')\n\n if not user.is_active:\n messages.error(request, _('User account is deactivated.'))\n return redirect('orga:login')\n\n login(request, user)\n url = urllib.parse.unquote(request.GET.get('next', ''))\n if url and is_safe_url(url, request.get_host()):\n return redirect(url)\n\n # check where to reasonably redirect:\n # orga of a running event? go to that event.\n # speaker of a running event? go to that event.\n # neither? go to (a) current cfp\n # no current cfp? dummy page\n\n messages.success(request, random.choice([\n _('Hi, nice to see you!'),\n _('Welcome!'),\n _('I hope you are having a good day :)'),\n _('Remember: organizing events is lots of work, but it pays off.'),\n _('If you are waiting for feedback from your speakers, try sending a mail to a subset of them.'),\n _('Remember to provide your speakers with all information they need ahead of time.'),\n _('Even the busiest event organizers should make time to see at least one talk ;)'),\n ]))\n return redirect(reverse('orga:dashboard'))\n\n\ndef logout_view(request: HttpRequest) -> HttpResponseRedirect:\n logout(request)\n return redirect(reverse('orga:login'))\n", "path": "src/pretalx/orga/views/auth.py"}]}
| 2,612 | 394 |
gh_patches_debug_20596
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-262
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AuthorizedSession attempts to refresh token when no refresh token was provided
Using google-auth 1.4.1
If `google.auth.transport.requests.AuthorizedSession` is used with an expired token, it will automatically try to refresh the token even if no refresh token was provided to the credentials object.
This causes the unreadable exception
```TransportError: Invalid URL 'None': No schema supplied. Perhaps you meant http://None?```
There should be a sanity check for a non-existing refresh token before any refresh attempt is made. A proper exception should be raised if the token is expired.
Sample code:
```python
import google.oauth2.credentials
from google.auth.transport.requests import AuthorizedSession
credentials = google.oauth2.credentials.Credentials('an_expired_token')
authed_session = AuthorizedSession(credentials)
response = authed_session.get('some_url_requiring_authentication')
```
Traceback:
```
File "/usr/lib/python3.6/site-packages/requests/sessions.py", line 521, in get
return self.request('GET', url, **kwargs)
File "/usr/lib/python3.6/site-packages/google/auth/transport/requests.py", line 218, in request
self.credentials.refresh(auth_request_with_timeout)
File "/usr/lib/python3.6/site-packages/google/oauth2/credentials.py", line 126, in refresh
self._client_secret))
File "/usr/lib/python3.6/site-packages/google/oauth2/_client.py", line 237, in refresh_grant
response_data = _token_endpoint_request(request, token_uri, body)
File "/usr/lib/python3.6/site-packages/google/oauth2/_client.py", line 106, in _token_endpoint_request
method='POST', url=token_uri, headers=headers, body=body)
File "/usr/lib/python3.6/site-packages/google/auth/transport/requests.py", line 124, in __call__
six.raise_from(new_exc, caught_exc)
File "<string>", line 3, in raise_from
google.auth.exceptions.TransportError: Invalid URL 'None': No schema supplied. Perhaps you meant http://None?
```
</issue>
<code>
[start of google/oauth2/credentials.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """OAuth 2.0 Credentials.
16
17 This module provides credentials based on OAuth 2.0 access and refresh tokens.
18 These credentials usually access resources on behalf of a user (resource
19 owner).
20
21 Specifically, this is intended to use access tokens acquired using the
22 `Authorization Code grant`_ and can refresh those tokens using a
23 optional `refresh token`_.
24
25 Obtaining the initial access and refresh token is outside of the scope of this
26 module. Consult `rfc6749 section 4.1`_ for complete details on the
27 Authorization Code grant flow.
28
29 .. _Authorization Code grant: https://tools.ietf.org/html/rfc6749#section-1.3.1
30 .. _refresh token: https://tools.ietf.org/html/rfc6749#section-6
31 .. _rfc6749 section 4.1: https://tools.ietf.org/html/rfc6749#section-4.1
32 """
33
34 import io
35 import json
36
37 import six
38
39 from google.auth import _helpers
40 from google.auth import credentials
41 from google.oauth2 import _client
42
43
44 # The Google OAuth 2.0 token endpoint. Used for authorized user credentials.
45 _GOOGLE_OAUTH2_TOKEN_ENDPOINT = 'https://accounts.google.com/o/oauth2/token'
46
47
48 class Credentials(credentials.ReadOnlyScoped, credentials.Credentials):
49 """Credentials using OAuth 2.0 access and refresh tokens."""
50
51 def __init__(self, token, refresh_token=None, id_token=None,
52 token_uri=None, client_id=None, client_secret=None,
53 scopes=None):
54 """
55 Args:
56 token (Optional(str)): The OAuth 2.0 access token. Can be None
57 if refresh information is provided.
58 refresh_token (str): The OAuth 2.0 refresh token. If specified,
59 credentials can be refreshed.
60 id_token (str): The Open ID Connect ID Token.
61 token_uri (str): The OAuth 2.0 authorization server's token
62 endpoint URI. Must be specified for refresh, can be left as
63 None if the token can not be refreshed.
64 client_id (str): The OAuth 2.0 client ID. Must be specified for
65 refresh, can be left as None if the token can not be refreshed.
66 client_secret(str): The OAuth 2.0 client secret. Must be specified
67 for refresh, can be left as None if the token can not be
68 refreshed.
69 scopes (Sequence[str]): The scopes that were originally used
70 to obtain authorization. This is a purely informative parameter
71 that can be used by :meth:`has_scopes`. OAuth 2.0 credentials
72 can not request additional scopes after authorization.
73 """
74 super(Credentials, self).__init__()
75 self.token = token
76 self._refresh_token = refresh_token
77 self._id_token = id_token
78 self._scopes = scopes
79 self._token_uri = token_uri
80 self._client_id = client_id
81 self._client_secret = client_secret
82
83 @property
84 def refresh_token(self):
85 """Optional[str]: The OAuth 2.0 refresh token."""
86 return self._refresh_token
87
88 @property
89 def token_uri(self):
90 """Optional[str]: The OAuth 2.0 authorization server's token endpoint
91 URI."""
92 return self._token_uri
93
94 @property
95 def id_token(self):
96 """Optional[str]: The Open ID Connect ID Token.
97
98 Depending on the authorization server and the scopes requested, this
99 may be populated when credentials are obtained and updated when
100 :meth:`refresh` is called. This token is a JWT. It can be verified
101 and decoded using :func:`google.oauth2.id_token.verify_oauth2_token`.
102 """
103 return self._id_token
104
105 @property
106 def client_id(self):
107 """Optional[str]: The OAuth 2.0 client ID."""
108 return self._client_id
109
110 @property
111 def client_secret(self):
112 """Optional[str]: The OAuth 2.0 client secret."""
113 return self._client_secret
114
115 @property
116 def requires_scopes(self):
117 """False: OAuth 2.0 credentials have their scopes set when
118 the initial token is requested and can not be changed."""
119 return False
120
121 @_helpers.copy_docstring(credentials.Credentials)
122 def refresh(self, request):
123 access_token, refresh_token, expiry, grant_response = (
124 _client.refresh_grant(
125 request, self._token_uri, self._refresh_token, self._client_id,
126 self._client_secret))
127
128 self.token = access_token
129 self.expiry = expiry
130 self._refresh_token = refresh_token
131 self._id_token = grant_response.get('id_token')
132
133 @classmethod
134 def from_authorized_user_info(cls, info, scopes=None):
135 """Creates a Credentials instance from parsed authorized user info.
136
137 Args:
138 info (Mapping[str, str]): The authorized user info in Google
139 format.
140 scopes (Sequence[str]): Optional list of scopes to include in the
141 credentials.
142
143 Returns:
144 google.oauth2.credentials.Credentials: The constructed
145 credentials.
146
147 Raises:
148 ValueError: If the info is not in the expected format.
149 """
150 keys_needed = set(('refresh_token', 'client_id', 'client_secret'))
151 missing = keys_needed.difference(six.iterkeys(info))
152
153 if missing:
154 raise ValueError(
155 'Authorized user info was not in the expected format, missing '
156 'fields {}.'.format(', '.join(missing)))
157
158 return Credentials(
159 None, # No access token, must be refreshed.
160 refresh_token=info['refresh_token'],
161 token_uri=_GOOGLE_OAUTH2_TOKEN_ENDPOINT,
162 scopes=scopes,
163 client_id=info['client_id'],
164 client_secret=info['client_secret'])
165
166 @classmethod
167 def from_authorized_user_file(cls, filename, scopes=None):
168 """Creates a Credentials instance from an authorized user json file.
169
170 Args:
171 filename (str): The path to the authorized user json file.
172 scopes (Sequence[str]): Optional list of scopes to include in the
173 credentials.
174
175 Returns:
176 google.oauth2.credentials.Credentials: The constructed
177 credentials.
178
179 Raises:
180 ValueError: If the file is not in the expected format.
181 """
182 with io.open(filename, 'r', encoding='utf-8') as json_file:
183 data = json.load(json_file)
184 return cls.from_authorized_user_info(data, scopes)
185
[end of google/oauth2/credentials.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/oauth2/credentials.py b/google/oauth2/credentials.py
--- a/google/oauth2/credentials.py
+++ b/google/oauth2/credentials.py
@@ -38,6 +38,7 @@
from google.auth import _helpers
from google.auth import credentials
+from google.auth import exceptions
from google.oauth2 import _client
@@ -120,6 +121,15 @@
@_helpers.copy_docstring(credentials.Credentials)
def refresh(self, request):
+ if (self._refresh_token is None or
+ self._token_uri is None or
+ self._client_id is None or
+ self._client_secret is None):
+ raise exceptions.RefreshError(
+ 'The credentials do not contain the necessary fields need to '
+ 'refresh the access token. You must specify refresh_token, '
+ 'token_uri, client_id, and client_secret.')
+
access_token, refresh_token, expiry, grant_response = (
_client.refresh_grant(
request, self._token_uri, self._refresh_token, self._client_id,
|
{"golden_diff": "diff --git a/google/oauth2/credentials.py b/google/oauth2/credentials.py\n--- a/google/oauth2/credentials.py\n+++ b/google/oauth2/credentials.py\n@@ -38,6 +38,7 @@\n \n from google.auth import _helpers\n from google.auth import credentials\n+from google.auth import exceptions\n from google.oauth2 import _client\n \n \n@@ -120,6 +121,15 @@\n \n @_helpers.copy_docstring(credentials.Credentials)\n def refresh(self, request):\n+ if (self._refresh_token is None or\n+ self._token_uri is None or\n+ self._client_id is None or\n+ self._client_secret is None):\n+ raise exceptions.RefreshError(\n+ 'The credentials do not contain the necessary fields need to '\n+ 'refresh the access token. You must specify refresh_token, '\n+ 'token_uri, client_id, and client_secret.')\n+\n access_token, refresh_token, expiry, grant_response = (\n _client.refresh_grant(\n request, self._token_uri, self._refresh_token, self._client_id,\n", "issue": "AuthorizedSession attempts to refresh token when no refresh token was provided\nUsing google-auth 1.4.1\r\n\r\nIf `google.auth.transport.requests.AuthorizedSession` is used with an expired token, it will automatically try to refresh the token even if no refresh token was provided to the credentials object.\r\nThis causes the unreadable exception\r\n```TransportError: Invalid URL 'None': No schema supplied. Perhaps you meant http://None?```\r\n\r\nThere should be a sanity check for a non-existing refresh token before any refresh attempt is made. A proper exception should be raised if the token is expired.\r\n\r\nSample code:\r\n```python\r\nimport google.oauth2.credentials\r\nfrom google.auth.transport.requests import AuthorizedSession\r\ncredentials = google.oauth2.credentials.Credentials('an_expired_token')\r\nauthed_session = AuthorizedSession(credentials)\r\nresponse = authed_session.get('some_url_requiring_authentication')\r\n```\r\n\r\nTraceback:\r\n```\r\n File \"/usr/lib/python3.6/site-packages/requests/sessions.py\", line 521, in get\r\n return self.request('GET', url, **kwargs)\r\n File \"/usr/lib/python3.6/site-packages/google/auth/transport/requests.py\", line 218, in request\r\n self.credentials.refresh(auth_request_with_timeout)\r\n File \"/usr/lib/python3.6/site-packages/google/oauth2/credentials.py\", line 126, in refresh\r\n self._client_secret))\r\n File \"/usr/lib/python3.6/site-packages/google/oauth2/_client.py\", line 237, in refresh_grant\r\n response_data = _token_endpoint_request(request, token_uri, body)\r\n File \"/usr/lib/python3.6/site-packages/google/oauth2/_client.py\", line 106, in _token_endpoint_request\r\n method='POST', url=token_uri, headers=headers, body=body)\r\n File \"/usr/lib/python3.6/site-packages/google/auth/transport/requests.py\", line 124, in __call__\r\n six.raise_from(new_exc, caught_exc)\r\n File \"<string>\", line 3, in raise_from\r\ngoogle.auth.exceptions.TransportError: Invalid URL 'None': No schema supplied. Perhaps you meant http://None?\r\n```\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"OAuth 2.0 Credentials.\n\nThis module provides credentials based on OAuth 2.0 access and refresh tokens.\nThese credentials usually access resources on behalf of a user (resource\nowner).\n\nSpecifically, this is intended to use access tokens acquired using the\n`Authorization Code grant`_ and can refresh those tokens using a\noptional `refresh token`_.\n\nObtaining the initial access and refresh token is outside of the scope of this\nmodule. Consult `rfc6749 section 4.1`_ for complete details on the\nAuthorization Code grant flow.\n\n.. _Authorization Code grant: https://tools.ietf.org/html/rfc6749#section-1.3.1\n.. _refresh token: https://tools.ietf.org/html/rfc6749#section-6\n.. _rfc6749 section 4.1: https://tools.ietf.org/html/rfc6749#section-4.1\n\"\"\"\n\nimport io\nimport json\n\nimport six\n\nfrom google.auth import _helpers\nfrom google.auth import credentials\nfrom google.oauth2 import _client\n\n\n# The Google OAuth 2.0 token endpoint. Used for authorized user credentials.\n_GOOGLE_OAUTH2_TOKEN_ENDPOINT = 'https://accounts.google.com/o/oauth2/token'\n\n\nclass Credentials(credentials.ReadOnlyScoped, credentials.Credentials):\n \"\"\"Credentials using OAuth 2.0 access and refresh tokens.\"\"\"\n\n def __init__(self, token, refresh_token=None, id_token=None,\n token_uri=None, client_id=None, client_secret=None,\n scopes=None):\n \"\"\"\n Args:\n token (Optional(str)): The OAuth 2.0 access token. Can be None\n if refresh information is provided.\n refresh_token (str): The OAuth 2.0 refresh token. If specified,\n credentials can be refreshed.\n id_token (str): The Open ID Connect ID Token.\n token_uri (str): The OAuth 2.0 authorization server's token\n endpoint URI. Must be specified for refresh, can be left as\n None if the token can not be refreshed.\n client_id (str): The OAuth 2.0 client ID. Must be specified for\n refresh, can be left as None if the token can not be refreshed.\n client_secret(str): The OAuth 2.0 client secret. Must be specified\n for refresh, can be left as None if the token can not be\n refreshed.\n scopes (Sequence[str]): The scopes that were originally used\n to obtain authorization. This is a purely informative parameter\n that can be used by :meth:`has_scopes`. OAuth 2.0 credentials\n can not request additional scopes after authorization.\n \"\"\"\n super(Credentials, self).__init__()\n self.token = token\n self._refresh_token = refresh_token\n self._id_token = id_token\n self._scopes = scopes\n self._token_uri = token_uri\n self._client_id = client_id\n self._client_secret = client_secret\n\n @property\n def refresh_token(self):\n \"\"\"Optional[str]: The OAuth 2.0 refresh token.\"\"\"\n return self._refresh_token\n\n @property\n def token_uri(self):\n \"\"\"Optional[str]: The OAuth 2.0 authorization server's token endpoint\n URI.\"\"\"\n return self._token_uri\n\n @property\n def id_token(self):\n \"\"\"Optional[str]: The Open ID Connect ID Token.\n\n Depending on the authorization server and the scopes requested, this\n may be populated when credentials are obtained and updated when\n :meth:`refresh` is called. This token is a JWT. It can be verified\n and decoded using :func:`google.oauth2.id_token.verify_oauth2_token`.\n \"\"\"\n return self._id_token\n\n @property\n def client_id(self):\n \"\"\"Optional[str]: The OAuth 2.0 client ID.\"\"\"\n return self._client_id\n\n @property\n def client_secret(self):\n \"\"\"Optional[str]: The OAuth 2.0 client secret.\"\"\"\n return self._client_secret\n\n @property\n def requires_scopes(self):\n \"\"\"False: OAuth 2.0 credentials have their scopes set when\n the initial token is requested and can not be changed.\"\"\"\n return False\n\n @_helpers.copy_docstring(credentials.Credentials)\n def refresh(self, request):\n access_token, refresh_token, expiry, grant_response = (\n _client.refresh_grant(\n request, self._token_uri, self._refresh_token, self._client_id,\n self._client_secret))\n\n self.token = access_token\n self.expiry = expiry\n self._refresh_token = refresh_token\n self._id_token = grant_response.get('id_token')\n\n @classmethod\n def from_authorized_user_info(cls, info, scopes=None):\n \"\"\"Creates a Credentials instance from parsed authorized user info.\n\n Args:\n info (Mapping[str, str]): The authorized user info in Google\n format.\n scopes (Sequence[str]): Optional list of scopes to include in the\n credentials.\n\n Returns:\n google.oauth2.credentials.Credentials: The constructed\n credentials.\n\n Raises:\n ValueError: If the info is not in the expected format.\n \"\"\"\n keys_needed = set(('refresh_token', 'client_id', 'client_secret'))\n missing = keys_needed.difference(six.iterkeys(info))\n\n if missing:\n raise ValueError(\n 'Authorized user info was not in the expected format, missing '\n 'fields {}.'.format(', '.join(missing)))\n\n return Credentials(\n None, # No access token, must be refreshed.\n refresh_token=info['refresh_token'],\n token_uri=_GOOGLE_OAUTH2_TOKEN_ENDPOINT,\n scopes=scopes,\n client_id=info['client_id'],\n client_secret=info['client_secret'])\n\n @classmethod\n def from_authorized_user_file(cls, filename, scopes=None):\n \"\"\"Creates a Credentials instance from an authorized user json file.\n\n Args:\n filename (str): The path to the authorized user json file.\n scopes (Sequence[str]): Optional list of scopes to include in the\n credentials.\n\n Returns:\n google.oauth2.credentials.Credentials: The constructed\n credentials.\n\n Raises:\n ValueError: If the file is not in the expected format.\n \"\"\"\n with io.open(filename, 'r', encoding='utf-8') as json_file:\n data = json.load(json_file)\n return cls.from_authorized_user_info(data, scopes)\n", "path": "google/oauth2/credentials.py"}]}
| 2,966 | 240 |
gh_patches_debug_39047
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-2343
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tensorboard integration with integers for parameter boundaries
When using the `optuna.integration.tensorboard.TensorBoardCallback` with integer parameters for `suggest_uniform`, a `TypeError` is raised.
## Expected behavior
No TypeError should be raised, instead the integer should be casted to a float.
## Environment
- Optuna version: 2.5.0
- Python version: 3.7.5
- OS: Debian Testing
- (Optional) Other libraries and their versions: Tensorboard 2.4.1
## Error messages, stack traces, or logs
```
Traceback (most recent call last):
File "tensorboard_test.py", line 13, in <module>
study.optimize(objective, n_trials=10, timeout=600, callbacks=[tensorboard_callback])
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/study.py", line 385, in optimize
show_progress_bar=show_progress_bar,
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/_optimize.py", line 73, in _optimize
progress_bar=progress_bar,
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/_optimize.py", line 178, in _optimize_sequential
callback(study, frozen_trial)
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py", line 41, in __call__
self._initialization(study)
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py", line 102, in _initialization
self._add_distributions(trial.distributions)
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py", line 62, in _add_distributions
param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
File "/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/tensorboard/plugins/hparams/summary_v2.py", line 444, in __init__
raise TypeError("min_value must be a float: %r" % (min_value,))
TypeError: min_value must be a float: 0
```
## Steps to reproduce
1. Execute the example below
## Reproducible examples (optional)
```python
import optuna
from optuna.integration.tensorboard import TensorBoardCallback
def objective(trial: optuna.trial.Trial) -> float:
param = trial.suggest_uniform("param", 0, 1)
return param**2
tensorboard_callback = TensorBoardCallback("logs/", metric_name="value")
study = optuna.create_study()
study.optimize(objective, n_trials=10, callbacks=[tensorboard_callback])
```
</issue>
<code>
[start of optuna/integration/tensorboard.py]
1 import os
2 from typing import Dict
3
4 import optuna
5 from optuna._experimental import experimental
6 from optuna._imports import try_import
7
8
9 with try_import() as _imports:
10 from tensorboard.plugins.hparams import api as hp
11 import tensorflow as tf
12
13
14 @experimental("2.0.0")
15 class TensorBoardCallback(object):
16 """Callback to track Optuna trials with TensorBoard.
17
18 This callback adds relevant information that is tracked by Optuna to TensorBoard.
19
20 See `the example <https://github.com/optuna/optuna/blob/master/
21 examples/tensorboard_simple.py>`_.
22
23 Args:
24 dirname:
25 Directory to store TensorBoard logs.
26 metric_name:
27 Name of the metric. Since the metric itself is just a number,
28 `metric_name` can be used to give it a name. So you know later
29 if it was roc-auc or accuracy.
30
31 """
32
33 def __init__(self, dirname: str, metric_name: str) -> None:
34 _imports.check()
35 self._dirname = dirname
36 self._metric_name = metric_name
37 self._hp_params: Dict[str, hp.HParam] = {}
38
39 def __call__(self, study: optuna.study.Study, trial: optuna.trial.FrozenTrial) -> None:
40 if len(self._hp_params) == 0:
41 self._initialization(study)
42 if trial.state != optuna.trial.TrialState.COMPLETE:
43 return
44 trial_value = trial.value if trial.value is not None else float("nan")
45 hparams = {}
46 for param_name, param_value in trial.params.items():
47 if param_name not in self._hp_params:
48 self._add_distributions(trial.distributions)
49 hparams[self._hp_params[param_name]] = param_value
50 run_name = "trial-%d" % trial.number
51 run_dir = os.path.join(self._dirname, run_name)
52 with tf.summary.create_file_writer(run_dir).as_default():
53 hp.hparams(hparams, trial_id=run_name) # record the values used in this trial
54 tf.summary.scalar(self._metric_name, trial_value, step=trial.number)
55
56 def _add_distributions(
57 self, distributions: Dict[str, optuna.distributions.BaseDistribution]
58 ) -> None:
59 for param_name, param_distribution in distributions.items():
60 if isinstance(param_distribution, optuna.distributions.UniformDistribution):
61 self._hp_params[param_name] = hp.HParam(
62 param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
63 )
64 elif isinstance(param_distribution, optuna.distributions.LogUniformDistribution):
65 self._hp_params[param_name] = hp.HParam(
66 param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
67 )
68 elif isinstance(param_distribution, optuna.distributions.DiscreteUniformDistribution):
69 self._hp_params[param_name] = hp.HParam(
70 param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
71 )
72 elif isinstance(param_distribution, optuna.distributions.IntUniformDistribution):
73 self._hp_params[param_name] = hp.HParam(
74 param_name, hp.IntInterval(param_distribution.low, param_distribution.high)
75 )
76 elif isinstance(param_distribution, optuna.distributions.CategoricalDistribution):
77 self._hp_params[param_name] = hp.HParam(
78 param_name, hp.Discrete(param_distribution.choices)
79 )
80 else:
81 distribution_list = [
82 optuna.distributions.UniformDistribution.__name__,
83 optuna.distributions.LogUniformDistribution.__name__,
84 optuna.distributions.DiscreteUniformDistribution.__name__,
85 optuna.distributions.IntUniformDistribution.__name__,
86 optuna.distributions.CategoricalDistribution.__name__,
87 ]
88 raise NotImplementedError(
89 "The distribution {} is not implemented. "
90 "The parameter distribution should be one of the {}".format(
91 param_distribution, distribution_list
92 )
93 )
94
95 def _initialization(self, study: optuna.Study) -> None:
96 completed_trials = [
97 trial
98 for trial in study.get_trials(deepcopy=False)
99 if trial.state == optuna.trial.TrialState.COMPLETE
100 ]
101 for trial in completed_trials:
102 self._add_distributions(trial.distributions)
103
[end of optuna/integration/tensorboard.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/optuna/integration/tensorboard.py b/optuna/integration/tensorboard.py
--- a/optuna/integration/tensorboard.py
+++ b/optuna/integration/tensorboard.py
@@ -56,34 +56,36 @@
def _add_distributions(
self, distributions: Dict[str, optuna.distributions.BaseDistribution]
) -> None:
+ real_distributions = (
+ optuna.distributions.UniformDistribution,
+ optuna.distributions.LogUniformDistribution,
+ optuna.distributions.DiscreteUniformDistribution,
+ )
+ int_distributions = (optuna.distributions.IntUniformDistribution,)
+ categorical_distributions = (optuna.distributions.CategoricalDistribution,)
+ supported_distributions = (
+ real_distributions + int_distributions + categorical_distributions
+ )
+
for param_name, param_distribution in distributions.items():
- if isinstance(param_distribution, optuna.distributions.UniformDistribution):
- self._hp_params[param_name] = hp.HParam(
- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
- )
- elif isinstance(param_distribution, optuna.distributions.LogUniformDistribution):
- self._hp_params[param_name] = hp.HParam(
- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
- )
- elif isinstance(param_distribution, optuna.distributions.DiscreteUniformDistribution):
+ if isinstance(param_distribution, real_distributions):
self._hp_params[param_name] = hp.HParam(
- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)
+ param_name,
+ hp.RealInterval(float(param_distribution.low), float(param_distribution.high)),
)
- elif isinstance(param_distribution, optuna.distributions.IntUniformDistribution):
+ elif isinstance(param_distribution, int_distributions):
self._hp_params[param_name] = hp.HParam(
- param_name, hp.IntInterval(param_distribution.low, param_distribution.high)
+ param_name,
+ hp.IntInterval(param_distribution.low, param_distribution.high),
)
- elif isinstance(param_distribution, optuna.distributions.CategoricalDistribution):
+ elif isinstance(param_distribution, categorical_distributions):
self._hp_params[param_name] = hp.HParam(
- param_name, hp.Discrete(param_distribution.choices)
+ param_name,
+ hp.Discrete(param_distribution.choices),
)
else:
distribution_list = [
- optuna.distributions.UniformDistribution.__name__,
- optuna.distributions.LogUniformDistribution.__name__,
- optuna.distributions.DiscreteUniformDistribution.__name__,
- optuna.distributions.IntUniformDistribution.__name__,
- optuna.distributions.CategoricalDistribution.__name__,
+ distribution.__name__ for distribution in supported_distributions
]
raise NotImplementedError(
"The distribution {} is not implemented. "
|
{"golden_diff": "diff --git a/optuna/integration/tensorboard.py b/optuna/integration/tensorboard.py\n--- a/optuna/integration/tensorboard.py\n+++ b/optuna/integration/tensorboard.py\n@@ -56,34 +56,36 @@\n def _add_distributions(\n self, distributions: Dict[str, optuna.distributions.BaseDistribution]\n ) -> None:\n+ real_distributions = (\n+ optuna.distributions.UniformDistribution,\n+ optuna.distributions.LogUniformDistribution,\n+ optuna.distributions.DiscreteUniformDistribution,\n+ )\n+ int_distributions = (optuna.distributions.IntUniformDistribution,)\n+ categorical_distributions = (optuna.distributions.CategoricalDistribution,)\n+ supported_distributions = (\n+ real_distributions + int_distributions + categorical_distributions\n+ )\n+\n for param_name, param_distribution in distributions.items():\n- if isinstance(param_distribution, optuna.distributions.UniformDistribution):\n- self._hp_params[param_name] = hp.HParam(\n- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n- )\n- elif isinstance(param_distribution, optuna.distributions.LogUniformDistribution):\n- self._hp_params[param_name] = hp.HParam(\n- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n- )\n- elif isinstance(param_distribution, optuna.distributions.DiscreteUniformDistribution):\n+ if isinstance(param_distribution, real_distributions):\n self._hp_params[param_name] = hp.HParam(\n- param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n+ param_name,\n+ hp.RealInterval(float(param_distribution.low), float(param_distribution.high)),\n )\n- elif isinstance(param_distribution, optuna.distributions.IntUniformDistribution):\n+ elif isinstance(param_distribution, int_distributions):\n self._hp_params[param_name] = hp.HParam(\n- param_name, hp.IntInterval(param_distribution.low, param_distribution.high)\n+ param_name,\n+ hp.IntInterval(param_distribution.low, param_distribution.high),\n )\n- elif isinstance(param_distribution, optuna.distributions.CategoricalDistribution):\n+ elif isinstance(param_distribution, categorical_distributions):\n self._hp_params[param_name] = hp.HParam(\n- param_name, hp.Discrete(param_distribution.choices)\n+ param_name,\n+ hp.Discrete(param_distribution.choices),\n )\n else:\n distribution_list = [\n- optuna.distributions.UniformDistribution.__name__,\n- optuna.distributions.LogUniformDistribution.__name__,\n- optuna.distributions.DiscreteUniformDistribution.__name__,\n- optuna.distributions.IntUniformDistribution.__name__,\n- optuna.distributions.CategoricalDistribution.__name__,\n+ distribution.__name__ for distribution in supported_distributions\n ]\n raise NotImplementedError(\n \"The distribution {} is not implemented. \"\n", "issue": "Tensorboard integration with integers for parameter boundaries\nWhen using the `optuna.integration.tensorboard.TensorBoardCallback` with integer parameters for `suggest_uniform`, a `TypeError` is raised.\r\n\r\n## Expected behavior\r\nNo TypeError should be raised, instead the integer should be casted to a float.\r\n\r\n## Environment\r\n\r\n- Optuna version: 2.5.0\r\n- Python version: 3.7.5\r\n- OS: Debian Testing\r\n- (Optional) Other libraries and their versions: Tensorboard 2.4.1\r\n\r\n## Error messages, stack traces, or logs\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"tensorboard_test.py\", line 13, in <module>\r\n study.optimize(objective, n_trials=10, timeout=600, callbacks=[tensorboard_callback])\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/study.py\", line 385, in optimize\r\n show_progress_bar=show_progress_bar,\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/_optimize.py\", line 73, in _optimize\r\n progress_bar=progress_bar,\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/_optimize.py\", line 178, in _optimize_sequential\r\n callback(study, frozen_trial)\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py\", line 41, in __call__\r\n self._initialization(study)\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py\", line 102, in _initialization\r\n self._add_distributions(trial.distributions)\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/optuna/integration/tensorboard.py\", line 62, in _add_distributions\r\n param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\r\n File \"/home/timon/.pyenv/versions/3.7.5/lib/python3.7/site-packages/tensorboard/plugins/hparams/summary_v2.py\", line 444, in __init__\r\n raise TypeError(\"min_value must be a float: %r\" % (min_value,))\r\nTypeError: min_value must be a float: 0\r\n```\r\n\r\n## Steps to reproduce\r\n\r\n1. Execute the example below\r\n\r\n## Reproducible examples (optional)\r\n\r\n```python\r\nimport optuna\r\nfrom optuna.integration.tensorboard import TensorBoardCallback\r\n\r\ndef objective(trial: optuna.trial.Trial) -> float:\r\n param = trial.suggest_uniform(\"param\", 0, 1)\r\n return param**2\r\n\r\ntensorboard_callback = TensorBoardCallback(\"logs/\", metric_name=\"value\")\r\n\r\nstudy = optuna.create_study()\r\nstudy.optimize(objective, n_trials=10, callbacks=[tensorboard_callback])\r\n```\n", "before_files": [{"content": "import os\nfrom typing import Dict\n\nimport optuna\nfrom optuna._experimental import experimental\nfrom optuna._imports import try_import\n\n\nwith try_import() as _imports:\n from tensorboard.plugins.hparams import api as hp\n import tensorflow as tf\n\n\n@experimental(\"2.0.0\")\nclass TensorBoardCallback(object):\n \"\"\"Callback to track Optuna trials with TensorBoard.\n\n This callback adds relevant information that is tracked by Optuna to TensorBoard.\n\n See `the example <https://github.com/optuna/optuna/blob/master/\n examples/tensorboard_simple.py>`_.\n\n Args:\n dirname:\n Directory to store TensorBoard logs.\n metric_name:\n Name of the metric. Since the metric itself is just a number,\n `metric_name` can be used to give it a name. So you know later\n if it was roc-auc or accuracy.\n\n \"\"\"\n\n def __init__(self, dirname: str, metric_name: str) -> None:\n _imports.check()\n self._dirname = dirname\n self._metric_name = metric_name\n self._hp_params: Dict[str, hp.HParam] = {}\n\n def __call__(self, study: optuna.study.Study, trial: optuna.trial.FrozenTrial) -> None:\n if len(self._hp_params) == 0:\n self._initialization(study)\n if trial.state != optuna.trial.TrialState.COMPLETE:\n return\n trial_value = trial.value if trial.value is not None else float(\"nan\")\n hparams = {}\n for param_name, param_value in trial.params.items():\n if param_name not in self._hp_params:\n self._add_distributions(trial.distributions)\n hparams[self._hp_params[param_name]] = param_value\n run_name = \"trial-%d\" % trial.number\n run_dir = os.path.join(self._dirname, run_name)\n with tf.summary.create_file_writer(run_dir).as_default():\n hp.hparams(hparams, trial_id=run_name) # record the values used in this trial\n tf.summary.scalar(self._metric_name, trial_value, step=trial.number)\n\n def _add_distributions(\n self, distributions: Dict[str, optuna.distributions.BaseDistribution]\n ) -> None:\n for param_name, param_distribution in distributions.items():\n if isinstance(param_distribution, optuna.distributions.UniformDistribution):\n self._hp_params[param_name] = hp.HParam(\n param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n )\n elif isinstance(param_distribution, optuna.distributions.LogUniformDistribution):\n self._hp_params[param_name] = hp.HParam(\n param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n )\n elif isinstance(param_distribution, optuna.distributions.DiscreteUniformDistribution):\n self._hp_params[param_name] = hp.HParam(\n param_name, hp.RealInterval(param_distribution.low, param_distribution.high)\n )\n elif isinstance(param_distribution, optuna.distributions.IntUniformDistribution):\n self._hp_params[param_name] = hp.HParam(\n param_name, hp.IntInterval(param_distribution.low, param_distribution.high)\n )\n elif isinstance(param_distribution, optuna.distributions.CategoricalDistribution):\n self._hp_params[param_name] = hp.HParam(\n param_name, hp.Discrete(param_distribution.choices)\n )\n else:\n distribution_list = [\n optuna.distributions.UniformDistribution.__name__,\n optuna.distributions.LogUniformDistribution.__name__,\n optuna.distributions.DiscreteUniformDistribution.__name__,\n optuna.distributions.IntUniformDistribution.__name__,\n optuna.distributions.CategoricalDistribution.__name__,\n ]\n raise NotImplementedError(\n \"The distribution {} is not implemented. \"\n \"The parameter distribution should be one of the {}\".format(\n param_distribution, distribution_list\n )\n )\n\n def _initialization(self, study: optuna.Study) -> None:\n completed_trials = [\n trial\n for trial in study.get_trials(deepcopy=False)\n if trial.state == optuna.trial.TrialState.COMPLETE\n ]\n for trial in completed_trials:\n self._add_distributions(trial.distributions)\n", "path": "optuna/integration/tensorboard.py"}]}
| 2,321 | 606 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.