
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_7099
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-4053
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lutris doesn't create coverart folder
### Bug description
After upgrading Lutris to v0.5.10-beta1 at every start a popup is shown with the text
`[Errno 2] No such file or directory: '/home/user/.cache/lutris/coverart'`
After clicking 'OK' Lutris starts normal
Restarting Lutris displays the popup again since the folder isn't created
Manually creating the 'coverart' folder works and Lutris starts fine
### How to Reproduce
Steps to reproduce the behavior:
1. Have v0.5.9.1 installed
2. Install v0.5.10-beta1
3. Open Lutris
4. See popup
### Expected behavior
Lutris shouldn't display a popup but create the missing folder
### Log output
```shell
INFO 2022-02-12 17:06:00,408 [startup.init_lutris:164]:Starting Lutris 0.5.10
WARNING 2022-02-12 17:06:00,427 [libretro.get_libretro_cores:48]:No cores found
DEBUG 2022-02-12 17:06:00,432 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR
INFO 2022-02-12 17:06:00,458 [startup.check_driver:65]:Running AMD Mesa driver 21.3.6 on AMD Radeon RX 5700 (NAVI10, DRM 3.44.0, 5.13.0-generic, LLVM 13.0.0) (0x731f)
INFO 2022-02-12 17:06:00,458 [startup.check_driver:77]:GPU: 1002:731F 148C:2398 (amdgpu drivers)
ERROR 2022-02-12 17:06:00,489 [jobs.target:36]:Error while completing task <bound method LutrisInitDialog.initialize of <dialogs.LutrisInitDialog object at 0x7fa950b9aac0 (lutris+gui+dialogs+LutrisInitDialog at 0x1aac2b0)>>: <class 'FileNotFoundError'> [Errno 2] No such file or directory: '/home/user/.cache/lutris/coverart'
File "/usr/lib/python3/dist-packages/lutris/util/jobs.py", line 34, in target
result = self.function(*args, **kwargs)
File "/usr/lib/python3/dist-packages/lutris/gui/dialogs/__init__.py", line 195, in initialize
init_lutris()
File "/usr/lib/python3/dist-packages/lutris/startup.py", line 201, in update_runtime
sync_media()
File "/usr/lib/python3/dist-packages/lutris/services/lutris.py", line 159, in sync_media
covers_available = {fn.split(".")[0] for fn in os.listdir(settings.COVERART_PATH)}
```
### Checklist:
- [X] I'm not asking for support with a game or the wine runner.
- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.
- [X] I have checked for existing issues that describe my problem prior to opening this one.
- [X] I understand that improperly formatted bug reports may be closed without explanation.
</issue>
<code>
[start of lutris/startup.py]
1 """Check to run at program start"""
2 import os
3 import sqlite3
4 import time
5 from gettext import gettext as _
6
7 from lutris import runners, settings
8 from lutris.database.games import get_games
9 from lutris.database.schema import syncdb
10 from lutris.game import Game
11 from lutris.gui.dialogs import DontShowAgainDialog
12 from lutris.runners.json import load_json_runners
13 from lutris.runtime import RuntimeUpdater
14 from lutris.services import DEFAULT_SERVICES
15 from lutris.services.lutris import sync_media
16 from lutris.util import update_cache
17 from lutris.util.graphics import drivers, vkquery
18 from lutris.util.linux import LINUX_SYSTEM
19 from lutris.util.log import logger
20 from lutris.util.system import create_folder
21 from lutris.util.wine.d3d_extras import D3DExtrasManager
22 from lutris.util.wine.dgvoodoo2 import dgvoodoo2Manager
23 from lutris.util.wine.dxvk import DXVKManager
24 from lutris.util.wine.dxvk_nvapi import DXVKNVAPIManager
25 from lutris.util.wine.vkd3d import VKD3DManager
26
27
28 def init_dirs():
29 """Creates Lutris directories"""
30 directories = [
31 settings.CONFIG_DIR,
32 os.path.join(settings.CONFIG_DIR, "runners"),
33 os.path.join(settings.CONFIG_DIR, "games"),
34 settings.DATA_DIR,
35 os.path.join(settings.DATA_DIR, "covers"),
36 settings.ICON_PATH,
37 os.path.join(settings.CACHE_DIR, "banners"),
38 os.path.join(settings.DATA_DIR, "coverart"),
39 os.path.join(settings.DATA_DIR, "runners"),
40 os.path.join(settings.DATA_DIR, "lib"),
41 settings.RUNTIME_DIR,
42 settings.CACHE_DIR,
43 settings.SHADER_CACHE_DIR,
44 os.path.join(settings.CACHE_DIR, "installer"),
45 os.path.join(settings.CACHE_DIR, "tmp"),
46 ]
47 for directory in directories:
48 create_folder(directory)
49
50
51 def check_driver():
52 """Report on the currently running driver"""
53 driver_info = {}
54 if drivers.is_nvidia():
55 driver_info = drivers.get_nvidia_driver_info()
56 # pylint: disable=logging-format-interpolation
57 logger.info("Using {vendor} drivers {version} for {arch}".format(**driver_info["nvrm"]))
58 gpus = drivers.get_nvidia_gpu_ids()
59 for gpu_id in gpus:
60 gpu_info = drivers.get_nvidia_gpu_info(gpu_id)
61 logger.info("GPU: %s", gpu_info.get("Model"))
62 elif LINUX_SYSTEM.glxinfo:
63 # pylint: disable=no-member
64 if hasattr(LINUX_SYSTEM.glxinfo, "GLX_MESA_query_renderer"):
65 logger.info(
66 "Running %s Mesa driver %s on %s",
67 LINUX_SYSTEM.glxinfo.opengl_vendor,
68 LINUX_SYSTEM.glxinfo.GLX_MESA_query_renderer.version,
69 LINUX_SYSTEM.glxinfo.GLX_MESA_query_renderer.device,
70 )
71 else:
72 logger.warning("glxinfo is not available on your system, unable to detect driver version")
73
74 for card in drivers.get_gpus():
75 # pylint: disable=logging-format-interpolation
76 try:
77 logger.info("GPU: {PCI_ID} {PCI_SUBSYS_ID} ({DRIVER} drivers)".format(**drivers.get_gpu_info(card)))
78 except KeyError:
79 logger.error("Unable to get GPU information from '%s'", card)
80
81 if drivers.is_outdated():
82 setting = "hide-outdated-nvidia-driver-warning"
83 if settings.read_setting(setting) != "True":
84 DontShowAgainDialog(
85 setting,
86 _("Your NVIDIA driver is outdated."),
87 secondary_message=_(
88 "You are currently running driver %s which does not "
89 "fully support all features for Vulkan and DXVK games.\n"
90 "Please upgrade your driver as described in our "
91 "<a href='%s'>installation guide</a>"
92 ) % (
93 driver_info["nvrm"]["version"],
94 settings.DRIVER_HOWTO_URL,
95 )
96 )
97
98
99 def check_libs(all_components=False):
100 """Checks that required libraries are installed on the system"""
101 missing_libs = LINUX_SYSTEM.get_missing_libs()
102 if all_components:
103 components = LINUX_SYSTEM.requirements
104 else:
105 components = LINUX_SYSTEM.critical_requirements
106 missing_vulkan_libs = []
107 for req in components:
108 for index, arch in enumerate(LINUX_SYSTEM.runtime_architectures):
109 for lib in missing_libs[req][index]:
110 if req == "VULKAN":
111 missing_vulkan_libs.append(arch)
112 logger.error("%s %s missing (needed by %s)", arch, lib, req.lower())
113
114 if missing_vulkan_libs:
115 setting = "dismiss-missing-vulkan-library-warning"
116 if settings.read_setting(setting) != "True":
117 DontShowAgainDialog(
118 setting,
119 _("Missing vulkan libraries"),
120 secondary_message=_(
121 "Lutris was unable to detect Vulkan support for "
122 "the %s architecture.\n"
123 "This will prevent many games and programs from working.\n"
124 "To install it, please use the following guide: "
125 "<a href='%s'>Installing Graphics Drivers</a>"
126 ) % (
127 _(" and ").join(missing_vulkan_libs),
128 settings.DRIVER_HOWTO_URL,
129 )
130 )
131
132
133 def check_vulkan():
134 """Reports if Vulkan is enabled on the system"""
135 if not vkquery.is_vulkan_supported():
136 logger.warning("Vulkan is not available or your system isn't Vulkan capable")
137
138
139 def fill_missing_platforms():
140 """Sets the platform on games where it's missing.
141 This should never happen.
142 """
143 pga_games = get_games(filters={"installed": 1})
144 for pga_game in pga_games:
145 if pga_game.get("platform") or not pga_game["runner"]:
146 continue
147 game = Game(game_id=pga_game["id"])
148 game.set_platform_from_runner()
149 if game.platform:
150 logger.info("Platform for %s set to %s", game.name, game.platform)
151 game.save(save_config=False)
152
153
154 def run_all_checks():
155 """Run all startup checks"""
156 check_driver()
157 check_libs()
158 check_vulkan()
159 fill_missing_platforms()
160
161
162 def init_lutris():
163 """Run full initialization of Lutris"""
164 logger.info("Starting Lutris %s", settings.VERSION)
165 runners.inject_runners(load_json_runners())
166 # Load runner names and platforms
167 runners.RUNNER_NAMES = runners.get_runner_names()
168 runners.RUNNER_PLATFORMS = runners.get_platforms()
169 init_dirs()
170 try:
171 syncdb()
172 except sqlite3.DatabaseError as err:
173 raise RuntimeError(
174 "Failed to open database file in %s. Try renaming this file and relaunch Lutris" %
175 settings.PGA_DB
176 ) from err
177 for service in DEFAULT_SERVICES:
178 if not settings.read_setting(service, section="services"):
179 settings.write_setting(service, True, section="services")
180
181
182 def update_runtime(force=False):
183 """Update runtime components"""
184 runtime_call = update_cache.get_last_call("runtime")
185 if force or not runtime_call or runtime_call > 3600 * 12:
186 runtime_updater = RuntimeUpdater()
187 components_to_update = runtime_updater.update()
188 if components_to_update:
189 while runtime_updater.current_updates:
190 time.sleep(0.3)
191 update_cache.write_date_to_cache("runtime")
192 for dll_manager_class in (DXVKManager, DXVKNVAPIManager, VKD3DManager, D3DExtrasManager, dgvoodoo2Manager):
193 key = dll_manager_class.__name__
194 key_call = update_cache.get_last_call(key)
195 if force or not key_call or key_call > 3600 * 6:
196 dll_manager = dll_manager_class()
197 dll_manager.upgrade()
198 update_cache.write_date_to_cache(key)
199 media_call = update_cache.get_last_call("media")
200 if force or not media_call or media_call > 3600 * 24:
201 sync_media()
202 update_cache.write_date_to_cache("media")
203 logger.info("Startup complete")
204
[end of lutris/startup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/startup.py b/lutris/startup.py
--- a/lutris/startup.py
+++ b/lutris/startup.py
@@ -35,7 +35,7 @@
os.path.join(settings.DATA_DIR, "covers"),
settings.ICON_PATH,
os.path.join(settings.CACHE_DIR, "banners"),
- os.path.join(settings.DATA_DIR, "coverart"),
+ os.path.join(settings.CACHE_DIR, "coverart"),
os.path.join(settings.DATA_DIR, "runners"),
os.path.join(settings.DATA_DIR, "lib"),
settings.RUNTIME_DIR,
|
{"golden_diff": "diff --git a/lutris/startup.py b/lutris/startup.py\n--- a/lutris/startup.py\n+++ b/lutris/startup.py\n@@ -35,7 +35,7 @@\n os.path.join(settings.DATA_DIR, \"covers\"),\n settings.ICON_PATH,\n os.path.join(settings.CACHE_DIR, \"banners\"),\n- os.path.join(settings.DATA_DIR, \"coverart\"),\n+ os.path.join(settings.CACHE_DIR, \"coverart\"),\n os.path.join(settings.DATA_DIR, \"runners\"),\n os.path.join(settings.DATA_DIR, \"lib\"),\n settings.RUNTIME_DIR,\n", "issue": "Lutris doesn't create coverart folder\n### Bug description\r\n\r\nAfter upgrading Lutris to v0.5.10-beta1 at every start a popup is shown with the text\r\n`[Errno 2] No such file or directory: '/home/user/.cache/lutris/coverart'`\r\n\r\nAfter clicking 'OK' Lutris starts normal\r\nRestarting Lutris displays the popup again since the folder isn't created\r\n\r\nManually creating the 'coverart' folder works and Lutris starts fine\r\n\r\n### How to Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n1. Have v0.5.9.1 installed\r\n2. Install v0.5.10-beta1\r\n3. Open Lutris\r\n4. See popup\r\n\r\n### Expected behavior\r\n\r\nLutris shouldn't display a popup but create the missing folder\r\n\r\n### Log output\r\n\r\n```shell\r\nINFO 2022-02-12 17:06:00,408 [startup.init_lutris:164]:Starting Lutris 0.5.10\r\nWARNING 2022-02-12 17:06:00,427 [libretro.get_libretro_cores:48]:No cores found\r\nDEBUG 2022-02-12 17:06:00,432 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR\r\nINFO 2022-02-12 17:06:00,458 [startup.check_driver:65]:Running AMD Mesa driver 21.3.6 on AMD Radeon RX 5700 (NAVI10, DRM 3.44.0, 5.13.0-generic, LLVM 13.0.0) (0x731f)\r\nINFO 2022-02-12 17:06:00,458 [startup.check_driver:77]:GPU: 1002:731F 148C:2398 (amdgpu drivers)\r\nERROR 2022-02-12 17:06:00,489 [jobs.target:36]:Error while completing task <bound method LutrisInitDialog.initialize of <dialogs.LutrisInitDialog object at 0x7fa950b9aac0 (lutris+gui+dialogs+LutrisInitDialog at 0x1aac2b0)>>: <class 'FileNotFoundError'> [Errno 2] No such file or directory: '/home/user/.cache/lutris/coverart'\r\n File \"/usr/lib/python3/dist-packages/lutris/util/jobs.py\", line 34, in target\r\n result = self.function(*args, **kwargs)\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/dialogs/__init__.py\", line 195, in initialize\r\n init_lutris()\r\n File \"/usr/lib/python3/dist-packages/lutris/startup.py\", line 201, in update_runtime\r\n sync_media()\r\n File \"/usr/lib/python3/dist-packages/lutris/services/lutris.py\", line 159, in sync_media\r\n covers_available = {fn.split(\".\")[0] for fn in os.listdir(settings.COVERART_PATH)}\r\n```\r\n\r\n### Checklist:\r\n\r\n- [X] I'm not asking for support with a game or the wine runner.\r\n- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.\r\n- [X] I have checked for existing issues that describe my problem prior to opening this one.\r\n- [X] I understand that improperly formatted bug reports may be closed without explanation.\n", "before_files": [{"content": "\"\"\"Check to run at program start\"\"\"\nimport os\nimport sqlite3\nimport time\nfrom gettext import gettext as _\n\nfrom lutris import runners, settings\nfrom lutris.database.games import get_games\nfrom lutris.database.schema import syncdb\nfrom lutris.game import Game\nfrom lutris.gui.dialogs import DontShowAgainDialog\nfrom lutris.runners.json import load_json_runners\nfrom lutris.runtime import RuntimeUpdater\nfrom lutris.services import DEFAULT_SERVICES\nfrom lutris.services.lutris import sync_media\nfrom lutris.util import update_cache\nfrom lutris.util.graphics import drivers, vkquery\nfrom lutris.util.linux import LINUX_SYSTEM\nfrom lutris.util.log import logger\nfrom lutris.util.system import create_folder\nfrom lutris.util.wine.d3d_extras import D3DExtrasManager\nfrom lutris.util.wine.dgvoodoo2 import dgvoodoo2Manager\nfrom lutris.util.wine.dxvk import DXVKManager\nfrom lutris.util.wine.dxvk_nvapi import DXVKNVAPIManager\nfrom lutris.util.wine.vkd3d import VKD3DManager\n\n\ndef init_dirs():\n \"\"\"Creates Lutris directories\"\"\"\n directories = [\n settings.CONFIG_DIR,\n os.path.join(settings.CONFIG_DIR, \"runners\"),\n os.path.join(settings.CONFIG_DIR, \"games\"),\n settings.DATA_DIR,\n os.path.join(settings.DATA_DIR, \"covers\"),\n settings.ICON_PATH,\n os.path.join(settings.CACHE_DIR, \"banners\"),\n os.path.join(settings.DATA_DIR, \"coverart\"),\n os.path.join(settings.DATA_DIR, \"runners\"),\n os.path.join(settings.DATA_DIR, \"lib\"),\n settings.RUNTIME_DIR,\n settings.CACHE_DIR,\n settings.SHADER_CACHE_DIR,\n os.path.join(settings.CACHE_DIR, \"installer\"),\n os.path.join(settings.CACHE_DIR, \"tmp\"),\n ]\n for directory in directories:\n create_folder(directory)\n\n\ndef check_driver():\n \"\"\"Report on the currently running driver\"\"\"\n driver_info = {}\n if drivers.is_nvidia():\n driver_info = drivers.get_nvidia_driver_info()\n # pylint: disable=logging-format-interpolation\n logger.info(\"Using {vendor} drivers {version} for {arch}\".format(**driver_info[\"nvrm\"]))\n gpus = drivers.get_nvidia_gpu_ids()\n for gpu_id in gpus:\n gpu_info = drivers.get_nvidia_gpu_info(gpu_id)\n logger.info(\"GPU: %s\", gpu_info.get(\"Model\"))\n elif LINUX_SYSTEM.glxinfo:\n # pylint: disable=no-member\n if hasattr(LINUX_SYSTEM.glxinfo, \"GLX_MESA_query_renderer\"):\n logger.info(\n \"Running %s Mesa driver %s on %s\",\n LINUX_SYSTEM.glxinfo.opengl_vendor,\n LINUX_SYSTEM.glxinfo.GLX_MESA_query_renderer.version,\n LINUX_SYSTEM.glxinfo.GLX_MESA_query_renderer.device,\n )\n else:\n logger.warning(\"glxinfo is not available on your system, unable to detect driver version\")\n\n for card in drivers.get_gpus():\n # pylint: disable=logging-format-interpolation\n try:\n logger.info(\"GPU: {PCI_ID} {PCI_SUBSYS_ID} ({DRIVER} drivers)\".format(**drivers.get_gpu_info(card)))\n except KeyError:\n logger.error(\"Unable to get GPU information from '%s'\", card)\n\n if drivers.is_outdated():\n setting = \"hide-outdated-nvidia-driver-warning\"\n if settings.read_setting(setting) != \"True\":\n DontShowAgainDialog(\n setting,\n _(\"Your NVIDIA driver is outdated.\"),\n secondary_message=_(\n \"You are currently running driver %s which does not \"\n \"fully support all features for Vulkan and DXVK games.\\n\"\n \"Please upgrade your driver as described in our \"\n \"<a href='%s'>installation guide</a>\"\n ) % (\n driver_info[\"nvrm\"][\"version\"],\n settings.DRIVER_HOWTO_URL,\n )\n )\n\n\ndef check_libs(all_components=False):\n \"\"\"Checks that required libraries are installed on the system\"\"\"\n missing_libs = LINUX_SYSTEM.get_missing_libs()\n if all_components:\n components = LINUX_SYSTEM.requirements\n else:\n components = LINUX_SYSTEM.critical_requirements\n missing_vulkan_libs = []\n for req in components:\n for index, arch in enumerate(LINUX_SYSTEM.runtime_architectures):\n for lib in missing_libs[req][index]:\n if req == \"VULKAN\":\n missing_vulkan_libs.append(arch)\n logger.error(\"%s %s missing (needed by %s)\", arch, lib, req.lower())\n\n if missing_vulkan_libs:\n setting = \"dismiss-missing-vulkan-library-warning\"\n if settings.read_setting(setting) != \"True\":\n DontShowAgainDialog(\n setting,\n _(\"Missing vulkan libraries\"),\n secondary_message=_(\n \"Lutris was unable to detect Vulkan support for \"\n \"the %s architecture.\\n\"\n \"This will prevent many games and programs from working.\\n\"\n \"To install it, please use the following guide: \"\n \"<a href='%s'>Installing Graphics Drivers</a>\"\n ) % (\n _(\" and \").join(missing_vulkan_libs),\n settings.DRIVER_HOWTO_URL,\n )\n )\n\n\ndef check_vulkan():\n \"\"\"Reports if Vulkan is enabled on the system\"\"\"\n if not vkquery.is_vulkan_supported():\n logger.warning(\"Vulkan is not available or your system isn't Vulkan capable\")\n\n\ndef fill_missing_platforms():\n \"\"\"Sets the platform on games where it's missing.\n This should never happen.\n \"\"\"\n pga_games = get_games(filters={\"installed\": 1})\n for pga_game in pga_games:\n if pga_game.get(\"platform\") or not pga_game[\"runner\"]:\n continue\n game = Game(game_id=pga_game[\"id\"])\n game.set_platform_from_runner()\n if game.platform:\n logger.info(\"Platform for %s set to %s\", game.name, game.platform)\n game.save(save_config=False)\n\n\ndef run_all_checks():\n \"\"\"Run all startup checks\"\"\"\n check_driver()\n check_libs()\n check_vulkan()\n fill_missing_platforms()\n\n\ndef init_lutris():\n \"\"\"Run full initialization of Lutris\"\"\"\n logger.info(\"Starting Lutris %s\", settings.VERSION)\n runners.inject_runners(load_json_runners())\n # Load runner names and platforms\n runners.RUNNER_NAMES = runners.get_runner_names()\n runners.RUNNER_PLATFORMS = runners.get_platforms()\n init_dirs()\n try:\n syncdb()\n except sqlite3.DatabaseError as err:\n raise RuntimeError(\n \"Failed to open database file in %s. Try renaming this file and relaunch Lutris\" %\n settings.PGA_DB\n ) from err\n for service in DEFAULT_SERVICES:\n if not settings.read_setting(service, section=\"services\"):\n settings.write_setting(service, True, section=\"services\")\n\n\ndef update_runtime(force=False):\n \"\"\"Update runtime components\"\"\"\n runtime_call = update_cache.get_last_call(\"runtime\")\n if force or not runtime_call or runtime_call > 3600 * 12:\n runtime_updater = RuntimeUpdater()\n components_to_update = runtime_updater.update()\n if components_to_update:\n while runtime_updater.current_updates:\n time.sleep(0.3)\n update_cache.write_date_to_cache(\"runtime\")\n for dll_manager_class in (DXVKManager, DXVKNVAPIManager, VKD3DManager, D3DExtrasManager, dgvoodoo2Manager):\n key = dll_manager_class.__name__\n key_call = update_cache.get_last_call(key)\n if force or not key_call or key_call > 3600 * 6:\n dll_manager = dll_manager_class()\n dll_manager.upgrade()\n update_cache.write_date_to_cache(key)\n media_call = update_cache.get_last_call(\"media\")\n if force or not media_call or media_call > 3600 * 24:\n sync_media()\n update_cache.write_date_to_cache(\"media\")\n logger.info(\"Startup complete\")\n", "path": "lutris/startup.py"}]}
| 3,617 | 134 |
gh_patches_debug_26301
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-317
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add the option to apply augmentation while running `gandlf_preprocess`
**Is your feature request related to a problem? Please describe.**
`gandlf_preprocess` is currently applying all options in `data_preprocessing` key, but anything related to augmentations are not getting picked.
**Describe the solution you'd like**
Provide this as an option in CLI, so that users might save on this compute during training.
**Describe alternatives you've considered**
N.A.
**Additional context**
Useful for image-to-image generative tasks.
</issue>
<code>
[start of GANDLF/cli/preprocess_and_save.py]
1 import os, sys, pickle
2 from pathlib import Path
3 import numpy as np
4 import SimpleITK as sitk
5 import pandas as pd
6
7 from GANDLF.utils import (
8 get_filename_extension_sanitized,
9 parseTrainingCSV,
10 populate_header_in_parameters,
11 )
12 from GANDLF.parseConfig import parseConfig
13 from GANDLF.data.ImagesFromDataFrame import ImagesFromDataFrame
14 from torch.utils.data import DataLoader
15 from tqdm import tqdm
16
17 import torchio
18
19
20 def preprocess_and_save(data_csv, config_file, output_dir, label_pad_mode="constant"):
21 """
22 This function performs preprocessing based on parameters provided and saves the output.
23
24 Args:
25 data_csv (str): The CSV file of the training data.
26 config_file (str): The YAML file of the training configuration.
27 output_dir (str): The output directory.
28 label_pad_mode (str): The padding strategy for the label. Defaults to "constant".
29
30 Raises:
31 ValueError: Parameter check from previous
32 """
33 Path(output_dir).mkdir(parents=True, exist_ok=True)
34
35 # read the csv
36 # don't care if the dataframe gets shuffled or not
37 dataframe, headers = parseTrainingCSV(data_csv, train=False)
38 parameters = parseConfig(config_file)
39
40 # save the parameters so that the same compute doesn't happen once again
41 parameter_file = os.path.join(output_dir, "parameters.pkl")
42 if os.path.exists(parameter_file):
43 parameters_prev = pickle.load(open(parameter_file, "rb"))
44 if parameters != parameters_prev:
45 raise ValueError(
46 "The parameters are not the same as the ones stored in the previous run, please re-check."
47 )
48 else:
49 with open(parameter_file, "wb") as handle:
50 pickle.dump(parameters, handle, protocol=pickle.HIGHEST_PROTOCOL)
51
52 parameters = populate_header_in_parameters(parameters, headers)
53
54 data_for_processing = ImagesFromDataFrame(
55 dataframe, parameters, train=False, loader_type="full"
56 )
57
58 dataloader_for_processing = DataLoader(
59 data_for_processing,
60 batch_size=1,
61 pin_memory=False,
62 )
63
64 # initialize a new dict for the preprocessed data
65 base_df = pd.read_csv(data_csv)
66 # ensure csv only contains lower case columns
67 base_df.columns = base_df.columns.str.lower()
68 # only store the column names
69 output_columns_to_write = base_df.to_dict()
70 for key in output_columns_to_write.keys():
71 output_columns_to_write[key] = []
72
73 # keep a record of the keys which contains only images
74 keys_with_images = parameters["headers"]["channelHeaders"]
75 keys_with_images = [str(x) for x in keys_with_images]
76
77 ## to-do
78 # use dataloader_for_processing to loop through all images
79 # if padding is enabled, ensure that it gets applied to the images
80 # save the images to disk, but keep a record that these images are preprocessed.
81 # create new csv that contains new files.
82
83 # give warning if label sampler is present but number of patches to extract is > 1
84 if (
85 (parameters["patch_sampler"] == "label")
86 or (isinstance(parameters["patch_sampler"], dict))
87 ) and parameters["q_samples_per_volume"] > 1:
88 print(
89 "[WARNING] Label sampling has been enabled but q_samples_per_volume > 1; this has been known to cause issues, so q_samples_per_volume will be hard-coded to 1 during preprocessing. Please contact GaNDLF developers for more information",
90 file=sys.stderr,
91 flush=True,
92 )
93
94 for _, (subject) in enumerate(
95 tqdm(dataloader_for_processing, desc="Looping over data")
96 ):
97 # initialize the current_output_dir
98 current_output_dir = os.path.join(output_dir, str(subject["subject_id"][0]))
99 Path(current_output_dir).mkdir(parents=True, exist_ok=True)
100
101 output_columns_to_write["subjectid"].append(subject["subject_id"][0])
102
103 subject_dict_to_write, subject_process = {}, {}
104
105 # start constructing the torchio.Subject object
106 for channel in parameters["headers"]["channelHeaders"]:
107 # the "squeeze" is needed because the dataloader automatically
108 # constructs 5D tensor considering the batch_size as first
109 # dimension, but the constructor needs 4D tensor.
110 subject_process[str(channel)] = torchio.Image(
111 tensor=subject[str(channel)]["data"].squeeze(0),
112 type=torchio.INTENSITY,
113 path=subject[str(channel)]["path"],
114 )
115 if parameters["headers"]["labelHeader"] is not None:
116 subject_process["label"] = torchio.Image(
117 tensor=subject["label"]["data"].squeeze(0),
118 type=torchio.LABEL,
119 path=subject["label"]["path"],
120 )
121 subject_dict_to_write = torchio.Subject(subject_process)
122
123 # apply a different padding mode to image and label (so that label information is not duplicated)
124 if (parameters["patch_sampler"] == "label") or (
125 isinstance(parameters["patch_sampler"], dict)
126 ):
127 # get the padding size from the patch_size
128 psize_pad = list(
129 np.asarray(np.ceil(np.divide(parameters["patch_size"], 2)), dtype=int)
130 )
131 # initialize the padder for images
132 padder = torchio.transforms.Pad(
133 psize_pad, padding_mode="symmetric", include=keys_with_images
134 )
135 subject_dict_to_write = padder(subject_dict_to_write)
136
137 if parameters["headers"]["labelHeader"] is not None:
138 # initialize the padder for label
139 padder_label = torchio.transforms.Pad(
140 psize_pad, padding_mode=label_pad_mode, include="label"
141 )
142 subject_dict_to_write = padder_label(subject_dict_to_write)
143
144 sampler = torchio.data.LabelSampler(parameters["patch_size"])
145 generator = sampler(subject_dict_to_write, num_patches=1)
146 for patch in generator:
147 for channel in parameters["headers"]["channelHeaders"]:
148 subject_dict_to_write[str(channel)] = patch[str(channel)]
149
150 subject_dict_to_write["label"] = patch["label"]
151
152 # write new images
153 common_ext = get_filename_extension_sanitized(subject["1"]["path"][0])
154 # in cases where the original image has a file format that does not support
155 # RGB floats, use the "vtk" format
156 if common_ext in [".png", ".jpg", ".jpeg", ".bmp", ".tiff", ".tif"]:
157 common_ext = ".vtk"
158
159 if subject["1"]["path"][0] != "":
160 image_for_info_copy = sitk.ReadImage(subject["1"]["path"][0])
161 else:
162 image_for_info_copy = subject_dict_to_write["1"].as_sitk()
163 correct_spacing_for_info_copy = subject["spacing"][0].tolist()
164 for channel in parameters["headers"]["channelHeaders"]:
165 image_file = Path(
166 os.path.join(
167 current_output_dir,
168 subject["subject_id"][0] + "_" + str(channel) + common_ext,
169 )
170 ).as_posix()
171 output_columns_to_write["channel_" + str(channel - 1)].append(image_file)
172 image_to_write = subject_dict_to_write[str(channel)].as_sitk()
173 image_to_write.SetOrigin(image_for_info_copy.GetOrigin())
174 image_to_write.SetDirection(image_for_info_copy.GetDirection())
175 image_to_write.SetSpacing(correct_spacing_for_info_copy)
176 if not os.path.isfile(image_file):
177 try:
178 sitk.WriteImage(image_to_write, image_file)
179 except IOError:
180 IOError(
181 "Could not write image file: {}. Make sure that the file is not open and try again.".format(
182 image_file
183 )
184 )
185 sys.exit(1)
186
187 # now try to write the label
188 if "label" in subject_dict_to_write:
189 image_file = Path(
190 os.path.join(
191 current_output_dir, subject["subject_id"][0] + "_label" + common_ext
192 )
193 ).as_posix()
194 output_columns_to_write["label"].append(image_file)
195 image_to_write = subject_dict_to_write["label"].as_sitk()
196 image_to_write.SetOrigin(image_for_info_copy.GetOrigin())
197 image_to_write.SetDirection(image_for_info_copy.GetDirection())
198 image_to_write.SetSpacing(correct_spacing_for_info_copy)
199 if not os.path.isfile(image_file):
200 try:
201 sitk.WriteImage(image_to_write, image_file)
202 except IOError:
203 IOError(
204 "Could not write image file: {}. Make sure that the file is not open and try again.".format(
205 image_file
206 )
207 )
208 sys.exit(1)
209
210 # ensure prediction headers are getting saved, as well
211 if len(parameters["headers"]["predictionHeaders"]) > 1:
212 for key in parameters["headers"]["predictionHeaders"]:
213 output_columns_to_write["valuetopredict_" + str(key)].append(
214 str(subject["value_" + str(key)].numpy()[0])
215 )
216 elif len(parameters["headers"]["predictionHeaders"]) == 1:
217 output_columns_to_write["valuetopredict"].append(
218 str(subject["value_0"].numpy()[0])
219 )
220
221 path_for_csv = Path(os.path.join(output_dir, "data_processed.csv")).as_posix()
222 print("Writing final csv for subsequent training: ", path_for_csv)
223 pd.DataFrame.from_dict(data=output_columns_to_write).to_csv(
224 path_for_csv, header=True, index=False
225 )
226
[end of GANDLF/cli/preprocess_and_save.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/GANDLF/cli/preprocess_and_save.py b/GANDLF/cli/preprocess_and_save.py
--- a/GANDLF/cli/preprocess_and_save.py
+++ b/GANDLF/cli/preprocess_and_save.py
@@ -17,7 +17,9 @@
import torchio
-def preprocess_and_save(data_csv, config_file, output_dir, label_pad_mode="constant"):
+def preprocess_and_save(
+ data_csv, config_file, output_dir, label_pad_mode="constant", applyaugs=False
+):
"""
This function performs preprocessing based on parameters provided and saves the output.
@@ -26,6 +28,7 @@
config_file (str): The YAML file of the training configuration.
output_dir (str): The output directory.
label_pad_mode (str): The padding strategy for the label. Defaults to "constant".
+ applyaugs (bool): If data augmentation is to be applied before saving the image. Defaults to False.
Raises:
ValueError: Parameter check from previous
@@ -52,7 +55,7 @@
parameters = populate_header_in_parameters(parameters, headers)
data_for_processing = ImagesFromDataFrame(
- dataframe, parameters, train=False, loader_type="full"
+ dataframe, parameters, train=applyaugs, loader_type="full"
)
dataloader_for_processing = DataLoader(
|
{"golden_diff": "diff --git a/GANDLF/cli/preprocess_and_save.py b/GANDLF/cli/preprocess_and_save.py\n--- a/GANDLF/cli/preprocess_and_save.py\n+++ b/GANDLF/cli/preprocess_and_save.py\n@@ -17,7 +17,9 @@\n import torchio\n \n \n-def preprocess_and_save(data_csv, config_file, output_dir, label_pad_mode=\"constant\"):\n+def preprocess_and_save(\n+ data_csv, config_file, output_dir, label_pad_mode=\"constant\", applyaugs=False\n+):\n \"\"\"\n This function performs preprocessing based on parameters provided and saves the output.\n \n@@ -26,6 +28,7 @@\n config_file (str): The YAML file of the training configuration.\n output_dir (str): The output directory.\n label_pad_mode (str): The padding strategy for the label. Defaults to \"constant\".\n+ applyaugs (bool): If data augmentation is to be applied before saving the image. Defaults to False.\n \n Raises:\n ValueError: Parameter check from previous\n@@ -52,7 +55,7 @@\n parameters = populate_header_in_parameters(parameters, headers)\n \n data_for_processing = ImagesFromDataFrame(\n- dataframe, parameters, train=False, loader_type=\"full\"\n+ dataframe, parameters, train=applyaugs, loader_type=\"full\"\n )\n \n dataloader_for_processing = DataLoader(\n", "issue": "Add the option to apply augmentation while running `gandlf_preprocess`\n**Is your feature request related to a problem? Please describe.**\r\n`gandlf_preprocess` is currently applying all options in `data_preprocessing` key, but anything related to augmentations are not getting picked.\r\n\r\n**Describe the solution you'd like**\r\nProvide this as an option in CLI, so that users might save on this compute during training.\r\n\r\n**Describe alternatives you've considered**\r\nN.A.\r\n\r\n**Additional context**\r\nUseful for image-to-image generative tasks.\r\n\n", "before_files": [{"content": "import os, sys, pickle\nfrom pathlib import Path\nimport numpy as np\nimport SimpleITK as sitk\nimport pandas as pd\n\nfrom GANDLF.utils import (\n get_filename_extension_sanitized,\n parseTrainingCSV,\n populate_header_in_parameters,\n)\nfrom GANDLF.parseConfig import parseConfig\nfrom GANDLF.data.ImagesFromDataFrame import ImagesFromDataFrame\nfrom torch.utils.data import DataLoader\nfrom tqdm import tqdm\n\nimport torchio\n\n\ndef preprocess_and_save(data_csv, config_file, output_dir, label_pad_mode=\"constant\"):\n \"\"\"\n This function performs preprocessing based on parameters provided and saves the output.\n\n Args:\n data_csv (str): The CSV file of the training data.\n config_file (str): The YAML file of the training configuration.\n output_dir (str): The output directory.\n label_pad_mode (str): The padding strategy for the label. Defaults to \"constant\".\n\n Raises:\n ValueError: Parameter check from previous\n \"\"\"\n Path(output_dir).mkdir(parents=True, exist_ok=True)\n\n # read the csv\n # don't care if the dataframe gets shuffled or not\n dataframe, headers = parseTrainingCSV(data_csv, train=False)\n parameters = parseConfig(config_file)\n\n # save the parameters so that the same compute doesn't happen once again\n parameter_file = os.path.join(output_dir, \"parameters.pkl\")\n if os.path.exists(parameter_file):\n parameters_prev = pickle.load(open(parameter_file, \"rb\"))\n if parameters != parameters_prev:\n raise ValueError(\n \"The parameters are not the same as the ones stored in the previous run, please re-check.\"\n )\n else:\n with open(parameter_file, \"wb\") as handle:\n pickle.dump(parameters, handle, protocol=pickle.HIGHEST_PROTOCOL)\n\n parameters = populate_header_in_parameters(parameters, headers)\n\n data_for_processing = ImagesFromDataFrame(\n dataframe, parameters, train=False, loader_type=\"full\"\n )\n\n dataloader_for_processing = DataLoader(\n data_for_processing,\n batch_size=1,\n pin_memory=False,\n )\n\n # initialize a new dict for the preprocessed data\n base_df = pd.read_csv(data_csv)\n # ensure csv only contains lower case columns\n base_df.columns = base_df.columns.str.lower()\n # only store the column names\n output_columns_to_write = base_df.to_dict()\n for key in output_columns_to_write.keys():\n output_columns_to_write[key] = []\n\n # keep a record of the keys which contains only images\n keys_with_images = parameters[\"headers\"][\"channelHeaders\"]\n keys_with_images = [str(x) for x in keys_with_images]\n\n ## to-do\n # use dataloader_for_processing to loop through all images\n # if padding is enabled, ensure that it gets applied to the images\n # save the images to disk, but keep a record that these images are preprocessed.\n # create new csv that contains new files.\n\n # give warning if label sampler is present but number of patches to extract is > 1\n if (\n (parameters[\"patch_sampler\"] == \"label\")\n or (isinstance(parameters[\"patch_sampler\"], dict))\n ) and parameters[\"q_samples_per_volume\"] > 1:\n print(\n \"[WARNING] Label sampling has been enabled but q_samples_per_volume > 1; this has been known to cause issues, so q_samples_per_volume will be hard-coded to 1 during preprocessing. Please contact GaNDLF developers for more information\",\n file=sys.stderr,\n flush=True,\n )\n\n for _, (subject) in enumerate(\n tqdm(dataloader_for_processing, desc=\"Looping over data\")\n ):\n # initialize the current_output_dir\n current_output_dir = os.path.join(output_dir, str(subject[\"subject_id\"][0]))\n Path(current_output_dir).mkdir(parents=True, exist_ok=True)\n\n output_columns_to_write[\"subjectid\"].append(subject[\"subject_id\"][0])\n\n subject_dict_to_write, subject_process = {}, {}\n\n # start constructing the torchio.Subject object\n for channel in parameters[\"headers\"][\"channelHeaders\"]:\n # the \"squeeze\" is needed because the dataloader automatically\n # constructs 5D tensor considering the batch_size as first\n # dimension, but the constructor needs 4D tensor.\n subject_process[str(channel)] = torchio.Image(\n tensor=subject[str(channel)][\"data\"].squeeze(0),\n type=torchio.INTENSITY,\n path=subject[str(channel)][\"path\"],\n )\n if parameters[\"headers\"][\"labelHeader\"] is not None:\n subject_process[\"label\"] = torchio.Image(\n tensor=subject[\"label\"][\"data\"].squeeze(0),\n type=torchio.LABEL,\n path=subject[\"label\"][\"path\"],\n )\n subject_dict_to_write = torchio.Subject(subject_process)\n\n # apply a different padding mode to image and label (so that label information is not duplicated)\n if (parameters[\"patch_sampler\"] == \"label\") or (\n isinstance(parameters[\"patch_sampler\"], dict)\n ):\n # get the padding size from the patch_size\n psize_pad = list(\n np.asarray(np.ceil(np.divide(parameters[\"patch_size\"], 2)), dtype=int)\n )\n # initialize the padder for images\n padder = torchio.transforms.Pad(\n psize_pad, padding_mode=\"symmetric\", include=keys_with_images\n )\n subject_dict_to_write = padder(subject_dict_to_write)\n\n if parameters[\"headers\"][\"labelHeader\"] is not None:\n # initialize the padder for label\n padder_label = torchio.transforms.Pad(\n psize_pad, padding_mode=label_pad_mode, include=\"label\"\n )\n subject_dict_to_write = padder_label(subject_dict_to_write)\n\n sampler = torchio.data.LabelSampler(parameters[\"patch_size\"])\n generator = sampler(subject_dict_to_write, num_patches=1)\n for patch in generator:\n for channel in parameters[\"headers\"][\"channelHeaders\"]:\n subject_dict_to_write[str(channel)] = patch[str(channel)]\n\n subject_dict_to_write[\"label\"] = patch[\"label\"]\n\n # write new images\n common_ext = get_filename_extension_sanitized(subject[\"1\"][\"path\"][0])\n # in cases where the original image has a file format that does not support\n # RGB floats, use the \"vtk\" format\n if common_ext in [\".png\", \".jpg\", \".jpeg\", \".bmp\", \".tiff\", \".tif\"]:\n common_ext = \".vtk\"\n\n if subject[\"1\"][\"path\"][0] != \"\":\n image_for_info_copy = sitk.ReadImage(subject[\"1\"][\"path\"][0])\n else:\n image_for_info_copy = subject_dict_to_write[\"1\"].as_sitk()\n correct_spacing_for_info_copy = subject[\"spacing\"][0].tolist()\n for channel in parameters[\"headers\"][\"channelHeaders\"]:\n image_file = Path(\n os.path.join(\n current_output_dir,\n subject[\"subject_id\"][0] + \"_\" + str(channel) + common_ext,\n )\n ).as_posix()\n output_columns_to_write[\"channel_\" + str(channel - 1)].append(image_file)\n image_to_write = subject_dict_to_write[str(channel)].as_sitk()\n image_to_write.SetOrigin(image_for_info_copy.GetOrigin())\n image_to_write.SetDirection(image_for_info_copy.GetDirection())\n image_to_write.SetSpacing(correct_spacing_for_info_copy)\n if not os.path.isfile(image_file):\n try:\n sitk.WriteImage(image_to_write, image_file)\n except IOError:\n IOError(\n \"Could not write image file: {}. Make sure that the file is not open and try again.\".format(\n image_file\n )\n )\n sys.exit(1)\n\n # now try to write the label\n if \"label\" in subject_dict_to_write:\n image_file = Path(\n os.path.join(\n current_output_dir, subject[\"subject_id\"][0] + \"_label\" + common_ext\n )\n ).as_posix()\n output_columns_to_write[\"label\"].append(image_file)\n image_to_write = subject_dict_to_write[\"label\"].as_sitk()\n image_to_write.SetOrigin(image_for_info_copy.GetOrigin())\n image_to_write.SetDirection(image_for_info_copy.GetDirection())\n image_to_write.SetSpacing(correct_spacing_for_info_copy)\n if not os.path.isfile(image_file):\n try:\n sitk.WriteImage(image_to_write, image_file)\n except IOError:\n IOError(\n \"Could not write image file: {}. Make sure that the file is not open and try again.\".format(\n image_file\n )\n )\n sys.exit(1)\n\n # ensure prediction headers are getting saved, as well\n if len(parameters[\"headers\"][\"predictionHeaders\"]) > 1:\n for key in parameters[\"headers\"][\"predictionHeaders\"]:\n output_columns_to_write[\"valuetopredict_\" + str(key)].append(\n str(subject[\"value_\" + str(key)].numpy()[0])\n )\n elif len(parameters[\"headers\"][\"predictionHeaders\"]) == 1:\n output_columns_to_write[\"valuetopredict\"].append(\n str(subject[\"value_0\"].numpy()[0])\n )\n\n path_for_csv = Path(os.path.join(output_dir, \"data_processed.csv\")).as_posix()\n print(\"Writing final csv for subsequent training: \", path_for_csv)\n pd.DataFrame.from_dict(data=output_columns_to_write).to_csv(\n path_for_csv, header=True, index=False\n )\n", "path": "GANDLF/cli/preprocess_and_save.py"}]}
| 3,250 | 298 |
gh_patches_debug_43107
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-1467
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Warn users if they are using an old/different version
pip has a nice feature where they warn users if they are using an old version and prompt them to update. I think it would be neat to add something like this. The code they use for it is here: https://github.com/pypa/pip/blob/7.0.3/pip/utils/outdated.py#L95
</issue>
<code>
[start of mkdocs/commands/gh_deploy.py]
1 from __future__ import unicode_literals
2 import logging
3 import subprocess
4 import os
5
6 import mkdocs
7 from mkdocs.utils import ghp_import
8
9 log = logging.getLogger(__name__)
10
11 default_message = """Deployed {sha} with MkDocs version: {version}"""
12
13
14 def _is_cwd_git_repo():
15 proc = subprocess.Popen(['git', 'rev-parse', '--is-inside-work-tree'],
16 stdout=subprocess.PIPE, stderr=subprocess.PIPE)
17 proc.communicate()
18 return proc.wait() == 0
19
20
21 def _get_current_sha(repo_path):
22
23 proc = subprocess.Popen(['git', 'rev-parse', '--short', 'HEAD'], cwd=repo_path,
24 stdout=subprocess.PIPE, stderr=subprocess.PIPE)
25
26 stdout, _ = proc.communicate()
27 sha = stdout.decode('utf-8').strip()
28 return sha
29
30
31 def _get_remote_url(remote_name):
32
33 # No CNAME found. We will use the origin URL to determine the GitHub
34 # pages location.
35 remote = "remote.%s.url" % remote_name
36 proc = subprocess.Popen(["git", "config", "--get", remote],
37 stdout=subprocess.PIPE, stderr=subprocess.PIPE)
38
39 stdout, _ = proc.communicate()
40 url = stdout.decode('utf-8').strip()
41
42 host = None
43 path = None
44 if 'github.com/' in url:
45 host, path = url.split('github.com/', 1)
46 elif 'github.com:' in url:
47 host, path = url.split('github.com:', 1)
48
49 return host, path
50
51
52 def gh_deploy(config, message=None, force=False):
53
54 if not _is_cwd_git_repo():
55 log.error('Cannot deploy - this directory does not appear to be a git '
56 'repository')
57
58 if message is None:
59 message = default_message
60 sha = _get_current_sha(os.path.dirname(config.config_file_path))
61 message = message.format(version=mkdocs.__version__, sha=sha)
62
63 remote_branch = config['remote_branch']
64 remote_name = config['remote_name']
65
66 log.info("Copying '%s' to '%s' branch and pushing to GitHub.",
67 config['site_dir'], config['remote_branch'])
68
69 result, error = ghp_import.ghp_import(config['site_dir'], message, remote_name,
70 remote_branch, force)
71 if not result:
72 log.error("Failed to deploy to GitHub with error: \n%s", error)
73 raise SystemExit(1)
74 else:
75 cname_file = os.path.join(config['site_dir'], 'CNAME')
76 # Does this repository have a CNAME set for GitHub pages?
77 if os.path.isfile(cname_file):
78 # This GitHub pages repository has a CNAME configured.
79 with(open(cname_file, 'r')) as f:
80 cname_host = f.read().strip()
81 log.info('Based on your CNAME file, your documentation should be '
82 'available shortly at: http://%s', cname_host)
83 log.info('NOTE: Your DNS records must be configured appropriately for '
84 'your CNAME URL to work.')
85 return
86
87 host, path = _get_remote_url(remote_name)
88
89 if host is None:
90 # This could be a GitHub Enterprise deployment.
91 log.info('Your documentation should be available shortly.')
92 else:
93 username, repo = path.split('/', 1)
94 if repo.endswith('.git'):
95 repo = repo[:-len('.git')]
96 url = 'https://%s.github.io/%s/' % (username, repo)
97 log.info('Your documentation should shortly be available at: ' + url)
98
[end of mkdocs/commands/gh_deploy.py]
[start of mkdocs/__main__.py]
1 #!/usr/bin/env python
2 # coding: utf-8
3
4 from __future__ import unicode_literals
5 import os
6 import sys
7 import logging
8 import click
9 import socket
10
11 from mkdocs import __version__
12 from mkdocs import utils
13 from mkdocs import exceptions
14 from mkdocs import config
15 from mkdocs.commands import build, gh_deploy, new, serve
16
17 log = logging.getLogger(__name__)
18
19 # Disable the warning that Click displays (as of Click version 5.0) when users
20 # use unicode_literals in Python 2.
21 # See http://click.pocoo.org/dev/python3/#unicode-literals for more details.
22 click.disable_unicode_literals_warning = True
23
24
25 class State(object):
26 ''' Maintain logging level.'''
27
28 def __init__(self, log_name='mkdocs', level=logging.INFO):
29 self.logger = logging.getLogger(log_name)
30 self.logger.propagate = False
31 stream = logging.StreamHandler()
32 formatter = logging.Formatter("%(levelname)-7s - %(message)s ")
33 stream.setFormatter(formatter)
34 self.logger.addHandler(stream)
35
36 self.logger.setLevel(level)
37
38
39 pass_state = click.make_pass_decorator(State, ensure=True)
40
41
42 def verbose_option(f):
43 def callback(ctx, param, value):
44 state = ctx.ensure_object(State)
45 if value:
46 state.logger.setLevel(logging.DEBUG)
47 return click.option('-v', '--verbose',
48 is_flag=True,
49 expose_value=False,
50 help='Enable verbose output',
51 callback=callback)(f)
52
53
54 def quiet_option(f):
55 def callback(ctx, param, value):
56 state = ctx.ensure_object(State)
57 if value:
58 state.logger.setLevel(logging.ERROR)
59 return click.option('-q', '--quiet',
60 is_flag=True,
61 expose_value=False,
62 help='Silence warnings',
63 callback=callback)(f)
64
65
66 def common_options(f):
67 f = verbose_option(f)
68 f = quiet_option(f)
69 return f
70
71
72 clean_help = "Remove old files from the site_dir before building (the default)."
73 config_help = "Provide a specific MkDocs config"
74 dev_addr_help = ("IP address and port to serve documentation locally (default: "
75 "localhost:8000)")
76 strict_help = ("Enable strict mode. This will cause MkDocs to abort the build "
77 "on any warnings.")
78 theme_dir_help = "The theme directory to use when building your documentation."
79 theme_help = "The theme to use when building your documentation."
80 theme_choices = utils.get_theme_names()
81 site_dir_help = "The directory to output the result of the documentation build."
82 reload_help = "Enable the live reloading in the development server (this is the default)"
83 no_reload_help = "Disable the live reloading in the development server."
84 dirty_reload_help = "Enable the live reloading in the development server, but only re-build files that have changed"
85 commit_message_help = ("A commit message to use when committing to the "
86 "Github Pages remote branch. Commit {sha} and MkDocs {version} are available as expansions")
87 remote_branch_help = ("The remote branch to commit to for Github Pages. This "
88 "overrides the value specified in config")
89 remote_name_help = ("The remote name to commit to for Github Pages. This "
90 "overrides the value specified in config")
91 force_help = "Force the push to the repository."
92
93 pgk_dir = os.path.dirname(os.path.abspath(__file__))
94
95
96 @click.group(context_settings={'help_option_names': ['-h', '--help']})
97 @click.version_option(
98 '{0} from {1} (Python {2})'.format(__version__, pgk_dir, sys.version[:3]),
99 '-V', '--version')
100 @common_options
101 def cli():
102 """
103 MkDocs - Project documentation with Markdown.
104 """
105
106
107 @cli.command(name="serve")
108 @click.option('-f', '--config-file', type=click.File('rb'), help=config_help)
109 @click.option('-a', '--dev-addr', help=dev_addr_help, metavar='<IP:PORT>')
110 @click.option('-s', '--strict', is_flag=True, help=strict_help)
111 @click.option('-t', '--theme', type=click.Choice(theme_choices), help=theme_help)
112 @click.option('-e', '--theme-dir', type=click.Path(), help=theme_dir_help)
113 @click.option('--livereload', 'livereload', flag_value='livereload', help=reload_help, default=True)
114 @click.option('--no-livereload', 'livereload', flag_value='no-livereload', help=no_reload_help)
115 @click.option('--dirtyreload', 'livereload', flag_value='dirty', help=dirty_reload_help)
116 @common_options
117 def serve_command(dev_addr, config_file, strict, theme, theme_dir, livereload):
118 """Run the builtin development server"""
119
120 logging.getLogger('tornado').setLevel(logging.WARNING)
121
122 # Don't override config value if user did not specify --strict flag
123 # Conveniently, load_config drops None values
124 strict = strict or None
125
126 try:
127 serve.serve(
128 config_file=config_file,
129 dev_addr=dev_addr,
130 strict=strict,
131 theme=theme,
132 theme_dir=theme_dir,
133 livereload=livereload
134 )
135 except (exceptions.ConfigurationError, socket.error) as e: # pragma: no cover
136 # Avoid ugly, unhelpful traceback
137 raise SystemExit('\n' + str(e))
138
139
140 @cli.command(name="build")
141 @click.option('-c', '--clean/--dirty', is_flag=True, default=True, help=clean_help)
142 @click.option('-f', '--config-file', type=click.File('rb'), help=config_help)
143 @click.option('-s', '--strict', is_flag=True, help=strict_help)
144 @click.option('-t', '--theme', type=click.Choice(theme_choices), help=theme_help)
145 @click.option('-e', '--theme-dir', type=click.Path(), help=theme_dir_help)
146 @click.option('-d', '--site-dir', type=click.Path(), help=site_dir_help)
147 @common_options
148 def build_command(clean, config_file, strict, theme, theme_dir, site_dir):
149 """Build the MkDocs documentation"""
150
151 # Don't override config value if user did not specify --strict flag
152 # Conveniently, load_config drops None values
153 strict = strict or None
154
155 try:
156 build.build(config.load_config(
157 config_file=config_file,
158 strict=strict,
159 theme=theme,
160 theme_dir=theme_dir,
161 site_dir=site_dir
162 ), dirty=not clean)
163 except exceptions.ConfigurationError as e: # pragma: no cover
164 # Avoid ugly, unhelpful traceback
165 raise SystemExit('\n' + str(e))
166
167
168 @cli.command(name="gh-deploy")
169 @click.option('-c', '--clean/--dirty', is_flag=True, default=True, help=clean_help)
170 @click.option('-f', '--config-file', type=click.File('rb'), help=config_help)
171 @click.option('-m', '--message', help=commit_message_help)
172 @click.option('-b', '--remote-branch', help=remote_branch_help)
173 @click.option('-r', '--remote-name', help=remote_name_help)
174 @click.option('--force', is_flag=True, help=force_help)
175 @common_options
176 def gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force):
177 """Deploy your documentation to GitHub Pages"""
178 try:
179 cfg = config.load_config(
180 config_file=config_file,
181 remote_branch=remote_branch,
182 remote_name=remote_name
183 )
184 build.build(cfg, dirty=not clean)
185 gh_deploy.gh_deploy(cfg, message=message, force=force)
186 except exceptions.ConfigurationError as e: # pragma: no cover
187 # Avoid ugly, unhelpful traceback
188 raise SystemExit('\n' + str(e))
189
190
191 @cli.command(name="new")
192 @click.argument("project_directory")
193 @common_options
194 def new_command(project_directory):
195 """Create a new MkDocs project"""
196 new.new(project_directory)
197
198
199 if __name__ == '__main__': # pragma: no cover
200 cli()
201
[end of mkdocs/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/__main__.py b/mkdocs/__main__.py
--- a/mkdocs/__main__.py
+++ b/mkdocs/__main__.py
@@ -89,6 +89,7 @@
remote_name_help = ("The remote name to commit to for Github Pages. This "
"overrides the value specified in config")
force_help = "Force the push to the repository."
+ignore_version_help = "Ignore check that build is not being deployed with an older version of MkDocs."
pgk_dir = os.path.dirname(os.path.abspath(__file__))
@@ -172,8 +173,9 @@
@click.option('-b', '--remote-branch', help=remote_branch_help)
@click.option('-r', '--remote-name', help=remote_name_help)
@click.option('--force', is_flag=True, help=force_help)
[email protected]('--ignore-version', is_flag=True, help=ignore_version_help)
@common_options
-def gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force):
+def gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force, ignore_version):
"""Deploy your documentation to GitHub Pages"""
try:
cfg = config.load_config(
@@ -182,7 +184,7 @@
remote_name=remote_name
)
build.build(cfg, dirty=not clean)
- gh_deploy.gh_deploy(cfg, message=message, force=force)
+ gh_deploy.gh_deploy(cfg, message=message, force=force, ignore_version=ignore_version)
except exceptions.ConfigurationError as e: # pragma: no cover
# Avoid ugly, unhelpful traceback
raise SystemExit('\n' + str(e))
diff --git a/mkdocs/commands/gh_deploy.py b/mkdocs/commands/gh_deploy.py
--- a/mkdocs/commands/gh_deploy.py
+++ b/mkdocs/commands/gh_deploy.py
@@ -2,6 +2,8 @@
import logging
import subprocess
import os
+import re
+from pkg_resources import parse_version
import mkdocs
from mkdocs.utils import ghp_import
@@ -49,20 +51,49 @@
return host, path
-def gh_deploy(config, message=None, force=False):
+def _check_version(branch):
+
+ proc = subprocess.Popen(['git', 'show', '-s', '--format=%s', 'refs/heads/{}'.format(branch)],
+ stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+
+ stdout, _ = proc.communicate()
+ msg = stdout.decode('utf-8').strip()
+ m = re.search(r'\d+(\.\d+)+', msg, re.X | re.I)
+ previousv = parse_version(m.group()) if m else None
+ currentv = parse_version(mkdocs.__version__)
+ if not previousv:
+ log.warn('Version check skipped: No version specificed in previous deployment.')
+ elif currentv > previousv:
+ log.info(
+ 'Previous deployment was done with MkDocs version {}; '
+ 'you are deploying with a newer version ({})'.format(previousv, currentv)
+ )
+ elif currentv < previousv:
+ log.error(
+ 'Deployment terminated: Previous deployment was made with MkDocs version {}; '
+ 'you are attempting to deploy with an older version ({}). Use --ignore-version '
+ 'to deploy anyway.'.format(previousv, currentv)
+ )
+ raise SystemExit(1)
+
+
+def gh_deploy(config, message=None, force=False, ignore_version=False):
if not _is_cwd_git_repo():
log.error('Cannot deploy - this directory does not appear to be a git '
'repository')
+ remote_branch = config['remote_branch']
+ remote_name = config['remote_name']
+
+ if not ignore_version:
+ _check_version(remote_branch)
+
if message is None:
message = default_message
sha = _get_current_sha(os.path.dirname(config.config_file_path))
message = message.format(version=mkdocs.__version__, sha=sha)
- remote_branch = config['remote_branch']
- remote_name = config['remote_name']
-
log.info("Copying '%s' to '%s' branch and pushing to GitHub.",
config['site_dir'], config['remote_branch'])
|
{"golden_diff": "diff --git a/mkdocs/__main__.py b/mkdocs/__main__.py\n--- a/mkdocs/__main__.py\n+++ b/mkdocs/__main__.py\n@@ -89,6 +89,7 @@\n remote_name_help = (\"The remote name to commit to for Github Pages. This \"\n \"overrides the value specified in config\")\n force_help = \"Force the push to the repository.\"\n+ignore_version_help = \"Ignore check that build is not being deployed with an older version of MkDocs.\"\n \n pgk_dir = os.path.dirname(os.path.abspath(__file__))\n \n@@ -172,8 +173,9 @@\n @click.option('-b', '--remote-branch', help=remote_branch_help)\n @click.option('-r', '--remote-name', help=remote_name_help)\n @click.option('--force', is_flag=True, help=force_help)\[email protected]('--ignore-version', is_flag=True, help=ignore_version_help)\n @common_options\n-def gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force):\n+def gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force, ignore_version):\n \"\"\"Deploy your documentation to GitHub Pages\"\"\"\n try:\n cfg = config.load_config(\n@@ -182,7 +184,7 @@\n remote_name=remote_name\n )\n build.build(cfg, dirty=not clean)\n- gh_deploy.gh_deploy(cfg, message=message, force=force)\n+ gh_deploy.gh_deploy(cfg, message=message, force=force, ignore_version=ignore_version)\n except exceptions.ConfigurationError as e: # pragma: no cover\n # Avoid ugly, unhelpful traceback\n raise SystemExit('\\n' + str(e))\ndiff --git a/mkdocs/commands/gh_deploy.py b/mkdocs/commands/gh_deploy.py\n--- a/mkdocs/commands/gh_deploy.py\n+++ b/mkdocs/commands/gh_deploy.py\n@@ -2,6 +2,8 @@\n import logging\n import subprocess\n import os\n+import re\n+from pkg_resources import parse_version\n \n import mkdocs\n from mkdocs.utils import ghp_import\n@@ -49,20 +51,49 @@\n return host, path\n \n \n-def gh_deploy(config, message=None, force=False):\n+def _check_version(branch):\n+\n+ proc = subprocess.Popen(['git', 'show', '-s', '--format=%s', 'refs/heads/{}'.format(branch)],\n+ stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n+\n+ stdout, _ = proc.communicate()\n+ msg = stdout.decode('utf-8').strip()\n+ m = re.search(r'\\d+(\\.\\d+)+', msg, re.X | re.I)\n+ previousv = parse_version(m.group()) if m else None\n+ currentv = parse_version(mkdocs.__version__)\n+ if not previousv:\n+ log.warn('Version check skipped: No version specificed in previous deployment.')\n+ elif currentv > previousv:\n+ log.info(\n+ 'Previous deployment was done with MkDocs version {}; '\n+ 'you are deploying with a newer version ({})'.format(previousv, currentv)\n+ )\n+ elif currentv < previousv:\n+ log.error(\n+ 'Deployment terminated: Previous deployment was made with MkDocs version {}; '\n+ 'you are attempting to deploy with an older version ({}). Use --ignore-version '\n+ 'to deploy anyway.'.format(previousv, currentv)\n+ )\n+ raise SystemExit(1)\n+\n+\n+def gh_deploy(config, message=None, force=False, ignore_version=False):\n \n if not _is_cwd_git_repo():\n log.error('Cannot deploy - this directory does not appear to be a git '\n 'repository')\n \n+ remote_branch = config['remote_branch']\n+ remote_name = config['remote_name']\n+\n+ if not ignore_version:\n+ _check_version(remote_branch)\n+\n if message is None:\n message = default_message\n sha = _get_current_sha(os.path.dirname(config.config_file_path))\n message = message.format(version=mkdocs.__version__, sha=sha)\n \n- remote_branch = config['remote_branch']\n- remote_name = config['remote_name']\n-\n log.info(\"Copying '%s' to '%s' branch and pushing to GitHub.\",\n config['site_dir'], config['remote_branch'])\n", "issue": "Warn users if they are using an old/different version\npip has a nice feature where they warn users if they are using an old version and prompt them to update. I think it would be neat to add something like this. The code they use for it is here: https://github.com/pypa/pip/blob/7.0.3/pip/utils/outdated.py#L95\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nimport logging\nimport subprocess\nimport os\n\nimport mkdocs\nfrom mkdocs.utils import ghp_import\n\nlog = logging.getLogger(__name__)\n\ndefault_message = \"\"\"Deployed {sha} with MkDocs version: {version}\"\"\"\n\n\ndef _is_cwd_git_repo():\n proc = subprocess.Popen(['git', 'rev-parse', '--is-inside-work-tree'],\n stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n proc.communicate()\n return proc.wait() == 0\n\n\ndef _get_current_sha(repo_path):\n\n proc = subprocess.Popen(['git', 'rev-parse', '--short', 'HEAD'], cwd=repo_path,\n stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\n stdout, _ = proc.communicate()\n sha = stdout.decode('utf-8').strip()\n return sha\n\n\ndef _get_remote_url(remote_name):\n\n # No CNAME found. We will use the origin URL to determine the GitHub\n # pages location.\n remote = \"remote.%s.url\" % remote_name\n proc = subprocess.Popen([\"git\", \"config\", \"--get\", remote],\n stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\n stdout, _ = proc.communicate()\n url = stdout.decode('utf-8').strip()\n\n host = None\n path = None\n if 'github.com/' in url:\n host, path = url.split('github.com/', 1)\n elif 'github.com:' in url:\n host, path = url.split('github.com:', 1)\n\n return host, path\n\n\ndef gh_deploy(config, message=None, force=False):\n\n if not _is_cwd_git_repo():\n log.error('Cannot deploy - this directory does not appear to be a git '\n 'repository')\n\n if message is None:\n message = default_message\n sha = _get_current_sha(os.path.dirname(config.config_file_path))\n message = message.format(version=mkdocs.__version__, sha=sha)\n\n remote_branch = config['remote_branch']\n remote_name = config['remote_name']\n\n log.info(\"Copying '%s' to '%s' branch and pushing to GitHub.\",\n config['site_dir'], config['remote_branch'])\n\n result, error = ghp_import.ghp_import(config['site_dir'], message, remote_name,\n remote_branch, force)\n if not result:\n log.error(\"Failed to deploy to GitHub with error: \\n%s\", error)\n raise SystemExit(1)\n else:\n cname_file = os.path.join(config['site_dir'], 'CNAME')\n # Does this repository have a CNAME set for GitHub pages?\n if os.path.isfile(cname_file):\n # This GitHub pages repository has a CNAME configured.\n with(open(cname_file, 'r')) as f:\n cname_host = f.read().strip()\n log.info('Based on your CNAME file, your documentation should be '\n 'available shortly at: http://%s', cname_host)\n log.info('NOTE: Your DNS records must be configured appropriately for '\n 'your CNAME URL to work.')\n return\n\n host, path = _get_remote_url(remote_name)\n\n if host is None:\n # This could be a GitHub Enterprise deployment.\n log.info('Your documentation should be available shortly.')\n else:\n username, repo = path.split('/', 1)\n if repo.endswith('.git'):\n repo = repo[:-len('.git')]\n url = 'https://%s.github.io/%s/' % (username, repo)\n log.info('Your documentation should shortly be available at: ' + url)\n", "path": "mkdocs/commands/gh_deploy.py"}, {"content": "#!/usr/bin/env python\n# coding: utf-8\n\nfrom __future__ import unicode_literals\nimport os\nimport sys\nimport logging\nimport click\nimport socket\n\nfrom mkdocs import __version__\nfrom mkdocs import utils\nfrom mkdocs import exceptions\nfrom mkdocs import config\nfrom mkdocs.commands import build, gh_deploy, new, serve\n\nlog = logging.getLogger(__name__)\n\n# Disable the warning that Click displays (as of Click version 5.0) when users\n# use unicode_literals in Python 2.\n# See http://click.pocoo.org/dev/python3/#unicode-literals for more details.\nclick.disable_unicode_literals_warning = True\n\n\nclass State(object):\n ''' Maintain logging level.'''\n\n def __init__(self, log_name='mkdocs', level=logging.INFO):\n self.logger = logging.getLogger(log_name)\n self.logger.propagate = False\n stream = logging.StreamHandler()\n formatter = logging.Formatter(\"%(levelname)-7s - %(message)s \")\n stream.setFormatter(formatter)\n self.logger.addHandler(stream)\n\n self.logger.setLevel(level)\n\n\npass_state = click.make_pass_decorator(State, ensure=True)\n\n\ndef verbose_option(f):\n def callback(ctx, param, value):\n state = ctx.ensure_object(State)\n if value:\n state.logger.setLevel(logging.DEBUG)\n return click.option('-v', '--verbose',\n is_flag=True,\n expose_value=False,\n help='Enable verbose output',\n callback=callback)(f)\n\n\ndef quiet_option(f):\n def callback(ctx, param, value):\n state = ctx.ensure_object(State)\n if value:\n state.logger.setLevel(logging.ERROR)\n return click.option('-q', '--quiet',\n is_flag=True,\n expose_value=False,\n help='Silence warnings',\n callback=callback)(f)\n\n\ndef common_options(f):\n f = verbose_option(f)\n f = quiet_option(f)\n return f\n\n\nclean_help = \"Remove old files from the site_dir before building (the default).\"\nconfig_help = \"Provide a specific MkDocs config\"\ndev_addr_help = (\"IP address and port to serve documentation locally (default: \"\n \"localhost:8000)\")\nstrict_help = (\"Enable strict mode. This will cause MkDocs to abort the build \"\n \"on any warnings.\")\ntheme_dir_help = \"The theme directory to use when building your documentation.\"\ntheme_help = \"The theme to use when building your documentation.\"\ntheme_choices = utils.get_theme_names()\nsite_dir_help = \"The directory to output the result of the documentation build.\"\nreload_help = \"Enable the live reloading in the development server (this is the default)\"\nno_reload_help = \"Disable the live reloading in the development server.\"\ndirty_reload_help = \"Enable the live reloading in the development server, but only re-build files that have changed\"\ncommit_message_help = (\"A commit message to use when committing to the \"\n \"Github Pages remote branch. Commit {sha} and MkDocs {version} are available as expansions\")\nremote_branch_help = (\"The remote branch to commit to for Github Pages. This \"\n \"overrides the value specified in config\")\nremote_name_help = (\"The remote name to commit to for Github Pages. This \"\n \"overrides the value specified in config\")\nforce_help = \"Force the push to the repository.\"\n\npgk_dir = os.path.dirname(os.path.abspath(__file__))\n\n\[email protected](context_settings={'help_option_names': ['-h', '--help']})\[email protected]_option(\n '{0} from {1} (Python {2})'.format(__version__, pgk_dir, sys.version[:3]),\n '-V', '--version')\n@common_options\ndef cli():\n \"\"\"\n MkDocs - Project documentation with Markdown.\n \"\"\"\n\n\[email protected](name=\"serve\")\[email protected]('-f', '--config-file', type=click.File('rb'), help=config_help)\[email protected]('-a', '--dev-addr', help=dev_addr_help, metavar='<IP:PORT>')\[email protected]('-s', '--strict', is_flag=True, help=strict_help)\[email protected]('-t', '--theme', type=click.Choice(theme_choices), help=theme_help)\[email protected]('-e', '--theme-dir', type=click.Path(), help=theme_dir_help)\[email protected]('--livereload', 'livereload', flag_value='livereload', help=reload_help, default=True)\[email protected]('--no-livereload', 'livereload', flag_value='no-livereload', help=no_reload_help)\[email protected]('--dirtyreload', 'livereload', flag_value='dirty', help=dirty_reload_help)\n@common_options\ndef serve_command(dev_addr, config_file, strict, theme, theme_dir, livereload):\n \"\"\"Run the builtin development server\"\"\"\n\n logging.getLogger('tornado').setLevel(logging.WARNING)\n\n # Don't override config value if user did not specify --strict flag\n # Conveniently, load_config drops None values\n strict = strict or None\n\n try:\n serve.serve(\n config_file=config_file,\n dev_addr=dev_addr,\n strict=strict,\n theme=theme,\n theme_dir=theme_dir,\n livereload=livereload\n )\n except (exceptions.ConfigurationError, socket.error) as e: # pragma: no cover\n # Avoid ugly, unhelpful traceback\n raise SystemExit('\\n' + str(e))\n\n\[email protected](name=\"build\")\[email protected]('-c', '--clean/--dirty', is_flag=True, default=True, help=clean_help)\[email protected]('-f', '--config-file', type=click.File('rb'), help=config_help)\[email protected]('-s', '--strict', is_flag=True, help=strict_help)\[email protected]('-t', '--theme', type=click.Choice(theme_choices), help=theme_help)\[email protected]('-e', '--theme-dir', type=click.Path(), help=theme_dir_help)\[email protected]('-d', '--site-dir', type=click.Path(), help=site_dir_help)\n@common_options\ndef build_command(clean, config_file, strict, theme, theme_dir, site_dir):\n \"\"\"Build the MkDocs documentation\"\"\"\n\n # Don't override config value if user did not specify --strict flag\n # Conveniently, load_config drops None values\n strict = strict or None\n\n try:\n build.build(config.load_config(\n config_file=config_file,\n strict=strict,\n theme=theme,\n theme_dir=theme_dir,\n site_dir=site_dir\n ), dirty=not clean)\n except exceptions.ConfigurationError as e: # pragma: no cover\n # Avoid ugly, unhelpful traceback\n raise SystemExit('\\n' + str(e))\n\n\[email protected](name=\"gh-deploy\")\[email protected]('-c', '--clean/--dirty', is_flag=True, default=True, help=clean_help)\[email protected]('-f', '--config-file', type=click.File('rb'), help=config_help)\[email protected]('-m', '--message', help=commit_message_help)\[email protected]('-b', '--remote-branch', help=remote_branch_help)\[email protected]('-r', '--remote-name', help=remote_name_help)\[email protected]('--force', is_flag=True, help=force_help)\n@common_options\ndef gh_deploy_command(config_file, clean, message, remote_branch, remote_name, force):\n \"\"\"Deploy your documentation to GitHub Pages\"\"\"\n try:\n cfg = config.load_config(\n config_file=config_file,\n remote_branch=remote_branch,\n remote_name=remote_name\n )\n build.build(cfg, dirty=not clean)\n gh_deploy.gh_deploy(cfg, message=message, force=force)\n except exceptions.ConfigurationError as e: # pragma: no cover\n # Avoid ugly, unhelpful traceback\n raise SystemExit('\\n' + str(e))\n\n\[email protected](name=\"new\")\[email protected](\"project_directory\")\n@common_options\ndef new_command(project_directory):\n \"\"\"Create a new MkDocs project\"\"\"\n new.new(project_directory)\n\n\nif __name__ == '__main__': # pragma: no cover\n cli()\n", "path": "mkdocs/__main__.py"}]}
| 3,836 | 955 |
gh_patches_debug_24713
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.vmware-627
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
vmware_datastore_cluster_manager is always changed in checkmode
##### SUMMARY
When running in check mode the module is always reporting changed even when it is not detecting any changes.
I had a look at the code and I think there is an if statement missing to set changed=true depending on changed_datastores found or not when in check mode.
You can work around this issue by defining a changed_when clause:
```yaml
register: storage_cluster_datastore_result
changed_when: storage_cluster_datastore_result.datastore_cluster_info.changed_datastores|length > 0
```
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
vmware_datastore_cluster_manager
##### ANSIBLE VERSION
```paste below
ansible 2.10.2
config file = None
configured module search path = ['/Users/cneugum/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.8/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 3.8.5 (default, Oct 12 2020, 11:36:53) [Clang 12.0.0 (clang-1200.0.32.2)]
```
##### CONFIGURATION
Default
##### OS / ENVIRONMENT
Ansible running on: OSX 10.15.7
vCenter running on: vSphere 6.7
##### STEPS TO REPRODUCE
1. Create a play that uses the module and run it so datastores are added to the datastore cluster
2. Run the same play again
3. Run the same play in check mode
```yaml
- name: Test Datastore Cluster
hosts: localhost
gather_facts: no
vars:
vcenter:
hostname: 'vcsa.lab.local'
username: '[email protected]'
password: 'VMware1!'
datacenter_name: 'DC01'
datastore_cluster_name: 'StorageCluster01'
datastores:
- "DS01"
- "DS02"
- "DS03"
tasks:
- name: Create datastore cluster
community.vmware.vmware_datastore_cluster:
hostname: '{{ vcenter.hostname }}'
username: '{{ vcenter.username }}'
password: '{{ vcenter.password }}'
validate_certs: no
datacenter_name: '{{ datacenter_name }}'
datastore_cluster_name: '{{ datastore_cluster_name }}'
- name: Add Datastores to datastore cluster
community.vmware.vmware_datastore_cluster_manager:
hostname: '{{ vcenter.hostname }}'
username: '{{ vcenter.username }}'
password: '{{ vcenter.password }}'
validate_certs: no
datacenter_name: '{{ datacenter_name }}'
datastore_cluster_name: '{{ datastore_cluster_name }}'
datastores: '{{ datastores }}'
```
##### EXPECTED RESULTS
1. Play Recap should report changed tasks
2. Play Recap should report no changed tasks
3. Play Recap should report no changed tasks
##### ACTUAL RESULTS
1. Play Recap reports changed tasks
2. Play Recap reports no changed tasks
3. **_Play Recap reports changed tasks_**
</issue>
<code>
[start of plugins/modules/vmware_datastore_cluster_manager.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3 # Copyright (c) 2018, Ansible Project
4 # Copyright (c) 2020, Abhijeet Kasurde <[email protected]>
5 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
6
7 from __future__ import absolute_import, division, print_function
8 __metaclass__ = type
9
10
11 DOCUMENTATION = r'''
12 ---
13 module: vmware_datastore_cluster_manager
14 short_description: Manage VMware vSphere datastore cluster's members
15 description:
16 - This module can be used to add datastore in the datastore cluster.
17 - All parameters and VMware object values are case sensitive.
18 author:
19 - Abhijeet Kasurde (@Akasurde)
20 notes:
21 - Tested on vSphere 6.0, 6.5
22 requirements:
23 - "python >= 2.7"
24 - PyVmomi
25 options:
26 datacenter_name:
27 description:
28 - The name of the datacenter.
29 required: False
30 aliases: [ datacenter ]
31 type: str
32 datastore_cluster_name:
33 description:
34 - The name of the datastore cluster.
35 required: True
36 type: str
37 aliases: [ datastore_cluster ]
38 state:
39 description:
40 - If set to I(present), datastores specified by I(datastores) will be added to the given datastore cluster.
41 - If set to I(absent), datastores specified by I(datastores) will be moved from the given datastore cluster to datstore folder of the parent datacenter.
42 choices: [ present, absent ]
43 default: present
44 type: str
45 datastores:
46 description:
47 - A list of datastores to be manage.
48 type: list
49 elements: str
50 required: True
51 extends_documentation_fragment:
52 - community.vmware.vmware.documentation
53 '''
54
55 EXAMPLES = r'''
56 - name: Add datastore to the given datastore cluster
57 community.vmware.vmware_datastore_cluster_manager:
58 hostname: '{{ vcenter_hostname }}'
59 username: '{{ vcenter_username }}'
60 password: '{{ vcenter_password }}'
61 datacenter_name: '{{ datacenter_name }}'
62 datastore_cluster_name: '{{ datastore_cluster_name }}'
63 datastores:
64 - ds_001
65 - ds_002
66 - ds_003
67 state: present
68 delegate_to: localhost
69
70 - name: Move datastore from the given datastore cluster
71 community.vmware.vmware_datastore_cluster_manager:
72 hostname: '{{ vcenter_hostname }}'
73 username: '{{ vcenter_username }}'
74 password: '{{ vcenter_password }}'
75 datacenter_name: '{{ datacenter_name }}'
76 datastore_cluster_name: '{{ datastore_cluster_name }}'
77 datastores:
78 - ds_001
79 state: absent
80 delegate_to: localhost
81 '''
82
83 RETURN = r'''
84 datastore_cluster_info:
85 description: information about datastore cluster
86 returned: always
87 type: str
88 sample: {
89 "changed_datastores": ["ds_171_1"],
90 "current_datastores": [],
91 "msg": null,
92 "previous_datastores": ["ds_171_1"]
93 }
94 '''
95
96 try:
97 from pyVmomi import vim
98 except ImportError:
99 pass
100
101 from ansible.module_utils.basic import AnsibleModule
102 from ansible_collections.community.vmware.plugins.module_utils.vmware import PyVmomi, vmware_argument_spec, wait_for_task, TaskError
103 from ansible.module_utils._text import to_native
104
105
106 class VMwareDatastoreClusterManager(PyVmomi):
107 def __init__(self, module):
108 """
109 Constructor
110
111 """
112 super(VMwareDatastoreClusterManager, self).__init__(module)
113 datacenter_name = self.params.get('datacenter_name')
114 datacenter_obj = self.find_datacenter_by_name(datacenter_name)
115 if not datacenter_obj:
116 self.module.fail_json(msg="Failed to find datacenter '%s' required"
117 " for managing datastore cluster." % datacenter_name)
118 self.folder_obj = datacenter_obj.datastoreFolder
119
120 self.datastore_cluster_name = self.params.get('datastore_cluster_name')
121 self.datastore_cluster_obj = self.find_datastore_cluster_by_name(self.datastore_cluster_name, datacenter=datacenter_obj)
122 if not self.datastore_cluster_obj:
123 self.module.fail_json(msg="Failed to find the datastore cluster '%s'" % self.datastore_cluster_name)
124
125 def get_datastore_cluster_children(self):
126 """
127 Return Datastore from the given datastore cluster object
128
129 """
130 return [ds for ds in self.datastore_cluster_obj.childEntity if isinstance(ds, vim.Datastore)]
131
132 def ensure(self):
133 """
134 Manage internal state of datastore cluster
135
136 """
137 changed = False
138 results = dict(
139 changed=changed,
140 )
141 temp_result = dict(
142 previous_datastores=[],
143 current_datastores=[],
144 msg=""
145 )
146 state = self.module.params.get('state')
147 datastores = self.module.params.get('datastores') or []
148 datastore_obj_list = []
149 dsc_child_obj = self.get_datastore_cluster_children()
150
151 if state == 'present':
152 temp_result['previous_datastores'] = [ds.name for ds in dsc_child_obj]
153 for datastore_name in datastores:
154 datastore_obj = self.find_datastore_by_name(datastore_name)
155 if not datastore_obj:
156 self.module.fail_json(msg="Failed to find datastore '%s'" % datastore_name)
157 if datastore_obj not in dsc_child_obj and datastore_obj not in datastore_obj_list:
158 datastore_obj_list.append(datastore_obj)
159
160 if self.module.check_mode:
161 changed_list = [ds.name for ds in datastore_obj_list]
162 temp_result['current_datastores'] = temp_result['previous_datastores'].extend(changed_list)
163 temp_result['changed_datastores'] = changed_list
164 results['changed'] = True
165 results['datastore_cluster_info'] = temp_result
166 self.module.exit_json(**results)
167
168 try:
169 if datastore_obj_list:
170 task = self.datastore_cluster_obj.MoveIntoFolder_Task(list=datastore_obj_list)
171 changed, result = wait_for_task(task)
172 temp_result['msg'] = result
173 temp_result['changed_datastores'] = [ds.name for ds in datastore_obj_list]
174 temp_result['current_datastores'] = [ds.name for ds in self.get_datastore_cluster_children()]
175 except TaskError as generic_exc:
176 self.module.fail_json(msg=to_native(generic_exc))
177 except Exception as task_e:
178 self.module.fail_json(msg=to_native(task_e))
179 elif state == 'absent':
180 temp_result['previous_datastores'] = [ds.name for ds in dsc_child_obj]
181 temp_result['current_datastores'] = [ds.name for ds in dsc_child_obj]
182 for datastore_name in datastores:
183 datastore_obj = self.find_datastore_by_name(datastore_name)
184 if not datastore_obj:
185 self.module.fail_json(msg="Failed to find datastore '%s'" % datastore_name)
186 if datastore_obj in dsc_child_obj and datastore_obj not in datastore_obj_list:
187 datastore_obj_list.append(datastore_obj)
188
189 if self.module.check_mode:
190 changed_list = [ds.name for ds in datastore_obj_list]
191 for ds in changed_list:
192 temp_result['current_datastores'].pop(ds)
193 temp_result['changed_datastores'] = changed_list
194 results['changed'] = True
195 results['datastore_cluster_info'] = temp_result
196 self.module.exit_json(**results)
197
198 try:
199 if datastore_obj_list:
200 task = self.folder_obj.MoveIntoFolder_Task(list=datastore_obj_list)
201 changed, result = wait_for_task(task)
202 temp_result['msg'] = result
203 temp_result['changed_datastores'] = [ds.name for ds in datastore_obj_list]
204 temp_result['current_datastores'] = [ds.name for ds in self.get_datastore_cluster_children()]
205 except TaskError as generic_exc:
206 self.module.fail_json(msg=to_native(generic_exc))
207 except Exception as task_e:
208 self.module.fail_json(msg=to_native(task_e))
209
210 results['changed'] = changed
211 results['datastore_cluster_info'] = temp_result
212 self.module.exit_json(**results)
213
214
215 def main():
216 argument_spec = vmware_argument_spec()
217 argument_spec.update(
218 dict(
219 datacenter_name=dict(type='str', required=False, aliases=['datacenter']),
220 datastore_cluster_name=dict(type='str', required=True, aliases=['datastore_cluster']),
221 state=dict(default='present', choices=['present', 'absent'], type='str'),
222 datastores=dict(type='list', required=True, elements='str'),
223 )
224 )
225 module = AnsibleModule(
226 argument_spec=argument_spec,
227 supports_check_mode=True,
228 )
229
230 datastore_cluster_mgr = VMwareDatastoreClusterManager(module)
231 datastore_cluster_mgr.ensure()
232
233
234 if __name__ == '__main__':
235 main()
236
[end of plugins/modules/vmware_datastore_cluster_manager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/modules/vmware_datastore_cluster_manager.py b/plugins/modules/vmware_datastore_cluster_manager.py
--- a/plugins/modules/vmware_datastore_cluster_manager.py
+++ b/plugins/modules/vmware_datastore_cluster_manager.py
@@ -161,7 +161,7 @@
changed_list = [ds.name for ds in datastore_obj_list]
temp_result['current_datastores'] = temp_result['previous_datastores'].extend(changed_list)
temp_result['changed_datastores'] = changed_list
- results['changed'] = True
+ results['changed'] = len(datastore_obj_list) > 0
results['datastore_cluster_info'] = temp_result
self.module.exit_json(**results)
@@ -191,7 +191,7 @@
for ds in changed_list:
temp_result['current_datastores'].pop(ds)
temp_result['changed_datastores'] = changed_list
- results['changed'] = True
+ results['changed'] = len(datastore_obj_list) > 0
results['datastore_cluster_info'] = temp_result
self.module.exit_json(**results)
|
{"golden_diff": "diff --git a/plugins/modules/vmware_datastore_cluster_manager.py b/plugins/modules/vmware_datastore_cluster_manager.py\n--- a/plugins/modules/vmware_datastore_cluster_manager.py\n+++ b/plugins/modules/vmware_datastore_cluster_manager.py\n@@ -161,7 +161,7 @@\n changed_list = [ds.name for ds in datastore_obj_list]\n temp_result['current_datastores'] = temp_result['previous_datastores'].extend(changed_list)\n temp_result['changed_datastores'] = changed_list\n- results['changed'] = True\n+ results['changed'] = len(datastore_obj_list) > 0\n results['datastore_cluster_info'] = temp_result\n self.module.exit_json(**results)\n \n@@ -191,7 +191,7 @@\n for ds in changed_list:\n temp_result['current_datastores'].pop(ds)\n temp_result['changed_datastores'] = changed_list\n- results['changed'] = True\n+ results['changed'] = len(datastore_obj_list) > 0\n results['datastore_cluster_info'] = temp_result\n self.module.exit_json(**results)\n", "issue": "vmware_datastore_cluster_manager is always changed in checkmode\n##### SUMMARY\r\nWhen running in check mode the module is always reporting changed even when it is not detecting any changes.\r\n\r\nI had a look at the code and I think there is an if statement missing to set changed=true depending on changed_datastores found or not when in check mode.\r\n\r\nYou can work around this issue by defining a changed_when clause:\r\n```yaml\r\nregister: storage_cluster_datastore_result\r\nchanged_when: storage_cluster_datastore_result.datastore_cluster_info.changed_datastores|length > 0\r\n```\r\n\r\n##### ISSUE TYPE\r\n- Bug Report\r\n\r\n##### COMPONENT NAME\r\nvmware_datastore_cluster_manager\r\n\r\n##### ANSIBLE VERSION\r\n```paste below\r\nansible 2.10.2\r\n config file = None\r\n configured module search path = ['/Users/cneugum/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/local/lib/python3.8/site-packages/ansible\r\n executable location = /usr/local/bin/ansible\r\n python version = 3.8.5 (default, Oct 12 2020, 11:36:53) [Clang 12.0.0 (clang-1200.0.32.2)]\r\n```\r\n\r\n##### CONFIGURATION\r\nDefault\r\n\r\n##### OS / ENVIRONMENT\r\nAnsible running on: OSX 10.15.7\r\nvCenter running on: vSphere 6.7\r\n\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\n1. Create a play that uses the module and run it so datastores are added to the datastore cluster\r\n2. Run the same play again\r\n3. Run the same play in check mode\r\n\r\n```yaml\r\n- name: Test Datastore Cluster\r\n hosts: localhost\r\n gather_facts: no\r\n vars:\r\n vcenter:\r\n hostname: 'vcsa.lab.local'\r\n username: '[email protected]'\r\n password: 'VMware1!'\r\n datacenter_name: 'DC01'\r\n datastore_cluster_name: 'StorageCluster01'\r\n datastores: \r\n - \"DS01\"\r\n - \"DS02\"\r\n - \"DS03\"\r\n tasks:\r\n - name: Create datastore cluster\r\n community.vmware.vmware_datastore_cluster:\r\n hostname: '{{ vcenter.hostname }}'\r\n username: '{{ vcenter.username }}'\r\n password: '{{ vcenter.password }}'\r\n validate_certs: no\r\n datacenter_name: '{{ datacenter_name }}'\r\n datastore_cluster_name: '{{ datastore_cluster_name }}'\r\n - name: Add Datastores to datastore cluster\r\n community.vmware.vmware_datastore_cluster_manager:\r\n hostname: '{{ vcenter.hostname }}'\r\n username: '{{ vcenter.username }}'\r\n password: '{{ vcenter.password }}'\r\n validate_certs: no\r\n datacenter_name: '{{ datacenter_name }}'\r\n datastore_cluster_name: '{{ datastore_cluster_name }}'\r\n datastores: '{{ datastores }}'\r\n```\r\n\r\n##### EXPECTED RESULTS\r\n\r\n1. Play Recap should report changed tasks\r\n2. Play Recap should report no changed tasks\r\n3. Play Recap should report no changed tasks\r\n\r\n\r\n##### ACTUAL RESULTS\r\n\r\n1. Play Recap reports changed tasks\r\n2. Play Recap reports no changed tasks\r\n3. **_Play Recap reports changed tasks_**\r\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n# Copyright (c) 2018, Ansible Project\n# Copyright (c) 2020, Abhijeet Kasurde <[email protected]>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: vmware_datastore_cluster_manager\nshort_description: Manage VMware vSphere datastore cluster's members\ndescription:\n - This module can be used to add datastore in the datastore cluster.\n - All parameters and VMware object values are case sensitive.\nauthor:\n- Abhijeet Kasurde (@Akasurde)\nnotes:\n - Tested on vSphere 6.0, 6.5\nrequirements:\n - \"python >= 2.7\"\n - PyVmomi\noptions:\n datacenter_name:\n description:\n - The name of the datacenter.\n required: False\n aliases: [ datacenter ]\n type: str\n datastore_cluster_name:\n description:\n - The name of the datastore cluster.\n required: True\n type: str\n aliases: [ datastore_cluster ]\n state:\n description:\n - If set to I(present), datastores specified by I(datastores) will be added to the given datastore cluster.\n - If set to I(absent), datastores specified by I(datastores) will be moved from the given datastore cluster to datstore folder of the parent datacenter.\n choices: [ present, absent ]\n default: present\n type: str\n datastores:\n description:\n - A list of datastores to be manage.\n type: list\n elements: str\n required: True\nextends_documentation_fragment:\n- community.vmware.vmware.documentation\n'''\n\nEXAMPLES = r'''\n- name: Add datastore to the given datastore cluster\n community.vmware.vmware_datastore_cluster_manager:\n hostname: '{{ vcenter_hostname }}'\n username: '{{ vcenter_username }}'\n password: '{{ vcenter_password }}'\n datacenter_name: '{{ datacenter_name }}'\n datastore_cluster_name: '{{ datastore_cluster_name }}'\n datastores:\n - ds_001\n - ds_002\n - ds_003\n state: present\n delegate_to: localhost\n\n- name: Move datastore from the given datastore cluster\n community.vmware.vmware_datastore_cluster_manager:\n hostname: '{{ vcenter_hostname }}'\n username: '{{ vcenter_username }}'\n password: '{{ vcenter_password }}'\n datacenter_name: '{{ datacenter_name }}'\n datastore_cluster_name: '{{ datastore_cluster_name }}'\n datastores:\n - ds_001\n state: absent\n delegate_to: localhost\n'''\n\nRETURN = r'''\ndatastore_cluster_info:\n description: information about datastore cluster\n returned: always\n type: str\n sample: {\n \"changed_datastores\": [\"ds_171_1\"],\n \"current_datastores\": [],\n \"msg\": null,\n \"previous_datastores\": [\"ds_171_1\"]\n }\n'''\n\ntry:\n from pyVmomi import vim\nexcept ImportError:\n pass\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible_collections.community.vmware.plugins.module_utils.vmware import PyVmomi, vmware_argument_spec, wait_for_task, TaskError\nfrom ansible.module_utils._text import to_native\n\n\nclass VMwareDatastoreClusterManager(PyVmomi):\n def __init__(self, module):\n \"\"\"\n Constructor\n\n \"\"\"\n super(VMwareDatastoreClusterManager, self).__init__(module)\n datacenter_name = self.params.get('datacenter_name')\n datacenter_obj = self.find_datacenter_by_name(datacenter_name)\n if not datacenter_obj:\n self.module.fail_json(msg=\"Failed to find datacenter '%s' required\"\n \" for managing datastore cluster.\" % datacenter_name)\n self.folder_obj = datacenter_obj.datastoreFolder\n\n self.datastore_cluster_name = self.params.get('datastore_cluster_name')\n self.datastore_cluster_obj = self.find_datastore_cluster_by_name(self.datastore_cluster_name, datacenter=datacenter_obj)\n if not self.datastore_cluster_obj:\n self.module.fail_json(msg=\"Failed to find the datastore cluster '%s'\" % self.datastore_cluster_name)\n\n def get_datastore_cluster_children(self):\n \"\"\"\n Return Datastore from the given datastore cluster object\n\n \"\"\"\n return [ds for ds in self.datastore_cluster_obj.childEntity if isinstance(ds, vim.Datastore)]\n\n def ensure(self):\n \"\"\"\n Manage internal state of datastore cluster\n\n \"\"\"\n changed = False\n results = dict(\n changed=changed,\n )\n temp_result = dict(\n previous_datastores=[],\n current_datastores=[],\n msg=\"\"\n )\n state = self.module.params.get('state')\n datastores = self.module.params.get('datastores') or []\n datastore_obj_list = []\n dsc_child_obj = self.get_datastore_cluster_children()\n\n if state == 'present':\n temp_result['previous_datastores'] = [ds.name for ds in dsc_child_obj]\n for datastore_name in datastores:\n datastore_obj = self.find_datastore_by_name(datastore_name)\n if not datastore_obj:\n self.module.fail_json(msg=\"Failed to find datastore '%s'\" % datastore_name)\n if datastore_obj not in dsc_child_obj and datastore_obj not in datastore_obj_list:\n datastore_obj_list.append(datastore_obj)\n\n if self.module.check_mode:\n changed_list = [ds.name for ds in datastore_obj_list]\n temp_result['current_datastores'] = temp_result['previous_datastores'].extend(changed_list)\n temp_result['changed_datastores'] = changed_list\n results['changed'] = True\n results['datastore_cluster_info'] = temp_result\n self.module.exit_json(**results)\n\n try:\n if datastore_obj_list:\n task = self.datastore_cluster_obj.MoveIntoFolder_Task(list=datastore_obj_list)\n changed, result = wait_for_task(task)\n temp_result['msg'] = result\n temp_result['changed_datastores'] = [ds.name for ds in datastore_obj_list]\n temp_result['current_datastores'] = [ds.name for ds in self.get_datastore_cluster_children()]\n except TaskError as generic_exc:\n self.module.fail_json(msg=to_native(generic_exc))\n except Exception as task_e:\n self.module.fail_json(msg=to_native(task_e))\n elif state == 'absent':\n temp_result['previous_datastores'] = [ds.name for ds in dsc_child_obj]\n temp_result['current_datastores'] = [ds.name for ds in dsc_child_obj]\n for datastore_name in datastores:\n datastore_obj = self.find_datastore_by_name(datastore_name)\n if not datastore_obj:\n self.module.fail_json(msg=\"Failed to find datastore '%s'\" % datastore_name)\n if datastore_obj in dsc_child_obj and datastore_obj not in datastore_obj_list:\n datastore_obj_list.append(datastore_obj)\n\n if self.module.check_mode:\n changed_list = [ds.name for ds in datastore_obj_list]\n for ds in changed_list:\n temp_result['current_datastores'].pop(ds)\n temp_result['changed_datastores'] = changed_list\n results['changed'] = True\n results['datastore_cluster_info'] = temp_result\n self.module.exit_json(**results)\n\n try:\n if datastore_obj_list:\n task = self.folder_obj.MoveIntoFolder_Task(list=datastore_obj_list)\n changed, result = wait_for_task(task)\n temp_result['msg'] = result\n temp_result['changed_datastores'] = [ds.name for ds in datastore_obj_list]\n temp_result['current_datastores'] = [ds.name for ds in self.get_datastore_cluster_children()]\n except TaskError as generic_exc:\n self.module.fail_json(msg=to_native(generic_exc))\n except Exception as task_e:\n self.module.fail_json(msg=to_native(task_e))\n\n results['changed'] = changed\n results['datastore_cluster_info'] = temp_result\n self.module.exit_json(**results)\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(\n dict(\n datacenter_name=dict(type='str', required=False, aliases=['datacenter']),\n datastore_cluster_name=dict(type='str', required=True, aliases=['datastore_cluster']),\n state=dict(default='present', choices=['present', 'absent'], type='str'),\n datastores=dict(type='list', required=True, elements='str'),\n )\n )\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True,\n )\n\n datastore_cluster_mgr = VMwareDatastoreClusterManager(module)\n datastore_cluster_mgr.ensure()\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/vmware_datastore_cluster_manager.py"}]}
| 3,786 | 250 |
gh_patches_debug_6779
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-1043
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Invoice information consistency
During checkout, if I choose "business customer", enter a company name, and then reconsider and switch to the individual customer interface, the "company name" name field gets hidden, but its value is still visible in the next step.
</issue>
<code>
[start of src/pretix/base/forms/questions.py]
1 import logging
2 from decimal import Decimal
3
4 import dateutil.parser
5 import pytz
6 import vat_moss.errors
7 import vat_moss.id
8 from django import forms
9 from django.contrib import messages
10 from django.core.exceptions import ValidationError
11 from django.utils.translation import ugettext_lazy as _
12
13 from pretix.base.forms.widgets import (
14 BusinessBooleanRadio, DatePickerWidget, SplitDateTimePickerWidget,
15 TimePickerWidget, UploadedFileWidget,
16 )
17 from pretix.base.models import InvoiceAddress, Question
18 from pretix.base.models.tax import EU_COUNTRIES
19 from pretix.control.forms import SplitDateTimeField
20 from pretix.helpers.i18n import get_format_without_seconds
21 from pretix.presale.signals import question_form_fields
22
23 logger = logging.getLogger(__name__)
24
25
26 class BaseQuestionsForm(forms.Form):
27 """
28 This form class is responsible for asking order-related questions. This includes
29 the attendee name for admission tickets, if the corresponding setting is enabled,
30 as well as additional questions defined by the organizer.
31 """
32
33 def __init__(self, *args, **kwargs):
34 """
35 Takes two additional keyword arguments:
36
37 :param cartpos: The cart position the form should be for
38 :param event: The event this belongs to
39 """
40 cartpos = self.cartpos = kwargs.pop('cartpos', None)
41 orderpos = self.orderpos = kwargs.pop('orderpos', None)
42 pos = cartpos or orderpos
43 item = pos.item
44 questions = pos.item.questions_to_ask
45 event = kwargs.pop('event')
46
47 super().__init__(*args, **kwargs)
48
49 if item.admission and event.settings.attendee_names_asked:
50 self.fields['attendee_name'] = forms.CharField(
51 max_length=255, required=event.settings.attendee_names_required,
52 label=_('Attendee name'),
53 initial=(cartpos.attendee_name if cartpos else orderpos.attendee_name),
54 )
55 if item.admission and event.settings.attendee_emails_asked:
56 self.fields['attendee_email'] = forms.EmailField(
57 required=event.settings.attendee_emails_required,
58 label=_('Attendee email'),
59 initial=(cartpos.attendee_email if cartpos else orderpos.attendee_email)
60 )
61
62 for q in questions:
63 # Do we already have an answer? Provide it as the initial value
64 answers = [a for a in pos.answerlist if a.question_id == q.id]
65 if answers:
66 initial = answers[0]
67 else:
68 initial = None
69 tz = pytz.timezone(event.settings.timezone)
70 if q.type == Question.TYPE_BOOLEAN:
71 if q.required:
72 # For some reason, django-bootstrap3 does not set the required attribute
73 # itself.
74 widget = forms.CheckboxInput(attrs={'required': 'required'})
75 else:
76 widget = forms.CheckboxInput()
77
78 if initial:
79 initialbool = (initial.answer == "True")
80 else:
81 initialbool = False
82
83 field = forms.BooleanField(
84 label=q.question, required=q.required,
85 help_text=q.help_text,
86 initial=initialbool, widget=widget,
87 )
88 elif q.type == Question.TYPE_NUMBER:
89 field = forms.DecimalField(
90 label=q.question, required=q.required,
91 help_text=q.help_text,
92 initial=initial.answer if initial else None,
93 min_value=Decimal('0.00'),
94 )
95 elif q.type == Question.TYPE_STRING:
96 field = forms.CharField(
97 label=q.question, required=q.required,
98 help_text=q.help_text,
99 initial=initial.answer if initial else None,
100 )
101 elif q.type == Question.TYPE_TEXT:
102 field = forms.CharField(
103 label=q.question, required=q.required,
104 help_text=q.help_text,
105 widget=forms.Textarea,
106 initial=initial.answer if initial else None,
107 )
108 elif q.type == Question.TYPE_CHOICE:
109 field = forms.ModelChoiceField(
110 queryset=q.options,
111 label=q.question, required=q.required,
112 help_text=q.help_text,
113 widget=forms.Select,
114 empty_label='',
115 initial=initial.options.first() if initial else None,
116 )
117 elif q.type == Question.TYPE_CHOICE_MULTIPLE:
118 field = forms.ModelMultipleChoiceField(
119 queryset=q.options,
120 label=q.question, required=q.required,
121 help_text=q.help_text,
122 widget=forms.CheckboxSelectMultiple,
123 initial=initial.options.all() if initial else None,
124 )
125 elif q.type == Question.TYPE_FILE:
126 field = forms.FileField(
127 label=q.question, required=q.required,
128 help_text=q.help_text,
129 initial=initial.file if initial else None,
130 widget=UploadedFileWidget(position=pos, event=event, answer=initial),
131 )
132 elif q.type == Question.TYPE_DATE:
133 field = forms.DateField(
134 label=q.question, required=q.required,
135 help_text=q.help_text,
136 initial=dateutil.parser.parse(initial.answer).date() if initial and initial.answer else None,
137 widget=DatePickerWidget(),
138 )
139 elif q.type == Question.TYPE_TIME:
140 field = forms.TimeField(
141 label=q.question, required=q.required,
142 help_text=q.help_text,
143 initial=dateutil.parser.parse(initial.answer).time() if initial and initial.answer else None,
144 widget=TimePickerWidget(time_format=get_format_without_seconds('TIME_INPUT_FORMATS')),
145 )
146 elif q.type == Question.TYPE_DATETIME:
147 field = SplitDateTimeField(
148 label=q.question, required=q.required,
149 help_text=q.help_text,
150 initial=dateutil.parser.parse(initial.answer).astimezone(tz) if initial and initial.answer else None,
151 widget=SplitDateTimePickerWidget(time_format=get_format_without_seconds('TIME_INPUT_FORMATS')),
152 )
153 field.question = q
154 if answers:
155 # Cache the answer object for later use
156 field.answer = answers[0]
157 self.fields['question_%s' % q.id] = field
158
159 responses = question_form_fields.send(sender=event, position=pos)
160 data = pos.meta_info_data
161 for r, response in sorted(responses, key=lambda r: str(r[0])):
162 for key, value in response.items():
163 # We need to be this explicit, since OrderedDict.update does not retain ordering
164 self.fields[key] = value
165 value.initial = data.get('question_form_data', {}).get(key)
166
167
168 class BaseInvoiceAddressForm(forms.ModelForm):
169 vat_warning = False
170
171 class Meta:
172 model = InvoiceAddress
173 fields = ('is_business', 'company', 'name', 'street', 'zipcode', 'city', 'country', 'vat_id',
174 'internal_reference')
175 widgets = {
176 'is_business': BusinessBooleanRadio,
177 'street': forms.Textarea(attrs={'rows': 2, 'placeholder': _('Street and Number')}),
178 'company': forms.TextInput(attrs={'data-display-dependency': '#id_is_business_1'}),
179 'name': forms.TextInput(attrs={}),
180 'vat_id': forms.TextInput(attrs={'data-display-dependency': '#id_is_business_1'}),
181 'internal_reference': forms.TextInput,
182 }
183 labels = {
184 'is_business': ''
185 }
186
187 def __init__(self, *args, **kwargs):
188 self.event = event = kwargs.pop('event')
189 self.request = kwargs.pop('request', None)
190 self.validate_vat_id = kwargs.pop('validate_vat_id')
191 super().__init__(*args, **kwargs)
192 if not event.settings.invoice_address_vatid:
193 del self.fields['vat_id']
194 if not event.settings.invoice_address_required:
195 for k, f in self.fields.items():
196 f.required = False
197 f.widget.is_required = False
198 if 'required' in f.widget.attrs:
199 del f.widget.attrs['required']
200
201 if event.settings.invoice_name_required:
202 self.fields['name'].required = True
203 elif event.settings.invoice_address_company_required:
204 self.initial['is_business'] = True
205
206 self.fields['is_business'].widget = BusinessBooleanRadio(require_business=True)
207 self.fields['company'].required = True
208 self.fields['company'].widget.is_required = True
209 self.fields['company'].widget.attrs['required'] = 'required'
210 del self.fields['company'].widget.attrs['data-display-dependency']
211 if 'vat_id' in self.fields:
212 del self.fields['vat_id'].widget.attrs['data-display-dependency']
213 else:
214 self.fields['company'].widget.attrs['data-required-if'] = '#id_is_business_1'
215 self.fields['name'].widget.attrs['data-required-if'] = '#id_is_business_0'
216
217 def clean(self):
218 data = self.cleaned_data
219 if not data.get('name') and not data.get('company') and self.event.settings.invoice_address_required:
220 raise ValidationError(_('You need to provide either a company name or your name.'))
221
222 if 'vat_id' in self.changed_data or not data.get('vat_id'):
223 self.instance.vat_id_validated = False
224
225 if self.validate_vat_id and self.instance.vat_id_validated and 'vat_id' not in self.changed_data:
226 pass
227 elif self.validate_vat_id and data.get('is_business') and data.get('country') in EU_COUNTRIES and data.get('vat_id'):
228 if data.get('vat_id')[:2] != str(data.get('country')):
229 raise ValidationError(_('Your VAT ID does not match the selected country.'))
230 try:
231 result = vat_moss.id.validate(data.get('vat_id'))
232 if result:
233 country_code, normalized_id, company_name = result
234 self.instance.vat_id_validated = True
235 self.instance.vat_id = normalized_id
236 except vat_moss.errors.InvalidError:
237 raise ValidationError(_('This VAT ID is not valid. Please re-check your input.'))
238 except vat_moss.errors.WebServiceUnavailableError:
239 logger.exception('VAT ID checking failed for country {}'.format(data.get('country')))
240 self.instance.vat_id_validated = False
241 if self.request and self.vat_warning:
242 messages.warning(self.request, _('Your VAT ID could not be checked, as the VAT checking service of '
243 'your country is currently not available. We will therefore '
244 'need to charge VAT on your invoice. You can get the tax amount '
245 'back via the VAT reimbursement process.'))
246 except vat_moss.errors.WebServiceError:
247 logger.exception('VAT ID checking failed for country {}'.format(data.get('country')))
248 self.instance.vat_id_validated = False
249 if self.request and self.vat_warning:
250 messages.warning(self.request, _('Your VAT ID could not be checked, as the VAT checking service of '
251 'your country returned an incorrect result. We will therefore '
252 'need to charge VAT on your invoice. Please contact support to '
253 'resolve this manually.'))
254 else:
255 self.instance.vat_id_validated = False
256
257
258 class BaseInvoiceNameForm(BaseInvoiceAddressForm):
259
260 def __init__(self, *args, **kwargs):
261 super().__init__(*args, **kwargs)
262 for f in list(self.fields.keys()):
263 if f != 'name':
264 del self.fields[f]
265
[end of src/pretix/base/forms/questions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretix/base/forms/questions.py b/src/pretix/base/forms/questions.py
--- a/src/pretix/base/forms/questions.py
+++ b/src/pretix/base/forms/questions.py
@@ -216,6 +216,8 @@
def clean(self):
data = self.cleaned_data
+ if not data.get('is_business'):
+ data['company'] = ''
if not data.get('name') and not data.get('company') and self.event.settings.invoice_address_required:
raise ValidationError(_('You need to provide either a company name or your name.'))
|
{"golden_diff": "diff --git a/src/pretix/base/forms/questions.py b/src/pretix/base/forms/questions.py\n--- a/src/pretix/base/forms/questions.py\n+++ b/src/pretix/base/forms/questions.py\n@@ -216,6 +216,8 @@\n \n def clean(self):\n data = self.cleaned_data\n+ if not data.get('is_business'):\n+ data['company'] = ''\n if not data.get('name') and not data.get('company') and self.event.settings.invoice_address_required:\n raise ValidationError(_('You need to provide either a company name or your name.'))\n", "issue": "Invoice information consistency\nDuring checkout, if I choose \"business customer\", enter a company name, and then reconsider and switch to the individual customer interface, the \"company name\" name field gets hidden, but its value is still visible in the next step.\n", "before_files": [{"content": "import logging\nfrom decimal import Decimal\n\nimport dateutil.parser\nimport pytz\nimport vat_moss.errors\nimport vat_moss.id\nfrom django import forms\nfrom django.contrib import messages\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom pretix.base.forms.widgets import (\n BusinessBooleanRadio, DatePickerWidget, SplitDateTimePickerWidget,\n TimePickerWidget, UploadedFileWidget,\n)\nfrom pretix.base.models import InvoiceAddress, Question\nfrom pretix.base.models.tax import EU_COUNTRIES\nfrom pretix.control.forms import SplitDateTimeField\nfrom pretix.helpers.i18n import get_format_without_seconds\nfrom pretix.presale.signals import question_form_fields\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseQuestionsForm(forms.Form):\n \"\"\"\n This form class is responsible for asking order-related questions. This includes\n the attendee name for admission tickets, if the corresponding setting is enabled,\n as well as additional questions defined by the organizer.\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Takes two additional keyword arguments:\n\n :param cartpos: The cart position the form should be for\n :param event: The event this belongs to\n \"\"\"\n cartpos = self.cartpos = kwargs.pop('cartpos', None)\n orderpos = self.orderpos = kwargs.pop('orderpos', None)\n pos = cartpos or orderpos\n item = pos.item\n questions = pos.item.questions_to_ask\n event = kwargs.pop('event')\n\n super().__init__(*args, **kwargs)\n\n if item.admission and event.settings.attendee_names_asked:\n self.fields['attendee_name'] = forms.CharField(\n max_length=255, required=event.settings.attendee_names_required,\n label=_('Attendee name'),\n initial=(cartpos.attendee_name if cartpos else orderpos.attendee_name),\n )\n if item.admission and event.settings.attendee_emails_asked:\n self.fields['attendee_email'] = forms.EmailField(\n required=event.settings.attendee_emails_required,\n label=_('Attendee email'),\n initial=(cartpos.attendee_email if cartpos else orderpos.attendee_email)\n )\n\n for q in questions:\n # Do we already have an answer? Provide it as the initial value\n answers = [a for a in pos.answerlist if a.question_id == q.id]\n if answers:\n initial = answers[0]\n else:\n initial = None\n tz = pytz.timezone(event.settings.timezone)\n if q.type == Question.TYPE_BOOLEAN:\n if q.required:\n # For some reason, django-bootstrap3 does not set the required attribute\n # itself.\n widget = forms.CheckboxInput(attrs={'required': 'required'})\n else:\n widget = forms.CheckboxInput()\n\n if initial:\n initialbool = (initial.answer == \"True\")\n else:\n initialbool = False\n\n field = forms.BooleanField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=initialbool, widget=widget,\n )\n elif q.type == Question.TYPE_NUMBER:\n field = forms.DecimalField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=initial.answer if initial else None,\n min_value=Decimal('0.00'),\n )\n elif q.type == Question.TYPE_STRING:\n field = forms.CharField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=initial.answer if initial else None,\n )\n elif q.type == Question.TYPE_TEXT:\n field = forms.CharField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n widget=forms.Textarea,\n initial=initial.answer if initial else None,\n )\n elif q.type == Question.TYPE_CHOICE:\n field = forms.ModelChoiceField(\n queryset=q.options,\n label=q.question, required=q.required,\n help_text=q.help_text,\n widget=forms.Select,\n empty_label='',\n initial=initial.options.first() if initial else None,\n )\n elif q.type == Question.TYPE_CHOICE_MULTIPLE:\n field = forms.ModelMultipleChoiceField(\n queryset=q.options,\n label=q.question, required=q.required,\n help_text=q.help_text,\n widget=forms.CheckboxSelectMultiple,\n initial=initial.options.all() if initial else None,\n )\n elif q.type == Question.TYPE_FILE:\n field = forms.FileField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=initial.file if initial else None,\n widget=UploadedFileWidget(position=pos, event=event, answer=initial),\n )\n elif q.type == Question.TYPE_DATE:\n field = forms.DateField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=dateutil.parser.parse(initial.answer).date() if initial and initial.answer else None,\n widget=DatePickerWidget(),\n )\n elif q.type == Question.TYPE_TIME:\n field = forms.TimeField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=dateutil.parser.parse(initial.answer).time() if initial and initial.answer else None,\n widget=TimePickerWidget(time_format=get_format_without_seconds('TIME_INPUT_FORMATS')),\n )\n elif q.type == Question.TYPE_DATETIME:\n field = SplitDateTimeField(\n label=q.question, required=q.required,\n help_text=q.help_text,\n initial=dateutil.parser.parse(initial.answer).astimezone(tz) if initial and initial.answer else None,\n widget=SplitDateTimePickerWidget(time_format=get_format_without_seconds('TIME_INPUT_FORMATS')),\n )\n field.question = q\n if answers:\n # Cache the answer object for later use\n field.answer = answers[0]\n self.fields['question_%s' % q.id] = field\n\n responses = question_form_fields.send(sender=event, position=pos)\n data = pos.meta_info_data\n for r, response in sorted(responses, key=lambda r: str(r[0])):\n for key, value in response.items():\n # We need to be this explicit, since OrderedDict.update does not retain ordering\n self.fields[key] = value\n value.initial = data.get('question_form_data', {}).get(key)\n\n\nclass BaseInvoiceAddressForm(forms.ModelForm):\n vat_warning = False\n\n class Meta:\n model = InvoiceAddress\n fields = ('is_business', 'company', 'name', 'street', 'zipcode', 'city', 'country', 'vat_id',\n 'internal_reference')\n widgets = {\n 'is_business': BusinessBooleanRadio,\n 'street': forms.Textarea(attrs={'rows': 2, 'placeholder': _('Street and Number')}),\n 'company': forms.TextInput(attrs={'data-display-dependency': '#id_is_business_1'}),\n 'name': forms.TextInput(attrs={}),\n 'vat_id': forms.TextInput(attrs={'data-display-dependency': '#id_is_business_1'}),\n 'internal_reference': forms.TextInput,\n }\n labels = {\n 'is_business': ''\n }\n\n def __init__(self, *args, **kwargs):\n self.event = event = kwargs.pop('event')\n self.request = kwargs.pop('request', None)\n self.validate_vat_id = kwargs.pop('validate_vat_id')\n super().__init__(*args, **kwargs)\n if not event.settings.invoice_address_vatid:\n del self.fields['vat_id']\n if not event.settings.invoice_address_required:\n for k, f in self.fields.items():\n f.required = False\n f.widget.is_required = False\n if 'required' in f.widget.attrs:\n del f.widget.attrs['required']\n\n if event.settings.invoice_name_required:\n self.fields['name'].required = True\n elif event.settings.invoice_address_company_required:\n self.initial['is_business'] = True\n\n self.fields['is_business'].widget = BusinessBooleanRadio(require_business=True)\n self.fields['company'].required = True\n self.fields['company'].widget.is_required = True\n self.fields['company'].widget.attrs['required'] = 'required'\n del self.fields['company'].widget.attrs['data-display-dependency']\n if 'vat_id' in self.fields:\n del self.fields['vat_id'].widget.attrs['data-display-dependency']\n else:\n self.fields['company'].widget.attrs['data-required-if'] = '#id_is_business_1'\n self.fields['name'].widget.attrs['data-required-if'] = '#id_is_business_0'\n\n def clean(self):\n data = self.cleaned_data\n if not data.get('name') and not data.get('company') and self.event.settings.invoice_address_required:\n raise ValidationError(_('You need to provide either a company name or your name.'))\n\n if 'vat_id' in self.changed_data or not data.get('vat_id'):\n self.instance.vat_id_validated = False\n\n if self.validate_vat_id and self.instance.vat_id_validated and 'vat_id' not in self.changed_data:\n pass\n elif self.validate_vat_id and data.get('is_business') and data.get('country') in EU_COUNTRIES and data.get('vat_id'):\n if data.get('vat_id')[:2] != str(data.get('country')):\n raise ValidationError(_('Your VAT ID does not match the selected country.'))\n try:\n result = vat_moss.id.validate(data.get('vat_id'))\n if result:\n country_code, normalized_id, company_name = result\n self.instance.vat_id_validated = True\n self.instance.vat_id = normalized_id\n except vat_moss.errors.InvalidError:\n raise ValidationError(_('This VAT ID is not valid. Please re-check your input.'))\n except vat_moss.errors.WebServiceUnavailableError:\n logger.exception('VAT ID checking failed for country {}'.format(data.get('country')))\n self.instance.vat_id_validated = False\n if self.request and self.vat_warning:\n messages.warning(self.request, _('Your VAT ID could not be checked, as the VAT checking service of '\n 'your country is currently not available. We will therefore '\n 'need to charge VAT on your invoice. You can get the tax amount '\n 'back via the VAT reimbursement process.'))\n except vat_moss.errors.WebServiceError:\n logger.exception('VAT ID checking failed for country {}'.format(data.get('country')))\n self.instance.vat_id_validated = False\n if self.request and self.vat_warning:\n messages.warning(self.request, _('Your VAT ID could not be checked, as the VAT checking service of '\n 'your country returned an incorrect result. We will therefore '\n 'need to charge VAT on your invoice. Please contact support to '\n 'resolve this manually.'))\n else:\n self.instance.vat_id_validated = False\n\n\nclass BaseInvoiceNameForm(BaseInvoiceAddressForm):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n for f in list(self.fields.keys()):\n if f != 'name':\n del self.fields[f]\n", "path": "src/pretix/base/forms/questions.py"}]}
| 3,645 | 129 |
gh_patches_debug_4472
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1529
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
rabbitmq_parameter fails when passing dynamically generated json
##### Issue Type:
“Bug Report”
##### Ansible Version:
ansible 1.8.2
configured module search path = None
Tested also on ansible 1.9
ansible 1.9 (devel 8f06ba2bc1) last updated 2015/02/05 11:16:37 (GMT +200)
lib/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:16:50 (GMT +200)
lib/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:01 (GMT +200)
v2/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:17:13 (GMT +200)
v2/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:36 (GMT +200)
configured module search path = None
##### Environment:
OS X 10.9.5 > Ubuntu 14.04
##### Summary:
Passing non-hardcoded json (through templating) to rabbitmq_parameter's "value" argument raises an exception. It works when hardcoding the json though.
##### Steps To Reproduce:
Here's an example playbook with one successful task (the first one), and two failing tasks (the next two) which both raise the same exception (see below). All of them are supposed to do the same thing.
```
- hosts: my-host
tasks:
- set_fact:
upstream_list:
- upstream: "test"
- upstream: "test2"
json_upstreams: '[{"upstream":"test1"},{"upstream":"test2"}]'
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '[{"upstream":"test1"},{"upstream":"test2"}]'
sudo: yes
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '{{ json_upstreams }}'
sudo: yes
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '{{ upstream_list|to_json }}'
sudo: yes
```
##### Expected Results:
Set a federation-upstream-set parameter to the default vhost.
##### Actual Results:
The two failing tasks raise the same exception. The output from ansible with -vvvv is as follows:
```
<my-host> ESTABLISH CONNECTION FOR USER: xxxx
<my-host> REMOTE_MODULE rabbitmq_parameter name=test-upstream-set component=federation-upstream-set vhost=/
<my-host> EXEC ssh -C -vvv -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=30m -o ControlPath="xxxx/.ansible/cp/ansible-ssh-%h-%p-%r" -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-k
eyex,hostbased,publickey -o PasswordAuthentication=no -o User=xxxx -o ConnectTimeout=10 my- host /bin/sh -c 'sudo -k && sudo -H -S -p "[sudo via ansible, key=xxxxxx] password: " -u root /bin/sh -c '"'"'echo SUDO-SUCCESS-xxxxxx; LANG=en_US.UTF-8 LC_CTYPE=en_US.UTF-8 /usr/bin/python'"'"''
failed: [my-host] => {"failed": true, "parsed": false}
SUDO-SUCCESS-xxxxxx
OpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec 2011
debug1: Reading configuration data /xxxxx/.ssh/config
debug1: Reading configuration data /etc/ssh_config
debug1: /etc/ssh_config line 20: Applying options for *
debug1: /etc/ssh_config line 102: Applying options for *
debug1: auto-mux: Trying existing master
debug2: fd 3 setting O_NONBLOCK
debug2: mux_client_hello_exchange: master version 4
debug3: mux_client_forwards: request forwardings: 0 local, 0 remote
debug3: mux_client_request_session: entering
debug3: mux_client_request_alive: entering
debug3: mux_client_request_alive: done pid = 58450
debug3: mux_client_request_session: session request sent
debug1: mux_client_request_session: master session id: 2
[sudo via ansible, key=xxxxx] password: Traceback (most recent call last):
File "<stdin>", line 1717, in <module>
File "<stdin>", line 142, in main
File "<stdin>", line 104, in set
File "<stdin>", line 88, in _exec
File "<stdin>", line 1566, in run_command
File "/usr/lib/python2.7/posixpath.py", line 261, in expanduser
if not path.startswith('~'):
AttributeError: 'list' object has no attribute 'startswith'
debug3: mux_client_read_packet: read header failed: Broken pipe
debug2: Received exit status from master 1
```
##### Tentative solution:
From what I've seen while troubleshooting the issue, the problem comes from the rabbitmq_parameter module being passed a list to its "value" argument. It is then passed to AnsibleModule::run_command, which assumes it is a string and passes it through os.path.expanduser.
I've managed to correct this behavior by setting the value to `value if type(value) == str else json.dumps(value)`.
I can submit a more complete patch or pull request if this is indeed a bug and not an issue in my playbook.
</issue>
<code>
[start of messaging/rabbitmq_parameter.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Chatham Financial <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 DOCUMENTATION = '''
22 ---
23 module: rabbitmq_parameter
24 short_description: Adds or removes parameters to RabbitMQ
25 description:
26 - Manage dynamic, cluster-wide parameters for RabbitMQ
27 version_added: "1.1"
28 author: Chris Hoffman
29 options:
30 component:
31 description:
32 - Name of the component of which the parameter is being set
33 required: true
34 default: null
35 name:
36 description:
37 - Name of the parameter being set
38 required: true
39 default: null
40 value:
41 description:
42 - Value of the parameter, as a JSON term
43 required: false
44 default: null
45 vhost:
46 description:
47 - vhost to apply access privileges.
48 required: false
49 default: /
50 node:
51 description:
52 - erlang node name of the rabbit we wish to configure
53 required: false
54 default: rabbit
55 version_added: "1.2"
56 state:
57 description:
58 - Specify if user is to be added or removed
59 required: false
60 default: present
61 choices: [ 'present', 'absent']
62 '''
63
64 EXAMPLES = """
65 # Set the federation parameter 'local_username' to a value of 'guest' (in quotes)
66 - rabbitmq_parameter: component=federation
67 name=local-username
68 value='"guest"'
69 state=present
70 """
71
72 class RabbitMqParameter(object):
73 def __init__(self, module, component, name, value, vhost, node):
74 self.module = module
75 self.component = component
76 self.name = name
77 self.value = value
78 self.vhost = vhost
79 self.node = node
80
81 self._value = None
82
83 self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)
84
85 def _exec(self, args, run_in_check_mode=False):
86 if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):
87 cmd = [self._rabbitmqctl, '-q', '-n', self.node]
88 rc, out, err = self.module.run_command(cmd + args, check_rc=True)
89 return out.splitlines()
90 return list()
91
92 def get(self):
93 parameters = self._exec(['list_parameters', '-p', self.vhost], True)
94
95 for param_item in parameters:
96 component, name, value = param_item.split('\t')
97
98 if component == self.component and name == self.name:
99 self._value = value
100 return True
101 return False
102
103 def set(self):
104 self._exec(['set_parameter', '-p', self.vhost, self.component, self.name, self.value])
105
106 def delete(self):
107 self._exec(['clear_parameter', '-p', self.vhost, self.component, self.name])
108
109 def has_modifications(self):
110 return self.value != self._value
111
112 def main():
113 arg_spec = dict(
114 component=dict(required=True),
115 name=dict(required=True),
116 value=dict(default=None),
117 vhost=dict(default='/'),
118 state=dict(default='present', choices=['present', 'absent']),
119 node=dict(default='rabbit')
120 )
121 module = AnsibleModule(
122 argument_spec=arg_spec,
123 supports_check_mode=True
124 )
125
126 component = module.params['component']
127 name = module.params['name']
128 value = module.params['value']
129 if not isinstance(value, str):
130 value = json.dumps(value)
131 vhost = module.params['vhost']
132 state = module.params['state']
133 node = module.params['node']
134
135 rabbitmq_parameter = RabbitMqParameter(module, component, name, value, vhost, node)
136
137 changed = False
138 if rabbitmq_parameter.get():
139 if state == 'absent':
140 rabbitmq_parameter.delete()
141 changed = True
142 else:
143 if rabbitmq_parameter.has_modifications():
144 rabbitmq_parameter.set()
145 changed = True
146 elif state == 'present':
147 rabbitmq_parameter.set()
148 changed = True
149
150 module.exit_json(changed=changed, component=component, name=name, vhost=vhost, state=state)
151
152 # import module snippets
153 from ansible.module_utils.basic import *
154 main()
155
[end of messaging/rabbitmq_parameter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/messaging/rabbitmq_parameter.py b/messaging/rabbitmq_parameter.py
--- a/messaging/rabbitmq_parameter.py
+++ b/messaging/rabbitmq_parameter.py
@@ -126,8 +126,6 @@
component = module.params['component']
name = module.params['name']
value = module.params['value']
- if not isinstance(value, str):
- value = json.dumps(value)
vhost = module.params['vhost']
state = module.params['state']
node = module.params['node']
|
{"golden_diff": "diff --git a/messaging/rabbitmq_parameter.py b/messaging/rabbitmq_parameter.py\n--- a/messaging/rabbitmq_parameter.py\n+++ b/messaging/rabbitmq_parameter.py\n@@ -126,8 +126,6 @@\n component = module.params['component']\n name = module.params['name']\n value = module.params['value']\n- if not isinstance(value, str):\n- value = json.dumps(value)\n vhost = module.params['vhost']\n state = module.params['state']\n node = module.params['node']\n", "issue": "rabbitmq_parameter fails when passing dynamically generated json\n##### Issue Type:\n\n\u201cBug Report\u201d\n##### Ansible Version:\n\nansible 1.8.2\n configured module search path = None\n\nTested also on ansible 1.9\nansible 1.9 (devel 8f06ba2bc1) last updated 2015/02/05 11:16:37 (GMT +200)\n lib/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:16:50 (GMT +200)\n lib/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:01 (GMT +200)\n v2/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:17:13 (GMT +200)\n v2/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:36 (GMT +200)\n configured module search path = None\n##### Environment:\n\nOS X 10.9.5 > Ubuntu 14.04\n##### Summary:\n\nPassing non-hardcoded json (through templating) to rabbitmq_parameter's \"value\" argument raises an exception. It works when hardcoding the json though.\n##### Steps To Reproduce:\n\nHere's an example playbook with one successful task (the first one), and two failing tasks (the next two) which both raise the same exception (see below). All of them are supposed to do the same thing.\n\n```\n- hosts: my-host\n tasks:\n - set_fact:\n upstream_list:\n - upstream: \"test\"\n - upstream: \"test2\"\n json_upstreams: '[{\"upstream\":\"test1\"},{\"upstream\":\"test2\"}]'\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '[{\"upstream\":\"test1\"},{\"upstream\":\"test2\"}]'\n sudo: yes\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '{{ json_upstreams }}'\n sudo: yes\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '{{ upstream_list|to_json }}'\n sudo: yes\n```\n##### Expected Results:\n\nSet a federation-upstream-set parameter to the default vhost.\n##### Actual Results:\n\nThe two failing tasks raise the same exception. The output from ansible with -vvvv is as follows:\n\n```\n<my-host> ESTABLISH CONNECTION FOR USER: xxxx\n<my-host> REMOTE_MODULE rabbitmq_parameter name=test-upstream-set component=federation-upstream-set vhost=/\n<my-host> EXEC ssh -C -vvv -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=30m -o ControlPath=\"xxxx/.ansible/cp/ansible-ssh-%h-%p-%r\" -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-k\neyex,hostbased,publickey -o PasswordAuthentication=no -o User=xxxx -o ConnectTimeout=10 my- host /bin/sh -c 'sudo -k && sudo -H -S -p \"[sudo via ansible, key=xxxxxx] password: \" -u root /bin/sh -c '\"'\"'echo SUDO-SUCCESS-xxxxxx; LANG=en_US.UTF-8 LC_CTYPE=en_US.UTF-8 /usr/bin/python'\"'\"''\nfailed: [my-host] => {\"failed\": true, \"parsed\": false}\nSUDO-SUCCESS-xxxxxx\nOpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec 2011\ndebug1: Reading configuration data /xxxxx/.ssh/config\ndebug1: Reading configuration data /etc/ssh_config\ndebug1: /etc/ssh_config line 20: Applying options for *\ndebug1: /etc/ssh_config line 102: Applying options for *\ndebug1: auto-mux: Trying existing master\ndebug2: fd 3 setting O_NONBLOCK\ndebug2: mux_client_hello_exchange: master version 4\ndebug3: mux_client_forwards: request forwardings: 0 local, 0 remote\ndebug3: mux_client_request_session: entering\ndebug3: mux_client_request_alive: entering\ndebug3: mux_client_request_alive: done pid = 58450\ndebug3: mux_client_request_session: session request sent\ndebug1: mux_client_request_session: master session id: 2\n[sudo via ansible, key=xxxxx] password: Traceback (most recent call last):\n File \"<stdin>\", line 1717, in <module>\n File \"<stdin>\", line 142, in main\n File \"<stdin>\", line 104, in set\n File \"<stdin>\", line 88, in _exec\n File \"<stdin>\", line 1566, in run_command\n File \"/usr/lib/python2.7/posixpath.py\", line 261, in expanduser\n if not path.startswith('~'):\nAttributeError: 'list' object has no attribute 'startswith'\ndebug3: mux_client_read_packet: read header failed: Broken pipe\ndebug2: Received exit status from master 1\n```\n##### Tentative solution:\n\nFrom what I've seen while troubleshooting the issue, the problem comes from the rabbitmq_parameter module being passed a list to its \"value\" argument. It is then passed to AnsibleModule::run_command, which assumes it is a string and passes it through os.path.expanduser.\nI've managed to correct this behavior by setting the value to `value if type(value) == str else json.dumps(value)`.\nI can submit a more complete patch or pull request if this is indeed a bug and not an issue in my playbook.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_parameter\nshort_description: Adds or removes parameters to RabbitMQ\ndescription:\n - Manage dynamic, cluster-wide parameters for RabbitMQ\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n component:\n description:\n - Name of the component of which the parameter is being set\n required: true\n default: null\n name:\n description:\n - Name of the parameter being set\n required: true\n default: null\n value:\n description:\n - Value of the parameter, as a JSON term\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [ 'present', 'absent']\n'''\n\nEXAMPLES = \"\"\"\n# Set the federation parameter 'local_username' to a value of 'guest' (in quotes)\n- rabbitmq_parameter: component=federation\n name=local-username\n value='\"guest\"'\n state=present\n\"\"\"\n\nclass RabbitMqParameter(object):\n def __init__(self, module, component, name, value, vhost, node):\n self.module = module\n self.component = component\n self.name = name\n self.value = value\n self.vhost = vhost\n self.node = node\n\n self._value = None\n\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n parameters = self._exec(['list_parameters', '-p', self.vhost], True)\n\n for param_item in parameters:\n component, name, value = param_item.split('\\t')\n\n if component == self.component and name == self.name:\n self._value = value\n return True\n return False\n\n def set(self):\n self._exec(['set_parameter', '-p', self.vhost, self.component, self.name, self.value])\n\n def delete(self):\n self._exec(['clear_parameter', '-p', self.vhost, self.component, self.name])\n\n def has_modifications(self):\n return self.value != self._value\n\ndef main():\n arg_spec = dict(\n component=dict(required=True),\n name=dict(required=True),\n value=dict(default=None),\n vhost=dict(default='/'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n component = module.params['component']\n name = module.params['name']\n value = module.params['value']\n if not isinstance(value, str):\n value = json.dumps(value)\n vhost = module.params['vhost']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_parameter = RabbitMqParameter(module, component, name, value, vhost, node)\n\n changed = False\n if rabbitmq_parameter.get():\n if state == 'absent':\n rabbitmq_parameter.delete()\n changed = True\n else:\n if rabbitmq_parameter.has_modifications():\n rabbitmq_parameter.set()\n changed = True\n elif state == 'present':\n rabbitmq_parameter.set()\n changed = True\n\n module.exit_json(changed=changed, component=component, name=name, vhost=vhost, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_parameter.py"}]}
| 3,355 | 121 |
gh_patches_debug_16748
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-375
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`val_split` + `overfit_batches` gives infinite recursion error
## 🐛 Bug
`val_split` + `overfit_batches` gives infinite recursion error on master
</issue>
<code>
[start of flash/core/data/splits.py]
1 from typing import Any, List
2
3 import numpy as np
4 from pytorch_lightning.utilities.exceptions import MisconfigurationException
5 from torch.utils.data import Dataset
6
7
8 class SplitDataset(Dataset):
9 """
10 SplitDataset is used to create Dataset Subset using indices.
11
12 Args:
13
14 dataset: A dataset to be splitted
15 indices: List of indices to expose from the dataset
16 use_duplicated_indices: Wether to allow duplicated indices.
17
18 Example::
19
20 split_ds = SplitDataset(dataset, indices=[10, 14, 25])
21
22 split_ds = SplitDataset(dataset, indices=[10, 10, 10, 14, 25], use_duplicated_indices=True)
23
24 """
25
26 _INTERNAL_KEYS = ("dataset", "indices", "data")
27
28 def __init__(self, dataset: Any, indices: List[int] = [], use_duplicated_indices: bool = False) -> None:
29 if not isinstance(indices, list):
30 raise MisconfigurationException("indices should be a list")
31
32 if use_duplicated_indices:
33 indices = list(indices)
34 else:
35 indices = list(np.unique(indices))
36
37 if np.max(indices) >= len(dataset) or np.min(indices) < 0:
38 raise MisconfigurationException(f"`indices` should be within [0, {len(dataset) -1}].")
39
40 self.dataset = dataset
41 self.indices = indices
42
43 def __getattr__(self, key: str):
44 if key in self._INTERNAL_KEYS:
45 return getattr(self, key)
46 return getattr(self.dataset, key)
47
48 def __setattr__(self, name: str, value: Any) -> None:
49 if name in self._INTERNAL_KEYS:
50 self.__dict__[name] = value
51 else:
52 setattr(self.dataset, name, value)
53
54 def __getitem__(self, index: int) -> Any:
55 return self.dataset[self.indices[index]]
56
57 def __len__(self) -> int:
58 return len(self.indices)
59
[end of flash/core/data/splits.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flash/core/data/splits.py b/flash/core/data/splits.py
--- a/flash/core/data/splits.py
+++ b/flash/core/data/splits.py
@@ -13,7 +13,7 @@
dataset: A dataset to be splitted
indices: List of indices to expose from the dataset
- use_duplicated_indices: Wether to allow duplicated indices.
+ use_duplicated_indices: Whether to allow duplicated indices.
Example::
@@ -41,9 +41,9 @@
self.indices = indices
def __getattr__(self, key: str):
- if key in self._INTERNAL_KEYS:
- return getattr(self, key)
- return getattr(self.dataset, key)
+ if key not in self._INTERNAL_KEYS:
+ return self.dataset.__getattribute__(key)
+ raise AttributeError
def __setattr__(self, name: str, value: Any) -> None:
if name in self._INTERNAL_KEYS:
|
{"golden_diff": "diff --git a/flash/core/data/splits.py b/flash/core/data/splits.py\n--- a/flash/core/data/splits.py\n+++ b/flash/core/data/splits.py\n@@ -13,7 +13,7 @@\n \n dataset: A dataset to be splitted\n indices: List of indices to expose from the dataset\n- use_duplicated_indices: Wether to allow duplicated indices.\n+ use_duplicated_indices: Whether to allow duplicated indices.\n \n Example::\n \n@@ -41,9 +41,9 @@\n self.indices = indices\n \n def __getattr__(self, key: str):\n- if key in self._INTERNAL_KEYS:\n- return getattr(self, key)\n- return getattr(self.dataset, key)\n+ if key not in self._INTERNAL_KEYS:\n+ return self.dataset.__getattribute__(key)\n+ raise AttributeError\n \n def __setattr__(self, name: str, value: Any) -> None:\n if name in self._INTERNAL_KEYS:\n", "issue": "`val_split` + `overfit_batches` gives infinite recursion error\n## \ud83d\udc1b Bug\r\n\r\n`val_split` + `overfit_batches` gives infinite recursion error on master\n", "before_files": [{"content": "from typing import Any, List\n\nimport numpy as np\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.utils.data import Dataset\n\n\nclass SplitDataset(Dataset):\n \"\"\"\n SplitDataset is used to create Dataset Subset using indices.\n\n Args:\n\n dataset: A dataset to be splitted\n indices: List of indices to expose from the dataset\n use_duplicated_indices: Wether to allow duplicated indices.\n\n Example::\n\n split_ds = SplitDataset(dataset, indices=[10, 14, 25])\n\n split_ds = SplitDataset(dataset, indices=[10, 10, 10, 14, 25], use_duplicated_indices=True)\n\n \"\"\"\n\n _INTERNAL_KEYS = (\"dataset\", \"indices\", \"data\")\n\n def __init__(self, dataset: Any, indices: List[int] = [], use_duplicated_indices: bool = False) -> None:\n if not isinstance(indices, list):\n raise MisconfigurationException(\"indices should be a list\")\n\n if use_duplicated_indices:\n indices = list(indices)\n else:\n indices = list(np.unique(indices))\n\n if np.max(indices) >= len(dataset) or np.min(indices) < 0:\n raise MisconfigurationException(f\"`indices` should be within [0, {len(dataset) -1}].\")\n\n self.dataset = dataset\n self.indices = indices\n\n def __getattr__(self, key: str):\n if key in self._INTERNAL_KEYS:\n return getattr(self, key)\n return getattr(self.dataset, key)\n\n def __setattr__(self, name: str, value: Any) -> None:\n if name in self._INTERNAL_KEYS:\n self.__dict__[name] = value\n else:\n setattr(self.dataset, name, value)\n\n def __getitem__(self, index: int) -> Any:\n return self.dataset[self.indices[index]]\n\n def __len__(self) -> int:\n return len(self.indices)\n", "path": "flash/core/data/splits.py"}]}
| 1,116 | 216 |
gh_patches_debug_17309
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-2149
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pkgutil: the values of update_catalog get always translated to true or false, but the module expects yes or no.
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
packaging/os/pkgutil.py
##### ANSIBLE VERSION
```
ansible 2.1.0.0-RC1
ansible 2.1.0.0 (detached HEAD 5954a82dd6) last updated 2016/05/02 13:45:40 (GMT +200)
lib/ansible/modules/core: (detached HEAD ce79e7c72d) last updated 2016/05/02 13:46:30 (GMT +200)
lib/ansible/modules/extras: (detached HEAD 156a8cd0b3) last updated 2016/05/02 13:46:30 (GMT +200)
```
##### CONFIGURATION
##### OS / ENVIRONMENT
Running on MacOS X 10.11.4 against Solaris 10
##### SUMMARY
Argument update_catalog gets wrong values false and true instead of no and yes
##### STEPS TO REPRODUCE
```
ansible myhost -m pkgutil -a "name=CSWgnupg state=present" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"name": "CSWgnupg",
"state": "present",
"update_catalog": false
},
"module_name": "pkgutil"
},
"msg": "value of update_catalog must be one of: yes,no, got: False"
}
```
##### EXPECTED RESULTS
CSW package gnupg should be installed.
##### ACTUAL RESULTS
The values of update_catalog get always translated to true or false, but the module expects yes or no.
```
ansible myhost -m pkgutil -a "name=CSWgnupg state=present" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"name": "CSWgnupg",
"state": "present",
"update_catalog": false
},
"module_name": "pkgutil"
},
"msg": "value of update_catalog must be one of: yes,no, got: False"
}
ansible myhost -m pkgutil -a "name=CSWgnupg state=present update_catalog=no" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"name": "CSWgnupg",
"state": "present",
"update_catalog": false
},
"module_name": "pkgutil"
},
"msg": "value of update_catalog must be one of: yes,no, got: False"
}
ansible myhost -m pkgutil -a "name=CSWgnupg state=present update_catalog=false" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"name": "CSWgnupg",
"state": "present",
"update_catalog": false
},
"module_name": "pkgutil"
},
"msg": "value of update_catalog must be one of: yes,no, got: False"
}
ansible myhost -m pkgutil -a "name=CSWgnupg state=present update_catalog=yes" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"name": "CSWgnupg",
"state": "present",
"update_catalog": true
},
"module_name": "pkgutil"
},
"msg": "value of update_catalog must be one of: yes,no, got: True"
}
ansible myhost -m pkgutil -a "name=CSWgnupg state=present update_catalog=true" -u root
myhost | FAILED! => {
"changed": false,
"failed": true,
"msg": "value of update_catalog must be one of: yes,no, got: True"
}
```
</issue>
<code>
[start of packaging/os/pkgutil.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Alexander Winkler <mail () winkler-alexander.de>
5 # based on svr4pkg by
6 # Boyd Adamson <boyd () boydadamson.com> (2012)
7 #
8 # This file is part of Ansible
9 #
10 # Ansible is free software: you can redistribute it and/or modify
11 # it under the terms of the GNU General Public License as published by
12 # the Free Software Foundation, either version 3 of the License, or
13 # (at your option) any later version.
14 #
15 # Ansible is distributed in the hope that it will be useful,
16 # but WITHOUT ANY WARRANTY; without even the implied warranty of
17 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
18 # GNU General Public License for more details.
19 #
20 # You should have received a copy of the GNU General Public License
21 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
22 #
23
24 DOCUMENTATION = '''
25 ---
26 module: pkgutil
27 short_description: Manage CSW-Packages on Solaris
28 description:
29 - Manages CSW packages (SVR4 format) on Solaris 10 and 11.
30 - These were the native packages on Solaris <= 10 and are available
31 as a legacy feature in Solaris 11.
32 - Pkgutil is an advanced packaging system, which resolves dependency on installation.
33 It is designed for CSW packages.
34 version_added: "1.3"
35 author: "Alexander Winkler (@dermute)"
36 options:
37 name:
38 description:
39 - Package name, e.g. (C(CSWnrpe))
40 required: true
41 site:
42 description:
43 - Specifies the repository path to install the package from.
44 - Its global definition is done in C(/etc/opt/csw/pkgutil.conf).
45 required: false
46 state:
47 description:
48 - Whether to install (C(present)), or remove (C(absent)) a package.
49 - The upgrade (C(latest)) operation will update/install the package to the latest version available.
50 - "Note: The module has a limitation that (C(latest)) only works for one package, not lists of them."
51 required: true
52 choices: ["present", "absent", "latest"]
53 update_catalog:
54 description:
55 - If you want to refresh your catalog from the mirror, set this to (C(yes)).
56 required: false
57 choices: ["yes", "no"]
58 default: no
59 version_added: "2.1"
60 '''
61
62 EXAMPLES = '''
63 # Install a package
64 pkgutil: name=CSWcommon state=present
65
66 # Install a package from a specific repository
67 pkgutil: name=CSWnrpe site='ftp://myinternal.repo/opencsw/kiel state=latest'
68 '''
69
70 import os
71 import pipes
72
73 def package_installed(module, name):
74 cmd = ['pkginfo']
75 cmd.append('-q')
76 cmd.append(name)
77 rc, out, err = run_command(module, cmd)
78 if rc == 0:
79 return True
80 else:
81 return False
82
83 def package_latest(module, name, site):
84 # Only supports one package
85 cmd = [ 'pkgutil', '-U', '--single', '-c' ]
86 if site is not None:
87 cmd += [ '-t', site]
88 cmd.append(name)
89 rc, out, err = run_command(module, cmd)
90 # replace | tail -1 |grep -v SAME
91 # use -2, because splitting on \n create a empty line
92 # at the end of the list
93 return 'SAME' in out.split('\n')[-2]
94
95 def run_command(module, cmd, **kwargs):
96 progname = cmd[0]
97 cmd[0] = module.get_bin_path(progname, True, ['/opt/csw/bin'])
98 return module.run_command(cmd, **kwargs)
99
100 def package_install(module, state, name, site, update_catalog):
101 cmd = [ 'pkgutil', '-iy' ]
102 if update_catalog:
103 cmd += [ '-U' ]
104 if site is not None:
105 cmd += [ '-t', site ]
106 if state == 'latest':
107 cmd += [ '-f' ]
108 cmd.append(name)
109 (rc, out, err) = run_command(module, cmd)
110 return (rc, out, err)
111
112 def package_upgrade(module, name, site, update_catalog):
113 cmd = [ 'pkgutil', '-ufy' ]
114 if update_catalog:
115 cmd += [ '-U' ]
116 if site is not None:
117 cmd += [ '-t', site ]
118 cmd.append(name)
119 (rc, out, err) = run_command(module, cmd)
120 return (rc, out, err)
121
122 def package_uninstall(module, name):
123 cmd = [ 'pkgutil', '-ry', name]
124 (rc, out, err) = run_command(module, cmd)
125 return (rc, out, err)
126
127 def main():
128 module = AnsibleModule(
129 argument_spec = dict(
130 name = dict(required = True),
131 state = dict(required = True, choices=['present', 'absent','latest']),
132 site = dict(default = None),
133 update_catalog = dict(required = False, default = "no", type='bool', choices=["yes","no"]),
134 ),
135 supports_check_mode=True
136 )
137 name = module.params['name']
138 state = module.params['state']
139 site = module.params['site']
140 update_catalog = module.params['update_catalog']
141 rc = None
142 out = ''
143 err = ''
144 result = {}
145 result['name'] = name
146 result['state'] = state
147
148 if state == 'present':
149 if not package_installed(module, name):
150 if module.check_mode:
151 module.exit_json(changed=True)
152 (rc, out, err) = package_install(module, state, name, site, update_catalog)
153 # Stdout is normally empty but for some packages can be
154 # very long and is not often useful
155 if len(out) > 75:
156 out = out[:75] + '...'
157 if rc != 0:
158 if err:
159 msg = err
160 else:
161 msg = out
162 module.fail_json(msg=msg)
163
164 elif state == 'latest':
165 if not package_installed(module, name):
166 if module.check_mode:
167 module.exit_json(changed=True)
168 (rc, out, err) = package_install(module, state, name, site, update_catalog)
169 if len(out) > 75:
170 out = out[:75] + '...'
171 if rc != 0:
172 if err:
173 msg = err
174 else:
175 msg = out
176 module.fail_json(msg=msg)
177
178 else:
179 if not package_latest(module, name, site):
180 if module.check_mode:
181 module.exit_json(changed=True)
182 (rc, out, err) = package_upgrade(module, name, site, update_catalog)
183 if len(out) > 75:
184 out = out[:75] + '...'
185 if rc != 0:
186 if err:
187 msg = err
188 else:
189 msg = out
190 module.fail_json(msg=msg)
191
192 elif state == 'absent':
193 if package_installed(module, name):
194 if module.check_mode:
195 module.exit_json(changed=True)
196 (rc, out, err) = package_uninstall(module, name)
197 if len(out) > 75:
198 out = out[:75] + '...'
199 if rc != 0:
200 if err:
201 msg = err
202 else:
203 msg = out
204 module.fail_json(msg=msg)
205
206 if rc is None:
207 # pkgutil was not executed because the package was already present/absent
208 result['changed'] = False
209 elif rc == 0:
210 result['changed'] = True
211 else:
212 result['changed'] = False
213 result['failed'] = True
214
215 if out:
216 result['stdout'] = out
217 if err:
218 result['stderr'] = err
219
220 module.exit_json(**result)
221
222 # import module snippets
223 from ansible.module_utils.basic import *
224 main()
225
[end of packaging/os/pkgutil.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packaging/os/pkgutil.py b/packaging/os/pkgutil.py
--- a/packaging/os/pkgutil.py
+++ b/packaging/os/pkgutil.py
@@ -54,8 +54,7 @@
description:
- If you want to refresh your catalog from the mirror, set this to (C(yes)).
required: false
- choices: ["yes", "no"]
- default: no
+ default: False
version_added: "2.1"
'''
@@ -130,7 +129,7 @@
name = dict(required = True),
state = dict(required = True, choices=['present', 'absent','latest']),
site = dict(default = None),
- update_catalog = dict(required = False, default = "no", type='bool', choices=["yes","no"]),
+ update_catalog = dict(required = False, default = False, type='bool'),
),
supports_check_mode=True
)
|
{"golden_diff": "diff --git a/packaging/os/pkgutil.py b/packaging/os/pkgutil.py\n--- a/packaging/os/pkgutil.py\n+++ b/packaging/os/pkgutil.py\n@@ -54,8 +54,7 @@\n description:\n - If you want to refresh your catalog from the mirror, set this to (C(yes)).\n required: false\n- choices: [\"yes\", \"no\"]\n- default: no\n+ default: False\n version_added: \"2.1\"\n '''\n \n@@ -130,7 +129,7 @@\n name = dict(required = True),\n state = dict(required = True, choices=['present', 'absent','latest']),\n site = dict(default = None),\n- update_catalog = dict(required = False, default = \"no\", type='bool', choices=[\"yes\",\"no\"]),\n+ update_catalog = dict(required = False, default = False, type='bool'),\n ),\n supports_check_mode=True\n )\n", "issue": "pkgutil: the values of update_catalog get always translated to true or false, but the module expects yes or no.\n##### ISSUE TYPE\n- Bug Report\n##### COMPONENT NAME\n\npackaging/os/pkgutil.py\n##### ANSIBLE VERSION\n\n```\nansible 2.1.0.0-RC1\nansible 2.1.0.0 (detached HEAD 5954a82dd6) last updated 2016/05/02 13:45:40 (GMT +200)\n lib/ansible/modules/core: (detached HEAD ce79e7c72d) last updated 2016/05/02 13:46:30 (GMT +200)\n lib/ansible/modules/extras: (detached HEAD 156a8cd0b3) last updated 2016/05/02 13:46:30 (GMT +200)\n```\n##### CONFIGURATION\n##### OS / ENVIRONMENT\n\nRunning on MacOS X 10.11.4 against Solaris 10\n##### SUMMARY\n\nArgument update_catalog gets wrong values false and true instead of no and yes \n##### STEPS TO REPRODUCE\n\n```\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present\" -u root\nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"invocation\": {\n \"module_args\": {\n \"name\": \"CSWgnupg\", \n \"state\": \"present\", \n \"update_catalog\": false\n }, \n \"module_name\": \"pkgutil\"\n }, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: False\"\n}\n```\n##### EXPECTED RESULTS\n\nCSW package gnupg should be installed.\n##### ACTUAL RESULTS\n\nThe values of update_catalog get always translated to true or false, but the module expects yes or no.\n\n```\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present\" -u root\nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"invocation\": {\n \"module_args\": {\n \"name\": \"CSWgnupg\", \n \"state\": \"present\", \n \"update_catalog\": false\n }, \n \"module_name\": \"pkgutil\"\n }, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: False\"\n}\n\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present update_catalog=no\" -u root\nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"invocation\": {\n \"module_args\": {\n \"name\": \"CSWgnupg\", \n \"state\": \"present\", \n \"update_catalog\": false\n }, \n \"module_name\": \"pkgutil\"\n }, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: False\"\n}\n\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present update_catalog=false\" -u root\nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"invocation\": {\n \"module_args\": {\n \"name\": \"CSWgnupg\", \n \"state\": \"present\", \n \"update_catalog\": false\n }, \n \"module_name\": \"pkgutil\"\n }, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: False\"\n}\n\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present update_catalog=yes\" -u root\nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"invocation\": {\n \"module_args\": {\n \"name\": \"CSWgnupg\", \n \"state\": \"present\", \n \"update_catalog\": true\n }, \n \"module_name\": \"pkgutil\"\n }, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: True\"\n}\n\nansible myhost -m pkgutil -a \"name=CSWgnupg state=present update_catalog=true\" -u root \nmyhost | FAILED! => {\n \"changed\": false, \n \"failed\": true, \n \"msg\": \"value of update_catalog must be one of: yes,no, got: True\"\n}\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Alexander Winkler <mail () winkler-alexander.de>\n# based on svr4pkg by\n# Boyd Adamson <boyd () boydadamson.com> (2012)\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nDOCUMENTATION = '''\n---\nmodule: pkgutil \nshort_description: Manage CSW-Packages on Solaris\ndescription:\n - Manages CSW packages (SVR4 format) on Solaris 10 and 11.\n - These were the native packages on Solaris <= 10 and are available\n as a legacy feature in Solaris 11.\n - Pkgutil is an advanced packaging system, which resolves dependency on installation.\n It is designed for CSW packages.\nversion_added: \"1.3\"\nauthor: \"Alexander Winkler (@dermute)\"\noptions:\n name:\n description:\n - Package name, e.g. (C(CSWnrpe))\n required: true\n site:\n description:\n - Specifies the repository path to install the package from.\n - Its global definition is done in C(/etc/opt/csw/pkgutil.conf).\n required: false\n state:\n description:\n - Whether to install (C(present)), or remove (C(absent)) a package.\n - The upgrade (C(latest)) operation will update/install the package to the latest version available.\n - \"Note: The module has a limitation that (C(latest)) only works for one package, not lists of them.\"\n required: true\n choices: [\"present\", \"absent\", \"latest\"]\n update_catalog:\n description:\n - If you want to refresh your catalog from the mirror, set this to (C(yes)).\n required: false\n choices: [\"yes\", \"no\"]\n default: no\n version_added: \"2.1\"\n'''\n\nEXAMPLES = '''\n# Install a package\npkgutil: name=CSWcommon state=present\n\n# Install a package from a specific repository\npkgutil: name=CSWnrpe site='ftp://myinternal.repo/opencsw/kiel state=latest'\n'''\n\nimport os\nimport pipes\n\ndef package_installed(module, name):\n cmd = ['pkginfo']\n cmd.append('-q')\n cmd.append(name)\n rc, out, err = run_command(module, cmd)\n if rc == 0:\n return True\n else:\n return False\n\ndef package_latest(module, name, site):\n # Only supports one package\n cmd = [ 'pkgutil', '-U', '--single', '-c' ]\n if site is not None:\n cmd += [ '-t', site]\n cmd.append(name)\n rc, out, err = run_command(module, cmd)\n # replace | tail -1 |grep -v SAME\n # use -2, because splitting on \\n create a empty line\n # at the end of the list\n return 'SAME' in out.split('\\n')[-2]\n\ndef run_command(module, cmd, **kwargs):\n progname = cmd[0]\n cmd[0] = module.get_bin_path(progname, True, ['/opt/csw/bin'])\n return module.run_command(cmd, **kwargs)\n\ndef package_install(module, state, name, site, update_catalog):\n cmd = [ 'pkgutil', '-iy' ]\n if update_catalog:\n cmd += [ '-U' ]\n if site is not None:\n cmd += [ '-t', site ]\n if state == 'latest':\n cmd += [ '-f' ] \n cmd.append(name)\n (rc, out, err) = run_command(module, cmd)\n return (rc, out, err)\n\ndef package_upgrade(module, name, site, update_catalog):\n cmd = [ 'pkgutil', '-ufy' ]\n if update_catalog:\n cmd += [ '-U' ]\n if site is not None:\n cmd += [ '-t', site ]\n cmd.append(name)\n (rc, out, err) = run_command(module, cmd)\n return (rc, out, err)\n\ndef package_uninstall(module, name):\n cmd = [ 'pkgutil', '-ry', name]\n (rc, out, err) = run_command(module, cmd)\n return (rc, out, err)\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required = True),\n state = dict(required = True, choices=['present', 'absent','latest']),\n site = dict(default = None),\n update_catalog = dict(required = False, default = \"no\", type='bool', choices=[\"yes\",\"no\"]),\n ),\n supports_check_mode=True\n )\n name = module.params['name']\n state = module.params['state']\n site = module.params['site']\n update_catalog = module.params['update_catalog']\n rc = None\n out = ''\n err = ''\n result = {}\n result['name'] = name\n result['state'] = state\n\n if state == 'present':\n if not package_installed(module, name):\n if module.check_mode:\n module.exit_json(changed=True)\n (rc, out, err) = package_install(module, state, name, site, update_catalog)\n # Stdout is normally empty but for some packages can be\n # very long and is not often useful\n if len(out) > 75:\n out = out[:75] + '...'\n if rc != 0:\n if err:\n msg = err\n else:\n msg = out\n module.fail_json(msg=msg)\n\n elif state == 'latest':\n if not package_installed(module, name):\n if module.check_mode:\n module.exit_json(changed=True)\n (rc, out, err) = package_install(module, state, name, site, update_catalog)\n if len(out) > 75:\n out = out[:75] + '...'\n if rc != 0:\n if err:\n msg = err\n else:\n msg = out\n module.fail_json(msg=msg)\n\n else:\n if not package_latest(module, name, site):\n if module.check_mode:\n module.exit_json(changed=True) \n (rc, out, err) = package_upgrade(module, name, site, update_catalog)\n if len(out) > 75:\n out = out[:75] + '...'\n if rc != 0:\n if err:\n msg = err\n else:\n msg = out\n module.fail_json(msg=msg)\n\n elif state == 'absent':\n if package_installed(module, name):\n if module.check_mode:\n module.exit_json(changed=True)\n (rc, out, err) = package_uninstall(module, name)\n if len(out) > 75:\n out = out[:75] + '...'\n if rc != 0:\n if err:\n msg = err\n else:\n msg = out\n module.fail_json(msg=msg)\n\n if rc is None:\n # pkgutil was not executed because the package was already present/absent\n result['changed'] = False\n elif rc == 0:\n result['changed'] = True\n else:\n result['changed'] = False\n result['failed'] = True\n\n if out:\n result['stdout'] = out\n if err:\n result['stderr'] = err\n\n module.exit_json(**result)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "packaging/os/pkgutil.py"}]}
| 3,907 | 215 |
gh_patches_debug_31553
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-17384
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
torch.nn.functional.affine_grid
</issue>
<code>
[start of ivy/functional/frontends/torch/nn/functional/vision_functions.py]
1 # global
2 import math
3
4 # local
5 import ivy
6 from ivy import with_unsupported_dtypes
7 from ivy.functional.frontends.torch.func_wrapper import to_ivy_arrays_and_back
8 from ivy.utils.exceptions import IvyNotImplementedException
9
10
11 @to_ivy_arrays_and_back
12 def pixel_shuffle(input, upscale_factor):
13 input_shape = ivy.shape(input)
14
15 ivy.utils.assertions.check_equal(
16 ivy.get_num_dims(input),
17 4,
18 message="pixel_shuffle expects 4D input, but got input with sizes "
19 + str(input_shape),
20 as_array=False,
21 )
22 b = input_shape[0]
23 c = input_shape[1]
24 h = input_shape[2]
25 w = input_shape[3]
26 upscale_factor_squared = upscale_factor * upscale_factor
27 ivy.utils.assertions.check_equal(
28 c % upscale_factor_squared,
29 0,
30 message="pixel_shuffle expects input channel to be divisible by square "
31 + "of upscale_factor, but got input with sizes "
32 + str(input_shape)
33 + ", upscale_factor="
34 + str(upscale_factor)
35 + ", and self.size(1)="
36 + str(c)
37 + " is not divisible by "
38 + str(upscale_factor_squared),
39 as_array=False,
40 )
41 oc = int(c / upscale_factor_squared)
42 oh = h * upscale_factor
43 ow = w * upscale_factor
44
45 input_reshaped = ivy.reshape(input, (b, oc, upscale_factor, upscale_factor, h, w))
46 return ivy.reshape(
47 ivy.permute_dims(input_reshaped, (0, 1, 4, 2, 5, 3)), (b, oc, oh, ow)
48 )
49
50
51 @to_ivy_arrays_and_back
52 def pixel_unshuffle(input, downscale_factor):
53 input_shape = ivy.shape(input)
54
55 ivy.utils.assertions.check_equal(
56 ivy.get_num_dims(input),
57 4,
58 message=(
59 f"pixel_unshuffle expects 4D input, but got input with sizes {input_shape}"
60 ),
61 as_array=False,
62 ),
63
64 b = input_shape[0]
65 c = input_shape[1]
66 h = input_shape[2]
67 w = input_shape[3]
68 downscale_factor_squared = downscale_factor * downscale_factor
69
70 ivy.utils.assertions.check_equal(
71 [h % downscale_factor, w % downscale_factor],
72 [0, 0], # Assert h % downscale_factor == 0 and w % downscale_factor == 0
73 message=(
74 "pixel_unshuffle expects input height and width to be divisible by "
75 f"downscale_factor, but got input with sizes {input_shape}"
76 f", downscale_factor= {downscale_factor}"
77 f", and either self.size(2)= {h}"
78 f" or self.size(3)= {w}"
79 f" is not divisible by {downscale_factor}"
80 ),
81 as_array=False,
82 )
83 oc = c * downscale_factor_squared
84 oh = int(h / downscale_factor)
85 ow = int(w / downscale_factor)
86
87 input_reshaped = ivy.reshape(
88 input, (b, c, oh, downscale_factor, ow, downscale_factor)
89 )
90 return ivy.reshape(
91 ivy.permute_dims(input_reshaped, (0, 1, 3, 5, 2, 4)), (b, oc, oh, ow)
92 )
93
94
95 def _handle_padding_shape(padding, n, mode):
96 padding = tuple(
97 [
98 (padding[i * 2], padding[i * 2 + 1])
99 for i in range(int(len(padding) / 2) - 1, -1, -1)
100 ]
101 )
102 while len(padding) < n:
103 if mode == "circular":
104 padding = padding + ((0, 0),)
105 else:
106 padding = ((0, 0),) + padding
107 if mode == "circular":
108 padding = tuple(list(padding)[::-1])
109 return padding
110
111
112 @to_ivy_arrays_and_back
113 def pad(input, pad, mode="constant", value=0):
114 mode_dict = {
115 "constant": "constant",
116 "reflect": "reflect",
117 "replicate": "edge",
118 "circular": "wrap",
119 }
120 if mode not in mode_dict:
121 raise ValueError(f"Unsupported padding mode: {mode}")
122 pad = _handle_padding_shape(pad, len(input.shape), mode)
123 return ivy.pad(input, pad, mode=mode_dict[mode], constant_values=value)
124
125
126 def _get_new_width_height(w_old, h_old, size=None, scale_factor=None):
127 if scale_factor and (not size):
128 if type(scale_factor) == int:
129 h_new = int(w_old * scale_factor)
130 w_new = int(h_old * scale_factor)
131 elif type(scale_factor) == tuple:
132 h_new = int(w_old * scale_factor[0])
133 w_new = int(h_old * scale_factor[1])
134 elif (not scale_factor) and size:
135 if type(size) == int:
136 h_new = size
137 w_new = size
138 elif type(size) == tuple:
139 h_new, w_new = size
140 return h_new, w_new
141
142
143 @with_unsupported_dtypes(
144 {
145 "2.0.1 and below": (
146 "bfloat16",
147 "float16",
148 )
149 },
150 "torch",
151 )
152 @to_ivy_arrays_and_back
153 def interpolate(
154 input,
155 size=None,
156 scale_factor=None,
157 mode="nearest",
158 align_corners=None,
159 recompute_scale_factor=None,
160 antialias=False,
161 ):
162 if mode in ["nearest", "area", "nearest-exact"]:
163 ivy.utils.assertions.check_exists(
164 align_corners,
165 inverse=True,
166 message=(
167 "align_corners option can only be set with the interpolating modes:"
168 " linear | bilinear | bicubic | trilinear"
169 ),
170 )
171 else:
172 if not ivy.exists(align_corners):
173 align_corners = False
174
175 dim = ivy.get_num_dims(input) - 2 # Number of spatial dimensions.
176
177 if ivy.exists(size) and ivy.exists(scale_factor):
178 raise ivy.utils.exceptions.IvyException(
179 "only one of size or scale_factor should be defined"
180 )
181
182 elif ivy.exists(size) and not ivy.exists(scale_factor):
183 scale_factors = None
184
185 if isinstance(size, (list, tuple)):
186 ivy.utils.assertions.check_equal(
187 len(size),
188 dim,
189 inverse=False,
190 message=(
191 "Input and output must have the "
192 "same number of spatial dimensions,"
193 f" but got input with spatial dimensions of {list(input.shape[2:])}"
194 f" and output size of {size}. "
195 "Please provide input tensor in (N, C, d1, d2, ...,dK) format"
196 " and output size in (o1, o2, ...,oK) format."
197 ),
198 as_array=False,
199 )
200 output_size = size
201 else:
202 output_size = [size for _ in range(dim)]
203
204 elif ivy.exists(scale_factor) and not ivy.exists(size):
205 output_size = None
206
207 if isinstance(scale_factor, (list, tuple)):
208 ivy.utils.assertions.check_equal(
209 len(scale_factor),
210 dim,
211 inverse=False,
212 message=(
213 "Input and scale_factor must have the "
214 "same number of spatial dimensions,"
215 f" but got input with spatial dimensions of {list(input.shape[2:])}"
216 f" and scale_factor of shape {scale_factor}. "
217 "Please provide input tensor in (N, C, d1, d2, ...,dK) format"
218 " and scale_factor in (s1, s2, ...,sK) format."
219 ),
220 as_array=False,
221 )
222 scale_factors = scale_factor
223 else:
224 scale_factors = [scale_factor for _ in range(dim)]
225
226 else:
227 ivy.utils.assertions.check_any(
228 [ivy.exists(size), ivy.exists(scale_factor)],
229 message="either size or scale_factor should be defined",
230 as_array=False,
231 )
232
233 if (
234 ivy.exists(size)
235 and ivy.exists(recompute_scale_factor)
236 and bool(recompute_scale_factor)
237 ):
238 raise ivy.utils.exceptions.IvyException(
239 "recompute_scale_factor is not meaningful with an explicit size."
240 )
241
242 if ivy.exists(scale_factors):
243 output_size = [
244 math.floor(ivy.shape(input)[i + 2] * scale_factors[i]) for i in range(dim)
245 ]
246
247 if (
248 bool(antialias)
249 and not (mode in ["bilinear", "bicubic"])
250 and ivy.get_num_dims(input) == 4
251 ):
252 raise ivy.utils.exceptions.IvyException(
253 "recompute_scale_factor is not meaningful with an explicit size."
254 )
255
256 if ivy.get_num_dims(input) == 3 and mode == "bilinear":
257 raise IvyNotImplementedException(
258 "Got 3D input, but bilinear mode needs 4D input"
259 )
260 if ivy.get_num_dims(input) == 3 and mode == "trilinear":
261 raise IvyNotImplementedException(
262 "Got 3D input, but trilinear mode needs 5D input"
263 )
264 if ivy.get_num_dims(input) == 4 and mode == "linear":
265 raise IvyNotImplementedException("Got 4D input, but linear mode needs 3D input")
266 if ivy.get_num_dims(input) == 4 and mode == "trilinear":
267 raise IvyNotImplementedException(
268 "Got 4D input, but trilinear mode needs 5D input"
269 )
270 if ivy.get_num_dims(input) == 5 and mode == "linear":
271 raise IvyNotImplementedException("Got 5D input, but linear mode needs 3D input")
272 if ivy.get_num_dims(input) == 5 and mode == "bilinear":
273 raise IvyNotImplementedException(
274 "Got 5D input, but bilinear mode needs 4D input"
275 )
276
277 ivy.utils.assertions.check_elem_in_list(
278 ivy.get_num_dims(input),
279 range(3, 6),
280 message=(
281 "Input Error: Only 3D, 4D and 5D input Tensors supported (got"
282 f" {ivy.get_num_dims(input)}D) for the modes: nearest | linear | bilinear |"
283 f" bicubic | trilinear | area | nearest-exact (got {mode})"
284 ),
285 )
286
287 return ivy.interpolate(
288 input, output_size, mode=mode, align_corners=align_corners, antialias=antialias
289 )
290
291
292 @with_unsupported_dtypes({"2.0.1 and below": ("float16", "bfloat16")}, "torch")
293 @to_ivy_arrays_and_back
294 def upsample(
295 input,
296 size=None,
297 scale_factor=None,
298 mode="nearest",
299 align_corners=None,
300 ):
301 return interpolate(
302 input,
303 size=size,
304 scale_factor=scale_factor,
305 mode=mode,
306 align_corners=align_corners,
307 )
308
309
310 @with_unsupported_dtypes({"2.0.1 and below": ("float16", "bfloat16")}, "torch")
311 @to_ivy_arrays_and_back
312 def upsample_nearest(input, size=None, scale_factor=None):
313 return interpolate(input, size=size, scale_factor=scale_factor, mode="nearest")
314
315
316 @with_unsupported_dtypes({"2.0.1 and below": ("float16", "bfloat16")}, "torch")
317 @to_ivy_arrays_and_back
318 def upsample_bilinear(input, size=None, scale_factor=None):
319 return interpolate(
320 input, size=size, scale_factor=scale_factor, mode="bilinear", align_corners=True
321 )
322
[end of ivy/functional/frontends/torch/nn/functional/vision_functions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/torch/nn/functional/vision_functions.py b/ivy/functional/frontends/torch/nn/functional/vision_functions.py
--- a/ivy/functional/frontends/torch/nn/functional/vision_functions.py
+++ b/ivy/functional/frontends/torch/nn/functional/vision_functions.py
@@ -319,3 +319,48 @@
return interpolate(
input, size=size, scale_factor=scale_factor, mode="bilinear", align_corners=True
)
+
+
+@with_unsupported_dtypes({"2.0.1 and below": ("float16", "bfloat16")}, "torch")
+@to_ivy_arrays_and_back
+def affine_grid(theta, size, align_corners=False):
+ if len(size) == 4:
+ N, C, H, W = size
+ base_grid = ivy.empty((N, H, W, 3))
+ if align_corners:
+ base_grid[:, :, :, 0] = ivy.linspace(-1, 1, W)
+ base_grid[:, :, :, 1] = ivy.expand_dims(ivy.linspace(-1, 1, H), axis=-1)
+ base_grid[:, :, :, 2] = ivy.full((H, W), 1)
+ grid = ivy.matmul(base_grid.view((N, H * W, 3)), theta.swapaxes(1, 2))
+ return grid.view((N, H, W, 2))
+ else:
+ base_grid[:, :, :, 0] = ivy.linspace(-1, 1, W) * (W - 1) / W
+ base_grid[:, :, :, 1] = ivy.expand_dims(
+ ivy.linspace(-1, 1, H) * (H - 1) / H, axis=-1
+ )
+ base_grid[:, :, :, 2] = ivy.full((H, W), 1)
+ grid = ivy.matmul(base_grid.view((N, H * W, 3)), ivy.swapaxes(theta, 1, 2))
+ return grid.view((N, H, W, 2))
+ else:
+ N, C, D, H, W = size
+ base_grid = ivy.empty((N, D, H, W, 4))
+ if align_corners:
+ base_grid[:, :, :, :, 0] = ivy.linspace(-1, 1, W)
+ base_grid[:, :, :, :, 1] = ivy.expand_dims(ivy.linspace(-1, 1, H), axis=-1)
+ base_grid[:, :, :, :, 2] = ivy.expand_dims(
+ ivy.expand_dims(ivy.linspace(-1, 1, D), axis=-1), axis=-1
+ )
+ base_grid[:, :, :, :, 3] = ivy.full((D, H, W), 1)
+ grid = ivy.matmul(base_grid.view((N, D * H * W, 4)), theta.swapaxes(1, 2))
+ return grid.view((N, D, H, W, 3))
+ else:
+ base_grid[:, :, :, :, 0] = ivy.linspace(-1, 1, W) * (W - 1) / W
+ base_grid[:, :, :, :, 1] = ivy.expand_dims(
+ ivy.linspace(-1, 1, H) * (H - 1) / H, axis=-1
+ )
+ base_grid[:, :, :, :, 2] = ivy.expand_dims(
+ ivy.expand_dims(ivy.linspace(-1, 1, D) * (D - 1) / D, axis=-1), axis=-1
+ )
+ base_grid[:, :, :, :, 3] = ivy.full((D, H, W), 1)
+ grid = ivy.matmul(base_grid.view((N, D * H * W, 4)), theta.swapaxes(1, 2))
+ return grid.view((N, D, H, W, 3))
|
{"golden_diff": "diff --git a/ivy/functional/frontends/torch/nn/functional/vision_functions.py b/ivy/functional/frontends/torch/nn/functional/vision_functions.py\n--- a/ivy/functional/frontends/torch/nn/functional/vision_functions.py\n+++ b/ivy/functional/frontends/torch/nn/functional/vision_functions.py\n@@ -319,3 +319,48 @@\n return interpolate(\n input, size=size, scale_factor=scale_factor, mode=\"bilinear\", align_corners=True\n )\n+\n+\n+@with_unsupported_dtypes({\"2.0.1 and below\": (\"float16\", \"bfloat16\")}, \"torch\")\n+@to_ivy_arrays_and_back\n+def affine_grid(theta, size, align_corners=False):\n+ if len(size) == 4:\n+ N, C, H, W = size\n+ base_grid = ivy.empty((N, H, W, 3))\n+ if align_corners:\n+ base_grid[:, :, :, 0] = ivy.linspace(-1, 1, W)\n+ base_grid[:, :, :, 1] = ivy.expand_dims(ivy.linspace(-1, 1, H), axis=-1)\n+ base_grid[:, :, :, 2] = ivy.full((H, W), 1)\n+ grid = ivy.matmul(base_grid.view((N, H * W, 3)), theta.swapaxes(1, 2))\n+ return grid.view((N, H, W, 2))\n+ else:\n+ base_grid[:, :, :, 0] = ivy.linspace(-1, 1, W) * (W - 1) / W\n+ base_grid[:, :, :, 1] = ivy.expand_dims(\n+ ivy.linspace(-1, 1, H) * (H - 1) / H, axis=-1\n+ )\n+ base_grid[:, :, :, 2] = ivy.full((H, W), 1)\n+ grid = ivy.matmul(base_grid.view((N, H * W, 3)), ivy.swapaxes(theta, 1, 2))\n+ return grid.view((N, H, W, 2))\n+ else:\n+ N, C, D, H, W = size\n+ base_grid = ivy.empty((N, D, H, W, 4))\n+ if align_corners:\n+ base_grid[:, :, :, :, 0] = ivy.linspace(-1, 1, W)\n+ base_grid[:, :, :, :, 1] = ivy.expand_dims(ivy.linspace(-1, 1, H), axis=-1)\n+ base_grid[:, :, :, :, 2] = ivy.expand_dims(\n+ ivy.expand_dims(ivy.linspace(-1, 1, D), axis=-1), axis=-1\n+ )\n+ base_grid[:, :, :, :, 3] = ivy.full((D, H, W), 1)\n+ grid = ivy.matmul(base_grid.view((N, D * H * W, 4)), theta.swapaxes(1, 2))\n+ return grid.view((N, D, H, W, 3))\n+ else:\n+ base_grid[:, :, :, :, 0] = ivy.linspace(-1, 1, W) * (W - 1) / W\n+ base_grid[:, :, :, :, 1] = ivy.expand_dims(\n+ ivy.linspace(-1, 1, H) * (H - 1) / H, axis=-1\n+ )\n+ base_grid[:, :, :, :, 2] = ivy.expand_dims(\n+ ivy.expand_dims(ivy.linspace(-1, 1, D) * (D - 1) / D, axis=-1), axis=-1\n+ )\n+ base_grid[:, :, :, :, 3] = ivy.full((D, H, W), 1)\n+ grid = ivy.matmul(base_grid.view((N, D * H * W, 4)), theta.swapaxes(1, 2))\n+ return grid.view((N, D, H, W, 3))\n", "issue": "torch.nn.functional.affine_grid\n\n", "before_files": [{"content": "# global\nimport math\n\n# local\nimport ivy\nfrom ivy import with_unsupported_dtypes\nfrom ivy.functional.frontends.torch.func_wrapper import to_ivy_arrays_and_back\nfrom ivy.utils.exceptions import IvyNotImplementedException\n\n\n@to_ivy_arrays_and_back\ndef pixel_shuffle(input, upscale_factor):\n input_shape = ivy.shape(input)\n\n ivy.utils.assertions.check_equal(\n ivy.get_num_dims(input),\n 4,\n message=\"pixel_shuffle expects 4D input, but got input with sizes \"\n + str(input_shape),\n as_array=False,\n )\n b = input_shape[0]\n c = input_shape[1]\n h = input_shape[2]\n w = input_shape[3]\n upscale_factor_squared = upscale_factor * upscale_factor\n ivy.utils.assertions.check_equal(\n c % upscale_factor_squared,\n 0,\n message=\"pixel_shuffle expects input channel to be divisible by square \"\n + \"of upscale_factor, but got input with sizes \"\n + str(input_shape)\n + \", upscale_factor=\"\n + str(upscale_factor)\n + \", and self.size(1)=\"\n + str(c)\n + \" is not divisible by \"\n + str(upscale_factor_squared),\n as_array=False,\n )\n oc = int(c / upscale_factor_squared)\n oh = h * upscale_factor\n ow = w * upscale_factor\n\n input_reshaped = ivy.reshape(input, (b, oc, upscale_factor, upscale_factor, h, w))\n return ivy.reshape(\n ivy.permute_dims(input_reshaped, (0, 1, 4, 2, 5, 3)), (b, oc, oh, ow)\n )\n\n\n@to_ivy_arrays_and_back\ndef pixel_unshuffle(input, downscale_factor):\n input_shape = ivy.shape(input)\n\n ivy.utils.assertions.check_equal(\n ivy.get_num_dims(input),\n 4,\n message=(\n f\"pixel_unshuffle expects 4D input, but got input with sizes {input_shape}\"\n ),\n as_array=False,\n ),\n\n b = input_shape[0]\n c = input_shape[1]\n h = input_shape[2]\n w = input_shape[3]\n downscale_factor_squared = downscale_factor * downscale_factor\n\n ivy.utils.assertions.check_equal(\n [h % downscale_factor, w % downscale_factor],\n [0, 0], # Assert h % downscale_factor == 0 and w % downscale_factor == 0\n message=(\n \"pixel_unshuffle expects input height and width to be divisible by \"\n f\"downscale_factor, but got input with sizes {input_shape}\"\n f\", downscale_factor= {downscale_factor}\"\n f\", and either self.size(2)= {h}\"\n f\" or self.size(3)= {w}\"\n f\" is not divisible by {downscale_factor}\"\n ),\n as_array=False,\n )\n oc = c * downscale_factor_squared\n oh = int(h / downscale_factor)\n ow = int(w / downscale_factor)\n\n input_reshaped = ivy.reshape(\n input, (b, c, oh, downscale_factor, ow, downscale_factor)\n )\n return ivy.reshape(\n ivy.permute_dims(input_reshaped, (0, 1, 3, 5, 2, 4)), (b, oc, oh, ow)\n )\n\n\ndef _handle_padding_shape(padding, n, mode):\n padding = tuple(\n [\n (padding[i * 2], padding[i * 2 + 1])\n for i in range(int(len(padding) / 2) - 1, -1, -1)\n ]\n )\n while len(padding) < n:\n if mode == \"circular\":\n padding = padding + ((0, 0),)\n else:\n padding = ((0, 0),) + padding\n if mode == \"circular\":\n padding = tuple(list(padding)[::-1])\n return padding\n\n\n@to_ivy_arrays_and_back\ndef pad(input, pad, mode=\"constant\", value=0):\n mode_dict = {\n \"constant\": \"constant\",\n \"reflect\": \"reflect\",\n \"replicate\": \"edge\",\n \"circular\": \"wrap\",\n }\n if mode not in mode_dict:\n raise ValueError(f\"Unsupported padding mode: {mode}\")\n pad = _handle_padding_shape(pad, len(input.shape), mode)\n return ivy.pad(input, pad, mode=mode_dict[mode], constant_values=value)\n\n\ndef _get_new_width_height(w_old, h_old, size=None, scale_factor=None):\n if scale_factor and (not size):\n if type(scale_factor) == int:\n h_new = int(w_old * scale_factor)\n w_new = int(h_old * scale_factor)\n elif type(scale_factor) == tuple:\n h_new = int(w_old * scale_factor[0])\n w_new = int(h_old * scale_factor[1])\n elif (not scale_factor) and size:\n if type(size) == int:\n h_new = size\n w_new = size\n elif type(size) == tuple:\n h_new, w_new = size\n return h_new, w_new\n\n\n@with_unsupported_dtypes(\n {\n \"2.0.1 and below\": (\n \"bfloat16\",\n \"float16\",\n )\n },\n \"torch\",\n)\n@to_ivy_arrays_and_back\ndef interpolate(\n input,\n size=None,\n scale_factor=None,\n mode=\"nearest\",\n align_corners=None,\n recompute_scale_factor=None,\n antialias=False,\n):\n if mode in [\"nearest\", \"area\", \"nearest-exact\"]:\n ivy.utils.assertions.check_exists(\n align_corners,\n inverse=True,\n message=(\n \"align_corners option can only be set with the interpolating modes:\"\n \" linear | bilinear | bicubic | trilinear\"\n ),\n )\n else:\n if not ivy.exists(align_corners):\n align_corners = False\n\n dim = ivy.get_num_dims(input) - 2 # Number of spatial dimensions.\n\n if ivy.exists(size) and ivy.exists(scale_factor):\n raise ivy.utils.exceptions.IvyException(\n \"only one of size or scale_factor should be defined\"\n )\n\n elif ivy.exists(size) and not ivy.exists(scale_factor):\n scale_factors = None\n\n if isinstance(size, (list, tuple)):\n ivy.utils.assertions.check_equal(\n len(size),\n dim,\n inverse=False,\n message=(\n \"Input and output must have the \"\n \"same number of spatial dimensions,\"\n f\" but got input with spatial dimensions of {list(input.shape[2:])}\"\n f\" and output size of {size}. \"\n \"Please provide input tensor in (N, C, d1, d2, ...,dK) format\"\n \" and output size in (o1, o2, ...,oK) format.\"\n ),\n as_array=False,\n )\n output_size = size\n else:\n output_size = [size for _ in range(dim)]\n\n elif ivy.exists(scale_factor) and not ivy.exists(size):\n output_size = None\n\n if isinstance(scale_factor, (list, tuple)):\n ivy.utils.assertions.check_equal(\n len(scale_factor),\n dim,\n inverse=False,\n message=(\n \"Input and scale_factor must have the \"\n \"same number of spatial dimensions,\"\n f\" but got input with spatial dimensions of {list(input.shape[2:])}\"\n f\" and scale_factor of shape {scale_factor}. \"\n \"Please provide input tensor in (N, C, d1, d2, ...,dK) format\"\n \" and scale_factor in (s1, s2, ...,sK) format.\"\n ),\n as_array=False,\n )\n scale_factors = scale_factor\n else:\n scale_factors = [scale_factor for _ in range(dim)]\n\n else:\n ivy.utils.assertions.check_any(\n [ivy.exists(size), ivy.exists(scale_factor)],\n message=\"either size or scale_factor should be defined\",\n as_array=False,\n )\n\n if (\n ivy.exists(size)\n and ivy.exists(recompute_scale_factor)\n and bool(recompute_scale_factor)\n ):\n raise ivy.utils.exceptions.IvyException(\n \"recompute_scale_factor is not meaningful with an explicit size.\"\n )\n\n if ivy.exists(scale_factors):\n output_size = [\n math.floor(ivy.shape(input)[i + 2] * scale_factors[i]) for i in range(dim)\n ]\n\n if (\n bool(antialias)\n and not (mode in [\"bilinear\", \"bicubic\"])\n and ivy.get_num_dims(input) == 4\n ):\n raise ivy.utils.exceptions.IvyException(\n \"recompute_scale_factor is not meaningful with an explicit size.\"\n )\n\n if ivy.get_num_dims(input) == 3 and mode == \"bilinear\":\n raise IvyNotImplementedException(\n \"Got 3D input, but bilinear mode needs 4D input\"\n )\n if ivy.get_num_dims(input) == 3 and mode == \"trilinear\":\n raise IvyNotImplementedException(\n \"Got 3D input, but trilinear mode needs 5D input\"\n )\n if ivy.get_num_dims(input) == 4 and mode == \"linear\":\n raise IvyNotImplementedException(\"Got 4D input, but linear mode needs 3D input\")\n if ivy.get_num_dims(input) == 4 and mode == \"trilinear\":\n raise IvyNotImplementedException(\n \"Got 4D input, but trilinear mode needs 5D input\"\n )\n if ivy.get_num_dims(input) == 5 and mode == \"linear\":\n raise IvyNotImplementedException(\"Got 5D input, but linear mode needs 3D input\")\n if ivy.get_num_dims(input) == 5 and mode == \"bilinear\":\n raise IvyNotImplementedException(\n \"Got 5D input, but bilinear mode needs 4D input\"\n )\n\n ivy.utils.assertions.check_elem_in_list(\n ivy.get_num_dims(input),\n range(3, 6),\n message=(\n \"Input Error: Only 3D, 4D and 5D input Tensors supported (got\"\n f\" {ivy.get_num_dims(input)}D) for the modes: nearest | linear | bilinear |\"\n f\" bicubic | trilinear | area | nearest-exact (got {mode})\"\n ),\n )\n\n return ivy.interpolate(\n input, output_size, mode=mode, align_corners=align_corners, antialias=antialias\n )\n\n\n@with_unsupported_dtypes({\"2.0.1 and below\": (\"float16\", \"bfloat16\")}, \"torch\")\n@to_ivy_arrays_and_back\ndef upsample(\n input,\n size=None,\n scale_factor=None,\n mode=\"nearest\",\n align_corners=None,\n):\n return interpolate(\n input,\n size=size,\n scale_factor=scale_factor,\n mode=mode,\n align_corners=align_corners,\n )\n\n\n@with_unsupported_dtypes({\"2.0.1 and below\": (\"float16\", \"bfloat16\")}, \"torch\")\n@to_ivy_arrays_and_back\ndef upsample_nearest(input, size=None, scale_factor=None):\n return interpolate(input, size=size, scale_factor=scale_factor, mode=\"nearest\")\n\n\n@with_unsupported_dtypes({\"2.0.1 and below\": (\"float16\", \"bfloat16\")}, \"torch\")\n@to_ivy_arrays_and_back\ndef upsample_bilinear(input, size=None, scale_factor=None):\n return interpolate(\n input, size=size, scale_factor=scale_factor, mode=\"bilinear\", align_corners=True\n )\n", "path": "ivy/functional/frontends/torch/nn/functional/vision_functions.py"}]}
| 4,033 | 915 |
gh_patches_debug_31849
|
rasdani/github-patches
|
git_diff
|
Textualize__rich-2296
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Text wrapping edge case
Discovered a possible edge case with text wrapping, probably connected to when a "word" is greater than the available width.
Consider the following:
```python
console.print("Hello, World...123 ", width=10)
```
This produces:
```
Hello, Wor
ld...123
```
I think this occurs because "World...123" doesn't fit in to 10 characters, so folds on to the next line.
I would expect there to be an additional new line after the Hello, like this:
```
Hello,
World...12
3
```
</issue>
<code>
[start of rich/_wrap.py]
1 import re
2 from typing import Iterable, List, Tuple
3
4 from .cells import cell_len, chop_cells
5 from ._loop import loop_last
6
7 re_word = re.compile(r"\s*\S+\s*")
8
9
10 def words(text: str) -> Iterable[Tuple[int, int, str]]:
11 position = 0
12 word_match = re_word.match(text, position)
13 while word_match is not None:
14 start, end = word_match.span()
15 word = word_match.group(0)
16 yield start, end, word
17 word_match = re_word.match(text, end)
18
19
20 def divide_line(text: str, width: int, fold: bool = True) -> List[int]:
21 divides: List[int] = []
22 append = divides.append
23 line_position = 0
24 _cell_len = cell_len
25 for start, _end, word in words(text):
26 word_length = _cell_len(word.rstrip())
27 if line_position + word_length > width:
28 if word_length > width:
29 if fold:
30 for last, line in loop_last(
31 chop_cells(word, width, position=line_position)
32 ):
33 if last:
34 line_position = _cell_len(line)
35 else:
36 start += len(line)
37 append(start)
38 else:
39 if start:
40 append(start)
41 line_position = _cell_len(word)
42 elif line_position and start:
43 append(start)
44 line_position = _cell_len(word)
45 else:
46 line_position += _cell_len(word)
47 return divides
48
49
50 if __name__ == "__main__": # pragma: no cover
51 from .console import Console
52
53 console = Console(width=10)
54 console.print("12345 abcdefghijklmnopqrstuvwyxzABCDEFGHIJKLMNOPQRSTUVWXYZ 12345")
55 print(chop_cells("abcdefghijklmnopqrstuvwxyz", 10, position=2))
56
[end of rich/_wrap.py]
[start of rich/cells.py]
1 import re
2 from functools import lru_cache
3 from typing import Dict, List
4
5 from ._cell_widths import CELL_WIDTHS
6 from ._lru_cache import LRUCache
7
8 # Regex to match sequence of the most common character ranges
9 _is_single_cell_widths = re.compile("^[\u0020-\u006f\u00a0\u02ff\u0370-\u0482]*$").match
10
11
12 def cell_len(text: str, _cache: Dict[str, int] = LRUCache(1024 * 4)) -> int:
13 """Get the number of cells required to display text.
14
15 Args:
16 text (str): Text to display.
17
18 Returns:
19 int: Get the number of cells required to display text.
20 """
21 cached_result = _cache.get(text, None)
22 if cached_result is not None:
23 return cached_result
24
25 _get_size = get_character_cell_size
26 total_size = sum(_get_size(character) for character in text)
27 if len(text) <= 512:
28 _cache[text] = total_size
29 return total_size
30
31
32 @lru_cache(maxsize=4096)
33 def get_character_cell_size(character: str) -> int:
34 """Get the cell size of a character.
35
36 Args:
37 character (str): A single character.
38
39 Returns:
40 int: Number of cells (0, 1 or 2) occupied by that character.
41 """
42 return _get_codepoint_cell_size(ord(character))
43
44
45 @lru_cache(maxsize=4096)
46 def _get_codepoint_cell_size(codepoint: int) -> int:
47 """Get the cell size of a character.
48
49 Args:
50 character (str): A single character.
51
52 Returns:
53 int: Number of cells (0, 1 or 2) occupied by that character.
54 """
55
56 _table = CELL_WIDTHS
57 lower_bound = 0
58 upper_bound = len(_table) - 1
59 index = (lower_bound + upper_bound) // 2
60 while True:
61 start, end, width = _table[index]
62 if codepoint < start:
63 upper_bound = index - 1
64 elif codepoint > end:
65 lower_bound = index + 1
66 else:
67 return 0 if width == -1 else width
68 if upper_bound < lower_bound:
69 break
70 index = (lower_bound + upper_bound) // 2
71 return 1
72
73
74 def set_cell_size(text: str, total: int) -> str:
75 """Set the length of a string to fit within given number of cells."""
76
77 if _is_single_cell_widths(text):
78 size = len(text)
79 if size < total:
80 return text + " " * (total - size)
81 return text[:total]
82
83 if not total:
84 return ""
85 cell_size = cell_len(text)
86 if cell_size == total:
87 return text
88 if cell_size < total:
89 return text + " " * (total - cell_size)
90
91 start = 0
92 end = len(text)
93
94 # Binary search until we find the right size
95 while True:
96 pos = (start + end) // 2
97 before = text[: pos + 1]
98 before_len = cell_len(before)
99 if before_len == total + 1 and cell_len(before[-1]) == 2:
100 return before[:-1] + " "
101 if before_len == total:
102 return before
103 if before_len > total:
104 end = pos
105 else:
106 start = pos
107
108
109 # TODO: This is inefficient
110 # TODO: This might not work with CWJ type characters
111 def chop_cells(text: str, max_size: int, position: int = 0) -> List[str]:
112 """Break text in to equal (cell) length strings."""
113 _get_character_cell_size = get_character_cell_size
114 characters = [
115 (character, _get_character_cell_size(character)) for character in text
116 ]
117 total_size = position
118 lines: List[List[str]] = [[]]
119 append = lines[-1].append
120
121 for character, size in reversed(characters):
122 if total_size + size > max_size:
123 lines.append([character])
124 append = lines[-1].append
125 total_size = size
126 else:
127 total_size += size
128 append(character)
129
130 return ["".join(line) for line in lines]
131
132
133 if __name__ == "__main__": # pragma: no cover
134
135 print(get_character_cell_size("😽"))
136 for line in chop_cells("""这是对亚洲语言支持的测试。面对模棱两可的想法,拒绝猜测的诱惑。""", 8):
137 print(line)
138 for n in range(80, 1, -1):
139 print(set_cell_size("""这是对亚洲语言支持的测试。面对模棱两可的想法,拒绝猜测的诱惑。""", n) + "|")
140 print("x" * n)
141
[end of rich/cells.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rich/_wrap.py b/rich/_wrap.py
--- a/rich/_wrap.py
+++ b/rich/_wrap.py
@@ -1,8 +1,8 @@
import re
from typing import Iterable, List, Tuple
-from .cells import cell_len, chop_cells
from ._loop import loop_last
+from .cells import cell_len, chop_cells
re_word = re.compile(r"\s*\S+\s*")
@@ -27,14 +27,15 @@
if line_position + word_length > width:
if word_length > width:
if fold:
- for last, line in loop_last(
- chop_cells(word, width, position=line_position)
- ):
+ chopped_words = chop_cells(word, max_size=width, position=0)
+ for last, line in loop_last(chopped_words):
+ if start:
+ append(start)
+
if last:
line_position = _cell_len(line)
else:
start += len(line)
- append(start)
else:
if start:
append(start)
diff --git a/rich/cells.py b/rich/cells.py
--- a/rich/cells.py
+++ b/rich/cells.py
@@ -109,7 +109,8 @@
# TODO: This is inefficient
# TODO: This might not work with CWJ type characters
def chop_cells(text: str, max_size: int, position: int = 0) -> List[str]:
- """Break text in to equal (cell) length strings."""
+ """Break text in to equal (cell) length strings, returning the characters in reverse
+ order"""
_get_character_cell_size = get_character_cell_size
characters = [
(character, _get_character_cell_size(character)) for character in text
|
{"golden_diff": "diff --git a/rich/_wrap.py b/rich/_wrap.py\n--- a/rich/_wrap.py\n+++ b/rich/_wrap.py\n@@ -1,8 +1,8 @@\n import re\n from typing import Iterable, List, Tuple\n \n-from .cells import cell_len, chop_cells\n from ._loop import loop_last\n+from .cells import cell_len, chop_cells\n \n re_word = re.compile(r\"\\s*\\S+\\s*\")\n \n@@ -27,14 +27,15 @@\n if line_position + word_length > width:\n if word_length > width:\n if fold:\n- for last, line in loop_last(\n- chop_cells(word, width, position=line_position)\n- ):\n+ chopped_words = chop_cells(word, max_size=width, position=0)\n+ for last, line in loop_last(chopped_words):\n+ if start:\n+ append(start)\n+\n if last:\n line_position = _cell_len(line)\n else:\n start += len(line)\n- append(start)\n else:\n if start:\n append(start)\ndiff --git a/rich/cells.py b/rich/cells.py\n--- a/rich/cells.py\n+++ b/rich/cells.py\n@@ -109,7 +109,8 @@\n # TODO: This is inefficient\n # TODO: This might not work with CWJ type characters\n def chop_cells(text: str, max_size: int, position: int = 0) -> List[str]:\n- \"\"\"Break text in to equal (cell) length strings.\"\"\"\n+ \"\"\"Break text in to equal (cell) length strings, returning the characters in reverse\n+ order\"\"\"\n _get_character_cell_size = get_character_cell_size\n characters = [\n (character, _get_character_cell_size(character)) for character in text\n", "issue": "[BUG] Text wrapping edge case\nDiscovered a possible edge case with text wrapping, probably connected to when a \"word\" is greater than the available width.\r\n\r\nConsider the following:\r\n\r\n```python\r\nconsole.print(\"Hello, World...123 \", width=10)\r\n```\r\n\r\nThis produces:\r\n\r\n```\r\nHello, Wor\r\nld...123\r\n```\r\n\r\nI think this occurs because \"World...123\" doesn't fit in to 10 characters, so folds on to the next line.\r\n\r\nI would expect there to be an additional new line after the Hello, like this:\r\n\r\n```\r\nHello,\r\nWorld...12\r\n3\r\n```\n", "before_files": [{"content": "import re\nfrom typing import Iterable, List, Tuple\n\nfrom .cells import cell_len, chop_cells\nfrom ._loop import loop_last\n\nre_word = re.compile(r\"\\s*\\S+\\s*\")\n\n\ndef words(text: str) -> Iterable[Tuple[int, int, str]]:\n position = 0\n word_match = re_word.match(text, position)\n while word_match is not None:\n start, end = word_match.span()\n word = word_match.group(0)\n yield start, end, word\n word_match = re_word.match(text, end)\n\n\ndef divide_line(text: str, width: int, fold: bool = True) -> List[int]:\n divides: List[int] = []\n append = divides.append\n line_position = 0\n _cell_len = cell_len\n for start, _end, word in words(text):\n word_length = _cell_len(word.rstrip())\n if line_position + word_length > width:\n if word_length > width:\n if fold:\n for last, line in loop_last(\n chop_cells(word, width, position=line_position)\n ):\n if last:\n line_position = _cell_len(line)\n else:\n start += len(line)\n append(start)\n else:\n if start:\n append(start)\n line_position = _cell_len(word)\n elif line_position and start:\n append(start)\n line_position = _cell_len(word)\n else:\n line_position += _cell_len(word)\n return divides\n\n\nif __name__ == \"__main__\": # pragma: no cover\n from .console import Console\n\n console = Console(width=10)\n console.print(\"12345 abcdefghijklmnopqrstuvwyxzABCDEFGHIJKLMNOPQRSTUVWXYZ 12345\")\n print(chop_cells(\"abcdefghijklmnopqrstuvwxyz\", 10, position=2))\n", "path": "rich/_wrap.py"}, {"content": "import re\nfrom functools import lru_cache\nfrom typing import Dict, List\n\nfrom ._cell_widths import CELL_WIDTHS\nfrom ._lru_cache import LRUCache\n\n# Regex to match sequence of the most common character ranges\n_is_single_cell_widths = re.compile(\"^[\\u0020-\\u006f\\u00a0\\u02ff\\u0370-\\u0482]*$\").match\n\n\ndef cell_len(text: str, _cache: Dict[str, int] = LRUCache(1024 * 4)) -> int:\n \"\"\"Get the number of cells required to display text.\n\n Args:\n text (str): Text to display.\n\n Returns:\n int: Get the number of cells required to display text.\n \"\"\"\n cached_result = _cache.get(text, None)\n if cached_result is not None:\n return cached_result\n\n _get_size = get_character_cell_size\n total_size = sum(_get_size(character) for character in text)\n if len(text) <= 512:\n _cache[text] = total_size\n return total_size\n\n\n@lru_cache(maxsize=4096)\ndef get_character_cell_size(character: str) -> int:\n \"\"\"Get the cell size of a character.\n\n Args:\n character (str): A single character.\n\n Returns:\n int: Number of cells (0, 1 or 2) occupied by that character.\n \"\"\"\n return _get_codepoint_cell_size(ord(character))\n\n\n@lru_cache(maxsize=4096)\ndef _get_codepoint_cell_size(codepoint: int) -> int:\n \"\"\"Get the cell size of a character.\n\n Args:\n character (str): A single character.\n\n Returns:\n int: Number of cells (0, 1 or 2) occupied by that character.\n \"\"\"\n\n _table = CELL_WIDTHS\n lower_bound = 0\n upper_bound = len(_table) - 1\n index = (lower_bound + upper_bound) // 2\n while True:\n start, end, width = _table[index]\n if codepoint < start:\n upper_bound = index - 1\n elif codepoint > end:\n lower_bound = index + 1\n else:\n return 0 if width == -1 else width\n if upper_bound < lower_bound:\n break\n index = (lower_bound + upper_bound) // 2\n return 1\n\n\ndef set_cell_size(text: str, total: int) -> str:\n \"\"\"Set the length of a string to fit within given number of cells.\"\"\"\n\n if _is_single_cell_widths(text):\n size = len(text)\n if size < total:\n return text + \" \" * (total - size)\n return text[:total]\n\n if not total:\n return \"\"\n cell_size = cell_len(text)\n if cell_size == total:\n return text\n if cell_size < total:\n return text + \" \" * (total - cell_size)\n\n start = 0\n end = len(text)\n\n # Binary search until we find the right size\n while True:\n pos = (start + end) // 2\n before = text[: pos + 1]\n before_len = cell_len(before)\n if before_len == total + 1 and cell_len(before[-1]) == 2:\n return before[:-1] + \" \"\n if before_len == total:\n return before\n if before_len > total:\n end = pos\n else:\n start = pos\n\n\n# TODO: This is inefficient\n# TODO: This might not work with CWJ type characters\ndef chop_cells(text: str, max_size: int, position: int = 0) -> List[str]:\n \"\"\"Break text in to equal (cell) length strings.\"\"\"\n _get_character_cell_size = get_character_cell_size\n characters = [\n (character, _get_character_cell_size(character)) for character in text\n ]\n total_size = position\n lines: List[List[str]] = [[]]\n append = lines[-1].append\n\n for character, size in reversed(characters):\n if total_size + size > max_size:\n lines.append([character])\n append = lines[-1].append\n total_size = size\n else:\n total_size += size\n append(character)\n\n return [\"\".join(line) for line in lines]\n\n\nif __name__ == \"__main__\": # pragma: no cover\n\n print(get_character_cell_size(\"\ud83d\ude3d\"))\n for line in chop_cells(\"\"\"\u8fd9\u662f\u5bf9\u4e9a\u6d32\u8bed\u8a00\u652f\u6301\u7684\u6d4b\u8bd5\u3002\u9762\u5bf9\u6a21\u68f1\u4e24\u53ef\u7684\u60f3\u6cd5\uff0c\u62d2\u7edd\u731c\u6d4b\u7684\u8bf1\u60d1\u3002\"\"\", 8):\n print(line)\n for n in range(80, 1, -1):\n print(set_cell_size(\"\"\"\u8fd9\u662f\u5bf9\u4e9a\u6d32\u8bed\u8a00\u652f\u6301\u7684\u6d4b\u8bd5\u3002\u9762\u5bf9\u6a21\u68f1\u4e24\u53ef\u7684\u60f3\u6cd5\uff0c\u62d2\u7edd\u731c\u6d4b\u7684\u8bf1\u60d1\u3002\"\"\", n) + \"|\")\n print(\"x\" * n)\n", "path": "rich/cells.py"}]}
| 2,596 | 396 |
gh_patches_debug_43159
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-8770
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
manual: when not using hooks, tell the user they need to wait for DNS propagation
One of the usability things I came across in #8514 was that it's not terribly obvious when setting up TXT records manually that with some DNS hosts, you need to wait a while.
https://github.com/certbot/certbot/blob/adb7e5e62f4c96be678c5af3e55a82ddcc717590/certbot/certbot/_internal/plugins/manual.py#L45-L51
This bit of vague text could be rewritten in order to convey the advice more directly:
> Before continuing, verify the record is deployed
I think it would be ideal if we only showed this on the very last DNS challenge, but I'm not sure whether the logic of Certbot will permit that. I don't think it's a big deal to show it every time.
</issue>
<code>
[start of certbot/certbot/_internal/plugins/manual.py]
1 """Manual authenticator plugin"""
2 from typing import Dict
3
4 import zope.component
5 import zope.interface
6
7 from acme import challenges
8 from certbot import achallenges
9 from certbot import errors
10 from certbot import interfaces
11 from certbot import reverter
12 from certbot import util
13 from certbot._internal import hooks
14 from certbot.compat import misc
15 from certbot.compat import os
16 from certbot.plugins import common
17
18
19 @zope.interface.implementer(interfaces.IAuthenticator)
20 @zope.interface.provider(interfaces.IPluginFactory)
21 class Authenticator(common.Plugin):
22 """Manual authenticator
23
24 This plugin allows the user to perform the domain validation
25 challenge(s) themselves. This either be done manually by the user or
26 through shell scripts provided to Certbot.
27
28 """
29
30 description = 'Manual configuration or run your own shell scripts'
31 hidden = True
32 long_description = (
33 'Authenticate through manual configuration or custom shell scripts. '
34 'When using shell scripts, an authenticator script must be provided. '
35 'The environment variables available to this script depend on the '
36 'type of challenge. $CERTBOT_DOMAIN will always contain the domain '
37 'being authenticated. For HTTP-01 and DNS-01, $CERTBOT_VALIDATION '
38 'is the validation string, and $CERTBOT_TOKEN is the filename of the '
39 'resource requested when performing an HTTP-01 challenge. An additional '
40 'cleanup script can also be provided and can use the additional variable '
41 '$CERTBOT_AUTH_OUTPUT which contains the stdout output from the auth script. '
42 'For both authenticator and cleanup script, on HTTP-01 and DNS-01 challenges, '
43 '$CERTBOT_REMAINING_CHALLENGES will be equal to the number of challenges that '
44 'remain after the current one, and $CERTBOT_ALL_DOMAINS contains a comma-separated '
45 'list of all domains that are challenged for the current certificate.')
46 _DNS_INSTRUCTIONS = """\
47 Please deploy a DNS TXT record under the name
48 {domain} with the following value:
49
50 {validation}
51
52 Before continuing, verify the record is deployed."""
53 _HTTP_INSTRUCTIONS = """\
54 Create a file containing just this data:
55
56 {validation}
57
58 And make it available on your web server at this URL:
59
60 {uri}
61 """
62 _SUBSEQUENT_CHALLENGE_INSTRUCTIONS = """
63 (This must be set up in addition to the previous challenges; do not remove,
64 replace, or undo the previous challenge tasks yet.)
65 """
66 _SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS = """
67 (This must be set up in addition to the previous challenges; do not remove,
68 replace, or undo the previous challenge tasks yet. Note that you might be
69 asked to create multiple distinct TXT records with the same name. This is
70 permitted by DNS standards.)
71 """
72
73 def __init__(self, *args, **kwargs):
74 super(Authenticator, self).__init__(*args, **kwargs)
75 self.reverter = reverter.Reverter(self.config)
76 self.reverter.recovery_routine()
77 self.env: Dict[achallenges.KeyAuthorizationAnnotatedChallenge, Dict[str, str]] = {}
78 self.subsequent_dns_challenge = False
79 self.subsequent_any_challenge = False
80
81 @classmethod
82 def add_parser_arguments(cls, add):
83 add('auth-hook',
84 help='Path or command to execute for the authentication script')
85 add('cleanup-hook',
86 help='Path or command to execute for the cleanup script')
87 util.add_deprecated_argument(add, 'public-ip-logging-ok', 0)
88
89 def prepare(self): # pylint: disable=missing-function-docstring
90 if self.config.noninteractive_mode and not self.conf('auth-hook'):
91 raise errors.PluginError(
92 'An authentication script must be provided with --{0} when '
93 'using the manual plugin non-interactively.'.format(
94 self.option_name('auth-hook')))
95 self._validate_hooks()
96
97 def _validate_hooks(self):
98 if self.config.validate_hooks:
99 for name in ('auth-hook', 'cleanup-hook'):
100 hook = self.conf(name)
101 if hook is not None:
102 hook_prefix = self.option_name(name)[:-len('-hook')]
103 hooks.validate_hook(hook, hook_prefix)
104
105 def more_info(self): # pylint: disable=missing-function-docstring
106 return (
107 'This plugin allows the user to customize setup for domain '
108 'validation challenges either through shell scripts provided by '
109 'the user or by performing the setup manually.')
110
111 def get_chall_pref(self, domain):
112 # pylint: disable=unused-argument,missing-function-docstring
113 return [challenges.HTTP01, challenges.DNS01]
114
115 def perform(self, achalls): # pylint: disable=missing-function-docstring
116 responses = []
117 for achall in achalls:
118 if self.conf('auth-hook'):
119 self._perform_achall_with_script(achall, achalls)
120 else:
121 self._perform_achall_manually(achall)
122 responses.append(achall.response(achall.account_key))
123 return responses
124
125 def _perform_achall_with_script(self, achall, achalls):
126 env = dict(CERTBOT_DOMAIN=achall.domain,
127 CERTBOT_VALIDATION=achall.validation(achall.account_key),
128 CERTBOT_ALL_DOMAINS=','.join(one_achall.domain for one_achall in achalls),
129 CERTBOT_REMAINING_CHALLENGES=str(len(achalls) - achalls.index(achall) - 1))
130 if isinstance(achall.chall, challenges.HTTP01):
131 env['CERTBOT_TOKEN'] = achall.chall.encode('token')
132 else:
133 os.environ.pop('CERTBOT_TOKEN', None)
134 os.environ.update(env)
135 _, out = self._execute_hook('auth-hook')
136 env['CERTBOT_AUTH_OUTPUT'] = out.strip()
137 self.env[achall] = env
138
139 def _perform_achall_manually(self, achall):
140 validation = achall.validation(achall.account_key)
141 if isinstance(achall.chall, challenges.HTTP01):
142 msg = self._HTTP_INSTRUCTIONS.format(
143 achall=achall, encoded_token=achall.chall.encode('token'),
144 port=self.config.http01_port,
145 uri=achall.chall.uri(achall.domain), validation=validation)
146 else:
147 assert isinstance(achall.chall, challenges.DNS01)
148 msg = self._DNS_INSTRUCTIONS.format(
149 domain=achall.validation_domain_name(achall.domain),
150 validation=validation)
151 if isinstance(achall.chall, challenges.DNS01):
152 if self.subsequent_dns_challenge:
153 # 2nd or later dns-01 challenge
154 msg += self._SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS
155 self.subsequent_dns_challenge = True
156 elif self.subsequent_any_challenge:
157 # 2nd or later challenge of another type
158 msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS
159 display = zope.component.getUtility(interfaces.IDisplay)
160 display.notification(msg, wrap=False, force_interactive=True)
161 self.subsequent_any_challenge = True
162
163 def cleanup(self, achalls): # pylint: disable=missing-function-docstring
164 if self.conf('cleanup-hook'):
165 for achall in achalls:
166 env = self.env.pop(achall)
167 if 'CERTBOT_TOKEN' not in env:
168 os.environ.pop('CERTBOT_TOKEN', None)
169 os.environ.update(env)
170 self._execute_hook('cleanup-hook')
171 self.reverter.recovery_routine()
172
173 def _execute_hook(self, hook_name):
174 return misc.execute_command(self.option_name(hook_name), self.conf(hook_name),
175 env=util.env_no_snap_for_external_calls())
176
[end of certbot/certbot/_internal/plugins/manual.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/certbot/certbot/_internal/plugins/manual.py b/certbot/certbot/_internal/plugins/manual.py
--- a/certbot/certbot/_internal/plugins/manual.py
+++ b/certbot/certbot/_internal/plugins/manual.py
@@ -43,13 +43,30 @@
'$CERTBOT_REMAINING_CHALLENGES will be equal to the number of challenges that '
'remain after the current one, and $CERTBOT_ALL_DOMAINS contains a comma-separated '
'list of all domains that are challenged for the current certificate.')
+ # Include the full stop at the end of the FQDN in the instructions below for the null
+ # label of the DNS root, as stated in section 3.1 of RFC 1035. While not necessary
+ # for most day to day usage of hostnames, when adding FQDNs to a DNS zone editor, this
+ # full stop is often mandatory. Without a full stop, the entered name is often seen as
+ # relative to the DNS zone origin, which could lead to entries for, e.g.:
+ # _acme-challenge.example.com.example.com. For users unaware of this subtle detail,
+ # including the trailing full stop in the DNS instructions below might avert this issue.
_DNS_INSTRUCTIONS = """\
-Please deploy a DNS TXT record under the name
-{domain} with the following value:
+Please deploy a DNS TXT record under the name:
-{validation}
+{domain}.
+
+with the following value:
-Before continuing, verify the record is deployed."""
+{validation}
+"""
+ _DNS_VERIFY_INSTRUCTIONS = """
+Before continuing, verify the TXT record has been deployed. Depending on the DNS
+provider, this may take some time, from a few seconds to multiple minutes. You can
+check if it has finished deploying with aid of online tools, such as the Google
+Admin Toolbox: https://toolbox.googleapps.com/apps/dig/#TXT/{domain}.
+Look for one or more bolded line(s) below the line ';ANSWER'. It should show the
+value(s) you've just added.
+"""
_HTTP_INSTRUCTIONS = """\
Create a file containing just this data:
@@ -114,11 +131,15 @@
def perform(self, achalls): # pylint: disable=missing-function-docstring
responses = []
- for achall in achalls:
+ last_dns_achall = 0
+ for i, achall in enumerate(achalls):
+ if isinstance(achall.chall, challenges.DNS01):
+ last_dns_achall = i
+ for i, achall in enumerate(achalls):
if self.conf('auth-hook'):
self._perform_achall_with_script(achall, achalls)
else:
- self._perform_achall_manually(achall)
+ self._perform_achall_manually(achall, i == last_dns_achall)
responses.append(achall.response(achall.account_key))
return responses
@@ -136,7 +157,7 @@
env['CERTBOT_AUTH_OUTPUT'] = out.strip()
self.env[achall] = env
- def _perform_achall_manually(self, achall):
+ def _perform_achall_manually(self, achall, last_dns_achall=False):
validation = achall.validation(achall.account_key)
if isinstance(achall.chall, challenges.HTTP01):
msg = self._HTTP_INSTRUCTIONS.format(
@@ -152,7 +173,15 @@
if self.subsequent_dns_challenge:
# 2nd or later dns-01 challenge
msg += self._SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS
+ elif self.subsequent_any_challenge:
+ # 1st dns-01 challenge, but 2nd or later *any* challenge, so
+ # instruct user not to remove any previous http-01 challenge
+ msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS
self.subsequent_dns_challenge = True
+ if last_dns_achall:
+ # last dns-01 challenge
+ msg += self._DNS_VERIFY_INSTRUCTIONS.format(
+ domain=achall.validation_domain_name(achall.domain))
elif self.subsequent_any_challenge:
# 2nd or later challenge of another type
msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS
|
{"golden_diff": "diff --git a/certbot/certbot/_internal/plugins/manual.py b/certbot/certbot/_internal/plugins/manual.py\n--- a/certbot/certbot/_internal/plugins/manual.py\n+++ b/certbot/certbot/_internal/plugins/manual.py\n@@ -43,13 +43,30 @@\n '$CERTBOT_REMAINING_CHALLENGES will be equal to the number of challenges that '\n 'remain after the current one, and $CERTBOT_ALL_DOMAINS contains a comma-separated '\n 'list of all domains that are challenged for the current certificate.')\n+ # Include the full stop at the end of the FQDN in the instructions below for the null\n+ # label of the DNS root, as stated in section 3.1 of RFC 1035. While not necessary\n+ # for most day to day usage of hostnames, when adding FQDNs to a DNS zone editor, this\n+ # full stop is often mandatory. Without a full stop, the entered name is often seen as\n+ # relative to the DNS zone origin, which could lead to entries for, e.g.:\n+ # _acme-challenge.example.com.example.com. For users unaware of this subtle detail,\n+ # including the trailing full stop in the DNS instructions below might avert this issue.\n _DNS_INSTRUCTIONS = \"\"\"\\\n-Please deploy a DNS TXT record under the name\n-{domain} with the following value:\n+Please deploy a DNS TXT record under the name:\n \n-{validation}\n+{domain}.\n+\n+with the following value:\n \n-Before continuing, verify the record is deployed.\"\"\"\n+{validation}\n+\"\"\"\n+ _DNS_VERIFY_INSTRUCTIONS = \"\"\"\n+Before continuing, verify the TXT record has been deployed. Depending on the DNS \n+provider, this may take some time, from a few seconds to multiple minutes. You can\n+check if it has finished deploying with aid of online tools, such as the Google\n+Admin Toolbox: https://toolbox.googleapps.com/apps/dig/#TXT/{domain}.\n+Look for one or more bolded line(s) below the line ';ANSWER'. It should show the\n+value(s) you've just added.\n+\"\"\"\n _HTTP_INSTRUCTIONS = \"\"\"\\\n Create a file containing just this data:\n \n@@ -114,11 +131,15 @@\n \n def perform(self, achalls): # pylint: disable=missing-function-docstring\n responses = []\n- for achall in achalls:\n+ last_dns_achall = 0\n+ for i, achall in enumerate(achalls):\n+ if isinstance(achall.chall, challenges.DNS01):\n+ last_dns_achall = i\n+ for i, achall in enumerate(achalls):\n if self.conf('auth-hook'):\n self._perform_achall_with_script(achall, achalls)\n else:\n- self._perform_achall_manually(achall)\n+ self._perform_achall_manually(achall, i == last_dns_achall)\n responses.append(achall.response(achall.account_key))\n return responses\n \n@@ -136,7 +157,7 @@\n env['CERTBOT_AUTH_OUTPUT'] = out.strip()\n self.env[achall] = env\n \n- def _perform_achall_manually(self, achall):\n+ def _perform_achall_manually(self, achall, last_dns_achall=False):\n validation = achall.validation(achall.account_key)\n if isinstance(achall.chall, challenges.HTTP01):\n msg = self._HTTP_INSTRUCTIONS.format(\n@@ -152,7 +173,15 @@\n if self.subsequent_dns_challenge:\n # 2nd or later dns-01 challenge\n msg += self._SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS\n+ elif self.subsequent_any_challenge:\n+ # 1st dns-01 challenge, but 2nd or later *any* challenge, so\n+ # instruct user not to remove any previous http-01 challenge\n+ msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS\n self.subsequent_dns_challenge = True\n+ if last_dns_achall:\n+ # last dns-01 challenge\n+ msg += self._DNS_VERIFY_INSTRUCTIONS.format(\n+ domain=achall.validation_domain_name(achall.domain))\n elif self.subsequent_any_challenge:\n # 2nd or later challenge of another type\n msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS\n", "issue": "manual: when not using hooks, tell the user they need to wait for DNS propagation\nOne of the usability things I came across in #8514 was that it's not terribly obvious when setting up TXT records manually that with some DNS hosts, you need to wait a while. \r\n\r\nhttps://github.com/certbot/certbot/blob/adb7e5e62f4c96be678c5af3e55a82ddcc717590/certbot/certbot/_internal/plugins/manual.py#L45-L51\r\n\r\nThis bit of vague text could be rewritten in order to convey the advice more directly: \r\n\r\n> Before continuing, verify the record is deployed\r\n\r\nI think it would be ideal if we only showed this on the very last DNS challenge, but I'm not sure whether the logic of Certbot will permit that. I don't think it's a big deal to show it every time. \n", "before_files": [{"content": "\"\"\"Manual authenticator plugin\"\"\"\nfrom typing import Dict\n\nimport zope.component\nimport zope.interface\n\nfrom acme import challenges\nfrom certbot import achallenges\nfrom certbot import errors\nfrom certbot import interfaces\nfrom certbot import reverter\nfrom certbot import util\nfrom certbot._internal import hooks\nfrom certbot.compat import misc\nfrom certbot.compat import os\nfrom certbot.plugins import common\n\n\[email protected](interfaces.IAuthenticator)\[email protected](interfaces.IPluginFactory)\nclass Authenticator(common.Plugin):\n \"\"\"Manual authenticator\n\n This plugin allows the user to perform the domain validation\n challenge(s) themselves. This either be done manually by the user or\n through shell scripts provided to Certbot.\n\n \"\"\"\n\n description = 'Manual configuration or run your own shell scripts'\n hidden = True\n long_description = (\n 'Authenticate through manual configuration or custom shell scripts. '\n 'When using shell scripts, an authenticator script must be provided. '\n 'The environment variables available to this script depend on the '\n 'type of challenge. $CERTBOT_DOMAIN will always contain the domain '\n 'being authenticated. For HTTP-01 and DNS-01, $CERTBOT_VALIDATION '\n 'is the validation string, and $CERTBOT_TOKEN is the filename of the '\n 'resource requested when performing an HTTP-01 challenge. An additional '\n 'cleanup script can also be provided and can use the additional variable '\n '$CERTBOT_AUTH_OUTPUT which contains the stdout output from the auth script. '\n 'For both authenticator and cleanup script, on HTTP-01 and DNS-01 challenges, '\n '$CERTBOT_REMAINING_CHALLENGES will be equal to the number of challenges that '\n 'remain after the current one, and $CERTBOT_ALL_DOMAINS contains a comma-separated '\n 'list of all domains that are challenged for the current certificate.')\n _DNS_INSTRUCTIONS = \"\"\"\\\nPlease deploy a DNS TXT record under the name\n{domain} with the following value:\n\n{validation}\n\nBefore continuing, verify the record is deployed.\"\"\"\n _HTTP_INSTRUCTIONS = \"\"\"\\\nCreate a file containing just this data:\n\n{validation}\n\nAnd make it available on your web server at this URL:\n\n{uri}\n\"\"\"\n _SUBSEQUENT_CHALLENGE_INSTRUCTIONS = \"\"\"\n(This must be set up in addition to the previous challenges; do not remove,\nreplace, or undo the previous challenge tasks yet.)\n\"\"\"\n _SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS = \"\"\"\n(This must be set up in addition to the previous challenges; do not remove,\nreplace, or undo the previous challenge tasks yet. Note that you might be\nasked to create multiple distinct TXT records with the same name. This is\npermitted by DNS standards.)\n\"\"\"\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n self.reverter = reverter.Reverter(self.config)\n self.reverter.recovery_routine()\n self.env: Dict[achallenges.KeyAuthorizationAnnotatedChallenge, Dict[str, str]] = {}\n self.subsequent_dns_challenge = False\n self.subsequent_any_challenge = False\n\n @classmethod\n def add_parser_arguments(cls, add):\n add('auth-hook',\n help='Path or command to execute for the authentication script')\n add('cleanup-hook',\n help='Path or command to execute for the cleanup script')\n util.add_deprecated_argument(add, 'public-ip-logging-ok', 0)\n\n def prepare(self): # pylint: disable=missing-function-docstring\n if self.config.noninteractive_mode and not self.conf('auth-hook'):\n raise errors.PluginError(\n 'An authentication script must be provided with --{0} when '\n 'using the manual plugin non-interactively.'.format(\n self.option_name('auth-hook')))\n self._validate_hooks()\n\n def _validate_hooks(self):\n if self.config.validate_hooks:\n for name in ('auth-hook', 'cleanup-hook'):\n hook = self.conf(name)\n if hook is not None:\n hook_prefix = self.option_name(name)[:-len('-hook')]\n hooks.validate_hook(hook, hook_prefix)\n\n def more_info(self): # pylint: disable=missing-function-docstring\n return (\n 'This plugin allows the user to customize setup for domain '\n 'validation challenges either through shell scripts provided by '\n 'the user or by performing the setup manually.')\n\n def get_chall_pref(self, domain):\n # pylint: disable=unused-argument,missing-function-docstring\n return [challenges.HTTP01, challenges.DNS01]\n\n def perform(self, achalls): # pylint: disable=missing-function-docstring\n responses = []\n for achall in achalls:\n if self.conf('auth-hook'):\n self._perform_achall_with_script(achall, achalls)\n else:\n self._perform_achall_manually(achall)\n responses.append(achall.response(achall.account_key))\n return responses\n\n def _perform_achall_with_script(self, achall, achalls):\n env = dict(CERTBOT_DOMAIN=achall.domain,\n CERTBOT_VALIDATION=achall.validation(achall.account_key),\n CERTBOT_ALL_DOMAINS=','.join(one_achall.domain for one_achall in achalls),\n CERTBOT_REMAINING_CHALLENGES=str(len(achalls) - achalls.index(achall) - 1))\n if isinstance(achall.chall, challenges.HTTP01):\n env['CERTBOT_TOKEN'] = achall.chall.encode('token')\n else:\n os.environ.pop('CERTBOT_TOKEN', None)\n os.environ.update(env)\n _, out = self._execute_hook('auth-hook')\n env['CERTBOT_AUTH_OUTPUT'] = out.strip()\n self.env[achall] = env\n\n def _perform_achall_manually(self, achall):\n validation = achall.validation(achall.account_key)\n if isinstance(achall.chall, challenges.HTTP01):\n msg = self._HTTP_INSTRUCTIONS.format(\n achall=achall, encoded_token=achall.chall.encode('token'),\n port=self.config.http01_port,\n uri=achall.chall.uri(achall.domain), validation=validation)\n else:\n assert isinstance(achall.chall, challenges.DNS01)\n msg = self._DNS_INSTRUCTIONS.format(\n domain=achall.validation_domain_name(achall.domain),\n validation=validation)\n if isinstance(achall.chall, challenges.DNS01):\n if self.subsequent_dns_challenge:\n # 2nd or later dns-01 challenge\n msg += self._SUBSEQUENT_DNS_CHALLENGE_INSTRUCTIONS\n self.subsequent_dns_challenge = True\n elif self.subsequent_any_challenge:\n # 2nd or later challenge of another type\n msg += self._SUBSEQUENT_CHALLENGE_INSTRUCTIONS\n display = zope.component.getUtility(interfaces.IDisplay)\n display.notification(msg, wrap=False, force_interactive=True)\n self.subsequent_any_challenge = True\n\n def cleanup(self, achalls): # pylint: disable=missing-function-docstring\n if self.conf('cleanup-hook'):\n for achall in achalls:\n env = self.env.pop(achall)\n if 'CERTBOT_TOKEN' not in env:\n os.environ.pop('CERTBOT_TOKEN', None)\n os.environ.update(env)\n self._execute_hook('cleanup-hook')\n self.reverter.recovery_routine()\n\n def _execute_hook(self, hook_name):\n return misc.execute_command(self.option_name(hook_name), self.conf(hook_name),\n env=util.env_no_snap_for_external_calls())\n", "path": "certbot/certbot/_internal/plugins/manual.py"}]}
| 2,838 | 995 |
gh_patches_debug_10571
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6873
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: alembic downgrade from 6828cc5b1a4f to 5b43800443d1 fails.
### Meltano Version
downgrading from 2+ to 1.76
### Python Version
3.7
### Bug scope
Other
### Operating System
Windows, but this probably isn't OS specific.
### Description
Relates to #6870. Ran `meltano repl` (as advised by @DouweM) then:
```python
from alembic import command
from alembic.config import Config
from meltano.migrations import MIGRATION_DIR
from alembic.runtime.migration import MigrationContext
from alembic.script import ScriptDirectory
engine, session = project_engine(project, default=True)
conn = engine.connect()
cfg = Config()
cfg.attributes["connection"] = conn
cfg.set_main_option("script_location", str(MIGRATION_DIR))
script = ScriptDirectory.from_config(cfg)
context = MigrationContext.configure(conn)
command.downgrade(cfg, "d135f52a6f49")
```
Tracelog:
```
2022-10-11T11:24:19.745585Z [info ] Context impl PostgresqlImpl.
2022-10-11T11:24:19.747541Z [info ] Will assume transactional DDL.
2022-10-11T11:24:19.853452Z [info ] Running downgrade 6828cc5b1a4f -> f4c225a9492f, Create dedicated state table
2022-10-11T11:24:19.898474Z [info ] Running downgrade f4c225a9492f -> 5b43800443d1, Create dedicated job_state table ---------------------------------------------------------------------------
UndefinedTable Traceback (most recent call last)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)
1900 self.dialect.do_execute(
-> 1901 cursor, statement, parameters, context
1902 )
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\default.py in do_execute(self, cursor, statement, parameters, context)
735 def do_execute(self, cursor, statement, parameters, context=None):
--> 736 cursor.execute(statement, parameters)
737
UndefinedTable: table "state" does not exist
The above exception was the direct cause of the following exception:
ProgrammingError Traceback (most recent call last)
<ipython-input-14-8baf3a7dd97e> in <module>
----> 1 command.downgrade(cfg, "d135f52a6f49")
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\command.py in downgrade(config, revision, sql, tag)
366 tag=tag,
367 ):
--> 368 script.run_env()
369
370
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\script\base.py in run_env(self)
567
568 """
--> 569 util.load_python_file(self.dir, "env.py")
570
571 @property
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\util\pyfiles.py in load_python_file(dir_, filename)
92 if ext == ".py":
93 if os.path.exists(path):
---> 94 module = load_module_py(module_id, path)
95 else:
96 pyc_path = pyc_file_from_path(path)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\util\pyfiles.py in load_module_py(module_id, path)
108 assert spec
109 module = importlib.util.module_from_spec(spec)
--> 110 spec.loader.exec_module(module) # type: ignore
111 return module
~\AppData\Local\Programs\Python\Python37\lib\importlib\_bootstrap_external.py in exec_module(self, module)
~\AppData\Local\Programs\Python\Python37\lib\importlib\_bootstrap.py in _call_with_frames_removed(f, *args, **kwds)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\meltano\migrations\env.py in <module>
58 run_migrations_offline()
59 else:
---> 60 run_migrations_online()
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\meltano\migrations\env.py in run_migrations_online()
35 connection = config.attributes.get("connection")
36 if connection:
---> 37 _run_migrations_online(connection)
38 return
39
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\meltano\migrations\env.py in _run_migrations_online(connection)
52
53 with context.begin_transaction():
---> 54 context.run_migrations()
55
56
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\context.py in run_migrations(*args, **kw)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\runtime\environment.py in run_migrations(self, **kw)
851 assert self._migration_context is not None
852 with Operations.context(self._migration_context):
--> 853 self.get_context().run_migrations(**kw)
854
855 def execute(self, sql, execution_options=None):
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\runtime\migration.py in run_migrations(self, **kw)
621 "-- Running %s" % (step.short_log,)
622 )
--> 623 step.migration_fn(**kw)
624
625 # previously, we wouldn't stamp per migration
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\meltano\migrations\versions\f4c225a9492f_create_dedicated_job_state_table.py in downgrade()
25 # Remove job_state table
26 # Job run history is still maintained, so no need to copy
---> 27 op.drop_table("state")
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\op.py in drop_table(*args, **kw)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\operations\base.py in drop_table(self, table_name, schema, **kw)
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\operations\ops.py in drop_table(cls, operations, table_name, schema, **kw)
1347 """
1348 op = cls(table_name, schema=schema, table_kw=kw)
-> 1349 operations.invoke(op)
1350
1351
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\operations\base.py in invoke(self, operation)
397 operation, self.migration_context.impl.__dialect__
398 )
--> 399 return fn(self, operation)
400
401 def f(self, name: str) -> "conv":
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\operations\toimpl.py in drop_table(operations, operation)
78 def drop_table(operations: "Operations", operation: "ops.DropTableOp") -> None:
79 operations.impl.drop_table(
---> 80 operation.to_table(operations.migration_context)
81 )
82
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\ddl\impl.py in drop_table(self, table)
375 table, self.connection, checkfirst=False, _ddl_runner=self
376 )
--> 377 self._exec(schema.DropTable(table))
378 table.dispatch.after_drop(
379 table, self.connection, checkfirst=False, _ddl_runner=self
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\alembic\ddl\impl.py in _exec(self, construct, execution_options, multiparams, params)
193 multiparams += (params,)
194
--> 195 return conn.execute(construct, multiparams)
196
197 def execute(
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in execute(self, statement, *multiparams, **params)
1378 )
1379 else:
-> 1380 return meth(self, multiparams, params, _EMPTY_EXECUTION_OPTS)
1381
1382 def _execute_function(self, func, multiparams, params, execution_options):
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\sql\ddl.py in _execute_on_connection(self, connection, multiparams, params, execution_options)
79 ):
80 return connection._execute_ddl(
---> 81 self, multiparams, params, execution_options
82 )
83
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in _execute_ddl(self, ddl, multiparams, params, execution_options)
1476 None,
1477 execution_options,
-> 1478 compiled,
1479 )
1480 if self._has_events or self.engine._has_events:
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)
1942 except BaseException as e:
1943 self._handle_dbapi_exception(
-> 1944 e, statement, parameters, cursor, context
1945 )
1946
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in _handle_dbapi_exception(self, e, statement, parameters, cursor, context)
2123 elif should_wrap:
2124 util.raise_(
-> 2125 sqlalchemy_exception, with_traceback=exc_info[2], from_=e
2126 )
2127 else:
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\util\compat.py in raise_(***failed resolving arguments***)
206
207 try:
--> 208 raise exception
209 finally:
210 # credit to
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)
1899 if not evt_handled:
1900 self.dialect.do_execute(
-> 1901 cursor, statement, parameters, context
1902 )
1903
~\.virtualenvs\meltano-9aGVMBGe\lib\site-packages\sqlalchemy\engine\default.py in do_execute(self, cursor, statement, parameters, context)
734
735 def do_execute(self, cursor, statement, parameters, context=None):
--> 736 cursor.execute(statement, parameters)
737
738 def do_execute_no_params(self, cursor, statement, context=None):
ProgrammingError: (psycopg2.errors.UndefinedTable) table "state" does not exist
```
# Diagnosis
- Downgrade path in first migration drops table `state`: https://github.com/meltano/meltano/blob/v2.7.2/src/meltano/migrations/versions/6828cc5b1a4f_create_dedicated_state_table.py#L367
- Downgrade path in second migration also drops table `state`: https://github.com/meltano/meltano/blob/v2.7.2/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py#L27
The second step fails because `state` is already dropped.
# Suggested Fix
Remove the `f4c225a9492f` migration. It does nothing during upgrade, and only causes problems on downgrade.
### Code
_No response_
</issue>
<code>
[start of src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py]
1 """Create dedicated job_state table
2
3 Revision ID: f4c225a9492f
4 Revises: 5b43800443d1
5 Create Date: 2022-09-02 09:44:05.581824
6
7 """
8 from __future__ import annotations
9
10 from alembic import op
11
12 # revision identifiers, used by Alembic.
13 revision = "f4c225a9492f"
14 down_revision = "5b43800443d1"
15 branch_labels = None
16 depends_on = None
17
18
19 def upgrade():
20 # Create state table
21 pass
22
23
24 def downgrade():
25 # Remove job_state table
26 # Job run history is still maintained, so no need to copy
27 op.drop_table("state")
28
[end of src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py b/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py
--- a/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py
+++ b/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py
@@ -1,4 +1,7 @@
-"""Create dedicated job_state table
+"""THIS IS A NO-OP.
+
+IT EXISTS ONLY TO PREVENT USERS WHO APPLIED THIS MIGRATION
+FROM ENDING UP WITH AN ORPHANED alembic_version IN THEIR DB.
Revision ID: f4c225a9492f
Revises: 5b43800443d1
@@ -17,11 +20,8 @@
def upgrade():
- # Create state table
pass
def downgrade():
- # Remove job_state table
- # Job run history is still maintained, so no need to copy
- op.drop_table("state")
+ pass
|
{"golden_diff": "diff --git a/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py b/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py\n--- a/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py\n+++ b/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py\n@@ -1,4 +1,7 @@\n-\"\"\"Create dedicated job_state table\n+\"\"\"THIS IS A NO-OP.\n+\n+IT EXISTS ONLY TO PREVENT USERS WHO APPLIED THIS MIGRATION\n+FROM ENDING UP WITH AN ORPHANED alembic_version IN THEIR DB.\n \n Revision ID: f4c225a9492f\n Revises: 5b43800443d1\n@@ -17,11 +20,8 @@\n \n \n def upgrade():\n- # Create state table\n pass\n \n \n def downgrade():\n- # Remove job_state table\n- # Job run history is still maintained, so no need to copy\n- op.drop_table(\"state\")\n+ pass\n", "issue": "bug: alembic downgrade from 6828cc5b1a4f to 5b43800443d1 fails.\n### Meltano Version\n\ndowngrading from 2+ to 1.76\n\n### Python Version\n\n3.7\n\n### Bug scope\n\nOther\n\n### Operating System\n\nWindows, but this probably isn't OS specific.\n\n### Description\n\nRelates to #6870. Ran `meltano repl` (as advised by @DouweM) then:\r\n\r\n```python\r\nfrom alembic import command\r\nfrom alembic.config import Config\r\nfrom meltano.migrations import MIGRATION_DIR\r\nfrom alembic.runtime.migration import MigrationContext\r\nfrom alembic.script import ScriptDirectory\r\n\r\nengine, session = project_engine(project, default=True)\r\nconn = engine.connect()\r\ncfg = Config()\r\ncfg.attributes[\"connection\"] = conn\r\ncfg.set_main_option(\"script_location\", str(MIGRATION_DIR))\r\nscript = ScriptDirectory.from_config(cfg)\r\ncontext = MigrationContext.configure(conn)\r\ncommand.downgrade(cfg, \"d135f52a6f49\")\r\n```\r\n\r\nTracelog:\r\n\r\n```\r\n2022-10-11T11:24:19.745585Z [info ] Context impl PostgresqlImpl.\r\n2022-10-11T11:24:19.747541Z [info ] Will assume transactional DDL.\r\n2022-10-11T11:24:19.853452Z [info ] Running downgrade 6828cc5b1a4f -> f4c225a9492f, Create dedicated state table\r\n2022-10-11T11:24:19.898474Z [info ] Running downgrade f4c225a9492f -> 5b43800443d1, Create dedicated job_state table ---------------------------------------------------------------------------\r\nUndefinedTable Traceback (most recent call last)\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)\r\n 1900 self.dialect.do_execute(\r\n-> 1901 cursor, statement, parameters, context\r\n 1902 )\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\default.py in do_execute(self, cursor, statement, parameters, context)\r\n 735 def do_execute(self, cursor, statement, parameters, context=None):\r\n--> 736 cursor.execute(statement, parameters)\r\n 737\r\n\r\nUndefinedTable: table \"state\" does not exist\r\n\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nProgrammingError Traceback (most recent call last)\r\n<ipython-input-14-8baf3a7dd97e> in <module>\r\n----> 1 command.downgrade(cfg, \"d135f52a6f49\")\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\command.py in downgrade(config, revision, sql, tag)\r\n 366 tag=tag,\r\n 367 ):\r\n--> 368 script.run_env()\r\n 369\r\n 370\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\script\\base.py in run_env(self)\r\n 567\r\n 568 \"\"\"\r\n--> 569 util.load_python_file(self.dir, \"env.py\")\r\n 570\r\n 571 @property\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\util\\pyfiles.py in load_python_file(dir_, filename)\r\n 92 if ext == \".py\":\r\n 93 if os.path.exists(path):\r\n---> 94 module = load_module_py(module_id, path)\r\n 95 else:\r\n 96 pyc_path = pyc_file_from_path(path)\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\util\\pyfiles.py in load_module_py(module_id, path)\r\n 108 assert spec\r\n 109 module = importlib.util.module_from_spec(spec)\r\n--> 110 spec.loader.exec_module(module) # type: ignore\r\n 111 return module\r\n\r\n~\\AppData\\Local\\Programs\\Python\\Python37\\lib\\importlib\\_bootstrap_external.py in exec_module(self, module)\r\n\r\n~\\AppData\\Local\\Programs\\Python\\Python37\\lib\\importlib\\_bootstrap.py in _call_with_frames_removed(f, *args, **kwds)\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\meltano\\migrations\\env.py in <module>\r\n 58 run_migrations_offline()\r\n 59 else:\r\n---> 60 run_migrations_online()\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\meltano\\migrations\\env.py in run_migrations_online()\r\n 35 connection = config.attributes.get(\"connection\")\r\n 36 if connection:\r\n---> 37 _run_migrations_online(connection)\r\n 38 return\r\n 39\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\meltano\\migrations\\env.py in _run_migrations_online(connection)\r\n 52\r\n 53 with context.begin_transaction():\r\n---> 54 context.run_migrations()\r\n 55\r\n 56\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\context.py in run_migrations(*args, **kw)\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\runtime\\environment.py in run_migrations(self, **kw)\r\n 851 assert self._migration_context is not None\r\n 852 with Operations.context(self._migration_context):\r\n--> 853 self.get_context().run_migrations(**kw)\r\n 854\r\n 855 def execute(self, sql, execution_options=None):\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\runtime\\migration.py in run_migrations(self, **kw)\r\n 621 \"-- Running %s\" % (step.short_log,)\r\n 622 )\r\n--> 623 step.migration_fn(**kw)\r\n 624\r\n 625 # previously, we wouldn't stamp per migration\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\meltano\\migrations\\versions\\f4c225a9492f_create_dedicated_job_state_table.py in downgrade()\r\n 25 # Remove job_state table\r\n 26 # Job run history is still maintained, so no need to copy\r\n---> 27 op.drop_table(\"state\")\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\op.py in drop_table(*args, **kw)\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\operations\\base.py in drop_table(self, table_name, schema, **kw)\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\operations\\ops.py in drop_table(cls, operations, table_name, schema, **kw)\r\n 1347 \"\"\"\r\n 1348 op = cls(table_name, schema=schema, table_kw=kw)\r\n-> 1349 operations.invoke(op)\r\n 1350\r\n 1351\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\operations\\base.py in invoke(self, operation)\r\n 397 operation, self.migration_context.impl.__dialect__\r\n 398 )\r\n--> 399 return fn(self, operation)\r\n 400\r\n 401 def f(self, name: str) -> \"conv\":\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\operations\\toimpl.py in drop_table(operations, operation)\r\n 78 def drop_table(operations: \"Operations\", operation: \"ops.DropTableOp\") -> None:\r\n 79 operations.impl.drop_table(\r\n---> 80 operation.to_table(operations.migration_context)\r\n 81 )\r\n 82\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\ddl\\impl.py in drop_table(self, table)\r\n 375 table, self.connection, checkfirst=False, _ddl_runner=self\r\n 376 )\r\n--> 377 self._exec(schema.DropTable(table))\r\n 378 table.dispatch.after_drop(\r\n 379 table, self.connection, checkfirst=False, _ddl_runner=self\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\alembic\\ddl\\impl.py in _exec(self, construct, execution_options, multiparams, params)\r\n 193 multiparams += (params,)\r\n 194\r\n--> 195 return conn.execute(construct, multiparams)\r\n 196\r\n 197 def execute(\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in execute(self, statement, *multiparams, **params)\r\n 1378 )\r\n 1379 else:\r\n-> 1380 return meth(self, multiparams, params, _EMPTY_EXECUTION_OPTS)\r\n 1381\r\n 1382 def _execute_function(self, func, multiparams, params, execution_options):\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\sql\\ddl.py in _execute_on_connection(self, connection, multiparams, params, execution_options)\r\n 79 ):\r\n 80 return connection._execute_ddl(\r\n---> 81 self, multiparams, params, execution_options\r\n 82 )\r\n 83\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in _execute_ddl(self, ddl, multiparams, params, execution_options)\r\n 1476 None,\r\n 1477 execution_options,\r\n-> 1478 compiled,\r\n 1479 )\r\n 1480 if self._has_events or self.engine._has_events:\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)\r\n 1942 except BaseException as e:\r\n 1943 self._handle_dbapi_exception(\r\n-> 1944 e, statement, parameters, cursor, context\r\n 1945 )\r\n 1946\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in _handle_dbapi_exception(self, e, statement, parameters, cursor, context)\r\n 2123 elif should_wrap:\r\n 2124 util.raise_(\r\n-> 2125 sqlalchemy_exception, with_traceback=exc_info[2], from_=e\r\n 2126 )\r\n 2127 else:\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\util\\compat.py in raise_(***failed resolving arguments***)\r\n 206\r\n 207 try:\r\n--> 208 raise exception\r\n 209 finally:\r\n 210 # credit to\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\base.py in _execute_context(self, dialect, constructor, statement, parameters, execution_options, *args, **kw)\r\n 1899 if not evt_handled:\r\n 1900 self.dialect.do_execute(\r\n-> 1901 cursor, statement, parameters, context\r\n 1902 )\r\n 1903\r\n\r\n~\\.virtualenvs\\meltano-9aGVMBGe\\lib\\site-packages\\sqlalchemy\\engine\\default.py in do_execute(self, cursor, statement, parameters, context)\r\n 734\r\n 735 def do_execute(self, cursor, statement, parameters, context=None):\r\n--> 736 cursor.execute(statement, parameters)\r\n 737\r\n 738 def do_execute_no_params(self, cursor, statement, context=None):\r\n\r\nProgrammingError: (psycopg2.errors.UndefinedTable) table \"state\" does not exist\r\n```\r\n\r\n# Diagnosis\r\n- Downgrade path in first migration drops table `state`: https://github.com/meltano/meltano/blob/v2.7.2/src/meltano/migrations/versions/6828cc5b1a4f_create_dedicated_state_table.py#L367\r\n- Downgrade path in second migration also drops table `state`: https://github.com/meltano/meltano/blob/v2.7.2/src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py#L27\r\n\r\nThe second step fails because `state` is already dropped.\r\n\r\n# Suggested Fix\r\n\r\nRemove the `f4c225a9492f` migration. It does nothing during upgrade, and only causes problems on downgrade.\n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Create dedicated job_state table\n\nRevision ID: f4c225a9492f\nRevises: 5b43800443d1\nCreate Date: 2022-09-02 09:44:05.581824\n\n\"\"\"\nfrom __future__ import annotations\n\nfrom alembic import op\n\n# revision identifiers, used by Alembic.\nrevision = \"f4c225a9492f\"\ndown_revision = \"5b43800443d1\"\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # Create state table\n pass\n\n\ndef downgrade():\n # Remove job_state table\n # Job run history is still maintained, so no need to copy\n op.drop_table(\"state\")\n", "path": "src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py"}]}
| 4,080 | 289 |
gh_patches_debug_7021
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-26839
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update documentation on previews permissions
The help center should be updated following #27783.
</issue>
<code>
[start of zerver/lib/url_redirects.py]
1 from dataclasses import dataclass
2 from typing import List
3
4
5 @dataclass
6 class URLRedirect:
7 old_url: str
8 new_url: str
9
10
11 API_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
12 # Add URL redirects for REST API documentation here:
13 URLRedirect("/api/delete-stream", "/api/archive-stream"),
14 ]
15
16 POLICY_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
17 # Add URL redirects for policy documentation here:
18 URLRedirect("/privacy/", "/policies/privacy"),
19 URLRedirect("/terms/", "/policies/terms"),
20 ]
21
22 HELP_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
23 # Add URL redirects for help center documentation here:
24 URLRedirect("/help/pm-mention-alert-notifications", "/help/dm-mention-alert-notifications"),
25 URLRedirect("/help/restrict-private-messages", "/help/restrict-direct-messages"),
26 URLRedirect("/help/reading-pms", "/help/reading-dms"),
27 URLRedirect("/help/private-messages", "/help/direct-messages"),
28 URLRedirect("/help/configure-who-can-edit-topics", "/help/restrict-moving-messages"),
29 URLRedirect(
30 "/help/configure-message-editing-and-deletion",
31 "/help/restrict-message-editing-and-deletion",
32 ),
33 URLRedirect("/help/restrict-visibility-of-email-addresses", "/help/configure-email-visibility"),
34 URLRedirect("/help/change-default-view", "/help/configure-default-view"),
35 URLRedirect("/help/recent-topics", "/help/recent-conversations"),
36 URLRedirect(
37 "/help/add-custom-profile-fields",
38 "/help/custom-profile-fields",
39 ),
40 URLRedirect(
41 "/help/enable-enter-to-send",
42 "/help/mastering-the-compose-box#toggle-between-ctrl-enter-and-enter-to-send-a-message",
43 ),
44 URLRedirect(
45 "/help/change-the-default-language-for-your-organization",
46 "/help/configure-organization-language",
47 ),
48 URLRedirect("/help/delete-a-stream", "/help/archive-a-stream"),
49 URLRedirect("/help/change-the-topic-of-a-message", "/help/rename-a-topic"),
50 URLRedirect("/help/configure-missed-message-emails", "/help/email-notifications"),
51 URLRedirect("/help/add-an-alert-word", "/help/dm-mention-alert-notifications#alert-words"),
52 URLRedirect("/help/test-mobile-notifications", "/help/mobile-notifications"),
53 URLRedirect(
54 "/help/troubleshooting-desktop-notifications",
55 "/help/desktop-notifications#troubleshooting-desktop-notifications",
56 ),
57 URLRedirect(
58 "/help/change-notification-sound", "/help/desktop-notifications#change-notification-sound"
59 ),
60 URLRedirect("/help/configure-message-notification-emails", "/help/email-notifications"),
61 URLRedirect("/help/disable-new-login-emails", "/help/email-notifications#new-login-emails"),
62 # The `help/about-streams-and-topics` redirect is particularly important,
63 # because the old URL appears in links from Welcome Bot messages.
64 URLRedirect("/help/about-streams-and-topics", "/help/streams-and-topics"),
65 URLRedirect("/help/community-topic-edits", "/help/restrict-moving-messages"),
66 URLRedirect(
67 "/help/only-allow-admins-to-add-emoji", "/help/custom-emoji#change-who-can-add-custom-emoji"
68 ),
69 URLRedirect(
70 "/help/configure-who-can-add-custom-emoji",
71 "/help/custom-emoji#change-who-can-add-custom-emoji",
72 ),
73 URLRedirect("/help/add-custom-emoji", "/help/custom-emoji"),
74 URLRedirect("/help/night-mode", "/help/dark-theme"),
75 URLRedirect("/help/enable-emoticon-translations", "/help/configure-emoticon-translations"),
76 URLRedirect("/help/web-public-streams", "/help/public-access-option"),
77 URLRedirect("/help/starting-a-new-private-thread", "/help/starting-a-new-direct-message"),
78 URLRedirect("/help/edit-or-delete-a-message", "/help/delete-a-message"),
79 URLRedirect("/help/start-a-new-topic", "/help/starting-a-new-topic"),
80 URLRedirect("/help/configure-default-view", "/help/configure-home-view"),
81 URLRedirect("/help/reading-topics", "/help/reading-conversations"),
82 URLRedirect("/help/finding-a-topic-to-read", "/help/finding-a-conversation-to-read"),
83 ]
84
85 LANDING_PAGE_REDIRECTS = [
86 # Add URL redirects for corporate landing pages here.
87 URLRedirect("/new-user/", "/hello/"),
88 URLRedirect("/developer-community/", "/development-community"),
89 URLRedirect("/for/companies/", "/for/business"),
90 URLRedirect("/for/working-groups-and-communities/", "/for/communities"),
91 ]
92
93 DOCUMENTATION_REDIRECTS = (
94 API_DOCUMENTATION_REDIRECTS + POLICY_DOCUMENTATION_REDIRECTS + HELP_DOCUMENTATION_REDIRECTS
95 )
96
[end of zerver/lib/url_redirects.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/lib/url_redirects.py b/zerver/lib/url_redirects.py
--- a/zerver/lib/url_redirects.py
+++ b/zerver/lib/url_redirects.py
@@ -80,6 +80,7 @@
URLRedirect("/help/configure-default-view", "/help/configure-home-view"),
URLRedirect("/help/reading-topics", "/help/reading-conversations"),
URLRedirect("/help/finding-a-topic-to-read", "/help/finding-a-conversation-to-read"),
+ URLRedirect("/help/view-and-browse-images", "/help/view-images-and-videos"),
]
LANDING_PAGE_REDIRECTS = [
|
{"golden_diff": "diff --git a/zerver/lib/url_redirects.py b/zerver/lib/url_redirects.py\n--- a/zerver/lib/url_redirects.py\n+++ b/zerver/lib/url_redirects.py\n@@ -80,6 +80,7 @@\n URLRedirect(\"/help/configure-default-view\", \"/help/configure-home-view\"),\n URLRedirect(\"/help/reading-topics\", \"/help/reading-conversations\"),\n URLRedirect(\"/help/finding-a-topic-to-read\", \"/help/finding-a-conversation-to-read\"),\n+ URLRedirect(\"/help/view-and-browse-images\", \"/help/view-images-and-videos\"),\n ]\n \n LANDING_PAGE_REDIRECTS = [\n", "issue": "Update documentation on previews permissions\nThe help center should be updated following #27783.\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import List\n\n\n@dataclass\nclass URLRedirect:\n old_url: str\n new_url: str\n\n\nAPI_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for REST API documentation here:\n URLRedirect(\"/api/delete-stream\", \"/api/archive-stream\"),\n]\n\nPOLICY_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for policy documentation here:\n URLRedirect(\"/privacy/\", \"/policies/privacy\"),\n URLRedirect(\"/terms/\", \"/policies/terms\"),\n]\n\nHELP_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for help center documentation here:\n URLRedirect(\"/help/pm-mention-alert-notifications\", \"/help/dm-mention-alert-notifications\"),\n URLRedirect(\"/help/restrict-private-messages\", \"/help/restrict-direct-messages\"),\n URLRedirect(\"/help/reading-pms\", \"/help/reading-dms\"),\n URLRedirect(\"/help/private-messages\", \"/help/direct-messages\"),\n URLRedirect(\"/help/configure-who-can-edit-topics\", \"/help/restrict-moving-messages\"),\n URLRedirect(\n \"/help/configure-message-editing-and-deletion\",\n \"/help/restrict-message-editing-and-deletion\",\n ),\n URLRedirect(\"/help/restrict-visibility-of-email-addresses\", \"/help/configure-email-visibility\"),\n URLRedirect(\"/help/change-default-view\", \"/help/configure-default-view\"),\n URLRedirect(\"/help/recent-topics\", \"/help/recent-conversations\"),\n URLRedirect(\n \"/help/add-custom-profile-fields\",\n \"/help/custom-profile-fields\",\n ),\n URLRedirect(\n \"/help/enable-enter-to-send\",\n \"/help/mastering-the-compose-box#toggle-between-ctrl-enter-and-enter-to-send-a-message\",\n ),\n URLRedirect(\n \"/help/change-the-default-language-for-your-organization\",\n \"/help/configure-organization-language\",\n ),\n URLRedirect(\"/help/delete-a-stream\", \"/help/archive-a-stream\"),\n URLRedirect(\"/help/change-the-topic-of-a-message\", \"/help/rename-a-topic\"),\n URLRedirect(\"/help/configure-missed-message-emails\", \"/help/email-notifications\"),\n URLRedirect(\"/help/add-an-alert-word\", \"/help/dm-mention-alert-notifications#alert-words\"),\n URLRedirect(\"/help/test-mobile-notifications\", \"/help/mobile-notifications\"),\n URLRedirect(\n \"/help/troubleshooting-desktop-notifications\",\n \"/help/desktop-notifications#troubleshooting-desktop-notifications\",\n ),\n URLRedirect(\n \"/help/change-notification-sound\", \"/help/desktop-notifications#change-notification-sound\"\n ),\n URLRedirect(\"/help/configure-message-notification-emails\", \"/help/email-notifications\"),\n URLRedirect(\"/help/disable-new-login-emails\", \"/help/email-notifications#new-login-emails\"),\n # The `help/about-streams-and-topics` redirect is particularly important,\n # because the old URL appears in links from Welcome Bot messages.\n URLRedirect(\"/help/about-streams-and-topics\", \"/help/streams-and-topics\"),\n URLRedirect(\"/help/community-topic-edits\", \"/help/restrict-moving-messages\"),\n URLRedirect(\n \"/help/only-allow-admins-to-add-emoji\", \"/help/custom-emoji#change-who-can-add-custom-emoji\"\n ),\n URLRedirect(\n \"/help/configure-who-can-add-custom-emoji\",\n \"/help/custom-emoji#change-who-can-add-custom-emoji\",\n ),\n URLRedirect(\"/help/add-custom-emoji\", \"/help/custom-emoji\"),\n URLRedirect(\"/help/night-mode\", \"/help/dark-theme\"),\n URLRedirect(\"/help/enable-emoticon-translations\", \"/help/configure-emoticon-translations\"),\n URLRedirect(\"/help/web-public-streams\", \"/help/public-access-option\"),\n URLRedirect(\"/help/starting-a-new-private-thread\", \"/help/starting-a-new-direct-message\"),\n URLRedirect(\"/help/edit-or-delete-a-message\", \"/help/delete-a-message\"),\n URLRedirect(\"/help/start-a-new-topic\", \"/help/starting-a-new-topic\"),\n URLRedirect(\"/help/configure-default-view\", \"/help/configure-home-view\"),\n URLRedirect(\"/help/reading-topics\", \"/help/reading-conversations\"),\n URLRedirect(\"/help/finding-a-topic-to-read\", \"/help/finding-a-conversation-to-read\"),\n]\n\nLANDING_PAGE_REDIRECTS = [\n # Add URL redirects for corporate landing pages here.\n URLRedirect(\"/new-user/\", \"/hello/\"),\n URLRedirect(\"/developer-community/\", \"/development-community\"),\n URLRedirect(\"/for/companies/\", \"/for/business\"),\n URLRedirect(\"/for/working-groups-and-communities/\", \"/for/communities\"),\n]\n\nDOCUMENTATION_REDIRECTS = (\n API_DOCUMENTATION_REDIRECTS + POLICY_DOCUMENTATION_REDIRECTS + HELP_DOCUMENTATION_REDIRECTS\n)\n", "path": "zerver/lib/url_redirects.py"}]}
| 1,760 | 137 |
gh_patches_debug_20137
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-5373
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PROFILE_DIR with forward slashes
hi there,
I want to use the ```PROFILE_DIR``` variable in my profiles to access a path relative to the value of that variable. Now I do cross-compiling with a compiler that cannot parse backslashes.
An example yaml like this:
```yaml
[env]
ABC=$PROFILE_DIR/path/abc
```
will result in a malformed path as the compiler tries to interpret the slashes as excape characters:
compiler parsed: ... C:UsersNAME.conanprofiles/path/abc ...
Would it be possible to provide an POSIX style path (like PROFILE_DIR_POSIX)?
</issue>
<code>
[start of conans/client/profile_loader.py]
1 import os
2 from collections import OrderedDict, defaultdict
3
4 from conans.errors import ConanException
5 from conans.model.env_info import EnvValues, unquote
6 from conans.model.options import OptionsValues
7 from conans.model.profile import Profile
8 from conans.model.ref import ConanFileReference
9 from conans.util.config_parser import ConfigParser
10 from conans.util.files import load, mkdir
11 from conans.util.log import logger
12
13
14 class ProfileParser(object):
15
16 def __init__(self, text):
17 self.vars = OrderedDict() # Order matters, if user declares F=1 and then FOO=12,
18 # and in profile MYVAR=$FOO, it will
19 self.includes = []
20 self.profile_text = ""
21
22 for counter, line in enumerate(text.splitlines()):
23 if not line.strip() or line.strip().startswith("#"):
24 continue
25 elif line.strip().startswith("["):
26 self.profile_text = "\n".join(text.splitlines()[counter:])
27 break
28 elif line.strip().startswith("include("):
29 include = line.split("include(", 1)[1]
30 if not include.endswith(")"):
31 raise ConanException("Invalid include statement")
32 include = include[:-1]
33 self.includes.append(include)
34 else:
35 name, value = line.split("=", 1)
36 name = name.strip()
37 if " " in name:
38 raise ConanException("The names of the variables cannot contain spaces")
39 value = unquote(value)
40 self.vars[name] = value
41
42 def apply_vars(self, repl_vars):
43 self.vars = self._apply_in_vars(repl_vars)
44 self.includes = self._apply_in_includes(repl_vars)
45 self.profile_text = self._apply_in_profile_text(repl_vars)
46
47 def _apply_in_vars(self, repl_vars):
48 tmp_vars = OrderedDict()
49 for key, value in self.vars.items():
50 for repl_key, repl_value in repl_vars.items():
51 key = key.replace("$%s" % repl_key, repl_value)
52 value = value.replace("$%s" % repl_key, repl_value)
53 tmp_vars[key] = value
54 return tmp_vars
55
56 def _apply_in_includes(self, repl_vars):
57 tmp_includes = []
58 for include in self.includes:
59 for repl_key, repl_value in repl_vars.items():
60 include = include.replace("$%s" % repl_key, repl_value)
61 tmp_includes.append(include)
62 return tmp_includes
63
64 def _apply_in_profile_text(self, repl_vars):
65 tmp_text = self.profile_text
66 for repl_key, repl_value in repl_vars.items():
67 tmp_text = tmp_text.replace("$%s" % repl_key, repl_value)
68 return tmp_text
69
70
71 def get_profile_path(profile_name, default_folder, cwd, exists=True):
72 def valid_path(profile_path):
73 if exists and not os.path.isfile(profile_path):
74 raise ConanException("Profile not found: %s" % profile_path)
75 return profile_path
76
77 if os.path.isabs(profile_name):
78 return valid_path(profile_name)
79
80 if profile_name[:2] in ("./", ".\\"): # local
81 profile_path = os.path.abspath(os.path.join(cwd, profile_name))
82 return valid_path(profile_path)
83
84 if not os.path.exists(default_folder):
85 mkdir(default_folder)
86 profile_path = os.path.join(default_folder, profile_name)
87 if exists:
88 if not os.path.isfile(profile_path):
89 profile_path = os.path.abspath(os.path.join(cwd, profile_name))
90 if not os.path.isfile(profile_path):
91 raise ConanException("Profile not found: %s" % profile_name)
92 return profile_path
93
94
95 def read_profile(profile_name, cwd, default_folder):
96 """ Will look for "profile_name" in disk if profile_name is absolute path,
97 in current folder if path is relative or in the default folder otherwise.
98 return: a Profile object
99 """
100 if not profile_name:
101 return None, None
102
103 profile_path = get_profile_path(profile_name, default_folder, cwd)
104 logger.debug("PROFILE LOAD: %s" % profile_path)
105 text = load(profile_path)
106
107 try:
108 return _load_profile(text, profile_path, default_folder)
109 except ConanException as exc:
110 raise ConanException("Error reading '%s' profile: %s" % (profile_name, exc))
111
112
113 def _load_profile(text, profile_path, default_folder):
114 """ Parse and return a Profile object from a text config like representation.
115 cwd is needed to be able to load the includes
116 """
117
118 try:
119 inherited_profile = Profile()
120 cwd = os.path.dirname(os.path.abspath(profile_path)) if profile_path else None
121 profile_parser = ProfileParser(text)
122 inherited_vars = profile_parser.vars
123 # Iterate the includes and call recursive to get the profile and variables
124 # from parent profiles
125 for include in profile_parser.includes:
126 # Recursion !!
127 profile, declared_vars = read_profile(include, cwd, default_folder)
128 inherited_profile.update(profile)
129 inherited_vars.update(declared_vars)
130
131 # Apply the automatic PROFILE_DIR variable
132 if cwd:
133 inherited_vars["PROFILE_DIR"] = os.path.abspath(cwd)
134 # Allows PYTHONPATH=$PROFILE_DIR/pythontools
135
136 # Replace the variables from parents in the current profile
137 profile_parser.apply_vars(inherited_vars)
138
139 # Current profile before update with parents (but parent variables already applied)
140 doc = ConfigParser(profile_parser.profile_text,
141 allowed_fields=["build_requires", "settings", "env",
142 "scopes", "options"])
143
144 # Merge the inherited profile with the readed from current profile
145 _apply_inner_profile(doc, inherited_profile)
146
147 # Return the intherited vars to apply them in the parent profile if exists
148 inherited_vars.update(profile_parser.vars)
149 return inherited_profile, inherited_vars
150
151 except ConanException:
152 raise
153 except Exception as exc:
154 raise ConanException("Error parsing the profile text file: %s" % str(exc))
155
156
157 def _load_single_build_require(profile, line):
158
159 tokens = line.split(":", 1)
160 if len(tokens) == 1:
161 pattern, req_list = "*", line
162 else:
163 pattern, req_list = tokens
164 refs = [ConanFileReference.loads(reference.strip()) for reference in req_list.split(",")]
165 profile.build_requires.setdefault(pattern, []).extend(refs)
166
167
168 def _apply_inner_profile(doc, base_profile):
169 """
170
171 :param doc: ConfigParser object from the current profile (excluding includes and vars,
172 and with values already replaced)
173 :param base_profile: Profile inherited, it's used as a base profile to modify it.
174 :return: None
175 """
176
177 def get_package_name_value(item):
178 """Parse items like package:name=value or name=value"""
179 package_name = None
180 if ":" in item:
181 tmp = item.split(":", 1)
182 package_name, item = tmp
183
184 name, value = item.split("=", 1)
185 name = name.strip()
186 value = unquote(value)
187 return package_name, name, value
188
189 for setting in doc.settings.splitlines():
190 setting = setting.strip()
191 if setting and not setting.startswith("#"):
192 if "=" not in setting:
193 raise ConanException("Invalid setting line '%s'" % setting)
194 package_name, name, value = get_package_name_value(setting)
195 if package_name:
196 base_profile.package_settings[package_name][name] = value
197 else:
198 base_profile.settings[name] = value
199
200 if doc.build_requires:
201 # FIXME CHECKS OF DUPLICATED?
202 for req in doc.build_requires.splitlines():
203 _load_single_build_require(base_profile, req)
204
205 if doc.options:
206 base_profile.options.update(OptionsValues.loads(doc.options))
207
208 # The env vars from the current profile (read in doc)
209 # are updated with the included profiles (base_profile)
210 # the current env values has priority
211 current_env_values = EnvValues.loads(doc.env)
212 current_env_values.update(base_profile.env_values)
213 base_profile.env_values = current_env_values
214
215
216 def profile_from_args(profiles, settings, options, env, cwd, cache):
217 """ Return a Profile object, as the result of merging a potentially existing Profile
218 file and the args command-line arguments
219 """
220 default_profile = cache.default_profile # Ensures a default profile creating
221
222 if profiles is None:
223 result = default_profile
224 else:
225 result = Profile()
226 for p in profiles:
227 tmp, _ = read_profile(p, cwd, cache.profiles_path)
228 result.update(tmp)
229
230 args_profile = _profile_parse_args(settings, options, env)
231
232 if result:
233 result.update(args_profile)
234 else:
235 result = args_profile
236 return result
237
238
239 def _profile_parse_args(settings, options, envs):
240 """ return a Profile object result of parsing raw data
241 """
242 def _get_tuples_list_from_extender_arg(items):
243 if not items:
244 return []
245 # Validate the pairs
246 for item in items:
247 chunks = item.split("=", 1)
248 if len(chunks) != 2:
249 raise ConanException("Invalid input '%s', use 'name=value'" % item)
250 return [(item[0], item[1]) for item in [item.split("=", 1) for item in items]]
251
252 def _get_simple_and_package_tuples(items):
253 """Parse items like "thing:item=value or item2=value2 and returns a tuple list for
254 the simple items (name, value) and a dict for the package items
255 {package: [(item, value)...)], ...}
256 """
257 simple_items = []
258 package_items = defaultdict(list)
259 tuples = _get_tuples_list_from_extender_arg(items)
260 for name, value in tuples:
261 if ":" in name: # Scoped items
262 tmp = name.split(":", 1)
263 ref_name = tmp[0]
264 name = tmp[1]
265 package_items[ref_name].append((name, value))
266 else:
267 simple_items.append((name, value))
268 return simple_items, package_items
269
270 def _get_env_values(env, package_env):
271 env_values = EnvValues()
272 for name, value in env:
273 env_values.add(name, EnvValues.load_value(value))
274 for package, data in package_env.items():
275 for name, value in data:
276 env_values.add(name, EnvValues.load_value(value), package)
277 return env_values
278
279 result = Profile()
280 options = _get_tuples_list_from_extender_arg(options)
281 result.options = OptionsValues(options)
282 env, package_env = _get_simple_and_package_tuples(envs)
283 env_values = _get_env_values(env, package_env)
284 result.env_values = env_values
285 settings, package_settings = _get_simple_and_package_tuples(settings)
286 result.settings = OrderedDict(settings)
287 for pkg, values in package_settings.items():
288 result.package_settings[pkg] = OrderedDict(values)
289 return result
290
[end of conans/client/profile_loader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/profile_loader.py b/conans/client/profile_loader.py
--- a/conans/client/profile_loader.py
+++ b/conans/client/profile_loader.py
@@ -130,7 +130,7 @@
# Apply the automatic PROFILE_DIR variable
if cwd:
- inherited_vars["PROFILE_DIR"] = os.path.abspath(cwd)
+ inherited_vars["PROFILE_DIR"] = os.path.abspath(cwd).replace('\\', '/')
# Allows PYTHONPATH=$PROFILE_DIR/pythontools
# Replace the variables from parents in the current profile
@@ -144,7 +144,7 @@
# Merge the inherited profile with the readed from current profile
_apply_inner_profile(doc, inherited_profile)
- # Return the intherited vars to apply them in the parent profile if exists
+ # Return the inherited vars to apply them in the parent profile if exists
inherited_vars.update(profile_parser.vars)
return inherited_profile, inherited_vars
|
{"golden_diff": "diff --git a/conans/client/profile_loader.py b/conans/client/profile_loader.py\n--- a/conans/client/profile_loader.py\n+++ b/conans/client/profile_loader.py\n@@ -130,7 +130,7 @@\n \n # Apply the automatic PROFILE_DIR variable\n if cwd:\n- inherited_vars[\"PROFILE_DIR\"] = os.path.abspath(cwd)\n+ inherited_vars[\"PROFILE_DIR\"] = os.path.abspath(cwd).replace('\\\\', '/')\n # Allows PYTHONPATH=$PROFILE_DIR/pythontools\n \n # Replace the variables from parents in the current profile\n@@ -144,7 +144,7 @@\n # Merge the inherited profile with the readed from current profile\n _apply_inner_profile(doc, inherited_profile)\n \n- # Return the intherited vars to apply them in the parent profile if exists\n+ # Return the inherited vars to apply them in the parent profile if exists\n inherited_vars.update(profile_parser.vars)\n return inherited_profile, inherited_vars\n", "issue": "PROFILE_DIR with forward slashes\nhi there,\r\nI want to use the ```PROFILE_DIR``` variable in my profiles to access a path relative to the value of that variable. Now I do cross-compiling with a compiler that cannot parse backslashes.\r\n\r\nAn example yaml like this:\r\n```yaml\r\n[env]\r\nABC=$PROFILE_DIR/path/abc\r\n```\r\nwill result in a malformed path as the compiler tries to interpret the slashes as excape characters:\r\ncompiler parsed: ... C:UsersNAME.conanprofiles/path/abc ...\r\n\r\nWould it be possible to provide an POSIX style path (like PROFILE_DIR_POSIX)?\n", "before_files": [{"content": "import os\nfrom collections import OrderedDict, defaultdict\n\nfrom conans.errors import ConanException\nfrom conans.model.env_info import EnvValues, unquote\nfrom conans.model.options import OptionsValues\nfrom conans.model.profile import Profile\nfrom conans.model.ref import ConanFileReference\nfrom conans.util.config_parser import ConfigParser\nfrom conans.util.files import load, mkdir\nfrom conans.util.log import logger\n\n\nclass ProfileParser(object):\n\n def __init__(self, text):\n self.vars = OrderedDict() # Order matters, if user declares F=1 and then FOO=12,\n # and in profile MYVAR=$FOO, it will\n self.includes = []\n self.profile_text = \"\"\n\n for counter, line in enumerate(text.splitlines()):\n if not line.strip() or line.strip().startswith(\"#\"):\n continue\n elif line.strip().startswith(\"[\"):\n self.profile_text = \"\\n\".join(text.splitlines()[counter:])\n break\n elif line.strip().startswith(\"include(\"):\n include = line.split(\"include(\", 1)[1]\n if not include.endswith(\")\"):\n raise ConanException(\"Invalid include statement\")\n include = include[:-1]\n self.includes.append(include)\n else:\n name, value = line.split(\"=\", 1)\n name = name.strip()\n if \" \" in name:\n raise ConanException(\"The names of the variables cannot contain spaces\")\n value = unquote(value)\n self.vars[name] = value\n\n def apply_vars(self, repl_vars):\n self.vars = self._apply_in_vars(repl_vars)\n self.includes = self._apply_in_includes(repl_vars)\n self.profile_text = self._apply_in_profile_text(repl_vars)\n\n def _apply_in_vars(self, repl_vars):\n tmp_vars = OrderedDict()\n for key, value in self.vars.items():\n for repl_key, repl_value in repl_vars.items():\n key = key.replace(\"$%s\" % repl_key, repl_value)\n value = value.replace(\"$%s\" % repl_key, repl_value)\n tmp_vars[key] = value\n return tmp_vars\n\n def _apply_in_includes(self, repl_vars):\n tmp_includes = []\n for include in self.includes:\n for repl_key, repl_value in repl_vars.items():\n include = include.replace(\"$%s\" % repl_key, repl_value)\n tmp_includes.append(include)\n return tmp_includes\n\n def _apply_in_profile_text(self, repl_vars):\n tmp_text = self.profile_text\n for repl_key, repl_value in repl_vars.items():\n tmp_text = tmp_text.replace(\"$%s\" % repl_key, repl_value)\n return tmp_text\n\n\ndef get_profile_path(profile_name, default_folder, cwd, exists=True):\n def valid_path(profile_path):\n if exists and not os.path.isfile(profile_path):\n raise ConanException(\"Profile not found: %s\" % profile_path)\n return profile_path\n\n if os.path.isabs(profile_name):\n return valid_path(profile_name)\n\n if profile_name[:2] in (\"./\", \".\\\\\"): # local\n profile_path = os.path.abspath(os.path.join(cwd, profile_name))\n return valid_path(profile_path)\n\n if not os.path.exists(default_folder):\n mkdir(default_folder)\n profile_path = os.path.join(default_folder, profile_name)\n if exists:\n if not os.path.isfile(profile_path):\n profile_path = os.path.abspath(os.path.join(cwd, profile_name))\n if not os.path.isfile(profile_path):\n raise ConanException(\"Profile not found: %s\" % profile_name)\n return profile_path\n\n\ndef read_profile(profile_name, cwd, default_folder):\n \"\"\" Will look for \"profile_name\" in disk if profile_name is absolute path,\n in current folder if path is relative or in the default folder otherwise.\n return: a Profile object\n \"\"\"\n if not profile_name:\n return None, None\n\n profile_path = get_profile_path(profile_name, default_folder, cwd)\n logger.debug(\"PROFILE LOAD: %s\" % profile_path)\n text = load(profile_path)\n\n try:\n return _load_profile(text, profile_path, default_folder)\n except ConanException as exc:\n raise ConanException(\"Error reading '%s' profile: %s\" % (profile_name, exc))\n\n\ndef _load_profile(text, profile_path, default_folder):\n \"\"\" Parse and return a Profile object from a text config like representation.\n cwd is needed to be able to load the includes\n \"\"\"\n\n try:\n inherited_profile = Profile()\n cwd = os.path.dirname(os.path.abspath(profile_path)) if profile_path else None\n profile_parser = ProfileParser(text)\n inherited_vars = profile_parser.vars\n # Iterate the includes and call recursive to get the profile and variables\n # from parent profiles\n for include in profile_parser.includes:\n # Recursion !!\n profile, declared_vars = read_profile(include, cwd, default_folder)\n inherited_profile.update(profile)\n inherited_vars.update(declared_vars)\n\n # Apply the automatic PROFILE_DIR variable\n if cwd:\n inherited_vars[\"PROFILE_DIR\"] = os.path.abspath(cwd)\n # Allows PYTHONPATH=$PROFILE_DIR/pythontools\n\n # Replace the variables from parents in the current profile\n profile_parser.apply_vars(inherited_vars)\n\n # Current profile before update with parents (but parent variables already applied)\n doc = ConfigParser(profile_parser.profile_text,\n allowed_fields=[\"build_requires\", \"settings\", \"env\",\n \"scopes\", \"options\"])\n\n # Merge the inherited profile with the readed from current profile\n _apply_inner_profile(doc, inherited_profile)\n\n # Return the intherited vars to apply them in the parent profile if exists\n inherited_vars.update(profile_parser.vars)\n return inherited_profile, inherited_vars\n\n except ConanException:\n raise\n except Exception as exc:\n raise ConanException(\"Error parsing the profile text file: %s\" % str(exc))\n\n\ndef _load_single_build_require(profile, line):\n\n tokens = line.split(\":\", 1)\n if len(tokens) == 1:\n pattern, req_list = \"*\", line\n else:\n pattern, req_list = tokens\n refs = [ConanFileReference.loads(reference.strip()) for reference in req_list.split(\",\")]\n profile.build_requires.setdefault(pattern, []).extend(refs)\n\n\ndef _apply_inner_profile(doc, base_profile):\n \"\"\"\n\n :param doc: ConfigParser object from the current profile (excluding includes and vars,\n and with values already replaced)\n :param base_profile: Profile inherited, it's used as a base profile to modify it.\n :return: None\n \"\"\"\n\n def get_package_name_value(item):\n \"\"\"Parse items like package:name=value or name=value\"\"\"\n package_name = None\n if \":\" in item:\n tmp = item.split(\":\", 1)\n package_name, item = tmp\n\n name, value = item.split(\"=\", 1)\n name = name.strip()\n value = unquote(value)\n return package_name, name, value\n\n for setting in doc.settings.splitlines():\n setting = setting.strip()\n if setting and not setting.startswith(\"#\"):\n if \"=\" not in setting:\n raise ConanException(\"Invalid setting line '%s'\" % setting)\n package_name, name, value = get_package_name_value(setting)\n if package_name:\n base_profile.package_settings[package_name][name] = value\n else:\n base_profile.settings[name] = value\n\n if doc.build_requires:\n # FIXME CHECKS OF DUPLICATED?\n for req in doc.build_requires.splitlines():\n _load_single_build_require(base_profile, req)\n\n if doc.options:\n base_profile.options.update(OptionsValues.loads(doc.options))\n\n # The env vars from the current profile (read in doc)\n # are updated with the included profiles (base_profile)\n # the current env values has priority\n current_env_values = EnvValues.loads(doc.env)\n current_env_values.update(base_profile.env_values)\n base_profile.env_values = current_env_values\n\n\ndef profile_from_args(profiles, settings, options, env, cwd, cache):\n \"\"\" Return a Profile object, as the result of merging a potentially existing Profile\n file and the args command-line arguments\n \"\"\"\n default_profile = cache.default_profile # Ensures a default profile creating\n\n if profiles is None:\n result = default_profile\n else:\n result = Profile()\n for p in profiles:\n tmp, _ = read_profile(p, cwd, cache.profiles_path)\n result.update(tmp)\n\n args_profile = _profile_parse_args(settings, options, env)\n\n if result:\n result.update(args_profile)\n else:\n result = args_profile\n return result\n\n\ndef _profile_parse_args(settings, options, envs):\n \"\"\" return a Profile object result of parsing raw data\n \"\"\"\n def _get_tuples_list_from_extender_arg(items):\n if not items:\n return []\n # Validate the pairs\n for item in items:\n chunks = item.split(\"=\", 1)\n if len(chunks) != 2:\n raise ConanException(\"Invalid input '%s', use 'name=value'\" % item)\n return [(item[0], item[1]) for item in [item.split(\"=\", 1) for item in items]]\n\n def _get_simple_and_package_tuples(items):\n \"\"\"Parse items like \"thing:item=value or item2=value2 and returns a tuple list for\n the simple items (name, value) and a dict for the package items\n {package: [(item, value)...)], ...}\n \"\"\"\n simple_items = []\n package_items = defaultdict(list)\n tuples = _get_tuples_list_from_extender_arg(items)\n for name, value in tuples:\n if \":\" in name: # Scoped items\n tmp = name.split(\":\", 1)\n ref_name = tmp[0]\n name = tmp[1]\n package_items[ref_name].append((name, value))\n else:\n simple_items.append((name, value))\n return simple_items, package_items\n\n def _get_env_values(env, package_env):\n env_values = EnvValues()\n for name, value in env:\n env_values.add(name, EnvValues.load_value(value))\n for package, data in package_env.items():\n for name, value in data:\n env_values.add(name, EnvValues.load_value(value), package)\n return env_values\n\n result = Profile()\n options = _get_tuples_list_from_extender_arg(options)\n result.options = OptionsValues(options)\n env, package_env = _get_simple_and_package_tuples(envs)\n env_values = _get_env_values(env, package_env)\n result.env_values = env_values\n settings, package_settings = _get_simple_and_package_tuples(settings)\n result.settings = OrderedDict(settings)\n for pkg, values in package_settings.items():\n result.package_settings[pkg] = OrderedDict(values)\n return result\n", "path": "conans/client/profile_loader.py"}]}
| 3,784 | 214 |
gh_patches_debug_32222
|
rasdani/github-patches
|
git_diff
|
explosion__spaCy-3281
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect tokenization of dash punctuation in Spanish
In Spanish text, the conventions for using dashes and em-dashes as punctuation seems to be considerably different than in English. Spacy often does not tokenize the dash or em-dash as a separate token, instead keeping it attached to the closest word.
For example, the Spanish sentence:
—Yo me llamo... –murmuró el niño– Emilio Sánchez Pérez.
English Translation:
"My name is...", murmured the boy, "Emilio Sanchez Perez."
Here, the Spanish dash is used like a comma. The em-dash at the beginning of the sentence is used like a double quote. I believe that the fact that there is no space between the dash and word is throwing off the tokenizer.
The Spanish sentence above is tokenized as:
—Yo
me
llamo
...
–murmuró
el
niño–
Emilio
Sánchez
Pérez
.
I would expect the tokenization to be
—
Yo
me
llamo
...
–
murmuró
el
niño
–
Emilio
Sánchez
Pérez
.
## Your Environment
* **spaCy version:** 2.0.12
* **Platform:** Darwin-18.0.0-x86_64-i386-64bit
* **Python version:** 3.7.0
* **Models:** de, es, en
</issue>
<code>
[start of spacy/lang/punctuation.py]
1 # coding: utf8
2 from __future__ import unicode_literals
3
4 from .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY, LIST_ICONS
5 from .char_classes import HYPHENS
6 from .char_classes import CURRENCY, UNITS
7 from .char_classes import CONCAT_QUOTES, ALPHA_LOWER, ALPHA_UPPER, ALPHA
8
9
10 _prefixes = (
11 ["§", "%", "=", r"\+(?![0-9])"]
12 + LIST_PUNCT
13 + LIST_ELLIPSES
14 + LIST_QUOTES
15 + LIST_CURRENCY
16 + LIST_ICONS
17 )
18
19
20 _suffixes = (
21 LIST_PUNCT
22 + LIST_ELLIPSES
23 + LIST_QUOTES
24 + LIST_ICONS
25 + ["'s", "'S", "’s", "’S"]
26 + [
27 r"(?<=[0-9])\+",
28 r"(?<=°[FfCcKk])\.",
29 r"(?<=[0-9])(?:{c})".format(c=CURRENCY),
30 r"(?<=[0-9])(?:{u})".format(u=UNITS),
31 r"(?<=[0-9{al}{e}(?:{q})])\.".format(al=ALPHA_LOWER, e=r"%²\-\+", q=CONCAT_QUOTES),
32 r"(?<=[{au}][{au}])\.".format(au=ALPHA_UPPER),
33 ]
34 )
35
36 _infixes = (
37 LIST_ELLIPSES
38 + LIST_ICONS
39 + [
40 r"(?<=[0-9])[+\-\*^](?=[0-9-])",
41 r"(?<=[{al}])\.(?=[{au}])".format(al=ALPHA_LOWER, au=ALPHA_UPPER),
42 r"(?<=[{a}]),(?=[{a}])".format(a=ALPHA),
43 r'(?<=[{a}])(?:{h})(?=[{a}])'.format(a=ALPHA, h=HYPHENS),
44 r'(?<=[{a}])[:<>=/](?=[{a}])'.format(a=ALPHA),
45 ]
46 )
47
48 TOKENIZER_PREFIXES = _prefixes
49 TOKENIZER_SUFFIXES = _suffixes
50 TOKENIZER_INFIXES = _infixes
51
[end of spacy/lang/punctuation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/spacy/lang/punctuation.py b/spacy/lang/punctuation.py
--- a/spacy/lang/punctuation.py
+++ b/spacy/lang/punctuation.py
@@ -1,14 +1,13 @@
# coding: utf8
from __future__ import unicode_literals
-from .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY, LIST_ICONS
-from .char_classes import HYPHENS
-from .char_classes import CURRENCY, UNITS
+from .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY
+from .char_classes import LIST_ICONS, HYPHENS, CURRENCY, UNITS
from .char_classes import CONCAT_QUOTES, ALPHA_LOWER, ALPHA_UPPER, ALPHA
_prefixes = (
- ["§", "%", "=", r"\+(?![0-9])"]
+ ["§", "%", "=", "—", "–", r"\+(?![0-9])"]
+ LIST_PUNCT
+ LIST_ELLIPSES
+ LIST_QUOTES
@@ -22,13 +21,15 @@
+ LIST_ELLIPSES
+ LIST_QUOTES
+ LIST_ICONS
- + ["'s", "'S", "’s", "’S"]
+ + ["'s", "'S", "’s", "’S", "—", "–"]
+ [
r"(?<=[0-9])\+",
r"(?<=°[FfCcKk])\.",
r"(?<=[0-9])(?:{c})".format(c=CURRENCY),
r"(?<=[0-9])(?:{u})".format(u=UNITS),
- r"(?<=[0-9{al}{e}(?:{q})])\.".format(al=ALPHA_LOWER, e=r"%²\-\+", q=CONCAT_QUOTES),
+ r"(?<=[0-9{al}{e}(?:{q})])\.".format(
+ al=ALPHA_LOWER, e=r"%²\-\+", q=CONCAT_QUOTES
+ ),
r"(?<=[{au}][{au}])\.".format(au=ALPHA_UPPER),
]
)
@@ -40,8 +41,8 @@
r"(?<=[0-9])[+\-\*^](?=[0-9-])",
r"(?<=[{al}])\.(?=[{au}])".format(al=ALPHA_LOWER, au=ALPHA_UPPER),
r"(?<=[{a}]),(?=[{a}])".format(a=ALPHA),
- r'(?<=[{a}])(?:{h})(?=[{a}])'.format(a=ALPHA, h=HYPHENS),
- r'(?<=[{a}])[:<>=/](?=[{a}])'.format(a=ALPHA),
+ r"(?<=[{a}])(?:{h})(?=[{a}])".format(a=ALPHA, h=HYPHENS),
+ r"(?<=[{a}])[:<>=/](?=[{a}])".format(a=ALPHA),
]
)
|
{"golden_diff": "diff --git a/spacy/lang/punctuation.py b/spacy/lang/punctuation.py\n--- a/spacy/lang/punctuation.py\n+++ b/spacy/lang/punctuation.py\n@@ -1,14 +1,13 @@\n # coding: utf8\n from __future__ import unicode_literals\n \n-from .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY, LIST_ICONS\n-from .char_classes import HYPHENS\n-from .char_classes import CURRENCY, UNITS\n+from .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY\n+from .char_classes import LIST_ICONS, HYPHENS, CURRENCY, UNITS\n from .char_classes import CONCAT_QUOTES, ALPHA_LOWER, ALPHA_UPPER, ALPHA\n \n \n _prefixes = (\n- [\"\u00a7\", \"%\", \"=\", r\"\\+(?![0-9])\"]\n+ [\"\u00a7\", \"%\", \"=\", \"\u2014\", \"\u2013\", r\"\\+(?![0-9])\"]\n + LIST_PUNCT\n + LIST_ELLIPSES\n + LIST_QUOTES\n@@ -22,13 +21,15 @@\n + LIST_ELLIPSES\n + LIST_QUOTES\n + LIST_ICONS\n- + [\"'s\", \"'S\", \"\u2019s\", \"\u2019S\"]\n+ + [\"'s\", \"'S\", \"\u2019s\", \"\u2019S\", \"\u2014\", \"\u2013\"]\n + [\n r\"(?<=[0-9])\\+\",\n r\"(?<=\u00b0[FfCcKk])\\.\",\n r\"(?<=[0-9])(?:{c})\".format(c=CURRENCY),\n r\"(?<=[0-9])(?:{u})\".format(u=UNITS),\n- r\"(?<=[0-9{al}{e}(?:{q})])\\.\".format(al=ALPHA_LOWER, e=r\"%\u00b2\\-\\+\", q=CONCAT_QUOTES),\n+ r\"(?<=[0-9{al}{e}(?:{q})])\\.\".format(\n+ al=ALPHA_LOWER, e=r\"%\u00b2\\-\\+\", q=CONCAT_QUOTES\n+ ),\n r\"(?<=[{au}][{au}])\\.\".format(au=ALPHA_UPPER),\n ]\n )\n@@ -40,8 +41,8 @@\n r\"(?<=[0-9])[+\\-\\*^](?=[0-9-])\",\n r\"(?<=[{al}])\\.(?=[{au}])\".format(al=ALPHA_LOWER, au=ALPHA_UPPER),\n r\"(?<=[{a}]),(?=[{a}])\".format(a=ALPHA),\n- r'(?<=[{a}])(?:{h})(?=[{a}])'.format(a=ALPHA, h=HYPHENS),\n- r'(?<=[{a}])[:<>=/](?=[{a}])'.format(a=ALPHA),\n+ r\"(?<=[{a}])(?:{h})(?=[{a}])\".format(a=ALPHA, h=HYPHENS),\n+ r\"(?<=[{a}])[:<>=/](?=[{a}])\".format(a=ALPHA),\n ]\n )\n", "issue": "Incorrect tokenization of dash punctuation in Spanish\nIn Spanish text, the conventions for using dashes and em-dashes as punctuation seems to be considerably different than in English. Spacy often does not tokenize the dash or em-dash as a separate token, instead keeping it attached to the closest word.\r\n\r\nFor example, the Spanish sentence:\r\n\u2014Yo me llamo... \u2013murmur\u00f3 el ni\u00f1o\u2013 Emilio S\u00e1nchez P\u00e9rez.\r\nEnglish Translation:\r\n\"My name is...\", murmured the boy, \"Emilio Sanchez Perez.\"\r\n\r\nHere, the Spanish dash is used like a comma. The em-dash at the beginning of the sentence is used like a double quote. I believe that the fact that there is no space between the dash and word is throwing off the tokenizer.\r\n\r\nThe Spanish sentence above is tokenized as:\r\n\u2014Yo\r\nme\r\nllamo\r\n...\r\n\u2013murmur\u00f3\r\nel\r\nni\u00f1o\u2013\r\nEmilio\r\nS\u00e1nchez\r\nP\u00e9rez\r\n.\r\n\r\nI would expect the tokenization to be\r\n\u2014\r\nYo\r\nme\r\nllamo\r\n...\r\n\u2013\r\nmurmur\u00f3\r\nel\r\nni\u00f1o\r\n\u2013\r\nEmilio\r\nS\u00e1nchez\r\nP\u00e9rez\r\n.\r\n\r\n## Your Environment\r\n* **spaCy version:** 2.0.12\r\n* **Platform:** Darwin-18.0.0-x86_64-i386-64bit\r\n* **Python version:** 3.7.0\r\n* **Models:** de, es, en\r\n\n", "before_files": [{"content": "# coding: utf8\nfrom __future__ import unicode_literals\n\nfrom .char_classes import LIST_PUNCT, LIST_ELLIPSES, LIST_QUOTES, LIST_CURRENCY, LIST_ICONS\nfrom .char_classes import HYPHENS\nfrom .char_classes import CURRENCY, UNITS\nfrom .char_classes import CONCAT_QUOTES, ALPHA_LOWER, ALPHA_UPPER, ALPHA\n\n\n_prefixes = (\n [\"\u00a7\", \"%\", \"=\", r\"\\+(?![0-9])\"]\n + LIST_PUNCT\n + LIST_ELLIPSES\n + LIST_QUOTES\n + LIST_CURRENCY\n + LIST_ICONS\n)\n\n\n_suffixes = (\n LIST_PUNCT\n + LIST_ELLIPSES\n + LIST_QUOTES\n + LIST_ICONS\n + [\"'s\", \"'S\", \"\u2019s\", \"\u2019S\"]\n + [\n r\"(?<=[0-9])\\+\",\n r\"(?<=\u00b0[FfCcKk])\\.\",\n r\"(?<=[0-9])(?:{c})\".format(c=CURRENCY),\n r\"(?<=[0-9])(?:{u})\".format(u=UNITS),\n r\"(?<=[0-9{al}{e}(?:{q})])\\.\".format(al=ALPHA_LOWER, e=r\"%\u00b2\\-\\+\", q=CONCAT_QUOTES),\n r\"(?<=[{au}][{au}])\\.\".format(au=ALPHA_UPPER),\n ]\n)\n\n_infixes = (\n LIST_ELLIPSES\n + LIST_ICONS\n + [\n r\"(?<=[0-9])[+\\-\\*^](?=[0-9-])\",\n r\"(?<=[{al}])\\.(?=[{au}])\".format(al=ALPHA_LOWER, au=ALPHA_UPPER),\n r\"(?<=[{a}]),(?=[{a}])\".format(a=ALPHA),\n r'(?<=[{a}])(?:{h})(?=[{a}])'.format(a=ALPHA, h=HYPHENS),\n r'(?<=[{a}])[:<>=/](?=[{a}])'.format(a=ALPHA),\n ]\n)\n\nTOKENIZER_PREFIXES = _prefixes\nTOKENIZER_SUFFIXES = _suffixes\nTOKENIZER_INFIXES = _infixes\n", "path": "spacy/lang/punctuation.py"}]}
| 1,448 | 710 |
gh_patches_debug_24468
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-5005
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
proposal list - url params are not remembered correctly after adding a token
**URL:** https://meinberlin-dev.liqd.net/projekte/module/burgerinnenhaushalt-3-phasen-23/
**user:**
**expected behaviour:** filtering is kept after posting a token
**behaviour:** filtering gets lost if it was applied on react list
**important screensize:**
**device & browser:**
**Comment/Question:** The filters/query params are passed via a tempatetag [here](https://github.com/liqd/a4-meinberlin/blob/7c6f2c3add38af5a4383a871a1d04d3c3adb3c63/meinberlin/apps/budgeting/templates/meinberlin_budgeting/proposal_list.html#L26). The problem is that request.GET does not get updated unless the page is reloaded, so it will not reflect any filters that have been changed by react. Instead, it will keep the filters from last page reload (e.g. when coming from map with filters, those filters will be passed, no matter what was changed in the meantime).
Screenshot?
</issue>
<code>
[start of meinberlin/apps/budgeting/views.py]
1 import datetime
2 from urllib.parse import parse_qs
3 from urllib.parse import urlparse
4
5 import django_filters
6 from django.urls import resolve
7 from django.urls import reverse
8 from django.utils.translation import gettext_lazy as _
9
10 from adhocracy4.categories import filters as category_filters
11 from adhocracy4.exports.views import DashboardExportView
12 from adhocracy4.filters import filters as a4_filters
13 from adhocracy4.labels import filters as label_filters
14 from adhocracy4.modules.predicates import module_is_between_phases
15 from adhocracy4.projects.mixins import DisplayProjectOrModuleMixin
16 from meinberlin.apps.ideas import views as idea_views
17 from meinberlin.apps.moderatorremark.forms import ModeratorRemarkForm
18 from meinberlin.apps.projects.views import ArchivedWidget
19 from meinberlin.apps.votes.forms import TokenForm
20 from meinberlin.apps.votes.models import VotingToken
21
22 from . import forms
23 from . import models
24
25 TOKEN_SESSION_EXPIRE = datetime.timedelta(hours=12)
26
27
28 def get_ordering_choices(view):
29 choices = (("-created", _("Most recent")),)
30 if view.module.has_feature("rate", models.Proposal):
31 choices += (("-positive_rating_count", _("Most popular")),)
32 elif view.module.has_feature("support", models.Proposal):
33 choices += (("-positive_rating_count", _("Most support")),)
34 choices += (
35 ("-comment_count", _("Most commented")),
36 ("dailyrandom", _("Random")),
37 )
38 return choices
39
40
41 def get_default_ordering(view):
42 if module_is_between_phases(
43 "meinberlin_budgeting:support", "meinberlin_budgeting:voting", view.module
44 ):
45 return "-positive_rating_count"
46 elif (
47 view.module.has_feature("vote", models.Proposal)
48 and view.module.module_has_finished
49 ):
50 return "-token_vote_count"
51 return "dailyrandom"
52
53
54 class ProposalFilterSet(a4_filters.DefaultsFilterSet):
55 defaults = {"is_archived": "false"}
56 category = category_filters.CategoryFilter()
57 labels = label_filters.LabelFilter()
58 ordering = a4_filters.DistinctOrderingWithDailyRandomFilter(
59 choices=get_ordering_choices
60 )
61 is_archived = django_filters.BooleanFilter(widget=ArchivedWidget)
62
63 class Meta:
64 model = models.Proposal
65 fields = ["category", "labels", "is_archived"]
66
67 def __init__(self, data, *args, **kwargs):
68 self.defaults["ordering"] = get_default_ordering(kwargs["view"])
69 super().__init__(data, *args, **kwargs)
70
71
72 class ProposalListView(idea_views.AbstractIdeaListView, DisplayProjectOrModuleMixin):
73 model = models.Proposal
74 filter_set = ProposalFilterSet
75
76 def has_valid_token_in_session(self, request):
77 """Return whether a valid token is stored in the session.
78
79 The token is valid if it is valid for the respective module.
80 """
81 if "voting_tokens" in request.session:
82 module_key = str(self.module.id)
83 if module_key in request.session["voting_tokens"]:
84 return (
85 VotingToken.get_voting_token_by_hash(
86 token_hash=request.session["voting_tokens"][module_key],
87 module=self.module,
88 )
89 is not None
90 )
91 return False
92
93 def dispatch(self, request, **kwargs):
94 self.mode = request.GET.get("mode", "map")
95 if self.mode == "map":
96 self.paginate_by = 0
97 return super().dispatch(request, **kwargs)
98
99 def get_queryset(self):
100 return super().get_queryset().filter(module=self.module)
101
102 def get_context_data(self, **kwargs):
103 if "token_form" not in kwargs:
104 token_form = TokenForm(module_id=self.module.id)
105 kwargs["token_form"] = token_form
106 kwargs["valid_token_present"] = self.has_valid_token_in_session(self.request)
107 return super().get_context_data(**kwargs)
108
109 def post(self, request, *args, **kwargs):
110 self.object_list = self.get_queryset()
111 token_form = TokenForm(request.POST, module_id=self.module.id)
112 if token_form.is_valid():
113 if "voting_tokens" in request.session:
114 request.session["voting_tokens"][
115 str(self.module.id)
116 ] = token_form.cleaned_data["token"]
117 request.session.modified = True
118 else:
119 request.session["voting_tokens"] = {
120 str(self.module.id): token_form.cleaned_data["token"]
121 }
122 request.session["token_expire_date"] = (
123 datetime.datetime.now() + TOKEN_SESSION_EXPIRE
124 ).timestamp()
125 kwargs["valid_token_present"] = True
126 kwargs["token_form"] = token_form
127 context = super().get_context_data(**kwargs)
128 return self.render_to_response(context)
129
130
131 class ProposalDetailView(idea_views.AbstractIdeaDetailView):
132 model = models.Proposal
133 queryset = (
134 models.Proposal.objects.annotate_positive_rating_count()
135 .annotate_negative_rating_count()
136 .annotate_token_vote_count()
137 )
138 permission_required = "meinberlin_budgeting.view_proposal"
139
140 def get_back(self):
141 """
142 Get last page to return to if was project or module view.
143
144 To make sure all the filters and the display mode (map or list)
145 are remembered when going back, we check if the referer is a
146 module or project detail view and add the appropriate back url.
147 """
148 back_link = self.module.get_detail_url
149 back_string = _("map")
150 if "Referer" in self.request.headers:
151 referer = self.request.headers["Referer"]
152 parsed_url = urlparse(referer)
153 match = resolve(parsed_url.path)
154 if match.url_name == "project-detail" or match.url_name == "module-detail":
155 if "mode" in parse_qs(parsed_url.query):
156 back_mode = parse_qs(parsed_url.query)["mode"][0]
157 if back_mode == "list":
158 back_string = _("list")
159 back_link = referer + "#proposal_{}".format(self.object.id)
160 return back_link, back_string
161 return back_link, back_string
162 return back_link, back_string
163
164 def has_valid_token_in_session(self, request):
165 """Return whether a valid token is stored in the session.
166
167 The token is valid if it is valid for the respective module.
168 """
169 if "voting_tokens" in request.session:
170 module_key = str(self.module.id)
171 if module_key in request.session["voting_tokens"]:
172 return (
173 VotingToken.get_voting_token_by_hash(
174 token_hash=request.session["voting_tokens"][module_key],
175 module=self.module,
176 )
177 is not None
178 )
179 return False
180
181 def get_context_data(self, **kwargs):
182 context = super().get_context_data(**kwargs)
183 back_link, back_string = self.get_back()
184 context["back"] = back_link
185 context["back_string"] = back_string
186 context["has_valid_token_in_session"] = self.has_valid_token_in_session(
187 self.request
188 )
189 return context
190
191
192 class ProposalCreateView(idea_views.AbstractIdeaCreateView):
193 model = models.Proposal
194 form_class = forms.ProposalForm
195 permission_required = "meinberlin_budgeting.add_proposal"
196 template_name = "meinberlin_budgeting/proposal_create_form.html"
197
198 def get_form_kwargs(self):
199 kwargs = super().get_form_kwargs()
200 kwargs["user"] = self.request.user
201 return kwargs
202
203
204 class ProposalUpdateView(idea_views.AbstractIdeaUpdateView):
205 model = models.Proposal
206 form_class = forms.ProposalForm
207 permission_required = "meinberlin_budgeting.change_proposal"
208 template_name = "meinberlin_budgeting/proposal_update_form.html"
209
210 def get_form_kwargs(self):
211 kwargs = super().get_form_kwargs()
212 kwargs["user"] = self.request.user
213 return kwargs
214
215
216 class ProposalDeleteView(idea_views.AbstractIdeaDeleteView):
217 model = models.Proposal
218 success_message = _("Your budget request has been deleted")
219 permission_required = "meinberlin_budgeting.change_proposal"
220 template_name = "meinberlin_budgeting/proposal_confirm_delete.html"
221
222
223 class ProposalModerateView(idea_views.AbstractIdeaModerateView):
224 model = models.Proposal
225 permission_required = "meinberlin_budgeting.moderate_proposal"
226 template_name = "meinberlin_budgeting/proposal_moderate_form.html"
227 moderateable_form_class = forms.ProposalModerateForm
228 remark_form_class = ModeratorRemarkForm
229
230
231 class ProposalDashboardExportView(DashboardExportView):
232 template_name = "a4exports/export_dashboard.html"
233
234 def get_context_data(self, **kwargs):
235 context = super().get_context_data(**kwargs)
236 context["export"] = reverse(
237 "a4dashboard:budgeting-export", kwargs={"module_slug": self.module.slug}
238 )
239 context["comment_export"] = reverse(
240 "a4dashboard:budgeting-comment-export",
241 kwargs={"module_slug": self.module.slug},
242 )
243 return context
244
[end of meinberlin/apps/budgeting/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/budgeting/views.py b/meinberlin/apps/budgeting/views.py
--- a/meinberlin/apps/budgeting/views.py
+++ b/meinberlin/apps/budgeting/views.py
@@ -3,6 +3,7 @@
from urllib.parse import urlparse
import django_filters
+from django.shortcuts import redirect
from django.urls import resolve
from django.urls import reverse
from django.utils.translation import gettext_lazy as _
@@ -123,6 +124,16 @@
datetime.datetime.now() + TOKEN_SESSION_EXPIRE
).timestamp()
kwargs["valid_token_present"] = True
+ # redirect to the list view, but keep filters after successful
+ # token addition
+ list_url = request.path
+ parameter = request.GET.copy()
+ if not parameter.get("mode") or "list" not in parameter.get("mode"):
+ parameter.setlist("mode", ["list"])
+ encoded_parameter = "?" + parameter.urlencode()
+ return redirect(list_url + encoded_parameter)
+ # stay on the same page if the token form has errors,
+ # add the form including errors so that they are displayed.
kwargs["token_form"] = token_form
context = super().get_context_data(**kwargs)
return self.render_to_response(context)
|
{"golden_diff": "diff --git a/meinberlin/apps/budgeting/views.py b/meinberlin/apps/budgeting/views.py\n--- a/meinberlin/apps/budgeting/views.py\n+++ b/meinberlin/apps/budgeting/views.py\n@@ -3,6 +3,7 @@\n from urllib.parse import urlparse\n \n import django_filters\n+from django.shortcuts import redirect\n from django.urls import resolve\n from django.urls import reverse\n from django.utils.translation import gettext_lazy as _\n@@ -123,6 +124,16 @@\n datetime.datetime.now() + TOKEN_SESSION_EXPIRE\n ).timestamp()\n kwargs[\"valid_token_present\"] = True\n+ # redirect to the list view, but keep filters after successful\n+ # token addition\n+ list_url = request.path\n+ parameter = request.GET.copy()\n+ if not parameter.get(\"mode\") or \"list\" not in parameter.get(\"mode\"):\n+ parameter.setlist(\"mode\", [\"list\"])\n+ encoded_parameter = \"?\" + parameter.urlencode()\n+ return redirect(list_url + encoded_parameter)\n+ # stay on the same page if the token form has errors,\n+ # add the form including errors so that they are displayed.\n kwargs[\"token_form\"] = token_form\n context = super().get_context_data(**kwargs)\n return self.render_to_response(context)\n", "issue": "proposal list - url params are not remembered correctly after adding a token\n**URL:** https://meinberlin-dev.liqd.net/projekte/module/burgerinnenhaushalt-3-phasen-23/ \r\n**user:** \r\n**expected behaviour:** filtering is kept after posting a token\r\n**behaviour:** filtering gets lost if it was applied on react list\r\n**important screensize:**\r\n**device & browser:** \r\n**Comment/Question:** The filters/query params are passed via a tempatetag [here](https://github.com/liqd/a4-meinberlin/blob/7c6f2c3add38af5a4383a871a1d04d3c3adb3c63/meinberlin/apps/budgeting/templates/meinberlin_budgeting/proposal_list.html#L26). The problem is that request.GET does not get updated unless the page is reloaded, so it will not reflect any filters that have been changed by react. Instead, it will keep the filters from last page reload (e.g. when coming from map with filters, those filters will be passed, no matter what was changed in the meantime).\r\n\r\nScreenshot?\r\n\n", "before_files": [{"content": "import datetime\nfrom urllib.parse import parse_qs\nfrom urllib.parse import urlparse\n\nimport django_filters\nfrom django.urls import resolve\nfrom django.urls import reverse\nfrom django.utils.translation import gettext_lazy as _\n\nfrom adhocracy4.categories import filters as category_filters\nfrom adhocracy4.exports.views import DashboardExportView\nfrom adhocracy4.filters import filters as a4_filters\nfrom adhocracy4.labels import filters as label_filters\nfrom adhocracy4.modules.predicates import module_is_between_phases\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom meinberlin.apps.ideas import views as idea_views\nfrom meinberlin.apps.moderatorremark.forms import ModeratorRemarkForm\nfrom meinberlin.apps.projects.views import ArchivedWidget\nfrom meinberlin.apps.votes.forms import TokenForm\nfrom meinberlin.apps.votes.models import VotingToken\n\nfrom . import forms\nfrom . import models\n\nTOKEN_SESSION_EXPIRE = datetime.timedelta(hours=12)\n\n\ndef get_ordering_choices(view):\n choices = ((\"-created\", _(\"Most recent\")),)\n if view.module.has_feature(\"rate\", models.Proposal):\n choices += ((\"-positive_rating_count\", _(\"Most popular\")),)\n elif view.module.has_feature(\"support\", models.Proposal):\n choices += ((\"-positive_rating_count\", _(\"Most support\")),)\n choices += (\n (\"-comment_count\", _(\"Most commented\")),\n (\"dailyrandom\", _(\"Random\")),\n )\n return choices\n\n\ndef get_default_ordering(view):\n if module_is_between_phases(\n \"meinberlin_budgeting:support\", \"meinberlin_budgeting:voting\", view.module\n ):\n return \"-positive_rating_count\"\n elif (\n view.module.has_feature(\"vote\", models.Proposal)\n and view.module.module_has_finished\n ):\n return \"-token_vote_count\"\n return \"dailyrandom\"\n\n\nclass ProposalFilterSet(a4_filters.DefaultsFilterSet):\n defaults = {\"is_archived\": \"false\"}\n category = category_filters.CategoryFilter()\n labels = label_filters.LabelFilter()\n ordering = a4_filters.DistinctOrderingWithDailyRandomFilter(\n choices=get_ordering_choices\n )\n is_archived = django_filters.BooleanFilter(widget=ArchivedWidget)\n\n class Meta:\n model = models.Proposal\n fields = [\"category\", \"labels\", \"is_archived\"]\n\n def __init__(self, data, *args, **kwargs):\n self.defaults[\"ordering\"] = get_default_ordering(kwargs[\"view\"])\n super().__init__(data, *args, **kwargs)\n\n\nclass ProposalListView(idea_views.AbstractIdeaListView, DisplayProjectOrModuleMixin):\n model = models.Proposal\n filter_set = ProposalFilterSet\n\n def has_valid_token_in_session(self, request):\n \"\"\"Return whether a valid token is stored in the session.\n\n The token is valid if it is valid for the respective module.\n \"\"\"\n if \"voting_tokens\" in request.session:\n module_key = str(self.module.id)\n if module_key in request.session[\"voting_tokens\"]:\n return (\n VotingToken.get_voting_token_by_hash(\n token_hash=request.session[\"voting_tokens\"][module_key],\n module=self.module,\n )\n is not None\n )\n return False\n\n def dispatch(self, request, **kwargs):\n self.mode = request.GET.get(\"mode\", \"map\")\n if self.mode == \"map\":\n self.paginate_by = 0\n return super().dispatch(request, **kwargs)\n\n def get_queryset(self):\n return super().get_queryset().filter(module=self.module)\n\n def get_context_data(self, **kwargs):\n if \"token_form\" not in kwargs:\n token_form = TokenForm(module_id=self.module.id)\n kwargs[\"token_form\"] = token_form\n kwargs[\"valid_token_present\"] = self.has_valid_token_in_session(self.request)\n return super().get_context_data(**kwargs)\n\n def post(self, request, *args, **kwargs):\n self.object_list = self.get_queryset()\n token_form = TokenForm(request.POST, module_id=self.module.id)\n if token_form.is_valid():\n if \"voting_tokens\" in request.session:\n request.session[\"voting_tokens\"][\n str(self.module.id)\n ] = token_form.cleaned_data[\"token\"]\n request.session.modified = True\n else:\n request.session[\"voting_tokens\"] = {\n str(self.module.id): token_form.cleaned_data[\"token\"]\n }\n request.session[\"token_expire_date\"] = (\n datetime.datetime.now() + TOKEN_SESSION_EXPIRE\n ).timestamp()\n kwargs[\"valid_token_present\"] = True\n kwargs[\"token_form\"] = token_form\n context = super().get_context_data(**kwargs)\n return self.render_to_response(context)\n\n\nclass ProposalDetailView(idea_views.AbstractIdeaDetailView):\n model = models.Proposal\n queryset = (\n models.Proposal.objects.annotate_positive_rating_count()\n .annotate_negative_rating_count()\n .annotate_token_vote_count()\n )\n permission_required = \"meinberlin_budgeting.view_proposal\"\n\n def get_back(self):\n \"\"\"\n Get last page to return to if was project or module view.\n\n To make sure all the filters and the display mode (map or list)\n are remembered when going back, we check if the referer is a\n module or project detail view and add the appropriate back url.\n \"\"\"\n back_link = self.module.get_detail_url\n back_string = _(\"map\")\n if \"Referer\" in self.request.headers:\n referer = self.request.headers[\"Referer\"]\n parsed_url = urlparse(referer)\n match = resolve(parsed_url.path)\n if match.url_name == \"project-detail\" or match.url_name == \"module-detail\":\n if \"mode\" in parse_qs(parsed_url.query):\n back_mode = parse_qs(parsed_url.query)[\"mode\"][0]\n if back_mode == \"list\":\n back_string = _(\"list\")\n back_link = referer + \"#proposal_{}\".format(self.object.id)\n return back_link, back_string\n return back_link, back_string\n return back_link, back_string\n\n def has_valid_token_in_session(self, request):\n \"\"\"Return whether a valid token is stored in the session.\n\n The token is valid if it is valid for the respective module.\n \"\"\"\n if \"voting_tokens\" in request.session:\n module_key = str(self.module.id)\n if module_key in request.session[\"voting_tokens\"]:\n return (\n VotingToken.get_voting_token_by_hash(\n token_hash=request.session[\"voting_tokens\"][module_key],\n module=self.module,\n )\n is not None\n )\n return False\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n back_link, back_string = self.get_back()\n context[\"back\"] = back_link\n context[\"back_string\"] = back_string\n context[\"has_valid_token_in_session\"] = self.has_valid_token_in_session(\n self.request\n )\n return context\n\n\nclass ProposalCreateView(idea_views.AbstractIdeaCreateView):\n model = models.Proposal\n form_class = forms.ProposalForm\n permission_required = \"meinberlin_budgeting.add_proposal\"\n template_name = \"meinberlin_budgeting/proposal_create_form.html\"\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs[\"user\"] = self.request.user\n return kwargs\n\n\nclass ProposalUpdateView(idea_views.AbstractIdeaUpdateView):\n model = models.Proposal\n form_class = forms.ProposalForm\n permission_required = \"meinberlin_budgeting.change_proposal\"\n template_name = \"meinberlin_budgeting/proposal_update_form.html\"\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs[\"user\"] = self.request.user\n return kwargs\n\n\nclass ProposalDeleteView(idea_views.AbstractIdeaDeleteView):\n model = models.Proposal\n success_message = _(\"Your budget request has been deleted\")\n permission_required = \"meinberlin_budgeting.change_proposal\"\n template_name = \"meinberlin_budgeting/proposal_confirm_delete.html\"\n\n\nclass ProposalModerateView(idea_views.AbstractIdeaModerateView):\n model = models.Proposal\n permission_required = \"meinberlin_budgeting.moderate_proposal\"\n template_name = \"meinberlin_budgeting/proposal_moderate_form.html\"\n moderateable_form_class = forms.ProposalModerateForm\n remark_form_class = ModeratorRemarkForm\n\n\nclass ProposalDashboardExportView(DashboardExportView):\n template_name = \"a4exports/export_dashboard.html\"\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context[\"export\"] = reverse(\n \"a4dashboard:budgeting-export\", kwargs={\"module_slug\": self.module.slug}\n )\n context[\"comment_export\"] = reverse(\n \"a4dashboard:budgeting-comment-export\",\n kwargs={\"module_slug\": self.module.slug},\n )\n return context\n", "path": "meinberlin/apps/budgeting/views.py"}]}
| 3,380 | 287 |
gh_patches_debug_19156
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-2784
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Pyfunc artifact paths created on Windows use Windows path separators.
### Willingness to contribute
The MLflow Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix
for this bug to the MLflow code base?
- [ ] Yes. I can contribute a fix for this bug independently.
- [x] Yes. I would be willing to contribute a fix for this bug with guidance from the MLflow community.
- [ ] No. I cannot contribute a bug fix at this time.
### System information
- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: No
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Windows 10
- **MLflow installed from (source or binary)**: Binary
- **MLflow version (run ``mlflow --version``)**: 1.8.0
- **Python version**: 3.6
- **Exact command to reproduce**:
N/A
### Describe the problem
Creating pyfunc model on windows using the `artifacts` arguments results in an MLModel file with windows separators in the paths:
```
flavors:
python_function:
artifacts:
artifact:
path: artifacts\some_artifact
uri: some_artifact
cloudpickle_version: 1.3.0
env: conda.yaml
loader_module: mlflow.pyfunc.model
python_model: python_model.pkl
python_version: 3.6.10
utc_time_created: '2020-04-28 15:59:25.211458'
```
The problem with this is portability. E.g. running a docker container fails miserably.
The fix is probably to always use forward slashes for this.
### Code to reproduce issue
```python
import mlflow.pyfunc
class PythonModelWrapper(mlflow.pyfunc.PythonModel):
pass
artifact_path='some_artifact'
with open(artifact_path, 'w') as f:
f.write('example')
artifacts = {
'artifact' : artifact_path
}
mlflow_pyfunc_model_path = "mlflow_pyfunc"
mlflow.pyfunc.save_model(
path=mlflow_pyfunc_model_path, python_model=PythonModelWrapper(), artifacts=artifacts)
```
</issue>
<code>
[start of mlflow/pyfunc/model.py]
1 """
2 The ``mlflow.pyfunc.model`` module defines logic for saving and loading custom "python_function"
3 models with a user-defined ``PythonModel`` subclass.
4 """
5
6 import os
7 import shutil
8 import yaml
9 from abc import ABCMeta, abstractmethod
10
11 import cloudpickle
12
13 import mlflow.pyfunc
14 import mlflow.utils
15 from mlflow.exceptions import MlflowException
16 from mlflow.models import Model
17 from mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE, RESOURCE_ALREADY_EXISTS
18 from mlflow.tracking.artifact_utils import _download_artifact_from_uri
19 from mlflow.utils.environment import _mlflow_conda_env
20 from mlflow.utils.model_utils import _get_flavor_configuration
21 from mlflow.utils.file_utils import TempDir, _copy_file_or_tree
22
23 CONFIG_KEY_ARTIFACTS = "artifacts"
24 CONFIG_KEY_ARTIFACT_RELATIVE_PATH = "path"
25 CONFIG_KEY_ARTIFACT_URI = "uri"
26 CONFIG_KEY_PYTHON_MODEL = "python_model"
27 CONFIG_KEY_CLOUDPICKLE_VERSION = "cloudpickle_version"
28
29
30 def get_default_conda_env():
31 """
32 :return: The default Conda environment for MLflow Models produced by calls to
33 :func:`save_model() <mlflow.pyfunc.save_model>`
34 and :func:`log_model() <mlflow.pyfunc.log_model>` when a user-defined subclass of
35 :class:`PythonModel` is provided.
36 """
37 return _mlflow_conda_env(
38 additional_conda_deps=None,
39 additional_pip_deps=[
40 "cloudpickle=={}".format(cloudpickle.__version__),
41 ],
42 additional_conda_channels=None)
43
44
45 class PythonModel(object):
46 """
47 Represents a generic Python model that evaluates inputs and produces API-compatible outputs.
48 By subclassing :class:`~PythonModel`, users can create customized MLflow models with the
49 "python_function" ("pyfunc") flavor, leveraging custom inference logic and artifact
50 dependencies.
51 """
52 __metaclass__ = ABCMeta
53
54 def load_context(self, context):
55 """
56 Loads artifacts from the specified :class:`~PythonModelContext` that can be used by
57 :func:`~PythonModel.predict` when evaluating inputs. When loading an MLflow model with
58 :func:`~load_pyfunc`, this method is called as soon as the :class:`~PythonModel` is
59 constructed.
60
61 The same :class:`~PythonModelContext` will also be available during calls to
62 :func:`~PythonModel.predict`, but it may be more efficient to override this method
63 and load artifacts from the context at model load time.
64
65 :param context: A :class:`~PythonModelContext` instance containing artifacts that the model
66 can use to perform inference.
67 """
68
69 @abstractmethod
70 def predict(self, context, model_input):
71 """
72 Evaluates a pyfunc-compatible input and produces a pyfunc-compatible output.
73 For more information about the pyfunc input/output API, see the :ref:`pyfunc-inference-api`.
74
75 :param context: A :class:`~PythonModelContext` instance containing artifacts that the model
76 can use to perform inference.
77 :param model_input: A pyfunc-compatible input for the model to evaluate.
78 """
79
80
81 class PythonModelContext(object):
82 """
83 A collection of artifacts that a :class:`~PythonModel` can use when performing inference.
84 :class:`~PythonModelContext` objects are created *implicitly* by the
85 :func:`save_model() <mlflow.pyfunc.save_model>` and
86 :func:`log_model() <mlflow.pyfunc.log_model>` persistence methods, using the contents specified
87 by the ``artifacts`` parameter of these methods.
88 """
89
90 def __init__(self, artifacts):
91 """
92 :param artifacts: A dictionary of ``<name, artifact_path>`` entries, where ``artifact_path``
93 is an absolute filesystem path to a given artifact.
94 """
95 self._artifacts = artifacts
96
97 @property
98 def artifacts(self):
99 """
100 A dictionary containing ``<name, artifact_path>`` entries, where ``artifact_path`` is an
101 absolute filesystem path to the artifact.
102 """
103 return self._artifacts
104
105
106 def _save_model_with_class_artifacts_params(path, python_model, artifacts=None, conda_env=None,
107 code_paths=None, mlflow_model=Model()):
108 """
109 :param path: The path to which to save the Python model.
110 :param python_model: An instance of a subclass of :class:`~PythonModel`. ``python_model``
111 defines how the model loads artifacts and how it performs inference.
112 :param artifacts: A dictionary containing ``<name, artifact_uri>`` entries.
113 Remote artifact URIs
114 are resolved to absolute filesystem paths, producing a dictionary of
115 ``<name, absolute_path>`` entries. ``python_model`` can reference these
116 resolved entries as the ``artifacts`` property of the ``context``
117 attribute. If ``None``, no artifacts are added to the model.
118 :param conda_env: Either a dictionary representation of a Conda environment or the
119 path to a Conda environment yaml file. If provided, this decsribes the
120 environment this model should be run in. At minimum, it should specify
121 the dependencies
122 contained in :func:`get_default_conda_env()`. If ``None``, the default
123 :func:`get_default_conda_env()` environment is added to the model.
124 :param code_paths: A list of local filesystem paths to Python file dependencies (or directories
125 containing file dependencies). These files are *prepended* to the system
126 path before the model is loaded.
127 :param mlflow_model: The model configuration to which to add the ``mlflow.pyfunc`` flavor.
128 """
129 if os.path.exists(path):
130 raise MlflowException(
131 message="Path '{}' already exists".format(path),
132 error_code=RESOURCE_ALREADY_EXISTS)
133 os.makedirs(path)
134
135 custom_model_config_kwargs = {
136 CONFIG_KEY_CLOUDPICKLE_VERSION: cloudpickle.__version__,
137 }
138 if isinstance(python_model, PythonModel):
139 saved_python_model_subpath = "python_model.pkl"
140 with open(os.path.join(path, saved_python_model_subpath), "wb") as out:
141 cloudpickle.dump(python_model, out)
142 custom_model_config_kwargs[CONFIG_KEY_PYTHON_MODEL] = saved_python_model_subpath
143 else:
144 raise MlflowException(
145 message=("`python_model` must be a subclass of `PythonModel`. Instead, found an"
146 " object of type: {python_model_type}".format(
147 python_model_type=type(python_model))),
148 error_code=INVALID_PARAMETER_VALUE)
149
150 if artifacts:
151 saved_artifacts_config = {}
152 with TempDir() as tmp_artifacts_dir:
153 tmp_artifacts_config = {}
154 saved_artifacts_dir_subpath = "artifacts"
155 for artifact_name, artifact_uri in artifacts.items():
156 tmp_artifact_path = _download_artifact_from_uri(
157 artifact_uri=artifact_uri, output_path=tmp_artifacts_dir.path())
158 tmp_artifacts_config[artifact_name] = tmp_artifact_path
159 saved_artifact_subpath = os.path.join(
160 saved_artifacts_dir_subpath,
161 os.path.relpath(path=tmp_artifact_path, start=tmp_artifacts_dir.path()))
162 saved_artifacts_config[artifact_name] = {
163 CONFIG_KEY_ARTIFACT_RELATIVE_PATH: saved_artifact_subpath,
164 CONFIG_KEY_ARTIFACT_URI: artifact_uri,
165 }
166
167 shutil.move(tmp_artifacts_dir.path(), os.path.join(path, saved_artifacts_dir_subpath))
168 custom_model_config_kwargs[CONFIG_KEY_ARTIFACTS] = saved_artifacts_config
169
170 conda_env_subpath = "conda.yaml"
171 if conda_env is None:
172 conda_env = get_default_conda_env()
173 elif not isinstance(conda_env, dict):
174 with open(conda_env, "r") as f:
175 conda_env = yaml.safe_load(f)
176 with open(os.path.join(path, conda_env_subpath), "w") as f:
177 yaml.safe_dump(conda_env, stream=f, default_flow_style=False)
178
179 saved_code_subpath = None
180 if code_paths is not None:
181 saved_code_subpath = "code"
182 for code_path in code_paths:
183 _copy_file_or_tree(src=code_path, dst=path, dst_dir=saved_code_subpath)
184
185 mlflow.pyfunc.add_to_model(model=mlflow_model, loader_module=__name__, code=saved_code_subpath,
186 env=conda_env_subpath, **custom_model_config_kwargs)
187 mlflow_model.save(os.path.join(path, 'MLmodel'))
188
189
190 def _load_pyfunc(model_path):
191 pyfunc_config = _get_flavor_configuration(
192 model_path=model_path, flavor_name=mlflow.pyfunc.FLAVOR_NAME)
193
194 python_model_cloudpickle_version = pyfunc_config.get(CONFIG_KEY_CLOUDPICKLE_VERSION, None)
195 if python_model_cloudpickle_version is None:
196 mlflow.pyfunc._logger.warning(
197 "The version of CloudPickle used to save the model could not be found in the MLmodel"
198 " configuration")
199 elif python_model_cloudpickle_version != cloudpickle.__version__:
200 # CloudPickle does not have a well-defined cross-version compatibility policy. Micro version
201 # releases have been known to cause incompatibilities. Therefore, we match on the full
202 # library version
203 mlflow.pyfunc._logger.warning(
204 "The version of CloudPickle that was used to save the model, `CloudPickle %s`, differs"
205 " from the version of CloudPickle that is currently running, `CloudPickle %s`, and may"
206 " be incompatible",
207 python_model_cloudpickle_version, cloudpickle.__version__)
208
209 python_model_subpath = pyfunc_config.get(CONFIG_KEY_PYTHON_MODEL, None)
210 if python_model_subpath is None:
211 raise MlflowException(
212 "Python model path was not specified in the model configuration")
213 with open(os.path.join(model_path, python_model_subpath), "rb") as f:
214 python_model = cloudpickle.load(f)
215
216 artifacts = {}
217 for saved_artifact_name, saved_artifact_info in\
218 pyfunc_config.get(CONFIG_KEY_ARTIFACTS, {}).items():
219 artifacts[saved_artifact_name] = os.path.join(
220 model_path, saved_artifact_info[CONFIG_KEY_ARTIFACT_RELATIVE_PATH])
221
222 context = PythonModelContext(artifacts=artifacts)
223 python_model.load_context(context=context)
224 return _PythonModelPyfuncWrapper(python_model=python_model, context=context)
225
226
227 class _PythonModelPyfuncWrapper(object):
228 """
229 Wrapper class that creates a predict function such that
230 predict(model_input: pd.DataFrame) -> model's output as pd.DataFrame (pandas DataFrame)
231 """
232
233 def __init__(self, python_model, context):
234 """
235 :param python_model: An instance of a subclass of :class:`~PythonModel`.
236 :param context: A :class:`~PythonModelContext` instance containing artifacts that
237 ``python_model`` may use when performing inference.
238 """
239 self.python_model = python_model
240 self.context = context
241
242 def predict(self, model_input):
243 return self.python_model.predict(self.context, model_input)
244
[end of mlflow/pyfunc/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlflow/pyfunc/model.py b/mlflow/pyfunc/model.py
--- a/mlflow/pyfunc/model.py
+++ b/mlflow/pyfunc/model.py
@@ -4,6 +4,7 @@
"""
import os
+import posixpath
import shutil
import yaml
from abc import ABCMeta, abstractmethod
@@ -156,7 +157,7 @@
tmp_artifact_path = _download_artifact_from_uri(
artifact_uri=artifact_uri, output_path=tmp_artifacts_dir.path())
tmp_artifacts_config[artifact_name] = tmp_artifact_path
- saved_artifact_subpath = os.path.join(
+ saved_artifact_subpath = posixpath.join(
saved_artifacts_dir_subpath,
os.path.relpath(path=tmp_artifact_path, start=tmp_artifacts_dir.path()))
saved_artifacts_config[artifact_name] = {
|
{"golden_diff": "diff --git a/mlflow/pyfunc/model.py b/mlflow/pyfunc/model.py\n--- a/mlflow/pyfunc/model.py\n+++ b/mlflow/pyfunc/model.py\n@@ -4,6 +4,7 @@\n \"\"\"\n \n import os\n+import posixpath\n import shutil\n import yaml\n from abc import ABCMeta, abstractmethod\n@@ -156,7 +157,7 @@\n tmp_artifact_path = _download_artifact_from_uri(\n artifact_uri=artifact_uri, output_path=tmp_artifacts_dir.path())\n tmp_artifacts_config[artifact_name] = tmp_artifact_path\n- saved_artifact_subpath = os.path.join(\n+ saved_artifact_subpath = posixpath.join(\n saved_artifacts_dir_subpath,\n os.path.relpath(path=tmp_artifact_path, start=tmp_artifacts_dir.path()))\n saved_artifacts_config[artifact_name] = {\n", "issue": "[BUG] Pyfunc artifact paths created on Windows use Windows path separators.\n### Willingness to contribute\r\nThe MLflow Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix\r\nfor this bug to the MLflow code base?\r\n\r\n- [ ] Yes. I can contribute a fix for this bug independently.\r\n- [x] Yes. I would be willing to contribute a fix for this bug with guidance from the MLflow community.\r\n- [ ] No. I cannot contribute a bug fix at this time.\r\n\r\n### System information\r\n- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**: No\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Windows 10\r\n- **MLflow installed from (source or binary)**: Binary\r\n- **MLflow version (run ``mlflow --version``)**: 1.8.0\r\n- **Python version**: 3.6\r\n- **Exact command to reproduce**:\r\nN/A\r\n\r\n\r\n### Describe the problem\r\nCreating pyfunc model on windows using the `artifacts` arguments results in an MLModel file with windows separators in the paths: \r\n\r\n```\r\nflavors:\r\n python_function:\r\n artifacts:\r\n artifact:\r\n path: artifacts\\some_artifact\r\n uri: some_artifact\r\n cloudpickle_version: 1.3.0\r\n env: conda.yaml\r\n loader_module: mlflow.pyfunc.model\r\n python_model: python_model.pkl\r\n python_version: 3.6.10\r\nutc_time_created: '2020-04-28 15:59:25.211458'\r\n```\r\n\r\nThe problem with this is portability. E.g. running a docker container fails miserably. \r\n\r\nThe fix is probably to always use forward slashes for this. \r\n\r\n### Code to reproduce issue\r\n```python\r\nimport mlflow.pyfunc\r\n\r\nclass PythonModelWrapper(mlflow.pyfunc.PythonModel):\r\n pass\r\n\r\nartifact_path='some_artifact'\r\nwith open(artifact_path, 'w') as f:\r\n f.write('example')\r\n\r\nartifacts = {\r\n 'artifact' : artifact_path\r\n}\r\n\r\nmlflow_pyfunc_model_path = \"mlflow_pyfunc\"\r\nmlflow.pyfunc.save_model(\r\n path=mlflow_pyfunc_model_path, python_model=PythonModelWrapper(), artifacts=artifacts)\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nThe ``mlflow.pyfunc.model`` module defines logic for saving and loading custom \"python_function\"\nmodels with a user-defined ``PythonModel`` subclass.\n\"\"\"\n\nimport os\nimport shutil\nimport yaml\nfrom abc import ABCMeta, abstractmethod\n\nimport cloudpickle\n\nimport mlflow.pyfunc\nimport mlflow.utils\nfrom mlflow.exceptions import MlflowException\nfrom mlflow.models import Model\nfrom mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE, RESOURCE_ALREADY_EXISTS\nfrom mlflow.tracking.artifact_utils import _download_artifact_from_uri\nfrom mlflow.utils.environment import _mlflow_conda_env\nfrom mlflow.utils.model_utils import _get_flavor_configuration\nfrom mlflow.utils.file_utils import TempDir, _copy_file_or_tree\n\nCONFIG_KEY_ARTIFACTS = \"artifacts\"\nCONFIG_KEY_ARTIFACT_RELATIVE_PATH = \"path\"\nCONFIG_KEY_ARTIFACT_URI = \"uri\"\nCONFIG_KEY_PYTHON_MODEL = \"python_model\"\nCONFIG_KEY_CLOUDPICKLE_VERSION = \"cloudpickle_version\"\n\n\ndef get_default_conda_env():\n \"\"\"\n :return: The default Conda environment for MLflow Models produced by calls to\n :func:`save_model() <mlflow.pyfunc.save_model>`\n and :func:`log_model() <mlflow.pyfunc.log_model>` when a user-defined subclass of\n :class:`PythonModel` is provided.\n \"\"\"\n return _mlflow_conda_env(\n additional_conda_deps=None,\n additional_pip_deps=[\n \"cloudpickle=={}\".format(cloudpickle.__version__),\n ],\n additional_conda_channels=None)\n\n\nclass PythonModel(object):\n \"\"\"\n Represents a generic Python model that evaluates inputs and produces API-compatible outputs.\n By subclassing :class:`~PythonModel`, users can create customized MLflow models with the\n \"python_function\" (\"pyfunc\") flavor, leveraging custom inference logic and artifact\n dependencies.\n \"\"\"\n __metaclass__ = ABCMeta\n\n def load_context(self, context):\n \"\"\"\n Loads artifacts from the specified :class:`~PythonModelContext` that can be used by\n :func:`~PythonModel.predict` when evaluating inputs. When loading an MLflow model with\n :func:`~load_pyfunc`, this method is called as soon as the :class:`~PythonModel` is\n constructed.\n\n The same :class:`~PythonModelContext` will also be available during calls to\n :func:`~PythonModel.predict`, but it may be more efficient to override this method\n and load artifacts from the context at model load time.\n\n :param context: A :class:`~PythonModelContext` instance containing artifacts that the model\n can use to perform inference.\n \"\"\"\n\n @abstractmethod\n def predict(self, context, model_input):\n \"\"\"\n Evaluates a pyfunc-compatible input and produces a pyfunc-compatible output.\n For more information about the pyfunc input/output API, see the :ref:`pyfunc-inference-api`.\n\n :param context: A :class:`~PythonModelContext` instance containing artifacts that the model\n can use to perform inference.\n :param model_input: A pyfunc-compatible input for the model to evaluate.\n \"\"\"\n\n\nclass PythonModelContext(object):\n \"\"\"\n A collection of artifacts that a :class:`~PythonModel` can use when performing inference.\n :class:`~PythonModelContext` objects are created *implicitly* by the\n :func:`save_model() <mlflow.pyfunc.save_model>` and\n :func:`log_model() <mlflow.pyfunc.log_model>` persistence methods, using the contents specified\n by the ``artifacts`` parameter of these methods.\n \"\"\"\n\n def __init__(self, artifacts):\n \"\"\"\n :param artifacts: A dictionary of ``<name, artifact_path>`` entries, where ``artifact_path``\n is an absolute filesystem path to a given artifact.\n \"\"\"\n self._artifacts = artifacts\n\n @property\n def artifacts(self):\n \"\"\"\n A dictionary containing ``<name, artifact_path>`` entries, where ``artifact_path`` is an\n absolute filesystem path to the artifact.\n \"\"\"\n return self._artifacts\n\n\ndef _save_model_with_class_artifacts_params(path, python_model, artifacts=None, conda_env=None,\n code_paths=None, mlflow_model=Model()):\n \"\"\"\n :param path: The path to which to save the Python model.\n :param python_model: An instance of a subclass of :class:`~PythonModel`. ``python_model``\n defines how the model loads artifacts and how it performs inference.\n :param artifacts: A dictionary containing ``<name, artifact_uri>`` entries.\n Remote artifact URIs\n are resolved to absolute filesystem paths, producing a dictionary of\n ``<name, absolute_path>`` entries. ``python_model`` can reference these\n resolved entries as the ``artifacts`` property of the ``context``\n attribute. If ``None``, no artifacts are added to the model.\n :param conda_env: Either a dictionary representation of a Conda environment or the\n path to a Conda environment yaml file. If provided, this decsribes the\n environment this model should be run in. At minimum, it should specify\n the dependencies\n contained in :func:`get_default_conda_env()`. If ``None``, the default\n :func:`get_default_conda_env()` environment is added to the model.\n :param code_paths: A list of local filesystem paths to Python file dependencies (or directories\n containing file dependencies). These files are *prepended* to the system\n path before the model is loaded.\n :param mlflow_model: The model configuration to which to add the ``mlflow.pyfunc`` flavor.\n \"\"\"\n if os.path.exists(path):\n raise MlflowException(\n message=\"Path '{}' already exists\".format(path),\n error_code=RESOURCE_ALREADY_EXISTS)\n os.makedirs(path)\n\n custom_model_config_kwargs = {\n CONFIG_KEY_CLOUDPICKLE_VERSION: cloudpickle.__version__,\n }\n if isinstance(python_model, PythonModel):\n saved_python_model_subpath = \"python_model.pkl\"\n with open(os.path.join(path, saved_python_model_subpath), \"wb\") as out:\n cloudpickle.dump(python_model, out)\n custom_model_config_kwargs[CONFIG_KEY_PYTHON_MODEL] = saved_python_model_subpath\n else:\n raise MlflowException(\n message=(\"`python_model` must be a subclass of `PythonModel`. Instead, found an\"\n \" object of type: {python_model_type}\".format(\n python_model_type=type(python_model))),\n error_code=INVALID_PARAMETER_VALUE)\n\n if artifacts:\n saved_artifacts_config = {}\n with TempDir() as tmp_artifacts_dir:\n tmp_artifacts_config = {}\n saved_artifacts_dir_subpath = \"artifacts\"\n for artifact_name, artifact_uri in artifacts.items():\n tmp_artifact_path = _download_artifact_from_uri(\n artifact_uri=artifact_uri, output_path=tmp_artifacts_dir.path())\n tmp_artifacts_config[artifact_name] = tmp_artifact_path\n saved_artifact_subpath = os.path.join(\n saved_artifacts_dir_subpath,\n os.path.relpath(path=tmp_artifact_path, start=tmp_artifacts_dir.path()))\n saved_artifacts_config[artifact_name] = {\n CONFIG_KEY_ARTIFACT_RELATIVE_PATH: saved_artifact_subpath,\n CONFIG_KEY_ARTIFACT_URI: artifact_uri,\n }\n\n shutil.move(tmp_artifacts_dir.path(), os.path.join(path, saved_artifacts_dir_subpath))\n custom_model_config_kwargs[CONFIG_KEY_ARTIFACTS] = saved_artifacts_config\n\n conda_env_subpath = \"conda.yaml\"\n if conda_env is None:\n conda_env = get_default_conda_env()\n elif not isinstance(conda_env, dict):\n with open(conda_env, \"r\") as f:\n conda_env = yaml.safe_load(f)\n with open(os.path.join(path, conda_env_subpath), \"w\") as f:\n yaml.safe_dump(conda_env, stream=f, default_flow_style=False)\n\n saved_code_subpath = None\n if code_paths is not None:\n saved_code_subpath = \"code\"\n for code_path in code_paths:\n _copy_file_or_tree(src=code_path, dst=path, dst_dir=saved_code_subpath)\n\n mlflow.pyfunc.add_to_model(model=mlflow_model, loader_module=__name__, code=saved_code_subpath,\n env=conda_env_subpath, **custom_model_config_kwargs)\n mlflow_model.save(os.path.join(path, 'MLmodel'))\n\n\ndef _load_pyfunc(model_path):\n pyfunc_config = _get_flavor_configuration(\n model_path=model_path, flavor_name=mlflow.pyfunc.FLAVOR_NAME)\n\n python_model_cloudpickle_version = pyfunc_config.get(CONFIG_KEY_CLOUDPICKLE_VERSION, None)\n if python_model_cloudpickle_version is None:\n mlflow.pyfunc._logger.warning(\n \"The version of CloudPickle used to save the model could not be found in the MLmodel\"\n \" configuration\")\n elif python_model_cloudpickle_version != cloudpickle.__version__:\n # CloudPickle does not have a well-defined cross-version compatibility policy. Micro version\n # releases have been known to cause incompatibilities. Therefore, we match on the full\n # library version\n mlflow.pyfunc._logger.warning(\n \"The version of CloudPickle that was used to save the model, `CloudPickle %s`, differs\"\n \" from the version of CloudPickle that is currently running, `CloudPickle %s`, and may\"\n \" be incompatible\",\n python_model_cloudpickle_version, cloudpickle.__version__)\n\n python_model_subpath = pyfunc_config.get(CONFIG_KEY_PYTHON_MODEL, None)\n if python_model_subpath is None:\n raise MlflowException(\n \"Python model path was not specified in the model configuration\")\n with open(os.path.join(model_path, python_model_subpath), \"rb\") as f:\n python_model = cloudpickle.load(f)\n\n artifacts = {}\n for saved_artifact_name, saved_artifact_info in\\\n pyfunc_config.get(CONFIG_KEY_ARTIFACTS, {}).items():\n artifacts[saved_artifact_name] = os.path.join(\n model_path, saved_artifact_info[CONFIG_KEY_ARTIFACT_RELATIVE_PATH])\n\n context = PythonModelContext(artifacts=artifacts)\n python_model.load_context(context=context)\n return _PythonModelPyfuncWrapper(python_model=python_model, context=context)\n\n\nclass _PythonModelPyfuncWrapper(object):\n \"\"\"\n Wrapper class that creates a predict function such that\n predict(model_input: pd.DataFrame) -> model's output as pd.DataFrame (pandas DataFrame)\n \"\"\"\n\n def __init__(self, python_model, context):\n \"\"\"\n :param python_model: An instance of a subclass of :class:`~PythonModel`.\n :param context: A :class:`~PythonModelContext` instance containing artifacts that\n ``python_model`` may use when performing inference.\n \"\"\"\n self.python_model = python_model\n self.context = context\n\n def predict(self, model_input):\n return self.python_model.predict(self.context, model_input)\n", "path": "mlflow/pyfunc/model.py"}]}
| 4,088 | 189 |
gh_patches_debug_47933
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-583
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
when I log out while I am on my profile page I get a 500
</issue>
<code>
[start of euth/follows/templatetags/follow_tags.py]
1 from django import template
2
3 from .. import models
4
5 register = template.Library()
6
7
8 @register.assignment_tag()
9 def is_following(user, project):
10 return models.Follow.objects.filter(
11 enabled=True,
12 project=project,
13 creator=user
14 ).exists()
15
[end of euth/follows/templatetags/follow_tags.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/euth/follows/templatetags/follow_tags.py b/euth/follows/templatetags/follow_tags.py
--- a/euth/follows/templatetags/follow_tags.py
+++ b/euth/follows/templatetags/follow_tags.py
@@ -7,8 +7,11 @@
@register.assignment_tag()
def is_following(user, project):
- return models.Follow.objects.filter(
- enabled=True,
- project=project,
- creator=user
- ).exists()
+ if not user.is_anonymous():
+ return models.Follow.objects.filter(
+ enabled=True,
+ project=project,
+ creator=user
+ ).exists()
+ else:
+ return False
|
{"golden_diff": "diff --git a/euth/follows/templatetags/follow_tags.py b/euth/follows/templatetags/follow_tags.py\n--- a/euth/follows/templatetags/follow_tags.py\n+++ b/euth/follows/templatetags/follow_tags.py\n@@ -7,8 +7,11 @@\n \n @register.assignment_tag()\n def is_following(user, project):\n- return models.Follow.objects.filter(\n- enabled=True,\n- project=project,\n- creator=user\n- ).exists()\n+ if not user.is_anonymous():\n+ return models.Follow.objects.filter(\n+ enabled=True,\n+ project=project,\n+ creator=user\n+ ).exists()\n+ else:\n+ return False\n", "issue": "when I log out while I am on my profile page I get a 500\n\n", "before_files": [{"content": "from django import template\n\nfrom .. import models\n\nregister = template.Library()\n\n\[email protected]_tag()\ndef is_following(user, project):\n return models.Follow.objects.filter(\n enabled=True,\n project=project,\n creator=user\n ).exists()\n", "path": "euth/follows/templatetags/follow_tags.py"}]}
| 649 | 171 |
gh_patches_debug_10257
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-48159
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to disable issue alert notifications for specific projects on old sentry accounts.
### Environment
SaaS (https://sentry.io/)
### Version
_No response_
### Link
_No response_
### DSN
_No response_
### Steps to Reproduce
In old accounts the default option for Fine tuning issue alert notifications was `--`, which no longer exists. (User Settings -> Notifications -> Issue alert notifications -> Fine Tune).
It seems to have been replaced with "Default" and in cases a user wants to disable the notifications for a project that currently has `--` selected, the changes to "Off" is not saved and notifications continue to be sent.
There is no workaround as turning issue alerts notifications to OFF completely disable the notifications for all projects in all organisation, not allowing to enable for projects that man wants to receive notifications from.
As a side note: This design is not optimal as having "On" and "Default" is redundant -> you can only set default to On, and when it is off there are no options available (Default(Off) does not exist).
There is a recoding available in this [internal ticket (contains personal information)](https://sentry.zendesk.com/agent/tickets/84240)
### Expected Result
Changing the notification from `--` to `Off` saves and stop sending emails.
### Actual Result
The change is not saved.
</issue>
<code>
[start of src/sentry/incidents/endpoints/bases.py]
1 from rest_framework.exceptions import PermissionDenied
2 from rest_framework.request import Request
3
4 from sentry import features
5 from sentry.api.bases.organization import OrganizationAlertRulePermission, OrganizationEndpoint
6 from sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint
7 from sentry.api.exceptions import ResourceDoesNotExist
8 from sentry.incidents.models import AlertRule, AlertRuleTrigger, AlertRuleTriggerAction
9
10
11 class ProjectAlertRuleEndpoint(ProjectEndpoint):
12 permission_classes = (ProjectAlertRulePermission,)
13
14 def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):
15 args, kwargs = super().convert_args(request, *args, **kwargs)
16 project = kwargs["project"]
17
18 if not features.has("organizations:incidents", project.organization, actor=request.user):
19 raise ResourceDoesNotExist
20
21 if not request.access.has_project_access(project):
22 raise PermissionDenied
23
24 try:
25 kwargs["alert_rule"] = AlertRule.objects.get(
26 snuba_query__subscriptions__project=project, id=alert_rule_id
27 )
28 except AlertRule.DoesNotExist:
29 raise ResourceDoesNotExist
30
31 return args, kwargs
32
33
34 class OrganizationAlertRuleEndpoint(OrganizationEndpoint):
35 permission_classes = (OrganizationAlertRulePermission,)
36
37 def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):
38 args, kwargs = super().convert_args(request, *args, **kwargs)
39 organization = kwargs["organization"]
40
41 # Allow orgs that have downgraded plans to delete metric alerts
42 if request.method != "DELETE" and not features.has(
43 "organizations:incidents", organization, actor=request.user
44 ):
45 raise ResourceDoesNotExist
46
47 try:
48 kwargs["alert_rule"] = AlertRule.objects.get(
49 organization=organization, id=alert_rule_id
50 )
51 except AlertRule.DoesNotExist:
52 raise ResourceDoesNotExist
53
54 return args, kwargs
55
56
57 class OrganizationAlertRuleTriggerEndpoint(OrganizationAlertRuleEndpoint):
58 def convert_args(self, request: Request, alert_rule_trigger_id, *args, **kwargs):
59 args, kwargs = super().convert_args(request, *args, **kwargs)
60 organization = kwargs["organization"]
61 alert_rule = kwargs["alert_rule"]
62
63 if not features.has("organizations:incidents", organization, actor=request.user):
64 raise ResourceDoesNotExist
65
66 try:
67 kwargs["alert_rule_trigger"] = AlertRuleTrigger.objects.get(
68 alert_rule=alert_rule, id=alert_rule_trigger_id
69 )
70 except AlertRuleTrigger.DoesNotExist:
71 raise ResourceDoesNotExist
72
73 return args, kwargs
74
75
76 class OrganizationAlertRuleTriggerActionEndpoint(OrganizationAlertRuleTriggerEndpoint):
77 def convert_args(self, request: Request, alert_rule_trigger_action_id, *args, **kwargs):
78 args, kwargs = super().convert_args(request, *args, **kwargs)
79 organization = kwargs["organization"]
80 trigger = kwargs["alert_rule_trigger"]
81
82 if not features.has("organizations:incidents", organization, actor=request.user):
83 raise ResourceDoesNotExist
84
85 try:
86 kwargs["alert_rule_trigger_action"] = AlertRuleTriggerAction.objects.get(
87 alert_rule_trigger=trigger, id=alert_rule_trigger_action_id
88 )
89 except AlertRuleTriggerAction.DoesNotExist:
90 raise ResourceDoesNotExist
91
92 return args, kwargs
93
[end of src/sentry/incidents/endpoints/bases.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/incidents/endpoints/bases.py b/src/sentry/incidents/endpoints/bases.py
--- a/src/sentry/incidents/endpoints/bases.py
+++ b/src/sentry/incidents/endpoints/bases.py
@@ -15,7 +15,10 @@
args, kwargs = super().convert_args(request, *args, **kwargs)
project = kwargs["project"]
- if not features.has("organizations:incidents", project.organization, actor=request.user):
+ # Allow orgs that have downgraded plans to delete metric alerts
+ if request.method != "DELETE" and not features.has(
+ "organizations:incidents", project.organization, actor=request.user
+ ):
raise ResourceDoesNotExist
if not request.access.has_project_access(project):
|
{"golden_diff": "diff --git a/src/sentry/incidents/endpoints/bases.py b/src/sentry/incidents/endpoints/bases.py\n--- a/src/sentry/incidents/endpoints/bases.py\n+++ b/src/sentry/incidents/endpoints/bases.py\n@@ -15,7 +15,10 @@\n args, kwargs = super().convert_args(request, *args, **kwargs)\n project = kwargs[\"project\"]\n \n- if not features.has(\"organizations:incidents\", project.organization, actor=request.user):\n+ # Allow orgs that have downgraded plans to delete metric alerts\n+ if request.method != \"DELETE\" and not features.has(\n+ \"organizations:incidents\", project.organization, actor=request.user\n+ ):\n raise ResourceDoesNotExist\n \n if not request.access.has_project_access(project):\n", "issue": "Unable to disable issue alert notifications for specific projects on old sentry accounts.\n### Environment\n\nSaaS (https://sentry.io/)\n\n### Version\n\n_No response_\n\n### Link\n\n_No response_\n\n### DSN\n\n_No response_\n\n### Steps to Reproduce\n\nIn old accounts the default option for Fine tuning issue alert notifications was `--`, which no longer exists. (User Settings -> Notifications -> Issue alert notifications -> Fine Tune).\r\n\r\nIt seems to have been replaced with \"Default\" and in cases a user wants to disable the notifications for a project that currently has `--` selected, the changes to \"Off\" is not saved and notifications continue to be sent. \r\n\r\nThere is no workaround as turning issue alerts notifications to OFF completely disable the notifications for all projects in all organisation, not allowing to enable for projects that man wants to receive notifications from. \r\n\r\nAs a side note: This design is not optimal as having \"On\" and \"Default\" is redundant -> you can only set default to On, and when it is off there are no options available (Default(Off) does not exist). \r\n\r\nThere is a recoding available in this [internal ticket (contains personal information)](https://sentry.zendesk.com/agent/tickets/84240)\n\n### Expected Result\n\nChanging the notification from `--` to `Off` saves and stop sending emails.\n\n### Actual Result\n\nThe change is not saved.\n", "before_files": [{"content": "from rest_framework.exceptions import PermissionDenied\nfrom rest_framework.request import Request\n\nfrom sentry import features\nfrom sentry.api.bases.organization import OrganizationAlertRulePermission, OrganizationEndpoint\nfrom sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint\nfrom sentry.api.exceptions import ResourceDoesNotExist\nfrom sentry.incidents.models import AlertRule, AlertRuleTrigger, AlertRuleTriggerAction\n\n\nclass ProjectAlertRuleEndpoint(ProjectEndpoint):\n permission_classes = (ProjectAlertRulePermission,)\n\n def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n project = kwargs[\"project\"]\n\n if not features.has(\"organizations:incidents\", project.organization, actor=request.user):\n raise ResourceDoesNotExist\n\n if not request.access.has_project_access(project):\n raise PermissionDenied\n\n try:\n kwargs[\"alert_rule\"] = AlertRule.objects.get(\n snuba_query__subscriptions__project=project, id=alert_rule_id\n )\n except AlertRule.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleEndpoint(OrganizationEndpoint):\n permission_classes = (OrganizationAlertRulePermission,)\n\n def convert_args(self, request: Request, alert_rule_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n\n # Allow orgs that have downgraded plans to delete metric alerts\n if request.method != \"DELETE\" and not features.has(\n \"organizations:incidents\", organization, actor=request.user\n ):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule\"] = AlertRule.objects.get(\n organization=organization, id=alert_rule_id\n )\n except AlertRule.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleTriggerEndpoint(OrganizationAlertRuleEndpoint):\n def convert_args(self, request: Request, alert_rule_trigger_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n alert_rule = kwargs[\"alert_rule\"]\n\n if not features.has(\"organizations:incidents\", organization, actor=request.user):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule_trigger\"] = AlertRuleTrigger.objects.get(\n alert_rule=alert_rule, id=alert_rule_trigger_id\n )\n except AlertRuleTrigger.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n\n\nclass OrganizationAlertRuleTriggerActionEndpoint(OrganizationAlertRuleTriggerEndpoint):\n def convert_args(self, request: Request, alert_rule_trigger_action_id, *args, **kwargs):\n args, kwargs = super().convert_args(request, *args, **kwargs)\n organization = kwargs[\"organization\"]\n trigger = kwargs[\"alert_rule_trigger\"]\n\n if not features.has(\"organizations:incidents\", organization, actor=request.user):\n raise ResourceDoesNotExist\n\n try:\n kwargs[\"alert_rule_trigger_action\"] = AlertRuleTriggerAction.objects.get(\n alert_rule_trigger=trigger, id=alert_rule_trigger_action_id\n )\n except AlertRuleTriggerAction.DoesNotExist:\n raise ResourceDoesNotExist\n\n return args, kwargs\n", "path": "src/sentry/incidents/endpoints/bases.py"}]}
| 1,718 | 173 |
gh_patches_debug_5127
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1064
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Duplicate email to algorithm user that is also an editor when job fails
A tiny improvement request: When an algorithm job fails, the editors and the job creator are emailed (#1018), but there is apparently no check whether the job creator is one of the algorithm editor and would receive an email anyway - I was testing a new algorithm and always received two emails when a job failed.
</issue>
<code>
[start of app/grandchallenge/algorithms/emails.py]
1 from django.conf import settings
2 from django.contrib.sites.models import Site
3 from django.core.mail import send_mail
4
5 from grandchallenge.core.utils.email import send_templated_email
6 from grandchallenge.evaluation.templatetags.evaluation_extras import user_error
7
8
9 def send_permission_request_email(obj):
10 """
11 Emails the editors that someone has requested to view an algorithm.
12
13 Parameters
14 ----------
15 obj:
16 AlgorithmPermissionRequest object containing info on which
17 user requested access to which algorithm.
18 """
19 title = f"[{obj.algorithm.title}] New access request"
20 kwargs = {
21 "user": obj.user,
22 "site": Site.objects.get_current(),
23 "algorithm": obj.algorithm,
24 }
25 for editor in obj.algorithm.editors_group.user_set.all():
26 kwargs["editor"] = editor
27 send_templated_email(
28 title,
29 "algorithms/emails/access_request.html",
30 kwargs,
31 [editor.email],
32 )
33
34
35 def send_permission_granted_email(obj):
36 """
37 Emails the requester that their request has been approved.
38
39 Parameters
40 ----------
41 obj:
42 AlgorithmPermissionRequest object containing info on which
43 user requested access to which algorithm.
44 """
45 title = f"[{obj.algorithm.title}] Access granted"
46 kwargs = {
47 "user": obj.user,
48 "site": Site.objects.get_current(),
49 "algorithm": obj.algorithm,
50 }
51 send_templated_email(
52 title,
53 "algorithms/emails/access_granted.html",
54 kwargs,
55 [obj.user.email],
56 )
57
58
59 def send_permission_denied_email(obj):
60 """
61 Emails the requester that their request has been approved.
62
63 Parameters
64 ----------
65 obj:
66 AlgorithmPermissionRequest object containing info on which
67 user requested access to which algorithm and optionally the
68 reason for rejection.
69 """
70 title = f"[{obj.algorithm.title}] Access denied"
71 kwargs = {
72 "user": obj.user,
73 "site": Site.objects.get_current(),
74 "algorithm": obj.algorithm,
75 "permission_request": obj,
76 }
77 send_templated_email(
78 title,
79 "algorithms/emails/access_denied.html",
80 kwargs,
81 [obj.user.email],
82 )
83
84
85 def send_failed_job_email(job):
86 algorithm = job.algorithm_image.algorithm
87 message = (
88 f"Unfortunately your job for algorithm "
89 f"'{algorithm.title}' failed with an error. "
90 f"The error message is:\n\n"
91 f"{user_error(job.output)}\n\n"
92 f"You may wish to try and correct this, or contact the challenge "
93 f"organizers. The following information may help them:\n"
94 f"User: {job.creator.username}\n"
95 f"Job ID: {job.pk}\n"
96 f"Submission ID: {job.pk}"
97 )
98 recipient_emails = [
99 o.email for o in algorithm.editors_group.user_set.all()
100 ]
101 recipient_emails.append(job.creator.email)
102 for email in recipient_emails:
103 send_mail(
104 subject=(
105 f"[{Site.objects.get_current().domain.lower()}] "
106 f"[{algorithm.title.lower()}] "
107 f"Job Failed"
108 ),
109 message=message,
110 from_email=settings.DEFAULT_FROM_EMAIL,
111 recipient_list=[email],
112 )
113
[end of app/grandchallenge/algorithms/emails.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/algorithms/emails.py b/app/grandchallenge/algorithms/emails.py
--- a/app/grandchallenge/algorithms/emails.py
+++ b/app/grandchallenge/algorithms/emails.py
@@ -99,7 +99,8 @@
o.email for o in algorithm.editors_group.user_set.all()
]
recipient_emails.append(job.creator.email)
- for email in recipient_emails:
+
+ for email in {*recipient_emails}:
send_mail(
subject=(
f"[{Site.objects.get_current().domain.lower()}] "
|
{"golden_diff": "diff --git a/app/grandchallenge/algorithms/emails.py b/app/grandchallenge/algorithms/emails.py\n--- a/app/grandchallenge/algorithms/emails.py\n+++ b/app/grandchallenge/algorithms/emails.py\n@@ -99,7 +99,8 @@\n o.email for o in algorithm.editors_group.user_set.all()\n ]\n recipient_emails.append(job.creator.email)\n- for email in recipient_emails:\n+\n+ for email in {*recipient_emails}:\n send_mail(\n subject=(\n f\"[{Site.objects.get_current().domain.lower()}] \"\n", "issue": "Duplicate email to algorithm user that is also an editor when job fails\nA tiny improvement request: When an algorithm job fails, the editors and the job creator are emailed (#1018), but there is apparently no check whether the job creator is one of the algorithm editor and would receive an email anyway - I was testing a new algorithm and always received two emails when a job failed.\n", "before_files": [{"content": "from django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.mail import send_mail\n\nfrom grandchallenge.core.utils.email import send_templated_email\nfrom grandchallenge.evaluation.templatetags.evaluation_extras import user_error\n\n\ndef send_permission_request_email(obj):\n \"\"\"\n Emails the editors that someone has requested to view an algorithm.\n\n Parameters\n ----------\n obj:\n AlgorithmPermissionRequest object containing info on which\n user requested access to which algorithm.\n \"\"\"\n title = f\"[{obj.algorithm.title}] New access request\"\n kwargs = {\n \"user\": obj.user,\n \"site\": Site.objects.get_current(),\n \"algorithm\": obj.algorithm,\n }\n for editor in obj.algorithm.editors_group.user_set.all():\n kwargs[\"editor\"] = editor\n send_templated_email(\n title,\n \"algorithms/emails/access_request.html\",\n kwargs,\n [editor.email],\n )\n\n\ndef send_permission_granted_email(obj):\n \"\"\"\n Emails the requester that their request has been approved.\n\n Parameters\n ----------\n obj:\n AlgorithmPermissionRequest object containing info on which\n user requested access to which algorithm.\n \"\"\"\n title = f\"[{obj.algorithm.title}] Access granted\"\n kwargs = {\n \"user\": obj.user,\n \"site\": Site.objects.get_current(),\n \"algorithm\": obj.algorithm,\n }\n send_templated_email(\n title,\n \"algorithms/emails/access_granted.html\",\n kwargs,\n [obj.user.email],\n )\n\n\ndef send_permission_denied_email(obj):\n \"\"\"\n Emails the requester that their request has been approved.\n\n Parameters\n ----------\n obj:\n AlgorithmPermissionRequest object containing info on which\n user requested access to which algorithm and optionally the\n reason for rejection.\n \"\"\"\n title = f\"[{obj.algorithm.title}] Access denied\"\n kwargs = {\n \"user\": obj.user,\n \"site\": Site.objects.get_current(),\n \"algorithm\": obj.algorithm,\n \"permission_request\": obj,\n }\n send_templated_email(\n title,\n \"algorithms/emails/access_denied.html\",\n kwargs,\n [obj.user.email],\n )\n\n\ndef send_failed_job_email(job):\n algorithm = job.algorithm_image.algorithm\n message = (\n f\"Unfortunately your job for algorithm \"\n f\"'{algorithm.title}' failed with an error. \"\n f\"The error message is:\\n\\n\"\n f\"{user_error(job.output)}\\n\\n\"\n f\"You may wish to try and correct this, or contact the challenge \"\n f\"organizers. The following information may help them:\\n\"\n f\"User: {job.creator.username}\\n\"\n f\"Job ID: {job.pk}\\n\"\n f\"Submission ID: {job.pk}\"\n )\n recipient_emails = [\n o.email for o in algorithm.editors_group.user_set.all()\n ]\n recipient_emails.append(job.creator.email)\n for email in recipient_emails:\n send_mail(\n subject=(\n f\"[{Site.objects.get_current().domain.lower()}] \"\n f\"[{algorithm.title.lower()}] \"\n f\"Job Failed\"\n ),\n message=message,\n from_email=settings.DEFAULT_FROM_EMAIL,\n recipient_list=[email],\n )\n", "path": "app/grandchallenge/algorithms/emails.py"}]}
| 1,548 | 124 |
gh_patches_debug_10637
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5043
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
inconsistent 'difficult question' reports between learners
### Observed behavior
reported by @jtamiace during last week's bug bash
Clicking a “difficult question” in an exercise does not all show the same question for each learner. Number of learners for a question does not match what the overview says
Question 1 for Jamie and Laura are different:
| Page | Image |
|--|--|
| Question table | 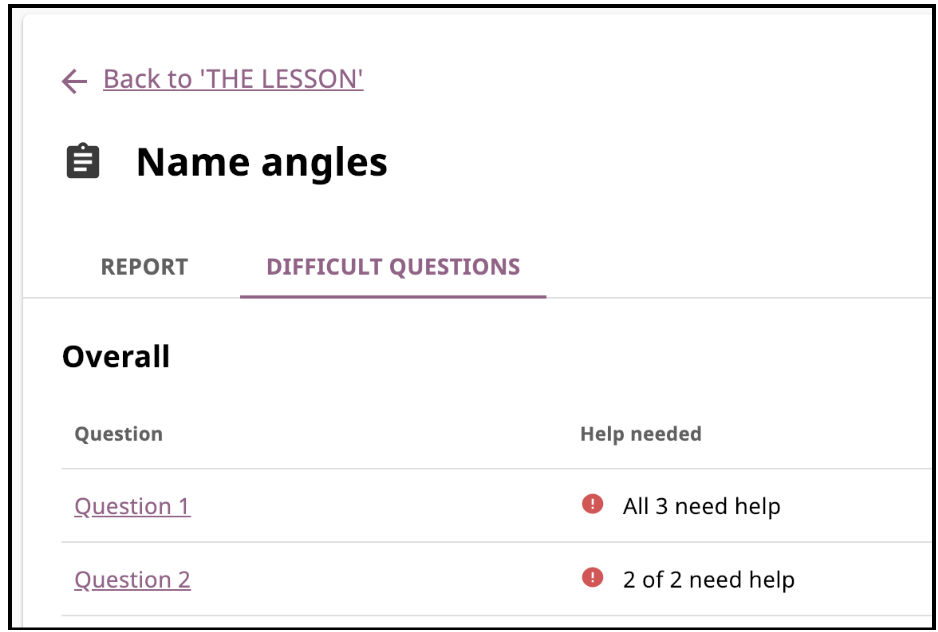|
| Jamie's report | 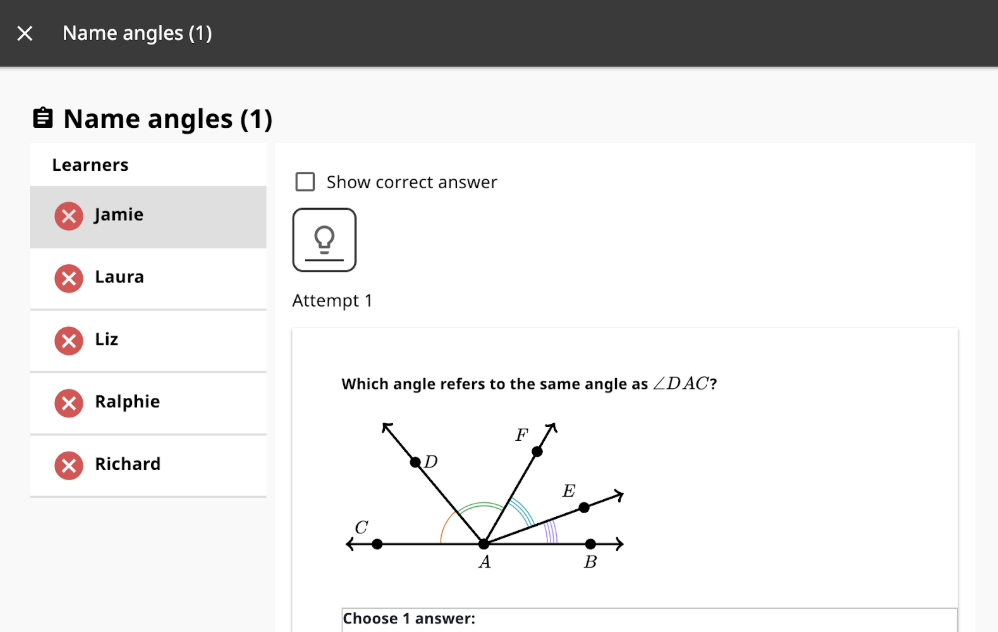 |
| Laura's report | 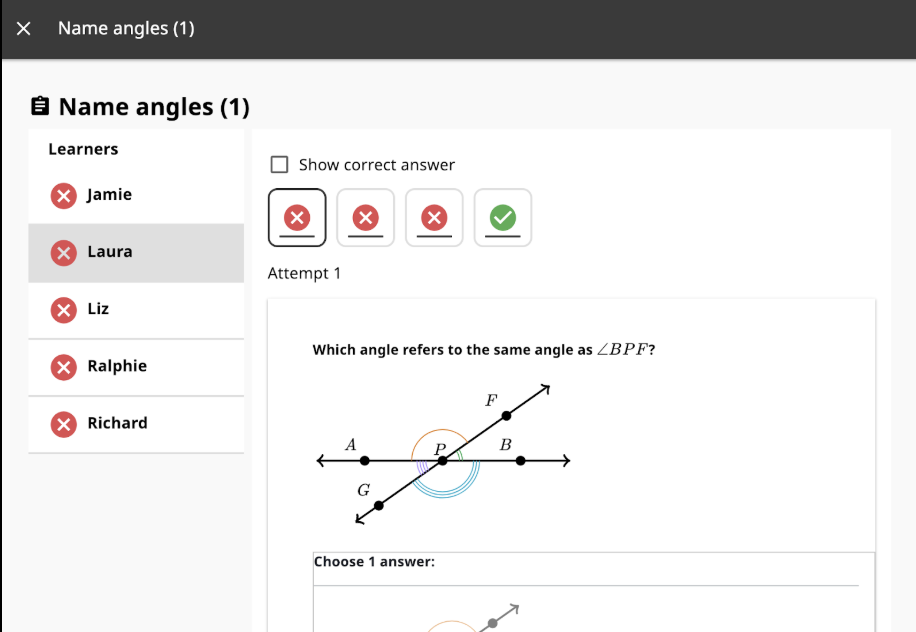|
### Expected behavior
A 'difficult question' as reported should be consistent
### User-facing consequences
can't effectively use feature
### Errors and logs
<!--
Relevant logs from:
* the command line
* ~/.kolibri/kolibri.log
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
…
### Steps to reproduce
<!--
Precise steps that someone else can follow in order to see this behavior
-->
…
### Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
…
</issue>
<code>
[start of kolibri/core/logger/api.py]
1 from django.core.exceptions import ObjectDoesNotExist
2 from django.db.models.query import F
3 from django.http import Http404
4 from django_filters import ModelChoiceFilter
5 from django_filters.rest_framework import CharFilter
6 from django_filters.rest_framework import DjangoFilterBackend
7 from django_filters.rest_framework import FilterSet
8 from rest_framework import filters
9 from rest_framework import viewsets
10 from rest_framework.response import Response
11
12 from .models import AttemptLog
13 from .models import ContentSessionLog
14 from .models import ContentSummaryLog
15 from .models import ExamAttemptLog
16 from .models import ExamLog
17 from .models import MasteryLog
18 from .models import UserSessionLog
19 from .permissions import ExamActivePermissions
20 from .serializers import AttemptLogSerializer
21 from .serializers import ContentSessionLogSerializer
22 from .serializers import ContentSummaryLogSerializer
23 from .serializers import ExamAttemptLogSerializer
24 from .serializers import ExamLogSerializer
25 from .serializers import MasteryLogSerializer
26 from .serializers import TotalContentProgressSerializer
27 from .serializers import UserSessionLogSerializer
28 from kolibri.core.auth.api import KolibriAuthPermissions
29 from kolibri.core.auth.api import KolibriAuthPermissionsFilter
30 from kolibri.core.auth.filters import HierarchyRelationsFilter
31 from kolibri.core.auth.models import Classroom
32 from kolibri.core.auth.models import Collection
33 from kolibri.core.auth.models import Facility
34 from kolibri.core.auth.models import FacilityUser
35 from kolibri.core.auth.models import LearnerGroup
36 from kolibri.core.content.api import OptionalPageNumberPagination
37 from kolibri.core.exams.models import Exam
38
39
40 class BaseLogFilter(FilterSet):
41 facility = ModelChoiceFilter(method="filter_facility", queryset=Facility.objects.all())
42 classroom = ModelChoiceFilter(method="filter_classroom", queryset=Classroom.objects.all())
43 learner_group = ModelChoiceFilter(method="filter_learner_group", queryset=LearnerGroup.objects.all())
44
45 # Only a superuser can filter by facilities
46 def filter_facility(self, queryset, name, value):
47 return queryset.filter(user__facility=value)
48
49 def filter_classroom(self, queryset, name, value):
50 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
51 ancestor_collection=value,
52 target_user=F("user"),
53 )
54
55 def filter_learner_group(self, queryset, name, value):
56 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
57 ancestor_collection=value,
58 target_user=F("user"),
59 )
60
61
62 class LoggerViewSet(viewsets.ModelViewSet):
63 def update(self, request, *args, **kwargs):
64 partial = kwargs.pop('partial', False)
65 model = self.queryset.model
66 lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
67 try:
68 instance = model.objects.get(id=self.kwargs[lookup_url_kwarg])
69 self.check_object_permissions(request, instance)
70 except (ValueError, ObjectDoesNotExist):
71 raise Http404
72 serializer = self.get_serializer(instance, data=request.data, partial=partial)
73 serializer.is_valid(raise_exception=True)
74 self.perform_update(serializer)
75
76 if getattr(instance, '_prefetched_objects_cache', None):
77 # If 'prefetch_related' has been applied to a queryset, we need to
78 # forcibly invalidate the prefetch cache on the instance.
79 instance._prefetched_objects_cache = {}
80 default_response = dict(request.data)
81 # First look if the computed fields to be updated are listed:
82 updating_fields = getattr(serializer.root, 'update_fields', None)
83 # If not, fetch all the fields that are computed methods:
84 if updating_fields is None:
85 updating_fields = [field for field in serializer.fields if getattr(serializer.fields[field], 'method_name', None)]
86 for field in updating_fields:
87 method_name = getattr(serializer.fields[field], 'method_name', None)
88 if method_name:
89 method = getattr(serializer.root, method_name)
90 default_response[field] = method(instance)
91 return Response(default_response)
92
93
94 class ContentSessionLogFilter(BaseLogFilter):
95
96 class Meta:
97 model = ContentSessionLog
98 fields = ['user_id', 'content_id']
99
100
101 class ContentSessionLogViewSet(LoggerViewSet):
102 permission_classes = (KolibriAuthPermissions,)
103 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
104 queryset = ContentSessionLog.objects.all()
105 serializer_class = ContentSessionLogSerializer
106 pagination_class = OptionalPageNumberPagination
107 filter_class = ContentSessionLogFilter
108
109
110 class ContentSummaryLogFilter(BaseLogFilter):
111
112 class Meta:
113 model = ContentSummaryLog
114 fields = ['user_id', 'content_id']
115
116
117 class ContentSummaryLogViewSet(LoggerViewSet):
118 permission_classes = (KolibriAuthPermissions,)
119 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
120 queryset = ContentSummaryLog.objects.all()
121 serializer_class = ContentSummaryLogSerializer
122 pagination_class = OptionalPageNumberPagination
123 filter_class = ContentSummaryLogFilter
124
125
126 class TotalContentProgressViewSet(viewsets.ModelViewSet):
127 permission_classes = (KolibriAuthPermissions,)
128 filter_backends = (KolibriAuthPermissionsFilter,)
129 queryset = FacilityUser.objects.all()
130 serializer_class = TotalContentProgressSerializer
131
132
133 class UserSessionLogFilter(BaseLogFilter):
134
135 class Meta:
136 model = UserSessionLog
137 fields = ['user_id']
138
139
140 class UserSessionLogViewSet(LoggerViewSet):
141 permission_classes = (KolibriAuthPermissions,)
142 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
143 queryset = UserSessionLog.objects.all()
144 serializer_class = UserSessionLogSerializer
145 pagination_class = OptionalPageNumberPagination
146 filter_class = UserSessionLogFilter
147
148
149 class MasteryFilter(FilterSet):
150
151 class Meta:
152 model = MasteryLog
153 fields = ['summarylog']
154
155
156 class MasteryLogViewSet(LoggerViewSet):
157 permission_classes = (KolibriAuthPermissions,)
158 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
159 queryset = MasteryLog.objects.all()
160 serializer_class = MasteryLogSerializer
161 pagination_class = OptionalPageNumberPagination
162 filter_class = MasteryFilter
163
164
165 class AttemptFilter(BaseLogFilter):
166 content = CharFilter(method="filter_content")
167
168 def filter_content(self, queryset, name, value):
169 return queryset.filter(masterylog__summarylog__content_id=value)
170
171 class Meta:
172 model = AttemptLog
173 fields = ['masterylog', 'complete', 'user', 'content']
174
175
176 class AttemptLogViewSet(LoggerViewSet):
177 permission_classes = (KolibriAuthPermissions,)
178 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend, filters.OrderingFilter)
179 queryset = AttemptLog.objects.all()
180 serializer_class = AttemptLogSerializer
181 pagination_class = OptionalPageNumberPagination
182 filter_class = AttemptFilter
183 ordering_fields = ('end_timestamp',)
184 ordering = ('end_timestamp',)
185
186
187 class ExamAttemptFilter(BaseLogFilter):
188 exam = ModelChoiceFilter(method="filter_exam", queryset=Exam.objects.all())
189 user = ModelChoiceFilter(method="filter_user", queryset=FacilityUser.objects.all())
190 content = CharFilter(field_name="content_id")
191
192 def filter_exam(self, queryset, name, value):
193 return queryset.filter(examlog__exam=value)
194
195 def filter_user(self, queryset, name, value):
196 return queryset.filter(examlog__user=value)
197
198 class Meta:
199 model = ExamAttemptLog
200 fields = ['examlog', 'exam', 'user', 'content']
201
202
203 class ExamAttemptLogViewSet(LoggerViewSet):
204 permission_classes = (ExamActivePermissions, KolibriAuthPermissions, )
205 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend, filters.OrderingFilter)
206 queryset = ExamAttemptLog.objects.all()
207 serializer_class = ExamAttemptLogSerializer
208 pagination_class = OptionalPageNumberPagination
209 filter_class = ExamAttemptFilter
210
211
212 class ExamLogFilter(BaseLogFilter):
213
214 collection = ModelChoiceFilter(method="filter_collection", queryset=Collection.objects.all())
215
216 def filter_collection(self, queryset, name, collection):
217 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
218 target_user=F('user'),
219 ancestor_collection=collection,
220 )
221
222 class Meta:
223 model = ExamLog
224 fields = ['user', 'exam']
225
226
227 class ExamLogViewSet(viewsets.ModelViewSet):
228 permission_classes = (KolibriAuthPermissions,)
229 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
230 queryset = ExamLog.objects.all()
231 serializer_class = ExamLogSerializer
232 pagination_class = OptionalPageNumberPagination
233 filter_class = ExamLogFilter
234
[end of kolibri/core/logger/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/logger/api.py b/kolibri/core/logger/api.py
--- a/kolibri/core/logger/api.py
+++ b/kolibri/core/logger/api.py
@@ -170,7 +170,7 @@
class Meta:
model = AttemptLog
- fields = ['masterylog', 'complete', 'user', 'content']
+ fields = ['masterylog', 'complete', 'user', 'content', 'item']
class AttemptLogViewSet(LoggerViewSet):
@@ -197,7 +197,7 @@
class Meta:
model = ExamAttemptLog
- fields = ['examlog', 'exam', 'user', 'content']
+ fields = ['examlog', 'exam', 'user', 'content', 'item']
class ExamAttemptLogViewSet(LoggerViewSet):
|
{"golden_diff": "diff --git a/kolibri/core/logger/api.py b/kolibri/core/logger/api.py\n--- a/kolibri/core/logger/api.py\n+++ b/kolibri/core/logger/api.py\n@@ -170,7 +170,7 @@\n \n class Meta:\n model = AttemptLog\n- fields = ['masterylog', 'complete', 'user', 'content']\n+ fields = ['masterylog', 'complete', 'user', 'content', 'item']\n \n \n class AttemptLogViewSet(LoggerViewSet):\n@@ -197,7 +197,7 @@\n \n class Meta:\n model = ExamAttemptLog\n- fields = ['examlog', 'exam', 'user', 'content']\n+ fields = ['examlog', 'exam', 'user', 'content', 'item']\n \n \n class ExamAttemptLogViewSet(LoggerViewSet):\n", "issue": "inconsistent 'difficult question' reports between learners\n\r\n### Observed behavior\r\n\r\nreported by @jtamiace during last week's bug bash\r\n\r\nClicking a \u201cdifficult question\u201d in an exercise does not all show the same question for each learner. Number of learners for a question does not match what the overview says\r\n\r\nQuestion 1 for Jamie and Laura are different:\r\n\r\n\r\n\r\n| Page | Image |\r\n|--|--|\r\n| Question table | | \r\n| Jamie's report |  |\r\n| Laura's report | |\r\n\r\n\r\n\r\n\r\n### Expected behavior\r\n\r\nA 'difficult question' as reported should be consistent\r\n\r\n### User-facing consequences\r\n\r\ncan't effectively use feature \r\n\r\n\r\n### Errors and logs\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/kolibri.log\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\n\r\n\u2026\r\n\r\n### Steps to reproduce\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\n\u2026\r\n\r\n### Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n\r\n\u2026\r\n\n", "before_files": [{"content": "from django.core.exceptions import ObjectDoesNotExist\nfrom django.db.models.query import F\nfrom django.http import Http404\nfrom django_filters import ModelChoiceFilter\nfrom django_filters.rest_framework import CharFilter\nfrom django_filters.rest_framework import DjangoFilterBackend\nfrom django_filters.rest_framework import FilterSet\nfrom rest_framework import filters\nfrom rest_framework import viewsets\nfrom rest_framework.response import Response\n\nfrom .models import AttemptLog\nfrom .models import ContentSessionLog\nfrom .models import ContentSummaryLog\nfrom .models import ExamAttemptLog\nfrom .models import ExamLog\nfrom .models import MasteryLog\nfrom .models import UserSessionLog\nfrom .permissions import ExamActivePermissions\nfrom .serializers import AttemptLogSerializer\nfrom .serializers import ContentSessionLogSerializer\nfrom .serializers import ContentSummaryLogSerializer\nfrom .serializers import ExamAttemptLogSerializer\nfrom .serializers import ExamLogSerializer\nfrom .serializers import MasteryLogSerializer\nfrom .serializers import TotalContentProgressSerializer\nfrom .serializers import UserSessionLogSerializer\nfrom kolibri.core.auth.api import KolibriAuthPermissions\nfrom kolibri.core.auth.api import KolibriAuthPermissionsFilter\nfrom kolibri.core.auth.filters import HierarchyRelationsFilter\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.auth.models import Collection\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.auth.models import FacilityUser\nfrom kolibri.core.auth.models import LearnerGroup\nfrom kolibri.core.content.api import OptionalPageNumberPagination\nfrom kolibri.core.exams.models import Exam\n\n\nclass BaseLogFilter(FilterSet):\n facility = ModelChoiceFilter(method=\"filter_facility\", queryset=Facility.objects.all())\n classroom = ModelChoiceFilter(method=\"filter_classroom\", queryset=Classroom.objects.all())\n learner_group = ModelChoiceFilter(method=\"filter_learner_group\", queryset=LearnerGroup.objects.all())\n\n # Only a superuser can filter by facilities\n def filter_facility(self, queryset, name, value):\n return queryset.filter(user__facility=value)\n\n def filter_classroom(self, queryset, name, value):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n ancestor_collection=value,\n target_user=F(\"user\"),\n )\n\n def filter_learner_group(self, queryset, name, value):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n ancestor_collection=value,\n target_user=F(\"user\"),\n )\n\n\nclass LoggerViewSet(viewsets.ModelViewSet):\n def update(self, request, *args, **kwargs):\n partial = kwargs.pop('partial', False)\n model = self.queryset.model\n lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field\n try:\n instance = model.objects.get(id=self.kwargs[lookup_url_kwarg])\n self.check_object_permissions(request, instance)\n except (ValueError, ObjectDoesNotExist):\n raise Http404\n serializer = self.get_serializer(instance, data=request.data, partial=partial)\n serializer.is_valid(raise_exception=True)\n self.perform_update(serializer)\n\n if getattr(instance, '_prefetched_objects_cache', None):\n # If 'prefetch_related' has been applied to a queryset, we need to\n # forcibly invalidate the prefetch cache on the instance.\n instance._prefetched_objects_cache = {}\n default_response = dict(request.data)\n # First look if the computed fields to be updated are listed:\n updating_fields = getattr(serializer.root, 'update_fields', None)\n # If not, fetch all the fields that are computed methods:\n if updating_fields is None:\n updating_fields = [field for field in serializer.fields if getattr(serializer.fields[field], 'method_name', None)]\n for field in updating_fields:\n method_name = getattr(serializer.fields[field], 'method_name', None)\n if method_name:\n method = getattr(serializer.root, method_name)\n default_response[field] = method(instance)\n return Response(default_response)\n\n\nclass ContentSessionLogFilter(BaseLogFilter):\n\n class Meta:\n model = ContentSessionLog\n fields = ['user_id', 'content_id']\n\n\nclass ContentSessionLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ContentSessionLog.objects.all()\n serializer_class = ContentSessionLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ContentSessionLogFilter\n\n\nclass ContentSummaryLogFilter(BaseLogFilter):\n\n class Meta:\n model = ContentSummaryLog\n fields = ['user_id', 'content_id']\n\n\nclass ContentSummaryLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ContentSummaryLog.objects.all()\n serializer_class = ContentSummaryLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ContentSummaryLogFilter\n\n\nclass TotalContentProgressViewSet(viewsets.ModelViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter,)\n queryset = FacilityUser.objects.all()\n serializer_class = TotalContentProgressSerializer\n\n\nclass UserSessionLogFilter(BaseLogFilter):\n\n class Meta:\n model = UserSessionLog\n fields = ['user_id']\n\n\nclass UserSessionLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = UserSessionLog.objects.all()\n serializer_class = UserSessionLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = UserSessionLogFilter\n\n\nclass MasteryFilter(FilterSet):\n\n class Meta:\n model = MasteryLog\n fields = ['summarylog']\n\n\nclass MasteryLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = MasteryLog.objects.all()\n serializer_class = MasteryLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = MasteryFilter\n\n\nclass AttemptFilter(BaseLogFilter):\n content = CharFilter(method=\"filter_content\")\n\n def filter_content(self, queryset, name, value):\n return queryset.filter(masterylog__summarylog__content_id=value)\n\n class Meta:\n model = AttemptLog\n fields = ['masterylog', 'complete', 'user', 'content']\n\n\nclass AttemptLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend, filters.OrderingFilter)\n queryset = AttemptLog.objects.all()\n serializer_class = AttemptLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = AttemptFilter\n ordering_fields = ('end_timestamp',)\n ordering = ('end_timestamp',)\n\n\nclass ExamAttemptFilter(BaseLogFilter):\n exam = ModelChoiceFilter(method=\"filter_exam\", queryset=Exam.objects.all())\n user = ModelChoiceFilter(method=\"filter_user\", queryset=FacilityUser.objects.all())\n content = CharFilter(field_name=\"content_id\")\n\n def filter_exam(self, queryset, name, value):\n return queryset.filter(examlog__exam=value)\n\n def filter_user(self, queryset, name, value):\n return queryset.filter(examlog__user=value)\n\n class Meta:\n model = ExamAttemptLog\n fields = ['examlog', 'exam', 'user', 'content']\n\n\nclass ExamAttemptLogViewSet(LoggerViewSet):\n permission_classes = (ExamActivePermissions, KolibriAuthPermissions, )\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend, filters.OrderingFilter)\n queryset = ExamAttemptLog.objects.all()\n serializer_class = ExamAttemptLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ExamAttemptFilter\n\n\nclass ExamLogFilter(BaseLogFilter):\n\n collection = ModelChoiceFilter(method=\"filter_collection\", queryset=Collection.objects.all())\n\n def filter_collection(self, queryset, name, collection):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n target_user=F('user'),\n ancestor_collection=collection,\n )\n\n class Meta:\n model = ExamLog\n fields = ['user', 'exam']\n\n\nclass ExamLogViewSet(viewsets.ModelViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ExamLog.objects.all()\n serializer_class = ExamLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ExamLogFilter\n", "path": "kolibri/core/logger/api.py"}]}
| 3,409 | 184 |
gh_patches_debug_39961
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-8524
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GenericCheckpointsMixin missing methods
In the commit https://github.com/ipython/ipython/commit/82dcba3ba9ffa3ee3193602e2d5df3ef3c3de106 two new methods were introduced `get_notebook_checkpoint` and `get_file_checkpoint` but the definition of
`GenericCheckpointsMixin` itself was not updated.
It still has `get_checkpoint` method. Subclasses work now, but just thought of notifying it.
The file in question is: `ipython/IPython/html/services/contents/checkpoints.py` and the branch https://github.com/ipython/ipython/releases/tag/rel-3.1.0
</issue>
<code>
[start of IPython/html/services/contents/checkpoints.py]
1 """
2 Classes for managing Checkpoints.
3 """
4
5 # Copyright (c) IPython Development Team.
6 # Distributed under the terms of the Modified BSD License.
7
8 from tornado.web import HTTPError
9
10 from IPython.config.configurable import LoggingConfigurable
11
12
13 class Checkpoints(LoggingConfigurable):
14 """
15 Base class for managing checkpoints for a ContentsManager.
16
17 Subclasses are required to implement:
18
19 create_checkpoint(self, contents_mgr, path)
20 restore_checkpoint(self, contents_mgr, checkpoint_id, path)
21 rename_checkpoint(self, checkpoint_id, old_path, new_path)
22 delete_checkpoint(self, checkpoint_id, path)
23 list_checkpoints(self, path)
24 """
25 def create_checkpoint(self, contents_mgr, path):
26 """Create a checkpoint."""
27 raise NotImplementedError("must be implemented in a subclass")
28
29 def restore_checkpoint(self, contents_mgr, checkpoint_id, path):
30 """Restore a checkpoint"""
31 raise NotImplementedError("must be implemented in a subclass")
32
33 def rename_checkpoint(self, checkpoint_id, old_path, new_path):
34 """Rename a single checkpoint from old_path to new_path."""
35 raise NotImplementedError("must be implemented in a subclass")
36
37 def delete_checkpoint(self, checkpoint_id, path):
38 """delete a checkpoint for a file"""
39 raise NotImplementedError("must be implemented in a subclass")
40
41 def list_checkpoints(self, path):
42 """Return a list of checkpoints for a given file"""
43 raise NotImplementedError("must be implemented in a subclass")
44
45 def rename_all_checkpoints(self, old_path, new_path):
46 """Rename all checkpoints for old_path to new_path."""
47 for cp in self.list_checkpoints(old_path):
48 self.rename_checkpoint(cp['id'], old_path, new_path)
49
50 def delete_all_checkpoints(self, path):
51 """Delete all checkpoints for the given path."""
52 for checkpoint in self.list_checkpoints(path):
53 self.delete_checkpoint(checkpoint['id'], path)
54
55
56 class GenericCheckpointsMixin(object):
57 """
58 Helper for creating Checkpoints subclasses that can be used with any
59 ContentsManager.
60
61 Provides a ContentsManager-agnostic implementation of `create_checkpoint`
62 and `restore_checkpoint` in terms of the following operations:
63
64 - create_file_checkpoint(self, content, format, path)
65 - create_notebook_checkpoint(self, nb, path)
66 - get_file_checkpoint(self, checkpoint_id, path)
67 - get_notebook_checkpoint(self, checkpoint_id, path)
68
69 To create a generic CheckpointManager, add this mixin to a class that
70 implement the above three methods plus the remaining Checkpoints API
71 methods:
72
73 - delete_checkpoint(self, checkpoint_id, path)
74 - list_checkpoints(self, path)
75 - rename_checkpoint(self, checkpoint_id, old_path, new_path)
76 """
77
78 def create_checkpoint(self, contents_mgr, path):
79 model = contents_mgr.get(path, content=True)
80 type = model['type']
81 if type == 'notebook':
82 return self.create_notebook_checkpoint(
83 model['content'],
84 path,
85 )
86 elif type == 'file':
87 return self.create_file_checkpoint(
88 model['content'],
89 model['format'],
90 path,
91 )
92 else:
93 raise HTTPError(500, u'Unexpected type %s' % type)
94
95 def restore_checkpoint(self, contents_mgr, checkpoint_id, path):
96 """Restore a checkpoint."""
97 type = contents_mgr.get(path, content=False)['type']
98 if type == 'notebook':
99 model = self.get_notebook_checkpoint(checkpoint_id, path)
100 elif type == 'file':
101 model = self.get_file_checkpoint(checkpoint_id, path)
102 else:
103 raise HTTPError(500, u'Unexpected type %s' % type)
104 contents_mgr.save(model, path)
105
106 # Required Methods
107 def create_file_checkpoint(self, content, format, path):
108 """Create a checkpoint of the current state of a file
109
110 Returns a checkpoint model for the new checkpoint.
111 """
112 raise NotImplementedError("must be implemented in a subclass")
113
114 def create_notebook_checkpoint(self, nb, path):
115 """Create a checkpoint of the current state of a file
116
117 Returns a checkpoint model for the new checkpoint.
118 """
119 raise NotImplementedError("must be implemented in a subclass")
120
121 def get_checkpoint(self, checkpoint_id, path, type):
122 """Get the content of a checkpoint.
123
124 Returns an unvalidated model with the same structure as
125 the return value of ContentsManager.get
126 """
127 raise NotImplementedError("must be implemented in a subclass")
128
[end of IPython/html/services/contents/checkpoints.py]
[start of IPython/html/services/contents/filecheckpoints.py]
1 """
2 File-based Checkpoints implementations.
3 """
4 import os
5 import shutil
6
7 from tornado.web import HTTPError
8
9 from .checkpoints import (
10 Checkpoints,
11 GenericCheckpointsMixin,
12 )
13 from .fileio import FileManagerMixin
14
15 from IPython.utils import tz
16 from IPython.utils.path import ensure_dir_exists
17 from IPython.utils.py3compat import getcwd
18 from IPython.utils.traitlets import Unicode
19
20
21 class FileCheckpoints(FileManagerMixin, Checkpoints):
22 """
23 A Checkpoints that caches checkpoints for files in adjacent
24 directories.
25
26 Only works with FileContentsManager. Use GenericFileCheckpoints if
27 you want file-based checkpoints with another ContentsManager.
28 """
29
30 checkpoint_dir = Unicode(
31 '.ipynb_checkpoints',
32 config=True,
33 help="""The directory name in which to keep file checkpoints
34
35 This is a path relative to the file's own directory.
36
37 By default, it is .ipynb_checkpoints
38 """,
39 )
40
41 root_dir = Unicode(config=True)
42
43 def _root_dir_default(self):
44 try:
45 return self.parent.root_dir
46 except AttributeError:
47 return getcwd()
48
49 # ContentsManager-dependent checkpoint API
50 def create_checkpoint(self, contents_mgr, path):
51 """Create a checkpoint."""
52 checkpoint_id = u'checkpoint'
53 src_path = contents_mgr._get_os_path(path)
54 dest_path = self.checkpoint_path(checkpoint_id, path)
55 self._copy(src_path, dest_path)
56 return self.checkpoint_model(checkpoint_id, dest_path)
57
58 def restore_checkpoint(self, contents_mgr, checkpoint_id, path):
59 """Restore a checkpoint."""
60 src_path = self.checkpoint_path(checkpoint_id, path)
61 dest_path = contents_mgr._get_os_path(path)
62 self._copy(src_path, dest_path)
63
64 # ContentsManager-independent checkpoint API
65 def rename_checkpoint(self, checkpoint_id, old_path, new_path):
66 """Rename a checkpoint from old_path to new_path."""
67 old_cp_path = self.checkpoint_path(checkpoint_id, old_path)
68 new_cp_path = self.checkpoint_path(checkpoint_id, new_path)
69 if os.path.isfile(old_cp_path):
70 self.log.debug(
71 "Renaming checkpoint %s -> %s",
72 old_cp_path,
73 new_cp_path,
74 )
75 with self.perm_to_403():
76 shutil.move(old_cp_path, new_cp_path)
77
78 def delete_checkpoint(self, checkpoint_id, path):
79 """delete a file's checkpoint"""
80 path = path.strip('/')
81 cp_path = self.checkpoint_path(checkpoint_id, path)
82 if not os.path.isfile(cp_path):
83 self.no_such_checkpoint(path, checkpoint_id)
84
85 self.log.debug("unlinking %s", cp_path)
86 with self.perm_to_403():
87 os.unlink(cp_path)
88
89 def list_checkpoints(self, path):
90 """list the checkpoints for a given file
91
92 This contents manager currently only supports one checkpoint per file.
93 """
94 path = path.strip('/')
95 checkpoint_id = "checkpoint"
96 os_path = self.checkpoint_path(checkpoint_id, path)
97 if not os.path.isfile(os_path):
98 return []
99 else:
100 return [self.checkpoint_model(checkpoint_id, os_path)]
101
102 # Checkpoint-related utilities
103 def checkpoint_path(self, checkpoint_id, path):
104 """find the path to a checkpoint"""
105 path = path.strip('/')
106 parent, name = ('/' + path).rsplit('/', 1)
107 parent = parent.strip('/')
108 basename, ext = os.path.splitext(name)
109 filename = u"{name}-{checkpoint_id}{ext}".format(
110 name=basename,
111 checkpoint_id=checkpoint_id,
112 ext=ext,
113 )
114 os_path = self._get_os_path(path=parent)
115 cp_dir = os.path.join(os_path, self.checkpoint_dir)
116 with self.perm_to_403():
117 ensure_dir_exists(cp_dir)
118 cp_path = os.path.join(cp_dir, filename)
119 return cp_path
120
121 def checkpoint_model(self, checkpoint_id, os_path):
122 """construct the info dict for a given checkpoint"""
123 stats = os.stat(os_path)
124 last_modified = tz.utcfromtimestamp(stats.st_mtime)
125 info = dict(
126 id=checkpoint_id,
127 last_modified=last_modified,
128 )
129 return info
130
131 # Error Handling
132 def no_such_checkpoint(self, path, checkpoint_id):
133 raise HTTPError(
134 404,
135 u'Checkpoint does not exist: %s@%s' % (path, checkpoint_id)
136 )
137
138
139 class GenericFileCheckpoints(GenericCheckpointsMixin, FileCheckpoints):
140 """
141 Local filesystem Checkpoints that works with any conforming
142 ContentsManager.
143 """
144 def create_file_checkpoint(self, content, format, path):
145 """Create a checkpoint from the current content of a notebook."""
146 path = path.strip('/')
147 # only the one checkpoint ID:
148 checkpoint_id = u"checkpoint"
149 os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
150 self.log.debug("creating checkpoint for %s", path)
151 with self.perm_to_403():
152 self._save_file(os_checkpoint_path, content, format=format)
153
154 # return the checkpoint info
155 return self.checkpoint_model(checkpoint_id, os_checkpoint_path)
156
157 def create_notebook_checkpoint(self, nb, path):
158 """Create a checkpoint from the current content of a notebook."""
159 path = path.strip('/')
160 # only the one checkpoint ID:
161 checkpoint_id = u"checkpoint"
162 os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
163 self.log.debug("creating checkpoint for %s", path)
164 with self.perm_to_403():
165 self._save_notebook(os_checkpoint_path, nb)
166
167 # return the checkpoint info
168 return self.checkpoint_model(checkpoint_id, os_checkpoint_path)
169
170 def get_notebook_checkpoint(self, checkpoint_id, path):
171
172 path = path.strip('/')
173 self.log.info("restoring %s from checkpoint %s", path, checkpoint_id)
174 os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
175
176 if not os.path.isfile(os_checkpoint_path):
177 self.no_such_checkpoint(path, checkpoint_id)
178
179 return {
180 'type': 'notebook',
181 'content': self._read_notebook(
182 os_checkpoint_path,
183 as_version=4,
184 ),
185 }
186
187 def get_file_checkpoint(self, checkpoint_id, path):
188 path = path.strip('/')
189 self.log.info("restoring %s from checkpoint %s", path, checkpoint_id)
190 os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
191
192 if not os.path.isfile(os_checkpoint_path):
193 self.no_such_checkpoint(path, checkpoint_id)
194
195 content, format = self._read_file(os_checkpoint_path, format=None)
196 return {
197 'type': 'file',
198 'content': content,
199 'format': format,
200 }
201
[end of IPython/html/services/contents/filecheckpoints.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/html/services/contents/checkpoints.py b/IPython/html/services/contents/checkpoints.py
--- a/IPython/html/services/contents/checkpoints.py
+++ b/IPython/html/services/contents/checkpoints.py
@@ -67,7 +67,7 @@
- get_notebook_checkpoint(self, checkpoint_id, path)
To create a generic CheckpointManager, add this mixin to a class that
- implement the above three methods plus the remaining Checkpoints API
+ implement the above four methods plus the remaining Checkpoints API
methods:
- delete_checkpoint(self, checkpoint_id, path)
@@ -118,10 +118,25 @@
"""
raise NotImplementedError("must be implemented in a subclass")
- def get_checkpoint(self, checkpoint_id, path, type):
- """Get the content of a checkpoint.
+ def get_file_checkpoint(self, checkpoint_id, path):
+ """Get the content of a checkpoint for a non-notebook file.
- Returns an unvalidated model with the same structure as
- the return value of ContentsManager.get
+ Returns a dict of the form:
+ {
+ 'type': 'file',
+ 'content': <str>,
+ 'format': {'text','base64'},
+ }
+ """
+ raise NotImplementedError("must be implemented in a subclass")
+
+ def get_notebook_checkpoint(self, checkpoint_id, path):
+ """Get the content of a checkpoint for a notebook.
+
+ Returns a dict of the form:
+ {
+ 'type': 'notebook',
+ 'content': <output of nbformat.read>,
+ }
"""
raise NotImplementedError("must be implemented in a subclass")
diff --git a/IPython/html/services/contents/filecheckpoints.py b/IPython/html/services/contents/filecheckpoints.py
--- a/IPython/html/services/contents/filecheckpoints.py
+++ b/IPython/html/services/contents/filecheckpoints.py
@@ -142,7 +142,7 @@
ContentsManager.
"""
def create_file_checkpoint(self, content, format, path):
- """Create a checkpoint from the current content of a notebook."""
+ """Create a checkpoint from the current content of a file."""
path = path.strip('/')
# only the one checkpoint ID:
checkpoint_id = u"checkpoint"
@@ -168,7 +168,7 @@
return self.checkpoint_model(checkpoint_id, os_checkpoint_path)
def get_notebook_checkpoint(self, checkpoint_id, path):
-
+ """Get a checkpoint for a notebook."""
path = path.strip('/')
self.log.info("restoring %s from checkpoint %s", path, checkpoint_id)
os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
@@ -185,6 +185,7 @@
}
def get_file_checkpoint(self, checkpoint_id, path):
+ """Get a checkpoint for a file."""
path = path.strip('/')
self.log.info("restoring %s from checkpoint %s", path, checkpoint_id)
os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)
|
{"golden_diff": "diff --git a/IPython/html/services/contents/checkpoints.py b/IPython/html/services/contents/checkpoints.py\n--- a/IPython/html/services/contents/checkpoints.py\n+++ b/IPython/html/services/contents/checkpoints.py\n@@ -67,7 +67,7 @@\n - get_notebook_checkpoint(self, checkpoint_id, path)\n \n To create a generic CheckpointManager, add this mixin to a class that\n- implement the above three methods plus the remaining Checkpoints API\n+ implement the above four methods plus the remaining Checkpoints API\n methods:\n \n - delete_checkpoint(self, checkpoint_id, path)\n@@ -118,10 +118,25 @@\n \"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n \n- def get_checkpoint(self, checkpoint_id, path, type):\n- \"\"\"Get the content of a checkpoint.\n+ def get_file_checkpoint(self, checkpoint_id, path):\n+ \"\"\"Get the content of a checkpoint for a non-notebook file.\n \n- Returns an unvalidated model with the same structure as\n- the return value of ContentsManager.get\n+ Returns a dict of the form:\n+ {\n+ 'type': 'file',\n+ 'content': <str>,\n+ 'format': {'text','base64'},\n+ }\n+ \"\"\"\n+ raise NotImplementedError(\"must be implemented in a subclass\")\n+\n+ def get_notebook_checkpoint(self, checkpoint_id, path):\n+ \"\"\"Get the content of a checkpoint for a notebook.\n+\n+ Returns a dict of the form:\n+ {\n+ 'type': 'notebook',\n+ 'content': <output of nbformat.read>,\n+ }\n \"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\ndiff --git a/IPython/html/services/contents/filecheckpoints.py b/IPython/html/services/contents/filecheckpoints.py\n--- a/IPython/html/services/contents/filecheckpoints.py\n+++ b/IPython/html/services/contents/filecheckpoints.py\n@@ -142,7 +142,7 @@\n ContentsManager.\n \"\"\"\n def create_file_checkpoint(self, content, format, path):\n- \"\"\"Create a checkpoint from the current content of a notebook.\"\"\"\n+ \"\"\"Create a checkpoint from the current content of a file.\"\"\"\n path = path.strip('/')\n # only the one checkpoint ID:\n checkpoint_id = u\"checkpoint\"\n@@ -168,7 +168,7 @@\n return self.checkpoint_model(checkpoint_id, os_checkpoint_path)\n \n def get_notebook_checkpoint(self, checkpoint_id, path):\n-\n+ \"\"\"Get a checkpoint for a notebook.\"\"\"\n path = path.strip('/')\n self.log.info(\"restoring %s from checkpoint %s\", path, checkpoint_id)\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n@@ -185,6 +185,7 @@\n }\n \n def get_file_checkpoint(self, checkpoint_id, path):\n+ \"\"\"Get a checkpoint for a file.\"\"\"\n path = path.strip('/')\n self.log.info(\"restoring %s from checkpoint %s\", path, checkpoint_id)\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n", "issue": "GenericCheckpointsMixin missing methods\nIn the commit https://github.com/ipython/ipython/commit/82dcba3ba9ffa3ee3193602e2d5df3ef3c3de106 two new methods were introduced `get_notebook_checkpoint` and `get_file_checkpoint` but the definition of \n`GenericCheckpointsMixin` itself was not updated. \n\nIt still has `get_checkpoint` method. Subclasses work now, but just thought of notifying it.\n\nThe file in question is: `ipython/IPython/html/services/contents/checkpoints.py` and the branch https://github.com/ipython/ipython/releases/tag/rel-3.1.0\n\n", "before_files": [{"content": "\"\"\"\nClasses for managing Checkpoints.\n\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nfrom tornado.web import HTTPError\n\nfrom IPython.config.configurable import LoggingConfigurable\n\n\nclass Checkpoints(LoggingConfigurable):\n \"\"\"\n Base class for managing checkpoints for a ContentsManager.\n\n Subclasses are required to implement:\n\n create_checkpoint(self, contents_mgr, path)\n restore_checkpoint(self, contents_mgr, checkpoint_id, path)\n rename_checkpoint(self, checkpoint_id, old_path, new_path)\n delete_checkpoint(self, checkpoint_id, path)\n list_checkpoints(self, path)\n \"\"\"\n def create_checkpoint(self, contents_mgr, path):\n \"\"\"Create a checkpoint.\"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def restore_checkpoint(self, contents_mgr, checkpoint_id, path):\n \"\"\"Restore a checkpoint\"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def rename_checkpoint(self, checkpoint_id, old_path, new_path):\n \"\"\"Rename a single checkpoint from old_path to new_path.\"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def delete_checkpoint(self, checkpoint_id, path):\n \"\"\"delete a checkpoint for a file\"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def list_checkpoints(self, path):\n \"\"\"Return a list of checkpoints for a given file\"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def rename_all_checkpoints(self, old_path, new_path):\n \"\"\"Rename all checkpoints for old_path to new_path.\"\"\"\n for cp in self.list_checkpoints(old_path):\n self.rename_checkpoint(cp['id'], old_path, new_path)\n\n def delete_all_checkpoints(self, path):\n \"\"\"Delete all checkpoints for the given path.\"\"\"\n for checkpoint in self.list_checkpoints(path):\n self.delete_checkpoint(checkpoint['id'], path)\n\n\nclass GenericCheckpointsMixin(object):\n \"\"\"\n Helper for creating Checkpoints subclasses that can be used with any\n ContentsManager.\n\n Provides a ContentsManager-agnostic implementation of `create_checkpoint`\n and `restore_checkpoint` in terms of the following operations:\n\n - create_file_checkpoint(self, content, format, path)\n - create_notebook_checkpoint(self, nb, path)\n - get_file_checkpoint(self, checkpoint_id, path)\n - get_notebook_checkpoint(self, checkpoint_id, path)\n\n To create a generic CheckpointManager, add this mixin to a class that\n implement the above three methods plus the remaining Checkpoints API\n methods:\n\n - delete_checkpoint(self, checkpoint_id, path)\n - list_checkpoints(self, path)\n - rename_checkpoint(self, checkpoint_id, old_path, new_path)\n \"\"\"\n\n def create_checkpoint(self, contents_mgr, path):\n model = contents_mgr.get(path, content=True)\n type = model['type']\n if type == 'notebook':\n return self.create_notebook_checkpoint(\n model['content'],\n path,\n )\n elif type == 'file':\n return self.create_file_checkpoint(\n model['content'],\n model['format'],\n path,\n )\n else:\n raise HTTPError(500, u'Unexpected type %s' % type)\n\n def restore_checkpoint(self, contents_mgr, checkpoint_id, path):\n \"\"\"Restore a checkpoint.\"\"\"\n type = contents_mgr.get(path, content=False)['type']\n if type == 'notebook':\n model = self.get_notebook_checkpoint(checkpoint_id, path)\n elif type == 'file':\n model = self.get_file_checkpoint(checkpoint_id, path)\n else:\n raise HTTPError(500, u'Unexpected type %s' % type)\n contents_mgr.save(model, path)\n\n # Required Methods\n def create_file_checkpoint(self, content, format, path):\n \"\"\"Create a checkpoint of the current state of a file\n\n Returns a checkpoint model for the new checkpoint.\n \"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def create_notebook_checkpoint(self, nb, path):\n \"\"\"Create a checkpoint of the current state of a file\n\n Returns a checkpoint model for the new checkpoint.\n \"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n\n def get_checkpoint(self, checkpoint_id, path, type):\n \"\"\"Get the content of a checkpoint.\n\n Returns an unvalidated model with the same structure as\n the return value of ContentsManager.get\n \"\"\"\n raise NotImplementedError(\"must be implemented in a subclass\")\n", "path": "IPython/html/services/contents/checkpoints.py"}, {"content": "\"\"\"\nFile-based Checkpoints implementations.\n\"\"\"\nimport os\nimport shutil\n\nfrom tornado.web import HTTPError\n\nfrom .checkpoints import (\n Checkpoints,\n GenericCheckpointsMixin,\n)\nfrom .fileio import FileManagerMixin\n\nfrom IPython.utils import tz\nfrom IPython.utils.path import ensure_dir_exists\nfrom IPython.utils.py3compat import getcwd\nfrom IPython.utils.traitlets import Unicode\n\n\nclass FileCheckpoints(FileManagerMixin, Checkpoints):\n \"\"\"\n A Checkpoints that caches checkpoints for files in adjacent\n directories.\n\n Only works with FileContentsManager. Use GenericFileCheckpoints if\n you want file-based checkpoints with another ContentsManager.\n \"\"\"\n\n checkpoint_dir = Unicode(\n '.ipynb_checkpoints',\n config=True,\n help=\"\"\"The directory name in which to keep file checkpoints\n\n This is a path relative to the file's own directory.\n\n By default, it is .ipynb_checkpoints\n \"\"\",\n )\n\n root_dir = Unicode(config=True)\n\n def _root_dir_default(self):\n try:\n return self.parent.root_dir\n except AttributeError:\n return getcwd()\n\n # ContentsManager-dependent checkpoint API\n def create_checkpoint(self, contents_mgr, path):\n \"\"\"Create a checkpoint.\"\"\"\n checkpoint_id = u'checkpoint'\n src_path = contents_mgr._get_os_path(path)\n dest_path = self.checkpoint_path(checkpoint_id, path)\n self._copy(src_path, dest_path)\n return self.checkpoint_model(checkpoint_id, dest_path)\n\n def restore_checkpoint(self, contents_mgr, checkpoint_id, path):\n \"\"\"Restore a checkpoint.\"\"\"\n src_path = self.checkpoint_path(checkpoint_id, path)\n dest_path = contents_mgr._get_os_path(path)\n self._copy(src_path, dest_path)\n\n # ContentsManager-independent checkpoint API\n def rename_checkpoint(self, checkpoint_id, old_path, new_path):\n \"\"\"Rename a checkpoint from old_path to new_path.\"\"\"\n old_cp_path = self.checkpoint_path(checkpoint_id, old_path)\n new_cp_path = self.checkpoint_path(checkpoint_id, new_path)\n if os.path.isfile(old_cp_path):\n self.log.debug(\n \"Renaming checkpoint %s -> %s\",\n old_cp_path,\n new_cp_path,\n )\n with self.perm_to_403():\n shutil.move(old_cp_path, new_cp_path)\n\n def delete_checkpoint(self, checkpoint_id, path):\n \"\"\"delete a file's checkpoint\"\"\"\n path = path.strip('/')\n cp_path = self.checkpoint_path(checkpoint_id, path)\n if not os.path.isfile(cp_path):\n self.no_such_checkpoint(path, checkpoint_id)\n\n self.log.debug(\"unlinking %s\", cp_path)\n with self.perm_to_403():\n os.unlink(cp_path)\n\n def list_checkpoints(self, path):\n \"\"\"list the checkpoints for a given file\n\n This contents manager currently only supports one checkpoint per file.\n \"\"\"\n path = path.strip('/')\n checkpoint_id = \"checkpoint\"\n os_path = self.checkpoint_path(checkpoint_id, path)\n if not os.path.isfile(os_path):\n return []\n else:\n return [self.checkpoint_model(checkpoint_id, os_path)]\n\n # Checkpoint-related utilities\n def checkpoint_path(self, checkpoint_id, path):\n \"\"\"find the path to a checkpoint\"\"\"\n path = path.strip('/')\n parent, name = ('/' + path).rsplit('/', 1)\n parent = parent.strip('/')\n basename, ext = os.path.splitext(name)\n filename = u\"{name}-{checkpoint_id}{ext}\".format(\n name=basename,\n checkpoint_id=checkpoint_id,\n ext=ext,\n )\n os_path = self._get_os_path(path=parent)\n cp_dir = os.path.join(os_path, self.checkpoint_dir)\n with self.perm_to_403():\n ensure_dir_exists(cp_dir)\n cp_path = os.path.join(cp_dir, filename)\n return cp_path\n\n def checkpoint_model(self, checkpoint_id, os_path):\n \"\"\"construct the info dict for a given checkpoint\"\"\"\n stats = os.stat(os_path)\n last_modified = tz.utcfromtimestamp(stats.st_mtime)\n info = dict(\n id=checkpoint_id,\n last_modified=last_modified,\n )\n return info\n\n # Error Handling\n def no_such_checkpoint(self, path, checkpoint_id):\n raise HTTPError(\n 404,\n u'Checkpoint does not exist: %s@%s' % (path, checkpoint_id)\n )\n\n\nclass GenericFileCheckpoints(GenericCheckpointsMixin, FileCheckpoints):\n \"\"\"\n Local filesystem Checkpoints that works with any conforming\n ContentsManager.\n \"\"\"\n def create_file_checkpoint(self, content, format, path):\n \"\"\"Create a checkpoint from the current content of a notebook.\"\"\"\n path = path.strip('/')\n # only the one checkpoint ID:\n checkpoint_id = u\"checkpoint\"\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n self.log.debug(\"creating checkpoint for %s\", path)\n with self.perm_to_403():\n self._save_file(os_checkpoint_path, content, format=format)\n\n # return the checkpoint info\n return self.checkpoint_model(checkpoint_id, os_checkpoint_path)\n\n def create_notebook_checkpoint(self, nb, path):\n \"\"\"Create a checkpoint from the current content of a notebook.\"\"\"\n path = path.strip('/')\n # only the one checkpoint ID:\n checkpoint_id = u\"checkpoint\"\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n self.log.debug(\"creating checkpoint for %s\", path)\n with self.perm_to_403():\n self._save_notebook(os_checkpoint_path, nb)\n\n # return the checkpoint info\n return self.checkpoint_model(checkpoint_id, os_checkpoint_path)\n\n def get_notebook_checkpoint(self, checkpoint_id, path):\n\n path = path.strip('/')\n self.log.info(\"restoring %s from checkpoint %s\", path, checkpoint_id)\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n\n if not os.path.isfile(os_checkpoint_path):\n self.no_such_checkpoint(path, checkpoint_id)\n\n return {\n 'type': 'notebook',\n 'content': self._read_notebook(\n os_checkpoint_path,\n as_version=4,\n ),\n }\n\n def get_file_checkpoint(self, checkpoint_id, path):\n path = path.strip('/')\n self.log.info(\"restoring %s from checkpoint %s\", path, checkpoint_id)\n os_checkpoint_path = self.checkpoint_path(checkpoint_id, path)\n\n if not os.path.isfile(os_checkpoint_path):\n self.no_such_checkpoint(path, checkpoint_id)\n\n content, format = self._read_file(os_checkpoint_path, format=None)\n return {\n 'type': 'file',\n 'content': content,\n 'format': format,\n }\n", "path": "IPython/html/services/contents/filecheckpoints.py"}]}
| 3,936 | 684 |
gh_patches_debug_23994
|
rasdani/github-patches
|
git_diff
|
jupyter__docker-stacks-2074
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Healthcheck fails when using a custom runtime dir
### What docker image(s) are you using?
scipy-notebook (but applies to all images based on the `base-notebook` image)
### Host OS system
RHEL 8.0
### Host architecture
x86_64
### What Docker command are you running?
The following command DOES work as expected (default runtime dir):
```
docker run --rm -p 8888:8888 --name jupyter quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh
```
The following command does NOT work as expected (customized runtime dir):
```
docker run --rm -p 8888:8888 --name jupyter -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh
```
### How to Reproduce the problem?
1. Start the Jupyter container using the commands above.
2. In another terminal, run the healtcheck script: `docker exec jupyter /etc/jupyter/docker_healthcheck.py`
3. Observe the healthcheck script failing due to server state JSON file(s) not being found.
### Command output
```bash session
$ docker run --rm -p 8888:8888 --name jupyter quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh
$ docker exec jupyter /etc/jupyter/docker_healthcheck.py
b'{"version": "2.12.1"}'
$ docker run --rm -p 8888:8888 --name jupyter -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh
$ docker exec jupyter /etc/jupyter/docker_healthcheck.py
Traceback (most recent call last):
File "/etc/jupyter/docker_healthcheck.py", line 14, in <module>
json_file = next(runtime_dir.glob("*server-*.json"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
StopIteration
```
### Expected behavior
Healthcheck script to not fail, e.g. to display `b'{"version": "2.12.1"}'`, even with a customized runtime dir.
### Actual behavior
The healthcheck script fails because it cannot find server state JSON files in the hard-coded default runtime dir.
### Anything else?
The problem is that the `/etc/jupyter/docker_healthcheck.py` healtcheck script hard-codes the default runtime directory to search for server JSON state files as below:
https://github.com/jupyter/docker-stacks/blob/fcb20a914ed20e44a96053caf43eef6e12fb4c04/images/base-notebook/docker_healthcheck.py#L13
When this directory is customized for example via `JUPYTER_RUNTIME_DIR`, then the healthcheck script does not work.
The actual problem is when deploying Jupyter containers as services.
The Jupyter images have a default healthcheck configured as below:
https://github.com/jupyter/docker-stacks/blob/fcb20a914ed20e44a96053caf43eef6e12fb4c04/images/base-notebook/Dockerfile#L66-L70
When the healthcheck fails due to a custom runtime dir, the service is restarted continuously.
I think the healthcheck script should use the output of `jupyter --runtime-dir` which respects customizations:
```
$ docker run --rm -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 jupyter --runtime-dir
/home/jovyan/custom-runtime
```
If you agree with the above, I can send a PR with this fix.
### Latest Docker version
- [X] I've updated my Docker version to the latest available, and the issue persists
</issue>
<code>
[start of images/base-notebook/docker_healthcheck.py]
1 #!/usr/bin/env python3
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4 import json
5 import os
6 from pathlib import Path
7
8 import requests
9
10 # Several operations below deliberately don't check for possible errors
11 # As this is a healthcheck, it should succeed or raise an exception on error
12
13 runtime_dir = Path("/home/") / os.environ["NB_USER"] / ".local/share/jupyter/runtime/"
14 json_file = next(runtime_dir.glob("*server-*.json"))
15
16 url = json.loads(json_file.read_bytes())["url"]
17 url = url + "api"
18
19 proxies = {
20 "http": "",
21 "https": "",
22 }
23
24 r = requests.get(url, proxies=proxies, verify=False) # request without SSL verification
25 r.raise_for_status()
26 print(r.content)
27
[end of images/base-notebook/docker_healthcheck.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/images/base-notebook/docker_healthcheck.py b/images/base-notebook/docker_healthcheck.py
--- a/images/base-notebook/docker_healthcheck.py
+++ b/images/base-notebook/docker_healthcheck.py
@@ -3,6 +3,7 @@
# Distributed under the terms of the Modified BSD License.
import json
import os
+import subprocess
from pathlib import Path
import requests
@@ -10,7 +11,19 @@
# Several operations below deliberately don't check for possible errors
# As this is a healthcheck, it should succeed or raise an exception on error
-runtime_dir = Path("/home/") / os.environ["NB_USER"] / ".local/share/jupyter/runtime/"
+# Docker runs healtchecks using an exec
+# It uses the default user configured when running the image: root for the case of a custom NB_USER or jovyan for the case of the default image user.
+# We manually change HOME to make `jupyter --runtime-dir` report a correct path
+# More information: <https://github.com/jupyter/docker-stacks/pull/2074#issuecomment-1879778409>
+result = subprocess.run(
+ ["jupyter", "--runtime-dir"],
+ check=True,
+ capture_output=True,
+ text=True,
+ env=dict(os.environ) | {"HOME": "/home/" + os.environ["NB_USER"]},
+)
+runtime_dir = Path(result.stdout.rstrip())
+
json_file = next(runtime_dir.glob("*server-*.json"))
url = json.loads(json_file.read_bytes())["url"]
|
{"golden_diff": "diff --git a/images/base-notebook/docker_healthcheck.py b/images/base-notebook/docker_healthcheck.py\n--- a/images/base-notebook/docker_healthcheck.py\n+++ b/images/base-notebook/docker_healthcheck.py\n@@ -3,6 +3,7 @@\n # Distributed under the terms of the Modified BSD License.\n import json\n import os\n+import subprocess\n from pathlib import Path\n \n import requests\n@@ -10,7 +11,19 @@\n # Several operations below deliberately don't check for possible errors\n # As this is a healthcheck, it should succeed or raise an exception on error\n \n-runtime_dir = Path(\"/home/\") / os.environ[\"NB_USER\"] / \".local/share/jupyter/runtime/\"\n+# Docker runs healtchecks using an exec\n+# It uses the default user configured when running the image: root for the case of a custom NB_USER or jovyan for the case of the default image user.\n+# We manually change HOME to make `jupyter --runtime-dir` report a correct path\n+# More information: <https://github.com/jupyter/docker-stacks/pull/2074#issuecomment-1879778409>\n+result = subprocess.run(\n+ [\"jupyter\", \"--runtime-dir\"],\n+ check=True,\n+ capture_output=True,\n+ text=True,\n+ env=dict(os.environ) | {\"HOME\": \"/home/\" + os.environ[\"NB_USER\"]},\n+)\n+runtime_dir = Path(result.stdout.rstrip())\n+\n json_file = next(runtime_dir.glob(\"*server-*.json\"))\n \n url = json.loads(json_file.read_bytes())[\"url\"]\n", "issue": "[BUG] Healthcheck fails when using a custom runtime dir\n### What docker image(s) are you using?\r\n\r\nscipy-notebook (but applies to all images based on the `base-notebook` image)\r\n\r\n### Host OS system\r\n\r\nRHEL 8.0\r\n\r\n### Host architecture\r\n\r\nx86_64\r\n\r\n### What Docker command are you running?\r\n\r\nThe following command DOES work as expected (default runtime dir):\r\n```\r\ndocker run --rm -p 8888:8888 --name jupyter quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh\r\n```\r\n\r\nThe following command does NOT work as expected (customized runtime dir):\r\n```\r\ndocker run --rm -p 8888:8888 --name jupyter -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh\r\n```\r\n\r\n### How to Reproduce the problem?\r\n\r\n1. Start the Jupyter container using the commands above.\r\n2. In another terminal, run the healtcheck script: `docker exec jupyter /etc/jupyter/docker_healthcheck.py`\r\n3. Observe the healthcheck script failing due to server state JSON file(s) not being found.\r\n\r\n### Command output\r\n\r\n```bash session\r\n$ docker run --rm -p 8888:8888 --name jupyter quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh\r\n$ docker exec jupyter /etc/jupyter/docker_healthcheck.py\r\nb'{\"version\": \"2.12.1\"}'\r\n\r\n$ docker run --rm -p 8888:8888 --name jupyter -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 start-notebook.sh\r\n$ docker exec jupyter /etc/jupyter/docker_healthcheck.py\r\nTraceback (most recent call last):\r\n File \"/etc/jupyter/docker_healthcheck.py\", line 14, in <module>\r\n json_file = next(runtime_dir.glob(\"*server-*.json\"))\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nStopIteration\r\n```\r\n\r\n\r\n### Expected behavior\r\n\r\nHealthcheck script to not fail, e.g. to display `b'{\"version\": \"2.12.1\"}'`, even with a customized runtime dir.\r\n\r\n### Actual behavior\r\n\r\nThe healthcheck script fails because it cannot find server state JSON files in the hard-coded default runtime dir.\r\n\r\n### Anything else?\r\n\r\nThe problem is that the `/etc/jupyter/docker_healthcheck.py` healtcheck script hard-codes the default runtime directory to search for server JSON state files as below:\r\nhttps://github.com/jupyter/docker-stacks/blob/fcb20a914ed20e44a96053caf43eef6e12fb4c04/images/base-notebook/docker_healthcheck.py#L13\r\n\r\nWhen this directory is customized for example via `JUPYTER_RUNTIME_DIR`, then the healthcheck script does not work.\r\n\r\nThe actual problem is when deploying Jupyter containers as services.\r\nThe Jupyter images have a default healthcheck configured as below:\r\nhttps://github.com/jupyter/docker-stacks/blob/fcb20a914ed20e44a96053caf43eef6e12fb4c04/images/base-notebook/Dockerfile#L66-L70\r\n\r\nWhen the healthcheck fails due to a custom runtime dir, the service is restarted continuously.\r\n\r\nI think the healthcheck script should use the output of `jupyter --runtime-dir` which respects customizations:\r\n```\r\n$ docker run --rm -e JUPYTER_RUNTIME_DIR=/home/jovyan/custom-runtime quay.io/jupyter/scipy-notebook:2023-12-25 jupyter --runtime-dir\r\n/home/jovyan/custom-runtime\r\n```\r\n\r\nIf you agree with the above, I can send a PR with this fix.\r\n\r\n### Latest Docker version\r\n\r\n- [X] I've updated my Docker version to the latest available, and the issue persists\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\nimport json\nimport os\nfrom pathlib import Path\n\nimport requests\n\n# Several operations below deliberately don't check for possible errors\n# As this is a healthcheck, it should succeed or raise an exception on error\n\nruntime_dir = Path(\"/home/\") / os.environ[\"NB_USER\"] / \".local/share/jupyter/runtime/\"\njson_file = next(runtime_dir.glob(\"*server-*.json\"))\n\nurl = json.loads(json_file.read_bytes())[\"url\"]\nurl = url + \"api\"\n\nproxies = {\n \"http\": \"\",\n \"https\": \"\",\n}\n\nr = requests.get(url, proxies=proxies, verify=False) # request without SSL verification\nr.raise_for_status()\nprint(r.content)\n", "path": "images/base-notebook/docker_healthcheck.py"}]}
| 1,674 | 338 |
gh_patches_debug_24008
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-4806
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change is-ticketing-enabled field of Event to dump_only
**I'm submitting a ...** (check one with "x")
- [ ] bug report
- [x] feature request
- [ ] support request => Please do not submit support requests here, instead ask your query in out Gitter channel at https://gitter.im/fossasia/open-event-server
**Current behavior:**
It is possible to create tickets for an event in which is-ticketing-enabled field is set to false.
**Expected behavior:**
Either the field should be made dump_only or appropiate constraints must be imposed to ckeck this behaviour.
**Steps to reproduce:**
1. Create an event with is-ticketing-enabled attribute to false.
2. Create Ticket for that Event.
</issue>
<code>
[start of app/api/tickets.py]
1 from flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship
2 from flask_rest_jsonapi.exceptions import ObjectNotFound
3
4 from app.api.bootstrap import api
5 from app.api.helpers.db import safe_query
6 from app.api.helpers.permission_manager import has_access
7 from app.api.helpers.query import event_query
8 from app.api.helpers.utilities import require_relationship
9 from app.api.schema.tickets import TicketSchema, TicketSchemaPublic
10 from app.models import db
11 from app.models.access_code import AccessCode
12 from app.models.order import Order
13 from app.models.ticket import Ticket, TicketTag, ticket_tags_table
14 from app.models.ticket_holder import TicketHolder
15 from app.api.helpers.exceptions import ConflictException
16 from app.api.helpers.db import get_count
17
18
19 class TicketListPost(ResourceList):
20 """
21 Create and List Tickets
22 """
23 def before_post(self, args, kwargs, data):
24 """
25 before post method to check for required relationship and proper permission
26 :param args:
27 :param kwargs:
28 :param data:
29 :return:
30 """
31 require_relationship(['event'], data)
32 if not has_access('is_coorganizer', event_id=data['event']):
33 raise ObjectNotFound({'parameter': 'event_id'},
34 "Event: {} not found".format(data['event_id']))
35
36 if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']))) > 0:
37 raise ConflictException({'pointer': '/data/attributes/name'}, "Ticket already exists")
38
39 schema = TicketSchema
40 methods = ['POST', ]
41 data_layer = {'session': db.session,
42 'model': Ticket}
43
44
45 class TicketList(ResourceList):
46 """
47 List Tickets based on different params
48 """
49 def before_get(self, args, view_kwargs):
50 """
51 before get method to get the resource id for assigning schema
52 :param args:
53 :param view_kwargs:
54 :return:
55 """
56 if view_kwargs.get('ticket_tag_id') or view_kwargs.get('access_code_id') or view_kwargs.get('order_identifier'):
57 self.schema = TicketSchemaPublic
58
59 def query(self, view_kwargs):
60 """
61 query method for resource list
62 :param view_kwargs:
63 :return:
64 """
65 query_ = self.session.query(Ticket).filter_by(is_hidden=False)
66 if view_kwargs.get('ticket_tag_id'):
67 ticket_tag = safe_query(self, TicketTag, 'id', view_kwargs['ticket_tag_id'], 'ticket_tag_id')
68 query_ = query_.join(ticket_tags_table).filter_by(ticket_tag_id=ticket_tag.id)
69 query_ = event_query(self, query_, view_kwargs)
70 if view_kwargs.get('access_code_id'):
71 access_code = safe_query(self, AccessCode, 'id', view_kwargs['access_code_id'], 'access_code_id')
72 # access_code - ticket :: many-to-many relationship
73 query_ = Ticket.query.filter(Ticket.access_codes.any(id=access_code.id))
74
75 if view_kwargs.get('order_identifier'):
76 order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')
77 ticket_ids = []
78 for ticket in order.tickets:
79 ticket_ids.append(ticket.id)
80 query_ = query_.filter(Ticket.id.in_(tuple(ticket_ids)))
81
82 return query_
83
84 view_kwargs = True
85 methods = ['GET', ]
86 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
87 fetch_as="event_id", model=Ticket, methods="POST",
88 check=lambda a: a.get('event_id') or a.get('event_identifier')),)
89 schema = TicketSchema
90 data_layer = {'session': db.session,
91 'model': Ticket,
92 'methods': {
93 'query': query,
94 }}
95
96
97 class TicketDetail(ResourceDetail):
98 """
99 Ticket Resource
100 """
101 def before_get(self, args, view_kwargs):
102 """
103 before get method to get the resource id for assigning schema
104 :param args:
105 :param view_kwargs:
106 :return:
107 """
108 if view_kwargs.get('attendee_id'):
109 self.schema = TicketSchemaPublic
110
111 def before_get_object(self, view_kwargs):
112 """
113 before get object method to get the resource id for fetching details
114 :param view_kwargs:
115 :return:
116 """
117 if view_kwargs.get('attendee_id') is not None:
118 attendee = safe_query(self, TicketHolder, 'id', view_kwargs['attendee_id'], 'attendee_id')
119 if attendee.ticket_id is not None:
120 view_kwargs['id'] = attendee.ticket_id
121 else:
122 view_kwargs['id'] = None
123
124 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
125 fetch_as="event_id", model=Ticket, methods="PATCH,DELETE"),)
126 schema = TicketSchema
127 data_layer = {'session': db.session,
128 'model': Ticket,
129 'methods': {
130 'before_get_object': before_get_object
131 }}
132
133
134 class TicketRelationshipRequired(ResourceRelationship):
135 """
136 Tickets Relationship (Required)
137 """
138 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
139 fetch_as="event_id", model=Ticket, methods="PATCH"),)
140 methods = ['GET', 'PATCH']
141 schema = TicketSchema
142 data_layer = {'session': db.session,
143 'model': Ticket}
144
145
146 class TicketRelationshipOptional(ResourceRelationship):
147 """
148 Tickets Relationship (Optional)
149 """
150 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
151 fetch_as="event_id", model=Ticket, methods="PATCH,DELETE"),)
152 schema = TicketSchema
153 data_layer = {'session': db.session,
154 'model': Ticket}
155
[end of app/api/tickets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/api/tickets.py b/app/api/tickets.py
--- a/app/api/tickets.py
+++ b/app/api/tickets.py
@@ -11,8 +11,9 @@
from app.models.access_code import AccessCode
from app.models.order import Order
from app.models.ticket import Ticket, TicketTag, ticket_tags_table
+from app.models.event import Event
from app.models.ticket_holder import TicketHolder
-from app.api.helpers.exceptions import ConflictException
+from app.api.helpers.exceptions import ConflictException, MethodNotAllowed
from app.api.helpers.db import get_count
@@ -36,6 +37,9 @@
if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']))) > 0:
raise ConflictException({'pointer': '/data/attributes/name'}, "Ticket already exists")
+ if get_count(db.session.query(Event).filter_by(id=int(data['event']), is_ticketing_enabled=False)) > 0:
+ raise MethodNotAllowed({'parameter': 'event_id'}, "Ticketing is disabled for this Event")
+
schema = TicketSchema
methods = ['POST', ]
data_layer = {'session': db.session,
|
{"golden_diff": "diff --git a/app/api/tickets.py b/app/api/tickets.py\n--- a/app/api/tickets.py\n+++ b/app/api/tickets.py\n@@ -11,8 +11,9 @@\n from app.models.access_code import AccessCode\n from app.models.order import Order\n from app.models.ticket import Ticket, TicketTag, ticket_tags_table\n+from app.models.event import Event\n from app.models.ticket_holder import TicketHolder\n-from app.api.helpers.exceptions import ConflictException\n+from app.api.helpers.exceptions import ConflictException, MethodNotAllowed\n from app.api.helpers.db import get_count\n \n \n@@ -36,6 +37,9 @@\n if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']))) > 0:\n raise ConflictException({'pointer': '/data/attributes/name'}, \"Ticket already exists\")\n \n+ if get_count(db.session.query(Event).filter_by(id=int(data['event']), is_ticketing_enabled=False)) > 0:\n+ raise MethodNotAllowed({'parameter': 'event_id'}, \"Ticketing is disabled for this Event\")\n+\n schema = TicketSchema\n methods = ['POST', ]\n data_layer = {'session': db.session,\n", "issue": "Change is-ticketing-enabled field of Event to dump_only\n**I'm submitting a ...** (check one with \"x\")\r\n- [ ] bug report\r\n- [x] feature request\r\n- [ ] support request => Please do not submit support requests here, instead ask your query in out Gitter channel at https://gitter.im/fossasia/open-event-server\r\n\r\n**Current behavior:**\r\nIt is possible to create tickets for an event in which is-ticketing-enabled field is set to false.\r\n\r\n**Expected behavior:**\r\nEither the field should be made dump_only or appropiate constraints must be imposed to ckeck this behaviour.\r\n\r\n**Steps to reproduce:**\r\n1. Create an event with is-ticketing-enabled attribute to false.\r\n2. Create Ticket for that Event.\r\n\n", "before_files": [{"content": "from flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship\nfrom flask_rest_jsonapi.exceptions import ObjectNotFound\n\nfrom app.api.bootstrap import api\nfrom app.api.helpers.db import safe_query\nfrom app.api.helpers.permission_manager import has_access\nfrom app.api.helpers.query import event_query\nfrom app.api.helpers.utilities import require_relationship\nfrom app.api.schema.tickets import TicketSchema, TicketSchemaPublic\nfrom app.models import db\nfrom app.models.access_code import AccessCode\nfrom app.models.order import Order\nfrom app.models.ticket import Ticket, TicketTag, ticket_tags_table\nfrom app.models.ticket_holder import TicketHolder\nfrom app.api.helpers.exceptions import ConflictException\nfrom app.api.helpers.db import get_count\n\n\nclass TicketListPost(ResourceList):\n \"\"\"\n Create and List Tickets\n \"\"\"\n def before_post(self, args, kwargs, data):\n \"\"\"\n before post method to check for required relationship and proper permission\n :param args:\n :param kwargs:\n :param data:\n :return:\n \"\"\"\n require_relationship(['event'], data)\n if not has_access('is_coorganizer', event_id=data['event']):\n raise ObjectNotFound({'parameter': 'event_id'},\n \"Event: {} not found\".format(data['event_id']))\n\n if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']))) > 0:\n raise ConflictException({'pointer': '/data/attributes/name'}, \"Ticket already exists\")\n\n schema = TicketSchema\n methods = ['POST', ]\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketList(ResourceList):\n \"\"\"\n List Tickets based on different params\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('ticket_tag_id') or view_kwargs.get('access_code_id') or view_kwargs.get('order_identifier'):\n self.schema = TicketSchemaPublic\n\n def query(self, view_kwargs):\n \"\"\"\n query method for resource list\n :param view_kwargs:\n :return:\n \"\"\"\n query_ = self.session.query(Ticket).filter_by(is_hidden=False)\n if view_kwargs.get('ticket_tag_id'):\n ticket_tag = safe_query(self, TicketTag, 'id', view_kwargs['ticket_tag_id'], 'ticket_tag_id')\n query_ = query_.join(ticket_tags_table).filter_by(ticket_tag_id=ticket_tag.id)\n query_ = event_query(self, query_, view_kwargs)\n if view_kwargs.get('access_code_id'):\n access_code = safe_query(self, AccessCode, 'id', view_kwargs['access_code_id'], 'access_code_id')\n # access_code - ticket :: many-to-many relationship\n query_ = Ticket.query.filter(Ticket.access_codes.any(id=access_code.id))\n\n if view_kwargs.get('order_identifier'):\n order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')\n ticket_ids = []\n for ticket in order.tickets:\n ticket_ids.append(ticket.id)\n query_ = query_.filter(Ticket.id.in_(tuple(ticket_ids)))\n\n return query_\n\n view_kwargs = True\n methods = ['GET', ]\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"POST\",\n check=lambda a: a.get('event_id') or a.get('event_identifier')),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'query': query,\n }}\n\n\nclass TicketDetail(ResourceDetail):\n \"\"\"\n Ticket Resource\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id'):\n self.schema = TicketSchemaPublic\n\n def before_get_object(self, view_kwargs):\n \"\"\"\n before get object method to get the resource id for fetching details\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id') is not None:\n attendee = safe_query(self, TicketHolder, 'id', view_kwargs['attendee_id'], 'attendee_id')\n if attendee.ticket_id is not None:\n view_kwargs['id'] = attendee.ticket_id\n else:\n view_kwargs['id'] = None\n\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'before_get_object': before_get_object\n }}\n\n\nclass TicketRelationshipRequired(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Required)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH\"),)\n methods = ['GET', 'PATCH']\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketRelationshipOptional(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Optional)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n", "path": "app/api/tickets.py"}]}
| 2,273 | 257 |
gh_patches_debug_4691
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-608
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
:wrench: Colored terminal output
## Task
Modify the lightwood [logger class](https://github.com/mindsdb/lightwood/blob/stable/lightwood/helpers/log.py) so that its output is colored, depending on the log level. Color scheme is not set in stone, but should be something that makes sense, e.g.: red for `CRITICAL`, orange for `ERROR`, yellow for `WARNING`, green for `INFO`, uncolored for `DEBUG`.
## Steps :male_detective: :female_detective:
- Fork the Lightwood repository, checkout the `staging` branch and from it create a new one.
- Implement the necessary changes. The package to achieve colored logging can be chosen as part of the PR, but we suggest using lightweight alternatives like [colored](https://pypi.org/project/colored/) or [termcolor](https://pypi.org/project/termcolor/).
- Check the logs are using the new color scheme. For this, you can run any of the integration tests, like [`test_boston_housing`](https://github.com/mindsdb/lightwood/blob/stable/tests/integration/basic/test_boston_housing.py), and analyze the output.
- Make the PR and address any comments that reviewers might make.
## Additional rewards :1st_place_medal:
Each documentation PR brings :one: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/
</issue>
<code>
[start of lightwood/helpers/log.py]
1 import logging
2 import os
3
4
5 def initialize_log():
6 pid = os.getpid()
7 logging.basicConfig()
8 log = logging.getLogger(f'lightwood-{pid}')
9 log.setLevel(logging.DEBUG)
10 return log
11
12
13 log = initialize_log()
14
[end of lightwood/helpers/log.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightwood/helpers/log.py b/lightwood/helpers/log.py
--- a/lightwood/helpers/log.py
+++ b/lightwood/helpers/log.py
@@ -1,10 +1,15 @@
import logging
import os
+import colorlog
def initialize_log():
pid = os.getpid()
- logging.basicConfig()
+
+ handler = colorlog.StreamHandler()
+ handler.setFormatter(colorlog.ColoredFormatter())
+
+ logging.basicConfig(handlers=[handler])
log = logging.getLogger(f'lightwood-{pid}')
log.setLevel(logging.DEBUG)
return log
|
{"golden_diff": "diff --git a/lightwood/helpers/log.py b/lightwood/helpers/log.py\n--- a/lightwood/helpers/log.py\n+++ b/lightwood/helpers/log.py\n@@ -1,10 +1,15 @@\n import logging\n import os\n+import colorlog\n \n \n def initialize_log():\n pid = os.getpid()\n- logging.basicConfig()\n+\n+ handler = colorlog.StreamHandler()\n+ handler.setFormatter(colorlog.ColoredFormatter())\n+\n+ logging.basicConfig(handlers=[handler])\n log = logging.getLogger(f'lightwood-{pid}')\n log.setLevel(logging.DEBUG)\n return log\n", "issue": ":wrench: Colored terminal output\n## Task\r\n\r\nModify the lightwood [logger class](https://github.com/mindsdb/lightwood/blob/stable/lightwood/helpers/log.py) so that its output is colored, depending on the log level. Color scheme is not set in stone, but should be something that makes sense, e.g.: red for `CRITICAL`, orange for `ERROR`, yellow for `WARNING`, green for `INFO`, uncolored for `DEBUG`.\r\n\r\n## Steps :male_detective: :female_detective: \r\n\r\n- Fork the Lightwood repository, checkout the `staging` branch and from it create a new one.\r\n- Implement the necessary changes. The package to achieve colored logging can be chosen as part of the PR, but we suggest using lightweight alternatives like [colored](https://pypi.org/project/colored/) or [termcolor](https://pypi.org/project/termcolor/).\r\n- Check the logs are using the new color scheme. For this, you can run any of the integration tests, like [`test_boston_housing`](https://github.com/mindsdb/lightwood/blob/stable/tests/integration/basic/test_boston_housing.py), and analyze the output.\r\n- Make the PR and address any comments that reviewers might make.\r\n\r\n## Additional rewards :1st_place_medal: \r\n\r\nEach documentation PR brings :one: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/\n", "before_files": [{"content": "import logging\nimport os\n\n\ndef initialize_log():\n pid = os.getpid()\n logging.basicConfig()\n log = logging.getLogger(f'lightwood-{pid}')\n log.setLevel(logging.DEBUG)\n return log\n\n\nlog = initialize_log()\n", "path": "lightwood/helpers/log.py"}]}
| 945 | 125 |
gh_patches_debug_40903
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-916
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tune the check for training metrics
We currently set an arbitrary max 5% worse result, we might need to tune it
</issue>
<code>
[start of scripts/analyze_training_metrics.py]
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5 """ Given a directory containing training metrics, generate SVF graphs and check that the metrics are not getting worse than before.
6 """
7
8 import argparse
9 import json
10 import logging
11 import sys
12 from collections import defaultdict
13 from datetime import datetime, timezone
14 from pathlib import Path
15 from typing import Dict
16
17 import matplotlib.dates as mdates
18 import matplotlib.pyplot as plt
19
20 LOGGER = logging.getLogger(__name__)
21
22 logging.basicConfig(level=logging.INFO)
23
24 # If the latest metric point is 5% lower than the previous one, show a warning and exit with 1.
25 WARNING_THRESHOLD = 0.95
26
27 REPORT_METRICS = ["accuracy", "precision", "recall"]
28
29
30 def plot_graph(
31 model_name: str,
32 metric_name: str,
33 values_dict: Dict[datetime, float],
34 output_directory: Path,
35 ) -> bool:
36 sorted_metrics = sorted(values_dict.items())
37 x, y = zip(*sorted_metrics)
38
39 # Compute the threshold
40 if len(y) >= 2:
41 before_last_value = y[-2]
42 else:
43 before_last_value = y[-1]
44 metric_threshold = before_last_value * WARNING_THRESHOLD
45
46 figure = plt.figure()
47 axes = plt.axes()
48
49 # Formatting of the figure
50 figure.autofmt_xdate()
51 axes.fmt_xdata = mdates.DateFormatter("%Y-%m-%d-%H-%M")
52 axes.set_title(f"{model_name} {metric_name}")
53
54 # Display threshold
55 axes.axhline(y=metric_threshold, linestyle="--", color="red")
56 plt.annotate(
57 "{:.4f}".format(metric_threshold),
58 (x[-1], metric_threshold),
59 textcoords="offset points", # how to position the text
60 xytext=(-10, 10), # distance from text to points (x,y)
61 ha="center",
62 color="red",
63 )
64
65 # Display point values
66 for single_x, single_y in zip(x, y):
67 label = "{:.4f}".format(single_y)
68
69 plt.annotate(
70 label,
71 (single_x, single_y),
72 textcoords="offset points",
73 xytext=(0, 10),
74 ha="center",
75 )
76
77 axes.plot_date(x, y, marker=".", fmt="-")
78
79 output_file_path = output_directory.resolve() / f"{model_name}_{metric_name}.svg"
80 LOGGER.info("Saving %s figure", output_file_path)
81 plt.savefig(output_file_path)
82
83 plt.close(figure)
84
85 # Check if the threshold has been crossed
86 return y[-1] < metric_threshold
87
88
89 def analyze_metrics(metrics_directory: str, output_directory: str):
90 root = Path(metrics_directory)
91
92 metrics: Dict[str, Dict[str, Dict[datetime, float]]] = defaultdict(
93 lambda: defaultdict(dict)
94 )
95
96 threshold_ever_crossed = False
97
98 for metric_file_path in root.glob("metric*.json"):
99
100 # Load the metric
101 with open(metric_file_path, "r") as metric_file:
102 metric = json.load(metric_file)
103
104 # Get the model, date and version from the file
105 # TODO: Might be better storing it in the file
106 file_path_parts = metric_file_path.stem.split("_")
107
108 assert file_path_parts[:5] == ["metric", "project", "relman", "bugbug", "train"]
109 model_name = file_path_parts[5]
110 assert file_path_parts[6:8] == ["per", "date"]
111 date_parts = list(map(int, file_path_parts[8:14]))
112 date = datetime(
113 date_parts[0],
114 date_parts[1],
115 date_parts[2],
116 date_parts[3],
117 date_parts[4],
118 date_parts[5],
119 tzinfo=timezone.utc,
120 )
121 # version = file_path_parts[14:] # TODO: Use version
122
123 # Then process the report
124 for key, value in metric["report"]["average"].items():
125 if key not in REPORT_METRICS:
126 continue
127
128 metrics[model_name][key][date] = value
129
130 # Also process the test_* metrics
131 for key, value in metric.items():
132 if not key.startswith("test_"):
133 continue
134
135 metrics[model_name][f"{key}_mean"][date] = value["mean"]
136 metrics[model_name][f"{key}_std"][date] = value["std"]
137
138 for model_name in metrics:
139 for metric_name, values in metrics[model_name].items():
140 threshold_crossed = plot_graph(
141 model_name, metric_name, values, Path(output_directory)
142 )
143
144 if threshold_crossed:
145 LOGGER.warning(
146 "Last metric %r for model %s is 5%% worse than the previous one",
147 metric_name,
148 model_name,
149 )
150
151 threshold_ever_crossed = threshold_ever_crossed or threshold_crossed
152
153 if threshold_ever_crossed:
154 sys.exit(1)
155
156
157 def main():
158 parser = argparse.ArgumentParser(description=__doc__)
159
160 parser.add_argument(
161 "metrics_directory",
162 metavar="metrics-directory",
163 help="In which directory the script can find the metrics JSON files",
164 )
165 parser.add_argument(
166 "output_directory",
167 metavar="output-directory",
168 help="In which directory the script will save the generated graphs",
169 )
170
171 args = parser.parse_args()
172
173 analyze_metrics(args.metrics_directory, args.output_directory)
174
175
176 if __name__ == "__main__":
177 main()
178
[end of scripts/analyze_training_metrics.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/analyze_training_metrics.py b/scripts/analyze_training_metrics.py
--- a/scripts/analyze_training_metrics.py
+++ b/scripts/analyze_training_metrics.py
@@ -21,7 +21,8 @@
logging.basicConfig(level=logging.INFO)
-# If the latest metric point is 5% lower than the previous one, show a warning and exit with 1.
+# By default, if the latest metric point is 5% lower than the previous one, show a warning and exit
+# with 1.
WARNING_THRESHOLD = 0.95
REPORT_METRICS = ["accuracy", "precision", "recall"]
@@ -32,6 +33,7 @@
metric_name: str,
values_dict: Dict[datetime, float],
output_directory: Path,
+ warning_threshold: float,
) -> bool:
sorted_metrics = sorted(values_dict.items())
x, y = zip(*sorted_metrics)
@@ -41,7 +43,7 @@
before_last_value = y[-2]
else:
before_last_value = y[-1]
- metric_threshold = before_last_value * WARNING_THRESHOLD
+ metric_threshold = before_last_value * warning_threshold
figure = plt.figure()
axes = plt.axes()
@@ -86,7 +88,9 @@
return y[-1] < metric_threshold
-def analyze_metrics(metrics_directory: str, output_directory: str):
+def analyze_metrics(
+ metrics_directory: str, output_directory: str, warning_threshold: float
+):
root = Path(metrics_directory)
metrics: Dict[str, Dict[str, Dict[datetime, float]]] = defaultdict(
@@ -138,14 +142,21 @@
for model_name in metrics:
for metric_name, values in metrics[model_name].items():
threshold_crossed = plot_graph(
- model_name, metric_name, values, Path(output_directory)
+ model_name,
+ metric_name,
+ values,
+ Path(output_directory),
+ warning_threshold,
)
+ diff = (1 - warning_threshold) * 100
+
if threshold_crossed:
LOGGER.warning(
- "Last metric %r for model %s is 5%% worse than the previous one",
+ "Last metric %r for model %s is %f%% worse than the previous one",
metric_name,
model_name,
+ diff,
)
threshold_ever_crossed = threshold_ever_crossed or threshold_crossed
@@ -167,10 +178,18 @@
metavar="output-directory",
help="In which directory the script will save the generated graphs",
)
+ parser.add_argument(
+ "--warning_threshold",
+ default=WARNING_THRESHOLD,
+ type=float,
+ help="If the last metric value is below the previous one*warning_threshold, fails. Default to 0.95",
+ )
args = parser.parse_args()
- analyze_metrics(args.metrics_directory, args.output_directory)
+ analyze_metrics(
+ args.metrics_directory, args.output_directory, args.warning_threshold
+ )
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/scripts/analyze_training_metrics.py b/scripts/analyze_training_metrics.py\n--- a/scripts/analyze_training_metrics.py\n+++ b/scripts/analyze_training_metrics.py\n@@ -21,7 +21,8 @@\n \n logging.basicConfig(level=logging.INFO)\n \n-# If the latest metric point is 5% lower than the previous one, show a warning and exit with 1.\n+# By default, if the latest metric point is 5% lower than the previous one, show a warning and exit\n+# with 1.\n WARNING_THRESHOLD = 0.95\n \n REPORT_METRICS = [\"accuracy\", \"precision\", \"recall\"]\n@@ -32,6 +33,7 @@\n metric_name: str,\n values_dict: Dict[datetime, float],\n output_directory: Path,\n+ warning_threshold: float,\n ) -> bool:\n sorted_metrics = sorted(values_dict.items())\n x, y = zip(*sorted_metrics)\n@@ -41,7 +43,7 @@\n before_last_value = y[-2]\n else:\n before_last_value = y[-1]\n- metric_threshold = before_last_value * WARNING_THRESHOLD\n+ metric_threshold = before_last_value * warning_threshold\n \n figure = plt.figure()\n axes = plt.axes()\n@@ -86,7 +88,9 @@\n return y[-1] < metric_threshold\n \n \n-def analyze_metrics(metrics_directory: str, output_directory: str):\n+def analyze_metrics(\n+ metrics_directory: str, output_directory: str, warning_threshold: float\n+):\n root = Path(metrics_directory)\n \n metrics: Dict[str, Dict[str, Dict[datetime, float]]] = defaultdict(\n@@ -138,14 +142,21 @@\n for model_name in metrics:\n for metric_name, values in metrics[model_name].items():\n threshold_crossed = plot_graph(\n- model_name, metric_name, values, Path(output_directory)\n+ model_name,\n+ metric_name,\n+ values,\n+ Path(output_directory),\n+ warning_threshold,\n )\n \n+ diff = (1 - warning_threshold) * 100\n+\n if threshold_crossed:\n LOGGER.warning(\n- \"Last metric %r for model %s is 5%% worse than the previous one\",\n+ \"Last metric %r for model %s is %f%% worse than the previous one\",\n metric_name,\n model_name,\n+ diff,\n )\n \n threshold_ever_crossed = threshold_ever_crossed or threshold_crossed\n@@ -167,10 +178,18 @@\n metavar=\"output-directory\",\n help=\"In which directory the script will save the generated graphs\",\n )\n+ parser.add_argument(\n+ \"--warning_threshold\",\n+ default=WARNING_THRESHOLD,\n+ type=float,\n+ help=\"If the last metric value is below the previous one*warning_threshold, fails. Default to 0.95\",\n+ )\n \n args = parser.parse_args()\n \n- analyze_metrics(args.metrics_directory, args.output_directory)\n+ analyze_metrics(\n+ args.metrics_directory, args.output_directory, args.warning_threshold\n+ )\n \n \n if __name__ == \"__main__\":\n", "issue": "Tune the check for training metrics\nWe currently set an arbitrary max 5% worse result, we might need to tune it\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\"\"\" Given a directory containing training metrics, generate SVF graphs and check that the metrics are not getting worse than before.\n\"\"\"\n\nimport argparse\nimport json\nimport logging\nimport sys\nfrom collections import defaultdict\nfrom datetime import datetime, timezone\nfrom pathlib import Path\nfrom typing import Dict\n\nimport matplotlib.dates as mdates\nimport matplotlib.pyplot as plt\n\nLOGGER = logging.getLogger(__name__)\n\nlogging.basicConfig(level=logging.INFO)\n\n# If the latest metric point is 5% lower than the previous one, show a warning and exit with 1.\nWARNING_THRESHOLD = 0.95\n\nREPORT_METRICS = [\"accuracy\", \"precision\", \"recall\"]\n\n\ndef plot_graph(\n model_name: str,\n metric_name: str,\n values_dict: Dict[datetime, float],\n output_directory: Path,\n) -> bool:\n sorted_metrics = sorted(values_dict.items())\n x, y = zip(*sorted_metrics)\n\n # Compute the threshold\n if len(y) >= 2:\n before_last_value = y[-2]\n else:\n before_last_value = y[-1]\n metric_threshold = before_last_value * WARNING_THRESHOLD\n\n figure = plt.figure()\n axes = plt.axes()\n\n # Formatting of the figure\n figure.autofmt_xdate()\n axes.fmt_xdata = mdates.DateFormatter(\"%Y-%m-%d-%H-%M\")\n axes.set_title(f\"{model_name} {metric_name}\")\n\n # Display threshold\n axes.axhline(y=metric_threshold, linestyle=\"--\", color=\"red\")\n plt.annotate(\n \"{:.4f}\".format(metric_threshold),\n (x[-1], metric_threshold),\n textcoords=\"offset points\", # how to position the text\n xytext=(-10, 10), # distance from text to points (x,y)\n ha=\"center\",\n color=\"red\",\n )\n\n # Display point values\n for single_x, single_y in zip(x, y):\n label = \"{:.4f}\".format(single_y)\n\n plt.annotate(\n label,\n (single_x, single_y),\n textcoords=\"offset points\",\n xytext=(0, 10),\n ha=\"center\",\n )\n\n axes.plot_date(x, y, marker=\".\", fmt=\"-\")\n\n output_file_path = output_directory.resolve() / f\"{model_name}_{metric_name}.svg\"\n LOGGER.info(\"Saving %s figure\", output_file_path)\n plt.savefig(output_file_path)\n\n plt.close(figure)\n\n # Check if the threshold has been crossed\n return y[-1] < metric_threshold\n\n\ndef analyze_metrics(metrics_directory: str, output_directory: str):\n root = Path(metrics_directory)\n\n metrics: Dict[str, Dict[str, Dict[datetime, float]]] = defaultdict(\n lambda: defaultdict(dict)\n )\n\n threshold_ever_crossed = False\n\n for metric_file_path in root.glob(\"metric*.json\"):\n\n # Load the metric\n with open(metric_file_path, \"r\") as metric_file:\n metric = json.load(metric_file)\n\n # Get the model, date and version from the file\n # TODO: Might be better storing it in the file\n file_path_parts = metric_file_path.stem.split(\"_\")\n\n assert file_path_parts[:5] == [\"metric\", \"project\", \"relman\", \"bugbug\", \"train\"]\n model_name = file_path_parts[5]\n assert file_path_parts[6:8] == [\"per\", \"date\"]\n date_parts = list(map(int, file_path_parts[8:14]))\n date = datetime(\n date_parts[0],\n date_parts[1],\n date_parts[2],\n date_parts[3],\n date_parts[4],\n date_parts[5],\n tzinfo=timezone.utc,\n )\n # version = file_path_parts[14:] # TODO: Use version\n\n # Then process the report\n for key, value in metric[\"report\"][\"average\"].items():\n if key not in REPORT_METRICS:\n continue\n\n metrics[model_name][key][date] = value\n\n # Also process the test_* metrics\n for key, value in metric.items():\n if not key.startswith(\"test_\"):\n continue\n\n metrics[model_name][f\"{key}_mean\"][date] = value[\"mean\"]\n metrics[model_name][f\"{key}_std\"][date] = value[\"std\"]\n\n for model_name in metrics:\n for metric_name, values in metrics[model_name].items():\n threshold_crossed = plot_graph(\n model_name, metric_name, values, Path(output_directory)\n )\n\n if threshold_crossed:\n LOGGER.warning(\n \"Last metric %r for model %s is 5%% worse than the previous one\",\n metric_name,\n model_name,\n )\n\n threshold_ever_crossed = threshold_ever_crossed or threshold_crossed\n\n if threshold_ever_crossed:\n sys.exit(1)\n\n\ndef main():\n parser = argparse.ArgumentParser(description=__doc__)\n\n parser.add_argument(\n \"metrics_directory\",\n metavar=\"metrics-directory\",\n help=\"In which directory the script can find the metrics JSON files\",\n )\n parser.add_argument(\n \"output_directory\",\n metavar=\"output-directory\",\n help=\"In which directory the script will save the generated graphs\",\n )\n\n args = parser.parse_args()\n\n analyze_metrics(args.metrics_directory, args.output_directory)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "scripts/analyze_training_metrics.py"}]}
| 2,238 | 686 |
gh_patches_debug_5795
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-7148
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fido query for GBM data only matches files with v00.pha and misses those that have been version updated (e.g. v01.pha)
### Describe the bug
The way the source client for GBM is currently implemented, scraper only looks for files ending with `v00.pha`, and hence wont return data if its instead `v01.pha`
I'll make a PR now
### To Reproduce
```python
>>> from sunpy.net import Fido, attrs as a
>>> res_gbm = Fido.search(a.Time("2014-10-14 00:00", "2014-10-15"), a.Instrument.gbm, a.Resolution.cspec, a.Detector("n5"))
Results from 1 Provider:
1 Results from the GBMClient:
Source: https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily
Start Time End Time Instrument Physobs Source Provider Resolution Detector
----------------------- ----------------------- ---------- ------- ------ -------- ---------- --------
2014-10-15 00:00:00.000 2014-10-15 23:59:59.999 GBM flux FERMI NASA cspec n5
```
however data exists for the 14th but not returned here.
</issue>
<code>
[start of sunpy/net/dataretriever/sources/fermi_gbm.py]
1 from sunpy.net.dataretriever import GenericClient
2
3 __all__ = ['GBMClient']
4
5
6 class GBMClient(GenericClient):
7 """
8 Provides access to data from the Gamma-Ray Burst Monitor (GBM) instrument
9 on board the Fermi satellite.
10
11 Although GBMs primary objective is to detect gamma-ray bursts,
12 it provides high quality high energy solar flare observations.
13
14 The instrument consists of 12 Sodium Iodide (NaI) scintillation
15 detectors, which are sensitive to an energy range of 4keV to 1MeV.
16 At any one time, 6 of the NaI detectors are Sunward facing.
17 The detectors are numbered 'n1' to 'n11'. This client supports the user
18 to choose which detector to use through the `a.Detector <sunpy.net.attrs.Detector>` attribute.
19 The default detector is 'n5'.
20
21 The GBM data comes in daily version files in two formats:
22
23 * CSPEC - counts accumulated every 4.096 seconds in 128 energy channels for each detector.
24 * CTIME - counts accumulated every 0.256 seconds in 8 energy channels
25
26 Both of which can be accessed through the attrs `a.Resolution <sunpy.net.attrs.Resolution>`.
27 The default data type is CSPEC unless the user defines.
28
29 Examples
30 --------
31 >>> from sunpy.net import Fido, attrs as a
32 >>> res = Fido.search(a.Time('2015-06-21 00:00', '2015-06-23 23:59'),
33 ... a.Instrument.gbm, a.Detector.n3,
34 ... a.Resolution.ctime) # doctest: +REMOTE_DATA
35 >>> res # doctest: +REMOTE_DATA
36 <sunpy.net.fido_factory.UnifiedResponse object at ...>
37 Results from 1 Provider:
38 <BLANKLINE>
39 3 Results from the GBMClient:
40 Source: https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily
41 <BLANKLINE>
42 Start Time End Time ... Resolution Detector
43 ----------------------- ----------------------- ... ---------- --------
44 2015-06-21 00:00:00.000 2015-06-21 23:59:59.999 ... ctime n3
45 2015-06-22 00:00:00.000 2015-06-22 23:59:59.999 ... ctime n3
46 2015-06-23 00:00:00.000 2015-06-23 23:59:59.999 ... ctime n3
47 <BLANKLINE>
48 <BLANKLINE>
49
50 """
51 baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\w){5}_(\w){2}_%y%m%d_v00.pha'
52 pattern = '{}/daily/{year:4d}/{month:2d}/{day:2d}/current/glg_{Resolution:5}_{Detector:2}_{:6d}{}'
53
54 @property
55 def info_url(self):
56 return 'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily'
57
58 @classmethod
59 def register_values(cls):
60 from sunpy.net import attrs
61 adict = {attrs.Instrument: [('GBM', 'Gamma-Ray Burst Monitor on board the Fermi satellite.')],
62 attrs.Physobs: [('flux', 'a measure of the amount of radiation received by an object from a given source.')],
63 attrs.Source: [('FERMI', 'The Fermi Gamma-ray Space Telescope.')],
64 attrs.Provider: [('NASA', 'The National Aeronautics and Space Administration.')],
65 attrs.Resolution: [
66 ("cspec", "CSPEC 128 channel spectra every 4.096 seconds."),
67 ("ctime", "CTIME provides 8 channel spectra every 0.256 seconds.")],
68 attrs.Detector: [(f"n{x}", f"GBM Detector short name for the detector NAI_{x:02}") for x in range(12)]}
69 return adict
70
[end of sunpy/net/dataretriever/sources/fermi_gbm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/net/dataretriever/sources/fermi_gbm.py b/sunpy/net/dataretriever/sources/fermi_gbm.py
--- a/sunpy/net/dataretriever/sources/fermi_gbm.py
+++ b/sunpy/net/dataretriever/sources/fermi_gbm.py
@@ -48,7 +48,8 @@
<BLANKLINE>
"""
- baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\w){5}_(\w){2}_%y%m%d_v00.pha'
+
+ baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\w){5}_(\w){2}_%y%m%d_.*\.pha'
pattern = '{}/daily/{year:4d}/{month:2d}/{day:2d}/current/glg_{Resolution:5}_{Detector:2}_{:6d}{}'
@property
|
{"golden_diff": "diff --git a/sunpy/net/dataretriever/sources/fermi_gbm.py b/sunpy/net/dataretriever/sources/fermi_gbm.py\n--- a/sunpy/net/dataretriever/sources/fermi_gbm.py\n+++ b/sunpy/net/dataretriever/sources/fermi_gbm.py\n@@ -48,7 +48,8 @@\n <BLANKLINE>\n \n \"\"\"\n- baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\\w){5}_(\\w){2}_%y%m%d_v00.pha'\n+\n+ baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\\w){5}_(\\w){2}_%y%m%d_.*\\.pha'\n pattern = '{}/daily/{year:4d}/{month:2d}/{day:2d}/current/glg_{Resolution:5}_{Detector:2}_{:6d}{}'\n \n @property\n", "issue": "Fido query for GBM data only matches files with v00.pha and misses those that have been version updated (e.g. v01.pha)\n### Describe the bug\r\n\r\nThe way the source client for GBM is currently implemented, scraper only looks for files ending with `v00.pha`, and hence wont return data if its instead `v01.pha`\r\n\r\nI'll make a PR now\r\n\r\n\r\n\r\n### To Reproduce\r\n\r\n```python\r\n>>> from sunpy.net import Fido, attrs as a\r\n>>> res_gbm = Fido.search(a.Time(\"2014-10-14 00:00\", \"2014-10-15\"), a.Instrument.gbm, a.Resolution.cspec, a.Detector(\"n5\"))\r\nResults from 1 Provider:\r\n\r\n1 Results from the GBMClient:\r\nSource: https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily\r\n\r\n Start Time End Time Instrument Physobs Source Provider Resolution Detector\r\n----------------------- ----------------------- ---------- ------- ------ -------- ---------- --------\r\n2014-10-15 00:00:00.000 2014-10-15 23:59:59.999 GBM flux FERMI NASA cspec n5\r\n```\r\nhowever data exists for the 14th but not returned here.\r\n\r\n\n", "before_files": [{"content": "from sunpy.net.dataretriever import GenericClient\n\n__all__ = ['GBMClient']\n\n\nclass GBMClient(GenericClient):\n \"\"\"\n Provides access to data from the Gamma-Ray Burst Monitor (GBM) instrument\n on board the Fermi satellite.\n\n Although GBMs primary objective is to detect gamma-ray bursts,\n it provides high quality high energy solar flare observations.\n\n The instrument consists of 12 Sodium Iodide (NaI) scintillation\n detectors, which are sensitive to an energy range of 4keV to 1MeV.\n At any one time, 6 of the NaI detectors are Sunward facing.\n The detectors are numbered 'n1' to 'n11'. This client supports the user\n to choose which detector to use through the `a.Detector <sunpy.net.attrs.Detector>` attribute.\n The default detector is 'n5'.\n\n The GBM data comes in daily version files in two formats:\n\n * CSPEC - counts accumulated every 4.096 seconds in 128 energy channels for each detector.\n * CTIME - counts accumulated every 0.256 seconds in 8 energy channels\n\n Both of which can be accessed through the attrs `a.Resolution <sunpy.net.attrs.Resolution>`.\n The default data type is CSPEC unless the user defines.\n\n Examples\n --------\n >>> from sunpy.net import Fido, attrs as a\n >>> res = Fido.search(a.Time('2015-06-21 00:00', '2015-06-23 23:59'),\n ... a.Instrument.gbm, a.Detector.n3,\n ... a.Resolution.ctime) # doctest: +REMOTE_DATA\n >>> res # doctest: +REMOTE_DATA\n <sunpy.net.fido_factory.UnifiedResponse object at ...>\n Results from 1 Provider:\n <BLANKLINE>\n 3 Results from the GBMClient:\n Source: https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily\n <BLANKLINE>\n Start Time End Time ... Resolution Detector\n ----------------------- ----------------------- ... ---------- --------\n 2015-06-21 00:00:00.000 2015-06-21 23:59:59.999 ... ctime n3\n 2015-06-22 00:00:00.000 2015-06-22 23:59:59.999 ... ctime n3\n 2015-06-23 00:00:00.000 2015-06-23 23:59:59.999 ... ctime n3\n <BLANKLINE>\n <BLANKLINE>\n\n \"\"\"\n baseurl = r'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily/%Y/%m/%d/current/glg_(\\w){5}_(\\w){2}_%y%m%d_v00.pha'\n pattern = '{}/daily/{year:4d}/{month:2d}/{day:2d}/current/glg_{Resolution:5}_{Detector:2}_{:6d}{}'\n\n @property\n def info_url(self):\n return 'https://heasarc.gsfc.nasa.gov/FTP/fermi/data/gbm/daily'\n\n @classmethod\n def register_values(cls):\n from sunpy.net import attrs\n adict = {attrs.Instrument: [('GBM', 'Gamma-Ray Burst Monitor on board the Fermi satellite.')],\n attrs.Physobs: [('flux', 'a measure of the amount of radiation received by an object from a given source.')],\n attrs.Source: [('FERMI', 'The Fermi Gamma-ray Space Telescope.')],\n attrs.Provider: [('NASA', 'The National Aeronautics and Space Administration.')],\n attrs.Resolution: [\n (\"cspec\", \"CSPEC 128 channel spectra every 4.096 seconds.\"),\n (\"ctime\", \"CTIME provides 8 channel spectra every 0.256 seconds.\")],\n attrs.Detector: [(f\"n{x}\", f\"GBM Detector short name for the detector NAI_{x:02}\") for x in range(12)]}\n return adict\n", "path": "sunpy/net/dataretriever/sources/fermi_gbm.py"}]}
| 2,012 | 250 |
gh_patches_debug_7002
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7050
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove number_input -/+ step toggles option
Is there an option to remove the -/+ number_input step toggles? If not, I would suggest that for a future release. Thank you!
Also, is it possible to increase the precision?
Right now I am just using a text_input and type casting to float to get around this.
---
Community voting on feature requests enables the Streamlit team to understand which features are most important to our users.
**If you'd like the Streamlit team to prioritize this feature request, please use the 👍 (thumbs up emoji) reaction in response to the initial post.**
</issue>
<code>
[start of e2e/scripts/st_number_input.py]
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16 from streamlit import runtime
17
18 i1 = st.number_input("number input 1")
19 st.write('value 1: "', i1, '"')
20
21 i2 = st.number_input("number input 2", value=1)
22 st.write('value 2: "', i2, '"')
23
24 i3 = st.number_input("number input 3", 1, 10)
25 st.write('value 3: "', i3, '"')
26
27 i4 = st.number_input("number input 4", step=2)
28 st.write('value 4: "', i4, '"')
29
30 i5 = st.number_input("number input 5", max_value=10)
31 st.write('value 5: "', i5, '"')
32
33 i6 = st.number_input("number input 6", disabled=True)
34 st.write('value 6: "', i6, '"')
35
36 i7 = st.number_input("number input 7", label_visibility="hidden")
37 st.write('value 7: "', i7, '"')
38
39 i8 = st.number_input("number input 8", label_visibility="collapsed")
40 st.write('value 8: "', i8, '"')
41
42 if runtime.exists():
43
44 def on_change():
45 st.session_state.number_input_changed = True
46
47 st.number_input("number input 9", key="number_input9", on_change=on_change)
48 st.write('value 9: "', st.session_state.number_input9, '"')
49 st.write("number input changed:", "number_input_changed" in st.session_state)
50
[end of e2e/scripts/st_number_input.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/e2e/scripts/st_number_input.py b/e2e/scripts/st_number_input.py
--- a/e2e/scripts/st_number_input.py
+++ b/e2e/scripts/st_number_input.py
@@ -47,3 +47,9 @@
st.number_input("number input 9", key="number_input9", on_change=on_change)
st.write('value 9: "', st.session_state.number_input9, '"')
st.write("number input changed:", "number_input_changed" in st.session_state)
+
+[col1, col2, col3, col4, col5, col6] = st.columns(6)
+
+with col1:
+ i10 = st.number_input("number input 10", max_value=10)
+ st.write('value 10: "', i10, '"')
|
{"golden_diff": "diff --git a/e2e/scripts/st_number_input.py b/e2e/scripts/st_number_input.py\n--- a/e2e/scripts/st_number_input.py\n+++ b/e2e/scripts/st_number_input.py\n@@ -47,3 +47,9 @@\n st.number_input(\"number input 9\", key=\"number_input9\", on_change=on_change)\n st.write('value 9: \"', st.session_state.number_input9, '\"')\n st.write(\"number input changed:\", \"number_input_changed\" in st.session_state)\n+\n+[col1, col2, col3, col4, col5, col6] = st.columns(6)\n+\n+with col1:\n+ i10 = st.number_input(\"number input 10\", max_value=10)\n+ st.write('value 10: \"', i10, '\"')\n", "issue": "Remove number_input -/+ step toggles option\nIs there an option to remove the -/+ number_input step toggles? If not, I would suggest that for a future release. Thank you! \r\n\r\nAlso, is it possible to increase the precision? \r\n\r\nRight now I am just using a text_input and type casting to float to get around this.\r\n\r\n---\r\n\r\nCommunity voting on feature requests enables the Streamlit team to understand which features are most important to our users.\r\n\r\n**If you'd like the Streamlit team to prioritize this feature request, please use the \ud83d\udc4d (thumbs up emoji) reaction in response to the initial post.**\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\nfrom streamlit import runtime\n\ni1 = st.number_input(\"number input 1\")\nst.write('value 1: \"', i1, '\"')\n\ni2 = st.number_input(\"number input 2\", value=1)\nst.write('value 2: \"', i2, '\"')\n\ni3 = st.number_input(\"number input 3\", 1, 10)\nst.write('value 3: \"', i3, '\"')\n\ni4 = st.number_input(\"number input 4\", step=2)\nst.write('value 4: \"', i4, '\"')\n\ni5 = st.number_input(\"number input 5\", max_value=10)\nst.write('value 5: \"', i5, '\"')\n\ni6 = st.number_input(\"number input 6\", disabled=True)\nst.write('value 6: \"', i6, '\"')\n\ni7 = st.number_input(\"number input 7\", label_visibility=\"hidden\")\nst.write('value 7: \"', i7, '\"')\n\ni8 = st.number_input(\"number input 8\", label_visibility=\"collapsed\")\nst.write('value 8: \"', i8, '\"')\n\nif runtime.exists():\n\n def on_change():\n st.session_state.number_input_changed = True\n\n st.number_input(\"number input 9\", key=\"number_input9\", on_change=on_change)\n st.write('value 9: \"', st.session_state.number_input9, '\"')\n st.write(\"number input changed:\", \"number_input_changed\" in st.session_state)\n", "path": "e2e/scripts/st_number_input.py"}]}
| 1,245 | 185 |
gh_patches_debug_20980
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1359
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reorder trove classifiers on search sidebar
It strikes me that the current ordering is probably not the most useful.
Maybe we reorder to be:
- By Topic
- By Intended Audience
- By Framework
- By Environment
- By License
- By Programming Language
- By Operating System
- By Natural Language
- By Development Status
Thoughts @dstufft ?
</issue>
<code>
[start of warehouse/views.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import collections
14
15 from pyramid.httpexceptions import (
16 HTTPException, HTTPSeeOther, HTTPMovedPermanently, HTTPNotFound,
17 HTTPBadRequest,
18 )
19 from pyramid.view import (
20 notfound_view_config, forbidden_view_config, view_config,
21 )
22 from elasticsearch_dsl import Q
23 from sqlalchemy import func
24 from sqlalchemy.orm import aliased, joinedload
25
26 from warehouse.accounts import REDIRECT_FIELD_NAME
27 from warehouse.accounts.models import User
28 from warehouse.cache.origin import origin_cache
29 from warehouse.cache.http import cache_control
30 from warehouse.classifiers.models import Classifier
31 from warehouse.packaging.models import Project, Release, File
32 from warehouse.utils.row_counter import RowCount
33 from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory
34
35
36 SEARCH_FIELDS = [
37 "author", "author_email", "description", "download_url", "home_page",
38 "keywords", "license", "maintainer", "maintainer_email", "normalized_name",
39 "platform", "summary",
40 ]
41 SEARCH_BOOSTS = {
42 "normalized_name": 10,
43 "description": 5,
44 "keywords": 5,
45 "summary": 5,
46 }
47
48
49 @view_config(context=HTTPException)
50 @notfound_view_config(append_slash=HTTPMovedPermanently)
51 def httpexception_view(exc, request):
52 return exc
53
54
55 @forbidden_view_config()
56 def forbidden(exc, request):
57 # If the forbidden error is because the user isn't logged in, then we'll
58 # redirect them to the log in page.
59 if request.authenticated_userid is None:
60 url = request.route_url(
61 "accounts.login",
62 _query={REDIRECT_FIELD_NAME: request.path_qs},
63 )
64 return HTTPSeeOther(url)
65
66 # If we've reached here, then the user is logged in and they are genuinely
67 # not allowed to access this page.
68 # TODO: Style the forbidden page.
69 return exc
70
71
72 @view_config(
73 route_name="robots.txt",
74 renderer="robots.txt",
75 decorator=[
76 cache_control(1 * 24 * 60 * 60), # 1 day
77 origin_cache(
78 1 * 24 * 60 * 60, # 1 day
79 stale_while_revalidate=6 * 60 * 60, # 6 hours
80 stale_if_error=1 * 24 * 60 * 60, # 1 day
81 ),
82 ],
83 )
84 def robotstxt(request):
85 request.response.content_type = "text/plain"
86 return {}
87
88
89 @view_config(
90 route_name="index",
91 renderer="index.html",
92 decorator=[
93 origin_cache(
94 1 * 60 * 60, # 1 hour
95 stale_while_revalidate=10 * 60, # 10 minutes
96 stale_if_error=1 * 24 * 60 * 60, # 1 day
97 keys=["all-projects"],
98 ),
99 ]
100 )
101 def index(request):
102 project_names = [
103 r[0] for r in (
104 request.db.query(File.name)
105 .group_by(File.name)
106 .order_by(func.sum(File.downloads).desc())
107 .limit(5)
108 .all())
109 ]
110 release_a = aliased(
111 Release,
112 request.db.query(Release)
113 .distinct(Release.name)
114 .filter(Release.name.in_(project_names))
115 .order_by(Release.name, Release._pypi_ordering.desc())
116 .subquery(),
117 )
118 top_projects = (
119 request.db.query(release_a)
120 .options(joinedload(release_a.project))
121 .order_by(func.array_idx(project_names, release_a.name))
122 .all()
123 )
124
125 latest_releases = (
126 request.db.query(Release)
127 .options(joinedload(Release.project))
128 .order_by(Release.created.desc())
129 .limit(5)
130 .all()
131 )
132
133 counts = dict(
134 request.db.query(RowCount.table_name, RowCount.count)
135 .filter(
136 RowCount.table_name.in_([
137 Project.__tablename__,
138 Release.__tablename__,
139 File.__tablename__,
140 User.__tablename__,
141 ]))
142 .all()
143 )
144
145 return {
146 "latest_releases": latest_releases,
147 "top_projects": top_projects,
148 "num_projects": counts.get(Project.__tablename__, 0),
149 "num_releases": counts.get(Release.__tablename__, 0),
150 "num_files": counts.get(File.__tablename__, 0),
151 "num_users": counts.get(User.__tablename__, 0),
152 }
153
154
155 @view_config(
156 route_name="search",
157 renderer="search/results.html",
158 decorator=[
159 origin_cache(
160 1 * 60 * 60, # 1 hour
161 stale_while_revalidate=10 * 60, # 10 minutes
162 stale_if_error=1 * 24 * 60 * 60, # 1 day
163 keys=["all-projects"],
164 )
165 ],
166 )
167 def search(request):
168
169 q = request.params.get("q", '')
170
171 if q:
172 should = []
173 for field in SEARCH_FIELDS:
174 kw = {"query": q}
175 if field in SEARCH_BOOSTS:
176 kw["boost"] = SEARCH_BOOSTS[field]
177 should.append(Q("match", **{field: kw}))
178
179 # Add a prefix query if ``q`` is longer than one character.
180 if len(q) > 1:
181 should.append(Q('prefix', normalized_name=q))
182
183 query = request.es.query("dis_max", queries=should)
184 query = query.suggest("name_suggestion", q, term={"field": "name"})
185 else:
186 query = request.es.query()
187
188 if request.params.get("o"):
189 query = query.sort(request.params["o"])
190
191 if request.params.getall("c"):
192 query = query.filter("terms", classifiers=request.params.getall("c"))
193
194 try:
195 page_num = int(request.params.get("page", 1))
196 except ValueError:
197 raise HTTPBadRequest("'page' must be an integer.")
198
199 page = ElasticsearchPage(
200 query,
201 page=page_num,
202 url_maker=paginate_url_factory(request),
203 )
204
205 if page.page_count and page_num > page.page_count:
206 return HTTPNotFound()
207
208 available_filters = collections.defaultdict(list)
209
210 for cls in request.db.query(Classifier).order_by(Classifier.classifier):
211 first, *_ = cls.classifier.split(' :: ')
212 available_filters[first].append(cls.classifier)
213
214 return {
215 "page": page,
216 "term": q,
217 "order": request.params.get("o", ''),
218 "available_filters": sorted(available_filters.items()),
219 "applied_filters": request.params.getall("c"),
220 }
221
222
223 @view_config(
224 route_name="includes.current-user-indicator",
225 renderer="includes/current-user-indicator.html",
226 uses_session=True,
227 )
228 def current_user_indicator(request):
229 return {}
230
231
232 @view_config(route_name="health", renderer="string")
233 def health(request):
234 # This will ensure that we can access the database and run queries against
235 # it without doing anything that will take a lock or block other queries.
236 request.db.execute("SELECT 1")
237
238 # Nothing will actually check this, but it's a little nicer to have
239 # something to return besides an empty body.
240 return "OK"
241
[end of warehouse/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/views.py b/warehouse/views.py
--- a/warehouse/views.py
+++ b/warehouse/views.py
@@ -44,6 +44,17 @@
"keywords": 5,
"summary": 5,
}
+SEARCH_FILTER_ORDER = (
+ "Programming Language",
+ "License",
+ "Framework",
+ "Topic",
+ "Intended Audience",
+ "Environment",
+ "Operating System",
+ "Natural Language",
+ "Development Status",
+)
@view_config(context=HTTPException)
@@ -211,11 +222,17 @@
first, *_ = cls.classifier.split(' :: ')
available_filters[first].append(cls.classifier)
+ def filter_key(item):
+ try:
+ return 0, SEARCH_FILTER_ORDER.index(item[0]), item[0]
+ except ValueError:
+ return 1, 0, item[0]
+
return {
"page": page,
"term": q,
"order": request.params.get("o", ''),
- "available_filters": sorted(available_filters.items()),
+ "available_filters": sorted(available_filters.items(), key=filter_key),
"applied_filters": request.params.getall("c"),
}
|
{"golden_diff": "diff --git a/warehouse/views.py b/warehouse/views.py\n--- a/warehouse/views.py\n+++ b/warehouse/views.py\n@@ -44,6 +44,17 @@\n \"keywords\": 5,\n \"summary\": 5,\n }\n+SEARCH_FILTER_ORDER = (\n+ \"Programming Language\",\n+ \"License\",\n+ \"Framework\",\n+ \"Topic\",\n+ \"Intended Audience\",\n+ \"Environment\",\n+ \"Operating System\",\n+ \"Natural Language\",\n+ \"Development Status\",\n+)\n \n \n @view_config(context=HTTPException)\n@@ -211,11 +222,17 @@\n first, *_ = cls.classifier.split(' :: ')\n available_filters[first].append(cls.classifier)\n \n+ def filter_key(item):\n+ try:\n+ return 0, SEARCH_FILTER_ORDER.index(item[0]), item[0]\n+ except ValueError:\n+ return 1, 0, item[0]\n+\n return {\n \"page\": page,\n \"term\": q,\n \"order\": request.params.get(\"o\", ''),\n- \"available_filters\": sorted(available_filters.items()),\n+ \"available_filters\": sorted(available_filters.items(), key=filter_key),\n \"applied_filters\": request.params.getall(\"c\"),\n }\n", "issue": "Reorder trove classifiers on search sidebar\nIt strikes me that the current ordering is probably not the most useful.\n\nMaybe we reorder to be:\n- By Topic\n- By Intended Audience\n- By Framework\n- By Environment\n- By License\n- By Programming Language\n- By Operating System\n- By Natural Language\n- By Development Status\n\nThoughts @dstufft ?\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport collections\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently, HTTPNotFound,\n HTTPBadRequest,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom elasticsearch_dsl import Q\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.classifiers.models import Classifier\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\nSEARCH_FIELDS = [\n \"author\", \"author_email\", \"description\", \"download_url\", \"home_page\",\n \"keywords\", \"license\", \"maintainer\", \"maintainer_email\", \"normalized_name\",\n \"platform\", \"summary\",\n]\nSEARCH_BOOSTS = {\n \"normalized_name\": 10,\n \"description\": 5,\n \"keywords\": 5,\n \"summary\": 5,\n}\n\n\n@view_config(context=HTTPException)\n@notfound_view_config(append_slash=HTTPMovedPermanently)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n\n q = request.params.get(\"q\", '')\n\n if q:\n should = []\n for field in SEARCH_FIELDS:\n kw = {\"query\": q}\n if field in SEARCH_BOOSTS:\n kw[\"boost\"] = SEARCH_BOOSTS[field]\n should.append(Q(\"match\", **{field: kw}))\n\n # Add a prefix query if ``q`` is longer than one character.\n if len(q) > 1:\n should.append(Q('prefix', normalized_name=q))\n\n query = request.es.query(\"dis_max\", queries=should)\n query = query.suggest(\"name_suggestion\", q, term={\"field\": \"name\"})\n else:\n query = request.es.query()\n\n if request.params.get(\"o\"):\n query = query.sort(request.params[\"o\"])\n\n if request.params.getall(\"c\"):\n query = query.filter(\"terms\", classifiers=request.params.getall(\"c\"))\n\n try:\n page_num = int(request.params.get(\"page\", 1))\n except ValueError:\n raise HTTPBadRequest(\"'page' must be an integer.\")\n\n page = ElasticsearchPage(\n query,\n page=page_num,\n url_maker=paginate_url_factory(request),\n )\n\n if page.page_count and page_num > page.page_count:\n return HTTPNotFound()\n\n available_filters = collections.defaultdict(list)\n\n for cls in request.db.query(Classifier).order_by(Classifier.classifier):\n first, *_ = cls.classifier.split(' :: ')\n available_filters[first].append(cls.classifier)\n\n return {\n \"page\": page,\n \"term\": q,\n \"order\": request.params.get(\"o\", ''),\n \"available_filters\": sorted(available_filters.items()),\n \"applied_filters\": request.params.getall(\"c\"),\n }\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n uses_session=True,\n)\ndef current_user_indicator(request):\n return {}\n\n\n@view_config(route_name=\"health\", renderer=\"string\")\ndef health(request):\n # This will ensure that we can access the database and run queries against\n # it without doing anything that will take a lock or block other queries.\n request.db.execute(\"SELECT 1\")\n\n # Nothing will actually check this, but it's a little nicer to have\n # something to return besides an empty body.\n return \"OK\"\n", "path": "warehouse/views.py"}]}
| 2,956 | 281 |
gh_patches_debug_36185
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-397
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Heat map to show all data in the catalog
We should add a new heatmap page to show a heat map of all of the data in the catalog.
It would be nice to also show this heatmap during the search, but I'm not sure how best to handle that since we do want the footprints of the paginated search results to show up too
</issue>
<code>
[start of rgd/geodata/views.py]
1 import json
2
3 from django.contrib.gis.db.models import Collect, Extent
4 from django.shortcuts import redirect
5 from django.views import generic
6 from django.views.generic import DetailView
7 from rest_framework.reverse import reverse
8
9 from rgd.geodata import permissions
10
11 from .filters import RasterMetaEntryFilter, SpatialEntryFilter
12 from .models.common import SpatialEntry
13 from .models.fmv.base import FMVEntry
14 from .models.geometry import GeometryEntry
15 from .models.imagery import RasterMetaEntry
16 from .models.threed import PointCloudEntry, PointCloudMetaEntry
17
18
19 class PermissionDetailView(DetailView):
20 def get_object(self):
21 obj = super().get_object()
22 permissions.check_read_perm(self.request.user, obj)
23 return obj
24
25
26 def query_params(params):
27 query = params.copy()
28
29 if query.get('page'):
30 del query['page']
31
32 return '&' + query.urlencode() if query.urlencode() else ''
33
34
35 class _SpatialListView(generic.ListView):
36 paginate_by = 15
37
38 def get_queryset(self):
39 filterset = self.filter(data=self.request.GET)
40 assert filterset.is_valid()
41 queryset = filterset.filter_queryset(self.model.objects.all())
42 return permissions.filter_read_perm(self.request.user, queryset).order_by('spatial_id')
43
44 def _get_extent_summary(self, object_list):
45 ids = [o.spatial_id for o in object_list]
46 queryset = self.model.objects.filter(spatial_id__in=ids)
47 summary = queryset.aggregate(
48 Collect('outline'),
49 Extent('outline'),
50 )
51 extents = {
52 'count': queryset.count(),
53 }
54 if queryset.count():
55 extents.update(
56 {
57 'collect': json.loads(summary['outline__collect'].geojson),
58 'convex_hull': json.loads(summary['outline__collect'].convex_hull.geojson),
59 'extent': {
60 'xmin': summary['outline__extent'][0],
61 'ymin': summary['outline__extent'][1],
62 'xmax': summary['outline__extent'][2],
63 'ymax': summary['outline__extent'][3],
64 },
65 }
66 )
67 return extents
68
69 def get_context_data(self, *args, **kwargs):
70 # Pagination happens here
71 context = super().get_context_data(*args, **kwargs)
72 summary = self._get_extent_summary(context['object_list'])
73 context['extents'] = json.dumps(summary)
74 # Have a smaller dict of meta fields to parse for menu bar
75 # This keeps us from parsing long GeoJSON fields twice
76 meta = {
77 'count': self.get_queryset().count(), # This is the amount in the full results
78 }
79 context['extents_meta'] = json.dumps(meta)
80 context['search_params'] = json.dumps(self.request.GET)
81 context['query_params'] = query_params(self.request.GET)
82 return context
83
84
85 class SpatialEntriesListView(_SpatialListView):
86 model = SpatialEntry
87 filter = SpatialEntryFilter
88 context_object_name = 'spatial_entries'
89 template_name = 'geodata/spatial_entries.html'
90
91
92 class RasterMetaEntriesListView(_SpatialListView):
93 model = RasterMetaEntry
94 filter = RasterMetaEntryFilter
95 context_object_name = 'spatial_entries'
96 template_name = 'geodata/raster_entries.html'
97
98
99 class _SpatialDetailView(PermissionDetailView):
100 def get_object(self):
101 obj = super().get_object()
102 permissions.check_read_perm(self.request.user, obj)
103 return obj
104
105 def _get_extent(self):
106 extent = {
107 'count': 0,
108 }
109 if self.object.footprint:
110 extent.update(
111 {
112 'count': 1,
113 'collect': self.object.footprint.json,
114 'outline': self.object.outline.json,
115 'extent': {
116 'xmin': self.object.footprint.extent[0],
117 'ymin': self.object.footprint.extent[1],
118 'xmax': self.object.footprint.extent[2],
119 'ymax': self.object.footprint.extent[3],
120 },
121 }
122 )
123 return extent
124
125 def get_context_data(self, *args, **kwargs):
126 context = super().get_context_data(*args, **kwargs)
127 context['extents'] = json.dumps(self._get_extent())
128 return context
129
130
131 class RasterEntryDetailView(_SpatialDetailView):
132 model = RasterMetaEntry
133
134
135 class FMVEntryDetailView(_SpatialDetailView):
136 model = FMVEntry
137
138 def _get_extent(self):
139 extent = super()._get_extent()
140 if self.object.ground_union is not None:
141 # All or none of these will be set, only check one
142 extent['collect'] = self.object.ground_union.json
143 extent['ground_frames'] = self.object.ground_frames.json
144 extent['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)
145 return extent
146
147 def get_context_data(self, *args, **kwargs):
148 context = super().get_context_data(*args, **kwargs)
149 context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)
150 return context
151
152
153 class GeometryEntryDetailView(_SpatialDetailView):
154 model = GeometryEntry
155
156 def _get_extent(self):
157 extent = super()._get_extent()
158 extent['data'] = self.object.data.json
159 return extent
160
161
162 def spatial_entry_redirect_view(request, pk):
163 spat = SpatialEntry.objects.get(pk=pk)
164 sub = spat.subentry
165 if isinstance(sub, RasterMetaEntry):
166 name = 'raster-entry-detail'
167 elif isinstance(sub, GeometryEntry):
168 name = 'geometry-entry-detail'
169 elif isinstance(sub, FMVEntry):
170 name = 'fmv-entry-detail'
171 elif isinstance(sub, PointCloudMetaEntry):
172 name = 'point-cloud-entry-detail'
173 sub = sub.parent_point_cloud
174 else:
175 raise ValueError()
176 return redirect(reverse(name, kwargs={'pk': sub.pk}))
177
178
179 class PointCloudEntryDetailView(PermissionDetailView):
180 model = PointCloudEntry
181
[end of rgd/geodata/views.py]
[start of rgd/geodata/urls.py]
1 from django.urls import path
2
3 from . import api, views
4
5 urlpatterns = [
6 # Pages
7 path(r'', views.SpatialEntriesListView.as_view(), name='index'),
8 path(r'geodata/raster/', views.RasterMetaEntriesListView.as_view(), name='raster-search'),
9 path(
10 'geodata/spatial_entries/<int:pk>/',
11 views.spatial_entry_redirect_view,
12 name='spatial-entry-detail',
13 ),
14 path(
15 'geodata/raster/<int:pk>/',
16 views.RasterEntryDetailView.as_view(),
17 name='raster-entry-detail',
18 ),
19 path(
20 'geodata/fmv/<int:pk>/',
21 views.FMVEntryDetailView.as_view(),
22 name='fmv-entry-detail',
23 ),
24 path(
25 'geodata/geometry/<int:pk>/',
26 views.GeometryEntryDetailView.as_view(),
27 name='geometry-entry-detail',
28 ),
29 path(
30 'geodata/point_cloud/<int:pk>/',
31 views.PointCloudEntryDetailView.as_view(),
32 name='point-cloud-entry-detail',
33 ),
34 #############
35 # Search
36 path('api/geosearch', api.search.SearchSpatialEntryView.as_view()),
37 path('api/geosearch/raster', api.search.SearchRasterMetaEntrySTACView.as_view()),
38 #############
39 # Other
40 path(
41 'api/geodata/status/<model>/<int:pk>',
42 api.download.get_status,
43 name='get-status',
44 ),
45 path(
46 'api/geodata/common/spatial_entry/<int:spatial_id>',
47 api.get.GetSpatialEntry.as_view(),
48 name='spatial-entry',
49 ),
50 path(
51 'api/geodata/common/spatial_entry/<int:spatial_id>/footprint',
52 api.get.GetSpatialEntryFootprint.as_view(),
53 name='spatial-entry-footprint',
54 ),
55 path(
56 'api/geodata/common/checksum_file/<int:pk>',
57 api.get.GetChecksumFile.as_view(),
58 name='checksum-file',
59 ),
60 path(
61 'api/geodata/common/checksum_file/<int:pk>/data',
62 api.download.download_checksum_file,
63 name='checksum-file-data',
64 ),
65 path(
66 'api/geodata/geometry/<int:pk>',
67 api.get.GetGeometryEntry.as_view(),
68 name='geometry-entry',
69 ),
70 path(
71 'api/geodata/geometry/<int:pk>/data',
72 api.get.GetGeometryEntryData.as_view(),
73 name='geometry-entry-data',
74 ),
75 path(
76 'api/geodata/imagery/<int:pk>',
77 api.get.GetImageEntry.as_view(),
78 name='image-entry',
79 ),
80 path(
81 'api/geodata/imagery/<int:pk>/data',
82 api.download.download_image_entry_file,
83 name='image-entry-data',
84 ),
85 path(
86 'api/geodata/imagery/image_set/<int:pk>',
87 api.get.GetImageSet.as_view(),
88 name='image-set',
89 ),
90 path(
91 'api/geodata/imagery/raster/<int:pk>',
92 api.get.GetRasterMetaEntry.as_view(),
93 name='raster-meta-entry',
94 ),
95 path(
96 'api/geodata/imagery/raster/<int:pk>/stac',
97 api.get.GetRasterMetaEntrySTAC.as_view(),
98 name='raster-meta-entry-stac',
99 ),
100 path(
101 'api/geodata/fmv/<int:pk>',
102 api.get.GetFMVEntry.as_view(),
103 name='fmv-entry',
104 ),
105 path(
106 'api/geodata/fmv/<int:pk>/data',
107 api.get.GetFMVDataEntry.as_view(),
108 name='fmv-entry-data',
109 ),
110 path(
111 'api/geodata/point_cloud/<int:pk>',
112 api.get.GetPointCloudEntry.as_view(),
113 name='point-cloud-entry',
114 ),
115 path(
116 'api/geodata/point_cloud/<int:pk>/base64',
117 api.get.GetPointCloudEntryData.as_view(),
118 name='point-cloud-entry-data',
119 ),
120 #############
121 # Geoprocessing
122 path(
123 'api/geoprocess/imagery/<int:pk>/tiles',
124 api.tiles.TileMetadataView.as_view(),
125 name='image-tile-metadata',
126 ),
127 path(
128 'api/geoprocess/imagery/<int:pk>/tiles/<int:z>/<int:x>/<int:y>.png',
129 api.tiles.TileView.as_view(),
130 name='image-tiles',
131 ),
132 path(
133 'api/geoprocess/imagery/<int:pk>/thumbnail',
134 api.tiles.TileThumnailView.as_view(),
135 name='image-thumbnail',
136 ),
137 path('api/geoprocess/imagery/cog', api.post.CreateConvertedImageFile.as_view()),
138 path(
139 'api/geoprocess/imagery/cog/<int:pk>',
140 api.get.GetConvertedImageStatus.as_view(),
141 name='cog',
142 ),
143 path(
144 'api/geoprocess/imagery/cog/<int:pk>/data',
145 api.download.download_cog_file,
146 name='cog-data',
147 ),
148 path(
149 'api/geoprocess/imagery/subsample',
150 api.post.CreateSubsampledImage.as_view(),
151 ),
152 path(
153 'api/geoprocess/imagery/subsample/<int:pk>',
154 api.get.GetSubsampledImage.as_view(),
155 name='subsampled',
156 ),
157 path(
158 'api/geoprocess/imagery/subsample/<int:pk>/status',
159 api.download.get_status_subsampled_image,
160 name='subsampled-status',
161 ),
162 ]
163
[end of rgd/geodata/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rgd/geodata/urls.py b/rgd/geodata/urls.py
--- a/rgd/geodata/urls.py
+++ b/rgd/geodata/urls.py
@@ -6,6 +6,11 @@
# Pages
path(r'', views.SpatialEntriesListView.as_view(), name='index'),
path(r'geodata/raster/', views.RasterMetaEntriesListView.as_view(), name='raster-search'),
+ path(
+ 'geodata/statistics',
+ views.StatisticsView.as_view(),
+ name='statistics',
+ ),
path(
'geodata/spatial_entries/<int:pk>/',
views.spatial_entry_redirect_view,
diff --git a/rgd/geodata/views.py b/rgd/geodata/views.py
--- a/rgd/geodata/views.py
+++ b/rgd/geodata/views.py
@@ -1,6 +1,7 @@
import json
from django.contrib.gis.db.models import Collect, Extent
+from django.db.models import Max, Min
from django.shortcuts import redirect
from django.views import generic
from django.views.generic import DetailView
@@ -89,6 +90,44 @@
template_name = 'geodata/spatial_entries.html'
+class StatisticsView(generic.ListView):
+ paginate_by = None
+ model = SpatialEntry
+ context_object_name = 'spatial_entries'
+ template_name = 'geodata/statistics.html'
+
+ def get_queryset(self):
+ queryset = self.model.objects.all()
+ return permissions.filter_read_perm(self.request.user, queryset).order_by('spatial_id')
+
+ def get_context_data(self, *args, **kwargs):
+ context = super().get_context_data(*args, **kwargs)
+ q = self.get_queryset()
+ context['count'] = q.count()
+ context['coordinates'] = json.dumps([o.footprint.centroid.json for o in self.object_list])
+ context['raster_count'] = q.filter(rastermetaentry__isnull=False).count()
+ instrumentation = (
+ q.filter(instrumentation__isnull=False).values_list('instrumentation').distinct()
+ )
+ context['instrumentation_count'] = instrumentation.count()
+ dates = q.filter(acquisition_date__isnull=False).aggregate(
+ Min('acquisition_date'),
+ Max('acquisition_date'),
+ )
+ context['acquisition_date__min'] = dates['acquisition_date__min']
+ context['acquisition_date__max'] = dates['acquisition_date__max']
+ extent = q.aggregate(Extent('outline'))
+ context['extents'] = json.dumps(
+ {
+ 'xmin': extent['outline__extent'][0],
+ 'ymin': extent['outline__extent'][1],
+ 'xmax': extent['outline__extent'][2],
+ 'ymax': extent['outline__extent'][3],
+ }
+ )
+ return context
+
+
class RasterMetaEntriesListView(_SpatialListView):
model = RasterMetaEntry
filter = RasterMetaEntryFilter
|
{"golden_diff": "diff --git a/rgd/geodata/urls.py b/rgd/geodata/urls.py\n--- a/rgd/geodata/urls.py\n+++ b/rgd/geodata/urls.py\n@@ -6,6 +6,11 @@\n # Pages\n path(r'', views.SpatialEntriesListView.as_view(), name='index'),\n path(r'geodata/raster/', views.RasterMetaEntriesListView.as_view(), name='raster-search'),\n+ path(\n+ 'geodata/statistics',\n+ views.StatisticsView.as_view(),\n+ name='statistics',\n+ ),\n path(\n 'geodata/spatial_entries/<int:pk>/',\n views.spatial_entry_redirect_view,\ndiff --git a/rgd/geodata/views.py b/rgd/geodata/views.py\n--- a/rgd/geodata/views.py\n+++ b/rgd/geodata/views.py\n@@ -1,6 +1,7 @@\n import json\n \n from django.contrib.gis.db.models import Collect, Extent\n+from django.db.models import Max, Min\n from django.shortcuts import redirect\n from django.views import generic\n from django.views.generic import DetailView\n@@ -89,6 +90,44 @@\n template_name = 'geodata/spatial_entries.html'\n \n \n+class StatisticsView(generic.ListView):\n+ paginate_by = None\n+ model = SpatialEntry\n+ context_object_name = 'spatial_entries'\n+ template_name = 'geodata/statistics.html'\n+\n+ def get_queryset(self):\n+ queryset = self.model.objects.all()\n+ return permissions.filter_read_perm(self.request.user, queryset).order_by('spatial_id')\n+\n+ def get_context_data(self, *args, **kwargs):\n+ context = super().get_context_data(*args, **kwargs)\n+ q = self.get_queryset()\n+ context['count'] = q.count()\n+ context['coordinates'] = json.dumps([o.footprint.centroid.json for o in self.object_list])\n+ context['raster_count'] = q.filter(rastermetaentry__isnull=False).count()\n+ instrumentation = (\n+ q.filter(instrumentation__isnull=False).values_list('instrumentation').distinct()\n+ )\n+ context['instrumentation_count'] = instrumentation.count()\n+ dates = q.filter(acquisition_date__isnull=False).aggregate(\n+ Min('acquisition_date'),\n+ Max('acquisition_date'),\n+ )\n+ context['acquisition_date__min'] = dates['acquisition_date__min']\n+ context['acquisition_date__max'] = dates['acquisition_date__max']\n+ extent = q.aggregate(Extent('outline'))\n+ context['extents'] = json.dumps(\n+ {\n+ 'xmin': extent['outline__extent'][0],\n+ 'ymin': extent['outline__extent'][1],\n+ 'xmax': extent['outline__extent'][2],\n+ 'ymax': extent['outline__extent'][3],\n+ }\n+ )\n+ return context\n+\n+\n class RasterMetaEntriesListView(_SpatialListView):\n model = RasterMetaEntry\n filter = RasterMetaEntryFilter\n", "issue": "Heat map to show all data in the catalog\nWe should add a new heatmap page to show a heat map of all of the data in the catalog.\r\n\r\nIt would be nice to also show this heatmap during the search, but I'm not sure how best to handle that since we do want the footprints of the paginated search results to show up too\n", "before_files": [{"content": "import json\n\nfrom django.contrib.gis.db.models import Collect, Extent\nfrom django.shortcuts import redirect\nfrom django.views import generic\nfrom django.views.generic import DetailView\nfrom rest_framework.reverse import reverse\n\nfrom rgd.geodata import permissions\n\nfrom .filters import RasterMetaEntryFilter, SpatialEntryFilter\nfrom .models.common import SpatialEntry\nfrom .models.fmv.base import FMVEntry\nfrom .models.geometry import GeometryEntry\nfrom .models.imagery import RasterMetaEntry\nfrom .models.threed import PointCloudEntry, PointCloudMetaEntry\n\n\nclass PermissionDetailView(DetailView):\n def get_object(self):\n obj = super().get_object()\n permissions.check_read_perm(self.request.user, obj)\n return obj\n\n\ndef query_params(params):\n query = params.copy()\n\n if query.get('page'):\n del query['page']\n\n return '&' + query.urlencode() if query.urlencode() else ''\n\n\nclass _SpatialListView(generic.ListView):\n paginate_by = 15\n\n def get_queryset(self):\n filterset = self.filter(data=self.request.GET)\n assert filterset.is_valid()\n queryset = filterset.filter_queryset(self.model.objects.all())\n return permissions.filter_read_perm(self.request.user, queryset).order_by('spatial_id')\n\n def _get_extent_summary(self, object_list):\n ids = [o.spatial_id for o in object_list]\n queryset = self.model.objects.filter(spatial_id__in=ids)\n summary = queryset.aggregate(\n Collect('outline'),\n Extent('outline'),\n )\n extents = {\n 'count': queryset.count(),\n }\n if queryset.count():\n extents.update(\n {\n 'collect': json.loads(summary['outline__collect'].geojson),\n 'convex_hull': json.loads(summary['outline__collect'].convex_hull.geojson),\n 'extent': {\n 'xmin': summary['outline__extent'][0],\n 'ymin': summary['outline__extent'][1],\n 'xmax': summary['outline__extent'][2],\n 'ymax': summary['outline__extent'][3],\n },\n }\n )\n return extents\n\n def get_context_data(self, *args, **kwargs):\n # Pagination happens here\n context = super().get_context_data(*args, **kwargs)\n summary = self._get_extent_summary(context['object_list'])\n context['extents'] = json.dumps(summary)\n # Have a smaller dict of meta fields to parse for menu bar\n # This keeps us from parsing long GeoJSON fields twice\n meta = {\n 'count': self.get_queryset().count(), # This is the amount in the full results\n }\n context['extents_meta'] = json.dumps(meta)\n context['search_params'] = json.dumps(self.request.GET)\n context['query_params'] = query_params(self.request.GET)\n return context\n\n\nclass SpatialEntriesListView(_SpatialListView):\n model = SpatialEntry\n filter = SpatialEntryFilter\n context_object_name = 'spatial_entries'\n template_name = 'geodata/spatial_entries.html'\n\n\nclass RasterMetaEntriesListView(_SpatialListView):\n model = RasterMetaEntry\n filter = RasterMetaEntryFilter\n context_object_name = 'spatial_entries'\n template_name = 'geodata/raster_entries.html'\n\n\nclass _SpatialDetailView(PermissionDetailView):\n def get_object(self):\n obj = super().get_object()\n permissions.check_read_perm(self.request.user, obj)\n return obj\n\n def _get_extent(self):\n extent = {\n 'count': 0,\n }\n if self.object.footprint:\n extent.update(\n {\n 'count': 1,\n 'collect': self.object.footprint.json,\n 'outline': self.object.outline.json,\n 'extent': {\n 'xmin': self.object.footprint.extent[0],\n 'ymin': self.object.footprint.extent[1],\n 'xmax': self.object.footprint.extent[2],\n 'ymax': self.object.footprint.extent[3],\n },\n }\n )\n return extent\n\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n context['extents'] = json.dumps(self._get_extent())\n return context\n\n\nclass RasterEntryDetailView(_SpatialDetailView):\n model = RasterMetaEntry\n\n\nclass FMVEntryDetailView(_SpatialDetailView):\n model = FMVEntry\n\n def _get_extent(self):\n extent = super()._get_extent()\n if self.object.ground_union is not None:\n # All or none of these will be set, only check one\n extent['collect'] = self.object.ground_union.json\n extent['ground_frames'] = self.object.ground_frames.json\n extent['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)\n return extent\n\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)\n return context\n\n\nclass GeometryEntryDetailView(_SpatialDetailView):\n model = GeometryEntry\n\n def _get_extent(self):\n extent = super()._get_extent()\n extent['data'] = self.object.data.json\n return extent\n\n\ndef spatial_entry_redirect_view(request, pk):\n spat = SpatialEntry.objects.get(pk=pk)\n sub = spat.subentry\n if isinstance(sub, RasterMetaEntry):\n name = 'raster-entry-detail'\n elif isinstance(sub, GeometryEntry):\n name = 'geometry-entry-detail'\n elif isinstance(sub, FMVEntry):\n name = 'fmv-entry-detail'\n elif isinstance(sub, PointCloudMetaEntry):\n name = 'point-cloud-entry-detail'\n sub = sub.parent_point_cloud\n else:\n raise ValueError()\n return redirect(reverse(name, kwargs={'pk': sub.pk}))\n\n\nclass PointCloudEntryDetailView(PermissionDetailView):\n model = PointCloudEntry\n", "path": "rgd/geodata/views.py"}, {"content": "from django.urls import path\n\nfrom . import api, views\n\nurlpatterns = [\n # Pages\n path(r'', views.SpatialEntriesListView.as_view(), name='index'),\n path(r'geodata/raster/', views.RasterMetaEntriesListView.as_view(), name='raster-search'),\n path(\n 'geodata/spatial_entries/<int:pk>/',\n views.spatial_entry_redirect_view,\n name='spatial-entry-detail',\n ),\n path(\n 'geodata/raster/<int:pk>/',\n views.RasterEntryDetailView.as_view(),\n name='raster-entry-detail',\n ),\n path(\n 'geodata/fmv/<int:pk>/',\n views.FMVEntryDetailView.as_view(),\n name='fmv-entry-detail',\n ),\n path(\n 'geodata/geometry/<int:pk>/',\n views.GeometryEntryDetailView.as_view(),\n name='geometry-entry-detail',\n ),\n path(\n 'geodata/point_cloud/<int:pk>/',\n views.PointCloudEntryDetailView.as_view(),\n name='point-cloud-entry-detail',\n ),\n #############\n # Search\n path('api/geosearch', api.search.SearchSpatialEntryView.as_view()),\n path('api/geosearch/raster', api.search.SearchRasterMetaEntrySTACView.as_view()),\n #############\n # Other\n path(\n 'api/geodata/status/<model>/<int:pk>',\n api.download.get_status,\n name='get-status',\n ),\n path(\n 'api/geodata/common/spatial_entry/<int:spatial_id>',\n api.get.GetSpatialEntry.as_view(),\n name='spatial-entry',\n ),\n path(\n 'api/geodata/common/spatial_entry/<int:spatial_id>/footprint',\n api.get.GetSpatialEntryFootprint.as_view(),\n name='spatial-entry-footprint',\n ),\n path(\n 'api/geodata/common/checksum_file/<int:pk>',\n api.get.GetChecksumFile.as_view(),\n name='checksum-file',\n ),\n path(\n 'api/geodata/common/checksum_file/<int:pk>/data',\n api.download.download_checksum_file,\n name='checksum-file-data',\n ),\n path(\n 'api/geodata/geometry/<int:pk>',\n api.get.GetGeometryEntry.as_view(),\n name='geometry-entry',\n ),\n path(\n 'api/geodata/geometry/<int:pk>/data',\n api.get.GetGeometryEntryData.as_view(),\n name='geometry-entry-data',\n ),\n path(\n 'api/geodata/imagery/<int:pk>',\n api.get.GetImageEntry.as_view(),\n name='image-entry',\n ),\n path(\n 'api/geodata/imagery/<int:pk>/data',\n api.download.download_image_entry_file,\n name='image-entry-data',\n ),\n path(\n 'api/geodata/imagery/image_set/<int:pk>',\n api.get.GetImageSet.as_view(),\n name='image-set',\n ),\n path(\n 'api/geodata/imagery/raster/<int:pk>',\n api.get.GetRasterMetaEntry.as_view(),\n name='raster-meta-entry',\n ),\n path(\n 'api/geodata/imagery/raster/<int:pk>/stac',\n api.get.GetRasterMetaEntrySTAC.as_view(),\n name='raster-meta-entry-stac',\n ),\n path(\n 'api/geodata/fmv/<int:pk>',\n api.get.GetFMVEntry.as_view(),\n name='fmv-entry',\n ),\n path(\n 'api/geodata/fmv/<int:pk>/data',\n api.get.GetFMVDataEntry.as_view(),\n name='fmv-entry-data',\n ),\n path(\n 'api/geodata/point_cloud/<int:pk>',\n api.get.GetPointCloudEntry.as_view(),\n name='point-cloud-entry',\n ),\n path(\n 'api/geodata/point_cloud/<int:pk>/base64',\n api.get.GetPointCloudEntryData.as_view(),\n name='point-cloud-entry-data',\n ),\n #############\n # Geoprocessing\n path(\n 'api/geoprocess/imagery/<int:pk>/tiles',\n api.tiles.TileMetadataView.as_view(),\n name='image-tile-metadata',\n ),\n path(\n 'api/geoprocess/imagery/<int:pk>/tiles/<int:z>/<int:x>/<int:y>.png',\n api.tiles.TileView.as_view(),\n name='image-tiles',\n ),\n path(\n 'api/geoprocess/imagery/<int:pk>/thumbnail',\n api.tiles.TileThumnailView.as_view(),\n name='image-thumbnail',\n ),\n path('api/geoprocess/imagery/cog', api.post.CreateConvertedImageFile.as_view()),\n path(\n 'api/geoprocess/imagery/cog/<int:pk>',\n api.get.GetConvertedImageStatus.as_view(),\n name='cog',\n ),\n path(\n 'api/geoprocess/imagery/cog/<int:pk>/data',\n api.download.download_cog_file,\n name='cog-data',\n ),\n path(\n 'api/geoprocess/imagery/subsample',\n api.post.CreateSubsampledImage.as_view(),\n ),\n path(\n 'api/geoprocess/imagery/subsample/<int:pk>',\n api.get.GetSubsampledImage.as_view(),\n name='subsampled',\n ),\n path(\n 'api/geoprocess/imagery/subsample/<int:pk>/status',\n api.download.get_status_subsampled_image,\n name='subsampled-status',\n ),\n]\n", "path": "rgd/geodata/urls.py"}]}
| 3,919 | 680 |
gh_patches_debug_29309
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1131
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FEAT] add tests for more model types
we should test any model with predict and predict_proba functions, including the common ones:
Scikitlearn (also pipelines)
CatBoost
LGBM
XGBoost
Custom binary classification model that implements the predict_proba and predict functions
Custom multiclass classification model that implements the predict_proba and predict functions
Custom regression model that implements the predict function
</issue>
<code>
[start of deepchecks/tabular/checks/performance/confusion_matrix_report.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """The confusion_matrix_report check module."""
12 import pandas as pd
13 import sklearn
14 import plotly.express as px
15
16 from deepchecks.core import CheckResult
17 from deepchecks.tabular import Context, SingleDatasetCheck
18
19
20 __all__ = ['ConfusionMatrixReport']
21
22
23 class ConfusionMatrixReport(SingleDatasetCheck):
24 """Calculate the confusion matrix of the model on the given dataset."""
25
26 def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:
27 """Run check.
28
29 Returns
30 -------
31 CheckResult
32 value is numpy array of the confusion matrix, displays the confusion matrix
33
34 Raises
35 ------
36 DeepchecksValueError
37 If the data is not a Dataset instance with a label
38 """
39 if dataset_type == 'train':
40 dataset = context.train
41 else:
42 dataset = context.test
43
44 context.assert_classification_task()
45 ds_y = dataset.label_col
46 ds_x = dataset.features_columns
47 model = context.model
48
49 y_pred = model.predict(ds_x)
50 total_classes = sorted(list(set(pd.concat([ds_y, pd.Series(y_pred)]).to_list())))
51 confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
52
53 # Figure
54 fig = px.imshow(confusion_matrix, x=total_classes, y=total_classes, text_auto=True)
55 fig.update_layout(width=600, height=600)
56 fig.update_xaxes(title='Predicted Value', type='category')
57 fig.update_yaxes(title='True value', type='category')
58
59 return CheckResult(confusion_matrix, display=fig)
60
[end of deepchecks/tabular/checks/performance/confusion_matrix_report.py]
[start of deepchecks/tabular/checks/overview/model_info.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module contains model_info check."""
12 import warnings
13
14 import pandas as pd
15
16 from deepchecks.tabular import Context, ModelOnlyCheck
17 from deepchecks.core import CheckResult
18 from deepchecks.utils.model import get_model_of_pipeline
19
20
21 __all__ = ['ModelInfo']
22
23
24 class ModelInfo(ModelOnlyCheck):
25 """Summarize given model parameters."""
26
27 def run_logic(self, context: Context) -> CheckResult:
28 """Run check.
29
30 Returns
31 -------
32 CheckResult
33 value is dictionary in format {type: <model_type>, params: <model_params_dict>}
34 """
35 model = context.model
36 estimator = get_model_of_pipeline(model)
37 model_type = type(estimator).__name__
38 model_params = estimator.get_params()
39 default_params = type(estimator)().get_params()
40
41 # Create dataframe to show
42 model_param_df = pd.DataFrame(model_params.items(), columns=['Parameter', 'Value'])
43 model_param_df['Default'] = model_param_df['Parameter'].map(lambda x: default_params.get(x, ''))
44
45 def highlight_not_default(data):
46 n = len(data)
47 if data['Value'] != data['Default']:
48 return n * ['background-color: lightblue']
49 else:
50 return n * ['']
51 with warnings.catch_warnings():
52 warnings.simplefilter(action='ignore', category=FutureWarning)
53 model_param_df = model_param_df.style.apply(highlight_not_default, axis=1).hide_index()
54
55 value = {'type': model_type, 'params': model_params}
56 footnote = '<p style="font-size:0.7em"><i>Colored rows are parameters with non-default values</i></p>'
57 display = [f'Model Type: {model_type}', model_param_df, footnote]
58
59 return CheckResult(value, header='Model Info', display=display)
60
[end of deepchecks/tabular/checks/overview/model_info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/tabular/checks/overview/model_info.py b/deepchecks/tabular/checks/overview/model_info.py
--- a/deepchecks/tabular/checks/overview/model_info.py
+++ b/deepchecks/tabular/checks/overview/model_info.py
@@ -35,8 +35,12 @@
model = context.model
estimator = get_model_of_pipeline(model)
model_type = type(estimator).__name__
- model_params = estimator.get_params()
- default_params = type(estimator)().get_params()
+ try:
+ model_params = estimator.get_params()
+ default_params = type(estimator)().get_params()
+ except AttributeError:
+ model_params = {}
+ default_params = {}
# Create dataframe to show
model_param_df = pd.DataFrame(model_params.items(), columns=['Parameter', 'Value'])
diff --git a/deepchecks/tabular/checks/performance/confusion_matrix_report.py b/deepchecks/tabular/checks/performance/confusion_matrix_report.py
--- a/deepchecks/tabular/checks/performance/confusion_matrix_report.py
+++ b/deepchecks/tabular/checks/performance/confusion_matrix_report.py
@@ -9,6 +9,7 @@
# ----------------------------------------------------------------------------
#
"""The confusion_matrix_report check module."""
+import numpy as np
import pandas as pd
import sklearn
import plotly.express as px
@@ -46,7 +47,7 @@
ds_x = dataset.features_columns
model = context.model
- y_pred = model.predict(ds_x)
+ y_pred = np.array(model.predict(ds_x)).reshape(len(ds_y), )
total_classes = sorted(list(set(pd.concat([ds_y, pd.Series(y_pred)]).to_list())))
confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
|
{"golden_diff": "diff --git a/deepchecks/tabular/checks/overview/model_info.py b/deepchecks/tabular/checks/overview/model_info.py\n--- a/deepchecks/tabular/checks/overview/model_info.py\n+++ b/deepchecks/tabular/checks/overview/model_info.py\n@@ -35,8 +35,12 @@\n model = context.model\n estimator = get_model_of_pipeline(model)\n model_type = type(estimator).__name__\n- model_params = estimator.get_params()\n- default_params = type(estimator)().get_params()\n+ try:\n+ model_params = estimator.get_params()\n+ default_params = type(estimator)().get_params()\n+ except AttributeError:\n+ model_params = {}\n+ default_params = {}\n \n # Create dataframe to show\n model_param_df = pd.DataFrame(model_params.items(), columns=['Parameter', 'Value'])\ndiff --git a/deepchecks/tabular/checks/performance/confusion_matrix_report.py b/deepchecks/tabular/checks/performance/confusion_matrix_report.py\n--- a/deepchecks/tabular/checks/performance/confusion_matrix_report.py\n+++ b/deepchecks/tabular/checks/performance/confusion_matrix_report.py\n@@ -9,6 +9,7 @@\n # ----------------------------------------------------------------------------\n #\n \"\"\"The confusion_matrix_report check module.\"\"\"\n+import numpy as np\n import pandas as pd\n import sklearn\n import plotly.express as px\n@@ -46,7 +47,7 @@\n ds_x = dataset.features_columns\n model = context.model\n \n- y_pred = model.predict(ds_x)\n+ y_pred = np.array(model.predict(ds_x)).reshape(len(ds_y), )\n total_classes = sorted(list(set(pd.concat([ds_y, pd.Series(y_pred)]).to_list())))\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n", "issue": "[FEAT] add tests for more model types\nwe should test any model with predict and predict_proba functions, including the common ones:\r\n\r\nScikitlearn (also pipelines)\r\nCatBoost\r\nLGBM\r\nXGBoost\r\nCustom binary classification model that implements the predict_proba and predict functions\r\nCustom multiclass classification model that implements the predict_proba and predict functions\r\nCustom regression model that implements the predict function\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The confusion_matrix_report check module.\"\"\"\nimport pandas as pd\nimport sklearn\nimport plotly.express as px\n\nfrom deepchecks.core import CheckResult\nfrom deepchecks.tabular import Context, SingleDatasetCheck\n\n\n__all__ = ['ConfusionMatrixReport']\n\n\nclass ConfusionMatrixReport(SingleDatasetCheck):\n \"\"\"Calculate the confusion matrix of the model on the given dataset.\"\"\"\n\n def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:\n \"\"\"Run check.\n\n Returns\n -------\n CheckResult\n value is numpy array of the confusion matrix, displays the confusion matrix\n\n Raises\n ------\n DeepchecksValueError\n If the data is not a Dataset instance with a label\n \"\"\"\n if dataset_type == 'train':\n dataset = context.train\n else:\n dataset = context.test\n\n context.assert_classification_task()\n ds_y = dataset.label_col\n ds_x = dataset.features_columns\n model = context.model\n\n y_pred = model.predict(ds_x)\n total_classes = sorted(list(set(pd.concat([ds_y, pd.Series(y_pred)]).to_list())))\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n\n # Figure\n fig = px.imshow(confusion_matrix, x=total_classes, y=total_classes, text_auto=True)\n fig.update_layout(width=600, height=600)\n fig.update_xaxes(title='Predicted Value', type='category')\n fig.update_yaxes(title='True value', type='category')\n\n return CheckResult(confusion_matrix, display=fig)\n", "path": "deepchecks/tabular/checks/performance/confusion_matrix_report.py"}, {"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module contains model_info check.\"\"\"\nimport warnings\n\nimport pandas as pd\n\nfrom deepchecks.tabular import Context, ModelOnlyCheck\nfrom deepchecks.core import CheckResult\nfrom deepchecks.utils.model import get_model_of_pipeline\n\n\n__all__ = ['ModelInfo']\n\n\nclass ModelInfo(ModelOnlyCheck):\n \"\"\"Summarize given model parameters.\"\"\"\n\n def run_logic(self, context: Context) -> CheckResult:\n \"\"\"Run check.\n\n Returns\n -------\n CheckResult\n value is dictionary in format {type: <model_type>, params: <model_params_dict>}\n \"\"\"\n model = context.model\n estimator = get_model_of_pipeline(model)\n model_type = type(estimator).__name__\n model_params = estimator.get_params()\n default_params = type(estimator)().get_params()\n\n # Create dataframe to show\n model_param_df = pd.DataFrame(model_params.items(), columns=['Parameter', 'Value'])\n model_param_df['Default'] = model_param_df['Parameter'].map(lambda x: default_params.get(x, ''))\n\n def highlight_not_default(data):\n n = len(data)\n if data['Value'] != data['Default']:\n return n * ['background-color: lightblue']\n else:\n return n * ['']\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n model_param_df = model_param_df.style.apply(highlight_not_default, axis=1).hide_index()\n\n value = {'type': model_type, 'params': model_params}\n footnote = '<p style=\"font-size:0.7em\"><i>Colored rows are parameters with non-default values</i></p>'\n display = [f'Model Type: {model_type}', model_param_df, footnote]\n\n return CheckResult(value, header='Model Info', display=display)\n", "path": "deepchecks/tabular/checks/overview/model_info.py"}]}
| 1,823 | 391 |
gh_patches_debug_38337
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-606
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Training process is crashing if OpenVINO is not found in the environment
**Describe the bug**
When OpenVINO is not present in the environment, the training process crashes after a single epoch.
**To Reproduce**
Steps to reproduce the behavior:
1. Ensure OpenVINO is not installed in the environment (even `mo` should not be present)
2. Run `python -c "from testing.test_full import test_train_inference_optimize_segmentation_rad_2d;test_train_inference_optimize_segmentation_rad_2d('cpu')"`
3. See error:
```powershell
[SNIP!]
FileNotFoundError: [WinError 2] The system cannot find the file specified
```
OR:
```bash
[SNIP!]
Best model could not be loaded, error: [Errno 2] No such file or directory: 'mo'
```
**Expected behavior**
If `mo` or openvino is not found, continue the training process, just without doing any post-training optimization.
**Screenshots**
N.A.
**GaNDLF Version**
<!-- Put the output of the following command:
python -c 'import GANDLF as g;print(g.__version__)'
-->
0.0.16-dev
**Desktop (please complete the following information):**
N.A.
**Additional context**
N.A.
</issue>
<code>
[start of GANDLF/utils/modelio.py]
1 import os, hashlib, pkg_resources, subprocess
2 import torch
3
4 from .generic import get_unique_timestamp
5
6 # these are the base keys for the model dictionary to save
7 model_dict_full = {
8 "epoch": 0,
9 "model_state_dict": None,
10 "optimizer_state_dict": None,
11 "loss": None,
12 "timestamp": None,
13 "timestamp_hash": None,
14 "git_hash": None,
15 "version": None,
16 }
17
18 model_dict_required = {
19 "model_state_dict": None,
20 "optimizer_state_dict": None,
21 }
22
23 best_model_path_end = "_best.pth.tar"
24 latest_model_path_end = "_latest.pth.tar"
25 initial_model_path_end = "_initial.pth.tar"
26
27
28 def optimize_and_save_model(model, params, path, onnx_export=True):
29 """
30 Perform post-training optimization and save it to a file.
31
32 Args:
33 model (torch model): Trained torch model.
34 params (dict): The parameter dictionary.
35 path (str): The path to save the model dictionary to.
36 onnx_export (bool): Whether to export to ONNX and OpenVINO.
37 """
38 onnx_export = params["model"].get("onnx_export", onnx_export)
39 # check for incompatible topologies and disable onnx export
40 # customized imagenet_vgg no longer supported for onnx export: https://github.com/pytorch/pytorch/issues/42653
41 if onnx_export:
42 if (params["model"]["architecture"] in ["sdnet", "brain_age"]) or (
43 "imagenet_vgg" in params["model"]["architecture"]
44 ):
45 onnx_export = False
46
47 if not (onnx_export):
48 if "onnx_print" not in params:
49 print("WARNING: Current model is not supported by ONNX/OpenVINO!")
50 params["onnx_print"] = True
51 return
52 else:
53 try:
54 print("Optimizing best model.")
55 num_channel = params["model"]["num_channels"]
56 model_dimension = params["model"]["dimension"]
57 ov_output_data_type = params["model"].get("data_type", "FP32")
58 input_shape = params["patch_size"]
59 onnx_path = path
60 if not (onnx_path.endswith(".onnx")):
61 onnx_path = onnx_path.replace("pth.tar", "onnx")
62 if model_dimension == 2:
63 dummy_input = torch.randn(
64 (1, num_channel, input_shape[0], input_shape[1])
65 )
66 else:
67 dummy_input = torch.randn(
68 (1, num_channel, input_shape[0], input_shape[1], input_shape[2])
69 )
70
71 with torch.no_grad():
72 torch.onnx.export(
73 model.to("cpu"),
74 dummy_input.to("cpu"),
75 onnx_path,
76 opset_version=11,
77 export_params=True,
78 verbose=True,
79 input_names=["input"],
80 output_names=["output"],
81 )
82
83 ov_output_dir = os.path.dirname(os.path.abspath(path))
84 except RuntimeWarning:
85 print("WARNING: Cannot export to ONNX model.")
86 return
87
88 try:
89 if model_dimension == 2:
90 subprocess.call(
91 [
92 "mo",
93 "--input_model",
94 "{0}".format(onnx_path),
95 "--input_shape",
96 "[1,{0},{1},{2}]".format(
97 num_channel, input_shape[0], input_shape[1]
98 ),
99 "--data_type",
100 "{0}".format(ov_output_data_type),
101 "--output_dir",
102 "{0}".format(ov_output_dir),
103 ],
104 )
105 else:
106 subprocess.call(
107 [
108 "mo",
109 "--input_model",
110 "{0}".format(onnx_path),
111 "--input_shape",
112 "[1,{0},{1},{2},{3}]".format(
113 num_channel, input_shape[0], input_shape[1], input_shape[2]
114 ),
115 "--data_type",
116 "{0}".format(ov_output_data_type),
117 "--output_dir",
118 "{0}".format(ov_output_dir),
119 ],
120 )
121 except subprocess.CalledProcessError:
122 print("WARNING: OpenVINO Model Optimizer IR conversion failed.")
123
124
125 def save_model(model_dict, model, params, path, onnx_export=True):
126 """
127 Save the model dictionary to a file.
128
129 Args:
130 model_dict (dict): Model dictionary to save.
131 model (torch model): Trained torch model.
132 params (dict): The parameter dictionary.
133 path (str): The path to save the model dictionary to.
134 onnx_export (bool): Whether to export to ONNX and OpenVINO.
135 """
136 model_dict["timestamp"] = get_unique_timestamp()
137 model_dict["timestamp_hash"] = hashlib.sha256(
138 str(model_dict["timestamp"]).encode("utf-8")
139 ).hexdigest()
140 model_dict["version"] = pkg_resources.require("GANDLF")[0].version
141 try:
142 model_dict["git_hash"] = (
143 subprocess.check_output(["git", "rev-parse", "HEAD"])
144 .decode("ascii")
145 .strip()
146 )
147 except subprocess.CalledProcessError:
148 model_dict["git_hash"] = None
149 torch.save(model_dict, path)
150
151 # post-training optimization
152 optimize_and_save_model(model, params, path, onnx_export=onnx_export)
153
154
155 def load_model(path, device, full_sanity_check=True):
156 """
157 Load a model dictionary from a file.
158
159 Args:
160 path (str): The path to save the model dictionary to.
161 device (torch.device): The device to run the model on.
162 full_sanity_check (bool): Whether to run full sanity checking on model.
163
164 Returns:
165 dict: Model dictionary containing model parameters and metadata.
166 """
167 model_dict = torch.load(path, map_location=device)
168
169 # check if the model dictionary is complete
170 if full_sanity_check:
171 incomplete_keys = [
172 key for key in model_dict_full.keys() if key not in model_dict.keys()
173 ]
174 if len(incomplete_keys) > 0:
175 raise RuntimeWarning(
176 "Model dictionary is incomplete; the following keys are missing:",
177 incomplete_keys,
178 )
179
180 # check if required keys are absent, and if so raise an error
181 incomplete_required_keys = [
182 key for key in model_dict_required.keys() if key not in model_dict.keys()
183 ]
184 if len(incomplete_required_keys) > 0:
185 raise KeyError(
186 "Model dictionary is incomplete; the following keys are missing:",
187 incomplete_required_keys,
188 )
189
190 return model_dict
191
192
193 def load_ov_model(path, device="CPU"):
194 """
195 Load an OpenVINO IR model from an .xml file.
196
197 Args:
198 path (str): The path to the OpenVINO .xml file.
199 device (str): The device to run inference, can be "CPU", "GPU" or "MULTI:CPU,GPU". Default to be "CPU".
200
201 Returns:
202 exec_net (OpenVINO executable net): executable OpenVINO model.
203 input_blob (str): Input name.
204 output_blob (str): Output name.
205 """
206
207 try:
208 from openvino import runtime as ov
209 except ImportError:
210 raise ImportError("OpenVINO inference engine is not configured correctly.")
211
212 core = ov.Core()
213 if device.lower() == "cuda":
214 device = "GPU"
215
216 if device == "GPU":
217 core.set_property({"CACHE_DIR": os.path.dirname(os.path.abspath(path))})
218
219 model = core.read_model(model=path, weights=path.replace("xml", "bin"))
220 compiled_model = core.compile_model(model=model, device_name=device.upper())
221 input_layer = compiled_model.inputs
222 output_layer = compiled_model.outputs
223
224 return compiled_model, input_layer, output_layer
225
[end of GANDLF/utils/modelio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/GANDLF/utils/modelio.py b/GANDLF/utils/modelio.py
--- a/GANDLF/utils/modelio.py
+++ b/GANDLF/utils/modelio.py
@@ -85,41 +85,50 @@
print("WARNING: Cannot export to ONNX model.")
return
+ # https://github.com/mlcommons/GaNDLF/issues/605
+ openvino_present = False
try:
- if model_dimension == 2:
- subprocess.call(
- [
- "mo",
- "--input_model",
- "{0}".format(onnx_path),
- "--input_shape",
- "[1,{0},{1},{2}]".format(
- num_channel, input_shape[0], input_shape[1]
- ),
- "--data_type",
- "{0}".format(ov_output_data_type),
- "--output_dir",
- "{0}".format(ov_output_dir),
- ],
- )
- else:
- subprocess.call(
- [
- "mo",
- "--input_model",
- "{0}".format(onnx_path),
- "--input_shape",
- "[1,{0},{1},{2},{3}]".format(
- num_channel, input_shape[0], input_shape[1], input_shape[2]
- ),
- "--data_type",
- "{0}".format(ov_output_data_type),
- "--output_dir",
- "{0}".format(ov_output_dir),
- ],
- )
- except subprocess.CalledProcessError:
- print("WARNING: OpenVINO Model Optimizer IR conversion failed.")
+ import openvino
+ openvino_present = True
+ except ImportError:
+ print("WARNING: OpenVINO is not present.")
+
+ if openvino_present:
+ try:
+ if model_dimension == 2:
+ subprocess.call(
+ [
+ "mo",
+ "--input_model",
+ "{0}".format(onnx_path),
+ "--input_shape",
+ "[1,{0},{1},{2}]".format(
+ num_channel, input_shape[0], input_shape[1]
+ ),
+ "--data_type",
+ "{0}".format(ov_output_data_type),
+ "--output_dir",
+ "{0}".format(ov_output_dir),
+ ],
+ )
+ else:
+ subprocess.call(
+ [
+ "mo",
+ "--input_model",
+ "{0}".format(onnx_path),
+ "--input_shape",
+ "[1,{0},{1},{2},{3}]".format(
+ num_channel, input_shape[0], input_shape[1], input_shape[2]
+ ),
+ "--data_type",
+ "{0}".format(ov_output_data_type),
+ "--output_dir",
+ "{0}".format(ov_output_dir),
+ ],
+ )
+ except subprocess.CalledProcessError:
+ print("WARNING: OpenVINO Model Optimizer IR conversion failed.")
def save_model(model_dict, model, params, path, onnx_export=True):
|
{"golden_diff": "diff --git a/GANDLF/utils/modelio.py b/GANDLF/utils/modelio.py\n--- a/GANDLF/utils/modelio.py\n+++ b/GANDLF/utils/modelio.py\n@@ -85,41 +85,50 @@\n print(\"WARNING: Cannot export to ONNX model.\")\n return\n \n+ # https://github.com/mlcommons/GaNDLF/issues/605\n+ openvino_present = False\n try:\n- if model_dimension == 2:\n- subprocess.call(\n- [\n- \"mo\",\n- \"--input_model\",\n- \"{0}\".format(onnx_path),\n- \"--input_shape\",\n- \"[1,{0},{1},{2}]\".format(\n- num_channel, input_shape[0], input_shape[1]\n- ),\n- \"--data_type\",\n- \"{0}\".format(ov_output_data_type),\n- \"--output_dir\",\n- \"{0}\".format(ov_output_dir),\n- ],\n- )\n- else:\n- subprocess.call(\n- [\n- \"mo\",\n- \"--input_model\",\n- \"{0}\".format(onnx_path),\n- \"--input_shape\",\n- \"[1,{0},{1},{2},{3}]\".format(\n- num_channel, input_shape[0], input_shape[1], input_shape[2]\n- ),\n- \"--data_type\",\n- \"{0}\".format(ov_output_data_type),\n- \"--output_dir\",\n- \"{0}\".format(ov_output_dir),\n- ],\n- )\n- except subprocess.CalledProcessError:\n- print(\"WARNING: OpenVINO Model Optimizer IR conversion failed.\")\n+ import openvino\n+ openvino_present = True\n+ except ImportError:\n+ print(\"WARNING: OpenVINO is not present.\")\n+ \n+ if openvino_present:\n+ try:\n+ if model_dimension == 2:\n+ subprocess.call(\n+ [\n+ \"mo\",\n+ \"--input_model\",\n+ \"{0}\".format(onnx_path),\n+ \"--input_shape\",\n+ \"[1,{0},{1},{2}]\".format(\n+ num_channel, input_shape[0], input_shape[1]\n+ ),\n+ \"--data_type\",\n+ \"{0}\".format(ov_output_data_type),\n+ \"--output_dir\",\n+ \"{0}\".format(ov_output_dir),\n+ ],\n+ )\n+ else:\n+ subprocess.call(\n+ [\n+ \"mo\",\n+ \"--input_model\",\n+ \"{0}\".format(onnx_path),\n+ \"--input_shape\",\n+ \"[1,{0},{1},{2},{3}]\".format(\n+ num_channel, input_shape[0], input_shape[1], input_shape[2]\n+ ),\n+ \"--data_type\",\n+ \"{0}\".format(ov_output_data_type),\n+ \"--output_dir\",\n+ \"{0}\".format(ov_output_dir),\n+ ],\n+ )\n+ except subprocess.CalledProcessError:\n+ print(\"WARNING: OpenVINO Model Optimizer IR conversion failed.\")\n \n \n def save_model(model_dict, model, params, path, onnx_export=True):\n", "issue": "Training process is crashing if OpenVINO is not found in the environment\n**Describe the bug**\r\nWhen OpenVINO is not present in the environment, the training process crashes after a single epoch.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Ensure OpenVINO is not installed in the environment (even `mo` should not be present)\r\n2. Run `python -c \"from testing.test_full import test_train_inference_optimize_segmentation_rad_2d;test_train_inference_optimize_segmentation_rad_2d('cpu')\"`\r\n3. See error:\r\n```powershell\r\n[SNIP!]\r\nFileNotFoundError: [WinError 2] The system cannot find the file specified\r\n```\r\nOR:\r\n```bash\r\n[SNIP!]\r\nBest model could not be loaded, error: [Errno 2] No such file or directory: 'mo'\r\n```\r\n\r\n**Expected behavior**\r\nIf `mo` or openvino is not found, continue the training process, just without doing any post-training optimization.\r\n\r\n**Screenshots**\r\nN.A.\r\n\r\n**GaNDLF Version**\r\n<!-- Put the output of the following command:\r\npython -c 'import GANDLF as g;print(g.__version__)'\r\n-->\r\n0.0.16-dev\r\n\r\n**Desktop (please complete the following information):**\r\nN.A.\r\n\r\n**Additional context**\r\nN.A.\n", "before_files": [{"content": "import os, hashlib, pkg_resources, subprocess\nimport torch\n\nfrom .generic import get_unique_timestamp\n\n# these are the base keys for the model dictionary to save\nmodel_dict_full = {\n \"epoch\": 0,\n \"model_state_dict\": None,\n \"optimizer_state_dict\": None,\n \"loss\": None,\n \"timestamp\": None,\n \"timestamp_hash\": None,\n \"git_hash\": None,\n \"version\": None,\n}\n\nmodel_dict_required = {\n \"model_state_dict\": None,\n \"optimizer_state_dict\": None,\n}\n\nbest_model_path_end = \"_best.pth.tar\"\nlatest_model_path_end = \"_latest.pth.tar\"\ninitial_model_path_end = \"_initial.pth.tar\"\n\n\ndef optimize_and_save_model(model, params, path, onnx_export=True):\n \"\"\"\n Perform post-training optimization and save it to a file.\n\n Args:\n model (torch model): Trained torch model.\n params (dict): The parameter dictionary.\n path (str): The path to save the model dictionary to.\n onnx_export (bool): Whether to export to ONNX and OpenVINO.\n \"\"\"\n onnx_export = params[\"model\"].get(\"onnx_export\", onnx_export)\n # check for incompatible topologies and disable onnx export\n # customized imagenet_vgg no longer supported for onnx export: https://github.com/pytorch/pytorch/issues/42653\n if onnx_export:\n if (params[\"model\"][\"architecture\"] in [\"sdnet\", \"brain_age\"]) or (\n \"imagenet_vgg\" in params[\"model\"][\"architecture\"]\n ):\n onnx_export = False\n\n if not (onnx_export):\n if \"onnx_print\" not in params:\n print(\"WARNING: Current model is not supported by ONNX/OpenVINO!\")\n params[\"onnx_print\"] = True\n return\n else:\n try:\n print(\"Optimizing best model.\")\n num_channel = params[\"model\"][\"num_channels\"]\n model_dimension = params[\"model\"][\"dimension\"]\n ov_output_data_type = params[\"model\"].get(\"data_type\", \"FP32\")\n input_shape = params[\"patch_size\"]\n onnx_path = path\n if not (onnx_path.endswith(\".onnx\")):\n onnx_path = onnx_path.replace(\"pth.tar\", \"onnx\")\n if model_dimension == 2:\n dummy_input = torch.randn(\n (1, num_channel, input_shape[0], input_shape[1])\n )\n else:\n dummy_input = torch.randn(\n (1, num_channel, input_shape[0], input_shape[1], input_shape[2])\n )\n\n with torch.no_grad():\n torch.onnx.export(\n model.to(\"cpu\"),\n dummy_input.to(\"cpu\"),\n onnx_path,\n opset_version=11,\n export_params=True,\n verbose=True,\n input_names=[\"input\"],\n output_names=[\"output\"],\n )\n\n ov_output_dir = os.path.dirname(os.path.abspath(path))\n except RuntimeWarning:\n print(\"WARNING: Cannot export to ONNX model.\")\n return\n\n try:\n if model_dimension == 2:\n subprocess.call(\n [\n \"mo\",\n \"--input_model\",\n \"{0}\".format(onnx_path),\n \"--input_shape\",\n \"[1,{0},{1},{2}]\".format(\n num_channel, input_shape[0], input_shape[1]\n ),\n \"--data_type\",\n \"{0}\".format(ov_output_data_type),\n \"--output_dir\",\n \"{0}\".format(ov_output_dir),\n ],\n )\n else:\n subprocess.call(\n [\n \"mo\",\n \"--input_model\",\n \"{0}\".format(onnx_path),\n \"--input_shape\",\n \"[1,{0},{1},{2},{3}]\".format(\n num_channel, input_shape[0], input_shape[1], input_shape[2]\n ),\n \"--data_type\",\n \"{0}\".format(ov_output_data_type),\n \"--output_dir\",\n \"{0}\".format(ov_output_dir),\n ],\n )\n except subprocess.CalledProcessError:\n print(\"WARNING: OpenVINO Model Optimizer IR conversion failed.\")\n\n\ndef save_model(model_dict, model, params, path, onnx_export=True):\n \"\"\"\n Save the model dictionary to a file.\n\n Args:\n model_dict (dict): Model dictionary to save.\n model (torch model): Trained torch model.\n params (dict): The parameter dictionary.\n path (str): The path to save the model dictionary to.\n onnx_export (bool): Whether to export to ONNX and OpenVINO.\n \"\"\"\n model_dict[\"timestamp\"] = get_unique_timestamp()\n model_dict[\"timestamp_hash\"] = hashlib.sha256(\n str(model_dict[\"timestamp\"]).encode(\"utf-8\")\n ).hexdigest()\n model_dict[\"version\"] = pkg_resources.require(\"GANDLF\")[0].version\n try:\n model_dict[\"git_hash\"] = (\n subprocess.check_output([\"git\", \"rev-parse\", \"HEAD\"])\n .decode(\"ascii\")\n .strip()\n )\n except subprocess.CalledProcessError:\n model_dict[\"git_hash\"] = None\n torch.save(model_dict, path)\n\n # post-training optimization\n optimize_and_save_model(model, params, path, onnx_export=onnx_export)\n\n\ndef load_model(path, device, full_sanity_check=True):\n \"\"\"\n Load a model dictionary from a file.\n\n Args:\n path (str): The path to save the model dictionary to.\n device (torch.device): The device to run the model on.\n full_sanity_check (bool): Whether to run full sanity checking on model.\n\n Returns:\n dict: Model dictionary containing model parameters and metadata.\n \"\"\"\n model_dict = torch.load(path, map_location=device)\n\n # check if the model dictionary is complete\n if full_sanity_check:\n incomplete_keys = [\n key for key in model_dict_full.keys() if key not in model_dict.keys()\n ]\n if len(incomplete_keys) > 0:\n raise RuntimeWarning(\n \"Model dictionary is incomplete; the following keys are missing:\",\n incomplete_keys,\n )\n\n # check if required keys are absent, and if so raise an error\n incomplete_required_keys = [\n key for key in model_dict_required.keys() if key not in model_dict.keys()\n ]\n if len(incomplete_required_keys) > 0:\n raise KeyError(\n \"Model dictionary is incomplete; the following keys are missing:\",\n incomplete_required_keys,\n )\n\n return model_dict\n\n\ndef load_ov_model(path, device=\"CPU\"):\n \"\"\"\n Load an OpenVINO IR model from an .xml file.\n\n Args:\n path (str): The path to the OpenVINO .xml file.\n device (str): The device to run inference, can be \"CPU\", \"GPU\" or \"MULTI:CPU,GPU\". Default to be \"CPU\".\n\n Returns:\n exec_net (OpenVINO executable net): executable OpenVINO model.\n input_blob (str): Input name.\n output_blob (str): Output name.\n \"\"\"\n\n try:\n from openvino import runtime as ov\n except ImportError:\n raise ImportError(\"OpenVINO inference engine is not configured correctly.\")\n\n core = ov.Core()\n if device.lower() == \"cuda\":\n device = \"GPU\"\n\n if device == \"GPU\":\n core.set_property({\"CACHE_DIR\": os.path.dirname(os.path.abspath(path))})\n\n model = core.read_model(model=path, weights=path.replace(\"xml\", \"bin\"))\n compiled_model = core.compile_model(model=model, device_name=device.upper())\n input_layer = compiled_model.inputs\n output_layer = compiled_model.outputs\n\n return compiled_model, input_layer, output_layer\n", "path": "GANDLF/utils/modelio.py"}]}
| 3,069 | 688 |
gh_patches_debug_5115
|
rasdani/github-patches
|
git_diff
|
magenta__magenta-1347
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Melody_rnn Create Dataset get_pipeline missing arg
`melody_rnn_create_dataset --config=basic_rnn --input=notesequences.tfrecord --output_dir=sequence_examples` fails with this error:
```
File "/Users/ericcacciavillani/anaconda3/envs/Magenta_Testing/lib/python3.6/site-packages/magenta/pipelines/note_sequence_pipelines.py", line 184, in transform
for amount in self._transposition_range:
TypeError: 'float' object is not iterable
```
We're trying to train our own melody rnn and we get this error, also we don't see a mention of transposition range in the melody rnn readme?
Looks like in `melody_rnn_create_dataset.py` at line 52 its calling `melody_rnn_pipeline.get_pipeline(config, FLAGS.eval_ratio)`
but `get_pipeline` in `melody_rnn_pipeline.py` takes 3 args `config`, `transposition_range`, and `eval ratio` so it looks like transposition_range is being set as eval_ratio.
Working with @robindiddams on this.
</issue>
<code>
[start of magenta/models/melody_rnn/melody_rnn_create_dataset.py]
1 # Copyright 2016 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Create a dataset of SequenceExamples from NoteSequence protos.
15
16 This script will extract melodies from NoteSequence protos and save them to
17 TensorFlow's SequenceExample protos for input to the melody RNN models.
18 """
19
20 import os
21
22 import tensorflow as tf
23
24 from magenta.models.melody_rnn import melody_rnn_config_flags
25 from magenta.models.melody_rnn import melody_rnn_pipeline
26 from magenta.pipelines import pipeline
27
28 flags = tf.app.flags
29 FLAGS = tf.app.flags.FLAGS
30 flags.DEFINE_string(
31 'input', None,
32 'TFRecord to read NoteSequence protos from.')
33 flags.DEFINE_string(
34 'output_dir', None,
35 'Directory to write training and eval TFRecord files. The TFRecord files '
36 'are populated with SequenceExample protos.')
37 flags.DEFINE_float(
38 'eval_ratio', 0.1,
39 'Fraction of input to set aside for eval set. Partition is randomly '
40 'selected.')
41 flags.DEFINE_string(
42 'log', 'INFO',
43 'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '
44 'or FATAL.')
45
46
47 def main(unused_argv):
48 tf.logging.set_verbosity(FLAGS.log)
49
50 config = melody_rnn_config_flags.config_from_flags()
51 pipeline_instance = melody_rnn_pipeline.get_pipeline(
52 config, FLAGS.eval_ratio)
53
54 FLAGS.input = os.path.expanduser(FLAGS.input)
55 FLAGS.output_dir = os.path.expanduser(FLAGS.output_dir)
56 pipeline.run_pipeline_serial(
57 pipeline_instance,
58 pipeline.tf_record_iterator(FLAGS.input, pipeline_instance.input_type),
59 FLAGS.output_dir)
60
61
62 def console_entry_point():
63 tf.app.run(main)
64
65
66 if __name__ == '__main__':
67 console_entry_point()
68
[end of magenta/models/melody_rnn/melody_rnn_create_dataset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/magenta/models/melody_rnn/melody_rnn_create_dataset.py b/magenta/models/melody_rnn/melody_rnn_create_dataset.py
--- a/magenta/models/melody_rnn/melody_rnn_create_dataset.py
+++ b/magenta/models/melody_rnn/melody_rnn_create_dataset.py
@@ -49,7 +49,7 @@
config = melody_rnn_config_flags.config_from_flags()
pipeline_instance = melody_rnn_pipeline.get_pipeline(
- config, FLAGS.eval_ratio)
+ config, eval_ratio=FLAGS.eval_ratio)
FLAGS.input = os.path.expanduser(FLAGS.input)
FLAGS.output_dir = os.path.expanduser(FLAGS.output_dir)
|
{"golden_diff": "diff --git a/magenta/models/melody_rnn/melody_rnn_create_dataset.py b/magenta/models/melody_rnn/melody_rnn_create_dataset.py\n--- a/magenta/models/melody_rnn/melody_rnn_create_dataset.py\n+++ b/magenta/models/melody_rnn/melody_rnn_create_dataset.py\n@@ -49,7 +49,7 @@\n \n config = melody_rnn_config_flags.config_from_flags()\n pipeline_instance = melody_rnn_pipeline.get_pipeline(\n- config, FLAGS.eval_ratio)\n+ config, eval_ratio=FLAGS.eval_ratio)\n \n FLAGS.input = os.path.expanduser(FLAGS.input)\n FLAGS.output_dir = os.path.expanduser(FLAGS.output_dir)\n", "issue": "[Bug] Melody_rnn Create Dataset get_pipeline missing arg\n`melody_rnn_create_dataset --config=basic_rnn --input=notesequences.tfrecord --output_dir=sequence_examples` fails with this error:\r\n```\r\nFile \"/Users/ericcacciavillani/anaconda3/envs/Magenta_Testing/lib/python3.6/site-packages/magenta/pipelines/note_sequence_pipelines.py\", line 184, in transform\r\n for amount in self._transposition_range:\r\nTypeError: 'float' object is not iterable\r\n```\r\nWe're trying to train our own melody rnn and we get this error, also we don't see a mention of transposition range in the melody rnn readme?\r\n\r\nLooks like in `melody_rnn_create_dataset.py` at line 52 its calling `melody_rnn_pipeline.get_pipeline(config, FLAGS.eval_ratio)`\r\nbut `get_pipeline` in `melody_rnn_pipeline.py` takes 3 args `config`, `transposition_range`, and `eval ratio` so it looks like transposition_range is being set as eval_ratio.\r\n\r\nWorking with @robindiddams on this.\n", "before_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Create a dataset of SequenceExamples from NoteSequence protos.\n\nThis script will extract melodies from NoteSequence protos and save them to\nTensorFlow's SequenceExample protos for input to the melody RNN models.\n\"\"\"\n\nimport os\n\nimport tensorflow as tf\n\nfrom magenta.models.melody_rnn import melody_rnn_config_flags\nfrom magenta.models.melody_rnn import melody_rnn_pipeline\nfrom magenta.pipelines import pipeline\n\nflags = tf.app.flags\nFLAGS = tf.app.flags.FLAGS\nflags.DEFINE_string(\n 'input', None,\n 'TFRecord to read NoteSequence protos from.')\nflags.DEFINE_string(\n 'output_dir', None,\n 'Directory to write training and eval TFRecord files. The TFRecord files '\n 'are populated with SequenceExample protos.')\nflags.DEFINE_float(\n 'eval_ratio', 0.1,\n 'Fraction of input to set aside for eval set. Partition is randomly '\n 'selected.')\nflags.DEFINE_string(\n 'log', 'INFO',\n 'The threshold for what messages will be logged DEBUG, INFO, WARN, ERROR, '\n 'or FATAL.')\n\n\ndef main(unused_argv):\n tf.logging.set_verbosity(FLAGS.log)\n\n config = melody_rnn_config_flags.config_from_flags()\n pipeline_instance = melody_rnn_pipeline.get_pipeline(\n config, FLAGS.eval_ratio)\n\n FLAGS.input = os.path.expanduser(FLAGS.input)\n FLAGS.output_dir = os.path.expanduser(FLAGS.output_dir)\n pipeline.run_pipeline_serial(\n pipeline_instance,\n pipeline.tf_record_iterator(FLAGS.input, pipeline_instance.input_type),\n FLAGS.output_dir)\n\n\ndef console_entry_point():\n tf.app.run(main)\n\n\nif __name__ == '__main__':\n console_entry_point()\n", "path": "magenta/models/melody_rnn/melody_rnn_create_dataset.py"}]}
| 1,412 | 146 |
gh_patches_debug_7562
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-960
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Time skew between login.gov and cloud.gov ('issued in the future') causing a 401 on login
### Current Behavior
User gets a 401 error screen on login occasionally (about 60% of the time). Issue seems more prevalent on sandboxes and in fresh browsers with clear cache.
User is usually able to bypass this error screen by clicking login again or clicking on the .gov site logo (sometimes it takes more than one attempt).
### Expected Behavior
Succefull login and no error screen.
### Steps to Reproduce
1. Log into a sandbox in a fresh browser or incognito window.
2. Try a couple of times if the error does not trigger at first.
### Environment
_No response_
### Additional Context
_No response_
### Issue Links
_No response_
</issue>
<code>
[start of src/djangooidc/oidc.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import logging
5 import json
6
7 from django.conf import settings
8 from django.http import HttpResponseRedirect
9 from Cryptodome.PublicKey.RSA import importKey
10 from jwkest.jwk import RSAKey # type: ignore
11 from oic import oic, rndstr, utils
12 from oic.oauth2 import ErrorResponse
13 from oic.oic import AuthorizationRequest, AuthorizationResponse, RegistrationResponse
14 from oic.oic.message import AccessTokenResponse
15 from oic.utils.authn.client import CLIENT_AUTHN_METHOD
16 from oic.utils import keyio
17
18 from . import exceptions as o_e
19
20 __author__ = "roland"
21
22 logger = logging.getLogger(__name__)
23
24
25 class Client(oic.Client):
26 def __init__(self, op):
27 """Step 1: Configure the OpenID Connect client."""
28 logger.debug("Initializing the OpenID Connect client...")
29 try:
30 provider = settings.OIDC_PROVIDERS[op]
31 verify_ssl = getattr(settings, "OIDC_VERIFY_SSL", True)
32 except Exception as err:
33 logger.error(err)
34 logger.error("Configuration missing for OpenID Connect client")
35 raise o_e.InternalError()
36
37 try:
38 # prepare private key for authentication method of private_key_jwt
39 key_bundle = keyio.KeyBundle()
40 rsa_key = importKey(provider["client_registration"]["sp_private_key"])
41 key = RSAKey(key=rsa_key, use="sig")
42 key_bundle.append(key)
43 keyjar = keyio.KeyJar(verify_ssl=verify_ssl)
44 keyjar.add_kb("", key_bundle)
45 except Exception as err:
46 logger.error(err)
47 logger.error(
48 "Key jar preparation failed for %s",
49 provider["srv_discovery_url"],
50 )
51 raise o_e.InternalError()
52
53 try:
54 # create the oic client instance
55 super().__init__(
56 client_id=None,
57 client_authn_method=CLIENT_AUTHN_METHOD,
58 keyjar=keyjar,
59 settings=utils.settings.OicClientSettings(verify_ssl=verify_ssl),
60 config=None,
61 )
62 # must be set after client is initialized
63 self.behaviour = provider["behaviour"]
64 except Exception as err:
65 logger.error(err)
66 logger.error(
67 "Client creation failed for %s",
68 provider["srv_discovery_url"],
69 )
70 raise o_e.InternalError()
71
72 try:
73 # discover and store the provider (OP) urls, etc
74 self.provider_config(provider["srv_discovery_url"])
75 self.store_registration_info(
76 RegistrationResponse(**provider["client_registration"])
77 )
78 except Exception as err:
79 logger.error(err)
80 logger.error(
81 "Provider info discovery failed for %s",
82 provider["srv_discovery_url"],
83 )
84 raise o_e.InternalError()
85
86 def create_authn_request(
87 self,
88 session,
89 extra_args=None,
90 ):
91 """Step 2: Construct a login URL at OP's domain and send the user to it."""
92 logger.debug("Creating the OpenID Connect authn request...")
93 state = rndstr(size=32)
94 try:
95 session["state"] = state
96 session["nonce"] = rndstr(size=32)
97 scopes = list(self.behaviour.get("scope", []))
98 scopes.append("openid")
99 request_args = {
100 "response_type": self.behaviour.get("response_type"),
101 "scope": " ".join(set(scopes)),
102 "state": session["state"],
103 "nonce": session["nonce"],
104 "redirect_uri": self.registration_response["redirect_uris"][0],
105 "acr_values": self.behaviour.get("acr_value"),
106 }
107
108 if extra_args is not None:
109 request_args.update(extra_args)
110 except Exception as err:
111 logger.error(err)
112 logger.error("Failed to assemble request arguments for %s" % state)
113 raise o_e.InternalError(locator=state)
114
115 logger.debug("request args: %s" % request_args)
116
117 try:
118 # prepare the request for sending
119 cis = self.construct_AuthorizationRequest(request_args=request_args)
120 logger.debug("request: %s" % cis)
121
122 # obtain the url and headers from the prepared request
123 url, body, headers, cis = self.uri_and_body(
124 AuthorizationRequest,
125 cis,
126 method="GET",
127 request_args=request_args,
128 )
129 logger.debug("body: %s" % body)
130 logger.debug("URL: %s" % url)
131 logger.debug("headers: %s" % headers)
132 except Exception as err:
133 logger.error(err)
134 logger.error("Failed to prepare request for %s" % state)
135 raise o_e.InternalError(locator=state)
136
137 try:
138 # create the redirect object
139 response = HttpResponseRedirect(str(url))
140 # add headers to the object, if any
141 if headers:
142 for key, value in headers.items():
143 response[key] = value
144 except Exception as err:
145 logger.error(err)
146 logger.error("Failed to create redirect object for %s" % state)
147 raise o_e.InternalError(locator=state)
148
149 return response
150
151 def callback(self, unparsed_response, session):
152 """Step 3: Receive OP's response, request an access token, and user info."""
153 logger.debug("Processing the OpenID Connect callback response...")
154 state = session.get("state", "")
155 try:
156 # parse the response from OP
157 authn_response = self.parse_response(
158 AuthorizationResponse,
159 unparsed_response,
160 sformat="dict",
161 keyjar=self.keyjar,
162 )
163 except Exception as err:
164 logger.error(err)
165 logger.error("Unable to parse response for %s" % state)
166 raise o_e.AuthenticationFailed(locator=state)
167
168 # ErrorResponse is not raised, it is passed back...
169 if isinstance(authn_response, ErrorResponse):
170 error = authn_response.get("error", "")
171 if error == "login_required":
172 logger.warning(
173 "User was not logged in (%s), trying again for %s" % (error, state)
174 )
175 return self.create_authn_request(session)
176 else:
177 logger.error("Unable to process response %s for %s" % (error, state))
178 raise o_e.AuthenticationFailed(locator=state)
179
180 logger.debug("authn_response %s" % authn_response)
181
182 if not authn_response.get("state", None):
183 logger.error("State value not received from OP for %s" % state)
184 raise o_e.AuthenticationFailed(locator=state)
185
186 if authn_response["state"] != session.get("state", None):
187 # this most likely means the user's Django session vanished
188 logger.error("Received state not the same as expected for %s" % state)
189 raise o_e.AuthenticationFailed(locator=state)
190
191 if self.behaviour.get("response_type") == "code":
192 # need an access token to get user info (and to log the user out later)
193 self._request_token(
194 authn_response["state"], authn_response["code"], session
195 )
196
197 user_info = self._get_user_info(state, session)
198
199 return user_info
200
201 def _get_user_info(self, state, session):
202 """Get information from OP about the user."""
203 scopes = list(self.behaviour.get("user_info_request", []))
204 scopes.append("openid")
205 try:
206 # get info about the user from OP
207 info_response = self.do_user_info_request(
208 state=session["state"],
209 method="GET",
210 scope=" ".join(set(scopes)),
211 )
212 except Exception as err:
213 logger.error(err)
214 logger.error("Unable to request user info for %s" % state)
215 raise o_e.AuthenticationFailed(locator=state)
216
217 # ErrorResponse is not raised, it is passed back...
218 if isinstance(info_response, ErrorResponse):
219 logger.error(
220 "Unable to get user info (%s) for %s"
221 % (info_response.get("error", ""), state)
222 )
223 raise o_e.AuthenticationFailed(locator=state)
224
225 logger.debug("user info: %s" % info_response)
226 return info_response.to_dict()
227
228 def _request_token(self, state, code, session):
229 """Request a token from OP to allow us to then request user info."""
230 try:
231 token_response = self.do_access_token_request(
232 scope="openid",
233 state=state,
234 request_args={
235 "code": code,
236 "redirect_uri": self.registration_response["redirect_uris"][0],
237 "client_id": self.client_id,
238 "client_secret": self.client_secret,
239 },
240 authn_method=self.registration_response["token_endpoint_auth_method"],
241 )
242 except Exception as err:
243 logger.error(err)
244 logger.error("Unable to obtain access token for %s" % state)
245 raise o_e.AuthenticationFailed(locator=state)
246
247 # ErrorResponse is not raised, it is passed back...
248 if isinstance(token_response, ErrorResponse):
249 logger.error(
250 "Unable to get token (%s) for %s"
251 % (token_response.get("error", ""), state)
252 )
253 raise o_e.AuthenticationFailed(locator=state)
254
255 logger.debug("token response %s" % token_response)
256
257 try:
258 # get the token and other bits of info
259 id_token = token_response["id_token"]._dict
260
261 if id_token["nonce"] != session["nonce"]:
262 logger.error("Received nonce not the same as expected for %s" % state)
263 raise o_e.AuthenticationFailed(locator=state)
264
265 session["id_token"] = id_token
266 session["id_token_raw"] = getattr(self, "id_token_raw", None)
267 session["access_token"] = token_response["access_token"]
268 session["refresh_token"] = token_response.get("refresh_token", "")
269 session["expires_in"] = token_response.get("expires_in", "")
270 self.id_token[state] = getattr(self, "id_token_raw", None)
271 except Exception as err:
272 logger.error(err)
273 logger.error("Unable to parse access token response for %s" % state)
274 raise o_e.AuthenticationFailed(locator=state)
275
276 def store_response(self, resp, info):
277 """Make raw ID token available for internal use."""
278 if isinstance(resp, AccessTokenResponse):
279 info = json.loads(info)
280 self.id_token_raw = info["id_token"]
281
282 super(Client, self).store_response(resp, info)
283
284 def __repr__(self):
285 return "Client {} {} {}".format(
286 self.client_id,
287 self.client_prefs,
288 self.behaviour,
289 )
290
[end of src/djangooidc/oidc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/djangooidc/oidc.py b/src/djangooidc/oidc.py
--- a/src/djangooidc/oidc.py
+++ b/src/djangooidc/oidc.py
@@ -238,6 +238,9 @@
"client_secret": self.client_secret,
},
authn_method=self.registration_response["token_endpoint_auth_method"],
+ # There is a time desync issue between login.gov and cloud
+ # this addresses that by adding a clock skew.
+ skew=10,
)
except Exception as err:
logger.error(err)
|
{"golden_diff": "diff --git a/src/djangooidc/oidc.py b/src/djangooidc/oidc.py\n--- a/src/djangooidc/oidc.py\n+++ b/src/djangooidc/oidc.py\n@@ -238,6 +238,9 @@\n \"client_secret\": self.client_secret,\n },\n authn_method=self.registration_response[\"token_endpoint_auth_method\"],\n+ # There is a time desync issue between login.gov and cloud\n+ # this addresses that by adding a clock skew.\n+ skew=10,\n )\n except Exception as err:\n logger.error(err)\n", "issue": "Time skew between login.gov and cloud.gov ('issued in the future') causing a 401 on login\n### Current Behavior\n\nUser gets a 401 error screen on login occasionally (about 60% of the time). Issue seems more prevalent on sandboxes and in fresh browsers with clear cache.\r\n\r\nUser is usually able to bypass this error screen by clicking login again or clicking on the .gov site logo (sometimes it takes more than one attempt).\n\n### Expected Behavior\n\nSuccefull login and no error screen.\n\n### Steps to Reproduce\n\n1. Log into a sandbox in a fresh browser or incognito window.\r\n2. Try a couple of times if the error does not trigger at first.\r\n\n\n### Environment\n\n_No response_\n\n### Additional Context\n\n_No response_\n\n### Issue Links\n\n_No response_\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport logging\nimport json\n\nfrom django.conf import settings\nfrom django.http import HttpResponseRedirect\nfrom Cryptodome.PublicKey.RSA import importKey\nfrom jwkest.jwk import RSAKey # type: ignore\nfrom oic import oic, rndstr, utils\nfrom oic.oauth2 import ErrorResponse\nfrom oic.oic import AuthorizationRequest, AuthorizationResponse, RegistrationResponse\nfrom oic.oic.message import AccessTokenResponse\nfrom oic.utils.authn.client import CLIENT_AUTHN_METHOD\nfrom oic.utils import keyio\n\nfrom . import exceptions as o_e\n\n__author__ = \"roland\"\n\nlogger = logging.getLogger(__name__)\n\n\nclass Client(oic.Client):\n def __init__(self, op):\n \"\"\"Step 1: Configure the OpenID Connect client.\"\"\"\n logger.debug(\"Initializing the OpenID Connect client...\")\n try:\n provider = settings.OIDC_PROVIDERS[op]\n verify_ssl = getattr(settings, \"OIDC_VERIFY_SSL\", True)\n except Exception as err:\n logger.error(err)\n logger.error(\"Configuration missing for OpenID Connect client\")\n raise o_e.InternalError()\n\n try:\n # prepare private key for authentication method of private_key_jwt\n key_bundle = keyio.KeyBundle()\n rsa_key = importKey(provider[\"client_registration\"][\"sp_private_key\"])\n key = RSAKey(key=rsa_key, use=\"sig\")\n key_bundle.append(key)\n keyjar = keyio.KeyJar(verify_ssl=verify_ssl)\n keyjar.add_kb(\"\", key_bundle)\n except Exception as err:\n logger.error(err)\n logger.error(\n \"Key jar preparation failed for %s\",\n provider[\"srv_discovery_url\"],\n )\n raise o_e.InternalError()\n\n try:\n # create the oic client instance\n super().__init__(\n client_id=None,\n client_authn_method=CLIENT_AUTHN_METHOD,\n keyjar=keyjar,\n settings=utils.settings.OicClientSettings(verify_ssl=verify_ssl),\n config=None,\n )\n # must be set after client is initialized\n self.behaviour = provider[\"behaviour\"]\n except Exception as err:\n logger.error(err)\n logger.error(\n \"Client creation failed for %s\",\n provider[\"srv_discovery_url\"],\n )\n raise o_e.InternalError()\n\n try:\n # discover and store the provider (OP) urls, etc\n self.provider_config(provider[\"srv_discovery_url\"])\n self.store_registration_info(\n RegistrationResponse(**provider[\"client_registration\"])\n )\n except Exception as err:\n logger.error(err)\n logger.error(\n \"Provider info discovery failed for %s\",\n provider[\"srv_discovery_url\"],\n )\n raise o_e.InternalError()\n\n def create_authn_request(\n self,\n session,\n extra_args=None,\n ):\n \"\"\"Step 2: Construct a login URL at OP's domain and send the user to it.\"\"\"\n logger.debug(\"Creating the OpenID Connect authn request...\")\n state = rndstr(size=32)\n try:\n session[\"state\"] = state\n session[\"nonce\"] = rndstr(size=32)\n scopes = list(self.behaviour.get(\"scope\", []))\n scopes.append(\"openid\")\n request_args = {\n \"response_type\": self.behaviour.get(\"response_type\"),\n \"scope\": \" \".join(set(scopes)),\n \"state\": session[\"state\"],\n \"nonce\": session[\"nonce\"],\n \"redirect_uri\": self.registration_response[\"redirect_uris\"][0],\n \"acr_values\": self.behaviour.get(\"acr_value\"),\n }\n\n if extra_args is not None:\n request_args.update(extra_args)\n except Exception as err:\n logger.error(err)\n logger.error(\"Failed to assemble request arguments for %s\" % state)\n raise o_e.InternalError(locator=state)\n\n logger.debug(\"request args: %s\" % request_args)\n\n try:\n # prepare the request for sending\n cis = self.construct_AuthorizationRequest(request_args=request_args)\n logger.debug(\"request: %s\" % cis)\n\n # obtain the url and headers from the prepared request\n url, body, headers, cis = self.uri_and_body(\n AuthorizationRequest,\n cis,\n method=\"GET\",\n request_args=request_args,\n )\n logger.debug(\"body: %s\" % body)\n logger.debug(\"URL: %s\" % url)\n logger.debug(\"headers: %s\" % headers)\n except Exception as err:\n logger.error(err)\n logger.error(\"Failed to prepare request for %s\" % state)\n raise o_e.InternalError(locator=state)\n\n try:\n # create the redirect object\n response = HttpResponseRedirect(str(url))\n # add headers to the object, if any\n if headers:\n for key, value in headers.items():\n response[key] = value\n except Exception as err:\n logger.error(err)\n logger.error(\"Failed to create redirect object for %s\" % state)\n raise o_e.InternalError(locator=state)\n\n return response\n\n def callback(self, unparsed_response, session):\n \"\"\"Step 3: Receive OP's response, request an access token, and user info.\"\"\"\n logger.debug(\"Processing the OpenID Connect callback response...\")\n state = session.get(\"state\", \"\")\n try:\n # parse the response from OP\n authn_response = self.parse_response(\n AuthorizationResponse,\n unparsed_response,\n sformat=\"dict\",\n keyjar=self.keyjar,\n )\n except Exception as err:\n logger.error(err)\n logger.error(\"Unable to parse response for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n # ErrorResponse is not raised, it is passed back...\n if isinstance(authn_response, ErrorResponse):\n error = authn_response.get(\"error\", \"\")\n if error == \"login_required\":\n logger.warning(\n \"User was not logged in (%s), trying again for %s\" % (error, state)\n )\n return self.create_authn_request(session)\n else:\n logger.error(\"Unable to process response %s for %s\" % (error, state))\n raise o_e.AuthenticationFailed(locator=state)\n\n logger.debug(\"authn_response %s\" % authn_response)\n\n if not authn_response.get(\"state\", None):\n logger.error(\"State value not received from OP for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n if authn_response[\"state\"] != session.get(\"state\", None):\n # this most likely means the user's Django session vanished\n logger.error(\"Received state not the same as expected for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n if self.behaviour.get(\"response_type\") == \"code\":\n # need an access token to get user info (and to log the user out later)\n self._request_token(\n authn_response[\"state\"], authn_response[\"code\"], session\n )\n\n user_info = self._get_user_info(state, session)\n\n return user_info\n\n def _get_user_info(self, state, session):\n \"\"\"Get information from OP about the user.\"\"\"\n scopes = list(self.behaviour.get(\"user_info_request\", []))\n scopes.append(\"openid\")\n try:\n # get info about the user from OP\n info_response = self.do_user_info_request(\n state=session[\"state\"],\n method=\"GET\",\n scope=\" \".join(set(scopes)),\n )\n except Exception as err:\n logger.error(err)\n logger.error(\"Unable to request user info for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n # ErrorResponse is not raised, it is passed back...\n if isinstance(info_response, ErrorResponse):\n logger.error(\n \"Unable to get user info (%s) for %s\"\n % (info_response.get(\"error\", \"\"), state)\n )\n raise o_e.AuthenticationFailed(locator=state)\n\n logger.debug(\"user info: %s\" % info_response)\n return info_response.to_dict()\n\n def _request_token(self, state, code, session):\n \"\"\"Request a token from OP to allow us to then request user info.\"\"\"\n try:\n token_response = self.do_access_token_request(\n scope=\"openid\",\n state=state,\n request_args={\n \"code\": code,\n \"redirect_uri\": self.registration_response[\"redirect_uris\"][0],\n \"client_id\": self.client_id,\n \"client_secret\": self.client_secret,\n },\n authn_method=self.registration_response[\"token_endpoint_auth_method\"],\n )\n except Exception as err:\n logger.error(err)\n logger.error(\"Unable to obtain access token for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n # ErrorResponse is not raised, it is passed back...\n if isinstance(token_response, ErrorResponse):\n logger.error(\n \"Unable to get token (%s) for %s\"\n % (token_response.get(\"error\", \"\"), state)\n )\n raise o_e.AuthenticationFailed(locator=state)\n\n logger.debug(\"token response %s\" % token_response)\n\n try:\n # get the token and other bits of info\n id_token = token_response[\"id_token\"]._dict\n\n if id_token[\"nonce\"] != session[\"nonce\"]:\n logger.error(\"Received nonce not the same as expected for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n session[\"id_token\"] = id_token\n session[\"id_token_raw\"] = getattr(self, \"id_token_raw\", None)\n session[\"access_token\"] = token_response[\"access_token\"]\n session[\"refresh_token\"] = token_response.get(\"refresh_token\", \"\")\n session[\"expires_in\"] = token_response.get(\"expires_in\", \"\")\n self.id_token[state] = getattr(self, \"id_token_raw\", None)\n except Exception as err:\n logger.error(err)\n logger.error(\"Unable to parse access token response for %s\" % state)\n raise o_e.AuthenticationFailed(locator=state)\n\n def store_response(self, resp, info):\n \"\"\"Make raw ID token available for internal use.\"\"\"\n if isinstance(resp, AccessTokenResponse):\n info = json.loads(info)\n self.id_token_raw = info[\"id_token\"]\n\n super(Client, self).store_response(resp, info)\n\n def __repr__(self):\n return \"Client {} {} {}\".format(\n self.client_id,\n self.client_prefs,\n self.behaviour,\n )\n", "path": "src/djangooidc/oidc.py"}]}
| 3,738 | 134 |
gh_patches_debug_38528
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-9050
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to receive pdf from [/v1/badge-forms/print-badge-pdf]
**Describe the bug**
Internal server error 500 returned with no response of the type of error on the server side.
**To Reproduce**
Steps to reproduce the behavior:
1. Send POST to [/v1/badge-forms/print-badge-pdf] with payload
2. Error 500 with no response received
</issue>
<code>
[start of app/api/helpers/badge_forms.py]
1 import base64
2 import io
3 from datetime import datetime
4
5 import qrcode
6 from flask import render_template
7 from sqlalchemy import asc
8
9 from app.api.helpers.db import save_to_db
10 from app.api.helpers.files import create_save_pdf
11 from app.api.helpers.storage import UPLOAD_PATHS, generate_hash
12 from app.api.helpers.utilities import to_snake_case
13 from app.models.badge_field_form import BadgeFieldForms
14 from app.models.custom_form import CustomForms
15 from app.models.ticket_holder import TicketHolder
16
17
18 def file_pdf_path(self) -> str:
19 """Contructor path of File PDF"""
20 key = UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=self.badge_id)
21 return f'static/media/{key}/{generate_hash(key)}/{self.badge_id}.pdf'
22
23
24 def create_preivew_badge_pdf(badgeForms):
25 """
26 Create tickets and invoices for the holders of an order.
27 :param badgeForms: The order for which to create tickets for.
28 """
29 badgeForms = badgeForms[0]
30 badgeFieldForms = badgeForms['badgeFields']
31 badgeId = badgeForms['badgeID']
32 for badge_field in badgeFieldForms:
33 font_weight = []
34 font_style = []
35 text_decoration = []
36 if badge_field.get('font_weight'):
37 for item in badge_field.get('font_weight'):
38 if item.get('font_weight'):
39 font_weight.append(item.get('font_weight'))
40 if item.get('font_style'):
41 font_style.append(item.get('font_style'))
42 if item.get('text_decoration'):
43 text_decoration.append(item.get('text_decoration'))
44 if not font_weight:
45 badge_field['font_weight'] = 'none'
46 else:
47 badge_field['font_weight'] = ','.join(font_weight)
48 if not font_style:
49 badge_field['font_style'] = 'none'
50 else:
51 badge_field['font_style'] = ','.join(font_style)
52 if not text_decoration:
53 badge_field['text_decoration'] = 'none'
54 else:
55 badge_field['text_decoration'] = ','.join(text_decoration)
56 create_save_pdf(
57 render_template(
58 'pdf/badge_forms.html', badgeForms=badgeForms, badgeFieldForms=badgeFieldForms
59 ),
60 UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badgeId),
61 identifier=badgeId,
62 )
63 key = UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badgeId)
64 return f'static/media/{key}/{generate_hash(key)}/{badgeId}.pdf'
65
66
67 def get_value_from_field_indentifier(field: BadgeFieldForms, ticket_holder: TicketHolder):
68 """Get the value of a field."""
69 snake_case_field_identifier = to_snake_case(field.field_identifier)
70 try:
71 field.sample_text = getattr(ticket_holder, snake_case_field_identifier)
72 except AttributeError:
73 try:
74 field.sample_text = ticket_holder.complex_field_values[field.field_identifier]
75 except AttributeError:
76 print(snake_case_field_identifier)
77
78
79 def get_value_from_qr_filed(field: BadgeFieldForms, ticket_holder: TicketHolder) -> dict:
80 """Get the value of a QR code field."""
81 qr_value = {}
82 custom_fields = []
83 for field_identifier in field.qr_custom_field:
84 value_ = ""
85 try:
86 snake_case_field_identifier = to_snake_case(field_identifier)
87 value_ = getattr(ticket_holder, snake_case_field_identifier)
88 except AttributeError:
89 try:
90 value_ = ticket_holder.complex_field_values[field_identifier]
91 # Get the field description then Capitalize first letter and remove space.
92 custom_form = CustomForms.query.filter_by(
93 field_identifier=field_identifier,
94 form_id=ticket_holder.ticket.form_id,
95 ).first()
96 field_description = custom_form.description.title().replace(' ', '')
97 custom_fields.append({field_description: value_})
98 except AttributeError:
99 print(field_identifier)
100
101 qr_value.update({field_identifier: str(value_)})
102 qr_value.update({'custom_fields': custom_fields, 'ticket_id': ticket_holder.id})
103 return qr_value
104
105
106 def create_base64_img_qr(qr_code_data: str) -> str:
107 """Create a base64 image of a QR code."""
108 qr = qrcode.QRCode(
109 version=1,
110 error_correction=qrcode.constants.ERROR_CORRECT_L,
111 box_size=10,
112 border=2,
113 )
114 qr.add_data(qr_code_data)
115 qr.make(fit=True)
116 img = qr.make_image(fill_color="black", back_color="white")
117 io_buffer = io.BytesIO()
118 img.save(io_buffer)
119 qr_img_str = base64.b64encode(io_buffer.getvalue()).decode()
120 return qr_img_str
121
122
123 def create_print_badge_pdf(badge_form, ticket_holder, list_field_show):
124 """
125 Create tickets and invoices for the holders of an order.
126 :param badgeForms: The order for which to create tickets for.
127 """
128 badgeFieldForms = (
129 BadgeFieldForms.query.filter_by(badge_form_id=badge_form.id)
130 .filter_by(badge_id=badge_form.badge_id)
131 .order_by(asc("id"))
132 .all()
133 )
134 for field in badgeFieldForms:
135 if field.custom_field.lower() == 'qr':
136 qr_code_data = get_value_from_qr_filed(field, ticket_holder)
137 qr_rendered = render_template('cvf/badge_qr_template.cvf', **qr_code_data)
138
139 field.sample_text = create_base64_img_qr(qr_rendered)
140 continue
141 if list_field_show is None or field.field_identifier not in list_field_show:
142 field.sample_text = ' '
143 continue
144
145 get_value_from_field_indentifier(field, ticket_holder)
146
147 for badge_field in badgeFieldForms:
148 font_weight = []
149 font_style = []
150 text_decoration = []
151 if badge_field.get('font_weight'):
152 for item in badge_field.get('font_weight'):
153 if item.get('font_weight'):
154 font_weight.append(item.get('font_weight'))
155 if item.get('font_style'):
156 font_style.append(item.get('font_style'))
157 if item.get('text_decoration'):
158 text_decoration.append(item.get('text_decoration'))
159 if not font_weight:
160 badge_field['font_weight'] = 'none'
161 else:
162 badge_field['font_weight'] = ','.join(font_weight)
163 if not font_style:
164 badge_field['font_style'] = 'none'
165 else:
166 badge_field['font_style'] = ','.join(font_style)
167 if not text_decoration:
168 badge_field['text_decoration'] = 'none'
169 else:
170 badge_field['text_decoration'] = ','.join(text_decoration)
171
172 create_save_pdf(
173 render_template(
174 'pdf/badge_forms.html', badgeForms=badge_form, badgeFieldForms=badgeFieldForms
175 ),
176 UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badge_form.badge_id),
177 identifier=badge_form.badge_id,
178 )
179 ticket_holder.is_badge_printed = True
180 ticket_holder.badge_printed_at = datetime.now()
181 save_to_db(ticket_holder, 'Ticket Holder saved')
182 return file_pdf_path(badge_form)
183
[end of app/api/helpers/badge_forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/api/helpers/badge_forms.py b/app/api/helpers/badge_forms.py
--- a/app/api/helpers/badge_forms.py
+++ b/app/api/helpers/badge_forms.py
@@ -33,8 +33,8 @@
font_weight = []
font_style = []
text_decoration = []
- if badge_field.get('font_weight'):
- for item in badge_field.get('font_weight'):
+ if badge_field['font_weight']:
+ for item in badge_field['font_weight']:
if item.get('font_weight'):
font_weight.append(item.get('font_weight'))
if item.get('font_style'):
@@ -148,8 +148,9 @@
font_weight = []
font_style = []
text_decoration = []
- if badge_field.get('font_weight'):
- for item in badge_field.get('font_weight'):
+ badge_field.font_weight_tmp = badge_field.font_weight
+ if badge_field.font_weight:
+ for item in badge_field.font_weight:
if item.get('font_weight'):
font_weight.append(item.get('font_weight'))
if item.get('font_style'):
@@ -157,18 +158,17 @@
if item.get('text_decoration'):
text_decoration.append(item.get('text_decoration'))
if not font_weight:
- badge_field['font_weight'] = 'none'
+ badge_field.font_weight = 'none'
else:
- badge_field['font_weight'] = ','.join(font_weight)
+ badge_field.font_weight = ','.join(font_weight)
if not font_style:
- badge_field['font_style'] = 'none'
+ badge_field.font_style = 'none'
else:
- badge_field['font_style'] = ','.join(font_style)
+ badge_field.font_style = ','.join(font_style)
if not text_decoration:
- badge_field['text_decoration'] = 'none'
+ badge_field.text_decoration = 'none'
else:
- badge_field['text_decoration'] = ','.join(text_decoration)
-
+ badge_field.text_decoration = ','.join(text_decoration)
create_save_pdf(
render_template(
'pdf/badge_forms.html', badgeForms=badge_form, badgeFieldForms=badgeFieldForms
@@ -178,5 +178,7 @@
)
ticket_holder.is_badge_printed = True
ticket_holder.badge_printed_at = datetime.now()
+ for badge_field in badgeFieldForms:
+ badge_field.font_weight = badge_field.font_weight_tmp
save_to_db(ticket_holder, 'Ticket Holder saved')
return file_pdf_path(badge_form)
|
{"golden_diff": "diff --git a/app/api/helpers/badge_forms.py b/app/api/helpers/badge_forms.py\n--- a/app/api/helpers/badge_forms.py\n+++ b/app/api/helpers/badge_forms.py\n@@ -33,8 +33,8 @@\n font_weight = []\n font_style = []\n text_decoration = []\n- if badge_field.get('font_weight'):\n- for item in badge_field.get('font_weight'):\n+ if badge_field['font_weight']:\n+ for item in badge_field['font_weight']:\n if item.get('font_weight'):\n font_weight.append(item.get('font_weight'))\n if item.get('font_style'):\n@@ -148,8 +148,9 @@\n font_weight = []\n font_style = []\n text_decoration = []\n- if badge_field.get('font_weight'):\n- for item in badge_field.get('font_weight'):\n+ badge_field.font_weight_tmp = badge_field.font_weight\n+ if badge_field.font_weight:\n+ for item in badge_field.font_weight:\n if item.get('font_weight'):\n font_weight.append(item.get('font_weight'))\n if item.get('font_style'):\n@@ -157,18 +158,17 @@\n if item.get('text_decoration'):\n text_decoration.append(item.get('text_decoration'))\n if not font_weight:\n- badge_field['font_weight'] = 'none'\n+ badge_field.font_weight = 'none'\n else:\n- badge_field['font_weight'] = ','.join(font_weight)\n+ badge_field.font_weight = ','.join(font_weight)\n if not font_style:\n- badge_field['font_style'] = 'none'\n+ badge_field.font_style = 'none'\n else:\n- badge_field['font_style'] = ','.join(font_style)\n+ badge_field.font_style = ','.join(font_style)\n if not text_decoration:\n- badge_field['text_decoration'] = 'none'\n+ badge_field.text_decoration = 'none'\n else:\n- badge_field['text_decoration'] = ','.join(text_decoration)\n-\n+ badge_field.text_decoration = ','.join(text_decoration)\n create_save_pdf(\n render_template(\n 'pdf/badge_forms.html', badgeForms=badge_form, badgeFieldForms=badgeFieldForms\n@@ -178,5 +178,7 @@\n )\n ticket_holder.is_badge_printed = True\n ticket_holder.badge_printed_at = datetime.now()\n+ for badge_field in badgeFieldForms:\n+ badge_field.font_weight = badge_field.font_weight_tmp\n save_to_db(ticket_holder, 'Ticket Holder saved')\n return file_pdf_path(badge_form)\n", "issue": "Unable to receive pdf from [/v1/badge-forms/print-badge-pdf]\n**Describe the bug**\r\nInternal server error 500 returned with no response of the type of error on the server side.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Send POST to [/v1/badge-forms/print-badge-pdf] with payload\r\n2. Error 500 with no response received\r\n\r\n\r\n\n", "before_files": [{"content": "import base64\nimport io\nfrom datetime import datetime\n\nimport qrcode\nfrom flask import render_template\nfrom sqlalchemy import asc\n\nfrom app.api.helpers.db import save_to_db\nfrom app.api.helpers.files import create_save_pdf\nfrom app.api.helpers.storage import UPLOAD_PATHS, generate_hash\nfrom app.api.helpers.utilities import to_snake_case\nfrom app.models.badge_field_form import BadgeFieldForms\nfrom app.models.custom_form import CustomForms\nfrom app.models.ticket_holder import TicketHolder\n\n\ndef file_pdf_path(self) -> str:\n \"\"\"Contructor path of File PDF\"\"\"\n key = UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=self.badge_id)\n return f'static/media/{key}/{generate_hash(key)}/{self.badge_id}.pdf'\n\n\ndef create_preivew_badge_pdf(badgeForms):\n \"\"\"\n Create tickets and invoices for the holders of an order.\n :param badgeForms: The order for which to create tickets for.\n \"\"\"\n badgeForms = badgeForms[0]\n badgeFieldForms = badgeForms['badgeFields']\n badgeId = badgeForms['badgeID']\n for badge_field in badgeFieldForms:\n font_weight = []\n font_style = []\n text_decoration = []\n if badge_field.get('font_weight'):\n for item in badge_field.get('font_weight'):\n if item.get('font_weight'):\n font_weight.append(item.get('font_weight'))\n if item.get('font_style'):\n font_style.append(item.get('font_style'))\n if item.get('text_decoration'):\n text_decoration.append(item.get('text_decoration'))\n if not font_weight:\n badge_field['font_weight'] = 'none'\n else:\n badge_field['font_weight'] = ','.join(font_weight)\n if not font_style:\n badge_field['font_style'] = 'none'\n else:\n badge_field['font_style'] = ','.join(font_style)\n if not text_decoration:\n badge_field['text_decoration'] = 'none'\n else:\n badge_field['text_decoration'] = ','.join(text_decoration)\n create_save_pdf(\n render_template(\n 'pdf/badge_forms.html', badgeForms=badgeForms, badgeFieldForms=badgeFieldForms\n ),\n UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badgeId),\n identifier=badgeId,\n )\n key = UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badgeId)\n return f'static/media/{key}/{generate_hash(key)}/{badgeId}.pdf'\n\n\ndef get_value_from_field_indentifier(field: BadgeFieldForms, ticket_holder: TicketHolder):\n \"\"\"Get the value of a field.\"\"\"\n snake_case_field_identifier = to_snake_case(field.field_identifier)\n try:\n field.sample_text = getattr(ticket_holder, snake_case_field_identifier)\n except AttributeError:\n try:\n field.sample_text = ticket_holder.complex_field_values[field.field_identifier]\n except AttributeError:\n print(snake_case_field_identifier)\n\n\ndef get_value_from_qr_filed(field: BadgeFieldForms, ticket_holder: TicketHolder) -> dict:\n \"\"\"Get the value of a QR code field.\"\"\"\n qr_value = {}\n custom_fields = []\n for field_identifier in field.qr_custom_field:\n value_ = \"\"\n try:\n snake_case_field_identifier = to_snake_case(field_identifier)\n value_ = getattr(ticket_holder, snake_case_field_identifier)\n except AttributeError:\n try:\n value_ = ticket_holder.complex_field_values[field_identifier]\n # Get the field description then Capitalize first letter and remove space.\n custom_form = CustomForms.query.filter_by(\n field_identifier=field_identifier,\n form_id=ticket_holder.ticket.form_id,\n ).first()\n field_description = custom_form.description.title().replace(' ', '')\n custom_fields.append({field_description: value_})\n except AttributeError:\n print(field_identifier)\n\n qr_value.update({field_identifier: str(value_)})\n qr_value.update({'custom_fields': custom_fields, 'ticket_id': ticket_holder.id})\n return qr_value\n\n\ndef create_base64_img_qr(qr_code_data: str) -> str:\n \"\"\"Create a base64 image of a QR code.\"\"\"\n qr = qrcode.QRCode(\n version=1,\n error_correction=qrcode.constants.ERROR_CORRECT_L,\n box_size=10,\n border=2,\n )\n qr.add_data(qr_code_data)\n qr.make(fit=True)\n img = qr.make_image(fill_color=\"black\", back_color=\"white\")\n io_buffer = io.BytesIO()\n img.save(io_buffer)\n qr_img_str = base64.b64encode(io_buffer.getvalue()).decode()\n return qr_img_str\n\n\ndef create_print_badge_pdf(badge_form, ticket_holder, list_field_show):\n \"\"\"\n Create tickets and invoices for the holders of an order.\n :param badgeForms: The order for which to create tickets for.\n \"\"\"\n badgeFieldForms = (\n BadgeFieldForms.query.filter_by(badge_form_id=badge_form.id)\n .filter_by(badge_id=badge_form.badge_id)\n .order_by(asc(\"id\"))\n .all()\n )\n for field in badgeFieldForms:\n if field.custom_field.lower() == 'qr':\n qr_code_data = get_value_from_qr_filed(field, ticket_holder)\n qr_rendered = render_template('cvf/badge_qr_template.cvf', **qr_code_data)\n\n field.sample_text = create_base64_img_qr(qr_rendered)\n continue\n if list_field_show is None or field.field_identifier not in list_field_show:\n field.sample_text = ' '\n continue\n\n get_value_from_field_indentifier(field, ticket_holder)\n\n for badge_field in badgeFieldForms:\n font_weight = []\n font_style = []\n text_decoration = []\n if badge_field.get('font_weight'):\n for item in badge_field.get('font_weight'):\n if item.get('font_weight'):\n font_weight.append(item.get('font_weight'))\n if item.get('font_style'):\n font_style.append(item.get('font_style'))\n if item.get('text_decoration'):\n text_decoration.append(item.get('text_decoration'))\n if not font_weight:\n badge_field['font_weight'] = 'none'\n else:\n badge_field['font_weight'] = ','.join(font_weight)\n if not font_style:\n badge_field['font_style'] = 'none'\n else:\n badge_field['font_style'] = ','.join(font_style)\n if not text_decoration:\n badge_field['text_decoration'] = 'none'\n else:\n badge_field['text_decoration'] = ','.join(text_decoration)\n\n create_save_pdf(\n render_template(\n 'pdf/badge_forms.html', badgeForms=badge_form, badgeFieldForms=badgeFieldForms\n ),\n UPLOAD_PATHS['pdf']['badge_forms_pdf'].format(identifier=badge_form.badge_id),\n identifier=badge_form.badge_id,\n )\n ticket_holder.is_badge_printed = True\n ticket_holder.badge_printed_at = datetime.now()\n save_to_db(ticket_holder, 'Ticket Holder saved')\n return file_pdf_path(badge_form)\n", "path": "app/api/helpers/badge_forms.py"}]}
| 2,609 | 575 |
gh_patches_debug_36104
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-1135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: [UI] image model does not show `cache` status
Note that the issue tracker is NOT the place for general support.
</issue>
<code>
[start of xinference/model/image/core.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import collections.abc
15 import logging
16 import os
17 from collections import defaultdict
18 from typing import Dict, List, Optional, Tuple
19
20 from ...constants import XINFERENCE_CACHE_DIR
21 from ..core import CacheableModelSpec, ModelDescription
22 from ..utils import valid_model_revision
23 from .stable_diffusion.core import DiffusionModel
24
25 MAX_ATTEMPTS = 3
26
27 logger = logging.getLogger(__name__)
28
29 IMAGE_MODEL_DESCRIPTIONS: Dict[str, List[Dict]] = defaultdict(list)
30
31
32 def get_image_model_descriptions():
33 import copy
34
35 return copy.deepcopy(IMAGE_MODEL_DESCRIPTIONS)
36
37
38 class ImageModelFamilyV1(CacheableModelSpec):
39 model_family: str
40 model_name: str
41 model_id: str
42 model_revision: str
43 model_hub: str = "huggingface"
44 controlnet: Optional[List["ImageModelFamilyV1"]]
45
46
47 class ImageModelDescription(ModelDescription):
48 def __init__(
49 self,
50 address: Optional[str],
51 devices: Optional[List[str]],
52 model_spec: ImageModelFamilyV1,
53 model_path: Optional[str] = None,
54 ):
55 super().__init__(address, devices, model_path=model_path)
56 self._model_spec = model_spec
57
58 def to_dict(self):
59 if self._model_spec.controlnet is not None:
60 controlnet = [cn.dict() for cn in self._model_spec.controlnet]
61 else:
62 controlnet = self._model_spec.controlnet
63 return {
64 "model_type": "image",
65 "address": self.address,
66 "accelerators": self.devices,
67 "model_name": self._model_spec.model_name,
68 "model_family": self._model_spec.model_family,
69 "model_revision": self._model_spec.model_revision,
70 "controlnet": controlnet,
71 }
72
73 def to_version_info(self):
74 from .utils import get_model_version
75
76 if self._model_path is None:
77 is_cached = get_cache_status(self._model_spec)
78 file_location = get_cache_dir(self._model_spec)
79 else:
80 is_cached = True
81 file_location = self._model_path
82
83 if self._model_spec.controlnet is None:
84 return [
85 {
86 "model_version": get_model_version(self._model_spec, None),
87 "model_file_location": file_location,
88 "cache_status": is_cached,
89 "controlnet": "zoe-depth",
90 }
91 ]
92 else:
93 res = []
94 for cn in self._model_spec.controlnet:
95 res.append(
96 {
97 "model_version": get_model_version(self._model_spec, cn),
98 "model_file_location": file_location,
99 "cache_status": is_cached,
100 "controlnet": cn.model_name,
101 }
102 )
103 return res
104
105
106 def generate_image_description(
107 image_model: ImageModelFamilyV1,
108 ) -> Dict[str, List[Dict]]:
109 res = defaultdict(list)
110 res[image_model.model_name].extend(
111 ImageModelDescription(None, None, image_model).to_version_info()
112 )
113 return res
114
115
116 def match_diffusion(model_name: str) -> ImageModelFamilyV1:
117 from ..utils import download_from_modelscope
118 from . import BUILTIN_IMAGE_MODELS, MODELSCOPE_IMAGE_MODELS
119
120 if download_from_modelscope():
121 if model_name in MODELSCOPE_IMAGE_MODELS:
122 logger.debug(f"Image model {model_name} found in ModelScope.")
123 return MODELSCOPE_IMAGE_MODELS[model_name]
124 else:
125 logger.debug(
126 f"Image model {model_name} not found in ModelScope, "
127 f"now try to load it via builtin way."
128 )
129
130 if model_name in BUILTIN_IMAGE_MODELS:
131 return BUILTIN_IMAGE_MODELS[model_name]
132 else:
133 raise ValueError(
134 f"Image model {model_name} not found, available"
135 f"model list: {BUILTIN_IMAGE_MODELS.keys()}"
136 )
137
138
139 def cache(model_spec: ImageModelFamilyV1):
140 from ..utils import cache
141
142 return cache(model_spec, ImageModelDescription)
143
144
145 def get_cache_dir(model_spec: ImageModelFamilyV1):
146 return os.path.realpath(os.path.join(XINFERENCE_CACHE_DIR, model_spec.model_name))
147
148
149 def get_cache_status(
150 model_spec: ImageModelFamilyV1,
151 ) -> bool:
152 cache_dir = get_cache_dir(model_spec)
153 meta_path = os.path.join(cache_dir, "__valid_download")
154 return valid_model_revision(meta_path, model_spec.model_revision)
155
156
157 def create_image_model_instance(
158 subpool_addr: str,
159 devices: List[str],
160 model_uid: str,
161 model_name: str,
162 lora_model_path: Optional[str] = None,
163 lora_load_kwargs: Optional[Dict] = None,
164 lora_fuse_kwargs: Optional[Dict] = None,
165 **kwargs,
166 ) -> Tuple[DiffusionModel, ImageModelDescription]:
167 model_spec = match_diffusion(model_name)
168 controlnet = kwargs.get("controlnet")
169 # Handle controlnet
170 if controlnet is not None:
171 if isinstance(controlnet, str):
172 controlnet = [controlnet]
173 elif not isinstance(controlnet, collections.abc.Sequence):
174 raise ValueError("controlnet should be a str or a list of str.")
175 elif set(controlnet) != len(controlnet):
176 raise ValueError("controlnet should be a list of unique str.")
177 elif not model_spec.controlnet:
178 raise ValueError(f"Model {model_name} has empty controlnet list.")
179
180 controlnet_model_paths = []
181 assert model_spec.controlnet is not None
182 for name in controlnet:
183 for cn_model_spec in model_spec.controlnet:
184 if cn_model_spec.model_name == name:
185 model_path = cache(cn_model_spec)
186 controlnet_model_paths.append(model_path)
187 break
188 else:
189 raise ValueError(
190 f"controlnet `{name}` is not supported for model `{model_name}`."
191 )
192 if len(controlnet_model_paths) == 1:
193 kwargs["controlnet"] = controlnet_model_paths[0]
194 else:
195 kwargs["controlnet"] = controlnet_model_paths
196 model_path = cache(model_spec)
197 model = DiffusionModel(
198 model_uid,
199 model_path,
200 lora_model_path=lora_model_path,
201 lora_load_kwargs=lora_load_kwargs,
202 lora_fuse_kwargs=lora_fuse_kwargs,
203 **kwargs,
204 )
205 model_description = ImageModelDescription(
206 subpool_addr, devices, model_spec, model_path=model_path
207 )
208 return model, model_description
209
[end of xinference/model/image/core.py]
[start of xinference/model/image/__init__.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import codecs
16 import json
17 import os
18 from itertools import chain
19
20 from .core import (
21 IMAGE_MODEL_DESCRIPTIONS,
22 ImageModelFamilyV1,
23 generate_image_description,
24 get_cache_status,
25 get_image_model_descriptions,
26 )
27
28 _model_spec_json = os.path.join(os.path.dirname(__file__), "model_spec.json")
29 _model_spec_modelscope_json = os.path.join(
30 os.path.dirname(__file__), "model_spec_modelscope.json"
31 )
32 BUILTIN_IMAGE_MODELS = dict(
33 (spec["model_name"], ImageModelFamilyV1(**spec))
34 for spec in json.load(codecs.open(_model_spec_json, "r", encoding="utf-8"))
35 )
36 MODELSCOPE_IMAGE_MODELS = dict(
37 (spec["model_name"], ImageModelFamilyV1(**spec))
38 for spec in json.load(
39 codecs.open(_model_spec_modelscope_json, "r", encoding="utf-8")
40 )
41 )
42
43 # register model description
44 for model_name, model_spec in chain(
45 MODELSCOPE_IMAGE_MODELS.items(), BUILTIN_IMAGE_MODELS.items()
46 ):
47 IMAGE_MODEL_DESCRIPTIONS.update(generate_image_description(model_spec))
48
49 del _model_spec_json
50
[end of xinference/model/image/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xinference/model/image/__init__.py b/xinference/model/image/__init__.py
--- a/xinference/model/image/__init__.py
+++ b/xinference/model/image/__init__.py
@@ -18,7 +18,9 @@
from itertools import chain
from .core import (
+ BUILTIN_IMAGE_MODELS,
IMAGE_MODEL_DESCRIPTIONS,
+ MODELSCOPE_IMAGE_MODELS,
ImageModelFamilyV1,
generate_image_description,
get_cache_status,
@@ -29,14 +31,18 @@
_model_spec_modelscope_json = os.path.join(
os.path.dirname(__file__), "model_spec_modelscope.json"
)
-BUILTIN_IMAGE_MODELS = dict(
- (spec["model_name"], ImageModelFamilyV1(**spec))
- for spec in json.load(codecs.open(_model_spec_json, "r", encoding="utf-8"))
+BUILTIN_IMAGE_MODELS.update(
+ dict(
+ (spec["model_name"], ImageModelFamilyV1(**spec))
+ for spec in json.load(codecs.open(_model_spec_json, "r", encoding="utf-8"))
+ )
)
-MODELSCOPE_IMAGE_MODELS = dict(
- (spec["model_name"], ImageModelFamilyV1(**spec))
- for spec in json.load(
- codecs.open(_model_spec_modelscope_json, "r", encoding="utf-8")
+MODELSCOPE_IMAGE_MODELS.update(
+ dict(
+ (spec["model_name"], ImageModelFamilyV1(**spec))
+ for spec in json.load(
+ codecs.open(_model_spec_modelscope_json, "r", encoding="utf-8")
+ )
)
)
diff --git a/xinference/model/image/core.py b/xinference/model/image/core.py
--- a/xinference/model/image/core.py
+++ b/xinference/model/image/core.py
@@ -27,6 +27,8 @@
logger = logging.getLogger(__name__)
IMAGE_MODEL_DESCRIPTIONS: Dict[str, List[Dict]] = defaultdict(list)
+BUILTIN_IMAGE_MODELS: Dict[str, "ImageModelFamilyV1"] = {}
+MODELSCOPE_IMAGE_MODELS: Dict[str, "ImageModelFamilyV1"] = {}
def get_image_model_descriptions():
@@ -151,7 +153,21 @@
) -> bool:
cache_dir = get_cache_dir(model_spec)
meta_path = os.path.join(cache_dir, "__valid_download")
- return valid_model_revision(meta_path, model_spec.model_revision)
+
+ model_name = model_spec.model_name
+ if model_name in BUILTIN_IMAGE_MODELS and model_name in MODELSCOPE_IMAGE_MODELS:
+ hf_spec = BUILTIN_IMAGE_MODELS[model_name]
+ ms_spec = MODELSCOPE_IMAGE_MODELS[model_name]
+
+ return any(
+ [
+ valid_model_revision(meta_path, hf_spec.model_revision),
+ valid_model_revision(meta_path, ms_spec.model_revision),
+ ]
+ )
+ else: # Usually for UT
+ logger.warning(f"Cannot find builtin image model spec: {model_name}")
+ return valid_model_revision(meta_path, model_spec.model_revision)
def create_image_model_instance(
|
{"golden_diff": "diff --git a/xinference/model/image/__init__.py b/xinference/model/image/__init__.py\n--- a/xinference/model/image/__init__.py\n+++ b/xinference/model/image/__init__.py\n@@ -18,7 +18,9 @@\n from itertools import chain\n \n from .core import (\n+ BUILTIN_IMAGE_MODELS,\n IMAGE_MODEL_DESCRIPTIONS,\n+ MODELSCOPE_IMAGE_MODELS,\n ImageModelFamilyV1,\n generate_image_description,\n get_cache_status,\n@@ -29,14 +31,18 @@\n _model_spec_modelscope_json = os.path.join(\n os.path.dirname(__file__), \"model_spec_modelscope.json\"\n )\n-BUILTIN_IMAGE_MODELS = dict(\n- (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n- for spec in json.load(codecs.open(_model_spec_json, \"r\", encoding=\"utf-8\"))\n+BUILTIN_IMAGE_MODELS.update(\n+ dict(\n+ (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n+ for spec in json.load(codecs.open(_model_spec_json, \"r\", encoding=\"utf-8\"))\n+ )\n )\n-MODELSCOPE_IMAGE_MODELS = dict(\n- (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n- for spec in json.load(\n- codecs.open(_model_spec_modelscope_json, \"r\", encoding=\"utf-8\")\n+MODELSCOPE_IMAGE_MODELS.update(\n+ dict(\n+ (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n+ for spec in json.load(\n+ codecs.open(_model_spec_modelscope_json, \"r\", encoding=\"utf-8\")\n+ )\n )\n )\n \ndiff --git a/xinference/model/image/core.py b/xinference/model/image/core.py\n--- a/xinference/model/image/core.py\n+++ b/xinference/model/image/core.py\n@@ -27,6 +27,8 @@\n logger = logging.getLogger(__name__)\n \n IMAGE_MODEL_DESCRIPTIONS: Dict[str, List[Dict]] = defaultdict(list)\n+BUILTIN_IMAGE_MODELS: Dict[str, \"ImageModelFamilyV1\"] = {}\n+MODELSCOPE_IMAGE_MODELS: Dict[str, \"ImageModelFamilyV1\"] = {}\n \n \n def get_image_model_descriptions():\n@@ -151,7 +153,21 @@\n ) -> bool:\n cache_dir = get_cache_dir(model_spec)\n meta_path = os.path.join(cache_dir, \"__valid_download\")\n- return valid_model_revision(meta_path, model_spec.model_revision)\n+\n+ model_name = model_spec.model_name\n+ if model_name in BUILTIN_IMAGE_MODELS and model_name in MODELSCOPE_IMAGE_MODELS:\n+ hf_spec = BUILTIN_IMAGE_MODELS[model_name]\n+ ms_spec = MODELSCOPE_IMAGE_MODELS[model_name]\n+\n+ return any(\n+ [\n+ valid_model_revision(meta_path, hf_spec.model_revision),\n+ valid_model_revision(meta_path, ms_spec.model_revision),\n+ ]\n+ )\n+ else: # Usually for UT\n+ logger.warning(f\"Cannot find builtin image model spec: {model_name}\")\n+ return valid_model_revision(meta_path, model_spec.model_revision)\n \n \n def create_image_model_instance(\n", "issue": "BUG: [UI] image model does not show `cache` status\nNote that the issue tracker is NOT the place for general support.\r\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport collections.abc\nimport logging\nimport os\nfrom collections import defaultdict\nfrom typing import Dict, List, Optional, Tuple\n\nfrom ...constants import XINFERENCE_CACHE_DIR\nfrom ..core import CacheableModelSpec, ModelDescription\nfrom ..utils import valid_model_revision\nfrom .stable_diffusion.core import DiffusionModel\n\nMAX_ATTEMPTS = 3\n\nlogger = logging.getLogger(__name__)\n\nIMAGE_MODEL_DESCRIPTIONS: Dict[str, List[Dict]] = defaultdict(list)\n\n\ndef get_image_model_descriptions():\n import copy\n\n return copy.deepcopy(IMAGE_MODEL_DESCRIPTIONS)\n\n\nclass ImageModelFamilyV1(CacheableModelSpec):\n model_family: str\n model_name: str\n model_id: str\n model_revision: str\n model_hub: str = \"huggingface\"\n controlnet: Optional[List[\"ImageModelFamilyV1\"]]\n\n\nclass ImageModelDescription(ModelDescription):\n def __init__(\n self,\n address: Optional[str],\n devices: Optional[List[str]],\n model_spec: ImageModelFamilyV1,\n model_path: Optional[str] = None,\n ):\n super().__init__(address, devices, model_path=model_path)\n self._model_spec = model_spec\n\n def to_dict(self):\n if self._model_spec.controlnet is not None:\n controlnet = [cn.dict() for cn in self._model_spec.controlnet]\n else:\n controlnet = self._model_spec.controlnet\n return {\n \"model_type\": \"image\",\n \"address\": self.address,\n \"accelerators\": self.devices,\n \"model_name\": self._model_spec.model_name,\n \"model_family\": self._model_spec.model_family,\n \"model_revision\": self._model_spec.model_revision,\n \"controlnet\": controlnet,\n }\n\n def to_version_info(self):\n from .utils import get_model_version\n\n if self._model_path is None:\n is_cached = get_cache_status(self._model_spec)\n file_location = get_cache_dir(self._model_spec)\n else:\n is_cached = True\n file_location = self._model_path\n\n if self._model_spec.controlnet is None:\n return [\n {\n \"model_version\": get_model_version(self._model_spec, None),\n \"model_file_location\": file_location,\n \"cache_status\": is_cached,\n \"controlnet\": \"zoe-depth\",\n }\n ]\n else:\n res = []\n for cn in self._model_spec.controlnet:\n res.append(\n {\n \"model_version\": get_model_version(self._model_spec, cn),\n \"model_file_location\": file_location,\n \"cache_status\": is_cached,\n \"controlnet\": cn.model_name,\n }\n )\n return res\n\n\ndef generate_image_description(\n image_model: ImageModelFamilyV1,\n) -> Dict[str, List[Dict]]:\n res = defaultdict(list)\n res[image_model.model_name].extend(\n ImageModelDescription(None, None, image_model).to_version_info()\n )\n return res\n\n\ndef match_diffusion(model_name: str) -> ImageModelFamilyV1:\n from ..utils import download_from_modelscope\n from . import BUILTIN_IMAGE_MODELS, MODELSCOPE_IMAGE_MODELS\n\n if download_from_modelscope():\n if model_name in MODELSCOPE_IMAGE_MODELS:\n logger.debug(f\"Image model {model_name} found in ModelScope.\")\n return MODELSCOPE_IMAGE_MODELS[model_name]\n else:\n logger.debug(\n f\"Image model {model_name} not found in ModelScope, \"\n f\"now try to load it via builtin way.\"\n )\n\n if model_name in BUILTIN_IMAGE_MODELS:\n return BUILTIN_IMAGE_MODELS[model_name]\n else:\n raise ValueError(\n f\"Image model {model_name} not found, available\"\n f\"model list: {BUILTIN_IMAGE_MODELS.keys()}\"\n )\n\n\ndef cache(model_spec: ImageModelFamilyV1):\n from ..utils import cache\n\n return cache(model_spec, ImageModelDescription)\n\n\ndef get_cache_dir(model_spec: ImageModelFamilyV1):\n return os.path.realpath(os.path.join(XINFERENCE_CACHE_DIR, model_spec.model_name))\n\n\ndef get_cache_status(\n model_spec: ImageModelFamilyV1,\n) -> bool:\n cache_dir = get_cache_dir(model_spec)\n meta_path = os.path.join(cache_dir, \"__valid_download\")\n return valid_model_revision(meta_path, model_spec.model_revision)\n\n\ndef create_image_model_instance(\n subpool_addr: str,\n devices: List[str],\n model_uid: str,\n model_name: str,\n lora_model_path: Optional[str] = None,\n lora_load_kwargs: Optional[Dict] = None,\n lora_fuse_kwargs: Optional[Dict] = None,\n **kwargs,\n) -> Tuple[DiffusionModel, ImageModelDescription]:\n model_spec = match_diffusion(model_name)\n controlnet = kwargs.get(\"controlnet\")\n # Handle controlnet\n if controlnet is not None:\n if isinstance(controlnet, str):\n controlnet = [controlnet]\n elif not isinstance(controlnet, collections.abc.Sequence):\n raise ValueError(\"controlnet should be a str or a list of str.\")\n elif set(controlnet) != len(controlnet):\n raise ValueError(\"controlnet should be a list of unique str.\")\n elif not model_spec.controlnet:\n raise ValueError(f\"Model {model_name} has empty controlnet list.\")\n\n controlnet_model_paths = []\n assert model_spec.controlnet is not None\n for name in controlnet:\n for cn_model_spec in model_spec.controlnet:\n if cn_model_spec.model_name == name:\n model_path = cache(cn_model_spec)\n controlnet_model_paths.append(model_path)\n break\n else:\n raise ValueError(\n f\"controlnet `{name}` is not supported for model `{model_name}`.\"\n )\n if len(controlnet_model_paths) == 1:\n kwargs[\"controlnet\"] = controlnet_model_paths[0]\n else:\n kwargs[\"controlnet\"] = controlnet_model_paths\n model_path = cache(model_spec)\n model = DiffusionModel(\n model_uid,\n model_path,\n lora_model_path=lora_model_path,\n lora_load_kwargs=lora_load_kwargs,\n lora_fuse_kwargs=lora_fuse_kwargs,\n **kwargs,\n )\n model_description = ImageModelDescription(\n subpool_addr, devices, model_spec, model_path=model_path\n )\n return model, model_description\n", "path": "xinference/model/image/core.py"}, {"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport codecs\nimport json\nimport os\nfrom itertools import chain\n\nfrom .core import (\n IMAGE_MODEL_DESCRIPTIONS,\n ImageModelFamilyV1,\n generate_image_description,\n get_cache_status,\n get_image_model_descriptions,\n)\n\n_model_spec_json = os.path.join(os.path.dirname(__file__), \"model_spec.json\")\n_model_spec_modelscope_json = os.path.join(\n os.path.dirname(__file__), \"model_spec_modelscope.json\"\n)\nBUILTIN_IMAGE_MODELS = dict(\n (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n for spec in json.load(codecs.open(_model_spec_json, \"r\", encoding=\"utf-8\"))\n)\nMODELSCOPE_IMAGE_MODELS = dict(\n (spec[\"model_name\"], ImageModelFamilyV1(**spec))\n for spec in json.load(\n codecs.open(_model_spec_modelscope_json, \"r\", encoding=\"utf-8\")\n )\n)\n\n# register model description\nfor model_name, model_spec in chain(\n MODELSCOPE_IMAGE_MODELS.items(), BUILTIN_IMAGE_MODELS.items()\n):\n IMAGE_MODEL_DESCRIPTIONS.update(generate_image_description(model_spec))\n\ndel _model_spec_json\n", "path": "xinference/model/image/__init__.py"}]}
| 3,136 | 700 |
gh_patches_debug_22874
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-719
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unreadable error message appears when `nvcc` command is not found
Only "No suche file or directory" is shown in such case.
related to #698
</issue>
<code>
[start of cupy/cuda/compiler.py]
1 import hashlib
2 import os
3 import re
4 import subprocess
5 import sys
6 import tempfile
7
8 import filelock
9 import six
10
11 from cupy.cuda import device
12 from cupy.cuda import function
13
14
15 def _get_arch():
16 cc = device.Device().compute_capability
17 return 'sm_%s' % cc
18
19
20 class TemporaryDirectory(object):
21
22 def __enter__(self):
23 self.path = tempfile.mkdtemp()
24 return self.path
25
26 def __exit__(self, exc_type, exc_value, traceback):
27 if exc_value is not None:
28 return
29
30 for name in os.listdir(self.path):
31 os.unlink(os.path.join(self.path, name))
32 os.rmdir(self.path)
33
34
35 def nvcc(source, options=(), arch=None):
36 if not arch:
37 arch = _get_arch()
38 cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)
39
40 with TemporaryDirectory() as root_dir:
41 path = os.path.join(root_dir, 'kern')
42 cu_path = '%s.cu' % path
43 cubin_path = '%s.cubin' % path
44
45 with open(cu_path, 'w') as cu_file:
46 cu_file.write(source)
47
48 cmd.append(cu_path)
49 subprocess.check_output(cmd, cwd=root_dir)
50
51 with open(cubin_path, 'rb') as bin_file:
52 return bin_file.read()
53
54
55 def preprocess(source, options=()):
56 cmd = ['nvcc', '--preprocess'] + list(options)
57 with TemporaryDirectory() as root_dir:
58 path = os.path.join(root_dir, 'kern')
59 cu_path = '%s.cu' % path
60
61 with open(cu_path, 'w') as cu_file:
62 cu_file.write(source)
63
64 cmd.append(cu_path)
65 pp_src = subprocess.check_output(cmd, cwd=root_dir)
66
67 if isinstance(pp_src, six.binary_type):
68 pp_src = pp_src.decode('utf-8')
69 return re.sub('(?m)^#.*$', '', pp_src)
70
71
72 _default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')
73
74
75 def get_cache_dir():
76 return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)
77
78
79 _empty_file_preprocess_cache = {}
80
81
82 def compile_with_cache(source, options=(), arch=None, cache_dir=None):
83 global _empty_file_preprocess_cache
84 if cache_dir is None:
85 cache_dir = get_cache_dir()
86 if arch is None:
87 arch = _get_arch()
88
89 if 'win32' == sys.platform:
90 options += ('-Xcompiler', '/wd 4819')
91 if sys.maxsize == 9223372036854775807:
92 options += '-m64',
93 elif sys.maxsize == 2147483647:
94 options += '-m32',
95
96 env = (arch, options)
97 if '#include' in source:
98 pp_src = '%s %s' % (env, preprocess(source, options))
99 else:
100 base = _empty_file_preprocess_cache.get(env, None)
101 if base is None:
102 base = _empty_file_preprocess_cache[env] = preprocess('', options)
103 pp_src = '%s %s %s' % (env, base, source)
104
105 if isinstance(pp_src, six.text_type):
106 pp_src = pp_src.encode('utf-8')
107 name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()
108
109 mod = function.Module()
110
111 if not os.path.exists(cache_dir):
112 os.makedirs(cache_dir)
113
114 lock_path = os.path.join(cache_dir, 'lock_file.lock')
115
116 path = os.path.join(cache_dir, name)
117 with filelock.FileLock(lock_path) as lock:
118 if os.path.exists(path):
119 with open(path, 'rb') as file:
120 cubin = file.read()
121 mod.load(cubin)
122 else:
123 lock.release()
124 cubin = nvcc(source, options, arch)
125 mod.load(cubin)
126 lock.acquire()
127 with open(path, 'wb') as cubin_file:
128 cubin_file.write(cubin)
129
130 return mod
131
[end of cupy/cuda/compiler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py
--- a/cupy/cuda/compiler.py
+++ b/cupy/cuda/compiler.py
@@ -32,6 +32,15 @@
os.rmdir(self.path)
+def _run_nvcc(cmd, cwd):
+ try:
+ return subprocess.check_output(cmd, cwd=cwd)
+ except OSError as e:
+ trace = sys.exc_info()[2]
+ msg = 'Failed to run `nvcc` command: ' + str(e)
+ six.reraise(OSError, msg, trace)
+
+
def nvcc(source, options=(), arch=None):
if not arch:
arch = _get_arch()
@@ -46,7 +55,7 @@
cu_file.write(source)
cmd.append(cu_path)
- subprocess.check_output(cmd, cwd=root_dir)
+ _run_nvcc(cmd, root_dir)
with open(cubin_path, 'rb') as bin_file:
return bin_file.read()
@@ -62,7 +71,7 @@
cu_file.write(source)
cmd.append(cu_path)
- pp_src = subprocess.check_output(cmd, cwd=root_dir)
+ pp_src = _run_nvcc(cmd, root_dir)
if isinstance(pp_src, six.binary_type):
pp_src = pp_src.decode('utf-8')
|
{"golden_diff": "diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py\n--- a/cupy/cuda/compiler.py\n+++ b/cupy/cuda/compiler.py\n@@ -32,6 +32,15 @@\n os.rmdir(self.path)\n \n \n+def _run_nvcc(cmd, cwd):\n+ try:\n+ return subprocess.check_output(cmd, cwd=cwd)\n+ except OSError as e:\n+ trace = sys.exc_info()[2]\n+ msg = 'Failed to run `nvcc` command: ' + str(e)\n+ six.reraise(OSError, msg, trace)\n+\n+\n def nvcc(source, options=(), arch=None):\n if not arch:\n arch = _get_arch()\n@@ -46,7 +55,7 @@\n cu_file.write(source)\n \n cmd.append(cu_path)\n- subprocess.check_output(cmd, cwd=root_dir)\n+ _run_nvcc(cmd, root_dir)\n \n with open(cubin_path, 'rb') as bin_file:\n return bin_file.read()\n@@ -62,7 +71,7 @@\n cu_file.write(source)\n \n cmd.append(cu_path)\n- pp_src = subprocess.check_output(cmd, cwd=root_dir)\n+ pp_src = _run_nvcc(cmd, root_dir)\n \n if isinstance(pp_src, six.binary_type):\n pp_src = pp_src.decode('utf-8')\n", "issue": "Unreadable error message appears when `nvcc` command is not found\nOnly \"No suche file or directory\" is shown in such case.\n\nrelated to #698\n\n", "before_files": [{"content": "import hashlib\nimport os\nimport re\nimport subprocess\nimport sys\nimport tempfile\n\nimport filelock\nimport six\n\nfrom cupy.cuda import device\nfrom cupy.cuda import function\n\n\ndef _get_arch():\n cc = device.Device().compute_capability\n return 'sm_%s' % cc\n\n\nclass TemporaryDirectory(object):\n\n def __enter__(self):\n self.path = tempfile.mkdtemp()\n return self.path\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value is not None:\n return\n\n for name in os.listdir(self.path):\n os.unlink(os.path.join(self.path, name))\n os.rmdir(self.path)\n\n\ndef nvcc(source, options=(), arch=None):\n if not arch:\n arch = _get_arch()\n cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)\n\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n cubin_path = '%s.cubin' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n subprocess.check_output(cmd, cwd=root_dir)\n\n with open(cubin_path, 'rb') as bin_file:\n return bin_file.read()\n\n\ndef preprocess(source, options=()):\n cmd = ['nvcc', '--preprocess'] + list(options)\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n pp_src = subprocess.check_output(cmd, cwd=root_dir)\n\n if isinstance(pp_src, six.binary_type):\n pp_src = pp_src.decode('utf-8')\n return re.sub('(?m)^#.*$', '', pp_src)\n\n\n_default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')\n\n\ndef get_cache_dir():\n return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)\n\n\n_empty_file_preprocess_cache = {}\n\n\ndef compile_with_cache(source, options=(), arch=None, cache_dir=None):\n global _empty_file_preprocess_cache\n if cache_dir is None:\n cache_dir = get_cache_dir()\n if arch is None:\n arch = _get_arch()\n\n if 'win32' == sys.platform:\n options += ('-Xcompiler', '/wd 4819')\n if sys.maxsize == 9223372036854775807:\n options += '-m64',\n elif sys.maxsize == 2147483647:\n options += '-m32',\n\n env = (arch, options)\n if '#include' in source:\n pp_src = '%s %s' % (env, preprocess(source, options))\n else:\n base = _empty_file_preprocess_cache.get(env, None)\n if base is None:\n base = _empty_file_preprocess_cache[env] = preprocess('', options)\n pp_src = '%s %s %s' % (env, base, source)\n\n if isinstance(pp_src, six.text_type):\n pp_src = pp_src.encode('utf-8')\n name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()\n\n mod = function.Module()\n\n if not os.path.exists(cache_dir):\n os.makedirs(cache_dir)\n\n lock_path = os.path.join(cache_dir, 'lock_file.lock')\n\n path = os.path.join(cache_dir, name)\n with filelock.FileLock(lock_path) as lock:\n if os.path.exists(path):\n with open(path, 'rb') as file:\n cubin = file.read()\n mod.load(cubin)\n else:\n lock.release()\n cubin = nvcc(source, options, arch)\n mod.load(cubin)\n lock.acquire()\n with open(path, 'wb') as cubin_file:\n cubin_file.write(cubin)\n\n return mod\n", "path": "cupy/cuda/compiler.py"}]}
| 1,787 | 304 |
gh_patches_debug_27343
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5115
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
update-locale triggers CKV_DOCKER_5
**Describe the issue**
CKV_DOCKER_5 (Ensure update instructions are not use alone in the Dockerfile) fails in anything that has `update` in it. From reading the source, it. seems that CKV_DOCKER_5 is geared towards `apt-get update` and `apt-get install` which, from the code, are cancelling each other out so the `update_cnt` variable remains 0. I have other `update` command like `update-locale`. I'm not sure if it's part of the issue in my Dockerfile that I need to deal or I could just ignore the failure message.
**Examples**
```
RUN sed -i -e 's/# en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/' /etc/locale.gen && \
dpkg-reconfigure --frontend noninteractive locales && \
update-locale LANG=en_US.UTF-8
```
**Version (please complete the following information):**
- Checkov Version 2.2.229
</issue>
<code>
[start of checkov/dockerfile/checks/UpdateNotAlone.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from checkov.common.models.enums import CheckCategories, CheckResult
6 from checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck
7
8 if TYPE_CHECKING:
9 from dockerfile_parse.parser import _Instruction
10
11 install_commands = (
12 "install",
13 "source-install",
14 "reinstall",
15 "groupinstall",
16 "localinstall",
17 "add",
18 )
19 update_commands = (
20 "update",
21 "--update",
22 )
23
24
25 class UpdateNotAlone(BaseDockerfileCheck):
26 def __init__(self) -> None:
27 name = "Ensure update instructions are not use alone in the Dockerfile"
28 id = "CKV_DOCKER_5"
29 supported_instructions = ("RUN",)
30 categories = (CheckCategories.APPLICATION_SECURITY,)
31 super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)
32
33 def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:
34 update_instructions = []
35 update_cnt = 0
36 i = 0
37 for instruction in conf:
38 content = instruction["content"]
39 if instruction["instruction"] in self.supported_instructions:
40
41 if any(x in content for x in update_commands):
42 update_cnt = update_cnt + 1
43 update_instructions.append(i)
44 if any(x in content for x in install_commands):
45 update_cnt = update_cnt - 1
46 i = i + 1
47
48 if update_cnt <= 0:
49 return CheckResult.PASSED, None
50 output = []
51 for i in update_instructions:
52 output.append(conf[i])
53
54 return CheckResult.FAILED, output
55
56
57 check = UpdateNotAlone()
58
[end of checkov/dockerfile/checks/UpdateNotAlone.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/dockerfile/checks/UpdateNotAlone.py b/checkov/dockerfile/checks/UpdateNotAlone.py
--- a/checkov/dockerfile/checks/UpdateNotAlone.py
+++ b/checkov/dockerfile/checks/UpdateNotAlone.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import re
from typing import TYPE_CHECKING
from checkov.common.models.enums import CheckCategories, CheckResult
@@ -8,6 +9,8 @@
if TYPE_CHECKING:
from dockerfile_parse.parser import _Instruction
+UPDATE_COMMANDS_PATTERN = re.compile(r"\s+(?:--)?update(?!\S)")
+
install_commands = (
"install",
"source-install",
@@ -15,10 +18,7 @@
"groupinstall",
"localinstall",
"add",
-)
-update_commands = (
- "update",
- "--update",
+ "upgrade"
)
@@ -38,7 +38,7 @@
content = instruction["content"]
if instruction["instruction"] in self.supported_instructions:
- if any(x in content for x in update_commands):
+ if re.search(UPDATE_COMMANDS_PATTERN, content):
update_cnt = update_cnt + 1
update_instructions.append(i)
if any(x in content for x in install_commands):
|
{"golden_diff": "diff --git a/checkov/dockerfile/checks/UpdateNotAlone.py b/checkov/dockerfile/checks/UpdateNotAlone.py\n--- a/checkov/dockerfile/checks/UpdateNotAlone.py\n+++ b/checkov/dockerfile/checks/UpdateNotAlone.py\n@@ -1,5 +1,6 @@\n from __future__ import annotations\n \n+import re\n from typing import TYPE_CHECKING\n \n from checkov.common.models.enums import CheckCategories, CheckResult\n@@ -8,6 +9,8 @@\n if TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n \n+UPDATE_COMMANDS_PATTERN = re.compile(r\"\\s+(?:--)?update(?!\\S)\")\n+\n install_commands = (\n \"install\",\n \"source-install\",\n@@ -15,10 +18,7 @@\n \"groupinstall\",\n \"localinstall\",\n \"add\",\n-)\n-update_commands = (\n- \"update\",\n- \"--update\",\n+ \"upgrade\"\n )\n \n \n@@ -38,7 +38,7 @@\n content = instruction[\"content\"]\n if instruction[\"instruction\"] in self.supported_instructions:\n \n- if any(x in content for x in update_commands):\n+ if re.search(UPDATE_COMMANDS_PATTERN, content):\n update_cnt = update_cnt + 1\n update_instructions.append(i)\n if any(x in content for x in install_commands):\n", "issue": "update-locale triggers CKV_DOCKER_5\n**Describe the issue**\r\nCKV_DOCKER_5 (Ensure update instructions are not use alone in the Dockerfile) fails in anything that has `update` in it. From reading the source, it. seems that CKV_DOCKER_5 is geared towards `apt-get update` and `apt-get install` which, from the code, are cancelling each other out so the `update_cnt` variable remains 0. I have other `update` command like `update-locale`. I'm not sure if it's part of the issue in my Dockerfile that I need to deal or I could just ignore the failure message.\r\n\r\n**Examples**\r\n```\r\nRUN sed -i -e 's/# en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/' /etc/locale.gen && \\\r\n dpkg-reconfigure --frontend noninteractive locales && \\\r\n update-locale LANG=en_US.UTF-8\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.2.229\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.dockerfile.base_dockerfile_check import BaseDockerfileCheck\n\nif TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction\n\ninstall_commands = (\n \"install\",\n \"source-install\",\n \"reinstall\",\n \"groupinstall\",\n \"localinstall\",\n \"add\",\n)\nupdate_commands = (\n \"update\",\n \"--update\",\n)\n\n\nclass UpdateNotAlone(BaseDockerfileCheck):\n def __init__(self) -> None:\n name = \"Ensure update instructions are not use alone in the Dockerfile\"\n id = \"CKV_DOCKER_5\"\n supported_instructions = (\"RUN\",)\n categories = (CheckCategories.APPLICATION_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_instructions=supported_instructions)\n\n def scan_resource_conf(self, conf: list[_Instruction]) -> tuple[CheckResult, list[_Instruction] | None]:\n update_instructions = []\n update_cnt = 0\n i = 0\n for instruction in conf:\n content = instruction[\"content\"]\n if instruction[\"instruction\"] in self.supported_instructions:\n\n if any(x in content for x in update_commands):\n update_cnt = update_cnt + 1\n update_instructions.append(i)\n if any(x in content for x in install_commands):\n update_cnt = update_cnt - 1\n i = i + 1\n\n if update_cnt <= 0:\n return CheckResult.PASSED, None\n output = []\n for i in update_instructions:\n output.append(conf[i])\n\n return CheckResult.FAILED, output\n\n\ncheck = UpdateNotAlone()\n", "path": "checkov/dockerfile/checks/UpdateNotAlone.py"}]}
| 1,267 | 296 |
gh_patches_debug_7160
|
rasdani/github-patches
|
git_diff
|
sopel-irc__sopel-495
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[core] idiot-proof Willie: prevent running as root
We should add a check in willie.py to refuse running willie as root.
</issue>
<code>
[start of willie.py]
1 #!/usr/bin/env python2.7
2 #coding: utf8
3 """
4 Willie - An IRC Bot
5 Copyright 2008, Sean B. Palmer, inamidst.com
6 Copyright © 2012-2014, Elad Alfassa <[email protected]>
7 Licensed under the Eiffel Forum License 2.
8
9 http://willie.dftba.net
10 """
11 from __future__ import unicode_literals
12 from __future__ import print_function
13
14 import sys
15 from willie.tools import stderr
16
17 if sys.version_info < (2, 7):
18 stderr('Error: Requires Python 2.7 or later. Try python2.7 willie')
19 sys.exit(1)
20 if sys.version_info.major == 3 and sys.version_info.minor < 3:
21 stderr('Error: When running on Python 3, Python 3.3 is required.')
22 sys.exit(1)
23
24 import os
25 import argparse
26 import signal
27
28 from willie.__init__ import run
29 from willie.config import Config, create_config, ConfigurationError, wizard
30 import willie.tools as tools
31 import willie.web
32
33 homedir = os.path.join(os.path.expanduser('~'), '.willie')
34
35 def enumerate_configs(extension='.cfg'):
36 configfiles = []
37 if os.path.isdir(homedir):
38 willie_dotdirfiles = os.listdir(homedir) # Preferred
39 for item in willie_dotdirfiles:
40 if item.endswith(extension):
41 configfiles.append(item)
42
43 return configfiles
44
45
46 def find_config(name, extension='.cfg'):
47 if os.path.isfile(name):
48 return name
49 configs = enumerate_configs(extension)
50 if name in configs or name + extension in configs:
51 if name + extension in configs:
52 name = name + extension
53
54 return os.path.join(homedir, name)
55
56
57 def main(argv=None):
58 global homedir
59 # Step One: Parse The Command Line
60 try:
61 parser = argparse.ArgumentParser(description='Willie IRC Bot',
62 usage='%(prog)s [options]')
63 parser.add_argument('-c', '--config', metavar='filename',
64 help='use a specific configuration file')
65 parser.add_argument("-d", '--fork', action="store_true",
66 dest="deamonize", help="Deamonize willie")
67 parser.add_argument("-q", '--quit', action="store_true", dest="quit",
68 help="Gracefully quit Willie")
69 parser.add_argument("-k", '--kill', action="store_true", dest="kill",
70 help="Kill Willie")
71 parser.add_argument('--exit-on-error', action="store_true",
72 dest="exit_on_error", help=(
73 "Exit immediately on every error instead of "
74 "trying to recover"))
75 parser.add_argument("-l", '--list', action="store_true",
76 dest="list_configs",
77 help="List all config files found")
78 parser.add_argument("-m", '--migrate', action="store_true",
79 dest="migrate_configs",
80 help="Migrate config files to the new format")
81 parser.add_argument('--quiet', action="store_true", dest="quiet",
82 help="Supress all output")
83 parser.add_argument('-w', '--configure-all', action='store_true',
84 dest='wizard', help='Run the configuration wizard.')
85 parser.add_argument('--configure-modules', action='store_true',
86 dest='mod_wizard', help=(
87 'Run the configuration wizard, but only for the '
88 'module configuration options.'))
89 parser.add_argument('--configure-database', action='store_true',
90 dest='db_wizard', help=(
91 'Run the configuration wizard, but only for the '
92 'database configuration options.'))
93 opts = parser.parse_args()
94
95 if opts.wizard:
96 wizard('all', opts.config)
97 return
98 elif opts.mod_wizard:
99 wizard('mod', opts.config)
100 return
101 elif opts.db_wizard:
102 wizard('db', opts.config)
103 return
104
105 if opts.list_configs:
106 configs = enumerate_configs()
107 print('Config files in ~/.willie:')
108 if len(configs) is 0:
109 print('\tNone found')
110 else:
111 for config in configs:
112 print('\t%s' % config)
113 print('-------------------------')
114 return
115
116 config_name = opts.config or 'default'
117
118 configpath = find_config(config_name)
119 if not os.path.isfile(configpath):
120 print("Welcome to Willie!\nI can't seem to find the configuration file, so let's generate it!\n")
121 if not configpath.endswith('.cfg'):
122 configpath = configpath + '.cfg'
123 create_config(configpath)
124 configpath = find_config(config_name)
125 try:
126 config_module = Config(configpath)
127 except ConfigurationError as e:
128 stderr(e)
129 sys.exit(2)
130
131 if config_module.core.not_configured:
132 stderr('Bot is not configured, can\'t start')
133 # exit with code 2 to prevent auto restart on fail by systemd
134 sys.exit(2)
135
136 if not config_module.has_option('core', 'homedir'):
137 config_module.dotdir = homedir
138 config_module.homedir = homedir
139 else:
140 homedir = config_module.core.homedir
141 config_module.dotdir = config_module.core.homedir
142
143 if not config_module.core.logdir:
144 config_module.core.logdir = os.path.join(homedir, 'logs')
145 logfile = os.path.os.path.join(config_module.logdir, 'stdio.log')
146 if not os.path.isdir(config_module.logdir):
147 os.mkdir(config_module.logdir)
148
149 config_module.exit_on_error = opts.exit_on_error
150
151 sys.stderr = tools.OutputRedirect(logfile, True, opts.quiet)
152 sys.stdout = tools.OutputRedirect(logfile, False, opts.quiet)
153
154 #Handle --quit, --kill and saving the PID to file
155 pid_dir = config_module.core.pid_dir or homedir
156 if opts.config is None:
157 pid_file_path = os.path.join(pid_dir, 'willie.pid')
158 else:
159 basename = os.path.basename(opts.config)
160 if basename.endswith('.cfg'):
161 basename = basename[:-4]
162 pid_file_path = os.path.join(pid_dir, 'willie-%s.pid' % basename)
163 if os.path.isfile(pid_file_path):
164 pid_file = open(pid_file_path, 'r')
165 old_pid = int(pid_file.read())
166 pid_file.close()
167 if tools.check_pid(old_pid):
168 if not opts.quit and not opts.kill:
169 stderr('There\'s already a Willie instance running with this config file')
170 stderr('Try using the --quit or the --kill options')
171 sys.exit(1)
172 elif opts.kill:
173 stderr('Killing the willie')
174 os.kill(old_pid, signal.SIGKILL)
175 sys.exit(0)
176 elif opts.quit:
177 stderr('Signaling Willie to stop gracefully')
178 if hasattr(signal, 'SIGUSR1'):
179 os.kill(old_pid, signal.SIGUSR1)
180 else:
181 os.kill(old_pid, signal.SIGTERM)
182 sys.exit(0)
183 elif not tools.check_pid(old_pid) and (opts.kill or opts.quit):
184 stderr('Willie is not running!')
185 sys.exit(1)
186 elif opts.quit or opts.kill:
187 stderr('Willie is not running!')
188 sys.exit(1)
189 if opts.deamonize:
190 child_pid = os.fork()
191 if child_pid is not 0:
192 sys.exit()
193 pid_file = open(pid_file_path, 'w')
194 pid_file.write(str(os.getpid()))
195 pid_file.close()
196 config_module.pid_file_path = pid_file_path
197
198 # Step Five: Initialise And Run willie
199 run(config_module)
200 except KeyboardInterrupt:
201 print("\n\nInterrupted")
202 os._exit(1)
203 if __name__ == '__main__':
204 main()
205
[end of willie.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/willie.py b/willie.py
--- a/willie.py
+++ b/willie.py
@@ -92,6 +92,14 @@
'database configuration options.'))
opts = parser.parse_args()
+ try:
+ if os.getuid() == 0 or os.geteuid() == 0:
+ stderr('Error: Do not run Willie with root privileges.')
+ sys.exit(1)
+ except AttributeError:
+ # Windows don't have os.getuid/os.geteuid
+ pass
+
if opts.wizard:
wizard('all', opts.config)
return
|
{"golden_diff": "diff --git a/willie.py b/willie.py\n--- a/willie.py\n+++ b/willie.py\n@@ -92,6 +92,14 @@\n 'database configuration options.'))\n opts = parser.parse_args()\n \n+ try:\n+ if os.getuid() == 0 or os.geteuid() == 0:\n+ stderr('Error: Do not run Willie with root privileges.')\n+ sys.exit(1)\n+ except AttributeError:\n+ # Windows don't have os.getuid/os.geteuid\n+ pass\n+\n if opts.wizard:\n wizard('all', opts.config)\n return\n", "issue": "[core] idiot-proof Willie: prevent running as root\nWe should add a check in willie.py to refuse running willie as root.\n\n", "before_files": [{"content": "#!/usr/bin/env python2.7\n#coding: utf8\n\"\"\"\nWillie - An IRC Bot\nCopyright 2008, Sean B. Palmer, inamidst.com\nCopyright \u00a9 2012-2014, Elad Alfassa <[email protected]>\nLicensed under the Eiffel Forum License 2.\n\nhttp://willie.dftba.net\n\"\"\"\nfrom __future__ import unicode_literals\nfrom __future__ import print_function\n\nimport sys\nfrom willie.tools import stderr\n\nif sys.version_info < (2, 7):\n stderr('Error: Requires Python 2.7 or later. Try python2.7 willie')\n sys.exit(1)\nif sys.version_info.major == 3 and sys.version_info.minor < 3:\n stderr('Error: When running on Python 3, Python 3.3 is required.')\n sys.exit(1)\n\nimport os\nimport argparse\nimport signal\n\nfrom willie.__init__ import run\nfrom willie.config import Config, create_config, ConfigurationError, wizard\nimport willie.tools as tools\nimport willie.web\n\nhomedir = os.path.join(os.path.expanduser('~'), '.willie')\n\ndef enumerate_configs(extension='.cfg'):\n configfiles = []\n if os.path.isdir(homedir):\n willie_dotdirfiles = os.listdir(homedir) # Preferred\n for item in willie_dotdirfiles:\n if item.endswith(extension):\n configfiles.append(item)\n\n return configfiles\n\n\ndef find_config(name, extension='.cfg'):\n if os.path.isfile(name):\n return name\n configs = enumerate_configs(extension)\n if name in configs or name + extension in configs:\n if name + extension in configs:\n name = name + extension\n\n return os.path.join(homedir, name)\n\n\ndef main(argv=None):\n global homedir\n # Step One: Parse The Command Line\n try:\n parser = argparse.ArgumentParser(description='Willie IRC Bot',\n usage='%(prog)s [options]')\n parser.add_argument('-c', '--config', metavar='filename',\n help='use a specific configuration file')\n parser.add_argument(\"-d\", '--fork', action=\"store_true\",\n dest=\"deamonize\", help=\"Deamonize willie\")\n parser.add_argument(\"-q\", '--quit', action=\"store_true\", dest=\"quit\",\n help=\"Gracefully quit Willie\")\n parser.add_argument(\"-k\", '--kill', action=\"store_true\", dest=\"kill\",\n help=\"Kill Willie\")\n parser.add_argument('--exit-on-error', action=\"store_true\",\n dest=\"exit_on_error\", help=(\n \"Exit immediately on every error instead of \"\n \"trying to recover\"))\n parser.add_argument(\"-l\", '--list', action=\"store_true\",\n dest=\"list_configs\",\n help=\"List all config files found\")\n parser.add_argument(\"-m\", '--migrate', action=\"store_true\",\n dest=\"migrate_configs\",\n help=\"Migrate config files to the new format\")\n parser.add_argument('--quiet', action=\"store_true\", dest=\"quiet\",\n help=\"Supress all output\")\n parser.add_argument('-w', '--configure-all', action='store_true',\n dest='wizard', help='Run the configuration wizard.')\n parser.add_argument('--configure-modules', action='store_true',\n dest='mod_wizard', help=(\n 'Run the configuration wizard, but only for the '\n 'module configuration options.'))\n parser.add_argument('--configure-database', action='store_true',\n dest='db_wizard', help=(\n 'Run the configuration wizard, but only for the '\n 'database configuration options.'))\n opts = parser.parse_args()\n\n if opts.wizard:\n wizard('all', opts.config)\n return\n elif opts.mod_wizard:\n wizard('mod', opts.config)\n return\n elif opts.db_wizard:\n wizard('db', opts.config)\n return\n\n if opts.list_configs:\n configs = enumerate_configs()\n print('Config files in ~/.willie:')\n if len(configs) is 0:\n print('\\tNone found')\n else:\n for config in configs:\n print('\\t%s' % config)\n print('-------------------------')\n return\n\n config_name = opts.config or 'default'\n\n configpath = find_config(config_name)\n if not os.path.isfile(configpath):\n print(\"Welcome to Willie!\\nI can't seem to find the configuration file, so let's generate it!\\n\")\n if not configpath.endswith('.cfg'):\n configpath = configpath + '.cfg'\n create_config(configpath)\n configpath = find_config(config_name)\n try:\n config_module = Config(configpath)\n except ConfigurationError as e:\n stderr(e)\n sys.exit(2)\n\n if config_module.core.not_configured:\n stderr('Bot is not configured, can\\'t start')\n # exit with code 2 to prevent auto restart on fail by systemd\n sys.exit(2)\n\n if not config_module.has_option('core', 'homedir'):\n config_module.dotdir = homedir\n config_module.homedir = homedir\n else:\n homedir = config_module.core.homedir\n config_module.dotdir = config_module.core.homedir\n\n if not config_module.core.logdir:\n config_module.core.logdir = os.path.join(homedir, 'logs')\n logfile = os.path.os.path.join(config_module.logdir, 'stdio.log')\n if not os.path.isdir(config_module.logdir):\n os.mkdir(config_module.logdir)\n\n config_module.exit_on_error = opts.exit_on_error\n\n sys.stderr = tools.OutputRedirect(logfile, True, opts.quiet)\n sys.stdout = tools.OutputRedirect(logfile, False, opts.quiet)\n\n #Handle --quit, --kill and saving the PID to file\n pid_dir = config_module.core.pid_dir or homedir\n if opts.config is None:\n pid_file_path = os.path.join(pid_dir, 'willie.pid')\n else:\n basename = os.path.basename(opts.config)\n if basename.endswith('.cfg'):\n basename = basename[:-4]\n pid_file_path = os.path.join(pid_dir, 'willie-%s.pid' % basename)\n if os.path.isfile(pid_file_path):\n pid_file = open(pid_file_path, 'r')\n old_pid = int(pid_file.read())\n pid_file.close()\n if tools.check_pid(old_pid):\n if not opts.quit and not opts.kill:\n stderr('There\\'s already a Willie instance running with this config file')\n stderr('Try using the --quit or the --kill options')\n sys.exit(1)\n elif opts.kill:\n stderr('Killing the willie')\n os.kill(old_pid, signal.SIGKILL)\n sys.exit(0)\n elif opts.quit:\n stderr('Signaling Willie to stop gracefully')\n if hasattr(signal, 'SIGUSR1'):\n os.kill(old_pid, signal.SIGUSR1)\n else:\n os.kill(old_pid, signal.SIGTERM)\n sys.exit(0)\n elif not tools.check_pid(old_pid) and (opts.kill or opts.quit):\n stderr('Willie is not running!')\n sys.exit(1)\n elif opts.quit or opts.kill:\n stderr('Willie is not running!')\n sys.exit(1)\n if opts.deamonize:\n child_pid = os.fork()\n if child_pid is not 0:\n sys.exit()\n pid_file = open(pid_file_path, 'w')\n pid_file.write(str(os.getpid()))\n pid_file.close()\n config_module.pid_file_path = pid_file_path\n\n # Step Five: Initialise And Run willie\n run(config_module)\n except KeyboardInterrupt:\n print(\"\\n\\nInterrupted\")\n os._exit(1)\nif __name__ == '__main__':\n main()\n", "path": "willie.py"}]}
| 2,766 | 143 |
gh_patches_debug_57147
|
rasdani/github-patches
|
git_diff
|
pymeasure__pymeasure-433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pyvisa no longer support ask, replace with query
In resources.py
`idn = res.ask('*idn?')[:-1]`
Should be:
`idn = res.query('*idn?')[:-1]`
</issue>
<code>
[start of pymeasure/instruments/resources.py]
1 #
2 # This file is part of the PyMeasure package.
3 #
4 # Copyright (c) 2013-2021 PyMeasure Developers
5 #
6 # Permission is hereby granted, free of charge, to any person obtaining a copy
7 # of this software and associated documentation files (the "Software"), to deal
8 # in the Software without restriction, including without limitation the rights
9 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 # copies of the Software, and to permit persons to whom the Software is
11 # furnished to do so, subject to the following conditions:
12 #
13 # The above copyright notice and this permission notice shall be included in
14 # all copies or substantial portions of the Software.
15 #
16 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
22 # THE SOFTWARE.
23 #
24
25 import pyvisa
26
27
28 def list_resources():
29 """
30 Prints the available resources, and returns a list of VISA resource names
31
32 .. code-block:: python
33
34 resources = list_resources()
35 #prints (e.g.)
36 #0 : GPIB0::22::INSTR : Agilent Technologies,34410A,******
37 #1 : GPIB0::26::INSTR : Keithley Instruments Inc., Model 2612, *****
38 dmm = Agilent34410(resources[0])
39
40 """
41 rm = pyvisa.ResourceManager()
42 instrs = rm.list_resources()
43 for n, instr in enumerate(instrs):
44 # trying to catch errors in comunication
45 try:
46 res = rm.open_resource(instr)
47 # try to avoid errors from *idn?
48 try:
49 # noinspection PyUnresolvedReferences
50 idn = res.ask('*idn?')[:-1]
51 except pyvisa.Error:
52 idn = "Not known"
53 finally:
54 res.close()
55 print(n, ":", instr, ":", idn)
56 except pyvisa.VisaIOError as e:
57 print(n, ":", instr, ":", "Visa IO Error: check connections")
58 print(e)
59 rm.close()
60 return instrs
61
[end of pymeasure/instruments/resources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pymeasure/instruments/resources.py b/pymeasure/instruments/resources.py
--- a/pymeasure/instruments/resources.py
+++ b/pymeasure/instruments/resources.py
@@ -47,7 +47,7 @@
# try to avoid errors from *idn?
try:
# noinspection PyUnresolvedReferences
- idn = res.ask('*idn?')[:-1]
+ idn = res.query('*idn?')[:-1]
except pyvisa.Error:
idn = "Not known"
finally:
|
{"golden_diff": "diff --git a/pymeasure/instruments/resources.py b/pymeasure/instruments/resources.py\n--- a/pymeasure/instruments/resources.py\n+++ b/pymeasure/instruments/resources.py\n@@ -47,7 +47,7 @@\n # try to avoid errors from *idn?\n try:\n # noinspection PyUnresolvedReferences\n- idn = res.ask('*idn?')[:-1]\n+ idn = res.query('*idn?')[:-1]\n except pyvisa.Error:\n idn = \"Not known\"\n finally:\n", "issue": "Pyvisa no longer support ask, replace with query\nIn resources.py\r\n`idn = res.ask('*idn?')[:-1]`\r\nShould be:\r\n`idn = res.query('*idn?')[:-1]`\n", "before_files": [{"content": "#\n# This file is part of the PyMeasure package.\n#\n# Copyright (c) 2013-2021 PyMeasure Developers\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n# THE SOFTWARE.\n#\n\nimport pyvisa\n\n\ndef list_resources():\n \"\"\"\n Prints the available resources, and returns a list of VISA resource names\n \n .. code-block:: python\n\n resources = list_resources()\n #prints (e.g.)\n #0 : GPIB0::22::INSTR : Agilent Technologies,34410A,******\n #1 : GPIB0::26::INSTR : Keithley Instruments Inc., Model 2612, *****\n dmm = Agilent34410(resources[0])\n \n \"\"\"\n rm = pyvisa.ResourceManager()\n instrs = rm.list_resources()\n for n, instr in enumerate(instrs):\n # trying to catch errors in comunication\n try:\n res = rm.open_resource(instr)\n # try to avoid errors from *idn?\n try:\n # noinspection PyUnresolvedReferences\n idn = res.ask('*idn?')[:-1]\n except pyvisa.Error:\n idn = \"Not known\"\n finally:\n res.close()\n print(n, \":\", instr, \":\", idn)\n except pyvisa.VisaIOError as e:\n print(n, \":\", instr, \":\", \"Visa IO Error: check connections\")\n print(e)\n rm.close()\n return instrs\n", "path": "pymeasure/instruments/resources.py"}]}
| 1,238 | 122 |
gh_patches_debug_56463
|
rasdani/github-patches
|
git_diff
|
acl-org__acl-anthology-3109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reingestion Request: ROCLING (10-20-2023)
### General information about this request
- [X] I confirm that I have read the [Information for Submitters](https://aclanthology.org/info/contrib/).
- [ ] I am submitting a request for a **new venue** that does not exist in the ACL Anthology yet.
### Venue Identifier
ROCLING
### Volume Title
Proceedings of the 35th Conference on Computational Linguistics and Speech Processing (ROCLING 2023)
### Venue Name (only if you are submitting a new venue)
Conference on Computational Linguistics and Speech Processing
### Venue Website (only if you are submitting a new venue)
https://rocling2023.github.io/
### Date of Publication
2023-10-20
### Supporting Information
Dear Anthology Director,
I'm Hou-Chiang Tseng who the publication chair of the 35th annual Conference on Computational Linguistics and Speech Processing (ROCLING 2023).
The conference website: https://rocling2023.github.io/
We want to register the ROCLING 2023 to ACL Anthology. Please see following two items:
(a) the complete list of volumes: please see the attached file,
and (b) all the new material can be downloaded from the following URL:
https://drive.google.com/drive/folders/1dxt_gYlUvmuLiNETgDRg9cGpiJxVGwbD?usp=sharing
If there is any question, please let me know.
[Anthology.Volume_ROCLING.2023.xlsx](https://github.com/acl-org/acl-anthology/files/14318157/Anthology.Volume_ROCLING.2023.xlsx)
Best regards,
Dr. Hou-Chiang Tseng
</issue>
<code>
[start of bin/volumes_from_diff.py]
1 #!/usr/bin/env python3
2
3 """
4 Takes a list of XML files on STDIN, and prints all the volumes
5 within each of those files. e.g.,
6
7 git diff --name-only master | ./bin/volumes_from_xml.py https://preview.aclanthology.org/BRANCH
8
9 Used to find the list of volumes to generate previews for.
10 """
11
12 import sys
13 import argparse
14 import lxml.etree as etree
15
16
17 parser = argparse.ArgumentParser()
18 parser.add_argument("url_root")
19 args = parser.parse_args()
20
21 volumes = []
22 for filepath in sys.stdin:
23 if filepath.startswith("python/") or not filepath.endswith(".xml"):
24 continue
25
26 try:
27 tree = etree.parse(filepath.rstrip())
28 except Exception:
29 continue
30
31 root = tree.getroot()
32 collection_id = root.attrib["id"]
33 for volume in root.findall("./volume"):
34 volume_name = volume.attrib["id"]
35 volume_id = f"{collection_id}-{volume_name}"
36 volumes.append(f"[{volume_id}]({args.url_root}/{volume_id})")
37
38 if len(volumes) > 50:
39 volumes = volumes[0:50] + [f"(plus {len(volumes)-50} more...)"]
40
41 print(", ".join(volumes))
42
[end of bin/volumes_from_diff.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bin/volumes_from_diff.py b/bin/volumes_from_diff.py
--- a/bin/volumes_from_diff.py
+++ b/bin/volumes_from_diff.py
@@ -20,6 +20,7 @@
volumes = []
for filepath in sys.stdin:
+ filepath = filepath.rstrip()
if filepath.startswith("python/") or not filepath.endswith(".xml"):
continue
|
{"golden_diff": "diff --git a/bin/volumes_from_diff.py b/bin/volumes_from_diff.py\n--- a/bin/volumes_from_diff.py\n+++ b/bin/volumes_from_diff.py\n@@ -20,6 +20,7 @@\n \n volumes = []\n for filepath in sys.stdin:\n+ filepath = filepath.rstrip()\n if filepath.startswith(\"python/\") or not filepath.endswith(\".xml\"):\n continue\n", "issue": "Reingestion Request: ROCLING (10-20-2023)\n### General information about this request\n\n- [X] I confirm that I have read the [Information for Submitters](https://aclanthology.org/info/contrib/).\n- [ ] I am submitting a request for a **new venue** that does not exist in the ACL Anthology yet.\n\n### Venue Identifier\n\nROCLING\n\n### Volume Title\n\nProceedings of the 35th Conference on Computational Linguistics and Speech Processing (ROCLING 2023)\n\n### Venue Name (only if you are submitting a new venue)\n\nConference on Computational Linguistics and Speech Processing\n\n### Venue Website (only if you are submitting a new venue)\n\nhttps://rocling2023.github.io/\n\n### Date of Publication\n\n2023-10-20\n\n### Supporting Information\n\nDear Anthology Director,\r\n\r\nI'm Hou-Chiang Tseng who the publication chair of the 35th annual Conference on Computational Linguistics and Speech Processing (ROCLING 2023).\r\n\r\nThe conference website: https://rocling2023.github.io/\r\n\r\nWe want to register the ROCLING 2023 to ACL Anthology. Please see following two items:\r\n(a) the complete list of volumes: please see the attached file,\r\nand (b) all the new material can be downloaded from the following URL:\r\nhttps://drive.google.com/drive/folders/1dxt_gYlUvmuLiNETgDRg9cGpiJxVGwbD?usp=sharing\r\n\r\nIf there is any question, please let me know.\r\n[Anthology.Volume_ROCLING.2023.xlsx](https://github.com/acl-org/acl-anthology/files/14318157/Anthology.Volume_ROCLING.2023.xlsx)\r\n\r\nBest regards,\r\nDr. Hou-Chiang Tseng\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"\nTakes a list of XML files on STDIN, and prints all the volumes\nwithin each of those files. e.g.,\n\n git diff --name-only master | ./bin/volumes_from_xml.py https://preview.aclanthology.org/BRANCH\n\nUsed to find the list of volumes to generate previews for.\n\"\"\"\n\nimport sys\nimport argparse\nimport lxml.etree as etree\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"url_root\")\nargs = parser.parse_args()\n\nvolumes = []\nfor filepath in sys.stdin:\n if filepath.startswith(\"python/\") or not filepath.endswith(\".xml\"):\n continue\n\n try:\n tree = etree.parse(filepath.rstrip())\n except Exception:\n continue\n\n root = tree.getroot()\n collection_id = root.attrib[\"id\"]\n for volume in root.findall(\"./volume\"):\n volume_name = volume.attrib[\"id\"]\n volume_id = f\"{collection_id}-{volume_name}\"\n volumes.append(f\"[{volume_id}]({args.url_root}/{volume_id})\")\n\nif len(volumes) > 50:\n volumes = volumes[0:50] + [f\"(plus {len(volumes)-50} more...)\"]\n\nprint(\", \".join(volumes))\n", "path": "bin/volumes_from_diff.py"}]}
| 1,284 | 82 |
gh_patches_debug_2740
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-200
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use 'product' and 'component' features in the models
b7369ea8bf282941ce4b378ad5ad3c832db20668 introduced the features, but we are still not using them.
</issue>
<code>
[start of bugbug/models/bug.py]
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import xgboost
7 from imblearn.over_sampling import BorderlineSMOTE
8 from sklearn.compose import ColumnTransformer
9 from sklearn.feature_extraction import DictVectorizer
10 from sklearn.pipeline import Pipeline
11
12 from bugbug import bug_features
13 from bugbug import bugzilla
14 from bugbug import labels
15 from bugbug.model import Model
16
17
18 class BugModel(Model):
19 def __init__(self, lemmatization=False):
20 Model.__init__(self, lemmatization)
21
22 self.sampler = BorderlineSMOTE(random_state=0)
23
24 feature_extractors = [
25 bug_features.has_str(),
26 bug_features.severity(),
27 # Ignore keywords that would make the ML completely skewed
28 # (we are going to use them as 100% rules in the evaluation phase).
29 bug_features.keywords({'regression', 'talos-regression', 'feature'}),
30 bug_features.is_coverity_issue(),
31 bug_features.has_crash_signature(),
32 bug_features.has_url(),
33 bug_features.has_w3c_url(),
34 bug_features.has_github_url(),
35 bug_features.whiteboard(),
36 bug_features.patches(),
37 bug_features.landings(),
38 bug_features.title(),
39 bug_features.blocked_bugs_number(),
40 bug_features.ever_affected(),
41 bug_features.affected_then_unaffected(),
42 ]
43
44 cleanup_functions = [
45 bug_features.cleanup_url,
46 bug_features.cleanup_fileref,
47 bug_features.cleanup_synonyms,
48 ]
49
50 self.extraction_pipeline = Pipeline([
51 ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions)),
52 ('union', ColumnTransformer([
53 ('data', DictVectorizer(), 'data'),
54
55 ('title', self.text_vectorizer(min_df=0.001), 'title'),
56
57 ('first_comment', self.text_vectorizer(min_df=0.001), 'first_comment'),
58
59 ('comments', self.text_vectorizer(min_df=0.001), 'comments'),
60 ])),
61 ])
62
63 self.clf = xgboost.XGBClassifier(n_jobs=16)
64 self.clf.set_params(predictor='cpu_predictor')
65
66 def get_bugbug_labels(self, kind='bug'):
67 assert kind in ['bug', 'regression', 'defect_feature_task']
68
69 classes = {}
70
71 for bug_id, category in labels.get_labels('bug_nobug'):
72 assert category in ['True', 'False'], f'unexpected category {category}'
73 if kind == 'bug':
74 classes[int(bug_id)] = 1 if category == 'True' else 0
75 elif kind == 'regression':
76 if category == 'False':
77 classes[int(bug_id)] = 0
78 elif kind == 'defect_feature_task':
79 if category == 'True':
80 classes[int(bug_id)] = 'd'
81
82 for bug_id, category in labels.get_labels('regression_bug_nobug'):
83 assert category in ['nobug', 'bug_unknown_regression', 'bug_no_regression', 'regression'], f'unexpected category {category}'
84 if kind == 'bug':
85 classes[int(bug_id)] = 1 if category != 'nobug' else 0
86 elif kind == 'regression':
87 if category == 'bug_unknown_regression':
88 continue
89
90 classes[int(bug_id)] = 1 if category == 'regression' else 0
91 elif kind == 'defect_feature_task':
92 if category != 'nobug':
93 classes[int(bug_id)] = 'd'
94
95 for bug_id, category in labels.get_labels('defect_feature_task'):
96 assert category in ['d', 'f', 't']
97 if kind == 'bug':
98 classes[int(bug_id)] = 1 if category == 'd' else 0
99 elif kind == 'regression':
100 if category in ['f', 't']:
101 classes[int(bug_id)] = 0
102 elif kind == 'defect_feature_task':
103 classes[int(bug_id)] = category
104
105 # Augment labes by using bugs marked as 'regression' or 'feature', as they are basically labelled.
106 bug_ids = set()
107 for bug in bugzilla.get_bugs():
108 bug_id = int(bug['id'])
109
110 bug_ids.add(bug_id)
111
112 if bug_id in classes:
113 continue
114
115 if any(keyword in bug['keywords'] for keyword in ['regression', 'talos-regression']) or ('cf_has_regression_range' in bug and bug['cf_has_regression_range'] == 'yes'):
116 if kind in ['bug', 'regression']:
117 classes[bug_id] = 1
118 else:
119 classes[bug_id] = 'd'
120 elif any(keyword in bug['keywords'] for keyword in ['feature']):
121 if kind in ['bug', 'regression']:
122 classes[bug_id] = 0
123 else:
124 classes[bug_id] = 'f'
125 elif kind == 'regression':
126 for history in bug['history']:
127 for change in history['changes']:
128 if change['field_name'] == 'keywords' and change['removed'] == 'regression':
129 classes[bug_id] = 0
130
131 # Remove labels which belong to bugs for which we have no data.
132 return {bug_id: label for bug_id, label in classes.items() if bug_id in bug_ids}
133
134 def get_labels(self):
135 return self.get_bugbug_labels('bug')
136
137 def get_feature_names(self):
138 return self.extraction_pipeline.named_steps['union'].get_feature_names()
139
140 def overwrite_classes(self, bugs, classes, probabilities):
141 for i, bug in enumerate(bugs):
142 if any(keyword in bug['keywords'] for keyword in ['regression', 'talos-regression']) or ('cf_has_regression_range' in bug and bug['cf_has_regression_range'] == 'yes'):
143 classes[i] = 1 if not probabilities else [0., 1.]
144 elif 'feature' in bug['keywords']:
145 classes[i] = 0 if not probabilities else [1., 0.]
146
147 return classes
148
[end of bugbug/models/bug.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bugbug/models/bug.py b/bugbug/models/bug.py
--- a/bugbug/models/bug.py
+++ b/bugbug/models/bug.py
@@ -39,6 +39,8 @@
bug_features.blocked_bugs_number(),
bug_features.ever_affected(),
bug_features.affected_then_unaffected(),
+ bug_features.product(),
+ bug_features.component(),
]
cleanup_functions = [
|
{"golden_diff": "diff --git a/bugbug/models/bug.py b/bugbug/models/bug.py\n--- a/bugbug/models/bug.py\n+++ b/bugbug/models/bug.py\n@@ -39,6 +39,8 @@\n bug_features.blocked_bugs_number(),\n bug_features.ever_affected(),\n bug_features.affected_then_unaffected(),\n+ bug_features.product(),\n+ bug_features.component(),\n ]\n \n cleanup_functions = [\n", "issue": "Use 'product' and 'component' features in the models\nb7369ea8bf282941ce4b378ad5ad3c832db20668 introduced the features, but we are still not using them.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport xgboost\nfrom imblearn.over_sampling import BorderlineSMOTE\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features\nfrom bugbug import bugzilla\nfrom bugbug import labels\nfrom bugbug.model import Model\n\n\nclass BugModel(Model):\n def __init__(self, lemmatization=False):\n Model.__init__(self, lemmatization)\n\n self.sampler = BorderlineSMOTE(random_state=0)\n\n feature_extractors = [\n bug_features.has_str(),\n bug_features.severity(),\n # Ignore keywords that would make the ML completely skewed\n # (we are going to use them as 100% rules in the evaluation phase).\n bug_features.keywords({'regression', 'talos-regression', 'feature'}),\n bug_features.is_coverity_issue(),\n bug_features.has_crash_signature(),\n bug_features.has_url(),\n bug_features.has_w3c_url(),\n bug_features.has_github_url(),\n bug_features.whiteboard(),\n bug_features.patches(),\n bug_features.landings(),\n bug_features.title(),\n bug_features.blocked_bugs_number(),\n bug_features.ever_affected(),\n bug_features.affected_then_unaffected(),\n ]\n\n cleanup_functions = [\n bug_features.cleanup_url,\n bug_features.cleanup_fileref,\n bug_features.cleanup_synonyms,\n ]\n\n self.extraction_pipeline = Pipeline([\n ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions)),\n ('union', ColumnTransformer([\n ('data', DictVectorizer(), 'data'),\n\n ('title', self.text_vectorizer(min_df=0.001), 'title'),\n\n ('first_comment', self.text_vectorizer(min_df=0.001), 'first_comment'),\n\n ('comments', self.text_vectorizer(min_df=0.001), 'comments'),\n ])),\n ])\n\n self.clf = xgboost.XGBClassifier(n_jobs=16)\n self.clf.set_params(predictor='cpu_predictor')\n\n def get_bugbug_labels(self, kind='bug'):\n assert kind in ['bug', 'regression', 'defect_feature_task']\n\n classes = {}\n\n for bug_id, category in labels.get_labels('bug_nobug'):\n assert category in ['True', 'False'], f'unexpected category {category}'\n if kind == 'bug':\n classes[int(bug_id)] = 1 if category == 'True' else 0\n elif kind == 'regression':\n if category == 'False':\n classes[int(bug_id)] = 0\n elif kind == 'defect_feature_task':\n if category == 'True':\n classes[int(bug_id)] = 'd'\n\n for bug_id, category in labels.get_labels('regression_bug_nobug'):\n assert category in ['nobug', 'bug_unknown_regression', 'bug_no_regression', 'regression'], f'unexpected category {category}'\n if kind == 'bug':\n classes[int(bug_id)] = 1 if category != 'nobug' else 0\n elif kind == 'regression':\n if category == 'bug_unknown_regression':\n continue\n\n classes[int(bug_id)] = 1 if category == 'regression' else 0\n elif kind == 'defect_feature_task':\n if category != 'nobug':\n classes[int(bug_id)] = 'd'\n\n for bug_id, category in labels.get_labels('defect_feature_task'):\n assert category in ['d', 'f', 't']\n if kind == 'bug':\n classes[int(bug_id)] = 1 if category == 'd' else 0\n elif kind == 'regression':\n if category in ['f', 't']:\n classes[int(bug_id)] = 0\n elif kind == 'defect_feature_task':\n classes[int(bug_id)] = category\n\n # Augment labes by using bugs marked as 'regression' or 'feature', as they are basically labelled.\n bug_ids = set()\n for bug in bugzilla.get_bugs():\n bug_id = int(bug['id'])\n\n bug_ids.add(bug_id)\n\n if bug_id in classes:\n continue\n\n if any(keyword in bug['keywords'] for keyword in ['regression', 'talos-regression']) or ('cf_has_regression_range' in bug and bug['cf_has_regression_range'] == 'yes'):\n if kind in ['bug', 'regression']:\n classes[bug_id] = 1\n else:\n classes[bug_id] = 'd'\n elif any(keyword in bug['keywords'] for keyword in ['feature']):\n if kind in ['bug', 'regression']:\n classes[bug_id] = 0\n else:\n classes[bug_id] = 'f'\n elif kind == 'regression':\n for history in bug['history']:\n for change in history['changes']:\n if change['field_name'] == 'keywords' and change['removed'] == 'regression':\n classes[bug_id] = 0\n\n # Remove labels which belong to bugs for which we have no data.\n return {bug_id: label for bug_id, label in classes.items() if bug_id in bug_ids}\n\n def get_labels(self):\n return self.get_bugbug_labels('bug')\n\n def get_feature_names(self):\n return self.extraction_pipeline.named_steps['union'].get_feature_names()\n\n def overwrite_classes(self, bugs, classes, probabilities):\n for i, bug in enumerate(bugs):\n if any(keyword in bug['keywords'] for keyword in ['regression', 'talos-regression']) or ('cf_has_regression_range' in bug and bug['cf_has_regression_range'] == 'yes'):\n classes[i] = 1 if not probabilities else [0., 1.]\n elif 'feature' in bug['keywords']:\n classes[i] = 0 if not probabilities else [1., 0.]\n\n return classes\n", "path": "bugbug/models/bug.py"}]}
| 2,290 | 98 |
gh_patches_debug_50396
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-2467
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow simple loading of "dummy" configuration
A simple method to load a minimal configuration should be added.
This can be handy for some data-analysis tasks in notebooks, where no full configuration is needed or necessary.
Something like `Configuration.get_empty_config()`, which contains the minimum required keys set to default values
</issue>
<code>
[start of freqtrade/configuration/check_exchange.py]
1 import logging
2 from typing import Any, Dict
3
4 from freqtrade import OperationalException
5 from freqtrade.exchange import (available_exchanges, get_exchange_bad_reason,
6 is_exchange_known_ccxt, is_exchange_bad,
7 is_exchange_officially_supported)
8 from freqtrade.state import RunMode
9
10 logger = logging.getLogger(__name__)
11
12
13 def check_exchange(config: Dict[str, Any], check_for_bad: bool = True) -> bool:
14 """
15 Check if the exchange name in the config file is supported by Freqtrade
16 :param check_for_bad: if True, check the exchange against the list of known 'bad'
17 exchanges
18 :return: False if exchange is 'bad', i.e. is known to work with the bot with
19 critical issues or does not work at all, crashes, etc. True otherwise.
20 raises an exception if the exchange if not supported by ccxt
21 and thus is not known for the Freqtrade at all.
22 """
23
24 if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE]
25 and not config.get('exchange', {}).get('name')):
26 # Skip checking exchange in plot mode, since it requires no exchange
27 return True
28 logger.info("Checking exchange...")
29
30 exchange = config.get('exchange', {}).get('name').lower()
31 if not exchange:
32 raise OperationalException(
33 f'This command requires a configured exchange. You should either use '
34 f'`--exchange <exchange_name>` or specify a configuration file via `--config`.\n'
35 f'The following exchanges are available for Freqtrade: '
36 f'{", ".join(available_exchanges())}'
37 )
38
39 if not is_exchange_known_ccxt(exchange):
40 raise OperationalException(
41 f'Exchange "{exchange}" is not known to the ccxt library '
42 f'and therefore not available for the bot.\n'
43 f'The following exchanges are available for Freqtrade: '
44 f'{", ".join(available_exchanges())}'
45 )
46
47 if check_for_bad and is_exchange_bad(exchange):
48 raise OperationalException(f'Exchange "{exchange}" is known to not work with the bot yet. '
49 f'Reason: {get_exchange_bad_reason(exchange)}')
50
51 if is_exchange_officially_supported(exchange):
52 logger.info(f'Exchange "{exchange}" is officially supported '
53 f'by the Freqtrade development team.')
54 else:
55 logger.warning(f'Exchange "{exchange}" is known to the the ccxt library, '
56 f'available for the bot, but not officially supported '
57 f'by the Freqtrade development team. '
58 f'It may work flawlessly (please report back) or have serious issues. '
59 f'Use it at your own discretion.')
60
61 return True
62
[end of freqtrade/configuration/check_exchange.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/freqtrade/configuration/check_exchange.py b/freqtrade/configuration/check_exchange.py
--- a/freqtrade/configuration/check_exchange.py
+++ b/freqtrade/configuration/check_exchange.py
@@ -21,7 +21,7 @@
and thus is not known for the Freqtrade at all.
"""
- if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE]
+ if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE, RunMode.OTHER]
and not config.get('exchange', {}).get('name')):
# Skip checking exchange in plot mode, since it requires no exchange
return True
|
{"golden_diff": "diff --git a/freqtrade/configuration/check_exchange.py b/freqtrade/configuration/check_exchange.py\n--- a/freqtrade/configuration/check_exchange.py\n+++ b/freqtrade/configuration/check_exchange.py\n@@ -21,7 +21,7 @@\n and thus is not known for the Freqtrade at all.\n \"\"\"\n \n- if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE]\n+ if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE, RunMode.OTHER]\n and not config.get('exchange', {}).get('name')):\n # Skip checking exchange in plot mode, since it requires no exchange\n return True\n", "issue": "Allow simple loading of \"dummy\" configuration\nA simple method to load a minimal configuration should be added.\r\n\r\nThis can be handy for some data-analysis tasks in notebooks, where no full configuration is needed or necessary.\r\n\r\nSomething like `Configuration.get_empty_config()`, which contains the minimum required keys set to default values\n", "before_files": [{"content": "import logging\nfrom typing import Any, Dict\n\nfrom freqtrade import OperationalException\nfrom freqtrade.exchange import (available_exchanges, get_exchange_bad_reason,\n is_exchange_known_ccxt, is_exchange_bad,\n is_exchange_officially_supported)\nfrom freqtrade.state import RunMode\n\nlogger = logging.getLogger(__name__)\n\n\ndef check_exchange(config: Dict[str, Any], check_for_bad: bool = True) -> bool:\n \"\"\"\n Check if the exchange name in the config file is supported by Freqtrade\n :param check_for_bad: if True, check the exchange against the list of known 'bad'\n exchanges\n :return: False if exchange is 'bad', i.e. is known to work with the bot with\n critical issues or does not work at all, crashes, etc. True otherwise.\n raises an exception if the exchange if not supported by ccxt\n and thus is not known for the Freqtrade at all.\n \"\"\"\n\n if (config['runmode'] in [RunMode.PLOT, RunMode.UTIL_NO_EXCHANGE]\n and not config.get('exchange', {}).get('name')):\n # Skip checking exchange in plot mode, since it requires no exchange\n return True\n logger.info(\"Checking exchange...\")\n\n exchange = config.get('exchange', {}).get('name').lower()\n if not exchange:\n raise OperationalException(\n f'This command requires a configured exchange. You should either use '\n f'`--exchange <exchange_name>` or specify a configuration file via `--config`.\\n'\n f'The following exchanges are available for Freqtrade: '\n f'{\", \".join(available_exchanges())}'\n )\n\n if not is_exchange_known_ccxt(exchange):\n raise OperationalException(\n f'Exchange \"{exchange}\" is not known to the ccxt library '\n f'and therefore not available for the bot.\\n'\n f'The following exchanges are available for Freqtrade: '\n f'{\", \".join(available_exchanges())}'\n )\n\n if check_for_bad and is_exchange_bad(exchange):\n raise OperationalException(f'Exchange \"{exchange}\" is known to not work with the bot yet. '\n f'Reason: {get_exchange_bad_reason(exchange)}')\n\n if is_exchange_officially_supported(exchange):\n logger.info(f'Exchange \"{exchange}\" is officially supported '\n f'by the Freqtrade development team.')\n else:\n logger.warning(f'Exchange \"{exchange}\" is known to the the ccxt library, '\n f'available for the bot, but not officially supported '\n f'by the Freqtrade development team. '\n f'It may work flawlessly (please report back) or have serious issues. '\n f'Use it at your own discretion.')\n\n return True\n", "path": "freqtrade/configuration/check_exchange.py"}]}
| 1,311 | 154 |
gh_patches_debug_13009
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1229
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow PatientID, PatientName and StudyDate through in metadata of mha/mhd,zraw
See title. This metadata is scrubbed of during import, but should stay, because it can be used by the ImageInfoPlugin
</issue>
<code>
[start of app/grandchallenge/cases/image_builders/metaio_utils.py]
1 import re
2 import zlib
3 from pathlib import Path
4 from typing import Any, Dict, List, Mapping, Pattern, Tuple, Union
5
6 import SimpleITK
7 import SimpleITK._SimpleITK as _SimpleITK
8 from django.core.files import File
9
10 METAIO_IMAGE_TYPES = {
11 "MET_NONE": None,
12 "MET_ASCII_CHAR": None,
13 "MET_CHAR": SimpleITK.sitkInt8,
14 "MET_UCHAR": SimpleITK.sitkUInt8,
15 "MET_SHORT": SimpleITK.sitkInt16,
16 "MET_USHORT": SimpleITK.sitkUInt16,
17 "MET_INT": SimpleITK.sitkInt32,
18 "MET_UINT": SimpleITK.sitkUInt32,
19 "MET_LONG": SimpleITK.sitkInt64,
20 "MET_ULONG": SimpleITK.sitkUInt64,
21 "MET_LONG_LONG": None,
22 "MET_ULONG_LONG": None,
23 "MET_FLOAT": SimpleITK.sitkFloat32,
24 "MET_DOUBLE": SimpleITK.sitkFloat64,
25 "MET_STRING": None,
26 "MET_CHAR_ARRAY": SimpleITK.sitkVectorInt8,
27 "MET_UCHAR_ARRAY": SimpleITK.sitkVectorUInt8,
28 "MET_SHORT_ARRAY": SimpleITK.sitkVectorInt16,
29 "MET_USHORT_ARRAY": SimpleITK.sitkVectorUInt16,
30 "MET_INT_ARRAY": SimpleITK.sitkVectorInt32,
31 "MET_UINT_ARRAY": SimpleITK.sitkVectorUInt32,
32 "MET_LONG_ARRAY": SimpleITK.sitkVectorInt64,
33 "MET_ULONG_ARRAY": SimpleITK.sitkVectorUInt64,
34 "MET_LONG_LONG_ARRAY": None,
35 "MET_ULONG_LONG_ARRAY": None,
36 "MET_FLOAT_ARRAY": SimpleITK.sitkVectorFloat32,
37 "MET_DOUBLE_ARRAY": SimpleITK.sitkVectorFloat64,
38 "MET_FLOAT_MATRIX": None,
39 "MET_OTHER": None,
40 }
41
42 FLOAT_MATCH_REGEXP: Pattern = re.compile(
43 r"^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$"
44 )
45 FLOAT_LIST_MATCH_REGEXP: Pattern = re.compile(
46 r"^([-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?)"
47 r"(\s[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?)*$"
48 )
49 CONTENT_TIMES_LIST_MATCH_REGEXP: Pattern = re.compile(
50 r"^((2[0-3]|[0-1]\d)[0-5]\d[0-5]\d(\.\d\d\d)?)"
51 r"(\s(2[0-3]|[0-1]\d)[0-5]\d[0-5]\d(\.\d\d\d)?)*$"
52 )
53
54 ADDITIONAL_HEADERS: Dict[str, Pattern] = {
55 "Exposures": FLOAT_LIST_MATCH_REGEXP,
56 "ContentTimes": CONTENT_TIMES_LIST_MATCH_REGEXP,
57 "t0": FLOAT_MATCH_REGEXP,
58 "t1": FLOAT_MATCH_REGEXP,
59 }
60
61 HEADERS_MATCHING_NUM_TIMEPOINTS: List[str] = ["Exposures", "ContentTimes"]
62
63 EXPECTED_HEADERS: List[str] = [
64 "ObjectType",
65 "NDims",
66 "BinaryData",
67 "BinaryDataByteOrderMSB",
68 "CompressedData",
69 "CompressedDataSize",
70 "TransformMatrix",
71 "Offset",
72 "CenterOfRotation",
73 "AnatomicalOrientation",
74 "ElementSpacing",
75 "ElementNumberOfChannels",
76 "DimSize",
77 "ElementType",
78 "ElementDataFile",
79 ]
80
81
82 def parse_mh_header(file: File) -> Mapping[str, Union[str, None]]:
83 """
84 Attempts to parse the headers of an mhd file.
85
86 This function must be secure to safeguard against any untrusted uploaded
87 file.
88
89 Parameters
90 ----------
91 filename
92
93 Returns
94 -------
95 The extracted header from the mhd file as key value pairs.
96
97 Raises
98 ------
99 ValueError
100 Raised when the file contains problems making it impossible to
101 read.
102 """
103
104 # attempt to limit number of read headers to prevent overflow attacks
105 read_line_limit = 10000
106
107 result = {}
108 with file.open("rb") as f:
109 bin_line = True
110 while bin_line is not None:
111 read_line_limit -= 1
112 if read_line_limit < 0:
113 raise ValueError("Files contains too many header lines")
114
115 bin_line = f.readline(10000)
116 if not bin_line:
117 bin_line = None
118 continue
119 if len(bin_line) >= 10000:
120 raise ValueError("Line length is too long")
121
122 try:
123 line = bin_line.decode("utf-8")
124 except UnicodeDecodeError:
125 raise ValueError("Header contains invalid UTF-8")
126 else:
127 extract_key_value_pairs(line, result)
128 if "ElementDataFile" in result:
129 break # last parsed header...
130 return result
131
132
133 def extract_key_value_pairs(line: str, result: Dict[str, str]):
134 line = line.rstrip("\n\r")
135 if line.strip():
136 if "=" in line:
137 key, value = line.split("=", 1)
138 result[key.strip()] = value.strip()
139 else:
140 result[line.strip()] = None
141
142
143 def extract_header_listing(
144 property: str, headers: Mapping[str, Union[str, None]], dtype: type = float
145 ) -> List[Any]:
146 return [dtype(e) for e in headers[property].strip().split(" ")]
147
148
149 def load_sitk_image_with_nd_support(mhd_file: Path,) -> SimpleITK.Image:
150 headers = parse_mh_header(mhd_file)
151 is_mha = headers["ElementDataFile"].strip() == "LOCAL"
152 data_file_path = resolve_mh_data_file_path(headers, is_mha, mhd_file)
153
154 shape = extract_header_listing("DimSize", headers=headers, dtype=int)
155
156 dtype, num_components = determine_mh_components_and_dtype(headers)
157
158 sitk_image = create_sitk_img_from_mh_data(
159 data_file_path, dtype, headers, is_mha, num_components, shape
160 )
161
162 sitk_image.SetDirection(
163 extract_header_listing("TransformMatrix", headers=headers)
164 )
165 sitk_image.SetSpacing(
166 extract_header_listing("ElementSpacing", headers=headers)
167 )
168 sitk_image.SetOrigin(extract_header_listing("Offset", headers=headers))
169
170 return sitk_image
171
172
173 def determine_mh_components_and_dtype(
174 headers: Mapping[str, Union[str, None]]
175 ) -> Tuple[int, int]:
176 num_components = 1
177 if "ElementNumberOfChannels" in headers:
178 num_components = int(headers["ElementNumberOfChannels"])
179 if "_ARRAY" not in headers["ElementType"] and num_components > 1:
180 headers["ElementType"] = headers["ElementType"] + "_ARRAY"
181 dtype = METAIO_IMAGE_TYPES[headers["ElementType"]]
182 if dtype is None:
183 error_msg = (
184 f"MetaIO datatype: {headers['ElementType']} is not supported"
185 )
186 raise NotImplementedError(error_msg)
187 return dtype, num_components
188
189
190 def resolve_mh_data_file_path(
191 headers: Mapping[str, Union[str, None]], is_mha: bool, mhd_file: Path
192 ) -> Path:
193 if is_mha:
194 data_file_path = mhd_file
195 else:
196 data_file_path = (
197 mhd_file.resolve().parent / Path(headers["ElementDataFile"]).name
198 )
199 if not data_file_path.exists():
200 raise IOError("cannot find data file")
201 return data_file_path
202
203
204 def create_sitk_img_from_mh_data(
205 data_file_path: Path,
206 dtype: int,
207 headers: Mapping[str, Union[str, None]],
208 is_mha: bool,
209 num_components: int,
210 shape,
211 ) -> SimpleITK.Image:
212 is_compressed = headers["CompressedData"] == "True"
213 with open(str(data_file_path), "rb") as f:
214 if is_mha:
215 line = ""
216 while "ElementDataFile = LOCAL" not in str(line):
217 line = f.readline()
218 if not is_compressed:
219 s = f.read()
220 else:
221 s = zlib.decompress(f.read())
222 sitk_image = SimpleITK.Image(shape, dtype, num_components)
223 _SimpleITK._SetImageFromArray(s, sitk_image)
224 return sitk_image
225
226
227 def validate_and_clean_additional_mh_headers(
228 headers: Mapping[str, Union[str, None]]
229 ) -> Mapping[str, Union[str, None]]:
230 cleaned_headers = {}
231 for key, value in headers.items():
232 if key in EXPECTED_HEADERS:
233 cleaned_headers[key] = value
234 else:
235 if key in ADDITIONAL_HEADERS:
236 match_pattern = ADDITIONAL_HEADERS[key]
237 if not re.match(match_pattern, value):
238 raise ValueError(
239 f"Invalid data type found for "
240 f"additional header key: {key}"
241 )
242 cleaned_headers[key] = value
243 if key in HEADERS_MATCHING_NUM_TIMEPOINTS:
244 validate_list_data_matches_num_timepoints(
245 headers=headers, key=key, value=value
246 )
247
248 return cleaned_headers
249
250
251 def validate_list_data_matches_num_timepoints(
252 headers: Mapping[str, Union[str, None]], key: str, value: str
253 ):
254 num_timepoints = len(value.split(" "))
255 expected_timepoints = (
256 int(headers["DimSize"].split(" ")[3])
257 if int(headers["NDims"]) >= 4
258 else 1
259 )
260 if num_timepoints != expected_timepoints:
261 raise ValueError(
262 f"Found {num_timepoints} values for {key}, "
263 f"but expected {expected_timepoints} (1/timepoint)"
264 )
265
266
267 def add_additional_mh_headers_to_sitk_image(
268 sitk_image: SimpleITK.Image, headers: Mapping[str, Union[str, None]]
269 ):
270 cleaned_headers = validate_and_clean_additional_mh_headers(headers)
271 for header in ADDITIONAL_HEADERS:
272 if header in cleaned_headers:
273 value = cleaned_headers[header]
274 if isinstance(value, (list, tuple)):
275 value = " ".format([str(v) for v in value])
276 else:
277 value = str(value)
278 sitk_image.SetMetaData(header, value)
279
280
281 def load_sitk_image(mhd_file: Path) -> SimpleITK.Image:
282 headers = parse_mh_header(mhd_file)
283 headers = validate_and_clean_additional_mh_headers(headers=headers)
284 ndims = int(headers["NDims"])
285 if ndims < 4:
286 sitk_image = SimpleITK.ReadImage(str(mhd_file))
287 for key in sitk_image.GetMetaDataKeys():
288 if key not in ADDITIONAL_HEADERS:
289 sitk_image.EraseMetaData(key)
290 elif ndims <= 4:
291 sitk_image = load_sitk_image_with_nd_support(mhd_file=mhd_file)
292 else:
293 error_msg = (
294 "SimpleITK images with more than 4 dimensions are not supported"
295 )
296 raise NotImplementedError(error_msg)
297 add_additional_mh_headers_to_sitk_image(
298 sitk_image=sitk_image, headers=headers
299 )
300 return sitk_image
301
[end of app/grandchallenge/cases/image_builders/metaio_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/cases/image_builders/metaio_utils.py b/app/grandchallenge/cases/image_builders/metaio_utils.py
--- a/app/grandchallenge/cases/image_builders/metaio_utils.py
+++ b/app/grandchallenge/cases/image_builders/metaio_utils.py
@@ -51,7 +51,16 @@
r"(\s(2[0-3]|[0-1]\d)[0-5]\d[0-5]\d(\.\d\d\d)?)*$"
)
+LENGTH_LIMIT_MATCH_REGEXP: Pattern = re.compile(r"^.{0,128}$")
+
+STUDYDATE_MATCH_REGEXP: Pattern = re.compile(r"^\d{4}\d{1,2}\d{1,2}$")
+
ADDITIONAL_HEADERS: Dict[str, Pattern] = {
+ "PatientID": LENGTH_LIMIT_MATCH_REGEXP,
+ "PatientName": LENGTH_LIMIT_MATCH_REGEXP,
+ "StudyDate": STUDYDATE_MATCH_REGEXP,
+ "StudyInstanceUID": LENGTH_LIMIT_MATCH_REGEXP,
+ "SeriesInstanceUID": LENGTH_LIMIT_MATCH_REGEXP,
"Exposures": FLOAT_LIST_MATCH_REGEXP,
"ContentTimes": CONTENT_TIMES_LIST_MATCH_REGEXP,
"t0": FLOAT_MATCH_REGEXP,
|
{"golden_diff": "diff --git a/app/grandchallenge/cases/image_builders/metaio_utils.py b/app/grandchallenge/cases/image_builders/metaio_utils.py\n--- a/app/grandchallenge/cases/image_builders/metaio_utils.py\n+++ b/app/grandchallenge/cases/image_builders/metaio_utils.py\n@@ -51,7 +51,16 @@\n r\"(\\s(2[0-3]|[0-1]\\d)[0-5]\\d[0-5]\\d(\\.\\d\\d\\d)?)*$\"\n )\n \n+LENGTH_LIMIT_MATCH_REGEXP: Pattern = re.compile(r\"^.{0,128}$\")\n+\n+STUDYDATE_MATCH_REGEXP: Pattern = re.compile(r\"^\\d{4}\\d{1,2}\\d{1,2}$\")\n+\n ADDITIONAL_HEADERS: Dict[str, Pattern] = {\n+ \"PatientID\": LENGTH_LIMIT_MATCH_REGEXP,\n+ \"PatientName\": LENGTH_LIMIT_MATCH_REGEXP,\n+ \"StudyDate\": STUDYDATE_MATCH_REGEXP,\n+ \"StudyInstanceUID\": LENGTH_LIMIT_MATCH_REGEXP,\n+ \"SeriesInstanceUID\": LENGTH_LIMIT_MATCH_REGEXP,\n \"Exposures\": FLOAT_LIST_MATCH_REGEXP,\n \"ContentTimes\": CONTENT_TIMES_LIST_MATCH_REGEXP,\n \"t0\": FLOAT_MATCH_REGEXP,\n", "issue": "Allow PatientID, PatientName and StudyDate through in metadata of mha/mhd,zraw\nSee title. This metadata is scrubbed of during import, but should stay, because it can be used by the ImageInfoPlugin\n", "before_files": [{"content": "import re\nimport zlib\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Mapping, Pattern, Tuple, Union\n\nimport SimpleITK\nimport SimpleITK._SimpleITK as _SimpleITK\nfrom django.core.files import File\n\nMETAIO_IMAGE_TYPES = {\n \"MET_NONE\": None,\n \"MET_ASCII_CHAR\": None,\n \"MET_CHAR\": SimpleITK.sitkInt8,\n \"MET_UCHAR\": SimpleITK.sitkUInt8,\n \"MET_SHORT\": SimpleITK.sitkInt16,\n \"MET_USHORT\": SimpleITK.sitkUInt16,\n \"MET_INT\": SimpleITK.sitkInt32,\n \"MET_UINT\": SimpleITK.sitkUInt32,\n \"MET_LONG\": SimpleITK.sitkInt64,\n \"MET_ULONG\": SimpleITK.sitkUInt64,\n \"MET_LONG_LONG\": None,\n \"MET_ULONG_LONG\": None,\n \"MET_FLOAT\": SimpleITK.sitkFloat32,\n \"MET_DOUBLE\": SimpleITK.sitkFloat64,\n \"MET_STRING\": None,\n \"MET_CHAR_ARRAY\": SimpleITK.sitkVectorInt8,\n \"MET_UCHAR_ARRAY\": SimpleITK.sitkVectorUInt8,\n \"MET_SHORT_ARRAY\": SimpleITK.sitkVectorInt16,\n \"MET_USHORT_ARRAY\": SimpleITK.sitkVectorUInt16,\n \"MET_INT_ARRAY\": SimpleITK.sitkVectorInt32,\n \"MET_UINT_ARRAY\": SimpleITK.sitkVectorUInt32,\n \"MET_LONG_ARRAY\": SimpleITK.sitkVectorInt64,\n \"MET_ULONG_ARRAY\": SimpleITK.sitkVectorUInt64,\n \"MET_LONG_LONG_ARRAY\": None,\n \"MET_ULONG_LONG_ARRAY\": None,\n \"MET_FLOAT_ARRAY\": SimpleITK.sitkVectorFloat32,\n \"MET_DOUBLE_ARRAY\": SimpleITK.sitkVectorFloat64,\n \"MET_FLOAT_MATRIX\": None,\n \"MET_OTHER\": None,\n}\n\nFLOAT_MATCH_REGEXP: Pattern = re.compile(\n r\"^[-+]?[0-9]*\\.?[0-9]+([eE][-+]?[0-9]+)?$\"\n)\nFLOAT_LIST_MATCH_REGEXP: Pattern = re.compile(\n r\"^([-+]?[0-9]*\\.?[0-9]+([eE][-+]?[0-9]+)?)\"\n r\"(\\s[-+]?[0-9]*\\.?[0-9]+([eE][-+]?[0-9]+)?)*$\"\n)\nCONTENT_TIMES_LIST_MATCH_REGEXP: Pattern = re.compile(\n r\"^((2[0-3]|[0-1]\\d)[0-5]\\d[0-5]\\d(\\.\\d\\d\\d)?)\"\n r\"(\\s(2[0-3]|[0-1]\\d)[0-5]\\d[0-5]\\d(\\.\\d\\d\\d)?)*$\"\n)\n\nADDITIONAL_HEADERS: Dict[str, Pattern] = {\n \"Exposures\": FLOAT_LIST_MATCH_REGEXP,\n \"ContentTimes\": CONTENT_TIMES_LIST_MATCH_REGEXP,\n \"t0\": FLOAT_MATCH_REGEXP,\n \"t1\": FLOAT_MATCH_REGEXP,\n}\n\nHEADERS_MATCHING_NUM_TIMEPOINTS: List[str] = [\"Exposures\", \"ContentTimes\"]\n\nEXPECTED_HEADERS: List[str] = [\n \"ObjectType\",\n \"NDims\",\n \"BinaryData\",\n \"BinaryDataByteOrderMSB\",\n \"CompressedData\",\n \"CompressedDataSize\",\n \"TransformMatrix\",\n \"Offset\",\n \"CenterOfRotation\",\n \"AnatomicalOrientation\",\n \"ElementSpacing\",\n \"ElementNumberOfChannels\",\n \"DimSize\",\n \"ElementType\",\n \"ElementDataFile\",\n]\n\n\ndef parse_mh_header(file: File) -> Mapping[str, Union[str, None]]:\n \"\"\"\n Attempts to parse the headers of an mhd file.\n\n This function must be secure to safeguard against any untrusted uploaded\n file.\n\n Parameters\n ----------\n filename\n\n Returns\n -------\n The extracted header from the mhd file as key value pairs.\n\n Raises\n ------\n ValueError\n Raised when the file contains problems making it impossible to\n read.\n \"\"\"\n\n # attempt to limit number of read headers to prevent overflow attacks\n read_line_limit = 10000\n\n result = {}\n with file.open(\"rb\") as f:\n bin_line = True\n while bin_line is not None:\n read_line_limit -= 1\n if read_line_limit < 0:\n raise ValueError(\"Files contains too many header lines\")\n\n bin_line = f.readline(10000)\n if not bin_line:\n bin_line = None\n continue\n if len(bin_line) >= 10000:\n raise ValueError(\"Line length is too long\")\n\n try:\n line = bin_line.decode(\"utf-8\")\n except UnicodeDecodeError:\n raise ValueError(\"Header contains invalid UTF-8\")\n else:\n extract_key_value_pairs(line, result)\n if \"ElementDataFile\" in result:\n break # last parsed header...\n return result\n\n\ndef extract_key_value_pairs(line: str, result: Dict[str, str]):\n line = line.rstrip(\"\\n\\r\")\n if line.strip():\n if \"=\" in line:\n key, value = line.split(\"=\", 1)\n result[key.strip()] = value.strip()\n else:\n result[line.strip()] = None\n\n\ndef extract_header_listing(\n property: str, headers: Mapping[str, Union[str, None]], dtype: type = float\n) -> List[Any]:\n return [dtype(e) for e in headers[property].strip().split(\" \")]\n\n\ndef load_sitk_image_with_nd_support(mhd_file: Path,) -> SimpleITK.Image:\n headers = parse_mh_header(mhd_file)\n is_mha = headers[\"ElementDataFile\"].strip() == \"LOCAL\"\n data_file_path = resolve_mh_data_file_path(headers, is_mha, mhd_file)\n\n shape = extract_header_listing(\"DimSize\", headers=headers, dtype=int)\n\n dtype, num_components = determine_mh_components_and_dtype(headers)\n\n sitk_image = create_sitk_img_from_mh_data(\n data_file_path, dtype, headers, is_mha, num_components, shape\n )\n\n sitk_image.SetDirection(\n extract_header_listing(\"TransformMatrix\", headers=headers)\n )\n sitk_image.SetSpacing(\n extract_header_listing(\"ElementSpacing\", headers=headers)\n )\n sitk_image.SetOrigin(extract_header_listing(\"Offset\", headers=headers))\n\n return sitk_image\n\n\ndef determine_mh_components_and_dtype(\n headers: Mapping[str, Union[str, None]]\n) -> Tuple[int, int]:\n num_components = 1\n if \"ElementNumberOfChannels\" in headers:\n num_components = int(headers[\"ElementNumberOfChannels\"])\n if \"_ARRAY\" not in headers[\"ElementType\"] and num_components > 1:\n headers[\"ElementType\"] = headers[\"ElementType\"] + \"_ARRAY\"\n dtype = METAIO_IMAGE_TYPES[headers[\"ElementType\"]]\n if dtype is None:\n error_msg = (\n f\"MetaIO datatype: {headers['ElementType']} is not supported\"\n )\n raise NotImplementedError(error_msg)\n return dtype, num_components\n\n\ndef resolve_mh_data_file_path(\n headers: Mapping[str, Union[str, None]], is_mha: bool, mhd_file: Path\n) -> Path:\n if is_mha:\n data_file_path = mhd_file\n else:\n data_file_path = (\n mhd_file.resolve().parent / Path(headers[\"ElementDataFile\"]).name\n )\n if not data_file_path.exists():\n raise IOError(\"cannot find data file\")\n return data_file_path\n\n\ndef create_sitk_img_from_mh_data(\n data_file_path: Path,\n dtype: int,\n headers: Mapping[str, Union[str, None]],\n is_mha: bool,\n num_components: int,\n shape,\n) -> SimpleITK.Image:\n is_compressed = headers[\"CompressedData\"] == \"True\"\n with open(str(data_file_path), \"rb\") as f:\n if is_mha:\n line = \"\"\n while \"ElementDataFile = LOCAL\" not in str(line):\n line = f.readline()\n if not is_compressed:\n s = f.read()\n else:\n s = zlib.decompress(f.read())\n sitk_image = SimpleITK.Image(shape, dtype, num_components)\n _SimpleITK._SetImageFromArray(s, sitk_image)\n return sitk_image\n\n\ndef validate_and_clean_additional_mh_headers(\n headers: Mapping[str, Union[str, None]]\n) -> Mapping[str, Union[str, None]]:\n cleaned_headers = {}\n for key, value in headers.items():\n if key in EXPECTED_HEADERS:\n cleaned_headers[key] = value\n else:\n if key in ADDITIONAL_HEADERS:\n match_pattern = ADDITIONAL_HEADERS[key]\n if not re.match(match_pattern, value):\n raise ValueError(\n f\"Invalid data type found for \"\n f\"additional header key: {key}\"\n )\n cleaned_headers[key] = value\n if key in HEADERS_MATCHING_NUM_TIMEPOINTS:\n validate_list_data_matches_num_timepoints(\n headers=headers, key=key, value=value\n )\n\n return cleaned_headers\n\n\ndef validate_list_data_matches_num_timepoints(\n headers: Mapping[str, Union[str, None]], key: str, value: str\n):\n num_timepoints = len(value.split(\" \"))\n expected_timepoints = (\n int(headers[\"DimSize\"].split(\" \")[3])\n if int(headers[\"NDims\"]) >= 4\n else 1\n )\n if num_timepoints != expected_timepoints:\n raise ValueError(\n f\"Found {num_timepoints} values for {key}, \"\n f\"but expected {expected_timepoints} (1/timepoint)\"\n )\n\n\ndef add_additional_mh_headers_to_sitk_image(\n sitk_image: SimpleITK.Image, headers: Mapping[str, Union[str, None]]\n):\n cleaned_headers = validate_and_clean_additional_mh_headers(headers)\n for header in ADDITIONAL_HEADERS:\n if header in cleaned_headers:\n value = cleaned_headers[header]\n if isinstance(value, (list, tuple)):\n value = \" \".format([str(v) for v in value])\n else:\n value = str(value)\n sitk_image.SetMetaData(header, value)\n\n\ndef load_sitk_image(mhd_file: Path) -> SimpleITK.Image:\n headers = parse_mh_header(mhd_file)\n headers = validate_and_clean_additional_mh_headers(headers=headers)\n ndims = int(headers[\"NDims\"])\n if ndims < 4:\n sitk_image = SimpleITK.ReadImage(str(mhd_file))\n for key in sitk_image.GetMetaDataKeys():\n if key not in ADDITIONAL_HEADERS:\n sitk_image.EraseMetaData(key)\n elif ndims <= 4:\n sitk_image = load_sitk_image_with_nd_support(mhd_file=mhd_file)\n else:\n error_msg = (\n \"SimpleITK images with more than 4 dimensions are not supported\"\n )\n raise NotImplementedError(error_msg)\n add_additional_mh_headers_to_sitk_image(\n sitk_image=sitk_image, headers=headers\n )\n return sitk_image\n", "path": "app/grandchallenge/cases/image_builders/metaio_utils.py"}]}
| 3,892 | 281 |
gh_patches_debug_34359
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-975
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_103 should not trigger for TCP NLB's
Hi!
CKV_AWS_103 throws an error when using an NLB with TCP protocol.
However, setting an `ssl_policy` only make sense for ELB's with protocol HTTPS or TLS.
```
14 | resource "aws_lb_listener" "nlb_listener_https" {
15 | load_balancer_arn = aws_lb.nlb.arn
16 | port = xxxxxxxx
17 | protocol = "TCP"
18 | default_action {
19 | target_group_arn = aws_lb_target_group.nlb_target_group.id
20 | type = "forward"
21 | }
22 | }
```
`Check: CKV_AWS_103: "Ensure that load balancer is using TLS 1.2"
FAILED for resource: aws_lb_listener.nlb_listener_https
File: /nlb.tf:14-22
Guide: https://docs.bridgecrew.io/docs/bc_aws_general_43`
**Expected behavior**
Check is PASSED instead of FAILED.
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py]
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4
5 class AppLoadBalancerTLS12(BaseResourceCheck):
6 def __init__(self):
7 name = "Ensure that load balancer is using TLS 1.2"
8 id = "CKV_AWS_103"
9 supported_resources = ['aws_lb_listener']
10 categories = [CheckCategories.GENERAL_SECURITY]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def scan_resource_conf(self, conf):
14 key="protocol"
15 if key in conf.keys():
16 if conf[key] in (["HTTPS"], ["TLS"]):
17 # Only interested in HTTPS & TLS listeners
18 policy="ssl_policy"
19 if policy in conf.keys():
20 name=str(conf[policy]).strip("['']")
21 if name.startswith("ELBSecurityPolicy-FS-1-2") or name.startswith("ELBSecurityPolicy-TLS-1-2"):
22 return CheckResult.PASSED
23 else:
24 return CheckResult.FAILED
25 else:
26 return CheckResult.FAILED
27 else:
28 for action in conf.get('default_action',[]):
29 for redirect in action.get('redirect',[]):
30 if redirect.get('protocol',[]) == ["HTTPS"]:
31 return CheckResult.PASSED
32 return CheckResult.FAILED
33 else:
34 return CheckResult.FAILED
35
36
37 check = AppLoadBalancerTLS12()
38
[end of checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
--- a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
+++ b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py
@@ -6,28 +6,35 @@
def __init__(self):
name = "Ensure that load balancer is using TLS 1.2"
id = "CKV_AWS_103"
- supported_resources = ['aws_lb_listener']
+ supported_resources = ["aws_lb_listener"]
categories = [CheckCategories.GENERAL_SECURITY]
- super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
+ super().__init__(
+ name=name,
+ id=id,
+ categories=categories,
+ supported_resources=supported_resources,
+ )
def scan_resource_conf(self, conf):
- key="protocol"
+ key = "protocol"
if key in conf.keys():
if conf[key] in (["HTTPS"], ["TLS"]):
- # Only interested in HTTPS & TLS listeners
- policy="ssl_policy"
+ # Only interested in HTTPS & TLS listeners
+ policy = "ssl_policy"
if policy in conf.keys():
- name=str(conf[policy]).strip("['']")
- if name.startswith("ELBSecurityPolicy-FS-1-2") or name.startswith("ELBSecurityPolicy-TLS-1-2"):
- return CheckResult.PASSED
- else:
- return CheckResult.FAILED
+ name = str(conf[policy]).strip("['']")
+ if name.startswith("ELBSecurityPolicy-FS-1-2") or name.startswith("ELBSecurityPolicy-TLS-1-2"):
+ return CheckResult.PASSED
+ else:
+ return CheckResult.FAILED
else:
- return CheckResult.FAILED
+ return CheckResult.FAILED
+ elif conf[key] in (["TCP"], ["UDP"], ["TCP_UDP"]):
+ return CheckResult.PASSED
else:
- for action in conf.get('default_action',[]):
- for redirect in action.get('redirect',[]):
- if redirect.get('protocol',[]) == ["HTTPS"]:
+ for action in conf.get("default_action", []):
+ for redirect in action.get("redirect", []):
+ if redirect.get("protocol", []) == ["HTTPS"]:
return CheckResult.PASSED
return CheckResult.FAILED
else:
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n--- a/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n+++ b/checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py\n@@ -6,28 +6,35 @@\n def __init__(self):\n name = \"Ensure that load balancer is using TLS 1.2\"\n id = \"CKV_AWS_103\"\n- supported_resources = ['aws_lb_listener']\n+ supported_resources = [\"aws_lb_listener\"]\n categories = [CheckCategories.GENERAL_SECURITY]\n- super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n+ super().__init__(\n+ name=name,\n+ id=id,\n+ categories=categories,\n+ supported_resources=supported_resources,\n+ )\n \n def scan_resource_conf(self, conf):\n- key=\"protocol\"\n+ key = \"protocol\"\n if key in conf.keys():\n if conf[key] in ([\"HTTPS\"], [\"TLS\"]):\n- # Only interested in HTTPS & TLS listeners\n- policy=\"ssl_policy\"\n+ # Only interested in HTTPS & TLS listeners\n+ policy = \"ssl_policy\"\n if policy in conf.keys():\n- name=str(conf[policy]).strip(\"['']\") \n- if name.startswith(\"ELBSecurityPolicy-FS-1-2\") or name.startswith(\"ELBSecurityPolicy-TLS-1-2\"):\n- return CheckResult.PASSED\n- else:\n- return CheckResult.FAILED\n+ name = str(conf[policy]).strip(\"['']\")\n+ if name.startswith(\"ELBSecurityPolicy-FS-1-2\") or name.startswith(\"ELBSecurityPolicy-TLS-1-2\"):\n+ return CheckResult.PASSED\n+ else:\n+ return CheckResult.FAILED\n else:\n- return CheckResult.FAILED\n+ return CheckResult.FAILED\n+ elif conf[key] in ([\"TCP\"], [\"UDP\"], [\"TCP_UDP\"]):\n+ return CheckResult.PASSED\n else:\n- for action in conf.get('default_action',[]):\n- for redirect in action.get('redirect',[]):\n- if redirect.get('protocol',[]) == [\"HTTPS\"]:\n+ for action in conf.get(\"default_action\", []):\n+ for redirect in action.get(\"redirect\", []):\n+ if redirect.get(\"protocol\", []) == [\"HTTPS\"]:\n return CheckResult.PASSED\n return CheckResult.FAILED\n else:\n", "issue": "CKV_AWS_103 should not trigger for TCP NLB's\nHi!\r\n\r\nCKV_AWS_103 throws an error when using an NLB with TCP protocol.\r\nHowever, setting an `ssl_policy` only make sense for ELB's with protocol HTTPS or TLS.\r\n\r\n```\r\n 14 | resource \"aws_lb_listener\" \"nlb_listener_https\" {\r\n 15 | load_balancer_arn = aws_lb.nlb.arn\r\n 16 | port = xxxxxxxx\r\n 17 | protocol = \"TCP\"\r\n 18 | default_action {\r\n 19 | target_group_arn = aws_lb_target_group.nlb_target_group.id\r\n 20 | type = \"forward\"\r\n 21 | }\r\n 22 | }\r\n```\r\n\r\n`Check: CKV_AWS_103: \"Ensure that load balancer is using TLS 1.2\"\r\n FAILED for resource: aws_lb_listener.nlb_listener_https\r\n File: /nlb.tf:14-22\r\n Guide: https://docs.bridgecrew.io/docs/bc_aws_general_43`\r\n\r\n**Expected behavior**\r\nCheck is PASSED instead of FAILED.\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass AppLoadBalancerTLS12(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure that load balancer is using TLS 1.2\"\n id = \"CKV_AWS_103\"\n supported_resources = ['aws_lb_listener']\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n key=\"protocol\"\n if key in conf.keys():\n if conf[key] in ([\"HTTPS\"], [\"TLS\"]):\n # Only interested in HTTPS & TLS listeners\n policy=\"ssl_policy\"\n if policy in conf.keys():\n name=str(conf[policy]).strip(\"['']\") \n if name.startswith(\"ELBSecurityPolicy-FS-1-2\") or name.startswith(\"ELBSecurityPolicy-TLS-1-2\"):\n return CheckResult.PASSED\n else:\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n else:\n for action in conf.get('default_action',[]):\n for redirect in action.get('redirect',[]):\n if redirect.get('protocol',[]) == [\"HTTPS\"]:\n return CheckResult.PASSED\n return CheckResult.FAILED\n else:\n return CheckResult.FAILED\n\n\ncheck = AppLoadBalancerTLS12()\n", "path": "checkov/terraform/checks/resource/aws/AppLoadBalancerTLS12.py"}]}
| 1,218 | 577 |
gh_patches_debug_56358
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-2371
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Websockets do not respect subpath
### Discussed in https://github.com/paperless-ngx/paperless-ngx/discussions/2236
<div type='discussions-op-text'>
<sup>Originally posted by **davidgiga1993** December 21, 2022</sup>
I migrated from paprless-ng to paperless-ngx and the websocket connection isn't working anymore:
```
WebSocket connection to 'wss://home.dev-core.org/paperless/ws/status/' failed:
```
The server returns status code 500.
I'm using `/paperless` as path and configured it according to the [documentation](https://docs.paperless-ngx.com/configuration/#hosting-and-security)
```
PAPERLESS_FORCE_SCRIPT_NAME=/paperless
PAPERLESS_STATIC_URL=/paperless/static/
PAPERLESS_MEDIA_URL=/paperless/media/
PAPERLESS_URL=https://my-domain.com
```
my nginx config hasn't changed since and worked fine before:
```
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $http_host;
proxy_set_header X-Forwarded-Uri $request_uri;
proxy_set_header X-Forwarded-Ssl on;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header X-Real-IP $remote_addr;
client_body_buffer_size 128k;
proxy_next_upstream error timeout;
proxy_redirect http:// $scheme://;
proxy_http_version 1.1;
proxy_cache_bypass $cookie_session;
proxy_no_cache $cookie_session;
proxy_buffers 64 256k;
# Allow websockets
proxy_cache_bypass $http_upgrade;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
real_ip_header X-Forwarded-For;
real_ip_recursive on;
send_timeout 5m;
proxy_read_timeout 360;
proxy_send_timeout 360;
proxy_connect_timeout 360;
```
It looks like paperless ngx isn't using the context path for the websockets - here is a test using curl. The first request (with the correct path) returns `500`, the second one without any context path returns correctly `403`
```
nas paperless # curl -i -N -H "Connection: Upgrade" -H "Upgrade: websocket" -H "Host: my-domain.com" -H "Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==" -H "Sec-WebSocket-Version: 13" localhost:8000/paperless/ws/status/
HTTP/1.1 500 Internal Server Error
content-type: text/plain; charset=utf-8
content-length: 21
connection: close
Internal Server Error#
nas paperless # curl -i -N -H "Connection: Upgrade" -H "Upgrade: websocket" -H "Host: my-domain.com" -H "Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==" -H "Sec-WebSocket-Version: 13" localhost:8000/ws/status/
HTTP/1.1 403 Forbidden
Date: Sun, 11 Dec 2022 10:03:35 GMT
Server: Python/3.9 websockets/10.4
Content-Length: 0
Content-Type: text/plain
Connection: close
```
any ideas? Anything else I should test?
</div>
</issue>
<code>
[start of src/paperless/urls.py]
1 from django.conf import settings
2 from django.conf.urls import include
3 from django.contrib import admin
4 from django.contrib.auth.decorators import login_required
5 from django.urls import path
6 from django.urls import re_path
7 from django.utils.translation import gettext_lazy as _
8 from django.views.decorators.csrf import csrf_exempt
9 from django.views.generic import RedirectView
10 from documents.views import AcknowledgeTasksView
11 from documents.views import BulkDownloadView
12 from documents.views import BulkEditView
13 from documents.views import CorrespondentViewSet
14 from documents.views import DocumentTypeViewSet
15 from documents.views import IndexView
16 from documents.views import LogViewSet
17 from documents.views import PostDocumentView
18 from documents.views import RemoteVersionView
19 from documents.views import SavedViewViewSet
20 from documents.views import SearchAutoCompleteView
21 from documents.views import SelectionDataView
22 from documents.views import StatisticsView
23 from documents.views import StoragePathViewSet
24 from documents.views import TagViewSet
25 from documents.views import TasksViewSet
26 from documents.views import UiSettingsView
27 from documents.views import UnifiedSearchViewSet
28 from paperless.consumers import StatusConsumer
29 from paperless.views import FaviconView
30 from paperless_mail.views import MailAccountViewSet
31 from paperless_mail.views import MailRuleViewSet
32 from rest_framework.authtoken import views
33 from rest_framework.routers import DefaultRouter
34
35 api_router = DefaultRouter()
36 api_router.register(r"correspondents", CorrespondentViewSet)
37 api_router.register(r"document_types", DocumentTypeViewSet)
38 api_router.register(r"documents", UnifiedSearchViewSet)
39 api_router.register(r"logs", LogViewSet, basename="logs")
40 api_router.register(r"tags", TagViewSet)
41 api_router.register(r"saved_views", SavedViewViewSet)
42 api_router.register(r"storage_paths", StoragePathViewSet)
43 api_router.register(r"tasks", TasksViewSet, basename="tasks")
44 api_router.register(r"mail_accounts", MailAccountViewSet)
45 api_router.register(r"mail_rules", MailRuleViewSet)
46
47
48 urlpatterns = [
49 re_path(
50 r"^api/",
51 include(
52 [
53 re_path(
54 r"^auth/",
55 include(
56 ("rest_framework.urls", "rest_framework"),
57 namespace="rest_framework",
58 ),
59 ),
60 re_path(
61 r"^search/autocomplete/",
62 SearchAutoCompleteView.as_view(),
63 name="autocomplete",
64 ),
65 re_path(r"^statistics/", StatisticsView.as_view(), name="statistics"),
66 re_path(
67 r"^documents/post_document/",
68 PostDocumentView.as_view(),
69 name="post_document",
70 ),
71 re_path(
72 r"^documents/bulk_edit/",
73 BulkEditView.as_view(),
74 name="bulk_edit",
75 ),
76 re_path(
77 r"^documents/selection_data/",
78 SelectionDataView.as_view(),
79 name="selection_data",
80 ),
81 re_path(
82 r"^documents/bulk_download/",
83 BulkDownloadView.as_view(),
84 name="bulk_download",
85 ),
86 re_path(
87 r"^remote_version/",
88 RemoteVersionView.as_view(),
89 name="remoteversion",
90 ),
91 re_path(
92 r"^ui_settings/",
93 UiSettingsView.as_view(),
94 name="ui_settings",
95 ),
96 re_path(
97 r"^acknowledge_tasks/",
98 AcknowledgeTasksView.as_view(),
99 name="acknowledge_tasks",
100 ),
101 path("token/", views.obtain_auth_token),
102 ]
103 + api_router.urls,
104 ),
105 ),
106 re_path(r"^favicon.ico$", FaviconView.as_view(), name="favicon"),
107 re_path(r"admin/", admin.site.urls),
108 re_path(
109 r"^fetch/",
110 include(
111 [
112 re_path(
113 r"^doc/(?P<pk>\d+)$",
114 RedirectView.as_view(
115 url=settings.BASE_URL + "api/documents/%(pk)s/download/",
116 ),
117 ),
118 re_path(
119 r"^thumb/(?P<pk>\d+)$",
120 RedirectView.as_view(
121 url=settings.BASE_URL + "api/documents/%(pk)s/thumb/",
122 ),
123 ),
124 re_path(
125 r"^preview/(?P<pk>\d+)$",
126 RedirectView.as_view(
127 url=settings.BASE_URL + "api/documents/%(pk)s/preview/",
128 ),
129 ),
130 ],
131 ),
132 ),
133 re_path(
134 r"^push$",
135 csrf_exempt(
136 RedirectView.as_view(
137 url=settings.BASE_URL + "api/documents/post_document/",
138 ),
139 ),
140 ),
141 # Frontend assets TODO: this is pretty bad, but it works.
142 path(
143 "assets/<path:path>",
144 RedirectView.as_view(
145 url=settings.STATIC_URL + "frontend/en-US/assets/%(path)s",
146 ),
147 ),
148 # TODO: with localization, this is even worse! :/
149 # login, logout
150 path("accounts/", include("django.contrib.auth.urls")),
151 # Root of the Frontent
152 re_path(r".*", login_required(IndexView.as_view()), name="base"),
153 ]
154
155
156 websocket_urlpatterns = [
157 re_path(r"ws/status/$", StatusConsumer.as_asgi()),
158 ]
159
160 # Text in each page's <h1> (and above login form).
161 admin.site.site_header = "Paperless-ngx"
162 # Text at the end of each page's <title>.
163 admin.site.site_title = "Paperless-ngx"
164 # Text at the top of the admin index page.
165 admin.site.index_title = _("Paperless-ngx administration")
166
[end of src/paperless/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/paperless/urls.py b/src/paperless/urls.py
--- a/src/paperless/urls.py
+++ b/src/paperless/urls.py
@@ -154,7 +154,7 @@
websocket_urlpatterns = [
- re_path(r"ws/status/$", StatusConsumer.as_asgi()),
+ path(settings.BASE_URL.lstrip("/") + "ws/status/", StatusConsumer.as_asgi()),
]
# Text in each page's <h1> (and above login form).
|
{"golden_diff": "diff --git a/src/paperless/urls.py b/src/paperless/urls.py\n--- a/src/paperless/urls.py\n+++ b/src/paperless/urls.py\n@@ -154,7 +154,7 @@\n \n \n websocket_urlpatterns = [\n- re_path(r\"ws/status/$\", StatusConsumer.as_asgi()),\n+ path(settings.BASE_URL.lstrip(\"/\") + \"ws/status/\", StatusConsumer.as_asgi()),\n ]\n \n # Text in each page's <h1> (and above login form).\n", "issue": "[Bug] Websockets do not respect subpath\n### Discussed in https://github.com/paperless-ngx/paperless-ngx/discussions/2236\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **davidgiga1993** December 21, 2022</sup>\r\nI migrated from paprless-ng to paperless-ngx and the websocket connection isn't working anymore:\r\n```\r\nWebSocket connection to 'wss://home.dev-core.org/paperless/ws/status/' failed:\r\n```\r\nThe server returns status code 500.\r\n\r\nI'm using `/paperless` as path and configured it according to the [documentation](https://docs.paperless-ngx.com/configuration/#hosting-and-security)\r\n```\r\nPAPERLESS_FORCE_SCRIPT_NAME=/paperless\r\nPAPERLESS_STATIC_URL=/paperless/static/\r\nPAPERLESS_MEDIA_URL=/paperless/media/\r\n\r\nPAPERLESS_URL=https://my-domain.com\r\n```\r\n\r\nmy nginx config hasn't changed since and worked fine before:\r\n```\r\nproxy_set_header Host $host;\r\nproxy_set_header X-Forwarded-Proto $scheme;\r\nproxy_set_header X-Forwarded-Host $http_host;\r\nproxy_set_header X-Forwarded-Uri $request_uri;\r\nproxy_set_header X-Forwarded-Ssl on;\r\nproxy_set_header X-Forwarded-For $remote_addr;\r\nproxy_set_header X-Real-IP $remote_addr;\r\n\r\nclient_body_buffer_size 128k;\r\nproxy_next_upstream error timeout;\r\nproxy_redirect http:// $scheme://;\r\nproxy_http_version 1.1;\r\nproxy_cache_bypass $cookie_session;\r\nproxy_no_cache $cookie_session;\r\nproxy_buffers 64 256k;\r\n\r\n# Allow websockets\r\nproxy_cache_bypass $http_upgrade;\r\nproxy_set_header Upgrade $http_upgrade;\r\nproxy_set_header Connection \"upgrade\";\r\n\r\nreal_ip_header X-Forwarded-For;\r\nreal_ip_recursive on;\r\n\r\nsend_timeout 5m;\r\nproxy_read_timeout 360;\r\nproxy_send_timeout 360;\r\nproxy_connect_timeout 360;\r\n```\r\n\r\nIt looks like paperless ngx isn't using the context path for the websockets - here is a test using curl. The first request (with the correct path) returns `500`, the second one without any context path returns correctly `403`\r\n```\r\nnas paperless # curl -i -N -H \"Connection: Upgrade\" -H \"Upgrade: websocket\" -H \"Host: my-domain.com\" -H \"Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==\" -H \"Sec-WebSocket-Version: 13\" localhost:8000/paperless/ws/status/\r\nHTTP/1.1 500 Internal Server Error\r\ncontent-type: text/plain; charset=utf-8\r\ncontent-length: 21\r\nconnection: close\r\n\r\nInternal Server Error#\r\nnas paperless # curl -i -N -H \"Connection: Upgrade\" -H \"Upgrade: websocket\" -H \"Host: my-domain.com\" -H \"Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==\" -H \"Sec-WebSocket-Version: 13\" localhost:8000/ws/status/\r\nHTTP/1.1 403 Forbidden\r\nDate: Sun, 11 Dec 2022 10:03:35 GMT\r\nServer: Python/3.9 websockets/10.4\r\nContent-Length: 0\r\nContent-Type: text/plain\r\nConnection: close\r\n```\r\n\r\nany ideas? Anything else I should test?\r\n </div>\n", "before_files": [{"content": "from django.conf import settings\nfrom django.conf.urls import include\nfrom django.contrib import admin\nfrom django.contrib.auth.decorators import login_required\nfrom django.urls import path\nfrom django.urls import re_path\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.generic import RedirectView\nfrom documents.views import AcknowledgeTasksView\nfrom documents.views import BulkDownloadView\nfrom documents.views import BulkEditView\nfrom documents.views import CorrespondentViewSet\nfrom documents.views import DocumentTypeViewSet\nfrom documents.views import IndexView\nfrom documents.views import LogViewSet\nfrom documents.views import PostDocumentView\nfrom documents.views import RemoteVersionView\nfrom documents.views import SavedViewViewSet\nfrom documents.views import SearchAutoCompleteView\nfrom documents.views import SelectionDataView\nfrom documents.views import StatisticsView\nfrom documents.views import StoragePathViewSet\nfrom documents.views import TagViewSet\nfrom documents.views import TasksViewSet\nfrom documents.views import UiSettingsView\nfrom documents.views import UnifiedSearchViewSet\nfrom paperless.consumers import StatusConsumer\nfrom paperless.views import FaviconView\nfrom paperless_mail.views import MailAccountViewSet\nfrom paperless_mail.views import MailRuleViewSet\nfrom rest_framework.authtoken import views\nfrom rest_framework.routers import DefaultRouter\n\napi_router = DefaultRouter()\napi_router.register(r\"correspondents\", CorrespondentViewSet)\napi_router.register(r\"document_types\", DocumentTypeViewSet)\napi_router.register(r\"documents\", UnifiedSearchViewSet)\napi_router.register(r\"logs\", LogViewSet, basename=\"logs\")\napi_router.register(r\"tags\", TagViewSet)\napi_router.register(r\"saved_views\", SavedViewViewSet)\napi_router.register(r\"storage_paths\", StoragePathViewSet)\napi_router.register(r\"tasks\", TasksViewSet, basename=\"tasks\")\napi_router.register(r\"mail_accounts\", MailAccountViewSet)\napi_router.register(r\"mail_rules\", MailRuleViewSet)\n\n\nurlpatterns = [\n re_path(\n r\"^api/\",\n include(\n [\n re_path(\n r\"^auth/\",\n include(\n (\"rest_framework.urls\", \"rest_framework\"),\n namespace=\"rest_framework\",\n ),\n ),\n re_path(\n r\"^search/autocomplete/\",\n SearchAutoCompleteView.as_view(),\n name=\"autocomplete\",\n ),\n re_path(r\"^statistics/\", StatisticsView.as_view(), name=\"statistics\"),\n re_path(\n r\"^documents/post_document/\",\n PostDocumentView.as_view(),\n name=\"post_document\",\n ),\n re_path(\n r\"^documents/bulk_edit/\",\n BulkEditView.as_view(),\n name=\"bulk_edit\",\n ),\n re_path(\n r\"^documents/selection_data/\",\n SelectionDataView.as_view(),\n name=\"selection_data\",\n ),\n re_path(\n r\"^documents/bulk_download/\",\n BulkDownloadView.as_view(),\n name=\"bulk_download\",\n ),\n re_path(\n r\"^remote_version/\",\n RemoteVersionView.as_view(),\n name=\"remoteversion\",\n ),\n re_path(\n r\"^ui_settings/\",\n UiSettingsView.as_view(),\n name=\"ui_settings\",\n ),\n re_path(\n r\"^acknowledge_tasks/\",\n AcknowledgeTasksView.as_view(),\n name=\"acknowledge_tasks\",\n ),\n path(\"token/\", views.obtain_auth_token),\n ]\n + api_router.urls,\n ),\n ),\n re_path(r\"^favicon.ico$\", FaviconView.as_view(), name=\"favicon\"),\n re_path(r\"admin/\", admin.site.urls),\n re_path(\n r\"^fetch/\",\n include(\n [\n re_path(\n r\"^doc/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/download/\",\n ),\n ),\n re_path(\n r\"^thumb/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/thumb/\",\n ),\n ),\n re_path(\n r\"^preview/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/preview/\",\n ),\n ),\n ],\n ),\n ),\n re_path(\n r\"^push$\",\n csrf_exempt(\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/post_document/\",\n ),\n ),\n ),\n # Frontend assets TODO: this is pretty bad, but it works.\n path(\n \"assets/<path:path>\",\n RedirectView.as_view(\n url=settings.STATIC_URL + \"frontend/en-US/assets/%(path)s\",\n ),\n ),\n # TODO: with localization, this is even worse! :/\n # login, logout\n path(\"accounts/\", include(\"django.contrib.auth.urls\")),\n # Root of the Frontent\n re_path(r\".*\", login_required(IndexView.as_view()), name=\"base\"),\n]\n\n\nwebsocket_urlpatterns = [\n re_path(r\"ws/status/$\", StatusConsumer.as_asgi()),\n]\n\n# Text in each page's <h1> (and above login form).\nadmin.site.site_header = \"Paperless-ngx\"\n# Text at the end of each page's <title>.\nadmin.site.site_title = \"Paperless-ngx\"\n# Text at the top of the admin index page.\nadmin.site.index_title = _(\"Paperless-ngx administration\")\n", "path": "src/paperless/urls.py"}]}
| 2,816 | 114 |
gh_patches_debug_29263
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-266
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
use environment markers and reactivate universal wheels + distribute wheels
right now pip install is broken due to the released package claiming to be universal wheel but not using environment markers
so pip makes a wheel for all pythons with the first python its run on, then its used on all other pythons,
so a pip install on python2.6 would create a broken wheel with the extra dependency which is then subsequently tried in other pythons, and will utterly break them
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # coding=utf-8
3
4 import os
5 import io
6 import sys
7 from setuptools import setup, find_packages
8
9 here = os.path.abspath(os.path.dirname(__file__))
10 README = io.open(os.path.join(here, 'README.rst'), encoding="utf8").read()
11 NEWS = io.open(os.path.join(here, 'CHANGELOG.rst'), encoding="utf8").read()
12
13
14 version = '0.5.3'
15
16 install_requires = []
17 if ((sys.version_info[0] == 2 and sys.version_info[1] < 7) or
18 (sys.version_info[0] == 3 and sys.version_info[1] < 1)):
19 install_requires.append('importlib')
20
21 # this module can be zip-safe if the zipimporter implements iter_modules or if
22 # pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.
23 try:
24 import pkgutil
25 import zipimport
26 zip_safe = hasattr(zipimport.zipimporter, "iter_modules") or \
27 zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()
28 except (ImportError, AttributeError):
29 zip_safe = False
30
31 setup(
32 name='fake-factory',
33 version=version,
34 description="Faker is a Python package that generates fake data for you.",
35 long_description=README + '\n\n' + NEWS,
36 scripts=['faker/bin/faker'],
37 classifiers=[
38 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
39 'Development Status :: 3 - Alpha',
40 'Environment :: Console',
41 'Intended Audience :: Developers',
42 'Programming Language :: Python',
43 'Programming Language :: Python :: 2',
44 'Programming Language :: Python :: 3',
45 'Programming Language :: Python :: 3.4',
46 'Topic :: Software Development :: Libraries :: Python Modules',
47 'Topic :: Software Development :: Testing',
48 'Topic :: Utilities',
49 'License :: OSI Approved :: MIT License'
50 ],
51 keywords='faker fixtures data test mock generator',
52 author='joke2k',
53 author_email='[email protected]',
54 url='http://github.com/joke2k/faker',
55 license='MIT License',
56 packages=find_packages(exclude=['*.tests']),
57 platforms=["any"],
58 test_suite='faker.tests',
59 zip_safe=zip_safe,
60 install_requires=install_requires
61 )
62
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,6 @@
import os
import io
-import sys
from setuptools import setup, find_packages
here = os.path.abspath(os.path.dirname(__file__))
@@ -13,11 +12,6 @@
version = '0.5.3'
-install_requires = []
-if ((sys.version_info[0] == 2 and sys.version_info[1] < 7) or
- (sys.version_info[0] == 3 and sys.version_info[1] < 1)):
- install_requires.append('importlib')
-
# this module can be zip-safe if the zipimporter implements iter_modules or if
# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.
try:
@@ -33,7 +27,9 @@
version=version,
description="Faker is a Python package that generates fake data for you.",
long_description=README + '\n\n' + NEWS,
- scripts=['faker/bin/faker'],
+ entry_points={
+ 'console_scripts': ['faker=faker.cli:execute_from_command_line'],
+ },
classifiers=[
# See https://pypi.python.org/pypi?%3Aaction=list_classifiers
'Development Status :: 3 - Alpha',
@@ -57,5 +53,8 @@
platforms=["any"],
test_suite='faker.tests',
zip_safe=zip_safe,
- install_requires=install_requires
+ extras_require={
+ ':python_version=="2.6"': ['importlib'],
+ ':python_version=="3.0"': ['importlib'],
+ }
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -3,7 +3,6 @@\n \n import os\n import io\n-import sys\n from setuptools import setup, find_packages\n \n here = os.path.abspath(os.path.dirname(__file__))\n@@ -13,11 +12,6 @@\n \n version = '0.5.3'\n \n-install_requires = []\n-if ((sys.version_info[0] == 2 and sys.version_info[1] < 7) or\n- (sys.version_info[0] == 3 and sys.version_info[1] < 1)):\n- install_requires.append('importlib')\n-\n # this module can be zip-safe if the zipimporter implements iter_modules or if\n # pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\n try:\n@@ -33,7 +27,9 @@\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README + '\\n\\n' + NEWS,\n- scripts=['faker/bin/faker'],\n+ entry_points={\n+ 'console_scripts': ['faker=faker.cli:execute_from_command_line'],\n+ },\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n@@ -57,5 +53,8 @@\n platforms=[\"any\"],\n test_suite='faker.tests',\n zip_safe=zip_safe,\n- install_requires=install_requires\n+ extras_require={\n+ ':python_version==\"2.6\"': ['importlib'],\n+ ':python_version==\"3.0\"': ['importlib'],\n+ }\n )\n", "issue": "use environment markers and reactivate universal wheels + distribute wheels\nright now pip install is broken due to the released package claiming to be universal wheel but not using environment markers\n\nso pip makes a wheel for all pythons with the first python its run on, then its used on all other pythons,\nso a pip install on python2.6 would create a broken wheel with the extra dependency which is then subsequently tried in other pythons, and will utterly break them\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport os\nimport io\nimport sys\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = io.open(os.path.join(here, 'README.rst'), encoding=\"utf8\").read()\nNEWS = io.open(os.path.join(here, 'CHANGELOG.rst'), encoding=\"utf8\").read()\n\n\nversion = '0.5.3'\n\ninstall_requires = []\nif ((sys.version_info[0] == 2 and sys.version_info[1] < 7) or\n (sys.version_info[0] == 3 and sys.version_info[1] < 1)):\n install_requires.append('importlib')\n\n# this module can be zip-safe if the zipimporter implements iter_modules or if\n# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\ntry:\n import pkgutil\n import zipimport\n zip_safe = hasattr(zipimport.zipimporter, \"iter_modules\") or \\\n zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()\nexcept (ImportError, AttributeError):\n zip_safe = False\n\nsetup(\n name='fake-factory',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README + '\\n\\n' + NEWS,\n scripts=['faker/bin/faker'],\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='http://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=['*.tests']),\n platforms=[\"any\"],\n test_suite='faker.tests',\n zip_safe=zip_safe,\n install_requires=install_requires\n)\n", "path": "setup.py"}]}
| 1,257 | 372 |
gh_patches_debug_36755
|
rasdani/github-patches
|
git_diff
|
evennia__evennia-670
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error 500 when trying to Add Object from Admin Panel (Fresh Install)
(Full Pastebin)
http://pastebin.com/v1FbmBhq
Environment:
Request Method: GET
Request URL: http://localhost:8000/admin/objects/objectdb/add/
Django Version: 1.7.4
Python Version: 2.7.9
Installed Applications:
('django.contrib.auth',
'django.contrib.sites',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.admin',
'django.contrib.admindocs',
'django.contrib.flatpages',
'django.contrib.staticfiles',
'src.server',
'src.typeclasses',
'src.players',
'src.objects',
'src.comms',
'src.help',
'src.scripts',
'src.web.webclient')
Installed Middleware:
('django.middleware.common.CommonMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.admindocs.middleware.XViewMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware')
Traceback:
File "C:\Python27\lib\site-packages\django\core\handlers\base.py" in get_response
1. response = wrapped_callback(request, _callback_args, *_callback_kwargs)
File "C:\Python27\lib\site-packages\django\contrib\admin\options.py" in wrapper
2. return self.admin_site.admin_view(view)(_args, *_kwargs)
File "C:\Python27\lib\site-packages\django\utils\decorators.py" in _wrapped_view
3. response = view_func(request, _args, *_kwargs)
File "C:\Python27\lib\site-packages\django\views\decorators\cache.py" in _wrapped_view_func
4. response = view_func(request, _args, *_kwargs)
File "C:\Python27\lib\site-packages\django\contrib\admin\sites.py" in inner
5. return view(request, _args, *_kwargs)
File "C:\Python27\lib\site-packages\django\contrib\admin\options.py" in add_view
6. return self.changeform_view(request, None, form_url, extra_context)
File "C:\Python27\lib\site-packages\django\utils\decorators.py" in _wrapper
7. return bound_func(_args, *_kwargs)
File "C:\Python27\lib\site-packages\django\utils\decorators.py" in _wrapped_view
8. response = view_func(request, _args, *_kwargs)
File "C:\Python27\lib\site-packages\django\utils\decorators.py" in bound_func
9. return func.**get**(self, type(self))(_args2, *_kwargs2)
File "C:\Python27\lib\site-packages\django\db\transaction.py" in inner
10. return func(_args, *_kwargs)
File "C:\Python27\lib\site-packages\django\contrib\admin\options.py" in changeform_view
11. ModelForm = self.get_form(request, obj)
File "C:\Users\codyp.PIPECOSRV0\Desktop\evennia-master\evennia\src\objects\admin.py" in get_form
12. 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),
Exception Type: AttributeError at /admin/objects/objectdb/add/
Exception Value: 'module' object has no attribute 'util'
</issue>
<code>
[start of src/objects/admin.py]
1 #
2 # This sets up how models are displayed
3 # in the web admin interface.
4 #
5
6 from django import forms
7 from django.conf import settings
8 from django.contrib import admin
9 from src.typeclasses.admin import AttributeInline, TagInline
10 from src.objects.models import ObjectDB
11
12
13 class ObjectAttributeInline(AttributeInline):
14 model = ObjectDB.db_attributes.through
15
16
17 class ObjectTagInline(TagInline):
18 model = ObjectDB.db_tags.through
19
20
21 class ObjectCreateForm(forms.ModelForm):
22 "This form details the look of the fields"
23 class Meta:
24 model = ObjectDB
25 fields = '__all__'
26 db_key = forms.CharField(label="Name/Key",
27 widget=forms.TextInput(attrs={'size': '78'}),
28 help_text="Main identifier, like 'apple', 'strong guy', 'Elizabeth' etc. If creating a Character, check so the name is unique among characters!",)
29 db_typeclass_path = forms.CharField(label="Typeclass",
30 initial=settings.BASE_OBJECT_TYPECLASS,
31 widget=forms.TextInput(attrs={'size': '78'}),
32 help_text="This defines what 'type' of entity this is. This variable holds a Python path to a module with a valid Evennia Typeclass. If you are creating a Character you should use the typeclass defined by settings.BASE_CHARACTER_TYPECLASS or one derived from that.")
33 db_cmdset_storage = forms.CharField(label="CmdSet",
34 initial="",
35 required=False,
36 widget=forms.TextInput(attrs={'size': '78'}),
37 help_text="Most non-character objects don't need a cmdset and can leave this field blank.")
38 raw_id_fields = ('db_destination', 'db_location', 'db_home')
39
40
41 class ObjectEditForm(ObjectCreateForm):
42 "Form used for editing. Extends the create one with more fields"
43
44 class Meta:
45 fields = '__all__'
46 db_lock_storage = forms.CharField(label="Locks",
47 required=False,
48 widget=forms.Textarea(attrs={'cols':'100', 'rows':'2'}),
49 help_text="In-game lock definition string. If not given, defaults will be used. This string should be on the form <i>type:lockfunction(args);type2:lockfunction2(args);...")
50
51
52 class ObjectDBAdmin(admin.ModelAdmin):
53
54 inlines = [ObjectTagInline, ObjectAttributeInline]
55 list_display = ('id', 'db_key', 'db_player', 'db_typeclass_path')
56 list_display_links = ('id', 'db_key')
57 ordering = ['db_player', 'db_typeclass_path', 'id']
58 search_fields = ['^db_key', 'db_typeclass_path']
59 raw_id_fields = ('db_destination', 'db_location', 'db_home')
60
61 save_as = True
62 save_on_top = True
63 list_select_related = True
64 list_filter = ('db_typeclass_path',)
65 #list_filter = ('db_permissions', 'db_typeclass_path')
66
67 # editing fields setup
68
69 form = ObjectEditForm
70 fieldsets = (
71 (None, {
72 'fields': (('db_key','db_typeclass_path'), ('db_lock_storage', ),
73 ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'
74 )}),
75 )
76 #fieldsets = (
77 # (None, {
78 # 'fields': (('db_key','db_typeclass_path'), ('db_permissions', 'db_lock_storage'),
79 # ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'
80 # )}),
81 # )
82
83 #deactivated temporarily, they cause empty objects to be created in admin
84
85 # Custom modification to give two different forms wether adding or not.
86 add_form = ObjectCreateForm
87 add_fieldsets = (
88 (None, {
89 'fields': (('db_key','db_typeclass_path'),
90 ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'
91 )}),
92 )
93
94 #add_fieldsets = (
95 # (None, {
96 # 'fields': (('db_key','db_typeclass_path'), 'db_permissions',
97 # ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'
98 # )}),
99 # )
100 def get_fieldsets(self, request, obj=None):
101 if not obj:
102 return self.add_fieldsets
103 return super(ObjectDBAdmin, self).get_fieldsets(request, obj)
104
105 def get_form(self, request, obj=None, **kwargs):
106 """
107 Use special form during creation
108 """
109 defaults = {}
110 if obj is None:
111 defaults.update({
112 'form': self.add_form,
113 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),
114 })
115 defaults.update(kwargs)
116 return super(ObjectDBAdmin, self).get_form(request, obj, **defaults)
117
118 def save_model(self, request, obj, form, change):
119 obj.save()
120 if not change:
121 # adding a new object
122 obj = obj.typeclass
123 obj.basetype_setup()
124 obj.basetype_posthook_setup()
125 obj.at_object_creation()
126 obj.at_init()
127
128
129 admin.site.register(ObjectDB, ObjectDBAdmin)
130
[end of src/objects/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/objects/admin.py b/src/objects/admin.py
--- a/src/objects/admin.py
+++ b/src/objects/admin.py
@@ -6,6 +6,7 @@
from django import forms
from django.conf import settings
from django.contrib import admin
+from django.contrib.admin.utils import flatten_fieldsets
from src.typeclasses.admin import AttributeInline, TagInline
from src.objects.models import ObjectDB
@@ -62,7 +63,6 @@
save_on_top = True
list_select_related = True
list_filter = ('db_typeclass_path',)
- #list_filter = ('db_permissions', 'db_typeclass_path')
# editing fields setup
@@ -73,16 +73,7 @@
('db_location', 'db_home'), 'db_destination','db_cmdset_storage'
)}),
)
- #fieldsets = (
- # (None, {
- # 'fields': (('db_key','db_typeclass_path'), ('db_permissions', 'db_lock_storage'),
- # ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'
- # )}),
- # )
- #deactivated temporarily, they cause empty objects to be created in admin
-
- # Custom modification to give two different forms wether adding or not.
add_form = ObjectCreateForm
add_fieldsets = (
(None, {
@@ -91,12 +82,6 @@
)}),
)
- #add_fieldsets = (
- # (None, {
- # 'fields': (('db_key','db_typeclass_path'), 'db_permissions',
- # ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'
- # )}),
- # )
def get_fieldsets(self, request, obj=None):
if not obj:
return self.add_fieldsets
@@ -109,9 +94,9 @@
defaults = {}
if obj is None:
defaults.update({
- 'form': self.add_form,
- 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),
- })
+ 'form': self.add_form,
+ 'fields': flatten_fieldsets(self.add_fieldsets),
+ })
defaults.update(kwargs)
return super(ObjectDBAdmin, self).get_form(request, obj, **defaults)
|
{"golden_diff": "diff --git a/src/objects/admin.py b/src/objects/admin.py\n--- a/src/objects/admin.py\n+++ b/src/objects/admin.py\n@@ -6,6 +6,7 @@\n from django import forms\n from django.conf import settings\n from django.contrib import admin\n+from django.contrib.admin.utils import flatten_fieldsets\n from src.typeclasses.admin import AttributeInline, TagInline\n from src.objects.models import ObjectDB\n \n@@ -62,7 +63,6 @@\n save_on_top = True\n list_select_related = True\n list_filter = ('db_typeclass_path',)\n- #list_filter = ('db_permissions', 'db_typeclass_path')\n \n # editing fields setup\n \n@@ -73,16 +73,7 @@\n ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'\n )}),\n )\n- #fieldsets = (\n- # (None, {\n- # 'fields': (('db_key','db_typeclass_path'), ('db_permissions', 'db_lock_storage'),\n- # ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'\n- # )}),\n- # )\n \n- #deactivated temporarily, they cause empty objects to be created in admin\n-\n- # Custom modification to give two different forms wether adding or not.\n add_form = ObjectCreateForm\n add_fieldsets = (\n (None, {\n@@ -91,12 +82,6 @@\n )}),\n )\n \n- #add_fieldsets = (\n- # (None, {\n- # 'fields': (('db_key','db_typeclass_path'), 'db_permissions',\n- # ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'\n- # )}),\n- # )\n def get_fieldsets(self, request, obj=None):\n if not obj:\n return self.add_fieldsets\n@@ -109,9 +94,9 @@\n defaults = {}\n if obj is None:\n defaults.update({\n- 'form': self.add_form,\n- 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),\n- })\n+ 'form': self.add_form,\n+ 'fields': flatten_fieldsets(self.add_fieldsets),\n+ })\n defaults.update(kwargs)\n return super(ObjectDBAdmin, self).get_form(request, obj, **defaults)\n", "issue": "Error 500 when trying to Add Object from Admin Panel (Fresh Install)\n(Full Pastebin)\nhttp://pastebin.com/v1FbmBhq\n\nEnvironment:\n\nRequest Method: GET\nRequest URL: http://localhost:8000/admin/objects/objectdb/add/\n\nDjango Version: 1.7.4\nPython Version: 2.7.9\nInstalled Applications:\n('django.contrib.auth',\n 'django.contrib.sites',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.admin',\n 'django.contrib.admindocs',\n 'django.contrib.flatpages',\n 'django.contrib.staticfiles',\n 'src.server',\n 'src.typeclasses',\n 'src.players',\n 'src.objects',\n 'src.comms',\n 'src.help',\n 'src.scripts',\n 'src.web.webclient')\nInstalled Middleware:\n('django.middleware.common.CommonMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.admindocs.middleware.XViewMiddleware',\n 'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware')\n\nTraceback:\nFile \"C:\\Python27\\lib\\site-packages\\django\\core\\handlers\\base.py\" in get_response\n1. response = wrapped_callback(request, _callback_args, *_callback_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\contrib\\admin\\options.py\" in wrapper\n2. return self.admin_site.admin_view(view)(_args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\utils\\decorators.py\" in _wrapped_view\n3. response = view_func(request, _args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\views\\decorators\\cache.py\" in _wrapped_view_func\n4. response = view_func(request, _args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\contrib\\admin\\sites.py\" in inner\n5. return view(request, _args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\contrib\\admin\\options.py\" in add_view\n6. return self.changeform_view(request, None, form_url, extra_context)\n File \"C:\\Python27\\lib\\site-packages\\django\\utils\\decorators.py\" in _wrapper\n7. return bound_func(_args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\utils\\decorators.py\" in _wrapped_view\n8. response = view_func(request, _args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\utils\\decorators.py\" in bound_func\n9. return func.**get**(self, type(self))(_args2, *_kwargs2)\n File \"C:\\Python27\\lib\\site-packages\\django\\db\\transaction.py\" in inner\n10. return func(_args, *_kwargs)\n File \"C:\\Python27\\lib\\site-packages\\django\\contrib\\admin\\options.py\" in changeform_view\n11. ModelForm = self.get_form(request, obj)\n File \"C:\\Users\\codyp.PIPECOSRV0\\Desktop\\evennia-master\\evennia\\src\\objects\\admin.py\" in get_form\n12. 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),\n\nException Type: AttributeError at /admin/objects/objectdb/add/\nException Value: 'module' object has no attribute 'util'\n\n", "before_files": [{"content": "#\n# This sets up how models are displayed\n# in the web admin interface.\n#\n\nfrom django import forms\nfrom django.conf import settings\nfrom django.contrib import admin\nfrom src.typeclasses.admin import AttributeInline, TagInline\nfrom src.objects.models import ObjectDB\n\n\nclass ObjectAttributeInline(AttributeInline):\n model = ObjectDB.db_attributes.through\n\n\nclass ObjectTagInline(TagInline):\n model = ObjectDB.db_tags.through\n\n\nclass ObjectCreateForm(forms.ModelForm):\n \"This form details the look of the fields\"\n class Meta:\n model = ObjectDB\n fields = '__all__'\n db_key = forms.CharField(label=\"Name/Key\",\n widget=forms.TextInput(attrs={'size': '78'}),\n help_text=\"Main identifier, like 'apple', 'strong guy', 'Elizabeth' etc. If creating a Character, check so the name is unique among characters!\",)\n db_typeclass_path = forms.CharField(label=\"Typeclass\",\n initial=settings.BASE_OBJECT_TYPECLASS,\n widget=forms.TextInput(attrs={'size': '78'}),\n help_text=\"This defines what 'type' of entity this is. This variable holds a Python path to a module with a valid Evennia Typeclass. If you are creating a Character you should use the typeclass defined by settings.BASE_CHARACTER_TYPECLASS or one derived from that.\")\n db_cmdset_storage = forms.CharField(label=\"CmdSet\",\n initial=\"\",\n required=False,\n widget=forms.TextInput(attrs={'size': '78'}),\n help_text=\"Most non-character objects don't need a cmdset and can leave this field blank.\")\n raw_id_fields = ('db_destination', 'db_location', 'db_home')\n\n\nclass ObjectEditForm(ObjectCreateForm):\n \"Form used for editing. Extends the create one with more fields\"\n\n class Meta:\n fields = '__all__'\n db_lock_storage = forms.CharField(label=\"Locks\",\n required=False,\n widget=forms.Textarea(attrs={'cols':'100', 'rows':'2'}),\n help_text=\"In-game lock definition string. If not given, defaults will be used. This string should be on the form <i>type:lockfunction(args);type2:lockfunction2(args);...\")\n\n\nclass ObjectDBAdmin(admin.ModelAdmin):\n\n inlines = [ObjectTagInline, ObjectAttributeInline]\n list_display = ('id', 'db_key', 'db_player', 'db_typeclass_path')\n list_display_links = ('id', 'db_key')\n ordering = ['db_player', 'db_typeclass_path', 'id']\n search_fields = ['^db_key', 'db_typeclass_path']\n raw_id_fields = ('db_destination', 'db_location', 'db_home')\n\n save_as = True\n save_on_top = True\n list_select_related = True\n list_filter = ('db_typeclass_path',)\n #list_filter = ('db_permissions', 'db_typeclass_path')\n\n # editing fields setup\n\n form = ObjectEditForm\n fieldsets = (\n (None, {\n 'fields': (('db_key','db_typeclass_path'), ('db_lock_storage', ),\n ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'\n )}),\n )\n #fieldsets = (\n # (None, {\n # 'fields': (('db_key','db_typeclass_path'), ('db_permissions', 'db_lock_storage'),\n # ('db_location', 'db_home'), 'db_destination','db_cmdset_storage'\n # )}),\n # )\n\n #deactivated temporarily, they cause empty objects to be created in admin\n\n # Custom modification to give two different forms wether adding or not.\n add_form = ObjectCreateForm\n add_fieldsets = (\n (None, {\n 'fields': (('db_key','db_typeclass_path'),\n ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'\n )}),\n )\n\n #add_fieldsets = (\n # (None, {\n # 'fields': (('db_key','db_typeclass_path'), 'db_permissions',\n # ('db_location', 'db_home'), 'db_destination', 'db_cmdset_storage'\n # )}),\n # )\n def get_fieldsets(self, request, obj=None):\n if not obj:\n return self.add_fieldsets\n return super(ObjectDBAdmin, self).get_fieldsets(request, obj)\n\n def get_form(self, request, obj=None, **kwargs):\n \"\"\"\n Use special form during creation\n \"\"\"\n defaults = {}\n if obj is None:\n defaults.update({\n 'form': self.add_form,\n 'fields': admin.util.flatten_fieldsets(self.add_fieldsets),\n })\n defaults.update(kwargs)\n return super(ObjectDBAdmin, self).get_form(request, obj, **defaults)\n\n def save_model(self, request, obj, form, change):\n obj.save()\n if not change:\n # adding a new object\n obj = obj.typeclass\n obj.basetype_setup()\n obj.basetype_posthook_setup()\n obj.at_object_creation()\n obj.at_init()\n\n\nadmin.site.register(ObjectDB, ObjectDBAdmin)\n", "path": "src/objects/admin.py"}]}
| 2,685 | 525 |
gh_patches_debug_8279
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create release version of ptvsd
Create a release version of ptvsd version 4.1.1
- [x] Change development status to production from alpha
- [x] Set version to 4.1.1
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 # Copyright (c) Microsoft Corporation. All rights reserved.
4 # Licensed under the MIT License. See LICENSE in the project root
5 # for license information.
6
7 import os
8 import os.path
9 import subprocess
10 import sys
11
12 from setuptools import setup
13
14 import versioneer
15 import ptvsd
16 import ptvsd._vendored
17
18
19 PYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')
20 PTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))
21
22
23 def cython_build():
24 print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')
25 subprocess.call([
26 sys.executable,
27 os.path.join(PYDEVD_ROOT, 'setup_cython.py'),
28 'build_ext',
29 '-i',
30 ])
31
32
33 def iter_vendored_files():
34 # Add pydevd files as data files for this package. They are not
35 # treated as a package of their own, because we don't actually
36 # want to provide pydevd - just use our own copy internally.
37 for project in ptvsd._vendored.list_all():
38 for filename in ptvsd._vendored.iter_packaging_files(project):
39 yield filename
40
41
42 with open('DESCRIPTION.md', 'r') as fh:
43 long_description = fh.read()
44
45
46 if __name__ == '__main__':
47 if not os.getenv('SKIP_CYTHON_BUILD'):
48 cython_build()
49
50 setup(
51 name='ptvsd',
52 version=versioneer.get_version(),
53 description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa
54 long_description=long_description,
55 long_description_content_type='text/markdown',
56 license='MIT',
57 author='Microsoft Corporation',
58 author_email='[email protected]',
59 url='https://aka.ms/ptvs',
60 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
61 classifiers=[
62 'Development Status :: 3 - Alpha',
63 'Programming Language :: Python :: 2.7',
64 'Programming Language :: Python :: 3.4',
65 'Programming Language :: Python :: 3.5',
66 'Programming Language :: Python :: 3.6',
67 'Programming Language :: Python :: 3.7',
68 'Topic :: Software Development :: Debuggers',
69 'Operating System :: OS Independent',
70 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',
71 'License :: OSI Approved :: MIT License',
72 ],
73 packages=[
74 'ptvsd',
75 'ptvsd._vendored',
76 ],
77 package_data={
78 'ptvsd': ['ThirdPartyNotices.txt'],
79 'ptvsd._vendored': list(iter_vendored_files()),
80 },
81 cmdclass=versioneer.get_cmdclass(),
82 )
83
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -59,7 +59,7 @@
url='https://aka.ms/ptvs',
python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
classifiers=[
- 'Development Status :: 3 - Alpha',
+ 'Development Status :: 5 - Production/Stable',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -59,7 +59,7 @@\n url='https://aka.ms/ptvs',\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n classifiers=[\n- 'Development Status :: 3 - Alpha',\n+ 'Development Status :: 5 - Production/Stable',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n", "issue": "Create release version of ptvsd\nCreate a release version of ptvsd version 4.1.1\r\n- [x] Change development status to production from alpha\r\n- [x] Set version to 4.1.1\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport os\nimport os.path\nimport subprocess\nimport sys\n\nfrom setuptools import setup\n\nimport versioneer\nimport ptvsd\nimport ptvsd._vendored\n\n\nPYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')\nPTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))\n\n\ndef cython_build():\n print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')\n subprocess.call([\n sys.executable,\n os.path.join(PYDEVD_ROOT, 'setup_cython.py'),\n 'build_ext',\n '-i',\n ])\n\n\ndef iter_vendored_files():\n # Add pydevd files as data files for this package. They are not\n # treated as a package of their own, because we don't actually\n # want to provide pydevd - just use our own copy internally.\n for project in ptvsd._vendored.list_all():\n for filename in ptvsd._vendored.iter_packaging_files(project):\n yield filename\n\n\nwith open('DESCRIPTION.md', 'r') as fh:\n long_description = fh.read()\n\n\nif __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n\n setup(\n name='ptvsd',\n version=versioneer.get_version(),\n description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa\n long_description=long_description,\n long_description_content_type='text/markdown',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Software Development :: Debuggers',\n 'Operating System :: OS Independent',\n 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',\n 'License :: OSI Approved :: MIT License',\n ],\n packages=[\n 'ptvsd',\n 'ptvsd._vendored',\n ],\n package_data={\n 'ptvsd': ['ThirdPartyNotices.txt'],\n 'ptvsd._vendored': list(iter_vendored_files()),\n },\n cmdclass=versioneer.get_cmdclass(),\n )\n", "path": "setup.py"}]}
| 1,371 | 136 |
gh_patches_debug_24618
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-660
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fastai efficientdet fails on learn.validate() with AttributeError: 'NoneType' object has no attribute 'shape'
## 🐛 Bug
when trying to simply validate metrics for an efficientdet model with fastai
```python
KeyError: 'image_id'
```
```python
AttributeError: 'NoneType' object has no attribute 'shape'
```
it fails when trying to read the batch size automatically: in `accumulate, find_bs`
```python
class AvgLoss(Metric):
"Average the losses taking into account potential different batch sizes"
def reset(self): self.total,self.count = 0.,0
def accumulate(self, learn):
bs = find_bs(learn.yb)
self.total += learn.to_detach(learn.loss.mean())*bs
self.count += bs
@property
def value(self): return self.total/self.count if self.count != 0 else None
@property
def name(self): return "loss"
```
**To Reproduce**
Steps to reproduce the behavior:
1. Go to https://colab.research.google.com/drive/1i4aXYu4wIKA7eLUK86GwTm7lq7zku_oF?usp=sharing
</issue>
<code>
[start of icevision/models/torchvision/fastai/learner.py]
1 __all__ = ["RCNNCallback", "rcnn_learner"]
2
3 from icevision.imports import *
4 from icevision.engines.fastai import *
5 from icevision.models.torchvision.loss_fn import loss_fn
6 from icevision.models.torchvision.fastai.callbacks import *
7
8
9 def noop_watch(models, criterion=None, log="gradients", log_freq=1000, idx=None):
10 return []
11
12
13 def rcnn_learner(
14 dls: List[Union[DataLoader, fastai.DataLoader]],
15 model: nn.Module,
16 cbs=None,
17 **kwargs,
18 ):
19 learn = adapted_fastai_learner(
20 dls=dls,
21 model=model,
22 cbs=cbs,
23 loss_func=loss_fn,
24 **kwargs,
25 )
26
27 # HACK: patch AvgLoss (in original, find_bs gives errors)
28 class RCNNAvgLoss(fastai.AvgLoss):
29 def accumulate(self, learn):
30 bs = len(learn.yb)
31 self.total += fastai.to_detach(learn.loss.mean()) * bs
32 self.count += bs
33
34 recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]
35 recorder.loss = RCNNAvgLoss()
36
37 is_wandb = [cb for cb in learn.cbs if "WandbCallback" in str(type(cb))]
38 if len(is_wandb) == 1:
39 logger.warning("Wandb quickfix implemented, for more info check issue #527")
40 wandb.watch = noop_watch
41 if len(is_wandb) > 1:
42 raise ValueError(
43 f"It seems you are passing {len(is_wandb)} `WandbCallback` instances to the `learner`. Only 1 is allowed."
44 )
45
46 return learn
47
[end of icevision/models/torchvision/fastai/learner.py]
[start of icevision/models/ross/efficientdet/fastai/learner.py]
1 __all__ = ["learner"]
2
3 from icevision.imports import *
4 from icevision.engines.fastai import *
5 from icevision.models.ross.efficientdet.loss_fn import loss_fn
6 from icevision.models.ross.efficientdet.fastai.callbacks import EfficientDetCallback
7
8
9 def learner(
10 dls: List[Union[DataLoader, fastai.DataLoader]],
11 model: nn.Module,
12 cbs=None,
13 **learner_kwargs,
14 ):
15 """Fastai `Learner` adapted for EfficientDet.
16
17 # Arguments
18 dls: `Sequence` of `DataLoaders` passed to the `Learner`.
19 The first one will be used for training and the second for validation.
20 model: The model to train.
21 cbs: Optional `Sequence` of callbacks.
22 **learner_kwargs: Keyword arguments that will be internally passed to `Learner`.
23
24 # Returns
25 A fastai `Learner`.
26 """
27 cbs = [EfficientDetCallback()] + L(cbs)
28
29 learn = adapted_fastai_learner(
30 dls=dls,
31 model=model,
32 cbs=cbs,
33 loss_func=loss_fn,
34 **learner_kwargs,
35 )
36
37 # HACK: patch AvgLoss (in original, find_bs gives errors)
38 class PatchedAvgLoss(fastai.AvgLoss):
39 def accumulate(self, learn):
40 bs = len(learn.yb)
41 self.total += fastai.to_detach(learn.loss.mean()) * bs
42 self.count += bs
43
44 recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]
45 recorder.loss = PatchedAvgLoss()
46
47 return learn
48
[end of icevision/models/ross/efficientdet/fastai/learner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/ross/efficientdet/fastai/learner.py b/icevision/models/ross/efficientdet/fastai/learner.py
--- a/icevision/models/ross/efficientdet/fastai/learner.py
+++ b/icevision/models/ross/efficientdet/fastai/learner.py
@@ -34,14 +34,14 @@
**learner_kwargs,
)
- # HACK: patch AvgLoss (in original, find_bs gives errors)
- class PatchedAvgLoss(fastai.AvgLoss):
+ # HACK: patch AvgLoss (in original, find_bs looks at the first element in dictionary and gives errors)
+ class EffDetAvgLoss(fastai.AvgLoss):
def accumulate(self, learn):
- bs = len(learn.yb)
- self.total += fastai.to_detach(learn.loss.mean()) * bs
+ bs = len(first(learn.yb)["cls"])
+ self.total += learn.to_detach(learn.loss.mean()) * bs
self.count += bs
recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]
- recorder.loss = PatchedAvgLoss()
+ recorder.loss = EffDetAvgLoss()
return learn
diff --git a/icevision/models/torchvision/fastai/learner.py b/icevision/models/torchvision/fastai/learner.py
--- a/icevision/models/torchvision/fastai/learner.py
+++ b/icevision/models/torchvision/fastai/learner.py
@@ -27,7 +27,7 @@
# HACK: patch AvgLoss (in original, find_bs gives errors)
class RCNNAvgLoss(fastai.AvgLoss):
def accumulate(self, learn):
- bs = len(learn.yb)
+ bs = len(first(learn.yb))
self.total += fastai.to_detach(learn.loss.mean()) * bs
self.count += bs
|
{"golden_diff": "diff --git a/icevision/models/ross/efficientdet/fastai/learner.py b/icevision/models/ross/efficientdet/fastai/learner.py\n--- a/icevision/models/ross/efficientdet/fastai/learner.py\n+++ b/icevision/models/ross/efficientdet/fastai/learner.py\n@@ -34,14 +34,14 @@\n **learner_kwargs,\n )\n \n- # HACK: patch AvgLoss (in original, find_bs gives errors)\n- class PatchedAvgLoss(fastai.AvgLoss):\n+ # HACK: patch AvgLoss (in original, find_bs looks at the first element in dictionary and gives errors)\n+ class EffDetAvgLoss(fastai.AvgLoss):\n def accumulate(self, learn):\n- bs = len(learn.yb)\n- self.total += fastai.to_detach(learn.loss.mean()) * bs\n+ bs = len(first(learn.yb)[\"cls\"])\n+ self.total += learn.to_detach(learn.loss.mean()) * bs\n self.count += bs\n \n recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]\n- recorder.loss = PatchedAvgLoss()\n+ recorder.loss = EffDetAvgLoss()\n \n return learn\ndiff --git a/icevision/models/torchvision/fastai/learner.py b/icevision/models/torchvision/fastai/learner.py\n--- a/icevision/models/torchvision/fastai/learner.py\n+++ b/icevision/models/torchvision/fastai/learner.py\n@@ -27,7 +27,7 @@\n # HACK: patch AvgLoss (in original, find_bs gives errors)\n class RCNNAvgLoss(fastai.AvgLoss):\n def accumulate(self, learn):\n- bs = len(learn.yb)\n+ bs = len(first(learn.yb))\n self.total += fastai.to_detach(learn.loss.mean()) * bs\n self.count += bs\n", "issue": "fastai efficientdet fails on learn.validate() with AttributeError: 'NoneType' object has no attribute 'shape'\n## \ud83d\udc1b Bug\r\nwhen trying to simply validate metrics for an efficientdet model with fastai \r\n```python\r\nKeyError: 'image_id'\r\n```\r\n```python\r\nAttributeError: 'NoneType' object has no attribute 'shape'\r\n```\r\n\r\nit fails when trying to read the batch size automatically: in `accumulate, find_bs`\r\n```python\r\nclass AvgLoss(Metric):\r\n \"Average the losses taking into account potential different batch sizes\"\r\n def reset(self): self.total,self.count = 0.,0\r\n def accumulate(self, learn):\r\n bs = find_bs(learn.yb)\r\n self.total += learn.to_detach(learn.loss.mean())*bs\r\n self.count += bs\r\n @property\r\n def value(self): return self.total/self.count if self.count != 0 else None\r\n @property\r\n def name(self): return \"loss\"\r\n```\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to https://colab.research.google.com/drive/1i4aXYu4wIKA7eLUK86GwTm7lq7zku_oF?usp=sharing\r\n\r\n\n", "before_files": [{"content": "__all__ = [\"RCNNCallback\", \"rcnn_learner\"]\n\nfrom icevision.imports import *\nfrom icevision.engines.fastai import *\nfrom icevision.models.torchvision.loss_fn import loss_fn\nfrom icevision.models.torchvision.fastai.callbacks import *\n\n\ndef noop_watch(models, criterion=None, log=\"gradients\", log_freq=1000, idx=None):\n return []\n\n\ndef rcnn_learner(\n dls: List[Union[DataLoader, fastai.DataLoader]],\n model: nn.Module,\n cbs=None,\n **kwargs,\n):\n learn = adapted_fastai_learner(\n dls=dls,\n model=model,\n cbs=cbs,\n loss_func=loss_fn,\n **kwargs,\n )\n\n # HACK: patch AvgLoss (in original, find_bs gives errors)\n class RCNNAvgLoss(fastai.AvgLoss):\n def accumulate(self, learn):\n bs = len(learn.yb)\n self.total += fastai.to_detach(learn.loss.mean()) * bs\n self.count += bs\n\n recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]\n recorder.loss = RCNNAvgLoss()\n\n is_wandb = [cb for cb in learn.cbs if \"WandbCallback\" in str(type(cb))]\n if len(is_wandb) == 1:\n logger.warning(\"Wandb quickfix implemented, for more info check issue #527\")\n wandb.watch = noop_watch\n if len(is_wandb) > 1:\n raise ValueError(\n f\"It seems you are passing {len(is_wandb)} `WandbCallback` instances to the `learner`. Only 1 is allowed.\"\n )\n\n return learn\n", "path": "icevision/models/torchvision/fastai/learner.py"}, {"content": "__all__ = [\"learner\"]\n\nfrom icevision.imports import *\nfrom icevision.engines.fastai import *\nfrom icevision.models.ross.efficientdet.loss_fn import loss_fn\nfrom icevision.models.ross.efficientdet.fastai.callbacks import EfficientDetCallback\n\n\ndef learner(\n dls: List[Union[DataLoader, fastai.DataLoader]],\n model: nn.Module,\n cbs=None,\n **learner_kwargs,\n):\n \"\"\"Fastai `Learner` adapted for EfficientDet.\n\n # Arguments\n dls: `Sequence` of `DataLoaders` passed to the `Learner`.\n The first one will be used for training and the second for validation.\n model: The model to train.\n cbs: Optional `Sequence` of callbacks.\n **learner_kwargs: Keyword arguments that will be internally passed to `Learner`.\n\n # Returns\n A fastai `Learner`.\n \"\"\"\n cbs = [EfficientDetCallback()] + L(cbs)\n\n learn = adapted_fastai_learner(\n dls=dls,\n model=model,\n cbs=cbs,\n loss_func=loss_fn,\n **learner_kwargs,\n )\n\n # HACK: patch AvgLoss (in original, find_bs gives errors)\n class PatchedAvgLoss(fastai.AvgLoss):\n def accumulate(self, learn):\n bs = len(learn.yb)\n self.total += fastai.to_detach(learn.loss.mean()) * bs\n self.count += bs\n\n recorder = [cb for cb in learn.cbs if isinstance(cb, fastai.Recorder)][0]\n recorder.loss = PatchedAvgLoss()\n\n return learn\n", "path": "icevision/models/ross/efficientdet/fastai/learner.py"}]}
| 1,774 | 428 |
gh_patches_debug_28546
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-5258
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Query order as service account
I'm not able to query order by id as a service account.
`resolve_order` have `login_required` this decorator doesn't allow to run the function as a service account.
</issue>
<code>
[start of saleor/graphql/order/resolvers.py]
1 import graphene
2 import graphene_django_optimizer as gql_optimizer
3
4 from ...core.permissions import OrderPermissions
5 from ...order import OrderStatus, models
6 from ...order.events import OrderEvents
7 from ...order.models import OrderEvent
8 from ...order.utils import sum_order_totals
9 from ..utils import filter_by_period, filter_by_query_param, sort_queryset
10 from .enums import OrderStatusFilter
11 from .sorters import OrderSortField
12 from .types import Order
13
14 ORDER_SEARCH_FIELDS = ("id", "discount_name", "token", "user_email", "user__email")
15
16
17 def filter_orders(qs, info, created, status, query):
18 qs = filter_by_query_param(qs, query, ORDER_SEARCH_FIELDS)
19
20 # DEPRECATED: Will be removed in Saleor 2.11, use the `filter` field instead.
21 # filter orders by status
22 if status is not None:
23 if status == OrderStatusFilter.READY_TO_FULFILL:
24 qs = qs.ready_to_fulfill()
25 elif status == OrderStatusFilter.READY_TO_CAPTURE:
26 qs = qs.ready_to_capture()
27
28 # DEPRECATED: Will be removed in Saleor 2.11, use the `filter` field instead.
29 # filter orders by creation date
30 if created is not None:
31 qs = filter_by_period(qs, created, "created")
32
33 return gql_optimizer.query(qs, info)
34
35
36 def resolve_orders(info, created, status, query, sort_by=None):
37 qs = models.Order.objects.confirmed()
38 qs = sort_queryset(qs, sort_by, OrderSortField)
39 return filter_orders(qs, info, created, status, query)
40
41
42 def resolve_draft_orders(info, created, query, sort_by=None):
43 qs = models.Order.objects.drafts()
44 qs = sort_queryset(qs, sort_by, OrderSortField)
45 return filter_orders(qs, info, created, None, query)
46
47
48 def resolve_orders_total(_info, period):
49 qs = models.Order.objects.confirmed().exclude(status=OrderStatus.CANCELED)
50 qs = filter_by_period(qs, period, "created")
51 return sum_order_totals(qs)
52
53
54 def resolve_order(info, order_id):
55 """Return order only for user assigned to it or proper staff user."""
56 user = info.context.user
57 order = graphene.Node.get_node_from_global_id(info, order_id, Order)
58 if user.has_perm(OrderPermissions.MANAGE_ORDERS) or order.user == user:
59 return order
60 return None
61
62
63 def resolve_homepage_events():
64 # Filter only selected events to be displayed on homepage.
65 types = [
66 OrderEvents.PLACED,
67 OrderEvents.PLACED_FROM_DRAFT,
68 OrderEvents.ORDER_FULLY_PAID,
69 ]
70 return OrderEvent.objects.filter(type__in=types)
71
72
73 def resolve_order_by_token(token):
74 return models.Order.objects.filter(token=token).first()
75
[end of saleor/graphql/order/resolvers.py]
[start of saleor/graphql/order/schema.py]
1 import graphene
2 from graphql_jwt.decorators import login_required
3
4 from ...core.permissions import OrderPermissions
5 from ..core.enums import ReportingPeriod
6 from ..core.fields import FilterInputConnectionField, PrefetchingConnectionField
7 from ..core.types import FilterInputObjectType, TaxedMoney
8 from ..decorators import permission_required
9 from .bulk_mutations.draft_orders import DraftOrderBulkDelete, DraftOrderLinesBulkDelete
10 from .bulk_mutations.orders import OrderBulkCancel
11 from .enums import OrderStatusFilter
12 from .filters import DraftOrderFilter, OrderFilter
13 from .mutations.draft_orders import (
14 DraftOrderComplete,
15 DraftOrderCreate,
16 DraftOrderDelete,
17 DraftOrderLineDelete,
18 DraftOrderLinesCreate,
19 DraftOrderLineUpdate,
20 DraftOrderUpdate,
21 )
22 from .mutations.fulfillments import (
23 FulfillmentCancel,
24 FulfillmentClearMeta,
25 FulfillmentClearPrivateMeta,
26 FulfillmentCreate,
27 FulfillmentUpdateMeta,
28 FulfillmentUpdatePrivateMeta,
29 FulfillmentUpdateTracking,
30 )
31 from .mutations.orders import (
32 OrderAddNote,
33 OrderCancel,
34 OrderCapture,
35 OrderClearMeta,
36 OrderClearPrivateMeta,
37 OrderMarkAsPaid,
38 OrderRefund,
39 OrderUpdate,
40 OrderUpdateMeta,
41 OrderUpdatePrivateMeta,
42 OrderUpdateShipping,
43 OrderVoid,
44 )
45 from .resolvers import (
46 resolve_draft_orders,
47 resolve_homepage_events,
48 resolve_order,
49 resolve_order_by_token,
50 resolve_orders,
51 resolve_orders_total,
52 )
53 from .sorters import OrderSortingInput
54 from .types import Order, OrderEvent
55
56
57 class OrderFilterInput(FilterInputObjectType):
58 class Meta:
59 filterset_class = OrderFilter
60
61
62 class OrderDraftFilterInput(FilterInputObjectType):
63 class Meta:
64 filterset_class = DraftOrderFilter
65
66
67 class OrderQueries(graphene.ObjectType):
68 homepage_events = PrefetchingConnectionField(
69 OrderEvent,
70 description=(
71 "List of activity events to display on "
72 "homepage (at the moment it only contains order-events)."
73 ),
74 )
75 order = graphene.Field(
76 Order,
77 description="Look up an order by ID.",
78 id=graphene.Argument(graphene.ID, description="ID of an order.", required=True),
79 )
80 orders = FilterInputConnectionField(
81 Order,
82 sort_by=OrderSortingInput(description="Sort orders."),
83 filter=OrderFilterInput(description="Filtering options for orders."),
84 created=graphene.Argument(
85 ReportingPeriod,
86 description=(
87 "Filter orders from a selected timespan. "
88 "DEPRECATED: Will be removed in Saleor 2.11, "
89 "use the `filter` field instead."
90 ),
91 ),
92 status=graphene.Argument(
93 OrderStatusFilter,
94 description=(
95 "Filter order by status. "
96 "DEPRECATED: Will be removed in Saleor 2.11, "
97 "use the `filter` field instead."
98 ),
99 ),
100 description="List of orders.",
101 )
102 draft_orders = FilterInputConnectionField(
103 Order,
104 sort_by=OrderSortingInput(description="Sort draft orders."),
105 filter=OrderDraftFilterInput(description="Filtering options for draft orders."),
106 created=graphene.Argument(
107 ReportingPeriod,
108 description=(
109 "Filter draft orders from a selected timespan. "
110 "DEPRECATED: Will be removed in Saleor 2.11, "
111 "use the `filter` field instead."
112 ),
113 ),
114 description="List of draft orders.",
115 )
116 orders_total = graphene.Field(
117 TaxedMoney,
118 description="Return the total sales amount from a specific period.",
119 period=graphene.Argument(ReportingPeriod, description="A period of time."),
120 )
121 order_by_token = graphene.Field(
122 Order,
123 description="Look up an order by token.",
124 token=graphene.Argument(
125 graphene.UUID, description="The order's token.", required=True
126 ),
127 )
128
129 @permission_required(OrderPermissions.MANAGE_ORDERS)
130 def resolve_homepage_events(self, *_args, **_kwargs):
131 return resolve_homepage_events()
132
133 @login_required
134 def resolve_order(self, info, **data):
135 return resolve_order(info, data.get("id"))
136
137 @permission_required(OrderPermissions.MANAGE_ORDERS)
138 def resolve_orders(
139 self, info, created=None, status=None, query=None, sort_by=None, **_kwargs
140 ):
141 return resolve_orders(info, created, status, query, sort_by)
142
143 @permission_required(OrderPermissions.MANAGE_ORDERS)
144 def resolve_draft_orders(
145 self, info, created=None, query=None, sort_by=None, **_kwargs
146 ):
147 return resolve_draft_orders(info, created, query, sort_by)
148
149 @permission_required(OrderPermissions.MANAGE_ORDERS)
150 def resolve_orders_total(self, info, period, **_kwargs):
151 return resolve_orders_total(info, period)
152
153 def resolve_order_by_token(self, _info, token):
154 return resolve_order_by_token(token)
155
156
157 class OrderMutations(graphene.ObjectType):
158 draft_order_complete = DraftOrderComplete.Field()
159 draft_order_create = DraftOrderCreate.Field()
160 draft_order_delete = DraftOrderDelete.Field()
161 draft_order_bulk_delete = DraftOrderBulkDelete.Field()
162 draft_order_lines_bulk_delete = DraftOrderLinesBulkDelete.Field()
163 draft_order_lines_create = DraftOrderLinesCreate.Field()
164 draft_order_line_delete = DraftOrderLineDelete.Field()
165 draft_order_line_update = DraftOrderLineUpdate.Field()
166 draft_order_update = DraftOrderUpdate.Field()
167
168 order_add_note = OrderAddNote.Field()
169 order_cancel = OrderCancel.Field()
170 order_capture = OrderCapture.Field()
171 order_clear_private_meta = OrderClearPrivateMeta.Field()
172 order_clear_meta = OrderClearMeta.Field()
173 order_fulfillment_cancel = FulfillmentCancel.Field()
174 order_fulfillment_create = FulfillmentCreate.Field()
175 order_fulfillment_update_tracking = FulfillmentUpdateTracking.Field()
176 order_fulfillment_clear_meta = FulfillmentClearMeta.Field()
177 order_fulfillment_clear_private_meta = FulfillmentClearPrivateMeta.Field()
178 order_fulfillment_update_meta = FulfillmentUpdateMeta.Field()
179 order_fulfillment_update_private_meta = FulfillmentUpdatePrivateMeta.Field()
180 order_mark_as_paid = OrderMarkAsPaid.Field()
181 order_refund = OrderRefund.Field()
182 order_update = OrderUpdate.Field()
183 order_update_meta = OrderUpdateMeta.Field()
184 order_update_private_meta = OrderUpdatePrivateMeta.Field()
185 order_update_shipping = OrderUpdateShipping.Field()
186 order_void = OrderVoid.Field()
187
188 order_bulk_cancel = OrderBulkCancel.Field()
189
[end of saleor/graphql/order/schema.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/graphql/order/resolvers.py b/saleor/graphql/order/resolvers.py
--- a/saleor/graphql/order/resolvers.py
+++ b/saleor/graphql/order/resolvers.py
@@ -1,7 +1,6 @@
import graphene
import graphene_django_optimizer as gql_optimizer
-from ...core.permissions import OrderPermissions
from ...order import OrderStatus, models
from ...order.events import OrderEvents
from ...order.models import OrderEvent
@@ -52,12 +51,7 @@
def resolve_order(info, order_id):
- """Return order only for user assigned to it or proper staff user."""
- user = info.context.user
- order = graphene.Node.get_node_from_global_id(info, order_id, Order)
- if user.has_perm(OrderPermissions.MANAGE_ORDERS) or order.user == user:
- return order
- return None
+ return graphene.Node.get_node_from_global_id(info, order_id, Order)
def resolve_homepage_events():
diff --git a/saleor/graphql/order/schema.py b/saleor/graphql/order/schema.py
--- a/saleor/graphql/order/schema.py
+++ b/saleor/graphql/order/schema.py
@@ -1,5 +1,4 @@
import graphene
-from graphql_jwt.decorators import login_required
from ...core.permissions import OrderPermissions
from ..core.enums import ReportingPeriod
@@ -130,7 +129,7 @@
def resolve_homepage_events(self, *_args, **_kwargs):
return resolve_homepage_events()
- @login_required
+ @permission_required(OrderPermissions.MANAGE_ORDERS)
def resolve_order(self, info, **data):
return resolve_order(info, data.get("id"))
|
{"golden_diff": "diff --git a/saleor/graphql/order/resolvers.py b/saleor/graphql/order/resolvers.py\n--- a/saleor/graphql/order/resolvers.py\n+++ b/saleor/graphql/order/resolvers.py\n@@ -1,7 +1,6 @@\n import graphene\n import graphene_django_optimizer as gql_optimizer\n \n-from ...core.permissions import OrderPermissions\n from ...order import OrderStatus, models\n from ...order.events import OrderEvents\n from ...order.models import OrderEvent\n@@ -52,12 +51,7 @@\n \n \n def resolve_order(info, order_id):\n- \"\"\"Return order only for user assigned to it or proper staff user.\"\"\"\n- user = info.context.user\n- order = graphene.Node.get_node_from_global_id(info, order_id, Order)\n- if user.has_perm(OrderPermissions.MANAGE_ORDERS) or order.user == user:\n- return order\n- return None\n+ return graphene.Node.get_node_from_global_id(info, order_id, Order)\n \n \n def resolve_homepage_events():\ndiff --git a/saleor/graphql/order/schema.py b/saleor/graphql/order/schema.py\n--- a/saleor/graphql/order/schema.py\n+++ b/saleor/graphql/order/schema.py\n@@ -1,5 +1,4 @@\n import graphene\n-from graphql_jwt.decorators import login_required\n \n from ...core.permissions import OrderPermissions\n from ..core.enums import ReportingPeriod\n@@ -130,7 +129,7 @@\n def resolve_homepage_events(self, *_args, **_kwargs):\n return resolve_homepage_events()\n \n- @login_required\n+ @permission_required(OrderPermissions.MANAGE_ORDERS)\n def resolve_order(self, info, **data):\n return resolve_order(info, data.get(\"id\"))\n", "issue": "Query order as service account \nI'm not able to query order by id as a service account. \r\n`resolve_order` have `login_required` this decorator doesn't allow to run the function as a service account. \n", "before_files": [{"content": "import graphene\nimport graphene_django_optimizer as gql_optimizer\n\nfrom ...core.permissions import OrderPermissions\nfrom ...order import OrderStatus, models\nfrom ...order.events import OrderEvents\nfrom ...order.models import OrderEvent\nfrom ...order.utils import sum_order_totals\nfrom ..utils import filter_by_period, filter_by_query_param, sort_queryset\nfrom .enums import OrderStatusFilter\nfrom .sorters import OrderSortField\nfrom .types import Order\n\nORDER_SEARCH_FIELDS = (\"id\", \"discount_name\", \"token\", \"user_email\", \"user__email\")\n\n\ndef filter_orders(qs, info, created, status, query):\n qs = filter_by_query_param(qs, query, ORDER_SEARCH_FIELDS)\n\n # DEPRECATED: Will be removed in Saleor 2.11, use the `filter` field instead.\n # filter orders by status\n if status is not None:\n if status == OrderStatusFilter.READY_TO_FULFILL:\n qs = qs.ready_to_fulfill()\n elif status == OrderStatusFilter.READY_TO_CAPTURE:\n qs = qs.ready_to_capture()\n\n # DEPRECATED: Will be removed in Saleor 2.11, use the `filter` field instead.\n # filter orders by creation date\n if created is not None:\n qs = filter_by_period(qs, created, \"created\")\n\n return gql_optimizer.query(qs, info)\n\n\ndef resolve_orders(info, created, status, query, sort_by=None):\n qs = models.Order.objects.confirmed()\n qs = sort_queryset(qs, sort_by, OrderSortField)\n return filter_orders(qs, info, created, status, query)\n\n\ndef resolve_draft_orders(info, created, query, sort_by=None):\n qs = models.Order.objects.drafts()\n qs = sort_queryset(qs, sort_by, OrderSortField)\n return filter_orders(qs, info, created, None, query)\n\n\ndef resolve_orders_total(_info, period):\n qs = models.Order.objects.confirmed().exclude(status=OrderStatus.CANCELED)\n qs = filter_by_period(qs, period, \"created\")\n return sum_order_totals(qs)\n\n\ndef resolve_order(info, order_id):\n \"\"\"Return order only for user assigned to it or proper staff user.\"\"\"\n user = info.context.user\n order = graphene.Node.get_node_from_global_id(info, order_id, Order)\n if user.has_perm(OrderPermissions.MANAGE_ORDERS) or order.user == user:\n return order\n return None\n\n\ndef resolve_homepage_events():\n # Filter only selected events to be displayed on homepage.\n types = [\n OrderEvents.PLACED,\n OrderEvents.PLACED_FROM_DRAFT,\n OrderEvents.ORDER_FULLY_PAID,\n ]\n return OrderEvent.objects.filter(type__in=types)\n\n\ndef resolve_order_by_token(token):\n return models.Order.objects.filter(token=token).first()\n", "path": "saleor/graphql/order/resolvers.py"}, {"content": "import graphene\nfrom graphql_jwt.decorators import login_required\n\nfrom ...core.permissions import OrderPermissions\nfrom ..core.enums import ReportingPeriod\nfrom ..core.fields import FilterInputConnectionField, PrefetchingConnectionField\nfrom ..core.types import FilterInputObjectType, TaxedMoney\nfrom ..decorators import permission_required\nfrom .bulk_mutations.draft_orders import DraftOrderBulkDelete, DraftOrderLinesBulkDelete\nfrom .bulk_mutations.orders import OrderBulkCancel\nfrom .enums import OrderStatusFilter\nfrom .filters import DraftOrderFilter, OrderFilter\nfrom .mutations.draft_orders import (\n DraftOrderComplete,\n DraftOrderCreate,\n DraftOrderDelete,\n DraftOrderLineDelete,\n DraftOrderLinesCreate,\n DraftOrderLineUpdate,\n DraftOrderUpdate,\n)\nfrom .mutations.fulfillments import (\n FulfillmentCancel,\n FulfillmentClearMeta,\n FulfillmentClearPrivateMeta,\n FulfillmentCreate,\n FulfillmentUpdateMeta,\n FulfillmentUpdatePrivateMeta,\n FulfillmentUpdateTracking,\n)\nfrom .mutations.orders import (\n OrderAddNote,\n OrderCancel,\n OrderCapture,\n OrderClearMeta,\n OrderClearPrivateMeta,\n OrderMarkAsPaid,\n OrderRefund,\n OrderUpdate,\n OrderUpdateMeta,\n OrderUpdatePrivateMeta,\n OrderUpdateShipping,\n OrderVoid,\n)\nfrom .resolvers import (\n resolve_draft_orders,\n resolve_homepage_events,\n resolve_order,\n resolve_order_by_token,\n resolve_orders,\n resolve_orders_total,\n)\nfrom .sorters import OrderSortingInput\nfrom .types import Order, OrderEvent\n\n\nclass OrderFilterInput(FilterInputObjectType):\n class Meta:\n filterset_class = OrderFilter\n\n\nclass OrderDraftFilterInput(FilterInputObjectType):\n class Meta:\n filterset_class = DraftOrderFilter\n\n\nclass OrderQueries(graphene.ObjectType):\n homepage_events = PrefetchingConnectionField(\n OrderEvent,\n description=(\n \"List of activity events to display on \"\n \"homepage (at the moment it only contains order-events).\"\n ),\n )\n order = graphene.Field(\n Order,\n description=\"Look up an order by ID.\",\n id=graphene.Argument(graphene.ID, description=\"ID of an order.\", required=True),\n )\n orders = FilterInputConnectionField(\n Order,\n sort_by=OrderSortingInput(description=\"Sort orders.\"),\n filter=OrderFilterInput(description=\"Filtering options for orders.\"),\n created=graphene.Argument(\n ReportingPeriod,\n description=(\n \"Filter orders from a selected timespan. \"\n \"DEPRECATED: Will be removed in Saleor 2.11, \"\n \"use the `filter` field instead.\"\n ),\n ),\n status=graphene.Argument(\n OrderStatusFilter,\n description=(\n \"Filter order by status. \"\n \"DEPRECATED: Will be removed in Saleor 2.11, \"\n \"use the `filter` field instead.\"\n ),\n ),\n description=\"List of orders.\",\n )\n draft_orders = FilterInputConnectionField(\n Order,\n sort_by=OrderSortingInput(description=\"Sort draft orders.\"),\n filter=OrderDraftFilterInput(description=\"Filtering options for draft orders.\"),\n created=graphene.Argument(\n ReportingPeriod,\n description=(\n \"Filter draft orders from a selected timespan. \"\n \"DEPRECATED: Will be removed in Saleor 2.11, \"\n \"use the `filter` field instead.\"\n ),\n ),\n description=\"List of draft orders.\",\n )\n orders_total = graphene.Field(\n TaxedMoney,\n description=\"Return the total sales amount from a specific period.\",\n period=graphene.Argument(ReportingPeriod, description=\"A period of time.\"),\n )\n order_by_token = graphene.Field(\n Order,\n description=\"Look up an order by token.\",\n token=graphene.Argument(\n graphene.UUID, description=\"The order's token.\", required=True\n ),\n )\n\n @permission_required(OrderPermissions.MANAGE_ORDERS)\n def resolve_homepage_events(self, *_args, **_kwargs):\n return resolve_homepage_events()\n\n @login_required\n def resolve_order(self, info, **data):\n return resolve_order(info, data.get(\"id\"))\n\n @permission_required(OrderPermissions.MANAGE_ORDERS)\n def resolve_orders(\n self, info, created=None, status=None, query=None, sort_by=None, **_kwargs\n ):\n return resolve_orders(info, created, status, query, sort_by)\n\n @permission_required(OrderPermissions.MANAGE_ORDERS)\n def resolve_draft_orders(\n self, info, created=None, query=None, sort_by=None, **_kwargs\n ):\n return resolve_draft_orders(info, created, query, sort_by)\n\n @permission_required(OrderPermissions.MANAGE_ORDERS)\n def resolve_orders_total(self, info, period, **_kwargs):\n return resolve_orders_total(info, period)\n\n def resolve_order_by_token(self, _info, token):\n return resolve_order_by_token(token)\n\n\nclass OrderMutations(graphene.ObjectType):\n draft_order_complete = DraftOrderComplete.Field()\n draft_order_create = DraftOrderCreate.Field()\n draft_order_delete = DraftOrderDelete.Field()\n draft_order_bulk_delete = DraftOrderBulkDelete.Field()\n draft_order_lines_bulk_delete = DraftOrderLinesBulkDelete.Field()\n draft_order_lines_create = DraftOrderLinesCreate.Field()\n draft_order_line_delete = DraftOrderLineDelete.Field()\n draft_order_line_update = DraftOrderLineUpdate.Field()\n draft_order_update = DraftOrderUpdate.Field()\n\n order_add_note = OrderAddNote.Field()\n order_cancel = OrderCancel.Field()\n order_capture = OrderCapture.Field()\n order_clear_private_meta = OrderClearPrivateMeta.Field()\n order_clear_meta = OrderClearMeta.Field()\n order_fulfillment_cancel = FulfillmentCancel.Field()\n order_fulfillment_create = FulfillmentCreate.Field()\n order_fulfillment_update_tracking = FulfillmentUpdateTracking.Field()\n order_fulfillment_clear_meta = FulfillmentClearMeta.Field()\n order_fulfillment_clear_private_meta = FulfillmentClearPrivateMeta.Field()\n order_fulfillment_update_meta = FulfillmentUpdateMeta.Field()\n order_fulfillment_update_private_meta = FulfillmentUpdatePrivateMeta.Field()\n order_mark_as_paid = OrderMarkAsPaid.Field()\n order_refund = OrderRefund.Field()\n order_update = OrderUpdate.Field()\n order_update_meta = OrderUpdateMeta.Field()\n order_update_private_meta = OrderUpdatePrivateMeta.Field()\n order_update_shipping = OrderUpdateShipping.Field()\n order_void = OrderVoid.Field()\n\n order_bulk_cancel = OrderBulkCancel.Field()\n", "path": "saleor/graphql/order/schema.py"}]}
| 3,246 | 372 |
gh_patches_debug_24853
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2188
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use a FS cache for Jinja to speed it up a bit
http://jinja.pocoo.org/docs/dev/api/#bytecode-cache
</issue>
<code>
[start of nikola/plugins/template/jinja.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2015 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27
28 """Jinja template handler."""
29
30 from __future__ import unicode_literals
31 import os
32 import json
33 from collections import deque
34 try:
35 import jinja2
36 from jinja2 import meta
37 except ImportError:
38 jinja2 = None # NOQA
39
40 from nikola.plugin_categories import TemplateSystem
41 from nikola.utils import makedirs, req_missing
42
43
44 class JinjaTemplates(TemplateSystem):
45 """Support for Jinja2 templates."""
46
47 name = "jinja"
48 lookup = None
49 dependency_cache = {}
50
51 def __init__(self):
52 """Initialize Jinja2 environment with extended set of filters."""
53 if jinja2 is None:
54 return
55 self.lookup = jinja2.Environment()
56 self.lookup.trim_blocks = True
57 self.lookup.lstrip_blocks = True
58 self.lookup.filters['tojson'] = json.dumps
59 self.lookup.globals['enumerate'] = enumerate
60 self.lookup.globals['isinstance'] = isinstance
61 self.lookup.globals['tuple'] = tuple
62
63 def set_directories(self, directories, cache_folder):
64 """Create a new template lookup with set directories."""
65 if jinja2 is None:
66 req_missing(['jinja2'], 'use this theme')
67 self.directories = directories
68 self.create_lookup()
69
70 def inject_directory(self, directory):
71 """Add a directory to the lookup and recreate it if it's not there yet."""
72 if directory not in self.directories:
73 self.directories.append(directory)
74 self.create_lookup()
75
76 def create_lookup(self):
77 """Create a template lookup."""
78 self.lookup.loader = jinja2.FileSystemLoader(self.directories,
79 encoding='utf-8')
80
81 def set_site(self, site):
82 """Set the Nikola site."""
83 self.site = site
84 self.lookup.filters.update(self.site.config['TEMPLATE_FILTERS'])
85
86 def render_template(self, template_name, output_name, context):
87 """Render the template into output_name using context."""
88 if jinja2 is None:
89 req_missing(['jinja2'], 'use this theme')
90 template = self.lookup.get_template(template_name)
91 output = template.render(**context)
92 if output_name is not None:
93 makedirs(os.path.dirname(output_name))
94 with open(output_name, 'w+') as output:
95 output.write(output.encode('utf8'))
96 return output
97
98 def render_template_to_string(self, template, context):
99 """Render template to a string using context."""
100 return self.lookup.from_string(template).render(**context)
101
102 def template_deps(self, template_name):
103 """Generate list of dependencies for a template."""
104 # Cache the lists of dependencies for each template name.
105 if self.dependency_cache.get(template_name) is None:
106 # Use a breadth-first search to find all templates this one
107 # depends on.
108 queue = deque([template_name])
109 visited_templates = set([template_name])
110 deps = []
111 while len(queue) > 0:
112 curr = queue.popleft()
113 source, filename = self.lookup.loader.get_source(self.lookup,
114 curr)[:2]
115 deps.append(filename)
116 ast = self.lookup.parse(source)
117 dep_names = meta.find_referenced_templates(ast)
118 for dep_name in dep_names:
119 if (dep_name not in visited_templates and dep_name is not None):
120 visited_templates.add(dep_name)
121 queue.append(dep_name)
122 self.dependency_cache[template_name] = deps
123 return self.dependency_cache[template_name]
124
[end of nikola/plugins/template/jinja.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/template/jinja.py b/nikola/plugins/template/jinja.py
--- a/nikola/plugins/template/jinja.py
+++ b/nikola/plugins/template/jinja.py
@@ -52,18 +52,21 @@
"""Initialize Jinja2 environment with extended set of filters."""
if jinja2 is None:
return
- self.lookup = jinja2.Environment()
+
+ def set_directories(self, directories, cache_folder):
+ """Create a new template lookup with set directories."""
+ if jinja2 is None:
+ req_missing(['jinja2'], 'use this theme')
+ cache_folder = os.path.join(cache_folder, 'jinja')
+ makedirs(cache_folder)
+ cache = jinja2.FileSystemBytecodeCache(cache_folder)
+ self.lookup = jinja2.Environment(bytecode_cache=cache)
self.lookup.trim_blocks = True
self.lookup.lstrip_blocks = True
self.lookup.filters['tojson'] = json.dumps
self.lookup.globals['enumerate'] = enumerate
self.lookup.globals['isinstance'] = isinstance
self.lookup.globals['tuple'] = tuple
-
- def set_directories(self, directories, cache_folder):
- """Create a new template lookup with set directories."""
- if jinja2 is None:
- req_missing(['jinja2'], 'use this theme')
self.directories = directories
self.create_lookup()
|
{"golden_diff": "diff --git a/nikola/plugins/template/jinja.py b/nikola/plugins/template/jinja.py\n--- a/nikola/plugins/template/jinja.py\n+++ b/nikola/plugins/template/jinja.py\n@@ -52,18 +52,21 @@\n \"\"\"Initialize Jinja2 environment with extended set of filters.\"\"\"\n if jinja2 is None:\n return\n- self.lookup = jinja2.Environment()\n+\n+ def set_directories(self, directories, cache_folder):\n+ \"\"\"Create a new template lookup with set directories.\"\"\"\n+ if jinja2 is None:\n+ req_missing(['jinja2'], 'use this theme')\n+ cache_folder = os.path.join(cache_folder, 'jinja')\n+ makedirs(cache_folder)\n+ cache = jinja2.FileSystemBytecodeCache(cache_folder)\n+ self.lookup = jinja2.Environment(bytecode_cache=cache)\n self.lookup.trim_blocks = True\n self.lookup.lstrip_blocks = True\n self.lookup.filters['tojson'] = json.dumps\n self.lookup.globals['enumerate'] = enumerate\n self.lookup.globals['isinstance'] = isinstance\n self.lookup.globals['tuple'] = tuple\n-\n- def set_directories(self, directories, cache_folder):\n- \"\"\"Create a new template lookup with set directories.\"\"\"\n- if jinja2 is None:\n- req_missing(['jinja2'], 'use this theme')\n self.directories = directories\n self.create_lookup()\n", "issue": "Use a FS cache for Jinja to speed it up a bit\nhttp://jinja.pocoo.org/docs/dev/api/#bytecode-cache\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\"Jinja template handler.\"\"\"\n\nfrom __future__ import unicode_literals\nimport os\nimport json\nfrom collections import deque\ntry:\n import jinja2\n from jinja2 import meta\nexcept ImportError:\n jinja2 = None # NOQA\n\nfrom nikola.plugin_categories import TemplateSystem\nfrom nikola.utils import makedirs, req_missing\n\n\nclass JinjaTemplates(TemplateSystem):\n \"\"\"Support for Jinja2 templates.\"\"\"\n\n name = \"jinja\"\n lookup = None\n dependency_cache = {}\n\n def __init__(self):\n \"\"\"Initialize Jinja2 environment with extended set of filters.\"\"\"\n if jinja2 is None:\n return\n self.lookup = jinja2.Environment()\n self.lookup.trim_blocks = True\n self.lookup.lstrip_blocks = True\n self.lookup.filters['tojson'] = json.dumps\n self.lookup.globals['enumerate'] = enumerate\n self.lookup.globals['isinstance'] = isinstance\n self.lookup.globals['tuple'] = tuple\n\n def set_directories(self, directories, cache_folder):\n \"\"\"Create a new template lookup with set directories.\"\"\"\n if jinja2 is None:\n req_missing(['jinja2'], 'use this theme')\n self.directories = directories\n self.create_lookup()\n\n def inject_directory(self, directory):\n \"\"\"Add a directory to the lookup and recreate it if it's not there yet.\"\"\"\n if directory not in self.directories:\n self.directories.append(directory)\n self.create_lookup()\n\n def create_lookup(self):\n \"\"\"Create a template lookup.\"\"\"\n self.lookup.loader = jinja2.FileSystemLoader(self.directories,\n encoding='utf-8')\n\n def set_site(self, site):\n \"\"\"Set the Nikola site.\"\"\"\n self.site = site\n self.lookup.filters.update(self.site.config['TEMPLATE_FILTERS'])\n\n def render_template(self, template_name, output_name, context):\n \"\"\"Render the template into output_name using context.\"\"\"\n if jinja2 is None:\n req_missing(['jinja2'], 'use this theme')\n template = self.lookup.get_template(template_name)\n output = template.render(**context)\n if output_name is not None:\n makedirs(os.path.dirname(output_name))\n with open(output_name, 'w+') as output:\n output.write(output.encode('utf8'))\n return output\n\n def render_template_to_string(self, template, context):\n \"\"\"Render template to a string using context.\"\"\"\n return self.lookup.from_string(template).render(**context)\n\n def template_deps(self, template_name):\n \"\"\"Generate list of dependencies for a template.\"\"\"\n # Cache the lists of dependencies for each template name.\n if self.dependency_cache.get(template_name) is None:\n # Use a breadth-first search to find all templates this one\n # depends on.\n queue = deque([template_name])\n visited_templates = set([template_name])\n deps = []\n while len(queue) > 0:\n curr = queue.popleft()\n source, filename = self.lookup.loader.get_source(self.lookup,\n curr)[:2]\n deps.append(filename)\n ast = self.lookup.parse(source)\n dep_names = meta.find_referenced_templates(ast)\n for dep_name in dep_names:\n if (dep_name not in visited_templates and dep_name is not None):\n visited_templates.add(dep_name)\n queue.append(dep_name)\n self.dependency_cache[template_name] = deps\n return self.dependency_cache[template_name]\n", "path": "nikola/plugins/template/jinja.py"}]}
| 1,829 | 316 |
gh_patches_debug_9404
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
scrypt bounds checking
```
[11:23:58] <Alex_Gaynor> reaperhulk: what happens if you pass a non-even n?
[11:24:10] <Alex_Gaynor> Or a negative value for any of the params?
```
Presumably it will fail with an assertion error on return from the call to `EVP_PBE_scrypt`, but we shouldn't allow those types of errors.
cc @Ayrx.
</issue>
<code>
[start of src/cryptography/hazmat/primitives/kdf/scrypt.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 from cryptography import utils
8 from cryptography.exceptions import (
9 AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons
10 )
11 from cryptography.hazmat.backends.interfaces import ScryptBackend
12 from cryptography.hazmat.primitives import constant_time
13 from cryptography.hazmat.primitives.kdf import KeyDerivationFunction
14
15
16 @utils.register_interface(KeyDerivationFunction)
17 class Scrypt(object):
18 def __init__(self, salt, length, n, r, p, backend):
19 if not isinstance(backend, ScryptBackend):
20 raise UnsupportedAlgorithm(
21 "Backend object does not implement ScryptBackend.",
22 _Reasons.BACKEND_MISSING_INTERFACE
23 )
24
25 self._length = length
26 if not isinstance(salt, bytes):
27 raise TypeError("salt must be bytes.")
28 self._used = False
29 self._salt = salt
30 self._n = n
31 self._r = r
32 self._p = p
33 self._backend = backend
34
35 def derive(self, key_material):
36 if self._used:
37 raise AlreadyFinalized("Scrypt instances can only be used once.")
38 self._used = True
39
40 if not isinstance(key_material, bytes):
41 raise TypeError("key_material must be bytes.")
42 return self._backend.derive_scrypt(
43 key_material, self._salt, self._length, self._n, self._r, self._p
44 )
45
46 def verify(self, key_material, expected_key):
47 derived_key = self.derive(key_material)
48 if not constant_time.bytes_eq(derived_key, expected_key):
49 raise InvalidKey("Keys do not match.")
50
[end of src/cryptography/hazmat/primitives/kdf/scrypt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/kdf/scrypt.py b/src/cryptography/hazmat/primitives/kdf/scrypt.py
--- a/src/cryptography/hazmat/primitives/kdf/scrypt.py
+++ b/src/cryptography/hazmat/primitives/kdf/scrypt.py
@@ -25,6 +25,16 @@
self._length = length
if not isinstance(salt, bytes):
raise TypeError("salt must be bytes.")
+
+ if n < 2 or (n & (n - 1)) != 0:
+ raise ValueError("n must be greater than 1 and be a power of 2.")
+
+ if r < 1:
+ raise ValueError("r must be greater than or equal to 1.")
+
+ if p < 1:
+ raise ValueError("p must be greater than or equal to 1.")
+
self._used = False
self._salt = salt
self._n = n
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/kdf/scrypt.py b/src/cryptography/hazmat/primitives/kdf/scrypt.py\n--- a/src/cryptography/hazmat/primitives/kdf/scrypt.py\n+++ b/src/cryptography/hazmat/primitives/kdf/scrypt.py\n@@ -25,6 +25,16 @@\n self._length = length\n if not isinstance(salt, bytes):\n raise TypeError(\"salt must be bytes.\")\n+\n+ if n < 2 or (n & (n - 1)) != 0:\n+ raise ValueError(\"n must be greater than 1 and be a power of 2.\")\n+\n+ if r < 1:\n+ raise ValueError(\"r must be greater than or equal to 1.\")\n+\n+ if p < 1:\n+ raise ValueError(\"p must be greater than or equal to 1.\")\n+\n self._used = False\n self._salt = salt\n self._n = n\n", "issue": "scrypt bounds checking\n```\n[11:23:58] <Alex_Gaynor> reaperhulk: what happens if you pass a non-even n?\n[11:24:10] <Alex_Gaynor> Or a negative value for any of the params?\n```\n\nPresumably it will fail with an assertion error on return from the call to `EVP_PBE_scrypt`, but we shouldn't allow those types of errors.\n\ncc @Ayrx.\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.backends.interfaces import ScryptBackend\nfrom cryptography.hazmat.primitives import constant_time\nfrom cryptography.hazmat.primitives.kdf import KeyDerivationFunction\n\n\[email protected]_interface(KeyDerivationFunction)\nclass Scrypt(object):\n def __init__(self, salt, length, n, r, p, backend):\n if not isinstance(backend, ScryptBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement ScryptBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._length = length\n if not isinstance(salt, bytes):\n raise TypeError(\"salt must be bytes.\")\n self._used = False\n self._salt = salt\n self._n = n\n self._r = r\n self._p = p\n self._backend = backend\n\n def derive(self, key_material):\n if self._used:\n raise AlreadyFinalized(\"Scrypt instances can only be used once.\")\n self._used = True\n\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n return self._backend.derive_scrypt(\n key_material, self._salt, self._length, self._n, self._r, self._p\n )\n\n def verify(self, key_material, expected_key):\n derived_key = self.derive(key_material)\n if not constant_time.bytes_eq(derived_key, expected_key):\n raise InvalidKey(\"Keys do not match.\")\n", "path": "src/cryptography/hazmat/primitives/kdf/scrypt.py"}]}
| 1,153 | 216 |
gh_patches_debug_26534
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-2029
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
StrawberryUnion's type resolver does not prioritise types in the Union
## Describe the Bug
StrawberryUnion's type resolver iterates over all known types and returns the first type which successfully implements the returned object from the resolver.
Due to limitations of `TypeDefinition.is_implemented_by` when checking generic fields, this check might succeed prematurely for an object with the same top level structure.
If the wrong type is selected a `UnallowedReturnTypeForUnion` error is raised shortly afterwards.
Potentially it might be possible to improve `TypeDefinition.is_implemented_by` check for generic fields but that is beyond the scope of this issue.
This issue suggests a simple fix of first checking the types given in the union before falling back to checking all types. This might also be a small performance improvement if it is true that in most cases the correct type is listed in the Union.
Minimal reproduceable example: https://play.strawberry.rocks/?gist=f7d88898d127e65b12140fdd763f9ef2
## Existing Code
The below check is logically incorrect as `possible_type.is_implemented_by(root)` might be True for a similar object that is not the correct type.
```python
# Iterate over all of our known types and find the first concrete type that
# implements the type
for possible_concrete_type in type_map.values():
possible_type = possible_concrete_type.definition
if not isinstance(possible_type, TypeDefinition):
continue
if possible_type.is_implemented_by(root):
return_type = possible_concrete_type.implementation
break
else:
return_type = None
```
## Example Fix
Here we check the types explicitly listed in the Union first, and then fallback to checking all types.
```python
# Iterate over the given types in the union and check if any provide a
# concrete type that implements the type.
for gql_object_type in type_.types:
type_name = gql_object_type.name
possible_concrete_type = type_map.get(type_name)
if possible_concrete_type:
possible_type = possible_concrete_type.definition
if not isinstance(possible_type, TypeDefinition):
continue
if possible_type.is_implemented_by(root):
return_type = possible_concrete_type.implementation
break
else:
return_type = None
# Otherwise, iterate over all of our known types and find the first concrete
# type that implements the type.
if return_type is None:
for possible_concrete_type in type_map.values():
possible_type = possible_concrete_type.definition
if not isinstance(possible_type, TypeDefinition):
continue
if possible_type.is_implemented_by(root):
return_type = possible_concrete_type.implementation
break
```
## System Information
- Operating system: N/A
- Strawberry version (if applicable): 0.119.1
</issue>
<code>
[start of strawberry/union.py]
1 import itertools
2 from typing import (
3 TYPE_CHECKING,
4 Any,
5 List,
6 Mapping,
7 NoReturn,
8 Optional,
9 Tuple,
10 Type,
11 TypeVar,
12 Union,
13 cast,
14 )
15
16 from graphql import (
17 GraphQLAbstractType,
18 GraphQLNamedType,
19 GraphQLResolveInfo,
20 GraphQLType,
21 GraphQLTypeResolver,
22 GraphQLUnionType,
23 )
24
25 from strawberry.annotation import StrawberryAnnotation
26 from strawberry.exceptions import (
27 InvalidUnionType,
28 UnallowedReturnTypeForUnion,
29 WrongReturnTypeForUnion,
30 )
31 from strawberry.type import StrawberryOptional, StrawberryType
32
33
34 if TYPE_CHECKING:
35 from strawberry.schema.types.concrete_type import TypeMap
36 from strawberry.types.types import TypeDefinition
37
38
39 class StrawberryUnion(StrawberryType):
40 def __init__(
41 self,
42 name: Optional[str] = None,
43 type_annotations: Tuple["StrawberryAnnotation", ...] = tuple(),
44 description: Optional[str] = None,
45 ):
46 self.graphql_name = name
47 self.type_annotations = type_annotations
48 self.description = description
49
50 def __eq__(self, other: object) -> bool:
51 if isinstance(other, StrawberryType):
52 if isinstance(other, StrawberryUnion):
53 return (
54 self.graphql_name == other.graphql_name
55 and self.type_annotations == other.type_annotations
56 and self.description == other.description
57 )
58 return False
59
60 return super().__eq__(other)
61
62 def __hash__(self) -> int:
63 # TODO: Is this a bad idea? __eq__ objects are supposed to have the same hash
64 return id(self)
65
66 def __or__(self, other: Union[StrawberryType, type]) -> StrawberryType:
67 if other is None:
68 # Return the correct notation when using `StrawberryUnion | None`.
69 return StrawberryOptional(of_type=self)
70
71 # Raise an error in any other case.
72 # There is Work in progress to deal with more merging cases, see:
73 # https://github.com/strawberry-graphql/strawberry/pull/1455
74 raise InvalidUnionType(other)
75
76 @property
77 def types(self) -> Tuple[StrawberryType, ...]:
78 return tuple(
79 cast(StrawberryType, annotation.resolve())
80 for annotation in self.type_annotations
81 )
82
83 @property
84 def type_params(self) -> List[TypeVar]:
85 def _get_type_params(type_: StrawberryType):
86 if hasattr(type_, "_type_definition"):
87 parameters = getattr(type_, "__parameters__", None)
88
89 return list(parameters) if parameters else []
90
91 return type_.type_params
92
93 # TODO: check if order is important:
94 # https://github.com/strawberry-graphql/strawberry/issues/445
95 return list(
96 set(itertools.chain(*(_get_type_params(type_) for type_ in self.types)))
97 )
98
99 @property
100 def is_generic(self) -> bool:
101 return len(self.type_params) > 0
102
103 def copy_with(
104 self, type_var_map: Mapping[TypeVar, Union[StrawberryType, type]]
105 ) -> StrawberryType:
106 if not self.is_generic:
107 return self
108
109 new_types = []
110 for type_ in self.types:
111 new_type: Union[StrawberryType, type]
112
113 if hasattr(type_, "_type_definition"):
114 type_definition: TypeDefinition = type_._type_definition # type: ignore
115
116 if type_definition.is_generic:
117 new_type = type_definition.copy_with(type_var_map)
118 if isinstance(type_, StrawberryType) and type_.is_generic:
119 new_type = type_.copy_with(type_var_map)
120 else:
121 new_type = type_
122
123 new_types.append(new_type)
124
125 return StrawberryUnion(
126 type_annotations=tuple(map(StrawberryAnnotation, new_types)),
127 description=self.description,
128 )
129
130 def __call__(self, *_args, **_kwargs) -> NoReturn:
131 """Do not use.
132
133 Used to bypass
134 https://github.com/python/cpython/blob/5efb1a77e75648012f8b52960c8637fc296a5c6d/Lib/typing.py#L148-L149
135 """
136 raise ValueError("Cannot use union type directly")
137
138 def get_type_resolver(self, type_map: "TypeMap") -> GraphQLTypeResolver:
139 def _resolve_union_type(
140 root: Any, info: GraphQLResolveInfo, type_: GraphQLAbstractType
141 ) -> str:
142 assert isinstance(type_, GraphQLUnionType)
143
144 from strawberry.types.types import TypeDefinition
145
146 # If the type given is not an Object type, try resolving using `is_type_of`
147 # defined on the union's inner types
148 if not hasattr(root, "_type_definition"):
149 for inner_type in type_.types:
150 if inner_type.is_type_of is not None and inner_type.is_type_of(
151 root, info
152 ):
153 return inner_type.name
154
155 # Couldn't resolve using `is_type_of``
156 raise WrongReturnTypeForUnion(info.field_name, str(type(root)))
157
158 return_type: Optional[GraphQLType]
159
160 # Iterate over all of our known types and find the first concrete type that
161 # implements the type
162 for possible_concrete_type in type_map.values():
163 possible_type = possible_concrete_type.definition
164 if not isinstance(possible_type, TypeDefinition):
165 continue
166 if possible_type.is_implemented_by(root):
167 return_type = possible_concrete_type.implementation
168 break
169 else:
170 return_type = None
171
172 # Make sure the found type is expected by the Union
173 if return_type is None or return_type not in type_.types:
174 raise UnallowedReturnTypeForUnion(
175 info.field_name, str(type(root)), set(type_.types)
176 )
177
178 # Return the name of the type. Returning the actual type is now deprecated
179 if isinstance(return_type, GraphQLNamedType):
180 # TODO: Can return_type ever _not_ be a GraphQLNamedType?
181 return return_type.name
182 else:
183 # todo: check if this is correct
184 return return_type.__name__ # type: ignore
185
186 return _resolve_union_type
187
188
189 Types = TypeVar("Types", bound=Type)
190
191
192 # We return a Union type here in order to allow to use the union type as type
193 # annotation.
194 # For the `types` argument we'd ideally use a TypeVarTuple, but that's not
195 # yet supported in any python implementation (or in typing_extensions).
196 # See https://www.python.org/dev/peps/pep-0646/ for more information
197 def union(
198 name: str, types: Tuple[Types, ...], *, description: str = None
199 ) -> Union[Types]:
200 """Creates a new named Union type.
201
202 Example usages:
203
204 >>> @strawberry.type
205 ... class A: ...
206 >>> @strawberry.type
207 ... class B: ...
208 >>> strawberry.union("Name", (A, Optional[B]))
209 """
210
211 # Validate types
212 if len(types) == 0:
213 raise TypeError("No types passed to `union`")
214
215 for _type in types:
216 if not isinstance(_type, TypeVar) and not hasattr(_type, "_type_definition"):
217 raise InvalidUnionType(
218 f"Type `{_type.__name__}` cannot be used in a GraphQL Union"
219 )
220
221 union_definition = StrawberryUnion(
222 name=name,
223 type_annotations=tuple(StrawberryAnnotation(type_) for type_ in types),
224 description=description,
225 )
226
227 return union_definition # type: ignore
228
[end of strawberry/union.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/union.py b/strawberry/union.py
--- a/strawberry/union.py
+++ b/strawberry/union.py
@@ -1,4 +1,5 @@
import itertools
+from itertools import chain
from typing import (
TYPE_CHECKING,
Any,
@@ -152,14 +153,20 @@
):
return inner_type.name
- # Couldn't resolve using `is_type_of``
+ # Couldn't resolve using `is_type_of`
raise WrongReturnTypeForUnion(info.field_name, str(type(root)))
return_type: Optional[GraphQLType]
- # Iterate over all of our known types and find the first concrete type that
- # implements the type
- for possible_concrete_type in type_map.values():
+ # Iterate over all of our known types and find the first concrete
+ # type that implements the type. We prioritise checking types named in the
+ # Union in case a nested generic object matches against more than one type.
+ concrete_types_for_union = (type_map[x.name] for x in type_.types)
+
+ # TODO: do we still need to iterate over all types in `type_map`?
+ for possible_concrete_type in chain(
+ concrete_types_for_union, type_map.values()
+ ):
possible_type = possible_concrete_type.definition
if not isinstance(possible_type, TypeDefinition):
continue
|
{"golden_diff": "diff --git a/strawberry/union.py b/strawberry/union.py\n--- a/strawberry/union.py\n+++ b/strawberry/union.py\n@@ -1,4 +1,5 @@\n import itertools\n+from itertools import chain\n from typing import (\n TYPE_CHECKING,\n Any,\n@@ -152,14 +153,20 @@\n ):\n return inner_type.name\n \n- # Couldn't resolve using `is_type_of``\n+ # Couldn't resolve using `is_type_of`\n raise WrongReturnTypeForUnion(info.field_name, str(type(root)))\n \n return_type: Optional[GraphQLType]\n \n- # Iterate over all of our known types and find the first concrete type that\n- # implements the type\n- for possible_concrete_type in type_map.values():\n+ # Iterate over all of our known types and find the first concrete\n+ # type that implements the type. We prioritise checking types named in the\n+ # Union in case a nested generic object matches against more than one type.\n+ concrete_types_for_union = (type_map[x.name] for x in type_.types)\n+\n+ # TODO: do we still need to iterate over all types in `type_map`?\n+ for possible_concrete_type in chain(\n+ concrete_types_for_union, type_map.values()\n+ ):\n possible_type = possible_concrete_type.definition\n if not isinstance(possible_type, TypeDefinition):\n continue\n", "issue": "StrawberryUnion's type resolver does not prioritise types in the Union\n## Describe the Bug\r\n\r\nStrawberryUnion's type resolver iterates over all known types and returns the first type which successfully implements the returned object from the resolver.\r\n\r\nDue to limitations of `TypeDefinition.is_implemented_by` when checking generic fields, this check might succeed prematurely for an object with the same top level structure.\r\n\r\nIf the wrong type is selected a `UnallowedReturnTypeForUnion` error is raised shortly afterwards.\r\n\r\nPotentially it might be possible to improve `TypeDefinition.is_implemented_by` check for generic fields but that is beyond the scope of this issue.\r\n\r\nThis issue suggests a simple fix of first checking the types given in the union before falling back to checking all types. This might also be a small performance improvement if it is true that in most cases the correct type is listed in the Union.\r\n\r\nMinimal reproduceable example: https://play.strawberry.rocks/?gist=f7d88898d127e65b12140fdd763f9ef2\r\n\r\n## Existing Code\r\nThe below check is logically incorrect as `possible_type.is_implemented_by(root)` might be True for a similar object that is not the correct type.\r\n\r\n```python\r\n# Iterate over all of our known types and find the first concrete type that\r\n# implements the type\r\nfor possible_concrete_type in type_map.values():\r\n possible_type = possible_concrete_type.definition\r\n if not isinstance(possible_type, TypeDefinition):\r\n continue\r\n if possible_type.is_implemented_by(root):\r\n return_type = possible_concrete_type.implementation\r\n break\r\nelse:\r\n return_type = None\r\n```\r\n\r\n## Example Fix\r\nHere we check the types explicitly listed in the Union first, and then fallback to checking all types.\r\n\r\n```python\r\n# Iterate over the given types in the union and check if any provide a\r\n# concrete type that implements the type.\r\nfor gql_object_type in type_.types:\r\n type_name = gql_object_type.name\r\n possible_concrete_type = type_map.get(type_name)\r\n if possible_concrete_type:\r\n possible_type = possible_concrete_type.definition\r\n if not isinstance(possible_type, TypeDefinition):\r\n continue\r\n if possible_type.is_implemented_by(root):\r\n return_type = possible_concrete_type.implementation\r\n break\r\nelse:\r\n return_type = None\r\n\r\n# Otherwise, iterate over all of our known types and find the first concrete\r\n# type that implements the type.\r\nif return_type is None:\r\n for possible_concrete_type in type_map.values():\r\n possible_type = possible_concrete_type.definition\r\n if not isinstance(possible_type, TypeDefinition):\r\n continue\r\n if possible_type.is_implemented_by(root):\r\n return_type = possible_concrete_type.implementation\r\n break\r\n```\r\n\r\n## System Information\r\n\r\n - Operating system: N/A\r\n - Strawberry version (if applicable): 0.119.1\r\n\n", "before_files": [{"content": "import itertools\nfrom typing import (\n TYPE_CHECKING,\n Any,\n List,\n Mapping,\n NoReturn,\n Optional,\n Tuple,\n Type,\n TypeVar,\n Union,\n cast,\n)\n\nfrom graphql import (\n GraphQLAbstractType,\n GraphQLNamedType,\n GraphQLResolveInfo,\n GraphQLType,\n GraphQLTypeResolver,\n GraphQLUnionType,\n)\n\nfrom strawberry.annotation import StrawberryAnnotation\nfrom strawberry.exceptions import (\n InvalidUnionType,\n UnallowedReturnTypeForUnion,\n WrongReturnTypeForUnion,\n)\nfrom strawberry.type import StrawberryOptional, StrawberryType\n\n\nif TYPE_CHECKING:\n from strawberry.schema.types.concrete_type import TypeMap\n from strawberry.types.types import TypeDefinition\n\n\nclass StrawberryUnion(StrawberryType):\n def __init__(\n self,\n name: Optional[str] = None,\n type_annotations: Tuple[\"StrawberryAnnotation\", ...] = tuple(),\n description: Optional[str] = None,\n ):\n self.graphql_name = name\n self.type_annotations = type_annotations\n self.description = description\n\n def __eq__(self, other: object) -> bool:\n if isinstance(other, StrawberryType):\n if isinstance(other, StrawberryUnion):\n return (\n self.graphql_name == other.graphql_name\n and self.type_annotations == other.type_annotations\n and self.description == other.description\n )\n return False\n\n return super().__eq__(other)\n\n def __hash__(self) -> int:\n # TODO: Is this a bad idea? __eq__ objects are supposed to have the same hash\n return id(self)\n\n def __or__(self, other: Union[StrawberryType, type]) -> StrawberryType:\n if other is None:\n # Return the correct notation when using `StrawberryUnion | None`.\n return StrawberryOptional(of_type=self)\n\n # Raise an error in any other case.\n # There is Work in progress to deal with more merging cases, see:\n # https://github.com/strawberry-graphql/strawberry/pull/1455\n raise InvalidUnionType(other)\n\n @property\n def types(self) -> Tuple[StrawberryType, ...]:\n return tuple(\n cast(StrawberryType, annotation.resolve())\n for annotation in self.type_annotations\n )\n\n @property\n def type_params(self) -> List[TypeVar]:\n def _get_type_params(type_: StrawberryType):\n if hasattr(type_, \"_type_definition\"):\n parameters = getattr(type_, \"__parameters__\", None)\n\n return list(parameters) if parameters else []\n\n return type_.type_params\n\n # TODO: check if order is important:\n # https://github.com/strawberry-graphql/strawberry/issues/445\n return list(\n set(itertools.chain(*(_get_type_params(type_) for type_ in self.types)))\n )\n\n @property\n def is_generic(self) -> bool:\n return len(self.type_params) > 0\n\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, type]]\n ) -> StrawberryType:\n if not self.is_generic:\n return self\n\n new_types = []\n for type_ in self.types:\n new_type: Union[StrawberryType, type]\n\n if hasattr(type_, \"_type_definition\"):\n type_definition: TypeDefinition = type_._type_definition # type: ignore\n\n if type_definition.is_generic:\n new_type = type_definition.copy_with(type_var_map)\n if isinstance(type_, StrawberryType) and type_.is_generic:\n new_type = type_.copy_with(type_var_map)\n else:\n new_type = type_\n\n new_types.append(new_type)\n\n return StrawberryUnion(\n type_annotations=tuple(map(StrawberryAnnotation, new_types)),\n description=self.description,\n )\n\n def __call__(self, *_args, **_kwargs) -> NoReturn:\n \"\"\"Do not use.\n\n Used to bypass\n https://github.com/python/cpython/blob/5efb1a77e75648012f8b52960c8637fc296a5c6d/Lib/typing.py#L148-L149\n \"\"\"\n raise ValueError(\"Cannot use union type directly\")\n\n def get_type_resolver(self, type_map: \"TypeMap\") -> GraphQLTypeResolver:\n def _resolve_union_type(\n root: Any, info: GraphQLResolveInfo, type_: GraphQLAbstractType\n ) -> str:\n assert isinstance(type_, GraphQLUnionType)\n\n from strawberry.types.types import TypeDefinition\n\n # If the type given is not an Object type, try resolving using `is_type_of`\n # defined on the union's inner types\n if not hasattr(root, \"_type_definition\"):\n for inner_type in type_.types:\n if inner_type.is_type_of is not None and inner_type.is_type_of(\n root, info\n ):\n return inner_type.name\n\n # Couldn't resolve using `is_type_of``\n raise WrongReturnTypeForUnion(info.field_name, str(type(root)))\n\n return_type: Optional[GraphQLType]\n\n # Iterate over all of our known types and find the first concrete type that\n # implements the type\n for possible_concrete_type in type_map.values():\n possible_type = possible_concrete_type.definition\n if not isinstance(possible_type, TypeDefinition):\n continue\n if possible_type.is_implemented_by(root):\n return_type = possible_concrete_type.implementation\n break\n else:\n return_type = None\n\n # Make sure the found type is expected by the Union\n if return_type is None or return_type not in type_.types:\n raise UnallowedReturnTypeForUnion(\n info.field_name, str(type(root)), set(type_.types)\n )\n\n # Return the name of the type. Returning the actual type is now deprecated\n if isinstance(return_type, GraphQLNamedType):\n # TODO: Can return_type ever _not_ be a GraphQLNamedType?\n return return_type.name\n else:\n # todo: check if this is correct\n return return_type.__name__ # type: ignore\n\n return _resolve_union_type\n\n\nTypes = TypeVar(\"Types\", bound=Type)\n\n\n# We return a Union type here in order to allow to use the union type as type\n# annotation.\n# For the `types` argument we'd ideally use a TypeVarTuple, but that's not\n# yet supported in any python implementation (or in typing_extensions).\n# See https://www.python.org/dev/peps/pep-0646/ for more information\ndef union(\n name: str, types: Tuple[Types, ...], *, description: str = None\n) -> Union[Types]:\n \"\"\"Creates a new named Union type.\n\n Example usages:\n\n >>> @strawberry.type\n ... class A: ...\n >>> @strawberry.type\n ... class B: ...\n >>> strawberry.union(\"Name\", (A, Optional[B]))\n \"\"\"\n\n # Validate types\n if len(types) == 0:\n raise TypeError(\"No types passed to `union`\")\n\n for _type in types:\n if not isinstance(_type, TypeVar) and not hasattr(_type, \"_type_definition\"):\n raise InvalidUnionType(\n f\"Type `{_type.__name__}` cannot be used in a GraphQL Union\"\n )\n\n union_definition = StrawberryUnion(\n name=name,\n type_annotations=tuple(StrawberryAnnotation(type_) for type_ in types),\n description=description,\n )\n\n return union_definition # type: ignore\n", "path": "strawberry/union.py"}]}
| 3,390 | 321 |
gh_patches_debug_32814
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-645
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
skill container is broken
When the intent skill became the intent class the skill container wasn't updated to match the new structure and is currently not working.
</issue>
<code>
[start of mycroft/skills/container.py]
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18
19 import argparse
20 import sys
21 from os.path import dirname, exists, isdir
22
23 from mycroft.configuration import ConfigurationManager
24 from mycroft.messagebus.client.ws import WebsocketClient
25 from mycroft.skills.core import create_skill_descriptor, load_skill
26 from mycroft.skills.intent import create_skill as create_intent_skill
27 from mycroft.util.log import getLogger
28
29 __author__ = 'seanfitz'
30
31 LOG = getLogger("SkillContainer")
32
33
34 class SkillContainer(object):
35 def __init__(self, args):
36 params = self.__build_params(args)
37
38 if params.config:
39 ConfigurationManager.load_local([params.config])
40
41 if exists(params.lib) and isdir(params.lib):
42 sys.path.append(params.lib)
43
44 sys.path.append(params.dir)
45 self.dir = params.dir
46
47 self.enable_intent_skill = params.enable_intent_skill
48
49 self.__init_client(params)
50
51 @staticmethod
52 def __build_params(args):
53 parser = argparse.ArgumentParser()
54 parser.add_argument("--config", default="./mycroft.conf")
55 parser.add_argument("dir", nargs='?', default=dirname(__file__))
56 parser.add_argument("--lib", default="./lib")
57 parser.add_argument("--host", default=None)
58 parser.add_argument("--port", default=None)
59 parser.add_argument("--use-ssl", action='store_true', default=False)
60 parser.add_argument("--enable-intent-skill", action='store_true',
61 default=False)
62 return parser.parse_args(args)
63
64 def __init_client(self, params):
65 config = ConfigurationManager.get().get("websocket")
66
67 if not params.host:
68 params.host = config.get('host')
69 if not params.port:
70 params.port = config.get('port')
71
72 self.ws = WebsocketClient(host=params.host,
73 port=params.port,
74 ssl=params.use_ssl)
75
76 def load_skill(self):
77 if self.enable_intent_skill:
78 intent_skill = create_intent_skill()
79 intent_skill.bind(self.ws)
80 intent_skill.initialize()
81 skill_descriptor = create_skill_descriptor(self.dir)
82 self.skill = load_skill(skill_descriptor, self.ws)
83
84 def run(self):
85 try:
86 self.ws.on('message', LOG.debug)
87 self.ws.on('open', self.load_skill)
88 self.ws.on('error', LOG.error)
89 self.ws.run_forever()
90 except Exception as e:
91 LOG.error("Error: {0}".format(e))
92 self.stop()
93
94 def stop(self):
95 if self.skill:
96 self.skill.shutdown()
97
98
99 def main():
100 container = SkillContainer(sys.argv[1:])
101 try:
102 container.run()
103 except KeyboardInterrupt:
104 container.stop()
105 finally:
106 sys.exit()
107
108
109 if __name__ == "__main__":
110 main()
111
[end of mycroft/skills/container.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/skills/container.py b/mycroft/skills/container.py
--- a/mycroft/skills/container.py
+++ b/mycroft/skills/container.py
@@ -23,7 +23,7 @@
from mycroft.configuration import ConfigurationManager
from mycroft.messagebus.client.ws import WebsocketClient
from mycroft.skills.core import create_skill_descriptor, load_skill
-from mycroft.skills.intent import create_skill as create_intent_skill
+from mycroft.skills.intent import Intent
from mycroft.util.log import getLogger
__author__ = 'seanfitz'
@@ -44,7 +44,7 @@
sys.path.append(params.dir)
self.dir = params.dir
- self.enable_intent_skill = params.enable_intent_skill
+ self.enable_intent = params.enable_intent
self.__init_client(params)
@@ -57,7 +57,7 @@
parser.add_argument("--host", default=None)
parser.add_argument("--port", default=None)
parser.add_argument("--use-ssl", action='store_true', default=False)
- parser.add_argument("--enable-intent-skill", action='store_true',
+ parser.add_argument("--enable-intent", action='store_true',
default=False)
return parser.parse_args(args)
@@ -74,10 +74,9 @@
ssl=params.use_ssl)
def load_skill(self):
- if self.enable_intent_skill:
- intent_skill = create_intent_skill()
- intent_skill.bind(self.ws)
- intent_skill.initialize()
+ if self.enable_intent:
+ Intent(self.ws)
+
skill_descriptor = create_skill_descriptor(self.dir)
self.skill = load_skill(skill_descriptor, self.ws)
|
{"golden_diff": "diff --git a/mycroft/skills/container.py b/mycroft/skills/container.py\n--- a/mycroft/skills/container.py\n+++ b/mycroft/skills/container.py\n@@ -23,7 +23,7 @@\n from mycroft.configuration import ConfigurationManager\n from mycroft.messagebus.client.ws import WebsocketClient\n from mycroft.skills.core import create_skill_descriptor, load_skill\n-from mycroft.skills.intent import create_skill as create_intent_skill\n+from mycroft.skills.intent import Intent\n from mycroft.util.log import getLogger\n \n __author__ = 'seanfitz'\n@@ -44,7 +44,7 @@\n sys.path.append(params.dir)\n self.dir = params.dir\n \n- self.enable_intent_skill = params.enable_intent_skill\n+ self.enable_intent = params.enable_intent\n \n self.__init_client(params)\n \n@@ -57,7 +57,7 @@\n parser.add_argument(\"--host\", default=None)\n parser.add_argument(\"--port\", default=None)\n parser.add_argument(\"--use-ssl\", action='store_true', default=False)\n- parser.add_argument(\"--enable-intent-skill\", action='store_true',\n+ parser.add_argument(\"--enable-intent\", action='store_true',\n default=False)\n return parser.parse_args(args)\n \n@@ -74,10 +74,9 @@\n ssl=params.use_ssl)\n \n def load_skill(self):\n- if self.enable_intent_skill:\n- intent_skill = create_intent_skill()\n- intent_skill.bind(self.ws)\n- intent_skill.initialize()\n+ if self.enable_intent:\n+ Intent(self.ws)\n+\n skill_descriptor = create_skill_descriptor(self.dir)\n self.skill = load_skill(skill_descriptor, self.ws)\n", "issue": "skill container is broken\nWhen the intent skill became the intent class the skill container wasn't updated to match the new structure and is currently not working.\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport argparse\nimport sys\nfrom os.path import dirname, exists, isdir\n\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.messagebus.client.ws import WebsocketClient\nfrom mycroft.skills.core import create_skill_descriptor, load_skill\nfrom mycroft.skills.intent import create_skill as create_intent_skill\nfrom mycroft.util.log import getLogger\n\n__author__ = 'seanfitz'\n\nLOG = getLogger(\"SkillContainer\")\n\n\nclass SkillContainer(object):\n def __init__(self, args):\n params = self.__build_params(args)\n\n if params.config:\n ConfigurationManager.load_local([params.config])\n\n if exists(params.lib) and isdir(params.lib):\n sys.path.append(params.lib)\n\n sys.path.append(params.dir)\n self.dir = params.dir\n\n self.enable_intent_skill = params.enable_intent_skill\n\n self.__init_client(params)\n\n @staticmethod\n def __build_params(args):\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--config\", default=\"./mycroft.conf\")\n parser.add_argument(\"dir\", nargs='?', default=dirname(__file__))\n parser.add_argument(\"--lib\", default=\"./lib\")\n parser.add_argument(\"--host\", default=None)\n parser.add_argument(\"--port\", default=None)\n parser.add_argument(\"--use-ssl\", action='store_true', default=False)\n parser.add_argument(\"--enable-intent-skill\", action='store_true',\n default=False)\n return parser.parse_args(args)\n\n def __init_client(self, params):\n config = ConfigurationManager.get().get(\"websocket\")\n\n if not params.host:\n params.host = config.get('host')\n if not params.port:\n params.port = config.get('port')\n\n self.ws = WebsocketClient(host=params.host,\n port=params.port,\n ssl=params.use_ssl)\n\n def load_skill(self):\n if self.enable_intent_skill:\n intent_skill = create_intent_skill()\n intent_skill.bind(self.ws)\n intent_skill.initialize()\n skill_descriptor = create_skill_descriptor(self.dir)\n self.skill = load_skill(skill_descriptor, self.ws)\n\n def run(self):\n try:\n self.ws.on('message', LOG.debug)\n self.ws.on('open', self.load_skill)\n self.ws.on('error', LOG.error)\n self.ws.run_forever()\n except Exception as e:\n LOG.error(\"Error: {0}\".format(e))\n self.stop()\n\n def stop(self):\n if self.skill:\n self.skill.shutdown()\n\n\ndef main():\n container = SkillContainer(sys.argv[1:])\n try:\n container.run()\n except KeyboardInterrupt:\n container.stop()\n finally:\n sys.exit()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/skills/container.py"}]}
| 1,533 | 362 |
gh_patches_debug_25563
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-426
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
E2507 error when using using policy statements for serverless functions
*cfn-lint version: 0.8.2* (and doesn't happen with earlier versions)
The template below produces the following error when processing it with `cfn-lint`:
```
E0002 Unknown exception while processing rule E2507: 'str' object has no attribute 'start_mark'
function_with_policy_templates.yaml:1:1
````
```yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Resources:
Test:
Type: 'AWS::Serverless::Function'
Properties:
CodeUri: ./
Handler: hello.handler
Runtime: python3.6
Policies:
- Statement:
- Action: [ 'dynamodb:*' ]
Effect: Allow
Resource: '*'
```
That issue goes away when removing the `Transform: 'AWS::Serverless-2016-10-31'`, but that's of course no fix, as that would prevent transformation of the `AWS::Serverless::Function`.
</issue>
<code>
[start of src/cfnlint/helpers.py]
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import sys
18 import fnmatch
19 import json
20 import os
21 import imp
22 import logging
23 import re
24 import inspect
25 import pkg_resources
26 from cfnlint.decode.node import dict_node, list_node
27
28 LOGGER = logging.getLogger(__name__)
29
30 TAG_MAP = 'tag:yaml.org,2002:map'
31 UNCONVERTED_SUFFIXES = ['Ref', 'Condition']
32 FN_PREFIX = 'Fn::'
33 CONDITION_FUNCTIONS = ['Fn::If']
34 REGIONS = ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ca-central-1',
35 'eu-central-1', 'eu-west-1', 'eu-west-2', 'ap-northeast-1',
36 'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-south-1',
37 'sa-east-1']
38
39 REGEX_ALPHANUMERIC = re.compile('^[a-zA-Z0-9]*$')
40 REGEX_CIDR = re.compile(r'^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])(\/([0-9]|[1-2][0-9]|3[0-2]))$')
41 REGEX_IPV4 = re.compile(r'^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)){3}$')
42 REGEX_IPV6 = re.compile(r'^(((?=.*(::))(?!.*\3.+\3))\3?|[\dA-F]{1,4}:)([\dA-F]{1,4}(\3|:\b)|\2){5}(([\dA-F]{1,4}(\3|:\b|$)|\2){2}|(((2[0-4]|1\d|[1-9])?\d|25[0-5])\.?\b){4})\Z', re.I | re.S)
43 REGEX_DYN_REF = re.compile(r'^.*{{resolve:.+}}.*$')
44 REGEX_DYN_REF_SSM = re.compile(r'^.*{{resolve:ssm:[a-zA-Z0-9_\.\-/]+:\d+}}.*$')
45 REGEX_DYN_REF_SSM_SECURE = re.compile(r'^.*{{resolve:ssm-secure:[a-zA-Z0-9_\.\-/]+:\d+}}.*$')
46
47
48 AVAILABILITY_ZONES = [
49 'us-east-1a', 'us-east-1b', 'us-east-1c', 'us-east-1d', 'us-east-1e', 'us-east-1f',
50 'us-east-2a' 'us-east-2b' 'us-east-2c',
51 'us-west-1a', 'us-west-1b', 'us-west-1c',
52 'us-west-2a', 'us-west-2b', 'us-west-2c',
53 'ca-central-1a', 'ca-central-1b',
54 'sa-east-1a', 'sa-east-1b', 'sa-east-1c',
55 'eu-west-1a', 'eu-west-1b', 'eu-west-1c',
56 'eu-west-2a', 'eu-west-2b', 'eu-west-2c',
57 'eu-west-3a', 'eu-west-3b', 'eu-west-3c',
58 'eu-central-1a', 'eu-central-1b', 'eu-central-1c',
59 'eu-central-2a', 'eu-central-2b', 'eu-central-2c',
60 'ap-northeast-1a', 'ap-northeast-1b', 'ap-northeast-1c', 'ap-northeast-1d',
61 'ap-northeast-2a', 'ap-northeast-2b',
62 'ap-northeast-3a',
63 'ap-southeast-1a', 'ap-southeast-1b', 'ap-southeast-1c',
64 'ap-southeast-2a', 'ap-southeast-2b', 'ap-southeast-2c',
65 'ap-south-1a', 'ap-south-1b',
66 'cn-north-1a', 'cn-north-1b',
67 ]
68
69 FUNCTIONS = [
70 'Fn::Base64', 'Fn::GetAtt', 'Fn::GetAZs', 'Fn::ImportValue',
71 'Fn::Join', 'Fn::Split', 'Fn::FindInMap', 'Fn::Select', 'Ref',
72 'Fn::If', 'Fn::Contains', 'Fn::Sub', 'Fn::Cidr']
73
74 LIMITS = {
75 'mappings': {
76 'number': 100,
77 'attributes': 64,
78 'name': 255 # in characters
79 },
80 'outputs': {
81 'number': 60,
82 'name': 255, # in characters
83 'description': 1024 # in bytes
84 },
85 'parameters': {
86 'number': 60,
87 'name': 255, # in characters
88 'value': 4096 # in bytes
89 },
90 'resources': {
91 'number': 200,
92 'name': 255 # in characters
93 },
94 'template': {
95 'body': 460800, # in bytes
96 'description': 1024 # in bytes
97 }
98 }
99
100
101 def load_resources(filename='/data/CloudSpecs/us-east-1.json'):
102 """Load resources"""
103
104 filename = pkg_resources.resource_filename(
105 __name__,
106 filename
107 )
108
109 with open(filename) as fp:
110 return json.load(fp)
111
112
113 RESOURCE_SPECS = {}
114
115
116 def merge_spec(source, destination):
117 """ Recursive merge spec dict """
118
119 for key, value in source.items():
120 if isinstance(value, dict):
121 node = destination.setdefault(key, {})
122 merge_spec(value, node)
123 else:
124 destination[key] = value
125
126 return destination
127
128
129 def set_specs(override_spec_data):
130 """ Override Resource Specs """
131
132 excludes = []
133 includes = []
134
135 # Extract the exclude list from the override file
136 if 'ExcludeResourceTypes' in override_spec_data:
137 excludes = override_spec_data.pop('ExcludeResourceTypes')
138 if 'IncludeResourceTypes' in override_spec_data:
139 includes = override_spec_data.pop('IncludeResourceTypes')
140
141 for region, spec in RESOURCE_SPECS.items():
142
143 # Merge override spec file into the AWS Resource specification
144 if override_spec_data:
145 RESOURCE_SPECS[region] = merge_spec(override_spec_data, spec)
146
147 # Grab a list of all resources
148 all_resources = list(RESOURCE_SPECS[region]['ResourceTypes'].keys())[:]
149
150 resources = []
151
152 # Remove unsupported resource using includes
153 if includes:
154 for include in includes:
155 regex = re.compile(include.replace('*', '(.*)') + '$')
156 matches = [string for string in all_resources if re.match(regex, string)]
157
158 resources.extend(matches)
159 else:
160 resources = all_resources[:]
161
162 # Remove unsupported resources using the excludes
163 if excludes:
164 for exclude in excludes:
165 regex = re.compile(exclude.replace('*', '(.*)') + '$')
166 matches = [string for string in resources if re.match(regex, string)]
167
168 for match in matches:
169 resources.remove(match)
170
171 # Remove unsupported resources
172 for resource in all_resources:
173 if resource not in resources:
174 del RESOURCE_SPECS[region]['ResourceTypes'][resource]
175
176
177 def initialize_specs():
178 """ Reload Resource Specs """
179 for reg in REGIONS:
180 RESOURCE_SPECS[reg] = load_resources(filename=('/data/CloudSpecs/%s.json' % reg))
181
182
183 initialize_specs()
184
185
186 def load_plugins(directory):
187 """Load plugins"""
188 result = []
189 fh = None
190
191 def onerror(os_error):
192 """Raise an error"""
193 raise os_error
194
195 for root, _, filenames in os.walk(directory, onerror=onerror):
196 for filename in fnmatch.filter(filenames, '[A-Za-z]*.py'):
197 pluginname = filename.replace('.py', '')
198 try:
199 fh, filename, desc = imp.find_module(pluginname, [root])
200 mod = imp.load_module(pluginname, fh, filename, desc)
201 for _, clazz in inspect.getmembers(mod, inspect.isclass):
202 method_resolution = inspect.getmro(clazz)
203 if [clz for clz in method_resolution[1:] if clz.__module__ == 'cfnlint' and clz.__name__ == 'CloudFormationLintRule']:
204 # create and instance of subclasses of CloudFormationLintRule
205 obj = clazz()
206 result.append(obj)
207 finally:
208 if fh:
209 fh.close()
210
211 return result
212
213
214 def convert_dict(template, start_mark=(0, 0), end_mark=(0, 0)):
215 """Convert dict to template"""
216 if isinstance(template, dict):
217 if not isinstance(template, dict_node):
218 template = dict_node(template, start_mark, end_mark)
219 for k, v in template.items():
220 template[k] = convert_dict(v)
221 elif isinstance(template, list):
222 if not isinstance(template, list_node):
223 template = list_node(template, start_mark, end_mark)
224 for i, v in enumerate(template):
225 template[i] = convert_dict(v)
226
227 return template
228
229
230 def override_specs(override_spec_file):
231 """Override specs file"""
232 try:
233 filename = override_spec_file
234 with open(filename) as fp:
235 custom_spec_data = json.load(fp)
236
237 set_specs(custom_spec_data)
238 except IOError as e:
239 if e.errno == 2:
240 LOGGER.error('Override spec file not found: %s', filename)
241 sys.exit(1)
242 elif e.errno == 21:
243 LOGGER.error('Override spec file references a directory, not a file: %s', filename)
244 sys.exit(1)
245 elif e.errno == 13:
246 LOGGER.error('Permission denied when accessing override spec file: %s', filename)
247 sys.exit(1)
248 except (ValueError) as err:
249 LOGGER.error('Override spec file %s is malformed: %s', filename, err)
250 sys.exit(1)
251
[end of src/cfnlint/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/helpers.py b/src/cfnlint/helpers.py
--- a/src/cfnlint/helpers.py
+++ b/src/cfnlint/helpers.py
@@ -23,7 +23,7 @@
import re
import inspect
import pkg_resources
-from cfnlint.decode.node import dict_node, list_node
+from cfnlint.decode.node import dict_node, list_node, str_node
LOGGER = logging.getLogger(__name__)
@@ -216,13 +216,20 @@
if isinstance(template, dict):
if not isinstance(template, dict_node):
template = dict_node(template, start_mark, end_mark)
- for k, v in template.items():
- template[k] = convert_dict(v)
+ for k, v in template.copy().items():
+ k_start_mark = start_mark
+ k_end_mark = end_mark
+ if isinstance(k, str_node):
+ k_start_mark = k.start_mark
+ k_end_mark = k.end_mark
+ new_k = str_node(k, k_start_mark, k_end_mark)
+ del template[k]
+ template[new_k] = convert_dict(v, k_start_mark, k_end_mark)
elif isinstance(template, list):
if not isinstance(template, list_node):
template = list_node(template, start_mark, end_mark)
for i, v in enumerate(template):
- template[i] = convert_dict(v)
+ template[i] = convert_dict(v, start_mark, end_mark)
return template
|
{"golden_diff": "diff --git a/src/cfnlint/helpers.py b/src/cfnlint/helpers.py\n--- a/src/cfnlint/helpers.py\n+++ b/src/cfnlint/helpers.py\n@@ -23,7 +23,7 @@\n import re\n import inspect\n import pkg_resources\n-from cfnlint.decode.node import dict_node, list_node\n+from cfnlint.decode.node import dict_node, list_node, str_node\n \n LOGGER = logging.getLogger(__name__)\n \n@@ -216,13 +216,20 @@\n if isinstance(template, dict):\n if not isinstance(template, dict_node):\n template = dict_node(template, start_mark, end_mark)\n- for k, v in template.items():\n- template[k] = convert_dict(v)\n+ for k, v in template.copy().items():\n+ k_start_mark = start_mark\n+ k_end_mark = end_mark\n+ if isinstance(k, str_node):\n+ k_start_mark = k.start_mark\n+ k_end_mark = k.end_mark\n+ new_k = str_node(k, k_start_mark, k_end_mark)\n+ del template[k]\n+ template[new_k] = convert_dict(v, k_start_mark, k_end_mark)\n elif isinstance(template, list):\n if not isinstance(template, list_node):\n template = list_node(template, start_mark, end_mark)\n for i, v in enumerate(template):\n- template[i] = convert_dict(v)\n+ template[i] = convert_dict(v, start_mark, end_mark)\n \n return template\n", "issue": "E2507 error when using using policy statements for serverless functions\n*cfn-lint version: 0.8.2* (and doesn't happen with earlier versions)\r\n\r\nThe template below produces the following error when processing it with `cfn-lint`:\r\n```\r\nE0002 Unknown exception while processing rule E2507: 'str' object has no attribute 'start_mark'\r\nfunction_with_policy_templates.yaml:1:1\r\n````\r\n\r\n```yaml\r\nAWSTemplateFormatVersion: '2010-09-09'\r\n\r\nTransform: 'AWS::Serverless-2016-10-31'\r\n\r\nResources:\r\n Test:\r\n Type: 'AWS::Serverless::Function'\r\n Properties:\r\n CodeUri: ./\r\n Handler: hello.handler\r\n Runtime: python3.6\r\n Policies:\r\n - Statement:\r\n - Action: [ 'dynamodb:*' ]\r\n Effect: Allow\r\n Resource: '*'\r\n```\r\n\r\nThat issue goes away when removing the `Transform: 'AWS::Serverless-2016-10-31'`, but that's of course no fix, as that would prevent transformation of the `AWS::Serverless::Function`.\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport sys\nimport fnmatch\nimport json\nimport os\nimport imp\nimport logging\nimport re\nimport inspect\nimport pkg_resources\nfrom cfnlint.decode.node import dict_node, list_node\n\nLOGGER = logging.getLogger(__name__)\n\nTAG_MAP = 'tag:yaml.org,2002:map'\nUNCONVERTED_SUFFIXES = ['Ref', 'Condition']\nFN_PREFIX = 'Fn::'\nCONDITION_FUNCTIONS = ['Fn::If']\nREGIONS = ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ca-central-1',\n 'eu-central-1', 'eu-west-1', 'eu-west-2', 'ap-northeast-1',\n 'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-south-1',\n 'sa-east-1']\n\nREGEX_ALPHANUMERIC = re.compile('^[a-zA-Z0-9]*$')\nREGEX_CIDR = re.compile(r'^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])(\\/([0-9]|[1-2][0-9]|3[0-2]))$')\nREGEX_IPV4 = re.compile(r'^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(\\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)){3}$')\nREGEX_IPV6 = re.compile(r'^(((?=.*(::))(?!.*\\3.+\\3))\\3?|[\\dA-F]{1,4}:)([\\dA-F]{1,4}(\\3|:\\b)|\\2){5}(([\\dA-F]{1,4}(\\3|:\\b|$)|\\2){2}|(((2[0-4]|1\\d|[1-9])?\\d|25[0-5])\\.?\\b){4})\\Z', re.I | re.S)\nREGEX_DYN_REF = re.compile(r'^.*{{resolve:.+}}.*$')\nREGEX_DYN_REF_SSM = re.compile(r'^.*{{resolve:ssm:[a-zA-Z0-9_\\.\\-/]+:\\d+}}.*$')\nREGEX_DYN_REF_SSM_SECURE = re.compile(r'^.*{{resolve:ssm-secure:[a-zA-Z0-9_\\.\\-/]+:\\d+}}.*$')\n\n\nAVAILABILITY_ZONES = [\n 'us-east-1a', 'us-east-1b', 'us-east-1c', 'us-east-1d', 'us-east-1e', 'us-east-1f',\n 'us-east-2a' 'us-east-2b' 'us-east-2c',\n 'us-west-1a', 'us-west-1b', 'us-west-1c',\n 'us-west-2a', 'us-west-2b', 'us-west-2c',\n 'ca-central-1a', 'ca-central-1b',\n 'sa-east-1a', 'sa-east-1b', 'sa-east-1c',\n 'eu-west-1a', 'eu-west-1b', 'eu-west-1c',\n 'eu-west-2a', 'eu-west-2b', 'eu-west-2c',\n 'eu-west-3a', 'eu-west-3b', 'eu-west-3c',\n 'eu-central-1a', 'eu-central-1b', 'eu-central-1c',\n 'eu-central-2a', 'eu-central-2b', 'eu-central-2c',\n 'ap-northeast-1a', 'ap-northeast-1b', 'ap-northeast-1c', 'ap-northeast-1d',\n 'ap-northeast-2a', 'ap-northeast-2b',\n 'ap-northeast-3a',\n 'ap-southeast-1a', 'ap-southeast-1b', 'ap-southeast-1c',\n 'ap-southeast-2a', 'ap-southeast-2b', 'ap-southeast-2c',\n 'ap-south-1a', 'ap-south-1b',\n 'cn-north-1a', 'cn-north-1b',\n]\n\nFUNCTIONS = [\n 'Fn::Base64', 'Fn::GetAtt', 'Fn::GetAZs', 'Fn::ImportValue',\n 'Fn::Join', 'Fn::Split', 'Fn::FindInMap', 'Fn::Select', 'Ref',\n 'Fn::If', 'Fn::Contains', 'Fn::Sub', 'Fn::Cidr']\n\nLIMITS = {\n 'mappings': {\n 'number': 100,\n 'attributes': 64,\n 'name': 255 # in characters\n },\n 'outputs': {\n 'number': 60,\n 'name': 255, # in characters\n 'description': 1024 # in bytes\n },\n 'parameters': {\n 'number': 60,\n 'name': 255, # in characters\n 'value': 4096 # in bytes\n },\n 'resources': {\n 'number': 200,\n 'name': 255 # in characters\n },\n 'template': {\n 'body': 460800, # in bytes\n 'description': 1024 # in bytes\n }\n}\n\n\ndef load_resources(filename='/data/CloudSpecs/us-east-1.json'):\n \"\"\"Load resources\"\"\"\n\n filename = pkg_resources.resource_filename(\n __name__,\n filename\n )\n\n with open(filename) as fp:\n return json.load(fp)\n\n\nRESOURCE_SPECS = {}\n\n\ndef merge_spec(source, destination):\n \"\"\" Recursive merge spec dict \"\"\"\n\n for key, value in source.items():\n if isinstance(value, dict):\n node = destination.setdefault(key, {})\n merge_spec(value, node)\n else:\n destination[key] = value\n\n return destination\n\n\ndef set_specs(override_spec_data):\n \"\"\" Override Resource Specs \"\"\"\n\n excludes = []\n includes = []\n\n # Extract the exclude list from the override file\n if 'ExcludeResourceTypes' in override_spec_data:\n excludes = override_spec_data.pop('ExcludeResourceTypes')\n if 'IncludeResourceTypes' in override_spec_data:\n includes = override_spec_data.pop('IncludeResourceTypes')\n\n for region, spec in RESOURCE_SPECS.items():\n\n # Merge override spec file into the AWS Resource specification\n if override_spec_data:\n RESOURCE_SPECS[region] = merge_spec(override_spec_data, spec)\n\n # Grab a list of all resources\n all_resources = list(RESOURCE_SPECS[region]['ResourceTypes'].keys())[:]\n\n resources = []\n\n # Remove unsupported resource using includes\n if includes:\n for include in includes:\n regex = re.compile(include.replace('*', '(.*)') + '$')\n matches = [string for string in all_resources if re.match(regex, string)]\n\n resources.extend(matches)\n else:\n resources = all_resources[:]\n\n # Remove unsupported resources using the excludes\n if excludes:\n for exclude in excludes:\n regex = re.compile(exclude.replace('*', '(.*)') + '$')\n matches = [string for string in resources if re.match(regex, string)]\n\n for match in matches:\n resources.remove(match)\n\n # Remove unsupported resources\n for resource in all_resources:\n if resource not in resources:\n del RESOURCE_SPECS[region]['ResourceTypes'][resource]\n\n\ndef initialize_specs():\n \"\"\" Reload Resource Specs \"\"\"\n for reg in REGIONS:\n RESOURCE_SPECS[reg] = load_resources(filename=('/data/CloudSpecs/%s.json' % reg))\n\n\ninitialize_specs()\n\n\ndef load_plugins(directory):\n \"\"\"Load plugins\"\"\"\n result = []\n fh = None\n\n def onerror(os_error):\n \"\"\"Raise an error\"\"\"\n raise os_error\n\n for root, _, filenames in os.walk(directory, onerror=onerror):\n for filename in fnmatch.filter(filenames, '[A-Za-z]*.py'):\n pluginname = filename.replace('.py', '')\n try:\n fh, filename, desc = imp.find_module(pluginname, [root])\n mod = imp.load_module(pluginname, fh, filename, desc)\n for _, clazz in inspect.getmembers(mod, inspect.isclass):\n method_resolution = inspect.getmro(clazz)\n if [clz for clz in method_resolution[1:] if clz.__module__ == 'cfnlint' and clz.__name__ == 'CloudFormationLintRule']:\n # create and instance of subclasses of CloudFormationLintRule\n obj = clazz()\n result.append(obj)\n finally:\n if fh:\n fh.close()\n\n return result\n\n\ndef convert_dict(template, start_mark=(0, 0), end_mark=(0, 0)):\n \"\"\"Convert dict to template\"\"\"\n if isinstance(template, dict):\n if not isinstance(template, dict_node):\n template = dict_node(template, start_mark, end_mark)\n for k, v in template.items():\n template[k] = convert_dict(v)\n elif isinstance(template, list):\n if not isinstance(template, list_node):\n template = list_node(template, start_mark, end_mark)\n for i, v in enumerate(template):\n template[i] = convert_dict(v)\n\n return template\n\n\ndef override_specs(override_spec_file):\n \"\"\"Override specs file\"\"\"\n try:\n filename = override_spec_file\n with open(filename) as fp:\n custom_spec_data = json.load(fp)\n\n set_specs(custom_spec_data)\n except IOError as e:\n if e.errno == 2:\n LOGGER.error('Override spec file not found: %s', filename)\n sys.exit(1)\n elif e.errno == 21:\n LOGGER.error('Override spec file references a directory, not a file: %s', filename)\n sys.exit(1)\n elif e.errno == 13:\n LOGGER.error('Permission denied when accessing override spec file: %s', filename)\n sys.exit(1)\n except (ValueError) as err:\n LOGGER.error('Override spec file %s is malformed: %s', filename, err)\n sys.exit(1)\n", "path": "src/cfnlint/helpers.py"}]}
| 4,002 | 331 |
gh_patches_debug_25137
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-1072
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HDF5Exporter: throws error when curves aren't the same length
When trying to save data from a graph as an hdf5 file, the HDF5Exporter throws and error when you have multiple curves with differing lengths. This looks to be because the numpy.array(data).astype('double') can't handle lists with different lengths. Below is a traceback from the error. This occurs when trying to save data from the "Multiple curves" graph in the "Basic Plotting" example.
````
Traceback (most recent call last):
File "/home/jchrist/PycharmProjects/lib/python3.5/site-packages/pyqtgraph/exporters/Exporter.py", line 77, in fileSaveFinished
self.export(fileName=fileName, **self.fileDialog.opts)
File "/home/jchrist/PycharmProjects/lib/python3.5/site-packages/pyqtgraph/exporters/HDF5Exporter.py", line 55, in export
fdata = numpy.array(data).astype('double')
ValueError: setting an array element with a sequence.
````
</issue>
<code>
[start of pyqtgraph/exporters/HDF5Exporter.py]
1 from ..Qt import QtGui, QtCore
2 from .Exporter import Exporter
3 from ..parametertree import Parameter
4 from .. import PlotItem
5
6 import numpy
7 try:
8 import h5py
9 HAVE_HDF5 = True
10 except ImportError:
11 HAVE_HDF5 = False
12
13 __all__ = ['HDF5Exporter']
14
15
16 class HDF5Exporter(Exporter):
17 Name = "HDF5 Export: plot (x,y)"
18 windows = []
19 allowCopy = False
20
21 def __init__(self, item):
22 Exporter.__init__(self, item)
23 self.params = Parameter(name='params', type='group', children=[
24 {'name': 'Name', 'type': 'str', 'value': 'Export',},
25 {'name': 'columnMode', 'type': 'list', 'values': ['(x,y) per plot', '(x,y,y,y) for all plots']},
26 ])
27
28 def parameters(self):
29 return self.params
30
31 def export(self, fileName=None):
32 if not HAVE_HDF5:
33 raise RuntimeError("This exporter requires the h5py package, "
34 "but it was not importable.")
35
36 if not isinstance(self.item, PlotItem):
37 raise Exception("Must have a PlotItem selected for HDF5 export.")
38
39 if fileName is None:
40 self.fileSaveDialog(filter=["*.h5", "*.hdf", "*.hd5"])
41 return
42 dsname = self.params['Name']
43 fd = h5py.File(fileName, 'a') # forces append to file... 'w' doesn't seem to "delete/overwrite"
44 data = []
45
46 appendAllX = self.params['columnMode'] == '(x,y) per plot'
47 #print dir(self.item.curves[0])
48 tlen = 0
49 for i, c in enumerate(self.item.curves):
50 d = c.getData()
51 if i > 0 and len(d[0]) != tlen:
52 raise ValueError ("HDF5 Export requires all curves in plot to have same length")
53 if appendAllX or i == 0:
54 data.append(d[0])
55 tlen = len(d[0])
56 data.append(d[1])
57
58
59 fdata = numpy.array(data).astype('double')
60 dset = fd.create_dataset(dsname, data=fdata)
61 fd.close()
62
63 if HAVE_HDF5:
64 HDF5Exporter.register()
65
[end of pyqtgraph/exporters/HDF5Exporter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyqtgraph/exporters/HDF5Exporter.py b/pyqtgraph/exporters/HDF5Exporter.py
--- a/pyqtgraph/exporters/HDF5Exporter.py
+++ b/pyqtgraph/exporters/HDF5Exporter.py
@@ -44,20 +44,27 @@
data = []
appendAllX = self.params['columnMode'] == '(x,y) per plot'
- #print dir(self.item.curves[0])
- tlen = 0
- for i, c in enumerate(self.item.curves):
- d = c.getData()
- if i > 0 and len(d[0]) != tlen:
- raise ValueError ("HDF5 Export requires all curves in plot to have same length")
- if appendAllX or i == 0:
- data.append(d[0])
- tlen = len(d[0])
- data.append(d[1])
+ # Check if the arrays are ragged
+ len_first = len(self.item.curves[0].getData()[0]) if self.item.curves[0] else None
+ ragged = any(len(i.getData()[0]) != len_first for i in self.item.curves)
+ if ragged:
+ dgroup = fd.create_group(dsname)
+ for i, c in enumerate(self.item.curves):
+ d = c.getData()
+ fdata = numpy.array([d[0], d[1]]).astype('double')
+ cname = c.name() if c.name() is not None else str(i)
+ dset = dgroup.create_dataset(cname, data=fdata)
+ else:
+ for i, c in enumerate(self.item.curves):
+ d = c.getData()
+ if appendAllX or i == 0:
+ data.append(d[0])
+ data.append(d[1])
+
+ fdata = numpy.array(data).astype('double')
+ dset = fd.create_dataset(dsname, data=fdata)
- fdata = numpy.array(data).astype('double')
- dset = fd.create_dataset(dsname, data=fdata)
fd.close()
if HAVE_HDF5:
|
{"golden_diff": "diff --git a/pyqtgraph/exporters/HDF5Exporter.py b/pyqtgraph/exporters/HDF5Exporter.py\n--- a/pyqtgraph/exporters/HDF5Exporter.py\n+++ b/pyqtgraph/exporters/HDF5Exporter.py\n@@ -44,20 +44,27 @@\n data = []\n \n appendAllX = self.params['columnMode'] == '(x,y) per plot'\n- #print dir(self.item.curves[0])\n- tlen = 0\n- for i, c in enumerate(self.item.curves):\n- d = c.getData()\n- if i > 0 and len(d[0]) != tlen:\n- raise ValueError (\"HDF5 Export requires all curves in plot to have same length\")\n- if appendAllX or i == 0:\n- data.append(d[0])\n- tlen = len(d[0])\n- data.append(d[1])\n+ # Check if the arrays are ragged\n+ len_first = len(self.item.curves[0].getData()[0]) if self.item.curves[0] else None\n+ ragged = any(len(i.getData()[0]) != len_first for i in self.item.curves)\n \n+ if ragged:\n+ dgroup = fd.create_group(dsname)\n+ for i, c in enumerate(self.item.curves):\n+ d = c.getData()\n+ fdata = numpy.array([d[0], d[1]]).astype('double')\n+ cname = c.name() if c.name() is not None else str(i)\n+ dset = dgroup.create_dataset(cname, data=fdata)\n+ else:\n+ for i, c in enumerate(self.item.curves):\n+ d = c.getData()\n+ if appendAllX or i == 0:\n+ data.append(d[0])\n+ data.append(d[1])\n+\n+ fdata = numpy.array(data).astype('double')\n+ dset = fd.create_dataset(dsname, data=fdata)\n \n- fdata = numpy.array(data).astype('double')\n- dset = fd.create_dataset(dsname, data=fdata)\n fd.close()\n \n if HAVE_HDF5:\n", "issue": "HDF5Exporter: throws error when curves aren't the same length\nWhen trying to save data from a graph as an hdf5 file, the HDF5Exporter throws and error when you have multiple curves with differing lengths. This looks to be because the numpy.array(data).astype('double') can't handle lists with different lengths. Below is a traceback from the error. This occurs when trying to save data from the \"Multiple curves\" graph in the \"Basic Plotting\" example.\r\n\r\n````\r\nTraceback (most recent call last):\r\n File \"/home/jchrist/PycharmProjects/lib/python3.5/site-packages/pyqtgraph/exporters/Exporter.py\", line 77, in fileSaveFinished\r\n self.export(fileName=fileName, **self.fileDialog.opts)\r\n File \"/home/jchrist/PycharmProjects/lib/python3.5/site-packages/pyqtgraph/exporters/HDF5Exporter.py\", line 55, in export\r\n fdata = numpy.array(data).astype('double')\r\nValueError: setting an array element with a sequence.\r\n````\n", "before_files": [{"content": "from ..Qt import QtGui, QtCore\nfrom .Exporter import Exporter\nfrom ..parametertree import Parameter\nfrom .. import PlotItem\n\nimport numpy \ntry:\n import h5py\n HAVE_HDF5 = True\nexcept ImportError:\n HAVE_HDF5 = False\n \n__all__ = ['HDF5Exporter']\n\n \nclass HDF5Exporter(Exporter):\n Name = \"HDF5 Export: plot (x,y)\"\n windows = []\n allowCopy = False\n\n def __init__(self, item):\n Exporter.__init__(self, item)\n self.params = Parameter(name='params', type='group', children=[\n {'name': 'Name', 'type': 'str', 'value': 'Export',},\n {'name': 'columnMode', 'type': 'list', 'values': ['(x,y) per plot', '(x,y,y,y) for all plots']},\n ])\n \n def parameters(self):\n return self.params\n \n def export(self, fileName=None):\n if not HAVE_HDF5:\n raise RuntimeError(\"This exporter requires the h5py package, \"\n \"but it was not importable.\")\n \n if not isinstance(self.item, PlotItem):\n raise Exception(\"Must have a PlotItem selected for HDF5 export.\")\n \n if fileName is None:\n self.fileSaveDialog(filter=[\"*.h5\", \"*.hdf\", \"*.hd5\"])\n return\n dsname = self.params['Name']\n fd = h5py.File(fileName, 'a') # forces append to file... 'w' doesn't seem to \"delete/overwrite\"\n data = []\n\n appendAllX = self.params['columnMode'] == '(x,y) per plot'\n #print dir(self.item.curves[0])\n tlen = 0\n for i, c in enumerate(self.item.curves):\n d = c.getData()\n if i > 0 and len(d[0]) != tlen:\n raise ValueError (\"HDF5 Export requires all curves in plot to have same length\")\n if appendAllX or i == 0:\n data.append(d[0])\n tlen = len(d[0])\n data.append(d[1])\n\n\n fdata = numpy.array(data).astype('double')\n dset = fd.create_dataset(dsname, data=fdata)\n fd.close()\n\nif HAVE_HDF5:\n HDF5Exporter.register()\n", "path": "pyqtgraph/exporters/HDF5Exporter.py"}]}
| 1,401 | 480 |
gh_patches_debug_209
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2648
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Schema generation partially broken since litestar version 2.3.0
### Description
2.2.1 is my last working version of litestar.
Before:
<img width="467" alt="image" src="https://github.com/litestar-org/litestar/assets/85191795/dc9594b1-4b09-4607-9061-dcd65bf0a09f">
After:
I first get this `internal server error` when i first try to go to my Swagger URL
<img width="436" alt="image" src="https://github.com/litestar-org/litestar/assets/85191795/90112884-907e-4ee0-a14c-a92c338ef761">
And then when i refresh once more, it goes to my swagger page, but only 2/3 of it.
<img width="217" alt="image" src="https://github.com/litestar-org/litestar/assets/85191795/74f16208-e80a-46de-b580-3dd566e0f14b">
With no changes in my code, the problems just start at version 2.3.0 and beyond. Just wanted to bring attention to this, as I will now be sticking to litestar 2.2.1 until this is resolved.
### URL to code causing the issue
_No response_
### MCVE
```python
How my app code looks like when passing in my controllers:
app = Litestar(
route_handlers=[
read_root,
refresh_templates,
LinuxPXEController,
WindowsPXEController,
ESXiPXEController
],
...
```
### Steps to reproduce
_No response_
### Screenshots
```bash
""
```
### Logs
_No response_
### Litestar Version
2.3.0
### Platform
- [X] Linux
- [X] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/2635">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2635/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2635/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/contrib/pydantic/utils.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any
4
5 from typing_extensions import get_type_hints
6
7 from litestar.types import Empty
8 from litestar.utils import is_class_and_subclass
9 from litestar.utils.predicates import is_generic
10 from litestar.utils.typing import (
11 _substitute_typevars,
12 get_origin_or_inner_type,
13 get_type_hints_with_generics_resolved,
14 instantiable_type_mapping,
15 )
16
17 # isort: off
18 try:
19 from pydantic import v1 as pydantic_v1
20 import pydantic as pydantic_v2
21 from pydantic.fields import PydanticUndefined as Pydantic2Undefined # type: ignore[attr-defined]
22 from pydantic.v1.fields import Undefined as Pydantic1Undefined
23
24 PYDANTIC_UNDEFINED_SENTINELS = {Pydantic1Undefined, Pydantic2Undefined}
25 except ImportError:
26 try:
27 import pydantic as pydantic_v1 # type: ignore[no-redef]
28 from pydantic.fields import Undefined as Pydantic1Undefined # type: ignore[attr-defined, no-redef]
29
30 pydantic_v2 = Empty # type: ignore[assignment]
31 PYDANTIC_UNDEFINED_SENTINELS = {Pydantic1Undefined}
32
33 except ImportError: # pyright: ignore
34 pydantic_v1 = Empty # type: ignore[assignment]
35 pydantic_v2 = Empty # type: ignore[assignment]
36 PYDANTIC_UNDEFINED_SENTINELS = set()
37 # isort: on
38
39
40 if TYPE_CHECKING:
41 from typing_extensions import TypeGuard
42
43
44 def is_pydantic_model_class(
45 annotation: Any,
46 ) -> TypeGuard[type[pydantic_v1.BaseModel | pydantic_v2.BaseModel]]: # pyright: ignore
47 """Given a type annotation determine if the annotation is a subclass of pydantic's BaseModel.
48
49 Args:
50 annotation: A type.
51
52 Returns:
53 A typeguard determining whether the type is :data:`BaseModel pydantic.BaseModel>`.
54 """
55 if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover
56 return False
57
58 if pydantic_v2 is Empty: # type: ignore[comparison-overlap] # pragma: no cover
59 return is_class_and_subclass(annotation, pydantic_v1.BaseModel)
60
61 return is_class_and_subclass(annotation, (pydantic_v1.BaseModel, pydantic_v2.BaseModel))
62
63
64 def is_pydantic_model_instance(
65 annotation: Any,
66 ) -> TypeGuard[pydantic_v1.BaseModel | pydantic_v2.BaseModel]: # pyright: ignore
67 """Given a type annotation determine if the annotation is an instance of pydantic's BaseModel.
68
69 Args:
70 annotation: A type.
71
72 Returns:
73 A typeguard determining whether the type is :data:`BaseModel pydantic.BaseModel>`.
74 """
75 if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover
76 return False
77
78 if pydantic_v2 is Empty: # type: ignore[comparison-overlap] # pragma: no cover
79 return isinstance(annotation, pydantic_v1.BaseModel)
80
81 return isinstance(annotation, (pydantic_v1.BaseModel, pydantic_v2.BaseModel))
82
83
84 def is_pydantic_constrained_field(annotation: Any) -> bool:
85 """Check if the given annotation is a constrained pydantic type.
86
87 Args:
88 annotation: A type annotation
89
90 Returns:
91 True if pydantic is installed and the type is a constrained type, otherwise False.
92 """
93 if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover
94 return False
95
96 return any(
97 is_class_and_subclass(annotation, constrained_type) # pyright: ignore
98 for constrained_type in (
99 pydantic_v1.ConstrainedBytes,
100 pydantic_v1.ConstrainedDate,
101 pydantic_v1.ConstrainedDecimal,
102 pydantic_v1.ConstrainedFloat,
103 pydantic_v1.ConstrainedFrozenSet,
104 pydantic_v1.ConstrainedInt,
105 pydantic_v1.ConstrainedList,
106 pydantic_v1.ConstrainedSet,
107 pydantic_v1.ConstrainedStr,
108 )
109 )
110
111
112 def pydantic_unwrap_and_get_origin(annotation: Any) -> Any | None:
113 if pydantic_v2 is Empty or is_class_and_subclass(annotation, pydantic_v1.BaseModel): # type: ignore[comparison-overlap]
114 return get_origin_or_inner_type(annotation)
115
116 origin = annotation.__pydantic_generic_metadata__["origin"]
117 return instantiable_type_mapping.get(origin, origin)
118
119
120 def pydantic_get_type_hints_with_generics_resolved(
121 annotation: Any,
122 globalns: dict[str, Any] | None = None,
123 localns: dict[str, Any] | None = None,
124 include_extras: bool = False,
125 ) -> dict[str, Any]:
126 if pydantic_v2 is Empty or is_class_and_subclass(annotation, pydantic_v1.BaseModel): # type: ignore[comparison-overlap]
127 return get_type_hints_with_generics_resolved(annotation)
128
129 origin = pydantic_unwrap_and_get_origin(annotation)
130 if origin is None:
131 type_hints = get_type_hints(annotation, globalns=globalns, localns=localns, include_extras=include_extras)
132 typevar_map = {p: p for p in annotation.__pydantic_generic_metadata__["parameters"]}
133 else:
134 type_hints = get_type_hints(origin, globalns=globalns, localns=localns, include_extras=include_extras)
135 args = annotation.__pydantic_generic_metadata__["args"]
136 parameters = origin.__pydantic_generic_metadata__["parameters"]
137 typevar_map = dict(zip(parameters, args))
138
139 return {n: _substitute_typevars(type_, typevar_map) for n, type_ in type_hints.items()}
140
141
142 def pydantic_get_unwrapped_annotation_and_type_hints(annotation: Any) -> tuple[Any, dict[str, Any]]:
143 """Get the unwrapped annotation and the type hints after resolving generics.
144
145 Args:
146 annotation: A type annotation.
147
148 Returns:
149 A tuple containing the unwrapped annotation and the type hints.
150 """
151
152 if is_generic(annotation):
153 origin = pydantic_unwrap_and_get_origin(annotation)
154 return origin or annotation, pydantic_get_type_hints_with_generics_resolved(annotation, include_extras=True)
155 return annotation, get_type_hints(annotation, include_extras=True)
156
157
158 def is_pydantic_2_model(
159 obj: type[pydantic_v1.BaseModel | pydantic_v2.BaseModel], # pyright: ignore
160 ) -> TypeGuard[pydantic_v2.BaseModel]: # pyright: ignore
161 return issubclass(obj, pydantic_v2.BaseModel) # pyright: ignore
162
163
164 def is_pydantic_undefined(value: Any) -> bool:
165 return value in PYDANTIC_UNDEFINED_SENTINELS
166
[end of litestar/contrib/pydantic/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/contrib/pydantic/utils.py b/litestar/contrib/pydantic/utils.py
--- a/litestar/contrib/pydantic/utils.py
+++ b/litestar/contrib/pydantic/utils.py
@@ -162,4 +162,4 @@
def is_pydantic_undefined(value: Any) -> bool:
- return value in PYDANTIC_UNDEFINED_SENTINELS
+ return any(v is value for v in PYDANTIC_UNDEFINED_SENTINELS)
|
{"golden_diff": "diff --git a/litestar/contrib/pydantic/utils.py b/litestar/contrib/pydantic/utils.py\n--- a/litestar/contrib/pydantic/utils.py\n+++ b/litestar/contrib/pydantic/utils.py\n@@ -162,4 +162,4 @@\n \n \n def is_pydantic_undefined(value: Any) -> bool:\n- return value in PYDANTIC_UNDEFINED_SENTINELS\n+ return any(v is value for v in PYDANTIC_UNDEFINED_SENTINELS)\n", "issue": "Bug: Schema generation partially broken since litestar version 2.3.0\n### Description\n\n2.2.1 is my last working version of litestar. \r\n\r\nBefore:\r\n<img width=\"467\" alt=\"image\" src=\"https://github.com/litestar-org/litestar/assets/85191795/dc9594b1-4b09-4607-9061-dcd65bf0a09f\">\r\n\r\nAfter:\r\nI first get this `internal server error` when i first try to go to my Swagger URL\r\n\r\n<img width=\"436\" alt=\"image\" src=\"https://github.com/litestar-org/litestar/assets/85191795/90112884-907e-4ee0-a14c-a92c338ef761\">\r\n\r\nAnd then when i refresh once more, it goes to my swagger page, but only 2/3 of it.\r\n\r\n\r\n\r\n<img width=\"217\" alt=\"image\" src=\"https://github.com/litestar-org/litestar/assets/85191795/74f16208-e80a-46de-b580-3dd566e0f14b\">\r\n\r\nWith no changes in my code, the problems just start at version 2.3.0 and beyond. Just wanted to bring attention to this, as I will now be sticking to litestar 2.2.1 until this is resolved.\n\n### URL to code causing the issue\n\n_No response_\n\n### MCVE\n\n```python\nHow my app code looks like when passing in my controllers:\r\n\r\napp = Litestar(\r\n route_handlers=[\r\n read_root,\r\n refresh_templates,\r\n LinuxPXEController,\r\n WindowsPXEController,\r\n ESXiPXEController\r\n ],\r\n ...\n```\n\n\n### Steps to reproduce\n\n_No response_\n\n### Screenshots\n\n```bash\n\"\"\n```\n\n\n### Logs\n\n_No response_\n\n### Litestar Version\n\n2.3.0\n\n### Platform\n\n- [X] Linux\n- [X] Mac\n- [ ] Windows\n- [ ] Other (Please specify in the description above)\n\n<!-- POLAR PLEDGE BADGE START -->\n---\n> [!NOTE] \n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\n>\n> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)\n> * If you would like to see an issue prioritized, make a pledge towards it!\n> * We receive the pledge once the issue is completed & verified\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\n\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2635\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2635/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2635/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any\n\nfrom typing_extensions import get_type_hints\n\nfrom litestar.types import Empty\nfrom litestar.utils import is_class_and_subclass\nfrom litestar.utils.predicates import is_generic\nfrom litestar.utils.typing import (\n _substitute_typevars,\n get_origin_or_inner_type,\n get_type_hints_with_generics_resolved,\n instantiable_type_mapping,\n)\n\n# isort: off\ntry:\n from pydantic import v1 as pydantic_v1\n import pydantic as pydantic_v2\n from pydantic.fields import PydanticUndefined as Pydantic2Undefined # type: ignore[attr-defined]\n from pydantic.v1.fields import Undefined as Pydantic1Undefined\n\n PYDANTIC_UNDEFINED_SENTINELS = {Pydantic1Undefined, Pydantic2Undefined}\nexcept ImportError:\n try:\n import pydantic as pydantic_v1 # type: ignore[no-redef]\n from pydantic.fields import Undefined as Pydantic1Undefined # type: ignore[attr-defined, no-redef]\n\n pydantic_v2 = Empty # type: ignore[assignment]\n PYDANTIC_UNDEFINED_SENTINELS = {Pydantic1Undefined}\n\n except ImportError: # pyright: ignore\n pydantic_v1 = Empty # type: ignore[assignment]\n pydantic_v2 = Empty # type: ignore[assignment]\n PYDANTIC_UNDEFINED_SENTINELS = set()\n# isort: on\n\n\nif TYPE_CHECKING:\n from typing_extensions import TypeGuard\n\n\ndef is_pydantic_model_class(\n annotation: Any,\n) -> TypeGuard[type[pydantic_v1.BaseModel | pydantic_v2.BaseModel]]: # pyright: ignore\n \"\"\"Given a type annotation determine if the annotation is a subclass of pydantic's BaseModel.\n\n Args:\n annotation: A type.\n\n Returns:\n A typeguard determining whether the type is :data:`BaseModel pydantic.BaseModel>`.\n \"\"\"\n if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover\n return False\n\n if pydantic_v2 is Empty: # type: ignore[comparison-overlap] # pragma: no cover\n return is_class_and_subclass(annotation, pydantic_v1.BaseModel)\n\n return is_class_and_subclass(annotation, (pydantic_v1.BaseModel, pydantic_v2.BaseModel))\n\n\ndef is_pydantic_model_instance(\n annotation: Any,\n) -> TypeGuard[pydantic_v1.BaseModel | pydantic_v2.BaseModel]: # pyright: ignore\n \"\"\"Given a type annotation determine if the annotation is an instance of pydantic's BaseModel.\n\n Args:\n annotation: A type.\n\n Returns:\n A typeguard determining whether the type is :data:`BaseModel pydantic.BaseModel>`.\n \"\"\"\n if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover\n return False\n\n if pydantic_v2 is Empty: # type: ignore[comparison-overlap] # pragma: no cover\n return isinstance(annotation, pydantic_v1.BaseModel)\n\n return isinstance(annotation, (pydantic_v1.BaseModel, pydantic_v2.BaseModel))\n\n\ndef is_pydantic_constrained_field(annotation: Any) -> bool:\n \"\"\"Check if the given annotation is a constrained pydantic type.\n\n Args:\n annotation: A type annotation\n\n Returns:\n True if pydantic is installed and the type is a constrained type, otherwise False.\n \"\"\"\n if pydantic_v1 is Empty: # type: ignore[comparison-overlap] # pragma: no cover\n return False\n\n return any(\n is_class_and_subclass(annotation, constrained_type) # pyright: ignore\n for constrained_type in (\n pydantic_v1.ConstrainedBytes,\n pydantic_v1.ConstrainedDate,\n pydantic_v1.ConstrainedDecimal,\n pydantic_v1.ConstrainedFloat,\n pydantic_v1.ConstrainedFrozenSet,\n pydantic_v1.ConstrainedInt,\n pydantic_v1.ConstrainedList,\n pydantic_v1.ConstrainedSet,\n pydantic_v1.ConstrainedStr,\n )\n )\n\n\ndef pydantic_unwrap_and_get_origin(annotation: Any) -> Any | None:\n if pydantic_v2 is Empty or is_class_and_subclass(annotation, pydantic_v1.BaseModel): # type: ignore[comparison-overlap]\n return get_origin_or_inner_type(annotation)\n\n origin = annotation.__pydantic_generic_metadata__[\"origin\"]\n return instantiable_type_mapping.get(origin, origin)\n\n\ndef pydantic_get_type_hints_with_generics_resolved(\n annotation: Any,\n globalns: dict[str, Any] | None = None,\n localns: dict[str, Any] | None = None,\n include_extras: bool = False,\n) -> dict[str, Any]:\n if pydantic_v2 is Empty or is_class_and_subclass(annotation, pydantic_v1.BaseModel): # type: ignore[comparison-overlap]\n return get_type_hints_with_generics_resolved(annotation)\n\n origin = pydantic_unwrap_and_get_origin(annotation)\n if origin is None:\n type_hints = get_type_hints(annotation, globalns=globalns, localns=localns, include_extras=include_extras)\n typevar_map = {p: p for p in annotation.__pydantic_generic_metadata__[\"parameters\"]}\n else:\n type_hints = get_type_hints(origin, globalns=globalns, localns=localns, include_extras=include_extras)\n args = annotation.__pydantic_generic_metadata__[\"args\"]\n parameters = origin.__pydantic_generic_metadata__[\"parameters\"]\n typevar_map = dict(zip(parameters, args))\n\n return {n: _substitute_typevars(type_, typevar_map) for n, type_ in type_hints.items()}\n\n\ndef pydantic_get_unwrapped_annotation_and_type_hints(annotation: Any) -> tuple[Any, dict[str, Any]]:\n \"\"\"Get the unwrapped annotation and the type hints after resolving generics.\n\n Args:\n annotation: A type annotation.\n\n Returns:\n A tuple containing the unwrapped annotation and the type hints.\n \"\"\"\n\n if is_generic(annotation):\n origin = pydantic_unwrap_and_get_origin(annotation)\n return origin or annotation, pydantic_get_type_hints_with_generics_resolved(annotation, include_extras=True)\n return annotation, get_type_hints(annotation, include_extras=True)\n\n\ndef is_pydantic_2_model(\n obj: type[pydantic_v1.BaseModel | pydantic_v2.BaseModel], # pyright: ignore\n) -> TypeGuard[pydantic_v2.BaseModel]: # pyright: ignore\n return issubclass(obj, pydantic_v2.BaseModel) # pyright: ignore\n\n\ndef is_pydantic_undefined(value: Any) -> bool:\n return value in PYDANTIC_UNDEFINED_SENTINELS\n", "path": "litestar/contrib/pydantic/utils.py"}]}
| 3,304 | 114 |
gh_patches_debug_25737
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-1301
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
allow utils.save_image to write to a file object
Currently, the `torchvision.utils.save_image` function only allows to save to a file on disk.
https://github.com/pytorch/vision/blob/26c9630bc7add88685400e54457203816c06e750/torchvision/utils.py#L90-L105
It cannot write to file objects as that requires the [`format` parameter](https://pillow.readthedocs.io/en/stable/reference/Image.html#PIL.Image.Image.save) to be passed which `torchvision.utils.save_image` does not support as of yet.
Can you add this parameter to `torchvision.utils.save_image`?
</issue>
<code>
[start of torchvision/utils.py]
1 import torch
2 import math
3 irange = range
4
5
6 def make_grid(tensor, nrow=8, padding=2,
7 normalize=False, range=None, scale_each=False, pad_value=0):
8 """Make a grid of images.
9
10 Args:
11 tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W)
12 or a list of images all of the same size.
13 nrow (int, optional): Number of images displayed in each row of the grid.
14 The final grid size is ``(B / nrow, nrow)``. Default: ``8``.
15 padding (int, optional): amount of padding. Default: ``2``.
16 normalize (bool, optional): If True, shift the image to the range (0, 1),
17 by the min and max values specified by :attr:`range`. Default: ``False``.
18 range (tuple, optional): tuple (min, max) where min and max are numbers,
19 then these numbers are used to normalize the image. By default, min and max
20 are computed from the tensor.
21 scale_each (bool, optional): If ``True``, scale each image in the batch of
22 images separately rather than the (min, max) over all images. Default: ``False``.
23 pad_value (float, optional): Value for the padded pixels. Default: ``0``.
24
25 Example:
26 See this notebook `here <https://gist.github.com/anonymous/bf16430f7750c023141c562f3e9f2a91>`_
27
28 """
29 if not (torch.is_tensor(tensor) or
30 (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):
31 raise TypeError('tensor or list of tensors expected, got {}'.format(type(tensor)))
32
33 # if list of tensors, convert to a 4D mini-batch Tensor
34 if isinstance(tensor, list):
35 tensor = torch.stack(tensor, dim=0)
36
37 if tensor.dim() == 2: # single image H x W
38 tensor = tensor.unsqueeze(0)
39 if tensor.dim() == 3: # single image
40 if tensor.size(0) == 1: # if single-channel, convert to 3-channel
41 tensor = torch.cat((tensor, tensor, tensor), 0)
42 tensor = tensor.unsqueeze(0)
43
44 if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel images
45 tensor = torch.cat((tensor, tensor, tensor), 1)
46
47 if normalize is True:
48 tensor = tensor.clone() # avoid modifying tensor in-place
49 if range is not None:
50 assert isinstance(range, tuple), \
51 "range has to be a tuple (min, max) if specified. min and max are numbers"
52
53 def norm_ip(img, min, max):
54 img.clamp_(min=min, max=max)
55 img.add_(-min).div_(max - min + 1e-5)
56
57 def norm_range(t, range):
58 if range is not None:
59 norm_ip(t, range[0], range[1])
60 else:
61 norm_ip(t, float(t.min()), float(t.max()))
62
63 if scale_each is True:
64 for t in tensor: # loop over mini-batch dimension
65 norm_range(t, range)
66 else:
67 norm_range(tensor, range)
68
69 if tensor.size(0) == 1:
70 return tensor.squeeze(0)
71
72 # make the mini-batch of images into a grid
73 nmaps = tensor.size(0)
74 xmaps = min(nrow, nmaps)
75 ymaps = int(math.ceil(float(nmaps) / xmaps))
76 height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding)
77 grid = tensor.new_full((3, height * ymaps + padding, width * xmaps + padding), pad_value)
78 k = 0
79 for y in irange(ymaps):
80 for x in irange(xmaps):
81 if k >= nmaps:
82 break
83 grid.narrow(1, y * height + padding, height - padding)\
84 .narrow(2, x * width + padding, width - padding)\
85 .copy_(tensor[k])
86 k = k + 1
87 return grid
88
89
90 def save_image(tensor, filename, nrow=8, padding=2,
91 normalize=False, range=None, scale_each=False, pad_value=0):
92 """Save a given Tensor into an image file.
93
94 Args:
95 tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,
96 saves the tensor as a grid of images by calling ``make_grid``.
97 **kwargs: Other arguments are documented in ``make_grid``.
98 """
99 from PIL import Image
100 grid = make_grid(tensor, nrow=nrow, padding=padding, pad_value=pad_value,
101 normalize=normalize, range=range, scale_each=scale_each)
102 # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer
103 ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
104 im = Image.fromarray(ndarr)
105 im.save(filename)
106
[end of torchvision/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/utils.py b/torchvision/utils.py
--- a/torchvision/utils.py
+++ b/torchvision/utils.py
@@ -87,13 +87,16 @@
return grid
-def save_image(tensor, filename, nrow=8, padding=2,
- normalize=False, range=None, scale_each=False, pad_value=0):
+def save_image(tensor, fp, nrow=8, padding=2,
+ normalize=False, range=None, scale_each=False, pad_value=0, format=None):
"""Save a given Tensor into an image file.
Args:
tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,
saves the tensor as a grid of images by calling ``make_grid``.
+ fp - A filename(string) or file object
+ format(Optional): If omitted, the format to use is determined from the filename extension.
+ If a file object was used instead of a filename, this parameter should always be used.
**kwargs: Other arguments are documented in ``make_grid``.
"""
from PIL import Image
@@ -102,4 +105,4 @@
# Add 0.5 after unnormalizing to [0, 255] to round to nearest integer
ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
im = Image.fromarray(ndarr)
- im.save(filename)
+ im.save(fp, format=format)
|
{"golden_diff": "diff --git a/torchvision/utils.py b/torchvision/utils.py\n--- a/torchvision/utils.py\n+++ b/torchvision/utils.py\n@@ -87,13 +87,16 @@\n return grid\n \n \n-def save_image(tensor, filename, nrow=8, padding=2,\n- normalize=False, range=None, scale_each=False, pad_value=0):\n+def save_image(tensor, fp, nrow=8, padding=2,\n+ normalize=False, range=None, scale_each=False, pad_value=0, format=None):\n \"\"\"Save a given Tensor into an image file.\n \n Args:\n tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,\n saves the tensor as a grid of images by calling ``make_grid``.\n+ fp - A filename(string) or file object\n+ format(Optional): If omitted, the format to use is determined from the filename extension.\n+ If a file object was used instead of a filename, this parameter should always be used.\n **kwargs: Other arguments are documented in ``make_grid``.\n \"\"\"\n from PIL import Image\n@@ -102,4 +105,4 @@\n # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer\n ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()\n im = Image.fromarray(ndarr)\n- im.save(filename)\n+ im.save(fp, format=format)\n", "issue": "allow utils.save_image to write to a file object\nCurrently, the `torchvision.utils.save_image` function only allows to save to a file on disk.\r\nhttps://github.com/pytorch/vision/blob/26c9630bc7add88685400e54457203816c06e750/torchvision/utils.py#L90-L105\r\n\r\nIt cannot write to file objects as that requires the [`format` parameter](https://pillow.readthedocs.io/en/stable/reference/Image.html#PIL.Image.Image.save) to be passed which `torchvision.utils.save_image` does not support as of yet.\r\n\r\nCan you add this parameter to `torchvision.utils.save_image`?\n", "before_files": [{"content": "import torch\nimport math\nirange = range\n\n\ndef make_grid(tensor, nrow=8, padding=2,\n normalize=False, range=None, scale_each=False, pad_value=0):\n \"\"\"Make a grid of images.\n\n Args:\n tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W)\n or a list of images all of the same size.\n nrow (int, optional): Number of images displayed in each row of the grid.\n The final grid size is ``(B / nrow, nrow)``. Default: ``8``.\n padding (int, optional): amount of padding. Default: ``2``.\n normalize (bool, optional): If True, shift the image to the range (0, 1),\n by the min and max values specified by :attr:`range`. Default: ``False``.\n range (tuple, optional): tuple (min, max) where min and max are numbers,\n then these numbers are used to normalize the image. By default, min and max\n are computed from the tensor.\n scale_each (bool, optional): If ``True``, scale each image in the batch of\n images separately rather than the (min, max) over all images. Default: ``False``.\n pad_value (float, optional): Value for the padded pixels. Default: ``0``.\n\n Example:\n See this notebook `here <https://gist.github.com/anonymous/bf16430f7750c023141c562f3e9f2a91>`_\n\n \"\"\"\n if not (torch.is_tensor(tensor) or\n (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):\n raise TypeError('tensor or list of tensors expected, got {}'.format(type(tensor)))\n\n # if list of tensors, convert to a 4D mini-batch Tensor\n if isinstance(tensor, list):\n tensor = torch.stack(tensor, dim=0)\n\n if tensor.dim() == 2: # single image H x W\n tensor = tensor.unsqueeze(0)\n if tensor.dim() == 3: # single image\n if tensor.size(0) == 1: # if single-channel, convert to 3-channel\n tensor = torch.cat((tensor, tensor, tensor), 0)\n tensor = tensor.unsqueeze(0)\n\n if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel images\n tensor = torch.cat((tensor, tensor, tensor), 1)\n\n if normalize is True:\n tensor = tensor.clone() # avoid modifying tensor in-place\n if range is not None:\n assert isinstance(range, tuple), \\\n \"range has to be a tuple (min, max) if specified. min and max are numbers\"\n\n def norm_ip(img, min, max):\n img.clamp_(min=min, max=max)\n img.add_(-min).div_(max - min + 1e-5)\n\n def norm_range(t, range):\n if range is not None:\n norm_ip(t, range[0], range[1])\n else:\n norm_ip(t, float(t.min()), float(t.max()))\n\n if scale_each is True:\n for t in tensor: # loop over mini-batch dimension\n norm_range(t, range)\n else:\n norm_range(tensor, range)\n\n if tensor.size(0) == 1:\n return tensor.squeeze(0)\n\n # make the mini-batch of images into a grid\n nmaps = tensor.size(0)\n xmaps = min(nrow, nmaps)\n ymaps = int(math.ceil(float(nmaps) / xmaps))\n height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding)\n grid = tensor.new_full((3, height * ymaps + padding, width * xmaps + padding), pad_value)\n k = 0\n for y in irange(ymaps):\n for x in irange(xmaps):\n if k >= nmaps:\n break\n grid.narrow(1, y * height + padding, height - padding)\\\n .narrow(2, x * width + padding, width - padding)\\\n .copy_(tensor[k])\n k = k + 1\n return grid\n\n\ndef save_image(tensor, filename, nrow=8, padding=2,\n normalize=False, range=None, scale_each=False, pad_value=0):\n \"\"\"Save a given Tensor into an image file.\n\n Args:\n tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,\n saves the tensor as a grid of images by calling ``make_grid``.\n **kwargs: Other arguments are documented in ``make_grid``.\n \"\"\"\n from PIL import Image\n grid = make_grid(tensor, nrow=nrow, padding=padding, pad_value=pad_value,\n normalize=normalize, range=range, scale_each=scale_each)\n # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer\n ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()\n im = Image.fromarray(ndarr)\n im.save(filename)\n", "path": "torchvision/utils.py"}]}
| 2,087 | 357 |
gh_patches_debug_22364
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-923
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make sure `WrongMagicCommentViolation` also catches `noqa WPS100` comments
There are wrong comments that are widely used by newcomers: `# noqa WPS100`
But, it is simply wrong.
We need to be sure that `WrongMagicCommentViolation` catches that.
Make sure `WrongMagicCommentViolation` also catches `noqa WPS100` comments
There are wrong comments that are widely used by newcomers: `# noqa WPS100`
But, it is simply wrong.
We need to be sure that `WrongMagicCommentViolation` catches that.
</issue>
<code>
[start of wemake_python_styleguide/visitors/tokenize/comments.py]
1 # -*- coding: utf-8 -*-
2
3 r"""
4 Disallows to use incorrect magic comments.
5
6 That's how a basic ``comment`` type token looks like:
7
8 .. code:: python
9
10 TokenInfo(
11 type=57 (COMMENT),
12 string='# noqa: WPS100',
13 start=(1, 4),
14 end=(1, 16),
15 line="u'' # noqa: WPS100\n",
16 )
17
18 All comments have the same type.
19 """
20
21 import re
22 import tokenize
23 from typing import ClassVar, FrozenSet
24 from typing.re import Pattern
25
26 from typing_extensions import final
27
28 from wemake_python_styleguide.constants import MAX_NO_COVER_COMMENTS
29 from wemake_python_styleguide.logic.tokens import get_comment_text
30 from wemake_python_styleguide.violations.best_practices import (
31 OveruseOfNoCoverCommentViolation,
32 OveruseOfNoqaCommentViolation,
33 WrongDocCommentViolation,
34 WrongMagicCommentViolation,
35 )
36 from wemake_python_styleguide.violations.consistency import (
37 EmptyLineAfterCodingViolation,
38 )
39 from wemake_python_styleguide.visitors.base import BaseTokenVisitor
40
41
42 @final
43 class WrongCommentVisitor(BaseTokenVisitor):
44 """Checks comment tokens."""
45
46 _no_cover: ClassVar[Pattern] = re.compile(r'^pragma:\s+no\s+cover')
47 _noqa_check: ClassVar[Pattern] = re.compile(r'^noqa:?($|[A-Z\d\,\s]+)')
48 _type_check: ClassVar[Pattern] = re.compile(
49 r'^type:\s?([\w\d\[\]\'\"\.]+)$',
50 )
51
52 def __init__(self, *args, **kwargs) -> None:
53 """Initializes a counter."""
54 super().__init__(*args, **kwargs)
55 self._noqa_count = 0
56 self._no_cover_count = 0
57
58 def visit_comment(self, token: tokenize.TokenInfo) -> None:
59 """
60 Performs comment checks.
61
62 Raises:
63 OveruseOfNoqaCommentViolation
64 WrongDocCommentViolation
65 WrongMagicCommentViolation
66
67 """
68 self._check_noqa(token)
69 self._check_typed_ast(token)
70 self._check_empty_doc_comment(token)
71 self._check_cover_comments(token)
72
73 def _check_noqa(self, token: tokenize.TokenInfo) -> None:
74 comment_text = get_comment_text(token)
75 match = self._noqa_check.match(comment_text)
76 if not match:
77 return
78
79 self._noqa_count += 1
80 excludes = match.groups()[0].strip()
81 if not excludes:
82 # We cannot pass the actual line here,
83 # since it will be ignored due to `# noqa` comment:
84 self.add_violation(WrongMagicCommentViolation(text=comment_text))
85
86 def _check_typed_ast(self, token: tokenize.TokenInfo) -> None:
87 comment_text = get_comment_text(token)
88 match = self._type_check.match(comment_text)
89 if not match:
90 return
91
92 declared_type = match.groups()[0].strip()
93 if declared_type != 'ignore':
94 self.add_violation(
95 WrongMagicCommentViolation(token, text=comment_text),
96 )
97
98 def _check_empty_doc_comment(self, token: tokenize.TokenInfo) -> None:
99 if get_comment_text(token) == ':':
100 self.add_violation(WrongDocCommentViolation(token))
101
102 def _check_cover_comments(self, token: tokenize.TokenInfo) -> None:
103 comment_text = get_comment_text(token)
104 match = self._no_cover.match(comment_text)
105 if not match:
106 return
107
108 self._no_cover_count += 1
109
110 def _post_visit(self) -> None:
111 if self._noqa_count > self.options.max_noqa_comments:
112 self.add_violation(
113 OveruseOfNoqaCommentViolation(text=str(self._noqa_count)),
114 )
115 if self._no_cover_count > MAX_NO_COVER_COMMENTS:
116 self.add_violation(
117 OveruseOfNoCoverCommentViolation(
118 text=str(self._no_cover_count),
119 ),
120 )
121
122
123 @final
124 class FileMagicCommentsVisitor(BaseTokenVisitor):
125 """Checks comments for the whole file."""
126
127 _allowed_newlines: ClassVar[FrozenSet[int]] = frozenset((
128 tokenize.NL,
129 tokenize.NEWLINE,
130 tokenize.ENDMARKER,
131 ))
132
133 def visit_comment(self, token: tokenize.TokenInfo) -> None:
134 """
135 Checks special comments that are magic per each file.
136
137 Raises:
138 EmptyLineAfterCoddingViolation
139
140 """
141 self._check_empty_line_after_codding(token)
142
143 def _offset_for_comment_line(self, token: tokenize.TokenInfo) -> int:
144 if token.exact_type == tokenize.COMMENT:
145 return 2
146 return 0
147
148 def _check_empty_line_after_codding(
149 self,
150 token: tokenize.TokenInfo,
151 ) -> None:
152 """
153 Checks that we have a blank line after the magic comments.
154
155 PEP-263 says: a magic comment must be placed into the source
156 files either as first or second line in the file
157
158 See also:
159 https://www.python.org/dev/peps/pep-0263/
160
161 """
162 if token.start == (1, 0):
163 tokens = iter(self.file_tokens[self.file_tokens.index(token):])
164 available_offset = 2 # comment + newline
165 while True:
166 next_token = next(tokens)
167 if not available_offset:
168 available_offset = self._offset_for_comment_line(
169 next_token,
170 )
171
172 if available_offset > 0:
173 available_offset -= 1
174 continue
175
176 if next_token.exact_type not in self._allowed_newlines:
177 self.add_violation(EmptyLineAfterCodingViolation(token))
178 break
179
[end of wemake_python_styleguide/visitors/tokenize/comments.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wemake_python_styleguide/visitors/tokenize/comments.py b/wemake_python_styleguide/visitors/tokenize/comments.py
--- a/wemake_python_styleguide/visitors/tokenize/comments.py
+++ b/wemake_python_styleguide/visitors/tokenize/comments.py
@@ -44,7 +44,7 @@
"""Checks comment tokens."""
_no_cover: ClassVar[Pattern] = re.compile(r'^pragma:\s+no\s+cover')
- _noqa_check: ClassVar[Pattern] = re.compile(r'^noqa:?($|[A-Z\d\,\s]+)')
+ _noqa_check: ClassVar[Pattern] = re.compile(r'^(noqa:?)($|[A-Z\d\,\s]+)')
_type_check: ClassVar[Pattern] = re.compile(
r'^type:\s?([\w\d\[\]\'\"\.]+)$',
)
@@ -77,8 +77,10 @@
return
self._noqa_count += 1
- excludes = match.groups()[0].strip()
- if not excludes:
+ excludes = match.groups()[1].strip()
+ prefix = match.groups()[0].strip()
+
+ if not excludes or prefix[-1] != ':':
# We cannot pass the actual line here,
# since it will be ignored due to `# noqa` comment:
self.add_violation(WrongMagicCommentViolation(text=comment_text))
|
{"golden_diff": "diff --git a/wemake_python_styleguide/visitors/tokenize/comments.py b/wemake_python_styleguide/visitors/tokenize/comments.py\n--- a/wemake_python_styleguide/visitors/tokenize/comments.py\n+++ b/wemake_python_styleguide/visitors/tokenize/comments.py\n@@ -44,7 +44,7 @@\n \"\"\"Checks comment tokens.\"\"\"\n \n _no_cover: ClassVar[Pattern] = re.compile(r'^pragma:\\s+no\\s+cover')\n- _noqa_check: ClassVar[Pattern] = re.compile(r'^noqa:?($|[A-Z\\d\\,\\s]+)')\n+ _noqa_check: ClassVar[Pattern] = re.compile(r'^(noqa:?)($|[A-Z\\d\\,\\s]+)')\n _type_check: ClassVar[Pattern] = re.compile(\n r'^type:\\s?([\\w\\d\\[\\]\\'\\\"\\.]+)$',\n )\n@@ -77,8 +77,10 @@\n return\n \n self._noqa_count += 1\n- excludes = match.groups()[0].strip()\n- if not excludes:\n+ excludes = match.groups()[1].strip()\n+ prefix = match.groups()[0].strip()\n+\n+ if not excludes or prefix[-1] != ':':\n # We cannot pass the actual line here,\n # since it will be ignored due to `# noqa` comment:\n self.add_violation(WrongMagicCommentViolation(text=comment_text))\n", "issue": "Make sure `WrongMagicCommentViolation` also catches `noqa WPS100` comments\nThere are wrong comments that are widely used by newcomers: `# noqa WPS100`\r\nBut, it is simply wrong. \r\n\r\nWe need to be sure that `WrongMagicCommentViolation` catches that.\nMake sure `WrongMagicCommentViolation` also catches `noqa WPS100` comments\nThere are wrong comments that are widely used by newcomers: `# noqa WPS100`\r\nBut, it is simply wrong. \r\n\r\nWe need to be sure that `WrongMagicCommentViolation` catches that.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nr\"\"\"\nDisallows to use incorrect magic comments.\n\nThat's how a basic ``comment`` type token looks like:\n\n.. code:: python\n\n TokenInfo(\n type=57 (COMMENT),\n string='# noqa: WPS100',\n start=(1, 4),\n end=(1, 16),\n line=\"u'' # noqa: WPS100\\n\",\n )\n\nAll comments have the same type.\n\"\"\"\n\nimport re\nimport tokenize\nfrom typing import ClassVar, FrozenSet\nfrom typing.re import Pattern\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.constants import MAX_NO_COVER_COMMENTS\nfrom wemake_python_styleguide.logic.tokens import get_comment_text\nfrom wemake_python_styleguide.violations.best_practices import (\n OveruseOfNoCoverCommentViolation,\n OveruseOfNoqaCommentViolation,\n WrongDocCommentViolation,\n WrongMagicCommentViolation,\n)\nfrom wemake_python_styleguide.violations.consistency import (\n EmptyLineAfterCodingViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseTokenVisitor\n\n\n@final\nclass WrongCommentVisitor(BaseTokenVisitor):\n \"\"\"Checks comment tokens.\"\"\"\n\n _no_cover: ClassVar[Pattern] = re.compile(r'^pragma:\\s+no\\s+cover')\n _noqa_check: ClassVar[Pattern] = re.compile(r'^noqa:?($|[A-Z\\d\\,\\s]+)')\n _type_check: ClassVar[Pattern] = re.compile(\n r'^type:\\s?([\\w\\d\\[\\]\\'\\\"\\.]+)$',\n )\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Initializes a counter.\"\"\"\n super().__init__(*args, **kwargs)\n self._noqa_count = 0\n self._no_cover_count = 0\n\n def visit_comment(self, token: tokenize.TokenInfo) -> None:\n \"\"\"\n Performs comment checks.\n\n Raises:\n OveruseOfNoqaCommentViolation\n WrongDocCommentViolation\n WrongMagicCommentViolation\n\n \"\"\"\n self._check_noqa(token)\n self._check_typed_ast(token)\n self._check_empty_doc_comment(token)\n self._check_cover_comments(token)\n\n def _check_noqa(self, token: tokenize.TokenInfo) -> None:\n comment_text = get_comment_text(token)\n match = self._noqa_check.match(comment_text)\n if not match:\n return\n\n self._noqa_count += 1\n excludes = match.groups()[0].strip()\n if not excludes:\n # We cannot pass the actual line here,\n # since it will be ignored due to `# noqa` comment:\n self.add_violation(WrongMagicCommentViolation(text=comment_text))\n\n def _check_typed_ast(self, token: tokenize.TokenInfo) -> None:\n comment_text = get_comment_text(token)\n match = self._type_check.match(comment_text)\n if not match:\n return\n\n declared_type = match.groups()[0].strip()\n if declared_type != 'ignore':\n self.add_violation(\n WrongMagicCommentViolation(token, text=comment_text),\n )\n\n def _check_empty_doc_comment(self, token: tokenize.TokenInfo) -> None:\n if get_comment_text(token) == ':':\n self.add_violation(WrongDocCommentViolation(token))\n\n def _check_cover_comments(self, token: tokenize.TokenInfo) -> None:\n comment_text = get_comment_text(token)\n match = self._no_cover.match(comment_text)\n if not match:\n return\n\n self._no_cover_count += 1\n\n def _post_visit(self) -> None:\n if self._noqa_count > self.options.max_noqa_comments:\n self.add_violation(\n OveruseOfNoqaCommentViolation(text=str(self._noqa_count)),\n )\n if self._no_cover_count > MAX_NO_COVER_COMMENTS:\n self.add_violation(\n OveruseOfNoCoverCommentViolation(\n text=str(self._no_cover_count),\n ),\n )\n\n\n@final\nclass FileMagicCommentsVisitor(BaseTokenVisitor):\n \"\"\"Checks comments for the whole file.\"\"\"\n\n _allowed_newlines: ClassVar[FrozenSet[int]] = frozenset((\n tokenize.NL,\n tokenize.NEWLINE,\n tokenize.ENDMARKER,\n ))\n\n def visit_comment(self, token: tokenize.TokenInfo) -> None:\n \"\"\"\n Checks special comments that are magic per each file.\n\n Raises:\n EmptyLineAfterCoddingViolation\n\n \"\"\"\n self._check_empty_line_after_codding(token)\n\n def _offset_for_comment_line(self, token: tokenize.TokenInfo) -> int:\n if token.exact_type == tokenize.COMMENT:\n return 2\n return 0\n\n def _check_empty_line_after_codding(\n self,\n token: tokenize.TokenInfo,\n ) -> None:\n \"\"\"\n Checks that we have a blank line after the magic comments.\n\n PEP-263 says: a magic comment must be placed into the source\n files either as first or second line in the file\n\n See also:\n https://www.python.org/dev/peps/pep-0263/\n\n \"\"\"\n if token.start == (1, 0):\n tokens = iter(self.file_tokens[self.file_tokens.index(token):])\n available_offset = 2 # comment + newline\n while True:\n next_token = next(tokens)\n if not available_offset:\n available_offset = self._offset_for_comment_line(\n next_token,\n )\n\n if available_offset > 0:\n available_offset -= 1\n continue\n\n if next_token.exact_type not in self._allowed_newlines:\n self.add_violation(EmptyLineAfterCodingViolation(token))\n break\n", "path": "wemake_python_styleguide/visitors/tokenize/comments.py"}]}
| 2,378 | 324 |
gh_patches_debug_24096
|
rasdani/github-patches
|
git_diff
|
pretalx__pretalx-406
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Prevent removing the last organiser of an event
… because this is a really bad idea.
</issue>
<code>
[start of src/pretalx/orga/views/event.py]
1 from csp.decorators import csp_update
2 from django import forms
3 from django.contrib import messages
4 from django.contrib.auth import login
5 from django.core.exceptions import PermissionDenied
6 from django.db import transaction
7 from django.shortcuts import get_object_or_404, redirect
8 from django.urls import reverse
9 from django.utils.decorators import method_decorator
10 from django.utils.functional import cached_property
11 from django.utils.translation import ugettext_lazy as _
12 from django.views.generic import FormView, TemplateView
13 from rest_framework.authtoken.models import Token
14
15 from pretalx.common.mixins.views import ActionFromUrl, PermissionRequired
16 from pretalx.common.phrases import phrases
17 from pretalx.common.tasks import regenerate_css
18 from pretalx.common.views import CreateOrUpdateView
19 from pretalx.event.models import Event
20 from pretalx.orga.forms import EventForm, EventSettingsForm
21 from pretalx.orga.forms.event import MailSettingsForm
22 from pretalx.person.forms import LoginInfoForm, OrgaProfileForm, UserForm
23 from pretalx.person.models import EventPermission, User
24
25
26 class EventSettingsPermission(PermissionRequired):
27 permission_required = 'orga.change_settings'
28
29 def get_permission_object(self):
30 return self.request.event
31
32
33 class EventDetail(ActionFromUrl, CreateOrUpdateView):
34 model = Event
35 form_class = EventForm
36 write_permission_required = 'orga.change_settings'
37
38 @cached_property
39 def _action(self):
40 if 'event' not in self.kwargs:
41 return 'create'
42 if self.request.user.has_perm(self.write_permission_required, self.object):
43 return 'edit'
44 return 'view'
45
46 def get_template_names(self):
47 if self._action == 'create':
48 return 'orga/settings/create_event.html'
49 return 'orga/settings/form.html'
50
51 def dispatch(self, request, *args, **kwargs):
52 if self._action == 'create':
53 if not request.user.is_anonymous and not request.user.is_administrator:
54 raise PermissionDenied()
55 else:
56 if not request.user.has_perm('orga.change_settings', self.object):
57 raise PermissionDenied()
58 return super().dispatch(request, *args, **kwargs)
59
60 def get_object(self):
61 return self.object
62
63 @cached_property
64 def object(self):
65 try:
66 return self.request.event
67 except AttributeError:
68 return
69
70 @cached_property
71 def sform(self):
72 if not hasattr(self.request, 'event') or not self.request.event:
73 return
74 return EventSettingsForm(
75 read_only=(self._action == 'view'),
76 locales=self.request.event.locales,
77 obj=self.request.event,
78 attribute_name='settings',
79 data=self.request.POST if self.request.method == "POST" else None,
80 prefix='settings'
81 )
82
83 def get_context_data(self, *args, **kwargs):
84 context = super().get_context_data(*args, **kwargs)
85 context['sform'] = self.sform
86 context['url_placeholder'] = f'https://{self.request.host}/'
87 return context
88
89 def get_success_url(self) -> str:
90 return self.object.orga_urls.settings
91
92 def form_valid(self, form):
93 new_event = not bool(form.instance.pk)
94 if not new_event:
95 if not self.sform.is_valid():
96 return self.form_invalid(form)
97
98 ret = super().form_valid(form)
99
100 if new_event:
101 url = form.instance.cfp.urls.base
102 messages.success(self.request, _('Yay, a new event! Check these settings and <a href="{url}">configure a CfP</a> and you\'re good to go!').format(url=url))
103 form.instance.log_action('pretalx.event.create', person=self.request.user, orga=True)
104 EventPermission.objects.create(
105 event=form.instance,
106 user=self.request.user,
107 is_orga=True,
108 )
109 else:
110 self.sform.save()
111 form.instance.log_action('pretalx.event.update', person=self.request.user, orga=True)
112 messages.success(self.request, _('The event settings have been saved.'))
113 regenerate_css.apply_async(args=(form.instance.pk,))
114 return ret
115
116
117 class EventMailSettings(EventSettingsPermission, ActionFromUrl, FormView):
118 form_class = MailSettingsForm
119 template_name = 'orga/settings/mail.html'
120 write_permission_required = 'orga.change_settings'
121
122 def get_success_url(self) -> str:
123 return self.request.event.orga_urls.mail_settings
124
125 def get_form_kwargs(self):
126 kwargs = super().get_form_kwargs()
127 kwargs['obj'] = self.request.event
128 kwargs['attribute_name'] = 'settings'
129 kwargs['locales'] = self.request.event.locales
130 return kwargs
131
132 def form_valid(self, form):
133 form.save()
134
135 if self.request.POST.get('test', '0').strip() == '1':
136 backend = self.request.event.get_mail_backend(force_custom=True)
137 try:
138 backend.test(self.request.event.settings.mail_from)
139 except Exception as e:
140 messages.warning(self.request, _('An error occured while contacting the SMTP server: %s') % str(e))
141 return redirect(self.request.event.orga_urls.mail_settings)
142 else:
143 if form.cleaned_data.get('smtp_use_custom'):
144 messages.success(self.request, _('Yay, your changes have been saved and the connection attempt to '
145 'your SMTP server was successful.'))
146 else:
147 messages.success(self.request, _('We\'ve been able to contact the SMTP server you configured. '
148 'Remember to check the "use custom SMTP server" checkbox, '
149 'otherwise your SMTP server will not be used.'))
150 else:
151 messages.success(self.request, _('Yay! We saved your changes.'))
152
153 ret = super().form_valid(form)
154 return ret
155
156
157 @method_decorator(csp_update(SCRIPT_SRC="'self' 'unsafe-inline'"), name='get')
158 class EventTeam(EventSettingsPermission, TemplateView):
159 template_name = 'orga/settings/team.html'
160
161 @cached_property
162 def formset(self):
163 formset_class = forms.inlineformset_factory(
164 Event, EventPermission, can_delete=True, extra=0,
165 fields=[
166 'is_orga',
167 'is_reviewer',
168 'review_override_count',
169 'invitation_email',
170 ],
171 )
172 return formset_class(
173 self.request.POST if self.request.method == 'POST' else None,
174 queryset=EventPermission.objects.filter(event=self.request.event),
175 instance=self.request.event,
176 )
177
178 def get_context_data(self, *args, **kwargs):
179 ctx = super().get_context_data(*args, **kwargs)
180 ctx['formset'] = self.formset
181 return ctx
182
183 @classmethod
184 def _find_user(cls, email):
185 from pretalx.person.models import User
186 return User.objects.filter(nick=email).first() or User.objects.filter(email=email).first()
187
188 @transaction.atomic
189 def post(self, request, *args, **kwargs):
190 if not self.formset.is_valid():
191 messages.error(request, phrases.base.error_saving_changes)
192 return redirect(self.request.event.orga_urls.team_settings)
193 permissions = self.formset.save(commit=False)
194 mails = []
195
196 for permission in self.formset.deleted_objects:
197 permission.delete()
198
199 for permission in permissions:
200 if permission.invitation_email:
201 user = self._find_user(permission.invitation_email)
202
203 if user:
204 permission.user = user
205 permission.invitation_email = None
206 permission.invitation_token = None
207 mails.append(permission.send_invite_email())
208 request.event.log_action('pretalx.invite.orga.send', person=request.user, orga=True)
209 messages.success(
210 request,
211 _('<{email}> has been invited to your team - more team members help distribute the workload, so … yay!').format(email=permission.invitation_email)
212 )
213
214 permission.save()
215
216 for permission in permissions:
217 if permission.user:
218 EventPermission.objects \
219 .filter(event=permission.event, user=permission.user) \
220 .exclude(id=permission.id) \
221 .delete()
222
223 for mail in mails:
224 mail.send()
225
226 return redirect(self.request.event.orga_urls.team_settings)
227
228
229 @method_decorator(csp_update(SCRIPT_SRC="'self' 'unsafe-inline'"), name='dispatch')
230 class InvitationView(FormView):
231 template_name = 'orga/invitation.html'
232 form_class = UserForm
233
234 @cached_property
235 def object(self):
236 return get_object_or_404(
237 EventPermission,
238 invitation_token__iexact=self.kwargs.get('code'),
239 user__isnull=True,
240 )
241
242 def get_context_data(self, *args, **kwargs):
243 ctx = super().get_context_data(*args, **kwargs)
244 ctx['invitation'] = self.object
245 return ctx
246
247 def form_valid(self, form):
248 form.save()
249 permission = self.object
250 user = User.objects.filter(pk=form.cleaned_data.get('user_id')).first()
251 if not user:
252 messages.error(self.request, _('There was a problem with your authentication. Please contact the organiser for further help.'))
253 return redirect(self.request.event.urls.base)
254
255 perm = EventPermission.objects.filter(user=user, event=permission.event).exclude(pk=permission.pk).first()
256 event = permission.event
257
258 if perm:
259 if permission.is_orga:
260 perm.is_orga = True
261 if permission.is_reviewer:
262 perm.is_reviewer = True
263 perm.save()
264 permission.delete()
265 permission = perm
266
267 permission.user = user
268 permission.save()
269 permission.event.log_action('pretalx.invite.orga.accept', person=user, orga=True)
270 messages.info(self.request, _('You are now part of the event team!'))
271
272 login(self.request, user, backend='django.contrib.auth.backends.ModelBackend')
273 return redirect(event.orga_urls.base)
274
275
276 @method_decorator(csp_update(SCRIPT_SRC="'self' 'unsafe-inline'"), name='dispatch')
277 class UserSettings(TemplateView):
278 form_class = LoginInfoForm
279 template_name = 'orga/user.html'
280
281 def get_success_url(self) -> str:
282 return reverse('orga:user.view')
283
284 @cached_property
285 def login_form(self):
286 bind = self.request.method == 'POST' and self.request.POST.get('action') == 'login'
287 return LoginInfoForm(
288 user=self.request.user,
289 data=self.request.POST if bind else None
290 )
291
292 @cached_property
293 def profile_form(self):
294 bind = self.request.method == 'POST' and self.request.POST.get('action') == 'profile'
295 return OrgaProfileForm(
296 instance=self.request.user,
297 data=self.request.POST if bind else None
298 )
299
300 def get_context_data(self, **kwargs):
301 ctx = super().get_context_data(**kwargs)
302 ctx['token'] = Token.objects.filter(user=self.request.user).first() or Token.objects.create(user=self.request.user)
303 ctx['login_form'] = self.login_form
304 ctx['profile_form'] = self.profile_form
305 return ctx
306
307 def post(self, request, *args, **kwargs):
308 if self.login_form.is_bound and self.login_form.is_valid():
309 self.login_form.save()
310 messages.success(request, _('Your changes have been saved.'))
311 request.user.log_action('pretalx.user.password.update')
312 elif self.profile_form.is_bound and self.profile_form.is_valid():
313 self.profile_form.save()
314 messages.success(request, _('Your changes have been saved.'))
315 request.user.log_action('pretalx.user.profile.update')
316 elif request.POST.get('form') == 'token':
317 request.user.regenerate_token()
318 messages.success(request, _('Your API token has been regenerated. The previous token will not be usable any longer.'))
319 else:
320 messages.error(self.request, _('Oh :( We had trouble saving your input. See below for details.'))
321 return redirect(self.get_success_url())
322
[end of src/pretalx/orga/views/event.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretalx/orga/views/event.py b/src/pretalx/orga/views/event.py
--- a/src/pretalx/orga/views/event.py
+++ b/src/pretalx/orga/views/event.py
@@ -185,6 +185,16 @@
from pretalx.person.models import User
return User.objects.filter(nick=email).first() or User.objects.filter(email=email).first()
+ def _count_orga_permissions(self, permissions):
+ return len([p for p in permissions if p.is_orga])
+
+ def has_remaining_team(self):
+ return (
+ self._count_orga_permissions(self.formset.new_objects)
+ + self._count_orga_permissions(self.formset.changed_objects)
+ - self._count_orga_permissions(self.formset.deleted_objects)
+ ) > 0
+
@transaction.atomic
def post(self, request, *args, **kwargs):
if not self.formset.is_valid():
@@ -193,6 +203,10 @@
permissions = self.formset.save(commit=False)
mails = []
+ if not self.has_remaining_team():
+ messages.error(request, _("That would be a pretty lonely event. You can't remove the last remaining team member."))
+ return redirect(self.request.event.orga_urls.team_settings)
+
for permission in self.formset.deleted_objects:
permission.delete()
|
{"golden_diff": "diff --git a/src/pretalx/orga/views/event.py b/src/pretalx/orga/views/event.py\n--- a/src/pretalx/orga/views/event.py\n+++ b/src/pretalx/orga/views/event.py\n@@ -185,6 +185,16 @@\n from pretalx.person.models import User\n return User.objects.filter(nick=email).first() or User.objects.filter(email=email).first()\n \n+ def _count_orga_permissions(self, permissions):\n+ return len([p for p in permissions if p.is_orga])\n+\n+ def has_remaining_team(self):\n+ return (\n+ self._count_orga_permissions(self.formset.new_objects)\n+ + self._count_orga_permissions(self.formset.changed_objects)\n+ - self._count_orga_permissions(self.formset.deleted_objects)\n+ ) > 0\n+\n @transaction.atomic\n def post(self, request, *args, **kwargs):\n if not self.formset.is_valid():\n@@ -193,6 +203,10 @@\n permissions = self.formset.save(commit=False)\n mails = []\n \n+ if not self.has_remaining_team():\n+ messages.error(request, _(\"That would be a pretty lonely event. You can't remove the last remaining team member.\"))\n+ return redirect(self.request.event.orga_urls.team_settings)\n+\n for permission in self.formset.deleted_objects:\n permission.delete()\n", "issue": "Prevent removing the last organiser of an event\n\u2026 because this is a really bad idea.\n", "before_files": [{"content": "from csp.decorators import csp_update\nfrom django import forms\nfrom django.contrib import messages\nfrom django.contrib.auth import login\nfrom django.core.exceptions import PermissionDenied\nfrom django.db import transaction\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.urls import reverse\nfrom django.utils.decorators import method_decorator\nfrom django.utils.functional import cached_property\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.generic import FormView, TemplateView\nfrom rest_framework.authtoken.models import Token\n\nfrom pretalx.common.mixins.views import ActionFromUrl, PermissionRequired\nfrom pretalx.common.phrases import phrases\nfrom pretalx.common.tasks import regenerate_css\nfrom pretalx.common.views import CreateOrUpdateView\nfrom pretalx.event.models import Event\nfrom pretalx.orga.forms import EventForm, EventSettingsForm\nfrom pretalx.orga.forms.event import MailSettingsForm\nfrom pretalx.person.forms import LoginInfoForm, OrgaProfileForm, UserForm\nfrom pretalx.person.models import EventPermission, User\n\n\nclass EventSettingsPermission(PermissionRequired):\n permission_required = 'orga.change_settings'\n\n def get_permission_object(self):\n return self.request.event\n\n\nclass EventDetail(ActionFromUrl, CreateOrUpdateView):\n model = Event\n form_class = EventForm\n write_permission_required = 'orga.change_settings'\n\n @cached_property\n def _action(self):\n if 'event' not in self.kwargs:\n return 'create'\n if self.request.user.has_perm(self.write_permission_required, self.object):\n return 'edit'\n return 'view'\n\n def get_template_names(self):\n if self._action == 'create':\n return 'orga/settings/create_event.html'\n return 'orga/settings/form.html'\n\n def dispatch(self, request, *args, **kwargs):\n if self._action == 'create':\n if not request.user.is_anonymous and not request.user.is_administrator:\n raise PermissionDenied()\n else:\n if not request.user.has_perm('orga.change_settings', self.object):\n raise PermissionDenied()\n return super().dispatch(request, *args, **kwargs)\n\n def get_object(self):\n return self.object\n\n @cached_property\n def object(self):\n try:\n return self.request.event\n except AttributeError:\n return\n\n @cached_property\n def sform(self):\n if not hasattr(self.request, 'event') or not self.request.event:\n return\n return EventSettingsForm(\n read_only=(self._action == 'view'),\n locales=self.request.event.locales,\n obj=self.request.event,\n attribute_name='settings',\n data=self.request.POST if self.request.method == \"POST\" else None,\n prefix='settings'\n )\n\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n context['sform'] = self.sform\n context['url_placeholder'] = f'https://{self.request.host}/'\n return context\n\n def get_success_url(self) -> str:\n return self.object.orga_urls.settings\n\n def form_valid(self, form):\n new_event = not bool(form.instance.pk)\n if not new_event:\n if not self.sform.is_valid():\n return self.form_invalid(form)\n\n ret = super().form_valid(form)\n\n if new_event:\n url = form.instance.cfp.urls.base\n messages.success(self.request, _('Yay, a new event! Check these settings and <a href=\"{url}\">configure a CfP</a> and you\\'re good to go!').format(url=url))\n form.instance.log_action('pretalx.event.create', person=self.request.user, orga=True)\n EventPermission.objects.create(\n event=form.instance,\n user=self.request.user,\n is_orga=True,\n )\n else:\n self.sform.save()\n form.instance.log_action('pretalx.event.update', person=self.request.user, orga=True)\n messages.success(self.request, _('The event settings have been saved.'))\n regenerate_css.apply_async(args=(form.instance.pk,))\n return ret\n\n\nclass EventMailSettings(EventSettingsPermission, ActionFromUrl, FormView):\n form_class = MailSettingsForm\n template_name = 'orga/settings/mail.html'\n write_permission_required = 'orga.change_settings'\n\n def get_success_url(self) -> str:\n return self.request.event.orga_urls.mail_settings\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['obj'] = self.request.event\n kwargs['attribute_name'] = 'settings'\n kwargs['locales'] = self.request.event.locales\n return kwargs\n\n def form_valid(self, form):\n form.save()\n\n if self.request.POST.get('test', '0').strip() == '1':\n backend = self.request.event.get_mail_backend(force_custom=True)\n try:\n backend.test(self.request.event.settings.mail_from)\n except Exception as e:\n messages.warning(self.request, _('An error occured while contacting the SMTP server: %s') % str(e))\n return redirect(self.request.event.orga_urls.mail_settings)\n else:\n if form.cleaned_data.get('smtp_use_custom'):\n messages.success(self.request, _('Yay, your changes have been saved and the connection attempt to '\n 'your SMTP server was successful.'))\n else:\n messages.success(self.request, _('We\\'ve been able to contact the SMTP server you configured. '\n 'Remember to check the \"use custom SMTP server\" checkbox, '\n 'otherwise your SMTP server will not be used.'))\n else:\n messages.success(self.request, _('Yay! We saved your changes.'))\n\n ret = super().form_valid(form)\n return ret\n\n\n@method_decorator(csp_update(SCRIPT_SRC=\"'self' 'unsafe-inline'\"), name='get')\nclass EventTeam(EventSettingsPermission, TemplateView):\n template_name = 'orga/settings/team.html'\n\n @cached_property\n def formset(self):\n formset_class = forms.inlineformset_factory(\n Event, EventPermission, can_delete=True, extra=0,\n fields=[\n 'is_orga',\n 'is_reviewer',\n 'review_override_count',\n 'invitation_email',\n ],\n )\n return formset_class(\n self.request.POST if self.request.method == 'POST' else None,\n queryset=EventPermission.objects.filter(event=self.request.event),\n instance=self.request.event,\n )\n\n def get_context_data(self, *args, **kwargs):\n ctx = super().get_context_data(*args, **kwargs)\n ctx['formset'] = self.formset\n return ctx\n\n @classmethod\n def _find_user(cls, email):\n from pretalx.person.models import User\n return User.objects.filter(nick=email).first() or User.objects.filter(email=email).first()\n\n @transaction.atomic\n def post(self, request, *args, **kwargs):\n if not self.formset.is_valid():\n messages.error(request, phrases.base.error_saving_changes)\n return redirect(self.request.event.orga_urls.team_settings)\n permissions = self.formset.save(commit=False)\n mails = []\n\n for permission in self.formset.deleted_objects:\n permission.delete()\n\n for permission in permissions:\n if permission.invitation_email:\n user = self._find_user(permission.invitation_email)\n\n if user:\n permission.user = user\n permission.invitation_email = None\n permission.invitation_token = None\n mails.append(permission.send_invite_email())\n request.event.log_action('pretalx.invite.orga.send', person=request.user, orga=True)\n messages.success(\n request,\n _('<{email}> has been invited to your team - more team members help distribute the workload, so \u2026 yay!').format(email=permission.invitation_email)\n )\n\n permission.save()\n\n for permission in permissions:\n if permission.user:\n EventPermission.objects \\\n .filter(event=permission.event, user=permission.user) \\\n .exclude(id=permission.id) \\\n .delete()\n\n for mail in mails:\n mail.send()\n\n return redirect(self.request.event.orga_urls.team_settings)\n\n\n@method_decorator(csp_update(SCRIPT_SRC=\"'self' 'unsafe-inline'\"), name='dispatch')\nclass InvitationView(FormView):\n template_name = 'orga/invitation.html'\n form_class = UserForm\n\n @cached_property\n def object(self):\n return get_object_or_404(\n EventPermission,\n invitation_token__iexact=self.kwargs.get('code'),\n user__isnull=True,\n )\n\n def get_context_data(self, *args, **kwargs):\n ctx = super().get_context_data(*args, **kwargs)\n ctx['invitation'] = self.object\n return ctx\n\n def form_valid(self, form):\n form.save()\n permission = self.object\n user = User.objects.filter(pk=form.cleaned_data.get('user_id')).first()\n if not user:\n messages.error(self.request, _('There was a problem with your authentication. Please contact the organiser for further help.'))\n return redirect(self.request.event.urls.base)\n\n perm = EventPermission.objects.filter(user=user, event=permission.event).exclude(pk=permission.pk).first()\n event = permission.event\n\n if perm:\n if permission.is_orga:\n perm.is_orga = True\n if permission.is_reviewer:\n perm.is_reviewer = True\n perm.save()\n permission.delete()\n permission = perm\n\n permission.user = user\n permission.save()\n permission.event.log_action('pretalx.invite.orga.accept', person=user, orga=True)\n messages.info(self.request, _('You are now part of the event team!'))\n\n login(self.request, user, backend='django.contrib.auth.backends.ModelBackend')\n return redirect(event.orga_urls.base)\n\n\n@method_decorator(csp_update(SCRIPT_SRC=\"'self' 'unsafe-inline'\"), name='dispatch')\nclass UserSettings(TemplateView):\n form_class = LoginInfoForm\n template_name = 'orga/user.html'\n\n def get_success_url(self) -> str:\n return reverse('orga:user.view')\n\n @cached_property\n def login_form(self):\n bind = self.request.method == 'POST' and self.request.POST.get('action') == 'login'\n return LoginInfoForm(\n user=self.request.user,\n data=self.request.POST if bind else None\n )\n\n @cached_property\n def profile_form(self):\n bind = self.request.method == 'POST' and self.request.POST.get('action') == 'profile'\n return OrgaProfileForm(\n instance=self.request.user,\n data=self.request.POST if bind else None\n )\n\n def get_context_data(self, **kwargs):\n ctx = super().get_context_data(**kwargs)\n ctx['token'] = Token.objects.filter(user=self.request.user).first() or Token.objects.create(user=self.request.user)\n ctx['login_form'] = self.login_form\n ctx['profile_form'] = self.profile_form\n return ctx\n\n def post(self, request, *args, **kwargs):\n if self.login_form.is_bound and self.login_form.is_valid():\n self.login_form.save()\n messages.success(request, _('Your changes have been saved.'))\n request.user.log_action('pretalx.user.password.update')\n elif self.profile_form.is_bound and self.profile_form.is_valid():\n self.profile_form.save()\n messages.success(request, _('Your changes have been saved.'))\n request.user.log_action('pretalx.user.profile.update')\n elif request.POST.get('form') == 'token':\n request.user.regenerate_token()\n messages.success(request, _('Your API token has been regenerated. The previous token will not be usable any longer.'))\n else:\n messages.error(self.request, _('Oh :( We had trouble saving your input. See below for details.'))\n return redirect(self.get_success_url())\n", "path": "src/pretalx/orga/views/event.py"}]}
| 3,984 | 311 |
gh_patches_debug_15759
|
rasdani/github-patches
|
git_diff
|
psf__black-4290
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix AST safety check false negative
Fixes #4268
Previously we would allow whitespace changes in all strings, now
only in docstrings.
</issue>
<code>
[start of src/black/parsing.py]
1 """
2 Parse Python code and perform AST validation.
3 """
4
5 import ast
6 import sys
7 import warnings
8 from typing import Iterable, Iterator, List, Set, Tuple
9
10 from black.mode import VERSION_TO_FEATURES, Feature, TargetVersion, supports_feature
11 from black.nodes import syms
12 from blib2to3 import pygram
13 from blib2to3.pgen2 import driver
14 from blib2to3.pgen2.grammar import Grammar
15 from blib2to3.pgen2.parse import ParseError
16 from blib2to3.pgen2.tokenize import TokenError
17 from blib2to3.pytree import Leaf, Node
18
19
20 class InvalidInput(ValueError):
21 """Raised when input source code fails all parse attempts."""
22
23
24 def get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:
25 if not target_versions:
26 # No target_version specified, so try all grammars.
27 return [
28 # Python 3.7-3.9
29 pygram.python_grammar_async_keywords,
30 # Python 3.0-3.6
31 pygram.python_grammar,
32 # Python 3.10+
33 pygram.python_grammar_soft_keywords,
34 ]
35
36 grammars = []
37 # If we have to parse both, try to parse async as a keyword first
38 if not supports_feature(
39 target_versions, Feature.ASYNC_IDENTIFIERS
40 ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):
41 # Python 3.7-3.9
42 grammars.append(pygram.python_grammar_async_keywords)
43 if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):
44 # Python 3.0-3.6
45 grammars.append(pygram.python_grammar)
46 if any(Feature.PATTERN_MATCHING in VERSION_TO_FEATURES[v] for v in target_versions):
47 # Python 3.10+
48 grammars.append(pygram.python_grammar_soft_keywords)
49
50 # At least one of the above branches must have been taken, because every Python
51 # version has exactly one of the two 'ASYNC_*' flags
52 return grammars
53
54
55 def lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:
56 """Given a string with source, return the lib2to3 Node."""
57 if not src_txt.endswith("\n"):
58 src_txt += "\n"
59
60 grammars = get_grammars(set(target_versions))
61 errors = {}
62 for grammar in grammars:
63 drv = driver.Driver(grammar)
64 try:
65 result = drv.parse_string(src_txt, True)
66 break
67
68 except ParseError as pe:
69 lineno, column = pe.context[1]
70 lines = src_txt.splitlines()
71 try:
72 faulty_line = lines[lineno - 1]
73 except IndexError:
74 faulty_line = "<line number missing in source>"
75 errors[grammar.version] = InvalidInput(
76 f"Cannot parse: {lineno}:{column}: {faulty_line}"
77 )
78
79 except TokenError as te:
80 # In edge cases these are raised; and typically don't have a "faulty_line".
81 lineno, column = te.args[1]
82 errors[grammar.version] = InvalidInput(
83 f"Cannot parse: {lineno}:{column}: {te.args[0]}"
84 )
85
86 else:
87 # Choose the latest version when raising the actual parsing error.
88 assert len(errors) >= 1
89 exc = errors[max(errors)]
90 raise exc from None
91
92 if isinstance(result, Leaf):
93 result = Node(syms.file_input, [result])
94 return result
95
96
97 def matches_grammar(src_txt: str, grammar: Grammar) -> bool:
98 drv = driver.Driver(grammar)
99 try:
100 drv.parse_string(src_txt, True)
101 except (ParseError, TokenError, IndentationError):
102 return False
103 else:
104 return True
105
106
107 def lib2to3_unparse(node: Node) -> str:
108 """Given a lib2to3 node, return its string representation."""
109 code = str(node)
110 return code
111
112
113 class ASTSafetyError(Exception):
114 """Raised when Black's generated code is not equivalent to the old AST."""
115
116
117 def _parse_single_version(
118 src: str, version: Tuple[int, int], *, type_comments: bool
119 ) -> ast.AST:
120 filename = "<unknown>"
121 with warnings.catch_warnings():
122 warnings.simplefilter("ignore", SyntaxWarning)
123 warnings.simplefilter("ignore", DeprecationWarning)
124 return ast.parse(
125 src, filename, feature_version=version, type_comments=type_comments
126 )
127
128
129 def parse_ast(src: str) -> ast.AST:
130 # TODO: support Python 4+ ;)
131 versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]
132
133 first_error = ""
134 for version in sorted(versions, reverse=True):
135 try:
136 return _parse_single_version(src, version, type_comments=True)
137 except SyntaxError as e:
138 if not first_error:
139 first_error = str(e)
140
141 # Try to parse without type comments
142 for version in sorted(versions, reverse=True):
143 try:
144 return _parse_single_version(src, version, type_comments=False)
145 except SyntaxError:
146 pass
147
148 raise SyntaxError(first_error)
149
150
151 def _normalize(lineend: str, value: str) -> str:
152 # To normalize, we strip any leading and trailing space from
153 # each line...
154 stripped: List[str] = [i.strip() for i in value.splitlines()]
155 normalized = lineend.join(stripped)
156 # ...and remove any blank lines at the beginning and end of
157 # the whole string
158 return normalized.strip()
159
160
161 def stringify_ast(node: ast.AST) -> Iterator[str]:
162 """Simple visitor generating strings to compare ASTs by content."""
163 return _stringify_ast(node, [])
164
165
166 def _stringify_ast_with_new_parent(
167 node: ast.AST, parent_stack: List[ast.AST], new_parent: ast.AST
168 ) -> Iterator[str]:
169 parent_stack.append(new_parent)
170 yield from _stringify_ast(node, parent_stack)
171 parent_stack.pop()
172
173
174 def _stringify_ast(node: ast.AST, parent_stack: List[ast.AST]) -> Iterator[str]:
175 if (
176 isinstance(node, ast.Constant)
177 and isinstance(node.value, str)
178 and node.kind == "u"
179 ):
180 # It's a quirk of history that we strip the u prefix over here. We used to
181 # rewrite the AST nodes for Python version compatibility and we never copied
182 # over the kind
183 node.kind = None
184
185 yield f"{' ' * len(parent_stack)}{node.__class__.__name__}("
186
187 for field in sorted(node._fields): # noqa: F402
188 # TypeIgnore has only one field 'lineno' which breaks this comparison
189 if isinstance(node, ast.TypeIgnore):
190 break
191
192 try:
193 value: object = getattr(node, field)
194 except AttributeError:
195 continue
196
197 yield f"{' ' * (len(parent_stack) + 1)}{field}="
198
199 if isinstance(value, list):
200 for item in value:
201 # Ignore nested tuples within del statements, because we may insert
202 # parentheses and they change the AST.
203 if (
204 field == "targets"
205 and isinstance(node, ast.Delete)
206 and isinstance(item, ast.Tuple)
207 ):
208 for elt in item.elts:
209 yield from _stringify_ast_with_new_parent(
210 elt, parent_stack, node
211 )
212
213 elif isinstance(item, ast.AST):
214 yield from _stringify_ast_with_new_parent(item, parent_stack, node)
215
216 elif isinstance(value, ast.AST):
217 yield from _stringify_ast_with_new_parent(value, parent_stack, node)
218
219 else:
220 normalized: object
221 if (
222 isinstance(node, ast.Constant)
223 and field == "value"
224 and isinstance(value, str)
225 and len(parent_stack) >= 2
226 and isinstance(parent_stack[-1], ast.Expr)
227 and isinstance(
228 parent_stack[-2],
229 (ast.FunctionDef, ast.AsyncFunctionDef, ast.Module, ast.ClassDef),
230 )
231 ):
232 # Constant strings may be indented across newlines, if they are
233 # docstrings; fold spaces after newlines when comparing. Similarly,
234 # trailing and leading space may be removed.
235 normalized = _normalize("\n", value)
236 elif field == "type_comment" and isinstance(value, str):
237 # Trailing whitespace in type comments is removed.
238 normalized = value.rstrip()
239 else:
240 normalized = value
241 yield (
242 f"{' ' * (len(parent_stack) + 1)}{normalized!r}, #"
243 f" {value.__class__.__name__}"
244 )
245
246 yield f"{' ' * len(parent_stack)}) # /{node.__class__.__name__}"
247
[end of src/black/parsing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/black/parsing.py b/src/black/parsing.py
--- a/src/black/parsing.py
+++ b/src/black/parsing.py
@@ -223,11 +223,9 @@
and field == "value"
and isinstance(value, str)
and len(parent_stack) >= 2
+ # Any standalone string, ideally this would
+ # exactly match black.nodes.is_docstring
and isinstance(parent_stack[-1], ast.Expr)
- and isinstance(
- parent_stack[-2],
- (ast.FunctionDef, ast.AsyncFunctionDef, ast.Module, ast.ClassDef),
- )
):
# Constant strings may be indented across newlines, if they are
# docstrings; fold spaces after newlines when comparing. Similarly,
|
{"golden_diff": "diff --git a/src/black/parsing.py b/src/black/parsing.py\n--- a/src/black/parsing.py\n+++ b/src/black/parsing.py\n@@ -223,11 +223,9 @@\n and field == \"value\"\n and isinstance(value, str)\n and len(parent_stack) >= 2\n+ # Any standalone string, ideally this would\n+ # exactly match black.nodes.is_docstring\n and isinstance(parent_stack[-1], ast.Expr)\n- and isinstance(\n- parent_stack[-2],\n- (ast.FunctionDef, ast.AsyncFunctionDef, ast.Module, ast.ClassDef),\n- )\n ):\n # Constant strings may be indented across newlines, if they are\n # docstrings; fold spaces after newlines when comparing. Similarly,\n", "issue": "Fix AST safety check false negative\nFixes #4268\r\n\r\nPreviously we would allow whitespace changes in all strings, now\r\nonly in docstrings.\r\n\n", "before_files": [{"content": "\"\"\"\nParse Python code and perform AST validation.\n\"\"\"\n\nimport ast\nimport sys\nimport warnings\nfrom typing import Iterable, Iterator, List, Set, Tuple\n\nfrom black.mode import VERSION_TO_FEATURES, Feature, TargetVersion, supports_feature\nfrom black.nodes import syms\nfrom blib2to3 import pygram\nfrom blib2to3.pgen2 import driver\nfrom blib2to3.pgen2.grammar import Grammar\nfrom blib2to3.pgen2.parse import ParseError\nfrom blib2to3.pgen2.tokenize import TokenError\nfrom blib2to3.pytree import Leaf, Node\n\n\nclass InvalidInput(ValueError):\n \"\"\"Raised when input source code fails all parse attempts.\"\"\"\n\n\ndef get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:\n if not target_versions:\n # No target_version specified, so try all grammars.\n return [\n # Python 3.7-3.9\n pygram.python_grammar_async_keywords,\n # Python 3.0-3.6\n pygram.python_grammar,\n # Python 3.10+\n pygram.python_grammar_soft_keywords,\n ]\n\n grammars = []\n # If we have to parse both, try to parse async as a keyword first\n if not supports_feature(\n target_versions, Feature.ASYNC_IDENTIFIERS\n ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):\n # Python 3.7-3.9\n grammars.append(pygram.python_grammar_async_keywords)\n if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):\n # Python 3.0-3.6\n grammars.append(pygram.python_grammar)\n if any(Feature.PATTERN_MATCHING in VERSION_TO_FEATURES[v] for v in target_versions):\n # Python 3.10+\n grammars.append(pygram.python_grammar_soft_keywords)\n\n # At least one of the above branches must have been taken, because every Python\n # version has exactly one of the two 'ASYNC_*' flags\n return grammars\n\n\ndef lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:\n \"\"\"Given a string with source, return the lib2to3 Node.\"\"\"\n if not src_txt.endswith(\"\\n\"):\n src_txt += \"\\n\"\n\n grammars = get_grammars(set(target_versions))\n errors = {}\n for grammar in grammars:\n drv = driver.Driver(grammar)\n try:\n result = drv.parse_string(src_txt, True)\n break\n\n except ParseError as pe:\n lineno, column = pe.context[1]\n lines = src_txt.splitlines()\n try:\n faulty_line = lines[lineno - 1]\n except IndexError:\n faulty_line = \"<line number missing in source>\"\n errors[grammar.version] = InvalidInput(\n f\"Cannot parse: {lineno}:{column}: {faulty_line}\"\n )\n\n except TokenError as te:\n # In edge cases these are raised; and typically don't have a \"faulty_line\".\n lineno, column = te.args[1]\n errors[grammar.version] = InvalidInput(\n f\"Cannot parse: {lineno}:{column}: {te.args[0]}\"\n )\n\n else:\n # Choose the latest version when raising the actual parsing error.\n assert len(errors) >= 1\n exc = errors[max(errors)]\n raise exc from None\n\n if isinstance(result, Leaf):\n result = Node(syms.file_input, [result])\n return result\n\n\ndef matches_grammar(src_txt: str, grammar: Grammar) -> bool:\n drv = driver.Driver(grammar)\n try:\n drv.parse_string(src_txt, True)\n except (ParseError, TokenError, IndentationError):\n return False\n else:\n return True\n\n\ndef lib2to3_unparse(node: Node) -> str:\n \"\"\"Given a lib2to3 node, return its string representation.\"\"\"\n code = str(node)\n return code\n\n\nclass ASTSafetyError(Exception):\n \"\"\"Raised when Black's generated code is not equivalent to the old AST.\"\"\"\n\n\ndef _parse_single_version(\n src: str, version: Tuple[int, int], *, type_comments: bool\n) -> ast.AST:\n filename = \"<unknown>\"\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\", SyntaxWarning)\n warnings.simplefilter(\"ignore\", DeprecationWarning)\n return ast.parse(\n src, filename, feature_version=version, type_comments=type_comments\n )\n\n\ndef parse_ast(src: str) -> ast.AST:\n # TODO: support Python 4+ ;)\n versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]\n\n first_error = \"\"\n for version in sorted(versions, reverse=True):\n try:\n return _parse_single_version(src, version, type_comments=True)\n except SyntaxError as e:\n if not first_error:\n first_error = str(e)\n\n # Try to parse without type comments\n for version in sorted(versions, reverse=True):\n try:\n return _parse_single_version(src, version, type_comments=False)\n except SyntaxError:\n pass\n\n raise SyntaxError(first_error)\n\n\ndef _normalize(lineend: str, value: str) -> str:\n # To normalize, we strip any leading and trailing space from\n # each line...\n stripped: List[str] = [i.strip() for i in value.splitlines()]\n normalized = lineend.join(stripped)\n # ...and remove any blank lines at the beginning and end of\n # the whole string\n return normalized.strip()\n\n\ndef stringify_ast(node: ast.AST) -> Iterator[str]:\n \"\"\"Simple visitor generating strings to compare ASTs by content.\"\"\"\n return _stringify_ast(node, [])\n\n\ndef _stringify_ast_with_new_parent(\n node: ast.AST, parent_stack: List[ast.AST], new_parent: ast.AST\n) -> Iterator[str]:\n parent_stack.append(new_parent)\n yield from _stringify_ast(node, parent_stack)\n parent_stack.pop()\n\n\ndef _stringify_ast(node: ast.AST, parent_stack: List[ast.AST]) -> Iterator[str]:\n if (\n isinstance(node, ast.Constant)\n and isinstance(node.value, str)\n and node.kind == \"u\"\n ):\n # It's a quirk of history that we strip the u prefix over here. We used to\n # rewrite the AST nodes for Python version compatibility and we never copied\n # over the kind\n node.kind = None\n\n yield f\"{' ' * len(parent_stack)}{node.__class__.__name__}(\"\n\n for field in sorted(node._fields): # noqa: F402\n # TypeIgnore has only one field 'lineno' which breaks this comparison\n if isinstance(node, ast.TypeIgnore):\n break\n\n try:\n value: object = getattr(node, field)\n except AttributeError:\n continue\n\n yield f\"{' ' * (len(parent_stack) + 1)}{field}=\"\n\n if isinstance(value, list):\n for item in value:\n # Ignore nested tuples within del statements, because we may insert\n # parentheses and they change the AST.\n if (\n field == \"targets\"\n and isinstance(node, ast.Delete)\n and isinstance(item, ast.Tuple)\n ):\n for elt in item.elts:\n yield from _stringify_ast_with_new_parent(\n elt, parent_stack, node\n )\n\n elif isinstance(item, ast.AST):\n yield from _stringify_ast_with_new_parent(item, parent_stack, node)\n\n elif isinstance(value, ast.AST):\n yield from _stringify_ast_with_new_parent(value, parent_stack, node)\n\n else:\n normalized: object\n if (\n isinstance(node, ast.Constant)\n and field == \"value\"\n and isinstance(value, str)\n and len(parent_stack) >= 2\n and isinstance(parent_stack[-1], ast.Expr)\n and isinstance(\n parent_stack[-2],\n (ast.FunctionDef, ast.AsyncFunctionDef, ast.Module, ast.ClassDef),\n )\n ):\n # Constant strings may be indented across newlines, if they are\n # docstrings; fold spaces after newlines when comparing. Similarly,\n # trailing and leading space may be removed.\n normalized = _normalize(\"\\n\", value)\n elif field == \"type_comment\" and isinstance(value, str):\n # Trailing whitespace in type comments is removed.\n normalized = value.rstrip()\n else:\n normalized = value\n yield (\n f\"{' ' * (len(parent_stack) + 1)}{normalized!r}, #\"\n f\" {value.__class__.__name__}\"\n )\n\n yield f\"{' ' * len(parent_stack)}) # /{node.__class__.__name__}\"\n", "path": "src/black/parsing.py"}]}
| 3,143 | 171 |
gh_patches_debug_7270
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-18551
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`Failed to write to remote cache` when running `ruff`
**Describe the bug**
When running `pants lint --only=ruff ::` I see many `WARN` logs like:
```
14:18:48.60 [WARN] Failed to write to remote cache (1 occurrences so far): Declared output directory path RelativePath("src/django_apps/preventive_care/consults/automatic_refer_out/__init__.py") in output digest Digest { hash: Fingerprint<b4c4a7e44c3d23b8eac247bfdd5ed723d054947915bbfb808e0ee16e4fa75430>, size_bytes: 77 } contained a file instead.
```
**Pants version**
`PANTS_SHA=254f69b3f111fb620206bbfe72b262520849484f` (on the 2.16.x branch)
**OS**
MacOS
</issue>
<code>
[start of src/python/pants/backend/python/lint/ruff/rules.py]
1 # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 from pants.backend.python.lint.ruff.subsystem import Ruff, RuffFieldSet
7 from pants.backend.python.util_rules import pex
8 from pants.backend.python.util_rules.pex import PexRequest, VenvPex, VenvPexProcess
9 from pants.core.goals.fix import FixResult, FixTargetsRequest
10 from pants.core.util_rules.config_files import ConfigFiles, ConfigFilesRequest
11 from pants.core.util_rules.partitions import PartitionerType
12 from pants.engine.fs import Digest, MergeDigests
13 from pants.engine.process import FallibleProcessResult
14 from pants.engine.rules import Get, MultiGet, collect_rules, rule
15 from pants.util.logging import LogLevel
16 from pants.util.strutil import pluralize
17
18
19 class RuffRequest(FixTargetsRequest):
20 field_set_type = RuffFieldSet
21 tool_subsystem = Ruff
22 partitioner_type = PartitionerType.DEFAULT_SINGLE_PARTITION
23
24
25 @rule(desc="Fix with ruff", level=LogLevel.DEBUG)
26 async def ruff_fix(request: RuffRequest.Batch, ruff: Ruff) -> FixResult:
27 ruff_pex_get = Get(VenvPex, PexRequest, ruff.to_pex_request())
28
29 config_files_get = Get(
30 ConfigFiles, ConfigFilesRequest, ruff.config_request(request.snapshot.dirs)
31 )
32
33 ruff_pex, config_files = await MultiGet(ruff_pex_get, config_files_get)
34
35 input_digest = await Get(
36 Digest,
37 MergeDigests((request.snapshot.digest, config_files.snapshot.digest)),
38 )
39
40 conf_args = [f"--config={ruff.config}"] if ruff.config else []
41
42 result = await Get(
43 FallibleProcessResult,
44 VenvPexProcess(
45 ruff_pex,
46 argv=("--fix", *conf_args, *ruff.args, *request.files),
47 input_digest=input_digest,
48 output_directories=request.files,
49 description=f"Run ruff on {pluralize(len(request.elements), 'file')}.",
50 level=LogLevel.DEBUG,
51 ),
52 )
53 return await FixResult.create(request, result, strip_chroot_path=True)
54
55
56 def rules():
57 return [*collect_rules(), *RuffRequest.rules(), *pex.rules()]
58
[end of src/python/pants/backend/python/lint/ruff/rules.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/backend/python/lint/ruff/rules.py b/src/python/pants/backend/python/lint/ruff/rules.py
--- a/src/python/pants/backend/python/lint/ruff/rules.py
+++ b/src/python/pants/backend/python/lint/ruff/rules.py
@@ -45,7 +45,7 @@
ruff_pex,
argv=("--fix", *conf_args, *ruff.args, *request.files),
input_digest=input_digest,
- output_directories=request.files,
+ output_files=request.files,
description=f"Run ruff on {pluralize(len(request.elements), 'file')}.",
level=LogLevel.DEBUG,
),
|
{"golden_diff": "diff --git a/src/python/pants/backend/python/lint/ruff/rules.py b/src/python/pants/backend/python/lint/ruff/rules.py\n--- a/src/python/pants/backend/python/lint/ruff/rules.py\n+++ b/src/python/pants/backend/python/lint/ruff/rules.py\n@@ -45,7 +45,7 @@\n ruff_pex,\n argv=(\"--fix\", *conf_args, *ruff.args, *request.files),\n input_digest=input_digest,\n- output_directories=request.files,\n+ output_files=request.files,\n description=f\"Run ruff on {pluralize(len(request.elements), 'file')}.\",\n level=LogLevel.DEBUG,\n ),\n", "issue": "`Failed to write to remote cache` when running `ruff`\n**Describe the bug**\r\n\r\nWhen running `pants lint --only=ruff ::` I see many `WARN` logs like:\r\n```\r\n14:18:48.60 [WARN] Failed to write to remote cache (1 occurrences so far): Declared output directory path RelativePath(\"src/django_apps/preventive_care/consults/automatic_refer_out/__init__.py\") in output digest Digest { hash: Fingerprint<b4c4a7e44c3d23b8eac247bfdd5ed723d054947915bbfb808e0ee16e4fa75430>, size_bytes: 77 } contained a file instead.\r\n```\r\n\r\n**Pants version**\r\n\r\n`PANTS_SHA=254f69b3f111fb620206bbfe72b262520849484f` (on the 2.16.x branch)\r\n\r\n**OS**\r\n\r\nMacOS\n", "before_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nfrom pants.backend.python.lint.ruff.subsystem import Ruff, RuffFieldSet\nfrom pants.backend.python.util_rules import pex\nfrom pants.backend.python.util_rules.pex import PexRequest, VenvPex, VenvPexProcess\nfrom pants.core.goals.fix import FixResult, FixTargetsRequest\nfrom pants.core.util_rules.config_files import ConfigFiles, ConfigFilesRequest\nfrom pants.core.util_rules.partitions import PartitionerType\nfrom pants.engine.fs import Digest, MergeDigests\nfrom pants.engine.process import FallibleProcessResult\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.util.logging import LogLevel\nfrom pants.util.strutil import pluralize\n\n\nclass RuffRequest(FixTargetsRequest):\n field_set_type = RuffFieldSet\n tool_subsystem = Ruff\n partitioner_type = PartitionerType.DEFAULT_SINGLE_PARTITION\n\n\n@rule(desc=\"Fix with ruff\", level=LogLevel.DEBUG)\nasync def ruff_fix(request: RuffRequest.Batch, ruff: Ruff) -> FixResult:\n ruff_pex_get = Get(VenvPex, PexRequest, ruff.to_pex_request())\n\n config_files_get = Get(\n ConfigFiles, ConfigFilesRequest, ruff.config_request(request.snapshot.dirs)\n )\n\n ruff_pex, config_files = await MultiGet(ruff_pex_get, config_files_get)\n\n input_digest = await Get(\n Digest,\n MergeDigests((request.snapshot.digest, config_files.snapshot.digest)),\n )\n\n conf_args = [f\"--config={ruff.config}\"] if ruff.config else []\n\n result = await Get(\n FallibleProcessResult,\n VenvPexProcess(\n ruff_pex,\n argv=(\"--fix\", *conf_args, *ruff.args, *request.files),\n input_digest=input_digest,\n output_directories=request.files,\n description=f\"Run ruff on {pluralize(len(request.elements), 'file')}.\",\n level=LogLevel.DEBUG,\n ),\n )\n return await FixResult.create(request, result, strip_chroot_path=True)\n\n\ndef rules():\n return [*collect_rules(), *RuffRequest.rules(), *pex.rules()]\n", "path": "src/python/pants/backend/python/lint/ruff/rules.py"}]}
| 1,413 | 146 |
gh_patches_debug_17915
|
rasdani/github-patches
|
git_diff
|
localstack__localstack-821
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Firehose fails without S3DestinationConfiguration.Prefix
Despite the AWS SDK not requiring a prefix, it seems like localstack fails without one:
```2018-05-14T17:28:43:ERROR:firehose_api: Exception on / [POST]
Traceback (most recent call last):
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1817, in wsgi_app
response = self.full_dispatch_request()
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1477, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1381, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1475, in full_dispatch_request
rv = self.dispatch_request()
File "/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1461, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/opt/code/localstack/localstack/services/firehose/firehose_api.py", line 183, in post_request
put_record(stream_name, record)
File "/opt/code/localstack/localstack/services/firehose/firehose_api.py", line 40, in put_record
return put_records(stream_name, [record])
File "/opt/code/localstack/localstack/services/firehose/firehose_api.py", line 63, in put_records
prefix = s3_dest['Prefix']
KeyError: 'Prefix'```
</issue>
<code>
[start of localstack/services/firehose/firehose_api.py]
1 from __future__ import print_function
2
3 import json
4 import uuid
5 import time
6 import logging
7 import base64
8 import traceback
9 from flask import Flask, jsonify, request
10 from six import iteritems
11 from localstack.constants import TEST_AWS_ACCOUNT_ID
12 from localstack.services import generic_proxy
13 from localstack.utils.common import short_uid, to_str
14 from localstack.utils.aws import aws_responses
15 from localstack.utils.aws.aws_stack import get_s3_client, firehose_stream_arn, connect_elasticsearch
16 from boto3.dynamodb.types import TypeDeserializer
17
18 APP_NAME = 'firehose_api'
19 app = Flask(APP_NAME)
20 ACTION_HEADER_PREFIX = 'Firehose_20150804'
21
22 # logger
23 LOG = logging.getLogger(__name__)
24
25 # maps stream names to details
26 DELIVERY_STREAMS = {}
27
28 # dynamodb deserializer
29 deser = TypeDeserializer()
30
31
32 def get_delivery_stream_names():
33 names = []
34 for name, stream in iteritems(DELIVERY_STREAMS):
35 names.append(stream['DeliveryStreamName'])
36 return names
37
38
39 def put_record(stream_name, record):
40 return put_records(stream_name, [record])
41
42
43 def put_records(stream_name, records):
44 stream = get_stream(stream_name)
45 for dest in stream['Destinations']:
46 if 'ESDestinationDescription' in dest:
47 es_dest = dest['ESDestinationDescription']
48 es_index = es_dest['IndexName']
49 es_type = es_dest['TypeName']
50 es = connect_elasticsearch()
51 for record in records:
52 obj_id = uuid.uuid4()
53 data = base64.b64decode(record['Data'])
54 body = json.loads(data)
55 try:
56 es.create(index=es_index, doc_type=es_type, id=obj_id, body=body)
57 except Exception as e:
58 LOG.error('Unable to put record to stream: %s %s' % (e, traceback.format_exc()))
59 raise e
60 if 'S3DestinationDescription' in dest:
61 s3_dest = dest['S3DestinationDescription']
62 bucket = bucket_name(s3_dest['BucketARN'])
63 prefix = s3_dest['Prefix']
64 s3 = get_s3_client()
65 for record in records:
66 data = base64.b64decode(record['Data'])
67 obj_name = str(uuid.uuid4())
68 obj_path = '%s%s' % (prefix, obj_name)
69 try:
70 s3.Object(bucket, obj_path).put(Body=data)
71 except Exception as e:
72 LOG.error('Unable to put record to stream: %s %s' % (e, traceback.format_exc()))
73 raise e
74
75
76 def get_destination(stream_name, destination_id):
77 stream = get_stream(stream_name)
78 destinations = stream['Destinations']
79 for dest in destinations:
80 if dest['DestinationId'] == destination_id:
81 return dest
82 dest = {}
83 dest['DestinationId'] = destination_id
84 destinations.append(dest)
85 return dest
86
87
88 def update_destination(stream_name, destination_id,
89 s3_update=None, elasticsearch_update=None, version_id=None):
90 dest = get_destination(stream_name, destination_id)
91 if elasticsearch_update:
92 if 'ESDestinationDescription' not in dest:
93 dest['ESDestinationDescription'] = {}
94 for k, v in iteritems(elasticsearch_update):
95 dest['ESDestinationDescription'][k] = v
96 if s3_update:
97 if 'S3DestinationDescription' not in dest:
98 dest['S3DestinationDescription'] = {}
99 for k, v in iteritems(s3_update):
100 dest['S3DestinationDescription'][k] = v
101 return dest
102
103
104 def create_stream(stream_name, s3_destination=None, elasticsearch_destination=None):
105 stream = {
106 'HasMoreDestinations': False,
107 'VersionId': '1',
108 'CreateTimestamp': time.time(),
109 'DeliveryStreamARN': firehose_stream_arn(stream_name),
110 'DeliveryStreamStatus': 'ACTIVE',
111 'DeliveryStreamName': stream_name,
112 'Destinations': []
113 }
114 DELIVERY_STREAMS[stream_name] = stream
115 if elasticsearch_destination:
116 update_destination(stream_name=stream_name,
117 destination_id=short_uid(),
118 elasticsearch_update=elasticsearch_destination)
119 if s3_destination:
120 update_destination(stream_name=stream_name, destination_id=short_uid(), s3_update=s3_destination)
121 return stream
122
123
124 def delete_stream(stream_name):
125 stream = DELIVERY_STREAMS.pop(stream_name, {})
126 if not stream:
127 return error_not_found(stream_name)
128 return {}
129
130
131 def get_stream(stream_name):
132 if stream_name not in DELIVERY_STREAMS:
133 return None
134 return DELIVERY_STREAMS[stream_name]
135
136
137 def bucket_name(bucket_arn):
138 return bucket_arn.split(':::')[-1]
139
140
141 def role_arn(stream_name):
142 return 'arn:aws:iam::%s:role/%s' % (TEST_AWS_ACCOUNT_ID, stream_name)
143
144
145 def error_not_found(stream_name):
146 msg = 'Firehose %s under account %s not found.' % (stream_name, TEST_AWS_ACCOUNT_ID)
147 return error_response(msg, code=400, error_type='ResourceNotFoundException')
148
149
150 def error_response(msg, code=500, error_type='InternalFailure'):
151 return aws_responses.flask_error_response(msg, code=code, error_type=error_type)
152
153
154 @app.route('/', methods=['POST'])
155 def post_request():
156 action = request.headers.get('x-amz-target')
157 data = json.loads(to_str(request.data))
158 response = None
159 if action == '%s.ListDeliveryStreams' % ACTION_HEADER_PREFIX:
160 response = {
161 'DeliveryStreamNames': get_delivery_stream_names(),
162 'HasMoreDeliveryStreams': False
163 }
164 elif action == '%s.CreateDeliveryStream' % ACTION_HEADER_PREFIX:
165 stream_name = data['DeliveryStreamName']
166 response = create_stream(stream_name,
167 s3_destination=data.get('S3DestinationConfiguration'),
168 elasticsearch_destination=data.get('ElasticsearchDestinationConfiguration'))
169 elif action == '%s.DeleteDeliveryStream' % ACTION_HEADER_PREFIX:
170 stream_name = data['DeliveryStreamName']
171 response = delete_stream(stream_name)
172 elif action == '%s.DescribeDeliveryStream' % ACTION_HEADER_PREFIX:
173 stream_name = data['DeliveryStreamName']
174 response = get_stream(stream_name)
175 if not response:
176 return error_not_found(stream_name)
177 response = {
178 'DeliveryStreamDescription': response
179 }
180 elif action == '%s.PutRecord' % ACTION_HEADER_PREFIX:
181 stream_name = data['DeliveryStreamName']
182 record = data['Record']
183 put_record(stream_name, record)
184 response = {
185 'RecordId': str(uuid.uuid4())
186 }
187 elif action == '%s.PutRecordBatch' % ACTION_HEADER_PREFIX:
188 stream_name = data['DeliveryStreamName']
189 records = data['Records']
190 put_records(stream_name, records)
191 response = {
192 'FailedPutCount': 0,
193 'RequestResponses': []
194 }
195 elif action == '%s.UpdateDestination' % ACTION_HEADER_PREFIX:
196 stream_name = data['DeliveryStreamName']
197 version_id = data['CurrentDeliveryStreamVersionId']
198 destination_id = data['DestinationId']
199 s3_update = data['S3DestinationUpdate'] if 'S3DestinationUpdate' in data else None
200 update_destination(stream_name=stream_name, destination_id=destination_id,
201 s3_update=s3_update, version_id=version_id)
202 es_update = data['ESDestinationUpdate'] if 'ESDestinationUpdate' in data else None
203 update_destination(stream_name=stream_name, destination_id=destination_id,
204 es_update=es_update, version_id=version_id)
205 response = {}
206 else:
207 response = error_response('Unknown action "%s"' % action, code=400, error_type='InvalidAction')
208
209 if isinstance(response, dict):
210 response = jsonify(response)
211 return response
212
213
214 def serve(port, quiet=True):
215 generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)
216
[end of localstack/services/firehose/firehose_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/localstack/services/firehose/firehose_api.py b/localstack/services/firehose/firehose_api.py
--- a/localstack/services/firehose/firehose_api.py
+++ b/localstack/services/firehose/firehose_api.py
@@ -60,12 +60,12 @@
if 'S3DestinationDescription' in dest:
s3_dest = dest['S3DestinationDescription']
bucket = bucket_name(s3_dest['BucketARN'])
- prefix = s3_dest['Prefix']
+ prefix = s3_dest.get('Prefix', '')
s3 = get_s3_client()
for record in records:
data = base64.b64decode(record['Data'])
obj_name = str(uuid.uuid4())
- obj_path = '%s%s' % (prefix, obj_name)
+ obj_path = '%s%s%s' % (prefix, '' if prefix.endswith('/') else '/', obj_name)
try:
s3.Object(bucket, obj_path).put(Body=data)
except Exception as e:
|
{"golden_diff": "diff --git a/localstack/services/firehose/firehose_api.py b/localstack/services/firehose/firehose_api.py\n--- a/localstack/services/firehose/firehose_api.py\n+++ b/localstack/services/firehose/firehose_api.py\n@@ -60,12 +60,12 @@\n if 'S3DestinationDescription' in dest:\n s3_dest = dest['S3DestinationDescription']\n bucket = bucket_name(s3_dest['BucketARN'])\n- prefix = s3_dest['Prefix']\n+ prefix = s3_dest.get('Prefix', '')\n s3 = get_s3_client()\n for record in records:\n data = base64.b64decode(record['Data'])\n obj_name = str(uuid.uuid4())\n- obj_path = '%s%s' % (prefix, obj_name)\n+ obj_path = '%s%s%s' % (prefix, '' if prefix.endswith('/') else '/', obj_name)\n try:\n s3.Object(bucket, obj_path).put(Body=data)\n except Exception as e:\n", "issue": "Firehose fails without S3DestinationConfiguration.Prefix \nDespite the AWS SDK not requiring a prefix, it seems like localstack fails without one:\r\n\r\n```2018-05-14T17:28:43:ERROR:firehose_api: Exception on / [POST]\r\nTraceback (most recent call last):\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1817, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1477, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1381, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1475, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/opt/code/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1461, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/opt/code/localstack/localstack/services/firehose/firehose_api.py\", line 183, in post_request\r\n put_record(stream_name, record)\r\n File \"/opt/code/localstack/localstack/services/firehose/firehose_api.py\", line 40, in put_record\r\n return put_records(stream_name, [record])\r\n File \"/opt/code/localstack/localstack/services/firehose/firehose_api.py\", line 63, in put_records\r\n prefix = s3_dest['Prefix']\r\nKeyError: 'Prefix'```\n", "before_files": [{"content": "from __future__ import print_function\n\nimport json\nimport uuid\nimport time\nimport logging\nimport base64\nimport traceback\nfrom flask import Flask, jsonify, request\nfrom six import iteritems\nfrom localstack.constants import TEST_AWS_ACCOUNT_ID\nfrom localstack.services import generic_proxy\nfrom localstack.utils.common import short_uid, to_str\nfrom localstack.utils.aws import aws_responses\nfrom localstack.utils.aws.aws_stack import get_s3_client, firehose_stream_arn, connect_elasticsearch\nfrom boto3.dynamodb.types import TypeDeserializer\n\nAPP_NAME = 'firehose_api'\napp = Flask(APP_NAME)\nACTION_HEADER_PREFIX = 'Firehose_20150804'\n\n# logger\nLOG = logging.getLogger(__name__)\n\n# maps stream names to details\nDELIVERY_STREAMS = {}\n\n# dynamodb deserializer\ndeser = TypeDeserializer()\n\n\ndef get_delivery_stream_names():\n names = []\n for name, stream in iteritems(DELIVERY_STREAMS):\n names.append(stream['DeliveryStreamName'])\n return names\n\n\ndef put_record(stream_name, record):\n return put_records(stream_name, [record])\n\n\ndef put_records(stream_name, records):\n stream = get_stream(stream_name)\n for dest in stream['Destinations']:\n if 'ESDestinationDescription' in dest:\n es_dest = dest['ESDestinationDescription']\n es_index = es_dest['IndexName']\n es_type = es_dest['TypeName']\n es = connect_elasticsearch()\n for record in records:\n obj_id = uuid.uuid4()\n data = base64.b64decode(record['Data'])\n body = json.loads(data)\n try:\n es.create(index=es_index, doc_type=es_type, id=obj_id, body=body)\n except Exception as e:\n LOG.error('Unable to put record to stream: %s %s' % (e, traceback.format_exc()))\n raise e\n if 'S3DestinationDescription' in dest:\n s3_dest = dest['S3DestinationDescription']\n bucket = bucket_name(s3_dest['BucketARN'])\n prefix = s3_dest['Prefix']\n s3 = get_s3_client()\n for record in records:\n data = base64.b64decode(record['Data'])\n obj_name = str(uuid.uuid4())\n obj_path = '%s%s' % (prefix, obj_name)\n try:\n s3.Object(bucket, obj_path).put(Body=data)\n except Exception as e:\n LOG.error('Unable to put record to stream: %s %s' % (e, traceback.format_exc()))\n raise e\n\n\ndef get_destination(stream_name, destination_id):\n stream = get_stream(stream_name)\n destinations = stream['Destinations']\n for dest in destinations:\n if dest['DestinationId'] == destination_id:\n return dest\n dest = {}\n dest['DestinationId'] = destination_id\n destinations.append(dest)\n return dest\n\n\ndef update_destination(stream_name, destination_id,\n s3_update=None, elasticsearch_update=None, version_id=None):\n dest = get_destination(stream_name, destination_id)\n if elasticsearch_update:\n if 'ESDestinationDescription' not in dest:\n dest['ESDestinationDescription'] = {}\n for k, v in iteritems(elasticsearch_update):\n dest['ESDestinationDescription'][k] = v\n if s3_update:\n if 'S3DestinationDescription' not in dest:\n dest['S3DestinationDescription'] = {}\n for k, v in iteritems(s3_update):\n dest['S3DestinationDescription'][k] = v\n return dest\n\n\ndef create_stream(stream_name, s3_destination=None, elasticsearch_destination=None):\n stream = {\n 'HasMoreDestinations': False,\n 'VersionId': '1',\n 'CreateTimestamp': time.time(),\n 'DeliveryStreamARN': firehose_stream_arn(stream_name),\n 'DeliveryStreamStatus': 'ACTIVE',\n 'DeliveryStreamName': stream_name,\n 'Destinations': []\n }\n DELIVERY_STREAMS[stream_name] = stream\n if elasticsearch_destination:\n update_destination(stream_name=stream_name,\n destination_id=short_uid(),\n elasticsearch_update=elasticsearch_destination)\n if s3_destination:\n update_destination(stream_name=stream_name, destination_id=short_uid(), s3_update=s3_destination)\n return stream\n\n\ndef delete_stream(stream_name):\n stream = DELIVERY_STREAMS.pop(stream_name, {})\n if not stream:\n return error_not_found(stream_name)\n return {}\n\n\ndef get_stream(stream_name):\n if stream_name not in DELIVERY_STREAMS:\n return None\n return DELIVERY_STREAMS[stream_name]\n\n\ndef bucket_name(bucket_arn):\n return bucket_arn.split(':::')[-1]\n\n\ndef role_arn(stream_name):\n return 'arn:aws:iam::%s:role/%s' % (TEST_AWS_ACCOUNT_ID, stream_name)\n\n\ndef error_not_found(stream_name):\n msg = 'Firehose %s under account %s not found.' % (stream_name, TEST_AWS_ACCOUNT_ID)\n return error_response(msg, code=400, error_type='ResourceNotFoundException')\n\n\ndef error_response(msg, code=500, error_type='InternalFailure'):\n return aws_responses.flask_error_response(msg, code=code, error_type=error_type)\n\n\[email protected]('/', methods=['POST'])\ndef post_request():\n action = request.headers.get('x-amz-target')\n data = json.loads(to_str(request.data))\n response = None\n if action == '%s.ListDeliveryStreams' % ACTION_HEADER_PREFIX:\n response = {\n 'DeliveryStreamNames': get_delivery_stream_names(),\n 'HasMoreDeliveryStreams': False\n }\n elif action == '%s.CreateDeliveryStream' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n response = create_stream(stream_name,\n s3_destination=data.get('S3DestinationConfiguration'),\n elasticsearch_destination=data.get('ElasticsearchDestinationConfiguration'))\n elif action == '%s.DeleteDeliveryStream' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n response = delete_stream(stream_name)\n elif action == '%s.DescribeDeliveryStream' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n response = get_stream(stream_name)\n if not response:\n return error_not_found(stream_name)\n response = {\n 'DeliveryStreamDescription': response\n }\n elif action == '%s.PutRecord' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n record = data['Record']\n put_record(stream_name, record)\n response = {\n 'RecordId': str(uuid.uuid4())\n }\n elif action == '%s.PutRecordBatch' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n records = data['Records']\n put_records(stream_name, records)\n response = {\n 'FailedPutCount': 0,\n 'RequestResponses': []\n }\n elif action == '%s.UpdateDestination' % ACTION_HEADER_PREFIX:\n stream_name = data['DeliveryStreamName']\n version_id = data['CurrentDeliveryStreamVersionId']\n destination_id = data['DestinationId']\n s3_update = data['S3DestinationUpdate'] if 'S3DestinationUpdate' in data else None\n update_destination(stream_name=stream_name, destination_id=destination_id,\n s3_update=s3_update, version_id=version_id)\n es_update = data['ESDestinationUpdate'] if 'ESDestinationUpdate' in data else None\n update_destination(stream_name=stream_name, destination_id=destination_id,\n es_update=es_update, version_id=version_id)\n response = {}\n else:\n response = error_response('Unknown action \"%s\"' % action, code=400, error_type='InvalidAction')\n\n if isinstance(response, dict):\n response = jsonify(response)\n return response\n\n\ndef serve(port, quiet=True):\n generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)\n", "path": "localstack/services/firehose/firehose_api.py"}]}
| 3,285 | 228 |
gh_patches_debug_14644
|
rasdani/github-patches
|
git_diff
|
liqd__adhocracy4-1524
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Custom model delete method deprecated: after django upgrade
**expected behaviour:** Custom deletion logic should move to form_valid() for django > 4
**behaviour:** During the upgrade, we missed updating one of the custom deletion methods in dashboard/mixins.py
`https://github.com/liqd/adhocracy4/blob/main/adhocracy4/dashboard/mixins.py#L132`
**Comment/Question:** *Is this easy to do? What ideas do you have? Would this be a story?*
It is easy to fix.

</issue>
<code>
[start of adhocracy4/dashboard/mixins.py]
1 from copy import deepcopy
2
3 from django.apps import apps
4 from django.conf import settings
5 from django.contrib import messages
6 from django.core.exceptions import PermissionDenied
7 from django.shortcuts import get_object_or_404
8 from django.shortcuts import redirect
9 from django.urls import NoReverseMatch
10 from django.utils import timezone
11 from django.utils.translation import gettext_lazy as _
12 from django.views.generic import base
13 from django.views.generic import edit
14
15 from adhocracy4.projects import models as project_models
16 from adhocracy4.rules import mixins as rules_mixins
17
18 from . import components
19 from . import get_project_dashboard
20 from . import signals
21
22 Organisation = apps.get_model(settings.A4_ORGANISATIONS_MODEL)
23
24
25 class DashboardBaseMixin(rules_mixins.PermissionRequiredMixin):
26 organisation_lookup_field = "slug"
27 organisation_url_kwarg = "organisation_slug"
28
29 @property
30 def organisation(self):
31 if self.organisation_url_kwarg and self.organisation_url_kwarg in self.kwargs:
32 lookup = {
33 self.organisation_lookup_field: self.kwargs[self.organisation_url_kwarg]
34 }
35 return get_object_or_404(Organisation, **lookup)
36
37 return self.project.organisation
38
39 @property
40 def other_organisations_of_user(self):
41 user = self.request.user
42 if self.organisation:
43 initiator_orgs = user.organisation_set.all()
44 if hasattr(Organisation, "groups") and user.groups.all():
45 user_groups = user.groups.all().values_list("id", flat=True)
46 group_orgs = Organisation.objects.filter(groups__in=user_groups)
47 orgs = initiator_orgs | group_orgs
48 return orgs.distinct().exclude(pk=self.organisation.pk)
49 return initiator_orgs.exclude(pk=self.organisation.pk)
50 else:
51 return None
52
53 def get_permission_object(self):
54 raise NotImplementedError("Set permission object.")
55
56 def get_success_url(self):
57 return self.request.path
58
59
60 class BlueprintMixin:
61 @property
62 def blueprint(self):
63 from .blueprints import get_blueprints
64
65 return dict(get_blueprints())[self.blueprint_key]
66
67 @property
68 def blueprint_key(self):
69 return self.kwargs["blueprint_slug"]
70
71
72 class DashboardComponentMixin(base.ContextMixin):
73 """Set the menu_item and add dashboard information to the context data.
74
75 Assumes self.project, self.module and self.component are set.
76 """
77
78 menu_item = "project"
79 component = None
80
81 def get_context_data(self, **kwargs):
82 context = super().get_context_data(**kwargs)
83
84 # Workaround Djangos update behavior:
85 # All fields from the POST data will be set on the view.object model
86 # instance, regardless of validation errors.
87 # Thus it is not reliable to check on empty fields on the view.object
88 # but it has to be ensured that the model reflects the database.
89 project = deepcopy(self.project)
90 if project:
91 project.refresh_from_db()
92
93 dashboard = get_project_dashboard(project)
94
95 context["dashboard_menu"] = dashboard.get_menu(self.module, self.component)
96
97 num_valid, num_required = dashboard.get_progress()
98 project_num_valid, project_num_required = dashboard.get_project_progress()
99 project_is_complete = project_num_valid == project_num_required
100 context["project_progress"] = {
101 "valid": num_valid,
102 "required": num_required,
103 "project_is_complete": project_is_complete,
104 }
105
106 return context
107
108
109 class DashboardComponentFormSignalMixin(edit.FormMixin):
110 def form_valid(self, form):
111 response = super().form_valid(form)
112
113 component = self.component
114 if component.identifier in components.projects:
115 signals.project_component_updated.send(
116 sender=component.__class__,
117 project=self.project,
118 component=component,
119 user=self.request.user,
120 )
121 else:
122 signals.module_component_updated.send(
123 sender=component.__class__,
124 module=self.module,
125 component=component,
126 user=self.request.user,
127 )
128 return response
129
130
131 class DashboardComponentDeleteSignalMixin(edit.DeletionMixin):
132 def delete(self, request, *args, **kwargs):
133 # Project and module have to be stored before delete is called as
134 # they may rely on the still existing db object.
135 project = self.project
136 module = self.module
137
138 response = super().delete(request, *args, **kwargs)
139
140 component = self.component
141 if component.identifier in components.projects:
142 signals.project_component_updated.send(
143 sender=component.__class__,
144 project=project,
145 component=component,
146 user=self.request.user,
147 )
148 else:
149 signals.module_component_updated.send(
150 sender=component.__class__,
151 module=module,
152 component=component,
153 user=self.request.user,
154 )
155 return response
156
157
158 class DashboardProjectDuplicateMixin:
159 def post(self, request, *args, **kwargs):
160 if "duplicate" in request.POST:
161 pk = int(request.POST["project_pk"])
162 project = get_object_or_404(project_models.Project, pk=pk)
163 can_add = request.user.has_perm("a4projects.add_project", project)
164
165 if not can_add:
166 raise PermissionDenied()
167
168 project_clone = deepcopy(project)
169 project_clone.pk = None
170 if project_clone.tile_image:
171 project_clone.tile_image.save(
172 project.tile_image.name, project.tile_image, False
173 )
174 if project_clone.image:
175 project_clone.image.save(project.image.name, project.image, False)
176 project_clone.created = timezone.now()
177 project_clone.is_draft = True
178 project_clone.is_archived = False
179 project_clone.save()
180 signals.project_created.send(
181 sender=None, project=project_clone, user=self.request.user
182 )
183
184 for moderator in project.moderators.all():
185 project_clone.moderators.add(moderator)
186
187 for module in project.module_set.all():
188 module_clone = deepcopy(module)
189 module_clone.project = project_clone
190 module_clone.pk = None
191 module_clone.save()
192 signals.module_created.send(
193 sender=None, module=module_clone, user=self.request.user
194 )
195
196 for phase in module.phase_set.all():
197 phase_clone = deepcopy(phase)
198 phase_clone.module = module_clone
199 phase_clone.pk = None
200 phase_clone.save()
201
202 settings_instance = module.settings_instance
203 if settings_instance:
204 settings_instance_clone = deepcopy(settings_instance)
205 settings_instance_clone.pk = None
206 settings_instance_clone.module = module_clone
207 settings_instance_clone.save()
208
209 messages.success(request, _("Project successfully duplicated."))
210
211 try:
212 org_slug = project_clone.organisation.slug
213 return redirect(
214 "a4dashboard:project-edit",
215 organisation_slug=org_slug,
216 project_slug=project_clone.slug,
217 )
218 except NoReverseMatch:
219 return redirect(
220 "a4dashboard:project-edit", project_slug=project_clone.slug
221 )
222 else:
223 return super().post(request, *args, **kwargs)
224
[end of adhocracy4/dashboard/mixins.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/adhocracy4/dashboard/mixins.py b/adhocracy4/dashboard/mixins.py
--- a/adhocracy4/dashboard/mixins.py
+++ b/adhocracy4/dashboard/mixins.py
@@ -129,13 +129,13 @@
class DashboardComponentDeleteSignalMixin(edit.DeletionMixin):
- def delete(self, request, *args, **kwargs):
+ def form_valid(self, request, *args, **kwargs):
# Project and module have to be stored before delete is called as
# they may rely on the still existing db object.
project = self.project
module = self.module
- response = super().delete(request, *args, **kwargs)
+ response = super().form_valid(request, *args, **kwargs)
component = self.component
if component.identifier in components.projects:
|
{"golden_diff": "diff --git a/adhocracy4/dashboard/mixins.py b/adhocracy4/dashboard/mixins.py\n--- a/adhocracy4/dashboard/mixins.py\n+++ b/adhocracy4/dashboard/mixins.py\n@@ -129,13 +129,13 @@\n \n \n class DashboardComponentDeleteSignalMixin(edit.DeletionMixin):\n- def delete(self, request, *args, **kwargs):\n+ def form_valid(self, request, *args, **kwargs):\n # Project and module have to be stored before delete is called as\n # they may rely on the still existing db object.\n project = self.project\n module = self.module\n \n- response = super().delete(request, *args, **kwargs)\n+ response = super().form_valid(request, *args, **kwargs)\n \n component = self.component\n if component.identifier in components.projects:\n", "issue": "Custom model delete method deprecated: after django upgrade\n**expected behaviour:** Custom deletion logic should move to form_valid() for django > 4\r\n\r\n**behaviour:** During the upgrade, we missed updating one of the custom deletion methods in dashboard/mixins.py\r\n\r\n`https://github.com/liqd/adhocracy4/blob/main/adhocracy4/dashboard/mixins.py#L132`\r\n\r\n**Comment/Question:** *Is this easy to do? What ideas do you have? Would this be a story?* \r\nIt is easy to fix.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from copy import deepcopy\n\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.shortcuts import get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.urls import NoReverseMatch\nfrom django.utils import timezone\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.generic import base\nfrom django.views.generic import edit\n\nfrom adhocracy4.projects import models as project_models\nfrom adhocracy4.rules import mixins as rules_mixins\n\nfrom . import components\nfrom . import get_project_dashboard\nfrom . import signals\n\nOrganisation = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n\n\nclass DashboardBaseMixin(rules_mixins.PermissionRequiredMixin):\n organisation_lookup_field = \"slug\"\n organisation_url_kwarg = \"organisation_slug\"\n\n @property\n def organisation(self):\n if self.organisation_url_kwarg and self.organisation_url_kwarg in self.kwargs:\n lookup = {\n self.organisation_lookup_field: self.kwargs[self.organisation_url_kwarg]\n }\n return get_object_or_404(Organisation, **lookup)\n\n return self.project.organisation\n\n @property\n def other_organisations_of_user(self):\n user = self.request.user\n if self.organisation:\n initiator_orgs = user.organisation_set.all()\n if hasattr(Organisation, \"groups\") and user.groups.all():\n user_groups = user.groups.all().values_list(\"id\", flat=True)\n group_orgs = Organisation.objects.filter(groups__in=user_groups)\n orgs = initiator_orgs | group_orgs\n return orgs.distinct().exclude(pk=self.organisation.pk)\n return initiator_orgs.exclude(pk=self.organisation.pk)\n else:\n return None\n\n def get_permission_object(self):\n raise NotImplementedError(\"Set permission object.\")\n\n def get_success_url(self):\n return self.request.path\n\n\nclass BlueprintMixin:\n @property\n def blueprint(self):\n from .blueprints import get_blueprints\n\n return dict(get_blueprints())[self.blueprint_key]\n\n @property\n def blueprint_key(self):\n return self.kwargs[\"blueprint_slug\"]\n\n\nclass DashboardComponentMixin(base.ContextMixin):\n \"\"\"Set the menu_item and add dashboard information to the context data.\n\n Assumes self.project, self.module and self.component are set.\n \"\"\"\n\n menu_item = \"project\"\n component = None\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n # Workaround Djangos update behavior:\n # All fields from the POST data will be set on the view.object model\n # instance, regardless of validation errors.\n # Thus it is not reliable to check on empty fields on the view.object\n # but it has to be ensured that the model reflects the database.\n project = deepcopy(self.project)\n if project:\n project.refresh_from_db()\n\n dashboard = get_project_dashboard(project)\n\n context[\"dashboard_menu\"] = dashboard.get_menu(self.module, self.component)\n\n num_valid, num_required = dashboard.get_progress()\n project_num_valid, project_num_required = dashboard.get_project_progress()\n project_is_complete = project_num_valid == project_num_required\n context[\"project_progress\"] = {\n \"valid\": num_valid,\n \"required\": num_required,\n \"project_is_complete\": project_is_complete,\n }\n\n return context\n\n\nclass DashboardComponentFormSignalMixin(edit.FormMixin):\n def form_valid(self, form):\n response = super().form_valid(form)\n\n component = self.component\n if component.identifier in components.projects:\n signals.project_component_updated.send(\n sender=component.__class__,\n project=self.project,\n component=component,\n user=self.request.user,\n )\n else:\n signals.module_component_updated.send(\n sender=component.__class__,\n module=self.module,\n component=component,\n user=self.request.user,\n )\n return response\n\n\nclass DashboardComponentDeleteSignalMixin(edit.DeletionMixin):\n def delete(self, request, *args, **kwargs):\n # Project and module have to be stored before delete is called as\n # they may rely on the still existing db object.\n project = self.project\n module = self.module\n\n response = super().delete(request, *args, **kwargs)\n\n component = self.component\n if component.identifier in components.projects:\n signals.project_component_updated.send(\n sender=component.__class__,\n project=project,\n component=component,\n user=self.request.user,\n )\n else:\n signals.module_component_updated.send(\n sender=component.__class__,\n module=module,\n component=component,\n user=self.request.user,\n )\n return response\n\n\nclass DashboardProjectDuplicateMixin:\n def post(self, request, *args, **kwargs):\n if \"duplicate\" in request.POST:\n pk = int(request.POST[\"project_pk\"])\n project = get_object_or_404(project_models.Project, pk=pk)\n can_add = request.user.has_perm(\"a4projects.add_project\", project)\n\n if not can_add:\n raise PermissionDenied()\n\n project_clone = deepcopy(project)\n project_clone.pk = None\n if project_clone.tile_image:\n project_clone.tile_image.save(\n project.tile_image.name, project.tile_image, False\n )\n if project_clone.image:\n project_clone.image.save(project.image.name, project.image, False)\n project_clone.created = timezone.now()\n project_clone.is_draft = True\n project_clone.is_archived = False\n project_clone.save()\n signals.project_created.send(\n sender=None, project=project_clone, user=self.request.user\n )\n\n for moderator in project.moderators.all():\n project_clone.moderators.add(moderator)\n\n for module in project.module_set.all():\n module_clone = deepcopy(module)\n module_clone.project = project_clone\n module_clone.pk = None\n module_clone.save()\n signals.module_created.send(\n sender=None, module=module_clone, user=self.request.user\n )\n\n for phase in module.phase_set.all():\n phase_clone = deepcopy(phase)\n phase_clone.module = module_clone\n phase_clone.pk = None\n phase_clone.save()\n\n settings_instance = module.settings_instance\n if settings_instance:\n settings_instance_clone = deepcopy(settings_instance)\n settings_instance_clone.pk = None\n settings_instance_clone.module = module_clone\n settings_instance_clone.save()\n\n messages.success(request, _(\"Project successfully duplicated.\"))\n\n try:\n org_slug = project_clone.organisation.slug\n return redirect(\n \"a4dashboard:project-edit\",\n organisation_slug=org_slug,\n project_slug=project_clone.slug,\n )\n except NoReverseMatch:\n return redirect(\n \"a4dashboard:project-edit\", project_slug=project_clone.slug\n )\n else:\n return super().post(request, *args, **kwargs)\n", "path": "adhocracy4/dashboard/mixins.py"}]}
| 2,760 | 190 |
gh_patches_debug_32389
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-4106
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix IATI export for qualitative indicators
</issue>
<code>
[start of akvo/iati/exports/elements/result.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from lxml import etree
8
9 from akvo.iati.exports.elements.utils import has_data, has_qs_data
10 from akvo.rsr.models.result.utils import QUANTITATIVE, QUALITATIVE
11
12 DGIS_VALIDATION_SET_NAME = "DGIS IATI"
13 NOT_AVAILABLE = "N/A"
14 NOT_AVAILABLE_YEAR = "1"
15
16
17 def result(project):
18 """
19 Generate the result elements.
20
21 :param project: Project object
22 :return: A list of Etree elements
23 """
24 result_elements = []
25
26 DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1
27
28 for res in project.results.all():
29 if (has_data(res, ['type', 'title', 'description', ])
30 or res.aggregation_status is not None
31 or res.indicators.all()):
32 element = etree.Element("result")
33
34 if res.type:
35 element.attrib['type'] = res.type
36
37 if res.aggregation_status is not None:
38 element.attrib['aggregation-status'] = '1' if res.aggregation_status else '0'
39
40 if res.title:
41 title_element = etree.SubElement(element, "title")
42 narrative_element = etree.SubElement(title_element, "narrative")
43 narrative_element.text = res.title
44
45 if res.description:
46 description_element = etree.SubElement(element, "description")
47 narrative_element = etree.SubElement(description_element, "narrative")
48 narrative_element.text = res.description
49
50 for indicator in res.indicators.all():
51 if not indicator.export_to_iati:
52 continue
53
54 if (has_data(indicator, ['measure', 'title', 'description', 'baseline_year',
55 'baseline_value', 'baseline_comment', ])
56 or indicator.ascending is not None
57 or has_qs_data(indicator, ['references', 'periods', ])):
58 add_indicator_element(element, indicator, DGIS_PROJECT)
59
60 result_elements.append(element)
61
62 return result_elements
63
64
65 def add_indicator_element(result_element, indicator, is_dgis_project):
66 indicator_element = etree.SubElement(result_element, "indicator")
67
68 if indicator.type == QUALITATIVE:
69 indicator_element.attrib['measure'] = '5'
70
71 elif indicator.measure:
72 indicator_element.attrib['measure'] = indicator.measure
73
74 if indicator.ascending is not None:
75 indicator_element.attrib['ascending'] = '1' if indicator.ascending else '0'
76
77 if indicator.title:
78 title_element = etree.SubElement(indicator_element, "title")
79 narrative_element = etree.SubElement(title_element, "narrative")
80 narrative_element.text = indicator.title
81
82 if indicator.description:
83 description_element = etree.SubElement(indicator_element, "description")
84 narrative_element = etree.SubElement(description_element, "narrative")
85 narrative_element.text = indicator.description
86
87 for reference in indicator.references.all():
88 add_reference_element(indicator_element, reference)
89
90 add_baseline_element(is_dgis_project, indicator_element, indicator)
91
92 for period in indicator.periods.all():
93 add_period_element(is_dgis_project, indicator_element, period)
94
95
96 def add_reference_element(indicator_element, reference):
97 if has_data(reference, ['vocabulary', 'reference', 'vocabulary_uri', ]):
98 reference_element = etree.SubElement(indicator_element, "reference")
99
100 if reference.vocabulary:
101 reference_element.attrib['vocabulary'] = reference.vocabulary
102
103 if reference.reference:
104 reference_element.attrib['code'] = reference.reference
105
106 if reference.vocabulary_uri:
107 reference_element.attrib['indicator-uri'] = reference.vocabulary_uri
108
109
110 def add_baseline_element(is_dgis_project, indicator_element, indicator):
111 if is_dgis_project or has_data(indicator,
112 ['baseline_year', 'baseline_value', 'baseline_comment', ]):
113 baseline_element = etree.SubElement(indicator_element, "baseline")
114
115 if indicator.baseline_year:
116 baseline_element.attrib['year'] = str(indicator.baseline_year)
117 elif is_dgis_project:
118 baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR
119
120 if indicator.baseline_value:
121 baseline_element.attrib['value'] = indicator.baseline_value
122 elif is_dgis_project:
123 baseline_element.attrib['value'] = NOT_AVAILABLE
124
125 if indicator.baseline_comment:
126 comment_element = etree.SubElement(baseline_element, "comment")
127 narrative_element = etree.SubElement(comment_element, "narrative")
128 narrative_element.text = indicator.baseline_comment
129
130
131 def add_period_element(is_dgis_project, indicator_element, period):
132 if (has_data(period, ['period_start', 'period_end', 'target_value', 'target_comment',
133 'actual_value', 'narrative', 'actual_comment'])
134 or has_qs_data(period, ['target_locations', 'actual_locations'])):
135 period_element = etree.SubElement(indicator_element, "period")
136
137 if period.period_start:
138 period_start_element = etree.SubElement(period_element,
139 "period-start")
140 period_start_element.attrib['iso-date'] = str(period.period_start)
141
142 if period.period_end:
143 period_end_element = etree.SubElement(period_element, "period-end")
144 period_end_element.attrib['iso-date'] = str(period.period_end)
145
146 add_target_element(is_dgis_project, period, period_element)
147 # FIXME: We don't yet allow disaggregations on targets
148
149 add_actual_element(is_dgis_project, period, period_element)
150 add_actual_dimension_elements(is_dgis_project, period, period_element)
151
152
153 def add_target_element(is_dgis_project, period, period_element):
154 if (is_dgis_project or has_data(period, ['target_value', 'target_comment', ])
155 or has_qs_data(period, ['target_locations', ])):
156 target_element = etree.SubElement(period_element, "target")
157
158 if period.target_value:
159 target_element.attrib['value'] = period.target_value
160 elif is_dgis_project:
161 target_element.attrib['value'] = NOT_AVAILABLE
162
163 for target_location in period.target_locations.all():
164 target_location_element = etree.SubElement(target_element,
165 "location")
166 target_location_element.attrib['ref'] = target_location.location
167
168 if period.target_comment:
169 comment_element = etree.SubElement(target_element, "comment")
170 narrative_element = etree.SubElement(comment_element,
171 "narrative")
172 narrative_element.text = period.target_comment
173
174
175 def add_actual_element(is_dgis_project, period, period_element):
176 if (is_dgis_project
177 or has_data(period, ['actual_value', 'narrative', 'actual_comment', ])
178 or has_qs_data(period, ['actual_locations'])):
179 actual_element = etree.SubElement(period_element, "actual")
180
181 if period.indicator.type == QUANTITATIVE:
182 if period.actual_value:
183 actual_element.attrib['value'] = period.actual_value
184 elif is_dgis_project:
185 actual_element.attrib['value'] = NOT_AVAILABLE
186
187 else:
188 if period.narrative:
189 actual_element.attrib['value'] = period.narrative
190
191 for actual_location in period.actual_locations.all():
192 actual_location_element = etree.SubElement(actual_element,
193 "location")
194 actual_location_element.attrib['ref'] = actual_location.location
195
196 if period.actual_comment:
197 comment_element = etree.SubElement(actual_element, "comment")
198 narrative_element = etree.SubElement(comment_element,
199 "narrative")
200 narrative_element.text = period.actual_comment
201
202
203 def add_actual_dimension_elements(is_dgis_project, period, period_element):
204 if (is_dgis_project
205 or has_data(period, ['actual_value', 'narrative', 'actual_comment', ])
206 or has_qs_data(period, ['actual_locations'])):
207
208 qs = period.disaggregations.select_related('dimension_value', 'dimension_value__name')
209 for period_disaggregation in qs.all():
210 actual_element = etree.SubElement(period_element, "actual")
211
212 if period_disaggregation.value:
213 actual_element.attrib['value'] = str(period_disaggregation.value)
214
215 elif is_dgis_project:
216 actual_element.attrib['value'] = NOT_AVAILABLE
217
218 dimension_element = etree.SubElement(actual_element, 'dimension')
219 dimension_element.attrib['value'] = period_disaggregation.dimension_value.value
220 dimension_element.attrib['name'] = period_disaggregation.dimension_value.name.name
221
[end of akvo/iati/exports/elements/result.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/iati/exports/elements/result.py b/akvo/iati/exports/elements/result.py
--- a/akvo/iati/exports/elements/result.py
+++ b/akvo/iati/exports/elements/result.py
@@ -67,7 +67,6 @@
if indicator.type == QUALITATIVE:
indicator_element.attrib['measure'] = '5'
-
elif indicator.measure:
indicator_element.attrib['measure'] = indicator.measure
@@ -117,10 +116,11 @@
elif is_dgis_project:
baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR
- if indicator.baseline_value:
- baseline_element.attrib['value'] = indicator.baseline_value
- elif is_dgis_project:
- baseline_element.attrib['value'] = NOT_AVAILABLE
+ if indicator.type == QUANTITATIVE:
+ if indicator.baseline_value:
+ baseline_element.attrib['value'] = indicator.baseline_value
+ elif is_dgis_project:
+ baseline_element.attrib['value'] = NOT_AVAILABLE
if indicator.baseline_comment:
comment_element = etree.SubElement(baseline_element, "comment")
@@ -155,10 +155,11 @@
or has_qs_data(period, ['target_locations', ])):
target_element = etree.SubElement(period_element, "target")
- if period.target_value:
- target_element.attrib['value'] = period.target_value
- elif is_dgis_project:
- target_element.attrib['value'] = NOT_AVAILABLE
+ if period.indicator.type == QUANTITATIVE:
+ if period.target_value:
+ target_element.attrib['value'] = period.target_value
+ elif is_dgis_project:
+ target_element.attrib['value'] = NOT_AVAILABLE
for target_location in period.target_locations.all():
target_location_element = etree.SubElement(target_element,
|
{"golden_diff": "diff --git a/akvo/iati/exports/elements/result.py b/akvo/iati/exports/elements/result.py\n--- a/akvo/iati/exports/elements/result.py\n+++ b/akvo/iati/exports/elements/result.py\n@@ -67,7 +67,6 @@\n \n if indicator.type == QUALITATIVE:\n indicator_element.attrib['measure'] = '5'\n-\n elif indicator.measure:\n indicator_element.attrib['measure'] = indicator.measure\n \n@@ -117,10 +116,11 @@\n elif is_dgis_project:\n baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR\n \n- if indicator.baseline_value:\n- baseline_element.attrib['value'] = indicator.baseline_value\n- elif is_dgis_project:\n- baseline_element.attrib['value'] = NOT_AVAILABLE\n+ if indicator.type == QUANTITATIVE:\n+ if indicator.baseline_value:\n+ baseline_element.attrib['value'] = indicator.baseline_value\n+ elif is_dgis_project:\n+ baseline_element.attrib['value'] = NOT_AVAILABLE\n \n if indicator.baseline_comment:\n comment_element = etree.SubElement(baseline_element, \"comment\")\n@@ -155,10 +155,11 @@\n or has_qs_data(period, ['target_locations', ])):\n target_element = etree.SubElement(period_element, \"target\")\n \n- if period.target_value:\n- target_element.attrib['value'] = period.target_value\n- elif is_dgis_project:\n- target_element.attrib['value'] = NOT_AVAILABLE\n+ if period.indicator.type == QUANTITATIVE:\n+ if period.target_value:\n+ target_element.attrib['value'] = period.target_value\n+ elif is_dgis_project:\n+ target_element.attrib['value'] = NOT_AVAILABLE\n \n for target_location in period.target_locations.all():\n target_location_element = etree.SubElement(target_element,\n", "issue": "Fix IATI export for qualitative indicators\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom lxml import etree\n\nfrom akvo.iati.exports.elements.utils import has_data, has_qs_data\nfrom akvo.rsr.models.result.utils import QUANTITATIVE, QUALITATIVE\n\nDGIS_VALIDATION_SET_NAME = \"DGIS IATI\"\nNOT_AVAILABLE = \"N/A\"\nNOT_AVAILABLE_YEAR = \"1\"\n\n\ndef result(project):\n \"\"\"\n Generate the result elements.\n\n :param project: Project object\n :return: A list of Etree elements\n \"\"\"\n result_elements = []\n\n DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1\n\n for res in project.results.all():\n if (has_data(res, ['type', 'title', 'description', ])\n or res.aggregation_status is not None\n or res.indicators.all()):\n element = etree.Element(\"result\")\n\n if res.type:\n element.attrib['type'] = res.type\n\n if res.aggregation_status is not None:\n element.attrib['aggregation-status'] = '1' if res.aggregation_status else '0'\n\n if res.title:\n title_element = etree.SubElement(element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = res.title\n\n if res.description:\n description_element = etree.SubElement(element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = res.description\n\n for indicator in res.indicators.all():\n if not indicator.export_to_iati:\n continue\n\n if (has_data(indicator, ['measure', 'title', 'description', 'baseline_year',\n 'baseline_value', 'baseline_comment', ])\n or indicator.ascending is not None\n or has_qs_data(indicator, ['references', 'periods', ])):\n add_indicator_element(element, indicator, DGIS_PROJECT)\n\n result_elements.append(element)\n\n return result_elements\n\n\ndef add_indicator_element(result_element, indicator, is_dgis_project):\n indicator_element = etree.SubElement(result_element, \"indicator\")\n\n if indicator.type == QUALITATIVE:\n indicator_element.attrib['measure'] = '5'\n\n elif indicator.measure:\n indicator_element.attrib['measure'] = indicator.measure\n\n if indicator.ascending is not None:\n indicator_element.attrib['ascending'] = '1' if indicator.ascending else '0'\n\n if indicator.title:\n title_element = etree.SubElement(indicator_element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = indicator.title\n\n if indicator.description:\n description_element = etree.SubElement(indicator_element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = indicator.description\n\n for reference in indicator.references.all():\n add_reference_element(indicator_element, reference)\n\n add_baseline_element(is_dgis_project, indicator_element, indicator)\n\n for period in indicator.periods.all():\n add_period_element(is_dgis_project, indicator_element, period)\n\n\ndef add_reference_element(indicator_element, reference):\n if has_data(reference, ['vocabulary', 'reference', 'vocabulary_uri', ]):\n reference_element = etree.SubElement(indicator_element, \"reference\")\n\n if reference.vocabulary:\n reference_element.attrib['vocabulary'] = reference.vocabulary\n\n if reference.reference:\n reference_element.attrib['code'] = reference.reference\n\n if reference.vocabulary_uri:\n reference_element.attrib['indicator-uri'] = reference.vocabulary_uri\n\n\ndef add_baseline_element(is_dgis_project, indicator_element, indicator):\n if is_dgis_project or has_data(indicator,\n ['baseline_year', 'baseline_value', 'baseline_comment', ]):\n baseline_element = etree.SubElement(indicator_element, \"baseline\")\n\n if indicator.baseline_year:\n baseline_element.attrib['year'] = str(indicator.baseline_year)\n elif is_dgis_project:\n baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR\n\n if indicator.baseline_value:\n baseline_element.attrib['value'] = indicator.baseline_value\n elif is_dgis_project:\n baseline_element.attrib['value'] = NOT_AVAILABLE\n\n if indicator.baseline_comment:\n comment_element = etree.SubElement(baseline_element, \"comment\")\n narrative_element = etree.SubElement(comment_element, \"narrative\")\n narrative_element.text = indicator.baseline_comment\n\n\ndef add_period_element(is_dgis_project, indicator_element, period):\n if (has_data(period, ['period_start', 'period_end', 'target_value', 'target_comment',\n 'actual_value', 'narrative', 'actual_comment'])\n or has_qs_data(period, ['target_locations', 'actual_locations'])):\n period_element = etree.SubElement(indicator_element, \"period\")\n\n if period.period_start:\n period_start_element = etree.SubElement(period_element,\n \"period-start\")\n period_start_element.attrib['iso-date'] = str(period.period_start)\n\n if period.period_end:\n period_end_element = etree.SubElement(period_element, \"period-end\")\n period_end_element.attrib['iso-date'] = str(period.period_end)\n\n add_target_element(is_dgis_project, period, period_element)\n # FIXME: We don't yet allow disaggregations on targets\n\n add_actual_element(is_dgis_project, period, period_element)\n add_actual_dimension_elements(is_dgis_project, period, period_element)\n\n\ndef add_target_element(is_dgis_project, period, period_element):\n if (is_dgis_project or has_data(period, ['target_value', 'target_comment', ])\n or has_qs_data(period, ['target_locations', ])):\n target_element = etree.SubElement(period_element, \"target\")\n\n if period.target_value:\n target_element.attrib['value'] = period.target_value\n elif is_dgis_project:\n target_element.attrib['value'] = NOT_AVAILABLE\n\n for target_location in period.target_locations.all():\n target_location_element = etree.SubElement(target_element,\n \"location\")\n target_location_element.attrib['ref'] = target_location.location\n\n if period.target_comment:\n comment_element = etree.SubElement(target_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.target_comment\n\n\ndef add_actual_element(is_dgis_project, period, period_element):\n if (is_dgis_project\n or has_data(period, ['actual_value', 'narrative', 'actual_comment', ])\n or has_qs_data(period, ['actual_locations'])):\n actual_element = etree.SubElement(period_element, \"actual\")\n\n if period.indicator.type == QUANTITATIVE:\n if period.actual_value:\n actual_element.attrib['value'] = period.actual_value\n elif is_dgis_project:\n actual_element.attrib['value'] = NOT_AVAILABLE\n\n else:\n if period.narrative:\n actual_element.attrib['value'] = period.narrative\n\n for actual_location in period.actual_locations.all():\n actual_location_element = etree.SubElement(actual_element,\n \"location\")\n actual_location_element.attrib['ref'] = actual_location.location\n\n if period.actual_comment:\n comment_element = etree.SubElement(actual_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.actual_comment\n\n\ndef add_actual_dimension_elements(is_dgis_project, period, period_element):\n if (is_dgis_project\n or has_data(period, ['actual_value', 'narrative', 'actual_comment', ])\n or has_qs_data(period, ['actual_locations'])):\n\n qs = period.disaggregations.select_related('dimension_value', 'dimension_value__name')\n for period_disaggregation in qs.all():\n actual_element = etree.SubElement(period_element, \"actual\")\n\n if period_disaggregation.value:\n actual_element.attrib['value'] = str(period_disaggregation.value)\n\n elif is_dgis_project:\n actual_element.attrib['value'] = NOT_AVAILABLE\n\n dimension_element = etree.SubElement(actual_element, 'dimension')\n dimension_element.attrib['value'] = period_disaggregation.dimension_value.value\n dimension_element.attrib['name'] = period_disaggregation.dimension_value.name.name\n", "path": "akvo/iati/exports/elements/result.py"}]}
| 2,921 | 411 |
gh_patches_debug_3369
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1925
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Annual documents does not show drop-down menu for year
### Describe the bug
When I try to add an annual document to the site, I am not able to select a year, the dropdown menu does not contain any entries.
### Steps to reproduce
1.
</issue>
<code>
[start of website/documents/forms.py]
1 """The forms defined by the documents package."""
2 from django import forms
3 from django.contrib import admin
4 from django.forms import widgets
5 from django.utils import timezone
6
7 from documents import models
8 from utils.snippets import datetime_to_lectureyear
9
10
11 class DocumentFileInput(widgets.ClearableFileInput):
12 """Wrapper around Django's :class:`~django.forms.widgets.ClearableFileInput`.
13
14 It overrides the URL of the associated file when it is fetched.
15 """
16
17 template_name = "widgets/clearable_file_input.html"
18
19 def get_context(self, name, value, attrs):
20 context = super().get_context(name, value, attrs)
21 if hasattr(value, "url"):
22 doc = models.Document.objects.get(file=value)
23 context["document_id"] = doc.pk
24 context["language"] = "en"
25 return context
26
27
28 class MinutesForm(forms.ModelForm):
29 """Form that overrides the widgets for the files."""
30
31 class Meta:
32 model = models.Minutes
33 fields = (
34 "file",
35 "members_only",
36 )
37 widgets = {
38 "file": DocumentFileInput,
39 }
40
41
42 class AnnualDocumentForm(forms.ModelForm):
43 """Form that provides custom functionality for annual documents."""
44
45 class Meta:
46 model = models.AnnualDocument
47 fields = "__all__"
48 widgets = {
49 "year": forms.Select,
50 "file": DocumentFileInput,
51 }
52
53 @staticmethod
54 def _current_year():
55 """Get the current lecture year."""
56 return datetime_to_lectureyear(timezone.now())
57
58 @staticmethod
59 def _year_choices():
60 """Get the lecture years."""
61 current = datetime_to_lectureyear(timezone.now())
62 return [
63 (year, "{}-{}".format(year, year + 1))
64 for year in range(current + 1, 1989, -1)
65 ]
66
67
68 class AssociationDocumentForm(forms.ModelForm):
69 """Form that overrides the widgets for the files."""
70
71 class Meta:
72 model = models.AssociationDocument
73 fields = (
74 "name",
75 "file",
76 "members_only",
77 )
78 widgets = {
79 "file": DocumentFileInput,
80 }
81
82
83 class EventDocumentForm(forms.ModelForm):
84 """Form that overrides the widgets for the files."""
85
86 class Meta:
87 model = models.EventDocument
88 fields = (
89 "name",
90 "file",
91 "members_only",
92 "owner",
93 )
94 widgets = {
95 "file": DocumentFileInput,
96 }
97
98
99 class MiscellaneousDocumentForm(forms.ModelForm):
100 """Form that overrides the widgets for the files."""
101
102 class Meta:
103 model = models.MiscellaneousDocument
104 fields = (
105 "name",
106 "file",
107 "members_only",
108 )
109 widgets = {
110 "file": DocumentFileInput,
111 }
112
113
114 class GeneralMeetingForm(forms.ModelForm):
115 """Custom form for general meetings with a custom widget for documents."""
116
117 class Meta:
118 model = models.GeneralMeeting
119 fields = "__all__"
120 widgets = {
121 "documents": admin.widgets.FilteredSelectMultiple(
122 "documents", is_stacked=False
123 )
124 }
125
[end of website/documents/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/documents/forms.py b/website/documents/forms.py
--- a/website/documents/forms.py
+++ b/website/documents/forms.py
@@ -64,6 +64,10 @@
for year in range(current + 1, 1989, -1)
]
+ year = forms.TypedChoiceField(
+ coerce=int, choices=_year_choices.__func__, initial=_current_year.__func__
+ )
+
class AssociationDocumentForm(forms.ModelForm):
"""Form that overrides the widgets for the files."""
|
{"golden_diff": "diff --git a/website/documents/forms.py b/website/documents/forms.py\n--- a/website/documents/forms.py\n+++ b/website/documents/forms.py\n@@ -64,6 +64,10 @@\n for year in range(current + 1, 1989, -1)\n ]\n \n+ year = forms.TypedChoiceField(\n+ coerce=int, choices=_year_choices.__func__, initial=_current_year.__func__\n+ )\n+\n \n class AssociationDocumentForm(forms.ModelForm):\n \"\"\"Form that overrides the widgets for the files.\"\"\"\n", "issue": "Annual documents does not show drop-down menu for year\n### Describe the bug\r\n\r\nWhen I try to add an annual document to the site, I am not able to select a year, the dropdown menu does not contain any entries. \r\n\r\n### Steps to reproduce\r\n\r\n1. \n", "before_files": [{"content": "\"\"\"The forms defined by the documents package.\"\"\"\nfrom django import forms\nfrom django.contrib import admin\nfrom django.forms import widgets\nfrom django.utils import timezone\n\nfrom documents import models\nfrom utils.snippets import datetime_to_lectureyear\n\n\nclass DocumentFileInput(widgets.ClearableFileInput):\n \"\"\"Wrapper around Django's :class:`~django.forms.widgets.ClearableFileInput`.\n\n It overrides the URL of the associated file when it is fetched.\n \"\"\"\n\n template_name = \"widgets/clearable_file_input.html\"\n\n def get_context(self, name, value, attrs):\n context = super().get_context(name, value, attrs)\n if hasattr(value, \"url\"):\n doc = models.Document.objects.get(file=value)\n context[\"document_id\"] = doc.pk\n context[\"language\"] = \"en\"\n return context\n\n\nclass MinutesForm(forms.ModelForm):\n \"\"\"Form that overrides the widgets for the files.\"\"\"\n\n class Meta:\n model = models.Minutes\n fields = (\n \"file\",\n \"members_only\",\n )\n widgets = {\n \"file\": DocumentFileInput,\n }\n\n\nclass AnnualDocumentForm(forms.ModelForm):\n \"\"\"Form that provides custom functionality for annual documents.\"\"\"\n\n class Meta:\n model = models.AnnualDocument\n fields = \"__all__\"\n widgets = {\n \"year\": forms.Select,\n \"file\": DocumentFileInput,\n }\n\n @staticmethod\n def _current_year():\n \"\"\"Get the current lecture year.\"\"\"\n return datetime_to_lectureyear(timezone.now())\n\n @staticmethod\n def _year_choices():\n \"\"\"Get the lecture years.\"\"\"\n current = datetime_to_lectureyear(timezone.now())\n return [\n (year, \"{}-{}\".format(year, year + 1))\n for year in range(current + 1, 1989, -1)\n ]\n\n\nclass AssociationDocumentForm(forms.ModelForm):\n \"\"\"Form that overrides the widgets for the files.\"\"\"\n\n class Meta:\n model = models.AssociationDocument\n fields = (\n \"name\",\n \"file\",\n \"members_only\",\n )\n widgets = {\n \"file\": DocumentFileInput,\n }\n\n\nclass EventDocumentForm(forms.ModelForm):\n \"\"\"Form that overrides the widgets for the files.\"\"\"\n\n class Meta:\n model = models.EventDocument\n fields = (\n \"name\",\n \"file\",\n \"members_only\",\n \"owner\",\n )\n widgets = {\n \"file\": DocumentFileInput,\n }\n\n\nclass MiscellaneousDocumentForm(forms.ModelForm):\n \"\"\"Form that overrides the widgets for the files.\"\"\"\n\n class Meta:\n model = models.MiscellaneousDocument\n fields = (\n \"name\",\n \"file\",\n \"members_only\",\n )\n widgets = {\n \"file\": DocumentFileInput,\n }\n\n\nclass GeneralMeetingForm(forms.ModelForm):\n \"\"\"Custom form for general meetings with a custom widget for documents.\"\"\"\n\n class Meta:\n model = models.GeneralMeeting\n fields = \"__all__\"\n widgets = {\n \"documents\": admin.widgets.FilteredSelectMultiple(\n \"documents\", is_stacked=False\n )\n }\n", "path": "website/documents/forms.py"}]}
| 1,525 | 118 |
gh_patches_debug_26217
|
rasdani/github-patches
|
git_diff
|
google__jax-3110
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Zero gradient when resampling an image at grid location using map_coordinates
Sorry if this not a very minimal test case but let me explain my use case and issue as I believe the context will help.
I am trying to use jax for a toy image registration problem. Given two images `x1` and `x2` I want to find the translation `u` that minimises the difference between `x1(.)` and `x2(.+u)` as measured in terms of mean square error (MSE). The resampled version of `x2` after the (non-integer) translation is computed with `map_coordinates`.
The computation of the gradient of the cost funcrtion in this context is usually done by assuming the images are continuous, computing the gradient of the MSE as `-2(x1-x2)∇x2` and computing `∇x2` with something similar to `np.gradient`.
Trying to mimick this setup with jax to avoid computing the gradient manually (this would be useful for example as soon as one wants to change the MSE loss for something else) fails to converge to a suitable translation (at least if initialised with an integer translation) as the gradient from jax is **exactly** zero for integer translations.
Below is a test case to illustrate the zero gradient issue. I understand there is a discontinuity of the gradient at such integer points but I was expecting to nonetheless get a proper **sub-gradient**.
I am not sure if I am doing something wrong or simply misunderstanding something but so far I haven't managed to get the image registration to converge with jax derivatives even though it does with a numerical approximation of the gradient, or the classical continous approximation I was refering to.
```python
import jax
import jax.numpy as jnp
import numpy as onp
from jax.scipy import ndimage as jndimage
from scipy import ndimage as ondimage
import scipy as oscipy
# This needs to run at startup
# https://jax.readthedocs.io/en/latest/notebooks/Common_Gotchas_in_JAX.html#Double-(64bit)-precision
jax.config.update('jax_enable_x64', True)
# Exclude a border in hte computation of the loss to try and avoid numerical issues
excl_border = 2
def run(np,ndimage):
print(f"\nRunning on {np}")
onp.random.seed(0)
x1 = onp.random.randn(20,10)
x2 = onp.random.randn(20,10)
grid_x, grid_y = np.meshgrid(np.arange(x1.shape[1]), np.arange(x1.shape[0]))
def lossfunc(du):
# Get translated grid
def_grid_x = grid_x + du[0]
def_grid_y = grid_y + du[1]
# Resample image
tmpx2_warped = jndimage.map_coordinates(x2, [def_grid_y, def_grid_x], order=1)
# Compute the MSE between the warped image an the fixed image
diff_im = tmpx2_warped[excl_border:-excl_border,excl_border:-excl_border]-x1[excl_border:-excl_border,excl_border:-excl_border]
imloss = np.mean((diff_im)**2)
return imloss
def mg_lossfunc(du):
#Get translated grid
def_grid_x = grid_x + du[0]
def_grid_y = grid_y + du[1]
# Resample image
tmpx2_warped = ndimage.map_coordinates(x2, [def_grid_y, def_grid_x], order=1)
# Compute the MSE between the warped image an the fixed image
diff_im = tmpx2_warped[excl_border:-excl_border,excl_border:-excl_border]-x1[excl_border:-excl_border,excl_border:-excl_border]
jm = np.gradient(tmpx2_warped)
jmrx = jm[0][excl_border:-excl_border,excl_border:-excl_border]
jmry = jm[1][excl_border:-excl_border,excl_border:-excl_border]
jdmx = -2.*diff_im*jmrx
jdmy = -2.*diff_im*jmry
return np.array([np.mean(jdmx), np.mean(jdmy)])
print(f"loss at 0,0: {lossfunc([0., 0.])}")
print(f"loss at 0.1,0.1: {lossfunc([0.1, 0.1])}")
print(f"Manual approx gradient at 0,0: {mg_lossfunc([0., 0.])}")
print(f"Manual approx gradient at 0.1,0.1: {mg_lossfunc([0.1, 0.1])}")
# Finite difference gradient with a large step as the image is sampled on a grid and interpolated
epsgrad = 0.1
print(f"Numerical approx gradient at 0,0: {oscipy.optimize.approx_fprime([0., 0.],lossfunc,epsgrad)}")
print(f"Numerical approx gradient at 0.1,0.1: {oscipy.optimize.approx_fprime([0.1, 0.1],lossfunc,epsgrad)}")
if np==jnp:
jg_lossfunc = lambda du:np.asarray(jax.jit(jax.grad(lossfunc))(du))
print(f"Jax gradient at 0,0: {jg_lossfunc([0., 0.])}")
print(f"Jax gradient at 0.1,0.1: {jg_lossfunc([0.1, 0.1])}")
run(onp,ondimage)
run(jnp,jndimage)
```
Outputs:
```
Running on <module 'numpy' from '/usr/local/lib/python3.6/dist-packages/numpy/__init__.py'>
loss at 0,0: 1.9514397057693333
loss at 0.1,0.1: 1.6584230856711766
Manual approx gradient at 0,0: [ 0.01189463 -0.21033731]
Manual approx gradient at 0.1,0.1: [-0.00626396 -0.12798883]
Numerical approx gradient at 0,0: [-1.72714353 -1.47912221]
Numerical approx gradient at 0.1,0.1: [-1.15234194 -0.9063109 ]
Running on <module 'jax.numpy' from '/usr/local/lib/python3.6/dist-packages/jax/numpy/__init__.py'>
loss at 0,0: 1.9514397057693333
loss at 0.1,0.1: 1.6584230856711766
Manual approx gradient at 0,0: [ 0.01189463 -0.21033731]
Manual approx gradient at 0.1,0.1: [-0.00626396 -0.12798883]
Numerical approx gradient at 0,0: [-1.72714353 -1.47912221]
Numerical approx gradient at 0.1,0.1: [-1.15234194 -0.9063109 ]
Jax gradient at 0,0: [0. 0.]
Jax gradient at 0.1,0.1: [-1.30169297 -1.05466678]
```
</issue>
<code>
[start of jax/scipy/ndimage.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import functools
17 import itertools
18 import operator
19 import textwrap
20
21 import scipy.ndimage
22
23 from .. import api
24 from ..numpy import lax_numpy as jnp
25 from ..numpy._util import _wraps
26 from ..util import safe_zip as zip
27
28
29 _nonempty_prod = functools.partial(functools.reduce, operator.mul)
30 _nonempty_sum = functools.partial(functools.reduce, operator.add)
31
32 _INDEX_FIXERS = {
33 'constant': lambda index, size: index,
34 'nearest': lambda index, size: jnp.clip(index, 0, size - 1),
35 'wrap': lambda index, size: index % size,
36 }
37
38
39 def _nearest_indices_and_weights(coordinate):
40 index = jnp.around(coordinate).astype(jnp.int32)
41 weight = coordinate.dtype.type(1)
42 return [(index, weight)]
43
44
45 def _linear_indices_and_weights(coordinate):
46 lower = jnp.floor(coordinate)
47 upper = jnp.ceil(coordinate)
48 l_index = lower.astype(jnp.int32)
49 u_index = upper.astype(jnp.int32)
50 one = coordinate.dtype.type(1)
51 l_weight = one - (coordinate - lower)
52 u_weight = one - l_weight # handles the edge case lower==upper
53 return [(l_index, l_weight), (u_index, u_weight)]
54
55
56 @functools.partial(api.jit, static_argnums=(2, 3, 4))
57 def _map_coordinates(input, coordinates, order, mode, cval):
58 input = jnp.asarray(input)
59 coordinates = [jnp.asarray(c, input.dtype) for c in coordinates]
60 cval = jnp.asarray(cval, input.dtype)
61
62 if len(coordinates) != input.ndim:
63 raise ValueError('coordinates must be a sequence of length input.ndim, but '
64 '{} != {}'.format(len(coordinates), input.ndim))
65
66 index_fixer = _INDEX_FIXERS.get(mode)
67 if index_fixer is None:
68 raise NotImplementedError(
69 'jax.scipy.ndimage.map_coordinates does not yet support mode {}. '
70 'Currently supported modes are {}.'.format(mode, set(_INDEX_FIXERS)))
71
72 if mode == 'constant':
73 is_valid = lambda index, size: (0 <= index) & (index < size)
74 else:
75 is_valid = lambda index, size: True
76
77 if order == 0:
78 interp_fun = _nearest_indices_and_weights
79 elif order == 1:
80 interp_fun = _linear_indices_and_weights
81 else:
82 raise NotImplementedError(
83 'jax.scipy.ndimage.map_coordinates currently requires order<=1')
84
85 valid_1d_interpolations = []
86 for coordinate, size in zip(coordinates, input.shape):
87 interp_nodes = interp_fun(coordinate)
88 valid_interp = []
89 for index, weight in interp_nodes:
90 fixed_index = index_fixer(index, size)
91 valid = is_valid(index, size)
92 valid_interp.append((fixed_index, valid, weight))
93 valid_1d_interpolations.append(valid_interp)
94
95 outputs = []
96 for items in itertools.product(*valid_1d_interpolations):
97 indices, validities, weights = zip(*items)
98 if any(valid is not True for valid in validities):
99 all_valid = functools.reduce(operator.and_, validities)
100 contribution = jnp.where(all_valid, input[indices], cval)
101 else:
102 contribution = input[indices]
103 outputs.append(_nonempty_prod(weights) * contribution)
104 result = _nonempty_sum(outputs)
105 return result
106
107
108 @_wraps(scipy.ndimage.map_coordinates, lax_description=textwrap.dedent("""\
109 Only linear interpolation (``order=1``) and modes ``'constant'``,
110 ``'nearest'`` and ``'wrap'`` are currently supported. Note that
111 interpolation near boundaries differs from the scipy function, because we
112 fixed an outstanding bug (https://github.com/scipy/scipy/issues/2640);
113 this function interprets the ``mode`` argument as documented by SciPy, but
114 not as implemented by SciPy.
115 """))
116 def map_coordinates(
117 input, coordinates, order, mode='constant', cval=0.0,
118 ):
119 return _map_coordinates(input, coordinates, order, mode, cval)
120
[end of jax/scipy/ndimage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jax/scipy/ndimage.py b/jax/scipy/ndimage.py
--- a/jax/scipy/ndimage.py
+++ b/jax/scipy/ndimage.py
@@ -44,13 +44,10 @@
def _linear_indices_and_weights(coordinate):
lower = jnp.floor(coordinate)
- upper = jnp.ceil(coordinate)
- l_index = lower.astype(jnp.int32)
- u_index = upper.astype(jnp.int32)
- one = coordinate.dtype.type(1)
- l_weight = one - (coordinate - lower)
- u_weight = one - l_weight # handles the edge case lower==upper
- return [(l_index, l_weight), (u_index, u_weight)]
+ upper_weight = coordinate - lower
+ lower_weight = 1 - upper_weight
+ index = lower.astype(jnp.int32)
+ return [(index, lower_weight), (index + 1, upper_weight)]
@functools.partial(api.jit, static_argnums=(2, 3, 4))
@@ -95,11 +92,12 @@
outputs = []
for items in itertools.product(*valid_1d_interpolations):
indices, validities, weights = zip(*items)
- if any(valid is not True for valid in validities):
+ if all(valid is True for valid in validities):
+ # fast path
+ contribution = input[indices]
+ else:
all_valid = functools.reduce(operator.and_, validities)
contribution = jnp.where(all_valid, input[indices], cval)
- else:
- contribution = input[indices]
outputs.append(_nonempty_prod(weights) * contribution)
result = _nonempty_sum(outputs)
return result
|
{"golden_diff": "diff --git a/jax/scipy/ndimage.py b/jax/scipy/ndimage.py\n--- a/jax/scipy/ndimage.py\n+++ b/jax/scipy/ndimage.py\n@@ -44,13 +44,10 @@\n \n def _linear_indices_and_weights(coordinate):\n lower = jnp.floor(coordinate)\n- upper = jnp.ceil(coordinate)\n- l_index = lower.astype(jnp.int32)\n- u_index = upper.astype(jnp.int32)\n- one = coordinate.dtype.type(1)\n- l_weight = one - (coordinate - lower)\n- u_weight = one - l_weight # handles the edge case lower==upper\n- return [(l_index, l_weight), (u_index, u_weight)]\n+ upper_weight = coordinate - lower\n+ lower_weight = 1 - upper_weight\n+ index = lower.astype(jnp.int32)\n+ return [(index, lower_weight), (index + 1, upper_weight)]\n \n \n @functools.partial(api.jit, static_argnums=(2, 3, 4))\n@@ -95,11 +92,12 @@\n outputs = []\n for items in itertools.product(*valid_1d_interpolations):\n indices, validities, weights = zip(*items)\n- if any(valid is not True for valid in validities):\n+ if all(valid is True for valid in validities):\n+ # fast path\n+ contribution = input[indices]\n+ else:\n all_valid = functools.reduce(operator.and_, validities)\n contribution = jnp.where(all_valid, input[indices], cval)\n- else:\n- contribution = input[indices]\n outputs.append(_nonempty_prod(weights) * contribution)\n result = _nonempty_sum(outputs)\n return result\n", "issue": "Zero gradient when resampling an image at grid location using map_coordinates\nSorry if this not a very minimal test case but let me explain my use case and issue as I believe the context will help.\r\n\r\nI am trying to use jax for a toy image registration problem. Given two images `x1` and `x2` I want to find the translation `u` that minimises the difference between `x1(.)` and `x2(.+u)` as measured in terms of mean square error (MSE). The resampled version of `x2` after the (non-integer) translation is computed with `map_coordinates`.\r\n\r\nThe computation of the gradient of the cost funcrtion in this context is usually done by assuming the images are continuous, computing the gradient of the MSE as `-2(x1-x2)\u2207x2` and computing `\u2207x2` with something similar to `np.gradient`.\r\n\r\nTrying to mimick this setup with jax to avoid computing the gradient manually (this would be useful for example as soon as one wants to change the MSE loss for something else) fails to converge to a suitable translation (at least if initialised with an integer translation) as the gradient from jax is **exactly** zero for integer translations.\r\n\r\nBelow is a test case to illustrate the zero gradient issue. I understand there is a discontinuity of the gradient at such integer points but I was expecting to nonetheless get a proper **sub-gradient**.\r\n\r\nI am not sure if I am doing something wrong or simply misunderstanding something but so far I haven't managed to get the image registration to converge with jax derivatives even though it does with a numerical approximation of the gradient, or the classical continous approximation I was refering to.\r\n\r\n```python\r\nimport jax\r\nimport jax.numpy as jnp\r\nimport numpy as onp\r\nfrom jax.scipy import ndimage as jndimage\r\nfrom scipy import ndimage as ondimage\r\nimport scipy as oscipy\r\n\r\n# This needs to run at startup\r\n# https://jax.readthedocs.io/en/latest/notebooks/Common_Gotchas_in_JAX.html#Double-(64bit)-precision\r\njax.config.update('jax_enable_x64', True)\r\n\r\n# Exclude a border in hte computation of the loss to try and avoid numerical issues\r\nexcl_border = 2\r\n\r\ndef run(np,ndimage):\r\n print(f\"\\nRunning on {np}\")\r\n onp.random.seed(0)\r\n x1 = onp.random.randn(20,10)\r\n x2 = onp.random.randn(20,10)\r\n\r\n grid_x, grid_y = np.meshgrid(np.arange(x1.shape[1]), np.arange(x1.shape[0]))\r\n\r\n def lossfunc(du):\r\n # Get translated grid\r\n def_grid_x = grid_x + du[0]\r\n def_grid_y = grid_y + du[1]\r\n\r\n # Resample image\r\n tmpx2_warped = jndimage.map_coordinates(x2, [def_grid_y, def_grid_x], order=1)\r\n\r\n # Compute the MSE between the warped image an the fixed image\r\n diff_im = tmpx2_warped[excl_border:-excl_border,excl_border:-excl_border]-x1[excl_border:-excl_border,excl_border:-excl_border]\r\n\r\n imloss = np.mean((diff_im)**2)\r\n\r\n return imloss\r\n\r\n def mg_lossfunc(du):\r\n #Get translated grid\r\n def_grid_x = grid_x + du[0]\r\n def_grid_y = grid_y + du[1]\r\n\r\n # Resample image\r\n tmpx2_warped = ndimage.map_coordinates(x2, [def_grid_y, def_grid_x], order=1)\r\n\r\n # Compute the MSE between the warped image an the fixed image\r\n diff_im = tmpx2_warped[excl_border:-excl_border,excl_border:-excl_border]-x1[excl_border:-excl_border,excl_border:-excl_border]\r\n jm = np.gradient(tmpx2_warped)\r\n jmrx = jm[0][excl_border:-excl_border,excl_border:-excl_border]\r\n jmry = jm[1][excl_border:-excl_border,excl_border:-excl_border]\r\n jdmx = -2.*diff_im*jmrx\r\n jdmy = -2.*diff_im*jmry\r\n\r\n return np.array([np.mean(jdmx), np.mean(jdmy)])\r\n\r\n print(f\"loss at 0,0: {lossfunc([0., 0.])}\")\r\n print(f\"loss at 0.1,0.1: {lossfunc([0.1, 0.1])}\")\r\n\r\n print(f\"Manual approx gradient at 0,0: {mg_lossfunc([0., 0.])}\")\r\n print(f\"Manual approx gradient at 0.1,0.1: {mg_lossfunc([0.1, 0.1])}\")\r\n # Finite difference gradient with a large step as the image is sampled on a grid and interpolated\r\n epsgrad = 0.1\r\n print(f\"Numerical approx gradient at 0,0: {oscipy.optimize.approx_fprime([0., 0.],lossfunc,epsgrad)}\")\r\n print(f\"Numerical approx gradient at 0.1,0.1: {oscipy.optimize.approx_fprime([0.1, 0.1],lossfunc,epsgrad)}\")\r\n if np==jnp:\r\n jg_lossfunc = lambda du:np.asarray(jax.jit(jax.grad(lossfunc))(du))\r\n print(f\"Jax gradient at 0,0: {jg_lossfunc([0., 0.])}\")\r\n print(f\"Jax gradient at 0.1,0.1: {jg_lossfunc([0.1, 0.1])}\")\r\n\r\nrun(onp,ondimage)\r\nrun(jnp,jndimage)\r\n```\r\nOutputs:\r\n```\r\nRunning on <module 'numpy' from '/usr/local/lib/python3.6/dist-packages/numpy/__init__.py'>\r\nloss at 0,0: 1.9514397057693333\r\nloss at 0.1,0.1: 1.6584230856711766\r\nManual approx gradient at 0,0: [ 0.01189463 -0.21033731]\r\nManual approx gradient at 0.1,0.1: [-0.00626396 -0.12798883]\r\nNumerical approx gradient at 0,0: [-1.72714353 -1.47912221]\r\nNumerical approx gradient at 0.1,0.1: [-1.15234194 -0.9063109 ]\r\n\r\nRunning on <module 'jax.numpy' from '/usr/local/lib/python3.6/dist-packages/jax/numpy/__init__.py'>\r\nloss at 0,0: 1.9514397057693333\r\nloss at 0.1,0.1: 1.6584230856711766\r\nManual approx gradient at 0,0: [ 0.01189463 -0.21033731]\r\nManual approx gradient at 0.1,0.1: [-0.00626396 -0.12798883]\r\nNumerical approx gradient at 0,0: [-1.72714353 -1.47912221]\r\nNumerical approx gradient at 0.1,0.1: [-1.15234194 -0.9063109 ]\r\nJax gradient at 0,0: [0. 0.]\r\nJax gradient at 0.1,0.1: [-1.30169297 -1.05466678]\r\n```\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport functools\nimport itertools\nimport operator\nimport textwrap\n\nimport scipy.ndimage\n\nfrom .. import api\nfrom ..numpy import lax_numpy as jnp\nfrom ..numpy._util import _wraps\nfrom ..util import safe_zip as zip\n\n\n_nonempty_prod = functools.partial(functools.reduce, operator.mul)\n_nonempty_sum = functools.partial(functools.reduce, operator.add)\n\n_INDEX_FIXERS = {\n 'constant': lambda index, size: index,\n 'nearest': lambda index, size: jnp.clip(index, 0, size - 1),\n 'wrap': lambda index, size: index % size,\n}\n\n\ndef _nearest_indices_and_weights(coordinate):\n index = jnp.around(coordinate).astype(jnp.int32)\n weight = coordinate.dtype.type(1)\n return [(index, weight)]\n\n\ndef _linear_indices_and_weights(coordinate):\n lower = jnp.floor(coordinate)\n upper = jnp.ceil(coordinate)\n l_index = lower.astype(jnp.int32)\n u_index = upper.astype(jnp.int32)\n one = coordinate.dtype.type(1)\n l_weight = one - (coordinate - lower)\n u_weight = one - l_weight # handles the edge case lower==upper\n return [(l_index, l_weight), (u_index, u_weight)]\n\n\[email protected](api.jit, static_argnums=(2, 3, 4))\ndef _map_coordinates(input, coordinates, order, mode, cval):\n input = jnp.asarray(input)\n coordinates = [jnp.asarray(c, input.dtype) for c in coordinates]\n cval = jnp.asarray(cval, input.dtype)\n\n if len(coordinates) != input.ndim:\n raise ValueError('coordinates must be a sequence of length input.ndim, but '\n '{} != {}'.format(len(coordinates), input.ndim))\n\n index_fixer = _INDEX_FIXERS.get(mode)\n if index_fixer is None:\n raise NotImplementedError(\n 'jax.scipy.ndimage.map_coordinates does not yet support mode {}. '\n 'Currently supported modes are {}.'.format(mode, set(_INDEX_FIXERS)))\n\n if mode == 'constant':\n is_valid = lambda index, size: (0 <= index) & (index < size)\n else:\n is_valid = lambda index, size: True\n\n if order == 0:\n interp_fun = _nearest_indices_and_weights\n elif order == 1:\n interp_fun = _linear_indices_and_weights\n else:\n raise NotImplementedError(\n 'jax.scipy.ndimage.map_coordinates currently requires order<=1')\n\n valid_1d_interpolations = []\n for coordinate, size in zip(coordinates, input.shape):\n interp_nodes = interp_fun(coordinate)\n valid_interp = []\n for index, weight in interp_nodes:\n fixed_index = index_fixer(index, size)\n valid = is_valid(index, size)\n valid_interp.append((fixed_index, valid, weight))\n valid_1d_interpolations.append(valid_interp)\n\n outputs = []\n for items in itertools.product(*valid_1d_interpolations):\n indices, validities, weights = zip(*items)\n if any(valid is not True for valid in validities):\n all_valid = functools.reduce(operator.and_, validities)\n contribution = jnp.where(all_valid, input[indices], cval)\n else:\n contribution = input[indices]\n outputs.append(_nonempty_prod(weights) * contribution)\n result = _nonempty_sum(outputs)\n return result\n\n\n@_wraps(scipy.ndimage.map_coordinates, lax_description=textwrap.dedent(\"\"\"\\\n Only linear interpolation (``order=1``) and modes ``'constant'``,\n ``'nearest'`` and ``'wrap'`` are currently supported. Note that\n interpolation near boundaries differs from the scipy function, because we\n fixed an outstanding bug (https://github.com/scipy/scipy/issues/2640);\n this function interprets the ``mode`` argument as documented by SciPy, but\n not as implemented by SciPy.\n \"\"\"))\ndef map_coordinates(\n input, coordinates, order, mode='constant', cval=0.0,\n):\n return _map_coordinates(input, coordinates, order, mode, cval)\n", "path": "jax/scipy/ndimage.py"}]}
| 3,614 | 398 |
gh_patches_debug_28224
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-435
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
confusing error message with simple configs
Using this config:
```
config = Config(executors=[ThreadPoolExecutor()])
```
parsl startup logs this message to the logger:
```
$ ./c.py
2018-07-11 08:04:42 parsl.config:66 [DEBUG] Checkpoint period only has an effect with checkpoint_mode='periodic'
```
This appears to be in config creation, as it happens even without passing that config to create a DataFlowKernel.
This might cause user confusion that something is broken/misconfigured.
</issue>
<code>
[start of parsl/config.py]
1 import logging
2
3 from libsubmit.utils import RepresentationMixin
4 from parsl.executors.threads import ThreadPoolExecutor
5 from parsl.dataflow.error import ConfigurationError
6
7 logger = logging.getLogger(__name__)
8
9
10 class Config(RepresentationMixin):
11 """
12 Specification of Parsl configuration options.
13
14 Parameters
15 ----------
16 executors : list of ParslExecutor, optional
17 List of executor instances to use. Possible executors include :class:`~parsl.executors.threads.ThreadPoolExecutor`,
18 :class:`~parsl.executors.ipp.IPyParallelExecutor`, or :class:`~parsl.executors.swift_t.TurbineExecutor`. Default
19 is [:class:`~parsl.executors.threads.ThreadPoolExecutor()`].
20 app_cache : bool, optional
21 Enable app caching. Default is True.
22 checkpoint_files : list of str, optional
23 List of paths to checkpoint files. Default is None.
24 checkpoint_mode : str, optional
25 Checkpoint mode to use, can be 'dfk_exit', 'task_exit', or 'periodic'. If set to
26 `None`, checkpointing will be disabled. Default is None.
27 checkpoint_period : str, optional
28 Time interval (in "HH:MM:SS") at which to checkpoint completed tasks. Only has an effect if
29 `checkpoint_mode='periodic'`.
30 data_management_max_threads : int, optional
31 Maximum number of threads to allocate for the data manager to use for managing input and output transfers.
32 Default is 10.
33 lazy_errors : bool, optional
34 If True, errors from task failures will not be raised until `future.result()` is called. Otherwise, they will
35 be raised as soon as the task returns. Default is True.
36 retries : int, optional
37 Set the number of retries in case of failure. Default is 0.
38 run_dir : str, optional
39 Path to run directory. Default is 'runinfo'.
40 strategy : str, optional
41 Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic
42 scaling will be disabled. Default is 'simple'.
43 usage_tracking : bool, optional
44 Enable usage tracking. Default is True.
45 """
46 def __init__(self,
47 executors=None,
48 app_cache=True,
49 checkpoint_files=None,
50 checkpoint_mode=None,
51 checkpoint_period="00:30:00",
52 data_management_max_threads=10,
53 lazy_errors=True,
54 retries=0,
55 run_dir='runinfo',
56 strategy='simple',
57 db_logger_config=None,
58 usage_tracking=True):
59 if executors is None:
60 executors = [ThreadPoolExecutor()]
61 self.executors = executors
62 self.app_cache = app_cache
63 self.checkpoint_files = checkpoint_files
64 self.checkpoint_mode = checkpoint_mode
65 if checkpoint_mode is not 'periodic' and checkpoint_period is not None:
66 logger.debug("Checkpoint period only has an effect with checkpoint_mode='periodic'")
67 self.checkpoint_period = checkpoint_period
68 self.data_management_max_threads = data_management_max_threads
69 self.lazy_errors = lazy_errors
70 self.retries = retries
71 self.run_dir = run_dir
72 self.strategy = strategy
73 self.usage_tracking = usage_tracking
74 self.db_logger_config = db_logger_config
75
76 @property
77 def executors(self):
78 return self._executors
79
80 @executors.setter
81 def executors(self, executors):
82 labels = [e.label for e in executors]
83 duplicates = [e for n, e in enumerate(labels) if e in labels[:n]]
84 if len(duplicates) > 0:
85 raise ConfigurationError('Executors must have unique labels ({})'.format(
86 ', '.join(['label={}'.format(repr(d)) for d in duplicates])))
87 self._executors = executors
88
[end of parsl/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/config.py b/parsl/config.py
--- a/parsl/config.py
+++ b/parsl/config.py
@@ -48,7 +48,7 @@
app_cache=True,
checkpoint_files=None,
checkpoint_mode=None,
- checkpoint_period="00:30:00",
+ checkpoint_period=None,
data_management_max_threads=10,
lazy_errors=True,
retries=0,
@@ -62,8 +62,17 @@
self.app_cache = app_cache
self.checkpoint_files = checkpoint_files
self.checkpoint_mode = checkpoint_mode
- if checkpoint_mode is not 'periodic' and checkpoint_period is not None:
- logger.debug("Checkpoint period only has an effect with checkpoint_mode='periodic'")
+ if checkpoint_period is not None:
+ if checkpoint_mode is None:
+ logger.debug('The requested `checkpoint_period={}` will have no effect because `checkpoint_mode=None`'.format(
+ checkpoint_period)
+ )
+ elif checkpoint_mode is not 'periodic':
+ logger.debug("Requested checkpoint period of {} only has an effect with checkpoint_mode='periodic'".format(
+ checkpoint_period)
+ )
+ if checkpoint_mode is 'periodic' and checkpoint_period is None:
+ checkpoint_period = "00:30:00"
self.checkpoint_period = checkpoint_period
self.data_management_max_threads = data_management_max_threads
self.lazy_errors = lazy_errors
|
{"golden_diff": "diff --git a/parsl/config.py b/parsl/config.py\n--- a/parsl/config.py\n+++ b/parsl/config.py\n@@ -48,7 +48,7 @@\n app_cache=True,\n checkpoint_files=None,\n checkpoint_mode=None,\n- checkpoint_period=\"00:30:00\",\n+ checkpoint_period=None,\n data_management_max_threads=10,\n lazy_errors=True,\n retries=0,\n@@ -62,8 +62,17 @@\n self.app_cache = app_cache\n self.checkpoint_files = checkpoint_files\n self.checkpoint_mode = checkpoint_mode\n- if checkpoint_mode is not 'periodic' and checkpoint_period is not None:\n- logger.debug(\"Checkpoint period only has an effect with checkpoint_mode='periodic'\")\n+ if checkpoint_period is not None:\n+ if checkpoint_mode is None:\n+ logger.debug('The requested `checkpoint_period={}` will have no effect because `checkpoint_mode=None`'.format(\n+ checkpoint_period)\n+ )\n+ elif checkpoint_mode is not 'periodic':\n+ logger.debug(\"Requested checkpoint period of {} only has an effect with checkpoint_mode='periodic'\".format(\n+ checkpoint_period)\n+ )\n+ if checkpoint_mode is 'periodic' and checkpoint_period is None:\n+ checkpoint_period = \"00:30:00\"\n self.checkpoint_period = checkpoint_period\n self.data_management_max_threads = data_management_max_threads\n self.lazy_errors = lazy_errors\n", "issue": "confusing error message with simple configs\nUsing this config:\r\n\r\n```\r\nconfig = Config(executors=[ThreadPoolExecutor()])\r\n```\r\n\r\nparsl startup logs this message to the logger:\r\n\r\n```\r\n$ ./c.py \r\n2018-07-11 08:04:42 parsl.config:66 [DEBUG] Checkpoint period only has an effect with checkpoint_mode='periodic'\r\n```\r\n\r\nThis appears to be in config creation, as it happens even without passing that config to create a DataFlowKernel.\r\n\r\nThis might cause user confusion that something is broken/misconfigured.\r\n\n", "before_files": [{"content": "import logging\n\nfrom libsubmit.utils import RepresentationMixin\nfrom parsl.executors.threads import ThreadPoolExecutor\nfrom parsl.dataflow.error import ConfigurationError\n\nlogger = logging.getLogger(__name__)\n\n\nclass Config(RepresentationMixin):\n \"\"\"\n Specification of Parsl configuration options.\n\n Parameters\n ----------\n executors : list of ParslExecutor, optional\n List of executor instances to use. Possible executors include :class:`~parsl.executors.threads.ThreadPoolExecutor`,\n :class:`~parsl.executors.ipp.IPyParallelExecutor`, or :class:`~parsl.executors.swift_t.TurbineExecutor`. Default\n is [:class:`~parsl.executors.threads.ThreadPoolExecutor()`].\n app_cache : bool, optional\n Enable app caching. Default is True.\n checkpoint_files : list of str, optional\n List of paths to checkpoint files. Default is None.\n checkpoint_mode : str, optional\n Checkpoint mode to use, can be 'dfk_exit', 'task_exit', or 'periodic'. If set to\n `None`, checkpointing will be disabled. Default is None.\n checkpoint_period : str, optional\n Time interval (in \"HH:MM:SS\") at which to checkpoint completed tasks. Only has an effect if\n `checkpoint_mode='periodic'`.\n data_management_max_threads : int, optional\n Maximum number of threads to allocate for the data manager to use for managing input and output transfers.\n Default is 10.\n lazy_errors : bool, optional\n If True, errors from task failures will not be raised until `future.result()` is called. Otherwise, they will\n be raised as soon as the task returns. Default is True.\n retries : int, optional\n Set the number of retries in case of failure. Default is 0.\n run_dir : str, optional\n Path to run directory. Default is 'runinfo'.\n strategy : str, optional\n Strategy to use for scaling resources according to workflow needs. Can be 'simple' or `None`. If `None`, dynamic\n scaling will be disabled. Default is 'simple'.\n usage_tracking : bool, optional\n Enable usage tracking. Default is True.\n \"\"\"\n def __init__(self,\n executors=None,\n app_cache=True,\n checkpoint_files=None,\n checkpoint_mode=None,\n checkpoint_period=\"00:30:00\",\n data_management_max_threads=10,\n lazy_errors=True,\n retries=0,\n run_dir='runinfo',\n strategy='simple',\n db_logger_config=None,\n usage_tracking=True):\n if executors is None:\n executors = [ThreadPoolExecutor()]\n self.executors = executors\n self.app_cache = app_cache\n self.checkpoint_files = checkpoint_files\n self.checkpoint_mode = checkpoint_mode\n if checkpoint_mode is not 'periodic' and checkpoint_period is not None:\n logger.debug(\"Checkpoint period only has an effect with checkpoint_mode='periodic'\")\n self.checkpoint_period = checkpoint_period\n self.data_management_max_threads = data_management_max_threads\n self.lazy_errors = lazy_errors\n self.retries = retries\n self.run_dir = run_dir\n self.strategy = strategy\n self.usage_tracking = usage_tracking\n self.db_logger_config = db_logger_config\n\n @property\n def executors(self):\n return self._executors\n\n @executors.setter\n def executors(self, executors):\n labels = [e.label for e in executors]\n duplicates = [e for n, e in enumerate(labels) if e in labels[:n]]\n if len(duplicates) > 0:\n raise ConfigurationError('Executors must have unique labels ({})'.format(\n ', '.join(['label={}'.format(repr(d)) for d in duplicates])))\n self._executors = executors\n", "path": "parsl/config.py"}]}
| 1,649 | 326 |
gh_patches_debug_15003
|
rasdani/github-patches
|
git_diff
|
canonical__microk8s-4284
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Internet connectivity check fails if ICMP traffic is restricted
<!--
Thank you for submitting an issue. Please fill in the template below
information about the bug you encountered.
-->
#### Summary
<!-- Please explain the bug in a few short sentences -->
When trying to install on macOS I get a failure to connect to the internet, the check is done via a ping (ICMP) traffic which isn't allowed on my corp network. However http/https (which are the connections actually required) are fine. I can't see any other use of ping other than a test.
#### What Should Happen Instead?
<!-- Please explain what the expected behavior is -->
The internet check should check for http(s) connectivity instead of using ping.
#### Reproduction Steps
<!-- Are you able to consistently reproduce the issue? Please add a list of steps that lead to the bug. -->
1. be on network that disallows ICMP traffic
2. microk8s install
#### Introspection Report
<!-- Please run `microk8s inspect` and attach the generated tarball. -->
N/A
#### Can you suggest a fix?
<!-- (This section is optional). How do you propose that the issue be fixed? -->
https://github.com/canonical/microk8s/blob/master/installer/vm_providers/_base_provider.py#L131
`curl --fail --head https://snapcraft.io` instead perhaps?
#### Are you interested in contributing with a fix?
<!-- yes/no, or @mention maintainers. Community contributions are welcome. -->
Yes
<!-- Thank you for making MicroK8s better -->
</issue>
<code>
[start of installer/vm_providers/_base_provider.py]
1 # -*- Mode:Python; indent-tabs-mode:nil; tab-width:4 -*-
2 #
3 # Copyright (C) 2018-2019 Canonical Ltd
4 #
5 # This program is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License version 3 as
7 # published by the Free Software Foundation.
8 #
9 # This program is distributed in the hope that it will be useful,
10 # but WITHOUT ANY WARRANTY; without even the implied warranty of
11 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
12 # GNU General Public License for more details.
13 #
14 # You should have received a copy of the GNU General Public License
15 # along with this program. If not, see <http://www.gnu.org/licenses/>.
16
17 import abc
18 import logging
19 import os
20 import pathlib
21 import shlex
22 import sys
23 from typing import Dict
24 from typing import Optional, Sequence
25
26 from . import errors
27 from ._multipass._instance_info import InstanceInfo
28
29 logger = logging.getLogger(__name__)
30
31
32 class Provider(abc.ABC):
33 def __init__(
34 self,
35 *,
36 echoer,
37 is_ephemeral: bool = False,
38 build_provider_flags: Dict[str, str] = None,
39 ) -> None:
40 self.echoer = echoer
41 self._is_ephemeral = is_ephemeral
42
43 self.instance_name = "microk8s-vm"
44
45 if build_provider_flags is None:
46 build_provider_flags = dict()
47 self.build_provider_flags = build_provider_flags.copy()
48
49 self._cached_home_directory: Optional[pathlib.Path] = None
50
51 @classmethod
52 def ensure_provider(cls) -> None:
53 """Necessary steps to ensure the provider is correctly setup."""
54
55 @classmethod
56 def setup_provider(cls, *, echoer) -> None:
57 """Necessary steps to install the provider on the host."""
58
59 @classmethod
60 def _get_provider_name(cls) -> str:
61 """Return the provider name."""
62
63 @classmethod
64 def _get_is_snap_injection_capable(cls) -> bool:
65 """Return whether the provider can install snaps from the host."""
66
67 @abc.abstractmethod
68 def create(self) -> None:
69 """Provider steps needed to create a fully functioning environment."""
70
71 @abc.abstractmethod
72 def destroy(self) -> None:
73 """Provider steps needed to ensure the instance is destroyed.
74
75 This method should be safe to call multiple times and do nothing
76 if the instance to destroy is already destroyed.
77 """
78
79 @abc.abstractmethod
80 def get_instance_info(self) -> InstanceInfo:
81 """Return the instance info."""
82
83 @abc.abstractmethod
84 def run(self, command: Sequence[str], hide_output: bool = False) -> Optional[bytes]:
85 """Run a command on the instance."""
86
87 @abc.abstractmethod
88 def _launch(self, specs: Dict):
89 """Launch the instance."""
90
91 @abc.abstractmethod
92 def _start(self):
93 """Start an existing the instance."""
94
95 @abc.abstractmethod
96 def _push_file(self, *, source: str, destination: str) -> None:
97 """Push a file into the instance."""
98
99 @abc.abstractmethod
100 def pull_file(self, name: str, destination: str, delete: bool = False) -> None:
101 """
102 Provider steps needed to retrieve a file from the instance, optionally
103 deleting the source file after a successful retrieval.
104
105 :param name: the remote filename.
106 :type name: str
107 :param destination: the local filename.
108 :type destination: str
109 :param delete: whether the file should be deleted.
110 :type delete: bool
111 """
112
113 @abc.abstractmethod
114 def shell(self) -> None:
115 """Provider steps to provide a shell into the instance."""
116
117 def launch_instance(self, specs: Dict) -> None:
118 try:
119 # An ProviderStartError exception here means we need to create.
120 self._start()
121 except errors.ProviderInstanceNotFoundError:
122 self._launch(specs)
123 self._check_connectivity()
124 # We need to setup MicroK8s and scan for cli commands.
125 self._setup_microk8s(specs)
126 self._copy_kubeconfig_to_kubectl(specs)
127
128 def _check_connectivity(self) -> None:
129 """Check that the VM can access the internet."""
130 try:
131 self.run("ping -c 1 snapcraft.io".split(), hide_output=True)
132 except errors.ProviderLaunchError:
133 self.destroy()
134 url = None
135 if sys.platform == "win32":
136 url = "https://multipass.run/docs/troubleshooting-networking-on-windows"
137 elif sys.platform == "darwin":
138 url = "https://multipass.run/docs/troubleshooting-networking-on-macos"
139
140 if url:
141 raise errors.ConnectivityError(
142 "The VM cannot connect to snapcraft.io, please see {}".format(url)
143 )
144 else:
145 raise
146
147 def _copy_kubeconfig_to_kubectl(self, specs: Dict):
148 kubeconfig_path = specs.get("kubeconfig")
149 kubeconfig = self.run(command=["microk8s", "config"], hide_output=True)
150
151 if not os.path.isdir(os.path.dirname(kubeconfig_path)):
152 os.mkdir(os.path.dirname(kubeconfig_path))
153
154 with open(kubeconfig_path, "wb") as f:
155 f.write(kubeconfig)
156
157 def _setup_microk8s(self, specs: Dict) -> None:
158 self.run("snap install microk8s --classic --channel {}".format(specs["channel"]).split())
159 if sys.platform == "win32":
160 self.run("snap install microk8s-integrator-windows".split())
161 elif sys.platform == "darwin":
162 self.run("snap install microk8s-integrator-macos".split())
163
164 def _get_env_command(self) -> Sequence[str]:
165 """Get command sequence for `env` with configured flags."""
166
167 env_list = ["env"]
168
169 # Pass through configurable environment variables.
170 for key in ["http_proxy", "https_proxy"]:
171 value = self.build_provider_flags.get(key)
172 if not value:
173 continue
174
175 # Ensure item is treated as string and append it.
176 value = str(value)
177 env_list.append(f"{key}={value}")
178
179 return env_list
180
181 def _get_home_directory(self) -> pathlib.Path:
182 """Get user's home directory path."""
183 if self._cached_home_directory is not None:
184 return self._cached_home_directory
185
186 command = ["printenv", "HOME"]
187 run_output = self.run(command=command, hide_output=True)
188
189 # Shouldn't happen, but due to _run()'s return type as being Optional,
190 # we need to check for it anyways for mypy.
191 if not run_output:
192 provider_name = self._get_provider_name()
193 raise errors.ProviderExecError(
194 provider_name=provider_name, command=command, exit_code=2
195 )
196
197 cached_home_directory = pathlib.Path(run_output.decode().strip())
198
199 self._cached_home_directory = cached_home_directory
200 return cached_home_directory
201
202 def _base_has_changed(self, base: str, provider_base: str) -> bool:
203 # Make it backwards compatible with instances without project info
204 if base == "core18" and provider_base is None:
205 return False
206 elif base != provider_base:
207 return True
208
209 return False
210
211 def _log_run(self, command: Sequence[str]) -> None:
212 cmd_string = " ".join([shlex.quote(c) for c in command])
213 logger.debug(f"Running: {cmd_string}")
214
215 @abc.abstractmethod
216 def stop(self) -> None:
217 pass
218
[end of installer/vm_providers/_base_provider.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/installer/vm_providers/_base_provider.py b/installer/vm_providers/_base_provider.py
--- a/installer/vm_providers/_base_provider.py
+++ b/installer/vm_providers/_base_provider.py
@@ -18,6 +18,7 @@
import logging
import os
import pathlib
+import requests
import shlex
import sys
from typing import Dict
@@ -128,8 +129,8 @@
def _check_connectivity(self) -> None:
"""Check that the VM can access the internet."""
try:
- self.run("ping -c 1 snapcraft.io".split(), hide_output=True)
- except errors.ProviderLaunchError:
+ requests.get("https://snapcraft.io")
+ except requests.exceptions.RequestException:
self.destroy()
url = None
if sys.platform == "win32":
|
{"golden_diff": "diff --git a/installer/vm_providers/_base_provider.py b/installer/vm_providers/_base_provider.py\n--- a/installer/vm_providers/_base_provider.py\n+++ b/installer/vm_providers/_base_provider.py\n@@ -18,6 +18,7 @@\n import logging\n import os\n import pathlib\n+import requests\n import shlex\n import sys\n from typing import Dict\n@@ -128,8 +129,8 @@\n def _check_connectivity(self) -> None:\n \"\"\"Check that the VM can access the internet.\"\"\"\n try:\n- self.run(\"ping -c 1 snapcraft.io\".split(), hide_output=True)\n- except errors.ProviderLaunchError:\n+ requests.get(\"https://snapcraft.io\")\n+ except requests.exceptions.RequestException:\n self.destroy()\n url = None\n if sys.platform == \"win32\":\n", "issue": "Internet connectivity check fails if ICMP traffic is restricted\n<!--\r\n Thank you for submitting an issue. Please fill in the template below\r\n information about the bug you encountered.\r\n-->\r\n\r\n#### Summary\r\n<!-- Please explain the bug in a few short sentences -->\r\nWhen trying to install on macOS I get a failure to connect to the internet, the check is done via a ping (ICMP) traffic which isn't allowed on my corp network. However http/https (which are the connections actually required) are fine. I can't see any other use of ping other than a test.\r\n\r\n#### What Should Happen Instead?\r\n<!-- Please explain what the expected behavior is -->\r\nThe internet check should check for http(s) connectivity instead of using ping.\r\n\r\n#### Reproduction Steps\r\n<!-- Are you able to consistently reproduce the issue? Please add a list of steps that lead to the bug. -->\r\n\r\n1. be on network that disallows ICMP traffic\r\n2. microk8s install\r\n\r\n#### Introspection Report\r\n<!-- Please run `microk8s inspect` and attach the generated tarball. -->\r\nN/A\r\n\r\n#### Can you suggest a fix?\r\n<!-- (This section is optional). How do you propose that the issue be fixed? -->\r\nhttps://github.com/canonical/microk8s/blob/master/installer/vm_providers/_base_provider.py#L131\r\n\r\n`curl --fail --head https://snapcraft.io` instead perhaps?\r\n\r\n#### Are you interested in contributing with a fix?\r\n<!-- yes/no, or @mention maintainers. Community contributions are welcome. -->\r\nYes\r\n\r\n<!-- Thank you for making MicroK8s better -->\r\n\n", "before_files": [{"content": "# -*- Mode:Python; indent-tabs-mode:nil; tab-width:4 -*-\n#\n# Copyright (C) 2018-2019 Canonical Ltd\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License version 3 as\n# published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n\nimport abc\nimport logging\nimport os\nimport pathlib\nimport shlex\nimport sys\nfrom typing import Dict\nfrom typing import Optional, Sequence\n\nfrom . import errors\nfrom ._multipass._instance_info import InstanceInfo\n\nlogger = logging.getLogger(__name__)\n\n\nclass Provider(abc.ABC):\n def __init__(\n self,\n *,\n echoer,\n is_ephemeral: bool = False,\n build_provider_flags: Dict[str, str] = None,\n ) -> None:\n self.echoer = echoer\n self._is_ephemeral = is_ephemeral\n\n self.instance_name = \"microk8s-vm\"\n\n if build_provider_flags is None:\n build_provider_flags = dict()\n self.build_provider_flags = build_provider_flags.copy()\n\n self._cached_home_directory: Optional[pathlib.Path] = None\n\n @classmethod\n def ensure_provider(cls) -> None:\n \"\"\"Necessary steps to ensure the provider is correctly setup.\"\"\"\n\n @classmethod\n def setup_provider(cls, *, echoer) -> None:\n \"\"\"Necessary steps to install the provider on the host.\"\"\"\n\n @classmethod\n def _get_provider_name(cls) -> str:\n \"\"\"Return the provider name.\"\"\"\n\n @classmethod\n def _get_is_snap_injection_capable(cls) -> bool:\n \"\"\"Return whether the provider can install snaps from the host.\"\"\"\n\n @abc.abstractmethod\n def create(self) -> None:\n \"\"\"Provider steps needed to create a fully functioning environment.\"\"\"\n\n @abc.abstractmethod\n def destroy(self) -> None:\n \"\"\"Provider steps needed to ensure the instance is destroyed.\n\n This method should be safe to call multiple times and do nothing\n if the instance to destroy is already destroyed.\n \"\"\"\n\n @abc.abstractmethod\n def get_instance_info(self) -> InstanceInfo:\n \"\"\"Return the instance info.\"\"\"\n\n @abc.abstractmethod\n def run(self, command: Sequence[str], hide_output: bool = False) -> Optional[bytes]:\n \"\"\"Run a command on the instance.\"\"\"\n\n @abc.abstractmethod\n def _launch(self, specs: Dict):\n \"\"\"Launch the instance.\"\"\"\n\n @abc.abstractmethod\n def _start(self):\n \"\"\"Start an existing the instance.\"\"\"\n\n @abc.abstractmethod\n def _push_file(self, *, source: str, destination: str) -> None:\n \"\"\"Push a file into the instance.\"\"\"\n\n @abc.abstractmethod\n def pull_file(self, name: str, destination: str, delete: bool = False) -> None:\n \"\"\"\n Provider steps needed to retrieve a file from the instance, optionally\n deleting the source file after a successful retrieval.\n\n :param name: the remote filename.\n :type name: str\n :param destination: the local filename.\n :type destination: str\n :param delete: whether the file should be deleted.\n :type delete: bool\n \"\"\"\n\n @abc.abstractmethod\n def shell(self) -> None:\n \"\"\"Provider steps to provide a shell into the instance.\"\"\"\n\n def launch_instance(self, specs: Dict) -> None:\n try:\n # An ProviderStartError exception here means we need to create.\n self._start()\n except errors.ProviderInstanceNotFoundError:\n self._launch(specs)\n self._check_connectivity()\n # We need to setup MicroK8s and scan for cli commands.\n self._setup_microk8s(specs)\n self._copy_kubeconfig_to_kubectl(specs)\n\n def _check_connectivity(self) -> None:\n \"\"\"Check that the VM can access the internet.\"\"\"\n try:\n self.run(\"ping -c 1 snapcraft.io\".split(), hide_output=True)\n except errors.ProviderLaunchError:\n self.destroy()\n url = None\n if sys.platform == \"win32\":\n url = \"https://multipass.run/docs/troubleshooting-networking-on-windows\"\n elif sys.platform == \"darwin\":\n url = \"https://multipass.run/docs/troubleshooting-networking-on-macos\"\n\n if url:\n raise errors.ConnectivityError(\n \"The VM cannot connect to snapcraft.io, please see {}\".format(url)\n )\n else:\n raise\n\n def _copy_kubeconfig_to_kubectl(self, specs: Dict):\n kubeconfig_path = specs.get(\"kubeconfig\")\n kubeconfig = self.run(command=[\"microk8s\", \"config\"], hide_output=True)\n\n if not os.path.isdir(os.path.dirname(kubeconfig_path)):\n os.mkdir(os.path.dirname(kubeconfig_path))\n\n with open(kubeconfig_path, \"wb\") as f:\n f.write(kubeconfig)\n\n def _setup_microk8s(self, specs: Dict) -> None:\n self.run(\"snap install microk8s --classic --channel {}\".format(specs[\"channel\"]).split())\n if sys.platform == \"win32\":\n self.run(\"snap install microk8s-integrator-windows\".split())\n elif sys.platform == \"darwin\":\n self.run(\"snap install microk8s-integrator-macos\".split())\n\n def _get_env_command(self) -> Sequence[str]:\n \"\"\"Get command sequence for `env` with configured flags.\"\"\"\n\n env_list = [\"env\"]\n\n # Pass through configurable environment variables.\n for key in [\"http_proxy\", \"https_proxy\"]:\n value = self.build_provider_flags.get(key)\n if not value:\n continue\n\n # Ensure item is treated as string and append it.\n value = str(value)\n env_list.append(f\"{key}={value}\")\n\n return env_list\n\n def _get_home_directory(self) -> pathlib.Path:\n \"\"\"Get user's home directory path.\"\"\"\n if self._cached_home_directory is not None:\n return self._cached_home_directory\n\n command = [\"printenv\", \"HOME\"]\n run_output = self.run(command=command, hide_output=True)\n\n # Shouldn't happen, but due to _run()'s return type as being Optional,\n # we need to check for it anyways for mypy.\n if not run_output:\n provider_name = self._get_provider_name()\n raise errors.ProviderExecError(\n provider_name=provider_name, command=command, exit_code=2\n )\n\n cached_home_directory = pathlib.Path(run_output.decode().strip())\n\n self._cached_home_directory = cached_home_directory\n return cached_home_directory\n\n def _base_has_changed(self, base: str, provider_base: str) -> bool:\n # Make it backwards compatible with instances without project info\n if base == \"core18\" and provider_base is None:\n return False\n elif base != provider_base:\n return True\n\n return False\n\n def _log_run(self, command: Sequence[str]) -> None:\n cmd_string = \" \".join([shlex.quote(c) for c in command])\n logger.debug(f\"Running: {cmd_string}\")\n\n @abc.abstractmethod\n def stop(self) -> None:\n pass\n", "path": "installer/vm_providers/_base_provider.py"}]}
| 3,093 | 194 |
gh_patches_debug_576
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-975
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.10
On the docket:
+ [x] Improve Pex packaging. (#961)
+ [x] Make the interpreter cache deterministic. (#960)
+ [x] Fix deprecation warning for `rU` mode (#956)
+ [x] Fix runtime resolve error message generation. (#955)
+ [x] Kill dead code. (#954)
+ [x] Many Pex tests fail under Python 2.7 in CI #967
+ [x] Add a `--local` mode for packaging the Pex PEX. #971
+ [x] Split Pex resolve API. (#970)
+ [x] Can't run PEX file when a dependency's wheel includes a build tag #964
+ [x] Expose network configuration in pex options. #803
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '2.1.9'
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '2.1.9'
+__version__ = '2.1.10'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '2.1.9'\n+__version__ = '2.1.10'\n", "issue": "Release 2.1.10\nOn the docket:\r\n+ [x] Improve Pex packaging. (#961)\r\n+ [x] Make the interpreter cache deterministic. (#960)\r\n+ [x] Fix deprecation warning for `rU` mode (#956)\r\n+ [x] Fix runtime resolve error message generation. (#955)\r\n+ [x] Kill dead code. (#954)\r\n+ [x] Many Pex tests fail under Python 2.7 in CI #967\r\n+ [x] Add a `--local` mode for packaging the Pex PEX. #971\r\n+ [x] Split Pex resolve API. (#970)\r\n+ [x] Can't run PEX file when a dependency's wheel includes a build tag #964\r\n+ [x] Expose network configuration in pex options. #803\r\n\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '2.1.9'\n", "path": "pex/version.py"}]}
| 776 | 95 |
gh_patches_debug_15828
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-2446
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document date_filter parameter for timetable endpoint
**Is your feature request related to a problem? Please describe.**
The /timetable/personal endpoint accepts an undocumented `date_filter` query parameter in ISO 8601 format, i.e. YYYY-MM-DD
**Describe the solution you'd like**
Document this in uclapi.com/docs
</issue>
<code>
[start of backend/uclapi/timetable/views.py]
1 from distutils.util import strtobool
2 from django.conf import settings
3
4
5 from rest_framework.decorators import api_view
6
7 from common.helpers import PrettyJsonResponse as JsonResponse
8
9 from .models import Course
10
11 from .app_helpers import (
12 get_custom_timetable,
13 get_departmental_modules,
14 get_departments,
15 get_student_timetable,
16 get_course_modules,
17 validate_amp_query_params
18 )
19
20 from common.decorators import uclapi_protected_endpoint
21
22 _SETID = settings.ROOMBOOKINGS_SETID
23
24
25 @api_view(["GET"])
26 @uclapi_protected_endpoint(
27 personal_data=True,
28 required_scopes=['timetable'],
29 last_modified_redis_key='gencache'
30 )
31 def get_personal_timetable_endpoint(request, *args, **kwargs):
32 """
33 Returns a personal timetable of a user. Requires OAuth permissions.
34 """
35 token = kwargs['token']
36 user = token.user
37 try:
38 date_filter = request.GET["date_filter"]
39 timetable = get_student_timetable(user.employee_id, date_filter)
40 except KeyError:
41 timetable = get_student_timetable(user.employee_id)
42
43 response = {
44 "ok": True,
45 "timetable": timetable
46 }
47 return JsonResponse(response, custom_header_data=kwargs)
48
49
50 @api_view(["GET"])
51 @uclapi_protected_endpoint(
52 last_modified_redis_key='gencache'
53 )
54 def get_modules_timetable_endpoint(request, *args, **kwargs):
55 """
56 Returns a timetabe for a module or set of modules.
57 """
58 module_ids = request.GET.get("modules")
59 if module_ids is None or module_ids == '':
60 response = JsonResponse({
61 "ok": False,
62 "error": "No module IDs provided."
63 }, custom_header_data=kwargs)
64 response.status_code = 400
65 return response
66
67 modules = module_ids.split(',')
68
69 date_filter = request.GET.get("date_filter")
70 custom_timetable = get_custom_timetable(modules, date_filter)
71
72 if custom_timetable:
73 response_json = {
74 "ok": True,
75 "timetable": custom_timetable
76 }
77 return JsonResponse(response_json, custom_header_data=kwargs)
78 else:
79 response_json = {
80 "ok": False,
81 "error": "One or more invalid Module IDs supplied."
82 }
83 response = JsonResponse(response_json, custom_header_data=kwargs)
84 response.status_code = 400
85 return response
86
87
88 @api_view(["GET"])
89 @uclapi_protected_endpoint(
90 last_modified_redis_key='gencache'
91 )
92 def get_departments_endpoint(request, *args, **kwargs):
93 """
94 Returns all departments at UCL
95 """
96 departments = {
97 "ok": True,
98 "departments": get_departments()
99 }
100 return JsonResponse(departments, custom_header_data=kwargs)
101
102
103 @api_view(["GET"])
104 @uclapi_protected_endpoint(
105 last_modified_redis_key='gencache'
106 )
107 def get_department_courses_endpoint(request, *args, **kwargs):
108 """
109 Returns all the courses in UCL with relevant ID
110 """
111 try:
112 department_id = request.GET["department"]
113 except KeyError:
114 response = JsonResponse({
115 "ok": False,
116 "error": "No department ID provided."
117 }, custom_header_data=kwargs)
118 response.status_code = 400
119 return response
120
121 courses = {"ok": True, "courses": []}
122 for course in Course.objects.filter(owner=department_id,
123 setid=_SETID,
124 linkcode="YY"):
125 courses["courses"].append({
126 "course_name": course.name,
127 "course_id": course.courseid,
128 "years": course.numyears
129 })
130 return JsonResponse(courses, custom_header_data=kwargs)
131
132
133 @api_view(["GET"])
134 @uclapi_protected_endpoint(
135 last_modified_redis_key='gencache'
136 )
137 def get_department_modules_endpoint(request, *args, **kwargs):
138 """
139 Returns all modules taught by a particular department.
140 """
141 try:
142 department_id = request.GET["department"]
143 except KeyError:
144 response = JsonResponse({
145 "ok": False,
146 "error": "Supply a Department ID using the department parameter."
147 }, custom_header_data=kwargs)
148 response.status_code = 400
149 return response
150
151 modules = {
152 "ok": True,
153 "modules": get_departmental_modules(department_id)
154 }
155
156 return JsonResponse(modules, custom_header_data=kwargs)
157
158
159 @api_view(["GET"])
160 @uclapi_protected_endpoint(
161 last_modified_redis_key='timetable_gencache'
162 )
163 def get_course_modules_endpoint(request, *args, **kwargs):
164 """
165 Returns all modules taught on a particular course.
166 """
167 try:
168 course_id = request.GET["course"]
169 except KeyError:
170 response = JsonResponse({
171 "ok": False,
172 "error": "No course ID provided."
173 }, custom_header_data=kwargs)
174 response.status_code = 400
175 return response
176
177 if not validate_amp_query_params(request.query_params):
178 response = JsonResponse({
179 "ok": False,
180 "error": "Given parameter is not of corrrect type"
181 }, custom_header_data=kwargs)
182 response.status_code = 400
183 return response
184
185 if request.query_params.get('only_compulsory'):
186 try:
187 strtobool(request.query_params.get('only_compulsory'))
188 except ValueError:
189 response = JsonResponse({
190 "ok": False,
191 "error": "Given parameter is not of correct type"
192 }, custom_header_data=kwargs)
193 response.status_code = 400
194 return response
195
196 if request.query_params.get('only_available'):
197 try:
198 strtobool(request.query_params.get('only_available'))
199 except ValueError:
200 response = JsonResponse({
201 "ok": False,
202 "error": "Given parameter is not of correct type"
203 }, custom_header_data=kwargs)
204 response.status_code = 400
205 return response
206
207 if (request.query_params.get('only_available') and
208 request.query_params.get('only_compulsory')):
209 if (strtobool(request.query_params.get('only_available')) and
210 strtobool(request.query_params.get('only_compulsory'))):
211 response = JsonResponse({
212 "ok": False,
213 "error": "only_available and only_compulsory"
214 " cannot both be true"
215 }, custom_header_data=kwargs)
216 response.status_code = 400
217 return response
218
219 modules = {
220 "ok": True,
221 "modules": get_course_modules(course_id, request.query_params)
222 }
223
224 return JsonResponse(modules, custom_header_data=kwargs)
225
[end of backend/uclapi/timetable/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py
--- a/backend/uclapi/timetable/views.py
+++ b/backend/uclapi/timetable/views.py
@@ -34,11 +34,8 @@
"""
token = kwargs['token']
user = token.user
- try:
- date_filter = request.GET["date_filter"]
- timetable = get_student_timetable(user.employee_id, date_filter)
- except KeyError:
- timetable = get_student_timetable(user.employee_id)
+ date_filter = request.GET.get("date")
+ timetable = get_student_timetable(user.employee_id, date_filter)
response = {
"ok": True,
@@ -66,7 +63,7 @@
modules = module_ids.split(',')
- date_filter = request.GET.get("date_filter")
+ date_filter = request.GET.get("date")
custom_timetable = get_custom_timetable(modules, date_filter)
if custom_timetable:
|
{"golden_diff": "diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py\n--- a/backend/uclapi/timetable/views.py\n+++ b/backend/uclapi/timetable/views.py\n@@ -34,11 +34,8 @@\n \"\"\"\n token = kwargs['token']\n user = token.user\n- try:\n- date_filter = request.GET[\"date_filter\"]\n- timetable = get_student_timetable(user.employee_id, date_filter)\n- except KeyError:\n- timetable = get_student_timetable(user.employee_id)\n+ date_filter = request.GET.get(\"date\")\n+ timetable = get_student_timetable(user.employee_id, date_filter)\n \n response = {\n \"ok\": True,\n@@ -66,7 +63,7 @@\n \n modules = module_ids.split(',')\n \n- date_filter = request.GET.get(\"date_filter\")\n+ date_filter = request.GET.get(\"date\")\n custom_timetable = get_custom_timetable(modules, date_filter)\n \n if custom_timetable:\n", "issue": "Document date_filter parameter for timetable endpoint\n**Is your feature request related to a problem? Please describe.**\r\n\r\nThe /timetable/personal endpoint accepts an undocumented `date_filter` query parameter in ISO 8601 format, i.e. YYYY-MM-DD\r\n\r\n**Describe the solution you'd like**\r\n\r\nDocument this in uclapi.com/docs\n", "before_files": [{"content": "from distutils.util import strtobool\nfrom django.conf import settings\n\n\nfrom rest_framework.decorators import api_view\n\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom .models import Course\n\nfrom .app_helpers import (\n get_custom_timetable,\n get_departmental_modules,\n get_departments,\n get_student_timetable,\n get_course_modules,\n validate_amp_query_params\n)\n\nfrom common.decorators import uclapi_protected_endpoint\n\n_SETID = settings.ROOMBOOKINGS_SETID\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n personal_data=True,\n required_scopes=['timetable'],\n last_modified_redis_key='gencache'\n)\ndef get_personal_timetable_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns a personal timetable of a user. Requires OAuth permissions.\n \"\"\"\n token = kwargs['token']\n user = token.user\n try:\n date_filter = request.GET[\"date_filter\"]\n timetable = get_student_timetable(user.employee_id, date_filter)\n except KeyError:\n timetable = get_student_timetable(user.employee_id)\n\n response = {\n \"ok\": True,\n \"timetable\": timetable\n }\n return JsonResponse(response, custom_header_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n last_modified_redis_key='gencache'\n)\ndef get_modules_timetable_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns a timetabe for a module or set of modules.\n \"\"\"\n module_ids = request.GET.get(\"modules\")\n if module_ids is None or module_ids == '':\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"No module IDs provided.\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n modules = module_ids.split(',')\n\n date_filter = request.GET.get(\"date_filter\")\n custom_timetable = get_custom_timetable(modules, date_filter)\n\n if custom_timetable:\n response_json = {\n \"ok\": True,\n \"timetable\": custom_timetable\n }\n return JsonResponse(response_json, custom_header_data=kwargs)\n else:\n response_json = {\n \"ok\": False,\n \"error\": \"One or more invalid Module IDs supplied.\"\n }\n response = JsonResponse(response_json, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n last_modified_redis_key='gencache'\n)\ndef get_departments_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns all departments at UCL\n \"\"\"\n departments = {\n \"ok\": True,\n \"departments\": get_departments()\n }\n return JsonResponse(departments, custom_header_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n last_modified_redis_key='gencache'\n)\ndef get_department_courses_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns all the courses in UCL with relevant ID\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"No department ID provided.\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n courses = {\"ok\": True, \"courses\": []}\n for course in Course.objects.filter(owner=department_id,\n setid=_SETID,\n linkcode=\"YY\"):\n courses[\"courses\"].append({\n \"course_name\": course.name,\n \"course_id\": course.courseid,\n \"years\": course.numyears\n })\n return JsonResponse(courses, custom_header_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n last_modified_redis_key='gencache'\n)\ndef get_department_modules_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns all modules taught by a particular department.\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n modules = {\n \"ok\": True,\n \"modules\": get_departmental_modules(department_id)\n }\n\n return JsonResponse(modules, custom_header_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(\n last_modified_redis_key='timetable_gencache'\n)\ndef get_course_modules_endpoint(request, *args, **kwargs):\n \"\"\"\n Returns all modules taught on a particular course.\n \"\"\"\n try:\n course_id = request.GET[\"course\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"No course ID provided.\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n if not validate_amp_query_params(request.query_params):\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Given parameter is not of corrrect type\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n if request.query_params.get('only_compulsory'):\n try:\n strtobool(request.query_params.get('only_compulsory'))\n except ValueError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Given parameter is not of correct type\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n if request.query_params.get('only_available'):\n try:\n strtobool(request.query_params.get('only_available'))\n except ValueError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Given parameter is not of correct type\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n if (request.query_params.get('only_available') and\n request.query_params.get('only_compulsory')):\n if (strtobool(request.query_params.get('only_available')) and\n strtobool(request.query_params.get('only_compulsory'))):\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"only_available and only_compulsory\"\n \" cannot both be true\"\n }, custom_header_data=kwargs)\n response.status_code = 400\n return response\n\n modules = {\n \"ok\": True,\n \"modules\": get_course_modules(course_id, request.query_params)\n }\n\n return JsonResponse(modules, custom_header_data=kwargs)\n", "path": "backend/uclapi/timetable/views.py"}]}
| 2,624 | 226 |
gh_patches_debug_57411
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-2817
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Important typo in RandAugment default policy list
### Describe the bug
'translate_x' is in the default policy list twice, whereas 'translate_y' is missing.
### Reproduction steps
```bash
1. Open kornia/augmentation/auto/rand_augment/rand_augment.py
```
### Expected behavior
Current default_policy list:
```
default_policy: List[SUBPLOLICY_CONFIG] = [
[("auto_contrast", 0, 1)],
[("equalize", 0, 1)],
[("invert", 0, 1)],
[("rotate", -30.0, 30.0)],
[("posterize", 0.0, 4)],
[("solarize", 0.0, 1.0)],
[("solarize_add", 0.0, 0.43)],
[("color", 0.1, 1.9)],
[("contrast", 0.1, 1.9)],
[("brightness", 0.1, 1.9)],
[("sharpness", 0.1, 1.9)],
[("shear_x", -0.3, 0.3)],
[("shear_y", -0.3, 0.3)],
# (CutoutAbs, 0, 40),
[("translate_x", -0.1, 0.1)],
[("translate_x", -0.1, 0.1)],
]
```
Expected list:
```
default_policy: List[SUBPLOLICY_CONFIG] = [
[("auto_contrast", 0, 1)],
[("equalize", 0, 1)],
[("invert", 0, 1)],
[("rotate", -30.0, 30.0)],
[("posterize", 0.0, 4)],
[("solarize", 0.0, 1.0)],
[("solarize_add", 0.0, 0.43)],
[("color", 0.1, 1.9)],
[("contrast", 0.1, 1.9)],
[("brightness", 0.1, 1.9)],
[("sharpness", 0.1, 1.9)],
[("shear_x", -0.3, 0.3)],
[("shear_y", -0.3, 0.3)],
# (CutoutAbs, 0, 40),
[("translate_x", -0.1, 0.1)],
[("translate_y", -0.1, 0.1)],
]
```
### Environment
```shell
Irrelevant
```
### Additional context
_No response_
</issue>
<code>
[start of kornia/augmentation/auto/rand_augment/rand_augment.py]
1 from typing import Dict, Iterator, List, Optional, Tuple, Union, cast
2
3 import torch
4 from torch.distributions import Categorical
5
6 from kornia.augmentation.auto.base import SUBPLOLICY_CONFIG, PolicyAugmentBase
7 from kornia.augmentation.auto.operations import OperationBase
8 from kornia.augmentation.auto.operations.policy import PolicySequential
9 from kornia.augmentation.container.params import ParamItem
10 from kornia.core import Module, Tensor
11
12 from . import ops
13
14 default_policy: List[SUBPLOLICY_CONFIG] = [
15 [("auto_contrast", 0, 1)],
16 [("equalize", 0, 1)],
17 [("invert", 0, 1)],
18 [("rotate", -30.0, 30.0)],
19 [("posterize", 0.0, 4)],
20 [("solarize", 0.0, 1.0)],
21 [("solarize_add", 0.0, 0.43)],
22 [("color", 0.1, 1.9)],
23 [("contrast", 0.1, 1.9)],
24 [("brightness", 0.1, 1.9)],
25 [("sharpness", 0.1, 1.9)],
26 [("shear_x", -0.3, 0.3)],
27 [("shear_y", -0.3, 0.3)],
28 # (CutoutAbs, 0, 40),
29 [("translate_x", -0.1, 0.1)],
30 [("translate_x", -0.1, 0.1)],
31 ]
32
33
34 class RandAugment(PolicyAugmentBase):
35 """Apply RandAugment :cite:`cubuk2020randaugment` augmentation strategies.
36
37 Args:
38 n: the number of augmentations to apply sequentially.
39 m: magnitude for all the augmentations, ranged from [0, 30].
40 policy: candidate transformations. If None, a default candidate list will be used.
41 transformation_matrix_mode: computation mode for the chained transformation matrix, via `.transform_matrix`
42 attribute.
43 If `silent`, transformation matrix will be computed silently and the non-rigid
44 modules will be ignored as identity transformations.
45 If `rigid`, transformation matrix will be computed silently and the non-rigid
46 modules will trigger errors.
47 If `skip`, transformation matrix will be totally ignored.
48
49 Examples:
50 >>> import kornia.augmentation as K
51 >>> in_tensor = torch.rand(5, 3, 30, 30)
52 >>> aug = K.AugmentationSequential(RandAugment(n=2, m=10))
53 >>> aug(in_tensor).shape
54 torch.Size([5, 3, 30, 30])
55 """
56
57 def __init__(
58 self,
59 n: int,
60 m: int,
61 policy: Optional[List[SUBPLOLICY_CONFIG]] = None,
62 transformation_matrix_mode: str = "silent",
63 ) -> None:
64 if m <= 0 or m >= 30:
65 raise ValueError(f"Expect `m` in [0, 30]. Got {m}.")
66
67 if policy is None:
68 _policy = default_policy
69 else:
70 _policy = policy
71
72 super().__init__(_policy, transformation_matrix_mode=transformation_matrix_mode)
73 selection_weights = torch.tensor([1.0 / len(self)] * len(self))
74 self.rand_selector = Categorical(selection_weights)
75 self.n = n
76 self.m = m
77
78 def compose_subpolicy_sequential(self, subpolicy: SUBPLOLICY_CONFIG) -> PolicySequential:
79 if len(subpolicy) != 1:
80 raise RuntimeError(f"Each policy must have only one operation for RandAugment. Got {len(subpolicy)}.")
81 name, low, high = subpolicy[0]
82 return PolicySequential(*[getattr(ops, name)(low, high)])
83
84 def get_forward_sequence(self, params: Optional[List[ParamItem]] = None) -> Iterator[Tuple[str, Module]]:
85 if params is None:
86 idx = self.rand_selector.sample((self.n,))
87 return self.get_children_by_indices(idx)
88
89 return self.get_children_by_params(params)
90
91 def forward_parameters(self, batch_shape: torch.Size) -> List[ParamItem]:
92 named_modules: Iterator[Tuple[str, Module]] = self.get_forward_sequence()
93
94 params: List[ParamItem] = []
95 mod_param: Union[Dict[str, Tensor], List[ParamItem]]
96 m = torch.tensor([self.m / 30] * batch_shape[0])
97
98 for name, module in named_modules:
99 # The Input PolicySequential only got one child.
100 op = cast(PolicySequential, module)[0]
101 op = cast(OperationBase, op)
102 mag = None
103 if op.magnitude_range is not None:
104 minval, maxval = op.magnitude_range
105 mag = m * float(maxval - minval) + minval
106 mod_param = op.forward_parameters(batch_shape, mag=mag)
107 # Compose it
108 param = ParamItem(name, [ParamItem(next(iter(module.named_children()))[0], mod_param)])
109 params.append(param)
110
111 return params
112
[end of kornia/augmentation/auto/rand_augment/rand_augment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kornia/augmentation/auto/rand_augment/rand_augment.py b/kornia/augmentation/auto/rand_augment/rand_augment.py
--- a/kornia/augmentation/auto/rand_augment/rand_augment.py
+++ b/kornia/augmentation/auto/rand_augment/rand_augment.py
@@ -27,7 +27,7 @@
[("shear_y", -0.3, 0.3)],
# (CutoutAbs, 0, 40),
[("translate_x", -0.1, 0.1)],
- [("translate_x", -0.1, 0.1)],
+ [("translate_y", -0.1, 0.1)],
]
|
{"golden_diff": "diff --git a/kornia/augmentation/auto/rand_augment/rand_augment.py b/kornia/augmentation/auto/rand_augment/rand_augment.py\n--- a/kornia/augmentation/auto/rand_augment/rand_augment.py\n+++ b/kornia/augmentation/auto/rand_augment/rand_augment.py\n@@ -27,7 +27,7 @@\n [(\"shear_y\", -0.3, 0.3)],\n # (CutoutAbs, 0, 40),\n [(\"translate_x\", -0.1, 0.1)],\n- [(\"translate_x\", -0.1, 0.1)],\n+ [(\"translate_y\", -0.1, 0.1)],\n ]\n", "issue": "Important typo in RandAugment default policy list\n### Describe the bug\n\n'translate_x' is in the default policy list twice, whereas 'translate_y' is missing.\n\n### Reproduction steps\n\n```bash\n1. Open kornia/augmentation/auto/rand_augment/rand_augment.py\n```\n\n\n### Expected behavior\n\nCurrent default_policy list:\r\n```\r\ndefault_policy: List[SUBPLOLICY_CONFIG] = [\r\n [(\"auto_contrast\", 0, 1)],\r\n [(\"equalize\", 0, 1)],\r\n [(\"invert\", 0, 1)],\r\n [(\"rotate\", -30.0, 30.0)],\r\n [(\"posterize\", 0.0, 4)],\r\n [(\"solarize\", 0.0, 1.0)],\r\n [(\"solarize_add\", 0.0, 0.43)],\r\n [(\"color\", 0.1, 1.9)],\r\n [(\"contrast\", 0.1, 1.9)],\r\n [(\"brightness\", 0.1, 1.9)],\r\n [(\"sharpness\", 0.1, 1.9)],\r\n [(\"shear_x\", -0.3, 0.3)],\r\n [(\"shear_y\", -0.3, 0.3)],\r\n # (CutoutAbs, 0, 40),\r\n [(\"translate_x\", -0.1, 0.1)],\r\n [(\"translate_x\", -0.1, 0.1)],\r\n]\r\n```\r\n\r\nExpected list:\r\n```\r\ndefault_policy: List[SUBPLOLICY_CONFIG] = [\r\n [(\"auto_contrast\", 0, 1)],\r\n [(\"equalize\", 0, 1)],\r\n [(\"invert\", 0, 1)],\r\n [(\"rotate\", -30.0, 30.0)],\r\n [(\"posterize\", 0.0, 4)],\r\n [(\"solarize\", 0.0, 1.0)],\r\n [(\"solarize_add\", 0.0, 0.43)],\r\n [(\"color\", 0.1, 1.9)],\r\n [(\"contrast\", 0.1, 1.9)],\r\n [(\"brightness\", 0.1, 1.9)],\r\n [(\"sharpness\", 0.1, 1.9)],\r\n [(\"shear_x\", -0.3, 0.3)],\r\n [(\"shear_y\", -0.3, 0.3)],\r\n # (CutoutAbs, 0, 40),\r\n [(\"translate_x\", -0.1, 0.1)],\r\n [(\"translate_y\", -0.1, 0.1)],\r\n]\r\n```\n\n### Environment\n\n```shell\nIrrelevant\n```\n\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "from typing import Dict, Iterator, List, Optional, Tuple, Union, cast\n\nimport torch\nfrom torch.distributions import Categorical\n\nfrom kornia.augmentation.auto.base import SUBPLOLICY_CONFIG, PolicyAugmentBase\nfrom kornia.augmentation.auto.operations import OperationBase\nfrom kornia.augmentation.auto.operations.policy import PolicySequential\nfrom kornia.augmentation.container.params import ParamItem\nfrom kornia.core import Module, Tensor\n\nfrom . import ops\n\ndefault_policy: List[SUBPLOLICY_CONFIG] = [\n [(\"auto_contrast\", 0, 1)],\n [(\"equalize\", 0, 1)],\n [(\"invert\", 0, 1)],\n [(\"rotate\", -30.0, 30.0)],\n [(\"posterize\", 0.0, 4)],\n [(\"solarize\", 0.0, 1.0)],\n [(\"solarize_add\", 0.0, 0.43)],\n [(\"color\", 0.1, 1.9)],\n [(\"contrast\", 0.1, 1.9)],\n [(\"brightness\", 0.1, 1.9)],\n [(\"sharpness\", 0.1, 1.9)],\n [(\"shear_x\", -0.3, 0.3)],\n [(\"shear_y\", -0.3, 0.3)],\n # (CutoutAbs, 0, 40),\n [(\"translate_x\", -0.1, 0.1)],\n [(\"translate_x\", -0.1, 0.1)],\n]\n\n\nclass RandAugment(PolicyAugmentBase):\n \"\"\"Apply RandAugment :cite:`cubuk2020randaugment` augmentation strategies.\n\n Args:\n n: the number of augmentations to apply sequentially.\n m: magnitude for all the augmentations, ranged from [0, 30].\n policy: candidate transformations. If None, a default candidate list will be used.\n transformation_matrix_mode: computation mode for the chained transformation matrix, via `.transform_matrix`\n attribute.\n If `silent`, transformation matrix will be computed silently and the non-rigid\n modules will be ignored as identity transformations.\n If `rigid`, transformation matrix will be computed silently and the non-rigid\n modules will trigger errors.\n If `skip`, transformation matrix will be totally ignored.\n\n Examples:\n >>> import kornia.augmentation as K\n >>> in_tensor = torch.rand(5, 3, 30, 30)\n >>> aug = K.AugmentationSequential(RandAugment(n=2, m=10))\n >>> aug(in_tensor).shape\n torch.Size([5, 3, 30, 30])\n \"\"\"\n\n def __init__(\n self,\n n: int,\n m: int,\n policy: Optional[List[SUBPLOLICY_CONFIG]] = None,\n transformation_matrix_mode: str = \"silent\",\n ) -> None:\n if m <= 0 or m >= 30:\n raise ValueError(f\"Expect `m` in [0, 30]. Got {m}.\")\n\n if policy is None:\n _policy = default_policy\n else:\n _policy = policy\n\n super().__init__(_policy, transformation_matrix_mode=transformation_matrix_mode)\n selection_weights = torch.tensor([1.0 / len(self)] * len(self))\n self.rand_selector = Categorical(selection_weights)\n self.n = n\n self.m = m\n\n def compose_subpolicy_sequential(self, subpolicy: SUBPLOLICY_CONFIG) -> PolicySequential:\n if len(subpolicy) != 1:\n raise RuntimeError(f\"Each policy must have only one operation for RandAugment. Got {len(subpolicy)}.\")\n name, low, high = subpolicy[0]\n return PolicySequential(*[getattr(ops, name)(low, high)])\n\n def get_forward_sequence(self, params: Optional[List[ParamItem]] = None) -> Iterator[Tuple[str, Module]]:\n if params is None:\n idx = self.rand_selector.sample((self.n,))\n return self.get_children_by_indices(idx)\n\n return self.get_children_by_params(params)\n\n def forward_parameters(self, batch_shape: torch.Size) -> List[ParamItem]:\n named_modules: Iterator[Tuple[str, Module]] = self.get_forward_sequence()\n\n params: List[ParamItem] = []\n mod_param: Union[Dict[str, Tensor], List[ParamItem]]\n m = torch.tensor([self.m / 30] * batch_shape[0])\n\n for name, module in named_modules:\n # The Input PolicySequential only got one child.\n op = cast(PolicySequential, module)[0]\n op = cast(OperationBase, op)\n mag = None\n if op.magnitude_range is not None:\n minval, maxval = op.magnitude_range\n mag = m * float(maxval - minval) + minval\n mod_param = op.forward_parameters(batch_shape, mag=mag)\n # Compose it\n param = ParamItem(name, [ParamItem(next(iter(module.named_children()))[0], mod_param)])\n params.append(param)\n\n return params\n", "path": "kornia/augmentation/auto/rand_augment/rand_augment.py"}]}
| 2,543 | 158 |
gh_patches_debug_2746
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-3351
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BERT classifier doesn't work under distributed_train
The default tokenization is re, I think it's building the dictionary along the way...
**Logs**
Please paste the command line output:
```
ValueError: Dictionaries should be pre-built before distributed train.
ValueError: Dictionaries should be pre-built before distributed train.
```
</issue>
<code>
[start of parlai/agents/bert_ranker/bert_dictionary.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6 from parlai.core.dict import DictionaryAgent
7 from parlai.zoo.bert.build import download
8 from parlai.utils.misc import warn_once
9
10 try:
11 from pytorch_pretrained_bert import BertTokenizer
12 except ImportError:
13 raise ImportError(
14 'BERT rankers needs pytorch-pretrained-BERT installed. \n '
15 'pip install pytorch-pretrained-bert'
16 )
17 from .helpers import VOCAB_PATH
18
19 import os
20
21
22 class BertDictionaryAgent(DictionaryAgent):
23 """
24 Allow to use the Torch Agent with the wordpiece dictionary of Hugging Face.
25 """
26
27 def __init__(self, opt):
28 super().__init__(opt)
29 # initialize from vocab path
30 warn_once(
31 'WARNING: BERT uses a Hugging Face tokenizer; ParlAI dictionary args are ignored'
32 )
33 download(opt['datapath'])
34 vocab_path = os.path.join(opt['datapath'], 'models', 'bert_models', VOCAB_PATH)
35 self.tokenizer = BertTokenizer.from_pretrained(vocab_path)
36
37 self.start_token = '[CLS]'
38 self.end_token = '[SEP]'
39 self.null_token = '[PAD]'
40 self.start_idx = self.tokenizer.convert_tokens_to_ids(['[CLS]'])[
41 0
42 ] # should be 101
43 self.end_idx = self.tokenizer.convert_tokens_to_ids(['[SEP]'])[
44 0
45 ] # should be 102
46 self.pad_idx = self.tokenizer.convert_tokens_to_ids(['[PAD]'])[0] # should be 0
47 # set tok2ind for special tokens
48 self.tok2ind[self.start_token] = self.start_idx
49 self.tok2ind[self.end_token] = self.end_idx
50 self.tok2ind[self.null_token] = self.pad_idx
51 # set ind2tok for special tokens
52 self.ind2tok[self.start_idx] = self.start_token
53 self.ind2tok[self.end_idx] = self.end_token
54 self.ind2tok[self.pad_idx] = self.null_token
55
56 def txt2vec(self, text, vec_type=list):
57 tokens = self.tokenizer.tokenize(text)
58 tokens_id = self.tokenizer.convert_tokens_to_ids(tokens)
59 return tokens_id
60
61 def vec2txt(self, vec):
62 if not isinstance(vec, list):
63 # assume tensor
64 idxs = [idx.item() for idx in vec.cpu()]
65 else:
66 idxs = vec
67 toks = self.tokenizer.convert_ids_to_tokens(idxs)
68 return ' '.join(toks)
69
70 def act(self):
71 return {}
72
[end of parlai/agents/bert_ranker/bert_dictionary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parlai/agents/bert_ranker/bert_dictionary.py b/parlai/agents/bert_ranker/bert_dictionary.py
--- a/parlai/agents/bert_ranker/bert_dictionary.py
+++ b/parlai/agents/bert_ranker/bert_dictionary.py
@@ -24,6 +24,9 @@
Allow to use the Torch Agent with the wordpiece dictionary of Hugging Face.
"""
+ def is_prebuit(self):
+ return True
+
def __init__(self, opt):
super().__init__(opt)
# initialize from vocab path
|
{"golden_diff": "diff --git a/parlai/agents/bert_ranker/bert_dictionary.py b/parlai/agents/bert_ranker/bert_dictionary.py\n--- a/parlai/agents/bert_ranker/bert_dictionary.py\n+++ b/parlai/agents/bert_ranker/bert_dictionary.py\n@@ -24,6 +24,9 @@\n Allow to use the Torch Agent with the wordpiece dictionary of Hugging Face.\n \"\"\"\n \n+ def is_prebuit(self):\n+ return True\n+\n def __init__(self, opt):\n super().__init__(opt)\n # initialize from vocab path\n", "issue": "BERT classifier doesn't work under distributed_train\nThe default tokenization is re, I think it's building the dictionary along the way...\r\n\r\n**Logs**\r\nPlease paste the command line output:\r\n\r\n```\r\nValueError: Dictionaries should be pre-built before distributed train.\r\nValueError: Dictionaries should be pre-built before distributed train.\r\n```\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\nfrom parlai.core.dict import DictionaryAgent\nfrom parlai.zoo.bert.build import download\nfrom parlai.utils.misc import warn_once\n\ntry:\n from pytorch_pretrained_bert import BertTokenizer\nexcept ImportError:\n raise ImportError(\n 'BERT rankers needs pytorch-pretrained-BERT installed. \\n '\n 'pip install pytorch-pretrained-bert'\n )\nfrom .helpers import VOCAB_PATH\n\nimport os\n\n\nclass BertDictionaryAgent(DictionaryAgent):\n \"\"\"\n Allow to use the Torch Agent with the wordpiece dictionary of Hugging Face.\n \"\"\"\n\n def __init__(self, opt):\n super().__init__(opt)\n # initialize from vocab path\n warn_once(\n 'WARNING: BERT uses a Hugging Face tokenizer; ParlAI dictionary args are ignored'\n )\n download(opt['datapath'])\n vocab_path = os.path.join(opt['datapath'], 'models', 'bert_models', VOCAB_PATH)\n self.tokenizer = BertTokenizer.from_pretrained(vocab_path)\n\n self.start_token = '[CLS]'\n self.end_token = '[SEP]'\n self.null_token = '[PAD]'\n self.start_idx = self.tokenizer.convert_tokens_to_ids(['[CLS]'])[\n 0\n ] # should be 101\n self.end_idx = self.tokenizer.convert_tokens_to_ids(['[SEP]'])[\n 0\n ] # should be 102\n self.pad_idx = self.tokenizer.convert_tokens_to_ids(['[PAD]'])[0] # should be 0\n # set tok2ind for special tokens\n self.tok2ind[self.start_token] = self.start_idx\n self.tok2ind[self.end_token] = self.end_idx\n self.tok2ind[self.null_token] = self.pad_idx\n # set ind2tok for special tokens\n self.ind2tok[self.start_idx] = self.start_token\n self.ind2tok[self.end_idx] = self.end_token\n self.ind2tok[self.pad_idx] = self.null_token\n\n def txt2vec(self, text, vec_type=list):\n tokens = self.tokenizer.tokenize(text)\n tokens_id = self.tokenizer.convert_tokens_to_ids(tokens)\n return tokens_id\n\n def vec2txt(self, vec):\n if not isinstance(vec, list):\n # assume tensor\n idxs = [idx.item() for idx in vec.cpu()]\n else:\n idxs = vec\n toks = self.tokenizer.convert_ids_to_tokens(idxs)\n return ' '.join(toks)\n\n def act(self):\n return {}\n", "path": "parlai/agents/bert_ranker/bert_dictionary.py"}]}
| 1,361 | 138 |
gh_patches_debug_17982
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-820
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add separate button for Aalto login (aside Haka login)
In a recent change (pull request #804 ) Aalto (or other local organization) login button was replaced by general Haka login, that directs user to organization selector, to allow login also using other Haka organization accounts than Aalto. This was an intermediate step (due to difficulties in shibboleth configuration), and a separate button for local organization login should now be added back, as majority of students would be using it, and usually some additional guidance may need to be added, e.g. for open university students to use local organization account instead of other organization.
</issue>
<code>
[start of aplus/urls.py]
1 from django.conf import settings
2 from django.conf.urls import url, include
3 from django.contrib import admin
4 from django.contrib.sitemaps.views import sitemap
5 from django.urls import path
6
7 import shibboleth_login.urls
8 import social_django.urls
9 import userprofile.urls, userprofile.sitemaps
10 import course.urls, course.long_urls, course.sitemaps
11 import exercise.urls, exercise.sitemaps
12 import edit_course.urls
13 import deviations.urls
14 import notification.urls
15 import external_services.urls
16 import news.urls
17 import diploma.urls
18 import apps.urls
19 import api.urls_v2
20 import redirect_old_urls.urls
21
22
23 admin.autodiscover()
24
25 all_sitemaps = {
26 **course.sitemaps.all_sitemaps,
27 **exercise.sitemaps.all_sitemaps,
28 **userprofile.sitemaps.all_sitemaps,
29 }
30
31 # Pay attention to the order the URL patterns will be matched!
32 urlpatterns = [
33 url(r'^admin/', admin.site.urls),
34 url(r'^shibboleth/', include(shibboleth_login.urls)),
35 url('', include(social_django.urls, namespace='social')),
36 url(r'^api/v(?P<version>(2))/', include(api.urls_v2)), # why version in url? doc/api_versioning.md
37 url(r'^accounts/', include(userprofile.urls)),
38 url(r'^diploma/', include(diploma.urls)),
39 url(r'^', include(redirect_old_urls.urls)),
40 url(r'^', include(apps.urls)),
41 url(r'^', include(news.urls)),
42 url(r'^', include(external_services.urls)),
43 url(r'^', include(course.long_urls)),
44 url(r'^', include(deviations.urls)),
45 url(r'^', include(edit_course.urls)),
46 url(r'^', include(notification.urls)),
47 url(r'^', include(exercise.urls)),
48 url(r'^', include(course.urls)),
49 path('sitemap.xml', sitemap, { 'sitemaps': all_sitemaps },
50 name='django.contrib.sitemaps.views.sitemap'),
51 ]
52
53 if settings.DEBUG:
54 import django.views.static
55 urlpatterns.insert(0, url(r'^media/(?P<path>.*)$', django.views.static.serve,
56 { 'document_root': settings.MEDIA_ROOT }))
57
[end of aplus/urls.py]
[start of shibboleth_login/urls.py]
1 from django.conf import settings
2 from django.conf.urls import url
3
4 from . import views
5
6
7 urlpatterns = [
8 url(r'^login/$', views.login, name="shibboleth-login"),
9 ]
10
11 if settings.DEBUG:
12 urlpatterns.append(url(r'^debug/$', views.debug))
13
[end of shibboleth_login/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aplus/urls.py b/aplus/urls.py
--- a/aplus/urls.py
+++ b/aplus/urls.py
@@ -31,7 +31,7 @@
# Pay attention to the order the URL patterns will be matched!
urlpatterns = [
url(r'^admin/', admin.site.urls),
- url(r'^shibboleth/', include(shibboleth_login.urls)),
+ url(r'^', include(shibboleth_login.urls)),
url('', include(social_django.urls, namespace='social')),
url(r'^api/v(?P<version>(2))/', include(api.urls_v2)), # why version in url? doc/api_versioning.md
url(r'^accounts/', include(userprofile.urls)),
diff --git a/shibboleth_login/urls.py b/shibboleth_login/urls.py
--- a/shibboleth_login/urls.py
+++ b/shibboleth_login/urls.py
@@ -5,7 +5,8 @@
urlpatterns = [
- url(r'^login/$', views.login, name="shibboleth-login"),
+ url(r'^shibboleth/login/$', views.login, name="shibboleth-login"),
+ url(r'^Shibboleth.sso/haka_login$', views.login, name="haka-login"),
]
if settings.DEBUG:
|
{"golden_diff": "diff --git a/aplus/urls.py b/aplus/urls.py\n--- a/aplus/urls.py\n+++ b/aplus/urls.py\n@@ -31,7 +31,7 @@\n # Pay attention to the order the URL patterns will be matched!\n urlpatterns = [\n url(r'^admin/', admin.site.urls),\n- url(r'^shibboleth/', include(shibboleth_login.urls)),\n+ url(r'^', include(shibboleth_login.urls)),\n url('', include(social_django.urls, namespace='social')),\n url(r'^api/v(?P<version>(2))/', include(api.urls_v2)), # why version in url? doc/api_versioning.md\n url(r'^accounts/', include(userprofile.urls)),\ndiff --git a/shibboleth_login/urls.py b/shibboleth_login/urls.py\n--- a/shibboleth_login/urls.py\n+++ b/shibboleth_login/urls.py\n@@ -5,7 +5,8 @@\n \n \n urlpatterns = [\n- url(r'^login/$', views.login, name=\"shibboleth-login\"),\n+ url(r'^shibboleth/login/$', views.login, name=\"shibboleth-login\"),\n+ url(r'^Shibboleth.sso/haka_login$', views.login, name=\"haka-login\"),\n ]\n \n if settings.DEBUG:\n", "issue": "Add separate button for Aalto login (aside Haka login)\nIn a recent change (pull request #804 ) Aalto (or other local organization) login button was replaced by general Haka login, that directs user to organization selector, to allow login also using other Haka organization accounts than Aalto. This was an intermediate step (due to difficulties in shibboleth configuration), and a separate button for local organization login should now be added back, as majority of students would be using it, and usually some additional guidance may need to be added, e.g. for open university students to use local organization account instead of other organization.\n", "before_files": [{"content": "from django.conf import settings\nfrom django.conf.urls import url, include\nfrom django.contrib import admin\nfrom django.contrib.sitemaps.views import sitemap\nfrom django.urls import path\n\nimport shibboleth_login.urls\nimport social_django.urls\nimport userprofile.urls, userprofile.sitemaps\nimport course.urls, course.long_urls, course.sitemaps\nimport exercise.urls, exercise.sitemaps\nimport edit_course.urls\nimport deviations.urls\nimport notification.urls\nimport external_services.urls\nimport news.urls\nimport diploma.urls\nimport apps.urls\nimport api.urls_v2\nimport redirect_old_urls.urls\n\n\nadmin.autodiscover()\n\nall_sitemaps = {\n **course.sitemaps.all_sitemaps,\n **exercise.sitemaps.all_sitemaps,\n **userprofile.sitemaps.all_sitemaps,\n}\n\n# Pay attention to the order the URL patterns will be matched!\nurlpatterns = [\n url(r'^admin/', admin.site.urls),\n url(r'^shibboleth/', include(shibboleth_login.urls)),\n url('', include(social_django.urls, namespace='social')),\n url(r'^api/v(?P<version>(2))/', include(api.urls_v2)), # why version in url? doc/api_versioning.md\n url(r'^accounts/', include(userprofile.urls)),\n url(r'^diploma/', include(diploma.urls)),\n url(r'^', include(redirect_old_urls.urls)),\n url(r'^', include(apps.urls)),\n url(r'^', include(news.urls)),\n url(r'^', include(external_services.urls)),\n url(r'^', include(course.long_urls)),\n url(r'^', include(deviations.urls)),\n url(r'^', include(edit_course.urls)),\n url(r'^', include(notification.urls)),\n url(r'^', include(exercise.urls)),\n url(r'^', include(course.urls)),\n path('sitemap.xml', sitemap, { 'sitemaps': all_sitemaps },\n name='django.contrib.sitemaps.views.sitemap'),\n]\n\nif settings.DEBUG:\n import django.views.static\n urlpatterns.insert(0, url(r'^media/(?P<path>.*)$', django.views.static.serve,\n { 'document_root': settings.MEDIA_ROOT }))\n", "path": "aplus/urls.py"}, {"content": "from django.conf import settings\nfrom django.conf.urls import url\n\nfrom . import views\n\n\nurlpatterns = [\n url(r'^login/$', views.login, name=\"shibboleth-login\"),\n]\n\nif settings.DEBUG:\n urlpatterns.append(url(r'^debug/$', views.debug))\n", "path": "shibboleth_login/urls.py"}]}
| 1,339 | 288 |
gh_patches_debug_1555
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-733
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Engine without an about property raises an exception
**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**
current master branch
**How did you install SearXNG?**
Add an engine without an about property to your `settings.yml` / e.g.:
```yaml
- name: locate
engine: command
command: ['locate', '{{QUERY}}']
shortcut: locate
tokens: [ '123', '456' ]
disabled: true
delimiter:
chars: ' '
keys: ['line']
```
**What happened?**
$ make run
Open preferences ..
```
Traceback (most recent call last):
...
File "searxng/searx/webutils.py", line 162, in engine_sort_key
return (engine.about.get('language', ''), engine.name)
AttributeError: module 'command' has no attribute 'about'
```
**Additional context**
@not-my-profile if you have time, could you please have a look about / thanks!
</issue>
<code>
[start of searx/engines/__init__.py]
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 # lint: pylint
3 """This module implements the engine loader.
4
5 Load and initialize the ``engines``, see :py:func:`load_engines` and register
6 :py:obj:`engine_shortcuts`.
7
8 usage::
9
10 load_engines( settings['engines'] )
11
12 """
13
14 import sys
15 import copy
16 from typing import Dict, List, Optional
17
18 from os.path import realpath, dirname
19 from babel.localedata import locale_identifiers
20 from searx import logger, settings
21 from searx.data import ENGINES_LANGUAGES
22 from searx.network import get
23 from searx.utils import load_module, match_language, gen_useragent
24
25
26 logger = logger.getChild('engines')
27 ENGINE_DIR = dirname(realpath(__file__))
28 BABEL_LANGS = [
29 lang_parts[0] + '-' + lang_parts[-1] if len(lang_parts) > 1 else lang_parts[0]
30 for lang_parts in (lang_code.split('_') for lang_code in locale_identifiers())
31 ]
32 ENGINE_DEFAULT_ARGS = {
33 "engine_type": "online",
34 "inactive": False,
35 "disabled": False,
36 "timeout": settings["outgoing"]["request_timeout"],
37 "shortcut": "-",
38 "categories": ["general"],
39 "supported_languages": [],
40 "language_aliases": {},
41 "paging": False,
42 "safesearch": False,
43 "time_range_support": False,
44 "enable_http": False,
45 "display_error_messages": True,
46 "tokens": [],
47 }
48 # set automatically when an engine does not have any tab category
49 OTHER_CATEGORY = 'other'
50
51
52 class Engine: # pylint: disable=too-few-public-methods
53 """This class is currently never initialized and only used for type hinting."""
54
55 name: str
56 engine: str
57 shortcut: str
58 categories: List[str]
59 supported_languages: List[str]
60 about: dict
61 inactive: bool
62 disabled: bool
63 language_support: bool
64 paging: bool
65 safesearch: bool
66 time_range_support: bool
67 timeout: float
68
69
70 # Defaults for the namespace of an engine module, see :py:func:`load_engine`
71
72 categories = {'general': []}
73 engines: Dict[str, Engine] = {}
74 engine_shortcuts = {}
75 """Simple map of registered *shortcuts* to name of the engine (or ``None``).
76
77 ::
78
79 engine_shortcuts[engine.shortcut] = engine.name
80
81 """
82
83
84 def load_engine(engine_data: dict) -> Optional[Engine]:
85 """Load engine from ``engine_data``.
86
87 :param dict engine_data: Attributes from YAML ``settings:engines/<engine>``
88 :return: initialized namespace of the ``<engine>``.
89
90 1. create a namespace and load module of the ``<engine>``
91 2. update namespace with the defaults from :py:obj:`ENGINE_DEFAULT_ARGS`
92 3. update namespace with values from ``engine_data``
93
94 If engine *is active*, return namespace of the engine, otherwise return
95 ``None``.
96
97 This function also returns ``None`` if initialization of the namespace fails
98 for one of the following reasons:
99
100 - engine name contains underscore
101 - engine name is not lowercase
102 - required attribute is not set :py:func:`is_missing_required_attributes`
103
104 """
105
106 engine_name = engine_data['name']
107 if '_' in engine_name:
108 logger.error('Engine name contains underscore: "{}"'.format(engine_name))
109 return None
110
111 if engine_name.lower() != engine_name:
112 logger.warn('Engine name is not lowercase: "{}", converting to lowercase'.format(engine_name))
113 engine_name = engine_name.lower()
114 engine_data['name'] = engine_name
115
116 # load_module
117 engine_module = engine_data['engine']
118 try:
119 engine = load_module(engine_module + '.py', ENGINE_DIR)
120 except (SyntaxError, KeyboardInterrupt, SystemExit, SystemError, ImportError, RuntimeError):
121 logger.exception('Fatal exception in engine "{}"'.format(engine_module))
122 sys.exit(1)
123 except BaseException:
124 logger.exception('Cannot load engine "{}"'.format(engine_module))
125 return None
126
127 update_engine_attributes(engine, engine_data)
128 set_language_attributes(engine)
129 update_attributes_for_tor(engine)
130
131 if not is_engine_active(engine):
132 return None
133
134 if is_missing_required_attributes(engine):
135 return None
136
137 set_loggers(engine, engine_name)
138
139 if not any(cat in settings['categories_as_tabs'] for cat in engine.categories):
140 engine.categories.append(OTHER_CATEGORY)
141
142 return engine
143
144
145 def set_loggers(engine, engine_name):
146 # set the logger for engine
147 engine.logger = logger.getChild(engine_name)
148 # the engine may have load some other engines
149 # may sure the logger is initialized
150 for module_name, module in sys.modules.items():
151 if (
152 module_name.startswith("searx.engines")
153 and module_name != "searx.engines.__init__"
154 and not hasattr(module, "logger")
155 ):
156 module_engine_name = module_name.split(".")[-1]
157 module.logger = logger.getChild(module_engine_name)
158
159
160 def update_engine_attributes(engine: Engine, engine_data):
161 # set engine attributes from engine_data
162 for param_name, param_value in engine_data.items():
163 if param_name == 'categories':
164 if isinstance(param_value, str):
165 param_value = list(map(str.strip, param_value.split(',')))
166 engine.categories = param_value
167 elif hasattr(engine, 'about') and param_name == 'about':
168 engine.about = {**engine.about, **engine_data['about']}
169 else:
170 setattr(engine, param_name, param_value)
171
172 # set default attributes
173 for arg_name, arg_value in ENGINE_DEFAULT_ARGS.items():
174 if not hasattr(engine, arg_name):
175 setattr(engine, arg_name, copy.deepcopy(arg_value))
176
177
178 def set_language_attributes(engine: Engine):
179 # assign supported languages from json file
180 if engine.name in ENGINES_LANGUAGES:
181 engine.supported_languages = ENGINES_LANGUAGES[engine.name]
182
183 elif engine.engine in ENGINES_LANGUAGES:
184 # The key of the dictionary ENGINES_LANGUAGES is the *engine name*
185 # configured in settings.xml. When multiple engines are configured in
186 # settings.yml to use the same origin engine (python module) these
187 # additional engines can use the languages from the origin engine.
188 # For this use the configured ``engine: ...`` from settings.yml
189 engine.supported_languages = ENGINES_LANGUAGES[engine.engine]
190
191 if hasattr(engine, 'language'):
192 # For an engine, when there is `language: ...` in the YAML settings, the
193 # engine supports only one language, in this case
194 # engine.supported_languages should contains this value defined in
195 # settings.yml
196 if engine.language not in engine.supported_languages:
197 raise ValueError(
198 "settings.yml - engine: '%s' / language: '%s' not supported" % (engine.name, engine.language)
199 )
200
201 if isinstance(engine.supported_languages, dict):
202 engine.supported_languages = {engine.language: engine.supported_languages[engine.language]}
203 else:
204 engine.supported_languages = [engine.language]
205
206 # find custom aliases for non standard language codes
207 for engine_lang in engine.supported_languages:
208 iso_lang = match_language(engine_lang, BABEL_LANGS, fallback=None)
209 if (
210 iso_lang
211 and iso_lang != engine_lang
212 and not engine_lang.startswith(iso_lang)
213 and iso_lang not in engine.supported_languages
214 ):
215 engine.language_aliases[iso_lang] = engine_lang
216
217 # language_support
218 engine.language_support = len(engine.supported_languages) > 0
219
220 # assign language fetching method if auxiliary method exists
221 if hasattr(engine, '_fetch_supported_languages'):
222 headers = {
223 'User-Agent': gen_useragent(),
224 'Accept-Language': "en-US,en;q=0.5", # bing needs to set the English language
225 }
226 engine.fetch_supported_languages = (
227 # pylint: disable=protected-access
228 lambda: engine._fetch_supported_languages(get(engine.supported_languages_url, headers=headers))
229 )
230
231
232 def update_attributes_for_tor(engine):
233 if settings['outgoing'].get('using_tor_proxy') and hasattr(engine, 'onion_url'):
234 engine.search_url = engine.onion_url + getattr(engine, 'search_path', '')
235 engine.timeout += settings['outgoing'].get('extra_proxy_timeout', 0)
236
237
238 def is_missing_required_attributes(engine):
239 """An attribute is required when its name doesn't start with ``_`` (underline).
240 Required attributes must not be ``None``.
241
242 """
243 missing = False
244 for engine_attr in dir(engine):
245 if not engine_attr.startswith('_') and getattr(engine, engine_attr) is None:
246 logger.error('Missing engine config attribute: "{0}.{1}"'.format(engine.name, engine_attr))
247 missing = True
248 return missing
249
250
251 def is_engine_active(engine: Engine):
252 # check if engine is inactive
253 if engine.inactive is True:
254 return False
255
256 # exclude onion engines if not using tor
257 if 'onions' in engine.categories and not settings['outgoing'].get('using_tor_proxy'):
258 return False
259
260 return True
261
262
263 def register_engine(engine: Engine):
264 if engine.name in engines:
265 logger.error('Engine config error: ambigious name: {0}'.format(engine.name))
266 sys.exit(1)
267 engines[engine.name] = engine
268
269 if engine.shortcut in engine_shortcuts:
270 logger.error('Engine config error: ambigious shortcut: {0}'.format(engine.shortcut))
271 sys.exit(1)
272 engine_shortcuts[engine.shortcut] = engine.name
273
274 for category_name in engine.categories:
275 categories.setdefault(category_name, []).append(engine)
276
277
278 def load_engines(engine_list):
279 """usage: ``engine_list = settings['engines']``"""
280 engines.clear()
281 engine_shortcuts.clear()
282 categories.clear()
283 categories['general'] = []
284 for engine_data in engine_list:
285 engine = load_engine(engine_data)
286 if engine:
287 register_engine(engine)
288 return engines
289
[end of searx/engines/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/engines/__init__.py b/searx/engines/__init__.py
--- a/searx/engines/__init__.py
+++ b/searx/engines/__init__.py
@@ -44,6 +44,7 @@
"enable_http": False,
"display_error_messages": True,
"tokens": [],
+ "about": {},
}
# set automatically when an engine does not have any tab category
OTHER_CATEGORY = 'other'
|
{"golden_diff": "diff --git a/searx/engines/__init__.py b/searx/engines/__init__.py\n--- a/searx/engines/__init__.py\n+++ b/searx/engines/__init__.py\n@@ -44,6 +44,7 @@\n \"enable_http\": False,\n \"display_error_messages\": True,\n \"tokens\": [],\n+ \"about\": {},\n }\n # set automatically when an engine does not have any tab category\n OTHER_CATEGORY = 'other'\n", "issue": "Engine without an about property raises an exception\n**Version of SearXNG, commit number if you are using on master branch and stipulate if you forked SearXNG**\r\n\r\ncurrent master branch\r\n\r\n**How did you install SearXNG?**\r\n\r\nAdd an engine without an about property to your `settings.yml` / e.g.:\r\n\r\n```yaml\r\n - name: locate\r\n engine: command\r\n command: ['locate', '{{QUERY}}']\r\n shortcut: locate\r\n tokens: [ '123', '456' ]\r\n disabled: true\r\n delimiter:\r\n chars: ' '\r\n keys: ['line']\r\n```\r\n\r\n**What happened?**\r\n\r\n $ make run\r\n\r\nOpen preferences ..\r\n\r\n```\r\nTraceback (most recent call last):\r\n ...\r\n File \"searxng/searx/webutils.py\", line 162, in engine_sort_key\r\n return (engine.about.get('language', ''), engine.name)\r\nAttributeError: module 'command' has no attribute 'about'\r\n```\r\n\r\n**Additional context**\r\n\r\n@not-my-profile if you have time, could you please have a look about / thanks!\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n# lint: pylint\n\"\"\"This module implements the engine loader.\n\nLoad and initialize the ``engines``, see :py:func:`load_engines` and register\n:py:obj:`engine_shortcuts`.\n\nusage::\n\n load_engines( settings['engines'] )\n\n\"\"\"\n\nimport sys\nimport copy\nfrom typing import Dict, List, Optional\n\nfrom os.path import realpath, dirname\nfrom babel.localedata import locale_identifiers\nfrom searx import logger, settings\nfrom searx.data import ENGINES_LANGUAGES\nfrom searx.network import get\nfrom searx.utils import load_module, match_language, gen_useragent\n\n\nlogger = logger.getChild('engines')\nENGINE_DIR = dirname(realpath(__file__))\nBABEL_LANGS = [\n lang_parts[0] + '-' + lang_parts[-1] if len(lang_parts) > 1 else lang_parts[0]\n for lang_parts in (lang_code.split('_') for lang_code in locale_identifiers())\n]\nENGINE_DEFAULT_ARGS = {\n \"engine_type\": \"online\",\n \"inactive\": False,\n \"disabled\": False,\n \"timeout\": settings[\"outgoing\"][\"request_timeout\"],\n \"shortcut\": \"-\",\n \"categories\": [\"general\"],\n \"supported_languages\": [],\n \"language_aliases\": {},\n \"paging\": False,\n \"safesearch\": False,\n \"time_range_support\": False,\n \"enable_http\": False,\n \"display_error_messages\": True,\n \"tokens\": [],\n}\n# set automatically when an engine does not have any tab category\nOTHER_CATEGORY = 'other'\n\n\nclass Engine: # pylint: disable=too-few-public-methods\n \"\"\"This class is currently never initialized and only used for type hinting.\"\"\"\n\n name: str\n engine: str\n shortcut: str\n categories: List[str]\n supported_languages: List[str]\n about: dict\n inactive: bool\n disabled: bool\n language_support: bool\n paging: bool\n safesearch: bool\n time_range_support: bool\n timeout: float\n\n\n# Defaults for the namespace of an engine module, see :py:func:`load_engine`\n\ncategories = {'general': []}\nengines: Dict[str, Engine] = {}\nengine_shortcuts = {}\n\"\"\"Simple map of registered *shortcuts* to name of the engine (or ``None``).\n\n::\n\n engine_shortcuts[engine.shortcut] = engine.name\n\n\"\"\"\n\n\ndef load_engine(engine_data: dict) -> Optional[Engine]:\n \"\"\"Load engine from ``engine_data``.\n\n :param dict engine_data: Attributes from YAML ``settings:engines/<engine>``\n :return: initialized namespace of the ``<engine>``.\n\n 1. create a namespace and load module of the ``<engine>``\n 2. update namespace with the defaults from :py:obj:`ENGINE_DEFAULT_ARGS`\n 3. update namespace with values from ``engine_data``\n\n If engine *is active*, return namespace of the engine, otherwise return\n ``None``.\n\n This function also returns ``None`` if initialization of the namespace fails\n for one of the following reasons:\n\n - engine name contains underscore\n - engine name is not lowercase\n - required attribute is not set :py:func:`is_missing_required_attributes`\n\n \"\"\"\n\n engine_name = engine_data['name']\n if '_' in engine_name:\n logger.error('Engine name contains underscore: \"{}\"'.format(engine_name))\n return None\n\n if engine_name.lower() != engine_name:\n logger.warn('Engine name is not lowercase: \"{}\", converting to lowercase'.format(engine_name))\n engine_name = engine_name.lower()\n engine_data['name'] = engine_name\n\n # load_module\n engine_module = engine_data['engine']\n try:\n engine = load_module(engine_module + '.py', ENGINE_DIR)\n except (SyntaxError, KeyboardInterrupt, SystemExit, SystemError, ImportError, RuntimeError):\n logger.exception('Fatal exception in engine \"{}\"'.format(engine_module))\n sys.exit(1)\n except BaseException:\n logger.exception('Cannot load engine \"{}\"'.format(engine_module))\n return None\n\n update_engine_attributes(engine, engine_data)\n set_language_attributes(engine)\n update_attributes_for_tor(engine)\n\n if not is_engine_active(engine):\n return None\n\n if is_missing_required_attributes(engine):\n return None\n\n set_loggers(engine, engine_name)\n\n if not any(cat in settings['categories_as_tabs'] for cat in engine.categories):\n engine.categories.append(OTHER_CATEGORY)\n\n return engine\n\n\ndef set_loggers(engine, engine_name):\n # set the logger for engine\n engine.logger = logger.getChild(engine_name)\n # the engine may have load some other engines\n # may sure the logger is initialized\n for module_name, module in sys.modules.items():\n if (\n module_name.startswith(\"searx.engines\")\n and module_name != \"searx.engines.__init__\"\n and not hasattr(module, \"logger\")\n ):\n module_engine_name = module_name.split(\".\")[-1]\n module.logger = logger.getChild(module_engine_name)\n\n\ndef update_engine_attributes(engine: Engine, engine_data):\n # set engine attributes from engine_data\n for param_name, param_value in engine_data.items():\n if param_name == 'categories':\n if isinstance(param_value, str):\n param_value = list(map(str.strip, param_value.split(',')))\n engine.categories = param_value\n elif hasattr(engine, 'about') and param_name == 'about':\n engine.about = {**engine.about, **engine_data['about']}\n else:\n setattr(engine, param_name, param_value)\n\n # set default attributes\n for arg_name, arg_value in ENGINE_DEFAULT_ARGS.items():\n if not hasattr(engine, arg_name):\n setattr(engine, arg_name, copy.deepcopy(arg_value))\n\n\ndef set_language_attributes(engine: Engine):\n # assign supported languages from json file\n if engine.name in ENGINES_LANGUAGES:\n engine.supported_languages = ENGINES_LANGUAGES[engine.name]\n\n elif engine.engine in ENGINES_LANGUAGES:\n # The key of the dictionary ENGINES_LANGUAGES is the *engine name*\n # configured in settings.xml. When multiple engines are configured in\n # settings.yml to use the same origin engine (python module) these\n # additional engines can use the languages from the origin engine.\n # For this use the configured ``engine: ...`` from settings.yml\n engine.supported_languages = ENGINES_LANGUAGES[engine.engine]\n\n if hasattr(engine, 'language'):\n # For an engine, when there is `language: ...` in the YAML settings, the\n # engine supports only one language, in this case\n # engine.supported_languages should contains this value defined in\n # settings.yml\n if engine.language not in engine.supported_languages:\n raise ValueError(\n \"settings.yml - engine: '%s' / language: '%s' not supported\" % (engine.name, engine.language)\n )\n\n if isinstance(engine.supported_languages, dict):\n engine.supported_languages = {engine.language: engine.supported_languages[engine.language]}\n else:\n engine.supported_languages = [engine.language]\n\n # find custom aliases for non standard language codes\n for engine_lang in engine.supported_languages:\n iso_lang = match_language(engine_lang, BABEL_LANGS, fallback=None)\n if (\n iso_lang\n and iso_lang != engine_lang\n and not engine_lang.startswith(iso_lang)\n and iso_lang not in engine.supported_languages\n ):\n engine.language_aliases[iso_lang] = engine_lang\n\n # language_support\n engine.language_support = len(engine.supported_languages) > 0\n\n # assign language fetching method if auxiliary method exists\n if hasattr(engine, '_fetch_supported_languages'):\n headers = {\n 'User-Agent': gen_useragent(),\n 'Accept-Language': \"en-US,en;q=0.5\", # bing needs to set the English language\n }\n engine.fetch_supported_languages = (\n # pylint: disable=protected-access\n lambda: engine._fetch_supported_languages(get(engine.supported_languages_url, headers=headers))\n )\n\n\ndef update_attributes_for_tor(engine):\n if settings['outgoing'].get('using_tor_proxy') and hasattr(engine, 'onion_url'):\n engine.search_url = engine.onion_url + getattr(engine, 'search_path', '')\n engine.timeout += settings['outgoing'].get('extra_proxy_timeout', 0)\n\n\ndef is_missing_required_attributes(engine):\n \"\"\"An attribute is required when its name doesn't start with ``_`` (underline).\n Required attributes must not be ``None``.\n\n \"\"\"\n missing = False\n for engine_attr in dir(engine):\n if not engine_attr.startswith('_') and getattr(engine, engine_attr) is None:\n logger.error('Missing engine config attribute: \"{0}.{1}\"'.format(engine.name, engine_attr))\n missing = True\n return missing\n\n\ndef is_engine_active(engine: Engine):\n # check if engine is inactive\n if engine.inactive is True:\n return False\n\n # exclude onion engines if not using tor\n if 'onions' in engine.categories and not settings['outgoing'].get('using_tor_proxy'):\n return False\n\n return True\n\n\ndef register_engine(engine: Engine):\n if engine.name in engines:\n logger.error('Engine config error: ambigious name: {0}'.format(engine.name))\n sys.exit(1)\n engines[engine.name] = engine\n\n if engine.shortcut in engine_shortcuts:\n logger.error('Engine config error: ambigious shortcut: {0}'.format(engine.shortcut))\n sys.exit(1)\n engine_shortcuts[engine.shortcut] = engine.name\n\n for category_name in engine.categories:\n categories.setdefault(category_name, []).append(engine)\n\n\ndef load_engines(engine_list):\n \"\"\"usage: ``engine_list = settings['engines']``\"\"\"\n engines.clear()\n engine_shortcuts.clear()\n categories.clear()\n categories['general'] = []\n for engine_data in engine_list:\n engine = load_engine(engine_data)\n if engine:\n register_engine(engine)\n return engines\n", "path": "searx/engines/__init__.py"}]}
| 3,777 | 110 |
gh_patches_debug_30577
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-3054
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Helpful exceptions on "a named thing was not found"
[This was originally mentioned in #1601](https://github.com/Pylons/pyramid/issues/1601), but @mmerickel wanted it to be a separate issue, so here goes:
Whenever one uses an invalid kwarg name in `view_config`, or provides an invalid route name for a view, one gets an exception that just states that the given name was wrong. As this is an exceptional condition at startup time, and more so usually meaning that the whole application startup failed, it really would not matter if we used some extra cycles to make the error messages more helpful.
Especially with lots of 3rd-party stuff `include`d in the configurations, it might be really hard to remember how _exactly_ to write the name of a certain predicate, and usually this means more than 5 minutes of googling again. Thus I propose that the exception message would list close matches to these values, so that using `@view_config(method='POST')` would state `Unknown predicate values: {'method': 'POST'}; did you mean request_method`, for example I modified the [raise for invalid predicate names](https://github.com/Pylons/pyramid/blob/master/pyramid/config/util.py#L157) to
```
try:
from difflib import get_close_matches
closest = []
names = [ name for name, _ in ordered ]
for name in kw:
closest.extend(get_close_matches(name, names, 3))
raise ConfigurationError(
'Unknown predicate values: %r (did you mean %s)'
% (kw, ','.join(closest)))
except ImportError:
pass
raise ConfigurationError('Unknown predicate values: %r' % (kw,))
```
Which produces the aforementioned message. The runtime overhead of this is 0 (excepting for a few more bytecodes loaded on startup) for successful configuration and minimal overhead in mostly fatal errors that would make the server not start anyway. The `difflib.get_close_matches` function itself has been in the Python stdlib since 2.1... refactored in a utility function, this close matching could be used for all the cases where the configurator could at configuration time list the allowed values for something.
</issue>
<code>
[start of pyramid/config/util.py]
1 from hashlib import md5
2 import inspect
3
4 from pyramid.compat import (
5 bytes_,
6 getargspec,
7 is_nonstr_iter
8 )
9
10 from pyramid.compat import im_func
11 from pyramid.exceptions import ConfigurationError
12 from pyramid.registry import predvalseq
13
14 from pyramid.util import (
15 TopologicalSorter,
16 action_method,
17 ActionInfo,
18 )
19
20 action_method = action_method # support bw compat imports
21 ActionInfo = ActionInfo # support bw compat imports
22
23 MAX_ORDER = 1 << 30
24 DEFAULT_PHASH = md5().hexdigest()
25
26 class not_(object):
27 """
28
29 You can invert the meaning of any predicate value by wrapping it in a call
30 to :class:`pyramid.config.not_`.
31
32 .. code-block:: python
33 :linenos:
34
35 from pyramid.config import not_
36
37 config.add_view(
38 'mypackage.views.my_view',
39 route_name='ok',
40 request_method=not_('POST')
41 )
42
43 The above example will ensure that the view is called if the request method
44 is *not* ``POST``, at least if no other view is more specific.
45
46 This technique of wrapping a predicate value in ``not_`` can be used
47 anywhere predicate values are accepted:
48
49 - :meth:`pyramid.config.Configurator.add_view`
50
51 - :meth:`pyramid.config.Configurator.add_route`
52
53 - :meth:`pyramid.config.Configurator.add_subscriber`
54
55 - :meth:`pyramid.view.view_config`
56
57 - :meth:`pyramid.events.subscriber`
58
59 .. versionadded:: 1.5
60 """
61 def __init__(self, value):
62 self.value = value
63
64 class Notted(object):
65 def __init__(self, predicate):
66 self.predicate = predicate
67
68 def _notted_text(self, val):
69 # if the underlying predicate doesnt return a value, it's not really
70 # a predicate, it's just something pretending to be a predicate,
71 # so dont update the hash
72 if val:
73 val = '!' + val
74 return val
75
76 def text(self):
77 return self._notted_text(self.predicate.text())
78
79 def phash(self):
80 return self._notted_text(self.predicate.phash())
81
82 def __call__(self, context, request):
83 result = self.predicate(context, request)
84 phash = self.phash()
85 if phash:
86 result = not result
87 return result
88
89 # under = after
90 # over = before
91
92 class PredicateList(object):
93
94 def __init__(self):
95 self.sorter = TopologicalSorter()
96 self.last_added = None
97
98 def add(self, name, factory, weighs_more_than=None, weighs_less_than=None):
99 # Predicates should be added to a predicate list in (presumed)
100 # computation expense order.
101 ## if weighs_more_than is None and weighs_less_than is None:
102 ## weighs_more_than = self.last_added or FIRST
103 ## weighs_less_than = LAST
104 self.last_added = name
105 self.sorter.add(
106 name,
107 factory,
108 after=weighs_more_than,
109 before=weighs_less_than,
110 )
111
112 def names(self):
113 # Return the list of valid predicate names.
114 return self.sorter.names
115
116 def make(self, config, **kw):
117 # Given a configurator and a list of keywords, a predicate list is
118 # computed. Elsewhere in the code, we evaluate predicates using a
119 # generator expression. All predicates associated with a view or
120 # route must evaluate true for the view or route to "match" during a
121 # request. The fastest predicate should be evaluated first, then the
122 # next fastest, and so on, as if one returns false, the remainder of
123 # the predicates won't need to be evaluated.
124 #
125 # While we compute predicates, we also compute a predicate hash (aka
126 # phash) that can be used by a caller to identify identical predicate
127 # lists.
128 ordered = self.sorter.sorted()
129 phash = md5()
130 weights = []
131 preds = []
132 for n, (name, predicate_factory) in enumerate(ordered):
133 vals = kw.pop(name, None)
134 if vals is None: # XXX should this be a sentinel other than None?
135 continue
136 if not isinstance(vals, predvalseq):
137 vals = (vals,)
138 for val in vals:
139 realval = val
140 notted = False
141 if isinstance(val, not_):
142 realval = val.value
143 notted = True
144 pred = predicate_factory(realval, config)
145 if notted:
146 pred = Notted(pred)
147 hashes = pred.phash()
148 if not is_nonstr_iter(hashes):
149 hashes = [hashes]
150 for h in hashes:
151 phash.update(bytes_(h))
152 weights.append(1 << n + 1)
153 preds.append(pred)
154 if kw:
155 raise ConfigurationError('Unknown predicate values: %r' % (kw,))
156 # A "order" is computed for the predicate list. An order is
157 # a scoring.
158 #
159 # Each predicate is associated with a weight value. The weight of a
160 # predicate symbolizes the relative potential "importance" of the
161 # predicate to all other predicates. A larger weight indicates
162 # greater importance.
163 #
164 # All weights for a given predicate list are bitwise ORed together
165 # to create a "score"; this score is then subtracted from
166 # MAX_ORDER and divided by an integer representing the number of
167 # predicates+1 to determine the order.
168 #
169 # For views, the order represents the ordering in which a "multiview"
170 # ( a collection of views that share the same context/request/name
171 # triad but differ in other ways via predicates) will attempt to call
172 # its set of views. Views with lower orders will be tried first.
173 # The intent is to a) ensure that views with more predicates are
174 # always evaluated before views with fewer predicates and b) to
175 # ensure a stable call ordering of views that share the same number
176 # of predicates. Views which do not have any predicates get an order
177 # of MAX_ORDER, meaning that they will be tried very last.
178 score = 0
179 for bit in weights:
180 score = score | bit
181 order = (MAX_ORDER - score) / (len(preds) + 1)
182 return order, preds, phash.hexdigest()
183
184 def takes_one_arg(callee, attr=None, argname=None):
185 ismethod = False
186 if attr is None:
187 attr = '__call__'
188 if inspect.isroutine(callee):
189 fn = callee
190 elif inspect.isclass(callee):
191 try:
192 fn = callee.__init__
193 except AttributeError:
194 return False
195 ismethod = hasattr(fn, '__call__')
196 else:
197 try:
198 fn = getattr(callee, attr)
199 except AttributeError:
200 return False
201
202 try:
203 argspec = getargspec(fn)
204 except TypeError:
205 return False
206
207 args = argspec[0]
208
209 if hasattr(fn, im_func) or ismethod:
210 # it's an instance method (or unbound method on py2)
211 if not args:
212 return False
213 args = args[1:]
214
215 if not args:
216 return False
217
218 if len(args) == 1:
219 return True
220
221 if argname:
222
223 defaults = argspec[3]
224 if defaults is None:
225 defaults = ()
226
227 if args[0] == argname:
228 if len(args) - len(defaults) == 1:
229 return True
230
231 return False
232
[end of pyramid/config/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyramid/config/util.py b/pyramid/config/util.py
--- a/pyramid/config/util.py
+++ b/pyramid/config/util.py
@@ -36,7 +36,7 @@
config.add_view(
'mypackage.views.my_view',
- route_name='ok',
+ route_name='ok',
request_method=not_('POST')
)
@@ -69,7 +69,7 @@
# if the underlying predicate doesnt return a value, it's not really
# a predicate, it's just something pretending to be a predicate,
# so dont update the hash
- if val:
+ if val:
val = '!' + val
return val
@@ -90,7 +90,7 @@
# over = before
class PredicateList(object):
-
+
def __init__(self):
self.sorter = TopologicalSorter()
self.last_added = None
@@ -152,7 +152,16 @@
weights.append(1 << n + 1)
preds.append(pred)
if kw:
- raise ConfigurationError('Unknown predicate values: %r' % (kw,))
+ from difflib import get_close_matches
+ closest = []
+ names = [ name for name, _ in ordered ]
+ for name in kw:
+ closest.extend(get_close_matches(name, names, 3))
+
+ raise ConfigurationError(
+ 'Unknown predicate values: %r (did you mean %s)'
+ % (kw, ','.join(closest))
+ )
# A "order" is computed for the predicate list. An order is
# a scoring.
#
|
{"golden_diff": "diff --git a/pyramid/config/util.py b/pyramid/config/util.py\n--- a/pyramid/config/util.py\n+++ b/pyramid/config/util.py\n@@ -36,7 +36,7 @@\n \n config.add_view(\n 'mypackage.views.my_view',\n- route_name='ok', \n+ route_name='ok',\n request_method=not_('POST')\n )\n \n@@ -69,7 +69,7 @@\n # if the underlying predicate doesnt return a value, it's not really\n # a predicate, it's just something pretending to be a predicate,\n # so dont update the hash\n- if val: \n+ if val:\n val = '!' + val\n return val\n \n@@ -90,7 +90,7 @@\n # over = before\n \n class PredicateList(object):\n- \n+\n def __init__(self):\n self.sorter = TopologicalSorter()\n self.last_added = None\n@@ -152,7 +152,16 @@\n weights.append(1 << n + 1)\n preds.append(pred)\n if kw:\n- raise ConfigurationError('Unknown predicate values: %r' % (kw,))\n+ from difflib import get_close_matches\n+ closest = []\n+ names = [ name for name, _ in ordered ]\n+ for name in kw:\n+ closest.extend(get_close_matches(name, names, 3))\n+\n+ raise ConfigurationError(\n+ 'Unknown predicate values: %r (did you mean %s)'\n+ % (kw, ','.join(closest))\n+ )\n # A \"order\" is computed for the predicate list. An order is\n # a scoring.\n #\n", "issue": "Helpful exceptions on \"a named thing was not found\"\n[This was originally mentioned in #1601](https://github.com/Pylons/pyramid/issues/1601), but @mmerickel wanted it to be a separate issue, so here goes:\n\nWhenever one uses an invalid kwarg name in `view_config`, or provides an invalid route name for a view, one gets an exception that just states that the given name was wrong. As this is an exceptional condition at startup time, and more so usually meaning that the whole application startup failed, it really would not matter if we used some extra cycles to make the error messages more helpful.\n\nEspecially with lots of 3rd-party stuff `include`d in the configurations, it might be really hard to remember how _exactly_ to write the name of a certain predicate, and usually this means more than 5 minutes of googling again. Thus I propose that the exception message would list close matches to these values, so that using `@view_config(method='POST')` would state `Unknown predicate values: {'method': 'POST'}; did you mean request_method`, for example I modified the [raise for invalid predicate names](https://github.com/Pylons/pyramid/blob/master/pyramid/config/util.py#L157) to\n\n```\ntry:\n from difflib import get_close_matches\n closest = []\n names = [ name for name, _ in ordered ]\n for name in kw:\n closest.extend(get_close_matches(name, names, 3))\n\n raise ConfigurationError(\n 'Unknown predicate values: %r (did you mean %s)'\n % (kw, ','.join(closest)))\n\nexcept ImportError:\n pass\n\nraise ConfigurationError('Unknown predicate values: %r' % (kw,))\n```\n\nWhich produces the aforementioned message. The runtime overhead of this is 0 (excepting for a few more bytecodes loaded on startup) for successful configuration and minimal overhead in mostly fatal errors that would make the server not start anyway. The `difflib.get_close_matches` function itself has been in the Python stdlib since 2.1... refactored in a utility function, this close matching could be used for all the cases where the configurator could at configuration time list the allowed values for something.\n\n", "before_files": [{"content": "from hashlib import md5\nimport inspect\n\nfrom pyramid.compat import (\n bytes_,\n getargspec,\n is_nonstr_iter\n )\n\nfrom pyramid.compat import im_func\nfrom pyramid.exceptions import ConfigurationError\nfrom pyramid.registry import predvalseq\n\nfrom pyramid.util import (\n TopologicalSorter,\n action_method,\n ActionInfo,\n )\n\naction_method = action_method # support bw compat imports\nActionInfo = ActionInfo # support bw compat imports\n\nMAX_ORDER = 1 << 30\nDEFAULT_PHASH = md5().hexdigest()\n\nclass not_(object):\n \"\"\"\n\n You can invert the meaning of any predicate value by wrapping it in a call\n to :class:`pyramid.config.not_`.\n\n .. code-block:: python\n :linenos:\n\n from pyramid.config import not_\n\n config.add_view(\n 'mypackage.views.my_view',\n route_name='ok', \n request_method=not_('POST')\n )\n\n The above example will ensure that the view is called if the request method\n is *not* ``POST``, at least if no other view is more specific.\n\n This technique of wrapping a predicate value in ``not_`` can be used\n anywhere predicate values are accepted:\n\n - :meth:`pyramid.config.Configurator.add_view`\n\n - :meth:`pyramid.config.Configurator.add_route`\n\n - :meth:`pyramid.config.Configurator.add_subscriber`\n\n - :meth:`pyramid.view.view_config`\n\n - :meth:`pyramid.events.subscriber`\n\n .. versionadded:: 1.5\n \"\"\"\n def __init__(self, value):\n self.value = value\n\nclass Notted(object):\n def __init__(self, predicate):\n self.predicate = predicate\n\n def _notted_text(self, val):\n # if the underlying predicate doesnt return a value, it's not really\n # a predicate, it's just something pretending to be a predicate,\n # so dont update the hash\n if val: \n val = '!' + val\n return val\n\n def text(self):\n return self._notted_text(self.predicate.text())\n\n def phash(self):\n return self._notted_text(self.predicate.phash())\n\n def __call__(self, context, request):\n result = self.predicate(context, request)\n phash = self.phash()\n if phash:\n result = not result\n return result\n\n# under = after\n# over = before\n\nclass PredicateList(object):\n \n def __init__(self):\n self.sorter = TopologicalSorter()\n self.last_added = None\n\n def add(self, name, factory, weighs_more_than=None, weighs_less_than=None):\n # Predicates should be added to a predicate list in (presumed)\n # computation expense order.\n ## if weighs_more_than is None and weighs_less_than is None:\n ## weighs_more_than = self.last_added or FIRST\n ## weighs_less_than = LAST\n self.last_added = name\n self.sorter.add(\n name,\n factory,\n after=weighs_more_than,\n before=weighs_less_than,\n )\n\n def names(self):\n # Return the list of valid predicate names.\n return self.sorter.names\n\n def make(self, config, **kw):\n # Given a configurator and a list of keywords, a predicate list is\n # computed. Elsewhere in the code, we evaluate predicates using a\n # generator expression. All predicates associated with a view or\n # route must evaluate true for the view or route to \"match\" during a\n # request. The fastest predicate should be evaluated first, then the\n # next fastest, and so on, as if one returns false, the remainder of\n # the predicates won't need to be evaluated.\n #\n # While we compute predicates, we also compute a predicate hash (aka\n # phash) that can be used by a caller to identify identical predicate\n # lists.\n ordered = self.sorter.sorted()\n phash = md5()\n weights = []\n preds = []\n for n, (name, predicate_factory) in enumerate(ordered):\n vals = kw.pop(name, None)\n if vals is None: # XXX should this be a sentinel other than None?\n continue\n if not isinstance(vals, predvalseq):\n vals = (vals,)\n for val in vals:\n realval = val\n notted = False\n if isinstance(val, not_):\n realval = val.value\n notted = True\n pred = predicate_factory(realval, config)\n if notted:\n pred = Notted(pred)\n hashes = pred.phash()\n if not is_nonstr_iter(hashes):\n hashes = [hashes]\n for h in hashes:\n phash.update(bytes_(h))\n weights.append(1 << n + 1)\n preds.append(pred)\n if kw:\n raise ConfigurationError('Unknown predicate values: %r' % (kw,))\n # A \"order\" is computed for the predicate list. An order is\n # a scoring.\n #\n # Each predicate is associated with a weight value. The weight of a\n # predicate symbolizes the relative potential \"importance\" of the\n # predicate to all other predicates. A larger weight indicates\n # greater importance.\n #\n # All weights for a given predicate list are bitwise ORed together\n # to create a \"score\"; this score is then subtracted from\n # MAX_ORDER and divided by an integer representing the number of\n # predicates+1 to determine the order.\n #\n # For views, the order represents the ordering in which a \"multiview\"\n # ( a collection of views that share the same context/request/name\n # triad but differ in other ways via predicates) will attempt to call\n # its set of views. Views with lower orders will be tried first.\n # The intent is to a) ensure that views with more predicates are\n # always evaluated before views with fewer predicates and b) to\n # ensure a stable call ordering of views that share the same number\n # of predicates. Views which do not have any predicates get an order\n # of MAX_ORDER, meaning that they will be tried very last.\n score = 0\n for bit in weights:\n score = score | bit\n order = (MAX_ORDER - score) / (len(preds) + 1)\n return order, preds, phash.hexdigest()\n\ndef takes_one_arg(callee, attr=None, argname=None):\n ismethod = False\n if attr is None:\n attr = '__call__'\n if inspect.isroutine(callee):\n fn = callee\n elif inspect.isclass(callee):\n try:\n fn = callee.__init__\n except AttributeError:\n return False\n ismethod = hasattr(fn, '__call__')\n else:\n try:\n fn = getattr(callee, attr)\n except AttributeError:\n return False\n\n try:\n argspec = getargspec(fn)\n except TypeError:\n return False\n\n args = argspec[0]\n\n if hasattr(fn, im_func) or ismethod:\n # it's an instance method (or unbound method on py2)\n if not args:\n return False\n args = args[1:]\n\n if not args:\n return False\n\n if len(args) == 1:\n return True\n\n if argname:\n\n defaults = argspec[3]\n if defaults is None:\n defaults = ()\n\n if args[0] == argname:\n if len(args) - len(defaults) == 1:\n return True\n\n return False\n", "path": "pyramid/config/util.py"}]}
| 3,285 | 371 |
gh_patches_debug_2281
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-438
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
polygonize method no longer in use / use shapes instead?
Hi,
just going through the examples folders.
If I ran the python interpreter on `poligonize.py` it complains about a missing attribute:
```
(venv)[] ~/Progetti/pyhton-usergroup/rasterio <master> ✗ python examples/polygonize.py
sys:1: FutureWarning: read_band() is deprecated and will be removed by Rasterio 1.0. Please use read() instead.
Traceback (most recent call last):
File "examples/polygonize.py", line 10, in <module>
list(ftrz.polygonize(image)))
AttributeError: 'module' object has no attribute 'polygonize'
```
But, going trough the commits history w/ @ligthyear it seems like instead of poligonize, one should use shapes.
If I ran it in fact with the new method it works smoothly
```
pprint.pprint(
list(ftrz.shapes(image)))
```
Cheers
</issue>
<code>
[start of examples/polygonize.py]
1 import pprint
2
3 import rasterio
4 import rasterio._features as ftrz
5
6 with rasterio.open('box.png') as src:
7 image = src.read_band(1)
8
9 pprint.pprint(
10 list(ftrz.polygonize(image)))
11
[end of examples/polygonize.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/polygonize.py b/examples/polygonize.py
--- a/examples/polygonize.py
+++ b/examples/polygonize.py
@@ -1,10 +1,12 @@
import pprint
import rasterio
-import rasterio._features as ftrz
+from rasterio.features import shapes
-with rasterio.open('box.png') as src:
- image = src.read_band(1)
+with rasterio.open('tests/data/shade.tif') as src:
+ image = src.read(1)
+# Print the first two shapes...
pprint.pprint(
- list(ftrz.polygonize(image)))
+ list(shapes(image))[:2]
+)
|
{"golden_diff": "diff --git a/examples/polygonize.py b/examples/polygonize.py\n--- a/examples/polygonize.py\n+++ b/examples/polygonize.py\n@@ -1,10 +1,12 @@\n import pprint\n \n import rasterio\n-import rasterio._features as ftrz\n+from rasterio.features import shapes\n \n-with rasterio.open('box.png') as src:\n- image = src.read_band(1)\n+with rasterio.open('tests/data/shade.tif') as src:\n+ image = src.read(1)\n \n+# Print the first two shapes...\n pprint.pprint(\n- list(ftrz.polygonize(image)))\n+ list(shapes(image))[:2]\n+)\n", "issue": "polygonize method no longer in use / use shapes instead?\nHi,\n\njust going through the examples folders.\nIf I ran the python interpreter on `poligonize.py` it complains about a missing attribute:\n\n```\n(venv)[] ~/Progetti/pyhton-usergroup/rasterio <master> \u2717 python examples/polygonize.py\nsys:1: FutureWarning: read_band() is deprecated and will be removed by Rasterio 1.0. Please use read() instead.\nTraceback (most recent call last):\n File \"examples/polygonize.py\", line 10, in <module>\n list(ftrz.polygonize(image)))\nAttributeError: 'module' object has no attribute 'polygonize'\n```\n\nBut, going trough the commits history w/ @ligthyear it seems like instead of poligonize, one should use shapes. \nIf I ran it in fact with the new method it works smoothly\n\n```\npprint.pprint(\n list(ftrz.shapes(image)))\n```\n\nCheers\n\n", "before_files": [{"content": "import pprint\n\nimport rasterio\nimport rasterio._features as ftrz\n\nwith rasterio.open('box.png') as src:\n image = src.read_band(1)\n\npprint.pprint(\n list(ftrz.polygonize(image)))\n", "path": "examples/polygonize.py"}]}
| 816 | 149 |
gh_patches_debug_6609
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1249
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Undefined variable issue in 0.77.6
With the latest release of #1213, this [line](https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/types/nodes.py#L40) raises a KeyError when a variable is used in a query, but not defined in the payload under the key `variables`.
This used to work, and, I guess, is ok when the variable/argument is optional.
I do not know what the specs are, meaning if variable definition should be enforced all the way. If it's the way to go, maybe there should be a validation step/graceful way to handle such a case.
If not, `return info.variable_values.get(name)` should do the trick.
</issue>
<code>
[start of strawberry/types/nodes.py]
1 """
2 Abstraction layer for graphql-core field nodes.
3
4 Call `convert_sections` on a list of GraphQL `FieldNode`s, such as in `info.field_nodes`.
5
6 If a node has only one useful value, it's value is inlined.
7
8 If a list of nodes have unique names, it's transformed into a mapping.
9 Note Python dicts maintain ordering (for all supported versions).
10 """
11
12 import dataclasses
13 from typing import Any, Dict, Iterable, List, Optional, Union
14
15 from graphql import GraphQLResolveInfo
16 from graphql.language import (
17 ArgumentNode as GQLArgumentNode,
18 DirectiveNode as GQLDirectiveNode,
19 FieldNode as GQLFieldNode,
20 FragmentSpreadNode as GQLFragmentSpreadNode,
21 InlineFragmentNode as GQLInlineFragment,
22 InlineFragmentNode as GQLInlineFragmentNode,
23 ListValueNode as GQLListValueNode,
24 ObjectValueNode as GQLObjectValueNode,
25 ValueNode as GQLValueNode,
26 VariableNode as GQLVariableNode,
27 )
28
29
30 Arguments = Dict[str, Any]
31 Directives = Dict[str, Arguments]
32 Selection = Union["SelectedField", "FragmentSpread", "InlineFragment"]
33
34
35 def convert_value(info: GraphQLResolveInfo, node: GQLValueNode) -> Any:
36 """Return useful value from any node."""
37 if isinstance(node, GQLVariableNode):
38 # Look up variable
39 name = node.name.value
40 return info.variable_values[name]
41 if isinstance(node, GQLListValueNode):
42 return [convert_value(info, value) for value in node.values]
43 if isinstance(node, GQLObjectValueNode):
44 return {
45 field.name.value: convert_value(info, field.value) for field in node.fields
46 }
47 return getattr(node, "value", None)
48
49
50 def convert_arguments(
51 info: GraphQLResolveInfo, nodes: Iterable[GQLArgumentNode]
52 ) -> Arguments:
53 """Return mapping of arguments."""
54 return {node.name.value: convert_value(info, node.value) for node in nodes}
55
56
57 def convert_directives(
58 info: GraphQLResolveInfo, nodes: Iterable[GQLDirectiveNode]
59 ) -> Directives:
60 """Return mapping of directives."""
61 return {node.name.value: convert_arguments(info, node.arguments) for node in nodes}
62
63
64 def convert_selections(
65 info: GraphQLResolveInfo, field_nodes: List[GQLFieldNode]
66 ) -> List[Selection]:
67 """Return typed `Selection` based on node type."""
68 selections: List[Selection] = []
69 for node in field_nodes:
70 if isinstance(node, GQLFieldNode):
71 selections.append(SelectedField.from_node(info, node))
72 elif isinstance(node, GQLInlineFragment):
73 selections.append(InlineFragment.from_node(info, node))
74 elif isinstance(node, GQLFragmentSpreadNode):
75 selections.append(FragmentSpread.from_node(info, node))
76 else:
77 raise TypeError(f"Unknown node type: {node}")
78
79 return selections
80
81
82 @dataclasses.dataclass
83 class FragmentSpread:
84 """Wrapper for a FragmentSpreadNode."""
85
86 name: str
87 type_condition: str
88 directives: Directives
89 selections: List[Selection]
90
91 @classmethod
92 def from_node(cls, info: GraphQLResolveInfo, node: GQLFragmentSpreadNode):
93 # Look up fragment
94 name = node.name.value
95 fragment = info.fragments[name]
96 return cls(
97 name=name,
98 directives=convert_directives(info, node.directives),
99 type_condition=fragment.type_condition.name.value,
100 selections=convert_selections(
101 info, getattr(fragment.selection_set, "selections", [])
102 ),
103 )
104
105
106 @dataclasses.dataclass
107 class InlineFragment:
108 """Wrapper for a InlineFragmentNode."""
109
110 type_condition: str
111 selections: List[Selection]
112 directives: Directives
113
114 @classmethod
115 def from_node(cls, info: GraphQLResolveInfo, node: GQLInlineFragmentNode):
116 return cls(
117 type_condition=node.type_condition.name.value,
118 selections=convert_selections(
119 info, getattr(node.selection_set, "selections", [])
120 ),
121 directives=convert_directives(info, node.directives),
122 )
123
124
125 @dataclasses.dataclass
126 class SelectedField:
127 """Wrapper for a FieldNode."""
128
129 name: str
130 directives: Directives
131 arguments: Arguments
132 selections: List[Selection]
133 alias: Optional[str] = None
134
135 @classmethod
136 def from_node(cls, info: GraphQLResolveInfo, node: GQLFieldNode):
137 return cls(
138 name=node.name.value,
139 directives=convert_directives(info, node.directives),
140 alias=getattr(node.alias, "value", None),
141 arguments=convert_arguments(info, node.arguments),
142 selections=convert_selections(
143 info, getattr(node.selection_set, "selections", [])
144 ),
145 )
146
[end of strawberry/types/nodes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/types/nodes.py b/strawberry/types/nodes.py
--- a/strawberry/types/nodes.py
+++ b/strawberry/types/nodes.py
@@ -37,7 +37,7 @@
if isinstance(node, GQLVariableNode):
# Look up variable
name = node.name.value
- return info.variable_values[name]
+ return info.variable_values.get(name)
if isinstance(node, GQLListValueNode):
return [convert_value(info, value) for value in node.values]
if isinstance(node, GQLObjectValueNode):
|
{"golden_diff": "diff --git a/strawberry/types/nodes.py b/strawberry/types/nodes.py\n--- a/strawberry/types/nodes.py\n+++ b/strawberry/types/nodes.py\n@@ -37,7 +37,7 @@\n if isinstance(node, GQLVariableNode):\n # Look up variable\n name = node.name.value\n- return info.variable_values[name]\n+ return info.variable_values.get(name)\n if isinstance(node, GQLListValueNode):\n return [convert_value(info, value) for value in node.values]\n if isinstance(node, GQLObjectValueNode):\n", "issue": "Undefined variable issue in 0.77.6\nWith the latest release of #1213, this [line](https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/types/nodes.py#L40) raises a KeyError when a variable is used in a query, but not defined in the payload under the key `variables`.\r\n\r\nThis used to work, and, I guess, is ok when the variable/argument is optional.\r\n\r\nI do not know what the specs are, meaning if variable definition should be enforced all the way. If it's the way to go, maybe there should be a validation step/graceful way to handle such a case.\r\n\r\nIf not, `return info.variable_values.get(name)` should do the trick.\n", "before_files": [{"content": "\"\"\"\nAbstraction layer for graphql-core field nodes.\n\nCall `convert_sections` on a list of GraphQL `FieldNode`s, such as in `info.field_nodes`.\n\nIf a node has only one useful value, it's value is inlined.\n\nIf a list of nodes have unique names, it's transformed into a mapping.\nNote Python dicts maintain ordering (for all supported versions).\n\"\"\"\n\nimport dataclasses\nfrom typing import Any, Dict, Iterable, List, Optional, Union\n\nfrom graphql import GraphQLResolveInfo\nfrom graphql.language import (\n ArgumentNode as GQLArgumentNode,\n DirectiveNode as GQLDirectiveNode,\n FieldNode as GQLFieldNode,\n FragmentSpreadNode as GQLFragmentSpreadNode,\n InlineFragmentNode as GQLInlineFragment,\n InlineFragmentNode as GQLInlineFragmentNode,\n ListValueNode as GQLListValueNode,\n ObjectValueNode as GQLObjectValueNode,\n ValueNode as GQLValueNode,\n VariableNode as GQLVariableNode,\n)\n\n\nArguments = Dict[str, Any]\nDirectives = Dict[str, Arguments]\nSelection = Union[\"SelectedField\", \"FragmentSpread\", \"InlineFragment\"]\n\n\ndef convert_value(info: GraphQLResolveInfo, node: GQLValueNode) -> Any:\n \"\"\"Return useful value from any node.\"\"\"\n if isinstance(node, GQLVariableNode):\n # Look up variable\n name = node.name.value\n return info.variable_values[name]\n if isinstance(node, GQLListValueNode):\n return [convert_value(info, value) for value in node.values]\n if isinstance(node, GQLObjectValueNode):\n return {\n field.name.value: convert_value(info, field.value) for field in node.fields\n }\n return getattr(node, \"value\", None)\n\n\ndef convert_arguments(\n info: GraphQLResolveInfo, nodes: Iterable[GQLArgumentNode]\n) -> Arguments:\n \"\"\"Return mapping of arguments.\"\"\"\n return {node.name.value: convert_value(info, node.value) for node in nodes}\n\n\ndef convert_directives(\n info: GraphQLResolveInfo, nodes: Iterable[GQLDirectiveNode]\n) -> Directives:\n \"\"\"Return mapping of directives.\"\"\"\n return {node.name.value: convert_arguments(info, node.arguments) for node in nodes}\n\n\ndef convert_selections(\n info: GraphQLResolveInfo, field_nodes: List[GQLFieldNode]\n) -> List[Selection]:\n \"\"\"Return typed `Selection` based on node type.\"\"\"\n selections: List[Selection] = []\n for node in field_nodes:\n if isinstance(node, GQLFieldNode):\n selections.append(SelectedField.from_node(info, node))\n elif isinstance(node, GQLInlineFragment):\n selections.append(InlineFragment.from_node(info, node))\n elif isinstance(node, GQLFragmentSpreadNode):\n selections.append(FragmentSpread.from_node(info, node))\n else:\n raise TypeError(f\"Unknown node type: {node}\")\n\n return selections\n\n\[email protected]\nclass FragmentSpread:\n \"\"\"Wrapper for a FragmentSpreadNode.\"\"\"\n\n name: str\n type_condition: str\n directives: Directives\n selections: List[Selection]\n\n @classmethod\n def from_node(cls, info: GraphQLResolveInfo, node: GQLFragmentSpreadNode):\n # Look up fragment\n name = node.name.value\n fragment = info.fragments[name]\n return cls(\n name=name,\n directives=convert_directives(info, node.directives),\n type_condition=fragment.type_condition.name.value,\n selections=convert_selections(\n info, getattr(fragment.selection_set, \"selections\", [])\n ),\n )\n\n\[email protected]\nclass InlineFragment:\n \"\"\"Wrapper for a InlineFragmentNode.\"\"\"\n\n type_condition: str\n selections: List[Selection]\n directives: Directives\n\n @classmethod\n def from_node(cls, info: GraphQLResolveInfo, node: GQLInlineFragmentNode):\n return cls(\n type_condition=node.type_condition.name.value,\n selections=convert_selections(\n info, getattr(node.selection_set, \"selections\", [])\n ),\n directives=convert_directives(info, node.directives),\n )\n\n\[email protected]\nclass SelectedField:\n \"\"\"Wrapper for a FieldNode.\"\"\"\n\n name: str\n directives: Directives\n arguments: Arguments\n selections: List[Selection]\n alias: Optional[str] = None\n\n @classmethod\n def from_node(cls, info: GraphQLResolveInfo, node: GQLFieldNode):\n return cls(\n name=node.name.value,\n directives=convert_directives(info, node.directives),\n alias=getattr(node.alias, \"value\", None),\n arguments=convert_arguments(info, node.arguments),\n selections=convert_selections(\n info, getattr(node.selection_set, \"selections\", [])\n ),\n )\n", "path": "strawberry/types/nodes.py"}]}
| 2,055 | 133 |
gh_patches_debug_23648
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-385
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Unverified" page should use translation fields on EligibilityVerifier
### To reproduce
Go through the eligibility verification flow such that you will see the "unverified" page that an ineligible user would see.
### Expected result
The page shows with translated content.
### Actual result
The page shows with translation strings.

### Thoughts
I think we forgot to update the `unverified` function in the eligibility app's views when we did #338.
</issue>
<code>
[start of benefits/eligibility/views.py]
1 """
2 The eligibility application: view definitions for the eligibility verification flow.
3 """
4 from django.contrib import messages
5 from django.shortcuts import redirect
6 from django.urls import reverse
7 from django.utils.decorators import decorator_from_middleware
8 from django.utils.translation import pgettext, gettext as _
9
10 from benefits.core import middleware, recaptcha, session, viewmodels
11 from benefits.core.models import EligibilityVerifier
12 from benefits.core.views import PageTemplateResponse
13 from . import analytics, api, forms
14
15
16 @decorator_from_middleware(middleware.AgencySessionRequired)
17 def index(request):
18 """View handler for the eligibility verifier selection form."""
19
20 session.update(request, eligibility_types=[], origin=reverse("eligibility:index"))
21 agency = session.agency(request)
22
23 eligibility_start = reverse("eligibility:start")
24
25 page = viewmodels.Page(
26 title=_("eligibility.pages.index.title"),
27 content_title=_("eligibility.pages.index.content_title"),
28 forms=forms.EligibilityVerifierSelectionForm(agency=agency),
29 )
30
31 if request.method == "POST":
32 form = forms.EligibilityVerifierSelectionForm(data=request.POST, agency=agency)
33
34 if form.is_valid():
35 verifier_id = form.cleaned_data.get("verifier")
36 verifier = EligibilityVerifier.objects.get(id=verifier_id)
37 session.update(request, verifier=verifier)
38
39 response = redirect(eligibility_start)
40 else:
41 # form was not valid, allow for correction/resubmission
42 page.forms = [form]
43 response = PageTemplateResponse(request, page)
44 else:
45 if agency.eligibility_verifiers.count() == 1:
46 verifier = agency.eligibility_verifiers.first()
47 session.update(request, verifier=verifier)
48 response = redirect(eligibility_start)
49 else:
50 response = PageTemplateResponse(request, page)
51
52 return response
53
54
55 @decorator_from_middleware(middleware.AgencySessionRequired)
56 @decorator_from_middleware(middleware.VerifierSessionRequired)
57 def start(request):
58 """View handler for the eligibility verification getting started screen."""
59
60 session.update(request, eligibility_types=[])
61 verifier = session.verifier(request)
62
63 page = viewmodels.Page(
64 title=_("eligibility.pages.start.title"),
65 content_title=_(verifier.start_content_title),
66 media=[
67 viewmodels.MediaItem(
68 icon=viewmodels.Icon("idcardcheck", pgettext("image alt text", "core.icons.idcardcheck")),
69 heading=_(verifier.start_item_name),
70 details=_(verifier.start_item_description),
71 ),
72 viewmodels.MediaItem(
73 icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
74 heading=_("eligibility.pages.start.items[1].title"),
75 details=_("eligibility.pages.start.items[1].text"),
76 ),
77 ],
78 paragraphs=[_(verifier.start_blurb)],
79 button=viewmodels.Button.primary(text=_("eligibility.buttons.continue"), url=reverse("eligibility:confirm")),
80 )
81
82 return PageTemplateResponse(request, page)
83
84
85 @decorator_from_middleware(middleware.AgencySessionRequired)
86 @decorator_from_middleware(middleware.RateLimit)
87 @decorator_from_middleware(middleware.VerifierSessionRequired)
88 def confirm(request):
89 """View handler for the eligibility verification form."""
90
91 verifier = session.verifier(request)
92
93 page = viewmodels.Page(
94 title=_(verifier.form_title),
95 content_title=_(verifier.form_content_title),
96 paragraphs=[_(verifier.form_blurb)],
97 form=forms.EligibilityVerificationForm(auto_id=True, label_suffix="", verifier=verifier),
98 classes="text-lg-center",
99 )
100
101 if request.method == "POST":
102 analytics.started_eligibility(request)
103
104 form = forms.EligibilityVerificationForm(data=request.POST, verifier=verifier)
105 response = _verify(request, form)
106
107 if response is None:
108 # form was not valid, allow for correction/resubmission
109 analytics.returned_error(request, form.errors)
110 page.forms = [form]
111 response = PageTemplateResponse(request, page)
112 elif session.eligible(request):
113 eligibility = session.eligibility(request)
114 response = verified(request, [eligibility.name])
115 else:
116 response = PageTemplateResponse(request, page)
117
118 return response
119
120
121 def _verify(request, form):
122 """Helper calls the eligibility verification API with user input."""
123
124 if not form.is_valid():
125 if recaptcha.has_error(form):
126 messages.error(request, "Recaptcha failed. Please try again.")
127 return None
128
129 sub, name = form.cleaned_data.get("sub"), form.cleaned_data.get("name")
130
131 agency = session.agency(request)
132 verifier = session.verifier(request)
133 client = api.Client(agency, verifier)
134
135 response = client.verify(sub, name)
136
137 if response.error and any(response.error):
138 form.add_api_errors(response.error)
139 return None
140 elif any(response.eligibility):
141 return verified(request, response.eligibility)
142 else:
143 return unverified(request)
144
145
146 @decorator_from_middleware(middleware.AgencySessionRequired)
147 def verified(request, verified_types):
148 """View handler for the verified eligibility page."""
149
150 analytics.returned_success(request)
151
152 enrollment_index = reverse("enrollment:index")
153 session.update(request, eligibility_types=verified_types, origin=enrollment_index)
154
155 return redirect(enrollment_index)
156
157
158 @decorator_from_middleware(middleware.AgencySessionRequired)
159 def unverified(request):
160 """View handler for the unverified eligibility page."""
161
162 analytics.returned_fail(request)
163
164 # tel: link to agency phone number
165 agency = session.agency(request)
166 buttons = viewmodels.Button.agency_contact_links(agency)
167
168 page = viewmodels.Page(
169 title=_("eligibility.pages.unverified.title"),
170 content_title=_("eligibility.pages.unverified.content_title"),
171 icon=viewmodels.Icon("idcardquestion", pgettext("image alt text", "core.icons.idcardquestion")),
172 paragraphs=[_("eligibility.pages.unverified.p[0]"), _("eligibility.pages.unverified.p[1]")],
173 buttons=buttons,
174 classes="text-lg-center",
175 )
176
177 return PageTemplateResponse(request, page)
178
[end of benefits/eligibility/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py
--- a/benefits/eligibility/views.py
+++ b/benefits/eligibility/views.py
@@ -156,6 +156,7 @@
@decorator_from_middleware(middleware.AgencySessionRequired)
+@decorator_from_middleware(middleware.VerifierSessionRequired)
def unverified(request):
"""View handler for the unverified eligibility page."""
@@ -165,11 +166,13 @@
agency = session.agency(request)
buttons = viewmodels.Button.agency_contact_links(agency)
+ verifier = session.verifier(request)
+
page = viewmodels.Page(
- title=_("eligibility.pages.unverified.title"),
- content_title=_("eligibility.pages.unverified.content_title"),
+ title=_(verifier.unverified_title),
+ content_title=_(verifier.unverified_content_title),
icon=viewmodels.Icon("idcardquestion", pgettext("image alt text", "core.icons.idcardquestion")),
- paragraphs=[_("eligibility.pages.unverified.p[0]"), _("eligibility.pages.unverified.p[1]")],
+ paragraphs=[_(verifier.unverified_blurb), _("eligibility.pages.unverified.p[1]")],
buttons=buttons,
classes="text-lg-center",
)
|
{"golden_diff": "diff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py\n--- a/benefits/eligibility/views.py\n+++ b/benefits/eligibility/views.py\n@@ -156,6 +156,7 @@\n \n \n @decorator_from_middleware(middleware.AgencySessionRequired)\n+@decorator_from_middleware(middleware.VerifierSessionRequired)\n def unverified(request):\n \"\"\"View handler for the unverified eligibility page.\"\"\"\n \n@@ -165,11 +166,13 @@\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n \n+ verifier = session.verifier(request)\n+\n page = viewmodels.Page(\n- title=_(\"eligibility.pages.unverified.title\"),\n- content_title=_(\"eligibility.pages.unverified.content_title\"),\n+ title=_(verifier.unverified_title),\n+ content_title=_(verifier.unverified_content_title),\n icon=viewmodels.Icon(\"idcardquestion\", pgettext(\"image alt text\", \"core.icons.idcardquestion\")),\n- paragraphs=[_(\"eligibility.pages.unverified.p[0]\"), _(\"eligibility.pages.unverified.p[1]\")],\n+ paragraphs=[_(verifier.unverified_blurb), _(\"eligibility.pages.unverified.p[1]\")],\n buttons=buttons,\n classes=\"text-lg-center\",\n )\n", "issue": "\"Unverified\" page should use translation fields on EligibilityVerifier\n### To reproduce\r\nGo through the eligibility verification flow such that you will see the \"unverified\" page that an ineligible user would see.\r\n\r\n### Expected result\r\nThe page shows with translated content.\r\n\r\n### Actual result\r\nThe page shows with translation strings.\r\n\r\n\r\n\r\n\r\n### Thoughts\r\nI think we forgot to update the `unverified` function in the eligibility app's views when we did #338.\n", "before_files": [{"content": "\"\"\"\nThe eligibility application: view definitions for the eligibility verification flow.\n\"\"\"\nfrom django.contrib import messages\nfrom django.shortcuts import redirect\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.translation import pgettext, gettext as _\n\nfrom benefits.core import middleware, recaptcha, session, viewmodels\nfrom benefits.core.models import EligibilityVerifier\nfrom benefits.core.views import PageTemplateResponse\nfrom . import analytics, api, forms\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef index(request):\n \"\"\"View handler for the eligibility verifier selection form.\"\"\"\n\n session.update(request, eligibility_types=[], origin=reverse(\"eligibility:index\"))\n agency = session.agency(request)\n\n eligibility_start = reverse(\"eligibility:start\")\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.index.title\"),\n content_title=_(\"eligibility.pages.index.content_title\"),\n forms=forms.EligibilityVerifierSelectionForm(agency=agency),\n )\n\n if request.method == \"POST\":\n form = forms.EligibilityVerifierSelectionForm(data=request.POST, agency=agency)\n\n if form.is_valid():\n verifier_id = form.cleaned_data.get(\"verifier\")\n verifier = EligibilityVerifier.objects.get(id=verifier_id)\n session.update(request, verifier=verifier)\n\n response = redirect(eligibility_start)\n else:\n # form was not valid, allow for correction/resubmission\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n else:\n if agency.eligibility_verifiers.count() == 1:\n verifier = agency.eligibility_verifiers.first()\n session.update(request, verifier=verifier)\n response = redirect(eligibility_start)\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\n@decorator_from_middleware(middleware.VerifierSessionRequired)\ndef start(request):\n \"\"\"View handler for the eligibility verification getting started screen.\"\"\"\n\n session.update(request, eligibility_types=[])\n verifier = session.verifier(request)\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.start.title\"),\n content_title=_(verifier.start_content_title),\n media=[\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n heading=_(verifier.start_item_name),\n details=_(verifier.start_item_description),\n ),\n viewmodels.MediaItem(\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n heading=_(\"eligibility.pages.start.items[1].title\"),\n details=_(\"eligibility.pages.start.items[1].text\"),\n ),\n ],\n paragraphs=[_(verifier.start_blurb)],\n button=viewmodels.Button.primary(text=_(\"eligibility.buttons.continue\"), url=reverse(\"eligibility:confirm\")),\n )\n\n return PageTemplateResponse(request, page)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\n@decorator_from_middleware(middleware.RateLimit)\n@decorator_from_middleware(middleware.VerifierSessionRequired)\ndef confirm(request):\n \"\"\"View handler for the eligibility verification form.\"\"\"\n\n verifier = session.verifier(request)\n\n page = viewmodels.Page(\n title=_(verifier.form_title),\n content_title=_(verifier.form_content_title),\n paragraphs=[_(verifier.form_blurb)],\n form=forms.EligibilityVerificationForm(auto_id=True, label_suffix=\"\", verifier=verifier),\n classes=\"text-lg-center\",\n )\n\n if request.method == \"POST\":\n analytics.started_eligibility(request)\n\n form = forms.EligibilityVerificationForm(data=request.POST, verifier=verifier)\n response = _verify(request, form)\n\n if response is None:\n # form was not valid, allow for correction/resubmission\n analytics.returned_error(request, form.errors)\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n elif session.eligible(request):\n eligibility = session.eligibility(request)\n response = verified(request, [eligibility.name])\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\ndef _verify(request, form):\n \"\"\"Helper calls the eligibility verification API with user input.\"\"\"\n\n if not form.is_valid():\n if recaptcha.has_error(form):\n messages.error(request, \"Recaptcha failed. Please try again.\")\n return None\n\n sub, name = form.cleaned_data.get(\"sub\"), form.cleaned_data.get(\"name\")\n\n agency = session.agency(request)\n verifier = session.verifier(request)\n client = api.Client(agency, verifier)\n\n response = client.verify(sub, name)\n\n if response.error and any(response.error):\n form.add_api_errors(response.error)\n return None\n elif any(response.eligibility):\n return verified(request, response.eligibility)\n else:\n return unverified(request)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef verified(request, verified_types):\n \"\"\"View handler for the verified eligibility page.\"\"\"\n\n analytics.returned_success(request)\n\n enrollment_index = reverse(\"enrollment:index\")\n session.update(request, eligibility_types=verified_types, origin=enrollment_index)\n\n return redirect(enrollment_index)\n\n\n@decorator_from_middleware(middleware.AgencySessionRequired)\ndef unverified(request):\n \"\"\"View handler for the unverified eligibility page.\"\"\"\n\n analytics.returned_fail(request)\n\n # tel: link to agency phone number\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.unverified.title\"),\n content_title=_(\"eligibility.pages.unverified.content_title\"),\n icon=viewmodels.Icon(\"idcardquestion\", pgettext(\"image alt text\", \"core.icons.idcardquestion\")),\n paragraphs=[_(\"eligibility.pages.unverified.p[0]\"), _(\"eligibility.pages.unverified.p[1]\")],\n buttons=buttons,\n classes=\"text-lg-center\",\n )\n\n return PageTemplateResponse(request, page)\n", "path": "benefits/eligibility/views.py"}]}
| 2,430 | 293 |
gh_patches_debug_2475
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-597
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
A little bug in Buffer class
There is a litttle bug in pwnlib.tubes.Buffer class.The class method unget has a type error in line 117.add a buffer and a list
```
Traceback (most recent call last):
File "<input>", line 1, in <module>
a.unget(b)
File "buffer.py", line 117, in unget
self.data = data + self.data
TypeError: unsupported operand type(s) for +: 'Buffer' and 'list'
```
</issue>
<code>
[start of pwnlib/tubes/buffer.py]
1 #!/usr/bin/env python2
2
3 class Buffer(Exception):
4 """
5 List of strings with some helper routines.
6
7 Example:
8
9 >>> b = Buffer()
10 >>> b.add("A" * 10)
11 >>> b.add("B" * 10)
12 >>> len(b)
13 20
14 >>> b.get(1)
15 'A'
16 >>> len(b)
17 19
18 >>> b.get(9999)
19 'AAAAAAAAABBBBBBBBBB'
20 >>> len(b)
21 0
22 >>> b.get(1)
23 ''
24
25 Implementation Details:
26
27 Implemented as a list. Strings are added onto the end.
28 The ``0th`` item in the buffer is the oldest item, and
29 will be received first.
30 """
31 def __init__(self):
32 self.data = [] # Buffer
33 self.size = 0 # Length
34
35
36 def __len__(self):
37 """
38 >>> b = Buffer()
39 >>> b.add('lol')
40 >>> len(b) == 3
41 True
42 >>> b.add('foobar')
43 >>> len(b) == 9
44 True
45 """
46 return self.size
47
48 def __nonzero__(self):
49 return len(self) > 0
50
51 def __contains__(self, x):
52 """
53 >>> b = Buffer()
54 >>> b.add('asdf')
55 >>> 'x' in b
56 False
57 >>> b.add('x')
58 >>> 'x' in b
59 True
60 """
61 for b in self.data:
62 if x in b:
63 return True
64 return False
65
66 def index(self, x):
67 """
68 >>> b = Buffer()
69 >>> b.add('asdf')
70 >>> b.add('qwert')
71 >>> b.index('t') == len(b) - 1
72 True
73 """
74 sofar = 0
75 for b in self.data:
76 if x in b:
77 return sofar + b.index(x)
78 sofar += len(b)
79 raise IndexError()
80
81 def add(self, data):
82 """
83 Adds data to the buffer.
84
85 Arguments:
86 data(str,Buffer): Data to add
87 """
88 # Fast path for ''
89 if not data: return
90
91 if isinstance(data, Buffer):
92 self.size += data.size
93 self.data += data.data
94 else:
95 self.size += len(data)
96 self.data.append(data)
97
98 def unget(self, data):
99 """
100 Places data at the front of the buffer.
101
102 Arguments:
103 data(str,Buffer): Data to place at the beginning of the buffer.
104
105 Example:
106
107 >>> b = Buffer()
108 >>> b.add("hello")
109 >>> b.add("world")
110 >>> b.get(5)
111 'hello'
112 >>> b.unget("goodbye")
113 >>> b.get()
114 'goodbyeworld'
115 """
116 if isinstance(data, Buffer):
117 self.data = data + self.data
118 self.size += data.size
119 else:
120 self.data.insert(0, data)
121 self.size += len(data)
122
123 def get(self, want=float('inf')):
124 """
125 Retrieves bytes from the buffer.
126
127 Arguments:
128 want(int): Maximum number of bytes to fetch
129
130 Returns:
131 Data as string
132
133 Example:
134
135 >>> b = Buffer()
136 >>> b.add('hello')
137 >>> b.add('world')
138 >>> b.get(1)
139 'h'
140 >>> b.get()
141 'elloworld'
142 """
143 # Fast path, get all of the data
144 if want >= self.size:
145 data = ''.join(self.data)
146 self.size = 0
147 self.data = []
148 return data
149
150 # Slow path, find the correct-index chunk
151 have = 0
152 i = 0
153 while want >= have:
154 have += len(self.data[i])
155 i += 1
156
157 # Join the chunks, evict from the buffer
158 data = ''.join(self.data[:i])
159 self.data = self.data[i:]
160
161 # If the last chunk puts us over the limit,
162 # stick the extra back at the beginning.
163 if have > want:
164 extra = data[want:]
165 data = data[:want]
166 self.data.insert(0, extra)
167
168 # Size update
169 self.size -= len(data)
170
171 return data
172
[end of pwnlib/tubes/buffer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwnlib/tubes/buffer.py b/pwnlib/tubes/buffer.py
--- a/pwnlib/tubes/buffer.py
+++ b/pwnlib/tubes/buffer.py
@@ -114,7 +114,7 @@
'goodbyeworld'
"""
if isinstance(data, Buffer):
- self.data = data + self.data
+ self.data = data.data + self.data
self.size += data.size
else:
self.data.insert(0, data)
|
{"golden_diff": "diff --git a/pwnlib/tubes/buffer.py b/pwnlib/tubes/buffer.py\n--- a/pwnlib/tubes/buffer.py\n+++ b/pwnlib/tubes/buffer.py\n@@ -114,7 +114,7 @@\n 'goodbyeworld'\n \"\"\"\n if isinstance(data, Buffer):\n- self.data = data + self.data\n+ self.data = data.data + self.data\n self.size += data.size\n else:\n self.data.insert(0, data)\n", "issue": "A little bug in Buffer class\nThere is a litttle bug in pwnlib.tubes.Buffer class.The class method unget has a type error in line 117.add a buffer and a list\n\n```\nTraceback (most recent call last):\n File \"<input>\", line 1, in <module>\n a.unget(b)\n File \"buffer.py\", line 117, in unget\n self.data = data + self.data\nTypeError: unsupported operand type(s) for +: 'Buffer' and 'list'\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python2\n\nclass Buffer(Exception):\n \"\"\"\n List of strings with some helper routines.\n\n Example:\n\n >>> b = Buffer()\n >>> b.add(\"A\" * 10)\n >>> b.add(\"B\" * 10)\n >>> len(b)\n 20\n >>> b.get(1)\n 'A'\n >>> len(b)\n 19\n >>> b.get(9999)\n 'AAAAAAAAABBBBBBBBBB'\n >>> len(b)\n 0\n >>> b.get(1)\n ''\n\n Implementation Details:\n\n Implemented as a list. Strings are added onto the end.\n The ``0th`` item in the buffer is the oldest item, and\n will be received first.\n \"\"\"\n def __init__(self):\n self.data = [] # Buffer\n self.size = 0 # Length\n\n\n def __len__(self):\n \"\"\"\n >>> b = Buffer()\n >>> b.add('lol')\n >>> len(b) == 3\n True\n >>> b.add('foobar')\n >>> len(b) == 9\n True\n \"\"\"\n return self.size\n\n def __nonzero__(self):\n return len(self) > 0\n\n def __contains__(self, x):\n \"\"\"\n >>> b = Buffer()\n >>> b.add('asdf')\n >>> 'x' in b\n False\n >>> b.add('x')\n >>> 'x' in b\n True\n \"\"\"\n for b in self.data:\n if x in b:\n return True\n return False\n\n def index(self, x):\n \"\"\"\n >>> b = Buffer()\n >>> b.add('asdf')\n >>> b.add('qwert')\n >>> b.index('t') == len(b) - 1\n True\n \"\"\"\n sofar = 0\n for b in self.data:\n if x in b:\n return sofar + b.index(x)\n sofar += len(b)\n raise IndexError()\n\n def add(self, data):\n \"\"\"\n Adds data to the buffer.\n\n Arguments:\n data(str,Buffer): Data to add\n \"\"\"\n # Fast path for ''\n if not data: return\n\n if isinstance(data, Buffer):\n self.size += data.size\n self.data += data.data\n else:\n self.size += len(data)\n self.data.append(data)\n\n def unget(self, data):\n \"\"\"\n Places data at the front of the buffer.\n\n Arguments:\n data(str,Buffer): Data to place at the beginning of the buffer.\n\n Example:\n\n >>> b = Buffer()\n >>> b.add(\"hello\")\n >>> b.add(\"world\")\n >>> b.get(5)\n 'hello'\n >>> b.unget(\"goodbye\")\n >>> b.get()\n 'goodbyeworld'\n \"\"\"\n if isinstance(data, Buffer):\n self.data = data + self.data\n self.size += data.size\n else:\n self.data.insert(0, data)\n self.size += len(data)\n\n def get(self, want=float('inf')):\n \"\"\"\n Retrieves bytes from the buffer.\n\n Arguments:\n want(int): Maximum number of bytes to fetch\n\n Returns:\n Data as string\n\n Example:\n\n >>> b = Buffer()\n >>> b.add('hello')\n >>> b.add('world')\n >>> b.get(1)\n 'h'\n >>> b.get()\n 'elloworld'\n \"\"\"\n # Fast path, get all of the data\n if want >= self.size:\n data = ''.join(self.data)\n self.size = 0\n self.data = []\n return data\n\n # Slow path, find the correct-index chunk\n have = 0\n i = 0\n while want >= have:\n have += len(self.data[i])\n i += 1\n\n # Join the chunks, evict from the buffer\n data = ''.join(self.data[:i])\n self.data = self.data[i:]\n\n # If the last chunk puts us over the limit,\n # stick the extra back at the beginning.\n if have > want:\n extra = data[want:]\n data = data[:want]\n self.data.insert(0, extra)\n\n # Size update\n self.size -= len(data)\n\n return data\n", "path": "pwnlib/tubes/buffer.py"}]}
| 2,018 | 113 |
gh_patches_debug_11967
|
rasdani/github-patches
|
git_diff
|
translate__pootle-6574
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Configurable logo url and favicon
It would be nice to have a configurable logo in the config file like you did for the name of pootle site (`POOTLE_TITLE`) instead of creating a custom template or editing the css of the default one.
</issue>
<code>
[start of pootle/apps/pootle_misc/context_processors.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 from django.conf import settings
10
11 from pootle.core.markup import get_markup_filter_name
12 from pootle_project.models import Project
13 from staticpages.models import LegalPage
14
15
16 def _agreement_context(request):
17 """Returns whether the agreement box should be displayed or not."""
18 request_path = request.META['PATH_INFO']
19 nocheck = filter(lambda x: request_path.startswith(x),
20 settings.POOTLE_LEGALPAGE_NOCHECK_PREFIXES)
21
22 if (request.user.is_authenticated and not nocheck and
23 LegalPage.objects.has_pending_agreement(request.user)):
24 return True
25
26 return False
27
28
29 def _get_social_auth_providers(request):
30 if 'allauth.socialaccount' not in settings.INSTALLED_APPS:
31 return []
32
33 from allauth.socialaccount import providers
34 return [{'name': provider.name, 'url': provider.get_login_url(request)}
35 for provider in providers.registry.get_list()]
36
37
38 def pootle_context(request):
39 """Exposes settings to templates."""
40 # FIXME: maybe we should expose relevant settings only?
41
42 return {
43 'settings': {
44 'POOTLE_CUSTOM_LOGO': getattr(settings, "POOTLE_CUSTOM_LOGO", ""),
45 'POOTLE_TITLE': settings.POOTLE_TITLE,
46 'POOTLE_INSTANCE_ID': settings.POOTLE_INSTANCE_ID,
47 'POOTLE_CONTACT_ENABLED': (settings.POOTLE_CONTACT_ENABLED and
48 settings.POOTLE_CONTACT_EMAIL),
49 'POOTLE_MARKUP_FILTER': get_markup_filter_name(),
50 'POOTLE_SIGNUP_ENABLED': settings.POOTLE_SIGNUP_ENABLED,
51 'SCRIPT_NAME': settings.SCRIPT_NAME,
52 'POOTLE_CACHE_TIMEOUT': settings.POOTLE_CACHE_TIMEOUT,
53 'DEBUG': settings.DEBUG,
54 },
55 'custom': settings.POOTLE_CUSTOM_TEMPLATE_CONTEXT,
56 'ALL_PROJECTS': Project.objects.cached_dict(request.user),
57 'SOCIAL_AUTH_PROVIDERS': _get_social_auth_providers(request),
58 'display_agreement': _agreement_context(request),
59 }
60
[end of pootle/apps/pootle_misc/context_processors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/apps/pootle_misc/context_processors.py b/pootle/apps/pootle_misc/context_processors.py
--- a/pootle/apps/pootle_misc/context_processors.py
+++ b/pootle/apps/pootle_misc/context_processors.py
@@ -43,6 +43,7 @@
'settings': {
'POOTLE_CUSTOM_LOGO': getattr(settings, "POOTLE_CUSTOM_LOGO", ""),
'POOTLE_TITLE': settings.POOTLE_TITLE,
+ 'POOTLE_FAVICONS_PATH': settings.POOTLE_FAVICONS_PATH,
'POOTLE_INSTANCE_ID': settings.POOTLE_INSTANCE_ID,
'POOTLE_CONTACT_ENABLED': (settings.POOTLE_CONTACT_ENABLED and
settings.POOTLE_CONTACT_EMAIL),
|
{"golden_diff": "diff --git a/pootle/apps/pootle_misc/context_processors.py b/pootle/apps/pootle_misc/context_processors.py\n--- a/pootle/apps/pootle_misc/context_processors.py\n+++ b/pootle/apps/pootle_misc/context_processors.py\n@@ -43,6 +43,7 @@\n 'settings': {\n 'POOTLE_CUSTOM_LOGO': getattr(settings, \"POOTLE_CUSTOM_LOGO\", \"\"),\n 'POOTLE_TITLE': settings.POOTLE_TITLE,\n+ 'POOTLE_FAVICONS_PATH': settings.POOTLE_FAVICONS_PATH,\n 'POOTLE_INSTANCE_ID': settings.POOTLE_INSTANCE_ID,\n 'POOTLE_CONTACT_ENABLED': (settings.POOTLE_CONTACT_ENABLED and\n settings.POOTLE_CONTACT_EMAIL),\n", "issue": "Configurable logo url and favicon\nIt would be nice to have a configurable logo in the config file like you did for the name of pootle site (`POOTLE_TITLE`) instead of creating a custom template or editing the css of the default one.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django.conf import settings\n\nfrom pootle.core.markup import get_markup_filter_name\nfrom pootle_project.models import Project\nfrom staticpages.models import LegalPage\n\n\ndef _agreement_context(request):\n \"\"\"Returns whether the agreement box should be displayed or not.\"\"\"\n request_path = request.META['PATH_INFO']\n nocheck = filter(lambda x: request_path.startswith(x),\n settings.POOTLE_LEGALPAGE_NOCHECK_PREFIXES)\n\n if (request.user.is_authenticated and not nocheck and\n LegalPage.objects.has_pending_agreement(request.user)):\n return True\n\n return False\n\n\ndef _get_social_auth_providers(request):\n if 'allauth.socialaccount' not in settings.INSTALLED_APPS:\n return []\n\n from allauth.socialaccount import providers\n return [{'name': provider.name, 'url': provider.get_login_url(request)}\n for provider in providers.registry.get_list()]\n\n\ndef pootle_context(request):\n \"\"\"Exposes settings to templates.\"\"\"\n # FIXME: maybe we should expose relevant settings only?\n\n return {\n 'settings': {\n 'POOTLE_CUSTOM_LOGO': getattr(settings, \"POOTLE_CUSTOM_LOGO\", \"\"),\n 'POOTLE_TITLE': settings.POOTLE_TITLE,\n 'POOTLE_INSTANCE_ID': settings.POOTLE_INSTANCE_ID,\n 'POOTLE_CONTACT_ENABLED': (settings.POOTLE_CONTACT_ENABLED and\n settings.POOTLE_CONTACT_EMAIL),\n 'POOTLE_MARKUP_FILTER': get_markup_filter_name(),\n 'POOTLE_SIGNUP_ENABLED': settings.POOTLE_SIGNUP_ENABLED,\n 'SCRIPT_NAME': settings.SCRIPT_NAME,\n 'POOTLE_CACHE_TIMEOUT': settings.POOTLE_CACHE_TIMEOUT,\n 'DEBUG': settings.DEBUG,\n },\n 'custom': settings.POOTLE_CUSTOM_TEMPLATE_CONTEXT,\n 'ALL_PROJECTS': Project.objects.cached_dict(request.user),\n 'SOCIAL_AUTH_PROVIDERS': _get_social_auth_providers(request),\n 'display_agreement': _agreement_context(request),\n }\n", "path": "pootle/apps/pootle_misc/context_processors.py"}]}
| 1,210 | 169 |
gh_patches_debug_39585
|
rasdani/github-patches
|
git_diff
|
ansible-collections__amazon.aws-2028
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`lookup` environment variables `aws_ec2.yml` file
### Summary
I'm trying to `lookup` environment variables in `aws_ec2.yml` file but the `lookup` seems to be not working as expected, is this something intentionally not allowed?
### Issue Type
Bug Report
### Component Name
ec2_instnace
### Ansible Version
```console (paste below)
$ ansible --version
ansible [core 2.15.2]
config file = /Users/<user>/.ansible.cfg
configured module search path = ['/Users/<user>/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /opt/homebrew/lib/python3.11/site-packages/ansible
ansible collection location = /Users/<user>/.ansible/collections:/usr/share/ansible/collections
executable location = /opt/homebrew/bin/ansible
python version = 3.11.6 (main, Oct 2 2023, 20:46:14) [Clang 14.0.3 (clang-1403.0.22.14.1)] (/opt/homebrew/opt/[email protected]/bin/python3.11)
jinja version = 3.1.2
libyaml = True
```
### Collection Versions
```console (paste below)
$ ansible-galaxy collection list
# /Users/<user>/.ansible/collections/ansible_collections
Collection Version
--------------------- -------
amazon.aws 6.5.0
ansible.windows 2.0.0
awx.awx 21.0.0
chocolatey.chocolatey 1.5.1
community.mysql 3.7.2
community.windows 2.0.0
lowlydba.sqlserver 0.7.0
microsoft.ad 1.4.1 ****
```
### AWS SDK versions
```console (paste below)
$ pip show boto boto3 botocore
Name: boto3
Version: 1.28.21
Summary: The AWS SDK for Python
Home-page: https://github.com/boto/boto3
Author: Amazon Web Services
Author-email:
License: Apache License 2.0
Location: /opt/homebrew/lib/python3.11/site-packages
Requires: botocore, jmespath, s3transfer
Required-by:
---
Name: botocore
Version: 1.31.21
Summary: Low-level, data-driven core of boto 3.
Home-page: https://github.com/boto/botocore
Author: Amazon Web Services
Author-email:
License: Apache License 2.0
Location: /opt/homebrew/lib/python3.11/site-packages
Requires: jmespath, python-dateutil, urllib3
Required-by: aws-secretsmanager-caching, boto3, **s3transfer**
```
### Configuration
```console (paste below)
$ ansible-config dump --only-changed
CONFIG_FILE() = /Users/<user>/.ansible.cfg
PAGER(env: PAGER) = less
```
### OS / Environment
macOS Ventura Version 13.6.2 (22G320)
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
plugin: aws_ec2
assume_role_arn: "arn:aws:iam::{{ lookup('env', 'AWS_ACCOUNT_ID') | default('XXXXXXXXXXX', true) }}:role/ansible-manager"
regions:
- "{{ lookup('env', 'AWS_REGION') | default('us-east-1', true) }}"
```
i have this `yml` file which is something i was expecting it would lookup the env variables and get the authorization
### Expected Results
Expected result that `lookup` would happen and assume role/region would get set right, instead it is being parsed as plain text and `lookup` is not being recognized is what i understand looking at the result below
### Actual Results
```console (paste below)
aws_ec2.yml with auto plugin: An error occurred (AccessDenied) when calling the AssumeRole operation: User:
<UserName> is not
authorized to perform: sts:AssumeRole on resource: arn:aws:iam::{{ lookup('ansible.builtin.env', 'AWS_ACCOUNT_ID') |
default('XXXXXXXXXXX', True) }}:role/ansible-manager
aws_ec2.yml with auto plugin: Couldn't connect to AWS: Provided region_name '{{ lookup('env', 'AWS_REGION') |
default('us-east-1', true) }}' doesn't match a supported format.
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/plugin_utils/inventory.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright: (c) 2022, Ansible Project
4 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
5
6 try:
7 import boto3
8 import botocore
9 except ImportError:
10 pass # will be captured by imported HAS_BOTO3
11
12 from ansible.plugins.inventory import BaseInventoryPlugin
13 from ansible.plugins.inventory import Cacheable
14 from ansible.plugins.inventory import Constructable
15
16 from ansible_collections.amazon.aws.plugins.module_utils.botocore import is_boto3_error_code
17 from ansible_collections.amazon.aws.plugins.plugin_utils.base import AWSPluginBase
18 from ansible_collections.amazon.aws.plugins.plugin_utils.botocore import AnsibleBotocoreError
19
20
21 def _boto3_session(profile_name=None):
22 if profile_name is None:
23 return boto3.Session()
24 return boto3.session.Session(profile_name=profile_name)
25
26
27 class AWSInventoryBase(BaseInventoryPlugin, Constructable, Cacheable, AWSPluginBase):
28 class TemplatedOptions:
29 # When someone looks up the TEMPLATABLE_OPTIONS using get() any templates
30 # will be templated using the loader passed to parse.
31 TEMPLATABLE_OPTIONS = (
32 "access_key",
33 "secret_key",
34 "session_token",
35 "profile",
36 "iam_role_name",
37 )
38
39 def __init__(self, templar, options):
40 self.original_options = options
41 self.templar = templar
42
43 def __getitem__(self, *args):
44 return self.original_options.__getitem__(self, *args)
45
46 def __setitem__(self, *args):
47 return self.original_options.__setitem__(self, *args)
48
49 def get(self, *args):
50 value = self.original_options.get(*args)
51 if not value:
52 return value
53 if args[0] not in self.TEMPLATABLE_OPTIONS:
54 return value
55 if not self.templar.is_template(value):
56 return value
57
58 return self.templar.template(variable=value, disable_lookups=False)
59
60 def get_options(self, *args):
61 original_options = super().get_options(*args)
62 if not self.templar:
63 return original_options
64 return self.TemplatedOptions(self.templar, original_options)
65
66 def __init__(self):
67 super().__init__()
68 self._frozen_credentials = {}
69
70 # pylint: disable=too-many-arguments
71 def parse(self, inventory, loader, path, cache=True, botocore_version=None, boto3_version=None):
72 super().parse(inventory, loader, path)
73 self.require_aws_sdk(botocore_version=botocore_version, boto3_version=boto3_version)
74 self._read_config_data(path)
75 self._set_frozen_credentials()
76
77 def client(self, *args, **kwargs):
78 kw_args = dict(self._frozen_credentials)
79 kw_args.update(kwargs)
80 return super().client(*args, **kw_args)
81
82 def resource(self, *args, **kwargs):
83 kw_args = dict(self._frozen_credentials)
84 kw_args.update(kwargs)
85 return super().resource(*args, **kw_args)
86
87 def _freeze_iam_role(self, iam_role_arn):
88 if hasattr(self, "ansible_name"):
89 role_session_name = f"ansible_aws_{self.ansible_name}_dynamic_inventory"
90 else:
91 role_session_name = "ansible_aws_dynamic_inventory"
92 assume_params = {"RoleArn": iam_role_arn, "RoleSessionName": role_session_name}
93
94 try:
95 sts = self.client("sts")
96 assumed_role = sts.assume_role(**assume_params)
97 except AnsibleBotocoreError as e:
98 self.fail_aws(f"Unable to assume role {iam_role_arn}", exception=e)
99
100 credentials = assumed_role.get("Credentials")
101 if not credentials:
102 self.fail_aws(f"Unable to assume role {iam_role_arn}")
103
104 self._frozen_credentials = {
105 "profile_name": None,
106 "aws_access_key_id": credentials.get("AccessKeyId"),
107 "aws_secret_access_key": credentials.get("SecretAccessKey"),
108 "aws_session_token": credentials.get("SessionToken"),
109 }
110
111 def _set_frozen_credentials(self):
112 options = self.get_options()
113 iam_role_arn = options.get("assume_role_arn")
114 if iam_role_arn:
115 self._freeze_iam_role(iam_role_arn)
116
117 def _describe_regions(self, service):
118 # Try pulling a list of regions from the service
119 try:
120 initial_region = self.region or "us-east-1"
121 client = self.client(service, region=initial_region)
122 resp = client.describe_regions()
123 except AttributeError:
124 # Not all clients support describe
125 pass
126 except is_boto3_error_code("UnauthorizedOperation"):
127 self.warn(f"UnauthorizedOperation when trying to list {service} regions")
128 except botocore.exceptions.NoRegionError:
129 self.warn(f"NoRegionError when trying to list {service} regions")
130 except (botocore.exceptions.BotoCoreError, botocore.exceptions.ClientError) as e:
131 self.warn(f"Unexpected error while trying to list {service} regions: {e}")
132 else:
133 regions = [x["RegionName"] for x in resp.get("Regions", [])]
134 if regions:
135 return regions
136 return None
137
138 def _boto3_regions(self, service):
139 options = self.get_options()
140
141 if options.get("regions"):
142 return options.get("regions")
143
144 # boto3 has hard coded lists of available regions for resources, however this does bit-rot
145 # As such we try to query the service, and fall back to ec2 for a list of regions
146 for resource_type in list({service, "ec2"}):
147 regions = self._describe_regions(resource_type)
148 if regions:
149 return regions
150
151 # fallback to local list hardcoded in boto3 if still no regions
152 session = _boto3_session(options.get("profile"))
153 regions = session.get_available_regions(service)
154
155 if not regions:
156 # I give up, now you MUST give me regions
157 self.fail_aws(
158 "Unable to get regions list from available methods, you must specify the 'regions' option to continue."
159 )
160
161 return regions
162
163 def all_clients(self, service):
164 """
165 Generator that yields a boto3 client and the region
166
167 :param service: The boto3 service to connect to.
168
169 Note: For services which don't support 'DescribeRegions' this may include bad
170 endpoints, and as such EndpointConnectionError should be cleanly handled as a non-fatal
171 error.
172 """
173 regions = self._boto3_regions(service=service)
174
175 for region in regions:
176 connection = self.client(service, region=region)
177 yield connection, region
178
179 def get_cached_result(self, path, cache):
180 # false when refresh_cache or --flush-cache is used
181 if not cache:
182 return False, None
183 # get the user-specified directive
184 if not self.get_option("cache"):
185 return False, None
186
187 cache_key = self.get_cache_key(path)
188 try:
189 cached_value = self._cache[cache_key]
190 except KeyError:
191 # if cache expires or cache file doesn"t exist
192 return False, None
193
194 return True, cached_value
195
196 def update_cached_result(self, path, cache, result):
197 if not self.get_option("cache"):
198 return
199
200 cache_key = self.get_cache_key(path)
201 # We weren't explicitly told to flush the cache, and there's already a cache entry,
202 # this means that the result we're being passed came from the cache. As such we don't
203 # want to "update" the cache as that could reset a TTL on the cache entry.
204 if cache and cache_key in self._cache:
205 return
206
207 self._cache[cache_key] = result
208
209 def verify_file(self, path):
210 """
211 :param path: the path to the inventory config file
212 :return the contents of the config file
213 """
214 if not super().verify_file(path):
215 return False
216
217 if hasattr(self, "INVENTORY_FILE_SUFFIXES"):
218 if not path.endswith(self.INVENTORY_FILE_SUFFIXES):
219 return False
220
221 return True
222
[end of plugins/plugin_utils/inventory.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/plugin_utils/inventory.py b/plugins/plugin_utils/inventory.py
--- a/plugins/plugin_utils/inventory.py
+++ b/plugins/plugin_utils/inventory.py
@@ -33,7 +33,10 @@
"secret_key",
"session_token",
"profile",
- "iam_role_name",
+ "endpoint_url",
+ "assume_role_arn",
+ "region",
+ "regions",
)
def __init__(self, templar, options):
@@ -48,20 +51,21 @@
def get(self, *args):
value = self.original_options.get(*args)
- if not value:
- return value
- if args[0] not in self.TEMPLATABLE_OPTIONS:
- return value
- if not self.templar.is_template(value):
+ if (
+ not value
+ or not self.templar
+ or args[0] not in self.TEMPLATABLE_OPTIONS
+ or not self.templar.is_template(value)
+ ):
return value
return self.templar.template(variable=value, disable_lookups=False)
def get_options(self, *args):
- original_options = super().get_options(*args)
- if not self.templar:
- return original_options
- return self.TemplatedOptions(self.templar, original_options)
+ return self.TemplatedOptions(self.templar, super().get_options(*args))
+
+ def get_option(self, option, hostvars=None):
+ return self.TemplatedOptions(self.templar, {option: super().get_option(option, hostvars)}).get(option)
def __init__(self):
super().__init__()
@@ -109,8 +113,7 @@
}
def _set_frozen_credentials(self):
- options = self.get_options()
- iam_role_arn = options.get("assume_role_arn")
+ iam_role_arn = self.get_option("assume_role_arn")
if iam_role_arn:
self._freeze_iam_role(iam_role_arn)
@@ -136,10 +139,9 @@
return None
def _boto3_regions(self, service):
- options = self.get_options()
-
- if options.get("regions"):
- return options.get("regions")
+ regions = self.get_option("regions")
+ if regions:
+ return regions
# boto3 has hard coded lists of available regions for resources, however this does bit-rot
# As such we try to query the service, and fall back to ec2 for a list of regions
@@ -149,7 +151,7 @@
return regions
# fallback to local list hardcoded in boto3 if still no regions
- session = _boto3_session(options.get("profile"))
+ session = _boto3_session(self.get_option("profile"))
regions = session.get_available_regions(service)
if not regions:
|
{"golden_diff": "diff --git a/plugins/plugin_utils/inventory.py b/plugins/plugin_utils/inventory.py\n--- a/plugins/plugin_utils/inventory.py\n+++ b/plugins/plugin_utils/inventory.py\n@@ -33,7 +33,10 @@\n \"secret_key\",\n \"session_token\",\n \"profile\",\n- \"iam_role_name\",\n+ \"endpoint_url\",\n+ \"assume_role_arn\",\n+ \"region\",\n+ \"regions\",\n )\n \n def __init__(self, templar, options):\n@@ -48,20 +51,21 @@\n \n def get(self, *args):\n value = self.original_options.get(*args)\n- if not value:\n- return value\n- if args[0] not in self.TEMPLATABLE_OPTIONS:\n- return value\n- if not self.templar.is_template(value):\n+ if (\n+ not value\n+ or not self.templar\n+ or args[0] not in self.TEMPLATABLE_OPTIONS\n+ or not self.templar.is_template(value)\n+ ):\n return value\n \n return self.templar.template(variable=value, disable_lookups=False)\n \n def get_options(self, *args):\n- original_options = super().get_options(*args)\n- if not self.templar:\n- return original_options\n- return self.TemplatedOptions(self.templar, original_options)\n+ return self.TemplatedOptions(self.templar, super().get_options(*args))\n+\n+ def get_option(self, option, hostvars=None):\n+ return self.TemplatedOptions(self.templar, {option: super().get_option(option, hostvars)}).get(option)\n \n def __init__(self):\n super().__init__()\n@@ -109,8 +113,7 @@\n }\n \n def _set_frozen_credentials(self):\n- options = self.get_options()\n- iam_role_arn = options.get(\"assume_role_arn\")\n+ iam_role_arn = self.get_option(\"assume_role_arn\")\n if iam_role_arn:\n self._freeze_iam_role(iam_role_arn)\n \n@@ -136,10 +139,9 @@\n return None\n \n def _boto3_regions(self, service):\n- options = self.get_options()\n-\n- if options.get(\"regions\"):\n- return options.get(\"regions\")\n+ regions = self.get_option(\"regions\")\n+ if regions:\n+ return regions\n \n # boto3 has hard coded lists of available regions for resources, however this does bit-rot\n # As such we try to query the service, and fall back to ec2 for a list of regions\n@@ -149,7 +151,7 @@\n return regions\n \n # fallback to local list hardcoded in boto3 if still no regions\n- session = _boto3_session(options.get(\"profile\"))\n+ session = _boto3_session(self.get_option(\"profile\"))\n regions = session.get_available_regions(service)\n \n if not regions:\n", "issue": "`lookup` environment variables `aws_ec2.yml` file\n### Summary\n\nI'm trying to `lookup` environment variables in `aws_ec2.yml` file but the `lookup` seems to be not working as expected, is this something intentionally not allowed? \n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nec2_instnace\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\nansible [core 2.15.2]\r\n config file = /Users/<user>/.ansible.cfg\r\n configured module search path = ['/Users/<user>/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /opt/homebrew/lib/python3.11/site-packages/ansible\r\n ansible collection location = /Users/<user>/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /opt/homebrew/bin/ansible\r\n python version = 3.11.6 (main, Oct 2 2023, 20:46:14) [Clang 14.0.3 (clang-1403.0.22.14.1)] (/opt/homebrew/opt/[email protected]/bin/python3.11)\r\n jinja version = 3.1.2\r\n libyaml = True\r\n```\r\n\n\n### Collection Versions\n\n```console (paste below)\r\n$ ansible-galaxy collection list\r\n\r\n# /Users/<user>/.ansible/collections/ansible_collections\r\nCollection Version\r\n--------------------- -------\r\namazon.aws 6.5.0 \r\nansible.windows 2.0.0 \r\nawx.awx 21.0.0 \r\nchocolatey.chocolatey 1.5.1 \r\ncommunity.mysql 3.7.2 \r\ncommunity.windows 2.0.0 \r\nlowlydba.sqlserver 0.7.0 \r\nmicrosoft.ad 1.4.1 ****\r\n```\r\n\n\n### AWS SDK versions\n\n```console (paste below)\r\n$ pip show boto boto3 botocore\r\nName: boto3\r\nVersion: 1.28.21\r\nSummary: The AWS SDK for Python\r\nHome-page: https://github.com/boto/boto3\r\nAuthor: Amazon Web Services\r\nAuthor-email: \r\nLicense: Apache License 2.0\r\nLocation: /opt/homebrew/lib/python3.11/site-packages\r\nRequires: botocore, jmespath, s3transfer\r\nRequired-by: \r\n---\r\nName: botocore\r\nVersion: 1.31.21\r\nSummary: Low-level, data-driven core of boto 3.\r\nHome-page: https://github.com/boto/botocore\r\nAuthor: Amazon Web Services\r\nAuthor-email: \r\nLicense: Apache License 2.0\r\nLocation: /opt/homebrew/lib/python3.11/site-packages\r\nRequires: jmespath, python-dateutil, urllib3\r\nRequired-by: aws-secretsmanager-caching, boto3, **s3transfer**\r\n```\r\n\n\n### Configuration\n\n```console (paste below)\r\n$ ansible-config dump --only-changed\r\nCONFIG_FILE() = /Users/<user>/.ansible.cfg\r\nPAGER(env: PAGER) = less\r\n```\r\n\n\n### OS / Environment\n\nmacOS Ventura Version 13.6.2 (22G320)\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\nplugin: aws_ec2\r\nassume_role_arn: \"arn:aws:iam::{{ lookup('env', 'AWS_ACCOUNT_ID') | default('XXXXXXXXXXX', true) }}:role/ansible-manager\"\r\nregions:\r\n - \"{{ lookup('env', 'AWS_REGION') | default('us-east-1', true) }}\"\r\n```\r\n\r\ni have this `yml` file which is something i was expecting it would lookup the env variables and get the authorization \n\n### Expected Results\n\nExpected result that `lookup` would happen and assume role/region would get set right, instead it is being parsed as plain text and `lookup` is not being recognized is what i understand looking at the result below\r\n\n\n### Actual Results\n\n```console (paste below)\r\naws_ec2.yml with auto plugin: An error occurred (AccessDenied) when calling the AssumeRole operation: User:\r\n<UserName> is not\r\nauthorized to perform: sts:AssumeRole on resource: arn:aws:iam::{{ lookup('ansible.builtin.env', 'AWS_ACCOUNT_ID') |\r\ndefault('XXXXXXXXXXX', True) }}:role/ansible-manager\r\n\r\naws_ec2.yml with auto plugin: Couldn't connect to AWS: Provided region_name '{{ lookup('env', 'AWS_REGION') |\r\ndefault('us-east-1', true) }}' doesn't match a supported format.\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright: (c) 2022, Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\ntry:\n import boto3\n import botocore\nexcept ImportError:\n pass # will be captured by imported HAS_BOTO3\n\nfrom ansible.plugins.inventory import BaseInventoryPlugin\nfrom ansible.plugins.inventory import Cacheable\nfrom ansible.plugins.inventory import Constructable\n\nfrom ansible_collections.amazon.aws.plugins.module_utils.botocore import is_boto3_error_code\nfrom ansible_collections.amazon.aws.plugins.plugin_utils.base import AWSPluginBase\nfrom ansible_collections.amazon.aws.plugins.plugin_utils.botocore import AnsibleBotocoreError\n\n\ndef _boto3_session(profile_name=None):\n if profile_name is None:\n return boto3.Session()\n return boto3.session.Session(profile_name=profile_name)\n\n\nclass AWSInventoryBase(BaseInventoryPlugin, Constructable, Cacheable, AWSPluginBase):\n class TemplatedOptions:\n # When someone looks up the TEMPLATABLE_OPTIONS using get() any templates\n # will be templated using the loader passed to parse.\n TEMPLATABLE_OPTIONS = (\n \"access_key\",\n \"secret_key\",\n \"session_token\",\n \"profile\",\n \"iam_role_name\",\n )\n\n def __init__(self, templar, options):\n self.original_options = options\n self.templar = templar\n\n def __getitem__(self, *args):\n return self.original_options.__getitem__(self, *args)\n\n def __setitem__(self, *args):\n return self.original_options.__setitem__(self, *args)\n\n def get(self, *args):\n value = self.original_options.get(*args)\n if not value:\n return value\n if args[0] not in self.TEMPLATABLE_OPTIONS:\n return value\n if not self.templar.is_template(value):\n return value\n\n return self.templar.template(variable=value, disable_lookups=False)\n\n def get_options(self, *args):\n original_options = super().get_options(*args)\n if not self.templar:\n return original_options\n return self.TemplatedOptions(self.templar, original_options)\n\n def __init__(self):\n super().__init__()\n self._frozen_credentials = {}\n\n # pylint: disable=too-many-arguments\n def parse(self, inventory, loader, path, cache=True, botocore_version=None, boto3_version=None):\n super().parse(inventory, loader, path)\n self.require_aws_sdk(botocore_version=botocore_version, boto3_version=boto3_version)\n self._read_config_data(path)\n self._set_frozen_credentials()\n\n def client(self, *args, **kwargs):\n kw_args = dict(self._frozen_credentials)\n kw_args.update(kwargs)\n return super().client(*args, **kw_args)\n\n def resource(self, *args, **kwargs):\n kw_args = dict(self._frozen_credentials)\n kw_args.update(kwargs)\n return super().resource(*args, **kw_args)\n\n def _freeze_iam_role(self, iam_role_arn):\n if hasattr(self, \"ansible_name\"):\n role_session_name = f\"ansible_aws_{self.ansible_name}_dynamic_inventory\"\n else:\n role_session_name = \"ansible_aws_dynamic_inventory\"\n assume_params = {\"RoleArn\": iam_role_arn, \"RoleSessionName\": role_session_name}\n\n try:\n sts = self.client(\"sts\")\n assumed_role = sts.assume_role(**assume_params)\n except AnsibleBotocoreError as e:\n self.fail_aws(f\"Unable to assume role {iam_role_arn}\", exception=e)\n\n credentials = assumed_role.get(\"Credentials\")\n if not credentials:\n self.fail_aws(f\"Unable to assume role {iam_role_arn}\")\n\n self._frozen_credentials = {\n \"profile_name\": None,\n \"aws_access_key_id\": credentials.get(\"AccessKeyId\"),\n \"aws_secret_access_key\": credentials.get(\"SecretAccessKey\"),\n \"aws_session_token\": credentials.get(\"SessionToken\"),\n }\n\n def _set_frozen_credentials(self):\n options = self.get_options()\n iam_role_arn = options.get(\"assume_role_arn\")\n if iam_role_arn:\n self._freeze_iam_role(iam_role_arn)\n\n def _describe_regions(self, service):\n # Try pulling a list of regions from the service\n try:\n initial_region = self.region or \"us-east-1\"\n client = self.client(service, region=initial_region)\n resp = client.describe_regions()\n except AttributeError:\n # Not all clients support describe\n pass\n except is_boto3_error_code(\"UnauthorizedOperation\"):\n self.warn(f\"UnauthorizedOperation when trying to list {service} regions\")\n except botocore.exceptions.NoRegionError:\n self.warn(f\"NoRegionError when trying to list {service} regions\")\n except (botocore.exceptions.BotoCoreError, botocore.exceptions.ClientError) as e:\n self.warn(f\"Unexpected error while trying to list {service} regions: {e}\")\n else:\n regions = [x[\"RegionName\"] for x in resp.get(\"Regions\", [])]\n if regions:\n return regions\n return None\n\n def _boto3_regions(self, service):\n options = self.get_options()\n\n if options.get(\"regions\"):\n return options.get(\"regions\")\n\n # boto3 has hard coded lists of available regions for resources, however this does bit-rot\n # As such we try to query the service, and fall back to ec2 for a list of regions\n for resource_type in list({service, \"ec2\"}):\n regions = self._describe_regions(resource_type)\n if regions:\n return regions\n\n # fallback to local list hardcoded in boto3 if still no regions\n session = _boto3_session(options.get(\"profile\"))\n regions = session.get_available_regions(service)\n\n if not regions:\n # I give up, now you MUST give me regions\n self.fail_aws(\n \"Unable to get regions list from available methods, you must specify the 'regions' option to continue.\"\n )\n\n return regions\n\n def all_clients(self, service):\n \"\"\"\n Generator that yields a boto3 client and the region\n\n :param service: The boto3 service to connect to.\n\n Note: For services which don't support 'DescribeRegions' this may include bad\n endpoints, and as such EndpointConnectionError should be cleanly handled as a non-fatal\n error.\n \"\"\"\n regions = self._boto3_regions(service=service)\n\n for region in regions:\n connection = self.client(service, region=region)\n yield connection, region\n\n def get_cached_result(self, path, cache):\n # false when refresh_cache or --flush-cache is used\n if not cache:\n return False, None\n # get the user-specified directive\n if not self.get_option(\"cache\"):\n return False, None\n\n cache_key = self.get_cache_key(path)\n try:\n cached_value = self._cache[cache_key]\n except KeyError:\n # if cache expires or cache file doesn\"t exist\n return False, None\n\n return True, cached_value\n\n def update_cached_result(self, path, cache, result):\n if not self.get_option(\"cache\"):\n return\n\n cache_key = self.get_cache_key(path)\n # We weren't explicitly told to flush the cache, and there's already a cache entry,\n # this means that the result we're being passed came from the cache. As such we don't\n # want to \"update\" the cache as that could reset a TTL on the cache entry.\n if cache and cache_key in self._cache:\n return\n\n self._cache[cache_key] = result\n\n def verify_file(self, path):\n \"\"\"\n :param path: the path to the inventory config file\n :return the contents of the config file\n \"\"\"\n if not super().verify_file(path):\n return False\n\n if hasattr(self, \"INVENTORY_FILE_SUFFIXES\"):\n if not path.endswith(self.INVENTORY_FILE_SUFFIXES):\n return False\n\n return True\n", "path": "plugins/plugin_utils/inventory.py"}]}
| 3,944 | 665 |
gh_patches_debug_6623
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-14901
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Changing event rule action type messes up Conditions field
### Deployment Type
Self-hosted
### NetBox Version
v3.7.1
### Python Version
3.11
### Steps to Reproduce
1. Go to **Operations - Event Rules - Add**
2. Set Conditions = `{ "and": [{"attr": "status.value", "value": "deprecated"}]}`
3. Select Action type = Script
### Expected Behavior
Conditions field stays as-is
### Observed Behavior
Conditions field is rewritten as invalid JSON:
`"{ \"and\": [{\"attr\": \"status.value\", \"value\": \"deprecated\"}]}"`
The quoting is added with every change of the Action type.
This also happens if editing an existing event rule and changing the Action type.
### Workaround
- Copy the Conditions field somewhere
- Change the Action type
- Paste the Conditions field back
</issue>
<code>
[start of netbox/utilities/forms/fields/fields.py]
1 import json
2
3 from django import forms
4 from django.db.models import Count
5 from django.forms.fields import JSONField as _JSONField, InvalidJSONInput
6 from django.templatetags.static import static
7 from django.utils.translation import gettext_lazy as _
8 from netaddr import AddrFormatError, EUI
9
10 from utilities.forms import widgets
11 from utilities.validators import EnhancedURLValidator
12
13 __all__ = (
14 'ColorField',
15 'CommentField',
16 'JSONField',
17 'LaxURLField',
18 'MACAddressField',
19 'SlugField',
20 'TagFilterField',
21 )
22
23
24 class CommentField(forms.CharField):
25 """
26 A textarea with support for Markdown rendering. Exists mostly just to add a standard `help_text`.
27 """
28 widget = widgets.MarkdownWidget
29 label = _('Comments')
30 help_text = _(
31 '<i class="mdi mdi-information-outline"></i> '
32 '<a href="{url}" target="_blank" tabindex="-1">Markdown</a> syntax is supported'
33 ).format(url=static('docs/reference/markdown/'))
34
35 def __init__(self, *, label=label, help_text=help_text, required=False, **kwargs):
36 super().__init__(label=label, help_text=help_text, required=required, **kwargs)
37
38
39 class SlugField(forms.SlugField):
40 """
41 Extend Django's built-in SlugField to automatically populate from a field called `name` unless otherwise specified.
42
43 Parameters:
44 slug_source: Name of the form field from which the slug value will be derived
45 """
46 widget = widgets.SlugWidget
47 label = _('Slug')
48 help_text = _("URL-friendly unique shorthand")
49
50 def __init__(self, *, slug_source='name', label=label, help_text=help_text, **kwargs):
51 super().__init__(label=label, help_text=help_text, **kwargs)
52
53 self.widget.attrs['slug-source'] = slug_source
54
55
56 class ColorField(forms.CharField):
57 """
58 A field which represents a color value in hexadecimal `RRGGBB` format. Utilizes NetBox's `ColorSelect` widget to
59 render choices.
60 """
61 widget = widgets.ColorSelect
62
63
64 class TagFilterField(forms.MultipleChoiceField):
65 """
66 A filter field for the tags of a model. Only the tags used by a model are displayed.
67
68 :param model: The model of the filter
69 """
70
71 def __init__(self, model, *args, **kwargs):
72 def get_choices():
73 tags = model.tags.annotate(
74 count=Count('extras_taggeditem_items')
75 ).order_by('name')
76 return [
77 (str(tag.slug), '{} ({})'.format(tag.name, tag.count)) for tag in tags
78 ]
79
80 # Choices are fetched each time the form is initialized
81 super().__init__(label=_('Tags'), choices=get_choices, required=False, *args, **kwargs)
82
83
84 class LaxURLField(forms.URLField):
85 """
86 Modifies Django's built-in URLField to remove the requirement for fully-qualified domain names
87 (e.g. http://myserver/ is valid)
88 """
89 default_validators = [EnhancedURLValidator()]
90
91
92 class JSONField(_JSONField):
93 """
94 Custom wrapper around Django's built-in JSONField to avoid presenting "null" as the default text.
95 """
96 def __init__(self, *args, **kwargs):
97 super().__init__(*args, **kwargs)
98 if not self.help_text:
99 self.help_text = _('Enter context data in <a href="https://json.org/">JSON</a> format.')
100 self.widget.attrs['placeholder'] = ''
101 self.widget.attrs['class'] = 'font-monospace'
102
103 def prepare_value(self, value):
104 if isinstance(value, InvalidJSONInput):
105 return value
106 if value in ('', None):
107 return ''
108 return json.dumps(value, sort_keys=True, indent=4)
109
110
111 class MACAddressField(forms.Field):
112 """
113 Validates a 48-bit MAC address.
114 """
115 widget = forms.CharField
116 default_error_messages = {
117 'invalid': _('MAC address must be in EUI-48 format'),
118 }
119
120 def to_python(self, value):
121 value = super().to_python(value)
122
123 # Validate MAC address format
124 try:
125 value = EUI(value.strip())
126 except AddrFormatError:
127 raise forms.ValidationError(self.error_messages['invalid'], code='invalid')
128
129 return value
130
[end of netbox/utilities/forms/fields/fields.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/utilities/forms/fields/fields.py b/netbox/utilities/forms/fields/fields.py
--- a/netbox/utilities/forms/fields/fields.py
+++ b/netbox/utilities/forms/fields/fields.py
@@ -105,7 +105,12 @@
return value
if value in ('', None):
return ''
- return json.dumps(value, sort_keys=True, indent=4)
+ if type(value) is str:
+ try:
+ value = json.loads(value, cls=self.decoder)
+ except json.decoder.JSONDecodeError:
+ return value
+ return json.dumps(value, sort_keys=True, indent=4, ensure_ascii=False, cls=self.encoder)
class MACAddressField(forms.Field):
|
{"golden_diff": "diff --git a/netbox/utilities/forms/fields/fields.py b/netbox/utilities/forms/fields/fields.py\n--- a/netbox/utilities/forms/fields/fields.py\n+++ b/netbox/utilities/forms/fields/fields.py\n@@ -105,7 +105,12 @@\n return value\n if value in ('', None):\n return ''\n- return json.dumps(value, sort_keys=True, indent=4)\n+ if type(value) is str:\n+ try:\n+ value = json.loads(value, cls=self.decoder)\n+ except json.decoder.JSONDecodeError:\n+ return value\n+ return json.dumps(value, sort_keys=True, indent=4, ensure_ascii=False, cls=self.encoder)\n \n \n class MACAddressField(forms.Field):\n", "issue": "Changing event rule action type messes up Conditions field\n### Deployment Type\r\n\r\nSelf-hosted\r\n\r\n### NetBox Version\r\n\r\nv3.7.1\r\n\r\n### Python Version\r\n\r\n3.11\r\n\r\n### Steps to Reproduce\r\n\r\n1. Go to **Operations - Event Rules - Add**\r\n2. Set Conditions = `{ \"and\": [{\"attr\": \"status.value\", \"value\": \"deprecated\"}]}`\r\n3. Select Action type = Script\r\n\r\n### Expected Behavior\r\n\r\nConditions field stays as-is\r\n\r\n### Observed Behavior\r\n\r\nConditions field is rewritten as invalid JSON:\r\n\r\n`\"{ \\\"and\\\": [{\\\"attr\\\": \\\"status.value\\\", \\\"value\\\": \\\"deprecated\\\"}]}\"`\r\n\r\nThe quoting is added with every change of the Action type.\r\n\r\nThis also happens if editing an existing event rule and changing the Action type.\r\n\r\n### Workaround\r\n\r\n- Copy the Conditions field somewhere\r\n- Change the Action type\r\n- Paste the Conditions field back\n", "before_files": [{"content": "import json\n\nfrom django import forms\nfrom django.db.models import Count\nfrom django.forms.fields import JSONField as _JSONField, InvalidJSONInput\nfrom django.templatetags.static import static\nfrom django.utils.translation import gettext_lazy as _\nfrom netaddr import AddrFormatError, EUI\n\nfrom utilities.forms import widgets\nfrom utilities.validators import EnhancedURLValidator\n\n__all__ = (\n 'ColorField',\n 'CommentField',\n 'JSONField',\n 'LaxURLField',\n 'MACAddressField',\n 'SlugField',\n 'TagFilterField',\n)\n\n\nclass CommentField(forms.CharField):\n \"\"\"\n A textarea with support for Markdown rendering. Exists mostly just to add a standard `help_text`.\n \"\"\"\n widget = widgets.MarkdownWidget\n label = _('Comments')\n help_text = _(\n '<i class=\"mdi mdi-information-outline\"></i> '\n '<a href=\"{url}\" target=\"_blank\" tabindex=\"-1\">Markdown</a> syntax is supported'\n ).format(url=static('docs/reference/markdown/'))\n\n def __init__(self, *, label=label, help_text=help_text, required=False, **kwargs):\n super().__init__(label=label, help_text=help_text, required=required, **kwargs)\n\n\nclass SlugField(forms.SlugField):\n \"\"\"\n Extend Django's built-in SlugField to automatically populate from a field called `name` unless otherwise specified.\n\n Parameters:\n slug_source: Name of the form field from which the slug value will be derived\n \"\"\"\n widget = widgets.SlugWidget\n label = _('Slug')\n help_text = _(\"URL-friendly unique shorthand\")\n\n def __init__(self, *, slug_source='name', label=label, help_text=help_text, **kwargs):\n super().__init__(label=label, help_text=help_text, **kwargs)\n\n self.widget.attrs['slug-source'] = slug_source\n\n\nclass ColorField(forms.CharField):\n \"\"\"\n A field which represents a color value in hexadecimal `RRGGBB` format. Utilizes NetBox's `ColorSelect` widget to\n render choices.\n \"\"\"\n widget = widgets.ColorSelect\n\n\nclass TagFilterField(forms.MultipleChoiceField):\n \"\"\"\n A filter field for the tags of a model. Only the tags used by a model are displayed.\n\n :param model: The model of the filter\n \"\"\"\n\n def __init__(self, model, *args, **kwargs):\n def get_choices():\n tags = model.tags.annotate(\n count=Count('extras_taggeditem_items')\n ).order_by('name')\n return [\n (str(tag.slug), '{} ({})'.format(tag.name, tag.count)) for tag in tags\n ]\n\n # Choices are fetched each time the form is initialized\n super().__init__(label=_('Tags'), choices=get_choices, required=False, *args, **kwargs)\n\n\nclass LaxURLField(forms.URLField):\n \"\"\"\n Modifies Django's built-in URLField to remove the requirement for fully-qualified domain names\n (e.g. http://myserver/ is valid)\n \"\"\"\n default_validators = [EnhancedURLValidator()]\n\n\nclass JSONField(_JSONField):\n \"\"\"\n Custom wrapper around Django's built-in JSONField to avoid presenting \"null\" as the default text.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n if not self.help_text:\n self.help_text = _('Enter context data in <a href=\"https://json.org/\">JSON</a> format.')\n self.widget.attrs['placeholder'] = ''\n self.widget.attrs['class'] = 'font-monospace'\n\n def prepare_value(self, value):\n if isinstance(value, InvalidJSONInput):\n return value\n if value in ('', None):\n return ''\n return json.dumps(value, sort_keys=True, indent=4)\n\n\nclass MACAddressField(forms.Field):\n \"\"\"\n Validates a 48-bit MAC address.\n \"\"\"\n widget = forms.CharField\n default_error_messages = {\n 'invalid': _('MAC address must be in EUI-48 format'),\n }\n\n def to_python(self, value):\n value = super().to_python(value)\n\n # Validate MAC address format\n try:\n value = EUI(value.strip())\n except AddrFormatError:\n raise forms.ValidationError(self.error_messages['invalid'], code='invalid')\n\n return value\n", "path": "netbox/utilities/forms/fields/fields.py"}]}
| 1,966 | 167 |
gh_patches_debug_23338
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-3950
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ImageGrab fails with multiple monitors
When calling ImageGrab.grab() passing in a bounding box that is outside the area of my primary monitor, I just get black.
For example, my primary monitor is 1920x1200, flanked on either side by monitors running at 1600x1200, making my total desktop size 5120x1200. Also, because my primary monitor is in the middle, the horizontal coordinates for the full virtual desktop go from -1600 to 3519, where 0 is the left-most pixel of my primary monitor. If I try to capture my rightmost monitor using the following code, all I get is a black image:
``` Python
from PIL import ImageGrab
img = ImageGrab.grab([1920, 0, 3519, 1199])
img.save("test.jpg")
```
Poking around the code, it looks like `ImageGrab.grab()` calls into `Image.core.grabscreen` which is an alias for [`PyImaging_GrabScreenWin32()`](https://github.com/python-pillow/Pillow/blob/2be12dec2b231d31400f44bfa855966484997c16/display.c#L323) in `display.c`. That function does retrieve a DC handle to the entire desktop, but the subsequent calls to `GetDeviceCaps` with `HORZRES` and `VERTRES` only return the x/y size of the primary monitor, not the entire desktop.
``` C
screen = CreateDC("DISPLAY", NULL, NULL, NULL);
// ...
width = GetDeviceCaps(screen, HORZRES);
height = GetDeviceCaps(screen, VERTRES);
// ...
if (!BitBlt(screen_copy, 0, 0, width, height, screen, 0, 0, SRCCOPY))
goto error;
```
Another problem with the above code is that monitors to the left of or above the primary display have negative coordinates in the `screen` DC. So, for example, capturing the monitor to the left of my primary display (which has a resolution of 1600x1200) would need to call BitBlt with the following coordinates:
``` C
left = -1600
top = 0
width = 1600
height = 1200
BitBlt(screen_copy, 0, 0, width, height, screen, left, top, SRCCOPY)
```
Similarly, if I was trying to capture a monitor above my primary display, then `top` would be negative. Because of the negative coordinates issue, I don't see any way of fixing this without passing in `left, top, width, height` from the calling python code, which could be calculated easily from the `bbox` parameter. Then it's simply up to the caller to know the coordinates of the monitor they want to capture. If no `bbox` is provided, then the coordinates would default to the primary display (0, 0, HORZRES, VERTRES), keeping the current functionality unchanged so as not to break existing code that uses `ImageGrab.grab()`.
</issue>
<code>
[start of src/PIL/ImageGrab.py]
1 #
2 # The Python Imaging Library
3 # $Id$
4 #
5 # screen grabber (macOS and Windows only)
6 #
7 # History:
8 # 2001-04-26 fl created
9 # 2001-09-17 fl use builtin driver, if present
10 # 2002-11-19 fl added grabclipboard support
11 #
12 # Copyright (c) 2001-2002 by Secret Labs AB
13 # Copyright (c) 2001-2002 by Fredrik Lundh
14 #
15 # See the README file for information on usage and redistribution.
16 #
17
18 import sys
19
20 from . import Image
21
22 if sys.platform == "win32":
23 grabber = Image.core.grabscreen
24 elif sys.platform == "darwin":
25 import os
26 import tempfile
27 import subprocess
28 else:
29 raise ImportError("ImageGrab is macOS and Windows only")
30
31
32 def grab(bbox=None, include_layered_windows=False):
33 if sys.platform == "darwin":
34 fh, filepath = tempfile.mkstemp(".png")
35 os.close(fh)
36 subprocess.call(["screencapture", "-x", filepath])
37 im = Image.open(filepath)
38 im.load()
39 os.unlink(filepath)
40 else:
41 size, data = grabber(include_layered_windows)
42 im = Image.frombytes(
43 "RGB",
44 size,
45 data,
46 # RGB, 32-bit line padding, origin lower left corner
47 "raw",
48 "BGR",
49 (size[0] * 3 + 3) & -4,
50 -1,
51 )
52 if bbox:
53 im = im.crop(bbox)
54 return im
55
56
57 def grabclipboard():
58 if sys.platform == "darwin":
59 fh, filepath = tempfile.mkstemp(".jpg")
60 os.close(fh)
61 commands = [
62 'set theFile to (open for access POSIX file "'
63 + filepath
64 + '" with write permission)',
65 "try",
66 " write (the clipboard as JPEG picture) to theFile",
67 "end try",
68 "close access theFile",
69 ]
70 script = ["osascript"]
71 for command in commands:
72 script += ["-e", command]
73 subprocess.call(script)
74
75 im = None
76 if os.stat(filepath).st_size != 0:
77 im = Image.open(filepath)
78 im.load()
79 os.unlink(filepath)
80 return im
81 else:
82 data = Image.core.grabclipboard()
83 if isinstance(data, bytes):
84 from . import BmpImagePlugin
85 import io
86
87 return BmpImagePlugin.DibImageFile(io.BytesIO(data))
88 return data
89
[end of src/PIL/ImageGrab.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/PIL/ImageGrab.py b/src/PIL/ImageGrab.py
--- a/src/PIL/ImageGrab.py
+++ b/src/PIL/ImageGrab.py
@@ -29,7 +29,7 @@
raise ImportError("ImageGrab is macOS and Windows only")
-def grab(bbox=None, include_layered_windows=False):
+def grab(bbox=None, include_layered_windows=False, all_screens=False):
if sys.platform == "darwin":
fh, filepath = tempfile.mkstemp(".png")
os.close(fh)
@@ -37,8 +37,10 @@
im = Image.open(filepath)
im.load()
os.unlink(filepath)
+ if bbox:
+ im = im.crop(bbox)
else:
- size, data = grabber(include_layered_windows)
+ offset, size, data = grabber(include_layered_windows, all_screens)
im = Image.frombytes(
"RGB",
size,
@@ -49,8 +51,10 @@
(size[0] * 3 + 3) & -4,
-1,
)
- if bbox:
- im = im.crop(bbox)
+ if bbox:
+ x0, y0 = offset
+ left, top, right, bottom = bbox
+ im = im.crop((left - x0, top - y0, right - x0, bottom - y0))
return im
|
{"golden_diff": "diff --git a/src/PIL/ImageGrab.py b/src/PIL/ImageGrab.py\n--- a/src/PIL/ImageGrab.py\n+++ b/src/PIL/ImageGrab.py\n@@ -29,7 +29,7 @@\n raise ImportError(\"ImageGrab is macOS and Windows only\")\n \n \n-def grab(bbox=None, include_layered_windows=False):\n+def grab(bbox=None, include_layered_windows=False, all_screens=False):\n if sys.platform == \"darwin\":\n fh, filepath = tempfile.mkstemp(\".png\")\n os.close(fh)\n@@ -37,8 +37,10 @@\n im = Image.open(filepath)\n im.load()\n os.unlink(filepath)\n+ if bbox:\n+ im = im.crop(bbox)\n else:\n- size, data = grabber(include_layered_windows)\n+ offset, size, data = grabber(include_layered_windows, all_screens)\n im = Image.frombytes(\n \"RGB\",\n size,\n@@ -49,8 +51,10 @@\n (size[0] * 3 + 3) & -4,\n -1,\n )\n- if bbox:\n- im = im.crop(bbox)\n+ if bbox:\n+ x0, y0 = offset\n+ left, top, right, bottom = bbox\n+ im = im.crop((left - x0, top - y0, right - x0, bottom - y0))\n return im\n", "issue": "ImageGrab fails with multiple monitors\nWhen calling ImageGrab.grab() passing in a bounding box that is outside the area of my primary monitor, I just get black.\n\nFor example, my primary monitor is 1920x1200, flanked on either side by monitors running at 1600x1200, making my total desktop size 5120x1200. Also, because my primary monitor is in the middle, the horizontal coordinates for the full virtual desktop go from -1600 to 3519, where 0 is the left-most pixel of my primary monitor. If I try to capture my rightmost monitor using the following code, all I get is a black image:\n\n``` Python\nfrom PIL import ImageGrab\nimg = ImageGrab.grab([1920, 0, 3519, 1199])\nimg.save(\"test.jpg\")\n```\n\nPoking around the code, it looks like `ImageGrab.grab()` calls into `Image.core.grabscreen` which is an alias for [`PyImaging_GrabScreenWin32()`](https://github.com/python-pillow/Pillow/blob/2be12dec2b231d31400f44bfa855966484997c16/display.c#L323) in `display.c`. That function does retrieve a DC handle to the entire desktop, but the subsequent calls to `GetDeviceCaps` with `HORZRES` and `VERTRES` only return the x/y size of the primary monitor, not the entire desktop.\n\n``` C\nscreen = CreateDC(\"DISPLAY\", NULL, NULL, NULL);\n// ...\nwidth = GetDeviceCaps(screen, HORZRES);\nheight = GetDeviceCaps(screen, VERTRES);\n// ...\nif (!BitBlt(screen_copy, 0, 0, width, height, screen, 0, 0, SRCCOPY))\n goto error;\n```\n\nAnother problem with the above code is that monitors to the left of or above the primary display have negative coordinates in the `screen` DC. So, for example, capturing the monitor to the left of my primary display (which has a resolution of 1600x1200) would need to call BitBlt with the following coordinates:\n\n``` C\nleft = -1600\ntop = 0\nwidth = 1600\nheight = 1200\nBitBlt(screen_copy, 0, 0, width, height, screen, left, top, SRCCOPY)\n```\n\nSimilarly, if I was trying to capture a monitor above my primary display, then `top` would be negative. Because of the negative coordinates issue, I don't see any way of fixing this without passing in `left, top, width, height` from the calling python code, which could be calculated easily from the `bbox` parameter. Then it's simply up to the caller to know the coordinates of the monitor they want to capture. If no `bbox` is provided, then the coordinates would default to the primary display (0, 0, HORZRES, VERTRES), keeping the current functionality unchanged so as not to break existing code that uses `ImageGrab.grab()`.\n\n", "before_files": [{"content": "#\n# The Python Imaging Library\n# $Id$\n#\n# screen grabber (macOS and Windows only)\n#\n# History:\n# 2001-04-26 fl created\n# 2001-09-17 fl use builtin driver, if present\n# 2002-11-19 fl added grabclipboard support\n#\n# Copyright (c) 2001-2002 by Secret Labs AB\n# Copyright (c) 2001-2002 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport sys\n\nfrom . import Image\n\nif sys.platform == \"win32\":\n grabber = Image.core.grabscreen\nelif sys.platform == \"darwin\":\n import os\n import tempfile\n import subprocess\nelse:\n raise ImportError(\"ImageGrab is macOS and Windows only\")\n\n\ndef grab(bbox=None, include_layered_windows=False):\n if sys.platform == \"darwin\":\n fh, filepath = tempfile.mkstemp(\".png\")\n os.close(fh)\n subprocess.call([\"screencapture\", \"-x\", filepath])\n im = Image.open(filepath)\n im.load()\n os.unlink(filepath)\n else:\n size, data = grabber(include_layered_windows)\n im = Image.frombytes(\n \"RGB\",\n size,\n data,\n # RGB, 32-bit line padding, origin lower left corner\n \"raw\",\n \"BGR\",\n (size[0] * 3 + 3) & -4,\n -1,\n )\n if bbox:\n im = im.crop(bbox)\n return im\n\n\ndef grabclipboard():\n if sys.platform == \"darwin\":\n fh, filepath = tempfile.mkstemp(\".jpg\")\n os.close(fh)\n commands = [\n 'set theFile to (open for access POSIX file \"'\n + filepath\n + '\" with write permission)',\n \"try\",\n \" write (the clipboard as JPEG picture) to theFile\",\n \"end try\",\n \"close access theFile\",\n ]\n script = [\"osascript\"]\n for command in commands:\n script += [\"-e\", command]\n subprocess.call(script)\n\n im = None\n if os.stat(filepath).st_size != 0:\n im = Image.open(filepath)\n im.load()\n os.unlink(filepath)\n return im\n else:\n data = Image.core.grabclipboard()\n if isinstance(data, bytes):\n from . import BmpImagePlugin\n import io\n\n return BmpImagePlugin.DibImageFile(io.BytesIO(data))\n return data\n", "path": "src/PIL/ImageGrab.py"}]}
| 1,983 | 312 |
gh_patches_debug_11151
|
rasdani/github-patches
|
git_diff
|
benoitc__gunicorn-1483
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrading to 19.7.0 means can't bind anymore
Upgraded to latest gunicorn and could not bind ip address anymore (simple wsgi app, ipv4 or ipv6 same story).
```
foo@xxx:~$ cd current
foo@xxx:~/current$ . env/bin/activate
foo@xxx:~/current$ gunicorn my.wsgi.package
[2017-03-10 18:50:46 +0000] [9242] [INFO] Starting gunicorn 19.7.0
[2017-03-10 18:50:46 +0000] [9242] [ERROR] Retrying in 1 second.
[2017-03-10 18:50:47 +0000] [9242] [ERROR] Retrying in 1 second.
[2017-03-10 18:50:48 +0000] [9242] [ERROR] Retrying in 1 second.
[2017-03-10 18:50:49 +0000] [9242] [ERROR] Retrying in 1 second.
[2017-03-10 18:50:50 +0000] [9242] [ERROR] Retrying in 1 second.
[2017-03-10 18:50:51 +0000] [9242] [ERROR] Can't connect to ('127.0.0.1', 8000)
```
Reverting to 19.6.0 fixes the problem.
System version : Linux xxx 3.2.0-4-amd64 #1 SMP Debian 3.2.68-1+deb7u1 x86_64 GNU/Linux
Let me know if I can provide more info, 19.6.0 is acceptable solution for me but I guess that's a regression you wanna at least understand ?
</issue>
<code>
[start of gunicorn/sock.py]
1 # -*- coding: utf-8 -
2 #
3 # This file is part of gunicorn released under the MIT license.
4 # See the NOTICE for more information.
5
6 import errno
7 import os
8 import socket
9 import stat
10 import sys
11 import time
12
13 from gunicorn import util
14 from gunicorn.six import string_types
15
16
17 class BaseSocket(object):
18
19 def __init__(self, address, conf, log, fd=None):
20 self.log = log
21 self.conf = conf
22
23 self.cfg_addr = address
24 if fd is None:
25 sock = socket.socket(self.FAMILY, socket.SOCK_STREAM)
26 bound = False
27 else:
28 sock = socket.fromfd(fd, self.FAMILY, socket.SOCK_STREAM)
29 os.close(fd)
30 bound = True
31
32 self.sock = self.set_options(sock, bound=bound)
33
34 def __str__(self, name):
35 return "<socket %d>" % self.sock.fileno()
36
37 def __getattr__(self, name):
38 return getattr(self.sock, name)
39
40 def set_options(self, sock, bound=False):
41 sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
42 if hasattr(socket, 'SO_REUSEPORT'):
43 sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
44 if not bound:
45 self.bind(sock)
46 sock.setblocking(0)
47
48 # make sure that the socket can be inherited
49 if hasattr(sock, "set_inheritable"):
50 sock.set_inheritable(True)
51
52 sock.listen(self.conf.backlog)
53 return sock
54
55 def bind(self, sock):
56 sock.bind(self.cfg_addr)
57
58 def close(self):
59 if self.sock is None:
60 return
61
62 try:
63 self.sock.close()
64 except socket.error as e:
65 self.log.info("Error while closing socket %s", str(e))
66
67 self.sock = None
68
69
70 class TCPSocket(BaseSocket):
71
72 FAMILY = socket.AF_INET
73
74 def __str__(self):
75 if self.conf.is_ssl:
76 scheme = "https"
77 else:
78 scheme = "http"
79
80 addr = self.sock.getsockname()
81 return "%s://%s:%d" % (scheme, addr[0], addr[1])
82
83 def set_options(self, sock, bound=False):
84 sock.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
85 return super(TCPSocket, self).set_options(sock, bound=bound)
86
87
88 class TCP6Socket(TCPSocket):
89
90 FAMILY = socket.AF_INET6
91
92 def __str__(self):
93 (host, port, fl, sc) = self.sock.getsockname()
94 return "http://[%s]:%d" % (host, port)
95
96
97 class UnixSocket(BaseSocket):
98
99 FAMILY = socket.AF_UNIX
100
101 def __init__(self, addr, conf, log, fd=None):
102 if fd is None:
103 try:
104 st = os.stat(addr)
105 except OSError as e:
106 if e.args[0] != errno.ENOENT:
107 raise
108 else:
109 if stat.S_ISSOCK(st.st_mode):
110 os.remove(addr)
111 else:
112 raise ValueError("%r is not a socket" % addr)
113 super(UnixSocket, self).__init__(addr, conf, log, fd=fd)
114
115 def __str__(self):
116 return "unix:%s" % self.cfg_addr
117
118 def bind(self, sock):
119 old_umask = os.umask(self.conf.umask)
120 sock.bind(self.cfg_addr)
121 util.chown(self.cfg_addr, self.conf.uid, self.conf.gid)
122 os.umask(old_umask)
123
124
125 def _sock_type(addr):
126 if isinstance(addr, tuple):
127 if util.is_ipv6(addr[0]):
128 sock_type = TCP6Socket
129 else:
130 sock_type = TCPSocket
131 elif isinstance(addr, string_types):
132 sock_type = UnixSocket
133 else:
134 raise TypeError("Unable to create socket from: %r" % addr)
135 return sock_type
136
137
138 def create_sockets(conf, log, fds=None):
139 """
140 Create a new socket for the configured addresses or file descriptors.
141
142 If a configured address is a tuple then a TCP socket is created.
143 If it is a string, a Unix socket is created. Otherwise, a TypeError is
144 raised.
145 """
146 listeners = []
147
148 # get it only once
149 laddr = conf.address
150
151 # check ssl config early to raise the error on startup
152 # only the certfile is needed since it can contains the keyfile
153 if conf.certfile and not os.path.exists(conf.certfile):
154 raise ValueError('certfile "%s" does not exist' % conf.certfile)
155
156 if conf.keyfile and not os.path.exists(conf.keyfile):
157 raise ValueError('keyfile "%s" does not exist' % conf.keyfile)
158
159 # sockets are already bound
160 if fds is not None:
161 for fd in fds:
162 sock = socket.fromfd(fd, socket.AF_UNIX, socket.SOCK_STREAM)
163 sock_name = sock.getsockname()
164 sock_type = _sock_type(sock_name)
165 listener = sock_type(sock_name, conf, log, fd=fd)
166 listeners.append(listener)
167
168 return listeners
169
170 # no sockets is bound, first initialization of gunicorn in this env.
171 for addr in laddr:
172 sock_type = _sock_type(addr)
173 sock = None
174 for i in range(5):
175 try:
176 sock = sock_type(addr, conf, log)
177 except socket.error as e:
178 if e.args[0] == errno.EADDRINUSE:
179 log.error("Connection in use: %s", str(addr))
180 if e.args[0] == errno.EADDRNOTAVAIL:
181 log.error("Invalid address: %s", str(addr))
182 if i < 5:
183 msg = "connection to {addr} failed: {error}"
184 log.debug(msg.format(addr=str(addr), error=str(e)))
185 log.error("Retrying in 1 second.")
186 time.sleep(1)
187 else:
188 break
189
190 if sock is None:
191 log.error("Can't connect to %s", str(addr))
192 sys.exit(1)
193
194 listeners.append(sock)
195
196 return listeners
197
198
199 def close_sockets(listeners, unlink=True):
200 for sock in listeners:
201 sock_name = sock.getsockname()
202 sock.close()
203 if unlink and _sock_type(sock_name) is UnixSocket:
204 os.unlink(sock_name)
205
[end of gunicorn/sock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gunicorn/sock.py b/gunicorn/sock.py
--- a/gunicorn/sock.py
+++ b/gunicorn/sock.py
@@ -39,8 +39,12 @@
def set_options(self, sock, bound=False):
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
- if hasattr(socket, 'SO_REUSEPORT'):
- sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
+ if hasattr(socket, 'SO_REUSEPORT'): # pragma: no cover
+ try:
+ sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
+ except socket.error as err:
+ if err[0] not in (errno.ENOPROTOOPT, errno.EINVAL):
+ raise
if not bound:
self.bind(sock)
sock.setblocking(0)
|
{"golden_diff": "diff --git a/gunicorn/sock.py b/gunicorn/sock.py\n--- a/gunicorn/sock.py\n+++ b/gunicorn/sock.py\n@@ -39,8 +39,12 @@\n \n def set_options(self, sock, bound=False):\n sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)\n- if hasattr(socket, 'SO_REUSEPORT'):\n- sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)\n+ if hasattr(socket, 'SO_REUSEPORT'): # pragma: no cover\n+ try:\n+ sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)\n+ except socket.error as err:\n+ if err[0] not in (errno.ENOPROTOOPT, errno.EINVAL):\n+ raise\n if not bound:\n self.bind(sock)\n sock.setblocking(0)\n", "issue": "Upgrading to 19.7.0 means can't bind anymore\nUpgraded to latest gunicorn and could not bind ip address anymore (simple wsgi app, ipv4 or ipv6 same story).\r\n\r\n```\r\nfoo@xxx:~$ cd current\r\nfoo@xxx:~/current$ . env/bin/activate\r\nfoo@xxx:~/current$ gunicorn my.wsgi.package\r\n[2017-03-10 18:50:46 +0000] [9242] [INFO] Starting gunicorn 19.7.0\r\n[2017-03-10 18:50:46 +0000] [9242] [ERROR] Retrying in 1 second.\r\n[2017-03-10 18:50:47 +0000] [9242] [ERROR] Retrying in 1 second.\r\n[2017-03-10 18:50:48 +0000] [9242] [ERROR] Retrying in 1 second.\r\n[2017-03-10 18:50:49 +0000] [9242] [ERROR] Retrying in 1 second.\r\n[2017-03-10 18:50:50 +0000] [9242] [ERROR] Retrying in 1 second.\r\n[2017-03-10 18:50:51 +0000] [9242] [ERROR] Can't connect to ('127.0.0.1', 8000)\r\n```\r\n\r\nReverting to 19.6.0 fixes the problem.\r\n\r\nSystem version : Linux xxx 3.2.0-4-amd64 #1 SMP Debian 3.2.68-1+deb7u1 x86_64 GNU/Linux\r\n\r\nLet me know if I can provide more info, 19.6.0 is acceptable solution for me but I guess that's a regression you wanna at least understand ?\n", "before_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport errno\nimport os\nimport socket\nimport stat\nimport sys\nimport time\n\nfrom gunicorn import util\nfrom gunicorn.six import string_types\n\n\nclass BaseSocket(object):\n\n def __init__(self, address, conf, log, fd=None):\n self.log = log\n self.conf = conf\n\n self.cfg_addr = address\n if fd is None:\n sock = socket.socket(self.FAMILY, socket.SOCK_STREAM)\n bound = False\n else:\n sock = socket.fromfd(fd, self.FAMILY, socket.SOCK_STREAM)\n os.close(fd)\n bound = True\n\n self.sock = self.set_options(sock, bound=bound)\n\n def __str__(self, name):\n return \"<socket %d>\" % self.sock.fileno()\n\n def __getattr__(self, name):\n return getattr(self.sock, name)\n\n def set_options(self, sock, bound=False):\n sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)\n if hasattr(socket, 'SO_REUSEPORT'):\n sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)\n if not bound:\n self.bind(sock)\n sock.setblocking(0)\n\n # make sure that the socket can be inherited\n if hasattr(sock, \"set_inheritable\"):\n sock.set_inheritable(True)\n\n sock.listen(self.conf.backlog)\n return sock\n\n def bind(self, sock):\n sock.bind(self.cfg_addr)\n\n def close(self):\n if self.sock is None:\n return\n\n try:\n self.sock.close()\n except socket.error as e:\n self.log.info(\"Error while closing socket %s\", str(e))\n\n self.sock = None\n\n\nclass TCPSocket(BaseSocket):\n\n FAMILY = socket.AF_INET\n\n def __str__(self):\n if self.conf.is_ssl:\n scheme = \"https\"\n else:\n scheme = \"http\"\n\n addr = self.sock.getsockname()\n return \"%s://%s:%d\" % (scheme, addr[0], addr[1])\n\n def set_options(self, sock, bound=False):\n sock.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)\n return super(TCPSocket, self).set_options(sock, bound=bound)\n\n\nclass TCP6Socket(TCPSocket):\n\n FAMILY = socket.AF_INET6\n\n def __str__(self):\n (host, port, fl, sc) = self.sock.getsockname()\n return \"http://[%s]:%d\" % (host, port)\n\n\nclass UnixSocket(BaseSocket):\n\n FAMILY = socket.AF_UNIX\n\n def __init__(self, addr, conf, log, fd=None):\n if fd is None:\n try:\n st = os.stat(addr)\n except OSError as e:\n if e.args[0] != errno.ENOENT:\n raise\n else:\n if stat.S_ISSOCK(st.st_mode):\n os.remove(addr)\n else:\n raise ValueError(\"%r is not a socket\" % addr)\n super(UnixSocket, self).__init__(addr, conf, log, fd=fd)\n\n def __str__(self):\n return \"unix:%s\" % self.cfg_addr\n\n def bind(self, sock):\n old_umask = os.umask(self.conf.umask)\n sock.bind(self.cfg_addr)\n util.chown(self.cfg_addr, self.conf.uid, self.conf.gid)\n os.umask(old_umask)\n\n\ndef _sock_type(addr):\n if isinstance(addr, tuple):\n if util.is_ipv6(addr[0]):\n sock_type = TCP6Socket\n else:\n sock_type = TCPSocket\n elif isinstance(addr, string_types):\n sock_type = UnixSocket\n else:\n raise TypeError(\"Unable to create socket from: %r\" % addr)\n return sock_type\n\n\ndef create_sockets(conf, log, fds=None):\n \"\"\"\n Create a new socket for the configured addresses or file descriptors.\n\n If a configured address is a tuple then a TCP socket is created.\n If it is a string, a Unix socket is created. Otherwise, a TypeError is\n raised.\n \"\"\"\n listeners = []\n\n # get it only once\n laddr = conf.address\n\n # check ssl config early to raise the error on startup\n # only the certfile is needed since it can contains the keyfile\n if conf.certfile and not os.path.exists(conf.certfile):\n raise ValueError('certfile \"%s\" does not exist' % conf.certfile)\n\n if conf.keyfile and not os.path.exists(conf.keyfile):\n raise ValueError('keyfile \"%s\" does not exist' % conf.keyfile)\n\n # sockets are already bound\n if fds is not None:\n for fd in fds:\n sock = socket.fromfd(fd, socket.AF_UNIX, socket.SOCK_STREAM)\n sock_name = sock.getsockname()\n sock_type = _sock_type(sock_name)\n listener = sock_type(sock_name, conf, log, fd=fd)\n listeners.append(listener)\n\n return listeners\n\n # no sockets is bound, first initialization of gunicorn in this env.\n for addr in laddr:\n sock_type = _sock_type(addr)\n sock = None\n for i in range(5):\n try:\n sock = sock_type(addr, conf, log)\n except socket.error as e:\n if e.args[0] == errno.EADDRINUSE:\n log.error(\"Connection in use: %s\", str(addr))\n if e.args[0] == errno.EADDRNOTAVAIL:\n log.error(\"Invalid address: %s\", str(addr))\n if i < 5:\n msg = \"connection to {addr} failed: {error}\"\n log.debug(msg.format(addr=str(addr), error=str(e)))\n log.error(\"Retrying in 1 second.\")\n time.sleep(1)\n else:\n break\n\n if sock is None:\n log.error(\"Can't connect to %s\", str(addr))\n sys.exit(1)\n\n listeners.append(sock)\n\n return listeners\n\n\ndef close_sockets(listeners, unlink=True):\n for sock in listeners:\n sock_name = sock.getsockname()\n sock.close()\n if unlink and _sock_type(sock_name) is UnixSocket:\n os.unlink(sock_name)\n", "path": "gunicorn/sock.py"}]}
| 2,938 | 192 |
gh_patches_debug_14757
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2121
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ENV - Variables - Strip Whitespace + Make "Add" better
- Make "Add" better: When adding ENV variables to a game, you click ADD. Space is allocated for the ENV variable, but nothing actually happens visually (perhaps depending on Color Scheme?).
Expected: When you click add, cursor is set to input field of the ENV variable. This indicated where you should put it, and most likely will give a blinking cursor indicating where it is.
- Strip Whitespace: Accidental whitespace in front / behind ENV variable gets stored. Perhaps it would be better to strip it.
</issue>
<code>
[start of lutris/gui/widgets/common.py]
1 """Misc widgets used in the GUI."""
2 import os
3
4 from gi.repository import Gtk, GObject, Pango
5
6 from lutris.util.log import logger
7 from lutris.util import system
8 from lutris.util.linux import LINUX_SYSTEM
9 from lutris.gui.widgets.utils import get_stock_icon
10
11
12 class SlugEntry(Gtk.Entry, Gtk.Editable):
13 def __init__(self):
14 super(SlugEntry, self).__init__()
15
16 def do_insert_text(self, new_text, length, position):
17 """Filter inserted characters to only accept alphanumeric and dashes"""
18 new_text = "".join([c for c in new_text if c.isalnum() or c == "-"]).lower()
19 length = len(new_text)
20 self.get_buffer().insert_text(position, new_text, length)
21 return position + length
22
23
24 class NumberEntry(Gtk.Entry, Gtk.Editable):
25 def __init__(self):
26 super(NumberEntry, self).__init__()
27
28 def do_insert_text(self, new_text, length, position):
29 """Filter inserted characters to only accept numbers"""
30 new_text = "".join([c for c in new_text if c.isnumeric()])
31 if new_text:
32 self.get_buffer().insert_text(position, new_text, length)
33 return position + length
34 return position
35
36
37 class FileChooserEntry(Gtk.Box):
38 """Editable entry with a file picker button"""
39
40 max_completion_items = 15 # Maximum number of items to display in the autocompletion dropdown.
41
42 def __init__(
43 self,
44 title="Select file",
45 action=Gtk.FileChooserAction.OPEN,
46 path=None,
47 default_path=None,
48 warn_if_non_empty=False,
49 warn_if_ntfs=False
50 ):
51 super().__init__(
52 orientation=Gtk.Orientation.VERTICAL,
53 spacing=12,
54 visible=True
55 )
56 self.title = title
57 self.action = action
58 self.path = os.path.expanduser(path) if path else None
59 self.default_path = os.path.expanduser(default_path) if default_path else path
60 self.warn_if_non_empty = warn_if_non_empty
61 self.warn_if_ntfs = warn_if_ntfs
62
63 self.path_completion = Gtk.ListStore(str)
64
65 self.entry = Gtk.Entry(visible=True)
66 self.entry.set_completion(self.get_completion())
67 self.entry.connect("changed", self.on_entry_changed)
68 if path:
69 self.entry.set_text(path)
70
71 browse_button = Gtk.Button("Browse...", visible=True)
72 browse_button.connect("clicked", self.on_browse_clicked)
73
74 box = Gtk.Box(spacing=6, visible=True)
75 box.pack_start(self.entry, True, True, 0)
76 box.add(browse_button)
77 self.add(box)
78
79 def get_text(self):
80 """Return the entry's text"""
81 return self.entry.get_text()
82
83 def get_filename(self):
84 """Deprecated"""
85 logger.warning("Just use get_text")
86 return self.get_text()
87
88 def get_completion(self):
89 """Return an EntryCompletion widget"""
90 completion = Gtk.EntryCompletion()
91 completion.set_model(self.path_completion)
92 completion.set_text_column(0)
93 return completion
94
95 def get_filechooser_dialog(self):
96 """Return an instance of a FileChooserDialog configured for this widget"""
97 dialog = Gtk.FileChooserDialog(
98 title=self.title, transient_for=None, action=self.action
99 )
100 dialog.add_buttons(
101 "_Cancel", Gtk.ResponseType.CLOSE,
102 "_OK", Gtk.ResponseType.OK
103 )
104 dialog.set_create_folders(True)
105 dialog.set_current_folder(self.get_default_folder())
106 dialog.connect("response", self.on_select_file)
107 return dialog
108
109 def get_default_folder(self):
110 """Return the default folder for the file picker"""
111 default_path = self.path or self.default_path or ""
112 if not default_path or not system.path_exists(default_path):
113 current_entry = self.get_text()
114 if system.path_exists(current_entry):
115 default_path = current_entry
116 if not os.path.isdir(default_path):
117 default_path = os.path.dirname(default_path)
118 return os.path.expanduser(default_path or "~")
119
120 def on_browse_clicked(self, _widget):
121 """Browse button click callback"""
122 file_chooser_dialog = self.get_filechooser_dialog()
123 file_chooser_dialog.run()
124
125 def on_entry_changed(self, widget):
126 """Entry changed callback"""
127 self.clear_warnings()
128 path = widget.get_text()
129 if not path:
130 return
131 path = os.path.expanduser(path)
132 self.update_completion(path)
133 if self.warn_if_ntfs and LINUX_SYSTEM.get_fs_type_for_path(path) == "ntfs":
134 ntfs_box = Gtk.Box(spacing=6, visible=True)
135 warning_image = Gtk.Image(visible=True)
136 warning_image.set_from_pixbuf(get_stock_icon("dialog-warning", 32))
137 ntfs_box.add(warning_image)
138 ntfs_label = Gtk.Label(visible=True)
139 ntfs_label.set_markup(
140 "<b>Warning!</b> The selected path is located on a NTFS drive.\n"
141 "Installing games on NTFS partitions is known to cause issues."
142 )
143 ntfs_box.add(ntfs_label)
144 self.pack_end(ntfs_box, False, False, 10)
145 if self.warn_if_non_empty and os.path.exists(path) and os.listdir(path):
146 non_empty_label = Gtk.Label(visible=True)
147 non_empty_label.set_markup(
148 "<b>Warning!</b> The selected path "
149 "contains files. Installation might not work properly."
150 )
151 self.pack_end(non_empty_label, False, False, 10)
152
153 def on_select_file(self, dialog, response):
154 """FileChooserDialog response callback"""
155 if response == Gtk.ResponseType.OK:
156 target_path = dialog.get_filename()
157 if target_path:
158 dialog.set_current_folder(target_path)
159 self.entry.set_text(system.reverse_expanduser(target_path))
160 dialog.hide()
161
162 def update_completion(self, current_path):
163 """Update the auto-completion widget with the current path"""
164 self.path_completion.clear()
165
166 if not os.path.exists(current_path):
167 current_path, filefilter = os.path.split(current_path)
168 else:
169 filefilter = None
170
171 if os.path.isdir(current_path):
172 index = 0
173 for filename in sorted(os.listdir(current_path)):
174 if filename.startswith("."):
175 continue
176 if filefilter is not None and not filename.startswith(filefilter):
177 continue
178 self.path_completion.append([os.path.join(current_path, filename)])
179 index += 1
180 if index > self.max_completion_items:
181 break
182
183 def clear_warnings(self):
184 """Delete all the warning labels from the container"""
185 for index, child in enumerate(self.get_children()):
186 if index > 0:
187 child.destroy()
188
189
190 class Label(Gtk.Label):
191 """Standardised label for config vboxes."""
192
193 def __init__(self, message=None):
194 """Custom init of label."""
195 super().__init__(label=message)
196 self.set_line_wrap(True)
197 self.set_max_width_chars(22)
198 self.set_line_wrap_mode(Pango.WrapMode.WORD_CHAR)
199 self.set_size_request(230, -1)
200 self.set_alignment(0, 0.5)
201 self.set_justify(Gtk.Justification.LEFT)
202
203
204 class VBox(Gtk.Box):
205 def __init__(self, **kwargs):
206 super().__init__(orientation=Gtk.Orientation.VERTICAL, margin_top=18, **kwargs)
207
208
209 class EditableGrid(Gtk.Grid):
210 __gsignals__ = {"changed": (GObject.SIGNAL_RUN_FIRST, None, ())}
211
212 def __init__(self, data, columns):
213 self.columns = columns
214 super().__init__()
215 self.set_column_homogeneous(True)
216 self.set_row_homogeneous(True)
217 self.set_row_spacing(10)
218 self.set_column_spacing(10)
219
220 self.liststore = Gtk.ListStore(str, str)
221 for item in data:
222 self.liststore.append([str(value) for value in item])
223
224 self.treeview = Gtk.TreeView.new_with_model(self.liststore)
225 self.treeview.set_grid_lines(Gtk.TreeViewGridLines.BOTH)
226 for i, column_title in enumerate(self.columns):
227 renderer = Gtk.CellRendererText()
228 renderer.set_property("editable", True)
229 renderer.connect("edited", self.on_text_edited, i)
230
231 column = Gtk.TreeViewColumn(column_title, renderer, text=i)
232 column.set_resizable(True)
233 column.set_min_width(100)
234 column.set_sort_column_id(0)
235 self.treeview.append_column(column)
236
237 self.buttons = []
238 self.add_button = Gtk.Button("Add")
239 self.buttons.append(self.add_button)
240 self.add_button.connect("clicked", self.on_add)
241
242 self.delete_button = Gtk.Button("Delete")
243 self.buttons.append(self.delete_button)
244 self.delete_button.connect("clicked", self.on_delete)
245
246 self.scrollable_treelist = Gtk.ScrolledWindow()
247 self.scrollable_treelist.set_vexpand(True)
248 self.scrollable_treelist.add(self.treeview)
249
250 self.attach(self.scrollable_treelist, 0, 0, 5, 5)
251 self.attach(self.add_button, 5 - len(self.buttons), 6, 1, 1)
252 for i, button in enumerate(self.buttons[1:]):
253 self.attach_next_to(button, self.buttons[i], Gtk.PositionType.RIGHT, 1, 1)
254 self.show_all()
255
256 def on_add(self, widget):
257 self.liststore.append(["", ""])
258 self.emit("changed")
259
260 def on_delete(self, widget):
261 selection = self.treeview.get_selection()
262 liststore, iter = selection.get_selected()
263 self.liststore.remove(iter)
264 self.emit("changed")
265
266 def on_text_edited(self, widget, path, text, field):
267 self.liststore[path][field] = text
268 self.emit("changed")
269
270 def get_data(self):
271 model_data = []
272 for row in self.liststore:
273 model_data.append([col for col in row])
274 return model_data
275
[end of lutris/gui/widgets/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/gui/widgets/common.py b/lutris/gui/widgets/common.py
--- a/lutris/gui/widgets/common.py
+++ b/lutris/gui/widgets/common.py
@@ -255,6 +255,9 @@
def on_add(self, widget):
self.liststore.append(["", ""])
+ row_position = len(self.liststore)-1
+ self.treeview.set_cursor(row_position, None, False)
+ self.treeview.scroll_to_cell(row_position, None, False, 0.0, 0.0)
self.emit("changed")
def on_delete(self, widget):
@@ -264,7 +267,7 @@
self.emit("changed")
def on_text_edited(self, widget, path, text, field):
- self.liststore[path][field] = text
+ self.liststore[path][field] = text.strip()
self.emit("changed")
def get_data(self):
|
{"golden_diff": "diff --git a/lutris/gui/widgets/common.py b/lutris/gui/widgets/common.py\n--- a/lutris/gui/widgets/common.py\n+++ b/lutris/gui/widgets/common.py\n@@ -255,6 +255,9 @@\n \n def on_add(self, widget):\n self.liststore.append([\"\", \"\"])\n+ row_position = len(self.liststore)-1\n+ self.treeview.set_cursor(row_position, None, False)\n+ self.treeview.scroll_to_cell(row_position, None, False, 0.0, 0.0)\n self.emit(\"changed\")\n \n def on_delete(self, widget):\n@@ -264,7 +267,7 @@\n self.emit(\"changed\")\n \n def on_text_edited(self, widget, path, text, field):\n- self.liststore[path][field] = text\n+ self.liststore[path][field] = text.strip()\n self.emit(\"changed\")\n \n def get_data(self):\n", "issue": "ENV - Variables - Strip Whitespace + Make \"Add\" better\n- Make \"Add\" better: When adding ENV variables to a game, you click ADD. Space is allocated for the ENV variable, but nothing actually happens visually (perhaps depending on Color Scheme?).\r\n\r\nExpected: When you click add, cursor is set to input field of the ENV variable. This indicated where you should put it, and most likely will give a blinking cursor indicating where it is.\r\n\r\n- Strip Whitespace: Accidental whitespace in front / behind ENV variable gets stored. Perhaps it would be better to strip it.\n", "before_files": [{"content": "\"\"\"Misc widgets used in the GUI.\"\"\"\nimport os\n\nfrom gi.repository import Gtk, GObject, Pango\n\nfrom lutris.util.log import logger\nfrom lutris.util import system\nfrom lutris.util.linux import LINUX_SYSTEM\nfrom lutris.gui.widgets.utils import get_stock_icon\n\n\nclass SlugEntry(Gtk.Entry, Gtk.Editable):\n def __init__(self):\n super(SlugEntry, self).__init__()\n\n def do_insert_text(self, new_text, length, position):\n \"\"\"Filter inserted characters to only accept alphanumeric and dashes\"\"\"\n new_text = \"\".join([c for c in new_text if c.isalnum() or c == \"-\"]).lower()\n length = len(new_text)\n self.get_buffer().insert_text(position, new_text, length)\n return position + length\n\n\nclass NumberEntry(Gtk.Entry, Gtk.Editable):\n def __init__(self):\n super(NumberEntry, self).__init__()\n\n def do_insert_text(self, new_text, length, position):\n \"\"\"Filter inserted characters to only accept numbers\"\"\"\n new_text = \"\".join([c for c in new_text if c.isnumeric()])\n if new_text:\n self.get_buffer().insert_text(position, new_text, length)\n return position + length\n return position\n\n\nclass FileChooserEntry(Gtk.Box):\n \"\"\"Editable entry with a file picker button\"\"\"\n\n max_completion_items = 15 # Maximum number of items to display in the autocompletion dropdown.\n\n def __init__(\n self,\n title=\"Select file\",\n action=Gtk.FileChooserAction.OPEN,\n path=None,\n default_path=None,\n warn_if_non_empty=False,\n warn_if_ntfs=False\n ):\n super().__init__(\n orientation=Gtk.Orientation.VERTICAL,\n spacing=12,\n visible=True\n )\n self.title = title\n self.action = action\n self.path = os.path.expanduser(path) if path else None\n self.default_path = os.path.expanduser(default_path) if default_path else path\n self.warn_if_non_empty = warn_if_non_empty\n self.warn_if_ntfs = warn_if_ntfs\n\n self.path_completion = Gtk.ListStore(str)\n\n self.entry = Gtk.Entry(visible=True)\n self.entry.set_completion(self.get_completion())\n self.entry.connect(\"changed\", self.on_entry_changed)\n if path:\n self.entry.set_text(path)\n\n browse_button = Gtk.Button(\"Browse...\", visible=True)\n browse_button.connect(\"clicked\", self.on_browse_clicked)\n\n box = Gtk.Box(spacing=6, visible=True)\n box.pack_start(self.entry, True, True, 0)\n box.add(browse_button)\n self.add(box)\n\n def get_text(self):\n \"\"\"Return the entry's text\"\"\"\n return self.entry.get_text()\n\n def get_filename(self):\n \"\"\"Deprecated\"\"\"\n logger.warning(\"Just use get_text\")\n return self.get_text()\n\n def get_completion(self):\n \"\"\"Return an EntryCompletion widget\"\"\"\n completion = Gtk.EntryCompletion()\n completion.set_model(self.path_completion)\n completion.set_text_column(0)\n return completion\n\n def get_filechooser_dialog(self):\n \"\"\"Return an instance of a FileChooserDialog configured for this widget\"\"\"\n dialog = Gtk.FileChooserDialog(\n title=self.title, transient_for=None, action=self.action\n )\n dialog.add_buttons(\n \"_Cancel\", Gtk.ResponseType.CLOSE,\n \"_OK\", Gtk.ResponseType.OK\n )\n dialog.set_create_folders(True)\n dialog.set_current_folder(self.get_default_folder())\n dialog.connect(\"response\", self.on_select_file)\n return dialog\n\n def get_default_folder(self):\n \"\"\"Return the default folder for the file picker\"\"\"\n default_path = self.path or self.default_path or \"\"\n if not default_path or not system.path_exists(default_path):\n current_entry = self.get_text()\n if system.path_exists(current_entry):\n default_path = current_entry\n if not os.path.isdir(default_path):\n default_path = os.path.dirname(default_path)\n return os.path.expanduser(default_path or \"~\")\n\n def on_browse_clicked(self, _widget):\n \"\"\"Browse button click callback\"\"\"\n file_chooser_dialog = self.get_filechooser_dialog()\n file_chooser_dialog.run()\n\n def on_entry_changed(self, widget):\n \"\"\"Entry changed callback\"\"\"\n self.clear_warnings()\n path = widget.get_text()\n if not path:\n return\n path = os.path.expanduser(path)\n self.update_completion(path)\n if self.warn_if_ntfs and LINUX_SYSTEM.get_fs_type_for_path(path) == \"ntfs\":\n ntfs_box = Gtk.Box(spacing=6, visible=True)\n warning_image = Gtk.Image(visible=True)\n warning_image.set_from_pixbuf(get_stock_icon(\"dialog-warning\", 32))\n ntfs_box.add(warning_image)\n ntfs_label = Gtk.Label(visible=True)\n ntfs_label.set_markup(\n \"<b>Warning!</b> The selected path is located on a NTFS drive.\\n\"\n \"Installing games on NTFS partitions is known to cause issues.\"\n )\n ntfs_box.add(ntfs_label)\n self.pack_end(ntfs_box, False, False, 10)\n if self.warn_if_non_empty and os.path.exists(path) and os.listdir(path):\n non_empty_label = Gtk.Label(visible=True)\n non_empty_label.set_markup(\n \"<b>Warning!</b> The selected path \"\n \"contains files. Installation might not work properly.\"\n )\n self.pack_end(non_empty_label, False, False, 10)\n\n def on_select_file(self, dialog, response):\n \"\"\"FileChooserDialog response callback\"\"\"\n if response == Gtk.ResponseType.OK:\n target_path = dialog.get_filename()\n if target_path:\n dialog.set_current_folder(target_path)\n self.entry.set_text(system.reverse_expanduser(target_path))\n dialog.hide()\n\n def update_completion(self, current_path):\n \"\"\"Update the auto-completion widget with the current path\"\"\"\n self.path_completion.clear()\n\n if not os.path.exists(current_path):\n current_path, filefilter = os.path.split(current_path)\n else:\n filefilter = None\n\n if os.path.isdir(current_path):\n index = 0\n for filename in sorted(os.listdir(current_path)):\n if filename.startswith(\".\"):\n continue\n if filefilter is not None and not filename.startswith(filefilter):\n continue\n self.path_completion.append([os.path.join(current_path, filename)])\n index += 1\n if index > self.max_completion_items:\n break\n\n def clear_warnings(self):\n \"\"\"Delete all the warning labels from the container\"\"\"\n for index, child in enumerate(self.get_children()):\n if index > 0:\n child.destroy()\n\n\nclass Label(Gtk.Label):\n \"\"\"Standardised label for config vboxes.\"\"\"\n\n def __init__(self, message=None):\n \"\"\"Custom init of label.\"\"\"\n super().__init__(label=message)\n self.set_line_wrap(True)\n self.set_max_width_chars(22)\n self.set_line_wrap_mode(Pango.WrapMode.WORD_CHAR)\n self.set_size_request(230, -1)\n self.set_alignment(0, 0.5)\n self.set_justify(Gtk.Justification.LEFT)\n\n\nclass VBox(Gtk.Box):\n def __init__(self, **kwargs):\n super().__init__(orientation=Gtk.Orientation.VERTICAL, margin_top=18, **kwargs)\n\n\nclass EditableGrid(Gtk.Grid):\n __gsignals__ = {\"changed\": (GObject.SIGNAL_RUN_FIRST, None, ())}\n\n def __init__(self, data, columns):\n self.columns = columns\n super().__init__()\n self.set_column_homogeneous(True)\n self.set_row_homogeneous(True)\n self.set_row_spacing(10)\n self.set_column_spacing(10)\n\n self.liststore = Gtk.ListStore(str, str)\n for item in data:\n self.liststore.append([str(value) for value in item])\n\n self.treeview = Gtk.TreeView.new_with_model(self.liststore)\n self.treeview.set_grid_lines(Gtk.TreeViewGridLines.BOTH)\n for i, column_title in enumerate(self.columns):\n renderer = Gtk.CellRendererText()\n renderer.set_property(\"editable\", True)\n renderer.connect(\"edited\", self.on_text_edited, i)\n\n column = Gtk.TreeViewColumn(column_title, renderer, text=i)\n column.set_resizable(True)\n column.set_min_width(100)\n column.set_sort_column_id(0)\n self.treeview.append_column(column)\n\n self.buttons = []\n self.add_button = Gtk.Button(\"Add\")\n self.buttons.append(self.add_button)\n self.add_button.connect(\"clicked\", self.on_add)\n\n self.delete_button = Gtk.Button(\"Delete\")\n self.buttons.append(self.delete_button)\n self.delete_button.connect(\"clicked\", self.on_delete)\n\n self.scrollable_treelist = Gtk.ScrolledWindow()\n self.scrollable_treelist.set_vexpand(True)\n self.scrollable_treelist.add(self.treeview)\n\n self.attach(self.scrollable_treelist, 0, 0, 5, 5)\n self.attach(self.add_button, 5 - len(self.buttons), 6, 1, 1)\n for i, button in enumerate(self.buttons[1:]):\n self.attach_next_to(button, self.buttons[i], Gtk.PositionType.RIGHT, 1, 1)\n self.show_all()\n\n def on_add(self, widget):\n self.liststore.append([\"\", \"\"])\n self.emit(\"changed\")\n\n def on_delete(self, widget):\n selection = self.treeview.get_selection()\n liststore, iter = selection.get_selected()\n self.liststore.remove(iter)\n self.emit(\"changed\")\n\n def on_text_edited(self, widget, path, text, field):\n self.liststore[path][field] = text\n self.emit(\"changed\")\n\n def get_data(self):\n model_data = []\n for row in self.liststore:\n model_data.append([col for col in row])\n return model_data\n", "path": "lutris/gui/widgets/common.py"}]}
| 3,520 | 213 |
gh_patches_debug_8772
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1509
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug in `mac_platform_token`
* Faker version: Latest
* OS: Any
`mac_platform_token` generates a MacOS platform token used in user agent strings. However, during https://github.com/joke2k/faker/commit/da1ae11a06a8f64bd4b0f7d1391d7661521e4caf#diff-7d7f34af58b0ae686b413e6ed3463229243aacfb0891fbc544cb951224c5af97L220, looks like it got missing underscore. Now, it generates `Macintosh; PPC Mac OS X 10 6_5` where as it should be `Macintosh; PPC Mac OS X 10_6_5`
### Expected behavior
Output of `mac_platform_token` should be `Macintosh; PPC Mac OS X 10_6_5`
### Actual behavior
`Macintosh; PPC Mac OS X 10 6_5`
</issue>
<code>
[start of faker/providers/user_agent/__init__.py]
1 import string
2
3 from datetime import datetime
4
5 from .. import BaseProvider
6
7
8 class Provider(BaseProvider):
9 """Implement default user agent provider for Faker."""
10
11 user_agents = (
12 'chrome', 'firefox', 'internet_explorer', 'opera', 'safari',
13 )
14
15 windows_platform_tokens = (
16 'Windows 95', 'Windows 98', 'Windows 98; Win 9x 4.90', 'Windows CE',
17 'Windows NT 4.0', 'Windows NT 5.0', 'Windows NT 5.01',
18 'Windows NT 5.1', 'Windows NT 5.2', 'Windows NT 6.0', 'Windows NT 6.1',
19 'Windows NT 6.2', 'Windows NT 10.0',
20 )
21
22 linux_processors = ('i686', 'x86_64')
23
24 mac_processors = ('Intel', 'PPC', 'U; Intel', 'U; PPC')
25
26 android_versions = (
27 '1.0', '1.1', '1.5', '1.6', '2.0', '2.0.1', '2.1', '2.2', '2.2.1', '2.2.2', '2.2.3', '2.3', '2.3.1', '2.3.2',
28 '2.3.3', '2.3.4', '2.3.5', '2.3.6', '2.3.7', '3.0', '3.1', '3.2', '3.2.1', '3.2.2', '3.2.3', '3.2.4', '3.2.5',
29 '3.2.6', '4.0', '4.0.1', '4.0.2', '4.0.3', '4.0.4', '4.1', '4.1.1', '4.1.2', '4.2', '4.2.1', '4.2.2', '4.3',
30 '4.3.1', '4.4', '4.4.1', '4.4.2', '4.4.3', '4.4.4', '5.0', '5.0.1', '5.0.2', '5.1', '5.1.1', '6.0', '6.0.1',
31 '7.0', '7.1', '7.1.1', '7.1.2', '8.0.0', '8.1.0', '9', '10', '11',
32 )
33
34 apple_devices = ('iPhone', 'iPad')
35
36 ios_versions = (
37 '3.1.3', '4.2.1', '5.1.1', '6.1.6', '7.1.2', '9.3.5', '9.3.6', '10.3.3', '10.3.4', '12.4.8', '14.2', '14.2.1',
38 )
39
40 def mac_processor(self):
41 """Generate a MacOS processor token used in user agent strings."""
42 return self.random_element(self.mac_processors)
43
44 def linux_processor(self):
45 """Generate a Linux processor token used in user agent strings."""
46 return self.random_element(self.linux_processors)
47
48 def user_agent(self):
49 """Generate a random web browser user agent string."""
50 name = self.random_element(self.user_agents)
51 return getattr(self, name)()
52
53 def chrome(self, version_from=13, version_to=63,
54 build_from=800, build_to=899):
55 """Generate a Chrome web browser user agent string."""
56 saf = f'{self.generator.random.randint(531, 536)}.{self.generator.random.randint(0, 2)}'
57 bld = self.lexify(self.numerify('##?###'), string.ascii_uppercase)
58 tmplt = '({0}) AppleWebKit/{1} (KHTML, like Gecko)' \
59 ' Chrome/{2}.0.{3}.0 Safari/{4}'
60 tmplt_ios = '({0}) AppleWebKit/{1} (KHTML, like Gecko)' \
61 ' CriOS/{2}.0.{3}.0 Mobile/{4} Safari/{1}'
62 platforms = (
63 tmplt.format(self.linux_platform_token(),
64 saf,
65 self.generator.random.randint(version_from, version_to),
66 self.generator.random.randint(build_from, build_to),
67 saf),
68 tmplt.format(self.windows_platform_token(),
69 saf,
70 self.generator.random.randint(version_from, version_to),
71 self.generator.random.randint(build_from, build_to),
72 saf),
73 tmplt.format(self.mac_platform_token(),
74 saf,
75 self.generator.random.randint(version_from, version_to),
76 self.generator.random.randint(build_from, build_to),
77 saf),
78 tmplt.format('Linux; {}'.format(self.android_platform_token()),
79 saf,
80 self.generator.random.randint(version_from, version_to),
81 self.generator.random.randint(build_from, build_to),
82 saf),
83 tmplt_ios.format(self.ios_platform_token(),
84 saf,
85 self.generator.random.randint(version_from, version_to),
86 self.generator.random.randint(build_from, build_to),
87 bld),
88 )
89
90 return 'Mozilla/5.0 ' + self.random_element(platforms)
91
92 def firefox(self):
93 """Generate a Mozilla Firefox web browser user agent string."""
94 ver = (
95 (f'Gecko/{self.generator.date_time_between(datetime(2011, 1, 1))} '
96 f'Firefox/{self.generator.random.randint(4, 15)}.0'),
97 (f'Gecko/{self.generator.date_time_between(datetime(2010, 1, 1))} '
98 f'Firefox/3.6.{self.generator.random.randint(1, 20)}'),
99 f'Gecko/{self.generator.date_time_between(datetime(2010, 1, 1))} Firefox/3.8',
100 )
101 tmplt_win = '({0}; {1}; rv:1.9.{2}.20) {3}'
102 tmplt_lin = '({0}; rv:1.9.{1}.20) {2}'
103 tmplt_mac = '({0}; rv:1.9.{1}.20) {2}'
104 tmplt_and = '({0}; Mobile; rv:{1}.0) Gecko/{1}.0 Firefox/{1}.0'
105 tmplt_ios = '({0}) AppleWebKit/{1} (KHTML, like Gecko) FxiOS/{2}.{3}.0 Mobile/{4} Safari/{1}'
106 saf = '{}.{}'.format(self.generator.random.randint(531, 536),
107 self.generator.random.randint(0, 2))
108 bld = self.lexify(self.numerify('##?###'), string.ascii_uppercase)
109 bld2 = self.lexify(self.numerify('#?####'), string.ascii_lowercase)
110 platforms = (
111 tmplt_win.format(self.windows_platform_token(),
112 self.generator.locale().replace('_', '-'),
113 self.generator.random.randint(0, 2),
114 self.generator.random.choice(ver)),
115 tmplt_lin.format(self.linux_platform_token(),
116 self.generator.random.randint(5, 7),
117 self.generator.random.choice(ver)),
118 tmplt_mac.format(self.mac_platform_token(),
119 self.generator.random.randint(2, 6),
120 self.generator.random.choice(ver)),
121 tmplt_and.format(self.android_platform_token(),
122 self.generator.random.randint(5, 68)),
123 tmplt_ios.format(self.ios_platform_token(),
124 saf,
125 self.generator.random.randint(9, 18),
126 bld2,
127 bld),
128 )
129
130 return 'Mozilla/5.0 ' + self.random_element(platforms)
131
132 def safari(self):
133 """Generate a Safari web browser user agent string."""
134 saf = (f'{self.generator.random.randint(531, 535)}.'
135 f'{self.generator.random.randint(1, 50)}.'
136 f'{self.generator.random.randint(1, 7)}')
137 if not self.generator.random.getrandbits(1):
138 ver = f'{self.generator.random.randint(4, 5)}.{self.generator.random.randint(0, 1)}'
139 else:
140 ver = f'{self.generator.random.randint(4, 5)}.0.{self.generator.random.randint(1, 5)}'
141 tmplt_win = '(Windows; U; {0}) AppleWebKit/{1} (KHTML, like Gecko)' \
142 ' Version/{2} Safari/{3}'
143 tmplt_mac = '({0} rv:{1}.0; {2}) AppleWebKit/{3} (KHTML, like Gecko)' \
144 ' Version/{4} Safari/{5}'
145 tmplt_ipod = '(iPod; U; CPU iPhone OS {0}_{1} like Mac OS X; {2})' \
146 ' AppleWebKit/{3} (KHTML, like Gecko) Version/{4}.0.5' \
147 ' Mobile/8B{5} Safari/6{6}'
148 locale = self.generator.locale().replace('_', '-')
149 platforms = (
150 tmplt_win.format(self.windows_platform_token(),
151 saf,
152 ver,
153 saf),
154 tmplt_mac.format(self.mac_platform_token(),
155 self.generator.random.randint(2, 6),
156 locale,
157 saf,
158 ver,
159 saf),
160 tmplt_ipod.format(self.generator.random.randint(3, 4),
161 self.generator.random.randint(0, 3),
162 locale,
163 saf,
164 self.generator.random.randint(3, 4),
165 self.generator.random.randint(111, 119),
166 saf),
167 )
168
169 return 'Mozilla/5.0 ' + self.random_element(platforms)
170
171 def opera(self):
172 """Generate an Opera web browser user agent string."""
173 token = self.linux_platform_token() if self.generator.random.getrandbits(1) else self.windows_platform_token()
174 locale = self.generator.locale().replace('_', '-')
175 platform = (f'({token}; {locale}) Presto/2.9.{self.generator.random.randint(160, 190)} '
176 f'Version/{self.generator.random.randint(10, 12)}.00')
177 return f'Opera/{self.generator.random.randint(8, 9)}.{self.generator.random.randint(10, 99)}.{platform}'
178
179 def internet_explorer(self):
180 """Generate an IE web browser user agent string."""
181 return (f'Mozilla/5.0 (compatible; MSIE {self.generator.random.randint(5, 9)}.0; '
182 f'{self.windows_platform_token()}; '
183 f'Trident/{self.generator.random.randint(3, 5)}.{self.generator.random.randint(0, 1)})')
184
185 def windows_platform_token(self):
186 """Generate a Windows platform token used in user agent strings."""
187 return self.random_element(self.windows_platform_tokens)
188
189 def linux_platform_token(self):
190 """Generate a Linux platform token used in user agent strings."""
191 return f'X11; Linux {self.random_element(self.linux_processors)}'
192
193 def mac_platform_token(self):
194 """Generate a MacOS platform token used in user agent strings."""
195 return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10 '
196 f'{self.generator.random.randint(5, 12)}_{self.generator.random.randint(0, 9)}')
197
198 def android_platform_token(self):
199 """Generate an Android platform token used in user agent strings."""
200 return f'Android {self.random_element(self.android_versions)}'
201
202 def ios_platform_token(self):
203 """Generate an iOS platform token used in user agent strings."""
204 apple_device = self.random_element(self.apple_devices)
205 return (f'{apple_device}; CPU {apple_device} '
206 f'OS {self.random_element(self.ios_versions).replace(".", "_")} like Mac OS X')
207
[end of faker/providers/user_agent/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/faker/providers/user_agent/__init__.py b/faker/providers/user_agent/__init__.py
--- a/faker/providers/user_agent/__init__.py
+++ b/faker/providers/user_agent/__init__.py
@@ -192,7 +192,7 @@
def mac_platform_token(self):
"""Generate a MacOS platform token used in user agent strings."""
- return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10 '
+ return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10_'
f'{self.generator.random.randint(5, 12)}_{self.generator.random.randint(0, 9)}')
def android_platform_token(self):
|
{"golden_diff": "diff --git a/faker/providers/user_agent/__init__.py b/faker/providers/user_agent/__init__.py\n--- a/faker/providers/user_agent/__init__.py\n+++ b/faker/providers/user_agent/__init__.py\n@@ -192,7 +192,7 @@\n \n def mac_platform_token(self):\n \"\"\"Generate a MacOS platform token used in user agent strings.\"\"\"\n- return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10 '\n+ return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10_'\n f'{self.generator.random.randint(5, 12)}_{self.generator.random.randint(0, 9)}')\n \n def android_platform_token(self):\n", "issue": "Bug in `mac_platform_token`\n* Faker version: Latest\r\n* OS: Any\r\n\r\n`mac_platform_token` generates a MacOS platform token used in user agent strings. However, during https://github.com/joke2k/faker/commit/da1ae11a06a8f64bd4b0f7d1391d7661521e4caf#diff-7d7f34af58b0ae686b413e6ed3463229243aacfb0891fbc544cb951224c5af97L220, looks like it got missing underscore. Now, it generates `Macintosh; PPC Mac OS X 10 6_5` where as it should be `Macintosh; PPC Mac OS X 10_6_5`\r\n\r\n### Expected behavior\r\n\r\nOutput of `mac_platform_token` should be `Macintosh; PPC Mac OS X 10_6_5`\r\n\r\n### Actual behavior\r\n`Macintosh; PPC Mac OS X 10 6_5`\r\n\n", "before_files": [{"content": "import string\n\nfrom datetime import datetime\n\nfrom .. import BaseProvider\n\n\nclass Provider(BaseProvider):\n \"\"\"Implement default user agent provider for Faker.\"\"\"\n\n user_agents = (\n 'chrome', 'firefox', 'internet_explorer', 'opera', 'safari',\n )\n\n windows_platform_tokens = (\n 'Windows 95', 'Windows 98', 'Windows 98; Win 9x 4.90', 'Windows CE',\n 'Windows NT 4.0', 'Windows NT 5.0', 'Windows NT 5.01',\n 'Windows NT 5.1', 'Windows NT 5.2', 'Windows NT 6.0', 'Windows NT 6.1',\n 'Windows NT 6.2', 'Windows NT 10.0',\n )\n\n linux_processors = ('i686', 'x86_64')\n\n mac_processors = ('Intel', 'PPC', 'U; Intel', 'U; PPC')\n\n android_versions = (\n '1.0', '1.1', '1.5', '1.6', '2.0', '2.0.1', '2.1', '2.2', '2.2.1', '2.2.2', '2.2.3', '2.3', '2.3.1', '2.3.2',\n '2.3.3', '2.3.4', '2.3.5', '2.3.6', '2.3.7', '3.0', '3.1', '3.2', '3.2.1', '3.2.2', '3.2.3', '3.2.4', '3.2.5',\n '3.2.6', '4.0', '4.0.1', '4.0.2', '4.0.3', '4.0.4', '4.1', '4.1.1', '4.1.2', '4.2', '4.2.1', '4.2.2', '4.3',\n '4.3.1', '4.4', '4.4.1', '4.4.2', '4.4.3', '4.4.4', '5.0', '5.0.1', '5.0.2', '5.1', '5.1.1', '6.0', '6.0.1',\n '7.0', '7.1', '7.1.1', '7.1.2', '8.0.0', '8.1.0', '9', '10', '11',\n )\n\n apple_devices = ('iPhone', 'iPad')\n\n ios_versions = (\n '3.1.3', '4.2.1', '5.1.1', '6.1.6', '7.1.2', '9.3.5', '9.3.6', '10.3.3', '10.3.4', '12.4.8', '14.2', '14.2.1',\n )\n\n def mac_processor(self):\n \"\"\"Generate a MacOS processor token used in user agent strings.\"\"\"\n return self.random_element(self.mac_processors)\n\n def linux_processor(self):\n \"\"\"Generate a Linux processor token used in user agent strings.\"\"\"\n return self.random_element(self.linux_processors)\n\n def user_agent(self):\n \"\"\"Generate a random web browser user agent string.\"\"\"\n name = self.random_element(self.user_agents)\n return getattr(self, name)()\n\n def chrome(self, version_from=13, version_to=63,\n build_from=800, build_to=899):\n \"\"\"Generate a Chrome web browser user agent string.\"\"\"\n saf = f'{self.generator.random.randint(531, 536)}.{self.generator.random.randint(0, 2)}'\n bld = self.lexify(self.numerify('##?###'), string.ascii_uppercase)\n tmplt = '({0}) AppleWebKit/{1} (KHTML, like Gecko)' \\\n ' Chrome/{2}.0.{3}.0 Safari/{4}'\n tmplt_ios = '({0}) AppleWebKit/{1} (KHTML, like Gecko)' \\\n ' CriOS/{2}.0.{3}.0 Mobile/{4} Safari/{1}'\n platforms = (\n tmplt.format(self.linux_platform_token(),\n saf,\n self.generator.random.randint(version_from, version_to),\n self.generator.random.randint(build_from, build_to),\n saf),\n tmplt.format(self.windows_platform_token(),\n saf,\n self.generator.random.randint(version_from, version_to),\n self.generator.random.randint(build_from, build_to),\n saf),\n tmplt.format(self.mac_platform_token(),\n saf,\n self.generator.random.randint(version_from, version_to),\n self.generator.random.randint(build_from, build_to),\n saf),\n tmplt.format('Linux; {}'.format(self.android_platform_token()),\n saf,\n self.generator.random.randint(version_from, version_to),\n self.generator.random.randint(build_from, build_to),\n saf),\n tmplt_ios.format(self.ios_platform_token(),\n saf,\n self.generator.random.randint(version_from, version_to),\n self.generator.random.randint(build_from, build_to),\n bld),\n )\n\n return 'Mozilla/5.0 ' + self.random_element(platforms)\n\n def firefox(self):\n \"\"\"Generate a Mozilla Firefox web browser user agent string.\"\"\"\n ver = (\n (f'Gecko/{self.generator.date_time_between(datetime(2011, 1, 1))} '\n f'Firefox/{self.generator.random.randint(4, 15)}.0'),\n (f'Gecko/{self.generator.date_time_between(datetime(2010, 1, 1))} '\n f'Firefox/3.6.{self.generator.random.randint(1, 20)}'),\n f'Gecko/{self.generator.date_time_between(datetime(2010, 1, 1))} Firefox/3.8',\n )\n tmplt_win = '({0}; {1}; rv:1.9.{2}.20) {3}'\n tmplt_lin = '({0}; rv:1.9.{1}.20) {2}'\n tmplt_mac = '({0}; rv:1.9.{1}.20) {2}'\n tmplt_and = '({0}; Mobile; rv:{1}.0) Gecko/{1}.0 Firefox/{1}.0'\n tmplt_ios = '({0}) AppleWebKit/{1} (KHTML, like Gecko) FxiOS/{2}.{3}.0 Mobile/{4} Safari/{1}'\n saf = '{}.{}'.format(self.generator.random.randint(531, 536),\n self.generator.random.randint(0, 2))\n bld = self.lexify(self.numerify('##?###'), string.ascii_uppercase)\n bld2 = self.lexify(self.numerify('#?####'), string.ascii_lowercase)\n platforms = (\n tmplt_win.format(self.windows_platform_token(),\n self.generator.locale().replace('_', '-'),\n self.generator.random.randint(0, 2),\n self.generator.random.choice(ver)),\n tmplt_lin.format(self.linux_platform_token(),\n self.generator.random.randint(5, 7),\n self.generator.random.choice(ver)),\n tmplt_mac.format(self.mac_platform_token(),\n self.generator.random.randint(2, 6),\n self.generator.random.choice(ver)),\n tmplt_and.format(self.android_platform_token(),\n self.generator.random.randint(5, 68)),\n tmplt_ios.format(self.ios_platform_token(),\n saf,\n self.generator.random.randint(9, 18),\n bld2,\n bld),\n )\n\n return 'Mozilla/5.0 ' + self.random_element(platforms)\n\n def safari(self):\n \"\"\"Generate a Safari web browser user agent string.\"\"\"\n saf = (f'{self.generator.random.randint(531, 535)}.'\n f'{self.generator.random.randint(1, 50)}.'\n f'{self.generator.random.randint(1, 7)}')\n if not self.generator.random.getrandbits(1):\n ver = f'{self.generator.random.randint(4, 5)}.{self.generator.random.randint(0, 1)}'\n else:\n ver = f'{self.generator.random.randint(4, 5)}.0.{self.generator.random.randint(1, 5)}'\n tmplt_win = '(Windows; U; {0}) AppleWebKit/{1} (KHTML, like Gecko)' \\\n ' Version/{2} Safari/{3}'\n tmplt_mac = '({0} rv:{1}.0; {2}) AppleWebKit/{3} (KHTML, like Gecko)' \\\n ' Version/{4} Safari/{5}'\n tmplt_ipod = '(iPod; U; CPU iPhone OS {0}_{1} like Mac OS X; {2})' \\\n ' AppleWebKit/{3} (KHTML, like Gecko) Version/{4}.0.5' \\\n ' Mobile/8B{5} Safari/6{6}'\n locale = self.generator.locale().replace('_', '-')\n platforms = (\n tmplt_win.format(self.windows_platform_token(),\n saf,\n ver,\n saf),\n tmplt_mac.format(self.mac_platform_token(),\n self.generator.random.randint(2, 6),\n locale,\n saf,\n ver,\n saf),\n tmplt_ipod.format(self.generator.random.randint(3, 4),\n self.generator.random.randint(0, 3),\n locale,\n saf,\n self.generator.random.randint(3, 4),\n self.generator.random.randint(111, 119),\n saf),\n )\n\n return 'Mozilla/5.0 ' + self.random_element(platforms)\n\n def opera(self):\n \"\"\"Generate an Opera web browser user agent string.\"\"\"\n token = self.linux_platform_token() if self.generator.random.getrandbits(1) else self.windows_platform_token()\n locale = self.generator.locale().replace('_', '-')\n platform = (f'({token}; {locale}) Presto/2.9.{self.generator.random.randint(160, 190)} '\n f'Version/{self.generator.random.randint(10, 12)}.00')\n return f'Opera/{self.generator.random.randint(8, 9)}.{self.generator.random.randint(10, 99)}.{platform}'\n\n def internet_explorer(self):\n \"\"\"Generate an IE web browser user agent string.\"\"\"\n return (f'Mozilla/5.0 (compatible; MSIE {self.generator.random.randint(5, 9)}.0; '\n f'{self.windows_platform_token()}; '\n f'Trident/{self.generator.random.randint(3, 5)}.{self.generator.random.randint(0, 1)})')\n\n def windows_platform_token(self):\n \"\"\"Generate a Windows platform token used in user agent strings.\"\"\"\n return self.random_element(self.windows_platform_tokens)\n\n def linux_platform_token(self):\n \"\"\"Generate a Linux platform token used in user agent strings.\"\"\"\n return f'X11; Linux {self.random_element(self.linux_processors)}'\n\n def mac_platform_token(self):\n \"\"\"Generate a MacOS platform token used in user agent strings.\"\"\"\n return (f'Macintosh; {self.random_element(self.mac_processors)} Mac OS X 10 '\n f'{self.generator.random.randint(5, 12)}_{self.generator.random.randint(0, 9)}')\n\n def android_platform_token(self):\n \"\"\"Generate an Android platform token used in user agent strings.\"\"\"\n return f'Android {self.random_element(self.android_versions)}'\n\n def ios_platform_token(self):\n \"\"\"Generate an iOS platform token used in user agent strings.\"\"\"\n apple_device = self.random_element(self.apple_devices)\n return (f'{apple_device}; CPU {apple_device} '\n f'OS {self.random_element(self.ios_versions).replace(\".\", \"_\")} like Mac OS X')\n", "path": "faker/providers/user_agent/__init__.py"}]}
| 3,932 | 166 |
gh_patches_debug_20985
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-295
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] pip package 0.1.3 fails to install
Both `python3.8 -m pip install fairscale --verbose` and `python3.8 -m pip install fairscale --no-build-isolation --verbose` trigger
```
ninja: error: '/tmp/pip-install-zqe21k7a/fairscale_4066f1fa225242299ead5fd852fd2ce8/fairscale/clib/fused_adam_cuda/fused_adam_cuda.cpp', needed by '/t
mp/pip-install-zqe21k7a/fairscale_4066f1fa225242299ead5fd852fd2ce8/build/temp.linux-x86_64-3.8/fairscale/clib/fused_adam_cuda/fused_adam_cuda.o', missin
g and no known rule to make it
```
Cloning the repository and running `python3.8 -m pip install . --verbose` from within the directory works fine.
</issue>
<code>
[start of fairscale/__init__.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 __version__ = "0.1.3"
7
8 ################################################################################
9 # Import most common subpackages
10 ################################################################################
11
12 from . import nn
13
[end of fairscale/__init__.py]
[start of setup.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
4
5 import os
6 import re
7 import warnings
8
9 import setuptools
10 import torch
11 from torch.utils.cpp_extension import CUDA_HOME, BuildExtension, CUDAExtension
12
13 this_dir = os.path.dirname(os.path.abspath(__file__))
14
15
16 def fetch_requirements():
17 with open("requirements.txt") as f:
18 reqs = f.read().strip().split("\n")
19 return reqs
20
21
22 # https://packaging.python.org/guides/single-sourcing-package-version/
23 def find_version(version_file_path):
24 with open(version_file_path) as version_file:
25 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]", version_file.read(), re.M)
26 if version_match:
27 return version_match.group(1)
28 raise RuntimeError("Unable to find version string.")
29
30
31 extensions = []
32 cmdclass = {}
33
34 force_cuda = os.getenv("FORCE_CUDA", "0") == "1"
35 if (torch.cuda.is_available() and CUDA_HOME is not None) or force_cuda:
36 extensions.extend(
37 [
38 CUDAExtension(
39 name="fairscale.fused_adam_cuda",
40 include_dirs=[os.path.join(this_dir, "fairscale/clib/fused_adam_cuda")],
41 sources=[
42 "fairscale/clib/fused_adam_cuda/fused_adam_cuda.cpp",
43 "fairscale/clib/fused_adam_cuda/fused_adam_cuda_kernel.cu",
44 ],
45 extra_compile_args={"cxx": ["-O3"], "nvcc": ["-O3", "--use_fast_math"]},
46 )
47 ]
48 )
49
50 cmdclass["build_ext"] = BuildExtension
51 else:
52 warnings.warn("Cannot install FusedAdam cuda.")
53
54
55 if __name__ == "__main__":
56 setuptools.setup(
57 name="fairscale",
58 description="fairscale: A PyTorch library for large-scale and high-performance training.",
59 version=find_version("fairscale/__init__.py"),
60 install_requires=fetch_requirements(),
61 include_package_data=True,
62 packages=setuptools.find_packages(exclude=("tests", "tests.*")),
63 ext_modules=extensions,
64 cmdclass=cmdclass,
65 python_requires=">=3.6",
66 author="Facebook AI Research",
67 author_email="[email protected]",
68 classifiers=[
69 "Programming Language :: Python :: 3.6",
70 "Programming Language :: Python :: 3.7",
71 "Programming Language :: Python :: 3.8",
72 "License :: OSI Approved :: BSD License",
73 "Topic :: Scientific/Engineering :: Artificial Intelligence",
74 "Operating System :: OS Independent",
75 ],
76 )
77
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fairscale/__init__.py b/fairscale/__init__.py
--- a/fairscale/__init__.py
+++ b/fairscale/__init__.py
@@ -3,7 +3,7 @@
# This source code is licensed under the BSD license found in the
# LICENSE file in the root directory of this source tree.
-__version__ = "0.1.3"
+__version__ = "0.1.4"
################################################################################
# Import most common subpackages
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,6 +65,8 @@
python_requires=">=3.6",
author="Facebook AI Research",
author_email="[email protected]",
+ long_description="FairScale is a PyTorch extension library for high performance and large scale training on one or multiple machines/nodes. This library extends basic PyTorch capabilities while adding new experimental ones.",
+ long_description_content_type="text/markdown",
classifiers=[
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
|
{"golden_diff": "diff --git a/fairscale/__init__.py b/fairscale/__init__.py\n--- a/fairscale/__init__.py\n+++ b/fairscale/__init__.py\n@@ -3,7 +3,7 @@\n # This source code is licensed under the BSD license found in the\n # LICENSE file in the root directory of this source tree.\n \n-__version__ = \"0.1.3\"\n+__version__ = \"0.1.4\"\n \n ################################################################################\n # Import most common subpackages\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -65,6 +65,8 @@\n python_requires=\">=3.6\",\n author=\"Facebook AI Research\",\n author_email=\"[email protected]\",\n+ long_description=\"FairScale is a PyTorch extension library for high performance and large scale training on one or multiple machines/nodes. This library extends basic PyTorch capabilities while adding new experimental ones.\",\n+ long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n", "issue": "[bug] pip package 0.1.3 fails to install\nBoth `python3.8 -m pip install fairscale --verbose` and `python3.8 -m pip install fairscale --no-build-isolation --verbose` trigger\r\n\r\n```\r\nninja: error: '/tmp/pip-install-zqe21k7a/fairscale_4066f1fa225242299ead5fd852fd2ce8/fairscale/clib/fused_adam_cuda/fused_adam_cuda.cpp', needed by '/t\r\nmp/pip-install-zqe21k7a/fairscale_4066f1fa225242299ead5fd852fd2ce8/build/temp.linux-x86_64-3.8/fairscale/clib/fused_adam_cuda/fused_adam_cuda.o', missin\r\ng and no known rule to make it\r\n```\r\n\r\nCloning the repository and running `python3.8 -m pip install . --verbose` from within the directory works fine.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n__version__ = \"0.1.3\"\n\n################################################################################\n# Import most common subpackages\n################################################################################\n\nfrom . import nn\n", "path": "fairscale/__init__.py"}, {"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n\nimport os\nimport re\nimport warnings\n\nimport setuptools\nimport torch\nfrom torch.utils.cpp_extension import CUDA_HOME, BuildExtension, CUDAExtension\n\nthis_dir = os.path.dirname(os.path.abspath(__file__))\n\n\ndef fetch_requirements():\n with open(\"requirements.txt\") as f:\n reqs = f.read().strip().split(\"\\n\")\n return reqs\n\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\ndef find_version(version_file_path):\n with open(version_file_path) as version_file:\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\", version_file.read(), re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\nextensions = []\ncmdclass = {}\n\nforce_cuda = os.getenv(\"FORCE_CUDA\", \"0\") == \"1\"\nif (torch.cuda.is_available() and CUDA_HOME is not None) or force_cuda:\n extensions.extend(\n [\n CUDAExtension(\n name=\"fairscale.fused_adam_cuda\",\n include_dirs=[os.path.join(this_dir, \"fairscale/clib/fused_adam_cuda\")],\n sources=[\n \"fairscale/clib/fused_adam_cuda/fused_adam_cuda.cpp\",\n \"fairscale/clib/fused_adam_cuda/fused_adam_cuda_kernel.cu\",\n ],\n extra_compile_args={\"cxx\": [\"-O3\"], \"nvcc\": [\"-O3\", \"--use_fast_math\"]},\n )\n ]\n )\n\n cmdclass[\"build_ext\"] = BuildExtension\nelse:\n warnings.warn(\"Cannot install FusedAdam cuda.\")\n\n\nif __name__ == \"__main__\":\n setuptools.setup(\n name=\"fairscale\",\n description=\"fairscale: A PyTorch library for large-scale and high-performance training.\",\n version=find_version(\"fairscale/__init__.py\"),\n install_requires=fetch_requirements(),\n include_package_data=True,\n packages=setuptools.find_packages(exclude=(\"tests\", \"tests.*\")),\n ext_modules=extensions,\n cmdclass=cmdclass,\n python_requires=\">=3.6\",\n author=\"Facebook AI Research\",\n author_email=\"[email protected]\",\n classifiers=[\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"License :: OSI Approved :: BSD License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Operating System :: OS Independent\",\n ],\n )\n", "path": "setup.py"}]}
| 1,599 | 249 |
gh_patches_debug_21204
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-782
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: MessageTemplate 存在CQ码注入问题
**描述问题:**
使用 Message.template 的 format 时可能存在CQ码注入问题
**如何复现?**
```python
>>> from nonebot.adapters.onebot.v11 import Message
>>> Message.template(Message("{nickname}是我老婆!")).format(nickname="[CQ:at,qq=all]")
[MessageSegment(type='at', data={'qq': 'all'}), MessageSegment(type='text', data={'text': '是我老婆!'})]
```
**期望的结果**
上面的例子中,`"[CQ:at,qq=all]"` 应被解析为文本,而不是 `at` 类型
**环境信息:**
- OS: Linux Ubuntu 20.04
- Python Version: 3.8.10
- Nonebot Version: 2.0.0b1
**截图或日志**

Bug: MessageTemplate 存在CQ码注入问题
**描述问题:**
使用 Message.template 的 format 时可能存在CQ码注入问题
**如何复现?**
```python
>>> from nonebot.adapters.onebot.v11 import Message
>>> Message.template(Message("{nickname}是我老婆!")).format(nickname="[CQ:at,qq=all]")
[MessageSegment(type='at', data={'qq': 'all'}), MessageSegment(type='text', data={'text': '是我老婆!'})]
```
**期望的结果**
上面的例子中,`"[CQ:at,qq=all]"` 应被解析为文本,而不是 `at` 类型
**环境信息:**
- OS: Linux Ubuntu 20.04
- Python Version: 3.8.10
- Nonebot Version: 2.0.0b1
**截图或日志**

</issue>
<code>
[start of nonebot/internal/adapter/template.py]
1 import functools
2 from string import Formatter
3 from typing import (
4 TYPE_CHECKING,
5 Any,
6 Set,
7 Dict,
8 List,
9 Type,
10 Tuple,
11 Union,
12 Generic,
13 Mapping,
14 TypeVar,
15 Callable,
16 Optional,
17 Sequence,
18 cast,
19 overload,
20 )
21
22 if TYPE_CHECKING:
23 from .message import Message, MessageSegment
24
25 TM = TypeVar("TM", bound="Message")
26 TF = TypeVar("TF", str, "Message")
27
28 FormatSpecFunc = Callable[[Any], str]
29 FormatSpecFunc_T = TypeVar("FormatSpecFunc_T", bound=FormatSpecFunc)
30
31
32 class MessageTemplate(Formatter, Generic[TF]):
33 """消息模板格式化实现类。
34
35 参数:
36 template: 模板
37 factory: 消息类型工厂,默认为 `str`
38 """
39
40 @overload
41 def __init__(
42 self: "MessageTemplate[str]", template: str, factory: Type[str] = str
43 ) -> None:
44 ...
45
46 @overload
47 def __init__(
48 self: "MessageTemplate[TM]", template: Union[str, TM], factory: Type[TM]
49 ) -> None:
50 ...
51
52 def __init__(self, template, factory=str) -> None:
53 self.template: TF = template
54 self.factory: Type[TF] = factory
55 self.format_specs: Dict[str, FormatSpecFunc] = {}
56
57 def add_format_spec(
58 self, spec: FormatSpecFunc_T, name: Optional[str] = None
59 ) -> FormatSpecFunc_T:
60 name = name or spec.__name__
61 if name in self.format_specs:
62 raise ValueError(f"Format spec {name} already exists!")
63 self.format_specs[name] = spec
64 return spec
65
66 def format(self, *args, **kwargs):
67 """根据传入参数和模板生成消息对象"""
68 return self._format(args, kwargs)
69
70 def format_map(self, mapping: Mapping[str, Any]) -> TF:
71 """根据传入字典和模板生成消息对象, 在传入字段名不是有效标识符时有用"""
72 return self._format([], mapping)
73
74 def _format(self, args: Sequence[Any], kwargs: Mapping[str, Any]) -> TF:
75 msg = self.factory()
76 if isinstance(self.template, str):
77 msg += self.vformat(self.template, args, kwargs)
78 elif isinstance(self.template, self.factory):
79 template = cast("Message[MessageSegment]", self.template)
80 for seg in template:
81 msg += self.vformat(str(seg), args, kwargs) if seg.is_text() else seg
82 else:
83 raise TypeError("template must be a string or instance of Message!")
84
85 return msg # type:ignore
86
87 def vformat(
88 self, format_string: str, args: Sequence[Any], kwargs: Mapping[str, Any]
89 ) -> TF:
90 used_args = set()
91 result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
92 self.check_unused_args(list(used_args), args, kwargs)
93 return result
94
95 def _vformat(
96 self,
97 format_string: str,
98 args: Sequence[Any],
99 kwargs: Mapping[str, Any],
100 used_args: Set[Union[int, str]],
101 recursion_depth: int,
102 auto_arg_index: int = 0,
103 ) -> Tuple[TF, int]:
104 if recursion_depth < 0:
105 raise ValueError("Max string recursion exceeded")
106
107 results: List[Any] = []
108
109 for (literal_text, field_name, format_spec, conversion) in self.parse(
110 format_string
111 ):
112
113 # output the literal text
114 if literal_text:
115 results.append(literal_text)
116
117 # if there's a field, output it
118 if field_name is not None:
119 # this is some markup, find the object and do
120 # the formatting
121
122 # handle arg indexing when empty field_names are given.
123 if field_name == "":
124 if auto_arg_index is False:
125 raise ValueError(
126 "cannot switch from manual field specification to "
127 "automatic field numbering"
128 )
129 field_name = str(auto_arg_index)
130 auto_arg_index += 1
131 elif field_name.isdigit():
132 if auto_arg_index:
133 raise ValueError(
134 "cannot switch from manual field specification to "
135 "automatic field numbering"
136 )
137 # disable auto arg incrementing, if it gets
138 # used later on, then an exception will be raised
139 auto_arg_index = False
140
141 # given the field_name, find the object it references
142 # and the argument it came from
143 obj, arg_used = self.get_field(field_name, args, kwargs)
144 used_args.add(arg_used)
145
146 assert format_spec is not None
147
148 # do any conversion on the resulting object
149 obj = self.convert_field(obj, conversion) if conversion else obj
150
151 # expand the format spec, if needed
152 format_control, auto_arg_index = self._vformat(
153 format_spec,
154 args,
155 kwargs,
156 used_args,
157 recursion_depth - 1,
158 auto_arg_index,
159 )
160
161 # format the object and append to the result
162 formatted_text = self.format_field(obj, str(format_control))
163 results.append(formatted_text)
164
165 return (
166 self.factory(functools.reduce(self._add, results or [""])),
167 auto_arg_index,
168 )
169
170 def format_field(self, value: Any, format_spec: str) -> Any:
171 formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)
172 if formatter is None and not issubclass(self.factory, str):
173 segment_class: Type["MessageSegment"] = self.factory.get_segment_class()
174 method = getattr(segment_class, format_spec, None)
175 if callable(method) and not cast(str, method.__name__).startswith("_"):
176 formatter = getattr(segment_class, format_spec)
177 return (
178 super().format_field(value, format_spec)
179 if formatter is None
180 else formatter(value)
181 )
182
183 def _add(self, a: Any, b: Any) -> Any:
184 try:
185 return a + b
186 except TypeError:
187 return a + str(b)
188
[end of nonebot/internal/adapter/template.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nonebot/internal/adapter/template.py b/nonebot/internal/adapter/template.py
--- a/nonebot/internal/adapter/template.py
+++ b/nonebot/internal/adapter/template.py
@@ -104,7 +104,7 @@
if recursion_depth < 0:
raise ValueError("Max string recursion exceeded")
- results: List[Any] = []
+ results: List[Any] = [self.factory()]
for (literal_text, field_name, format_spec, conversion) in self.parse(
format_string
@@ -162,10 +162,7 @@
formatted_text = self.format_field(obj, str(format_control))
results.append(formatted_text)
- return (
- self.factory(functools.reduce(self._add, results or [""])),
- auto_arg_index,
- )
+ return functools.reduce(self._add, results), auto_arg_index
def format_field(self, value: Any, format_spec: str) -> Any:
formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)
|
{"golden_diff": "diff --git a/nonebot/internal/adapter/template.py b/nonebot/internal/adapter/template.py\n--- a/nonebot/internal/adapter/template.py\n+++ b/nonebot/internal/adapter/template.py\n@@ -104,7 +104,7 @@\n if recursion_depth < 0:\n raise ValueError(\"Max string recursion exceeded\")\n \n- results: List[Any] = []\n+ results: List[Any] = [self.factory()]\n \n for (literal_text, field_name, format_spec, conversion) in self.parse(\n format_string\n@@ -162,10 +162,7 @@\n formatted_text = self.format_field(obj, str(format_control))\n results.append(formatted_text)\n \n- return (\n- self.factory(functools.reduce(self._add, results or [\"\"])),\n- auto_arg_index,\n- )\n+ return functools.reduce(self._add, results), auto_arg_index\n \n def format_field(self, value: Any, format_spec: str) -> Any:\n formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)\n", "issue": "Bug: MessageTemplate \u5b58\u5728CQ\u7801\u6ce8\u5165\u95ee\u9898\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u4f7f\u7528 Message.template \u7684 format \u65f6\u53ef\u80fd\u5b58\u5728CQ\u7801\u6ce8\u5165\u95ee\u9898\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n```python\r\n>>> from nonebot.adapters.onebot.v11 import Message\r\n>>> Message.template(Message(\"{nickname}\u662f\u6211\u8001\u5a46!\")).format(nickname=\"[CQ:at,qq=all]\")\r\n[MessageSegment(type='at', data={'qq': 'all'}), MessageSegment(type='text', data={'text': '\u662f\u6211\u8001\u5a46!'})]\r\n```\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\u4e0a\u9762\u7684\u4f8b\u5b50\u4e2d\uff0c`\"[CQ:at,qq=all]\"` \u5e94\u88ab\u89e3\u6790\u4e3a\u6587\u672c\uff0c\u800c\u4e0d\u662f `at` \u7c7b\u578b\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: Linux Ubuntu 20.04\r\n - Python Version: 3.8.10\r\n - Nonebot Version: 2.0.0b1\r\n\r\n**\u622a\u56fe\u6216\u65e5\u5fd7**\r\n\r\n\r\n\nBug: MessageTemplate \u5b58\u5728CQ\u7801\u6ce8\u5165\u95ee\u9898\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u4f7f\u7528 Message.template \u7684 format \u65f6\u53ef\u80fd\u5b58\u5728CQ\u7801\u6ce8\u5165\u95ee\u9898\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n```python\r\n>>> from nonebot.adapters.onebot.v11 import Message\r\n>>> Message.template(Message(\"{nickname}\u662f\u6211\u8001\u5a46!\")).format(nickname=\"[CQ:at,qq=all]\")\r\n[MessageSegment(type='at', data={'qq': 'all'}), MessageSegment(type='text', data={'text': '\u662f\u6211\u8001\u5a46!'})]\r\n```\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\u4e0a\u9762\u7684\u4f8b\u5b50\u4e2d\uff0c`\"[CQ:at,qq=all]\"` \u5e94\u88ab\u89e3\u6790\u4e3a\u6587\u672c\uff0c\u800c\u4e0d\u662f `at` \u7c7b\u578b\r\n\r\n**\u73af\u5883\u4fe1\u606f\uff1a**\r\n\r\n - OS: Linux Ubuntu 20.04\r\n - Python Version: 3.8.10\r\n - Nonebot Version: 2.0.0b1\r\n\r\n**\u622a\u56fe\u6216\u65e5\u5fd7**\r\n\r\n\r\n\n", "before_files": [{"content": "import functools\nfrom string import Formatter\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Set,\n Dict,\n List,\n Type,\n Tuple,\n Union,\n Generic,\n Mapping,\n TypeVar,\n Callable,\n Optional,\n Sequence,\n cast,\n overload,\n)\n\nif TYPE_CHECKING:\n from .message import Message, MessageSegment\n\nTM = TypeVar(\"TM\", bound=\"Message\")\nTF = TypeVar(\"TF\", str, \"Message\")\n\nFormatSpecFunc = Callable[[Any], str]\nFormatSpecFunc_T = TypeVar(\"FormatSpecFunc_T\", bound=FormatSpecFunc)\n\n\nclass MessageTemplate(Formatter, Generic[TF]):\n \"\"\"\u6d88\u606f\u6a21\u677f\u683c\u5f0f\u5316\u5b9e\u73b0\u7c7b\u3002\n\n \u53c2\u6570:\n template: \u6a21\u677f\n factory: \u6d88\u606f\u7c7b\u578b\u5de5\u5382\uff0c\u9ed8\u8ba4\u4e3a `str`\n \"\"\"\n\n @overload\n def __init__(\n self: \"MessageTemplate[str]\", template: str, factory: Type[str] = str\n ) -> None:\n ...\n\n @overload\n def __init__(\n self: \"MessageTemplate[TM]\", template: Union[str, TM], factory: Type[TM]\n ) -> None:\n ...\n\n def __init__(self, template, factory=str) -> None:\n self.template: TF = template\n self.factory: Type[TF] = factory\n self.format_specs: Dict[str, FormatSpecFunc] = {}\n\n def add_format_spec(\n self, spec: FormatSpecFunc_T, name: Optional[str] = None\n ) -> FormatSpecFunc_T:\n name = name or spec.__name__\n if name in self.format_specs:\n raise ValueError(f\"Format spec {name} already exists!\")\n self.format_specs[name] = spec\n return spec\n\n def format(self, *args, **kwargs):\n \"\"\"\u6839\u636e\u4f20\u5165\u53c2\u6570\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61\"\"\"\n return self._format(args, kwargs)\n\n def format_map(self, mapping: Mapping[str, Any]) -> TF:\n \"\"\"\u6839\u636e\u4f20\u5165\u5b57\u5178\u548c\u6a21\u677f\u751f\u6210\u6d88\u606f\u5bf9\u8c61, \u5728\u4f20\u5165\u5b57\u6bb5\u540d\u4e0d\u662f\u6709\u6548\u6807\u8bc6\u7b26\u65f6\u6709\u7528\"\"\"\n return self._format([], mapping)\n\n def _format(self, args: Sequence[Any], kwargs: Mapping[str, Any]) -> TF:\n msg = self.factory()\n if isinstance(self.template, str):\n msg += self.vformat(self.template, args, kwargs)\n elif isinstance(self.template, self.factory):\n template = cast(\"Message[MessageSegment]\", self.template)\n for seg in template:\n msg += self.vformat(str(seg), args, kwargs) if seg.is_text() else seg\n else:\n raise TypeError(\"template must be a string or instance of Message!\")\n\n return msg # type:ignore\n\n def vformat(\n self, format_string: str, args: Sequence[Any], kwargs: Mapping[str, Any]\n ) -> TF:\n used_args = set()\n result, _ = self._vformat(format_string, args, kwargs, used_args, 2)\n self.check_unused_args(list(used_args), args, kwargs)\n return result\n\n def _vformat(\n self,\n format_string: str,\n args: Sequence[Any],\n kwargs: Mapping[str, Any],\n used_args: Set[Union[int, str]],\n recursion_depth: int,\n auto_arg_index: int = 0,\n ) -> Tuple[TF, int]:\n if recursion_depth < 0:\n raise ValueError(\"Max string recursion exceeded\")\n\n results: List[Any] = []\n\n for (literal_text, field_name, format_spec, conversion) in self.parse(\n format_string\n ):\n\n # output the literal text\n if literal_text:\n results.append(literal_text)\n\n # if there's a field, output it\n if field_name is not None:\n # this is some markup, find the object and do\n # the formatting\n\n # handle arg indexing when empty field_names are given.\n if field_name == \"\":\n if auto_arg_index is False:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n field_name = str(auto_arg_index)\n auto_arg_index += 1\n elif field_name.isdigit():\n if auto_arg_index:\n raise ValueError(\n \"cannot switch from manual field specification to \"\n \"automatic field numbering\"\n )\n # disable auto arg incrementing, if it gets\n # used later on, then an exception will be raised\n auto_arg_index = False\n\n # given the field_name, find the object it references\n # and the argument it came from\n obj, arg_used = self.get_field(field_name, args, kwargs)\n used_args.add(arg_used)\n\n assert format_spec is not None\n\n # do any conversion on the resulting object\n obj = self.convert_field(obj, conversion) if conversion else obj\n\n # expand the format spec, if needed\n format_control, auto_arg_index = self._vformat(\n format_spec,\n args,\n kwargs,\n used_args,\n recursion_depth - 1,\n auto_arg_index,\n )\n\n # format the object and append to the result\n formatted_text = self.format_field(obj, str(format_control))\n results.append(formatted_text)\n\n return (\n self.factory(functools.reduce(self._add, results or [\"\"])),\n auto_arg_index,\n )\n\n def format_field(self, value: Any, format_spec: str) -> Any:\n formatter: Optional[FormatSpecFunc] = self.format_specs.get(format_spec)\n if formatter is None and not issubclass(self.factory, str):\n segment_class: Type[\"MessageSegment\"] = self.factory.get_segment_class()\n method = getattr(segment_class, format_spec, None)\n if callable(method) and not cast(str, method.__name__).startswith(\"_\"):\n formatter = getattr(segment_class, format_spec)\n return (\n super().format_field(value, format_spec)\n if formatter is None\n else formatter(value)\n )\n\n def _add(self, a: Any, b: Any) -> Any:\n try:\n return a + b\n except TypeError:\n return a + str(b)\n", "path": "nonebot/internal/adapter/template.py"}]}
| 2,853 | 236 |
gh_patches_debug_26947
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-4194
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Detecting and alerting of duplication keys/components/entries in YAML file
### Is your feature request related to a problem? Please describe
it was found in release 1.3.11 , a PR to update [manifest](https://github.com/opensearch-project/opensearch-build/blob/main/manifests/1.3.11/opensearch-1.3.11.yml) has duplicated components name.
It would cause the resource wasted on CI to rebuild the duplicated components
### Describe the solution you'd like
We want to have a check to detect if there is any duplication entries based on keys/components/names and probably fail the GitHub check
### Describe alternatives you've considered
Manually check for duplicate values
### Acceptance Criteria
* The manifest check should fail at CI level for components with duplicate components.name values in opensearch and opensearch-dashboard as well as test manifests. See what are [manifests](https://github.com/opensearch-project/opensearch-build/wiki/Building-an-OpenSearch-and-OpenSearch-Dashboards-Distribution#what-are-manifests)
</issue>
<code>
[start of src/ci_workflow/ci_manifests.py]
1 # Copyright OpenSearch Contributors
2 # SPDX-License-Identifier: Apache-2.0
3 #
4 # The OpenSearch Contributors require contributions made to
5 # this file be licensed under the Apache-2.0 license or a
6 # compatible open source license.
7
8
9 import re
10 from collections import Counter
11 from io import TextIOWrapper
12 from typing import Type, Union
13
14 import yaml
15
16 from ci_workflow.ci_args import CiArgs
17 from ci_workflow.ci_input_manifest import CiInputManifest
18 from ci_workflow.ci_test_manifest import CiTestManifest
19
20
21 class CiManifests:
22 @staticmethod
23 def __klass(filename: str) -> Union[Type[CiTestManifest], Type[CiInputManifest]]:
24 if re.search("-test.yml$", filename):
25 return CiTestManifest
26 else:
27 return CiInputManifest
28
29 @staticmethod
30 def __get_duplicate_component_names(count_component_names: Counter) -> list:
31 duplicate_component_names = []
32 for component_name, count in count_component_names.items():
33 if count > 1:
34 duplicate_component_names.append(component_name)
35 return duplicate_component_names
36
37 @staticmethod
38 def __check_duplicate_component_names(file: TextIOWrapper) -> None:
39 yaml_dict = yaml.safe_load(file)
40 component_names = []
41 for component in yaml_dict['components']:
42 component_names.append(component['name'])
43 count_component_names = Counter(component_names)
44
45 if set(count_component_names.values()) != set([1]):
46 duplicate_component_names = CiManifests.__get_duplicate_component_names(count_component_names)
47 duplicate_component_names_string = ', '.join(duplicate_component_names)
48 raise ValueError(f"Found {duplicate_component_names_string} as a duplicate component(s) in manifest {file.name}. ")
49 file.seek(0)
50
51 @classmethod
52 def from_file(cls, file: TextIOWrapper, args: CiArgs) -> Union[CiTestManifest, CiInputManifest]:
53 cls.__check_duplicate_component_names(file)
54 return cls.__klass(file.name)(file, args)
55
[end of src/ci_workflow/ci_manifests.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/ci_workflow/ci_manifests.py b/src/ci_workflow/ci_manifests.py
--- a/src/ci_workflow/ci_manifests.py
+++ b/src/ci_workflow/ci_manifests.py
@@ -26,25 +26,16 @@
else:
return CiInputManifest
- @staticmethod
- def __get_duplicate_component_names(count_component_names: Counter) -> list:
- duplicate_component_names = []
- for component_name, count in count_component_names.items():
- if count > 1:
- duplicate_component_names.append(component_name)
- return duplicate_component_names
-
@staticmethod
def __check_duplicate_component_names(file: TextIOWrapper) -> None:
yaml_dict = yaml.safe_load(file)
component_names = []
for component in yaml_dict['components']:
component_names.append(component['name'])
- count_component_names = Counter(component_names)
- if set(count_component_names.values()) != set([1]):
- duplicate_component_names = CiManifests.__get_duplicate_component_names(count_component_names)
- duplicate_component_names_string = ', '.join(duplicate_component_names)
+ duplicate_component_names = [comp for comp, count in Counter(component_names).items() if count > 1]
+ duplicate_component_names_string = ', '.join(duplicate_component_names)
+ if len(duplicate_component_names) > 0:
raise ValueError(f"Found {duplicate_component_names_string} as a duplicate component(s) in manifest {file.name}. ")
file.seek(0)
|
{"golden_diff": "diff --git a/src/ci_workflow/ci_manifests.py b/src/ci_workflow/ci_manifests.py\n--- a/src/ci_workflow/ci_manifests.py\n+++ b/src/ci_workflow/ci_manifests.py\n@@ -26,25 +26,16 @@\n else:\n return CiInputManifest\n \n- @staticmethod\n- def __get_duplicate_component_names(count_component_names: Counter) -> list:\n- duplicate_component_names = []\n- for component_name, count in count_component_names.items():\n- if count > 1:\n- duplicate_component_names.append(component_name)\n- return duplicate_component_names\n-\n @staticmethod\n def __check_duplicate_component_names(file: TextIOWrapper) -> None:\n yaml_dict = yaml.safe_load(file)\n component_names = []\n for component in yaml_dict['components']:\n component_names.append(component['name'])\n- count_component_names = Counter(component_names)\n \n- if set(count_component_names.values()) != set([1]):\n- duplicate_component_names = CiManifests.__get_duplicate_component_names(count_component_names)\n- duplicate_component_names_string = ', '.join(duplicate_component_names)\n+ duplicate_component_names = [comp for comp, count in Counter(component_names).items() if count > 1]\n+ duplicate_component_names_string = ', '.join(duplicate_component_names)\n+ if len(duplicate_component_names) > 0:\n raise ValueError(f\"Found {duplicate_component_names_string} as a duplicate component(s) in manifest {file.name}. \")\n file.seek(0)\n", "issue": "Detecting and alerting of duplication keys/components/entries in YAML file\n### Is your feature request related to a problem? Please describe\r\n\r\nit was found in release 1.3.11 , a PR to update [manifest](https://github.com/opensearch-project/opensearch-build/blob/main/manifests/1.3.11/opensearch-1.3.11.yml) has duplicated components name.\r\nIt would cause the resource wasted on CI to rebuild the duplicated components \r\n\r\n### Describe the solution you'd like\r\n\r\nWe want to have a check to detect if there is any duplication entries based on keys/components/names and probably fail the GitHub check\r\n\r\n### Describe alternatives you've considered\r\n\r\nManually check for duplicate values\r\n\r\n### Acceptance Criteria\r\n* The manifest check should fail at CI level for components with duplicate components.name values in opensearch and opensearch-dashboard as well as test manifests. See what are [manifests](https://github.com/opensearch-project/opensearch-build/wiki/Building-an-OpenSearch-and-OpenSearch-Dashboards-Distribution#what-are-manifests)\n", "before_files": [{"content": "# Copyright OpenSearch Contributors\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\n\nimport re\nfrom collections import Counter\nfrom io import TextIOWrapper\nfrom typing import Type, Union\n\nimport yaml\n\nfrom ci_workflow.ci_args import CiArgs\nfrom ci_workflow.ci_input_manifest import CiInputManifest\nfrom ci_workflow.ci_test_manifest import CiTestManifest\n\n\nclass CiManifests:\n @staticmethod\n def __klass(filename: str) -> Union[Type[CiTestManifest], Type[CiInputManifest]]:\n if re.search(\"-test.yml$\", filename):\n return CiTestManifest\n else:\n return CiInputManifest\n\n @staticmethod\n def __get_duplicate_component_names(count_component_names: Counter) -> list:\n duplicate_component_names = []\n for component_name, count in count_component_names.items():\n if count > 1:\n duplicate_component_names.append(component_name)\n return duplicate_component_names\n\n @staticmethod\n def __check_duplicate_component_names(file: TextIOWrapper) -> None:\n yaml_dict = yaml.safe_load(file)\n component_names = []\n for component in yaml_dict['components']:\n component_names.append(component['name'])\n count_component_names = Counter(component_names)\n\n if set(count_component_names.values()) != set([1]):\n duplicate_component_names = CiManifests.__get_duplicate_component_names(count_component_names)\n duplicate_component_names_string = ', '.join(duplicate_component_names)\n raise ValueError(f\"Found {duplicate_component_names_string} as a duplicate component(s) in manifest {file.name}. \")\n file.seek(0)\n\n @classmethod\n def from_file(cls, file: TextIOWrapper, args: CiArgs) -> Union[CiTestManifest, CiInputManifest]:\n cls.__check_duplicate_component_names(file)\n return cls.__klass(file.name)(file, args)\n", "path": "src/ci_workflow/ci_manifests.py"}]}
| 1,298 | 332 |
gh_patches_debug_62586
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-907
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
locale.Error: unsupported locale setting exception when glibc locale files are not present
**Information**
- Solaar version: 1.0.3
- Distribution: Fedora
- Kernel version (ex. `uname -srmo`): `Linux 5.7.11-200.fc32.x86_64 x86_64 GNU/Linux`
- Output of `solaar show`: N/A
**Describe the bug**
Any solaar invocation is failing with a traceback when locale.setlocale() call fails, e.g. due to missing glibc locale files for the currently set locale.
**To Reproduce**
Steps to reproduce the behavior:
```
$ sudo dnf remove glibc-langpack-de
$ export LC_ALL=de_CH.UTF-8
$ export LANG=de_CH.UTF-8
$ solaar --help
Traceback (most recent call last):
File "/usr/bin/solaar", line 59, in <module>
import solaar.gtk
File "/usr/lib/python3.8/site-packages/solaar/gtk.py", line 29, in <module>
import solaar.i18n as _i18n
File "/usr/lib/python3.8/site-packages/solaar/i18n.py", line 50, in <module>
locale.setlocale(locale.LC_ALL, '')
File "/usr/lib64/python3.8/locale.py", line 608, in setlocale
return _setlocale(category, locale)
locale.Error: unsupported locale setting
$
```
**Additional context**
Looks like #190 is still unfixed. Downstream bug report: https://bugzilla.redhat.com/show_bug.cgi?id=1811313 .
</issue>
<code>
[start of lib/solaar/i18n.py]
1 # -*- python-mode -*-
2 # -*- coding: UTF-8 -*-
3
4 ## Copyright (C) 2012-2013 Daniel Pavel
5 ##
6 ## This program is free software; you can redistribute it and/or modify
7 ## it under the terms of the GNU General Public License as published by
8 ## the Free Software Foundation; either version 2 of the License, or
9 ## (at your option) any later version.
10 ##
11 ## This program is distributed in the hope that it will be useful,
12 ## but WITHOUT ANY WARRANTY; without even the implied warranty of
13 ## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 ## GNU General Public License for more details.
15 ##
16 ## You should have received a copy of the GNU General Public License along
17 ## with this program; if not, write to the Free Software Foundation, Inc.,
18 ## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
19
20 from __future__ import absolute_import, division, print_function, unicode_literals
21
22 import gettext as _gettext
23 import locale
24
25 from solaar import NAME as _NAME
26
27 #
28 #
29 #
30
31
32 def _find_locale_path(lc_domain):
33 import os.path as _path
34
35 import sys as _sys
36 prefix_share = _path.normpath(_path.join(_path.realpath(_sys.path[0]), '..'))
37 src_share = _path.normpath(_path.join(_path.realpath(_sys.path[0]), '..', 'share'))
38 del _sys
39
40 from glob import glob as _glob
41
42 for location in prefix_share, src_share:
43 mo_files = _glob(_path.join(location, 'locale', '*', 'LC_MESSAGES', lc_domain + '.mo'))
44 if mo_files:
45 return _path.join(location, 'locale')
46
47 # del _path
48
49
50 locale.setlocale(locale.LC_ALL, '')
51 language, encoding = locale.getlocale()
52 del locale
53
54 _LOCALE_DOMAIN = _NAME.lower()
55 path = _find_locale_path(_LOCALE_DOMAIN)
56
57 _gettext.bindtextdomain(_LOCALE_DOMAIN, path)
58 _gettext.textdomain(_LOCALE_DOMAIN)
59 _gettext.install(_LOCALE_DOMAIN)
60
61 try:
62 unicode # noqa: F821
63 _ = lambda x: _gettext.gettext(x).decode('UTF-8')
64 ngettext = lambda *x: _gettext.ngettext(*x).decode('UTF-8')
65 except Exception:
66 _ = _gettext.gettext
67 ngettext = _gettext.ngettext
68
[end of lib/solaar/i18n.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/solaar/i18n.py b/lib/solaar/i18n.py
--- a/lib/solaar/i18n.py
+++ b/lib/solaar/i18n.py
@@ -47,7 +47,11 @@
# del _path
-locale.setlocale(locale.LC_ALL, '')
+try:
+ locale.setlocale(locale.LC_ALL, '')
+except Exception:
+ pass
+
language, encoding = locale.getlocale()
del locale
|
{"golden_diff": "diff --git a/lib/solaar/i18n.py b/lib/solaar/i18n.py\n--- a/lib/solaar/i18n.py\n+++ b/lib/solaar/i18n.py\n@@ -47,7 +47,11 @@\n # del _path\n \n \n-locale.setlocale(locale.LC_ALL, '')\n+try:\n+ locale.setlocale(locale.LC_ALL, '')\n+except Exception:\n+ pass\n+\n language, encoding = locale.getlocale()\n del locale\n", "issue": "locale.Error: unsupported locale setting exception when glibc locale files are not present\n**Information**\r\n- Solaar version: 1.0.3\r\n- Distribution: Fedora\r\n- Kernel version (ex. `uname -srmo`): `Linux 5.7.11-200.fc32.x86_64 x86_64 GNU/Linux`\r\n- Output of `solaar show`: N/A\r\n\r\n**Describe the bug**\r\nAny solaar invocation is failing with a traceback when locale.setlocale() call fails, e.g. due to missing glibc locale files for the currently set locale.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n```\r\n$ sudo dnf remove glibc-langpack-de\r\n$ export LC_ALL=de_CH.UTF-8\r\n$ export LANG=de_CH.UTF-8\r\n$ solaar --help\r\nTraceback (most recent call last):\r\n File \"/usr/bin/solaar\", line 59, in <module>\r\n import solaar.gtk\r\n File \"/usr/lib/python3.8/site-packages/solaar/gtk.py\", line 29, in <module>\r\n import solaar.i18n as _i18n\r\n File \"/usr/lib/python3.8/site-packages/solaar/i18n.py\", line 50, in <module>\r\n locale.setlocale(locale.LC_ALL, '')\r\n File \"/usr/lib64/python3.8/locale.py\", line 608, in setlocale\r\n return _setlocale(category, locale)\r\nlocale.Error: unsupported locale setting\r\n$ \r\n```\r\n\r\n**Additional context**\r\nLooks like #190 is still unfixed. Downstream bug report: https://bugzilla.redhat.com/show_bug.cgi?id=1811313 .\n", "before_files": [{"content": "# -*- python-mode -*-\n# -*- coding: UTF-8 -*-\n\n## Copyright (C) 2012-2013 Daniel Pavel\n##\n## This program is free software; you can redistribute it and/or modify\n## it under the terms of the GNU General Public License as published by\n## the Free Software Foundation; either version 2 of the License, or\n## (at your option) any later version.\n##\n## This program is distributed in the hope that it will be useful,\n## but WITHOUT ANY WARRANTY; without even the implied warranty of\n## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n## GNU General Public License for more details.\n##\n## You should have received a copy of the GNU General Public License along\n## with this program; if not, write to the Free Software Foundation, Inc.,\n## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport gettext as _gettext\nimport locale\n\nfrom solaar import NAME as _NAME\n\n#\n#\n#\n\n\ndef _find_locale_path(lc_domain):\n import os.path as _path\n\n import sys as _sys\n prefix_share = _path.normpath(_path.join(_path.realpath(_sys.path[0]), '..'))\n src_share = _path.normpath(_path.join(_path.realpath(_sys.path[0]), '..', 'share'))\n del _sys\n\n from glob import glob as _glob\n\n for location in prefix_share, src_share:\n mo_files = _glob(_path.join(location, 'locale', '*', 'LC_MESSAGES', lc_domain + '.mo'))\n if mo_files:\n return _path.join(location, 'locale')\n\n # del _path\n\n\nlocale.setlocale(locale.LC_ALL, '')\nlanguage, encoding = locale.getlocale()\ndel locale\n\n_LOCALE_DOMAIN = _NAME.lower()\npath = _find_locale_path(_LOCALE_DOMAIN)\n\n_gettext.bindtextdomain(_LOCALE_DOMAIN, path)\n_gettext.textdomain(_LOCALE_DOMAIN)\n_gettext.install(_LOCALE_DOMAIN)\n\ntry:\n unicode # noqa: F821\n _ = lambda x: _gettext.gettext(x).decode('UTF-8')\n ngettext = lambda *x: _gettext.ngettext(*x).decode('UTF-8')\nexcept Exception:\n _ = _gettext.gettext\n ngettext = _gettext.ngettext\n", "path": "lib/solaar/i18n.py"}]}
| 1,583 | 112 |
gh_patches_debug_8134
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-2257
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Shortly example cannot redirect to the expected link
**Bug**
In Shortly example, if I want to follow a short link with `http://127.0.0.1:5000/1`, the following error occurs:
```
Traceback (most recent call last):
File "/werkzeug/src/werkzeug/serving.py", line 319, in run_wsgi
execute(self.server.app)
File "/werkzeug/src/werkzeug/serving.py", line 308, in execute
application_iter = app(environ, start_response)
File "/werkzeug/examples/shortly/shortly.py", line 121, in __call__
return self.wsgi_app(environ, start_response)
File "/werkzeug/src/werkzeug/middleware/shared_data.py", line 287, in __call__
return self.app(environ, start_response)
File "/werkzeug/examples/shortly/shortly.py", line 117, in wsgi_app
response = self.dispatch_request(request)
File "/werkzeug/examples/shortly/shortly.py", line 109, in dispatch_request
return getattr(self, f"on_{endpoint}")(request, **values)
File "/werkzeug/examples/shortly/shortly.py", line 72, in on_follow_short_link
return redirect(link_target)
File "/werkzeug/src/werkzeug/utils.py", line 554, in redirect
display_location = html.escape(location)
File "/.pyenv/versions/3.8.10/lib/python3.8/html/__init__.py", line 19, in escape
s = s.replace("&", "&") # Must be done first!
TypeError: a bytes-like object is required, not 'str'
```
**Expected Behavior**
The browser should redirect to the link based on the short id.
**Reason**
redis-py package saves value as string but returns bytes by default. The `link_target` is bytes at the moment, but str is needed for `redirect` function
**Environment:**
- Python version: 3.8.10
- Werkzeug version: 2.0.1
- Redis-py version: 3.5.3
</issue>
<code>
[start of examples/shortly/shortly.py]
1 """A simple URL shortener using Werkzeug and redis."""
2 import os
3
4 import redis
5 from jinja2 import Environment
6 from jinja2 import FileSystemLoader
7 from werkzeug.exceptions import HTTPException
8 from werkzeug.exceptions import NotFound
9 from werkzeug.middleware.shared_data import SharedDataMiddleware
10 from werkzeug.routing import Map
11 from werkzeug.routing import Rule
12 from werkzeug.urls import url_parse
13 from werkzeug.utils import redirect
14 from werkzeug.wrappers import Request
15 from werkzeug.wrappers import Response
16
17
18 def base36_encode(number):
19 assert number >= 0, "positive integer required"
20 if number == 0:
21 return "0"
22 base36 = []
23 while number != 0:
24 number, i = divmod(number, 36)
25 base36.append("0123456789abcdefghijklmnopqrstuvwxyz"[i])
26 return "".join(reversed(base36))
27
28
29 def is_valid_url(url):
30 parts = url_parse(url)
31 return parts.scheme in ("http", "https")
32
33
34 def get_hostname(url):
35 return url_parse(url).netloc
36
37
38 class Shortly:
39 def __init__(self, config):
40 self.redis = redis.Redis(config["redis_host"], config["redis_port"])
41 template_path = os.path.join(os.path.dirname(__file__), "templates")
42 self.jinja_env = Environment(
43 loader=FileSystemLoader(template_path), autoescape=True
44 )
45 self.jinja_env.filters["hostname"] = get_hostname
46
47 self.url_map = Map(
48 [
49 Rule("/", endpoint="new_url"),
50 Rule("/<short_id>", endpoint="follow_short_link"),
51 Rule("/<short_id>+", endpoint="short_link_details"),
52 ]
53 )
54
55 def on_new_url(self, request):
56 error = None
57 url = ""
58 if request.method == "POST":
59 url = request.form["url"]
60 if not is_valid_url(url):
61 error = "Please enter a valid URL"
62 else:
63 short_id = self.insert_url(url)
64 return redirect(f"/{short_id}+")
65 return self.render_template("new_url.html", error=error, url=url)
66
67 def on_follow_short_link(self, request, short_id):
68 link_target = self.redis.get(f"url-target:{short_id}")
69 if link_target is None:
70 raise NotFound()
71 self.redis.incr(f"click-count:{short_id}")
72 return redirect(link_target)
73
74 def on_short_link_details(self, request, short_id):
75 link_target = self.redis.get(f"url-target:{short_id}")
76 if link_target is None:
77 raise NotFound()
78 click_count = int(self.redis.get(f"click-count:{short_id}") or 0)
79 return self.render_template(
80 "short_link_details.html",
81 link_target=link_target,
82 short_id=short_id,
83 click_count=click_count,
84 )
85
86 def error_404(self):
87 response = self.render_template("404.html")
88 response.status_code = 404
89 return response
90
91 def insert_url(self, url):
92 short_id = self.redis.get(f"reverse-url:{url}")
93 if short_id is not None:
94 return short_id
95 url_num = self.redis.incr("last-url-id")
96 short_id = base36_encode(url_num)
97 self.redis.set(f"url-target:{short_id}", url)
98 self.redis.set(f"reverse-url:{url}", short_id)
99 return short_id
100
101 def render_template(self, template_name, **context):
102 t = self.jinja_env.get_template(template_name)
103 return Response(t.render(context), mimetype="text/html")
104
105 def dispatch_request(self, request):
106 adapter = self.url_map.bind_to_environ(request.environ)
107 try:
108 endpoint, values = adapter.match()
109 return getattr(self, f"on_{endpoint}")(request, **values)
110 except NotFound:
111 return self.error_404()
112 except HTTPException as e:
113 return e
114
115 def wsgi_app(self, environ, start_response):
116 request = Request(environ)
117 response = self.dispatch_request(request)
118 return response(environ, start_response)
119
120 def __call__(self, environ, start_response):
121 return self.wsgi_app(environ, start_response)
122
123
124 def create_app(redis_host="localhost", redis_port=6379, with_static=True):
125 app = Shortly({"redis_host": redis_host, "redis_port": redis_port})
126 if with_static:
127 app.wsgi_app = SharedDataMiddleware(
128 app.wsgi_app, {"/static": os.path.join(os.path.dirname(__file__), "static")}
129 )
130 return app
131
132
133 if __name__ == "__main__":
134 from werkzeug.serving import run_simple
135
136 app = create_app()
137 run_simple("127.0.0.1", 5000, app, use_debugger=True, use_reloader=True)
138
[end of examples/shortly/shortly.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/shortly/shortly.py b/examples/shortly/shortly.py
--- a/examples/shortly/shortly.py
+++ b/examples/shortly/shortly.py
@@ -37,7 +37,9 @@
class Shortly:
def __init__(self, config):
- self.redis = redis.Redis(config["redis_host"], config["redis_port"])
+ self.redis = redis.Redis(
+ config["redis_host"], config["redis_port"], decode_responses=True
+ )
template_path = os.path.join(os.path.dirname(__file__), "templates")
self.jinja_env = Environment(
loader=FileSystemLoader(template_path), autoescape=True
|
{"golden_diff": "diff --git a/examples/shortly/shortly.py b/examples/shortly/shortly.py\n--- a/examples/shortly/shortly.py\n+++ b/examples/shortly/shortly.py\n@@ -37,7 +37,9 @@\n \n class Shortly:\n def __init__(self, config):\n- self.redis = redis.Redis(config[\"redis_host\"], config[\"redis_port\"])\n+ self.redis = redis.Redis(\n+ config[\"redis_host\"], config[\"redis_port\"], decode_responses=True\n+ )\n template_path = os.path.join(os.path.dirname(__file__), \"templates\")\n self.jinja_env = Environment(\n loader=FileSystemLoader(template_path), autoescape=True\n", "issue": "Shortly example cannot redirect to the expected link\n**Bug**\r\n\r\nIn Shortly example, if I want to follow a short link with `http://127.0.0.1:5000/1`, the following error occurs:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/werkzeug/src/werkzeug/serving.py\", line 319, in run_wsgi\r\n execute(self.server.app)\r\n File \"/werkzeug/src/werkzeug/serving.py\", line 308, in execute\r\n application_iter = app(environ, start_response)\r\n File \"/werkzeug/examples/shortly/shortly.py\", line 121, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/werkzeug/src/werkzeug/middleware/shared_data.py\", line 287, in __call__\r\n return self.app(environ, start_response)\r\n File \"/werkzeug/examples/shortly/shortly.py\", line 117, in wsgi_app\r\n response = self.dispatch_request(request)\r\n File \"/werkzeug/examples/shortly/shortly.py\", line 109, in dispatch_request\r\n return getattr(self, f\"on_{endpoint}\")(request, **values)\r\n File \"/werkzeug/examples/shortly/shortly.py\", line 72, in on_follow_short_link\r\n return redirect(link_target)\r\n File \"/werkzeug/src/werkzeug/utils.py\", line 554, in redirect\r\n display_location = html.escape(location)\r\n File \"/.pyenv/versions/3.8.10/lib/python3.8/html/__init__.py\", line 19, in escape\r\n s = s.replace(\"&\", \"&\") # Must be done first!\r\nTypeError: a bytes-like object is required, not 'str'\r\n```\r\n\r\n**Expected Behavior**\r\n\r\nThe browser should redirect to the link based on the short id.\r\n\r\n**Reason**\r\n\r\nredis-py package saves value as string but returns bytes by default. The `link_target` is bytes at the moment, but str is needed for `redirect` function\r\n\r\n**Environment:**\r\n\r\n- Python version: 3.8.10\r\n- Werkzeug version: 2.0.1\r\n- Redis-py version: 3.5.3\n", "before_files": [{"content": "\"\"\"A simple URL shortener using Werkzeug and redis.\"\"\"\nimport os\n\nimport redis\nfrom jinja2 import Environment\nfrom jinja2 import FileSystemLoader\nfrom werkzeug.exceptions import HTTPException\nfrom werkzeug.exceptions import NotFound\nfrom werkzeug.middleware.shared_data import SharedDataMiddleware\nfrom werkzeug.routing import Map\nfrom werkzeug.routing import Rule\nfrom werkzeug.urls import url_parse\nfrom werkzeug.utils import redirect\nfrom werkzeug.wrappers import Request\nfrom werkzeug.wrappers import Response\n\n\ndef base36_encode(number):\n assert number >= 0, \"positive integer required\"\n if number == 0:\n return \"0\"\n base36 = []\n while number != 0:\n number, i = divmod(number, 36)\n base36.append(\"0123456789abcdefghijklmnopqrstuvwxyz\"[i])\n return \"\".join(reversed(base36))\n\n\ndef is_valid_url(url):\n parts = url_parse(url)\n return parts.scheme in (\"http\", \"https\")\n\n\ndef get_hostname(url):\n return url_parse(url).netloc\n\n\nclass Shortly:\n def __init__(self, config):\n self.redis = redis.Redis(config[\"redis_host\"], config[\"redis_port\"])\n template_path = os.path.join(os.path.dirname(__file__), \"templates\")\n self.jinja_env = Environment(\n loader=FileSystemLoader(template_path), autoescape=True\n )\n self.jinja_env.filters[\"hostname\"] = get_hostname\n\n self.url_map = Map(\n [\n Rule(\"/\", endpoint=\"new_url\"),\n Rule(\"/<short_id>\", endpoint=\"follow_short_link\"),\n Rule(\"/<short_id>+\", endpoint=\"short_link_details\"),\n ]\n )\n\n def on_new_url(self, request):\n error = None\n url = \"\"\n if request.method == \"POST\":\n url = request.form[\"url\"]\n if not is_valid_url(url):\n error = \"Please enter a valid URL\"\n else:\n short_id = self.insert_url(url)\n return redirect(f\"/{short_id}+\")\n return self.render_template(\"new_url.html\", error=error, url=url)\n\n def on_follow_short_link(self, request, short_id):\n link_target = self.redis.get(f\"url-target:{short_id}\")\n if link_target is None:\n raise NotFound()\n self.redis.incr(f\"click-count:{short_id}\")\n return redirect(link_target)\n\n def on_short_link_details(self, request, short_id):\n link_target = self.redis.get(f\"url-target:{short_id}\")\n if link_target is None:\n raise NotFound()\n click_count = int(self.redis.get(f\"click-count:{short_id}\") or 0)\n return self.render_template(\n \"short_link_details.html\",\n link_target=link_target,\n short_id=short_id,\n click_count=click_count,\n )\n\n def error_404(self):\n response = self.render_template(\"404.html\")\n response.status_code = 404\n return response\n\n def insert_url(self, url):\n short_id = self.redis.get(f\"reverse-url:{url}\")\n if short_id is not None:\n return short_id\n url_num = self.redis.incr(\"last-url-id\")\n short_id = base36_encode(url_num)\n self.redis.set(f\"url-target:{short_id}\", url)\n self.redis.set(f\"reverse-url:{url}\", short_id)\n return short_id\n\n def render_template(self, template_name, **context):\n t = self.jinja_env.get_template(template_name)\n return Response(t.render(context), mimetype=\"text/html\")\n\n def dispatch_request(self, request):\n adapter = self.url_map.bind_to_environ(request.environ)\n try:\n endpoint, values = adapter.match()\n return getattr(self, f\"on_{endpoint}\")(request, **values)\n except NotFound:\n return self.error_404()\n except HTTPException as e:\n return e\n\n def wsgi_app(self, environ, start_response):\n request = Request(environ)\n response = self.dispatch_request(request)\n return response(environ, start_response)\n\n def __call__(self, environ, start_response):\n return self.wsgi_app(environ, start_response)\n\n\ndef create_app(redis_host=\"localhost\", redis_port=6379, with_static=True):\n app = Shortly({\"redis_host\": redis_host, \"redis_port\": redis_port})\n if with_static:\n app.wsgi_app = SharedDataMiddleware(\n app.wsgi_app, {\"/static\": os.path.join(os.path.dirname(__file__), \"static\")}\n )\n return app\n\n\nif __name__ == \"__main__\":\n from werkzeug.serving import run_simple\n\n app = create_app()\n run_simple(\"127.0.0.1\", 5000, app, use_debugger=True, use_reloader=True)\n", "path": "examples/shortly/shortly.py"}]}
| 2,396 | 149 |
gh_patches_debug_32615
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-446
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve documentation of view decorators
Explain what our view decorators are doing and add docstrings of the following format:
```
"""
[Summary]
:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]
:type [ParamName]: [ParamType](, optional)
...
:raises [ErrorType]: [ErrorDescription]
...
:return: [ReturnDescription]
:rtype: [ReturnType]
"""
```
Improve documentation of view decorators
Explain what our view decorators are doing and add docstrings of the following format:
```
"""
[Summary]
:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]
:type [ParamName]: [ParamType](, optional)
...
:raises [ErrorType]: [ErrorDescription]
...
:return: [ReturnDescription]
:rtype: [ReturnType]
"""
```
</issue>
<code>
[start of src/cms/decorators.py]
1 import time
2 from functools import wraps
3
4 from django.core.exceptions import PermissionDenied
5 from django.shortcuts import redirect
6
7 from .models import Region
8
9
10 def staff_required(function):
11 @wraps(function)
12 def wrap(request, *args, **kwargs):
13 user = request.user
14 # superusers and staff have access to this areas
15 if user.is_superuser or user.is_staff:
16 return function(request, *args, **kwargs)
17 raise PermissionDenied
18 return wrap
19
20
21 def region_permission_required(function):
22 @wraps(function)
23 def wrap(request, *args, **kwargs):
24 user = request.user
25 # superusers and staff have permissions for all regions
26 if user.is_superuser or user.is_staff:
27 return function(request, *args, **kwargs)
28 region = Region.get_current_region(request)
29 if region in user.profile.regions.all():
30 return function(request, *args, **kwargs)
31 raise PermissionDenied
32 return wrap
33
34 def modify_mfa_authenticated(function):
35 @wraps(function)
36 def wrap(request, *args, **kwargs):
37 if not 'modify_mfa_authentication_time' in request.session or request.session['modify_mfa_authentication_time'] < (time.time() - 5 * 60):
38 request.session['mfa_redirect_url'] = request.path
39 return redirect('user_settings_auth_modify_mfa')
40 return function(request, *args, **kwargs)
41 return wrap
42
[end of src/cms/decorators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cms/decorators.py b/src/cms/decorators.py
--- a/src/cms/decorators.py
+++ b/src/cms/decorators.py
@@ -1,3 +1,8 @@
+"""
+Django view decorators can be used to restrict the execution of a view function on certain conditions.
+
+For more information, see :doc:`topics/http/decorators`.
+"""
import time
from functools import wraps
@@ -8,6 +13,15 @@
def staff_required(function):
+ """
+ This decorator can be used to make sure a view can only be retrieved by users who are either staff or superusers.
+
+ :param function: The view function which should be protected
+ :type function: ~collections.abc.Callable
+
+ :return: The decorated function
+ :rtype: ~collections.abc.Callable
+ """
@wraps(function)
def wrap(request, *args, **kwargs):
user = request.user
@@ -19,6 +33,15 @@
def region_permission_required(function):
+ """
+ This decorator can be used to make sure a view can only be retrieved by users of the requested region.
+
+ :param function: The view function which should be protected
+ :type function: ~collections.abc.Callable
+
+ :return: The decorated function
+ :rtype: ~collections.abc.Callable
+ """
@wraps(function)
def wrap(request, *args, **kwargs):
user = request.user
@@ -32,6 +55,15 @@
return wrap
def modify_mfa_authenticated(function):
+ """
+ This decorator can be used to make sure a user can only modify his 2FA settings when he has a valid 2FA session.
+
+ :param function: The view function which should be protected
+ :type function: ~collections.abc.Callable
+
+ :return: The decorated function
+ :rtype: ~collections.abc.Callable
+ """
@wraps(function)
def wrap(request, *args, **kwargs):
if not 'modify_mfa_authentication_time' in request.session or request.session['modify_mfa_authentication_time'] < (time.time() - 5 * 60):
|
{"golden_diff": "diff --git a/src/cms/decorators.py b/src/cms/decorators.py\n--- a/src/cms/decorators.py\n+++ b/src/cms/decorators.py\n@@ -1,3 +1,8 @@\n+\"\"\"\n+Django view decorators can be used to restrict the execution of a view function on certain conditions.\n+\n+For more information, see :doc:`topics/http/decorators`.\n+\"\"\"\n import time\n from functools import wraps\n \n@@ -8,6 +13,15 @@\n \n \n def staff_required(function):\n+ \"\"\"\n+ This decorator can be used to make sure a view can only be retrieved by users who are either staff or superusers.\n+\n+ :param function: The view function which should be protected\n+ :type function: ~collections.abc.Callable\n+\n+ :return: The decorated function\n+ :rtype: ~collections.abc.Callable\n+ \"\"\"\n @wraps(function)\n def wrap(request, *args, **kwargs):\n user = request.user\n@@ -19,6 +33,15 @@\n \n \n def region_permission_required(function):\n+ \"\"\"\n+ This decorator can be used to make sure a view can only be retrieved by users of the requested region.\n+\n+ :param function: The view function which should be protected\n+ :type function: ~collections.abc.Callable\n+\n+ :return: The decorated function\n+ :rtype: ~collections.abc.Callable\n+ \"\"\"\n @wraps(function)\n def wrap(request, *args, **kwargs):\n user = request.user\n@@ -32,6 +55,15 @@\n return wrap\n \n def modify_mfa_authenticated(function):\n+ \"\"\"\n+ This decorator can be used to make sure a user can only modify his 2FA settings when he has a valid 2FA session.\n+\n+ :param function: The view function which should be protected\n+ :type function: ~collections.abc.Callable\n+\n+ :return: The decorated function\n+ :rtype: ~collections.abc.Callable\n+ \"\"\"\n @wraps(function)\n def wrap(request, *args, **kwargs):\n if not 'modify_mfa_authentication_time' in request.session or request.session['modify_mfa_authentication_time'] < (time.time() - 5 * 60):\n", "issue": "Improve documentation of view decorators\nExplain what our view decorators are doing and add docstrings of the following format:\r\n```\r\n\"\"\"\r\n[Summary]\r\n\r\n:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]\r\n:type [ParamName]: [ParamType](, optional)\r\n...\r\n:raises [ErrorType]: [ErrorDescription]\r\n...\r\n:return: [ReturnDescription]\r\n:rtype: [ReturnType]\r\n\"\"\"\r\n```\nImprove documentation of view decorators\nExplain what our view decorators are doing and add docstrings of the following format:\r\n```\r\n\"\"\"\r\n[Summary]\r\n\r\n:param [ParamName]: [ParamDescription], defaults to [DefaultParamVal]\r\n:type [ParamName]: [ParamType](, optional)\r\n...\r\n:raises [ErrorType]: [ErrorDescription]\r\n...\r\n:return: [ReturnDescription]\r\n:rtype: [ReturnType]\r\n\"\"\"\r\n```\n", "before_files": [{"content": "import time\nfrom functools import wraps\n\nfrom django.core.exceptions import PermissionDenied\nfrom django.shortcuts import redirect\n\nfrom .models import Region\n\n\ndef staff_required(function):\n @wraps(function)\n def wrap(request, *args, **kwargs):\n user = request.user\n # superusers and staff have access to this areas\n if user.is_superuser or user.is_staff:\n return function(request, *args, **kwargs)\n raise PermissionDenied\n return wrap\n\n\ndef region_permission_required(function):\n @wraps(function)\n def wrap(request, *args, **kwargs):\n user = request.user\n # superusers and staff have permissions for all regions\n if user.is_superuser or user.is_staff:\n return function(request, *args, **kwargs)\n region = Region.get_current_region(request)\n if region in user.profile.regions.all():\n return function(request, *args, **kwargs)\n raise PermissionDenied\n return wrap\n\ndef modify_mfa_authenticated(function):\n @wraps(function)\n def wrap(request, *args, **kwargs):\n if not 'modify_mfa_authentication_time' in request.session or request.session['modify_mfa_authentication_time'] < (time.time() - 5 * 60):\n request.session['mfa_redirect_url'] = request.path\n return redirect('user_settings_auth_modify_mfa')\n return function(request, *args, **kwargs)\n return wrap\n", "path": "src/cms/decorators.py"}]}
| 1,087 | 502 |
gh_patches_debug_23713
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-406
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: Active Learning agent not working with Scorer.model_output being a generator
We allow the `Scorer.model_output` to be a generator, as this is need for the huge memory sizes of segmentation:
https://github.com/lightly-ai/lightly/blob/ca83601cd72fde73ade02a156c213f0b0c07d034/lightly/active_learning/scorers/semantic_segmentation.py#L95-L97
In the `ActiveLearningAgent` it is checked if the length of the model output is as expected:
https://github.com/lightly-ai/lightly/blob/ca83601cd72fde73ade02a156c213f0b0c07d034/lightly/active_learning/agents/agent.py#L194-L196
However, this fails for generators: `TypeError: object of type 'generator' has no len()`
## Tasks
- [x] reproduce the error by creating a corresponding unittest
- [x] fix the error, e.g. by making the check on the values of the scores_dict, not on the model_output
</issue>
<code>
[start of lightly/active_learning/agents/agent.py]
1 from typing import *
2 import warnings
3
4 from lightly.active_learning.config.sampler_config import SamplerConfig
5 from lightly.active_learning.scorers.scorer import Scorer
6 from lightly.api.api_workflow_client import ApiWorkflowClient
7 from lightly.api.bitmask import BitMask
8 from lightly.openapi_generated.swagger_client.models import TagData
9
10
11 class ActiveLearningAgent:
12 """Interface for active learning queries.
13
14 Attributes:
15 api_workflow_client:
16 The client to connect to the api.
17 query_set:
18 Set of filenames corresponding to samples which can possibly be selected.
19 Set to all samples in the query tag or to the whole dataset by default.
20 labeled_set:
21 Set of filenames corresponding to samples in the labeled set.
22 Set to all samples in the preselected tag or to an empty list by default.
23 unlabeled_set:
24 Set of filenames corresponding to samples which are in the query set
25 but not in the labeled set.
26 added_set:
27 Set of filenames corresponding to samples which were added to the
28 labeled set in the last query.
29
30 Examples:
31 >>> # set the token and dataset id
32 >>> token = '123'
33 >>> dataset_id = 'XYZ'
34 >>>
35 >>> # create an active learning agent
36 >>> client = ApiWorkflowClient(token, dataset_id)
37 >>> agent = ActiveLearningAgent(client)
38 >>>
39 >>> # make an initial active learning query
40 >>> sampler_config = SamplerConfig(n_samples=100, name='initial-set')
41 >>> agent.query(sampler_config)
42 >>> initial_set = agent.labeled_set
43 >>>
44 >>> # train and evaluate a model on the initial set
45 >>> # make predictions on the query set:
46 >>> query_set = agent.query_set
47 >>> # important:
48 >>> # be sure to keep the order of the query set when you make predictions
49 >>>
50 >>> # create active learning scorer
51 >>> scorer = ScorerClassification(predictions)
52 >>>
53 >>> # make a second active learning query
54 >>> sampler_config = SamplerConfig(n_samples=200, name='second-set')
55 >>> agent.query(sampler_config, scorer)
56 >>> added_set = agent.added_set # access only the samples added by this query
57
58 """
59
60 def __init__(self,
61 api_workflow_client: ApiWorkflowClient,
62 query_tag_name: str = 'initial-tag',
63 preselected_tag_name: str = None):
64
65 self.api_workflow_client = api_workflow_client
66
67 # set the query_tag_id and preselected_tag_id
68 self._query_tag_id = None
69 self._preselected_tag_id = None
70
71 # build lookup table for tag_name to tag_id
72 tag_name_id_dict = {}
73 for tag in self.api_workflow_client._get_all_tags():
74 tag_name_id_dict[tag.name] = tag.id
75 # use lookup table to set ids
76 self._query_tag_id = tag_name_id_dict[query_tag_name]
77 if preselected_tag_name is not None:
78 self._preselected_tag_id = tag_name_id_dict[preselected_tag_name]
79
80 # set the filename lists based on preselected and query tag
81 self._query_tag_bitmask = self._get_query_tag_bitmask()
82 self._preselected_tag_bitmask = self._get_preselected_tag_bitmask()
83 # keep track of the last preselected tag to compute added samples
84 self._old_preselected_tag_bitmask = None
85
86
87 def _get_query_tag_bitmask(self):
88 """Initializes the query tag bitmask.
89
90 """
91 # get query tag from api and set bitmask accordingly
92 query_tag_data = self.api_workflow_client.tags_api.get_tag_by_tag_id(
93 self.api_workflow_client.dataset_id,
94 tag_id=self._query_tag_id
95 )
96 query_tag_bitmask = BitMask.from_hex(query_tag_data.bit_mask_data)
97
98 return query_tag_bitmask
99
100 def _get_preselected_tag_bitmask(self):
101 """Initializes the preselected tag bitmask.
102
103 """
104 if self._preselected_tag_id is None:
105 # if not specified, no samples belong to the preselected tag
106 preselected_tag_bitmask = BitMask.from_hex('0x0')
107 else:
108 # get preselected tag from api and set bitmask accordingly
109 preselected_tag_data = self.api_workflow_client.tags_api.get_tag_by_tag_id(
110 self.api_workflow_client.dataset_id,
111 tag_id=self._preselected_tag_id
112 )
113 preselected_tag_bitmask = BitMask.from_hex(preselected_tag_data.bit_mask_data)
114
115 return preselected_tag_bitmask
116
117 @property
118 def query_set(self):
119 """List of filenames for which to calculate active learning scores.
120
121 """
122 return self._query_tag_bitmask.masked_select_from_list(
123 self.api_workflow_client.filenames_on_server
124 )
125
126 @property
127 def labeled_set(self):
128 """List of filenames indicating selected samples.
129
130 """
131 return self._preselected_tag_bitmask.masked_select_from_list(
132 self.api_workflow_client.filenames_on_server
133 )
134
135 @property
136 def unlabeled_set(self):
137 """List of filenames which belong to the query set but are not selected.
138
139 """
140 # unlabeled set is the query set minus the preselected set
141 unlabeled_tag_bitmask = self._query_tag_bitmask - self._preselected_tag_bitmask
142 return unlabeled_tag_bitmask.masked_select_from_list(
143 self.api_workflow_client.filenames_on_server
144 )
145
146 @property
147 def added_set(self):
148 """List of filenames of newly added samples (in the last query).
149
150 Raises:
151 RuntimeError if executed before a query.
152
153 """
154 # the added set only exists after a query
155 if self._old_preselected_tag_bitmask is None:
156 raise RuntimeError('Cannot compute \"added set\" before querying.')
157 # added set is new preselected set minus the old one
158 added_tag_bitmask = self._preselected_tag_bitmask - self._old_preselected_tag_bitmask
159 return added_tag_bitmask.masked_select_from_list(
160 self.api_workflow_client.filenames_on_server
161 )
162
163
164 def query(self,
165 sampler_config: SamplerConfig,
166 al_scorer: Scorer = None) -> Tuple[List[str], List[str]]:
167 """Performs an active learning query.
168
169 After the query, the labeled set is updated to contain all selected samples,
170 the added set is recalculated as (new labeled set - old labeled set), and
171 the query set stays the same.
172
173 Args:
174 sampler_config:
175 The sampling configuration.
176 al_scorer:
177 An instance of a class inheriting from Scorer, e.g. a ClassificationScorer.
178
179 """
180
181 # handle illogical stopping condition
182 if sampler_config.n_samples < len(self.labeled_set):
183 warnings.warn(
184 f'ActiveLearningAgent.query: The number of samples ({sampler_config.n_samples}) is '
185 f'smaller than the number of preselected samples ({len(self.labeled_set)}).'
186 'Skipping the active learning query.'
187 )
188 return
189
190 # calculate active learning scores
191 scores_dict = None
192 if al_scorer is not None:
193 no_query_samples = len(self.query_set)
194 no_query_samples_with_scores = len(al_scorer.model_output)
195 if no_query_samples != no_query_samples_with_scores:
196 raise ValueError(
197 f'Number of query samples ({no_query_samples}) must match '
198 f'the number of predictions ({no_query_samples_with_scores})!'
199 )
200 scores_dict = al_scorer.calculate_scores()
201
202 # perform the sampling
203 new_tag_data = self.api_workflow_client.sampling(
204 sampler_config=sampler_config,
205 al_scores=scores_dict,
206 preselected_tag_id=self._preselected_tag_id,
207 query_tag_id=self._query_tag_id
208 )
209
210 # update the old preselected_tag
211 self._old_preselected_tag_bitmask = self._preselected_tag_bitmask
212 # set the newly chosen tag as the new preselected_tag
213 self._preselected_tag_id = new_tag_data.id
214 self._preselected_tag_bitmask = self._get_preselected_tag_bitmask()
215
[end of lightly/active_learning/agents/agent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightly/active_learning/agents/agent.py b/lightly/active_learning/agents/agent.py
--- a/lightly/active_learning/agents/agent.py
+++ b/lightly/active_learning/agents/agent.py
@@ -190,15 +190,19 @@
# calculate active learning scores
scores_dict = None
if al_scorer is not None:
- no_query_samples = len(self.query_set)
- no_query_samples_with_scores = len(al_scorer.model_output)
- if no_query_samples != no_query_samples_with_scores:
- raise ValueError(
- f'Number of query samples ({no_query_samples}) must match '
- f'the number of predictions ({no_query_samples_with_scores})!'
- )
scores_dict = al_scorer.calculate_scores()
+ # Check if the length of the query_set and each of the scores are the same
+ no_query_samples = len(self.query_set)
+ for score in scores_dict.values():
+ no_query_samples_with_scores = len(score)
+ if no_query_samples != no_query_samples_with_scores:
+ raise ValueError(
+ f'Number of query samples ({no_query_samples}) must match '
+ f'the number of predictions ({no_query_samples_with_scores})!'
+ )
+
+
# perform the sampling
new_tag_data = self.api_workflow_client.sampling(
sampler_config=sampler_config,
|
{"golden_diff": "diff --git a/lightly/active_learning/agents/agent.py b/lightly/active_learning/agents/agent.py\n--- a/lightly/active_learning/agents/agent.py\n+++ b/lightly/active_learning/agents/agent.py\n@@ -190,15 +190,19 @@\n # calculate active learning scores\n scores_dict = None\n if al_scorer is not None:\n- no_query_samples = len(self.query_set)\n- no_query_samples_with_scores = len(al_scorer.model_output)\n- if no_query_samples != no_query_samples_with_scores:\n- raise ValueError(\n- f'Number of query samples ({no_query_samples}) must match '\n- f'the number of predictions ({no_query_samples_with_scores})!'\n- )\n scores_dict = al_scorer.calculate_scores()\n \n+ # Check if the length of the query_set and each of the scores are the same\n+ no_query_samples = len(self.query_set)\n+ for score in scores_dict.values():\n+ no_query_samples_with_scores = len(score)\n+ if no_query_samples != no_query_samples_with_scores:\n+ raise ValueError(\n+ f'Number of query samples ({no_query_samples}) must match '\n+ f'the number of predictions ({no_query_samples_with_scores})!'\n+ )\n+\n+\n # perform the sampling\n new_tag_data = self.api_workflow_client.sampling(\n sampler_config=sampler_config,\n", "issue": "BUG: Active Learning agent not working with Scorer.model_output being a generator\nWe allow the `Scorer.model_output` to be a generator, as this is need for the huge memory sizes of segmentation:\r\nhttps://github.com/lightly-ai/lightly/blob/ca83601cd72fde73ade02a156c213f0b0c07d034/lightly/active_learning/scorers/semantic_segmentation.py#L95-L97\r\nIn the `ActiveLearningAgent` it is checked if the length of the model output is as expected:\r\nhttps://github.com/lightly-ai/lightly/blob/ca83601cd72fde73ade02a156c213f0b0c07d034/lightly/active_learning/agents/agent.py#L194-L196\r\n\r\nHowever, this fails for generators: `TypeError: object of type 'generator' has no len()`\r\n\r\n## Tasks\r\n\r\n- [x] reproduce the error by creating a corresponding unittest\r\n- [x] fix the error, e.g. by making the check on the values of the scores_dict, not on the model_output\r\n\r\n\n", "before_files": [{"content": "from typing import *\nimport warnings\n\nfrom lightly.active_learning.config.sampler_config import SamplerConfig\nfrom lightly.active_learning.scorers.scorer import Scorer\nfrom lightly.api.api_workflow_client import ApiWorkflowClient\nfrom lightly.api.bitmask import BitMask\nfrom lightly.openapi_generated.swagger_client.models import TagData\n\n\nclass ActiveLearningAgent:\n \"\"\"Interface for active learning queries.\n\n Attributes:\n api_workflow_client:\n The client to connect to the api.\n query_set:\n Set of filenames corresponding to samples which can possibly be selected.\n Set to all samples in the query tag or to the whole dataset by default.\n labeled_set:\n Set of filenames corresponding to samples in the labeled set.\n Set to all samples in the preselected tag or to an empty list by default.\n unlabeled_set:\n Set of filenames corresponding to samples which are in the query set\n but not in the labeled set.\n added_set:\n Set of filenames corresponding to samples which were added to the \n labeled set in the last query.\n\n Examples:\n >>> # set the token and dataset id\n >>> token = '123'\n >>> dataset_id = 'XYZ'\n >>>\n >>> # create an active learning agent\n >>> client = ApiWorkflowClient(token, dataset_id)\n >>> agent = ActiveLearningAgent(client)\n >>>\n >>> # make an initial active learning query\n >>> sampler_config = SamplerConfig(n_samples=100, name='initial-set')\n >>> agent.query(sampler_config)\n >>> initial_set = agent.labeled_set\n >>>\n >>> # train and evaluate a model on the initial set\n >>> # make predictions on the query set:\n >>> query_set = agent.query_set\n >>> # important:\n >>> # be sure to keep the order of the query set when you make predictions\n >>>\n >>> # create active learning scorer\n >>> scorer = ScorerClassification(predictions)\n >>>\n >>> # make a second active learning query\n >>> sampler_config = SamplerConfig(n_samples=200, name='second-set')\n >>> agent.query(sampler_config, scorer)\n >>> added_set = agent.added_set # access only the samples added by this query\n\n \"\"\"\n\n def __init__(self,\n api_workflow_client: ApiWorkflowClient,\n query_tag_name: str = 'initial-tag',\n preselected_tag_name: str = None):\n\n self.api_workflow_client = api_workflow_client\n\n # set the query_tag_id and preselected_tag_id\n self._query_tag_id = None\n self._preselected_tag_id = None\n\n # build lookup table for tag_name to tag_id\n tag_name_id_dict = {}\n for tag in self.api_workflow_client._get_all_tags():\n tag_name_id_dict[tag.name] = tag.id\n # use lookup table to set ids\n self._query_tag_id = tag_name_id_dict[query_tag_name]\n if preselected_tag_name is not None:\n self._preselected_tag_id = tag_name_id_dict[preselected_tag_name]\n\n # set the filename lists based on preselected and query tag\n self._query_tag_bitmask = self._get_query_tag_bitmask()\n self._preselected_tag_bitmask = self._get_preselected_tag_bitmask()\n # keep track of the last preselected tag to compute added samples\n self._old_preselected_tag_bitmask = None\n\n\n def _get_query_tag_bitmask(self):\n \"\"\"Initializes the query tag bitmask.\n\n \"\"\"\n # get query tag from api and set bitmask accordingly\n query_tag_data = self.api_workflow_client.tags_api.get_tag_by_tag_id(\n self.api_workflow_client.dataset_id,\n tag_id=self._query_tag_id\n )\n query_tag_bitmask = BitMask.from_hex(query_tag_data.bit_mask_data)\n\n return query_tag_bitmask\n\n def _get_preselected_tag_bitmask(self):\n \"\"\"Initializes the preselected tag bitmask.\n\n \"\"\"\n if self._preselected_tag_id is None:\n # if not specified, no samples belong to the preselected tag\n preselected_tag_bitmask = BitMask.from_hex('0x0')\n else:\n # get preselected tag from api and set bitmask accordingly\n preselected_tag_data = self.api_workflow_client.tags_api.get_tag_by_tag_id(\n self.api_workflow_client.dataset_id,\n tag_id=self._preselected_tag_id\n )\n preselected_tag_bitmask = BitMask.from_hex(preselected_tag_data.bit_mask_data)\n\n return preselected_tag_bitmask\n\n @property\n def query_set(self):\n \"\"\"List of filenames for which to calculate active learning scores.\n\n \"\"\"\n return self._query_tag_bitmask.masked_select_from_list(\n self.api_workflow_client.filenames_on_server\n )\n\n @property\n def labeled_set(self):\n \"\"\"List of filenames indicating selected samples.\n\n \"\"\"\n return self._preselected_tag_bitmask.masked_select_from_list(\n self.api_workflow_client.filenames_on_server\n )\n\n @property\n def unlabeled_set(self):\n \"\"\"List of filenames which belong to the query set but are not selected.\n\n \"\"\"\n # unlabeled set is the query set minus the preselected set\n unlabeled_tag_bitmask = self._query_tag_bitmask - self._preselected_tag_bitmask\n return unlabeled_tag_bitmask.masked_select_from_list(\n self.api_workflow_client.filenames_on_server\n )\n\n @property\n def added_set(self):\n \"\"\"List of filenames of newly added samples (in the last query).\n\n Raises:\n RuntimeError if executed before a query.\n\n \"\"\"\n # the added set only exists after a query\n if self._old_preselected_tag_bitmask is None:\n raise RuntimeError('Cannot compute \\\"added set\\\" before querying.')\n # added set is new preselected set minus the old one\n added_tag_bitmask = self._preselected_tag_bitmask - self._old_preselected_tag_bitmask\n return added_tag_bitmask.masked_select_from_list(\n self.api_workflow_client.filenames_on_server\n )\n\n\n def query(self,\n sampler_config: SamplerConfig,\n al_scorer: Scorer = None) -> Tuple[List[str], List[str]]:\n \"\"\"Performs an active learning query.\n\n After the query, the labeled set is updated to contain all selected samples,\n the added set is recalculated as (new labeled set - old labeled set), and\n the query set stays the same.\n\n Args:\n sampler_config:\n The sampling configuration.\n al_scorer:\n An instance of a class inheriting from Scorer, e.g. a ClassificationScorer.\n\n \"\"\"\n\n # handle illogical stopping condition\n if sampler_config.n_samples < len(self.labeled_set):\n warnings.warn(\n f'ActiveLearningAgent.query: The number of samples ({sampler_config.n_samples}) is '\n f'smaller than the number of preselected samples ({len(self.labeled_set)}).'\n 'Skipping the active learning query.'\n )\n return\n\n # calculate active learning scores\n scores_dict = None\n if al_scorer is not None:\n no_query_samples = len(self.query_set)\n no_query_samples_with_scores = len(al_scorer.model_output)\n if no_query_samples != no_query_samples_with_scores:\n raise ValueError(\n f'Number of query samples ({no_query_samples}) must match '\n f'the number of predictions ({no_query_samples_with_scores})!'\n )\n scores_dict = al_scorer.calculate_scores()\n\n # perform the sampling\n new_tag_data = self.api_workflow_client.sampling(\n sampler_config=sampler_config,\n al_scores=scores_dict,\n preselected_tag_id=self._preselected_tag_id,\n query_tag_id=self._query_tag_id\n )\n\n # update the old preselected_tag\n self._old_preselected_tag_bitmask = self._preselected_tag_bitmask\n # set the newly chosen tag as the new preselected_tag\n self._preselected_tag_id = new_tag_data.id\n self._preselected_tag_bitmask = self._get_preselected_tag_bitmask()\n", "path": "lightly/active_learning/agents/agent.py"}]}
| 3,102 | 314 |
gh_patches_debug_15148
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1977
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FIX #565 (Import for apollo tracing extension requires telemetry)
## Description
FIX #565
## Types of Changes
<!--- What types of changes does your pull request introduce? Put an `x` in all the boxes that apply. -->
- [ ] Core
- [x] Bugfix
- [ ] New feature
- [ ] Enhancement/optimization
- [ ] Documentation
## Issues Fixed or Closed by This PR
* #565
## Checklist
<!--- Go over all the following points, and put an `x` in all the boxes that apply. -->
<!--- If you're unsure about any of these, don't hesitate to ask. We're here to help! -->
- [x] My code follows the code style of this project.
- [ ] My change requires a change to the documentation.
- [ ] I have updated the documentation accordingly.
- [x] I have read the CONTRIBUTING document.
- [ ] I have added tests to cover my changes.
- [x] I have tested the changes and verified that they work and don't break anything (as well as I can manage).
</issue>
<code>
[start of strawberry/extensions/tracing/__init__.py]
1 from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa
2 from .opentelemetry import OpenTelemetryExtension, OpenTelemetryExtensionSync # noqa
3
[end of strawberry/extensions/tracing/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/extensions/tracing/__init__.py b/strawberry/extensions/tracing/__init__.py
--- a/strawberry/extensions/tracing/__init__.py
+++ b/strawberry/extensions/tracing/__init__.py
@@ -1,2 +1,27 @@
-from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa
-from .opentelemetry import OpenTelemetryExtension, OpenTelemetryExtensionSync # noqa
+import importlib
+from typing import TYPE_CHECKING
+
+
+if TYPE_CHECKING:
+ from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa
+ from .opentelemetry import ( # noqa
+ OpenTelemetryExtension,
+ OpenTelemetryExtensionSync,
+ )
+
+__all__ = [
+ "ApolloTracingExtension",
+ "ApolloTracingExtensionSync",
+ "OpenTelemetryExtension",
+ "OpenTelemetryExtensionSync",
+]
+
+
+def __getattr__(name: str):
+ if name in {"ApolloTracingExtension", "ApolloTracingExtensionSync"}:
+ return getattr(importlib.import_module(".apollo", __name__), name)
+
+ if name in {"OpenTelemetryExtension", "OpenTelemetryExtensionSync"}:
+ return getattr(importlib.import_module(".opentelemetry", __name__), name)
+
+ raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
|
{"golden_diff": "diff --git a/strawberry/extensions/tracing/__init__.py b/strawberry/extensions/tracing/__init__.py\n--- a/strawberry/extensions/tracing/__init__.py\n+++ b/strawberry/extensions/tracing/__init__.py\n@@ -1,2 +1,27 @@\n-from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa\n-from .opentelemetry import OpenTelemetryExtension, OpenTelemetryExtensionSync # noqa\n+import importlib\n+from typing import TYPE_CHECKING\n+\n+\n+if TYPE_CHECKING:\n+ from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa\n+ from .opentelemetry import ( # noqa\n+ OpenTelemetryExtension,\n+ OpenTelemetryExtensionSync,\n+ )\n+\n+__all__ = [\n+ \"ApolloTracingExtension\",\n+ \"ApolloTracingExtensionSync\",\n+ \"OpenTelemetryExtension\",\n+ \"OpenTelemetryExtensionSync\",\n+]\n+\n+\n+def __getattr__(name: str):\n+ if name in {\"ApolloTracingExtension\", \"ApolloTracingExtensionSync\"}:\n+ return getattr(importlib.import_module(\".apollo\", __name__), name)\n+\n+ if name in {\"OpenTelemetryExtension\", \"OpenTelemetryExtensionSync\"}:\n+ return getattr(importlib.import_module(\".opentelemetry\", __name__), name)\n+\n+ raise AttributeError(f\"module {__name__!r} has no attribute {name!r}\")\n", "issue": "FIX #565 (Import for apollo tracing extension requires telemetry)\n## Description\r\n\r\nFIX #565 \r\n\r\n## Types of Changes\r\n\r\n<!--- What types of changes does your pull request introduce? Put an `x` in all the boxes that apply. -->\r\n- [ ] Core\r\n- [x] Bugfix\r\n- [ ] New feature\r\n- [ ] Enhancement/optimization\r\n- [ ] Documentation\r\n\r\n## Issues Fixed or Closed by This PR\r\n\r\n* #565 \r\n\r\n## Checklist\r\n\r\n<!--- Go over all the following points, and put an `x` in all the boxes that apply. -->\r\n<!--- If you're unsure about any of these, don't hesitate to ask. We're here to help! -->\r\n- [x] My code follows the code style of this project.\r\n- [ ] My change requires a change to the documentation.\r\n- [ ] I have updated the documentation accordingly.\r\n- [x] I have read the CONTRIBUTING document.\r\n- [ ] I have added tests to cover my changes.\r\n- [x] I have tested the changes and verified that they work and don't break anything (as well as I can manage).\r\n\n", "before_files": [{"content": "from .apollo import ApolloTracingExtension, ApolloTracingExtensionSync # noqa\nfrom .opentelemetry import OpenTelemetryExtension, OpenTelemetryExtensionSync # noqa\n", "path": "strawberry/extensions/tracing/__init__.py"}]}
| 821 | 327 |
gh_patches_debug_35676
|
rasdani/github-patches
|
git_diff
|
pytorch__examples-228
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
VAE loss
According to the expression in line 95, the KL-divergence term is calculated from
`0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)`
but I think the code in line 96-97 represents
`0.5 * sum(1 + log(sigma^2) - mu^2 - sigma)`
This might not be essential because whether the last term is squared or not, the loss descending behavior stays unchanged.
</issue>
<code>
[start of vae/main.py]
1 from __future__ import print_function
2 import argparse
3 import torch
4 import torch.utils.data
5 from torch import nn, optim
6 from torch.autograd import Variable
7 from torchvision import datasets, transforms
8 from torchvision.utils import save_image
9
10
11 parser = argparse.ArgumentParser(description='VAE MNIST Example')
12 parser.add_argument('--batch-size', type=int, default=128, metavar='N',
13 help='input batch size for training (default: 128)')
14 parser.add_argument('--epochs', type=int, default=10, metavar='N',
15 help='number of epochs to train (default: 10)')
16 parser.add_argument('--no-cuda', action='store_true', default=False,
17 help='enables CUDA training')
18 parser.add_argument('--seed', type=int, default=1, metavar='S',
19 help='random seed (default: 1)')
20 parser.add_argument('--log-interval', type=int, default=10, metavar='N',
21 help='how many batches to wait before logging training status')
22 args = parser.parse_args()
23 args.cuda = not args.no_cuda and torch.cuda.is_available()
24
25
26 torch.manual_seed(args.seed)
27 if args.cuda:
28 torch.cuda.manual_seed(args.seed)
29
30
31 kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
32 train_loader = torch.utils.data.DataLoader(
33 datasets.MNIST('../data', train=True, download=True,
34 transform=transforms.ToTensor()),
35 batch_size=args.batch_size, shuffle=True, **kwargs)
36 test_loader = torch.utils.data.DataLoader(
37 datasets.MNIST('../data', train=False, transform=transforms.ToTensor()),
38 batch_size=args.batch_size, shuffle=True, **kwargs)
39
40
41 class VAE(nn.Module):
42 def __init__(self):
43 super(VAE, self).__init__()
44
45 self.fc1 = nn.Linear(784, 400)
46 self.fc21 = nn.Linear(400, 20)
47 self.fc22 = nn.Linear(400, 20)
48 self.fc3 = nn.Linear(20, 400)
49 self.fc4 = nn.Linear(400, 784)
50
51 self.relu = nn.ReLU()
52 self.sigmoid = nn.Sigmoid()
53
54 def encode(self, x):
55 h1 = self.relu(self.fc1(x))
56 return self.fc21(h1), self.fc22(h1)
57
58 def reparameterize(self, mu, logvar):
59 if self.training:
60 std = logvar.mul(0.5).exp_()
61 eps = Variable(std.data.new(std.size()).normal_())
62 return eps.mul(std).add_(mu)
63 else:
64 return mu
65
66 def decode(self, z):
67 h3 = self.relu(self.fc3(z))
68 return self.sigmoid(self.fc4(h3))
69
70 def forward(self, x):
71 mu, logvar = self.encode(x.view(-1, 784))
72 z = self.reparameterize(mu, logvar)
73 return self.decode(z), mu, logvar
74
75
76 model = VAE()
77 if args.cuda:
78 model.cuda()
79
80 reconstruction_function = nn.BCELoss()
81
82
83 def loss_function(recon_x, x, mu, logvar):
84 BCE = reconstruction_function(recon_x, x.view(-1, 784))
85
86 # see Appendix B from VAE paper:
87 # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
88 # https://arxiv.org/abs/1312.6114
89 # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
90 KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
91 KLD = torch.sum(KLD_element).mul_(-0.5)
92 # Normalise by same number of elements as in reconstruction
93 KLD /= args.batch_size * 784
94
95 return BCE + KLD
96
97
98 optimizer = optim.Adam(model.parameters(), lr=1e-3)
99
100
101 def train(epoch):
102 model.train()
103 train_loss = 0
104 for batch_idx, (data, _) in enumerate(train_loader):
105 data = Variable(data)
106 if args.cuda:
107 data = data.cuda()
108 optimizer.zero_grad()
109 recon_batch, mu, logvar = model(data)
110 loss = loss_function(recon_batch, data, mu, logvar)
111 loss.backward()
112 train_loss += loss.data[0]
113 optimizer.step()
114 if batch_idx % args.log_interval == 0:
115 print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
116 epoch, batch_idx * len(data), len(train_loader.dataset),
117 100. * batch_idx / len(train_loader),
118 loss.data[0] / len(data)))
119
120 print('====> Epoch: {} Average loss: {:.4f}'.format(
121 epoch, train_loss / len(train_loader.dataset)))
122
123
124 def test(epoch):
125 model.eval()
126 test_loss = 0
127 for i, (data, _) in enumerate(test_loader):
128 if args.cuda:
129 data = data.cuda()
130 data = Variable(data, volatile=True)
131 recon_batch, mu, logvar = model(data)
132 test_loss += loss_function(recon_batch, data, mu, logvar).data[0]
133 if i == 0:
134 save_image(recon_batch.data.cpu().view(args.batch_size, 1, 28, 28),
135 'reconstruction_' + str(epoch) + '.png')
136
137 test_loss /= len(test_loader.dataset)
138 print('====> Test set loss: {:.4f}'.format(test_loss))
139
140
141 for epoch in range(1, args.epochs + 1):
142 train(epoch)
143 test(epoch)
144 sample = Variable(torch.randn(64, 20))
145 if args.cuda:
146 sample = sample.cuda()
147 sample = model.decode(sample).cpu()
148 save_image(sample.data.view(64, 1, 28, 28), 'sample_' + str(epoch) + '.png')
149
[end of vae/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vae/main.py b/vae/main.py
--- a/vae/main.py
+++ b/vae/main.py
@@ -4,6 +4,7 @@
import torch.utils.data
from torch import nn, optim
from torch.autograd import Variable
+from torch.nn import functional as F
from torchvision import datasets, transforms
from torchvision.utils import save_image
@@ -77,18 +78,15 @@
if args.cuda:
model.cuda()
-reconstruction_function = nn.BCELoss()
-
def loss_function(recon_x, x, mu, logvar):
- BCE = reconstruction_function(recon_x, x.view(-1, 784))
+ BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784))
# see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
- KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
- KLD = torch.sum(KLD_element).mul_(-0.5)
+ KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
# Normalise by same number of elements as in reconstruction
KLD /= args.batch_size * 784
@@ -131,8 +129,11 @@
recon_batch, mu, logvar = model(data)
test_loss += loss_function(recon_batch, data, mu, logvar).data[0]
if i == 0:
- save_image(recon_batch.data.cpu().view(args.batch_size, 1, 28, 28),
- 'reconstruction_' + str(epoch) + '.png')
+ n = min(data.size(0), 8)
+ comparison = torch.cat([data[:n],
+ recon_batch.view(args.batch_size, 1, 28, 28)[:n]])
+ save_image(comparison.data.cpu(),
+ 'results/reconstruction_' + str(epoch) + '.png', nrow=n)
test_loss /= len(test_loader.dataset)
print('====> Test set loss: {:.4f}'.format(test_loss))
@@ -145,4 +146,5 @@
if args.cuda:
sample = sample.cuda()
sample = model.decode(sample).cpu()
- save_image(sample.data.view(64, 1, 28, 28), 'sample_' + str(epoch) + '.png')
+ save_image(sample.data.view(64, 1, 28, 28),
+ 'results/sample_' + str(epoch) + '.png')
|
{"golden_diff": "diff --git a/vae/main.py b/vae/main.py\n--- a/vae/main.py\n+++ b/vae/main.py\n@@ -4,6 +4,7 @@\n import torch.utils.data\n from torch import nn, optim\n from torch.autograd import Variable\n+from torch.nn import functional as F\n from torchvision import datasets, transforms\n from torchvision.utils import save_image\n \n@@ -77,18 +78,15 @@\n if args.cuda:\n model.cuda()\n \n-reconstruction_function = nn.BCELoss()\n-\n \n def loss_function(recon_x, x, mu, logvar):\n- BCE = reconstruction_function(recon_x, x.view(-1, 784))\n+ BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784))\n \n # see Appendix B from VAE paper:\n # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014\n # https://arxiv.org/abs/1312.6114\n # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)\n- KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)\n- KLD = torch.sum(KLD_element).mul_(-0.5)\n+ KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())\n # Normalise by same number of elements as in reconstruction\n KLD /= args.batch_size * 784\n \n@@ -131,8 +129,11 @@\n recon_batch, mu, logvar = model(data)\n test_loss += loss_function(recon_batch, data, mu, logvar).data[0]\n if i == 0:\n- save_image(recon_batch.data.cpu().view(args.batch_size, 1, 28, 28),\n- 'reconstruction_' + str(epoch) + '.png')\n+ n = min(data.size(0), 8)\n+ comparison = torch.cat([data[:n],\n+ recon_batch.view(args.batch_size, 1, 28, 28)[:n]])\n+ save_image(comparison.data.cpu(),\n+ 'results/reconstruction_' + str(epoch) + '.png', nrow=n)\n \n test_loss /= len(test_loader.dataset)\n print('====> Test set loss: {:.4f}'.format(test_loss))\n@@ -145,4 +146,5 @@\n if args.cuda:\n sample = sample.cuda()\n sample = model.decode(sample).cpu()\n- save_image(sample.data.view(64, 1, 28, 28), 'sample_' + str(epoch) + '.png')\n+ save_image(sample.data.view(64, 1, 28, 28),\n+ 'results/sample_' + str(epoch) + '.png')\n", "issue": "VAE loss\nAccording to the expression in line 95, the KL-divergence term is calculated from\r\n`0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)`\r\nbut I think the code in line 96-97 represents\r\n`0.5 * sum(1 + log(sigma^2) - mu^2 - sigma)`\r\n\r\nThis might not be essential because whether the last term is squared or not, the loss descending behavior stays unchanged.\n", "before_files": [{"content": "from __future__ import print_function\nimport argparse\nimport torch\nimport torch.utils.data\nfrom torch import nn, optim\nfrom torch.autograd import Variable\nfrom torchvision import datasets, transforms\nfrom torchvision.utils import save_image\n\n\nparser = argparse.ArgumentParser(description='VAE MNIST Example')\nparser.add_argument('--batch-size', type=int, default=128, metavar='N',\n help='input batch size for training (default: 128)')\nparser.add_argument('--epochs', type=int, default=10, metavar='N',\n help='number of epochs to train (default: 10)')\nparser.add_argument('--no-cuda', action='store_true', default=False,\n help='enables CUDA training')\nparser.add_argument('--seed', type=int, default=1, metavar='S',\n help='random seed (default: 1)')\nparser.add_argument('--log-interval', type=int, default=10, metavar='N',\n help='how many batches to wait before logging training status')\nargs = parser.parse_args()\nargs.cuda = not args.no_cuda and torch.cuda.is_available()\n\n\ntorch.manual_seed(args.seed)\nif args.cuda:\n torch.cuda.manual_seed(args.seed)\n\n\nkwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}\ntrain_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=True, download=True,\n transform=transforms.ToTensor()),\n batch_size=args.batch_size, shuffle=True, **kwargs)\ntest_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=False, transform=transforms.ToTensor()),\n batch_size=args.batch_size, shuffle=True, **kwargs)\n\n\nclass VAE(nn.Module):\n def __init__(self):\n super(VAE, self).__init__()\n\n self.fc1 = nn.Linear(784, 400)\n self.fc21 = nn.Linear(400, 20)\n self.fc22 = nn.Linear(400, 20)\n self.fc3 = nn.Linear(20, 400)\n self.fc4 = nn.Linear(400, 784)\n\n self.relu = nn.ReLU()\n self.sigmoid = nn.Sigmoid()\n\n def encode(self, x):\n h1 = self.relu(self.fc1(x))\n return self.fc21(h1), self.fc22(h1)\n\n def reparameterize(self, mu, logvar):\n if self.training:\n std = logvar.mul(0.5).exp_()\n eps = Variable(std.data.new(std.size()).normal_())\n return eps.mul(std).add_(mu)\n else:\n return mu\n\n def decode(self, z):\n h3 = self.relu(self.fc3(z))\n return self.sigmoid(self.fc4(h3))\n\n def forward(self, x):\n mu, logvar = self.encode(x.view(-1, 784))\n z = self.reparameterize(mu, logvar)\n return self.decode(z), mu, logvar\n\n\nmodel = VAE()\nif args.cuda:\n model.cuda()\n\nreconstruction_function = nn.BCELoss()\n\n\ndef loss_function(recon_x, x, mu, logvar):\n BCE = reconstruction_function(recon_x, x.view(-1, 784))\n\n # see Appendix B from VAE paper:\n # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014\n # https://arxiv.org/abs/1312.6114\n # 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)\n KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)\n KLD = torch.sum(KLD_element).mul_(-0.5)\n # Normalise by same number of elements as in reconstruction\n KLD /= args.batch_size * 784\n\n return BCE + KLD\n\n\noptimizer = optim.Adam(model.parameters(), lr=1e-3)\n\n\ndef train(epoch):\n model.train()\n train_loss = 0\n for batch_idx, (data, _) in enumerate(train_loader):\n data = Variable(data)\n if args.cuda:\n data = data.cuda()\n optimizer.zero_grad()\n recon_batch, mu, logvar = model(data)\n loss = loss_function(recon_batch, data, mu, logvar)\n loss.backward()\n train_loss += loss.data[0]\n optimizer.step()\n if batch_idx % args.log_interval == 0:\n print('Train Epoch: {} [{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(\n epoch, batch_idx * len(data), len(train_loader.dataset),\n 100. * batch_idx / len(train_loader),\n loss.data[0] / len(data)))\n\n print('====> Epoch: {} Average loss: {:.4f}'.format(\n epoch, train_loss / len(train_loader.dataset)))\n\n\ndef test(epoch):\n model.eval()\n test_loss = 0\n for i, (data, _) in enumerate(test_loader):\n if args.cuda:\n data = data.cuda()\n data = Variable(data, volatile=True)\n recon_batch, mu, logvar = model(data)\n test_loss += loss_function(recon_batch, data, mu, logvar).data[0]\n if i == 0:\n save_image(recon_batch.data.cpu().view(args.batch_size, 1, 28, 28),\n 'reconstruction_' + str(epoch) + '.png')\n\n test_loss /= len(test_loader.dataset)\n print('====> Test set loss: {:.4f}'.format(test_loss))\n\n\nfor epoch in range(1, args.epochs + 1):\n train(epoch)\n test(epoch)\n sample = Variable(torch.randn(64, 20))\n if args.cuda:\n sample = sample.cuda()\n sample = model.decode(sample).cpu()\n save_image(sample.data.view(64, 1, 28, 28), 'sample_' + str(epoch) + '.png')\n", "path": "vae/main.py"}]}
| 2,320 | 652 |
gh_patches_debug_523
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-2217
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Streamlit fails to start without Git executable
# Summary
Streamlit version `0.69.1` fails to start when run inside a Docker container that doesn't have Git installed.
# Steps to reproduce
1. Create a `Dockerfile` with the following contents:
```dockerfile
FROM python:3.8-slim
RUN pip install streamlit
CMD ["streamlit", "hello"]
```
2. Build the image:
```bash
docker build -t demo .
```
3. Run the app:
```bash
docker run -it --rm demo
```
## Expected behavior:
Streamlit starts without issues.
## Actual behavior:
Streamlit fails to start and displays the following error message:
```bash
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/git/__init__.py", line 83, in <module>
refresh()
File "/usr/local/lib/python3.8/site-packages/git/__init__.py", line 73, in refresh
if not Git.refresh(path=path):
File "/usr/local/lib/python3.8/site-packages/git/cmd.py", line 278, in refresh
raise ImportError(err)
ImportError: Bad git executable.
The git executable must be specified in one of the following ways:
- be included in your $PATH
- be set via $GIT_PYTHON_GIT_EXECUTABLE
- explicitly set via git.refresh()
All git commands will error until this is rectified.
This initial warning can be silenced or aggravated in the future by setting the
$GIT_PYTHON_REFRESH environment variable. Use one of the following values:
- quiet|q|silence|s|none|n|0: for no warning or exception
- warn|w|warning|1: for a printed warning
- error|e|raise|r|2: for a raised exception
Example:
export GIT_PYTHON_REFRESH=quiet
```
## Is this a regression?
**yes** (worked up until at least version `0.67.1`)
# Debug info
- Streamlit version: `0.69.1`
- Python version: `3.8.6`
- Using Conda? PipEnv? PyEnv? Pex? **NO**
- OS version: `4.19.76-linuxkit`
# Additional information
This bug can be worked around by setting `GIT_PYTHON_REFRESH=quiet` environment variable inside the Docker image.
</issue>
<code>
[start of lib/setup.py]
1 import os
2 import platform
3 import setuptools
4 import subprocess
5 import sys
6
7 from pipenv.project import Project
8 from pipenv.utils import convert_deps_to_pip
9 from setuptools.command.install import install
10
11 VERSION = "0.69.1" # PEP-440
12
13 NAME = "streamlit"
14
15 DESCRIPTION = "The fastest way to build data apps in Python"
16
17 LONG_DESCRIPTION = (
18 "Streamlit's open-source app framework is the easiest way "
19 "for data scientists and machine learning engineers to "
20 "create beautiful, performant apps in only a few hours! "
21 "All in pure Python. All for free."
22 )
23
24 pipfile = Project(chdir=False).parsed_pipfile
25
26 packages = pipfile["packages"].copy()
27 requirements = convert_deps_to_pip(packages, r=False)
28
29 # Check whether xcode tools are available before making watchdog a
30 # dependency (only if the current system is a Mac).
31 if platform.system() == "Darwin":
32 has_xcode = subprocess.call(["xcode-select", "--version"], shell=False) == 0
33 has_gcc = subprocess.call(["gcc", "--version"], shell=False) == 0
34
35 if not (has_xcode and has_gcc):
36 try:
37 requirements.remove("watchdog")
38 except ValueError:
39 pass
40
41
42 class VerifyVersionCommand(install):
43 """Custom command to verify that the git tag matches our version"""
44
45 description = "verify that the git tag matches our version"
46
47 def run(self):
48 tag = os.getenv("CIRCLE_TAG")
49
50 if tag != VERSION:
51 info = "Git tag: {0} does not match the version of this app: {1}".format(
52 tag, VERSION
53 )
54 sys.exit(info)
55
56
57 setuptools.setup(
58 name=NAME,
59 version=VERSION,
60 description=DESCRIPTION,
61 long_description=LONG_DESCRIPTION,
62 url="https://streamlit.io",
63 author="Streamlit Inc",
64 author_email="[email protected]",
65 python_requires=">=3.6",
66 license="Apache 2",
67 packages=setuptools.find_packages(exclude=["tests", "tests.*"]),
68 # Requirements
69 install_requires=requirements,
70 zip_safe=False, # install source files not egg
71 include_package_data=True, # copy html and friends
72 entry_points={"console_scripts": ["streamlit = streamlit.cli:main"]},
73 # For Windows so that streamlit * commands work ie.
74 # - streamlit version
75 # - streamlit hello
76 scripts=["bin/streamlit.cmd"],
77 cmdclass={
78 "verify": VerifyVersionCommand,
79 },
80 )
81
[end of lib/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/setup.py b/lib/setup.py
--- a/lib/setup.py
+++ b/lib/setup.py
@@ -8,7 +8,7 @@
from pipenv.utils import convert_deps_to_pip
from setuptools.command.install import install
-VERSION = "0.69.1" # PEP-440
+VERSION = "0.69.2" # PEP-440
NAME = "streamlit"
|
{"golden_diff": "diff --git a/lib/setup.py b/lib/setup.py\n--- a/lib/setup.py\n+++ b/lib/setup.py\n@@ -8,7 +8,7 @@\n from pipenv.utils import convert_deps_to_pip\n from setuptools.command.install import install\n \n-VERSION = \"0.69.1\" # PEP-440\n+VERSION = \"0.69.2\" # PEP-440\n \n NAME = \"streamlit\"\n", "issue": "Streamlit fails to start without Git executable\n# Summary\r\n\r\nStreamlit version `0.69.1` fails to start when run inside a Docker container that doesn't have Git installed.\r\n\r\n# Steps to reproduce\r\n\r\n1. Create a `Dockerfile` with the following contents:\r\n```dockerfile\r\nFROM python:3.8-slim\r\nRUN pip install streamlit\r\nCMD [\"streamlit\", \"hello\"]\r\n```\r\n2. Build the image:\r\n```bash\r\ndocker build -t demo .\r\n```\r\n3. Run the app:\r\n```bash\r\ndocker run -it --rm demo\r\n```\r\n\r\n## Expected behavior:\r\n\r\nStreamlit starts without issues.\r\n\r\n## Actual behavior:\r\n\r\nStreamlit fails to start and displays the following error message:\r\n\r\n```bash\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/site-packages/git/__init__.py\", line 83, in <module>\r\n refresh()\r\n File \"/usr/local/lib/python3.8/site-packages/git/__init__.py\", line 73, in refresh\r\n if not Git.refresh(path=path):\r\n File \"/usr/local/lib/python3.8/site-packages/git/cmd.py\", line 278, in refresh\r\n raise ImportError(err)\r\nImportError: Bad git executable.\r\nThe git executable must be specified in one of the following ways:\r\n - be included in your $PATH\r\n - be set via $GIT_PYTHON_GIT_EXECUTABLE\r\n - explicitly set via git.refresh()\r\n\r\nAll git commands will error until this is rectified.\r\n\r\nThis initial warning can be silenced or aggravated in the future by setting the\r\n$GIT_PYTHON_REFRESH environment variable. Use one of the following values:\r\n - quiet|q|silence|s|none|n|0: for no warning or exception\r\n - warn|w|warning|1: for a printed warning\r\n - error|e|raise|r|2: for a raised exception\r\n\r\nExample:\r\n export GIT_PYTHON_REFRESH=quiet\r\n```\r\n\r\n## Is this a regression?\r\n\r\n**yes** (worked up until at least version `0.67.1`)\r\n\r\n# Debug info\r\n\r\n- Streamlit version: `0.69.1`\r\n- Python version: `3.8.6`\r\n- Using Conda? PipEnv? PyEnv? Pex? **NO**\r\n- OS version: `4.19.76-linuxkit`\r\n\r\n# Additional information\r\n\r\nThis bug can be worked around by setting `GIT_PYTHON_REFRESH=quiet` environment variable inside the Docker image.\r\n\n", "before_files": [{"content": "import os\nimport platform\nimport setuptools\nimport subprocess\nimport sys\n\nfrom pipenv.project import Project\nfrom pipenv.utils import convert_deps_to_pip\nfrom setuptools.command.install import install\n\nVERSION = \"0.69.1\" # PEP-440\n\nNAME = \"streamlit\"\n\nDESCRIPTION = \"The fastest way to build data apps in Python\"\n\nLONG_DESCRIPTION = (\n \"Streamlit's open-source app framework is the easiest way \"\n \"for data scientists and machine learning engineers to \"\n \"create beautiful, performant apps in only a few hours! \"\n \"All in pure Python. All for free.\"\n)\n\npipfile = Project(chdir=False).parsed_pipfile\n\npackages = pipfile[\"packages\"].copy()\nrequirements = convert_deps_to_pip(packages, r=False)\n\n# Check whether xcode tools are available before making watchdog a\n# dependency (only if the current system is a Mac).\nif platform.system() == \"Darwin\":\n has_xcode = subprocess.call([\"xcode-select\", \"--version\"], shell=False) == 0\n has_gcc = subprocess.call([\"gcc\", \"--version\"], shell=False) == 0\n\n if not (has_xcode and has_gcc):\n try:\n requirements.remove(\"watchdog\")\n except ValueError:\n pass\n\n\nclass VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n\n description = \"verify that the git tag matches our version\"\n\n def run(self):\n tag = os.getenv(\"CIRCLE_TAG\")\n\n if tag != VERSION:\n info = \"Git tag: {0} does not match the version of this app: {1}\".format(\n tag, VERSION\n )\n sys.exit(info)\n\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=\"https://streamlit.io\",\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n python_requires=\">=3.6\",\n license=\"Apache 2\",\n packages=setuptools.find_packages(exclude=[\"tests\", \"tests.*\"]),\n # Requirements\n install_requires=requirements,\n zip_safe=False, # install source files not egg\n include_package_data=True, # copy html and friends\n entry_points={\"console_scripts\": [\"streamlit = streamlit.cli:main\"]},\n # For Windows so that streamlit * commands work ie.\n # - streamlit version\n # - streamlit hello\n scripts=[\"bin/streamlit.cmd\"],\n cmdclass={\n \"verify\": VerifyVersionCommand,\n },\n)\n", "path": "lib/setup.py"}]}
| 1,781 | 98 |
gh_patches_debug_35142
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-380
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Flash `Trainer.from_argparse_args` not working
## 🐛 Bug
Looks like from_argparse_args isn't working for flash trainer. Likely related to #343
cc @aribornstein
</issue>
<code>
[start of flash/core/trainer.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import warnings
15 from argparse import ArgumentParser
16 from functools import wraps
17 from typing import Callable, List, Optional, Union
18
19 import torch
20 from pytorch_lightning import LightningDataModule, LightningModule
21 from pytorch_lightning import Trainer as PlTrainer
22 from pytorch_lightning.callbacks import BaseFinetuning
23 from pytorch_lightning.utilities import rank_zero_warn
24 from pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables
25 from pytorch_lightning.utilities.exceptions import MisconfigurationException
26 from torch.utils.data import DataLoader
27
28 import flash
29 from flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks
30
31
32 def _defaults_from_env_vars(fn: Callable) -> Callable:
33 """Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix
34 build error in readthedocs."""
35
36 @wraps(fn)
37 def insert_env_defaults(self, *args, **kwargs):
38 cls = self.__class__ # get the class
39 if args: # inace any args passed move them to kwargs
40 # parse only the argument names
41 cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]
42 # convert args to kwargs
43 kwargs.update({k: v for k, v in zip(cls_arg_names, args)})
44 env_variables = vars(parse_env_variables(cls))
45 # update the kwargs by env variables
46 kwargs = dict(list(env_variables.items()) + list(kwargs.items()))
47
48 # all args were already moved to kwargs
49 return fn(self, **kwargs)
50
51 return insert_env_defaults
52
53
54 class Trainer(PlTrainer):
55
56 @_defaults_from_env_vars
57 def __init__(self, *args, **kwargs):
58 if flash._IS_TESTING:
59 if torch.cuda.is_available():
60 kwargs["gpus"] = 1
61 kwargs["max_epochs"] = 3
62 kwargs["limit_train_batches"] = 1.0
63 kwargs["limit_val_batches"] = 1.0
64 kwargs["limit_test_batches"] = 1.0
65 kwargs["fast_dev_run"] = False
66 else:
67 kwargs["fast_dev_run"] = True
68 super().__init__(*args, **kwargs)
69
70 def fit(
71 self,
72 model: LightningModule,
73 train_dataloader: Optional[DataLoader] = None,
74 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
75 datamodule: Optional[LightningDataModule] = None,
76 ):
77 r"""
78 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`
79
80 Args:
81 datamodule: A instance of :class:`LightningDataModule`.
82
83 model: Model to fit.
84
85 train_dataloader: A Pytorch DataLoader with training samples. If the model has
86 a predefined train_dataloader method this will be skipped.
87
88 val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.
89 If the model has a predefined val_dataloaders method this will be skipped
90 """
91 if any(isinstance(c, BaseFinetuning) for c in self.callbacks):
92 # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?
93 warnings.warn("Warning: You are calling fit(), but your trainer is using a fine-tuning callback")
94 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
95
96 def finetune(
97 self,
98 model: LightningModule,
99 train_dataloader: Optional[DataLoader] = None,
100 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
101 datamodule: Optional[LightningDataModule] = None,
102 strategy: Optional[Union[str, BaseFinetuning]] = None,
103 ):
104 r"""
105
106 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers
107 of the backbone throughout training layers of the backbone throughout training.
108
109 Args:
110 datamodule: A instance of :class:`LightningDataModule`.
111
112 model: Model to fit.
113
114 train_dataloader: A PyTorch DataLoader with training samples. If the model has
115 a predefined train_dataloader method this will be skipped.
116
117 val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.
118 If the model has a predefined val_dataloaders method this will be skipped
119
120 strategy: Should either be a string or a finetuning callback subclassing
121 :class:`pytorch_lightning.callbacks.BaseFinetuning`.
122
123 Default strategies can be enabled with these strings:
124
125 - ``"no_freeze"``,
126 - ``"freeze"``,
127 - ``"freeze_unfreeze"``,
128 - ``"unfreeze_milestones"``.
129 """
130 self._resolve_callbacks(model, strategy)
131 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
132
133 def _resolve_callbacks(self, model, strategy):
134 """
135 This function is used to select the `BaseFinetuning` to be used for finetuning.
136 """
137 if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):
138 raise MisconfigurationException(
139 "strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``"
140 f"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}"
141 )
142
143 if isinstance(strategy, BaseFinetuning):
144 callback = [strategy]
145 else:
146 # todo: change to ``configure_callbacks`` when merged to Lightning.
147 model_callback = model.configure_finetune_callback()
148 if len(model_callback) > 1:
149 raise MisconfigurationException(
150 f"{model} configure_finetune_callback should create a list with only 1 callback"
151 )
152 if len(model_callback) == 1:
153 if strategy is not None:
154 rank_zero_warn(
155 "The model contains a default finetune callback. The provided {strategy} will be overriden.\n"
156 " HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. ", UserWarning
157 )
158 callback = model_callback
159 else:
160 callback = instantiate_default_finetuning_callbacks(strategy)
161
162 self.callbacks = self._merge_callbacks(self.callbacks, callback)
163
164 @staticmethod
165 def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:
166 """
167 This function keeps only 1 instance of each callback type,
168 extending new_callbacks with old_callbacks
169 """
170 if len(new_callbacks) == 0:
171 return old_callbacks
172 new_callbacks_types = set(type(c) for c in new_callbacks)
173 old_callbacks_types = set(type(c) for c in old_callbacks)
174 override_types = new_callbacks_types.intersection(old_callbacks_types)
175 new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)
176 return new_callbacks
177
178 @classmethod
179 def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:
180 # the lightning trainer implementation does not support subclasses.
181 # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
182 return add_argparse_args(PlTrainer, *args, **kwargs)
183
[end of flash/core/trainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flash/core/trainer.py b/flash/core/trainer.py
--- a/flash/core/trainer.py
+++ b/flash/core/trainer.py
@@ -11,8 +11,9 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import inspect
import warnings
-from argparse import ArgumentParser
+from argparse import ArgumentParser, Namespace
from functools import wraps
from typing import Callable, List, Optional, Union
@@ -29,6 +30,22 @@
from flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks
+def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs):
+ """Modified version of ``pytorch_lightning.utilities.argparse.from_argparse_args`` which populates ``valid_kwargs``
+ from ``pytorch_lightning.Trainer``."""
+ if isinstance(args, ArgumentParser):
+ args = cls.parse_argparser(args)
+
+ params = vars(args)
+
+ # we only want to pass in valid PLTrainer args, the rest may be user specific
+ valid_kwargs = inspect.signature(PlTrainer.__init__).parameters
+ trainer_kwargs = dict((name, params[name]) for name in valid_kwargs if name in params)
+ trainer_kwargs.update(**kwargs)
+
+ return cls(**trainer_kwargs)
+
+
def _defaults_from_env_vars(fn: Callable) -> Callable:
"""Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix
build error in readthedocs."""
@@ -180,3 +197,9 @@
# the lightning trainer implementation does not support subclasses.
# context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
return add_argparse_args(PlTrainer, *args, **kwargs)
+
+ @classmethod
+ def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs) -> 'Trainer':
+ # the lightning trainer implementation does not support subclasses.
+ # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
+ return from_argparse_args(PlTrainer, args, **kwargs)
|
{"golden_diff": "diff --git a/flash/core/trainer.py b/flash/core/trainer.py\n--- a/flash/core/trainer.py\n+++ b/flash/core/trainer.py\n@@ -11,8 +11,9 @@\n # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n # See the License for the specific language governing permissions and\n # limitations under the License.\n+import inspect\n import warnings\n-from argparse import ArgumentParser\n+from argparse import ArgumentParser, Namespace\n from functools import wraps\n from typing import Callable, List, Optional, Union\n \n@@ -29,6 +30,22 @@\n from flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks\n \n \n+def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs):\n+ \"\"\"Modified version of ``pytorch_lightning.utilities.argparse.from_argparse_args`` which populates ``valid_kwargs``\n+ from ``pytorch_lightning.Trainer``.\"\"\"\n+ if isinstance(args, ArgumentParser):\n+ args = cls.parse_argparser(args)\n+\n+ params = vars(args)\n+\n+ # we only want to pass in valid PLTrainer args, the rest may be user specific\n+ valid_kwargs = inspect.signature(PlTrainer.__init__).parameters\n+ trainer_kwargs = dict((name, params[name]) for name in valid_kwargs if name in params)\n+ trainer_kwargs.update(**kwargs)\n+\n+ return cls(**trainer_kwargs)\n+\n+\n def _defaults_from_env_vars(fn: Callable) -> Callable:\n \"\"\"Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix\n build error in readthedocs.\"\"\"\n@@ -180,3 +197,9 @@\n # the lightning trainer implementation does not support subclasses.\n # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n return add_argparse_args(PlTrainer, *args, **kwargs)\n+\n+ @classmethod\n+ def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs) -> 'Trainer':\n+ # the lightning trainer implementation does not support subclasses.\n+ # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n+ return from_argparse_args(PlTrainer, args, **kwargs)\n", "issue": "Flash `Trainer.from_argparse_args` not working\n## \ud83d\udc1b Bug\r\n\r\nLooks like from_argparse_args isn't working for flash trainer. Likely related to #343\r\n\r\ncc @aribornstein \n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport warnings\nfrom argparse import ArgumentParser\nfrom functools import wraps\nfrom typing import Callable, List, Optional, Union\n\nimport torch\nfrom pytorch_lightning import LightningDataModule, LightningModule\nfrom pytorch_lightning import Trainer as PlTrainer\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities import rank_zero_warn\nfrom pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.utils.data import DataLoader\n\nimport flash\nfrom flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks\n\n\ndef _defaults_from_env_vars(fn: Callable) -> Callable:\n \"\"\"Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix\n build error in readthedocs.\"\"\"\n\n @wraps(fn)\n def insert_env_defaults(self, *args, **kwargs):\n cls = self.__class__ # get the class\n if args: # inace any args passed move them to kwargs\n # parse only the argument names\n cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]\n # convert args to kwargs\n kwargs.update({k: v for k, v in zip(cls_arg_names, args)})\n env_variables = vars(parse_env_variables(cls))\n # update the kwargs by env variables\n kwargs = dict(list(env_variables.items()) + list(kwargs.items()))\n\n # all args were already moved to kwargs\n return fn(self, **kwargs)\n\n return insert_env_defaults\n\n\nclass Trainer(PlTrainer):\n\n @_defaults_from_env_vars\n def __init__(self, *args, **kwargs):\n if flash._IS_TESTING:\n if torch.cuda.is_available():\n kwargs[\"gpus\"] = 1\n kwargs[\"max_epochs\"] = 3\n kwargs[\"limit_train_batches\"] = 1.0\n kwargs[\"limit_val_batches\"] = 1.0\n kwargs[\"limit_test_batches\"] = 1.0\n kwargs[\"fast_dev_run\"] = False\n else:\n kwargs[\"fast_dev_run\"] = True\n super().__init__(*args, **kwargs)\n\n def fit(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n ):\n r\"\"\"\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A Pytorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n \"\"\"\n if any(isinstance(c, BaseFinetuning) for c in self.callbacks):\n # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?\n warnings.warn(\"Warning: You are calling fit(), but your trainer is using a fine-tuning callback\")\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def finetune(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n strategy: Optional[Union[str, BaseFinetuning]] = None,\n ):\n r\"\"\"\n\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers\n of the backbone throughout training layers of the backbone throughout training.\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A PyTorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n\n strategy: Should either be a string or a finetuning callback subclassing\n :class:`pytorch_lightning.callbacks.BaseFinetuning`.\n\n Default strategies can be enabled with these strings:\n\n - ``\"no_freeze\"``,\n - ``\"freeze\"``,\n - ``\"freeze_unfreeze\"``,\n - ``\"unfreeze_milestones\"``.\n \"\"\"\n self._resolve_callbacks(model, strategy)\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def _resolve_callbacks(self, model, strategy):\n \"\"\"\n This function is used to select the `BaseFinetuning` to be used for finetuning.\n \"\"\"\n if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):\n raise MisconfigurationException(\n \"strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``\"\n f\"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}\"\n )\n\n if isinstance(strategy, BaseFinetuning):\n callback = [strategy]\n else:\n # todo: change to ``configure_callbacks`` when merged to Lightning.\n model_callback = model.configure_finetune_callback()\n if len(model_callback) > 1:\n raise MisconfigurationException(\n f\"{model} configure_finetune_callback should create a list with only 1 callback\"\n )\n if len(model_callback) == 1:\n if strategy is not None:\n rank_zero_warn(\n \"The model contains a default finetune callback. The provided {strategy} will be overriden.\\n\"\n \" HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. \", UserWarning\n )\n callback = model_callback\n else:\n callback = instantiate_default_finetuning_callbacks(strategy)\n\n self.callbacks = self._merge_callbacks(self.callbacks, callback)\n\n @staticmethod\n def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:\n \"\"\"\n This function keeps only 1 instance of each callback type,\n extending new_callbacks with old_callbacks\n \"\"\"\n if len(new_callbacks) == 0:\n return old_callbacks\n new_callbacks_types = set(type(c) for c in new_callbacks)\n old_callbacks_types = set(type(c) for c in old_callbacks)\n override_types = new_callbacks_types.intersection(old_callbacks_types)\n new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)\n return new_callbacks\n\n @classmethod\n def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:\n # the lightning trainer implementation does not support subclasses.\n # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n return add_argparse_args(PlTrainer, *args, **kwargs)\n", "path": "flash/core/trainer.py"}]}
| 2,787 | 545 |
gh_patches_debug_34311
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2084
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
False positive for CKV_AZURE_43: check storage account name
I'm building my Storage Account names like this
```
name = "${local.saname_prefix}diagnostics${module.tf-var-project.random_id}
```
With https://github.com/bridgecrewio/checkov/pull/429 merged I now get a Check failure on the SA name:
```
Check: CKV_AZURE_43: "Ensure the Storage Account naming rules"
FAILED for resource: azurerm_storage_account.diagnostics
File: /az_diag_sa.tf:8-22
8 | resource "azurerm_storage_account" "diagnostics" {
9 | #checkov:skip=CKV_AZURE_35:Public access is allowed
10 | name = "${local.saname_prefix}diagnostics${module.tf-var-project.random_id}"
````
</issue>
<code>
[start of checkov/terraform/checks/resource/azure/StorageAccountName.py]
1 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
2 from checkov.common.models.enums import CheckResult, CheckCategories
3 import re
4 from typing import List
5
6 STO_NAME_REGEX = re.compile('^[a-z0-9]{3,24}$')
7
8
9 class StorageAccountName(BaseResourceCheck):
10 def __init__(self):
11 name = "Ensure Storage Accounts adhere to the naming rules"
12 id = "CKV_AZURE_43"
13 supported_resources = ['azurerm_storage_account']
14 categories = [CheckCategories.CONVENTION]
15 super().__init__(name=name, id=id, categories=categories,
16 supported_resources=supported_resources)
17
18 def scan_resource_conf(self, conf):
19 """
20 The Storage Account naming reference:
21 https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts
22 :param conf: azurerm_storage_account configuration
23 :return: <CheckResult>
24 """
25 return CheckResult.PASSED if conf.get('name') and re.findall(STO_NAME_REGEX, str(conf['name'][0])) else CheckResult.FAILED
26
27 def get_evaluated_keys(self) -> List[str]:
28 return ['name']
29
30
31 check = StorageAccountName()
32
[end of checkov/terraform/checks/resource/azure/StorageAccountName.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/azure/StorageAccountName.py b/checkov/terraform/checks/resource/azure/StorageAccountName.py
--- a/checkov/terraform/checks/resource/azure/StorageAccountName.py
+++ b/checkov/terraform/checks/resource/azure/StorageAccountName.py
@@ -1,31 +1,41 @@
+import re
+from typing import List, Dict, Any
+
from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
from checkov.common.models.enums import CheckResult, CheckCategories
-import re
-from typing import List
-STO_NAME_REGEX = re.compile('^[a-z0-9]{3,24}$')
+STO_NAME_REGEX = re.compile(r"^[a-z0-9]{3,24}$")
+VARIABLE_REFS = ("local.", "module.", "var.")
class StorageAccountName(BaseResourceCheck):
- def __init__(self):
+ def __init__(self) -> None:
name = "Ensure Storage Accounts adhere to the naming rules"
id = "CKV_AZURE_43"
- supported_resources = ['azurerm_storage_account']
+ supported_resources = ["azurerm_storage_account"]
categories = [CheckCategories.CONVENTION]
- super().__init__(name=name, id=id, categories=categories,
- supported_resources=supported_resources)
+ super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
- def scan_resource_conf(self, conf):
+ def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:
"""
The Storage Account naming reference:
https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts
:param conf: azurerm_storage_account configuration
:return: <CheckResult>
"""
- return CheckResult.PASSED if conf.get('name') and re.findall(STO_NAME_REGEX, str(conf['name'][0])) else CheckResult.FAILED
+ name = conf.get("name")
+ if name:
+ name = name[0]
+ if any(x in name for x in VARIABLE_REFS):
+ # in the case we couldn't evaluate the name, just ignore
+ return CheckResult.UNKNOWN
+ if re.findall(STO_NAME_REGEX, str(conf["name"][0])):
+ return CheckResult.PASSED
+
+ return CheckResult.FAILED
def get_evaluated_keys(self) -> List[str]:
- return ['name']
+ return ["name"]
check = StorageAccountName()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/StorageAccountName.py b/checkov/terraform/checks/resource/azure/StorageAccountName.py\n--- a/checkov/terraform/checks/resource/azure/StorageAccountName.py\n+++ b/checkov/terraform/checks/resource/azure/StorageAccountName.py\n@@ -1,31 +1,41 @@\n+import re\n+from typing import List, Dict, Any\n+\n from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n from checkov.common.models.enums import CheckResult, CheckCategories\n-import re\n-from typing import List\n \n-STO_NAME_REGEX = re.compile('^[a-z0-9]{3,24}$')\n+STO_NAME_REGEX = re.compile(r\"^[a-z0-9]{3,24}$\")\n+VARIABLE_REFS = (\"local.\", \"module.\", \"var.\")\n \n \n class StorageAccountName(BaseResourceCheck):\n- def __init__(self):\n+ def __init__(self) -> None:\n name = \"Ensure Storage Accounts adhere to the naming rules\"\n id = \"CKV_AZURE_43\"\n- supported_resources = ['azurerm_storage_account']\n+ supported_resources = [\"azurerm_storage_account\"]\n categories = [CheckCategories.CONVENTION]\n- super().__init__(name=name, id=id, categories=categories,\n- supported_resources=supported_resources)\n+ super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n- def scan_resource_conf(self, conf):\n+ def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:\n \"\"\"\n The Storage Account naming reference:\n https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts\n :param conf: azurerm_storage_account configuration\n :return: <CheckResult>\n \"\"\"\n- return CheckResult.PASSED if conf.get('name') and re.findall(STO_NAME_REGEX, str(conf['name'][0])) else CheckResult.FAILED\n+ name = conf.get(\"name\")\n+ if name:\n+ name = name[0]\n+ if any(x in name for x in VARIABLE_REFS):\n+ # in the case we couldn't evaluate the name, just ignore\n+ return CheckResult.UNKNOWN\n+ if re.findall(STO_NAME_REGEX, str(conf[\"name\"][0])):\n+ return CheckResult.PASSED\n+\n+ return CheckResult.FAILED\n \n def get_evaluated_keys(self) -> List[str]:\n- return ['name']\n+ return [\"name\"]\n \n \n check = StorageAccountName()\n", "issue": "False positive for CKV_AZURE_43: check storage account name\nI'm building my Storage Account names like this\r\n```\r\nname = \"${local.saname_prefix}diagnostics${module.tf-var-project.random_id}\r\n```\r\n\r\nWith https://github.com/bridgecrewio/checkov/pull/429 merged I now get a Check failure on the SA name:\r\n\r\n```\r\nCheck: CKV_AZURE_43: \"Ensure the Storage Account naming rules\"\r\n\tFAILED for resource: azurerm_storage_account.diagnostics\r\n\tFile: /az_diag_sa.tf:8-22\r\n\r\n\t\t8 | resource \"azurerm_storage_account\" \"diagnostics\" {\r\n\t\t9 | #checkov:skip=CKV_AZURE_35:Public access is allowed\r\n\t\t10 | name = \"${local.saname_prefix}diagnostics${module.tf-var-project.random_id}\"\r\n\r\n````\n", "before_files": [{"content": "from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckResult, CheckCategories\nimport re\nfrom typing import List\n\nSTO_NAME_REGEX = re.compile('^[a-z0-9]{3,24}$')\n\n\nclass StorageAccountName(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure Storage Accounts adhere to the naming rules\"\n id = \"CKV_AZURE_43\"\n supported_resources = ['azurerm_storage_account']\n categories = [CheckCategories.CONVENTION]\n super().__init__(name=name, id=id, categories=categories,\n supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n \"\"\"\n The Storage Account naming reference:\n https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts\n :param conf: azurerm_storage_account configuration\n :return: <CheckResult>\n \"\"\"\n return CheckResult.PASSED if conf.get('name') and re.findall(STO_NAME_REGEX, str(conf['name'][0])) else CheckResult.FAILED\n\n def get_evaluated_keys(self) -> List[str]:\n return ['name']\n\n\ncheck = StorageAccountName()\n", "path": "checkov/terraform/checks/resource/azure/StorageAccountName.py"}]}
| 1,077 | 571 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.