
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_643
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1925
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.107
On the docket:
+ [x] `git` username replaced with `****` redaction in lockfile for `git+ssh` direct references #1918
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.106"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.106"
+__version__ = "2.1.107"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.106\"\n+__version__ = \"2.1.107\"\n", "issue": "Release 2.1.107\nOn the docket:\r\n+ [x] `git` username replaced with `****` redaction in lockfile for `git+ssh` direct references #1918\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.106\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.107\"\n", "path": "pex/version.py"}]}
| 355 | 98 |
gh_patches_debug_37259
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-25990
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cloud/vmware/vmware_vswitch.py nic_name should be optional
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
cloud/vmware/vmware_vswitch.py
##### ANSIBLE VERSION
```
ansible 2.3.1.0
config file = /etc/ansible/ansible.cfg
configured module search path = Default w/o overrides
python version = 2.7.12 (default, Nov 19 2016, 06:48:10) [GCC 5.4.0 20160609]
```
##### CONFIGURATION
n/a
##### OS / ENVIRONMENT
n/a
##### SUMMARY
The vmware_vswitch module erroneously assumes that 'nic_name' is required. It is valid (and sometimes desired) to make a vmware virtual switch that does not have any uplink nics at all - the use case is multiple isolated port-groups for isolated networking.
After the vswitch is created, we create a port-group with VLAN 4095 (all vlans), with network policy permitting mac changes, forged transmit, and promiscuous all enabled.
In /ansible/modules/cloud/vmware/vmware_vswitch.py , we can omit this line if nic_name is not specified and the port-group is created as desired.
```python
if self.nic_name:
vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])
```
##### STEPS TO REPRODUCE
Run ansible-playbook against a task using the vmware_vswitch module, omitting nic_name.
```
- name: add test_switch
local_action:
module: vmware_vswitch
hostname: esxi_host
username: esxi_username
password: esxi_password
switch_name: item
mtu: 9000
validate_certs: no
number_of_ports: 8
#nic_name: 'null'
```
##### EXPECTED RESULTS
I expect the vmware vswitch to be created, but without any uplink nics.
##### ACTUAL RESULTS
```
fatal: [localhost -> localhost]: FAILED! => {"changed": false, "failed": true, "msg": "missing required arguments: nic_name"}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/modules/cloud/vmware/vmware_vswitch.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2015, Joseph Callen <jcallen () csc.com>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 ANSIBLE_METADATA = {'metadata_version': '1.0',
22 'status': ['preview'],
23 'supported_by': 'community'}
24
25
26 DOCUMENTATION = '''
27 ---
28 module: vmware_vswitch
29 short_description: Add a VMware Standard Switch to an ESXi host
30 description:
31 - Add a VMware Standard Switch to an ESXi host
32 version_added: 2.0
33 author: "Joseph Callen (@jcpowermac), Russell Teague (@mtnbikenc)"
34 notes:
35 - Tested on vSphere 5.5
36 requirements:
37 - "python >= 2.6"
38 - PyVmomi
39 options:
40 switch_name:
41 description:
42 - vSwitch name to add
43 required: True
44 nic_name:
45 description:
46 - vmnic name to attach to vswitch
47 required: True
48 number_of_ports:
49 description:
50 - Number of port to configure on vswitch
51 default: 128
52 required: False
53 mtu:
54 description:
55 - MTU to configure on vswitch
56 required: False
57 state:
58 description:
59 - Add or remove the switch
60 default: 'present'
61 choices:
62 - 'present'
63 - 'absent'
64 required: False
65 extends_documentation_fragment: vmware.documentation
66 '''
67
68 EXAMPLES = '''
69 # Example from Ansible playbook
70
71 - name: Add a VMware vSwitch
72 local_action:
73 module: vmware_vswitch
74 hostname: esxi_hostname
75 username: esxi_username
76 password: esxi_password
77 switch_name: vswitch_name
78 nic_name: vmnic_name
79 mtu: 9000
80 '''
81
82 try:
83 from pyVmomi import vim, vmodl
84 HAS_PYVMOMI = True
85 except ImportError:
86 HAS_PYVMOMI = False
87
88
89 def find_vswitch_by_name(host, vswitch_name):
90 for vss in host.config.network.vswitch:
91 if vss.name == vswitch_name:
92 return vss
93 return None
94
95
96 class VMwareHostVirtualSwitch(object):
97
98 def __init__(self, module):
99 self.host_system = None
100 self.content = None
101 self.vss = None
102 self.module = module
103 self.switch_name = module.params['switch_name']
104 self.number_of_ports = module.params['number_of_ports']
105 self.nic_name = module.params['nic_name']
106 self.mtu = module.params['mtu']
107 self.state = module.params['state']
108 self.content = connect_to_api(self.module)
109
110 def process_state(self):
111 try:
112 vswitch_states = {
113 'absent': {
114 'present': self.state_destroy_vswitch,
115 'absent': self.state_exit_unchanged,
116 },
117 'present': {
118 'update': self.state_update_vswitch,
119 'present': self.state_exit_unchanged,
120 'absent': self.state_create_vswitch,
121 }
122 }
123
124 vswitch_states[self.state][self.check_vswitch_configuration()]()
125
126 except vmodl.RuntimeFault as runtime_fault:
127 self.module.fail_json(msg=runtime_fault.msg)
128 except vmodl.MethodFault as method_fault:
129 self.module.fail_json(msg=method_fault.msg)
130 except Exception as e:
131 self.module.fail_json(msg=str(e))
132
133
134 # Source from
135 # https://github.com/rreubenur/pyvmomi-community-samples/blob/patch-1/samples/create_vswitch.py
136
137 def state_create_vswitch(self):
138 vss_spec = vim.host.VirtualSwitch.Specification()
139 vss_spec.numPorts = self.number_of_ports
140 vss_spec.mtu = self.mtu
141 vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])
142 self.host_system.configManager.networkSystem.AddVirtualSwitch(vswitchName=self.switch_name, spec=vss_spec)
143 self.module.exit_json(changed=True)
144
145 def state_exit_unchanged(self):
146 self.module.exit_json(changed=False)
147
148 def state_destroy_vswitch(self):
149 config = vim.host.NetworkConfig()
150
151 for portgroup in self.host_system.configManager.networkSystem.networkInfo.portgroup:
152 if portgroup.spec.vswitchName == self.vss.name:
153 portgroup_config = vim.host.PortGroup.Config()
154 portgroup_config.changeOperation = "remove"
155 portgroup_config.spec = vim.host.PortGroup.Specification()
156 portgroup_config.spec.name = portgroup.spec.name
157 portgroup_config.spec.name = portgroup.spec.name
158 portgroup_config.spec.vlanId = portgroup.spec.vlanId
159 portgroup_config.spec.vswitchName = portgroup.spec.vswitchName
160 portgroup_config.spec.policy = vim.host.NetworkPolicy()
161 config.portgroup.append(portgroup_config)
162
163 self.host_system.configManager.networkSystem.UpdateNetworkConfig(config, "modify")
164 self.host_system.configManager.networkSystem.RemoveVirtualSwitch(self.vss.name)
165 self.module.exit_json(changed=True)
166
167 def state_update_vswitch(self):
168 self.module.exit_json(changed=False, msg="Currently not implemented.")
169
170 def check_vswitch_configuration(self):
171 host = get_all_objs(self.content, [vim.HostSystem])
172 if not host:
173 self.module.fail_json(msg="Unable to find host")
174
175 self.host_system = host.keys()[0]
176 self.vss = find_vswitch_by_name(self.host_system, self.switch_name)
177
178 if self.vss is None:
179 return 'absent'
180 else:
181 return 'present'
182
183
184 def main():
185 argument_spec = vmware_argument_spec()
186 argument_spec.update(dict(switch_name=dict(required=True, type='str'),
187 nic_name=dict(required=True, type='str'),
188 number_of_ports=dict(required=False, type='int', default=128),
189 mtu=dict(required=False, type='int', default=1500),
190 state=dict(default='present', choices=['present', 'absent'], type='str')))
191
192 module = AnsibleModule(argument_spec=argument_spec, supports_check_mode=False)
193
194 if not HAS_PYVMOMI:
195 module.fail_json(msg='pyvmomi is required for this module')
196
197 host_virtual_switch = VMwareHostVirtualSwitch(module)
198 host_virtual_switch.process_state()
199
200 from ansible.module_utils.vmware import *
201 from ansible.module_utils.basic import *
202
203 if __name__ == '__main__':
204 main()
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/ansible/modules/cloud/vmware/vmware_vswitch.py b/lib/ansible/modules/cloud/vmware/vmware_vswitch.py
--- a/lib/ansible/modules/cloud/vmware/vmware_vswitch.py
+++ b/lib/ansible/modules/cloud/vmware/vmware_vswitch.py
@@ -44,7 +44,7 @@
nic_name:
description:
- vmnic name to attach to vswitch
- required: True
+ required: False
number_of_ports:
description:
- Number of port to configure on vswitch
@@ -66,17 +66,24 @@
'''
EXAMPLES = '''
-# Example from Ansible playbook
-
- - name: Add a VMware vSwitch
- local_action:
- module: vmware_vswitch
- hostname: esxi_hostname
- username: esxi_username
- password: esxi_password
- switch_name: vswitch_name
- nic_name: vmnic_name
- mtu: 9000
+- name: Add a VMware vSwitch
+ local_action:
+ module: vmware_vswitch
+ hostname: esxi_hostname
+ username: esxi_username
+ password: esxi_password
+ switch_name: vswitch_name
+ nic_name: vmnic_name
+ mtu: 9000
+
+- name: Add a VMWare vSwitch without any physical NIC attached
+ vmware_vswitch:
+ hostname: 192.168.10.1
+ username: admin
+ password: password123
+ switch_name: vswitch_0001
+ mtu: 9000
+
'''
try:
@@ -138,7 +145,8 @@
vss_spec = vim.host.VirtualSwitch.Specification()
vss_spec.numPorts = self.number_of_ports
vss_spec.mtu = self.mtu
- vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])
+ if self.nic_name:
+ vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])
self.host_system.configManager.networkSystem.AddVirtualSwitch(vswitchName=self.switch_name, spec=vss_spec)
self.module.exit_json(changed=True)
@@ -184,7 +192,7 @@
def main():
argument_spec = vmware_argument_spec()
argument_spec.update(dict(switch_name=dict(required=True, type='str'),
- nic_name=dict(required=True, type='str'),
+ nic_name=dict(required=False, type='str'),
number_of_ports=dict(required=False, type='int', default=128),
mtu=dict(required=False, type='int', default=1500),
state=dict(default='present', choices=['present', 'absent'], type='str')))
|
{"golden_diff": "diff --git a/lib/ansible/modules/cloud/vmware/vmware_vswitch.py b/lib/ansible/modules/cloud/vmware/vmware_vswitch.py\n--- a/lib/ansible/modules/cloud/vmware/vmware_vswitch.py\n+++ b/lib/ansible/modules/cloud/vmware/vmware_vswitch.py\n@@ -44,7 +44,7 @@\n nic_name:\n description:\n - vmnic name to attach to vswitch\n- required: True\n+ required: False\n number_of_ports:\n description:\n - Number of port to configure on vswitch\n@@ -66,17 +66,24 @@\n '''\n \n EXAMPLES = '''\n-# Example from Ansible playbook\n-\n- - name: Add a VMware vSwitch\n- local_action:\n- module: vmware_vswitch\n- hostname: esxi_hostname\n- username: esxi_username\n- password: esxi_password\n- switch_name: vswitch_name\n- nic_name: vmnic_name\n- mtu: 9000\n+- name: Add a VMware vSwitch\n+ local_action:\n+ module: vmware_vswitch\n+ hostname: esxi_hostname\n+ username: esxi_username\n+ password: esxi_password\n+ switch_name: vswitch_name\n+ nic_name: vmnic_name\n+ mtu: 9000\n+\n+- name: Add a VMWare vSwitch without any physical NIC attached\n+ vmware_vswitch:\n+ hostname: 192.168.10.1\n+ username: admin\n+ password: password123\n+ switch_name: vswitch_0001\n+ mtu: 9000\n+\n '''\n \n try:\n@@ -138,7 +145,8 @@\n vss_spec = vim.host.VirtualSwitch.Specification()\n vss_spec.numPorts = self.number_of_ports\n vss_spec.mtu = self.mtu\n- vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])\n+ if self.nic_name:\n+ vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])\n self.host_system.configManager.networkSystem.AddVirtualSwitch(vswitchName=self.switch_name, spec=vss_spec)\n self.module.exit_json(changed=True)\n \n@@ -184,7 +192,7 @@\n def main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(dict(switch_name=dict(required=True, type='str'),\n- nic_name=dict(required=True, type='str'),\n+ nic_name=dict(required=False, type='str'),\n number_of_ports=dict(required=False, type='int', default=128),\n mtu=dict(required=False, type='int', default=1500),\n state=dict(default='present', choices=['present', 'absent'], type='str')))\n", "issue": "cloud/vmware/vmware_vswitch.py nic_name should be optional\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\ncloud/vmware/vmware_vswitch.py\r\n\r\n##### ANSIBLE VERSION\r\n```\r\nansible 2.3.1.0\r\n config file = /etc/ansible/ansible.cfg\r\n configured module search path = Default w/o overrides\r\n python version = 2.7.12 (default, Nov 19 2016, 06:48:10) [GCC 5.4.0 20160609]\r\n\r\n```\r\n\r\n##### CONFIGURATION\r\nn/a\r\n##### OS / ENVIRONMENT\r\nn/a\r\n##### SUMMARY\r\nThe vmware_vswitch module erroneously assumes that 'nic_name' is required. It is valid (and sometimes desired) to make a vmware virtual switch that does not have any uplink nics at all - the use case is multiple isolated port-groups for isolated networking. \r\n\r\nAfter the vswitch is created, we create a port-group with VLAN 4095 (all vlans), with network policy permitting mac changes, forged transmit, and promiscuous all enabled.\r\n\r\nIn /ansible/modules/cloud/vmware/vmware_vswitch.py , we can omit this line if nic_name is not specified and the port-group is created as desired.\r\n\r\n```python\r\nif self.nic_name:\r\n vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])\r\n```\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\nRun ansible-playbook against a task using the vmware_vswitch module, omitting nic_name.\r\n```\r\n - name: add test_switch\r\n local_action:\r\n module: vmware_vswitch\r\n hostname: esxi_host\r\n username: esxi_username\r\n password: esxi_password\r\n switch_name: item\r\n mtu: 9000\r\n validate_certs: no\r\n number_of_ports: 8\r\n #nic_name: 'null'\r\n\r\n```\r\n\r\n##### EXPECTED RESULTS\r\nI expect the vmware vswitch to be created, but without any uplink nics.\r\n\r\n##### ACTUAL RESULTS\r\n```\r\nfatal: [localhost -> localhost]: FAILED! => {\"changed\": false, \"failed\": true, \"msg\": \"missing required arguments: nic_name\"}\r\n```\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2015, Joseph Callen <jcallen () csc.com>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nANSIBLE_METADATA = {'metadata_version': '1.0',\n 'status': ['preview'],\n 'supported_by': 'community'}\n\n\nDOCUMENTATION = '''\n---\nmodule: vmware_vswitch\nshort_description: Add a VMware Standard Switch to an ESXi host\ndescription:\n - Add a VMware Standard Switch to an ESXi host\nversion_added: 2.0\nauthor: \"Joseph Callen (@jcpowermac), Russell Teague (@mtnbikenc)\"\nnotes:\n - Tested on vSphere 5.5\nrequirements:\n - \"python >= 2.6\"\n - PyVmomi\noptions:\n switch_name:\n description:\n - vSwitch name to add\n required: True\n nic_name:\n description:\n - vmnic name to attach to vswitch\n required: True\n number_of_ports:\n description:\n - Number of port to configure on vswitch\n default: 128\n required: False\n mtu:\n description:\n - MTU to configure on vswitch\n required: False\n state:\n description:\n - Add or remove the switch\n default: 'present'\n choices:\n - 'present'\n - 'absent'\n required: False\nextends_documentation_fragment: vmware.documentation\n'''\n\nEXAMPLES = '''\n# Example from Ansible playbook\n\n - name: Add a VMware vSwitch\n local_action:\n module: vmware_vswitch\n hostname: esxi_hostname\n username: esxi_username\n password: esxi_password\n switch_name: vswitch_name\n nic_name: vmnic_name\n mtu: 9000\n'''\n\ntry:\n from pyVmomi import vim, vmodl\n HAS_PYVMOMI = True\nexcept ImportError:\n HAS_PYVMOMI = False\n\n\ndef find_vswitch_by_name(host, vswitch_name):\n for vss in host.config.network.vswitch:\n if vss.name == vswitch_name:\n return vss\n return None\n\n\nclass VMwareHostVirtualSwitch(object):\n\n def __init__(self, module):\n self.host_system = None\n self.content = None\n self.vss = None\n self.module = module\n self.switch_name = module.params['switch_name']\n self.number_of_ports = module.params['number_of_ports']\n self.nic_name = module.params['nic_name']\n self.mtu = module.params['mtu']\n self.state = module.params['state']\n self.content = connect_to_api(self.module)\n\n def process_state(self):\n try:\n vswitch_states = {\n 'absent': {\n 'present': self.state_destroy_vswitch,\n 'absent': self.state_exit_unchanged,\n },\n 'present': {\n 'update': self.state_update_vswitch,\n 'present': self.state_exit_unchanged,\n 'absent': self.state_create_vswitch,\n }\n }\n\n vswitch_states[self.state][self.check_vswitch_configuration()]()\n\n except vmodl.RuntimeFault as runtime_fault:\n self.module.fail_json(msg=runtime_fault.msg)\n except vmodl.MethodFault as method_fault:\n self.module.fail_json(msg=method_fault.msg)\n except Exception as e:\n self.module.fail_json(msg=str(e))\n\n\n # Source from\n # https://github.com/rreubenur/pyvmomi-community-samples/blob/patch-1/samples/create_vswitch.py\n\n def state_create_vswitch(self):\n vss_spec = vim.host.VirtualSwitch.Specification()\n vss_spec.numPorts = self.number_of_ports\n vss_spec.mtu = self.mtu\n vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])\n self.host_system.configManager.networkSystem.AddVirtualSwitch(vswitchName=self.switch_name, spec=vss_spec)\n self.module.exit_json(changed=True)\n\n def state_exit_unchanged(self):\n self.module.exit_json(changed=False)\n\n def state_destroy_vswitch(self):\n config = vim.host.NetworkConfig()\n\n for portgroup in self.host_system.configManager.networkSystem.networkInfo.portgroup:\n if portgroup.spec.vswitchName == self.vss.name:\n portgroup_config = vim.host.PortGroup.Config()\n portgroup_config.changeOperation = \"remove\"\n portgroup_config.spec = vim.host.PortGroup.Specification()\n portgroup_config.spec.name = portgroup.spec.name\n portgroup_config.spec.name = portgroup.spec.name\n portgroup_config.spec.vlanId = portgroup.spec.vlanId\n portgroup_config.spec.vswitchName = portgroup.spec.vswitchName\n portgroup_config.spec.policy = vim.host.NetworkPolicy()\n config.portgroup.append(portgroup_config)\n\n self.host_system.configManager.networkSystem.UpdateNetworkConfig(config, \"modify\")\n self.host_system.configManager.networkSystem.RemoveVirtualSwitch(self.vss.name)\n self.module.exit_json(changed=True)\n\n def state_update_vswitch(self):\n self.module.exit_json(changed=False, msg=\"Currently not implemented.\")\n\n def check_vswitch_configuration(self):\n host = get_all_objs(self.content, [vim.HostSystem])\n if not host:\n self.module.fail_json(msg=\"Unable to find host\")\n\n self.host_system = host.keys()[0]\n self.vss = find_vswitch_by_name(self.host_system, self.switch_name)\n\n if self.vss is None:\n return 'absent'\n else:\n return 'present'\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(dict(switch_name=dict(required=True, type='str'),\n nic_name=dict(required=True, type='str'),\n number_of_ports=dict(required=False, type='int', default=128),\n mtu=dict(required=False, type='int', default=1500),\n state=dict(default='present', choices=['present', 'absent'], type='str')))\n\n module = AnsibleModule(argument_spec=argument_spec, supports_check_mode=False)\n\n if not HAS_PYVMOMI:\n module.fail_json(msg='pyvmomi is required for this module')\n\n host_virtual_switch = VMwareHostVirtualSwitch(module)\n host_virtual_switch.process_state()\n\nfrom ansible.module_utils.vmware import *\nfrom ansible.module_utils.basic import *\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/cloud/vmware/vmware_vswitch.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2015, Joseph Callen <jcallen () csc.com>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nANSIBLE_METADATA = {'metadata_version': '1.0',\n 'status': ['preview'],\n 'supported_by': 'community'}\n\n\nDOCUMENTATION = '''\n---\nmodule: vmware_vswitch\nshort_description: Add a VMware Standard Switch to an ESXi host\ndescription:\n - Add a VMware Standard Switch to an ESXi host\nversion_added: 2.0\nauthor: \"Joseph Callen (@jcpowermac), Russell Teague (@mtnbikenc)\"\nnotes:\n - Tested on vSphere 5.5\nrequirements:\n - \"python >= 2.6\"\n - PyVmomi\noptions:\n switch_name:\n description:\n - vSwitch name to add\n required: True\n nic_name:\n description:\n - vmnic name to attach to vswitch\n required: False\n number_of_ports:\n description:\n - Number of port to configure on vswitch\n default: 128\n required: False\n mtu:\n description:\n - MTU to configure on vswitch\n required: False\n state:\n description:\n - Add or remove the switch\n default: 'present'\n choices:\n - 'present'\n - 'absent'\n required: False\nextends_documentation_fragment: vmware.documentation\n'''\n\nEXAMPLES = '''\n- name: Add a VMware vSwitch\n local_action:\n module: vmware_vswitch\n hostname: esxi_hostname\n username: esxi_username\n password: esxi_password\n switch_name: vswitch_name\n nic_name: vmnic_name\n mtu: 9000\n\n- name: Add a VMWare vSwitch without any physical NIC attached\n vmware_vswitch:\n hostname: 192.168.10.1\n username: admin\n password: password123\n switch_name: vswitch_0001\n mtu: 9000\n\n'''\n\ntry:\n from pyVmomi import vim, vmodl\n HAS_PYVMOMI = True\nexcept ImportError:\n HAS_PYVMOMI = False\n\n\ndef find_vswitch_by_name(host, vswitch_name):\n for vss in host.config.network.vswitch:\n if vss.name == vswitch_name:\n return vss\n return None\n\n\nclass VMwareHostVirtualSwitch(object):\n\n def __init__(self, module):\n self.host_system = None\n self.content = None\n self.vss = None\n self.module = module\n self.switch_name = module.params['switch_name']\n self.number_of_ports = module.params['number_of_ports']\n self.nic_name = module.params['nic_name']\n self.mtu = module.params['mtu']\n self.state = module.params['state']\n self.content = connect_to_api(self.module)\n\n def process_state(self):\n try:\n vswitch_states = {\n 'absent': {\n 'present': self.state_destroy_vswitch,\n 'absent': self.state_exit_unchanged,\n },\n 'present': {\n 'update': self.state_update_vswitch,\n 'present': self.state_exit_unchanged,\n 'absent': self.state_create_vswitch,\n }\n }\n\n vswitch_states[self.state][self.check_vswitch_configuration()]()\n\n except vmodl.RuntimeFault as runtime_fault:\n self.module.fail_json(msg=runtime_fault.msg)\n except vmodl.MethodFault as method_fault:\n self.module.fail_json(msg=method_fault.msg)\n except Exception as e:\n self.module.fail_json(msg=str(e))\n\n\n # Source from\n # https://github.com/rreubenur/pyvmomi-community-samples/blob/patch-1/samples/create_vswitch.py\n\n def state_create_vswitch(self):\n vss_spec = vim.host.VirtualSwitch.Specification()\n vss_spec.numPorts = self.number_of_ports\n vss_spec.mtu = self.mtu\n if self.nic_name:\n vss_spec.bridge = vim.host.VirtualSwitch.BondBridge(nicDevice=[self.nic_name])\n self.host_system.configManager.networkSystem.AddVirtualSwitch(vswitchName=self.switch_name, spec=vss_spec)\n self.module.exit_json(changed=True)\n\n def state_exit_unchanged(self):\n self.module.exit_json(changed=False)\n\n def state_destroy_vswitch(self):\n config = vim.host.NetworkConfig()\n\n for portgroup in self.host_system.configManager.networkSystem.networkInfo.portgroup:\n if portgroup.spec.vswitchName == self.vss.name:\n portgroup_config = vim.host.PortGroup.Config()\n portgroup_config.changeOperation = \"remove\"\n portgroup_config.spec = vim.host.PortGroup.Specification()\n portgroup_config.spec.name = portgroup.spec.name\n portgroup_config.spec.name = portgroup.spec.name\n portgroup_config.spec.vlanId = portgroup.spec.vlanId\n portgroup_config.spec.vswitchName = portgroup.spec.vswitchName\n portgroup_config.spec.policy = vim.host.NetworkPolicy()\n config.portgroup.append(portgroup_config)\n\n self.host_system.configManager.networkSystem.UpdateNetworkConfig(config, \"modify\")\n self.host_system.configManager.networkSystem.RemoveVirtualSwitch(self.vss.name)\n self.module.exit_json(changed=True)\n\n def state_update_vswitch(self):\n self.module.exit_json(changed=False, msg=\"Currently not implemented.\")\n\n def check_vswitch_configuration(self):\n host = get_all_objs(self.content, [vim.HostSystem])\n if not host:\n self.module.fail_json(msg=\"Unable to find host\")\n\n self.host_system = host.keys()[0]\n self.vss = find_vswitch_by_name(self.host_system, self.switch_name)\n\n if self.vss is None:\n return 'absent'\n else:\n return 'present'\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(dict(switch_name=dict(required=True, type='str'),\n nic_name=dict(required=False, type='str'),\n number_of_ports=dict(required=False, type='int', default=128),\n mtu=dict(required=False, type='int', default=1500),\n state=dict(default='present', choices=['present', 'absent'], type='str')))\n\n module = AnsibleModule(argument_spec=argument_spec, supports_check_mode=False)\n\n if not HAS_PYVMOMI:\n module.fail_json(msg='pyvmomi is required for this module')\n\n host_virtual_switch = VMwareHostVirtualSwitch(module)\n host_virtual_switch.process_state()\n\nfrom ansible.module_utils.vmware import *\nfrom ansible.module_utils.basic import *\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/cloud/vmware/vmware_vswitch.py"}]}
| 2,835 | 654 |
gh_patches_debug_1877
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-2921
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
local cache inconsistent after enabling short_paths in a recipe
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
Conan Version 1.3.3
Windows 10
With a package in local cache whose recipe does NOT have `short_paths=True`, modify in normal development folder the recipe and set `short_paths=True` and run conan create.
Folders in local cache become inconsistent showing both folders from previous conan create run and .conan_link files pointing to the short paths folders.
This seems no not affect conan tool behavior when running commands and works well if `short_paths` is removed once again.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/util/windows.py`
Content:
```
1 import os
2 import subprocess
3
4 from conans.util.files import load, mkdir, save, rmdir
5 import tempfile
6
7
8 CONAN_LINK = ".conan_link"
9
10
11 def conan_expand_user(path):
12 """ wrapper to the original expanduser function, to workaround python returning
13 verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar
14 """
15 # In win these variables should exist and point to user directory, which
16 # must exist. Using context to avoid permanent modification of os.environ
17 old_env = dict(os.environ)
18 try:
19 home = os.environ.get("HOME")
20 # Problematic cases of wrong HOME variable
21 # - HOME = %USERPROFILE% verbatim, as messed by some other tools
22 # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx
23 # In these cases, it is safe to remove it and rely on USERPROFILE directly
24 if home and (not os.path.exists(home) or
25 (os.getenv("MSYSTEM") and os.getenv("USERPROFILE"))):
26 del os.environ["HOME"]
27 result = os.path.expanduser(path)
28 finally:
29 os.environ.clear()
30 os.environ.update(old_env)
31 return result
32
33
34 def path_shortener(path, short_paths):
35 """ short_paths is 4-state:
36 False: Never shorten the path
37 True: Always shorten the path, create link if not existing
38 None: Use shorten path only if already exists, not create
39 """
40 if short_paths is False or os.getenv("CONAN_USER_HOME_SHORT") == "None":
41 return path
42 link = os.path.join(path, CONAN_LINK)
43 if os.path.exists(link):
44 return load(link)
45 elif short_paths is None:
46 return path
47
48 short_home = os.getenv("CONAN_USER_HOME_SHORT")
49 if not short_home:
50 drive = os.path.splitdrive(path)[0]
51 short_home = drive + "/.conan"
52 mkdir(short_home)
53
54 # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid
55 # access problems in cygwin/msys2 windows subsystems when using short_home folder
56 try:
57 username = os.getenv("USERDOMAIN")
58 domainname = "%s\%s" % (username, os.environ["USERNAME"]) if username else os.environ["USERNAME"]
59 cmd = r'cacls %s /E /G "%s":F' % (short_home, domainname)
60 subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet
61 except subprocess.CalledProcessError:
62 # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.
63 pass
64
65 redirect = tempfile.mkdtemp(dir=short_home, prefix="")
66 # This "1" is the way to have a non-existing directory, so commands like
67 # shutil.copytree() to it, works. It can be removed without compromising the
68 # temp folder generator and conan-links consistency
69 redirect = os.path.join(redirect, "1")
70 save(link, redirect)
71 return redirect
72
73
74 def ignore_long_path_files(src_folder, build_folder, output):
75 def _filter(src, files):
76 filtered_files = []
77 for the_file in files:
78 source_path = os.path.join(src, the_file)
79 # Without storage path, just relative
80 rel_path = os.path.relpath(source_path, src_folder)
81 dest_path = os.path.normpath(os.path.join(build_folder, rel_path))
82 # it is NOT that "/" is counted as "\\" so it counts double
83 # seems a bug in python, overflows paths near the limit of 260,
84 if len(dest_path) >= 249:
85 filtered_files.append(the_file)
86 output.warn("Filename too long, file excluded: %s" % dest_path)
87 return filtered_files
88 return _filter
89
90
91 def rm_conandir(path):
92 """removal of a directory that might contain a link to a short path"""
93 link = os.path.join(path, CONAN_LINK)
94 if os.path.exists(link):
95 short_path = load(link)
96 rmdir(os.path.dirname(short_path))
97 rmdir(path)
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/util/windows.py b/conans/util/windows.py
--- a/conans/util/windows.py
+++ b/conans/util/windows.py
@@ -45,6 +45,9 @@
elif short_paths is None:
return path
+ if os.path.exists(path):
+ rmdir(path)
+
short_home = os.getenv("CONAN_USER_HOME_SHORT")
if not short_home:
drive = os.path.splitdrive(path)[0]
|
{"golden_diff": "diff --git a/conans/util/windows.py b/conans/util/windows.py\n--- a/conans/util/windows.py\n+++ b/conans/util/windows.py\n@@ -45,6 +45,9 @@\n elif short_paths is None:\n return path\n \n+ if os.path.exists(path):\n+ rmdir(path)\n+\n short_home = os.getenv(\"CONAN_USER_HOME_SHORT\")\n if not short_home:\n drive = os.path.splitdrive(path)[0]\n", "issue": "local cache inconsistent after enabling short_paths in a recipe\nTo help us debug your issue please explain:\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [x] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\nConan Version 1.3.3\r\nWindows 10\r\n\r\nWith a package in local cache whose recipe does NOT have `short_paths=True`, modify in normal development folder the recipe and set `short_paths=True` and run conan create.\r\n\r\nFolders in local cache become inconsistent showing both folders from previous conan create run and .conan_link files pointing to the short paths folders.\r\n\r\nThis seems no not affect conan tool behavior when running commands and works well if `short_paths` is removed once again.\r\n\r\n\n", "before_files": [{"content": "import os\nimport subprocess\n\nfrom conans.util.files import load, mkdir, save, rmdir\nimport tempfile\n\n\nCONAN_LINK = \".conan_link\"\n\n\ndef conan_expand_user(path):\n \"\"\" wrapper to the original expanduser function, to workaround python returning\n verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar\n \"\"\"\n # In win these variables should exist and point to user directory, which\n # must exist. Using context to avoid permanent modification of os.environ\n old_env = dict(os.environ)\n try:\n home = os.environ.get(\"HOME\")\n # Problematic cases of wrong HOME variable\n # - HOME = %USERPROFILE% verbatim, as messed by some other tools\n # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx\n # In these cases, it is safe to remove it and rely on USERPROFILE directly\n if home and (not os.path.exists(home) or\n (os.getenv(\"MSYSTEM\") and os.getenv(\"USERPROFILE\"))):\n del os.environ[\"HOME\"]\n result = os.path.expanduser(path)\n finally:\n os.environ.clear()\n os.environ.update(old_env)\n return result\n\n\ndef path_shortener(path, short_paths):\n \"\"\" short_paths is 4-state:\n False: Never shorten the path\n True: Always shorten the path, create link if not existing\n None: Use shorten path only if already exists, not create\n \"\"\"\n if short_paths is False or os.getenv(\"CONAN_USER_HOME_SHORT\") == \"None\":\n return path\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n return load(link)\n elif short_paths is None:\n return path\n\n short_home = os.getenv(\"CONAN_USER_HOME_SHORT\")\n if not short_home:\n drive = os.path.splitdrive(path)[0]\n short_home = drive + \"/.conan\"\n mkdir(short_home)\n\n # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid\n # access problems in cygwin/msys2 windows subsystems when using short_home folder\n try:\n username = os.getenv(\"USERDOMAIN\")\n domainname = \"%s\\%s\" % (username, os.environ[\"USERNAME\"]) if username else os.environ[\"USERNAME\"]\n cmd = r'cacls %s /E /G \"%s\":F' % (short_home, domainname)\n subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet\n except subprocess.CalledProcessError:\n # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.\n pass\n\n redirect = tempfile.mkdtemp(dir=short_home, prefix=\"\")\n # This \"1\" is the way to have a non-existing directory, so commands like\n # shutil.copytree() to it, works. It can be removed without compromising the\n # temp folder generator and conan-links consistency\n redirect = os.path.join(redirect, \"1\")\n save(link, redirect)\n return redirect\n\n\ndef ignore_long_path_files(src_folder, build_folder, output):\n def _filter(src, files):\n filtered_files = []\n for the_file in files:\n source_path = os.path.join(src, the_file)\n # Without storage path, just relative\n rel_path = os.path.relpath(source_path, src_folder)\n dest_path = os.path.normpath(os.path.join(build_folder, rel_path))\n # it is NOT that \"/\" is counted as \"\\\\\" so it counts double\n # seems a bug in python, overflows paths near the limit of 260,\n if len(dest_path) >= 249:\n filtered_files.append(the_file)\n output.warn(\"Filename too long, file excluded: %s\" % dest_path)\n return filtered_files\n return _filter\n\n\ndef rm_conandir(path):\n \"\"\"removal of a directory that might contain a link to a short path\"\"\"\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n short_path = load(link)\n rmdir(os.path.dirname(short_path))\n rmdir(path)\n", "path": "conans/util/windows.py"}], "after_files": [{"content": "import os\nimport subprocess\n\nfrom conans.util.files import load, mkdir, save, rmdir\nimport tempfile\n\n\nCONAN_LINK = \".conan_link\"\n\n\ndef conan_expand_user(path):\n \"\"\" wrapper to the original expanduser function, to workaround python returning\n verbatim %USERPROFILE% when some other app (git for windows) sets HOME envvar\n \"\"\"\n # In win these variables should exist and point to user directory, which\n # must exist. Using context to avoid permanent modification of os.environ\n old_env = dict(os.environ)\n try:\n home = os.environ.get(\"HOME\")\n # Problematic cases of wrong HOME variable\n # - HOME = %USERPROFILE% verbatim, as messed by some other tools\n # - MSYS console, that defines a different user home in /c/mingw/msys/users/xxx\n # In these cases, it is safe to remove it and rely on USERPROFILE directly\n if home and (not os.path.exists(home) or\n (os.getenv(\"MSYSTEM\") and os.getenv(\"USERPROFILE\"))):\n del os.environ[\"HOME\"]\n result = os.path.expanduser(path)\n finally:\n os.environ.clear()\n os.environ.update(old_env)\n return result\n\n\ndef path_shortener(path, short_paths):\n \"\"\" short_paths is 4-state:\n False: Never shorten the path\n True: Always shorten the path, create link if not existing\n None: Use shorten path only if already exists, not create\n \"\"\"\n if short_paths is False or os.getenv(\"CONAN_USER_HOME_SHORT\") == \"None\":\n return path\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n return load(link)\n elif short_paths is None:\n return path\n\n if os.path.exists(path):\n rmdir(path)\n\n short_home = os.getenv(\"CONAN_USER_HOME_SHORT\")\n if not short_home:\n drive = os.path.splitdrive(path)[0]\n short_home = drive + \"/.conan\"\n mkdir(short_home)\n\n # Workaround for short_home living in NTFS file systems. Give full control permission to current user to avoid\n # access problems in cygwin/msys2 windows subsystems when using short_home folder\n try:\n username = os.getenv(\"USERDOMAIN\")\n domainname = \"%s\\%s\" % (username, os.environ[\"USERNAME\"]) if username else os.environ[\"USERNAME\"]\n cmd = r'cacls %s /E /G \"%s\":F' % (short_home, domainname)\n subprocess.check_output(cmd, stderr=subprocess.STDOUT) # Ignoring any returned output, make command quiet\n except subprocess.CalledProcessError:\n # cmd can fail if trying to set ACL in non NTFS drives, ignoring it.\n pass\n\n redirect = tempfile.mkdtemp(dir=short_home, prefix=\"\")\n # This \"1\" is the way to have a non-existing directory, so commands like\n # shutil.copytree() to it, works. It can be removed without compromising the\n # temp folder generator and conan-links consistency\n redirect = os.path.join(redirect, \"1\")\n save(link, redirect)\n return redirect\n\n\ndef ignore_long_path_files(src_folder, build_folder, output):\n def _filter(src, files):\n filtered_files = []\n for the_file in files:\n source_path = os.path.join(src, the_file)\n # Without storage path, just relative\n rel_path = os.path.relpath(source_path, src_folder)\n dest_path = os.path.normpath(os.path.join(build_folder, rel_path))\n # it is NOT that \"/\" is counted as \"\\\\\" so it counts double\n # seems a bug in python, overflows paths near the limit of 260,\n if len(dest_path) >= 249:\n filtered_files.append(the_file)\n output.warn(\"Filename too long, file excluded: %s\" % dest_path)\n return filtered_files\n return _filter\n\n\ndef rm_conandir(path):\n \"\"\"removal of a directory that might contain a link to a short path\"\"\"\n link = os.path.join(path, CONAN_LINK)\n if os.path.exists(link):\n short_path = load(link)\n rmdir(os.path.dirname(short_path))\n rmdir(path)\n", "path": "conans/util/windows.py"}]}
| 1,576 | 100 |
gh_patches_debug_28256
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-8355
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
feature: Install multiple plugins of any type
### Feature scope
CLI (options, error messages, logging, etc.)
### Description
Currently, you can only leverage `meltano install` in parallel for all plugin types or all plugins of a specific type:
```sh
# all plugins
meltano install
# all extractors
meltano install [extractor|extractors]
# all loaders
meltano install [loader|loaders]
```
It would be great if you could install multiple plugins of any type - something like:
```sh
meltano install <extractor> <loader> <transformer> <utility>
```
This change would remove the need to specify a plugin type at all, since a plugin name is already unique to a Meltano project. This is currently not possible without a breaking change however, since a plugin type is required as the first argument to `meltano install` when specifying plugin names. #8228 introduced the `--from-file` option for `meltano config <plugin> set`, which accepts a special character `-` to refer to stdin - `meltano install` could reuse this or a similar concept to skip the plugin type argument and leverage parallel install:
```sh
meltano install - <extractor> <loader> <transformer> <utility>
```
Once a convention is established, this feature could be extended to `meltano remove` as well.
I have a POC of this working for `meltano install` locally, so happy to open a PR.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/cli/install.py`
Content:
```
1 """CLI command `meltano install`."""
2
3 from __future__ import annotations
4
5 import typing as t
6
7 import click
8 import structlog
9
10 from meltano.cli.params import pass_project
11 from meltano.cli.utils import CliError, PartialInstrumentedCmd, install_plugins
12 from meltano.core.block.parser import BlockParser
13 from meltano.core.plugin import PluginType
14 from meltano.core.schedule_service import ScheduleService
15 from meltano.core.tracking.contexts import CliEvent, PluginsTrackingContext
16
17 if t.TYPE_CHECKING:
18 from meltano.core.project import Project
19 from meltano.core.tracking import Tracker
20
21 logger = structlog.getLogger(__name__)
22
23
24 @click.command(cls=PartialInstrumentedCmd, short_help="Install project dependencies.")
25 @click.argument(
26 "plugin_type",
27 type=click.Choice(PluginType.cli_arguments()),
28 required=False,
29 )
30 @click.argument("plugin_name", nargs=-1, required=False)
31 @click.option(
32 "--clean",
33 is_flag=True,
34 help="Completely reinstall a plugin rather than simply upgrading if necessary.",
35 )
36 @click.option(
37 "--parallelism",
38 "-p",
39 type=click.INT,
40 default=None,
41 help=(
42 "Limit the number of plugins to install in parallel. "
43 "Defaults to the number of cores."
44 ),
45 )
46 @click.option(
47 "--force",
48 "-f",
49 is_flag=True,
50 help="Ignore the required Python version declared by the plugins.",
51 )
52 @click.option(
53 "--schedule",
54 "-s",
55 "schedule_name",
56 help="Install all plugins from the given schedule.",
57 )
58 @click.pass_context
59 @pass_project(migrate=True)
60 def install( # noqa: C901
61 project: Project,
62 ctx: click.Context,
63 plugin_type: str,
64 plugin_name: str,
65 clean: bool,
66 parallelism: int,
67 force: bool,
68 schedule_name: str,
69 ):
70 """
71 Install all the dependencies of your project based on the meltano.yml file.
72
73 \b\nRead more at https://docs.meltano.com/reference/command-line-interface#install
74 """
75 tracker: Tracker = ctx.obj["tracker"]
76 try:
77 if plugin_type:
78 plugin_type = PluginType.from_cli_argument(plugin_type)
79 plugins = project.plugins.get_plugins_of_type(plugin_type)
80 if plugin_name:
81 plugins = [plugin for plugin in plugins if plugin.name in plugin_name]
82 else:
83 plugins = list(project.plugins.plugins())
84
85 if schedule_name:
86 schedule_plugins = _get_schedule_plugins(
87 ctx.obj["project"],
88 schedule_name,
89 )
90 plugins = list(set(plugins) & set(schedule_plugins))
91 except Exception:
92 tracker.track_command_event(CliEvent.aborted)
93 raise
94
95 click.echo(f"Installing {len(plugins)} plugins...")
96 tracker.add_contexts(
97 PluginsTrackingContext([(candidate, None) for candidate in plugins]),
98 )
99 tracker.track_command_event(CliEvent.inflight)
100
101 success = install_plugins(
102 project,
103 plugins,
104 parallelism=parallelism,
105 clean=clean,
106 force=force,
107 )
108 if not success:
109 tracker.track_command_event(CliEvent.failed)
110 raise CliError("Failed to install plugin(s)") # noqa: EM101
111 tracker.track_command_event(CliEvent.completed)
112
113
114 def _get_schedule_plugins(project: Project, schedule_name: str):
115 schedule_service = ScheduleService(project)
116 schedule_obj = schedule_service.find_schedule(schedule_name)
117 schedule_plugins = set()
118 if schedule_obj.elt_schedule:
119 for plugin_name in (schedule_obj.extractor, schedule_obj.loader):
120 schedule_plugins.add(project.plugins.find_plugin(plugin_name))
121 else:
122 task_sets = schedule_service.task_sets_service.get(schedule_obj.job)
123 for blocks in task_sets.flat_args_per_set:
124 parser = BlockParser(logger, project, blocks)
125 for plugin in parser.plugins:
126 schedule_plugins.add(
127 project.plugins.find_plugin(plugin.info.get("name"))
128 if plugin.type == PluginType.MAPPERS
129 else plugin,
130 )
131 return schedule_plugins
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/cli/install.py b/src/meltano/cli/install.py
--- a/src/meltano/cli/install.py
+++ b/src/meltano/cli/install.py
@@ -18,13 +18,15 @@
from meltano.core.project import Project
from meltano.core.tracking import Tracker
+ANY = "-"
+
logger = structlog.getLogger(__name__)
@click.command(cls=PartialInstrumentedCmd, short_help="Install project dependencies.")
@click.argument(
"plugin_type",
- type=click.Choice(PluginType.cli_arguments()),
+ type=click.Choice((*PluginType.cli_arguments(), ANY)),
required=False,
)
@click.argument("plugin_name", nargs=-1, required=False)
@@ -74,14 +76,15 @@
"""
tracker: Tracker = ctx.obj["tracker"]
try:
- if plugin_type:
+ if plugin_type and plugin_type != ANY:
plugin_type = PluginType.from_cli_argument(plugin_type)
plugins = project.plugins.get_plugins_of_type(plugin_type)
- if plugin_name:
- plugins = [plugin for plugin in plugins if plugin.name in plugin_name]
else:
plugins = list(project.plugins.plugins())
+ if plugin_name:
+ plugins = [plugin for plugin in plugins if plugin.name in plugin_name]
+
if schedule_name:
schedule_plugins = _get_schedule_plugins(
ctx.obj["project"],
|
{"golden_diff": "diff --git a/src/meltano/cli/install.py b/src/meltano/cli/install.py\n--- a/src/meltano/cli/install.py\n+++ b/src/meltano/cli/install.py\n@@ -18,13 +18,15 @@\n from meltano.core.project import Project\n from meltano.core.tracking import Tracker\n \n+ANY = \"-\"\n+\n logger = structlog.getLogger(__name__)\n \n \n @click.command(cls=PartialInstrumentedCmd, short_help=\"Install project dependencies.\")\n @click.argument(\n \"plugin_type\",\n- type=click.Choice(PluginType.cli_arguments()),\n+ type=click.Choice((*PluginType.cli_arguments(), ANY)),\n required=False,\n )\n @click.argument(\"plugin_name\", nargs=-1, required=False)\n@@ -74,14 +76,15 @@\n \"\"\"\n tracker: Tracker = ctx.obj[\"tracker\"]\n try:\n- if plugin_type:\n+ if plugin_type and plugin_type != ANY:\n plugin_type = PluginType.from_cli_argument(plugin_type)\n plugins = project.plugins.get_plugins_of_type(plugin_type)\n- if plugin_name:\n- plugins = [plugin for plugin in plugins if plugin.name in plugin_name]\n else:\n plugins = list(project.plugins.plugins())\n \n+ if plugin_name:\n+ plugins = [plugin for plugin in plugins if plugin.name in plugin_name]\n+\n if schedule_name:\n schedule_plugins = _get_schedule_plugins(\n ctx.obj[\"project\"],\n", "issue": "feature: Install multiple plugins of any type\n### Feature scope\r\n\r\nCLI (options, error messages, logging, etc.)\r\n\r\n### Description\r\n\r\nCurrently, you can only leverage `meltano install` in parallel for all plugin types or all plugins of a specific type:\r\n\r\n```sh\r\n# all plugins\r\nmeltano install\r\n\r\n# all extractors\r\nmeltano install [extractor|extractors]\r\n\r\n# all loaders\r\nmeltano install [loader|loaders]\r\n```\r\n\r\nIt would be great if you could install multiple plugins of any type - something like:\r\n\r\n```sh\r\nmeltano install <extractor> <loader> <transformer> <utility>\r\n```\r\n\r\nThis change would remove the need to specify a plugin type at all, since a plugin name is already unique to a Meltano project. This is currently not possible without a breaking change however, since a plugin type is required as the first argument to `meltano install` when specifying plugin names. #8228 introduced the `--from-file` option for `meltano config <plugin> set`, which accepts a special character `-` to refer to stdin - `meltano install` could reuse this or a similar concept to skip the plugin type argument and leverage parallel install:\r\n\r\n```sh\r\nmeltano install - <extractor> <loader> <transformer> <utility>\r\n```\r\n\r\nOnce a convention is established, this feature could be extended to `meltano remove` as well.\r\n\r\nI have a POC of this working for `meltano install` locally, so happy to open a PR.\n", "before_files": [{"content": "\"\"\"CLI command `meltano install`.\"\"\"\n\nfrom __future__ import annotations\n\nimport typing as t\n\nimport click\nimport structlog\n\nfrom meltano.cli.params import pass_project\nfrom meltano.cli.utils import CliError, PartialInstrumentedCmd, install_plugins\nfrom meltano.core.block.parser import BlockParser\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.schedule_service import ScheduleService\nfrom meltano.core.tracking.contexts import CliEvent, PluginsTrackingContext\n\nif t.TYPE_CHECKING:\n from meltano.core.project import Project\n from meltano.core.tracking import Tracker\n\nlogger = structlog.getLogger(__name__)\n\n\[email protected](cls=PartialInstrumentedCmd, short_help=\"Install project dependencies.\")\[email protected](\n \"plugin_type\",\n type=click.Choice(PluginType.cli_arguments()),\n required=False,\n)\[email protected](\"plugin_name\", nargs=-1, required=False)\[email protected](\n \"--clean\",\n is_flag=True,\n help=\"Completely reinstall a plugin rather than simply upgrading if necessary.\",\n)\[email protected](\n \"--parallelism\",\n \"-p\",\n type=click.INT,\n default=None,\n help=(\n \"Limit the number of plugins to install in parallel. \"\n \"Defaults to the number of cores.\"\n ),\n)\[email protected](\n \"--force\",\n \"-f\",\n is_flag=True,\n help=\"Ignore the required Python version declared by the plugins.\",\n)\[email protected](\n \"--schedule\",\n \"-s\",\n \"schedule_name\",\n help=\"Install all plugins from the given schedule.\",\n)\[email protected]_context\n@pass_project(migrate=True)\ndef install( # noqa: C901\n project: Project,\n ctx: click.Context,\n plugin_type: str,\n plugin_name: str,\n clean: bool,\n parallelism: int,\n force: bool,\n schedule_name: str,\n):\n \"\"\"\n Install all the dependencies of your project based on the meltano.yml file.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#install\n \"\"\"\n tracker: Tracker = ctx.obj[\"tracker\"]\n try:\n if plugin_type:\n plugin_type = PluginType.from_cli_argument(plugin_type)\n plugins = project.plugins.get_plugins_of_type(plugin_type)\n if plugin_name:\n plugins = [plugin for plugin in plugins if plugin.name in plugin_name]\n else:\n plugins = list(project.plugins.plugins())\n\n if schedule_name:\n schedule_plugins = _get_schedule_plugins(\n ctx.obj[\"project\"],\n schedule_name,\n )\n plugins = list(set(plugins) & set(schedule_plugins))\n except Exception:\n tracker.track_command_event(CliEvent.aborted)\n raise\n\n click.echo(f\"Installing {len(plugins)} plugins...\")\n tracker.add_contexts(\n PluginsTrackingContext([(candidate, None) for candidate in plugins]),\n )\n tracker.track_command_event(CliEvent.inflight)\n\n success = install_plugins(\n project,\n plugins,\n parallelism=parallelism,\n clean=clean,\n force=force,\n )\n if not success:\n tracker.track_command_event(CliEvent.failed)\n raise CliError(\"Failed to install plugin(s)\") # noqa: EM101\n tracker.track_command_event(CliEvent.completed)\n\n\ndef _get_schedule_plugins(project: Project, schedule_name: str):\n schedule_service = ScheduleService(project)\n schedule_obj = schedule_service.find_schedule(schedule_name)\n schedule_plugins = set()\n if schedule_obj.elt_schedule:\n for plugin_name in (schedule_obj.extractor, schedule_obj.loader):\n schedule_plugins.add(project.plugins.find_plugin(plugin_name))\n else:\n task_sets = schedule_service.task_sets_service.get(schedule_obj.job)\n for blocks in task_sets.flat_args_per_set:\n parser = BlockParser(logger, project, blocks)\n for plugin in parser.plugins:\n schedule_plugins.add(\n project.plugins.find_plugin(plugin.info.get(\"name\"))\n if plugin.type == PluginType.MAPPERS\n else plugin,\n )\n return schedule_plugins\n", "path": "src/meltano/cli/install.py"}], "after_files": [{"content": "\"\"\"CLI command `meltano install`.\"\"\"\n\nfrom __future__ import annotations\n\nimport typing as t\n\nimport click\nimport structlog\n\nfrom meltano.cli.params import pass_project\nfrom meltano.cli.utils import CliError, PartialInstrumentedCmd, install_plugins\nfrom meltano.core.block.parser import BlockParser\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.schedule_service import ScheduleService\nfrom meltano.core.tracking.contexts import CliEvent, PluginsTrackingContext\n\nif t.TYPE_CHECKING:\n from meltano.core.project import Project\n from meltano.core.tracking import Tracker\n\nANY = \"-\"\n\nlogger = structlog.getLogger(__name__)\n\n\[email protected](cls=PartialInstrumentedCmd, short_help=\"Install project dependencies.\")\[email protected](\n \"plugin_type\",\n type=click.Choice((*PluginType.cli_arguments(), ANY)),\n required=False,\n)\[email protected](\"plugin_name\", nargs=-1, required=False)\[email protected](\n \"--clean\",\n is_flag=True,\n help=\"Completely reinstall a plugin rather than simply upgrading if necessary.\",\n)\[email protected](\n \"--parallelism\",\n \"-p\",\n type=click.INT,\n default=None,\n help=(\n \"Limit the number of plugins to install in parallel. \"\n \"Defaults to the number of cores.\"\n ),\n)\[email protected](\n \"--force\",\n \"-f\",\n is_flag=True,\n help=\"Ignore the required Python version declared by the plugins.\",\n)\[email protected](\n \"--schedule\",\n \"-s\",\n \"schedule_name\",\n help=\"Install all plugins from the given schedule.\",\n)\[email protected]_context\n@pass_project(migrate=True)\ndef install( # noqa: C901\n project: Project,\n ctx: click.Context,\n plugin_type: str,\n plugin_name: str,\n clean: bool,\n parallelism: int,\n force: bool,\n schedule_name: str,\n):\n \"\"\"\n Install all the dependencies of your project based on the meltano.yml file.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#install\n \"\"\"\n tracker: Tracker = ctx.obj[\"tracker\"]\n try:\n if plugin_type and plugin_type != ANY:\n plugin_type = PluginType.from_cli_argument(plugin_type)\n plugins = project.plugins.get_plugins_of_type(plugin_type)\n else:\n plugins = list(project.plugins.plugins())\n\n if plugin_name:\n plugins = [plugin for plugin in plugins if plugin.name in plugin_name]\n\n if schedule_name:\n schedule_plugins = _get_schedule_plugins(\n ctx.obj[\"project\"],\n schedule_name,\n )\n plugins = list(set(plugins) & set(schedule_plugins))\n except Exception:\n tracker.track_command_event(CliEvent.aborted)\n raise\n\n click.echo(f\"Installing {len(plugins)} plugins...\")\n tracker.add_contexts(\n PluginsTrackingContext([(candidate, None) for candidate in plugins]),\n )\n tracker.track_command_event(CliEvent.inflight)\n\n success = install_plugins(\n project,\n plugins,\n parallelism=parallelism,\n clean=clean,\n force=force,\n )\n if not success:\n tracker.track_command_event(CliEvent.failed)\n raise CliError(\"Failed to install plugin(s)\") # noqa: EM101\n tracker.track_command_event(CliEvent.completed)\n\n\ndef _get_schedule_plugins(project: Project, schedule_name: str):\n schedule_service = ScheduleService(project)\n schedule_obj = schedule_service.find_schedule(schedule_name)\n schedule_plugins = set()\n if schedule_obj.elt_schedule:\n for plugin_name in (schedule_obj.extractor, schedule_obj.loader):\n schedule_plugins.add(project.plugins.find_plugin(plugin_name))\n else:\n task_sets = schedule_service.task_sets_service.get(schedule_obj.job)\n for blocks in task_sets.flat_args_per_set:\n parser = BlockParser(logger, project, blocks)\n for plugin in parser.plugins:\n schedule_plugins.add(\n project.plugins.find_plugin(plugin.info.get(\"name\"))\n if plugin.type == PluginType.MAPPERS\n else plugin,\n )\n return schedule_plugins\n", "path": "src/meltano/cli/install.py"}]}
| 1,742 | 309 |
gh_patches_debug_31034
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-688
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Encode error when downloading files with non-ASCII filenames.
<!--
Thanks for reporting issues of python-telegram-bot!
To make it easier for us to help you please enter detailed information below.
Please note, we only support the latest version of python-telegram-bot and
master branch. Please make sure to upgrade & recreate the issue on the latest
version prior to opening an issue.
-->
### Steps to reproduce
1. `head /dev/random > 凵冂工匚口わ巨` and send the file to a bot.
2.
```python
import telegram
b = telegram.Bot(TOKEN)
file_id = b.getUpdates()[0].message.document.file_id
b.getFile(file_id).download("./storage")
```
### Expected behaviour
Tell us what should happen
Download the file to specified directory.
### Actual behaviour
Tell us what happens instead
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/site-packages/telegram/file.py", line 106, in download
self.bot.request.download(url, filename, timeout=timeout)
File "/usr/local/lib/python3.6/site-packages/telegram/utils/request.py", line 284, in download
buf = self.retrieve(url, timeout=timeout)
File "/usr/local/lib/python3.6/site-packages/telegram/utils/request.py", line 270, in retrieve
return self._request_wrapper('GET', url, **urlopen_kwargs)
File "/usr/local/lib/python3.6/site-packages/telegram/utils/request.py", line 174, in _request_wrapper
resp = self._con_pool.request(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/request.py", line 66, in request
**urlopen_kw)
File "/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/request.py", line 87, in request_encode_url
return self.urlopen(method, url, **extra_kw)
File "/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/poolmanager.py", line 244, in urlopen
response = conn.urlopen(method, u.request_uri, **kw)
File "/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/connectionpool.py", line 617, in urlopen
chunked=chunked)
File "/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/connectionpool.py", line 390, in _make_request
conn.request(method, url, **httplib_request_kw)
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py", line 1239, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py", line 1250, in _send_request
self.putrequest(method, url, **skips)
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py", line 1117, in putrequest
self._output(request.encode('ascii'))
UnicodeEncodeError: 'ascii' codec can't encode characters in position 69-75: ordinal not in range(128)
'ascii' codec can't encode characters in position 69-75: ordinal not in range(128)
```
### Configuration
**Operating System:**
Tested on:
- Mac OS X 10.11
- Ubuntu 16.04
**Version of Python, python-telegram-bot & dependencies:**
``$ python -m telegram``
```
python-telegram-bot 6.0.3
urllib3 1.21.1
certifi 2017.04.17
future 0.16.0
Python 3.6.1 (default, Mar 23 2017, 16:49:01) [GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.42.1)]
```
### Possible Solution
URL escape the "download path" given by `getFile`, then download.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `telegram/files/file.py`
Content:
```
1 #!/usr/bin/env python
2 #
3 # A library that provides a Python interface to the Telegram Bot API
4 # Copyright (C) 2015-2017
5 # Leandro Toledo de Souza <[email protected]>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Lesser Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Lesser Public License for more details.
16 #
17 # You should have received a copy of the GNU Lesser Public License
18 # along with this program. If not, see [http://www.gnu.org/licenses/].
19 """This module contains an object that represents a Telegram File."""
20
21 from os.path import basename
22
23 from telegram import TelegramObject
24
25
26 class File(TelegramObject):
27 """This object represents a Telegram File.
28
29 Attributes:
30 file_id (str):
31 file_size (str):
32 file_path (str):
33
34 Args:
35 file_id (str):
36 bot (telegram.Bot):
37 file_size (Optional[int]):
38 file_path (Optional[str]):
39 **kwargs (dict): Arbitrary keyword arguments.
40
41 """
42
43 def __init__(self, file_id, bot, file_size=None, file_path=None, **kwargs):
44 # Required
45 self.file_id = str(file_id)
46
47 # Optionals
48 self.file_size = file_size
49 if file_path:
50 self.file_path = str(file_path)
51
52 self.bot = bot
53
54 self._id_attrs = (self.file_id,)
55
56 @staticmethod
57 def de_json(data, bot):
58 """
59 Args:
60 data (dict):
61 bot (telegram.Bot):
62
63 Returns:
64 telegram.File:
65 """
66 if not data:
67 return None
68
69 return File(bot=bot, **data)
70
71 def download(self, custom_path=None, out=None, timeout=None):
72 """
73 Download this file. By default, the file is saved in the current working directory with its
74 original filename as reported by Telegram. If a ``custom_path`` is supplied, it will be
75 saved to that path instead. If ``out`` is defined, the file contents will be saved to that
76 object using the ``out.write`` method. ``custom_path`` and ``out`` are mutually exclusive.
77
78 Args:
79 custom_path (Optional[str]): Custom path.
80 out (Optional[object]): A file-like object. Must be opened in binary mode, if
81 applicable.
82 timeout (Optional[int|float]): If this value is specified, use it as the read timeout
83 from the server (instead of the one specified during creation of the connection
84 pool).
85
86 Raises:
87 ValueError: If both ``custom_path`` and ``out`` are passed.
88
89 """
90
91 if custom_path is not None and out is not None:
92 raise ValueError('custom_path and out are mutually exclusive')
93
94 url = self.file_path
95
96 if out:
97 buf = self.bot.request.retrieve(url)
98 out.write(buf)
99
100 else:
101 if custom_path:
102 filename = custom_path
103 else:
104 filename = basename(url)
105
106 self.bot.request.download(url, filename, timeout=timeout)
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/telegram/files/file.py b/telegram/files/file.py
--- a/telegram/files/file.py
+++ b/telegram/files/file.py
@@ -17,9 +17,10 @@
# You should have received a copy of the GNU Lesser Public License
# along with this program. If not, see [http://www.gnu.org/licenses/].
"""This module contains an object that represents a Telegram File."""
-
from os.path import basename
+from future.backports.urllib import parse as urllib_parse
+
from telegram import TelegramObject
@@ -46,8 +47,7 @@
# Optionals
self.file_size = file_size
- if file_path:
- self.file_path = str(file_path)
+ self.file_path = file_path
self.bot = bot
@@ -91,7 +91,10 @@
if custom_path is not None and out is not None:
raise ValueError('custom_path and out are mutually exclusive')
- url = self.file_path
+ # Convert any UTF-8 char into a url encoded ASCII string.
+ sres = urllib_parse.urlsplit(self.file_path)
+ url = urllib_parse.urlunsplit(urllib_parse.SplitResult(
+ sres.scheme, sres.netloc, urllib_parse.quote(sres.path), sres.query, sres.fragment))
if out:
buf = self.bot.request.retrieve(url)
@@ -101,6 +104,6 @@
if custom_path:
filename = custom_path
else:
- filename = basename(url)
+ filename = basename(self.file_path)
self.bot.request.download(url, filename, timeout=timeout)
|
{"golden_diff": "diff --git a/telegram/files/file.py b/telegram/files/file.py\n--- a/telegram/files/file.py\n+++ b/telegram/files/file.py\n@@ -17,9 +17,10 @@\n # You should have received a copy of the GNU Lesser Public License\n # along with this program. If not, see [http://www.gnu.org/licenses/].\n \"\"\"This module contains an object that represents a Telegram File.\"\"\"\n-\n from os.path import basename\n \n+from future.backports.urllib import parse as urllib_parse\n+\n from telegram import TelegramObject\n \n \n@@ -46,8 +47,7 @@\n \n # Optionals\n self.file_size = file_size\n- if file_path:\n- self.file_path = str(file_path)\n+ self.file_path = file_path\n \n self.bot = bot\n \n@@ -91,7 +91,10 @@\n if custom_path is not None and out is not None:\n raise ValueError('custom_path and out are mutually exclusive')\n \n- url = self.file_path\n+ # Convert any UTF-8 char into a url encoded ASCII string.\n+ sres = urllib_parse.urlsplit(self.file_path)\n+ url = urllib_parse.urlunsplit(urllib_parse.SplitResult(\n+ sres.scheme, sres.netloc, urllib_parse.quote(sres.path), sres.query, sres.fragment))\n \n if out:\n buf = self.bot.request.retrieve(url)\n@@ -101,6 +104,6 @@\n if custom_path:\n filename = custom_path\n else:\n- filename = basename(url)\n+ filename = basename(self.file_path)\n \n self.bot.request.download(url, filename, timeout=timeout)\n", "issue": "Encode error when downloading files with non-ASCII filenames.\n<!--\r\nThanks for reporting issues of python-telegram-bot!\r\nTo make it easier for us to help you please enter detailed information below.\r\n\r\nPlease note, we only support the latest version of python-telegram-bot and\r\nmaster branch. Please make sure to upgrade & recreate the issue on the latest\r\nversion prior to opening an issue.\r\n-->\r\n### Steps to reproduce\r\n1. `head /dev/random > \u51f5\u5182\u5de5\u531a\u53e3\u308f\u5de8` and send the file to a bot.\r\n2. \r\n```python\r\nimport telegram\r\nb = telegram.Bot(TOKEN)\r\nfile_id = b.getUpdates()[0].message.document.file_id\r\nb.getFile(file_id).download(\"./storage\")\r\n```\r\n### Expected behaviour\r\nTell us what should happen\r\n\r\nDownload the file to specified directory.\r\n\r\n### Actual behaviour\r\nTell us what happens instead\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/file.py\", line 106, in download\r\n self.bot.request.download(url, filename, timeout=timeout)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/utils/request.py\", line 284, in download\r\n buf = self.retrieve(url, timeout=timeout)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/utils/request.py\", line 270, in retrieve\r\n return self._request_wrapper('GET', url, **urlopen_kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/utils/request.py\", line 174, in _request_wrapper\r\n resp = self._con_pool.request(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/request.py\", line 66, in request\r\n **urlopen_kw)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/request.py\", line 87, in request_encode_url\r\n return self.urlopen(method, url, **extra_kw)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/poolmanager.py\", line 244, in urlopen\r\n response = conn.urlopen(method, u.request_uri, **kw)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/connectionpool.py\", line 617, in urlopen\r\n chunked=chunked)\r\n File \"/usr/local/lib/python3.6/site-packages/telegram/vendor/ptb_urllib3/urllib3/connectionpool.py\", line 390, in _make_request\r\n conn.request(method, url, **httplib_request_kw)\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py\", line 1239, in request\r\n self._send_request(method, url, body, headers, encode_chunked)\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py\", line 1250, in _send_request\r\n self.putrequest(method, url, **skips)\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py\", line 1117, in putrequest\r\n self._output(request.encode('ascii'))\r\nUnicodeEncodeError: 'ascii' codec can't encode characters in position 69-75: ordinal not in range(128)\r\n'ascii' codec can't encode characters in position 69-75: ordinal not in range(128)\r\n```\r\n\r\n### Configuration\r\n**Operating System:**\r\nTested on:\r\n- Mac OS X 10.11\r\n- Ubuntu 16.04\r\n\r\n**Version of Python, python-telegram-bot & dependencies:**\r\n\r\n``$ python -m telegram``\r\n\r\n```\r\npython-telegram-bot 6.0.3\r\nurllib3 1.21.1\r\ncertifi 2017.04.17\r\nfuture 0.16.0\r\nPython 3.6.1 (default, Mar 23 2017, 16:49:01) [GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.42.1)]\r\n```\r\n\r\n### Possible Solution\r\nURL escape the \"download path\" given by `getFile`, then download.\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains an object that represents a Telegram File.\"\"\"\n\nfrom os.path import basename\n\nfrom telegram import TelegramObject\n\n\nclass File(TelegramObject):\n \"\"\"This object represents a Telegram File.\n\n Attributes:\n file_id (str):\n file_size (str):\n file_path (str):\n\n Args:\n file_id (str):\n bot (telegram.Bot):\n file_size (Optional[int]):\n file_path (Optional[str]):\n **kwargs (dict): Arbitrary keyword arguments.\n\n \"\"\"\n\n def __init__(self, file_id, bot, file_size=None, file_path=None, **kwargs):\n # Required\n self.file_id = str(file_id)\n\n # Optionals\n self.file_size = file_size\n if file_path:\n self.file_path = str(file_path)\n\n self.bot = bot\n\n self._id_attrs = (self.file_id,)\n\n @staticmethod\n def de_json(data, bot):\n \"\"\"\n Args:\n data (dict):\n bot (telegram.Bot):\n\n Returns:\n telegram.File:\n \"\"\"\n if not data:\n return None\n\n return File(bot=bot, **data)\n\n def download(self, custom_path=None, out=None, timeout=None):\n \"\"\"\n Download this file. By default, the file is saved in the current working directory with its\n original filename as reported by Telegram. If a ``custom_path`` is supplied, it will be\n saved to that path instead. If ``out`` is defined, the file contents will be saved to that\n object using the ``out.write`` method. ``custom_path`` and ``out`` are mutually exclusive.\n\n Args:\n custom_path (Optional[str]): Custom path.\n out (Optional[object]): A file-like object. Must be opened in binary mode, if\n applicable.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Raises:\n ValueError: If both ``custom_path`` and ``out`` are passed.\n\n \"\"\"\n\n if custom_path is not None and out is not None:\n raise ValueError('custom_path and out are mutually exclusive')\n\n url = self.file_path\n\n if out:\n buf = self.bot.request.retrieve(url)\n out.write(buf)\n\n else:\n if custom_path:\n filename = custom_path\n else:\n filename = basename(url)\n\n self.bot.request.download(url, filename, timeout=timeout)\n", "path": "telegram/files/file.py"}], "after_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\"This module contains an object that represents a Telegram File.\"\"\"\nfrom os.path import basename\n\nfrom future.backports.urllib import parse as urllib_parse\n\nfrom telegram import TelegramObject\n\n\nclass File(TelegramObject):\n \"\"\"This object represents a Telegram File.\n\n Attributes:\n file_id (str):\n file_size (str):\n file_path (str):\n\n Args:\n file_id (str):\n bot (telegram.Bot):\n file_size (Optional[int]):\n file_path (Optional[str]):\n **kwargs (dict): Arbitrary keyword arguments.\n\n \"\"\"\n\n def __init__(self, file_id, bot, file_size=None, file_path=None, **kwargs):\n # Required\n self.file_id = str(file_id)\n\n # Optionals\n self.file_size = file_size\n self.file_path = file_path\n\n self.bot = bot\n\n self._id_attrs = (self.file_id,)\n\n @staticmethod\n def de_json(data, bot):\n \"\"\"\n Args:\n data (dict):\n bot (telegram.Bot):\n\n Returns:\n telegram.File:\n \"\"\"\n if not data:\n return None\n\n return File(bot=bot, **data)\n\n def download(self, custom_path=None, out=None, timeout=None):\n \"\"\"\n Download this file. By default, the file is saved in the current working directory with its\n original filename as reported by Telegram. If a ``custom_path`` is supplied, it will be\n saved to that path instead. If ``out`` is defined, the file contents will be saved to that\n object using the ``out.write`` method. ``custom_path`` and ``out`` are mutually exclusive.\n\n Args:\n custom_path (Optional[str]): Custom path.\n out (Optional[object]): A file-like object. Must be opened in binary mode, if\n applicable.\n timeout (Optional[int|float]): If this value is specified, use it as the read timeout\n from the server (instead of the one specified during creation of the connection\n pool).\n\n Raises:\n ValueError: If both ``custom_path`` and ``out`` are passed.\n\n \"\"\"\n\n if custom_path is not None and out is not None:\n raise ValueError('custom_path and out are mutually exclusive')\n\n # Convert any UTF-8 char into a url encoded ASCII string.\n sres = urllib_parse.urlsplit(self.file_path)\n url = urllib_parse.urlunsplit(urllib_parse.SplitResult(\n sres.scheme, sres.netloc, urllib_parse.quote(sres.path), sres.query, sres.fragment))\n\n if out:\n buf = self.bot.request.retrieve(url)\n out.write(buf)\n\n else:\n if custom_path:\n filename = custom_path\n else:\n filename = basename(self.file_path)\n\n self.bot.request.download(url, filename, timeout=timeout)\n", "path": "telegram/files/file.py"}]}
| 2,245 | 365 |
gh_patches_debug_39120
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-887
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add label to pod so that users know the job has finished
TensorBoard needs to keep running even when tasks are finished. We should add labels to master pod so that users know the job has finished.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/master/k8s_worker_manager.py`
Content:
```
1 import itertools
2 import logging
3 import threading
4 from collections import Counter
5
6 from elasticdl.python.common import k8s_client as k8s
7 from elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient
8
9
10 class WorkerManager(object):
11 def __init__(
12 self,
13 task_d,
14 command,
15 args,
16 num_workers=1,
17 worker_resource_request="cpu=1,memory=4096Mi",
18 worker_resource_limit="cpu=1,memory=4096Mi",
19 pod_priority=None,
20 volume=None,
21 image_pull_policy=None,
22 restart_policy="Never",
23 **kwargs
24 ):
25 self._logger = logging.getLogger(__name__)
26 self._command = command
27 self._args = args
28 self._num_workers = num_workers
29
30 self._resource_requests = worker_resource_request
31 self._resource_limits = worker_resource_limit
32 self._restart_policy = restart_policy
33 self._pod_priority = pod_priority
34 self._volume = volume
35 self._image_pull_policy = image_pull_policy
36 self._task_d = task_d
37 self._next_worker_id = itertools.count().__next__
38
39 # protects followed variables, which are accessed from event_cb.
40 self._lock = threading.Lock()
41 # worker id to (pod name, phase) mapping
42 # phase: None/Pending/Running/Succeeded/Failed/Unknown
43 # None: worker was just launched, haven't received event yet.
44 # Pending: worker pod not started yet
45 # Running: worker pod is running
46 # Succeeded: worker pod finishes all tasks and terminates with
47 # no issue.
48 # Failed: worker pod is killed for some reason
49 # Unknown: unknown
50 self._pods_phase = {}
51 # pod name to worker id mapping
52 self._pod_name_to_id = {}
53
54 self._relaunch_deleted_live_worker = True
55
56 self._k8s_client = k8s.Client(event_callback=self._event_cb, **kwargs)
57
58 def set_relaunch_deleted_live_worker(self, val):
59 self._relaunch_deleted_live_worker = bool(val)
60
61 def _start_worker(self, worker_id):
62 self._logger.info("Starting worker: %d" % worker_id)
63 with self._lock:
64 pod = self._k8s_client.create_worker(
65 worker_id=worker_id,
66 resource_requests=self._resource_requests,
67 resource_limits=self._resource_limits,
68 pod_priority=self._pod_priority,
69 volume=self._volume,
70 image_pull_policy=self._image_pull_policy,
71 command=self._command,
72 args=self._args + ["--worker_id", str(worker_id)],
73 restart_policy=self._restart_policy,
74 )
75 name = pod.metadata.name
76 self._pod_name_to_id[name] = worker_id
77 self._pods_phase[worker_id] = (name, None)
78
79 def start_workers(self):
80 for i in range(self._num_workers):
81 self._start_worker(self._next_worker_id())
82
83 def start_tensorboard_service(self):
84 tb_client = TensorBoardClient(self._k8s_client)
85 tb_client.create_tensorboard_service()
86 tb_external_ip = tb_client.get_tensorboard_external_ip()
87 self._logger.info(
88 "TensorBoard service is available at external IP: %s"
89 % tb_external_ip
90 )
91
92 def _remove_worker(self, worker_id):
93 self._logger.info("Removing worker: %d", worker_id)
94 with self._lock:
95 if worker_id not in self._pods_phase:
96 self._logger.error("Unknown worker id: %s" % worker_id)
97 return
98
99 # TODO: change _k8s_client to accept pod name instead of worker id.
100 self._k8s_client.delete_worker(worker_id)
101
102 def stop_relaunch_and_remove_workers(self):
103 with self._lock:
104 self._relaunch_deleted_live_worker = False
105 for worker_id in self._pods_phase:
106 self._k8s_client.delete_worker(worker_id)
107
108 def get_counters(self):
109 with self._lock:
110 return Counter([v for _, v in self._pods_phase.values()])
111
112 def _event_cb(self, event):
113 evt_obj = event.get("object")
114 evt_type = event.get("type")
115 if not evt_obj or not evt_type:
116 self._logger.error("Event doesn't have object or type: %s" % event)
117 return
118
119 pod_name = evt_obj.metadata.name
120 phase = evt_obj.status.phase
121 self._logger.info(
122 "Got event %s, phase %s for pod: %s" % (evt_type, phase, pod_name)
123 )
124
125 relaunch = False
126 with self._lock:
127 worker_id = self._pod_name_to_id.get(pod_name)
128 if (
129 worker_id is None
130 and pod_name != self._k8s_client.get_master_pod_name()
131 ):
132 self._logger.error("Unknown worker pod name: %s" % pod_name)
133 return
134
135 self._pods_phase[worker_id] = (pod_name, phase)
136 if evt_type == "DELETED":
137 del self._pods_phase[worker_id]
138 del self._pod_name_to_id[pod_name]
139 self._task_d.recover_tasks(worker_id)
140
141 # If a deleted pod was not "Succeeded", relaunch a worker.
142 relaunch = (
143 self._relaunch_deleted_live_worker and phase != "Succeeded"
144 )
145 if relaunch:
146 self._logger.info("Relaunching worker.")
147 self._start_worker(self._next_worker_id())
148
```
Path: `elasticdl/python/common/constants.py`
Content:
```
1 class GRPC(object):
2 # gRPC limits the size of message by default to 4MB.
3 # It's too small to send model parameters.
4 MAX_SEND_MESSAGE_LENGTH = 256 * 1024 * 1024
5 MAX_RECEIVE_MESSAGE_LENGTH = 256 * 1024 * 1024
6
```
Path: `elasticdl/python/master/main.py`
Content:
```
1 import logging
2 import os
3 import time
4 from concurrent import futures
5 from contextlib import closing
6
7 import grpc
8 import recordio
9
10 from elasticdl.proto import elasticdl_pb2_grpc
11 from elasticdl.python.common.constants import GRPC
12 from elasticdl.python.common.model_helper import get_model_file, load_module
13 from elasticdl.python.master.args import parse_args
14 from elasticdl.python.master.checkpoint_service import CheckpointService
15 from elasticdl.python.master.evaluation_service import EvaluationService
16 from elasticdl.python.master.k8s_worker_manager import WorkerManager
17 from elasticdl.python.master.servicer import MasterServicer
18 from elasticdl.python.master.task_dispatcher import _TaskDispatcher
19 from elasticdl.python.master.tensorboard_service import TensorboardService
20
21
22 def _make_task_dispatcher(
23 training_data_dir,
24 evaluation_data_dir,
25 prediction_data_dir,
26 records_per_task,
27 num_epochs,
28 ):
29 def _collect_file_records_from_dir(data_dir):
30 if not data_dir:
31 return {}
32 f_records = {}
33 for f in os.listdir(data_dir):
34 p = os.path.join(data_dir, f)
35 with closing(recordio.Index(p)) as rio:
36 f_records[p] = rio.num_records()
37 return f_records
38
39 training_f_records = _collect_file_records_from_dir(training_data_dir)
40 evaluation_f_records = _collect_file_records_from_dir(evaluation_data_dir)
41 prediction_f_records = _collect_file_records_from_dir(prediction_data_dir)
42
43 return _TaskDispatcher(
44 training_f_records,
45 evaluation_f_records,
46 prediction_f_records,
47 records_per_task,
48 # Only generate prediction tasks for 1 epoch
49 1 if prediction_f_records else num_epochs,
50 )
51
52
53 def main():
54 args = parse_args()
55
56 # Initialize logger and set level for ROOT logger
57 logging.basicConfig(
58 format="%(asctime)s %(name)s %(levelname)-8s "
59 "[%(filename)s:%(lineno)d] %(message)s"
60 )
61 logging.getLogger().setLevel(args.log_level)
62 logger = logging.getLogger(__name__)
63
64 # Start tensorboard service if required
65 if args.tensorboard_log_dir:
66 logger.info(
67 "Starting tensorboard service with log directory %s",
68 args.tensorboard_log_dir,
69 )
70 tb_service = TensorboardService(args.tensorboard_log_dir)
71 tb_service.start()
72 else:
73 tb_service = None
74
75 # Start task queue
76 logger.info(
77 "Starting task queue with training data directory %s "
78 "and evaluation data directory %s",
79 args.training_data_dir,
80 args.evaluation_data_dir,
81 )
82 task_d = _make_task_dispatcher(
83 args.training_data_dir,
84 args.evaluation_data_dir,
85 args.prediction_data_dir,
86 args.records_per_task,
87 args.num_epochs,
88 )
89 model_module = load_module(get_model_file(args.model_def))
90 model_inst = model_module.model
91 optimizer = model_module.optimizer()
92
93 evaluation_while_training = all(
94 (
95 args.training_data_dir,
96 args.evaluation_data_dir,
97 args.evaluation_throttle_secs or args.evaluation_steps,
98 )
99 )
100 evaluation_only = args.evaluation_data_dir and not args.training_data_dir
101
102 # Initialize checkpoint service
103 if args.checkpoint_steps or evaluation_while_training:
104 logger.info("Starting checkpoint service")
105 checkpoint_service = CheckpointService(
106 args.checkpoint_dir,
107 args.checkpoint_steps,
108 args.keep_checkpoint_max,
109 evaluation_while_training,
110 )
111 else:
112 checkpoint_service = None
113
114 # Initialize evaluation service
115 evaluation_service = None
116 if evaluation_while_training or evaluation_only:
117 logger.info(
118 "Starting evaluation service with throttle seconds %d ",
119 " and evaluation steps %d",
120 args.evaluation_throttle_secs,
121 args.evaluation_steps,
122 )
123 evaluation_service = EvaluationService(
124 checkpoint_service,
125 tb_service,
126 task_d,
127 args.evaluation_start_delay_secs,
128 args.evaluation_throttle_secs,
129 args.evaluation_steps,
130 evaluation_only,
131 )
132 evaluation_service.start()
133 task_d.set_evaluation_service(evaluation_service)
134
135 # The master service
136 logger.info("Starting master service")
137 server = grpc.server(
138 futures.ThreadPoolExecutor(max_workers=64),
139 options=[
140 ("grpc.max_send_message_length", GRPC.MAX_SEND_MESSAGE_LENGTH),
141 (
142 "grpc.max_receive_message_length",
143 GRPC.MAX_RECEIVE_MESSAGE_LENGTH,
144 ),
145 ],
146 )
147 master_servicer = MasterServicer(
148 args.grads_to_wait,
149 args.minibatch_size,
150 optimizer,
151 task_d,
152 init_var=model_inst.trainable_variables if model_inst.built else [],
153 checkpoint_filename_for_init=args.checkpoint_filename_for_init,
154 checkpoint_service=checkpoint_service,
155 evaluation_service=evaluation_service,
156 )
157 elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)
158 server.add_insecure_port("[::]:{}".format(args.port))
159 server.start()
160 logger.info("Server started at port: %d", args.port)
161
162 if args.num_workers:
163 assert args.worker_image, "Worker image cannot be empty"
164
165 master_addr = "%s:%d" % (
166 os.getenv("MY_POD_IP", "localhost"),
167 args.port,
168 )
169 worker_command = ["python"]
170 worker_args = [
171 "-m",
172 "elasticdl.python.worker.main",
173 "--model_def",
174 args.model_def,
175 "--master_addr",
176 master_addr,
177 "--log_level",
178 args.log_level,
179 ]
180
181 args.worker_resource_limit = (
182 args.worker_resource_limit
183 if args.worker_resource_limit
184 else args.worker_resource_request
185 )
186
187 worker_manager = WorkerManager(
188 task_d,
189 job_name=args.job_name,
190 image_name=args.worker_image,
191 command=worker_command,
192 args=worker_args,
193 namespace=args.namespace,
194 num_workers=args.num_workers,
195 worker_resource_request=args.worker_resource_request,
196 worker_resource_limit=args.worker_resource_limit,
197 pod_priority=args.worker_pod_priority,
198 volume=args.volume,
199 image_pull_policy=args.image_pull_policy,
200 restart_policy=args.restart_policy,
201 )
202 logger.info("Launching %d workers", args.num_workers)
203 worker_manager.start_workers()
204
205 if tb_service:
206 worker_manager.start_tensorboard_service()
207
208 try:
209 while True:
210 if task_d.finished():
211 break
212 time.sleep(30)
213 except KeyboardInterrupt:
214 logger.warning("Server stopping")
215
216 if evaluation_service:
217 logger.info("Stopping evaluation service")
218 evaluation_service.stop()
219
220 logger.info("Stopping RPC server")
221 server.stop(0)
222
223 # Keep TensorBoard running when all the tasks are finished
224 if tb_service:
225 logger.info(
226 "All tasks finished. Keeping TensorBoard service running..."
227 )
228 tb_service.keep_running()
229 logger.info("Master stopped")
230
231
232 if __name__ == "__main__":
233 main()
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/common/constants.py b/elasticdl/python/common/constants.py
--- a/elasticdl/python/common/constants.py
+++ b/elasticdl/python/common/constants.py
@@ -3,3 +3,9 @@
# It's too small to send model parameters.
MAX_SEND_MESSAGE_LENGTH = 256 * 1024 * 1024
MAX_RECEIVE_MESSAGE_LENGTH = 256 * 1024 * 1024
+
+
+class WorkerManagerStatus(object):
+ PENDING = "Pending"
+ RUNNING = "Running"
+ FINISHED = "Finished"
diff --git a/elasticdl/python/master/k8s_worker_manager.py b/elasticdl/python/master/k8s_worker_manager.py
--- a/elasticdl/python/master/k8s_worker_manager.py
+++ b/elasticdl/python/master/k8s_worker_manager.py
@@ -76,6 +76,12 @@
self._pod_name_to_id[name] = worker_id
self._pods_phase[worker_id] = (name, None)
+ def update_status(self, status):
+ master_name = self._k8s_client.get_master_pod_name()
+ self._k8s_client.patch_labels_to_pod(
+ master_name, labels_dict={"status": status}
+ )
+
def start_workers(self):
for i in range(self._num_workers):
self._start_worker(self._next_worker_id())
diff --git a/elasticdl/python/master/main.py b/elasticdl/python/master/main.py
--- a/elasticdl/python/master/main.py
+++ b/elasticdl/python/master/main.py
@@ -8,7 +8,7 @@
import recordio
from elasticdl.proto import elasticdl_pb2_grpc
-from elasticdl.python.common.constants import GRPC
+from elasticdl.python.common.constants import GRPC, WorkerManagerStatus
from elasticdl.python.common.model_helper import get_model_file, load_module
from elasticdl.python.master.args import parse_args
from elasticdl.python.master.checkpoint_service import CheckpointService
@@ -159,6 +159,7 @@
server.start()
logger.info("Server started at port: %d", args.port)
+ worker_manager = None
if args.num_workers:
assert args.worker_image, "Worker image cannot be empty"
@@ -199,8 +200,10 @@
image_pull_policy=args.image_pull_policy,
restart_policy=args.restart_policy,
)
+ worker_manager.update_status(WorkerManagerStatus.PENDING)
logger.info("Launching %d workers", args.num_workers)
worker_manager.start_workers()
+ worker_manager.update_status(WorkerManagerStatus.RUNNING)
if tb_service:
worker_manager.start_tensorboard_service()
@@ -208,6 +211,8 @@
try:
while True:
if task_d.finished():
+ if worker_manager:
+ worker_manager.update_status(WorkerManagerStatus.FINISHED)
break
time.sleep(30)
except KeyboardInterrupt:
|
{"golden_diff": "diff --git a/elasticdl/python/common/constants.py b/elasticdl/python/common/constants.py\n--- a/elasticdl/python/common/constants.py\n+++ b/elasticdl/python/common/constants.py\n@@ -3,3 +3,9 @@\n # It's too small to send model parameters.\n MAX_SEND_MESSAGE_LENGTH = 256 * 1024 * 1024\n MAX_RECEIVE_MESSAGE_LENGTH = 256 * 1024 * 1024\n+\n+\n+class WorkerManagerStatus(object):\n+ PENDING = \"Pending\"\n+ RUNNING = \"Running\"\n+ FINISHED = \"Finished\"\ndiff --git a/elasticdl/python/master/k8s_worker_manager.py b/elasticdl/python/master/k8s_worker_manager.py\n--- a/elasticdl/python/master/k8s_worker_manager.py\n+++ b/elasticdl/python/master/k8s_worker_manager.py\n@@ -76,6 +76,12 @@\n self._pod_name_to_id[name] = worker_id\n self._pods_phase[worker_id] = (name, None)\n \n+ def update_status(self, status):\n+ master_name = self._k8s_client.get_master_pod_name()\n+ self._k8s_client.patch_labels_to_pod(\n+ master_name, labels_dict={\"status\": status}\n+ )\n+\n def start_workers(self):\n for i in range(self._num_workers):\n self._start_worker(self._next_worker_id())\ndiff --git a/elasticdl/python/master/main.py b/elasticdl/python/master/main.py\n--- a/elasticdl/python/master/main.py\n+++ b/elasticdl/python/master/main.py\n@@ -8,7 +8,7 @@\n import recordio\n \n from elasticdl.proto import elasticdl_pb2_grpc\n-from elasticdl.python.common.constants import GRPC\n+from elasticdl.python.common.constants import GRPC, WorkerManagerStatus\n from elasticdl.python.common.model_helper import get_model_file, load_module\n from elasticdl.python.master.args import parse_args\n from elasticdl.python.master.checkpoint_service import CheckpointService\n@@ -159,6 +159,7 @@\n server.start()\n logger.info(\"Server started at port: %d\", args.port)\n \n+ worker_manager = None\n if args.num_workers:\n assert args.worker_image, \"Worker image cannot be empty\"\n \n@@ -199,8 +200,10 @@\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n )\n+ worker_manager.update_status(WorkerManagerStatus.PENDING)\n logger.info(\"Launching %d workers\", args.num_workers)\n worker_manager.start_workers()\n+ worker_manager.update_status(WorkerManagerStatus.RUNNING)\n \n if tb_service:\n worker_manager.start_tensorboard_service()\n@@ -208,6 +211,8 @@\n try:\n while True:\n if task_d.finished():\n+ if worker_manager:\n+ worker_manager.update_status(WorkerManagerStatus.FINISHED)\n break\n time.sleep(30)\n except KeyboardInterrupt:\n", "issue": "Add label to pod so that users know the job has finished\nTensorBoard needs to keep running even when tasks are finished. We should add labels to master pod so that users know the job has finished.\n", "before_files": [{"content": "import itertools\nimport logging\nimport threading\nfrom collections import Counter\n\nfrom elasticdl.python.common import k8s_client as k8s\nfrom elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient\n\n\nclass WorkerManager(object):\n def __init__(\n self,\n task_d,\n command,\n args,\n num_workers=1,\n worker_resource_request=\"cpu=1,memory=4096Mi\",\n worker_resource_limit=\"cpu=1,memory=4096Mi\",\n pod_priority=None,\n volume=None,\n image_pull_policy=None,\n restart_policy=\"Never\",\n **kwargs\n ):\n self._logger = logging.getLogger(__name__)\n self._command = command\n self._args = args\n self._num_workers = num_workers\n\n self._resource_requests = worker_resource_request\n self._resource_limits = worker_resource_limit\n self._restart_policy = restart_policy\n self._pod_priority = pod_priority\n self._volume = volume\n self._image_pull_policy = image_pull_policy\n self._task_d = task_d\n self._next_worker_id = itertools.count().__next__\n\n # protects followed variables, which are accessed from event_cb.\n self._lock = threading.Lock()\n # worker id to (pod name, phase) mapping\n # phase: None/Pending/Running/Succeeded/Failed/Unknown\n # None: worker was just launched, haven't received event yet.\n # Pending: worker pod not started yet\n # Running: worker pod is running\n # Succeeded: worker pod finishes all tasks and terminates with\n # no issue.\n # Failed: worker pod is killed for some reason\n # Unknown: unknown\n self._pods_phase = {}\n # pod name to worker id mapping\n self._pod_name_to_id = {}\n\n self._relaunch_deleted_live_worker = True\n\n self._k8s_client = k8s.Client(event_callback=self._event_cb, **kwargs)\n\n def set_relaunch_deleted_live_worker(self, val):\n self._relaunch_deleted_live_worker = bool(val)\n\n def _start_worker(self, worker_id):\n self._logger.info(\"Starting worker: %d\" % worker_id)\n with self._lock:\n pod = self._k8s_client.create_worker(\n worker_id=worker_id,\n resource_requests=self._resource_requests,\n resource_limits=self._resource_limits,\n pod_priority=self._pod_priority,\n volume=self._volume,\n image_pull_policy=self._image_pull_policy,\n command=self._command,\n args=self._args + [\"--worker_id\", str(worker_id)],\n restart_policy=self._restart_policy,\n )\n name = pod.metadata.name\n self._pod_name_to_id[name] = worker_id\n self._pods_phase[worker_id] = (name, None)\n\n def start_workers(self):\n for i in range(self._num_workers):\n self._start_worker(self._next_worker_id())\n\n def start_tensorboard_service(self):\n tb_client = TensorBoardClient(self._k8s_client)\n tb_client.create_tensorboard_service()\n tb_external_ip = tb_client.get_tensorboard_external_ip()\n self._logger.info(\n \"TensorBoard service is available at external IP: %s\"\n % tb_external_ip\n )\n\n def _remove_worker(self, worker_id):\n self._logger.info(\"Removing worker: %d\", worker_id)\n with self._lock:\n if worker_id not in self._pods_phase:\n self._logger.error(\"Unknown worker id: %s\" % worker_id)\n return\n\n # TODO: change _k8s_client to accept pod name instead of worker id.\n self._k8s_client.delete_worker(worker_id)\n\n def stop_relaunch_and_remove_workers(self):\n with self._lock:\n self._relaunch_deleted_live_worker = False\n for worker_id in self._pods_phase:\n self._k8s_client.delete_worker(worker_id)\n\n def get_counters(self):\n with self._lock:\n return Counter([v for _, v in self._pods_phase.values()])\n\n def _event_cb(self, event):\n evt_obj = event.get(\"object\")\n evt_type = event.get(\"type\")\n if not evt_obj or not evt_type:\n self._logger.error(\"Event doesn't have object or type: %s\" % event)\n return\n\n pod_name = evt_obj.metadata.name\n phase = evt_obj.status.phase\n self._logger.info(\n \"Got event %s, phase %s for pod: %s\" % (evt_type, phase, pod_name)\n )\n\n relaunch = False\n with self._lock:\n worker_id = self._pod_name_to_id.get(pod_name)\n if (\n worker_id is None\n and pod_name != self._k8s_client.get_master_pod_name()\n ):\n self._logger.error(\"Unknown worker pod name: %s\" % pod_name)\n return\n\n self._pods_phase[worker_id] = (pod_name, phase)\n if evt_type == \"DELETED\":\n del self._pods_phase[worker_id]\n del self._pod_name_to_id[pod_name]\n self._task_d.recover_tasks(worker_id)\n\n # If a deleted pod was not \"Succeeded\", relaunch a worker.\n relaunch = (\n self._relaunch_deleted_live_worker and phase != \"Succeeded\"\n )\n if relaunch:\n self._logger.info(\"Relaunching worker.\")\n self._start_worker(self._next_worker_id())\n", "path": "elasticdl/python/master/k8s_worker_manager.py"}, {"content": "class GRPC(object):\n # gRPC limits the size of message by default to 4MB.\n # It's too small to send model parameters.\n MAX_SEND_MESSAGE_LENGTH = 256 * 1024 * 1024\n MAX_RECEIVE_MESSAGE_LENGTH = 256 * 1024 * 1024\n", "path": "elasticdl/python/common/constants.py"}, {"content": "import logging\nimport os\nimport time\nfrom concurrent import futures\nfrom contextlib import closing\n\nimport grpc\nimport recordio\n\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.common.constants import GRPC\nfrom elasticdl.python.common.model_helper import get_model_file, load_module\nfrom elasticdl.python.master.args import parse_args\nfrom elasticdl.python.master.checkpoint_service import CheckpointService\nfrom elasticdl.python.master.evaluation_service import EvaluationService\nfrom elasticdl.python.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.python.master.servicer import MasterServicer\nfrom elasticdl.python.master.task_dispatcher import _TaskDispatcher\nfrom elasticdl.python.master.tensorboard_service import TensorboardService\n\n\ndef _make_task_dispatcher(\n training_data_dir,\n evaluation_data_dir,\n prediction_data_dir,\n records_per_task,\n num_epochs,\n):\n def _collect_file_records_from_dir(data_dir):\n if not data_dir:\n return {}\n f_records = {}\n for f in os.listdir(data_dir):\n p = os.path.join(data_dir, f)\n with closing(recordio.Index(p)) as rio:\n f_records[p] = rio.num_records()\n return f_records\n\n training_f_records = _collect_file_records_from_dir(training_data_dir)\n evaluation_f_records = _collect_file_records_from_dir(evaluation_data_dir)\n prediction_f_records = _collect_file_records_from_dir(prediction_data_dir)\n\n return _TaskDispatcher(\n training_f_records,\n evaluation_f_records,\n prediction_f_records,\n records_per_task,\n # Only generate prediction tasks for 1 epoch\n 1 if prediction_f_records else num_epochs,\n )\n\n\ndef main():\n args = parse_args()\n\n # Initialize logger and set level for ROOT logger\n logging.basicConfig(\n format=\"%(asctime)s %(name)s %(levelname)-8s \"\n \"[%(filename)s:%(lineno)d] %(message)s\"\n )\n logging.getLogger().setLevel(args.log_level)\n logger = logging.getLogger(__name__)\n\n # Start tensorboard service if required\n if args.tensorboard_log_dir:\n logger.info(\n \"Starting tensorboard service with log directory %s\",\n args.tensorboard_log_dir,\n )\n tb_service = TensorboardService(args.tensorboard_log_dir)\n tb_service.start()\n else:\n tb_service = None\n\n # Start task queue\n logger.info(\n \"Starting task queue with training data directory %s \"\n \"and evaluation data directory %s\",\n args.training_data_dir,\n args.evaluation_data_dir,\n )\n task_d = _make_task_dispatcher(\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n args.records_per_task,\n args.num_epochs,\n )\n model_module = load_module(get_model_file(args.model_def))\n model_inst = model_module.model\n optimizer = model_module.optimizer()\n\n evaluation_while_training = all(\n (\n args.training_data_dir,\n args.evaluation_data_dir,\n args.evaluation_throttle_secs or args.evaluation_steps,\n )\n )\n evaluation_only = args.evaluation_data_dir and not args.training_data_dir\n\n # Initialize checkpoint service\n if args.checkpoint_steps or evaluation_while_training:\n logger.info(\"Starting checkpoint service\")\n checkpoint_service = CheckpointService(\n args.checkpoint_dir,\n args.checkpoint_steps,\n args.keep_checkpoint_max,\n evaluation_while_training,\n )\n else:\n checkpoint_service = None\n\n # Initialize evaluation service\n evaluation_service = None\n if evaluation_while_training or evaluation_only:\n logger.info(\n \"Starting evaluation service with throttle seconds %d \",\n \" and evaluation steps %d\",\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n )\n evaluation_service = EvaluationService(\n checkpoint_service,\n tb_service,\n task_d,\n args.evaluation_start_delay_secs,\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n evaluation_only,\n )\n evaluation_service.start()\n task_d.set_evaluation_service(evaluation_service)\n\n # The master service\n logger.info(\"Starting master service\")\n server = grpc.server(\n futures.ThreadPoolExecutor(max_workers=64),\n options=[\n (\"grpc.max_send_message_length\", GRPC.MAX_SEND_MESSAGE_LENGTH),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n master_servicer = MasterServicer(\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_d,\n init_var=model_inst.trainable_variables if model_inst.built else [],\n checkpoint_filename_for_init=args.checkpoint_filename_for_init,\n checkpoint_service=checkpoint_service,\n evaluation_service=evaluation_service,\n )\n elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)\n server.add_insecure_port(\"[::]:{}\".format(args.port))\n server.start()\n logger.info(\"Server started at port: %d\", args.port)\n\n if args.num_workers:\n assert args.worker_image, \"Worker image cannot be empty\"\n\n master_addr = \"%s:%d\" % (\n os.getenv(\"MY_POD_IP\", \"localhost\"),\n args.port,\n )\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.python.worker.main\",\n \"--model_def\",\n args.model_def,\n \"--master_addr\",\n master_addr,\n \"--log_level\",\n args.log_level,\n ]\n\n args.worker_resource_limit = (\n args.worker_resource_limit\n if args.worker_resource_limit\n else args.worker_resource_request\n )\n\n worker_manager = WorkerManager(\n task_d,\n job_name=args.job_name,\n image_name=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=args.namespace,\n num_workers=args.num_workers,\n worker_resource_request=args.worker_resource_request,\n worker_resource_limit=args.worker_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n )\n logger.info(\"Launching %d workers\", args.num_workers)\n worker_manager.start_workers()\n\n if tb_service:\n worker_manager.start_tensorboard_service()\n\n try:\n while True:\n if task_d.finished():\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if evaluation_service:\n logger.info(\"Stopping evaluation service\")\n evaluation_service.stop()\n\n logger.info(\"Stopping RPC server\")\n server.stop(0)\n\n # Keep TensorBoard running when all the tasks are finished\n if tb_service:\n logger.info(\n \"All tasks finished. Keeping TensorBoard service running...\"\n )\n tb_service.keep_running()\n logger.info(\"Master stopped\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/master/main.py"}], "after_files": [{"content": "import itertools\nimport logging\nimport threading\nfrom collections import Counter\n\nfrom elasticdl.python.common import k8s_client as k8s\nfrom elasticdl.python.common.k8s_tensorboard_client import TensorBoardClient\n\n\nclass WorkerManager(object):\n def __init__(\n self,\n task_d,\n command,\n args,\n num_workers=1,\n worker_resource_request=\"cpu=1,memory=4096Mi\",\n worker_resource_limit=\"cpu=1,memory=4096Mi\",\n pod_priority=None,\n volume=None,\n image_pull_policy=None,\n restart_policy=\"Never\",\n **kwargs\n ):\n self._logger = logging.getLogger(__name__)\n self._command = command\n self._args = args\n self._num_workers = num_workers\n\n self._resource_requests = worker_resource_request\n self._resource_limits = worker_resource_limit\n self._restart_policy = restart_policy\n self._pod_priority = pod_priority\n self._volume = volume\n self._image_pull_policy = image_pull_policy\n self._task_d = task_d\n self._next_worker_id = itertools.count().__next__\n\n # protects followed variables, which are accessed from event_cb.\n self._lock = threading.Lock()\n # worker id to (pod name, phase) mapping\n # phase: None/Pending/Running/Succeeded/Failed/Unknown\n # None: worker was just launched, haven't received event yet.\n # Pending: worker pod not started yet\n # Running: worker pod is running\n # Succeeded: worker pod finishes all tasks and terminates with\n # no issue.\n # Failed: worker pod is killed for some reason\n # Unknown: unknown\n self._pods_phase = {}\n # pod name to worker id mapping\n self._pod_name_to_id = {}\n\n self._relaunch_deleted_live_worker = True\n\n self._k8s_client = k8s.Client(event_callback=self._event_cb, **kwargs)\n\n def set_relaunch_deleted_live_worker(self, val):\n self._relaunch_deleted_live_worker = bool(val)\n\n def _start_worker(self, worker_id):\n self._logger.info(\"Starting worker: %d\" % worker_id)\n with self._lock:\n pod = self._k8s_client.create_worker(\n worker_id=worker_id,\n resource_requests=self._resource_requests,\n resource_limits=self._resource_limits,\n pod_priority=self._pod_priority,\n volume=self._volume,\n image_pull_policy=self._image_pull_policy,\n command=self._command,\n args=self._args + [\"--worker_id\", str(worker_id)],\n restart_policy=self._restart_policy,\n )\n name = pod.metadata.name\n self._pod_name_to_id[name] = worker_id\n self._pods_phase[worker_id] = (name, None)\n\n def update_status(self, status):\n master_name = self._k8s_client.get_master_pod_name()\n self._k8s_client.patch_labels_to_pod(\n master_name, labels_dict={\"status\": status}\n )\n\n def start_workers(self):\n for i in range(self._num_workers):\n self._start_worker(self._next_worker_id())\n\n def start_tensorboard_service(self):\n tb_client = TensorBoardClient(self._k8s_client)\n tb_client.create_tensorboard_service()\n tb_external_ip = tb_client.get_tensorboard_external_ip()\n self._logger.info(\n \"TensorBoard service is available at external IP: %s\"\n % tb_external_ip\n )\n\n def _remove_worker(self, worker_id):\n self._logger.info(\"Removing worker: %d\", worker_id)\n with self._lock:\n if worker_id not in self._pods_phase:\n self._logger.error(\"Unknown worker id: %s\" % worker_id)\n return\n\n # TODO: change _k8s_client to accept pod name instead of worker id.\n self._k8s_client.delete_worker(worker_id)\n\n def stop_relaunch_and_remove_workers(self):\n with self._lock:\n self._relaunch_deleted_live_worker = False\n for worker_id in self._pods_phase:\n self._k8s_client.delete_worker(worker_id)\n\n def get_counters(self):\n with self._lock:\n return Counter([v for _, v in self._pods_phase.values()])\n\n def _event_cb(self, event):\n evt_obj = event.get(\"object\")\n evt_type = event.get(\"type\")\n if not evt_obj or not evt_type:\n self._logger.error(\"Event doesn't have object or type: %s\" % event)\n return\n\n pod_name = evt_obj.metadata.name\n phase = evt_obj.status.phase\n self._logger.info(\n \"Got event %s, phase %s for pod: %s\" % (evt_type, phase, pod_name)\n )\n\n relaunch = False\n with self._lock:\n worker_id = self._pod_name_to_id.get(pod_name)\n if (\n worker_id is None\n and pod_name != self._k8s_client.get_master_pod_name()\n ):\n self._logger.error(\"Unknown worker pod name: %s\" % pod_name)\n return\n\n self._pods_phase[worker_id] = (pod_name, phase)\n if evt_type == \"DELETED\":\n del self._pods_phase[worker_id]\n del self._pod_name_to_id[pod_name]\n self._task_d.recover_tasks(worker_id)\n\n # If a deleted pod was not \"Succeeded\", relaunch a worker.\n relaunch = (\n self._relaunch_deleted_live_worker and phase != \"Succeeded\"\n )\n if relaunch:\n self._logger.info(\"Relaunching worker.\")\n self._start_worker(self._next_worker_id())\n", "path": "elasticdl/python/master/k8s_worker_manager.py"}, {"content": "class GRPC(object):\n # gRPC limits the size of message by default to 4MB.\n # It's too small to send model parameters.\n MAX_SEND_MESSAGE_LENGTH = 256 * 1024 * 1024\n MAX_RECEIVE_MESSAGE_LENGTH = 256 * 1024 * 1024\n\n\nclass WorkerManagerStatus(object):\n PENDING = \"Pending\"\n RUNNING = \"Running\"\n FINISHED = \"Finished\"\n", "path": "elasticdl/python/common/constants.py"}, {"content": "import logging\nimport os\nimport time\nfrom concurrent import futures\nfrom contextlib import closing\n\nimport grpc\nimport recordio\n\nfrom elasticdl.proto import elasticdl_pb2_grpc\nfrom elasticdl.python.common.constants import GRPC, WorkerManagerStatus\nfrom elasticdl.python.common.model_helper import get_model_file, load_module\nfrom elasticdl.python.master.args import parse_args\nfrom elasticdl.python.master.checkpoint_service import CheckpointService\nfrom elasticdl.python.master.evaluation_service import EvaluationService\nfrom elasticdl.python.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.python.master.servicer import MasterServicer\nfrom elasticdl.python.master.task_dispatcher import _TaskDispatcher\nfrom elasticdl.python.master.tensorboard_service import TensorboardService\n\n\ndef _make_task_dispatcher(\n training_data_dir,\n evaluation_data_dir,\n prediction_data_dir,\n records_per_task,\n num_epochs,\n):\n def _collect_file_records_from_dir(data_dir):\n if not data_dir:\n return {}\n f_records = {}\n for f in os.listdir(data_dir):\n p = os.path.join(data_dir, f)\n with closing(recordio.Index(p)) as rio:\n f_records[p] = rio.num_records()\n return f_records\n\n training_f_records = _collect_file_records_from_dir(training_data_dir)\n evaluation_f_records = _collect_file_records_from_dir(evaluation_data_dir)\n prediction_f_records = _collect_file_records_from_dir(prediction_data_dir)\n\n return _TaskDispatcher(\n training_f_records,\n evaluation_f_records,\n prediction_f_records,\n records_per_task,\n # Only generate prediction tasks for 1 epoch\n 1 if prediction_f_records else num_epochs,\n )\n\n\ndef main():\n args = parse_args()\n\n # Initialize logger and set level for ROOT logger\n logging.basicConfig(\n format=\"%(asctime)s %(name)s %(levelname)-8s \"\n \"[%(filename)s:%(lineno)d] %(message)s\"\n )\n logging.getLogger().setLevel(args.log_level)\n logger = logging.getLogger(__name__)\n\n # Start tensorboard service if required\n if args.tensorboard_log_dir:\n logger.info(\n \"Starting tensorboard service with log directory %s\",\n args.tensorboard_log_dir,\n )\n tb_service = TensorboardService(args.tensorboard_log_dir)\n tb_service.start()\n else:\n tb_service = None\n\n # Start task queue\n logger.info(\n \"Starting task queue with training data directory %s \"\n \"and evaluation data directory %s\",\n args.training_data_dir,\n args.evaluation_data_dir,\n )\n task_d = _make_task_dispatcher(\n args.training_data_dir,\n args.evaluation_data_dir,\n args.prediction_data_dir,\n args.records_per_task,\n args.num_epochs,\n )\n model_module = load_module(get_model_file(args.model_def))\n model_inst = model_module.model\n optimizer = model_module.optimizer()\n\n evaluation_while_training = all(\n (\n args.training_data_dir,\n args.evaluation_data_dir,\n args.evaluation_throttle_secs or args.evaluation_steps,\n )\n )\n evaluation_only = args.evaluation_data_dir and not args.training_data_dir\n\n # Initialize checkpoint service\n if args.checkpoint_steps or evaluation_while_training:\n logger.info(\"Starting checkpoint service\")\n checkpoint_service = CheckpointService(\n args.checkpoint_dir,\n args.checkpoint_steps,\n args.keep_checkpoint_max,\n evaluation_while_training,\n )\n else:\n checkpoint_service = None\n\n # Initialize evaluation service\n evaluation_service = None\n if evaluation_while_training or evaluation_only:\n logger.info(\n \"Starting evaluation service with throttle seconds %d \",\n \" and evaluation steps %d\",\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n )\n evaluation_service = EvaluationService(\n checkpoint_service,\n tb_service,\n task_d,\n args.evaluation_start_delay_secs,\n args.evaluation_throttle_secs,\n args.evaluation_steps,\n evaluation_only,\n )\n evaluation_service.start()\n task_d.set_evaluation_service(evaluation_service)\n\n # The master service\n logger.info(\"Starting master service\")\n server = grpc.server(\n futures.ThreadPoolExecutor(max_workers=64),\n options=[\n (\"grpc.max_send_message_length\", GRPC.MAX_SEND_MESSAGE_LENGTH),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n master_servicer = MasterServicer(\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_d,\n init_var=model_inst.trainable_variables if model_inst.built else [],\n checkpoint_filename_for_init=args.checkpoint_filename_for_init,\n checkpoint_service=checkpoint_service,\n evaluation_service=evaluation_service,\n )\n elasticdl_pb2_grpc.add_MasterServicer_to_server(master_servicer, server)\n server.add_insecure_port(\"[::]:{}\".format(args.port))\n server.start()\n logger.info(\"Server started at port: %d\", args.port)\n\n worker_manager = None\n if args.num_workers:\n assert args.worker_image, \"Worker image cannot be empty\"\n\n master_addr = \"%s:%d\" % (\n os.getenv(\"MY_POD_IP\", \"localhost\"),\n args.port,\n )\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.python.worker.main\",\n \"--model_def\",\n args.model_def,\n \"--master_addr\",\n master_addr,\n \"--log_level\",\n args.log_level,\n ]\n\n args.worker_resource_limit = (\n args.worker_resource_limit\n if args.worker_resource_limit\n else args.worker_resource_request\n )\n\n worker_manager = WorkerManager(\n task_d,\n job_name=args.job_name,\n image_name=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=args.namespace,\n num_workers=args.num_workers,\n worker_resource_request=args.worker_resource_request,\n worker_resource_limit=args.worker_resource_limit,\n pod_priority=args.worker_pod_priority,\n volume=args.volume,\n image_pull_policy=args.image_pull_policy,\n restart_policy=args.restart_policy,\n )\n worker_manager.update_status(WorkerManagerStatus.PENDING)\n logger.info(\"Launching %d workers\", args.num_workers)\n worker_manager.start_workers()\n worker_manager.update_status(WorkerManagerStatus.RUNNING)\n\n if tb_service:\n worker_manager.start_tensorboard_service()\n\n try:\n while True:\n if task_d.finished():\n if worker_manager:\n worker_manager.update_status(WorkerManagerStatus.FINISHED)\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if evaluation_service:\n logger.info(\"Stopping evaluation service\")\n evaluation_service.stop()\n\n logger.info(\"Stopping RPC server\")\n server.stop(0)\n\n # Keep TensorBoard running when all the tasks are finished\n if tb_service:\n logger.info(\n \"All tasks finished. Keeping TensorBoard service running...\"\n )\n tb_service.keep_running()\n logger.info(\"Master stopped\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/master/main.py"}]}
| 4,033 | 663 |
gh_patches_debug_27992
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-1919
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip-sync 7.0.0 reinstalls packages due to case difference
#### Description
pip-sync 7.0.0 reinstalls all packages which have non-lowercase letters in their names
For instance in `*.in` and `*.txt` files we have the following data:
```
django
```
and
```
django==4.2.0
...
```
When we run pip sync, it will uninstall and install django because in `pip-freeze` the same package mentioned as `Django`
#### Environment Versions
| Required | Information |
| ---------- | -------------- |
| OS Type | MacOs/Linux |
| Python version: `$ python -V` | Python 3.11.4 |
| pip version: `$ pip --version`: |pip 23.2 from /home/user/venv/lib/python3.11/site-packages/pip (python 3.11) |
| pip-tools version: `$ pip-compile --version` | pip-compile, version 7.0.0 |
#### Steps to replicate
1. Create `*.in` file with `django` requirement
2. Compile requirements to generate `*.txt` file
3. Run pip-sync on the txt file
4. Run pip-sync on the txt file again
#### Expected result
The output should be `Everything up-to-date`
#### Actual result
The requirement is reinstalled every time you run `pip-sync`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/sync.py`
Content:
```
1 from __future__ import annotations
2
3 import collections
4 import os
5 import sys
6 import tempfile
7 from subprocess import run # nosec
8 from typing import Deque, Iterable, Mapping, ValuesView
9
10 import click
11 from pip._internal.models.direct_url import ArchiveInfo
12 from pip._internal.req import InstallRequirement
13 from pip._internal.utils.compat import stdlib_pkgs
14 from pip._internal.utils.direct_url_helpers import (
15 direct_url_as_pep440_direct_reference,
16 direct_url_from_link,
17 )
18
19 from ._compat import Distribution, get_dev_pkgs
20 from .exceptions import IncompatibleRequirements
21 from .logging import log
22 from .utils import (
23 flat_map,
24 format_requirement,
25 get_hashes_from_ireq,
26 is_url_requirement,
27 key_from_ireq,
28 key_from_req,
29 )
30
31 PACKAGES_TO_IGNORE = [
32 "-markerlib",
33 "pip",
34 "pip-tools",
35 "pip-review",
36 "pkg-resources",
37 *stdlib_pkgs,
38 *get_dev_pkgs(),
39 ]
40
41
42 def dependency_tree(
43 installed_keys: Mapping[str, Distribution], root_key: str
44 ) -> set[str]:
45 """
46 Calculate the dependency tree for the package `root_key` and return
47 a collection of all its dependencies. Uses a DFS traversal algorithm.
48
49 `installed_keys` should be a {key: requirement} mapping, e.g.
50 {'django': from_line('django==1.8')}
51 `root_key` should be the key to return the dependency tree for.
52 """
53 dependencies = set()
54 queue: Deque[Distribution] = collections.deque()
55
56 if root_key in installed_keys:
57 dep = installed_keys[root_key]
58 queue.append(dep)
59
60 while queue:
61 v = queue.popleft()
62 key = v.key
63 if key in dependencies:
64 continue
65
66 dependencies.add(key)
67
68 for dep_specifier in v.requires:
69 dep_name = key_from_req(dep_specifier)
70 if dep_name in installed_keys:
71 dep = installed_keys[dep_name]
72
73 if dep_specifier.specifier.contains(dep.version):
74 queue.append(dep)
75
76 return dependencies
77
78
79 def get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:
80 """
81 Returns a collection of package names to ignore when performing pip-sync,
82 based on the currently installed environment. For example, when pip-tools
83 is installed in the local environment, it should be ignored, including all
84 of its dependencies (e.g. click). When pip-tools is not installed
85 locally, click should also be installed/uninstalled depending on the given
86 requirements.
87 """
88 installed_keys = {r.key: r for r in installed}
89 return list(
90 flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)
91 )
92
93
94 def merge(
95 requirements: Iterable[InstallRequirement], ignore_conflicts: bool
96 ) -> ValuesView[InstallRequirement]:
97 by_key: dict[str, InstallRequirement] = {}
98
99 for ireq in requirements:
100 # Limitation: URL requirements are merged by precise string match, so
101 # "file:///example.zip#egg=example", "file:///example.zip", and
102 # "example==1.0" will not merge with each other
103 if ireq.match_markers():
104 key = key_from_ireq(ireq)
105
106 if not ignore_conflicts:
107 existing_ireq = by_key.get(key)
108 if existing_ireq:
109 # NOTE: We check equality here since we can assume that the
110 # requirements are all pinned
111 if (
112 ireq.req
113 and existing_ireq.req
114 and ireq.specifier != existing_ireq.specifier
115 ):
116 raise IncompatibleRequirements(ireq, existing_ireq)
117
118 # TODO: Always pick the largest specifier in case of a conflict
119 by_key[key] = ireq
120 return by_key.values()
121
122
123 def diff_key_from_ireq(ireq: InstallRequirement) -> str:
124 """
125 Calculate a key for comparing a compiled requirement with installed modules.
126 For URL requirements, only provide a useful key if the url includes
127 a hash, e.g. #sha1=..., in any of the supported hash algorithms.
128 Otherwise return ireq.link so the key will not match and the package will
129 reinstall. Reinstall is necessary to ensure that packages will reinstall
130 if the contents at the URL have changed but the version has not.
131 """
132 if is_url_requirement(ireq):
133 if getattr(ireq.req, "name", None) and ireq.link.has_hash:
134 return str(
135 direct_url_as_pep440_direct_reference(
136 direct_url_from_link(ireq.link), ireq.req.name
137 )
138 )
139 # TODO: Also support VCS and editable installs.
140 return str(ireq.link)
141 return key_from_ireq(ireq)
142
143
144 def diff_key_from_req(req: Distribution) -> str:
145 """Get a unique key for the requirement."""
146 key = req.key
147 if (
148 req.direct_url
149 and isinstance(req.direct_url.info, ArchiveInfo)
150 and req.direct_url.info.hash
151 ):
152 key = direct_url_as_pep440_direct_reference(req.direct_url, key)
153 # TODO: Also support VCS and editable installs.
154 return key
155
156
157 def diff(
158 compiled_requirements: Iterable[InstallRequirement],
159 installed_dists: Iterable[Distribution],
160 ) -> tuple[set[InstallRequirement], set[str]]:
161 """
162 Calculate which packages should be installed or uninstalled, given a set
163 of compiled requirements and a list of currently installed modules.
164 """
165 requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}
166
167 satisfied = set() # holds keys
168 to_install = set() # holds InstallRequirement objects
169 to_uninstall = set() # holds keys
170
171 pkgs_to_ignore = get_dists_to_ignore(installed_dists)
172 for dist in installed_dists:
173 key = diff_key_from_req(dist)
174 if key not in requirements_lut or not requirements_lut[key].match_markers():
175 to_uninstall.add(key)
176 elif requirements_lut[key].specifier.contains(dist.version):
177 satisfied.add(key)
178
179 for key, requirement in requirements_lut.items():
180 if key not in satisfied and requirement.match_markers():
181 to_install.add(requirement)
182
183 # Make sure to not uninstall any packages that should be ignored
184 to_uninstall -= set(pkgs_to_ignore)
185
186 return (to_install, to_uninstall)
187
188
189 def sync(
190 to_install: Iterable[InstallRequirement],
191 to_uninstall: Iterable[InstallRequirement],
192 dry_run: bool = False,
193 install_flags: list[str] | None = None,
194 ask: bool = False,
195 python_executable: str | None = None,
196 ) -> int:
197 """
198 Install and uninstalls the given sets of modules.
199 """
200 exit_code = 0
201
202 python_executable = python_executable or sys.executable
203
204 if not to_uninstall and not to_install:
205 log.info("Everything up-to-date", err=False)
206 return exit_code
207
208 pip_flags = []
209 if log.verbosity < 0:
210 pip_flags += ["-q"]
211
212 if ask:
213 dry_run = True
214
215 if dry_run:
216 if to_uninstall:
217 click.echo("Would uninstall:")
218 for pkg in sorted(to_uninstall):
219 click.echo(f" {pkg}")
220
221 if to_install:
222 click.echo("Would install:")
223 for ireq in sorted(to_install, key=key_from_ireq):
224 click.echo(f" {format_requirement(ireq)}")
225
226 exit_code = 1
227
228 if ask and click.confirm("Would you like to proceed with these changes?"):
229 dry_run = False
230 exit_code = 0
231
232 if not dry_run:
233 if to_uninstall:
234 run( # nosec
235 [
236 python_executable,
237 "-m",
238 "pip",
239 "uninstall",
240 "-y",
241 *pip_flags,
242 *sorted(to_uninstall),
243 ],
244 check=True,
245 )
246
247 if to_install:
248 if install_flags is None:
249 install_flags = []
250 # prepare requirement lines
251 req_lines = []
252 for ireq in sorted(to_install, key=key_from_ireq):
253 ireq_hashes = get_hashes_from_ireq(ireq)
254 req_lines.append(format_requirement(ireq, hashes=ireq_hashes))
255
256 # save requirement lines to a temporary file
257 tmp_req_file = tempfile.NamedTemporaryFile(mode="wt", delete=False)
258 tmp_req_file.write("\n".join(req_lines))
259 tmp_req_file.close()
260
261 try:
262 run( # nosec
263 [
264 python_executable,
265 "-m",
266 "pip",
267 "install",
268 "-r",
269 tmp_req_file.name,
270 *pip_flags,
271 *install_flags,
272 ],
273 check=True,
274 )
275 finally:
276 os.unlink(tmp_req_file.name)
277
278 return exit_code
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/sync.py b/piptools/sync.py
--- a/piptools/sync.py
+++ b/piptools/sync.py
@@ -15,6 +15,7 @@
direct_url_as_pep440_direct_reference,
direct_url_from_link,
)
+from pip._vendor.packaging.utils import canonicalize_name
from ._compat import Distribution, get_dev_pkgs
from .exceptions import IncompatibleRequirements
@@ -59,7 +60,7 @@
while queue:
v = queue.popleft()
- key = v.key
+ key = str(canonicalize_name(v.key))
if key in dependencies:
continue
@@ -85,7 +86,7 @@
locally, click should also be installed/uninstalled depending on the given
requirements.
"""
- installed_keys = {r.key: r for r in installed}
+ installed_keys = {str(canonicalize_name(r.key)): r for r in installed}
return list(
flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)
)
@@ -143,7 +144,7 @@
def diff_key_from_req(req: Distribution) -> str:
"""Get a unique key for the requirement."""
- key = req.key
+ key = str(canonicalize_name(req.key))
if (
req.direct_url
and isinstance(req.direct_url.info, ArchiveInfo)
|
{"golden_diff": "diff --git a/piptools/sync.py b/piptools/sync.py\n--- a/piptools/sync.py\n+++ b/piptools/sync.py\n@@ -15,6 +15,7 @@\n direct_url_as_pep440_direct_reference,\n direct_url_from_link,\n )\n+from pip._vendor.packaging.utils import canonicalize_name\n \n from ._compat import Distribution, get_dev_pkgs\n from .exceptions import IncompatibleRequirements\n@@ -59,7 +60,7 @@\n \n while queue:\n v = queue.popleft()\n- key = v.key\n+ key = str(canonicalize_name(v.key))\n if key in dependencies:\n continue\n \n@@ -85,7 +86,7 @@\n locally, click should also be installed/uninstalled depending on the given\n requirements.\n \"\"\"\n- installed_keys = {r.key: r for r in installed}\n+ installed_keys = {str(canonicalize_name(r.key)): r for r in installed}\n return list(\n flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)\n )\n@@ -143,7 +144,7 @@\n \n def diff_key_from_req(req: Distribution) -> str:\n \"\"\"Get a unique key for the requirement.\"\"\"\n- key = req.key\n+ key = str(canonicalize_name(req.key))\n if (\n req.direct_url\n and isinstance(req.direct_url.info, ArchiveInfo)\n", "issue": "pip-sync 7.0.0 reinstalls packages due to case difference\n#### Description\r\n\r\npip-sync 7.0.0 reinstalls all packages which have non-lowercase letters in their names\r\n\r\nFor instance in `*.in` and `*.txt` files we have the following data:\r\n```\r\ndjango\r\n```\r\nand\r\n```\r\ndjango==4.2.0\r\n ...\r\n```\r\nWhen we run pip sync, it will uninstall and install django because in `pip-freeze` the same package mentioned as `Django`\r\n\r\n#### Environment Versions\r\n\r\n| Required | Information |\r\n| ---------- | -------------- |\r\n| OS Type | MacOs/Linux |\r\n| Python version: `$ python -V` | Python 3.11.4 |\r\n| pip version: `$ pip --version`: |pip 23.2 from /home/user/venv/lib/python3.11/site-packages/pip (python 3.11) |\r\n| pip-tools version: `$ pip-compile --version` | pip-compile, version 7.0.0 |\r\n\r\n#### Steps to replicate\r\n\r\n1. Create `*.in` file with `django` requirement\r\n2. Compile requirements to generate `*.txt` file\r\n3. Run pip-sync on the txt file\r\n4. Run pip-sync on the txt file again\r\n\r\n#### Expected result\r\n\r\nThe output should be `Everything up-to-date`\r\n\r\n#### Actual result\r\n\r\nThe requirement is reinstalled every time you run `pip-sync`\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport collections\nimport os\nimport sys\nimport tempfile\nfrom subprocess import run # nosec\nfrom typing import Deque, Iterable, Mapping, ValuesView\n\nimport click\nfrom pip._internal.models.direct_url import ArchiveInfo\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.utils.compat import stdlib_pkgs\nfrom pip._internal.utils.direct_url_helpers import (\n direct_url_as_pep440_direct_reference,\n direct_url_from_link,\n)\n\nfrom ._compat import Distribution, get_dev_pkgs\nfrom .exceptions import IncompatibleRequirements\nfrom .logging import log\nfrom .utils import (\n flat_map,\n format_requirement,\n get_hashes_from_ireq,\n is_url_requirement,\n key_from_ireq,\n key_from_req,\n)\n\nPACKAGES_TO_IGNORE = [\n \"-markerlib\",\n \"pip\",\n \"pip-tools\",\n \"pip-review\",\n \"pkg-resources\",\n *stdlib_pkgs,\n *get_dev_pkgs(),\n]\n\n\ndef dependency_tree(\n installed_keys: Mapping[str, Distribution], root_key: str\n) -> set[str]:\n \"\"\"\n Calculate the dependency tree for the package `root_key` and return\n a collection of all its dependencies. Uses a DFS traversal algorithm.\n\n `installed_keys` should be a {key: requirement} mapping, e.g.\n {'django': from_line('django==1.8')}\n `root_key` should be the key to return the dependency tree for.\n \"\"\"\n dependencies = set()\n queue: Deque[Distribution] = collections.deque()\n\n if root_key in installed_keys:\n dep = installed_keys[root_key]\n queue.append(dep)\n\n while queue:\n v = queue.popleft()\n key = v.key\n if key in dependencies:\n continue\n\n dependencies.add(key)\n\n for dep_specifier in v.requires:\n dep_name = key_from_req(dep_specifier)\n if dep_name in installed_keys:\n dep = installed_keys[dep_name]\n\n if dep_specifier.specifier.contains(dep.version):\n queue.append(dep)\n\n return dependencies\n\n\ndef get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:\n \"\"\"\n Returns a collection of package names to ignore when performing pip-sync,\n based on the currently installed environment. For example, when pip-tools\n is installed in the local environment, it should be ignored, including all\n of its dependencies (e.g. click). When pip-tools is not installed\n locally, click should also be installed/uninstalled depending on the given\n requirements.\n \"\"\"\n installed_keys = {r.key: r for r in installed}\n return list(\n flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)\n )\n\n\ndef merge(\n requirements: Iterable[InstallRequirement], ignore_conflicts: bool\n) -> ValuesView[InstallRequirement]:\n by_key: dict[str, InstallRequirement] = {}\n\n for ireq in requirements:\n # Limitation: URL requirements are merged by precise string match, so\n # \"file:///example.zip#egg=example\", \"file:///example.zip\", and\n # \"example==1.0\" will not merge with each other\n if ireq.match_markers():\n key = key_from_ireq(ireq)\n\n if not ignore_conflicts:\n existing_ireq = by_key.get(key)\n if existing_ireq:\n # NOTE: We check equality here since we can assume that the\n # requirements are all pinned\n if (\n ireq.req\n and existing_ireq.req\n and ireq.specifier != existing_ireq.specifier\n ):\n raise IncompatibleRequirements(ireq, existing_ireq)\n\n # TODO: Always pick the largest specifier in case of a conflict\n by_key[key] = ireq\n return by_key.values()\n\n\ndef diff_key_from_ireq(ireq: InstallRequirement) -> str:\n \"\"\"\n Calculate a key for comparing a compiled requirement with installed modules.\n For URL requirements, only provide a useful key if the url includes\n a hash, e.g. #sha1=..., in any of the supported hash algorithms.\n Otherwise return ireq.link so the key will not match and the package will\n reinstall. Reinstall is necessary to ensure that packages will reinstall\n if the contents at the URL have changed but the version has not.\n \"\"\"\n if is_url_requirement(ireq):\n if getattr(ireq.req, \"name\", None) and ireq.link.has_hash:\n return str(\n direct_url_as_pep440_direct_reference(\n direct_url_from_link(ireq.link), ireq.req.name\n )\n )\n # TODO: Also support VCS and editable installs.\n return str(ireq.link)\n return key_from_ireq(ireq)\n\n\ndef diff_key_from_req(req: Distribution) -> str:\n \"\"\"Get a unique key for the requirement.\"\"\"\n key = req.key\n if (\n req.direct_url\n and isinstance(req.direct_url.info, ArchiveInfo)\n and req.direct_url.info.hash\n ):\n key = direct_url_as_pep440_direct_reference(req.direct_url, key)\n # TODO: Also support VCS and editable installs.\n return key\n\n\ndef diff(\n compiled_requirements: Iterable[InstallRequirement],\n installed_dists: Iterable[Distribution],\n) -> tuple[set[InstallRequirement], set[str]]:\n \"\"\"\n Calculate which packages should be installed or uninstalled, given a set\n of compiled requirements and a list of currently installed modules.\n \"\"\"\n requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}\n\n satisfied = set() # holds keys\n to_install = set() # holds InstallRequirement objects\n to_uninstall = set() # holds keys\n\n pkgs_to_ignore = get_dists_to_ignore(installed_dists)\n for dist in installed_dists:\n key = diff_key_from_req(dist)\n if key not in requirements_lut or not requirements_lut[key].match_markers():\n to_uninstall.add(key)\n elif requirements_lut[key].specifier.contains(dist.version):\n satisfied.add(key)\n\n for key, requirement in requirements_lut.items():\n if key not in satisfied and requirement.match_markers():\n to_install.add(requirement)\n\n # Make sure to not uninstall any packages that should be ignored\n to_uninstall -= set(pkgs_to_ignore)\n\n return (to_install, to_uninstall)\n\n\ndef sync(\n to_install: Iterable[InstallRequirement],\n to_uninstall: Iterable[InstallRequirement],\n dry_run: bool = False,\n install_flags: list[str] | None = None,\n ask: bool = False,\n python_executable: str | None = None,\n) -> int:\n \"\"\"\n Install and uninstalls the given sets of modules.\n \"\"\"\n exit_code = 0\n\n python_executable = python_executable or sys.executable\n\n if not to_uninstall and not to_install:\n log.info(\"Everything up-to-date\", err=False)\n return exit_code\n\n pip_flags = []\n if log.verbosity < 0:\n pip_flags += [\"-q\"]\n\n if ask:\n dry_run = True\n\n if dry_run:\n if to_uninstall:\n click.echo(\"Would uninstall:\")\n for pkg in sorted(to_uninstall):\n click.echo(f\" {pkg}\")\n\n if to_install:\n click.echo(\"Would install:\")\n for ireq in sorted(to_install, key=key_from_ireq):\n click.echo(f\" {format_requirement(ireq)}\")\n\n exit_code = 1\n\n if ask and click.confirm(\"Would you like to proceed with these changes?\"):\n dry_run = False\n exit_code = 0\n\n if not dry_run:\n if to_uninstall:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"uninstall\",\n \"-y\",\n *pip_flags,\n *sorted(to_uninstall),\n ],\n check=True,\n )\n\n if to_install:\n if install_flags is None:\n install_flags = []\n # prepare requirement lines\n req_lines = []\n for ireq in sorted(to_install, key=key_from_ireq):\n ireq_hashes = get_hashes_from_ireq(ireq)\n req_lines.append(format_requirement(ireq, hashes=ireq_hashes))\n\n # save requirement lines to a temporary file\n tmp_req_file = tempfile.NamedTemporaryFile(mode=\"wt\", delete=False)\n tmp_req_file.write(\"\\n\".join(req_lines))\n tmp_req_file.close()\n\n try:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"install\",\n \"-r\",\n tmp_req_file.name,\n *pip_flags,\n *install_flags,\n ],\n check=True,\n )\n finally:\n os.unlink(tmp_req_file.name)\n\n return exit_code\n", "path": "piptools/sync.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport collections\nimport os\nimport sys\nimport tempfile\nfrom subprocess import run # nosec\nfrom typing import Deque, Iterable, Mapping, ValuesView\n\nimport click\nfrom pip._internal.models.direct_url import ArchiveInfo\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.utils.compat import stdlib_pkgs\nfrom pip._internal.utils.direct_url_helpers import (\n direct_url_as_pep440_direct_reference,\n direct_url_from_link,\n)\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom ._compat import Distribution, get_dev_pkgs\nfrom .exceptions import IncompatibleRequirements\nfrom .logging import log\nfrom .utils import (\n flat_map,\n format_requirement,\n get_hashes_from_ireq,\n is_url_requirement,\n key_from_ireq,\n key_from_req,\n)\n\nPACKAGES_TO_IGNORE = [\n \"-markerlib\",\n \"pip\",\n \"pip-tools\",\n \"pip-review\",\n \"pkg-resources\",\n *stdlib_pkgs,\n *get_dev_pkgs(),\n]\n\n\ndef dependency_tree(\n installed_keys: Mapping[str, Distribution], root_key: str\n) -> set[str]:\n \"\"\"\n Calculate the dependency tree for the package `root_key` and return\n a collection of all its dependencies. Uses a DFS traversal algorithm.\n\n `installed_keys` should be a {key: requirement} mapping, e.g.\n {'django': from_line('django==1.8')}\n `root_key` should be the key to return the dependency tree for.\n \"\"\"\n dependencies = set()\n queue: Deque[Distribution] = collections.deque()\n\n if root_key in installed_keys:\n dep = installed_keys[root_key]\n queue.append(dep)\n\n while queue:\n v = queue.popleft()\n key = str(canonicalize_name(v.key))\n if key in dependencies:\n continue\n\n dependencies.add(key)\n\n for dep_specifier in v.requires:\n dep_name = key_from_req(dep_specifier)\n if dep_name in installed_keys:\n dep = installed_keys[dep_name]\n\n if dep_specifier.specifier.contains(dep.version):\n queue.append(dep)\n\n return dependencies\n\n\ndef get_dists_to_ignore(installed: Iterable[Distribution]) -> list[str]:\n \"\"\"\n Returns a collection of package names to ignore when performing pip-sync,\n based on the currently installed environment. For example, when pip-tools\n is installed in the local environment, it should be ignored, including all\n of its dependencies (e.g. click). When pip-tools is not installed\n locally, click should also be installed/uninstalled depending on the given\n requirements.\n \"\"\"\n installed_keys = {str(canonicalize_name(r.key)): r for r in installed}\n return list(\n flat_map(lambda req: dependency_tree(installed_keys, req), PACKAGES_TO_IGNORE)\n )\n\n\ndef merge(\n requirements: Iterable[InstallRequirement], ignore_conflicts: bool\n) -> ValuesView[InstallRequirement]:\n by_key: dict[str, InstallRequirement] = {}\n\n for ireq in requirements:\n # Limitation: URL requirements are merged by precise string match, so\n # \"file:///example.zip#egg=example\", \"file:///example.zip\", and\n # \"example==1.0\" will not merge with each other\n if ireq.match_markers():\n key = key_from_ireq(ireq)\n\n if not ignore_conflicts:\n existing_ireq = by_key.get(key)\n if existing_ireq:\n # NOTE: We check equality here since we can assume that the\n # requirements are all pinned\n if (\n ireq.req\n and existing_ireq.req\n and ireq.specifier != existing_ireq.specifier\n ):\n raise IncompatibleRequirements(ireq, existing_ireq)\n\n # TODO: Always pick the largest specifier in case of a conflict\n by_key[key] = ireq\n return by_key.values()\n\n\ndef diff_key_from_ireq(ireq: InstallRequirement) -> str:\n \"\"\"\n Calculate a key for comparing a compiled requirement with installed modules.\n For URL requirements, only provide a useful key if the url includes\n a hash, e.g. #sha1=..., in any of the supported hash algorithms.\n Otherwise return ireq.link so the key will not match and the package will\n reinstall. Reinstall is necessary to ensure that packages will reinstall\n if the contents at the URL have changed but the version has not.\n \"\"\"\n if is_url_requirement(ireq):\n if getattr(ireq.req, \"name\", None) and ireq.link.has_hash:\n return str(\n direct_url_as_pep440_direct_reference(\n direct_url_from_link(ireq.link), ireq.req.name\n )\n )\n # TODO: Also support VCS and editable installs.\n return str(ireq.link)\n return key_from_ireq(ireq)\n\n\ndef diff_key_from_req(req: Distribution) -> str:\n \"\"\"Get a unique key for the requirement.\"\"\"\n key = str(canonicalize_name(req.key))\n if (\n req.direct_url\n and isinstance(req.direct_url.info, ArchiveInfo)\n and req.direct_url.info.hash\n ):\n key = direct_url_as_pep440_direct_reference(req.direct_url, key)\n # TODO: Also support VCS and editable installs.\n return key\n\n\ndef diff(\n compiled_requirements: Iterable[InstallRequirement],\n installed_dists: Iterable[Distribution],\n) -> tuple[set[InstallRequirement], set[str]]:\n \"\"\"\n Calculate which packages should be installed or uninstalled, given a set\n of compiled requirements and a list of currently installed modules.\n \"\"\"\n requirements_lut = {diff_key_from_ireq(r): r for r in compiled_requirements}\n\n satisfied = set() # holds keys\n to_install = set() # holds InstallRequirement objects\n to_uninstall = set() # holds keys\n\n pkgs_to_ignore = get_dists_to_ignore(installed_dists)\n for dist in installed_dists:\n key = diff_key_from_req(dist)\n if key not in requirements_lut or not requirements_lut[key].match_markers():\n to_uninstall.add(key)\n elif requirements_lut[key].specifier.contains(dist.version):\n satisfied.add(key)\n\n for key, requirement in requirements_lut.items():\n if key not in satisfied and requirement.match_markers():\n to_install.add(requirement)\n\n # Make sure to not uninstall any packages that should be ignored\n to_uninstall -= set(pkgs_to_ignore)\n\n return (to_install, to_uninstall)\n\n\ndef sync(\n to_install: Iterable[InstallRequirement],\n to_uninstall: Iterable[InstallRequirement],\n dry_run: bool = False,\n install_flags: list[str] | None = None,\n ask: bool = False,\n python_executable: str | None = None,\n) -> int:\n \"\"\"\n Install and uninstalls the given sets of modules.\n \"\"\"\n exit_code = 0\n\n python_executable = python_executable or sys.executable\n\n if not to_uninstall and not to_install:\n log.info(\"Everything up-to-date\", err=False)\n return exit_code\n\n pip_flags = []\n if log.verbosity < 0:\n pip_flags += [\"-q\"]\n\n if ask:\n dry_run = True\n\n if dry_run:\n if to_uninstall:\n click.echo(\"Would uninstall:\")\n for pkg in sorted(to_uninstall):\n click.echo(f\" {pkg}\")\n\n if to_install:\n click.echo(\"Would install:\")\n for ireq in sorted(to_install, key=key_from_ireq):\n click.echo(f\" {format_requirement(ireq)}\")\n\n exit_code = 1\n\n if ask and click.confirm(\"Would you like to proceed with these changes?\"):\n dry_run = False\n exit_code = 0\n\n if not dry_run:\n if to_uninstall:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"uninstall\",\n \"-y\",\n *pip_flags,\n *sorted(to_uninstall),\n ],\n check=True,\n )\n\n if to_install:\n if install_flags is None:\n install_flags = []\n # prepare requirement lines\n req_lines = []\n for ireq in sorted(to_install, key=key_from_ireq):\n ireq_hashes = get_hashes_from_ireq(ireq)\n req_lines.append(format_requirement(ireq, hashes=ireq_hashes))\n\n # save requirement lines to a temporary file\n tmp_req_file = tempfile.NamedTemporaryFile(mode=\"wt\", delete=False)\n tmp_req_file.write(\"\\n\".join(req_lines))\n tmp_req_file.close()\n\n try:\n run( # nosec\n [\n python_executable,\n \"-m\",\n \"pip\",\n \"install\",\n \"-r\",\n tmp_req_file.name,\n *pip_flags,\n *install_flags,\n ],\n check=True,\n )\n finally:\n os.unlink(tmp_req_file.name)\n\n return exit_code\n", "path": "piptools/sync.py"}]}
| 3,265 | 318 |
gh_patches_debug_11206
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-3656
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PermissionError not defined in Python 2.7
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Ubuntu 16
- **Ray installed from (source or binary)**: binary
- **Ray version**: 0.6.1
- **Python version**: 2.7
- **Exact command to reproduce**:
I don't have access to `/tmp`, and I get this following error:
```
cluster_tests.py:55: in _start_new_cluster
"num_heartbeats_timeout": 10
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/test/cluster_utils.py:43: in __init__
self.add_node(**head_node_args)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/test/cluster_utils.py:86: in add_node
**node_kwargs)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:1777: in start_ray_head
_internal_config=_internal_config)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:1436: in start_ray_processes
redis_max_memory=redis_max_memory)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:458: in start_redis
redis_stdout_file, redis_stderr_file = new_redis_log_file(redirect_output)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:182: in new_redis_log_file
"redis", redirect_output)
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:166: in new_log_files
try_to_create_directory("/tmp/ray")
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
directory_path = '/tmp/ray'
def try_to_create_directory(directory_path):
"""Attempt to create a directory that is globally readable/writable.
Args:
directory_path: The path of the directory to create.
"""
directory_path = os.path.expanduser(directory_path)
if not os.path.exists(directory_path):
try:
os.makedirs(directory_path)
except OSError as e:
if e.errno != os.errno.EEXIST:
raise e
logger.warning(
"Attempted to create '{}', but the directory already "
"exists.".format(directory_path))
# Change the log directory permissions so others can use it. This is
# important when multiple people are using the same machine.
try:
os.chmod(directory_path, 0o0777)
> except PermissionError:
E NameError: global name 'PermissionError' is not defined
/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:69: NameError
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/tempfile_services.py`
Content:
```
1 import binascii
2 import collections
3 import datetime
4 import errno
5 import logging
6 import os
7 import shutil
8 import tempfile
9
10 import ray.utils
11
12 logger = logging.getLogger(__name__)
13 _incremental_dict = collections.defaultdict(lambda: 0)
14 _temp_root = None
15
16
17 def make_inc_temp(suffix="", prefix="", directory_name="/tmp/ray"):
18 """Return a incremental temporary file name. The file is not created.
19
20 Args:
21 suffix (str): The suffix of the temp file.
22 prefix (str): The prefix of the temp file.
23 directory_name (str) : The base directory of the temp file.
24
25 Returns:
26 A string of file name. If there existing a file having the same name,
27 the returned name will look like
28 "{directory_name}/{prefix}.{unique_index}{suffix}"
29 """
30 directory_name = os.path.expanduser(directory_name)
31 index = _incremental_dict[suffix, prefix, directory_name]
32 # `tempfile.TMP_MAX` could be extremely large,
33 # so using `range` in Python2.x should be avoided.
34 while index < tempfile.TMP_MAX:
35 if index == 0:
36 filename = os.path.join(directory_name, prefix + suffix)
37 else:
38 filename = os.path.join(directory_name,
39 prefix + "." + str(index) + suffix)
40 index += 1
41 if not os.path.exists(filename):
42 _incremental_dict[suffix, prefix,
43 directory_name] = index # Save the index.
44 return filename
45
46 raise FileExistsError(errno.EEXIST, "No usable temporary filename found")
47
48
49 def try_to_create_directory(directory_path):
50 """Attempt to create a directory that is globally readable/writable.
51
52 Args:
53 directory_path: The path of the directory to create.
54 """
55 directory_path = os.path.expanduser(directory_path)
56 if not os.path.exists(directory_path):
57 try:
58 os.makedirs(directory_path)
59 except OSError as e:
60 if e.errno != os.errno.EEXIST:
61 raise e
62 logger.warning(
63 "Attempted to create '{}', but the directory already "
64 "exists.".format(directory_path))
65 # Change the log directory permissions so others can use it. This is
66 # important when multiple people are using the same machine.
67 try:
68 os.chmod(directory_path, 0o0777)
69 except PermissionError:
70 pass
71
72
73 def get_temp_root():
74 """Get the path of the temporary root. If not existing, it will be created.
75 """
76 global _temp_root
77
78 date_str = datetime.datetime.today().strftime("%Y-%m-%d_%H-%M-%S")
79
80 # Lazy creation. Avoid creating directories never used.
81 if _temp_root is None:
82 _temp_root = make_inc_temp(
83 prefix="session_{date_str}_{pid}".format(
84 pid=os.getpid(), date_str=date_str),
85 directory_name="/tmp/ray")
86 try_to_create_directory(_temp_root)
87 return _temp_root
88
89
90 def set_temp_root(path):
91 """Set the path of the temporary root. It will be created lazily."""
92 global _temp_root
93 _temp_root = path
94
95
96 def get_logs_dir_path():
97 """Get a temp dir for logging."""
98 logs_dir = os.path.join(get_temp_root(), "logs")
99 try_to_create_directory(logs_dir)
100 return logs_dir
101
102
103 def get_sockets_dir_path():
104 """Get a temp dir for sockets."""
105 sockets_dir = os.path.join(get_temp_root(), "sockets")
106 try_to_create_directory(sockets_dir)
107 return sockets_dir
108
109
110 def get_raylet_socket_name(suffix=""):
111 """Get a socket name for raylet."""
112 sockets_dir = get_sockets_dir_path()
113
114 raylet_socket_name = make_inc_temp(
115 prefix="raylet", directory_name=sockets_dir, suffix=suffix)
116 return raylet_socket_name
117
118
119 def get_object_store_socket_name():
120 """Get a socket name for plasma object store."""
121 sockets_dir = get_sockets_dir_path()
122 return make_inc_temp(prefix="plasma_store", directory_name=sockets_dir)
123
124
125 def get_ipython_notebook_path(port):
126 """Get a new ipython notebook path"""
127
128 notebook_filepath = os.path.join(
129 os.path.dirname(os.path.abspath(__file__)), "WebUI.ipynb")
130 # We copy the notebook file so that the original doesn't get modified by
131 # the user.
132 notebook_name = make_inc_temp(
133 suffix=".ipynb", prefix="ray_ui", directory_name=get_temp_root())
134 shutil.copy(notebook_filepath, notebook_name)
135 new_notebook_directory = os.path.dirname(notebook_name)
136 token = ray.utils.decode(binascii.hexlify(os.urandom(24)))
137 webui_url = ("http://localhost:{}/notebooks/{}?token={}".format(
138 port, os.path.basename(notebook_name), token))
139 return new_notebook_directory, webui_url, token
140
141
142 def new_log_files(name, redirect_output):
143 """Generate partially randomized filenames for log files.
144
145 Args:
146 name (str): descriptive string for this log file.
147 redirect_output (bool): True if files should be generated for logging
148 stdout and stderr and false if stdout and stderr should not be
149 redirected.
150
151 Returns:
152 If redirect_output is true, this will return a tuple of two
153 filehandles. The first is for redirecting stdout and the second is
154 for redirecting stderr. If redirect_output is false, this will
155 return a tuple of two None objects.
156 """
157 if not redirect_output:
158 return None, None
159
160 # Create a directory to be used for process log files.
161 logs_dir = get_logs_dir_path()
162 # Create another directory that will be used by some of the RL algorithms.
163
164 # TODO(suquark): This is done by the old code.
165 # We should be able to control its path later.
166 try_to_create_directory("/tmp/ray")
167
168 log_stdout = make_inc_temp(
169 suffix=".out", prefix=name, directory_name=logs_dir)
170 log_stderr = make_inc_temp(
171 suffix=".err", prefix=name, directory_name=logs_dir)
172 # Line-buffer the output (mode 1)
173 log_stdout_file = open(log_stdout, "a", buffering=1)
174 log_stderr_file = open(log_stderr, "a", buffering=1)
175 return log_stdout_file, log_stderr_file
176
177
178 def new_redis_log_file(redirect_output, shard_number=None):
179 """Create new logging files for redis"""
180 if shard_number is None:
181 redis_stdout_file, redis_stderr_file = new_log_files(
182 "redis", redirect_output)
183 else:
184 redis_stdout_file, redis_stderr_file = new_log_files(
185 "redis-shard_{}".format(shard_number), redirect_output)
186 return redis_stdout_file, redis_stderr_file
187
188
189 def new_raylet_log_file(local_scheduler_index, redirect_output):
190 """Create new logging files for raylet."""
191 raylet_stdout_file, raylet_stderr_file = new_log_files(
192 "raylet_{}".format(local_scheduler_index),
193 redirect_output=redirect_output)
194 return raylet_stdout_file, raylet_stderr_file
195
196
197 def new_webui_log_file():
198 """Create new logging files for web ui."""
199 ui_stdout_file, ui_stderr_file = new_log_files(
200 "webui", redirect_output=True)
201 return ui_stdout_file, ui_stderr_file
202
203
204 def new_worker_redirected_log_file(worker_id):
205 """Create new logging files for workers to redirect its output."""
206 worker_stdout_file, worker_stderr_file = (new_log_files(
207 "worker-" + ray.utils.binary_to_hex(worker_id), True))
208 return worker_stdout_file, worker_stderr_file
209
210
211 def new_log_monitor_log_file():
212 """Create new logging files for the log monitor."""
213 log_monitor_stdout_file, log_monitor_stderr_file = new_log_files(
214 "log_monitor", redirect_output=True)
215 return log_monitor_stdout_file, log_monitor_stderr_file
216
217
218 def new_plasma_store_log_file(local_scheduler_index, redirect_output):
219 """Create new logging files for the plasma store."""
220 plasma_store_stdout_file, plasma_store_stderr_file = new_log_files(
221 "plasma_store_{}".format(local_scheduler_index), redirect_output)
222 return plasma_store_stdout_file, plasma_store_stderr_file
223
224
225 def new_monitor_log_file(redirect_output):
226 """Create new logging files for the monitor."""
227 monitor_stdout_file, monitor_stderr_file = new_log_files(
228 "monitor", redirect_output)
229 return monitor_stdout_file, monitor_stderr_file
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/ray/tempfile_services.py b/python/ray/tempfile_services.py
--- a/python/ray/tempfile_services.py
+++ b/python/ray/tempfile_services.py
@@ -66,8 +66,16 @@
# important when multiple people are using the same machine.
try:
os.chmod(directory_path, 0o0777)
- except PermissionError:
- pass
+ except OSError as e:
+ # Silently suppress the PermissionError that is thrown by the chmod.
+ # This is done because the user attempting to change the permissions
+ # on a directory may not own it. The chmod is attempted whether the
+ # directory is new or not to avoid race conditions.
+ # ray-project/ray/#3591
+ if e.errno in [errno.EACCES, errno.EPERM]:
+ pass
+ else:
+ raise
def get_temp_root():
|
{"golden_diff": "diff --git a/python/ray/tempfile_services.py b/python/ray/tempfile_services.py\n--- a/python/ray/tempfile_services.py\n+++ b/python/ray/tempfile_services.py\n@@ -66,8 +66,16 @@\n # important when multiple people are using the same machine.\n try:\n os.chmod(directory_path, 0o0777)\n- except PermissionError:\n- pass\n+ except OSError as e:\n+ # Silently suppress the PermissionError that is thrown by the chmod.\n+ # This is done because the user attempting to change the permissions\n+ # on a directory may not own it. The chmod is attempted whether the\n+ # directory is new or not to avoid race conditions.\n+ # ray-project/ray/#3591\n+ if e.errno in [errno.EACCES, errno.EPERM]:\n+ pass\n+ else:\n+ raise\n \n \n def get_temp_root():\n", "issue": "PermissionError not defined in Python 2.7\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Ubuntu 16\r\n- **Ray installed from (source or binary)**: binary\r\n- **Ray version**: 0.6.1\r\n- **Python version**: 2.7\r\n- **Exact command to reproduce**:\r\n\r\nI don't have access to `/tmp`, and I get this following error:\r\n\r\n```\r\ncluster_tests.py:55: in _start_new_cluster\r\n \"num_heartbeats_timeout\": 10\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/test/cluster_utils.py:43: in __init__\r\n self.add_node(**head_node_args)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/test/cluster_utils.py:86: in add_node\r\n **node_kwargs)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:1777: in start_ray_head\r\n _internal_config=_internal_config)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:1436: in start_ray_processes\r\n redis_max_memory=redis_max_memory)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/services.py:458: in start_redis\r\n redis_stdout_file, redis_stderr_file = new_redis_log_file(redirect_output)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:182: in new_redis_log_file\r\n \"redis\", redirect_output)\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:166: in new_log_files\r\n try_to_create_directory(\"/tmp/ray\")\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\ndirectory_path = '/tmp/ray'\r\n\r\n def try_to_create_directory(directory_path):\r\n \"\"\"Attempt to create a directory that is globally readable/writable.\r\n\r\n Args:\r\n directory_path: The path of the directory to create.\r\n \"\"\"\r\n directory_path = os.path.expanduser(directory_path)\r\n if not os.path.exists(directory_path):\r\n try:\r\n os.makedirs(directory_path)\r\n except OSError as e:\r\n if e.errno != os.errno.EEXIST:\r\n raise e\r\n logger.warning(\r\n \"Attempted to create '{}', but the directory already \"\r\n \"exists.\".format(directory_path))\r\n # Change the log directory permissions so others can use it. This is\r\n # important when multiple people are using the same machine.\r\n try:\r\n os.chmod(directory_path, 0o0777)\r\n> except PermissionError:\r\nE NameError: global name 'PermissionError' is not defined\r\n\r\n/data/rliaw/miniconda3/envs/py2/lib/python2.7/site-packages/ray/tempfile_services.py:69: NameError\r\n```\n", "before_files": [{"content": "import binascii\nimport collections\nimport datetime\nimport errno\nimport logging\nimport os\nimport shutil\nimport tempfile\n\nimport ray.utils\n\nlogger = logging.getLogger(__name__)\n_incremental_dict = collections.defaultdict(lambda: 0)\n_temp_root = None\n\n\ndef make_inc_temp(suffix=\"\", prefix=\"\", directory_name=\"/tmp/ray\"):\n \"\"\"Return a incremental temporary file name. The file is not created.\n\n Args:\n suffix (str): The suffix of the temp file.\n prefix (str): The prefix of the temp file.\n directory_name (str) : The base directory of the temp file.\n\n Returns:\n A string of file name. If there existing a file having the same name,\n the returned name will look like\n \"{directory_name}/{prefix}.{unique_index}{suffix}\"\n \"\"\"\n directory_name = os.path.expanduser(directory_name)\n index = _incremental_dict[suffix, prefix, directory_name]\n # `tempfile.TMP_MAX` could be extremely large,\n # so using `range` in Python2.x should be avoided.\n while index < tempfile.TMP_MAX:\n if index == 0:\n filename = os.path.join(directory_name, prefix + suffix)\n else:\n filename = os.path.join(directory_name,\n prefix + \".\" + str(index) + suffix)\n index += 1\n if not os.path.exists(filename):\n _incremental_dict[suffix, prefix,\n directory_name] = index # Save the index.\n return filename\n\n raise FileExistsError(errno.EEXIST, \"No usable temporary filename found\")\n\n\ndef try_to_create_directory(directory_path):\n \"\"\"Attempt to create a directory that is globally readable/writable.\n\n Args:\n directory_path: The path of the directory to create.\n \"\"\"\n directory_path = os.path.expanduser(directory_path)\n if not os.path.exists(directory_path):\n try:\n os.makedirs(directory_path)\n except OSError as e:\n if e.errno != os.errno.EEXIST:\n raise e\n logger.warning(\n \"Attempted to create '{}', but the directory already \"\n \"exists.\".format(directory_path))\n # Change the log directory permissions so others can use it. This is\n # important when multiple people are using the same machine.\n try:\n os.chmod(directory_path, 0o0777)\n except PermissionError:\n pass\n\n\ndef get_temp_root():\n \"\"\"Get the path of the temporary root. If not existing, it will be created.\n \"\"\"\n global _temp_root\n\n date_str = datetime.datetime.today().strftime(\"%Y-%m-%d_%H-%M-%S\")\n\n # Lazy creation. Avoid creating directories never used.\n if _temp_root is None:\n _temp_root = make_inc_temp(\n prefix=\"session_{date_str}_{pid}\".format(\n pid=os.getpid(), date_str=date_str),\n directory_name=\"/tmp/ray\")\n try_to_create_directory(_temp_root)\n return _temp_root\n\n\ndef set_temp_root(path):\n \"\"\"Set the path of the temporary root. It will be created lazily.\"\"\"\n global _temp_root\n _temp_root = path\n\n\ndef get_logs_dir_path():\n \"\"\"Get a temp dir for logging.\"\"\"\n logs_dir = os.path.join(get_temp_root(), \"logs\")\n try_to_create_directory(logs_dir)\n return logs_dir\n\n\ndef get_sockets_dir_path():\n \"\"\"Get a temp dir for sockets.\"\"\"\n sockets_dir = os.path.join(get_temp_root(), \"sockets\")\n try_to_create_directory(sockets_dir)\n return sockets_dir\n\n\ndef get_raylet_socket_name(suffix=\"\"):\n \"\"\"Get a socket name for raylet.\"\"\"\n sockets_dir = get_sockets_dir_path()\n\n raylet_socket_name = make_inc_temp(\n prefix=\"raylet\", directory_name=sockets_dir, suffix=suffix)\n return raylet_socket_name\n\n\ndef get_object_store_socket_name():\n \"\"\"Get a socket name for plasma object store.\"\"\"\n sockets_dir = get_sockets_dir_path()\n return make_inc_temp(prefix=\"plasma_store\", directory_name=sockets_dir)\n\n\ndef get_ipython_notebook_path(port):\n \"\"\"Get a new ipython notebook path\"\"\"\n\n notebook_filepath = os.path.join(\n os.path.dirname(os.path.abspath(__file__)), \"WebUI.ipynb\")\n # We copy the notebook file so that the original doesn't get modified by\n # the user.\n notebook_name = make_inc_temp(\n suffix=\".ipynb\", prefix=\"ray_ui\", directory_name=get_temp_root())\n shutil.copy(notebook_filepath, notebook_name)\n new_notebook_directory = os.path.dirname(notebook_name)\n token = ray.utils.decode(binascii.hexlify(os.urandom(24)))\n webui_url = (\"http://localhost:{}/notebooks/{}?token={}\".format(\n port, os.path.basename(notebook_name), token))\n return new_notebook_directory, webui_url, token\n\n\ndef new_log_files(name, redirect_output):\n \"\"\"Generate partially randomized filenames for log files.\n\n Args:\n name (str): descriptive string for this log file.\n redirect_output (bool): True if files should be generated for logging\n stdout and stderr and false if stdout and stderr should not be\n redirected.\n\n Returns:\n If redirect_output is true, this will return a tuple of two\n filehandles. The first is for redirecting stdout and the second is\n for redirecting stderr. If redirect_output is false, this will\n return a tuple of two None objects.\n \"\"\"\n if not redirect_output:\n return None, None\n\n # Create a directory to be used for process log files.\n logs_dir = get_logs_dir_path()\n # Create another directory that will be used by some of the RL algorithms.\n\n # TODO(suquark): This is done by the old code.\n # We should be able to control its path later.\n try_to_create_directory(\"/tmp/ray\")\n\n log_stdout = make_inc_temp(\n suffix=\".out\", prefix=name, directory_name=logs_dir)\n log_stderr = make_inc_temp(\n suffix=\".err\", prefix=name, directory_name=logs_dir)\n # Line-buffer the output (mode 1)\n log_stdout_file = open(log_stdout, \"a\", buffering=1)\n log_stderr_file = open(log_stderr, \"a\", buffering=1)\n return log_stdout_file, log_stderr_file\n\n\ndef new_redis_log_file(redirect_output, shard_number=None):\n \"\"\"Create new logging files for redis\"\"\"\n if shard_number is None:\n redis_stdout_file, redis_stderr_file = new_log_files(\n \"redis\", redirect_output)\n else:\n redis_stdout_file, redis_stderr_file = new_log_files(\n \"redis-shard_{}\".format(shard_number), redirect_output)\n return redis_stdout_file, redis_stderr_file\n\n\ndef new_raylet_log_file(local_scheduler_index, redirect_output):\n \"\"\"Create new logging files for raylet.\"\"\"\n raylet_stdout_file, raylet_stderr_file = new_log_files(\n \"raylet_{}\".format(local_scheduler_index),\n redirect_output=redirect_output)\n return raylet_stdout_file, raylet_stderr_file\n\n\ndef new_webui_log_file():\n \"\"\"Create new logging files for web ui.\"\"\"\n ui_stdout_file, ui_stderr_file = new_log_files(\n \"webui\", redirect_output=True)\n return ui_stdout_file, ui_stderr_file\n\n\ndef new_worker_redirected_log_file(worker_id):\n \"\"\"Create new logging files for workers to redirect its output.\"\"\"\n worker_stdout_file, worker_stderr_file = (new_log_files(\n \"worker-\" + ray.utils.binary_to_hex(worker_id), True))\n return worker_stdout_file, worker_stderr_file\n\n\ndef new_log_monitor_log_file():\n \"\"\"Create new logging files for the log monitor.\"\"\"\n log_monitor_stdout_file, log_monitor_stderr_file = new_log_files(\n \"log_monitor\", redirect_output=True)\n return log_monitor_stdout_file, log_monitor_stderr_file\n\n\ndef new_plasma_store_log_file(local_scheduler_index, redirect_output):\n \"\"\"Create new logging files for the plasma store.\"\"\"\n plasma_store_stdout_file, plasma_store_stderr_file = new_log_files(\n \"plasma_store_{}\".format(local_scheduler_index), redirect_output)\n return plasma_store_stdout_file, plasma_store_stderr_file\n\n\ndef new_monitor_log_file(redirect_output):\n \"\"\"Create new logging files for the monitor.\"\"\"\n monitor_stdout_file, monitor_stderr_file = new_log_files(\n \"monitor\", redirect_output)\n return monitor_stdout_file, monitor_stderr_file\n", "path": "python/ray/tempfile_services.py"}], "after_files": [{"content": "import binascii\nimport collections\nimport datetime\nimport errno\nimport logging\nimport os\nimport shutil\nimport tempfile\n\nimport ray.utils\n\nlogger = logging.getLogger(__name__)\n_incremental_dict = collections.defaultdict(lambda: 0)\n_temp_root = None\n\n\ndef make_inc_temp(suffix=\"\", prefix=\"\", directory_name=\"/tmp/ray\"):\n \"\"\"Return a incremental temporary file name. The file is not created.\n\n Args:\n suffix (str): The suffix of the temp file.\n prefix (str): The prefix of the temp file.\n directory_name (str) : The base directory of the temp file.\n\n Returns:\n A string of file name. If there existing a file having the same name,\n the returned name will look like\n \"{directory_name}/{prefix}.{unique_index}{suffix}\"\n \"\"\"\n directory_name = os.path.expanduser(directory_name)\n index = _incremental_dict[suffix, prefix, directory_name]\n # `tempfile.TMP_MAX` could be extremely large,\n # so using `range` in Python2.x should be avoided.\n while index < tempfile.TMP_MAX:\n if index == 0:\n filename = os.path.join(directory_name, prefix + suffix)\n else:\n filename = os.path.join(directory_name,\n prefix + \".\" + str(index) + suffix)\n index += 1\n if not os.path.exists(filename):\n _incremental_dict[suffix, prefix,\n directory_name] = index # Save the index.\n return filename\n\n raise FileExistsError(errno.EEXIST, \"No usable temporary filename found\")\n\n\ndef try_to_create_directory(directory_path):\n \"\"\"Attempt to create a directory that is globally readable/writable.\n\n Args:\n directory_path: The path of the directory to create.\n \"\"\"\n directory_path = os.path.expanduser(directory_path)\n if not os.path.exists(directory_path):\n try:\n os.makedirs(directory_path)\n except OSError as e:\n if e.errno != os.errno.EEXIST:\n raise e\n logger.warning(\n \"Attempted to create '{}', but the directory already \"\n \"exists.\".format(directory_path))\n # Change the log directory permissions so others can use it. This is\n # important when multiple people are using the same machine.\n try:\n os.chmod(directory_path, 0o0777)\n except OSError as e:\n # Silently suppress the PermissionError that is thrown by the chmod.\n # This is done because the user attempting to change the permissions\n # on a directory may not own it. The chmod is attempted whether the\n # directory is new or not to avoid race conditions.\n # ray-project/ray/#3591\n if e.errno in [errno.EACCES, errno.EPERM]:\n pass\n else:\n raise\n\n\ndef get_temp_root():\n \"\"\"Get the path of the temporary root. If not existing, it will be created.\n \"\"\"\n global _temp_root\n\n date_str = datetime.datetime.today().strftime(\"%Y-%m-%d_%H-%M-%S\")\n\n # Lazy creation. Avoid creating directories never used.\n if _temp_root is None:\n _temp_root = make_inc_temp(\n prefix=\"session_{date_str}_{pid}\".format(\n pid=os.getpid(), date_str=date_str),\n directory_name=\"/tmp/ray\")\n try_to_create_directory(_temp_root)\n return _temp_root\n\n\ndef set_temp_root(path):\n \"\"\"Set the path of the temporary root. It will be created lazily.\"\"\"\n global _temp_root\n _temp_root = path\n\n\ndef get_logs_dir_path():\n \"\"\"Get a temp dir for logging.\"\"\"\n logs_dir = os.path.join(get_temp_root(), \"logs\")\n try_to_create_directory(logs_dir)\n return logs_dir\n\n\ndef get_sockets_dir_path():\n \"\"\"Get a temp dir for sockets.\"\"\"\n sockets_dir = os.path.join(get_temp_root(), \"sockets\")\n try_to_create_directory(sockets_dir)\n return sockets_dir\n\n\ndef get_raylet_socket_name(suffix=\"\"):\n \"\"\"Get a socket name for raylet.\"\"\"\n sockets_dir = get_sockets_dir_path()\n\n raylet_socket_name = make_inc_temp(\n prefix=\"raylet\", directory_name=sockets_dir, suffix=suffix)\n return raylet_socket_name\n\n\ndef get_object_store_socket_name():\n \"\"\"Get a socket name for plasma object store.\"\"\"\n sockets_dir = get_sockets_dir_path()\n return make_inc_temp(prefix=\"plasma_store\", directory_name=sockets_dir)\n\n\ndef get_ipython_notebook_path(port):\n \"\"\"Get a new ipython notebook path\"\"\"\n\n notebook_filepath = os.path.join(\n os.path.dirname(os.path.abspath(__file__)), \"WebUI.ipynb\")\n # We copy the notebook file so that the original doesn't get modified by\n # the user.\n notebook_name = make_inc_temp(\n suffix=\".ipynb\", prefix=\"ray_ui\", directory_name=get_temp_root())\n shutil.copy(notebook_filepath, notebook_name)\n new_notebook_directory = os.path.dirname(notebook_name)\n token = ray.utils.decode(binascii.hexlify(os.urandom(24)))\n webui_url = (\"http://localhost:{}/notebooks/{}?token={}\".format(\n port, os.path.basename(notebook_name), token))\n return new_notebook_directory, webui_url, token\n\n\ndef new_log_files(name, redirect_output):\n \"\"\"Generate partially randomized filenames for log files.\n\n Args:\n name (str): descriptive string for this log file.\n redirect_output (bool): True if files should be generated for logging\n stdout and stderr and false if stdout and stderr should not be\n redirected.\n\n Returns:\n If redirect_output is true, this will return a tuple of two\n filehandles. The first is for redirecting stdout and the second is\n for redirecting stderr. If redirect_output is false, this will\n return a tuple of two None objects.\n \"\"\"\n if not redirect_output:\n return None, None\n\n # Create a directory to be used for process log files.\n logs_dir = get_logs_dir_path()\n # Create another directory that will be used by some of the RL algorithms.\n\n # TODO(suquark): This is done by the old code.\n # We should be able to control its path later.\n try_to_create_directory(\"/tmp/ray\")\n\n log_stdout = make_inc_temp(\n suffix=\".out\", prefix=name, directory_name=logs_dir)\n log_stderr = make_inc_temp(\n suffix=\".err\", prefix=name, directory_name=logs_dir)\n # Line-buffer the output (mode 1)\n log_stdout_file = open(log_stdout, \"a\", buffering=1)\n log_stderr_file = open(log_stderr, \"a\", buffering=1)\n return log_stdout_file, log_stderr_file\n\n\ndef new_redis_log_file(redirect_output, shard_number=None):\n \"\"\"Create new logging files for redis\"\"\"\n if shard_number is None:\n redis_stdout_file, redis_stderr_file = new_log_files(\n \"redis\", redirect_output)\n else:\n redis_stdout_file, redis_stderr_file = new_log_files(\n \"redis-shard_{}\".format(shard_number), redirect_output)\n return redis_stdout_file, redis_stderr_file\n\n\ndef new_raylet_log_file(local_scheduler_index, redirect_output):\n \"\"\"Create new logging files for raylet.\"\"\"\n raylet_stdout_file, raylet_stderr_file = new_log_files(\n \"raylet_{}\".format(local_scheduler_index),\n redirect_output=redirect_output)\n return raylet_stdout_file, raylet_stderr_file\n\n\ndef new_webui_log_file():\n \"\"\"Create new logging files for web ui.\"\"\"\n ui_stdout_file, ui_stderr_file = new_log_files(\n \"webui\", redirect_output=True)\n return ui_stdout_file, ui_stderr_file\n\n\ndef new_worker_redirected_log_file(worker_id):\n \"\"\"Create new logging files for workers to redirect its output.\"\"\"\n worker_stdout_file, worker_stderr_file = (new_log_files(\n \"worker-\" + ray.utils.binary_to_hex(worker_id), True))\n return worker_stdout_file, worker_stderr_file\n\n\ndef new_log_monitor_log_file():\n \"\"\"Create new logging files for the log monitor.\"\"\"\n log_monitor_stdout_file, log_monitor_stderr_file = new_log_files(\n \"log_monitor\", redirect_output=True)\n return log_monitor_stdout_file, log_monitor_stderr_file\n\n\ndef new_plasma_store_log_file(local_scheduler_index, redirect_output):\n \"\"\"Create new logging files for the plasma store.\"\"\"\n plasma_store_stdout_file, plasma_store_stderr_file = new_log_files(\n \"plasma_store_{}\".format(local_scheduler_index), redirect_output)\n return plasma_store_stdout_file, plasma_store_stderr_file\n\n\ndef new_monitor_log_file(redirect_output):\n \"\"\"Create new logging files for the monitor.\"\"\"\n monitor_stdout_file, monitor_stderr_file = new_log_files(\n \"monitor\", redirect_output)\n return monitor_stdout_file, monitor_stderr_file\n", "path": "python/ray/tempfile_services.py"}]}
| 3,451 | 211 |
gh_patches_debug_42792
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1064
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support env variables for Zipkin exporter
The spec describes environment variables that should be supported to configure the Zipkin exporter, this feature request is to add support in the current implementation.
https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/sdk-environment-variables.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 This library allows to export tracing data to `Zipkin <https://zipkin.io/>`_.
17
18 Usage
19 -----
20
21 The **OpenTelemetry Zipkin Exporter** allows to export `OpenTelemetry`_ traces to `Zipkin`_.
22 This exporter always send traces to the configured Zipkin collector using HTTP.
23
24
25 .. _Zipkin: https://zipkin.io/
26 .. _OpenTelemetry: https://github.com/open-telemetry/opentelemetry-python/
27
28 .. code:: python
29
30 from opentelemetry import trace
31 from opentelemetry.exporter import zipkin
32 from opentelemetry.sdk.trace import TracerProvider
33 from opentelemetry.sdk.trace.export import BatchExportSpanProcessor
34
35 trace.set_tracer_provider(TracerProvider())
36 tracer = trace.get_tracer(__name__)
37
38 # create a ZipkinSpanExporter
39 zipkin_exporter = zipkin.ZipkinSpanExporter(
40 service_name="my-helloworld-service",
41 # optional:
42 # host_name="localhost",
43 # port=9411,
44 # endpoint="/api/v2/spans",
45 # protocol="http",
46 # ipv4="",
47 # ipv6="",
48 # retry=False,
49 )
50
51 # Create a BatchExportSpanProcessor and add the exporter to it
52 span_processor = BatchExportSpanProcessor(zipkin_exporter)
53
54 # add to the tracer
55 trace.get_tracer_provider().add_span_processor(span_processor)
56
57 with tracer.start_as_current_span("foo"):
58 print("Hello world!")
59
60 API
61 ---
62 """
63
64 import json
65 import logging
66 from typing import Optional, Sequence
67
68 import requests
69
70 from opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult
71 from opentelemetry.trace import Span, SpanContext, SpanKind
72
73 DEFAULT_ENDPOINT = "/api/v2/spans"
74 DEFAULT_HOST_NAME = "localhost"
75 DEFAULT_PORT = 9411
76 DEFAULT_PROTOCOL = "http"
77 DEFAULT_RETRY = False
78 ZIPKIN_HEADERS = {"Content-Type": "application/json"}
79
80 SPAN_KIND_MAP = {
81 SpanKind.INTERNAL: None,
82 SpanKind.SERVER: "SERVER",
83 SpanKind.CLIENT: "CLIENT",
84 SpanKind.PRODUCER: "PRODUCER",
85 SpanKind.CONSUMER: "CONSUMER",
86 }
87
88 SUCCESS_STATUS_CODES = (200, 202)
89
90 logger = logging.getLogger(__name__)
91
92
93 class ZipkinSpanExporter(SpanExporter):
94 """Zipkin span exporter for OpenTelemetry.
95
96 Args:
97 service_name: Service that logged an annotation in a trace.Classifier
98 when query for spans.
99 host_name: The host name of the Zipkin server
100 port: The port of the Zipkin server
101 endpoint: The endpoint of the Zipkin server
102 protocol: The protocol used for the request.
103 ipv4: Primary IPv4 address associated with this connection.
104 ipv6: Primary IPv6 address associated with this connection.
105 retry: Set to True to configure the exporter to retry on failure.
106 """
107
108 def __init__(
109 self,
110 service_name: str,
111 host_name: str = DEFAULT_HOST_NAME,
112 port: int = DEFAULT_PORT,
113 endpoint: str = DEFAULT_ENDPOINT,
114 protocol: str = DEFAULT_PROTOCOL,
115 ipv4: Optional[str] = None,
116 ipv6: Optional[str] = None,
117 retry: Optional[str] = DEFAULT_RETRY,
118 ):
119 self.service_name = service_name
120 self.host_name = host_name
121 self.port = port
122 self.endpoint = endpoint
123 self.protocol = protocol
124 self.url = "{}://{}:{}{}".format(
125 self.protocol, self.host_name, self.port, self.endpoint
126 )
127 self.ipv4 = ipv4
128 self.ipv6 = ipv6
129 self.retry = retry
130
131 def export(self, spans: Sequence[Span]) -> SpanExportResult:
132 zipkin_spans = self._translate_to_zipkin(spans)
133 result = requests.post(
134 url=self.url, data=json.dumps(zipkin_spans), headers=ZIPKIN_HEADERS
135 )
136
137 if result.status_code not in SUCCESS_STATUS_CODES:
138 logger.error(
139 "Traces cannot be uploaded; status code: %s, message %s",
140 result.status_code,
141 result.text,
142 )
143
144 if self.retry:
145 return SpanExportResult.FAILURE
146 return SpanExportResult.FAILURE
147 return SpanExportResult.SUCCESS
148
149 def _translate_to_zipkin(self, spans: Sequence[Span]):
150
151 local_endpoint = {"serviceName": self.service_name, "port": self.port}
152
153 if self.ipv4 is not None:
154 local_endpoint["ipv4"] = self.ipv4
155
156 if self.ipv6 is not None:
157 local_endpoint["ipv6"] = self.ipv6
158
159 zipkin_spans = []
160 for span in spans:
161 context = span.get_context()
162 trace_id = context.trace_id
163 span_id = context.span_id
164
165 # Timestamp in zipkin spans is int of microseconds.
166 # see: https://zipkin.io/pages/instrumenting.html
167 start_timestamp_mus = _nsec_to_usec_round(span.start_time)
168 duration_mus = _nsec_to_usec_round(span.end_time - span.start_time)
169
170 zipkin_span = {
171 # Ensure left-zero-padding of traceId, spanId, parentId
172 "traceId": format(trace_id, "032x"),
173 "id": format(span_id, "016x"),
174 "name": span.name,
175 "timestamp": start_timestamp_mus,
176 "duration": duration_mus,
177 "localEndpoint": local_endpoint,
178 "kind": SPAN_KIND_MAP[span.kind],
179 "tags": _extract_tags_from_span(span),
180 "annotations": _extract_annotations_from_events(span.events),
181 }
182
183 if context.trace_flags.sampled:
184 zipkin_span["debug"] = True
185
186 if isinstance(span.parent, Span):
187 zipkin_span["parentId"] = format(
188 span.parent.get_context().span_id, "016x"
189 )
190 elif isinstance(span.parent, SpanContext):
191 zipkin_span["parentId"] = format(span.parent.span_id, "016x")
192
193 zipkin_spans.append(zipkin_span)
194 return zipkin_spans
195
196 def shutdown(self) -> None:
197 pass
198
199
200 def _extract_tags_from_dict(tags_dict):
201 tags = {}
202 if not tags_dict:
203 return tags
204 for attribute_key, attribute_value in tags_dict.items():
205 if isinstance(attribute_value, (int, bool, float)):
206 value = str(attribute_value)
207 elif isinstance(attribute_value, str):
208 value = attribute_value[:128]
209 else:
210 logger.warning("Could not serialize tag %s", attribute_key)
211 continue
212 tags[attribute_key] = value
213 return tags
214
215
216 def _extract_tags_from_span(span: Span):
217 tags = _extract_tags_from_dict(getattr(span, "attributes", None))
218 if span.resource:
219 tags.update(_extract_tags_from_dict(span.resource.labels))
220 return tags
221
222
223 def _extract_annotations_from_events(events):
224 return (
225 [
226 {"timestamp": _nsec_to_usec_round(e.timestamp), "value": e.name}
227 for e in events
228 ]
229 if events
230 else None
231 )
232
233
234 def _nsec_to_usec_round(nsec):
235 """Round nanoseconds to microseconds"""
236 return (nsec + 500) // 10 ** 3
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py b/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py
--- a/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py
+++ b/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py
@@ -24,6 +24,7 @@
.. _Zipkin: https://zipkin.io/
.. _OpenTelemetry: https://github.com/open-telemetry/opentelemetry-python/
+.. _Specification: https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/sdk-environment-variables.md#zipkin-exporter
.. code:: python
@@ -39,10 +40,7 @@
zipkin_exporter = zipkin.ZipkinSpanExporter(
service_name="my-helloworld-service",
# optional:
- # host_name="localhost",
- # port=9411,
- # endpoint="/api/v2/spans",
- # protocol="http",
+ # url="http://localhost:9411/api/v2/spans",
# ipv4="",
# ipv6="",
# retry=False,
@@ -57,24 +55,25 @@
with tracer.start_as_current_span("foo"):
print("Hello world!")
+The exporter supports endpoint configuration via the OTEL_EXPORTER_ZIPKIN_ENDPOINT environment variables as defined in the `Specification`_
+
API
---
"""
import json
import logging
+import os
from typing import Optional, Sequence
+from urllib.parse import urlparse
import requests
from opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult
from opentelemetry.trace import Span, SpanContext, SpanKind
-DEFAULT_ENDPOINT = "/api/v2/spans"
-DEFAULT_HOST_NAME = "localhost"
-DEFAULT_PORT = 9411
-DEFAULT_PROTOCOL = "http"
DEFAULT_RETRY = False
+DEFAULT_URL = "http://localhost:9411/api/v2/spans"
ZIPKIN_HEADERS = {"Content-Type": "application/json"}
SPAN_KIND_MAP = {
@@ -96,10 +95,7 @@
Args:
service_name: Service that logged an annotation in a trace.Classifier
when query for spans.
- host_name: The host name of the Zipkin server
- port: The port of the Zipkin server
- endpoint: The endpoint of the Zipkin server
- protocol: The protocol used for the request.
+ url: The Zipkin endpoint URL
ipv4: Primary IPv4 address associated with this connection.
ipv6: Primary IPv6 address associated with this connection.
retry: Set to True to configure the exporter to retry on failure.
@@ -108,22 +104,21 @@
def __init__(
self,
service_name: str,
- host_name: str = DEFAULT_HOST_NAME,
- port: int = DEFAULT_PORT,
- endpoint: str = DEFAULT_ENDPOINT,
- protocol: str = DEFAULT_PROTOCOL,
+ url: str = None,
ipv4: Optional[str] = None,
ipv6: Optional[str] = None,
retry: Optional[str] = DEFAULT_RETRY,
):
self.service_name = service_name
- self.host_name = host_name
- self.port = port
- self.endpoint = endpoint
- self.protocol = protocol
- self.url = "{}://{}:{}{}".format(
- self.protocol, self.host_name, self.port, self.endpoint
- )
+ if url is None:
+ self.url = os.environ.get(
+ "OTEL_EXPORTER_ZIPKIN_ENDPOINT", DEFAULT_URL
+ )
+ else:
+ self.url = url
+
+ self.port = urlparse(self.url).port
+
self.ipv4 = ipv4
self.ipv6 = ipv6
self.retry = retry
|
{"golden_diff": "diff --git a/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py b/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py\n--- a/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py\n+++ b/exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py\n@@ -24,6 +24,7 @@\n \n .. _Zipkin: https://zipkin.io/\n .. _OpenTelemetry: https://github.com/open-telemetry/opentelemetry-python/\n+.. _Specification: https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/sdk-environment-variables.md#zipkin-exporter\n \n .. code:: python\n \n@@ -39,10 +40,7 @@\n zipkin_exporter = zipkin.ZipkinSpanExporter(\n service_name=\"my-helloworld-service\",\n # optional:\n- # host_name=\"localhost\",\n- # port=9411,\n- # endpoint=\"/api/v2/spans\",\n- # protocol=\"http\",\n+ # url=\"http://localhost:9411/api/v2/spans\",\n # ipv4=\"\",\n # ipv6=\"\",\n # retry=False,\n@@ -57,24 +55,25 @@\n with tracer.start_as_current_span(\"foo\"):\n print(\"Hello world!\")\n \n+The exporter supports endpoint configuration via the OTEL_EXPORTER_ZIPKIN_ENDPOINT environment variables as defined in the `Specification`_\n+\n API\n ---\n \"\"\"\n \n import json\n import logging\n+import os\n from typing import Optional, Sequence\n+from urllib.parse import urlparse\n \n import requests\n \n from opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult\n from opentelemetry.trace import Span, SpanContext, SpanKind\n \n-DEFAULT_ENDPOINT = \"/api/v2/spans\"\n-DEFAULT_HOST_NAME = \"localhost\"\n-DEFAULT_PORT = 9411\n-DEFAULT_PROTOCOL = \"http\"\n DEFAULT_RETRY = False\n+DEFAULT_URL = \"http://localhost:9411/api/v2/spans\"\n ZIPKIN_HEADERS = {\"Content-Type\": \"application/json\"}\n \n SPAN_KIND_MAP = {\n@@ -96,10 +95,7 @@\n Args:\n service_name: Service that logged an annotation in a trace.Classifier\n when query for spans.\n- host_name: The host name of the Zipkin server\n- port: The port of the Zipkin server\n- endpoint: The endpoint of the Zipkin server\n- protocol: The protocol used for the request.\n+ url: The Zipkin endpoint URL\n ipv4: Primary IPv4 address associated with this connection.\n ipv6: Primary IPv6 address associated with this connection.\n retry: Set to True to configure the exporter to retry on failure.\n@@ -108,22 +104,21 @@\n def __init__(\n self,\n service_name: str,\n- host_name: str = DEFAULT_HOST_NAME,\n- port: int = DEFAULT_PORT,\n- endpoint: str = DEFAULT_ENDPOINT,\n- protocol: str = DEFAULT_PROTOCOL,\n+ url: str = None,\n ipv4: Optional[str] = None,\n ipv6: Optional[str] = None,\n retry: Optional[str] = DEFAULT_RETRY,\n ):\n self.service_name = service_name\n- self.host_name = host_name\n- self.port = port\n- self.endpoint = endpoint\n- self.protocol = protocol\n- self.url = \"{}://{}:{}{}\".format(\n- self.protocol, self.host_name, self.port, self.endpoint\n- )\n+ if url is None:\n+ self.url = os.environ.get(\n+ \"OTEL_EXPORTER_ZIPKIN_ENDPOINT\", DEFAULT_URL\n+ )\n+ else:\n+ self.url = url\n+\n+ self.port = urlparse(self.url).port\n+\n self.ipv4 = ipv4\n self.ipv6 = ipv6\n self.retry = retry\n", "issue": "Support env variables for Zipkin exporter\nThe spec describes environment variables that should be supported to configure the Zipkin exporter, this feature request is to add support in the current implementation.\r\n\r\nhttps://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/sdk-environment-variables.md\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library allows to export tracing data to `Zipkin <https://zipkin.io/>`_.\n\nUsage\n-----\n\nThe **OpenTelemetry Zipkin Exporter** allows to export `OpenTelemetry`_ traces to `Zipkin`_.\nThis exporter always send traces to the configured Zipkin collector using HTTP.\n\n\n.. _Zipkin: https://zipkin.io/\n.. _OpenTelemetry: https://github.com/open-telemetry/opentelemetry-python/\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.exporter import zipkin\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import BatchExportSpanProcessor\n\n trace.set_tracer_provider(TracerProvider())\n tracer = trace.get_tracer(__name__)\n\n # create a ZipkinSpanExporter\n zipkin_exporter = zipkin.ZipkinSpanExporter(\n service_name=\"my-helloworld-service\",\n # optional:\n # host_name=\"localhost\",\n # port=9411,\n # endpoint=\"/api/v2/spans\",\n # protocol=\"http\",\n # ipv4=\"\",\n # ipv6=\"\",\n # retry=False,\n )\n\n # Create a BatchExportSpanProcessor and add the exporter to it\n span_processor = BatchExportSpanProcessor(zipkin_exporter)\n\n # add to the tracer\n trace.get_tracer_provider().add_span_processor(span_processor)\n\n with tracer.start_as_current_span(\"foo\"):\n print(\"Hello world!\")\n\nAPI\n---\n\"\"\"\n\nimport json\nimport logging\nfrom typing import Optional, Sequence\n\nimport requests\n\nfrom opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult\nfrom opentelemetry.trace import Span, SpanContext, SpanKind\n\nDEFAULT_ENDPOINT = \"/api/v2/spans\"\nDEFAULT_HOST_NAME = \"localhost\"\nDEFAULT_PORT = 9411\nDEFAULT_PROTOCOL = \"http\"\nDEFAULT_RETRY = False\nZIPKIN_HEADERS = {\"Content-Type\": \"application/json\"}\n\nSPAN_KIND_MAP = {\n SpanKind.INTERNAL: None,\n SpanKind.SERVER: \"SERVER\",\n SpanKind.CLIENT: \"CLIENT\",\n SpanKind.PRODUCER: \"PRODUCER\",\n SpanKind.CONSUMER: \"CONSUMER\",\n}\n\nSUCCESS_STATUS_CODES = (200, 202)\n\nlogger = logging.getLogger(__name__)\n\n\nclass ZipkinSpanExporter(SpanExporter):\n \"\"\"Zipkin span exporter for OpenTelemetry.\n\n Args:\n service_name: Service that logged an annotation in a trace.Classifier\n when query for spans.\n host_name: The host name of the Zipkin server\n port: The port of the Zipkin server\n endpoint: The endpoint of the Zipkin server\n protocol: The protocol used for the request.\n ipv4: Primary IPv4 address associated with this connection.\n ipv6: Primary IPv6 address associated with this connection.\n retry: Set to True to configure the exporter to retry on failure.\n \"\"\"\n\n def __init__(\n self,\n service_name: str,\n host_name: str = DEFAULT_HOST_NAME,\n port: int = DEFAULT_PORT,\n endpoint: str = DEFAULT_ENDPOINT,\n protocol: str = DEFAULT_PROTOCOL,\n ipv4: Optional[str] = None,\n ipv6: Optional[str] = None,\n retry: Optional[str] = DEFAULT_RETRY,\n ):\n self.service_name = service_name\n self.host_name = host_name\n self.port = port\n self.endpoint = endpoint\n self.protocol = protocol\n self.url = \"{}://{}:{}{}\".format(\n self.protocol, self.host_name, self.port, self.endpoint\n )\n self.ipv4 = ipv4\n self.ipv6 = ipv6\n self.retry = retry\n\n def export(self, spans: Sequence[Span]) -> SpanExportResult:\n zipkin_spans = self._translate_to_zipkin(spans)\n result = requests.post(\n url=self.url, data=json.dumps(zipkin_spans), headers=ZIPKIN_HEADERS\n )\n\n if result.status_code not in SUCCESS_STATUS_CODES:\n logger.error(\n \"Traces cannot be uploaded; status code: %s, message %s\",\n result.status_code,\n result.text,\n )\n\n if self.retry:\n return SpanExportResult.FAILURE\n return SpanExportResult.FAILURE\n return SpanExportResult.SUCCESS\n\n def _translate_to_zipkin(self, spans: Sequence[Span]):\n\n local_endpoint = {\"serviceName\": self.service_name, \"port\": self.port}\n\n if self.ipv4 is not None:\n local_endpoint[\"ipv4\"] = self.ipv4\n\n if self.ipv6 is not None:\n local_endpoint[\"ipv6\"] = self.ipv6\n\n zipkin_spans = []\n for span in spans:\n context = span.get_context()\n trace_id = context.trace_id\n span_id = context.span_id\n\n # Timestamp in zipkin spans is int of microseconds.\n # see: https://zipkin.io/pages/instrumenting.html\n start_timestamp_mus = _nsec_to_usec_round(span.start_time)\n duration_mus = _nsec_to_usec_round(span.end_time - span.start_time)\n\n zipkin_span = {\n # Ensure left-zero-padding of traceId, spanId, parentId\n \"traceId\": format(trace_id, \"032x\"),\n \"id\": format(span_id, \"016x\"),\n \"name\": span.name,\n \"timestamp\": start_timestamp_mus,\n \"duration\": duration_mus,\n \"localEndpoint\": local_endpoint,\n \"kind\": SPAN_KIND_MAP[span.kind],\n \"tags\": _extract_tags_from_span(span),\n \"annotations\": _extract_annotations_from_events(span.events),\n }\n\n if context.trace_flags.sampled:\n zipkin_span[\"debug\"] = True\n\n if isinstance(span.parent, Span):\n zipkin_span[\"parentId\"] = format(\n span.parent.get_context().span_id, \"016x\"\n )\n elif isinstance(span.parent, SpanContext):\n zipkin_span[\"parentId\"] = format(span.parent.span_id, \"016x\")\n\n zipkin_spans.append(zipkin_span)\n return zipkin_spans\n\n def shutdown(self) -> None:\n pass\n\n\ndef _extract_tags_from_dict(tags_dict):\n tags = {}\n if not tags_dict:\n return tags\n for attribute_key, attribute_value in tags_dict.items():\n if isinstance(attribute_value, (int, bool, float)):\n value = str(attribute_value)\n elif isinstance(attribute_value, str):\n value = attribute_value[:128]\n else:\n logger.warning(\"Could not serialize tag %s\", attribute_key)\n continue\n tags[attribute_key] = value\n return tags\n\n\ndef _extract_tags_from_span(span: Span):\n tags = _extract_tags_from_dict(getattr(span, \"attributes\", None))\n if span.resource:\n tags.update(_extract_tags_from_dict(span.resource.labels))\n return tags\n\n\ndef _extract_annotations_from_events(events):\n return (\n [\n {\"timestamp\": _nsec_to_usec_round(e.timestamp), \"value\": e.name}\n for e in events\n ]\n if events\n else None\n )\n\n\ndef _nsec_to_usec_round(nsec):\n \"\"\"Round nanoseconds to microseconds\"\"\"\n return (nsec + 500) // 10 ** 3\n", "path": "exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library allows to export tracing data to `Zipkin <https://zipkin.io/>`_.\n\nUsage\n-----\n\nThe **OpenTelemetry Zipkin Exporter** allows to export `OpenTelemetry`_ traces to `Zipkin`_.\nThis exporter always send traces to the configured Zipkin collector using HTTP.\n\n\n.. _Zipkin: https://zipkin.io/\n.. _OpenTelemetry: https://github.com/open-telemetry/opentelemetry-python/\n.. _Specification: https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/sdk-environment-variables.md#zipkin-exporter\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.exporter import zipkin\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import BatchExportSpanProcessor\n\n trace.set_tracer_provider(TracerProvider())\n tracer = trace.get_tracer(__name__)\n\n # create a ZipkinSpanExporter\n zipkin_exporter = zipkin.ZipkinSpanExporter(\n service_name=\"my-helloworld-service\",\n # optional:\n # url=\"http://localhost:9411/api/v2/spans\",\n # ipv4=\"\",\n # ipv6=\"\",\n # retry=False,\n )\n\n # Create a BatchExportSpanProcessor and add the exporter to it\n span_processor = BatchExportSpanProcessor(zipkin_exporter)\n\n # add to the tracer\n trace.get_tracer_provider().add_span_processor(span_processor)\n\n with tracer.start_as_current_span(\"foo\"):\n print(\"Hello world!\")\n\nThe exporter supports endpoint configuration via the OTEL_EXPORTER_ZIPKIN_ENDPOINT environment variables as defined in the `Specification`_\n\nAPI\n---\n\"\"\"\n\nimport json\nimport logging\nimport os\nfrom typing import Optional, Sequence\nfrom urllib.parse import urlparse\n\nimport requests\n\nfrom opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult\nfrom opentelemetry.trace import Span, SpanContext, SpanKind\n\nDEFAULT_RETRY = False\nDEFAULT_URL = \"http://localhost:9411/api/v2/spans\"\nZIPKIN_HEADERS = {\"Content-Type\": \"application/json\"}\n\nSPAN_KIND_MAP = {\n SpanKind.INTERNAL: None,\n SpanKind.SERVER: \"SERVER\",\n SpanKind.CLIENT: \"CLIENT\",\n SpanKind.PRODUCER: \"PRODUCER\",\n SpanKind.CONSUMER: \"CONSUMER\",\n}\n\nSUCCESS_STATUS_CODES = (200, 202)\n\nlogger = logging.getLogger(__name__)\n\n\nclass ZipkinSpanExporter(SpanExporter):\n \"\"\"Zipkin span exporter for OpenTelemetry.\n\n Args:\n service_name: Service that logged an annotation in a trace.Classifier\n when query for spans.\n url: The Zipkin endpoint URL\n ipv4: Primary IPv4 address associated with this connection.\n ipv6: Primary IPv6 address associated with this connection.\n retry: Set to True to configure the exporter to retry on failure.\n \"\"\"\n\n def __init__(\n self,\n service_name: str,\n url: str = None,\n ipv4: Optional[str] = None,\n ipv6: Optional[str] = None,\n retry: Optional[str] = DEFAULT_RETRY,\n ):\n self.service_name = service_name\n if url is None:\n self.url = os.environ.get(\n \"OTEL_EXPORTER_ZIPKIN_ENDPOINT\", DEFAULT_URL\n )\n else:\n self.url = url\n\n self.port = urlparse(self.url).port\n\n self.ipv4 = ipv4\n self.ipv6 = ipv6\n self.retry = retry\n\n def export(self, spans: Sequence[Span]) -> SpanExportResult:\n zipkin_spans = self._translate_to_zipkin(spans)\n result = requests.post(\n url=self.url, data=json.dumps(zipkin_spans), headers=ZIPKIN_HEADERS\n )\n\n if result.status_code not in SUCCESS_STATUS_CODES:\n logger.error(\n \"Traces cannot be uploaded; status code: %s, message %s\",\n result.status_code,\n result.text,\n )\n\n if self.retry:\n return SpanExportResult.FAILURE\n return SpanExportResult.FAILURE\n return SpanExportResult.SUCCESS\n\n def _translate_to_zipkin(self, spans: Sequence[Span]):\n\n local_endpoint = {\"serviceName\": self.service_name, \"port\": self.port}\n\n if self.ipv4 is not None:\n local_endpoint[\"ipv4\"] = self.ipv4\n\n if self.ipv6 is not None:\n local_endpoint[\"ipv6\"] = self.ipv6\n\n zipkin_spans = []\n for span in spans:\n context = span.get_context()\n trace_id = context.trace_id\n span_id = context.span_id\n\n # Timestamp in zipkin spans is int of microseconds.\n # see: https://zipkin.io/pages/instrumenting.html\n start_timestamp_mus = _nsec_to_usec_round(span.start_time)\n duration_mus = _nsec_to_usec_round(span.end_time - span.start_time)\n\n zipkin_span = {\n # Ensure left-zero-padding of traceId, spanId, parentId\n \"traceId\": format(trace_id, \"032x\"),\n \"id\": format(span_id, \"016x\"),\n \"name\": span.name,\n \"timestamp\": start_timestamp_mus,\n \"duration\": duration_mus,\n \"localEndpoint\": local_endpoint,\n \"kind\": SPAN_KIND_MAP[span.kind],\n \"tags\": _extract_tags_from_span(span),\n \"annotations\": _extract_annotations_from_events(span.events),\n }\n\n if context.trace_flags.sampled:\n zipkin_span[\"debug\"] = True\n\n if isinstance(span.parent, Span):\n zipkin_span[\"parentId\"] = format(\n span.parent.get_context().span_id, \"016x\"\n )\n elif isinstance(span.parent, SpanContext):\n zipkin_span[\"parentId\"] = format(span.parent.span_id, \"016x\")\n\n zipkin_spans.append(zipkin_span)\n return zipkin_spans\n\n def shutdown(self) -> None:\n pass\n\n\ndef _extract_tags_from_dict(tags_dict):\n tags = {}\n if not tags_dict:\n return tags\n for attribute_key, attribute_value in tags_dict.items():\n if isinstance(attribute_value, (int, bool, float)):\n value = str(attribute_value)\n elif isinstance(attribute_value, str):\n value = attribute_value[:128]\n else:\n logger.warning(\"Could not serialize tag %s\", attribute_key)\n continue\n tags[attribute_key] = value\n return tags\n\n\ndef _extract_tags_from_span(span: Span):\n tags = _extract_tags_from_dict(getattr(span, \"attributes\", None))\n if span.resource:\n tags.update(_extract_tags_from_dict(span.resource.labels))\n return tags\n\n\ndef _extract_annotations_from_events(events):\n return (\n [\n {\"timestamp\": _nsec_to_usec_round(e.timestamp), \"value\": e.name}\n for e in events\n ]\n if events\n else None\n )\n\n\ndef _nsec_to_usec_round(nsec):\n \"\"\"Round nanoseconds to microseconds\"\"\"\n return (nsec + 500) // 10 ** 3\n", "path": "exporter/opentelemetry-exporter-zipkin/src/opentelemetry/exporter/zipkin/__init__.py"}]}
| 2,671 | 889 |
gh_patches_debug_1751
|
rasdani/github-patches
|
git_diff
|
vispy__vispy-245
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
glsl-sandbox-cube GL_DEPTH issue (Linux Python 2.7.6)
I get the following issue when running glsl-sanbox-cube; setting `GL_DEPTH` doesn't seem to work.
```
Traceback (most recent call last):
File "glsl-sandbox-cube.py", line 82, in on_initialize
gloo.set_state(depth=True)
File "/usr/local/lib/python2.7/dist-packages/vispy-0.2.1-py2.7.egg/vispy/gloo/wrappers.py", line 531, in set_state
func(_gl_attr(key))
File "/usr/local/lib/python2.7/dist-packages/vispy-0.2.1-py2.7.egg/vispy/gloo/wrappers.py", line 43, in _gl_attr
% (x, y))
ValueError: gl has no attribute corresponding to name depth (GL_DEPTH)
```
However when I check `PyOpenGL`:
```
import OpenGL.GL as gl
print gl.GL_DEPTH
>> GL_DEPTH (6145)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/glsl-sandbox-cube.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 A GLSL sandbox application based on the spinning cube. Requires PySide
5 or PyQt4.
6 """
7
8 import numpy as np
9 from vispy import app, gloo, dataio
10 from vispy.util.transforms import perspective, translate, rotate
11
12 # Force using qt and take QtCore+QtGui from backend module,
13 # since we do not know whether PySide or PyQt4 is used
14 app.use('qt')
15 QtCore = app.default_app.backend_module.QtCore,
16 QtGui = app.default_app.backend_module.QtGui
17
18
19 VERT_CODE = """
20 uniform mat4 u_model;
21 uniform mat4 u_view;
22 uniform mat4 u_projection;
23
24 attribute vec3 a_position;
25 attribute vec2 a_texcoord;
26
27 varying vec2 v_texcoord;
28
29 void main()
30 {
31 v_texcoord = a_texcoord;
32 gl_Position = u_projection * u_view * u_model * vec4(a_position,1.0);
33 //gl_Position = vec4(a_position,1.0);
34 }
35 """
36
37
38 FRAG_CODE = """
39 uniform sampler2D u_texture;
40 varying vec2 v_texcoord;
41
42 void main()
43 {
44 float ty = v_texcoord.y;
45 float tx = sin(ty*50.0)*0.01 + v_texcoord.x;
46 gl_FragColor = texture2D(u_texture, vec2(tx, ty));
47
48 }
49 """
50
51
52 # Read cube data
53 positions, faces, normals, texcoords = dataio.read_mesh('cube.obj')
54 colors = np.random.uniform(0, 1, positions.shape).astype('float32')
55
56 faces_buffer = gloo.IndexBuffer(faces.astype(np.uint16))
57
58
59 class Canvas(app.Canvas):
60
61 def __init__(self, **kwargs):
62 app.Canvas.__init__(self, **kwargs)
63 self.geometry = 0, 0, 400, 400
64
65 self.program = gloo.Program(VERT_CODE, FRAG_CODE)
66
67 # Set attributes
68 self.program['a_position'] = gloo.VertexBuffer(positions)
69 self.program['a_texcoord'] = gloo.VertexBuffer(texcoords)
70
71 self.program['u_texture'] = gloo.Texture2D(dataio.crate())
72
73 # Handle transformations
74 self.init_transforms()
75
76 self.timer = app.Timer(1.0 / 60)
77 self.timer.connect(self.update_transforms)
78 self.timer.start()
79
80 def on_initialize(self, event):
81 gloo.set_clear_color((1, 1, 1, 1))
82 gloo.set_state(depth=True)
83
84 def on_resize(self, event):
85 width, height = event.size
86 gloo.set_viewport(0, 0, width, height)
87 self.projection = perspective(45.0, width / float(height), 2.0, 10.0)
88 self.program['u_projection'] = self.projection
89
90 def on_paint(self, event):
91
92 gloo.clear()
93 self.program.draw('triangles', faces_buffer)
94
95 def init_transforms(self):
96 self.view = np.eye(4, dtype=np.float32)
97 self.model = np.eye(4, dtype=np.float32)
98 self.projection = np.eye(4, dtype=np.float32)
99
100 self.theta = 0
101 self.phi = 0
102
103 translate(self.view, 0, 0, -5)
104 self.program['u_model'] = self.model
105 self.program['u_view'] = self.view
106
107 def update_transforms(self, event):
108 self.theta += .5
109 self.phi += .5
110 self.model = np.eye(4, dtype=np.float32)
111 rotate(self.model, self.theta, 0, 0, 1)
112 rotate(self.model, self.phi, 0, 1, 0)
113 self.program['u_model'] = self.model
114 self.update()
115
116
117 class TextField(QtGui.QPlainTextEdit):
118
119 def __init__(self, parent):
120 QtGui.QPlainTextEdit.__init__(self, parent)
121 # Set font to monospaced (TypeWriter)
122 font = QtGui.QFont('')
123 font.setStyleHint(font.TypeWriter, font.PreferDefault)
124 font.setPointSize(8)
125 self.setFont(font)
126
127
128 class MainWindow(QtGui.QWidget):
129
130 def __init__(self):
131 QtGui.QWidget.__init__(self, None)
132
133 self.setMinimumSize(600, 400)
134
135 # Create two labels and a button
136 self.vertLabel = QtGui.QLabel("Vertex code", self)
137 self.fragLabel = QtGui.QLabel("Fragment code", self)
138 self.theButton = QtGui.QPushButton("Compile!", self)
139 self.theButton.clicked.connect(self.on_compile)
140
141 # Create two editors
142 self.vertEdit = TextField(self)
143 self.vertEdit.setPlainText(VERT_CODE)
144 self.fragEdit = TextField(self)
145 self.fragEdit.setPlainText(FRAG_CODE)
146
147 # Create a canvas
148 self.canvas = Canvas()
149 self.canvas.create_native()
150 self.canvas.native.setParent(self)
151
152 # Layout
153 hlayout = QtGui.QHBoxLayout(self)
154 self.setLayout(hlayout)
155 vlayout = QtGui.QVBoxLayout()
156 #
157 hlayout.addLayout(vlayout, 1)
158 hlayout.addWidget(self.canvas.native, 1)
159 #
160 vlayout.addWidget(self.vertLabel, 0)
161 vlayout.addWidget(self.vertEdit, 1)
162 vlayout.addWidget(self.fragLabel, 0)
163 vlayout.addWidget(self.fragEdit, 1)
164 vlayout.addWidget(self.theButton, 0)
165
166 def on_compile(self):
167 vert_code = str(self.vertEdit.toPlainText())
168 frag_code = str(self.fragEdit.toPlainText())
169 self.canvas.program.shaders[0].code = vert_code
170 self.canvas.program.shaders[1].code = frag_code
171
172
173 if __name__ == '__main__':
174 app.create()
175 m = MainWindow()
176 m.show()
177 app.run()
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/glsl-sandbox-cube.py b/examples/glsl-sandbox-cube.py
--- a/examples/glsl-sandbox-cube.py
+++ b/examples/glsl-sandbox-cube.py
@@ -79,7 +79,7 @@
def on_initialize(self, event):
gloo.set_clear_color((1, 1, 1, 1))
- gloo.set_state(depth=True)
+ gloo.set_state(depth_test=True)
def on_resize(self, event):
width, height = event.size
|
{"golden_diff": "diff --git a/examples/glsl-sandbox-cube.py b/examples/glsl-sandbox-cube.py\n--- a/examples/glsl-sandbox-cube.py\n+++ b/examples/glsl-sandbox-cube.py\n@@ -79,7 +79,7 @@\n \n def on_initialize(self, event):\n gloo.set_clear_color((1, 1, 1, 1))\n- gloo.set_state(depth=True)\n+ gloo.set_state(depth_test=True)\n \n def on_resize(self, event):\n width, height = event.size\n", "issue": "glsl-sandbox-cube GL_DEPTH issue (Linux Python 2.7.6)\nI get the following issue when running glsl-sanbox-cube; setting `GL_DEPTH` doesn't seem to work. \n\n```\nTraceback (most recent call last):\n File \"glsl-sandbox-cube.py\", line 82, in on_initialize\n gloo.set_state(depth=True)\n File \"/usr/local/lib/python2.7/dist-packages/vispy-0.2.1-py2.7.egg/vispy/gloo/wrappers.py\", line 531, in set_state\n func(_gl_attr(key))\n File \"/usr/local/lib/python2.7/dist-packages/vispy-0.2.1-py2.7.egg/vispy/gloo/wrappers.py\", line 43, in _gl_attr\n % (x, y))\nValueError: gl has no attribute corresponding to name depth (GL_DEPTH)\n```\n\nHowever when I check `PyOpenGL`:\n\n```\nimport OpenGL.GL as gl\nprint gl.GL_DEPTH\n>> GL_DEPTH (6145)\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nA GLSL sandbox application based on the spinning cube. Requires PySide\nor PyQt4.\n\"\"\"\n\nimport numpy as np\nfrom vispy import app, gloo, dataio\nfrom vispy.util.transforms import perspective, translate, rotate\n\n# Force using qt and take QtCore+QtGui from backend module,\n# since we do not know whether PySide or PyQt4 is used\napp.use('qt')\nQtCore = app.default_app.backend_module.QtCore,\nQtGui = app.default_app.backend_module.QtGui\n\n\nVERT_CODE = \"\"\"\nuniform mat4 u_model;\nuniform mat4 u_view;\nuniform mat4 u_projection;\n\nattribute vec3 a_position;\nattribute vec2 a_texcoord;\n\nvarying vec2 v_texcoord;\n\nvoid main()\n{\n v_texcoord = a_texcoord;\n gl_Position = u_projection * u_view * u_model * vec4(a_position,1.0);\n //gl_Position = vec4(a_position,1.0);\n}\n\"\"\"\n\n\nFRAG_CODE = \"\"\"\nuniform sampler2D u_texture;\nvarying vec2 v_texcoord;\n\nvoid main()\n{\n float ty = v_texcoord.y;\n float tx = sin(ty*50.0)*0.01 + v_texcoord.x;\n gl_FragColor = texture2D(u_texture, vec2(tx, ty));\n \n}\n\"\"\"\n\n\n# Read cube data\npositions, faces, normals, texcoords = dataio.read_mesh('cube.obj')\ncolors = np.random.uniform(0, 1, positions.shape).astype('float32')\n\nfaces_buffer = gloo.IndexBuffer(faces.astype(np.uint16))\n\n\nclass Canvas(app.Canvas):\n\n def __init__(self, **kwargs):\n app.Canvas.__init__(self, **kwargs)\n self.geometry = 0, 0, 400, 400\n\n self.program = gloo.Program(VERT_CODE, FRAG_CODE)\n\n # Set attributes\n self.program['a_position'] = gloo.VertexBuffer(positions)\n self.program['a_texcoord'] = gloo.VertexBuffer(texcoords)\n\n self.program['u_texture'] = gloo.Texture2D(dataio.crate())\n\n # Handle transformations\n self.init_transforms()\n\n self.timer = app.Timer(1.0 / 60)\n self.timer.connect(self.update_transforms)\n self.timer.start()\n\n def on_initialize(self, event):\n gloo.set_clear_color((1, 1, 1, 1))\n gloo.set_state(depth=True)\n\n def on_resize(self, event):\n width, height = event.size\n gloo.set_viewport(0, 0, width, height)\n self.projection = perspective(45.0, width / float(height), 2.0, 10.0)\n self.program['u_projection'] = self.projection\n\n def on_paint(self, event):\n\n gloo.clear()\n self.program.draw('triangles', faces_buffer)\n\n def init_transforms(self):\n self.view = np.eye(4, dtype=np.float32)\n self.model = np.eye(4, dtype=np.float32)\n self.projection = np.eye(4, dtype=np.float32)\n\n self.theta = 0\n self.phi = 0\n\n translate(self.view, 0, 0, -5)\n self.program['u_model'] = self.model\n self.program['u_view'] = self.view\n\n def update_transforms(self, event):\n self.theta += .5\n self.phi += .5\n self.model = np.eye(4, dtype=np.float32)\n rotate(self.model, self.theta, 0, 0, 1)\n rotate(self.model, self.phi, 0, 1, 0)\n self.program['u_model'] = self.model\n self.update()\n\n\nclass TextField(QtGui.QPlainTextEdit):\n\n def __init__(self, parent):\n QtGui.QPlainTextEdit.__init__(self, parent)\n # Set font to monospaced (TypeWriter)\n font = QtGui.QFont('')\n font.setStyleHint(font.TypeWriter, font.PreferDefault)\n font.setPointSize(8)\n self.setFont(font)\n\n\nclass MainWindow(QtGui.QWidget):\n\n def __init__(self):\n QtGui.QWidget.__init__(self, None)\n\n self.setMinimumSize(600, 400)\n\n # Create two labels and a button\n self.vertLabel = QtGui.QLabel(\"Vertex code\", self)\n self.fragLabel = QtGui.QLabel(\"Fragment code\", self)\n self.theButton = QtGui.QPushButton(\"Compile!\", self)\n self.theButton.clicked.connect(self.on_compile)\n\n # Create two editors\n self.vertEdit = TextField(self)\n self.vertEdit.setPlainText(VERT_CODE)\n self.fragEdit = TextField(self)\n self.fragEdit.setPlainText(FRAG_CODE)\n\n # Create a canvas\n self.canvas = Canvas()\n self.canvas.create_native()\n self.canvas.native.setParent(self)\n\n # Layout\n hlayout = QtGui.QHBoxLayout(self)\n self.setLayout(hlayout)\n vlayout = QtGui.QVBoxLayout()\n #\n hlayout.addLayout(vlayout, 1)\n hlayout.addWidget(self.canvas.native, 1)\n #\n vlayout.addWidget(self.vertLabel, 0)\n vlayout.addWidget(self.vertEdit, 1)\n vlayout.addWidget(self.fragLabel, 0)\n vlayout.addWidget(self.fragEdit, 1)\n vlayout.addWidget(self.theButton, 0)\n\n def on_compile(self):\n vert_code = str(self.vertEdit.toPlainText())\n frag_code = str(self.fragEdit.toPlainText())\n self.canvas.program.shaders[0].code = vert_code\n self.canvas.program.shaders[1].code = frag_code\n\n\nif __name__ == '__main__':\n app.create()\n m = MainWindow()\n m.show()\n app.run()\n", "path": "examples/glsl-sandbox-cube.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nA GLSL sandbox application based on the spinning cube. Requires PySide\nor PyQt4.\n\"\"\"\n\nimport numpy as np\nfrom vispy import app, gloo, dataio\nfrom vispy.util.transforms import perspective, translate, rotate\n\n# Force using qt and take QtCore+QtGui from backend module,\n# since we do not know whether PySide or PyQt4 is used\napp.use('qt')\nQtCore = app.default_app.backend_module.QtCore,\nQtGui = app.default_app.backend_module.QtGui\n\n\nVERT_CODE = \"\"\"\nuniform mat4 u_model;\nuniform mat4 u_view;\nuniform mat4 u_projection;\n\nattribute vec3 a_position;\nattribute vec2 a_texcoord;\n\nvarying vec2 v_texcoord;\n\nvoid main()\n{\n v_texcoord = a_texcoord;\n gl_Position = u_projection * u_view * u_model * vec4(a_position,1.0);\n //gl_Position = vec4(a_position,1.0);\n}\n\"\"\"\n\n\nFRAG_CODE = \"\"\"\nuniform sampler2D u_texture;\nvarying vec2 v_texcoord;\n\nvoid main()\n{\n float ty = v_texcoord.y;\n float tx = sin(ty*50.0)*0.01 + v_texcoord.x;\n gl_FragColor = texture2D(u_texture, vec2(tx, ty));\n \n}\n\"\"\"\n\n\n# Read cube data\npositions, faces, normals, texcoords = dataio.read_mesh('cube.obj')\ncolors = np.random.uniform(0, 1, positions.shape).astype('float32')\n\nfaces_buffer = gloo.IndexBuffer(faces.astype(np.uint16))\n\n\nclass Canvas(app.Canvas):\n\n def __init__(self, **kwargs):\n app.Canvas.__init__(self, **kwargs)\n self.geometry = 0, 0, 400, 400\n\n self.program = gloo.Program(VERT_CODE, FRAG_CODE)\n\n # Set attributes\n self.program['a_position'] = gloo.VertexBuffer(positions)\n self.program['a_texcoord'] = gloo.VertexBuffer(texcoords)\n\n self.program['u_texture'] = gloo.Texture2D(dataio.crate())\n\n # Handle transformations\n self.init_transforms()\n\n self.timer = app.Timer(1.0 / 60)\n self.timer.connect(self.update_transforms)\n self.timer.start()\n\n def on_initialize(self, event):\n gloo.set_clear_color((1, 1, 1, 1))\n gloo.set_state(depth_test=True)\n\n def on_resize(self, event):\n width, height = event.size\n gloo.set_viewport(0, 0, width, height)\n self.projection = perspective(45.0, width / float(height), 2.0, 10.0)\n self.program['u_projection'] = self.projection\n\n def on_paint(self, event):\n\n gloo.clear()\n self.program.draw('triangles', faces_buffer)\n\n def init_transforms(self):\n self.view = np.eye(4, dtype=np.float32)\n self.model = np.eye(4, dtype=np.float32)\n self.projection = np.eye(4, dtype=np.float32)\n\n self.theta = 0\n self.phi = 0\n\n translate(self.view, 0, 0, -5)\n self.program['u_model'] = self.model\n self.program['u_view'] = self.view\n\n def update_transforms(self, event):\n self.theta += .5\n self.phi += .5\n self.model = np.eye(4, dtype=np.float32)\n rotate(self.model, self.theta, 0, 0, 1)\n rotate(self.model, self.phi, 0, 1, 0)\n self.program['u_model'] = self.model\n self.update()\n\n\nclass TextField(QtGui.QPlainTextEdit):\n\n def __init__(self, parent):\n QtGui.QPlainTextEdit.__init__(self, parent)\n # Set font to monospaced (TypeWriter)\n font = QtGui.QFont('')\n font.setStyleHint(font.TypeWriter, font.PreferDefault)\n font.setPointSize(8)\n self.setFont(font)\n\n\nclass MainWindow(QtGui.QWidget):\n\n def __init__(self):\n QtGui.QWidget.__init__(self, None)\n\n self.setMinimumSize(600, 400)\n\n # Create two labels and a button\n self.vertLabel = QtGui.QLabel(\"Vertex code\", self)\n self.fragLabel = QtGui.QLabel(\"Fragment code\", self)\n self.theButton = QtGui.QPushButton(\"Compile!\", self)\n self.theButton.clicked.connect(self.on_compile)\n\n # Create two editors\n self.vertEdit = TextField(self)\n self.vertEdit.setPlainText(VERT_CODE)\n self.fragEdit = TextField(self)\n self.fragEdit.setPlainText(FRAG_CODE)\n\n # Create a canvas\n self.canvas = Canvas()\n self.canvas.create_native()\n self.canvas.native.setParent(self)\n\n # Layout\n hlayout = QtGui.QHBoxLayout(self)\n self.setLayout(hlayout)\n vlayout = QtGui.QVBoxLayout()\n #\n hlayout.addLayout(vlayout, 1)\n hlayout.addWidget(self.canvas.native, 1)\n #\n vlayout.addWidget(self.vertLabel, 0)\n vlayout.addWidget(self.vertEdit, 1)\n vlayout.addWidget(self.fragLabel, 0)\n vlayout.addWidget(self.fragEdit, 1)\n vlayout.addWidget(self.theButton, 0)\n\n def on_compile(self):\n vert_code = str(self.vertEdit.toPlainText())\n frag_code = str(self.fragEdit.toPlainText())\n self.canvas.program.shaders[0].code = vert_code\n self.canvas.program.shaders[1].code = frag_code\n\n\nif __name__ == '__main__':\n app.create()\n m = MainWindow()\n m.show()\n app.run()\n", "path": "examples/glsl-sandbox-cube.py"}]}
| 2,229 | 119 |
gh_patches_debug_42384
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1500
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feedback] - Mail text is borked
The feedback notification mail is broken.
Probably after the python upgrade.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/feedback/mommy.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import locale
4 import logging
5
6 from django.conf import settings
7 from django.core.mail import EmailMessage
8 from django.utils import timezone
9
10 from apps.feedback.models import FeedbackRelation
11 from apps.marks.models import Mark, MarkUser
12 from apps.mommy import schedule
13 from apps.mommy.registry import Task
14
15
16 class FeedbackMail(Task):
17
18 @staticmethod
19 def run():
20 logger = logging.getLogger("feedback")
21 logger.info("Feedback job started")
22 locale.setlocale(locale.LC_ALL, "nb_NO.UTF-8")
23 active_feedbacks = FeedbackRelation.objects.filter(active=True)
24
25 for feedback in active_feedbacks:
26 message = FeedbackMail.generate_message(feedback, logger)
27 logger.info("Status: " + message.status)
28
29 if message.send:
30 EmailMessage(
31 message.subject,
32 str(message),
33 message.committee_mail,
34 [],
35 message.attended_mails
36 ).send()
37 logger.info('Emails sent to: ' + str(message.attended_mails))
38
39 if message.results_message:
40 EmailMessage(
41 "Feedback resultat",
42 message.results_message,
43 "[email protected]",
44 [message.committee_mail]
45 ).send()
46 logger.info('Results mail sent to :' + message.committee_mail)
47
48 @staticmethod
49 def generate_message(feedback, logger):
50 logger.info('Processing: "' + feedback.content_title() + '"')
51
52 today = timezone.now().date()
53 end_date = feedback.content_end_date()
54
55 message = Message()
56
57 if not end_date:
58 message.status = "Content object has no date"
59 return message
60
61 # Return if the event has not yet happened
62 if end_date.date() >= today:
63 message.status = "Event not done"
64 return message
65
66 not_responded = FeedbackMail.get_users(feedback)
67 logger.info('Not responded: ' + str(not_responded))
68
69 # Return if everyone has answered
70 if not not_responded:
71 feedback.active = False
72 feedback.save()
73 message.status = 'Everyone has answered'
74 return message
75
76 message.attended_mails = FeedbackMail.get_user_mails(not_responded)
77
78 message.committee_mail = FeedbackMail.get_committee_email(feedback)
79 deadline = feedback.deadline.strftime("%d. %B").encode("utf-8")
80 title = FeedbackMail.get_title(feedback)
81 message.link = str("\n\n" + FeedbackMail.get_link(feedback)).encode()
82 results_link = str(FeedbackMail.get_link(feedback) + "results").encode()
83
84 deadline_diff = (feedback.deadline - today).days
85
86 message.subject = "Feedback: " + title
87 message.intro = "Hei, vi ønsker tilbakemelding på \"" + title + "\""
88 message.mark = FeedbackMail.mark_message(feedback)
89 message.contact = "\n\nEventuelle spørsmål sendes til %s " % message.committee_mail
90 message.date = FeedbackMail.date_message(end_date)
91
92 if deadline_diff < 0: # Deadline passed
93 feedback.active = False
94 feedback.save()
95 logger.info("Deadline passed feedback set to inactive")
96 message.status = "Deadine passed"
97
98 if feedback.gives_mark:
99 FeedbackMail.set_marks(title, not_responded)
100
101 message.intro = "Fristen for å svare på \"%s\" har gått ut og du har fått en prikk." % title
102 message.mark = ""
103 message.date = ""
104 message.link = ""
105 message.send = True
106
107 logger.info("Marks given to: " + str(not_responded))
108
109 elif deadline_diff < 1: # Last warning
110 message.deadline = "\n\nI dag innen 23:59 er siste frist til å svare på skjemaet."
111
112 message.results_message = """
113 Hei, siste purremail på feedback skjema har blitt sendt til alle
114 gjenværende deltagere på \"{}\".\nDere kan se feedback-resultatene på:\n{}\n
115 """.format(title, results_link)
116 message.send = True
117 message.status = "Last warning"
118 elif deadline_diff < 3 and feedback.gives_mark: # 3 days from the deadline
119 message.deadline = "\n\nFristen for å svare på skjema er %s innen kl 23:59." % deadline
120 message.send = True
121 message.status = "Warning message"
122 elif not feedback.first_mail_sent:
123 message.deadline = "\n\nFristen for å svare på skjema er %s innen kl 23:59." % deadline
124
125 message.results_message = """
126 Hei, nå har feedbackmail blitt sendt til alle
127 deltagere på \"{}\".\nDere kan se feedback-resultatene på:\n{}\n
128 """.format(title, results_link)
129 message.send = True
130 message.status = "First message"
131 feedback.first_mail_sent = True
132 feedback.save()
133 logger.info("first_mail_sent set")
134 else:
135 message.status = "No message generated"
136 return message
137
138 @staticmethod
139 def end_date(feedback):
140 end_date = feedback.content_end_date()
141
142 if end_date:
143 return end_date.date()
144 else:
145 return False
146
147 @staticmethod
148 def date_message(date):
149 # If the object(event) doesnt have start date it will send
150 # The first notification the day after the feedbackrelation is made
151 if date:
152 date_string = date.strftime("%d. %B").encode("utf-8")
153 message_date = "som du var med på den %s:" % date_string
154 else:
155 message_date = ""
156
157 return message_date
158
159 @staticmethod
160 def get_users(feedback):
161 return feedback.not_answered()
162
163 @staticmethod
164 def get_user_mails(not_responded):
165 return [user.email for user in not_responded]
166
167 @staticmethod
168 def get_link(feedback):
169 return str(settings.BASE_URL + feedback.get_absolute_url())
170
171 @staticmethod
172 def get_title(feedback):
173 return str(feedback.content_title())
174
175 @staticmethod
176 def get_committee_email(feedback):
177 return feedback.content_email()
178
179 @staticmethod
180 def mark_message(feedback):
181 if feedback.gives_mark:
182 return """
183 \nVær oppmerksom på at du får prikk dersom du ikke svarer
184 på disse spørsmålene innen fristen.
185 """
186 else:
187 return ""
188
189 @staticmethod
190 def set_marks(title, not_responded):
191 mark = Mark()
192 mark.title = "Manglende tilbakemelding på %s" % title
193 mark.category = 4 # Missed feedback
194 mark.description = "Du har fått en prikk fordi du ikke har levert tilbakemelding."
195 mark.save()
196
197 for user in not_responded:
198 user_entry = MarkUser()
199 user_entry.user = user
200 user_entry.mark = mark
201 user_entry.save()
202
203
204 class Message(object):
205 subject = ""
206 intro = ""
207 date = ""
208 deadline = ""
209 mark = ""
210 contact = ""
211 link = ""
212 send = False
213 end = "\n\nMvh\nLinjeforeningen Online"
214 results_message = False
215 status = "-"
216
217 committee_mail = ""
218 attended_mails = False
219
220 def __str__(self):
221 message = "%s %s %s %s %s %s %s" % (
222 self.intro,
223 self.date,
224 self.link,
225 self.deadline,
226 self.mark,
227 self.contact,
228 self.end
229 )
230 return message
231
232 schedule.register(FeedbackMail, day_of_week='mon-sun', hour=8, minute=00)
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/feedback/mommy.py b/apps/feedback/mommy.py
--- a/apps/feedback/mommy.py
+++ b/apps/feedback/mommy.py
@@ -76,10 +76,10 @@
message.attended_mails = FeedbackMail.get_user_mails(not_responded)
message.committee_mail = FeedbackMail.get_committee_email(feedback)
- deadline = feedback.deadline.strftime("%d. %B").encode("utf-8")
+ deadline = feedback.deadline.strftime("%d. %B")
title = FeedbackMail.get_title(feedback)
- message.link = str("\n\n" + FeedbackMail.get_link(feedback)).encode()
- results_link = str(FeedbackMail.get_link(feedback) + "results").encode()
+ message.link = str("\n\n" + FeedbackMail.get_link(feedback))
+ results_link = str(FeedbackMail.get_link(feedback) + "results")
deadline_diff = (feedback.deadline - today).days
@@ -109,10 +109,8 @@
elif deadline_diff < 1: # Last warning
message.deadline = "\n\nI dag innen 23:59 er siste frist til å svare på skjemaet."
- message.results_message = """
- Hei, siste purremail på feedback skjema har blitt sendt til alle
- gjenværende deltagere på \"{}\".\nDere kan se feedback-resultatene på:\n{}\n
- """.format(title, results_link)
+ message.results_message = "Hei, siste purremail på feedback skjema har blitt sendt til alle gjenværende " \
+ "deltagere på \"{}\".\nDere kan se feedback-resultatene på:\n{}\n".format(title, results_link)
message.send = True
message.status = "Last warning"
elif deadline_diff < 3 and feedback.gives_mark: # 3 days from the deadline
@@ -121,13 +119,11 @@
message.status = "Warning message"
elif not feedback.first_mail_sent:
message.deadline = "\n\nFristen for å svare på skjema er %s innen kl 23:59." % deadline
-
- message.results_message = """
- Hei, nå har feedbackmail blitt sendt til alle
- deltagere på \"{}\".\nDere kan se feedback-resultatene på:\n{}\n
- """.format(title, results_link)
+ message.results_message = "Hei, nå har feedbackmail blitt sendt til alle deltagere på \"{}\"." \
+ "\nDere kan se resultatene på:\n{}\n".format(title, results_link)
message.send = True
message.status = "First message"
+
feedback.first_mail_sent = True
feedback.save()
logger.info("first_mail_sent set")
@@ -149,7 +145,7 @@
# If the object(event) doesnt have start date it will send
# The first notification the day after the feedbackrelation is made
if date:
- date_string = date.strftime("%d. %B").encode("utf-8")
+ date_string = date.strftime("%d. %B")
message_date = "som du var med på den %s:" % date_string
else:
message_date = ""
@@ -179,10 +175,8 @@
@staticmethod
def mark_message(feedback):
if feedback.gives_mark:
- return """
- \nVær oppmerksom på at du får prikk dersom du ikke svarer
- på disse spørsmålene innen fristen.
- """
+ return "\nVær oppmerksom på at du får prikk dersom du ikke svarer " \
+ "på disse spørsmålene innen fristen."
else:
return ""
|
{"golden_diff": "diff --git a/apps/feedback/mommy.py b/apps/feedback/mommy.py\n--- a/apps/feedback/mommy.py\n+++ b/apps/feedback/mommy.py\n@@ -76,10 +76,10 @@\n message.attended_mails = FeedbackMail.get_user_mails(not_responded)\n \n message.committee_mail = FeedbackMail.get_committee_email(feedback)\n- deadline = feedback.deadline.strftime(\"%d. %B\").encode(\"utf-8\")\n+ deadline = feedback.deadline.strftime(\"%d. %B\")\n title = FeedbackMail.get_title(feedback)\n- message.link = str(\"\\n\\n\" + FeedbackMail.get_link(feedback)).encode()\n- results_link = str(FeedbackMail.get_link(feedback) + \"results\").encode()\n+ message.link = str(\"\\n\\n\" + FeedbackMail.get_link(feedback))\n+ results_link = str(FeedbackMail.get_link(feedback) + \"results\")\n \n deadline_diff = (feedback.deadline - today).days\n \n@@ -109,10 +109,8 @@\n elif deadline_diff < 1: # Last warning\n message.deadline = \"\\n\\nI dag innen 23:59 er siste frist til \u00e5 svare p\u00e5 skjemaet.\"\n \n- message.results_message = \"\"\"\n- Hei, siste purremail p\u00e5 feedback skjema har blitt sendt til alle\n- gjenv\u00e6rende deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\n- \"\"\".format(title, results_link)\n+ message.results_message = \"Hei, siste purremail p\u00e5 feedback skjema har blitt sendt til alle gjenv\u00e6rende \" \\\n+ \"deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\".format(title, results_link)\n message.send = True\n message.status = \"Last warning\"\n elif deadline_diff < 3 and feedback.gives_mark: # 3 days from the deadline\n@@ -121,13 +119,11 @@\n message.status = \"Warning message\"\n elif not feedback.first_mail_sent:\n message.deadline = \"\\n\\nFristen for \u00e5 svare p\u00e5 skjema er %s innen kl 23:59.\" % deadline\n-\n- message.results_message = \"\"\"\n- Hei, n\u00e5 har feedbackmail blitt sendt til alle\n- deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\n- \"\"\".format(title, results_link)\n+ message.results_message = \"Hei, n\u00e5 har feedbackmail blitt sendt til alle deltagere p\u00e5 \\\"{}\\\".\" \\\n+ \"\\nDere kan se resultatene p\u00e5:\\n{}\\n\".format(title, results_link)\n message.send = True\n message.status = \"First message\"\n+\n feedback.first_mail_sent = True\n feedback.save()\n logger.info(\"first_mail_sent set\")\n@@ -149,7 +145,7 @@\n # If the object(event) doesnt have start date it will send\n # The first notification the day after the feedbackrelation is made\n if date:\n- date_string = date.strftime(\"%d. %B\").encode(\"utf-8\")\n+ date_string = date.strftime(\"%d. %B\")\n message_date = \"som du var med p\u00e5 den %s:\" % date_string\n else:\n message_date = \"\"\n@@ -179,10 +175,8 @@\n @staticmethod\n def mark_message(feedback):\n if feedback.gives_mark:\n- return \"\"\"\n- \\nV\u00e6r oppmerksom p\u00e5 at du f\u00e5r prikk dersom du ikke svarer\n- p\u00e5 disse sp\u00f8rsm\u00e5lene innen fristen.\n- \"\"\"\n+ return \"\\nV\u00e6r oppmerksom p\u00e5 at du f\u00e5r prikk dersom du ikke svarer \" \\\n+ \"p\u00e5 disse sp\u00f8rsm\u00e5lene innen fristen.\"\n else:\n return \"\"\n", "issue": "[Feedback] - Mail text is borked\nThe feedback notification mail is broken.\nProbably after the python upgrade.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport locale\nimport logging\n\nfrom django.conf import settings\nfrom django.core.mail import EmailMessage\nfrom django.utils import timezone\n\nfrom apps.feedback.models import FeedbackRelation\nfrom apps.marks.models import Mark, MarkUser\nfrom apps.mommy import schedule\nfrom apps.mommy.registry import Task\n\n\nclass FeedbackMail(Task):\n\n @staticmethod\n def run():\n logger = logging.getLogger(\"feedback\")\n logger.info(\"Feedback job started\")\n locale.setlocale(locale.LC_ALL, \"nb_NO.UTF-8\")\n active_feedbacks = FeedbackRelation.objects.filter(active=True)\n\n for feedback in active_feedbacks:\n message = FeedbackMail.generate_message(feedback, logger)\n logger.info(\"Status: \" + message.status)\n\n if message.send:\n EmailMessage(\n message.subject,\n str(message),\n message.committee_mail,\n [],\n message.attended_mails\n ).send()\n logger.info('Emails sent to: ' + str(message.attended_mails))\n\n if message.results_message:\n EmailMessage(\n \"Feedback resultat\",\n message.results_message,\n \"[email protected]\",\n [message.committee_mail]\n ).send()\n logger.info('Results mail sent to :' + message.committee_mail)\n\n @staticmethod\n def generate_message(feedback, logger):\n logger.info('Processing: \"' + feedback.content_title() + '\"')\n\n today = timezone.now().date()\n end_date = feedback.content_end_date()\n\n message = Message()\n\n if not end_date:\n message.status = \"Content object has no date\"\n return message\n\n # Return if the event has not yet happened\n if end_date.date() >= today:\n message.status = \"Event not done\"\n return message\n\n not_responded = FeedbackMail.get_users(feedback)\n logger.info('Not responded: ' + str(not_responded))\n\n # Return if everyone has answered\n if not not_responded:\n feedback.active = False\n feedback.save()\n message.status = 'Everyone has answered'\n return message\n\n message.attended_mails = FeedbackMail.get_user_mails(not_responded)\n\n message.committee_mail = FeedbackMail.get_committee_email(feedback)\n deadline = feedback.deadline.strftime(\"%d. %B\").encode(\"utf-8\")\n title = FeedbackMail.get_title(feedback)\n message.link = str(\"\\n\\n\" + FeedbackMail.get_link(feedback)).encode()\n results_link = str(FeedbackMail.get_link(feedback) + \"results\").encode()\n\n deadline_diff = (feedback.deadline - today).days\n\n message.subject = \"Feedback: \" + title\n message.intro = \"Hei, vi \u00f8nsker tilbakemelding p\u00e5 \\\"\" + title + \"\\\"\"\n message.mark = FeedbackMail.mark_message(feedback)\n message.contact = \"\\n\\nEventuelle sp\u00f8rsm\u00e5l sendes til %s \" % message.committee_mail\n message.date = FeedbackMail.date_message(end_date)\n\n if deadline_diff < 0: # Deadline passed\n feedback.active = False\n feedback.save()\n logger.info(\"Deadline passed feedback set to inactive\")\n message.status = \"Deadine passed\"\n\n if feedback.gives_mark:\n FeedbackMail.set_marks(title, not_responded)\n\n message.intro = \"Fristen for \u00e5 svare p\u00e5 \\\"%s\\\" har g\u00e5tt ut og du har f\u00e5tt en prikk.\" % title\n message.mark = \"\"\n message.date = \"\"\n message.link = \"\"\n message.send = True\n\n logger.info(\"Marks given to: \" + str(not_responded))\n\n elif deadline_diff < 1: # Last warning\n message.deadline = \"\\n\\nI dag innen 23:59 er siste frist til \u00e5 svare p\u00e5 skjemaet.\"\n\n message.results_message = \"\"\"\n Hei, siste purremail p\u00e5 feedback skjema har blitt sendt til alle\n gjenv\u00e6rende deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\n \"\"\".format(title, results_link)\n message.send = True\n message.status = \"Last warning\"\n elif deadline_diff < 3 and feedback.gives_mark: # 3 days from the deadline\n message.deadline = \"\\n\\nFristen for \u00e5 svare p\u00e5 skjema er %s innen kl 23:59.\" % deadline\n message.send = True\n message.status = \"Warning message\"\n elif not feedback.first_mail_sent:\n message.deadline = \"\\n\\nFristen for \u00e5 svare p\u00e5 skjema er %s innen kl 23:59.\" % deadline\n\n message.results_message = \"\"\"\n Hei, n\u00e5 har feedbackmail blitt sendt til alle\n deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\n \"\"\".format(title, results_link)\n message.send = True\n message.status = \"First message\"\n feedback.first_mail_sent = True\n feedback.save()\n logger.info(\"first_mail_sent set\")\n else:\n message.status = \"No message generated\"\n return message\n\n @staticmethod\n def end_date(feedback):\n end_date = feedback.content_end_date()\n\n if end_date:\n return end_date.date()\n else:\n return False\n\n @staticmethod\n def date_message(date):\n # If the object(event) doesnt have start date it will send\n # The first notification the day after the feedbackrelation is made\n if date:\n date_string = date.strftime(\"%d. %B\").encode(\"utf-8\")\n message_date = \"som du var med p\u00e5 den %s:\" % date_string\n else:\n message_date = \"\"\n\n return message_date\n\n @staticmethod\n def get_users(feedback):\n return feedback.not_answered()\n\n @staticmethod\n def get_user_mails(not_responded):\n return [user.email for user in not_responded]\n\n @staticmethod\n def get_link(feedback):\n return str(settings.BASE_URL + feedback.get_absolute_url())\n\n @staticmethod\n def get_title(feedback):\n return str(feedback.content_title())\n\n @staticmethod\n def get_committee_email(feedback):\n return feedback.content_email()\n\n @staticmethod\n def mark_message(feedback):\n if feedback.gives_mark:\n return \"\"\"\n \\nV\u00e6r oppmerksom p\u00e5 at du f\u00e5r prikk dersom du ikke svarer\n p\u00e5 disse sp\u00f8rsm\u00e5lene innen fristen.\n \"\"\"\n else:\n return \"\"\n\n @staticmethod\n def set_marks(title, not_responded):\n mark = Mark()\n mark.title = \"Manglende tilbakemelding p\u00e5 %s\" % title\n mark.category = 4 # Missed feedback\n mark.description = \"Du har f\u00e5tt en prikk fordi du ikke har levert tilbakemelding.\"\n mark.save()\n\n for user in not_responded:\n user_entry = MarkUser()\n user_entry.user = user\n user_entry.mark = mark\n user_entry.save()\n\n\nclass Message(object):\n subject = \"\"\n intro = \"\"\n date = \"\"\n deadline = \"\"\n mark = \"\"\n contact = \"\"\n link = \"\"\n send = False\n end = \"\\n\\nMvh\\nLinjeforeningen Online\"\n results_message = False\n status = \"-\"\n\n committee_mail = \"\"\n attended_mails = False\n\n def __str__(self):\n message = \"%s %s %s %s %s %s %s\" % (\n self.intro,\n self.date,\n self.link,\n self.deadline,\n self.mark,\n self.contact,\n self.end\n )\n return message\n\nschedule.register(FeedbackMail, day_of_week='mon-sun', hour=8, minute=00)\n", "path": "apps/feedback/mommy.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport locale\nimport logging\n\nfrom django.conf import settings\nfrom django.core.mail import EmailMessage\nfrom django.utils import timezone\n\nfrom apps.feedback.models import FeedbackRelation\nfrom apps.marks.models import Mark, MarkUser\nfrom apps.mommy import schedule\nfrom apps.mommy.registry import Task\n\n\nclass FeedbackMail(Task):\n\n @staticmethod\n def run():\n logger = logging.getLogger(\"feedback\")\n logger.info(\"Feedback job started\")\n locale.setlocale(locale.LC_ALL, \"nb_NO.UTF-8\")\n active_feedbacks = FeedbackRelation.objects.filter(active=True)\n\n for feedback in active_feedbacks:\n message = FeedbackMail.generate_message(feedback, logger)\n logger.info(\"Status: \" + message.status)\n\n if message.send:\n EmailMessage(\n message.subject,\n str(message),\n message.committee_mail,\n [],\n message.attended_mails\n ).send()\n logger.info('Emails sent to: ' + str(message.attended_mails))\n\n if message.results_message:\n EmailMessage(\n \"Feedback resultat\",\n message.results_message,\n \"[email protected]\",\n [message.committee_mail]\n ).send()\n logger.info('Results mail sent to :' + message.committee_mail)\n\n @staticmethod\n def generate_message(feedback, logger):\n logger.info('Processing: \"' + feedback.content_title() + '\"')\n\n today = timezone.now().date()\n end_date = feedback.content_end_date()\n\n message = Message()\n\n if not end_date:\n message.status = \"Content object has no date\"\n return message\n\n # Return if the event has not yet happened\n if end_date.date() >= today:\n message.status = \"Event not done\"\n return message\n\n not_responded = FeedbackMail.get_users(feedback)\n logger.info('Not responded: ' + str(not_responded))\n\n # Return if everyone has answered\n if not not_responded:\n feedback.active = False\n feedback.save()\n message.status = 'Everyone has answered'\n return message\n\n message.attended_mails = FeedbackMail.get_user_mails(not_responded)\n\n message.committee_mail = FeedbackMail.get_committee_email(feedback)\n deadline = feedback.deadline.strftime(\"%d. %B\")\n title = FeedbackMail.get_title(feedback)\n message.link = str(\"\\n\\n\" + FeedbackMail.get_link(feedback))\n results_link = str(FeedbackMail.get_link(feedback) + \"results\")\n\n deadline_diff = (feedback.deadline - today).days\n\n message.subject = \"Feedback: \" + title\n message.intro = \"Hei, vi \u00f8nsker tilbakemelding p\u00e5 \\\"\" + title + \"\\\"\"\n message.mark = FeedbackMail.mark_message(feedback)\n message.contact = \"\\n\\nEventuelle sp\u00f8rsm\u00e5l sendes til %s \" % message.committee_mail\n message.date = FeedbackMail.date_message(end_date)\n\n if deadline_diff < 0: # Deadline passed\n feedback.active = False\n feedback.save()\n logger.info(\"Deadline passed feedback set to inactive\")\n message.status = \"Deadine passed\"\n\n if feedback.gives_mark:\n FeedbackMail.set_marks(title, not_responded)\n\n message.intro = \"Fristen for \u00e5 svare p\u00e5 \\\"%s\\\" har g\u00e5tt ut og du har f\u00e5tt en prikk.\" % title\n message.mark = \"\"\n message.date = \"\"\n message.link = \"\"\n message.send = True\n\n logger.info(\"Marks given to: \" + str(not_responded))\n\n elif deadline_diff < 1: # Last warning\n message.deadline = \"\\n\\nI dag innen 23:59 er siste frist til \u00e5 svare p\u00e5 skjemaet.\"\n\n message.results_message = \"Hei, siste purremail p\u00e5 feedback skjema har blitt sendt til alle gjenv\u00e6rende \" \\\n \"deltagere p\u00e5 \\\"{}\\\".\\nDere kan se feedback-resultatene p\u00e5:\\n{}\\n\".format(title, results_link)\n message.send = True\n message.status = \"Last warning\"\n elif deadline_diff < 3 and feedback.gives_mark: # 3 days from the deadline\n message.deadline = \"\\n\\nFristen for \u00e5 svare p\u00e5 skjema er %s innen kl 23:59.\" % deadline\n message.send = True\n message.status = \"Warning message\"\n elif not feedback.first_mail_sent:\n message.deadline = \"\\n\\nFristen for \u00e5 svare p\u00e5 skjema er %s innen kl 23:59.\" % deadline\n message.results_message = \"Hei, n\u00e5 har feedbackmail blitt sendt til alle deltagere p\u00e5 \\\"{}\\\".\" \\\n \"\\nDere kan se resultatene p\u00e5:\\n{}\\n\".format(title, results_link)\n message.send = True\n message.status = \"First message\"\n\n feedback.first_mail_sent = True\n feedback.save()\n logger.info(\"first_mail_sent set\")\n else:\n message.status = \"No message generated\"\n return message\n\n @staticmethod\n def end_date(feedback):\n end_date = feedback.content_end_date()\n\n if end_date:\n return end_date.date()\n else:\n return False\n\n @staticmethod\n def date_message(date):\n # If the object(event) doesnt have start date it will send\n # The first notification the day after the feedbackrelation is made\n if date:\n date_string = date.strftime(\"%d. %B\")\n message_date = \"som du var med p\u00e5 den %s:\" % date_string\n else:\n message_date = \"\"\n\n return message_date\n\n @staticmethod\n def get_users(feedback):\n return feedback.not_answered()\n\n @staticmethod\n def get_user_mails(not_responded):\n return [user.email for user in not_responded]\n\n @staticmethod\n def get_link(feedback):\n return str(settings.BASE_URL + feedback.get_absolute_url())\n\n @staticmethod\n def get_title(feedback):\n return str(feedback.content_title())\n\n @staticmethod\n def get_committee_email(feedback):\n return feedback.content_email()\n\n @staticmethod\n def mark_message(feedback):\n if feedback.gives_mark:\n return \"\\nV\u00e6r oppmerksom p\u00e5 at du f\u00e5r prikk dersom du ikke svarer \" \\\n \"p\u00e5 disse sp\u00f8rsm\u00e5lene innen fristen.\"\n else:\n return \"\"\n\n @staticmethod\n def set_marks(title, not_responded):\n mark = Mark()\n mark.title = \"Manglende tilbakemelding p\u00e5 %s\" % title\n mark.category = 4 # Missed feedback\n mark.description = \"Du har f\u00e5tt en prikk fordi du ikke har levert tilbakemelding.\"\n mark.save()\n\n for user in not_responded:\n user_entry = MarkUser()\n user_entry.user = user\n user_entry.mark = mark\n user_entry.save()\n\n\nclass Message(object):\n subject = \"\"\n intro = \"\"\n date = \"\"\n deadline = \"\"\n mark = \"\"\n contact = \"\"\n link = \"\"\n send = False\n end = \"\\n\\nMvh\\nLinjeforeningen Online\"\n results_message = False\n status = \"-\"\n\n committee_mail = \"\"\n attended_mails = False\n\n def __str__(self):\n message = \"%s %s %s %s %s %s %s\" % (\n self.intro,\n self.date,\n self.link,\n self.deadline,\n self.mark,\n self.contact,\n self.end\n )\n return message\n\nschedule.register(FeedbackMail, day_of_week='mon-sun', hour=8, minute=00)\n", "path": "apps/feedback/mommy.py"}]}
| 2,604 | 899 |
gh_patches_debug_9613
|
rasdani/github-patches
|
git_diff
|
azavea__raster-vision-550
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Changelog
We need a changelog in the docs that we can update for every PR that adds a fix or a feature.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 from pallets_sphinx_themes import ProjectLink, get_version
2
3 # -*- coding: utf-8 -*-
4 #
5 # Configuration file for the Sphinx documentation builder.
6 #
7 # This file does only contain a selection of the most common options. For a
8 # full list see the documentation:
9 # http://www.sphinx-doc.org/en/stable/config
10
11 # -- Path setup --------------------------------------------------------------
12
13 # If extensions (or modules to document with autodoc) are in another directory,
14 # add these directories to sys.path here. If the directory is relative to the
15 # documentation root, use os.path.abspath to make it absolute, like shown here.
16 #
17 # import os
18 # import sys
19 # sys.path.insert(0, os.path.abspath('.'))
20
21
22 # -- Project information -----------------------------------------------------
23
24 project = 'Raster Vision'
25 copyright = '2018, Azavea'
26 author = 'Azavea'
27
28 # The short X.Y version
29 version = '0.8'
30 # The full version, including alpha/beta/rc tags
31 release = '0.8.0'
32
33
34 # -- General configuration ---------------------------------------------------
35
36 # If your documentation needs a minimal Sphinx version, state it here.
37 #
38 # needs_sphinx = '1.0'
39
40 # Add any Sphinx extension module names here, as strings. They can be
41 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
42 # ones.
43 extensions = [
44 'sphinx.ext.autodoc',
45 'sphinx.ext.intersphinx',
46 'pallets_sphinx_themes',
47 'sphinxcontrib.programoutput'
48 ]
49
50 intersphinx_mapping = {'python': ('https://docs.python.org/3/', None)}
51
52 # Add any paths that contain templates here, relative to this directory.
53 templates_path = ['_templates']
54
55 # The suffix(es) of source filenames.
56 # You can specify multiple suffix as a list of string:
57 #
58 # source_suffix = ['.rst', '.md']
59 source_suffix = '.rst'
60
61 # The master toctree document.
62 master_doc = 'index'
63
64 # The language for content autogenerated by Sphinx. Refer to documentation
65 # for a list of supported languages.
66 #
67 # This is also used if you do content translation via gettext catalogs.
68 # Usually you set "language" from the command line for these cases.
69 language = None
70
71 # List of patterns, relative to source directory, that match files and
72 # directories to ignore when looking for source files.
73 # This pattern also affects html_static_path and html_extra_path .
74 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.md']
75
76 # The name of the Pygments (syntax highlighting) style to use.
77 # pygments_style = 'sphinx'
78
79 # HTML -----------------------------------------------------------------
80
81 html_theme = 'click'
82 html_theme_options = {'index_sidebar_logo': False}
83 html_context = {
84 'project_links': [
85 ProjectLink('Documentation TOC', 'index.html#documentation'),
86 ProjectLink('API Reference TOC', 'index.html#api-reference'),
87 ProjectLink('Project Website', 'https://rastervision.io/'),
88 ProjectLink('PyPI releases', 'https://pypi.org/project/rastervision/'),
89 ProjectLink('GitHub', 'https://github.com/azavea/raster-vision'),
90 ProjectLink('Gitter Channel', 'https://gitter.im/azavea/raster-vision'),
91 ProjectLink('Raster Vision Examples', 'https://github.com/azavea/raster-vision-examples'),
92 ProjectLink('QGIS Plugin', 'https://github.com/azavea/raster-vision-qgis'),
93 ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),
94 ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),
95 ProjectLink('Azavea', 'https://www.azavea.com/'),
96 ],
97 'css_files': [
98 '_static/rastervision.css',
99 'https://media.readthedocs.org/css/badge_only.css'
100 ]
101 }
102 html_sidebars = {
103 'index': ['project.html', 'versions.html', 'searchbox.html'],
104 '**': ['project.html', 'localtoc.html', 'relations.html', 'versions.html', 'searchbox.html'],
105 }
106 singlehtml_sidebars = {'index': ['project.html', 'versions.html', 'localtoc.html']}
107 html_static_path = ['_static']
108 html_favicon = '_static/raster-vision-icon.png'
109 html_logo = '_static/raster-vision-logo.png'
110 html_title = 'Raster Vision Documentation ({})'.format(version)
111 html_show_sourcelink = False
112 html_domain_indices = False
113 html_experimental_html5_writer = True
114
115 # -- Options for HTMLHelp output ---------------------------------------------
116
117 # Output file base name for HTML help builder.
118 htmlhelp_basename = 'RasterVisiondoc'
119
120
121 # -- Options for LaTeX output ------------------------------------------------
122
123 latex_elements = {
124 # The paper size ('letterpaper' or 'a4paper').
125 #
126 # 'papersize': 'letterpaper',
127
128 # The font size ('10pt', '11pt' or '12pt').
129 #
130 # 'pointsize': '10pt',
131
132 # Additional stuff for the LaTeX preamble.
133 #
134 # 'preamble': '',
135
136 # Latex figure (float) alignment
137 #
138 # 'figure_align': 'htbp',
139 }
140
141 # Grouping the document tree into LaTeX files. List of tuples
142 # (source start file, target name, title,
143 # author, documentclass [howto, manual, or own class]).
144 latex_documents = [
145 (master_doc, 'RasterVision.tex', 'Raster Vision Documentation',
146 'Azavea', 'manual'),
147 ]
148
149
150 # -- Options for manual page output ------------------------------------------
151
152 # One entry per manual page. List of tuples
153 # (source start file, name, description, authors, manual section).
154 man_pages = [
155 (master_doc, 'RasterVisoin-{}.tex', html_title,
156 [author], 'manual')
157 ]
158
159
160 # -- Options for Texinfo output ----------------------------------------------
161
162 # Grouping the document tree into Texinfo files. List of tuples
163 # (source start file, target name, title, author,
164 # dir menu entry, description, category)
165 texinfo_documents = [
166 (master_doc, 'RasterVision', 'Raster Vision Documentation',
167 author, 'RasterVision', 'One line description of project.',
168 'Miscellaneous'),
169 ]
170
171
172 # -- Extension configuration -------------------------------------------------
173
174 programoutput_prompt_template = '> {command}\n{output}'
175
176 # -- Options for todo extension ----------------------------------------------
177
178 # If true, `todo` and `todoList` produce output, else they produce nothing.
179 todo_include_todos = True
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -92,6 +92,7 @@
ProjectLink('QGIS Plugin', 'https://github.com/azavea/raster-vision-qgis'),
ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),
ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),
+ ProjectLink('CHANGELOG', 'changelog.html'),
ProjectLink('Azavea', 'https://www.azavea.com/'),
],
'css_files': [
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -92,6 +92,7 @@\n ProjectLink('QGIS Plugin', 'https://github.com/azavea/raster-vision-qgis'),\n ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),\n ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),\n+ ProjectLink('CHANGELOG', 'changelog.html'),\n ProjectLink('Azavea', 'https://www.azavea.com/'),\n ],\n 'css_files': [\n", "issue": "Add Changelog\nWe need a changelog in the docs that we can update for every PR that adds a fix or a feature.\n", "before_files": [{"content": "from pallets_sphinx_themes import ProjectLink, get_version\n\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'Raster Vision'\ncopyright = '2018, Azavea'\nauthor = 'Azavea'\n\n# The short X.Y version\nversion = '0.8'\n# The full version, including alpha/beta/rc tags\nrelease = '0.8.0'\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'pallets_sphinx_themes',\n 'sphinxcontrib.programoutput'\n]\n\nintersphinx_mapping = {'python': ('https://docs.python.org/3/', None)}\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.md']\n\n# The name of the Pygments (syntax highlighting) style to use.\n# pygments_style = 'sphinx'\n\n# HTML -----------------------------------------------------------------\n\nhtml_theme = 'click'\nhtml_theme_options = {'index_sidebar_logo': False}\nhtml_context = {\n 'project_links': [\n ProjectLink('Documentation TOC', 'index.html#documentation'),\n ProjectLink('API Reference TOC', 'index.html#api-reference'),\n ProjectLink('Project Website', 'https://rastervision.io/'),\n ProjectLink('PyPI releases', 'https://pypi.org/project/rastervision/'),\n ProjectLink('GitHub', 'https://github.com/azavea/raster-vision'),\n ProjectLink('Gitter Channel', 'https://gitter.im/azavea/raster-vision'),\n ProjectLink('Raster Vision Examples', 'https://github.com/azavea/raster-vision-examples'),\n ProjectLink('QGIS Plugin', 'https://github.com/azavea/raster-vision-qgis'),\n ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),\n ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),\n ProjectLink('Azavea', 'https://www.azavea.com/'),\n ],\n 'css_files': [\n '_static/rastervision.css',\n 'https://media.readthedocs.org/css/badge_only.css'\n ]\n}\nhtml_sidebars = {\n 'index': ['project.html', 'versions.html', 'searchbox.html'],\n '**': ['project.html', 'localtoc.html', 'relations.html', 'versions.html', 'searchbox.html'],\n}\nsinglehtml_sidebars = {'index': ['project.html', 'versions.html', 'localtoc.html']}\nhtml_static_path = ['_static']\nhtml_favicon = '_static/raster-vision-icon.png'\nhtml_logo = '_static/raster-vision-logo.png'\nhtml_title = 'Raster Vision Documentation ({})'.format(version)\nhtml_show_sourcelink = False\nhtml_domain_indices = False\nhtml_experimental_html5_writer = True\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'RasterVisiondoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'RasterVision.tex', 'Raster Vision Documentation',\n 'Azavea', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'RasterVisoin-{}.tex', html_title,\n [author], 'manual')\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'RasterVision', 'Raster Vision Documentation',\n author, 'RasterVision', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\nprogramoutput_prompt_template = '> {command}\\n{output}'\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n", "path": "docs/conf.py"}], "after_files": [{"content": "from pallets_sphinx_themes import ProjectLink, get_version\n\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'Raster Vision'\ncopyright = '2018, Azavea'\nauthor = 'Azavea'\n\n# The short X.Y version\nversion = '0.8'\n# The full version, including alpha/beta/rc tags\nrelease = '0.8.0'\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'pallets_sphinx_themes',\n 'sphinxcontrib.programoutput'\n]\n\nintersphinx_mapping = {'python': ('https://docs.python.org/3/', None)}\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.md']\n\n# The name of the Pygments (syntax highlighting) style to use.\n# pygments_style = 'sphinx'\n\n# HTML -----------------------------------------------------------------\n\nhtml_theme = 'click'\nhtml_theme_options = {'index_sidebar_logo': False}\nhtml_context = {\n 'project_links': [\n ProjectLink('Documentation TOC', 'index.html#documentation'),\n ProjectLink('API Reference TOC', 'index.html#api-reference'),\n ProjectLink('Project Website', 'https://rastervision.io/'),\n ProjectLink('PyPI releases', 'https://pypi.org/project/rastervision/'),\n ProjectLink('GitHub', 'https://github.com/azavea/raster-vision'),\n ProjectLink('Gitter Channel', 'https://gitter.im/azavea/raster-vision'),\n ProjectLink('Raster Vision Examples', 'https://github.com/azavea/raster-vision-examples'),\n ProjectLink('QGIS Plugin', 'https://github.com/azavea/raster-vision-qgis'),\n ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),\n ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),\n ProjectLink('CHANGELOG', 'changelog.html'),\n ProjectLink('Azavea', 'https://www.azavea.com/'),\n ],\n 'css_files': [\n '_static/rastervision.css',\n 'https://media.readthedocs.org/css/badge_only.css'\n ]\n}\nhtml_sidebars = {\n 'index': ['project.html', 'versions.html', 'searchbox.html'],\n '**': ['project.html', 'localtoc.html', 'relations.html', 'versions.html', 'searchbox.html'],\n}\nsinglehtml_sidebars = {'index': ['project.html', 'versions.html', 'localtoc.html']}\nhtml_static_path = ['_static']\nhtml_favicon = '_static/raster-vision-icon.png'\nhtml_logo = '_static/raster-vision-logo.png'\nhtml_title = 'Raster Vision Documentation ({})'.format(version)\nhtml_show_sourcelink = False\nhtml_domain_indices = False\nhtml_experimental_html5_writer = True\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'RasterVisiondoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'RasterVision.tex', 'Raster Vision Documentation',\n 'Azavea', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'RasterVisoin-{}.tex', html_title,\n [author], 'manual')\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'RasterVision', 'Raster Vision Documentation',\n author, 'RasterVision', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\nprogramoutput_prompt_template = '> {command}\\n{output}'\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n", "path": "docs/conf.py"}]}
| 2,151 | 147 |
gh_patches_debug_52067
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-7279
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Pulling docker image fails when skipping image build
### Issues Policy acknowledgement
- [X] I have read and agree to submit bug reports in accordance with the [issues policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)
### Willingness to contribute
Yes. I can contribute a fix for this bug independently.
### MLflow version
- Client: 1.30.0
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux Ubuntu 20.04
- **Python version**: 3.8.10
- **yarn version, if running the dev UI**: N/A
### Describe the problem
The `mlflow run --skip-image-build ...` will fail when a specified docker image has not already been pulled before running the command.
This is because an incorrect URI is used for downloading the image.
For concrete, we should refer to `base_image` rather than `image_uri` at https://github.com/mlflow/mlflow/blob/v1.30.0/mlflow/projects/docker.py#L84.
### Tracking information
_No response_
### Code to reproduce issue
```bash
#! /bin/bash
IMAGE=${1:-"python:3.6"}
echo "Log: Use $IMAGE for reproducing the bug."
ret=`docker images ${IMAGE} --format "{{.ID}}"`
if [ -n "$ret" ]; then
echo "Error: $IMAGE has already pulled (image-id: $ret)"
echo "This bug only occurs when the specfied image has not pulled yet."
echo "Please run: docker rmi <the printed id> and rerun this script."
echo "Or, specify another image that you have not downloaded yet."
exit 1
fi
cat <<EOF > MLproject
name: mlflow-project-debug
docker_env:
image: ${IMAGE}
entry_points:
main:
command: "echo Hi"
EOF
echo "Log: === MLproject ==="
cat MLproject
echo "Log: === End of MLproject ==="
mlflow run --skip-image-build .
```
### Stack trace
```
2022/11/08 10:18:16 INFO mlflow.projects.docker: Pulling python:3.9
Traceback (most recent call last):
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/client.py", line 268, in _raise_for_status
response.raise_for_status()
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: http+docker://localhost/v1.41/images/create?tag=latest&fromImage=mlflow-project-debug
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/takafumi.kubota/.local/bin/mlflow", line 8, in <module>
sys.exit(cli())
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/cli.py", line 195, in run
projects.run(
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/__init__.py", line 344, in run
submitted_run_obj = _run(
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/__init__.py", line 103, in _run
submitted_run = backend.run(
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/backend/local.py", line 116, in run
image = build_docker_image(
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/docker.py", line 84, in build_docker_image
image = client.images.pull(image_uri)
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/models/images.py", line 465, in pull
pull_log = self.client.api.pull(
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/image.py", line 429, in pull
self._raise_for_status(response)
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/client.py", line 270, in _raise_for_status
raise create_api_error_from_http_exception(e) from e
File "/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/errors.py", line 39, in create_api_error_from_http_exception
raise cls(e, response=response, explanation=explanation) from e
docker.errors.ImageNotFound: 404 Client Error for http+docker://localhost/v1.41/images/create?tag=latest&fromImage=mlflow-project-debug: Not Found ("pull access denied for mlflow-project-debug, repository does not exist or may require 'docker login': denied: requested access to the resource is denied")
```
### Other info / logs
_No response_
### What component(s) does this bug affect?
- [ ] `area/artifacts`: Artifact stores and artifact logging
- [ ] `area/build`: Build and test infrastructure for MLflow
- [ ] `area/docs`: MLflow documentation pages
- [ ] `area/examples`: Example code
- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry
- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors
- [ ] `area/recipes`: Recipes, Recipe APIs, Recipe configs, Recipe Templates
- [X] `area/projects`: MLproject format, project running backends
- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs
- [ ] `area/server-infra`: MLflow Tracking server backend
- [ ] `area/tracking`: Tracking Service, tracking client APIs, autologging
### What interface(s) does this bug affect?
- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server
- [X] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models
- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry
- [ ] `area/windows`: Windows support
### What language(s) does this bug affect?
- [ ] `language/r`: R APIs and clients
- [ ] `language/java`: Java APIs and clients
- [ ] `language/new`: Proposals for new client languages
### What integration(s) does this bug affect?
- [ ] `integrations/azure`: Azure and Azure ML integrations
- [ ] `integrations/sagemaker`: SageMaker integrations
- [ ] `integrations/databricks`: Databricks integrations
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/projects/docker.py`
Content:
```
1 import logging
2 import os
3 import posixpath
4 import shutil
5 import tempfile
6 import urllib.parse
7 import urllib.request
8 import subprocess
9
10 import docker
11
12 from mlflow import tracking
13 from mlflow.projects.utils import get_databricks_env_vars
14 from mlflow.exceptions import ExecutionException
15 from mlflow.projects.utils import MLFLOW_DOCKER_WORKDIR_PATH
16 from mlflow.utils import process, file_utils
17 from mlflow.utils.mlflow_tags import MLFLOW_DOCKER_IMAGE_URI, MLFLOW_DOCKER_IMAGE_ID
18 from mlflow.utils.file_utils import _handle_readonly_on_windows
19 from mlflow.utils.git_utils import get_git_commit
20
21 _logger = logging.getLogger(__name__)
22
23 _GENERATED_DOCKERFILE_NAME = "Dockerfile.mlflow-autogenerated"
24 _MLFLOW_DOCKER_TRACKING_DIR_PATH = "/mlflow/tmp/mlruns"
25 _PROJECT_TAR_ARCHIVE_NAME = "mlflow-project-docker-build-context"
26
27
28 def validate_docker_installation():
29 """
30 Verify if Docker is installed and running on host machine.
31 """
32 if shutil.which("docker") is None:
33 raise ExecutionException(
34 "Could not find Docker executable. "
35 "Ensure Docker is installed as per the instructions "
36 "at https://docs.docker.com/install/overview/."
37 )
38
39 cmd = ["docker", "info"]
40 prc = process._exec_cmd(
41 cmd,
42 throw_on_error=False,
43 capture_output=False,
44 stdout=subprocess.PIPE,
45 stderr=subprocess.STDOUT,
46 )
47 if prc.returncode != 0:
48 joined_cmd = " ".join(cmd)
49 raise ExecutionException(
50 f"Ran `{joined_cmd}` to ensure docker daemon is running but it failed "
51 f"with the following output:\n{prc.stdout}"
52 )
53
54
55 def validate_docker_env(project):
56 if not project.name:
57 raise ExecutionException(
58 "Project name in MLProject must be specified when using docker for image tagging."
59 )
60 if not project.docker_env.get("image"):
61 raise ExecutionException(
62 "Project with docker environment must specify the docker image "
63 "to use via an 'image' field under the 'docker_env' field."
64 )
65
66
67 def build_docker_image(work_dir, repository_uri, base_image, run_id, build_image):
68 """
69 Build a docker image containing the project in `work_dir`, using the base image.
70 """
71 image_uri = _get_docker_image_uri(repository_uri=repository_uri, work_dir=work_dir)
72 dockerfile = (
73 "FROM {imagename}\n COPY {build_context_path}/ {workdir}\n WORKDIR {workdir}\n"
74 ).format(
75 imagename=base_image,
76 build_context_path=_PROJECT_TAR_ARCHIVE_NAME,
77 workdir=MLFLOW_DOCKER_WORKDIR_PATH,
78 )
79 build_ctx_path = _create_docker_build_ctx(work_dir, dockerfile)
80 client = docker.from_env()
81 if not build_image:
82 if not client.images.list(name=base_image):
83 _logger.info(f"Pulling {base_image}")
84 image = client.images.pull(image_uri)
85 else:
86 _logger.info(f"{base_image} already exists")
87 image = client.images.get(base_image)
88 image_uri = base_image
89 else:
90 with open(build_ctx_path, "rb") as docker_build_ctx:
91 _logger.info("=== Building docker image %s ===", image_uri)
92 image, _ = client.images.build(
93 tag=image_uri,
94 forcerm=True,
95 dockerfile=posixpath.join(_PROJECT_TAR_ARCHIVE_NAME, _GENERATED_DOCKERFILE_NAME),
96 fileobj=docker_build_ctx,
97 custom_context=True,
98 encoding="gzip",
99 )
100 try:
101 os.remove(build_ctx_path)
102 except Exception:
103 _logger.info("Temporary docker context file %s was not deleted.", build_ctx_path)
104 tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_URI, image_uri)
105 tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_ID, image.id)
106 return image
107
108
109 def _get_docker_image_uri(repository_uri, work_dir):
110 """
111 Returns an appropriate Docker image URI for a project based on the git hash of the specified
112 working directory.
113
114 :param repository_uri: The URI of the Docker repository with which to tag the image. The
115 repository URI is used as the prefix of the image URI.
116 :param work_dir: Path to the working directory in which to search for a git commit hash
117 """
118 repository_uri = repository_uri if repository_uri else "docker-project"
119 # Optionally include first 7 digits of git SHA in tag name, if available.
120 git_commit = get_git_commit(work_dir)
121 version_string = ":" + git_commit[:7] if git_commit else ""
122 return repository_uri + version_string
123
124
125 def _create_docker_build_ctx(work_dir, dockerfile_contents):
126 """
127 Creates build context tarfile containing Dockerfile and project code, returning path to tarfile
128 """
129 directory = tempfile.mkdtemp()
130 try:
131 dst_path = os.path.join(directory, "mlflow-project-contents")
132 shutil.copytree(src=work_dir, dst=dst_path)
133 with open(os.path.join(dst_path, _GENERATED_DOCKERFILE_NAME), "w") as handle:
134 handle.write(dockerfile_contents)
135 _, result_path = tempfile.mkstemp()
136 file_utils.make_tarfile(
137 output_filename=result_path, source_dir=dst_path, archive_name=_PROJECT_TAR_ARCHIVE_NAME
138 )
139 finally:
140 shutil.rmtree(directory, onerror=_handle_readonly_on_windows)
141 return result_path
142
143
144 def get_docker_tracking_cmd_and_envs(tracking_uri):
145 cmds = []
146 env_vars = {}
147
148 local_path, container_tracking_uri = _get_local_uri_or_none(tracking_uri)
149 if local_path is not None:
150 cmds = ["-v", "%s:%s" % (local_path, _MLFLOW_DOCKER_TRACKING_DIR_PATH)]
151 env_vars[tracking._TRACKING_URI_ENV_VAR] = container_tracking_uri
152 env_vars.update(get_databricks_env_vars(tracking_uri))
153 return cmds, env_vars
154
155
156 def _get_local_uri_or_none(uri):
157 if uri == "databricks":
158 return None, None
159 parsed_uri = urllib.parse.urlparse(uri)
160 if not parsed_uri.netloc and parsed_uri.scheme in ("", "file", "sqlite"):
161 path = urllib.request.url2pathname(parsed_uri.path)
162 if parsed_uri.scheme == "sqlite":
163 uri = file_utils.path_to_local_sqlite_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)
164 else:
165 uri = file_utils.path_to_local_file_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)
166 return path, uri
167 else:
168 return None, None
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/projects/docker.py b/mlflow/projects/docker.py
--- a/mlflow/projects/docker.py
+++ b/mlflow/projects/docker.py
@@ -81,7 +81,7 @@
if not build_image:
if not client.images.list(name=base_image):
_logger.info(f"Pulling {base_image}")
- image = client.images.pull(image_uri)
+ image = client.images.pull(base_image)
else:
_logger.info(f"{base_image} already exists")
image = client.images.get(base_image)
|
{"golden_diff": "diff --git a/mlflow/projects/docker.py b/mlflow/projects/docker.py\n--- a/mlflow/projects/docker.py\n+++ b/mlflow/projects/docker.py\n@@ -81,7 +81,7 @@\n if not build_image:\n if not client.images.list(name=base_image):\n _logger.info(f\"Pulling {base_image}\")\n- image = client.images.pull(image_uri)\n+ image = client.images.pull(base_image)\n else:\n _logger.info(f\"{base_image} already exists\")\n image = client.images.get(base_image)\n", "issue": "[BUG] Pulling docker image fails when skipping image build\n### Issues Policy acknowledgement\n\n- [X] I have read and agree to submit bug reports in accordance with the [issues policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)\n\n### Willingness to contribute\n\nYes. I can contribute a fix for this bug independently.\n\n### MLflow version\n\n- Client: 1.30.0\r\n\n\n### System information\n\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux Ubuntu 20.04\r\n- **Python version**: 3.8.10\r\n- **yarn version, if running the dev UI**: N/A\r\n\n\n### Describe the problem\n\nThe `mlflow run --skip-image-build ...` will fail when a specified docker image has not already been pulled before running the command.\r\nThis is because an incorrect URI is used for downloading the image.\r\nFor concrete, we should refer to `base_image` rather than `image_uri` at https://github.com/mlflow/mlflow/blob/v1.30.0/mlflow/projects/docker.py#L84.\n\n### Tracking information\n\n_No response_\n\n### Code to reproduce issue\n\n\r\n```bash\r\n#! /bin/bash\r\n\r\nIMAGE=${1:-\"python:3.6\"}\r\necho \"Log: Use $IMAGE for reproducing the bug.\"\r\n\r\nret=`docker images ${IMAGE} --format \"{{.ID}}\"`\r\n\r\nif [ -n \"$ret\" ]; then\r\n echo \"Error: $IMAGE has already pulled (image-id: $ret)\"\r\n echo \"This bug only occurs when the specfied image has not pulled yet.\"\r\n echo \"Please run: docker rmi <the printed id> and rerun this script.\"\r\n echo \"Or, specify another image that you have not downloaded yet.\"\r\n exit 1\r\nfi\r\n\r\ncat <<EOF > MLproject\r\nname: mlflow-project-debug\r\n\r\ndocker_env:\r\n image: ${IMAGE}\r\n\r\nentry_points:\r\n main:\r\n command: \"echo Hi\"\r\nEOF\r\n\r\necho \"Log: === MLproject ===\"\r\ncat MLproject\r\necho \"Log: === End of MLproject ===\"\r\n\r\nmlflow run --skip-image-build .\r\n```\n\n### Stack trace\n\n```\r\n2022/11/08 10:18:16 INFO mlflow.projects.docker: Pulling python:3.9\r\nTraceback (most recent call last):\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/client.py\", line 268, in _raise_for_status\r\n response.raise_for_status()\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/requests/models.py\", line 1021, in raise_for_status\r\n raise HTTPError(http_error_msg, response=self)\r\nrequests.exceptions.HTTPError: 404 Client Error: Not Found for url: http+docker://localhost/v1.41/images/create?tag=latest&fromImage=mlflow-project-debug\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/takafumi.kubota/.local/bin/mlflow\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py\", line 1130, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py\", line 1055, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py\", line 1657, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/takafumi.kubota/.pyenv/versions/3.8.10/lib/python3.8/site-packages/click/core.py\", line 760, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/cli.py\", line 195, in run\r\n projects.run(\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/__init__.py\", line 344, in run\r\n submitted_run_obj = _run(\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/__init__.py\", line 103, in _run\r\n submitted_run = backend.run(\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/backend/local.py\", line 116, in run\r\n image = build_docker_image(\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/mlflow/projects/docker.py\", line 84, in build_docker_image\r\n image = client.images.pull(image_uri)\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/models/images.py\", line 465, in pull\r\n pull_log = self.client.api.pull(\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/image.py\", line 429, in pull\r\n self._raise_for_status(response)\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/api/client.py\", line 270, in _raise_for_status\r\n raise create_api_error_from_http_exception(e) from e\r\n File \"/home/takafumi.kubota/.local/lib/python3.8/site-packages/docker/errors.py\", line 39, in create_api_error_from_http_exception\r\n raise cls(e, response=response, explanation=explanation) from e\r\ndocker.errors.ImageNotFound: 404 Client Error for http+docker://localhost/v1.41/images/create?tag=latest&fromImage=mlflow-project-debug: Not Found (\"pull access denied for mlflow-project-debug, repository does not exist or may require 'docker login': denied: requested access to the resource is denied\")\r\n\r\n```\n\n### Other info / logs\n\n_No response_\n\n### What component(s) does this bug affect?\n\n- [ ] `area/artifacts`: Artifact stores and artifact logging\n- [ ] `area/build`: Build and test infrastructure for MLflow\n- [ ] `area/docs`: MLflow documentation pages\n- [ ] `area/examples`: Example code\n- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry\n- [ ] `area/models`: MLmodel format, model serialization/deserialization, flavors\n- [ ] `area/recipes`: Recipes, Recipe APIs, Recipe configs, Recipe Templates\n- [X] `area/projects`: MLproject format, project running backends\n- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs\n- [ ] `area/server-infra`: MLflow Tracking server backend\n- [ ] `area/tracking`: Tracking Service, tracking client APIs, autologging\n\n### What interface(s) does this bug affect?\n\n- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server\n- [X] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models\n- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry\n- [ ] `area/windows`: Windows support\n\n### What language(s) does this bug affect?\n\n- [ ] `language/r`: R APIs and clients\n- [ ] `language/java`: Java APIs and clients\n- [ ] `language/new`: Proposals for new client languages\n\n### What integration(s) does this bug affect?\n\n- [ ] `integrations/azure`: Azure and Azure ML integrations\n- [ ] `integrations/sagemaker`: SageMaker integrations\n- [ ] `integrations/databricks`: Databricks integrations\n", "before_files": [{"content": "import logging\nimport os\nimport posixpath\nimport shutil\nimport tempfile\nimport urllib.parse\nimport urllib.request\nimport subprocess\n\nimport docker\n\nfrom mlflow import tracking\nfrom mlflow.projects.utils import get_databricks_env_vars\nfrom mlflow.exceptions import ExecutionException\nfrom mlflow.projects.utils import MLFLOW_DOCKER_WORKDIR_PATH\nfrom mlflow.utils import process, file_utils\nfrom mlflow.utils.mlflow_tags import MLFLOW_DOCKER_IMAGE_URI, MLFLOW_DOCKER_IMAGE_ID\nfrom mlflow.utils.file_utils import _handle_readonly_on_windows\nfrom mlflow.utils.git_utils import get_git_commit\n\n_logger = logging.getLogger(__name__)\n\n_GENERATED_DOCKERFILE_NAME = \"Dockerfile.mlflow-autogenerated\"\n_MLFLOW_DOCKER_TRACKING_DIR_PATH = \"/mlflow/tmp/mlruns\"\n_PROJECT_TAR_ARCHIVE_NAME = \"mlflow-project-docker-build-context\"\n\n\ndef validate_docker_installation():\n \"\"\"\n Verify if Docker is installed and running on host machine.\n \"\"\"\n if shutil.which(\"docker\") is None:\n raise ExecutionException(\n \"Could not find Docker executable. \"\n \"Ensure Docker is installed as per the instructions \"\n \"at https://docs.docker.com/install/overview/.\"\n )\n\n cmd = [\"docker\", \"info\"]\n prc = process._exec_cmd(\n cmd,\n throw_on_error=False,\n capture_output=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n if prc.returncode != 0:\n joined_cmd = \" \".join(cmd)\n raise ExecutionException(\n f\"Ran `{joined_cmd}` to ensure docker daemon is running but it failed \"\n f\"with the following output:\\n{prc.stdout}\"\n )\n\n\ndef validate_docker_env(project):\n if not project.name:\n raise ExecutionException(\n \"Project name in MLProject must be specified when using docker for image tagging.\"\n )\n if not project.docker_env.get(\"image\"):\n raise ExecutionException(\n \"Project with docker environment must specify the docker image \"\n \"to use via an 'image' field under the 'docker_env' field.\"\n )\n\n\ndef build_docker_image(work_dir, repository_uri, base_image, run_id, build_image):\n \"\"\"\n Build a docker image containing the project in `work_dir`, using the base image.\n \"\"\"\n image_uri = _get_docker_image_uri(repository_uri=repository_uri, work_dir=work_dir)\n dockerfile = (\n \"FROM {imagename}\\n COPY {build_context_path}/ {workdir}\\n WORKDIR {workdir}\\n\"\n ).format(\n imagename=base_image,\n build_context_path=_PROJECT_TAR_ARCHIVE_NAME,\n workdir=MLFLOW_DOCKER_WORKDIR_PATH,\n )\n build_ctx_path = _create_docker_build_ctx(work_dir, dockerfile)\n client = docker.from_env()\n if not build_image:\n if not client.images.list(name=base_image):\n _logger.info(f\"Pulling {base_image}\")\n image = client.images.pull(image_uri)\n else:\n _logger.info(f\"{base_image} already exists\")\n image = client.images.get(base_image)\n image_uri = base_image\n else:\n with open(build_ctx_path, \"rb\") as docker_build_ctx:\n _logger.info(\"=== Building docker image %s ===\", image_uri)\n image, _ = client.images.build(\n tag=image_uri,\n forcerm=True,\n dockerfile=posixpath.join(_PROJECT_TAR_ARCHIVE_NAME, _GENERATED_DOCKERFILE_NAME),\n fileobj=docker_build_ctx,\n custom_context=True,\n encoding=\"gzip\",\n )\n try:\n os.remove(build_ctx_path)\n except Exception:\n _logger.info(\"Temporary docker context file %s was not deleted.\", build_ctx_path)\n tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_URI, image_uri)\n tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_ID, image.id)\n return image\n\n\ndef _get_docker_image_uri(repository_uri, work_dir):\n \"\"\"\n Returns an appropriate Docker image URI for a project based on the git hash of the specified\n working directory.\n\n :param repository_uri: The URI of the Docker repository with which to tag the image. The\n repository URI is used as the prefix of the image URI.\n :param work_dir: Path to the working directory in which to search for a git commit hash\n \"\"\"\n repository_uri = repository_uri if repository_uri else \"docker-project\"\n # Optionally include first 7 digits of git SHA in tag name, if available.\n git_commit = get_git_commit(work_dir)\n version_string = \":\" + git_commit[:7] if git_commit else \"\"\n return repository_uri + version_string\n\n\ndef _create_docker_build_ctx(work_dir, dockerfile_contents):\n \"\"\"\n Creates build context tarfile containing Dockerfile and project code, returning path to tarfile\n \"\"\"\n directory = tempfile.mkdtemp()\n try:\n dst_path = os.path.join(directory, \"mlflow-project-contents\")\n shutil.copytree(src=work_dir, dst=dst_path)\n with open(os.path.join(dst_path, _GENERATED_DOCKERFILE_NAME), \"w\") as handle:\n handle.write(dockerfile_contents)\n _, result_path = tempfile.mkstemp()\n file_utils.make_tarfile(\n output_filename=result_path, source_dir=dst_path, archive_name=_PROJECT_TAR_ARCHIVE_NAME\n )\n finally:\n shutil.rmtree(directory, onerror=_handle_readonly_on_windows)\n return result_path\n\n\ndef get_docker_tracking_cmd_and_envs(tracking_uri):\n cmds = []\n env_vars = {}\n\n local_path, container_tracking_uri = _get_local_uri_or_none(tracking_uri)\n if local_path is not None:\n cmds = [\"-v\", \"%s:%s\" % (local_path, _MLFLOW_DOCKER_TRACKING_DIR_PATH)]\n env_vars[tracking._TRACKING_URI_ENV_VAR] = container_tracking_uri\n env_vars.update(get_databricks_env_vars(tracking_uri))\n return cmds, env_vars\n\n\ndef _get_local_uri_or_none(uri):\n if uri == \"databricks\":\n return None, None\n parsed_uri = urllib.parse.urlparse(uri)\n if not parsed_uri.netloc and parsed_uri.scheme in (\"\", \"file\", \"sqlite\"):\n path = urllib.request.url2pathname(parsed_uri.path)\n if parsed_uri.scheme == \"sqlite\":\n uri = file_utils.path_to_local_sqlite_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)\n else:\n uri = file_utils.path_to_local_file_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)\n return path, uri\n else:\n return None, None\n", "path": "mlflow/projects/docker.py"}], "after_files": [{"content": "import logging\nimport os\nimport posixpath\nimport shutil\nimport tempfile\nimport urllib.parse\nimport urllib.request\nimport subprocess\n\nimport docker\n\nfrom mlflow import tracking\nfrom mlflow.projects.utils import get_databricks_env_vars\nfrom mlflow.exceptions import ExecutionException\nfrom mlflow.projects.utils import MLFLOW_DOCKER_WORKDIR_PATH\nfrom mlflow.utils import process, file_utils\nfrom mlflow.utils.mlflow_tags import MLFLOW_DOCKER_IMAGE_URI, MLFLOW_DOCKER_IMAGE_ID\nfrom mlflow.utils.file_utils import _handle_readonly_on_windows\nfrom mlflow.utils.git_utils import get_git_commit\n\n_logger = logging.getLogger(__name__)\n\n_GENERATED_DOCKERFILE_NAME = \"Dockerfile.mlflow-autogenerated\"\n_MLFLOW_DOCKER_TRACKING_DIR_PATH = \"/mlflow/tmp/mlruns\"\n_PROJECT_TAR_ARCHIVE_NAME = \"mlflow-project-docker-build-context\"\n\n\ndef validate_docker_installation():\n \"\"\"\n Verify if Docker is installed and running on host machine.\n \"\"\"\n if shutil.which(\"docker\") is None:\n raise ExecutionException(\n \"Could not find Docker executable. \"\n \"Ensure Docker is installed as per the instructions \"\n \"at https://docs.docker.com/install/overview/.\"\n )\n\n cmd = [\"docker\", \"info\"]\n prc = process._exec_cmd(\n cmd,\n throw_on_error=False,\n capture_output=False,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n if prc.returncode != 0:\n joined_cmd = \" \".join(cmd)\n raise ExecutionException(\n f\"Ran `{joined_cmd}` to ensure docker daemon is running but it failed \"\n f\"with the following output:\\n{prc.stdout}\"\n )\n\n\ndef validate_docker_env(project):\n if not project.name:\n raise ExecutionException(\n \"Project name in MLProject must be specified when using docker for image tagging.\"\n )\n if not project.docker_env.get(\"image\"):\n raise ExecutionException(\n \"Project with docker environment must specify the docker image \"\n \"to use via an 'image' field under the 'docker_env' field.\"\n )\n\n\ndef build_docker_image(work_dir, repository_uri, base_image, run_id, build_image):\n \"\"\"\n Build a docker image containing the project in `work_dir`, using the base image.\n \"\"\"\n image_uri = _get_docker_image_uri(repository_uri=repository_uri, work_dir=work_dir)\n dockerfile = (\n \"FROM {imagename}\\n COPY {build_context_path}/ {workdir}\\n WORKDIR {workdir}\\n\"\n ).format(\n imagename=base_image,\n build_context_path=_PROJECT_TAR_ARCHIVE_NAME,\n workdir=MLFLOW_DOCKER_WORKDIR_PATH,\n )\n build_ctx_path = _create_docker_build_ctx(work_dir, dockerfile)\n client = docker.from_env()\n if not build_image:\n if not client.images.list(name=base_image):\n _logger.info(f\"Pulling {base_image}\")\n image = client.images.pull(base_image)\n else:\n _logger.info(f\"{base_image} already exists\")\n image = client.images.get(base_image)\n image_uri = base_image\n else:\n with open(build_ctx_path, \"rb\") as docker_build_ctx:\n _logger.info(\"=== Building docker image %s ===\", image_uri)\n image, _ = client.images.build(\n tag=image_uri,\n forcerm=True,\n dockerfile=posixpath.join(_PROJECT_TAR_ARCHIVE_NAME, _GENERATED_DOCKERFILE_NAME),\n fileobj=docker_build_ctx,\n custom_context=True,\n encoding=\"gzip\",\n )\n try:\n os.remove(build_ctx_path)\n except Exception:\n _logger.info(\"Temporary docker context file %s was not deleted.\", build_ctx_path)\n tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_URI, image_uri)\n tracking.MlflowClient().set_tag(run_id, MLFLOW_DOCKER_IMAGE_ID, image.id)\n return image\n\n\ndef _get_docker_image_uri(repository_uri, work_dir):\n \"\"\"\n Returns an appropriate Docker image URI for a project based on the git hash of the specified\n working directory.\n\n :param repository_uri: The URI of the Docker repository with which to tag the image. The\n repository URI is used as the prefix of the image URI.\n :param work_dir: Path to the working directory in which to search for a git commit hash\n \"\"\"\n repository_uri = repository_uri if repository_uri else \"docker-project\"\n # Optionally include first 7 digits of git SHA in tag name, if available.\n git_commit = get_git_commit(work_dir)\n version_string = \":\" + git_commit[:7] if git_commit else \"\"\n return repository_uri + version_string\n\n\ndef _create_docker_build_ctx(work_dir, dockerfile_contents):\n \"\"\"\n Creates build context tarfile containing Dockerfile and project code, returning path to tarfile\n \"\"\"\n directory = tempfile.mkdtemp()\n try:\n dst_path = os.path.join(directory, \"mlflow-project-contents\")\n shutil.copytree(src=work_dir, dst=dst_path)\n with open(os.path.join(dst_path, _GENERATED_DOCKERFILE_NAME), \"w\") as handle:\n handle.write(dockerfile_contents)\n _, result_path = tempfile.mkstemp()\n file_utils.make_tarfile(\n output_filename=result_path, source_dir=dst_path, archive_name=_PROJECT_TAR_ARCHIVE_NAME\n )\n finally:\n shutil.rmtree(directory, onerror=_handle_readonly_on_windows)\n return result_path\n\n\ndef get_docker_tracking_cmd_and_envs(tracking_uri):\n cmds = []\n env_vars = {}\n\n local_path, container_tracking_uri = _get_local_uri_or_none(tracking_uri)\n if local_path is not None:\n cmds = [\"-v\", \"%s:%s\" % (local_path, _MLFLOW_DOCKER_TRACKING_DIR_PATH)]\n env_vars[tracking._TRACKING_URI_ENV_VAR] = container_tracking_uri\n env_vars.update(get_databricks_env_vars(tracking_uri))\n return cmds, env_vars\n\n\ndef _get_local_uri_or_none(uri):\n if uri == \"databricks\":\n return None, None\n parsed_uri = urllib.parse.urlparse(uri)\n if not parsed_uri.netloc and parsed_uri.scheme in (\"\", \"file\", \"sqlite\"):\n path = urllib.request.url2pathname(parsed_uri.path)\n if parsed_uri.scheme == \"sqlite\":\n uri = file_utils.path_to_local_sqlite_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)\n else:\n uri = file_utils.path_to_local_file_uri(_MLFLOW_DOCKER_TRACKING_DIR_PATH)\n return path, uri\n else:\n return None, None\n", "path": "mlflow/projects/docker.py"}]}
| 3,978 | 117 |
gh_patches_debug_3785
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-744
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Why a print statement in this code?
@kaiyou, according git blame this is yours. I wonder if it was included for debugging purposes and not taken out anymore?
https://github.com/Mailu/Mailu/blob/5c2439011413a114c470862f95206f8487fa4568/core/admin/mailu/internal/views/dovecot.py#L18
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/admin/mailu/internal/views/dovecot.py`
Content:
```
1 from mailu import models
2 from mailu.internal import internal
3 from flask import current_app as app
4
5 import flask
6 import socket
7 import os
8
9 @internal.route("/dovecot/passdb/<user_email>")
10 def dovecot_passdb_dict(user_email):
11 user = models.User.query.get(user_email) or flask.abort(404)
12 allow_nets = []
13 allow_nets.append(app.config["SUBNET"])
14 if app.config["POD_ADDRESS_RANGE"]:
15 allow_nets.append(app.config["POD_ADDRESS_RANGE"])
16 print(allow_nets)
17 return flask.jsonify({
18 "password": None,
19 "nopassword": "Y",
20 "allow_nets": ",".join(allow_nets)
21 })
22
23
24 @internal.route("/dovecot/userdb/<user_email>")
25 def dovecot_userdb_dict(user_email):
26 user = models.User.query.get(user_email) or flask.abort(404)
27 return flask.jsonify({
28 "quota_rule": "*:bytes={}".format(user.quota_bytes)
29 })
30
31
32 @internal.route("/dovecot/quota/<ns>/<user_email>", methods=["POST"])
33 def dovecot_quota(ns, user_email):
34 user = models.User.query.get(user_email) or flask.abort(404)
35 if ns == "storage":
36 user.quota_bytes_used = flask.request.get_json()
37 models.db.session.commit()
38 return flask.jsonify(None)
39
40
41 @internal.route("/dovecot/sieve/name/<script>/<user_email>")
42 def dovecot_sieve_name(script, user_email):
43 return flask.jsonify(script)
44
45
46 @internal.route("/dovecot/sieve/data/default/<user_email>")
47 def dovecot_sieve_data(user_email):
48 user = models.User.query.get(user_email) or flask.abort(404)
49 return flask.jsonify(flask.render_template("default.sieve", user=user))
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/admin/mailu/internal/views/dovecot.py b/core/admin/mailu/internal/views/dovecot.py
--- a/core/admin/mailu/internal/views/dovecot.py
+++ b/core/admin/mailu/internal/views/dovecot.py
@@ -13,7 +13,6 @@
allow_nets.append(app.config["SUBNET"])
if app.config["POD_ADDRESS_RANGE"]:
allow_nets.append(app.config["POD_ADDRESS_RANGE"])
- print(allow_nets)
return flask.jsonify({
"password": None,
"nopassword": "Y",
|
{"golden_diff": "diff --git a/core/admin/mailu/internal/views/dovecot.py b/core/admin/mailu/internal/views/dovecot.py\n--- a/core/admin/mailu/internal/views/dovecot.py\n+++ b/core/admin/mailu/internal/views/dovecot.py\n@@ -13,7 +13,6 @@\n allow_nets.append(app.config[\"SUBNET\"])\n if app.config[\"POD_ADDRESS_RANGE\"]:\n allow_nets.append(app.config[\"POD_ADDRESS_RANGE\"])\n- print(allow_nets)\n return flask.jsonify({\n \"password\": None,\n \"nopassword\": \"Y\",\n", "issue": "Why a print statement in this code?\n@kaiyou, according git blame this is yours. I wonder if it was included for debugging purposes and not taken out anymore?\r\n\r\nhttps://github.com/Mailu/Mailu/blob/5c2439011413a114c470862f95206f8487fa4568/core/admin/mailu/internal/views/dovecot.py#L18\n", "before_files": [{"content": "from mailu import models\nfrom mailu.internal import internal\nfrom flask import current_app as app\n\nimport flask\nimport socket\nimport os\n\[email protected](\"/dovecot/passdb/<user_email>\")\ndef dovecot_passdb_dict(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n allow_nets = []\n allow_nets.append(app.config[\"SUBNET\"])\n if app.config[\"POD_ADDRESS_RANGE\"]:\n allow_nets.append(app.config[\"POD_ADDRESS_RANGE\"])\n print(allow_nets)\n return flask.jsonify({\n \"password\": None,\n \"nopassword\": \"Y\",\n \"allow_nets\": \",\".join(allow_nets)\n })\n\n\[email protected](\"/dovecot/userdb/<user_email>\")\ndef dovecot_userdb_dict(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n return flask.jsonify({\n \"quota_rule\": \"*:bytes={}\".format(user.quota_bytes)\n })\n\n\[email protected](\"/dovecot/quota/<ns>/<user_email>\", methods=[\"POST\"])\ndef dovecot_quota(ns, user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n if ns == \"storage\":\n user.quota_bytes_used = flask.request.get_json()\n models.db.session.commit()\n return flask.jsonify(None)\n\n\[email protected](\"/dovecot/sieve/name/<script>/<user_email>\")\ndef dovecot_sieve_name(script, user_email):\n return flask.jsonify(script)\n\n\[email protected](\"/dovecot/sieve/data/default/<user_email>\")\ndef dovecot_sieve_data(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n return flask.jsonify(flask.render_template(\"default.sieve\", user=user))\n", "path": "core/admin/mailu/internal/views/dovecot.py"}], "after_files": [{"content": "from mailu import models\nfrom mailu.internal import internal\nfrom flask import current_app as app\n\nimport flask\nimport socket\nimport os\n\[email protected](\"/dovecot/passdb/<user_email>\")\ndef dovecot_passdb_dict(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n allow_nets = []\n allow_nets.append(app.config[\"SUBNET\"])\n if app.config[\"POD_ADDRESS_RANGE\"]:\n allow_nets.append(app.config[\"POD_ADDRESS_RANGE\"])\n return flask.jsonify({\n \"password\": None,\n \"nopassword\": \"Y\",\n \"allow_nets\": \",\".join(allow_nets)\n })\n\n\[email protected](\"/dovecot/userdb/<user_email>\")\ndef dovecot_userdb_dict(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n return flask.jsonify({\n \"quota_rule\": \"*:bytes={}\".format(user.quota_bytes)\n })\n\n\[email protected](\"/dovecot/quota/<ns>/<user_email>\", methods=[\"POST\"])\ndef dovecot_quota(ns, user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n if ns == \"storage\":\n user.quota_bytes_used = flask.request.get_json()\n models.db.session.commit()\n return flask.jsonify(None)\n\n\[email protected](\"/dovecot/sieve/name/<script>/<user_email>\")\ndef dovecot_sieve_name(script, user_email):\n return flask.jsonify(script)\n\n\[email protected](\"/dovecot/sieve/data/default/<user_email>\")\ndef dovecot_sieve_data(user_email):\n user = models.User.query.get(user_email) or flask.abort(404)\n return flask.jsonify(flask.render_template(\"default.sieve\", user=user))\n", "path": "core/admin/mailu/internal/views/dovecot.py"}]}
| 860 | 126 |
gh_patches_debug_10468
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-70
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Breadcrumbs type error
We're having an issue with v0.3.2 where `popleft` is called on a list type:
```
File "/srv/frontend/project/lib/python3.5/site-packages/sentry_sdk/hub.py" in add_breadcrumb
209. scope._breadcrumbs.popleft()
Exception Type: AttributeError at /
Exception Value: 'list' object has no attribute 'popleft'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/hub.py`
Content:
```
1 import sys
2 import copy
3 from datetime import datetime
4 from contextlib import contextmanager
5
6 from sentry_sdk._compat import with_metaclass
7 from sentry_sdk.scope import Scope
8 from sentry_sdk.utils import (
9 exc_info_from_error,
10 event_from_exception,
11 logger,
12 ContextVar,
13 )
14
15
16 _local = ContextVar("sentry_current_hub")
17
18
19 def _get_client_options():
20 hub = Hub.current
21 if hub and hub.client:
22 return hub.client.options
23
24
25 def _should_send_default_pii():
26 client = Hub.current.client
27 if not client:
28 return False
29 return client.options["send_default_pii"]
30
31
32 class HubMeta(type):
33 @property
34 def current(self):
35 """Returns the current instance of the hub."""
36 rv = _local.get(None)
37 if rv is None:
38 rv = Hub(GLOBAL_HUB)
39 _local.set(rv)
40 return rv
41
42 @property
43 def main(self):
44 """Returns the main instance of the hub."""
45 return GLOBAL_HUB
46
47
48 class _HubManager(object):
49 def __init__(self, hub):
50 self._old = Hub.current
51 _local.set(hub)
52
53 def __exit__(self, exc_type, exc_value, tb):
54 _local.set(self._old)
55
56
57 class _ScopeManager(object):
58 def __init__(self, hub, layer):
59 self._hub = hub
60 self._layer = layer
61
62 def __enter__(self):
63 scope = self._layer[1]
64 if scope is None:
65 scope = Scope()
66 return scope
67
68 def __exit__(self, exc_type, exc_value, tb):
69 assert self._hub.pop_scope_unsafe() == self._layer, "popped wrong scope"
70
71
72 class Hub(with_metaclass(HubMeta)):
73 """The hub wraps the concurrency management of the SDK. Each thread has
74 its own hub but the hub might transfer with the flow of execution if
75 context vars are available.
76
77 If the hub is used with a with statement it's temporarily activated.
78 """
79
80 def __init__(self, client_or_hub=None, scope=None):
81 if isinstance(client_or_hub, Hub):
82 hub = client_or_hub
83 client, other_scope = hub._stack[-1]
84 if scope is None:
85 scope = copy.copy(other_scope)
86 else:
87 client = client_or_hub
88 if scope is None:
89 scope = Scope()
90 self._stack = [(client, scope)]
91 self._last_event_id = None
92 self._old_hubs = []
93
94 def __enter__(self):
95 self._old_hubs.append(Hub.current)
96 _local.set(self)
97 return self
98
99 def __exit__(self, exc_type, exc_value, tb):
100 old = self._old_hubs.pop()
101 _local.set(old)
102
103 def run(self, callback):
104 """Runs a callback in the context of the hub. Alternatively the
105 with statement can be used on the hub directly.
106 """
107 with self:
108 return callback()
109
110 @property
111 def client(self):
112 """Returns the current client on the hub."""
113 return self._stack[-1][0]
114
115 def last_event_id(self):
116 """Returns the last event ID."""
117 return self._last_event_id
118
119 def bind_client(self, new):
120 """Binds a new client to the hub."""
121 top = self._stack[-1]
122 self._stack[-1] = (new, top[1])
123
124 def capture_event(self, event, hint=None):
125 """Captures an event. The return value is the ID of the event.
126
127 The event is a dictionary following the Sentry v7/v8 protocol
128 specification. Optionally an event hint dict can be passed that
129 is used by processors to extract additional information from it.
130 Typically the event hint object would contain exception information.
131 """
132 client, scope = self._stack[-1]
133 if client is not None:
134 rv = client.capture_event(event, hint, scope)
135 if rv is not None:
136 self._last_event_id = rv
137 return rv
138
139 def capture_message(self, message, level=None):
140 """Captures a message. The message is just a string. If no level
141 is provided the default level is `info`.
142 """
143 if self.client is None:
144 return
145 if level is None:
146 level = "info"
147 return self.capture_event({"message": message, "level": level})
148
149 def capture_exception(self, error=None):
150 """Captures an exception.
151
152 The argument passed can be `None` in which case the last exception
153 will be reported, otherwise an exception object or an `exc_info`
154 tuple.
155 """
156 client = self.client
157 if client is None:
158 return
159 if error is None:
160 exc_info = sys.exc_info()
161 else:
162 exc_info = exc_info_from_error(error)
163
164 event, hint = event_from_exception(
165 exc_info, with_locals=client.options["with_locals"]
166 )
167 try:
168 return self.capture_event(event, hint=hint)
169 except Exception:
170 self._capture_internal_exception(sys.exc_info())
171
172 def _capture_internal_exception(self, exc_info):
173 """Capture an exception that is likely caused by a bug in the SDK
174 itself."""
175 logger.debug("Internal error in sentry_sdk", exc_info=exc_info)
176
177 def add_breadcrumb(self, crumb=None, hint=None, **kwargs):
178 """Adds a breadcrumb. The breadcrumbs are a dictionary with the
179 data as the sentry v7/v8 protocol expects. `hint` is an optional
180 value that can be used by `before_breadcrumb` to customize the
181 breadcrumbs that are emitted.
182 """
183 client, scope = self._stack[-1]
184 if client is None:
185 logger.info("Dropped breadcrumb because no client bound")
186 return
187
188 crumb = dict(crumb or ())
189 crumb.update(kwargs)
190 if not crumb:
191 return
192
193 hint = dict(hint or ())
194
195 if crumb.get("timestamp") is None:
196 crumb["timestamp"] = datetime.utcnow()
197 if crumb.get("type") is None:
198 crumb["type"] = "default"
199
200 original_crumb = crumb
201 if client.options["before_breadcrumb"] is not None:
202 crumb = client.options["before_breadcrumb"](crumb, hint)
203
204 if crumb is not None:
205 scope._breadcrumbs.append(crumb)
206 else:
207 logger.info("before breadcrumb dropped breadcrumb (%s)", original_crumb)
208 while len(scope._breadcrumbs) >= client.options["max_breadcrumbs"]:
209 scope._breadcrumbs.popleft()
210
211 def push_scope(self, callback=None):
212 """Pushes a new layer on the scope stack. Returns a context manager
213 that should be used to pop the scope again. Alternatively a callback
214 can be provided that is executed in the context of the scope.
215 """
216 client, scope = self._stack[-1]
217 new_layer = (client, copy.copy(scope))
218 self._stack.append(new_layer)
219
220 if callback is not None:
221 if client is not None:
222 callback(scope)
223 else:
224 return _ScopeManager(self, new_layer)
225
226 def pop_scope_unsafe(self):
227 """Pops a scope layer from the stack. Try to use the context manager
228 `push_scope()` instead."""
229 rv = self._stack.pop()
230 assert self._stack
231 return rv
232
233 def configure_scope(self, callback=None):
234 """Reconfigures the scope."""
235 client, scope = self._stack[-1]
236 if callback is not None:
237 if client is not None:
238 callback(scope)
239 return
240
241 @contextmanager
242 def inner():
243 if client is not None:
244 yield scope
245 else:
246 yield Scope()
247
248 return inner()
249
250 def scope(self, callback=None):
251 """Pushes a new scope and yields it for configuration.
252
253 The scope is dropped at the end of the with statement. Alternatively
254 a callback can be provided similar to `configure_scope`.
255 """
256 with self.push_scope():
257 client, scope = self._stack[-1]
258 return self.configure_scope(callback)
259
260
261 GLOBAL_HUB = Hub()
262
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/hub.py b/sentry_sdk/hub.py
--- a/sentry_sdk/hub.py
+++ b/sentry_sdk/hub.py
@@ -205,8 +205,8 @@
scope._breadcrumbs.append(crumb)
else:
logger.info("before breadcrumb dropped breadcrumb (%s)", original_crumb)
- while len(scope._breadcrumbs) >= client.options["max_breadcrumbs"]:
- scope._breadcrumbs.popleft()
+ while len(scope._breadcrumbs) > client.options["max_breadcrumbs"]:
+ scope._breadcrumbs.pop(0)
def push_scope(self, callback=None):
"""Pushes a new layer on the scope stack. Returns a context manager
|
{"golden_diff": "diff --git a/sentry_sdk/hub.py b/sentry_sdk/hub.py\n--- a/sentry_sdk/hub.py\n+++ b/sentry_sdk/hub.py\n@@ -205,8 +205,8 @@\n scope._breadcrumbs.append(crumb)\n else:\n logger.info(\"before breadcrumb dropped breadcrumb (%s)\", original_crumb)\n- while len(scope._breadcrumbs) >= client.options[\"max_breadcrumbs\"]:\n- scope._breadcrumbs.popleft()\n+ while len(scope._breadcrumbs) > client.options[\"max_breadcrumbs\"]:\n+ scope._breadcrumbs.pop(0)\n \n def push_scope(self, callback=None):\n \"\"\"Pushes a new layer on the scope stack. Returns a context manager\n", "issue": "Breadcrumbs type error\nWe're having an issue with v0.3.2 where `popleft` is called on a list type:\r\n\r\n```\r\nFile \"/srv/frontend/project/lib/python3.5/site-packages/sentry_sdk/hub.py\" in add_breadcrumb\r\n 209. scope._breadcrumbs.popleft()\r\n\r\nException Type: AttributeError at /\r\nException Value: 'list' object has no attribute 'popleft'\r\n```\n", "before_files": [{"content": "import sys\nimport copy\nfrom datetime import datetime\nfrom contextlib import contextmanager\n\nfrom sentry_sdk._compat import with_metaclass\nfrom sentry_sdk.scope import Scope\nfrom sentry_sdk.utils import (\n exc_info_from_error,\n event_from_exception,\n logger,\n ContextVar,\n)\n\n\n_local = ContextVar(\"sentry_current_hub\")\n\n\ndef _get_client_options():\n hub = Hub.current\n if hub and hub.client:\n return hub.client.options\n\n\ndef _should_send_default_pii():\n client = Hub.current.client\n if not client:\n return False\n return client.options[\"send_default_pii\"]\n\n\nclass HubMeta(type):\n @property\n def current(self):\n \"\"\"Returns the current instance of the hub.\"\"\"\n rv = _local.get(None)\n if rv is None:\n rv = Hub(GLOBAL_HUB)\n _local.set(rv)\n return rv\n\n @property\n def main(self):\n \"\"\"Returns the main instance of the hub.\"\"\"\n return GLOBAL_HUB\n\n\nclass _HubManager(object):\n def __init__(self, hub):\n self._old = Hub.current\n _local.set(hub)\n\n def __exit__(self, exc_type, exc_value, tb):\n _local.set(self._old)\n\n\nclass _ScopeManager(object):\n def __init__(self, hub, layer):\n self._hub = hub\n self._layer = layer\n\n def __enter__(self):\n scope = self._layer[1]\n if scope is None:\n scope = Scope()\n return scope\n\n def __exit__(self, exc_type, exc_value, tb):\n assert self._hub.pop_scope_unsafe() == self._layer, \"popped wrong scope\"\n\n\nclass Hub(with_metaclass(HubMeta)):\n \"\"\"The hub wraps the concurrency management of the SDK. Each thread has\n its own hub but the hub might transfer with the flow of execution if\n context vars are available.\n\n If the hub is used with a with statement it's temporarily activated.\n \"\"\"\n\n def __init__(self, client_or_hub=None, scope=None):\n if isinstance(client_or_hub, Hub):\n hub = client_or_hub\n client, other_scope = hub._stack[-1]\n if scope is None:\n scope = copy.copy(other_scope)\n else:\n client = client_or_hub\n if scope is None:\n scope = Scope()\n self._stack = [(client, scope)]\n self._last_event_id = None\n self._old_hubs = []\n\n def __enter__(self):\n self._old_hubs.append(Hub.current)\n _local.set(self)\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n old = self._old_hubs.pop()\n _local.set(old)\n\n def run(self, callback):\n \"\"\"Runs a callback in the context of the hub. Alternatively the\n with statement can be used on the hub directly.\n \"\"\"\n with self:\n return callback()\n\n @property\n def client(self):\n \"\"\"Returns the current client on the hub.\"\"\"\n return self._stack[-1][0]\n\n def last_event_id(self):\n \"\"\"Returns the last event ID.\"\"\"\n return self._last_event_id\n\n def bind_client(self, new):\n \"\"\"Binds a new client to the hub.\"\"\"\n top = self._stack[-1]\n self._stack[-1] = (new, top[1])\n\n def capture_event(self, event, hint=None):\n \"\"\"Captures an event. The return value is the ID of the event.\n\n The event is a dictionary following the Sentry v7/v8 protocol\n specification. Optionally an event hint dict can be passed that\n is used by processors to extract additional information from it.\n Typically the event hint object would contain exception information.\n \"\"\"\n client, scope = self._stack[-1]\n if client is not None:\n rv = client.capture_event(event, hint, scope)\n if rv is not None:\n self._last_event_id = rv\n return rv\n\n def capture_message(self, message, level=None):\n \"\"\"Captures a message. The message is just a string. If no level\n is provided the default level is `info`.\n \"\"\"\n if self.client is None:\n return\n if level is None:\n level = \"info\"\n return self.capture_event({\"message\": message, \"level\": level})\n\n def capture_exception(self, error=None):\n \"\"\"Captures an exception.\n\n The argument passed can be `None` in which case the last exception\n will be reported, otherwise an exception object or an `exc_info`\n tuple.\n \"\"\"\n client = self.client\n if client is None:\n return\n if error is None:\n exc_info = sys.exc_info()\n else:\n exc_info = exc_info_from_error(error)\n\n event, hint = event_from_exception(\n exc_info, with_locals=client.options[\"with_locals\"]\n )\n try:\n return self.capture_event(event, hint=hint)\n except Exception:\n self._capture_internal_exception(sys.exc_info())\n\n def _capture_internal_exception(self, exc_info):\n \"\"\"Capture an exception that is likely caused by a bug in the SDK\n itself.\"\"\"\n logger.debug(\"Internal error in sentry_sdk\", exc_info=exc_info)\n\n def add_breadcrumb(self, crumb=None, hint=None, **kwargs):\n \"\"\"Adds a breadcrumb. The breadcrumbs are a dictionary with the\n data as the sentry v7/v8 protocol expects. `hint` is an optional\n value that can be used by `before_breadcrumb` to customize the\n breadcrumbs that are emitted.\n \"\"\"\n client, scope = self._stack[-1]\n if client is None:\n logger.info(\"Dropped breadcrumb because no client bound\")\n return\n\n crumb = dict(crumb or ())\n crumb.update(kwargs)\n if not crumb:\n return\n\n hint = dict(hint or ())\n\n if crumb.get(\"timestamp\") is None:\n crumb[\"timestamp\"] = datetime.utcnow()\n if crumb.get(\"type\") is None:\n crumb[\"type\"] = \"default\"\n\n original_crumb = crumb\n if client.options[\"before_breadcrumb\"] is not None:\n crumb = client.options[\"before_breadcrumb\"](crumb, hint)\n\n if crumb is not None:\n scope._breadcrumbs.append(crumb)\n else:\n logger.info(\"before breadcrumb dropped breadcrumb (%s)\", original_crumb)\n while len(scope._breadcrumbs) >= client.options[\"max_breadcrumbs\"]:\n scope._breadcrumbs.popleft()\n\n def push_scope(self, callback=None):\n \"\"\"Pushes a new layer on the scope stack. Returns a context manager\n that should be used to pop the scope again. Alternatively a callback\n can be provided that is executed in the context of the scope.\n \"\"\"\n client, scope = self._stack[-1]\n new_layer = (client, copy.copy(scope))\n self._stack.append(new_layer)\n\n if callback is not None:\n if client is not None:\n callback(scope)\n else:\n return _ScopeManager(self, new_layer)\n\n def pop_scope_unsafe(self):\n \"\"\"Pops a scope layer from the stack. Try to use the context manager\n `push_scope()` instead.\"\"\"\n rv = self._stack.pop()\n assert self._stack\n return rv\n\n def configure_scope(self, callback=None):\n \"\"\"Reconfigures the scope.\"\"\"\n client, scope = self._stack[-1]\n if callback is not None:\n if client is not None:\n callback(scope)\n return\n\n @contextmanager\n def inner():\n if client is not None:\n yield scope\n else:\n yield Scope()\n\n return inner()\n\n def scope(self, callback=None):\n \"\"\"Pushes a new scope and yields it for configuration.\n\n The scope is dropped at the end of the with statement. Alternatively\n a callback can be provided similar to `configure_scope`.\n \"\"\"\n with self.push_scope():\n client, scope = self._stack[-1]\n return self.configure_scope(callback)\n\n\nGLOBAL_HUB = Hub()\n", "path": "sentry_sdk/hub.py"}], "after_files": [{"content": "import sys\nimport copy\nfrom datetime import datetime\nfrom contextlib import contextmanager\n\nfrom sentry_sdk._compat import with_metaclass\nfrom sentry_sdk.scope import Scope\nfrom sentry_sdk.utils import (\n exc_info_from_error,\n event_from_exception,\n logger,\n ContextVar,\n)\n\n\n_local = ContextVar(\"sentry_current_hub\")\n\n\ndef _get_client_options():\n hub = Hub.current\n if hub and hub.client:\n return hub.client.options\n\n\ndef _should_send_default_pii():\n client = Hub.current.client\n if not client:\n return False\n return client.options[\"send_default_pii\"]\n\n\nclass HubMeta(type):\n @property\n def current(self):\n \"\"\"Returns the current instance of the hub.\"\"\"\n rv = _local.get(None)\n if rv is None:\n rv = Hub(GLOBAL_HUB)\n _local.set(rv)\n return rv\n\n @property\n def main(self):\n \"\"\"Returns the main instance of the hub.\"\"\"\n return GLOBAL_HUB\n\n\nclass _HubManager(object):\n def __init__(self, hub):\n self._old = Hub.current\n _local.set(hub)\n\n def __exit__(self, exc_type, exc_value, tb):\n _local.set(self._old)\n\n\nclass _ScopeManager(object):\n def __init__(self, hub, layer):\n self._hub = hub\n self._layer = layer\n\n def __enter__(self):\n scope = self._layer[1]\n if scope is None:\n scope = Scope()\n return scope\n\n def __exit__(self, exc_type, exc_value, tb):\n assert self._hub.pop_scope_unsafe() == self._layer, \"popped wrong scope\"\n\n\nclass Hub(with_metaclass(HubMeta)):\n \"\"\"The hub wraps the concurrency management of the SDK. Each thread has\n its own hub but the hub might transfer with the flow of execution if\n context vars are available.\n\n If the hub is used with a with statement it's temporarily activated.\n \"\"\"\n\n def __init__(self, client_or_hub=None, scope=None):\n if isinstance(client_or_hub, Hub):\n hub = client_or_hub\n client, other_scope = hub._stack[-1]\n if scope is None:\n scope = copy.copy(other_scope)\n else:\n client = client_or_hub\n if scope is None:\n scope = Scope()\n self._stack = [(client, scope)]\n self._last_event_id = None\n self._old_hubs = []\n\n def __enter__(self):\n self._old_hubs.append(Hub.current)\n _local.set(self)\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n old = self._old_hubs.pop()\n _local.set(old)\n\n def run(self, callback):\n \"\"\"Runs a callback in the context of the hub. Alternatively the\n with statement can be used on the hub directly.\n \"\"\"\n with self:\n return callback()\n\n @property\n def client(self):\n \"\"\"Returns the current client on the hub.\"\"\"\n return self._stack[-1][0]\n\n def last_event_id(self):\n \"\"\"Returns the last event ID.\"\"\"\n return self._last_event_id\n\n def bind_client(self, new):\n \"\"\"Binds a new client to the hub.\"\"\"\n top = self._stack[-1]\n self._stack[-1] = (new, top[1])\n\n def capture_event(self, event, hint=None):\n \"\"\"Captures an event. The return value is the ID of the event.\n\n The event is a dictionary following the Sentry v7/v8 protocol\n specification. Optionally an event hint dict can be passed that\n is used by processors to extract additional information from it.\n Typically the event hint object would contain exception information.\n \"\"\"\n client, scope = self._stack[-1]\n if client is not None:\n rv = client.capture_event(event, hint, scope)\n if rv is not None:\n self._last_event_id = rv\n return rv\n\n def capture_message(self, message, level=None):\n \"\"\"Captures a message. The message is just a string. If no level\n is provided the default level is `info`.\n \"\"\"\n if self.client is None:\n return\n if level is None:\n level = \"info\"\n return self.capture_event({\"message\": message, \"level\": level})\n\n def capture_exception(self, error=None):\n \"\"\"Captures an exception.\n\n The argument passed can be `None` in which case the last exception\n will be reported, otherwise an exception object or an `exc_info`\n tuple.\n \"\"\"\n client = self.client\n if client is None:\n return\n if error is None:\n exc_info = sys.exc_info()\n else:\n exc_info = exc_info_from_error(error)\n\n event, hint = event_from_exception(\n exc_info, with_locals=client.options[\"with_locals\"]\n )\n try:\n return self.capture_event(event, hint=hint)\n except Exception:\n self._capture_internal_exception(sys.exc_info())\n\n def _capture_internal_exception(self, exc_info):\n \"\"\"Capture an exception that is likely caused by a bug in the SDK\n itself.\"\"\"\n logger.debug(\"Internal error in sentry_sdk\", exc_info=exc_info)\n\n def add_breadcrumb(self, crumb=None, hint=None, **kwargs):\n \"\"\"Adds a breadcrumb. The breadcrumbs are a dictionary with the\n data as the sentry v7/v8 protocol expects. `hint` is an optional\n value that can be used by `before_breadcrumb` to customize the\n breadcrumbs that are emitted.\n \"\"\"\n client, scope = self._stack[-1]\n if client is None:\n logger.info(\"Dropped breadcrumb because no client bound\")\n return\n\n crumb = dict(crumb or ())\n crumb.update(kwargs)\n if not crumb:\n return\n\n hint = dict(hint or ())\n\n if crumb.get(\"timestamp\") is None:\n crumb[\"timestamp\"] = datetime.utcnow()\n if crumb.get(\"type\") is None:\n crumb[\"type\"] = \"default\"\n\n original_crumb = crumb\n if client.options[\"before_breadcrumb\"] is not None:\n crumb = client.options[\"before_breadcrumb\"](crumb, hint)\n\n if crumb is not None:\n scope._breadcrumbs.append(crumb)\n else:\n logger.info(\"before breadcrumb dropped breadcrumb (%s)\", original_crumb)\n while len(scope._breadcrumbs) > client.options[\"max_breadcrumbs\"]:\n scope._breadcrumbs.pop(0)\n\n def push_scope(self, callback=None):\n \"\"\"Pushes a new layer on the scope stack. Returns a context manager\n that should be used to pop the scope again. Alternatively a callback\n can be provided that is executed in the context of the scope.\n \"\"\"\n client, scope = self._stack[-1]\n new_layer = (client, copy.copy(scope))\n self._stack.append(new_layer)\n\n if callback is not None:\n if client is not None:\n callback(scope)\n else:\n return _ScopeManager(self, new_layer)\n\n def pop_scope_unsafe(self):\n \"\"\"Pops a scope layer from the stack. Try to use the context manager\n `push_scope()` instead.\"\"\"\n rv = self._stack.pop()\n assert self._stack\n return rv\n\n def configure_scope(self, callback=None):\n \"\"\"Reconfigures the scope.\"\"\"\n client, scope = self._stack[-1]\n if callback is not None:\n if client is not None:\n callback(scope)\n return\n\n @contextmanager\n def inner():\n if client is not None:\n yield scope\n else:\n yield Scope()\n\n return inner()\n\n def scope(self, callback=None):\n \"\"\"Pushes a new scope and yields it for configuration.\n\n The scope is dropped at the end of the with statement. Alternatively\n a callback can be provided similar to `configure_scope`.\n \"\"\"\n with self.push_scope():\n client, scope = self._stack[-1]\n return self.configure_scope(callback)\n\n\nGLOBAL_HUB = Hub()\n", "path": "sentry_sdk/hub.py"}]}
| 2,826 | 152 |
gh_patches_debug_28595
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-1900
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Offline events an more info of private projects visible even if not logged in
If I type in/ link to the URL of an offline event, I can see the event’s content and the info tab’s content of a private project.
For example, if you take this URL:
https://opin-stage.liqd.net/de/offlineevents/53/
you can access the information even if you are not logged in with an account.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/offlinephases/rules.py`
Content:
```
1 import rules
2 from rules.predicates import is_superuser
3
4 from .predicates import is_offlinephase_moderator
5
6 rules.add_perm(
7 'euth_offlinephases.modify_offlinephase',
8 is_offlinephase_moderator | is_superuser)
9
```
Path: `euth/offlinephases/views.py`
Content:
```
1 from django.contrib import messages
2 from django.db import transaction
3 from django.shortcuts import redirect, render
4 from django.urls import reverse
5 from django.utils.translation import ugettext_lazy as _
6 from django.views import generic
7
8 from adhocracy4.dashboard import mixins
9 from adhocracy4.projects.mixins import ProjectMixin
10
11 from . import forms, models
12 from .mixins import OfflineEventFormMixin
13
14
15 class OfflineEventDetailView(
16 generic.DetailView
17 ):
18 model = models.OfflineEvent
19
20 @property
21 def project(self):
22 return self.object.project
23
24
25 class OfflineEventListView(ProjectMixin,
26 mixins.DashboardBaseMixin,
27 mixins.DashboardComponentMixin,
28 generic.ListView):
29
30 model = models.OfflineEvent
31 template_name = 'euth_offlinephases/offlineevent_list.html'
32 permission_required = 'a4projects.change_project'
33
34 def get_queryset(self):
35 return super().get_queryset().filter(project=self.project)
36
37 def get_permission_object(self):
38 return self.project
39
40
41 class OfflineEventCreateView(
42 ProjectMixin,
43 mixins.DashboardBaseMixin,
44 mixins.DashboardComponentMixin,
45 generic.TemplateView,
46 OfflineEventFormMixin
47 ):
48 template_name = 'euth_offlinephases/offlineevent_form.html'
49 permission_required = 'a4projects.change_project'
50 project_url_kwarg = 'project_slug'
51
52 def get_permission_object(self):
53 return self.project
54
55 def get_success_url(self):
56 return reverse(
57 'a4dashboard:offlineevent-list',
58 kwargs={'project_slug': self.project.slug})
59
60 def get_context_data(self, form=None, upload_forms=None, **kwargs):
61 context = super().get_context_data(**kwargs)
62 if not form:
63 form = forms.OfflineEventForm()
64 if not upload_forms:
65 upload_forms = self.empty_upload_formset()
66 context['form'] = form
67 context['upload_forms'] = upload_forms
68 return context
69
70 def _process_formdata(self, form, upload_forms):
71 form.instance.project = self.project
72 with transaction.atomic():
73 object = form.save()
74 intstances = upload_forms.save(commit=False)
75 for instance in intstances:
76 instance.offlineevent = object
77 instance.save()
78
79 def post(self, request, *args, **kwargs):
80 form = forms.OfflineEventForm(request.POST)
81 upload_forms = self.filled_upload_formset(request)
82 if form.is_valid() and upload_forms.is_valid():
83 self._process_formdata(form, upload_forms)
84 messages.add_message(request,
85 messages.SUCCESS,
86 _('Offline events '
87 'have been updated'))
88 response = redirect(self.get_success_url())
89 else:
90 response = render(request,
91 self.template_name,
92 self.get_context_data(form=form,
93 upload_forms=upload_forms))
94 return response
95
96
97 class OfflineEventUpdateView(ProjectMixin,
98 mixins.DashboardBaseMixin,
99 mixins.DashboardComponentMixin,
100 generic.detail.SingleObjectMixin,
101 generic.TemplateView,
102 OfflineEventFormMixin):
103
104 model = models.OfflineEvent
105 permission_required = 'a4projects.change_project'
106 template_name = 'euth_offlinephases/offlineevent_form.html'
107 get_context_from_object = True
108
109 def dispatch(self, *args, **kwargs):
110 self.object = self.get_object()
111 return super().dispatch(*args, **kwargs)
112
113 def get_context_data(self, form=None, upload_forms=None, **kwargs):
114 context = super().get_context_data(**kwargs)
115 if not form:
116 form = forms.OfflineEventForm(instance=self.get_object())
117 if not upload_forms:
118 queryset = \
119 models.OfflineEventFileUpload\
120 .objects.filter(offlineevent=self.get_object())
121 upload_forms = self.update_upload_formset(queryset)
122 context['form'] = form
123 context['upload_forms'] = upload_forms
124 return context
125
126 def get_success_url(self):
127 return reverse(
128 'a4dashboard:offlineevent-list',
129 kwargs={'project_slug': self.project.slug})
130
131 def get_permission_object(self):
132 return self.project
133
134 def _process_formdata(self, form, upload_forms):
135 with transaction.atomic():
136 form.save()
137 intstances = upload_forms.save(commit=False)
138 for obj in upload_forms.deleted_objects:
139 obj.delete()
140 for instance in intstances:
141 instance.offlineevent = self.object
142 instance.save()
143
144 def post(self, request, *args, **kwargs):
145 upload_forms = self.filled_upload_formset(request)
146 form = forms.OfflineEventForm(request.POST, instance=self.object)
147 if upload_forms.is_valid() and form.is_valid():
148 self._process_formdata(form, upload_forms)
149 messages.add_message(request,
150 messages.SUCCESS,
151 _('Offline events '
152 'have been updated'))
153 response = redirect(self.get_success_url())
154 else:
155 response = render(request,
156 self.template_name,
157 self.get_context_data(
158 form=form, upload_forms=upload_forms))
159 return response
160
161
162 class OfflineEventDeleteView(ProjectMixin,
163 mixins.DashboardBaseMixin,
164 mixins.DashboardComponentMixin,
165 mixins.DashboardComponentDeleteSignalMixin,
166 generic.DeleteView):
167 model = models.OfflineEvent
168 success_message = _('The offline event has been deleted')
169 permission_required = ''
170 template_name = 'euth_offlinephases/offlineevent_confirm_delete.html'
171 get_context_from_object = True
172
173 def delete(self, request, *args, **kwargs):
174 messages.success(self.request, self.success_message)
175 return super().delete(request, *args, **kwargs)
176
177 def get_success_url(self):
178 return reverse(
179 'a4dashboard:offlineevent-list',
180 kwargs={'project_slug': self.project.slug})
181
182 @property
183 def organisation(self):
184 return self.project.organisation
185
186 def get_permission_object(self):
187 return self.project
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/offlinephases/rules.py b/euth/offlinephases/rules.py
--- a/euth/offlinephases/rules.py
+++ b/euth/offlinephases/rules.py
@@ -1,8 +1,17 @@
import rules
from rules.predicates import is_superuser
+from adhocracy4.modules.predicates import (is_context_initiator,
+ is_context_member,
+ is_context_moderator,
+ is_public_context)
+
from .predicates import is_offlinephase_moderator
rules.add_perm(
'euth_offlinephases.modify_offlinephase',
is_offlinephase_moderator | is_superuser)
+
+rules.add_perm('euth_offlinephases.view_offlineevent',
+ is_superuser | is_context_moderator | is_context_initiator |
+ is_context_member | is_public_context)
diff --git a/euth/offlinephases/views.py b/euth/offlinephases/views.py
--- a/euth/offlinephases/views.py
+++ b/euth/offlinephases/views.py
@@ -4,6 +4,7 @@
from django.urls import reverse
from django.utils.translation import ugettext_lazy as _
from django.views import generic
+from rules.contrib.views import PermissionRequiredMixin
from adhocracy4.dashboard import mixins
from adhocracy4.projects.mixins import ProjectMixin
@@ -12,10 +13,10 @@
from .mixins import OfflineEventFormMixin
-class OfflineEventDetailView(
- generic.DetailView
-):
+class OfflineEventDetailView(PermissionRequiredMixin,
+ generic.DetailView):
model = models.OfflineEvent
+ permission_required = 'euth_offlinephases.view_offlineevent'
@property
def project(self):
|
{"golden_diff": "diff --git a/euth/offlinephases/rules.py b/euth/offlinephases/rules.py\n--- a/euth/offlinephases/rules.py\n+++ b/euth/offlinephases/rules.py\n@@ -1,8 +1,17 @@\n import rules\n from rules.predicates import is_superuser\n \n+from adhocracy4.modules.predicates import (is_context_initiator,\n+ is_context_member,\n+ is_context_moderator,\n+ is_public_context)\n+\n from .predicates import is_offlinephase_moderator\n \n rules.add_perm(\n 'euth_offlinephases.modify_offlinephase',\n is_offlinephase_moderator | is_superuser)\n+\n+rules.add_perm('euth_offlinephases.view_offlineevent',\n+ is_superuser | is_context_moderator | is_context_initiator |\n+ is_context_member | is_public_context)\ndiff --git a/euth/offlinephases/views.py b/euth/offlinephases/views.py\n--- a/euth/offlinephases/views.py\n+++ b/euth/offlinephases/views.py\n@@ -4,6 +4,7 @@\n from django.urls import reverse\n from django.utils.translation import ugettext_lazy as _\n from django.views import generic\n+from rules.contrib.views import PermissionRequiredMixin\n \n from adhocracy4.dashboard import mixins\n from adhocracy4.projects.mixins import ProjectMixin\n@@ -12,10 +13,10 @@\n from .mixins import OfflineEventFormMixin\n \n \n-class OfflineEventDetailView(\n- generic.DetailView\n-):\n+class OfflineEventDetailView(PermissionRequiredMixin,\n+ generic.DetailView):\n model = models.OfflineEvent\n+ permission_required = 'euth_offlinephases.view_offlineevent'\n \n @property\n def project(self):\n", "issue": "Offline events an more info of private projects visible even if not logged in\nIf I type in/ link to the URL of an offline event, I can see the event\u2019s content and the info tab\u2019s content of a private project.\r\n\r\nFor example, if you take this URL:\r\nhttps://opin-stage.liqd.net/de/offlineevents/53/\r\n\r\nyou can access the information even if you are not logged in with an account.\n", "before_files": [{"content": "import rules\nfrom rules.predicates import is_superuser\n\nfrom .predicates import is_offlinephase_moderator\n\nrules.add_perm(\n 'euth_offlinephases.modify_offlinephase',\n is_offlinephase_moderator | is_superuser)\n", "path": "euth/offlinephases/rules.py"}, {"content": "from django.contrib import messages\nfrom django.db import transaction\nfrom django.shortcuts import redirect, render\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins\nfrom adhocracy4.projects.mixins import ProjectMixin\n\nfrom . import forms, models\nfrom .mixins import OfflineEventFormMixin\n\n\nclass OfflineEventDetailView(\n generic.DetailView\n):\n model = models.OfflineEvent\n\n @property\n def project(self):\n return self.object.project\n\n\nclass OfflineEventListView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.ListView):\n\n model = models.OfflineEvent\n template_name = 'euth_offlinephases/offlineevent_list.html'\n permission_required = 'a4projects.change_project'\n\n def get_queryset(self):\n return super().get_queryset().filter(project=self.project)\n\n def get_permission_object(self):\n return self.project\n\n\nclass OfflineEventCreateView(\n ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.TemplateView,\n OfflineEventFormMixin\n):\n template_name = 'euth_offlinephases/offlineevent_form.html'\n permission_required = 'a4projects.change_project'\n project_url_kwarg = 'project_slug'\n\n def get_permission_object(self):\n return self.project\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n def get_context_data(self, form=None, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n if not form:\n form = forms.OfflineEventForm()\n if not upload_forms:\n upload_forms = self.empty_upload_formset()\n context['form'] = form\n context['upload_forms'] = upload_forms\n return context\n\n def _process_formdata(self, form, upload_forms):\n form.instance.project = self.project\n with transaction.atomic():\n object = form.save()\n intstances = upload_forms.save(commit=False)\n for instance in intstances:\n instance.offlineevent = object\n instance.save()\n\n def post(self, request, *args, **kwargs):\n form = forms.OfflineEventForm(request.POST)\n upload_forms = self.filled_upload_formset(request)\n if form.is_valid() and upload_forms.is_valid():\n self._process_formdata(form, upload_forms)\n messages.add_message(request,\n messages.SUCCESS,\n _('Offline events '\n 'have been updated'))\n response = redirect(self.get_success_url())\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(form=form,\n upload_forms=upload_forms))\n return response\n\n\nclass OfflineEventUpdateView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.detail.SingleObjectMixin,\n generic.TemplateView,\n OfflineEventFormMixin):\n\n model = models.OfflineEvent\n permission_required = 'a4projects.change_project'\n template_name = 'euth_offlinephases/offlineevent_form.html'\n get_context_from_object = True\n\n def dispatch(self, *args, **kwargs):\n self.object = self.get_object()\n return super().dispatch(*args, **kwargs)\n\n def get_context_data(self, form=None, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n if not form:\n form = forms.OfflineEventForm(instance=self.get_object())\n if not upload_forms:\n queryset = \\\n models.OfflineEventFileUpload\\\n .objects.filter(offlineevent=self.get_object())\n upload_forms = self.update_upload_formset(queryset)\n context['form'] = form\n context['upload_forms'] = upload_forms\n return context\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n def get_permission_object(self):\n return self.project\n\n def _process_formdata(self, form, upload_forms):\n with transaction.atomic():\n form.save()\n intstances = upload_forms.save(commit=False)\n for obj in upload_forms.deleted_objects:\n obj.delete()\n for instance in intstances:\n instance.offlineevent = self.object\n instance.save()\n\n def post(self, request, *args, **kwargs):\n upload_forms = self.filled_upload_formset(request)\n form = forms.OfflineEventForm(request.POST, instance=self.object)\n if upload_forms.is_valid() and form.is_valid():\n self._process_formdata(form, upload_forms)\n messages.add_message(request,\n messages.SUCCESS,\n _('Offline events '\n 'have been updated'))\n response = redirect(self.get_success_url())\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(\n form=form, upload_forms=upload_forms))\n return response\n\n\nclass OfflineEventDeleteView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n mixins.DashboardComponentDeleteSignalMixin,\n generic.DeleteView):\n model = models.OfflineEvent\n success_message = _('The offline event has been deleted')\n permission_required = ''\n template_name = 'euth_offlinephases/offlineevent_confirm_delete.html'\n get_context_from_object = True\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super().delete(request, *args, **kwargs)\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n @property\n def organisation(self):\n return self.project.organisation\n\n def get_permission_object(self):\n return self.project\n", "path": "euth/offlinephases/views.py"}], "after_files": [{"content": "import rules\nfrom rules.predicates import is_superuser\n\nfrom adhocracy4.modules.predicates import (is_context_initiator,\n is_context_member,\n is_context_moderator,\n is_public_context)\n\nfrom .predicates import is_offlinephase_moderator\n\nrules.add_perm(\n 'euth_offlinephases.modify_offlinephase',\n is_offlinephase_moderator | is_superuser)\n\nrules.add_perm('euth_offlinephases.view_offlineevent',\n is_superuser | is_context_moderator | is_context_initiator |\n is_context_member | is_public_context)\n", "path": "euth/offlinephases/rules.py"}, {"content": "from django.contrib import messages\nfrom django.db import transaction\nfrom django.shortcuts import redirect, render\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\nfrom rules.contrib.views import PermissionRequiredMixin\n\nfrom adhocracy4.dashboard import mixins\nfrom adhocracy4.projects.mixins import ProjectMixin\n\nfrom . import forms, models\nfrom .mixins import OfflineEventFormMixin\n\n\nclass OfflineEventDetailView(PermissionRequiredMixin,\n generic.DetailView):\n model = models.OfflineEvent\n permission_required = 'euth_offlinephases.view_offlineevent'\n\n @property\n def project(self):\n return self.object.project\n\n\nclass OfflineEventListView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.ListView):\n\n model = models.OfflineEvent\n template_name = 'euth_offlinephases/offlineevent_list.html'\n permission_required = 'a4projects.change_project'\n\n def get_queryset(self):\n return super().get_queryset().filter(project=self.project)\n\n def get_permission_object(self):\n return self.project\n\n\nclass OfflineEventCreateView(\n ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.TemplateView,\n OfflineEventFormMixin\n):\n template_name = 'euth_offlinephases/offlineevent_form.html'\n permission_required = 'a4projects.change_project'\n project_url_kwarg = 'project_slug'\n\n def get_permission_object(self):\n return self.project\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n def get_context_data(self, form=None, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n if not form:\n form = forms.OfflineEventForm()\n if not upload_forms:\n upload_forms = self.empty_upload_formset()\n context['form'] = form\n context['upload_forms'] = upload_forms\n return context\n\n def _process_formdata(self, form, upload_forms):\n form.instance.project = self.project\n with transaction.atomic():\n object = form.save()\n intstances = upload_forms.save(commit=False)\n for instance in intstances:\n instance.offlineevent = object\n instance.save()\n\n def post(self, request, *args, **kwargs):\n form = forms.OfflineEventForm(request.POST)\n upload_forms = self.filled_upload_formset(request)\n if form.is_valid() and upload_forms.is_valid():\n self._process_formdata(form, upload_forms)\n messages.add_message(request,\n messages.SUCCESS,\n _('Offline events '\n 'have been updated'))\n response = redirect(self.get_success_url())\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(form=form,\n upload_forms=upload_forms))\n return response\n\n\nclass OfflineEventUpdateView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n generic.detail.SingleObjectMixin,\n generic.TemplateView,\n OfflineEventFormMixin):\n\n model = models.OfflineEvent\n permission_required = 'a4projects.change_project'\n template_name = 'euth_offlinephases/offlineevent_form.html'\n get_context_from_object = True\n\n def dispatch(self, *args, **kwargs):\n self.object = self.get_object()\n return super().dispatch(*args, **kwargs)\n\n def get_context_data(self, form=None, upload_forms=None, **kwargs):\n context = super().get_context_data(**kwargs)\n if not form:\n form = forms.OfflineEventForm(instance=self.get_object())\n if not upload_forms:\n queryset = \\\n models.OfflineEventFileUpload\\\n .objects.filter(offlineevent=self.get_object())\n upload_forms = self.update_upload_formset(queryset)\n context['form'] = form\n context['upload_forms'] = upload_forms\n return context\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n def get_permission_object(self):\n return self.project\n\n def _process_formdata(self, form, upload_forms):\n with transaction.atomic():\n form.save()\n intstances = upload_forms.save(commit=False)\n for obj in upload_forms.deleted_objects:\n obj.delete()\n for instance in intstances:\n instance.offlineevent = self.object\n instance.save()\n\n def post(self, request, *args, **kwargs):\n upload_forms = self.filled_upload_formset(request)\n form = forms.OfflineEventForm(request.POST, instance=self.object)\n if upload_forms.is_valid() and form.is_valid():\n self._process_formdata(form, upload_forms)\n messages.add_message(request,\n messages.SUCCESS,\n _('Offline events '\n 'have been updated'))\n response = redirect(self.get_success_url())\n else:\n response = render(request,\n self.template_name,\n self.get_context_data(\n form=form, upload_forms=upload_forms))\n return response\n\n\nclass OfflineEventDeleteView(ProjectMixin,\n mixins.DashboardBaseMixin,\n mixins.DashboardComponentMixin,\n mixins.DashboardComponentDeleteSignalMixin,\n generic.DeleteView):\n model = models.OfflineEvent\n success_message = _('The offline event has been deleted')\n permission_required = ''\n template_name = 'euth_offlinephases/offlineevent_confirm_delete.html'\n get_context_from_object = True\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super().delete(request, *args, **kwargs)\n\n def get_success_url(self):\n return reverse(\n 'a4dashboard:offlineevent-list',\n kwargs={'project_slug': self.project.slug})\n\n @property\n def organisation(self):\n return self.project.organisation\n\n def get_permission_object(self):\n return self.project\n", "path": "euth/offlinephases/views.py"}]}
| 2,146 | 382 |
gh_patches_debug_23963
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-3182
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve visualization tutorial
<!-- Please write a clear and concise description of what content in https://optuna.readthedocs.io/ is an issue. -->
I suggest updating the [visualization tutorial](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/005_visualization.html) as follows
- Add missing [`visualization.plot_pareto_front`](https://optuna.readthedocs.io/en/stable/reference/visualization/generated/optuna.visualization.plot_pareto_front.html#optuna.visualization.plot_pareto_front) example; since this function needs multi-objective function unlike other visualization examples, we might need to define such an objective function after the other examples. If adding such an example is not appropriate, at least we need to mention the existence of `visualization.plot_pareto_front`.
- Mention the availability of matplotlib version in the first paragraph.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tutorial/10_key_features/005_visualization.py`
Content:
```
1 """
2 .. _visualization:
3
4 Quick Visualization for Hyperparameter Optimization Analysis
5 ============================================================
6
7 Optuna provides various visualization features in :mod:`optuna.visualization` to analyze optimization results visually.
8
9 This tutorial walks you through this module by visualizing the history of lightgbm model for breast cancer dataset.
10 """
11
12 ###################################################################################################
13 import lightgbm as lgb
14 import numpy as np
15 import sklearn.datasets
16 import sklearn.metrics
17 from sklearn.model_selection import train_test_split
18
19 import optuna
20 from optuna.visualization import plot_contour
21 from optuna.visualization import plot_edf
22 from optuna.visualization import plot_intermediate_values
23 from optuna.visualization import plot_optimization_history
24 from optuna.visualization import plot_parallel_coordinate
25 from optuna.visualization import plot_param_importances
26 from optuna.visualization import plot_slice
27
28 SEED = 42
29
30 np.random.seed(SEED)
31
32
33 ###################################################################################################
34 # Define the objective function.
35 def objective(trial):
36 data, target = sklearn.datasets.load_breast_cancer(return_X_y=True)
37 train_x, valid_x, train_y, valid_y = train_test_split(data, target, test_size=0.25)
38 dtrain = lgb.Dataset(train_x, label=train_y)
39 dvalid = lgb.Dataset(valid_x, label=valid_y)
40
41 param = {
42 "objective": "binary",
43 "metric": "auc",
44 "verbosity": -1,
45 "boosting_type": "gbdt",
46 "bagging_fraction": trial.suggest_float("bagging_fraction", 0.4, 1.0),
47 "bagging_freq": trial.suggest_int("bagging_freq", 1, 7),
48 "min_child_samples": trial.suggest_int("min_child_samples", 5, 100),
49 }
50
51 # Add a callback for pruning.
52 pruning_callback = optuna.integration.LightGBMPruningCallback(trial, "auc")
53 gbm = lgb.train(
54 param, dtrain, valid_sets=[dvalid], verbose_eval=False, callbacks=[pruning_callback]
55 )
56
57 preds = gbm.predict(valid_x)
58 pred_labels = np.rint(preds)
59 accuracy = sklearn.metrics.accuracy_score(valid_y, pred_labels)
60 return accuracy
61
62
63 ###################################################################################################
64 study = optuna.create_study(
65 direction="maximize",
66 sampler=optuna.samplers.TPESampler(seed=SEED),
67 pruner=optuna.pruners.MedianPruner(n_warmup_steps=10),
68 )
69 study.optimize(objective, n_trials=100, timeout=600)
70
71 ###################################################################################################
72 # Plot functions
73 # --------------
74 # Visualize the optimization history. See :func:`~optuna.visualization.plot_optimization_history` for the details.
75 plot_optimization_history(study)
76
77 ###################################################################################################
78 # Visualize the learning curves of the trials. See :func:`~optuna.visualization.plot_intermediate_values` for the details.
79 plot_intermediate_values(study)
80
81 ###################################################################################################
82 # Visualize high-dimensional parameter relationships. See :func:`~optuna.visualization.plot_parallel_coordinate` for the details.
83 plot_parallel_coordinate(study)
84
85 ###################################################################################################
86 # Select parameters to visualize.
87 plot_parallel_coordinate(study, params=["bagging_freq", "bagging_fraction"])
88
89 ###################################################################################################
90 # Visualize hyperparameter relationships. See :func:`~optuna.visualization.plot_contour` for the details.
91 plot_contour(study)
92
93 ###################################################################################################
94 # Select parameters to visualize.
95 plot_contour(study, params=["bagging_freq", "bagging_fraction"])
96
97 ###################################################################################################
98 # Visualize individual hyperparameters as slice plot. See :func:`~optuna.visualization.plot_slice` for the details.
99 plot_slice(study)
100
101 ###################################################################################################
102 # Select parameters to visualize.
103 plot_slice(study, params=["bagging_freq", "bagging_fraction"])
104
105 ###################################################################################################
106 # Visualize parameter importances. See :func:`~optuna.visualization.plot_param_importances` for the details.
107 plot_param_importances(study)
108
109 ###################################################################################################
110 # Learn which hyperparameters are affecting the trial duration with hyperparameter importance.
111 optuna.visualization.plot_param_importances(
112 study, target=lambda t: t.duration.total_seconds(), target_name="duration"
113 )
114
115 ###################################################################################################
116 # Visualize empirical distribution function. See :func:`~optuna.visualization.plot_edf` for the details.
117 plot_edf(study)
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tutorial/10_key_features/005_visualization.py b/tutorial/10_key_features/005_visualization.py
--- a/tutorial/10_key_features/005_visualization.py
+++ b/tutorial/10_key_features/005_visualization.py
@@ -7,6 +7,9 @@
Optuna provides various visualization features in :mod:`optuna.visualization` to analyze optimization results visually.
This tutorial walks you through this module by visualizing the history of lightgbm model for breast cancer dataset.
+
+For visualizing multi-objective optimization (i.e., the usage of :func:`optuna.visualization.plot_pareto_front`),
+please refer to the tutorial of :ref:`multi_objective`.
"""
###################################################################################################
@@ -17,6 +20,9 @@
from sklearn.model_selection import train_test_split
import optuna
+
+# You can use Matplotlib instead of Plotly for visualization by simply replacing `optuna.visualization` with
+# `optuna.visualization.matplotlib` in the following examples.
from optuna.visualization import plot_contour
from optuna.visualization import plot_edf
from optuna.visualization import plot_intermediate_values
|
{"golden_diff": "diff --git a/tutorial/10_key_features/005_visualization.py b/tutorial/10_key_features/005_visualization.py\n--- a/tutorial/10_key_features/005_visualization.py\n+++ b/tutorial/10_key_features/005_visualization.py\n@@ -7,6 +7,9 @@\n Optuna provides various visualization features in :mod:`optuna.visualization` to analyze optimization results visually.\n \n This tutorial walks you through this module by visualizing the history of lightgbm model for breast cancer dataset.\n+\n+For visualizing multi-objective optimization (i.e., the usage of :func:`optuna.visualization.plot_pareto_front`),\n+please refer to the tutorial of :ref:`multi_objective`.\n \"\"\"\n \n ###################################################################################################\n@@ -17,6 +20,9 @@\n from sklearn.model_selection import train_test_split\n \n import optuna\n+\n+# You can use Matplotlib instead of Plotly for visualization by simply replacing `optuna.visualization` with\n+# `optuna.visualization.matplotlib` in the following examples.\n from optuna.visualization import plot_contour\n from optuna.visualization import plot_edf\n from optuna.visualization import plot_intermediate_values\n", "issue": "Improve visualization tutorial\n<!-- Please write a clear and concise description of what content in https://optuna.readthedocs.io/ is an issue. -->\r\n\r\nI suggest updating the [visualization tutorial](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/005_visualization.html) as follows\r\n\r\n- Add missing [`visualization.plot_pareto_front`](https://optuna.readthedocs.io/en/stable/reference/visualization/generated/optuna.visualization.plot_pareto_front.html#optuna.visualization.plot_pareto_front) example; since this function needs multi-objective function unlike other visualization examples, we might need to define such an objective function after the other examples. If adding such an example is not appropriate, at least we need to mention the existence of `visualization.plot_pareto_front`.\r\n- Mention the availability of matplotlib version in the first paragraph. \r\n\n", "before_files": [{"content": "\"\"\"\n.. _visualization:\n\nQuick Visualization for Hyperparameter Optimization Analysis\n============================================================\n\nOptuna provides various visualization features in :mod:`optuna.visualization` to analyze optimization results visually.\n\nThis tutorial walks you through this module by visualizing the history of lightgbm model for breast cancer dataset.\n\"\"\"\n\n###################################################################################################\nimport lightgbm as lgb\nimport numpy as np\nimport sklearn.datasets\nimport sklearn.metrics\nfrom sklearn.model_selection import train_test_split\n\nimport optuna\nfrom optuna.visualization import plot_contour\nfrom optuna.visualization import plot_edf\nfrom optuna.visualization import plot_intermediate_values\nfrom optuna.visualization import plot_optimization_history\nfrom optuna.visualization import plot_parallel_coordinate\nfrom optuna.visualization import plot_param_importances\nfrom optuna.visualization import plot_slice\n\nSEED = 42\n\nnp.random.seed(SEED)\n\n\n###################################################################################################\n# Define the objective function.\ndef objective(trial):\n data, target = sklearn.datasets.load_breast_cancer(return_X_y=True)\n train_x, valid_x, train_y, valid_y = train_test_split(data, target, test_size=0.25)\n dtrain = lgb.Dataset(train_x, label=train_y)\n dvalid = lgb.Dataset(valid_x, label=valid_y)\n\n param = {\n \"objective\": \"binary\",\n \"metric\": \"auc\",\n \"verbosity\": -1,\n \"boosting_type\": \"gbdt\",\n \"bagging_fraction\": trial.suggest_float(\"bagging_fraction\", 0.4, 1.0),\n \"bagging_freq\": trial.suggest_int(\"bagging_freq\", 1, 7),\n \"min_child_samples\": trial.suggest_int(\"min_child_samples\", 5, 100),\n }\n\n # Add a callback for pruning.\n pruning_callback = optuna.integration.LightGBMPruningCallback(trial, \"auc\")\n gbm = lgb.train(\n param, dtrain, valid_sets=[dvalid], verbose_eval=False, callbacks=[pruning_callback]\n )\n\n preds = gbm.predict(valid_x)\n pred_labels = np.rint(preds)\n accuracy = sklearn.metrics.accuracy_score(valid_y, pred_labels)\n return accuracy\n\n\n###################################################################################################\nstudy = optuna.create_study(\n direction=\"maximize\",\n sampler=optuna.samplers.TPESampler(seed=SEED),\n pruner=optuna.pruners.MedianPruner(n_warmup_steps=10),\n)\nstudy.optimize(objective, n_trials=100, timeout=600)\n\n###################################################################################################\n# Plot functions\n# --------------\n# Visualize the optimization history. See :func:`~optuna.visualization.plot_optimization_history` for the details.\nplot_optimization_history(study)\n\n###################################################################################################\n# Visualize the learning curves of the trials. See :func:`~optuna.visualization.plot_intermediate_values` for the details.\nplot_intermediate_values(study)\n\n###################################################################################################\n# Visualize high-dimensional parameter relationships. See :func:`~optuna.visualization.plot_parallel_coordinate` for the details.\nplot_parallel_coordinate(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_parallel_coordinate(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize hyperparameter relationships. See :func:`~optuna.visualization.plot_contour` for the details.\nplot_contour(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_contour(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize individual hyperparameters as slice plot. See :func:`~optuna.visualization.plot_slice` for the details.\nplot_slice(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_slice(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize parameter importances. See :func:`~optuna.visualization.plot_param_importances` for the details.\nplot_param_importances(study)\n\n###################################################################################################\n# Learn which hyperparameters are affecting the trial duration with hyperparameter importance.\noptuna.visualization.plot_param_importances(\n study, target=lambda t: t.duration.total_seconds(), target_name=\"duration\"\n)\n\n###################################################################################################\n# Visualize empirical distribution function. See :func:`~optuna.visualization.plot_edf` for the details.\nplot_edf(study)\n", "path": "tutorial/10_key_features/005_visualization.py"}], "after_files": [{"content": "\"\"\"\n.. _visualization:\n\nQuick Visualization for Hyperparameter Optimization Analysis\n============================================================\n\nOptuna provides various visualization features in :mod:`optuna.visualization` to analyze optimization results visually.\n\nThis tutorial walks you through this module by visualizing the history of lightgbm model for breast cancer dataset.\n\nFor visualizing multi-objective optimization (i.e., the usage of :func:`optuna.visualization.plot_pareto_front`),\nplease refer to the tutorial of :ref:`multi_objective`.\n\"\"\"\n\n###################################################################################################\nimport lightgbm as lgb\nimport numpy as np\nimport sklearn.datasets\nimport sklearn.metrics\nfrom sklearn.model_selection import train_test_split\n\nimport optuna\n\n# You can use Matplotlib instead of Plotly for visualization by simply replacing `optuna.visualization` with\n# `optuna.visualization.matplotlib` in the following examples.\nfrom optuna.visualization import plot_contour\nfrom optuna.visualization import plot_edf\nfrom optuna.visualization import plot_intermediate_values\nfrom optuna.visualization import plot_optimization_history\nfrom optuna.visualization import plot_parallel_coordinate\nfrom optuna.visualization import plot_param_importances\nfrom optuna.visualization import plot_slice\n\nSEED = 42\n\nnp.random.seed(SEED)\n\n\n###################################################################################################\n# Define the objective function.\ndef objective(trial):\n data, target = sklearn.datasets.load_breast_cancer(return_X_y=True)\n train_x, valid_x, train_y, valid_y = train_test_split(data, target, test_size=0.25)\n dtrain = lgb.Dataset(train_x, label=train_y)\n dvalid = lgb.Dataset(valid_x, label=valid_y)\n\n param = {\n \"objective\": \"binary\",\n \"metric\": \"auc\",\n \"verbosity\": -1,\n \"boosting_type\": \"gbdt\",\n \"bagging_fraction\": trial.suggest_float(\"bagging_fraction\", 0.4, 1.0),\n \"bagging_freq\": trial.suggest_int(\"bagging_freq\", 1, 7),\n \"min_child_samples\": trial.suggest_int(\"min_child_samples\", 5, 100),\n }\n\n # Add a callback for pruning.\n pruning_callback = optuna.integration.LightGBMPruningCallback(trial, \"auc\")\n gbm = lgb.train(\n param, dtrain, valid_sets=[dvalid], verbose_eval=False, callbacks=[pruning_callback]\n )\n\n preds = gbm.predict(valid_x)\n pred_labels = np.rint(preds)\n accuracy = sklearn.metrics.accuracy_score(valid_y, pred_labels)\n return accuracy\n\n\n###################################################################################################\nstudy = optuna.create_study(\n direction=\"maximize\",\n sampler=optuna.samplers.TPESampler(seed=SEED),\n pruner=optuna.pruners.MedianPruner(n_warmup_steps=10),\n)\nstudy.optimize(objective, n_trials=100, timeout=600)\n\n###################################################################################################\n# Plot functions\n# --------------\n# Visualize the optimization history. See :func:`~optuna.visualization.plot_optimization_history` for the details.\nplot_optimization_history(study)\n\n###################################################################################################\n# Visualize the learning curves of the trials. See :func:`~optuna.visualization.plot_intermediate_values` for the details.\nplot_intermediate_values(study)\n\n###################################################################################################\n# Visualize high-dimensional parameter relationships. See :func:`~optuna.visualization.plot_parallel_coordinate` for the details.\nplot_parallel_coordinate(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_parallel_coordinate(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize hyperparameter relationships. See :func:`~optuna.visualization.plot_contour` for the details.\nplot_contour(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_contour(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize individual hyperparameters as slice plot. See :func:`~optuna.visualization.plot_slice` for the details.\nplot_slice(study)\n\n###################################################################################################\n# Select parameters to visualize.\nplot_slice(study, params=[\"bagging_freq\", \"bagging_fraction\"])\n\n###################################################################################################\n# Visualize parameter importances. See :func:`~optuna.visualization.plot_param_importances` for the details.\nplot_param_importances(study)\n\n###################################################################################################\n# Learn which hyperparameters are affecting the trial duration with hyperparameter importance.\noptuna.visualization.plot_param_importances(\n study, target=lambda t: t.duration.total_seconds(), target_name=\"duration\"\n)\n\n###################################################################################################\n# Visualize empirical distribution function. See :func:`~optuna.visualization.plot_edf` for the details.\nplot_edf(study)\n", "path": "tutorial/10_key_features/005_visualization.py"}]}
| 1,613 | 253 |
gh_patches_debug_9964
|
rasdani/github-patches
|
git_diff
|
google__clusterfuzz-2474
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
attach issue filing exception/error to testcase
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/appengine/handlers/cron/triage.py`
Content:
```
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Automated bug filing."""
15
16 import datetime
17 import itertools
18 import json
19
20 from clusterfuzz._internal.base import dates
21 from clusterfuzz._internal.base import errors
22 from clusterfuzz._internal.base import utils
23 from clusterfuzz._internal.datastore import data_handler
24 from clusterfuzz._internal.datastore import data_types
25 from clusterfuzz._internal.datastore import ndb_utils
26 from clusterfuzz._internal.metrics import crash_stats
27 from clusterfuzz._internal.metrics import logs
28 from handlers import base_handler
29 from libs import handler
30 from libs.issue_management import issue_filer
31 from libs.issue_management import issue_tracker_policy
32 from libs.issue_management import issue_tracker_utils
33
34 from . import grouper
35
36 UNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES = [
37 'Out-of-memory', 'Stack-overflow', 'Timeout'
38 ]
39 TRIAGE_MESSAGE_KEY = 'triage_message'
40
41
42 def _add_triage_message(testcase, message):
43 """Add a triage message."""
44 if testcase.get_metadata(TRIAGE_MESSAGE_KEY) == message:
45 # Message already exists, skip update.
46 return
47 # Re-fetch testcase to get latest entity and avoid race condition in updates.
48 testcase = data_handler.get_testcase_by_id(testcase.key.id())
49 testcase.set_metadata(TRIAGE_MESSAGE_KEY, message)
50
51
52 def _create_filed_bug_metadata(testcase):
53 """Create a dummy bug entry for a test case."""
54 metadata = data_types.FiledBug()
55 metadata.timestamp = datetime.datetime.utcnow()
56 metadata.testcase_id = testcase.key.id()
57 metadata.bug_information = int(testcase.bug_information)
58 metadata.group_id = testcase.group_id
59 metadata.crash_type = testcase.crash_type
60 metadata.crash_state = testcase.crash_state
61 metadata.security_flag = testcase.security_flag
62 metadata.platform_id = testcase.platform_id
63 metadata.put()
64
65
66 def _get_excluded_jobs():
67 """Return list of jobs excluded from bug filing."""
68 excluded_jobs = []
69
70 jobs = ndb_utils.get_all_from_model(data_types.Job)
71 for job in jobs:
72 job_environment = job.get_environment()
73
74 # Exclude experimental jobs.
75 if utils.string_is_true(job_environment.get('EXPERIMENTAL')):
76 excluded_jobs.append(job.name)
77
78 return excluded_jobs
79
80
81 def _is_bug_filed(testcase):
82 """Indicate if the bug is already filed."""
83 # Check if the testcase is already associated with a bug.
84 if testcase.bug_information:
85 return True
86
87 # Re-check our stored metadata so that we don't file the same testcase twice.
88 is_bug_filed_for_testcase = data_types.FiledBug.query(
89 data_types.FiledBug.testcase_id == testcase.key.id()).get()
90 if is_bug_filed_for_testcase:
91 return True
92
93 return False
94
95
96 def _is_crash_important(testcase):
97 """Indicate if the crash is important to file."""
98 if not testcase.one_time_crasher_flag:
99 # A reproducible crash is an important crash.
100 return True
101
102 if testcase.status != 'Processed':
103 # A duplicate or unreproducible crash is not an important crash.
104 return False
105
106 # Testcase is unreproducible. Only those crashes that are crashing frequently
107 # are important.
108
109 if testcase.crash_type in UNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES:
110 return False
111
112 # Ensure that there is no reproducible testcase in our group.
113 if testcase.group_id:
114 other_reproducible_testcase = data_types.Testcase.query(
115 data_types.Testcase.group_id == testcase.group_id,
116 ndb_utils.is_false(data_types.Testcase.one_time_crasher_flag)).get()
117 if other_reproducible_testcase:
118 # There is another reproducible testcase in our group. So, this crash is
119 # not important.
120 return False
121
122 # Get crash statistics data on this unreproducible crash for last X days.
123 last_hour = crash_stats.get_last_successful_hour()
124 if not last_hour:
125 # No crash stats available, skip.
126 return False
127
128 _, rows = crash_stats.get(
129 end=last_hour,
130 block='day',
131 days=data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE,
132 group_by='reproducible_flag',
133 where_clause=(
134 'crash_type = %s AND crash_state = %s AND security_flag = %s' %
135 (json.dumps(testcase.crash_type), json.dumps(testcase.crash_state),
136 json.dumps(testcase.security_flag))),
137 group_having_clause='',
138 sort_by='total_count',
139 offset=0,
140 limit=1)
141
142 # Calculate total crash count and crash days count.
143 crash_days_indices = set([])
144 total_crash_count = 0
145 for row in rows:
146 if 'groups' not in row:
147 continue
148
149 total_crash_count += row['totalCount']
150 for group in row['groups']:
151 for index in group['indices']:
152 crash_days_indices.add(index['hour'])
153
154 crash_days_count = len(crash_days_indices)
155
156 # Only those unreproducible testcases are important that happened atleast once
157 # everyday for the last X days and total crash count exceeded our threshold
158 # limit.
159 return (crash_days_count ==
160 data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE and
161 total_crash_count >=
162 data_types.FILE_UNREPRODUCIBLE_TESTCASE_MIN_CRASH_THRESHOLD)
163
164
165 def _check_and_update_similar_bug(testcase, issue_tracker):
166 """Get list of similar open issues and ones that were recently closed."""
167 # Get similar testcases from the same group.
168 similar_testcases_from_group = []
169 if testcase.group_id:
170 group_query = data_types.Testcase.query(
171 data_types.Testcase.group_id == testcase.group_id)
172 similar_testcases_from_group = ndb_utils.get_all_from_query(
173 group_query, batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)
174
175 # Get testcases with the same crash params. These might not be in the a group
176 # if they were just fixed.
177 same_crash_params_query = data_types.Testcase.query(
178 data_types.Testcase.crash_type == testcase.crash_type,
179 data_types.Testcase.crash_state == testcase.crash_state,
180 data_types.Testcase.security_flag == testcase.security_flag,
181 data_types.Testcase.project_name == testcase.project_name,
182 data_types.Testcase.status == 'Processed')
183
184 similar_testcases_from_query = ndb_utils.get_all_from_query(
185 same_crash_params_query,
186 batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)
187 for similar_testcase in itertools.chain(similar_testcases_from_group,
188 similar_testcases_from_query):
189 # Exclude ourself from comparison.
190 if similar_testcase.key.id() == testcase.key.id():
191 continue
192
193 # Exclude similar testcases without bug information.
194 if not similar_testcase.bug_information:
195 continue
196
197 # Get the issue object given its ID.
198 issue = issue_tracker.get_issue(similar_testcase.bug_information)
199 if not issue:
200 continue
201
202 # If the reproducible issue is not verified yet, bug is still valid and
203 # might be caused by non-availability of latest builds. In that case,
204 # don't file a new bug yet.
205 if similar_testcase.open and not similar_testcase.one_time_crasher_flag:
206 return True
207
208 # If the issue is still open, no need to file a duplicate bug.
209 if issue.is_open:
210 return True
211
212 # If the issue indicates that this crash needs to be ignored, no need to
213 # file another one.
214 policy = issue_tracker_policy.get(issue_tracker.project)
215 ignore_label = policy.label('ignore')
216 if ignore_label in issue.labels:
217 _add_triage_message(
218 testcase,
219 ('Skipping filing a bug since similar testcase ({testcase_id}) in '
220 'issue ({issue_id}) is blacklisted with {ignore_label} label.'
221 ).format(
222 testcase_id=similar_testcase.key.id(),
223 issue_id=issue.id,
224 ignore_label=ignore_label))
225 return True
226
227 # If the issue is recently closed, wait certain time period to make sure
228 # our fixed verification has completed.
229 if (issue.closed_time and not dates.time_has_expired(
230 issue.closed_time, hours=data_types.MIN_ELAPSED_TIME_SINCE_FIXED)):
231 _add_triage_message(
232 testcase,
233 ('Delaying filing a bug since similar testcase '
234 '({testcase_id}) in issue ({issue_id}) was just fixed.').format(
235 testcase_id=similar_testcase.key.id(), issue_id=issue.id))
236 return True
237
238 return False
239
240
241 class Handler(base_handler.Handler):
242 """Triage testcases."""
243
244 @handler.cron()
245 def get(self):
246 """Handle a get request."""
247 try:
248 grouper.group_testcases()
249 except:
250 logs.log_error('Error occurred while grouping test cases.')
251 return
252
253 # Free up memory after group task run.
254 utils.python_gc()
255
256 # Get a list of jobs excluded from bug filing.
257 excluded_jobs = _get_excluded_jobs()
258
259 # Get a list of all jobs. This is used to filter testcases whose jobs have
260 # been removed.
261 all_jobs = data_handler.get_all_job_type_names()
262
263 for testcase_id in data_handler.get_open_testcase_id_iterator():
264 try:
265 testcase = data_handler.get_testcase_by_id(testcase_id)
266 except errors.InvalidTestcaseError:
267 # Already deleted.
268 continue
269
270 # Skip if testcase's job is removed.
271 if testcase.job_type not in all_jobs:
272 continue
273
274 # Skip if testcase's job is in exclusions list.
275 if testcase.job_type in excluded_jobs:
276 continue
277
278 # Skip if we are running progression task at this time.
279 if testcase.get_metadata('progression_pending'):
280 continue
281
282 # If the testcase has a bug filed already, no triage is needed.
283 if _is_bug_filed(testcase):
284 continue
285
286 # Check if the crash is important, i.e. it is either a reproducible crash
287 # or an unreproducible crash happening frequently.
288 if not _is_crash_important(testcase):
289 continue
290
291 # Require that all tasks like minimizaton, regression testing, etc have
292 # finished.
293 if not data_handler.critical_tasks_completed(testcase):
294 continue
295
296 # For testcases that are not part of a group, wait an additional time to
297 # make sure it is grouped.
298 # The grouper runs prior to this step in the same cron, but there is a
299 # window of time where new testcases can come in after the grouper starts.
300 # This delay needs to be longer than the maximum time the grouper can take
301 # to account for that.
302 # FIXME: In future, grouping might be dependent on regression range, so we
303 # would have to add an additional wait time.
304 if not testcase.group_id and not dates.time_has_expired(
305 testcase.timestamp, hours=data_types.MIN_ELAPSED_TIME_SINCE_REPORT):
306 continue
307
308 # If this project does not have an associated issue tracker, we cannot
309 # file this crash anywhere.
310 issue_tracker = issue_tracker_utils.get_issue_tracker_for_testcase(
311 testcase)
312 if not issue_tracker:
313 issue_filer.notify_issue_update(testcase, 'new')
314 continue
315
316 # If there are similar issues to this test case already filed or recently
317 # closed, skip filing a duplicate bug.
318 if _check_and_update_similar_bug(testcase, issue_tracker):
319 continue
320
321 # Clean up old triage messages that would be not applicable now.
322 testcase.delete_metadata(TRIAGE_MESSAGE_KEY, update_testcase=False)
323
324 # File the bug first and then create filed bug metadata.
325 try:
326 issue_filer.file_issue(testcase, issue_tracker)
327 except Exception:
328 logs.log_error('Failed to file issue for testcase %d.' % testcase_id)
329 continue
330
331 _create_filed_bug_metadata(testcase)
332 issue_filer.notify_issue_update(testcase, 'new')
333
334 logs.log('Filed new issue %s for testcase %d.' %
335 (testcase.bug_information, testcase_id))
336
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/appengine/handlers/cron/triage.py b/src/appengine/handlers/cron/triage.py
--- a/src/appengine/handlers/cron/triage.py
+++ b/src/appengine/handlers/cron/triage.py
@@ -324,8 +324,11 @@
# File the bug first and then create filed bug metadata.
try:
issue_filer.file_issue(testcase, issue_tracker)
- except Exception:
+ except Exception as e:
logs.log_error('Failed to file issue for testcase %d.' % testcase_id)
+ _add_triage_message(testcase,
+ f'Failed to file issue due to exception: {str(e)}')
+
continue
_create_filed_bug_metadata(testcase)
|
{"golden_diff": "diff --git a/src/appengine/handlers/cron/triage.py b/src/appengine/handlers/cron/triage.py\n--- a/src/appengine/handlers/cron/triage.py\n+++ b/src/appengine/handlers/cron/triage.py\n@@ -324,8 +324,11 @@\n # File the bug first and then create filed bug metadata.\n try:\n issue_filer.file_issue(testcase, issue_tracker)\n- except Exception:\n+ except Exception as e:\n logs.log_error('Failed to file issue for testcase %d.' % testcase_id)\n+ _add_triage_message(testcase,\n+ f'Failed to file issue due to exception: {str(e)}')\n+\n continue\n \n _create_filed_bug_metadata(testcase)\n", "issue": "attach issue filing exception/error to testcase\n\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Automated bug filing.\"\"\"\n\nimport datetime\nimport itertools\nimport json\n\nfrom clusterfuzz._internal.base import dates\nfrom clusterfuzz._internal.base import errors\nfrom clusterfuzz._internal.base import utils\nfrom clusterfuzz._internal.datastore import data_handler\nfrom clusterfuzz._internal.datastore import data_types\nfrom clusterfuzz._internal.datastore import ndb_utils\nfrom clusterfuzz._internal.metrics import crash_stats\nfrom clusterfuzz._internal.metrics import logs\nfrom handlers import base_handler\nfrom libs import handler\nfrom libs.issue_management import issue_filer\nfrom libs.issue_management import issue_tracker_policy\nfrom libs.issue_management import issue_tracker_utils\n\nfrom . import grouper\n\nUNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES = [\n 'Out-of-memory', 'Stack-overflow', 'Timeout'\n]\nTRIAGE_MESSAGE_KEY = 'triage_message'\n\n\ndef _add_triage_message(testcase, message):\n \"\"\"Add a triage message.\"\"\"\n if testcase.get_metadata(TRIAGE_MESSAGE_KEY) == message:\n # Message already exists, skip update.\n return\n # Re-fetch testcase to get latest entity and avoid race condition in updates.\n testcase = data_handler.get_testcase_by_id(testcase.key.id())\n testcase.set_metadata(TRIAGE_MESSAGE_KEY, message)\n\n\ndef _create_filed_bug_metadata(testcase):\n \"\"\"Create a dummy bug entry for a test case.\"\"\"\n metadata = data_types.FiledBug()\n metadata.timestamp = datetime.datetime.utcnow()\n metadata.testcase_id = testcase.key.id()\n metadata.bug_information = int(testcase.bug_information)\n metadata.group_id = testcase.group_id\n metadata.crash_type = testcase.crash_type\n metadata.crash_state = testcase.crash_state\n metadata.security_flag = testcase.security_flag\n metadata.platform_id = testcase.platform_id\n metadata.put()\n\n\ndef _get_excluded_jobs():\n \"\"\"Return list of jobs excluded from bug filing.\"\"\"\n excluded_jobs = []\n\n jobs = ndb_utils.get_all_from_model(data_types.Job)\n for job in jobs:\n job_environment = job.get_environment()\n\n # Exclude experimental jobs.\n if utils.string_is_true(job_environment.get('EXPERIMENTAL')):\n excluded_jobs.append(job.name)\n\n return excluded_jobs\n\n\ndef _is_bug_filed(testcase):\n \"\"\"Indicate if the bug is already filed.\"\"\"\n # Check if the testcase is already associated with a bug.\n if testcase.bug_information:\n return True\n\n # Re-check our stored metadata so that we don't file the same testcase twice.\n is_bug_filed_for_testcase = data_types.FiledBug.query(\n data_types.FiledBug.testcase_id == testcase.key.id()).get()\n if is_bug_filed_for_testcase:\n return True\n\n return False\n\n\ndef _is_crash_important(testcase):\n \"\"\"Indicate if the crash is important to file.\"\"\"\n if not testcase.one_time_crasher_flag:\n # A reproducible crash is an important crash.\n return True\n\n if testcase.status != 'Processed':\n # A duplicate or unreproducible crash is not an important crash.\n return False\n\n # Testcase is unreproducible. Only those crashes that are crashing frequently\n # are important.\n\n if testcase.crash_type in UNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES:\n return False\n\n # Ensure that there is no reproducible testcase in our group.\n if testcase.group_id:\n other_reproducible_testcase = data_types.Testcase.query(\n data_types.Testcase.group_id == testcase.group_id,\n ndb_utils.is_false(data_types.Testcase.one_time_crasher_flag)).get()\n if other_reproducible_testcase:\n # There is another reproducible testcase in our group. So, this crash is\n # not important.\n return False\n\n # Get crash statistics data on this unreproducible crash for last X days.\n last_hour = crash_stats.get_last_successful_hour()\n if not last_hour:\n # No crash stats available, skip.\n return False\n\n _, rows = crash_stats.get(\n end=last_hour,\n block='day',\n days=data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE,\n group_by='reproducible_flag',\n where_clause=(\n 'crash_type = %s AND crash_state = %s AND security_flag = %s' %\n (json.dumps(testcase.crash_type), json.dumps(testcase.crash_state),\n json.dumps(testcase.security_flag))),\n group_having_clause='',\n sort_by='total_count',\n offset=0,\n limit=1)\n\n # Calculate total crash count and crash days count.\n crash_days_indices = set([])\n total_crash_count = 0\n for row in rows:\n if 'groups' not in row:\n continue\n\n total_crash_count += row['totalCount']\n for group in row['groups']:\n for index in group['indices']:\n crash_days_indices.add(index['hour'])\n\n crash_days_count = len(crash_days_indices)\n\n # Only those unreproducible testcases are important that happened atleast once\n # everyday for the last X days and total crash count exceeded our threshold\n # limit.\n return (crash_days_count ==\n data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE and\n total_crash_count >=\n data_types.FILE_UNREPRODUCIBLE_TESTCASE_MIN_CRASH_THRESHOLD)\n\n\ndef _check_and_update_similar_bug(testcase, issue_tracker):\n \"\"\"Get list of similar open issues and ones that were recently closed.\"\"\"\n # Get similar testcases from the same group.\n similar_testcases_from_group = []\n if testcase.group_id:\n group_query = data_types.Testcase.query(\n data_types.Testcase.group_id == testcase.group_id)\n similar_testcases_from_group = ndb_utils.get_all_from_query(\n group_query, batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)\n\n # Get testcases with the same crash params. These might not be in the a group\n # if they were just fixed.\n same_crash_params_query = data_types.Testcase.query(\n data_types.Testcase.crash_type == testcase.crash_type,\n data_types.Testcase.crash_state == testcase.crash_state,\n data_types.Testcase.security_flag == testcase.security_flag,\n data_types.Testcase.project_name == testcase.project_name,\n data_types.Testcase.status == 'Processed')\n\n similar_testcases_from_query = ndb_utils.get_all_from_query(\n same_crash_params_query,\n batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)\n for similar_testcase in itertools.chain(similar_testcases_from_group,\n similar_testcases_from_query):\n # Exclude ourself from comparison.\n if similar_testcase.key.id() == testcase.key.id():\n continue\n\n # Exclude similar testcases without bug information.\n if not similar_testcase.bug_information:\n continue\n\n # Get the issue object given its ID.\n issue = issue_tracker.get_issue(similar_testcase.bug_information)\n if not issue:\n continue\n\n # If the reproducible issue is not verified yet, bug is still valid and\n # might be caused by non-availability of latest builds. In that case,\n # don't file a new bug yet.\n if similar_testcase.open and not similar_testcase.one_time_crasher_flag:\n return True\n\n # If the issue is still open, no need to file a duplicate bug.\n if issue.is_open:\n return True\n\n # If the issue indicates that this crash needs to be ignored, no need to\n # file another one.\n policy = issue_tracker_policy.get(issue_tracker.project)\n ignore_label = policy.label('ignore')\n if ignore_label in issue.labels:\n _add_triage_message(\n testcase,\n ('Skipping filing a bug since similar testcase ({testcase_id}) in '\n 'issue ({issue_id}) is blacklisted with {ignore_label} label.'\n ).format(\n testcase_id=similar_testcase.key.id(),\n issue_id=issue.id,\n ignore_label=ignore_label))\n return True\n\n # If the issue is recently closed, wait certain time period to make sure\n # our fixed verification has completed.\n if (issue.closed_time and not dates.time_has_expired(\n issue.closed_time, hours=data_types.MIN_ELAPSED_TIME_SINCE_FIXED)):\n _add_triage_message(\n testcase,\n ('Delaying filing a bug since similar testcase '\n '({testcase_id}) in issue ({issue_id}) was just fixed.').format(\n testcase_id=similar_testcase.key.id(), issue_id=issue.id))\n return True\n\n return False\n\n\nclass Handler(base_handler.Handler):\n \"\"\"Triage testcases.\"\"\"\n\n @handler.cron()\n def get(self):\n \"\"\"Handle a get request.\"\"\"\n try:\n grouper.group_testcases()\n except:\n logs.log_error('Error occurred while grouping test cases.')\n return\n\n # Free up memory after group task run.\n utils.python_gc()\n\n # Get a list of jobs excluded from bug filing.\n excluded_jobs = _get_excluded_jobs()\n\n # Get a list of all jobs. This is used to filter testcases whose jobs have\n # been removed.\n all_jobs = data_handler.get_all_job_type_names()\n\n for testcase_id in data_handler.get_open_testcase_id_iterator():\n try:\n testcase = data_handler.get_testcase_by_id(testcase_id)\n except errors.InvalidTestcaseError:\n # Already deleted.\n continue\n\n # Skip if testcase's job is removed.\n if testcase.job_type not in all_jobs:\n continue\n\n # Skip if testcase's job is in exclusions list.\n if testcase.job_type in excluded_jobs:\n continue\n\n # Skip if we are running progression task at this time.\n if testcase.get_metadata('progression_pending'):\n continue\n\n # If the testcase has a bug filed already, no triage is needed.\n if _is_bug_filed(testcase):\n continue\n\n # Check if the crash is important, i.e. it is either a reproducible crash\n # or an unreproducible crash happening frequently.\n if not _is_crash_important(testcase):\n continue\n\n # Require that all tasks like minimizaton, regression testing, etc have\n # finished.\n if not data_handler.critical_tasks_completed(testcase):\n continue\n\n # For testcases that are not part of a group, wait an additional time to\n # make sure it is grouped.\n # The grouper runs prior to this step in the same cron, but there is a\n # window of time where new testcases can come in after the grouper starts.\n # This delay needs to be longer than the maximum time the grouper can take\n # to account for that.\n # FIXME: In future, grouping might be dependent on regression range, so we\n # would have to add an additional wait time.\n if not testcase.group_id and not dates.time_has_expired(\n testcase.timestamp, hours=data_types.MIN_ELAPSED_TIME_SINCE_REPORT):\n continue\n\n # If this project does not have an associated issue tracker, we cannot\n # file this crash anywhere.\n issue_tracker = issue_tracker_utils.get_issue_tracker_for_testcase(\n testcase)\n if not issue_tracker:\n issue_filer.notify_issue_update(testcase, 'new')\n continue\n\n # If there are similar issues to this test case already filed or recently\n # closed, skip filing a duplicate bug.\n if _check_and_update_similar_bug(testcase, issue_tracker):\n continue\n\n # Clean up old triage messages that would be not applicable now.\n testcase.delete_metadata(TRIAGE_MESSAGE_KEY, update_testcase=False)\n\n # File the bug first and then create filed bug metadata.\n try:\n issue_filer.file_issue(testcase, issue_tracker)\n except Exception:\n logs.log_error('Failed to file issue for testcase %d.' % testcase_id)\n continue\n\n _create_filed_bug_metadata(testcase)\n issue_filer.notify_issue_update(testcase, 'new')\n\n logs.log('Filed new issue %s for testcase %d.' %\n (testcase.bug_information, testcase_id))\n", "path": "src/appengine/handlers/cron/triage.py"}], "after_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Automated bug filing.\"\"\"\n\nimport datetime\nimport itertools\nimport json\n\nfrom clusterfuzz._internal.base import dates\nfrom clusterfuzz._internal.base import errors\nfrom clusterfuzz._internal.base import utils\nfrom clusterfuzz._internal.datastore import data_handler\nfrom clusterfuzz._internal.datastore import data_types\nfrom clusterfuzz._internal.datastore import ndb_utils\nfrom clusterfuzz._internal.metrics import crash_stats\nfrom clusterfuzz._internal.metrics import logs\nfrom handlers import base_handler\nfrom libs import handler\nfrom libs.issue_management import issue_filer\nfrom libs.issue_management import issue_tracker_policy\nfrom libs.issue_management import issue_tracker_utils\n\nfrom . import grouper\n\nUNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES = [\n 'Out-of-memory', 'Stack-overflow', 'Timeout'\n]\nTRIAGE_MESSAGE_KEY = 'triage_message'\n\n\ndef _add_triage_message(testcase, message):\n \"\"\"Add a triage message.\"\"\"\n if testcase.get_metadata(TRIAGE_MESSAGE_KEY) == message:\n # Message already exists, skip update.\n return\n # Re-fetch testcase to get latest entity and avoid race condition in updates.\n testcase = data_handler.get_testcase_by_id(testcase.key.id())\n testcase.set_metadata(TRIAGE_MESSAGE_KEY, message)\n\n\ndef _create_filed_bug_metadata(testcase):\n \"\"\"Create a dummy bug entry for a test case.\"\"\"\n metadata = data_types.FiledBug()\n metadata.timestamp = datetime.datetime.utcnow()\n metadata.testcase_id = testcase.key.id()\n metadata.bug_information = int(testcase.bug_information)\n metadata.group_id = testcase.group_id\n metadata.crash_type = testcase.crash_type\n metadata.crash_state = testcase.crash_state\n metadata.security_flag = testcase.security_flag\n metadata.platform_id = testcase.platform_id\n metadata.put()\n\n\ndef _get_excluded_jobs():\n \"\"\"Return list of jobs excluded from bug filing.\"\"\"\n excluded_jobs = []\n\n jobs = ndb_utils.get_all_from_model(data_types.Job)\n for job in jobs:\n job_environment = job.get_environment()\n\n # Exclude experimental jobs.\n if utils.string_is_true(job_environment.get('EXPERIMENTAL')):\n excluded_jobs.append(job.name)\n\n return excluded_jobs\n\n\ndef _is_bug_filed(testcase):\n \"\"\"Indicate if the bug is already filed.\"\"\"\n # Check if the testcase is already associated with a bug.\n if testcase.bug_information:\n return True\n\n # Re-check our stored metadata so that we don't file the same testcase twice.\n is_bug_filed_for_testcase = data_types.FiledBug.query(\n data_types.FiledBug.testcase_id == testcase.key.id()).get()\n if is_bug_filed_for_testcase:\n return True\n\n return False\n\n\ndef _is_crash_important(testcase):\n \"\"\"Indicate if the crash is important to file.\"\"\"\n if not testcase.one_time_crasher_flag:\n # A reproducible crash is an important crash.\n return True\n\n if testcase.status != 'Processed':\n # A duplicate or unreproducible crash is not an important crash.\n return False\n\n # Testcase is unreproducible. Only those crashes that are crashing frequently\n # are important.\n\n if testcase.crash_type in UNREPRODUCIBLE_CRASH_IGNORE_CRASH_TYPES:\n return False\n\n # Ensure that there is no reproducible testcase in our group.\n if testcase.group_id:\n other_reproducible_testcase = data_types.Testcase.query(\n data_types.Testcase.group_id == testcase.group_id,\n ndb_utils.is_false(data_types.Testcase.one_time_crasher_flag)).get()\n if other_reproducible_testcase:\n # There is another reproducible testcase in our group. So, this crash is\n # not important.\n return False\n\n # Get crash statistics data on this unreproducible crash for last X days.\n last_hour = crash_stats.get_last_successful_hour()\n if not last_hour:\n # No crash stats available, skip.\n return False\n\n _, rows = crash_stats.get(\n end=last_hour,\n block='day',\n days=data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE,\n group_by='reproducible_flag',\n where_clause=(\n 'crash_type = %s AND crash_state = %s AND security_flag = %s' %\n (json.dumps(testcase.crash_type), json.dumps(testcase.crash_state),\n json.dumps(testcase.security_flag))),\n group_having_clause='',\n sort_by='total_count',\n offset=0,\n limit=1)\n\n # Calculate total crash count and crash days count.\n crash_days_indices = set([])\n total_crash_count = 0\n for row in rows:\n if 'groups' not in row:\n continue\n\n total_crash_count += row['totalCount']\n for group in row['groups']:\n for index in group['indices']:\n crash_days_indices.add(index['hour'])\n\n crash_days_count = len(crash_days_indices)\n\n # Only those unreproducible testcases are important that happened atleast once\n # everyday for the last X days and total crash count exceeded our threshold\n # limit.\n return (crash_days_count ==\n data_types.FILE_CONSISTENT_UNREPRODUCIBLE_TESTCASE_DEADLINE and\n total_crash_count >=\n data_types.FILE_UNREPRODUCIBLE_TESTCASE_MIN_CRASH_THRESHOLD)\n\n\ndef _check_and_update_similar_bug(testcase, issue_tracker):\n \"\"\"Get list of similar open issues and ones that were recently closed.\"\"\"\n # Get similar testcases from the same group.\n similar_testcases_from_group = []\n if testcase.group_id:\n group_query = data_types.Testcase.query(\n data_types.Testcase.group_id == testcase.group_id)\n similar_testcases_from_group = ndb_utils.get_all_from_query(\n group_query, batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)\n\n # Get testcases with the same crash params. These might not be in the a group\n # if they were just fixed.\n same_crash_params_query = data_types.Testcase.query(\n data_types.Testcase.crash_type == testcase.crash_type,\n data_types.Testcase.crash_state == testcase.crash_state,\n data_types.Testcase.security_flag == testcase.security_flag,\n data_types.Testcase.project_name == testcase.project_name,\n data_types.Testcase.status == 'Processed')\n\n similar_testcases_from_query = ndb_utils.get_all_from_query(\n same_crash_params_query,\n batch_size=data_types.TESTCASE_ENTITY_QUERY_LIMIT // 2)\n for similar_testcase in itertools.chain(similar_testcases_from_group,\n similar_testcases_from_query):\n # Exclude ourself from comparison.\n if similar_testcase.key.id() == testcase.key.id():\n continue\n\n # Exclude similar testcases without bug information.\n if not similar_testcase.bug_information:\n continue\n\n # Get the issue object given its ID.\n issue = issue_tracker.get_issue(similar_testcase.bug_information)\n if not issue:\n continue\n\n # If the reproducible issue is not verified yet, bug is still valid and\n # might be caused by non-availability of latest builds. In that case,\n # don't file a new bug yet.\n if similar_testcase.open and not similar_testcase.one_time_crasher_flag:\n return True\n\n # If the issue is still open, no need to file a duplicate bug.\n if issue.is_open:\n return True\n\n # If the issue indicates that this crash needs to be ignored, no need to\n # file another one.\n policy = issue_tracker_policy.get(issue_tracker.project)\n ignore_label = policy.label('ignore')\n if ignore_label in issue.labels:\n _add_triage_message(\n testcase,\n ('Skipping filing a bug since similar testcase ({testcase_id}) in '\n 'issue ({issue_id}) is blacklisted with {ignore_label} label.'\n ).format(\n testcase_id=similar_testcase.key.id(),\n issue_id=issue.id,\n ignore_label=ignore_label))\n return True\n\n # If the issue is recently closed, wait certain time period to make sure\n # our fixed verification has completed.\n if (issue.closed_time and not dates.time_has_expired(\n issue.closed_time, hours=data_types.MIN_ELAPSED_TIME_SINCE_FIXED)):\n _add_triage_message(\n testcase,\n ('Delaying filing a bug since similar testcase '\n '({testcase_id}) in issue ({issue_id}) was just fixed.').format(\n testcase_id=similar_testcase.key.id(), issue_id=issue.id))\n return True\n\n return False\n\n\nclass Handler(base_handler.Handler):\n \"\"\"Triage testcases.\"\"\"\n\n @handler.cron()\n def get(self):\n \"\"\"Handle a get request.\"\"\"\n try:\n grouper.group_testcases()\n except:\n logs.log_error('Error occurred while grouping test cases.')\n return\n\n # Free up memory after group task run.\n utils.python_gc()\n\n # Get a list of jobs excluded from bug filing.\n excluded_jobs = _get_excluded_jobs()\n\n # Get a list of all jobs. This is used to filter testcases whose jobs have\n # been removed.\n all_jobs = data_handler.get_all_job_type_names()\n\n for testcase_id in data_handler.get_open_testcase_id_iterator():\n try:\n testcase = data_handler.get_testcase_by_id(testcase_id)\n except errors.InvalidTestcaseError:\n # Already deleted.\n continue\n\n # Skip if testcase's job is removed.\n if testcase.job_type not in all_jobs:\n continue\n\n # Skip if testcase's job is in exclusions list.\n if testcase.job_type in excluded_jobs:\n continue\n\n # Skip if we are running progression task at this time.\n if testcase.get_metadata('progression_pending'):\n continue\n\n # If the testcase has a bug filed already, no triage is needed.\n if _is_bug_filed(testcase):\n continue\n\n # Check if the crash is important, i.e. it is either a reproducible crash\n # or an unreproducible crash happening frequently.\n if not _is_crash_important(testcase):\n continue\n\n # Require that all tasks like minimizaton, regression testing, etc have\n # finished.\n if not data_handler.critical_tasks_completed(testcase):\n continue\n\n # For testcases that are not part of a group, wait an additional time to\n # make sure it is grouped.\n # The grouper runs prior to this step in the same cron, but there is a\n # window of time where new testcases can come in after the grouper starts.\n # This delay needs to be longer than the maximum time the grouper can take\n # to account for that.\n # FIXME: In future, grouping might be dependent on regression range, so we\n # would have to add an additional wait time.\n if not testcase.group_id and not dates.time_has_expired(\n testcase.timestamp, hours=data_types.MIN_ELAPSED_TIME_SINCE_REPORT):\n continue\n\n # If this project does not have an associated issue tracker, we cannot\n # file this crash anywhere.\n issue_tracker = issue_tracker_utils.get_issue_tracker_for_testcase(\n testcase)\n if not issue_tracker:\n issue_filer.notify_issue_update(testcase, 'new')\n continue\n\n # If there are similar issues to this test case already filed or recently\n # closed, skip filing a duplicate bug.\n if _check_and_update_similar_bug(testcase, issue_tracker):\n continue\n\n # Clean up old triage messages that would be not applicable now.\n testcase.delete_metadata(TRIAGE_MESSAGE_KEY, update_testcase=False)\n\n # File the bug first and then create filed bug metadata.\n try:\n issue_filer.file_issue(testcase, issue_tracker)\n except Exception as e:\n logs.log_error('Failed to file issue for testcase %d.' % testcase_id)\n _add_triage_message(testcase,\n f'Failed to file issue due to exception: {str(e)}')\n\n continue\n\n _create_filed_bug_metadata(testcase)\n issue_filer.notify_issue_update(testcase, 'new')\n\n logs.log('Filed new issue %s for testcase %d.' %\n (testcase.bug_information, testcase_id))\n", "path": "src/appengine/handlers/cron/triage.py"}]}
| 3,963 | 170 |
gh_patches_debug_17011
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-1778
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add explicit support for Python 3.9
Start testing on 3.9, add testing on Python 3.8 where there is finally support.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `noxfile.py`
Content:
```
1 import os
2 import shutil
3
4 import nox
5
6
7 def tests_impl(session, extras="socks,secure,brotli"):
8 # Install deps and the package itself.
9 session.install("-r", "dev-requirements.txt")
10 session.install(".[{extras}]".format(extras=extras))
11
12 # Show the pip version.
13 session.run("pip", "--version")
14 # Print the Python version and bytesize.
15 session.run("python", "--version")
16 session.run("python", "-c", "import struct; print(struct.calcsize('P') * 8)")
17 # Print OpenSSL information.
18 session.run("python", "-m", "OpenSSL.debug")
19
20 # Inspired from https://github.com/pyca/cryptography
21 # We use parallel mode and then combine here so that coverage.py will take
22 # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py
23 # and collapse them into src/urllib3/__init__.py.
24
25 session.run(
26 "coverage",
27 "run",
28 "--parallel-mode",
29 "-m",
30 "pytest",
31 "-r",
32 "a",
33 "--tb=native",
34 "--no-success-flaky-report",
35 *(session.posargs or ("test/",)),
36 env={"PYTHONWARNINGS": "always::DeprecationWarning"}
37 )
38 session.run("coverage", "combine")
39 session.run("coverage", "report", "-m")
40
41
42 @nox.session(python=["2.7", "3.5", "3.6", "3.7", "3.8", "pypy"])
43 def test(session):
44 tests_impl(session)
45
46
47 @nox.session(python=["2", "3"])
48 def google_brotli(session):
49 # https://pypi.org/project/Brotli/ is the Google version of brotli, so
50 # install it separately and don't install our brotli extra (which installs
51 # brotlipy).
52 session.install("brotli")
53 tests_impl(session, extras="socks,secure")
54
55
56 @nox.session(python="2.7")
57 def app_engine(session):
58 session.install("-r", "dev-requirements.txt")
59 session.install(".")
60 session.run(
61 "coverage",
62 "run",
63 "--parallel-mode",
64 "-m",
65 "pytest",
66 "-r",
67 "sx",
68 "test/appengine",
69 *session.posargs
70 )
71 session.run("coverage", "combine")
72 session.run("coverage", "report", "-m")
73
74
75 @nox.session()
76 def blacken(session):
77 """Run black code formatter."""
78 session.install("black")
79 session.run("black", "src", "dummyserver", "test", "noxfile.py", "setup.py")
80
81 lint(session)
82
83
84 @nox.session
85 def lint(session):
86 session.install("flake8", "black")
87 session.run("flake8", "--version")
88 session.run("black", "--version")
89 session.run(
90 "black", "--check", "src", "dummyserver", "test", "noxfile.py", "setup.py"
91 )
92 session.run("flake8", "setup.py", "docs", "dummyserver", "src", "test")
93
94
95 @nox.session
96 def docs(session):
97 session.install("-r", "docs/requirements.txt")
98 session.install(".[socks,secure,brotli]")
99
100 session.chdir("docs")
101 if os.path.exists("_build"):
102 shutil.rmtree("_build")
103 session.run("sphinx-build", "-W", ".", "_build/html")
104
```
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup
4
5 import os
6 import re
7 import codecs
8
9 base_path = os.path.dirname(__file__)
10
11 # Get the version (borrowed from SQLAlchemy)
12 with open(os.path.join(base_path, "src", "urllib3", "__init__.py")) as fp:
13 VERSION = (
14 re.compile(r""".*__version__ = ["'](.*?)['"]""", re.S).match(fp.read()).group(1)
15 )
16
17
18 with codecs.open("README.rst", encoding="utf-8") as fp:
19 readme = fp.read()
20
21 with codecs.open("CHANGES.rst", encoding="utf-8") as fp:
22 changes = fp.read()
23
24 version = VERSION
25
26 setup(
27 name="urllib3",
28 version=version,
29 description="HTTP library with thread-safe connection pooling, file post, and more.",
30 long_description=u"\n\n".join([readme, changes]),
31 classifiers=[
32 "Environment :: Web Environment",
33 "Intended Audience :: Developers",
34 "License :: OSI Approved :: MIT License",
35 "Operating System :: OS Independent",
36 "Programming Language :: Python",
37 "Programming Language :: Python :: 2",
38 "Programming Language :: Python :: 2.7",
39 "Programming Language :: Python :: 3",
40 "Programming Language :: Python :: 3.5",
41 "Programming Language :: Python :: 3.6",
42 "Programming Language :: Python :: 3.7",
43 "Programming Language :: Python :: 3.8",
44 "Programming Language :: Python :: Implementation :: CPython",
45 "Programming Language :: Python :: Implementation :: PyPy",
46 "Topic :: Internet :: WWW/HTTP",
47 "Topic :: Software Development :: Libraries",
48 ],
49 keywords="urllib httplib threadsafe filepost http https ssl pooling",
50 author="Andrey Petrov",
51 author_email="[email protected]",
52 url="https://urllib3.readthedocs.io/",
53 project_urls={
54 "Documentation": "https://urllib3.readthedocs.io/",
55 "Code": "https://github.com/urllib3/urllib3",
56 "Issue tracker": "https://github.com/urllib3/urllib3/issues",
57 },
58 license="MIT",
59 packages=[
60 "urllib3",
61 "urllib3.packages",
62 "urllib3.packages.ssl_match_hostname",
63 "urllib3.packages.backports",
64 "urllib3.contrib",
65 "urllib3.contrib._securetransport",
66 "urllib3.util",
67 ],
68 package_dir={"": "src"},
69 requires=[],
70 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, <4",
71 tests_require=[
72 # These are a less-specific subset of dev-requirements.txt, for the
73 # convenience of distro package maintainers.
74 "pytest",
75 "mock",
76 "tornado",
77 ],
78 test_suite="test",
79 extras_require={
80 "brotli": ["brotlipy>=0.6.0"],
81 "secure": [
82 "pyOpenSSL>=0.14",
83 "cryptography>=1.3.4",
84 "idna>=2.0.0",
85 "certifi",
86 "ipaddress; python_version=='2.7'",
87 ],
88 "socks": ["PySocks>=1.5.6,<2.0,!=1.5.7"],
89 },
90 )
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -39,7 +39,7 @@
session.run("coverage", "report", "-m")
[email protected](python=["2.7", "3.5", "3.6", "3.7", "3.8", "pypy"])
[email protected](python=["2.7", "3.5", "3.6", "3.7", "3.8", "3.9", "pypy"])
def test(session):
tests_impl(session)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -41,6 +41,7 @@
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Topic :: Internet :: WWW/HTTP",
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -39,7 +39,7 @@\n session.run(\"coverage\", \"report\", \"-m\")\n \n \[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\", \"3.8\", \"pypy\"])\[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\", \"3.8\", \"3.9\", \"pypy\"])\n def test(session):\n tests_impl(session)\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -41,6 +41,7 @@\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n", "issue": "Add explicit support for Python 3.9\nStart testing on 3.9, add testing on Python 3.8 where there is finally support.\n", "before_files": [{"content": "import os\nimport shutil\n\nimport nox\n\n\ndef tests_impl(session, extras=\"socks,secure,brotli\"):\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(\".[{extras}]\".format(extras=extras))\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"}\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n\n\[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\", \"3.8\", \"pypy\"])\ndef test(session):\n tests_impl(session)\n\n\[email protected](python=[\"2\", \"3\"])\ndef google_brotli(session):\n # https://pypi.org/project/Brotli/ is the Google version of brotli, so\n # install it separately and don't install our brotli extra (which installs\n # brotlipy).\n session.install(\"brotli\")\n tests_impl(session, extras=\"socks,secure\")\n\n\[email protected](python=\"2.7\")\ndef app_engine(session):\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(\".\")\n session.run(\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"sx\",\n \"test/appengine\",\n *session.posargs\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n\n\[email protected]()\ndef blacken(session):\n \"\"\"Run black code formatter.\"\"\"\n session.install(\"black\")\n session.run(\"black\", \"src\", \"dummyserver\", \"test\", \"noxfile.py\", \"setup.py\")\n\n lint(session)\n\n\[email protected]\ndef lint(session):\n session.install(\"flake8\", \"black\")\n session.run(\"flake8\", \"--version\")\n session.run(\"black\", \"--version\")\n session.run(\n \"black\", \"--check\", \"src\", \"dummyserver\", \"test\", \"noxfile.py\", \"setup.py\"\n )\n session.run(\"flake8\", \"setup.py\", \"docs\", \"dummyserver\", \"src\", \"test\")\n\n\[email protected]\ndef docs(session):\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}, {"content": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nimport os\nimport re\nimport codecs\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nwith open(os.path.join(base_path, \"src\", \"urllib3\", \"__init__.py\")) as fp:\n VERSION = (\n re.compile(r\"\"\".*__version__ = [\"'](.*?)['\"]\"\"\", re.S).match(fp.read()).group(1)\n )\n\n\nwith codecs.open(\"README.rst\", encoding=\"utf-8\") as fp:\n readme = fp.read()\n\nwith codecs.open(\"CHANGES.rst\", encoding=\"utf-8\") as fp:\n changes = fp.read()\n\nversion = VERSION\n\nsetup(\n name=\"urllib3\",\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=u\"\\n\\n\".join([readme, changes]),\n classifiers=[\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Software Development :: Libraries\",\n ],\n keywords=\"urllib httplib threadsafe filepost http https ssl pooling\",\n author=\"Andrey Petrov\",\n author_email=\"[email protected]\",\n url=\"https://urllib3.readthedocs.io/\",\n project_urls={\n \"Documentation\": \"https://urllib3.readthedocs.io/\",\n \"Code\": \"https://github.com/urllib3/urllib3\",\n \"Issue tracker\": \"https://github.com/urllib3/urllib3/issues\",\n },\n license=\"MIT\",\n packages=[\n \"urllib3\",\n \"urllib3.packages\",\n \"urllib3.packages.ssl_match_hostname\",\n \"urllib3.packages.backports\",\n \"urllib3.contrib\",\n \"urllib3.contrib._securetransport\",\n \"urllib3.util\",\n ],\n package_dir={\"\": \"src\"},\n requires=[],\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, <4\",\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n \"pytest\",\n \"mock\",\n \"tornado\",\n ],\n test_suite=\"test\",\n extras_require={\n \"brotli\": [\"brotlipy>=0.6.0\"],\n \"secure\": [\n \"pyOpenSSL>=0.14\",\n \"cryptography>=1.3.4\",\n \"idna>=2.0.0\",\n \"certifi\",\n \"ipaddress; python_version=='2.7'\",\n ],\n \"socks\": [\"PySocks>=1.5.6,<2.0,!=1.5.7\"],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport shutil\n\nimport nox\n\n\ndef tests_impl(session, extras=\"socks,secure,brotli\"):\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(\".[{extras}]\".format(extras=extras))\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"}\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n\n\[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\", \"3.8\", \"3.9\", \"pypy\"])\ndef test(session):\n tests_impl(session)\n\n\[email protected](python=[\"2\", \"3\"])\ndef google_brotli(session):\n # https://pypi.org/project/Brotli/ is the Google version of brotli, so\n # install it separately and don't install our brotli extra (which installs\n # brotlipy).\n session.install(\"brotli\")\n tests_impl(session, extras=\"socks,secure\")\n\n\[email protected](python=\"2.7\")\ndef app_engine(session):\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(\".\")\n session.run(\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"sx\",\n \"test/appengine\",\n *session.posargs\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n\n\[email protected]()\ndef blacken(session):\n \"\"\"Run black code formatter.\"\"\"\n session.install(\"black\")\n session.run(\"black\", \"src\", \"dummyserver\", \"test\", \"noxfile.py\", \"setup.py\")\n\n lint(session)\n\n\[email protected]\ndef lint(session):\n session.install(\"flake8\", \"black\")\n session.run(\"flake8\", \"--version\")\n session.run(\"black\", \"--version\")\n session.run(\n \"black\", \"--check\", \"src\", \"dummyserver\", \"test\", \"noxfile.py\", \"setup.py\"\n )\n session.run(\"flake8\", \"setup.py\", \"docs\", \"dummyserver\", \"src\", \"test\")\n\n\[email protected]\ndef docs(session):\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}, {"content": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nimport os\nimport re\nimport codecs\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nwith open(os.path.join(base_path, \"src\", \"urllib3\", \"__init__.py\")) as fp:\n VERSION = (\n re.compile(r\"\"\".*__version__ = [\"'](.*?)['\"]\"\"\", re.S).match(fp.read()).group(1)\n )\n\n\nwith codecs.open(\"README.rst\", encoding=\"utf-8\") as fp:\n readme = fp.read()\n\nwith codecs.open(\"CHANGES.rst\", encoding=\"utf-8\") as fp:\n changes = fp.read()\n\nversion = VERSION\n\nsetup(\n name=\"urllib3\",\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=u\"\\n\\n\".join([readme, changes]),\n classifiers=[\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Software Development :: Libraries\",\n ],\n keywords=\"urllib httplib threadsafe filepost http https ssl pooling\",\n author=\"Andrey Petrov\",\n author_email=\"[email protected]\",\n url=\"https://urllib3.readthedocs.io/\",\n project_urls={\n \"Documentation\": \"https://urllib3.readthedocs.io/\",\n \"Code\": \"https://github.com/urllib3/urllib3\",\n \"Issue tracker\": \"https://github.com/urllib3/urllib3/issues\",\n },\n license=\"MIT\",\n packages=[\n \"urllib3\",\n \"urllib3.packages\",\n \"urllib3.packages.ssl_match_hostname\",\n \"urllib3.packages.backports\",\n \"urllib3.contrib\",\n \"urllib3.contrib._securetransport\",\n \"urllib3.util\",\n ],\n package_dir={\"\": \"src\"},\n requires=[],\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, <4\",\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n \"pytest\",\n \"mock\",\n \"tornado\",\n ],\n test_suite=\"test\",\n extras_require={\n \"brotli\": [\"brotlipy>=0.6.0\"],\n \"secure\": [\n \"pyOpenSSL>=0.14\",\n \"cryptography>=1.3.4\",\n \"idna>=2.0.0\",\n \"certifi\",\n \"ipaddress; python_version=='2.7'\",\n ],\n \"socks\": [\"PySocks>=1.5.6,<2.0,!=1.5.7\"],\n },\n)\n", "path": "setup.py"}]}
| 2,207 | 253 |
gh_patches_debug_5287
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Extra field in rating results
Feedback rating results display the extra blank field after it was changed in #1129
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/feedback/views.py`
Content:
```
1 #-*- coding: utf-8 -*-
2 import json
3
4 from collections import namedtuple, defaultdict
5
6 from django.http import Http404, HttpResponse
7 from django.shortcuts import render, redirect, get_object_or_404
8 from django.template import RequestContext
9 from django.contrib.contenttypes.models import ContentType
10 from django.contrib import messages
11 from django.contrib.admin.views.decorators import staff_member_required
12 from django.contrib.auth.decorators import login_required
13 from django.core.exceptions import ObjectDoesNotExist
14 from django.utils.translation import ugettext_lazy as _
15 from django.utils.safestring import SafeString
16
17 from apps.feedback.models import FeedbackRelation, FieldOfStudyAnswer, RATING_CHOICES, TextQuestion, TextAnswer, RegisterToken
18 from apps.feedback.forms import create_answer_forms
19 from apps.events.models import Event
20
21 @login_required
22 def feedback(request, applabel, appmodel, object_id, feedback_id):
23 fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)
24
25 if not fbr.can_answer(request.user):
26 messages.error(request, fbr.answer_error_message(request.user))
27 return redirect("home")
28
29 if request.method == "POST":
30 answers = create_answer_forms(fbr, post_data=request.POST)
31 if all([a.is_valid() for a in answers]):
32 for a in answers:
33 a.save()
34
35 # mark that the user has answered
36 fbr.answered.add(request.user)
37 fbr.save()
38
39 # Set field of study automaticly
40 fosa = FieldOfStudyAnswer(feedback_relation = fbr, answer = request.user.field_of_study)
41 fosa.save()
42
43 messages.success(request, _(u"Takk for at du svarte."))
44 return redirect("home")
45 else:
46 messages.error(request, _(u"Du må svare på alle påkrevde felt."))
47 else:
48 answers = create_answer_forms(fbr)
49
50 description = fbr.description
51
52 return render(request, 'feedback/answer.html',
53 {'answers': answers, 'description':description})
54
55 @staff_member_required
56 def result(request, applabel, appmodel, object_id, feedback_id):
57 return feedback_results(request, applabel, appmodel, object_id, feedback_id)
58
59 def results_token(request, applabel, appmodel, object_id, feedback_id, token):
60 fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)
61 rt = get_object_or_404(RegisterToken, token = token)
62
63 if rt.is_valid(fbr):
64 return feedback_results(request, applabel, appmodel, object_id, feedback_id, True)
65 else:
66 return HttpResponse('Unauthorized', status=401)
67
68 def feedback_results(request, applabel, appmodel, object_id, feedback_id, token=False):
69 fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)
70
71 Qa = namedtuple("Qa", "question, answers")
72 question_and_answers = []
73
74 for question in fbr.questions:
75 if (question.display or not token) and isinstance(question, TextQuestion):
76 question_and_answers.append(Qa(question, fbr.answers_to_question(question)))
77
78 info = None
79
80 if(fbr.feedback.display_info or not token):
81 info = fbr.content_info()
82 info[_(u'Besvarelser')] = fbr.answered.count()
83
84
85 rt = get_object_or_404(RegisterToken, fbr=fbr)
86
87 token_url = u"%s%sresults/%s" % (request.META['HTTP_HOST'], fbr.get_absolute_url(), rt.token)
88
89 return render(request, 'feedback/results.html',{'question_and_answers': question_and_answers,
90 'description': fbr.description, 'token_url' : token_url,'token' : token, 'info': info})
91
92 @staff_member_required
93 def chart_data(request, applabel, appmodel, object_id, feedback_id):
94 return get_chart_data(request, applabel, appmodel, object_id, feedback_id)
95
96 def chart_data_token(request, applabel, appmodel, object_id, feedback_id, token):
97 fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)
98 rt = get_object_or_404(RegisterToken, token = token)
99
100 if rt.is_valid(fbr):
101 return get_chart_data(request, applabel, appmodel, object_id, feedback_id, True)
102 else:
103 return HttpResponse('Unauthorized', status=401)
104
105 def get_chart_data(request, applabel, appmodel, object_id, feedback_id, token=False):
106 fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)
107
108 rating_answers = []
109 rating_titles = []
110 answer_collection = dict()
111 answer_collection['replies'] = dict()
112 answer_length = int(len(RATING_CHOICES) +1)
113 for question in fbr.ratingquestion:
114 if question.display or not token:
115 rating_titles.append(str(question))
116 answers = fbr.answers_to_question(question)
117 answer_count = [0] * answer_length
118 for answer in answers:
119 answer_count[int(answer.answer)] += 1
120 rating_answers.append(answer_count[1:])
121
122 fos_answer_count = defaultdict(int)
123
124 if fbr.feedback.display_field_of_study or not token:
125 fos = fbr.field_of_study_answers.all()
126 for answer in fos:
127 fos_answer_count[str(answer)] += 1
128
129
130 mc_questions = []
131 mc_answer_count = []
132
133 for question in fbr.multiple_choice_question:
134 if question.display or not token:
135 mc_questions.append(unicode(question))
136 answer_count = defaultdict(int)
137 for answer in fbr.answers_to_question(question):
138 answer_count[str(answer)] += 1
139 mc_answer_count.append(answer_count.items())
140
141 answer_collection['replies']['ratings'] = rating_answers
142 answer_collection['replies']['titles'] = rating_titles
143 answer_collection['replies']['mc_questions'] = mc_questions
144 answer_collection['replies']['mc_answers'] = mc_answer_count
145 answer_collection['replies']['fos'] = fos_answer_count.items()
146
147 return HttpResponse(json.dumps(answer_collection), content_type='application/json')
148
149 @staff_member_required
150 def index(request):
151 feedbacks = FeedbackRelation.objects.all()
152 return render(request, 'feedback/index.html', {'feedbacks': feedbacks})
153
154 @staff_member_required
155 def delete_answer(request):
156 if request.method == 'POST':
157 answer_id = request.POST.get('answer_id')
158 answer = get_object_or_404(TextAnswer, pk=answer_id)
159 answer.delete()
160 return HttpResponse(status = 200)
161 return HttpResponse(status=401)
162
163 def _get_fbr_or_404(app_label, app_model, object_id, feedback_id):
164 """
165 Get FeedbackRelation or raise Http404
166 """
167 try:
168 ct = ContentType.objects.get(app_label=app_label, model=app_model)
169 fbr = FeedbackRelation.objects.get(content_type=ct,
170 object_id=object_id,
171 feedback_id=feedback_id)
172 except ObjectDoesNotExist:
173 raise Http404
174
175 return fbr
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/feedback/views.py b/apps/feedback/views.py
--- a/apps/feedback/views.py
+++ b/apps/feedback/views.py
@@ -109,7 +109,7 @@
rating_titles = []
answer_collection = dict()
answer_collection['replies'] = dict()
- answer_length = int(len(RATING_CHOICES) +1)
+ answer_length = int(len(RATING_CHOICES))
for question in fbr.ratingquestion:
if question.display or not token:
rating_titles.append(str(question))
|
{"golden_diff": "diff --git a/apps/feedback/views.py b/apps/feedback/views.py\n--- a/apps/feedback/views.py\n+++ b/apps/feedback/views.py\n@@ -109,7 +109,7 @@\n rating_titles = []\n answer_collection = dict()\n answer_collection['replies'] = dict()\n- answer_length = int(len(RATING_CHOICES) +1)\n+ answer_length = int(len(RATING_CHOICES))\n for question in fbr.ratingquestion:\n if question.display or not token:\n rating_titles.append(str(question))\n", "issue": "Extra field in rating results\nFeedback rating results display the extra blank field after it was changed in #1129 \n\n", "before_files": [{"content": "#-*- coding: utf-8 -*-\nimport json\n\nfrom collections import namedtuple, defaultdict\n\nfrom django.http import Http404, HttpResponse\nfrom django.shortcuts import render, redirect, get_object_or_404\nfrom django.template import RequestContext\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.contrib import messages\nfrom django.contrib.admin.views.decorators import staff_member_required\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.utils.safestring import SafeString\n\nfrom apps.feedback.models import FeedbackRelation, FieldOfStudyAnswer, RATING_CHOICES, TextQuestion, TextAnswer, RegisterToken\nfrom apps.feedback.forms import create_answer_forms\nfrom apps.events.models import Event\n\n@login_required\ndef feedback(request, applabel, appmodel, object_id, feedback_id):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n\n if not fbr.can_answer(request.user):\n messages.error(request, fbr.answer_error_message(request.user))\n return redirect(\"home\")\n\n if request.method == \"POST\":\n answers = create_answer_forms(fbr, post_data=request.POST)\n if all([a.is_valid() for a in answers]):\n for a in answers:\n a.save()\n\n # mark that the user has answered\n fbr.answered.add(request.user)\n fbr.save()\n\n # Set field of study automaticly\n fosa = FieldOfStudyAnswer(feedback_relation = fbr, answer = request.user.field_of_study)\n fosa.save()\n\n messages.success(request, _(u\"Takk for at du svarte.\"))\n return redirect(\"home\")\n else:\n messages.error(request, _(u\"Du m\u00e5 svare p\u00e5 alle p\u00e5krevde felt.\"))\n else:\n answers = create_answer_forms(fbr)\n\n description = fbr.description\n\n return render(request, 'feedback/answer.html',\n {'answers': answers, 'description':description})\n\n@staff_member_required\ndef result(request, applabel, appmodel, object_id, feedback_id):\n return feedback_results(request, applabel, appmodel, object_id, feedback_id)\n\ndef results_token(request, applabel, appmodel, object_id, feedback_id, token):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n rt = get_object_or_404(RegisterToken, token = token)\n\n if rt.is_valid(fbr):\n return feedback_results(request, applabel, appmodel, object_id, feedback_id, True)\n else:\n return HttpResponse('Unauthorized', status=401)\n\ndef feedback_results(request, applabel, appmodel, object_id, feedback_id, token=False):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n\n Qa = namedtuple(\"Qa\", \"question, answers\")\n question_and_answers = []\n\n for question in fbr.questions:\n if (question.display or not token) and isinstance(question, TextQuestion):\n question_and_answers.append(Qa(question, fbr.answers_to_question(question)))\n \n info = None\n\n if(fbr.feedback.display_info or not token):\n info = fbr.content_info()\n info[_(u'Besvarelser')] = fbr.answered.count()\n \n \n rt = get_object_or_404(RegisterToken, fbr=fbr)\n\n token_url = u\"%s%sresults/%s\" % (request.META['HTTP_HOST'], fbr.get_absolute_url(), rt.token)\n \n return render(request, 'feedback/results.html',{'question_and_answers': question_and_answers, \n 'description': fbr.description, 'token_url' : token_url,'token' : token, 'info': info})\n\n@staff_member_required\ndef chart_data(request, applabel, appmodel, object_id, feedback_id):\n return get_chart_data(request, applabel, appmodel, object_id, feedback_id)\n\ndef chart_data_token(request, applabel, appmodel, object_id, feedback_id, token):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n rt = get_object_or_404(RegisterToken, token = token)\n\n if rt.is_valid(fbr):\n return get_chart_data(request, applabel, appmodel, object_id, feedback_id, True)\n else:\n return HttpResponse('Unauthorized', status=401)\n\ndef get_chart_data(request, applabel, appmodel, object_id, feedback_id, token=False):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n \n rating_answers = []\n rating_titles = []\n answer_collection = dict()\n answer_collection['replies'] = dict()\n answer_length = int(len(RATING_CHOICES) +1)\n for question in fbr.ratingquestion:\n if question.display or not token:\n rating_titles.append(str(question))\n answers = fbr.answers_to_question(question)\n answer_count = [0] * answer_length\n for answer in answers:\n answer_count[int(answer.answer)] += 1\n rating_answers.append(answer_count[1:])\n\n fos_answer_count = defaultdict(int)\n \n if fbr.feedback.display_field_of_study or not token:\n fos = fbr.field_of_study_answers.all()\n for answer in fos:\n fos_answer_count[str(answer)] += 1\n \n\n mc_questions = []\n mc_answer_count = []\n \n for question in fbr.multiple_choice_question:\n if question.display or not token:\n mc_questions.append(unicode(question))\n answer_count = defaultdict(int)\n for answer in fbr.answers_to_question(question):\n answer_count[str(answer)] += 1\n mc_answer_count.append(answer_count.items())\n\n answer_collection['replies']['ratings'] = rating_answers\n answer_collection['replies']['titles'] = rating_titles\n answer_collection['replies']['mc_questions'] = mc_questions\n answer_collection['replies']['mc_answers'] = mc_answer_count\n answer_collection['replies']['fos'] = fos_answer_count.items()\n \n return HttpResponse(json.dumps(answer_collection), content_type='application/json')\n\n@staff_member_required\ndef index(request):\n feedbacks = FeedbackRelation.objects.all()\n return render(request, 'feedback/index.html', {'feedbacks': feedbacks})\n\n@staff_member_required\ndef delete_answer(request):\n if request.method == 'POST':\n answer_id = request.POST.get('answer_id')\n answer = get_object_or_404(TextAnswer, pk=answer_id)\n answer.delete()\n return HttpResponse(status = 200)\n return HttpResponse(status=401)\n\ndef _get_fbr_or_404(app_label, app_model, object_id, feedback_id):\n \"\"\"\n Get FeedbackRelation or raise Http404\n \"\"\"\n try:\n ct = ContentType.objects.get(app_label=app_label, model=app_model)\n fbr = FeedbackRelation.objects.get(content_type=ct,\n object_id=object_id,\n feedback_id=feedback_id)\n except ObjectDoesNotExist:\n raise Http404\n\n return fbr\n", "path": "apps/feedback/views.py"}], "after_files": [{"content": "#-*- coding: utf-8 -*-\nimport json\n\nfrom collections import namedtuple, defaultdict\n\nfrom django.http import Http404, HttpResponse\nfrom django.shortcuts import render, redirect, get_object_or_404\nfrom django.template import RequestContext\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.contrib import messages\nfrom django.contrib.admin.views.decorators import staff_member_required\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.utils.safestring import SafeString\n\nfrom apps.feedback.models import FeedbackRelation, FieldOfStudyAnswer, RATING_CHOICES, TextQuestion, TextAnswer, RegisterToken\nfrom apps.feedback.forms import create_answer_forms\nfrom apps.events.models import Event\n\n@login_required\ndef feedback(request, applabel, appmodel, object_id, feedback_id):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n\n if not fbr.can_answer(request.user):\n messages.error(request, fbr.answer_error_message(request.user))\n return redirect(\"home\")\n\n if request.method == \"POST\":\n answers = create_answer_forms(fbr, post_data=request.POST)\n if all([a.is_valid() for a in answers]):\n for a in answers:\n a.save()\n\n # mark that the user has answered\n fbr.answered.add(request.user)\n fbr.save()\n\n # Set field of study automaticly\n fosa = FieldOfStudyAnswer(feedback_relation = fbr, answer = request.user.field_of_study)\n fosa.save()\n\n messages.success(request, _(u\"Takk for at du svarte.\"))\n return redirect(\"home\")\n else:\n messages.error(request, _(u\"Du m\u00e5 svare p\u00e5 alle p\u00e5krevde felt.\"))\n else:\n answers = create_answer_forms(fbr)\n\n description = fbr.description\n\n return render(request, 'feedback/answer.html',\n {'answers': answers, 'description':description})\n\n@staff_member_required\ndef result(request, applabel, appmodel, object_id, feedback_id):\n return feedback_results(request, applabel, appmodel, object_id, feedback_id)\n\ndef results_token(request, applabel, appmodel, object_id, feedback_id, token):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n rt = get_object_or_404(RegisterToken, token = token)\n\n if rt.is_valid(fbr):\n return feedback_results(request, applabel, appmodel, object_id, feedback_id, True)\n else:\n return HttpResponse('Unauthorized', status=401)\n\ndef feedback_results(request, applabel, appmodel, object_id, feedback_id, token=False):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n\n Qa = namedtuple(\"Qa\", \"question, answers\")\n question_and_answers = []\n\n for question in fbr.questions:\n if (question.display or not token) and isinstance(question, TextQuestion):\n question_and_answers.append(Qa(question, fbr.answers_to_question(question)))\n \n info = None\n\n if(fbr.feedback.display_info or not token):\n info = fbr.content_info()\n info[_(u'Besvarelser')] = fbr.answered.count()\n \n \n rt = get_object_or_404(RegisterToken, fbr=fbr)\n\n token_url = u\"%s%sresults/%s\" % (request.META['HTTP_HOST'], fbr.get_absolute_url(), rt.token)\n \n return render(request, 'feedback/results.html',{'question_and_answers': question_and_answers, \n 'description': fbr.description, 'token_url' : token_url,'token' : token, 'info': info})\n\n@staff_member_required\ndef chart_data(request, applabel, appmodel, object_id, feedback_id):\n return get_chart_data(request, applabel, appmodel, object_id, feedback_id)\n\ndef chart_data_token(request, applabel, appmodel, object_id, feedback_id, token):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n rt = get_object_or_404(RegisterToken, token = token)\n\n if rt.is_valid(fbr):\n return get_chart_data(request, applabel, appmodel, object_id, feedback_id, True)\n else:\n return HttpResponse('Unauthorized', status=401)\n\ndef get_chart_data(request, applabel, appmodel, object_id, feedback_id, token=False):\n fbr = _get_fbr_or_404(applabel, appmodel, object_id, feedback_id)\n \n rating_answers = []\n rating_titles = []\n answer_collection = dict()\n answer_collection['replies'] = dict()\n answer_length = int(len(RATING_CHOICES))\n for question in fbr.ratingquestion:\n if question.display or not token:\n rating_titles.append(str(question))\n answers = fbr.answers_to_question(question)\n answer_count = [0] * answer_length\n for answer in answers:\n answer_count[int(answer.answer)] += 1\n rating_answers.append(answer_count[1:])\n\n fos_answer_count = defaultdict(int)\n \n if fbr.feedback.display_field_of_study or not token:\n fos = fbr.field_of_study_answers.all()\n for answer in fos:\n fos_answer_count[str(answer)] += 1\n \n\n mc_questions = []\n mc_answer_count = []\n \n for question in fbr.multiple_choice_question:\n if question.display or not token:\n mc_questions.append(unicode(question))\n answer_count = defaultdict(int)\n for answer in fbr.answers_to_question(question):\n answer_count[str(answer)] += 1\n mc_answer_count.append(answer_count.items())\n\n answer_collection['replies']['ratings'] = rating_answers\n answer_collection['replies']['titles'] = rating_titles\n answer_collection['replies']['mc_questions'] = mc_questions\n answer_collection['replies']['mc_answers'] = mc_answer_count\n answer_collection['replies']['fos'] = fos_answer_count.items()\n \n return HttpResponse(json.dumps(answer_collection), content_type='application/json')\n\n@staff_member_required\ndef index(request):\n feedbacks = FeedbackRelation.objects.all()\n return render(request, 'feedback/index.html', {'feedbacks': feedbacks})\n\n@staff_member_required\ndef delete_answer(request):\n if request.method == 'POST':\n answer_id = request.POST.get('answer_id')\n answer = get_object_or_404(TextAnswer, pk=answer_id)\n answer.delete()\n return HttpResponse(status = 200)\n return HttpResponse(status=401)\n\ndef _get_fbr_or_404(app_label, app_model, object_id, feedback_id):\n \"\"\"\n Get FeedbackRelation or raise Http404\n \"\"\"\n try:\n ct = ContentType.objects.get(app_label=app_label, model=app_model)\n fbr = FeedbackRelation.objects.get(content_type=ct,\n object_id=object_id,\n feedback_id=feedback_id)\n except ObjectDoesNotExist:\n raise Http404\n\n return fbr\n", "path": "apps/feedback/views.py"}]}
| 2,273 | 116 |
gh_patches_debug_58736
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-6081
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not sure that OAuth2 client source should use authorization header
I've been testing authentik using an Auth0 openIDC source as well as a google source. I have gotten both to work, but Auth0 was not working before a fix to prevent adding the access token to the authorizaton Bearer headers. Google auth works fine with or without this fix.
https://auth0.com/blog/id-token-access-token-what-is-the-difference/ suggests that many endpoints should not be given the access token. Not sure this is relevant.
I think Auth0 is less permissive and prefers the access_token param rather than the Authorization Bearer token
in sources/oauth/clients/oauth2.py
```
class OAuth2Client(BaseOAuthClient):
"""OAuth2 Client"""
...
def do_request(self, method: str, url: str, **kwargs) -> Response:
"""Build remote url request. Constructs necessary auth."""
if "token" in kwargs:
token = kwargs.pop("token")
params = kwargs.get("params", {})
params["access_token"] = token["access_token"]
kwargs["params"] = params
headers = kwargs.get("headers", {})
# Note this fix
# headers["Authorization"] = f"{token['token_type']} {token['access_token']}"
kwargs["headers"] = headers
return super().do_request(method, url, **kwargs)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/sources/oauth/types/oidc.py`
Content:
```
1 """OpenID Connect OAuth Views"""
2 from typing import Any
3
4 from authentik.sources.oauth.clients.oauth2 import UserprofileHeaderAuthClient
5 from authentik.sources.oauth.models import OAuthSource
6 from authentik.sources.oauth.types.registry import SourceType, registry
7 from authentik.sources.oauth.views.callback import OAuthCallback
8 from authentik.sources.oauth.views.redirect import OAuthRedirect
9
10
11 class OpenIDConnectOAuthRedirect(OAuthRedirect):
12 """OpenIDConnect OAuth2 Redirect"""
13
14 def get_additional_parameters(self, source: OAuthSource): # pragma: no cover
15 return {
16 "scope": ["openid", "email", "profile"],
17 }
18
19
20 class OpenIDConnectOAuth2Callback(OAuthCallback):
21 """OpenIDConnect OAuth2 Callback"""
22
23 client_class: UserprofileHeaderAuthClient
24
25 def get_user_id(self, info: dict[str, str]) -> str:
26 return info.get("sub", "")
27
28 def get_user_enroll_context(
29 self,
30 info: dict[str, Any],
31 ) -> dict[str, Any]:
32 return {
33 "username": info.get("nickname", info.get("preferred_username")),
34 "email": info.get("email"),
35 "name": info.get("name"),
36 }
37
38
39 @registry.register()
40 class OpenIDConnectType(SourceType):
41 """OpenIDConnect Type definition"""
42
43 callback_view = OpenIDConnectOAuth2Callback
44 redirect_view = OpenIDConnectOAuthRedirect
45 name = "OpenID Connect"
46 slug = "openidconnect"
47
48 urls_customizable = True
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/authentik/sources/oauth/types/oidc.py b/authentik/sources/oauth/types/oidc.py
--- a/authentik/sources/oauth/types/oidc.py
+++ b/authentik/sources/oauth/types/oidc.py
@@ -20,7 +20,7 @@
class OpenIDConnectOAuth2Callback(OAuthCallback):
"""OpenIDConnect OAuth2 Callback"""
- client_class: UserprofileHeaderAuthClient
+ client_class = UserprofileHeaderAuthClient
def get_user_id(self, info: dict[str, str]) -> str:
return info.get("sub", "")
|
{"golden_diff": "diff --git a/authentik/sources/oauth/types/oidc.py b/authentik/sources/oauth/types/oidc.py\n--- a/authentik/sources/oauth/types/oidc.py\n+++ b/authentik/sources/oauth/types/oidc.py\n@@ -20,7 +20,7 @@\n class OpenIDConnectOAuth2Callback(OAuthCallback):\n \"\"\"OpenIDConnect OAuth2 Callback\"\"\"\n \n- client_class: UserprofileHeaderAuthClient\n+ client_class = UserprofileHeaderAuthClient\n \n def get_user_id(self, info: dict[str, str]) -> str:\n return info.get(\"sub\", \"\")\n", "issue": "Not sure that OAuth2 client source should use authorization header\nI've been testing authentik using an Auth0 openIDC source as well as a google source. I have gotten both to work, but Auth0 was not working before a fix to prevent adding the access token to the authorizaton Bearer headers. Google auth works fine with or without this fix. \r\n\r\nhttps://auth0.com/blog/id-token-access-token-what-is-the-difference/ suggests that many endpoints should not be given the access token. Not sure this is relevant.\r\n\r\nI think Auth0 is less permissive and prefers the access_token param rather than the Authorization Bearer token\r\n\r\nin sources/oauth/clients/oauth2.py\r\n```\r\nclass OAuth2Client(BaseOAuthClient):\r\n \"\"\"OAuth2 Client\"\"\"\r\n\r\n ...\r\n\r\n def do_request(self, method: str, url: str, **kwargs) -> Response:\r\n \"\"\"Build remote url request. Constructs necessary auth.\"\"\"\r\n if \"token\" in kwargs:\r\n token = kwargs.pop(\"token\")\r\n\r\n params = kwargs.get(\"params\", {})\r\n params[\"access_token\"] = token[\"access_token\"]\r\n kwargs[\"params\"] = params\r\n\r\n headers = kwargs.get(\"headers\", {})\r\n # Note this fix\r\n # headers[\"Authorization\"] = f\"{token['token_type']} {token['access_token']}\"\r\n kwargs[\"headers\"] = headers\r\n return super().do_request(method, url, **kwargs)\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"OpenID Connect OAuth Views\"\"\"\nfrom typing import Any\n\nfrom authentik.sources.oauth.clients.oauth2 import UserprofileHeaderAuthClient\nfrom authentik.sources.oauth.models import OAuthSource\nfrom authentik.sources.oauth.types.registry import SourceType, registry\nfrom authentik.sources.oauth.views.callback import OAuthCallback\nfrom authentik.sources.oauth.views.redirect import OAuthRedirect\n\n\nclass OpenIDConnectOAuthRedirect(OAuthRedirect):\n \"\"\"OpenIDConnect OAuth2 Redirect\"\"\"\n\n def get_additional_parameters(self, source: OAuthSource): # pragma: no cover\n return {\n \"scope\": [\"openid\", \"email\", \"profile\"],\n }\n\n\nclass OpenIDConnectOAuth2Callback(OAuthCallback):\n \"\"\"OpenIDConnect OAuth2 Callback\"\"\"\n\n client_class: UserprofileHeaderAuthClient\n\n def get_user_id(self, info: dict[str, str]) -> str:\n return info.get(\"sub\", \"\")\n\n def get_user_enroll_context(\n self,\n info: dict[str, Any],\n ) -> dict[str, Any]:\n return {\n \"username\": info.get(\"nickname\", info.get(\"preferred_username\")),\n \"email\": info.get(\"email\"),\n \"name\": info.get(\"name\"),\n }\n\n\[email protected]()\nclass OpenIDConnectType(SourceType):\n \"\"\"OpenIDConnect Type definition\"\"\"\n\n callback_view = OpenIDConnectOAuth2Callback\n redirect_view = OpenIDConnectOAuthRedirect\n name = \"OpenID Connect\"\n slug = \"openidconnect\"\n\n urls_customizable = True\n", "path": "authentik/sources/oauth/types/oidc.py"}], "after_files": [{"content": "\"\"\"OpenID Connect OAuth Views\"\"\"\nfrom typing import Any\n\nfrom authentik.sources.oauth.clients.oauth2 import UserprofileHeaderAuthClient\nfrom authentik.sources.oauth.models import OAuthSource\nfrom authentik.sources.oauth.types.registry import SourceType, registry\nfrom authentik.sources.oauth.views.callback import OAuthCallback\nfrom authentik.sources.oauth.views.redirect import OAuthRedirect\n\n\nclass OpenIDConnectOAuthRedirect(OAuthRedirect):\n \"\"\"OpenIDConnect OAuth2 Redirect\"\"\"\n\n def get_additional_parameters(self, source: OAuthSource): # pragma: no cover\n return {\n \"scope\": [\"openid\", \"email\", \"profile\"],\n }\n\n\nclass OpenIDConnectOAuth2Callback(OAuthCallback):\n \"\"\"OpenIDConnect OAuth2 Callback\"\"\"\n\n client_class = UserprofileHeaderAuthClient\n\n def get_user_id(self, info: dict[str, str]) -> str:\n return info.get(\"sub\", \"\")\n\n def get_user_enroll_context(\n self,\n info: dict[str, Any],\n ) -> dict[str, Any]:\n return {\n \"username\": info.get(\"nickname\", info.get(\"preferred_username\")),\n \"email\": info.get(\"email\"),\n \"name\": info.get(\"name\"),\n }\n\n\[email protected]()\nclass OpenIDConnectType(SourceType):\n \"\"\"OpenIDConnect Type definition\"\"\"\n\n callback_view = OpenIDConnectOAuth2Callback\n redirect_view = OpenIDConnectOAuthRedirect\n name = \"OpenID Connect\"\n slug = \"openidconnect\"\n\n urls_customizable = True\n", "path": "authentik/sources/oauth/types/oidc.py"}]}
| 983 | 132 |
gh_patches_debug_18320
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-1453
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tornado 5.0 raises error on install with older Python versions.
changed to `"tornado>=4.1,<5.0"` in setup.py
This broke installation via pip for me.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 from __future__ import print_function
5 from setuptools import setup
6 import re
7 import os
8 import sys
9
10
11 long_description = (
12 "MkDocs is a fast, simple and downright gorgeous static site generator "
13 "that's geared towards building project documentation. Documentation "
14 "source files are written in Markdown, and configured with a single YAML "
15 "configuration file."
16 )
17
18
19 def get_version(package):
20 """Return package version as listed in `__version__` in `init.py`."""
21 init_py = open(os.path.join(package, '__init__.py')).read()
22 return re.search("__version__ = ['\"]([^'\"]+)['\"]", init_py).group(1)
23
24
25 def get_packages(package):
26 """Return root package and all sub-packages."""
27 return [dirpath
28 for dirpath, dirnames, filenames in os.walk(package)
29 if os.path.exists(os.path.join(dirpath, '__init__.py'))]
30
31
32 if sys.argv[-1] == 'publish':
33 if os.system("pip freeze | grep wheel"):
34 print("wheel not installed.\nUse `pip install wheel`.\nExiting.")
35 sys.exit()
36 if os.system("pip freeze | grep twine"):
37 print("twine not installed.\nUse `pip install twine`.\nExiting.")
38 sys.exit()
39 os.system("python setup.py sdist bdist_wheel")
40 os.system("twine upload dist/*")
41 print("You probably want to also tag the version now:")
42 print(" git tag -a {0} -m 'version {0}'".format(get_version("mkdocs")))
43 print(" git push --tags")
44 sys.exit()
45
46
47 setup(
48 name="mkdocs",
49 version=get_version("mkdocs"),
50 url='http://www.mkdocs.org',
51 license='BSD',
52 description='Project documentation with Markdown.',
53 long_description=long_description,
54 author='Tom Christie',
55 author_email='[email protected]', # SEE NOTE BELOW (*)
56 packages=get_packages("mkdocs"),
57 include_package_data=True,
58 install_requires=[
59 'click>=3.3',
60 'Jinja2>=2.7.1',
61 'livereload>=2.5.1',
62 'Markdown>=2.3.1',
63 'PyYAML>=3.10',
64 'tornado>=4.1',
65 ],
66 entry_points={
67 'console_scripts': [
68 'mkdocs = mkdocs.__main__:cli',
69 ],
70 'mkdocs.themes': [
71 'mkdocs = mkdocs.themes.mkdocs',
72 'readthedocs = mkdocs.themes.readthedocs',
73 ],
74 'mkdocs.plugins': [
75 'search = mkdocs.contrib.search:SearchPlugin',
76 ],
77 },
78 classifiers=[
79 'Development Status :: 5 - Production/Stable',
80 'Environment :: Console',
81 'Environment :: Web Environment',
82 'Intended Audience :: Developers',
83 'License :: OSI Approved :: BSD License',
84 'Operating System :: OS Independent',
85 'Programming Language :: Python',
86 'Programming Language :: Python :: 2',
87 'Programming Language :: Python :: 2.7',
88 'Programming Language :: Python :: 3',
89 'Programming Language :: Python :: 3.3',
90 'Programming Language :: Python :: 3.4',
91 'Programming Language :: Python :: 3.5',
92 'Programming Language :: Python :: 3.6',
93 "Programming Language :: Python :: Implementation :: CPython",
94 "Programming Language :: Python :: Implementation :: PyPy",
95 'Topic :: Documentation',
96 'Topic :: Text Processing',
97 ],
98 zip_safe=False,
99 )
100
101 # (*) Please direct queries to the discussion group:
102 # https://groups.google.com/forum/#!forum/mkdocs
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -61,8 +61,9 @@
'livereload>=2.5.1',
'Markdown>=2.3.1',
'PyYAML>=3.10',
- 'tornado>=4.1',
+ 'tornado>=5.0',
],
+ python_requires='>=2.7.9,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',
entry_points={
'console_scripts': [
'mkdocs = mkdocs.__main__:cli',
@@ -86,7 +87,6 @@
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
- 'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -61,8 +61,9 @@\n 'livereload>=2.5.1',\n 'Markdown>=2.3.1',\n 'PyYAML>=3.10',\n- 'tornado>=4.1',\n+ 'tornado>=5.0',\n ],\n+ python_requires='>=2.7.9,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n entry_points={\n 'console_scripts': [\n 'mkdocs = mkdocs.__main__:cli',\n@@ -86,7 +87,6 @@\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n- 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n", "issue": "Tornado 5.0 raises error on install with older Python versions.\nchanged to `\"tornado>=4.1,<5.0\"` in setup.py\r\n\r\nThis broke installation via pip for me. \n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import print_function\nfrom setuptools import setup\nimport re\nimport os\nimport sys\n\n\nlong_description = (\n \"MkDocs is a fast, simple and downright gorgeous static site generator \"\n \"that's geared towards building project documentation. Documentation \"\n \"source files are written in Markdown, and configured with a single YAML \"\n \"configuration file.\"\n)\n\n\ndef get_version(package):\n \"\"\"Return package version as listed in `__version__` in `init.py`.\"\"\"\n init_py = open(os.path.join(package, '__init__.py')).read()\n return re.search(\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", init_py).group(1)\n\n\ndef get_packages(package):\n \"\"\"Return root package and all sub-packages.\"\"\"\n return [dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, '__init__.py'))]\n\n\nif sys.argv[-1] == 'publish':\n if os.system(\"pip freeze | grep wheel\"):\n print(\"wheel not installed.\\nUse `pip install wheel`.\\nExiting.\")\n sys.exit()\n if os.system(\"pip freeze | grep twine\"):\n print(\"twine not installed.\\nUse `pip install twine`.\\nExiting.\")\n sys.exit()\n os.system(\"python setup.py sdist bdist_wheel\")\n os.system(\"twine upload dist/*\")\n print(\"You probably want to also tag the version now:\")\n print(\" git tag -a {0} -m 'version {0}'\".format(get_version(\"mkdocs\")))\n print(\" git push --tags\")\n sys.exit()\n\n\nsetup(\n name=\"mkdocs\",\n version=get_version(\"mkdocs\"),\n url='http://www.mkdocs.org',\n license='BSD',\n description='Project documentation with Markdown.',\n long_description=long_description,\n author='Tom Christie',\n author_email='[email protected]', # SEE NOTE BELOW (*)\n packages=get_packages(\"mkdocs\"),\n include_package_data=True,\n install_requires=[\n 'click>=3.3',\n 'Jinja2>=2.7.1',\n 'livereload>=2.5.1',\n 'Markdown>=2.3.1',\n 'PyYAML>=3.10',\n 'tornado>=4.1',\n ],\n entry_points={\n 'console_scripts': [\n 'mkdocs = mkdocs.__main__:cli',\n ],\n 'mkdocs.themes': [\n 'mkdocs = mkdocs.themes.mkdocs',\n 'readthedocs = mkdocs.themes.readthedocs',\n ],\n 'mkdocs.plugins': [\n 'search = mkdocs.contrib.search:SearchPlugin',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n 'Topic :: Documentation',\n 'Topic :: Text Processing',\n ],\n zip_safe=False,\n)\n\n# (*) Please direct queries to the discussion group:\n# https://groups.google.com/forum/#!forum/mkdocs\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import print_function\nfrom setuptools import setup\nimport re\nimport os\nimport sys\n\n\nlong_description = (\n \"MkDocs is a fast, simple and downright gorgeous static site generator \"\n \"that's geared towards building project documentation. Documentation \"\n \"source files are written in Markdown, and configured with a single YAML \"\n \"configuration file.\"\n)\n\n\ndef get_version(package):\n \"\"\"Return package version as listed in `__version__` in `init.py`.\"\"\"\n init_py = open(os.path.join(package, '__init__.py')).read()\n return re.search(\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", init_py).group(1)\n\n\ndef get_packages(package):\n \"\"\"Return root package and all sub-packages.\"\"\"\n return [dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, '__init__.py'))]\n\n\nif sys.argv[-1] == 'publish':\n if os.system(\"pip freeze | grep wheel\"):\n print(\"wheel not installed.\\nUse `pip install wheel`.\\nExiting.\")\n sys.exit()\n if os.system(\"pip freeze | grep twine\"):\n print(\"twine not installed.\\nUse `pip install twine`.\\nExiting.\")\n sys.exit()\n os.system(\"python setup.py sdist bdist_wheel\")\n os.system(\"twine upload dist/*\")\n print(\"You probably want to also tag the version now:\")\n print(\" git tag -a {0} -m 'version {0}'\".format(get_version(\"mkdocs\")))\n print(\" git push --tags\")\n sys.exit()\n\n\nsetup(\n name=\"mkdocs\",\n version=get_version(\"mkdocs\"),\n url='http://www.mkdocs.org',\n license='BSD',\n description='Project documentation with Markdown.',\n long_description=long_description,\n author='Tom Christie',\n author_email='[email protected]', # SEE NOTE BELOW (*)\n packages=get_packages(\"mkdocs\"),\n include_package_data=True,\n install_requires=[\n 'click>=3.3',\n 'Jinja2>=2.7.1',\n 'livereload>=2.5.1',\n 'Markdown>=2.3.1',\n 'PyYAML>=3.10',\n 'tornado>=5.0',\n ],\n python_requires='>=2.7.9,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n entry_points={\n 'console_scripts': [\n 'mkdocs = mkdocs.__main__:cli',\n ],\n 'mkdocs.themes': [\n 'mkdocs = mkdocs.themes.mkdocs',\n 'readthedocs = mkdocs.themes.readthedocs',\n ],\n 'mkdocs.plugins': [\n 'search = mkdocs.contrib.search:SearchPlugin',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n 'Topic :: Documentation',\n 'Topic :: Text Processing',\n ],\n zip_safe=False,\n)\n\n# (*) Please direct queries to the discussion group:\n# https://groups.google.com/forum/#!forum/mkdocs\n", "path": "setup.py"}]}
| 1,320 | 235 |
gh_patches_debug_38298
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
redirect loop on invalid single-user auth token
when the single-user server's API request fails with 403, it's handled as failed login (302) causing a redirect loop, when it should be handled as "500: oh noes, I can't do anything!"
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jupyterhub/singleuser.py`
Content:
```
1 #!/usr/bin/env python
2 """Extend regular notebook server to be aware of multiuser things."""
3
4 # Copyright (c) Jupyter Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 import os
8
9 import requests
10
11 from tornado import ioloop
12
13 from IPython.utils.traitlets import Unicode
14
15 from IPython.html.notebookapp import NotebookApp
16 from IPython.html.auth.login import LoginHandler
17 from IPython.html.auth.logout import LogoutHandler
18
19 from IPython.html.utils import url_path_join
20
21
22 from distutils.version import LooseVersion as V
23
24 import IPython
25 if V(IPython.__version__) < V('3.0'):
26 raise ImportError("JupyterHub Requires IPython >= 3.0, found %s" % IPython.__version__)
27
28 # Define two methods to attach to AuthenticatedHandler,
29 # which authenticate via the central auth server.
30
31 class JupyterHubLoginHandler(LoginHandler):
32 @staticmethod
33 def login_available(settings):
34 return True
35
36 @staticmethod
37 def verify_token(self, cookie_name, encrypted_cookie):
38 """monkeypatch method for token verification"""
39 cookie_cache = self.settings['cookie_cache']
40 if encrypted_cookie in cookie_cache:
41 # we've seen this token before, don't ask upstream again
42 return cookie_cache[encrypted_cookie]
43
44 hub_api_url = self.settings['hub_api_url']
45 hub_api_key = self.settings['hub_api_key']
46 r = requests.get(url_path_join(
47 hub_api_url, "authorizations/cookie", cookie_name,
48 ),
49 headers = {'Authorization' : 'token %s' % hub_api_key},
50 data=encrypted_cookie,
51 )
52 if r.status_code == 404:
53 data = {'user' : ''}
54 elif r.status_code >= 400:
55 self.log.warn("Failed to check authorization: [%i] %s", r.status_code, r.reason)
56 data = None
57 else:
58 data = r.json()
59 cookie_cache[encrypted_cookie] = data
60 return data
61
62 @staticmethod
63 def get_user(self):
64 """alternative get_current_user to query the central server"""
65 my_user = self.settings['user']
66 encrypted_cookie = self.get_cookie(self.cookie_name)
67 if encrypted_cookie:
68 auth_data = JupyterHubLoginHandler.verify_token(self, self.cookie_name, encrypted_cookie)
69 if not auth_data:
70 # treat invalid token the same as no token
71 return None
72 user = auth_data['user']
73 if user == my_user:
74 return user
75 else:
76 return None
77 else:
78 self.log.debug("No token cookie")
79 return None
80
81
82 class JupyterHubLogoutHandler(LogoutHandler):
83 def get(self):
84 self.redirect(url_path_join(self.settings['hub_prefix'], 'logout'))
85
86
87 # register new hub related command-line aliases
88 aliases = NotebookApp.aliases.get_default_value()
89 aliases.update({
90 'user' : 'SingleUserNotebookApp.user',
91 'cookie-name': 'SingleUserNotebookApp.cookie_name',
92 'hub-prefix': 'SingleUserNotebookApp.hub_prefix',
93 'hub-api-url': 'SingleUserNotebookApp.hub_api_url',
94 'base-url': 'SingleUserNotebookApp.base_url',
95 })
96
97 class SingleUserNotebookApp(NotebookApp):
98 """A Subclass of the regular NotebookApp that is aware of the parent multiuser context."""
99 user = Unicode(config=True)
100 cookie_name = Unicode(config=True)
101 hub_prefix = Unicode(config=True)
102 hub_api_url = Unicode(config=True)
103 aliases = aliases
104 open_browser = False
105 login_handler_class = JupyterHubLoginHandler
106 logout_handler_class = JupyterHubLogoutHandler
107
108 def _confirm_exit(self):
109 # disable the exit confirmation for background notebook processes
110 ioloop.IOLoop.instance().stop()
111
112 def init_webapp(self):
113 # load the hub related settings into the tornado settings dict
114 env = os.environ
115 s = self.tornado_settings
116 s['cookie_cache'] = {}
117 s['user'] = self.user
118 s['hub_api_key'] = env.pop('JPY_API_TOKEN')
119 s['hub_prefix'] = self.hub_prefix
120 s['cookie_name'] = self.cookie_name
121 s['login_url'] = url_path_join(self.hub_prefix, 'login')
122 s['hub_api_url'] = self.hub_api_url
123 super(SingleUserNotebookApp, self).init_webapp()
124
125
126 def main():
127 return SingleUserNotebookApp.launch_instance()
128
129
130 if __name__ == "__main__":
131 main()
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jupyterhub/singleuser.py b/jupyterhub/singleuser.py
--- a/jupyterhub/singleuser.py
+++ b/jupyterhub/singleuser.py
@@ -9,6 +9,7 @@
import requests
from tornado import ioloop
+from tornado.web import HTTPError
from IPython.utils.traitlets import Unicode
@@ -35,7 +36,7 @@
@staticmethod
def verify_token(self, cookie_name, encrypted_cookie):
- """monkeypatch method for token verification"""
+ """method for token verification"""
cookie_cache = self.settings['cookie_cache']
if encrypted_cookie in cookie_cache:
# we've seen this token before, don't ask upstream again
@@ -51,9 +52,15 @@
)
if r.status_code == 404:
data = {'user' : ''}
+ if r.status_code == 403:
+ self.log.error("I don't have permission to verify cookies, my auth token may have expired: [%i] %s", r.status_code, r.reason)
+ raise HTTPError(500, "Permission failure checking authorization, I may need to be restarted")
+ elif r.status_code >= 500:
+ self.log.error("Upstream failure verifying auth token: [%i] %s", r.status_code, r.reason)
+ raise HTTPError(502, "Failed to check authorization (upstream problem)")
elif r.status_code >= 400:
self.log.warn("Failed to check authorization: [%i] %s", r.status_code, r.reason)
- data = None
+ raise HTTPError(500, "Failed to check authorization")
else:
data = r.json()
cookie_cache[encrypted_cookie] = data
@@ -62,6 +69,13 @@
@staticmethod
def get_user(self):
"""alternative get_current_user to query the central server"""
+ # only allow this to be called once per handler
+ # avoids issues if an error is raised,
+ # since this may be called again when trying to render the error page
+ if hasattr(self, '_cached_user'):
+ return self._cached_user
+
+ self._cached_user = None
my_user = self.settings['user']
encrypted_cookie = self.get_cookie(self.cookie_name)
if encrypted_cookie:
@@ -71,6 +85,7 @@
return None
user = auth_data['user']
if user == my_user:
+ self._cached_user = user
return user
else:
return None
|
{"golden_diff": "diff --git a/jupyterhub/singleuser.py b/jupyterhub/singleuser.py\n--- a/jupyterhub/singleuser.py\n+++ b/jupyterhub/singleuser.py\n@@ -9,6 +9,7 @@\n import requests\n \n from tornado import ioloop\n+from tornado.web import HTTPError\n \n from IPython.utils.traitlets import Unicode\n \n@@ -35,7 +36,7 @@\n \n @staticmethod\n def verify_token(self, cookie_name, encrypted_cookie):\n- \"\"\"monkeypatch method for token verification\"\"\"\n+ \"\"\"method for token verification\"\"\"\n cookie_cache = self.settings['cookie_cache']\n if encrypted_cookie in cookie_cache:\n # we've seen this token before, don't ask upstream again\n@@ -51,9 +52,15 @@\n )\n if r.status_code == 404:\n data = {'user' : ''}\n+ if r.status_code == 403:\n+ self.log.error(\"I don't have permission to verify cookies, my auth token may have expired: [%i] %s\", r.status_code, r.reason)\n+ raise HTTPError(500, \"Permission failure checking authorization, I may need to be restarted\")\n+ elif r.status_code >= 500:\n+ self.log.error(\"Upstream failure verifying auth token: [%i] %s\", r.status_code, r.reason)\n+ raise HTTPError(502, \"Failed to check authorization (upstream problem)\")\n elif r.status_code >= 400:\n self.log.warn(\"Failed to check authorization: [%i] %s\", r.status_code, r.reason)\n- data = None\n+ raise HTTPError(500, \"Failed to check authorization\")\n else:\n data = r.json()\n cookie_cache[encrypted_cookie] = data\n@@ -62,6 +69,13 @@\n @staticmethod\n def get_user(self):\n \"\"\"alternative get_current_user to query the central server\"\"\"\n+ # only allow this to be called once per handler\n+ # avoids issues if an error is raised,\n+ # since this may be called again when trying to render the error page\n+ if hasattr(self, '_cached_user'):\n+ return self._cached_user\n+ \n+ self._cached_user = None\n my_user = self.settings['user']\n encrypted_cookie = self.get_cookie(self.cookie_name)\n if encrypted_cookie:\n@@ -71,6 +85,7 @@\n return None\n user = auth_data['user']\n if user == my_user:\n+ self._cached_user = user\n return user\n else:\n return None\n", "issue": "redirect loop on invalid single-user auth token\nwhen the single-user server's API request fails with 403, it's handled as failed login (302) causing a redirect loop, when it should be handled as \"500: oh noes, I can't do anything!\"\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"Extend regular notebook server to be aware of multiuser things.\"\"\"\n\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\n\nimport requests\n\nfrom tornado import ioloop\n\nfrom IPython.utils.traitlets import Unicode\n\nfrom IPython.html.notebookapp import NotebookApp\nfrom IPython.html.auth.login import LoginHandler\nfrom IPython.html.auth.logout import LogoutHandler\n\nfrom IPython.html.utils import url_path_join\n\n\nfrom distutils.version import LooseVersion as V\n\nimport IPython\nif V(IPython.__version__) < V('3.0'):\n raise ImportError(\"JupyterHub Requires IPython >= 3.0, found %s\" % IPython.__version__)\n\n# Define two methods to attach to AuthenticatedHandler,\n# which authenticate via the central auth server.\n\nclass JupyterHubLoginHandler(LoginHandler):\n @staticmethod\n def login_available(settings):\n return True\n \n @staticmethod\n def verify_token(self, cookie_name, encrypted_cookie):\n \"\"\"monkeypatch method for token verification\"\"\"\n cookie_cache = self.settings['cookie_cache']\n if encrypted_cookie in cookie_cache:\n # we've seen this token before, don't ask upstream again\n return cookie_cache[encrypted_cookie]\n \n hub_api_url = self.settings['hub_api_url']\n hub_api_key = self.settings['hub_api_key']\n r = requests.get(url_path_join(\n hub_api_url, \"authorizations/cookie\", cookie_name,\n ),\n headers = {'Authorization' : 'token %s' % hub_api_key},\n data=encrypted_cookie,\n )\n if r.status_code == 404:\n data = {'user' : ''}\n elif r.status_code >= 400:\n self.log.warn(\"Failed to check authorization: [%i] %s\", r.status_code, r.reason)\n data = None\n else:\n data = r.json()\n cookie_cache[encrypted_cookie] = data\n return data\n \n @staticmethod\n def get_user(self):\n \"\"\"alternative get_current_user to query the central server\"\"\"\n my_user = self.settings['user']\n encrypted_cookie = self.get_cookie(self.cookie_name)\n if encrypted_cookie:\n auth_data = JupyterHubLoginHandler.verify_token(self, self.cookie_name, encrypted_cookie)\n if not auth_data:\n # treat invalid token the same as no token\n return None\n user = auth_data['user']\n if user == my_user:\n return user\n else:\n return None\n else:\n self.log.debug(\"No token cookie\")\n return None\n\n\nclass JupyterHubLogoutHandler(LogoutHandler):\n def get(self):\n self.redirect(url_path_join(self.settings['hub_prefix'], 'logout'))\n\n\n# register new hub related command-line aliases\naliases = NotebookApp.aliases.get_default_value()\naliases.update({\n 'user' : 'SingleUserNotebookApp.user',\n 'cookie-name': 'SingleUserNotebookApp.cookie_name',\n 'hub-prefix': 'SingleUserNotebookApp.hub_prefix',\n 'hub-api-url': 'SingleUserNotebookApp.hub_api_url',\n 'base-url': 'SingleUserNotebookApp.base_url',\n})\n\nclass SingleUserNotebookApp(NotebookApp):\n \"\"\"A Subclass of the regular NotebookApp that is aware of the parent multiuser context.\"\"\"\n user = Unicode(config=True)\n cookie_name = Unicode(config=True)\n hub_prefix = Unicode(config=True)\n hub_api_url = Unicode(config=True)\n aliases = aliases\n open_browser = False\n login_handler_class = JupyterHubLoginHandler\n logout_handler_class = JupyterHubLogoutHandler\n \n def _confirm_exit(self):\n # disable the exit confirmation for background notebook processes\n ioloop.IOLoop.instance().stop()\n \n def init_webapp(self):\n # load the hub related settings into the tornado settings dict\n env = os.environ\n s = self.tornado_settings\n s['cookie_cache'] = {}\n s['user'] = self.user\n s['hub_api_key'] = env.pop('JPY_API_TOKEN')\n s['hub_prefix'] = self.hub_prefix\n s['cookie_name'] = self.cookie_name\n s['login_url'] = url_path_join(self.hub_prefix, 'login')\n s['hub_api_url'] = self.hub_api_url\n super(SingleUserNotebookApp, self).init_webapp()\n\n\ndef main():\n return SingleUserNotebookApp.launch_instance()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "jupyterhub/singleuser.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"Extend regular notebook server to be aware of multiuser things.\"\"\"\n\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\n\nimport requests\n\nfrom tornado import ioloop\nfrom tornado.web import HTTPError\n\nfrom IPython.utils.traitlets import Unicode\n\nfrom IPython.html.notebookapp import NotebookApp\nfrom IPython.html.auth.login import LoginHandler\nfrom IPython.html.auth.logout import LogoutHandler\n\nfrom IPython.html.utils import url_path_join\n\n\nfrom distutils.version import LooseVersion as V\n\nimport IPython\nif V(IPython.__version__) < V('3.0'):\n raise ImportError(\"JupyterHub Requires IPython >= 3.0, found %s\" % IPython.__version__)\n\n# Define two methods to attach to AuthenticatedHandler,\n# which authenticate via the central auth server.\n\nclass JupyterHubLoginHandler(LoginHandler):\n @staticmethod\n def login_available(settings):\n return True\n \n @staticmethod\n def verify_token(self, cookie_name, encrypted_cookie):\n \"\"\"method for token verification\"\"\"\n cookie_cache = self.settings['cookie_cache']\n if encrypted_cookie in cookie_cache:\n # we've seen this token before, don't ask upstream again\n return cookie_cache[encrypted_cookie]\n \n hub_api_url = self.settings['hub_api_url']\n hub_api_key = self.settings['hub_api_key']\n r = requests.get(url_path_join(\n hub_api_url, \"authorizations/cookie\", cookie_name,\n ),\n headers = {'Authorization' : 'token %s' % hub_api_key},\n data=encrypted_cookie,\n )\n if r.status_code == 404:\n data = {'user' : ''}\n if r.status_code == 403:\n self.log.error(\"I don't have permission to verify cookies, my auth token may have expired: [%i] %s\", r.status_code, r.reason)\n raise HTTPError(500, \"Permission failure checking authorization, I may need to be restarted\")\n elif r.status_code >= 500:\n self.log.error(\"Upstream failure verifying auth token: [%i] %s\", r.status_code, r.reason)\n raise HTTPError(502, \"Failed to check authorization (upstream problem)\")\n elif r.status_code >= 400:\n self.log.warn(\"Failed to check authorization: [%i] %s\", r.status_code, r.reason)\n raise HTTPError(500, \"Failed to check authorization\")\n else:\n data = r.json()\n cookie_cache[encrypted_cookie] = data\n return data\n \n @staticmethod\n def get_user(self):\n \"\"\"alternative get_current_user to query the central server\"\"\"\n # only allow this to be called once per handler\n # avoids issues if an error is raised,\n # since this may be called again when trying to render the error page\n if hasattr(self, '_cached_user'):\n return self._cached_user\n \n self._cached_user = None\n my_user = self.settings['user']\n encrypted_cookie = self.get_cookie(self.cookie_name)\n if encrypted_cookie:\n auth_data = JupyterHubLoginHandler.verify_token(self, self.cookie_name, encrypted_cookie)\n if not auth_data:\n # treat invalid token the same as no token\n return None\n user = auth_data['user']\n if user == my_user:\n self._cached_user = user\n return user\n else:\n return None\n else:\n self.log.debug(\"No token cookie\")\n return None\n\n\nclass JupyterHubLogoutHandler(LogoutHandler):\n def get(self):\n self.redirect(url_path_join(self.settings['hub_prefix'], 'logout'))\n\n\n# register new hub related command-line aliases\naliases = NotebookApp.aliases.get_default_value()\naliases.update({\n 'user' : 'SingleUserNotebookApp.user',\n 'cookie-name': 'SingleUserNotebookApp.cookie_name',\n 'hub-prefix': 'SingleUserNotebookApp.hub_prefix',\n 'hub-api-url': 'SingleUserNotebookApp.hub_api_url',\n 'base-url': 'SingleUserNotebookApp.base_url',\n})\n\nclass SingleUserNotebookApp(NotebookApp):\n \"\"\"A Subclass of the regular NotebookApp that is aware of the parent multiuser context.\"\"\"\n user = Unicode(config=True)\n cookie_name = Unicode(config=True)\n hub_prefix = Unicode(config=True)\n hub_api_url = Unicode(config=True)\n aliases = aliases\n open_browser = False\n login_handler_class = JupyterHubLoginHandler\n logout_handler_class = JupyterHubLogoutHandler\n \n def _confirm_exit(self):\n # disable the exit confirmation for background notebook processes\n ioloop.IOLoop.instance().stop()\n \n def init_webapp(self):\n # load the hub related settings into the tornado settings dict\n env = os.environ\n s = self.tornado_settings\n s['cookie_cache'] = {}\n s['user'] = self.user\n s['hub_api_key'] = env.pop('JPY_API_TOKEN')\n s['hub_prefix'] = self.hub_prefix\n s['cookie_name'] = self.cookie_name\n s['login_url'] = url_path_join(self.hub_prefix, 'login')\n s['hub_api_url'] = self.hub_api_url\n super(SingleUserNotebookApp, self).init_webapp()\n\n\ndef main():\n return SingleUserNotebookApp.launch_instance()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "jupyterhub/singleuser.py"}]}
| 1,601 | 573 |
gh_patches_debug_43614
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-201
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E1024 should allow Fn::ImportValue
cfn-lint version: 0.3.3
The following template:
```
---
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
SubnetIndex:
Description: 'Index of the subnet'
Type: Number
MinValue: 0
MaxValue: 5
SubnetCount:
Description: 'To slice the IP address ranges you need to specify how many subnets you want to create in the VPC'
Type: Number
MinValue: 1
MaxValue: 6
Resources:
Subnet:
Type: 'AWS::EC2::Subnet'
Properties:
CidrBlock: !Select [!Ref SubnetIndex, !Cidr [{'Fn::ImportValue': 'vpc-CidrBlock'}, !Ref SubnetCount, 12]]
VpcId: 'vpc-123456'
```
Produces the following exceptions and findings:
```
# not sure about this
E0002 Unknown exception while processing rule E1017: too many values to unpack
bug.yml:1:1
# looks like Cidr also supports Fn::ImportValue (at least the template works, documentation says it does not work https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html)
E1024 Cidr ipBlock should be Cidr Range, Ref, or Select for Resources/Subnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/0
bug.yml:18:7
# not quiet sure about that, 12 should be a int?
E1024 Cidr sizeMask should be a int for Resources/Subnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/2
bug.yml:18:7
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/functions/Cidr.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 import six
19 from cfnlint import CloudFormationLintRule
20 from cfnlint import RuleMatch
21
22 from cfnlint.helpers import REGEX_CIDR
23
24 class Cidr(CloudFormationLintRule):
25 """Check if Cidr values are correct"""
26 id = 'E1024'
27 shortdesc = 'Cidr validation of parameters'
28 description = 'Making sure the function CIDR is a list with valid values'
29 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html'
30 tags = ['functions', 'cidr']
31
32 def check_parameter_count(self, cfn, parameter_name):
33 """Check Count Parameter if used"""
34 matches = list()
35 parameter_obj = cfn.get_parameters().get(parameter_name, {})
36 if parameter_obj:
37 tree = ['Parameters', parameter_name]
38 parameter_type = parameter_obj.get('Type')
39 if parameter_type == 'Number':
40 max_value = parameter_obj.get('MaxValue')
41 min_value = parameter_obj.get('MinValue')
42 if (not min_value) or min_value < 1 or min_value > 256:
43 message = 'Parameter for Cidr count have MinValue between 1 and 256 at {0}'
44 matches.append(RuleMatch(
45 tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))
46 if (not max_value) or max_value < 1 or max_value > 256:
47 message = 'Parameter for Cidr count have MaxValue between 1 and 256 at {0}'
48 matches.append(RuleMatch(
49 tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))
50 else:
51 message = 'Parameter for Cidr count have be of Type Number at {0}'
52 matches.append(RuleMatch(
53 tree, message.format('/'.join(map(str, tree)))))
54
55 return matches
56
57 def check_parameter_size_mask(self, cfn, parameter_name):
58 """Check SizeMask Parameter if used"""
59 matches = list()
60 parameter_obj = cfn.get_parameters().get(parameter_name, {})
61 if parameter_obj:
62 tree = ['Parameters', parameter_name]
63 parameter_type = parameter_obj.get('Type')
64 if parameter_type == 'Number':
65 max_value = parameter_obj.get('MaxValue')
66 min_value = parameter_obj.get('MinValue')
67 if (not min_value) or min_value < 1 or min_value > 256:
68 message = 'Parameter for Cidr sizeMask have MinValue between 1 and ' \
69 '128 (for ipv6) and 32 (for ipv4) at {0}'
70 matches.append(RuleMatch(
71 tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))
72 if (not max_value) or max_value < 1 or max_value > 256:
73 message = 'Parameter for Cidr count have MaxValue between 1 and ' \
74 '128 (for ipv6) and 32 (for ipv4) at {0}'
75 matches.append(RuleMatch(
76 tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))
77 else:
78 message = 'Parameter for Cidr count have be of Type Number at {0}'
79 matches.append(RuleMatch(
80 tree, message.format('/'.join(map(str, tree)))))
81
82 return matches
83
84 def match(self, cfn):
85 """Check CloudFormation Cidr"""
86
87 matches = list()
88
89 cidr_objs = cfn.search_deep_keys('Fn::Cidr')
90
91 supported_functions = [
92 'Fn::Select',
93 'Ref'
94 ]
95
96 count_parameters = []
97 size_mask_parameters = []
98
99 for cidr_obj in cidr_objs:
100 cidr_value_obj = cidr_obj[-1]
101 tree = cidr_obj[:-1]
102 if isinstance(cidr_value_obj, list):
103 if len(cidr_value_obj) in [2, 3]:
104 ip_block_obj = cidr_value_obj[0]
105 count_obj = cidr_value_obj[1]
106 if len(cidr_value_obj) == 3:
107 size_mask_obj = cidr_value_obj[2]
108 else:
109 size_mask_obj = None
110
111 if isinstance(ip_block_obj, dict):
112 if len(ip_block_obj) == 1:
113 for index_key, _ in ip_block_obj.items():
114 if index_key not in supported_functions:
115 message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'
116 matches.append(RuleMatch(
117 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
118 elif isinstance(ip_block_obj, (six.text_type, six.string_types)):
119 if not re.match(REGEX_CIDR, ip_block_obj):
120 message = 'Cidr ipBlock should be a Cidr Range based string for {0}'
121 matches.append(RuleMatch(
122 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
123 else:
124 message = 'Cidr ipBlock should be a string for {0}'
125 matches.append(RuleMatch(
126 tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))
127
128 if isinstance(count_obj, dict):
129 if len(count_obj) == 1:
130 for index_key, index_value in count_obj.items():
131 if index_key not in supported_functions:
132 message = 'Cidr count should be Int, Ref, or Select for {0}'
133 matches.append(RuleMatch(
134 tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))
135 if index_key == 'Ref':
136 count_parameters.append(index_value)
137 elif not isinstance(count_obj, six.integer_types):
138 message = 'Cidr count should be a int for {0}'
139 matches.append(RuleMatch(
140 tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))
141
142 if isinstance(size_mask_obj, dict):
143 if len(size_mask_obj) == 1:
144 for index_key, index_value in size_mask_obj.items():
145 if index_key not in supported_functions:
146 message = 'Cidr sizeMask should be Int, Ref, or Select for {0}'
147 matches.append(RuleMatch(
148 tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
149 if index_key == 'Ref':
150 size_mask_parameters.append(index_value)
151 elif not isinstance(count_obj, six.integer_types):
152 message = 'Cidr sizeMask should be a int for {0}'
153 matches.append(RuleMatch(
154 tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
155
156 else:
157 message = 'Cidr should be a list of 2 or 3 elements for {0}'
158 matches.append(RuleMatch(
159 tree, message.format('/'.join(map(str, tree)))))
160 else:
161 message = 'Cidr should be a list of 2 or 3 elements for {0}'
162 matches.append(RuleMatch(
163 tree, message.format('/'.join(map(str, tree)))))
164
165 for count_parameter in set(count_parameters):
166 matches.extend(self.check_parameter_count(cfn, count_parameter))
167 for size_mask_parameter in set(size_mask_parameters):
168 matches.extend(self.check_parameter_size_mask(cfn, size_mask_parameter))
169
170 return matches
171
```
Path: `src/cfnlint/rules/functions/Select.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import six
18 from cfnlint import CloudFormationLintRule
19 from cfnlint import RuleMatch
20
21
22 class Select(CloudFormationLintRule):
23 """Check if Select values are correct"""
24 id = 'E1017'
25 shortdesc = 'Select validation of parameters'
26 description = 'Making sure the function not is of list'
27 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'
28 tags = ['functions', 'select']
29
30 def match(self, cfn):
31 """Check CloudFormation Select"""
32
33 matches = list()
34
35 select_objs = cfn.search_deep_keys('Fn::Select')
36
37 supported_functions = [
38 'Fn::FindInMap',
39 'Fn::GetAtt',
40 'Fn::GetAZs',
41 'Fn::If',
42 'Fn::Split',
43 'Fn::Cidr',
44 'Ref'
45 ]
46
47 for select_obj in select_objs:
48 select_value_obj = select_obj[-1]
49 tree = select_obj[:-1]
50 if isinstance(select_value_obj, list):
51 if len(select_value_obj) == 2:
52 index_obj = select_value_obj[0]
53 list_of_objs = select_value_obj[1]
54 if isinstance(index_obj, dict):
55 if len(index_obj) == 1:
56 for index_key, _ in index_obj:
57 if index_key not in ['Ref', 'Fn::FindInMap']:
58 message = 'Select index should be int, Ref, FindInMap for {0}'
59 matches.append(RuleMatch(
60 tree, message.format('/'.join(map(str, tree)))))
61 elif not isinstance(index_obj, six.integer_types):
62 try:
63 int(index_obj)
64 except ValueError:
65 message = 'Select index should be int, Ref, FindInMap for {0}'
66 matches.append(RuleMatch(
67 tree, message.format('/'.join(map(str, tree)))))
68 if isinstance(list_of_objs, dict):
69 if len(list_of_objs) == 1:
70 for key, _ in list_of_objs.items():
71 if key not in supported_functions:
72 message = 'Key {0} should be a list for {1}'
73 matches.append(RuleMatch(
74 tree, message.format(key, '/'.join(map(str, tree)))))
75 else:
76 message = 'Select should be a list of 2 elements for {0}'
77 matches.append(RuleMatch(
78 tree, message.format('/'.join(map(str, tree)))))
79 else:
80 message = 'Select should be an array of values for {0}'
81 matches.append(RuleMatch(
82 tree, message.format('/'.join(map(str, tree)))))
83 else:
84 message = 'Select should be a list of 2 elements for {0}'
85 matches.append(RuleMatch(
86 tree, message.format('/'.join(map(str, tree)))))
87 else:
88 message = 'Select should be a list of 2 elements for {0}'
89 matches.append(RuleMatch(
90 tree, message.format('/'.join(map(str, tree)))))
91 return matches
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/functions/Cidr.py b/src/cfnlint/rules/functions/Cidr.py
--- a/src/cfnlint/rules/functions/Cidr.py
+++ b/src/cfnlint/rules/functions/Cidr.py
@@ -90,7 +90,8 @@
supported_functions = [
'Fn::Select',
- 'Ref'
+ 'Ref',
+ 'Fn::ImportValue'
]
count_parameters = []
@@ -148,7 +149,7 @@
tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
if index_key == 'Ref':
size_mask_parameters.append(index_value)
- elif not isinstance(count_obj, six.integer_types):
+ elif not isinstance(size_mask_obj, six.integer_types):
message = 'Cidr sizeMask should be a int for {0}'
matches.append(RuleMatch(
tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))
diff --git a/src/cfnlint/rules/functions/Select.py b/src/cfnlint/rules/functions/Select.py
--- a/src/cfnlint/rules/functions/Select.py
+++ b/src/cfnlint/rules/functions/Select.py
@@ -53,30 +53,30 @@
list_of_objs = select_value_obj[1]
if isinstance(index_obj, dict):
if len(index_obj) == 1:
- for index_key, _ in index_obj:
+ for index_key, _ in index_obj.items():
if index_key not in ['Ref', 'Fn::FindInMap']:
- message = 'Select index should be int, Ref, FindInMap for {0}'
+ message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'
matches.append(RuleMatch(
tree, message.format('/'.join(map(str, tree)))))
elif not isinstance(index_obj, six.integer_types):
try:
int(index_obj)
except ValueError:
- message = 'Select index should be int, Ref, FindInMap for {0}'
+ message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'
matches.append(RuleMatch(
tree, message.format('/'.join(map(str, tree)))))
if isinstance(list_of_objs, dict):
if len(list_of_objs) == 1:
for key, _ in list_of_objs.items():
if key not in supported_functions:
- message = 'Key {0} should be a list for {1}'
+ message = 'Select should use a supported function of {0}'
matches.append(RuleMatch(
- tree, message.format(key, '/'.join(map(str, tree)))))
+ tree, message.format(', '.join(map(str, supported_functions)))))
else:
- message = 'Select should be a list of 2 elements for {0}'
+ message = 'Select should use a supported function of {0}'
matches.append(RuleMatch(
- tree, message.format('/'.join(map(str, tree)))))
- else:
+ tree, message.format(', '.join(map(str, supported_functions)))))
+ elif not isinstance(list_of_objs, list):
message = 'Select should be an array of values for {0}'
matches.append(RuleMatch(
tree, message.format('/'.join(map(str, tree)))))
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/Cidr.py b/src/cfnlint/rules/functions/Cidr.py\n--- a/src/cfnlint/rules/functions/Cidr.py\n+++ b/src/cfnlint/rules/functions/Cidr.py\n@@ -90,7 +90,8 @@\n \n supported_functions = [\n 'Fn::Select',\n- 'Ref'\n+ 'Ref',\n+ 'Fn::ImportValue'\n ]\n \n count_parameters = []\n@@ -148,7 +149,7 @@\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n if index_key == 'Ref':\n size_mask_parameters.append(index_value)\n- elif not isinstance(count_obj, six.integer_types):\n+ elif not isinstance(size_mask_obj, six.integer_types):\n message = 'Cidr sizeMask should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\ndiff --git a/src/cfnlint/rules/functions/Select.py b/src/cfnlint/rules/functions/Select.py\n--- a/src/cfnlint/rules/functions/Select.py\n+++ b/src/cfnlint/rules/functions/Select.py\n@@ -53,30 +53,30 @@\n list_of_objs = select_value_obj[1]\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n- for index_key, _ in index_obj:\n+ for index_key, _ in index_obj.items():\n if index_key not in ['Ref', 'Fn::FindInMap']:\n- message = 'Select index should be int, Ref, FindInMap for {0}'\n+ message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(index_obj, six.integer_types):\n try:\n int(index_obj)\n except ValueError:\n- message = 'Select index should be int, Ref, FindInMap for {0}'\n+ message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n if isinstance(list_of_objs, dict):\n if len(list_of_objs) == 1:\n for key, _ in list_of_objs.items():\n if key not in supported_functions:\n- message = 'Key {0} should be a list for {1}'\n+ message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n- tree, message.format(key, '/'.join(map(str, tree)))))\n+ tree, message.format(', '.join(map(str, supported_functions)))))\n else:\n- message = 'Select should be a list of 2 elements for {0}'\n+ message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n- tree, message.format('/'.join(map(str, tree)))))\n- else:\n+ tree, message.format(', '.join(map(str, supported_functions)))))\n+ elif not isinstance(list_of_objs, list):\n message = 'Select should be an array of values for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n", "issue": "E1024 should allow Fn::ImportValue\ncfn-lint version: 0.3.3\r\n\r\nThe following template:\r\n\r\n```\r\n---\r\nAWSTemplateFormatVersion: '2010-09-09'\r\nParameters:\r\n SubnetIndex:\r\n Description: 'Index of the subnet'\r\n Type: Number\r\n MinValue: 0\r\n MaxValue: 5\r\n SubnetCount:\r\n Description: 'To slice the IP address ranges you need to specify how many subnets you want to create in the VPC'\r\n Type: Number\r\n MinValue: 1\r\n MaxValue: 6\r\nResources:\r\n Subnet:\r\n Type: 'AWS::EC2::Subnet'\r\n Properties:\r\n CidrBlock: !Select [!Ref SubnetIndex, !Cidr [{'Fn::ImportValue': 'vpc-CidrBlock'}, !Ref SubnetCount, 12]]\r\n VpcId: 'vpc-123456'\r\n```\r\n\r\nProduces the following exceptions and findings:\r\n\r\n```\r\n# not sure about this\r\nE0002 Unknown exception while processing rule E1017: too many values to unpack\r\nbug.yml:1:1\r\n\r\n# looks like Cidr also supports Fn::ImportValue (at least the template works, documentation says it does not work https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html)\r\nE1024 Cidr ipBlock should be Cidr Range, Ref, or Select for Resources/Subnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/0\r\nbug.yml:18:7\r\n\r\n# not quiet sure about that, 12 should be a int?\r\nE1024 Cidr sizeMask should be a int for Resources/Subnet/Properties/CidrBlock/Fn::Select/1/Fn::Cidr/2\r\nbug.yml:18:7\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nfrom cfnlint.helpers import REGEX_CIDR\n\nclass Cidr(CloudFormationLintRule):\n \"\"\"Check if Cidr values are correct\"\"\"\n id = 'E1024'\n shortdesc = 'Cidr validation of parameters'\n description = 'Making sure the function CIDR is a list with valid values'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html'\n tags = ['functions', 'cidr']\n\n def check_parameter_count(self, cfn, parameter_name):\n \"\"\"Check Count Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr count have MinValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def check_parameter_size_mask(self, cfn, parameter_name):\n \"\"\"Check SizeMask Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr sizeMask have MinValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Cidr\"\"\"\n\n matches = list()\n\n cidr_objs = cfn.search_deep_keys('Fn::Cidr')\n\n supported_functions = [\n 'Fn::Select',\n 'Ref'\n ]\n\n count_parameters = []\n size_mask_parameters = []\n\n for cidr_obj in cidr_objs:\n cidr_value_obj = cidr_obj[-1]\n tree = cidr_obj[:-1]\n if isinstance(cidr_value_obj, list):\n if len(cidr_value_obj) in [2, 3]:\n ip_block_obj = cidr_value_obj[0]\n count_obj = cidr_value_obj[1]\n if len(cidr_value_obj) == 3:\n size_mask_obj = cidr_value_obj[2]\n else:\n size_mask_obj = None\n\n if isinstance(ip_block_obj, dict):\n if len(ip_block_obj) == 1:\n for index_key, _ in ip_block_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n elif isinstance(ip_block_obj, (six.text_type, six.string_types)):\n if not re.match(REGEX_CIDR, ip_block_obj):\n message = 'Cidr ipBlock should be a Cidr Range based string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n else:\n message = 'Cidr ipBlock should be a string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n\n if isinstance(count_obj, dict):\n if len(count_obj) == 1:\n for index_key, index_value in count_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr count should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n if index_key == 'Ref':\n count_parameters.append(index_value)\n elif not isinstance(count_obj, six.integer_types):\n message = 'Cidr count should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n\n if isinstance(size_mask_obj, dict):\n if len(size_mask_obj) == 1:\n for index_key, index_value in size_mask_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr sizeMask should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n if index_key == 'Ref':\n size_mask_parameters.append(index_value)\n elif not isinstance(count_obj, six.integer_types):\n message = 'Cidr sizeMask should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n for count_parameter in set(count_parameters):\n matches.extend(self.check_parameter_count(cfn, count_parameter))\n for size_mask_parameter in set(size_mask_parameters):\n matches.extend(self.check_parameter_size_mask(cfn, size_mask_parameter))\n\n return matches\n", "path": "src/cfnlint/rules/functions/Cidr.py"}, {"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Select(CloudFormationLintRule):\n \"\"\"Check if Select values are correct\"\"\"\n id = 'E1017'\n shortdesc = 'Select validation of parameters'\n description = 'Making sure the function not is of list'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'\n tags = ['functions', 'select']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Select\"\"\"\n\n matches = list()\n\n select_objs = cfn.search_deep_keys('Fn::Select')\n\n supported_functions = [\n 'Fn::FindInMap',\n 'Fn::GetAtt',\n 'Fn::GetAZs',\n 'Fn::If',\n 'Fn::Split',\n 'Fn::Cidr',\n 'Ref'\n ]\n\n for select_obj in select_objs:\n select_value_obj = select_obj[-1]\n tree = select_obj[:-1]\n if isinstance(select_value_obj, list):\n if len(select_value_obj) == 2:\n index_obj = select_value_obj[0]\n list_of_objs = select_value_obj[1]\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n for index_key, _ in index_obj:\n if index_key not in ['Ref', 'Fn::FindInMap']:\n message = 'Select index should be int, Ref, FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(index_obj, six.integer_types):\n try:\n int(index_obj)\n except ValueError:\n message = 'Select index should be int, Ref, FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n if isinstance(list_of_objs, dict):\n if len(list_of_objs) == 1:\n for key, _ in list_of_objs.items():\n if key not in supported_functions:\n message = 'Key {0} should be a list for {1}'\n matches.append(RuleMatch(\n tree, message.format(key, '/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be an array of values for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n return matches\n", "path": "src/cfnlint/rules/functions/Select.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nfrom cfnlint.helpers import REGEX_CIDR\n\nclass Cidr(CloudFormationLintRule):\n \"\"\"Check if Cidr values are correct\"\"\"\n id = 'E1024'\n shortdesc = 'Cidr validation of parameters'\n description = 'Making sure the function CIDR is a list with valid values'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-cidr.html'\n tags = ['functions', 'cidr']\n\n def check_parameter_count(self, cfn, parameter_name):\n \"\"\"Check Count Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr count have MinValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and 256 at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def check_parameter_size_mask(self, cfn, parameter_name):\n \"\"\"Check SizeMask Parameter if used\"\"\"\n matches = list()\n parameter_obj = cfn.get_parameters().get(parameter_name, {})\n if parameter_obj:\n tree = ['Parameters', parameter_name]\n parameter_type = parameter_obj.get('Type')\n if parameter_type == 'Number':\n max_value = parameter_obj.get('MaxValue')\n min_value = parameter_obj.get('MinValue')\n if (not min_value) or min_value < 1 or min_value > 256:\n message = 'Parameter for Cidr sizeMask have MinValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MinValue'], message.format('/'.join(map(str, tree + ['MinValue'])))))\n if (not max_value) or max_value < 1 or max_value > 256:\n message = 'Parameter for Cidr count have MaxValue between 1 and ' \\\n '128 (for ipv6) and 32 (for ipv4) at {0}'\n matches.append(RuleMatch(\n tree + ['MaxValue'], message.format('/'.join(map(str, tree + ['MaxValue'])))))\n else:\n message = 'Parameter for Cidr count have be of Type Number at {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Cidr\"\"\"\n\n matches = list()\n\n cidr_objs = cfn.search_deep_keys('Fn::Cidr')\n\n supported_functions = [\n 'Fn::Select',\n 'Ref',\n 'Fn::ImportValue'\n ]\n\n count_parameters = []\n size_mask_parameters = []\n\n for cidr_obj in cidr_objs:\n cidr_value_obj = cidr_obj[-1]\n tree = cidr_obj[:-1]\n if isinstance(cidr_value_obj, list):\n if len(cidr_value_obj) in [2, 3]:\n ip_block_obj = cidr_value_obj[0]\n count_obj = cidr_value_obj[1]\n if len(cidr_value_obj) == 3:\n size_mask_obj = cidr_value_obj[2]\n else:\n size_mask_obj = None\n\n if isinstance(ip_block_obj, dict):\n if len(ip_block_obj) == 1:\n for index_key, _ in ip_block_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr ipBlock should be Cidr Range, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n elif isinstance(ip_block_obj, (six.text_type, six.string_types)):\n if not re.match(REGEX_CIDR, ip_block_obj):\n message = 'Cidr ipBlock should be a Cidr Range based string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n else:\n message = 'Cidr ipBlock should be a string for {0}'\n matches.append(RuleMatch(\n tree[:] + [0], message.format('/'.join(map(str, tree[:] + [0])))))\n\n if isinstance(count_obj, dict):\n if len(count_obj) == 1:\n for index_key, index_value in count_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr count should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n if index_key == 'Ref':\n count_parameters.append(index_value)\n elif not isinstance(count_obj, six.integer_types):\n message = 'Cidr count should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [1], message.format('/'.join(map(str, tree[:] + [1])))))\n\n if isinstance(size_mask_obj, dict):\n if len(size_mask_obj) == 1:\n for index_key, index_value in size_mask_obj.items():\n if index_key not in supported_functions:\n message = 'Cidr sizeMask should be Int, Ref, or Select for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n if index_key == 'Ref':\n size_mask_parameters.append(index_value)\n elif not isinstance(size_mask_obj, six.integer_types):\n message = 'Cidr sizeMask should be a int for {0}'\n matches.append(RuleMatch(\n tree[:] + [2], message.format('/'.join(map(str, tree[:] + [2])))))\n\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Cidr should be a list of 2 or 3 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n for count_parameter in set(count_parameters):\n matches.extend(self.check_parameter_count(cfn, count_parameter))\n for size_mask_parameter in set(size_mask_parameters):\n matches.extend(self.check_parameter_size_mask(cfn, size_mask_parameter))\n\n return matches\n", "path": "src/cfnlint/rules/functions/Cidr.py"}, {"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Select(CloudFormationLintRule):\n \"\"\"Check if Select values are correct\"\"\"\n id = 'E1017'\n shortdesc = 'Select validation of parameters'\n description = 'Making sure the function not is of list'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'\n tags = ['functions', 'select']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Select\"\"\"\n\n matches = list()\n\n select_objs = cfn.search_deep_keys('Fn::Select')\n\n supported_functions = [\n 'Fn::FindInMap',\n 'Fn::GetAtt',\n 'Fn::GetAZs',\n 'Fn::If',\n 'Fn::Split',\n 'Fn::Cidr',\n 'Ref'\n ]\n\n for select_obj in select_objs:\n select_value_obj = select_obj[-1]\n tree = select_obj[:-1]\n if isinstance(select_value_obj, list):\n if len(select_value_obj) == 2:\n index_obj = select_value_obj[0]\n list_of_objs = select_value_obj[1]\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n for index_key, _ in index_obj.items():\n if index_key not in ['Ref', 'Fn::FindInMap']:\n message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(index_obj, six.integer_types):\n try:\n int(index_obj)\n except ValueError:\n message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n if isinstance(list_of_objs, dict):\n if len(list_of_objs) == 1:\n for key, _ in list_of_objs.items():\n if key not in supported_functions:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n else:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n elif not isinstance(list_of_objs, list):\n message = 'Select should be an array of values for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n return matches\n", "path": "src/cfnlint/rules/functions/Select.py"}]}
| 3,999 | 736 |
gh_patches_debug_19594
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2778
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Traceback appears, when trying to set mitmproxy's address as upstream server for reverse/upstream mode
##### Steps to reproduce the problem:
1. Run mitmproxy in **reverse** or **upstream** mode, using its own address as upstream server address:
`mitmproxy --mode reverse:http://127.0.0.1:8080` or
`mitmproxy --mode upstream:http://127.0.0.1:8080`
2. Make a request using pathoc `pathoc 127.0.0.1:8080 "get:/"` or a browser.
I am seeing:
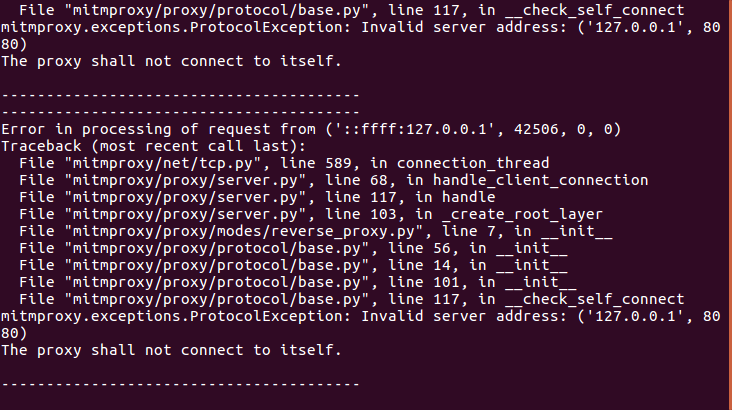
##### Any other comments? What have you tried so far?
https://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/proxy/protocol/base.py#L115
should be handled.
##### System information
Mitmproxy: 3.0.0.dev1101 (commit d9d4d15) binary
Python: 3.5.2
OpenSSL: OpenSSL 1.1.0g 2 Nov 2017
Platform: Linux-4.4.0-104-generic-x86_64-with-debian-stretch-sid
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/proxy/server.py`
Content:
```
1 import sys
2 import traceback
3
4 from mitmproxy import exceptions
5 from mitmproxy import connections
6 from mitmproxy import controller # noqa
7 from mitmproxy import http
8 from mitmproxy import log
9 from mitmproxy import platform
10 from mitmproxy.proxy import config
11 from mitmproxy.proxy import modes
12 from mitmproxy.proxy import root_context
13 from mitmproxy.net import tcp
14 from mitmproxy.net.http import http1
15 from mitmproxy.utils import human
16
17
18 class DummyServer:
19 bound = False
20
21 def __init__(self, config=None):
22 self.config = config
23 self.address = "dummy"
24
25 def set_channel(self, channel):
26 pass
27
28 def serve_forever(self):
29 pass
30
31 def shutdown(self):
32 pass
33
34
35 class ProxyServer(tcp.TCPServer):
36 allow_reuse_address = True
37 bound = True
38
39 def __init__(self, config: config.ProxyConfig) -> None:
40 """
41 Raises ServerException if there's a startup problem.
42 """
43 self.config = config
44 try:
45 super().__init__(
46 (config.options.listen_host, config.options.listen_port)
47 )
48 if config.options.mode == "transparent":
49 platform.init_transparent_mode()
50 except Exception as e:
51 if self.socket:
52 self.socket.close()
53 raise exceptions.ServerException(
54 'Error starting proxy server: ' + repr(e)
55 ) from e
56 self.channel = None # type: controller.Channel
57
58 def set_channel(self, channel):
59 self.channel = channel
60
61 def handle_client_connection(self, conn, client_address):
62 h = ConnectionHandler(
63 conn,
64 client_address,
65 self.config,
66 self.channel
67 )
68 h.handle()
69
70
71 class ConnectionHandler:
72
73 def __init__(self, client_conn, client_address, config, channel):
74 self.config = config # type: config.ProxyConfig
75 self.client_conn = connections.ClientConnection(
76 client_conn,
77 client_address,
78 None)
79 """@type: mitmproxy.proxy.connection.ClientConnection"""
80 self.channel = channel
81 """@type: mitmproxy.controller.Channel"""
82
83 def _create_root_layer(self):
84 root_ctx = root_context.RootContext(
85 self.client_conn,
86 self.config,
87 self.channel
88 )
89
90 mode = self.config.options.mode
91 if mode.startswith("upstream:"):
92 return modes.HttpUpstreamProxy(
93 root_ctx,
94 self.config.upstream_server.address
95 )
96 elif mode == "transparent":
97 return modes.TransparentProxy(root_ctx)
98 elif mode.startswith("reverse:"):
99 server_tls = self.config.upstream_server.scheme == "https"
100 return modes.ReverseProxy(
101 root_ctx,
102 self.config.upstream_server.address,
103 server_tls
104 )
105 elif mode == "socks5":
106 return modes.Socks5Proxy(root_ctx)
107 elif mode == "regular":
108 return modes.HttpProxy(root_ctx)
109 elif callable(mode): # pragma: no cover
110 return mode(root_ctx)
111 else: # pragma: no cover
112 raise ValueError("Unknown proxy mode: %s" % mode)
113
114 def handle(self):
115 self.log("clientconnect", "info")
116
117 root_layer = self._create_root_layer()
118
119 try:
120 root_layer = self.channel.ask("clientconnect", root_layer)
121 root_layer()
122 except exceptions.Kill:
123 self.log("Connection killed", "info")
124 except exceptions.ProtocolException as e:
125 if isinstance(e, exceptions.ClientHandshakeException):
126 self.log(
127 "Client Handshake failed. "
128 "The client may not trust the proxy's certificate for {}.".format(e.server),
129 "warn"
130 )
131 self.log(repr(e), "debug")
132 elif isinstance(e, exceptions.InvalidServerCertificate):
133 self.log(str(e), "warn")
134 self.log("Invalid certificate, closing connection. Pass --insecure to disable validation.", "warn")
135 else:
136 self.log(str(e), "warn")
137
138 self.log(repr(e), "debug")
139 # If an error propagates to the topmost level,
140 # we send an HTTP error response, which is both
141 # understandable by HTTP clients and humans.
142 try:
143 error_response = http.make_error_response(502, repr(e))
144 self.client_conn.send(http1.assemble_response(error_response))
145 except exceptions.TcpException:
146 pass
147 except Exception:
148 self.log(traceback.format_exc(), "error")
149 print(traceback.format_exc(), file=sys.stderr)
150 print("mitmproxy has crashed!", file=sys.stderr)
151 print("Please lodge a bug report at: https://github.com/mitmproxy/mitmproxy", file=sys.stderr)
152
153 self.log("clientdisconnect", "info")
154 self.channel.tell("clientdisconnect", root_layer)
155 self.client_conn.finish()
156
157 def log(self, msg, level):
158 msg = "{}: {}".format(human.format_address(self.client_conn.address), msg)
159 self.channel.tell("log", log.LogEntry(msg, level))
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/proxy/server.py b/mitmproxy/proxy/server.py
--- a/mitmproxy/proxy/server.py
+++ b/mitmproxy/proxy/server.py
@@ -114,9 +114,9 @@
def handle(self):
self.log("clientconnect", "info")
- root_layer = self._create_root_layer()
-
+ root_layer = None
try:
+ root_layer = self._create_root_layer()
root_layer = self.channel.ask("clientconnect", root_layer)
root_layer()
except exceptions.Kill:
@@ -151,7 +151,8 @@
print("Please lodge a bug report at: https://github.com/mitmproxy/mitmproxy", file=sys.stderr)
self.log("clientdisconnect", "info")
- self.channel.tell("clientdisconnect", root_layer)
+ if root_layer is not None:
+ self.channel.tell("clientdisconnect", root_layer)
self.client_conn.finish()
def log(self, msg, level):
|
{"golden_diff": "diff --git a/mitmproxy/proxy/server.py b/mitmproxy/proxy/server.py\n--- a/mitmproxy/proxy/server.py\n+++ b/mitmproxy/proxy/server.py\n@@ -114,9 +114,9 @@\n def handle(self):\n self.log(\"clientconnect\", \"info\")\n \n- root_layer = self._create_root_layer()\n-\n+ root_layer = None\n try:\n+ root_layer = self._create_root_layer()\n root_layer = self.channel.ask(\"clientconnect\", root_layer)\n root_layer()\n except exceptions.Kill:\n@@ -151,7 +151,8 @@\n print(\"Please lodge a bug report at: https://github.com/mitmproxy/mitmproxy\", file=sys.stderr)\n \n self.log(\"clientdisconnect\", \"info\")\n- self.channel.tell(\"clientdisconnect\", root_layer)\n+ if root_layer is not None:\n+ self.channel.tell(\"clientdisconnect\", root_layer)\n self.client_conn.finish()\n \n def log(self, msg, level):\n", "issue": "Traceback appears, when trying to set mitmproxy's address as upstream server for reverse/upstream mode\n##### Steps to reproduce the problem:\r\n\r\n1. Run mitmproxy in **reverse** or **upstream** mode, using its own address as upstream server address:\r\n`mitmproxy --mode reverse:http://127.0.0.1:8080` or\r\n`mitmproxy --mode upstream:http://127.0.0.1:8080`\r\n2. Make a request using pathoc `pathoc 127.0.0.1:8080 \"get:/\"` or a browser.\r\n\r\nI am seeing:\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\nhttps://github.com/mitmproxy/mitmproxy/blob/master/mitmproxy/proxy/protocol/base.py#L115\r\nshould be handled.\r\n\r\n##### System information\r\n\r\nMitmproxy: 3.0.0.dev1101 (commit d9d4d15) binary\r\nPython: 3.5.2\r\nOpenSSL: OpenSSL 1.1.0g 2 Nov 2017\r\nPlatform: Linux-4.4.0-104-generic-x86_64-with-debian-stretch-sid\r\n\n", "before_files": [{"content": "import sys\nimport traceback\n\nfrom mitmproxy import exceptions\nfrom mitmproxy import connections\nfrom mitmproxy import controller # noqa\nfrom mitmproxy import http\nfrom mitmproxy import log\nfrom mitmproxy import platform\nfrom mitmproxy.proxy import config\nfrom mitmproxy.proxy import modes\nfrom mitmproxy.proxy import root_context\nfrom mitmproxy.net import tcp\nfrom mitmproxy.net.http import http1\nfrom mitmproxy.utils import human\n\n\nclass DummyServer:\n bound = False\n\n def __init__(self, config=None):\n self.config = config\n self.address = \"dummy\"\n\n def set_channel(self, channel):\n pass\n\n def serve_forever(self):\n pass\n\n def shutdown(self):\n pass\n\n\nclass ProxyServer(tcp.TCPServer):\n allow_reuse_address = True\n bound = True\n\n def __init__(self, config: config.ProxyConfig) -> None:\n \"\"\"\n Raises ServerException if there's a startup problem.\n \"\"\"\n self.config = config\n try:\n super().__init__(\n (config.options.listen_host, config.options.listen_port)\n )\n if config.options.mode == \"transparent\":\n platform.init_transparent_mode()\n except Exception as e:\n if self.socket:\n self.socket.close()\n raise exceptions.ServerException(\n 'Error starting proxy server: ' + repr(e)\n ) from e\n self.channel = None # type: controller.Channel\n\n def set_channel(self, channel):\n self.channel = channel\n\n def handle_client_connection(self, conn, client_address):\n h = ConnectionHandler(\n conn,\n client_address,\n self.config,\n self.channel\n )\n h.handle()\n\n\nclass ConnectionHandler:\n\n def __init__(self, client_conn, client_address, config, channel):\n self.config = config # type: config.ProxyConfig\n self.client_conn = connections.ClientConnection(\n client_conn,\n client_address,\n None)\n \"\"\"@type: mitmproxy.proxy.connection.ClientConnection\"\"\"\n self.channel = channel\n \"\"\"@type: mitmproxy.controller.Channel\"\"\"\n\n def _create_root_layer(self):\n root_ctx = root_context.RootContext(\n self.client_conn,\n self.config,\n self.channel\n )\n\n mode = self.config.options.mode\n if mode.startswith(\"upstream:\"):\n return modes.HttpUpstreamProxy(\n root_ctx,\n self.config.upstream_server.address\n )\n elif mode == \"transparent\":\n return modes.TransparentProxy(root_ctx)\n elif mode.startswith(\"reverse:\"):\n server_tls = self.config.upstream_server.scheme == \"https\"\n return modes.ReverseProxy(\n root_ctx,\n self.config.upstream_server.address,\n server_tls\n )\n elif mode == \"socks5\":\n return modes.Socks5Proxy(root_ctx)\n elif mode == \"regular\":\n return modes.HttpProxy(root_ctx)\n elif callable(mode): # pragma: no cover\n return mode(root_ctx)\n else: # pragma: no cover\n raise ValueError(\"Unknown proxy mode: %s\" % mode)\n\n def handle(self):\n self.log(\"clientconnect\", \"info\")\n\n root_layer = self._create_root_layer()\n\n try:\n root_layer = self.channel.ask(\"clientconnect\", root_layer)\n root_layer()\n except exceptions.Kill:\n self.log(\"Connection killed\", \"info\")\n except exceptions.ProtocolException as e:\n if isinstance(e, exceptions.ClientHandshakeException):\n self.log(\n \"Client Handshake failed. \"\n \"The client may not trust the proxy's certificate for {}.\".format(e.server),\n \"warn\"\n )\n self.log(repr(e), \"debug\")\n elif isinstance(e, exceptions.InvalidServerCertificate):\n self.log(str(e), \"warn\")\n self.log(\"Invalid certificate, closing connection. Pass --insecure to disable validation.\", \"warn\")\n else:\n self.log(str(e), \"warn\")\n\n self.log(repr(e), \"debug\")\n # If an error propagates to the topmost level,\n # we send an HTTP error response, which is both\n # understandable by HTTP clients and humans.\n try:\n error_response = http.make_error_response(502, repr(e))\n self.client_conn.send(http1.assemble_response(error_response))\n except exceptions.TcpException:\n pass\n except Exception:\n self.log(traceback.format_exc(), \"error\")\n print(traceback.format_exc(), file=sys.stderr)\n print(\"mitmproxy has crashed!\", file=sys.stderr)\n print(\"Please lodge a bug report at: https://github.com/mitmproxy/mitmproxy\", file=sys.stderr)\n\n self.log(\"clientdisconnect\", \"info\")\n self.channel.tell(\"clientdisconnect\", root_layer)\n self.client_conn.finish()\n\n def log(self, msg, level):\n msg = \"{}: {}\".format(human.format_address(self.client_conn.address), msg)\n self.channel.tell(\"log\", log.LogEntry(msg, level))\n", "path": "mitmproxy/proxy/server.py"}], "after_files": [{"content": "import sys\nimport traceback\n\nfrom mitmproxy import exceptions\nfrom mitmproxy import connections\nfrom mitmproxy import controller # noqa\nfrom mitmproxy import http\nfrom mitmproxy import log\nfrom mitmproxy import platform\nfrom mitmproxy.proxy import config\nfrom mitmproxy.proxy import modes\nfrom mitmproxy.proxy import root_context\nfrom mitmproxy.net import tcp\nfrom mitmproxy.net.http import http1\nfrom mitmproxy.utils import human\n\n\nclass DummyServer:\n bound = False\n\n def __init__(self, config=None):\n self.config = config\n self.address = \"dummy\"\n\n def set_channel(self, channel):\n pass\n\n def serve_forever(self):\n pass\n\n def shutdown(self):\n pass\n\n\nclass ProxyServer(tcp.TCPServer):\n allow_reuse_address = True\n bound = True\n\n def __init__(self, config: config.ProxyConfig) -> None:\n \"\"\"\n Raises ServerException if there's a startup problem.\n \"\"\"\n self.config = config\n try:\n super().__init__(\n (config.options.listen_host, config.options.listen_port)\n )\n if config.options.mode == \"transparent\":\n platform.init_transparent_mode()\n except Exception as e:\n if self.socket:\n self.socket.close()\n raise exceptions.ServerException(\n 'Error starting proxy server: ' + repr(e)\n ) from e\n self.channel = None # type: controller.Channel\n\n def set_channel(self, channel):\n self.channel = channel\n\n def handle_client_connection(self, conn, client_address):\n h = ConnectionHandler(\n conn,\n client_address,\n self.config,\n self.channel\n )\n h.handle()\n\n\nclass ConnectionHandler:\n\n def __init__(self, client_conn, client_address, config, channel):\n self.config = config # type: config.ProxyConfig\n self.client_conn = connections.ClientConnection(\n client_conn,\n client_address,\n None)\n \"\"\"@type: mitmproxy.proxy.connection.ClientConnection\"\"\"\n self.channel = channel\n \"\"\"@type: mitmproxy.controller.Channel\"\"\"\n\n def _create_root_layer(self):\n root_ctx = root_context.RootContext(\n self.client_conn,\n self.config,\n self.channel\n )\n\n mode = self.config.options.mode\n if mode.startswith(\"upstream:\"):\n return modes.HttpUpstreamProxy(\n root_ctx,\n self.config.upstream_server.address\n )\n elif mode == \"transparent\":\n return modes.TransparentProxy(root_ctx)\n elif mode.startswith(\"reverse:\"):\n server_tls = self.config.upstream_server.scheme == \"https\"\n return modes.ReverseProxy(\n root_ctx,\n self.config.upstream_server.address,\n server_tls\n )\n elif mode == \"socks5\":\n return modes.Socks5Proxy(root_ctx)\n elif mode == \"regular\":\n return modes.HttpProxy(root_ctx)\n elif callable(mode): # pragma: no cover\n return mode(root_ctx)\n else: # pragma: no cover\n raise ValueError(\"Unknown proxy mode: %s\" % mode)\n\n def handle(self):\n self.log(\"clientconnect\", \"info\")\n\n root_layer = None\n try:\n root_layer = self._create_root_layer()\n root_layer = self.channel.ask(\"clientconnect\", root_layer)\n root_layer()\n except exceptions.Kill:\n self.log(\"Connection killed\", \"info\")\n except exceptions.ProtocolException as e:\n if isinstance(e, exceptions.ClientHandshakeException):\n self.log(\n \"Client Handshake failed. \"\n \"The client may not trust the proxy's certificate for {}.\".format(e.server),\n \"warn\"\n )\n self.log(repr(e), \"debug\")\n elif isinstance(e, exceptions.InvalidServerCertificate):\n self.log(str(e), \"warn\")\n self.log(\"Invalid certificate, closing connection. Pass --insecure to disable validation.\", \"warn\")\n else:\n self.log(str(e), \"warn\")\n\n self.log(repr(e), \"debug\")\n # If an error propagates to the topmost level,\n # we send an HTTP error response, which is both\n # understandable by HTTP clients and humans.\n try:\n error_response = http.make_error_response(502, repr(e))\n self.client_conn.send(http1.assemble_response(error_response))\n except exceptions.TcpException:\n pass\n except Exception:\n self.log(traceback.format_exc(), \"error\")\n print(traceback.format_exc(), file=sys.stderr)\n print(\"mitmproxy has crashed!\", file=sys.stderr)\n print(\"Please lodge a bug report at: https://github.com/mitmproxy/mitmproxy\", file=sys.stderr)\n\n self.log(\"clientdisconnect\", \"info\")\n if root_layer is not None:\n self.channel.tell(\"clientdisconnect\", root_layer)\n self.client_conn.finish()\n\n def log(self, msg, level):\n msg = \"{}: {}\".format(human.format_address(self.client_conn.address), msg)\n self.channel.tell(\"log\", log.LogEntry(msg, level))\n", "path": "mitmproxy/proxy/server.py"}]}
| 2,071 | 226 |
gh_patches_debug_40215
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2869
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider regis_uk is broken
During the global build at 2021-05-26-14-42-23, spider **regis_uk** failed with **33 features** and **35 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/regis_uk.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/regis_uk.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/regis_uk.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/regis_salon_uk.py`
Content:
```
1 import scrapy
2 from locations.items import GeojsonPointItem
3 import re
4
5 regex_am = r"\s?([Aa][Mm])"
6 regex_pm = r"\s?([Pp][Mm])"
7
8
9 class RegisUKSpider(scrapy.Spider):
10 name = "regis_uk"
11 item_attributes = { 'brand': "Regis Salon" }
12 allowed_domains = ["www.regissalons.co.uk"]
13 start_urls = ['https://www.regissalons.co.uk/salon-locator?show-all=yes']
14
15 def convert_hours(self, hours):
16 hours = [x.strip() for x in hours]
17 hours = [x for x in hours if x]
18 for i in range(len(hours)):
19 converted_times = ''
20 if hours[i] != "Closed":
21 from_hr, to_hr = [hr.strip() for hr in hours[i].split('–')]
22 if re.search(regex_am, from_hr):
23 from_hr = re.sub(regex_am, '', from_hr)
24 hour_min = from_hr.split(':')
25 if len(hour_min[0]) < 2:
26 hour_min[0].zfill(2)
27 converted_times += (":".join(hour_min)) + ' - '
28 else:
29 from_hr = re.sub(regex_pm, '', from_hr)
30 hour_min = from_hr.split(':')
31 if int(hour_min[0]) < 12:
32 hour_min[0] = str(12 + int(hour_min[0]))
33 converted_times += (":".join(hour_min)) + ' - '
34
35 if re.search(regex_am, to_hr):
36 to_hr = re.sub(regex_am, '', to_hr)
37 hour_min = to_hr.split(':')
38 if len(hour_min[0]) < 2:
39 hour_min[0].zfill(2)
40 if int(hour_min[0]) == 12:
41 hour_min[0] = '00'
42 converted_times += (":".join(hour_min))
43 else:
44 to_hr = re.sub(regex_pm, '', to_hr)
45 hour_min = to_hr.split(':')
46 if int(hour_min[0]) < 12:
47 hour_min[0] = str(12 + int(hour_min[0]))
48 converted_times += (":".join(hour_min))
49 else:
50 converted_times += "off"
51 hours[i] = converted_times
52 days = ["Mo", "Tu", "We", "Th", "Fr", "Sa", "Su"]
53 hours = ''.join('{} {} '.format(*t) for t in zip(days, hours))
54 return hours
55
56 def parse_store(self, response):
57 phone = response.xpath(
58 '//a[@class="phone-tracked-link"]/text()').extract_first().strip()
59 lat = response.xpath(
60 '//div[@id="map-aside"]/@data-lat').extract_first()
61 lon = response.xpath(
62 '//div[@id="map-aside"]/@data-lng').extract_first()
63 hours = response.xpath(
64 '//div[@class="container"]//p[contains(., "am")'
65 ' or contains(., "Closed")]/text()').extract()
66 hours = self.convert_hours(hours)
67
68 yield GeojsonPointItem(
69 ref=response.url,
70 phone=phone,
71 lat=lat,
72 lon=lon,
73 opening_hours=hours,
74 website=response.url
75 )
76
77 def parse(self, response):
78 stores = response.xpath('//ul[@class="list"]//a/@href').extract()
79 for store in stores:
80 yield scrapy.Request(store, callback=self.parse_store)
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/regis_salon_uk.py b/locations/spiders/regis_salon_uk.py
--- a/locations/spiders/regis_salon_uk.py
+++ b/locations/spiders/regis_salon_uk.py
@@ -11,6 +11,7 @@
item_attributes = { 'brand': "Regis Salon" }
allowed_domains = ["www.regissalons.co.uk"]
start_urls = ['https://www.regissalons.co.uk/salon-locator?show-all=yes']
+ download_delay = 4.0
def convert_hours(self, hours):
hours = [x.strip() for x in hours]
@@ -21,20 +22,20 @@
from_hr, to_hr = [hr.strip() for hr in hours[i].split('–')]
if re.search(regex_am, from_hr):
from_hr = re.sub(regex_am, '', from_hr)
- hour_min = from_hr.split(':')
+ hour_min = re.split('[:.]', from_hr)
if len(hour_min[0]) < 2:
hour_min[0].zfill(2)
converted_times += (":".join(hour_min)) + ' - '
else:
from_hr = re.sub(regex_pm, '', from_hr)
- hour_min = from_hr.split(':')
+ hour_min = re.split('[:.]', from_hr)
if int(hour_min[0]) < 12:
hour_min[0] = str(12 + int(hour_min[0]))
converted_times += (":".join(hour_min)) + ' - '
if re.search(regex_am, to_hr):
to_hr = re.sub(regex_am, '', to_hr)
- hour_min = to_hr.split(':')
+ hour_min = re.split('[:.]', to_hr)
if len(hour_min[0]) < 2:
hour_min[0].zfill(2)
if int(hour_min[0]) == 12:
@@ -42,7 +43,7 @@
converted_times += (":".join(hour_min))
else:
to_hr = re.sub(regex_pm, '', to_hr)
- hour_min = to_hr.split(':')
+ hour_min = re.split('[:.]', to_hr)
if int(hour_min[0]) < 12:
hour_min[0] = str(12 + int(hour_min[0]))
converted_times += (":".join(hour_min))
@@ -77,4 +78,6 @@
def parse(self, response):
stores = response.xpath('//ul[@class="list"]//a/@href').extract()
for store in stores:
+ if '/salon-region/' in store:
+ continue
yield scrapy.Request(store, callback=self.parse_store)
|
{"golden_diff": "diff --git a/locations/spiders/regis_salon_uk.py b/locations/spiders/regis_salon_uk.py\n--- a/locations/spiders/regis_salon_uk.py\n+++ b/locations/spiders/regis_salon_uk.py\n@@ -11,6 +11,7 @@\n item_attributes = { 'brand': \"Regis Salon\" }\n allowed_domains = [\"www.regissalons.co.uk\"]\n start_urls = ['https://www.regissalons.co.uk/salon-locator?show-all=yes']\n+ download_delay = 4.0\n \n def convert_hours(self, hours):\n hours = [x.strip() for x in hours]\n@@ -21,20 +22,20 @@\n from_hr, to_hr = [hr.strip() for hr in hours[i].split('\u2013')]\n if re.search(regex_am, from_hr):\n from_hr = re.sub(regex_am, '', from_hr)\n- hour_min = from_hr.split(':')\n+ hour_min = re.split('[:.]', from_hr)\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n converted_times += (\":\".join(hour_min)) + ' - '\n else:\n from_hr = re.sub(regex_pm, '', from_hr)\n- hour_min = from_hr.split(':')\n+ hour_min = re.split('[:.]', from_hr)\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min)) + ' - '\n \n if re.search(regex_am, to_hr):\n to_hr = re.sub(regex_am, '', to_hr)\n- hour_min = to_hr.split(':')\n+ hour_min = re.split('[:.]', to_hr)\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n if int(hour_min[0]) == 12:\n@@ -42,7 +43,7 @@\n converted_times += (\":\".join(hour_min))\n else:\n to_hr = re.sub(regex_pm, '', to_hr)\n- hour_min = to_hr.split(':')\n+ hour_min = re.split('[:.]', to_hr)\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min))\n@@ -77,4 +78,6 @@\n def parse(self, response):\n stores = response.xpath('//ul[@class=\"list\"]//a/@href').extract()\n for store in stores:\n+ if '/salon-region/' in store:\n+ continue\n yield scrapy.Request(store, callback=self.parse_store)\n", "issue": "Spider regis_uk is broken\nDuring the global build at 2021-05-26-14-42-23, spider **regis_uk** failed with **33 features** and **35 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/regis_uk.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/regis_uk.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/regis_uk.geojson))\n", "before_files": [{"content": "import scrapy\nfrom locations.items import GeojsonPointItem\nimport re\n\nregex_am = r\"\\s?([Aa][Mm])\"\nregex_pm = r\"\\s?([Pp][Mm])\"\n\n\nclass RegisUKSpider(scrapy.Spider):\n name = \"regis_uk\"\n item_attributes = { 'brand': \"Regis Salon\" }\n allowed_domains = [\"www.regissalons.co.uk\"]\n start_urls = ['https://www.regissalons.co.uk/salon-locator?show-all=yes']\n\n def convert_hours(self, hours):\n hours = [x.strip() for x in hours]\n hours = [x for x in hours if x]\n for i in range(len(hours)):\n converted_times = ''\n if hours[i] != \"Closed\":\n from_hr, to_hr = [hr.strip() for hr in hours[i].split('\u2013')]\n if re.search(regex_am, from_hr):\n from_hr = re.sub(regex_am, '', from_hr)\n hour_min = from_hr.split(':')\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n converted_times += (\":\".join(hour_min)) + ' - '\n else:\n from_hr = re.sub(regex_pm, '', from_hr)\n hour_min = from_hr.split(':')\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min)) + ' - '\n\n if re.search(regex_am, to_hr):\n to_hr = re.sub(regex_am, '', to_hr)\n hour_min = to_hr.split(':')\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n if int(hour_min[0]) == 12:\n hour_min[0] = '00'\n converted_times += (\":\".join(hour_min))\n else:\n to_hr = re.sub(regex_pm, '', to_hr)\n hour_min = to_hr.split(':')\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min))\n else:\n converted_times += \"off\"\n hours[i] = converted_times\n days = [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\", \"Su\"]\n hours = ''.join('{} {} '.format(*t) for t in zip(days, hours))\n return hours\n\n def parse_store(self, response):\n phone = response.xpath(\n '//a[@class=\"phone-tracked-link\"]/text()').extract_first().strip()\n lat = response.xpath(\n '//div[@id=\"map-aside\"]/@data-lat').extract_first()\n lon = response.xpath(\n '//div[@id=\"map-aside\"]/@data-lng').extract_first()\n hours = response.xpath(\n '//div[@class=\"container\"]//p[contains(., \"am\")'\n ' or contains(., \"Closed\")]/text()').extract()\n hours = self.convert_hours(hours)\n\n yield GeojsonPointItem(\n ref=response.url,\n phone=phone,\n lat=lat,\n lon=lon,\n opening_hours=hours,\n website=response.url\n )\n\n def parse(self, response):\n stores = response.xpath('//ul[@class=\"list\"]//a/@href').extract()\n for store in stores:\n yield scrapy.Request(store, callback=self.parse_store)\n", "path": "locations/spiders/regis_salon_uk.py"}], "after_files": [{"content": "import scrapy\nfrom locations.items import GeojsonPointItem\nimport re\n\nregex_am = r\"\\s?([Aa][Mm])\"\nregex_pm = r\"\\s?([Pp][Mm])\"\n\n\nclass RegisUKSpider(scrapy.Spider):\n name = \"regis_uk\"\n item_attributes = { 'brand': \"Regis Salon\" }\n allowed_domains = [\"www.regissalons.co.uk\"]\n start_urls = ['https://www.regissalons.co.uk/salon-locator?show-all=yes']\n download_delay = 4.0\n\n def convert_hours(self, hours):\n hours = [x.strip() for x in hours]\n hours = [x for x in hours if x]\n for i in range(len(hours)):\n converted_times = ''\n if hours[i] != \"Closed\":\n from_hr, to_hr = [hr.strip() for hr in hours[i].split('\u2013')]\n if re.search(regex_am, from_hr):\n from_hr = re.sub(regex_am, '', from_hr)\n hour_min = re.split('[:.]', from_hr)\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n converted_times += (\":\".join(hour_min)) + ' - '\n else:\n from_hr = re.sub(regex_pm, '', from_hr)\n hour_min = re.split('[:.]', from_hr)\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min)) + ' - '\n\n if re.search(regex_am, to_hr):\n to_hr = re.sub(regex_am, '', to_hr)\n hour_min = re.split('[:.]', to_hr)\n if len(hour_min[0]) < 2:\n hour_min[0].zfill(2)\n if int(hour_min[0]) == 12:\n hour_min[0] = '00'\n converted_times += (\":\".join(hour_min))\n else:\n to_hr = re.sub(regex_pm, '', to_hr)\n hour_min = re.split('[:.]', to_hr)\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n converted_times += (\":\".join(hour_min))\n else:\n converted_times += \"off\"\n hours[i] = converted_times\n days = [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\", \"Su\"]\n hours = ''.join('{} {} '.format(*t) for t in zip(days, hours))\n return hours\n\n def parse_store(self, response):\n phone = response.xpath(\n '//a[@class=\"phone-tracked-link\"]/text()').extract_first().strip()\n lat = response.xpath(\n '//div[@id=\"map-aside\"]/@data-lat').extract_first()\n lon = response.xpath(\n '//div[@id=\"map-aside\"]/@data-lng').extract_first()\n hours = response.xpath(\n '//div[@class=\"container\"]//p[contains(., \"am\")'\n ' or contains(., \"Closed\")]/text()').extract()\n hours = self.convert_hours(hours)\n\n yield GeojsonPointItem(\n ref=response.url,\n phone=phone,\n lat=lat,\n lon=lon,\n opening_hours=hours,\n website=response.url\n )\n\n def parse(self, response):\n stores = response.xpath('//ul[@class=\"list\"]//a/@href').extract()\n for store in stores:\n if '/salon-region/' in store:\n continue\n yield scrapy.Request(store, callback=self.parse_store)\n", "path": "locations/spiders/regis_salon_uk.py"}]}
| 1,379 | 613 |
gh_patches_debug_52723
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-895
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NEOS error
Our current build is failing because of the error below, I speculate due to usually-untested code being triggered by a transient network failure.
```
======================================================================
ERROR: test_kestrel_plugin (pyomo.neos.tests.test_neos.TestKestrel)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/travis/build/Pyomo/pyomo/pyomo/neos/tests/test_neos.py", line 90, in test_kestrel_plugin
results = solver_manager.solve(m, opt='cbc')
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/async_solver.py", line 28, in solve
return self.execute(*args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py", line 107, in execute
ah = self.queue(*args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py", line 122, in queue
return self._perform_queue(ah, *args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/neos/plugins/kestrel_plugin.py", line 127, in _perform_queue
raise ActionManagerError(
NameError: name 'ActionManagerError' is not defined
```
NEOS error
Our current build is failing because of the error below, I speculate due to usually-untested code being triggered by a transient network failure.
```
======================================================================
ERROR: test_kestrel_plugin (pyomo.neos.tests.test_neos.TestKestrel)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/travis/build/Pyomo/pyomo/pyomo/neos/tests/test_neos.py", line 90, in test_kestrel_plugin
results = solver_manager.solve(m, opt='cbc')
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/async_solver.py", line 28, in solve
return self.execute(*args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py", line 107, in execute
ah = self.queue(*args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py", line 122, in queue
return self._perform_queue(ah, *args, **kwds)
File "/home/travis/build/Pyomo/pyomo/pyomo/neos/plugins/kestrel_plugin.py", line 127, in _perform_queue
raise ActionManagerError(
NameError: name 'ActionManagerError' is not defined
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyomo/neos/plugins/kestrel_plugin.py`
Content:
```
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 import logging
12 import os
13 import re
14 import six
15
16 from six.moves.xmlrpc_client import ProtocolError
17
18 from pyomo.opt import SolverFactory, SolverManagerFactory, OptSolver
19 from pyomo.opt.parallel.async_solver import (
20 AsynchronousSolverManager, ActionStatus
21 )
22 from pyomo.opt.base import OptSolver
23 from pyomo.core.base import Block
24 import pyomo.neos.kestrel
25
26
27 logger = logging.getLogger('pyomo.neos')
28
29
30 def _neos_error(msg, results, current_message):
31 error_re = re.compile('error', flags=re.I)
32 warn_re = re.compile('warn', flags=re.I)
33
34 logger.error("%s NEOS log:\n%s" % ( msg, current_message, ))
35 soln_data = results.data
36 if six.PY3:
37 soln_data = soln_data.decode('utf-8')
38 for line in soln_data.splitlines():
39 if error_re.search(line):
40 logger.error(line)
41 elif warn_re.search(line):
42 logger.warn(line)
43
44
45 @SolverManagerFactory.register(
46 'neos', doc="Asynchronously execute solvers on the NEOS server")
47 class SolverManager_NEOS(AsynchronousSolverManager):
48
49 def clear(self):
50 """
51 Clear manager state
52 """
53 AsynchronousSolverManager.clear(self)
54 self.kestrel = pyomo.neos.kestrel.kestrelAMPL()
55 self._ah = {} # maps NEOS job numbers to their corresponding
56 # action handle.
57 self._args = {}
58 self._opt_data = {}
59
60 # to grab streamed output from NEOS, need to keep
61 # map of action handle to the to-date string of
62 # extracted output.
63 # TBD: The following entries aren't currently cleaned up, but
64 # we're still trying to get the basics down.
65 # store pairs of NEOS message offset and NEOS message string.
66 # index into the map is the NEOS job number
67 self._neos_log = {}
68 self._solvers = {}
69
70 def _perform_queue(self, ah, *args, **kwds):
71 """
72 Perform the queue operation. This method returns the ActionHandle,
73 and the ActionHandle status indicates whether the queue was successful.
74 """
75 solver = kwds.pop('solver', kwds.pop('opt', None))
76 if solver is None:
77 raise ActionManagerError(
78 "No solver passed to %s, use keyword option 'solver'"
79 % (type(self).__name__) )
80 if not isinstance(solver, six.string_types):
81 solver_name = solver.name
82 if solver_name == 'asl':
83 solver_name = \
84 os.path.basename(solver.executable())
85 else:
86 solver_name = solver
87 solver = None
88
89 #
90 # Handle ephemeral solvers options here. These
91 # will override whatever is currently in the options
92 # dictionary, but we will reset these options to
93 # their original value at the end of this method.
94 #
95 user_solver_options = {}
96 # make sure to transfer the options dict on the
97 # solver plugin if the user does not use a string
98 # to identify the neos solver. The ephemeral
99 # options must also go after these.
100 if solver is not None:
101 user_solver_options.update(solver.options)
102 _options = kwds.pop('options', {})
103 if isinstance(_options, six.string_types):
104 _options = OptSolver._options_string_to_dict(_options)
105 user_solver_options.update(_options)
106 user_solver_options.update(
107 OptSolver._options_string_to_dict(kwds.pop('options_string', '')))
108
109 # JDS: [5/13/17] The following is a HACK. This timeout flag is
110 # set by pyomo/scripting/util.py:apply_optimizer. If we do not
111 # remove it, it will get passed to the NEOS solver. For solvers
112 # like CPLEX 12.7.0, this will cause a fatal error as it is not
113 # a known option.
114 if user_solver_options.get('timelimit',0) is None:
115 del user_solver_options['timelimit']
116
117 opt = SolverFactory('_neos')
118 opt._presolve(*args, **kwds)
119 #
120 # Map NEOS name, using lowercase convention in Pyomo
121 #
122 if len(self._solvers) == 0:
123 for name in self.kestrel.solvers():
124 if name.endswith('AMPL'):
125 self._solvers[ name[:-5].lower() ] = name[:-5]
126 if solver_name not in self._solvers:
127 raise ActionManagerError(
128 "Solver '%s' is not recognized by NEOS. "
129 "Solver names recognized:\n%s"
130 % (solver_name, str(sorted(self._solvers.keys()))))
131 #
132 # Apply kestrel
133 #
134 # Set the kestrel_options environment
135 #
136 neos_sname = self._solvers[solver_name].lower()
137 os.environ['kestrel_options'] = 'solver=%s' % self._solvers[solver_name]
138 #
139 # Set the <solver>_options environment
140 #
141 solver_options = {}
142 for key in opt.options:
143 solver_options[key]=opt.options[key]
144 solver_options.update(user_solver_options)
145 options = opt._get_options_string(solver_options)
146 if not options == "":
147 os.environ[neos_sname+'_options'] = options
148 #
149 # Generate an XML string using these two environment variables
150 #
151 xml = self.kestrel.formXML(opt._problem_files[0])
152 (jobNumber, password) = self.kestrel.submit(xml)
153 ah.job = jobNumber
154 ah.password = password
155 #
156 # Cleanup
157 #
158 del os.environ['kestrel_options']
159 try:
160 del os.environ[neos_sname+"_options"]
161 except:
162 pass
163 #
164 # Store action handle, and return
165 #
166 self._ah[jobNumber] = ah
167 self._neos_log[jobNumber] = (0, "")
168 self._opt_data[jobNumber] = (opt,
169 opt._smap_id,
170 opt._load_solutions,
171 opt._select_index,
172 opt._default_variable_value)
173 self._args[jobNumber] = args
174 return ah
175
176 def _perform_wait_any(self):
177 """
178 Perform the wait_any operation. This method returns an
179 ActionHandle with the results of waiting. If None is returned
180 then the ActionManager assumes that it can call this method again.
181 Note that an ActionHandle can be returned with a dummy value,
182 to indicate an error.
183 """
184 for jobNumber in self._ah:
185
186 status = self.kestrel.neos.getJobStatus(jobNumber,
187 self._ah[jobNumber].password)
188
189 if status not in ("Running", "Waiting"):
190 # the job is done.
191 ah = self._ah[jobNumber]
192 del self._ah[jobNumber]
193 ah.status = ActionStatus.done
194
195 (opt,
196 smap_id,
197 load_solutions,
198 select_index,
199 default_variable_value) = self._opt_data[jobNumber]
200 del self._opt_data[jobNumber]
201
202 args = self._args[jobNumber]
203 del self._args[jobNumber]
204
205 # retrieve the final results, which are in message/log format.
206 results = self.kestrel.neos.getFinalResults(jobNumber, ah.password)
207
208 (current_offset, current_message) = self._neos_log[jobNumber]
209 with open(opt._log_file, 'w') as OUTPUT:
210 OUTPUT.write(current_message)
211 with open(opt._soln_file, 'w') as OUTPUT:
212 if six.PY2:
213 OUTPUT.write(results.data)
214 else:
215 OUTPUT.write(results.data.decode('utf-8'))
216
217 rc = None
218 try:
219 solver_results = opt.process_output(rc)
220 except:
221 _neos_error( "Error parsing NEOS solution file",
222 results, current_message )
223 return ah
224
225 solver_results._smap_id = smap_id
226 self.results[ah.id] = solver_results
227
228 if isinstance(args[0], Block):
229 _model = args[0]
230 if load_solutions:
231 try:
232 _model.solutions.load_from(
233 solver_results,
234 select=select_index,
235 default_variable_value=default_variable_value)
236 except:
237 _neos_error(
238 "Error loading NEOS solution into model",
239 results, current_message )
240 solver_results._smap_id = None
241 solver_results.solution.clear()
242 else:
243 solver_results._smap = _model.solutions.symbol_map[smap_id]
244 _model.solutions.delete_symbol_map(smap_id)
245
246 return ah
247 else:
248 # The job is still running...
249 #
250 # Grab the partial messages from NEOS as you go, in case
251 # you want to output on-the-fly. You will only get data
252 # if the job was routed to the "short" priority queue.
253 (current_offset, current_message) = self._neos_log[jobNumber]
254 # TBD: blocking isn't the way to go, but non-blocking
255 # was triggering some exception in kestrel.
256 #
257 # [5/13/17]: The blocking fetch will timeout in 2
258 # minutes. If NEOS doesn't produce intermediate results
259 # by then we will need to catch (and eat) the exception
260 try:
261 (message_fragment, new_offset) \
262 = self.kestrel.neos.getIntermediateResults(
263 jobNumber,
264 self._ah[jobNumber].password,
265 current_offset )
266 logger.info(message_fragment)
267 self._neos_log[jobNumber] = (
268 new_offset,
269 current_message + (
270 message_fragment.data if six.PY2
271 else (message_fragment.data).decode('utf-8') ) )
272 except ProtocolError:
273 # The command probably timed out
274 pass
275
276 return None
277
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyomo/neos/plugins/kestrel_plugin.py b/pyomo/neos/plugins/kestrel_plugin.py
--- a/pyomo/neos/plugins/kestrel_plugin.py
+++ b/pyomo/neos/plugins/kestrel_plugin.py
@@ -16,6 +16,7 @@
from six.moves.xmlrpc_client import ProtocolError
from pyomo.opt import SolverFactory, SolverManagerFactory, OptSolver
+from pyomo.opt.parallel.manager import ActionManagerError
from pyomo.opt.parallel.async_solver import (
AsynchronousSolverManager, ActionStatus
)
|
{"golden_diff": "diff --git a/pyomo/neos/plugins/kestrel_plugin.py b/pyomo/neos/plugins/kestrel_plugin.py\n--- a/pyomo/neos/plugins/kestrel_plugin.py\n+++ b/pyomo/neos/plugins/kestrel_plugin.py\n@@ -16,6 +16,7 @@\n from six.moves.xmlrpc_client import ProtocolError\n \n from pyomo.opt import SolverFactory, SolverManagerFactory, OptSolver\n+from pyomo.opt.parallel.manager import ActionManagerError\n from pyomo.opt.parallel.async_solver import (\n AsynchronousSolverManager, ActionStatus\n )\n", "issue": "NEOS error\nOur current build is failing because of the error below, I speculate due to usually-untested code being triggered by a transient network failure.\r\n```\r\n======================================================================\r\nERROR: test_kestrel_plugin (pyomo.neos.tests.test_neos.TestKestrel)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/neos/tests/test_neos.py\", line 90, in test_kestrel_plugin\r\n results = solver_manager.solve(m, opt='cbc')\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/async_solver.py\", line 28, in solve\r\n return self.execute(*args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py\", line 107, in execute\r\n ah = self.queue(*args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py\", line 122, in queue\r\n return self._perform_queue(ah, *args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/neos/plugins/kestrel_plugin.py\", line 127, in _perform_queue\r\n raise ActionManagerError(\r\nNameError: name 'ActionManagerError' is not defined\r\n```\nNEOS error\nOur current build is failing because of the error below, I speculate due to usually-untested code being triggered by a transient network failure.\r\n```\r\n======================================================================\r\nERROR: test_kestrel_plugin (pyomo.neos.tests.test_neos.TestKestrel)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/neos/tests/test_neos.py\", line 90, in test_kestrel_plugin\r\n results = solver_manager.solve(m, opt='cbc')\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/async_solver.py\", line 28, in solve\r\n return self.execute(*args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py\", line 107, in execute\r\n ah = self.queue(*args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/opt/parallel/manager.py\", line 122, in queue\r\n return self._perform_queue(ah, *args, **kwds)\r\n File \"/home/travis/build/Pyomo/pyomo/pyomo/neos/plugins/kestrel_plugin.py\", line 127, in _perform_queue\r\n raise ActionManagerError(\r\nNameError: name 'ActionManagerError' is not defined\r\n```\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport logging\nimport os\nimport re\nimport six\n\nfrom six.moves.xmlrpc_client import ProtocolError\n\nfrom pyomo.opt import SolverFactory, SolverManagerFactory, OptSolver\nfrom pyomo.opt.parallel.async_solver import (\n AsynchronousSolverManager, ActionStatus\n)\nfrom pyomo.opt.base import OptSolver\nfrom pyomo.core.base import Block\nimport pyomo.neos.kestrel\n\n\nlogger = logging.getLogger('pyomo.neos')\n\n\ndef _neos_error(msg, results, current_message):\n error_re = re.compile('error', flags=re.I)\n warn_re = re.compile('warn', flags=re.I)\n\n logger.error(\"%s NEOS log:\\n%s\" % ( msg, current_message, ))\n soln_data = results.data\n if six.PY3:\n soln_data = soln_data.decode('utf-8')\n for line in soln_data.splitlines():\n if error_re.search(line):\n logger.error(line)\n elif warn_re.search(line):\n logger.warn(line)\n\n\[email protected](\n 'neos', doc=\"Asynchronously execute solvers on the NEOS server\")\nclass SolverManager_NEOS(AsynchronousSolverManager):\n\n def clear(self):\n \"\"\"\n Clear manager state\n \"\"\"\n AsynchronousSolverManager.clear(self)\n self.kestrel = pyomo.neos.kestrel.kestrelAMPL()\n self._ah = {} # maps NEOS job numbers to their corresponding\n # action handle.\n self._args = {}\n self._opt_data = {}\n\n # to grab streamed output from NEOS, need to keep\n # map of action handle to the to-date string of\n # extracted output.\n # TBD: The following entries aren't currently cleaned up, but\n # we're still trying to get the basics down.\n # store pairs of NEOS message offset and NEOS message string.\n # index into the map is the NEOS job number\n self._neos_log = {}\n self._solvers = {}\n\n def _perform_queue(self, ah, *args, **kwds):\n \"\"\"\n Perform the queue operation. This method returns the ActionHandle,\n and the ActionHandle status indicates whether the queue was successful.\n \"\"\"\n solver = kwds.pop('solver', kwds.pop('opt', None))\n if solver is None:\n raise ActionManagerError(\n \"No solver passed to %s, use keyword option 'solver'\"\n % (type(self).__name__) )\n if not isinstance(solver, six.string_types):\n solver_name = solver.name\n if solver_name == 'asl':\n solver_name = \\\n os.path.basename(solver.executable())\n else:\n solver_name = solver\n solver = None\n\n #\n # Handle ephemeral solvers options here. These\n # will override whatever is currently in the options\n # dictionary, but we will reset these options to\n # their original value at the end of this method.\n #\n user_solver_options = {}\n # make sure to transfer the options dict on the\n # solver plugin if the user does not use a string\n # to identify the neos solver. The ephemeral\n # options must also go after these.\n if solver is not None:\n user_solver_options.update(solver.options)\n _options = kwds.pop('options', {})\n if isinstance(_options, six.string_types):\n _options = OptSolver._options_string_to_dict(_options)\n user_solver_options.update(_options)\n user_solver_options.update(\n OptSolver._options_string_to_dict(kwds.pop('options_string', '')))\n\n # JDS: [5/13/17] The following is a HACK. This timeout flag is\n # set by pyomo/scripting/util.py:apply_optimizer. If we do not\n # remove it, it will get passed to the NEOS solver. For solvers\n # like CPLEX 12.7.0, this will cause a fatal error as it is not\n # a known option.\n if user_solver_options.get('timelimit',0) is None:\n del user_solver_options['timelimit']\n\n opt = SolverFactory('_neos')\n opt._presolve(*args, **kwds)\n #\n # Map NEOS name, using lowercase convention in Pyomo\n #\n if len(self._solvers) == 0:\n for name in self.kestrel.solvers():\n if name.endswith('AMPL'):\n self._solvers[ name[:-5].lower() ] = name[:-5]\n if solver_name not in self._solvers:\n raise ActionManagerError(\n \"Solver '%s' is not recognized by NEOS. \"\n \"Solver names recognized:\\n%s\"\n % (solver_name, str(sorted(self._solvers.keys()))))\n #\n # Apply kestrel\n #\n # Set the kestrel_options environment\n #\n neos_sname = self._solvers[solver_name].lower()\n os.environ['kestrel_options'] = 'solver=%s' % self._solvers[solver_name]\n #\n # Set the <solver>_options environment\n #\n solver_options = {}\n for key in opt.options:\n solver_options[key]=opt.options[key]\n solver_options.update(user_solver_options)\n options = opt._get_options_string(solver_options)\n if not options == \"\":\n os.environ[neos_sname+'_options'] = options\n #\n # Generate an XML string using these two environment variables\n #\n xml = self.kestrel.formXML(opt._problem_files[0])\n (jobNumber, password) = self.kestrel.submit(xml)\n ah.job = jobNumber\n ah.password = password\n #\n # Cleanup\n #\n del os.environ['kestrel_options']\n try:\n del os.environ[neos_sname+\"_options\"]\n except:\n pass\n #\n # Store action handle, and return\n #\n self._ah[jobNumber] = ah\n self._neos_log[jobNumber] = (0, \"\")\n self._opt_data[jobNumber] = (opt,\n opt._smap_id,\n opt._load_solutions,\n opt._select_index,\n opt._default_variable_value)\n self._args[jobNumber] = args\n return ah\n\n def _perform_wait_any(self):\n \"\"\"\n Perform the wait_any operation. This method returns an\n ActionHandle with the results of waiting. If None is returned\n then the ActionManager assumes that it can call this method again.\n Note that an ActionHandle can be returned with a dummy value,\n to indicate an error.\n \"\"\"\n for jobNumber in self._ah:\n\n status = self.kestrel.neos.getJobStatus(jobNumber,\n self._ah[jobNumber].password)\n\n if status not in (\"Running\", \"Waiting\"):\n # the job is done.\n ah = self._ah[jobNumber]\n del self._ah[jobNumber]\n ah.status = ActionStatus.done\n\n (opt,\n smap_id,\n load_solutions,\n select_index,\n default_variable_value) = self._opt_data[jobNumber]\n del self._opt_data[jobNumber]\n\n args = self._args[jobNumber]\n del self._args[jobNumber]\n\n # retrieve the final results, which are in message/log format.\n results = self.kestrel.neos.getFinalResults(jobNumber, ah.password)\n\n (current_offset, current_message) = self._neos_log[jobNumber]\n with open(opt._log_file, 'w') as OUTPUT:\n OUTPUT.write(current_message)\n with open(opt._soln_file, 'w') as OUTPUT:\n if six.PY2:\n OUTPUT.write(results.data)\n else:\n OUTPUT.write(results.data.decode('utf-8'))\n\n rc = None\n try:\n solver_results = opt.process_output(rc)\n except:\n _neos_error( \"Error parsing NEOS solution file\",\n results, current_message )\n return ah\n\n solver_results._smap_id = smap_id\n self.results[ah.id] = solver_results\n\n if isinstance(args[0], Block):\n _model = args[0]\n if load_solutions:\n try:\n _model.solutions.load_from(\n solver_results,\n select=select_index,\n default_variable_value=default_variable_value)\n except:\n _neos_error(\n \"Error loading NEOS solution into model\",\n results, current_message )\n solver_results._smap_id = None\n solver_results.solution.clear()\n else:\n solver_results._smap = _model.solutions.symbol_map[smap_id]\n _model.solutions.delete_symbol_map(smap_id)\n\n return ah\n else:\n # The job is still running...\n #\n # Grab the partial messages from NEOS as you go, in case\n # you want to output on-the-fly. You will only get data\n # if the job was routed to the \"short\" priority queue.\n (current_offset, current_message) = self._neos_log[jobNumber]\n # TBD: blocking isn't the way to go, but non-blocking\n # was triggering some exception in kestrel.\n #\n # [5/13/17]: The blocking fetch will timeout in 2\n # minutes. If NEOS doesn't produce intermediate results\n # by then we will need to catch (and eat) the exception\n try:\n (message_fragment, new_offset) \\\n = self.kestrel.neos.getIntermediateResults(\n jobNumber,\n self._ah[jobNumber].password,\n current_offset )\n logger.info(message_fragment)\n self._neos_log[jobNumber] = (\n new_offset,\n current_message + (\n message_fragment.data if six.PY2\n else (message_fragment.data).decode('utf-8') ) )\n except ProtocolError:\n # The command probably timed out\n pass\n\n return None\n\n", "path": "pyomo/neos/plugins/kestrel_plugin.py"}], "after_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport logging\nimport os\nimport re\nimport six\n\nfrom six.moves.xmlrpc_client import ProtocolError\n\nfrom pyomo.opt import SolverFactory, SolverManagerFactory, OptSolver\nfrom pyomo.opt.parallel.manager import ActionManagerError\nfrom pyomo.opt.parallel.async_solver import (\n AsynchronousSolverManager, ActionStatus\n)\nfrom pyomo.opt.base import OptSolver\nfrom pyomo.core.base import Block\nimport pyomo.neos.kestrel\n\n\nlogger = logging.getLogger('pyomo.neos')\n\n\ndef _neos_error(msg, results, current_message):\n error_re = re.compile('error', flags=re.I)\n warn_re = re.compile('warn', flags=re.I)\n\n logger.error(\"%s NEOS log:\\n%s\" % ( msg, current_message, ))\n soln_data = results.data\n if six.PY3:\n soln_data = soln_data.decode('utf-8')\n for line in soln_data.splitlines():\n if error_re.search(line):\n logger.error(line)\n elif warn_re.search(line):\n logger.warn(line)\n\n\[email protected](\n 'neos', doc=\"Asynchronously execute solvers on the NEOS server\")\nclass SolverManager_NEOS(AsynchronousSolverManager):\n\n def clear(self):\n \"\"\"\n Clear manager state\n \"\"\"\n AsynchronousSolverManager.clear(self)\n self.kestrel = pyomo.neos.kestrel.kestrelAMPL()\n self._ah = {} # maps NEOS job numbers to their corresponding\n # action handle.\n self._args = {}\n self._opt_data = {}\n\n # to grab streamed output from NEOS, need to keep\n # map of action handle to the to-date string of\n # extracted output.\n # TBD: The following entries aren't currently cleaned up, but\n # we're still trying to get the basics down.\n # store pairs of NEOS message offset and NEOS message string.\n # index into the map is the NEOS job number\n self._neos_log = {}\n self._solvers = {}\n\n def _perform_queue(self, ah, *args, **kwds):\n \"\"\"\n Perform the queue operation. This method returns the ActionHandle,\n and the ActionHandle status indicates whether the queue was successful.\n \"\"\"\n solver = kwds.pop('solver', kwds.pop('opt', None))\n if solver is None:\n raise ActionManagerError(\n \"No solver passed to %s, use keyword option 'solver'\"\n % (type(self).__name__) )\n if not isinstance(solver, six.string_types):\n solver_name = solver.name\n if solver_name == 'asl':\n solver_name = \\\n os.path.basename(solver.executable())\n else:\n solver_name = solver\n solver = None\n\n #\n # Handle ephemeral solvers options here. These\n # will override whatever is currently in the options\n # dictionary, but we will reset these options to\n # their original value at the end of this method.\n #\n user_solver_options = {}\n # make sure to transfer the options dict on the\n # solver plugin if the user does not use a string\n # to identify the neos solver. The ephemeral\n # options must also go after these.\n if solver is not None:\n user_solver_options.update(solver.options)\n _options = kwds.pop('options', {})\n if isinstance(_options, six.string_types):\n _options = OptSolver._options_string_to_dict(_options)\n user_solver_options.update(_options)\n user_solver_options.update(\n OptSolver._options_string_to_dict(kwds.pop('options_string', '')))\n\n # JDS: [5/13/17] The following is a HACK. This timeout flag is\n # set by pyomo/scripting/util.py:apply_optimizer. If we do not\n # remove it, it will get passed to the NEOS solver. For solvers\n # like CPLEX 12.7.0, this will cause a fatal error as it is not\n # a known option.\n if user_solver_options.get('timelimit',0) is None:\n del user_solver_options['timelimit']\n\n opt = SolverFactory('_neos')\n opt._presolve(*args, **kwds)\n #\n # Map NEOS name, using lowercase convention in Pyomo\n #\n if len(self._solvers) == 0:\n for name in self.kestrel.solvers():\n if name.endswith('AMPL'):\n self._solvers[ name[:-5].lower() ] = name[:-5]\n if solver_name not in self._solvers:\n raise ActionManagerError(\n \"Solver '%s' is not recognized by NEOS. \"\n \"Solver names recognized:\\n%s\"\n % (solver_name, str(sorted(self._solvers.keys()))))\n #\n # Apply kestrel\n #\n # Set the kestrel_options environment\n #\n neos_sname = self._solvers[solver_name].lower()\n os.environ['kestrel_options'] = 'solver=%s' % self._solvers[solver_name]\n #\n # Set the <solver>_options environment\n #\n solver_options = {}\n for key in opt.options:\n solver_options[key]=opt.options[key]\n solver_options.update(user_solver_options)\n options = opt._get_options_string(solver_options)\n if not options == \"\":\n os.environ[neos_sname+'_options'] = options\n #\n # Generate an XML string using these two environment variables\n #\n xml = self.kestrel.formXML(opt._problem_files[0])\n (jobNumber, password) = self.kestrel.submit(xml)\n ah.job = jobNumber\n ah.password = password\n #\n # Cleanup\n #\n del os.environ['kestrel_options']\n try:\n del os.environ[neos_sname+\"_options\"]\n except:\n pass\n #\n # Store action handle, and return\n #\n self._ah[jobNumber] = ah\n self._neos_log[jobNumber] = (0, \"\")\n self._opt_data[jobNumber] = (opt,\n opt._smap_id,\n opt._load_solutions,\n opt._select_index,\n opt._default_variable_value)\n self._args[jobNumber] = args\n return ah\n\n def _perform_wait_any(self):\n \"\"\"\n Perform the wait_any operation. This method returns an\n ActionHandle with the results of waiting. If None is returned\n then the ActionManager assumes that it can call this method again.\n Note that an ActionHandle can be returned with a dummy value,\n to indicate an error.\n \"\"\"\n for jobNumber in self._ah:\n\n status = self.kestrel.neos.getJobStatus(jobNumber,\n self._ah[jobNumber].password)\n\n if status not in (\"Running\", \"Waiting\"):\n # the job is done.\n ah = self._ah[jobNumber]\n del self._ah[jobNumber]\n ah.status = ActionStatus.done\n\n (opt,\n smap_id,\n load_solutions,\n select_index,\n default_variable_value) = self._opt_data[jobNumber]\n del self._opt_data[jobNumber]\n\n args = self._args[jobNumber]\n del self._args[jobNumber]\n\n # retrieve the final results, which are in message/log format.\n results = self.kestrel.neos.getFinalResults(jobNumber, ah.password)\n\n (current_offset, current_message) = self._neos_log[jobNumber]\n with open(opt._log_file, 'w') as OUTPUT:\n OUTPUT.write(current_message)\n with open(opt._soln_file, 'w') as OUTPUT:\n if six.PY2:\n OUTPUT.write(results.data)\n else:\n OUTPUT.write(results.data.decode('utf-8'))\n\n rc = None\n try:\n solver_results = opt.process_output(rc)\n except:\n _neos_error( \"Error parsing NEOS solution file\",\n results, current_message )\n return ah\n\n solver_results._smap_id = smap_id\n self.results[ah.id] = solver_results\n\n if isinstance(args[0], Block):\n _model = args[0]\n if load_solutions:\n try:\n _model.solutions.load_from(\n solver_results,\n select=select_index,\n default_variable_value=default_variable_value)\n except:\n _neos_error(\n \"Error loading NEOS solution into model\",\n results, current_message )\n solver_results._smap_id = None\n solver_results.solution.clear()\n else:\n solver_results._smap = _model.solutions.symbol_map[smap_id]\n _model.solutions.delete_symbol_map(smap_id)\n\n return ah\n else:\n # The job is still running...\n #\n # Grab the partial messages from NEOS as you go, in case\n # you want to output on-the-fly. You will only get data\n # if the job was routed to the \"short\" priority queue.\n (current_offset, current_message) = self._neos_log[jobNumber]\n # TBD: blocking isn't the way to go, but non-blocking\n # was triggering some exception in kestrel.\n #\n # [5/13/17]: The blocking fetch will timeout in 2\n # minutes. If NEOS doesn't produce intermediate results\n # by then we will need to catch (and eat) the exception\n try:\n (message_fragment, new_offset) \\\n = self.kestrel.neos.getIntermediateResults(\n jobNumber,\n self._ah[jobNumber].password,\n current_offset )\n logger.info(message_fragment)\n self._neos_log[jobNumber] = (\n new_offset,\n current_message + (\n message_fragment.data if six.PY2\n else (message_fragment.data).decode('utf-8') ) )\n except ProtocolError:\n # The command probably timed out\n pass\n\n return None\n\n", "path": "pyomo/neos/plugins/kestrel_plugin.py"}]}
| 3,870 | 120 |
gh_patches_debug_27291
|
rasdani/github-patches
|
git_diff
|
uccser__cs-unplugged-302
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Django Debug Toolbar doesn't display in local Docker development environment
Created from work in #193.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `csunplugged/config/settings/local.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Django settings for local development environment.
4
5 - Run in Debug mode
6 - Add custom dev application
7 - Add Django Debug Toolbar
8 - Add django-extensions
9 - Use console backend for emails
10 """
11
12 import socket
13 import os
14 from .base import * # noqa: F403
15
16 # DATABASE CONFIGURATION
17 # ----------------------------------------------------------------------------
18 # See: https://docs.djangoproject.com/en/dev/ref/settings/#databases
19 DATABASES = {
20 'default': env.db('DATABASE_URL'), # noqa: F405
21 }
22 DATABASES['default']['ATOMIC_REQUESTS'] = True
23
24 # DEBUG
25 # ----------------------------------------------------------------------------
26 DEBUG = env.bool('DJANGO_DEBUG', default=True) # noqa: F405
27 TEMPLATES[0]['OPTIONS']['debug'] = DEBUG # noqa: F405
28
29 # SECRET CONFIGURATION
30 # ----------------------------------------------------------------------------
31 # See: https://docs.djangoproject.com/en/dev/ref/settings/#secret-key
32 # Note: This key only used for development and testing.
33 SECRET_KEY = env('DJANGO_SECRET_KEY', default='l@@)w&&%&u37+sjz^lsx^+29y_333oid3ygxzucar^8o(axo*f') # noqa: F405
34
35 # Mail settings
36 # ----------------------------------------------------------------------------
37
38 EMAIL_PORT = 1025
39
40 EMAIL_HOST = 'localhost'
41 EMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.console.EmailBackend') # noqa: F405
42
43
44 # CACHING
45 # ----------------------------------------------------------------------------
46 CACHES = {
47 'default': {
48 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
49 'LOCATION': ''
50 }
51 }
52
53 # django-debug-toolbar
54 # ----------------------------------------------------------------------------
55 MIDDLEWARE += ['debug_toolbar.middleware.DebugToolbarMiddleware', ] # noqa: F405
56 INSTALLED_APPS += ['debug_toolbar', ] # noqa: F405
57
58 INTERNAL_IPS = ['127.0.0.1', '10.0.2.2', ]
59 # tricks to have debug toolbar when developing with docker
60 if os.environ.get('USE_DOCKER') == 'yes':
61 ip = socket.gethostbyname(socket.gethostname())
62 INTERNAL_IPS += [ip[:-1] + '1']
63
64 DEBUG_TOOLBAR_CONFIG = {
65 'DISABLE_PANELS': [
66 'debug_toolbar.panels.redirects.RedirectsPanel',
67 ],
68 'SHOW_TEMPLATE_CONTEXT': True,
69 }
70
71 # django-extensions
72 # ----------------------------------------------------------------------------
73 INSTALLED_APPS += ['django_extensions', ]
74
75 # TESTING
76 # ----------------------------------------------------------------------------
77 TEST_RUNNER = 'django.test.runner.DiscoverRunner'
78
79
80 # Your local stuff: Below this line define 3rd party library settings
81 # ----------------------------------------------------------------------------
82 LOCAL_APPS + ['dev.apps.DevConfig'] # noqa: F405
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/csunplugged/config/settings/local.py b/csunplugged/config/settings/local.py
--- a/csunplugged/config/settings/local.py
+++ b/csunplugged/config/settings/local.py
@@ -9,8 +9,6 @@
- Use console backend for emails
"""
-import socket
-import os
from .base import * # noqa: F403
# DATABASE CONFIGURATION
@@ -56,16 +54,23 @@
INSTALLED_APPS += ['debug_toolbar', ] # noqa: F405
INTERNAL_IPS = ['127.0.0.1', '10.0.2.2', ]
-# tricks to have debug toolbar when developing with docker
-if os.environ.get('USE_DOCKER') == 'yes':
- ip = socket.gethostbyname(socket.gethostname())
- INTERNAL_IPS += [ip[:-1] + '1']
+
+
+def show_django_debug_toolbar(request):
+ """Show Django Debug Toolbar in every request when running locally.
+
+ Args:
+ request: The request object.
+ """
+ return True
+
DEBUG_TOOLBAR_CONFIG = {
'DISABLE_PANELS': [
'debug_toolbar.panels.redirects.RedirectsPanel',
],
'SHOW_TEMPLATE_CONTEXT': True,
+ "SHOW_TOOLBAR_CALLBACK": show_django_debug_toolbar,
}
# django-extensions
@@ -79,4 +84,4 @@
# Your local stuff: Below this line define 3rd party library settings
# ----------------------------------------------------------------------------
-LOCAL_APPS + ['dev.apps.DevConfig'] # noqa: F405
+INSTALLED_APPS += ['dev.apps.DevConfig'] # noqa: F405
|
{"golden_diff": "diff --git a/csunplugged/config/settings/local.py b/csunplugged/config/settings/local.py\n--- a/csunplugged/config/settings/local.py\n+++ b/csunplugged/config/settings/local.py\n@@ -9,8 +9,6 @@\n - Use console backend for emails\n \"\"\"\n \n-import socket\n-import os\n from .base import * # noqa: F403\n \n # DATABASE CONFIGURATION\n@@ -56,16 +54,23 @@\n INSTALLED_APPS += ['debug_toolbar', ] # noqa: F405\n \n INTERNAL_IPS = ['127.0.0.1', '10.0.2.2', ]\n-# tricks to have debug toolbar when developing with docker\n-if os.environ.get('USE_DOCKER') == 'yes':\n- ip = socket.gethostbyname(socket.gethostname())\n- INTERNAL_IPS += [ip[:-1] + '1']\n+\n+\n+def show_django_debug_toolbar(request):\n+ \"\"\"Show Django Debug Toolbar in every request when running locally.\n+\n+ Args:\n+ request: The request object.\n+ \"\"\"\n+ return True\n+\n \n DEBUG_TOOLBAR_CONFIG = {\n 'DISABLE_PANELS': [\n 'debug_toolbar.panels.redirects.RedirectsPanel',\n ],\n 'SHOW_TEMPLATE_CONTEXT': True,\n+ \"SHOW_TOOLBAR_CALLBACK\": show_django_debug_toolbar,\n }\n \n # django-extensions\n@@ -79,4 +84,4 @@\n \n # Your local stuff: Below this line define 3rd party library settings\n # ----------------------------------------------------------------------------\n-LOCAL_APPS + ['dev.apps.DevConfig'] # noqa: F405\n+INSTALLED_APPS += ['dev.apps.DevConfig'] # noqa: F405\n", "issue": "Django Debug Toolbar doesn't display in local Docker development environment\nCreated from work in #193.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDjango settings for local development environment.\n\n- Run in Debug mode\n- Add custom dev application\n- Add Django Debug Toolbar\n- Add django-extensions\n- Use console backend for emails\n\"\"\"\n\nimport socket\nimport os\nfrom .base import * # noqa: F403\n\n# DATABASE CONFIGURATION\n# ----------------------------------------------------------------------------\n# See: https://docs.djangoproject.com/en/dev/ref/settings/#databases\nDATABASES = {\n 'default': env.db('DATABASE_URL'), # noqa: F405\n}\nDATABASES['default']['ATOMIC_REQUESTS'] = True\n\n# DEBUG\n# ----------------------------------------------------------------------------\nDEBUG = env.bool('DJANGO_DEBUG', default=True) # noqa: F405\nTEMPLATES[0]['OPTIONS']['debug'] = DEBUG # noqa: F405\n\n# SECRET CONFIGURATION\n# ----------------------------------------------------------------------------\n# See: https://docs.djangoproject.com/en/dev/ref/settings/#secret-key\n# Note: This key only used for development and testing.\nSECRET_KEY = env('DJANGO_SECRET_KEY', default='l@@)w&&%&u37+sjz^lsx^+29y_333oid3ygxzucar^8o(axo*f') # noqa: F405\n\n# Mail settings\n# ----------------------------------------------------------------------------\n\nEMAIL_PORT = 1025\n\nEMAIL_HOST = 'localhost'\nEMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.console.EmailBackend') # noqa: F405\n\n\n# CACHING\n# ----------------------------------------------------------------------------\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',\n 'LOCATION': ''\n }\n}\n\n# django-debug-toolbar\n# ----------------------------------------------------------------------------\nMIDDLEWARE += ['debug_toolbar.middleware.DebugToolbarMiddleware', ] # noqa: F405\nINSTALLED_APPS += ['debug_toolbar', ] # noqa: F405\n\nINTERNAL_IPS = ['127.0.0.1', '10.0.2.2', ]\n# tricks to have debug toolbar when developing with docker\nif os.environ.get('USE_DOCKER') == 'yes':\n ip = socket.gethostbyname(socket.gethostname())\n INTERNAL_IPS += [ip[:-1] + '1']\n\nDEBUG_TOOLBAR_CONFIG = {\n 'DISABLE_PANELS': [\n 'debug_toolbar.panels.redirects.RedirectsPanel',\n ],\n 'SHOW_TEMPLATE_CONTEXT': True,\n}\n\n# django-extensions\n# ----------------------------------------------------------------------------\nINSTALLED_APPS += ['django_extensions', ]\n\n# TESTING\n# ----------------------------------------------------------------------------\nTEST_RUNNER = 'django.test.runner.DiscoverRunner'\n\n\n# Your local stuff: Below this line define 3rd party library settings\n# ----------------------------------------------------------------------------\nLOCAL_APPS + ['dev.apps.DevConfig'] # noqa: F405\n", "path": "csunplugged/config/settings/local.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDjango settings for local development environment.\n\n- Run in Debug mode\n- Add custom dev application\n- Add Django Debug Toolbar\n- Add django-extensions\n- Use console backend for emails\n\"\"\"\n\nfrom .base import * # noqa: F403\n\n# DATABASE CONFIGURATION\n# ----------------------------------------------------------------------------\n# See: https://docs.djangoproject.com/en/dev/ref/settings/#databases\nDATABASES = {\n 'default': env.db('DATABASE_URL'), # noqa: F405\n}\nDATABASES['default']['ATOMIC_REQUESTS'] = True\n\n# DEBUG\n# ----------------------------------------------------------------------------\nDEBUG = env.bool('DJANGO_DEBUG', default=True) # noqa: F405\nTEMPLATES[0]['OPTIONS']['debug'] = DEBUG # noqa: F405\n\n# SECRET CONFIGURATION\n# ----------------------------------------------------------------------------\n# See: https://docs.djangoproject.com/en/dev/ref/settings/#secret-key\n# Note: This key only used for development and testing.\nSECRET_KEY = env('DJANGO_SECRET_KEY', default='l@@)w&&%&u37+sjz^lsx^+29y_333oid3ygxzucar^8o(axo*f') # noqa: F405\n\n# Mail settings\n# ----------------------------------------------------------------------------\n\nEMAIL_PORT = 1025\n\nEMAIL_HOST = 'localhost'\nEMAIL_BACKEND = env('DJANGO_EMAIL_BACKEND', default='django.core.mail.backends.console.EmailBackend') # noqa: F405\n\n\n# CACHING\n# ----------------------------------------------------------------------------\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',\n 'LOCATION': ''\n }\n}\n\n# django-debug-toolbar\n# ----------------------------------------------------------------------------\nMIDDLEWARE += ['debug_toolbar.middleware.DebugToolbarMiddleware', ] # noqa: F405\nINSTALLED_APPS += ['debug_toolbar', ] # noqa: F405\n\nINTERNAL_IPS = ['127.0.0.1', '10.0.2.2', ]\n\n\ndef show_django_debug_toolbar(request):\n \"\"\"Show Django Debug Toolbar in every request when running locally.\n\n Args:\n request: The request object.\n \"\"\"\n return True\n\n\nDEBUG_TOOLBAR_CONFIG = {\n 'DISABLE_PANELS': [\n 'debug_toolbar.panels.redirects.RedirectsPanel',\n ],\n 'SHOW_TEMPLATE_CONTEXT': True,\n \"SHOW_TOOLBAR_CALLBACK\": show_django_debug_toolbar,\n}\n\n# django-extensions\n# ----------------------------------------------------------------------------\nINSTALLED_APPS += ['django_extensions', ]\n\n# TESTING\n# ----------------------------------------------------------------------------\nTEST_RUNNER = 'django.test.runner.DiscoverRunner'\n\n\n# Your local stuff: Below this line define 3rd party library settings\n# ----------------------------------------------------------------------------\nINSTALLED_APPS += ['dev.apps.DevConfig'] # noqa: F405\n", "path": "csunplugged/config/settings/local.py"}]}
| 1,046 | 373 |
gh_patches_debug_32436
|
rasdani/github-patches
|
git_diff
|
translate__pootle-4193
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Uploads perform poorly when some non localisation error is picked up
On a Mac you could have stray `.DS_Store` files. Also when using POedit it will create a `.mo` files whenever you save the `.po` file.
Errors such as `Unknown filetype (en_ZA/firefox/browser/chrome/overrides/.DS_Store)` are reported in this case.
Whenever such an error occurs then the upload reports the error and fails to complete. We should I think ignore errors unrelated to the translations files we are uploading. And at least execute correctly for those where there are no errors.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_translationproject/views.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) Pootle contributors.
5 #
6 # This file is a part of the Pootle project. It is distributed under the GPL3
7 # or later license. See the LICENSE file for a copy of the license and the
8 # AUTHORS file for copyright and authorship information.
9
10 import json
11 from urllib import quote, unquote
12
13 from django.conf import settings
14 from django.shortcuts import render
15 from django.utils import dateformat
16
17 from pootle.core.browser import (get_children, get_table_headings, get_parent,
18 get_vfolders)
19 from pootle.core.decorators import (get_path_obj, get_resource,
20 permission_required)
21 from pootle.core.helpers import (get_export_view_context, get_browser_context,
22 get_translation_context)
23 from pootle.core.utils.json import jsonify
24 from pootle_app.models.permissions import check_permission
25 from pootle_app.views.admin.permissions import admin_permissions as admin_perms
26 from staticpages.models import StaticPage
27
28
29 SIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'
30
31
32 @get_path_obj
33 @permission_required('administrate')
34 def admin_permissions(request, translation_project):
35 language = translation_project.language
36 project = translation_project.project
37
38 ctx = {
39 'page': 'admin-permissions',
40
41 'translation_project': translation_project,
42 'project': project,
43 'language': language,
44 'directory': translation_project.directory,
45 }
46
47 return admin_perms(request, translation_project.directory,
48 'translation_projects/admin/permissions.html', ctx)
49
50
51 def get_sidebar_announcements_context(request, project_code, language_code):
52 announcements = []
53 new_cookie_data = {}
54 cookie_data = {}
55
56 if SIDEBAR_COOKIE_NAME in request.COOKIES:
57 json_str = unquote(request.COOKIES[SIDEBAR_COOKIE_NAME])
58 cookie_data = json.loads(json_str)
59
60 is_sidebar_open = cookie_data.get('isOpen', True)
61
62 def _get_announcement(language_code=None, project_code=None):
63 if language_code is None:
64 virtual_path = u'announcements/projects/%s' % project_code
65 else:
66 path = u'/'.join(filter(None, [language_code, project_code]))
67 virtual_path = u'announcements/%s' % path
68
69 try:
70 return StaticPage.objects.live(request.user).get(
71 virtual_path=virtual_path,
72 )
73 except StaticPage.DoesNotExist:
74 return None
75
76 args_list = [
77 (None, project_code),
78 (language_code, None),
79 (language_code, project_code),
80 ]
81
82 for args in args_list:
83 announcement = _get_announcement(*args)
84
85 if announcement is None:
86 continue
87
88 announcements.append(announcement)
89 # The virtual_path cannot be used as is for JSON.
90 ann_key = announcement.virtual_path.replace('/', '_')
91 ann_mtime = dateformat.format(announcement.modified_on, 'U')
92 stored_mtime = cookie_data.get(ann_key, None)
93
94 if ann_mtime != stored_mtime:
95 new_cookie_data[ann_key] = ann_mtime
96
97 if new_cookie_data:
98 # Some announcement has been changed or was never displayed before, so
99 # display sidebar and save the changed mtimes in the cookie to not
100 # display it next time unless it is necessary.
101 is_sidebar_open = True
102 cookie_data.update(new_cookie_data)
103 new_cookie_data = quote(json.dumps(cookie_data))
104
105 ctx = {
106 'announcements': announcements,
107 'is_sidebar_open': is_sidebar_open,
108 'has_sidebar': len(announcements) > 0,
109 }
110
111 return ctx, new_cookie_data
112
113
114 @get_path_obj
115 @permission_required('view')
116 @get_resource
117 def browse(request, translation_project, dir_path, filename=None):
118 project = translation_project.project
119 language = translation_project.language
120
121 directory = request.directory
122 store = request.store
123 is_admin = check_permission('administrate', request)
124
125 ctx, cookie_data = get_sidebar_announcements_context(request, project.code,
126 language.code)
127
128 ctx.update(get_browser_context(request))
129
130 # TODO improve plugin logic
131 if "import_export" in settings.INSTALLED_APPS and request.user.is_authenticated():
132 from import_export.views import handle_upload_form
133
134 ctx.update(handle_upload_form(request))
135
136 has_download = (not translation_project.is_terminology_project and
137 (check_permission('translate', request) or
138 check_permission('suggest', request)))
139 ctx.update({
140 'display_download': has_download,
141 'has_sidebar': True,
142 })
143
144 stats = request.resource_obj.get_stats()
145
146 if store is None:
147 table_fields = ['name', 'progress', 'total', 'need-translation',
148 'suggestions', 'critical', 'last-updated', 'activity']
149 ctx.update({
150 'table': {
151 'id': 'tp',
152 'fields': table_fields,
153 'headings': get_table_headings(table_fields),
154 'items': get_children(directory),
155 }
156 })
157
158 if 'virtualfolder' in settings.INSTALLED_APPS:
159 vfolders = get_vfolders(directory, all_vfolders=is_admin)
160 if len(vfolders) > 0:
161 table_fields = ['name', 'priority', 'progress', 'total',
162 'need-translation', 'suggestions', 'critical',
163 'last-updated', 'activity']
164 ctx.update({
165 'vfolders': {
166 'id': 'vfolders',
167 'fields': table_fields,
168 'headings': get_table_headings(table_fields),
169 'items': vfolders,
170 },
171 })
172
173 #FIXME: set vfolders stats in the resource, don't inject them here.
174 stats['vfolders'] = {}
175
176 for vfolder_treeitem in directory.vf_treeitems.iterator():
177 if request.user.is_superuser or vfolder_treeitem.is_visible:
178 stats['vfolders'][vfolder_treeitem.code] = \
179 vfolder_treeitem.get_stats(include_children=False)
180
181 ctx.update({
182 'parent': get_parent(directory if store is None else store),
183 'translation_project': translation_project,
184 'project': project,
185 'language': language,
186 'stats': jsonify(stats),
187 'is_admin': is_admin,
188 'is_store': store is not None,
189
190 'browser_extends': 'translation_projects/base.html',
191 })
192
193 response = render(request, 'browser/index.html', ctx)
194
195 if cookie_data:
196 response.set_cookie(SIDEBAR_COOKIE_NAME, cookie_data)
197
198 return response
199
200
201 @get_path_obj
202 @permission_required('view')
203 @get_resource
204 def translate(request, translation_project, dir_path, filename):
205 project = translation_project.project
206
207 ctx = get_translation_context(request)
208
209 ctx.update({
210 'language': translation_project.language,
211 'project': project,
212 'translation_project': translation_project,
213
214 'editor_extends': 'translation_projects/base.html',
215 })
216
217 return render(request, "editor/main.html", ctx)
218
219
220 @get_path_obj
221 @permission_required('view')
222 @get_resource
223 def export_view(request, translation_project, dir_path, filename=None):
224 """Displays a list of units with filters applied."""
225 ctx = get_export_view_context(request)
226 ctx.update({
227 'source_language': translation_project.project.source_language,
228 'language': translation_project.language,
229 'project': translation_project.project,
230 })
231
232 return render(request, 'editor/export_view.html', ctx)
233
```
Path: `pootle/apps/import_export/views.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) Pootle contributors.
5 #
6 # This file is a part of the Pootle project. It is distributed under the GPL3
7 # or later license. See the LICENSE file for a copy of the license and the
8 # AUTHORS file for copyright and authorship information.
9
10 import logging
11 import os
12 from io import BytesIO
13 from zipfile import ZipFile, is_zipfile
14
15 from django.http import Http404, HttpResponse
16
17 from pootle_store.models import Store
18
19 from .forms import UploadForm
20 from .utils import import_file
21
22
23 def download(contents, name, content_type):
24 response = HttpResponse(contents, content_type=content_type)
25 response["Content-Disposition"] = "attachment; filename=%s" % (name)
26 return response
27
28
29 def export(request):
30 path = request.GET.get("path")
31 if not path:
32 raise Http404
33
34 stores = Store.objects.live().filter(pootle_path__startswith=path)
35 num_items = stores.count()
36
37 if not num_items:
38 raise Http404
39
40 if num_items == 1:
41 store = stores.get()
42 contents = BytesIO(store.serialize())
43 name = os.path.basename(store.pootle_path)
44 contents.seek(0)
45 return download(contents.read(), name, "application/octet-stream")
46
47 # zip all the stores together
48 f = BytesIO()
49 prefix = path.strip("/").replace("/", "-")
50 if not prefix:
51 prefix = "export"
52 with BytesIO() as f:
53 with ZipFile(f, "w") as zf:
54 for store in stores:
55 if store.is_terminology:
56 continue
57 try:
58 data = store.serialize()
59 except Exception as e:
60 logging.error("Could not serialize %r: %s", store.pootle_path, e)
61 continue
62 zf.writestr(prefix + store.pootle_path, data)
63
64 return download(f.getvalue(), "%s.zip" % (prefix), "application/zip")
65
66
67 def handle_upload_form(request):
68 """Process the upload form."""
69 if request.method == "POST" and "file" in request.FILES:
70 upload_form = UploadForm(request.POST, request.FILES)
71
72 if upload_form.is_valid():
73 django_file = request.FILES["file"]
74 try:
75 if is_zipfile(django_file):
76 with ZipFile(django_file, "r") as zf:
77 for path in zf.namelist():
78 if path.endswith("/"):
79 # is a directory
80 continue
81 with zf.open(path, "r") as f:
82 import_file(f, user=request.user)
83 else:
84 # It is necessary to seek to the beginning because
85 # is_zipfile fucks the file, and thus cannot be read.
86 django_file.seek(0)
87 import_file(django_file, user=request.user)
88 except Exception as e:
89 upload_form.add_error("file", e.message)
90 return {
91 "upload_form": upload_form,
92 }
93
94 # Always return a blank upload form unless the upload form is not valid.
95 return {
96 "upload_form": UploadForm(),
97 }
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pootle/apps/import_export/views.py b/pootle/apps/import_export/views.py
--- a/pootle/apps/import_export/views.py
+++ b/pootle/apps/import_export/views.py
@@ -64,10 +64,12 @@
return download(f.getvalue(), "%s.zip" % (prefix), "application/zip")
-def handle_upload_form(request):
+def handle_upload_form(request, project):
"""Process the upload form."""
if request.method == "POST" and "file" in request.FILES:
upload_form = UploadForm(request.POST, request.FILES)
+ project_filetypes = [project.localfiletype,
+ project.get_template_filetype()]
if upload_form.is_valid():
django_file = request.FILES["file"]
@@ -78,6 +80,9 @@
if path.endswith("/"):
# is a directory
continue
+ ext = os.path.splitext(path)[1].strip(".")
+ if ext not in project_filetypes:
+ continue
with zf.open(path, "r") as f:
import_file(f, user=request.user)
else:
diff --git a/pootle/apps/pootle_translationproject/views.py b/pootle/apps/pootle_translationproject/views.py
--- a/pootle/apps/pootle_translationproject/views.py
+++ b/pootle/apps/pootle_translationproject/views.py
@@ -131,7 +131,7 @@
if "import_export" in settings.INSTALLED_APPS and request.user.is_authenticated():
from import_export.views import handle_upload_form
- ctx.update(handle_upload_form(request))
+ ctx.update(handle_upload_form(request, project))
has_download = (not translation_project.is_terminology_project and
(check_permission('translate', request) or
|
{"golden_diff": "diff --git a/pootle/apps/import_export/views.py b/pootle/apps/import_export/views.py\n--- a/pootle/apps/import_export/views.py\n+++ b/pootle/apps/import_export/views.py\n@@ -64,10 +64,12 @@\n return download(f.getvalue(), \"%s.zip\" % (prefix), \"application/zip\")\n \n \n-def handle_upload_form(request):\n+def handle_upload_form(request, project):\n \"\"\"Process the upload form.\"\"\"\n if request.method == \"POST\" and \"file\" in request.FILES:\n upload_form = UploadForm(request.POST, request.FILES)\n+ project_filetypes = [project.localfiletype,\n+ project.get_template_filetype()]\n \n if upload_form.is_valid():\n django_file = request.FILES[\"file\"]\n@@ -78,6 +80,9 @@\n if path.endswith(\"/\"):\n # is a directory\n continue\n+ ext = os.path.splitext(path)[1].strip(\".\")\n+ if ext not in project_filetypes:\n+ continue\n with zf.open(path, \"r\") as f:\n import_file(f, user=request.user)\n else:\ndiff --git a/pootle/apps/pootle_translationproject/views.py b/pootle/apps/pootle_translationproject/views.py\n--- a/pootle/apps/pootle_translationproject/views.py\n+++ b/pootle/apps/pootle_translationproject/views.py\n@@ -131,7 +131,7 @@\n if \"import_export\" in settings.INSTALLED_APPS and request.user.is_authenticated():\n from import_export.views import handle_upload_form\n \n- ctx.update(handle_upload_form(request))\n+ ctx.update(handle_upload_form(request, project))\n \n has_download = (not translation_project.is_terminology_project and\n (check_permission('translate', request) or\n", "issue": "Uploads perform poorly when some non localisation error is picked up\nOn a Mac you could have stray `.DS_Store` files. Also when using POedit it will create a `.mo` files whenever you save the `.po` file.\n\nErrors such as `Unknown filetype (en_ZA/firefox/browser/chrome/overrides/.DS_Store)` are reported in this case.\n\nWhenever such an error occurs then the upload reports the error and fails to complete. We should I think ignore errors unrelated to the translations files we are uploading. And at least execute correctly for those where there are no errors.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport json\nfrom urllib import quote, unquote\n\nfrom django.conf import settings\nfrom django.shortcuts import render\nfrom django.utils import dateformat\n\nfrom pootle.core.browser import (get_children, get_table_headings, get_parent,\n get_vfolders)\nfrom pootle.core.decorators import (get_path_obj, get_resource,\n permission_required)\nfrom pootle.core.helpers import (get_export_view_context, get_browser_context,\n get_translation_context)\nfrom pootle.core.utils.json import jsonify\nfrom pootle_app.models.permissions import check_permission\nfrom pootle_app.views.admin.permissions import admin_permissions as admin_perms\nfrom staticpages.models import StaticPage\n\n\nSIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'\n\n\n@get_path_obj\n@permission_required('administrate')\ndef admin_permissions(request, translation_project):\n language = translation_project.language\n project = translation_project.project\n\n ctx = {\n 'page': 'admin-permissions',\n\n 'translation_project': translation_project,\n 'project': project,\n 'language': language,\n 'directory': translation_project.directory,\n }\n\n return admin_perms(request, translation_project.directory,\n 'translation_projects/admin/permissions.html', ctx)\n\n\ndef get_sidebar_announcements_context(request, project_code, language_code):\n announcements = []\n new_cookie_data = {}\n cookie_data = {}\n\n if SIDEBAR_COOKIE_NAME in request.COOKIES:\n json_str = unquote(request.COOKIES[SIDEBAR_COOKIE_NAME])\n cookie_data = json.loads(json_str)\n\n is_sidebar_open = cookie_data.get('isOpen', True)\n\n def _get_announcement(language_code=None, project_code=None):\n if language_code is None:\n virtual_path = u'announcements/projects/%s' % project_code\n else:\n path = u'/'.join(filter(None, [language_code, project_code]))\n virtual_path = u'announcements/%s' % path\n\n try:\n return StaticPage.objects.live(request.user).get(\n virtual_path=virtual_path,\n )\n except StaticPage.DoesNotExist:\n return None\n\n args_list = [\n (None, project_code),\n (language_code, None),\n (language_code, project_code),\n ]\n\n for args in args_list:\n announcement = _get_announcement(*args)\n\n if announcement is None:\n continue\n\n announcements.append(announcement)\n # The virtual_path cannot be used as is for JSON.\n ann_key = announcement.virtual_path.replace('/', '_')\n ann_mtime = dateformat.format(announcement.modified_on, 'U')\n stored_mtime = cookie_data.get(ann_key, None)\n\n if ann_mtime != stored_mtime:\n new_cookie_data[ann_key] = ann_mtime\n\n if new_cookie_data:\n # Some announcement has been changed or was never displayed before, so\n # display sidebar and save the changed mtimes in the cookie to not\n # display it next time unless it is necessary.\n is_sidebar_open = True\n cookie_data.update(new_cookie_data)\n new_cookie_data = quote(json.dumps(cookie_data))\n\n ctx = {\n 'announcements': announcements,\n 'is_sidebar_open': is_sidebar_open,\n 'has_sidebar': len(announcements) > 0,\n }\n\n return ctx, new_cookie_data\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef browse(request, translation_project, dir_path, filename=None):\n project = translation_project.project\n language = translation_project.language\n\n directory = request.directory\n store = request.store\n is_admin = check_permission('administrate', request)\n\n ctx, cookie_data = get_sidebar_announcements_context(request, project.code,\n language.code)\n\n ctx.update(get_browser_context(request))\n\n # TODO improve plugin logic\n if \"import_export\" in settings.INSTALLED_APPS and request.user.is_authenticated():\n from import_export.views import handle_upload_form\n\n ctx.update(handle_upload_form(request))\n\n has_download = (not translation_project.is_terminology_project and\n (check_permission('translate', request) or\n check_permission('suggest', request)))\n ctx.update({\n 'display_download': has_download,\n 'has_sidebar': True,\n })\n\n stats = request.resource_obj.get_stats()\n\n if store is None:\n table_fields = ['name', 'progress', 'total', 'need-translation',\n 'suggestions', 'critical', 'last-updated', 'activity']\n ctx.update({\n 'table': {\n 'id': 'tp',\n 'fields': table_fields,\n 'headings': get_table_headings(table_fields),\n 'items': get_children(directory),\n }\n })\n\n if 'virtualfolder' in settings.INSTALLED_APPS:\n vfolders = get_vfolders(directory, all_vfolders=is_admin)\n if len(vfolders) > 0:\n table_fields = ['name', 'priority', 'progress', 'total',\n 'need-translation', 'suggestions', 'critical',\n 'last-updated', 'activity']\n ctx.update({\n 'vfolders': {\n 'id': 'vfolders',\n 'fields': table_fields,\n 'headings': get_table_headings(table_fields),\n 'items': vfolders,\n },\n })\n\n #FIXME: set vfolders stats in the resource, don't inject them here.\n stats['vfolders'] = {}\n\n for vfolder_treeitem in directory.vf_treeitems.iterator():\n if request.user.is_superuser or vfolder_treeitem.is_visible:\n stats['vfolders'][vfolder_treeitem.code] = \\\n vfolder_treeitem.get_stats(include_children=False)\n\n ctx.update({\n 'parent': get_parent(directory if store is None else store),\n 'translation_project': translation_project,\n 'project': project,\n 'language': language,\n 'stats': jsonify(stats),\n 'is_admin': is_admin,\n 'is_store': store is not None,\n\n 'browser_extends': 'translation_projects/base.html',\n })\n\n response = render(request, 'browser/index.html', ctx)\n\n if cookie_data:\n response.set_cookie(SIDEBAR_COOKIE_NAME, cookie_data)\n\n return response\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef translate(request, translation_project, dir_path, filename):\n project = translation_project.project\n\n ctx = get_translation_context(request)\n\n ctx.update({\n 'language': translation_project.language,\n 'project': project,\n 'translation_project': translation_project,\n\n 'editor_extends': 'translation_projects/base.html',\n })\n\n return render(request, \"editor/main.html\", ctx)\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef export_view(request, translation_project, dir_path, filename=None):\n \"\"\"Displays a list of units with filters applied.\"\"\"\n ctx = get_export_view_context(request)\n ctx.update({\n 'source_language': translation_project.project.source_language,\n 'language': translation_project.language,\n 'project': translation_project.project,\n })\n\n return render(request, 'editor/export_view.html', ctx)\n", "path": "pootle/apps/pootle_translationproject/views.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nfrom io import BytesIO\nfrom zipfile import ZipFile, is_zipfile\n\nfrom django.http import Http404, HttpResponse\n\nfrom pootle_store.models import Store\n\nfrom .forms import UploadForm\nfrom .utils import import_file\n\n\ndef download(contents, name, content_type):\n response = HttpResponse(contents, content_type=content_type)\n response[\"Content-Disposition\"] = \"attachment; filename=%s\" % (name)\n return response\n\n\ndef export(request):\n path = request.GET.get(\"path\")\n if not path:\n raise Http404\n\n stores = Store.objects.live().filter(pootle_path__startswith=path)\n num_items = stores.count()\n\n if not num_items:\n raise Http404\n\n if num_items == 1:\n store = stores.get()\n contents = BytesIO(store.serialize())\n name = os.path.basename(store.pootle_path)\n contents.seek(0)\n return download(contents.read(), name, \"application/octet-stream\")\n\n # zip all the stores together\n f = BytesIO()\n prefix = path.strip(\"/\").replace(\"/\", \"-\")\n if not prefix:\n prefix = \"export\"\n with BytesIO() as f:\n with ZipFile(f, \"w\") as zf:\n for store in stores:\n if store.is_terminology:\n continue\n try:\n data = store.serialize()\n except Exception as e:\n logging.error(\"Could not serialize %r: %s\", store.pootle_path, e)\n continue\n zf.writestr(prefix + store.pootle_path, data)\n\n return download(f.getvalue(), \"%s.zip\" % (prefix), \"application/zip\")\n\n\ndef handle_upload_form(request):\n \"\"\"Process the upload form.\"\"\"\n if request.method == \"POST\" and \"file\" in request.FILES:\n upload_form = UploadForm(request.POST, request.FILES)\n\n if upload_form.is_valid():\n django_file = request.FILES[\"file\"]\n try:\n if is_zipfile(django_file):\n with ZipFile(django_file, \"r\") as zf:\n for path in zf.namelist():\n if path.endswith(\"/\"):\n # is a directory\n continue\n with zf.open(path, \"r\") as f:\n import_file(f, user=request.user)\n else:\n # It is necessary to seek to the beginning because\n # is_zipfile fucks the file, and thus cannot be read.\n django_file.seek(0)\n import_file(django_file, user=request.user)\n except Exception as e:\n upload_form.add_error(\"file\", e.message)\n return {\n \"upload_form\": upload_form,\n }\n\n # Always return a blank upload form unless the upload form is not valid.\n return {\n \"upload_form\": UploadForm(),\n }\n", "path": "pootle/apps/import_export/views.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport json\nfrom urllib import quote, unquote\n\nfrom django.conf import settings\nfrom django.shortcuts import render\nfrom django.utils import dateformat\n\nfrom pootle.core.browser import (get_children, get_table_headings, get_parent,\n get_vfolders)\nfrom pootle.core.decorators import (get_path_obj, get_resource,\n permission_required)\nfrom pootle.core.helpers import (get_export_view_context, get_browser_context,\n get_translation_context)\nfrom pootle.core.utils.json import jsonify\nfrom pootle_app.models.permissions import check_permission\nfrom pootle_app.views.admin.permissions import admin_permissions as admin_perms\nfrom staticpages.models import StaticPage\n\n\nSIDEBAR_COOKIE_NAME = 'pootle-browser-sidebar'\n\n\n@get_path_obj\n@permission_required('administrate')\ndef admin_permissions(request, translation_project):\n language = translation_project.language\n project = translation_project.project\n\n ctx = {\n 'page': 'admin-permissions',\n\n 'translation_project': translation_project,\n 'project': project,\n 'language': language,\n 'directory': translation_project.directory,\n }\n\n return admin_perms(request, translation_project.directory,\n 'translation_projects/admin/permissions.html', ctx)\n\n\ndef get_sidebar_announcements_context(request, project_code, language_code):\n announcements = []\n new_cookie_data = {}\n cookie_data = {}\n\n if SIDEBAR_COOKIE_NAME in request.COOKIES:\n json_str = unquote(request.COOKIES[SIDEBAR_COOKIE_NAME])\n cookie_data = json.loads(json_str)\n\n is_sidebar_open = cookie_data.get('isOpen', True)\n\n def _get_announcement(language_code=None, project_code=None):\n if language_code is None:\n virtual_path = u'announcements/projects/%s' % project_code\n else:\n path = u'/'.join(filter(None, [language_code, project_code]))\n virtual_path = u'announcements/%s' % path\n\n try:\n return StaticPage.objects.live(request.user).get(\n virtual_path=virtual_path,\n )\n except StaticPage.DoesNotExist:\n return None\n\n args_list = [\n (None, project_code),\n (language_code, None),\n (language_code, project_code),\n ]\n\n for args in args_list:\n announcement = _get_announcement(*args)\n\n if announcement is None:\n continue\n\n announcements.append(announcement)\n # The virtual_path cannot be used as is for JSON.\n ann_key = announcement.virtual_path.replace('/', '_')\n ann_mtime = dateformat.format(announcement.modified_on, 'U')\n stored_mtime = cookie_data.get(ann_key, None)\n\n if ann_mtime != stored_mtime:\n new_cookie_data[ann_key] = ann_mtime\n\n if new_cookie_data:\n # Some announcement has been changed or was never displayed before, so\n # display sidebar and save the changed mtimes in the cookie to not\n # display it next time unless it is necessary.\n is_sidebar_open = True\n cookie_data.update(new_cookie_data)\n new_cookie_data = quote(json.dumps(cookie_data))\n\n ctx = {\n 'announcements': announcements,\n 'is_sidebar_open': is_sidebar_open,\n 'has_sidebar': len(announcements) > 0,\n }\n\n return ctx, new_cookie_data\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef browse(request, translation_project, dir_path, filename=None):\n project = translation_project.project\n language = translation_project.language\n\n directory = request.directory\n store = request.store\n is_admin = check_permission('administrate', request)\n\n ctx, cookie_data = get_sidebar_announcements_context(request, project.code,\n language.code)\n\n ctx.update(get_browser_context(request))\n\n # TODO improve plugin logic\n if \"import_export\" in settings.INSTALLED_APPS and request.user.is_authenticated():\n from import_export.views import handle_upload_form\n\n ctx.update(handle_upload_form(request, project))\n\n has_download = (not translation_project.is_terminology_project and\n (check_permission('translate', request) or\n check_permission('suggest', request)))\n ctx.update({\n 'display_download': has_download,\n 'has_sidebar': True,\n })\n\n stats = request.resource_obj.get_stats()\n\n if store is None:\n table_fields = ['name', 'progress', 'total', 'need-translation',\n 'suggestions', 'critical', 'last-updated', 'activity']\n ctx.update({\n 'table': {\n 'id': 'tp',\n 'fields': table_fields,\n 'headings': get_table_headings(table_fields),\n 'items': get_children(directory),\n }\n })\n\n if 'virtualfolder' in settings.INSTALLED_APPS:\n vfolders = get_vfolders(directory, all_vfolders=is_admin)\n if len(vfolders) > 0:\n table_fields = ['name', 'priority', 'progress', 'total',\n 'need-translation', 'suggestions', 'critical',\n 'last-updated', 'activity']\n ctx.update({\n 'vfolders': {\n 'id': 'vfolders',\n 'fields': table_fields,\n 'headings': get_table_headings(table_fields),\n 'items': vfolders,\n },\n })\n\n #FIXME: set vfolders stats in the resource, don't inject them here.\n stats['vfolders'] = {}\n\n for vfolder_treeitem in directory.vf_treeitems.iterator():\n if request.user.is_superuser or vfolder_treeitem.is_visible:\n stats['vfolders'][vfolder_treeitem.code] = \\\n vfolder_treeitem.get_stats(include_children=False)\n\n ctx.update({\n 'parent': get_parent(directory if store is None else store),\n 'translation_project': translation_project,\n 'project': project,\n 'language': language,\n 'stats': jsonify(stats),\n 'is_admin': is_admin,\n 'is_store': store is not None,\n\n 'browser_extends': 'translation_projects/base.html',\n })\n\n response = render(request, 'browser/index.html', ctx)\n\n if cookie_data:\n response.set_cookie(SIDEBAR_COOKIE_NAME, cookie_data)\n\n return response\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef translate(request, translation_project, dir_path, filename):\n project = translation_project.project\n\n ctx = get_translation_context(request)\n\n ctx.update({\n 'language': translation_project.language,\n 'project': project,\n 'translation_project': translation_project,\n\n 'editor_extends': 'translation_projects/base.html',\n })\n\n return render(request, \"editor/main.html\", ctx)\n\n\n@get_path_obj\n@permission_required('view')\n@get_resource\ndef export_view(request, translation_project, dir_path, filename=None):\n \"\"\"Displays a list of units with filters applied.\"\"\"\n ctx = get_export_view_context(request)\n ctx.update({\n 'source_language': translation_project.project.source_language,\n 'language': translation_project.language,\n 'project': translation_project.project,\n })\n\n return render(request, 'editor/export_view.html', ctx)\n", "path": "pootle/apps/pootle_translationproject/views.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nfrom io import BytesIO\nfrom zipfile import ZipFile, is_zipfile\n\nfrom django.http import Http404, HttpResponse\n\nfrom pootle_store.models import Store\n\nfrom .forms import UploadForm\nfrom .utils import import_file\n\n\ndef download(contents, name, content_type):\n response = HttpResponse(contents, content_type=content_type)\n response[\"Content-Disposition\"] = \"attachment; filename=%s\" % (name)\n return response\n\n\ndef export(request):\n path = request.GET.get(\"path\")\n if not path:\n raise Http404\n\n stores = Store.objects.live().filter(pootle_path__startswith=path)\n num_items = stores.count()\n\n if not num_items:\n raise Http404\n\n if num_items == 1:\n store = stores.get()\n contents = BytesIO(store.serialize())\n name = os.path.basename(store.pootle_path)\n contents.seek(0)\n return download(contents.read(), name, \"application/octet-stream\")\n\n # zip all the stores together\n f = BytesIO()\n prefix = path.strip(\"/\").replace(\"/\", \"-\")\n if not prefix:\n prefix = \"export\"\n with BytesIO() as f:\n with ZipFile(f, \"w\") as zf:\n for store in stores:\n if store.is_terminology:\n continue\n try:\n data = store.serialize()\n except Exception as e:\n logging.error(\"Could not serialize %r: %s\", store.pootle_path, e)\n continue\n zf.writestr(prefix + store.pootle_path, data)\n\n return download(f.getvalue(), \"%s.zip\" % (prefix), \"application/zip\")\n\n\ndef handle_upload_form(request, project):\n \"\"\"Process the upload form.\"\"\"\n if request.method == \"POST\" and \"file\" in request.FILES:\n upload_form = UploadForm(request.POST, request.FILES)\n project_filetypes = [project.localfiletype,\n project.get_template_filetype()]\n\n if upload_form.is_valid():\n django_file = request.FILES[\"file\"]\n try:\n if is_zipfile(django_file):\n with ZipFile(django_file, \"r\") as zf:\n for path in zf.namelist():\n if path.endswith(\"/\"):\n # is a directory\n continue\n ext = os.path.splitext(path)[1].strip(\".\")\n if ext not in project_filetypes:\n continue\n with zf.open(path, \"r\") as f:\n import_file(f, user=request.user)\n else:\n # It is necessary to seek to the beginning because\n # is_zipfile fucks the file, and thus cannot be read.\n django_file.seek(0)\n import_file(django_file, user=request.user)\n except Exception as e:\n upload_form.add_error(\"file\", e.message)\n return {\n \"upload_form\": upload_form,\n }\n\n # Always return a blank upload form unless the upload form is not valid.\n return {\n \"upload_form\": UploadForm(),\n }\n", "path": "pootle/apps/import_export/views.py"}]}
| 3,478 | 389 |
gh_patches_debug_3526
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4487
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check documentation links as part of docs linting
## Description
Sphinx [linkcheck](https://www.sphinx-doc.org/en/master/usage/builders/index.html#sphinx.builders.linkcheck.CheckExternalLinksBuilder) allows the verification of links with the `requests` library to ensure that the links are still valid and active. It might be useful to run this regularly or as part of CI to catch dead or broken links.
## User Stories
As a user, clicking on a link and getting a 404 can be a a frustrating experience.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # SecureDrop documentation build configuration file, created by
4 # sphinx-quickstart on Tue Oct 13 12:08:52 2015.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import os
16
17 # Detect if we're being built by Read the Docs
18 # https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs
19 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
20
21 # If extensions (or modules to document with autodoc) are in another directory,
22 # add these directories to sys.path here. If the directory is relative to the
23 # documentation root, use os.path.abspath to make it absolute, like shown here.
24 # sys.path.insert(0, os.path.abspath('.'))
25
26 # -- General configuration ------------------------------------------------
27
28 # If your documentation needs a minimal Sphinx version, state it here.
29 # needs_sphinx = '1.0'
30
31 # Add any Sphinx extension module names here, as strings. They can be
32 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
33 # ones.
34 extensions = ['sphinx.ext.todo', ]
35
36 # Add any paths that contain templates here, relative to this directory.
37 templates_path = ['_templates']
38
39 # The suffix(es) of source filenames.
40 # You can specify multiple suffix as a list of string:
41 # source_suffix = ['.rst', '.md']
42 source_suffix = '.rst'
43
44 # The encoding of source files.
45 # source_encoding = 'utf-8-sig'
46
47 # The master toctree document.
48 master_doc = 'index'
49
50 # General information about the project.
51 project = u'SecureDrop'
52 copyright = u'2017, Freedom of the Press Foundation'
53 author = u'SecureDrop Team and Contributors'
54
55 # The version info for the project you're documenting, acts as replacement for
56 # |version| and |release|, also used in various other places throughout the
57 # built documents.
58 #
59 # The short X.Y version.
60 version = '0.13.0'
61 # The full version, including alpha/beta/rc tags.
62 release = '0.13.0'
63
64 # The language for content autogenerated by Sphinx. Refer to documentation
65 # for a list of supported languages.
66 #
67 # This is also used if you do content translation via gettext catalogs.
68 # Usually you set "language" from the command line for these cases.
69 language = None
70
71 # There are two options for replacing |today|: either, you set today to some
72 # non-false value, then it is used:
73 # today = ''
74 # Else, today_fmt is used as the format for a strftime call.
75 # today_fmt = '%B %d, %Y'
76
77 # List of patterns, relative to source directory, that match files and
78 # directories to ignore when looking for source files.
79 exclude_patterns = ['_build']
80
81 # The reST default role (used for this markup: `text`) to use for all
82 # documents.
83 # default_role = None
84
85 # If true, '()' will be appended to :func: etc. cross-reference text.
86 # add_function_parentheses = True
87
88 # If true, the current module name will be prepended to all description
89 # unit titles (such as .. function::).
90 # add_module_names = True
91
92 # If true, sectionauthor and moduleauthor directives will be shown in the
93 # output. They are ignored by default.
94 # show_authors = False
95
96 # The name of the Pygments (syntax highlighting) style to use.
97 pygments_style = 'sphinx'
98
99 # A list of ignored prefixes for module index sorting.
100 # modindex_common_prefix = []
101
102 # If true, keep warnings as "system message" paragraphs in the built documents.
103 # keep_warnings = False
104
105 # If true, `todo` and `todoList` produce output, else they produce nothing.
106 todo_include_todos = False
107
108
109 # -- Options for HTML output ----------------------------------------------
110
111 # The theme to use for HTML and HTML Help pages. See the documentation for
112 # a list of builtin themes.
113 if on_rtd:
114 html_theme = 'default'
115 else:
116 try:
117 # If you want to build the docs locally using the RTD theme,
118 # you may need to install it: ``pip install sphinx_rtd_theme``.
119 # https://github.com/snide/sphinx_rtd_theme#via-package
120 import sphinx_rtd_theme
121 html_theme = "sphinx_rtd_theme"
122 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
123 except ImportError:
124 # This theme is included with Sphinx and is quite nice (based
125 # on the Pocoo themes), but since we're using the RTD theme
126 # for the production docs, it's best to use that to avoid
127 # issues due to discrepancies between the themes.
128 html_theme = 'alabaster'
129
130 # Theme options are theme-specific and customize the look and feel of a theme
131 # further. For a list of options available for each theme, see the
132 # documentation.
133 # html_theme_options = {}
134
135 # Add any paths that contain custom themes here, relative to this directory.
136 # html_theme_path = []
137
138 # The name for this set of Sphinx documents. If None, it defaults to
139 # "<project> v<release> documentation".
140 # html_title = None
141
142 # A shorter title for the navigation bar. Default is the same as html_title.
143 # html_short_title = None
144
145 # The name of an image file (relative to this directory) to place at the top
146 # of the sidebar.
147 html_logo = '../securedrop/static/i/favicon.png'
148
149 # The name of an image file (within the static path) to use as favicon of the
150 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
151 # pixels large.
152 # html_favicon = None
153
154 # Add any paths that contain custom static files (such as style sheets) here,
155 # relative to this directory. They are copied after the builtin static files,
156 # so a file named "default.css" will overwrite the builtin "default.css".
157 # html_static_path = ['_static']
158
159 # Add any extra paths that contain custom files (such as robots.txt or
160 # .htaccess) here, relative to this directory. These files are copied
161 # directly to the root of the documentation.
162 # html_extra_path = []
163
164 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
165 # using the given strftime format.
166 # html_last_updated_fmt = '%b %d, %Y'
167
168 # If true, SmartyPants will be used to convert quotes and dashes to
169 # typographically correct entities.
170 # html_use_smartypants = True
171
172 # Custom sidebar templates, maps document names to template names.
173 # html_sidebars = {}
174
175 # Additional templates that should be rendered to pages, maps page names to
176 # template names.
177 # html_additional_pages = {}
178
179 # If false, no module index is generated.
180 # html_domain_indices = True
181
182 # If false, no index is generated.
183 # html_use_index = True
184
185 # If true, the index is split into individual pages for each letter.
186 # html_split_index = False
187
188 # If true, links to the reST sources are added to the pages.
189 # html_show_sourcelink = True
190
191 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
192 # html_show_sphinx = True
193
194 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
195 # html_show_copyright = True
196
197 # If true, an OpenSearch description file will be output, and all pages will
198 # contain a <link> tag referring to it. The value of this option must be the
199 # base URL from which the finished HTML is served.
200 # html_use_opensearch = ''
201
202 # This is the file name suffix for HTML files (e.g. ".xhtml").
203 # html_file_suffix = None
204
205 # Language to be used for generating the HTML full-text search index.
206 # Sphinx supports the following languages:
207 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
208 # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
209 # html_search_language = 'en'
210
211 # A dictionary with options for the search language support, empty by default.
212 # Now only 'ja' uses this config value
213 # html_search_options = {'type': 'default'}
214
215 # The name of a javascript file (relative to the configuration directory) that
216 # implements a search results scorer. If empty, the default will be used.
217 # html_search_scorer = 'scorer.js'
218
219 # Output file base name for HTML help builder.
220 htmlhelp_basename = 'SecureDropdoc'
221
222 # -- Options for LaTeX output ---------------------------------------------
223
224 latex_elements = {
225 # The paper size ('letterpaper' or 'a4paper').
226 # 'papersize': 'letterpaper',
227
228 # The font size ('10pt', '11pt' or '12pt').
229 # 'pointsize': '10pt',
230
231 # Additional stuff for the LaTeX preamble.
232 # 'preamble': '',
233
234 # Latex figure (float) alignment
235 # 'figure_align': 'htbp',
236 }
237
238 # Grouping the document tree into LaTeX files. List of tuples
239 # (source start file, target name, title,
240 # author, documentclass [howto, manual, or own class]).
241 latex_documents = [
242 (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',
243 author, 'manual'),
244 ]
245
246 # The name of an image file (relative to this directory) to place at the top of
247 # the title page.
248 # latex_logo = None
249
250 # For "manual" documents, if this is true, then toplevel headings are parts,
251 # not chapters.
252 # latex_use_parts = False
253
254 # If true, show page references after internal links.
255 # latex_show_pagerefs = False
256
257 # If true, show URL addresses after external links.
258 # latex_show_urls = False
259
260 # Documents to append as an appendix to all manuals.
261 # latex_appendices = []
262
263 # If false, no module index is generated.
264 # latex_domain_indices = True
265
266
267 # -- Options for manual page output ---------------------------------------
268
269 # One entry per manual page. List of tuples
270 # (source start file, name, description, authors, manual section).
271 man_pages = [
272 (master_doc, 'securedrop', u'SecureDrop Documentation',
273 [author], 1)
274 ]
275
276 # If true, show URL addresses after external links.
277 # man_show_urls = False
278
279
280 # -- Options for Texinfo output -------------------------------------------
281
282 # Grouping the document tree into Texinfo files. List of tuples
283 # (source start file, target name, title, author,
284 # dir menu entry, description, category)
285 texinfo_documents = [
286 (master_doc, 'SecureDrop', u'SecureDrop Documentation',
287 author, 'SecureDrop', 'One line description of project.',
288 'Miscellaneous'),
289 ]
290
291 # Documents to append as an appendix to all manuals.
292 # texinfo_appendices = []
293
294 # If false, no module index is generated.
295 # texinfo_domain_indices = True
296
297 # How to display URL addresses: 'footnote', 'no', or 'inline'.
298 # texinfo_show_urls = 'footnote'
299
300 # If true, do not generate a @detailmenu in the "Top" node's menu.
301 # texinfo_no_detailmenu = False
302
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -299,3 +299,14 @@
# If true, do not generate a @detailmenu in the "Top" node's menu.
# texinfo_no_detailmenu = False
+
+# -- Options for linkcheck --
+
+linkcheck_retries = 3
+
+linkcheck_ignore = [
+ r'http://127.0.0.1(:\d+)?/?',
+ r'http://localhost(:\d+)?/?',
+ 'https://forum.securedrop.org/admin/users/list/active',
+ 'https://weblate.securedrop.org/projects/securedrop/securedrop/#repository',
+]
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -299,3 +299,14 @@\n \n # If true, do not generate a @detailmenu in the \"Top\" node's menu.\n # texinfo_no_detailmenu = False\n+\n+# -- Options for linkcheck --\n+\n+linkcheck_retries = 3\n+\n+linkcheck_ignore = [\n+ r'http://127.0.0.1(:\\d+)?/?',\n+ r'http://localhost(:\\d+)?/?',\n+ 'https://forum.securedrop.org/admin/users/list/active',\n+ 'https://weblate.securedrop.org/projects/securedrop/securedrop/#repository',\n+]\n", "issue": "Check documentation links as part of docs linting\n## Description\r\n\r\nSphinx [linkcheck](https://www.sphinx-doc.org/en/master/usage/builders/index.html#sphinx.builders.linkcheck.CheckExternalLinksBuilder) allows the verification of links with the `requests` library to ensure that the links are still valid and active. It might be useful to run this regularly or as part of CI to catch dead or broken links.\r\n## User Stories\r\nAs a user, clicking on a link and getting a 404 can be a a frustrating experience.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# SecureDrop documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 13 12:08:52 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\n\n# Detect if we're being built by Read the Docs\n# https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n# sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.todo', ]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'SecureDrop'\ncopyright = u'2017, Freedom of the Press Foundation'\nauthor = u'SecureDrop Team and Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.13.0'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.13.0'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n# default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nif on_rtd:\n html_theme = 'default'\nelse:\n try:\n # If you want to build the docs locally using the RTD theme,\n # you may need to install it: ``pip install sphinx_rtd_theme``.\n # https://github.com/snide/sphinx_rtd_theme#via-package\n import sphinx_rtd_theme\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n # This theme is included with Sphinx and is quite nice (based\n # on the Pocoo themes), but since we're using the RTD theme\n # for the production docs, it's best to use that to avoid\n # issues due to discrepancies between the themes.\n html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n# html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n# html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n# html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = '../securedrop/static/i/favicon.png'\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n# html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n# html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n# html_domain_indices = True\n\n# If false, no index is generated.\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# Now only 'ja' uses this config value\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'SecureDropdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n # 'preamble': '',\n\n # Latex figure (float) alignment\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',\n author, 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n# latex_appendices = []\n\n# If false, no module index is generated.\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'securedrop', u'SecureDrop Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'SecureDrop', u'SecureDrop Documentation',\n author, 'SecureDrop', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# SecureDrop documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 13 12:08:52 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\n\n# Detect if we're being built by Read the Docs\n# https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n# sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.todo', ]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'SecureDrop'\ncopyright = u'2017, Freedom of the Press Foundation'\nauthor = u'SecureDrop Team and Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.13.0'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.13.0'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n# default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nif on_rtd:\n html_theme = 'default'\nelse:\n try:\n # If you want to build the docs locally using the RTD theme,\n # you may need to install it: ``pip install sphinx_rtd_theme``.\n # https://github.com/snide/sphinx_rtd_theme#via-package\n import sphinx_rtd_theme\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n # This theme is included with Sphinx and is quite nice (based\n # on the Pocoo themes), but since we're using the RTD theme\n # for the production docs, it's best to use that to avoid\n # issues due to discrepancies between the themes.\n html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n# html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n# html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n# html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = '../securedrop/static/i/favicon.png'\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n# html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n# html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n# html_domain_indices = True\n\n# If false, no index is generated.\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# Now only 'ja' uses this config value\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'SecureDropdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n # 'preamble': '',\n\n # Latex figure (float) alignment\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',\n author, 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n# latex_appendices = []\n\n# If false, no module index is generated.\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'securedrop', u'SecureDrop Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'SecureDrop', u'SecureDrop Documentation',\n author, 'SecureDrop', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n# texinfo_no_detailmenu = False\n\n# -- Options for linkcheck --\n\nlinkcheck_retries = 3\n\nlinkcheck_ignore = [\n r'http://127.0.0.1(:\\d+)?/?',\n r'http://localhost(:\\d+)?/?',\n 'https://forum.securedrop.org/admin/users/list/active',\n 'https://weblate.securedrop.org/projects/securedrop/securedrop/#repository',\n]\n", "path": "docs/conf.py"}]}
| 3,736 | 168 |
gh_patches_debug_7664
|
rasdani/github-patches
|
git_diff
|
google__jax-11307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Line-search x64 type promotion bug
There seems to be a bug in the line-search when enabling x64 mode but optimizing a purely float32 function.
```python
import jax.numpy as jnp
import jax.scipy.optimize
jax.config.update("jax_enable_x64", True)
def f(x):
return jnp.sum(x ** 2)
x0 = jnp.zeros(2, dtype=jnp.float32)
jax.scipy.optimize.minimize(f, x0, method='BFGS')
```
```
TypeError: body_fun output and input must have identical types, got
_ZoomState(done=ShapedArray(bool[]), failed=ShapedArray(bool[]), j=ShapedArray(int64[], weak_type=True), a_lo=ShapedArray(float64[]), phi_lo=ShapedArray(float64[]), dphi_lo=ShapedArray(float64[]), a_hi=ShapedArray(float64[]), phi_hi=ShapedArray(float64[]), dphi_hi=ShapedArray(float64[]), a_rec=ShapedArray(float64[]), phi_rec=ShapedArray(float64[]), a_star=ShapedArray(float64[]), phi_star=ShapedArray(float64[]), dphi_star=ShapedArray(float64[]), g_star=ShapedArray(float64[2]), nfev=ShapedArray(int64[], weak_type=True), ngev=ShapedArray(int64[], weak_type=True))
and
_ZoomState(done=ShapedArray(bool[], weak_type=True), failed=ShapedArray(bool[], weak_type=True), j=ShapedArray(int64[], weak_type=True), a_lo=ShapedArray(float64[], weak_type=True), phi_lo=ShapedArray(float32[]), dphi_lo=ShapedArray(float64[]), a_hi=ShapedArray(float64[], weak_type=True), phi_hi=ShapedArray(float64[]), dphi_hi=ShapedArray(float64[]), a_rec=ShapedArray(float64[], weak_type=True), phi_rec=ShapedArray(float64[]), a_star=ShapedArray(float64[], weak_type=True), phi_star=ShapedArray(float32[]), dphi_star=ShapedArray(float64[]), g_star=ShapedArray(float32[2]), nfev=ShapedArray(int64[], weak_type=True), ngev=ShapedArray(int64[], weak_type=True)).
```
-> `g_star` type differs
Is this expected behavior or a bug?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jax/_src/scipy/optimize/bfgs.py`
Content:
```
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """The Broyden-Fletcher-Goldfarb-Shanno minimization algorithm."""
15 from functools import partial
16 from typing import Callable, NamedTuple, Optional, Union
17
18 import jax
19 import jax.numpy as jnp
20 from jax import lax
21 from jax._src.scipy.optimize.line_search import line_search
22
23
24 class _BFGSResults(NamedTuple):
25 """Results from BFGS optimization.
26
27 Parameters:
28 converged: True if minimization converged.
29 failed: True if line search failed.
30 k: integer the number of iterations of the BFGS update.
31 nfev: integer total number of objective evaluations performed.
32 ngev: integer total number of jacobian evaluations
33 nhev: integer total number of hessian evaluations
34 x_k: array containing the last argument value found during the search. If
35 the search converged, then this value is the argmin of the objective
36 function.
37 f_k: array containing the value of the objective function at `x_k`. If the
38 search converged, then this is the (local) minimum of the objective
39 function.
40 g_k: array containing the gradient of the objective function at `x_k`. If
41 the search converged the l2-norm of this tensor should be below the
42 tolerance.
43 H_k: array containing the inverse of the estimated Hessian.
44 status: int describing end state.
45 line_search_status: int describing line search end state (only means
46 something if line search fails).
47 """
48 converged: Union[bool, jnp.ndarray]
49 failed: Union[bool, jnp.ndarray]
50 k: Union[int, jnp.ndarray]
51 nfev: Union[int, jnp.ndarray]
52 ngev: Union[int, jnp.ndarray]
53 nhev: Union[int, jnp.ndarray]
54 x_k: jnp.ndarray
55 f_k: jnp.ndarray
56 g_k: jnp.ndarray
57 H_k: jnp.ndarray
58 old_old_fval: jnp.ndarray
59 status: Union[int, jnp.ndarray]
60 line_search_status: Union[int, jnp.ndarray]
61
62
63 _dot = partial(jnp.dot, precision=lax.Precision.HIGHEST)
64 _einsum = partial(jnp.einsum, precision=lax.Precision.HIGHEST)
65
66
67 def minimize_bfgs(
68 fun: Callable,
69 x0: jnp.ndarray,
70 maxiter: Optional[int] = None,
71 norm=jnp.inf,
72 gtol: float = 1e-5,
73 line_search_maxiter: int = 10,
74 ) -> _BFGSResults:
75 """Minimize a function using BFGS.
76
77 Implements the BFGS algorithm from
78 Algorithm 6.1 from Wright and Nocedal, 'Numerical Optimization', 1999, pg.
79 136-143.
80
81 Args:
82 fun: function of the form f(x) where x is a flat ndarray and returns a real
83 scalar. The function should be composed of operations with vjp defined.
84 x0: initial guess.
85 maxiter: maximum number of iterations.
86 norm: order of norm for convergence check. Default inf.
87 gtol: terminates minimization when |grad|_norm < g_tol.
88 line_search_maxiter: maximum number of linesearch iterations.
89
90 Returns:
91 Optimization result.
92 """
93
94 if maxiter is None:
95 maxiter = jnp.size(x0) * 200
96
97 d = x0.shape[0]
98
99 initial_H = jnp.eye(d, dtype=x0.dtype)
100 f_0, g_0 = jax.value_and_grad(fun)(x0)
101 state = _BFGSResults(
102 converged=jnp.linalg.norm(g_0, ord=norm) < gtol,
103 failed=False,
104 k=0,
105 nfev=1,
106 ngev=1,
107 nhev=0,
108 x_k=x0,
109 f_k=f_0,
110 g_k=g_0,
111 H_k=initial_H,
112 old_old_fval=f_0 + jnp.linalg.norm(g_0) / 2,
113 status=0,
114 line_search_status=0,
115 )
116
117 def cond_fun(state):
118 return (jnp.logical_not(state.converged)
119 & jnp.logical_not(state.failed)
120 & (state.k < maxiter))
121
122 def body_fun(state):
123 p_k = -_dot(state.H_k, state.g_k)
124 line_search_results = line_search(
125 fun,
126 state.x_k,
127 p_k,
128 old_fval=state.f_k,
129 old_old_fval=state.old_old_fval,
130 gfk=state.g_k,
131 maxiter=line_search_maxiter,
132 )
133 state = state._replace(
134 nfev=state.nfev + line_search_results.nfev,
135 ngev=state.ngev + line_search_results.ngev,
136 failed=line_search_results.failed,
137 line_search_status=line_search_results.status,
138 )
139 s_k = line_search_results.a_k * p_k
140 x_kp1 = state.x_k + s_k
141 f_kp1 = line_search_results.f_k
142 g_kp1 = line_search_results.g_k
143 y_k = g_kp1 - state.g_k
144 rho_k = jnp.reciprocal(_dot(y_k, s_k))
145
146 sy_k = s_k[:, jnp.newaxis] * y_k[jnp.newaxis, :]
147 w = jnp.eye(d) - rho_k * sy_k
148 H_kp1 = (_einsum('ij,jk,lk', w, state.H_k, w)
149 + rho_k * s_k[:, jnp.newaxis] * s_k[jnp.newaxis, :])
150 H_kp1 = jnp.where(jnp.isfinite(rho_k), H_kp1, state.H_k)
151 converged = jnp.linalg.norm(g_kp1, ord=norm) < gtol
152
153 state = state._replace(
154 converged=converged,
155 k=state.k + 1,
156 x_k=x_kp1,
157 f_k=f_kp1,
158 g_k=g_kp1,
159 H_k=H_kp1,
160 old_old_fval=state.f_k,
161 )
162 return state
163
164 state = lax.while_loop(cond_fun, body_fun, state)
165 status = jnp.where(
166 state.converged,
167 0, # converged
168 jnp.where(
169 state.k == maxiter,
170 1, # max iters reached
171 jnp.where(
172 state.failed,
173 2 + state.line_search_status, # ls failed (+ reason)
174 -1, # undefined
175 )
176 )
177 )
178 state = state._replace(status=status)
179 return state
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jax/_src/scipy/optimize/bfgs.py b/jax/_src/scipy/optimize/bfgs.py
--- a/jax/_src/scipy/optimize/bfgs.py
+++ b/jax/_src/scipy/optimize/bfgs.py
@@ -144,7 +144,7 @@
rho_k = jnp.reciprocal(_dot(y_k, s_k))
sy_k = s_k[:, jnp.newaxis] * y_k[jnp.newaxis, :]
- w = jnp.eye(d) - rho_k * sy_k
+ w = jnp.eye(d, dtype=rho_k.dtype) - rho_k * sy_k
H_kp1 = (_einsum('ij,jk,lk', w, state.H_k, w)
+ rho_k * s_k[:, jnp.newaxis] * s_k[jnp.newaxis, :])
H_kp1 = jnp.where(jnp.isfinite(rho_k), H_kp1, state.H_k)
|
{"golden_diff": "diff --git a/jax/_src/scipy/optimize/bfgs.py b/jax/_src/scipy/optimize/bfgs.py\n--- a/jax/_src/scipy/optimize/bfgs.py\n+++ b/jax/_src/scipy/optimize/bfgs.py\n@@ -144,7 +144,7 @@\n rho_k = jnp.reciprocal(_dot(y_k, s_k))\n \n sy_k = s_k[:, jnp.newaxis] * y_k[jnp.newaxis, :]\n- w = jnp.eye(d) - rho_k * sy_k\n+ w = jnp.eye(d, dtype=rho_k.dtype) - rho_k * sy_k\n H_kp1 = (_einsum('ij,jk,lk', w, state.H_k, w)\n + rho_k * s_k[:, jnp.newaxis] * s_k[jnp.newaxis, :])\n H_kp1 = jnp.where(jnp.isfinite(rho_k), H_kp1, state.H_k)\n", "issue": "Line-search x64 type promotion bug\nThere seems to be a bug in the line-search when enabling x64 mode but optimizing a purely float32 function.\r\n\r\n```python\r\nimport jax.numpy as jnp\r\nimport jax.scipy.optimize\r\n\r\njax.config.update(\"jax_enable_x64\", True)\r\n\r\n\r\ndef f(x):\r\n return jnp.sum(x ** 2)\r\n\r\n\r\nx0 = jnp.zeros(2, dtype=jnp.float32)\r\njax.scipy.optimize.minimize(f, x0, method='BFGS')\r\n```\r\n\r\n```\r\nTypeError: body_fun output and input must have identical types, got\r\n_ZoomState(done=ShapedArray(bool[]), failed=ShapedArray(bool[]), j=ShapedArray(int64[], weak_type=True), a_lo=ShapedArray(float64[]), phi_lo=ShapedArray(float64[]), dphi_lo=ShapedArray(float64[]), a_hi=ShapedArray(float64[]), phi_hi=ShapedArray(float64[]), dphi_hi=ShapedArray(float64[]), a_rec=ShapedArray(float64[]), phi_rec=ShapedArray(float64[]), a_star=ShapedArray(float64[]), phi_star=ShapedArray(float64[]), dphi_star=ShapedArray(float64[]), g_star=ShapedArray(float64[2]), nfev=ShapedArray(int64[], weak_type=True), ngev=ShapedArray(int64[], weak_type=True))\r\nand\r\n_ZoomState(done=ShapedArray(bool[], weak_type=True), failed=ShapedArray(bool[], weak_type=True), j=ShapedArray(int64[], weak_type=True), a_lo=ShapedArray(float64[], weak_type=True), phi_lo=ShapedArray(float32[]), dphi_lo=ShapedArray(float64[]), a_hi=ShapedArray(float64[], weak_type=True), phi_hi=ShapedArray(float64[]), dphi_hi=ShapedArray(float64[]), a_rec=ShapedArray(float64[], weak_type=True), phi_rec=ShapedArray(float64[]), a_star=ShapedArray(float64[], weak_type=True), phi_star=ShapedArray(float32[]), dphi_star=ShapedArray(float64[]), g_star=ShapedArray(float32[2]), nfev=ShapedArray(int64[], weak_type=True), ngev=ShapedArray(int64[], weak_type=True)).\r\n```\r\n\r\n-> `g_star` type differs\r\n\r\nIs this expected behavior or a bug?\r\n\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"The Broyden-Fletcher-Goldfarb-Shanno minimization algorithm.\"\"\"\nfrom functools import partial\nfrom typing import Callable, NamedTuple, Optional, Union\n\nimport jax\nimport jax.numpy as jnp\nfrom jax import lax\nfrom jax._src.scipy.optimize.line_search import line_search\n\n\nclass _BFGSResults(NamedTuple):\n \"\"\"Results from BFGS optimization.\n\n Parameters:\n converged: True if minimization converged.\n failed: True if line search failed.\n k: integer the number of iterations of the BFGS update.\n nfev: integer total number of objective evaluations performed.\n ngev: integer total number of jacobian evaluations\n nhev: integer total number of hessian evaluations\n x_k: array containing the last argument value found during the search. If\n the search converged, then this value is the argmin of the objective\n function.\n f_k: array containing the value of the objective function at `x_k`. If the\n search converged, then this is the (local) minimum of the objective\n function.\n g_k: array containing the gradient of the objective function at `x_k`. If\n the search converged the l2-norm of this tensor should be below the\n tolerance.\n H_k: array containing the inverse of the estimated Hessian.\n status: int describing end state.\n line_search_status: int describing line search end state (only means\n something if line search fails).\n \"\"\"\n converged: Union[bool, jnp.ndarray]\n failed: Union[bool, jnp.ndarray]\n k: Union[int, jnp.ndarray]\n nfev: Union[int, jnp.ndarray]\n ngev: Union[int, jnp.ndarray]\n nhev: Union[int, jnp.ndarray]\n x_k: jnp.ndarray\n f_k: jnp.ndarray\n g_k: jnp.ndarray\n H_k: jnp.ndarray\n old_old_fval: jnp.ndarray\n status: Union[int, jnp.ndarray]\n line_search_status: Union[int, jnp.ndarray]\n\n\n_dot = partial(jnp.dot, precision=lax.Precision.HIGHEST)\n_einsum = partial(jnp.einsum, precision=lax.Precision.HIGHEST)\n\n\ndef minimize_bfgs(\n fun: Callable,\n x0: jnp.ndarray,\n maxiter: Optional[int] = None,\n norm=jnp.inf,\n gtol: float = 1e-5,\n line_search_maxiter: int = 10,\n) -> _BFGSResults:\n \"\"\"Minimize a function using BFGS.\n\n Implements the BFGS algorithm from\n Algorithm 6.1 from Wright and Nocedal, 'Numerical Optimization', 1999, pg.\n 136-143.\n\n Args:\n fun: function of the form f(x) where x is a flat ndarray and returns a real\n scalar. The function should be composed of operations with vjp defined.\n x0: initial guess.\n maxiter: maximum number of iterations.\n norm: order of norm for convergence check. Default inf.\n gtol: terminates minimization when |grad|_norm < g_tol.\n line_search_maxiter: maximum number of linesearch iterations.\n\n Returns:\n Optimization result.\n \"\"\"\n\n if maxiter is None:\n maxiter = jnp.size(x0) * 200\n\n d = x0.shape[0]\n\n initial_H = jnp.eye(d, dtype=x0.dtype)\n f_0, g_0 = jax.value_and_grad(fun)(x0)\n state = _BFGSResults(\n converged=jnp.linalg.norm(g_0, ord=norm) < gtol,\n failed=False,\n k=0,\n nfev=1,\n ngev=1,\n nhev=0,\n x_k=x0,\n f_k=f_0,\n g_k=g_0,\n H_k=initial_H,\n old_old_fval=f_0 + jnp.linalg.norm(g_0) / 2,\n status=0,\n line_search_status=0,\n )\n\n def cond_fun(state):\n return (jnp.logical_not(state.converged)\n & jnp.logical_not(state.failed)\n & (state.k < maxiter))\n\n def body_fun(state):\n p_k = -_dot(state.H_k, state.g_k)\n line_search_results = line_search(\n fun,\n state.x_k,\n p_k,\n old_fval=state.f_k,\n old_old_fval=state.old_old_fval,\n gfk=state.g_k,\n maxiter=line_search_maxiter,\n )\n state = state._replace(\n nfev=state.nfev + line_search_results.nfev,\n ngev=state.ngev + line_search_results.ngev,\n failed=line_search_results.failed,\n line_search_status=line_search_results.status,\n )\n s_k = line_search_results.a_k * p_k\n x_kp1 = state.x_k + s_k\n f_kp1 = line_search_results.f_k\n g_kp1 = line_search_results.g_k\n y_k = g_kp1 - state.g_k\n rho_k = jnp.reciprocal(_dot(y_k, s_k))\n\n sy_k = s_k[:, jnp.newaxis] * y_k[jnp.newaxis, :]\n w = jnp.eye(d) - rho_k * sy_k\n H_kp1 = (_einsum('ij,jk,lk', w, state.H_k, w)\n + rho_k * s_k[:, jnp.newaxis] * s_k[jnp.newaxis, :])\n H_kp1 = jnp.where(jnp.isfinite(rho_k), H_kp1, state.H_k)\n converged = jnp.linalg.norm(g_kp1, ord=norm) < gtol\n\n state = state._replace(\n converged=converged,\n k=state.k + 1,\n x_k=x_kp1,\n f_k=f_kp1,\n g_k=g_kp1,\n H_k=H_kp1,\n old_old_fval=state.f_k,\n )\n return state\n\n state = lax.while_loop(cond_fun, body_fun, state)\n status = jnp.where(\n state.converged,\n 0, # converged\n jnp.where(\n state.k == maxiter,\n 1, # max iters reached\n jnp.where(\n state.failed,\n 2 + state.line_search_status, # ls failed (+ reason)\n -1, # undefined\n )\n )\n )\n state = state._replace(status=status)\n return state\n", "path": "jax/_src/scipy/optimize/bfgs.py"}], "after_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"The Broyden-Fletcher-Goldfarb-Shanno minimization algorithm.\"\"\"\nfrom functools import partial\nfrom typing import Callable, NamedTuple, Optional, Union\n\nimport jax\nimport jax.numpy as jnp\nfrom jax import lax\nfrom jax._src.scipy.optimize.line_search import line_search\n\n\nclass _BFGSResults(NamedTuple):\n \"\"\"Results from BFGS optimization.\n\n Parameters:\n converged: True if minimization converged.\n failed: True if line search failed.\n k: integer the number of iterations of the BFGS update.\n nfev: integer total number of objective evaluations performed.\n ngev: integer total number of jacobian evaluations\n nhev: integer total number of hessian evaluations\n x_k: array containing the last argument value found during the search. If\n the search converged, then this value is the argmin of the objective\n function.\n f_k: array containing the value of the objective function at `x_k`. If the\n search converged, then this is the (local) minimum of the objective\n function.\n g_k: array containing the gradient of the objective function at `x_k`. If\n the search converged the l2-norm of this tensor should be below the\n tolerance.\n H_k: array containing the inverse of the estimated Hessian.\n status: int describing end state.\n line_search_status: int describing line search end state (only means\n something if line search fails).\n \"\"\"\n converged: Union[bool, jnp.ndarray]\n failed: Union[bool, jnp.ndarray]\n k: Union[int, jnp.ndarray]\n nfev: Union[int, jnp.ndarray]\n ngev: Union[int, jnp.ndarray]\n nhev: Union[int, jnp.ndarray]\n x_k: jnp.ndarray\n f_k: jnp.ndarray\n g_k: jnp.ndarray\n H_k: jnp.ndarray\n old_old_fval: jnp.ndarray\n status: Union[int, jnp.ndarray]\n line_search_status: Union[int, jnp.ndarray]\n\n\n_dot = partial(jnp.dot, precision=lax.Precision.HIGHEST)\n_einsum = partial(jnp.einsum, precision=lax.Precision.HIGHEST)\n\n\ndef minimize_bfgs(\n fun: Callable,\n x0: jnp.ndarray,\n maxiter: Optional[int] = None,\n norm=jnp.inf,\n gtol: float = 1e-5,\n line_search_maxiter: int = 10,\n) -> _BFGSResults:\n \"\"\"Minimize a function using BFGS.\n\n Implements the BFGS algorithm from\n Algorithm 6.1 from Wright and Nocedal, 'Numerical Optimization', 1999, pg.\n 136-143.\n\n Args:\n fun: function of the form f(x) where x is a flat ndarray and returns a real\n scalar. The function should be composed of operations with vjp defined.\n x0: initial guess.\n maxiter: maximum number of iterations.\n norm: order of norm for convergence check. Default inf.\n gtol: terminates minimization when |grad|_norm < g_tol.\n line_search_maxiter: maximum number of linesearch iterations.\n\n Returns:\n Optimization result.\n \"\"\"\n\n if maxiter is None:\n maxiter = jnp.size(x0) * 200\n\n d = x0.shape[0]\n\n initial_H = jnp.eye(d, dtype=x0.dtype)\n f_0, g_0 = jax.value_and_grad(fun)(x0)\n state = _BFGSResults(\n converged=jnp.linalg.norm(g_0, ord=norm) < gtol,\n failed=False,\n k=0,\n nfev=1,\n ngev=1,\n nhev=0,\n x_k=x0,\n f_k=f_0,\n g_k=g_0,\n H_k=initial_H,\n old_old_fval=f_0 + jnp.linalg.norm(g_0) / 2,\n status=0,\n line_search_status=0,\n )\n\n def cond_fun(state):\n return (jnp.logical_not(state.converged)\n & jnp.logical_not(state.failed)\n & (state.k < maxiter))\n\n def body_fun(state):\n p_k = -_dot(state.H_k, state.g_k)\n line_search_results = line_search(\n fun,\n state.x_k,\n p_k,\n old_fval=state.f_k,\n old_old_fval=state.old_old_fval,\n gfk=state.g_k,\n maxiter=line_search_maxiter,\n )\n state = state._replace(\n nfev=state.nfev + line_search_results.nfev,\n ngev=state.ngev + line_search_results.ngev,\n failed=line_search_results.failed,\n line_search_status=line_search_results.status,\n )\n s_k = line_search_results.a_k * p_k\n x_kp1 = state.x_k + s_k\n f_kp1 = line_search_results.f_k\n g_kp1 = line_search_results.g_k\n y_k = g_kp1 - state.g_k\n rho_k = jnp.reciprocal(_dot(y_k, s_k))\n\n sy_k = s_k[:, jnp.newaxis] * y_k[jnp.newaxis, :]\n w = jnp.eye(d, dtype=rho_k.dtype) - rho_k * sy_k\n H_kp1 = (_einsum('ij,jk,lk', w, state.H_k, w)\n + rho_k * s_k[:, jnp.newaxis] * s_k[jnp.newaxis, :])\n H_kp1 = jnp.where(jnp.isfinite(rho_k), H_kp1, state.H_k)\n converged = jnp.linalg.norm(g_kp1, ord=norm) < gtol\n\n state = state._replace(\n converged=converged,\n k=state.k + 1,\n x_k=x_kp1,\n f_k=f_kp1,\n g_k=g_kp1,\n H_k=H_kp1,\n old_old_fval=state.f_k,\n )\n return state\n\n state = lax.while_loop(cond_fun, body_fun, state)\n status = jnp.where(\n state.converged,\n 0, # converged\n jnp.where(\n state.k == maxiter,\n 1, # max iters reached\n jnp.where(\n state.failed,\n 2 + state.line_search_status, # ls failed (+ reason)\n -1, # undefined\n )\n )\n )\n state = state._replace(status=status)\n return state\n", "path": "jax/_src/scipy/optimize/bfgs.py"}]}
| 2,875 | 220 |
gh_patches_debug_25154
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-1988
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CPython 3.10 support
CPython 3.10 has been released.
Although it may already work out of the box, we need to add official first class support anyway:
- [x] Add a CPython 3.10 CI gate: (https://github.com/falconry/falcon/pull/1922).
- [x] Build CPython 3.10 wheels.
- [x] Advertise support using ["trove classifiers"](https://pypi.org/classifiers/).
- [x] Check if anything needs an update in `CONTRIBUTING.md`.
In addition, check for any new warnings emitted when running tests, e.g., whether we are relying on any deprecated functionality that will be removed in future Python versions:
- [x] Multiple `DeprecationWarning`: non-integer arguments to randrange() have been deprecated since Python 3.10 and will be removed in a subsequent version https://github.com/falconry/falcon/pull/1972
- [x] `falcon/util/sync.py`:224: `DeprecationWarning`: There is no current event loop
loop = asyncio.get_event_loop()
[`asyncio.get_event_loop()`](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.get_event_loop): _Deprecated since version 3.10:_ Deprecation warning is emitted if there is no running event loop. In future Python releases, this function will be an alias of [`get_running_loop()`](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.get_running_loop).
- [x] `tests/asgi/test_ws.py`:344: `DeprecationWarning`: The explicit passing of coroutine objects to asyncio.wait() is deprecated since Python 3.8, and scheduled for removal in Python 3.11.
- [x] Anything else?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `falcon/util/sync.py`
Content:
```
1 import asyncio
2 from concurrent.futures import ThreadPoolExecutor
3 from functools import partial
4 from functools import wraps
5 import inspect
6 import os
7 from typing import Callable
8
9
10 __all__ = [
11 'async_to_sync',
12 'create_task',
13 'get_running_loop',
14 'runs_sync',
15 'sync_to_async',
16 'wrap_sync_to_async',
17 'wrap_sync_to_async_unsafe',
18 ]
19
20
21 _one_thread_to_rule_them_all = ThreadPoolExecutor(max_workers=1)
22
23
24 try:
25 get_running_loop = asyncio.get_running_loop
26 except AttributeError: # pragma: nocover
27 # NOTE(kgriffs): This branch is definitely covered under py35 and py36
28 # but for some reason the codecov gate doesn't pick this up, hence
29 # the pragma above.
30
31 get_running_loop = asyncio.get_event_loop
32
33
34 try:
35 create_task = asyncio.create_task
36 except AttributeError: # pragma: nocover
37 # NOTE(kgriffs): This branch is definitely covered under py35 and py36
38 # but for some reason the codecov gate doesn't pick this up, hence
39 # the pragma above.
40
41 def create_task(coro, name=None):
42 return asyncio.ensure_future(coro)
43
44
45 def wrap_sync_to_async_unsafe(func) -> Callable:
46 """Wrap a callable in a coroutine that executes the callable directly.
47
48 This helper makes it easier to use synchronous callables with ASGI
49 apps. However, it is considered "unsafe" because it calls the wrapped
50 function directly in the same thread as the asyncio loop. Generally, you
51 should use :func:`~.wrap_sync_to_async` instead.
52
53 Warning:
54 This helper is only to be used for functions that do not perform any
55 blocking I/O or lengthy CPU-bound operations, since the entire async
56 loop will be blocked while the wrapped function is executed.
57 For a safer, non-blocking alternative that runs the function in a
58 thread pool executor, use :func:`~.sync_to_async` instead.
59
60 Arguments:
61 func (callable): Function, method, or other callable to wrap
62
63 Returns:
64 function: An awaitable coroutine function that wraps the
65 synchronous callable.
66 """
67
68 @wraps(func)
69 async def wrapper(*args, **kwargs):
70 return func(*args, **kwargs)
71
72 return wrapper
73
74
75 def wrap_sync_to_async(func, threadsafe=None) -> Callable:
76 """Wrap a callable in a coroutine that executes the callable in the background.
77
78 This helper makes it easier to call functions that can not be
79 ported to use async natively (e.g., functions exported by a database
80 library that does not yet support asyncio).
81
82 To execute blocking operations safely, without stalling the async
83 loop, the wrapped callable is scheduled to run in the background, on a
84 separate thread, when the wrapper is called.
85
86 Normally, the default executor for the running loop is used to schedule the
87 synchronous callable. If the callable is not thread-safe, it can be
88 scheduled serially in a global single-threaded executor.
89
90 Warning:
91 Wrapping a synchronous function safely adds a fair amount of overhead
92 to the function call, and should only be used when a native async
93 library is not available for the operation you wish to perform.
94
95 Arguments:
96 func (callable): Function, method, or other callable to wrap
97
98 Keyword Arguments:
99 threadsafe (bool): Set to ``False`` when the callable is not
100 thread-safe (default ``True``). When this argument is ``False``,
101 the wrapped callable will be scheduled to run serially in a
102 global single-threaded executor.
103
104 Returns:
105 function: An awaitable coroutine function that wraps the
106 synchronous callable.
107 """
108
109 if threadsafe is None or threadsafe:
110 executor = None # Use default
111 else:
112 executor = _one_thread_to_rule_them_all
113
114 @wraps(func)
115 async def wrapper(*args, **kwargs):
116 return await get_running_loop().run_in_executor(
117 executor, partial(func, *args, **kwargs)
118 )
119
120 return wrapper
121
122
123 async def sync_to_async(func, *args, **kwargs):
124 """Schedule a synchronous callable on the loop's default executor and await the result.
125
126 This helper makes it easier to call functions that can not be
127 ported to use async natively (e.g., functions exported by a database
128 library that does not yet support asyncio).
129
130 To execute blocking operations safely, without stalling the async
131 loop, the wrapped callable is scheduled to run in the background, on a
132 separate thread, when the wrapper is called.
133
134 The default executor for the running loop is used to schedule the
135 synchronous callable.
136
137 Warning:
138 This helper can only be used to execute thread-safe callables. If
139 the callable is not thread-safe, it can be executed serially
140 by first wrapping it with :func:`~.wrap_sync_to_async`, and then
141 executing the wrapper directly.
142
143 Warning:
144 Calling a synchronous function safely from an asyncio event loop
145 adds a fair amount of overhead to the function call, and should
146 only be used when a native async library is not available for the
147 operation you wish to perform.
148
149 Arguments:
150 func (callable): Function, method, or other callable to wrap
151 *args: All additional arguments are passed through to the callable.
152
153 Keyword Arguments:
154 **kwargs: All keyword arguments are passed through to the callable.
155
156 Returns:
157 function: An awaitable coroutine function that wraps the
158 synchronous callable.
159 """
160
161 return await get_running_loop().run_in_executor(
162 None, partial(func, *args, **kwargs)
163 )
164
165
166 def _should_wrap_non_coroutines() -> bool:
167 """Return ``True`` IFF ``FALCON_ASGI_WRAP_NON_COROUTINES`` is set in the environ.
168
169 This should only be used for Falcon's own test suite.
170 """
171 return 'FALCON_ASGI_WRAP_NON_COROUTINES' in os.environ
172
173
174 def _wrap_non_coroutine_unsafe(func):
175 """Wrap a coroutine using ``wrap_sync_to_async_unsafe()`` for internal test cases.
176
177 This method is intended for Falcon's own test suite and should not be
178 used by apps themselves. It provides a convenient way to reuse sync
179 methods for ASGI test cases when it is safe to do so.
180
181 Arguments:
182 func (callable): Function, method, or other callable to wrap
183 Returns:
184 When not in test mode, this function simply returns the callable
185 unchanged. Otherwise, if the callable is not a coroutine function,
186 it will be wrapped using ``wrap_sync_to_async_unsafe()``.
187 """
188
189 if func is None:
190 return func
191
192 if not _should_wrap_non_coroutines():
193 return func
194
195 if inspect.iscoroutinefunction(func):
196 return func
197
198 return wrap_sync_to_async_unsafe(func)
199
200
201 def async_to_sync(coroutine, *args, **kwargs):
202 """Invoke a coroutine function from a synchronous caller.
203
204 This method can be used to invoke an asynchronous task from a synchronous
205 context. The coroutine will be scheduled to run on the current event
206 loop for the current OS thread. If an event loop is not already running,
207 one will be created.
208
209 Warning:
210 This method is very inefficient and is intended primarily for testing
211 and prototyping.
212
213 Additional arguments not mentioned below are bound to the given
214 coroutine function via :any:`functools.partial`.
215
216 Args:
217 coroutine: A coroutine function to invoke.
218 *args: Additional args are passed through to the coroutine function.
219
220 Keyword Args:
221 **kwargs: Additional args are passed through to the coroutine function.
222 """
223
224 loop = asyncio.get_event_loop()
225 return loop.run_until_complete(partial(coroutine, *args, **kwargs)())
226
227
228 def runs_sync(coroutine):
229 """Transform a coroutine function into a synchronous method.
230
231 This is achieved by always invoking the decorated coroutine function via
232 :meth:`async_to_sync`.
233
234 Warning:
235 This decorator is very inefficient and should only be used for adapting
236 asynchronous test functions for use with synchronous test runners such
237 as ``pytest`` or the ``unittest`` module.
238
239 It will create an event loop for the current thread if one is not
240 already running.
241
242 Args:
243 coroutine: A coroutine function to masquerade as a synchronous one.
244
245 Returns:
246 callable: A synchronous function.
247 """
248
249 @wraps(coroutine)
250 def invoke(*args, **kwargs):
251 return async_to_sync(coroutine, *args, **kwargs)
252
253 return invoke
254
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/falcon/util/sync.py b/falcon/util/sync.py
--- a/falcon/util/sync.py
+++ b/falcon/util/sync.py
@@ -210,9 +210,6 @@
This method is very inefficient and is intended primarily for testing
and prototyping.
- Additional arguments not mentioned below are bound to the given
- coroutine function via :any:`functools.partial`.
-
Args:
coroutine: A coroutine function to invoke.
*args: Additional args are passed through to the coroutine function.
@@ -221,8 +218,16 @@
**kwargs: Additional args are passed through to the coroutine function.
"""
- loop = asyncio.get_event_loop()
- return loop.run_until_complete(partial(coroutine, *args, **kwargs)())
+ # TODO(vytas): The canonical way of doing this for simple use cases is
+ # asyncio.run(), but that would be a breaking change wrt the above
+ # documented behaviour; breaking enough to break some of our own tests.
+
+ # NOTE(vytas): Work around get_event_loop deprecation in 3.10 by going via
+ # get_event_loop_policy(). This should be equivalent for async_to_sync's
+ # use case as it is currently impossible to invoke run_until_complete()
+ # from a running loop anyway.
+ loop = asyncio.get_event_loop_policy().get_event_loop()
+ return loop.run_until_complete(coroutine(*args, **kwargs))
def runs_sync(coroutine):
|
{"golden_diff": "diff --git a/falcon/util/sync.py b/falcon/util/sync.py\n--- a/falcon/util/sync.py\n+++ b/falcon/util/sync.py\n@@ -210,9 +210,6 @@\n This method is very inefficient and is intended primarily for testing\n and prototyping.\n \n- Additional arguments not mentioned below are bound to the given\n- coroutine function via :any:`functools.partial`.\n-\n Args:\n coroutine: A coroutine function to invoke.\n *args: Additional args are passed through to the coroutine function.\n@@ -221,8 +218,16 @@\n **kwargs: Additional args are passed through to the coroutine function.\n \"\"\"\n \n- loop = asyncio.get_event_loop()\n- return loop.run_until_complete(partial(coroutine, *args, **kwargs)())\n+ # TODO(vytas): The canonical way of doing this for simple use cases is\n+ # asyncio.run(), but that would be a breaking change wrt the above\n+ # documented behaviour; breaking enough to break some of our own tests.\n+\n+ # NOTE(vytas): Work around get_event_loop deprecation in 3.10 by going via\n+ # get_event_loop_policy(). This should be equivalent for async_to_sync's\n+ # use case as it is currently impossible to invoke run_until_complete()\n+ # from a running loop anyway.\n+ loop = asyncio.get_event_loop_policy().get_event_loop()\n+ return loop.run_until_complete(coroutine(*args, **kwargs))\n \n \n def runs_sync(coroutine):\n", "issue": "CPython 3.10 support\nCPython 3.10 has been released.\r\n\r\nAlthough it may already work out of the box, we need to add official first class support anyway:\r\n- [x] Add a CPython 3.10 CI gate: (https://github.com/falconry/falcon/pull/1922).\r\n- [x] Build CPython 3.10 wheels.\r\n- [x] Advertise support using [\"trove classifiers\"](https://pypi.org/classifiers/).\r\n- [x] Check if anything needs an update in `CONTRIBUTING.md`.\r\n\r\nIn addition, check for any new warnings emitted when running tests, e.g., whether we are relying on any deprecated functionality that will be removed in future Python versions:\r\n- [x] Multiple `DeprecationWarning`: non-integer arguments to randrange() have been deprecated since Python 3.10 and will be removed in a subsequent version https://github.com/falconry/falcon/pull/1972\r\n- [x] `falcon/util/sync.py`:224: `DeprecationWarning`: There is no current event loop\r\n loop = asyncio.get_event_loop()\r\n [`asyncio.get_event_loop()`](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.get_event_loop): _Deprecated since version 3.10:_ Deprecation warning is emitted if there is no running event loop. In future Python releases, this function will be an alias of [`get_running_loop()`](https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.get_running_loop).\r\n- [x] `tests/asgi/test_ws.py`:344: `DeprecationWarning`: The explicit passing of coroutine objects to asyncio.wait() is deprecated since Python 3.8, and scheduled for removal in Python 3.11.\r\n- [x] Anything else?\n", "before_files": [{"content": "import asyncio\nfrom concurrent.futures import ThreadPoolExecutor\nfrom functools import partial\nfrom functools import wraps\nimport inspect\nimport os\nfrom typing import Callable\n\n\n__all__ = [\n 'async_to_sync',\n 'create_task',\n 'get_running_loop',\n 'runs_sync',\n 'sync_to_async',\n 'wrap_sync_to_async',\n 'wrap_sync_to_async_unsafe',\n]\n\n\n_one_thread_to_rule_them_all = ThreadPoolExecutor(max_workers=1)\n\n\ntry:\n get_running_loop = asyncio.get_running_loop\nexcept AttributeError: # pragma: nocover\n # NOTE(kgriffs): This branch is definitely covered under py35 and py36\n # but for some reason the codecov gate doesn't pick this up, hence\n # the pragma above.\n\n get_running_loop = asyncio.get_event_loop\n\n\ntry:\n create_task = asyncio.create_task\nexcept AttributeError: # pragma: nocover\n # NOTE(kgriffs): This branch is definitely covered under py35 and py36\n # but for some reason the codecov gate doesn't pick this up, hence\n # the pragma above.\n\n def create_task(coro, name=None):\n return asyncio.ensure_future(coro)\n\n\ndef wrap_sync_to_async_unsafe(func) -> Callable:\n \"\"\"Wrap a callable in a coroutine that executes the callable directly.\n\n This helper makes it easier to use synchronous callables with ASGI\n apps. However, it is considered \"unsafe\" because it calls the wrapped\n function directly in the same thread as the asyncio loop. Generally, you\n should use :func:`~.wrap_sync_to_async` instead.\n\n Warning:\n This helper is only to be used for functions that do not perform any\n blocking I/O or lengthy CPU-bound operations, since the entire async\n loop will be blocked while the wrapped function is executed.\n For a safer, non-blocking alternative that runs the function in a\n thread pool executor, use :func:`~.sync_to_async` instead.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n @wraps(func)\n async def wrapper(*args, **kwargs):\n return func(*args, **kwargs)\n\n return wrapper\n\n\ndef wrap_sync_to_async(func, threadsafe=None) -> Callable:\n \"\"\"Wrap a callable in a coroutine that executes the callable in the background.\n\n This helper makes it easier to call functions that can not be\n ported to use async natively (e.g., functions exported by a database\n library that does not yet support asyncio).\n\n To execute blocking operations safely, without stalling the async\n loop, the wrapped callable is scheduled to run in the background, on a\n separate thread, when the wrapper is called.\n\n Normally, the default executor for the running loop is used to schedule the\n synchronous callable. If the callable is not thread-safe, it can be\n scheduled serially in a global single-threaded executor.\n\n Warning:\n Wrapping a synchronous function safely adds a fair amount of overhead\n to the function call, and should only be used when a native async\n library is not available for the operation you wish to perform.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n\n Keyword Arguments:\n threadsafe (bool): Set to ``False`` when the callable is not\n thread-safe (default ``True``). When this argument is ``False``,\n the wrapped callable will be scheduled to run serially in a\n global single-threaded executor.\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n if threadsafe is None or threadsafe:\n executor = None # Use default\n else:\n executor = _one_thread_to_rule_them_all\n\n @wraps(func)\n async def wrapper(*args, **kwargs):\n return await get_running_loop().run_in_executor(\n executor, partial(func, *args, **kwargs)\n )\n\n return wrapper\n\n\nasync def sync_to_async(func, *args, **kwargs):\n \"\"\"Schedule a synchronous callable on the loop's default executor and await the result.\n\n This helper makes it easier to call functions that can not be\n ported to use async natively (e.g., functions exported by a database\n library that does not yet support asyncio).\n\n To execute blocking operations safely, without stalling the async\n loop, the wrapped callable is scheduled to run in the background, on a\n separate thread, when the wrapper is called.\n\n The default executor for the running loop is used to schedule the\n synchronous callable.\n\n Warning:\n This helper can only be used to execute thread-safe callables. If\n the callable is not thread-safe, it can be executed serially\n by first wrapping it with :func:`~.wrap_sync_to_async`, and then\n executing the wrapper directly.\n\n Warning:\n Calling a synchronous function safely from an asyncio event loop\n adds a fair amount of overhead to the function call, and should\n only be used when a native async library is not available for the\n operation you wish to perform.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n *args: All additional arguments are passed through to the callable.\n\n Keyword Arguments:\n **kwargs: All keyword arguments are passed through to the callable.\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n return await get_running_loop().run_in_executor(\n None, partial(func, *args, **kwargs)\n )\n\n\ndef _should_wrap_non_coroutines() -> bool:\n \"\"\"Return ``True`` IFF ``FALCON_ASGI_WRAP_NON_COROUTINES`` is set in the environ.\n\n This should only be used for Falcon's own test suite.\n \"\"\"\n return 'FALCON_ASGI_WRAP_NON_COROUTINES' in os.environ\n\n\ndef _wrap_non_coroutine_unsafe(func):\n \"\"\"Wrap a coroutine using ``wrap_sync_to_async_unsafe()`` for internal test cases.\n\n This method is intended for Falcon's own test suite and should not be\n used by apps themselves. It provides a convenient way to reuse sync\n methods for ASGI test cases when it is safe to do so.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n Returns:\n When not in test mode, this function simply returns the callable\n unchanged. Otherwise, if the callable is not a coroutine function,\n it will be wrapped using ``wrap_sync_to_async_unsafe()``.\n \"\"\"\n\n if func is None:\n return func\n\n if not _should_wrap_non_coroutines():\n return func\n\n if inspect.iscoroutinefunction(func):\n return func\n\n return wrap_sync_to_async_unsafe(func)\n\n\ndef async_to_sync(coroutine, *args, **kwargs):\n \"\"\"Invoke a coroutine function from a synchronous caller.\n\n This method can be used to invoke an asynchronous task from a synchronous\n context. The coroutine will be scheduled to run on the current event\n loop for the current OS thread. If an event loop is not already running,\n one will be created.\n\n Warning:\n This method is very inefficient and is intended primarily for testing\n and prototyping.\n\n Additional arguments not mentioned below are bound to the given\n coroutine function via :any:`functools.partial`.\n\n Args:\n coroutine: A coroutine function to invoke.\n *args: Additional args are passed through to the coroutine function.\n\n Keyword Args:\n **kwargs: Additional args are passed through to the coroutine function.\n \"\"\"\n\n loop = asyncio.get_event_loop()\n return loop.run_until_complete(partial(coroutine, *args, **kwargs)())\n\n\ndef runs_sync(coroutine):\n \"\"\"Transform a coroutine function into a synchronous method.\n\n This is achieved by always invoking the decorated coroutine function via\n :meth:`async_to_sync`.\n\n Warning:\n This decorator is very inefficient and should only be used for adapting\n asynchronous test functions for use with synchronous test runners such\n as ``pytest`` or the ``unittest`` module.\n\n It will create an event loop for the current thread if one is not\n already running.\n\n Args:\n coroutine: A coroutine function to masquerade as a synchronous one.\n\n Returns:\n callable: A synchronous function.\n \"\"\"\n\n @wraps(coroutine)\n def invoke(*args, **kwargs):\n return async_to_sync(coroutine, *args, **kwargs)\n\n return invoke\n", "path": "falcon/util/sync.py"}], "after_files": [{"content": "import asyncio\nfrom concurrent.futures import ThreadPoolExecutor\nfrom functools import partial\nfrom functools import wraps\nimport inspect\nimport os\nfrom typing import Callable\n\n\n__all__ = [\n 'async_to_sync',\n 'create_task',\n 'get_running_loop',\n 'runs_sync',\n 'sync_to_async',\n 'wrap_sync_to_async',\n 'wrap_sync_to_async_unsafe',\n]\n\n\n_one_thread_to_rule_them_all = ThreadPoolExecutor(max_workers=1)\n\n\ntry:\n get_running_loop = asyncio.get_running_loop\nexcept AttributeError: # pragma: nocover\n # NOTE(kgriffs): This branch is definitely covered under py35 and py36\n # but for some reason the codecov gate doesn't pick this up, hence\n # the pragma above.\n\n get_running_loop = asyncio.get_event_loop\n\n\ntry:\n create_task = asyncio.create_task\nexcept AttributeError: # pragma: nocover\n # NOTE(kgriffs): This branch is definitely covered under py35 and py36\n # but for some reason the codecov gate doesn't pick this up, hence\n # the pragma above.\n\n def create_task(coro, name=None):\n return asyncio.ensure_future(coro)\n\n\ndef wrap_sync_to_async_unsafe(func) -> Callable:\n \"\"\"Wrap a callable in a coroutine that executes the callable directly.\n\n This helper makes it easier to use synchronous callables with ASGI\n apps. However, it is considered \"unsafe\" because it calls the wrapped\n function directly in the same thread as the asyncio loop. Generally, you\n should use :func:`~.wrap_sync_to_async` instead.\n\n Warning:\n This helper is only to be used for functions that do not perform any\n blocking I/O or lengthy CPU-bound operations, since the entire async\n loop will be blocked while the wrapped function is executed.\n For a safer, non-blocking alternative that runs the function in a\n thread pool executor, use :func:`~.sync_to_async` instead.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n @wraps(func)\n async def wrapper(*args, **kwargs):\n return func(*args, **kwargs)\n\n return wrapper\n\n\ndef wrap_sync_to_async(func, threadsafe=None) -> Callable:\n \"\"\"Wrap a callable in a coroutine that executes the callable in the background.\n\n This helper makes it easier to call functions that can not be\n ported to use async natively (e.g., functions exported by a database\n library that does not yet support asyncio).\n\n To execute blocking operations safely, without stalling the async\n loop, the wrapped callable is scheduled to run in the background, on a\n separate thread, when the wrapper is called.\n\n Normally, the default executor for the running loop is used to schedule the\n synchronous callable. If the callable is not thread-safe, it can be\n scheduled serially in a global single-threaded executor.\n\n Warning:\n Wrapping a synchronous function safely adds a fair amount of overhead\n to the function call, and should only be used when a native async\n library is not available for the operation you wish to perform.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n\n Keyword Arguments:\n threadsafe (bool): Set to ``False`` when the callable is not\n thread-safe (default ``True``). When this argument is ``False``,\n the wrapped callable will be scheduled to run serially in a\n global single-threaded executor.\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n if threadsafe is None or threadsafe:\n executor = None # Use default\n else:\n executor = _one_thread_to_rule_them_all\n\n @wraps(func)\n async def wrapper(*args, **kwargs):\n return await get_running_loop().run_in_executor(\n executor, partial(func, *args, **kwargs)\n )\n\n return wrapper\n\n\nasync def sync_to_async(func, *args, **kwargs):\n \"\"\"Schedule a synchronous callable on the loop's default executor and await the result.\n\n This helper makes it easier to call functions that can not be\n ported to use async natively (e.g., functions exported by a database\n library that does not yet support asyncio).\n\n To execute blocking operations safely, without stalling the async\n loop, the wrapped callable is scheduled to run in the background, on a\n separate thread, when the wrapper is called.\n\n The default executor for the running loop is used to schedule the\n synchronous callable.\n\n Warning:\n This helper can only be used to execute thread-safe callables. If\n the callable is not thread-safe, it can be executed serially\n by first wrapping it with :func:`~.wrap_sync_to_async`, and then\n executing the wrapper directly.\n\n Warning:\n Calling a synchronous function safely from an asyncio event loop\n adds a fair amount of overhead to the function call, and should\n only be used when a native async library is not available for the\n operation you wish to perform.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n *args: All additional arguments are passed through to the callable.\n\n Keyword Arguments:\n **kwargs: All keyword arguments are passed through to the callable.\n\n Returns:\n function: An awaitable coroutine function that wraps the\n synchronous callable.\n \"\"\"\n\n return await get_running_loop().run_in_executor(\n None, partial(func, *args, **kwargs)\n )\n\n\ndef _should_wrap_non_coroutines() -> bool:\n \"\"\"Return ``True`` IFF ``FALCON_ASGI_WRAP_NON_COROUTINES`` is set in the environ.\n\n This should only be used for Falcon's own test suite.\n \"\"\"\n return 'FALCON_ASGI_WRAP_NON_COROUTINES' in os.environ\n\n\ndef _wrap_non_coroutine_unsafe(func):\n \"\"\"Wrap a coroutine using ``wrap_sync_to_async_unsafe()`` for internal test cases.\n\n This method is intended for Falcon's own test suite and should not be\n used by apps themselves. It provides a convenient way to reuse sync\n methods for ASGI test cases when it is safe to do so.\n\n Arguments:\n func (callable): Function, method, or other callable to wrap\n Returns:\n When not in test mode, this function simply returns the callable\n unchanged. Otherwise, if the callable is not a coroutine function,\n it will be wrapped using ``wrap_sync_to_async_unsafe()``.\n \"\"\"\n\n if func is None:\n return func\n\n if not _should_wrap_non_coroutines():\n return func\n\n if inspect.iscoroutinefunction(func):\n return func\n\n return wrap_sync_to_async_unsafe(func)\n\n\ndef async_to_sync(coroutine, *args, **kwargs):\n \"\"\"Invoke a coroutine function from a synchronous caller.\n\n This method can be used to invoke an asynchronous task from a synchronous\n context. The coroutine will be scheduled to run on the current event\n loop for the current OS thread. If an event loop is not already running,\n one will be created.\n\n Warning:\n This method is very inefficient and is intended primarily for testing\n and prototyping.\n\n Args:\n coroutine: A coroutine function to invoke.\n *args: Additional args are passed through to the coroutine function.\n\n Keyword Args:\n **kwargs: Additional args are passed through to the coroutine function.\n \"\"\"\n\n # TODO(vytas): The canonical way of doing this for simple use cases is\n # asyncio.run(), but that would be a breaking change wrt the above\n # documented behaviour; breaking enough to break some of our own tests.\n\n # NOTE(vytas): Work around get_event_loop deprecation in 3.10 by going via\n # get_event_loop_policy(). This should be equivalent for async_to_sync's\n # use case as it is currently impossible to invoke run_until_complete()\n # from a running loop anyway.\n loop = asyncio.get_event_loop_policy().get_event_loop()\n return loop.run_until_complete(coroutine(*args, **kwargs))\n\n\ndef runs_sync(coroutine):\n \"\"\"Transform a coroutine function into a synchronous method.\n\n This is achieved by always invoking the decorated coroutine function via\n :meth:`async_to_sync`.\n\n Warning:\n This decorator is very inefficient and should only be used for adapting\n asynchronous test functions for use with synchronous test runners such\n as ``pytest`` or the ``unittest`` module.\n\n It will create an event loop for the current thread if one is not\n already running.\n\n Args:\n coroutine: A coroutine function to masquerade as a synchronous one.\n\n Returns:\n callable: A synchronous function.\n \"\"\"\n\n @wraps(coroutine)\n def invoke(*args, **kwargs):\n return async_to_sync(coroutine, *args, **kwargs)\n\n return invoke\n", "path": "falcon/util/sync.py"}]}
| 3,215 | 346 |
gh_patches_debug_43977
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3186
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/zero/init_ctx/init_context.py`
Content:
```
1 import contextlib
2 import functools
3 from typing import Optional
4 from contextlib import AbstractContextManager
5
6 import torch
7 import torch.nn as nn
8 import torch.distributed as dist
9
10 from colossalai.context.parallel_mode import ParallelMode
11 from colossalai.core import global_context as gpc
12 from colossalai.context.singleton_meta import SingletonMeta
13 from colossalai.logging import get_dist_logger
14 from colossalai.zero.shard_utils import BaseShardStrategy
15 from colossalai.zero.sharded_model._utils import cast_tensor_to_fp16
16 from colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2
17 from colossalai.zero.sharded_param import ShardedParamV2
18 from colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses
19
20
21 class ZeroContextConfig(object):
22 """The configuration used to control zero context initialization.
23
24 Args:
25 target_device (torch.device): The device where param data are after exiting the context.
26 replicated (bool, optional): Whether the param is replicated across data parallel group.
27 Some parameters are not replicated, e.g. parameters in MOE experts.
28 shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.
29 """
30
31 def __init__(self, target_device: torch.device, replicated: bool = True, shard_param: bool = False):
32 super().__init__()
33
34 if shard_param:
35 assert replicated, "Non-replicated parameters can't be sharded."
36
37 # replicated no-shard parameters should locate in cuda, since we will broadcast them soon
38 if replicated and not shard_param:
39 assert target_device.type == 'cuda', "Replicated no-shard paramters should locate in cuda."
40
41 self.target_device = target_device
42 self.is_replicated: bool = replicated
43 self.shard_param: bool = shard_param
44
45
46 class ZeroInitContext(InsertPostInitMethodToModuleSubClasses):
47 """A context to initialize model.
48
49 1. Convert the model to fp16.
50 2. The paramaters of the module are adapted to type ShardedParameter.
51 3. Shard the param and grad according to flags.
52
53 Args:
54 target_device (torch.device): The device where param data are after exiting the context.
55 shard_strategy (BaseShardStrategy): Shard strategy instance.
56 seed (int, optional): Random seed for weight initialization
57 shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.
58 default_dtype (torch.dtype, optional): If it's not None, parameters will be initialized as ``default_dtype`` then converted to fp16.
59 model_numel_tensor (torch.Tensor, optional): A tensor which will store the number of elements of model. Defaults to torch.zeros(1, dtype=torch.int).
60 """
61
62 def __init__(self,
63 target_device: torch.device,
64 shard_strategy: BaseShardStrategy,
65 seed: int = 2**10 - 1,
66 shard_param: bool = False,
67 default_dtype: Optional[torch.dtype] = None,
68 model_numel_tensor: torch.Tensor = torch.zeros(1, dtype=torch.long)):
69
70 super().__init__(default_dtype=default_dtype)
71 self.shard_strategy = shard_strategy
72 self.param_list = []
73 self.model_numel_tensor = model_numel_tensor
74 self.seed = seed
75 self.dp_process_group = gpc.get_group(ParallelMode.DATA)
76
77 self.config = ZeroContextConfig(target_device=target_device, replicated=True, shard_param=shard_param)
78
79 ZeroContextMgr().current_context = self
80
81 self.param_numel = {}
82 self.top_module = None
83
84 @property
85 def target_device(self):
86 return self.config.target_device
87
88 @property
89 def is_replicated(self):
90 return self.config.is_replicated
91
92 @property
93 def shard_param(self):
94 return self.config.shard_param
95
96 @staticmethod
97 def calc_fanin_fanout(tensor: torch.Tensor):
98 """We use this function to substitute fan-in and fan-out calculation in torch.nn.init.
99 This can help us get correct fan-in and fan-out for sharded tensor.
100 """
101 assert isinstance(tensor, nn.Parameter), "Sharded tensor initilization is only allowed for paramters"
102
103 # get correct shape of input tensor
104 if not hasattr(tensor, 'colo_attr') or not tensor.colo_attr.param_is_sharded:
105 tensor_shape = tensor.shape
106 else:
107 tensor_shape = tensor.colo_attr.sharded_data_tensor.origin_shape
108
109 dimensions = len(tensor_shape)
110 if dimensions < 2:
111 raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")
112
113 num_input_fmaps = tensor_shape[1]
114 num_output_fmaps = tensor_shape[0]
115 receptive_field_size = 1
116 if dimensions > 2:
117 # math.prod is not always available, accumulate the product manually
118 # we could use functools.reduce but that is not supported by TorchScript
119 for s in tensor_shape[2:]:
120 receptive_field_size *= s
121 fan_in = num_input_fmaps * receptive_field_size
122 fan_out = num_output_fmaps * receptive_field_size
123
124 return fan_in, fan_out
125
126 def _pre_context_exec(self):
127 """
128 The Callback function when entering the context
129 """
130 self.logger = get_dist_logger("ZeroInitContext")
131
132 # substitute fan-in and fan-out calculation
133 self.nn_fanin_fanout = nn.init._calculate_fan_in_and_fan_out
134 nn.init._calculate_fan_in_and_fan_out = self.calc_fanin_fanout
135
136 self.module_load_from_state_dict = nn.Module._load_from_state_dict
137 shard_strategy = self.shard_strategy if self.config.shard_param else None
138 nn.Module._load_from_state_dict = functools.partialmethod(ShardedModelV2._colo_load_from_state_dict,
139 shard_strategy=shard_strategy)
140 self.module_state_dict = nn.Module.state_dict
141 nn.Module.state_dict = functools.partialmethod(ShardedModelV2._colo_state_dict,
142 shard_strategy=shard_strategy,
143 state_dict_func=self.module_state_dict,
144 process_group=self.dp_process_group)
145
146 # reserve rng states
147 self.cpu_rng_state = torch.get_rng_state()
148 self.cuda_rng_state = torch.cuda.get_rng_state()
149
150 # set new seed for initialization, since we initialize sharded tensor separately
151 # we don't want all processes have the same seed
152 # otherwise all sharded tensors are same after init
153 offset = self.seed + 1 # we want to have more 1 in binary format seed
154 torch.manual_seed(self.seed + offset * dist.get_rank())
155
156 def _post_context_exec(self):
157 """The callback function when exiting context.
158 """
159 # broadcast replicated no-shard parameters
160 src_rank = gpc.get_ranks_in_group(ParallelMode.DATA)[0]
161 for param in self.param_list:
162 assert hasattr(param, 'colo_attr')
163 if not param.colo_attr.param_is_sharded and param.colo_attr.is_replicated:
164 dist.broadcast(tensor=param.data, src=src_rank, group=self.dp_process_group)
165 param.colo_attr.set_data_none()
166
167 del self.param_list
168
169 nn.init._calculate_fan_in_and_fan_out = self.nn_fanin_fanout
170 nn.Module.load_state_dict = self.module_load_from_state_dict
171 nn.Module.state_dict = self.module_state_dict
172 torch.set_rng_state(self.cpu_rng_state)
173 torch.cuda.set_rng_state(self.cuda_rng_state)
174
175 params = frozenset(self.top_module.parameters())
176 for param in self.param_numel.keys():
177 if param not in params:
178 self.param_numel[param] = 0
179 self.model_numel_tensor.fill_(sum(self.param_numel.values()))
180
181 def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):
182 """
183 The function to call at the end of the constructor of each module.
184 NOTE() The module may be passed to this function multiple times.
185 """
186 self.top_module = module
187
188 def half_fn(t: torch.Tensor):
189 return t.half() if t.is_floating_point() else t
190
191 for param in module.parameters(recurse=False):
192 # avoid adapting a param to ShardedParam twice
193 if hasattr(param, 'colo_attr'):
194 continue
195
196 self.param_numel[param] = param.numel()
197
198 # convert parameters to half
199 param_half = half_fn(param)
200 param.data = param_half
201 if param.grad is not None:
202 grad_half = half_fn(param.grad)
203 param.grad.data = grad_half
204
205 # move torch parameters to the target device
206 target_device = self.target_device
207 param.data = param.data.to(target_device)
208 if param.grad is not None:
209 param.grad = param.grad.to(target_device)
210
211 param.colo_attr = ShardedParamV2(param, set_data_none=True)
212
213 if self.shard_param:
214 self.shard_strategy.shard([param.colo_attr.sharded_data_tensor], self.dp_process_group)
215
216 param.data = param.colo_attr.data_payload # set param.data to payload
217
218 # mark whether the param is replicated
219 param.colo_attr.is_replicated = self.is_replicated
220
221 # mark whether the param should keep not sharded
222 # if True, the param is used as Zero stage 2
223 param.colo_attr.keep_not_shard = not self.shard_param
224
225 self.param_list.append(param)
226
227 # We must cast buffers
228 # If we use BN, buffers may be on CPU and Float
229 # We must cast them
230 for buffer in module.buffers(recurse=False):
231 buffer.data = buffer.data.to(device=torch.cuda.current_device())
232 buffer.data = cast_tensor_to_fp16(buffer.data)
233
234
235 class ZeroContextMgr(metaclass=SingletonMeta):
236 current_context: Optional[ZeroInitContext] = None
237
238 @contextlib.contextmanager
239 def hijack_context_config(self, **kwargs):
240 if self.current_context is None:
241 yield
242 else:
243 old_config = self.current_context.config
244 self.current_context.config = ZeroContextConfig(**kwargs)
245 yield
246 self.current_context.config = old_config
247
248
249 def no_shard_zero_context(is_replicated: bool = True) -> AbstractContextManager:
250 return ZeroContextMgr().hijack_context_config(target_device=torch.device('cuda', torch.cuda.current_device()),
251 replicated=is_replicated,
252 shard_param=False)
253
254
255 def no_shard_zero_decrator(is_replicated: bool = True):
256
257 def _wrapper(init_func):
258
259 def _no_shard(*args, **kwargs):
260 with no_shard_zero_context(is_replicated):
261 ret = init_func(*args, **kwargs)
262 return ret
263
264 return _no_shard
265
266 return _wrapper
267
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/zero/init_ctx/init_context.py b/colossalai/zero/init_ctx/init_context.py
--- a/colossalai/zero/init_ctx/init_context.py
+++ b/colossalai/zero/init_ctx/init_context.py
@@ -1,46 +1,45 @@
import contextlib
import functools
-from typing import Optional
from contextlib import AbstractContextManager
+from dataclasses import dataclass
+from typing import Optional
import torch
-import torch.nn as nn
import torch.distributed as dist
+import torch.nn as nn
from colossalai.context.parallel_mode import ParallelMode
-from colossalai.core import global_context as gpc
from colossalai.context.singleton_meta import SingletonMeta
+from colossalai.core import global_context as gpc
from colossalai.logging import get_dist_logger
+from colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses
from colossalai.zero.shard_utils import BaseShardStrategy
from colossalai.zero.sharded_model._utils import cast_tensor_to_fp16
from colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2
from colossalai.zero.sharded_param import ShardedParamV2
-from colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses
-class ZeroContextConfig(object):
+@dataclass
+class ZeroContextConfig:
"""The configuration used to control zero context initialization.
Args:
target_device (torch.device): The device where param data are after exiting the context.
- replicated (bool, optional): Whether the param is replicated across data parallel group.
+ is_replicated (bool, optional): Whether the param is replicated across data parallel group.
Some parameters are not replicated, e.g. parameters in MOE experts.
shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.
"""
- def __init__(self, target_device: torch.device, replicated: bool = True, shard_param: bool = False):
- super().__init__()
+ target_device: torch.device
+ is_replicated: bool = True
+ shard_param: bool = False
- if shard_param:
- assert replicated, "Non-replicated parameters can't be sharded."
+ def __post_init__(self):
+ if self.shard_param:
+ assert self.is_replicated, "Non-replicated parameters can't be sharded."
- # replicated no-shard parameters should locate in cuda, since we will broadcast them soon
- if replicated and not shard_param:
- assert target_device.type == 'cuda', "Replicated no-shard paramters should locate in cuda."
-
- self.target_device = target_device
- self.is_replicated: bool = replicated
- self.shard_param: bool = shard_param
+ if self.is_replicated and not self.shard_param:
+ assert self.target_device.type == 'cuda', "Replicated no-shard parameters should be located in cuda."
class ZeroInitContext(InsertPostInitMethodToModuleSubClasses):
@@ -74,7 +73,7 @@
self.seed = seed
self.dp_process_group = gpc.get_group(ParallelMode.DATA)
- self.config = ZeroContextConfig(target_device=target_device, replicated=True, shard_param=shard_param)
+ self.config = ZeroContextConfig(target_device=target_device, is_replicated=True, shard_param=shard_param)
ZeroContextMgr().current_context = self
@@ -124,7 +123,7 @@
return fan_in, fan_out
def _pre_context_exec(self):
- """
+ """
The Callback function when entering the context
"""
self.logger = get_dist_logger("ZeroInitContext")
@@ -248,7 +247,7 @@
def no_shard_zero_context(is_replicated: bool = True) -> AbstractContextManager:
return ZeroContextMgr().hijack_context_config(target_device=torch.device('cuda', torch.cuda.current_device()),
- replicated=is_replicated,
+ is_replicated=is_replicated,
shard_param=False)
|
{"golden_diff": "diff --git a/colossalai/zero/init_ctx/init_context.py b/colossalai/zero/init_ctx/init_context.py\n--- a/colossalai/zero/init_ctx/init_context.py\n+++ b/colossalai/zero/init_ctx/init_context.py\n@@ -1,46 +1,45 @@\n import contextlib\n import functools\n-from typing import Optional\n from contextlib import AbstractContextManager\n+from dataclasses import dataclass\n+from typing import Optional\n \n import torch\n-import torch.nn as nn\n import torch.distributed as dist\n+import torch.nn as nn\n \n from colossalai.context.parallel_mode import ParallelMode\n-from colossalai.core import global_context as gpc\n from colossalai.context.singleton_meta import SingletonMeta\n+from colossalai.core import global_context as gpc\n from colossalai.logging import get_dist_logger\n+from colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses\n from colossalai.zero.shard_utils import BaseShardStrategy\n from colossalai.zero.sharded_model._utils import cast_tensor_to_fp16\n from colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2\n from colossalai.zero.sharded_param import ShardedParamV2\n-from colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses\n \n \n-class ZeroContextConfig(object):\n+@dataclass\n+class ZeroContextConfig:\n \"\"\"The configuration used to control zero context initialization.\n \n Args:\n target_device (torch.device): The device where param data are after exiting the context.\n- replicated (bool, optional): Whether the param is replicated across data parallel group.\n+ is_replicated (bool, optional): Whether the param is replicated across data parallel group.\n Some parameters are not replicated, e.g. parameters in MOE experts.\n shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.\n \"\"\"\n \n- def __init__(self, target_device: torch.device, replicated: bool = True, shard_param: bool = False):\n- super().__init__()\n+ target_device: torch.device\n+ is_replicated: bool = True\n+ shard_param: bool = False\n \n- if shard_param:\n- assert replicated, \"Non-replicated parameters can't be sharded.\"\n+ def __post_init__(self):\n+ if self.shard_param:\n+ assert self.is_replicated, \"Non-replicated parameters can't be sharded.\"\n \n- # replicated no-shard parameters should locate in cuda, since we will broadcast them soon\n- if replicated and not shard_param:\n- assert target_device.type == 'cuda', \"Replicated no-shard paramters should locate in cuda.\"\n-\n- self.target_device = target_device\n- self.is_replicated: bool = replicated\n- self.shard_param: bool = shard_param\n+ if self.is_replicated and not self.shard_param:\n+ assert self.target_device.type == 'cuda', \"Replicated no-shard parameters should be located in cuda.\"\n \n \n class ZeroInitContext(InsertPostInitMethodToModuleSubClasses):\n@@ -74,7 +73,7 @@\n self.seed = seed\n self.dp_process_group = gpc.get_group(ParallelMode.DATA)\n \n- self.config = ZeroContextConfig(target_device=target_device, replicated=True, shard_param=shard_param)\n+ self.config = ZeroContextConfig(target_device=target_device, is_replicated=True, shard_param=shard_param)\n \n ZeroContextMgr().current_context = self\n \n@@ -124,7 +123,7 @@\n return fan_in, fan_out\n \n def _pre_context_exec(self):\n- \"\"\" \n+ \"\"\"\n The Callback function when entering the context\n \"\"\"\n self.logger = get_dist_logger(\"ZeroInitContext\")\n@@ -248,7 +247,7 @@\n \n def no_shard_zero_context(is_replicated: bool = True) -> AbstractContextManager:\n return ZeroContextMgr().hijack_context_config(target_device=torch.device('cuda', torch.cuda.current_device()),\n- replicated=is_replicated,\n+ is_replicated=is_replicated,\n shard_param=False)\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import contextlib\nimport functools\nfrom typing import Optional\nfrom contextlib import AbstractContextManager\n\nimport torch\nimport torch.nn as nn\nimport torch.distributed as dist\n\nfrom colossalai.context.parallel_mode import ParallelMode\nfrom colossalai.core import global_context as gpc\nfrom colossalai.context.singleton_meta import SingletonMeta\nfrom colossalai.logging import get_dist_logger\nfrom colossalai.zero.shard_utils import BaseShardStrategy\nfrom colossalai.zero.sharded_model._utils import cast_tensor_to_fp16\nfrom colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2\nfrom colossalai.zero.sharded_param import ShardedParamV2\nfrom colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses\n\n\nclass ZeroContextConfig(object):\n \"\"\"The configuration used to control zero context initialization.\n\n Args:\n target_device (torch.device): The device where param data are after exiting the context.\n replicated (bool, optional): Whether the param is replicated across data parallel group.\n Some parameters are not replicated, e.g. parameters in MOE experts.\n shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.\n \"\"\"\n\n def __init__(self, target_device: torch.device, replicated: bool = True, shard_param: bool = False):\n super().__init__()\n\n if shard_param:\n assert replicated, \"Non-replicated parameters can't be sharded.\"\n\n # replicated no-shard parameters should locate in cuda, since we will broadcast them soon\n if replicated and not shard_param:\n assert target_device.type == 'cuda', \"Replicated no-shard paramters should locate in cuda.\"\n\n self.target_device = target_device\n self.is_replicated: bool = replicated\n self.shard_param: bool = shard_param\n\n\nclass ZeroInitContext(InsertPostInitMethodToModuleSubClasses):\n \"\"\"A context to initialize model.\n\n 1. Convert the model to fp16.\n 2. The paramaters of the module are adapted to type ShardedParameter.\n 3. Shard the param and grad according to flags.\n\n Args:\n target_device (torch.device): The device where param data are after exiting the context.\n shard_strategy (BaseShardStrategy): Shard strategy instance.\n seed (int, optional): Random seed for weight initialization\n shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.\n default_dtype (torch.dtype, optional): If it's not None, parameters will be initialized as ``default_dtype`` then converted to fp16.\n model_numel_tensor (torch.Tensor, optional): A tensor which will store the number of elements of model. Defaults to torch.zeros(1, dtype=torch.int).\n \"\"\"\n\n def __init__(self,\n target_device: torch.device,\n shard_strategy: BaseShardStrategy,\n seed: int = 2**10 - 1,\n shard_param: bool = False,\n default_dtype: Optional[torch.dtype] = None,\n model_numel_tensor: torch.Tensor = torch.zeros(1, dtype=torch.long)):\n\n super().__init__(default_dtype=default_dtype)\n self.shard_strategy = shard_strategy\n self.param_list = []\n self.model_numel_tensor = model_numel_tensor\n self.seed = seed\n self.dp_process_group = gpc.get_group(ParallelMode.DATA)\n\n self.config = ZeroContextConfig(target_device=target_device, replicated=True, shard_param=shard_param)\n\n ZeroContextMgr().current_context = self\n\n self.param_numel = {}\n self.top_module = None\n\n @property\n def target_device(self):\n return self.config.target_device\n\n @property\n def is_replicated(self):\n return self.config.is_replicated\n\n @property\n def shard_param(self):\n return self.config.shard_param\n\n @staticmethod\n def calc_fanin_fanout(tensor: torch.Tensor):\n \"\"\"We use this function to substitute fan-in and fan-out calculation in torch.nn.init.\n This can help us get correct fan-in and fan-out for sharded tensor.\n \"\"\"\n assert isinstance(tensor, nn.Parameter), \"Sharded tensor initilization is only allowed for paramters\"\n\n # get correct shape of input tensor\n if not hasattr(tensor, 'colo_attr') or not tensor.colo_attr.param_is_sharded:\n tensor_shape = tensor.shape\n else:\n tensor_shape = tensor.colo_attr.sharded_data_tensor.origin_shape\n\n dimensions = len(tensor_shape)\n if dimensions < 2:\n raise ValueError(\"Fan in and fan out can not be computed for tensor with fewer than 2 dimensions\")\n\n num_input_fmaps = tensor_shape[1]\n num_output_fmaps = tensor_shape[0]\n receptive_field_size = 1\n if dimensions > 2:\n # math.prod is not always available, accumulate the product manually\n # we could use functools.reduce but that is not supported by TorchScript\n for s in tensor_shape[2:]:\n receptive_field_size *= s\n fan_in = num_input_fmaps * receptive_field_size\n fan_out = num_output_fmaps * receptive_field_size\n\n return fan_in, fan_out\n\n def _pre_context_exec(self):\n \"\"\" \n The Callback function when entering the context\n \"\"\"\n self.logger = get_dist_logger(\"ZeroInitContext\")\n\n # substitute fan-in and fan-out calculation\n self.nn_fanin_fanout = nn.init._calculate_fan_in_and_fan_out\n nn.init._calculate_fan_in_and_fan_out = self.calc_fanin_fanout\n\n self.module_load_from_state_dict = nn.Module._load_from_state_dict\n shard_strategy = self.shard_strategy if self.config.shard_param else None\n nn.Module._load_from_state_dict = functools.partialmethod(ShardedModelV2._colo_load_from_state_dict,\n shard_strategy=shard_strategy)\n self.module_state_dict = nn.Module.state_dict\n nn.Module.state_dict = functools.partialmethod(ShardedModelV2._colo_state_dict,\n shard_strategy=shard_strategy,\n state_dict_func=self.module_state_dict,\n process_group=self.dp_process_group)\n\n # reserve rng states\n self.cpu_rng_state = torch.get_rng_state()\n self.cuda_rng_state = torch.cuda.get_rng_state()\n\n # set new seed for initialization, since we initialize sharded tensor separately\n # we don't want all processes have the same seed\n # otherwise all sharded tensors are same after init\n offset = self.seed + 1 # we want to have more 1 in binary format seed\n torch.manual_seed(self.seed + offset * dist.get_rank())\n\n def _post_context_exec(self):\n \"\"\"The callback function when exiting context.\n \"\"\"\n # broadcast replicated no-shard parameters\n src_rank = gpc.get_ranks_in_group(ParallelMode.DATA)[0]\n for param in self.param_list:\n assert hasattr(param, 'colo_attr')\n if not param.colo_attr.param_is_sharded and param.colo_attr.is_replicated:\n dist.broadcast(tensor=param.data, src=src_rank, group=self.dp_process_group)\n param.colo_attr.set_data_none()\n\n del self.param_list\n\n nn.init._calculate_fan_in_and_fan_out = self.nn_fanin_fanout\n nn.Module.load_state_dict = self.module_load_from_state_dict\n nn.Module.state_dict = self.module_state_dict\n torch.set_rng_state(self.cpu_rng_state)\n torch.cuda.set_rng_state(self.cuda_rng_state)\n\n params = frozenset(self.top_module.parameters())\n for param in self.param_numel.keys():\n if param not in params:\n self.param_numel[param] = 0\n self.model_numel_tensor.fill_(sum(self.param_numel.values()))\n\n def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):\n \"\"\"\n The function to call at the end of the constructor of each module.\n NOTE() The module may be passed to this function multiple times.\n \"\"\"\n self.top_module = module\n\n def half_fn(t: torch.Tensor):\n return t.half() if t.is_floating_point() else t\n\n for param in module.parameters(recurse=False):\n # avoid adapting a param to ShardedParam twice\n if hasattr(param, 'colo_attr'):\n continue\n\n self.param_numel[param] = param.numel()\n\n # convert parameters to half\n param_half = half_fn(param)\n param.data = param_half\n if param.grad is not None:\n grad_half = half_fn(param.grad)\n param.grad.data = grad_half\n\n # move torch parameters to the target device\n target_device = self.target_device\n param.data = param.data.to(target_device)\n if param.grad is not None:\n param.grad = param.grad.to(target_device)\n\n param.colo_attr = ShardedParamV2(param, set_data_none=True)\n\n if self.shard_param:\n self.shard_strategy.shard([param.colo_attr.sharded_data_tensor], self.dp_process_group)\n\n param.data = param.colo_attr.data_payload # set param.data to payload\n\n # mark whether the param is replicated\n param.colo_attr.is_replicated = self.is_replicated\n\n # mark whether the param should keep not sharded\n # if True, the param is used as Zero stage 2\n param.colo_attr.keep_not_shard = not self.shard_param\n\n self.param_list.append(param)\n\n # We must cast buffers\n # If we use BN, buffers may be on CPU and Float\n # We must cast them\n for buffer in module.buffers(recurse=False):\n buffer.data = buffer.data.to(device=torch.cuda.current_device())\n buffer.data = cast_tensor_to_fp16(buffer.data)\n\n\nclass ZeroContextMgr(metaclass=SingletonMeta):\n current_context: Optional[ZeroInitContext] = None\n\n @contextlib.contextmanager\n def hijack_context_config(self, **kwargs):\n if self.current_context is None:\n yield\n else:\n old_config = self.current_context.config\n self.current_context.config = ZeroContextConfig(**kwargs)\n yield\n self.current_context.config = old_config\n\n\ndef no_shard_zero_context(is_replicated: bool = True) -> AbstractContextManager:\n return ZeroContextMgr().hijack_context_config(target_device=torch.device('cuda', torch.cuda.current_device()),\n replicated=is_replicated,\n shard_param=False)\n\n\ndef no_shard_zero_decrator(is_replicated: bool = True):\n\n def _wrapper(init_func):\n\n def _no_shard(*args, **kwargs):\n with no_shard_zero_context(is_replicated):\n ret = init_func(*args, **kwargs)\n return ret\n\n return _no_shard\n\n return _wrapper\n", "path": "colossalai/zero/init_ctx/init_context.py"}], "after_files": [{"content": "import contextlib\nimport functools\nfrom contextlib import AbstractContextManager\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport torch\nimport torch.distributed as dist\nimport torch.nn as nn\n\nfrom colossalai.context.parallel_mode import ParallelMode\nfrom colossalai.context.singleton_meta import SingletonMeta\nfrom colossalai.core import global_context as gpc\nfrom colossalai.logging import get_dist_logger\nfrom colossalai.utils.model.utils import InsertPostInitMethodToModuleSubClasses\nfrom colossalai.zero.shard_utils import BaseShardStrategy\nfrom colossalai.zero.sharded_model._utils import cast_tensor_to_fp16\nfrom colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2\nfrom colossalai.zero.sharded_param import ShardedParamV2\n\n\n@dataclass\nclass ZeroContextConfig:\n \"\"\"The configuration used to control zero context initialization.\n\n Args:\n target_device (torch.device): The device where param data are after exiting the context.\n is_replicated (bool, optional): Whether the param is replicated across data parallel group.\n Some parameters are not replicated, e.g. parameters in MOE experts.\n shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.\n \"\"\"\n\n target_device: torch.device\n is_replicated: bool = True\n shard_param: bool = False\n\n def __post_init__(self):\n if self.shard_param:\n assert self.is_replicated, \"Non-replicated parameters can't be sharded.\"\n\n if self.is_replicated and not self.shard_param:\n assert self.target_device.type == 'cuda', \"Replicated no-shard parameters should be located in cuda.\"\n\n\nclass ZeroInitContext(InsertPostInitMethodToModuleSubClasses):\n \"\"\"A context to initialize model.\n\n 1. Convert the model to fp16.\n 2. The paramaters of the module are adapted to type ShardedParameter.\n 3. Shard the param and grad according to flags.\n\n Args:\n target_device (torch.device): The device where param data are after exiting the context.\n shard_strategy (BaseShardStrategy): Shard strategy instance.\n seed (int, optional): Random seed for weight initialization\n shard_param (bool, optional): Is param sharded after exiting the context. Defaults to False.\n default_dtype (torch.dtype, optional): If it's not None, parameters will be initialized as ``default_dtype`` then converted to fp16.\n model_numel_tensor (torch.Tensor, optional): A tensor which will store the number of elements of model. Defaults to torch.zeros(1, dtype=torch.int).\n \"\"\"\n\n def __init__(self,\n target_device: torch.device,\n shard_strategy: BaseShardStrategy,\n seed: int = 2**10 - 1,\n shard_param: bool = False,\n default_dtype: Optional[torch.dtype] = None,\n model_numel_tensor: torch.Tensor = torch.zeros(1, dtype=torch.long)):\n\n super().__init__(default_dtype=default_dtype)\n self.shard_strategy = shard_strategy\n self.param_list = []\n self.model_numel_tensor = model_numel_tensor\n self.seed = seed\n self.dp_process_group = gpc.get_group(ParallelMode.DATA)\n\n self.config = ZeroContextConfig(target_device=target_device, is_replicated=True, shard_param=shard_param)\n\n ZeroContextMgr().current_context = self\n\n self.param_numel = {}\n self.top_module = None\n\n @property\n def target_device(self):\n return self.config.target_device\n\n @property\n def is_replicated(self):\n return self.config.is_replicated\n\n @property\n def shard_param(self):\n return self.config.shard_param\n\n @staticmethod\n def calc_fanin_fanout(tensor: torch.Tensor):\n \"\"\"We use this function to substitute fan-in and fan-out calculation in torch.nn.init.\n This can help us get correct fan-in and fan-out for sharded tensor.\n \"\"\"\n assert isinstance(tensor, nn.Parameter), \"Sharded tensor initilization is only allowed for paramters\"\n\n # get correct shape of input tensor\n if not hasattr(tensor, 'colo_attr') or not tensor.colo_attr.param_is_sharded:\n tensor_shape = tensor.shape\n else:\n tensor_shape = tensor.colo_attr.sharded_data_tensor.origin_shape\n\n dimensions = len(tensor_shape)\n if dimensions < 2:\n raise ValueError(\"Fan in and fan out can not be computed for tensor with fewer than 2 dimensions\")\n\n num_input_fmaps = tensor_shape[1]\n num_output_fmaps = tensor_shape[0]\n receptive_field_size = 1\n if dimensions > 2:\n # math.prod is not always available, accumulate the product manually\n # we could use functools.reduce but that is not supported by TorchScript\n for s in tensor_shape[2:]:\n receptive_field_size *= s\n fan_in = num_input_fmaps * receptive_field_size\n fan_out = num_output_fmaps * receptive_field_size\n\n return fan_in, fan_out\n\n def _pre_context_exec(self):\n \"\"\"\n The Callback function when entering the context\n \"\"\"\n self.logger = get_dist_logger(\"ZeroInitContext\")\n\n # substitute fan-in and fan-out calculation\n self.nn_fanin_fanout = nn.init._calculate_fan_in_and_fan_out\n nn.init._calculate_fan_in_and_fan_out = self.calc_fanin_fanout\n\n self.module_load_from_state_dict = nn.Module._load_from_state_dict\n shard_strategy = self.shard_strategy if self.config.shard_param else None\n nn.Module._load_from_state_dict = functools.partialmethod(ShardedModelV2._colo_load_from_state_dict,\n shard_strategy=shard_strategy)\n self.module_state_dict = nn.Module.state_dict\n nn.Module.state_dict = functools.partialmethod(ShardedModelV2._colo_state_dict,\n shard_strategy=shard_strategy,\n state_dict_func=self.module_state_dict,\n process_group=self.dp_process_group)\n\n # reserve rng states\n self.cpu_rng_state = torch.get_rng_state()\n self.cuda_rng_state = torch.cuda.get_rng_state()\n\n # set new seed for initialization, since we initialize sharded tensor separately\n # we don't want all processes have the same seed\n # otherwise all sharded tensors are same after init\n offset = self.seed + 1 # we want to have more 1 in binary format seed\n torch.manual_seed(self.seed + offset * dist.get_rank())\n\n def _post_context_exec(self):\n \"\"\"The callback function when exiting context.\n \"\"\"\n # broadcast replicated no-shard parameters\n src_rank = gpc.get_ranks_in_group(ParallelMode.DATA)[0]\n for param in self.param_list:\n assert hasattr(param, 'colo_attr')\n if not param.colo_attr.param_is_sharded and param.colo_attr.is_replicated:\n dist.broadcast(tensor=param.data, src=src_rank, group=self.dp_process_group)\n param.colo_attr.set_data_none()\n\n del self.param_list\n\n nn.init._calculate_fan_in_and_fan_out = self.nn_fanin_fanout\n nn.Module.load_state_dict = self.module_load_from_state_dict\n nn.Module.state_dict = self.module_state_dict\n torch.set_rng_state(self.cpu_rng_state)\n torch.cuda.set_rng_state(self.cuda_rng_state)\n\n params = frozenset(self.top_module.parameters())\n for param in self.param_numel.keys():\n if param not in params:\n self.param_numel[param] = 0\n self.model_numel_tensor.fill_(sum(self.param_numel.values()))\n\n def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):\n \"\"\"\n The function to call at the end of the constructor of each module.\n NOTE() The module may be passed to this function multiple times.\n \"\"\"\n self.top_module = module\n\n def half_fn(t: torch.Tensor):\n return t.half() if t.is_floating_point() else t\n\n for param in module.parameters(recurse=False):\n # avoid adapting a param to ShardedParam twice\n if hasattr(param, 'colo_attr'):\n continue\n\n self.param_numel[param] = param.numel()\n\n # convert parameters to half\n param_half = half_fn(param)\n param.data = param_half\n if param.grad is not None:\n grad_half = half_fn(param.grad)\n param.grad.data = grad_half\n\n # move torch parameters to the target device\n target_device = self.target_device\n param.data = param.data.to(target_device)\n if param.grad is not None:\n param.grad = param.grad.to(target_device)\n\n param.colo_attr = ShardedParamV2(param, set_data_none=True)\n\n if self.shard_param:\n self.shard_strategy.shard([param.colo_attr.sharded_data_tensor], self.dp_process_group)\n\n param.data = param.colo_attr.data_payload # set param.data to payload\n\n # mark whether the param is replicated\n param.colo_attr.is_replicated = self.is_replicated\n\n # mark whether the param should keep not sharded\n # if True, the param is used as Zero stage 2\n param.colo_attr.keep_not_shard = not self.shard_param\n\n self.param_list.append(param)\n\n # We must cast buffers\n # If we use BN, buffers may be on CPU and Float\n # We must cast them\n for buffer in module.buffers(recurse=False):\n buffer.data = buffer.data.to(device=torch.cuda.current_device())\n buffer.data = cast_tensor_to_fp16(buffer.data)\n\n\nclass ZeroContextMgr(metaclass=SingletonMeta):\n current_context: Optional[ZeroInitContext] = None\n\n @contextlib.contextmanager\n def hijack_context_config(self, **kwargs):\n if self.current_context is None:\n yield\n else:\n old_config = self.current_context.config\n self.current_context.config = ZeroContextConfig(**kwargs)\n yield\n self.current_context.config = old_config\n\n\ndef no_shard_zero_context(is_replicated: bool = True) -> AbstractContextManager:\n return ZeroContextMgr().hijack_context_config(target_device=torch.device('cuda', torch.cuda.current_device()),\n is_replicated=is_replicated,\n shard_param=False)\n\n\ndef no_shard_zero_decrator(is_replicated: bool = True):\n\n def _wrapper(init_func):\n\n def _no_shard(*args, **kwargs):\n with no_shard_zero_context(is_replicated):\n ret = init_func(*args, **kwargs)\n return ret\n\n return _no_shard\n\n return _wrapper\n", "path": "colossalai/zero/init_ctx/init_context.py"}]}
| 3,337 | 892 |
gh_patches_debug_12025
|
rasdani/github-patches
|
git_diff
|
Showndarya__Hacktoberfest-435
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Travis test ignore first letter of filename for some reason
I'll try and figure out why, thought about simply renaming every file in the travis script but that requires alot of work and overhead for little gain, it is certainly doable, you have to configure the git on the travis instance and make a new commit etc.
Might as well have a cron job or something to it recursively and periodically over the entirety of the repo and make a single commit...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `.travis.py`
Content:
```
1 import json
2 import os
3 import re
4 import subprocess
5
6 # Get a diff between master and current.
7 try:
8 commit_range = os.environ["TRAVIS_COMMIT_RANGE"]
9 changed_files = subprocess.check_output(["git", "diff", "--name-only", commit_range])
10 except KeyError:
11 print("🔥 This should be run on Travis. Otherwise make sure TRAVIS_BRANCH is set.")
12 exit(1)
13
14 # Filter JSON files only.
15 changed_files_json = []
16 if changed_files:
17 changed_files = changed_files.decode()
18 for changed_file in changed_files.split('\n'):
19 if re.search(r"\.json$", changed_file):
20 changed_files_json.append(changed_file)
21
22
23 # Iterate over list of changed JSON files.
24 for changed_file_json in changed_files_json:
25 print(f"Checking file {changed_file_json}...")
26 there_was_an_error = False
27
28 if not changed_file_json[0].isupper():
29 there_was_an_error = True
30 print("🔥 File name not capitalized.")
31
32 try:
33 with open(changed_file_json) as data_file:
34 file_content = json.loads(data_file.read())
35 except json.decoder.JSONDecodeError:
36 there_was_an_error = True
37 print("🔥 JSON could not be parsed.")
38
39 if 'word' not in file_content:
40 there_was_an_error = True
41 print("🔥 Key 'word' not found.")
42
43 if not file_content["word"]:
44 there_was_an_error = True
45 print("🔥 Value for 'word' appears to be empty.")
46
47 if 'definitions' not in file_content:
48 there_was_an_error = True
49 print("🔥 Key 'definitions' not found.")
50
51 if not file_content["definitions"]:
52 there_was_an_error = True
53 print("🔥 Value for 'definitions' appears to be empty.")
54
55 if 'parts-of-speech' not in file_content:
56 there_was_an_error = True
57 print("🔥 Key 'parts-of-speech' not found.")
58
59 if not file_content["parts-of-speech"]:
60 there_was_an_error = True
61 print("🔥 Value for 'parts-of-speech' appears to be empty.")
62
63 if there_was_an_error:
64 exit(1)
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/.travis.py b/.travis.py
--- a/.travis.py
+++ b/.travis.py
@@ -19,13 +19,13 @@
if re.search(r"\.json$", changed_file):
changed_files_json.append(changed_file)
-
+
# Iterate over list of changed JSON files.
for changed_file_json in changed_files_json:
print(f"Checking file {changed_file_json}...")
there_was_an_error = False
- if not changed_file_json[0].isupper():
+ if not os.path.basename(changed_file_json)[0].isupper():
there_was_an_error = True
print("🔥 File name not capitalized.")
|
{"golden_diff": "diff --git a/.travis.py b/.travis.py\n--- a/.travis.py\n+++ b/.travis.py\n@@ -19,13 +19,13 @@\n if re.search(r\"\\.json$\", changed_file):\n changed_files_json.append(changed_file)\n \n-\n+ \n # Iterate over list of changed JSON files.\n for changed_file_json in changed_files_json:\n print(f\"Checking file {changed_file_json}...\")\n there_was_an_error = False\n \n- if not changed_file_json[0].isupper():\n+ if not os.path.basename(changed_file_json)[0].isupper():\n there_was_an_error = True\n print(\"\ud83d\udd25 File name not capitalized.\")\n", "issue": "Travis test ignore first letter of filename for some reason\nI'll try and figure out why, thought about simply renaming every file in the travis script but that requires alot of work and overhead for little gain, it is certainly doable, you have to configure the git on the travis instance and make a new commit etc.\r\nMight as well have a cron job or something to it recursively and periodically over the entirety of the repo and make a single commit...\n", "before_files": [{"content": "import json\nimport os\nimport re\nimport subprocess\n\n# Get a diff between master and current.\ntry:\n commit_range = os.environ[\"TRAVIS_COMMIT_RANGE\"]\n changed_files = subprocess.check_output([\"git\", \"diff\", \"--name-only\", commit_range])\nexcept KeyError:\n print(\"\ud83d\udd25 This should be run on Travis. Otherwise make sure TRAVIS_BRANCH is set.\")\n exit(1)\n\n# Filter JSON files only.\nchanged_files_json = []\nif changed_files:\n changed_files = changed_files.decode()\n for changed_file in changed_files.split('\\n'):\n if re.search(r\"\\.json$\", changed_file):\n changed_files_json.append(changed_file)\n\n\n# Iterate over list of changed JSON files.\nfor changed_file_json in changed_files_json:\n print(f\"Checking file {changed_file_json}...\")\n there_was_an_error = False\n\n if not changed_file_json[0].isupper():\n there_was_an_error = True\n print(\"\ud83d\udd25 File name not capitalized.\")\n\n try:\n with open(changed_file_json) as data_file:\n file_content = json.loads(data_file.read())\n except json.decoder.JSONDecodeError:\n there_was_an_error = True\n print(\"\ud83d\udd25 JSON could not be parsed.\")\n\n if 'word' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'word' not found.\")\n\n if not file_content[\"word\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'word' appears to be empty.\")\n\n if 'definitions' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'definitions' not found.\")\n\n if not file_content[\"definitions\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'definitions' appears to be empty.\")\n\n if 'parts-of-speech' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'parts-of-speech' not found.\")\n\n if not file_content[\"parts-of-speech\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'parts-of-speech' appears to be empty.\")\n\n if there_was_an_error:\n exit(1)\n", "path": ".travis.py"}], "after_files": [{"content": "import json\nimport os\nimport re\nimport subprocess\n\n# Get a diff between master and current.\ntry:\n commit_range = os.environ[\"TRAVIS_COMMIT_RANGE\"]\n changed_files = subprocess.check_output([\"git\", \"diff\", \"--name-only\", commit_range])\nexcept KeyError:\n print(\"\ud83d\udd25 This should be run on Travis. Otherwise make sure TRAVIS_BRANCH is set.\")\n exit(1)\n\n# Filter JSON files only.\nchanged_files_json = []\nif changed_files:\n changed_files = changed_files.decode()\n for changed_file in changed_files.split('\\n'):\n if re.search(r\"\\.json$\", changed_file):\n changed_files_json.append(changed_file)\n\n \n# Iterate over list of changed JSON files.\nfor changed_file_json in changed_files_json:\n print(f\"Checking file {changed_file_json}...\")\n there_was_an_error = False\n\n if not os.path.basename(changed_file_json)[0].isupper():\n there_was_an_error = True\n print(\"\ud83d\udd25 File name not capitalized.\")\n\n try:\n with open(changed_file_json) as data_file:\n file_content = json.loads(data_file.read())\n except json.decoder.JSONDecodeError:\n there_was_an_error = True\n print(\"\ud83d\udd25 JSON could not be parsed.\")\n\n if 'word' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'word' not found.\")\n\n if not file_content[\"word\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'word' appears to be empty.\")\n\n if 'definitions' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'definitions' not found.\")\n\n if not file_content[\"definitions\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'definitions' appears to be empty.\")\n\n if 'parts-of-speech' not in file_content:\n there_was_an_error = True\n print(\"\ud83d\udd25 Key 'parts-of-speech' not found.\")\n\n if not file_content[\"parts-of-speech\"]:\n there_was_an_error = True\n print(\"\ud83d\udd25 Value for 'parts-of-speech' appears to be empty.\")\n\n if there_was_an_error:\n exit(1)\n", "path": ".travis.py"}]}
| 942 | 152 |
gh_patches_debug_1870
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-1743
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support for Snowflake Secure Views
### Adding support for Secure View in Snowflake
When using the Materialize feature where setting the type of materialization, adding secure-view to the {{ config(materialized='secure-view') }} would be beneficial.
### Current Work-around
Currently the solution for Snowflake secure views is running post-hook events to set the targeted views as secure, example: `alter view sv_mySecureTest set secure;`
This works, and each view that needs to be secured will need to be added to the post-hook event.
### Affects only Snowflake
This feature is specific to the Snowflake Cloud Data warehouse.
[https://docs.snowflake.net/manuals/user-guide/views-secure.html](url)
### This will help DBT Snowflake Developer / Non Developers
When creating a secure view in Snowflake, a developer can use 2 syntax commands
1. CREATE OR REPLACE SECURE VIEW...
2. Alter view <view_name> Set Secure
The first method will allow non-dbt user to render the DDL with the secure declaration as part of the DDL, the second statement is added to the end of the generated DDL however it may be ignored by developers unfamiliar with Snowflake Syntax, causing possible security issues, allowing unauthorized access to the View DDL by Read-Only roles in Snowflake.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/snowflake/dbt/adapters/snowflake/impl.py`
Content:
```
1 from dbt.adapters.sql import SQLAdapter
2 from dbt.adapters.snowflake import SnowflakeConnectionManager
3 from dbt.adapters.snowflake import SnowflakeRelation
4 from dbt.utils import filter_null_values
5
6
7 class SnowflakeAdapter(SQLAdapter):
8 Relation = SnowflakeRelation
9 ConnectionManager = SnowflakeConnectionManager
10
11 AdapterSpecificConfigs = frozenset(
12 {"transient", "cluster_by", "automatic_clustering"}
13 )
14
15 @classmethod
16 def date_function(cls):
17 return "CURRENT_TIMESTAMP()"
18
19 @classmethod
20 def _catalog_filter_table(cls, table, manifest):
21 # On snowflake, users can set QUOTED_IDENTIFIERS_IGNORE_CASE, so force
22 # the column names to their lowercased forms.
23 lowered = table.rename(
24 column_names=[c.lower() for c in table.column_names]
25 )
26 return super()._catalog_filter_table(lowered, manifest)
27
28 def _make_match_kwargs(self, database, schema, identifier):
29 quoting = self.config.quoting
30 if identifier is not None and quoting["identifier"] is False:
31 identifier = identifier.upper()
32
33 if schema is not None and quoting["schema"] is False:
34 schema = schema.upper()
35
36 if database is not None and quoting["database"] is False:
37 database = database.upper()
38
39 return filter_null_values(
40 {"identifier": identifier, "schema": schema, "database": database}
41 )
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/snowflake/dbt/adapters/snowflake/impl.py b/plugins/snowflake/dbt/adapters/snowflake/impl.py
--- a/plugins/snowflake/dbt/adapters/snowflake/impl.py
+++ b/plugins/snowflake/dbt/adapters/snowflake/impl.py
@@ -9,7 +9,7 @@
ConnectionManager = SnowflakeConnectionManager
AdapterSpecificConfigs = frozenset(
- {"transient", "cluster_by", "automatic_clustering"}
+ {"transient", "cluster_by", "automatic_clustering", "secure"}
)
@classmethod
|
{"golden_diff": "diff --git a/plugins/snowflake/dbt/adapters/snowflake/impl.py b/plugins/snowflake/dbt/adapters/snowflake/impl.py\n--- a/plugins/snowflake/dbt/adapters/snowflake/impl.py\n+++ b/plugins/snowflake/dbt/adapters/snowflake/impl.py\n@@ -9,7 +9,7 @@\n ConnectionManager = SnowflakeConnectionManager\n \n AdapterSpecificConfigs = frozenset(\n- {\"transient\", \"cluster_by\", \"automatic_clustering\"}\n+ {\"transient\", \"cluster_by\", \"automatic_clustering\", \"secure\"}\n )\n \n @classmethod\n", "issue": "Support for Snowflake Secure Views\n### Adding support for Secure View in Snowflake\r\nWhen using the Materialize feature where setting the type of materialization, adding secure-view to the {{ config(materialized='secure-view') }} would be beneficial.\r\n\r\n### Current Work-around\r\nCurrently the solution for Snowflake secure views is running post-hook events to set the targeted views as secure, example: `alter view sv_mySecureTest set secure;`\r\nThis works, and each view that needs to be secured will need to be added to the post-hook event.\r\n\r\n### Affects only Snowflake\r\nThis feature is specific to the Snowflake Cloud Data warehouse.\r\n[https://docs.snowflake.net/manuals/user-guide/views-secure.html](url)\r\n\r\n### This will help DBT Snowflake Developer / Non Developers\r\nWhen creating a secure view in Snowflake, a developer can use 2 syntax commands\r\n\r\n1. CREATE OR REPLACE SECURE VIEW...\r\n2. Alter view <view_name> Set Secure\r\n\r\nThe first method will allow non-dbt user to render the DDL with the secure declaration as part of the DDL, the second statement is added to the end of the generated DDL however it may be ignored by developers unfamiliar with Snowflake Syntax, causing possible security issues, allowing unauthorized access to the View DDL by Read-Only roles in Snowflake.\n", "before_files": [{"content": "from dbt.adapters.sql import SQLAdapter\nfrom dbt.adapters.snowflake import SnowflakeConnectionManager\nfrom dbt.adapters.snowflake import SnowflakeRelation\nfrom dbt.utils import filter_null_values\n\n\nclass SnowflakeAdapter(SQLAdapter):\n Relation = SnowflakeRelation\n ConnectionManager = SnowflakeConnectionManager\n\n AdapterSpecificConfigs = frozenset(\n {\"transient\", \"cluster_by\", \"automatic_clustering\"}\n )\n\n @classmethod\n def date_function(cls):\n return \"CURRENT_TIMESTAMP()\"\n\n @classmethod\n def _catalog_filter_table(cls, table, manifest):\n # On snowflake, users can set QUOTED_IDENTIFIERS_IGNORE_CASE, so force\n # the column names to their lowercased forms.\n lowered = table.rename(\n column_names=[c.lower() for c in table.column_names]\n )\n return super()._catalog_filter_table(lowered, manifest)\n\n def _make_match_kwargs(self, database, schema, identifier):\n quoting = self.config.quoting\n if identifier is not None and quoting[\"identifier\"] is False:\n identifier = identifier.upper()\n\n if schema is not None and quoting[\"schema\"] is False:\n schema = schema.upper()\n\n if database is not None and quoting[\"database\"] is False:\n database = database.upper()\n\n return filter_null_values(\n {\"identifier\": identifier, \"schema\": schema, \"database\": database}\n )\n", "path": "plugins/snowflake/dbt/adapters/snowflake/impl.py"}], "after_files": [{"content": "from dbt.adapters.sql import SQLAdapter\nfrom dbt.adapters.snowflake import SnowflakeConnectionManager\nfrom dbt.adapters.snowflake import SnowflakeRelation\nfrom dbt.utils import filter_null_values\n\n\nclass SnowflakeAdapter(SQLAdapter):\n Relation = SnowflakeRelation\n ConnectionManager = SnowflakeConnectionManager\n\n AdapterSpecificConfigs = frozenset(\n {\"transient\", \"cluster_by\", \"automatic_clustering\", \"secure\"}\n )\n\n @classmethod\n def date_function(cls):\n return \"CURRENT_TIMESTAMP()\"\n\n @classmethod\n def _catalog_filter_table(cls, table, manifest):\n # On snowflake, users can set QUOTED_IDENTIFIERS_IGNORE_CASE, so force\n # the column names to their lowercased forms.\n lowered = table.rename(\n column_names=[c.lower() for c in table.column_names]\n )\n return super()._catalog_filter_table(lowered, manifest)\n\n def _make_match_kwargs(self, database, schema, identifier):\n quoting = self.config.quoting\n if identifier is not None and quoting[\"identifier\"] is False:\n identifier = identifier.upper()\n\n if schema is not None and quoting[\"schema\"] is False:\n schema = schema.upper()\n\n if database is not None and quoting[\"database\"] is False:\n database = database.upper()\n\n return filter_null_values(\n {\"identifier\": identifier, \"schema\": schema, \"database\": database}\n )\n", "path": "plugins/snowflake/dbt/adapters/snowflake/impl.py"}]}
| 921 | 136 |
gh_patches_debug_57002
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-1129
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to create a shell shellcraft for MIPS
The problem is as follows:
```py
>>> from pwnlib.shellcraft import mips
>>> mips.sh()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 8, in sh
File "/usr/lib64/python2.7/site-packages/mako/template.py", line 462, in render
return runtime._render(self, self.callable_, args, data)
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 838, in _render
**_kwargs_for_callable(callable_, data))
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 873, in _render_context
_exec_template(inherit, lclcontext, args=args, kwargs=kwargs)
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 899, in _exec_template
callable_(context, *args, **kwargs)
File "/home/are/.pwntools-cache/mako/mips/linux/sh.asm.py", line 28, in render_body
__M_writer(unicode(mips.execve('//bin/sh', ['sh'], {})))
File "<string>", line 8, in execve
File "/usr/lib64/python2.7/site-packages/mako/template.py", line 462, in render
return runtime._render(self, self.callable_, args, data)
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 838, in _render
**_kwargs_for_callable(callable_, data))
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 873, in _render_context
_exec_template(inherit, lclcontext, args=args, kwargs=kwargs)
File "/usr/lib64/python2.7/site-packages/mako/runtime.py", line 899, in _exec_template
callable_(context, *args, **kwargs)
File "/home/are/.pwntools-cache/mako/mips/linux/syscalls/execve.asm.py", line 69, in render_body
if arg in allregs:
TypeError: unhashable type: 'list'
```
But it can be fixed by making sure that `shellcraft.registers.current()` returns a list rather than a dict (mips is the only architecture that it happens for, since `type(shellcraft.registers.mips)==dict`). A pull request is on its way.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/shellcraft/registers.py`
Content:
```
1 from __future__ import absolute_import
2
3 import re
4
5 from pwnlib.context import context
6 from pwnlib.util.misc import register_sizes
7
8 mips = {
9 '$0' : 0, '$zero': 0,
10 '$1' : 1, '$at': 1,
11 '$2' : 2, '$v0': 2,
12 '$3' : 3, '$v1': 3,
13 '$4' : 4, '$a0': 4,
14 '$5' : 5, '$a1': 5,
15 '$6' : 6, '$a2': 6,
16 '$7' : 7, '$a3': 7,
17 '$8' : 8, '$t0': 8,
18 '$9' : 9, '$t1': 9,
19 '$10': 10, '$t2': 10,
20 '$11': 11, '$t3': 11,
21 '$12': 12, '$t4': 12,
22 '$13': 13, '$t5': 13,
23 '$14': 14, '$t6': 14,
24 '$15': 15, '$t7': 15,
25 '$16': 16, '$s0': 16,
26 '$17': 17, '$s1': 17,
27 '$18': 18, '$s2': 18,
28 '$19': 19, '$s3': 19,
29 '$20': 20, '$s4': 20,
30 '$21': 21, '$s5': 21,
31 '$22': 22, '$s6': 22,
32 '$23': 23, '$s7': 23,
33 '$24': 24, '$t8': 24,
34 '$25': 25, '$t9': 25,
35 '$26': 26, '$k0': 26,
36 '$27': 27, '$k1': 27,
37 '$28': 28, '$gp': 28,
38 '$29': 29, '$sp': 29,
39 '$30': 30, '$s8': 30,
40 '$31': 31, '$ra': 31,
41 }
42
43 arm = map('r{}'.format, range(13))
44 arm += ["sp", "lr", "pc", "cpsr"]
45
46 thumb = arm
47
48 aarch64 = map('x{}'.format, range(32))
49 aarch64 += ["sp", "lr", "pc", "cpsr"]
50
51 i386_baseregs = [ "ax", "cx", "dx", "bx", "sp", "bp", "si", "di", "ip"]
52
53 i386 = map('e{}'.format, i386_baseregs)
54 i386 += i386_baseregs
55 i386 += [ "eflags", "cs", "ss", "ds", "es", "fs", "gs", ]
56
57 amd64 = map('r{}'.format, i386_baseregs)
58 amd64 += map('r{}'.format, range(8,16))
59 amd64 += map('r{}d'.format, range(8,16))
60 amd64 += i386
61
62 powerpc = map('r{}'.format, range(32))
63 powerpc += ["pc", "msr", "cr", "lr", "ctr", "xer", "orig_r3", "trap" ]
64 powerpc = map('%{}'.format, powerpc)
65
66 sparc = map('g{}'.format, range(8))
67 sparc += map('o{}'.format, range(5))
68 sparc += map('l{}'.format, range(8))
69 sparc += map('i{}'.format, range(5))
70 sparc += ["pc", "sp", "fp", "psr" ]
71 sparc = map('%{}'.format, sparc)
72
73
74
75 # x86/amd64 registers in decreasing size
76 i386_ordered = [
77 ['rax', 'eax', 'ax', 'al'],
78 ['rbx', 'ebx', 'bx', 'bl'],
79 ['rcx', 'ecx', 'cx', 'cl'],
80 ['rdx', 'edx', 'dx', 'dl'],
81 ['rdi', 'edi', 'di'],
82 ['rsi', 'esi', 'si'],
83 ['rbp', 'ebp', 'bp'],
84 ['rsp', 'esp', 'sp'],
85 ['r8', 'r8d', 'r8w', 'r8b'],
86 ['r9', 'r9d', 'r9w', 'r9b'],
87 ['r10', 'r10d', 'r10w', 'r10b'],
88 ['r11', 'r11d', 'r11w', 'r11b'],
89 ['r12', 'r12d', 'r12w', 'r12b'],
90 ['r13', 'r13d', 'r13w', 'r13b'],
91 ['r14', 'r14d', 'r14w', 'r14b'],
92 ['r15', 'r15d', 'r15w', 'r15b']
93 ]
94
95 all_regs, sizes, bigger, smaller = register_sizes(i386_ordered, [64, 32, 16, 8, 8])
96 native64 = {k:v[0] for k,v in bigger.items()}
97 native32 = {k:v[1] for k,v in bigger.items() if not k.startswith('r')}
98
99 class Register(object):
100 #: Register name
101 name = None
102
103 #: List of larger registers, in order from largest to smallest
104 bigger = None
105
106 #: List of smaller regsters, in order from smallest to largest
107 smaller = None
108
109 #: Size of the register, in bits
110 size = None
111
112 #: Does this register have a 'high' register for mask 0xff00
113 ff00 = None
114
115 #: Flags for 64-bit mode.64-bit
116 #: The first bit is set, if the register can be used with a REX-mode
117 #: The second bit is set, if the register can be used without a REX-prefix
118 rex_mode = 0
119
120 #: Is this a 64-bit only register?
121 is64bit = False
122
123 #: Name of the native 64-bit register
124 native64 = None
125
126 #: Name of the native 32-bit register
127 native32 = None
128
129 #: Name of the register which should be used to clear
130 #: this register, e.g. xor REG, REG.
131 #: Useful for AMD64 for xor eax, eax is shorter than
132 #: xor rax, rax and has the same effect.
133 xor = None
134
135 def __init__(self, name, size):
136 self.name = name
137 self.size = size
138
139 for row in i386_ordered:
140 if name in row:
141 self.bigger = row[0:row.index(name)]
142 self.smaller = row[row.index(name)+1:]
143 self.sizes = {64>>i:r for i,r in enumerate(row)}
144 self.native64 = row[0]
145 self.native32 = row[1]
146 self.xor = self.sizes[min(self.size, 32)]
147
148 if self.size >= 32 and name.endswith('x'):
149 self.ff00 = name[1] + 'h'
150
151 if name[-1] != 'h':
152 self.rex_mode |= 1
153
154 if name[0] != 'r':
155 self.rex_mode |= 2
156
157 if name.startswith('r') or name[1:3].isdigit():
158 self.is64bit = True
159
160 @property
161 def bits(self):
162 return self.size
163
164 @property
165 def bytes(self):
166 return self.bits / 8
167
168 def fits(self, value):
169 return self.size >= bits_required(value)
170
171 def __str__(self):
172 return self.name
173
174 def __repr__(self):
175 return "Register(%r)" % self.name
176
177 intel = {}
178
179 for row in i386_ordered:
180 for i, reg in enumerate(row):
181 intel[reg] = Register(reg, 64 >> i)
182
183 def get_register(name):
184 if isinstance(name, Register):
185 return name
186 if isinstance(name, str):
187 return intel.get(name, None)
188 return None
189
190 def is_register(obj):
191 if isinstance(obj, Register):
192 return True
193 return get_register(obj)
194
195
196 def bits_required(value):
197 bits = 0
198
199 if value < 0:
200 value = -(value)
201
202 while value:
203 value >>= 8
204 bits += 8
205 return bits
206
207 def current():
208 return {
209 'i386': i386,
210 'amd64': amd64,
211 'arm': arm,
212 'thumb': arm,
213 'aarch64': aarch64,
214 'mips': mips,
215 'powerpc': powerpc
216 }[context.arch]
217
218 # def is_register(sz):
219 # try:
220 # sz = sz.lower()
221 # return sz.lower() in {
222 # 'i386': i386,
223 # 'amd64': amd64,
224 # 'powerpc': powerpc,
225 # 'sparc': sparc,
226 # 'arm': arm,
227 # 'aarch64': arm,
228 # 'thumb': arm,
229 # 'mips': mips,
230 # 'mips64': mips
231 # }[context.arch]
232 # except:
233 # return False
234
235 def register_size(reg):
236 return sizes[reg]
237
238 def fits_in_register(reg, value):
239 return register_size(reg) >= bits_required(value)
240
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/shellcraft/registers.py b/pwnlib/shellcraft/registers.py
--- a/pwnlib/shellcraft/registers.py
+++ b/pwnlib/shellcraft/registers.py
@@ -211,7 +211,7 @@
'arm': arm,
'thumb': arm,
'aarch64': aarch64,
- 'mips': mips,
+ 'mips': list(mips),
'powerpc': powerpc
}[context.arch]
|
{"golden_diff": "diff --git a/pwnlib/shellcraft/registers.py b/pwnlib/shellcraft/registers.py\n--- a/pwnlib/shellcraft/registers.py\n+++ b/pwnlib/shellcraft/registers.py\n@@ -211,7 +211,7 @@\n 'arm': arm,\n 'thumb': arm,\n 'aarch64': aarch64,\n- 'mips': mips,\n+ 'mips': list(mips),\n 'powerpc': powerpc\n }[context.arch]\n", "issue": "Unable to create a shell shellcraft for MIPS\nThe problem is as follows:\r\n```py\r\n>>> from pwnlib.shellcraft import mips\r\n>>> mips.sh()\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"<string>\", line 8, in sh\r\n File \"/usr/lib64/python2.7/site-packages/mako/template.py\", line 462, in render\r\n return runtime._render(self, self.callable_, args, data)\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 838, in _render\r\n **_kwargs_for_callable(callable_, data))\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 873, in _render_context\r\n _exec_template(inherit, lclcontext, args=args, kwargs=kwargs)\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 899, in _exec_template\r\n callable_(context, *args, **kwargs)\r\n File \"/home/are/.pwntools-cache/mako/mips/linux/sh.asm.py\", line 28, in render_body\r\n __M_writer(unicode(mips.execve('//bin/sh', ['sh'], {})))\r\n File \"<string>\", line 8, in execve\r\n File \"/usr/lib64/python2.7/site-packages/mako/template.py\", line 462, in render\r\n return runtime._render(self, self.callable_, args, data)\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 838, in _render\r\n **_kwargs_for_callable(callable_, data))\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 873, in _render_context\r\n _exec_template(inherit, lclcontext, args=args, kwargs=kwargs)\r\n File \"/usr/lib64/python2.7/site-packages/mako/runtime.py\", line 899, in _exec_template\r\n callable_(context, *args, **kwargs)\r\n File \"/home/are/.pwntools-cache/mako/mips/linux/syscalls/execve.asm.py\", line 69, in render_body\r\n if arg in allregs:\r\nTypeError: unhashable type: 'list'\r\n```\r\nBut it can be fixed by making sure that `shellcraft.registers.current()` returns a list rather than a dict (mips is the only architecture that it happens for, since `type(shellcraft.registers.mips)==dict`). A pull request is on its way.\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport re\n\nfrom pwnlib.context import context\nfrom pwnlib.util.misc import register_sizes\n\nmips = {\n '$0' : 0, '$zero': 0,\n '$1' : 1, '$at': 1,\n '$2' : 2, '$v0': 2,\n '$3' : 3, '$v1': 3,\n '$4' : 4, '$a0': 4,\n '$5' : 5, '$a1': 5,\n '$6' : 6, '$a2': 6,\n '$7' : 7, '$a3': 7,\n '$8' : 8, '$t0': 8,\n '$9' : 9, '$t1': 9,\n '$10': 10, '$t2': 10,\n '$11': 11, '$t3': 11,\n '$12': 12, '$t4': 12,\n '$13': 13, '$t5': 13,\n '$14': 14, '$t6': 14,\n '$15': 15, '$t7': 15,\n '$16': 16, '$s0': 16,\n '$17': 17, '$s1': 17,\n '$18': 18, '$s2': 18,\n '$19': 19, '$s3': 19,\n '$20': 20, '$s4': 20,\n '$21': 21, '$s5': 21,\n '$22': 22, '$s6': 22,\n '$23': 23, '$s7': 23,\n '$24': 24, '$t8': 24,\n '$25': 25, '$t9': 25,\n '$26': 26, '$k0': 26,\n '$27': 27, '$k1': 27,\n '$28': 28, '$gp': 28,\n '$29': 29, '$sp': 29,\n '$30': 30, '$s8': 30,\n '$31': 31, '$ra': 31,\n}\n\narm = map('r{}'.format, range(13))\narm += [\"sp\", \"lr\", \"pc\", \"cpsr\"]\n\nthumb = arm\n\naarch64 = map('x{}'.format, range(32))\naarch64 += [\"sp\", \"lr\", \"pc\", \"cpsr\"]\n\ni386_baseregs = [ \"ax\", \"cx\", \"dx\", \"bx\", \"sp\", \"bp\", \"si\", \"di\", \"ip\"]\n\ni386 = map('e{}'.format, i386_baseregs)\ni386 += i386_baseregs\ni386 += [ \"eflags\", \"cs\", \"ss\", \"ds\", \"es\", \"fs\", \"gs\", ]\n\namd64 = map('r{}'.format, i386_baseregs)\namd64 += map('r{}'.format, range(8,16))\namd64 += map('r{}d'.format, range(8,16))\namd64 += i386\n\npowerpc = map('r{}'.format, range(32))\npowerpc += [\"pc\", \"msr\", \"cr\", \"lr\", \"ctr\", \"xer\", \"orig_r3\", \"trap\" ]\npowerpc = map('%{}'.format, powerpc)\n\nsparc = map('g{}'.format, range(8))\nsparc += map('o{}'.format, range(5))\nsparc += map('l{}'.format, range(8))\nsparc += map('i{}'.format, range(5))\nsparc += [\"pc\", \"sp\", \"fp\", \"psr\" ]\nsparc = map('%{}'.format, sparc)\n\n\n\n# x86/amd64 registers in decreasing size\ni386_ordered = [\n ['rax', 'eax', 'ax', 'al'],\n ['rbx', 'ebx', 'bx', 'bl'],\n ['rcx', 'ecx', 'cx', 'cl'],\n ['rdx', 'edx', 'dx', 'dl'],\n ['rdi', 'edi', 'di'],\n ['rsi', 'esi', 'si'],\n ['rbp', 'ebp', 'bp'],\n ['rsp', 'esp', 'sp'],\n ['r8', 'r8d', 'r8w', 'r8b'],\n ['r9', 'r9d', 'r9w', 'r9b'],\n ['r10', 'r10d', 'r10w', 'r10b'],\n ['r11', 'r11d', 'r11w', 'r11b'],\n ['r12', 'r12d', 'r12w', 'r12b'],\n ['r13', 'r13d', 'r13w', 'r13b'],\n ['r14', 'r14d', 'r14w', 'r14b'],\n ['r15', 'r15d', 'r15w', 'r15b']\n]\n\nall_regs, sizes, bigger, smaller = register_sizes(i386_ordered, [64, 32, 16, 8, 8])\nnative64 = {k:v[0] for k,v in bigger.items()}\nnative32 = {k:v[1] for k,v in bigger.items() if not k.startswith('r')}\n\nclass Register(object):\n #: Register name\n name = None\n\n #: List of larger registers, in order from largest to smallest\n bigger = None\n\n #: List of smaller regsters, in order from smallest to largest\n smaller = None\n\n #: Size of the register, in bits\n size = None\n\n #: Does this register have a 'high' register for mask 0xff00\n ff00 = None\n\n #: Flags for 64-bit mode.64-bit\n #: The first bit is set, if the register can be used with a REX-mode\n #: The second bit is set, if the register can be used without a REX-prefix\n rex_mode = 0\n\n #: Is this a 64-bit only register?\n is64bit = False\n\n #: Name of the native 64-bit register\n native64 = None\n\n #: Name of the native 32-bit register\n native32 = None\n\n #: Name of the register which should be used to clear\n #: this register, e.g. xor REG, REG.\n #: Useful for AMD64 for xor eax, eax is shorter than\n #: xor rax, rax and has the same effect.\n xor = None\n\n def __init__(self, name, size):\n self.name = name\n self.size = size\n\n for row in i386_ordered:\n if name in row:\n self.bigger = row[0:row.index(name)]\n self.smaller = row[row.index(name)+1:]\n self.sizes = {64>>i:r for i,r in enumerate(row)}\n self.native64 = row[0]\n self.native32 = row[1]\n self.xor = self.sizes[min(self.size, 32)]\n\n if self.size >= 32 and name.endswith('x'):\n self.ff00 = name[1] + 'h'\n\n if name[-1] != 'h':\n self.rex_mode |= 1\n\n if name[0] != 'r':\n self.rex_mode |= 2\n\n if name.startswith('r') or name[1:3].isdigit():\n self.is64bit = True\n\n @property\n def bits(self):\n return self.size\n\n @property\n def bytes(self):\n return self.bits / 8\n\n def fits(self, value):\n return self.size >= bits_required(value)\n\n def __str__(self):\n return self.name\n\n def __repr__(self):\n return \"Register(%r)\" % self.name\n\nintel = {}\n\nfor row in i386_ordered:\n for i, reg in enumerate(row):\n intel[reg] = Register(reg, 64 >> i)\n\ndef get_register(name):\n if isinstance(name, Register):\n return name\n if isinstance(name, str):\n return intel.get(name, None)\n return None\n\ndef is_register(obj):\n if isinstance(obj, Register):\n return True\n return get_register(obj)\n\n\ndef bits_required(value):\n bits = 0\n\n if value < 0:\n value = -(value)\n\n while value:\n value >>= 8\n bits += 8\n return bits\n\ndef current():\n return {\n 'i386': i386,\n 'amd64': amd64,\n 'arm': arm,\n 'thumb': arm,\n 'aarch64': aarch64,\n 'mips': mips,\n 'powerpc': powerpc\n }[context.arch]\n\n# def is_register(sz):\n# try:\n# sz = sz.lower()\n# return sz.lower() in {\n# 'i386': i386,\n# 'amd64': amd64,\n# 'powerpc': powerpc,\n# 'sparc': sparc,\n# 'arm': arm,\n# 'aarch64': arm,\n# 'thumb': arm,\n# 'mips': mips,\n# 'mips64': mips\n# }[context.arch]\n# except:\n# return False\n\ndef register_size(reg):\n return sizes[reg]\n\ndef fits_in_register(reg, value):\n return register_size(reg) >= bits_required(value)\n", "path": "pwnlib/shellcraft/registers.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport re\n\nfrom pwnlib.context import context\nfrom pwnlib.util.misc import register_sizes\n\nmips = {\n '$0' : 0, '$zero': 0,\n '$1' : 1, '$at': 1,\n '$2' : 2, '$v0': 2,\n '$3' : 3, '$v1': 3,\n '$4' : 4, '$a0': 4,\n '$5' : 5, '$a1': 5,\n '$6' : 6, '$a2': 6,\n '$7' : 7, '$a3': 7,\n '$8' : 8, '$t0': 8,\n '$9' : 9, '$t1': 9,\n '$10': 10, '$t2': 10,\n '$11': 11, '$t3': 11,\n '$12': 12, '$t4': 12,\n '$13': 13, '$t5': 13,\n '$14': 14, '$t6': 14,\n '$15': 15, '$t7': 15,\n '$16': 16, '$s0': 16,\n '$17': 17, '$s1': 17,\n '$18': 18, '$s2': 18,\n '$19': 19, '$s3': 19,\n '$20': 20, '$s4': 20,\n '$21': 21, '$s5': 21,\n '$22': 22, '$s6': 22,\n '$23': 23, '$s7': 23,\n '$24': 24, '$t8': 24,\n '$25': 25, '$t9': 25,\n '$26': 26, '$k0': 26,\n '$27': 27, '$k1': 27,\n '$28': 28, '$gp': 28,\n '$29': 29, '$sp': 29,\n '$30': 30, '$s8': 30,\n '$31': 31, '$ra': 31,\n}\n\narm = map('r{}'.format, range(13))\narm += [\"sp\", \"lr\", \"pc\", \"cpsr\"]\n\nthumb = arm\n\naarch64 = map('x{}'.format, range(32))\naarch64 += [\"sp\", \"lr\", \"pc\", \"cpsr\"]\n\ni386_baseregs = [ \"ax\", \"cx\", \"dx\", \"bx\", \"sp\", \"bp\", \"si\", \"di\", \"ip\"]\n\ni386 = map('e{}'.format, i386_baseregs)\ni386 += i386_baseregs\ni386 += [ \"eflags\", \"cs\", \"ss\", \"ds\", \"es\", \"fs\", \"gs\", ]\n\namd64 = map('r{}'.format, i386_baseregs)\namd64 += map('r{}'.format, range(8,16))\namd64 += map('r{}d'.format, range(8,16))\namd64 += i386\n\npowerpc = map('r{}'.format, range(32))\npowerpc += [\"pc\", \"msr\", \"cr\", \"lr\", \"ctr\", \"xer\", \"orig_r3\", \"trap\" ]\npowerpc = map('%{}'.format, powerpc)\n\nsparc = map('g{}'.format, range(8))\nsparc += map('o{}'.format, range(5))\nsparc += map('l{}'.format, range(8))\nsparc += map('i{}'.format, range(5))\nsparc += [\"pc\", \"sp\", \"fp\", \"psr\" ]\nsparc = map('%{}'.format, sparc)\n\n\n\n# x86/amd64 registers in decreasing size\ni386_ordered = [\n ['rax', 'eax', 'ax', 'al'],\n ['rbx', 'ebx', 'bx', 'bl'],\n ['rcx', 'ecx', 'cx', 'cl'],\n ['rdx', 'edx', 'dx', 'dl'],\n ['rdi', 'edi', 'di'],\n ['rsi', 'esi', 'si'],\n ['rbp', 'ebp', 'bp'],\n ['rsp', 'esp', 'sp'],\n ['r8', 'r8d', 'r8w', 'r8b'],\n ['r9', 'r9d', 'r9w', 'r9b'],\n ['r10', 'r10d', 'r10w', 'r10b'],\n ['r11', 'r11d', 'r11w', 'r11b'],\n ['r12', 'r12d', 'r12w', 'r12b'],\n ['r13', 'r13d', 'r13w', 'r13b'],\n ['r14', 'r14d', 'r14w', 'r14b'],\n ['r15', 'r15d', 'r15w', 'r15b']\n]\n\nall_regs, sizes, bigger, smaller = register_sizes(i386_ordered, [64, 32, 16, 8, 8])\nnative64 = {k:v[0] for k,v in bigger.items()}\nnative32 = {k:v[1] for k,v in bigger.items() if not k.startswith('r')}\n\nclass Register(object):\n #: Register name\n name = None\n\n #: List of larger registers, in order from largest to smallest\n bigger = None\n\n #: List of smaller regsters, in order from smallest to largest\n smaller = None\n\n #: Size of the register, in bits\n size = None\n\n #: Does this register have a 'high' register for mask 0xff00\n ff00 = None\n\n #: Flags for 64-bit mode.64-bit\n #: The first bit is set, if the register can be used with a REX-mode\n #: The second bit is set, if the register can be used without a REX-prefix\n rex_mode = 0\n\n #: Is this a 64-bit only register?\n is64bit = False\n\n #: Name of the native 64-bit register\n native64 = None\n\n #: Name of the native 32-bit register\n native32 = None\n\n #: Name of the register which should be used to clear\n #: this register, e.g. xor REG, REG.\n #: Useful for AMD64 for xor eax, eax is shorter than\n #: xor rax, rax and has the same effect.\n xor = None\n\n def __init__(self, name, size):\n self.name = name\n self.size = size\n\n for row in i386_ordered:\n if name in row:\n self.bigger = row[0:row.index(name)]\n self.smaller = row[row.index(name)+1:]\n self.sizes = {64>>i:r for i,r in enumerate(row)}\n self.native64 = row[0]\n self.native32 = row[1]\n self.xor = self.sizes[min(self.size, 32)]\n\n if self.size >= 32 and name.endswith('x'):\n self.ff00 = name[1] + 'h'\n\n if name[-1] != 'h':\n self.rex_mode |= 1\n\n if name[0] != 'r':\n self.rex_mode |= 2\n\n if name.startswith('r') or name[1:3].isdigit():\n self.is64bit = True\n\n @property\n def bits(self):\n return self.size\n\n @property\n def bytes(self):\n return self.bits / 8\n\n def fits(self, value):\n return self.size >= bits_required(value)\n\n def __str__(self):\n return self.name\n\n def __repr__(self):\n return \"Register(%r)\" % self.name\n\nintel = {}\n\nfor row in i386_ordered:\n for i, reg in enumerate(row):\n intel[reg] = Register(reg, 64 >> i)\n\ndef get_register(name):\n if isinstance(name, Register):\n return name\n if isinstance(name, str):\n return intel.get(name, None)\n return None\n\ndef is_register(obj):\n if isinstance(obj, Register):\n return True\n return get_register(obj)\n\n\ndef bits_required(value):\n bits = 0\n\n if value < 0:\n value = -(value)\n\n while value:\n value >>= 8\n bits += 8\n return bits\n\ndef current():\n return {\n 'i386': i386,\n 'amd64': amd64,\n 'arm': arm,\n 'thumb': arm,\n 'aarch64': aarch64,\n 'mips': list(mips),\n 'powerpc': powerpc\n }[context.arch]\n\n# def is_register(sz):\n# try:\n# sz = sz.lower()\n# return sz.lower() in {\n# 'i386': i386,\n# 'amd64': amd64,\n# 'powerpc': powerpc,\n# 'sparc': sparc,\n# 'arm': arm,\n# 'aarch64': arm,\n# 'thumb': arm,\n# 'mips': mips,\n# 'mips64': mips\n# }[context.arch]\n# except:\n# return False\n\ndef register_size(reg):\n return sizes[reg]\n\ndef fits_in_register(reg, value):\n return register_size(reg) >= bits_required(value)\n", "path": "pwnlib/shellcraft/registers.py"}]}
| 3,748 | 119 |
gh_patches_debug_1805
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-840
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Document the new setup utility
Title says all
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup/server.py`
Content:
```
1 import flask
2 import flask_bootstrap
3 import redis
4 import json
5 import os
6 import jinja2
7 import uuid
8 import string
9 import random
10 import ipaddress
11 import hashlib
12
13
14 version = os.getenv("this_version")
15 static_url_path = "/" + version + "/static"
16 app = flask.Flask(__name__, static_url_path=static_url_path)
17 flask_bootstrap.Bootstrap(app)
18 db = redis.StrictRedis(host='redis', port=6379, db=0)
19
20
21 def render_flavor(flavor, template, data):
22 return flask.render_template(
23 os.path.join(flavor, template),
24 **data
25 )
26
27
28 @app.add_template_global
29 def secret(length=16):
30 charset = string.ascii_uppercase + string.digits
31 return ''.join(
32 random.SystemRandom().choice(charset)
33 for _ in range(length)
34 )
35
36
37 def build_app(path):
38
39 app.jinja_env.trim_blocks = True
40 app.jinja_env.lstrip_blocks = True
41
42 @app.context_processor
43 def app_context():
44 return dict(versions=os.getenv("VERSIONS","master").split(','))
45
46 prefix_bp = flask.Blueprint(version, __name__)
47 prefix_bp.jinja_loader = jinja2.ChoiceLoader([
48 jinja2.FileSystemLoader(os.path.join(path, "templates")),
49 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
50 ])
51
52 root_bp = flask.Blueprint("root", __name__)
53 root_bp.jinja_loader = jinja2.ChoiceLoader([
54 jinja2.FileSystemLoader(os.path.join(path, "templates")),
55 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
56 ])
57
58 @prefix_bp.context_processor
59 @root_bp.context_processor
60 def bp_context(version=version):
61 return dict(version=version)
62
63 @prefix_bp.route("/")
64 @root_bp.route("/")
65 def wizard():
66 return flask.render_template('wizard.html')
67
68 @prefix_bp.route("/submit_flavor", methods=["POST"])
69 @root_bp.route("/submit_flavor", methods=["POST"])
70 def submit_flavor():
71 data = flask.request.form.copy()
72 steps = sorted(os.listdir(os.path.join(path, "templates", "steps", data["flavor"])))
73 return flask.render_template('wizard.html', flavor=data["flavor"], steps=steps)
74
75 @prefix_bp.route("/submit", methods=["POST"])
76 @root_bp.route("/submit", methods=["POST"])
77 def submit():
78 data = flask.request.form.copy()
79 data['uid'] = str(uuid.uuid4())
80 data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
81 db.set(data['uid'], json.dumps(data))
82 return flask.redirect(flask.url_for('.setup', uid=data['uid']))
83
84 @prefix_bp.route("/setup/<uid>", methods=["GET"])
85 @root_bp.route("/setup/<uid>", methods=["GET"])
86 def setup(uid):
87 data = json.loads(db.get(uid))
88 flavor = data.get("flavor", "compose")
89 rendered = render_flavor(flavor, "setup.html", data)
90 return flask.render_template("setup.html", contents=rendered)
91
92 @prefix_bp.route("/file/<uid>/<filepath>", methods=["GET"])
93 @root_bp.route("/file/<uid>/<filepath>", methods=["GET"])
94 def file(uid, filepath):
95 data = json.loads(db.get(uid))
96 flavor = data.get("flavor", "compose")
97 return flask.Response(
98 render_flavor(flavor, filepath, data),
99 mimetype="application/text"
100 )
101
102 app.register_blueprint(prefix_bp, url_prefix="/{}".format(version))
103 app.register_blueprint(root_bp)
104
105
106 if __name__ == "__main__":
107 build_app("/tmp/mailutest")
108 app.run(debug=True)
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup/server.py b/setup/server.py
--- a/setup/server.py
+++ b/setup/server.py
@@ -11,7 +11,7 @@
import hashlib
-version = os.getenv("this_version")
+version = os.getenv("this_version", "master")
static_url_path = "/" + version + "/static"
app = flask.Flask(__name__, static_url_path=static_url_path)
flask_bootstrap.Bootstrap(app)
|
{"golden_diff": "diff --git a/setup/server.py b/setup/server.py\n--- a/setup/server.py\n+++ b/setup/server.py\n@@ -11,7 +11,7 @@\n import hashlib\n \n \n-version = os.getenv(\"this_version\")\n+version = os.getenv(\"this_version\", \"master\")\n static_url_path = \"/\" + version + \"/static\"\n app = flask.Flask(__name__, static_url_path=static_url_path)\n flask_bootstrap.Bootstrap(app)\n", "issue": "Document the new setup utility\nTitle says all\n", "before_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\n\n\nversion = os.getenv(\"this_version\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}], "after_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}]}
| 1,296 | 93 |
gh_patches_debug_8556
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-7503
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dns-rfc2136 is unusable if packet loss present
certbot_dns_rfc2136 authenticator is not robust on a losing network.
During authenticating, the plugin have to send several SOA queries directly to the authoritative nameserver. The number of queries is depended on the specific configuration. In my case, it sends out 21 queries for a single certification with 6 dns-alt names.
Currently, it sends them out using UDP **without timeout** and without retry mechanism. Thus, any single packet lost on these queries will cause the certbot stuck forever.
https://github.com/certbot/certbot/blob/3c24ff88cc0106ac39e5b0f5bd6bf0f29572201e/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py#L209-L210
In my case, the network between my webserver and the nameserver regularly get a ~20% packet loss rate (since one of them is in China). The chance I pass the authentication is around 0.8 ^ 21 < 1%.
## Proposed solution
1. Add a timeout with proper retry mechanism; or
2. Simply use TCP and let the OS handle it for us.
dns-rfc2136 is unusable if packet loss present
certbot_dns_rfc2136 authenticator is not robust on a losing network.
During authenticating, the plugin have to send several SOA queries directly to the authoritative nameserver. The number of queries is depended on the specific configuration. In my case, it sends out 21 queries for a single certification with 6 dns-alt names.
Currently, it sends them out using UDP **without timeout** and without retry mechanism. Thus, any single packet lost on these queries will cause the certbot stuck forever.
https://github.com/certbot/certbot/blob/3c24ff88cc0106ac39e5b0f5bd6bf0f29572201e/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py#L209-L210
In my case, the network between my webserver and the nameserver regularly get a ~20% packet loss rate (since one of them is in China). The chance I pass the authentication is around 0.8 ^ 21 < 1%.
## Proposed solution
1. Add a timeout with proper retry mechanism; or
2. Simply use TCP and let the OS handle it for us.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py`
Content:
```
1 """DNS Authenticator using RFC 2136 Dynamic Updates."""
2 import logging
3
4 import dns.flags
5 import dns.message
6 import dns.name
7 import dns.query
8 import dns.rdataclass
9 import dns.rdatatype
10 import dns.tsig
11 import dns.tsigkeyring
12 import dns.update
13 import zope.interface
14
15 from certbot import errors
16 from certbot import interfaces
17 from certbot.plugins import dns_common
18
19 logger = logging.getLogger(__name__)
20
21
22 @zope.interface.implementer(interfaces.IAuthenticator)
23 @zope.interface.provider(interfaces.IPluginFactory)
24 class Authenticator(dns_common.DNSAuthenticator):
25 """DNS Authenticator using RFC 2136 Dynamic Updates
26
27 This Authenticator uses RFC 2136 Dynamic Updates to fulfull a dns-01 challenge.
28 """
29
30 ALGORITHMS = {
31 'HMAC-MD5': dns.tsig.HMAC_MD5,
32 'HMAC-SHA1': dns.tsig.HMAC_SHA1,
33 'HMAC-SHA224': dns.tsig.HMAC_SHA224,
34 'HMAC-SHA256': dns.tsig.HMAC_SHA256,
35 'HMAC-SHA384': dns.tsig.HMAC_SHA384,
36 'HMAC-SHA512': dns.tsig.HMAC_SHA512
37 }
38
39 PORT = 53
40
41 description = 'Obtain certificates using a DNS TXT record (if you are using BIND for DNS).'
42 ttl = 120
43
44 def __init__(self, *args, **kwargs):
45 super(Authenticator, self).__init__(*args, **kwargs)
46 self.credentials = None
47
48 @classmethod
49 def add_parser_arguments(cls, add): # pylint: disable=arguments-differ
50 super(Authenticator, cls).add_parser_arguments(add, default_propagation_seconds=60)
51 add('credentials', help='RFC 2136 credentials INI file.')
52
53 def more_info(self): # pylint: disable=missing-docstring,no-self-use
54 return 'This plugin configures a DNS TXT record to respond to a dns-01 challenge using ' + \
55 'RFC 2136 Dynamic Updates.'
56
57 def _validate_algorithm(self, credentials):
58 algorithm = credentials.conf('algorithm')
59 if algorithm:
60 if not self.ALGORITHMS.get(algorithm.upper()):
61 raise errors.PluginError("Unknown algorithm: {0}.".format(algorithm))
62
63 def _setup_credentials(self):
64 self.credentials = self._configure_credentials(
65 'credentials',
66 'RFC 2136 credentials INI file',
67 {
68 'name': 'TSIG key name',
69 'secret': 'TSIG key secret',
70 'server': 'The target DNS server'
71 },
72 self._validate_algorithm
73 )
74
75 def _perform(self, _domain, validation_name, validation):
76 self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)
77
78 def _cleanup(self, _domain, validation_name, validation):
79 self._get_rfc2136_client().del_txt_record(validation_name, validation)
80
81 def _get_rfc2136_client(self):
82 return _RFC2136Client(self.credentials.conf('server'),
83 int(self.credentials.conf('port') or self.PORT),
84 self.credentials.conf('name'),
85 self.credentials.conf('secret'),
86 self.ALGORITHMS.get(self.credentials.conf('algorithm'),
87 dns.tsig.HMAC_MD5))
88
89
90 class _RFC2136Client(object):
91 """
92 Encapsulates all communication with the target DNS server.
93 """
94 def __init__(self, server, port, key_name, key_secret, key_algorithm):
95 self.server = server
96 self.port = port
97 self.keyring = dns.tsigkeyring.from_text({
98 key_name: key_secret
99 })
100 self.algorithm = key_algorithm
101
102 def add_txt_record(self, record_name, record_content, record_ttl):
103 """
104 Add a TXT record using the supplied information.
105
106 :param str record_name: The record name (typically beginning with '_acme-challenge.').
107 :param str record_content: The record content (typically the challenge validation).
108 :param int record_ttl: The record TTL (number of seconds that the record may be cached).
109 :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server
110 """
111
112 domain = self._find_domain(record_name)
113
114 n = dns.name.from_text(record_name)
115 o = dns.name.from_text(domain)
116 rel = n.relativize(o)
117
118 update = dns.update.Update(
119 domain,
120 keyring=self.keyring,
121 keyalgorithm=self.algorithm)
122 update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)
123
124 try:
125 response = dns.query.tcp(update, self.server, port=self.port)
126 except Exception as e:
127 raise errors.PluginError('Encountered error adding TXT record: {0}'
128 .format(e))
129 rcode = response.rcode()
130
131 if rcode == dns.rcode.NOERROR:
132 logger.debug('Successfully added TXT record')
133 else:
134 raise errors.PluginError('Received response from server: {0}'
135 .format(dns.rcode.to_text(rcode)))
136
137 def del_txt_record(self, record_name, record_content):
138 """
139 Delete a TXT record using the supplied information.
140
141 :param str record_name: The record name (typically beginning with '_acme-challenge.').
142 :param str record_content: The record content (typically the challenge validation).
143 :param int record_ttl: The record TTL (number of seconds that the record may be cached).
144 :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server
145 """
146
147 domain = self._find_domain(record_name)
148
149 n = dns.name.from_text(record_name)
150 o = dns.name.from_text(domain)
151 rel = n.relativize(o)
152
153 update = dns.update.Update(
154 domain,
155 keyring=self.keyring,
156 keyalgorithm=self.algorithm)
157 update.delete(rel, dns.rdatatype.TXT, record_content)
158
159 try:
160 response = dns.query.tcp(update, self.server, port=self.port)
161 except Exception as e:
162 raise errors.PluginError('Encountered error deleting TXT record: {0}'
163 .format(e))
164 rcode = response.rcode()
165
166 if rcode == dns.rcode.NOERROR:
167 logger.debug('Successfully deleted TXT record')
168 else:
169 raise errors.PluginError('Received response from server: {0}'
170 .format(dns.rcode.to_text(rcode)))
171
172 def _find_domain(self, record_name):
173 """
174 Find the closest domain with an SOA record for a given domain name.
175
176 :param str record_name: The record name for which to find the closest SOA record.
177 :returns: The domain, if found.
178 :rtype: str
179 :raises certbot.errors.PluginError: if no SOA record can be found.
180 """
181
182 domain_name_guesses = dns_common.base_domain_name_guesses(record_name)
183
184 # Loop through until we find an authoritative SOA record
185 for guess in domain_name_guesses:
186 if self._query_soa(guess):
187 return guess
188
189 raise errors.PluginError('Unable to determine base domain for {0} using names: {1}.'
190 .format(record_name, domain_name_guesses))
191
192 def _query_soa(self, domain_name):
193 """
194 Query a domain name for an authoritative SOA record.
195
196 :param str domain_name: The domain name to query for an SOA record.
197 :returns: True if found, False otherwise.
198 :rtype: bool
199 :raises certbot.errors.PluginError: if no response is received.
200 """
201
202 domain = dns.name.from_text(domain_name)
203
204 request = dns.message.make_query(domain, dns.rdatatype.SOA, dns.rdataclass.IN)
205 # Turn off Recursion Desired bit in query
206 request.flags ^= dns.flags.RD
207
208 try:
209 response = dns.query.udp(request, self.server, port=self.port)
210 rcode = response.rcode()
211
212 # Authoritative Answer bit should be set
213 if (rcode == dns.rcode.NOERROR and response.get_rrset(response.answer,
214 domain, dns.rdataclass.IN, dns.rdatatype.SOA) and response.flags & dns.flags.AA):
215 logger.debug('Received authoritative SOA response for %s', domain_name)
216 return True
217
218 logger.debug('No authoritative SOA record found for %s', domain_name)
219 return False
220 except Exception as e:
221 raise errors.PluginError('Encountered error when making query: {0}'
222 .format(e))
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py
--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py
+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py
@@ -206,7 +206,11 @@
request.flags ^= dns.flags.RD
try:
- response = dns.query.udp(request, self.server, port=self.port)
+ try:
+ response = dns.query.tcp(request, self.server, port=self.port)
+ except OSError as e:
+ logger.debug('TCP query failed, fallback to UDP: %s', e)
+ response = dns.query.udp(request, self.server, port=self.port)
rcode = response.rcode()
# Authoritative Answer bit should be set
|
{"golden_diff": "diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py\n--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py\n+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py\n@@ -206,7 +206,11 @@\n request.flags ^= dns.flags.RD\n \n try:\n- response = dns.query.udp(request, self.server, port=self.port)\n+ try:\n+ response = dns.query.tcp(request, self.server, port=self.port)\n+ except OSError as e:\n+ logger.debug('TCP query failed, fallback to UDP: %s', e)\n+ response = dns.query.udp(request, self.server, port=self.port)\n rcode = response.rcode()\n \n # Authoritative Answer bit should be set\n", "issue": "dns-rfc2136 is unusable if packet loss present\ncertbot_dns_rfc2136 authenticator is not robust on a losing network.\r\n\r\nDuring authenticating, the plugin have to send several SOA queries directly to the authoritative nameserver. The number of queries is depended on the specific configuration. In my case, it sends out 21 queries for a single certification with 6 dns-alt names.\r\n\r\nCurrently, it sends them out using UDP **without timeout** and without retry mechanism. Thus, any single packet lost on these queries will cause the certbot stuck forever.\r\n\r\nhttps://github.com/certbot/certbot/blob/3c24ff88cc0106ac39e5b0f5bd6bf0f29572201e/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py#L209-L210\r\n\r\nIn my case, the network between my webserver and the nameserver regularly get a ~20% packet loss rate (since one of them is in China). The chance I pass the authentication is around 0.8 ^ 21 < 1%.\r\n\r\n## Proposed solution\r\n\r\n1. Add a timeout with proper retry mechanism; or\r\n2. Simply use TCP and let the OS handle it for us.\ndns-rfc2136 is unusable if packet loss present\ncertbot_dns_rfc2136 authenticator is not robust on a losing network.\r\n\r\nDuring authenticating, the plugin have to send several SOA queries directly to the authoritative nameserver. The number of queries is depended on the specific configuration. In my case, it sends out 21 queries for a single certification with 6 dns-alt names.\r\n\r\nCurrently, it sends them out using UDP **without timeout** and without retry mechanism. Thus, any single packet lost on these queries will cause the certbot stuck forever.\r\n\r\nhttps://github.com/certbot/certbot/blob/3c24ff88cc0106ac39e5b0f5bd6bf0f29572201e/certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py#L209-L210\r\n\r\nIn my case, the network between my webserver and the nameserver regularly get a ~20% packet loss rate (since one of them is in China). The chance I pass the authentication is around 0.8 ^ 21 < 1%.\r\n\r\n## Proposed solution\r\n\r\n1. Add a timeout with proper retry mechanism; or\r\n2. Simply use TCP and let the OS handle it for us.\n", "before_files": [{"content": "\"\"\"DNS Authenticator using RFC 2136 Dynamic Updates.\"\"\"\nimport logging\n\nimport dns.flags\nimport dns.message\nimport dns.name\nimport dns.query\nimport dns.rdataclass\nimport dns.rdatatype\nimport dns.tsig\nimport dns.tsigkeyring\nimport dns.update\nimport zope.interface\n\nfrom certbot import errors\nfrom certbot import interfaces\nfrom certbot.plugins import dns_common\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](interfaces.IAuthenticator)\[email protected](interfaces.IPluginFactory)\nclass Authenticator(dns_common.DNSAuthenticator):\n \"\"\"DNS Authenticator using RFC 2136 Dynamic Updates\n\n This Authenticator uses RFC 2136 Dynamic Updates to fulfull a dns-01 challenge.\n \"\"\"\n\n ALGORITHMS = {\n 'HMAC-MD5': dns.tsig.HMAC_MD5,\n 'HMAC-SHA1': dns.tsig.HMAC_SHA1,\n 'HMAC-SHA224': dns.tsig.HMAC_SHA224,\n 'HMAC-SHA256': dns.tsig.HMAC_SHA256,\n 'HMAC-SHA384': dns.tsig.HMAC_SHA384,\n 'HMAC-SHA512': dns.tsig.HMAC_SHA512\n }\n\n PORT = 53\n\n description = 'Obtain certificates using a DNS TXT record (if you are using BIND for DNS).'\n ttl = 120\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n self.credentials = None\n\n @classmethod\n def add_parser_arguments(cls, add): # pylint: disable=arguments-differ\n super(Authenticator, cls).add_parser_arguments(add, default_propagation_seconds=60)\n add('credentials', help='RFC 2136 credentials INI file.')\n\n def more_info(self): # pylint: disable=missing-docstring,no-self-use\n return 'This plugin configures a DNS TXT record to respond to a dns-01 challenge using ' + \\\n 'RFC 2136 Dynamic Updates.'\n\n def _validate_algorithm(self, credentials):\n algorithm = credentials.conf('algorithm')\n if algorithm:\n if not self.ALGORITHMS.get(algorithm.upper()):\n raise errors.PluginError(\"Unknown algorithm: {0}.\".format(algorithm))\n\n def _setup_credentials(self):\n self.credentials = self._configure_credentials(\n 'credentials',\n 'RFC 2136 credentials INI file',\n {\n 'name': 'TSIG key name',\n 'secret': 'TSIG key secret',\n 'server': 'The target DNS server'\n },\n self._validate_algorithm\n )\n\n def _perform(self, _domain, validation_name, validation):\n self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)\n\n def _cleanup(self, _domain, validation_name, validation):\n self._get_rfc2136_client().del_txt_record(validation_name, validation)\n\n def _get_rfc2136_client(self):\n return _RFC2136Client(self.credentials.conf('server'),\n int(self.credentials.conf('port') or self.PORT),\n self.credentials.conf('name'),\n self.credentials.conf('secret'),\n self.ALGORITHMS.get(self.credentials.conf('algorithm'),\n dns.tsig.HMAC_MD5))\n\n\nclass _RFC2136Client(object):\n \"\"\"\n Encapsulates all communication with the target DNS server.\n \"\"\"\n def __init__(self, server, port, key_name, key_secret, key_algorithm):\n self.server = server\n self.port = port\n self.keyring = dns.tsigkeyring.from_text({\n key_name: key_secret\n })\n self.algorithm = key_algorithm\n\n def add_txt_record(self, record_name, record_content, record_ttl):\n \"\"\"\n Add a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error adding TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully added TXT record')\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def del_txt_record(self, record_name, record_content):\n \"\"\"\n Delete a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.delete(rel, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error deleting TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully deleted TXT record')\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def _find_domain(self, record_name):\n \"\"\"\n Find the closest domain with an SOA record for a given domain name.\n\n :param str record_name: The record name for which to find the closest SOA record.\n :returns: The domain, if found.\n :rtype: str\n :raises certbot.errors.PluginError: if no SOA record can be found.\n \"\"\"\n\n domain_name_guesses = dns_common.base_domain_name_guesses(record_name)\n\n # Loop through until we find an authoritative SOA record\n for guess in domain_name_guesses:\n if self._query_soa(guess):\n return guess\n\n raise errors.PluginError('Unable to determine base domain for {0} using names: {1}.'\n .format(record_name, domain_name_guesses))\n\n def _query_soa(self, domain_name):\n \"\"\"\n Query a domain name for an authoritative SOA record.\n\n :param str domain_name: The domain name to query for an SOA record.\n :returns: True if found, False otherwise.\n :rtype: bool\n :raises certbot.errors.PluginError: if no response is received.\n \"\"\"\n\n domain = dns.name.from_text(domain_name)\n\n request = dns.message.make_query(domain, dns.rdatatype.SOA, dns.rdataclass.IN)\n # Turn off Recursion Desired bit in query\n request.flags ^= dns.flags.RD\n\n try:\n response = dns.query.udp(request, self.server, port=self.port)\n rcode = response.rcode()\n\n # Authoritative Answer bit should be set\n if (rcode == dns.rcode.NOERROR and response.get_rrset(response.answer,\n domain, dns.rdataclass.IN, dns.rdatatype.SOA) and response.flags & dns.flags.AA):\n logger.debug('Received authoritative SOA response for %s', domain_name)\n return True\n\n logger.debug('No authoritative SOA record found for %s', domain_name)\n return False\n except Exception as e:\n raise errors.PluginError('Encountered error when making query: {0}'\n .format(e))\n", "path": "certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py"}], "after_files": [{"content": "\"\"\"DNS Authenticator using RFC 2136 Dynamic Updates.\"\"\"\nimport logging\n\nimport dns.flags\nimport dns.message\nimport dns.name\nimport dns.query\nimport dns.rdataclass\nimport dns.rdatatype\nimport dns.tsig\nimport dns.tsigkeyring\nimport dns.update\nimport zope.interface\n\nfrom certbot import errors\nfrom certbot import interfaces\nfrom certbot.plugins import dns_common\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](interfaces.IAuthenticator)\[email protected](interfaces.IPluginFactory)\nclass Authenticator(dns_common.DNSAuthenticator):\n \"\"\"DNS Authenticator using RFC 2136 Dynamic Updates\n\n This Authenticator uses RFC 2136 Dynamic Updates to fulfull a dns-01 challenge.\n \"\"\"\n\n ALGORITHMS = {\n 'HMAC-MD5': dns.tsig.HMAC_MD5,\n 'HMAC-SHA1': dns.tsig.HMAC_SHA1,\n 'HMAC-SHA224': dns.tsig.HMAC_SHA224,\n 'HMAC-SHA256': dns.tsig.HMAC_SHA256,\n 'HMAC-SHA384': dns.tsig.HMAC_SHA384,\n 'HMAC-SHA512': dns.tsig.HMAC_SHA512\n }\n\n PORT = 53\n\n description = 'Obtain certificates using a DNS TXT record (if you are using BIND for DNS).'\n ttl = 120\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n self.credentials = None\n\n @classmethod\n def add_parser_arguments(cls, add): # pylint: disable=arguments-differ\n super(Authenticator, cls).add_parser_arguments(add, default_propagation_seconds=60)\n add('credentials', help='RFC 2136 credentials INI file.')\n\n def more_info(self): # pylint: disable=missing-docstring,no-self-use\n return 'This plugin configures a DNS TXT record to respond to a dns-01 challenge using ' + \\\n 'RFC 2136 Dynamic Updates.'\n\n def _validate_algorithm(self, credentials):\n algorithm = credentials.conf('algorithm')\n if algorithm:\n if not self.ALGORITHMS.get(algorithm.upper()):\n raise errors.PluginError(\"Unknown algorithm: {0}.\".format(algorithm))\n\n def _setup_credentials(self):\n self.credentials = self._configure_credentials(\n 'credentials',\n 'RFC 2136 credentials INI file',\n {\n 'name': 'TSIG key name',\n 'secret': 'TSIG key secret',\n 'server': 'The target DNS server'\n },\n self._validate_algorithm\n )\n\n def _perform(self, _domain, validation_name, validation):\n self._get_rfc2136_client().add_txt_record(validation_name, validation, self.ttl)\n\n def _cleanup(self, _domain, validation_name, validation):\n self._get_rfc2136_client().del_txt_record(validation_name, validation)\n\n def _get_rfc2136_client(self):\n return _RFC2136Client(self.credentials.conf('server'),\n int(self.credentials.conf('port') or self.PORT),\n self.credentials.conf('name'),\n self.credentials.conf('secret'),\n self.ALGORITHMS.get(self.credentials.conf('algorithm'),\n dns.tsig.HMAC_MD5))\n\n\nclass _RFC2136Client(object):\n \"\"\"\n Encapsulates all communication with the target DNS server.\n \"\"\"\n def __init__(self, server, port, key_name, key_secret, key_algorithm):\n self.server = server\n self.port = port\n self.keyring = dns.tsigkeyring.from_text({\n key_name: key_secret\n })\n self.algorithm = key_algorithm\n\n def add_txt_record(self, record_name, record_content, record_ttl):\n \"\"\"\n Add a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.add(rel, record_ttl, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error adding TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully added TXT record')\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def del_txt_record(self, record_name, record_content):\n \"\"\"\n Delete a TXT record using the supplied information.\n\n :param str record_name: The record name (typically beginning with '_acme-challenge.').\n :param str record_content: The record content (typically the challenge validation).\n :param int record_ttl: The record TTL (number of seconds that the record may be cached).\n :raises certbot.errors.PluginError: if an error occurs communicating with the DNS server\n \"\"\"\n\n domain = self._find_domain(record_name)\n\n n = dns.name.from_text(record_name)\n o = dns.name.from_text(domain)\n rel = n.relativize(o)\n\n update = dns.update.Update(\n domain,\n keyring=self.keyring,\n keyalgorithm=self.algorithm)\n update.delete(rel, dns.rdatatype.TXT, record_content)\n\n try:\n response = dns.query.tcp(update, self.server, port=self.port)\n except Exception as e:\n raise errors.PluginError('Encountered error deleting TXT record: {0}'\n .format(e))\n rcode = response.rcode()\n\n if rcode == dns.rcode.NOERROR:\n logger.debug('Successfully deleted TXT record')\n else:\n raise errors.PluginError('Received response from server: {0}'\n .format(dns.rcode.to_text(rcode)))\n\n def _find_domain(self, record_name):\n \"\"\"\n Find the closest domain with an SOA record for a given domain name.\n\n :param str record_name: The record name for which to find the closest SOA record.\n :returns: The domain, if found.\n :rtype: str\n :raises certbot.errors.PluginError: if no SOA record can be found.\n \"\"\"\n\n domain_name_guesses = dns_common.base_domain_name_guesses(record_name)\n\n # Loop through until we find an authoritative SOA record\n for guess in domain_name_guesses:\n if self._query_soa(guess):\n return guess\n\n raise errors.PluginError('Unable to determine base domain for {0} using names: {1}.'\n .format(record_name, domain_name_guesses))\n\n def _query_soa(self, domain_name):\n \"\"\"\n Query a domain name for an authoritative SOA record.\n\n :param str domain_name: The domain name to query for an SOA record.\n :returns: True if found, False otherwise.\n :rtype: bool\n :raises certbot.errors.PluginError: if no response is received.\n \"\"\"\n\n domain = dns.name.from_text(domain_name)\n\n request = dns.message.make_query(domain, dns.rdatatype.SOA, dns.rdataclass.IN)\n # Turn off Recursion Desired bit in query\n request.flags ^= dns.flags.RD\n\n try:\n try:\n response = dns.query.tcp(request, self.server, port=self.port)\n except OSError as e:\n logger.debug('TCP query failed, fallback to UDP: %s', e)\n response = dns.query.udp(request, self.server, port=self.port)\n rcode = response.rcode()\n\n # Authoritative Answer bit should be set\n if (rcode == dns.rcode.NOERROR and response.get_rrset(response.answer,\n domain, dns.rdataclass.IN, dns.rdatatype.SOA) and response.flags & dns.flags.AA):\n logger.debug('Received authoritative SOA response for %s', domain_name)\n return True\n\n logger.debug('No authoritative SOA record found for %s', domain_name)\n return False\n except Exception as e:\n raise errors.PluginError('Encountered error when making query: {0}'\n .format(e))\n", "path": "certbot-dns-rfc2136/certbot_dns_rfc2136/dns_rfc2136.py"}]}
| 3,320 | 257 |
gh_patches_debug_36956
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2998
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
can not print/run/transpile a circuit with the custom instruction
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**: the master
- **Python version**: 3.7.3
- **Operating system**: macOS
### What is the current behavior?
the circuit built with custom instruction can not be printed/ran/transpiled if there are classical registers/measure gates.
error trace
```
---------------------------------------------------------------------------
DAGCircuitError Traceback (most recent call last)
<ipython-input-36-ece1b508a302> in <module>
----> 1 execute(new_qc, backend=qasm_sim).result()
~/Developer/Quantum/qiskit-terra/qiskit/execute.py in execute(experiments, backend, basis_gates, coupling_map, backend_properties, initial_layout, seed_transpiler, optimization_level, pass_manager, qobj_id, qobj_header, shots, memory, max_credits, seed_simulator, default_qubit_los, default_meas_los, schedule_los, meas_level, meas_return, memory_slots, memory_slot_size, rep_time, parameter_binds, **run_config)
195 optimization_level=optimization_level,
196 backend=backend,
--> 197 pass_manager=pass_manager,
198 )
199
~/Developer/Quantum/qiskit-terra/qiskit/compiler/transpile.py in transpile(circuits, backend, basis_gates, coupling_map, backend_properties, initial_layout, seed_transpiler, optimization_level, pass_manager, callback)
186 'in the coupling_map')
187 # Transpile circuits in parallel
--> 188 circuits = parallel_map(_transpile_circuit, list(zip(circuits, transpile_configs)))
189
190 if len(circuits) == 1:
~/Developer/Quantum/qiskit-terra/qiskit/tools/parallel.py in parallel_map(task, values, task_args, task_kwargs, num_processes)
98 """
99 if len(values) == 1:
--> 100 return [task(values[0], *task_args, **task_kwargs)]
101
102 Publisher().publish("terra.parallel.start", len(values))
~/Developer/Quantum/qiskit-terra/qiskit/compiler/transpile.py in _transpile_circuit(circuit_config_tuple)
207 circuit, transpile_config = circuit_config_tuple
208
--> 209 return transpile_circuit(circuit, transpile_config)
210
211
~/Developer/Quantum/qiskit-terra/qiskit/transpiler/transpile_circuit.py in transpile_circuit(circuit, transpile_config)
60 pass_manager.callback = transpile_config.callback
61
---> 62 return pass_manager.run(circuit)
~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in run(***failed resolving arguments***)
169 for passset in self.working_list:
170 for pass_ in passset:
--> 171 dag = self._do_pass(pass_, dag, passset.options)
172
173 circuit = dag_to_circuit(dag)
~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in _do_pass(self, pass_, dag, options)
200 # Run the pass itself, if not already run
201 if pass_ not in self.valid_passes:
--> 202 dag = self._run_this_pass(pass_, dag)
203
204 # update the valid_passes property
~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in _run_this_pass(self, pass_, dag)
213 if self.log_passes or self.callback:
214 start_time = time()
--> 215 new_dag = pass_.run(dag)
216 if self.log_passes or self.callback:
217 end_time = time()
~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passes/unroller.py in run(self, dag)
78 decomposition.add_qreg(rule[0][1][0].register)
79 for inst in rule:
---> 80 decomposition.apply_operation_back(*inst)
81
82 unrolled_dag = self.run(decomposition) # recursively unroll ops
~/Developer/Quantum/qiskit-terra/qiskit/dagcircuit/dagcircuit.py in apply_operation_back(self, op, qargs, cargs, condition)
261 self._check_condition(op.name, condition)
262 self._check_bits(qargs, self.output_map)
--> 263 self._check_bits(all_cbits, self.output_map)
264
265 self._add_op_node(op, qargs, cargs, condition)
~/Developer/Quantum/qiskit-terra/qiskit/dagcircuit/dagcircuit.py in _check_bits(self, args, amap)
200 if wire not in amap:
201 raise DAGCircuitError("(qu)bit %s[%d] not found" %
--> 202 (wire[0].name, wire[1]))
203
204 def _bits_in_condition(self, cond):
DAGCircuitError: '(qu)bit c[0] not found'
```
### Steps to reproduce the problem
```python
from qiskit import QuantumCircuit, QuantumRegister, BasicAer, execute, ClassicalRegister
from qiskit.quantum_info import state_fidelity
from qiskit.compiler import transpile
qasm_sim = BasicAer.get_backend('qasm_simulator')
qr = QuantumRegister(2)
cr = ClassicalRegister(2)
qc = QuantumCircuit(qr, cr, name='inst')
qc.x(qr[0])
qc.h(qr[1])
qc.measure(qr[0], cr[0])
qc.measure(qr[1], cr[1])
inst = qc.to_instruction()
new_qc = QuantumCircuit(qr, cr, name='inst2')
new_qc.append(inst, qr[:], cr[:])
t_qc = transpile(new_qc, backend=qasm_sim)
# execute(new_qc, backend=qasm_sim).result()
```
### What is the expected behavior?
Print/run/transpile the circuit with the custom instruction
### Suggested solutions
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/transpiler/passes/unroll_3q_or_more.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """Pass for decomposing 3q (or more) gates into 2q or 1q gates."""
16
17 from qiskit.transpiler.basepasses import TransformationPass
18 from qiskit.dagcircuit import DAGCircuit
19 from qiskit.exceptions import QiskitError
20
21
22 class Unroll3qOrMore(TransformationPass):
23 """
24 Recursively expands 3+ qubit gates until the circuit only contains
25 1 qubit and 2qubit gates.
26 """
27
28 def run(self, dag):
29 """Expand 3+ qubit gates using their decomposition rules.
30
31 Args:
32 dag(DAGCircuit): input dag
33 Returns:
34 DAGCircuit: output dag with maximum node degrees of 2
35 Raises:
36 QiskitError: if a 3q+ gate is not decomposable
37 """
38 for node in dag.threeQ_or_more_gates():
39 # TODO: allow choosing other possible decompositions
40 rule = node.op.definition
41 if not rule:
42 raise QiskitError("Cannot unroll all 3q or more gates. "
43 "No rule to expand instruction %s." %
44 node.op.name)
45
46 # hacky way to build a dag on the same register as the rule is defined
47 # TODO: need anonymous rules to address wires by index
48 decomposition = DAGCircuit()
49 decomposition.add_qreg(rule[0][1][0].register)
50 for inst in rule:
51 decomposition.apply_operation_back(*inst)
52 decomposition = self.run(decomposition) # recursively unroll
53 dag.substitute_node_with_dag(node, decomposition)
54 return dag
55
```
Path: `qiskit/transpiler/passes/decompose.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """Pass for one layer of decomposing the gates in a circuit."""
16
17 from qiskit.transpiler.basepasses import TransformationPass
18 from qiskit.dagcircuit import DAGCircuit
19
20
21 class Decompose(TransformationPass):
22 """
23 Expand a gate in a circuit using its decomposition rules.
24 """
25
26 def __init__(self, gate=None):
27 """
28 Args:
29 gate (qiskit.circuit.gate.Gate): Gate to decompose.
30 """
31 super().__init__()
32 self.gate = gate
33
34 def run(self, dag):
35 """Expand a given gate into its decomposition.
36
37 Args:
38 dag(DAGCircuit): input dag
39 Returns:
40 DAGCircuit: output dag where gate was expanded.
41 """
42 # Walk through the DAG and expand each non-basis node
43 for node in dag.op_nodes(self.gate):
44 # opaque or built-in gates are not decomposable
45 if not node.op.definition:
46 continue
47 # TODO: allow choosing among multiple decomposition rules
48 rule = node.op.definition
49 # hacky way to build a dag on the same register as the rule is defined
50 # TODO: need anonymous rules to address wires by index
51 decomposition = DAGCircuit()
52 decomposition.add_qreg(rule[0][1][0].register)
53 if rule[0][2]:
54 decomposition.add_creg(rule[0][2][0].register)
55 for inst in rule:
56 decomposition.apply_operation_back(*inst)
57 dag.substitute_node_with_dag(node, decomposition)
58 return dag
59
```
Path: `qiskit/transpiler/passes/unroller.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """Pass for unrolling a circuit to a given basis."""
16
17 from qiskit.transpiler.basepasses import TransformationPass
18 from qiskit.dagcircuit import DAGCircuit
19 from qiskit.exceptions import QiskitError
20 from qiskit.circuit import ParameterExpression
21
22
23 class Unroller(TransformationPass):
24 """
25 Unroll (expand) non-basis, non-opaque instructions recursively
26 to a desired basis, using decomposition rules defined for each instruction.
27 """
28
29 def __init__(self, basis):
30 """
31 Args:
32 basis (list[str]): Target basis names to unroll to, e.g. `['u3', 'cx']` .
33 """
34 super().__init__()
35 self.basis = basis
36
37 def run(self, dag):
38 """Expand all op nodes to the given basis.
39
40 Args:
41 dag(DAGCircuit): input dag
42
43 Raises:
44 QiskitError: if unable to unroll given the basis due to undefined
45 decomposition rules (such as a bad basis) or excessive recursion.
46
47 Returns:
48 DAGCircuit: output unrolled dag
49 """
50 # Walk through the DAG and expand each non-basis node
51 for node in dag.op_nodes():
52 basic_insts = ['measure', 'reset', 'barrier', 'snapshot']
53 if node.name in basic_insts:
54 # TODO: this is legacy behavior.Basis_insts should be removed that these
55 # instructions should be part of the device-reported basis. Currently, no
56 # backend reports "measure", for example.
57 continue
58 if node.name in self.basis: # If already a base, ignore.
59 continue
60
61 # TODO: allow choosing other possible decompositions
62 try:
63 rule = node.op.definition
64 except TypeError as err:
65 if any(isinstance(p, ParameterExpression) for p in node.op.params):
66 raise QiskitError('Unrolling gates parameterized by expressions '
67 'is currently unsupported.')
68 raise QiskitError('Error decomposing node {}: {}'.format(node.name, err))
69
70 if not rule:
71 raise QiskitError("Cannot unroll the circuit to the given basis, %s. "
72 "No rule to expand instruction %s." %
73 (str(self.basis), node.op.name))
74
75 # hacky way to build a dag on the same register as the rule is defined
76 # TODO: need anonymous rules to address wires by index
77 decomposition = DAGCircuit()
78 decomposition.add_qreg(rule[0][1][0].register)
79 for inst in rule:
80 decomposition.apply_operation_back(*inst)
81
82 unrolled_dag = self.run(decomposition) # recursively unroll ops
83 dag.substitute_node_with_dag(node, unrolled_dag)
84 return dag
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/transpiler/passes/decompose.py b/qiskit/transpiler/passes/decompose.py
--- a/qiskit/transpiler/passes/decompose.py
+++ b/qiskit/transpiler/passes/decompose.py
@@ -49,9 +49,12 @@
# hacky way to build a dag on the same register as the rule is defined
# TODO: need anonymous rules to address wires by index
decomposition = DAGCircuit()
- decomposition.add_qreg(rule[0][1][0].register)
- if rule[0][2]:
- decomposition.add_creg(rule[0][2][0].register)
+ qregs = {qb.register for inst in rule for qb in inst[1]}
+ cregs = {cb.register for inst in rule for cb in inst[2]}
+ for qreg in qregs:
+ decomposition.add_qreg(qreg)
+ for creg in cregs:
+ decomposition.add_creg(creg)
for inst in rule:
decomposition.apply_operation_back(*inst)
dag.substitute_node_with_dag(node, decomposition)
diff --git a/qiskit/transpiler/passes/unroll_3q_or_more.py b/qiskit/transpiler/passes/unroll_3q_or_more.py
--- a/qiskit/transpiler/passes/unroll_3q_or_more.py
+++ b/qiskit/transpiler/passes/unroll_3q_or_more.py
@@ -46,7 +46,12 @@
# hacky way to build a dag on the same register as the rule is defined
# TODO: need anonymous rules to address wires by index
decomposition = DAGCircuit()
- decomposition.add_qreg(rule[0][1][0].register)
+ qregs = {qb.register for inst in rule for qb in inst[1]}
+ cregs = {cb.register for inst in rule for cb in inst[2]}
+ for qreg in qregs:
+ decomposition.add_qreg(qreg)
+ for creg in cregs:
+ decomposition.add_creg(creg)
for inst in rule:
decomposition.apply_operation_back(*inst)
decomposition = self.run(decomposition) # recursively unroll
diff --git a/qiskit/transpiler/passes/unroller.py b/qiskit/transpiler/passes/unroller.py
--- a/qiskit/transpiler/passes/unroller.py
+++ b/qiskit/transpiler/passes/unroller.py
@@ -75,7 +75,12 @@
# hacky way to build a dag on the same register as the rule is defined
# TODO: need anonymous rules to address wires by index
decomposition = DAGCircuit()
- decomposition.add_qreg(rule[0][1][0].register)
+ qregs = {qb.register for inst in rule for qb in inst[1]}
+ cregs = {cb.register for inst in rule for cb in inst[2]}
+ for qreg in qregs:
+ decomposition.add_qreg(qreg)
+ for creg in cregs:
+ decomposition.add_creg(creg)
for inst in rule:
decomposition.apply_operation_back(*inst)
|
{"golden_diff": "diff --git a/qiskit/transpiler/passes/decompose.py b/qiskit/transpiler/passes/decompose.py\n--- a/qiskit/transpiler/passes/decompose.py\n+++ b/qiskit/transpiler/passes/decompose.py\n@@ -49,9 +49,12 @@\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n- decomposition.add_qreg(rule[0][1][0].register)\n- if rule[0][2]:\n- decomposition.add_creg(rule[0][2][0].register)\n+ qregs = {qb.register for inst in rule for qb in inst[1]}\n+ cregs = {cb.register for inst in rule for cb in inst[2]}\n+ for qreg in qregs:\n+ decomposition.add_qreg(qreg)\n+ for creg in cregs:\n+ decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n dag.substitute_node_with_dag(node, decomposition)\ndiff --git a/qiskit/transpiler/passes/unroll_3q_or_more.py b/qiskit/transpiler/passes/unroll_3q_or_more.py\n--- a/qiskit/transpiler/passes/unroll_3q_or_more.py\n+++ b/qiskit/transpiler/passes/unroll_3q_or_more.py\n@@ -46,7 +46,12 @@\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n- decomposition.add_qreg(rule[0][1][0].register)\n+ qregs = {qb.register for inst in rule for qb in inst[1]}\n+ cregs = {cb.register for inst in rule for cb in inst[2]}\n+ for qreg in qregs:\n+ decomposition.add_qreg(qreg)\n+ for creg in cregs:\n+ decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n decomposition = self.run(decomposition) # recursively unroll\ndiff --git a/qiskit/transpiler/passes/unroller.py b/qiskit/transpiler/passes/unroller.py\n--- a/qiskit/transpiler/passes/unroller.py\n+++ b/qiskit/transpiler/passes/unroller.py\n@@ -75,7 +75,12 @@\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n- decomposition.add_qreg(rule[0][1][0].register)\n+ qregs = {qb.register for inst in rule for qb in inst[1]}\n+ cregs = {cb.register for inst in rule for cb in inst[2]}\n+ for qreg in qregs:\n+ decomposition.add_qreg(qreg)\n+ for creg in cregs:\n+ decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n", "issue": "can not print/run/transpile a circuit with the custom instruction\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**: the master\r\n- **Python version**: 3.7.3\r\n- **Operating system**: macOS\r\n\r\n### What is the current behavior?\r\nthe circuit built with custom instruction can not be printed/ran/transpiled if there are classical registers/measure gates.\r\n\r\nerror trace\r\n```\r\n---------------------------------------------------------------------------\r\nDAGCircuitError Traceback (most recent call last)\r\n<ipython-input-36-ece1b508a302> in <module>\r\n----> 1 execute(new_qc, backend=qasm_sim).result()\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/execute.py in execute(experiments, backend, basis_gates, coupling_map, backend_properties, initial_layout, seed_transpiler, optimization_level, pass_manager, qobj_id, qobj_header, shots, memory, max_credits, seed_simulator, default_qubit_los, default_meas_los, schedule_los, meas_level, meas_return, memory_slots, memory_slot_size, rep_time, parameter_binds, **run_config)\r\n 195 optimization_level=optimization_level,\r\n 196 backend=backend,\r\n--> 197 pass_manager=pass_manager,\r\n 198 )\r\n 199 \r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/compiler/transpile.py in transpile(circuits, backend, basis_gates, coupling_map, backend_properties, initial_layout, seed_transpiler, optimization_level, pass_manager, callback)\r\n 186 'in the coupling_map')\r\n 187 # Transpile circuits in parallel\r\n--> 188 circuits = parallel_map(_transpile_circuit, list(zip(circuits, transpile_configs)))\r\n 189 \r\n 190 if len(circuits) == 1:\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/tools/parallel.py in parallel_map(task, values, task_args, task_kwargs, num_processes)\r\n 98 \"\"\"\r\n 99 if len(values) == 1:\r\n--> 100 return [task(values[0], *task_args, **task_kwargs)]\r\n 101 \r\n 102 Publisher().publish(\"terra.parallel.start\", len(values))\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/compiler/transpile.py in _transpile_circuit(circuit_config_tuple)\r\n 207 circuit, transpile_config = circuit_config_tuple\r\n 208 \r\n--> 209 return transpile_circuit(circuit, transpile_config)\r\n 210 \r\n 211 \r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/transpiler/transpile_circuit.py in transpile_circuit(circuit, transpile_config)\r\n 60 pass_manager.callback = transpile_config.callback\r\n 61 \r\n---> 62 return pass_manager.run(circuit)\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in run(***failed resolving arguments***)\r\n 169 for passset in self.working_list:\r\n 170 for pass_ in passset:\r\n--> 171 dag = self._do_pass(pass_, dag, passset.options)\r\n 172 \r\n 173 circuit = dag_to_circuit(dag)\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in _do_pass(self, pass_, dag, options)\r\n 200 # Run the pass itself, if not already run\r\n 201 if pass_ not in self.valid_passes:\r\n--> 202 dag = self._run_this_pass(pass_, dag)\r\n 203 \r\n 204 # update the valid_passes property\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passmanager.py in _run_this_pass(self, pass_, dag)\r\n 213 if self.log_passes or self.callback:\r\n 214 start_time = time()\r\n--> 215 new_dag = pass_.run(dag)\r\n 216 if self.log_passes or self.callback:\r\n 217 end_time = time()\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/transpiler/passes/unroller.py in run(self, dag)\r\n 78 decomposition.add_qreg(rule[0][1][0].register)\r\n 79 for inst in rule:\r\n---> 80 decomposition.apply_operation_back(*inst)\r\n 81 \r\n 82 unrolled_dag = self.run(decomposition) # recursively unroll ops\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/dagcircuit/dagcircuit.py in apply_operation_back(self, op, qargs, cargs, condition)\r\n 261 self._check_condition(op.name, condition)\r\n 262 self._check_bits(qargs, self.output_map)\r\n--> 263 self._check_bits(all_cbits, self.output_map)\r\n 264 \r\n 265 self._add_op_node(op, qargs, cargs, condition)\r\n\r\n~/Developer/Quantum/qiskit-terra/qiskit/dagcircuit/dagcircuit.py in _check_bits(self, args, amap)\r\n 200 if wire not in amap:\r\n 201 raise DAGCircuitError(\"(qu)bit %s[%d] not found\" %\r\n--> 202 (wire[0].name, wire[1]))\r\n 203 \r\n 204 def _bits_in_condition(self, cond):\r\n\r\nDAGCircuitError: '(qu)bit c[0] not found'\r\n```\r\n\r\n### Steps to reproduce the problem\r\n```python\r\nfrom qiskit import QuantumCircuit, QuantumRegister, BasicAer, execute, ClassicalRegister\r\nfrom qiskit.quantum_info import state_fidelity\r\nfrom qiskit.compiler import transpile\r\n\r\nqasm_sim = BasicAer.get_backend('qasm_simulator')\r\n\r\nqr = QuantumRegister(2)\r\ncr = ClassicalRegister(2)\r\nqc = QuantumCircuit(qr, cr, name='inst')\r\n\r\nqc.x(qr[0])\r\nqc.h(qr[1])\r\nqc.measure(qr[0], cr[0])\r\nqc.measure(qr[1], cr[1])\r\n\r\ninst = qc.to_instruction()\r\nnew_qc = QuantumCircuit(qr, cr, name='inst2')\r\nnew_qc.append(inst, qr[:], cr[:])\r\n\r\nt_qc = transpile(new_qc, backend=qasm_sim)\r\n\r\n# execute(new_qc, backend=qasm_sim).result()\r\n```\r\n\r\n\r\n### What is the expected behavior?\r\nPrint/run/transpile the circuit with the custom instruction\r\n\r\n\r\n### Suggested solutions\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for decomposing 3q (or more) gates into 2q or 1q gates.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\nfrom qiskit.exceptions import QiskitError\n\n\nclass Unroll3qOrMore(TransformationPass):\n \"\"\"\n Recursively expands 3+ qubit gates until the circuit only contains\n 1 qubit and 2qubit gates.\n \"\"\"\n\n def run(self, dag):\n \"\"\"Expand 3+ qubit gates using their decomposition rules.\n\n Args:\n dag(DAGCircuit): input dag\n Returns:\n DAGCircuit: output dag with maximum node degrees of 2\n Raises:\n QiskitError: if a 3q+ gate is not decomposable\n \"\"\"\n for node in dag.threeQ_or_more_gates():\n # TODO: allow choosing other possible decompositions\n rule = node.op.definition\n if not rule:\n raise QiskitError(\"Cannot unroll all 3q or more gates. \"\n \"No rule to expand instruction %s.\" %\n node.op.name)\n\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n decomposition.add_qreg(rule[0][1][0].register)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n decomposition = self.run(decomposition) # recursively unroll\n dag.substitute_node_with_dag(node, decomposition)\n return dag\n", "path": "qiskit/transpiler/passes/unroll_3q_or_more.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for one layer of decomposing the gates in a circuit.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\n\n\nclass Decompose(TransformationPass):\n \"\"\"\n Expand a gate in a circuit using its decomposition rules.\n \"\"\"\n\n def __init__(self, gate=None):\n \"\"\"\n Args:\n gate (qiskit.circuit.gate.Gate): Gate to decompose.\n \"\"\"\n super().__init__()\n self.gate = gate\n\n def run(self, dag):\n \"\"\"Expand a given gate into its decomposition.\n\n Args:\n dag(DAGCircuit): input dag\n Returns:\n DAGCircuit: output dag where gate was expanded.\n \"\"\"\n # Walk through the DAG and expand each non-basis node\n for node in dag.op_nodes(self.gate):\n # opaque or built-in gates are not decomposable\n if not node.op.definition:\n continue\n # TODO: allow choosing among multiple decomposition rules\n rule = node.op.definition\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n decomposition.add_qreg(rule[0][1][0].register)\n if rule[0][2]:\n decomposition.add_creg(rule[0][2][0].register)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n dag.substitute_node_with_dag(node, decomposition)\n return dag\n", "path": "qiskit/transpiler/passes/decompose.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for unrolling a circuit to a given basis.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.circuit import ParameterExpression\n\n\nclass Unroller(TransformationPass):\n \"\"\"\n Unroll (expand) non-basis, non-opaque instructions recursively\n to a desired basis, using decomposition rules defined for each instruction.\n \"\"\"\n\n def __init__(self, basis):\n \"\"\"\n Args:\n basis (list[str]): Target basis names to unroll to, e.g. `['u3', 'cx']` .\n \"\"\"\n super().__init__()\n self.basis = basis\n\n def run(self, dag):\n \"\"\"Expand all op nodes to the given basis.\n\n Args:\n dag(DAGCircuit): input dag\n\n Raises:\n QiskitError: if unable to unroll given the basis due to undefined\n decomposition rules (such as a bad basis) or excessive recursion.\n\n Returns:\n DAGCircuit: output unrolled dag\n \"\"\"\n # Walk through the DAG and expand each non-basis node\n for node in dag.op_nodes():\n basic_insts = ['measure', 'reset', 'barrier', 'snapshot']\n if node.name in basic_insts:\n # TODO: this is legacy behavior.Basis_insts should be removed that these\n # instructions should be part of the device-reported basis. Currently, no\n # backend reports \"measure\", for example.\n continue\n if node.name in self.basis: # If already a base, ignore.\n continue\n\n # TODO: allow choosing other possible decompositions\n try:\n rule = node.op.definition\n except TypeError as err:\n if any(isinstance(p, ParameterExpression) for p in node.op.params):\n raise QiskitError('Unrolling gates parameterized by expressions '\n 'is currently unsupported.')\n raise QiskitError('Error decomposing node {}: {}'.format(node.name, err))\n\n if not rule:\n raise QiskitError(\"Cannot unroll the circuit to the given basis, %s. \"\n \"No rule to expand instruction %s.\" %\n (str(self.basis), node.op.name))\n\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n decomposition.add_qreg(rule[0][1][0].register)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n\n unrolled_dag = self.run(decomposition) # recursively unroll ops\n dag.substitute_node_with_dag(node, unrolled_dag)\n return dag\n", "path": "qiskit/transpiler/passes/unroller.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for decomposing 3q (or more) gates into 2q or 1q gates.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\nfrom qiskit.exceptions import QiskitError\n\n\nclass Unroll3qOrMore(TransformationPass):\n \"\"\"\n Recursively expands 3+ qubit gates until the circuit only contains\n 1 qubit and 2qubit gates.\n \"\"\"\n\n def run(self, dag):\n \"\"\"Expand 3+ qubit gates using their decomposition rules.\n\n Args:\n dag(DAGCircuit): input dag\n Returns:\n DAGCircuit: output dag with maximum node degrees of 2\n Raises:\n QiskitError: if a 3q+ gate is not decomposable\n \"\"\"\n for node in dag.threeQ_or_more_gates():\n # TODO: allow choosing other possible decompositions\n rule = node.op.definition\n if not rule:\n raise QiskitError(\"Cannot unroll all 3q or more gates. \"\n \"No rule to expand instruction %s.\" %\n node.op.name)\n\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n qregs = {qb.register for inst in rule for qb in inst[1]}\n cregs = {cb.register for inst in rule for cb in inst[2]}\n for qreg in qregs:\n decomposition.add_qreg(qreg)\n for creg in cregs:\n decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n decomposition = self.run(decomposition) # recursively unroll\n dag.substitute_node_with_dag(node, decomposition)\n return dag\n", "path": "qiskit/transpiler/passes/unroll_3q_or_more.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for one layer of decomposing the gates in a circuit.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\n\n\nclass Decompose(TransformationPass):\n \"\"\"\n Expand a gate in a circuit using its decomposition rules.\n \"\"\"\n\n def __init__(self, gate=None):\n \"\"\"\n Args:\n gate (qiskit.circuit.gate.Gate): Gate to decompose.\n \"\"\"\n super().__init__()\n self.gate = gate\n\n def run(self, dag):\n \"\"\"Expand a given gate into its decomposition.\n\n Args:\n dag(DAGCircuit): input dag\n Returns:\n DAGCircuit: output dag where gate was expanded.\n \"\"\"\n # Walk through the DAG and expand each non-basis node\n for node in dag.op_nodes(self.gate):\n # opaque or built-in gates are not decomposable\n if not node.op.definition:\n continue\n # TODO: allow choosing among multiple decomposition rules\n rule = node.op.definition\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n qregs = {qb.register for inst in rule for qb in inst[1]}\n cregs = {cb.register for inst in rule for cb in inst[2]}\n for qreg in qregs:\n decomposition.add_qreg(qreg)\n for creg in cregs:\n decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n dag.substitute_node_with_dag(node, decomposition)\n return dag\n", "path": "qiskit/transpiler/passes/decompose.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Pass for unrolling a circuit to a given basis.\"\"\"\n\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.dagcircuit import DAGCircuit\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.circuit import ParameterExpression\n\n\nclass Unroller(TransformationPass):\n \"\"\"\n Unroll (expand) non-basis, non-opaque instructions recursively\n to a desired basis, using decomposition rules defined for each instruction.\n \"\"\"\n\n def __init__(self, basis):\n \"\"\"\n Args:\n basis (list[str]): Target basis names to unroll to, e.g. `['u3', 'cx']` .\n \"\"\"\n super().__init__()\n self.basis = basis\n\n def run(self, dag):\n \"\"\"Expand all op nodes to the given basis.\n\n Args:\n dag(DAGCircuit): input dag\n\n Raises:\n QiskitError: if unable to unroll given the basis due to undefined\n decomposition rules (such as a bad basis) or excessive recursion.\n\n Returns:\n DAGCircuit: output unrolled dag\n \"\"\"\n # Walk through the DAG and expand each non-basis node\n for node in dag.op_nodes():\n basic_insts = ['measure', 'reset', 'barrier', 'snapshot']\n if node.name in basic_insts:\n # TODO: this is legacy behavior.Basis_insts should be removed that these\n # instructions should be part of the device-reported basis. Currently, no\n # backend reports \"measure\", for example.\n continue\n if node.name in self.basis: # If already a base, ignore.\n continue\n\n # TODO: allow choosing other possible decompositions\n try:\n rule = node.op.definition\n except TypeError as err:\n if any(isinstance(p, ParameterExpression) for p in node.op.params):\n raise QiskitError('Unrolling gates parameterized by expressions '\n 'is currently unsupported.')\n raise QiskitError('Error decomposing node {}: {}'.format(node.name, err))\n\n if not rule:\n raise QiskitError(\"Cannot unroll the circuit to the given basis, %s. \"\n \"No rule to expand instruction %s.\" %\n (str(self.basis), node.op.name))\n\n # hacky way to build a dag on the same register as the rule is defined\n # TODO: need anonymous rules to address wires by index\n decomposition = DAGCircuit()\n qregs = {qb.register for inst in rule for qb in inst[1]}\n cregs = {cb.register for inst in rule for cb in inst[2]}\n for qreg in qregs:\n decomposition.add_qreg(qreg)\n for creg in cregs:\n decomposition.add_creg(creg)\n for inst in rule:\n decomposition.apply_operation_back(*inst)\n\n unrolled_dag = self.run(decomposition) # recursively unroll ops\n dag.substitute_node_with_dag(node, unrolled_dag)\n return dag\n", "path": "qiskit/transpiler/passes/unroller.py"}]}
| 3,909 | 698 |
gh_patches_debug_35731
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-3029
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support for `_repr_html_` property on objects
From a user post here: https://discuss.streamlit.io/t/look-for-html-repr-on-objects-generally-a-method-called-repr-html/1939
> I have just started looking into streamlit after working on and using Panel 1. I am not sure if I missed this, but I was expecting an object with a _repr_html_ method to be automatically renderable with streamlit.
>
> If streamlit looked for that method, it would be easy for other libraries to make themselves renderable. Additionally, many libraries already have html reprs since they are renderable in notebooks. See this blog post 2 for examples of libraries that comply with this defacto standard.
This seems like a good thing to add alongside `st.iframe` (re #686)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/elements/write.py`
Content:
```
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import json as json
16 import types
17 from typing import cast, Any, List, Tuple, Type
18
19 import numpy as np
20
21 import streamlit
22 from streamlit import type_util
23 from streamlit.errors import StreamlitAPIException
24
25 # Special methods:
26
27 HELP_TYPES = (
28 types.BuiltinFunctionType,
29 types.BuiltinMethodType,
30 types.FunctionType,
31 types.MethodType,
32 types.ModuleType,
33 ) # type: Tuple[Type[Any], ...]
34
35
36 class WriteMixin:
37 def write(self, *args, **kwargs):
38 """Write arguments to the app.
39
40 This is the Swiss Army knife of Streamlit commands: it does different
41 things depending on what you throw at it. Unlike other Streamlit commands,
42 write() has some unique properties:
43
44 1. You can pass in multiple arguments, all of which will be written.
45 2. Its behavior depends on the input types as follows.
46 3. It returns None, so it's "slot" in the App cannot be reused.
47
48 Parameters
49 ----------
50 *args : any
51 One or many objects to print to the App.
52
53 Arguments are handled as follows:
54
55 - write(string) : Prints the formatted Markdown string, with
56 support for LaTeX expression and emoji shortcodes.
57 See docs for st.markdown for more.
58 - write(data_frame) : Displays the DataFrame as a table.
59 - write(error) : Prints an exception specially.
60 - write(func) : Displays information about a function.
61 - write(module) : Displays information about the module.
62 - write(dict) : Displays dict in an interactive widget.
63 - write(obj) : The default is to print str(obj).
64 - write(mpl_fig) : Displays a Matplotlib figure.
65 - write(altair) : Displays an Altair chart.
66 - write(keras) : Displays a Keras model.
67 - write(graphviz) : Displays a Graphviz graph.
68 - write(plotly_fig) : Displays a Plotly figure.
69 - write(bokeh_fig) : Displays a Bokeh figure.
70 - write(sympy_expr) : Prints SymPy expression using LaTeX.
71
72 unsafe_allow_html : bool
73 This is a keyword-only argument that defaults to False.
74
75 By default, any HTML tags found in strings will be escaped and
76 therefore treated as pure text. This behavior may be turned off by
77 setting this argument to True.
78
79 That said, *we strongly advise* against it*. It is hard to write secure
80 HTML, so by using this argument you may be compromising your users'
81 security. For more information, see:
82
83 https://github.com/streamlit/streamlit/issues/152
84
85 **Also note that `unsafe_allow_html` is a temporary measure and may be
86 removed from Streamlit at any time.**
87
88 If you decide to turn on HTML anyway, we ask you to please tell us your
89 exact use case here:
90 https://discuss.streamlit.io/t/96 .
91
92 This will help us come up with safe APIs that allow you to do what you
93 want.
94
95 Example
96 -------
97
98 Its basic use case is to draw Markdown-formatted text, whenever the
99 input is a string:
100
101 >>> write('Hello, *World!* :sunglasses:')
102
103 .. output::
104 https://static.streamlit.io/0.50.2-ZWk9/index.html?id=Pn5sjhgNs4a8ZbiUoSTRxE
105 height: 50px
106
107 As mentioned earlier, `st.write()` also accepts other data formats, such as
108 numbers, data frames, styled data frames, and assorted objects:
109
110 >>> st.write(1234)
111 >>> st.write(pd.DataFrame({
112 ... 'first column': [1, 2, 3, 4],
113 ... 'second column': [10, 20, 30, 40],
114 ... }))
115
116 .. output::
117 https://static.streamlit.io/0.25.0-2JkNY/index.html?id=FCp9AMJHwHRsWSiqMgUZGD
118 height: 250px
119
120 Finally, you can pass in multiple arguments to do things like:
121
122 >>> st.write('1 + 1 = ', 2)
123 >>> st.write('Below is a DataFrame:', data_frame, 'Above is a dataframe.')
124
125 .. output::
126 https://static.streamlit.io/0.25.0-2JkNY/index.html?id=DHkcU72sxYcGarkFbf4kK1
127 height: 300px
128
129 Oh, one more thing: `st.write` accepts chart objects too! For example:
130
131 >>> import pandas as pd
132 >>> import numpy as np
133 >>> import altair as alt
134 >>>
135 >>> df = pd.DataFrame(
136 ... np.random.randn(200, 3),
137 ... columns=['a', 'b', 'c'])
138 ...
139 >>> c = alt.Chart(df).mark_circle().encode(
140 ... x='a', y='b', size='c', color='c', tooltip=['a', 'b', 'c'])
141 >>>
142 >>> st.write(c)
143
144 .. output::
145 https://static.streamlit.io/0.25.0-2JkNY/index.html?id=8jmmXR8iKoZGV4kXaKGYV5
146 height: 200px
147
148 """
149 string_buffer = [] # type: List[str]
150 unsafe_allow_html = kwargs.get("unsafe_allow_html", False)
151
152 # This bans some valid cases like: e = st.empty(); e.write("a", "b").
153 # BUT: 1) such cases are rare, 2) this rule is easy to understand,
154 # and 3) this rule should be removed once we have st.container()
155 if not self.dg._is_top_level and len(args) > 1:
156 raise StreamlitAPIException(
157 "Cannot replace a single element with multiple elements.\n\n"
158 "The `write()` method only supports multiple elements when "
159 "inserting elements rather than replacing. That is, only "
160 "when called as `st.write()` or `st.sidebar.write()`."
161 )
162
163 def flush_buffer():
164 if string_buffer:
165 self.dg.markdown(
166 " ".join(string_buffer),
167 unsafe_allow_html=unsafe_allow_html,
168 )
169 string_buffer[:] = []
170
171 for arg in args:
172 # Order matters!
173 if isinstance(arg, str):
174 string_buffer.append(arg)
175 elif type_util.is_dataframe_like(arg):
176 flush_buffer()
177 if len(np.shape(arg)) > 2:
178 self.dg.text(arg)
179 else:
180 self.dg.dataframe(arg)
181 elif isinstance(arg, Exception):
182 flush_buffer()
183 self.dg.exception(arg)
184 elif isinstance(arg, HELP_TYPES):
185 flush_buffer()
186 self.dg.help(arg)
187 elif type_util.is_altair_chart(arg):
188 flush_buffer()
189 self.dg.altair_chart(arg)
190 elif type_util.is_type(arg, "matplotlib.figure.Figure"):
191 flush_buffer()
192 self.dg.pyplot(arg)
193 elif type_util.is_plotly_chart(arg):
194 flush_buffer()
195 self.dg.plotly_chart(arg)
196 elif type_util.is_type(arg, "bokeh.plotting.figure.Figure"):
197 flush_buffer()
198 self.dg.bokeh_chart(arg)
199 elif type_util.is_graphviz_chart(arg):
200 flush_buffer()
201 self.dg.graphviz_chart(arg)
202 elif type_util.is_sympy_expession(arg):
203 flush_buffer()
204 self.dg.latex(arg)
205 elif type_util.is_keras_model(arg):
206 from tensorflow.python.keras.utils import vis_utils
207
208 flush_buffer()
209 dot = vis_utils.model_to_dot(arg)
210 self.dg.graphviz_chart(dot.to_string())
211 elif isinstance(arg, (dict, list)):
212 flush_buffer()
213 self.dg.json(arg)
214 elif type_util.is_namedtuple(arg):
215 flush_buffer()
216 self.dg.json(json.dumps(arg._asdict()))
217 elif type_util.is_pydeck(arg):
218 flush_buffer()
219 self.dg.pydeck_chart(arg)
220 else:
221 string_buffer.append("`%s`" % str(arg).replace("`", "\\`"))
222
223 flush_buffer()
224
225 @property
226 def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
227 """Get our DeltaGenerator."""
228 return cast("streamlit.delta_generator.DeltaGenerator", self)
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/elements/write.py b/lib/streamlit/elements/write.py
--- a/lib/streamlit/elements/write.py
+++ b/lib/streamlit/elements/write.py
@@ -43,7 +43,7 @@
1. You can pass in multiple arguments, all of which will be written.
2. Its behavior depends on the input types as follows.
- 3. It returns None, so it's "slot" in the App cannot be reused.
+ 3. It returns None, so its "slot" in the App cannot be reused.
Parameters
----------
@@ -60,7 +60,6 @@
- write(func) : Displays information about a function.
- write(module) : Displays information about the module.
- write(dict) : Displays dict in an interactive widget.
- - write(obj) : The default is to print str(obj).
- write(mpl_fig) : Displays a Matplotlib figure.
- write(altair) : Displays an Altair chart.
- write(keras) : Displays a Keras model.
@@ -68,6 +67,8 @@
- write(plotly_fig) : Displays a Plotly figure.
- write(bokeh_fig) : Displays a Bokeh figure.
- write(sympy_expr) : Prints SymPy expression using LaTeX.
+ - write(htmlable) : Prints _repr_html_() for the object if available.
+ - write(obj) : Prints str(obj) if otherwise unknown.
unsafe_allow_html : bool
This is a keyword-only argument that defaults to False.
@@ -217,6 +218,11 @@
elif type_util.is_pydeck(arg):
flush_buffer()
self.dg.pydeck_chart(arg)
+ elif hasattr(arg, "_repr_html_"):
+ self.dg.markdown(
+ arg._repr_html_(),
+ unsafe_allow_html=True,
+ )
else:
string_buffer.append("`%s`" % str(arg).replace("`", "\\`"))
|
{"golden_diff": "diff --git a/lib/streamlit/elements/write.py b/lib/streamlit/elements/write.py\n--- a/lib/streamlit/elements/write.py\n+++ b/lib/streamlit/elements/write.py\n@@ -43,7 +43,7 @@\n \n 1. You can pass in multiple arguments, all of which will be written.\n 2. Its behavior depends on the input types as follows.\n- 3. It returns None, so it's \"slot\" in the App cannot be reused.\n+ 3. It returns None, so its \"slot\" in the App cannot be reused.\n \n Parameters\n ----------\n@@ -60,7 +60,6 @@\n - write(func) : Displays information about a function.\n - write(module) : Displays information about the module.\n - write(dict) : Displays dict in an interactive widget.\n- - write(obj) : The default is to print str(obj).\n - write(mpl_fig) : Displays a Matplotlib figure.\n - write(altair) : Displays an Altair chart.\n - write(keras) : Displays a Keras model.\n@@ -68,6 +67,8 @@\n - write(plotly_fig) : Displays a Plotly figure.\n - write(bokeh_fig) : Displays a Bokeh figure.\n - write(sympy_expr) : Prints SymPy expression using LaTeX.\n+ - write(htmlable) : Prints _repr_html_() for the object if available.\n+ - write(obj) : Prints str(obj) if otherwise unknown.\n \n unsafe_allow_html : bool\n This is a keyword-only argument that defaults to False.\n@@ -217,6 +218,11 @@\n elif type_util.is_pydeck(arg):\n flush_buffer()\n self.dg.pydeck_chart(arg)\n+ elif hasattr(arg, \"_repr_html_\"):\n+ self.dg.markdown(\n+ arg._repr_html_(),\n+ unsafe_allow_html=True,\n+ )\n else:\n string_buffer.append(\"`%s`\" % str(arg).replace(\"`\", \"\\\\`\"))\n", "issue": "Support for `_repr_html_` property on objects\nFrom a user post here: https://discuss.streamlit.io/t/look-for-html-repr-on-objects-generally-a-method-called-repr-html/1939\r\n\r\n> I have just started looking into streamlit after working on and using Panel 1. I am not sure if I missed this, but I was expecting an object with a _repr_html_ method to be automatically renderable with streamlit.\r\n> \r\n> If streamlit looked for that method, it would be easy for other libraries to make themselves renderable. Additionally, many libraries already have html reprs since they are renderable in notebooks. See this blog post 2 for examples of libraries that comply with this defacto standard.\r\n\r\nThis seems like a good thing to add alongside `st.iframe` (re #686)\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json as json\nimport types\nfrom typing import cast, Any, List, Tuple, Type\n\nimport numpy as np\n\nimport streamlit\nfrom streamlit import type_util\nfrom streamlit.errors import StreamlitAPIException\n\n# Special methods:\n\nHELP_TYPES = (\n types.BuiltinFunctionType,\n types.BuiltinMethodType,\n types.FunctionType,\n types.MethodType,\n types.ModuleType,\n) # type: Tuple[Type[Any], ...]\n\n\nclass WriteMixin:\n def write(self, *args, **kwargs):\n \"\"\"Write arguments to the app.\n\n This is the Swiss Army knife of Streamlit commands: it does different\n things depending on what you throw at it. Unlike other Streamlit commands,\n write() has some unique properties:\n\n 1. You can pass in multiple arguments, all of which will be written.\n 2. Its behavior depends on the input types as follows.\n 3. It returns None, so it's \"slot\" in the App cannot be reused.\n\n Parameters\n ----------\n *args : any\n One or many objects to print to the App.\n\n Arguments are handled as follows:\n\n - write(string) : Prints the formatted Markdown string, with\n support for LaTeX expression and emoji shortcodes.\n See docs for st.markdown for more.\n - write(data_frame) : Displays the DataFrame as a table.\n - write(error) : Prints an exception specially.\n - write(func) : Displays information about a function.\n - write(module) : Displays information about the module.\n - write(dict) : Displays dict in an interactive widget.\n - write(obj) : The default is to print str(obj).\n - write(mpl_fig) : Displays a Matplotlib figure.\n - write(altair) : Displays an Altair chart.\n - write(keras) : Displays a Keras model.\n - write(graphviz) : Displays a Graphviz graph.\n - write(plotly_fig) : Displays a Plotly figure.\n - write(bokeh_fig) : Displays a Bokeh figure.\n - write(sympy_expr) : Prints SymPy expression using LaTeX.\n\n unsafe_allow_html : bool\n This is a keyword-only argument that defaults to False.\n\n By default, any HTML tags found in strings will be escaped and\n therefore treated as pure text. This behavior may be turned off by\n setting this argument to True.\n\n That said, *we strongly advise* against it*. It is hard to write secure\n HTML, so by using this argument you may be compromising your users'\n security. For more information, see:\n\n https://github.com/streamlit/streamlit/issues/152\n\n **Also note that `unsafe_allow_html` is a temporary measure and may be\n removed from Streamlit at any time.**\n\n If you decide to turn on HTML anyway, we ask you to please tell us your\n exact use case here:\n https://discuss.streamlit.io/t/96 .\n\n This will help us come up with safe APIs that allow you to do what you\n want.\n\n Example\n -------\n\n Its basic use case is to draw Markdown-formatted text, whenever the\n input is a string:\n\n >>> write('Hello, *World!* :sunglasses:')\n\n .. output::\n https://static.streamlit.io/0.50.2-ZWk9/index.html?id=Pn5sjhgNs4a8ZbiUoSTRxE\n height: 50px\n\n As mentioned earlier, `st.write()` also accepts other data formats, such as\n numbers, data frames, styled data frames, and assorted objects:\n\n >>> st.write(1234)\n >>> st.write(pd.DataFrame({\n ... 'first column': [1, 2, 3, 4],\n ... 'second column': [10, 20, 30, 40],\n ... }))\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=FCp9AMJHwHRsWSiqMgUZGD\n height: 250px\n\n Finally, you can pass in multiple arguments to do things like:\n\n >>> st.write('1 + 1 = ', 2)\n >>> st.write('Below is a DataFrame:', data_frame, 'Above is a dataframe.')\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=DHkcU72sxYcGarkFbf4kK1\n height: 300px\n\n Oh, one more thing: `st.write` accepts chart objects too! For example:\n\n >>> import pandas as pd\n >>> import numpy as np\n >>> import altair as alt\n >>>\n >>> df = pd.DataFrame(\n ... np.random.randn(200, 3),\n ... columns=['a', 'b', 'c'])\n ...\n >>> c = alt.Chart(df).mark_circle().encode(\n ... x='a', y='b', size='c', color='c', tooltip=['a', 'b', 'c'])\n >>>\n >>> st.write(c)\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=8jmmXR8iKoZGV4kXaKGYV5\n height: 200px\n\n \"\"\"\n string_buffer = [] # type: List[str]\n unsafe_allow_html = kwargs.get(\"unsafe_allow_html\", False)\n\n # This bans some valid cases like: e = st.empty(); e.write(\"a\", \"b\").\n # BUT: 1) such cases are rare, 2) this rule is easy to understand,\n # and 3) this rule should be removed once we have st.container()\n if not self.dg._is_top_level and len(args) > 1:\n raise StreamlitAPIException(\n \"Cannot replace a single element with multiple elements.\\n\\n\"\n \"The `write()` method only supports multiple elements when \"\n \"inserting elements rather than replacing. That is, only \"\n \"when called as `st.write()` or `st.sidebar.write()`.\"\n )\n\n def flush_buffer():\n if string_buffer:\n self.dg.markdown(\n \" \".join(string_buffer),\n unsafe_allow_html=unsafe_allow_html,\n )\n string_buffer[:] = []\n\n for arg in args:\n # Order matters!\n if isinstance(arg, str):\n string_buffer.append(arg)\n elif type_util.is_dataframe_like(arg):\n flush_buffer()\n if len(np.shape(arg)) > 2:\n self.dg.text(arg)\n else:\n self.dg.dataframe(arg)\n elif isinstance(arg, Exception):\n flush_buffer()\n self.dg.exception(arg)\n elif isinstance(arg, HELP_TYPES):\n flush_buffer()\n self.dg.help(arg)\n elif type_util.is_altair_chart(arg):\n flush_buffer()\n self.dg.altair_chart(arg)\n elif type_util.is_type(arg, \"matplotlib.figure.Figure\"):\n flush_buffer()\n self.dg.pyplot(arg)\n elif type_util.is_plotly_chart(arg):\n flush_buffer()\n self.dg.plotly_chart(arg)\n elif type_util.is_type(arg, \"bokeh.plotting.figure.Figure\"):\n flush_buffer()\n self.dg.bokeh_chart(arg)\n elif type_util.is_graphviz_chart(arg):\n flush_buffer()\n self.dg.graphviz_chart(arg)\n elif type_util.is_sympy_expession(arg):\n flush_buffer()\n self.dg.latex(arg)\n elif type_util.is_keras_model(arg):\n from tensorflow.python.keras.utils import vis_utils\n\n flush_buffer()\n dot = vis_utils.model_to_dot(arg)\n self.dg.graphviz_chart(dot.to_string())\n elif isinstance(arg, (dict, list)):\n flush_buffer()\n self.dg.json(arg)\n elif type_util.is_namedtuple(arg):\n flush_buffer()\n self.dg.json(json.dumps(arg._asdict()))\n elif type_util.is_pydeck(arg):\n flush_buffer()\n self.dg.pydeck_chart(arg)\n else:\n string_buffer.append(\"`%s`\" % str(arg).replace(\"`\", \"\\\\`\"))\n\n flush_buffer()\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/write.py"}], "after_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json as json\nimport types\nfrom typing import cast, Any, List, Tuple, Type\n\nimport numpy as np\n\nimport streamlit\nfrom streamlit import type_util\nfrom streamlit.errors import StreamlitAPIException\n\n# Special methods:\n\nHELP_TYPES = (\n types.BuiltinFunctionType,\n types.BuiltinMethodType,\n types.FunctionType,\n types.MethodType,\n types.ModuleType,\n) # type: Tuple[Type[Any], ...]\n\n\nclass WriteMixin:\n def write(self, *args, **kwargs):\n \"\"\"Write arguments to the app.\n\n This is the Swiss Army knife of Streamlit commands: it does different\n things depending on what you throw at it. Unlike other Streamlit commands,\n write() has some unique properties:\n\n 1. You can pass in multiple arguments, all of which will be written.\n 2. Its behavior depends on the input types as follows.\n 3. It returns None, so its \"slot\" in the App cannot be reused.\n\n Parameters\n ----------\n *args : any\n One or many objects to print to the App.\n\n Arguments are handled as follows:\n\n - write(string) : Prints the formatted Markdown string, with\n support for LaTeX expression and emoji shortcodes.\n See docs for st.markdown for more.\n - write(data_frame) : Displays the DataFrame as a table.\n - write(error) : Prints an exception specially.\n - write(func) : Displays information about a function.\n - write(module) : Displays information about the module.\n - write(dict) : Displays dict in an interactive widget.\n - write(mpl_fig) : Displays a Matplotlib figure.\n - write(altair) : Displays an Altair chart.\n - write(keras) : Displays a Keras model.\n - write(graphviz) : Displays a Graphviz graph.\n - write(plotly_fig) : Displays a Plotly figure.\n - write(bokeh_fig) : Displays a Bokeh figure.\n - write(sympy_expr) : Prints SymPy expression using LaTeX.\n - write(htmlable) : Prints _repr_html_() for the object if available.\n - write(obj) : Prints str(obj) if otherwise unknown.\n\n unsafe_allow_html : bool\n This is a keyword-only argument that defaults to False.\n\n By default, any HTML tags found in strings will be escaped and\n therefore treated as pure text. This behavior may be turned off by\n setting this argument to True.\n\n That said, *we strongly advise* against it*. It is hard to write secure\n HTML, so by using this argument you may be compromising your users'\n security. For more information, see:\n\n https://github.com/streamlit/streamlit/issues/152\n\n **Also note that `unsafe_allow_html` is a temporary measure and may be\n removed from Streamlit at any time.**\n\n If you decide to turn on HTML anyway, we ask you to please tell us your\n exact use case here:\n https://discuss.streamlit.io/t/96 .\n\n This will help us come up with safe APIs that allow you to do what you\n want.\n\n Example\n -------\n\n Its basic use case is to draw Markdown-formatted text, whenever the\n input is a string:\n\n >>> write('Hello, *World!* :sunglasses:')\n\n .. output::\n https://static.streamlit.io/0.50.2-ZWk9/index.html?id=Pn5sjhgNs4a8ZbiUoSTRxE\n height: 50px\n\n As mentioned earlier, `st.write()` also accepts other data formats, such as\n numbers, data frames, styled data frames, and assorted objects:\n\n >>> st.write(1234)\n >>> st.write(pd.DataFrame({\n ... 'first column': [1, 2, 3, 4],\n ... 'second column': [10, 20, 30, 40],\n ... }))\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=FCp9AMJHwHRsWSiqMgUZGD\n height: 250px\n\n Finally, you can pass in multiple arguments to do things like:\n\n >>> st.write('1 + 1 = ', 2)\n >>> st.write('Below is a DataFrame:', data_frame, 'Above is a dataframe.')\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=DHkcU72sxYcGarkFbf4kK1\n height: 300px\n\n Oh, one more thing: `st.write` accepts chart objects too! For example:\n\n >>> import pandas as pd\n >>> import numpy as np\n >>> import altair as alt\n >>>\n >>> df = pd.DataFrame(\n ... np.random.randn(200, 3),\n ... columns=['a', 'b', 'c'])\n ...\n >>> c = alt.Chart(df).mark_circle().encode(\n ... x='a', y='b', size='c', color='c', tooltip=['a', 'b', 'c'])\n >>>\n >>> st.write(c)\n\n .. output::\n https://static.streamlit.io/0.25.0-2JkNY/index.html?id=8jmmXR8iKoZGV4kXaKGYV5\n height: 200px\n\n \"\"\"\n string_buffer = [] # type: List[str]\n unsafe_allow_html = kwargs.get(\"unsafe_allow_html\", False)\n\n # This bans some valid cases like: e = st.empty(); e.write(\"a\", \"b\").\n # BUT: 1) such cases are rare, 2) this rule is easy to understand,\n # and 3) this rule should be removed once we have st.container()\n if not self.dg._is_top_level and len(args) > 1:\n raise StreamlitAPIException(\n \"Cannot replace a single element with multiple elements.\\n\\n\"\n \"The `write()` method only supports multiple elements when \"\n \"inserting elements rather than replacing. That is, only \"\n \"when called as `st.write()` or `st.sidebar.write()`.\"\n )\n\n def flush_buffer():\n if string_buffer:\n self.dg.markdown(\n \" \".join(string_buffer),\n unsafe_allow_html=unsafe_allow_html,\n )\n string_buffer[:] = []\n\n for arg in args:\n # Order matters!\n if isinstance(arg, str):\n string_buffer.append(arg)\n elif type_util.is_dataframe_like(arg):\n flush_buffer()\n if len(np.shape(arg)) > 2:\n self.dg.text(arg)\n else:\n self.dg.dataframe(arg)\n elif isinstance(arg, Exception):\n flush_buffer()\n self.dg.exception(arg)\n elif isinstance(arg, HELP_TYPES):\n flush_buffer()\n self.dg.help(arg)\n elif type_util.is_altair_chart(arg):\n flush_buffer()\n self.dg.altair_chart(arg)\n elif type_util.is_type(arg, \"matplotlib.figure.Figure\"):\n flush_buffer()\n self.dg.pyplot(arg)\n elif type_util.is_plotly_chart(arg):\n flush_buffer()\n self.dg.plotly_chart(arg)\n elif type_util.is_type(arg, \"bokeh.plotting.figure.Figure\"):\n flush_buffer()\n self.dg.bokeh_chart(arg)\n elif type_util.is_graphviz_chart(arg):\n flush_buffer()\n self.dg.graphviz_chart(arg)\n elif type_util.is_sympy_expession(arg):\n flush_buffer()\n self.dg.latex(arg)\n elif type_util.is_keras_model(arg):\n from tensorflow.python.keras.utils import vis_utils\n\n flush_buffer()\n dot = vis_utils.model_to_dot(arg)\n self.dg.graphviz_chart(dot.to_string())\n elif isinstance(arg, (dict, list)):\n flush_buffer()\n self.dg.json(arg)\n elif type_util.is_namedtuple(arg):\n flush_buffer()\n self.dg.json(json.dumps(arg._asdict()))\n elif type_util.is_pydeck(arg):\n flush_buffer()\n self.dg.pydeck_chart(arg)\n elif hasattr(arg, \"_repr_html_\"):\n self.dg.markdown(\n arg._repr_html_(),\n unsafe_allow_html=True,\n )\n else:\n string_buffer.append(\"`%s`\" % str(arg).replace(\"`\", \"\\\\`\"))\n\n flush_buffer()\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/write.py"}]}
| 3,028 | 458 |
gh_patches_debug_1293
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-643
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for Django 4.0
Currently failing tests (See #632)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from glob import glob
2 import subprocess
3
4 from setuptools import find_packages, setup
5
6 REQUIRES = [
7 'Django>=2.2,<4',
8 'bleach',
9 'bleach-allowlist',
10 'diff-match-patch',
11 'django-bakery>=0.12.0',
12 'django-crispy-forms',
13 'django-markitup>=4.0.0',
14 'django-registration-redux',
15 'django-reversion',
16 'django-select2',
17 'djangorestframework',
18 'drf-extensions>=0.5.0',
19 'icalendar>=4.0',
20 'jsonfield',
21 'markdown>=2.5',
22 'pillow',
23 'py3dns',
24 'pyLibravatar',
25 'pytz',
26 'requests',
27 ]
28
29 SOURCES = []
30
31
32 with open('README.rst', 'r') as f:
33 long_description = f.read()
34
35
36 def compile_translations():
37 try:
38 subprocess.check_call(['./manage.py', 'compilemessages'])
39 except subprocess.CalledProcessError:
40 print("WARNING: cannot compile translations.")
41 return glob('wafer/locale/*/LC_MESSAGES/django.mo')
42
43
44 setup(
45 name="wafer",
46 version="0.13.1a",
47 url='http://github.com/CTPUG/wafer',
48 license='ISC',
49 description="A wafer-thin Django library for running small conferences.",
50 long_description=long_description,
51 long_description_content_type="text/x-rst",
52 author='CTPUG',
53 author_email='[email protected]',
54 packages=find_packages(),
55 include_package_data=True,
56 install_requires=REQUIRES,
57 dependency_links=SOURCES,
58 data_files=[
59 ('locale', compile_translations()),
60 ],
61 setup_requires=[
62 # Add setuptools-git, so we get correct behaviour for
63 # include_package_data
64 'setuptools_git >= 1.0',
65 ],
66 classifiers=[
67 'Development Status :: 4 - Beta',
68 'Intended Audience :: Developers',
69 'License :: OSI Approved :: ISC License (ISCL)',
70 'Operating System :: POSIX',
71 'Programming Language :: Python :: 3',
72 'Programming Language :: Python :: 3.6',
73 'Programming Language :: Python :: 3.7',
74 'Programming Language :: Python :: 3.8',
75 'Framework :: Django',
76 'Topic :: Software Development :: Libraries :: Python Modules',
77 'Topic :: Internet :: WWW/HTTP',
78 ],
79 )
80
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -8,7 +8,7 @@
'bleach',
'bleach-allowlist',
'diff-match-patch',
- 'django-bakery>=0.12.0',
+ 'django-bakery>=0.13.0',
'django-crispy-forms',
'django-markitup>=4.0.0',
'django-registration-redux',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -8,7 +8,7 @@\n 'bleach',\n 'bleach-allowlist',\n 'diff-match-patch',\n- 'django-bakery>=0.12.0',\n+ 'django-bakery>=0.13.0',\n 'django-crispy-forms',\n 'django-markitup>=4.0.0',\n 'django-registration-redux',\n", "issue": "Add support for Django 4.0\nCurrently failing tests (See #632)\n", "before_files": [{"content": "from glob import glob\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\nREQUIRES = [\n 'Django>=2.2,<4',\n 'bleach',\n 'bleach-allowlist',\n 'diff-match-patch',\n 'django-bakery>=0.12.0',\n 'django-crispy-forms',\n 'django-markitup>=4.0.0',\n 'django-registration-redux',\n 'django-reversion',\n 'django-select2',\n 'djangorestframework',\n 'drf-extensions>=0.5.0',\n 'icalendar>=4.0',\n 'jsonfield',\n 'markdown>=2.5',\n 'pillow',\n 'py3dns',\n 'pyLibravatar',\n 'pytz',\n 'requests',\n]\n\nSOURCES = []\n\n\nwith open('README.rst', 'r') as f:\n long_description = f.read()\n\n\ndef compile_translations():\n try:\n subprocess.check_call(['./manage.py', 'compilemessages'])\n except subprocess.CalledProcessError:\n print(\"WARNING: cannot compile translations.\")\n return glob('wafer/locale/*/LC_MESSAGES/django.mo')\n\n\nsetup(\n name=\"wafer\",\n version=\"0.13.1a\",\n url='http://github.com/CTPUG/wafer',\n license='ISC',\n description=\"A wafer-thin Django library for running small conferences.\",\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n author='CTPUG',\n author_email='[email protected]',\n packages=find_packages(),\n include_package_data=True,\n install_requires=REQUIRES,\n dependency_links=SOURCES,\n data_files=[\n ('locale', compile_translations()),\n ],\n setup_requires=[\n # Add setuptools-git, so we get correct behaviour for\n # include_package_data\n 'setuptools_git >= 1.0',\n ],\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: ISC License (ISCL)',\n 'Operating System :: POSIX',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Framework :: Django',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Internet :: WWW/HTTP',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "from glob import glob\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\nREQUIRES = [\n 'Django>=2.2,<4',\n 'bleach',\n 'bleach-allowlist',\n 'diff-match-patch',\n 'django-bakery>=0.13.0',\n 'django-crispy-forms',\n 'django-markitup>=4.0.0',\n 'django-registration-redux',\n 'django-reversion',\n 'django-select2',\n 'djangorestframework',\n 'drf-extensions>=0.5.0',\n 'icalendar>=4.0',\n 'jsonfield',\n 'markdown>=2.5',\n 'pillow',\n 'py3dns',\n 'pyLibravatar',\n 'pytz',\n 'requests',\n]\n\nSOURCES = []\n\n\nwith open('README.rst', 'r') as f:\n long_description = f.read()\n\n\ndef compile_translations():\n try:\n subprocess.check_call(['./manage.py', 'compilemessages'])\n except subprocess.CalledProcessError:\n print(\"WARNING: cannot compile translations.\")\n return glob('wafer/locale/*/LC_MESSAGES/django.mo')\n\n\nsetup(\n name=\"wafer\",\n version=\"0.13.1a\",\n url='http://github.com/CTPUG/wafer',\n license='ISC',\n description=\"A wafer-thin Django library for running small conferences.\",\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n author='CTPUG',\n author_email='[email protected]',\n packages=find_packages(),\n include_package_data=True,\n install_requires=REQUIRES,\n dependency_links=SOURCES,\n data_files=[\n ('locale', compile_translations()),\n ],\n setup_requires=[\n # Add setuptools-git, so we get correct behaviour for\n # include_package_data\n 'setuptools_git >= 1.0',\n ],\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: ISC License (ISCL)',\n 'Operating System :: POSIX',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Framework :: Django',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Internet :: WWW/HTTP',\n ],\n)\n", "path": "setup.py"}]}
| 969 | 108 |
gh_patches_debug_6105
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-348
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DotDict isn't JSON-serializable
`DotDicts` *feel* like dicts, until you try to ship them as JSON:
```python
In [1]: import json
In [2]: from prefect.utilities.collections import DotDict
In [3]: json.dumps(DotDict(x=1, y=2))
```
Results in the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-b595d5c6cfdf> in <module>()
----> 1 json.dumps(DotDict(x=1, y=2))
/anaconda3/lib/python3.6/json/__init__.py in dumps(obj, skipkeys, ensure_ascii, check_circular, allow_nan, cls, indent, separators, default, sort_keys, **kw)
229 cls is None and indent is None and separators is None and
230 default is None and not sort_keys and not kw):
--> 231 return _default_encoder.encode(obj)
232 if cls is None:
233 cls = JSONEncoder
/anaconda3/lib/python3.6/json/encoder.py in encode(self, o)
197 # exceptions aren't as detailed. The list call should be roughly
198 # equivalent to the PySequence_Fast that ''.join() would do.
--> 199 chunks = self.iterencode(o, _one_shot=True)
200 if not isinstance(chunks, (list, tuple)):
201 chunks = list(chunks)
/anaconda3/lib/python3.6/json/encoder.py in iterencode(self, o, _one_shot)
255 self.key_separator, self.item_separator, self.sort_keys,
256 self.skipkeys, _one_shot)
--> 257 return _iterencode(o, 0)
258
259 def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
/anaconda3/lib/python3.6/json/encoder.py in default(self, o)
178 """
179 raise TypeError("Object of type '%s' is not JSON serializable" %
--> 180 o.__class__.__name__)
181
182 def encode(self, o):
TypeError: Object of type 'DotDict' is not JSON serializable
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/utilities/collections.py`
Content:
```
1 # Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula
2 import collections
3 import json
4 from collections.abc import MutableMapping
5 from typing import Any, Generator, Iterable, Iterator, Union
6
7 DictLike = Union[dict, "DotDict"]
8
9
10 def flatten_seq(seq: Iterable) -> Generator:
11 """
12 Generator that returns a flattened list from a possibly nested list-of-lists
13 (or any sequence type).
14
15 Example:
16 ```python
17 flatten_seq([1, 2, [3, 4], 5, [6, [7]]])
18 >>> [1, 2, 3, 4, 5, 6, 7]
19 ```
20 Args:
21 - seq (Iterable): the sequence to flatten
22
23 Returns:
24 - generator: a generator that yields the flattened sequence
25 """
26 for item in seq:
27 if isinstance(item, collections.Iterable) and not isinstance(
28 item, (str, bytes)
29 ):
30 yield from flatten_seq(item)
31 else:
32 yield item
33
34
35 class DotDict(MutableMapping):
36 """
37 A `dict` that also supports attribute ("dot") access. Think of this as an extension
38 to the standard python `dict` object. **Note**: while any hashable object can be added to
39 a `DotDict`, _only_ valid Python identifiers can be accessed with the dot syntax; this excludes
40 strings which begin in numbers, special characters, or double underscores.
41
42 Args:
43 - init_dict (dict, optional): dictionary to initialize the `DotDict`
44 with
45 - **kwargs (optional): key, value pairs with which to initialize the
46 `DotDict`
47
48 **Example**:
49 ```python
50 dotdict = DotDict({'a': 34}, b=56, c=set())
51 dotdict.a # 34
52 dotdict['b'] # 56
53 dotdict.c # set()
54 ```
55 """
56
57 def __init__(self, init_dict: DictLike = None, **kwargs: Any) -> None:
58 if init_dict:
59 self.update(init_dict)
60 self.update(kwargs)
61
62 def __getitem__(self, key: str) -> Any:
63 return self.__dict__[key] # __dict__ expects string keys
64
65 def __setitem__(self, key: str, value: Any) -> None:
66 # prevent overwriting any critical attributes
67 if isinstance(key, str) and hasattr(MutableMapping, key):
68 raise ValueError('Invalid key: "{}"'.format(key))
69 self.__dict__[key] = value
70
71 def __setattr__(self, attr: str, value: Any) -> None:
72 self[attr] = value
73
74 def __iter__(self) -> Iterator[str]:
75 return iter(self.__dict__.keys())
76
77 def __delitem__(self, key: str) -> None:
78 del self.__dict__[key]
79
80 def __len__(self) -> int:
81 return len(self.__dict__)
82
83 def __repr__(self) -> str:
84 if len(self) > 0:
85 return "<{}: {}>".format(
86 type(self).__name__, ", ".join(sorted(repr(k) for k in self.keys()))
87 )
88 else:
89 return "<{}>".format(type(self).__name__)
90
91 def copy(self) -> "DotDict":
92 """Creates and returns a shallow copy of the current DotDict"""
93 return type(self)(self.__dict__.copy())
94
95 def __json__(self) -> dict:
96 return dict(self)
97
98
99 class GraphQLResult(DotDict):
100 def __repr__(self) -> str:
101 return json.dumps(as_nested_dict(self, dict), indent=4)
102
103
104 def merge_dicts(d1: DictLike, d2: DictLike) -> DictLike:
105 """
106 Updates `d1` from `d2` by replacing each `(k, v1)` pair in `d1` with the
107 corresponding `(k, v2)` pair in `d2`.
108
109 If the value of each pair is itself a dict, then the value is updated
110 recursively.
111
112 Args:
113 - d1 (MutableMapping): A dictionary to be replaced
114 - d2 (MutableMapping): A dictionary used for replacement
115
116 Returns:
117 - A `MutableMapping` with the two dictionary contents merged
118 """
119
120 new_dict = d1.copy()
121
122 for k, v in d2.items():
123 if isinstance(new_dict.get(k), MutableMapping) and isinstance(
124 v, MutableMapping
125 ):
126 new_dict[k] = merge_dicts(new_dict[k], d2[k])
127 else:
128 new_dict[k] = d2[k]
129 return new_dict
130
131
132 def as_nested_dict(
133 obj: Union[DictLike, Iterable[DictLike]], dct_class: type = DotDict
134 ) -> Union[DictLike, Iterable[DictLike]]:
135 """
136 Given a obj formatted as a dictionary, transforms it (and any nested dictionaries)
137 into the provided dct_class
138
139 Args:
140 - obj (Any): An object that is formatted as a `dict`
141 - dct_class (type): the `dict` class to use (defaults to DotDict)
142
143 Returns:
144 - A `dict_class` representation of the object passed in
145 ```
146 """
147 if isinstance(obj, (list, tuple, set)):
148 return type(obj)([as_nested_dict(d, dct_class) for d in obj])
149 elif isinstance(obj, (dict, DotDict)):
150 return dct_class({k: as_nested_dict(v, dct_class) for k, v in obj.items()})
151 return obj
152
153
154 class CompoundKey(tuple):
155 pass
156
157
158 def dict_to_flatdict(dct: dict, parent: CompoundKey = None) -> dict:
159 """Converts a (nested) dictionary to a flattened representation.
160
161 Each key of the flat dict will be a CompoundKey tuple containing the "chain of keys"
162 for the corresponding value.
163
164 Args:
165 - dct (dict): The dictionary to flatten
166 - parent (CompoundKey, optional): Defaults to `None`. The parent key
167 (you shouldn't need to set this)
168
169 Returns:
170 - dict: A flattened dict
171 """
172
173 items = [] # type: list
174 parent = parent or CompoundKey()
175 for k, v in dct.items():
176 k_parent = CompoundKey(parent + (k,))
177 if isinstance(v, dict):
178 items.extend(dict_to_flatdict(v, parent=k_parent).items())
179 else:
180 items.append((k_parent, v))
181 return dict(items)
182
183
184 def flatdict_to_dict(dct: dict, dct_class: type = None) -> MutableMapping:
185 """Converts a flattened dictionary back to a nested dictionary.
186
187 Args:
188 - dct (dict): The dictionary to be nested. Each key should be a
189 `CompoundKey`, as generated by `dict_to_flatdict()`
190 - dct_class (type, optional): the type of the result; defaults to `dict`
191
192 Returns:
193 - MutableMapping: A `MutableMapping` used to represent a nested dictionary
194 """
195
196 result = (dct_class or dict)()
197 for k, v in dct.items():
198 if isinstance(k, CompoundKey):
199 current_dict = result
200 for ki in k[:-1]:
201 current_dict = current_dict.setdefault( # type: ignore
202 ki, (dct_class or dict)()
203 )
204 current_dict[k[-1]] = v
205 else:
206 result[k] = v
207
208 return result
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/utilities/collections.py b/src/prefect/utilities/collections.py
--- a/src/prefect/utilities/collections.py
+++ b/src/prefect/utilities/collections.py
@@ -92,8 +92,9 @@
"""Creates and returns a shallow copy of the current DotDict"""
return type(self)(self.__dict__.copy())
- def __json__(self) -> dict:
- return dict(self)
+ def to_dict(self) -> dict:
+ """Converts current `DotDict` (and any `DotDict`s contained within) to an appropriate nested dictionary."""
+ return as_nested_dict(self, dct_class=dict)
class GraphQLResult(DotDict):
|
{"golden_diff": "diff --git a/src/prefect/utilities/collections.py b/src/prefect/utilities/collections.py\n--- a/src/prefect/utilities/collections.py\n+++ b/src/prefect/utilities/collections.py\n@@ -92,8 +92,9 @@\n \"\"\"Creates and returns a shallow copy of the current DotDict\"\"\"\n return type(self)(self.__dict__.copy())\n \n- def __json__(self) -> dict:\n- return dict(self)\n+ def to_dict(self) -> dict:\n+ \"\"\"Converts current `DotDict` (and any `DotDict`s contained within) to an appropriate nested dictionary.\"\"\"\n+ return as_nested_dict(self, dct_class=dict)\n \n \n class GraphQLResult(DotDict):\n", "issue": "DotDict isn't JSON-serializable\n`DotDicts` *feel* like dicts, until you try to ship them as JSON:\r\n\r\n```python\r\nIn [1]: import json\r\n\r\nIn [2]: from prefect.utilities.collections import DotDict\r\n\r\nIn [3]: json.dumps(DotDict(x=1, y=2))\r\n```\r\nResults in the following error:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-3-b595d5c6cfdf> in <module>()\r\n----> 1 json.dumps(DotDict(x=1, y=2))\r\n\r\n/anaconda3/lib/python3.6/json/__init__.py in dumps(obj, skipkeys, ensure_ascii, check_circular, allow_nan, cls, indent, separators, default, sort_keys, **kw)\r\n 229 cls is None and indent is None and separators is None and\r\n 230 default is None and not sort_keys and not kw):\r\n--> 231 return _default_encoder.encode(obj)\r\n 232 if cls is None:\r\n 233 cls = JSONEncoder\r\n\r\n/anaconda3/lib/python3.6/json/encoder.py in encode(self, o)\r\n 197 # exceptions aren't as detailed. The list call should be roughly\r\n 198 # equivalent to the PySequence_Fast that ''.join() would do.\r\n--> 199 chunks = self.iterencode(o, _one_shot=True)\r\n 200 if not isinstance(chunks, (list, tuple)):\r\n 201 chunks = list(chunks)\r\n\r\n/anaconda3/lib/python3.6/json/encoder.py in iterencode(self, o, _one_shot)\r\n 255 self.key_separator, self.item_separator, self.sort_keys,\r\n 256 self.skipkeys, _one_shot)\r\n--> 257 return _iterencode(o, 0)\r\n 258\r\n 259 def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,\r\n\r\n/anaconda3/lib/python3.6/json/encoder.py in default(self, o)\r\n 178 \"\"\"\r\n 179 raise TypeError(\"Object of type '%s' is not JSON serializable\" %\r\n--> 180 o.__class__.__name__)\r\n 181\r\n 182 def encode(self, o):\r\n\r\nTypeError: Object of type 'DotDict' is not JSON serializable\r\n```\n", "before_files": [{"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\nimport collections\nimport json\nfrom collections.abc import MutableMapping\nfrom typing import Any, Generator, Iterable, Iterator, Union\n\nDictLike = Union[dict, \"DotDict\"]\n\n\ndef flatten_seq(seq: Iterable) -> Generator:\n \"\"\"\n Generator that returns a flattened list from a possibly nested list-of-lists\n (or any sequence type).\n\n Example:\n ```python\n flatten_seq([1, 2, [3, 4], 5, [6, [7]]])\n >>> [1, 2, 3, 4, 5, 6, 7]\n ```\n Args:\n - seq (Iterable): the sequence to flatten\n\n Returns:\n - generator: a generator that yields the flattened sequence\n \"\"\"\n for item in seq:\n if isinstance(item, collections.Iterable) and not isinstance(\n item, (str, bytes)\n ):\n yield from flatten_seq(item)\n else:\n yield item\n\n\nclass DotDict(MutableMapping):\n \"\"\"\n A `dict` that also supports attribute (\"dot\") access. Think of this as an extension\n to the standard python `dict` object. **Note**: while any hashable object can be added to\n a `DotDict`, _only_ valid Python identifiers can be accessed with the dot syntax; this excludes\n strings which begin in numbers, special characters, or double underscores.\n\n Args:\n - init_dict (dict, optional): dictionary to initialize the `DotDict`\n with\n - **kwargs (optional): key, value pairs with which to initialize the\n `DotDict`\n\n **Example**:\n ```python\n dotdict = DotDict({'a': 34}, b=56, c=set())\n dotdict.a # 34\n dotdict['b'] # 56\n dotdict.c # set()\n ```\n \"\"\"\n\n def __init__(self, init_dict: DictLike = None, **kwargs: Any) -> None:\n if init_dict:\n self.update(init_dict)\n self.update(kwargs)\n\n def __getitem__(self, key: str) -> Any:\n return self.__dict__[key] # __dict__ expects string keys\n\n def __setitem__(self, key: str, value: Any) -> None:\n # prevent overwriting any critical attributes\n if isinstance(key, str) and hasattr(MutableMapping, key):\n raise ValueError('Invalid key: \"{}\"'.format(key))\n self.__dict__[key] = value\n\n def __setattr__(self, attr: str, value: Any) -> None:\n self[attr] = value\n\n def __iter__(self) -> Iterator[str]:\n return iter(self.__dict__.keys())\n\n def __delitem__(self, key: str) -> None:\n del self.__dict__[key]\n\n def __len__(self) -> int:\n return len(self.__dict__)\n\n def __repr__(self) -> str:\n if len(self) > 0:\n return \"<{}: {}>\".format(\n type(self).__name__, \", \".join(sorted(repr(k) for k in self.keys()))\n )\n else:\n return \"<{}>\".format(type(self).__name__)\n\n def copy(self) -> \"DotDict\":\n \"\"\"Creates and returns a shallow copy of the current DotDict\"\"\"\n return type(self)(self.__dict__.copy())\n\n def __json__(self) -> dict:\n return dict(self)\n\n\nclass GraphQLResult(DotDict):\n def __repr__(self) -> str:\n return json.dumps(as_nested_dict(self, dict), indent=4)\n\n\ndef merge_dicts(d1: DictLike, d2: DictLike) -> DictLike:\n \"\"\"\n Updates `d1` from `d2` by replacing each `(k, v1)` pair in `d1` with the\n corresponding `(k, v2)` pair in `d2`.\n\n If the value of each pair is itself a dict, then the value is updated\n recursively.\n\n Args:\n - d1 (MutableMapping): A dictionary to be replaced\n - d2 (MutableMapping): A dictionary used for replacement\n\n Returns:\n - A `MutableMapping` with the two dictionary contents merged\n \"\"\"\n\n new_dict = d1.copy()\n\n for k, v in d2.items():\n if isinstance(new_dict.get(k), MutableMapping) and isinstance(\n v, MutableMapping\n ):\n new_dict[k] = merge_dicts(new_dict[k], d2[k])\n else:\n new_dict[k] = d2[k]\n return new_dict\n\n\ndef as_nested_dict(\n obj: Union[DictLike, Iterable[DictLike]], dct_class: type = DotDict\n) -> Union[DictLike, Iterable[DictLike]]:\n \"\"\"\n Given a obj formatted as a dictionary, transforms it (and any nested dictionaries)\n into the provided dct_class\n\n Args:\n - obj (Any): An object that is formatted as a `dict`\n - dct_class (type): the `dict` class to use (defaults to DotDict)\n\n Returns:\n - A `dict_class` representation of the object passed in\n ```\n \"\"\"\n if isinstance(obj, (list, tuple, set)):\n return type(obj)([as_nested_dict(d, dct_class) for d in obj])\n elif isinstance(obj, (dict, DotDict)):\n return dct_class({k: as_nested_dict(v, dct_class) for k, v in obj.items()})\n return obj\n\n\nclass CompoundKey(tuple):\n pass\n\n\ndef dict_to_flatdict(dct: dict, parent: CompoundKey = None) -> dict:\n \"\"\"Converts a (nested) dictionary to a flattened representation.\n\n Each key of the flat dict will be a CompoundKey tuple containing the \"chain of keys\"\n for the corresponding value.\n\n Args:\n - dct (dict): The dictionary to flatten\n - parent (CompoundKey, optional): Defaults to `None`. The parent key\n (you shouldn't need to set this)\n\n Returns:\n - dict: A flattened dict\n \"\"\"\n\n items = [] # type: list\n parent = parent or CompoundKey()\n for k, v in dct.items():\n k_parent = CompoundKey(parent + (k,))\n if isinstance(v, dict):\n items.extend(dict_to_flatdict(v, parent=k_parent).items())\n else:\n items.append((k_parent, v))\n return dict(items)\n\n\ndef flatdict_to_dict(dct: dict, dct_class: type = None) -> MutableMapping:\n \"\"\"Converts a flattened dictionary back to a nested dictionary.\n\n Args:\n - dct (dict): The dictionary to be nested. Each key should be a\n `CompoundKey`, as generated by `dict_to_flatdict()`\n - dct_class (type, optional): the type of the result; defaults to `dict`\n\n Returns:\n - MutableMapping: A `MutableMapping` used to represent a nested dictionary\n \"\"\"\n\n result = (dct_class or dict)()\n for k, v in dct.items():\n if isinstance(k, CompoundKey):\n current_dict = result\n for ki in k[:-1]:\n current_dict = current_dict.setdefault( # type: ignore\n ki, (dct_class or dict)()\n )\n current_dict[k[-1]] = v\n else:\n result[k] = v\n\n return result\n", "path": "src/prefect/utilities/collections.py"}], "after_files": [{"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\nimport collections\nimport json\nfrom collections.abc import MutableMapping\nfrom typing import Any, Generator, Iterable, Iterator, Union\n\nDictLike = Union[dict, \"DotDict\"]\n\n\ndef flatten_seq(seq: Iterable) -> Generator:\n \"\"\"\n Generator that returns a flattened list from a possibly nested list-of-lists\n (or any sequence type).\n\n Example:\n ```python\n flatten_seq([1, 2, [3, 4], 5, [6, [7]]])\n >>> [1, 2, 3, 4, 5, 6, 7]\n ```\n Args:\n - seq (Iterable): the sequence to flatten\n\n Returns:\n - generator: a generator that yields the flattened sequence\n \"\"\"\n for item in seq:\n if isinstance(item, collections.Iterable) and not isinstance(\n item, (str, bytes)\n ):\n yield from flatten_seq(item)\n else:\n yield item\n\n\nclass DotDict(MutableMapping):\n \"\"\"\n A `dict` that also supports attribute (\"dot\") access. Think of this as an extension\n to the standard python `dict` object. **Note**: while any hashable object can be added to\n a `DotDict`, _only_ valid Python identifiers can be accessed with the dot syntax; this excludes\n strings which begin in numbers, special characters, or double underscores.\n\n Args:\n - init_dict (dict, optional): dictionary to initialize the `DotDict`\n with\n - **kwargs (optional): key, value pairs with which to initialize the\n `DotDict`\n\n **Example**:\n ```python\n dotdict = DotDict({'a': 34}, b=56, c=set())\n dotdict.a # 34\n dotdict['b'] # 56\n dotdict.c # set()\n ```\n \"\"\"\n\n def __init__(self, init_dict: DictLike = None, **kwargs: Any) -> None:\n if init_dict:\n self.update(init_dict)\n self.update(kwargs)\n\n def __getitem__(self, key: str) -> Any:\n return self.__dict__[key] # __dict__ expects string keys\n\n def __setitem__(self, key: str, value: Any) -> None:\n # prevent overwriting any critical attributes\n if isinstance(key, str) and hasattr(MutableMapping, key):\n raise ValueError('Invalid key: \"{}\"'.format(key))\n self.__dict__[key] = value\n\n def __setattr__(self, attr: str, value: Any) -> None:\n self[attr] = value\n\n def __iter__(self) -> Iterator[str]:\n return iter(self.__dict__.keys())\n\n def __delitem__(self, key: str) -> None:\n del self.__dict__[key]\n\n def __len__(self) -> int:\n return len(self.__dict__)\n\n def __repr__(self) -> str:\n if len(self) > 0:\n return \"<{}: {}>\".format(\n type(self).__name__, \", \".join(sorted(repr(k) for k in self.keys()))\n )\n else:\n return \"<{}>\".format(type(self).__name__)\n\n def copy(self) -> \"DotDict\":\n \"\"\"Creates and returns a shallow copy of the current DotDict\"\"\"\n return type(self)(self.__dict__.copy())\n\n def to_dict(self) -> dict:\n \"\"\"Converts current `DotDict` (and any `DotDict`s contained within) to an appropriate nested dictionary.\"\"\"\n return as_nested_dict(self, dct_class=dict)\n\n\nclass GraphQLResult(DotDict):\n def __repr__(self) -> str:\n return json.dumps(as_nested_dict(self, dict), indent=4)\n\n\ndef merge_dicts(d1: DictLike, d2: DictLike) -> DictLike:\n \"\"\"\n Updates `d1` from `d2` by replacing each `(k, v1)` pair in `d1` with the\n corresponding `(k, v2)` pair in `d2`.\n\n If the value of each pair is itself a dict, then the value is updated\n recursively.\n\n Args:\n - d1 (MutableMapping): A dictionary to be replaced\n - d2 (MutableMapping): A dictionary used for replacement\n\n Returns:\n - A `MutableMapping` with the two dictionary contents merged\n \"\"\"\n\n new_dict = d1.copy()\n\n for k, v in d2.items():\n if isinstance(new_dict.get(k), MutableMapping) and isinstance(\n v, MutableMapping\n ):\n new_dict[k] = merge_dicts(new_dict[k], d2[k])\n else:\n new_dict[k] = d2[k]\n return new_dict\n\n\ndef as_nested_dict(\n obj: Union[DictLike, Iterable[DictLike]], dct_class: type = DotDict\n) -> Union[DictLike, Iterable[DictLike]]:\n \"\"\"\n Given a obj formatted as a dictionary, transforms it (and any nested dictionaries)\n into the provided dct_class\n\n Args:\n - obj (Any): An object that is formatted as a `dict`\n - dct_class (type): the `dict` class to use (defaults to DotDict)\n\n Returns:\n - A `dict_class` representation of the object passed in\n ```\n \"\"\"\n if isinstance(obj, (list, tuple, set)):\n return type(obj)([as_nested_dict(d, dct_class) for d in obj])\n elif isinstance(obj, (dict, DotDict)):\n return dct_class({k: as_nested_dict(v, dct_class) for k, v in obj.items()})\n return obj\n\n\nclass CompoundKey(tuple):\n pass\n\n\ndef dict_to_flatdict(dct: dict, parent: CompoundKey = None) -> dict:\n \"\"\"Converts a (nested) dictionary to a flattened representation.\n\n Each key of the flat dict will be a CompoundKey tuple containing the \"chain of keys\"\n for the corresponding value.\n\n Args:\n - dct (dict): The dictionary to flatten\n - parent (CompoundKey, optional): Defaults to `None`. The parent key\n (you shouldn't need to set this)\n\n Returns:\n - dict: A flattened dict\n \"\"\"\n\n items = [] # type: list\n parent = parent or CompoundKey()\n for k, v in dct.items():\n k_parent = CompoundKey(parent + (k,))\n if isinstance(v, dict):\n items.extend(dict_to_flatdict(v, parent=k_parent).items())\n else:\n items.append((k_parent, v))\n return dict(items)\n\n\ndef flatdict_to_dict(dct: dict, dct_class: type = None) -> MutableMapping:\n \"\"\"Converts a flattened dictionary back to a nested dictionary.\n\n Args:\n - dct (dict): The dictionary to be nested. Each key should be a\n `CompoundKey`, as generated by `dict_to_flatdict()`\n - dct_class (type, optional): the type of the result; defaults to `dict`\n\n Returns:\n - MutableMapping: A `MutableMapping` used to represent a nested dictionary\n \"\"\"\n\n result = (dct_class or dict)()\n for k, v in dct.items():\n if isinstance(k, CompoundKey):\n current_dict = result\n for ki in k[:-1]:\n current_dict = current_dict.setdefault( # type: ignore\n ki, (dct_class or dict)()\n )\n current_dict[k[-1]] = v\n else:\n result[k] = v\n\n return result\n", "path": "src/prefect/utilities/collections.py"}]}
| 2,977 | 159 |
gh_patches_debug_20182
|
rasdani/github-patches
|
git_diff
|
pymodbus-dev__pymodbus-351
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Registers in Database DataStore cant be read from remote client
I try to implement a database backed TCP server so that my registers will be kept in database. For that task I modulated "Updating Server" example . When I run the code I can query regısters from inside. But I cant read same registers from a client located on another computer. With normal ModbusSlaveContext I was able to do that. Results are attached. and here is my code:
```
'''
Pymodbus Server With Updating Thread
--------------------------------------------------------------------------
This is an example of having a background thread updating the
context while the server is operating. This can also be done with
a python thread::
from threading import Thread
thread = Thread(target=updating_writer, args=(context,))
thread.start()
'''
#---------------------------------------------------------------------------#
# import the modbus libraries we need
#---------------------------------------------------------------------------#
from pymodbus.server.async import StartTcpServer
from pymodbus.device import ModbusDeviceIdentification
from pymodbus.datastore import ModbusSequentialDataBlock
from pymodbus.datastore import ModbusServerContext
from database_store import DatabaseSlaveContext
from pymodbus.transaction import ModbusRtuFramer, ModbusAsciiFramer
#---------------------------------------------------------------------------#
# import the twisted libraries we need
#---------------------------------------------------------------------------#
from twisted.internet.task import LoopingCall
#---------------------------------------------------------------------------#
# configure the service logging
#---------------------------------------------------------------------------#
import logging
logging.basicConfig()
log = logging.getLogger()
log.setLevel(logging.DEBUG)
#---------------------------------------------------------------------------#
# define your callback process
#---------------------------------------------------------------------------#
def updating_writer(a):
''' A worker process that runs every so often and
updates live values of the context. It should be noted
that there is a race condition for the update.
:param arguments: The input arguments to the call
'''
log.debug("updating the context")
context = a[0]
readfunction = 0x03 # read holding registers
writefunction = 0x10 # wrıte holding registers
slave_id = 0x00 # slave address
address = 16 # adress : 400017
values = context[slave_id].getValues(readfunction, address, count=3)
log.debug("new values: " + str(values))
#---------------------------------------------------------------------------#
# initialize your data store
#---------------------------------------------------------------------------#
block = ModbusSequentialDataBlock(0x00, [0]*0xff)
store = DatabaseSlaveContext(block)
context = ModbusServerContext(slaves=store, single=True)
#---------------------------------------------------------------------------#
# initialize the server information
#---------------------------------------------------------------------------#
identity = ModbusDeviceIdentification()
identity.VendorName = 'pymodbus'
identity.ProductCode = 'PM'
identity.VendorUrl = 'http://github.com/bashwork/pymodbus/'
identity.ProductName = 'pymodbus Server'
identity.ModelName = 'pymodbus Server'
identity.MajorMinorRevision = '1.0'
#---------------------------------------------------------------------------#
# run the server you want
#---------------------------------------------------------------------------#
time = 5 # 5 seconds delay
loop = LoopingCall(f=updating_writer, a=(context,))
loop.start(time, now=False) # initially delay by time
StartTcpServer(context, identity=identity, address=("", 5007))
```


--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pymodbus/datastore/database/sql_datastore.py`
Content:
```
1 import sqlalchemy
2 import sqlalchemy.types as sqltypes
3 from sqlalchemy.sql import and_
4 from sqlalchemy.schema import UniqueConstraint
5 from sqlalchemy.sql.expression import bindparam
6
7 from pymodbus.exceptions import NotImplementedException
8 from pymodbus.interfaces import IModbusSlaveContext
9
10 #---------------------------------------------------------------------------#
11 # Logging
12 #---------------------------------------------------------------------------#
13 import logging
14 _logger = logging.getLogger(__name__)
15
16
17 #---------------------------------------------------------------------------#
18 # Context
19 #---------------------------------------------------------------------------#
20 class SqlSlaveContext(IModbusSlaveContext):
21 '''
22 This creates a modbus data model with each data access
23 stored in its own personal block
24 '''
25
26 def __init__(self, *args, **kwargs):
27 ''' Initializes the datastores
28
29 :param kwargs: Each element is a ModbusDataBlock
30 '''
31 self.table = kwargs.get('table', 'pymodbus')
32 self.database = kwargs.get('database', 'sqlite:///pymodbus.db')
33 self._db_create(self.table, self.database)
34
35 def __str__(self):
36 ''' Returns a string representation of the context
37
38 :returns: A string representation of the context
39 '''
40 return "Modbus Slave Context"
41
42 def reset(self):
43 ''' Resets all the datastores to their default values '''
44 self._metadata.drop_all()
45 self._db_create(self.table, self.database)
46
47 def validate(self, fx, address, count=1):
48 ''' Validates the request to make sure it is in range
49
50 :param fx: The function we are working with
51 :param address: The starting address
52 :param count: The number of values to test
53 :returns: True if the request in within range, False otherwise
54 '''
55 address = address + 1 # section 4.4 of specification
56 _logger.debug("validate[%d] %d:%d" % (fx, address, count))
57 return self._validate(self.decode(fx), address, count)
58
59 def getValues(self, fx, address, count=1):
60 ''' Get `count` values from datastore
61
62 :param fx: The function we are working with
63 :param address: The starting address
64 :param count: The number of values to retrieve
65 :returns: The requested values from a:a+c
66 '''
67 address = address + 1 # section 4.4 of specification
68 _logger.debug("get-values[%d] %d:%d" % (fx, address, count))
69 return self._get(self.decode(fx), address, count)
70
71 def setValues(self, fx, address, values):
72 ''' Sets the datastore with the supplied values
73
74 :param fx: The function we are working with
75 :param address: The starting address
76 :param values: The new values to be set
77 '''
78 address = address + 1 # section 4.4 of specification
79 _logger.debug("set-values[%d] %d:%d" % (fx, address, len(values)))
80 self._set(self.decode(fx), address, values)
81
82 #--------------------------------------------------------------------------#
83 # Sqlite Helper Methods
84 #--------------------------------------------------------------------------#
85 def _db_create(self, table, database):
86 ''' A helper method to initialize the database and handles
87
88 :param table: The table name to create
89 :param database: The database uri to use
90 '''
91 self._engine = sqlalchemy.create_engine(database, echo=False)
92 self._metadata = sqlalchemy.MetaData(self._engine)
93 self._table = sqlalchemy.Table(table, self._metadata,
94 sqlalchemy.Column('type', sqltypes.String(1)),
95 sqlalchemy.Column('index', sqltypes.Integer),
96 sqlalchemy.Column('value', sqltypes.Integer),
97 UniqueConstraint('type', 'index', name='key'))
98 self._table.create(checkfirst=True)
99 self._connection = self._engine.connect()
100
101 def _get(self, type, offset, count):
102 '''
103 :param type: The key prefix to use
104 :param offset: The address offset to start at
105 :param count: The number of bits to read
106 :returns: The resulting values
107 '''
108 query = self._table.select(and_(
109 self._table.c.type == type,
110 self._table.c.index >= offset,
111 self._table.c.index <= offset + count)
112 )
113 query = query.order_by(self._table.c.index.asc())
114 result = self._connection.execute(query).fetchall()
115 return [row.value for row in result]
116
117 def _build_set(self, type, offset, values, prefix=''):
118 ''' A helper method to generate the sql update context
119
120 :param type: The key prefix to use
121 :param offset: The address offset to start at
122 :param values: The values to set
123 :param prefix: Prefix fields index and type, defaults to empty string
124 '''
125 result = []
126 for index, value in enumerate(values):
127 result.append({
128 prefix + 'type': type,
129 prefix + 'index': offset + index,
130 'value': value
131 })
132 return result
133
134 def _check(self, type, offset, values):
135 result = self._get(type, offset, count=1)
136 return False if len(result) > 0 else True
137
138 def _set(self, type, offset, values):
139 '''
140
141 :param key: The type prefix to use
142 :param offset: The address offset to start at
143 :param values: The values to set
144 '''
145 if self._check(type, offset, values):
146 context = self._build_set(type, offset, values)
147 query = self._table.insert()
148 result = self._connection.execute(query, context)
149 return result.rowcount == len(values)
150 else:
151 return False
152
153 def _update(self, type, offset, values):
154 '''
155
156 :param type: The type prefix to use
157 :param offset: The address offset to start at
158 :param values: The values to set
159 '''
160 context = self._build_set(type, offset, values, prefix='x_')
161 query = self._table.update().values(name='value')
162 query = query.where(and_(
163 self._table.c.type == bindparam('x_type'),
164 self._table.c.index == bindparam('x_index')))
165 result = self._connection.execute(query, context)
166 return result.rowcount == len(values)
167
168 def _validate(self, type, offset, count):
169 '''
170 :param key: The key prefix to use
171 :param offset: The address offset to start at
172 :param count: The number of bits to read
173 :returns: The result of the validation
174 '''
175 query = self._table.select(and_(
176 self._table.c.type == type,
177 self._table.c.index >= offset,
178 self._table.c.index <= offset + count))
179 result = self._connection.execute(query)
180 return result.rowcount == count
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pymodbus/datastore/database/sql_datastore.py b/pymodbus/datastore/database/sql_datastore.py
--- a/pymodbus/datastore/database/sql_datastore.py
+++ b/pymodbus/datastore/database/sql_datastore.py
@@ -108,7 +108,7 @@
query = self._table.select(and_(
self._table.c.type == type,
self._table.c.index >= offset,
- self._table.c.index <= offset + count)
+ self._table.c.index <= offset + count - 1)
)
query = query.order_by(self._table.c.index.asc())
result = self._connection.execute(query).fetchall()
@@ -175,6 +175,6 @@
query = self._table.select(and_(
self._table.c.type == type,
self._table.c.index >= offset,
- self._table.c.index <= offset + count))
- result = self._connection.execute(query)
- return result.rowcount == count
+ self._table.c.index <= offset + count - 1))
+ result = self._connection.execute(query).fetchall()
+ return len(result) == count
|
{"golden_diff": "diff --git a/pymodbus/datastore/database/sql_datastore.py b/pymodbus/datastore/database/sql_datastore.py\n--- a/pymodbus/datastore/database/sql_datastore.py\n+++ b/pymodbus/datastore/database/sql_datastore.py\n@@ -108,7 +108,7 @@\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n- self._table.c.index <= offset + count)\n+ self._table.c.index <= offset + count - 1)\n )\n query = query.order_by(self._table.c.index.asc())\n result = self._connection.execute(query).fetchall()\n@@ -175,6 +175,6 @@\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n- self._table.c.index <= offset + count))\n- result = self._connection.execute(query)\n- return result.rowcount == count\n+ self._table.c.index <= offset + count - 1))\n+ result = self._connection.execute(query).fetchall()\n+ return len(result) == count\n", "issue": "Registers in Database DataStore cant be read from remote client\nI try to implement a database backed TCP server so that my registers will be kept in database. For that task I modulated \"Updating Server\" example . When I run the code I can query reg\u0131sters from inside. But I cant read same registers from a client located on another computer. With normal ModbusSlaveContext I was able to do that. Results are attached. and here is my code:\r\n\r\n```\r\n'''\r\nPymodbus Server With Updating Thread\r\n--------------------------------------------------------------------------\r\nThis is an example of having a background thread updating the\r\ncontext while the server is operating. This can also be done with\r\na python thread::\r\n from threading import Thread\r\n thread = Thread(target=updating_writer, args=(context,))\r\n thread.start()\r\n'''\r\n#---------------------------------------------------------------------------# \r\n# import the modbus libraries we need\r\n#---------------------------------------------------------------------------# \r\nfrom pymodbus.server.async import StartTcpServer\r\nfrom pymodbus.device import ModbusDeviceIdentification\r\nfrom pymodbus.datastore import ModbusSequentialDataBlock\r\nfrom pymodbus.datastore import ModbusServerContext\r\nfrom database_store import DatabaseSlaveContext\r\nfrom pymodbus.transaction import ModbusRtuFramer, ModbusAsciiFramer\r\n\r\n#---------------------------------------------------------------------------# \r\n# import the twisted libraries we need\r\n#---------------------------------------------------------------------------# \r\nfrom twisted.internet.task import LoopingCall\r\n\r\n#---------------------------------------------------------------------------# \r\n# configure the service logging\r\n#---------------------------------------------------------------------------# \r\nimport logging\r\nlogging.basicConfig()\r\nlog = logging.getLogger()\r\nlog.setLevel(logging.DEBUG)\r\n\r\n#---------------------------------------------------------------------------# \r\n# define your callback process\r\n#---------------------------------------------------------------------------# \r\ndef updating_writer(a):\r\n ''' A worker process that runs every so often and\r\n updates live values of the context. It should be noted\r\n that there is a race condition for the update.\r\n :param arguments: The input arguments to the call\r\n '''\r\n log.debug(\"updating the context\")\r\n context = a[0]\r\n readfunction = 0x03 # read holding registers\r\n writefunction = 0x10 # wr\u0131te holding registers\r\n slave_id = 0x00 # slave address\r\n address = 16 # adress : 400017\r\n\r\n\r\n values = context[slave_id].getValues(readfunction, address, count=3)\r\n\r\n log.debug(\"new values: \" + str(values))\r\n\r\n\r\n#---------------------------------------------------------------------------# \r\n# initialize your data store\r\n#---------------------------------------------------------------------------#\r\nblock = ModbusSequentialDataBlock(0x00, [0]*0xff)\r\nstore = DatabaseSlaveContext(block)\r\n\r\ncontext = ModbusServerContext(slaves=store, single=True)\r\n\r\n\r\n#---------------------------------------------------------------------------# \r\n# initialize the server information\r\n#---------------------------------------------------------------------------# \r\nidentity = ModbusDeviceIdentification()\r\nidentity.VendorName = 'pymodbus'\r\nidentity.ProductCode = 'PM'\r\nidentity.VendorUrl = 'http://github.com/bashwork/pymodbus/'\r\nidentity.ProductName = 'pymodbus Server'\r\nidentity.ModelName = 'pymodbus Server'\r\nidentity.MajorMinorRevision = '1.0'\r\n\r\n#---------------------------------------------------------------------------# \r\n# run the server you want\r\n#---------------------------------------------------------------------------# \r\ntime = 5 # 5 seconds delay\r\nloop = LoopingCall(f=updating_writer, a=(context,))\r\nloop.start(time, now=False) # initially delay by time\r\nStartTcpServer(context, identity=identity, address=(\"\", 5007))\r\n\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n \n", "before_files": [{"content": "import sqlalchemy\nimport sqlalchemy.types as sqltypes\nfrom sqlalchemy.sql import and_\nfrom sqlalchemy.schema import UniqueConstraint\nfrom sqlalchemy.sql.expression import bindparam\n\nfrom pymodbus.exceptions import NotImplementedException\nfrom pymodbus.interfaces import IModbusSlaveContext\n\n#---------------------------------------------------------------------------#\n# Logging\n#---------------------------------------------------------------------------#\nimport logging\n_logger = logging.getLogger(__name__)\n\n\n#---------------------------------------------------------------------------#\n# Context\n#---------------------------------------------------------------------------#\nclass SqlSlaveContext(IModbusSlaveContext):\n '''\n This creates a modbus data model with each data access\n stored in its own personal block\n '''\n\n def __init__(self, *args, **kwargs):\n ''' Initializes the datastores\n\n :param kwargs: Each element is a ModbusDataBlock\n '''\n self.table = kwargs.get('table', 'pymodbus')\n self.database = kwargs.get('database', 'sqlite:///pymodbus.db')\n self._db_create(self.table, self.database)\n\n def __str__(self):\n ''' Returns a string representation of the context\n\n :returns: A string representation of the context\n '''\n return \"Modbus Slave Context\"\n\n def reset(self):\n ''' Resets all the datastores to their default values '''\n self._metadata.drop_all()\n self._db_create(self.table, self.database)\n\n def validate(self, fx, address, count=1):\n ''' Validates the request to make sure it is in range\n\n :param fx: The function we are working with\n :param address: The starting address\n :param count: The number of values to test\n :returns: True if the request in within range, False otherwise\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"validate[%d] %d:%d\" % (fx, address, count))\n return self._validate(self.decode(fx), address, count)\n\n def getValues(self, fx, address, count=1):\n ''' Get `count` values from datastore\n\n :param fx: The function we are working with\n :param address: The starting address\n :param count: The number of values to retrieve\n :returns: The requested values from a:a+c\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"get-values[%d] %d:%d\" % (fx, address, count))\n return self._get(self.decode(fx), address, count)\n\n def setValues(self, fx, address, values):\n ''' Sets the datastore with the supplied values\n\n :param fx: The function we are working with\n :param address: The starting address\n :param values: The new values to be set\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"set-values[%d] %d:%d\" % (fx, address, len(values)))\n self._set(self.decode(fx), address, values)\n\n #--------------------------------------------------------------------------#\n # Sqlite Helper Methods\n #--------------------------------------------------------------------------#\n def _db_create(self, table, database):\n ''' A helper method to initialize the database and handles\n\n :param table: The table name to create\n :param database: The database uri to use\n '''\n self._engine = sqlalchemy.create_engine(database, echo=False)\n self._metadata = sqlalchemy.MetaData(self._engine)\n self._table = sqlalchemy.Table(table, self._metadata,\n sqlalchemy.Column('type', sqltypes.String(1)),\n sqlalchemy.Column('index', sqltypes.Integer),\n sqlalchemy.Column('value', sqltypes.Integer),\n UniqueConstraint('type', 'index', name='key'))\n self._table.create(checkfirst=True)\n self._connection = self._engine.connect()\n\n def _get(self, type, offset, count):\n '''\n :param type: The key prefix to use\n :param offset: The address offset to start at\n :param count: The number of bits to read\n :returns: The resulting values\n '''\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n self._table.c.index <= offset + count)\n )\n query = query.order_by(self._table.c.index.asc())\n result = self._connection.execute(query).fetchall()\n return [row.value for row in result]\n\n def _build_set(self, type, offset, values, prefix=''):\n ''' A helper method to generate the sql update context\n\n :param type: The key prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n :param prefix: Prefix fields index and type, defaults to empty string\n '''\n result = []\n for index, value in enumerate(values):\n result.append({\n prefix + 'type': type,\n prefix + 'index': offset + index,\n 'value': value\n })\n return result\n\n def _check(self, type, offset, values):\n result = self._get(type, offset, count=1)\n return False if len(result) > 0 else True\n\n def _set(self, type, offset, values):\n '''\n\n :param key: The type prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n '''\n if self._check(type, offset, values):\n context = self._build_set(type, offset, values)\n query = self._table.insert()\n result = self._connection.execute(query, context)\n return result.rowcount == len(values)\n else:\n return False\n\n def _update(self, type, offset, values):\n '''\n\n :param type: The type prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n '''\n context = self._build_set(type, offset, values, prefix='x_')\n query = self._table.update().values(name='value')\n query = query.where(and_(\n self._table.c.type == bindparam('x_type'),\n self._table.c.index == bindparam('x_index')))\n result = self._connection.execute(query, context)\n return result.rowcount == len(values)\n\n def _validate(self, type, offset, count):\n '''\n :param key: The key prefix to use\n :param offset: The address offset to start at\n :param count: The number of bits to read\n :returns: The result of the validation\n '''\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n self._table.c.index <= offset + count))\n result = self._connection.execute(query)\n return result.rowcount == count\n", "path": "pymodbus/datastore/database/sql_datastore.py"}], "after_files": [{"content": "import sqlalchemy\nimport sqlalchemy.types as sqltypes\nfrom sqlalchemy.sql import and_\nfrom sqlalchemy.schema import UniqueConstraint\nfrom sqlalchemy.sql.expression import bindparam\n\nfrom pymodbus.exceptions import NotImplementedException\nfrom pymodbus.interfaces import IModbusSlaveContext\n\n#---------------------------------------------------------------------------#\n# Logging\n#---------------------------------------------------------------------------#\nimport logging\n_logger = logging.getLogger(__name__)\n\n\n#---------------------------------------------------------------------------#\n# Context\n#---------------------------------------------------------------------------#\nclass SqlSlaveContext(IModbusSlaveContext):\n '''\n This creates a modbus data model with each data access\n stored in its own personal block\n '''\n\n def __init__(self, *args, **kwargs):\n ''' Initializes the datastores\n\n :param kwargs: Each element is a ModbusDataBlock\n '''\n self.table = kwargs.get('table', 'pymodbus')\n self.database = kwargs.get('database', 'sqlite:///pymodbus.db')\n self._db_create(self.table, self.database)\n\n def __str__(self):\n ''' Returns a string representation of the context\n\n :returns: A string representation of the context\n '''\n return \"Modbus Slave Context\"\n\n def reset(self):\n ''' Resets all the datastores to their default values '''\n self._metadata.drop_all()\n self._db_create(self.table, self.database)\n\n def validate(self, fx, address, count=1):\n ''' Validates the request to make sure it is in range\n\n :param fx: The function we are working with\n :param address: The starting address\n :param count: The number of values to test\n :returns: True if the request in within range, False otherwise\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"validate[%d] %d:%d\" % (fx, address, count))\n return self._validate(self.decode(fx), address, count)\n\n def getValues(self, fx, address, count=1):\n ''' Get `count` values from datastore\n\n :param fx: The function we are working with\n :param address: The starting address\n :param count: The number of values to retrieve\n :returns: The requested values from a:a+c\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"get-values[%d] %d:%d\" % (fx, address, count))\n return self._get(self.decode(fx), address, count)\n\n def setValues(self, fx, address, values):\n ''' Sets the datastore with the supplied values\n\n :param fx: The function we are working with\n :param address: The starting address\n :param values: The new values to be set\n '''\n address = address + 1 # section 4.4 of specification\n _logger.debug(\"set-values[%d] %d:%d\" % (fx, address, len(values)))\n self._set(self.decode(fx), address, values)\n\n #--------------------------------------------------------------------------#\n # Sqlite Helper Methods\n #--------------------------------------------------------------------------#\n def _db_create(self, table, database):\n ''' A helper method to initialize the database and handles\n\n :param table: The table name to create\n :param database: The database uri to use\n '''\n self._engine = sqlalchemy.create_engine(database, echo=False)\n self._metadata = sqlalchemy.MetaData(self._engine)\n self._table = sqlalchemy.Table(table, self._metadata,\n sqlalchemy.Column('type', sqltypes.String(1)),\n sqlalchemy.Column('index', sqltypes.Integer),\n sqlalchemy.Column('value', sqltypes.Integer),\n UniqueConstraint('type', 'index', name='key'))\n self._table.create(checkfirst=True)\n self._connection = self._engine.connect()\n\n def _get(self, type, offset, count):\n '''\n :param type: The key prefix to use\n :param offset: The address offset to start at\n :param count: The number of bits to read\n :returns: The resulting values\n '''\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n self._table.c.index <= offset + count - 1)\n )\n query = query.order_by(self._table.c.index.asc())\n result = self._connection.execute(query).fetchall()\n return [row.value for row in result]\n\n def _build_set(self, type, offset, values, prefix=''):\n ''' A helper method to generate the sql update context\n\n :param type: The key prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n :param prefix: Prefix fields index and type, defaults to empty string\n '''\n result = []\n for index, value in enumerate(values):\n result.append({\n prefix + 'type': type,\n prefix + 'index': offset + index,\n 'value': value\n })\n return result\n\n def _check(self, type, offset, values):\n result = self._get(type, offset, count=1)\n return False if len(result) > 0 else True\n\n def _set(self, type, offset, values):\n '''\n\n :param key: The type prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n '''\n if self._check(type, offset, values):\n context = self._build_set(type, offset, values)\n query = self._table.insert()\n result = self._connection.execute(query, context)\n return result.rowcount == len(values)\n else:\n return False\n\n def _update(self, type, offset, values):\n '''\n\n :param type: The type prefix to use\n :param offset: The address offset to start at\n :param values: The values to set\n '''\n context = self._build_set(type, offset, values, prefix='x_')\n query = self._table.update().values(name='value')\n query = query.where(and_(\n self._table.c.type == bindparam('x_type'),\n self._table.c.index == bindparam('x_index')))\n result = self._connection.execute(query, context)\n return result.rowcount == len(values)\n\n def _validate(self, type, offset, count):\n '''\n :param key: The key prefix to use\n :param offset: The address offset to start at\n :param count: The number of bits to read\n :returns: The result of the validation\n '''\n query = self._table.select(and_(\n self._table.c.type == type,\n self._table.c.index >= offset,\n self._table.c.index <= offset + count - 1))\n result = self._connection.execute(query).fetchall()\n return len(result) == count\n", "path": "pymodbus/datastore/database/sql_datastore.py"}]}
| 3,017 | 262 |
gh_patches_debug_36691
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-147
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Route53: Public and Private Zones can't be distinguished.
I've been testing out lexicon for updating DNS records via Route53, and I have a Public and Private Zone with the same domain name.
I noticed that lexicon is only searching for the domain name by name, so in my case, my internal zone was the first created and so it's the only thing lexicon itself finds for my domain name.
I was going to have it update a record for my home IP address for dynamic IP issues, but what's happening is it is only updating the Private zone's record. I've specified --identifier with the ZoneID of the Public Zone, but that is not working either.
I didn't even have a record for home.mydomain.com in my Private Zone, and it ended up creating the record just to fullfill the update. I do see in the output of lexicon both private and public zones, including the <PrivateZone>true|false</PrivateZone> specifically identifying it as private or not.
I'd like to be able to update both, differently as needed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/route53.py`
Content:
```
1 """Provide support to Lexicon for AWS Route 53 DNS changes."""
2 from __future__ import absolute_import
3 from __future__ import print_function
4
5 import logging
6
7 from .base import Provider as BaseProvider
8
9 try:
10 import boto3 #optional dep
11 import botocore #optional dep
12 except ImportError:
13 pass
14
15 logger = logging.getLogger(__name__)
16
17
18 def ProviderParser(subparser):
19 """Specify arguments for AWS Route 53 Lexicon Provider."""
20 subparser.add_argument("--auth-access-key", help="specify ACCESS_KEY used to authenticate")
21 subparser.add_argument("--auth-access-secret", help="specify ACCESS_SECRET used authenticate")
22
23 #TODO: these are only required for testing, we should figure out a way to remove them & update the integration tests
24 # to dynamically populate the auth credentials that are required.
25 subparser.add_argument("--auth-username", help="alternative way to specify ACCESS_KEY used to authenticate")
26 subparser.add_argument("--auth-token", help="alternative way to specify ACCESS_SECRET used authenticate")
27
28
29 class RecordSetPaginator(object):
30 """Paginate through complete list of record sets."""
31
32 def __init__(self, r53_client, hosted_zone_id, max_items=None):
33 """Initialize paginator."""
34 self.r53_client = r53_client
35 self.hosted_zone_id = hosted_zone_id
36 self.max_items = max_items
37
38 def get_record_sets(self, **kwargs):
39 """Retrieve a page from API."""
40 return self.r53_client.list_resource_record_sets(**kwargs)
41
42 def get_base_kwargs(self):
43 """Get base kwargs for API call."""
44 kwargs = {
45 'HostedZoneId': self.hosted_zone_id
46 }
47 if self.max_items is not None:
48 kwargs.update({
49 'MaxItems': str(self.max_items)
50 })
51 return kwargs
52
53 def all_record_sets(self):
54 """Generator to loop through current record set.
55
56 Call next page if it exists.
57 """
58 is_truncated = True
59 start_record_name = None
60 start_record_type = None
61 kwargs = self.get_base_kwargs()
62 while is_truncated:
63 if start_record_name is not None:
64 kwargs.update({
65 'StartRecordName': start_record_name,
66 'StartRecordType': start_record_type
67 })
68 result = self.get_record_sets(**kwargs)
69 for record_set in result.get('ResourceRecordSets', []):
70 yield record_set
71
72 is_truncated = result.get('IsTruncated', False)
73
74 start_record_name = result.get('NextRecordName', None)
75 start_record_type = result.get('NextRecordType', None)
76
77
78 class Provider(BaseProvider):
79 """Provide AWS Route 53 implementation of Lexicon Provider interface."""
80
81 def __init__(self, options, engine_overrides=None):
82 """Initialize AWS Route 53 DNS provider."""
83 super(Provider, self).__init__(options, engine_overrides)
84 self.domain_id = None
85 # instantiate the client
86 self.r53_client = boto3.client(
87 'route53',
88 aws_access_key_id=self.options.get('auth_access_key', self.options.get('auth_username')),
89 aws_secret_access_key=self.options.get('auth_access_secret', self.options.get('auth_token'))
90 )
91
92 def authenticate(self):
93 """Determine the hosted zone id for the domain."""
94 try:
95 hosted_zones = self.r53_client.list_hosted_zones_by_name()[
96 'HostedZones'
97 ]
98 hosted_zone = next(
99 hz for hz in hosted_zones
100 if hz['Name'] == '{0}.'.format(self.options['domain'])
101 )
102 self.domain_id = hosted_zone['Id']
103 except StopIteration:
104 raise Exception('No domain found')
105
106 def _change_record_sets(self, action, type, name, content):
107 ttl = self.options['ttl']
108 value = '"{0}"'.format(content) if type in ['TXT', 'SPF'] else content
109 try:
110 self.r53_client.change_resource_record_sets(
111 HostedZoneId=self.domain_id,
112 ChangeBatch={
113 'Comment': '{0} using lexicon Route 53 provider'.format(
114 action
115 ),
116 'Changes': [
117 {
118 'Action': action,
119 'ResourceRecordSet': {
120 'Name': self._fqdn_name(name),
121 'Type': type,
122 'TTL': ttl if ttl is not None else 300,
123 'ResourceRecords': [
124 {
125 'Value': value
126 }
127 ]
128 }
129 }
130 ]
131 }
132 )
133 return True
134 except botocore.exceptions.ClientError as e:
135 logger.debug(e.message, exc_info=True)
136
137 def create_record(self, type, name, content):
138 """Create a record in the hosted zone."""
139 return self._change_record_sets('CREATE', type, name, content)
140
141 def update_record(self, identifier=None, type=None, name=None, content=None):
142 """Update a record from the hosted zone."""
143 return self._change_record_sets('UPSERT', type, name, content)
144
145 def delete_record(self, identifier=None, type=None, name=None, content=None):
146 """Delete a record from the hosted zone."""
147 return self._change_record_sets('DELETE', type, name, content)
148
149 def _format_content(self, type, content):
150 return content[1:-1] if type in ['TXT', 'SPF'] else content
151
152 def list_records(self, type=None, name=None, content=None):
153 """List all records for the hosted zone."""
154 records = []
155 paginator = RecordSetPaginator(self.r53_client, self.domain_id)
156 for record in paginator.all_record_sets():
157 if type is not None and record['Type'] != type:
158 continue
159 if name is not None and record['Name'] != self._fqdn_name(name):
160 continue
161 if record.get('AliasTarget', None) is not None:
162 record_content = [record['AliasTarget'].get('DNSName', None)]
163 if record.get('ResourceRecords', None) is not None:
164 record_content = [self._format_content(record['Type'], value['Value']) for value
165 in record['ResourceRecords']]
166 if content is not None and content not in record_content:
167 continue
168 logger.debug('record: %s', record)
169 records.append({
170 'type': record['Type'],
171 'name': self._full_name(record['Name']),
172 'ttl': record.get('TTL', None),
173 'content': record_content[0] if len(record_content) == 1 else record_content,
174 })
175 logger.debug('list_records: %s', records)
176 return records
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lexicon/providers/route53.py b/lexicon/providers/route53.py
--- a/lexicon/providers/route53.py
+++ b/lexicon/providers/route53.py
@@ -19,6 +19,7 @@
"""Specify arguments for AWS Route 53 Lexicon Provider."""
subparser.add_argument("--auth-access-key", help="specify ACCESS_KEY used to authenticate")
subparser.add_argument("--auth-access-secret", help="specify ACCESS_SECRET used authenticate")
+ subparser.add_argument("--private-zone", help="indicates what kind of hosted zone to use, if true, use only private zones, if false, use only public zones")
#TODO: these are only required for testing, we should figure out a way to remove them & update the integration tests
# to dynamically populate the auth credentials that are required.
@@ -82,6 +83,7 @@
"""Initialize AWS Route 53 DNS provider."""
super(Provider, self).__init__(options, engine_overrides)
self.domain_id = None
+ self.private_zone = options.get('private_zone', None)
# instantiate the client
self.r53_client = boto3.client(
'route53',
@@ -89,6 +91,20 @@
aws_secret_access_key=self.options.get('auth_access_secret', self.options.get('auth_token'))
)
+ def filter_zone(self, hz):
+ if self.private_zone is not None:
+ if hz['Config']['PrivateZone'] != self.str2bool(self.private_zone):
+ return False
+
+ if hz['Name'] != '{0}.'.format(self.options['domain']):
+ return False
+
+ return True
+
+ @staticmethod
+ def str2bool(input_string):
+ return input_string.lower() in ('true', 'yes')
+
def authenticate(self):
"""Determine the hosted zone id for the domain."""
try:
@@ -97,7 +113,7 @@
]
hosted_zone = next(
hz for hz in hosted_zones
- if hz['Name'] == '{0}.'.format(self.options['domain'])
+ if self.filter_zone(hz)
)
self.domain_id = hosted_zone['Id']
except StopIteration:
|
{"golden_diff": "diff --git a/lexicon/providers/route53.py b/lexicon/providers/route53.py\n--- a/lexicon/providers/route53.py\n+++ b/lexicon/providers/route53.py\n@@ -19,6 +19,7 @@\n \"\"\"Specify arguments for AWS Route 53 Lexicon Provider.\"\"\"\n subparser.add_argument(\"--auth-access-key\", help=\"specify ACCESS_KEY used to authenticate\")\n subparser.add_argument(\"--auth-access-secret\", help=\"specify ACCESS_SECRET used authenticate\")\n+ subparser.add_argument(\"--private-zone\", help=\"indicates what kind of hosted zone to use, if true, use only private zones, if false, use only public zones\")\n \n #TODO: these are only required for testing, we should figure out a way to remove them & update the integration tests\n # to dynamically populate the auth credentials that are required.\n@@ -82,6 +83,7 @@\n \"\"\"Initialize AWS Route 53 DNS provider.\"\"\"\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n+ self.private_zone = options.get('private_zone', None)\n # instantiate the client\n self.r53_client = boto3.client(\n 'route53',\n@@ -89,6 +91,20 @@\n aws_secret_access_key=self.options.get('auth_access_secret', self.options.get('auth_token'))\n )\n \n+ def filter_zone(self, hz):\n+ if self.private_zone is not None:\n+ if hz['Config']['PrivateZone'] != self.str2bool(self.private_zone):\n+ return False\n+\n+ if hz['Name'] != '{0}.'.format(self.options['domain']):\n+ return False\n+\n+ return True\n+\n+ @staticmethod\n+ def str2bool(input_string):\n+ return input_string.lower() in ('true', 'yes')\n+\n def authenticate(self):\n \"\"\"Determine the hosted zone id for the domain.\"\"\"\n try:\n@@ -97,7 +113,7 @@\n ]\n hosted_zone = next(\n hz for hz in hosted_zones\n- if hz['Name'] == '{0}.'.format(self.options['domain'])\n+ if self.filter_zone(hz)\n )\n self.domain_id = hosted_zone['Id']\n except StopIteration:\n", "issue": "Route53: Public and Private Zones can't be distinguished.\nI've been testing out lexicon for updating DNS records via Route53, and I have a Public and Private Zone with the same domain name.\r\nI noticed that lexicon is only searching for the domain name by name, so in my case, my internal zone was the first created and so it's the only thing lexicon itself finds for my domain name.\r\n\r\nI was going to have it update a record for my home IP address for dynamic IP issues, but what's happening is it is only updating the Private zone's record. I've specified --identifier with the ZoneID of the Public Zone, but that is not working either.\r\n\r\nI didn't even have a record for home.mydomain.com in my Private Zone, and it ended up creating the record just to fullfill the update. I do see in the output of lexicon both private and public zones, including the <PrivateZone>true|false</PrivateZone> specifically identifying it as private or not.\r\n\r\nI'd like to be able to update both, differently as needed.\n", "before_files": [{"content": "\"\"\"Provide support to Lexicon for AWS Route 53 DNS changes.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport logging\n\nfrom .base import Provider as BaseProvider\n\ntry:\n import boto3 #optional dep\n import botocore #optional dep\nexcept ImportError:\n pass\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n \"\"\"Specify arguments for AWS Route 53 Lexicon Provider.\"\"\"\n subparser.add_argument(\"--auth-access-key\", help=\"specify ACCESS_KEY used to authenticate\")\n subparser.add_argument(\"--auth-access-secret\", help=\"specify ACCESS_SECRET used authenticate\")\n\n #TODO: these are only required for testing, we should figure out a way to remove them & update the integration tests\n # to dynamically populate the auth credentials that are required.\n subparser.add_argument(\"--auth-username\", help=\"alternative way to specify ACCESS_KEY used to authenticate\")\n subparser.add_argument(\"--auth-token\", help=\"alternative way to specify ACCESS_SECRET used authenticate\")\n\n\nclass RecordSetPaginator(object):\n \"\"\"Paginate through complete list of record sets.\"\"\"\n\n def __init__(self, r53_client, hosted_zone_id, max_items=None):\n \"\"\"Initialize paginator.\"\"\"\n self.r53_client = r53_client\n self.hosted_zone_id = hosted_zone_id\n self.max_items = max_items\n\n def get_record_sets(self, **kwargs):\n \"\"\"Retrieve a page from API.\"\"\"\n return self.r53_client.list_resource_record_sets(**kwargs)\n\n def get_base_kwargs(self):\n \"\"\"Get base kwargs for API call.\"\"\"\n kwargs = {\n 'HostedZoneId': self.hosted_zone_id\n }\n if self.max_items is not None:\n kwargs.update({\n 'MaxItems': str(self.max_items)\n })\n return kwargs\n\n def all_record_sets(self):\n \"\"\"Generator to loop through current record set.\n\n Call next page if it exists.\n \"\"\"\n is_truncated = True\n start_record_name = None\n start_record_type = None\n kwargs = self.get_base_kwargs()\n while is_truncated:\n if start_record_name is not None:\n kwargs.update({\n 'StartRecordName': start_record_name,\n 'StartRecordType': start_record_type\n })\n result = self.get_record_sets(**kwargs)\n for record_set in result.get('ResourceRecordSets', []):\n yield record_set\n\n is_truncated = result.get('IsTruncated', False)\n\n start_record_name = result.get('NextRecordName', None)\n start_record_type = result.get('NextRecordType', None)\n\n\nclass Provider(BaseProvider):\n \"\"\"Provide AWS Route 53 implementation of Lexicon Provider interface.\"\"\"\n\n def __init__(self, options, engine_overrides=None):\n \"\"\"Initialize AWS Route 53 DNS provider.\"\"\"\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n # instantiate the client\n self.r53_client = boto3.client(\n 'route53',\n aws_access_key_id=self.options.get('auth_access_key', self.options.get('auth_username')),\n aws_secret_access_key=self.options.get('auth_access_secret', self.options.get('auth_token'))\n )\n\n def authenticate(self):\n \"\"\"Determine the hosted zone id for the domain.\"\"\"\n try:\n hosted_zones = self.r53_client.list_hosted_zones_by_name()[\n 'HostedZones'\n ]\n hosted_zone = next(\n hz for hz in hosted_zones\n if hz['Name'] == '{0}.'.format(self.options['domain'])\n )\n self.domain_id = hosted_zone['Id']\n except StopIteration:\n raise Exception('No domain found')\n\n def _change_record_sets(self, action, type, name, content):\n ttl = self.options['ttl']\n value = '\"{0}\"'.format(content) if type in ['TXT', 'SPF'] else content\n try:\n self.r53_client.change_resource_record_sets(\n HostedZoneId=self.domain_id,\n ChangeBatch={\n 'Comment': '{0} using lexicon Route 53 provider'.format(\n action\n ),\n 'Changes': [\n {\n 'Action': action,\n 'ResourceRecordSet': {\n 'Name': self._fqdn_name(name),\n 'Type': type,\n 'TTL': ttl if ttl is not None else 300,\n 'ResourceRecords': [\n {\n 'Value': value\n }\n ]\n }\n }\n ]\n }\n )\n return True\n except botocore.exceptions.ClientError as e:\n logger.debug(e.message, exc_info=True)\n\n def create_record(self, type, name, content):\n \"\"\"Create a record in the hosted zone.\"\"\"\n return self._change_record_sets('CREATE', type, name, content)\n\n def update_record(self, identifier=None, type=None, name=None, content=None):\n \"\"\"Update a record from the hosted zone.\"\"\"\n return self._change_record_sets('UPSERT', type, name, content)\n\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n \"\"\"Delete a record from the hosted zone.\"\"\"\n return self._change_record_sets('DELETE', type, name, content)\n\n def _format_content(self, type, content):\n return content[1:-1] if type in ['TXT', 'SPF'] else content\n\n def list_records(self, type=None, name=None, content=None):\n \"\"\"List all records for the hosted zone.\"\"\"\n records = []\n paginator = RecordSetPaginator(self.r53_client, self.domain_id)\n for record in paginator.all_record_sets():\n if type is not None and record['Type'] != type:\n continue\n if name is not None and record['Name'] != self._fqdn_name(name):\n continue\n if record.get('AliasTarget', None) is not None:\n record_content = [record['AliasTarget'].get('DNSName', None)]\n if record.get('ResourceRecords', None) is not None:\n record_content = [self._format_content(record['Type'], value['Value']) for value\n in record['ResourceRecords']]\n if content is not None and content not in record_content:\n continue\n logger.debug('record: %s', record)\n records.append({\n 'type': record['Type'],\n 'name': self._full_name(record['Name']),\n 'ttl': record.get('TTL', None),\n 'content': record_content[0] if len(record_content) == 1 else record_content,\n })\n logger.debug('list_records: %s', records)\n return records\n", "path": "lexicon/providers/route53.py"}], "after_files": [{"content": "\"\"\"Provide support to Lexicon for AWS Route 53 DNS changes.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport logging\n\nfrom .base import Provider as BaseProvider\n\ntry:\n import boto3 #optional dep\n import botocore #optional dep\nexcept ImportError:\n pass\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n \"\"\"Specify arguments for AWS Route 53 Lexicon Provider.\"\"\"\n subparser.add_argument(\"--auth-access-key\", help=\"specify ACCESS_KEY used to authenticate\")\n subparser.add_argument(\"--auth-access-secret\", help=\"specify ACCESS_SECRET used authenticate\")\n subparser.add_argument(\"--private-zone\", help=\"indicates what kind of hosted zone to use, if true, use only private zones, if false, use only public zones\")\n\n #TODO: these are only required for testing, we should figure out a way to remove them & update the integration tests\n # to dynamically populate the auth credentials that are required.\n subparser.add_argument(\"--auth-username\", help=\"alternative way to specify ACCESS_KEY used to authenticate\")\n subparser.add_argument(\"--auth-token\", help=\"alternative way to specify ACCESS_SECRET used authenticate\")\n\n\nclass RecordSetPaginator(object):\n \"\"\"Paginate through complete list of record sets.\"\"\"\n\n def __init__(self, r53_client, hosted_zone_id, max_items=None):\n \"\"\"Initialize paginator.\"\"\"\n self.r53_client = r53_client\n self.hosted_zone_id = hosted_zone_id\n self.max_items = max_items\n\n def get_record_sets(self, **kwargs):\n \"\"\"Retrieve a page from API.\"\"\"\n return self.r53_client.list_resource_record_sets(**kwargs)\n\n def get_base_kwargs(self):\n \"\"\"Get base kwargs for API call.\"\"\"\n kwargs = {\n 'HostedZoneId': self.hosted_zone_id\n }\n if self.max_items is not None:\n kwargs.update({\n 'MaxItems': str(self.max_items)\n })\n return kwargs\n\n def all_record_sets(self):\n \"\"\"Generator to loop through current record set.\n\n Call next page if it exists.\n \"\"\"\n is_truncated = True\n start_record_name = None\n start_record_type = None\n kwargs = self.get_base_kwargs()\n while is_truncated:\n if start_record_name is not None:\n kwargs.update({\n 'StartRecordName': start_record_name,\n 'StartRecordType': start_record_type\n })\n result = self.get_record_sets(**kwargs)\n for record_set in result.get('ResourceRecordSets', []):\n yield record_set\n\n is_truncated = result.get('IsTruncated', False)\n\n start_record_name = result.get('NextRecordName', None)\n start_record_type = result.get('NextRecordType', None)\n\n\nclass Provider(BaseProvider):\n \"\"\"Provide AWS Route 53 implementation of Lexicon Provider interface.\"\"\"\n\n def __init__(self, options, engine_overrides=None):\n \"\"\"Initialize AWS Route 53 DNS provider.\"\"\"\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.private_zone = options.get('private_zone', None)\n # instantiate the client\n self.r53_client = boto3.client(\n 'route53',\n aws_access_key_id=self.options.get('auth_access_key', self.options.get('auth_username')),\n aws_secret_access_key=self.options.get('auth_access_secret', self.options.get('auth_token'))\n )\n\n def filter_zone(self, hz):\n if self.private_zone is not None:\n if hz['Config']['PrivateZone'] != self.str2bool(self.private_zone):\n return False\n\n if hz['Name'] != '{0}.'.format(self.options['domain']):\n return False\n\n return True\n\n @staticmethod\n def str2bool(input_string):\n return input_string.lower() in ('true', 'yes')\n\n def authenticate(self):\n \"\"\"Determine the hosted zone id for the domain.\"\"\"\n try:\n hosted_zones = self.r53_client.list_hosted_zones_by_name()[\n 'HostedZones'\n ]\n hosted_zone = next(\n hz for hz in hosted_zones\n if self.filter_zone(hz)\n )\n self.domain_id = hosted_zone['Id']\n except StopIteration:\n raise Exception('No domain found')\n\n def _change_record_sets(self, action, type, name, content):\n ttl = self.options['ttl']\n value = '\"{0}\"'.format(content) if type in ['TXT', 'SPF'] else content\n try:\n self.r53_client.change_resource_record_sets(\n HostedZoneId=self.domain_id,\n ChangeBatch={\n 'Comment': '{0} using lexicon Route 53 provider'.format(\n action\n ),\n 'Changes': [\n {\n 'Action': action,\n 'ResourceRecordSet': {\n 'Name': self._fqdn_name(name),\n 'Type': type,\n 'TTL': ttl if ttl is not None else 300,\n 'ResourceRecords': [\n {\n 'Value': value\n }\n ]\n }\n }\n ]\n }\n )\n return True\n except botocore.exceptions.ClientError as e:\n logger.debug(e.message, exc_info=True)\n\n def create_record(self, type, name, content):\n \"\"\"Create a record in the hosted zone.\"\"\"\n return self._change_record_sets('CREATE', type, name, content)\n\n def update_record(self, identifier=None, type=None, name=None, content=None):\n \"\"\"Update a record from the hosted zone.\"\"\"\n return self._change_record_sets('UPSERT', type, name, content)\n\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n \"\"\"Delete a record from the hosted zone.\"\"\"\n return self._change_record_sets('DELETE', type, name, content)\n\n def _format_content(self, type, content):\n return content[1:-1] if type in ['TXT', 'SPF'] else content\n\n def list_records(self, type=None, name=None, content=None):\n \"\"\"List all records for the hosted zone.\"\"\"\n records = []\n paginator = RecordSetPaginator(self.r53_client, self.domain_id)\n for record in paginator.all_record_sets():\n if type is not None and record['Type'] != type:\n continue\n if name is not None and record['Name'] != self._fqdn_name(name):\n continue\n if record.get('AliasTarget', None) is not None:\n record_content = [record['AliasTarget'].get('DNSName', None)]\n if record.get('ResourceRecords', None) is not None:\n record_content = [self._format_content(record['Type'], value['Value']) for value\n in record['ResourceRecords']]\n if content is not None and content not in record_content:\n continue\n logger.debug('record: %s', record)\n records.append({\n 'type': record['Type'],\n 'name': self._full_name(record['Name']),\n 'ttl': record.get('TTL', None),\n 'content': record_content[0] if len(record_content) == 1 else record_content,\n })\n logger.debug('list_records: %s', records)\n return records\n", "path": "lexicon/providers/route53.py"}]}
| 2,351 | 510 |
gh_patches_debug_1390
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-758
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ca_cert_dir keyword argument may be passed to HTTPConnectionPool by accident.
Seems like as part of #701 I missed the `SSL_KEYWORDS` block in `poolmanager.py`. This means that `ca_cert_dir` may accidentally be passed to the `HTTPConnectionPool`. This leads to the following error when attempting to use `ca_cert_dir` with a `PoolManager` and then making a plaintext HTTP connection:
```
>>> import urllib3
>>> p = urllib3.PoolManager(ca_cert_dir='/usr/local/etc/openssl')
>>> p.urlopen('GET', 'http://http2bin.org/get')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "urllib3/poolmanager.py", line 162, in urlopen
response = conn.urlopen(method, u.request_uri, **kw)
File "urllib3/connectionpool.py", line 548, in urlopen
conn = self._get_conn(timeout=pool_timeout)
File "urllib3/connectionpool.py", line 250, in _get_conn
return conn or self._new_conn()
File "urllib3/connectionpool.py", line 211, in _new_conn
strict=self.strict, **self.conn_kw)
File "urllib3/connection.py", line 121, in __init__
_HTTPConnection.__init__(self, *args, **kw)
TypeError: __init__() got an unexpected keyword argument 'ca_cert_dir'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `urllib3/poolmanager.py`
Content:
```
1 from __future__ import absolute_import
2 import logging
3
4 try: # Python 3
5 from urllib.parse import urljoin
6 except ImportError:
7 from urlparse import urljoin
8
9 from ._collections import RecentlyUsedContainer
10 from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool
11 from .connectionpool import port_by_scheme
12 from .exceptions import LocationValueError, MaxRetryError, ProxySchemeUnknown
13 from .request import RequestMethods
14 from .util.url import parse_url
15 from .util.retry import Retry
16
17
18 __all__ = ['PoolManager', 'ProxyManager', 'proxy_from_url']
19
20
21 pool_classes_by_scheme = {
22 'http': HTTPConnectionPool,
23 'https': HTTPSConnectionPool,
24 }
25
26 log = logging.getLogger(__name__)
27
28 SSL_KEYWORDS = ('key_file', 'cert_file', 'cert_reqs', 'ca_certs',
29 'ssl_version')
30
31
32 class PoolManager(RequestMethods):
33 """
34 Allows for arbitrary requests while transparently keeping track of
35 necessary connection pools for you.
36
37 :param num_pools:
38 Number of connection pools to cache before discarding the least
39 recently used pool.
40
41 :param headers:
42 Headers to include with all requests, unless other headers are given
43 explicitly.
44
45 :param \**connection_pool_kw:
46 Additional parameters are used to create fresh
47 :class:`urllib3.connectionpool.ConnectionPool` instances.
48
49 Example::
50
51 >>> manager = PoolManager(num_pools=2)
52 >>> r = manager.request('GET', 'http://google.com/')
53 >>> r = manager.request('GET', 'http://google.com/mail')
54 >>> r = manager.request('GET', 'http://yahoo.com/')
55 >>> len(manager.pools)
56 2
57
58 """
59
60 proxy = None
61
62 def __init__(self, num_pools=10, headers=None, **connection_pool_kw):
63 RequestMethods.__init__(self, headers)
64 self.connection_pool_kw = connection_pool_kw
65 self.pools = RecentlyUsedContainer(num_pools,
66 dispose_func=lambda p: p.close())
67
68 def __enter__(self):
69 return self
70
71 def __exit__(self, exc_type, exc_val, exc_tb):
72 self.clear()
73 # Return False to re-raise any potential exceptions
74 return False
75
76 def _new_pool(self, scheme, host, port):
77 """
78 Create a new :class:`ConnectionPool` based on host, port and scheme.
79
80 This method is used to actually create the connection pools handed out
81 by :meth:`connection_from_url` and companion methods. It is intended
82 to be overridden for customization.
83 """
84 pool_cls = pool_classes_by_scheme[scheme]
85 kwargs = self.connection_pool_kw
86 if scheme == 'http':
87 kwargs = self.connection_pool_kw.copy()
88 for kw in SSL_KEYWORDS:
89 kwargs.pop(kw, None)
90
91 return pool_cls(host, port, **kwargs)
92
93 def clear(self):
94 """
95 Empty our store of pools and direct them all to close.
96
97 This will not affect in-flight connections, but they will not be
98 re-used after completion.
99 """
100 self.pools.clear()
101
102 def connection_from_host(self, host, port=None, scheme='http'):
103 """
104 Get a :class:`ConnectionPool` based on the host, port, and scheme.
105
106 If ``port`` isn't given, it will be derived from the ``scheme`` using
107 ``urllib3.connectionpool.port_by_scheme``.
108 """
109
110 if not host:
111 raise LocationValueError("No host specified.")
112
113 scheme = scheme or 'http'
114 port = port or port_by_scheme.get(scheme, 80)
115 pool_key = (scheme, host, port)
116
117 with self.pools.lock:
118 # If the scheme, host, or port doesn't match existing open
119 # connections, open a new ConnectionPool.
120 pool = self.pools.get(pool_key)
121 if pool:
122 return pool
123
124 # Make a fresh ConnectionPool of the desired type
125 pool = self._new_pool(scheme, host, port)
126 self.pools[pool_key] = pool
127
128 return pool
129
130 def connection_from_url(self, url):
131 """
132 Similar to :func:`urllib3.connectionpool.connection_from_url` but
133 doesn't pass any additional parameters to the
134 :class:`urllib3.connectionpool.ConnectionPool` constructor.
135
136 Additional parameters are taken from the :class:`.PoolManager`
137 constructor.
138 """
139 u = parse_url(url)
140 return self.connection_from_host(u.host, port=u.port, scheme=u.scheme)
141
142 def urlopen(self, method, url, redirect=True, **kw):
143 """
144 Same as :meth:`urllib3.connectionpool.HTTPConnectionPool.urlopen`
145 with custom cross-host redirect logic and only sends the request-uri
146 portion of the ``url``.
147
148 The given ``url`` parameter must be absolute, such that an appropriate
149 :class:`urllib3.connectionpool.ConnectionPool` can be chosen for it.
150 """
151 u = parse_url(url)
152 conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)
153
154 kw['assert_same_host'] = False
155 kw['redirect'] = False
156 if 'headers' not in kw:
157 kw['headers'] = self.headers
158
159 if self.proxy is not None and u.scheme == "http":
160 response = conn.urlopen(method, url, **kw)
161 else:
162 response = conn.urlopen(method, u.request_uri, **kw)
163
164 redirect_location = redirect and response.get_redirect_location()
165 if not redirect_location:
166 return response
167
168 # Support relative URLs for redirecting.
169 redirect_location = urljoin(url, redirect_location)
170
171 # RFC 7231, Section 6.4.4
172 if response.status == 303:
173 method = 'GET'
174
175 retries = kw.get('retries')
176 if not isinstance(retries, Retry):
177 retries = Retry.from_int(retries, redirect=redirect)
178
179 try:
180 retries = retries.increment(method, url, response=response, _pool=conn)
181 except MaxRetryError:
182 if retries.raise_on_redirect:
183 raise
184 return response
185
186 kw['retries'] = retries
187 kw['redirect'] = redirect
188
189 log.info("Redirecting %s -> %s" % (url, redirect_location))
190 return self.urlopen(method, redirect_location, **kw)
191
192
193 class ProxyManager(PoolManager):
194 """
195 Behaves just like :class:`PoolManager`, but sends all requests through
196 the defined proxy, using the CONNECT method for HTTPS URLs.
197
198 :param proxy_url:
199 The URL of the proxy to be used.
200
201 :param proxy_headers:
202 A dictionary contaning headers that will be sent to the proxy. In case
203 of HTTP they are being sent with each request, while in the
204 HTTPS/CONNECT case they are sent only once. Could be used for proxy
205 authentication.
206
207 Example:
208 >>> proxy = urllib3.ProxyManager('http://localhost:3128/')
209 >>> r1 = proxy.request('GET', 'http://google.com/')
210 >>> r2 = proxy.request('GET', 'http://httpbin.org/')
211 >>> len(proxy.pools)
212 1
213 >>> r3 = proxy.request('GET', 'https://httpbin.org/')
214 >>> r4 = proxy.request('GET', 'https://twitter.com/')
215 >>> len(proxy.pools)
216 3
217
218 """
219
220 def __init__(self, proxy_url, num_pools=10, headers=None,
221 proxy_headers=None, **connection_pool_kw):
222
223 if isinstance(proxy_url, HTTPConnectionPool):
224 proxy_url = '%s://%s:%i' % (proxy_url.scheme, proxy_url.host,
225 proxy_url.port)
226 proxy = parse_url(proxy_url)
227 if not proxy.port:
228 port = port_by_scheme.get(proxy.scheme, 80)
229 proxy = proxy._replace(port=port)
230
231 if proxy.scheme not in ("http", "https"):
232 raise ProxySchemeUnknown(proxy.scheme)
233
234 self.proxy = proxy
235 self.proxy_headers = proxy_headers or {}
236
237 connection_pool_kw['_proxy'] = self.proxy
238 connection_pool_kw['_proxy_headers'] = self.proxy_headers
239
240 super(ProxyManager, self).__init__(
241 num_pools, headers, **connection_pool_kw)
242
243 def connection_from_host(self, host, port=None, scheme='http'):
244 if scheme == "https":
245 return super(ProxyManager, self).connection_from_host(
246 host, port, scheme)
247
248 return super(ProxyManager, self).connection_from_host(
249 self.proxy.host, self.proxy.port, self.proxy.scheme)
250
251 def _set_proxy_headers(self, url, headers=None):
252 """
253 Sets headers needed by proxies: specifically, the Accept and Host
254 headers. Only sets headers not provided by the user.
255 """
256 headers_ = {'Accept': '*/*'}
257
258 netloc = parse_url(url).netloc
259 if netloc:
260 headers_['Host'] = netloc
261
262 if headers:
263 headers_.update(headers)
264 return headers_
265
266 def urlopen(self, method, url, redirect=True, **kw):
267 "Same as HTTP(S)ConnectionPool.urlopen, ``url`` must be absolute."
268 u = parse_url(url)
269
270 if u.scheme == "http":
271 # For proxied HTTPS requests, httplib sets the necessary headers
272 # on the CONNECT to the proxy. For HTTP, we'll definitely
273 # need to set 'Host' at the very least.
274 headers = kw.get('headers', self.headers)
275 kw['headers'] = self._set_proxy_headers(url, headers)
276
277 return super(ProxyManager, self).urlopen(method, url, redirect=redirect, **kw)
278
279
280 def proxy_from_url(url, **kw):
281 return ProxyManager(proxy_url=url, **kw)
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/urllib3/poolmanager.py b/urllib3/poolmanager.py
--- a/urllib3/poolmanager.py
+++ b/urllib3/poolmanager.py
@@ -26,7 +26,7 @@
log = logging.getLogger(__name__)
SSL_KEYWORDS = ('key_file', 'cert_file', 'cert_reqs', 'ca_certs',
- 'ssl_version')
+ 'ssl_version', 'ca_cert_dir')
class PoolManager(RequestMethods):
|
{"golden_diff": "diff --git a/urllib3/poolmanager.py b/urllib3/poolmanager.py\n--- a/urllib3/poolmanager.py\n+++ b/urllib3/poolmanager.py\n@@ -26,7 +26,7 @@\n log = logging.getLogger(__name__)\n \n SSL_KEYWORDS = ('key_file', 'cert_file', 'cert_reqs', 'ca_certs',\n- 'ssl_version')\n+ 'ssl_version', 'ca_cert_dir')\n \n \n class PoolManager(RequestMethods):\n", "issue": "ca_cert_dir keyword argument may be passed to HTTPConnectionPool by accident.\nSeems like as part of #701 I missed the `SSL_KEYWORDS` block in `poolmanager.py`. This means that `ca_cert_dir` may accidentally be passed to the `HTTPConnectionPool`. This leads to the following error when attempting to use `ca_cert_dir` with a `PoolManager` and then making a plaintext HTTP connection:\n\n```\n>>> import urllib3\n>>> p = urllib3.PoolManager(ca_cert_dir='/usr/local/etc/openssl')\n>>> p.urlopen('GET', 'http://http2bin.org/get')\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"urllib3/poolmanager.py\", line 162, in urlopen\n response = conn.urlopen(method, u.request_uri, **kw)\n File \"urllib3/connectionpool.py\", line 548, in urlopen\n conn = self._get_conn(timeout=pool_timeout)\n File \"urllib3/connectionpool.py\", line 250, in _get_conn\n return conn or self._new_conn()\n File \"urllib3/connectionpool.py\", line 211, in _new_conn\n strict=self.strict, **self.conn_kw)\n File \"urllib3/connection.py\", line 121, in __init__\n _HTTPConnection.__init__(self, *args, **kw)\nTypeError: __init__() got an unexpected keyword argument 'ca_cert_dir'\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\nimport logging\n\ntry: # Python 3\n from urllib.parse import urljoin\nexcept ImportError:\n from urlparse import urljoin\n\nfrom ._collections import RecentlyUsedContainer\nfrom .connectionpool import HTTPConnectionPool, HTTPSConnectionPool\nfrom .connectionpool import port_by_scheme\nfrom .exceptions import LocationValueError, MaxRetryError, ProxySchemeUnknown\nfrom .request import RequestMethods\nfrom .util.url import parse_url\nfrom .util.retry import Retry\n\n\n__all__ = ['PoolManager', 'ProxyManager', 'proxy_from_url']\n\n\npool_classes_by_scheme = {\n 'http': HTTPConnectionPool,\n 'https': HTTPSConnectionPool,\n}\n\nlog = logging.getLogger(__name__)\n\nSSL_KEYWORDS = ('key_file', 'cert_file', 'cert_reqs', 'ca_certs',\n 'ssl_version')\n\n\nclass PoolManager(RequestMethods):\n \"\"\"\n Allows for arbitrary requests while transparently keeping track of\n necessary connection pools for you.\n\n :param num_pools:\n Number of connection pools to cache before discarding the least\n recently used pool.\n\n :param headers:\n Headers to include with all requests, unless other headers are given\n explicitly.\n\n :param \\**connection_pool_kw:\n Additional parameters are used to create fresh\n :class:`urllib3.connectionpool.ConnectionPool` instances.\n\n Example::\n\n >>> manager = PoolManager(num_pools=2)\n >>> r = manager.request('GET', 'http://google.com/')\n >>> r = manager.request('GET', 'http://google.com/mail')\n >>> r = manager.request('GET', 'http://yahoo.com/')\n >>> len(manager.pools)\n 2\n\n \"\"\"\n\n proxy = None\n\n def __init__(self, num_pools=10, headers=None, **connection_pool_kw):\n RequestMethods.__init__(self, headers)\n self.connection_pool_kw = connection_pool_kw\n self.pools = RecentlyUsedContainer(num_pools,\n dispose_func=lambda p: p.close())\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.clear()\n # Return False to re-raise any potential exceptions\n return False\n\n def _new_pool(self, scheme, host, port):\n \"\"\"\n Create a new :class:`ConnectionPool` based on host, port and scheme.\n\n This method is used to actually create the connection pools handed out\n by :meth:`connection_from_url` and companion methods. It is intended\n to be overridden for customization.\n \"\"\"\n pool_cls = pool_classes_by_scheme[scheme]\n kwargs = self.connection_pool_kw\n if scheme == 'http':\n kwargs = self.connection_pool_kw.copy()\n for kw in SSL_KEYWORDS:\n kwargs.pop(kw, None)\n\n return pool_cls(host, port, **kwargs)\n\n def clear(self):\n \"\"\"\n Empty our store of pools and direct them all to close.\n\n This will not affect in-flight connections, but they will not be\n re-used after completion.\n \"\"\"\n self.pools.clear()\n\n def connection_from_host(self, host, port=None, scheme='http'):\n \"\"\"\n Get a :class:`ConnectionPool` based on the host, port, and scheme.\n\n If ``port`` isn't given, it will be derived from the ``scheme`` using\n ``urllib3.connectionpool.port_by_scheme``.\n \"\"\"\n\n if not host:\n raise LocationValueError(\"No host specified.\")\n\n scheme = scheme or 'http'\n port = port or port_by_scheme.get(scheme, 80)\n pool_key = (scheme, host, port)\n\n with self.pools.lock:\n # If the scheme, host, or port doesn't match existing open\n # connections, open a new ConnectionPool.\n pool = self.pools.get(pool_key)\n if pool:\n return pool\n\n # Make a fresh ConnectionPool of the desired type\n pool = self._new_pool(scheme, host, port)\n self.pools[pool_key] = pool\n\n return pool\n\n def connection_from_url(self, url):\n \"\"\"\n Similar to :func:`urllib3.connectionpool.connection_from_url` but\n doesn't pass any additional parameters to the\n :class:`urllib3.connectionpool.ConnectionPool` constructor.\n\n Additional parameters are taken from the :class:`.PoolManager`\n constructor.\n \"\"\"\n u = parse_url(url)\n return self.connection_from_host(u.host, port=u.port, scheme=u.scheme)\n\n def urlopen(self, method, url, redirect=True, **kw):\n \"\"\"\n Same as :meth:`urllib3.connectionpool.HTTPConnectionPool.urlopen`\n with custom cross-host redirect logic and only sends the request-uri\n portion of the ``url``.\n\n The given ``url`` parameter must be absolute, such that an appropriate\n :class:`urllib3.connectionpool.ConnectionPool` can be chosen for it.\n \"\"\"\n u = parse_url(url)\n conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)\n\n kw['assert_same_host'] = False\n kw['redirect'] = False\n if 'headers' not in kw:\n kw['headers'] = self.headers\n\n if self.proxy is not None and u.scheme == \"http\":\n response = conn.urlopen(method, url, **kw)\n else:\n response = conn.urlopen(method, u.request_uri, **kw)\n\n redirect_location = redirect and response.get_redirect_location()\n if not redirect_location:\n return response\n\n # Support relative URLs for redirecting.\n redirect_location = urljoin(url, redirect_location)\n\n # RFC 7231, Section 6.4.4\n if response.status == 303:\n method = 'GET'\n\n retries = kw.get('retries')\n if not isinstance(retries, Retry):\n retries = Retry.from_int(retries, redirect=redirect)\n\n try:\n retries = retries.increment(method, url, response=response, _pool=conn)\n except MaxRetryError:\n if retries.raise_on_redirect:\n raise\n return response\n\n kw['retries'] = retries\n kw['redirect'] = redirect\n\n log.info(\"Redirecting %s -> %s\" % (url, redirect_location))\n return self.urlopen(method, redirect_location, **kw)\n\n\nclass ProxyManager(PoolManager):\n \"\"\"\n Behaves just like :class:`PoolManager`, but sends all requests through\n the defined proxy, using the CONNECT method for HTTPS URLs.\n\n :param proxy_url:\n The URL of the proxy to be used.\n\n :param proxy_headers:\n A dictionary contaning headers that will be sent to the proxy. In case\n of HTTP they are being sent with each request, while in the\n HTTPS/CONNECT case they are sent only once. Could be used for proxy\n authentication.\n\n Example:\n >>> proxy = urllib3.ProxyManager('http://localhost:3128/')\n >>> r1 = proxy.request('GET', 'http://google.com/')\n >>> r2 = proxy.request('GET', 'http://httpbin.org/')\n >>> len(proxy.pools)\n 1\n >>> r3 = proxy.request('GET', 'https://httpbin.org/')\n >>> r4 = proxy.request('GET', 'https://twitter.com/')\n >>> len(proxy.pools)\n 3\n\n \"\"\"\n\n def __init__(self, proxy_url, num_pools=10, headers=None,\n proxy_headers=None, **connection_pool_kw):\n\n if isinstance(proxy_url, HTTPConnectionPool):\n proxy_url = '%s://%s:%i' % (proxy_url.scheme, proxy_url.host,\n proxy_url.port)\n proxy = parse_url(proxy_url)\n if not proxy.port:\n port = port_by_scheme.get(proxy.scheme, 80)\n proxy = proxy._replace(port=port)\n\n if proxy.scheme not in (\"http\", \"https\"):\n raise ProxySchemeUnknown(proxy.scheme)\n\n self.proxy = proxy\n self.proxy_headers = proxy_headers or {}\n\n connection_pool_kw['_proxy'] = self.proxy\n connection_pool_kw['_proxy_headers'] = self.proxy_headers\n\n super(ProxyManager, self).__init__(\n num_pools, headers, **connection_pool_kw)\n\n def connection_from_host(self, host, port=None, scheme='http'):\n if scheme == \"https\":\n return super(ProxyManager, self).connection_from_host(\n host, port, scheme)\n\n return super(ProxyManager, self).connection_from_host(\n self.proxy.host, self.proxy.port, self.proxy.scheme)\n\n def _set_proxy_headers(self, url, headers=None):\n \"\"\"\n Sets headers needed by proxies: specifically, the Accept and Host\n headers. Only sets headers not provided by the user.\n \"\"\"\n headers_ = {'Accept': '*/*'}\n\n netloc = parse_url(url).netloc\n if netloc:\n headers_['Host'] = netloc\n\n if headers:\n headers_.update(headers)\n return headers_\n\n def urlopen(self, method, url, redirect=True, **kw):\n \"Same as HTTP(S)ConnectionPool.urlopen, ``url`` must be absolute.\"\n u = parse_url(url)\n\n if u.scheme == \"http\":\n # For proxied HTTPS requests, httplib sets the necessary headers\n # on the CONNECT to the proxy. For HTTP, we'll definitely\n # need to set 'Host' at the very least.\n headers = kw.get('headers', self.headers)\n kw['headers'] = self._set_proxy_headers(url, headers)\n\n return super(ProxyManager, self).urlopen(method, url, redirect=redirect, **kw)\n\n\ndef proxy_from_url(url, **kw):\n return ProxyManager(proxy_url=url, **kw)\n", "path": "urllib3/poolmanager.py"}], "after_files": [{"content": "from __future__ import absolute_import\nimport logging\n\ntry: # Python 3\n from urllib.parse import urljoin\nexcept ImportError:\n from urlparse import urljoin\n\nfrom ._collections import RecentlyUsedContainer\nfrom .connectionpool import HTTPConnectionPool, HTTPSConnectionPool\nfrom .connectionpool import port_by_scheme\nfrom .exceptions import LocationValueError, MaxRetryError, ProxySchemeUnknown\nfrom .request import RequestMethods\nfrom .util.url import parse_url\nfrom .util.retry import Retry\n\n\n__all__ = ['PoolManager', 'ProxyManager', 'proxy_from_url']\n\n\npool_classes_by_scheme = {\n 'http': HTTPConnectionPool,\n 'https': HTTPSConnectionPool,\n}\n\nlog = logging.getLogger(__name__)\n\nSSL_KEYWORDS = ('key_file', 'cert_file', 'cert_reqs', 'ca_certs',\n 'ssl_version', 'ca_cert_dir')\n\n\nclass PoolManager(RequestMethods):\n \"\"\"\n Allows for arbitrary requests while transparently keeping track of\n necessary connection pools for you.\n\n :param num_pools:\n Number of connection pools to cache before discarding the least\n recently used pool.\n\n :param headers:\n Headers to include with all requests, unless other headers are given\n explicitly.\n\n :param \\**connection_pool_kw:\n Additional parameters are used to create fresh\n :class:`urllib3.connectionpool.ConnectionPool` instances.\n\n Example::\n\n >>> manager = PoolManager(num_pools=2)\n >>> r = manager.request('GET', 'http://google.com/')\n >>> r = manager.request('GET', 'http://google.com/mail')\n >>> r = manager.request('GET', 'http://yahoo.com/')\n >>> len(manager.pools)\n 2\n\n \"\"\"\n\n proxy = None\n\n def __init__(self, num_pools=10, headers=None, **connection_pool_kw):\n RequestMethods.__init__(self, headers)\n self.connection_pool_kw = connection_pool_kw\n self.pools = RecentlyUsedContainer(num_pools,\n dispose_func=lambda p: p.close())\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.clear()\n # Return False to re-raise any potential exceptions\n return False\n\n def _new_pool(self, scheme, host, port):\n \"\"\"\n Create a new :class:`ConnectionPool` based on host, port and scheme.\n\n This method is used to actually create the connection pools handed out\n by :meth:`connection_from_url` and companion methods. It is intended\n to be overridden for customization.\n \"\"\"\n pool_cls = pool_classes_by_scheme[scheme]\n kwargs = self.connection_pool_kw\n if scheme == 'http':\n kwargs = self.connection_pool_kw.copy()\n for kw in SSL_KEYWORDS:\n kwargs.pop(kw, None)\n\n return pool_cls(host, port, **kwargs)\n\n def clear(self):\n \"\"\"\n Empty our store of pools and direct them all to close.\n\n This will not affect in-flight connections, but they will not be\n re-used after completion.\n \"\"\"\n self.pools.clear()\n\n def connection_from_host(self, host, port=None, scheme='http'):\n \"\"\"\n Get a :class:`ConnectionPool` based on the host, port, and scheme.\n\n If ``port`` isn't given, it will be derived from the ``scheme`` using\n ``urllib3.connectionpool.port_by_scheme``.\n \"\"\"\n\n if not host:\n raise LocationValueError(\"No host specified.\")\n\n scheme = scheme or 'http'\n port = port or port_by_scheme.get(scheme, 80)\n pool_key = (scheme, host, port)\n\n with self.pools.lock:\n # If the scheme, host, or port doesn't match existing open\n # connections, open a new ConnectionPool.\n pool = self.pools.get(pool_key)\n if pool:\n return pool\n\n # Make a fresh ConnectionPool of the desired type\n pool = self._new_pool(scheme, host, port)\n self.pools[pool_key] = pool\n\n return pool\n\n def connection_from_url(self, url):\n \"\"\"\n Similar to :func:`urllib3.connectionpool.connection_from_url` but\n doesn't pass any additional parameters to the\n :class:`urllib3.connectionpool.ConnectionPool` constructor.\n\n Additional parameters are taken from the :class:`.PoolManager`\n constructor.\n \"\"\"\n u = parse_url(url)\n return self.connection_from_host(u.host, port=u.port, scheme=u.scheme)\n\n def urlopen(self, method, url, redirect=True, **kw):\n \"\"\"\n Same as :meth:`urllib3.connectionpool.HTTPConnectionPool.urlopen`\n with custom cross-host redirect logic and only sends the request-uri\n portion of the ``url``.\n\n The given ``url`` parameter must be absolute, such that an appropriate\n :class:`urllib3.connectionpool.ConnectionPool` can be chosen for it.\n \"\"\"\n u = parse_url(url)\n conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)\n\n kw['assert_same_host'] = False\n kw['redirect'] = False\n if 'headers' not in kw:\n kw['headers'] = self.headers\n\n if self.proxy is not None and u.scheme == \"http\":\n response = conn.urlopen(method, url, **kw)\n else:\n response = conn.urlopen(method, u.request_uri, **kw)\n\n redirect_location = redirect and response.get_redirect_location()\n if not redirect_location:\n return response\n\n # Support relative URLs for redirecting.\n redirect_location = urljoin(url, redirect_location)\n\n # RFC 7231, Section 6.4.4\n if response.status == 303:\n method = 'GET'\n\n retries = kw.get('retries')\n if not isinstance(retries, Retry):\n retries = Retry.from_int(retries, redirect=redirect)\n\n try:\n retries = retries.increment(method, url, response=response, _pool=conn)\n except MaxRetryError:\n if retries.raise_on_redirect:\n raise\n return response\n\n kw['retries'] = retries\n kw['redirect'] = redirect\n\n log.info(\"Redirecting %s -> %s\" % (url, redirect_location))\n return self.urlopen(method, redirect_location, **kw)\n\n\nclass ProxyManager(PoolManager):\n \"\"\"\n Behaves just like :class:`PoolManager`, but sends all requests through\n the defined proxy, using the CONNECT method for HTTPS URLs.\n\n :param proxy_url:\n The URL of the proxy to be used.\n\n :param proxy_headers:\n A dictionary contaning headers that will be sent to the proxy. In case\n of HTTP they are being sent with each request, while in the\n HTTPS/CONNECT case they are sent only once. Could be used for proxy\n authentication.\n\n Example:\n >>> proxy = urllib3.ProxyManager('http://localhost:3128/')\n >>> r1 = proxy.request('GET', 'http://google.com/')\n >>> r2 = proxy.request('GET', 'http://httpbin.org/')\n >>> len(proxy.pools)\n 1\n >>> r3 = proxy.request('GET', 'https://httpbin.org/')\n >>> r4 = proxy.request('GET', 'https://twitter.com/')\n >>> len(proxy.pools)\n 3\n\n \"\"\"\n\n def __init__(self, proxy_url, num_pools=10, headers=None,\n proxy_headers=None, **connection_pool_kw):\n\n if isinstance(proxy_url, HTTPConnectionPool):\n proxy_url = '%s://%s:%i' % (proxy_url.scheme, proxy_url.host,\n proxy_url.port)\n proxy = parse_url(proxy_url)\n if not proxy.port:\n port = port_by_scheme.get(proxy.scheme, 80)\n proxy = proxy._replace(port=port)\n\n if proxy.scheme not in (\"http\", \"https\"):\n raise ProxySchemeUnknown(proxy.scheme)\n\n self.proxy = proxy\n self.proxy_headers = proxy_headers or {}\n\n connection_pool_kw['_proxy'] = self.proxy\n connection_pool_kw['_proxy_headers'] = self.proxy_headers\n\n super(ProxyManager, self).__init__(\n num_pools, headers, **connection_pool_kw)\n\n def connection_from_host(self, host, port=None, scheme='http'):\n if scheme == \"https\":\n return super(ProxyManager, self).connection_from_host(\n host, port, scheme)\n\n return super(ProxyManager, self).connection_from_host(\n self.proxy.host, self.proxy.port, self.proxy.scheme)\n\n def _set_proxy_headers(self, url, headers=None):\n \"\"\"\n Sets headers needed by proxies: specifically, the Accept and Host\n headers. Only sets headers not provided by the user.\n \"\"\"\n headers_ = {'Accept': '*/*'}\n\n netloc = parse_url(url).netloc\n if netloc:\n headers_['Host'] = netloc\n\n if headers:\n headers_.update(headers)\n return headers_\n\n def urlopen(self, method, url, redirect=True, **kw):\n \"Same as HTTP(S)ConnectionPool.urlopen, ``url`` must be absolute.\"\n u = parse_url(url)\n\n if u.scheme == \"http\":\n # For proxied HTTPS requests, httplib sets the necessary headers\n # on the CONNECT to the proxy. For HTTP, we'll definitely\n # need to set 'Host' at the very least.\n headers = kw.get('headers', self.headers)\n kw['headers'] = self._set_proxy_headers(url, headers)\n\n return super(ProxyManager, self).urlopen(method, url, redirect=redirect, **kw)\n\n\ndef proxy_from_url(url, **kw):\n return ProxyManager(proxy_url=url, **kw)\n", "path": "urllib3/poolmanager.py"}]}
| 3,481 | 110 |
gh_patches_debug_23755
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2111
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Budget without value makes IATI export crash
## Test plan
GIVEN the IATI export (bottom right on project page)
WHEN a budget of the project has no value, but does have a value date / currency / label
THEN the `value` tag of the budget item should not be generated
AND no internal server error should be shown
## Issue description
See http://sentry.support.akvo-ops.org/rsr/live/group/832/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/iati/exports/elements/budget.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from lxml import etree
8
9
10 def budget(project):
11 """
12 Generate the budget elements.
13
14 :param project: Project object
15 :return: A list of Etree elements
16 """
17 budget_elements = []
18
19 for budget_item in project.budget_items.all():
20 if budget_item.amount or budget_item.period_start or budget_item.period_end or \
21 budget_item.type or budget_item.status or budget_item.value_date or \
22 budget_item.currency or budget_item.other_extra or budget_item.label:
23 element = etree.Element("budget")
24
25 if budget_item.type:
26 element.attrib['type'] = budget_item.type
27
28 if budget_item.status:
29 element.attrib['status'] = budget_item.status
30
31 if budget_item.period_start:
32 period_start_element = etree.SubElement(element, "period-start")
33 period_start_element.attrib['iso-date'] = str(budget_item.period_start)
34
35 if budget_item.period_end:
36 period_end_element = etree.SubElement(element, "period-end")
37 period_end_element.attrib['iso-date'] = str(budget_item.period_end)
38
39 if budget_item.amount == 0 or budget_item.amount:
40 value_element = etree.SubElement(element, "value")
41 value_element.text = str(budget_item.amount)
42
43 if budget_item.value_date:
44 value_element.attrib['value-date'] = str(budget_item.value_date)
45
46 if budget_item.currency:
47 value_element.attrib['currency'] = budget_item.currency
48
49 if budget_item.other_extra:
50 value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.\
51 other_extra
52 elif budget_item.label and budget_item.label.label:
53 value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.label.\
54 label
55
56 budget_elements.append(element)
57
58 return budget_elements
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/iati/exports/elements/budget.py b/akvo/iati/exports/elements/budget.py
--- a/akvo/iati/exports/elements/budget.py
+++ b/akvo/iati/exports/elements/budget.py
@@ -40,18 +40,17 @@
value_element = etree.SubElement(element, "value")
value_element.text = str(budget_item.amount)
- if budget_item.value_date:
- value_element.attrib['value-date'] = str(budget_item.value_date)
-
- if budget_item.currency:
- value_element.attrib['currency'] = budget_item.currency
-
- if budget_item.other_extra:
- value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.\
- other_extra
- elif budget_item.label and budget_item.label.label:
- value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.label.\
- label
+ if budget_item.value_date:
+ value_element.attrib['value-date'] = str(budget_item.value_date)
+
+ if budget_item.currency:
+ value_element.attrib['currency'] = budget_item.currency
+
+ akvo_label = '{http://akvo.org/iati-activities}label'
+ if budget_item.other_extra:
+ value_element.attrib[akvo_label] = budget_item.other_extra
+ elif budget_item.label and budget_item.label.label:
+ value_element.attrib[akvo_label] = budget_item.label.label
budget_elements.append(element)
|
{"golden_diff": "diff --git a/akvo/iati/exports/elements/budget.py b/akvo/iati/exports/elements/budget.py\n--- a/akvo/iati/exports/elements/budget.py\n+++ b/akvo/iati/exports/elements/budget.py\n@@ -40,18 +40,17 @@\n value_element = etree.SubElement(element, \"value\")\n value_element.text = str(budget_item.amount)\n \n- if budget_item.value_date:\n- value_element.attrib['value-date'] = str(budget_item.value_date)\n-\n- if budget_item.currency:\n- value_element.attrib['currency'] = budget_item.currency\n-\n- if budget_item.other_extra:\n- value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.\\\n- other_extra\n- elif budget_item.label and budget_item.label.label:\n- value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.label.\\\n- label\n+ if budget_item.value_date:\n+ value_element.attrib['value-date'] = str(budget_item.value_date)\n+\n+ if budget_item.currency:\n+ value_element.attrib['currency'] = budget_item.currency\n+\n+ akvo_label = '{http://akvo.org/iati-activities}label'\n+ if budget_item.other_extra:\n+ value_element.attrib[akvo_label] = budget_item.other_extra\n+ elif budget_item.label and budget_item.label.label:\n+ value_element.attrib[akvo_label] = budget_item.label.label\n \n budget_elements.append(element)\n", "issue": "Budget without value makes IATI export crash\n## Test plan\n\nGIVEN the IATI export (bottom right on project page)\nWHEN a budget of the project has no value, but does have a value date / currency / label\nTHEN the `value` tag of the budget item should not be generated\nAND no internal server error should be shown\n## Issue description\n\nSee http://sentry.support.akvo-ops.org/rsr/live/group/832/\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom lxml import etree\n\n\ndef budget(project):\n \"\"\"\n Generate the budget elements.\n\n :param project: Project object\n :return: A list of Etree elements\n \"\"\"\n budget_elements = []\n\n for budget_item in project.budget_items.all():\n if budget_item.amount or budget_item.period_start or budget_item.period_end or \\\n budget_item.type or budget_item.status or budget_item.value_date or \\\n budget_item.currency or budget_item.other_extra or budget_item.label:\n element = etree.Element(\"budget\")\n\n if budget_item.type:\n element.attrib['type'] = budget_item.type\n\n if budget_item.status:\n element.attrib['status'] = budget_item.status\n\n if budget_item.period_start:\n period_start_element = etree.SubElement(element, \"period-start\")\n period_start_element.attrib['iso-date'] = str(budget_item.period_start)\n\n if budget_item.period_end:\n period_end_element = etree.SubElement(element, \"period-end\")\n period_end_element.attrib['iso-date'] = str(budget_item.period_end)\n\n if budget_item.amount == 0 or budget_item.amount:\n value_element = etree.SubElement(element, \"value\")\n value_element.text = str(budget_item.amount)\n\n if budget_item.value_date:\n value_element.attrib['value-date'] = str(budget_item.value_date)\n\n if budget_item.currency:\n value_element.attrib['currency'] = budget_item.currency\n\n if budget_item.other_extra:\n value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.\\\n other_extra\n elif budget_item.label and budget_item.label.label:\n value_element.attrib['{http://akvo.org/iati-activities}label'] = budget_item.label.\\\n label\n\n budget_elements.append(element)\n\n return budget_elements\n", "path": "akvo/iati/exports/elements/budget.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom lxml import etree\n\n\ndef budget(project):\n \"\"\"\n Generate the budget elements.\n\n :param project: Project object\n :return: A list of Etree elements\n \"\"\"\n budget_elements = []\n\n for budget_item in project.budget_items.all():\n if budget_item.amount or budget_item.period_start or budget_item.period_end or \\\n budget_item.type or budget_item.status or budget_item.value_date or \\\n budget_item.currency or budget_item.other_extra or budget_item.label:\n element = etree.Element(\"budget\")\n\n if budget_item.type:\n element.attrib['type'] = budget_item.type\n\n if budget_item.status:\n element.attrib['status'] = budget_item.status\n\n if budget_item.period_start:\n period_start_element = etree.SubElement(element, \"period-start\")\n period_start_element.attrib['iso-date'] = str(budget_item.period_start)\n\n if budget_item.period_end:\n period_end_element = etree.SubElement(element, \"period-end\")\n period_end_element.attrib['iso-date'] = str(budget_item.period_end)\n\n if budget_item.amount == 0 or budget_item.amount:\n value_element = etree.SubElement(element, \"value\")\n value_element.text = str(budget_item.amount)\n\n if budget_item.value_date:\n value_element.attrib['value-date'] = str(budget_item.value_date)\n\n if budget_item.currency:\n value_element.attrib['currency'] = budget_item.currency\n\n akvo_label = '{http://akvo.org/iati-activities}label'\n if budget_item.other_extra:\n value_element.attrib[akvo_label] = budget_item.other_extra\n elif budget_item.label and budget_item.label.label:\n value_element.attrib[akvo_label] = budget_item.label.label\n\n budget_elements.append(element)\n\n return budget_elements\n", "path": "akvo/iati/exports/elements/budget.py"}]}
| 930 | 346 |
gh_patches_debug_1884
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-11463
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[DOC-FIX] Document that attribute RunInfo.lifecycle_stage is of type LifecycleStage
### Willingness to contribute
No. I cannot contribute a documentation fix at this time.
### URL(s) with the issue
https://mlflow.org/docs/latest/python_api/mlflow.entities.html#mlflow.entities.RunInfo.lifecycle_stage
### Description of proposal (what needs changing)
For [documentation on RunInfo](https://mlflow.org/docs/latest/python_api/mlflow.entities.html#mlflow.entities.RunInfo) class.
For the `RunInfo.lifecycle_stage` attribute we should mention that it's type is enum LifecycleStage. Analogous to the documentation for the `RunInfo.stage` attribute.
Should be
```
property lifecycle_stage[source]
One of the values in mlflow.entities.lifecycle_stage.LifecycleStage describing the lifecycle stage of the run.
```
similar to the existing
```
property status[source]
One of the values in mlflow.entities.RunStatus describing the status of the run.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/entities/run_info.py`
Content:
```
1 from mlflow.entities._mlflow_object import _MLflowObject
2 from mlflow.entities.lifecycle_stage import LifecycleStage
3 from mlflow.entities.run_status import RunStatus
4 from mlflow.exceptions import MlflowException
5 from mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE
6 from mlflow.protos.service_pb2 import RunInfo as ProtoRunInfo
7
8
9 def check_run_is_active(run_info):
10 if run_info.lifecycle_stage != LifecycleStage.ACTIVE:
11 raise MlflowException(
12 f"The run {run_info.run_id} must be in 'active' lifecycle_stage.",
13 error_code=INVALID_PARAMETER_VALUE,
14 )
15
16
17 class searchable_attribute(property):
18 # Wrapper class over property to designate some of the properties as searchable
19 # run attributes
20 pass
21
22
23 class orderable_attribute(property):
24 # Wrapper class over property to designate some of the properties as orderable
25 # run attributes
26 pass
27
28
29 class RunInfo(_MLflowObject):
30 """
31 Metadata about a run.
32 """
33
34 def __init__(
35 self,
36 run_uuid,
37 experiment_id,
38 user_id,
39 status,
40 start_time,
41 end_time,
42 lifecycle_stage,
43 artifact_uri=None,
44 run_id=None,
45 run_name=None,
46 ):
47 if experiment_id is None:
48 raise Exception("experiment_id cannot be None")
49 if user_id is None:
50 raise Exception("user_id cannot be None")
51 if status is None:
52 raise Exception("status cannot be None")
53 if start_time is None:
54 raise Exception("start_time cannot be None")
55 actual_run_id = run_id or run_uuid
56 if actual_run_id is None:
57 raise Exception("run_id and run_uuid cannot both be None")
58 self._run_uuid = actual_run_id
59 self._run_id = actual_run_id
60 self._experiment_id = experiment_id
61 self._user_id = user_id
62 self._status = status
63 self._start_time = start_time
64 self._end_time = end_time
65 self._lifecycle_stage = lifecycle_stage
66 self._artifact_uri = artifact_uri
67 self._run_name = run_name
68
69 def __eq__(self, other):
70 if type(other) is type(self):
71 # TODO deep equality here?
72 return self.__dict__ == other.__dict__
73 return False
74
75 def _copy_with_overrides(self, status=None, end_time=None, lifecycle_stage=None, run_name=None):
76 """A copy of the RunInfo with certain attributes modified."""
77 proto = self.to_proto()
78 if status:
79 proto.status = status
80 if end_time:
81 proto.end_time = end_time
82 if lifecycle_stage:
83 proto.lifecycle_stage = lifecycle_stage
84 if run_name:
85 proto.run_name = run_name
86 return RunInfo.from_proto(proto)
87
88 @property
89 def run_uuid(self):
90 """[Deprecated, use run_id instead] String containing run UUID."""
91 return self._run_uuid
92
93 @searchable_attribute
94 def run_id(self):
95 """String containing run id."""
96 return self._run_id
97
98 @property
99 def experiment_id(self):
100 """String ID of the experiment for the current run."""
101 return self._experiment_id
102
103 @searchable_attribute
104 def run_name(self):
105 """String containing run name."""
106 return self._run_name
107
108 def _set_run_name(self, new_name):
109 self._run_name = new_name
110
111 @searchable_attribute
112 def user_id(self):
113 """String ID of the user who initiated this run."""
114 return self._user_id
115
116 @searchable_attribute
117 def status(self):
118 """
119 One of the values in :py:class:`mlflow.entities.RunStatus`
120 describing the status of the run.
121 """
122 return self._status
123
124 @searchable_attribute
125 def start_time(self):
126 """Start time of the run, in number of milliseconds since the UNIX epoch."""
127 return self._start_time
128
129 @searchable_attribute
130 def end_time(self):
131 """End time of the run, in number of milliseconds since the UNIX epoch."""
132 return self._end_time
133
134 @searchable_attribute
135 def artifact_uri(self):
136 """String root artifact URI of the run."""
137 return self._artifact_uri
138
139 @property
140 def lifecycle_stage(self):
141 return self._lifecycle_stage
142
143 def to_proto(self):
144 proto = ProtoRunInfo()
145 proto.run_uuid = self.run_uuid
146 proto.run_id = self.run_id
147 if self.run_name is not None:
148 proto.run_name = self.run_name
149 proto.experiment_id = self.experiment_id
150 proto.user_id = self.user_id
151 proto.status = RunStatus.from_string(self.status)
152 proto.start_time = self.start_time
153 if self.end_time:
154 proto.end_time = self.end_time
155 if self.artifact_uri:
156 proto.artifact_uri = self.artifact_uri
157 proto.lifecycle_stage = self.lifecycle_stage
158 return proto
159
160 @classmethod
161 def from_proto(cls, proto):
162 end_time = proto.end_time
163 # The proto2 default scalar value of zero indicates that the run's end time is absent.
164 # An absent end time is represented with a NoneType in the `RunInfo` class
165 if end_time == 0:
166 end_time = None
167 return cls(
168 run_uuid=proto.run_uuid,
169 run_id=proto.run_id,
170 run_name=proto.run_name,
171 experiment_id=proto.experiment_id,
172 user_id=proto.user_id,
173 status=RunStatus.to_string(proto.status),
174 start_time=proto.start_time,
175 end_time=end_time,
176 lifecycle_stage=proto.lifecycle_stage,
177 artifact_uri=proto.artifact_uri,
178 )
179
180 @classmethod
181 def get_searchable_attributes(cls):
182 return sorted(
183 [p for p in cls.__dict__ if isinstance(getattr(cls, p), searchable_attribute)]
184 )
185
186 @classmethod
187 def get_orderable_attributes(cls):
188 # Note that all searchable attributes are also orderable.
189 return sorted(
190 [
191 p
192 for p in cls.__dict__
193 if isinstance(getattr(cls, p), (searchable_attribute, orderable_attribute))
194 ]
195 )
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/entities/run_info.py b/mlflow/entities/run_info.py
--- a/mlflow/entities/run_info.py
+++ b/mlflow/entities/run_info.py
@@ -138,6 +138,10 @@
@property
def lifecycle_stage(self):
+ """
+ One of the values in :py:class:`mlflow.entities.lifecycle_stage.LifecycleStage`
+ describing the lifecycle stage of the run.
+ """
return self._lifecycle_stage
def to_proto(self):
|
{"golden_diff": "diff --git a/mlflow/entities/run_info.py b/mlflow/entities/run_info.py\n--- a/mlflow/entities/run_info.py\n+++ b/mlflow/entities/run_info.py\n@@ -138,6 +138,10 @@\n \n @property\n def lifecycle_stage(self):\n+ \"\"\"\n+ One of the values in :py:class:`mlflow.entities.lifecycle_stage.LifecycleStage`\n+ describing the lifecycle stage of the run.\n+ \"\"\"\n return self._lifecycle_stage\n \n def to_proto(self):\n", "issue": "[DOC-FIX] Document that attribute RunInfo.lifecycle_stage is of type LifecycleStage\n### Willingness to contribute\n\nNo. I cannot contribute a documentation fix at this time.\n\n### URL(s) with the issue\n\nhttps://mlflow.org/docs/latest/python_api/mlflow.entities.html#mlflow.entities.RunInfo.lifecycle_stage\n\n### Description of proposal (what needs changing)\n\nFor [documentation on RunInfo](https://mlflow.org/docs/latest/python_api/mlflow.entities.html#mlflow.entities.RunInfo) class.\r\n\r\nFor the `RunInfo.lifecycle_stage` attribute we should mention that it's type is enum LifecycleStage. Analogous to the documentation for the `RunInfo.stage` attribute.\r\n\r\nShould be\r\n```\r\nproperty lifecycle_stage[source]\r\n One of the values in mlflow.entities.lifecycle_stage.LifecycleStage describing the lifecycle stage of the run.\r\n```\r\nsimilar to the existing\r\n```\r\nproperty status[source]\r\n One of the values in mlflow.entities.RunStatus describing the status of the run.\r\n```\r\n\n", "before_files": [{"content": "from mlflow.entities._mlflow_object import _MLflowObject\nfrom mlflow.entities.lifecycle_stage import LifecycleStage\nfrom mlflow.entities.run_status import RunStatus\nfrom mlflow.exceptions import MlflowException\nfrom mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE\nfrom mlflow.protos.service_pb2 import RunInfo as ProtoRunInfo\n\n\ndef check_run_is_active(run_info):\n if run_info.lifecycle_stage != LifecycleStage.ACTIVE:\n raise MlflowException(\n f\"The run {run_info.run_id} must be in 'active' lifecycle_stage.\",\n error_code=INVALID_PARAMETER_VALUE,\n )\n\n\nclass searchable_attribute(property):\n # Wrapper class over property to designate some of the properties as searchable\n # run attributes\n pass\n\n\nclass orderable_attribute(property):\n # Wrapper class over property to designate some of the properties as orderable\n # run attributes\n pass\n\n\nclass RunInfo(_MLflowObject):\n \"\"\"\n Metadata about a run.\n \"\"\"\n\n def __init__(\n self,\n run_uuid,\n experiment_id,\n user_id,\n status,\n start_time,\n end_time,\n lifecycle_stage,\n artifact_uri=None,\n run_id=None,\n run_name=None,\n ):\n if experiment_id is None:\n raise Exception(\"experiment_id cannot be None\")\n if user_id is None:\n raise Exception(\"user_id cannot be None\")\n if status is None:\n raise Exception(\"status cannot be None\")\n if start_time is None:\n raise Exception(\"start_time cannot be None\")\n actual_run_id = run_id or run_uuid\n if actual_run_id is None:\n raise Exception(\"run_id and run_uuid cannot both be None\")\n self._run_uuid = actual_run_id\n self._run_id = actual_run_id\n self._experiment_id = experiment_id\n self._user_id = user_id\n self._status = status\n self._start_time = start_time\n self._end_time = end_time\n self._lifecycle_stage = lifecycle_stage\n self._artifact_uri = artifact_uri\n self._run_name = run_name\n\n def __eq__(self, other):\n if type(other) is type(self):\n # TODO deep equality here?\n return self.__dict__ == other.__dict__\n return False\n\n def _copy_with_overrides(self, status=None, end_time=None, lifecycle_stage=None, run_name=None):\n \"\"\"A copy of the RunInfo with certain attributes modified.\"\"\"\n proto = self.to_proto()\n if status:\n proto.status = status\n if end_time:\n proto.end_time = end_time\n if lifecycle_stage:\n proto.lifecycle_stage = lifecycle_stage\n if run_name:\n proto.run_name = run_name\n return RunInfo.from_proto(proto)\n\n @property\n def run_uuid(self):\n \"\"\"[Deprecated, use run_id instead] String containing run UUID.\"\"\"\n return self._run_uuid\n\n @searchable_attribute\n def run_id(self):\n \"\"\"String containing run id.\"\"\"\n return self._run_id\n\n @property\n def experiment_id(self):\n \"\"\"String ID of the experiment for the current run.\"\"\"\n return self._experiment_id\n\n @searchable_attribute\n def run_name(self):\n \"\"\"String containing run name.\"\"\"\n return self._run_name\n\n def _set_run_name(self, new_name):\n self._run_name = new_name\n\n @searchable_attribute\n def user_id(self):\n \"\"\"String ID of the user who initiated this run.\"\"\"\n return self._user_id\n\n @searchable_attribute\n def status(self):\n \"\"\"\n One of the values in :py:class:`mlflow.entities.RunStatus`\n describing the status of the run.\n \"\"\"\n return self._status\n\n @searchable_attribute\n def start_time(self):\n \"\"\"Start time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._start_time\n\n @searchable_attribute\n def end_time(self):\n \"\"\"End time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._end_time\n\n @searchable_attribute\n def artifact_uri(self):\n \"\"\"String root artifact URI of the run.\"\"\"\n return self._artifact_uri\n\n @property\n def lifecycle_stage(self):\n return self._lifecycle_stage\n\n def to_proto(self):\n proto = ProtoRunInfo()\n proto.run_uuid = self.run_uuid\n proto.run_id = self.run_id\n if self.run_name is not None:\n proto.run_name = self.run_name\n proto.experiment_id = self.experiment_id\n proto.user_id = self.user_id\n proto.status = RunStatus.from_string(self.status)\n proto.start_time = self.start_time\n if self.end_time:\n proto.end_time = self.end_time\n if self.artifact_uri:\n proto.artifact_uri = self.artifact_uri\n proto.lifecycle_stage = self.lifecycle_stage\n return proto\n\n @classmethod\n def from_proto(cls, proto):\n end_time = proto.end_time\n # The proto2 default scalar value of zero indicates that the run's end time is absent.\n # An absent end time is represented with a NoneType in the `RunInfo` class\n if end_time == 0:\n end_time = None\n return cls(\n run_uuid=proto.run_uuid,\n run_id=proto.run_id,\n run_name=proto.run_name,\n experiment_id=proto.experiment_id,\n user_id=proto.user_id,\n status=RunStatus.to_string(proto.status),\n start_time=proto.start_time,\n end_time=end_time,\n lifecycle_stage=proto.lifecycle_stage,\n artifact_uri=proto.artifact_uri,\n )\n\n @classmethod\n def get_searchable_attributes(cls):\n return sorted(\n [p for p in cls.__dict__ if isinstance(getattr(cls, p), searchable_attribute)]\n )\n\n @classmethod\n def get_orderable_attributes(cls):\n # Note that all searchable attributes are also orderable.\n return sorted(\n [\n p\n for p in cls.__dict__\n if isinstance(getattr(cls, p), (searchable_attribute, orderable_attribute))\n ]\n )\n", "path": "mlflow/entities/run_info.py"}], "after_files": [{"content": "from mlflow.entities._mlflow_object import _MLflowObject\nfrom mlflow.entities.lifecycle_stage import LifecycleStage\nfrom mlflow.entities.run_status import RunStatus\nfrom mlflow.exceptions import MlflowException\nfrom mlflow.protos.databricks_pb2 import INVALID_PARAMETER_VALUE\nfrom mlflow.protos.service_pb2 import RunInfo as ProtoRunInfo\n\n\ndef check_run_is_active(run_info):\n if run_info.lifecycle_stage != LifecycleStage.ACTIVE:\n raise MlflowException(\n f\"The run {run_info.run_id} must be in 'active' lifecycle_stage.\",\n error_code=INVALID_PARAMETER_VALUE,\n )\n\n\nclass searchable_attribute(property):\n # Wrapper class over property to designate some of the properties as searchable\n # run attributes\n pass\n\n\nclass orderable_attribute(property):\n # Wrapper class over property to designate some of the properties as orderable\n # run attributes\n pass\n\n\nclass RunInfo(_MLflowObject):\n \"\"\"\n Metadata about a run.\n \"\"\"\n\n def __init__(\n self,\n run_uuid,\n experiment_id,\n user_id,\n status,\n start_time,\n end_time,\n lifecycle_stage,\n artifact_uri=None,\n run_id=None,\n run_name=None,\n ):\n if experiment_id is None:\n raise Exception(\"experiment_id cannot be None\")\n if user_id is None:\n raise Exception(\"user_id cannot be None\")\n if status is None:\n raise Exception(\"status cannot be None\")\n if start_time is None:\n raise Exception(\"start_time cannot be None\")\n actual_run_id = run_id or run_uuid\n if actual_run_id is None:\n raise Exception(\"run_id and run_uuid cannot both be None\")\n self._run_uuid = actual_run_id\n self._run_id = actual_run_id\n self._experiment_id = experiment_id\n self._user_id = user_id\n self._status = status\n self._start_time = start_time\n self._end_time = end_time\n self._lifecycle_stage = lifecycle_stage\n self._artifact_uri = artifact_uri\n self._run_name = run_name\n\n def __eq__(self, other):\n if type(other) is type(self):\n # TODO deep equality here?\n return self.__dict__ == other.__dict__\n return False\n\n def _copy_with_overrides(self, status=None, end_time=None, lifecycle_stage=None, run_name=None):\n \"\"\"A copy of the RunInfo with certain attributes modified.\"\"\"\n proto = self.to_proto()\n if status:\n proto.status = status\n if end_time:\n proto.end_time = end_time\n if lifecycle_stage:\n proto.lifecycle_stage = lifecycle_stage\n if run_name:\n proto.run_name = run_name\n return RunInfo.from_proto(proto)\n\n @property\n def run_uuid(self):\n \"\"\"[Deprecated, use run_id instead] String containing run UUID.\"\"\"\n return self._run_uuid\n\n @searchable_attribute\n def run_id(self):\n \"\"\"String containing run id.\"\"\"\n return self._run_id\n\n @property\n def experiment_id(self):\n \"\"\"String ID of the experiment for the current run.\"\"\"\n return self._experiment_id\n\n @searchable_attribute\n def run_name(self):\n \"\"\"String containing run name.\"\"\"\n return self._run_name\n\n def _set_run_name(self, new_name):\n self._run_name = new_name\n\n @searchable_attribute\n def user_id(self):\n \"\"\"String ID of the user who initiated this run.\"\"\"\n return self._user_id\n\n @searchable_attribute\n def status(self):\n \"\"\"\n One of the values in :py:class:`mlflow.entities.RunStatus`\n describing the status of the run.\n \"\"\"\n return self._status\n\n @searchable_attribute\n def start_time(self):\n \"\"\"Start time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._start_time\n\n @searchable_attribute\n def end_time(self):\n \"\"\"End time of the run, in number of milliseconds since the UNIX epoch.\"\"\"\n return self._end_time\n\n @searchable_attribute\n def artifact_uri(self):\n \"\"\"String root artifact URI of the run.\"\"\"\n return self._artifact_uri\n\n @property\n def lifecycle_stage(self):\n \"\"\"\n One of the values in :py:class:`mlflow.entities.lifecycle_stage.LifecycleStage`\n describing the lifecycle stage of the run.\n \"\"\"\n return self._lifecycle_stage\n\n def to_proto(self):\n proto = ProtoRunInfo()\n proto.run_uuid = self.run_uuid\n proto.run_id = self.run_id\n if self.run_name is not None:\n proto.run_name = self.run_name\n proto.experiment_id = self.experiment_id\n proto.user_id = self.user_id\n proto.status = RunStatus.from_string(self.status)\n proto.start_time = self.start_time\n if self.end_time:\n proto.end_time = self.end_time\n if self.artifact_uri:\n proto.artifact_uri = self.artifact_uri\n proto.lifecycle_stage = self.lifecycle_stage\n return proto\n\n @classmethod\n def from_proto(cls, proto):\n end_time = proto.end_time\n # The proto2 default scalar value of zero indicates that the run's end time is absent.\n # An absent end time is represented with a NoneType in the `RunInfo` class\n if end_time == 0:\n end_time = None\n return cls(\n run_uuid=proto.run_uuid,\n run_id=proto.run_id,\n run_name=proto.run_name,\n experiment_id=proto.experiment_id,\n user_id=proto.user_id,\n status=RunStatus.to_string(proto.status),\n start_time=proto.start_time,\n end_time=end_time,\n lifecycle_stage=proto.lifecycle_stage,\n artifact_uri=proto.artifact_uri,\n )\n\n @classmethod\n def get_searchable_attributes(cls):\n return sorted(\n [p for p in cls.__dict__ if isinstance(getattr(cls, p), searchable_attribute)]\n )\n\n @classmethod\n def get_orderable_attributes(cls):\n # Note that all searchable attributes are also orderable.\n return sorted(\n [\n p\n for p in cls.__dict__\n if isinstance(getattr(cls, p), (searchable_attribute, orderable_attribute))\n ]\n )\n", "path": "mlflow/entities/run_info.py"}]}
| 2,289 | 112 |
gh_patches_debug_14561
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6276
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Address warning in Airflow plugin version check
> not super urgent, but as we move into supporting newer Python versions
> (https://github.com/meltano/meltano/pull/6135) and bumping Meltano's dependencies (https://github.com/meltano/meltano/issues/6264), we might break Airflow support.
>
> It's also probably a very quick (< 1 hour) fix by replacing distutils.StrictVersion with the packaging.version equivalent.
>
```
src/meltano/core/plugin/airflow.py:110: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if StrictVersion(version) < StrictVersion("2.0.0")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/core/plugin/airflow.py`
Content:
```
1 """Plugin glue code for Airflow."""
2 import configparser
3 import logging
4 import os
5 import subprocess
6 from distutils.version import StrictVersion
7
8 from meltano.core.behavior.hookable import hook
9 from meltano.core.error import AsyncSubprocessError
10 from meltano.core.plugin_invoker import PluginInvoker
11 from meltano.core.utils import nest
12
13 from . import BasePlugin, PluginType
14
15
16 class AirflowInvoker(PluginInvoker):
17 """Invoker that prepares env for Airflow."""
18
19 def env(self):
20 """Environment variables for Airflow.
21
22 Returns:
23 Dictionary of environment variables.
24 """
25 env = super().env()
26
27 env["AIRFLOW_HOME"] = str(self.plugin_config_service.run_dir)
28 env["AIRFLOW_CONFIG"] = str(self.files["config"])
29
30 return env
31
32
33 class Airflow(BasePlugin):
34 """Plugin glue code for Airflow."""
35
36 __plugin_type__ = PluginType.ORCHESTRATORS
37
38 invoker_class = AirflowInvoker
39
40 @property
41 def config_files(self):
42 """Return the configuration files required by the plugin.
43
44 Returns:
45 Dictionary of config file identifiers and filenames
46 """
47 return {"config": "airflow.cfg"}
48
49 def process_config(self, flat_config):
50 """Unflatten the config.
51
52 Args:
53 flat_config: the flat config
54
55 Returns:
56 unflattened config
57 """
58 config = {}
59 for key, value in flat_config.items():
60 nest(config, key, str(value))
61 return config
62
63 @staticmethod
64 def update_config_file(invoker: AirflowInvoker) -> None:
65 """Update airflow.cfg with plugin configuration.
66
67 Args:
68 invoker: the active PluginInvoker
69 """
70 airflow_cfg_path = invoker.files["config"]
71 logging.debug(f"Generated default '{str(airflow_cfg_path)}'")
72
73 # open the configuration and update it
74 # now we let's update the config to use our stubs
75 airflow_cfg = configparser.ConfigParser()
76
77 with airflow_cfg_path.open() as airflow_cfg_file_to_read:
78 airflow_cfg.read_file(airflow_cfg_file_to_read)
79 logging.debug(f"Loaded '{str(airflow_cfg_path)}'")
80
81 config = invoker.plugin_config_processed
82 for section, section_config in config.items():
83 airflow_cfg[section].update(section_config)
84 logging.debug(f"\tUpdated section [{section}] with {section_config}")
85
86 with airflow_cfg_path.open("w") as airflow_cfg_file_to_write:
87 airflow_cfg.write(airflow_cfg_file_to_write)
88 logging.debug(f"Saved '{str(airflow_cfg_path)}'")
89
90 @hook("before_install")
91 async def setup_env(self, *args, **kwargs):
92 """Configure the env to make airflow installable without GPL deps.
93
94 Args:
95 args: Arbitrary args
96 kwargs: Arbitrary kwargs
97 """
98 os.environ["SLUGIFY_USES_TEXT_UNIDECODE"] = "yes"
99
100 @hook("before_configure")
101 async def before_configure(self, invoker: AirflowInvoker, session): # noqa: WPS217
102 """Generate config file and keep metadata database up-to-date.
103
104 Args:
105 invoker: the active PluginInvoker
106 session: metadata database session
107
108 Raises:
109 AsyncSubprocessError: if command failed to run
110 """
111 # generate the default `airflow.cfg`
112 handle = await invoker.invoke_async(
113 "--help",
114 require_preparation=False,
115 stdout=subprocess.DEVNULL,
116 stderr=subprocess.PIPE,
117 )
118 exit_code = await handle.wait()
119
120 if exit_code:
121 raise AsyncSubprocessError(
122 "Command `airflow --help` failed", process=handle
123 )
124
125 # Read and update airflow.cfg
126 self.update_config_file(invoker)
127
128 # we've changed the configuration here, so we need to call
129 # prepare again on the invoker so it re-reads the configuration
130 # for the Airflow plugin
131 await invoker.prepare(session)
132
133 # make sure we use correct db init
134 handle = await invoker.invoke_async(
135 "version",
136 stdout=subprocess.PIPE,
137 stderr=subprocess.PIPE,
138 )
139
140 stdout, stderr = await handle.communicate()
141
142 if handle.returncode:
143 raise AsyncSubprocessError(
144 "Command `airflow version` failed", process=handle
145 )
146
147 version = stdout.decode()
148 init_db_cmd = (
149 ["initdb"]
150 if StrictVersion(version) < StrictVersion("2.0.0")
151 else ["db", "init"]
152 )
153
154 handle = await invoker.invoke_async(
155 *init_db_cmd,
156 stdout=subprocess.PIPE,
157 stderr=subprocess.PIPE,
158 )
159 exit_code = await handle.wait()
160
161 if exit_code:
162 raise AsyncSubprocessError(
163 "Airflow metadata database could not be initialized: `airflow initdb` failed",
164 handle,
165 )
166
167 logging.debug("Completed `airflow initdb`")
168
169 @hook("before_cleanup")
170 async def before_cleanup(self, invoker: PluginInvoker):
171 """Delete the config file.
172
173 Args:
174 invoker: the active PluginInvoker
175 """
176 config_file = invoker.files["config"]
177 try:
178 config_file.unlink()
179 logging.debug(f"Deleted configuration at {config_file}")
180 except FileNotFoundError:
181 pass
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/core/plugin/airflow.py b/src/meltano/core/plugin/airflow.py
--- a/src/meltano/core/plugin/airflow.py
+++ b/src/meltano/core/plugin/airflow.py
@@ -3,7 +3,8 @@
import logging
import os
import subprocess
-from distutils.version import StrictVersion
+
+from packaging.version import Version
from meltano.core.behavior.hookable import hook
from meltano.core.error import AsyncSubprocessError
@@ -146,9 +147,7 @@
version = stdout.decode()
init_db_cmd = (
- ["initdb"]
- if StrictVersion(version) < StrictVersion("2.0.0")
- else ["db", "init"]
+ ["initdb"] if Version(version) < Version("2.0.0") else ["db", "init"]
)
handle = await invoker.invoke_async(
|
{"golden_diff": "diff --git a/src/meltano/core/plugin/airflow.py b/src/meltano/core/plugin/airflow.py\n--- a/src/meltano/core/plugin/airflow.py\n+++ b/src/meltano/core/plugin/airflow.py\n@@ -3,7 +3,8 @@\n import logging\n import os\n import subprocess\n-from distutils.version import StrictVersion\n+\n+from packaging.version import Version\n \n from meltano.core.behavior.hookable import hook\n from meltano.core.error import AsyncSubprocessError\n@@ -146,9 +147,7 @@\n \n version = stdout.decode()\n init_db_cmd = (\n- [\"initdb\"]\n- if StrictVersion(version) < StrictVersion(\"2.0.0\")\n- else [\"db\", \"init\"]\n+ [\"initdb\"] if Version(version) < Version(\"2.0.0\") else [\"db\", \"init\"]\n )\n \n handle = await invoker.invoke_async(\n", "issue": "Address warning in Airflow plugin version check\n> not super urgent, but as we move into supporting newer Python versions \r\n> (https://github.com/meltano/meltano/pull/6135) and bumping Meltano's dependencies (https://github.com/meltano/meltano/issues/6264), we might break Airflow support.\r\n> \r\n> It's also probably a very quick (< 1 hour) fix by replacing distutils.StrictVersion with the packaging.version equivalent.\r\n> \r\n\r\n```\r\nsrc/meltano/core/plugin/airflow.py:110: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.\r\n if StrictVersion(version) < StrictVersion(\"2.0.0\")\r\n```\n", "before_files": [{"content": "\"\"\"Plugin glue code for Airflow.\"\"\"\nimport configparser\nimport logging\nimport os\nimport subprocess\nfrom distutils.version import StrictVersion\n\nfrom meltano.core.behavior.hookable import hook\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.plugin_invoker import PluginInvoker\nfrom meltano.core.utils import nest\n\nfrom . import BasePlugin, PluginType\n\n\nclass AirflowInvoker(PluginInvoker):\n \"\"\"Invoker that prepares env for Airflow.\"\"\"\n\n def env(self):\n \"\"\"Environment variables for Airflow.\n\n Returns:\n Dictionary of environment variables.\n \"\"\"\n env = super().env()\n\n env[\"AIRFLOW_HOME\"] = str(self.plugin_config_service.run_dir)\n env[\"AIRFLOW_CONFIG\"] = str(self.files[\"config\"])\n\n return env\n\n\nclass Airflow(BasePlugin):\n \"\"\"Plugin glue code for Airflow.\"\"\"\n\n __plugin_type__ = PluginType.ORCHESTRATORS\n\n invoker_class = AirflowInvoker\n\n @property\n def config_files(self):\n \"\"\"Return the configuration files required by the plugin.\n\n Returns:\n Dictionary of config file identifiers and filenames\n \"\"\"\n return {\"config\": \"airflow.cfg\"}\n\n def process_config(self, flat_config):\n \"\"\"Unflatten the config.\n\n Args:\n flat_config: the flat config\n\n Returns:\n unflattened config\n \"\"\"\n config = {}\n for key, value in flat_config.items():\n nest(config, key, str(value))\n return config\n\n @staticmethod\n def update_config_file(invoker: AirflowInvoker) -> None:\n \"\"\"Update airflow.cfg with plugin configuration.\n\n Args:\n invoker: the active PluginInvoker\n \"\"\"\n airflow_cfg_path = invoker.files[\"config\"]\n logging.debug(f\"Generated default '{str(airflow_cfg_path)}'\")\n\n # open the configuration and update it\n # now we let's update the config to use our stubs\n airflow_cfg = configparser.ConfigParser()\n\n with airflow_cfg_path.open() as airflow_cfg_file_to_read:\n airflow_cfg.read_file(airflow_cfg_file_to_read)\n logging.debug(f\"Loaded '{str(airflow_cfg_path)}'\")\n\n config = invoker.plugin_config_processed\n for section, section_config in config.items():\n airflow_cfg[section].update(section_config)\n logging.debug(f\"\\tUpdated section [{section}] with {section_config}\")\n\n with airflow_cfg_path.open(\"w\") as airflow_cfg_file_to_write:\n airflow_cfg.write(airflow_cfg_file_to_write)\n logging.debug(f\"Saved '{str(airflow_cfg_path)}'\")\n\n @hook(\"before_install\")\n async def setup_env(self, *args, **kwargs):\n \"\"\"Configure the env to make airflow installable without GPL deps.\n\n Args:\n args: Arbitrary args\n kwargs: Arbitrary kwargs\n \"\"\"\n os.environ[\"SLUGIFY_USES_TEXT_UNIDECODE\"] = \"yes\"\n\n @hook(\"before_configure\")\n async def before_configure(self, invoker: AirflowInvoker, session): # noqa: WPS217\n \"\"\"Generate config file and keep metadata database up-to-date.\n\n Args:\n invoker: the active PluginInvoker\n session: metadata database session\n\n Raises:\n AsyncSubprocessError: if command failed to run\n \"\"\"\n # generate the default `airflow.cfg`\n handle = await invoker.invoke_async(\n \"--help\",\n require_preparation=False,\n stdout=subprocess.DEVNULL,\n stderr=subprocess.PIPE,\n )\n exit_code = await handle.wait()\n\n if exit_code:\n raise AsyncSubprocessError(\n \"Command `airflow --help` failed\", process=handle\n )\n\n # Read and update airflow.cfg\n self.update_config_file(invoker)\n\n # we've changed the configuration here, so we need to call\n # prepare again on the invoker so it re-reads the configuration\n # for the Airflow plugin\n await invoker.prepare(session)\n\n # make sure we use correct db init\n handle = await invoker.invoke_async(\n \"version\",\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n )\n\n stdout, stderr = await handle.communicate()\n\n if handle.returncode:\n raise AsyncSubprocessError(\n \"Command `airflow version` failed\", process=handle\n )\n\n version = stdout.decode()\n init_db_cmd = (\n [\"initdb\"]\n if StrictVersion(version) < StrictVersion(\"2.0.0\")\n else [\"db\", \"init\"]\n )\n\n handle = await invoker.invoke_async(\n *init_db_cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n )\n exit_code = await handle.wait()\n\n if exit_code:\n raise AsyncSubprocessError(\n \"Airflow metadata database could not be initialized: `airflow initdb` failed\",\n handle,\n )\n\n logging.debug(\"Completed `airflow initdb`\")\n\n @hook(\"before_cleanup\")\n async def before_cleanup(self, invoker: PluginInvoker):\n \"\"\"Delete the config file.\n\n Args:\n invoker: the active PluginInvoker\n \"\"\"\n config_file = invoker.files[\"config\"]\n try:\n config_file.unlink()\n logging.debug(f\"Deleted configuration at {config_file}\")\n except FileNotFoundError:\n pass\n", "path": "src/meltano/core/plugin/airflow.py"}], "after_files": [{"content": "\"\"\"Plugin glue code for Airflow.\"\"\"\nimport configparser\nimport logging\nimport os\nimport subprocess\n\nfrom packaging.version import Version\n\nfrom meltano.core.behavior.hookable import hook\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.plugin_invoker import PluginInvoker\nfrom meltano.core.utils import nest\n\nfrom . import BasePlugin, PluginType\n\n\nclass AirflowInvoker(PluginInvoker):\n \"\"\"Invoker that prepares env for Airflow.\"\"\"\n\n def env(self):\n \"\"\"Environment variables for Airflow.\n\n Returns:\n Dictionary of environment variables.\n \"\"\"\n env = super().env()\n\n env[\"AIRFLOW_HOME\"] = str(self.plugin_config_service.run_dir)\n env[\"AIRFLOW_CONFIG\"] = str(self.files[\"config\"])\n\n return env\n\n\nclass Airflow(BasePlugin):\n \"\"\"Plugin glue code for Airflow.\"\"\"\n\n __plugin_type__ = PluginType.ORCHESTRATORS\n\n invoker_class = AirflowInvoker\n\n @property\n def config_files(self):\n \"\"\"Return the configuration files required by the plugin.\n\n Returns:\n Dictionary of config file identifiers and filenames\n \"\"\"\n return {\"config\": \"airflow.cfg\"}\n\n def process_config(self, flat_config):\n \"\"\"Unflatten the config.\n\n Args:\n flat_config: the flat config\n\n Returns:\n unflattened config\n \"\"\"\n config = {}\n for key, value in flat_config.items():\n nest(config, key, str(value))\n return config\n\n @staticmethod\n def update_config_file(invoker: AirflowInvoker) -> None:\n \"\"\"Update airflow.cfg with plugin configuration.\n\n Args:\n invoker: the active PluginInvoker\n \"\"\"\n airflow_cfg_path = invoker.files[\"config\"]\n logging.debug(f\"Generated default '{str(airflow_cfg_path)}'\")\n\n # open the configuration and update it\n # now we let's update the config to use our stubs\n airflow_cfg = configparser.ConfigParser()\n\n with airflow_cfg_path.open() as airflow_cfg_file_to_read:\n airflow_cfg.read_file(airflow_cfg_file_to_read)\n logging.debug(f\"Loaded '{str(airflow_cfg_path)}'\")\n\n config = invoker.plugin_config_processed\n for section, section_config in config.items():\n airflow_cfg[section].update(section_config)\n logging.debug(f\"\\tUpdated section [{section}] with {section_config}\")\n\n with airflow_cfg_path.open(\"w\") as airflow_cfg_file_to_write:\n airflow_cfg.write(airflow_cfg_file_to_write)\n logging.debug(f\"Saved '{str(airflow_cfg_path)}'\")\n\n @hook(\"before_install\")\n async def setup_env(self, *args, **kwargs):\n \"\"\"Configure the env to make airflow installable without GPL deps.\n\n Args:\n args: Arbitrary args\n kwargs: Arbitrary kwargs\n \"\"\"\n os.environ[\"SLUGIFY_USES_TEXT_UNIDECODE\"] = \"yes\"\n\n @hook(\"before_configure\")\n async def before_configure(self, invoker: AirflowInvoker, session): # noqa: WPS217\n \"\"\"Generate config file and keep metadata database up-to-date.\n\n Args:\n invoker: the active PluginInvoker\n session: metadata database session\n\n Raises:\n AsyncSubprocessError: if command failed to run\n \"\"\"\n # generate the default `airflow.cfg`\n handle = await invoker.invoke_async(\n \"--help\",\n require_preparation=False,\n stdout=subprocess.DEVNULL,\n stderr=subprocess.PIPE,\n )\n exit_code = await handle.wait()\n\n if exit_code:\n raise AsyncSubprocessError(\n \"Command `airflow --help` failed\", process=handle\n )\n\n # Read and update airflow.cfg\n self.update_config_file(invoker)\n\n # we've changed the configuration here, so we need to call\n # prepare again on the invoker so it re-reads the configuration\n # for the Airflow plugin\n await invoker.prepare(session)\n\n # make sure we use correct db init\n handle = await invoker.invoke_async(\n \"version\",\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n )\n\n stdout, stderr = await handle.communicate()\n\n if handle.returncode:\n raise AsyncSubprocessError(\n \"Command `airflow version` failed\", process=handle\n )\n\n version = stdout.decode()\n init_db_cmd = (\n [\"initdb\"] if Version(version) < Version(\"2.0.0\") else [\"db\", \"init\"]\n )\n\n handle = await invoker.invoke_async(\n *init_db_cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n )\n exit_code = await handle.wait()\n\n if exit_code:\n raise AsyncSubprocessError(\n \"Airflow metadata database could not be initialized: `airflow initdb` failed\",\n handle,\n )\n\n logging.debug(\"Completed `airflow initdb`\")\n\n @hook(\"before_cleanup\")\n async def before_cleanup(self, invoker: PluginInvoker):\n \"\"\"Delete the config file.\n\n Args:\n invoker: the active PluginInvoker\n \"\"\"\n config_file = invoker.files[\"config\"]\n try:\n config_file.unlink()\n logging.debug(f\"Deleted configuration at {config_file}\")\n except FileNotFoundError:\n pass\n", "path": "src/meltano/core/plugin/airflow.py"}]}
| 2,013 | 207 |
gh_patches_debug_34867
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-3028
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NH: people scraper broken
State: NH (be sure to include in ticket title)
The NH people scraper is broken, because
http://www.gencourt.state.nh.us/downloads/Members.txt
no longer exists. Instead, there is a
http://www.gencourt.state.nh.us/downloads/Members.csv
I'll own this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/nh/people.py`
Content:
```
1 import re
2
3 from pupa.scrape import Person, Scraper
4 from openstates.utils import LXMLMixin
5
6
7 class NHPersonScraper(Scraper, LXMLMixin):
8 members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'
9 lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'
10 house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'
11 senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'
12
13 chamber_map = {'H': 'lower', 'S': 'upper'}
14 party_map = {
15 'D': 'Democratic',
16 'R': 'Republican',
17 'I': 'Independent',
18 'L': 'Libertarian',
19 }
20
21 def _get_photo(self, url, chamber):
22 """Attempts to find a portrait in the given legislator profile."""
23 try:
24 doc = self.lxmlize(url)
25 except Exception as e:
26 self.warning("skipping {}: {}".format(url, e))
27 return ""
28
29 if chamber == 'upper':
30 src = doc.xpath('//div[@id="page_content"]//img[contains(@src, '
31 '"images/senators") or contains(@src, "Senator")]/@src')
32 elif chamber == 'lower':
33 src = doc.xpath('//img[contains(@src, "images/memberpics")]/@src')
34
35 if src and 'nophoto' not in src[0]:
36 photo_url = src[0]
37 else:
38 photo_url = ''
39
40 return photo_url
41
42 def _parse_person(self, row, chamber, seat_map):
43 # Capture legislator vitals.
44 first_name = row['FirstName']
45 middle_name = row['MiddleName']
46 last_name = row['LastName']
47 full_name = '{} {} {}'.format(first_name, middle_name, last_name)
48 full_name = re.sub(r'[\s]{2,}', ' ', full_name)
49
50 if chamber == 'lower':
51 district = '{} {}'.format(row['County'], int(row['District'])).strip()
52 else:
53 district = str(int(row['District'])).strip()
54
55 party = self.party_map[row['party'].upper()]
56 email = row['WorkEmail']
57
58 if district == '0':
59 self.warning('Skipping {}, district is set to 0'.format(full_name))
60 return
61
62 # Temporary fix for Kari Lerner
63 if district == 'Rockingham 0' and last_name == 'Lerner':
64 district = 'Rockingham 4'
65
66 # Temporary fix for Casey Conley
67 if last_name == 'Conley':
68 if district == '13':
69 district = 'Strafford 13'
70 elif district == 'Strafford 13':
71 self.info('"Temporary fix for Casey Conley" can be removed')
72
73 person = Person(primary_org=chamber,
74 district=district,
75 name=full_name,
76 party=party)
77
78 extras = {
79 'first_name': first_name,
80 'middle_name': middle_name,
81 'last_name': last_name
82 }
83
84 person.extras = extras
85 if email:
86 office = 'Capitol' if email.endswith('@leg.state.nh.us') else 'District'
87 person.add_contact_detail(type='email', value=email, note=office + ' Office')
88
89 # Capture legislator office contact information.
90 district_address = '{}\n{}\n{}, {} {}'.format(row['Address'],
91 row['address2'],
92 row['city'], row['State'],
93 row['Zipcode']).strip()
94
95 phone = row['Phone'].strip()
96 if not phone:
97 phone = None
98
99 if district_address:
100 office = 'Capitol' if chamber == 'upper' else 'District'
101 person.add_contact_detail(type='address', value=district_address,
102 note=office + ' Office')
103 if phone:
104 office = 'Capitol' if '271-' in phone else 'District'
105 person.add_contact_detail(type='voice', value=phone, note=office + ' Office')
106
107 # Retrieve legislator portrait.
108 profile_url = None
109 if chamber == 'upper':
110 profile_url = self.senate_profile_url.format(row['District'])
111 elif chamber == 'lower':
112 try:
113 seat_number = seat_map[row['seatno']]
114 profile_url = self.house_profile_url.format(seat_number)
115 except KeyError:
116 pass
117
118 if profile_url:
119 person.image = self._get_photo(profile_url, chamber)
120 person.add_source(profile_url)
121
122 return person
123
124 def _parse_members_txt(self):
125 lines = self.get(self.members_url).text.splitlines()
126
127 header = lines[0].split('\t')
128
129 for line in lines[1:]:
130 yield dict(zip(header, line.split('\t')))
131
132 def _parse_seat_map(self):
133 """Get mapping between seat numbers and legislator identifiers."""
134 seat_map = {}
135 page = self.lxmlize(self.lookup_url)
136 options = page.xpath('//select[@id="member"]/option')
137 for option in options:
138 member_url = self.house_profile_url.format(option.attrib['value'])
139 member_page = self.lxmlize(member_url)
140 table = member_page.xpath('//table[@id="Table1"]')
141 if table:
142 res = re.search(r'seat #:(\d+)', table[0].text_content(), re.IGNORECASE)
143 if res:
144 seat_map[res.groups()[0]] = option.attrib['value']
145 return seat_map
146
147 def scrape(self, chamber=None):
148 chambers = [chamber] if chamber is not None else ['upper', 'lower']
149 seat_map = self._parse_seat_map()
150 for chamber in chambers:
151 for row in self._parse_members_txt():
152 print(row['electedStatus'])
153 if self.chamber_map[row['LegislativeBody']] == chamber:
154 person = self._parse_person(row, chamber, seat_map)
155
156 # allow for skipping
157 if not person:
158 continue
159
160 person.add_source(self.members_url)
161 person.add_link(self.members_url)
162 yield person
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/nh/people.py b/openstates/nh/people.py
--- a/openstates/nh/people.py
+++ b/openstates/nh/people.py
@@ -1,11 +1,12 @@
import re
-
+import csv
from pupa.scrape import Person, Scraper
from openstates.utils import LXMLMixin
+import requests
class NHPersonScraper(Scraper, LXMLMixin):
- members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'
+ members_url = 'http://www.gencourt.state.nh.us/downloads/Members.csv'
lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'
house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'
senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'
@@ -59,17 +60,6 @@
self.warning('Skipping {}, district is set to 0'.format(full_name))
return
- # Temporary fix for Kari Lerner
- if district == 'Rockingham 0' and last_name == 'Lerner':
- district = 'Rockingham 4'
-
- # Temporary fix for Casey Conley
- if last_name == 'Conley':
- if district == '13':
- district = 'Strafford 13'
- elif district == 'Strafford 13':
- self.info('"Temporary fix for Casey Conley" can be removed')
-
person = Person(primary_org=chamber,
district=district,
name=full_name,
@@ -122,12 +112,13 @@
return person
def _parse_members_txt(self):
- lines = self.get(self.members_url).text.splitlines()
+ response = requests.get(self.members_url)
+ lines = csv.reader(response.text.strip().split('\n'), delimiter=',')
- header = lines[0].split('\t')
+ header = next(lines)
- for line in lines[1:]:
- yield dict(zip(header, line.split('\t')))
+ for line in lines:
+ yield dict(zip(header, line))
def _parse_seat_map(self):
"""Get mapping between seat numbers and legislator identifiers."""
|
{"golden_diff": "diff --git a/openstates/nh/people.py b/openstates/nh/people.py\n--- a/openstates/nh/people.py\n+++ b/openstates/nh/people.py\n@@ -1,11 +1,12 @@\n import re\n-\n+import csv\n from pupa.scrape import Person, Scraper\n from openstates.utils import LXMLMixin\n+import requests\n \n \n class NHPersonScraper(Scraper, LXMLMixin):\n- members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'\n+ members_url = 'http://www.gencourt.state.nh.us/downloads/Members.csv'\n lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'\n house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'\n senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'\n@@ -59,17 +60,6 @@\n self.warning('Skipping {}, district is set to 0'.format(full_name))\n return\n \n- # Temporary fix for Kari Lerner\n- if district == 'Rockingham 0' and last_name == 'Lerner':\n- district = 'Rockingham 4'\n-\n- # Temporary fix for Casey Conley\n- if last_name == 'Conley':\n- if district == '13':\n- district = 'Strafford 13'\n- elif district == 'Strafford 13':\n- self.info('\"Temporary fix for Casey Conley\" can be removed')\n-\n person = Person(primary_org=chamber,\n district=district,\n name=full_name,\n@@ -122,12 +112,13 @@\n return person\n \n def _parse_members_txt(self):\n- lines = self.get(self.members_url).text.splitlines()\n+ response = requests.get(self.members_url)\n+ lines = csv.reader(response.text.strip().split('\\n'), delimiter=',')\n \n- header = lines[0].split('\\t')\n+ header = next(lines)\n \n- for line in lines[1:]:\n- yield dict(zip(header, line.split('\\t')))\n+ for line in lines:\n+ yield dict(zip(header, line))\n \n def _parse_seat_map(self):\n \"\"\"Get mapping between seat numbers and legislator identifiers.\"\"\"\n", "issue": "NH: people scraper broken\nState: NH (be sure to include in ticket title)\r\n\r\nThe NH people scraper is broken, because \r\n http://www.gencourt.state.nh.us/downloads/Members.txt\r\nno longer exists. Instead, there is a \r\n http://www.gencourt.state.nh.us/downloads/Members.csv\r\n\r\nI'll own this.\n", "before_files": [{"content": "import re\n\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin\n\n\nclass NHPersonScraper(Scraper, LXMLMixin):\n members_url = 'http://www.gencourt.state.nh.us/downloads/Members.txt'\n lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'\n house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'\n senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'\n\n chamber_map = {'H': 'lower', 'S': 'upper'}\n party_map = {\n 'D': 'Democratic',\n 'R': 'Republican',\n 'I': 'Independent',\n 'L': 'Libertarian',\n }\n\n def _get_photo(self, url, chamber):\n \"\"\"Attempts to find a portrait in the given legislator profile.\"\"\"\n try:\n doc = self.lxmlize(url)\n except Exception as e:\n self.warning(\"skipping {}: {}\".format(url, e))\n return \"\"\n\n if chamber == 'upper':\n src = doc.xpath('//div[@id=\"page_content\"]//img[contains(@src, '\n '\"images/senators\") or contains(@src, \"Senator\")]/@src')\n elif chamber == 'lower':\n src = doc.xpath('//img[contains(@src, \"images/memberpics\")]/@src')\n\n if src and 'nophoto' not in src[0]:\n photo_url = src[0]\n else:\n photo_url = ''\n\n return photo_url\n\n def _parse_person(self, row, chamber, seat_map):\n # Capture legislator vitals.\n first_name = row['FirstName']\n middle_name = row['MiddleName']\n last_name = row['LastName']\n full_name = '{} {} {}'.format(first_name, middle_name, last_name)\n full_name = re.sub(r'[\\s]{2,}', ' ', full_name)\n\n if chamber == 'lower':\n district = '{} {}'.format(row['County'], int(row['District'])).strip()\n else:\n district = str(int(row['District'])).strip()\n\n party = self.party_map[row['party'].upper()]\n email = row['WorkEmail']\n\n if district == '0':\n self.warning('Skipping {}, district is set to 0'.format(full_name))\n return\n\n # Temporary fix for Kari Lerner\n if district == 'Rockingham 0' and last_name == 'Lerner':\n district = 'Rockingham 4'\n\n # Temporary fix for Casey Conley\n if last_name == 'Conley':\n if district == '13':\n district = 'Strafford 13'\n elif district == 'Strafford 13':\n self.info('\"Temporary fix for Casey Conley\" can be removed')\n\n person = Person(primary_org=chamber,\n district=district,\n name=full_name,\n party=party)\n\n extras = {\n 'first_name': first_name,\n 'middle_name': middle_name,\n 'last_name': last_name\n }\n\n person.extras = extras\n if email:\n office = 'Capitol' if email.endswith('@leg.state.nh.us') else 'District'\n person.add_contact_detail(type='email', value=email, note=office + ' Office')\n\n # Capture legislator office contact information.\n district_address = '{}\\n{}\\n{}, {} {}'.format(row['Address'],\n row['address2'],\n row['city'], row['State'],\n row['Zipcode']).strip()\n\n phone = row['Phone'].strip()\n if not phone:\n phone = None\n\n if district_address:\n office = 'Capitol' if chamber == 'upper' else 'District'\n person.add_contact_detail(type='address', value=district_address,\n note=office + ' Office')\n if phone:\n office = 'Capitol' if '271-' in phone else 'District'\n person.add_contact_detail(type='voice', value=phone, note=office + ' Office')\n\n # Retrieve legislator portrait.\n profile_url = None\n if chamber == 'upper':\n profile_url = self.senate_profile_url.format(row['District'])\n elif chamber == 'lower':\n try:\n seat_number = seat_map[row['seatno']]\n profile_url = self.house_profile_url.format(seat_number)\n except KeyError:\n pass\n\n if profile_url:\n person.image = self._get_photo(profile_url, chamber)\n person.add_source(profile_url)\n\n return person\n\n def _parse_members_txt(self):\n lines = self.get(self.members_url).text.splitlines()\n\n header = lines[0].split('\\t')\n\n for line in lines[1:]:\n yield dict(zip(header, line.split('\\t')))\n\n def _parse_seat_map(self):\n \"\"\"Get mapping between seat numbers and legislator identifiers.\"\"\"\n seat_map = {}\n page = self.lxmlize(self.lookup_url)\n options = page.xpath('//select[@id=\"member\"]/option')\n for option in options:\n member_url = self.house_profile_url.format(option.attrib['value'])\n member_page = self.lxmlize(member_url)\n table = member_page.xpath('//table[@id=\"Table1\"]')\n if table:\n res = re.search(r'seat #:(\\d+)', table[0].text_content(), re.IGNORECASE)\n if res:\n seat_map[res.groups()[0]] = option.attrib['value']\n return seat_map\n\n def scrape(self, chamber=None):\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n seat_map = self._parse_seat_map()\n for chamber in chambers:\n for row in self._parse_members_txt():\n print(row['electedStatus'])\n if self.chamber_map[row['LegislativeBody']] == chamber:\n person = self._parse_person(row, chamber, seat_map)\n\n # allow for skipping\n if not person:\n continue\n\n person.add_source(self.members_url)\n person.add_link(self.members_url)\n yield person\n", "path": "openstates/nh/people.py"}], "after_files": [{"content": "import re\nimport csv\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin\nimport requests\n\n\nclass NHPersonScraper(Scraper, LXMLMixin):\n members_url = 'http://www.gencourt.state.nh.us/downloads/Members.csv'\n lookup_url = 'http://www.gencourt.state.nh.us/house/members/memberlookup.aspx'\n house_profile_url = 'http://www.gencourt.state.nh.us/house/members/member.aspx?member={}'\n senate_profile_url = 'http://www.gencourt.state.nh.us/Senate/members/webpages/district{}.aspx'\n\n chamber_map = {'H': 'lower', 'S': 'upper'}\n party_map = {\n 'D': 'Democratic',\n 'R': 'Republican',\n 'I': 'Independent',\n 'L': 'Libertarian',\n }\n\n def _get_photo(self, url, chamber):\n \"\"\"Attempts to find a portrait in the given legislator profile.\"\"\"\n try:\n doc = self.lxmlize(url)\n except Exception as e:\n self.warning(\"skipping {}: {}\".format(url, e))\n return \"\"\n\n if chamber == 'upper':\n src = doc.xpath('//div[@id=\"page_content\"]//img[contains(@src, '\n '\"images/senators\") or contains(@src, \"Senator\")]/@src')\n elif chamber == 'lower':\n src = doc.xpath('//img[contains(@src, \"images/memberpics\")]/@src')\n\n if src and 'nophoto' not in src[0]:\n photo_url = src[0]\n else:\n photo_url = ''\n\n return photo_url\n\n def _parse_person(self, row, chamber, seat_map):\n # Capture legislator vitals.\n first_name = row['FirstName']\n middle_name = row['MiddleName']\n last_name = row['LastName']\n full_name = '{} {} {}'.format(first_name, middle_name, last_name)\n full_name = re.sub(r'[\\s]{2,}', ' ', full_name)\n\n if chamber == 'lower':\n district = '{} {}'.format(row['County'], int(row['District'])).strip()\n else:\n district = str(int(row['District'])).strip()\n\n party = self.party_map[row['party'].upper()]\n email = row['WorkEmail']\n\n if district == '0':\n self.warning('Skipping {}, district is set to 0'.format(full_name))\n return\n\n person = Person(primary_org=chamber,\n district=district,\n name=full_name,\n party=party)\n\n extras = {\n 'first_name': first_name,\n 'middle_name': middle_name,\n 'last_name': last_name\n }\n\n person.extras = extras\n if email:\n office = 'Capitol' if email.endswith('@leg.state.nh.us') else 'District'\n person.add_contact_detail(type='email', value=email, note=office + ' Office')\n\n # Capture legislator office contact information.\n district_address = '{}\\n{}\\n{}, {} {}'.format(row['Address'],\n row['address2'],\n row['city'], row['State'],\n row['Zipcode']).strip()\n\n phone = row['Phone'].strip()\n if not phone:\n phone = None\n\n if district_address:\n office = 'Capitol' if chamber == 'upper' else 'District'\n person.add_contact_detail(type='address', value=district_address,\n note=office + ' Office')\n if phone:\n office = 'Capitol' if '271-' in phone else 'District'\n person.add_contact_detail(type='voice', value=phone, note=office + ' Office')\n\n # Retrieve legislator portrait.\n profile_url = None\n if chamber == 'upper':\n profile_url = self.senate_profile_url.format(row['District'])\n elif chamber == 'lower':\n try:\n seat_number = seat_map[row['seatno']]\n profile_url = self.house_profile_url.format(seat_number)\n except KeyError:\n pass\n\n if profile_url:\n person.image = self._get_photo(profile_url, chamber)\n person.add_source(profile_url)\n\n return person\n\n def _parse_members_txt(self):\n response = requests.get(self.members_url)\n lines = csv.reader(response.text.strip().split('\\n'), delimiter=',')\n\n header = next(lines)\n\n for line in lines:\n yield dict(zip(header, line))\n\n def _parse_seat_map(self):\n \"\"\"Get mapping between seat numbers and legislator identifiers.\"\"\"\n seat_map = {}\n page = self.lxmlize(self.lookup_url)\n options = page.xpath('//select[@id=\"member\"]/option')\n for option in options:\n member_url = self.house_profile_url.format(option.attrib['value'])\n member_page = self.lxmlize(member_url)\n table = member_page.xpath('//table[@id=\"Table1\"]')\n if table:\n res = re.search(r'seat #:(\\d+)', table[0].text_content(), re.IGNORECASE)\n if res:\n seat_map[res.groups()[0]] = option.attrib['value']\n return seat_map\n\n def scrape(self, chamber=None):\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n seat_map = self._parse_seat_map()\n for chamber in chambers:\n for row in self._parse_members_txt():\n print(row['electedStatus'])\n if self.chamber_map[row['LegislativeBody']] == chamber:\n person = self._parse_person(row, chamber, seat_map)\n\n # allow for skipping\n if not person:\n continue\n\n person.add_source(self.members_url)\n person.add_link(self.members_url)\n yield person\n", "path": "openstates/nh/people.py"}]}
| 2,061 | 528 |
gh_patches_debug_36742
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-2109
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Search query got emphasized even in the middle of another, unrelated word
<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->
**Version of SearXNG**
2023.01.09-afd71a6c
**How did you install SearXNG?**
Installed using docker with clone, docker build and run.
**What happened?**
Query letters got emphasized even in the middle of another unrelated word.
**How To Reproduce**
Do some search using alphabetic, English words with all language flag, such as `the :all`, `java :all`, `master :all`.
**Expected behavior**
Emphasization should occur on queries found in standalone words only, such as `java` query only emphasize '**java**' instead of '**java**script', or `master` only in '**Master**' or '**master**' instead of 'grand**master**'.
**Screenshots & Logs**
|  |
| --- |
| In the word 'o**the**rwise' |
|  |
| --- |
| In the word '**The**saurus' and '**the**ir' |
|  |
| --- |
| In the word '**master**ful', '**master**s', 'grand**master**' |
**Additional context**
Likely happened because the regex being used does not isolate the query for occurrences in standalone words and instead it looks for all occurrences in the whole text without requiring the presence of spaces before or after it. This regex actually works well for the emphasization of queries in Chinese characters, for example:
|  |
| --- |
| Query used: ’村上春樹’ |
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/webutils.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import os
3 import pathlib
4 import csv
5 import hashlib
6 import hmac
7 import re
8 import inspect
9 import itertools
10 from datetime import datetime, timedelta
11 from typing import Iterable, List, Tuple, Dict
12
13 from io import StringIO
14 from codecs import getincrementalencoder
15
16 from flask_babel import gettext, format_date
17
18 from searx import logger, settings
19 from searx.engines import Engine, OTHER_CATEGORY
20
21
22 VALID_LANGUAGE_CODE = re.compile(r'^[a-z]{2,3}(-[a-zA-Z]{2})?$')
23
24 logger = logger.getChild('webutils')
25
26
27 class UnicodeWriter:
28 """
29 A CSV writer which will write rows to CSV file "f",
30 which is encoded in the given encoding.
31 """
32
33 def __init__(self, f, dialect=csv.excel, encoding="utf-8", **kwds):
34 # Redirect output to a queue
35 self.queue = StringIO()
36 self.writer = csv.writer(self.queue, dialect=dialect, **kwds)
37 self.stream = f
38 self.encoder = getincrementalencoder(encoding)()
39
40 def writerow(self, row):
41 self.writer.writerow(row)
42 # Fetch UTF-8 output from the queue ...
43 data = self.queue.getvalue()
44 data = data.strip('\x00')
45 # ... and re-encode it into the target encoding
46 data = self.encoder.encode(data)
47 # write to the target stream
48 self.stream.write(data.decode())
49 # empty queue
50 self.queue.truncate(0)
51
52 def writerows(self, rows):
53 for row in rows:
54 self.writerow(row)
55
56
57 def get_themes(templates_path):
58 """Returns available themes list."""
59 return os.listdir(templates_path)
60
61
62 def get_hash_for_file(file: pathlib.Path) -> str:
63 m = hashlib.sha1()
64 with file.open('rb') as f:
65 m.update(f.read())
66 return m.hexdigest()
67
68
69 def get_static_files(static_path: str) -> Dict[str, str]:
70 static_files: Dict[str, str] = {}
71 static_path_path = pathlib.Path(static_path)
72
73 def walk(path: pathlib.Path):
74 for file in path.iterdir():
75 if file.name.startswith('.'):
76 # ignore hidden file
77 continue
78 if file.is_file():
79 static_files[str(file.relative_to(static_path_path))] = get_hash_for_file(file)
80 if file.is_dir() and file.name not in ('node_modules', 'src'):
81 # ignore "src" and "node_modules" directories
82 walk(file)
83
84 walk(static_path_path)
85 return static_files
86
87
88 def get_result_templates(templates_path):
89 result_templates = set()
90 templates_path_length = len(templates_path) + 1
91 for directory, _, files in os.walk(templates_path):
92 if directory.endswith('result_templates'):
93 for filename in files:
94 f = os.path.join(directory[templates_path_length:], filename)
95 result_templates.add(f)
96 return result_templates
97
98
99 def new_hmac(secret_key, url):
100 return hmac.new(secret_key.encode(), url, hashlib.sha256).hexdigest()
101
102
103 def is_hmac_of(secret_key, value, hmac_to_check):
104 hmac_of_value = new_hmac(secret_key, value)
105 return len(hmac_of_value) == len(hmac_to_check) and hmac.compare_digest(hmac_of_value, hmac_to_check)
106
107
108 def prettify_url(url, max_length=74):
109 if len(url) > max_length:
110 chunk_len = int(max_length / 2 + 1)
111 return '{0}[...]{1}'.format(url[:chunk_len], url[-chunk_len:])
112 else:
113 return url
114
115
116 def highlight_content(content, query):
117
118 if not content:
119 return None
120 # ignoring html contents
121 # TODO better html content detection
122 if content.find('<') != -1:
123 return content
124
125 if content.lower().find(query.lower()) > -1:
126 query_regex = '({0})'.format(re.escape(query))
127 content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
128 else:
129 regex_parts = []
130 for chunk in query.split():
131 chunk = chunk.replace('"', '')
132 if len(chunk) == 0:
133 continue
134 elif len(chunk) == 1:
135 regex_parts.append('\\W+{0}\\W+'.format(re.escape(chunk)))
136 else:
137 regex_parts.append('{0}'.format(re.escape(chunk)))
138 query_regex = '({0})'.format('|'.join(regex_parts))
139 content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
140
141 return content
142
143
144 def searxng_l10n_timespan(dt: datetime) -> str: # pylint: disable=invalid-name
145 """Returns a human-readable and translated string indicating how long ago
146 a date was in the past / the time span of the date to the present.
147
148 On January 1st, midnight, the returned string only indicates how many years
149 ago the date was.
150 """
151 # TODO, check if timezone is calculated right # pylint: disable=fixme
152 d = dt.date()
153 t = dt.time()
154 if d.month == 1 and d.day == 1 and t.hour == 0 and t.minute == 0 and t.second == 0:
155 return str(d.year)
156 if dt.replace(tzinfo=None) >= datetime.now() - timedelta(days=1):
157 timedifference = datetime.now() - dt.replace(tzinfo=None)
158 minutes = int((timedifference.seconds / 60) % 60)
159 hours = int(timedifference.seconds / 60 / 60)
160 if hours == 0:
161 return gettext('{minutes} minute(s) ago').format(minutes=minutes)
162 return gettext('{hours} hour(s), {minutes} minute(s) ago').format(hours=hours, minutes=minutes)
163 return format_date(dt)
164
165
166 def is_flask_run_cmdline():
167 """Check if the application was started using "flask run" command line
168
169 Inspect the callstack.
170 See https://github.com/pallets/flask/blob/master/src/flask/__main__.py
171
172 Returns:
173 bool: True if the application was started using "flask run".
174 """
175 frames = inspect.stack()
176 if len(frames) < 2:
177 return False
178 return frames[-2].filename.endswith('flask/cli.py')
179
180
181 DEFAULT_GROUP_NAME = 'others'
182
183
184 def group_engines_in_tab(engines: Iterable[Engine]) -> List[Tuple[str, Iterable[Engine]]]:
185 """Groups an Iterable of engines by their first non tab category"""
186
187 def get_group(eng):
188 non_tab_categories = [
189 c for c in eng.categories if c not in list(settings['categories_as_tabs'].keys()) + [OTHER_CATEGORY]
190 ]
191 return non_tab_categories[0] if len(non_tab_categories) > 0 else DEFAULT_GROUP_NAME
192
193 groups = itertools.groupby(sorted(engines, key=get_group), get_group)
194
195 def group_sort_key(group):
196 return (group[0] == DEFAULT_GROUP_NAME, group[0].lower())
197
198 sorted_groups = sorted(((name, list(engines)) for name, engines in groups), key=group_sort_key)
199
200 def engine_sort_key(engine):
201 return (engine.about.get('language', ''), engine.name)
202
203 return [(groupname, sorted(engines, key=engine_sort_key)) for groupname, engines in sorted_groups]
204
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/searx/webutils.py b/searx/webutils.py
--- a/searx/webutils.py
+++ b/searx/webutils.py
@@ -113,31 +113,68 @@
return url
+def contains_cjko(s: str) -> bool:
+ """This function check whether or not a string contains Chinese, Japanese,
+ or Korean characters. It employs regex and uses the u escape sequence to
+ match any character in a set of Unicode ranges.
+
+ Args:
+ s (str): string to be checked.
+
+ Returns:
+ bool: True if the input s contains the characters and False otherwise.
+ """
+ unicode_ranges = (
+ '\u4e00-\u9fff' # Chinese characters
+ '\u3040-\u309f' # Japanese hiragana
+ '\u30a0-\u30ff' # Japanese katakana
+ '\u4e00-\u9faf' # Japanese kanji
+ '\uac00-\ud7af' # Korean hangul syllables
+ '\u1100-\u11ff' # Korean hangul jamo
+ )
+ return bool(re.search(fr'[{unicode_ranges}]', s))
+
+
+def regex_highlight_cjk(word: str) -> str:
+ """Generate the regex pattern to match for a given word according
+ to whether or not the word contains CJK characters or not.
+ If the word is and/or contains CJK character, the regex pattern
+ will match standalone word by taking into account the presence
+ of whitespace before and after it; if not, it will match any presence
+ of the word throughout the text, ignoring the whitespace.
+
+ Args:
+ word (str): the word to be matched with regex pattern.
+
+ Returns:
+ str: the regex pattern for the word.
+ """
+ rword = re.escape(word)
+ if contains_cjko(rword):
+ return fr'({rword})'
+ else:
+ return fr'\b({rword})(?!\w)'
+
+
def highlight_content(content, query):
if not content:
return None
+
# ignoring html contents
# TODO better html content detection
if content.find('<') != -1:
return content
- if content.lower().find(query.lower()) > -1:
- query_regex = '({0})'.format(re.escape(query))
- content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
- else:
- regex_parts = []
- for chunk in query.split():
- chunk = chunk.replace('"', '')
- if len(chunk) == 0:
- continue
- elif len(chunk) == 1:
- regex_parts.append('\\W+{0}\\W+'.format(re.escape(chunk)))
- else:
- regex_parts.append('{0}'.format(re.escape(chunk)))
- query_regex = '({0})'.format('|'.join(regex_parts))
- content = re.sub(query_regex, '<span class="highlight">\\1</span>', content, flags=re.I | re.U)
-
+ querysplit = query.split()
+ queries = []
+ for qs in querysplit:
+ qs = qs.replace("'", "").replace('"', '').replace(" ", "")
+ if len(qs) > 0:
+ queries.extend(re.findall(regex_highlight_cjk(qs), content, flags=re.I | re.U))
+ if len(queries) > 0:
+ for q in set(queries):
+ content = re.sub(regex_highlight_cjk(q), f'<span class="highlight">{q}</span>', content)
return content
|
{"golden_diff": "diff --git a/searx/webutils.py b/searx/webutils.py\n--- a/searx/webutils.py\n+++ b/searx/webutils.py\n@@ -113,31 +113,68 @@\n return url\n \n \n+def contains_cjko(s: str) -> bool:\n+ \"\"\"This function check whether or not a string contains Chinese, Japanese,\n+ or Korean characters. It employs regex and uses the u escape sequence to\n+ match any character in a set of Unicode ranges.\n+\n+ Args:\n+ s (str): string to be checked.\n+\n+ Returns:\n+ bool: True if the input s contains the characters and False otherwise.\n+ \"\"\"\n+ unicode_ranges = (\n+ '\\u4e00-\\u9fff' # Chinese characters\n+ '\\u3040-\\u309f' # Japanese hiragana\n+ '\\u30a0-\\u30ff' # Japanese katakana\n+ '\\u4e00-\\u9faf' # Japanese kanji\n+ '\\uac00-\\ud7af' # Korean hangul syllables\n+ '\\u1100-\\u11ff' # Korean hangul jamo\n+ )\n+ return bool(re.search(fr'[{unicode_ranges}]', s))\n+\n+\n+def regex_highlight_cjk(word: str) -> str:\n+ \"\"\"Generate the regex pattern to match for a given word according\n+ to whether or not the word contains CJK characters or not.\n+ If the word is and/or contains CJK character, the regex pattern\n+ will match standalone word by taking into account the presence\n+ of whitespace before and after it; if not, it will match any presence\n+ of the word throughout the text, ignoring the whitespace.\n+\n+ Args:\n+ word (str): the word to be matched with regex pattern.\n+\n+ Returns:\n+ str: the regex pattern for the word.\n+ \"\"\"\n+ rword = re.escape(word)\n+ if contains_cjko(rword):\n+ return fr'({rword})'\n+ else:\n+ return fr'\\b({rword})(?!\\w)'\n+\n+\n def highlight_content(content, query):\n \n if not content:\n return None\n+\n # ignoring html contents\n # TODO better html content detection\n if content.find('<') != -1:\n return content\n \n- if content.lower().find(query.lower()) > -1:\n- query_regex = '({0})'.format(re.escape(query))\n- content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n- else:\n- regex_parts = []\n- for chunk in query.split():\n- chunk = chunk.replace('\"', '')\n- if len(chunk) == 0:\n- continue\n- elif len(chunk) == 1:\n- regex_parts.append('\\\\W+{0}\\\\W+'.format(re.escape(chunk)))\n- else:\n- regex_parts.append('{0}'.format(re.escape(chunk)))\n- query_regex = '({0})'.format('|'.join(regex_parts))\n- content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n-\n+ querysplit = query.split()\n+ queries = []\n+ for qs in querysplit:\n+ qs = qs.replace(\"'\", \"\").replace('\"', '').replace(\" \", \"\")\n+ if len(qs) > 0:\n+ queries.extend(re.findall(regex_highlight_cjk(qs), content, flags=re.I | re.U))\n+ if len(queries) > 0:\n+ for q in set(queries):\n+ content = re.sub(regex_highlight_cjk(q), f'<span class=\"highlight\">{q}</span>', content)\n return content\n", "issue": "Search query got emphasized even in the middle of another, unrelated word\n<!-- PLEASE FILL THESE FIELDS, IT REALLY HELPS THE MAINTAINERS OF SearXNG -->\r\n\r\n**Version of SearXNG**\r\n\r\n2023.01.09-afd71a6c\r\n\r\n**How did you install SearXNG?**\r\n\r\nInstalled using docker with clone, docker build and run.\r\n\r\n**What happened?**\r\n\r\nQuery letters got emphasized even in the middle of another unrelated word.\r\n\r\n**How To Reproduce**\r\n\r\nDo some search using alphabetic, English words with all language flag, such as `the :all`, `java :all`, `master :all`. \r\n\r\n**Expected behavior**\r\n\r\nEmphasization should occur on queries found in standalone words only, such as `java` query only emphasize '**java**' instead of '**java**script', or `master` only in '**Master**' or '**master**' instead of 'grand**master**'.\r\n\r\n**Screenshots & Logs**\r\n\r\n|  |\r\n| --- |\r\n| In the word 'o**the**rwise' |\r\n \r\n|  |\r\n| --- |\r\n| In the word '**The**saurus' and '**the**ir' |\r\n\r\n|  |\r\n| --- |\r\n| In the word '**master**ful', '**master**s', 'grand**master**' |\r\n\r\n**Additional context**\r\n\r\nLikely happened because the regex being used does not isolate the query for occurrences in standalone words and instead it looks for all occurrences in the whole text without requiring the presence of spaces before or after it. This regex actually works well for the emphasization of queries in Chinese characters, for example:\r\n\r\n|  |\r\n| --- |\r\n| Query used: \u2019\u6751\u4e0a\u6625\u6a39\u2019 |\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nimport pathlib\nimport csv\nimport hashlib\nimport hmac\nimport re\nimport inspect\nimport itertools\nfrom datetime import datetime, timedelta\nfrom typing import Iterable, List, Tuple, Dict\n\nfrom io import StringIO\nfrom codecs import getincrementalencoder\n\nfrom flask_babel import gettext, format_date\n\nfrom searx import logger, settings\nfrom searx.engines import Engine, OTHER_CATEGORY\n\n\nVALID_LANGUAGE_CODE = re.compile(r'^[a-z]{2,3}(-[a-zA-Z]{2})?$')\n\nlogger = logger.getChild('webutils')\n\n\nclass UnicodeWriter:\n \"\"\"\n A CSV writer which will write rows to CSV file \"f\",\n which is encoded in the given encoding.\n \"\"\"\n\n def __init__(self, f, dialect=csv.excel, encoding=\"utf-8\", **kwds):\n # Redirect output to a queue\n self.queue = StringIO()\n self.writer = csv.writer(self.queue, dialect=dialect, **kwds)\n self.stream = f\n self.encoder = getincrementalencoder(encoding)()\n\n def writerow(self, row):\n self.writer.writerow(row)\n # Fetch UTF-8 output from the queue ...\n data = self.queue.getvalue()\n data = data.strip('\\x00')\n # ... and re-encode it into the target encoding\n data = self.encoder.encode(data)\n # write to the target stream\n self.stream.write(data.decode())\n # empty queue\n self.queue.truncate(0)\n\n def writerows(self, rows):\n for row in rows:\n self.writerow(row)\n\n\ndef get_themes(templates_path):\n \"\"\"Returns available themes list.\"\"\"\n return os.listdir(templates_path)\n\n\ndef get_hash_for_file(file: pathlib.Path) -> str:\n m = hashlib.sha1()\n with file.open('rb') as f:\n m.update(f.read())\n return m.hexdigest()\n\n\ndef get_static_files(static_path: str) -> Dict[str, str]:\n static_files: Dict[str, str] = {}\n static_path_path = pathlib.Path(static_path)\n\n def walk(path: pathlib.Path):\n for file in path.iterdir():\n if file.name.startswith('.'):\n # ignore hidden file\n continue\n if file.is_file():\n static_files[str(file.relative_to(static_path_path))] = get_hash_for_file(file)\n if file.is_dir() and file.name not in ('node_modules', 'src'):\n # ignore \"src\" and \"node_modules\" directories\n walk(file)\n\n walk(static_path_path)\n return static_files\n\n\ndef get_result_templates(templates_path):\n result_templates = set()\n templates_path_length = len(templates_path) + 1\n for directory, _, files in os.walk(templates_path):\n if directory.endswith('result_templates'):\n for filename in files:\n f = os.path.join(directory[templates_path_length:], filename)\n result_templates.add(f)\n return result_templates\n\n\ndef new_hmac(secret_key, url):\n return hmac.new(secret_key.encode(), url, hashlib.sha256).hexdigest()\n\n\ndef is_hmac_of(secret_key, value, hmac_to_check):\n hmac_of_value = new_hmac(secret_key, value)\n return len(hmac_of_value) == len(hmac_to_check) and hmac.compare_digest(hmac_of_value, hmac_to_check)\n\n\ndef prettify_url(url, max_length=74):\n if len(url) > max_length:\n chunk_len = int(max_length / 2 + 1)\n return '{0}[...]{1}'.format(url[:chunk_len], url[-chunk_len:])\n else:\n return url\n\n\ndef highlight_content(content, query):\n\n if not content:\n return None\n # ignoring html contents\n # TODO better html content detection\n if content.find('<') != -1:\n return content\n\n if content.lower().find(query.lower()) > -1:\n query_regex = '({0})'.format(re.escape(query))\n content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n else:\n regex_parts = []\n for chunk in query.split():\n chunk = chunk.replace('\"', '')\n if len(chunk) == 0:\n continue\n elif len(chunk) == 1:\n regex_parts.append('\\\\W+{0}\\\\W+'.format(re.escape(chunk)))\n else:\n regex_parts.append('{0}'.format(re.escape(chunk)))\n query_regex = '({0})'.format('|'.join(regex_parts))\n content = re.sub(query_regex, '<span class=\"highlight\">\\\\1</span>', content, flags=re.I | re.U)\n\n return content\n\n\ndef searxng_l10n_timespan(dt: datetime) -> str: # pylint: disable=invalid-name\n \"\"\"Returns a human-readable and translated string indicating how long ago\n a date was in the past / the time span of the date to the present.\n\n On January 1st, midnight, the returned string only indicates how many years\n ago the date was.\n \"\"\"\n # TODO, check if timezone is calculated right # pylint: disable=fixme\n d = dt.date()\n t = dt.time()\n if d.month == 1 and d.day == 1 and t.hour == 0 and t.minute == 0 and t.second == 0:\n return str(d.year)\n if dt.replace(tzinfo=None) >= datetime.now() - timedelta(days=1):\n timedifference = datetime.now() - dt.replace(tzinfo=None)\n minutes = int((timedifference.seconds / 60) % 60)\n hours = int(timedifference.seconds / 60 / 60)\n if hours == 0:\n return gettext('{minutes} minute(s) ago').format(minutes=minutes)\n return gettext('{hours} hour(s), {minutes} minute(s) ago').format(hours=hours, minutes=minutes)\n return format_date(dt)\n\n\ndef is_flask_run_cmdline():\n \"\"\"Check if the application was started using \"flask run\" command line\n\n Inspect the callstack.\n See https://github.com/pallets/flask/blob/master/src/flask/__main__.py\n\n Returns:\n bool: True if the application was started using \"flask run\".\n \"\"\"\n frames = inspect.stack()\n if len(frames) < 2:\n return False\n return frames[-2].filename.endswith('flask/cli.py')\n\n\nDEFAULT_GROUP_NAME = 'others'\n\n\ndef group_engines_in_tab(engines: Iterable[Engine]) -> List[Tuple[str, Iterable[Engine]]]:\n \"\"\"Groups an Iterable of engines by their first non tab category\"\"\"\n\n def get_group(eng):\n non_tab_categories = [\n c for c in eng.categories if c not in list(settings['categories_as_tabs'].keys()) + [OTHER_CATEGORY]\n ]\n return non_tab_categories[0] if len(non_tab_categories) > 0 else DEFAULT_GROUP_NAME\n\n groups = itertools.groupby(sorted(engines, key=get_group), get_group)\n\n def group_sort_key(group):\n return (group[0] == DEFAULT_GROUP_NAME, group[0].lower())\n\n sorted_groups = sorted(((name, list(engines)) for name, engines in groups), key=group_sort_key)\n\n def engine_sort_key(engine):\n return (engine.about.get('language', ''), engine.name)\n\n return [(groupname, sorted(engines, key=engine_sort_key)) for groupname, engines in sorted_groups]\n", "path": "searx/webutils.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nimport pathlib\nimport csv\nimport hashlib\nimport hmac\nimport re\nimport inspect\nimport itertools\nfrom datetime import datetime, timedelta\nfrom typing import Iterable, List, Tuple, Dict\n\nfrom io import StringIO\nfrom codecs import getincrementalencoder\n\nfrom flask_babel import gettext, format_date\n\nfrom searx import logger, settings\nfrom searx.engines import Engine, OTHER_CATEGORY\n\n\nVALID_LANGUAGE_CODE = re.compile(r'^[a-z]{2,3}(-[a-zA-Z]{2})?$')\n\nlogger = logger.getChild('webutils')\n\n\nclass UnicodeWriter:\n \"\"\"\n A CSV writer which will write rows to CSV file \"f\",\n which is encoded in the given encoding.\n \"\"\"\n\n def __init__(self, f, dialect=csv.excel, encoding=\"utf-8\", **kwds):\n # Redirect output to a queue\n self.queue = StringIO()\n self.writer = csv.writer(self.queue, dialect=dialect, **kwds)\n self.stream = f\n self.encoder = getincrementalencoder(encoding)()\n\n def writerow(self, row):\n self.writer.writerow(row)\n # Fetch UTF-8 output from the queue ...\n data = self.queue.getvalue()\n data = data.strip('\\x00')\n # ... and re-encode it into the target encoding\n data = self.encoder.encode(data)\n # write to the target stream\n self.stream.write(data.decode())\n # empty queue\n self.queue.truncate(0)\n\n def writerows(self, rows):\n for row in rows:\n self.writerow(row)\n\n\ndef get_themes(templates_path):\n \"\"\"Returns available themes list.\"\"\"\n return os.listdir(templates_path)\n\n\ndef get_hash_for_file(file: pathlib.Path) -> str:\n m = hashlib.sha1()\n with file.open('rb') as f:\n m.update(f.read())\n return m.hexdigest()\n\n\ndef get_static_files(static_path: str) -> Dict[str, str]:\n static_files: Dict[str, str] = {}\n static_path_path = pathlib.Path(static_path)\n\n def walk(path: pathlib.Path):\n for file in path.iterdir():\n if file.name.startswith('.'):\n # ignore hidden file\n continue\n if file.is_file():\n static_files[str(file.relative_to(static_path_path))] = get_hash_for_file(file)\n if file.is_dir() and file.name not in ('node_modules', 'src'):\n # ignore \"src\" and \"node_modules\" directories\n walk(file)\n\n walk(static_path_path)\n return static_files\n\n\ndef get_result_templates(templates_path):\n result_templates = set()\n templates_path_length = len(templates_path) + 1\n for directory, _, files in os.walk(templates_path):\n if directory.endswith('result_templates'):\n for filename in files:\n f = os.path.join(directory[templates_path_length:], filename)\n result_templates.add(f)\n return result_templates\n\n\ndef new_hmac(secret_key, url):\n return hmac.new(secret_key.encode(), url, hashlib.sha256).hexdigest()\n\n\ndef is_hmac_of(secret_key, value, hmac_to_check):\n hmac_of_value = new_hmac(secret_key, value)\n return len(hmac_of_value) == len(hmac_to_check) and hmac.compare_digest(hmac_of_value, hmac_to_check)\n\n\ndef prettify_url(url, max_length=74):\n if len(url) > max_length:\n chunk_len = int(max_length / 2 + 1)\n return '{0}[...]{1}'.format(url[:chunk_len], url[-chunk_len:])\n else:\n return url\n\n\ndef contains_cjko(s: str) -> bool:\n \"\"\"This function check whether or not a string contains Chinese, Japanese,\n or Korean characters. It employs regex and uses the u escape sequence to\n match any character in a set of Unicode ranges.\n\n Args:\n s (str): string to be checked.\n\n Returns:\n bool: True if the input s contains the characters and False otherwise.\n \"\"\"\n unicode_ranges = (\n '\\u4e00-\\u9fff' # Chinese characters\n '\\u3040-\\u309f' # Japanese hiragana\n '\\u30a0-\\u30ff' # Japanese katakana\n '\\u4e00-\\u9faf' # Japanese kanji\n '\\uac00-\\ud7af' # Korean hangul syllables\n '\\u1100-\\u11ff' # Korean hangul jamo\n )\n return bool(re.search(fr'[{unicode_ranges}]', s))\n\n\ndef regex_highlight_cjk(word: str) -> str:\n \"\"\"Generate the regex pattern to match for a given word according\n to whether or not the word contains CJK characters or not.\n If the word is and/or contains CJK character, the regex pattern\n will match standalone word by taking into account the presence\n of whitespace before and after it; if not, it will match any presence\n of the word throughout the text, ignoring the whitespace.\n\n Args:\n word (str): the word to be matched with regex pattern.\n\n Returns:\n str: the regex pattern for the word.\n \"\"\"\n rword = re.escape(word)\n if contains_cjko(rword):\n return fr'({rword})'\n else:\n return fr'\\b({rword})(?!\\w)'\n\n\ndef highlight_content(content, query):\n\n if not content:\n return None\n\n # ignoring html contents\n # TODO better html content detection\n if content.find('<') != -1:\n return content\n\n querysplit = query.split()\n queries = []\n for qs in querysplit:\n qs = qs.replace(\"'\", \"\").replace('\"', '').replace(\" \", \"\")\n if len(qs) > 0:\n queries.extend(re.findall(regex_highlight_cjk(qs), content, flags=re.I | re.U))\n if len(queries) > 0:\n for q in set(queries):\n content = re.sub(regex_highlight_cjk(q), f'<span class=\"highlight\">{q}</span>', content)\n return content\n\n\ndef searxng_l10n_timespan(dt: datetime) -> str: # pylint: disable=invalid-name\n \"\"\"Returns a human-readable and translated string indicating how long ago\n a date was in the past / the time span of the date to the present.\n\n On January 1st, midnight, the returned string only indicates how many years\n ago the date was.\n \"\"\"\n # TODO, check if timezone is calculated right # pylint: disable=fixme\n d = dt.date()\n t = dt.time()\n if d.month == 1 and d.day == 1 and t.hour == 0 and t.minute == 0 and t.second == 0:\n return str(d.year)\n if dt.replace(tzinfo=None) >= datetime.now() - timedelta(days=1):\n timedifference = datetime.now() - dt.replace(tzinfo=None)\n minutes = int((timedifference.seconds / 60) % 60)\n hours = int(timedifference.seconds / 60 / 60)\n if hours == 0:\n return gettext('{minutes} minute(s) ago').format(minutes=minutes)\n return gettext('{hours} hour(s), {minutes} minute(s) ago').format(hours=hours, minutes=minutes)\n return format_date(dt)\n\n\ndef is_flask_run_cmdline():\n \"\"\"Check if the application was started using \"flask run\" command line\n\n Inspect the callstack.\n See https://github.com/pallets/flask/blob/master/src/flask/__main__.py\n\n Returns:\n bool: True if the application was started using \"flask run\".\n \"\"\"\n frames = inspect.stack()\n if len(frames) < 2:\n return False\n return frames[-2].filename.endswith('flask/cli.py')\n\n\nDEFAULT_GROUP_NAME = 'others'\n\n\ndef group_engines_in_tab(engines: Iterable[Engine]) -> List[Tuple[str, Iterable[Engine]]]:\n \"\"\"Groups an Iterable of engines by their first non tab category\"\"\"\n\n def get_group(eng):\n non_tab_categories = [\n c for c in eng.categories if c not in list(settings['categories_as_tabs'].keys()) + [OTHER_CATEGORY]\n ]\n return non_tab_categories[0] if len(non_tab_categories) > 0 else DEFAULT_GROUP_NAME\n\n groups = itertools.groupby(sorted(engines, key=get_group), get_group)\n\n def group_sort_key(group):\n return (group[0] == DEFAULT_GROUP_NAME, group[0].lower())\n\n sorted_groups = sorted(((name, list(engines)) for name, engines in groups), key=group_sort_key)\n\n def engine_sort_key(engine):\n return (engine.about.get('language', ''), engine.name)\n\n return [(groupname, sorted(engines, key=engine_sort_key)) for groupname, engines in sorted_groups]\n", "path": "searx/webutils.py"}]}
| 3,137 | 852 |
gh_patches_debug_23663
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-17663
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`deploy_jar` attempts to build Java source files that do not exist in the package
Attempting to build a `deploy_jar` results in:
```
FileNotFoundError: [Errno 2] No such file or directory: '/Users/chrisjrn/src/pants/src/python/pants/jvm/jar_tool/src/java/org/pantsbuild/args4j'
```
Took a look through the unzipped pants wheel, and the relevant files are nowhere to be found.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/jvm/jar_tool/jar_tool.py`
Content:
```
1 # Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os
7 from dataclasses import dataclass
8 from enum import Enum, unique
9 from typing import Iterable, Mapping
10
11 import pkg_resources
12
13 from pants.base.glob_match_error_behavior import GlobMatchErrorBehavior
14 from pants.core.goals.generate_lockfiles import DEFAULT_TOOL_LOCKFILE, GenerateToolLockfileSentinel
15 from pants.engine.fs import (
16 CreateDigest,
17 Digest,
18 DigestEntries,
19 DigestSubset,
20 Directory,
21 FileContent,
22 FileEntry,
23 MergeDigests,
24 PathGlobs,
25 RemovePrefix,
26 )
27 from pants.engine.process import ProcessResult
28 from pants.engine.rules import Get, MultiGet, collect_rules, rule
29 from pants.engine.unions import UnionRule
30 from pants.jvm.jdk_rules import InternalJdk, JvmProcess
31 from pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest
32 from pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool
33 from pants.util.frozendict import FrozenDict
34 from pants.util.logging import LogLevel
35 from pants.util.meta import frozen_after_init
36 from pants.util.ordered_set import FrozenOrderedSet
37
38
39 @unique
40 class JarDuplicateAction(Enum):
41 SKIP = "skip"
42 REPLACE = "replace"
43 CONCAT = "concat"
44 CONCAT_TEXT = "concat_text"
45 THROW = "throw"
46
47
48 @dataclass(unsafe_hash=True)
49 @frozen_after_init
50 class JarToolRequest:
51 jar_name: str
52 digest: Digest
53 main_class: str | None
54 classpath_entries: tuple[str, ...]
55 manifest: str | None
56 jars: tuple[str, ...]
57 file_mappings: FrozenDict[str, str]
58 default_action: JarDuplicateAction | None
59 policies: tuple[tuple[str, JarDuplicateAction], ...]
60 skip: tuple[str, ...]
61 compress: bool
62 update: bool
63
64 def __init__(
65 self,
66 *,
67 jar_name: str,
68 digest: Digest,
69 main_class: str | None = None,
70 classpath_entries: Iterable[str] | None = None,
71 manifest: str | None = None,
72 jars: Iterable[str] | None = None,
73 file_mappings: Mapping[str, str] | None = None,
74 default_action: JarDuplicateAction | None = None,
75 policies: Iterable[tuple[str, str | JarDuplicateAction]] | None = None,
76 skip: Iterable[str] | None = None,
77 compress: bool = False,
78 update: bool = False,
79 ) -> None:
80 self.jar_name = jar_name
81 self.digest = digest
82 self.main_class = main_class
83 self.manifest = manifest
84 self.classpath_entries = tuple(classpath_entries or ())
85 self.jars = tuple(jars or ())
86 self.file_mappings = FrozenDict(file_mappings or {})
87 self.default_action = default_action
88 self.policies = tuple(JarToolRequest.__parse_policies(policies or ()))
89 self.skip = tuple(skip or ())
90 self.compress = compress
91 self.update = update
92
93 @staticmethod
94 def __parse_policies(
95 policies: Iterable[tuple[str, str | JarDuplicateAction]]
96 ) -> Iterable[tuple[str, JarDuplicateAction]]:
97 return [
98 (
99 pattern,
100 action
101 if isinstance(action, JarDuplicateAction)
102 else JarDuplicateAction(action.lower()),
103 )
104 for (pattern, action) in policies
105 ]
106
107
108 _JAR_TOOL_MAIN_CLASS = "org.pantsbuild.tools.jar.Main"
109
110
111 class JarToolGenerateLockfileSentinel(GenerateToolLockfileSentinel):
112 resolve_name = "jar_tool"
113
114
115 @dataclass(frozen=True)
116 class JarToolCompiledClassfiles:
117 digest: Digest
118
119
120 @rule
121 async def run_jar_tool(
122 request: JarToolRequest, jdk: InternalJdk, jar_tool: JarToolCompiledClassfiles
123 ) -> Digest:
124 output_prefix = "__out"
125 output_jarname = os.path.join(output_prefix, request.jar_name)
126
127 lockfile_request, empty_output_digest = await MultiGet(
128 Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),
129 Get(Digest, CreateDigest([Directory(output_prefix)])),
130 )
131
132 tool_classpath = await Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request))
133
134 toolcp_prefix = "__toolcp"
135 jartoolcp_prefix = "__jartoolcp"
136 input_prefix = "__in"
137 immutable_input_digests = {
138 toolcp_prefix: tool_classpath.digest,
139 jartoolcp_prefix: jar_tool.digest,
140 input_prefix: request.digest,
141 }
142
143 policies = ",".join(
144 f"{pattern}={action.value.upper()}" for (pattern, action) in request.policies
145 )
146 file_mappings = ",".join(
147 f"{os.path.join(input_prefix, fs_path)}={jar_path}"
148 for fs_path, jar_path in request.file_mappings.items()
149 )
150
151 tool_process = JvmProcess(
152 jdk=jdk,
153 argv=[
154 _JAR_TOOL_MAIN_CLASS,
155 output_jarname,
156 *((f"-main={request.main_class}",) if request.main_class else ()),
157 *(
158 (f"-classpath={','.join(request.classpath_entries)}",)
159 if request.classpath_entries
160 else ()
161 ),
162 *(
163 (f"-manifest={os.path.join(input_prefix, request.manifest)}",)
164 if request.manifest
165 else ()
166 ),
167 *(
168 (f"-jars={','.join([os.path.join(input_prefix, jar) for jar in request.jars])}",)
169 if request.jars
170 else ()
171 ),
172 *((f"-files={file_mappings}",) if file_mappings else ()),
173 *(
174 (f"-default_action={request.default_action.value.upper()}",)
175 if request.default_action
176 else ()
177 ),
178 *((f"-policies={policies}",) if policies else ()),
179 *((f"-skip={','.join(request.skip)}",) if request.skip else ()),
180 *(("-compress",) if request.compress else ()),
181 *(("-update",) if request.update else ()),
182 ],
183 classpath_entries=[*tool_classpath.classpath_entries(toolcp_prefix), jartoolcp_prefix],
184 input_digest=empty_output_digest,
185 extra_immutable_input_digests=immutable_input_digests,
186 extra_nailgun_keys=immutable_input_digests.keys(),
187 description=f"Building jar {request.jar_name}",
188 output_directories=(output_prefix,),
189 level=LogLevel.DEBUG,
190 )
191
192 result = await Get(ProcessResult, JvmProcess, tool_process)
193 return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))
194
195
196 _JAR_TOOL_SRC_PACKAGES = ["org.pantsbuild.args4j", "org.pantsbuild.tools.jar"]
197
198
199 def _load_jar_tool_sources() -> list[FileContent]:
200 result = []
201 for package in _JAR_TOOL_SRC_PACKAGES:
202 pkg_path = package.replace(".", os.path.sep)
203 relative_folder = os.path.join("src", pkg_path)
204 for basename in pkg_resources.resource_listdir(__name__, relative_folder):
205 result.append(
206 FileContent(
207 path=os.path.join(pkg_path, basename),
208 content=pkg_resources.resource_string(
209 __name__, os.path.join(relative_folder, basename)
210 ),
211 )
212 )
213 return result
214
215
216 # TODO(13879): Consolidate compilation of wrapper binaries to common rules.
217 @rule
218 async def build_jar_tool(jdk: InternalJdk) -> JarToolCompiledClassfiles:
219 lockfile_request, source_digest = await MultiGet(
220 Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),
221 Get(
222 Digest,
223 CreateDigest(_load_jar_tool_sources()),
224 ),
225 )
226
227 dest_dir = "classfiles"
228 materialized_classpath, java_subset_digest, empty_dest_dir = await MultiGet(
229 Get(ToolClasspath, ToolClasspathRequest(prefix="__toolcp", lockfile=lockfile_request)),
230 Get(
231 Digest,
232 DigestSubset(
233 source_digest,
234 PathGlobs(
235 ["**/*.java"],
236 glob_match_error_behavior=GlobMatchErrorBehavior.error,
237 description_of_origin="jar tool sources",
238 ),
239 ),
240 ),
241 Get(Digest, CreateDigest([Directory(path=dest_dir)])),
242 )
243
244 merged_digest, src_entries = await MultiGet(
245 Get(
246 Digest,
247 MergeDigests([materialized_classpath.digest, source_digest, empty_dest_dir]),
248 ),
249 Get(DigestEntries, Digest, java_subset_digest),
250 )
251
252 compile_result = await Get(
253 ProcessResult,
254 JvmProcess(
255 jdk=jdk,
256 classpath_entries=[f"{jdk.java_home}/lib/tools.jar"],
257 argv=[
258 "com.sun.tools.javac.Main",
259 "-cp",
260 ":".join(materialized_classpath.classpath_entries()),
261 "-d",
262 dest_dir,
263 *[entry.path for entry in src_entries if isinstance(entry, FileEntry)],
264 ],
265 input_digest=merged_digest,
266 output_directories=(dest_dir,),
267 description="Compile jar-tool sources using javac.",
268 level=LogLevel.DEBUG,
269 use_nailgun=False,
270 ),
271 )
272
273 stripped_classfiles_digest = await Get(
274 Digest, RemovePrefix(compile_result.output_digest, dest_dir)
275 )
276 return JarToolCompiledClassfiles(digest=stripped_classfiles_digest)
277
278
279 @rule
280 async def generate_jartool_lockfile_request(
281 _: JarToolGenerateLockfileSentinel,
282 ) -> GenerateJvmLockfileFromTool:
283 return GenerateJvmLockfileFromTool(
284 artifact_inputs=FrozenOrderedSet(
285 {
286 "args4j:args4j:2.33",
287 "com.google.code.findbugs:jsr305:3.0.2",
288 "com.google.guava:guava:18.0",
289 }
290 ),
291 artifact_option_name="n/a",
292 lockfile_option_name="n/a",
293 resolve_name=JarToolGenerateLockfileSentinel.resolve_name,
294 read_lockfile_dest=DEFAULT_TOOL_LOCKFILE,
295 write_lockfile_dest="src/python/pants/jvm/jar_tool/jar_tool.lock",
296 default_lockfile_resource=("pants.jvm.jar_tool", "jar_tool.lock"),
297 )
298
299
300 def rules():
301 return [
302 *collect_rules(),
303 UnionRule(GenerateToolLockfileSentinel, JarToolGenerateLockfileSentinel),
304 ]
305
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/jvm/jar_tool/jar_tool.py b/src/python/pants/jvm/jar_tool/jar_tool.py
--- a/src/python/pants/jvm/jar_tool/jar_tool.py
+++ b/src/python/pants/jvm/jar_tool/jar_tool.py
@@ -193,20 +193,20 @@
return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))
-_JAR_TOOL_SRC_PACKAGES = ["org.pantsbuild.args4j", "org.pantsbuild.tools.jar"]
+_JAR_TOOL_SRC_PACKAGES = ["args4j", "jar_tool_source"]
def _load_jar_tool_sources() -> list[FileContent]:
result = []
for package in _JAR_TOOL_SRC_PACKAGES:
- pkg_path = package.replace(".", os.path.sep)
- relative_folder = os.path.join("src", pkg_path)
- for basename in pkg_resources.resource_listdir(__name__, relative_folder):
+ # pkg_path = package.replace(".", os.path.sep)
+ # relative_folder = os.path.join("src", pkg_path)
+ for basename in pkg_resources.resource_listdir(__name__, package):
result.append(
FileContent(
- path=os.path.join(pkg_path, basename),
+ path=os.path.join(package, basename),
content=pkg_resources.resource_string(
- __name__, os.path.join(relative_folder, basename)
+ __name__, os.path.join(package, basename)
),
)
)
|
{"golden_diff": "diff --git a/src/python/pants/jvm/jar_tool/jar_tool.py b/src/python/pants/jvm/jar_tool/jar_tool.py\n--- a/src/python/pants/jvm/jar_tool/jar_tool.py\n+++ b/src/python/pants/jvm/jar_tool/jar_tool.py\n@@ -193,20 +193,20 @@\n return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))\n \n \n-_JAR_TOOL_SRC_PACKAGES = [\"org.pantsbuild.args4j\", \"org.pantsbuild.tools.jar\"]\n+_JAR_TOOL_SRC_PACKAGES = [\"args4j\", \"jar_tool_source\"]\n \n \n def _load_jar_tool_sources() -> list[FileContent]:\n result = []\n for package in _JAR_TOOL_SRC_PACKAGES:\n- pkg_path = package.replace(\".\", os.path.sep)\n- relative_folder = os.path.join(\"src\", pkg_path)\n- for basename in pkg_resources.resource_listdir(__name__, relative_folder):\n+ # pkg_path = package.replace(\".\", os.path.sep)\n+ # relative_folder = os.path.join(\"src\", pkg_path)\n+ for basename in pkg_resources.resource_listdir(__name__, package):\n result.append(\n FileContent(\n- path=os.path.join(pkg_path, basename),\n+ path=os.path.join(package, basename),\n content=pkg_resources.resource_string(\n- __name__, os.path.join(relative_folder, basename)\n+ __name__, os.path.join(package, basename)\n ),\n )\n )\n", "issue": "`deploy_jar` attempts to build Java source files that do not exist in the package\nAttempting to build a `deploy_jar` results in:\r\n\r\n```\r\nFileNotFoundError: [Errno 2] No such file or directory: '/Users/chrisjrn/src/pants/src/python/pants/jvm/jar_tool/src/java/org/pantsbuild/args4j'\r\n```\r\n\r\nTook a look through the unzipped pants wheel, and the relevant files are nowhere to be found.\n", "before_files": [{"content": "# Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nfrom dataclasses import dataclass\nfrom enum import Enum, unique\nfrom typing import Iterable, Mapping\n\nimport pkg_resources\n\nfrom pants.base.glob_match_error_behavior import GlobMatchErrorBehavior\nfrom pants.core.goals.generate_lockfiles import DEFAULT_TOOL_LOCKFILE, GenerateToolLockfileSentinel\nfrom pants.engine.fs import (\n CreateDigest,\n Digest,\n DigestEntries,\n DigestSubset,\n Directory,\n FileContent,\n FileEntry,\n MergeDigests,\n PathGlobs,\n RemovePrefix,\n)\nfrom pants.engine.process import ProcessResult\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.jdk_rules import InternalJdk, JvmProcess\nfrom pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\nfrom pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\nfrom pants.util.frozendict import FrozenDict\nfrom pants.util.logging import LogLevel\nfrom pants.util.meta import frozen_after_init\nfrom pants.util.ordered_set import FrozenOrderedSet\n\n\n@unique\nclass JarDuplicateAction(Enum):\n SKIP = \"skip\"\n REPLACE = \"replace\"\n CONCAT = \"concat\"\n CONCAT_TEXT = \"concat_text\"\n THROW = \"throw\"\n\n\n@dataclass(unsafe_hash=True)\n@frozen_after_init\nclass JarToolRequest:\n jar_name: str\n digest: Digest\n main_class: str | None\n classpath_entries: tuple[str, ...]\n manifest: str | None\n jars: tuple[str, ...]\n file_mappings: FrozenDict[str, str]\n default_action: JarDuplicateAction | None\n policies: tuple[tuple[str, JarDuplicateAction], ...]\n skip: tuple[str, ...]\n compress: bool\n update: bool\n\n def __init__(\n self,\n *,\n jar_name: str,\n digest: Digest,\n main_class: str | None = None,\n classpath_entries: Iterable[str] | None = None,\n manifest: str | None = None,\n jars: Iterable[str] | None = None,\n file_mappings: Mapping[str, str] | None = None,\n default_action: JarDuplicateAction | None = None,\n policies: Iterable[tuple[str, str | JarDuplicateAction]] | None = None,\n skip: Iterable[str] | None = None,\n compress: bool = False,\n update: bool = False,\n ) -> None:\n self.jar_name = jar_name\n self.digest = digest\n self.main_class = main_class\n self.manifest = manifest\n self.classpath_entries = tuple(classpath_entries or ())\n self.jars = tuple(jars or ())\n self.file_mappings = FrozenDict(file_mappings or {})\n self.default_action = default_action\n self.policies = tuple(JarToolRequest.__parse_policies(policies or ()))\n self.skip = tuple(skip or ())\n self.compress = compress\n self.update = update\n\n @staticmethod\n def __parse_policies(\n policies: Iterable[tuple[str, str | JarDuplicateAction]]\n ) -> Iterable[tuple[str, JarDuplicateAction]]:\n return [\n (\n pattern,\n action\n if isinstance(action, JarDuplicateAction)\n else JarDuplicateAction(action.lower()),\n )\n for (pattern, action) in policies\n ]\n\n\n_JAR_TOOL_MAIN_CLASS = \"org.pantsbuild.tools.jar.Main\"\n\n\nclass JarToolGenerateLockfileSentinel(GenerateToolLockfileSentinel):\n resolve_name = \"jar_tool\"\n\n\n@dataclass(frozen=True)\nclass JarToolCompiledClassfiles:\n digest: Digest\n\n\n@rule\nasync def run_jar_tool(\n request: JarToolRequest, jdk: InternalJdk, jar_tool: JarToolCompiledClassfiles\n) -> Digest:\n output_prefix = \"__out\"\n output_jarname = os.path.join(output_prefix, request.jar_name)\n\n lockfile_request, empty_output_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(Digest, CreateDigest([Directory(output_prefix)])),\n )\n\n tool_classpath = await Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request))\n\n toolcp_prefix = \"__toolcp\"\n jartoolcp_prefix = \"__jartoolcp\"\n input_prefix = \"__in\"\n immutable_input_digests = {\n toolcp_prefix: tool_classpath.digest,\n jartoolcp_prefix: jar_tool.digest,\n input_prefix: request.digest,\n }\n\n policies = \",\".join(\n f\"{pattern}={action.value.upper()}\" for (pattern, action) in request.policies\n )\n file_mappings = \",\".join(\n f\"{os.path.join(input_prefix, fs_path)}={jar_path}\"\n for fs_path, jar_path in request.file_mappings.items()\n )\n\n tool_process = JvmProcess(\n jdk=jdk,\n argv=[\n _JAR_TOOL_MAIN_CLASS,\n output_jarname,\n *((f\"-main={request.main_class}\",) if request.main_class else ()),\n *(\n (f\"-classpath={','.join(request.classpath_entries)}\",)\n if request.classpath_entries\n else ()\n ),\n *(\n (f\"-manifest={os.path.join(input_prefix, request.manifest)}\",)\n if request.manifest\n else ()\n ),\n *(\n (f\"-jars={','.join([os.path.join(input_prefix, jar) for jar in request.jars])}\",)\n if request.jars\n else ()\n ),\n *((f\"-files={file_mappings}\",) if file_mappings else ()),\n *(\n (f\"-default_action={request.default_action.value.upper()}\",)\n if request.default_action\n else ()\n ),\n *((f\"-policies={policies}\",) if policies else ()),\n *((f\"-skip={','.join(request.skip)}\",) if request.skip else ()),\n *((\"-compress\",) if request.compress else ()),\n *((\"-update\",) if request.update else ()),\n ],\n classpath_entries=[*tool_classpath.classpath_entries(toolcp_prefix), jartoolcp_prefix],\n input_digest=empty_output_digest,\n extra_immutable_input_digests=immutable_input_digests,\n extra_nailgun_keys=immutable_input_digests.keys(),\n description=f\"Building jar {request.jar_name}\",\n output_directories=(output_prefix,),\n level=LogLevel.DEBUG,\n )\n\n result = await Get(ProcessResult, JvmProcess, tool_process)\n return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))\n\n\n_JAR_TOOL_SRC_PACKAGES = [\"org.pantsbuild.args4j\", \"org.pantsbuild.tools.jar\"]\n\n\ndef _load_jar_tool_sources() -> list[FileContent]:\n result = []\n for package in _JAR_TOOL_SRC_PACKAGES:\n pkg_path = package.replace(\".\", os.path.sep)\n relative_folder = os.path.join(\"src\", pkg_path)\n for basename in pkg_resources.resource_listdir(__name__, relative_folder):\n result.append(\n FileContent(\n path=os.path.join(pkg_path, basename),\n content=pkg_resources.resource_string(\n __name__, os.path.join(relative_folder, basename)\n ),\n )\n )\n return result\n\n\n# TODO(13879): Consolidate compilation of wrapper binaries to common rules.\n@rule\nasync def build_jar_tool(jdk: InternalJdk) -> JarToolCompiledClassfiles:\n lockfile_request, source_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(\n Digest,\n CreateDigest(_load_jar_tool_sources()),\n ),\n )\n\n dest_dir = \"classfiles\"\n materialized_classpath, java_subset_digest, empty_dest_dir = await MultiGet(\n Get(ToolClasspath, ToolClasspathRequest(prefix=\"__toolcp\", lockfile=lockfile_request)),\n Get(\n Digest,\n DigestSubset(\n source_digest,\n PathGlobs(\n [\"**/*.java\"],\n glob_match_error_behavior=GlobMatchErrorBehavior.error,\n description_of_origin=\"jar tool sources\",\n ),\n ),\n ),\n Get(Digest, CreateDigest([Directory(path=dest_dir)])),\n )\n\n merged_digest, src_entries = await MultiGet(\n Get(\n Digest,\n MergeDigests([materialized_classpath.digest, source_digest, empty_dest_dir]),\n ),\n Get(DigestEntries, Digest, java_subset_digest),\n )\n\n compile_result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=[f\"{jdk.java_home}/lib/tools.jar\"],\n argv=[\n \"com.sun.tools.javac.Main\",\n \"-cp\",\n \":\".join(materialized_classpath.classpath_entries()),\n \"-d\",\n dest_dir,\n *[entry.path for entry in src_entries if isinstance(entry, FileEntry)],\n ],\n input_digest=merged_digest,\n output_directories=(dest_dir,),\n description=\"Compile jar-tool sources using javac.\",\n level=LogLevel.DEBUG,\n use_nailgun=False,\n ),\n )\n\n stripped_classfiles_digest = await Get(\n Digest, RemovePrefix(compile_result.output_digest, dest_dir)\n )\n return JarToolCompiledClassfiles(digest=stripped_classfiles_digest)\n\n\n@rule\nasync def generate_jartool_lockfile_request(\n _: JarToolGenerateLockfileSentinel,\n) -> GenerateJvmLockfileFromTool:\n return GenerateJvmLockfileFromTool(\n artifact_inputs=FrozenOrderedSet(\n {\n \"args4j:args4j:2.33\",\n \"com.google.code.findbugs:jsr305:3.0.2\",\n \"com.google.guava:guava:18.0\",\n }\n ),\n artifact_option_name=\"n/a\",\n lockfile_option_name=\"n/a\",\n resolve_name=JarToolGenerateLockfileSentinel.resolve_name,\n read_lockfile_dest=DEFAULT_TOOL_LOCKFILE,\n write_lockfile_dest=\"src/python/pants/jvm/jar_tool/jar_tool.lock\",\n default_lockfile_resource=(\"pants.jvm.jar_tool\", \"jar_tool.lock\"),\n )\n\n\ndef rules():\n return [\n *collect_rules(),\n UnionRule(GenerateToolLockfileSentinel, JarToolGenerateLockfileSentinel),\n ]\n", "path": "src/python/pants/jvm/jar_tool/jar_tool.py"}], "after_files": [{"content": "# Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nfrom dataclasses import dataclass\nfrom enum import Enum, unique\nfrom typing import Iterable, Mapping\n\nimport pkg_resources\n\nfrom pants.base.glob_match_error_behavior import GlobMatchErrorBehavior\nfrom pants.core.goals.generate_lockfiles import DEFAULT_TOOL_LOCKFILE, GenerateToolLockfileSentinel\nfrom pants.engine.fs import (\n CreateDigest,\n Digest,\n DigestEntries,\n DigestSubset,\n Directory,\n FileContent,\n FileEntry,\n MergeDigests,\n PathGlobs,\n RemovePrefix,\n)\nfrom pants.engine.process import ProcessResult\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.jdk_rules import InternalJdk, JvmProcess\nfrom pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\nfrom pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\nfrom pants.util.frozendict import FrozenDict\nfrom pants.util.logging import LogLevel\nfrom pants.util.meta import frozen_after_init\nfrom pants.util.ordered_set import FrozenOrderedSet\n\n\n@unique\nclass JarDuplicateAction(Enum):\n SKIP = \"skip\"\n REPLACE = \"replace\"\n CONCAT = \"concat\"\n CONCAT_TEXT = \"concat_text\"\n THROW = \"throw\"\n\n\n@dataclass(unsafe_hash=True)\n@frozen_after_init\nclass JarToolRequest:\n jar_name: str\n digest: Digest\n main_class: str | None\n classpath_entries: tuple[str, ...]\n manifest: str | None\n jars: tuple[str, ...]\n file_mappings: FrozenDict[str, str]\n default_action: JarDuplicateAction | None\n policies: tuple[tuple[str, JarDuplicateAction], ...]\n skip: tuple[str, ...]\n compress: bool\n update: bool\n\n def __init__(\n self,\n *,\n jar_name: str,\n digest: Digest,\n main_class: str | None = None,\n classpath_entries: Iterable[str] | None = None,\n manifest: str | None = None,\n jars: Iterable[str] | None = None,\n file_mappings: Mapping[str, str] | None = None,\n default_action: JarDuplicateAction | None = None,\n policies: Iterable[tuple[str, str | JarDuplicateAction]] | None = None,\n skip: Iterable[str] | None = None,\n compress: bool = False,\n update: bool = False,\n ) -> None:\n self.jar_name = jar_name\n self.digest = digest\n self.main_class = main_class\n self.manifest = manifest\n self.classpath_entries = tuple(classpath_entries or ())\n self.jars = tuple(jars or ())\n self.file_mappings = FrozenDict(file_mappings or {})\n self.default_action = default_action\n self.policies = tuple(JarToolRequest.__parse_policies(policies or ()))\n self.skip = tuple(skip or ())\n self.compress = compress\n self.update = update\n\n @staticmethod\n def __parse_policies(\n policies: Iterable[tuple[str, str | JarDuplicateAction]]\n ) -> Iterable[tuple[str, JarDuplicateAction]]:\n return [\n (\n pattern,\n action\n if isinstance(action, JarDuplicateAction)\n else JarDuplicateAction(action.lower()),\n )\n for (pattern, action) in policies\n ]\n\n\n_JAR_TOOL_MAIN_CLASS = \"org.pantsbuild.tools.jar.Main\"\n\n\nclass JarToolGenerateLockfileSentinel(GenerateToolLockfileSentinel):\n resolve_name = \"jar_tool\"\n\n\n@dataclass(frozen=True)\nclass JarToolCompiledClassfiles:\n digest: Digest\n\n\n@rule\nasync def run_jar_tool(\n request: JarToolRequest, jdk: InternalJdk, jar_tool: JarToolCompiledClassfiles\n) -> Digest:\n output_prefix = \"__out\"\n output_jarname = os.path.join(output_prefix, request.jar_name)\n\n lockfile_request, empty_output_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(Digest, CreateDigest([Directory(output_prefix)])),\n )\n\n tool_classpath = await Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request))\n\n toolcp_prefix = \"__toolcp\"\n jartoolcp_prefix = \"__jartoolcp\"\n input_prefix = \"__in\"\n immutable_input_digests = {\n toolcp_prefix: tool_classpath.digest,\n jartoolcp_prefix: jar_tool.digest,\n input_prefix: request.digest,\n }\n\n policies = \",\".join(\n f\"{pattern}={action.value.upper()}\" for (pattern, action) in request.policies\n )\n file_mappings = \",\".join(\n f\"{os.path.join(input_prefix, fs_path)}={jar_path}\"\n for fs_path, jar_path in request.file_mappings.items()\n )\n\n tool_process = JvmProcess(\n jdk=jdk,\n argv=[\n _JAR_TOOL_MAIN_CLASS,\n output_jarname,\n *((f\"-main={request.main_class}\",) if request.main_class else ()),\n *(\n (f\"-classpath={','.join(request.classpath_entries)}\",)\n if request.classpath_entries\n else ()\n ),\n *(\n (f\"-manifest={os.path.join(input_prefix, request.manifest)}\",)\n if request.manifest\n else ()\n ),\n *(\n (f\"-jars={','.join([os.path.join(input_prefix, jar) for jar in request.jars])}\",)\n if request.jars\n else ()\n ),\n *((f\"-files={file_mappings}\",) if file_mappings else ()),\n *(\n (f\"-default_action={request.default_action.value.upper()}\",)\n if request.default_action\n else ()\n ),\n *((f\"-policies={policies}\",) if policies else ()),\n *((f\"-skip={','.join(request.skip)}\",) if request.skip else ()),\n *((\"-compress\",) if request.compress else ()),\n *((\"-update\",) if request.update else ()),\n ],\n classpath_entries=[*tool_classpath.classpath_entries(toolcp_prefix), jartoolcp_prefix],\n input_digest=empty_output_digest,\n extra_immutable_input_digests=immutable_input_digests,\n extra_nailgun_keys=immutable_input_digests.keys(),\n description=f\"Building jar {request.jar_name}\",\n output_directories=(output_prefix,),\n level=LogLevel.DEBUG,\n )\n\n result = await Get(ProcessResult, JvmProcess, tool_process)\n return await Get(Digest, RemovePrefix(result.output_digest, output_prefix))\n\n\n_JAR_TOOL_SRC_PACKAGES = [\"args4j\", \"jar_tool_source\"]\n\n\ndef _load_jar_tool_sources() -> list[FileContent]:\n result = []\n for package in _JAR_TOOL_SRC_PACKAGES:\n # pkg_path = package.replace(\".\", os.path.sep)\n # relative_folder = os.path.join(\"src\", pkg_path)\n for basename in pkg_resources.resource_listdir(__name__, package):\n result.append(\n FileContent(\n path=os.path.join(package, basename),\n content=pkg_resources.resource_string(\n __name__, os.path.join(package, basename)\n ),\n )\n )\n return result\n\n\n# TODO(13879): Consolidate compilation of wrapper binaries to common rules.\n@rule\nasync def build_jar_tool(jdk: InternalJdk) -> JarToolCompiledClassfiles:\n lockfile_request, source_digest = await MultiGet(\n Get(GenerateJvmLockfileFromTool, JarToolGenerateLockfileSentinel()),\n Get(\n Digest,\n CreateDigest(_load_jar_tool_sources()),\n ),\n )\n\n dest_dir = \"classfiles\"\n materialized_classpath, java_subset_digest, empty_dest_dir = await MultiGet(\n Get(ToolClasspath, ToolClasspathRequest(prefix=\"__toolcp\", lockfile=lockfile_request)),\n Get(\n Digest,\n DigestSubset(\n source_digest,\n PathGlobs(\n [\"**/*.java\"],\n glob_match_error_behavior=GlobMatchErrorBehavior.error,\n description_of_origin=\"jar tool sources\",\n ),\n ),\n ),\n Get(Digest, CreateDigest([Directory(path=dest_dir)])),\n )\n\n merged_digest, src_entries = await MultiGet(\n Get(\n Digest,\n MergeDigests([materialized_classpath.digest, source_digest, empty_dest_dir]),\n ),\n Get(DigestEntries, Digest, java_subset_digest),\n )\n\n compile_result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=[f\"{jdk.java_home}/lib/tools.jar\"],\n argv=[\n \"com.sun.tools.javac.Main\",\n \"-cp\",\n \":\".join(materialized_classpath.classpath_entries()),\n \"-d\",\n dest_dir,\n *[entry.path for entry in src_entries if isinstance(entry, FileEntry)],\n ],\n input_digest=merged_digest,\n output_directories=(dest_dir,),\n description=\"Compile jar-tool sources using javac.\",\n level=LogLevel.DEBUG,\n use_nailgun=False,\n ),\n )\n\n stripped_classfiles_digest = await Get(\n Digest, RemovePrefix(compile_result.output_digest, dest_dir)\n )\n return JarToolCompiledClassfiles(digest=stripped_classfiles_digest)\n\n\n@rule\nasync def generate_jartool_lockfile_request(\n _: JarToolGenerateLockfileSentinel,\n) -> GenerateJvmLockfileFromTool:\n return GenerateJvmLockfileFromTool(\n artifact_inputs=FrozenOrderedSet(\n {\n \"args4j:args4j:2.33\",\n \"com.google.code.findbugs:jsr305:3.0.2\",\n \"com.google.guava:guava:18.0\",\n }\n ),\n artifact_option_name=\"n/a\",\n lockfile_option_name=\"n/a\",\n resolve_name=JarToolGenerateLockfileSentinel.resolve_name,\n read_lockfile_dest=DEFAULT_TOOL_LOCKFILE,\n write_lockfile_dest=\"src/python/pants/jvm/jar_tool/jar_tool.lock\",\n default_lockfile_resource=(\"pants.jvm.jar_tool\", \"jar_tool.lock\"),\n )\n\n\ndef rules():\n return [\n *collect_rules(),\n UnionRule(GenerateToolLockfileSentinel, JarToolGenerateLockfileSentinel),\n ]\n", "path": "src/python/pants/jvm/jar_tool/jar_tool.py"}]}
| 3,457 | 324 |
gh_patches_debug_27381
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1985
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Regression using mutable default values in arguments.
<!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
Prior to v0.115
```python
@strawberry.input
class Options:
flag: str = ''
@strawberry.type
class Query:
@strawberry.field
def field(self, x: list[str] = [], y: Options = {}) -> str:
return f'{x} {y}'
```
would correctly resolve to
```graphql
type Query {
field(x: [String!]! = [], y: Options! = {}): String!
}
```
As of v0.115 it raises
```python
File "lib/python3.10/site-packages/strawberry/types/fields/resolver.py", line 87, in find
resolver._resolved_annotations[parameter] = resolved_annotation
File "/lib/python3.10/inspect.py", line 2740, in __hash__
return hash((self.name, self.kind, self.annotation, self.default))
TypeError: unhashable type: 'list'
```
For lists, there is a workaround to use a tuple instead, but it's not ideal because GraphQL type coercion will correctly supply a list. For objects, there's no clean workaround; one would have to use the equivalent of a `frozendict`.
## System Information
- Strawberry version 0.115
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/types/fields/resolver.py`
Content:
```
1 from __future__ import annotations as _
2
3 import builtins
4 import inspect
5 import sys
6 import warnings
7 from inspect import isasyncgenfunction, iscoroutinefunction
8 from typing import ( # type: ignore[attr-defined]
9 Any,
10 Callable,
11 Dict,
12 ForwardRef,
13 Generic,
14 List,
15 Mapping,
16 NamedTuple,
17 Optional,
18 Tuple,
19 Type,
20 TypeVar,
21 Union,
22 _eval_type,
23 )
24
25 from backports.cached_property import cached_property
26 from typing_extensions import Annotated, Protocol, get_args, get_origin
27
28 from strawberry.annotation import StrawberryAnnotation
29 from strawberry.arguments import StrawberryArgument
30 from strawberry.exceptions import MissingArgumentsAnnotationsError
31 from strawberry.type import StrawberryType
32 from strawberry.types.info import Info
33
34
35 class ReservedParameterSpecification(Protocol):
36 def find(
37 self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
38 ) -> Optional[inspect.Parameter]:
39 """Finds the reserved parameter from ``parameters``."""
40
41
42 class ReservedName(NamedTuple):
43 name: str
44
45 def find(
46 self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver
47 ) -> Optional[inspect.Parameter]:
48 return next((p for p in parameters if p.name == self.name), None)
49
50
51 class ReservedNameBoundParameter(NamedTuple):
52 name: str
53
54 def find(
55 self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver
56 ) -> Optional[inspect.Parameter]:
57 if parameters: # Add compatibility for resolvers with no arguments
58 first_parameter = parameters[0]
59 return first_parameter if first_parameter.name == self.name else None
60 else:
61 return None
62
63
64 class ReservedType(NamedTuple):
65 """Define a reserved type by name or by type.
66
67 To preserve backwards-comaptibility, if an annotation was defined but does not match
68 :attr:`type`, then the name is used as a fallback.
69 """
70
71 name: str
72 type: Type
73
74 def find(
75 self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
76 ) -> Optional[inspect.Parameter]:
77 for parameter in parameters:
78 annotation = parameter.annotation
79 try:
80 resolved_annotation = _eval_type(
81 ForwardRef(annotation)
82 if isinstance(annotation, str)
83 else annotation,
84 resolver._namespace,
85 None,
86 )
87 resolver._resolved_annotations[parameter] = resolved_annotation
88 except NameError:
89 # Type-annotation could not be resolved
90 resolved_annotation = annotation
91 if self.is_reserved_type(resolved_annotation):
92 return parameter
93
94 # Fallback to matching by name
95 reserved_name = ReservedName(name=self.name).find(parameters, resolver)
96 if reserved_name:
97 warning = DeprecationWarning(
98 f"Argument name-based matching of '{self.name}' is deprecated and will "
99 "be removed in v1.0. Ensure that reserved arguments are annotated "
100 "their respective types (i.e. use value: 'DirectiveValue[str]' instead "
101 "of 'value: str' and 'info: Info' instead of a plain 'info')."
102 )
103 warnings.warn(warning)
104 return reserved_name
105 else:
106 return None
107
108 def is_reserved_type(self, other: Type) -> bool:
109 if get_origin(other) is Annotated:
110 # Handle annotated arguments such as Private[str] and DirectiveValue[str]
111 return any(isinstance(argument, self.type) for argument in get_args(other))
112 else:
113 # Handle both concrete and generic types (i.e Info, and Info[Any, Any])
114 return other is self.type or get_origin(other) is self.type
115
116
117 SELF_PARAMSPEC = ReservedNameBoundParameter("self")
118 CLS_PARAMSPEC = ReservedNameBoundParameter("cls")
119 ROOT_PARAMSPEC = ReservedName("root")
120 INFO_PARAMSPEC = ReservedType("info", Info)
121
122 T = TypeVar("T")
123
124
125 class StrawberryResolver(Generic[T]):
126
127 RESERVED_PARAMSPEC: Tuple[ReservedParameterSpecification, ...] = (
128 SELF_PARAMSPEC,
129 CLS_PARAMSPEC,
130 ROOT_PARAMSPEC,
131 INFO_PARAMSPEC,
132 )
133
134 def __init__(
135 self,
136 func: Union[Callable[..., T], staticmethod, classmethod],
137 *,
138 description: Optional[str] = None,
139 type_override: Optional[Union[StrawberryType, type]] = None,
140 ):
141 self.wrapped_func = func
142 self._description = description
143 self._type_override = type_override
144 """Specify the type manually instead of calculating from wrapped func
145
146 This is used when creating copies of types w/ generics
147 """
148 self._resolved_annotations: Dict[inspect.Parameter, Any] = {}
149 """Populated during reserved parameter determination.
150
151 Caching resolved annotations this way prevents evaling them repeatedly.
152 """
153
154 # TODO: Use this when doing the actual resolving? How to deal with async resolvers?
155 def __call__(self, *args, **kwargs) -> T:
156 if not callable(self.wrapped_func):
157 raise UncallableResolverError(self)
158 return self.wrapped_func(*args, **kwargs)
159
160 @cached_property
161 def signature(self) -> inspect.Signature:
162 return inspect.signature(self._unbound_wrapped_func)
163
164 @cached_property
165 def reserved_parameters(
166 self,
167 ) -> Dict[ReservedParameterSpecification, Optional[inspect.Parameter]]:
168 """Mapping of reserved parameter specification to parameter."""
169 parameters = tuple(self.signature.parameters.values())
170 return {spec: spec.find(parameters, self) for spec in self.RESERVED_PARAMSPEC}
171
172 @cached_property
173 def arguments(self) -> List[StrawberryArgument]:
174 """Resolver arguments exposed in the GraphQL Schema."""
175 parameters = self.signature.parameters.values()
176 reserved_parameters = set(self.reserved_parameters.values())
177
178 missing_annotations = set()
179 arguments = []
180 user_parameters = (p for p in parameters if p not in reserved_parameters)
181 for param in user_parameters:
182 annotation = self._resolved_annotations.get(param, param.annotation)
183 if annotation is inspect.Signature.empty:
184 missing_annotations.add(param.name)
185 else:
186 argument = StrawberryArgument(
187 python_name=param.name,
188 graphql_name=None,
189 type_annotation=StrawberryAnnotation(
190 annotation=annotation, namespace=self._namespace
191 ),
192 default=param.default,
193 )
194 arguments.append(argument)
195 if missing_annotations:
196 raise MissingArgumentsAnnotationsError(self.name, missing_annotations)
197 return arguments
198
199 @cached_property
200 def info_parameter(self) -> Optional[inspect.Parameter]:
201 return self.reserved_parameters.get(INFO_PARAMSPEC)
202
203 @cached_property
204 def root_parameter(self) -> Optional[inspect.Parameter]:
205 return self.reserved_parameters.get(ROOT_PARAMSPEC)
206
207 @cached_property
208 def self_parameter(self) -> Optional[inspect.Parameter]:
209 return self.reserved_parameters.get(SELF_PARAMSPEC)
210
211 @cached_property
212 def name(self) -> str:
213 # TODO: What to do if resolver is a lambda?
214 return self._unbound_wrapped_func.__name__
215
216 @cached_property
217 def annotations(self) -> Dict[str, object]:
218 """Annotations for the resolver.
219
220 Does not include special args defined in `RESERVED_PARAMSPEC` (e.g. self, root,
221 info)
222 """
223 reserved_parameters = self.reserved_parameters
224 reserved_names = {p.name for p in reserved_parameters.values() if p is not None}
225
226 annotations = self._unbound_wrapped_func.__annotations__
227 annotations = {
228 name: annotation
229 for name, annotation in annotations.items()
230 if name not in reserved_names
231 }
232
233 return annotations
234
235 @cached_property
236 def type_annotation(self) -> Optional[StrawberryAnnotation]:
237 return_annotation = self.signature.return_annotation
238 if return_annotation is inspect.Signature.empty:
239 return None
240 else:
241 type_annotation = StrawberryAnnotation(
242 annotation=return_annotation, namespace=self._namespace
243 )
244 return type_annotation
245
246 @property
247 def type(self) -> Optional[Union[StrawberryType, type]]:
248 if self._type_override:
249 return self._type_override
250 if self.type_annotation is None:
251 return None
252 return self.type_annotation.resolve()
253
254 @cached_property
255 def is_async(self) -> bool:
256 return iscoroutinefunction(self._unbound_wrapped_func) or isasyncgenfunction(
257 self._unbound_wrapped_func
258 )
259
260 def copy_with(
261 self, type_var_map: Mapping[TypeVar, Union[StrawberryType, builtins.type]]
262 ) -> StrawberryResolver:
263 type_override = None
264
265 if self.type:
266 if isinstance(self.type, StrawberryType):
267 type_override = self.type.copy_with(type_var_map)
268 else:
269 type_override = self.type._type_definition.copy_with( # type: ignore
270 type_var_map,
271 )
272
273 return type(self)(
274 func=self.wrapped_func,
275 description=self._description,
276 type_override=type_override,
277 )
278
279 @cached_property
280 def _namespace(self) -> Dict[str, Any]:
281 return sys.modules[self._unbound_wrapped_func.__module__].__dict__
282
283 @cached_property
284 def _unbound_wrapped_func(self) -> Callable[..., T]:
285 if isinstance(self.wrapped_func, (staticmethod, classmethod)):
286 return self.wrapped_func.__func__
287
288 return self.wrapped_func
289
290
291 class UncallableResolverError(Exception):
292 def __init__(self, resolver: "StrawberryResolver"):
293 message = (
294 f"Attempted to call resolver {resolver} with uncallable function "
295 f"{resolver.wrapped_func}"
296 )
297 super().__init__(message)
298
299
300 __all__ = ["StrawberryResolver"]
301
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/types/fields/resolver.py b/strawberry/types/fields/resolver.py
--- a/strawberry/types/fields/resolver.py
+++ b/strawberry/types/fields/resolver.py
@@ -32,6 +32,29 @@
from strawberry.types.info import Info
+class Parameter(inspect.Parameter):
+ def __hash__(self):
+ """Override to exclude default value from hash.
+
+ This adds compatibility for using unhashable default values in resolvers such as
+ list and dict. The present use-case is limited to analyzing parameters from one
+ resolver. Therefore, the name, kind, and annotation combination are guaranteed
+ to be unique since two arguments cannot have the same name in a callable.
+
+ Furthermore, even though it is not currently a use-case to collect parameters
+ from different resolvers, the likelihood of collision from having the same hash
+ value but different defaults is mitigated by Python invoking the
+ :py:meth:`__eq__` method if two items have the same hash. See the verification
+ of this behavior in the `test_parameter_hash_collision` test.
+ """
+ return hash((self.name, self.kind, self.annotation))
+
+
+class Signature(inspect.Signature):
+
+ _parameter_cls = Parameter
+
+
class ReservedParameterSpecification(Protocol):
def find(
self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver
@@ -159,7 +182,7 @@
@cached_property
def signature(self) -> inspect.Signature:
- return inspect.signature(self._unbound_wrapped_func)
+ return Signature.from_callable(self._unbound_wrapped_func, follow_wrapped=True)
@cached_property
def reserved_parameters(
|
{"golden_diff": "diff --git a/strawberry/types/fields/resolver.py b/strawberry/types/fields/resolver.py\n--- a/strawberry/types/fields/resolver.py\n+++ b/strawberry/types/fields/resolver.py\n@@ -32,6 +32,29 @@\n from strawberry.types.info import Info\n \n \n+class Parameter(inspect.Parameter):\n+ def __hash__(self):\n+ \"\"\"Override to exclude default value from hash.\n+\n+ This adds compatibility for using unhashable default values in resolvers such as\n+ list and dict. The present use-case is limited to analyzing parameters from one\n+ resolver. Therefore, the name, kind, and annotation combination are guaranteed\n+ to be unique since two arguments cannot have the same name in a callable.\n+\n+ Furthermore, even though it is not currently a use-case to collect parameters\n+ from different resolvers, the likelihood of collision from having the same hash\n+ value but different defaults is mitigated by Python invoking the\n+ :py:meth:`__eq__` method if two items have the same hash. See the verification\n+ of this behavior in the `test_parameter_hash_collision` test.\n+ \"\"\"\n+ return hash((self.name, self.kind, self.annotation))\n+\n+\n+class Signature(inspect.Signature):\n+\n+ _parameter_cls = Parameter\n+\n+\n class ReservedParameterSpecification(Protocol):\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n@@ -159,7 +182,7 @@\n \n @cached_property\n def signature(self) -> inspect.Signature:\n- return inspect.signature(self._unbound_wrapped_func)\n+ return Signature.from_callable(self._unbound_wrapped_func, follow_wrapped=True)\n \n @cached_property\n def reserved_parameters(\n", "issue": "Regression using mutable default values in arguments.\n<!-- Provide a general summary of the bug in the title above. -->\r\n\r\n<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->\r\n<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->\r\n\r\n## Describe the Bug\r\nPrior to v0.115\r\n```python\r\[email protected]\r\nclass Options:\r\n flag: str = ''\r\n\r\n\r\[email protected]\r\nclass Query:\r\n @strawberry.field\r\n def field(self, x: list[str] = [], y: Options = {}) -> str:\r\n return f'{x} {y}'\r\n```\r\nwould correctly resolve to\r\n```graphql\r\ntype Query {\r\n field(x: [String!]! = [], y: Options! = {}): String!\r\n}\r\n```\r\nAs of v0.115 it raises\r\n```python\r\n File \"lib/python3.10/site-packages/strawberry/types/fields/resolver.py\", line 87, in find\r\n resolver._resolved_annotations[parameter] = resolved_annotation\r\n File \"/lib/python3.10/inspect.py\", line 2740, in __hash__\r\n return hash((self.name, self.kind, self.annotation, self.default))\r\nTypeError: unhashable type: 'list'\r\n\r\n```\r\n\r\nFor lists, there is a workaround to use a tuple instead, but it's not ideal because GraphQL type coercion will correctly supply a list. For objects, there's no clean workaround; one would have to use the equivalent of a `frozendict`.\r\n\r\n## System Information\r\n - Strawberry version 0.115\r\n\n", "before_files": [{"content": "from __future__ import annotations as _\n\nimport builtins\nimport inspect\nimport sys\nimport warnings\nfrom inspect import isasyncgenfunction, iscoroutinefunction\nfrom typing import ( # type: ignore[attr-defined]\n Any,\n Callable,\n Dict,\n ForwardRef,\n Generic,\n List,\n Mapping,\n NamedTuple,\n Optional,\n Tuple,\n Type,\n TypeVar,\n Union,\n _eval_type,\n)\n\nfrom backports.cached_property import cached_property\nfrom typing_extensions import Annotated, Protocol, get_args, get_origin\n\nfrom strawberry.annotation import StrawberryAnnotation\nfrom strawberry.arguments import StrawberryArgument\nfrom strawberry.exceptions import MissingArgumentsAnnotationsError\nfrom strawberry.type import StrawberryType\nfrom strawberry.types.info import Info\n\n\nclass ReservedParameterSpecification(Protocol):\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n \"\"\"Finds the reserved parameter from ``parameters``.\"\"\"\n\n\nclass ReservedName(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n return next((p for p in parameters if p.name == self.name), None)\n\n\nclass ReservedNameBoundParameter(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n if parameters: # Add compatibility for resolvers with no arguments\n first_parameter = parameters[0]\n return first_parameter if first_parameter.name == self.name else None\n else:\n return None\n\n\nclass ReservedType(NamedTuple):\n \"\"\"Define a reserved type by name or by type.\n\n To preserve backwards-comaptibility, if an annotation was defined but does not match\n :attr:`type`, then the name is used as a fallback.\n \"\"\"\n\n name: str\n type: Type\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n for parameter in parameters:\n annotation = parameter.annotation\n try:\n resolved_annotation = _eval_type(\n ForwardRef(annotation)\n if isinstance(annotation, str)\n else annotation,\n resolver._namespace,\n None,\n )\n resolver._resolved_annotations[parameter] = resolved_annotation\n except NameError:\n # Type-annotation could not be resolved\n resolved_annotation = annotation\n if self.is_reserved_type(resolved_annotation):\n return parameter\n\n # Fallback to matching by name\n reserved_name = ReservedName(name=self.name).find(parameters, resolver)\n if reserved_name:\n warning = DeprecationWarning(\n f\"Argument name-based matching of '{self.name}' is deprecated and will \"\n \"be removed in v1.0. Ensure that reserved arguments are annotated \"\n \"their respective types (i.e. use value: 'DirectiveValue[str]' instead \"\n \"of 'value: str' and 'info: Info' instead of a plain 'info').\"\n )\n warnings.warn(warning)\n return reserved_name\n else:\n return None\n\n def is_reserved_type(self, other: Type) -> bool:\n if get_origin(other) is Annotated:\n # Handle annotated arguments such as Private[str] and DirectiveValue[str]\n return any(isinstance(argument, self.type) for argument in get_args(other))\n else:\n # Handle both concrete and generic types (i.e Info, and Info[Any, Any])\n return other is self.type or get_origin(other) is self.type\n\n\nSELF_PARAMSPEC = ReservedNameBoundParameter(\"self\")\nCLS_PARAMSPEC = ReservedNameBoundParameter(\"cls\")\nROOT_PARAMSPEC = ReservedName(\"root\")\nINFO_PARAMSPEC = ReservedType(\"info\", Info)\n\nT = TypeVar(\"T\")\n\n\nclass StrawberryResolver(Generic[T]):\n\n RESERVED_PARAMSPEC: Tuple[ReservedParameterSpecification, ...] = (\n SELF_PARAMSPEC,\n CLS_PARAMSPEC,\n ROOT_PARAMSPEC,\n INFO_PARAMSPEC,\n )\n\n def __init__(\n self,\n func: Union[Callable[..., T], staticmethod, classmethod],\n *,\n description: Optional[str] = None,\n type_override: Optional[Union[StrawberryType, type]] = None,\n ):\n self.wrapped_func = func\n self._description = description\n self._type_override = type_override\n \"\"\"Specify the type manually instead of calculating from wrapped func\n\n This is used when creating copies of types w/ generics\n \"\"\"\n self._resolved_annotations: Dict[inspect.Parameter, Any] = {}\n \"\"\"Populated during reserved parameter determination.\n\n Caching resolved annotations this way prevents evaling them repeatedly.\n \"\"\"\n\n # TODO: Use this when doing the actual resolving? How to deal with async resolvers?\n def __call__(self, *args, **kwargs) -> T:\n if not callable(self.wrapped_func):\n raise UncallableResolverError(self)\n return self.wrapped_func(*args, **kwargs)\n\n @cached_property\n def signature(self) -> inspect.Signature:\n return inspect.signature(self._unbound_wrapped_func)\n\n @cached_property\n def reserved_parameters(\n self,\n ) -> Dict[ReservedParameterSpecification, Optional[inspect.Parameter]]:\n \"\"\"Mapping of reserved parameter specification to parameter.\"\"\"\n parameters = tuple(self.signature.parameters.values())\n return {spec: spec.find(parameters, self) for spec in self.RESERVED_PARAMSPEC}\n\n @cached_property\n def arguments(self) -> List[StrawberryArgument]:\n \"\"\"Resolver arguments exposed in the GraphQL Schema.\"\"\"\n parameters = self.signature.parameters.values()\n reserved_parameters = set(self.reserved_parameters.values())\n\n missing_annotations = set()\n arguments = []\n user_parameters = (p for p in parameters if p not in reserved_parameters)\n for param in user_parameters:\n annotation = self._resolved_annotations.get(param, param.annotation)\n if annotation is inspect.Signature.empty:\n missing_annotations.add(param.name)\n else:\n argument = StrawberryArgument(\n python_name=param.name,\n graphql_name=None,\n type_annotation=StrawberryAnnotation(\n annotation=annotation, namespace=self._namespace\n ),\n default=param.default,\n )\n arguments.append(argument)\n if missing_annotations:\n raise MissingArgumentsAnnotationsError(self.name, missing_annotations)\n return arguments\n\n @cached_property\n def info_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(INFO_PARAMSPEC)\n\n @cached_property\n def root_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(ROOT_PARAMSPEC)\n\n @cached_property\n def self_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(SELF_PARAMSPEC)\n\n @cached_property\n def name(self) -> str:\n # TODO: What to do if resolver is a lambda?\n return self._unbound_wrapped_func.__name__\n\n @cached_property\n def annotations(self) -> Dict[str, object]:\n \"\"\"Annotations for the resolver.\n\n Does not include special args defined in `RESERVED_PARAMSPEC` (e.g. self, root,\n info)\n \"\"\"\n reserved_parameters = self.reserved_parameters\n reserved_names = {p.name for p in reserved_parameters.values() if p is not None}\n\n annotations = self._unbound_wrapped_func.__annotations__\n annotations = {\n name: annotation\n for name, annotation in annotations.items()\n if name not in reserved_names\n }\n\n return annotations\n\n @cached_property\n def type_annotation(self) -> Optional[StrawberryAnnotation]:\n return_annotation = self.signature.return_annotation\n if return_annotation is inspect.Signature.empty:\n return None\n else:\n type_annotation = StrawberryAnnotation(\n annotation=return_annotation, namespace=self._namespace\n )\n return type_annotation\n\n @property\n def type(self) -> Optional[Union[StrawberryType, type]]:\n if self._type_override:\n return self._type_override\n if self.type_annotation is None:\n return None\n return self.type_annotation.resolve()\n\n @cached_property\n def is_async(self) -> bool:\n return iscoroutinefunction(self._unbound_wrapped_func) or isasyncgenfunction(\n self._unbound_wrapped_func\n )\n\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, builtins.type]]\n ) -> StrawberryResolver:\n type_override = None\n\n if self.type:\n if isinstance(self.type, StrawberryType):\n type_override = self.type.copy_with(type_var_map)\n else:\n type_override = self.type._type_definition.copy_with( # type: ignore\n type_var_map,\n )\n\n return type(self)(\n func=self.wrapped_func,\n description=self._description,\n type_override=type_override,\n )\n\n @cached_property\n def _namespace(self) -> Dict[str, Any]:\n return sys.modules[self._unbound_wrapped_func.__module__].__dict__\n\n @cached_property\n def _unbound_wrapped_func(self) -> Callable[..., T]:\n if isinstance(self.wrapped_func, (staticmethod, classmethod)):\n return self.wrapped_func.__func__\n\n return self.wrapped_func\n\n\nclass UncallableResolverError(Exception):\n def __init__(self, resolver: \"StrawberryResolver\"):\n message = (\n f\"Attempted to call resolver {resolver} with uncallable function \"\n f\"{resolver.wrapped_func}\"\n )\n super().__init__(message)\n\n\n__all__ = [\"StrawberryResolver\"]\n", "path": "strawberry/types/fields/resolver.py"}], "after_files": [{"content": "from __future__ import annotations as _\n\nimport builtins\nimport inspect\nimport sys\nimport warnings\nfrom inspect import isasyncgenfunction, iscoroutinefunction\nfrom typing import ( # type: ignore[attr-defined]\n Any,\n Callable,\n Dict,\n ForwardRef,\n Generic,\n List,\n Mapping,\n NamedTuple,\n Optional,\n Tuple,\n Type,\n TypeVar,\n Union,\n _eval_type,\n)\n\nfrom backports.cached_property import cached_property\nfrom typing_extensions import Annotated, Protocol, get_args, get_origin\n\nfrom strawberry.annotation import StrawberryAnnotation\nfrom strawberry.arguments import StrawberryArgument\nfrom strawberry.exceptions import MissingArgumentsAnnotationsError\nfrom strawberry.type import StrawberryType\nfrom strawberry.types.info import Info\n\n\nclass Parameter(inspect.Parameter):\n def __hash__(self):\n \"\"\"Override to exclude default value from hash.\n\n This adds compatibility for using unhashable default values in resolvers such as\n list and dict. The present use-case is limited to analyzing parameters from one\n resolver. Therefore, the name, kind, and annotation combination are guaranteed\n to be unique since two arguments cannot have the same name in a callable.\n\n Furthermore, even though it is not currently a use-case to collect parameters\n from different resolvers, the likelihood of collision from having the same hash\n value but different defaults is mitigated by Python invoking the\n :py:meth:`__eq__` method if two items have the same hash. See the verification\n of this behavior in the `test_parameter_hash_collision` test.\n \"\"\"\n return hash((self.name, self.kind, self.annotation))\n\n\nclass Signature(inspect.Signature):\n\n _parameter_cls = Parameter\n\n\nclass ReservedParameterSpecification(Protocol):\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n \"\"\"Finds the reserved parameter from ``parameters``.\"\"\"\n\n\nclass ReservedName(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n return next((p for p in parameters if p.name == self.name), None)\n\n\nclass ReservedNameBoundParameter(NamedTuple):\n name: str\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], _: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n if parameters: # Add compatibility for resolvers with no arguments\n first_parameter = parameters[0]\n return first_parameter if first_parameter.name == self.name else None\n else:\n return None\n\n\nclass ReservedType(NamedTuple):\n \"\"\"Define a reserved type by name or by type.\n\n To preserve backwards-comaptibility, if an annotation was defined but does not match\n :attr:`type`, then the name is used as a fallback.\n \"\"\"\n\n name: str\n type: Type\n\n def find(\n self, parameters: Tuple[inspect.Parameter, ...], resolver: StrawberryResolver\n ) -> Optional[inspect.Parameter]:\n for parameter in parameters:\n annotation = parameter.annotation\n try:\n resolved_annotation = _eval_type(\n ForwardRef(annotation)\n if isinstance(annotation, str)\n else annotation,\n resolver._namespace,\n None,\n )\n resolver._resolved_annotations[parameter] = resolved_annotation\n except NameError:\n # Type-annotation could not be resolved\n resolved_annotation = annotation\n if self.is_reserved_type(resolved_annotation):\n return parameter\n\n # Fallback to matching by name\n reserved_name = ReservedName(name=self.name).find(parameters, resolver)\n if reserved_name:\n warning = DeprecationWarning(\n f\"Argument name-based matching of '{self.name}' is deprecated and will \"\n \"be removed in v1.0. Ensure that reserved arguments are annotated \"\n \"their respective types (i.e. use value: 'DirectiveValue[str]' instead \"\n \"of 'value: str' and 'info: Info' instead of a plain 'info').\"\n )\n warnings.warn(warning)\n return reserved_name\n else:\n return None\n\n def is_reserved_type(self, other: Type) -> bool:\n if get_origin(other) is Annotated:\n # Handle annotated arguments such as Private[str] and DirectiveValue[str]\n return any(isinstance(argument, self.type) for argument in get_args(other))\n else:\n # Handle both concrete and generic types (i.e Info, and Info[Any, Any])\n return other is self.type or get_origin(other) is self.type\n\n\nSELF_PARAMSPEC = ReservedNameBoundParameter(\"self\")\nCLS_PARAMSPEC = ReservedNameBoundParameter(\"cls\")\nROOT_PARAMSPEC = ReservedName(\"root\")\nINFO_PARAMSPEC = ReservedType(\"info\", Info)\n\nT = TypeVar(\"T\")\n\n\nclass StrawberryResolver(Generic[T]):\n\n RESERVED_PARAMSPEC: Tuple[ReservedParameterSpecification, ...] = (\n SELF_PARAMSPEC,\n CLS_PARAMSPEC,\n ROOT_PARAMSPEC,\n INFO_PARAMSPEC,\n )\n\n def __init__(\n self,\n func: Union[Callable[..., T], staticmethod, classmethod],\n *,\n description: Optional[str] = None,\n type_override: Optional[Union[StrawberryType, type]] = None,\n ):\n self.wrapped_func = func\n self._description = description\n self._type_override = type_override\n \"\"\"Specify the type manually instead of calculating from wrapped func\n\n This is used when creating copies of types w/ generics\n \"\"\"\n self._resolved_annotations: Dict[inspect.Parameter, Any] = {}\n \"\"\"Populated during reserved parameter determination.\n\n Caching resolved annotations this way prevents evaling them repeatedly.\n \"\"\"\n\n # TODO: Use this when doing the actual resolving? How to deal with async resolvers?\n def __call__(self, *args, **kwargs) -> T:\n if not callable(self.wrapped_func):\n raise UncallableResolverError(self)\n return self.wrapped_func(*args, **kwargs)\n\n @cached_property\n def signature(self) -> inspect.Signature:\n return Signature.from_callable(self._unbound_wrapped_func, follow_wrapped=True)\n\n @cached_property\n def reserved_parameters(\n self,\n ) -> Dict[ReservedParameterSpecification, Optional[inspect.Parameter]]:\n \"\"\"Mapping of reserved parameter specification to parameter.\"\"\"\n parameters = tuple(self.signature.parameters.values())\n return {spec: spec.find(parameters, self) for spec in self.RESERVED_PARAMSPEC}\n\n @cached_property\n def arguments(self) -> List[StrawberryArgument]:\n \"\"\"Resolver arguments exposed in the GraphQL Schema.\"\"\"\n parameters = self.signature.parameters.values()\n reserved_parameters = set(self.reserved_parameters.values())\n\n missing_annotations = set()\n arguments = []\n user_parameters = (p for p in parameters if p not in reserved_parameters)\n for param in user_parameters:\n annotation = self._resolved_annotations.get(param, param.annotation)\n if annotation is inspect.Signature.empty:\n missing_annotations.add(param.name)\n else:\n argument = StrawberryArgument(\n python_name=param.name,\n graphql_name=None,\n type_annotation=StrawberryAnnotation(\n annotation=annotation, namespace=self._namespace\n ),\n default=param.default,\n )\n arguments.append(argument)\n if missing_annotations:\n raise MissingArgumentsAnnotationsError(self.name, missing_annotations)\n return arguments\n\n @cached_property\n def info_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(INFO_PARAMSPEC)\n\n @cached_property\n def root_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(ROOT_PARAMSPEC)\n\n @cached_property\n def self_parameter(self) -> Optional[inspect.Parameter]:\n return self.reserved_parameters.get(SELF_PARAMSPEC)\n\n @cached_property\n def name(self) -> str:\n # TODO: What to do if resolver is a lambda?\n return self._unbound_wrapped_func.__name__\n\n @cached_property\n def annotations(self) -> Dict[str, object]:\n \"\"\"Annotations for the resolver.\n\n Does not include special args defined in `RESERVED_PARAMSPEC` (e.g. self, root,\n info)\n \"\"\"\n reserved_parameters = self.reserved_parameters\n reserved_names = {p.name for p in reserved_parameters.values() if p is not None}\n\n annotations = self._unbound_wrapped_func.__annotations__\n annotations = {\n name: annotation\n for name, annotation in annotations.items()\n if name not in reserved_names\n }\n\n return annotations\n\n @cached_property\n def type_annotation(self) -> Optional[StrawberryAnnotation]:\n return_annotation = self.signature.return_annotation\n if return_annotation is inspect.Signature.empty:\n return None\n else:\n type_annotation = StrawberryAnnotation(\n annotation=return_annotation, namespace=self._namespace\n )\n return type_annotation\n\n @property\n def type(self) -> Optional[Union[StrawberryType, type]]:\n if self._type_override:\n return self._type_override\n if self.type_annotation is None:\n return None\n return self.type_annotation.resolve()\n\n @cached_property\n def is_async(self) -> bool:\n return iscoroutinefunction(self._unbound_wrapped_func) or isasyncgenfunction(\n self._unbound_wrapped_func\n )\n\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, builtins.type]]\n ) -> StrawberryResolver:\n type_override = None\n\n if self.type:\n if isinstance(self.type, StrawberryType):\n type_override = self.type.copy_with(type_var_map)\n else:\n type_override = self.type._type_definition.copy_with( # type: ignore\n type_var_map,\n )\n\n return type(self)(\n func=self.wrapped_func,\n description=self._description,\n type_override=type_override,\n )\n\n @cached_property\n def _namespace(self) -> Dict[str, Any]:\n return sys.modules[self._unbound_wrapped_func.__module__].__dict__\n\n @cached_property\n def _unbound_wrapped_func(self) -> Callable[..., T]:\n if isinstance(self.wrapped_func, (staticmethod, classmethod)):\n return self.wrapped_func.__func__\n\n return self.wrapped_func\n\n\nclass UncallableResolverError(Exception):\n def __init__(self, resolver: \"StrawberryResolver\"):\n message = (\n f\"Attempted to call resolver {resolver} with uncallable function \"\n f\"{resolver.wrapped_func}\"\n )\n super().__init__(message)\n\n\n__all__ = [\"StrawberryResolver\"]\n", "path": "strawberry/types/fields/resolver.py"}]}
| 3,505 | 397 |
gh_patches_debug_13904
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-2930
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Changed exportDialog
This pull request fixes #2367. The code has been changed as it was suggested in the issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/GraphicsScene/exportDialog.py`
Content:
```
1 from .. import exporters as exporters
2 from .. import functions as fn
3 from ..graphicsItems.PlotItem import PlotItem
4 from ..graphicsItems.ViewBox import ViewBox
5 from ..Qt import QtCore, QtWidgets
6
7 from . import exportDialogTemplate_generic as ui_template
8
9 class FormatExportListWidgetItem(QtWidgets.QListWidgetItem):
10 def __init__(self, expClass, *args, **kwargs):
11 QtWidgets.QListWidgetItem.__init__(self, *args, **kwargs)
12 self.expClass = expClass
13
14
15 class ExportDialog(QtWidgets.QWidget):
16 def __init__(self, scene):
17 QtWidgets.QWidget.__init__(self)
18 self.setVisible(False)
19 self.setWindowTitle("Export")
20 self.shown = False
21 self.currentExporter = None
22 self.scene = scene
23
24 self.selectBox = QtWidgets.QGraphicsRectItem()
25 self.selectBox.setPen(fn.mkPen('y', width=3, style=QtCore.Qt.PenStyle.DashLine))
26 self.selectBox.hide()
27 self.scene.addItem(self.selectBox)
28
29 self.ui = ui_template.Ui_Form()
30 self.ui.setupUi(self)
31
32 self.ui.closeBtn.clicked.connect(self.close)
33 self.ui.exportBtn.clicked.connect(self.exportClicked)
34 self.ui.copyBtn.clicked.connect(self.copyClicked)
35 self.ui.itemTree.currentItemChanged.connect(self.exportItemChanged)
36 self.ui.formatList.currentItemChanged.connect(self.exportFormatChanged)
37
38
39 def show(self, item=None):
40 if item is not None:
41 ## Select next exportable parent of the item originally clicked on
42 while not isinstance(item, ViewBox) and not isinstance(item, PlotItem) and item is not None:
43 item = item.parentItem()
44 ## if this is a ViewBox inside a PlotItem, select the parent instead.
45 if isinstance(item, ViewBox) and isinstance(item.parentItem(), PlotItem):
46 item = item.parentItem()
47 self.updateItemList(select=item)
48 self.setVisible(True)
49 self.activateWindow()
50 self.raise_()
51 self.selectBox.setVisible(True)
52 if not self.shown:
53 self.shown = True
54 vcenter = self.scene.getViewWidget().geometry().center()
55 x = max(0, int(vcenter.x() - self.width() / 2))
56 y = max(0, int(vcenter.y() - self.height() / 2))
57 self.move(x, y)
58
59 def updateItemList(self, select=None):
60 self.ui.itemTree.clear()
61 si = QtWidgets.QTreeWidgetItem(["Entire Scene"])
62 si.gitem = self.scene
63 self.ui.itemTree.addTopLevelItem(si)
64 self.ui.itemTree.setCurrentItem(si)
65 si.setExpanded(True)
66 for child in self.scene.items():
67 if child.parentItem() is None:
68 self.updateItemTree(child, si, select=select)
69
70 def updateItemTree(self, item, treeItem, select=None):
71 si = None
72 if isinstance(item, ViewBox):
73 si = QtWidgets.QTreeWidgetItem(['ViewBox'])
74 elif isinstance(item, PlotItem):
75 si = QtWidgets.QTreeWidgetItem(['Plot'])
76
77 if si is not None:
78 si.gitem = item
79 treeItem.addChild(si)
80 treeItem = si
81 if si.gitem is select:
82 self.ui.itemTree.setCurrentItem(si)
83
84 for ch in item.childItems():
85 self.updateItemTree(ch, treeItem, select=select)
86
87
88 def exportItemChanged(self, item, prev):
89 if item is None:
90 return
91 if item.gitem is self.scene:
92 newBounds = self.scene.views()[0].viewRect()
93 else:
94 newBounds = item.gitem.sceneBoundingRect()
95 self.selectBox.setRect(newBounds)
96 self.selectBox.show()
97 self.updateFormatList()
98
99 def updateFormatList(self):
100 current = self.ui.formatList.currentItem()
101
102 self.ui.formatList.clear()
103 gotCurrent = False
104 for exp in exporters.listExporters():
105 item = FormatExportListWidgetItem(exp, QtCore.QCoreApplication.translate('Exporter', exp.Name))
106 self.ui.formatList.addItem(item)
107 if item is current:
108 self.ui.formatList.setCurrentRow(self.ui.formatList.count() - 1)
109 gotCurrent = True
110
111 if not gotCurrent:
112 self.ui.formatList.setCurrentRow(0)
113
114 def exportFormatChanged(self, item, prev):
115 if item is None:
116 self.currentExporter = None
117 self.ui.paramTree.clear()
118 return
119 expClass = item.expClass
120 exp = expClass(item=self.ui.itemTree.currentItem().gitem)
121
122 params = exp.parameters()
123
124 if params is None:
125 self.ui.paramTree.clear()
126 else:
127 self.ui.paramTree.setParameters(params)
128 self.currentExporter = exp
129 self.ui.copyBtn.setEnabled(exp.allowCopy)
130
131 def exportClicked(self):
132 self.selectBox.hide()
133 self.currentExporter.export()
134
135 def copyClicked(self):
136 self.selectBox.hide()
137 self.currentExporter.export(copy=True)
138
139 def close(self):
140 self.selectBox.setVisible(False)
141 self.setVisible(False)
142
143 def closeEvent(self, event):
144 self.close()
145 super().closeEvent(event)
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyqtgraph/GraphicsScene/exportDialog.py b/pyqtgraph/GraphicsScene/exportDialog.py
--- a/pyqtgraph/GraphicsScene/exportDialog.py
+++ b/pyqtgraph/GraphicsScene/exportDialog.py
@@ -51,10 +51,11 @@
self.selectBox.setVisible(True)
if not self.shown:
self.shown = True
- vcenter = self.scene.getViewWidget().geometry().center()
- x = max(0, int(vcenter.x() - self.width() / 2))
- y = max(0, int(vcenter.y() - self.height() / 2))
- self.move(x, y)
+ screen = QtWidgets.QApplication.desktop().screenNumber(QtWidgets.QApplication.desktop().cursor().pos())
+ centre = QtWidgets.QDesktopWidget().availableGeometry(screen).center()
+ frame = self.frameGeometry()
+ frame.moveCenter(centre)
+ self.move(frame.topLeft())
def updateItemList(self, select=None):
self.ui.itemTree.clear()
|
{"golden_diff": "diff --git a/pyqtgraph/GraphicsScene/exportDialog.py b/pyqtgraph/GraphicsScene/exportDialog.py\n--- a/pyqtgraph/GraphicsScene/exportDialog.py\n+++ b/pyqtgraph/GraphicsScene/exportDialog.py\n@@ -51,10 +51,11 @@\n self.selectBox.setVisible(True)\n if not self.shown:\n self.shown = True\n- vcenter = self.scene.getViewWidget().geometry().center()\n- x = max(0, int(vcenter.x() - self.width() / 2))\n- y = max(0, int(vcenter.y() - self.height() / 2))\n- self.move(x, y)\n+ screen = QtWidgets.QApplication.desktop().screenNumber(QtWidgets.QApplication.desktop().cursor().pos())\n+ centre = QtWidgets.QDesktopWidget().availableGeometry(screen).center()\n+ frame = self.frameGeometry()\n+ frame.moveCenter(centre)\n+ self.move(frame.topLeft())\n \n def updateItemList(self, select=None):\n self.ui.itemTree.clear()\n", "issue": "Changed exportDialog\nThis pull request fixes #2367. The code has been changed as it was suggested in the issue.\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from .. import exporters as exporters\nfrom .. import functions as fn\nfrom ..graphicsItems.PlotItem import PlotItem\nfrom ..graphicsItems.ViewBox import ViewBox\nfrom ..Qt import QtCore, QtWidgets\n\nfrom . import exportDialogTemplate_generic as ui_template\n\nclass FormatExportListWidgetItem(QtWidgets.QListWidgetItem):\n def __init__(self, expClass, *args, **kwargs):\n QtWidgets.QListWidgetItem.__init__(self, *args, **kwargs)\n self.expClass = expClass\n\n\nclass ExportDialog(QtWidgets.QWidget):\n def __init__(self, scene):\n QtWidgets.QWidget.__init__(self)\n self.setVisible(False)\n self.setWindowTitle(\"Export\")\n self.shown = False\n self.currentExporter = None\n self.scene = scene\n\n self.selectBox = QtWidgets.QGraphicsRectItem()\n self.selectBox.setPen(fn.mkPen('y', width=3, style=QtCore.Qt.PenStyle.DashLine))\n self.selectBox.hide()\n self.scene.addItem(self.selectBox)\n \n self.ui = ui_template.Ui_Form()\n self.ui.setupUi(self)\n \n self.ui.closeBtn.clicked.connect(self.close)\n self.ui.exportBtn.clicked.connect(self.exportClicked)\n self.ui.copyBtn.clicked.connect(self.copyClicked)\n self.ui.itemTree.currentItemChanged.connect(self.exportItemChanged)\n self.ui.formatList.currentItemChanged.connect(self.exportFormatChanged)\n \n\n def show(self, item=None):\n if item is not None:\n ## Select next exportable parent of the item originally clicked on\n while not isinstance(item, ViewBox) and not isinstance(item, PlotItem) and item is not None:\n item = item.parentItem()\n ## if this is a ViewBox inside a PlotItem, select the parent instead.\n if isinstance(item, ViewBox) and isinstance(item.parentItem(), PlotItem):\n item = item.parentItem()\n self.updateItemList(select=item)\n self.setVisible(True)\n self.activateWindow()\n self.raise_()\n self.selectBox.setVisible(True)\n if not self.shown:\n self.shown = True\n vcenter = self.scene.getViewWidget().geometry().center()\n x = max(0, int(vcenter.x() - self.width() / 2))\n y = max(0, int(vcenter.y() - self.height() / 2))\n self.move(x, y)\n \n def updateItemList(self, select=None):\n self.ui.itemTree.clear()\n si = QtWidgets.QTreeWidgetItem([\"Entire Scene\"])\n si.gitem = self.scene\n self.ui.itemTree.addTopLevelItem(si)\n self.ui.itemTree.setCurrentItem(si)\n si.setExpanded(True)\n for child in self.scene.items():\n if child.parentItem() is None:\n self.updateItemTree(child, si, select=select)\n \n def updateItemTree(self, item, treeItem, select=None):\n si = None\n if isinstance(item, ViewBox):\n si = QtWidgets.QTreeWidgetItem(['ViewBox'])\n elif isinstance(item, PlotItem):\n si = QtWidgets.QTreeWidgetItem(['Plot'])\n \n if si is not None:\n si.gitem = item\n treeItem.addChild(si)\n treeItem = si\n if si.gitem is select:\n self.ui.itemTree.setCurrentItem(si)\n \n for ch in item.childItems():\n self.updateItemTree(ch, treeItem, select=select)\n \n \n def exportItemChanged(self, item, prev):\n if item is None:\n return\n if item.gitem is self.scene:\n newBounds = self.scene.views()[0].viewRect()\n else:\n newBounds = item.gitem.sceneBoundingRect()\n self.selectBox.setRect(newBounds)\n self.selectBox.show()\n self.updateFormatList()\n \n def updateFormatList(self):\n current = self.ui.formatList.currentItem()\n\n self.ui.formatList.clear()\n gotCurrent = False\n for exp in exporters.listExporters():\n item = FormatExportListWidgetItem(exp, QtCore.QCoreApplication.translate('Exporter', exp.Name))\n self.ui.formatList.addItem(item)\n if item is current:\n self.ui.formatList.setCurrentRow(self.ui.formatList.count() - 1)\n gotCurrent = True\n \n if not gotCurrent:\n self.ui.formatList.setCurrentRow(0)\n \n def exportFormatChanged(self, item, prev):\n if item is None:\n self.currentExporter = None\n self.ui.paramTree.clear()\n return\n expClass = item.expClass\n exp = expClass(item=self.ui.itemTree.currentItem().gitem)\n\n params = exp.parameters()\n\n if params is None:\n self.ui.paramTree.clear()\n else:\n self.ui.paramTree.setParameters(params)\n self.currentExporter = exp\n self.ui.copyBtn.setEnabled(exp.allowCopy)\n \n def exportClicked(self):\n self.selectBox.hide()\n self.currentExporter.export()\n \n def copyClicked(self):\n self.selectBox.hide()\n self.currentExporter.export(copy=True)\n \n def close(self):\n self.selectBox.setVisible(False)\n self.setVisible(False)\n\n def closeEvent(self, event):\n self.close()\n super().closeEvent(event)\n", "path": "pyqtgraph/GraphicsScene/exportDialog.py"}], "after_files": [{"content": "from .. import exporters as exporters\nfrom .. import functions as fn\nfrom ..graphicsItems.PlotItem import PlotItem\nfrom ..graphicsItems.ViewBox import ViewBox\nfrom ..Qt import QtCore, QtWidgets\n\nfrom . import exportDialogTemplate_generic as ui_template\n\nclass FormatExportListWidgetItem(QtWidgets.QListWidgetItem):\n def __init__(self, expClass, *args, **kwargs):\n QtWidgets.QListWidgetItem.__init__(self, *args, **kwargs)\n self.expClass = expClass\n\n\nclass ExportDialog(QtWidgets.QWidget):\n def __init__(self, scene):\n QtWidgets.QWidget.__init__(self)\n self.setVisible(False)\n self.setWindowTitle(\"Export\")\n self.shown = False\n self.currentExporter = None\n self.scene = scene\n\n self.selectBox = QtWidgets.QGraphicsRectItem()\n self.selectBox.setPen(fn.mkPen('y', width=3, style=QtCore.Qt.PenStyle.DashLine))\n self.selectBox.hide()\n self.scene.addItem(self.selectBox)\n \n self.ui = ui_template.Ui_Form()\n self.ui.setupUi(self)\n \n self.ui.closeBtn.clicked.connect(self.close)\n self.ui.exportBtn.clicked.connect(self.exportClicked)\n self.ui.copyBtn.clicked.connect(self.copyClicked)\n self.ui.itemTree.currentItemChanged.connect(self.exportItemChanged)\n self.ui.formatList.currentItemChanged.connect(self.exportFormatChanged)\n \n\n def show(self, item=None):\n if item is not None:\n ## Select next exportable parent of the item originally clicked on\n while not isinstance(item, ViewBox) and not isinstance(item, PlotItem) and item is not None:\n item = item.parentItem()\n ## if this is a ViewBox inside a PlotItem, select the parent instead.\n if isinstance(item, ViewBox) and isinstance(item.parentItem(), PlotItem):\n item = item.parentItem()\n self.updateItemList(select=item)\n self.setVisible(True)\n self.activateWindow()\n self.raise_()\n self.selectBox.setVisible(True)\n if not self.shown:\n self.shown = True\n screen = QtWidgets.QApplication.desktop().screenNumber(QtWidgets.QApplication.desktop().cursor().pos())\n centre = QtWidgets.QDesktopWidget().availableGeometry(screen).center()\n frame = self.frameGeometry()\n frame.moveCenter(centre)\n self.move(frame.topLeft())\n \n def updateItemList(self, select=None):\n self.ui.itemTree.clear()\n si = QtWidgets.QTreeWidgetItem([\"Entire Scene\"])\n si.gitem = self.scene\n self.ui.itemTree.addTopLevelItem(si)\n self.ui.itemTree.setCurrentItem(si)\n si.setExpanded(True)\n for child in self.scene.items():\n if child.parentItem() is None:\n self.updateItemTree(child, si, select=select)\n \n def updateItemTree(self, item, treeItem, select=None):\n si = None\n if isinstance(item, ViewBox):\n si = QtWidgets.QTreeWidgetItem(['ViewBox'])\n elif isinstance(item, PlotItem):\n si = QtWidgets.QTreeWidgetItem(['Plot'])\n \n if si is not None:\n si.gitem = item\n treeItem.addChild(si)\n treeItem = si\n if si.gitem is select:\n self.ui.itemTree.setCurrentItem(si)\n \n for ch in item.childItems():\n self.updateItemTree(ch, treeItem, select=select)\n \n \n def exportItemChanged(self, item, prev):\n if item is None:\n return\n if item.gitem is self.scene:\n newBounds = self.scene.views()[0].viewRect()\n else:\n newBounds = item.gitem.sceneBoundingRect()\n self.selectBox.setRect(newBounds)\n self.selectBox.show()\n self.updateFormatList()\n \n def updateFormatList(self):\n current = self.ui.formatList.currentItem()\n\n self.ui.formatList.clear()\n gotCurrent = False\n for exp in exporters.listExporters():\n item = FormatExportListWidgetItem(exp, QtCore.QCoreApplication.translate('Exporter', exp.Name))\n self.ui.formatList.addItem(item)\n if item is current:\n self.ui.formatList.setCurrentRow(self.ui.formatList.count() - 1)\n gotCurrent = True\n \n if not gotCurrent:\n self.ui.formatList.setCurrentRow(0)\n \n def exportFormatChanged(self, item, prev):\n if item is None:\n self.currentExporter = None\n self.ui.paramTree.clear()\n return\n expClass = item.expClass\n exp = expClass(item=self.ui.itemTree.currentItem().gitem)\n\n params = exp.parameters()\n\n if params is None:\n self.ui.paramTree.clear()\n else:\n self.ui.paramTree.setParameters(params)\n self.currentExporter = exp\n self.ui.copyBtn.setEnabled(exp.allowCopy)\n \n def exportClicked(self):\n self.selectBox.hide()\n self.currentExporter.export()\n \n def copyClicked(self):\n self.selectBox.hide()\n self.currentExporter.export(copy=True)\n \n def close(self):\n self.selectBox.setVisible(False)\n self.setVisible(False)\n\n def closeEvent(self, event):\n self.close()\n super().closeEvent(event)\n", "path": "pyqtgraph/GraphicsScene/exportDialog.py"}]}
| 1,781 | 220 |
gh_patches_debug_21441
|
rasdani/github-patches
|
git_diff
|
mozilla__bugbug-197
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
In the DevDocNeeded model, consider bugs for which the dev-doc-needed keyword was removed as negative examples
See also #79.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bugbug/models/devdocneeded.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This Source Code Form is subject to the terms of the Mozilla Public
3 # License, v. 2.0. If a copy of the MPL was not distributed with this file,
4 # You can obtain one at http://mozilla.org/MPL/2.0/.
5
6 import xgboost
7 from imblearn.under_sampling import RandomUnderSampler
8 from sklearn.compose import ColumnTransformer
9 from sklearn.feature_extraction import DictVectorizer
10 from sklearn.pipeline import Pipeline
11
12 from bugbug import bug_features
13 from bugbug import bugzilla
14 from bugbug.model import Model
15
16
17 class DevDocNeededModel(Model):
18 def __init__(self, lemmatization=False):
19 Model.__init__(self, lemmatization)
20
21 self.sampler = RandomUnderSampler(random_state=0)
22
23 feature_extractors = [
24 bug_features.has_str(),
25 bug_features.has_regression_range(),
26 bug_features.severity(),
27 bug_features.keywords({'dev-doc-needed', 'dev-doc-complete'}),
28 bug_features.is_coverity_issue(),
29 bug_features.has_crash_signature(),
30 bug_features.has_url(),
31 bug_features.has_w3c_url(),
32 bug_features.has_github_url(),
33 bug_features.whiteboard(),
34 bug_features.patches(),
35 bug_features.landings(),
36 bug_features.title(),
37 bug_features.product(),
38 bug_features.component(),
39
40 bug_features.commit_added(),
41 bug_features.commit_deleted(),
42 bug_features.commit_types(),
43 ]
44
45 cleanup_functions = [
46 bug_features.cleanup_fileref,
47 bug_features.cleanup_url,
48 bug_features.cleanup_synonyms,
49 ]
50
51 self.extraction_pipeline = Pipeline([
52 ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions, rollback=True, rollback_when=self.rollback, commit_data=True)),
53 ('union', ColumnTransformer([
54 ('data', DictVectorizer(), 'data'),
55
56 ('title', self.text_vectorizer(), 'title'),
57
58 ('comments', self.text_vectorizer(), 'comments'),
59 ])),
60 ])
61
62 self.clf = xgboost.XGBClassifier(n_jobs=16)
63 self.clf.set_params(predictor='cpu_predictor')
64
65 def rollback(self, change):
66 return change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete'])
67
68 def get_labels(self):
69 classes = {}
70
71 for bug_data in bugzilla.get_bugs():
72 bug_id = int(bug_data['id'])
73
74 for entry in bug_data['history']:
75 for change in entry['changes']:
76 if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
77 classes[bug_id] = 1
78
79 if bug_id not in classes:
80 classes[bug_id] = 0
81
82 return classes
83
84 def get_feature_names(self):
85 return self.extraction_pipeline.named_steps['union'].get_feature_names()
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bugbug/models/devdocneeded.py b/bugbug/models/devdocneeded.py
--- a/bugbug/models/devdocneeded.py
+++ b/bugbug/models/devdocneeded.py
@@ -73,7 +73,14 @@
for entry in bug_data['history']:
for change in entry['changes']:
- if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
+ # Bugs that get dev-doc-needed removed from them at some point after it's been added (this suggests a false positive among human-analyzed bugs)
+ if change['field_name'] == 'keywords' and 'dev-doc-needed' in change['removed'] and 'dev-doc-complete' not in change['added']:
+ classes[bug_id] = 0
+ # Bugs that go from dev-doc-needed to dev-doc-complete are guaranteed to be good
+ # Bugs that go from not having dev-doc-needed to having dev-doc-complete are bugs
+ # that were missed by previous scans through content but someone realized it
+ # should have been flagged and updated the docs, found the docs already updated.
+ elif change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):
classes[bug_id] = 1
if bug_id not in classes:
|
{"golden_diff": "diff --git a/bugbug/models/devdocneeded.py b/bugbug/models/devdocneeded.py\n--- a/bugbug/models/devdocneeded.py\n+++ b/bugbug/models/devdocneeded.py\n@@ -73,7 +73,14 @@\n \n for entry in bug_data['history']:\n for change in entry['changes']:\n- if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n+ # Bugs that get dev-doc-needed removed from them at some point after it's been added (this suggests a false positive among human-analyzed bugs)\n+ if change['field_name'] == 'keywords' and 'dev-doc-needed' in change['removed'] and 'dev-doc-complete' not in change['added']:\n+ classes[bug_id] = 0\n+ # Bugs that go from dev-doc-needed to dev-doc-complete are guaranteed to be good\n+ # Bugs that go from not having dev-doc-needed to having dev-doc-complete are bugs\n+ # that were missed by previous scans through content but someone realized it\n+ # should have been flagged and updated the docs, found the docs already updated.\n+ elif change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n classes[bug_id] = 1\n \n if bug_id not in classes:\n", "issue": "In the DevDocNeeded model, consider bugs for which the dev-doc-needed keyword was removed as negative examples\nSee also #79.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport xgboost\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features\nfrom bugbug import bugzilla\nfrom bugbug.model import Model\n\n\nclass DevDocNeededModel(Model):\n def __init__(self, lemmatization=False):\n Model.__init__(self, lemmatization)\n\n self.sampler = RandomUnderSampler(random_state=0)\n\n feature_extractors = [\n bug_features.has_str(),\n bug_features.has_regression_range(),\n bug_features.severity(),\n bug_features.keywords({'dev-doc-needed', 'dev-doc-complete'}),\n bug_features.is_coverity_issue(),\n bug_features.has_crash_signature(),\n bug_features.has_url(),\n bug_features.has_w3c_url(),\n bug_features.has_github_url(),\n bug_features.whiteboard(),\n bug_features.patches(),\n bug_features.landings(),\n bug_features.title(),\n bug_features.product(),\n bug_features.component(),\n\n bug_features.commit_added(),\n bug_features.commit_deleted(),\n bug_features.commit_types(),\n ]\n\n cleanup_functions = [\n bug_features.cleanup_fileref,\n bug_features.cleanup_url,\n bug_features.cleanup_synonyms,\n ]\n\n self.extraction_pipeline = Pipeline([\n ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions, rollback=True, rollback_when=self.rollback, commit_data=True)),\n ('union', ColumnTransformer([\n ('data', DictVectorizer(), 'data'),\n\n ('title', self.text_vectorizer(), 'title'),\n\n ('comments', self.text_vectorizer(), 'comments'),\n ])),\n ])\n\n self.clf = xgboost.XGBClassifier(n_jobs=16)\n self.clf.set_params(predictor='cpu_predictor')\n\n def rollback(self, change):\n return change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete'])\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n bug_id = int(bug_data['id'])\n\n for entry in bug_data['history']:\n for change in entry['changes']:\n if change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n classes[bug_id] = 1\n\n if bug_id not in classes:\n classes[bug_id] = 0\n\n return classes\n\n def get_feature_names(self):\n return self.extraction_pipeline.named_steps['union'].get_feature_names()\n", "path": "bugbug/models/devdocneeded.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This Source Code Form is subject to the terms of the Mozilla Public\n# License, v. 2.0. If a copy of the MPL was not distributed with this file,\n# You can obtain one at http://mozilla.org/MPL/2.0/.\n\nimport xgboost\nfrom imblearn.under_sampling import RandomUnderSampler\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.pipeline import Pipeline\n\nfrom bugbug import bug_features\nfrom bugbug import bugzilla\nfrom bugbug.model import Model\n\n\nclass DevDocNeededModel(Model):\n def __init__(self, lemmatization=False):\n Model.__init__(self, lemmatization)\n\n self.sampler = RandomUnderSampler(random_state=0)\n\n feature_extractors = [\n bug_features.has_str(),\n bug_features.has_regression_range(),\n bug_features.severity(),\n bug_features.keywords({'dev-doc-needed', 'dev-doc-complete'}),\n bug_features.is_coverity_issue(),\n bug_features.has_crash_signature(),\n bug_features.has_url(),\n bug_features.has_w3c_url(),\n bug_features.has_github_url(),\n bug_features.whiteboard(),\n bug_features.patches(),\n bug_features.landings(),\n bug_features.title(),\n bug_features.product(),\n bug_features.component(),\n\n bug_features.commit_added(),\n bug_features.commit_deleted(),\n bug_features.commit_types(),\n ]\n\n cleanup_functions = [\n bug_features.cleanup_fileref,\n bug_features.cleanup_url,\n bug_features.cleanup_synonyms,\n ]\n\n self.extraction_pipeline = Pipeline([\n ('bug_extractor', bug_features.BugExtractor(feature_extractors, cleanup_functions, rollback=True, rollback_when=self.rollback, commit_data=True)),\n ('union', ColumnTransformer([\n ('data', DictVectorizer(), 'data'),\n\n ('title', self.text_vectorizer(), 'title'),\n\n ('comments', self.text_vectorizer(), 'comments'),\n ])),\n ])\n\n self.clf = xgboost.XGBClassifier(n_jobs=16)\n self.clf.set_params(predictor='cpu_predictor')\n\n def rollback(self, change):\n return change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete'])\n\n def get_labels(self):\n classes = {}\n\n for bug_data in bugzilla.get_bugs():\n bug_id = int(bug_data['id'])\n\n for entry in bug_data['history']:\n for change in entry['changes']:\n # Bugs that get dev-doc-needed removed from them at some point after it's been added (this suggests a false positive among human-analyzed bugs)\n if change['field_name'] == 'keywords' and 'dev-doc-needed' in change['removed'] and 'dev-doc-complete' not in change['added']:\n classes[bug_id] = 0\n # Bugs that go from dev-doc-needed to dev-doc-complete are guaranteed to be good\n # Bugs that go from not having dev-doc-needed to having dev-doc-complete are bugs\n # that were missed by previous scans through content but someone realized it\n # should have been flagged and updated the docs, found the docs already updated.\n elif change['field_name'] == 'keywords' and any(keyword in change['added'] for keyword in ['dev-doc-needed', 'dev-doc-complete']):\n classes[bug_id] = 1\n\n if bug_id not in classes:\n classes[bug_id] = 0\n\n return classes\n\n def get_feature_names(self):\n return self.extraction_pipeline.named_steps['union'].get_feature_names()\n", "path": "bugbug/models/devdocneeded.py"}]}
| 1,080 | 311 |
gh_patches_debug_34208
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-353
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Grade preview
There must be an option for FSR members to see the grades for a course before publishing it.
This should be available in "in evaluation", "evaluated" and "reviewed".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/results/views.py`
Content:
```
1 from django.conf import settings
2 from django.http import HttpResponse
3 from django.shortcuts import get_object_or_404, render_to_response
4 from django.template import RequestContext
5 from django.utils.translation import get_language
6
7 from evap.evaluation.auth import login_required, fsr_required
8 from evap.evaluation.models import Semester
9 from evap.evaluation.tools import calculate_results, calculate_average_and_medium_grades, TextResult, can_publish_grades
10
11 from evap.results.exporters import ExcelExporter
12
13
14 @login_required
15 def index(request):
16 semesters = Semester.get_all_with_published_courses()
17
18 return render_to_response(
19 "results_index.html",
20 dict(semesters=semesters),
21 context_instance=RequestContext(request))
22
23
24 @login_required
25 def semester_detail(request, semester_id):
26 semester = get_object_or_404(Semester, id=semester_id)
27 courses = list(semester.course_set.filter(state="published"))
28
29 # annotate each course object with its grades
30 for course in courses:
31 # first, make sure that there are no preexisting grade attributes
32 course.avg_grade, course.med_grade = calculate_average_and_medium_grades(course)
33 course.can_publish_grades = can_publish_grades(course, request.user.is_staff)
34
35 return render_to_response(
36 "results_semester_detail.html",
37 dict(
38 semester=semester,
39 courses=courses
40 ),
41 context_instance=RequestContext(request))
42
43
44 @fsr_required
45 def semester_export(request, semester_id):
46 semester = get_object_or_404(Semester, id=semester_id)
47
48 filename = "Evaluation-%s-%s.xls" % (semester.name, get_language())
49
50 response = HttpResponse(mimetype="application/vnd.ms-excel")
51 response["Content-Disposition"] = "attachment; filename=\"%s\"" % filename
52
53 exporter = ExcelExporter(semester)
54
55 if 'all' in request.GET:
56 exporter.export(response, True)
57 else:
58 exporter.export(response)
59
60 return response
61
62
63 @login_required
64 def course_detail(request, semester_id, course_id):
65 semester = get_object_or_404(Semester, id=semester_id)
66 course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
67
68 sections = calculate_results(course, request.user.is_staff)
69
70 if (request.user.is_staff == False): # if user is not a student representative
71 # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)
72 for section in sections:
73 if not user_can_see_textresults(request.user, course, section):
74 for index, result in list(enumerate(section.results))[::-1]:
75 if isinstance(section.results[index], TextResult):
76 del section.results[index]
77
78 # remove empty sections
79 sections = [section for section in sections if section.results]
80
81 # check whether results are published
82 published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
83
84 # show a publishing warning to fsr members when the results are not publicly available
85 warning = (not published) and request.user.is_staff
86
87 return render_to_response(
88 "results_course_detail.html",
89 dict(
90 course=course,
91 sections=sections,
92 warning=warning
93 ),
94 context_instance=RequestContext(request))
95
96
97 def user_can_see_textresults(user, course, section):
98 if section.contributor == user:
99 return True
100 if course.is_user_responsible_or_delegate(user):
101 return True
102
103 represented_userprofiles = user.represented_users.all()
104 represented_users = [profile.user for profile in represented_userprofiles]
105 if section.contributor in represented_users:
106 return True
107
108 return False
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/results/views.py b/evap/results/views.py
--- a/evap/results/views.py
+++ b/evap/results/views.py
@@ -63,7 +63,13 @@
@login_required
def course_detail(request, semester_id, course_id):
semester = get_object_or_404(Semester, id=semester_id)
- course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
+
+ # staff can see preview of results even when course is not published
+ if request.user.is_staff:
+ course = get_object_or_404(semester.course_set.filter(state__in=['inEvaluation', 'evaluated', 'reviewed', 'published']), id=course_id)
+ # everyone else can only see published results
+ else:
+ course = get_object_or_404(semester.course_set.filter(state="published"), id=course_id)
sections = calculate_results(course, request.user.is_staff)
@@ -78,18 +84,24 @@
# remove empty sections
sections = [section for section in sections if section.results]
- # check whether results are published
- published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
+ # show a warning if course is still in evaluation (for staff preview)
+ evaluation_warning = course.state != 'published'
+
+ # check whether course has a sufficient number of votes for publishing it
+ sufficient_votes = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE
- # show a publishing warning to fsr members when the results are not publicly available
- warning = (not published) and request.user.is_staff
+ # results for a course might not be visible because there are not enough answers
+ # but it can still be "published" e.g. to show the comment results to lecturers
+ # the FSR can still see all results but gets a warning message
+ sufficient_votes_warning = (not sufficient_votes) and request.user.is_staff
return render_to_response(
"results_course_detail.html",
dict(
course=course,
sections=sections,
- warning=warning
+ evaluation_warning=evaluation_warning,
+ sufficient_votes_warning=sufficient_votes_warning
),
context_instance=RequestContext(request))
|
{"golden_diff": "diff --git a/evap/results/views.py b/evap/results/views.py\n--- a/evap/results/views.py\n+++ b/evap/results/views.py\n@@ -63,7 +63,13 @@\n @login_required\n def course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n- course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n+ \n+ # staff can see preview of results even when course is not published\n+ if request.user.is_staff:\n+ course = get_object_or_404(semester.course_set.filter(state__in=['inEvaluation', 'evaluated', 'reviewed', 'published']), id=course_id)\n+ # everyone else can only see published results\n+ else:\n+ course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n \n sections = calculate_results(course, request.user.is_staff)\n \n@@ -78,18 +84,24 @@\n # remove empty sections\n sections = [section for section in sections if section.results]\n \n- # check whether results are published\n- published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n+ # show a warning if course is still in evaluation (for staff preview)\n+ evaluation_warning = course.state != 'published'\n+\n+ # check whether course has a sufficient number of votes for publishing it\n+ sufficient_votes = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n \n- # show a publishing warning to fsr members when the results are not publicly available\n- warning = (not published) and request.user.is_staff\n+ # results for a course might not be visible because there are not enough answers\n+ # but it can still be \"published\" e.g. to show the comment results to lecturers\n+ # the FSR can still see all results but gets a warning message\n+ sufficient_votes_warning = (not sufficient_votes) and request.user.is_staff\n \n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n- warning=warning\n+ evaluation_warning=evaluation_warning,\n+ sufficient_votes_warning=sufficient_votes_warning\n ),\n context_instance=RequestContext(request))\n", "issue": "Grade preview\nThere must be an option for FSR members to see the grades for a course before publishing it.\nThis should be available in \"in evaluation\", \"evaluated\" and \"reviewed\".\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response\nfrom django.template import RequestContext\nfrom django.utils.translation import get_language\n\nfrom evap.evaluation.auth import login_required, fsr_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import calculate_results, calculate_average_and_medium_grades, TextResult, can_publish_grades\n\nfrom evap.results.exporters import ExcelExporter\n\n\n@login_required\ndef index(request):\n semesters = Semester.get_all_with_published_courses()\n\n return render_to_response(\n \"results_index.html\",\n dict(semesters=semesters),\n context_instance=RequestContext(request))\n\n\n@login_required\ndef semester_detail(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n courses = list(semester.course_set.filter(state=\"published\"))\n\n # annotate each course object with its grades\n for course in courses:\n # first, make sure that there are no preexisting grade attributes\n course.avg_grade, course.med_grade = calculate_average_and_medium_grades(course)\n course.can_publish_grades = can_publish_grades(course, request.user.is_staff)\n\n return render_to_response(\n \"results_semester_detail.html\",\n dict(\n semester=semester,\n courses=courses\n ),\n context_instance=RequestContext(request))\n\n\n@fsr_required\ndef semester_export(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n\n filename = \"Evaluation-%s-%s.xls\" % (semester.name, get_language())\n\n response = HttpResponse(mimetype=\"application/vnd.ms-excel\")\n response[\"Content-Disposition\"] = \"attachment; filename=\\\"%s\\\"\" % filename\n\n exporter = ExcelExporter(semester)\n\n if 'all' in request.GET:\n exporter.export(response, True)\n else:\n exporter.export(response)\n\n return response\n\n\n@login_required\ndef course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n\n sections = calculate_results(course, request.user.is_staff)\n\n if (request.user.is_staff == False): # if user is not a student representative\n # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)\n for section in sections:\n if not user_can_see_textresults(request.user, course, section):\n for index, result in list(enumerate(section.results))[::-1]:\n if isinstance(section.results[index], TextResult):\n del section.results[index]\n\n # remove empty sections\n sections = [section for section in sections if section.results]\n\n # check whether results are published\n published = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n\n # show a publishing warning to fsr members when the results are not publicly available\n warning = (not published) and request.user.is_staff\n\n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n warning=warning\n ),\n context_instance=RequestContext(request))\n\n\ndef user_can_see_textresults(user, course, section):\n if section.contributor == user:\n return True\n if course.is_user_responsible_or_delegate(user):\n return True\n\n represented_userprofiles = user.represented_users.all()\n represented_users = [profile.user for profile in represented_userprofiles]\n if section.contributor in represented_users:\n return True\n\n return False\n", "path": "evap/results/views.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response\nfrom django.template import RequestContext\nfrom django.utils.translation import get_language\n\nfrom evap.evaluation.auth import login_required, fsr_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import calculate_results, calculate_average_and_medium_grades, TextResult, can_publish_grades\n\nfrom evap.results.exporters import ExcelExporter\n\n\n@login_required\ndef index(request):\n semesters = Semester.get_all_with_published_courses()\n\n return render_to_response(\n \"results_index.html\",\n dict(semesters=semesters),\n context_instance=RequestContext(request))\n\n\n@login_required\ndef semester_detail(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n courses = list(semester.course_set.filter(state=\"published\"))\n\n # annotate each course object with its grades\n for course in courses:\n # first, make sure that there are no preexisting grade attributes\n course.avg_grade, course.med_grade = calculate_average_and_medium_grades(course)\n course.can_publish_grades = can_publish_grades(course, request.user.is_staff)\n\n return render_to_response(\n \"results_semester_detail.html\",\n dict(\n semester=semester,\n courses=courses\n ),\n context_instance=RequestContext(request))\n\n\n@fsr_required\ndef semester_export(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n\n filename = \"Evaluation-%s-%s.xls\" % (semester.name, get_language())\n\n response = HttpResponse(mimetype=\"application/vnd.ms-excel\")\n response[\"Content-Disposition\"] = \"attachment; filename=\\\"%s\\\"\" % filename\n\n exporter = ExcelExporter(semester)\n\n if 'all' in request.GET:\n exporter.export(response, True)\n else:\n exporter.export(response)\n\n return response\n\n\n@login_required\ndef course_detail(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n \n # staff can see preview of results even when course is not published\n if request.user.is_staff:\n course = get_object_or_404(semester.course_set.filter(state__in=['inEvaluation', 'evaluated', 'reviewed', 'published']), id=course_id)\n # everyone else can only see published results\n else:\n course = get_object_or_404(semester.course_set.filter(state=\"published\"), id=course_id)\n\n sections = calculate_results(course, request.user.is_staff)\n\n if (request.user.is_staff == False): # if user is not a student representative\n # remove TextResults if user is neither the evaluated person (or a delegate) nor responsible for the course (or a delegate)\n for section in sections:\n if not user_can_see_textresults(request.user, course, section):\n for index, result in list(enumerate(section.results))[::-1]:\n if isinstance(section.results[index], TextResult):\n del section.results[index]\n\n # remove empty sections\n sections = [section for section in sections if section.results]\n\n # show a warning if course is still in evaluation (for staff preview)\n evaluation_warning = course.state != 'published'\n\n # check whether course has a sufficient number of votes for publishing it\n sufficient_votes = course.num_voters >= settings.MIN_ANSWER_COUNT and float(course.num_voters) / course.num_participants >= settings.MIN_ANSWER_PERCENTAGE\n\n # results for a course might not be visible because there are not enough answers\n # but it can still be \"published\" e.g. to show the comment results to lecturers\n # the FSR can still see all results but gets a warning message\n sufficient_votes_warning = (not sufficient_votes) and request.user.is_staff\n\n return render_to_response(\n \"results_course_detail.html\",\n dict(\n course=course,\n sections=sections,\n evaluation_warning=evaluation_warning,\n sufficient_votes_warning=sufficient_votes_warning\n ),\n context_instance=RequestContext(request))\n\n\ndef user_can_see_textresults(user, course, section):\n if section.contributor == user:\n return True\n if course.is_user_responsible_or_delegate(user):\n return True\n\n represented_userprofiles = user.represented_users.all()\n represented_users = [profile.user for profile in represented_userprofiles]\n if section.contributor in represented_users:\n return True\n\n return False\n", "path": "evap/results/views.py"}]}
| 1,343 | 552 |
gh_patches_debug_33395
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-4092
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Commands] `ctx.tick()` - add optional message to send when bot can't react
# Feature request
#### Select the type of feature you are requesting:
- [ ] Cog
- [ ] Command
- [x] API functionality
#### Describe your requested feature
Change function definition of `ctx.tick()` to:
```py
async def tick(self, message: Optional[str] = None) -> bool:
```
So that we can set an optional message that will be sent if bot is unable to send the reaction. We could also make it possible through `ctx.react_quietly()` as well
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redbot/core/commands/context.py`
Content:
```
1 from __future__ import annotations
2
3 import asyncio
4 import contextlib
5 import os
6 import re
7 from typing import Iterable, List, Union, Optional, TYPE_CHECKING
8 import discord
9 from discord.ext.commands import Context as DPYContext
10
11 from .requires import PermState
12 from ..utils.chat_formatting import box
13 from ..utils.predicates import MessagePredicate
14 from ..utils import common_filters
15
16 if TYPE_CHECKING:
17 from .commands import Command
18 from ..bot import Red
19
20 TICK = "\N{WHITE HEAVY CHECK MARK}"
21
22 __all__ = ["Context", "GuildContext", "DMContext"]
23
24
25 class Context(DPYContext):
26 """Command invocation context for Red.
27
28 All context passed into commands will be of this type.
29
30 This class inherits from `discord.ext.commands.Context`.
31
32 Attributes
33 ----------
34 assume_yes: bool
35 Whether or not interactive checks should
36 be skipped and assumed to be confirmed.
37
38 This is intended for allowing automation of tasks.
39
40 An example of this would be scheduled commands
41 not requiring interaction if the cog developer
42 checks this value prior to confirming something interactively.
43
44 Depending on the potential impact of a command,
45 it may still be appropriate not to use this setting.
46 permission_state: PermState
47 The permission state the current context is in.
48 """
49
50 command: "Command"
51 invoked_subcommand: "Optional[Command]"
52 bot: "Red"
53
54 def __init__(self, **attrs):
55 self.assume_yes = attrs.pop("assume_yes", False)
56 super().__init__(**attrs)
57 self.permission_state: PermState = PermState.NORMAL
58
59 async def send(self, content=None, **kwargs):
60 """Sends a message to the destination with the content given.
61
62 This acts the same as `discord.ext.commands.Context.send`, with
63 one added keyword argument as detailed below in *Other Parameters*.
64
65 Parameters
66 ----------
67 content : str
68 The content of the message to send.
69
70 Other Parameters
71 ----------------
72 filter : callable (`str`) -> `str`, optional
73 A function which is used to filter the ``content`` before
74 it is sent.
75 This must take a single `str` as an argument, and return
76 the processed `str`. When `None` is passed, ``content`` won't be touched.
77 Defaults to `None`.
78 **kwargs
79 See `discord.ext.commands.Context.send`.
80
81 Returns
82 -------
83 discord.Message
84 The message that was sent.
85
86 """
87
88 _filter = kwargs.pop("filter", None)
89
90 if _filter and content:
91 content = _filter(str(content))
92
93 return await super().send(content=content, **kwargs)
94
95 async def send_help(self, command=None):
96 """ Send the command help message. """
97 # This allows people to manually use this similarly
98 # to the upstream d.py version, while retaining our use.
99 command = command or self.command
100 await self.bot.send_help_for(self, command)
101
102 async def tick(self) -> bool:
103 """Add a tick reaction to the command message.
104
105 Returns
106 -------
107 bool
108 :code:`True` if adding the reaction succeeded.
109
110 """
111 try:
112 await self.message.add_reaction(TICK)
113 except discord.HTTPException:
114 return False
115 else:
116 return True
117
118 async def react_quietly(
119 self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
120 ) -> bool:
121 """Adds a reaction to the command message.
122
123 Returns
124 -------
125 bool
126 :code:`True` if adding the reaction succeeded.
127 """
128 try:
129 await self.message.add_reaction(reaction)
130 except discord.HTTPException:
131 return False
132 else:
133 return True
134
135 async def send_interactive(
136 self, messages: Iterable[str], box_lang: str = None, timeout: int = 15
137 ) -> List[discord.Message]:
138 """Send multiple messages interactively.
139
140 The user will be prompted for whether or not they would like to view
141 the next message, one at a time. They will also be notified of how
142 many messages are remaining on each prompt.
143
144 Parameters
145 ----------
146 messages : `iterable` of `str`
147 The messages to send.
148 box_lang : str
149 If specified, each message will be contained within a codeblock of
150 this language.
151 timeout : int
152 How long the user has to respond to the prompt before it times out.
153 After timing out, the bot deletes its prompt message.
154
155 """
156 messages = tuple(messages)
157 ret = []
158
159 for idx, page in enumerate(messages, 1):
160 if box_lang is None:
161 msg = await self.send(page)
162 else:
163 msg = await self.send(box(page, lang=box_lang))
164 ret.append(msg)
165 n_remaining = len(messages) - idx
166 if n_remaining > 0:
167 if n_remaining == 1:
168 plural = ""
169 is_are = "is"
170 else:
171 plural = "s"
172 is_are = "are"
173 query = await self.send(
174 "There {} still {} message{} remaining. "
175 "Type `more` to continue."
176 "".format(is_are, n_remaining, plural)
177 )
178 try:
179 resp = await self.bot.wait_for(
180 "message",
181 check=MessagePredicate.lower_equal_to("more", self),
182 timeout=timeout,
183 )
184 except asyncio.TimeoutError:
185 with contextlib.suppress(discord.HTTPException):
186 await query.delete()
187 break
188 else:
189 try:
190 await self.channel.delete_messages((query, resp))
191 except (discord.HTTPException, AttributeError):
192 # In case the bot can't delete other users' messages,
193 # or is not a bot account
194 # or channel is a DM
195 with contextlib.suppress(discord.HTTPException):
196 await query.delete()
197 return ret
198
199 async def embed_colour(self):
200 """
201 Helper function to get the colour for an embed.
202
203 Returns
204 -------
205 discord.Colour:
206 The colour to be used
207 """
208 return await self.bot.get_embed_color(self)
209
210 @property
211 def embed_color(self):
212 # Rather than double awaiting.
213 return self.embed_colour
214
215 async def embed_requested(self):
216 """
217 Simple helper to call bot.embed_requested
218 with logic around if embed permissions are available
219
220 Returns
221 -------
222 bool:
223 :code:`True` if an embed is requested
224 """
225 if self.guild and not self.channel.permissions_for(self.guild.me).embed_links:
226 return False
227 return await self.bot.embed_requested(self.channel, self.author, command=self.command)
228
229 async def maybe_send_embed(self, message: str) -> discord.Message:
230 """
231 Simple helper to send a simple message to context
232 without manually checking ctx.embed_requested
233 This should only be used for simple messages.
234
235 Parameters
236 ----------
237 message: `str`
238 The string to send
239
240 Returns
241 -------
242 discord.Message:
243 the message which was sent
244
245 Raises
246 ------
247 discord.Forbidden
248 see `discord.abc.Messageable.send`
249 discord.HTTPException
250 see `discord.abc.Messageable.send`
251 ValueError
252 when the message's length is not between 1 and 2000 characters.
253 """
254 if not message or len(message) > 2000:
255 raise ValueError("Message length must be between 1 and 2000")
256 if await self.embed_requested():
257 return await self.send(
258 embed=discord.Embed(description=message, color=(await self.embed_colour()))
259 )
260 else:
261 return await self.send(
262 message,
263 allowed_mentions=discord.AllowedMentions(everyone=False, roles=False, users=False),
264 )
265
266 @property
267 def clean_prefix(self) -> str:
268 """
269 str: The command prefix, but with a sanitized version of the bot's mention if it was used as prefix.
270 This can be used in a context where discord user mentions might not render properly.
271 """
272 me = self.me
273 pattern = re.compile(rf"<@!?{me.id}>")
274 return pattern.sub(f"@{me.display_name}".replace("\\", r"\\"), self.prefix)
275
276 @property
277 def me(self) -> Union[discord.ClientUser, discord.Member]:
278 """
279 discord.abc.User: The bot member or user object.
280
281 If the context is DM, this will be a `discord.User` object.
282 """
283 if self.guild is not None:
284 return self.guild.me
285 else:
286 return self.bot.user
287
288
289 if TYPE_CHECKING or os.getenv("BUILDING_DOCS", False):
290
291 class DMContext(Context):
292 """
293 At runtime, this will still be a normal context object.
294
295 This lies about some type narrowing for type analysis in commands
296 using a dm_only decorator.
297
298 It is only correct to use when those types are already narrowed
299 """
300
301 @property
302 def author(self) -> discord.User:
303 ...
304
305 @property
306 def channel(self) -> discord.DMChannel:
307 ...
308
309 @property
310 def guild(self) -> None:
311 ...
312
313 @property
314 def me(self) -> discord.ClientUser:
315 ...
316
317 class GuildContext(Context):
318 """
319 At runtime, this will still be a normal context object.
320
321 This lies about some type narrowing for type analysis in commands
322 using a guild_only decorator.
323
324 It is only correct to use when those types are already narrowed
325 """
326
327 @property
328 def author(self) -> discord.Member:
329 ...
330
331 @property
332 def channel(self) -> discord.TextChannel:
333 ...
334
335 @property
336 def guild(self) -> discord.Guild:
337 ...
338
339 @property
340 def me(self) -> discord.Member:
341 ...
342
343
344 else:
345 GuildContext = Context
346 DMContext = Context
347
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redbot/core/commands/context.py b/redbot/core/commands/context.py
--- a/redbot/core/commands/context.py
+++ b/redbot/core/commands/context.py
@@ -99,35 +99,52 @@
command = command or self.command
await self.bot.send_help_for(self, command)
- async def tick(self) -> bool:
+ async def tick(self, *, message: Optional[str] = None) -> bool:
"""Add a tick reaction to the command message.
+ Keyword Arguments
+ -----------------
+ message : str, optional
+ The message to send if adding the reaction doesn't succeed.
+
Returns
-------
bool
:code:`True` if adding the reaction succeeded.
"""
- try:
- await self.message.add_reaction(TICK)
- except discord.HTTPException:
- return False
- else:
- return True
+ return await self.react_quietly(TICK, message=message)
async def react_quietly(
- self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
+ self,
+ reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str],
+ *,
+ message: Optional[str] = None,
) -> bool:
"""Adds a reaction to the command message.
+ Parameters
+ ----------
+ reaction : Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]
+ The emoji to react with.
+
+ Keyword Arguments
+ -----------------
+ message : str, optional
+ The message to send if adding the reaction doesn't succeed.
+
Returns
-------
bool
:code:`True` if adding the reaction succeeded.
"""
try:
+ if not self.channel.permissions_for(self.me).add_reactions:
+ raise RuntimeError
await self.message.add_reaction(reaction)
- except discord.HTTPException:
+ except (RuntimeError, discord.HTTPException):
+ if message is not None:
+ await self.send(message)
return False
else:
return True
|
{"golden_diff": "diff --git a/redbot/core/commands/context.py b/redbot/core/commands/context.py\n--- a/redbot/core/commands/context.py\n+++ b/redbot/core/commands/context.py\n@@ -99,35 +99,52 @@\n command = command or self.command\n await self.bot.send_help_for(self, command)\n \n- async def tick(self) -> bool:\n+ async def tick(self, *, message: Optional[str] = None) -> bool:\n \"\"\"Add a tick reaction to the command message.\n \n+ Keyword Arguments\n+ -----------------\n+ message : str, optional\n+ The message to send if adding the reaction doesn't succeed.\n+\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \n \"\"\"\n- try:\n- await self.message.add_reaction(TICK)\n- except discord.HTTPException:\n- return False\n- else:\n- return True\n+ return await self.react_quietly(TICK, message=message)\n \n async def react_quietly(\n- self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n+ self,\n+ reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str],\n+ *,\n+ message: Optional[str] = None,\n ) -> bool:\n \"\"\"Adds a reaction to the command message.\n \n+ Parameters\n+ ----------\n+ reaction : Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n+ The emoji to react with.\n+\n+ Keyword Arguments\n+ -----------------\n+ message : str, optional\n+ The message to send if adding the reaction doesn't succeed.\n+\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \"\"\"\n try:\n+ if not self.channel.permissions_for(self.me).add_reactions:\n+ raise RuntimeError\n await self.message.add_reaction(reaction)\n- except discord.HTTPException:\n+ except (RuntimeError, discord.HTTPException):\n+ if message is not None:\n+ await self.send(message)\n return False\n else:\n return True\n", "issue": "[Commands] `ctx.tick()` - add optional message to send when bot can't react\n# Feature request\r\n\r\n#### Select the type of feature you are requesting:\r\n\r\n- [ ] Cog\r\n- [ ] Command\r\n- [x] API functionality\r\n\r\n#### Describe your requested feature\r\n\r\nChange function definition of `ctx.tick()` to:\r\n```py\r\nasync def tick(self, message: Optional[str] = None) -> bool:\r\n```\r\nSo that we can set an optional message that will be sent if bot is unable to send the reaction. We could also make it possible through `ctx.react_quietly()` as well\n", "before_files": [{"content": "from __future__ import annotations\n\nimport asyncio\nimport contextlib\nimport os\nimport re\nfrom typing import Iterable, List, Union, Optional, TYPE_CHECKING\nimport discord\nfrom discord.ext.commands import Context as DPYContext\n\nfrom .requires import PermState\nfrom ..utils.chat_formatting import box\nfrom ..utils.predicates import MessagePredicate\nfrom ..utils import common_filters\n\nif TYPE_CHECKING:\n from .commands import Command\n from ..bot import Red\n\nTICK = \"\\N{WHITE HEAVY CHECK MARK}\"\n\n__all__ = [\"Context\", \"GuildContext\", \"DMContext\"]\n\n\nclass Context(DPYContext):\n \"\"\"Command invocation context for Red.\n\n All context passed into commands will be of this type.\n\n This class inherits from `discord.ext.commands.Context`.\n\n Attributes\n ----------\n assume_yes: bool\n Whether or not interactive checks should\n be skipped and assumed to be confirmed.\n\n This is intended for allowing automation of tasks.\n\n An example of this would be scheduled commands\n not requiring interaction if the cog developer\n checks this value prior to confirming something interactively.\n\n Depending on the potential impact of a command,\n it may still be appropriate not to use this setting.\n permission_state: PermState\n The permission state the current context is in.\n \"\"\"\n\n command: \"Command\"\n invoked_subcommand: \"Optional[Command]\"\n bot: \"Red\"\n\n def __init__(self, **attrs):\n self.assume_yes = attrs.pop(\"assume_yes\", False)\n super().__init__(**attrs)\n self.permission_state: PermState = PermState.NORMAL\n\n async def send(self, content=None, **kwargs):\n \"\"\"Sends a message to the destination with the content given.\n\n This acts the same as `discord.ext.commands.Context.send`, with\n one added keyword argument as detailed below in *Other Parameters*.\n\n Parameters\n ----------\n content : str\n The content of the message to send.\n\n Other Parameters\n ----------------\n filter : callable (`str`) -> `str`, optional\n A function which is used to filter the ``content`` before\n it is sent.\n This must take a single `str` as an argument, and return\n the processed `str`. When `None` is passed, ``content`` won't be touched.\n Defaults to `None`.\n **kwargs\n See `discord.ext.commands.Context.send`.\n\n Returns\n -------\n discord.Message\n The message that was sent.\n\n \"\"\"\n\n _filter = kwargs.pop(\"filter\", None)\n\n if _filter and content:\n content = _filter(str(content))\n\n return await super().send(content=content, **kwargs)\n\n async def send_help(self, command=None):\n \"\"\" Send the command help message. \"\"\"\n # This allows people to manually use this similarly\n # to the upstream d.py version, while retaining our use.\n command = command or self.command\n await self.bot.send_help_for(self, command)\n\n async def tick(self) -> bool:\n \"\"\"Add a tick reaction to the command message.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n\n \"\"\"\n try:\n await self.message.add_reaction(TICK)\n except discord.HTTPException:\n return False\n else:\n return True\n\n async def react_quietly(\n self, reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n ) -> bool:\n \"\"\"Adds a reaction to the command message.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \"\"\"\n try:\n await self.message.add_reaction(reaction)\n except discord.HTTPException:\n return False\n else:\n return True\n\n async def send_interactive(\n self, messages: Iterable[str], box_lang: str = None, timeout: int = 15\n ) -> List[discord.Message]:\n \"\"\"Send multiple messages interactively.\n\n The user will be prompted for whether or not they would like to view\n the next message, one at a time. They will also be notified of how\n many messages are remaining on each prompt.\n\n Parameters\n ----------\n messages : `iterable` of `str`\n The messages to send.\n box_lang : str\n If specified, each message will be contained within a codeblock of\n this language.\n timeout : int\n How long the user has to respond to the prompt before it times out.\n After timing out, the bot deletes its prompt message.\n\n \"\"\"\n messages = tuple(messages)\n ret = []\n\n for idx, page in enumerate(messages, 1):\n if box_lang is None:\n msg = await self.send(page)\n else:\n msg = await self.send(box(page, lang=box_lang))\n ret.append(msg)\n n_remaining = len(messages) - idx\n if n_remaining > 0:\n if n_remaining == 1:\n plural = \"\"\n is_are = \"is\"\n else:\n plural = \"s\"\n is_are = \"are\"\n query = await self.send(\n \"There {} still {} message{} remaining. \"\n \"Type `more` to continue.\"\n \"\".format(is_are, n_remaining, plural)\n )\n try:\n resp = await self.bot.wait_for(\n \"message\",\n check=MessagePredicate.lower_equal_to(\"more\", self),\n timeout=timeout,\n )\n except asyncio.TimeoutError:\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n break\n else:\n try:\n await self.channel.delete_messages((query, resp))\n except (discord.HTTPException, AttributeError):\n # In case the bot can't delete other users' messages,\n # or is not a bot account\n # or channel is a DM\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n return ret\n\n async def embed_colour(self):\n \"\"\"\n Helper function to get the colour for an embed.\n\n Returns\n -------\n discord.Colour:\n The colour to be used\n \"\"\"\n return await self.bot.get_embed_color(self)\n\n @property\n def embed_color(self):\n # Rather than double awaiting.\n return self.embed_colour\n\n async def embed_requested(self):\n \"\"\"\n Simple helper to call bot.embed_requested\n with logic around if embed permissions are available\n\n Returns\n -------\n bool:\n :code:`True` if an embed is requested\n \"\"\"\n if self.guild and not self.channel.permissions_for(self.guild.me).embed_links:\n return False\n return await self.bot.embed_requested(self.channel, self.author, command=self.command)\n\n async def maybe_send_embed(self, message: str) -> discord.Message:\n \"\"\"\n Simple helper to send a simple message to context\n without manually checking ctx.embed_requested\n This should only be used for simple messages.\n\n Parameters\n ----------\n message: `str`\n The string to send\n\n Returns\n -------\n discord.Message:\n the message which was sent\n\n Raises\n ------\n discord.Forbidden\n see `discord.abc.Messageable.send`\n discord.HTTPException\n see `discord.abc.Messageable.send`\n ValueError\n when the message's length is not between 1 and 2000 characters.\n \"\"\"\n if not message or len(message) > 2000:\n raise ValueError(\"Message length must be between 1 and 2000\")\n if await self.embed_requested():\n return await self.send(\n embed=discord.Embed(description=message, color=(await self.embed_colour()))\n )\n else:\n return await self.send(\n message,\n allowed_mentions=discord.AllowedMentions(everyone=False, roles=False, users=False),\n )\n\n @property\n def clean_prefix(self) -> str:\n \"\"\"\n str: The command prefix, but with a sanitized version of the bot's mention if it was used as prefix.\n This can be used in a context where discord user mentions might not render properly.\n \"\"\"\n me = self.me\n pattern = re.compile(rf\"<@!?{me.id}>\")\n return pattern.sub(f\"@{me.display_name}\".replace(\"\\\\\", r\"\\\\\"), self.prefix)\n\n @property\n def me(self) -> Union[discord.ClientUser, discord.Member]:\n \"\"\"\n discord.abc.User: The bot member or user object.\n\n If the context is DM, this will be a `discord.User` object.\n \"\"\"\n if self.guild is not None:\n return self.guild.me\n else:\n return self.bot.user\n\n\nif TYPE_CHECKING or os.getenv(\"BUILDING_DOCS\", False):\n\n class DMContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a dm_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.User:\n ...\n\n @property\n def channel(self) -> discord.DMChannel:\n ...\n\n @property\n def guild(self) -> None:\n ...\n\n @property\n def me(self) -> discord.ClientUser:\n ...\n\n class GuildContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a guild_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.Member:\n ...\n\n @property\n def channel(self) -> discord.TextChannel:\n ...\n\n @property\n def guild(self) -> discord.Guild:\n ...\n\n @property\n def me(self) -> discord.Member:\n ...\n\n\nelse:\n GuildContext = Context\n DMContext = Context\n", "path": "redbot/core/commands/context.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport asyncio\nimport contextlib\nimport os\nimport re\nfrom typing import Iterable, List, Union, Optional, TYPE_CHECKING\nimport discord\nfrom discord.ext.commands import Context as DPYContext\n\nfrom .requires import PermState\nfrom ..utils.chat_formatting import box\nfrom ..utils.predicates import MessagePredicate\nfrom ..utils import common_filters\n\nif TYPE_CHECKING:\n from .commands import Command\n from ..bot import Red\n\nTICK = \"\\N{WHITE HEAVY CHECK MARK}\"\n\n__all__ = [\"Context\", \"GuildContext\", \"DMContext\"]\n\n\nclass Context(DPYContext):\n \"\"\"Command invocation context for Red.\n\n All context passed into commands will be of this type.\n\n This class inherits from `discord.ext.commands.Context`.\n\n Attributes\n ----------\n assume_yes: bool\n Whether or not interactive checks should\n be skipped and assumed to be confirmed.\n\n This is intended for allowing automation of tasks.\n\n An example of this would be scheduled commands\n not requiring interaction if the cog developer\n checks this value prior to confirming something interactively.\n\n Depending on the potential impact of a command,\n it may still be appropriate not to use this setting.\n permission_state: PermState\n The permission state the current context is in.\n \"\"\"\n\n command: \"Command\"\n invoked_subcommand: \"Optional[Command]\"\n bot: \"Red\"\n\n def __init__(self, **attrs):\n self.assume_yes = attrs.pop(\"assume_yes\", False)\n super().__init__(**attrs)\n self.permission_state: PermState = PermState.NORMAL\n\n async def send(self, content=None, **kwargs):\n \"\"\"Sends a message to the destination with the content given.\n\n This acts the same as `discord.ext.commands.Context.send`, with\n one added keyword argument as detailed below in *Other Parameters*.\n\n Parameters\n ----------\n content : str\n The content of the message to send.\n\n Other Parameters\n ----------------\n filter : callable (`str`) -> `str`, optional\n A function which is used to filter the ``content`` before\n it is sent.\n This must take a single `str` as an argument, and return\n the processed `str`. When `None` is passed, ``content`` won't be touched.\n Defaults to `None`.\n **kwargs\n See `discord.ext.commands.Context.send`.\n\n Returns\n -------\n discord.Message\n The message that was sent.\n\n \"\"\"\n\n _filter = kwargs.pop(\"filter\", None)\n\n if _filter and content:\n content = _filter(str(content))\n\n return await super().send(content=content, **kwargs)\n\n async def send_help(self, command=None):\n \"\"\" Send the command help message. \"\"\"\n # This allows people to manually use this similarly\n # to the upstream d.py version, while retaining our use.\n command = command or self.command\n await self.bot.send_help_for(self, command)\n\n async def tick(self, *, message: Optional[str] = None) -> bool:\n \"\"\"Add a tick reaction to the command message.\n\n Keyword Arguments\n -----------------\n message : str, optional\n The message to send if adding the reaction doesn't succeed.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n\n \"\"\"\n return await self.react_quietly(TICK, message=message)\n\n async def react_quietly(\n self,\n reaction: Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str],\n *,\n message: Optional[str] = None,\n ) -> bool:\n \"\"\"Adds a reaction to the command message.\n\n Parameters\n ----------\n reaction : Union[discord.Emoji, discord.Reaction, discord.PartialEmoji, str]\n The emoji to react with.\n\n Keyword Arguments\n -----------------\n message : str, optional\n The message to send if adding the reaction doesn't succeed.\n\n Returns\n -------\n bool\n :code:`True` if adding the reaction succeeded.\n \"\"\"\n try:\n if not self.channel.permissions_for(self.me).add_reactions:\n raise RuntimeError\n await self.message.add_reaction(reaction)\n except (RuntimeError, discord.HTTPException):\n if message is not None:\n await self.send(message)\n return False\n else:\n return True\n\n async def send_interactive(\n self, messages: Iterable[str], box_lang: str = None, timeout: int = 15\n ) -> List[discord.Message]:\n \"\"\"Send multiple messages interactively.\n\n The user will be prompted for whether or not they would like to view\n the next message, one at a time. They will also be notified of how\n many messages are remaining on each prompt.\n\n Parameters\n ----------\n messages : `iterable` of `str`\n The messages to send.\n box_lang : str\n If specified, each message will be contained within a codeblock of\n this language.\n timeout : int\n How long the user has to respond to the prompt before it times out.\n After timing out, the bot deletes its prompt message.\n\n \"\"\"\n messages = tuple(messages)\n ret = []\n\n for idx, page in enumerate(messages, 1):\n if box_lang is None:\n msg = await self.send(page)\n else:\n msg = await self.send(box(page, lang=box_lang))\n ret.append(msg)\n n_remaining = len(messages) - idx\n if n_remaining > 0:\n if n_remaining == 1:\n plural = \"\"\n is_are = \"is\"\n else:\n plural = \"s\"\n is_are = \"are\"\n query = await self.send(\n \"There {} still {} message{} remaining. \"\n \"Type `more` to continue.\"\n \"\".format(is_are, n_remaining, plural)\n )\n try:\n resp = await self.bot.wait_for(\n \"message\",\n check=MessagePredicate.lower_equal_to(\"more\", self),\n timeout=timeout,\n )\n except asyncio.TimeoutError:\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n break\n else:\n try:\n await self.channel.delete_messages((query, resp))\n except (discord.HTTPException, AttributeError):\n # In case the bot can't delete other users' messages,\n # or is not a bot account\n # or channel is a DM\n with contextlib.suppress(discord.HTTPException):\n await query.delete()\n return ret\n\n async def embed_colour(self):\n \"\"\"\n Helper function to get the colour for an embed.\n\n Returns\n -------\n discord.Colour:\n The colour to be used\n \"\"\"\n return await self.bot.get_embed_color(self)\n\n @property\n def embed_color(self):\n # Rather than double awaiting.\n return self.embed_colour\n\n async def embed_requested(self):\n \"\"\"\n Simple helper to call bot.embed_requested\n with logic around if embed permissions are available\n\n Returns\n -------\n bool:\n :code:`True` if an embed is requested\n \"\"\"\n if self.guild and not self.channel.permissions_for(self.guild.me).embed_links:\n return False\n return await self.bot.embed_requested(self.channel, self.author, command=self.command)\n\n async def maybe_send_embed(self, message: str) -> discord.Message:\n \"\"\"\n Simple helper to send a simple message to context\n without manually checking ctx.embed_requested\n This should only be used for simple messages.\n\n Parameters\n ----------\n message: `str`\n The string to send\n\n Returns\n -------\n discord.Message:\n the message which was sent\n\n Raises\n ------\n discord.Forbidden\n see `discord.abc.Messageable.send`\n discord.HTTPException\n see `discord.abc.Messageable.send`\n ValueError\n when the message's length is not between 1 and 2000 characters.\n \"\"\"\n if not message or len(message) > 2000:\n raise ValueError(\"Message length must be between 1 and 2000\")\n if await self.embed_requested():\n return await self.send(\n embed=discord.Embed(description=message, color=(await self.embed_colour()))\n )\n else:\n return await self.send(\n message,\n allowed_mentions=discord.AllowedMentions(everyone=False, roles=False, users=False),\n )\n\n @property\n def clean_prefix(self) -> str:\n \"\"\"\n str: The command prefix, but with a sanitized version of the bot's mention if it was used as prefix.\n This can be used in a context where discord user mentions might not render properly.\n \"\"\"\n me = self.me\n pattern = re.compile(rf\"<@!?{me.id}>\")\n return pattern.sub(f\"@{me.display_name}\".replace(\"\\\\\", r\"\\\\\"), self.prefix)\n\n @property\n def me(self) -> Union[discord.ClientUser, discord.Member]:\n \"\"\"\n discord.abc.User: The bot member or user object.\n\n If the context is DM, this will be a `discord.User` object.\n \"\"\"\n if self.guild is not None:\n return self.guild.me\n else:\n return self.bot.user\n\n\nif TYPE_CHECKING or os.getenv(\"BUILDING_DOCS\", False):\n\n class DMContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a dm_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.User:\n ...\n\n @property\n def channel(self) -> discord.DMChannel:\n ...\n\n @property\n def guild(self) -> None:\n ...\n\n @property\n def me(self) -> discord.ClientUser:\n ...\n\n class GuildContext(Context):\n \"\"\"\n At runtime, this will still be a normal context object.\n\n This lies about some type narrowing for type analysis in commands\n using a guild_only decorator.\n\n It is only correct to use when those types are already narrowed\n \"\"\"\n\n @property\n def author(self) -> discord.Member:\n ...\n\n @property\n def channel(self) -> discord.TextChannel:\n ...\n\n @property\n def guild(self) -> discord.Guild:\n ...\n\n @property\n def me(self) -> discord.Member:\n ...\n\n\nelse:\n GuildContext = Context\n DMContext = Context\n", "path": "redbot/core/commands/context.py"}]}
| 3,483 | 473 |
gh_patches_debug_58558
|
rasdani/github-patches
|
git_diff
|
roboflow__supervision-219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Developement - version issue
### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
I have not installed `supervision` but running directly for developement purpose.
But I got an following error when I import supervision code:
```
raise PackageNotFoundError(name)
importlib.metadata.PackageNotFoundError: supervision
```
After a quick investigation, it is found that `__init__.py` of `supervision` where version information used. It is creating an issue. If I comment this line and the bug is gone.
@onuralpszr Can you take a look?
I think it should be ignorable, if valid version is not found then use `development` version. Though, I do not have concret idea, how to tackle it.
### Environment
_No response_
### Minimal Reproducible Example
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [X] Yes I'd like to help by submitting a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `supervision/__init__.py`
Content:
```
1 import importlib.metadata as importlib_metadata
2
3 __version__ = importlib_metadata.version(__package__)
4
5
6 from supervision.classification.core import Classifications
7 from supervision.dataset.core import (
8 BaseDataset,
9 ClassificationDataset,
10 DetectionDataset,
11 )
12 from supervision.detection.annotate import BoxAnnotator, MaskAnnotator
13 from supervision.detection.core import Detections
14 from supervision.detection.line_counter import LineZone, LineZoneAnnotator
15 from supervision.detection.tools.polygon_zone import PolygonZone, PolygonZoneAnnotator
16 from supervision.detection.utils import (
17 box_iou_batch,
18 filter_polygons_by_area,
19 mask_to_polygons,
20 mask_to_xyxy,
21 non_max_suppression,
22 polygon_to_mask,
23 polygon_to_xyxy,
24 )
25 from supervision.draw.color import Color, ColorPalette
26 from supervision.draw.utils import draw_filled_rectangle, draw_polygon, draw_text
27 from supervision.geometry.core import Point, Position, Rect
28 from supervision.geometry.utils import get_polygon_center
29 from supervision.metrics.detection import ConfusionMatrix
30 from supervision.utils.file import list_files_with_extensions
31 from supervision.utils.image import ImageSink, crop
32 from supervision.utils.notebook import plot_image, plot_images_grid
33 from supervision.utils.video import (
34 VideoInfo,
35 VideoSink,
36 get_video_frames_generator,
37 process_video,
38 )
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/supervision/__init__.py b/supervision/__init__.py
--- a/supervision/__init__.py
+++ b/supervision/__init__.py
@@ -1,6 +1,10 @@
import importlib.metadata as importlib_metadata
-__version__ = importlib_metadata.version(__package__)
+try:
+ # This will read version from pyproject.toml
+ __version__ = importlib_metadata.version(__package__ or __name__)
+except importlib_metadata.PackageNotFoundError:
+ __version__ = "development"
from supervision.classification.core import Classifications
|
{"golden_diff": "diff --git a/supervision/__init__.py b/supervision/__init__.py\n--- a/supervision/__init__.py\n+++ b/supervision/__init__.py\n@@ -1,6 +1,10 @@\n import importlib.metadata as importlib_metadata\n \n-__version__ = importlib_metadata.version(__package__)\n+try:\n+ # This will read version from pyproject.toml\n+ __version__ = importlib_metadata.version(__package__ or __name__)\n+except importlib_metadata.PackageNotFoundError:\n+ __version__ = \"development\"\n \n \n from supervision.classification.core import Classifications\n", "issue": "Developement - version issue\n### Search before asking\n\n- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.\n\n\n### Bug\n\nI have not installed `supervision` but running directly for developement purpose.\r\n\r\nBut I got an following error when I import supervision code:\r\n\r\n```\r\n raise PackageNotFoundError(name)\r\nimportlib.metadata.PackageNotFoundError: supervision\r\n```\r\n\r\nAfter a quick investigation, it is found that `__init__.py` of `supervision` where version information used. It is creating an issue. If I comment this line and the bug is gone.\r\n\r\n@onuralpszr Can you take a look?\r\n\r\n\r\nI think it should be ignorable, if valid version is not found then use `development` version. Though, I do not have concret idea, how to tackle it.\r\n\r\n\r\n\r\n\n\n### Environment\n\n_No response_\n\n### Minimal Reproducible Example\n\n_No response_\n\n### Additional\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [X] Yes I'd like to help by submitting a PR!\n", "before_files": [{"content": "import importlib.metadata as importlib_metadata\n\n__version__ = importlib_metadata.version(__package__)\n\n\nfrom supervision.classification.core import Classifications\nfrom supervision.dataset.core import (\n BaseDataset,\n ClassificationDataset,\n DetectionDataset,\n)\nfrom supervision.detection.annotate import BoxAnnotator, MaskAnnotator\nfrom supervision.detection.core import Detections\nfrom supervision.detection.line_counter import LineZone, LineZoneAnnotator\nfrom supervision.detection.tools.polygon_zone import PolygonZone, PolygonZoneAnnotator\nfrom supervision.detection.utils import (\n box_iou_batch,\n filter_polygons_by_area,\n mask_to_polygons,\n mask_to_xyxy,\n non_max_suppression,\n polygon_to_mask,\n polygon_to_xyxy,\n)\nfrom supervision.draw.color import Color, ColorPalette\nfrom supervision.draw.utils import draw_filled_rectangle, draw_polygon, draw_text\nfrom supervision.geometry.core import Point, Position, Rect\nfrom supervision.geometry.utils import get_polygon_center\nfrom supervision.metrics.detection import ConfusionMatrix\nfrom supervision.utils.file import list_files_with_extensions\nfrom supervision.utils.image import ImageSink, crop\nfrom supervision.utils.notebook import plot_image, plot_images_grid\nfrom supervision.utils.video import (\n VideoInfo,\n VideoSink,\n get_video_frames_generator,\n process_video,\n)\n", "path": "supervision/__init__.py"}], "after_files": [{"content": "import importlib.metadata as importlib_metadata\n\ntry:\n # This will read version from pyproject.toml\n __version__ = importlib_metadata.version(__package__ or __name__)\nexcept importlib_metadata.PackageNotFoundError:\n __version__ = \"development\"\n\n\nfrom supervision.classification.core import Classifications\nfrom supervision.dataset.core import (\n BaseDataset,\n ClassificationDataset,\n DetectionDataset,\n)\nfrom supervision.detection.annotate import BoxAnnotator, MaskAnnotator\nfrom supervision.detection.core import Detections\nfrom supervision.detection.line_counter import LineZone, LineZoneAnnotator\nfrom supervision.detection.tools.polygon_zone import PolygonZone, PolygonZoneAnnotator\nfrom supervision.detection.utils import (\n box_iou_batch,\n filter_polygons_by_area,\n mask_to_polygons,\n mask_to_xyxy,\n non_max_suppression,\n polygon_to_mask,\n polygon_to_xyxy,\n)\nfrom supervision.draw.color import Color, ColorPalette\nfrom supervision.draw.utils import draw_filled_rectangle, draw_polygon, draw_text\nfrom supervision.geometry.core import Point, Position, Rect\nfrom supervision.geometry.utils import get_polygon_center\nfrom supervision.metrics.detection import ConfusionMatrix\nfrom supervision.utils.file import list_files_with_extensions\nfrom supervision.utils.image import ImageSink, crop\nfrom supervision.utils.notebook import plot_image, plot_images_grid\nfrom supervision.utils.video import (\n VideoInfo,\n VideoSink,\n get_video_frames_generator,\n process_video,\n)\n", "path": "supervision/__init__.py"}]}
| 839 | 136 |
gh_patches_debug_5710
|
rasdani/github-patches
|
git_diff
|
getredash__redash-2062
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
More flexible widgets grid (allow finer control over height/width)
## User should be able to control widget's placement, width and height
### Current implementation
Currently editing a dashboard works as follow:
1. When adding a widget you select its width: regular (half width) or double (full width). Height is set based on the content.
2. When opening the "Edit Dashboard" dialog, you can rearrange the order of the widgets.

Issues with the current approach:
* You can't change widget size after placing it.
* You can't change widget's height.
* You can't control widget's width beyond the current two options.
### Solution
To solve this we want to have a flexible (_but still responsive_) grid that the user can freely place and move widgets on.
* Each visualization will define minimum width and height sizes (derived from the visualization type). This will be the default sizes for the widget when placed on the grid, but the user will be able to resize it to be larger (but not smaller) afterwards.
* Once entering dashboard "edit mode", the user will be able to move around and resize the widgets in place instead of a dedicated UI.
* We should probably change other behaviors in the UI (move add widget to be part of the edit mode, change dashboard title editing to be in place, etc), but we will leave it to second iteration after the grid behavior is implemented.
### Technical Notes
* We currently use `angular-gridster` to allow moving around the widgets in the Edit Dashboard dialog. Maybe we can use it for the grid or a similar library.
* Currently the widget knows nothing about its placement, but only its size (width). The dashboard has a layout property, which is an array of arrays of widgets ids (each item in the array is a row/array of widgets). This is error prone and makes layout changes harder. If possible, it will be better if each widget retains its own placement information.
* The API to update a widget currently supports only updating a textbox widget. We will need to extend it to support all widget types.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/handlers/widgets.py`
Content:
```
1 import json
2
3 from flask import request
4 from redash import models
5 from redash.handlers.base import BaseResource
6 from redash.permissions import (require_access,
7 require_object_modify_permission,
8 require_permission, view_only)
9
10
11 class WidgetListResource(BaseResource):
12 @require_permission('edit_dashboard')
13 def post(self):
14 """
15 Add a widget to a dashboard.
16
17 :<json number dashboard_id: The ID for the dashboard being added to
18 :<json visualization_id: The ID of the visualization to put in this widget
19 :<json object options: Widget options
20 :<json string text: Text box contents
21 :<json number width: Width for widget display
22
23 :>json object widget: The created widget
24 :>json array layout: The new layout of the dashboard this widget was added to
25 :>json boolean new_row: Whether this widget was added on a new row or not
26 :>json number version: The revision number of the dashboard
27 """
28 widget_properties = request.get_json(force=True)
29 dashboard = models.Dashboard.get_by_id_and_org(widget_properties.pop('dashboard_id'), self.current_org)
30 require_object_modify_permission(dashboard, self.current_user)
31
32 widget_properties['options'] = json.dumps(widget_properties['options'])
33 widget_properties.pop('id', None)
34 widget_properties['dashboard'] = dashboard
35
36 visualization_id = widget_properties.pop('visualization_id')
37 if visualization_id:
38 visualization = models.Visualization.get_by_id_and_org(visualization_id, self.current_org)
39 require_access(visualization.query_rel.groups, self.current_user, view_only)
40 else:
41 visualization = None
42
43 widget_properties['visualization'] = visualization
44
45 widget = models.Widget(**widget_properties)
46 models.db.session.add(widget)
47 models.db.session.commit()
48
49 layout = json.loads(widget.dashboard.layout)
50 new_row = True
51
52 if len(layout) == 0 or widget.width == 2:
53 layout.append([widget.id])
54 elif len(layout[-1]) == 1:
55 neighbour_widget = models.Widget.query.get(layout[-1][0])
56 if neighbour_widget.width == 1:
57 layout[-1].append(widget.id)
58 new_row = False
59 else:
60 layout.append([widget.id])
61 else:
62 layout.append([widget.id])
63
64 widget.dashboard.layout = json.dumps(layout)
65 models.db.session.add(widget.dashboard)
66 models.db.session.commit()
67 return {'widget': widget.to_dict(), 'layout': layout, 'new_row': new_row, 'version': dashboard.version}
68
69
70 class WidgetResource(BaseResource):
71 @require_permission('edit_dashboard')
72 def post(self, widget_id):
73 """
74 Updates a widget in a dashboard.
75 This method currently handles Text Box widgets only.
76
77 :param number widget_id: The ID of the widget to modify
78
79 :<json string text: The new contents of the text box
80 """
81 widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)
82 require_object_modify_permission(widget.dashboard, self.current_user)
83 widget_properties = request.get_json(force=True)
84 widget.text = widget_properties['text']
85 models.db.session.commit()
86 return widget.to_dict()
87
88 @require_permission('edit_dashboard')
89 def delete(self, widget_id):
90 """
91 Remove a widget from a dashboard.
92
93 :param number widget_id: ID of widget to remove
94
95 :>json array layout: New layout of dashboard this widget was removed from
96 :>json number version: Revision number of dashboard
97 """
98 widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)
99 require_object_modify_permission(widget.dashboard, self.current_user)
100 widget.delete()
101 models.db.session.commit()
102 return {'layout': widget.dashboard.layout, 'version': widget.dashboard.version}
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/handlers/widgets.py b/redash/handlers/widgets.py
--- a/redash/handlers/widgets.py
+++ b/redash/handlers/widgets.py
@@ -82,6 +82,7 @@
require_object_modify_permission(widget.dashboard, self.current_user)
widget_properties = request.get_json(force=True)
widget.text = widget_properties['text']
+ widget.options = json.dumps(widget_properties['options'])
models.db.session.commit()
return widget.to_dict()
|
{"golden_diff": "diff --git a/redash/handlers/widgets.py b/redash/handlers/widgets.py\n--- a/redash/handlers/widgets.py\n+++ b/redash/handlers/widgets.py\n@@ -82,6 +82,7 @@\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget_properties = request.get_json(force=True)\n widget.text = widget_properties['text']\n+ widget.options = json.dumps(widget_properties['options'])\n models.db.session.commit()\n return widget.to_dict()\n", "issue": "More flexible widgets grid (allow finer control over height/width)\n## User should be able to control widget's placement, width and height\r\n\r\n### Current implementation\r\n\r\nCurrently editing a dashboard works as follow:\r\n\r\n1. When adding a widget you select its width: regular (half width) or double (full width). Height is set based on the content.\r\n2. When opening the \"Edit Dashboard\" dialog, you can rearrange the order of the widgets.\r\n\r\n\r\n\r\nIssues with the current approach:\r\n\r\n* You can't change widget size after placing it.\r\n* You can't change widget's height.\r\n* You can't control widget's width beyond the current two options.\r\n\r\n### Solution\r\n\r\nTo solve this we want to have a flexible (_but still responsive_) grid that the user can freely place and move widgets on. \r\n\r\n* Each visualization will define minimum width and height sizes (derived from the visualization type). This will be the default sizes for the widget when placed on the grid, but the user will be able to resize it to be larger (but not smaller) afterwards.\r\n* Once entering dashboard \"edit mode\", the user will be able to move around and resize the widgets in place instead of a dedicated UI.\r\n* We should probably change other behaviors in the UI (move add widget to be part of the edit mode, change dashboard title editing to be in place, etc), but we will leave it to second iteration after the grid behavior is implemented.\r\n\r\n### Technical Notes\r\n\r\n* We currently use `angular-gridster` to allow moving around the widgets in the Edit Dashboard dialog. Maybe we can use it for the grid or a similar library.\r\n* Currently the widget knows nothing about its placement, but only its size (width). The dashboard has a layout property, which is an array of arrays of widgets ids (each item in the array is a row/array of widgets). This is error prone and makes layout changes harder. If possible, it will be better if each widget retains its own placement information.\r\n* The API to update a widget currently supports only updating a textbox widget. We will need to extend it to support all widget types.\n", "before_files": [{"content": "import json\n\nfrom flask import request\nfrom redash import models\nfrom redash.handlers.base import BaseResource\nfrom redash.permissions import (require_access,\n require_object_modify_permission,\n require_permission, view_only)\n\n\nclass WidgetListResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self):\n \"\"\"\n Add a widget to a dashboard.\n\n :<json number dashboard_id: The ID for the dashboard being added to\n :<json visualization_id: The ID of the visualization to put in this widget\n :<json object options: Widget options\n :<json string text: Text box contents\n :<json number width: Width for widget display\n\n :>json object widget: The created widget\n :>json array layout: The new layout of the dashboard this widget was added to\n :>json boolean new_row: Whether this widget was added on a new row or not\n :>json number version: The revision number of the dashboard\n \"\"\"\n widget_properties = request.get_json(force=True)\n dashboard = models.Dashboard.get_by_id_and_org(widget_properties.pop('dashboard_id'), self.current_org)\n require_object_modify_permission(dashboard, self.current_user)\n\n widget_properties['options'] = json.dumps(widget_properties['options'])\n widget_properties.pop('id', None)\n widget_properties['dashboard'] = dashboard\n\n visualization_id = widget_properties.pop('visualization_id')\n if visualization_id:\n visualization = models.Visualization.get_by_id_and_org(visualization_id, self.current_org)\n require_access(visualization.query_rel.groups, self.current_user, view_only)\n else:\n visualization = None\n\n widget_properties['visualization'] = visualization\n\n widget = models.Widget(**widget_properties)\n models.db.session.add(widget)\n models.db.session.commit()\n\n layout = json.loads(widget.dashboard.layout)\n new_row = True\n\n if len(layout) == 0 or widget.width == 2:\n layout.append([widget.id])\n elif len(layout[-1]) == 1:\n neighbour_widget = models.Widget.query.get(layout[-1][0])\n if neighbour_widget.width == 1:\n layout[-1].append(widget.id)\n new_row = False\n else:\n layout.append([widget.id])\n else:\n layout.append([widget.id])\n\n widget.dashboard.layout = json.dumps(layout)\n models.db.session.add(widget.dashboard)\n models.db.session.commit()\n return {'widget': widget.to_dict(), 'layout': layout, 'new_row': new_row, 'version': dashboard.version}\n\n\nclass WidgetResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self, widget_id):\n \"\"\"\n Updates a widget in a dashboard.\n This method currently handles Text Box widgets only.\n\n :param number widget_id: The ID of the widget to modify\n\n :<json string text: The new contents of the text box\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget_properties = request.get_json(force=True)\n widget.text = widget_properties['text']\n models.db.session.commit()\n return widget.to_dict()\n\n @require_permission('edit_dashboard')\n def delete(self, widget_id):\n \"\"\"\n Remove a widget from a dashboard.\n\n :param number widget_id: ID of widget to remove\n\n :>json array layout: New layout of dashboard this widget was removed from\n :>json number version: Revision number of dashboard\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget.delete()\n models.db.session.commit()\n return {'layout': widget.dashboard.layout, 'version': widget.dashboard.version}\n", "path": "redash/handlers/widgets.py"}], "after_files": [{"content": "import json\n\nfrom flask import request\nfrom redash import models\nfrom redash.handlers.base import BaseResource\nfrom redash.permissions import (require_access,\n require_object_modify_permission,\n require_permission, view_only)\n\n\nclass WidgetListResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self):\n \"\"\"\n Add a widget to a dashboard.\n\n :<json number dashboard_id: The ID for the dashboard being added to\n :<json visualization_id: The ID of the visualization to put in this widget\n :<json object options: Widget options\n :<json string text: Text box contents\n :<json number width: Width for widget display\n\n :>json object widget: The created widget\n :>json array layout: The new layout of the dashboard this widget was added to\n :>json boolean new_row: Whether this widget was added on a new row or not\n :>json number version: The revision number of the dashboard\n \"\"\"\n widget_properties = request.get_json(force=True)\n dashboard = models.Dashboard.get_by_id_and_org(widget_properties.pop('dashboard_id'), self.current_org)\n require_object_modify_permission(dashboard, self.current_user)\n\n widget_properties['options'] = json.dumps(widget_properties['options'])\n widget_properties.pop('id', None)\n widget_properties['dashboard'] = dashboard\n\n visualization_id = widget_properties.pop('visualization_id')\n if visualization_id:\n visualization = models.Visualization.get_by_id_and_org(visualization_id, self.current_org)\n require_access(visualization.query_rel.groups, self.current_user, view_only)\n else:\n visualization = None\n\n widget_properties['visualization'] = visualization\n\n widget = models.Widget(**widget_properties)\n models.db.session.add(widget)\n models.db.session.commit()\n\n layout = json.loads(widget.dashboard.layout)\n new_row = True\n\n if len(layout) == 0 or widget.width == 2:\n layout.append([widget.id])\n elif len(layout[-1]) == 1:\n neighbour_widget = models.Widget.query.get(layout[-1][0])\n if neighbour_widget.width == 1:\n layout[-1].append(widget.id)\n new_row = False\n else:\n layout.append([widget.id])\n else:\n layout.append([widget.id])\n\n widget.dashboard.layout = json.dumps(layout)\n models.db.session.add(widget.dashboard)\n models.db.session.commit()\n return {'widget': widget.to_dict(), 'layout': layout, 'new_row': new_row, 'version': dashboard.version}\n\n\nclass WidgetResource(BaseResource):\n @require_permission('edit_dashboard')\n def post(self, widget_id):\n \"\"\"\n Updates a widget in a dashboard.\n This method currently handles Text Box widgets only.\n\n :param number widget_id: The ID of the widget to modify\n\n :<json string text: The new contents of the text box\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget_properties = request.get_json(force=True)\n widget.text = widget_properties['text']\n widget.options = json.dumps(widget_properties['options'])\n models.db.session.commit()\n return widget.to_dict()\n\n @require_permission('edit_dashboard')\n def delete(self, widget_id):\n \"\"\"\n Remove a widget from a dashboard.\n\n :param number widget_id: ID of widget to remove\n\n :>json array layout: New layout of dashboard this widget was removed from\n :>json number version: Revision number of dashboard\n \"\"\"\n widget = models.Widget.get_by_id_and_org(widget_id, self.current_org)\n require_object_modify_permission(widget.dashboard, self.current_user)\n widget.delete()\n models.db.session.commit()\n return {'layout': widget.dashboard.layout, 'version': widget.dashboard.version}\n", "path": "redash/handlers/widgets.py"}]}
| 1,758 | 107 |
gh_patches_debug_3057
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-6303
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] At Splitting: Custom field leads to "The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist."
### Description
Document with custom field leads to error message on splittting. No workflow active.
"The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist."
### Steps to reproduce
1. Go to Ducuments
2. Edit document
3. Splitting into separate Pages
4. Error message appears
### Webserver logs
```bash
[2024-04-06 11:24:55,324] [DEBUG] [paperless.tasks] Skipping plugin CollatePlugin
[2024-04-06 11:24:55,325] [DEBUG] [paperless.tasks] Executing plugin BarcodePlugin
[2024-04-06 11:24:55,325] [DEBUG] [paperless.barcodes] Scanning for barcodes using PYZBAR
[2024-04-06 11:24:55,542] [INFO] [paperless.tasks] BarcodePlugin completed with no message
[2024-04-06 11:24:55,545] [DEBUG] [paperless.tasks] Executing plugin WorkflowTriggerPlugin
[2024-04-06 11:24:55,547] [INFO] [paperless.tasks] WorkflowTriggerPlugin completed with:
[2024-04-06 11:24:55,554] [INFO] [paperless.consumer] Consuming 15_2-2.pdf
[2024-04-06 11:24:55,556] [DEBUG] [paperless.consumer] Detected mime type: application/pdf
[2024-04-06 11:24:55,562] [DEBUG] [paperless.consumer] Parser: RasterisedDocumentParser
[2024-04-06 11:24:55,565] [DEBUG] [paperless.consumer] Parsing 15_2-2.pdf...
[2024-04-06 11:24:55,572] [INFO] [paperless.parsing.tesseract] pdftotext exited 0
[2024-04-06 11:24:55,711] [DEBUG] [paperless.parsing.tesseract] Calling OCRmyPDF with args: {'input_file': PosixPath('/tmp/paperless/paperless-ngx2bzkbofi/15_2-2.pdf'), 'output_file': PosixPath('/tmp/paperless/paperless-6d3y7xqr/archive.pdf'), 'use_threads': True, 'jobs': 4, 'language': 'deu+eng', 'output_type': 'pdfa', 'progress_bar': False, 'color_conversion_strategy': 'RGB', 'skip_text': True, 'clean': True, 'deskew': True, 'rotate_pages': True, 'rotate_pages_threshold': 6.0, 'sidecar': PosixPath('/tmp/paperless/paperless-6d3y7xqr/sidecar.txt')}
[2024-04-06 11:24:55,809] [INFO] [ocrmypdf._pipeline] skipping all processing on this page
[2024-04-06 11:24:55,812] [INFO] [ocrmypdf._pipelines.ocr] Postprocessing...
[2024-04-06 11:24:55,916] [INFO] [ocrmypdf._pipeline] Image optimization ratio: 1.00 savings: 0.0%
[2024-04-06 11:24:55,917] [INFO] [ocrmypdf._pipeline] Total file size ratio: 0.72 savings: -39.6%
[2024-04-06 11:24:55,918] [INFO] [ocrmypdf._pipelines._common] Output file is a PDF/A-2B (as expected)
[2024-04-06 11:24:55,922] [DEBUG] [paperless.parsing.tesseract] Incomplete sidecar file: discarding.
[2024-04-06 11:24:55,946] [INFO] [paperless.parsing.tesseract] pdftotext exited 0
[2024-04-06 11:24:55,946] [DEBUG] [paperless.consumer] Generating thumbnail for 15_2-2.pdf...
[2024-04-06 11:24:55,950] [DEBUG] [paperless.parsing] Execute: convert -density 300 -scale 500x5000> -alpha remove -strip -auto-orient -define pdf:use-cropbox=true /tmp/paperless/paperless-6d3y7xqr/archive.pdf[0] /tmp/paperless/paperless-6d3y7xqr/convert.webp
[2024-04-06 11:24:56,727] [INFO] [paperless.parsing] convert exited 0
[2024-04-06 11:24:56,797] [DEBUG] [paperless.consumer] Saving record to database
[2024-04-06 11:24:56,798] [DEBUG] [paperless.consumer] Creation date from st_mtime: 2024-04-06 11:24:52.835078+02:00
[2024-04-06 11:24:56,831] [ERROR] [paperless.consumer] The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist.
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/asgiref/sync.py", line 327, in main_wrap
raise exc_info[1]
File "/usr/src/paperless/src/documents/consumer.py", line 675, in try_consume_file
document = self._store(text=text, date=date, mime_type=mime_type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/src/paperless/src/documents/consumer.py", line 851, in _store
self.apply_overrides(document)
File "/usr/src/paperless/src/documents/consumer.py", line 905, in apply_overrides
field = CustomField.objects.get(pk=field_id)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/django/db/models/manager.py", line 87, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/django/db/models/query.py", line 637, in get
raise self.model.DoesNotExist(
documents.models.CustomField.DoesNotExist: CustomField matching query does not exist.
[2024-04-06 11:24:56,833] [DEBUG] [paperless.parsing.tesseract] Deleting directory /tmp/paperless/paperless-6d3y7xqr
```
### Browser logs
_No response_
### Paperless-ngx version
2.7.0
### Host OS
Docker on Synology NAS - DSM 7.2
### Installation method
Docker - official image
### Browser
Firefox
### Configuration changes
_No response_
### Other
_No response_
### Please confirm the following
- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.
- [X] I have already searched for relevant existing issues and discussions before opening this report.
- [X] I have updated the title field above with a concise description.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/documents/data_models.py`
Content:
```
1 import dataclasses
2 import datetime
3 from enum import IntEnum
4 from pathlib import Path
5 from typing import Optional
6
7 import magic
8 from guardian.shortcuts import get_groups_with_perms
9 from guardian.shortcuts import get_users_with_perms
10
11
12 @dataclasses.dataclass
13 class DocumentMetadataOverrides:
14 """
15 Manages overrides for document fields which normally would
16 be set from content or matching. All fields default to None,
17 meaning no override is happening
18 """
19
20 filename: Optional[str] = None
21 title: Optional[str] = None
22 correspondent_id: Optional[int] = None
23 document_type_id: Optional[int] = None
24 tag_ids: Optional[list[int]] = None
25 storage_path_id: Optional[int] = None
26 created: Optional[datetime.datetime] = None
27 asn: Optional[int] = None
28 owner_id: Optional[int] = None
29 view_users: Optional[list[int]] = None
30 view_groups: Optional[list[int]] = None
31 change_users: Optional[list[int]] = None
32 change_groups: Optional[list[int]] = None
33 custom_field_ids: Optional[list[int]] = None
34
35 def update(self, other: "DocumentMetadataOverrides") -> "DocumentMetadataOverrides":
36 """
37 Merges two DocumentMetadataOverrides objects such that object B's overrides
38 are applied to object A or merged if multiple are accepted.
39
40 The update is an in-place modification of self
41 """
42 # only if empty
43 if other.title is not None:
44 self.title = other.title
45 if other.correspondent_id is not None:
46 self.correspondent_id = other.correspondent_id
47 if other.document_type_id is not None:
48 self.document_type_id = other.document_type_id
49 if other.storage_path_id is not None:
50 self.storage_path_id = other.storage_path_id
51 if other.owner_id is not None:
52 self.owner_id = other.owner_id
53
54 # merge
55 if self.tag_ids is None:
56 self.tag_ids = other.tag_ids
57 elif other.tag_ids is not None:
58 self.tag_ids.extend(other.tag_ids)
59 self.tag_ids = list(set(self.tag_ids))
60
61 if self.view_users is None:
62 self.view_users = other.view_users
63 elif other.view_users is not None:
64 self.view_users.extend(other.view_users)
65 self.view_users = list(set(self.view_users))
66
67 if self.view_groups is None:
68 self.view_groups = other.view_groups
69 elif other.view_groups is not None:
70 self.view_groups.extend(other.view_groups)
71 self.view_groups = list(set(self.view_groups))
72
73 if self.change_users is None:
74 self.change_users = other.change_users
75 elif other.change_users is not None:
76 self.change_users.extend(other.change_users)
77 self.change_users = list(set(self.change_users))
78
79 if self.change_groups is None:
80 self.change_groups = other.change_groups
81 elif other.change_groups is not None:
82 self.change_groups.extend(other.change_groups)
83 self.change_groups = list(set(self.change_groups))
84
85 if self.custom_field_ids is None:
86 self.custom_field_ids = other.custom_field_ids
87 elif other.custom_field_ids is not None:
88 self.custom_field_ids.extend(other.custom_field_ids)
89 self.custom_field_ids = list(set(self.custom_field_ids))
90
91 return self
92
93 @staticmethod
94 def from_document(doc) -> "DocumentMetadataOverrides":
95 """
96 Fills in the overrides from a document object
97 """
98 overrides = DocumentMetadataOverrides()
99 overrides.title = doc.title
100 overrides.correspondent_id = doc.correspondent.id if doc.correspondent else None
101 overrides.document_type_id = doc.document_type.id if doc.document_type else None
102 overrides.storage_path_id = doc.storage_path.id if doc.storage_path else None
103 overrides.owner_id = doc.owner.id if doc.owner else None
104 overrides.tag_ids = list(doc.tags.values_list("id", flat=True))
105
106 overrides.view_users = list(
107 get_users_with_perms(
108 doc,
109 only_with_perms_in=["view_document"],
110 ).values_list("id", flat=True),
111 )
112 overrides.change_users = list(
113 get_users_with_perms(
114 doc,
115 only_with_perms_in=["change_document"],
116 ).values_list("id", flat=True),
117 )
118 overrides.custom_field_ids = list(
119 doc.custom_fields.values_list("id", flat=True),
120 )
121
122 groups_with_perms = get_groups_with_perms(
123 doc,
124 attach_perms=True,
125 )
126 overrides.view_groups = [
127 group.id
128 for group in groups_with_perms
129 if "view_document" in groups_with_perms[group]
130 ]
131 overrides.change_groups = [
132 group.id
133 for group in groups_with_perms
134 if "change_document" in groups_with_perms[group]
135 ]
136
137 return overrides
138
139
140 class DocumentSource(IntEnum):
141 """
142 The source of an incoming document. May have other uses in the future
143 """
144
145 ConsumeFolder = 1
146 ApiUpload = 2
147 MailFetch = 3
148
149
150 @dataclasses.dataclass
151 class ConsumableDocument:
152 """
153 Encapsulates an incoming document, either from consume folder, API upload
154 or mail fetching and certain useful operations on it.
155 """
156
157 source: DocumentSource
158 original_file: Path
159 mailrule_id: Optional[int] = None
160 mime_type: str = dataclasses.field(init=False, default=None)
161
162 def __post_init__(self):
163 """
164 After a dataclass is initialized, this is called to finalize some data
165 1. Make sure the original path is an absolute, fully qualified path
166 2. Get the mime type of the file
167 """
168 # Always fully qualify the path first thing
169 # Just in case, convert to a path if it's a str
170 self.original_file = Path(self.original_file).resolve()
171
172 # Get the file type once at init
173 # Note this function isn't called when the object is unpickled
174 self.mime_type = magic.from_file(self.original_file, mime=True)
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/documents/data_models.py b/src/documents/data_models.py
--- a/src/documents/data_models.py
+++ b/src/documents/data_models.py
@@ -116,7 +116,7 @@
).values_list("id", flat=True),
)
overrides.custom_field_ids = list(
- doc.custom_fields.values_list("id", flat=True),
+ doc.custom_fields.values_list("field", flat=True),
)
groups_with_perms = get_groups_with_perms(
|
{"golden_diff": "diff --git a/src/documents/data_models.py b/src/documents/data_models.py\n--- a/src/documents/data_models.py\n+++ b/src/documents/data_models.py\n@@ -116,7 +116,7 @@\n ).values_list(\"id\", flat=True),\n )\n overrides.custom_field_ids = list(\n- doc.custom_fields.values_list(\"id\", flat=True),\n+ doc.custom_fields.values_list(\"field\", flat=True),\n )\n \n groups_with_perms = get_groups_with_perms(\n", "issue": "[BUG] At Splitting: Custom field leads to \"The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist.\"\n### Description\n\nDocument with custom field leads to error message on splittting. No workflow active.\r\n\r\n\"The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist.\"\r\n\r\n\n\n### Steps to reproduce\n\n1. Go to Ducuments\r\n2. Edit document\r\n3. Splitting into separate Pages\r\n4. Error message appears\n\n### Webserver logs\n\n```bash\n[2024-04-06 11:24:55,324] [DEBUG] [paperless.tasks] Skipping plugin CollatePlugin\r\n[2024-04-06 11:24:55,325] [DEBUG] [paperless.tasks] Executing plugin BarcodePlugin\r\n[2024-04-06 11:24:55,325] [DEBUG] [paperless.barcodes] Scanning for barcodes using PYZBAR\r\n[2024-04-06 11:24:55,542] [INFO] [paperless.tasks] BarcodePlugin completed with no message\r\n[2024-04-06 11:24:55,545] [DEBUG] [paperless.tasks] Executing plugin WorkflowTriggerPlugin\r\n[2024-04-06 11:24:55,547] [INFO] [paperless.tasks] WorkflowTriggerPlugin completed with:\r\n[2024-04-06 11:24:55,554] [INFO] [paperless.consumer] Consuming 15_2-2.pdf\r\n[2024-04-06 11:24:55,556] [DEBUG] [paperless.consumer] Detected mime type: application/pdf\r\n[2024-04-06 11:24:55,562] [DEBUG] [paperless.consumer] Parser: RasterisedDocumentParser\r\n[2024-04-06 11:24:55,565] [DEBUG] [paperless.consumer] Parsing 15_2-2.pdf...\r\n[2024-04-06 11:24:55,572] [INFO] [paperless.parsing.tesseract] pdftotext exited 0\r\n[2024-04-06 11:24:55,711] [DEBUG] [paperless.parsing.tesseract] Calling OCRmyPDF with args: {'input_file': PosixPath('/tmp/paperless/paperless-ngx2bzkbofi/15_2-2.pdf'), 'output_file': PosixPath('/tmp/paperless/paperless-6d3y7xqr/archive.pdf'), 'use_threads': True, 'jobs': 4, 'language': 'deu+eng', 'output_type': 'pdfa', 'progress_bar': False, 'color_conversion_strategy': 'RGB', 'skip_text': True, 'clean': True, 'deskew': True, 'rotate_pages': True, 'rotate_pages_threshold': 6.0, 'sidecar': PosixPath('/tmp/paperless/paperless-6d3y7xqr/sidecar.txt')}\r\n[2024-04-06 11:24:55,809] [INFO] [ocrmypdf._pipeline] skipping all processing on this page\r\n[2024-04-06 11:24:55,812] [INFO] [ocrmypdf._pipelines.ocr] Postprocessing...\r\n[2024-04-06 11:24:55,916] [INFO] [ocrmypdf._pipeline] Image optimization ratio: 1.00 savings: 0.0%\r\n[2024-04-06 11:24:55,917] [INFO] [ocrmypdf._pipeline] Total file size ratio: 0.72 savings: -39.6%\r\n[2024-04-06 11:24:55,918] [INFO] [ocrmypdf._pipelines._common] Output file is a PDF/A-2B (as expected)\r\n[2024-04-06 11:24:55,922] [DEBUG] [paperless.parsing.tesseract] Incomplete sidecar file: discarding.\r\n[2024-04-06 11:24:55,946] [INFO] [paperless.parsing.tesseract] pdftotext exited 0\r\n[2024-04-06 11:24:55,946] [DEBUG] [paperless.consumer] Generating thumbnail for 15_2-2.pdf...\r\n[2024-04-06 11:24:55,950] [DEBUG] [paperless.parsing] Execute: convert -density 300 -scale 500x5000> -alpha remove -strip -auto-orient -define pdf:use-cropbox=true /tmp/paperless/paperless-6d3y7xqr/archive.pdf[0] /tmp/paperless/paperless-6d3y7xqr/convert.webp\r\n[2024-04-06 11:24:56,727] [INFO] [paperless.parsing] convert exited 0\r\n[2024-04-06 11:24:56,797] [DEBUG] [paperless.consumer] Saving record to database\r\n[2024-04-06 11:24:56,798] [DEBUG] [paperless.consumer] Creation date from st_mtime: 2024-04-06 11:24:52.835078+02:00\r\n[2024-04-06 11:24:56,831] [ERROR] [paperless.consumer] The following error occurred while storing document 15_2-2.pdf after parsing: CustomField matching query does not exist.\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.11/site-packages/asgiref/sync.py\", line 327, in main_wrap\r\n raise exc_info[1]\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 675, in try_consume_file\r\n document = self._store(text=text, date=date, mime_type=mime_type)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 851, in _store\r\n self.apply_overrides(document)\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 905, in apply_overrides\r\n field = CustomField.objects.get(pk=field_id)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/django/db/models/manager.py\", line 87, in manager_method\r\n return getattr(self.get_queryset(), name)(*args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/usr/local/lib/python3.11/site-packages/django/db/models/query.py\", line 637, in get\r\n raise self.model.DoesNotExist(\r\ndocuments.models.CustomField.DoesNotExist: CustomField matching query does not exist.\r\n[2024-04-06 11:24:56,833] [DEBUG] [paperless.parsing.tesseract] Deleting directory /tmp/paperless/paperless-6d3y7xqr\n```\n\n\n### Browser logs\n\n_No response_\n\n### Paperless-ngx version\n\n2.7.0\n\n### Host OS\n\nDocker on Synology NAS - DSM 7.2\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\nFirefox\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n\n### Please confirm the following\n\n- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.\n- [X] I have already searched for relevant existing issues and discussions before opening this report.\n- [X] I have updated the title field above with a concise description.\n", "before_files": [{"content": "import dataclasses\nimport datetime\nfrom enum import IntEnum\nfrom pathlib import Path\nfrom typing import Optional\n\nimport magic\nfrom guardian.shortcuts import get_groups_with_perms\nfrom guardian.shortcuts import get_users_with_perms\n\n\[email protected]\nclass DocumentMetadataOverrides:\n \"\"\"\n Manages overrides for document fields which normally would\n be set from content or matching. All fields default to None,\n meaning no override is happening\n \"\"\"\n\n filename: Optional[str] = None\n title: Optional[str] = None\n correspondent_id: Optional[int] = None\n document_type_id: Optional[int] = None\n tag_ids: Optional[list[int]] = None\n storage_path_id: Optional[int] = None\n created: Optional[datetime.datetime] = None\n asn: Optional[int] = None\n owner_id: Optional[int] = None\n view_users: Optional[list[int]] = None\n view_groups: Optional[list[int]] = None\n change_users: Optional[list[int]] = None\n change_groups: Optional[list[int]] = None\n custom_field_ids: Optional[list[int]] = None\n\n def update(self, other: \"DocumentMetadataOverrides\") -> \"DocumentMetadataOverrides\":\n \"\"\"\n Merges two DocumentMetadataOverrides objects such that object B's overrides\n are applied to object A or merged if multiple are accepted.\n\n The update is an in-place modification of self\n \"\"\"\n # only if empty\n if other.title is not None:\n self.title = other.title\n if other.correspondent_id is not None:\n self.correspondent_id = other.correspondent_id\n if other.document_type_id is not None:\n self.document_type_id = other.document_type_id\n if other.storage_path_id is not None:\n self.storage_path_id = other.storage_path_id\n if other.owner_id is not None:\n self.owner_id = other.owner_id\n\n # merge\n if self.tag_ids is None:\n self.tag_ids = other.tag_ids\n elif other.tag_ids is not None:\n self.tag_ids.extend(other.tag_ids)\n self.tag_ids = list(set(self.tag_ids))\n\n if self.view_users is None:\n self.view_users = other.view_users\n elif other.view_users is not None:\n self.view_users.extend(other.view_users)\n self.view_users = list(set(self.view_users))\n\n if self.view_groups is None:\n self.view_groups = other.view_groups\n elif other.view_groups is not None:\n self.view_groups.extend(other.view_groups)\n self.view_groups = list(set(self.view_groups))\n\n if self.change_users is None:\n self.change_users = other.change_users\n elif other.change_users is not None:\n self.change_users.extend(other.change_users)\n self.change_users = list(set(self.change_users))\n\n if self.change_groups is None:\n self.change_groups = other.change_groups\n elif other.change_groups is not None:\n self.change_groups.extend(other.change_groups)\n self.change_groups = list(set(self.change_groups))\n\n if self.custom_field_ids is None:\n self.custom_field_ids = other.custom_field_ids\n elif other.custom_field_ids is not None:\n self.custom_field_ids.extend(other.custom_field_ids)\n self.custom_field_ids = list(set(self.custom_field_ids))\n\n return self\n\n @staticmethod\n def from_document(doc) -> \"DocumentMetadataOverrides\":\n \"\"\"\n Fills in the overrides from a document object\n \"\"\"\n overrides = DocumentMetadataOverrides()\n overrides.title = doc.title\n overrides.correspondent_id = doc.correspondent.id if doc.correspondent else None\n overrides.document_type_id = doc.document_type.id if doc.document_type else None\n overrides.storage_path_id = doc.storage_path.id if doc.storage_path else None\n overrides.owner_id = doc.owner.id if doc.owner else None\n overrides.tag_ids = list(doc.tags.values_list(\"id\", flat=True))\n\n overrides.view_users = list(\n get_users_with_perms(\n doc,\n only_with_perms_in=[\"view_document\"],\n ).values_list(\"id\", flat=True),\n )\n overrides.change_users = list(\n get_users_with_perms(\n doc,\n only_with_perms_in=[\"change_document\"],\n ).values_list(\"id\", flat=True),\n )\n overrides.custom_field_ids = list(\n doc.custom_fields.values_list(\"id\", flat=True),\n )\n\n groups_with_perms = get_groups_with_perms(\n doc,\n attach_perms=True,\n )\n overrides.view_groups = [\n group.id\n for group in groups_with_perms\n if \"view_document\" in groups_with_perms[group]\n ]\n overrides.change_groups = [\n group.id\n for group in groups_with_perms\n if \"change_document\" in groups_with_perms[group]\n ]\n\n return overrides\n\n\nclass DocumentSource(IntEnum):\n \"\"\"\n The source of an incoming document. May have other uses in the future\n \"\"\"\n\n ConsumeFolder = 1\n ApiUpload = 2\n MailFetch = 3\n\n\[email protected]\nclass ConsumableDocument:\n \"\"\"\n Encapsulates an incoming document, either from consume folder, API upload\n or mail fetching and certain useful operations on it.\n \"\"\"\n\n source: DocumentSource\n original_file: Path\n mailrule_id: Optional[int] = None\n mime_type: str = dataclasses.field(init=False, default=None)\n\n def __post_init__(self):\n \"\"\"\n After a dataclass is initialized, this is called to finalize some data\n 1. Make sure the original path is an absolute, fully qualified path\n 2. Get the mime type of the file\n \"\"\"\n # Always fully qualify the path first thing\n # Just in case, convert to a path if it's a str\n self.original_file = Path(self.original_file).resolve()\n\n # Get the file type once at init\n # Note this function isn't called when the object is unpickled\n self.mime_type = magic.from_file(self.original_file, mime=True)\n", "path": "src/documents/data_models.py"}], "after_files": [{"content": "import dataclasses\nimport datetime\nfrom enum import IntEnum\nfrom pathlib import Path\nfrom typing import Optional\n\nimport magic\nfrom guardian.shortcuts import get_groups_with_perms\nfrom guardian.shortcuts import get_users_with_perms\n\n\[email protected]\nclass DocumentMetadataOverrides:\n \"\"\"\n Manages overrides for document fields which normally would\n be set from content or matching. All fields default to None,\n meaning no override is happening\n \"\"\"\n\n filename: Optional[str] = None\n title: Optional[str] = None\n correspondent_id: Optional[int] = None\n document_type_id: Optional[int] = None\n tag_ids: Optional[list[int]] = None\n storage_path_id: Optional[int] = None\n created: Optional[datetime.datetime] = None\n asn: Optional[int] = None\n owner_id: Optional[int] = None\n view_users: Optional[list[int]] = None\n view_groups: Optional[list[int]] = None\n change_users: Optional[list[int]] = None\n change_groups: Optional[list[int]] = None\n custom_field_ids: Optional[list[int]] = None\n\n def update(self, other: \"DocumentMetadataOverrides\") -> \"DocumentMetadataOverrides\":\n \"\"\"\n Merges two DocumentMetadataOverrides objects such that object B's overrides\n are applied to object A or merged if multiple are accepted.\n\n The update is an in-place modification of self\n \"\"\"\n # only if empty\n if other.title is not None:\n self.title = other.title\n if other.correspondent_id is not None:\n self.correspondent_id = other.correspondent_id\n if other.document_type_id is not None:\n self.document_type_id = other.document_type_id\n if other.storage_path_id is not None:\n self.storage_path_id = other.storage_path_id\n if other.owner_id is not None:\n self.owner_id = other.owner_id\n\n # merge\n if self.tag_ids is None:\n self.tag_ids = other.tag_ids\n elif other.tag_ids is not None:\n self.tag_ids.extend(other.tag_ids)\n self.tag_ids = list(set(self.tag_ids))\n\n if self.view_users is None:\n self.view_users = other.view_users\n elif other.view_users is not None:\n self.view_users.extend(other.view_users)\n self.view_users = list(set(self.view_users))\n\n if self.view_groups is None:\n self.view_groups = other.view_groups\n elif other.view_groups is not None:\n self.view_groups.extend(other.view_groups)\n self.view_groups = list(set(self.view_groups))\n\n if self.change_users is None:\n self.change_users = other.change_users\n elif other.change_users is not None:\n self.change_users.extend(other.change_users)\n self.change_users = list(set(self.change_users))\n\n if self.change_groups is None:\n self.change_groups = other.change_groups\n elif other.change_groups is not None:\n self.change_groups.extend(other.change_groups)\n self.change_groups = list(set(self.change_groups))\n\n if self.custom_field_ids is None:\n self.custom_field_ids = other.custom_field_ids\n elif other.custom_field_ids is not None:\n self.custom_field_ids.extend(other.custom_field_ids)\n self.custom_field_ids = list(set(self.custom_field_ids))\n\n return self\n\n @staticmethod\n def from_document(doc) -> \"DocumentMetadataOverrides\":\n \"\"\"\n Fills in the overrides from a document object\n \"\"\"\n overrides = DocumentMetadataOverrides()\n overrides.title = doc.title\n overrides.correspondent_id = doc.correspondent.id if doc.correspondent else None\n overrides.document_type_id = doc.document_type.id if doc.document_type else None\n overrides.storage_path_id = doc.storage_path.id if doc.storage_path else None\n overrides.owner_id = doc.owner.id if doc.owner else None\n overrides.tag_ids = list(doc.tags.values_list(\"id\", flat=True))\n\n overrides.view_users = list(\n get_users_with_perms(\n doc,\n only_with_perms_in=[\"view_document\"],\n ).values_list(\"id\", flat=True),\n )\n overrides.change_users = list(\n get_users_with_perms(\n doc,\n only_with_perms_in=[\"change_document\"],\n ).values_list(\"id\", flat=True),\n )\n overrides.custom_field_ids = list(\n doc.custom_fields.values_list(\"field\", flat=True),\n )\n\n groups_with_perms = get_groups_with_perms(\n doc,\n attach_perms=True,\n )\n overrides.view_groups = [\n group.id\n for group in groups_with_perms\n if \"view_document\" in groups_with_perms[group]\n ]\n overrides.change_groups = [\n group.id\n for group in groups_with_perms\n if \"change_document\" in groups_with_perms[group]\n ]\n\n return overrides\n\n\nclass DocumentSource(IntEnum):\n \"\"\"\n The source of an incoming document. May have other uses in the future\n \"\"\"\n\n ConsumeFolder = 1\n ApiUpload = 2\n MailFetch = 3\n\n\[email protected]\nclass ConsumableDocument:\n \"\"\"\n Encapsulates an incoming document, either from consume folder, API upload\n or mail fetching and certain useful operations on it.\n \"\"\"\n\n source: DocumentSource\n original_file: Path\n mailrule_id: Optional[int] = None\n mime_type: str = dataclasses.field(init=False, default=None)\n\n def __post_init__(self):\n \"\"\"\n After a dataclass is initialized, this is called to finalize some data\n 1. Make sure the original path is an absolute, fully qualified path\n 2. Get the mime type of the file\n \"\"\"\n # Always fully qualify the path first thing\n # Just in case, convert to a path if it's a str\n self.original_file = Path(self.original_file).resolve()\n\n # Get the file type once at init\n # Note this function isn't called when the object is unpickled\n self.mime_type = magic.from_file(self.original_file, mime=True)\n", "path": "src/documents/data_models.py"}]}
| 3,945 | 105 |
gh_patches_debug_4450
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-2248
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NiftiLabelsMasker.inverse_transform() appears to fail in current nilearn version
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-79-642858f1debf> in <module>
----> 1 masker.inverse_transform(labels_and_my.values)
~/anaconda3/lib/python3.7/site-packages/nilearn/input_data/nifti_labels_masker.py in inverse_transform(self, signals)
296 logger.log("computing image from signals", verbose=self.verbose)
297 return signal_extraction.signals_to_img_labels(
--> 298 signals, self._resampled_labels_img_, self.mask_img_,
299 background_label=self.background_label)
AttributeError: 'NiftiLabelsMasker' object has no attribute '_resampled_labels_img_'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nilearn/input_data/nifti_labels_masker.py`
Content:
```
1 """
2 Transformer for computing ROI signals.
3 """
4
5 import numpy as np
6
7 from nilearn._utils.compat import Memory
8
9 from .. import _utils
10 from .._utils import logger, CacheMixin, _compose_err_msg
11 from .._utils.class_inspect import get_params
12 from .._utils.niimg_conversions import _check_same_fov
13 from .. import masking
14 from .. import image
15 from .base_masker import filter_and_extract, BaseMasker
16
17
18 class _ExtractionFunctor(object):
19
20 func_name = 'nifti_labels_masker_extractor'
21
22 def __init__(self, _resampled_labels_img_, background_label, strategy):
23 self._resampled_labels_img_ = _resampled_labels_img_
24 self.background_label = background_label
25 self.strategy = strategy
26
27 def __call__(self, imgs):
28 from ..regions import signal_extraction
29
30 return signal_extraction.img_to_signals_labels(
31 imgs, self._resampled_labels_img_,
32 background_label=self.background_label, strategy=self.strategy)
33
34
35 class NiftiLabelsMasker(BaseMasker, CacheMixin):
36 """Class for masking of Niimg-like objects.
37
38 NiftiLabelsMasker is useful when data from non-overlapping volumes should
39 be extracted (contrarily to NiftiMapsMasker). Use case: Summarize brain
40 signals from clusters that were obtained by prior K-means or Ward
41 clustering.
42
43 Parameters
44 ----------
45 labels_img: Niimg-like object
46 See http://nilearn.github.io/manipulating_images/input_output.html
47 Region definitions, as one image of labels.
48
49 background_label: number, optional
50 Label used in labels_img to represent background.
51
52 mask_img: Niimg-like object, optional
53 See http://nilearn.github.io/manipulating_images/input_output.html
54 Mask to apply to regions before extracting signals.
55
56 smoothing_fwhm: float, optional
57 If smoothing_fwhm is not None, it gives the full-width half maximum in
58 millimeters of the spatial smoothing to apply to the signal.
59
60 standardize: {'zscore', 'psc', True, False}, default is 'zscore'
61 Strategy to standardize the signal.
62 'zscore': the signal is z-scored. Timeseries are shifted
63 to zero mean and scaled to unit variance.
64 'psc': Timeseries are shifted to zero mean value and scaled
65 to percent signal change (as compared to original mean signal).
66 True : the signal is z-scored. Timeseries are shifted
67 to zero mean and scaled to unit variance.
68 False : Do not standardize the data.
69
70 detrend: boolean, optional
71 This parameter is passed to signal.clean. Please see the related
72 documentation for details
73
74 low_pass: None or float, optional
75 This parameter is passed to signal.clean. Please see the related
76 documentation for details
77
78 high_pass: None or float, optional
79 This parameter is passed to signal.clean. Please see the related
80 documentation for details
81
82 t_r: float, optional
83 This parameter is passed to signal.clean. Please see the related
84 documentation for details
85
86 dtype: {dtype, "auto"}
87 Data type toward which the data should be converted. If "auto", the
88 data will be converted to int32 if dtype is discrete and float32 if it
89 is continuous.
90
91 resampling_target: {"data", "labels", None}, optional.
92 Gives which image gives the final shape/size. For example, if
93 `resampling_target` is "data", the atlas is resampled to the
94 shape of the data if needed. If it is "labels" then mask_img
95 and images provided to fit() are resampled to the shape and
96 affine of maps_img. "None" means no resampling: if shapes and
97 affines do not match, a ValueError is raised. Defaults to "data".
98
99 memory: joblib.Memory or str, optional
100 Used to cache the region extraction process.
101 By default, no caching is done. If a string is given, it is the
102 path to the caching directory.
103
104 memory_level: int, optional
105 Aggressiveness of memory caching. The higher the number, the higher
106 the number of functions that will be cached. Zero means no caching.
107
108 verbose: integer, optional
109 Indicate the level of verbosity. By default, nothing is printed
110
111 strategy: str
112 The name of a valid function to reduce the region with.
113 Must be one of: sum, mean, median, mininum, maximum, variance,
114 standard_deviation
115
116 See also
117 --------
118 nilearn.input_data.NiftiMasker
119 """
120 # memory and memory_level are used by CacheMixin.
121
122 def __init__(self, labels_img, background_label=0, mask_img=None,
123 smoothing_fwhm=None, standardize=False, detrend=False,
124 low_pass=None, high_pass=None, t_r=None, dtype=None,
125 resampling_target="data",
126 memory=Memory(cachedir=None, verbose=0), memory_level=1,
127 verbose=0, strategy="mean"):
128 self.labels_img = labels_img
129 self.background_label = background_label
130 self.mask_img = mask_img
131
132 # Parameters for _smooth_array
133 self.smoothing_fwhm = smoothing_fwhm
134
135 # Parameters for clean()
136 self.standardize = standardize
137 self.detrend = detrend
138 self.low_pass = low_pass
139 self.high_pass = high_pass
140 self.t_r = t_r
141 self.dtype = dtype
142
143 # Parameters for resampling
144 self.resampling_target = resampling_target
145
146 # Parameters for joblib
147 self.memory = memory
148 self.memory_level = memory_level
149 self.verbose = verbose
150
151 available_reduction_strategies = {'mean', 'median', 'sum',
152 'minimum', 'maximum',
153 'standard_deviation', 'variance'}
154
155 if strategy not in available_reduction_strategies:
156 raise ValueError(str.format(
157 "Invalid strategy '{}'. Valid strategies are {}.",
158 strategy,
159 available_reduction_strategies
160 ))
161
162 self.strategy = strategy
163
164 if resampling_target not in ("labels", "data", None):
165 raise ValueError("invalid value for 'resampling_target' "
166 "parameter: " + str(resampling_target))
167
168 def fit(self, X=None, y=None):
169 """Prepare signal extraction from regions.
170
171 All parameters are unused, they are for scikit-learn compatibility.
172 """
173 logger.log("loading data from %s" %
174 _utils._repr_niimgs(self.labels_img)[:200],
175 verbose=self.verbose)
176 self.labels_img_ = _utils.check_niimg_3d(self.labels_img)
177 if self.mask_img is not None:
178 logger.log("loading data from %s" %
179 _utils._repr_niimgs(self.mask_img)[:200],
180 verbose=self.verbose)
181 self.mask_img_ = _utils.check_niimg_3d(self.mask_img)
182 else:
183 self.mask_img_ = None
184
185 # Check shapes and affines or resample.
186 if self.mask_img_ is not None:
187 if self.resampling_target == "data":
188 # resampling will be done at transform time
189 pass
190 elif self.resampling_target is None:
191 if self.mask_img_.shape != self.labels_img_.shape[:3]:
192 raise ValueError(
193 _compose_err_msg(
194 "Regions and mask do not have the same shape",
195 mask_img=self.mask_img,
196 labels_img=self.labels_img))
197 if not np.allclose(self.mask_img_.affine,
198 self.labels_img_.affine):
199 raise ValueError(_compose_err_msg(
200 "Regions and mask do not have the same affine.",
201 mask_img=self.mask_img, labels_img=self.labels_img))
202
203 elif self.resampling_target == "labels":
204 logger.log("resampling the mask", verbose=self.verbose)
205 self.mask_img_ = image.resample_img(
206 self.mask_img_,
207 target_affine=self.labels_img_.affine,
208 target_shape=self.labels_img_.shape[:3],
209 interpolation="nearest",
210 copy=True)
211 else:
212 raise ValueError("Invalid value for resampling_target: " +
213 str(self.resampling_target))
214
215 mask_data, mask_affine = masking._load_mask_img(self.mask_img_)
216
217 return self
218
219 def fit_transform(self, imgs, confounds=None):
220 """ Prepare and perform signal extraction from regions.
221 """
222 return self.fit().transform(imgs, confounds=confounds)
223
224 def _check_fitted(self):
225 if not hasattr(self, "labels_img_"):
226 raise ValueError('It seems that %s has not been fitted. '
227 'You must call fit() before calling transform().'
228 % self.__class__.__name__)
229
230 def transform_single_imgs(self, imgs, confounds=None):
231 """Extract signals from a single 4D niimg.
232
233 Parameters
234 ----------
235 imgs: 3D/4D Niimg-like object
236 See http://nilearn.github.io/manipulating_images/input_output.html
237 Images to process. It must boil down to a 4D image with scans
238 number as last dimension.
239
240 confounds: CSV file or array-like, optional
241 This parameter is passed to signal.clean. Please see the related
242 documentation for details.
243 shape: (number of scans, number of confounds)
244
245 Returns
246 -------
247 region_signals: 2D numpy.ndarray
248 Signal for each label.
249 shape: (number of scans, number of labels)
250 """
251 # We handle the resampling of labels separately because the affine of
252 # the labels image should not impact the extraction of the signal.
253
254 if not hasattr(self, '_resampled_labels_img_'):
255 self._resampled_labels_img_ = self.labels_img_
256 if self.resampling_target == "data":
257 imgs_ = _utils.check_niimg_4d(imgs)
258 if not _check_same_fov(imgs_, self._resampled_labels_img_):
259 if self.verbose > 0:
260 print("Resampling labels")
261 self._resampled_labels_img_ = self._cache(
262 image.resample_img, func_memory_level=2)(
263 self.labels_img_, interpolation="nearest",
264 target_shape=imgs_.shape[:3],
265 target_affine=imgs_.affine)
266 # Remove imgs_ from memory before loading the same image
267 # in filter_and_extract.
268 del imgs_
269
270 target_shape = None
271 target_affine = None
272 if self.resampling_target == 'labels':
273 target_shape = self._resampled_labels_img_.shape[:3]
274 target_affine = self._resampled_labels_img_.affine
275
276 params = get_params(NiftiLabelsMasker, self,
277 ignore=['resampling_target'])
278 params['target_shape'] = target_shape
279 params['target_affine'] = target_affine
280
281 region_signals, labels_ = self._cache(
282 filter_and_extract,
283 ignore=['verbose', 'memory', 'memory_level'])(
284 # Images
285 imgs, _ExtractionFunctor(self._resampled_labels_img_,
286 self.background_label, self.strategy),
287 # Pre-processing
288 params,
289 confounds=confounds,
290 dtype=self.dtype,
291 # Caching
292 memory=self.memory,
293 memory_level=self.memory_level,
294 verbose=self.verbose)
295
296 self.labels_ = labels_
297
298 return region_signals
299
300 def inverse_transform(self, signals):
301 """Compute voxel signals from region signals
302
303 Any mask given at initialization is taken into account.
304
305 Parameters
306 ----------
307 signals (2D numpy.ndarray)
308 Signal for each region.
309 shape: (number of scans, number of regions)
310
311 Returns
312 -------
313 voxel_signals (Nifti1Image)
314 Signal for each voxel
315 shape: (number of scans, number of voxels)
316 """
317 from ..regions import signal_extraction
318
319 self._check_fitted()
320
321 logger.log("computing image from signals", verbose=self.verbose)
322 return signal_extraction.signals_to_img_labels(
323 signals, self._resampled_labels_img_, self.mask_img_,
324 background_label=self.background_label)
325
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nilearn/input_data/nifti_labels_masker.py b/nilearn/input_data/nifti_labels_masker.py
--- a/nilearn/input_data/nifti_labels_masker.py
+++ b/nilearn/input_data/nifti_labels_masker.py
@@ -214,6 +214,10 @@
mask_data, mask_affine = masking._load_mask_img(self.mask_img_)
+ if not hasattr(self, '_resampled_labels_img_'):
+ # obviates need to run .transform() before .inverse_transform()
+ self._resampled_labels_img_ = self.labels_img_
+
return self
def fit_transform(self, imgs, confounds=None):
|
{"golden_diff": "diff --git a/nilearn/input_data/nifti_labels_masker.py b/nilearn/input_data/nifti_labels_masker.py\n--- a/nilearn/input_data/nifti_labels_masker.py\n+++ b/nilearn/input_data/nifti_labels_masker.py\n@@ -214,6 +214,10 @@\n \n mask_data, mask_affine = masking._load_mask_img(self.mask_img_)\n \n+ if not hasattr(self, '_resampled_labels_img_'):\n+ # obviates need to run .transform() before .inverse_transform()\n+ self._resampled_labels_img_ = self.labels_img_\n+\n return self\n \n def fit_transform(self, imgs, confounds=None):\n", "issue": "NiftiLabelsMasker.inverse_transform() appears to fail in current nilearn version\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-79-642858f1debf> in <module>\r\n----> 1 masker.inverse_transform(labels_and_my.values)\r\n\r\n~/anaconda3/lib/python3.7/site-packages/nilearn/input_data/nifti_labels_masker.py in inverse_transform(self, signals)\r\n 296 logger.log(\"computing image from signals\", verbose=self.verbose)\r\n 297 return signal_extraction.signals_to_img_labels(\r\n--> 298 signals, self._resampled_labels_img_, self.mask_img_,\r\n 299 background_label=self.background_label)\r\n\r\nAttributeError: 'NiftiLabelsMasker' object has no attribute '_resampled_labels_img_'\n", "before_files": [{"content": "\"\"\"\nTransformer for computing ROI signals.\n\"\"\"\n\nimport numpy as np\n\nfrom nilearn._utils.compat import Memory\n\nfrom .. import _utils\nfrom .._utils import logger, CacheMixin, _compose_err_msg\nfrom .._utils.class_inspect import get_params\nfrom .._utils.niimg_conversions import _check_same_fov\nfrom .. import masking\nfrom .. import image\nfrom .base_masker import filter_and_extract, BaseMasker\n\n\nclass _ExtractionFunctor(object):\n\n func_name = 'nifti_labels_masker_extractor'\n\n def __init__(self, _resampled_labels_img_, background_label, strategy):\n self._resampled_labels_img_ = _resampled_labels_img_\n self.background_label = background_label\n self.strategy = strategy\n\n def __call__(self, imgs):\n from ..regions import signal_extraction\n\n return signal_extraction.img_to_signals_labels(\n imgs, self._resampled_labels_img_,\n background_label=self.background_label, strategy=self.strategy)\n\n\nclass NiftiLabelsMasker(BaseMasker, CacheMixin):\n \"\"\"Class for masking of Niimg-like objects.\n\n NiftiLabelsMasker is useful when data from non-overlapping volumes should\n be extracted (contrarily to NiftiMapsMasker). Use case: Summarize brain\n signals from clusters that were obtained by prior K-means or Ward\n clustering.\n\n Parameters\n ----------\n labels_img: Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Region definitions, as one image of labels.\n\n background_label: number, optional\n Label used in labels_img to represent background.\n\n mask_img: Niimg-like object, optional\n See http://nilearn.github.io/manipulating_images/input_output.html\n Mask to apply to regions before extracting signals.\n\n smoothing_fwhm: float, optional\n If smoothing_fwhm is not None, it gives the full-width half maximum in\n millimeters of the spatial smoothing to apply to the signal.\n\n standardize: {'zscore', 'psc', True, False}, default is 'zscore'\n Strategy to standardize the signal.\n 'zscore': the signal is z-scored. Timeseries are shifted\n to zero mean and scaled to unit variance.\n 'psc': Timeseries are shifted to zero mean value and scaled\n to percent signal change (as compared to original mean signal).\n True : the signal is z-scored. Timeseries are shifted\n to zero mean and scaled to unit variance.\n False : Do not standardize the data.\n\n detrend: boolean, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n low_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n high_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n t_r: float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n dtype: {dtype, \"auto\"}\n Data type toward which the data should be converted. If \"auto\", the\n data will be converted to int32 if dtype is discrete and float32 if it\n is continuous.\n\n resampling_target: {\"data\", \"labels\", None}, optional.\n Gives which image gives the final shape/size. For example, if\n `resampling_target` is \"data\", the atlas is resampled to the\n shape of the data if needed. If it is \"labels\" then mask_img\n and images provided to fit() are resampled to the shape and\n affine of maps_img. \"None\" means no resampling: if shapes and\n affines do not match, a ValueError is raised. Defaults to \"data\".\n\n memory: joblib.Memory or str, optional\n Used to cache the region extraction process.\n By default, no caching is done. If a string is given, it is the\n path to the caching directory.\n\n memory_level: int, optional\n Aggressiveness of memory caching. The higher the number, the higher\n the number of functions that will be cached. Zero means no caching.\n\n verbose: integer, optional\n Indicate the level of verbosity. By default, nothing is printed\n\n strategy: str\n The name of a valid function to reduce the region with.\n Must be one of: sum, mean, median, mininum, maximum, variance,\n standard_deviation\n\n See also\n --------\n nilearn.input_data.NiftiMasker\n \"\"\"\n # memory and memory_level are used by CacheMixin.\n\n def __init__(self, labels_img, background_label=0, mask_img=None,\n smoothing_fwhm=None, standardize=False, detrend=False,\n low_pass=None, high_pass=None, t_r=None, dtype=None,\n resampling_target=\"data\",\n memory=Memory(cachedir=None, verbose=0), memory_level=1,\n verbose=0, strategy=\"mean\"):\n self.labels_img = labels_img\n self.background_label = background_label\n self.mask_img = mask_img\n\n # Parameters for _smooth_array\n self.smoothing_fwhm = smoothing_fwhm\n\n # Parameters for clean()\n self.standardize = standardize\n self.detrend = detrend\n self.low_pass = low_pass\n self.high_pass = high_pass\n self.t_r = t_r\n self.dtype = dtype\n\n # Parameters for resampling\n self.resampling_target = resampling_target\n\n # Parameters for joblib\n self.memory = memory\n self.memory_level = memory_level\n self.verbose = verbose\n\n available_reduction_strategies = {'mean', 'median', 'sum',\n 'minimum', 'maximum',\n 'standard_deviation', 'variance'}\n\n if strategy not in available_reduction_strategies:\n raise ValueError(str.format(\n \"Invalid strategy '{}'. Valid strategies are {}.\",\n strategy,\n available_reduction_strategies\n ))\n\n self.strategy = strategy\n\n if resampling_target not in (\"labels\", \"data\", None):\n raise ValueError(\"invalid value for 'resampling_target' \"\n \"parameter: \" + str(resampling_target))\n\n def fit(self, X=None, y=None):\n \"\"\"Prepare signal extraction from regions.\n\n All parameters are unused, they are for scikit-learn compatibility.\n \"\"\"\n logger.log(\"loading data from %s\" %\n _utils._repr_niimgs(self.labels_img)[:200],\n verbose=self.verbose)\n self.labels_img_ = _utils.check_niimg_3d(self.labels_img)\n if self.mask_img is not None:\n logger.log(\"loading data from %s\" %\n _utils._repr_niimgs(self.mask_img)[:200],\n verbose=self.verbose)\n self.mask_img_ = _utils.check_niimg_3d(self.mask_img)\n else:\n self.mask_img_ = None\n\n # Check shapes and affines or resample.\n if self.mask_img_ is not None:\n if self.resampling_target == \"data\":\n # resampling will be done at transform time\n pass\n elif self.resampling_target is None:\n if self.mask_img_.shape != self.labels_img_.shape[:3]:\n raise ValueError(\n _compose_err_msg(\n \"Regions and mask do not have the same shape\",\n mask_img=self.mask_img,\n labels_img=self.labels_img))\n if not np.allclose(self.mask_img_.affine,\n self.labels_img_.affine):\n raise ValueError(_compose_err_msg(\n \"Regions and mask do not have the same affine.\",\n mask_img=self.mask_img, labels_img=self.labels_img))\n\n elif self.resampling_target == \"labels\":\n logger.log(\"resampling the mask\", verbose=self.verbose)\n self.mask_img_ = image.resample_img(\n self.mask_img_,\n target_affine=self.labels_img_.affine,\n target_shape=self.labels_img_.shape[:3],\n interpolation=\"nearest\",\n copy=True)\n else:\n raise ValueError(\"Invalid value for resampling_target: \" +\n str(self.resampling_target))\n\n mask_data, mask_affine = masking._load_mask_img(self.mask_img_)\n\n return self\n\n def fit_transform(self, imgs, confounds=None):\n \"\"\" Prepare and perform signal extraction from regions.\n \"\"\"\n return self.fit().transform(imgs, confounds=confounds)\n\n def _check_fitted(self):\n if not hasattr(self, \"labels_img_\"):\n raise ValueError('It seems that %s has not been fitted. '\n 'You must call fit() before calling transform().'\n % self.__class__.__name__)\n\n def transform_single_imgs(self, imgs, confounds=None):\n \"\"\"Extract signals from a single 4D niimg.\n\n Parameters\n ----------\n imgs: 3D/4D Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Images to process. It must boil down to a 4D image with scans\n number as last dimension.\n\n confounds: CSV file or array-like, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details.\n shape: (number of scans, number of confounds)\n\n Returns\n -------\n region_signals: 2D numpy.ndarray\n Signal for each label.\n shape: (number of scans, number of labels)\n \"\"\"\n # We handle the resampling of labels separately because the affine of\n # the labels image should not impact the extraction of the signal.\n\n if not hasattr(self, '_resampled_labels_img_'):\n self._resampled_labels_img_ = self.labels_img_\n if self.resampling_target == \"data\":\n imgs_ = _utils.check_niimg_4d(imgs)\n if not _check_same_fov(imgs_, self._resampled_labels_img_):\n if self.verbose > 0:\n print(\"Resampling labels\")\n self._resampled_labels_img_ = self._cache(\n image.resample_img, func_memory_level=2)(\n self.labels_img_, interpolation=\"nearest\",\n target_shape=imgs_.shape[:3],\n target_affine=imgs_.affine)\n # Remove imgs_ from memory before loading the same image\n # in filter_and_extract.\n del imgs_\n\n target_shape = None\n target_affine = None\n if self.resampling_target == 'labels':\n target_shape = self._resampled_labels_img_.shape[:3]\n target_affine = self._resampled_labels_img_.affine\n\n params = get_params(NiftiLabelsMasker, self,\n ignore=['resampling_target'])\n params['target_shape'] = target_shape\n params['target_affine'] = target_affine\n\n region_signals, labels_ = self._cache(\n filter_and_extract,\n ignore=['verbose', 'memory', 'memory_level'])(\n # Images\n imgs, _ExtractionFunctor(self._resampled_labels_img_,\n self.background_label, self.strategy),\n # Pre-processing\n params,\n confounds=confounds,\n dtype=self.dtype,\n # Caching\n memory=self.memory,\n memory_level=self.memory_level,\n verbose=self.verbose)\n\n self.labels_ = labels_\n\n return region_signals\n\n def inverse_transform(self, signals):\n \"\"\"Compute voxel signals from region signals\n\n Any mask given at initialization is taken into account.\n\n Parameters\n ----------\n signals (2D numpy.ndarray)\n Signal for each region.\n shape: (number of scans, number of regions)\n\n Returns\n -------\n voxel_signals (Nifti1Image)\n Signal for each voxel\n shape: (number of scans, number of voxels)\n \"\"\"\n from ..regions import signal_extraction\n\n self._check_fitted()\n\n logger.log(\"computing image from signals\", verbose=self.verbose)\n return signal_extraction.signals_to_img_labels(\n signals, self._resampled_labels_img_, self.mask_img_,\n background_label=self.background_label)\n", "path": "nilearn/input_data/nifti_labels_masker.py"}], "after_files": [{"content": "\"\"\"\nTransformer for computing ROI signals.\n\"\"\"\n\nimport numpy as np\n\nfrom nilearn._utils.compat import Memory\n\nfrom .. import _utils\nfrom .._utils import logger, CacheMixin, _compose_err_msg\nfrom .._utils.class_inspect import get_params\nfrom .._utils.niimg_conversions import _check_same_fov\nfrom .. import masking\nfrom .. import image\nfrom .base_masker import filter_and_extract, BaseMasker\n\n\nclass _ExtractionFunctor(object):\n\n func_name = 'nifti_labels_masker_extractor'\n\n def __init__(self, _resampled_labels_img_, background_label, strategy):\n self._resampled_labels_img_ = _resampled_labels_img_\n self.background_label = background_label\n self.strategy = strategy\n\n def __call__(self, imgs):\n from ..regions import signal_extraction\n\n return signal_extraction.img_to_signals_labels(\n imgs, self._resampled_labels_img_,\n background_label=self.background_label, strategy=self.strategy)\n\n\nclass NiftiLabelsMasker(BaseMasker, CacheMixin):\n \"\"\"Class for masking of Niimg-like objects.\n\n NiftiLabelsMasker is useful when data from non-overlapping volumes should\n be extracted (contrarily to NiftiMapsMasker). Use case: Summarize brain\n signals from clusters that were obtained by prior K-means or Ward\n clustering.\n\n Parameters\n ----------\n labels_img: Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Region definitions, as one image of labels.\n\n background_label: number, optional\n Label used in labels_img to represent background.\n\n mask_img: Niimg-like object, optional\n See http://nilearn.github.io/manipulating_images/input_output.html\n Mask to apply to regions before extracting signals.\n\n smoothing_fwhm: float, optional\n If smoothing_fwhm is not None, it gives the full-width half maximum in\n millimeters of the spatial smoothing to apply to the signal.\n\n standardize: {'zscore', 'psc', True, False}, default is 'zscore'\n Strategy to standardize the signal.\n 'zscore': the signal is z-scored. Timeseries are shifted\n to zero mean and scaled to unit variance.\n 'psc': Timeseries are shifted to zero mean value and scaled\n to percent signal change (as compared to original mean signal).\n True : the signal is z-scored. Timeseries are shifted\n to zero mean and scaled to unit variance.\n False : Do not standardize the data.\n\n detrend: boolean, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n low_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n high_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n t_r: float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n dtype: {dtype, \"auto\"}\n Data type toward which the data should be converted. If \"auto\", the\n data will be converted to int32 if dtype is discrete and float32 if it\n is continuous.\n\n resampling_target: {\"data\", \"labels\", None}, optional.\n Gives which image gives the final shape/size. For example, if\n `resampling_target` is \"data\", the atlas is resampled to the\n shape of the data if needed. If it is \"labels\" then mask_img\n and images provided to fit() are resampled to the shape and\n affine of maps_img. \"None\" means no resampling: if shapes and\n affines do not match, a ValueError is raised. Defaults to \"data\".\n\n memory: joblib.Memory or str, optional\n Used to cache the region extraction process.\n By default, no caching is done. If a string is given, it is the\n path to the caching directory.\n\n memory_level: int, optional\n Aggressiveness of memory caching. The higher the number, the higher\n the number of functions that will be cached. Zero means no caching.\n\n verbose: integer, optional\n Indicate the level of verbosity. By default, nothing is printed\n\n strategy: str\n The name of a valid function to reduce the region with.\n Must be one of: sum, mean, median, mininum, maximum, variance,\n standard_deviation\n\n See also\n --------\n nilearn.input_data.NiftiMasker\n \"\"\"\n # memory and memory_level are used by CacheMixin.\n\n def __init__(self, labels_img, background_label=0, mask_img=None,\n smoothing_fwhm=None, standardize=False, detrend=False,\n low_pass=None, high_pass=None, t_r=None, dtype=None,\n resampling_target=\"data\",\n memory=Memory(cachedir=None, verbose=0), memory_level=1,\n verbose=0, strategy=\"mean\"):\n self.labels_img = labels_img\n self.background_label = background_label\n self.mask_img = mask_img\n\n # Parameters for _smooth_array\n self.smoothing_fwhm = smoothing_fwhm\n\n # Parameters for clean()\n self.standardize = standardize\n self.detrend = detrend\n self.low_pass = low_pass\n self.high_pass = high_pass\n self.t_r = t_r\n self.dtype = dtype\n\n # Parameters for resampling\n self.resampling_target = resampling_target\n\n # Parameters for joblib\n self.memory = memory\n self.memory_level = memory_level\n self.verbose = verbose\n\n available_reduction_strategies = {'mean', 'median', 'sum',\n 'minimum', 'maximum',\n 'standard_deviation', 'variance'}\n\n if strategy not in available_reduction_strategies:\n raise ValueError(str.format(\n \"Invalid strategy '{}'. Valid strategies are {}.\",\n strategy,\n available_reduction_strategies\n ))\n\n self.strategy = strategy\n\n if resampling_target not in (\"labels\", \"data\", None):\n raise ValueError(\"invalid value for 'resampling_target' \"\n \"parameter: \" + str(resampling_target))\n\n def fit(self, X=None, y=None):\n \"\"\"Prepare signal extraction from regions.\n\n All parameters are unused, they are for scikit-learn compatibility.\n \"\"\"\n logger.log(\"loading data from %s\" %\n _utils._repr_niimgs(self.labels_img)[:200],\n verbose=self.verbose)\n self.labels_img_ = _utils.check_niimg_3d(self.labels_img)\n if self.mask_img is not None:\n logger.log(\"loading data from %s\" %\n _utils._repr_niimgs(self.mask_img)[:200],\n verbose=self.verbose)\n self.mask_img_ = _utils.check_niimg_3d(self.mask_img)\n else:\n self.mask_img_ = None\n\n # Check shapes and affines or resample.\n if self.mask_img_ is not None:\n if self.resampling_target == \"data\":\n # resampling will be done at transform time\n pass\n elif self.resampling_target is None:\n if self.mask_img_.shape != self.labels_img_.shape[:3]:\n raise ValueError(\n _compose_err_msg(\n \"Regions and mask do not have the same shape\",\n mask_img=self.mask_img,\n labels_img=self.labels_img))\n if not np.allclose(self.mask_img_.affine,\n self.labels_img_.affine):\n raise ValueError(_compose_err_msg(\n \"Regions and mask do not have the same affine.\",\n mask_img=self.mask_img, labels_img=self.labels_img))\n\n elif self.resampling_target == \"labels\":\n logger.log(\"resampling the mask\", verbose=self.verbose)\n self.mask_img_ = image.resample_img(\n self.mask_img_,\n target_affine=self.labels_img_.affine,\n target_shape=self.labels_img_.shape[:3],\n interpolation=\"nearest\",\n copy=True)\n else:\n raise ValueError(\"Invalid value for resampling_target: \" +\n str(self.resampling_target))\n\n mask_data, mask_affine = masking._load_mask_img(self.mask_img_)\n\n if not hasattr(self, '_resampled_labels_img_'):\n # obviates need to run .transform() before .inverse_transform()\n self._resampled_labels_img_ = self.labels_img_\n\n return self\n\n def fit_transform(self, imgs, confounds=None):\n \"\"\" Prepare and perform signal extraction from regions.\n \"\"\"\n return self.fit().transform(imgs, confounds=confounds)\n\n def _check_fitted(self):\n if not hasattr(self, \"labels_img_\"):\n raise ValueError('It seems that %s has not been fitted. '\n 'You must call fit() before calling transform().'\n % self.__class__.__name__)\n\n def transform_single_imgs(self, imgs, confounds=None):\n \"\"\"Extract signals from a single 4D niimg.\n\n Parameters\n ----------\n imgs: 3D/4D Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Images to process. It must boil down to a 4D image with scans\n number as last dimension.\n\n confounds: CSV file or array-like, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details.\n shape: (number of scans, number of confounds)\n\n Returns\n -------\n region_signals: 2D numpy.ndarray\n Signal for each label.\n shape: (number of scans, number of labels)\n \"\"\"\n # We handle the resampling of labels separately because the affine of\n # the labels image should not impact the extraction of the signal.\n\n if not hasattr(self, '_resampled_labels_img_'):\n self._resampled_labels_img_ = self.labels_img_\n if self.resampling_target == \"data\":\n imgs_ = _utils.check_niimg_4d(imgs)\n if not _check_same_fov(imgs_, self._resampled_labels_img_):\n if self.verbose > 0:\n print(\"Resampling labels\")\n self._resampled_labels_img_ = self._cache(\n image.resample_img, func_memory_level=2)(\n self.labels_img_, interpolation=\"nearest\",\n target_shape=imgs_.shape[:3],\n target_affine=imgs_.affine)\n # Remove imgs_ from memory before loading the same image\n # in filter_and_extract.\n del imgs_\n\n target_shape = None\n target_affine = None\n if self.resampling_target == 'labels':\n target_shape = self._resampled_labels_img_.shape[:3]\n target_affine = self._resampled_labels_img_.affine\n\n params = get_params(NiftiLabelsMasker, self,\n ignore=['resampling_target'])\n params['target_shape'] = target_shape\n params['target_affine'] = target_affine\n\n region_signals, labels_ = self._cache(\n filter_and_extract,\n ignore=['verbose', 'memory', 'memory_level'])(\n # Images\n imgs, _ExtractionFunctor(self._resampled_labels_img_,\n self.background_label, self.strategy),\n # Pre-processing\n params,\n confounds=confounds,\n dtype=self.dtype,\n # Caching\n memory=self.memory,\n memory_level=self.memory_level,\n verbose=self.verbose)\n\n self.labels_ = labels_\n\n return region_signals\n\n def inverse_transform(self, signals):\n \"\"\"Compute voxel signals from region signals\n\n Any mask given at initialization is taken into account.\n\n Parameters\n ----------\n signals (2D numpy.ndarray)\n Signal for each region.\n shape: (number of scans, number of regions)\n\n Returns\n -------\n voxel_signals (Nifti1Image)\n Signal for each voxel\n shape: (number of scans, number of voxels)\n \"\"\"\n from ..regions import signal_extraction\n\n self._check_fitted()\n\n logger.log(\"computing image from signals\", verbose=self.verbose)\n return signal_extraction.signals_to_img_labels(\n signals, self._resampled_labels_img_, self.mask_img_,\n background_label=self.background_label)\n", "path": "nilearn/input_data/nifti_labels_masker.py"}]}
| 3,975 | 156 |
gh_patches_debug_33015
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1050
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bump minimum OpenTelemetry version to support type checks
See the following comment for details: https://github.com/googleapis/python-bigquery/pull/1036#discussion_r739787329
If confirmed, we should bump to at least `opentelemetry-*==1.1.0`, and adjust our OpenTelemetry logic to the changes in the library API.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 pyarrow_dep = ["pyarrow >= 3.0.0, < 7.0dev"]
32 dependencies = [
33 "grpcio >= 1.38.1, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/695
34 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
35 # Until this issue is closed
36 # https://github.com/googleapis/google-cloud-python/issues/10566
37 "google-api-core[grpc] >= 1.29.0, <3.0.0dev",
38 "proto-plus >= 1.10.0",
39 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
40 # Until this issue is closed
41 # https://github.com/googleapis/google-cloud-python/issues/10566
42 "google-cloud-core >= 1.4.1, <3.0.0dev",
43 "google-resumable-media >= 0.6.0, < 3.0dev",
44 "packaging >= 14.3",
45 "protobuf >= 3.12.0",
46 "python-dateutil >= 2.7.2, <3.0dev",
47 "requests >= 2.18.0, < 3.0.0dev",
48 ]
49 extras = {
50 "bqstorage": [
51 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
52 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
53 # installed, even though `google-cloud-bigquery-storage` specifies it
54 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
55 # See: https://github.com/googleapis/python-bigquery/issues/83 The
56 # grpc.Channel.close() method isn't added until 1.32.0.
57 # https://github.com/grpc/grpc/pull/15254
58 "grpcio >= 1.38.1, < 2.0dev",
59 ]
60 + pyarrow_dep,
61 "geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.6.0, <2.0dev"],
62 "pandas": ["pandas>=0.24.2"] + pyarrow_dep,
63 "bignumeric_type": pyarrow_dep,
64 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
65 "opentelemetry": [
66 "opentelemetry-api >= 0.11b0",
67 "opentelemetry-sdk >= 0.11b0",
68 "opentelemetry-instrumentation >= 0.11b0",
69 ],
70 }
71
72 all_extras = []
73
74 for extra in extras:
75 # Exclude this extra from all to avoid overly strict dependencies on core
76 # libraries such as pyarrow.
77 # https://github.com/googleapis/python-bigquery/issues/563
78 if extra in {"bignumeric_type"}:
79 continue
80 all_extras.extend(extras[extra])
81
82 extras["all"] = all_extras
83
84 # Setup boilerplate below this line.
85
86 package_root = os.path.abspath(os.path.dirname(__file__))
87
88 readme_filename = os.path.join(package_root, "README.rst")
89 with io.open(readme_filename, encoding="utf-8") as readme_file:
90 readme = readme_file.read()
91
92 version = {}
93 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
94 exec(fp.read(), version)
95 version = version["__version__"]
96
97 # Only include packages under the 'google' namespace. Do not include tests,
98 # benchmarks, etc.
99 packages = [
100 package
101 for package in setuptools.PEP420PackageFinder.find()
102 if package.startswith("google")
103 ]
104
105 # Determine which namespaces are needed.
106 namespaces = ["google"]
107 if "google.cloud" in packages:
108 namespaces.append("google.cloud")
109
110
111 setuptools.setup(
112 name=name,
113 version=version,
114 description=description,
115 long_description=readme,
116 author="Google LLC",
117 author_email="[email protected]",
118 license="Apache 2.0",
119 url="https://github.com/googleapis/python-bigquery",
120 classifiers=[
121 release_status,
122 "Intended Audience :: Developers",
123 "License :: OSI Approved :: Apache Software License",
124 "Programming Language :: Python",
125 "Programming Language :: Python :: 3",
126 "Programming Language :: Python :: 3.6",
127 "Programming Language :: Python :: 3.7",
128 "Programming Language :: Python :: 3.8",
129 "Programming Language :: Python :: 3.9",
130 "Programming Language :: Python :: 3.10",
131 "Operating System :: OS Independent",
132 "Topic :: Internet",
133 ],
134 platforms="Posix; MacOS X; Windows",
135 packages=packages,
136 namespace_packages=namespaces,
137 install_requires=dependencies,
138 extras_require=extras,
139 python_requires=">=3.6, <3.11",
140 include_package_data=True,
141 zip_safe=False,
142 )
143
```
Path: `google/cloud/bigquery/opentelemetry_tracing.py`
Content:
```
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from contextlib import contextmanager
17 from google.api_core.exceptions import GoogleAPICallError
18
19 logger = logging.getLogger(__name__)
20 try:
21 from opentelemetry import trace
22 from opentelemetry.instrumentation.utils import http_status_to_canonical_code
23 from opentelemetry.trace.status import Status
24
25 HAS_OPENTELEMETRY = True
26 _warned_telemetry = True
27
28 except ImportError:
29 HAS_OPENTELEMETRY = False
30 _warned_telemetry = False
31
32 _default_attributes = {
33 "db.system": "BigQuery"
34 } # static, default values assigned to all spans
35
36
37 @contextmanager
38 def create_span(name, attributes=None, client=None, job_ref=None):
39 """Creates a ContextManager for a Span to be exported to the configured exporter.
40 If no configuration exists yields None.
41
42 Args:
43 name (str): Name that will be set for the span being created
44 attributes (Optional[dict]):
45 Additional attributes that pertain to
46 the specific API call (i.e. not a default attribute)
47 client (Optional[google.cloud.bigquery.client.Client]):
48 Pass in a Client object to extract any attributes that may be
49 relevant to it and add them to the created spans.
50 job_ref (Optional[google.cloud.bigquery.job._AsyncJob])
51 Pass in a _AsyncJob object to extract any attributes that may be
52 relevant to it and add them to the created spans.
53
54 Yields:
55 opentelemetry.trace.Span: Yields the newly created Span.
56
57 Raises:
58 google.api_core.exceptions.GoogleAPICallError:
59 Raised if a span could not be yielded or issue with call to
60 OpenTelemetry.
61 """
62 global _warned_telemetry
63 final_attributes = _get_final_span_attributes(attributes, client, job_ref)
64 if not HAS_OPENTELEMETRY:
65 if not _warned_telemetry:
66 logger.debug(
67 "This service is instrumented using OpenTelemetry. "
68 "OpenTelemetry could not be imported; please "
69 "add opentelemetry-api and opentelemetry-instrumentation "
70 "packages in order to get BigQuery Tracing data."
71 )
72 _warned_telemetry = True
73
74 yield None
75 return
76 tracer = trace.get_tracer(__name__)
77
78 # yield new span value
79 with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:
80 try:
81 yield span
82 except GoogleAPICallError as error:
83 if error.code is not None:
84 span.set_status(Status(http_status_to_canonical_code(error.code)))
85 raise
86
87
88 def _get_final_span_attributes(attributes=None, client=None, job_ref=None):
89 final_attributes = {}
90 final_attributes.update(_default_attributes.copy())
91 if client:
92 client_attributes = _set_client_attributes(client)
93 final_attributes.update(client_attributes)
94 if job_ref:
95 job_attributes = _set_job_attributes(job_ref)
96 final_attributes.update(job_attributes)
97 if attributes:
98 final_attributes.update(attributes)
99 return final_attributes
100
101
102 def _set_client_attributes(client):
103 return {"db.name": client.project, "location": client.location}
104
105
106 def _set_job_attributes(job_ref):
107 job_attributes = {
108 "db.name": job_ref.project,
109 "location": job_ref.location,
110 "num_child_jobs": job_ref.num_child_jobs,
111 "job_id": job_ref.job_id,
112 "parent_job_id": job_ref.parent_job_id,
113 "state": job_ref.state,
114 }
115
116 job_attributes["hasErrors"] = job_ref.error_result is not None
117
118 if job_ref.created is not None:
119 job_attributes["timeCreated"] = job_ref.created.isoformat()
120
121 if job_ref.started is not None:
122 job_attributes["timeStarted"] = job_ref.started.isoformat()
123
124 if job_ref.ended is not None:
125 job_attributes["timeEnded"] = job_ref.ended.isoformat()
126
127 return job_attributes
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py
--- a/google/cloud/bigquery/opentelemetry_tracing.py
+++ b/google/cloud/bigquery/opentelemetry_tracing.py
@@ -19,7 +19,7 @@
logger = logging.getLogger(__name__)
try:
from opentelemetry import trace
- from opentelemetry.instrumentation.utils import http_status_to_canonical_code
+ from opentelemetry.instrumentation.utils import http_status_to_status_code
from opentelemetry.trace.status import Status
HAS_OPENTELEMETRY = True
@@ -65,9 +65,10 @@
if not _warned_telemetry:
logger.debug(
"This service is instrumented using OpenTelemetry. "
- "OpenTelemetry could not be imported; please "
- "add opentelemetry-api and opentelemetry-instrumentation "
- "packages in order to get BigQuery Tracing data."
+ "OpenTelemetry or one of its components could not be imported; "
+ "please add compatible versions of opentelemetry-api and "
+ "opentelemetry-instrumentation packages in order to get BigQuery "
+ "Tracing data."
)
_warned_telemetry = True
@@ -81,7 +82,7 @@
yield span
except GoogleAPICallError as error:
if error.code is not None:
- span.set_status(Status(http_status_to_canonical_code(error.code)))
+ span.set_status(Status(http_status_to_status_code(error.code)))
raise
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -63,9 +63,9 @@
"bignumeric_type": pyarrow_dep,
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
"opentelemetry": [
- "opentelemetry-api >= 0.11b0",
- "opentelemetry-sdk >= 0.11b0",
- "opentelemetry-instrumentation >= 0.11b0",
+ "opentelemetry-api >= 1.1.0",
+ "opentelemetry-sdk >= 1.1.0",
+ "opentelemetry-instrumentation >= 0.20b0",
],
}
|
{"golden_diff": "diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py\n--- a/google/cloud/bigquery/opentelemetry_tracing.py\n+++ b/google/cloud/bigquery/opentelemetry_tracing.py\n@@ -19,7 +19,7 @@\n logger = logging.getLogger(__name__)\n try:\n from opentelemetry import trace\n- from opentelemetry.instrumentation.utils import http_status_to_canonical_code\n+ from opentelemetry.instrumentation.utils import http_status_to_status_code\n from opentelemetry.trace.status import Status\n \n HAS_OPENTELEMETRY = True\n@@ -65,9 +65,10 @@\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n- \"OpenTelemetry could not be imported; please \"\n- \"add opentelemetry-api and opentelemetry-instrumentation \"\n- \"packages in order to get BigQuery Tracing data.\"\n+ \"OpenTelemetry or one of its components could not be imported; \"\n+ \"please add compatible versions of opentelemetry-api and \"\n+ \"opentelemetry-instrumentation packages in order to get BigQuery \"\n+ \"Tracing data.\"\n )\n _warned_telemetry = True\n \n@@ -81,7 +82,7 @@\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n- span.set_status(Status(http_status_to_canonical_code(error.code)))\n+ span.set_status(Status(http_status_to_status_code(error.code)))\n raise\n \n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -63,9 +63,9 @@\n \"bignumeric_type\": pyarrow_dep,\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n- \"opentelemetry-api >= 0.11b0\",\n- \"opentelemetry-sdk >= 0.11b0\",\n- \"opentelemetry-instrumentation >= 0.11b0\",\n+ \"opentelemetry-api >= 1.1.0\",\n+ \"opentelemetry-sdk >= 1.1.0\",\n+ \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n }\n", "issue": "Bump minimum OpenTelemetry version to support type checks\nSee the following comment for details: https://github.com/googleapis/python-bigquery/pull/1036#discussion_r739787329\r\n\r\nIf confirmed, we should bump to at least `opentelemetry-*==1.1.0`, and adjust our OpenTelemetry logic to the changes in the library API.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\npyarrow_dep = [\"pyarrow >= 3.0.0, < 7.0dev\"]\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.29.0, <3.0.0dev\",\n \"proto-plus >= 1.10.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.38.1, < 2.0dev\",\n ]\n + pyarrow_dep,\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.6.0, <2.0dev\"],\n \"pandas\": [\"pandas>=0.24.2\"] + pyarrow_dep,\n \"bignumeric_type\": pyarrow_dep,\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 0.11b0\",\n \"opentelemetry-sdk >= 0.11b0\",\n \"opentelemetry-instrumentation >= 0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.11\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}, {"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom contextlib import contextmanager\nfrom google.api_core.exceptions import GoogleAPICallError\n\nlogger = logging.getLogger(__name__)\ntry:\n from opentelemetry import trace\n from opentelemetry.instrumentation.utils import http_status_to_canonical_code\n from opentelemetry.trace.status import Status\n\n HAS_OPENTELEMETRY = True\n _warned_telemetry = True\n\nexcept ImportError:\n HAS_OPENTELEMETRY = False\n _warned_telemetry = False\n\n_default_attributes = {\n \"db.system\": \"BigQuery\"\n} # static, default values assigned to all spans\n\n\n@contextmanager\ndef create_span(name, attributes=None, client=None, job_ref=None):\n \"\"\"Creates a ContextManager for a Span to be exported to the configured exporter.\n If no configuration exists yields None.\n\n Args:\n name (str): Name that will be set for the span being created\n attributes (Optional[dict]):\n Additional attributes that pertain to\n the specific API call (i.e. not a default attribute)\n client (Optional[google.cloud.bigquery.client.Client]):\n Pass in a Client object to extract any attributes that may be\n relevant to it and add them to the created spans.\n job_ref (Optional[google.cloud.bigquery.job._AsyncJob])\n Pass in a _AsyncJob object to extract any attributes that may be\n relevant to it and add them to the created spans.\n\n Yields:\n opentelemetry.trace.Span: Yields the newly created Span.\n\n Raises:\n google.api_core.exceptions.GoogleAPICallError:\n Raised if a span could not be yielded or issue with call to\n OpenTelemetry.\n \"\"\"\n global _warned_telemetry\n final_attributes = _get_final_span_attributes(attributes, client, job_ref)\n if not HAS_OPENTELEMETRY:\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n \"OpenTelemetry could not be imported; please \"\n \"add opentelemetry-api and opentelemetry-instrumentation \"\n \"packages in order to get BigQuery Tracing data.\"\n )\n _warned_telemetry = True\n\n yield None\n return\n tracer = trace.get_tracer(__name__)\n\n # yield new span value\n with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:\n try:\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n span.set_status(Status(http_status_to_canonical_code(error.code)))\n raise\n\n\ndef _get_final_span_attributes(attributes=None, client=None, job_ref=None):\n final_attributes = {}\n final_attributes.update(_default_attributes.copy())\n if client:\n client_attributes = _set_client_attributes(client)\n final_attributes.update(client_attributes)\n if job_ref:\n job_attributes = _set_job_attributes(job_ref)\n final_attributes.update(job_attributes)\n if attributes:\n final_attributes.update(attributes)\n return final_attributes\n\n\ndef _set_client_attributes(client):\n return {\"db.name\": client.project, \"location\": client.location}\n\n\ndef _set_job_attributes(job_ref):\n job_attributes = {\n \"db.name\": job_ref.project,\n \"location\": job_ref.location,\n \"num_child_jobs\": job_ref.num_child_jobs,\n \"job_id\": job_ref.job_id,\n \"parent_job_id\": job_ref.parent_job_id,\n \"state\": job_ref.state,\n }\n\n job_attributes[\"hasErrors\"] = job_ref.error_result is not None\n\n if job_ref.created is not None:\n job_attributes[\"timeCreated\"] = job_ref.created.isoformat()\n\n if job_ref.started is not None:\n job_attributes[\"timeStarted\"] = job_ref.started.isoformat()\n\n if job_ref.ended is not None:\n job_attributes[\"timeEnded\"] = job_ref.ended.isoformat()\n\n return job_attributes\n", "path": "google/cloud/bigquery/opentelemetry_tracing.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\npyarrow_dep = [\"pyarrow >= 3.0.0, < 7.0dev\"]\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.29.0, <3.0.0dev\",\n \"proto-plus >= 1.10.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.38.1, < 2.0dev\",\n ]\n + pyarrow_dep,\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.6.0, <2.0dev\"],\n \"pandas\": [\"pandas>=0.24.2\"] + pyarrow_dep,\n \"bignumeric_type\": pyarrow_dep,\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.11\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}, {"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom contextlib import contextmanager\nfrom google.api_core.exceptions import GoogleAPICallError\n\nlogger = logging.getLogger(__name__)\ntry:\n from opentelemetry import trace\n from opentelemetry.instrumentation.utils import http_status_to_status_code\n from opentelemetry.trace.status import Status\n\n HAS_OPENTELEMETRY = True\n _warned_telemetry = True\n\nexcept ImportError:\n HAS_OPENTELEMETRY = False\n _warned_telemetry = False\n\n_default_attributes = {\n \"db.system\": \"BigQuery\"\n} # static, default values assigned to all spans\n\n\n@contextmanager\ndef create_span(name, attributes=None, client=None, job_ref=None):\n \"\"\"Creates a ContextManager for a Span to be exported to the configured exporter.\n If no configuration exists yields None.\n\n Args:\n name (str): Name that will be set for the span being created\n attributes (Optional[dict]):\n Additional attributes that pertain to\n the specific API call (i.e. not a default attribute)\n client (Optional[google.cloud.bigquery.client.Client]):\n Pass in a Client object to extract any attributes that may be\n relevant to it and add them to the created spans.\n job_ref (Optional[google.cloud.bigquery.job._AsyncJob])\n Pass in a _AsyncJob object to extract any attributes that may be\n relevant to it and add them to the created spans.\n\n Yields:\n opentelemetry.trace.Span: Yields the newly created Span.\n\n Raises:\n google.api_core.exceptions.GoogleAPICallError:\n Raised if a span could not be yielded or issue with call to\n OpenTelemetry.\n \"\"\"\n global _warned_telemetry\n final_attributes = _get_final_span_attributes(attributes, client, job_ref)\n if not HAS_OPENTELEMETRY:\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n \"OpenTelemetry or one of its components could not be imported; \"\n \"please add compatible versions of opentelemetry-api and \"\n \"opentelemetry-instrumentation packages in order to get BigQuery \"\n \"Tracing data.\"\n )\n _warned_telemetry = True\n\n yield None\n return\n tracer = trace.get_tracer(__name__)\n\n # yield new span value\n with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:\n try:\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n span.set_status(Status(http_status_to_status_code(error.code)))\n raise\n\n\ndef _get_final_span_attributes(attributes=None, client=None, job_ref=None):\n final_attributes = {}\n final_attributes.update(_default_attributes.copy())\n if client:\n client_attributes = _set_client_attributes(client)\n final_attributes.update(client_attributes)\n if job_ref:\n job_attributes = _set_job_attributes(job_ref)\n final_attributes.update(job_attributes)\n if attributes:\n final_attributes.update(attributes)\n return final_attributes\n\n\ndef _set_client_attributes(client):\n return {\"db.name\": client.project, \"location\": client.location}\n\n\ndef _set_job_attributes(job_ref):\n job_attributes = {\n \"db.name\": job_ref.project,\n \"location\": job_ref.location,\n \"num_child_jobs\": job_ref.num_child_jobs,\n \"job_id\": job_ref.job_id,\n \"parent_job_id\": job_ref.parent_job_id,\n \"state\": job_ref.state,\n }\n\n job_attributes[\"hasErrors\"] = job_ref.error_result is not None\n\n if job_ref.created is not None:\n job_attributes[\"timeCreated\"] = job_ref.created.isoformat()\n\n if job_ref.started is not None:\n job_attributes[\"timeStarted\"] = job_ref.started.isoformat()\n\n if job_ref.ended is not None:\n job_attributes[\"timeEnded\"] = job_ref.ended.isoformat()\n\n return job_attributes\n", "path": "google/cloud/bigquery/opentelemetry_tracing.py"}]}
| 3,301 | 528 |
gh_patches_debug_20122
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-771
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[cliquet] Split tests from kinto package
original : https://github.com/mozilla-services/cliquet/issues/267
Should we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.
Another related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.
[cliquet] Split tests from kinto package
original : https://github.com/mozilla-services/cliquet/issues/267
Should we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.
Another related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import platform
2 import codecs
3 import os
4 from setuptools import setup, find_packages
5
6 here = os.path.abspath(os.path.dirname(__file__))
7
8
9 def read_file(filename):
10 """Open a related file and return its content."""
11 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
12 content = f.read()
13 return content
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 installed_with_pypy = platform.python_implementation() == 'PyPy'
20
21 REQUIREMENTS = [
22 'colander',
23 'colorama',
24 'cornice >= 1.1', # Fix cache CORS
25 'jsonschema',
26 'python-dateutil',
27 'pyramid_multiauth >= 0.8', # User on policy selected event.
28 'pyramid_tm',
29 'requests',
30 'six',
31 'structlog >= 16.1.0',
32 'enum34',
33 'waitress',
34 ]
35
36 if installed_with_pypy:
37 # We install psycopg2cffi instead of psycopg2 when dealing with pypy
38 # Note: JSONB support landed after psycopg2cffi 2.7.0
39 POSTGRESQL_REQUIRES = [
40 'SQLAlchemy',
41 'psycopg2cffi>2.7.0',
42 'zope.sqlalchemy',
43 ]
44 else:
45 # ujson is not pypy compliant, as it uses the CPython C API
46 REQUIREMENTS.append('ujson >= 1.35')
47 POSTGRESQL_REQUIRES = [
48 'SQLAlchemy',
49 'psycopg2>2.5',
50 'zope.sqlalchemy',
51 ]
52
53 REDIS_REQUIRES = [
54 'kinto_redis'
55 ]
56
57 DEPENDENCY_LINKS = [
58 ]
59
60 MONITORING_REQUIRES = [
61 'raven',
62 'statsd',
63 'newrelic',
64 'werkzeug',
65 ]
66
67 ENTRY_POINTS = {
68 'paste.app_factory': [
69 'main = kinto:main',
70 ],
71 'console_scripts': [
72 'kinto = kinto.__main__:main'
73 ],
74 }
75
76
77 setup(name='kinto',
78 version='4.1.0.dev0',
79 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
80 long_description=README + "\n\n" + CHANGELOG + "\n\n" + CONTRIBUTORS,
81 license='Apache License (2.0)',
82 classifiers=[
83 "Programming Language :: Python",
84 "Programming Language :: Python :: 2",
85 "Programming Language :: Python :: 2.7",
86 "Programming Language :: Python :: 3",
87 "Programming Language :: Python :: 3.4",
88 "Programming Language :: Python :: 3.5",
89 "Programming Language :: Python :: Implementation :: CPython",
90 "Programming Language :: Python :: Implementation :: PyPy",
91 "Topic :: Internet :: WWW/HTTP",
92 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
93 "License :: OSI Approved :: Apache Software License"
94 ],
95 keywords="web sync json storage services",
96 author='Mozilla Services',
97 author_email='[email protected]',
98 url='https://github.com/Kinto/kinto',
99 packages=find_packages(),
100 package_data={'': ['*.rst', '*.py']},
101 include_package_data=True,
102 zip_safe=False,
103 install_requires=REQUIREMENTS,
104 extras_require={
105 'redis': REDIS_REQUIRES,
106 'postgresql': POSTGRESQL_REQUIRES,
107 'monitoring': MONITORING_REQUIRES,
108 ":python_version=='2.7'": ["functools32", "futures"],
109 },
110 test_suite="kinto.tests",
111 dependency_links=DEPENDENCY_LINKS,
112 entry_points=ENTRY_POINTS)
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,6 +54,15 @@
'kinto_redis'
]
+SETUP_REQUIRES = [
+ 'pytest-runner'
+]
+
+TEST_REQUIREMENTS = [
+ 'pytest',
+ 'WebTest'
+]
+
DEPENDENCY_LINKS = [
]
@@ -100,6 +109,8 @@
package_data={'': ['*.rst', '*.py']},
include_package_data=True,
zip_safe=False,
+ setup_requires=SETUP_REQUIRES,
+ tests_require=TEST_REQUIREMENTS,
install_requires=REQUIREMENTS,
extras_require={
'redis': REDIS_REQUIRES,
@@ -107,6 +118,6 @@
'monitoring': MONITORING_REQUIRES,
":python_version=='2.7'": ["functools32", "futures"],
},
- test_suite="kinto.tests",
+ test_suite="tests",
dependency_links=DEPENDENCY_LINKS,
entry_points=ENTRY_POINTS)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,6 +54,15 @@\n 'kinto_redis'\n ]\n \n+SETUP_REQUIRES = [\n+ 'pytest-runner'\n+]\n+\n+TEST_REQUIREMENTS = [\n+ 'pytest',\n+ 'WebTest'\n+]\n+\n DEPENDENCY_LINKS = [\n ]\n \n@@ -100,6 +109,8 @@\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n+ setup_requires=SETUP_REQUIRES,\n+ tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n@@ -107,6 +118,6 @@\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n- test_suite=\"kinto.tests\",\n+ test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "issue": "[cliquet] Split tests from kinto package\noriginal : https://github.com/mozilla-services/cliquet/issues/267\n\nShould we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.\n\nAnother related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.\n\n[cliquet] Split tests from kinto package\noriginal : https://github.com/mozilla-services/cliquet/issues/267\n\nShould we have tests within the kinto package or outside ? that was discussed but I don't think a decision was made.\n\nAnother related question is not wether tests is in kinto/ or outside, but rather : do we ship tests when we release kinto ? some people strip them when they build the release.\n\n", "before_files": [{"content": "import platform\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\ninstalled_with_pypy = platform.python_implementation() == 'PyPy'\n\nREQUIREMENTS = [\n 'colander',\n 'colorama',\n 'cornice >= 1.1', # Fix cache CORS\n 'jsonschema',\n 'python-dateutil',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'pyramid_tm',\n 'requests',\n 'six',\n 'structlog >= 16.1.0',\n 'enum34',\n 'waitress',\n]\n\nif installed_with_pypy:\n # We install psycopg2cffi instead of psycopg2 when dealing with pypy\n # Note: JSONB support landed after psycopg2cffi 2.7.0\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2cffi>2.7.0',\n 'zope.sqlalchemy',\n ]\nelse:\n # ujson is not pypy compliant, as it uses the CPython C API\n REQUIREMENTS.append('ujson >= 1.35')\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2>2.5',\n 'zope.sqlalchemy',\n ]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='4.1.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=README + \"\\n\\n\" + CHANGELOG + \"\\n\\n\" + CONTRIBUTORS,\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n test_suite=\"kinto.tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}], "after_files": [{"content": "import platform\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\ninstalled_with_pypy = platform.python_implementation() == 'PyPy'\n\nREQUIREMENTS = [\n 'colander',\n 'colorama',\n 'cornice >= 1.1', # Fix cache CORS\n 'jsonschema',\n 'python-dateutil',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'pyramid_tm',\n 'requests',\n 'six',\n 'structlog >= 16.1.0',\n 'enum34',\n 'waitress',\n]\n\nif installed_with_pypy:\n # We install psycopg2cffi instead of psycopg2 when dealing with pypy\n # Note: JSONB support landed after psycopg2cffi 2.7.0\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2cffi>2.7.0',\n 'zope.sqlalchemy',\n ]\nelse:\n # ujson is not pypy compliant, as it uses the CPython C API\n REQUIREMENTS.append('ujson >= 1.35')\n POSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2>2.5',\n 'zope.sqlalchemy',\n ]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='4.1.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=README + \"\\n\\n\" + CHANGELOG + \"\\n\\n\" + CONTRIBUTORS,\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n \":python_version=='2.7'\": [\"functools32\", \"futures\"],\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 1,501 | 243 |
gh_patches_debug_22639
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-6608
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecated property "<AliasProperty name=filename>" of object "<kivy.core.audio(...)>" was accessed, it will be removed in a future version
### Versions
* Python: 3.7
* OS: independent
* Kivy: 1.11.1
* Kivy installation method: pip
### Description
The message displayed in title appears in the kivy logs when you load an audio using the default ```SoundLoader``` classes in ```kivy/core/audio``` files, excepting ```audio_ffpyplayer.py```. I was reading those files and realised that it happens because they are using ```self.filename``` instead of ```self.source```. As they belong to the kivy main files, the use of deprecated stuff should be replaced.
### Code and Logs
```python
from kivy.core.audio import SoundLoader
sound = SoundLoader.load('mytest.wav')
if sound:
print("Sound found at %s" % sound.source)
print("Sound is %.3f seconds" % sound.length)
sound.play()
```
Example, when using SDL2:
```python
[WARNING] Deprecated property "<AliasProperty name=filename>" of object "<kivy.core.audio.audio_sdl2.SoundSDL2>" was accessed, it will be removed in a future version
```
P.S: I don't know if the deprecation warnings in ```kivy/core/audio/__init__.py``` should be removed too.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kivy/core/audio/audio_gstplayer.py`
Content:
```
1 '''
2 Audio Gstplayer
3 ===============
4
5 .. versionadded:: 1.8.0
6
7 Implementation of a VideoBase with Kivy :class:`~kivy.lib.gstplayer.GstPlayer`
8 This player is the preferred player, using Gstreamer 1.0, working on both
9 Python 2 and 3.
10 '''
11
12 from kivy.lib.gstplayer import GstPlayer, get_gst_version
13 from kivy.core.audio import Sound, SoundLoader
14 from kivy.logger import Logger
15 from kivy.compat import PY2
16 from kivy.clock import Clock
17 from os.path import realpath
18
19 if PY2:
20 from urllib import pathname2url
21 else:
22 from urllib.request import pathname2url
23
24 Logger.info('AudioGstplayer: Using Gstreamer {}'.format(
25 '.'.join(map(str, get_gst_version()))))
26
27
28 def _on_gstplayer_message(mtype, message):
29 if mtype == 'error':
30 Logger.error('AudioGstplayer: {}'.format(message))
31 elif mtype == 'warning':
32 Logger.warning('AudioGstplayer: {}'.format(message))
33 elif mtype == 'info':
34 Logger.info('AudioGstplayer: {}'.format(message))
35
36
37 class SoundGstplayer(Sound):
38
39 @staticmethod
40 def extensions():
41 return ('wav', 'ogg', 'mp3', 'm4a', 'flac', 'mp4')
42
43 def __init__(self, **kwargs):
44 self.player = None
45 super(SoundGstplayer, self).__init__(**kwargs)
46
47 def _on_gst_eos_sync(self):
48 Clock.schedule_once(self._on_gst_eos, 0)
49
50 def _on_gst_eos(self, *dt):
51 if self.loop:
52 self.player.stop()
53 self.player.play()
54 else:
55 self.stop()
56
57 def load(self):
58 self.unload()
59 uri = self._get_uri()
60 self.player = GstPlayer(uri, None, self._on_gst_eos_sync,
61 _on_gstplayer_message)
62 self.player.load()
63
64 def play(self):
65 # we need to set the volume everytime, it seems that stopping + playing
66 # the sound reset the volume.
67 self.player.set_volume(self.volume)
68 self.player.play()
69 super(SoundGstplayer, self).play()
70
71 def stop(self):
72 self.player.stop()
73 super(SoundGstplayer, self).stop()
74
75 def unload(self):
76 if self.player:
77 self.player.unload()
78 self.player = None
79
80 def seek(self, position):
81 self.player.seek(position / self.length)
82
83 def get_pos(self):
84 return self.player.get_position()
85
86 def _get_length(self):
87 return self.player.get_duration()
88
89 def on_volume(self, instance, volume):
90 self.player.set_volume(volume)
91
92 def _get_uri(self):
93 uri = self.filename
94 if not uri:
95 return
96 if '://' not in uri:
97 uri = 'file:' + pathname2url(realpath(uri))
98 return uri
99
100
101 SoundLoader.register(SoundGstplayer)
102
```
Path: `kivy/core/audio/audio_pygame.py`
Content:
```
1 '''
2 AudioPygame: implementation of Sound with Pygame
3
4 .. warning::
5
6 Pygame has been deprecated and will be removed in the release after Kivy
7 1.11.0.
8 '''
9
10 __all__ = ('SoundPygame', )
11
12 from kivy.clock import Clock
13 from kivy.utils import platform, deprecated
14 from kivy.core.audio import Sound, SoundLoader
15
16 _platform = platform
17 try:
18 if _platform == 'android':
19 try:
20 import android.mixer as mixer
21 except ImportError:
22 # old python-for-android version
23 import android_mixer as mixer
24 else:
25 from pygame import mixer
26 except:
27 raise
28
29 # init pygame sound
30 mixer.pre_init(44100, -16, 2, 1024)
31 mixer.init()
32 mixer.set_num_channels(32)
33
34
35 class SoundPygame(Sound):
36
37 # XXX we don't set __slots__ here, to automatically add
38 # a dictionary. We need that to be able to use weakref for
39 # SoundPygame object. Otherwise, it failed with:
40 # TypeError: cannot create weak reference to 'SoundPygame' object
41 # We use our clock in play() method.
42 # __slots__ = ('_data', '_channel')
43 _check_play_ev = None
44
45 @staticmethod
46 def extensions():
47 if _platform == 'android':
48 return ('wav', 'ogg', 'mp3', 'm4a')
49 return ('wav', 'ogg')
50
51 @deprecated(
52 msg='Pygame has been deprecated and will be removed after 1.11.0')
53 def __init__(self, **kwargs):
54 self._data = None
55 self._channel = None
56 super(SoundPygame, self).__init__(**kwargs)
57
58 def _check_play(self, dt):
59 if self._channel is None:
60 return False
61 if self._channel.get_busy():
62 return
63 if self.loop:
64 def do_loop(dt):
65 self.play()
66 Clock.schedule_once(do_loop)
67 else:
68 self.stop()
69 return False
70
71 def play(self):
72 if not self._data:
73 return
74 self._data.set_volume(self.volume)
75 self._channel = self._data.play()
76 self.start_time = Clock.time()
77 # schedule event to check if the sound is still playing or not
78 self._check_play_ev = Clock.schedule_interval(self._check_play, 0.1)
79 super(SoundPygame, self).play()
80
81 def stop(self):
82 if not self._data:
83 return
84 self._data.stop()
85 # ensure we don't have anymore the callback
86 if self._check_play_ev is not None:
87 self._check_play_ev.cancel()
88 self._check_play_ev = None
89 self._channel = None
90 super(SoundPygame, self).stop()
91
92 def load(self):
93 self.unload()
94 if self.filename is None:
95 return
96 self._data = mixer.Sound(self.filename)
97
98 def unload(self):
99 self.stop()
100 self._data = None
101
102 def seek(self, position):
103 if not self._data:
104 return
105 if _platform == 'android' and self._channel:
106 self._channel.seek(position)
107
108 def get_pos(self):
109 if self._data is not None and self._channel:
110 if _platform == 'android':
111 return self._channel.get_pos()
112 return Clock.time() - self.start_time
113 return 0
114
115 def on_volume(self, instance, volume):
116 if self._data is not None:
117 self._data.set_volume(volume)
118
119 def _get_length(self):
120 if _platform == 'android' and self._channel:
121 return self._channel.get_length()
122 if self._data is not None:
123 return self._data.get_length()
124 return super(SoundPygame, self)._get_length()
125
126
127 SoundLoader.register(SoundPygame)
128
```
Path: `kivy/core/audio/audio_avplayer.py`
Content:
```
1 '''
2 AudioAvplayer: implementation of Sound using pyobjus / AVFoundation.
3 Works on iOS / OSX.
4 '''
5
6 __all__ = ('SoundAvplayer', )
7
8 from kivy.core.audio import Sound, SoundLoader
9 from pyobjus import autoclass
10 from pyobjus.dylib_manager import load_framework, INCLUDE
11
12 load_framework(INCLUDE.AVFoundation)
13 AVAudioPlayer = autoclass("AVAudioPlayer")
14 NSURL = autoclass("NSURL")
15 NSString = autoclass("NSString")
16
17
18 class SoundAvplayer(Sound):
19 @staticmethod
20 def extensions():
21 # taken from https://goo.gl/015kvU
22 return ("aac", "adts", "aif", "aiff", "aifc", "caf", "mp3", "mp4",
23 "m4a", "snd", "au", "sd2", "wav")
24
25 def __init__(self, **kwargs):
26 self._avplayer = None
27 super(SoundAvplayer, self).__init__(**kwargs)
28
29 def load(self):
30 self.unload()
31 fn = NSString.alloc().initWithUTF8String_(self.filename)
32 url = NSURL.alloc().initFileURLWithPath_(fn)
33 self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(
34 url, None)
35
36 def unload(self):
37 self.stop()
38 self._avplayer = None
39
40 def play(self):
41 if not self._avplayer:
42 return
43 self._avplayer.play()
44 super(SoundAvplayer, self).play()
45
46 def stop(self):
47 if not self._avplayer:
48 return
49 self._avplayer.stop()
50 super(SoundAvplayer, self).stop()
51
52 def seek(self, position):
53 if not self._avplayer:
54 return
55 self._avplayer.playAtTime_(float(position))
56
57 def get_pos(self):
58 if self._avplayer:
59 return self._avplayer.currentTime
60 return super(SoundAvplayer, self).get_pos()
61
62 def on_volume(self, instance, volume):
63 if self._avplayer:
64 self._avplayer.volume = float(volume)
65
66 def _get_length(self):
67 if self._avplayer:
68 return self._avplayer.duration
69 return super(SoundAvplayer, self)._get_length()
70
71
72 SoundLoader.register(SoundAvplayer)
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kivy/core/audio/audio_avplayer.py b/kivy/core/audio/audio_avplayer.py
--- a/kivy/core/audio/audio_avplayer.py
+++ b/kivy/core/audio/audio_avplayer.py
@@ -28,7 +28,7 @@
def load(self):
self.unload()
- fn = NSString.alloc().initWithUTF8String_(self.filename)
+ fn = NSString.alloc().initWithUTF8String_(self.source)
url = NSURL.alloc().initFileURLWithPath_(fn)
self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(
url, None)
diff --git a/kivy/core/audio/audio_gstplayer.py b/kivy/core/audio/audio_gstplayer.py
--- a/kivy/core/audio/audio_gstplayer.py
+++ b/kivy/core/audio/audio_gstplayer.py
@@ -90,7 +90,7 @@
self.player.set_volume(volume)
def _get_uri(self):
- uri = self.filename
+ uri = self.source
if not uri:
return
if '://' not in uri:
diff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py
--- a/kivy/core/audio/audio_pygame.py
+++ b/kivy/core/audio/audio_pygame.py
@@ -91,9 +91,9 @@
def load(self):
self.unload()
- if self.filename is None:
+ if self.source is None:
return
- self._data = mixer.Sound(self.filename)
+ self._data = mixer.Sound(self.source)
def unload(self):
self.stop()
|
{"golden_diff": "diff --git a/kivy/core/audio/audio_avplayer.py b/kivy/core/audio/audio_avplayer.py\n--- a/kivy/core/audio/audio_avplayer.py\n+++ b/kivy/core/audio/audio_avplayer.py\n@@ -28,7 +28,7 @@\n \n def load(self):\n self.unload()\n- fn = NSString.alloc().initWithUTF8String_(self.filename)\n+ fn = NSString.alloc().initWithUTF8String_(self.source)\n url = NSURL.alloc().initFileURLWithPath_(fn)\n self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(\n url, None)\ndiff --git a/kivy/core/audio/audio_gstplayer.py b/kivy/core/audio/audio_gstplayer.py\n--- a/kivy/core/audio/audio_gstplayer.py\n+++ b/kivy/core/audio/audio_gstplayer.py\n@@ -90,7 +90,7 @@\n self.player.set_volume(volume)\n \n def _get_uri(self):\n- uri = self.filename\n+ uri = self.source\n if not uri:\n return\n if '://' not in uri:\ndiff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py\n--- a/kivy/core/audio/audio_pygame.py\n+++ b/kivy/core/audio/audio_pygame.py\n@@ -91,9 +91,9 @@\n \n def load(self):\n self.unload()\n- if self.filename is None:\n+ if self.source is None:\n return\n- self._data = mixer.Sound(self.filename)\n+ self._data = mixer.Sound(self.source)\n \n def unload(self):\n self.stop()\n", "issue": "Deprecated property \"<AliasProperty name=filename>\" of object \"<kivy.core.audio(...)>\" was accessed, it will be removed in a future version\n### Versions\r\n\r\n* Python: 3.7\r\n* OS: independent\r\n* Kivy: 1.11.1\r\n* Kivy installation method: pip\r\n\r\n### Description\r\n\r\nThe message displayed in title appears in the kivy logs when you load an audio using the default ```SoundLoader``` classes in ```kivy/core/audio``` files, excepting ```audio_ffpyplayer.py```. I was reading those files and realised that it happens because they are using ```self.filename``` instead of ```self.source```. As they belong to the kivy main files, the use of deprecated stuff should be replaced.\r\n\r\n### Code and Logs\r\n```python\r\nfrom kivy.core.audio import SoundLoader\r\n\r\nsound = SoundLoader.load('mytest.wav')\r\nif sound:\r\n print(\"Sound found at %s\" % sound.source)\r\n print(\"Sound is %.3f seconds\" % sound.length)\r\n sound.play()\r\n```\r\n\r\nExample, when using SDL2:\r\n```python\r\n[WARNING] Deprecated property \"<AliasProperty name=filename>\" of object \"<kivy.core.audio.audio_sdl2.SoundSDL2>\" was accessed, it will be removed in a future version\r\n```\r\n\r\nP.S: I don't know if the deprecation warnings in ```kivy/core/audio/__init__.py``` should be removed too.\n", "before_files": [{"content": "'''\nAudio Gstplayer\n===============\n\n.. versionadded:: 1.8.0\n\nImplementation of a VideoBase with Kivy :class:`~kivy.lib.gstplayer.GstPlayer`\nThis player is the preferred player, using Gstreamer 1.0, working on both\nPython 2 and 3.\n'''\n\nfrom kivy.lib.gstplayer import GstPlayer, get_gst_version\nfrom kivy.core.audio import Sound, SoundLoader\nfrom kivy.logger import Logger\nfrom kivy.compat import PY2\nfrom kivy.clock import Clock\nfrom os.path import realpath\n\nif PY2:\n from urllib import pathname2url\nelse:\n from urllib.request import pathname2url\n\nLogger.info('AudioGstplayer: Using Gstreamer {}'.format(\n '.'.join(map(str, get_gst_version()))))\n\n\ndef _on_gstplayer_message(mtype, message):\n if mtype == 'error':\n Logger.error('AudioGstplayer: {}'.format(message))\n elif mtype == 'warning':\n Logger.warning('AudioGstplayer: {}'.format(message))\n elif mtype == 'info':\n Logger.info('AudioGstplayer: {}'.format(message))\n\n\nclass SoundGstplayer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', 'm4a', 'flac', 'mp4')\n\n def __init__(self, **kwargs):\n self.player = None\n super(SoundGstplayer, self).__init__(**kwargs)\n\n def _on_gst_eos_sync(self):\n Clock.schedule_once(self._on_gst_eos, 0)\n\n def _on_gst_eos(self, *dt):\n if self.loop:\n self.player.stop()\n self.player.play()\n else:\n self.stop()\n\n def load(self):\n self.unload()\n uri = self._get_uri()\n self.player = GstPlayer(uri, None, self._on_gst_eos_sync,\n _on_gstplayer_message)\n self.player.load()\n\n def play(self):\n # we need to set the volume everytime, it seems that stopping + playing\n # the sound reset the volume.\n self.player.set_volume(self.volume)\n self.player.play()\n super(SoundGstplayer, self).play()\n\n def stop(self):\n self.player.stop()\n super(SoundGstplayer, self).stop()\n\n def unload(self):\n if self.player:\n self.player.unload()\n self.player = None\n\n def seek(self, position):\n self.player.seek(position / self.length)\n\n def get_pos(self):\n return self.player.get_position()\n\n def _get_length(self):\n return self.player.get_duration()\n\n def on_volume(self, instance, volume):\n self.player.set_volume(volume)\n\n def _get_uri(self):\n uri = self.filename\n if not uri:\n return\n if '://' not in uri:\n uri = 'file:' + pathname2url(realpath(uri))\n return uri\n\n\nSoundLoader.register(SoundGstplayer)\n", "path": "kivy/core/audio/audio_gstplayer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n\n.. warning::\n\n Pygame has been deprecated and will be removed in the release after Kivy\n 1.11.0.\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform, deprecated\nfrom kivy.core.audio import Sound, SoundLoader\n\n_platform = platform\ntry:\n if _platform == 'android':\n try:\n import android.mixer as mixer\n except ImportError:\n # old python-for-android version\n import android_mixer as mixer\n else:\n from pygame import mixer\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automatically add\n # a dictionary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n _check_play_ev = None\n\n @staticmethod\n def extensions():\n if _platform == 'android':\n return ('wav', 'ogg', 'mp3', 'm4a')\n return ('wav', 'ogg')\n\n @deprecated(\n msg='Pygame has been deprecated and will be removed after 1.11.0')\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n if self.loop:\n def do_loop(dt):\n self.play()\n Clock.schedule_once(do_loop)\n else:\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._data.set_volume(self.volume)\n self._channel = self._data.play()\n self.start_time = Clock.time()\n # schedule event to check if the sound is still playing or not\n self._check_play_ev = Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n if self._check_play_ev is not None:\n self._check_play_ev.cancel()\n self._check_play_ev = None\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.filename is None:\n return\n self._data = mixer.Sound(self.filename)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if not self._data:\n return\n if _platform == 'android' and self._channel:\n self._channel.seek(position)\n\n def get_pos(self):\n if self._data is not None and self._channel:\n if _platform == 'android':\n return self._channel.get_pos()\n return Clock.time() - self.start_time\n return 0\n\n def on_volume(self, instance, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n\n def _get_length(self):\n if _platform == 'android' and self._channel:\n return self._channel.get_length()\n if self._data is not None:\n return self._data.get_length()\n return super(SoundPygame, self)._get_length()\n\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}, {"content": "'''\nAudioAvplayer: implementation of Sound using pyobjus / AVFoundation.\nWorks on iOS / OSX.\n'''\n\n__all__ = ('SoundAvplayer', )\n\nfrom kivy.core.audio import Sound, SoundLoader\nfrom pyobjus import autoclass\nfrom pyobjus.dylib_manager import load_framework, INCLUDE\n\nload_framework(INCLUDE.AVFoundation)\nAVAudioPlayer = autoclass(\"AVAudioPlayer\")\nNSURL = autoclass(\"NSURL\")\nNSString = autoclass(\"NSString\")\n\n\nclass SoundAvplayer(Sound):\n @staticmethod\n def extensions():\n # taken from https://goo.gl/015kvU\n return (\"aac\", \"adts\", \"aif\", \"aiff\", \"aifc\", \"caf\", \"mp3\", \"mp4\",\n \"m4a\", \"snd\", \"au\", \"sd2\", \"wav\")\n\n def __init__(self, **kwargs):\n self._avplayer = None\n super(SoundAvplayer, self).__init__(**kwargs)\n\n def load(self):\n self.unload()\n fn = NSString.alloc().initWithUTF8String_(self.filename)\n url = NSURL.alloc().initFileURLWithPath_(fn)\n self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(\n url, None)\n\n def unload(self):\n self.stop()\n self._avplayer = None\n\n def play(self):\n if not self._avplayer:\n return\n self._avplayer.play()\n super(SoundAvplayer, self).play()\n\n def stop(self):\n if not self._avplayer:\n return\n self._avplayer.stop()\n super(SoundAvplayer, self).stop()\n\n def seek(self, position):\n if not self._avplayer:\n return\n self._avplayer.playAtTime_(float(position))\n\n def get_pos(self):\n if self._avplayer:\n return self._avplayer.currentTime\n return super(SoundAvplayer, self).get_pos()\n\n def on_volume(self, instance, volume):\n if self._avplayer:\n self._avplayer.volume = float(volume)\n\n def _get_length(self):\n if self._avplayer:\n return self._avplayer.duration\n return super(SoundAvplayer, self)._get_length()\n\n\nSoundLoader.register(SoundAvplayer)\n", "path": "kivy/core/audio/audio_avplayer.py"}], "after_files": [{"content": "'''\nAudio Gstplayer\n===============\n\n.. versionadded:: 1.8.0\n\nImplementation of a VideoBase with Kivy :class:`~kivy.lib.gstplayer.GstPlayer`\nThis player is the preferred player, using Gstreamer 1.0, working on both\nPython 2 and 3.\n'''\n\nfrom kivy.lib.gstplayer import GstPlayer, get_gst_version\nfrom kivy.core.audio import Sound, SoundLoader\nfrom kivy.logger import Logger\nfrom kivy.compat import PY2\nfrom kivy.clock import Clock\nfrom os.path import realpath\n\nif PY2:\n from urllib import pathname2url\nelse:\n from urllib.request import pathname2url\n\nLogger.info('AudioGstplayer: Using Gstreamer {}'.format(\n '.'.join(map(str, get_gst_version()))))\n\n\ndef _on_gstplayer_message(mtype, message):\n if mtype == 'error':\n Logger.error('AudioGstplayer: {}'.format(message))\n elif mtype == 'warning':\n Logger.warning('AudioGstplayer: {}'.format(message))\n elif mtype == 'info':\n Logger.info('AudioGstplayer: {}'.format(message))\n\n\nclass SoundGstplayer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', 'm4a', 'flac', 'mp4')\n\n def __init__(self, **kwargs):\n self.player = None\n super(SoundGstplayer, self).__init__(**kwargs)\n\n def _on_gst_eos_sync(self):\n Clock.schedule_once(self._on_gst_eos, 0)\n\n def _on_gst_eos(self, *dt):\n if self.loop:\n self.player.stop()\n self.player.play()\n else:\n self.stop()\n\n def load(self):\n self.unload()\n uri = self._get_uri()\n self.player = GstPlayer(uri, None, self._on_gst_eos_sync,\n _on_gstplayer_message)\n self.player.load()\n\n def play(self):\n # we need to set the volume everytime, it seems that stopping + playing\n # the sound reset the volume.\n self.player.set_volume(self.volume)\n self.player.play()\n super(SoundGstplayer, self).play()\n\n def stop(self):\n self.player.stop()\n super(SoundGstplayer, self).stop()\n\n def unload(self):\n if self.player:\n self.player.unload()\n self.player = None\n\n def seek(self, position):\n self.player.seek(position / self.length)\n\n def get_pos(self):\n return self.player.get_position()\n\n def _get_length(self):\n return self.player.get_duration()\n\n def on_volume(self, instance, volume):\n self.player.set_volume(volume)\n\n def _get_uri(self):\n uri = self.source\n if not uri:\n return\n if '://' not in uri:\n uri = 'file:' + pathname2url(realpath(uri))\n return uri\n\n\nSoundLoader.register(SoundGstplayer)\n", "path": "kivy/core/audio/audio_gstplayer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n\n.. warning::\n\n Pygame has been deprecated and will be removed in the release after Kivy\n 1.11.0.\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform, deprecated\nfrom kivy.core.audio import Sound, SoundLoader\n\n_platform = platform\ntry:\n if _platform == 'android':\n try:\n import android.mixer as mixer\n except ImportError:\n # old python-for-android version\n import android_mixer as mixer\n else:\n from pygame import mixer\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automatically add\n # a dictionary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n _check_play_ev = None\n\n @staticmethod\n def extensions():\n if _platform == 'android':\n return ('wav', 'ogg', 'mp3', 'm4a')\n return ('wav', 'ogg')\n\n @deprecated(\n msg='Pygame has been deprecated and will be removed after 1.11.0')\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n if self.loop:\n def do_loop(dt):\n self.play()\n Clock.schedule_once(do_loop)\n else:\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._data.set_volume(self.volume)\n self._channel = self._data.play()\n self.start_time = Clock.time()\n # schedule event to check if the sound is still playing or not\n self._check_play_ev = Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n if self._check_play_ev is not None:\n self._check_play_ev.cancel()\n self._check_play_ev = None\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.source is None:\n return\n self._data = mixer.Sound(self.source)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if not self._data:\n return\n if _platform == 'android' and self._channel:\n self._channel.seek(position)\n\n def get_pos(self):\n if self._data is not None and self._channel:\n if _platform == 'android':\n return self._channel.get_pos()\n return Clock.time() - self.start_time\n return 0\n\n def on_volume(self, instance, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n\n def _get_length(self):\n if _platform == 'android' and self._channel:\n return self._channel.get_length()\n if self._data is not None:\n return self._data.get_length()\n return super(SoundPygame, self)._get_length()\n\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}, {"content": "'''\nAudioAvplayer: implementation of Sound using pyobjus / AVFoundation.\nWorks on iOS / OSX.\n'''\n\n__all__ = ('SoundAvplayer', )\n\nfrom kivy.core.audio import Sound, SoundLoader\nfrom pyobjus import autoclass\nfrom pyobjus.dylib_manager import load_framework, INCLUDE\n\nload_framework(INCLUDE.AVFoundation)\nAVAudioPlayer = autoclass(\"AVAudioPlayer\")\nNSURL = autoclass(\"NSURL\")\nNSString = autoclass(\"NSString\")\n\n\nclass SoundAvplayer(Sound):\n @staticmethod\n def extensions():\n # taken from https://goo.gl/015kvU\n return (\"aac\", \"adts\", \"aif\", \"aiff\", \"aifc\", \"caf\", \"mp3\", \"mp4\",\n \"m4a\", \"snd\", \"au\", \"sd2\", \"wav\")\n\n def __init__(self, **kwargs):\n self._avplayer = None\n super(SoundAvplayer, self).__init__(**kwargs)\n\n def load(self):\n self.unload()\n fn = NSString.alloc().initWithUTF8String_(self.source)\n url = NSURL.alloc().initFileURLWithPath_(fn)\n self._avplayer = AVAudioPlayer.alloc().initWithContentsOfURL_error_(\n url, None)\n\n def unload(self):\n self.stop()\n self._avplayer = None\n\n def play(self):\n if not self._avplayer:\n return\n self._avplayer.play()\n super(SoundAvplayer, self).play()\n\n def stop(self):\n if not self._avplayer:\n return\n self._avplayer.stop()\n super(SoundAvplayer, self).stop()\n\n def seek(self, position):\n if not self._avplayer:\n return\n self._avplayer.playAtTime_(float(position))\n\n def get_pos(self):\n if self._avplayer:\n return self._avplayer.currentTime\n return super(SoundAvplayer, self).get_pos()\n\n def on_volume(self, instance, volume):\n if self._avplayer:\n self._avplayer.volume = float(volume)\n\n def _get_length(self):\n if self._avplayer:\n return self._avplayer.duration\n return super(SoundAvplayer, self)._get_length()\n\n\nSoundLoader.register(SoundAvplayer)\n", "path": "kivy/core/audio/audio_avplayer.py"}]}
| 3,247 | 356 |
gh_patches_debug_32965
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-4197
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Regression of #3305? Or new issue/same behavior
### Bug description
[This issue](https://github.com/lutris/lutris/issues/3305) appears to have returned in 5.10. Had 5.9 installed through manjaro pamac. Removed and installed 5.10 through AUR script. Launching Lutris shows all the new option of 5.10, but regardless of view (tree or icon), non of my games installed from 5.9 will bring up the context menu. Even games I add as manual after install of 5.10 won't call up the context menu. This even prevents removing/deleting from Lutris.
### How to Reproduce
Steps to reproduce the behavior:
Have 5.9 installed
Remove 5.9
Install 5.10 for AUR
Start Lutris
Click on any preinstalled game
Context menu does not appear
### Expected behavior
Context menu should appear.
### Log output
```shell
> INFO 2022-04-05 20:39:22,054 [startup.init_lutris:173]:Starting Lutris 0.5.10
> WARNING 2022-04-05 20:39:22,119 [libretro.get_libretro_cores:24]:No folder at /home/crono141/.local/share/lutris/runners/retroarch/
> DEBUG 2022-04-05 20:39:22,133 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR
> INFO 2022-04-05 20:39:22,177 [startup.check_driver:65]:Running AMD Mesa driver 21.3.7 on AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1) (0x699f)
> INFO 2022-04-05 20:39:22,177 [startup.check_driver:77]:GPU: 1002:699F 1028:1712 (amdgpu drivers)
> INFO 2022-04-05 20:39:22,242 [startup.update_runtime:213]:Startup complete
> DEBUG 2022-04-05 20:39:22,385 [lutriswindow.update_store:437]:Showing 8 games
> Traceback (most recent call last):
> File "/usr/lib/python3.10/site-packages/lutris/gui/lutriswindow.py", line 399, in update_revealer
> self.game_bar = GameBar(game, self.game_actions, self.application)
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 61, in __init__
> self.update_view()
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 86, in update_view
> self.play_button = self.get_play_button()
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 226, in get_play_button
> popover = self.get_popover(self.get_game_buttons(), popover_button)
> File "/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py", line 233, in get_game_buttons
> displayed = self.game_actions.get_displayed_entries()
> File "/usr/lib/python3.10/site-packages/lutris/game_actions.py", line 141, in get_displayed_entries
> and not steam_shortcut.all_shortcuts_set(self.game)
> File "/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py", line 48, in all_shortcuts_set
> shortcut_found = [
> File "/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py", line 50, in <listcomp>
> if game.name in s['AppName']
> KeyError: 'AppName'
```
### System Information
```shell
> [System]
> OS: Manjaro Linux 21.2.5 Qonos
> Arch: x86_64
> Kernel: 5.15.28-1-MANJARO
> Desktop: KDE
> Display Server: x11
>
> [CPU]
> Vendor: GenuineIntel
> Model: Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz
> Physical cores: 2
> Logical cores: 4
>
> [Memory]
> RAM: 7.7 GB
> Swap: 0.5 GB
>
> [Graphics]
> Vendor: AMD
> OpenGL Renderer: AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1)
> OpenGL Version: 4.6 (Compatibility Profile) Mesa 21.3.7
> OpenGL Core: 4.6 (Core Profile) Mesa 21.3.7
> OpenGL ES: OpenGL ES 3.2 Mesa 21.3.7
> Vulkan: Supported
```
### Media (optional)
_No response_
### Checklist:
- [X] I'm not asking for support with a game or the wine runner.
- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.
- [X] I have checked for existing issues that describe my problem prior to opening this one.
- [X] I understand that improperly formatted bug reports may be closed without explanation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/steam/shortcut.py`
Content:
```
1 """Export lutris games to steam shortcuts"""
2 import binascii
3 import os
4 import shutil
5
6 from lutris.util import resources
7 from lutris.util.steam import vdf
8 from lutris.util.steam.config import search_recursive_in_steam_dirs
9
10
11 def get_shortcuts_vdf_paths():
12 path_suffix = "userdata/**/config/shortcuts.vdf"
13 shortcuts_vdf = search_recursive_in_steam_dirs(path_suffix)
14 return shortcuts_vdf
15
16
17 def get_artwork_target_paths():
18 path_suffix = "userdata/**/config/grid"
19 target_paths = search_recursive_in_steam_dirs(path_suffix)
20 return target_paths
21
22
23 def vdf_file_exists():
24 shortcuts_paths = get_shortcuts_vdf_paths()
25 if len(shortcuts_paths) > 0:
26 return True
27 return False
28
29
30 def shortcut_exists(game, shortcut_path):
31 with open(shortcut_path, "rb") as shortcut_file:
32 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
33 shortcut_found = [
34 s for s in shortcuts
35 if game.name in s['AppName']
36 ]
37 if not shortcut_found:
38 return False
39 return True
40
41
42 def all_shortcuts_set(game):
43 paths_shortcut = get_shortcuts_vdf_paths()
44 shortcuts_found = 0
45 for shortcut_path in paths_shortcut:
46 with open(shortcut_path, "rb") as shortcut_file:
47 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
48 shortcut_found = [
49 s for s in shortcuts
50 if game.name in s['AppName']
51 ]
52 shortcuts_found += len(shortcut_found)
53
54 if len(paths_shortcut) == shortcuts_found:
55 return True
56 return False
57
58
59 def has_steamtype_runner(game):
60 steamtype_runners = ['steam', 'winesteam']
61 for runner in steamtype_runners:
62 if runner == game.runner_name:
63 return True
64 return False
65
66
67 def update_shortcut(game):
68 if has_steamtype_runner(game):
69 return
70 for shortcut_path in get_shortcuts_vdf_paths():
71 if not shortcut_exists(game, shortcut_path):
72 create_shortcut(game, shortcut_path)
73
74
75 def remove_all_shortcuts(game):
76 for shortcut_path in get_shortcuts_vdf_paths():
77 remove_shortcut(game, shortcut_path)
78
79
80 def create_shortcut(game, shortcut_path):
81 with open(shortcut_path, "rb") as shortcut_file:
82 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
83 existing_shortcuts = list(shortcuts)
84 add_shortcut = [generate_shortcut(game)]
85 updated_shortcuts = {
86 'shortcuts': {
87 str(index): elem for index, elem in enumerate(existing_shortcuts + add_shortcut)
88 }
89 }
90 with open(shortcut_path, "wb") as shortcut_file:
91 shortcut_file.write(vdf.binary_dumps(updated_shortcuts))
92 set_artwork(game)
93
94
95 def remove_shortcut(game, shortcut_path):
96 with open(shortcut_path, "rb") as shortcut_file:
97 shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
98 shortcut_found = [
99 s for s in shortcuts
100 if game.name in s['AppName']
101 ]
102
103 if not shortcut_found:
104 return
105
106 other_shortcuts = [
107 s for s in shortcuts
108 if game.name not in s['AppName']
109 ]
110 updated_shortcuts = {
111 'shortcuts': {
112 str(index): elem for index, elem in enumerate(other_shortcuts)
113 }
114 }
115 with open(shortcut_path, "wb") as shortcut_file:
116 shortcut_file.write(vdf.binary_dumps(updated_shortcuts))
117
118
119 def generate_shortcut(game):
120 name = game.name
121 slug = game.slug
122 gameId = game.id
123 icon = resources.get_icon_path(slug)
124 lutris_binary = shutil.which("lutris")
125 start_dir = os.path.dirname(lutris_binary)
126
127 return {
128 'appid': "lutris-{}".format(slug),
129 'AllowDesktopConfig': 1,
130 'AllowOverlay': 1,
131 'AppName': name,
132 'Devkit': 0,
133 'DevkitGameID': '',
134 'Exe': f'"{lutris_binary}"',
135 'IsHidden': 0,
136 'LastPlayTime': 0,
137 'LaunchOptions': f'lutris:rungameid/{gameId}',
138 'OpenVR': 0,
139 'ShortcutPath': '',
140 'StartDir': f'"{start_dir}"',
141 'icon': icon,
142 'tags': { # has been replaced by "collections" in steam. Tags are not visible in the UI anymore.
143 '0': "Lutris" # to identify generated shortcuts
144 }
145 }
146
147
148 def get_steam_shortcut_id(game):
149 lutris_binary = shutil.which("lutris")
150 exe = f'"{lutris_binary}"'
151 appname = "{} ({})".format(game.name, game.runner_name)
152 unique_id = ''.join([exe, appname])
153 return binascii.crc32(str.encode(unique_id)) | 0x80000000
154
155
156 def set_artwork(game):
157 shortcut_id = get_steam_shortcut_id(game)
158 source_cover = resources.get_cover_path(game.slug)
159 source_banner = resources.get_banner_path(game.slug)
160 target_cover = "{}p.jpg".format(shortcut_id)
161 target_banner = "{}_hero.jpg".format(shortcut_id)
162 for target_path in get_artwork_target_paths():
163 target_cover = os.path.join(target_path, target_cover)
164 target_banner = os.path.join(target_path, target_banner)
165 try:
166 shutil.copyfile(source_cover, target_cover)
167 shutil.copyfile(source_banner, target_banner)
168 except FileNotFoundError:
169 pass
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/steam/shortcut.py b/lutris/util/steam/shortcut.py
--- a/lutris/util/steam/shortcut.py
+++ b/lutris/util/steam/shortcut.py
@@ -32,7 +32,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
if not shortcut_found:
return False
@@ -47,7 +47,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
shortcuts_found += len(shortcut_found)
@@ -97,7 +97,7 @@
shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()
shortcut_found = [
s for s in shortcuts
- if game.name in s['AppName']
+ if matches_appname(s, game)
]
if not shortcut_found:
@@ -105,7 +105,7 @@
other_shortcuts = [
s for s in shortcuts
- if game.name not in s['AppName']
+ if not matches_appname(s, game)
]
updated_shortcuts = {
'shortcuts': {
@@ -145,6 +145,12 @@
}
+def matches_appname(shortcut, game):
+ """Test if the game seems to be the one a shortcut refers to."""
+ appname = shortcut.get('AppName') or shortcut.get('appname')
+ return appname and game.name in appname
+
+
def get_steam_shortcut_id(game):
lutris_binary = shutil.which("lutris")
exe = f'"{lutris_binary}"'
|
{"golden_diff": "diff --git a/lutris/util/steam/shortcut.py b/lutris/util/steam/shortcut.py\n--- a/lutris/util/steam/shortcut.py\n+++ b/lutris/util/steam/shortcut.py\n@@ -32,7 +32,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n if not shortcut_found:\n return False\n@@ -47,7 +47,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n shortcuts_found += len(shortcut_found)\n \n@@ -97,7 +97,7 @@\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n- if game.name in s['AppName']\n+ if matches_appname(s, game)\n ]\n \n if not shortcut_found:\n@@ -105,7 +105,7 @@\n \n other_shortcuts = [\n s for s in shortcuts\n- if game.name not in s['AppName']\n+ if not matches_appname(s, game)\n ]\n updated_shortcuts = {\n 'shortcuts': {\n@@ -145,6 +145,12 @@\n }\n \n \n+def matches_appname(shortcut, game):\n+ \"\"\"Test if the game seems to be the one a shortcut refers to.\"\"\"\n+ appname = shortcut.get('AppName') or shortcut.get('appname')\n+ return appname and game.name in appname\n+\n+\n def get_steam_shortcut_id(game):\n lutris_binary = shutil.which(\"lutris\")\n exe = f'\"{lutris_binary}\"'\n", "issue": "Regression of #3305? Or new issue/same behavior\n### Bug description\n\n[This issue](https://github.com/lutris/lutris/issues/3305) appears to have returned in 5.10. Had 5.9 installed through manjaro pamac. Removed and installed 5.10 through AUR script. Launching Lutris shows all the new option of 5.10, but regardless of view (tree or icon), non of my games installed from 5.9 will bring up the context menu. Even games I add as manual after install of 5.10 won't call up the context menu. This even prevents removing/deleting from Lutris.\r\n\r\n\r\n\r\n\n\n### How to Reproduce\n\nSteps to reproduce the behavior:\r\nHave 5.9 installed\r\nRemove 5.9\r\nInstall 5.10 for AUR\r\nStart Lutris\r\nClick on any preinstalled game\r\nContext menu does not appear\r\n\n\n### Expected behavior\n\nContext menu should appear.\n\n### Log output\n\n```shell\n> INFO 2022-04-05 20:39:22,054 [startup.init_lutris:173]:Starting Lutris 0.5.10\r\n> WARNING 2022-04-05 20:39:22,119 [libretro.get_libretro_cores:24]:No folder at /home/crono141/.local/share/lutris/runners/retroarch/\r\n> DEBUG 2022-04-05 20:39:22,133 [xrandr._get_vidmodes:15]:Retrieving video modes from XrandR\r\n> INFO 2022-04-05 20:39:22,177 [startup.check_driver:65]:Running AMD Mesa driver 21.3.7 on AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1) (0x699f)\r\n> INFO 2022-04-05 20:39:22,177 [startup.check_driver:77]:GPU: 1002:699F 1028:1712 (amdgpu drivers)\r\n> INFO 2022-04-05 20:39:22,242 [startup.update_runtime:213]:Startup complete\r\n> DEBUG 2022-04-05 20:39:22,385 [lutriswindow.update_store:437]:Showing 8 games\r\n> Traceback (most recent call last):\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/lutriswindow.py\", line 399, in update_revealer\r\n> self.game_bar = GameBar(game, self.game_actions, self.application)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 61, in __init__\r\n> self.update_view()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 86, in update_view\r\n> self.play_button = self.get_play_button()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 226, in get_play_button\r\n> popover = self.get_popover(self.get_game_buttons(), popover_button)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/gui/widgets/game_bar.py\", line 233, in get_game_buttons\r\n> displayed = self.game_actions.get_displayed_entries()\r\n> File \"/usr/lib/python3.10/site-packages/lutris/game_actions.py\", line 141, in get_displayed_entries\r\n> and not steam_shortcut.all_shortcuts_set(self.game)\r\n> File \"/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py\", line 48, in all_shortcuts_set\r\n> shortcut_found = [\r\n> File \"/usr/lib/python3.10/site-packages/lutris/util/steam/shortcut.py\", line 50, in <listcomp>\r\n> if game.name in s['AppName']\r\n> KeyError: 'AppName'\n```\n\n\n### System Information\n\n```shell\n> [System]\r\n> OS: Manjaro Linux 21.2.5 Qonos\r\n> Arch: x86_64\r\n> Kernel: 5.15.28-1-MANJARO\r\n> Desktop: KDE\r\n> Display Server: x11\r\n> \r\n> [CPU]\r\n> Vendor: GenuineIntel\r\n> Model: Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz\r\n> Physical cores: 2\r\n> Logical cores: 4\r\n> \r\n> [Memory]\r\n> RAM: 7.7 GB\r\n> Swap: 0.5 GB\r\n> \r\n> [Graphics]\r\n> Vendor: AMD\r\n> OpenGL Renderer: AMD Radeon RX 550 / 550 Series (POLARIS12, DRM 3.42.0, 5.15.28-1-MANJARO, LLVM 13.0.1)\r\n> OpenGL Version: 4.6 (Compatibility Profile) Mesa 21.3.7\r\n> OpenGL Core: 4.6 (Core Profile) Mesa 21.3.7\r\n> OpenGL ES: OpenGL ES 3.2 Mesa 21.3.7\r\n> Vulkan: Supported\n```\n\n\n### Media (optional)\n\n_No response_\n\n### Checklist:\n\n- [X] I'm not asking for support with a game or the wine runner.\n- [X] I have followed the above mentioned guides and have all the graphics and wine dependencies installed.\n- [X] I have checked for existing issues that describe my problem prior to opening this one.\n- [X] I understand that improperly formatted bug reports may be closed without explanation.\n", "before_files": [{"content": "\"\"\"Export lutris games to steam shortcuts\"\"\"\nimport binascii\nimport os\nimport shutil\n\nfrom lutris.util import resources\nfrom lutris.util.steam import vdf\nfrom lutris.util.steam.config import search_recursive_in_steam_dirs\n\n\ndef get_shortcuts_vdf_paths():\n path_suffix = \"userdata/**/config/shortcuts.vdf\"\n shortcuts_vdf = search_recursive_in_steam_dirs(path_suffix)\n return shortcuts_vdf\n\n\ndef get_artwork_target_paths():\n path_suffix = \"userdata/**/config/grid\"\n target_paths = search_recursive_in_steam_dirs(path_suffix)\n return target_paths\n\n\ndef vdf_file_exists():\n shortcuts_paths = get_shortcuts_vdf_paths()\n if len(shortcuts_paths) > 0:\n return True\n return False\n\n\ndef shortcut_exists(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n if not shortcut_found:\n return False\n return True\n\n\ndef all_shortcuts_set(game):\n paths_shortcut = get_shortcuts_vdf_paths()\n shortcuts_found = 0\n for shortcut_path in paths_shortcut:\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n shortcuts_found += len(shortcut_found)\n\n if len(paths_shortcut) == shortcuts_found:\n return True\n return False\n\n\ndef has_steamtype_runner(game):\n steamtype_runners = ['steam', 'winesteam']\n for runner in steamtype_runners:\n if runner == game.runner_name:\n return True\n return False\n\n\ndef update_shortcut(game):\n if has_steamtype_runner(game):\n return\n for shortcut_path in get_shortcuts_vdf_paths():\n if not shortcut_exists(game, shortcut_path):\n create_shortcut(game, shortcut_path)\n\n\ndef remove_all_shortcuts(game):\n for shortcut_path in get_shortcuts_vdf_paths():\n remove_shortcut(game, shortcut_path)\n\n\ndef create_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n existing_shortcuts = list(shortcuts)\n add_shortcut = [generate_shortcut(game)]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(existing_shortcuts + add_shortcut)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n set_artwork(game)\n\n\ndef remove_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if game.name in s['AppName']\n ]\n\n if not shortcut_found:\n return\n\n other_shortcuts = [\n s for s in shortcuts\n if game.name not in s['AppName']\n ]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(other_shortcuts)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n\n\ndef generate_shortcut(game):\n name = game.name\n slug = game.slug\n gameId = game.id\n icon = resources.get_icon_path(slug)\n lutris_binary = shutil.which(\"lutris\")\n start_dir = os.path.dirname(lutris_binary)\n\n return {\n 'appid': \"lutris-{}\".format(slug),\n 'AllowDesktopConfig': 1,\n 'AllowOverlay': 1,\n 'AppName': name,\n 'Devkit': 0,\n 'DevkitGameID': '',\n 'Exe': f'\"{lutris_binary}\"',\n 'IsHidden': 0,\n 'LastPlayTime': 0,\n 'LaunchOptions': f'lutris:rungameid/{gameId}',\n 'OpenVR': 0,\n 'ShortcutPath': '',\n 'StartDir': f'\"{start_dir}\"',\n 'icon': icon,\n 'tags': { # has been replaced by \"collections\" in steam. Tags are not visible in the UI anymore.\n '0': \"Lutris\" # to identify generated shortcuts\n }\n }\n\n\ndef get_steam_shortcut_id(game):\n lutris_binary = shutil.which(\"lutris\")\n exe = f'\"{lutris_binary}\"'\n appname = \"{} ({})\".format(game.name, game.runner_name)\n unique_id = ''.join([exe, appname])\n return binascii.crc32(str.encode(unique_id)) | 0x80000000\n\n\ndef set_artwork(game):\n shortcut_id = get_steam_shortcut_id(game)\n source_cover = resources.get_cover_path(game.slug)\n source_banner = resources.get_banner_path(game.slug)\n target_cover = \"{}p.jpg\".format(shortcut_id)\n target_banner = \"{}_hero.jpg\".format(shortcut_id)\n for target_path in get_artwork_target_paths():\n target_cover = os.path.join(target_path, target_cover)\n target_banner = os.path.join(target_path, target_banner)\n try:\n shutil.copyfile(source_cover, target_cover)\n shutil.copyfile(source_banner, target_banner)\n except FileNotFoundError:\n pass\n", "path": "lutris/util/steam/shortcut.py"}], "after_files": [{"content": "\"\"\"Export lutris games to steam shortcuts\"\"\"\nimport binascii\nimport os\nimport shutil\n\nfrom lutris.util import resources\nfrom lutris.util.steam import vdf\nfrom lutris.util.steam.config import search_recursive_in_steam_dirs\n\n\ndef get_shortcuts_vdf_paths():\n path_suffix = \"userdata/**/config/shortcuts.vdf\"\n shortcuts_vdf = search_recursive_in_steam_dirs(path_suffix)\n return shortcuts_vdf\n\n\ndef get_artwork_target_paths():\n path_suffix = \"userdata/**/config/grid\"\n target_paths = search_recursive_in_steam_dirs(path_suffix)\n return target_paths\n\n\ndef vdf_file_exists():\n shortcuts_paths = get_shortcuts_vdf_paths()\n if len(shortcuts_paths) > 0:\n return True\n return False\n\n\ndef shortcut_exists(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if matches_appname(s, game)\n ]\n if not shortcut_found:\n return False\n return True\n\n\ndef all_shortcuts_set(game):\n paths_shortcut = get_shortcuts_vdf_paths()\n shortcuts_found = 0\n for shortcut_path in paths_shortcut:\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if matches_appname(s, game)\n ]\n shortcuts_found += len(shortcut_found)\n\n if len(paths_shortcut) == shortcuts_found:\n return True\n return False\n\n\ndef has_steamtype_runner(game):\n steamtype_runners = ['steam', 'winesteam']\n for runner in steamtype_runners:\n if runner == game.runner_name:\n return True\n return False\n\n\ndef update_shortcut(game):\n if has_steamtype_runner(game):\n return\n for shortcut_path in get_shortcuts_vdf_paths():\n if not shortcut_exists(game, shortcut_path):\n create_shortcut(game, shortcut_path)\n\n\ndef remove_all_shortcuts(game):\n for shortcut_path in get_shortcuts_vdf_paths():\n remove_shortcut(game, shortcut_path)\n\n\ndef create_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n existing_shortcuts = list(shortcuts)\n add_shortcut = [generate_shortcut(game)]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(existing_shortcuts + add_shortcut)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n set_artwork(game)\n\n\ndef remove_shortcut(game, shortcut_path):\n with open(shortcut_path, \"rb\") as shortcut_file:\n shortcuts = vdf.binary_loads(shortcut_file.read())['shortcuts'].values()\n shortcut_found = [\n s for s in shortcuts\n if matches_appname(s, game)\n ]\n\n if not shortcut_found:\n return\n\n other_shortcuts = [\n s for s in shortcuts\n if not matches_appname(s, game)\n ]\n updated_shortcuts = {\n 'shortcuts': {\n str(index): elem for index, elem in enumerate(other_shortcuts)\n }\n }\n with open(shortcut_path, \"wb\") as shortcut_file:\n shortcut_file.write(vdf.binary_dumps(updated_shortcuts))\n\n\ndef generate_shortcut(game):\n name = game.name\n slug = game.slug\n gameId = game.id\n icon = resources.get_icon_path(slug)\n lutris_binary = shutil.which(\"lutris\")\n start_dir = os.path.dirname(lutris_binary)\n\n return {\n 'appid': \"lutris-{}\".format(slug),\n 'AllowDesktopConfig': 1,\n 'AllowOverlay': 1,\n 'AppName': name,\n 'Devkit': 0,\n 'DevkitGameID': '',\n 'Exe': f'\"{lutris_binary}\"',\n 'IsHidden': 0,\n 'LastPlayTime': 0,\n 'LaunchOptions': f'lutris:rungameid/{gameId}',\n 'OpenVR': 0,\n 'ShortcutPath': '',\n 'StartDir': f'\"{start_dir}\"',\n 'icon': icon,\n 'tags': { # has been replaced by \"collections\" in steam. Tags are not visible in the UI anymore.\n '0': \"Lutris\" # to identify generated shortcuts\n }\n }\n\n\ndef matches_appname(shortcut, game):\n \"\"\"Test if the game seems to be the one a shortcut refers to.\"\"\"\n appname = shortcut.get('AppName') or shortcut.get('appname')\n return appname and game.name in appname\n\n\ndef get_steam_shortcut_id(game):\n lutris_binary = shutil.which(\"lutris\")\n exe = f'\"{lutris_binary}\"'\n appname = \"{} ({})\".format(game.name, game.runner_name)\n unique_id = ''.join([exe, appname])\n return binascii.crc32(str.encode(unique_id)) | 0x80000000\n\n\ndef set_artwork(game):\n shortcut_id = get_steam_shortcut_id(game)\n source_cover = resources.get_cover_path(game.slug)\n source_banner = resources.get_banner_path(game.slug)\n target_cover = \"{}p.jpg\".format(shortcut_id)\n target_banner = \"{}_hero.jpg\".format(shortcut_id)\n for target_path in get_artwork_target_paths():\n target_cover = os.path.join(target_path, target_cover)\n target_banner = os.path.join(target_path, target_banner)\n try:\n shutil.copyfile(source_cover, target_cover)\n shutil.copyfile(source_banner, target_banner)\n except FileNotFoundError:\n pass\n", "path": "lutris/util/steam/shortcut.py"}]}
| 3,327 | 441 |
gh_patches_debug_8204
|
rasdani/github-patches
|
git_diff
|
vas3k__vas3k.club-381
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Баг с пажинацией в разделе «Коммьюнити»
STR:
1. Открыть https://vas3k.club/people/
2. Отфильтровать по первым 4 фильтрам
3. Перейти на 2 страницу выдачи
ER: Фильтры сохранены
AR: Фильтры частично потеряны
Видео https://youtu.be/08cz2TOq60A
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `posts/templatetags/query_params.py`
Content:
```
1 from urllib.parse import urlencode
2
3 from django import template
4
5 register = template.Library()
6
7
8 @register.simple_tag(takes_context=True)
9 def append_query_param(context, **kwargs):
10 query_params = dict(context.request.GET.items())
11 query_params.update(kwargs)
12 return "?" + urlencode(query_params)
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/posts/templatetags/query_params.py b/posts/templatetags/query_params.py
--- a/posts/templatetags/query_params.py
+++ b/posts/templatetags/query_params.py
@@ -1,4 +1,4 @@
-from urllib.parse import urlencode
+from copy import deepcopy
from django import template
@@ -7,6 +7,6 @@
@register.simple_tag(takes_context=True)
def append_query_param(context, **kwargs):
- query_params = dict(context.request.GET.items())
+ query_params = deepcopy(context.request.GET)
query_params.update(kwargs)
- return "?" + urlencode(query_params)
+ return "?" + query_params.urlencode()
|
{"golden_diff": "diff --git a/posts/templatetags/query_params.py b/posts/templatetags/query_params.py\n--- a/posts/templatetags/query_params.py\n+++ b/posts/templatetags/query_params.py\n@@ -1,4 +1,4 @@\n-from urllib.parse import urlencode\n+from copy import deepcopy\n \n from django import template\n \n@@ -7,6 +7,6 @@\n \n @register.simple_tag(takes_context=True)\n def append_query_param(context, **kwargs):\n- query_params = dict(context.request.GET.items())\n+ query_params = deepcopy(context.request.GET)\n query_params.update(kwargs)\n- return \"?\" + urlencode(query_params)\n+ return \"?\" + query_params.urlencode()\n", "issue": "\u0411\u0430\u0433 \u0441 \u043f\u0430\u0436\u0438\u043d\u0430\u0446\u0438\u0435\u0439 \u0432 \u0440\u0430\u0437\u0434\u0435\u043b\u0435 \u00ab\u041a\u043e\u043c\u043c\u044c\u044e\u043d\u0438\u0442\u0438\u00bb\nSTR:\r\n1. \u041e\u0442\u043a\u0440\u044b\u0442\u044c https://vas3k.club/people/\r\n2. \u041e\u0442\u0444\u0438\u043b\u044c\u0442\u0440\u043e\u0432\u0430\u0442\u044c\u00a0\u043f\u043e \u043f\u0435\u0440\u0432\u044b\u043c 4 \u0444\u0438\u043b\u044c\u0442\u0440\u0430\u043c\r\n3. \u041f\u0435\u0440\u0435\u0439\u0442\u0438 \u043d\u0430 2 \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u0443 \u0432\u044b\u0434\u0430\u0447\u0438\r\n\r\nER: \u0424\u0438\u043b\u044c\u0442\u0440\u044b \u0441\u043e\u0445\u0440\u0430\u043d\u0435\u043d\u044b\r\nAR: \u0424\u0438\u043b\u044c\u0442\u0440\u044b \u0447\u0430\u0441\u0442\u0438\u0447\u043d\u043e \u043f\u043e\u0442\u0435\u0440\u044f\u043d\u044b\r\n\r\n\u0412\u0438\u0434\u0435\u043e\u00a0https://youtu.be/08cz2TOq60A\n", "before_files": [{"content": "from urllib.parse import urlencode\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=True)\ndef append_query_param(context, **kwargs):\n query_params = dict(context.request.GET.items())\n query_params.update(kwargs)\n return \"?\" + urlencode(query_params)\n", "path": "posts/templatetags/query_params.py"}], "after_files": [{"content": "from copy import deepcopy\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=True)\ndef append_query_param(context, **kwargs):\n query_params = deepcopy(context.request.GET)\n query_params.update(kwargs)\n return \"?\" + query_params.urlencode()\n", "path": "posts/templatetags/query_params.py"}]}
| 446 | 150 |
gh_patches_debug_10798
|
rasdani/github-patches
|
git_diff
|
spack__spack-14928
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Specifying more than one operating_system in the same compilers.yaml entry
For convenience, I'm using the same configuration files for two Macs that run a different MacOS version (one with Sierra, the other with High Sierra, but apart from that they are identical from spack's point of view: same compilers installed, same everything installed). Generated executables are exactly the same on both machines (exactly same compilers -custom build-, exactly same MacOS SDK, and exactly same ${MACOSX_DEPLOYMENT_TARGET} (ie: 10.12).
In fact, spack generates exactly the same `compilers.yaml` file on both machines, with the only difference that in one you see "sierra" for the `operating_system` entry, and in the other you see "highsierra".
Now, can I use the same `compilers.yaml` file for both machines? Apparently, `operating_system` will allow only one string, according to the schema. But is there any "dumb tag" that will allow both sierra and highsierra, or maybe even all MacOS versions? Or can I disable the `operating_system` entry in some way? If possible to disable, would it have any consequence on built packages?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/spack/spack/cmd/compiler.py`
Content:
```
1 # Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from __future__ import print_function
7
8 import argparse
9 import sys
10 from six import iteritems
11
12 import llnl.util.tty as tty
13 import spack.compilers
14 import spack.config
15 import spack.spec
16 from llnl.util.lang import index_by
17 from llnl.util.tty.colify import colify
18 from llnl.util.tty.color import colorize
19 from spack.spec import CompilerSpec, ArchSpec
20
21 description = "manage compilers"
22 section = "system"
23 level = "long"
24
25
26 def setup_parser(subparser):
27 sp = subparser.add_subparsers(
28 metavar='SUBCOMMAND', dest='compiler_command')
29
30 scopes = spack.config.scopes()
31 scopes_metavar = spack.config.scopes_metavar
32
33 # Find
34 find_parser = sp.add_parser(
35 'find', aliases=['add'],
36 help='search the system for compilers to add to Spack configuration')
37 find_parser.add_argument('add_paths', nargs=argparse.REMAINDER)
38 find_parser.add_argument(
39 '--scope', choices=scopes, metavar=scopes_metavar,
40 default=spack.config.default_modify_scope(),
41 help="configuration scope to modify")
42
43 # Remove
44 remove_parser = sp.add_parser(
45 'remove', aliases=['rm'], help='remove compiler by spec')
46 remove_parser.add_argument(
47 '-a', '--all', action='store_true',
48 help='remove ALL compilers that match spec')
49 remove_parser.add_argument('compiler_spec')
50 remove_parser.add_argument(
51 '--scope', choices=scopes, metavar=scopes_metavar,
52 default=spack.config.default_modify_scope(),
53 help="configuration scope to modify")
54
55 # List
56 list_parser = sp.add_parser('list', help='list available compilers')
57 list_parser.add_argument(
58 '--scope', choices=scopes, metavar=scopes_metavar,
59 default=spack.config.default_list_scope(),
60 help="configuration scope to read from")
61
62 # Info
63 info_parser = sp.add_parser('info', help='show compiler paths')
64 info_parser.add_argument('compiler_spec')
65 info_parser.add_argument(
66 '--scope', choices=scopes, metavar=scopes_metavar,
67 default=spack.config.default_list_scope(),
68 help="configuration scope to read from")
69
70
71 def compiler_find(args):
72 """Search either $PATH or a list of paths OR MODULES for compilers and
73 add them to Spack's configuration.
74
75 """
76 # None signals spack.compiler.find_compilers to use its default logic
77 paths = args.add_paths or None
78
79 # Don't initialize compilers config via compilers.get_compiler_config.
80 # Just let compiler_find do the
81 # entire process and return an empty config from all_compilers
82 # Default for any other process is init_config=True
83 compilers = [c for c in spack.compilers.find_compilers(paths)]
84 new_compilers = []
85 for c in compilers:
86 arch_spec = ArchSpec((None, c.operating_system, c.target))
87 same_specs = spack.compilers.compilers_for_spec(
88 c.spec, arch_spec, init_config=False)
89
90 if not same_specs:
91 new_compilers.append(c)
92
93 if new_compilers:
94 spack.compilers.add_compilers_to_config(new_compilers,
95 scope=args.scope,
96 init_config=False)
97 n = len(new_compilers)
98 s = 's' if n > 1 else ''
99
100 config = spack.config.config
101 filename = config.get_config_filename(args.scope, 'compilers')
102 tty.msg("Added %d new compiler%s to %s" % (n, s, filename))
103 colify(reversed(sorted(c.spec for c in new_compilers)), indent=4)
104 else:
105 tty.msg("Found no new compilers")
106 tty.msg("Compilers are defined in the following files:")
107 colify(spack.compilers.compiler_config_files(), indent=4)
108
109
110 def compiler_remove(args):
111 cspec = CompilerSpec(args.compiler_spec)
112 compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)
113 if not compilers:
114 tty.die("No compilers match spec %s" % cspec)
115 elif not args.all and len(compilers) > 1:
116 tty.error("Multiple compilers match spec %s. Choose one:" % cspec)
117 colify(reversed(sorted([c.spec for c in compilers])), indent=4)
118 tty.msg("Or, use `spack compiler remove -a` to remove all of them.")
119 sys.exit(1)
120
121 for compiler in compilers:
122 spack.compilers.remove_compiler_from_config(
123 compiler.spec, scope=args.scope)
124 tty.msg("Removed compiler %s" % compiler.spec)
125
126
127 def compiler_info(args):
128 """Print info about all compilers matching a spec."""
129 cspec = CompilerSpec(args.compiler_spec)
130 compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)
131
132 if not compilers:
133 tty.error("No compilers match spec %s" % cspec)
134 else:
135 for c in compilers:
136 print(str(c.spec) + ":")
137 print("\tpaths:")
138 for cpath in ['cc', 'cxx', 'f77', 'fc']:
139 print("\t\t%s = %s" % (cpath, getattr(c, cpath, None)))
140 if c.flags:
141 print("\tflags:")
142 for flag, flag_value in iteritems(c.flags):
143 print("\t\t%s = %s" % (flag, flag_value))
144 if len(c.environment) != 0:
145 if len(c.environment['set']) != 0:
146 print("\tenvironment:")
147 print("\t set:")
148 for key, value in iteritems(c.environment['set']):
149 print("\t %s = %s" % (key, value))
150 if c.extra_rpaths:
151 print("\tExtra rpaths:")
152 for extra_rpath in c.extra_rpaths:
153 print("\t\t%s" % extra_rpath)
154 print("\tmodules = %s" % c.modules)
155 print("\toperating system = %s" % c.operating_system)
156
157
158 def compiler_list(args):
159 tty.msg("Available compilers")
160 index = index_by(spack.compilers.all_compilers(scope=args.scope),
161 lambda c: (c.spec.name, c.operating_system, c.target))
162 ordered_sections = sorted(index.items(), key=lambda item: item[0])
163 for i, (key, compilers) in enumerate(ordered_sections):
164 if i >= 1:
165 print()
166 name, os, target = key
167 os_str = os
168 if target:
169 os_str += "-%s" % target
170 cname = "%s{%s} %s" % (spack.spec.compiler_color, name, os_str)
171 tty.hline(colorize(cname), char='-')
172 colify(reversed(sorted(c.spec for c in compilers)))
173
174
175 def compiler(parser, args):
176 action = {'add': compiler_find,
177 'find': compiler_find,
178 'remove': compiler_remove,
179 'rm': compiler_remove,
180 'info': compiler_info,
181 'list': compiler_list}
182 action[args.compiler_command](args)
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/spack/spack/cmd/compiler.py b/lib/spack/spack/cmd/compiler.py
--- a/lib/spack/spack/cmd/compiler.py
+++ b/lib/spack/spack/cmd/compiler.py
@@ -142,7 +142,7 @@
for flag, flag_value in iteritems(c.flags):
print("\t\t%s = %s" % (flag, flag_value))
if len(c.environment) != 0:
- if len(c.environment['set']) != 0:
+ if len(c.environment.get('set', {})) != 0:
print("\tenvironment:")
print("\t set:")
for key, value in iteritems(c.environment['set']):
|
{"golden_diff": "diff --git a/lib/spack/spack/cmd/compiler.py b/lib/spack/spack/cmd/compiler.py\n--- a/lib/spack/spack/cmd/compiler.py\n+++ b/lib/spack/spack/cmd/compiler.py\n@@ -142,7 +142,7 @@\n for flag, flag_value in iteritems(c.flags):\n print(\"\\t\\t%s = %s\" % (flag, flag_value))\n if len(c.environment) != 0:\n- if len(c.environment['set']) != 0:\n+ if len(c.environment.get('set', {})) != 0:\n print(\"\\tenvironment:\")\n print(\"\\t set:\")\n for key, value in iteritems(c.environment['set']):\n", "issue": "Specifying more than one operating_system in the same compilers.yaml entry\nFor convenience, I'm using the same configuration files for two Macs that run a different MacOS version (one with Sierra, the other with High Sierra, but apart from that they are identical from spack's point of view: same compilers installed, same everything installed). Generated executables are exactly the same on both machines (exactly same compilers -custom build-, exactly same MacOS SDK, and exactly same ${MACOSX_DEPLOYMENT_TARGET} (ie: 10.12).\r\n\r\nIn fact, spack generates exactly the same `compilers.yaml` file on both machines, with the only difference that in one you see \"sierra\" for the `operating_system` entry, and in the other you see \"highsierra\".\r\n\r\nNow, can I use the same `compilers.yaml` file for both machines? Apparently, `operating_system` will allow only one string, according to the schema. But is there any \"dumb tag\" that will allow both sierra and highsierra, or maybe even all MacOS versions? Or can I disable the `operating_system` entry in some way? If possible to disable, would it have any consequence on built packages?\n", "before_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport argparse\nimport sys\nfrom six import iteritems\n\nimport llnl.util.tty as tty\nimport spack.compilers\nimport spack.config\nimport spack.spec\nfrom llnl.util.lang import index_by\nfrom llnl.util.tty.colify import colify\nfrom llnl.util.tty.color import colorize\nfrom spack.spec import CompilerSpec, ArchSpec\n\ndescription = \"manage compilers\"\nsection = \"system\"\nlevel = \"long\"\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(\n metavar='SUBCOMMAND', dest='compiler_command')\n\n scopes = spack.config.scopes()\n scopes_metavar = spack.config.scopes_metavar\n\n # Find\n find_parser = sp.add_parser(\n 'find', aliases=['add'],\n help='search the system for compilers to add to Spack configuration')\n find_parser.add_argument('add_paths', nargs=argparse.REMAINDER)\n find_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # Remove\n remove_parser = sp.add_parser(\n 'remove', aliases=['rm'], help='remove compiler by spec')\n remove_parser.add_argument(\n '-a', '--all', action='store_true',\n help='remove ALL compilers that match spec')\n remove_parser.add_argument('compiler_spec')\n remove_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # List\n list_parser = sp.add_parser('list', help='list available compilers')\n list_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n # Info\n info_parser = sp.add_parser('info', help='show compiler paths')\n info_parser.add_argument('compiler_spec')\n info_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n\ndef compiler_find(args):\n \"\"\"Search either $PATH or a list of paths OR MODULES for compilers and\n add them to Spack's configuration.\n\n \"\"\"\n # None signals spack.compiler.find_compilers to use its default logic\n paths = args.add_paths or None\n\n # Don't initialize compilers config via compilers.get_compiler_config.\n # Just let compiler_find do the\n # entire process and return an empty config from all_compilers\n # Default for any other process is init_config=True\n compilers = [c for c in spack.compilers.find_compilers(paths)]\n new_compilers = []\n for c in compilers:\n arch_spec = ArchSpec((None, c.operating_system, c.target))\n same_specs = spack.compilers.compilers_for_spec(\n c.spec, arch_spec, init_config=False)\n\n if not same_specs:\n new_compilers.append(c)\n\n if new_compilers:\n spack.compilers.add_compilers_to_config(new_compilers,\n scope=args.scope,\n init_config=False)\n n = len(new_compilers)\n s = 's' if n > 1 else ''\n\n config = spack.config.config\n filename = config.get_config_filename(args.scope, 'compilers')\n tty.msg(\"Added %d new compiler%s to %s\" % (n, s, filename))\n colify(reversed(sorted(c.spec for c in new_compilers)), indent=4)\n else:\n tty.msg(\"Found no new compilers\")\n tty.msg(\"Compilers are defined in the following files:\")\n colify(spack.compilers.compiler_config_files(), indent=4)\n\n\ndef compiler_remove(args):\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n if not compilers:\n tty.die(\"No compilers match spec %s\" % cspec)\n elif not args.all and len(compilers) > 1:\n tty.error(\"Multiple compilers match spec %s. Choose one:\" % cspec)\n colify(reversed(sorted([c.spec for c in compilers])), indent=4)\n tty.msg(\"Or, use `spack compiler remove -a` to remove all of them.\")\n sys.exit(1)\n\n for compiler in compilers:\n spack.compilers.remove_compiler_from_config(\n compiler.spec, scope=args.scope)\n tty.msg(\"Removed compiler %s\" % compiler.spec)\n\n\ndef compiler_info(args):\n \"\"\"Print info about all compilers matching a spec.\"\"\"\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n\n if not compilers:\n tty.error(\"No compilers match spec %s\" % cspec)\n else:\n for c in compilers:\n print(str(c.spec) + \":\")\n print(\"\\tpaths:\")\n for cpath in ['cc', 'cxx', 'f77', 'fc']:\n print(\"\\t\\t%s = %s\" % (cpath, getattr(c, cpath, None)))\n if c.flags:\n print(\"\\tflags:\")\n for flag, flag_value in iteritems(c.flags):\n print(\"\\t\\t%s = %s\" % (flag, flag_value))\n if len(c.environment) != 0:\n if len(c.environment['set']) != 0:\n print(\"\\tenvironment:\")\n print(\"\\t set:\")\n for key, value in iteritems(c.environment['set']):\n print(\"\\t %s = %s\" % (key, value))\n if c.extra_rpaths:\n print(\"\\tExtra rpaths:\")\n for extra_rpath in c.extra_rpaths:\n print(\"\\t\\t%s\" % extra_rpath)\n print(\"\\tmodules = %s\" % c.modules)\n print(\"\\toperating system = %s\" % c.operating_system)\n\n\ndef compiler_list(args):\n tty.msg(\"Available compilers\")\n index = index_by(spack.compilers.all_compilers(scope=args.scope),\n lambda c: (c.spec.name, c.operating_system, c.target))\n ordered_sections = sorted(index.items(), key=lambda item: item[0])\n for i, (key, compilers) in enumerate(ordered_sections):\n if i >= 1:\n print()\n name, os, target = key\n os_str = os\n if target:\n os_str += \"-%s\" % target\n cname = \"%s{%s} %s\" % (spack.spec.compiler_color, name, os_str)\n tty.hline(colorize(cname), char='-')\n colify(reversed(sorted(c.spec for c in compilers)))\n\n\ndef compiler(parser, args):\n action = {'add': compiler_find,\n 'find': compiler_find,\n 'remove': compiler_remove,\n 'rm': compiler_remove,\n 'info': compiler_info,\n 'list': compiler_list}\n action[args.compiler_command](args)\n", "path": "lib/spack/spack/cmd/compiler.py"}], "after_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport argparse\nimport sys\nfrom six import iteritems\n\nimport llnl.util.tty as tty\nimport spack.compilers\nimport spack.config\nimport spack.spec\nfrom llnl.util.lang import index_by\nfrom llnl.util.tty.colify import colify\nfrom llnl.util.tty.color import colorize\nfrom spack.spec import CompilerSpec, ArchSpec\n\ndescription = \"manage compilers\"\nsection = \"system\"\nlevel = \"long\"\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(\n metavar='SUBCOMMAND', dest='compiler_command')\n\n scopes = spack.config.scopes()\n scopes_metavar = spack.config.scopes_metavar\n\n # Find\n find_parser = sp.add_parser(\n 'find', aliases=['add'],\n help='search the system for compilers to add to Spack configuration')\n find_parser.add_argument('add_paths', nargs=argparse.REMAINDER)\n find_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # Remove\n remove_parser = sp.add_parser(\n 'remove', aliases=['rm'], help='remove compiler by spec')\n remove_parser.add_argument(\n '-a', '--all', action='store_true',\n help='remove ALL compilers that match spec')\n remove_parser.add_argument('compiler_spec')\n remove_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_modify_scope(),\n help=\"configuration scope to modify\")\n\n # List\n list_parser = sp.add_parser('list', help='list available compilers')\n list_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n # Info\n info_parser = sp.add_parser('info', help='show compiler paths')\n info_parser.add_argument('compiler_spec')\n info_parser.add_argument(\n '--scope', choices=scopes, metavar=scopes_metavar,\n default=spack.config.default_list_scope(),\n help=\"configuration scope to read from\")\n\n\ndef compiler_find(args):\n \"\"\"Search either $PATH or a list of paths OR MODULES for compilers and\n add them to Spack's configuration.\n\n \"\"\"\n # None signals spack.compiler.find_compilers to use its default logic\n paths = args.add_paths or None\n\n # Don't initialize compilers config via compilers.get_compiler_config.\n # Just let compiler_find do the\n # entire process and return an empty config from all_compilers\n # Default for any other process is init_config=True\n compilers = [c for c in spack.compilers.find_compilers(paths)]\n new_compilers = []\n for c in compilers:\n arch_spec = ArchSpec((None, c.operating_system, c.target))\n same_specs = spack.compilers.compilers_for_spec(\n c.spec, arch_spec, init_config=False)\n\n if not same_specs:\n new_compilers.append(c)\n\n if new_compilers:\n spack.compilers.add_compilers_to_config(new_compilers,\n scope=args.scope,\n init_config=False)\n n = len(new_compilers)\n s = 's' if n > 1 else ''\n\n config = spack.config.config\n filename = config.get_config_filename(args.scope, 'compilers')\n tty.msg(\"Added %d new compiler%s to %s\" % (n, s, filename))\n colify(reversed(sorted(c.spec for c in new_compilers)), indent=4)\n else:\n tty.msg(\"Found no new compilers\")\n tty.msg(\"Compilers are defined in the following files:\")\n colify(spack.compilers.compiler_config_files(), indent=4)\n\n\ndef compiler_remove(args):\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n if not compilers:\n tty.die(\"No compilers match spec %s\" % cspec)\n elif not args.all and len(compilers) > 1:\n tty.error(\"Multiple compilers match spec %s. Choose one:\" % cspec)\n colify(reversed(sorted([c.spec for c in compilers])), indent=4)\n tty.msg(\"Or, use `spack compiler remove -a` to remove all of them.\")\n sys.exit(1)\n\n for compiler in compilers:\n spack.compilers.remove_compiler_from_config(\n compiler.spec, scope=args.scope)\n tty.msg(\"Removed compiler %s\" % compiler.spec)\n\n\ndef compiler_info(args):\n \"\"\"Print info about all compilers matching a spec.\"\"\"\n cspec = CompilerSpec(args.compiler_spec)\n compilers = spack.compilers.compilers_for_spec(cspec, scope=args.scope)\n\n if not compilers:\n tty.error(\"No compilers match spec %s\" % cspec)\n else:\n for c in compilers:\n print(str(c.spec) + \":\")\n print(\"\\tpaths:\")\n for cpath in ['cc', 'cxx', 'f77', 'fc']:\n print(\"\\t\\t%s = %s\" % (cpath, getattr(c, cpath, None)))\n if c.flags:\n print(\"\\tflags:\")\n for flag, flag_value in iteritems(c.flags):\n print(\"\\t\\t%s = %s\" % (flag, flag_value))\n if len(c.environment) != 0:\n if len(c.environment.get('set', {})) != 0:\n print(\"\\tenvironment:\")\n print(\"\\t set:\")\n for key, value in iteritems(c.environment['set']):\n print(\"\\t %s = %s\" % (key, value))\n if c.extra_rpaths:\n print(\"\\tExtra rpaths:\")\n for extra_rpath in c.extra_rpaths:\n print(\"\\t\\t%s\" % extra_rpath)\n print(\"\\tmodules = %s\" % c.modules)\n print(\"\\toperating system = %s\" % c.operating_system)\n\n\ndef compiler_list(args):\n tty.msg(\"Available compilers\")\n index = index_by(spack.compilers.all_compilers(scope=args.scope),\n lambda c: (c.spec.name, c.operating_system, c.target))\n ordered_sections = sorted(index.items(), key=lambda item: item[0])\n for i, (key, compilers) in enumerate(ordered_sections):\n if i >= 1:\n print()\n name, os, target = key\n os_str = os\n if target:\n os_str += \"-%s\" % target\n cname = \"%s{%s} %s\" % (spack.spec.compiler_color, name, os_str)\n tty.hline(colorize(cname), char='-')\n colify(reversed(sorted(c.spec for c in compilers)))\n\n\ndef compiler(parser, args):\n action = {'add': compiler_find,\n 'find': compiler_find,\n 'remove': compiler_remove,\n 'rm': compiler_remove,\n 'info': compiler_info,\n 'list': compiler_list}\n action[args.compiler_command](args)\n", "path": "lib/spack/spack/cmd/compiler.py"}]}
| 2,557 | 152 |
gh_patches_debug_3083
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-462
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Device Support Request] Philips Hue Power Cycle Attribute
Hi
It would be great to have the Philips Hue Power Cycle attribute added. This allows for the bulb to remain powered on, off or set to previous settings when powered on.
The vendor attribute is `0x4003` and falls part of the `0x0006` (on_off) cluster. The possible values (enum8) are
```
Off = 0x00
On = 0x01
Previous = 0xff
```
The device signature for the ambient color bulb is as follows:
```
{
"node_descriptor": "<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>",
"endpoints": {
"11": {
"profile_id": 49246,
"device_type": "0x0210",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x0300",
"0x1000",
"0xfc01"
],
"out_clusters": [
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [
"0x0021"
],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "Philips",
"model": "LCT015",
"class": "zigpy.device.Device"
}
```
The device signature for the dimmable white bulb is as follows:
```
{
"node_descriptor": "<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>",
"endpoints": {
"11": {
"profile_id": 49246,
"device_type": "0x0100",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x1000"
],
"out_clusters": [
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [
"0x0021"
],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "Philips",
"model": "LWB010",
"class": "zigpy.device.Device"
}
```
I hope this is all that is needed to implement this. Please let me know if there anything you need.
Thanks.
Kurt
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/philips/__init__.py`
Content:
```
1 """Module for Philips quirks implementations."""
2 import logging
3
4 from zigpy.quirks import CustomCluster
5 import zigpy.types as t
6 from zigpy.zcl.clusters.general import Basic, OnOff
7
8 from ..const import (
9 ARGS,
10 BUTTON,
11 COMMAND,
12 COMMAND_ID,
13 DIM_DOWN,
14 DIM_UP,
15 LONG_PRESS,
16 LONG_RELEASE,
17 PRESS_TYPE,
18 SHORT_PRESS,
19 SHORT_RELEASE,
20 TURN_OFF,
21 TURN_ON,
22 ZHA_SEND_EVENT,
23 )
24
25 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
26 PHILIPS = "Philips"
27 _LOGGER = logging.getLogger(__name__)
28
29 HUE_REMOTE_DEVICE_TRIGGERS = {
30 (SHORT_PRESS, TURN_ON): {COMMAND: "on_press"},
31 (SHORT_PRESS, TURN_OFF): {COMMAND: "off_press"},
32 (SHORT_PRESS, DIM_UP): {COMMAND: "up_press"},
33 (SHORT_PRESS, DIM_DOWN): {COMMAND: "down_press"},
34 (LONG_PRESS, TURN_ON): {COMMAND: "on_hold"},
35 (LONG_PRESS, TURN_OFF): {COMMAND: "off_hold"},
36 (LONG_PRESS, DIM_UP): {COMMAND: "up_hold"},
37 (LONG_PRESS, DIM_DOWN): {COMMAND: "down_hold"},
38 (SHORT_RELEASE, TURN_ON): {COMMAND: "on_short_release"},
39 (SHORT_RELEASE, TURN_OFF): {COMMAND: "off_short_release"},
40 (SHORT_RELEASE, DIM_UP): {COMMAND: "up_short_release"},
41 (SHORT_RELEASE, DIM_DOWN): {COMMAND: "down_short_release"},
42 (LONG_RELEASE, TURN_ON): {COMMAND: "on_long_release"},
43 (LONG_RELEASE, TURN_OFF): {COMMAND: "off_long_release"},
44 (LONG_RELEASE, DIM_UP): {COMMAND: "up_long_release"},
45 (LONG_RELEASE, DIM_DOWN): {COMMAND: "down_long_release"},
46 }
47
48
49 class PowerOnState(t.enum8):
50 """Philips power on state enum."""
51
52 Off = 0x00
53 On = 0x01
54 LastState = 0xFF
55
56
57 class PhilipsOnOffCluster(CustomCluster, OnOff):
58 """Philips OnOff cluster."""
59
60 manufacturer_attributes = {0x4003: ("power_on_state", PowerOnState)}
61
62
63 class PhilipsBasicCluster(CustomCluster, Basic):
64 """Philips Basic cluster."""
65
66 manufacturer_attributes = {0x0031: ("philips", t.bitmap16)}
67
68 attr_config = {0x0031: 0x000B}
69
70 async def bind(self):
71 """Bind cluster."""
72 result = await super().bind()
73 await self.write_attributes(self.attr_config, manufacturer=0x100B)
74 return result
75
76
77 class PhilipsRemoteCluster(CustomCluster):
78 """Philips remote cluster."""
79
80 cluster_id = 64512
81 name = "PhilipsRemoteCluster"
82 ep_attribute = "philips_remote_cluster"
83 manufacturer_client_commands = {
84 0x0000: (
85 "notification",
86 (t.uint8_t, t.uint24_t, t.uint8_t, t.uint8_t, t.uint8_t, t.uint8_t),
87 False,
88 )
89 }
90 BUTTONS = {1: "on", 2: "up", 3: "down", 4: "off"}
91 PRESS_TYPES = {0: "press", 1: "hold", 2: "short_release", 3: "long_release"}
92
93 def handle_cluster_request(self, tsn, command_id, args):
94 """Handle the cluster command."""
95 _LOGGER.debug(
96 "PhilipsRemoteCluster - handle_cluster_request tsn: [%s] command id: %s - args: [%s]",
97 tsn,
98 command_id,
99 args,
100 )
101 button = self.BUTTONS.get(args[0], args[0])
102 press_type = self.PRESS_TYPES.get(args[2], args[2])
103
104 event_args = {
105 BUTTON: button,
106 PRESS_TYPE: press_type,
107 COMMAND_ID: command_id,
108 ARGS: args,
109 }
110 action = "{}_{}".format(button, press_type)
111 self.listener_event(ZHA_SEND_EVENT, action, event_args)
112
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/philips/__init__.py b/zhaquirks/philips/__init__.py
--- a/zhaquirks/philips/__init__.py
+++ b/zhaquirks/philips/__init__.py
@@ -57,7 +57,8 @@
class PhilipsOnOffCluster(CustomCluster, OnOff):
"""Philips OnOff cluster."""
- manufacturer_attributes = {0x4003: ("power_on_state", PowerOnState)}
+ attributes = OnOff.attributes.copy()
+ attributes.update({0x4003: ("power_on_state", PowerOnState)})
class PhilipsBasicCluster(CustomCluster, Basic):
|
{"golden_diff": "diff --git a/zhaquirks/philips/__init__.py b/zhaquirks/philips/__init__.py\n--- a/zhaquirks/philips/__init__.py\n+++ b/zhaquirks/philips/__init__.py\n@@ -57,7 +57,8 @@\n class PhilipsOnOffCluster(CustomCluster, OnOff):\n \"\"\"Philips OnOff cluster.\"\"\"\n \n- manufacturer_attributes = {0x4003: (\"power_on_state\", PowerOnState)}\n+ attributes = OnOff.attributes.copy()\n+ attributes.update({0x4003: (\"power_on_state\", PowerOnState)})\n \n \n class PhilipsBasicCluster(CustomCluster, Basic):\n", "issue": "[Device Support Request] Philips Hue Power Cycle Attribute\nHi \r\n\r\nIt would be great to have the Philips Hue Power Cycle attribute added. This allows for the bulb to remain powered on, off or set to previous settings when powered on.\r\n\r\nThe vendor attribute is `0x4003` and falls part of the `0x0006` (on_off) cluster. The possible values (enum8) are \r\n\r\n```\r\nOff = 0x00\r\nOn = 0x01\r\nPrevious = 0xff\r\n```\r\n\r\nThe device signature for the ambient color bulb is as follows:\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>\",\r\n \"endpoints\": {\r\n \"11\": {\r\n \"profile_id\": 49246,\r\n \"device_type\": \"0x0210\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x0300\",\r\n \"0x1000\",\r\n \"0xfc01\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [\r\n \"0x0021\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"Philips\",\r\n \"model\": \"LCT015\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\nThe device signature for the dimmable white bulb is as follows:\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"<NodeDescriptor byte1=1 byte2=64 mac_capability_flags=142 manufacturer_code=4107 maximum_buffer_size=71 maximum_incoming_transfer_size=45 server_mask=0 maximum_outgoing_transfer_size=45 descriptor_capability_field=0>\",\r\n \"endpoints\": {\r\n \"11\": {\r\n \"profile_id\": 49246,\r\n \"device_type\": \"0x0100\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x1000\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [\r\n \"0x0021\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"Philips\",\r\n \"model\": \"LWB010\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\nI hope this is all that is needed to implement this. Please let me know if there anything you need.\r\n\r\nThanks.\r\n\r\nKurt \n", "before_files": [{"content": "\"\"\"Module for Philips quirks implementations.\"\"\"\nimport logging\n\nfrom zigpy.quirks import CustomCluster\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import Basic, OnOff\n\nfrom ..const import (\n ARGS,\n BUTTON,\n COMMAND,\n COMMAND_ID,\n DIM_DOWN,\n DIM_UP,\n LONG_PRESS,\n LONG_RELEASE,\n PRESS_TYPE,\n SHORT_PRESS,\n SHORT_RELEASE,\n TURN_OFF,\n TURN_ON,\n ZHA_SEND_EVENT,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nPHILIPS = \"Philips\"\n_LOGGER = logging.getLogger(__name__)\n\nHUE_REMOTE_DEVICE_TRIGGERS = {\n (SHORT_PRESS, TURN_ON): {COMMAND: \"on_press\"},\n (SHORT_PRESS, TURN_OFF): {COMMAND: \"off_press\"},\n (SHORT_PRESS, DIM_UP): {COMMAND: \"up_press\"},\n (SHORT_PRESS, DIM_DOWN): {COMMAND: \"down_press\"},\n (LONG_PRESS, TURN_ON): {COMMAND: \"on_hold\"},\n (LONG_PRESS, TURN_OFF): {COMMAND: \"off_hold\"},\n (LONG_PRESS, DIM_UP): {COMMAND: \"up_hold\"},\n (LONG_PRESS, DIM_DOWN): {COMMAND: \"down_hold\"},\n (SHORT_RELEASE, TURN_ON): {COMMAND: \"on_short_release\"},\n (SHORT_RELEASE, TURN_OFF): {COMMAND: \"off_short_release\"},\n (SHORT_RELEASE, DIM_UP): {COMMAND: \"up_short_release\"},\n (SHORT_RELEASE, DIM_DOWN): {COMMAND: \"down_short_release\"},\n (LONG_RELEASE, TURN_ON): {COMMAND: \"on_long_release\"},\n (LONG_RELEASE, TURN_OFF): {COMMAND: \"off_long_release\"},\n (LONG_RELEASE, DIM_UP): {COMMAND: \"up_long_release\"},\n (LONG_RELEASE, DIM_DOWN): {COMMAND: \"down_long_release\"},\n}\n\n\nclass PowerOnState(t.enum8):\n \"\"\"Philips power on state enum.\"\"\"\n\n Off = 0x00\n On = 0x01\n LastState = 0xFF\n\n\nclass PhilipsOnOffCluster(CustomCluster, OnOff):\n \"\"\"Philips OnOff cluster.\"\"\"\n\n manufacturer_attributes = {0x4003: (\"power_on_state\", PowerOnState)}\n\n\nclass PhilipsBasicCluster(CustomCluster, Basic):\n \"\"\"Philips Basic cluster.\"\"\"\n\n manufacturer_attributes = {0x0031: (\"philips\", t.bitmap16)}\n\n attr_config = {0x0031: 0x000B}\n\n async def bind(self):\n \"\"\"Bind cluster.\"\"\"\n result = await super().bind()\n await self.write_attributes(self.attr_config, manufacturer=0x100B)\n return result\n\n\nclass PhilipsRemoteCluster(CustomCluster):\n \"\"\"Philips remote cluster.\"\"\"\n\n cluster_id = 64512\n name = \"PhilipsRemoteCluster\"\n ep_attribute = \"philips_remote_cluster\"\n manufacturer_client_commands = {\n 0x0000: (\n \"notification\",\n (t.uint8_t, t.uint24_t, t.uint8_t, t.uint8_t, t.uint8_t, t.uint8_t),\n False,\n )\n }\n BUTTONS = {1: \"on\", 2: \"up\", 3: \"down\", 4: \"off\"}\n PRESS_TYPES = {0: \"press\", 1: \"hold\", 2: \"short_release\", 3: \"long_release\"}\n\n def handle_cluster_request(self, tsn, command_id, args):\n \"\"\"Handle the cluster command.\"\"\"\n _LOGGER.debug(\n \"PhilipsRemoteCluster - handle_cluster_request tsn: [%s] command id: %s - args: [%s]\",\n tsn,\n command_id,\n args,\n )\n button = self.BUTTONS.get(args[0], args[0])\n press_type = self.PRESS_TYPES.get(args[2], args[2])\n\n event_args = {\n BUTTON: button,\n PRESS_TYPE: press_type,\n COMMAND_ID: command_id,\n ARGS: args,\n }\n action = \"{}_{}\".format(button, press_type)\n self.listener_event(ZHA_SEND_EVENT, action, event_args)\n", "path": "zhaquirks/philips/__init__.py"}], "after_files": [{"content": "\"\"\"Module for Philips quirks implementations.\"\"\"\nimport logging\n\nfrom zigpy.quirks import CustomCluster\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import Basic, OnOff\n\nfrom ..const import (\n ARGS,\n BUTTON,\n COMMAND,\n COMMAND_ID,\n DIM_DOWN,\n DIM_UP,\n LONG_PRESS,\n LONG_RELEASE,\n PRESS_TYPE,\n SHORT_PRESS,\n SHORT_RELEASE,\n TURN_OFF,\n TURN_ON,\n ZHA_SEND_EVENT,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nPHILIPS = \"Philips\"\n_LOGGER = logging.getLogger(__name__)\n\nHUE_REMOTE_DEVICE_TRIGGERS = {\n (SHORT_PRESS, TURN_ON): {COMMAND: \"on_press\"},\n (SHORT_PRESS, TURN_OFF): {COMMAND: \"off_press\"},\n (SHORT_PRESS, DIM_UP): {COMMAND: \"up_press\"},\n (SHORT_PRESS, DIM_DOWN): {COMMAND: \"down_press\"},\n (LONG_PRESS, TURN_ON): {COMMAND: \"on_hold\"},\n (LONG_PRESS, TURN_OFF): {COMMAND: \"off_hold\"},\n (LONG_PRESS, DIM_UP): {COMMAND: \"up_hold\"},\n (LONG_PRESS, DIM_DOWN): {COMMAND: \"down_hold\"},\n (SHORT_RELEASE, TURN_ON): {COMMAND: \"on_short_release\"},\n (SHORT_RELEASE, TURN_OFF): {COMMAND: \"off_short_release\"},\n (SHORT_RELEASE, DIM_UP): {COMMAND: \"up_short_release\"},\n (SHORT_RELEASE, DIM_DOWN): {COMMAND: \"down_short_release\"},\n (LONG_RELEASE, TURN_ON): {COMMAND: \"on_long_release\"},\n (LONG_RELEASE, TURN_OFF): {COMMAND: \"off_long_release\"},\n (LONG_RELEASE, DIM_UP): {COMMAND: \"up_long_release\"},\n (LONG_RELEASE, DIM_DOWN): {COMMAND: \"down_long_release\"},\n}\n\n\nclass PowerOnState(t.enum8):\n \"\"\"Philips power on state enum.\"\"\"\n\n Off = 0x00\n On = 0x01\n LastState = 0xFF\n\n\nclass PhilipsOnOffCluster(CustomCluster, OnOff):\n \"\"\"Philips OnOff cluster.\"\"\"\n\n attributes = OnOff.attributes.copy()\n attributes.update({0x4003: (\"power_on_state\", PowerOnState)})\n\n\nclass PhilipsBasicCluster(CustomCluster, Basic):\n \"\"\"Philips Basic cluster.\"\"\"\n\n manufacturer_attributes = {0x0031: (\"philips\", t.bitmap16)}\n\n attr_config = {0x0031: 0x000B}\n\n async def bind(self):\n \"\"\"Bind cluster.\"\"\"\n result = await super().bind()\n await self.write_attributes(self.attr_config, manufacturer=0x100B)\n return result\n\n\nclass PhilipsRemoteCluster(CustomCluster):\n \"\"\"Philips remote cluster.\"\"\"\n\n cluster_id = 64512\n name = \"PhilipsRemoteCluster\"\n ep_attribute = \"philips_remote_cluster\"\n manufacturer_client_commands = {\n 0x0000: (\n \"notification\",\n (t.uint8_t, t.uint24_t, t.uint8_t, t.uint8_t, t.uint8_t, t.uint8_t),\n False,\n )\n }\n BUTTONS = {1: \"on\", 2: \"up\", 3: \"down\", 4: \"off\"}\n PRESS_TYPES = {0: \"press\", 1: \"hold\", 2: \"short_release\", 3: \"long_release\"}\n\n def handle_cluster_request(self, tsn, command_id, args):\n \"\"\"Handle the cluster command.\"\"\"\n _LOGGER.debug(\n \"PhilipsRemoteCluster - handle_cluster_request tsn: [%s] command id: %s - args: [%s]\",\n tsn,\n command_id,\n args,\n )\n button = self.BUTTONS.get(args[0], args[0])\n press_type = self.PRESS_TYPES.get(args[2], args[2])\n\n event_args = {\n BUTTON: button,\n PRESS_TYPE: press_type,\n COMMAND_ID: command_id,\n ARGS: args,\n }\n action = \"{}_{}\".format(button, press_type)\n self.listener_event(ZHA_SEND_EVENT, action, event_args)\n", "path": "zhaquirks/philips/__init__.py"}]}
| 2,191 | 152 |
gh_patches_debug_5500
|
rasdani/github-patches
|
git_diff
|
tensorflow__tfx-3813
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update tensorflow-hub requirement to allow 0.12.0?
If the feature is related to a specific library below, please raise an issue in
the respective repo directly:
[TensorFlow Data Validation Repo](https://github.com/tensorflow/data-validation/issues)
[TensorFlow Model Analysis Repo](https://github.com/tensorflow/model-analysis/issues)
[TensorFlow Transform Repo](https://github.com/tensorflow/transform/issues)
[TensorFlow Serving Repo](https://github.com/tensorflow/serving/issues)
**System information**
- TFX Version (you are using): 1.0.0-rc0
- Environment in which you plan to use the feature (e.g., Local
(Linux/MacOS/Windows), Interactive Notebook, Google Cloud, etc..): MacOS, AWS
- Are you willing to contribute it (Yes/No): Yes
**Describe the feature and the current behavior/state.**
tfx (1.0.0-rc0) currently depends on tensorflow-hub (>=0.9.0,<0.10)
I was wondering if we could update tensorflow-hub dependancy for tfx to allow tf-hub 0.12.0, so something like (>=0.9.0,<=0.12.0)?
I am not sure if that would break anything in tfx, but I am happy to investigate and contribute to this change
**Will this change the current API? How?**
No
**Who will benefit with this feature?**
tensorflow-hub has added some new features in 0.10.0 and beyond (specifically the one I'm interested in "`compute_output_shape` in `hub.KerasLayer`" which they added in 0.12.0). It would be cool to be able to take advantage of those while still being able to use tfx
**Do you have a workaround or are completely blocked by this?** :
Blocked
**Name of your Organization (Optional)**
**Any Other info.**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tfx/dependencies.py`
Content:
```
1 # Copyright 2019 Google LLC. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Package dependencies for TFX.
15
16 tfx and family libraries (such as tensorflow-model-analysis) adopts environment
17 variable (TFX_DEPENDENCY_SELECTOR) based dependency version selection. This
18 dependency will be baked in to the wheel, in other words you cannot change
19 dependency string once wheel is built.
20
21 - UNCONSTRAINED uses dependency without any version constraint string, which is
22 useful when you manually build wheels of parent library (e.g. tfx-bsl) of
23 arbitrary version, and install it without dependency constraints conflict.
24 - NIGHTLY uses x.(y+1).0.dev version as a lower version constraint. tfx nightly
25 will transitively depend on nightly versions of other TFX family libraries,
26 and this version constraint is required.
27 - GIT_MASTER uses github master branch URL of the dependency, which is useful
28 during development, or when depending on the github master HEAD version of
29 tfx. This is because tfx github master HEAD version is actually using github
30 master HEAD version of parent libraries.
31 Caveat: URL dependency is not upgraded with --upgrade flag, and you have to
32 specify --force-reinstall flag to fetch the latest change from each master
33 branch HEAD.
34 - For the release, we use a range of version, which is also used as a default.
35 """
36 import os
37
38
39 def select_constraint(default, nightly=None, git_master=None):
40 """Select dependency constraint based on TFX_DEPENDENCY_SELECTOR env var."""
41 selector = os.environ.get('TFX_DEPENDENCY_SELECTOR')
42 if selector == 'UNCONSTRAINED':
43 return ''
44 elif selector == 'NIGHTLY' and nightly is not None:
45 return nightly
46 elif selector == 'GIT_MASTER' and git_master is not None:
47 return git_master
48 else:
49 return default
50
51
52 def make_pipeline_sdk_required_install_packages():
53 return [
54 'absl-py>=0.9,<0.13',
55 'ml-metadata' + select_constraint(
56 # LINT.IfChange
57 default='>=0.30,<0.31',
58 # LINT.ThenChange(tfx/workspace.bzl)
59 nightly='>=0.31.0.dev',
60 git_master='@git+https://github.com/google/ml-metadata@master'),
61 'packaging>=20,<21',
62 'portpicker>=1.3.1,<2',
63 'protobuf>=3.12.2,<4',
64 'docker>=4.1,<5',
65 # TODO(b/176812386): Deprecate usage of jinja2 for placeholders.
66 'jinja2>=2.7.3,<3',
67 ]
68
69
70 def make_required_install_packages():
71 # Make sure to sync the versions of common dependencies (absl-py, numpy,
72 # and protobuf) with TF.
73 return make_pipeline_sdk_required_install_packages() + [
74 'apache-beam[gcp]>=2.29,<3',
75 'attrs>=19.3.0,<21',
76 'click>=7,<8',
77 'google-api-python-client>=1.7.8,<2',
78 'google-cloud-aiplatform>=0.5.0,<0.8',
79 'google-cloud-bigquery>=1.28.0,<3',
80 'grpcio>=1.28.1,<2',
81 # TODO(b/173976603): remove pinned keras-tuner upperbound when its
82 # dependency expecatation with TensorFlow is sorted out.
83 'keras-tuner>=1,<1.0.2',
84 'kubernetes>=10.0.1,<12',
85 # TODO(b/179195488): remove numpy dependency after 1.20 migration.
86 # This dependency was added only to limit numpy 1.20 installation.
87 'numpy>=1.16,<1.20',
88 'pyarrow>=1,<3',
89 'pyyaml>=3.12,<6',
90 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
91 'tensorflow-hub>=0.9.0,<0.10',
92 'tensorflow-data-validation' + select_constraint(
93 default='>=0.30,<0.31',
94 nightly='>=0.31.0.dev',
95 git_master='@git+https://github.com/tensorflow/data-validation@master'
96 ),
97 'tensorflow-model-analysis' + select_constraint(
98 default='>=0.30,<0.31',
99 nightly='>=0.31.0.dev',
100 git_master='@git+https://github.com/tensorflow/model-analysis@master'
101 ),
102 'tensorflow-serving-api>=1.15,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
103 'tensorflow-transform' + select_constraint(
104 default='>=0.30,<0.31',
105 nightly='>=0.31.0.dev',
106 git_master='@git+https://github.com/tensorflow/transform@master'),
107 'tfx-bsl' + select_constraint(
108 default='>=0.30,<0.31',
109 nightly='>=0.31.0.dev',
110 git_master='@git+https://github.com/tensorflow/tfx-bsl@master'),
111 ]
112
113
114 def make_extra_packages_airflow():
115 """Prepare extra packages needed for Apache Airflow orchestrator."""
116 return [
117 # TODO(b/188940096): update supported version.
118 'apache-airflow[mysql]>=1.10.14,!=2.1.*,<3',
119 # TODO(b/182848576): Delete pinned sqlalchemy after apache-airflow 2.0.2
120 # or later.(github.com/apache/airflow/issues/14811)
121 'sqlalchemy>=1.3,<1.4',
122 ]
123
124
125 def make_extra_packages_kfp():
126 """Prepare extra packages needed for Kubeflow Pipelines orchestrator."""
127 return [
128 'kfp>=1.1.0,<2',
129 'kfp-pipeline-spec>=0.1.7,<0.2',
130 ]
131
132
133 def make_extra_packages_test():
134 """Prepare extra packages needed for running unit tests."""
135 # Note: It is okay to pin packages to exact versions in this list to minimize
136 # conflicts.
137 return make_extra_packages_airflow() + make_extra_packages_kfp() + [
138 'pytest>=5,<6',
139 ]
140
141
142 def make_extra_packages_docker_image():
143 # Packages needed for tfx docker image.
144 return [
145 'kfp-pipeline-spec>=0.1.7,<0.2',
146 'mmh>=2.2,<3',
147 'python-snappy>=0.5,<0.6',
148 ]
149
150
151 def make_extra_packages_tfjs():
152 # Packages needed for tfjs.
153 return [
154 'tensorflowjs>=3.6.0,<4',
155 ]
156
157
158 def make_extra_packages_tf_ranking():
159 # Packages needed for tf-ranking which is used in tfx/examples/ranking.
160 return [
161 'tensorflow-ranking>=0.3.3,<0.4',
162 'struct2tensor' + select_constraint(
163 default='>=0.30,<0.31',
164 nightly='>=0.31.0.dev',
165 git_master='@git+https://github.com/google/struct2tensor@master'),
166 ]
167
168
169 def make_extra_packages_examples():
170 # Extra dependencies required for tfx/examples.
171 return [
172 # Required for presto ExampleGen custom component in
173 # tfx/examples/custom_components/presto_example_gen
174 'presto-python-client>=0.7,<0.8',
175 # Required for slack custom component in
176 # tfx/examples/custom_components/slack
177 'slackclient>=2.8.2,<3',
178 'websocket-client>=0.57,<1',
179 # Required for bert examples in tfx/examples/bert
180 'tensorflow-text>=1.15.1,<3',
181 # Required for tfx/examples/cifar10
182 'flatbuffers>=1.12,<2',
183 'tflite-support>=0.1.0a1,<0.1.1',
184 # Required for tfx/examples/penguin/experimental
185 # LINT.IfChange
186 'scikit-learn>=0.23,<0.24',
187 # LINT.ThenChange(
188 # examples/penguin/experimental/penguin_pipeline_sklearn_gcp.py)
189 # Required for the experimental tfx/examples using Flax, e.g.,
190 # tfx/examples/penguin.
191 'jax>=0.2.13,<0.3',
192 'jaxlib>=0.1.64,<0.2',
193 'flax>=0.3.3,<0.4',
194 # Required for tfx/examples/penguin/penguin_utils_cloud_tuner.py
195 'tensorflow-cloud>=0.1,<0.2',
196 ]
197
198
199 def make_extra_packages_all():
200 # All extra dependencies.
201 return [
202 *make_extra_packages_test(),
203 *make_extra_packages_tfjs(),
204 *make_extra_packages_tf_ranking(),
205 *make_extra_packages_examples(),
206 ]
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tfx/dependencies.py b/tfx/dependencies.py
--- a/tfx/dependencies.py
+++ b/tfx/dependencies.py
@@ -88,7 +88,7 @@
'pyarrow>=1,<3',
'pyyaml>=3.12,<6',
'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',
- 'tensorflow-hub>=0.9.0,<0.10',
+ 'tensorflow-hub>=0.9.0,<=0.12.0',
'tensorflow-data-validation' + select_constraint(
default='>=0.30,<0.31',
nightly='>=0.31.0.dev',
|
{"golden_diff": "diff --git a/tfx/dependencies.py b/tfx/dependencies.py\n--- a/tfx/dependencies.py\n+++ b/tfx/dependencies.py\n@@ -88,7 +88,7 @@\n 'pyarrow>=1,<3',\n 'pyyaml>=3.12,<6',\n 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n- 'tensorflow-hub>=0.9.0,<0.10',\n+ 'tensorflow-hub>=0.9.0,<=0.12.0',\n 'tensorflow-data-validation' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n", "issue": "Update tensorflow-hub requirement to allow 0.12.0?\nIf the feature is related to a specific library below, please raise an issue in\r\nthe respective repo directly:\r\n\r\n[TensorFlow Data Validation Repo](https://github.com/tensorflow/data-validation/issues)\r\n\r\n[TensorFlow Model Analysis Repo](https://github.com/tensorflow/model-analysis/issues)\r\n\r\n[TensorFlow Transform Repo](https://github.com/tensorflow/transform/issues)\r\n\r\n[TensorFlow Serving Repo](https://github.com/tensorflow/serving/issues)\r\n\r\n**System information**\r\n\r\n- TFX Version (you are using): 1.0.0-rc0\r\n- Environment in which you plan to use the feature (e.g., Local\r\n (Linux/MacOS/Windows), Interactive Notebook, Google Cloud, etc..): MacOS, AWS\r\n- Are you willing to contribute it (Yes/No): Yes\r\n\r\n**Describe the feature and the current behavior/state.**\r\ntfx (1.0.0-rc0) currently depends on tensorflow-hub (>=0.9.0,<0.10)\r\n\r\nI was wondering if we could update tensorflow-hub dependancy for tfx to allow tf-hub 0.12.0, so something like (>=0.9.0,<=0.12.0)?\r\n\r\nI am not sure if that would break anything in tfx, but I am happy to investigate and contribute to this change\r\n\r\n**Will this change the current API? How?**\r\nNo\r\n\r\n**Who will benefit with this feature?**\r\ntensorflow-hub has added some new features in 0.10.0 and beyond (specifically the one I'm interested in \"`compute_output_shape` in `hub.KerasLayer`\" which they added in 0.12.0). It would be cool to be able to take advantage of those while still being able to use tfx\r\n\r\n**Do you have a workaround or are completely blocked by this?** :\r\nBlocked\r\n\r\n**Name of your Organization (Optional)**\r\n\r\n\r\n**Any Other info.**\r\n\n", "before_files": [{"content": "# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Package dependencies for TFX.\n\ntfx and family libraries (such as tensorflow-model-analysis) adopts environment\nvariable (TFX_DEPENDENCY_SELECTOR) based dependency version selection. This\ndependency will be baked in to the wheel, in other words you cannot change\ndependency string once wheel is built.\n\n- UNCONSTRAINED uses dependency without any version constraint string, which is\n useful when you manually build wheels of parent library (e.g. tfx-bsl) of\n arbitrary version, and install it without dependency constraints conflict.\n- NIGHTLY uses x.(y+1).0.dev version as a lower version constraint. tfx nightly\n will transitively depend on nightly versions of other TFX family libraries,\n and this version constraint is required.\n- GIT_MASTER uses github master branch URL of the dependency, which is useful\n during development, or when depending on the github master HEAD version of\n tfx. This is because tfx github master HEAD version is actually using github\n master HEAD version of parent libraries.\n Caveat: URL dependency is not upgraded with --upgrade flag, and you have to\n specify --force-reinstall flag to fetch the latest change from each master\n branch HEAD.\n- For the release, we use a range of version, which is also used as a default.\n\"\"\"\nimport os\n\n\ndef select_constraint(default, nightly=None, git_master=None):\n \"\"\"Select dependency constraint based on TFX_DEPENDENCY_SELECTOR env var.\"\"\"\n selector = os.environ.get('TFX_DEPENDENCY_SELECTOR')\n if selector == 'UNCONSTRAINED':\n return ''\n elif selector == 'NIGHTLY' and nightly is not None:\n return nightly\n elif selector == 'GIT_MASTER' and git_master is not None:\n return git_master\n else:\n return default\n\n\ndef make_pipeline_sdk_required_install_packages():\n return [\n 'absl-py>=0.9,<0.13',\n 'ml-metadata' + select_constraint(\n # LINT.IfChange\n default='>=0.30,<0.31',\n # LINT.ThenChange(tfx/workspace.bzl)\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/ml-metadata@master'),\n 'packaging>=20,<21',\n 'portpicker>=1.3.1,<2',\n 'protobuf>=3.12.2,<4',\n 'docker>=4.1,<5',\n # TODO(b/176812386): Deprecate usage of jinja2 for placeholders.\n 'jinja2>=2.7.3,<3',\n ]\n\n\ndef make_required_install_packages():\n # Make sure to sync the versions of common dependencies (absl-py, numpy,\n # and protobuf) with TF.\n return make_pipeline_sdk_required_install_packages() + [\n 'apache-beam[gcp]>=2.29,<3',\n 'attrs>=19.3.0,<21',\n 'click>=7,<8',\n 'google-api-python-client>=1.7.8,<2',\n 'google-cloud-aiplatform>=0.5.0,<0.8',\n 'google-cloud-bigquery>=1.28.0,<3',\n 'grpcio>=1.28.1,<2',\n # TODO(b/173976603): remove pinned keras-tuner upperbound when its\n # dependency expecatation with TensorFlow is sorted out.\n 'keras-tuner>=1,<1.0.2',\n 'kubernetes>=10.0.1,<12',\n # TODO(b/179195488): remove numpy dependency after 1.20 migration.\n # This dependency was added only to limit numpy 1.20 installation.\n 'numpy>=1.16,<1.20',\n 'pyarrow>=1,<3',\n 'pyyaml>=3.12,<6',\n 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-hub>=0.9.0,<0.10',\n 'tensorflow-data-validation' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/data-validation@master'\n ),\n 'tensorflow-model-analysis' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/model-analysis@master'\n ),\n 'tensorflow-serving-api>=1.15,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-transform' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/transform@master'),\n 'tfx-bsl' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/tfx-bsl@master'),\n ]\n\n\ndef make_extra_packages_airflow():\n \"\"\"Prepare extra packages needed for Apache Airflow orchestrator.\"\"\"\n return [\n # TODO(b/188940096): update supported version.\n 'apache-airflow[mysql]>=1.10.14,!=2.1.*,<3',\n # TODO(b/182848576): Delete pinned sqlalchemy after apache-airflow 2.0.2\n # or later.(github.com/apache/airflow/issues/14811)\n 'sqlalchemy>=1.3,<1.4',\n ]\n\n\ndef make_extra_packages_kfp():\n \"\"\"Prepare extra packages needed for Kubeflow Pipelines orchestrator.\"\"\"\n return [\n 'kfp>=1.1.0,<2',\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n ]\n\n\ndef make_extra_packages_test():\n \"\"\"Prepare extra packages needed for running unit tests.\"\"\"\n # Note: It is okay to pin packages to exact versions in this list to minimize\n # conflicts.\n return make_extra_packages_airflow() + make_extra_packages_kfp() + [\n 'pytest>=5,<6',\n ]\n\n\ndef make_extra_packages_docker_image():\n # Packages needed for tfx docker image.\n return [\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n 'mmh>=2.2,<3',\n 'python-snappy>=0.5,<0.6',\n ]\n\n\ndef make_extra_packages_tfjs():\n # Packages needed for tfjs.\n return [\n 'tensorflowjs>=3.6.0,<4',\n ]\n\n\ndef make_extra_packages_tf_ranking():\n # Packages needed for tf-ranking which is used in tfx/examples/ranking.\n return [\n 'tensorflow-ranking>=0.3.3,<0.4',\n 'struct2tensor' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/struct2tensor@master'),\n ]\n\n\ndef make_extra_packages_examples():\n # Extra dependencies required for tfx/examples.\n return [\n # Required for presto ExampleGen custom component in\n # tfx/examples/custom_components/presto_example_gen\n 'presto-python-client>=0.7,<0.8',\n # Required for slack custom component in\n # tfx/examples/custom_components/slack\n 'slackclient>=2.8.2,<3',\n 'websocket-client>=0.57,<1',\n # Required for bert examples in tfx/examples/bert\n 'tensorflow-text>=1.15.1,<3',\n # Required for tfx/examples/cifar10\n 'flatbuffers>=1.12,<2',\n 'tflite-support>=0.1.0a1,<0.1.1',\n # Required for tfx/examples/penguin/experimental\n # LINT.IfChange\n 'scikit-learn>=0.23,<0.24',\n # LINT.ThenChange(\n # examples/penguin/experimental/penguin_pipeline_sklearn_gcp.py)\n # Required for the experimental tfx/examples using Flax, e.g.,\n # tfx/examples/penguin.\n 'jax>=0.2.13,<0.3',\n 'jaxlib>=0.1.64,<0.2',\n 'flax>=0.3.3,<0.4',\n # Required for tfx/examples/penguin/penguin_utils_cloud_tuner.py\n 'tensorflow-cloud>=0.1,<0.2',\n ]\n\n\ndef make_extra_packages_all():\n # All extra dependencies.\n return [\n *make_extra_packages_test(),\n *make_extra_packages_tfjs(),\n *make_extra_packages_tf_ranking(),\n *make_extra_packages_examples(),\n ]\n", "path": "tfx/dependencies.py"}], "after_files": [{"content": "# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Package dependencies for TFX.\n\ntfx and family libraries (such as tensorflow-model-analysis) adopts environment\nvariable (TFX_DEPENDENCY_SELECTOR) based dependency version selection. This\ndependency will be baked in to the wheel, in other words you cannot change\ndependency string once wheel is built.\n\n- UNCONSTRAINED uses dependency without any version constraint string, which is\n useful when you manually build wheels of parent library (e.g. tfx-bsl) of\n arbitrary version, and install it without dependency constraints conflict.\n- NIGHTLY uses x.(y+1).0.dev version as a lower version constraint. tfx nightly\n will transitively depend on nightly versions of other TFX family libraries,\n and this version constraint is required.\n- GIT_MASTER uses github master branch URL of the dependency, which is useful\n during development, or when depending on the github master HEAD version of\n tfx. This is because tfx github master HEAD version is actually using github\n master HEAD version of parent libraries.\n Caveat: URL dependency is not upgraded with --upgrade flag, and you have to\n specify --force-reinstall flag to fetch the latest change from each master\n branch HEAD.\n- For the release, we use a range of version, which is also used as a default.\n\"\"\"\nimport os\n\n\ndef select_constraint(default, nightly=None, git_master=None):\n \"\"\"Select dependency constraint based on TFX_DEPENDENCY_SELECTOR env var.\"\"\"\n selector = os.environ.get('TFX_DEPENDENCY_SELECTOR')\n if selector == 'UNCONSTRAINED':\n return ''\n elif selector == 'NIGHTLY' and nightly is not None:\n return nightly\n elif selector == 'GIT_MASTER' and git_master is not None:\n return git_master\n else:\n return default\n\n\ndef make_pipeline_sdk_required_install_packages():\n return [\n 'absl-py>=0.9,<0.13',\n 'ml-metadata' + select_constraint(\n # LINT.IfChange\n default='>=0.30,<0.31',\n # LINT.ThenChange(tfx/workspace.bzl)\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/ml-metadata@master'),\n 'packaging>=20,<21',\n 'portpicker>=1.3.1,<2',\n 'protobuf>=3.12.2,<4',\n 'docker>=4.1,<5',\n # TODO(b/176812386): Deprecate usage of jinja2 for placeholders.\n 'jinja2>=2.7.3,<3',\n ]\n\n\ndef make_required_install_packages():\n # Make sure to sync the versions of common dependencies (absl-py, numpy,\n # and protobuf) with TF.\n return make_pipeline_sdk_required_install_packages() + [\n 'apache-beam[gcp]>=2.29,<3',\n 'attrs>=19.3.0,<21',\n 'click>=7,<8',\n 'google-api-python-client>=1.7.8,<2',\n 'google-cloud-aiplatform>=0.5.0,<0.8',\n 'google-cloud-bigquery>=1.28.0,<3',\n 'grpcio>=1.28.1,<2',\n # TODO(b/173976603): remove pinned keras-tuner upperbound when its\n # dependency expecatation with TensorFlow is sorted out.\n 'keras-tuner>=1,<1.0.2',\n 'kubernetes>=10.0.1,<12',\n # TODO(b/179195488): remove numpy dependency after 1.20 migration.\n # This dependency was added only to limit numpy 1.20 installation.\n 'numpy>=1.16,<1.20',\n 'pyarrow>=1,<3',\n 'pyyaml>=3.12,<6',\n 'tensorflow>=1.15.2,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-hub>=0.9.0,<=0.12.0',\n 'tensorflow-data-validation' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/data-validation@master'\n ),\n 'tensorflow-model-analysis' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/model-analysis@master'\n ),\n 'tensorflow-serving-api>=1.15,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,<3',\n 'tensorflow-transform' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/transform@master'),\n 'tfx-bsl' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/tensorflow/tfx-bsl@master'),\n ]\n\n\ndef make_extra_packages_airflow():\n \"\"\"Prepare extra packages needed for Apache Airflow orchestrator.\"\"\"\n return [\n # TODO(b/188940096): update supported version.\n 'apache-airflow[mysql]>=1.10.14,!=2.1.*,<3',\n # TODO(b/182848576): Delete pinned sqlalchemy after apache-airflow 2.0.2\n # or later.(github.com/apache/airflow/issues/14811)\n 'sqlalchemy>=1.3,<1.4',\n ]\n\n\ndef make_extra_packages_kfp():\n \"\"\"Prepare extra packages needed for Kubeflow Pipelines orchestrator.\"\"\"\n return [\n 'kfp>=1.1.0,<2',\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n ]\n\n\ndef make_extra_packages_test():\n \"\"\"Prepare extra packages needed for running unit tests.\"\"\"\n # Note: It is okay to pin packages to exact versions in this list to minimize\n # conflicts.\n return make_extra_packages_airflow() + make_extra_packages_kfp() + [\n 'pytest>=5,<6',\n ]\n\n\ndef make_extra_packages_docker_image():\n # Packages needed for tfx docker image.\n return [\n 'kfp-pipeline-spec>=0.1.7,<0.2',\n 'mmh>=2.2,<3',\n 'python-snappy>=0.5,<0.6',\n ]\n\n\ndef make_extra_packages_tfjs():\n # Packages needed for tfjs.\n return [\n 'tensorflowjs>=3.6.0,<4',\n ]\n\n\ndef make_extra_packages_tf_ranking():\n # Packages needed for tf-ranking which is used in tfx/examples/ranking.\n return [\n 'tensorflow-ranking>=0.3.3,<0.4',\n 'struct2tensor' + select_constraint(\n default='>=0.30,<0.31',\n nightly='>=0.31.0.dev',\n git_master='@git+https://github.com/google/struct2tensor@master'),\n ]\n\n\ndef make_extra_packages_examples():\n # Extra dependencies required for tfx/examples.\n return [\n # Required for presto ExampleGen custom component in\n # tfx/examples/custom_components/presto_example_gen\n 'presto-python-client>=0.7,<0.8',\n # Required for slack custom component in\n # tfx/examples/custom_components/slack\n 'slackclient>=2.8.2,<3',\n 'websocket-client>=0.57,<1',\n # Required for bert examples in tfx/examples/bert\n 'tensorflow-text>=1.15.1,<3',\n # Required for tfx/examples/cifar10\n 'flatbuffers>=1.12,<2',\n 'tflite-support>=0.1.0a1,<0.1.1',\n # Required for tfx/examples/penguin/experimental\n # LINT.IfChange\n 'scikit-learn>=0.23,<0.24',\n # LINT.ThenChange(\n # examples/penguin/experimental/penguin_pipeline_sklearn_gcp.py)\n # Required for the experimental tfx/examples using Flax, e.g.,\n # tfx/examples/penguin.\n 'jax>=0.2.13,<0.3',\n 'jaxlib>=0.1.64,<0.2',\n 'flax>=0.3.3,<0.4',\n # Required for tfx/examples/penguin/penguin_utils_cloud_tuner.py\n 'tensorflow-cloud>=0.1,<0.2',\n ]\n\n\ndef make_extra_packages_all():\n # All extra dependencies.\n return [\n *make_extra_packages_test(),\n *make_extra_packages_tfjs(),\n *make_extra_packages_tf_ranking(),\n *make_extra_packages_examples(),\n ]\n", "path": "tfx/dependencies.py"}]}
| 3,369 | 179 |
gh_patches_debug_6040
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-2956
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ONNX error converting torch.mean
I've been working to convert some models using sentence embeddings via ONNX and have run into the following error while running `torch.onnx._export`:
`RuntimeError: PythonOp doesn't define symbolic Mean`
I also had this error when trying to implement my own "mean" operation using add and divide.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/autograd/_functions/reduce.py`
Content:
```
1 from functools import reduce
2
3 from ..function import Function
4 from ..variable import Variable
5 import torch
6
7
8 class Sum(Function):
9
10 @staticmethod
11 def forward(ctx, input, dim=None, keepdim=None):
12 ctx.dim = dim
13 ctx.keepdim = False if keepdim is None else keepdim
14 ctx.input_size = input.size()
15 if dim is None:
16 return input.new((input.sum(),))
17 else:
18 if keepdim is not None:
19 return input.sum(dim, keepdim=keepdim)
20 else:
21 return input.sum(dim)
22
23 @staticmethod
24 def backward(ctx, grad_output):
25 if ctx.dim is None:
26 return grad_output.expand(ctx.input_size), None, None
27 else:
28 if ctx.keepdim is False and len(ctx.input_size) != 1:
29 grad_output = grad_output.unsqueeze(ctx.dim)
30
31 repeats = [1 for _ in ctx.input_size]
32 repeats[ctx.dim] = ctx.input_size[ctx.dim]
33 return grad_output.repeat(*repeats), None, None
34
35
36 class Prod(Function):
37
38 @staticmethod
39 def forward(ctx, input, dim=None, keepdim=None):
40 ctx.dim = dim
41 ctx.keepdim = False if keepdim is None else keepdim
42 ctx.input_size = input.size()
43 if dim is None:
44 ctx.result = input.prod()
45 ctx.save_for_backward(input)
46 return input.new((ctx.result,))
47 else:
48 if keepdim is not None:
49 output = input.prod(dim, keepdim=keepdim)
50 else:
51 output = input.prod(dim)
52 ctx.save_for_backward(input, output)
53 return output
54
55 @staticmethod
56 def backward(ctx, grad_output):
57 def safe_zeros_backward(inp, dim):
58 # note that the gradient is equivalent to:
59 # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:
60 # input: [ a, b, c]
61 # cumprod(exclusive, normal): [1 , a, a * b]
62 # cumprod(exclusive, reverse): [b * c, c, 1]
63 # product: [b * c, a * c, a * b]
64 # and this is safe under input with 0s.
65 if inp.size(dim) == 1:
66 return grad_output
67
68 ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))
69 ones = Variable(grad_output.data.new(ones_size).fill_(1))
70 exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)
71 exclusive_normal = exclusive_normal_nocp.cumprod(dim)
72
73 def reverse_dim(var, dim):
74 index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))
75 return var.index_select(dim, index)
76
77 narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)
78 exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)
79 exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)
80
81 grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))
82 return grad_input
83
84 if ctx.dim is None:
85 input, = ctx.saved_variables
86 zero_idx = (input.data == 0).nonzero()
87 if zero_idx.dim() == 0:
88 return grad_output.mul(ctx.result).expand_as(input).div(input), None, None
89 elif zero_idx.size(0) > 1:
90 return (grad_output * 0).expand_as(input), None, None
91 else:
92 return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None
93
94 else:
95 input, output = ctx.saved_variables
96 dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()
97 if ctx.keepdim is False and len(ctx.input_size) != 1:
98 grad_output = grad_output.unsqueeze(dim)
99 output = output.unsqueeze(dim)
100
101 zero_mask = input == 0
102 slice_zero_count = zero_mask.sum(dim, True)
103 total_zeros = slice_zero_count.data.sum()
104 if total_zeros == 0:
105 grad_input = grad_output.mul(output).expand_as(input).div(input)
106 else:
107 grad_input = safe_zeros_backward(input, dim)
108
109 return grad_input, None, None
110
111
112 class Mean(Function):
113
114 @staticmethod
115 def forward(ctx, input, dim=None, keepdim=None):
116 ctx.dim = dim
117 ctx.keepdim = False if keepdim is None else keepdim
118 ctx.input_size = input.size()
119 if dim is None:
120 return input.new((input.mean(),))
121 else:
122 if keepdim is not None:
123 return input.mean(dim, keepdim=keepdim)
124 else:
125 return input.mean(dim)
126
127 @staticmethod
128 def backward(ctx, grad_output):
129 if ctx.dim is None:
130 grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)
131 return grad_input_val.expand(ctx.input_size), None, None
132 else:
133 if ctx.keepdim is False and len(ctx.input_size) != 1:
134 grad_output = grad_output.unsqueeze(ctx.dim)
135
136 repeats = [1 for _ in ctx.input_size]
137 dim_size = ctx.input_size[ctx.dim]
138 repeats[ctx.dim] = dim_size
139 return grad_output.repeat(*repeats).div_(dim_size), None, None
140
141
142 class _SelectionFunction(Function):
143 has_all_reduce = True
144 # additional_args is prepended before dim when calling the tensor
145 # function. It's a no-op for subclasses other than kthvalue.
146 # kthvalue not only requires us to pass a dim, but also precede it with k.
147
148 @classmethod
149 def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):
150 fn = getattr(input, cls.__name__.lower())
151 ctx.dim = dim
152 ctx.keepdim = False if keepdim is None else keepdim
153 ctx.additional_args = additional_args
154 ctx.input_size = input.size()
155 if ctx.dim is None and cls.has_all_reduce:
156 value = fn(*additional_args)
157 ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])
158 return input.new((value,))
159 else:
160 if ctx.dim is None:
161 dim = input.dim() - 1
162 else:
163 dim = ctx.dim
164 args = (dim,)
165 if additional_args:
166 args = additional_args + args
167 if keepdim is not None:
168 output, indices = fn(*args, keepdim=keepdim)
169 else:
170 output, indices = fn(*args)
171 ctx.save_for_backward(indices)
172 ctx.mark_non_differentiable(indices)
173 return output, indices
174
175 @classmethod
176 def backward(cls, ctx, grad_output, grad_indices=None):
177 grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())
178 if ctx.dim is None and cls.has_all_reduce:
179 grad_input[ctx.indices_tuple] = grad_output
180 else:
181 if ctx.dim is None:
182 dim = len(ctx.input_size) - 1
183 else:
184 dim = ctx.dim
185
186 indices, = ctx.saved_variables
187 if ctx.keepdim is False and len(ctx.input_size) != 1:
188 grad_output = grad_output.unsqueeze(dim)
189 grad_indices = grad_indices.unsqueeze(dim)
190 indices = indices.unsqueeze(dim)
191
192 grad_input.scatter_(dim, indices, grad_output)
193 return grad_input, None, None, None
194
195
196 class Max(_SelectionFunction):
197 pass
198
199
200 class Min(_SelectionFunction):
201 pass
202
203
204 class Mode(_SelectionFunction):
205 has_all_reduce = False
206
207
208 class Median(_SelectionFunction):
209 pass
210
211
212 class Kthvalue(_SelectionFunction):
213 has_all_reduce = False
214
215 @classmethod
216 def forward(cls, ctx, input, k, dim=None, keepdim=None):
217 return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))
218
219
220 class Norm(Function):
221
222 @staticmethod
223 def forward(ctx, input, p=2, dim=None, keepdim=None):
224 ctx.p = p
225 ctx.dim = dim
226 ctx.keepdim = False if keepdim is None else keepdim
227
228 if dim is None:
229 norm = input.norm(p)
230 output = input.new((norm,))
231 else:
232 if keepdim is not None:
233 output = input.norm(p, dim, keepdim=keepdim)
234 else:
235 output = input.norm(p, dim)
236 ctx.save_for_backward(input, output)
237 return output
238
239 @staticmethod
240 def backward(ctx, grad_output):
241 input, output = ctx.saved_variables
242 if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:
243 grad_output = grad_output.unsqueeze(ctx.dim)
244 output = output.unsqueeze(ctx.dim)
245
246 if ctx.p == 2:
247 grad_input = input.mul(grad_output).div(output)
248 else:
249 input_pow = input.abs().pow(ctx.p - 2)
250 output_pow = output.pow(ctx.p - 1)
251 grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)
252
253 # Special case at 0 where we return a subgradient containing 0
254 grad_input.masked_fill_(output == 0, 0)
255
256 return grad_input, None, None, None
257
258
259 # TODO: renorm
260 # TODO: std
261 # TODO: var
262
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py
--- a/torch/autograd/_functions/reduce.py
+++ b/torch/autograd/_functions/reduce.py
@@ -111,6 +111,15 @@
class Mean(Function):
+ @staticmethod
+ def symbolic(g, input, dim=None, keepdim=None):
+ output = g.create("ReduceMean", [input])
+ if dim is not None:
+ output = output.is_("axes", dim)
+ if keepdim is None or keepdim is False:
+ output = output.i_("keepdims", 0)
+ return g.appendNode(output)
+
@staticmethod
def forward(ctx, input, dim=None, keepdim=None):
ctx.dim = dim
|
{"golden_diff": "diff --git a/torch/autograd/_functions/reduce.py b/torch/autograd/_functions/reduce.py\n--- a/torch/autograd/_functions/reduce.py\n+++ b/torch/autograd/_functions/reduce.py\n@@ -111,6 +111,15 @@\n \n class Mean(Function):\n \n+ @staticmethod\n+ def symbolic(g, input, dim=None, keepdim=None):\n+ output = g.create(\"ReduceMean\", [input])\n+ if dim is not None:\n+ output = output.is_(\"axes\", dim)\n+ if keepdim is None or keepdim is False:\n+ output = output.i_(\"keepdims\", 0)\n+ return g.appendNode(output)\n+\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n", "issue": "ONNX error converting torch.mean\nI've been working to convert some models using sentence embeddings via ONNX and have run into the following error while running `torch.onnx._export`: \r\n`RuntimeError: PythonOp doesn't define symbolic Mean`\r\n\r\nI also had this error when trying to implement my own \"mean\" operation using add and divide. \n", "before_files": [{"content": "from functools import reduce\n\nfrom ..function import Function\nfrom ..variable import Variable\nimport torch\n\n\nclass Sum(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.sum(),))\n else:\n if keepdim is not None:\n return input.sum(dim, keepdim=keepdim)\n else:\n return input.sum(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n return grad_output.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n repeats[ctx.dim] = ctx.input_size[ctx.dim]\n return grad_output.repeat(*repeats), None, None\n\n\nclass Prod(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n ctx.result = input.prod()\n ctx.save_for_backward(input)\n return input.new((ctx.result,))\n else:\n if keepdim is not None:\n output = input.prod(dim, keepdim=keepdim)\n else:\n output = input.prod(dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n def safe_zeros_backward(inp, dim):\n # note that the gradient is equivalent to:\n # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:\n # input: [ a, b, c]\n # cumprod(exclusive, normal): [1 , a, a * b]\n # cumprod(exclusive, reverse): [b * c, c, 1]\n # product: [b * c, a * c, a * b]\n # and this is safe under input with 0s.\n if inp.size(dim) == 1:\n return grad_output\n\n ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))\n ones = Variable(grad_output.data.new(ones_size).fill_(1))\n exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)\n exclusive_normal = exclusive_normal_nocp.cumprod(dim)\n\n def reverse_dim(var, dim):\n index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))\n return var.index_select(dim, index)\n\n narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)\n exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)\n exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)\n\n grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))\n return grad_input\n\n if ctx.dim is None:\n input, = ctx.saved_variables\n zero_idx = (input.data == 0).nonzero()\n if zero_idx.dim() == 0:\n return grad_output.mul(ctx.result).expand_as(input).div(input), None, None\n elif zero_idx.size(0) > 1:\n return (grad_output * 0).expand_as(input), None, None\n else:\n return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None\n\n else:\n input, output = ctx.saved_variables\n dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n output = output.unsqueeze(dim)\n\n zero_mask = input == 0\n slice_zero_count = zero_mask.sum(dim, True)\n total_zeros = slice_zero_count.data.sum()\n if total_zeros == 0:\n grad_input = grad_output.mul(output).expand_as(input).div(input)\n else:\n grad_input = safe_zeros_backward(input, dim)\n\n return grad_input, None, None\n\n\nclass Mean(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.mean(),))\n else:\n if keepdim is not None:\n return input.mean(dim, keepdim=keepdim)\n else:\n return input.mean(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)\n return grad_input_val.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n dim_size = ctx.input_size[ctx.dim]\n repeats[ctx.dim] = dim_size\n return grad_output.repeat(*repeats).div_(dim_size), None, None\n\n\nclass _SelectionFunction(Function):\n has_all_reduce = True\n # additional_args is prepended before dim when calling the tensor\n # function. It's a no-op for subclasses other than kthvalue.\n # kthvalue not only requires us to pass a dim, but also precede it with k.\n\n @classmethod\n def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):\n fn = getattr(input, cls.__name__.lower())\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.additional_args = additional_args\n ctx.input_size = input.size()\n if ctx.dim is None and cls.has_all_reduce:\n value = fn(*additional_args)\n ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])\n return input.new((value,))\n else:\n if ctx.dim is None:\n dim = input.dim() - 1\n else:\n dim = ctx.dim\n args = (dim,)\n if additional_args:\n args = additional_args + args\n if keepdim is not None:\n output, indices = fn(*args, keepdim=keepdim)\n else:\n output, indices = fn(*args)\n ctx.save_for_backward(indices)\n ctx.mark_non_differentiable(indices)\n return output, indices\n\n @classmethod\n def backward(cls, ctx, grad_output, grad_indices=None):\n grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())\n if ctx.dim is None and cls.has_all_reduce:\n grad_input[ctx.indices_tuple] = grad_output\n else:\n if ctx.dim is None:\n dim = len(ctx.input_size) - 1\n else:\n dim = ctx.dim\n\n indices, = ctx.saved_variables\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n grad_indices = grad_indices.unsqueeze(dim)\n indices = indices.unsqueeze(dim)\n\n grad_input.scatter_(dim, indices, grad_output)\n return grad_input, None, None, None\n\n\nclass Max(_SelectionFunction):\n pass\n\n\nclass Min(_SelectionFunction):\n pass\n\n\nclass Mode(_SelectionFunction):\n has_all_reduce = False\n\n\nclass Median(_SelectionFunction):\n pass\n\n\nclass Kthvalue(_SelectionFunction):\n has_all_reduce = False\n\n @classmethod\n def forward(cls, ctx, input, k, dim=None, keepdim=None):\n return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))\n\n\nclass Norm(Function):\n\n @staticmethod\n def forward(ctx, input, p=2, dim=None, keepdim=None):\n ctx.p = p\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n\n if dim is None:\n norm = input.norm(p)\n output = input.new((norm,))\n else:\n if keepdim is not None:\n output = input.norm(p, dim, keepdim=keepdim)\n else:\n output = input.norm(p, dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n input, output = ctx.saved_variables\n if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n output = output.unsqueeze(ctx.dim)\n\n if ctx.p == 2:\n grad_input = input.mul(grad_output).div(output)\n else:\n input_pow = input.abs().pow(ctx.p - 2)\n output_pow = output.pow(ctx.p - 1)\n grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)\n\n # Special case at 0 where we return a subgradient containing 0\n grad_input.masked_fill_(output == 0, 0)\n\n return grad_input, None, None, None\n\n\n# TODO: renorm\n# TODO: std\n# TODO: var\n", "path": "torch/autograd/_functions/reduce.py"}], "after_files": [{"content": "from functools import reduce\n\nfrom ..function import Function\nfrom ..variable import Variable\nimport torch\n\n\nclass Sum(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.sum(),))\n else:\n if keepdim is not None:\n return input.sum(dim, keepdim=keepdim)\n else:\n return input.sum(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n return grad_output.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n repeats[ctx.dim] = ctx.input_size[ctx.dim]\n return grad_output.repeat(*repeats), None, None\n\n\nclass Prod(Function):\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n ctx.result = input.prod()\n ctx.save_for_backward(input)\n return input.new((ctx.result,))\n else:\n if keepdim is not None:\n output = input.prod(dim, keepdim=keepdim)\n else:\n output = input.prod(dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n def safe_zeros_backward(inp, dim):\n # note that the gradient is equivalent to:\n # cumprod(exclusive, normal) * cumprod(exclusive, reverse), e.g.:\n # input: [ a, b, c]\n # cumprod(exclusive, normal): [1 , a, a * b]\n # cumprod(exclusive, reverse): [b * c, c, 1]\n # product: [b * c, a * c, a * b]\n # and this is safe under input with 0s.\n if inp.size(dim) == 1:\n return grad_output\n\n ones_size = torch.Size((inp.size()[:dim] + (1,) + inp.size()[dim + 1:]))\n ones = Variable(grad_output.data.new(ones_size).fill_(1))\n exclusive_normal_nocp = torch.cat((ones, inp.narrow(dim, 0, inp.size(dim) - 1)), dim)\n exclusive_normal = exclusive_normal_nocp.cumprod(dim)\n\n def reverse_dim(var, dim):\n index = Variable(torch.arange(var.size(dim) - 1, -1, -1, out=var.data.new().long()))\n return var.index_select(dim, index)\n\n narrow_reverse = reverse_dim(inp.narrow(dim, 1, inp.size(dim) - 1), dim)\n exclusive_reverse_nocp = torch.cat((ones, narrow_reverse), dim)\n exclusive_reverse = reverse_dim(exclusive_reverse_nocp.cumprod(dim), dim)\n\n grad_input = grad_output.expand_as(exclusive_normal).mul(exclusive_normal.mul(exclusive_reverse))\n return grad_input\n\n if ctx.dim is None:\n input, = ctx.saved_variables\n zero_idx = (input.data == 0).nonzero()\n if zero_idx.dim() == 0:\n return grad_output.mul(ctx.result).expand_as(input).div(input), None, None\n elif zero_idx.size(0) > 1:\n return (grad_output * 0).expand_as(input), None, None\n else:\n return safe_zeros_backward(input.contiguous().view(-1), 0).view_as(input), None, None\n\n else:\n input, output = ctx.saved_variables\n dim = ctx.dim if ctx.dim >= 0 else ctx.dim + input.dim()\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n output = output.unsqueeze(dim)\n\n zero_mask = input == 0\n slice_zero_count = zero_mask.sum(dim, True)\n total_zeros = slice_zero_count.data.sum()\n if total_zeros == 0:\n grad_input = grad_output.mul(output).expand_as(input).div(input)\n else:\n grad_input = safe_zeros_backward(input, dim)\n\n return grad_input, None, None\n\n\nclass Mean(Function):\n\n @staticmethod\n def symbolic(g, input, dim=None, keepdim=None):\n output = g.create(\"ReduceMean\", [input])\n if dim is not None:\n output = output.is_(\"axes\", dim)\n if keepdim is None or keepdim is False:\n output = output.i_(\"keepdims\", 0)\n return g.appendNode(output)\n\n @staticmethod\n def forward(ctx, input, dim=None, keepdim=None):\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.input_size = input.size()\n if dim is None:\n return input.new((input.mean(),))\n else:\n if keepdim is not None:\n return input.mean(dim, keepdim=keepdim)\n else:\n return input.mean(dim)\n\n @staticmethod\n def backward(ctx, grad_output):\n if ctx.dim is None:\n grad_input_val = grad_output / reduce(lambda x, y: x * y, ctx.input_size, 1)\n return grad_input_val.expand(ctx.input_size), None, None\n else:\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n\n repeats = [1 for _ in ctx.input_size]\n dim_size = ctx.input_size[ctx.dim]\n repeats[ctx.dim] = dim_size\n return grad_output.repeat(*repeats).div_(dim_size), None, None\n\n\nclass _SelectionFunction(Function):\n has_all_reduce = True\n # additional_args is prepended before dim when calling the tensor\n # function. It's a no-op for subclasses other than kthvalue.\n # kthvalue not only requires us to pass a dim, but also precede it with k.\n\n @classmethod\n def forward(cls, ctx, input, dim=None, keepdim=None, additional_args=tuple()):\n fn = getattr(input, cls.__name__.lower())\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n ctx.additional_args = additional_args\n ctx.input_size = input.size()\n if ctx.dim is None and cls.has_all_reduce:\n value = fn(*additional_args)\n ctx.indices_tuple = tuple(input.eq(value).nonzero()[0])\n return input.new((value,))\n else:\n if ctx.dim is None:\n dim = input.dim() - 1\n else:\n dim = ctx.dim\n args = (dim,)\n if additional_args:\n args = additional_args + args\n if keepdim is not None:\n output, indices = fn(*args, keepdim=keepdim)\n else:\n output, indices = fn(*args)\n ctx.save_for_backward(indices)\n ctx.mark_non_differentiable(indices)\n return output, indices\n\n @classmethod\n def backward(cls, ctx, grad_output, grad_indices=None):\n grad_input = Variable(grad_output.data.new(*ctx.input_size).zero_())\n if ctx.dim is None and cls.has_all_reduce:\n grad_input[ctx.indices_tuple] = grad_output\n else:\n if ctx.dim is None:\n dim = len(ctx.input_size) - 1\n else:\n dim = ctx.dim\n\n indices, = ctx.saved_variables\n if ctx.keepdim is False and len(ctx.input_size) != 1:\n grad_output = grad_output.unsqueeze(dim)\n grad_indices = grad_indices.unsqueeze(dim)\n indices = indices.unsqueeze(dim)\n\n grad_input.scatter_(dim, indices, grad_output)\n return grad_input, None, None, None\n\n\nclass Max(_SelectionFunction):\n pass\n\n\nclass Min(_SelectionFunction):\n pass\n\n\nclass Mode(_SelectionFunction):\n has_all_reduce = False\n\n\nclass Median(_SelectionFunction):\n pass\n\n\nclass Kthvalue(_SelectionFunction):\n has_all_reduce = False\n\n @classmethod\n def forward(cls, ctx, input, k, dim=None, keepdim=None):\n return super(Kthvalue, cls).forward(ctx, input, dim, keepdim, (k,))\n\n\nclass Norm(Function):\n\n @staticmethod\n def forward(ctx, input, p=2, dim=None, keepdim=None):\n ctx.p = p\n ctx.dim = dim\n ctx.keepdim = False if keepdim is None else keepdim\n\n if dim is None:\n norm = input.norm(p)\n output = input.new((norm,))\n else:\n if keepdim is not None:\n output = input.norm(p, dim, keepdim=keepdim)\n else:\n output = input.norm(p, dim)\n ctx.save_for_backward(input, output)\n return output\n\n @staticmethod\n def backward(ctx, grad_output):\n input, output = ctx.saved_variables\n if ctx.dim is not None and ctx.keepdim is False and input.dim() != 1:\n grad_output = grad_output.unsqueeze(ctx.dim)\n output = output.unsqueeze(ctx.dim)\n\n if ctx.p == 2:\n grad_input = input.mul(grad_output).div(output)\n else:\n input_pow = input.abs().pow(ctx.p - 2)\n output_pow = output.pow(ctx.p - 1)\n grad_input = input.mul(input_pow).mul(grad_output).div(output_pow)\n\n # Special case at 0 where we return a subgradient containing 0\n grad_input.masked_fill_(output == 0, 0)\n\n return grad_input, None, None, None\n\n\n# TODO: renorm\n# TODO: std\n# TODO: var\n", "path": "torch/autograd/_functions/reduce.py"}]}
| 3,130 | 184 |
gh_patches_debug_12565
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-2305
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
evolve_all "all" is not working
### Expected Behavior
Bot would try to evolve all eligible pokemon when "evolve_all": "all" is set
### Actual Behavior
Bot does not evolve anything when "evolve_all": "all" is set. If I set it to "evolve_all": "all,Weedle" I get the following output:
```
[19:11:08] Starting PokemonGo Bot....
[19:11:09] [x] Current egg hatches in 0.85 km
[19:11:10] [#] Successfully evolved Weedle with 180 CP and 0.4 IV!
[19:11:13] [#] Successfully evolved Weedle with 113 CP and 0.51 IV!
```
### Steps to Reproduce
Set "evolve_all" to all on this commit
### Other Information
OS: Ubuntu 14.04.4 LTS
Git Commit: eee7ba49c5c4e6bb1b3efefcf9f99a7c72a48671
Python Version: python 2.7.6
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pokemongo_bot/cell_workers/evolve_all.py`
Content:
```
1 from pokemongo_bot import logger
2 from pokemongo_bot.human_behaviour import sleep
3 from pokemongo_bot.item_list import Item
4 from pokemongo_bot.cell_workers.base_task import BaseTask
5
6 class EvolveAll(BaseTask):
7 def initialize(self):
8 self.evolve_all = self.config.get('evolve_all', [])
9 self.evolve_speed = self.config.get('evolve_speed', 3.7)
10 self.evolve_cp_min = self.config.get('evolve_cp_min', 300)
11 self.use_lucky_egg = self.config.get('use_lucky_egg', False)
12
13 def _validate_config(self):
14 if isinstance(self.evolve_all, str):
15 self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]
16
17 def work(self):
18 if not self._should_run():
19 return
20
21 response_dict = self.bot.get_inventory()
22 cache = {}
23
24 try:
25 reduce(dict.__getitem__, [
26 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
27 except KeyError:
28 pass
29 else:
30 evolve_list = self._sort_by_cp_iv(
31 response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])
32 if self.evolve_all[0] != 'all':
33 # filter out non-listed pokemons
34 evolve_list = [x for x in evolve_list if str(x[1]) in self.evolve_all]
35
36 # enable to limit number of pokemons to evolve. Useful for testing.
37 # nn = 3
38 # if len(evolve_list) > nn:
39 # evolve_list = evolve_list[:nn]
40 #
41
42 id_list1 = self.count_pokemon_inventory()
43 for pokemon in evolve_list:
44 try:
45 self._execute_pokemon_evolve(pokemon, cache)
46 except Exception:
47 pass
48 id_list2 = self.count_pokemon_inventory()
49 release_cand_list_ids = list(set(id_list2) - set(id_list1))
50
51 if release_cand_list_ids:
52 logger.log('[#] Evolved {} pokemons! Checking if any of them needs to be released ...'.format(
53 len(release_cand_list_ids)
54 ))
55 self._release_evolved(release_cand_list_ids)
56
57 def _should_run(self):
58 # Will skip evolving if user wants to use an egg and there is none
59 if not self.evolve_all:
60 return False
61
62 # Evolve all is used - Don't run after the first tick or if the config flag is false
63 if self.bot.tick_count is not 1 or not self.use_lucky_egg:
64 return True
65
66 lucky_egg_count = self.bot.item_inventory_count(Item.ITEM_LUCKY_EGG.value)
67
68 # Lucky Egg should only be popped at the first tick
69 # Make sure the user has a lucky egg and skip if not
70 if lucky_egg_count > 0:
71 logger.log('Using lucky egg ... you have {}'.format(lucky_egg_count))
72 response_dict_lucky_egg = self.bot.use_lucky_egg()
73 if response_dict_lucky_egg and 'responses' in response_dict_lucky_egg and \
74 'USE_ITEM_XP_BOOST' in response_dict_lucky_egg['responses'] and \
75 'result' in response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']:
76 result = response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']['result']
77 if result is 1: # Request success
78 logger.log('Successfully used lucky egg... ({} left!)'.format(lucky_egg_count - 1), 'green')
79 return True
80 else:
81 logger.log('Failed to use lucky egg!', 'red')
82 return False
83 else:
84 # Skipping evolve so they aren't wasted
85 logger.log('No lucky eggs... skipping evolve!', 'yellow')
86 return False
87
88 def _release_evolved(self, release_cand_list_ids):
89 response_dict = self.bot.get_inventory()
90 cache = {}
91
92 try:
93 reduce(dict.__getitem__, [
94 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
95 except KeyError:
96 pass
97 else:
98 release_cand_list = self._sort_by_cp_iv(
99 response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])
100 release_cand_list = [x for x in release_cand_list if x[0] in release_cand_list_ids]
101
102 ## at this point release_cand_list contains evolved pokemons data
103 for cand in release_cand_list:
104 pokemon_id = cand[0]
105 pokemon_name = cand[1]
106 pokemon_cp = cand[2]
107 pokemon_potential = cand[3]
108
109 if self.should_release_pokemon(pokemon_name, pokemon_cp, pokemon_potential):
110 # Transfering Pokemon
111 self.transfer_pokemon(pokemon_id)
112 logger.log(
113 '[#] {} has been exchanged for candy!'.format(pokemon_name), 'red')
114
115 def _sort_by_cp_iv(self, inventory_items):
116 pokemons1 = []
117 pokemons2 = []
118 for item in inventory_items:
119 try:
120 reduce(dict.__getitem__, [
121 "inventory_item_data", "pokemon_data"], item)
122 except KeyError:
123 pass
124 else:
125 try:
126 pokemon = item['inventory_item_data']['pokemon_data']
127 pokemon_num = int(pokemon['pokemon_id']) - 1
128 pokemon_name = self.bot.pokemon_list[int(pokemon_num)]['Name']
129 v = [
130 pokemon['id'],
131 pokemon_name,
132 pokemon['cp'],
133 self._compute_iv(pokemon)
134 ]
135 if pokemon['cp'] > self.evolve_cp_min:
136 pokemons1.append(v)
137 else:
138 pokemons2.append(v)
139 except Exception:
140 pass
141
142 # Sort larger CP pokemons by IV, tie breaking by CP
143 pokemons1.sort(key=lambda x: (x[3], x[2]), reverse=True)
144
145 # Sort smaller CP pokemons by CP, tie breaking by IV
146 pokemons2.sort(key=lambda x: (x[2], x[3]), reverse=True)
147
148 return pokemons1 + pokemons2
149
150 def _execute_pokemon_evolve(self, pokemon, cache):
151 pokemon_id = pokemon[0]
152 pokemon_name = pokemon[1]
153 pokemon_cp = pokemon[2]
154 pokemon_iv = pokemon[3]
155
156 if pokemon_name in cache:
157 return
158
159 self.bot.api.evolve_pokemon(pokemon_id=pokemon_id)
160 response_dict = self.bot.api.call()
161 status = response_dict['responses']['EVOLVE_POKEMON']['result']
162 if status == 1:
163 logger.log('[#] Successfully evolved {} with {} CP and {} IV!'.format(
164 pokemon_name, pokemon_cp, pokemon_iv
165 ))
166
167 sleep(self.evolve_speed)
168
169 else:
170 # cache pokemons we can't evolve. Less server calls
171 cache[pokemon_name] = 1
172 sleep(0.7)
173
174 # TODO: move to utils. These methods are shared with other workers.
175 def transfer_pokemon(self, pid):
176 self.bot.api.release_pokemon(pokemon_id=pid)
177 response_dict = self.bot.api.call()
178
179 def count_pokemon_inventory(self):
180 response_dict = self.bot.get_inventory()
181 id_list = []
182 return self.counting_pokemon(response_dict, id_list)
183
184 def counting_pokemon(self, response_dict, id_list):
185 try:
186 reduce(dict.__getitem__, [
187 "responses", "GET_INVENTORY", "inventory_delta", "inventory_items"], response_dict)
188 except KeyError:
189 pass
190 else:
191 for item in response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items']:
192 try:
193 reduce(dict.__getitem__, [
194 "inventory_item_data", "pokemon_data"], item)
195 except KeyError:
196 pass
197 else:
198 pokemon = item['inventory_item_data']['pokemon_data']
199 if pokemon.get('is_egg', False):
200 continue
201 id_list.append(pokemon['id'])
202
203 return id_list
204
205 def should_release_pokemon(self, pokemon_name, cp, iv):
206 if self._check_always_capture_exception_for(pokemon_name):
207 return False
208 else:
209 release_config = self._get_release_config_for(pokemon_name)
210 cp_iv_logic = release_config.get('logic')
211 if not cp_iv_logic:
212 cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')
213
214 release_results = {
215 'cp': False,
216 'iv': False,
217 }
218
219 if 'release_below_cp' in release_config:
220 min_cp = release_config['release_below_cp']
221 if cp < min_cp:
222 release_results['cp'] = True
223
224 if 'release_below_iv' in release_config:
225 min_iv = release_config['release_below_iv']
226 if iv < min_iv:
227 release_results['iv'] = True
228
229 if release_config.get('always_release'):
230 return True
231
232 logic_to_function = {
233 'or': lambda x, y: x or y,
234 'and': lambda x, y: x and y
235 }
236
237 # logger.log(
238 # "[x] Release config for {}: CP {} {} IV {}".format(
239 # pokemon_name,
240 # min_cp,
241 # cp_iv_logic,
242 # min_iv
243 # ), 'yellow'
244 # )
245
246 return logic_to_function[cp_iv_logic](*release_results.values())
247
248 def _get_release_config_for(self, pokemon):
249 release_config = self.bot.config.release.get(pokemon)
250 if not release_config:
251 release_config = self.bot.config.release['any']
252 return release_config
253
254 def _get_exceptions(self):
255 exceptions = self.bot.config.release.get('exceptions')
256 if not exceptions:
257 return None
258 return exceptions
259
260 def _get_always_capture_list(self):
261 exceptions = self._get_exceptions()
262 if not exceptions:
263 return []
264 always_capture_list = exceptions['always_capture']
265 if not always_capture_list:
266 return []
267 return always_capture_list
268
269 def _check_always_capture_exception_for(self, pokemon_name):
270 always_capture_list = self._get_always_capture_list()
271 if not always_capture_list:
272 return False
273 else:
274 for pokemon in always_capture_list:
275 if pokemon_name == str(pokemon):
276 return True
277 return False
278
279 # TODO: should also go to util and refactor in catch worker
280 def _compute_iv(self, pokemon):
281 total_IV = 0.0
282 iv_stats = ['individual_attack', 'individual_defense', 'individual_stamina']
283
284 for individual_stat in iv_stats:
285 try:
286 total_IV += pokemon[individual_stat]
287 except Exception:
288 pokemon[individual_stat] = 0
289 continue
290 pokemon_potential = round((total_IV / 45.0), 2)
291 return pokemon_potential
292
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pokemongo_bot/cell_workers/evolve_all.py b/pokemongo_bot/cell_workers/evolve_all.py
--- a/pokemongo_bot/cell_workers/evolve_all.py
+++ b/pokemongo_bot/cell_workers/evolve_all.py
@@ -9,9 +9,10 @@
self.evolve_speed = self.config.get('evolve_speed', 3.7)
self.evolve_cp_min = self.config.get('evolve_cp_min', 300)
self.use_lucky_egg = self.config.get('use_lucky_egg', False)
+ self._validate_config()
def _validate_config(self):
- if isinstance(self.evolve_all, str):
+ if isinstance(self.evolve_all, basestring):
self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]
def work(self):
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/evolve_all.py b/pokemongo_bot/cell_workers/evolve_all.py\n--- a/pokemongo_bot/cell_workers/evolve_all.py\n+++ b/pokemongo_bot/cell_workers/evolve_all.py\n@@ -9,9 +9,10 @@\n self.evolve_speed = self.config.get('evolve_speed', 3.7)\n self.evolve_cp_min = self.config.get('evolve_cp_min', 300)\n self.use_lucky_egg = self.config.get('use_lucky_egg', False)\n+ self._validate_config()\n \n def _validate_config(self):\n- if isinstance(self.evolve_all, str):\n+ if isinstance(self.evolve_all, basestring):\n self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]\n \n def work(self):\n", "issue": "evolve_all \"all\" is not working\n### Expected Behavior\n\nBot would try to evolve all eligible pokemon when \"evolve_all\": \"all\" is set\n### Actual Behavior\n\nBot does not evolve anything when \"evolve_all\": \"all\" is set. If I set it to \"evolve_all\": \"all,Weedle\" I get the following output: \n\n```\n[19:11:08] Starting PokemonGo Bot....\n[19:11:09] [x] Current egg hatches in 0.85 km\n[19:11:10] [#] Successfully evolved Weedle with 180 CP and 0.4 IV!\n[19:11:13] [#] Successfully evolved Weedle with 113 CP and 0.51 IV!\n```\n### Steps to Reproduce\n\nSet \"evolve_all\" to all on this commit\n### Other Information\n\nOS: Ubuntu 14.04.4 LTS\nGit Commit: eee7ba49c5c4e6bb1b3efefcf9f99a7c72a48671\nPython Version: python 2.7.6\n\n", "before_files": [{"content": "from pokemongo_bot import logger\nfrom pokemongo_bot.human_behaviour import sleep\nfrom pokemongo_bot.item_list import Item\nfrom pokemongo_bot.cell_workers.base_task import BaseTask\n\nclass EvolveAll(BaseTask):\n def initialize(self):\n self.evolve_all = self.config.get('evolve_all', [])\n self.evolve_speed = self.config.get('evolve_speed', 3.7)\n self.evolve_cp_min = self.config.get('evolve_cp_min', 300)\n self.use_lucky_egg = self.config.get('use_lucky_egg', False)\n\n def _validate_config(self):\n if isinstance(self.evolve_all, str):\n self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]\n\n def work(self):\n if not self._should_run():\n return\n\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n evolve_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n if self.evolve_all[0] != 'all':\n # filter out non-listed pokemons\n evolve_list = [x for x in evolve_list if str(x[1]) in self.evolve_all]\n\n # enable to limit number of pokemons to evolve. Useful for testing.\n # nn = 3\n # if len(evolve_list) > nn:\n # evolve_list = evolve_list[:nn]\n #\n\n id_list1 = self.count_pokemon_inventory()\n for pokemon in evolve_list:\n try:\n self._execute_pokemon_evolve(pokemon, cache)\n except Exception:\n pass\n id_list2 = self.count_pokemon_inventory()\n release_cand_list_ids = list(set(id_list2) - set(id_list1))\n\n if release_cand_list_ids:\n logger.log('[#] Evolved {} pokemons! Checking if any of them needs to be released ...'.format(\n len(release_cand_list_ids)\n ))\n self._release_evolved(release_cand_list_ids)\n\n def _should_run(self):\n # Will skip evolving if user wants to use an egg and there is none\n if not self.evolve_all:\n return False\n\n # Evolve all is used - Don't run after the first tick or if the config flag is false\n if self.bot.tick_count is not 1 or not self.use_lucky_egg:\n return True\n\n lucky_egg_count = self.bot.item_inventory_count(Item.ITEM_LUCKY_EGG.value)\n\n # Lucky Egg should only be popped at the first tick\n # Make sure the user has a lucky egg and skip if not\n if lucky_egg_count > 0:\n logger.log('Using lucky egg ... you have {}'.format(lucky_egg_count))\n response_dict_lucky_egg = self.bot.use_lucky_egg()\n if response_dict_lucky_egg and 'responses' in response_dict_lucky_egg and \\\n 'USE_ITEM_XP_BOOST' in response_dict_lucky_egg['responses'] and \\\n 'result' in response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']:\n result = response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']['result']\n if result is 1: # Request success\n logger.log('Successfully used lucky egg... ({} left!)'.format(lucky_egg_count - 1), 'green')\n return True\n else:\n logger.log('Failed to use lucky egg!', 'red')\n return False\n else:\n # Skipping evolve so they aren't wasted\n logger.log('No lucky eggs... skipping evolve!', 'yellow')\n return False\n\n def _release_evolved(self, release_cand_list_ids):\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n release_cand_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n release_cand_list = [x for x in release_cand_list if x[0] in release_cand_list_ids]\n\n ## at this point release_cand_list contains evolved pokemons data\n for cand in release_cand_list:\n pokemon_id = cand[0]\n pokemon_name = cand[1]\n pokemon_cp = cand[2]\n pokemon_potential = cand[3]\n\n if self.should_release_pokemon(pokemon_name, pokemon_cp, pokemon_potential):\n # Transfering Pokemon\n self.transfer_pokemon(pokemon_id)\n logger.log(\n '[#] {} has been exchanged for candy!'.format(pokemon_name), 'red')\n\n def _sort_by_cp_iv(self, inventory_items):\n pokemons1 = []\n pokemons2 = []\n for item in inventory_items:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n try:\n pokemon = item['inventory_item_data']['pokemon_data']\n pokemon_num = int(pokemon['pokemon_id']) - 1\n pokemon_name = self.bot.pokemon_list[int(pokemon_num)]['Name']\n v = [\n pokemon['id'],\n pokemon_name,\n pokemon['cp'],\n self._compute_iv(pokemon)\n ]\n if pokemon['cp'] > self.evolve_cp_min:\n pokemons1.append(v)\n else:\n pokemons2.append(v)\n except Exception:\n pass\n\n # Sort larger CP pokemons by IV, tie breaking by CP\n pokemons1.sort(key=lambda x: (x[3], x[2]), reverse=True)\n\n # Sort smaller CP pokemons by CP, tie breaking by IV\n pokemons2.sort(key=lambda x: (x[2], x[3]), reverse=True)\n\n return pokemons1 + pokemons2\n\n def _execute_pokemon_evolve(self, pokemon, cache):\n pokemon_id = pokemon[0]\n pokemon_name = pokemon[1]\n pokemon_cp = pokemon[2]\n pokemon_iv = pokemon[3]\n\n if pokemon_name in cache:\n return\n\n self.bot.api.evolve_pokemon(pokemon_id=pokemon_id)\n response_dict = self.bot.api.call()\n status = response_dict['responses']['EVOLVE_POKEMON']['result']\n if status == 1:\n logger.log('[#] Successfully evolved {} with {} CP and {} IV!'.format(\n pokemon_name, pokemon_cp, pokemon_iv\n ))\n\n sleep(self.evolve_speed)\n\n else:\n # cache pokemons we can't evolve. Less server calls\n cache[pokemon_name] = 1\n sleep(0.7)\n\n # TODO: move to utils. These methods are shared with other workers.\n def transfer_pokemon(self, pid):\n self.bot.api.release_pokemon(pokemon_id=pid)\n response_dict = self.bot.api.call()\n\n def count_pokemon_inventory(self):\n response_dict = self.bot.get_inventory()\n id_list = []\n return self.counting_pokemon(response_dict, id_list)\n\n def counting_pokemon(self, response_dict, id_list):\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n for item in response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items']:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n pokemon = item['inventory_item_data']['pokemon_data']\n if pokemon.get('is_egg', False):\n continue\n id_list.append(pokemon['id'])\n\n return id_list\n\n def should_release_pokemon(self, pokemon_name, cp, iv):\n if self._check_always_capture_exception_for(pokemon_name):\n return False\n else:\n release_config = self._get_release_config_for(pokemon_name)\n cp_iv_logic = release_config.get('logic')\n if not cp_iv_logic:\n cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')\n\n release_results = {\n 'cp': False,\n 'iv': False,\n }\n\n if 'release_below_cp' in release_config:\n min_cp = release_config['release_below_cp']\n if cp < min_cp:\n release_results['cp'] = True\n\n if 'release_below_iv' in release_config:\n min_iv = release_config['release_below_iv']\n if iv < min_iv:\n release_results['iv'] = True\n\n if release_config.get('always_release'):\n return True\n\n logic_to_function = {\n 'or': lambda x, y: x or y,\n 'and': lambda x, y: x and y\n }\n\n # logger.log(\n # \"[x] Release config for {}: CP {} {} IV {}\".format(\n # pokemon_name,\n # min_cp,\n # cp_iv_logic,\n # min_iv\n # ), 'yellow'\n # )\n\n return logic_to_function[cp_iv_logic](*release_results.values())\n\n def _get_release_config_for(self, pokemon):\n release_config = self.bot.config.release.get(pokemon)\n if not release_config:\n release_config = self.bot.config.release['any']\n return release_config\n\n def _get_exceptions(self):\n exceptions = self.bot.config.release.get('exceptions')\n if not exceptions:\n return None\n return exceptions\n\n def _get_always_capture_list(self):\n exceptions = self._get_exceptions()\n if not exceptions:\n return []\n always_capture_list = exceptions['always_capture']\n if not always_capture_list:\n return []\n return always_capture_list\n\n def _check_always_capture_exception_for(self, pokemon_name):\n always_capture_list = self._get_always_capture_list()\n if not always_capture_list:\n return False\n else:\n for pokemon in always_capture_list:\n if pokemon_name == str(pokemon):\n return True\n return False\n\n # TODO: should also go to util and refactor in catch worker\n def _compute_iv(self, pokemon):\n total_IV = 0.0\n iv_stats = ['individual_attack', 'individual_defense', 'individual_stamina']\n\n for individual_stat in iv_stats:\n try:\n total_IV += pokemon[individual_stat]\n except Exception:\n pokemon[individual_stat] = 0\n continue\n pokemon_potential = round((total_IV / 45.0), 2)\n return pokemon_potential\n", "path": "pokemongo_bot/cell_workers/evolve_all.py"}], "after_files": [{"content": "from pokemongo_bot import logger\nfrom pokemongo_bot.human_behaviour import sleep\nfrom pokemongo_bot.item_list import Item\nfrom pokemongo_bot.cell_workers.base_task import BaseTask\n\nclass EvolveAll(BaseTask):\n def initialize(self):\n self.evolve_all = self.config.get('evolve_all', [])\n self.evolve_speed = self.config.get('evolve_speed', 3.7)\n self.evolve_cp_min = self.config.get('evolve_cp_min', 300)\n self.use_lucky_egg = self.config.get('use_lucky_egg', False)\n self._validate_config()\n\n def _validate_config(self):\n if isinstance(self.evolve_all, basestring):\n self.evolve_all = [str(pokemon_name) for pokemon_name in self.evolve_all.split(',')]\n\n def work(self):\n if not self._should_run():\n return\n\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n evolve_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n if self.evolve_all[0] != 'all':\n # filter out non-listed pokemons\n evolve_list = [x for x in evolve_list if str(x[1]) in self.evolve_all]\n\n # enable to limit number of pokemons to evolve. Useful for testing.\n # nn = 3\n # if len(evolve_list) > nn:\n # evolve_list = evolve_list[:nn]\n #\n\n id_list1 = self.count_pokemon_inventory()\n for pokemon in evolve_list:\n try:\n self._execute_pokemon_evolve(pokemon, cache)\n except Exception:\n pass\n id_list2 = self.count_pokemon_inventory()\n release_cand_list_ids = list(set(id_list2) - set(id_list1))\n\n if release_cand_list_ids:\n logger.log('[#] Evolved {} pokemons! Checking if any of them needs to be released ...'.format(\n len(release_cand_list_ids)\n ))\n self._release_evolved(release_cand_list_ids)\n\n def _should_run(self):\n # Will skip evolving if user wants to use an egg and there is none\n if not self.evolve_all:\n return False\n\n # Evolve all is used - Don't run after the first tick or if the config flag is false\n if self.bot.tick_count is not 1 or not self.use_lucky_egg:\n return True\n\n lucky_egg_count = self.bot.item_inventory_count(Item.ITEM_LUCKY_EGG.value)\n\n # Lucky Egg should only be popped at the first tick\n # Make sure the user has a lucky egg and skip if not\n if lucky_egg_count > 0:\n logger.log('Using lucky egg ... you have {}'.format(lucky_egg_count))\n response_dict_lucky_egg = self.bot.use_lucky_egg()\n if response_dict_lucky_egg and 'responses' in response_dict_lucky_egg and \\\n 'USE_ITEM_XP_BOOST' in response_dict_lucky_egg['responses'] and \\\n 'result' in response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']:\n result = response_dict_lucky_egg['responses']['USE_ITEM_XP_BOOST']['result']\n if result is 1: # Request success\n logger.log('Successfully used lucky egg... ({} left!)'.format(lucky_egg_count - 1), 'green')\n return True\n else:\n logger.log('Failed to use lucky egg!', 'red')\n return False\n else:\n # Skipping evolve so they aren't wasted\n logger.log('No lucky eggs... skipping evolve!', 'yellow')\n return False\n\n def _release_evolved(self, release_cand_list_ids):\n response_dict = self.bot.get_inventory()\n cache = {}\n\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n release_cand_list = self._sort_by_cp_iv(\n response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items'])\n release_cand_list = [x for x in release_cand_list if x[0] in release_cand_list_ids]\n\n ## at this point release_cand_list contains evolved pokemons data\n for cand in release_cand_list:\n pokemon_id = cand[0]\n pokemon_name = cand[1]\n pokemon_cp = cand[2]\n pokemon_potential = cand[3]\n\n if self.should_release_pokemon(pokemon_name, pokemon_cp, pokemon_potential):\n # Transfering Pokemon\n self.transfer_pokemon(pokemon_id)\n logger.log(\n '[#] {} has been exchanged for candy!'.format(pokemon_name), 'red')\n\n def _sort_by_cp_iv(self, inventory_items):\n pokemons1 = []\n pokemons2 = []\n for item in inventory_items:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n try:\n pokemon = item['inventory_item_data']['pokemon_data']\n pokemon_num = int(pokemon['pokemon_id']) - 1\n pokemon_name = self.bot.pokemon_list[int(pokemon_num)]['Name']\n v = [\n pokemon['id'],\n pokemon_name,\n pokemon['cp'],\n self._compute_iv(pokemon)\n ]\n if pokemon['cp'] > self.evolve_cp_min:\n pokemons1.append(v)\n else:\n pokemons2.append(v)\n except Exception:\n pass\n\n # Sort larger CP pokemons by IV, tie breaking by CP\n pokemons1.sort(key=lambda x: (x[3], x[2]), reverse=True)\n\n # Sort smaller CP pokemons by CP, tie breaking by IV\n pokemons2.sort(key=lambda x: (x[2], x[3]), reverse=True)\n\n return pokemons1 + pokemons2\n\n def _execute_pokemon_evolve(self, pokemon, cache):\n pokemon_id = pokemon[0]\n pokemon_name = pokemon[1]\n pokemon_cp = pokemon[2]\n pokemon_iv = pokemon[3]\n\n if pokemon_name in cache:\n return\n\n self.bot.api.evolve_pokemon(pokemon_id=pokemon_id)\n response_dict = self.bot.api.call()\n status = response_dict['responses']['EVOLVE_POKEMON']['result']\n if status == 1:\n logger.log('[#] Successfully evolved {} with {} CP and {} IV!'.format(\n pokemon_name, pokemon_cp, pokemon_iv\n ))\n\n sleep(self.evolve_speed)\n\n else:\n # cache pokemons we can't evolve. Less server calls\n cache[pokemon_name] = 1\n sleep(0.7)\n\n # TODO: move to utils. These methods are shared with other workers.\n def transfer_pokemon(self, pid):\n self.bot.api.release_pokemon(pokemon_id=pid)\n response_dict = self.bot.api.call()\n\n def count_pokemon_inventory(self):\n response_dict = self.bot.get_inventory()\n id_list = []\n return self.counting_pokemon(response_dict, id_list)\n\n def counting_pokemon(self, response_dict, id_list):\n try:\n reduce(dict.__getitem__, [\n \"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"], response_dict)\n except KeyError:\n pass\n else:\n for item in response_dict['responses']['GET_INVENTORY']['inventory_delta']['inventory_items']:\n try:\n reduce(dict.__getitem__, [\n \"inventory_item_data\", \"pokemon_data\"], item)\n except KeyError:\n pass\n else:\n pokemon = item['inventory_item_data']['pokemon_data']\n if pokemon.get('is_egg', False):\n continue\n id_list.append(pokemon['id'])\n\n return id_list\n\n def should_release_pokemon(self, pokemon_name, cp, iv):\n if self._check_always_capture_exception_for(pokemon_name):\n return False\n else:\n release_config = self._get_release_config_for(pokemon_name)\n cp_iv_logic = release_config.get('logic')\n if not cp_iv_logic:\n cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')\n\n release_results = {\n 'cp': False,\n 'iv': False,\n }\n\n if 'release_below_cp' in release_config:\n min_cp = release_config['release_below_cp']\n if cp < min_cp:\n release_results['cp'] = True\n\n if 'release_below_iv' in release_config:\n min_iv = release_config['release_below_iv']\n if iv < min_iv:\n release_results['iv'] = True\n\n if release_config.get('always_release'):\n return True\n\n logic_to_function = {\n 'or': lambda x, y: x or y,\n 'and': lambda x, y: x and y\n }\n\n # logger.log(\n # \"[x] Release config for {}: CP {} {} IV {}\".format(\n # pokemon_name,\n # min_cp,\n # cp_iv_logic,\n # min_iv\n # ), 'yellow'\n # )\n\n return logic_to_function[cp_iv_logic](*release_results.values())\n\n def _get_release_config_for(self, pokemon):\n release_config = self.bot.config.release.get(pokemon)\n if not release_config:\n release_config = self.bot.config.release['any']\n return release_config\n\n def _get_exceptions(self):\n exceptions = self.bot.config.release.get('exceptions')\n if not exceptions:\n return None\n return exceptions\n\n def _get_always_capture_list(self):\n exceptions = self._get_exceptions()\n if not exceptions:\n return []\n always_capture_list = exceptions['always_capture']\n if not always_capture_list:\n return []\n return always_capture_list\n\n def _check_always_capture_exception_for(self, pokemon_name):\n always_capture_list = self._get_always_capture_list()\n if not always_capture_list:\n return False\n else:\n for pokemon in always_capture_list:\n if pokemon_name == str(pokemon):\n return True\n return False\n\n # TODO: should also go to util and refactor in catch worker\n def _compute_iv(self, pokemon):\n total_IV = 0.0\n iv_stats = ['individual_attack', 'individual_defense', 'individual_stamina']\n\n for individual_stat in iv_stats:\n try:\n total_IV += pokemon[individual_stat]\n except Exception:\n pokemon[individual_stat] = 0\n continue\n pokemon_potential = round((total_IV / 45.0), 2)\n return pokemon_potential\n", "path": "pokemongo_bot/cell_workers/evolve_all.py"}]}
| 3,691 | 202 |
gh_patches_debug_10785
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-916
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Show output of nvcc after stacktrace
In the current implementation, `nvcc` prints error messages in stdout/stderr before stack trace is printed. It is hard to read.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/cuda/compiler.py`
Content:
```
1 import hashlib
2 import os
3 import re
4 import subprocess
5 import sys
6 import tempfile
7
8 import filelock
9 import six
10
11 from cupy.cuda import device
12 from cupy.cuda import function
13
14
15 def _get_arch():
16 cc = device.Device().compute_capability
17 return 'sm_%s' % cc
18
19
20 class TemporaryDirectory(object):
21
22 def __enter__(self):
23 self.path = tempfile.mkdtemp()
24 return self.path
25
26 def __exit__(self, exc_type, exc_value, traceback):
27 if exc_value is not None:
28 return
29
30 for name in os.listdir(self.path):
31 os.unlink(os.path.join(self.path, name))
32 os.rmdir(self.path)
33
34
35 def _run_nvcc(cmd, cwd):
36 try:
37 return subprocess.check_output(cmd, cwd=cwd)
38 except OSError as e:
39 msg = 'Failed to run `nvcc` command. ' \
40 'Check PATH environment variable: ' \
41 + str(e)
42 raise OSError(msg)
43
44
45 def nvcc(source, options=(), arch=None):
46 if not arch:
47 arch = _get_arch()
48 cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)
49
50 with TemporaryDirectory() as root_dir:
51 path = os.path.join(root_dir, 'kern')
52 cu_path = '%s.cu' % path
53 cubin_path = '%s.cubin' % path
54
55 with open(cu_path, 'w') as cu_file:
56 cu_file.write(source)
57
58 cmd.append(cu_path)
59 _run_nvcc(cmd, root_dir)
60
61 with open(cubin_path, 'rb') as bin_file:
62 return bin_file.read()
63
64
65 def preprocess(source, options=()):
66 cmd = ['nvcc', '--preprocess'] + list(options)
67 with TemporaryDirectory() as root_dir:
68 path = os.path.join(root_dir, 'kern')
69 cu_path = '%s.cu' % path
70
71 with open(cu_path, 'w') as cu_file:
72 cu_file.write(source)
73
74 cmd.append(cu_path)
75 pp_src = _run_nvcc(cmd, root_dir)
76
77 if isinstance(pp_src, six.binary_type):
78 pp_src = pp_src.decode('utf-8')
79 return re.sub('(?m)^#.*$', '', pp_src)
80
81
82 _default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')
83
84
85 def get_cache_dir():
86 return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)
87
88
89 _empty_file_preprocess_cache = {}
90
91
92 def compile_with_cache(source, options=(), arch=None, cache_dir=None):
93 global _empty_file_preprocess_cache
94 if cache_dir is None:
95 cache_dir = get_cache_dir()
96 if arch is None:
97 arch = _get_arch()
98
99 if 'win32' == sys.platform:
100 options += ('-Xcompiler', '/wd 4819')
101 if sys.maxsize == 9223372036854775807:
102 options += '-m64',
103 elif sys.maxsize == 2147483647:
104 options += '-m32',
105
106 env = (arch, options)
107 if '#include' in source:
108 pp_src = '%s %s' % (env, preprocess(source, options))
109 else:
110 base = _empty_file_preprocess_cache.get(env, None)
111 if base is None:
112 base = _empty_file_preprocess_cache[env] = preprocess('', options)
113 pp_src = '%s %s %s' % (env, base, source)
114
115 if isinstance(pp_src, six.text_type):
116 pp_src = pp_src.encode('utf-8')
117 name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()
118
119 mod = function.Module()
120
121 if not os.path.exists(cache_dir):
122 os.makedirs(cache_dir)
123
124 lock_path = os.path.join(cache_dir, 'lock_file.lock')
125
126 path = os.path.join(cache_dir, name)
127 with filelock.FileLock(lock_path) as lock:
128 if os.path.exists(path):
129 with open(path, 'rb') as file:
130 cubin = file.read()
131 mod.load(cubin)
132 else:
133 lock.release()
134 cubin = nvcc(source, options, arch)
135 mod.load(cubin)
136 lock.acquire()
137 with open(path, 'wb') as cubin_file:
138 cubin_file.write(cubin)
139
140 return mod
141
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py
--- a/cupy/cuda/compiler.py
+++ b/cupy/cuda/compiler.py
@@ -34,7 +34,14 @@
def _run_nvcc(cmd, cwd):
try:
- return subprocess.check_output(cmd, cwd=cwd)
+ return subprocess.check_output(cmd, cwd=cwd, stderr=subprocess.STDOUT)
+ except subprocess.CalledProcessError as e:
+ msg = ('`nvcc` command returns non-zero exit status. \n'
+ 'command: {0}\n'
+ 'return-code: {1}\n'
+ 'stdout/stderr: \n'
+ '{2}'.format(e.cmd, e.returncode, e.output))
+ raise RuntimeError(msg)
except OSError as e:
msg = 'Failed to run `nvcc` command. ' \
'Check PATH environment variable: ' \
|
{"golden_diff": "diff --git a/cupy/cuda/compiler.py b/cupy/cuda/compiler.py\n--- a/cupy/cuda/compiler.py\n+++ b/cupy/cuda/compiler.py\n@@ -34,7 +34,14 @@\n \n def _run_nvcc(cmd, cwd):\n try:\n- return subprocess.check_output(cmd, cwd=cwd)\n+ return subprocess.check_output(cmd, cwd=cwd, stderr=subprocess.STDOUT)\n+ except subprocess.CalledProcessError as e:\n+ msg = ('`nvcc` command returns non-zero exit status. \\n'\n+ 'command: {0}\\n'\n+ 'return-code: {1}\\n'\n+ 'stdout/stderr: \\n'\n+ '{2}'.format(e.cmd, e.returncode, e.output))\n+ raise RuntimeError(msg)\n except OSError as e:\n msg = 'Failed to run `nvcc` command. ' \\\n 'Check PATH environment variable: ' \\\n", "issue": "Show output of nvcc after stacktrace\nIn the current implementation, `nvcc` prints error messages in stdout/stderr before stack trace is printed. It is hard to read.\n\n", "before_files": [{"content": "import hashlib\nimport os\nimport re\nimport subprocess\nimport sys\nimport tempfile\n\nimport filelock\nimport six\n\nfrom cupy.cuda import device\nfrom cupy.cuda import function\n\n\ndef _get_arch():\n cc = device.Device().compute_capability\n return 'sm_%s' % cc\n\n\nclass TemporaryDirectory(object):\n\n def __enter__(self):\n self.path = tempfile.mkdtemp()\n return self.path\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value is not None:\n return\n\n for name in os.listdir(self.path):\n os.unlink(os.path.join(self.path, name))\n os.rmdir(self.path)\n\n\ndef _run_nvcc(cmd, cwd):\n try:\n return subprocess.check_output(cmd, cwd=cwd)\n except OSError as e:\n msg = 'Failed to run `nvcc` command. ' \\\n 'Check PATH environment variable: ' \\\n + str(e)\n raise OSError(msg)\n\n\ndef nvcc(source, options=(), arch=None):\n if not arch:\n arch = _get_arch()\n cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)\n\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n cubin_path = '%s.cubin' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n _run_nvcc(cmd, root_dir)\n\n with open(cubin_path, 'rb') as bin_file:\n return bin_file.read()\n\n\ndef preprocess(source, options=()):\n cmd = ['nvcc', '--preprocess'] + list(options)\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n pp_src = _run_nvcc(cmd, root_dir)\n\n if isinstance(pp_src, six.binary_type):\n pp_src = pp_src.decode('utf-8')\n return re.sub('(?m)^#.*$', '', pp_src)\n\n\n_default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')\n\n\ndef get_cache_dir():\n return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)\n\n\n_empty_file_preprocess_cache = {}\n\n\ndef compile_with_cache(source, options=(), arch=None, cache_dir=None):\n global _empty_file_preprocess_cache\n if cache_dir is None:\n cache_dir = get_cache_dir()\n if arch is None:\n arch = _get_arch()\n\n if 'win32' == sys.platform:\n options += ('-Xcompiler', '/wd 4819')\n if sys.maxsize == 9223372036854775807:\n options += '-m64',\n elif sys.maxsize == 2147483647:\n options += '-m32',\n\n env = (arch, options)\n if '#include' in source:\n pp_src = '%s %s' % (env, preprocess(source, options))\n else:\n base = _empty_file_preprocess_cache.get(env, None)\n if base is None:\n base = _empty_file_preprocess_cache[env] = preprocess('', options)\n pp_src = '%s %s %s' % (env, base, source)\n\n if isinstance(pp_src, six.text_type):\n pp_src = pp_src.encode('utf-8')\n name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()\n\n mod = function.Module()\n\n if not os.path.exists(cache_dir):\n os.makedirs(cache_dir)\n\n lock_path = os.path.join(cache_dir, 'lock_file.lock')\n\n path = os.path.join(cache_dir, name)\n with filelock.FileLock(lock_path) as lock:\n if os.path.exists(path):\n with open(path, 'rb') as file:\n cubin = file.read()\n mod.load(cubin)\n else:\n lock.release()\n cubin = nvcc(source, options, arch)\n mod.load(cubin)\n lock.acquire()\n with open(path, 'wb') as cubin_file:\n cubin_file.write(cubin)\n\n return mod\n", "path": "cupy/cuda/compiler.py"}], "after_files": [{"content": "import hashlib\nimport os\nimport re\nimport subprocess\nimport sys\nimport tempfile\n\nimport filelock\nimport six\n\nfrom cupy.cuda import device\nfrom cupy.cuda import function\n\n\ndef _get_arch():\n cc = device.Device().compute_capability\n return 'sm_%s' % cc\n\n\nclass TemporaryDirectory(object):\n\n def __enter__(self):\n self.path = tempfile.mkdtemp()\n return self.path\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value is not None:\n return\n\n for name in os.listdir(self.path):\n os.unlink(os.path.join(self.path, name))\n os.rmdir(self.path)\n\n\ndef _run_nvcc(cmd, cwd):\n try:\n return subprocess.check_output(cmd, cwd=cwd, stderr=subprocess.STDOUT)\n except subprocess.CalledProcessError as e:\n msg = ('`nvcc` command returns non-zero exit status. \\n'\n 'command: {0}\\n'\n 'return-code: {1}\\n'\n 'stdout/stderr: \\n'\n '{2}'.format(e.cmd, e.returncode, e.output))\n raise RuntimeError(msg)\n except OSError as e:\n msg = 'Failed to run `nvcc` command. ' \\\n 'Check PATH environment variable: ' \\\n + str(e)\n raise OSError(msg)\n\n\ndef nvcc(source, options=(), arch=None):\n if not arch:\n arch = _get_arch()\n cmd = ['nvcc', '--cubin', '-arch', arch] + list(options)\n\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n cubin_path = '%s.cubin' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n _run_nvcc(cmd, root_dir)\n\n with open(cubin_path, 'rb') as bin_file:\n return bin_file.read()\n\n\ndef preprocess(source, options=()):\n cmd = ['nvcc', '--preprocess'] + list(options)\n with TemporaryDirectory() as root_dir:\n path = os.path.join(root_dir, 'kern')\n cu_path = '%s.cu' % path\n\n with open(cu_path, 'w') as cu_file:\n cu_file.write(source)\n\n cmd.append(cu_path)\n pp_src = _run_nvcc(cmd, root_dir)\n\n if isinstance(pp_src, six.binary_type):\n pp_src = pp_src.decode('utf-8')\n return re.sub('(?m)^#.*$', '', pp_src)\n\n\n_default_cache_dir = os.path.expanduser('~/.cupy/kernel_cache')\n\n\ndef get_cache_dir():\n return os.environ.get('CUPY_CACHE_DIR', _default_cache_dir)\n\n\n_empty_file_preprocess_cache = {}\n\n\ndef compile_with_cache(source, options=(), arch=None, cache_dir=None):\n global _empty_file_preprocess_cache\n if cache_dir is None:\n cache_dir = get_cache_dir()\n if arch is None:\n arch = _get_arch()\n\n if 'win32' == sys.platform:\n options += ('-Xcompiler', '/wd 4819')\n if sys.maxsize == 9223372036854775807:\n options += '-m64',\n elif sys.maxsize == 2147483647:\n options += '-m32',\n\n env = (arch, options)\n if '#include' in source:\n pp_src = '%s %s' % (env, preprocess(source, options))\n else:\n base = _empty_file_preprocess_cache.get(env, None)\n if base is None:\n base = _empty_file_preprocess_cache[env] = preprocess('', options)\n pp_src = '%s %s %s' % (env, base, source)\n\n if isinstance(pp_src, six.text_type):\n pp_src = pp_src.encode('utf-8')\n name = '%s.cubin' % hashlib.md5(pp_src).hexdigest()\n\n mod = function.Module()\n\n if not os.path.exists(cache_dir):\n os.makedirs(cache_dir)\n\n lock_path = os.path.join(cache_dir, 'lock_file.lock')\n\n path = os.path.join(cache_dir, name)\n with filelock.FileLock(lock_path) as lock:\n if os.path.exists(path):\n with open(path, 'rb') as file:\n cubin = file.read()\n mod.load(cubin)\n else:\n lock.release()\n cubin = nvcc(source, options, arch)\n mod.load(cubin)\n lock.acquire()\n with open(path, 'wb') as cubin_file:\n cubin_file.write(cubin)\n\n return mod\n", "path": "cupy/cuda/compiler.py"}]}
| 1,605 | 205 |
gh_patches_debug_25333
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1246
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`nikola command --help` should work
Fix upcoming.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/__main__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 from __future__ import print_function, unicode_literals
28 from operator import attrgetter
29 import os
30 import shutil
31 try:
32 import readline # NOQA
33 except ImportError:
34 pass # This is only so raw_input/input does nicer things if it's available
35 import sys
36 import traceback
37
38 from doit.loader import generate_tasks
39 from doit.cmd_base import TaskLoader
40 from doit.reporter import ExecutedOnlyReporter
41 from doit.doit_cmd import DoitMain
42 from doit.cmd_help import Help as DoitHelp
43 from doit.cmd_run import Run as DoitRun
44 from doit.cmd_clean import Clean as DoitClean
45 from doit.cmd_auto import Auto as DoitAuto
46 from logbook import NullHandler
47
48 from . import __version__
49 from .nikola import Nikola
50 from .utils import _reload, sys_decode, get_root_dir, req_missing, LOGGER, STRICT_HANDLER
51
52
53 config = {}
54
55
56 def main(args=None):
57 if args is None:
58 args = sys.argv[1:]
59 quiet = False
60 if len(args) > 0 and args[0] == b'build' and b'--strict' in args:
61 LOGGER.notice('Running in strict mode')
62 STRICT_HANDLER.push_application()
63 if len(args) > 0 and args[0] == b'build' and b'-q' in args or b'--quiet' in args:
64 nullhandler = NullHandler()
65 nullhandler.push_application()
66 quiet = True
67 global config
68
69 colorful = False
70 if sys.stderr.isatty():
71 colorful = True
72 try:
73 import colorama
74 colorama.init()
75 except ImportError:
76 if os.name == 'nt':
77 colorful = False
78
79 # Those commands do not require a `conf.py`. (Issue #1132)
80 # Moreover, actually having one somewhere in the tree can be bad, putting
81 # the output of that command (the new site) in an unknown directory that is
82 # not the current working directory. (does not apply to `version`)
83 argname = args[0] if len(args) > 0 else None
84 # FIXME there are import plugins in the repo, so how do we handle this?
85 if argname not in ['init', 'import_wordpress', 'import_feed',
86 'import_blogger', 'version']:
87 root = get_root_dir()
88 if root:
89 os.chdir(root)
90
91 sys.path.append('')
92 try:
93 import conf
94 _reload(conf)
95 config = conf.__dict__
96 except Exception:
97 if os.path.exists('conf.py'):
98 msg = traceback.format_exc(0).splitlines()[1]
99 LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))
100 sys.exit(1)
101 config = {}
102
103 invariant = False
104
105 if len(args) > 0 and args[0] == b'build' and b'--invariant' in args:
106 try:
107 import freezegun
108 freeze = freezegun.freeze_time("2014-01-01")
109 freeze.start()
110 invariant = True
111 except ImportError:
112 req_missing(['freezegun'], 'perform invariant builds')
113
114 config['__colorful__'] = colorful
115 config['__invariant__'] = invariant
116
117 site = Nikola(**config)
118 _ = DoitNikola(site, quiet).run(args)
119
120 if site.invariant:
121 freeze.stop()
122 return _
123
124
125 class Help(DoitHelp):
126 """show Nikola usage instead of doit """
127
128 @staticmethod
129 def print_usage(cmds):
130 """print nikola "usage" (basic help) instructions"""
131 print("Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com/\n\n")
132 print("Available commands:")
133 for cmd in sorted(cmds.values(), key=attrgetter('name')):
134 print(" nikola %-*s %s" % (20, cmd.name, cmd.doc_purpose))
135 print("")
136 print(" nikola help show help / reference")
137 print(" nikola help <command> show command usage")
138 print(" nikola help <task-name> show task usage")
139
140
141 class Build(DoitRun):
142 """expose "run" command as "build" for backward compatibility"""
143 def __init__(self, *args, **kw):
144 opts = list(self.cmd_options)
145 opts.append(
146 {
147 'name': 'strict',
148 'long': 'strict',
149 'default': False,
150 'type': bool,
151 'help': "Fail on things that would normally be warnings.",
152 }
153 )
154 opts.append(
155 {
156 'name': 'invariant',
157 'long': 'invariant',
158 'default': False,
159 'type': bool,
160 'help': "Generate invariant output (for testing only!).",
161 }
162 )
163 opts.append(
164 {
165 'name': 'quiet',
166 'long': 'quiet',
167 'short': 'q',
168 'default': False,
169 'type': bool,
170 'help': "Run quietly.",
171 }
172 )
173 self.cmd_options = tuple(opts)
174 super(Build, self).__init__(*args, **kw)
175
176
177 class Clean(DoitClean):
178 """A clean that removes cache/"""
179
180 def clean_tasks(self, tasks, dryrun):
181 if not dryrun and config:
182 cache_folder = config.get('CACHE_FOLDER', 'cache')
183 if os.path.exists(cache_folder):
184 shutil.rmtree(cache_folder)
185 return super(Clean, self).clean_tasks(tasks, dryrun)
186
187 # Nikola has its own "auto" commands that uses livereload.
188 # Expose original doit "auto" command as "doit_auto".
189 DoitAuto.name = 'doit_auto'
190
191
192 class NikolaTaskLoader(TaskLoader):
193 """custom task loader to get tasks from Nikola instead of dodo.py file"""
194 def __init__(self, nikola, quiet=False):
195 self.nikola = nikola
196 self.quiet = quiet
197
198 def load_tasks(self, cmd, opt_values, pos_args):
199 if self.quiet:
200 DOIT_CONFIG = {
201 'verbosity': 0,
202 'reporter': 'zero',
203 }
204 else:
205 DOIT_CONFIG = {
206 'reporter': ExecutedOnlyReporter,
207 }
208 DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']
209 tasks = generate_tasks(
210 'render_site',
211 self.nikola.gen_tasks('render_site', "Task", 'Group of tasks to render the site.'))
212 latetasks = generate_tasks(
213 'post_render',
214 self.nikola.gen_tasks('post_render', "LateTask", 'Group of tasks to be executes after site is rendered.'))
215 return tasks + latetasks, DOIT_CONFIG
216
217
218 class DoitNikola(DoitMain):
219 # overwite help command
220 DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]
221 TASK_LOADER = NikolaTaskLoader
222
223 def __init__(self, nikola, quiet=False):
224 self.nikola = nikola
225 self.task_loader = self.TASK_LOADER(nikola, quiet)
226
227 def get_commands(self):
228 # core doit commands
229 cmds = DoitMain.get_commands(self)
230 # load nikola commands
231 for name, cmd in self.nikola.commands.items():
232 cmds[name] = cmd
233 return cmds
234
235 def run(self, cmd_args):
236 sub_cmds = self.get_commands()
237 args = self.process_args(cmd_args)
238 args = [sys_decode(arg) for arg in args]
239
240 if len(args) == 0 or any(arg in ["--help", '-h'] for arg in args):
241 cmd_args = ['help']
242 args = ['help']
243 # Hide run because Nikola uses build
244 sub_cmds.pop('run')
245 if len(args) == 0 or any(arg in ["--version", '-V'] for arg in args):
246 cmd_args = ['version']
247 args = ['version']
248 if len(args) == 0 or args[0] not in sub_cmds.keys() or \
249 args[0] in (
250 'build',
251 'list',
252 'clean',
253 'doit_auto',
254 'dumpdb',
255 'forget',
256 'ignore',
257 'run',
258 'strace'):
259 # Check for conf.py before launching run
260 if not self.nikola.configured:
261 LOGGER.error("This command needs to run inside an "
262 "existing Nikola site.")
263 return False
264 return super(DoitNikola, self).run(cmd_args)
265
266 @staticmethod
267 def print_version():
268 print("Nikola v" + __version__)
269
270 if __name__ == "__main__":
271 sys.exit(main(sys.argv[1:]))
272
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/__main__.py b/nikola/__main__.py
--- a/nikola/__main__.py
+++ b/nikola/__main__.py
@@ -237,15 +237,32 @@
args = self.process_args(cmd_args)
args = [sys_decode(arg) for arg in args]
- if len(args) == 0 or any(arg in ["--help", '-h'] for arg in args):
+ if len(args) == 0:
cmd_args = ['help']
args = ['help']
# Hide run because Nikola uses build
sub_cmds.pop('run')
- if len(args) == 0 or any(arg in ["--version", '-V'] for arg in args):
+
+ if '--help' in args or '-h' in args:
+ new_cmd_args = ['help'] + cmd_args
+ new_args = ['help'] + args
+
+ cmd_args = []
+ args = []
+
+ for arg in new_cmd_args:
+ if arg not in ('--help', '-h'):
+ cmd_args.append(arg)
+ for arg in new_args:
+ if arg not in ('--help', '-h'):
+ args.append(arg)
+ # Hide run because Nikola uses build
+ sub_cmds.pop('run')
+
+ if any(arg in ("--version", '-V') for arg in args):
cmd_args = ['version']
args = ['version']
- if len(args) == 0 or args[0] not in sub_cmds.keys() or \
+ if args[0] not in sub_cmds.keys() or \
args[0] in (
'build',
'list',
|
{"golden_diff": "diff --git a/nikola/__main__.py b/nikola/__main__.py\n--- a/nikola/__main__.py\n+++ b/nikola/__main__.py\n@@ -237,15 +237,32 @@\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n \n- if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n+ if len(args) == 0:\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n- if len(args) == 0 or any(arg in [\"--version\", '-V'] for arg in args):\n+\n+ if '--help' in args or '-h' in args:\n+ new_cmd_args = ['help'] + cmd_args\n+ new_args = ['help'] + args\n+\n+ cmd_args = []\n+ args = []\n+\n+ for arg in new_cmd_args:\n+ if arg not in ('--help', '-h'):\n+ cmd_args.append(arg)\n+ for arg in new_args:\n+ if arg not in ('--help', '-h'):\n+ args.append(arg)\n+ # Hide run because Nikola uses build\n+ sub_cmds.pop('run')\n+\n+ if any(arg in (\"--version\", '-V') for arg in args):\n cmd_args = ['version']\n args = ['version']\n- if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n+ if args[0] not in sub_cmds.keys() or \\\n args[0] in (\n 'build',\n 'list',\n", "issue": "`nikola command --help` should work\nFix upcoming.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\nfrom operator import attrgetter\nimport os\nimport shutil\ntry:\n import readline # NOQA\nexcept ImportError:\n pass # This is only so raw_input/input does nicer things if it's available\nimport sys\nimport traceback\n\nfrom doit.loader import generate_tasks\nfrom doit.cmd_base import TaskLoader\nfrom doit.reporter import ExecutedOnlyReporter\nfrom doit.doit_cmd import DoitMain\nfrom doit.cmd_help import Help as DoitHelp\nfrom doit.cmd_run import Run as DoitRun\nfrom doit.cmd_clean import Clean as DoitClean\nfrom doit.cmd_auto import Auto as DoitAuto\nfrom logbook import NullHandler\n\nfrom . import __version__\nfrom .nikola import Nikola\nfrom .utils import _reload, sys_decode, get_root_dir, req_missing, LOGGER, STRICT_HANDLER\n\n\nconfig = {}\n\n\ndef main(args=None):\n if args is None:\n args = sys.argv[1:]\n quiet = False\n if len(args) > 0 and args[0] == b'build' and b'--strict' in args:\n LOGGER.notice('Running in strict mode')\n STRICT_HANDLER.push_application()\n if len(args) > 0 and args[0] == b'build' and b'-q' in args or b'--quiet' in args:\n nullhandler = NullHandler()\n nullhandler.push_application()\n quiet = True\n global config\n\n colorful = False\n if sys.stderr.isatty():\n colorful = True\n try:\n import colorama\n colorama.init()\n except ImportError:\n if os.name == 'nt':\n colorful = False\n\n # Those commands do not require a `conf.py`. (Issue #1132)\n # Moreover, actually having one somewhere in the tree can be bad, putting\n # the output of that command (the new site) in an unknown directory that is\n # not the current working directory. (does not apply to `version`)\n argname = args[0] if len(args) > 0 else None\n # FIXME there are import plugins in the repo, so how do we handle this?\n if argname not in ['init', 'import_wordpress', 'import_feed',\n 'import_blogger', 'version']:\n root = get_root_dir()\n if root:\n os.chdir(root)\n\n sys.path.append('')\n try:\n import conf\n _reload(conf)\n config = conf.__dict__\n except Exception:\n if os.path.exists('conf.py'):\n msg = traceback.format_exc(0).splitlines()[1]\n LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))\n sys.exit(1)\n config = {}\n\n invariant = False\n\n if len(args) > 0 and args[0] == b'build' and b'--invariant' in args:\n try:\n import freezegun\n freeze = freezegun.freeze_time(\"2014-01-01\")\n freeze.start()\n invariant = True\n except ImportError:\n req_missing(['freezegun'], 'perform invariant builds')\n\n config['__colorful__'] = colorful\n config['__invariant__'] = invariant\n\n site = Nikola(**config)\n _ = DoitNikola(site, quiet).run(args)\n\n if site.invariant:\n freeze.stop()\n return _\n\n\nclass Help(DoitHelp):\n \"\"\"show Nikola usage instead of doit \"\"\"\n\n @staticmethod\n def print_usage(cmds):\n \"\"\"print nikola \"usage\" (basic help) instructions\"\"\"\n print(\"Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com/\\n\\n\")\n print(\"Available commands:\")\n for cmd in sorted(cmds.values(), key=attrgetter('name')):\n print(\" nikola %-*s %s\" % (20, cmd.name, cmd.doc_purpose))\n print(\"\")\n print(\" nikola help show help / reference\")\n print(\" nikola help <command> show command usage\")\n print(\" nikola help <task-name> show task usage\")\n\n\nclass Build(DoitRun):\n \"\"\"expose \"run\" command as \"build\" for backward compatibility\"\"\"\n def __init__(self, *args, **kw):\n opts = list(self.cmd_options)\n opts.append(\n {\n 'name': 'strict',\n 'long': 'strict',\n 'default': False,\n 'type': bool,\n 'help': \"Fail on things that would normally be warnings.\",\n }\n )\n opts.append(\n {\n 'name': 'invariant',\n 'long': 'invariant',\n 'default': False,\n 'type': bool,\n 'help': \"Generate invariant output (for testing only!).\",\n }\n )\n opts.append(\n {\n 'name': 'quiet',\n 'long': 'quiet',\n 'short': 'q',\n 'default': False,\n 'type': bool,\n 'help': \"Run quietly.\",\n }\n )\n self.cmd_options = tuple(opts)\n super(Build, self).__init__(*args, **kw)\n\n\nclass Clean(DoitClean):\n \"\"\"A clean that removes cache/\"\"\"\n\n def clean_tasks(self, tasks, dryrun):\n if not dryrun and config:\n cache_folder = config.get('CACHE_FOLDER', 'cache')\n if os.path.exists(cache_folder):\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n\n# Nikola has its own \"auto\" commands that uses livereload.\n# Expose original doit \"auto\" command as \"doit_auto\".\nDoitAuto.name = 'doit_auto'\n\n\nclass NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.quiet = quiet\n\n def load_tasks(self, cmd, opt_values, pos_args):\n if self.quiet:\n DOIT_CONFIG = {\n 'verbosity': 0,\n 'reporter': 'zero',\n }\n else:\n DOIT_CONFIG = {\n 'reporter': ExecutedOnlyReporter,\n }\n DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']\n tasks = generate_tasks(\n 'render_site',\n self.nikola.gen_tasks('render_site', \"Task\", 'Group of tasks to render the site.'))\n latetasks = generate_tasks(\n 'post_render',\n self.nikola.gen_tasks('post_render', \"LateTask\", 'Group of tasks to be executes after site is rendered.'))\n return tasks + latetasks, DOIT_CONFIG\n\n\nclass DoitNikola(DoitMain):\n # overwite help command\n DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]\n TASK_LOADER = NikolaTaskLoader\n\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.task_loader = self.TASK_LOADER(nikola, quiet)\n\n def get_commands(self):\n # core doit commands\n cmds = DoitMain.get_commands(self)\n # load nikola commands\n for name, cmd in self.nikola.commands.items():\n cmds[name] = cmd\n return cmds\n\n def run(self, cmd_args):\n sub_cmds = self.get_commands()\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n\n if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n if len(args) == 0 or any(arg in [\"--version\", '-V'] for arg in args):\n cmd_args = ['version']\n args = ['version']\n if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n args[0] in (\n 'build',\n 'list',\n 'clean',\n 'doit_auto',\n 'dumpdb',\n 'forget',\n 'ignore',\n 'run',\n 'strace'):\n # Check for conf.py before launching run\n if not self.nikola.configured:\n LOGGER.error(\"This command needs to run inside an \"\n \"existing Nikola site.\")\n return False\n return super(DoitNikola, self).run(cmd_args)\n\n @staticmethod\n def print_version():\n print(\"Nikola v\" + __version__)\n\nif __name__ == \"__main__\":\n sys.exit(main(sys.argv[1:]))\n", "path": "nikola/__main__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\nfrom operator import attrgetter\nimport os\nimport shutil\ntry:\n import readline # NOQA\nexcept ImportError:\n pass # This is only so raw_input/input does nicer things if it's available\nimport sys\nimport traceback\n\nfrom doit.loader import generate_tasks\nfrom doit.cmd_base import TaskLoader\nfrom doit.reporter import ExecutedOnlyReporter\nfrom doit.doit_cmd import DoitMain\nfrom doit.cmd_help import Help as DoitHelp\nfrom doit.cmd_run import Run as DoitRun\nfrom doit.cmd_clean import Clean as DoitClean\nfrom doit.cmd_auto import Auto as DoitAuto\nfrom logbook import NullHandler\n\nfrom . import __version__\nfrom .nikola import Nikola\nfrom .utils import _reload, sys_decode, get_root_dir, req_missing, LOGGER, STRICT_HANDLER\n\n\nconfig = {}\n\n\ndef main(args=None):\n if args is None:\n args = sys.argv[1:]\n quiet = False\n if len(args) > 0 and args[0] == b'build' and b'--strict' in args:\n LOGGER.notice('Running in strict mode')\n STRICT_HANDLER.push_application()\n if len(args) > 0 and args[0] == b'build' and b'-q' in args or b'--quiet' in args:\n nullhandler = NullHandler()\n nullhandler.push_application()\n quiet = True\n global config\n\n colorful = False\n if sys.stderr.isatty():\n colorful = True\n try:\n import colorama\n colorama.init()\n except ImportError:\n if os.name == 'nt':\n colorful = False\n\n # Those commands do not require a `conf.py`. (Issue #1132)\n # Moreover, actually having one somewhere in the tree can be bad, putting\n # the output of that command (the new site) in an unknown directory that is\n # not the current working directory. (does not apply to `version`)\n argname = args[0] if len(args) > 0 else None\n # FIXME there are import plugins in the repo, so how do we handle this?\n if argname not in ['init', 'import_wordpress', 'import_feed',\n 'import_blogger', 'version']:\n root = get_root_dir()\n if root:\n os.chdir(root)\n\n sys.path.append('')\n try:\n import conf\n _reload(conf)\n config = conf.__dict__\n except Exception:\n if os.path.exists('conf.py'):\n msg = traceback.format_exc(0).splitlines()[1]\n LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))\n sys.exit(1)\n config = {}\n\n invariant = False\n\n if len(args) > 0 and args[0] == b'build' and b'--invariant' in args:\n try:\n import freezegun\n freeze = freezegun.freeze_time(\"2014-01-01\")\n freeze.start()\n invariant = True\n except ImportError:\n req_missing(['freezegun'], 'perform invariant builds')\n\n config['__colorful__'] = colorful\n config['__invariant__'] = invariant\n\n site = Nikola(**config)\n _ = DoitNikola(site, quiet).run(args)\n\n if site.invariant:\n freeze.stop()\n return _\n\n\nclass Help(DoitHelp):\n \"\"\"show Nikola usage instead of doit \"\"\"\n\n @staticmethod\n def print_usage(cmds):\n \"\"\"print nikola \"usage\" (basic help) instructions\"\"\"\n print(\"Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com/\\n\\n\")\n print(\"Available commands:\")\n for cmd in sorted(cmds.values(), key=attrgetter('name')):\n print(\" nikola %-*s %s\" % (20, cmd.name, cmd.doc_purpose))\n print(\"\")\n print(\" nikola help show help / reference\")\n print(\" nikola help <command> show command usage\")\n print(\" nikola help <task-name> show task usage\")\n\n\nclass Build(DoitRun):\n \"\"\"expose \"run\" command as \"build\" for backward compatibility\"\"\"\n def __init__(self, *args, **kw):\n opts = list(self.cmd_options)\n opts.append(\n {\n 'name': 'strict',\n 'long': 'strict',\n 'default': False,\n 'type': bool,\n 'help': \"Fail on things that would normally be warnings.\",\n }\n )\n opts.append(\n {\n 'name': 'invariant',\n 'long': 'invariant',\n 'default': False,\n 'type': bool,\n 'help': \"Generate invariant output (for testing only!).\",\n }\n )\n opts.append(\n {\n 'name': 'quiet',\n 'long': 'quiet',\n 'short': 'q',\n 'default': False,\n 'type': bool,\n 'help': \"Run quietly.\",\n }\n )\n self.cmd_options = tuple(opts)\n super(Build, self).__init__(*args, **kw)\n\n\nclass Clean(DoitClean):\n \"\"\"A clean that removes cache/\"\"\"\n\n def clean_tasks(self, tasks, dryrun):\n if not dryrun and config:\n cache_folder = config.get('CACHE_FOLDER', 'cache')\n if os.path.exists(cache_folder):\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n\n# Nikola has its own \"auto\" commands that uses livereload.\n# Expose original doit \"auto\" command as \"doit_auto\".\nDoitAuto.name = 'doit_auto'\n\n\nclass NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.quiet = quiet\n\n def load_tasks(self, cmd, opt_values, pos_args):\n if self.quiet:\n DOIT_CONFIG = {\n 'verbosity': 0,\n 'reporter': 'zero',\n }\n else:\n DOIT_CONFIG = {\n 'reporter': ExecutedOnlyReporter,\n }\n DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']\n tasks = generate_tasks(\n 'render_site',\n self.nikola.gen_tasks('render_site', \"Task\", 'Group of tasks to render the site.'))\n latetasks = generate_tasks(\n 'post_render',\n self.nikola.gen_tasks('post_render', \"LateTask\", 'Group of tasks to be executes after site is rendered.'))\n return tasks + latetasks, DOIT_CONFIG\n\n\nclass DoitNikola(DoitMain):\n # overwite help command\n DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]\n TASK_LOADER = NikolaTaskLoader\n\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.task_loader = self.TASK_LOADER(nikola, quiet)\n\n def get_commands(self):\n # core doit commands\n cmds = DoitMain.get_commands(self)\n # load nikola commands\n for name, cmd in self.nikola.commands.items():\n cmds[name] = cmd\n return cmds\n\n def run(self, cmd_args):\n sub_cmds = self.get_commands()\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n\n if len(args) == 0:\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n\n if '--help' in args or '-h' in args:\n new_cmd_args = ['help'] + cmd_args\n new_args = ['help'] + args\n\n cmd_args = []\n args = []\n\n for arg in new_cmd_args:\n if arg not in ('--help', '-h'):\n cmd_args.append(arg)\n for arg in new_args:\n if arg not in ('--help', '-h'):\n args.append(arg)\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n\n if any(arg in (\"--version\", '-V') for arg in args):\n cmd_args = ['version']\n args = ['version']\n if args[0] not in sub_cmds.keys() or \\\n args[0] in (\n 'build',\n 'list',\n 'clean',\n 'doit_auto',\n 'dumpdb',\n 'forget',\n 'ignore',\n 'run',\n 'strace'):\n # Check for conf.py before launching run\n if not self.nikola.configured:\n LOGGER.error(\"This command needs to run inside an \"\n \"existing Nikola site.\")\n return False\n return super(DoitNikola, self).run(cmd_args)\n\n @staticmethod\n def print_version():\n print(\"Nikola v\" + __version__)\n\nif __name__ == \"__main__\":\n sys.exit(main(sys.argv[1:]))\n", "path": "nikola/__main__.py"}]}
| 3,179 | 379 |
gh_patches_debug_23660
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-3894
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tune Elasticsearch client for reindex separately from main search client
#3892 was necessary to alleviate the hard outage experienced due to ES cluster being down.
We were waiting 30s per request for Elasticsearch then retrying. This was added in #1471 to handle reindex issues.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/search/tasks.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import binascii
14 import os
15
16 from elasticsearch.helpers import parallel_bulk
17 from sqlalchemy import and_, func
18 from sqlalchemy.orm import aliased
19
20 from warehouse.packaging.models import (
21 Classifier, Project, Release, release_classifiers)
22 from warehouse.packaging.search import Project as ProjectDocType
23 from warehouse.search.utils import get_index
24 from warehouse import tasks
25 from warehouse.utils.db import windowed_query
26
27
28 def _project_docs(db):
29
30 releases_list = (
31 db.query(Release.name, Release.version)
32 .order_by(
33 Release.name,
34 Release.is_prerelease.nullslast(),
35 Release._pypi_ordering.desc(),
36 )
37 .distinct(Release.name)
38 .subquery("release_list")
39 )
40
41 r = aliased(Release, name="r")
42
43 all_versions = (
44 db.query(func.array_agg(r.version))
45 .filter(r.name == Release.name)
46 .correlate(Release)
47 .as_scalar()
48 .label("all_versions")
49 )
50
51 classifiers = (
52 db.query(func.array_agg(Classifier.classifier))
53 .select_from(release_classifiers)
54 .join(Classifier, Classifier.id == release_classifiers.c.trove_id)
55 .filter(Release.name == release_classifiers.c.name)
56 .filter(Release.version == release_classifiers.c.version)
57 .correlate(Release)
58 .as_scalar()
59 .label("classifiers")
60 )
61
62 release_data = (
63 db.query(
64 Release.description,
65 Release.name,
66 Release.version.label("latest_version"),
67 all_versions,
68 Release.author,
69 Release.author_email,
70 Release.maintainer,
71 Release.maintainer_email,
72 Release.home_page,
73 Release.summary,
74 Release.keywords,
75 Release.platform,
76 Release.download_url,
77 Release.created,
78 classifiers,
79 Project.normalized_name,
80 Project.name,
81 )
82 .select_from(releases_list)
83 .join(Release, and_(
84 Release.name == releases_list.c.name,
85 Release.version == releases_list.c.version))
86 .outerjoin(Release.project)
87 .order_by(Release.name)
88 )
89
90 for release in windowed_query(release_data, Release.name, 50000):
91 p = ProjectDocType.from_db(release)
92 p.full_clean()
93 yield p.to_dict(include_meta=True)
94
95
96 @tasks.task(ignore_result=True, acks_late=True)
97 def reindex(request):
98 """
99 Recreate the Search Index.
100 """
101 client = request.registry["elasticsearch.client"]
102 number_of_replicas = request.registry.get("elasticsearch.replicas", 0)
103 refresh_interval = request.registry.get("elasticsearch.interval", "1s")
104
105 # We use a randomly named index so that we can do a zero downtime reindex.
106 # Essentially we'll use a randomly named index which we will use until all
107 # of the data has been reindexed, at which point we'll point an alias at
108 # our randomly named index, and then delete the old randomly named index.
109
110 # Create the new index and associate all of our doc types with it.
111 index_base = request.registry["elasticsearch.index"]
112 random_token = binascii.hexlify(os.urandom(5)).decode("ascii")
113 new_index_name = "{}-{}".format(index_base, random_token)
114 doc_types = request.registry.get("search.doc_types", set())
115 shards = request.registry.get("elasticsearch.shards", 1)
116
117 # Create the new index with zero replicas and index refreshes disabled
118 # while we are bulk indexing.
119 new_index = get_index(
120 new_index_name,
121 doc_types,
122 using=client,
123 shards=shards,
124 replicas=0,
125 interval="-1",
126 )
127 new_index.create(wait_for_active_shards=shards)
128
129 # From this point on, if any error occurs, we want to be able to delete our
130 # in progress index.
131 try:
132 request.db.execute("SET statement_timeout = '600s'")
133
134 for _ in parallel_bulk(client, _project_docs(request.db)):
135 pass
136 except: # noqa
137 new_index.delete()
138 raise
139 finally:
140 request.db.rollback()
141 request.db.close()
142
143 # Now that we've finished indexing all of our data we can optimize it and
144 # update the replicas and refresh intervals.
145 client.indices.forcemerge(index=new_index_name)
146 client.indices.put_settings(
147 index=new_index_name,
148 body={
149 "index": {
150 "number_of_replicas": number_of_replicas,
151 "refresh_interval": refresh_interval,
152 }
153 }
154 )
155
156 # Point the alias at our new randomly named index and delete the old index.
157 if client.indices.exists_alias(name=index_base):
158 to_delete = set()
159 actions = []
160 for name in client.indices.get_alias(name=index_base):
161 to_delete.add(name)
162 actions.append({"remove": {"index": name, "alias": index_base}})
163 actions.append({"add": {"index": new_index_name, "alias": index_base}})
164 client.indices.update_aliases({"actions": actions})
165 client.indices.delete(",".join(to_delete))
166 else:
167 client.indices.put_alias(name=index_base, index=new_index_name)
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/search/tasks.py b/warehouse/search/tasks.py
--- a/warehouse/search/tasks.py
+++ b/warehouse/search/tasks.py
@@ -11,11 +11,15 @@
# limitations under the License.
import binascii
+import urllib
import os
from elasticsearch.helpers import parallel_bulk
+from elasticsearch_dsl import serializer
from sqlalchemy import and_, func
from sqlalchemy.orm import aliased
+import certifi
+import elasticsearch
from warehouse.packaging.models import (
Classifier, Project, Release, release_classifiers)
@@ -98,7 +102,15 @@
"""
Recreate the Search Index.
"""
- client = request.registry["elasticsearch.client"]
+ p = urllib.parse.urlparse(request.registry.settings["elasticsearch.url"])
+ client = elasticsearch.Elasticsearch(
+ [urllib.parse.urlunparse(p[:2] + ("",) * 4)],
+ verify_certs=True,
+ ca_certs=certifi.where(),
+ timeout=30,
+ retry_on_timeout=True,
+ serializer=serializer.serializer,
+ )
number_of_replicas = request.registry.get("elasticsearch.replicas", 0)
refresh_interval = request.registry.get("elasticsearch.interval", "1s")
|
{"golden_diff": "diff --git a/warehouse/search/tasks.py b/warehouse/search/tasks.py\n--- a/warehouse/search/tasks.py\n+++ b/warehouse/search/tasks.py\n@@ -11,11 +11,15 @@\n # limitations under the License.\n \n import binascii\n+import urllib\n import os\n \n from elasticsearch.helpers import parallel_bulk\n+from elasticsearch_dsl import serializer\n from sqlalchemy import and_, func\n from sqlalchemy.orm import aliased\n+import certifi\n+import elasticsearch\n \n from warehouse.packaging.models import (\n Classifier, Project, Release, release_classifiers)\n@@ -98,7 +102,15 @@\n \"\"\"\n Recreate the Search Index.\n \"\"\"\n- client = request.registry[\"elasticsearch.client\"]\n+ p = urllib.parse.urlparse(request.registry.settings[\"elasticsearch.url\"])\n+ client = elasticsearch.Elasticsearch(\n+ [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n+ verify_certs=True,\n+ ca_certs=certifi.where(),\n+ timeout=30,\n+ retry_on_timeout=True,\n+ serializer=serializer.serializer,\n+ )\n number_of_replicas = request.registry.get(\"elasticsearch.replicas\", 0)\n refresh_interval = request.registry.get(\"elasticsearch.interval\", \"1s\")\n", "issue": "Tune Elasticsearch client for reindex separately from main search client\n#3892 was necessary to alleviate the hard outage experienced due to ES cluster being down.\r\n\r\nWe were waiting 30s per request for Elasticsearch then retrying. This was added in #1471 to handle reindex issues.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport os\n\nfrom elasticsearch.helpers import parallel_bulk\nfrom sqlalchemy import and_, func\nfrom sqlalchemy.orm import aliased\n\nfrom warehouse.packaging.models import (\n Classifier, Project, Release, release_classifiers)\nfrom warehouse.packaging.search import Project as ProjectDocType\nfrom warehouse.search.utils import get_index\nfrom warehouse import tasks\nfrom warehouse.utils.db import windowed_query\n\n\ndef _project_docs(db):\n\n releases_list = (\n db.query(Release.name, Release.version)\n .order_by(\n Release.name,\n Release.is_prerelease.nullslast(),\n Release._pypi_ordering.desc(),\n )\n .distinct(Release.name)\n .subquery(\"release_list\")\n )\n\n r = aliased(Release, name=\"r\")\n\n all_versions = (\n db.query(func.array_agg(r.version))\n .filter(r.name == Release.name)\n .correlate(Release)\n .as_scalar()\n .label(\"all_versions\")\n )\n\n classifiers = (\n db.query(func.array_agg(Classifier.classifier))\n .select_from(release_classifiers)\n .join(Classifier, Classifier.id == release_classifiers.c.trove_id)\n .filter(Release.name == release_classifiers.c.name)\n .filter(Release.version == release_classifiers.c.version)\n .correlate(Release)\n .as_scalar()\n .label(\"classifiers\")\n )\n\n release_data = (\n db.query(\n Release.description,\n Release.name,\n Release.version.label(\"latest_version\"),\n all_versions,\n Release.author,\n Release.author_email,\n Release.maintainer,\n Release.maintainer_email,\n Release.home_page,\n Release.summary,\n Release.keywords,\n Release.platform,\n Release.download_url,\n Release.created,\n classifiers,\n Project.normalized_name,\n Project.name,\n )\n .select_from(releases_list)\n .join(Release, and_(\n Release.name == releases_list.c.name,\n Release.version == releases_list.c.version))\n .outerjoin(Release.project)\n .order_by(Release.name)\n )\n\n for release in windowed_query(release_data, Release.name, 50000):\n p = ProjectDocType.from_db(release)\n p.full_clean()\n yield p.to_dict(include_meta=True)\n\n\[email protected](ignore_result=True, acks_late=True)\ndef reindex(request):\n \"\"\"\n Recreate the Search Index.\n \"\"\"\n client = request.registry[\"elasticsearch.client\"]\n number_of_replicas = request.registry.get(\"elasticsearch.replicas\", 0)\n refresh_interval = request.registry.get(\"elasticsearch.interval\", \"1s\")\n\n # We use a randomly named index so that we can do a zero downtime reindex.\n # Essentially we'll use a randomly named index which we will use until all\n # of the data has been reindexed, at which point we'll point an alias at\n # our randomly named index, and then delete the old randomly named index.\n\n # Create the new index and associate all of our doc types with it.\n index_base = request.registry[\"elasticsearch.index\"]\n random_token = binascii.hexlify(os.urandom(5)).decode(\"ascii\")\n new_index_name = \"{}-{}\".format(index_base, random_token)\n doc_types = request.registry.get(\"search.doc_types\", set())\n shards = request.registry.get(\"elasticsearch.shards\", 1)\n\n # Create the new index with zero replicas and index refreshes disabled\n # while we are bulk indexing.\n new_index = get_index(\n new_index_name,\n doc_types,\n using=client,\n shards=shards,\n replicas=0,\n interval=\"-1\",\n )\n new_index.create(wait_for_active_shards=shards)\n\n # From this point on, if any error occurs, we want to be able to delete our\n # in progress index.\n try:\n request.db.execute(\"SET statement_timeout = '600s'\")\n\n for _ in parallel_bulk(client, _project_docs(request.db)):\n pass\n except: # noqa\n new_index.delete()\n raise\n finally:\n request.db.rollback()\n request.db.close()\n\n # Now that we've finished indexing all of our data we can optimize it and\n # update the replicas and refresh intervals.\n client.indices.forcemerge(index=new_index_name)\n client.indices.put_settings(\n index=new_index_name,\n body={\n \"index\": {\n \"number_of_replicas\": number_of_replicas,\n \"refresh_interval\": refresh_interval,\n }\n }\n )\n\n # Point the alias at our new randomly named index and delete the old index.\n if client.indices.exists_alias(name=index_base):\n to_delete = set()\n actions = []\n for name in client.indices.get_alias(name=index_base):\n to_delete.add(name)\n actions.append({\"remove\": {\"index\": name, \"alias\": index_base}})\n actions.append({\"add\": {\"index\": new_index_name, \"alias\": index_base}})\n client.indices.update_aliases({\"actions\": actions})\n client.indices.delete(\",\".join(to_delete))\n else:\n client.indices.put_alias(name=index_base, index=new_index_name)\n", "path": "warehouse/search/tasks.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport urllib\nimport os\n\nfrom elasticsearch.helpers import parallel_bulk\nfrom elasticsearch_dsl import serializer\nfrom sqlalchemy import and_, func\nfrom sqlalchemy.orm import aliased\nimport certifi\nimport elasticsearch\n\nfrom warehouse.packaging.models import (\n Classifier, Project, Release, release_classifiers)\nfrom warehouse.packaging.search import Project as ProjectDocType\nfrom warehouse.search.utils import get_index\nfrom warehouse import tasks\nfrom warehouse.utils.db import windowed_query\n\n\ndef _project_docs(db):\n\n releases_list = (\n db.query(Release.name, Release.version)\n .order_by(\n Release.name,\n Release.is_prerelease.nullslast(),\n Release._pypi_ordering.desc(),\n )\n .distinct(Release.name)\n .subquery(\"release_list\")\n )\n\n r = aliased(Release, name=\"r\")\n\n all_versions = (\n db.query(func.array_agg(r.version))\n .filter(r.name == Release.name)\n .correlate(Release)\n .as_scalar()\n .label(\"all_versions\")\n )\n\n classifiers = (\n db.query(func.array_agg(Classifier.classifier))\n .select_from(release_classifiers)\n .join(Classifier, Classifier.id == release_classifiers.c.trove_id)\n .filter(Release.name == release_classifiers.c.name)\n .filter(Release.version == release_classifiers.c.version)\n .correlate(Release)\n .as_scalar()\n .label(\"classifiers\")\n )\n\n release_data = (\n db.query(\n Release.description,\n Release.name,\n Release.version.label(\"latest_version\"),\n all_versions,\n Release.author,\n Release.author_email,\n Release.maintainer,\n Release.maintainer_email,\n Release.home_page,\n Release.summary,\n Release.keywords,\n Release.platform,\n Release.download_url,\n Release.created,\n classifiers,\n Project.normalized_name,\n Project.name,\n )\n .select_from(releases_list)\n .join(Release, and_(\n Release.name == releases_list.c.name,\n Release.version == releases_list.c.version))\n .outerjoin(Release.project)\n .order_by(Release.name)\n )\n\n for release in windowed_query(release_data, Release.name, 50000):\n p = ProjectDocType.from_db(release)\n p.full_clean()\n yield p.to_dict(include_meta=True)\n\n\[email protected](ignore_result=True, acks_late=True)\ndef reindex(request):\n \"\"\"\n Recreate the Search Index.\n \"\"\"\n p = urllib.parse.urlparse(request.registry.settings[\"elasticsearch.url\"])\n client = elasticsearch.Elasticsearch(\n [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n verify_certs=True,\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n serializer=serializer.serializer,\n )\n number_of_replicas = request.registry.get(\"elasticsearch.replicas\", 0)\n refresh_interval = request.registry.get(\"elasticsearch.interval\", \"1s\")\n\n # We use a randomly named index so that we can do a zero downtime reindex.\n # Essentially we'll use a randomly named index which we will use until all\n # of the data has been reindexed, at which point we'll point an alias at\n # our randomly named index, and then delete the old randomly named index.\n\n # Create the new index and associate all of our doc types with it.\n index_base = request.registry[\"elasticsearch.index\"]\n random_token = binascii.hexlify(os.urandom(5)).decode(\"ascii\")\n new_index_name = \"{}-{}\".format(index_base, random_token)\n doc_types = request.registry.get(\"search.doc_types\", set())\n shards = request.registry.get(\"elasticsearch.shards\", 1)\n\n # Create the new index with zero replicas and index refreshes disabled\n # while we are bulk indexing.\n new_index = get_index(\n new_index_name,\n doc_types,\n using=client,\n shards=shards,\n replicas=0,\n interval=\"-1\",\n )\n new_index.create(wait_for_active_shards=shards)\n\n # From this point on, if any error occurs, we want to be able to delete our\n # in progress index.\n try:\n request.db.execute(\"SET statement_timeout = '600s'\")\n\n for _ in parallel_bulk(client, _project_docs(request.db)):\n pass\n except: # noqa\n new_index.delete()\n raise\n finally:\n request.db.rollback()\n request.db.close()\n\n # Now that we've finished indexing all of our data we can optimize it and\n # update the replicas and refresh intervals.\n client.indices.forcemerge(index=new_index_name)\n client.indices.put_settings(\n index=new_index_name,\n body={\n \"index\": {\n \"number_of_replicas\": number_of_replicas,\n \"refresh_interval\": refresh_interval,\n }\n }\n )\n\n # Point the alias at our new randomly named index and delete the old index.\n if client.indices.exists_alias(name=index_base):\n to_delete = set()\n actions = []\n for name in client.indices.get_alias(name=index_base):\n to_delete.add(name)\n actions.append({\"remove\": {\"index\": name, \"alias\": index_base}})\n actions.append({\"add\": {\"index\": new_index_name, \"alias\": index_base}})\n client.indices.update_aliases({\"actions\": actions})\n client.indices.delete(\",\".join(to_delete))\n else:\n client.indices.put_alias(name=index_base, index=new_index_name)\n", "path": "warehouse/search/tasks.py"}]}
| 1,951 | 281 |
gh_patches_debug_5071
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1596
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Permission denied: '/tmp/logfile'
The submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:
```
(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI⟫ python scripts/workers/submission_worker.py settings.prod
Traceback (most recent call last):
File "scripts/workers/submission_worker.py", line 44, in <module>
django.setup()
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py", line 22, in setup
configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py", line 75, in configure_logging
logging_config_func(logging_settings)
File "/usr/lib/python2.7/logging/config.py", line 794, in dictConfig
dictConfigClass(config).configure()
File "/usr/lib/python2.7/logging/config.py", line 576, in configure
'%r: %s' % (name, e))
ValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'
```
Permission denied: '/tmp/logfile'
The submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:
```
(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI⟫ python scripts/workers/submission_worker.py settings.prod
Traceback (most recent call last):
File "scripts/workers/submission_worker.py", line 44, in <module>
django.setup()
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py", line 22, in setup
configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)
File "/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py", line 75, in configure_logging
logging_config_func(logging_settings)
File "/usr/lib/python2.7/logging/config.py", line 794, in dictConfig
dictConfigClass(config).configure()
File "/usr/lib/python2.7/logging/config.py", line 576, in configure
'%r: %s' % (name, e))
ValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `settings/common.py`
Content:
```
1 """
2 Django settings for evalai project.
3
4 Generated by 'django-admin startproject' using Django 1.10.2.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.10/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.10/ref/settings/
11 """
12
13 import datetime
14 import os
15 import sys
16
17 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
18 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
19 APPS_DIR = os.path.join(BASE_DIR, 'apps')
20
21 sys.path.append(APPS_DIR)
22
23 # Quick-start development settings - unsuitable for production
24 # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
25
26 # SECURITY WARNING: keep the secret key used in production secret!
27 SECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')
28
29 # SECURITY WARNING: don't run with debug turned on in production!
30 DEBUG = True
31
32 ALLOWED_HOSTS = []
33
34
35 # Application definition
36
37 DEFAULT_APPS = [
38 'django.contrib.admin',
39 'django.contrib.auth',
40 'django.contrib.contenttypes',
41 'django.contrib.sessions',
42 'django.contrib.messages',
43 'django.contrib.staticfiles',
44 'django.contrib.sites',
45 ]
46
47 OUR_APPS = [
48 'accounts',
49 'analytics',
50 'base',
51 'challenges',
52 'hosts',
53 'jobs',
54 'participants',
55 'web',
56 ]
57
58 THIRD_PARTY_APPS = [
59 'allauth',
60 'allauth.account',
61 'corsheaders',
62 'import_export',
63 'rest_auth',
64 'rest_auth.registration',
65 'rest_framework.authtoken',
66 'rest_framework',
67 'rest_framework_docs',
68 'rest_framework_expiring_authtoken',
69 ]
70
71 INSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS
72
73 MIDDLEWARE = [
74 'corsheaders.middleware.CorsMiddleware',
75 'django.middleware.security.SecurityMiddleware',
76 'django.contrib.sessions.middleware.SessionMiddleware',
77 'django.middleware.common.CommonMiddleware',
78 'django.middleware.csrf.CsrfViewMiddleware',
79 'django.contrib.auth.middleware.AuthenticationMiddleware',
80 'django.contrib.messages.middleware.MessageMiddleware',
81 'django.middleware.clickjacking.XFrameOptionsMiddleware',
82 ]
83
84 ROOT_URLCONF = 'evalai.urls'
85
86
87 TEMPLATES = [
88 {
89 'BACKEND': 'django.template.backends.django.DjangoTemplates',
90 'DIRS': [],
91 'APP_DIRS': True,
92 'OPTIONS': {
93 'context_processors': [
94 'django.template.context_processors.debug',
95 'django.template.context_processors.request',
96 'django.contrib.auth.context_processors.auth',
97 'django.contrib.messages.context_processors.messages',
98 ],
99 },
100 },
101 ]
102
103 WSGI_APPLICATION = 'evalai.wsgi.application'
104
105
106 # Password validation
107 # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
108
109 AUTH_PASSWORD_VALIDATORS = [
110 {
111 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa
112 },
113 {
114 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa
115 },
116 {
117 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa
118 },
119 {
120 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa
121 },
122 ]
123
124
125 # Internationalization
126 # https://docs.djangoproject.com/en/1.10/topics/i18n/
127
128 LANGUAGE_CODE = 'en-us'
129
130 TIME_ZONE = 'UTC'
131
132 USE_I18N = True
133
134 USE_L10N = True
135
136 USE_TZ = True
137
138 # Static files (CSS, JavaScript, Images)
139 # https://docs.djangoproject.com/en/1.10/howto/static-files/
140
141 STATIC_URL = '/static/'
142 STATIC_ROOT = os.path.join(BASE_DIR, 'static')
143 MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
144 MEDIA_URL = "/media/"
145
146 SITE_ID = 1
147
148 REST_FRAMEWORK = {
149 'DEFAULT_PAGINATION_CLASS': (
150 'rest_framework.pagination.LimitOffsetPagination'),
151 'PAGE_SIZE': 10,
152 'DEFAULT_PERMISSION_CLASSES': [
153 'rest_framework.permissions.IsAuthenticatedOrReadOnly'
154 ],
155 'DEFAULT_AUTHENTICATION_CLASSES': [
156 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',
157 ],
158 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
159 'DEFAULT_THROTTLE_CLASSES': (
160 'rest_framework.throttling.AnonRateThrottle',
161 'rest_framework.throttling.UserRateThrottle'
162 ),
163 'DEFAULT_THROTTLE_RATES': {
164 'anon': '100/minute',
165 'user': '100/minute'
166 },
167 'DEFAULT_RENDERER_CLASSES': (
168 'rest_framework.renderers.JSONRenderer',
169 )
170 }
171
172 # ALLAUTH SETTINGS
173 ACCOUNT_EMAIL_REQUIRED = True
174 OLD_PASSWORD_FIELD_ENABLED = True
175 ACCOUNT_CONFIRM_EMAIL_ON_GET = True
176 ACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'
177 ACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'
178
179 AUTHENTICATION_BACKENDS = (
180 # Needed to login by username in Django admin, regardless of `allauth`
181 'django.contrib.auth.backends.ModelBackend',
182 # `allauth` specific authentication methods, such as login by e-mail
183 'allauth.account.auth_backends.AuthenticationBackend',
184 )
185
186 # CORS Settings
187 CORS_ORIGIN_ALLOW_ALL = True
188
189 # REST Framework Expiring Tokens Configuration
190 EXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)
191
192 # Logging
193 LOGGING = {
194 'version': 1,
195 'disable_existing_loggers': False,
196 'root': {
197 'level': 'INFO',
198 'handlers': ['console'],
199 },
200 'filters': {
201 'require_debug_false': {
202 '()': 'django.utils.log.RequireDebugFalse',
203 },
204 'require_debug_true': {
205 '()': 'django.utils.log.RequireDebugTrue',
206 }
207 },
208 'formatters': {
209 'simple': {
210 'format': '[%(asctime)s] %(levelname)s %(message)s',
211 'datefmt': '%Y-%m-%d %H:%M:%S'
212 },
213 'verbose': {
214 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',
215 'datefmt': '%Y-%m-%d %H:%M:%S'
216 }
217 },
218 'handlers': {
219 'console': {
220 'level': 'INFO',
221 'filters': ['require_debug_true'],
222 'class': 'logging.StreamHandler',
223 'formatter': 'simple'
224 },
225 'logfile': {
226 'level': 'DEBUG',
227 'class': 'logging.handlers.RotatingFileHandler',
228 'filename': "/tmp/logfile",
229 'maxBytes': 50000,
230 'backupCount': 10,
231 'formatter': 'verbose'
232 },
233 'mail_admins': {
234 'level': 'ERROR',
235 'class': 'django.utils.log.AdminEmailHandler',
236 'filters': ['require_debug_false'],
237 }
238 },
239 'loggers': {
240 'django': {
241 'handlers': ['console'],
242 'propagate': False,
243 },
244 'django.request': {
245 'handlers': ['mail_admins'],
246 'level': 'ERROR',
247 'propagate': False,
248 },
249 'django.security': {
250 'handlers': ['mail_admins'],
251 'level': 'ERROR',
252 'propagate': False,
253 },
254 'django.db.backends': {
255 'handlers': ['mail_admins'],
256 'level': 'ERROR',
257 'propagate': False,
258 }
259 }
260 }
261
262 CACHES = {
263 'default': {
264 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
265 }
266 }
267
268 RABBITMQ_PARAMETERS = {
269 'HOST': os.environ.get("RABBITMQ_HOST", 'localhost'),
270 'EVALAI_EXCHANGE': {
271 'NAME': 'evalai_submissions',
272 'TYPE': 'topic',
273 },
274 'SUBMISSION_QUEUE': 'submission_task_queue',
275 }
276
277 # The maximum size in bytes for request body
278 # https://docs.djangoproject.com/en/1.10/ref/settings/#data-upload-max-memory-size
279 FILE_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB
280 DATA_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB
281
282 # To make usermame field read-only, customized serializer is defined.
283 REST_AUTH_SERIALIZERS = {
284 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',
285 }
286
287 # For inviting users to participant and host teams.
288 ADMIN_EMAIL = "[email protected]"
289
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/settings/common.py b/settings/common.py
--- a/settings/common.py
+++ b/settings/common.py
@@ -225,7 +225,7 @@
'logfile': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
- 'filename': "/tmp/logfile",
+ 'filename': os.path.join(BASE_DIR, 'django.log'),
'maxBytes': 50000,
'backupCount': 10,
'formatter': 'verbose'
|
{"golden_diff": "diff --git a/settings/common.py b/settings/common.py\n--- a/settings/common.py\n+++ b/settings/common.py\n@@ -225,7 +225,7 @@\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n- 'filename': \"/tmp/logfile\",\n+ 'filename': os.path.join(BASE_DIR, 'django.log'),\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n", "issue": "Permission denied: '/tmp/logfile'\nThe submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:\r\n\r\n```\r\n(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI\u27eb python scripts/workers/submission_worker.py settings.prod\r\nTraceback (most recent call last):\r\n File \"scripts/workers/submission_worker.py\", line 44, in <module>\r\n django.setup()\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py\", line 22, in setup\r\n configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py\", line 75, in configure_logging\r\n logging_config_func(logging_settings)\r\n File \"/usr/lib/python2.7/logging/config.py\", line 794, in dictConfig\r\n dictConfigClass(config).configure()\r\n File \"/usr/lib/python2.7/logging/config.py\", line 576, in configure\r\n '%r: %s' % (name, e))\r\nValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'\r\n```\nPermission denied: '/tmp/logfile'\nThe submission worker currently faces the problem of permission denied due to the dependency on `/tmp/logfile`. Here is the error log:\r\n\r\n```\r\n(EvalAI) 137 ubuntu@staging-evalai:~/Projects/EvalAI\u27eb python scripts/workers/submission_worker.py settings.prod\r\nTraceback (most recent call last):\r\n File \"scripts/workers/submission_worker.py\", line 44, in <module>\r\n django.setup()\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/__init__.py\", line 22, in setup\r\n configure_logging(settings.LOGGING_CONFIG, settings.LOGGING)\r\n File \"/home/ubuntu/.virtualenvs/EvalAI/local/lib/python2.7/site-packages/django/utils/log.py\", line 75, in configure_logging\r\n logging_config_func(logging_settings)\r\n File \"/usr/lib/python2.7/logging/config.py\", line 794, in dictConfig\r\n dictConfigClass(config).configure()\r\n File \"/usr/lib/python2.7/logging/config.py\", line 576, in configure\r\n '%r: %s' % (name, e))\r\nValueError: Unable to configure handler 'logfile': [Errno 13] Permission denied: '/tmp/logfile'\r\n```\n", "before_files": [{"content": "\"\"\"\nDjango settings for evalai project.\n\nGenerated by 'django-admin startproject' using Django 1.10.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport datetime\nimport os\nimport sys\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nAPPS_DIR = os.path.join(BASE_DIR, 'apps')\n\nsys.path.append(APPS_DIR)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n\n# Application definition\n\nDEFAULT_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.sites',\n]\n\nOUR_APPS = [\n 'accounts',\n 'analytics',\n 'base',\n 'challenges',\n 'hosts',\n 'jobs',\n 'participants',\n 'web',\n]\n\nTHIRD_PARTY_APPS = [\n 'allauth',\n 'allauth.account',\n 'corsheaders',\n 'import_export',\n 'rest_auth',\n 'rest_auth.registration',\n 'rest_framework.authtoken',\n 'rest_framework',\n 'rest_framework_docs',\n 'rest_framework_expiring_authtoken',\n]\n\nINSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS\n\nMIDDLEWARE = [\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'evalai.urls'\n\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'evalai.wsgi.application'\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.10/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = \"/media/\"\n\nSITE_ID = 1\n\nREST_FRAMEWORK = {\n 'DEFAULT_PAGINATION_CLASS': (\n 'rest_framework.pagination.LimitOffsetPagination'),\n 'PAGE_SIZE': 10,\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticatedOrReadOnly'\n ],\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',\n ],\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'DEFAULT_THROTTLE_CLASSES': (\n 'rest_framework.throttling.AnonRateThrottle',\n 'rest_framework.throttling.UserRateThrottle'\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'anon': '100/minute',\n 'user': '100/minute'\n },\n 'DEFAULT_RENDERER_CLASSES': (\n 'rest_framework.renderers.JSONRenderer',\n )\n}\n\n# ALLAUTH SETTINGS\nACCOUNT_EMAIL_REQUIRED = True\nOLD_PASSWORD_FIELD_ENABLED = True\nACCOUNT_CONFIRM_EMAIL_ON_GET = True\nACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'\nACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# REST Framework Expiring Tokens Configuration\nEXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)\n\n# Logging\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'root': {\n 'level': 'INFO',\n 'handlers': ['console'],\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse',\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue',\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '[%(asctime)s] %(levelname)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'verbose': {\n 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'console': {\n 'level': 'INFO',\n 'filters': ['require_debug_true'],\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n },\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n 'filename': \"/tmp/logfile\",\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n },\n 'mail_admins': {\n 'level': 'ERROR',\n 'class': 'django.utils.log.AdminEmailHandler',\n 'filters': ['require_debug_false'],\n }\n },\n 'loggers': {\n 'django': {\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.security': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.db.backends': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n }\n }\n}\n\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n }\n}\n\nRABBITMQ_PARAMETERS = {\n 'HOST': os.environ.get(\"RABBITMQ_HOST\", 'localhost'),\n 'EVALAI_EXCHANGE': {\n 'NAME': 'evalai_submissions',\n 'TYPE': 'topic',\n },\n 'SUBMISSION_QUEUE': 'submission_task_queue',\n}\n\n# The maximum size in bytes for request body\n# https://docs.djangoproject.com/en/1.10/ref/settings/#data-upload-max-memory-size\nFILE_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\nDATA_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\n\n# To make usermame field read-only, customized serializer is defined.\nREST_AUTH_SERIALIZERS = {\n 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',\n}\n\n# For inviting users to participant and host teams.\nADMIN_EMAIL = \"[email protected]\"\n", "path": "settings/common.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for evalai project.\n\nGenerated by 'django-admin startproject' using Django 1.10.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport datetime\nimport os\nimport sys\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nAPPS_DIR = os.path.join(BASE_DIR, 'apps')\n\nsys.path.append(APPS_DIR)\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get('SECRET_KEY', 'random_secret_key')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n\n# Application definition\n\nDEFAULT_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.sites',\n]\n\nOUR_APPS = [\n 'accounts',\n 'analytics',\n 'base',\n 'challenges',\n 'hosts',\n 'jobs',\n 'participants',\n 'web',\n]\n\nTHIRD_PARTY_APPS = [\n 'allauth',\n 'allauth.account',\n 'corsheaders',\n 'import_export',\n 'rest_auth',\n 'rest_auth.registration',\n 'rest_framework.authtoken',\n 'rest_framework',\n 'rest_framework_docs',\n 'rest_framework_expiring_authtoken',\n]\n\nINSTALLED_APPS = DEFAULT_APPS + OUR_APPS + THIRD_PARTY_APPS\n\nMIDDLEWARE = [\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'evalai.urls'\n\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'evalai.wsgi.application'\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.10/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = \"/media/\"\n\nSITE_ID = 1\n\nREST_FRAMEWORK = {\n 'DEFAULT_PAGINATION_CLASS': (\n 'rest_framework.pagination.LimitOffsetPagination'),\n 'PAGE_SIZE': 10,\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticatedOrReadOnly'\n ],\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework_expiring_authtoken.authentication.ExpiringTokenAuthentication',\n ],\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'DEFAULT_THROTTLE_CLASSES': (\n 'rest_framework.throttling.AnonRateThrottle',\n 'rest_framework.throttling.UserRateThrottle'\n ),\n 'DEFAULT_THROTTLE_RATES': {\n 'anon': '100/minute',\n 'user': '100/minute'\n },\n 'DEFAULT_RENDERER_CLASSES': (\n 'rest_framework.renderers.JSONRenderer',\n )\n}\n\n# ALLAUTH SETTINGS\nACCOUNT_EMAIL_REQUIRED = True\nOLD_PASSWORD_FIELD_ENABLED = True\nACCOUNT_CONFIRM_EMAIL_ON_GET = True\nACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = '/api/auth/email-confirmed/'\nACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = '/api/auth/email-confirmed/'\n\nAUTHENTICATION_BACKENDS = (\n # Needed to login by username in Django admin, regardless of `allauth`\n 'django.contrib.auth.backends.ModelBackend',\n # `allauth` specific authentication methods, such as login by e-mail\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\n\n# REST Framework Expiring Tokens Configuration\nEXPIRING_TOKEN_LIFESPAN = datetime.timedelta(days=7)\n\n# Logging\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'root': {\n 'level': 'INFO',\n 'handlers': ['console'],\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse',\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue',\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '[%(asctime)s] %(levelname)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'verbose': {\n 'format': '[%(asctime)s] %(levelname)s %(module)s %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'console': {\n 'level': 'INFO',\n 'filters': ['require_debug_true'],\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n },\n 'logfile': {\n 'level': 'DEBUG',\n 'class': 'logging.handlers.RotatingFileHandler',\n 'filename': os.path.join(BASE_DIR, 'django.log'),\n 'maxBytes': 50000,\n 'backupCount': 10,\n 'formatter': 'verbose'\n },\n 'mail_admins': {\n 'level': 'ERROR',\n 'class': 'django.utils.log.AdminEmailHandler',\n 'filters': ['require_debug_false'],\n }\n },\n 'loggers': {\n 'django': {\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.security': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n },\n 'django.db.backends': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': False,\n }\n }\n}\n\nCACHES = {\n 'default': {\n 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',\n }\n}\n\nRABBITMQ_PARAMETERS = {\n 'HOST': os.environ.get(\"RABBITMQ_HOST\", 'localhost'),\n 'EVALAI_EXCHANGE': {\n 'NAME': 'evalai_submissions',\n 'TYPE': 'topic',\n },\n 'SUBMISSION_QUEUE': 'submission_task_queue',\n}\n\n# The maximum size in bytes for request body\n# https://docs.djangoproject.com/en/1.10/ref/settings/#data-upload-max-memory-size\nFILE_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\nDATA_UPLOAD_MAX_MEMORY_SIZE = 524288000 # 500 MB\n\n# To make usermame field read-only, customized serializer is defined.\nREST_AUTH_SERIALIZERS = {\n 'USER_DETAILS_SERIALIZER': 'accounts.serializers.ProfileSerializer',\n}\n\n# For inviting users to participant and host teams.\nADMIN_EMAIL = \"[email protected]\"\n", "path": "settings/common.py"}]}
| 3,481 | 116 |
gh_patches_debug_14506
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-522
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clean up test fixtures in Hydra and plugins
Should use conftest.py to simplify
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `noxfile.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 import copy
4 import os
5 import platform
6 from typing import List
7
8 import nox
9 from nox.logger import logger
10
11 BASE = os.path.abspath(os.path.dirname(__file__))
12
13 DEFAULT_PYTHON_VERSIONS = ["3.6", "3.7", "3.8"]
14 DEFAULT_OS_NAMES = ["Linux", "MacOS", "Windows"]
15
16 PYTHON_VERSIONS = os.environ.get(
17 "NOX_PYTHON_VERSIONS", ",".join(DEFAULT_PYTHON_VERSIONS)
18 ).split(",")
19
20 PLUGINS_INSTALL_COMMANDS = (["pip", "install"], ["pip", "install", "-e"])
21
22 # Allow limiting testing to specific plugins
23 # The list ['ALL'] indicates all plugins
24 PLUGINS = os.environ.get("PLUGINS", "ALL").split(",")
25
26 SKIP_CORE_TESTS = "0"
27 SKIP_CORE_TESTS = os.environ.get("SKIP_CORE_TESTS", SKIP_CORE_TESTS) != "0"
28
29 SILENT = os.environ.get("VERBOSE", "0") == "0"
30
31
32 def get_current_os() -> str:
33 current_os = platform.system()
34 if current_os == "Darwin":
35 current_os = "MacOS"
36 return current_os
37
38
39 print(f"Operating system\t:\t{get_current_os()}")
40 print(f"PYTHON_VERSIONS\t\t:\t{PYTHON_VERSIONS}")
41 print(f"PLUGINS\t\t\t:\t{PLUGINS}")
42 print(f"SKIP_CORE_TESTS\t\t:\t{SKIP_CORE_TESTS}")
43
44
45 def find_python_files(folder):
46 for root, folders, files in os.walk(folder):
47 for filename in folders + files:
48 if filename.endswith(".py"):
49 yield os.path.join(root, filename)
50
51
52 def install_hydra(session, cmd):
53 # clean install hydra
54 session.chdir(BASE)
55 session.run(*cmd, ".", silent=SILENT)
56
57
58 def pytest_args(session, *args):
59 ret = ["pytest"]
60 ret.extend(args)
61 if len(session.posargs) > 0:
62 ret.extend(session.posargs)
63 return ret
64
65
66 def run_pytest(session, directory="."):
67 pytest_cmd = pytest_args(session, directory)
68 session.run(*pytest_cmd, silent=SILENT)
69
70
71 def get_setup_python_versions(classifiers):
72 pythons = filter(lambda line: "Programming Language :: Python" in line, classifiers)
73 return [p[len("Programming Language :: Python :: ") :] for p in pythons]
74
75
76 def get_plugin_os_names(classifiers: List[str]) -> List[str]:
77 oses = list(filter(lambda line: "Operating System" in line, classifiers))
78 if len(oses) == 0:
79 # No Os is specified so all oses are supported
80 return DEFAULT_OS_NAMES
81 if len(oses) == 1 and oses[0] == "Operating System :: OS Independent":
82 # All oses are supported
83 return DEFAULT_OS_NAMES
84 else:
85 return [p.split("::")[-1].strip() for p in oses]
86
87
88 def select_plugins(session):
89 """
90 Select all plugins that should be tested in this session.
91 Considers the current Python version and operating systems against the supported ones,
92 as well as the user plugins selection (via the PLUGINS environment variable).
93 """
94
95 assert session.python is not None, "Session python version is not specified"
96
97 example_plugins = [
98 {"name": x, "path": "examples/{}".format(x)}
99 for x in sorted(os.listdir(os.path.join(BASE, "plugins/examples")))
100 ]
101 plugins = [
102 {"name": x, "path": x}
103 for x in sorted(os.listdir(os.path.join(BASE, "plugins")))
104 if x != "examples"
105 ]
106 available_plugins = plugins + example_plugins
107
108 ret = []
109 skipped = []
110 for plugin in available_plugins:
111 if not (plugin["name"] in PLUGINS or PLUGINS == ["ALL"]):
112 skipped.append(f"Deselecting {plugin['name']}: User request")
113 continue
114
115 setup_py = os.path.join(BASE, "plugins", plugin["path"], "setup.py")
116 classifiers = session.run(
117 "python", setup_py, "--classifiers", silent=True
118 ).splitlines()
119
120 plugin_python_versions = get_setup_python_versions(classifiers)
121 python_supported = session.python in plugin_python_versions
122
123 plugin_os_names = get_plugin_os_names(classifiers)
124 os_supported = get_current_os() in plugin_os_names
125
126 if not python_supported:
127 py_str = ", ".join(plugin_python_versions)
128 skipped.append(
129 f"Deselecting {plugin['name']} : Incompatible Python {session.python}. Supports [{py_str}]"
130 )
131 continue
132
133 # Verify this plugin supports the OS we are testing on, skip otherwise
134 if not os_supported:
135 os_str = ", ".join(plugin_os_names)
136 skipped.append(
137 f"Deselecting {plugin['name']}: Incompatible OS {get_current_os()}. Supports [{os_str}]"
138 )
139 continue
140
141 ret.append(
142 {
143 "name": plugin["name"],
144 "path": plugin["path"],
145 "module": "hydra_plugins." + plugin["name"],
146 }
147 )
148
149 for msg in skipped:
150 logger.warn(msg)
151
152 if len(ret) == 0:
153 logger.warn("No plugins selected")
154 return ret
155
156
157 @nox.session(python=PYTHON_VERSIONS)
158 def lint(session):
159 session.install("--upgrade", "setuptools", "pip", silent=SILENT)
160 session.run("pip", "install", "-r", "requirements/dev.txt", silent=SILENT)
161 session.run("pip", "install", "-e", ".", silent=SILENT)
162 session.run("flake8", "--config", ".circleci/flake8_py3.cfg")
163
164 session.install("black")
165 # if this fails you need to format your code with black
166 session.run("black", "--check", ".", silent=SILENT)
167
168 session.run("isort", "--check", ".", silent=SILENT)
169
170 # Mypy
171 session.run("mypy", ".", "--strict", silent=SILENT)
172
173 # Mypy for plugins
174 for plugin in select_plugins(session):
175 session.run(
176 "mypy", os.path.join("plugins", plugin["path"]), "--strict", silent=SILENT
177 )
178
179 # Mypy for examples
180 for pyfie in find_python_files("examples"):
181 session.run("mypy", pyfie, "--strict", silent=SILENT)
182
183
184 @nox.session(python=PYTHON_VERSIONS)
185 @nox.parametrize(
186 "install_cmd",
187 PLUGINS_INSTALL_COMMANDS,
188 ids=[" ".join(x) for x in PLUGINS_INSTALL_COMMANDS],
189 )
190 def test_core(session, install_cmd):
191 session.install("--upgrade", "setuptools", "pip")
192 install_hydra(session, install_cmd)
193 session.install("pytest")
194 run_pytest(session, "tests")
195
196 # test discovery_test_plugin
197 run_pytest(session, "tests/test_plugins/discovery_test_plugin")
198
199 # Install and test example app
200 session.run(*install_cmd, "examples/advanced/hydra_app_example", silent=SILENT)
201 run_pytest(session, "examples/advanced/hydra_app_example")
202
203
204 @nox.session(python=PYTHON_VERSIONS)
205 @nox.parametrize(
206 "install_cmd",
207 PLUGINS_INSTALL_COMMANDS,
208 ids=[" ".join(x) for x in PLUGINS_INSTALL_COMMANDS],
209 )
210 def test_plugins(session, install_cmd):
211 session.install("--upgrade", "setuptools", "pip")
212 session.install("pytest")
213 install_hydra(session, install_cmd)
214 selected_plugin = select_plugins(session)
215 # Install all supported plugins in session
216 for plugin in selected_plugin:
217 cmd = list(install_cmd) + [os.path.join("plugins", plugin["path"])]
218 session.run(*cmd, silent=SILENT)
219
220 # Test that we can import Hydra
221 session.run("python", "-c", "from hydra import main", silent=SILENT)
222
223 # Test that we can import all installed plugins
224 for plugin in selected_plugin:
225 session.run("python", "-c", "import {}".format(plugin["module"]))
226
227 # Run Hydra tests to verify installed plugins did not break anything
228 if not SKIP_CORE_TESTS:
229 run_pytest(session, "tests")
230 else:
231 session.log("Skipping Hydra core tests")
232
233 # Run tests for all installed plugins
234 for plugin in selected_plugin:
235 # install all other plugins that are compatible with the current Python version
236 session.chdir(os.path.join(BASE, "plugins", plugin["path"]))
237 run_pytest(session)
238
239
240 @nox.session(python="3.8")
241 def coverage(session):
242 coverage_env = {
243 "COVERAGE_HOME": BASE,
244 "COVERAGE_FILE": f"{BASE}/.coverage",
245 "COVERAGE_RCFILE": f"{BASE}/.coveragerc",
246 }
247
248 session.install("--upgrade", "setuptools", "pip")
249 session.install("coverage", "pytest")
250 session.run("pip", "install", "-e", ".", silent=SILENT)
251 session.run("coverage", "erase")
252
253 selected_plugins = select_plugins(session)
254 for plugin in selected_plugins:
255 session.run(
256 "pip",
257 "install",
258 "-e",
259 os.path.join("plugins", plugin["path"]),
260 silent=SILENT,
261 )
262
263 session.run("coverage", "erase", env=coverage_env)
264 # run plugin coverage
265 for plugin in selected_plugins:
266 session.chdir(os.path.join("plugins", plugin["path"]))
267 cov_args = ["coverage", "run", "--append", "-m"]
268 cov_args.extend(pytest_args(session))
269 session.run(*cov_args, silent=SILENT, env=coverage_env)
270 session.chdir(BASE)
271
272 # run hydra-core coverage
273 session.run(
274 "coverage",
275 "run",
276 "--append",
277 "-m",
278 silent=SILENT,
279 env=coverage_env,
280 *pytest_args(session),
281 )
282
283 # Increase the fail_under as coverage improves
284 session.run("coverage", "report", "--fail-under=80", env=coverage_env)
285 session.run("coverage", "erase", env=coverage_env)
286
287
288 @nox.session(python=PYTHON_VERSIONS)
289 def test_jupyter_notebook(session):
290 versions = copy.copy(DEFAULT_PYTHON_VERSIONS)
291 if session.python not in versions:
292 session.skip(
293 f"Not testing Jupyter notebook on Python {session.python}, supports [{','.join(versions)}]"
294 )
295 session.install("--upgrade", "setuptools", "pip")
296 session.install("jupyter", "nbval")
297 install_hydra(session, ["pip", "install", "-e"])
298 session.run(
299 *pytest_args(
300 session, "--nbval", "examples/notebook/hydra_notebook_example.ipynb"
301 ),
302 silent=SILENT,
303 )
304
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -63,8 +63,8 @@
return ret
-def run_pytest(session, directory="."):
- pytest_cmd = pytest_args(session, directory)
+def run_pytest(session, directory=".", *args):
+ pytest_cmd = pytest_args(session, directory, *args)
session.run(*pytest_cmd, silent=SILENT)
@@ -194,7 +194,7 @@
run_pytest(session, "tests")
# test discovery_test_plugin
- run_pytest(session, "tests/test_plugins/discovery_test_plugin")
+ run_pytest(session, "tests/test_plugins/discovery_test_plugin", "--noconftest")
# Install and test example app
session.run(*install_cmd, "examples/advanced/hydra_app_example", silent=SILENT)
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -63,8 +63,8 @@\n return ret\n \n \n-def run_pytest(session, directory=\".\"):\n- pytest_cmd = pytest_args(session, directory)\n+def run_pytest(session, directory=\".\", *args):\n+ pytest_cmd = pytest_args(session, directory, *args)\n session.run(*pytest_cmd, silent=SILENT)\n \n \n@@ -194,7 +194,7 @@\n run_pytest(session, \"tests\")\n \n # test discovery_test_plugin\n- run_pytest(session, \"tests/test_plugins/discovery_test_plugin\")\n+ run_pytest(session, \"tests/test_plugins/discovery_test_plugin\", \"--noconftest\")\n \n # Install and test example app\n session.run(*install_cmd, \"examples/advanced/hydra_app_example\", silent=SILENT)\n", "issue": "Clean up test fixtures in Hydra and plugins\nShould use conftest.py to simplify\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nimport copy\nimport os\nimport platform\nfrom typing import List\n\nimport nox\nfrom nox.logger import logger\n\nBASE = os.path.abspath(os.path.dirname(__file__))\n\nDEFAULT_PYTHON_VERSIONS = [\"3.6\", \"3.7\", \"3.8\"]\nDEFAULT_OS_NAMES = [\"Linux\", \"MacOS\", \"Windows\"]\n\nPYTHON_VERSIONS = os.environ.get(\n \"NOX_PYTHON_VERSIONS\", \",\".join(DEFAULT_PYTHON_VERSIONS)\n).split(\",\")\n\nPLUGINS_INSTALL_COMMANDS = ([\"pip\", \"install\"], [\"pip\", \"install\", \"-e\"])\n\n# Allow limiting testing to specific plugins\n# The list ['ALL'] indicates all plugins\nPLUGINS = os.environ.get(\"PLUGINS\", \"ALL\").split(\",\")\n\nSKIP_CORE_TESTS = \"0\"\nSKIP_CORE_TESTS = os.environ.get(\"SKIP_CORE_TESTS\", SKIP_CORE_TESTS) != \"0\"\n\nSILENT = os.environ.get(\"VERBOSE\", \"0\") == \"0\"\n\n\ndef get_current_os() -> str:\n current_os = platform.system()\n if current_os == \"Darwin\":\n current_os = \"MacOS\"\n return current_os\n\n\nprint(f\"Operating system\\t:\\t{get_current_os()}\")\nprint(f\"PYTHON_VERSIONS\\t\\t:\\t{PYTHON_VERSIONS}\")\nprint(f\"PLUGINS\\t\\t\\t:\\t{PLUGINS}\")\nprint(f\"SKIP_CORE_TESTS\\t\\t:\\t{SKIP_CORE_TESTS}\")\n\n\ndef find_python_files(folder):\n for root, folders, files in os.walk(folder):\n for filename in folders + files:\n if filename.endswith(\".py\"):\n yield os.path.join(root, filename)\n\n\ndef install_hydra(session, cmd):\n # clean install hydra\n session.chdir(BASE)\n session.run(*cmd, \".\", silent=SILENT)\n\n\ndef pytest_args(session, *args):\n ret = [\"pytest\"]\n ret.extend(args)\n if len(session.posargs) > 0:\n ret.extend(session.posargs)\n return ret\n\n\ndef run_pytest(session, directory=\".\"):\n pytest_cmd = pytest_args(session, directory)\n session.run(*pytest_cmd, silent=SILENT)\n\n\ndef get_setup_python_versions(classifiers):\n pythons = filter(lambda line: \"Programming Language :: Python\" in line, classifiers)\n return [p[len(\"Programming Language :: Python :: \") :] for p in pythons]\n\n\ndef get_plugin_os_names(classifiers: List[str]) -> List[str]:\n oses = list(filter(lambda line: \"Operating System\" in line, classifiers))\n if len(oses) == 0:\n # No Os is specified so all oses are supported\n return DEFAULT_OS_NAMES\n if len(oses) == 1 and oses[0] == \"Operating System :: OS Independent\":\n # All oses are supported\n return DEFAULT_OS_NAMES\n else:\n return [p.split(\"::\")[-1].strip() for p in oses]\n\n\ndef select_plugins(session):\n \"\"\"\n Select all plugins that should be tested in this session.\n Considers the current Python version and operating systems against the supported ones,\n as well as the user plugins selection (via the PLUGINS environment variable).\n \"\"\"\n\n assert session.python is not None, \"Session python version is not specified\"\n\n example_plugins = [\n {\"name\": x, \"path\": \"examples/{}\".format(x)}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins/examples\")))\n ]\n plugins = [\n {\"name\": x, \"path\": x}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins\")))\n if x != \"examples\"\n ]\n available_plugins = plugins + example_plugins\n\n ret = []\n skipped = []\n for plugin in available_plugins:\n if not (plugin[\"name\"] in PLUGINS or PLUGINS == [\"ALL\"]):\n skipped.append(f\"Deselecting {plugin['name']}: User request\")\n continue\n\n setup_py = os.path.join(BASE, \"plugins\", plugin[\"path\"], \"setup.py\")\n classifiers = session.run(\n \"python\", setup_py, \"--classifiers\", silent=True\n ).splitlines()\n\n plugin_python_versions = get_setup_python_versions(classifiers)\n python_supported = session.python in plugin_python_versions\n\n plugin_os_names = get_plugin_os_names(classifiers)\n os_supported = get_current_os() in plugin_os_names\n\n if not python_supported:\n py_str = \", \".join(plugin_python_versions)\n skipped.append(\n f\"Deselecting {plugin['name']} : Incompatible Python {session.python}. Supports [{py_str}]\"\n )\n continue\n\n # Verify this plugin supports the OS we are testing on, skip otherwise\n if not os_supported:\n os_str = \", \".join(plugin_os_names)\n skipped.append(\n f\"Deselecting {plugin['name']}: Incompatible OS {get_current_os()}. Supports [{os_str}]\"\n )\n continue\n\n ret.append(\n {\n \"name\": plugin[\"name\"],\n \"path\": plugin[\"path\"],\n \"module\": \"hydra_plugins.\" + plugin[\"name\"],\n }\n )\n\n for msg in skipped:\n logger.warn(msg)\n\n if len(ret) == 0:\n logger.warn(\"No plugins selected\")\n return ret\n\n\[email protected](python=PYTHON_VERSIONS)\ndef lint(session):\n session.install(\"--upgrade\", \"setuptools\", \"pip\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-r\", \"requirements/dev.txt\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"flake8\", \"--config\", \".circleci/flake8_py3.cfg\")\n\n session.install(\"black\")\n # if this fails you need to format your code with black\n session.run(\"black\", \"--check\", \".\", silent=SILENT)\n\n session.run(\"isort\", \"--check\", \".\", silent=SILENT)\n\n # Mypy\n session.run(\"mypy\", \".\", \"--strict\", silent=SILENT)\n\n # Mypy for plugins\n for plugin in select_plugins(session):\n session.run(\n \"mypy\", os.path.join(\"plugins\", plugin[\"path\"]), \"--strict\", silent=SILENT\n )\n\n # Mypy for examples\n for pyfie in find_python_files(\"examples\"):\n session.run(\"mypy\", pyfie, \"--strict\", silent=SILENT)\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_core(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n install_hydra(session, install_cmd)\n session.install(\"pytest\")\n run_pytest(session, \"tests\")\n\n # test discovery_test_plugin\n run_pytest(session, \"tests/test_plugins/discovery_test_plugin\")\n\n # Install and test example app\n session.run(*install_cmd, \"examples/advanced/hydra_app_example\", silent=SILENT)\n run_pytest(session, \"examples/advanced/hydra_app_example\")\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_plugins(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"pytest\")\n install_hydra(session, install_cmd)\n selected_plugin = select_plugins(session)\n # Install all supported plugins in session\n for plugin in selected_plugin:\n cmd = list(install_cmd) + [os.path.join(\"plugins\", plugin[\"path\"])]\n session.run(*cmd, silent=SILENT)\n\n # Test that we can import Hydra\n session.run(\"python\", \"-c\", \"from hydra import main\", silent=SILENT)\n\n # Test that we can import all installed plugins\n for plugin in selected_plugin:\n session.run(\"python\", \"-c\", \"import {}\".format(plugin[\"module\"]))\n\n # Run Hydra tests to verify installed plugins did not break anything\n if not SKIP_CORE_TESTS:\n run_pytest(session, \"tests\")\n else:\n session.log(\"Skipping Hydra core tests\")\n\n # Run tests for all installed plugins\n for plugin in selected_plugin:\n # install all other plugins that are compatible with the current Python version\n session.chdir(os.path.join(BASE, \"plugins\", plugin[\"path\"]))\n run_pytest(session)\n\n\[email protected](python=\"3.8\")\ndef coverage(session):\n coverage_env = {\n \"COVERAGE_HOME\": BASE,\n \"COVERAGE_FILE\": f\"{BASE}/.coverage\",\n \"COVERAGE_RCFILE\": f\"{BASE}/.coveragerc\",\n }\n\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"coverage\", \"pytest\")\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"coverage\", \"erase\")\n\n selected_plugins = select_plugins(session)\n for plugin in selected_plugins:\n session.run(\n \"pip\",\n \"install\",\n \"-e\",\n os.path.join(\"plugins\", plugin[\"path\"]),\n silent=SILENT,\n )\n\n session.run(\"coverage\", \"erase\", env=coverage_env)\n # run plugin coverage\n for plugin in selected_plugins:\n session.chdir(os.path.join(\"plugins\", plugin[\"path\"]))\n cov_args = [\"coverage\", \"run\", \"--append\", \"-m\"]\n cov_args.extend(pytest_args(session))\n session.run(*cov_args, silent=SILENT, env=coverage_env)\n session.chdir(BASE)\n\n # run hydra-core coverage\n session.run(\n \"coverage\",\n \"run\",\n \"--append\",\n \"-m\",\n silent=SILENT,\n env=coverage_env,\n *pytest_args(session),\n )\n\n # Increase the fail_under as coverage improves\n session.run(\"coverage\", \"report\", \"--fail-under=80\", env=coverage_env)\n session.run(\"coverage\", \"erase\", env=coverage_env)\n\n\[email protected](python=PYTHON_VERSIONS)\ndef test_jupyter_notebook(session):\n versions = copy.copy(DEFAULT_PYTHON_VERSIONS)\n if session.python not in versions:\n session.skip(\n f\"Not testing Jupyter notebook on Python {session.python}, supports [{','.join(versions)}]\"\n )\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"jupyter\", \"nbval\")\n install_hydra(session, [\"pip\", \"install\", \"-e\"])\n session.run(\n *pytest_args(\n session, \"--nbval\", \"examples/notebook/hydra_notebook_example.ipynb\"\n ),\n silent=SILENT,\n )\n", "path": "noxfile.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nimport copy\nimport os\nimport platform\nfrom typing import List\n\nimport nox\nfrom nox.logger import logger\n\nBASE = os.path.abspath(os.path.dirname(__file__))\n\nDEFAULT_PYTHON_VERSIONS = [\"3.6\", \"3.7\", \"3.8\"]\nDEFAULT_OS_NAMES = [\"Linux\", \"MacOS\", \"Windows\"]\n\nPYTHON_VERSIONS = os.environ.get(\n \"NOX_PYTHON_VERSIONS\", \",\".join(DEFAULT_PYTHON_VERSIONS)\n).split(\",\")\n\nPLUGINS_INSTALL_COMMANDS = ([\"pip\", \"install\"], [\"pip\", \"install\", \"-e\"])\n\n# Allow limiting testing to specific plugins\n# The list ['ALL'] indicates all plugins\nPLUGINS = os.environ.get(\"PLUGINS\", \"ALL\").split(\",\")\n\nSKIP_CORE_TESTS = \"0\"\nSKIP_CORE_TESTS = os.environ.get(\"SKIP_CORE_TESTS\", SKIP_CORE_TESTS) != \"0\"\n\nSILENT = os.environ.get(\"VERBOSE\", \"0\") == \"0\"\n\n\ndef get_current_os() -> str:\n current_os = platform.system()\n if current_os == \"Darwin\":\n current_os = \"MacOS\"\n return current_os\n\n\nprint(f\"Operating system\\t:\\t{get_current_os()}\")\nprint(f\"PYTHON_VERSIONS\\t\\t:\\t{PYTHON_VERSIONS}\")\nprint(f\"PLUGINS\\t\\t\\t:\\t{PLUGINS}\")\nprint(f\"SKIP_CORE_TESTS\\t\\t:\\t{SKIP_CORE_TESTS}\")\n\n\ndef find_python_files(folder):\n for root, folders, files in os.walk(folder):\n for filename in folders + files:\n if filename.endswith(\".py\"):\n yield os.path.join(root, filename)\n\n\ndef install_hydra(session, cmd):\n # clean install hydra\n session.chdir(BASE)\n session.run(*cmd, \".\", silent=SILENT)\n\n\ndef pytest_args(session, *args):\n ret = [\"pytest\"]\n ret.extend(args)\n if len(session.posargs) > 0:\n ret.extend(session.posargs)\n return ret\n\n\ndef run_pytest(session, directory=\".\", *args):\n pytest_cmd = pytest_args(session, directory, *args)\n session.run(*pytest_cmd, silent=SILENT)\n\n\ndef get_setup_python_versions(classifiers):\n pythons = filter(lambda line: \"Programming Language :: Python\" in line, classifiers)\n return [p[len(\"Programming Language :: Python :: \") :] for p in pythons]\n\n\ndef get_plugin_os_names(classifiers: List[str]) -> List[str]:\n oses = list(filter(lambda line: \"Operating System\" in line, classifiers))\n if len(oses) == 0:\n # No Os is specified so all oses are supported\n return DEFAULT_OS_NAMES\n if len(oses) == 1 and oses[0] == \"Operating System :: OS Independent\":\n # All oses are supported\n return DEFAULT_OS_NAMES\n else:\n return [p.split(\"::\")[-1].strip() for p in oses]\n\n\ndef select_plugins(session):\n \"\"\"\n Select all plugins that should be tested in this session.\n Considers the current Python version and operating systems against the supported ones,\n as well as the user plugins selection (via the PLUGINS environment variable).\n \"\"\"\n\n assert session.python is not None, \"Session python version is not specified\"\n\n example_plugins = [\n {\"name\": x, \"path\": \"examples/{}\".format(x)}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins/examples\")))\n ]\n plugins = [\n {\"name\": x, \"path\": x}\n for x in sorted(os.listdir(os.path.join(BASE, \"plugins\")))\n if x != \"examples\"\n ]\n available_plugins = plugins + example_plugins\n\n ret = []\n skipped = []\n for plugin in available_plugins:\n if not (plugin[\"name\"] in PLUGINS or PLUGINS == [\"ALL\"]):\n skipped.append(f\"Deselecting {plugin['name']}: User request\")\n continue\n\n setup_py = os.path.join(BASE, \"plugins\", plugin[\"path\"], \"setup.py\")\n classifiers = session.run(\n \"python\", setup_py, \"--classifiers\", silent=True\n ).splitlines()\n\n plugin_python_versions = get_setup_python_versions(classifiers)\n python_supported = session.python in plugin_python_versions\n\n plugin_os_names = get_plugin_os_names(classifiers)\n os_supported = get_current_os() in plugin_os_names\n\n if not python_supported:\n py_str = \", \".join(plugin_python_versions)\n skipped.append(\n f\"Deselecting {plugin['name']} : Incompatible Python {session.python}. Supports [{py_str}]\"\n )\n continue\n\n # Verify this plugin supports the OS we are testing on, skip otherwise\n if not os_supported:\n os_str = \", \".join(plugin_os_names)\n skipped.append(\n f\"Deselecting {plugin['name']}: Incompatible OS {get_current_os()}. Supports [{os_str}]\"\n )\n continue\n\n ret.append(\n {\n \"name\": plugin[\"name\"],\n \"path\": plugin[\"path\"],\n \"module\": \"hydra_plugins.\" + plugin[\"name\"],\n }\n )\n\n for msg in skipped:\n logger.warn(msg)\n\n if len(ret) == 0:\n logger.warn(\"No plugins selected\")\n return ret\n\n\[email protected](python=PYTHON_VERSIONS)\ndef lint(session):\n session.install(\"--upgrade\", \"setuptools\", \"pip\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-r\", \"requirements/dev.txt\", silent=SILENT)\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"flake8\", \"--config\", \".circleci/flake8_py3.cfg\")\n\n session.install(\"black\")\n # if this fails you need to format your code with black\n session.run(\"black\", \"--check\", \".\", silent=SILENT)\n\n session.run(\"isort\", \"--check\", \".\", silent=SILENT)\n\n # Mypy\n session.run(\"mypy\", \".\", \"--strict\", silent=SILENT)\n\n # Mypy for plugins\n for plugin in select_plugins(session):\n session.run(\n \"mypy\", os.path.join(\"plugins\", plugin[\"path\"]), \"--strict\", silent=SILENT\n )\n\n # Mypy for examples\n for pyfie in find_python_files(\"examples\"):\n session.run(\"mypy\", pyfie, \"--strict\", silent=SILENT)\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_core(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n install_hydra(session, install_cmd)\n session.install(\"pytest\")\n run_pytest(session, \"tests\")\n\n # test discovery_test_plugin\n run_pytest(session, \"tests/test_plugins/discovery_test_plugin\", \"--noconftest\")\n\n # Install and test example app\n session.run(*install_cmd, \"examples/advanced/hydra_app_example\", silent=SILENT)\n run_pytest(session, \"examples/advanced/hydra_app_example\")\n\n\[email protected](python=PYTHON_VERSIONS)\[email protected](\n \"install_cmd\",\n PLUGINS_INSTALL_COMMANDS,\n ids=[\" \".join(x) for x in PLUGINS_INSTALL_COMMANDS],\n)\ndef test_plugins(session, install_cmd):\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"pytest\")\n install_hydra(session, install_cmd)\n selected_plugin = select_plugins(session)\n # Install all supported plugins in session\n for plugin in selected_plugin:\n cmd = list(install_cmd) + [os.path.join(\"plugins\", plugin[\"path\"])]\n session.run(*cmd, silent=SILENT)\n\n # Test that we can import Hydra\n session.run(\"python\", \"-c\", \"from hydra import main\", silent=SILENT)\n\n # Test that we can import all installed plugins\n for plugin in selected_plugin:\n session.run(\"python\", \"-c\", \"import {}\".format(plugin[\"module\"]))\n\n # Run Hydra tests to verify installed plugins did not break anything\n if not SKIP_CORE_TESTS:\n run_pytest(session, \"tests\")\n else:\n session.log(\"Skipping Hydra core tests\")\n\n # Run tests for all installed plugins\n for plugin in selected_plugin:\n # install all other plugins that are compatible with the current Python version\n session.chdir(os.path.join(BASE, \"plugins\", plugin[\"path\"]))\n run_pytest(session)\n\n\[email protected](python=\"3.8\")\ndef coverage(session):\n coverage_env = {\n \"COVERAGE_HOME\": BASE,\n \"COVERAGE_FILE\": f\"{BASE}/.coverage\",\n \"COVERAGE_RCFILE\": f\"{BASE}/.coveragerc\",\n }\n\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"coverage\", \"pytest\")\n session.run(\"pip\", \"install\", \"-e\", \".\", silent=SILENT)\n session.run(\"coverage\", \"erase\")\n\n selected_plugins = select_plugins(session)\n for plugin in selected_plugins:\n session.run(\n \"pip\",\n \"install\",\n \"-e\",\n os.path.join(\"plugins\", plugin[\"path\"]),\n silent=SILENT,\n )\n\n session.run(\"coverage\", \"erase\", env=coverage_env)\n # run plugin coverage\n for plugin in selected_plugins:\n session.chdir(os.path.join(\"plugins\", plugin[\"path\"]))\n cov_args = [\"coverage\", \"run\", \"--append\", \"-m\"]\n cov_args.extend(pytest_args(session))\n session.run(*cov_args, silent=SILENT, env=coverage_env)\n session.chdir(BASE)\n\n # run hydra-core coverage\n session.run(\n \"coverage\",\n \"run\",\n \"--append\",\n \"-m\",\n silent=SILENT,\n env=coverage_env,\n *pytest_args(session),\n )\n\n # Increase the fail_under as coverage improves\n session.run(\"coverage\", \"report\", \"--fail-under=80\", env=coverage_env)\n session.run(\"coverage\", \"erase\", env=coverage_env)\n\n\[email protected](python=PYTHON_VERSIONS)\ndef test_jupyter_notebook(session):\n versions = copy.copy(DEFAULT_PYTHON_VERSIONS)\n if session.python not in versions:\n session.skip(\n f\"Not testing Jupyter notebook on Python {session.python}, supports [{','.join(versions)}]\"\n )\n session.install(\"--upgrade\", \"setuptools\", \"pip\")\n session.install(\"jupyter\", \"nbval\")\n install_hydra(session, [\"pip\", \"install\", \"-e\"])\n session.run(\n *pytest_args(\n session, \"--nbval\", \"examples/notebook/hydra_notebook_example.ipynb\"\n ),\n silent=SILENT,\n )\n", "path": "noxfile.py"}]}
| 3,445 | 205 |
gh_patches_debug_26736
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-446
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add axis labels to ITER parameters plot
The ITER parameters plot [here](http://docs.plasmapy.org/en/stable/auto_examples/plot_physics.html#sphx-glr-auto-examples-plot-physics-py) could use some labels and units in said labels.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plasmapy/__init__.py`
Content:
```
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2
3 # Packages may add whatever they like to this file, but
4 # should keep this content at the top.
5 # ----------------------------------------------------------------------------
6 from ._base_init import *
7 # ----------------------------------------------------------------------------
8
9 # Enforce Python version check during package import.
10 # This is the same check as the one at the top of setup.py
11 import sys
12
13 __name__ = "plasmapy"
14
15 __doc__ = ("A community-developed and community-driven open source "
16 "core Python package for plasma physics.")
17
18
19 class UnsupportedPythonError(Exception):
20 pass
21
22
23 if sys.version_info < tuple((int(val) for val in "3.6".split('.'))):
24 raise UnsupportedPythonError("plasmapy does not support Python < {}".format(3.6))
25
26 if not _ASTROPY_SETUP_:
27 # For egg_info test builds to pass, put package imports here.
28 from . import atomic
29 from . import classes
30 from . import constants
31 from . import diagnostics
32 from . import mathematics
33 from . import physics
34 from . import utils
35
36 __citation__ = """@misc{plasmapy_community_2018_1238132,
37 author = {PlasmaPy Community and
38 Murphy, Nicholas A. and
39 Leonard, Andrew J. and
40 Sta\'nczak, Dominik and
41 Kozlowski, Pawel M. and
42 Langendorf, Samuel J. and
43 Haggerty, Colby C. and
44 Beckers, Jasper P. and
45 Mumford, Stuart J. and
46 Parashar, Tulasi N. and
47 Huang, Yi-Min},
48 title = {{PlasmaPy: an open source community-developed
49 Python package for plasma physics}},
50 month = apr,
51 year = 2018,
52 doi = {10.5281/zenodo.1238132},
53 url = {https://doi.org/10.5281/zenodo.1238132}
54 }"""
55
```
Path: `plasmapy/examples/plot_physics.py`
Content:
```
1 """
2 Analysing ITER parameters
3 =========================
4
5 Let's try to look at ITER plasma conditions using the `physics` subpackage.
6 """
7
8 from astropy import units as u
9 from plasmapy import physics
10 import matplotlib.pyplot as plt
11 import numpy as np
12 from mpl_toolkits.mplot3d import Axes3D
13
14 ######################################################
15 # The radius of electric field shielding clouds, also known as the Debye length,
16 # would be
17
18 electron_temperature = 8.8 * u.keV
19 electron_concentration = 10.1e19 / u.m**3
20 print(physics.Debye_length(electron_temperature, electron_concentration))
21
22 ############################################################
23 # Note that we can also neglect the unit for the concentration, as
24 # 1/m^3 is the a standard unit for this kind of Quantity:
25
26 print(physics.Debye_length(electron_temperature, 10.1e19))
27
28 ############################################################
29 # Assuming the magnetic field as 5.3 Teslas (which is the value at the major
30 # radius):
31
32 B = 5.3 * u.T
33
34 print(physics.gyrofrequency(B, particle='e'))
35
36 print(physics.gyroradius(B, T_i=electron_temperature, particle='e'))
37
38 ######################################################################
39 # The electron inertial length would be
40 print(physics.inertial_length(electron_concentration, particle='e'))
41
42 ######################################################################
43 # In these conditions, they should reach thermal velocities of about
44 print(physics.thermal_speed(T=electron_temperature, particle='e'))
45
46 ######################################################################
47 # And the Langmuir wave plasma frequency should be on the order of
48 print(physics.plasma_frequency(electron_concentration))
49
50 ############################################################
51 # Let's try to recreate some plots and get a feel for some of these quantities.
52
53 n_e = np.logspace(4, 30, 100) / u.m**3
54 plt.plot(n_e, physics.plasma_frequency(n_e))
55 plt.scatter(
56 electron_concentration,
57 physics.plasma_frequency(electron_concentration))
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py
--- a/plasmapy/__init__.py
+++ b/plasmapy/__init__.py
@@ -33,6 +33,29 @@
from . import physics
from . import utils
+def online_help(query):
+ """
+ Search the online PlasmaPy documentation for the given query from plasmapy.org
+ Opens the results in the default web browser.
+ Requires an active Internet connection.
+ Redirects to Astropy.units in case of query 'unit' or 'units'
+
+ Parameters
+ ----------
+ query : str
+ The search query.
+ """
+ from urllib.parse import urlencode
+ import webbrowser
+
+ url = 'http://docs.plasmapy.org/en/stable/search.html?\
+ {0}&check_keywords=yes&area=default'.format(urlencode({'q': query}))
+
+ if(query.lower() in ('unit', 'units')):
+ url = 'http://docs.astropy.org/en/stable/units/'
+
+ webbrowser.open(url)
+
__citation__ = """@misc{plasmapy_community_2018_1238132,
author = {PlasmaPy Community and
Murphy, Nicholas A. and
@@ -51,4 +74,4 @@
year = 2018,
doi = {10.5281/zenodo.1238132},
url = {https://doi.org/10.5281/zenodo.1238132}
-}"""
+}"""
\ No newline at end of file
diff --git a/plasmapy/examples/plot_physics.py b/plasmapy/examples/plot_physics.py
--- a/plasmapy/examples/plot_physics.py
+++ b/plasmapy/examples/plot_physics.py
@@ -55,3 +55,6 @@
plt.scatter(
electron_concentration,
physics.plasma_frequency(electron_concentration))
+plt.xlabel("Electron Concentration (m^-3)")
+plt.ylabel("Langmuir Wave Plasma Frequency (rad/s)")
+plt.show()
|
{"golden_diff": "diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py\n--- a/plasmapy/__init__.py\n+++ b/plasmapy/__init__.py\n@@ -33,6 +33,29 @@\n from . import physics\n from . import utils\n \n+def online_help(query):\n+ \"\"\"\n+ Search the online PlasmaPy documentation for the given query from plasmapy.org\n+ Opens the results in the default web browser.\n+ Requires an active Internet connection.\n+ Redirects to Astropy.units in case of query 'unit' or 'units'\n+\n+ Parameters\n+ ----------\n+ query : str\n+ The search query.\n+ \"\"\"\n+ from urllib.parse import urlencode\n+ import webbrowser\n+\n+ url = 'http://docs.plasmapy.org/en/stable/search.html?\\\n+ {0}&check_keywords=yes&area=default'.format(urlencode({'q': query}))\n+\n+ if(query.lower() in ('unit', 'units')):\n+ url = 'http://docs.astropy.org/en/stable/units/'\n+\n+ webbrowser.open(url)\n+\n __citation__ = \"\"\"@misc{plasmapy_community_2018_1238132,\n author = {PlasmaPy Community and\n Murphy, Nicholas A. and\n@@ -51,4 +74,4 @@\n year = 2018,\n doi = {10.5281/zenodo.1238132},\n url = {https://doi.org/10.5281/zenodo.1238132}\n-}\"\"\"\n+}\"\"\"\n\\ No newline at end of file\ndiff --git a/plasmapy/examples/plot_physics.py b/plasmapy/examples/plot_physics.py\n--- a/plasmapy/examples/plot_physics.py\n+++ b/plasmapy/examples/plot_physics.py\n@@ -55,3 +55,6 @@\n plt.scatter(\n electron_concentration,\n physics.plasma_frequency(electron_concentration))\n+plt.xlabel(\"Electron Concentration (m^-3)\")\n+plt.ylabel(\"Langmuir Wave Plasma Frequency (rad/s)\")\n+plt.show()\n", "issue": "add axis labels to ITER parameters plot\nThe ITER parameters plot [here](http://docs.plasmapy.org/en/stable/auto_examples/plot_physics.html#sphx-glr-auto-examples-plot-physics-py) could use some labels and units in said labels.\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\n# Packages may add whatever they like to this file, but\n# should keep this content at the top.\n# ----------------------------------------------------------------------------\nfrom ._base_init import *\n# ----------------------------------------------------------------------------\n\n# Enforce Python version check during package import.\n# This is the same check as the one at the top of setup.py\nimport sys\n\n__name__ = \"plasmapy\"\n\n__doc__ = (\"A community-developed and community-driven open source \"\n \"core Python package for plasma physics.\")\n\n\nclass UnsupportedPythonError(Exception):\n pass\n\n\nif sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n raise UnsupportedPythonError(\"plasmapy does not support Python < {}\".format(3.6))\n\nif not _ASTROPY_SETUP_:\n # For egg_info test builds to pass, put package imports here.\n from . import atomic\n from . import classes\n from . import constants\n from . import diagnostics\n from . import mathematics\n from . import physics\n from . import utils\n\n__citation__ = \"\"\"@misc{plasmapy_community_2018_1238132,\n author = {PlasmaPy Community and\n Murphy, Nicholas A. and\n Leonard, Andrew J. and\n Sta\\'nczak, Dominik and\n Kozlowski, Pawel M. and\n Langendorf, Samuel J. and\n Haggerty, Colby C. and\n Beckers, Jasper P. and\n Mumford, Stuart J. and\n Parashar, Tulasi N. and\n Huang, Yi-Min},\n title = {{PlasmaPy: an open source community-developed \n Python package for plasma physics}},\n month = apr,\n year = 2018,\n doi = {10.5281/zenodo.1238132},\n url = {https://doi.org/10.5281/zenodo.1238132}\n}\"\"\"\n", "path": "plasmapy/__init__.py"}, {"content": "\"\"\"\nAnalysing ITER parameters\n=========================\n\nLet's try to look at ITER plasma conditions using the `physics` subpackage.\n\"\"\"\n\nfrom astropy import units as u\nfrom plasmapy import physics\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom mpl_toolkits.mplot3d import Axes3D\n\n######################################################\n# The radius of electric field shielding clouds, also known as the Debye length,\n# would be\n\nelectron_temperature = 8.8 * u.keV\nelectron_concentration = 10.1e19 / u.m**3\nprint(physics.Debye_length(electron_temperature, electron_concentration))\n\n############################################################\n# Note that we can also neglect the unit for the concentration, as\n# 1/m^3 is the a standard unit for this kind of Quantity:\n\nprint(physics.Debye_length(electron_temperature, 10.1e19))\n\n############################################################\n# Assuming the magnetic field as 5.3 Teslas (which is the value at the major\n# radius):\n\nB = 5.3 * u.T\n\nprint(physics.gyrofrequency(B, particle='e'))\n\nprint(physics.gyroradius(B, T_i=electron_temperature, particle='e'))\n\n######################################################################\n# The electron inertial length would be\nprint(physics.inertial_length(electron_concentration, particle='e'))\n\n######################################################################\n# In these conditions, they should reach thermal velocities of about\nprint(physics.thermal_speed(T=electron_temperature, particle='e'))\n\n######################################################################\n# And the Langmuir wave plasma frequency should be on the order of\nprint(physics.plasma_frequency(electron_concentration))\n\n############################################################\n# Let's try to recreate some plots and get a feel for some of these quantities.\n\nn_e = np.logspace(4, 30, 100) / u.m**3\nplt.plot(n_e, physics.plasma_frequency(n_e))\nplt.scatter(\n electron_concentration,\n physics.plasma_frequency(electron_concentration))\n", "path": "plasmapy/examples/plot_physics.py"}], "after_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\n# Packages may add whatever they like to this file, but\n# should keep this content at the top.\n# ----------------------------------------------------------------------------\nfrom ._base_init import *\n# ----------------------------------------------------------------------------\n\n# Enforce Python version check during package import.\n# This is the same check as the one at the top of setup.py\nimport sys\n\n__name__ = \"plasmapy\"\n\n__doc__ = (\"A community-developed and community-driven open source \"\n \"core Python package for plasma physics.\")\n\n\nclass UnsupportedPythonError(Exception):\n pass\n\n\nif sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n raise UnsupportedPythonError(\"plasmapy does not support Python < {}\".format(3.6))\n\nif not _ASTROPY_SETUP_:\n # For egg_info test builds to pass, put package imports here.\n from . import atomic\n from . import classes\n from . import constants\n from . import diagnostics\n from . import mathematics\n from . import physics\n from . import utils\n\ndef online_help(query):\n \"\"\"\n Search the online PlasmaPy documentation for the given query from plasmapy.org\n Opens the results in the default web browser.\n Requires an active Internet connection.\n Redirects to Astropy.units in case of query 'unit' or 'units'\n\n Parameters\n ----------\n query : str\n The search query.\n \"\"\"\n from urllib.parse import urlencode\n import webbrowser\n\n url = 'http://docs.plasmapy.org/en/stable/search.html?\\\n {0}&check_keywords=yes&area=default'.format(urlencode({'q': query}))\n\n if(query.lower() in ('unit', 'units')):\n url = 'http://docs.astropy.org/en/stable/units/'\n\n webbrowser.open(url)\n\n__citation__ = \"\"\"@misc{plasmapy_community_2018_1238132,\n author = {PlasmaPy Community and\n Murphy, Nicholas A. and\n Leonard, Andrew J. and\n Sta\\'nczak, Dominik and\n Kozlowski, Pawel M. and\n Langendorf, Samuel J. and\n Haggerty, Colby C. and\n Beckers, Jasper P. and\n Mumford, Stuart J. and\n Parashar, Tulasi N. and\n Huang, Yi-Min},\n title = {{PlasmaPy: an open source community-developed \n Python package for plasma physics}},\n month = apr,\n year = 2018,\n doi = {10.5281/zenodo.1238132},\n url = {https://doi.org/10.5281/zenodo.1238132}\n}\"\"\"", "path": "plasmapy/__init__.py"}, {"content": "\"\"\"\nAnalysing ITER parameters\n=========================\n\nLet's try to look at ITER plasma conditions using the `physics` subpackage.\n\"\"\"\n\nfrom astropy import units as u\nfrom plasmapy import physics\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom mpl_toolkits.mplot3d import Axes3D\n\n######################################################\n# The radius of electric field shielding clouds, also known as the Debye length,\n# would be\n\nelectron_temperature = 8.8 * u.keV\nelectron_concentration = 10.1e19 / u.m**3\nprint(physics.Debye_length(electron_temperature, electron_concentration))\n\n############################################################\n# Note that we can also neglect the unit for the concentration, as\n# 1/m^3 is the a standard unit for this kind of Quantity:\n\nprint(physics.Debye_length(electron_temperature, 10.1e19))\n\n############################################################\n# Assuming the magnetic field as 5.3 Teslas (which is the value at the major\n# radius):\n\nB = 5.3 * u.T\n\nprint(physics.gyrofrequency(B, particle='e'))\n\nprint(physics.gyroradius(B, T_i=electron_temperature, particle='e'))\n\n######################################################################\n# The electron inertial length would be\nprint(physics.inertial_length(electron_concentration, particle='e'))\n\n######################################################################\n# In these conditions, they should reach thermal velocities of about\nprint(physics.thermal_speed(T=electron_temperature, particle='e'))\n\n######################################################################\n# And the Langmuir wave plasma frequency should be on the order of\nprint(physics.plasma_frequency(electron_concentration))\n\n############################################################\n# Let's try to recreate some plots and get a feel for some of these quantities.\n\nn_e = np.logspace(4, 30, 100) / u.m**3\nplt.plot(n_e, physics.plasma_frequency(n_e))\nplt.scatter(\n electron_concentration,\n physics.plasma_frequency(electron_concentration))\nplt.xlabel(\"Electron Concentration (m^-3)\")\nplt.ylabel(\"Langmuir Wave Plasma Frequency (rad/s)\")\nplt.show()\n", "path": "plasmapy/examples/plot_physics.py"}]}
| 1,450 | 501 |
gh_patches_debug_17999
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-629
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unidecode dependency GPL license
In commit adc1b1b a dependency on the Unidecode python package was introduced.
Unidecode is released under the GPL license while Faker is using MIT. I'm concerned that this might not be permitted by the GPL license and that users of the Faker library might not realise they are introducing GPL code into their dependencies. It could be argued that any code using the Faker library now has to be licensed under the GPL too.
See here for some opinions on using GPL libraries:
https://opensource.stackexchange.com/questions/1640/if-im-using-a-gpl-3-library-in-my-project-can-i-license-my-project-under-mit-l
https://softwareengineering.stackexchange.com/questions/87446/using-a-gplv3-python-module-will-my-entire-project-have-to-be-gplv3-licensed
https://opensource.stackexchange.com/questions/2139/can-i-license-python-project-under-3-clause-bsd-while-it-has-gpl-based-dependenc
https://opensource.stackexchange.com/questions/6062/using-gpl-library-with-mit-licensed-code
I'm not an expert in this area at all, just a concerned user!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # coding=utf-8
3
4 import os
5 import io
6
7 from setuptools import setup, find_packages
8
9 here = os.path.abspath(os.path.dirname(__file__))
10 README = io.open(os.path.join(here, 'README.rst'), encoding="utf8").read()
11
12
13 version = '0.8.5'
14
15 # this module can be zip-safe if the zipimporter implements iter_modules or if
16 # pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.
17 try:
18 import pkgutil
19 import zipimport
20 zip_safe = hasattr(zipimport.zipimporter, "iter_modules") or \
21 zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()
22 except (ImportError, AttributeError):
23 zip_safe = False
24
25 setup(
26 name='Faker',
27 version=version,
28 description="Faker is a Python package that generates fake data for you.",
29 long_description=README,
30 entry_points={
31 'console_scripts': ['faker=faker.cli:execute_from_command_line'],
32 },
33 classifiers=[
34 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
35 'Development Status :: 3 - Alpha',
36 'Environment :: Console',
37 'Intended Audience :: Developers',
38 'Programming Language :: Python',
39 'Programming Language :: Python :: 2',
40 'Programming Language :: Python :: 2.7',
41 'Programming Language :: Python :: 3',
42 'Programming Language :: Python :: 3.3',
43 'Programming Language :: Python :: 3.4',
44 'Programming Language :: Python :: 3.5',
45 'Programming Language :: Python :: 3.6',
46 'Programming Language :: Python :: Implementation :: CPython',
47 'Programming Language :: Python :: Implementation :: PyPy',
48 'Topic :: Software Development :: Libraries :: Python Modules',
49 'Topic :: Software Development :: Testing',
50 'Topic :: Utilities',
51 'License :: OSI Approved :: MIT License'
52 ],
53 keywords='faker fixtures data test mock generator',
54 author='joke2k',
55 author_email='[email protected]',
56 url='https://github.com/joke2k/faker',
57 license='MIT License',
58 packages=find_packages(exclude=["docs", "tests", "tests.*"]),
59 platforms=["any"],
60 test_suite='tests',
61 zip_safe=zip_safe,
62 install_requires=[
63 "python-dateutil>=2.4",
64 "six",
65 "unidecode",
66 ],
67 test_requires=[
68 "email_validator>=1.0.0,<1.1.0",
69 "ukpostcodeparser==1.1.1",
70 "mock",
71 ],
72 extras_require={
73 ':python_version=="2.7"': [
74 'ipaddress',
75 ],
76 ':python_version=="3.0"': [
77 'importlib',
78 ],
79 ':python_version=="3.2"': [
80 'ipaddress',
81 ],
82 }
83 )
84
```
Path: `faker/providers/internet/__init__.py`
Content:
```
1 # coding=utf-8
2 from __future__ import unicode_literals
3
4 import unidecode
5
6 from .. import BaseProvider
7
8 from ipaddress import ip_address, ip_network, IPV4LENGTH, IPV6LENGTH
9
10 # from faker.generator import random
11 # from faker.providers.lorem.la import Provider as Lorem
12 from faker.utils.decorators import lowercase, slugify, slugify_unicode
13
14
15 localized = True
16
17
18 class Provider(BaseProvider):
19 safe_email_tlds = ('org', 'com', 'net')
20 free_email_domains = ('gmail.com', 'yahoo.com', 'hotmail.com')
21 tlds = (
22 'com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org'
23 )
24
25 uri_pages = (
26 'index', 'home', 'search', 'main', 'post', 'homepage', 'category',
27 'register', 'login', 'faq', 'about', 'terms', 'privacy', 'author'
28 )
29 uri_paths = (
30 'app', 'main', 'wp-content', 'search', 'category', 'tag', 'categories',
31 'tags', 'blog', 'posts', 'list', 'explore'
32 )
33 uri_extensions = (
34 '.html', '.html', '.html', '.htm', '.htm', '.php', '.php', '.jsp',
35 '.asp'
36 )
37
38 user_name_formats = (
39 '{{last_name}}.{{first_name}}',
40 '{{first_name}}.{{last_name}}',
41 '{{first_name}}##',
42 '?{{last_name}}',
43 )
44 email_formats = (
45 '{{user_name}}@{{domain_name}}',
46 '{{user_name}}@{{free_email_domain}}',
47 )
48 url_formats = (
49 'http://www.{{domain_name}}/',
50 'http://{{domain_name}}/',
51 'https://www.{{domain_name}}/',
52 'https://{{domain_name}}/',
53 )
54 uri_formats = (
55 '{{url}}',
56 '{{url}}{{uri_page}}/',
57 '{{url}}{{uri_page}}{{uri_extension}}',
58 '{{url}}{{uri_path}}/{{uri_page}}/',
59 '{{url}}{{uri_path}}/{{uri_page}}{{uri_extension}}',
60 )
61 image_placeholder_services = (
62 'https://placeholdit.imgix.net/~text'
63 '?txtsize=55&txt={width}x{height}&w={width}&h={height}',
64 'https://www.lorempixel.com/{width}/{height}',
65 'https://dummyimage.com/{width}x{height}',
66 )
67
68 replacements = tuple()
69
70 def _to_ascii(self, string):
71 for search, replace in self.replacements:
72 string = string.replace(search, replace)
73
74 string = unidecode.unidecode(string)
75 return string
76
77 @lowercase
78 def email(self):
79 pattern = self.random_element(self.email_formats)
80 return "".join(self.generator.parse(pattern).split(" "))
81
82 @lowercase
83 def safe_email(self):
84 return '{}@example.{}'.format(
85 self.user_name(), self.random_element(self.safe_email_tlds)
86 )
87
88 @lowercase
89 def free_email(self):
90 return self.user_name() + '@' + self.free_email_domain()
91
92 @lowercase
93 def company_email(self):
94 return self.user_name() + '@' + self.domain_name()
95
96 @lowercase
97 def free_email_domain(self):
98 return self.random_element(self.free_email_domains)
99
100 @lowercase
101 def ascii_email(self):
102 pattern = self.random_element(self.email_formats)
103 return self._to_ascii(
104 "".join(self.generator.parse(pattern).split(" "))
105 )
106
107 @lowercase
108 def ascii_safe_email(self):
109 return self._to_ascii(
110 self.user_name() +
111 '@example.' +
112 self.random_element(self.safe_email_tlds)
113 )
114
115 @lowercase
116 def ascii_free_email(self):
117 return self._to_ascii(
118 self.user_name() + '@' + self.free_email_domain()
119 )
120
121 @lowercase
122 def ascii_company_email(self):
123 return self._to_ascii(
124 self.user_name() + '@' + self.domain_name()
125 )
126
127 @slugify_unicode
128 def user_name(self):
129 pattern = self.random_element(self.user_name_formats)
130 username = self._to_ascii(
131 self.bothify(self.generator.parse(pattern)).lower()
132 )
133 return username
134
135 @lowercase
136 def domain_name(self, levels=1):
137 """
138 Produce an Internet domain name with the specified number of
139 subdomain levels.
140
141 >>> domain_name()
142 nichols-phillips.com
143 >>> domain_name(2)
144 williamson-hopkins.jackson.com
145 """
146 if levels < 1:
147 raise ValueError("levels must be greater than or equal to 1")
148 if levels == 1:
149 return self.domain_word() + '.' + self.tld()
150 else:
151 return self.domain_word() + '.' + self.domain_name(levels - 1)
152
153 @lowercase
154 @slugify_unicode
155 def domain_word(self,):
156 company = self.generator.format('company')
157 company_elements = company.split(' ')
158 company = self._to_ascii(company_elements.pop(0))
159 return company
160
161 def tld(self):
162 return self.random_element(self.tlds)
163
164 def url(self):
165 pattern = self.random_element(self.url_formats)
166 return self.generator.parse(pattern)
167
168 def ipv4(self, network=False):
169 """Produce a random IPv4 address or network with a valid CIDR"""
170 address = str(ip_address(self.generator.random.randint(
171 0, (2 ** IPV4LENGTH) - 1)))
172 if network:
173 address += '/' + str(self.generator.random.randint(0, IPV4LENGTH))
174 address = str(ip_network(address, strict=False))
175 return address
176
177 def ipv6(self, network=False):
178 """Produce a random IPv6 address or network with a valid CIDR"""
179 address = str(ip_address(self.generator.random.randint(
180 2 ** IPV4LENGTH, (2 ** IPV6LENGTH) - 1)))
181 if network:
182 address += '/' + str(self.generator.random.randint(0, IPV6LENGTH))
183 address = str(ip_network(address, strict=False))
184 return address
185
186 def mac_address(self):
187 mac = [self.generator.random.randint(0x00, 0xff) for i in range(0, 6)]
188 return ":".join(map(lambda x: "%02x" % x, mac))
189
190 def uri_page(self):
191 return self.random_element(self.uri_pages)
192
193 def uri_path(self, deep=None):
194 deep = deep if deep else self.generator.random.randint(1, 3)
195 return "/".join(
196 [self.random_element(self.uri_paths) for _ in range(0, deep)]
197 )
198
199 def uri_extension(self):
200 return self.random_element(self.uri_extensions)
201
202 def uri(self):
203 pattern = self.random_element(self.uri_formats)
204 return self.generator.parse(pattern)
205
206 @slugify
207 def slug(self, value=None):
208 """Django algorithm"""
209 if value is None:
210 value = self.generator.text(20)
211 return value
212
213 def image_url(self, width=None, height=None):
214 """
215 Returns URL to placeholder image
216 Example: http://placehold.it/640x480
217 """
218 width_ = width or self.random_int(max=1024)
219 height_ = height or self.random_int(max=1024)
220 placeholder_url = self.random_element(self.image_placeholder_services)
221 return placeholder_url.format(width=width_, height=height_)
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/internet/__init__.py b/faker/providers/internet/__init__.py
--- a/faker/providers/internet/__init__.py
+++ b/faker/providers/internet/__init__.py
@@ -1,7 +1,7 @@
# coding=utf-8
from __future__ import unicode_literals
-import unidecode
+from text_unidecode import unidecode
from .. import BaseProvider
@@ -71,7 +71,7 @@
for search, replace in self.replacements:
string = string.replace(search, replace)
- string = unidecode.unidecode(string)
+ string = unidecode(string)
return string
@lowercase
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -62,7 +62,7 @@
install_requires=[
"python-dateutil>=2.4",
"six",
- "unidecode",
+ "text-unidecode",
],
test_requires=[
"email_validator>=1.0.0,<1.1.0",
|
{"golden_diff": "diff --git a/faker/providers/internet/__init__.py b/faker/providers/internet/__init__.py\n--- a/faker/providers/internet/__init__.py\n+++ b/faker/providers/internet/__init__.py\n@@ -1,7 +1,7 @@\n # coding=utf-8\n from __future__ import unicode_literals\n \n-import unidecode\n+from text_unidecode import unidecode\n \n from .. import BaseProvider\n \n@@ -71,7 +71,7 @@\n for search, replace in self.replacements:\n string = string.replace(search, replace)\n \n- string = unidecode.unidecode(string)\n+ string = unidecode(string)\n return string\n \n @lowercase\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -62,7 +62,7 @@\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n- \"unidecode\",\n+ \"text-unidecode\",\n ],\n test_requires=[\n \"email_validator>=1.0.0,<1.1.0\",\n", "issue": "Unidecode dependency GPL license\nIn commit adc1b1b a dependency on the Unidecode python package was introduced.\r\n\r\nUnidecode is released under the GPL license while Faker is using MIT. I'm concerned that this might not be permitted by the GPL license and that users of the Faker library might not realise they are introducing GPL code into their dependencies. It could be argued that any code using the Faker library now has to be licensed under the GPL too.\r\n\r\nSee here for some opinions on using GPL libraries:\r\n\r\nhttps://opensource.stackexchange.com/questions/1640/if-im-using-a-gpl-3-library-in-my-project-can-i-license-my-project-under-mit-l\r\nhttps://softwareengineering.stackexchange.com/questions/87446/using-a-gplv3-python-module-will-my-entire-project-have-to-be-gplv3-licensed\r\nhttps://opensource.stackexchange.com/questions/2139/can-i-license-python-project-under-3-clause-bsd-while-it-has-gpl-based-dependenc\r\nhttps://opensource.stackexchange.com/questions/6062/using-gpl-library-with-mit-licensed-code\r\n\r\nI'm not an expert in this area at all, just a concerned user!\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport os\nimport io\n\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = io.open(os.path.join(here, 'README.rst'), encoding=\"utf8\").read()\n\n\nversion = '0.8.5'\n\n# this module can be zip-safe if the zipimporter implements iter_modules or if\n# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\ntry:\n import pkgutil\n import zipimport\n zip_safe = hasattr(zipimport.zipimporter, \"iter_modules\") or \\\n zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()\nexcept (ImportError, AttributeError):\n zip_safe = False\n\nsetup(\n name='Faker',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README,\n entry_points={\n 'console_scripts': ['faker=faker.cli:execute_from_command_line'],\n },\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='https://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=[\"docs\", \"tests\", \"tests.*\"]),\n platforms=[\"any\"],\n test_suite='tests',\n zip_safe=zip_safe,\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n \"unidecode\",\n ],\n test_requires=[\n \"email_validator>=1.0.0,<1.1.0\",\n \"ukpostcodeparser==1.1.1\",\n \"mock\",\n ],\n extras_require={\n ':python_version==\"2.7\"': [\n 'ipaddress',\n ],\n ':python_version==\"3.0\"': [\n 'importlib',\n ],\n ':python_version==\"3.2\"': [\n 'ipaddress',\n ],\n }\n)\n", "path": "setup.py"}, {"content": "# coding=utf-8\nfrom __future__ import unicode_literals\n\nimport unidecode\n\nfrom .. import BaseProvider\n\nfrom ipaddress import ip_address, ip_network, IPV4LENGTH, IPV6LENGTH\n\n# from faker.generator import random\n# from faker.providers.lorem.la import Provider as Lorem\nfrom faker.utils.decorators import lowercase, slugify, slugify_unicode\n\n\nlocalized = True\n\n\nclass Provider(BaseProvider):\n safe_email_tlds = ('org', 'com', 'net')\n free_email_domains = ('gmail.com', 'yahoo.com', 'hotmail.com')\n tlds = (\n 'com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org'\n )\n\n uri_pages = (\n 'index', 'home', 'search', 'main', 'post', 'homepage', 'category',\n 'register', 'login', 'faq', 'about', 'terms', 'privacy', 'author'\n )\n uri_paths = (\n 'app', 'main', 'wp-content', 'search', 'category', 'tag', 'categories',\n 'tags', 'blog', 'posts', 'list', 'explore'\n )\n uri_extensions = (\n '.html', '.html', '.html', '.htm', '.htm', '.php', '.php', '.jsp',\n '.asp'\n )\n\n user_name_formats = (\n '{{last_name}}.{{first_name}}',\n '{{first_name}}.{{last_name}}',\n '{{first_name}}##',\n '?{{last_name}}',\n )\n email_formats = (\n '{{user_name}}@{{domain_name}}',\n '{{user_name}}@{{free_email_domain}}',\n )\n url_formats = (\n 'http://www.{{domain_name}}/',\n 'http://{{domain_name}}/',\n 'https://www.{{domain_name}}/',\n 'https://{{domain_name}}/',\n )\n uri_formats = (\n '{{url}}',\n '{{url}}{{uri_page}}/',\n '{{url}}{{uri_page}}{{uri_extension}}',\n '{{url}}{{uri_path}}/{{uri_page}}/',\n '{{url}}{{uri_path}}/{{uri_page}}{{uri_extension}}',\n )\n image_placeholder_services = (\n 'https://placeholdit.imgix.net/~text'\n '?txtsize=55&txt={width}x{height}&w={width}&h={height}',\n 'https://www.lorempixel.com/{width}/{height}',\n 'https://dummyimage.com/{width}x{height}',\n )\n\n replacements = tuple()\n\n def _to_ascii(self, string):\n for search, replace in self.replacements:\n string = string.replace(search, replace)\n\n string = unidecode.unidecode(string)\n return string\n\n @lowercase\n def email(self):\n pattern = self.random_element(self.email_formats)\n return \"\".join(self.generator.parse(pattern).split(\" \"))\n\n @lowercase\n def safe_email(self):\n return '{}@example.{}'.format(\n self.user_name(), self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def free_email(self):\n return self.user_name() + '@' + self.free_email_domain()\n\n @lowercase\n def company_email(self):\n return self.user_name() + '@' + self.domain_name()\n\n @lowercase\n def free_email_domain(self):\n return self.random_element(self.free_email_domains)\n\n @lowercase\n def ascii_email(self):\n pattern = self.random_element(self.email_formats)\n return self._to_ascii(\n \"\".join(self.generator.parse(pattern).split(\" \"))\n )\n\n @lowercase\n def ascii_safe_email(self):\n return self._to_ascii(\n self.user_name() +\n '@example.' +\n self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def ascii_free_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.free_email_domain()\n )\n\n @lowercase\n def ascii_company_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.domain_name()\n )\n\n @slugify_unicode\n def user_name(self):\n pattern = self.random_element(self.user_name_formats)\n username = self._to_ascii(\n self.bothify(self.generator.parse(pattern)).lower()\n )\n return username\n\n @lowercase\n def domain_name(self, levels=1):\n \"\"\"\n Produce an Internet domain name with the specified number of\n subdomain levels.\n\n >>> domain_name()\n nichols-phillips.com\n >>> domain_name(2)\n williamson-hopkins.jackson.com\n \"\"\"\n if levels < 1:\n raise ValueError(\"levels must be greater than or equal to 1\")\n if levels == 1:\n return self.domain_word() + '.' + self.tld()\n else:\n return self.domain_word() + '.' + self.domain_name(levels - 1)\n\n @lowercase\n @slugify_unicode\n def domain_word(self,):\n company = self.generator.format('company')\n company_elements = company.split(' ')\n company = self._to_ascii(company_elements.pop(0))\n return company\n\n def tld(self):\n return self.random_element(self.tlds)\n\n def url(self):\n pattern = self.random_element(self.url_formats)\n return self.generator.parse(pattern)\n\n def ipv4(self, network=False):\n \"\"\"Produce a random IPv4 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 0, (2 ** IPV4LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV4LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def ipv6(self, network=False):\n \"\"\"Produce a random IPv6 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 2 ** IPV4LENGTH, (2 ** IPV6LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV6LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def mac_address(self):\n mac = [self.generator.random.randint(0x00, 0xff) for i in range(0, 6)]\n return \":\".join(map(lambda x: \"%02x\" % x, mac))\n\n def uri_page(self):\n return self.random_element(self.uri_pages)\n\n def uri_path(self, deep=None):\n deep = deep if deep else self.generator.random.randint(1, 3)\n return \"/\".join(\n [self.random_element(self.uri_paths) for _ in range(0, deep)]\n )\n\n def uri_extension(self):\n return self.random_element(self.uri_extensions)\n\n def uri(self):\n pattern = self.random_element(self.uri_formats)\n return self.generator.parse(pattern)\n\n @slugify\n def slug(self, value=None):\n \"\"\"Django algorithm\"\"\"\n if value is None:\n value = self.generator.text(20)\n return value\n\n def image_url(self, width=None, height=None):\n \"\"\"\n Returns URL to placeholder image\n Example: http://placehold.it/640x480\n \"\"\"\n width_ = width or self.random_int(max=1024)\n height_ = height or self.random_int(max=1024)\n placeholder_url = self.random_element(self.image_placeholder_services)\n return placeholder_url.format(width=width_, height=height_)\n", "path": "faker/providers/internet/__init__.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport os\nimport io\n\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = io.open(os.path.join(here, 'README.rst'), encoding=\"utf8\").read()\n\n\nversion = '0.8.5'\n\n# this module can be zip-safe if the zipimporter implements iter_modules or if\n# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\ntry:\n import pkgutil\n import zipimport\n zip_safe = hasattr(zipimport.zipimporter, \"iter_modules\") or \\\n zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()\nexcept (ImportError, AttributeError):\n zip_safe = False\n\nsetup(\n name='Faker',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README,\n entry_points={\n 'console_scripts': ['faker=faker.cli:execute_from_command_line'],\n },\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='https://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=[\"docs\", \"tests\", \"tests.*\"]),\n platforms=[\"any\"],\n test_suite='tests',\n zip_safe=zip_safe,\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n \"text-unidecode\",\n ],\n test_requires=[\n \"email_validator>=1.0.0,<1.1.0\",\n \"ukpostcodeparser==1.1.1\",\n \"mock\",\n ],\n extras_require={\n ':python_version==\"2.7\"': [\n 'ipaddress',\n ],\n ':python_version==\"3.0\"': [\n 'importlib',\n ],\n ':python_version==\"3.2\"': [\n 'ipaddress',\n ],\n }\n)\n", "path": "setup.py"}, {"content": "# coding=utf-8\nfrom __future__ import unicode_literals\n\nfrom text_unidecode import unidecode\n\nfrom .. import BaseProvider\n\nfrom ipaddress import ip_address, ip_network, IPV4LENGTH, IPV6LENGTH\n\n# from faker.generator import random\n# from faker.providers.lorem.la import Provider as Lorem\nfrom faker.utils.decorators import lowercase, slugify, slugify_unicode\n\n\nlocalized = True\n\n\nclass Provider(BaseProvider):\n safe_email_tlds = ('org', 'com', 'net')\n free_email_domains = ('gmail.com', 'yahoo.com', 'hotmail.com')\n tlds = (\n 'com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org'\n )\n\n uri_pages = (\n 'index', 'home', 'search', 'main', 'post', 'homepage', 'category',\n 'register', 'login', 'faq', 'about', 'terms', 'privacy', 'author'\n )\n uri_paths = (\n 'app', 'main', 'wp-content', 'search', 'category', 'tag', 'categories',\n 'tags', 'blog', 'posts', 'list', 'explore'\n )\n uri_extensions = (\n '.html', '.html', '.html', '.htm', '.htm', '.php', '.php', '.jsp',\n '.asp'\n )\n\n user_name_formats = (\n '{{last_name}}.{{first_name}}',\n '{{first_name}}.{{last_name}}',\n '{{first_name}}##',\n '?{{last_name}}',\n )\n email_formats = (\n '{{user_name}}@{{domain_name}}',\n '{{user_name}}@{{free_email_domain}}',\n )\n url_formats = (\n 'http://www.{{domain_name}}/',\n 'http://{{domain_name}}/',\n 'https://www.{{domain_name}}/',\n 'https://{{domain_name}}/',\n )\n uri_formats = (\n '{{url}}',\n '{{url}}{{uri_page}}/',\n '{{url}}{{uri_page}}{{uri_extension}}',\n '{{url}}{{uri_path}}/{{uri_page}}/',\n '{{url}}{{uri_path}}/{{uri_page}}{{uri_extension}}',\n )\n image_placeholder_services = (\n 'https://placeholdit.imgix.net/~text'\n '?txtsize=55&txt={width}x{height}&w={width}&h={height}',\n 'https://www.lorempixel.com/{width}/{height}',\n 'https://dummyimage.com/{width}x{height}',\n )\n\n replacements = tuple()\n\n def _to_ascii(self, string):\n for search, replace in self.replacements:\n string = string.replace(search, replace)\n\n string = unidecode(string)\n return string\n\n @lowercase\n def email(self):\n pattern = self.random_element(self.email_formats)\n return \"\".join(self.generator.parse(pattern).split(\" \"))\n\n @lowercase\n def safe_email(self):\n return '{}@example.{}'.format(\n self.user_name(), self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def free_email(self):\n return self.user_name() + '@' + self.free_email_domain()\n\n @lowercase\n def company_email(self):\n return self.user_name() + '@' + self.domain_name()\n\n @lowercase\n def free_email_domain(self):\n return self.random_element(self.free_email_domains)\n\n @lowercase\n def ascii_email(self):\n pattern = self.random_element(self.email_formats)\n return self._to_ascii(\n \"\".join(self.generator.parse(pattern).split(\" \"))\n )\n\n @lowercase\n def ascii_safe_email(self):\n return self._to_ascii(\n self.user_name() +\n '@example.' +\n self.random_element(self.safe_email_tlds)\n )\n\n @lowercase\n def ascii_free_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.free_email_domain()\n )\n\n @lowercase\n def ascii_company_email(self):\n return self._to_ascii(\n self.user_name() + '@' + self.domain_name()\n )\n\n @slugify_unicode\n def user_name(self):\n pattern = self.random_element(self.user_name_formats)\n username = self._to_ascii(\n self.bothify(self.generator.parse(pattern)).lower()\n )\n return username\n\n @lowercase\n def domain_name(self, levels=1):\n \"\"\"\n Produce an Internet domain name with the specified number of\n subdomain levels.\n\n >>> domain_name()\n nichols-phillips.com\n >>> domain_name(2)\n williamson-hopkins.jackson.com\n \"\"\"\n if levels < 1:\n raise ValueError(\"levels must be greater than or equal to 1\")\n if levels == 1:\n return self.domain_word() + '.' + self.tld()\n else:\n return self.domain_word() + '.' + self.domain_name(levels - 1)\n\n @lowercase\n @slugify_unicode\n def domain_word(self,):\n company = self.generator.format('company')\n company_elements = company.split(' ')\n company = self._to_ascii(company_elements.pop(0))\n return company\n\n def tld(self):\n return self.random_element(self.tlds)\n\n def url(self):\n pattern = self.random_element(self.url_formats)\n return self.generator.parse(pattern)\n\n def ipv4(self, network=False):\n \"\"\"Produce a random IPv4 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 0, (2 ** IPV4LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV4LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def ipv6(self, network=False):\n \"\"\"Produce a random IPv6 address or network with a valid CIDR\"\"\"\n address = str(ip_address(self.generator.random.randint(\n 2 ** IPV4LENGTH, (2 ** IPV6LENGTH) - 1)))\n if network:\n address += '/' + str(self.generator.random.randint(0, IPV6LENGTH))\n address = str(ip_network(address, strict=False))\n return address\n\n def mac_address(self):\n mac = [self.generator.random.randint(0x00, 0xff) for i in range(0, 6)]\n return \":\".join(map(lambda x: \"%02x\" % x, mac))\n\n def uri_page(self):\n return self.random_element(self.uri_pages)\n\n def uri_path(self, deep=None):\n deep = deep if deep else self.generator.random.randint(1, 3)\n return \"/\".join(\n [self.random_element(self.uri_paths) for _ in range(0, deep)]\n )\n\n def uri_extension(self):\n return self.random_element(self.uri_extensions)\n\n def uri(self):\n pattern = self.random_element(self.uri_formats)\n return self.generator.parse(pattern)\n\n @slugify\n def slug(self, value=None):\n \"\"\"Django algorithm\"\"\"\n if value is None:\n value = self.generator.text(20)\n return value\n\n def image_url(self, width=None, height=None):\n \"\"\"\n Returns URL to placeholder image\n Example: http://placehold.it/640x480\n \"\"\"\n width_ = width or self.random_int(max=1024)\n height_ = height or self.random_int(max=1024)\n placeholder_url = self.random_element(self.image_placeholder_services)\n return placeholder_url.format(width=width_, height=height_)\n", "path": "faker/providers/internet/__init__.py"}]}
| 3,536 | 244 |
gh_patches_debug_1817
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-8318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incorrect docstrings in x25519 and x448 `.public_key()` methods
See:
https://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x25519.py#L60-L64
https://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x448.py#L60-L64
In both instances, the method does not return serialised bytes, but a public key object. The full [generated documentation](https://cryptography.io/en/latest/hazmat/primitives/asymmetric/x25519/#cryptography.hazmat.primitives.asymmetric.x25519.X25519PrivateKey.public_key) is correct, as are the Ed* docstrings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/primitives/asymmetric/x25519.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 import abc
7
8 from cryptography.exceptions import UnsupportedAlgorithm, _Reasons
9 from cryptography.hazmat.primitives import _serialization
10
11
12 class X25519PublicKey(metaclass=abc.ABCMeta):
13 @classmethod
14 def from_public_bytes(cls, data: bytes) -> "X25519PublicKey":
15 from cryptography.hazmat.backends.openssl.backend import backend
16
17 if not backend.x25519_supported():
18 raise UnsupportedAlgorithm(
19 "X25519 is not supported by this version of OpenSSL.",
20 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
21 )
22
23 return backend.x25519_load_public_bytes(data)
24
25 @abc.abstractmethod
26 def public_bytes(
27 self,
28 encoding: _serialization.Encoding,
29 format: _serialization.PublicFormat,
30 ) -> bytes:
31 """
32 The serialized bytes of the public key.
33 """
34
35
36 class X25519PrivateKey(metaclass=abc.ABCMeta):
37 @classmethod
38 def generate(cls) -> "X25519PrivateKey":
39 from cryptography.hazmat.backends.openssl.backend import backend
40
41 if not backend.x25519_supported():
42 raise UnsupportedAlgorithm(
43 "X25519 is not supported by this version of OpenSSL.",
44 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
45 )
46 return backend.x25519_generate_key()
47
48 @classmethod
49 def from_private_bytes(cls, data: bytes) -> "X25519PrivateKey":
50 from cryptography.hazmat.backends.openssl.backend import backend
51
52 if not backend.x25519_supported():
53 raise UnsupportedAlgorithm(
54 "X25519 is not supported by this version of OpenSSL.",
55 _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,
56 )
57
58 return backend.x25519_load_private_bytes(data)
59
60 @abc.abstractmethod
61 def public_key(self) -> X25519PublicKey:
62 """
63 The serialized bytes of the public key.
64 """
65
66 @abc.abstractmethod
67 def private_bytes(
68 self,
69 encoding: _serialization.Encoding,
70 format: _serialization.PrivateFormat,
71 encryption_algorithm: _serialization.KeySerializationEncryption,
72 ) -> bytes:
73 """
74 The serialized bytes of the private key.
75 """
76
77 @abc.abstractmethod
78 def exchange(self, peer_public_key: X25519PublicKey) -> bytes:
79 """
80 Performs a key exchange operation using the provided peer's public key.
81 """
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/primitives/asymmetric/x25519.py b/src/cryptography/hazmat/primitives/asymmetric/x25519.py
--- a/src/cryptography/hazmat/primitives/asymmetric/x25519.py
+++ b/src/cryptography/hazmat/primitives/asymmetric/x25519.py
@@ -60,7 +60,7 @@
@abc.abstractmethod
def public_key(self) -> X25519PublicKey:
"""
- The serialized bytes of the public key.
+ Returns the public key assosciated with this private key
"""
@abc.abstractmethod
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/asymmetric/x25519.py b/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n--- a/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n+++ b/src/cryptography/hazmat/primitives/asymmetric/x25519.py\n@@ -60,7 +60,7 @@\n @abc.abstractmethod\n def public_key(self) -> X25519PublicKey:\n \"\"\"\n- The serialized bytes of the public key.\n+ Returns the public key assosciated with this private key\n \"\"\"\n \n @abc.abstractmethod\n", "issue": "Incorrect docstrings in x25519 and x448 `.public_key()` methods\nSee:\r\n\r\nhttps://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x25519.py#L60-L64\r\n\r\nhttps://github.com/pyca/cryptography/blob/127a2860740c77f45362e68e0ed7d2d108a39033/src/cryptography/hazmat/primitives/asymmetric/x448.py#L60-L64\r\n\r\nIn both instances, the method does not return serialised bytes, but a public key object. The full [generated documentation](https://cryptography.io/en/latest/hazmat/primitives/asymmetric/x25519/#cryptography.hazmat.primitives.asymmetric.x25519.X25519PrivateKey.public_key) is correct, as are the Ed* docstrings.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nimport abc\n\nfrom cryptography.exceptions import UnsupportedAlgorithm, _Reasons\nfrom cryptography.hazmat.primitives import _serialization\n\n\nclass X25519PublicKey(metaclass=abc.ABCMeta):\n @classmethod\n def from_public_bytes(cls, data: bytes) -> \"X25519PublicKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_public_bytes(data)\n\n @abc.abstractmethod\n def public_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PublicFormat,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the public key.\n \"\"\"\n\n\nclass X25519PrivateKey(metaclass=abc.ABCMeta):\n @classmethod\n def generate(cls) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n return backend.x25519_generate_key()\n\n @classmethod\n def from_private_bytes(cls, data: bytes) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_private_bytes(data)\n\n @abc.abstractmethod\n def public_key(self) -> X25519PublicKey:\n \"\"\"\n The serialized bytes of the public key.\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PrivateFormat,\n encryption_algorithm: _serialization.KeySerializationEncryption,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the private key.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, peer_public_key: X25519PublicKey) -> bytes:\n \"\"\"\n Performs a key exchange operation using the provided peer's public key.\n \"\"\"\n", "path": "src/cryptography/hazmat/primitives/asymmetric/x25519.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nimport abc\n\nfrom cryptography.exceptions import UnsupportedAlgorithm, _Reasons\nfrom cryptography.hazmat.primitives import _serialization\n\n\nclass X25519PublicKey(metaclass=abc.ABCMeta):\n @classmethod\n def from_public_bytes(cls, data: bytes) -> \"X25519PublicKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_public_bytes(data)\n\n @abc.abstractmethod\n def public_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PublicFormat,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the public key.\n \"\"\"\n\n\nclass X25519PrivateKey(metaclass=abc.ABCMeta):\n @classmethod\n def generate(cls) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n return backend.x25519_generate_key()\n\n @classmethod\n def from_private_bytes(cls, data: bytes) -> \"X25519PrivateKey\":\n from cryptography.hazmat.backends.openssl.backend import backend\n\n if not backend.x25519_supported():\n raise UnsupportedAlgorithm(\n \"X25519 is not supported by this version of OpenSSL.\",\n _Reasons.UNSUPPORTED_EXCHANGE_ALGORITHM,\n )\n\n return backend.x25519_load_private_bytes(data)\n\n @abc.abstractmethod\n def public_key(self) -> X25519PublicKey:\n \"\"\"\n Returns the public key assosciated with this private key\n \"\"\"\n\n @abc.abstractmethod\n def private_bytes(\n self,\n encoding: _serialization.Encoding,\n format: _serialization.PrivateFormat,\n encryption_algorithm: _serialization.KeySerializationEncryption,\n ) -> bytes:\n \"\"\"\n The serialized bytes of the private key.\n \"\"\"\n\n @abc.abstractmethod\n def exchange(self, peer_public_key: X25519PublicKey) -> bytes:\n \"\"\"\n Performs a key exchange operation using the provided peer's public key.\n \"\"\"\n", "path": "src/cryptography/hazmat/primitives/asymmetric/x25519.py"}]}
| 1,270 | 148 |
gh_patches_debug_22657
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3674
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TD: IndexError: list index out of range
2018-01-25 20:40:04 ERROR FINDPROPERS :: [TorrentDay] :: [ad04c6b] Failed parsing provider.
Traceback (most recent call last):
File "/home/osmc/Medusa/medusa/providers/torrent/html/torrentday.py", line 158, in parse
name = cells[labels.index('name')]
IndexError: list index out of range
2018-01-25 20:40:03 INFO FINDPROPERS :: [TorrentDay] :: [ad04c6b] Searching for any new PROPER releases from TorrentDay
@p0psicles @OmgImAlexis
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/providers/torrent/html/torrentday.py`
Content:
```
1 # coding=utf-8
2
3 """Provider code for TorrentDay."""
4
5 from __future__ import unicode_literals
6
7 import logging
8
9 from medusa import tv
10 from medusa.bs4_parser import BS4Parser
11 from medusa.helper.common import convert_size, try_int
12 from medusa.logger.adapters.style import BraceAdapter
13 from medusa.providers.torrent.torrent_provider import TorrentProvider
14
15 from requests.compat import urljoin
16
17 log = BraceAdapter(logging.getLogger(__name__))
18 log.logger.addHandler(logging.NullHandler())
19
20
21 class TorrentDayProvider(TorrentProvider):
22 """TorrentDay Torrent provider."""
23
24 def __init__(self):
25 """Initialize the class."""
26 super(TorrentDayProvider, self).__init__('TorrentDay')
27
28 # URLs
29 self.url = 'https://www.torrentday.com'
30 self.urls = {
31 'search': urljoin(self.url, '/t'),
32 }
33
34 # Proper Strings
35
36 # Miscellaneous Options
37 self.freeleech = False
38 self.enable_cookies = True
39 self.cookies = ''
40 self.required_cookies = ('uid', 'pass')
41
42 # TV/480p - 24
43 # TV/Bluray - 32
44 # TV/DVD-R - 31
45 # TV/DVD-Rip - 33
46 # TV/Mobile - 46
47 # TV/Packs - 14
48 # TV/SD/x264 - 26
49 # TV/x264 - 7
50 # TV/x265 - 34
51 # TV/XviD - 2
52 # TV-all `-8`
53
54 self.categories = {
55 'Season': {'c14': 1},
56 'Episode': {'c2': 1, 'c7': 1, 'c24': 1, 'c26': 1, 'c31': 1, 'c32': 1, 'c33': 1, 'c34': 1, 'c46': 1},
57 'RSS': {'c2': 1, 'c26': 1, 'c7': 1, 'c24': 1, 'c14': 1}
58 }
59
60 # Torrent Stats
61 self.minseed = None
62 self.minleech = None
63
64 # Cache
65 self.cache = tv.Cache(self, min_time=10) # Only poll IPTorrents every 10 minutes max
66
67 def search(self, search_strings, age=0, ep_obj=None, **kwargs):
68 """
69 Search a provider and parse the results.
70
71 :param search_strings: A dict with mode (key) and the search value (value)
72 :param age: Not used
73 :param ep_obj: Not used
74 :returns: A list of search results (structure)
75 """
76 results = []
77 if not self.login():
78 return results
79
80 for mode in search_strings:
81 log.debug('Search mode: {0}', mode)
82
83 for search_string in search_strings[mode]:
84 if mode != 'RSS':
85 log.debug('Search string: {search}',
86 {'search': search_string})
87
88 search_string = '+'.join(search_string.split())
89
90 params = {
91 '24': '',
92 '32': '',
93 '31': '',
94 '33': '',
95 '46': '',
96 '26': '',
97 '7': '',
98 '34': '',
99 '2': ''
100 }
101
102 if self.freeleech:
103 params.update({'free': 'on'})
104
105 if search_string:
106 params.update({'q': search_string})
107
108 response = self.session.get(self.urls['search'], params=params)
109 if not response or not response.text:
110 log.debug('No data returned from provider')
111 continue
112
113 try:
114 data = response.text
115 except ValueError:
116 log.debug('No data returned from provider')
117 continue
118
119 try:
120 index = data.index('<form method="get"')
121 except ValueError:
122 log.debug('Could not find main torrent table')
123 continue
124
125 results += self.parse(data[index:], mode)
126
127 return results
128
129 def parse(self, data, mode):
130 """
131 Parse search results for items.
132
133 :param data: The raw response from a search
134 :param mode: The current mode used to search, e.g. RSS
135
136 :return: A list of items found
137 """
138 items = []
139
140 with BS4Parser(data, 'html5lib') as html:
141 torrent_table = html.find('table', {'id': 'torrentTable'})
142 torrent_rows = torrent_table('tr') if torrent_table else []
143
144 # Continue only if at least one release is found
145 if len(torrent_rows) < 2:
146 log.debug('Data returned from provider does not contain any torrents')
147 return items
148
149 # Adding the table column titles manually, as some are not titled. They can be used for easy referencing.
150 labels = ['category', 'name', 'download', 'bookmark', 'comments', 'size', 'seeders', 'leechers']
151
152 items = []
153 # Skip column headers
154 for row in torrent_rows[1:]:
155 cells = row('td')
156
157 try:
158 name = cells[labels.index('name')]
159 title = name.find('a').get_text(strip=True)
160 # details = name.find('a')['href']
161 download_url_raw = cells[labels.index('download')].find('a')['href']
162
163 if not all([title, download_url_raw]):
164 continue
165
166 download_url = urljoin(self.url, download_url_raw)
167
168 seeders = try_int(cells[labels.index('seeders')].get_text(strip=True))
169 leechers = try_int(cells[labels.index('leechers')].get_text(strip=True))
170
171 # Filter unseeded torrent
172 if seeders < min(self.minseed, 1):
173 if mode != 'RSS':
174 log.debug("Discarding torrent because it doesn't meet the"
175 " minimum seeders: {0}. Seeders: {1}",
176 title, seeders)
177 continue
178
179 torrent_size = cells[labels.index('size')].get_text()
180 size = convert_size(torrent_size) or -1
181
182 pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()
183 pubdate = self.parse_pubdate(pubdate_raw, human_time=True)
184
185 item = {
186 'title': title,
187 'link': download_url,
188 'size': size,
189 'seeders': seeders,
190 'leechers': leechers,
191 'pubdate': pubdate,
192 }
193 if mode != 'RSS':
194 log.debug('Found result: {0} with {1} seeders and {2} leechers',
195 title, seeders, leechers)
196
197 items.append(item)
198 except (AttributeError, TypeError, KeyError, ValueError, IndexError):
199 log.exception('Failed parsing provider.')
200
201 return items
202
203 def login(self):
204 """Login method used for logging in before doing search and torrent downloads."""
205 return self.cookie_login('sign In')
206
207
208 provider = TorrentDayProvider()
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/providers/torrent/html/torrentday.py b/medusa/providers/torrent/html/torrentday.py
--- a/medusa/providers/torrent/html/torrentday.py
+++ b/medusa/providers/torrent/html/torrentday.py
@@ -142,7 +142,7 @@
torrent_rows = torrent_table('tr') if torrent_table else []
# Continue only if at least one release is found
- if len(torrent_rows) < 2:
+ if len(torrent_rows) < 3 and 'no torrents found' in torrent_rows[-1].find('td').get_text().lower():
log.debug('Data returned from provider does not contain any torrents')
return items
@@ -179,7 +179,7 @@
torrent_size = cells[labels.index('size')].get_text()
size = convert_size(torrent_size) or -1
- pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()
+ pubdate_raw = name.find('div').get_text(strip=True).split('|')[-1].strip()
pubdate = self.parse_pubdate(pubdate_raw, human_time=True)
item = {
|
{"golden_diff": "diff --git a/medusa/providers/torrent/html/torrentday.py b/medusa/providers/torrent/html/torrentday.py\n--- a/medusa/providers/torrent/html/torrentday.py\n+++ b/medusa/providers/torrent/html/torrentday.py\n@@ -142,7 +142,7 @@\n torrent_rows = torrent_table('tr') if torrent_table else []\n \n # Continue only if at least one release is found\n- if len(torrent_rows) < 2:\n+ if len(torrent_rows) < 3 and 'no torrents found' in torrent_rows[-1].find('td').get_text().lower():\n log.debug('Data returned from provider does not contain any torrents')\n return items\n \n@@ -179,7 +179,7 @@\n torrent_size = cells[labels.index('size')].get_text()\n size = convert_size(torrent_size) or -1\n \n- pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()\n+ pubdate_raw = name.find('div').get_text(strip=True).split('|')[-1].strip()\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n \n item = {\n", "issue": "TD: IndexError: list index out of range\n2018-01-25 20:40:04 ERROR FINDPROPERS :: [TorrentDay] :: [ad04c6b] Failed parsing provider.\r\nTraceback (most recent call last):\r\n File \"/home/osmc/Medusa/medusa/providers/torrent/html/torrentday.py\", line 158, in parse\r\n name = cells[labels.index('name')]\r\nIndexError: list index out of range\r\n2018-01-25 20:40:03 INFO FINDPROPERS :: [TorrentDay] :: [ad04c6b] Searching for any new PROPER releases from TorrentDay\r\n\r\n@p0psicles @OmgImAlexis \n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for TorrentDay.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import convert_size, try_int\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass TorrentDayProvider(TorrentProvider):\n \"\"\"TorrentDay Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(TorrentDayProvider, self).__init__('TorrentDay')\n\n # URLs\n self.url = 'https://www.torrentday.com'\n self.urls = {\n 'search': urljoin(self.url, '/t'),\n }\n\n # Proper Strings\n\n # Miscellaneous Options\n self.freeleech = False\n self.enable_cookies = True\n self.cookies = ''\n self.required_cookies = ('uid', 'pass')\n\n # TV/480p - 24\n # TV/Bluray - 32\n # TV/DVD-R - 31\n # TV/DVD-Rip - 33\n # TV/Mobile - 46\n # TV/Packs - 14\n # TV/SD/x264 - 26\n # TV/x264 - 7\n # TV/x265 - 34\n # TV/XviD - 2\n # TV-all `-8`\n\n self.categories = {\n 'Season': {'c14': 1},\n 'Episode': {'c2': 1, 'c7': 1, 'c24': 1, 'c26': 1, 'c31': 1, 'c32': 1, 'c33': 1, 'c34': 1, 'c46': 1},\n 'RSS': {'c2': 1, 'c26': 1, 'c7': 1, 'c24': 1, 'c14': 1}\n }\n\n # Torrent Stats\n self.minseed = None\n self.minleech = None\n\n # Cache\n self.cache = tv.Cache(self, min_time=10) # Only poll IPTorrents every 10 minutes max\n\n def search(self, search_strings, age=0, ep_obj=None, **kwargs):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n if not self.login():\n return results\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n\n search_string = '+'.join(search_string.split())\n\n params = {\n '24': '',\n '32': '',\n '31': '',\n '33': '',\n '46': '',\n '26': '',\n '7': '',\n '34': '',\n '2': ''\n }\n\n if self.freeleech:\n params.update({'free': 'on'})\n\n if search_string:\n params.update({'q': search_string})\n\n response = self.session.get(self.urls['search'], params=params)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n try:\n data = response.text\n except ValueError:\n log.debug('No data returned from provider')\n continue\n\n try:\n index = data.index('<form method=\"get\"')\n except ValueError:\n log.debug('Could not find main torrent table')\n continue\n\n results += self.parse(data[index:], mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', {'id': 'torrentTable'})\n torrent_rows = torrent_table('tr') if torrent_table else []\n\n # Continue only if at least one release is found\n if len(torrent_rows) < 2:\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n # Adding the table column titles manually, as some are not titled. They can be used for easy referencing.\n labels = ['category', 'name', 'download', 'bookmark', 'comments', 'size', 'seeders', 'leechers']\n\n items = []\n # Skip column headers\n for row in torrent_rows[1:]:\n cells = row('td')\n\n try:\n name = cells[labels.index('name')]\n title = name.find('a').get_text(strip=True)\n # details = name.find('a')['href']\n download_url_raw = cells[labels.index('download')].find('a')['href']\n\n if not all([title, download_url_raw]):\n continue\n\n download_url = urljoin(self.url, download_url_raw)\n\n seeders = try_int(cells[labels.index('seeders')].get_text(strip=True))\n leechers = try_int(cells[labels.index('leechers')].get_text(strip=True))\n\n # Filter unseeded torrent\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n torrent_size = cells[labels.index('size')].get_text()\n size = convert_size(torrent_size) or -1\n\n pubdate_raw = name.find('div').get_text(strip=True).split('|')[1].strip()\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.exception('Failed parsing provider.')\n\n return items\n\n def login(self):\n \"\"\"Login method used for logging in before doing search and torrent downloads.\"\"\"\n return self.cookie_login('sign In')\n\n\nprovider = TorrentDayProvider()\n", "path": "medusa/providers/torrent/html/torrentday.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for TorrentDay.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import convert_size, try_int\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass TorrentDayProvider(TorrentProvider):\n \"\"\"TorrentDay Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(TorrentDayProvider, self).__init__('TorrentDay')\n\n # URLs\n self.url = 'https://www.torrentday.com'\n self.urls = {\n 'search': urljoin(self.url, '/t'),\n }\n\n # Proper Strings\n\n # Miscellaneous Options\n self.freeleech = False\n self.enable_cookies = True\n self.cookies = ''\n self.required_cookies = ('uid', 'pass')\n\n # TV/480p - 24\n # TV/Bluray - 32\n # TV/DVD-R - 31\n # TV/DVD-Rip - 33\n # TV/Mobile - 46\n # TV/Packs - 14\n # TV/SD/x264 - 26\n # TV/x264 - 7\n # TV/x265 - 34\n # TV/XviD - 2\n # TV-all `-8`\n\n self.categories = {\n 'Season': {'c14': 1},\n 'Episode': {'c2': 1, 'c7': 1, 'c24': 1, 'c26': 1, 'c31': 1, 'c32': 1, 'c33': 1, 'c34': 1, 'c46': 1},\n 'RSS': {'c2': 1, 'c26': 1, 'c7': 1, 'c24': 1, 'c14': 1}\n }\n\n # Torrent Stats\n self.minseed = None\n self.minleech = None\n\n # Cache\n self.cache = tv.Cache(self, min_time=10) # Only poll IPTorrents every 10 minutes max\n\n def search(self, search_strings, age=0, ep_obj=None, **kwargs):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n if not self.login():\n return results\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n\n search_string = '+'.join(search_string.split())\n\n params = {\n '24': '',\n '32': '',\n '31': '',\n '33': '',\n '46': '',\n '26': '',\n '7': '',\n '34': '',\n '2': ''\n }\n\n if self.freeleech:\n params.update({'free': 'on'})\n\n if search_string:\n params.update({'q': search_string})\n\n response = self.session.get(self.urls['search'], params=params)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n try:\n data = response.text\n except ValueError:\n log.debug('No data returned from provider')\n continue\n\n try:\n index = data.index('<form method=\"get\"')\n except ValueError:\n log.debug('Could not find main torrent table')\n continue\n\n results += self.parse(data[index:], mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', {'id': 'torrentTable'})\n torrent_rows = torrent_table('tr') if torrent_table else []\n\n # Continue only if at least one release is found\n if len(torrent_rows) < 3 and 'no torrents found' in torrent_rows[-1].find('td').get_text().lower():\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n # Adding the table column titles manually, as some are not titled. They can be used for easy referencing.\n labels = ['category', 'name', 'download', 'bookmark', 'comments', 'size', 'seeders', 'leechers']\n\n items = []\n # Skip column headers\n for row in torrent_rows[1:]:\n cells = row('td')\n\n try:\n name = cells[labels.index('name')]\n title = name.find('a').get_text(strip=True)\n # details = name.find('a')['href']\n download_url_raw = cells[labels.index('download')].find('a')['href']\n\n if not all([title, download_url_raw]):\n continue\n\n download_url = urljoin(self.url, download_url_raw)\n\n seeders = try_int(cells[labels.index('seeders')].get_text(strip=True))\n leechers = try_int(cells[labels.index('leechers')].get_text(strip=True))\n\n # Filter unseeded torrent\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n torrent_size = cells[labels.index('size')].get_text()\n size = convert_size(torrent_size) or -1\n\n pubdate_raw = name.find('div').get_text(strip=True).split('|')[-1].strip()\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.exception('Failed parsing provider.')\n\n return items\n\n def login(self):\n \"\"\"Login method used for logging in before doing search and torrent downloads.\"\"\"\n return self.cookie_login('sign In')\n\n\nprovider = TorrentDayProvider()\n", "path": "medusa/providers/torrent/html/torrentday.py"}]}
| 2,528 | 269 |
gh_patches_debug_28810
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-5496
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make /random/ path works
Currently hitting https://readthedocs.org/random/ produces 502 and hitting https://readthedocs.org/random/pip/ may return a `.js` file or a non `.html` file which is not useful.
We need to fix it and return always return a HTML file. For this, we could use the model `HTMLFile`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/core/views/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """
4 Core views, including the main homepage,
5
6 documentation and header rendering, and server errors.
7 """
8
9 import os
10 import logging
11 from urllib.parse import urlparse
12
13 from django.conf import settings
14 from django.http import HttpResponseRedirect, Http404, JsonResponse
15 from django.shortcuts import render, get_object_or_404, redirect
16 from django.views.generic import TemplateView
17
18
19 from readthedocs.builds.models import Version
20 from readthedocs.core.utils.general import wipe_version_via_slugs
21 from readthedocs.core.resolver import resolve_path
22 from readthedocs.core.symlink import PrivateSymlink, PublicSymlink
23 from readthedocs.core.utils import broadcast
24 from readthedocs.core.views.serve import _serve_file
25 from readthedocs.projects.constants import PRIVATE
26 from readthedocs.projects.models import Project, ImportedFile
27 from readthedocs.projects.tasks import remove_dirs
28 from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path
29
30 log = logging.getLogger(__name__)
31
32
33 class NoProjectException(Exception):
34 pass
35
36
37 class HomepageView(TemplateView):
38
39 template_name = 'homepage.html'
40
41 def get_context_data(self, **kwargs):
42 """Add latest builds and featured projects."""
43 context = super().get_context_data(**kwargs)
44 context['featured_list'] = Project.objects.filter(featured=True)
45 context['projects_count'] = Project.objects.count()
46 return context
47
48
49 class SupportView(TemplateView):
50 template_name = 'support.html'
51
52 def get_context_data(self, **kwargs):
53 context = super().get_context_data(**kwargs)
54 support_email = getattr(settings, 'SUPPORT_EMAIL', None)
55 if not support_email:
56 support_email = 'support@{domain}'.format(
57 domain=getattr(
58 settings,
59 'PRODUCTION_DOMAIN',
60 'readthedocs.org',
61 ),
62 )
63
64 context['support_email'] = support_email
65 return context
66
67
68 def random_page(request, project_slug=None): # pylint: disable=unused-argument
69 imported_file = ImportedFile.objects.order_by('?')
70 if project_slug:
71 imported_file = imported_file.filter(project__slug=project_slug)
72 imported_file = imported_file.first()
73 if imported_file is None:
74 raise Http404
75 url = imported_file.get_absolute_url()
76 return HttpResponseRedirect(url)
77
78
79 def wipe_version(request, project_slug, version_slug):
80 version = get_object_or_404(
81 Version,
82 project__slug=project_slug,
83 slug=version_slug,
84 )
85 # We need to check by ``for_admin_user`` here to allow members of the
86 # ``Admin`` team (which doesn't own the project) under the corporate site.
87 if version.project not in Project.objects.for_admin_user(user=request.user):
88 raise Http404('You must own this project to wipe it.')
89
90 if request.method == 'POST':
91 wipe_version_via_slugs(
92 version_slug=version_slug,
93 project_slug=project_slug
94 )
95 return redirect('project_version_list', project_slug)
96 return render(
97 request,
98 'wipe_version.html',
99 {'version': version, 'project': version.project},
100 )
101
102
103 def server_error_500(request, template_name='500.html'):
104 """A simple 500 handler so we get media."""
105 r = render(request, template_name)
106 r.status_code = 500
107 return r
108
109
110 def server_error_404(request, exception=None, template_name='404.html'): # pylint: disable=unused-argument # noqa
111 """
112 A simple 404 handler so we get media.
113
114 .. note::
115
116 Marking exception as optional to make /404/ testing page to work.
117 """
118 response = get_redirect_response(request, full_path=request.get_full_path())
119
120 # Return a redirect response if there is one
121 if response:
122 if response.url == request.build_absolute_uri():
123 # check that we do have a response and avoid infinite redirect
124 log.warning(
125 'Infinite Redirect: FROM URL is the same than TO URL. url=%s',
126 response.url,
127 )
128 else:
129 return response
130
131 # Try to serve custom 404 pages if it's a subdomain/cname
132 if getattr(request, 'subdomain', False) or getattr(request, 'cname', False):
133 return server_error_404_subdomain(request, template_name)
134
135 # Return the default 404 page generated by Read the Docs
136 r = render(request, template_name)
137 r.status_code = 404
138 return r
139
140
141 def server_error_404_subdomain(request, template_name='404.html'):
142 """
143 Handler for 404 pages on subdomains.
144
145 Check if the project associated has a custom ``404.html`` and serve this
146 page. First search for a 404 page in the current version, then continues
147 with the default version and finally, if none of them are found, the Read
148 the Docs default page (Maze Found) is rendered by Django and served.
149 """
150
151 def resolve_404_path(project, version_slug=None, language=None):
152 """
153 Helper to resolve the path of ``404.html`` for project.
154
155 The resolution is based on ``project`` object, version slug and
156 language.
157
158 :returns: tuple containing the (basepath, filename)
159 :rtype: tuple
160 """
161 filename = resolve_path(
162 project,
163 version_slug=version_slug,
164 language=language,
165 filename='404.html',
166 subdomain=True, # subdomain will make it a "full" path without a URL prefix
167 )
168
169 # This breaks path joining, by ignoring the root when given an "absolute" path
170 if filename[0] == '/':
171 filename = filename[1:]
172
173 version = None
174 if version_slug:
175 version_qs = project.versions.filter(slug=version_slug)
176 if version_qs.exists():
177 version = version_qs.first()
178
179 private = any([
180 version and version.privacy_level == PRIVATE,
181 not version and project.privacy_level == PRIVATE,
182 ])
183 if private:
184 symlink = PrivateSymlink(project)
185 else:
186 symlink = PublicSymlink(project)
187 basepath = symlink.project_root
188 fullpath = os.path.join(basepath, filename)
189 return (basepath, filename, fullpath)
190
191 project, full_path = project_and_path_from_request(request, request.get_full_path())
192
193 if project:
194 language = None
195 version_slug = None
196 schema, netloc, path, params, query, fragments = urlparse(full_path)
197 if not project.single_version:
198 language, version_slug, path = language_and_version_from_path(path)
199
200 # Firstly, attempt to serve the 404 of the current version (version_slug)
201 # Secondly, try to serve the 404 page for the default version (project.get_default_version())
202 for slug in (version_slug, project.get_default_version()):
203 basepath, filename, fullpath = resolve_404_path(project, slug, language)
204 if os.path.exists(fullpath):
205 log.debug(
206 'serving 404.html page current version: [project: %s] [version: %s]',
207 project.slug,
208 slug,
209 )
210 r = _serve_file(request, filename, basepath)
211 r.status_code = 404
212 return r
213
214 # Finally, return the default 404 page generated by Read the Docs
215 r = render(request, template_name)
216 r.status_code = 404
217 return r
218
219
220 def do_not_track(request):
221 dnt_header = request.META.get('HTTP_DNT')
222
223 # https://w3c.github.io/dnt/drafts/tracking-dnt.html#status-representation
224 return JsonResponse( # pylint: disable=redundant-content-type-for-json-response
225 {
226 'policy': 'https://docs.readthedocs.io/en/latest/privacy-policy.html',
227 'same-party': [
228 'readthedocs.org',
229 'readthedocs.com',
230 'readthedocs.io', # .org Documentation Sites
231 'readthedocs-hosted.com', # .com Documentation Sites
232 ],
233 'tracking': 'N' if dnt_header == '1' else 'T',
234 }, content_type='application/tracking-status+json',
235 )
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/core/views/__init__.py b/readthedocs/core/views/__init__.py
--- a/readthedocs/core/views/__init__.py
+++ b/readthedocs/core/views/__init__.py
@@ -20,12 +20,14 @@
from readthedocs.core.utils.general import wipe_version_via_slugs
from readthedocs.core.resolver import resolve_path
from readthedocs.core.symlink import PrivateSymlink, PublicSymlink
-from readthedocs.core.utils import broadcast
from readthedocs.core.views.serve import _serve_file
from readthedocs.projects.constants import PRIVATE
-from readthedocs.projects.models import Project, ImportedFile
-from readthedocs.projects.tasks import remove_dirs
-from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path
+from readthedocs.projects.models import HTMLFile, Project
+from readthedocs.redirects.utils import (
+ get_redirect_response,
+ project_and_path_from_request,
+ language_and_version_from_path
+)
log = logging.getLogger(__name__)
@@ -66,13 +68,13 @@
def random_page(request, project_slug=None): # pylint: disable=unused-argument
- imported_file = ImportedFile.objects.order_by('?')
+ html_file = HTMLFile.objects.order_by('?')
if project_slug:
- imported_file = imported_file.filter(project__slug=project_slug)
- imported_file = imported_file.first()
- if imported_file is None:
+ html_file = html_file.filter(project__slug=project_slug)
+ html_file = html_file.first()
+ if html_file is None:
raise Http404
- url = imported_file.get_absolute_url()
+ url = html_file.get_absolute_url()
return HttpResponseRedirect(url)
|
{"golden_diff": "diff --git a/readthedocs/core/views/__init__.py b/readthedocs/core/views/__init__.py\n--- a/readthedocs/core/views/__init__.py\n+++ b/readthedocs/core/views/__init__.py\n@@ -20,12 +20,14 @@\n from readthedocs.core.utils.general import wipe_version_via_slugs\n from readthedocs.core.resolver import resolve_path\n from readthedocs.core.symlink import PrivateSymlink, PublicSymlink\n-from readthedocs.core.utils import broadcast\n from readthedocs.core.views.serve import _serve_file\n from readthedocs.projects.constants import PRIVATE\n-from readthedocs.projects.models import Project, ImportedFile\n-from readthedocs.projects.tasks import remove_dirs\n-from readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path\n+from readthedocs.projects.models import HTMLFile, Project\n+from readthedocs.redirects.utils import (\n+ get_redirect_response,\n+ project_and_path_from_request,\n+ language_and_version_from_path\n+)\n \n log = logging.getLogger(__name__)\n \n@@ -66,13 +68,13 @@\n \n \n def random_page(request, project_slug=None): # pylint: disable=unused-argument\n- imported_file = ImportedFile.objects.order_by('?')\n+ html_file = HTMLFile.objects.order_by('?')\n if project_slug:\n- imported_file = imported_file.filter(project__slug=project_slug)\n- imported_file = imported_file.first()\n- if imported_file is None:\n+ html_file = html_file.filter(project__slug=project_slug)\n+ html_file = html_file.first()\n+ if html_file is None:\n raise Http404\n- url = imported_file.get_absolute_url()\n+ url = html_file.get_absolute_url()\n return HttpResponseRedirect(url)\n", "issue": "Make /random/ path works\nCurrently hitting https://readthedocs.org/random/ produces 502 and hitting https://readthedocs.org/random/pip/ may return a `.js` file or a non `.html` file which is not useful.\r\n\r\nWe need to fix it and return always return a HTML file. For this, we could use the model `HTMLFile`.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nCore views, including the main homepage,\n\ndocumentation and header rendering, and server errors.\n\"\"\"\n\nimport os\nimport logging\nfrom urllib.parse import urlparse\n\nfrom django.conf import settings\nfrom django.http import HttpResponseRedirect, Http404, JsonResponse\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.views.generic import TemplateView\n\n\nfrom readthedocs.builds.models import Version\nfrom readthedocs.core.utils.general import wipe_version_via_slugs\nfrom readthedocs.core.resolver import resolve_path\nfrom readthedocs.core.symlink import PrivateSymlink, PublicSymlink\nfrom readthedocs.core.utils import broadcast\nfrom readthedocs.core.views.serve import _serve_file\nfrom readthedocs.projects.constants import PRIVATE\nfrom readthedocs.projects.models import Project, ImportedFile\nfrom readthedocs.projects.tasks import remove_dirs\nfrom readthedocs.redirects.utils import get_redirect_response, project_and_path_from_request, language_and_version_from_path\n\nlog = logging.getLogger(__name__)\n\n\nclass NoProjectException(Exception):\n pass\n\n\nclass HomepageView(TemplateView):\n\n template_name = 'homepage.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Add latest builds and featured projects.\"\"\"\n context = super().get_context_data(**kwargs)\n context['featured_list'] = Project.objects.filter(featured=True)\n context['projects_count'] = Project.objects.count()\n return context\n\n\nclass SupportView(TemplateView):\n template_name = 'support.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n support_email = getattr(settings, 'SUPPORT_EMAIL', None)\n if not support_email:\n support_email = 'support@{domain}'.format(\n domain=getattr(\n settings,\n 'PRODUCTION_DOMAIN',\n 'readthedocs.org',\n ),\n )\n\n context['support_email'] = support_email\n return context\n\n\ndef random_page(request, project_slug=None): # pylint: disable=unused-argument\n imported_file = ImportedFile.objects.order_by('?')\n if project_slug:\n imported_file = imported_file.filter(project__slug=project_slug)\n imported_file = imported_file.first()\n if imported_file is None:\n raise Http404\n url = imported_file.get_absolute_url()\n return HttpResponseRedirect(url)\n\n\ndef wipe_version(request, project_slug, version_slug):\n version = get_object_or_404(\n Version,\n project__slug=project_slug,\n slug=version_slug,\n )\n # We need to check by ``for_admin_user`` here to allow members of the\n # ``Admin`` team (which doesn't own the project) under the corporate site.\n if version.project not in Project.objects.for_admin_user(user=request.user):\n raise Http404('You must own this project to wipe it.')\n\n if request.method == 'POST':\n wipe_version_via_slugs(\n version_slug=version_slug,\n project_slug=project_slug\n )\n return redirect('project_version_list', project_slug)\n return render(\n request,\n 'wipe_version.html',\n {'version': version, 'project': version.project},\n )\n\n\ndef server_error_500(request, template_name='500.html'):\n \"\"\"A simple 500 handler so we get media.\"\"\"\n r = render(request, template_name)\n r.status_code = 500\n return r\n\n\ndef server_error_404(request, exception=None, template_name='404.html'): # pylint: disable=unused-argument # noqa\n \"\"\"\n A simple 404 handler so we get media.\n\n .. note::\n\n Marking exception as optional to make /404/ testing page to work.\n \"\"\"\n response = get_redirect_response(request, full_path=request.get_full_path())\n\n # Return a redirect response if there is one\n if response:\n if response.url == request.build_absolute_uri():\n # check that we do have a response and avoid infinite redirect\n log.warning(\n 'Infinite Redirect: FROM URL is the same than TO URL. url=%s',\n response.url,\n )\n else:\n return response\n\n # Try to serve custom 404 pages if it's a subdomain/cname\n if getattr(request, 'subdomain', False) or getattr(request, 'cname', False):\n return server_error_404_subdomain(request, template_name)\n\n # Return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef server_error_404_subdomain(request, template_name='404.html'):\n \"\"\"\n Handler for 404 pages on subdomains.\n\n Check if the project associated has a custom ``404.html`` and serve this\n page. First search for a 404 page in the current version, then continues\n with the default version and finally, if none of them are found, the Read\n the Docs default page (Maze Found) is rendered by Django and served.\n \"\"\"\n\n def resolve_404_path(project, version_slug=None, language=None):\n \"\"\"\n Helper to resolve the path of ``404.html`` for project.\n\n The resolution is based on ``project`` object, version slug and\n language.\n\n :returns: tuple containing the (basepath, filename)\n :rtype: tuple\n \"\"\"\n filename = resolve_path(\n project,\n version_slug=version_slug,\n language=language,\n filename='404.html',\n subdomain=True, # subdomain will make it a \"full\" path without a URL prefix\n )\n\n # This breaks path joining, by ignoring the root when given an \"absolute\" path\n if filename[0] == '/':\n filename = filename[1:]\n\n version = None\n if version_slug:\n version_qs = project.versions.filter(slug=version_slug)\n if version_qs.exists():\n version = version_qs.first()\n\n private = any([\n version and version.privacy_level == PRIVATE,\n not version and project.privacy_level == PRIVATE,\n ])\n if private:\n symlink = PrivateSymlink(project)\n else:\n symlink = PublicSymlink(project)\n basepath = symlink.project_root\n fullpath = os.path.join(basepath, filename)\n return (basepath, filename, fullpath)\n\n project, full_path = project_and_path_from_request(request, request.get_full_path())\n\n if project:\n language = None\n version_slug = None\n schema, netloc, path, params, query, fragments = urlparse(full_path)\n if not project.single_version:\n language, version_slug, path = language_and_version_from_path(path)\n\n # Firstly, attempt to serve the 404 of the current version (version_slug)\n # Secondly, try to serve the 404 page for the default version (project.get_default_version())\n for slug in (version_slug, project.get_default_version()):\n basepath, filename, fullpath = resolve_404_path(project, slug, language)\n if os.path.exists(fullpath):\n log.debug(\n 'serving 404.html page current version: [project: %s] [version: %s]',\n project.slug,\n slug,\n )\n r = _serve_file(request, filename, basepath)\n r.status_code = 404\n return r\n\n # Finally, return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef do_not_track(request):\n dnt_header = request.META.get('HTTP_DNT')\n\n # https://w3c.github.io/dnt/drafts/tracking-dnt.html#status-representation\n return JsonResponse( # pylint: disable=redundant-content-type-for-json-response\n {\n 'policy': 'https://docs.readthedocs.io/en/latest/privacy-policy.html',\n 'same-party': [\n 'readthedocs.org',\n 'readthedocs.com',\n 'readthedocs.io', # .org Documentation Sites\n 'readthedocs-hosted.com', # .com Documentation Sites\n ],\n 'tracking': 'N' if dnt_header == '1' else 'T',\n }, content_type='application/tracking-status+json',\n )\n", "path": "readthedocs/core/views/__init__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nCore views, including the main homepage,\n\ndocumentation and header rendering, and server errors.\n\"\"\"\n\nimport os\nimport logging\nfrom urllib.parse import urlparse\n\nfrom django.conf import settings\nfrom django.http import HttpResponseRedirect, Http404, JsonResponse\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.views.generic import TemplateView\n\n\nfrom readthedocs.builds.models import Version\nfrom readthedocs.core.utils.general import wipe_version_via_slugs\nfrom readthedocs.core.resolver import resolve_path\nfrom readthedocs.core.symlink import PrivateSymlink, PublicSymlink\nfrom readthedocs.core.views.serve import _serve_file\nfrom readthedocs.projects.constants import PRIVATE\nfrom readthedocs.projects.models import HTMLFile, Project\nfrom readthedocs.redirects.utils import (\n get_redirect_response,\n project_and_path_from_request,\n language_and_version_from_path\n)\n\nlog = logging.getLogger(__name__)\n\n\nclass NoProjectException(Exception):\n pass\n\n\nclass HomepageView(TemplateView):\n\n template_name = 'homepage.html'\n\n def get_context_data(self, **kwargs):\n \"\"\"Add latest builds and featured projects.\"\"\"\n context = super().get_context_data(**kwargs)\n context['featured_list'] = Project.objects.filter(featured=True)\n context['projects_count'] = Project.objects.count()\n return context\n\n\nclass SupportView(TemplateView):\n template_name = 'support.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n support_email = getattr(settings, 'SUPPORT_EMAIL', None)\n if not support_email:\n support_email = 'support@{domain}'.format(\n domain=getattr(\n settings,\n 'PRODUCTION_DOMAIN',\n 'readthedocs.org',\n ),\n )\n\n context['support_email'] = support_email\n return context\n\n\ndef random_page(request, project_slug=None): # pylint: disable=unused-argument\n html_file = HTMLFile.objects.order_by('?')\n if project_slug:\n html_file = html_file.filter(project__slug=project_slug)\n html_file = html_file.first()\n if html_file is None:\n raise Http404\n url = html_file.get_absolute_url()\n return HttpResponseRedirect(url)\n\n\ndef wipe_version(request, project_slug, version_slug):\n version = get_object_or_404(\n Version,\n project__slug=project_slug,\n slug=version_slug,\n )\n # We need to check by ``for_admin_user`` here to allow members of the\n # ``Admin`` team (which doesn't own the project) under the corporate site.\n if version.project not in Project.objects.for_admin_user(user=request.user):\n raise Http404('You must own this project to wipe it.')\n\n if request.method == 'POST':\n wipe_version_via_slugs(\n version_slug=version_slug,\n project_slug=project_slug\n )\n return redirect('project_version_list', project_slug)\n return render(\n request,\n 'wipe_version.html',\n {'version': version, 'project': version.project},\n )\n\n\ndef server_error_500(request, template_name='500.html'):\n \"\"\"A simple 500 handler so we get media.\"\"\"\n r = render(request, template_name)\n r.status_code = 500\n return r\n\n\ndef server_error_404(request, exception=None, template_name='404.html'): # pylint: disable=unused-argument # noqa\n \"\"\"\n A simple 404 handler so we get media.\n\n .. note::\n\n Marking exception as optional to make /404/ testing page to work.\n \"\"\"\n response = get_redirect_response(request, full_path=request.get_full_path())\n\n # Return a redirect response if there is one\n if response:\n if response.url == request.build_absolute_uri():\n # check that we do have a response and avoid infinite redirect\n log.warning(\n 'Infinite Redirect: FROM URL is the same than TO URL. url=%s',\n response.url,\n )\n else:\n return response\n\n # Try to serve custom 404 pages if it's a subdomain/cname\n if getattr(request, 'subdomain', False) or getattr(request, 'cname', False):\n return server_error_404_subdomain(request, template_name)\n\n # Return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef server_error_404_subdomain(request, template_name='404.html'):\n \"\"\"\n Handler for 404 pages on subdomains.\n\n Check if the project associated has a custom ``404.html`` and serve this\n page. First search for a 404 page in the current version, then continues\n with the default version and finally, if none of them are found, the Read\n the Docs default page (Maze Found) is rendered by Django and served.\n \"\"\"\n\n def resolve_404_path(project, version_slug=None, language=None):\n \"\"\"\n Helper to resolve the path of ``404.html`` for project.\n\n The resolution is based on ``project`` object, version slug and\n language.\n\n :returns: tuple containing the (basepath, filename)\n :rtype: tuple\n \"\"\"\n filename = resolve_path(\n project,\n version_slug=version_slug,\n language=language,\n filename='404.html',\n subdomain=True, # subdomain will make it a \"full\" path without a URL prefix\n )\n\n # This breaks path joining, by ignoring the root when given an \"absolute\" path\n if filename[0] == '/':\n filename = filename[1:]\n\n version = None\n if version_slug:\n version_qs = project.versions.filter(slug=version_slug)\n if version_qs.exists():\n version = version_qs.first()\n\n private = any([\n version and version.privacy_level == PRIVATE,\n not version and project.privacy_level == PRIVATE,\n ])\n if private:\n symlink = PrivateSymlink(project)\n else:\n symlink = PublicSymlink(project)\n basepath = symlink.project_root\n fullpath = os.path.join(basepath, filename)\n return (basepath, filename, fullpath)\n\n project, full_path = project_and_path_from_request(request, request.get_full_path())\n\n if project:\n language = None\n version_slug = None\n schema, netloc, path, params, query, fragments = urlparse(full_path)\n if not project.single_version:\n language, version_slug, path = language_and_version_from_path(path)\n\n # Firstly, attempt to serve the 404 of the current version (version_slug)\n # Secondly, try to serve the 404 page for the default version (project.get_default_version())\n for slug in (version_slug, project.get_default_version()):\n basepath, filename, fullpath = resolve_404_path(project, slug, language)\n if os.path.exists(fullpath):\n log.debug(\n 'serving 404.html page current version: [project: %s] [version: %s]',\n project.slug,\n slug,\n )\n r = _serve_file(request, filename, basepath)\n r.status_code = 404\n return r\n\n # Finally, return the default 404 page generated by Read the Docs\n r = render(request, template_name)\n r.status_code = 404\n return r\n\n\ndef do_not_track(request):\n dnt_header = request.META.get('HTTP_DNT')\n\n # https://w3c.github.io/dnt/drafts/tracking-dnt.html#status-representation\n return JsonResponse( # pylint: disable=redundant-content-type-for-json-response\n {\n 'policy': 'https://docs.readthedocs.io/en/latest/privacy-policy.html',\n 'same-party': [\n 'readthedocs.org',\n 'readthedocs.com',\n 'readthedocs.io', # .org Documentation Sites\n 'readthedocs-hosted.com', # .com Documentation Sites\n ],\n 'tracking': 'N' if dnt_header == '1' else 'T',\n }, content_type='application/tracking-status+json',\n )\n", "path": "readthedocs/core/views/__init__.py"}]}
| 2,791 | 395 |
gh_patches_debug_18999
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-1270
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update regex pattern for the envvar construtor
You can use envvars on your configuration, but they need to follow this pattern `$ENVVARNAME` the regex pattern should be updated to allow users to use either `$ENVVARNAME` or `${ENVVARNAME}`.
While we are at it we should allow users to use other characters as well like `_` or `-`.
This change needs to be done on [opsdroid.loader.load_config_file](https://github.com/opsdroid/opsdroid/blob/674013037eab826640174407a73f8fed1a29b290/opsdroid/loader.py#L347)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opsdroid/const.py`
Content:
```
1 """Constants used by OpsDroid."""
2 import os
3 from appdirs import user_log_dir, user_config_dir, user_data_dir
4 import opsdroid
5 from opsdroid import __version__ # noqa # pylint: disable=unused-import
6
7 NAME = "opsdroid"
8 MODULE_ROOT = os.path.dirname(os.path.abspath(opsdroid.__file__))
9 DEFAULT_GIT_URL = "https://github.com/opsdroid/"
10 MODULES_DIRECTORY = "opsdroid-modules"
11 DEFAULT_ROOT_PATH = user_data_dir(NAME)
12 DEFAULT_LOG_FILENAME = os.path.join(user_log_dir(NAME, appauthor=False), "output.log")
13 DEFAULT_MODULES_PATH = user_data_dir(NAME, MODULES_DIRECTORY)
14 DEFAULT_MODULE_DEPS_PATH = os.path.join(
15 user_data_dir(NAME, MODULES_DIRECTORY), "site-packages"
16 )
17 DEFAULT_CONFIG_PATH = os.path.join(
18 user_config_dir(NAME, appauthor=False), "configuration.yaml"
19 )
20 DEFAULT_MODULE_BRANCH = "master"
21 DEFAULT_LANGUAGE = "en"
22 LOCALE_DIR = os.path.join(MODULE_ROOT, "locale")
23 EXAMPLE_CONFIG_FILE = os.path.join(
24 os.path.dirname(os.path.abspath(__file__)),
25 "configuration/example_configuration.yaml",
26 )
27 REGEX_PARSE_SCORE_FACTOR = 0.6
28
29 RASANLU_DEFAULT_URL = "http://localhost:5000"
30 RASANLU_DEFAULT_PROJECT = "opsdroid"
31
32 LUISAI_DEFAULT_URL = "https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/"
33
34 DIALOGFLOW_API_ENDPOINT = "https://api.dialogflow.com/v1/query"
35 DIALOGFLOW_API_VERSION = "20150910"
36
37 WITAI_DEFAULT_VERSION = "20170307"
38 WITAI_API_ENDPOINT = "https://api.wit.ai/message?"
39
40 SAPCAI_API_ENDPOINT = "https://api.cai.tools.sap/v2/request"
41
42 WATSON_API_ENDPOINT = "https://{gateway}.watsonplatform.net/assistant/api"
43 WATSON_API_VERSION = "2019-02-28"
44
```
Path: `opsdroid/configuration/__init__.py`
Content:
```
1 """Load configuration from yaml file."""
2
3 import os
4 import shutil
5 import sys
6 import re
7 import logging
8 import yaml
9
10 from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE
11 from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA
12 from opsdroid.helper import update_pre_0_17_config_format
13
14
15 _LOGGER = logging.getLogger(__name__)
16
17
18 def create_default_config(config_path):
19 """Create a default config file based on the example config file.
20
21 If we can't find any configuration.yaml, we will pull the whole
22 example_configuration.yaml and use this file as the configuration.
23
24 Args:
25 config_path: String containing the path to configuration.yaml
26 default install location
27
28 Returns:
29 str: path to configuration.yaml default install location
30
31 """
32 _LOGGER.info("Creating %s.", config_path)
33 config_dir, _ = os.path.split(config_path)
34 if not os.path.isdir(config_dir):
35 os.makedirs(config_dir)
36 shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)
37 return config_path
38
39
40 def get_config_path(config_paths):
41 """Get the path to configuration.yaml.
42
43 Opsdroid configuration.yaml can be located in different paths.
44 With this function, we will go through all of the possible paths and
45 return the correct path.
46
47 If we don't have any configuration.yaml we will just create one using
48 the example configuration file.
49
50 Args:
51 config_paths: List containing all the possible config paths.
52
53 Returns:
54 str: Path to the configuration file.
55
56 """
57 config_path = ""
58 for possible_path in config_paths:
59 if not os.path.isfile(possible_path):
60 _LOGGER.debug(_("Config file %s not found."), possible_path)
61 else:
62 config_path = possible_path
63 break
64
65 if not config_path:
66 _LOGGER.info(
67 _("No configuration files found. Creating %s"), DEFAULT_CONFIG_PATH
68 )
69 config_path = create_default_config(DEFAULT_CONFIG_PATH)
70
71 return config_path
72
73
74 env_var_pattern = re.compile(r"^\$([A-Z_]*)$")
75
76
77 def envvar_constructor(loader, node):
78 """Yaml parser for env vars."""
79 value = loader.construct_scalar(node)
80 [env_var] = env_var_pattern.match(value).groups()
81 return os.environ[env_var]
82
83
84 def load_config_file(config_paths):
85 """Load a yaml config file from path.
86
87 We get a path for the configuration file and then use the yaml
88 library to load this file - the configuration will be shown as a
89 dict. Here we also add constructors to our yaml loader and handle
90 different exceptions that could be raised when trying to load or
91 validate the file.
92
93 Args:
94 config_paths: List of paths to configuration.yaml files
95
96 Returns:
97 dict: Dict containing config fields
98
99 """
100
101 config_path = get_config_path(config_paths)
102
103 yaml.SafeLoader.add_implicit_resolver("!envvar", env_var_pattern, first="$")
104 yaml.SafeLoader.add_constructor("!envvar", envvar_constructor)
105
106 try:
107 with open(config_path, "r") as stream:
108 _LOGGER.info(_("Loaded config from %s."), config_path)
109
110 data = yaml.load(stream, Loader=yaml.SafeLoader)
111 configuration = update_pre_0_17_config_format(data)
112 validate_configuration(configuration, BASE_SCHEMA)
113
114 return configuration
115
116 except yaml.YAMLError as error:
117 _LOGGER.critical(error)
118 sys.exit(1)
119
120 except FileNotFoundError as error:
121 _LOGGER.critical(error)
122 sys.exit(1)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opsdroid/configuration/__init__.py b/opsdroid/configuration/__init__.py
--- a/opsdroid/configuration/__init__.py
+++ b/opsdroid/configuration/__init__.py
@@ -7,7 +7,7 @@
import logging
import yaml
-from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE
+from opsdroid.const import DEFAULT_CONFIG_PATH, ENV_VAR_REGEX, EXAMPLE_CONFIG_FILE
from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA
from opsdroid.helper import update_pre_0_17_config_format
@@ -71,7 +71,7 @@
return config_path
-env_var_pattern = re.compile(r"^\$([A-Z_]*)$")
+env_var_pattern = re.compile(ENV_VAR_REGEX)
def envvar_constructor(loader, node):
diff --git a/opsdroid/const.py b/opsdroid/const.py
--- a/opsdroid/const.py
+++ b/opsdroid/const.py
@@ -41,3 +41,4 @@
WATSON_API_ENDPOINT = "https://{gateway}.watsonplatform.net/assistant/api"
WATSON_API_VERSION = "2019-02-28"
+ENV_VAR_REGEX = r"^\"?\${?(?=\_?[A-Z])([A-Z-_]+)}?\"?$"
|
{"golden_diff": "diff --git a/opsdroid/configuration/__init__.py b/opsdroid/configuration/__init__.py\n--- a/opsdroid/configuration/__init__.py\n+++ b/opsdroid/configuration/__init__.py\n@@ -7,7 +7,7 @@\n import logging\n import yaml\n \n-from opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE\n+from opsdroid.const import DEFAULT_CONFIG_PATH, ENV_VAR_REGEX, EXAMPLE_CONFIG_FILE\n from opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA\n from opsdroid.helper import update_pre_0_17_config_format\n \n@@ -71,7 +71,7 @@\n return config_path\n \n \n-env_var_pattern = re.compile(r\"^\\$([A-Z_]*)$\")\n+env_var_pattern = re.compile(ENV_VAR_REGEX)\n \n \n def envvar_constructor(loader, node):\ndiff --git a/opsdroid/const.py b/opsdroid/const.py\n--- a/opsdroid/const.py\n+++ b/opsdroid/const.py\n@@ -41,3 +41,4 @@\n \n WATSON_API_ENDPOINT = \"https://{gateway}.watsonplatform.net/assistant/api\"\n WATSON_API_VERSION = \"2019-02-28\"\n+ENV_VAR_REGEX = r\"^\\\"?\\${?(?=\\_?[A-Z])([A-Z-_]+)}?\\\"?$\"\n", "issue": "Update regex pattern for the envvar construtor\nYou can use envvars on your configuration, but they need to follow this pattern `$ENVVARNAME` the regex pattern should be updated to allow users to use either `$ENVVARNAME` or `${ENVVARNAME}`. \r\n\r\nWhile we are at it we should allow users to use other characters as well like `_` or `-`. \r\n\r\nThis change needs to be done on [opsdroid.loader.load_config_file](https://github.com/opsdroid/opsdroid/blob/674013037eab826640174407a73f8fed1a29b290/opsdroid/loader.py#L347)\n", "before_files": [{"content": "\"\"\"Constants used by OpsDroid.\"\"\"\nimport os\nfrom appdirs import user_log_dir, user_config_dir, user_data_dir\nimport opsdroid\nfrom opsdroid import __version__ # noqa # pylint: disable=unused-import\n\nNAME = \"opsdroid\"\nMODULE_ROOT = os.path.dirname(os.path.abspath(opsdroid.__file__))\nDEFAULT_GIT_URL = \"https://github.com/opsdroid/\"\nMODULES_DIRECTORY = \"opsdroid-modules\"\nDEFAULT_ROOT_PATH = user_data_dir(NAME)\nDEFAULT_LOG_FILENAME = os.path.join(user_log_dir(NAME, appauthor=False), \"output.log\")\nDEFAULT_MODULES_PATH = user_data_dir(NAME, MODULES_DIRECTORY)\nDEFAULT_MODULE_DEPS_PATH = os.path.join(\n user_data_dir(NAME, MODULES_DIRECTORY), \"site-packages\"\n)\nDEFAULT_CONFIG_PATH = os.path.join(\n user_config_dir(NAME, appauthor=False), \"configuration.yaml\"\n)\nDEFAULT_MODULE_BRANCH = \"master\"\nDEFAULT_LANGUAGE = \"en\"\nLOCALE_DIR = os.path.join(MODULE_ROOT, \"locale\")\nEXAMPLE_CONFIG_FILE = os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n \"configuration/example_configuration.yaml\",\n)\nREGEX_PARSE_SCORE_FACTOR = 0.6\n\nRASANLU_DEFAULT_URL = \"http://localhost:5000\"\nRASANLU_DEFAULT_PROJECT = \"opsdroid\"\n\nLUISAI_DEFAULT_URL = \"https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/\"\n\nDIALOGFLOW_API_ENDPOINT = \"https://api.dialogflow.com/v1/query\"\nDIALOGFLOW_API_VERSION = \"20150910\"\n\nWITAI_DEFAULT_VERSION = \"20170307\"\nWITAI_API_ENDPOINT = \"https://api.wit.ai/message?\"\n\nSAPCAI_API_ENDPOINT = \"https://api.cai.tools.sap/v2/request\"\n\nWATSON_API_ENDPOINT = \"https://{gateway}.watsonplatform.net/assistant/api\"\nWATSON_API_VERSION = \"2019-02-28\"\n", "path": "opsdroid/const.py"}, {"content": "\"\"\"Load configuration from yaml file.\"\"\"\n\nimport os\nimport shutil\nimport sys\nimport re\nimport logging\nimport yaml\n\nfrom opsdroid.const import DEFAULT_CONFIG_PATH, EXAMPLE_CONFIG_FILE\nfrom opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA\nfrom opsdroid.helper import update_pre_0_17_config_format\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\ndef create_default_config(config_path):\n \"\"\"Create a default config file based on the example config file.\n\n If we can't find any configuration.yaml, we will pull the whole\n example_configuration.yaml and use this file as the configuration.\n\n Args:\n config_path: String containing the path to configuration.yaml\n default install location\n\n Returns:\n str: path to configuration.yaml default install location\n\n \"\"\"\n _LOGGER.info(\"Creating %s.\", config_path)\n config_dir, _ = os.path.split(config_path)\n if not os.path.isdir(config_dir):\n os.makedirs(config_dir)\n shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)\n return config_path\n\n\ndef get_config_path(config_paths):\n \"\"\"Get the path to configuration.yaml.\n\n Opsdroid configuration.yaml can be located in different paths.\n With this function, we will go through all of the possible paths and\n return the correct path.\n\n If we don't have any configuration.yaml we will just create one using\n the example configuration file.\n\n Args:\n config_paths: List containing all the possible config paths.\n\n Returns:\n str: Path to the configuration file.\n\n \"\"\"\n config_path = \"\"\n for possible_path in config_paths:\n if not os.path.isfile(possible_path):\n _LOGGER.debug(_(\"Config file %s not found.\"), possible_path)\n else:\n config_path = possible_path\n break\n\n if not config_path:\n _LOGGER.info(\n _(\"No configuration files found. Creating %s\"), DEFAULT_CONFIG_PATH\n )\n config_path = create_default_config(DEFAULT_CONFIG_PATH)\n\n return config_path\n\n\nenv_var_pattern = re.compile(r\"^\\$([A-Z_]*)$\")\n\n\ndef envvar_constructor(loader, node):\n \"\"\"Yaml parser for env vars.\"\"\"\n value = loader.construct_scalar(node)\n [env_var] = env_var_pattern.match(value).groups()\n return os.environ[env_var]\n\n\ndef load_config_file(config_paths):\n \"\"\"Load a yaml config file from path.\n\n We get a path for the configuration file and then use the yaml\n library to load this file - the configuration will be shown as a\n dict. Here we also add constructors to our yaml loader and handle\n different exceptions that could be raised when trying to load or\n validate the file.\n\n Args:\n config_paths: List of paths to configuration.yaml files\n\n Returns:\n dict: Dict containing config fields\n\n \"\"\"\n\n config_path = get_config_path(config_paths)\n\n yaml.SafeLoader.add_implicit_resolver(\"!envvar\", env_var_pattern, first=\"$\")\n yaml.SafeLoader.add_constructor(\"!envvar\", envvar_constructor)\n\n try:\n with open(config_path, \"r\") as stream:\n _LOGGER.info(_(\"Loaded config from %s.\"), config_path)\n\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n configuration = update_pre_0_17_config_format(data)\n validate_configuration(configuration, BASE_SCHEMA)\n\n return configuration\n\n except yaml.YAMLError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n\n except FileNotFoundError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n", "path": "opsdroid/configuration/__init__.py"}], "after_files": [{"content": "\"\"\"Constants used by OpsDroid.\"\"\"\nimport os\nfrom appdirs import user_log_dir, user_config_dir, user_data_dir\nimport opsdroid\nfrom opsdroid import __version__ # noqa # pylint: disable=unused-import\n\nNAME = \"opsdroid\"\nMODULE_ROOT = os.path.dirname(os.path.abspath(opsdroid.__file__))\nDEFAULT_GIT_URL = \"https://github.com/opsdroid/\"\nMODULES_DIRECTORY = \"opsdroid-modules\"\nDEFAULT_ROOT_PATH = user_data_dir(NAME)\nDEFAULT_LOG_FILENAME = os.path.join(user_log_dir(NAME, appauthor=False), \"output.log\")\nDEFAULT_MODULES_PATH = user_data_dir(NAME, MODULES_DIRECTORY)\nDEFAULT_MODULE_DEPS_PATH = os.path.join(\n user_data_dir(NAME, MODULES_DIRECTORY), \"site-packages\"\n)\nDEFAULT_CONFIG_PATH = os.path.join(\n user_config_dir(NAME, appauthor=False), \"configuration.yaml\"\n)\nDEFAULT_MODULE_BRANCH = \"master\"\nDEFAULT_LANGUAGE = \"en\"\nLOCALE_DIR = os.path.join(MODULE_ROOT, \"locale\")\nEXAMPLE_CONFIG_FILE = os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n \"configuration/example_configuration.yaml\",\n)\nREGEX_PARSE_SCORE_FACTOR = 0.6\n\nRASANLU_DEFAULT_URL = \"http://localhost:5000\"\nRASANLU_DEFAULT_PROJECT = \"opsdroid\"\n\nLUISAI_DEFAULT_URL = \"https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/\"\n\nDIALOGFLOW_API_ENDPOINT = \"https://api.dialogflow.com/v1/query\"\nDIALOGFLOW_API_VERSION = \"20150910\"\n\nWITAI_DEFAULT_VERSION = \"20170307\"\nWITAI_API_ENDPOINT = \"https://api.wit.ai/message?\"\n\nSAPCAI_API_ENDPOINT = \"https://api.cai.tools.sap/v2/request\"\n\nWATSON_API_ENDPOINT = \"https://{gateway}.watsonplatform.net/assistant/api\"\nWATSON_API_VERSION = \"2019-02-28\"\nENV_VAR_REGEX = r\"^\\\"?\\${?(?=\\_?[A-Z])([A-Z-_]+)}?\\\"?$\"\n", "path": "opsdroid/const.py"}, {"content": "\"\"\"Load configuration from yaml file.\"\"\"\n\nimport os\nimport shutil\nimport sys\nimport re\nimport logging\nimport yaml\n\nfrom opsdroid.const import DEFAULT_CONFIG_PATH, ENV_VAR_REGEX, EXAMPLE_CONFIG_FILE\nfrom opsdroid.configuration.validation import validate_configuration, BASE_SCHEMA\nfrom opsdroid.helper import update_pre_0_17_config_format\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\ndef create_default_config(config_path):\n \"\"\"Create a default config file based on the example config file.\n\n If we can't find any configuration.yaml, we will pull the whole\n example_configuration.yaml and use this file as the configuration.\n\n Args:\n config_path: String containing the path to configuration.yaml\n default install location\n\n Returns:\n str: path to configuration.yaml default install location\n\n \"\"\"\n _LOGGER.info(\"Creating %s.\", config_path)\n config_dir, _ = os.path.split(config_path)\n if not os.path.isdir(config_dir):\n os.makedirs(config_dir)\n shutil.copyfile(EXAMPLE_CONFIG_FILE, config_path)\n return config_path\n\n\ndef get_config_path(config_paths):\n \"\"\"Get the path to configuration.yaml.\n\n Opsdroid configuration.yaml can be located in different paths.\n With this function, we will go through all of the possible paths and\n return the correct path.\n\n If we don't have any configuration.yaml we will just create one using\n the example configuration file.\n\n Args:\n config_paths: List containing all the possible config paths.\n\n Returns:\n str: Path to the configuration file.\n\n \"\"\"\n config_path = \"\"\n for possible_path in config_paths:\n if not os.path.isfile(possible_path):\n _LOGGER.debug(_(\"Config file %s not found.\"), possible_path)\n else:\n config_path = possible_path\n break\n\n if not config_path:\n _LOGGER.info(\n _(\"No configuration files found. Creating %s\"), DEFAULT_CONFIG_PATH\n )\n config_path = create_default_config(DEFAULT_CONFIG_PATH)\n\n return config_path\n\n\nenv_var_pattern = re.compile(ENV_VAR_REGEX)\n\n\ndef envvar_constructor(loader, node):\n \"\"\"Yaml parser for env vars.\"\"\"\n value = loader.construct_scalar(node)\n [env_var] = env_var_pattern.match(value).groups()\n return os.environ[env_var]\n\n\ndef load_config_file(config_paths):\n \"\"\"Load a yaml config file from path.\n\n We get a path for the configuration file and then use the yaml\n library to load this file - the configuration will be shown as a\n dict. Here we also add constructors to our yaml loader and handle\n different exceptions that could be raised when trying to load or\n validate the file.\n\n Args:\n config_paths: List of paths to configuration.yaml files\n\n Returns:\n dict: Dict containing config fields\n\n \"\"\"\n\n config_path = get_config_path(config_paths)\n\n yaml.SafeLoader.add_implicit_resolver(\"!envvar\", env_var_pattern, first=\"$\")\n yaml.SafeLoader.add_constructor(\"!envvar\", envvar_constructor)\n\n try:\n with open(config_path, \"r\") as stream:\n _LOGGER.info(_(\"Loaded config from %s.\"), config_path)\n\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n configuration = update_pre_0_17_config_format(data)\n validate_configuration(configuration, BASE_SCHEMA)\n\n return configuration\n\n except yaml.YAMLError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n\n except FileNotFoundError as error:\n _LOGGER.critical(error)\n sys.exit(1)\n", "path": "opsdroid/configuration/__init__.py"}]}
| 1,983 | 299 |
gh_patches_debug_20188
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-2080
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Threading integration breaks OpenCensus' threading integration
### How do you use Sentry?
Sentry Saas (sentry.io)
### Version
1.21.1
### Steps to Reproduce
1. Enable threading Sentry integration (it seems to be enabled by default)
2. Enable [threading OpenCensus integration](https://pypi.org/project/opencensus-ext-threading/)
3. Start a thread
```python
import threading
import sentry_sdk.integrations.threading
import opencensus.trace.config_integration
sentry_sdk.init(integrations=[
sentry_sdk.integrations.threading.ThreadingIntegration(),
])
opencensus.trace.config_integration.trace_integrations(
integrations=["threading"],
)
thread = threading.Thread(target=print, args=("foo",))
thread.start()
thread.join()
```
### Expected Result
No error, output: `foo`
### Actual Result
Exceptions raised on every thread's startup
```python
Exception in thread Thread-1 (print):
Traceback (most recent call last):
File "/usr/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File ".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py", line 69, in run
reraise(*_capture_exception())
File ".venv/lib/python3.10/site-packages/sentry_sdk/_compat.py", line 60, in reraise
raise value
File ".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py", line 67, in run
return old_run_func(self, *a, **kw)
File ".venv/lib/python3.10/site-packages/opencensus/ext/threading/trace.py", line 80, in call
*self._opencensus_context
AttributeError: 'Thread' object has no attribute '_opencensus_context'
```
### Additional details
* Python: 3.10
* OpenCensus threading extension: 0.1.2
My suggestion is to use [`functools.update_wrapper`](https://docs.python.org/3/library/functools.html#functools.update_wrapper) (or the convenience decorator [`functools.wraps`](https://docs.python.org/3/library/functools.html#functools.wraps)) to set the name of [`sentry_start`](https://github.com/getsentry/sentry-python/blob/f763061ed9d9e99d85b3e95adc3ed63b623fc4a0/sentry_sdk/integrations/threading.py#L35-54) to `"start"` (and maybe the same for the result of `_wrap_run`, to `"run"`), so it "holds up to basic introspection".
PS: please include 'Additional details' block in issue template
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/integrations/threading.py`
Content:
```
1 from __future__ import absolute_import
2
3 import sys
4 from threading import Thread, current_thread
5
6 from sentry_sdk import Hub
7 from sentry_sdk._compat import reraise
8 from sentry_sdk._types import TYPE_CHECKING
9 from sentry_sdk.integrations import Integration
10 from sentry_sdk.utils import event_from_exception, capture_internal_exceptions
11
12 if TYPE_CHECKING:
13 from typing import Any
14 from typing import TypeVar
15 from typing import Callable
16 from typing import Optional
17
18 from sentry_sdk._types import ExcInfo
19
20 F = TypeVar("F", bound=Callable[..., Any])
21
22
23 class ThreadingIntegration(Integration):
24 identifier = "threading"
25
26 def __init__(self, propagate_hub=False):
27 # type: (bool) -> None
28 self.propagate_hub = propagate_hub
29
30 @staticmethod
31 def setup_once():
32 # type: () -> None
33 old_start = Thread.start
34
35 def sentry_start(self, *a, **kw):
36 # type: (Thread, *Any, **Any) -> Any
37 hub = Hub.current
38 integration = hub.get_integration(ThreadingIntegration)
39 if integration is not None:
40 if not integration.propagate_hub:
41 hub_ = None
42 else:
43 hub_ = Hub(hub)
44 # Patching instance methods in `start()` creates a reference cycle if
45 # done in a naive way. See
46 # https://github.com/getsentry/sentry-python/pull/434
47 #
48 # In threading module, using current_thread API will access current thread instance
49 # without holding it to avoid a reference cycle in an easier way.
50 with capture_internal_exceptions():
51 new_run = _wrap_run(hub_, getattr(self.run, "__func__", self.run))
52 self.run = new_run # type: ignore
53
54 return old_start(self, *a, **kw)
55
56 Thread.start = sentry_start # type: ignore
57
58
59 def _wrap_run(parent_hub, old_run_func):
60 # type: (Optional[Hub], F) -> F
61 def run(*a, **kw):
62 # type: (*Any, **Any) -> Any
63 hub = parent_hub or Hub.current
64 with hub:
65 try:
66 self = current_thread()
67 return old_run_func(self, *a, **kw)
68 except Exception:
69 reraise(*_capture_exception())
70
71 return run # type: ignore
72
73
74 def _capture_exception():
75 # type: () -> ExcInfo
76 hub = Hub.current
77 exc_info = sys.exc_info()
78
79 if hub.get_integration(ThreadingIntegration) is not None:
80 # If an integration is there, a client has to be there.
81 client = hub.client # type: Any
82
83 event, hint = event_from_exception(
84 exc_info,
85 client_options=client.options,
86 mechanism={"type": "threading", "handled": False},
87 )
88 hub.capture_event(event, hint=hint)
89
90 return exc_info
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/integrations/threading.py b/sentry_sdk/integrations/threading.py
--- a/sentry_sdk/integrations/threading.py
+++ b/sentry_sdk/integrations/threading.py
@@ -1,6 +1,7 @@
from __future__ import absolute_import
import sys
+from functools import wraps
from threading import Thread, current_thread
from sentry_sdk import Hub
@@ -32,6 +33,7 @@
# type: () -> None
old_start = Thread.start
+ @wraps(old_start)
def sentry_start(self, *a, **kw):
# type: (Thread, *Any, **Any) -> Any
hub = Hub.current
@@ -58,6 +60,7 @@
def _wrap_run(parent_hub, old_run_func):
# type: (Optional[Hub], F) -> F
+ @wraps(old_run_func)
def run(*a, **kw):
# type: (*Any, **Any) -> Any
hub = parent_hub or Hub.current
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/threading.py b/sentry_sdk/integrations/threading.py\n--- a/sentry_sdk/integrations/threading.py\n+++ b/sentry_sdk/integrations/threading.py\n@@ -1,6 +1,7 @@\n from __future__ import absolute_import\n \n import sys\n+from functools import wraps\n from threading import Thread, current_thread\n \n from sentry_sdk import Hub\n@@ -32,6 +33,7 @@\n # type: () -> None\n old_start = Thread.start\n \n+ @wraps(old_start)\n def sentry_start(self, *a, **kw):\n # type: (Thread, *Any, **Any) -> Any\n hub = Hub.current\n@@ -58,6 +60,7 @@\n \n def _wrap_run(parent_hub, old_run_func):\n # type: (Optional[Hub], F) -> F\n+ @wraps(old_run_func)\n def run(*a, **kw):\n # type: (*Any, **Any) -> Any\n hub = parent_hub or Hub.current\n", "issue": "Threading integration breaks OpenCensus' threading integration\n### How do you use Sentry?\r\n\r\nSentry Saas (sentry.io)\r\n\r\n### Version\r\n\r\n1.21.1\r\n\r\n### Steps to Reproduce\r\n\r\n1. Enable threading Sentry integration (it seems to be enabled by default)\r\n2. Enable [threading OpenCensus integration](https://pypi.org/project/opencensus-ext-threading/)\r\n3. Start a thread\r\n\r\n```python\r\nimport threading\r\n\r\nimport sentry_sdk.integrations.threading\r\nimport opencensus.trace.config_integration\r\n\r\nsentry_sdk.init(integrations=[\r\n sentry_sdk.integrations.threading.ThreadingIntegration(),\r\n])\r\n\r\nopencensus.trace.config_integration.trace_integrations(\r\n integrations=[\"threading\"],\r\n)\r\n\r\nthread = threading.Thread(target=print, args=(\"foo\",))\r\nthread.start()\r\nthread.join()\r\n```\r\n\r\n### Expected Result\r\n\r\nNo error, output: `foo`\r\n\r\n### Actual Result\r\n\r\nExceptions raised on every thread's startup\r\n\r\n```python\r\nException in thread Thread-1 (print):\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.10/threading.py\", line 1016, in _bootstrap_inner\r\n self.run()\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py\", line 69, in run\r\n reraise(*_capture_exception())\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/_compat.py\", line 60, in reraise\r\n raise value\r\n File \".venv/lib/python3.10/site-packages/sentry_sdk/integrations/threading.py\", line 67, in run\r\n return old_run_func(self, *a, **kw)\r\n File \".venv/lib/python3.10/site-packages/opencensus/ext/threading/trace.py\", line 80, in call\r\n *self._opencensus_context\r\nAttributeError: 'Thread' object has no attribute '_opencensus_context'\r\n```\r\n\r\n### Additional details\r\n\r\n* Python: 3.10\r\n* OpenCensus threading extension: 0.1.2\r\n\r\nMy suggestion is to use [`functools.update_wrapper`](https://docs.python.org/3/library/functools.html#functools.update_wrapper) (or the convenience decorator [`functools.wraps`](https://docs.python.org/3/library/functools.html#functools.wraps)) to set the name of [`sentry_start`](https://github.com/getsentry/sentry-python/blob/f763061ed9d9e99d85b3e95adc3ed63b623fc4a0/sentry_sdk/integrations/threading.py#L35-54) to `\"start\"` (and maybe the same for the result of `_wrap_run`, to `\"run\"`), so it \"holds up to basic introspection\".\r\n\r\nPS: please include 'Additional details' block in issue template\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport sys\nfrom threading import Thread, current_thread\n\nfrom sentry_sdk import Hub\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk._types import TYPE_CHECKING\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.utils import event_from_exception, capture_internal_exceptions\n\nif TYPE_CHECKING:\n from typing import Any\n from typing import TypeVar\n from typing import Callable\n from typing import Optional\n\n from sentry_sdk._types import ExcInfo\n\n F = TypeVar(\"F\", bound=Callable[..., Any])\n\n\nclass ThreadingIntegration(Integration):\n identifier = \"threading\"\n\n def __init__(self, propagate_hub=False):\n # type: (bool) -> None\n self.propagate_hub = propagate_hub\n\n @staticmethod\n def setup_once():\n # type: () -> None\n old_start = Thread.start\n\n def sentry_start(self, *a, **kw):\n # type: (Thread, *Any, **Any) -> Any\n hub = Hub.current\n integration = hub.get_integration(ThreadingIntegration)\n if integration is not None:\n if not integration.propagate_hub:\n hub_ = None\n else:\n hub_ = Hub(hub)\n # Patching instance methods in `start()` creates a reference cycle if\n # done in a naive way. See\n # https://github.com/getsentry/sentry-python/pull/434\n #\n # In threading module, using current_thread API will access current thread instance\n # without holding it to avoid a reference cycle in an easier way.\n with capture_internal_exceptions():\n new_run = _wrap_run(hub_, getattr(self.run, \"__func__\", self.run))\n self.run = new_run # type: ignore\n\n return old_start(self, *a, **kw)\n\n Thread.start = sentry_start # type: ignore\n\n\ndef _wrap_run(parent_hub, old_run_func):\n # type: (Optional[Hub], F) -> F\n def run(*a, **kw):\n # type: (*Any, **Any) -> Any\n hub = parent_hub or Hub.current\n with hub:\n try:\n self = current_thread()\n return old_run_func(self, *a, **kw)\n except Exception:\n reraise(*_capture_exception())\n\n return run # type: ignore\n\n\ndef _capture_exception():\n # type: () -> ExcInfo\n hub = Hub.current\n exc_info = sys.exc_info()\n\n if hub.get_integration(ThreadingIntegration) is not None:\n # If an integration is there, a client has to be there.\n client = hub.client # type: Any\n\n event, hint = event_from_exception(\n exc_info,\n client_options=client.options,\n mechanism={\"type\": \"threading\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n\n return exc_info\n", "path": "sentry_sdk/integrations/threading.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport sys\nfrom functools import wraps\nfrom threading import Thread, current_thread\n\nfrom sentry_sdk import Hub\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk._types import TYPE_CHECKING\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.utils import event_from_exception, capture_internal_exceptions\n\nif TYPE_CHECKING:\n from typing import Any\n from typing import TypeVar\n from typing import Callable\n from typing import Optional\n\n from sentry_sdk._types import ExcInfo\n\n F = TypeVar(\"F\", bound=Callable[..., Any])\n\n\nclass ThreadingIntegration(Integration):\n identifier = \"threading\"\n\n def __init__(self, propagate_hub=False):\n # type: (bool) -> None\n self.propagate_hub = propagate_hub\n\n @staticmethod\n def setup_once():\n # type: () -> None\n old_start = Thread.start\n\n @wraps(old_start)\n def sentry_start(self, *a, **kw):\n # type: (Thread, *Any, **Any) -> Any\n hub = Hub.current\n integration = hub.get_integration(ThreadingIntegration)\n if integration is not None:\n if not integration.propagate_hub:\n hub_ = None\n else:\n hub_ = Hub(hub)\n # Patching instance methods in `start()` creates a reference cycle if\n # done in a naive way. See\n # https://github.com/getsentry/sentry-python/pull/434\n #\n # In threading module, using current_thread API will access current thread instance\n # without holding it to avoid a reference cycle in an easier way.\n with capture_internal_exceptions():\n new_run = _wrap_run(hub_, getattr(self.run, \"__func__\", self.run))\n self.run = new_run # type: ignore\n\n return old_start(self, *a, **kw)\n\n Thread.start = sentry_start # type: ignore\n\n\ndef _wrap_run(parent_hub, old_run_func):\n # type: (Optional[Hub], F) -> F\n @wraps(old_run_func)\n def run(*a, **kw):\n # type: (*Any, **Any) -> Any\n hub = parent_hub or Hub.current\n with hub:\n try:\n self = current_thread()\n return old_run_func(self, *a, **kw)\n except Exception:\n reraise(*_capture_exception())\n\n return run # type: ignore\n\n\ndef _capture_exception():\n # type: () -> ExcInfo\n hub = Hub.current\n exc_info = sys.exc_info()\n\n if hub.get_integration(ThreadingIntegration) is not None:\n # If an integration is there, a client has to be there.\n client = hub.client # type: Any\n\n event, hint = event_from_exception(\n exc_info,\n client_options=client.options,\n mechanism={\"type\": \"threading\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n\n return exc_info\n", "path": "sentry_sdk/integrations/threading.py"}]}
| 1,729 | 238 |
gh_patches_debug_64193
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-1546
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ChrF score failing tests
ChrF score tests are failing with python 3.4 and python 3.5:
```
tox -e py34 nltk/nltk/translate/chrf_score.py
GLOB sdist-make: nltk/setup.py
py34 inst-nodeps: nltk/.tox/dist/nltk-3.2.1.zip
py34 installed: coverage==4.2,nltk==3.2.1,nose==1.3.7,numpy==1.11.2,oauthlib==2.0.0,pyparsing==2.1.10,python-crfsuite==0.8.4,requests==2.12.1,requests-oauthlib==0.7.0,scikit-learn==0.18.1,scipy==0.18.1,six==1.10.0,text-unidecode==1.0,twython==3.4.0
py34 runtests: PYTHONHASHSEED='300012027'
py34 runtests: commands[0] | pip install scipy scikit-learn
Requirement already satisfied: scipy in nltk/.tox/py34/lib/python3.4/site-packages
Requirement already satisfied: scikit-learn in nltk/.tox/py34/lib/python3.4/site-packages
py34 runtests: commands[1] | python runtests.py ../translate/chrf_score.py
.F
======================================================================
FAIL: Doctest: nltk.translate.chrf_score.sentence_chrf
----------------------------------------------------------------------
Traceback (most recent call last):
File "/usr/lib/python3.4/doctest.py", line 2187, in runTest
raise self.failureException(self.format_failure(new.getvalue()))
AssertionError: Failed doctest test for nltk.translate.chrf_score.sentence_chrf
File "nltk/nltk/translate/chrf_score.py", line 16, in sentence_chrf
----------------------------------------------------------------------
File "nltk/nltk/translate/chrf_score.py", line 58, in nltk.translate.chrf_score.sentence_chrf
Failed example:
type(ref1), type(hyp1)
Expected:
(<type 'str'>, <type 'str'>)
Got:
(<class 'str'>, <class 'str'>)
----------------------------------------------------------------------
Ran 2 tests in 0.013s
FAILED (failures=1)
```
@alvations could you please check?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/translate/chrf_score.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Natural Language Toolkit: ChrF score
3 #
4 # Copyright (C) 2001-2016 NLTK Project
5 # Authors: Maja Popovic
6 # Contributors: Liling Tan
7 # URL: <http://nltk.org/>
8 # For license information, see LICENSE.TXT
9
10 """ ChrF score implementation """
11 from __future__ import division
12 from collections import Counter
13
14 from nltk.util import ngrams, everygrams
15
16 def sentence_chrf(reference, hypothesis, min_len=1, max_len=6, beta=3.0):
17 """
18 Calculates the sentence level CHRF (Character n-gram F-score) described in
19 - Maja Popovic. 2015. CHRF: Character n-gram F-score for Automatic MT Evaluation.
20 In Proceedings of the 10th Workshop on Machine Translation.
21 http://www.statmt.org/wmt15/pdf/WMT49.pdf
22 - Maja Popovic. 2016. CHRF Deconstructed: β Parameters and n-gram Weights.
23 In Proceedings of the 1st Conference on Machine Translation.
24 http://www.statmt.org/wmt16/pdf/W16-2341.pdf
25
26 Unlike multi-reference BLEU, CHRF only supports a single reference.
27
28 An example from the original BLEU paper
29 http://www.aclweb.org/anthology/P02-1040.pdf
30
31 >>> ref1 = str('It is a guide to action that ensures that the military '
32 ... 'will forever heed Party commands').split()
33 >>> hyp1 = str('It is a guide to action which ensures that the military '
34 ... 'always obeys the commands of the party').split()
35 >>> hyp2 = str('It is to insure the troops forever hearing the activity '
36 ... 'guidebook that party direct').split()
37 >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
38 0.6768...
39 >>> sentence_chrf(ref1, hyp2) # doctest: +ELLIPSIS
40 0.4201...
41
42 The infamous "the the the ... " example
43
44 >>> ref = 'the cat is on the mat'.split()
45 >>> hyp = 'the the the the the the the'.split()
46 >>> sentence_chrf(ref, hyp) # doctest: +ELLIPSIS
47 0.2530...
48
49 An example to show that this function allows users to use strings instead of
50 tokens, i.e. list(str) as inputs.
51
52 >>> ref1 = str('It is a guide to action that ensures that the military '
53 ... 'will forever heed Party commands')
54 >>> hyp1 = str('It is a guide to action which ensures that the military '
55 ... 'always obeys the commands of the party')
56 >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
57 0.6768...
58 >>> type(ref1), type(hyp1)
59 (<type 'str'>, <type 'str'>)
60 >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS
61 0.6768...
62
63 To skip the unigrams and only use 2- to 3-grams:
64
65 >>> sentence_chrf(ref1, hyp1, min_len=2, max_len=3) # doctest: +ELLIPSIS
66 0.7018...
67
68 :param references: reference sentence
69 :type references: list(str) / str
70 :param hypothesis: a hypothesis sentence
71 :type hypothesis: list(str) / str
72 :param min_len: The minimum order of n-gram this function should extract.
73 :type min_len: int
74 :param max_len: The maximum order of n-gram this function should extract.
75 :type max_len: int
76 :param beta: the parameter to assign more importance to recall over precision
77 :type beta: float
78 :return: the sentence level CHRF score.
79 :rtype: float
80 """
81 return corpus_chrf([reference], [hypothesis], min_len, max_len, beta=beta)
82
83
84 def corpus_chrf(list_of_references, hypotheses, min_len=1, max_len=6, beta=3.0):
85 """
86 Calculates the corpus level CHRF (Character n-gram F-score), it is the
87 micro-averaged value of the sentence/segment level CHRF score.
88
89 CHRF only supports a single reference.
90
91 >>> ref1 = str('It is a guide to action that ensures that the military '
92 ... 'will forever heed Party commands').split()
93 >>> ref2 = str('It is the guiding principle which guarantees the military '
94 ... 'forces always being under the command of the Party').split()
95 >>>
96 >>> hyp1 = str('It is a guide to action which ensures that the military '
97 ... 'always obeys the commands of the party').split()
98 >>> hyp2 = str('It is to insure the troops forever hearing the activity '
99 ... 'guidebook that party direct')
100 >>> corpus_chrf([ref1, ref2, ref1, ref2], [hyp1, hyp2, hyp2, hyp1]) # doctest: +ELLIPSIS
101 0.4915...
102
103 :param references: a corpus of list of reference sentences, w.r.t. hypotheses
104 :type references: list(list(str)) / list(str)
105 :param hypotheses: a list of hypothesis sentences
106 :type hypotheses: list(list(str)) / list(str)
107 :param min_len: The minimum order of n-gram this function should extract.
108 :type min_len: int
109 :param max_len: The maximum order of n-gram this function should extract.
110 :type max_len: int
111 :param beta: the parameter to assign more importance to recall over precision
112 :type beta: float
113 :return: the sentence level CHRF score.
114 :rtype: float
115 """
116
117 assert len(list_of_references) == len(hypotheses), "The number of hypotheses and their references should be the same"
118
119 # Iterate through each hypothesis and their corresponding references.
120 for reference, hypothesis in zip(list_of_references, hypotheses):
121 # Cheating condition to allow users to input strings instead of tokens.
122 if type(reference) and type(hypothesis) != str:
123 reference, hypothesis = ' '.join(reference), ' '.join(hypothesis)
124 # For each order of ngram, calculate the no. of ngram matches and
125 # keep track of no. of ngram in references.
126 ref_ngrams = Counter(everygrams(reference, min_len, max_len))
127 hyp_ngrams = Counter(everygrams(hypothesis, min_len, max_len))
128 overlap_ngrams = ref_ngrams & hyp_ngrams
129 tp = sum(overlap_ngrams.values()) # True positives.
130 tpfp = sum(hyp_ngrams.values()) # True positives + False positives.
131 tffn = sum(ref_ngrams.values()) # True posities + False negatives.
132
133 precision = tp / tpfp
134 recall = tp / tffn
135 factor = beta**2
136 score = (1+ factor ) * (precision * recall) / ( factor * precision + recall)
137 return score
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nltk/translate/chrf_score.py b/nltk/translate/chrf_score.py
--- a/nltk/translate/chrf_score.py
+++ b/nltk/translate/chrf_score.py
@@ -55,8 +55,8 @@
... 'always obeys the commands of the party')
>>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS
0.6768...
- >>> type(ref1), type(hyp1)
- (<type 'str'>, <type 'str'>)
+ >>> type(ref1) == type(hyp1) == str
+ True
>>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS
0.6768...
|
{"golden_diff": "diff --git a/nltk/translate/chrf_score.py b/nltk/translate/chrf_score.py\n--- a/nltk/translate/chrf_score.py\n+++ b/nltk/translate/chrf_score.py\n@@ -55,8 +55,8 @@\n ... 'always obeys the commands of the party')\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n- >>> type(ref1), type(hyp1)\n- (<type 'str'>, <type 'str'>)\n+ >>> type(ref1) == type(hyp1) == str\n+ True\n >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS\n 0.6768...\n", "issue": "ChrF score failing tests\nChrF score tests are failing with python 3.4 and python 3.5:\r\n\r\n```\r\ntox -e py34 nltk/nltk/translate/chrf_score.py\r\n\r\nGLOB sdist-make: nltk/setup.py\r\npy34 inst-nodeps: nltk/.tox/dist/nltk-3.2.1.zip\r\npy34 installed: coverage==4.2,nltk==3.2.1,nose==1.3.7,numpy==1.11.2,oauthlib==2.0.0,pyparsing==2.1.10,python-crfsuite==0.8.4,requests==2.12.1,requests-oauthlib==0.7.0,scikit-learn==0.18.1,scipy==0.18.1,six==1.10.0,text-unidecode==1.0,twython==3.4.0\r\npy34 runtests: PYTHONHASHSEED='300012027'\r\npy34 runtests: commands[0] | pip install scipy scikit-learn\r\nRequirement already satisfied: scipy in nltk/.tox/py34/lib/python3.4/site-packages\r\nRequirement already satisfied: scikit-learn in nltk/.tox/py34/lib/python3.4/site-packages\r\npy34 runtests: commands[1] | python runtests.py ../translate/chrf_score.py\r\n.F\r\n======================================================================\r\nFAIL: Doctest: nltk.translate.chrf_score.sentence_chrf\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.4/doctest.py\", line 2187, in runTest\r\n raise self.failureException(self.format_failure(new.getvalue()))\r\nAssertionError: Failed doctest test for nltk.translate.chrf_score.sentence_chrf\r\n File \"nltk/nltk/translate/chrf_score.py\", line 16, in sentence_chrf\r\n\r\n----------------------------------------------------------------------\r\nFile \"nltk/nltk/translate/chrf_score.py\", line 58, in nltk.translate.chrf_score.sentence_chrf\r\nFailed example:\r\n type(ref1), type(hyp1)\r\nExpected:\r\n (<type 'str'>, <type 'str'>)\r\nGot:\r\n (<class 'str'>, <class 'str'>)\r\n\r\n\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.013s\r\n\r\nFAILED (failures=1)\r\n```\r\n\r\n@alvations could you please check?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Natural Language Toolkit: ChrF score\n#\n# Copyright (C) 2001-2016 NLTK Project\n# Authors: Maja Popovic\n# Contributors: Liling Tan\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\" ChrF score implementation \"\"\"\nfrom __future__ import division\nfrom collections import Counter\n\nfrom nltk.util import ngrams, everygrams\n\ndef sentence_chrf(reference, hypothesis, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the sentence level CHRF (Character n-gram F-score) described in\n - Maja Popovic. 2015. CHRF: Character n-gram F-score for Automatic MT Evaluation.\n In Proceedings of the 10th Workshop on Machine Translation.\n http://www.statmt.org/wmt15/pdf/WMT49.pdf\n - Maja Popovic. 2016. CHRF Deconstructed: \u03b2 Parameters and n-gram Weights.\n In Proceedings of the 1st Conference on Machine Translation.\n http://www.statmt.org/wmt16/pdf/W16-2341.pdf\n\n Unlike multi-reference BLEU, CHRF only supports a single reference.\n\n An example from the original BLEU paper\n http://www.aclweb.org/anthology/P02-1040.pdf\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct').split()\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> sentence_chrf(ref1, hyp2) # doctest: +ELLIPSIS\n 0.4201...\n\n The infamous \"the the the ... \" example\n\n >>> ref = 'the cat is on the mat'.split()\n >>> hyp = 'the the the the the the the'.split()\n >>> sentence_chrf(ref, hyp) # doctest: +ELLIPSIS\n 0.2530...\n\n An example to show that this function allows users to use strings instead of\n tokens, i.e. list(str) as inputs.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands')\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party')\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> type(ref1), type(hyp1)\n (<type 'str'>, <type 'str'>)\n >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS\n 0.6768...\n\n To skip the unigrams and only use 2- to 3-grams:\n\n >>> sentence_chrf(ref1, hyp1, min_len=2, max_len=3) # doctest: +ELLIPSIS\n 0.7018...\n\n :param references: reference sentence\n :type references: list(str) / str\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str) / str\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n return corpus_chrf([reference], [hypothesis], min_len, max_len, beta=beta)\n\n\ndef corpus_chrf(list_of_references, hypotheses, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the corpus level CHRF (Character n-gram F-score), it is the\n micro-averaged value of the sentence/segment level CHRF score.\n\n CHRF only supports a single reference.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> ref2 = str('It is the guiding principle which guarantees the military '\n ... 'forces always being under the command of the Party').split()\n >>>\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct')\n >>> corpus_chrf([ref1, ref2, ref1, ref2], [hyp1, hyp2, hyp2, hyp1]) # doctest: +ELLIPSIS\n 0.4915...\n\n :param references: a corpus of list of reference sentences, w.r.t. hypotheses\n :type references: list(list(str)) / list(str)\n :param hypotheses: a list of hypothesis sentences\n :type hypotheses: list(list(str)) / list(str)\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n\n assert len(list_of_references) == len(hypotheses), \"The number of hypotheses and their references should be the same\"\n\n # Iterate through each hypothesis and their corresponding references.\n for reference, hypothesis in zip(list_of_references, hypotheses):\n # Cheating condition to allow users to input strings instead of tokens.\n if type(reference) and type(hypothesis) != str:\n reference, hypothesis = ' '.join(reference), ' '.join(hypothesis)\n # For each order of ngram, calculate the no. of ngram matches and\n # keep track of no. of ngram in references.\n ref_ngrams = Counter(everygrams(reference, min_len, max_len))\n hyp_ngrams = Counter(everygrams(hypothesis, min_len, max_len))\n overlap_ngrams = ref_ngrams & hyp_ngrams\n tp = sum(overlap_ngrams.values()) # True positives.\n tpfp = sum(hyp_ngrams.values()) # True positives + False positives.\n tffn = sum(ref_ngrams.values()) # True posities + False negatives.\n\n precision = tp / tpfp\n recall = tp / tffn\n factor = beta**2\n score = (1+ factor ) * (precision * recall) / ( factor * precision + recall)\n return score\n", "path": "nltk/translate/chrf_score.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Natural Language Toolkit: ChrF score\n#\n# Copyright (C) 2001-2016 NLTK Project\n# Authors: Maja Popovic\n# Contributors: Liling Tan\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\" ChrF score implementation \"\"\"\nfrom __future__ import division\nfrom collections import Counter\n\nfrom nltk.util import ngrams, everygrams\n\ndef sentence_chrf(reference, hypothesis, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the sentence level CHRF (Character n-gram F-score) described in\n - Maja Popovic. 2015. CHRF: Character n-gram F-score for Automatic MT Evaluation.\n In Proceedings of the 10th Workshop on Machine Translation.\n http://www.statmt.org/wmt15/pdf/WMT49.pdf\n - Maja Popovic. 2016. CHRF Deconstructed: \u03b2 Parameters and n-gram Weights.\n In Proceedings of the 1st Conference on Machine Translation.\n http://www.statmt.org/wmt16/pdf/W16-2341.pdf\n\n Unlike multi-reference BLEU, CHRF only supports a single reference.\n\n An example from the original BLEU paper\n http://www.aclweb.org/anthology/P02-1040.pdf\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct').split()\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> sentence_chrf(ref1, hyp2) # doctest: +ELLIPSIS\n 0.4201...\n\n The infamous \"the the the ... \" example\n\n >>> ref = 'the cat is on the mat'.split()\n >>> hyp = 'the the the the the the the'.split()\n >>> sentence_chrf(ref, hyp) # doctest: +ELLIPSIS\n 0.2530...\n\n An example to show that this function allows users to use strings instead of\n tokens, i.e. list(str) as inputs.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands')\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party')\n >>> sentence_chrf(ref1, hyp1) # doctest: +ELLIPSIS\n 0.6768...\n >>> type(ref1) == type(hyp1) == str\n True\n >>> sentence_chrf(ref1.split(), hyp1.split()) # doctest: +ELLIPSIS\n 0.6768...\n\n To skip the unigrams and only use 2- to 3-grams:\n\n >>> sentence_chrf(ref1, hyp1, min_len=2, max_len=3) # doctest: +ELLIPSIS\n 0.7018...\n\n :param references: reference sentence\n :type references: list(str) / str\n :param hypothesis: a hypothesis sentence\n :type hypothesis: list(str) / str\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n return corpus_chrf([reference], [hypothesis], min_len, max_len, beta=beta)\n\n\ndef corpus_chrf(list_of_references, hypotheses, min_len=1, max_len=6, beta=3.0):\n \"\"\"\n Calculates the corpus level CHRF (Character n-gram F-score), it is the\n micro-averaged value of the sentence/segment level CHRF score.\n\n CHRF only supports a single reference.\n\n >>> ref1 = str('It is a guide to action that ensures that the military '\n ... 'will forever heed Party commands').split()\n >>> ref2 = str('It is the guiding principle which guarantees the military '\n ... 'forces always being under the command of the Party').split()\n >>>\n >>> hyp1 = str('It is a guide to action which ensures that the military '\n ... 'always obeys the commands of the party').split()\n >>> hyp2 = str('It is to insure the troops forever hearing the activity '\n ... 'guidebook that party direct')\n >>> corpus_chrf([ref1, ref2, ref1, ref2], [hyp1, hyp2, hyp2, hyp1]) # doctest: +ELLIPSIS\n 0.4915...\n\n :param references: a corpus of list of reference sentences, w.r.t. hypotheses\n :type references: list(list(str)) / list(str)\n :param hypotheses: a list of hypothesis sentences\n :type hypotheses: list(list(str)) / list(str)\n :param min_len: The minimum order of n-gram this function should extract.\n :type min_len: int\n :param max_len: The maximum order of n-gram this function should extract.\n :type max_len: int\n :param beta: the parameter to assign more importance to recall over precision\n :type beta: float\n :return: the sentence level CHRF score.\n :rtype: float\n \"\"\"\n\n assert len(list_of_references) == len(hypotheses), \"The number of hypotheses and their references should be the same\"\n\n # Iterate through each hypothesis and their corresponding references.\n for reference, hypothesis in zip(list_of_references, hypotheses):\n # Cheating condition to allow users to input strings instead of tokens.\n if type(reference) and type(hypothesis) != str:\n reference, hypothesis = ' '.join(reference), ' '.join(hypothesis)\n # For each order of ngram, calculate the no. of ngram matches and\n # keep track of no. of ngram in references.\n ref_ngrams = Counter(everygrams(reference, min_len, max_len))\n hyp_ngrams = Counter(everygrams(hypothesis, min_len, max_len))\n overlap_ngrams = ref_ngrams & hyp_ngrams\n tp = sum(overlap_ngrams.values()) # True positives.\n tpfp = sum(hyp_ngrams.values()) # True positives + False positives.\n tffn = sum(ref_ngrams.values()) # True posities + False negatives.\n\n precision = tp / tpfp\n recall = tp / tffn\n factor = beta**2\n score = (1+ factor ) * (precision * recall) / ( factor * precision + recall)\n return score\n", "path": "nltk/translate/chrf_score.py"}]}
| 2,716 | 175 |
gh_patches_debug_4147
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1013
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Interoperability of logging with ignite logger
## 🐛 Bug description
This bug is related to logger from module logging. Actually, (logging) handlers are attached to loggers created by user. https://github.com/pytorch/ignite/blob/bef668c152dc86334a8ab09e9ce9368c48e48102/ignite/utils.py#L64-L137
From `logging` documentation (https://docs.python.org/3/howto/logging.html#loggers)
> Child loggers propagate messages up to the handlers associated with their ancestor loggers. Because of this, it is unnecessary to define and configure handlers for all the loggers an application uses. It is sufficient to configure handlers for a top-level logger and create child loggers as needed. (You can, however, turn off propagation by setting the propagate attribute of a logger to False.)
This code shows the problem of propagation to ancestor
```python
# no ancestor so print is ok
logger = setup_logger("logger")
logger.info("message 1 from test logger")
# logging creates root ancestor of all loggers including one above
logging.info("message from default logging, a root logger is defined !")
# root + logger dump...
logger.info("message 2 from test logger")
```
Result is
```
> 2020-05-05 09:24:27,583 logger INFO: message 1 from test logger
> 2020-05-05 09:24:27,583 logger INFO: message 2 from test logger
> INFO:logger:message 2 from test logger
```
## Environment
- PyTorch Version (e.g., 1.4): 1.5
- Ignite Version (e.g., 0.3.0): 0.4
- OS (e.g., Linux): Linux
- How you installed Ignite (`conda`, `pip`, source): conda
- Python version: 3.7
- Any other relevant information:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/utils.py`
Content:
```
1 import random
2 import collections.abc as collections
3 import logging
4 from functools import wraps
5 from typing import Union, Optional, Callable, Any, Type, Tuple
6
7 import torch
8 import torch.distributed as dist
9
10 __all__ = ["convert_tensor", "apply_to_tensor", "apply_to_type", "to_onehot", "setup_logger", "one_rank_only"]
11
12
13 def convert_tensor(
14 input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes],
15 device: Optional[Union[str, torch.device]] = None,
16 non_blocking: bool = False,
17 ) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:
18 """Move tensors to relevant device."""
19
20 def _func(tensor: torch.Tensor) -> torch.Tensor:
21 return tensor.to(device=device, non_blocking=non_blocking) if device is not None else tensor
22
23 return apply_to_tensor(input_, _func)
24
25
26 def apply_to_tensor(
27 input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes], func: Callable
28 ) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:
29 """Apply a function on a tensor or mapping, or sequence of tensors.
30 """
31 return apply_to_type(input_, torch.Tensor, func)
32
33
34 def apply_to_type(
35 input_: Union[Any, collections.Sequence, collections.Mapping, str, bytes],
36 input_type: Union[Type, Tuple[Type[Any], Any]],
37 func: Callable,
38 ) -> Union[Any, collections.Sequence, collections.Mapping, str, bytes]:
39 """Apply a function on a object of `input_type` or mapping, or sequence of objects of `input_type`.
40 """
41 if isinstance(input_, input_type):
42 return func(input_)
43 elif isinstance(input_, (str, bytes)):
44 return input_
45 elif isinstance(input_, collections.Mapping):
46 return type(input_)({k: apply_to_type(sample, input_type, func) for k, sample in input_.items()})
47 elif isinstance(input_, tuple) and hasattr(input_, "_fields"): # namedtuple
48 return type(input_)(*(apply_to_type(sample, input_type, func) for sample in input_))
49 elif isinstance(input_, collections.Sequence):
50 return type(input_)([apply_to_type(sample, input_type, func) for sample in input_])
51 else:
52 raise TypeError(("input must contain {}, dicts or lists; found {}".format(input_type, type(input_))))
53
54
55 def to_onehot(indices: torch.Tensor, num_classes: int) -> torch.Tensor:
56 """Convert a tensor of indices of any shape `(N, ...)` to a
57 tensor of one-hot indicators of shape `(N, num_classes, ...) and of type uint8. Output's device is equal to the
58 input's device`.
59 """
60 onehot = torch.zeros(indices.shape[0], num_classes, *indices.shape[1:], dtype=torch.uint8, device=indices.device)
61 return onehot.scatter_(1, indices.unsqueeze(1), 1)
62
63
64 def setup_logger(
65 name: Optional[str] = None,
66 level: int = logging.INFO,
67 format: str = "%(asctime)s %(name)s %(levelname)s: %(message)s",
68 filepath: Optional[str] = None,
69 distributed_rank: Optional[int] = None,
70 ) -> logging.Logger:
71 """Setups logger: name, level, format etc.
72
73 Args:
74 name (str, optional): new name for the logger. If None, the standard logger is used.
75 level (int): logging level, e.g. CRITICAL, ERROR, WARNING, INFO, DEBUG
76 format (str): logging format. By default, `%(asctime)s %(name)s %(levelname)s: %(message)s`
77 filepath (str, optional): Optional logging file path. If not None, logs are written to the file.
78 distributed_rank (int, optional): Optional, rank in distributed configuration to avoid logger setup for workers.
79 If None, distributed_rank is initialized to the rank of process.
80
81 Returns:
82 logging.Logger
83
84 For example, to improve logs readability when training with a trainer and evaluator:
85
86 .. code-block:: python
87
88 from ignite.utils import setup_logger
89
90 trainer = ...
91 evaluator = ...
92
93 trainer.logger = setup_logger("trainer")
94 evaluator.logger = setup_logger("evaluator")
95
96 trainer.run(data, max_epochs=10)
97
98 # Logs will look like
99 # 2020-01-21 12:46:07,356 trainer INFO: Engine run starting with max_epochs=5.
100 # 2020-01-21 12:46:07,358 trainer INFO: Epoch[1] Complete. Time taken: 00:5:23
101 # 2020-01-21 12:46:07,358 evaluator INFO: Engine run starting with max_epochs=1.
102 # 2020-01-21 12:46:07,358 evaluator INFO: Epoch[1] Complete. Time taken: 00:01:02
103 # ...
104
105 """
106 logger = logging.getLogger(name)
107
108 # Remove previous handlers
109 if logger.hasHandlers():
110 for h in list(logger.handlers):
111 logger.removeHandler(h)
112
113 formatter = logging.Formatter(format)
114
115 if distributed_rank is None:
116 if dist.is_available() and dist.is_initialized():
117 distributed_rank = dist.get_rank()
118 else:
119 distributed_rank = 0
120
121 if distributed_rank > 0:
122 logger.addHandler(logging.NullHandler())
123 else:
124 logger.setLevel(level)
125
126 ch = logging.StreamHandler()
127 ch.setLevel(level)
128 ch.setFormatter(formatter)
129 logger.addHandler(ch)
130
131 if filepath is not None:
132 fh = logging.FileHandler(filepath)
133 fh.setLevel(level)
134 fh.setFormatter(formatter)
135 logger.addHandler(fh)
136
137 return logger
138
139
140 def manual_seed(seed: int) -> None:
141 """Setup random state from a seed for `torch`, `random` and optionally `numpy` (if can be imported).
142
143 Args:
144 seed (int): Random state seed
145
146 """
147 random.seed(seed)
148 torch.manual_seed(seed)
149 try:
150 import numpy as np
151
152 np.random.seed(seed)
153 except ImportError:
154 pass
155
156
157 def one_rank_only(rank: int = 0, barrier: bool = False):
158 """Decorator to filter handlers wrt a rank number
159
160 Args:
161 rank (int): rank number of the handler (default: 0).
162 barrier (bool): synchronisation with a barrier (default: False).
163
164 .. code-block:: python
165
166 engine = ...
167
168 @engine.on(...)
169 @one_rank_only() # means @one_rank_only(rank=0)
170 def some_handler(_):
171 ...
172
173 @engine.on(...)
174 @one_rank_only(rank=1)
175 def some_handler(_):
176 ...
177 """
178
179 def _one_rank_only(func):
180 @wraps(func)
181 def wrapper(*args, **kwargs):
182 ret = None
183 if dist.get_rank() == rank:
184 ret = func(*args, **kwargs)
185 if barrier:
186 dist.barrier()
187 return ret
188
189 return wrapper
190
191 return _one_rank_only
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/utils.py b/ignite/utils.py
--- a/ignite/utils.py
+++ b/ignite/utils.py
@@ -105,6 +105,12 @@
"""
logger = logging.getLogger(name)
+ # don't propagate to ancestors
+ # the problem here is to attach handlers to loggers
+ # should we provide a default configuration less open ?
+ if name is not None:
+ logger.propagate = False
+
# Remove previous handlers
if logger.hasHandlers():
for h in list(logger.handlers):
|
{"golden_diff": "diff --git a/ignite/utils.py b/ignite/utils.py\n--- a/ignite/utils.py\n+++ b/ignite/utils.py\n@@ -105,6 +105,12 @@\n \"\"\"\n logger = logging.getLogger(name)\n \n+ # don't propagate to ancestors\n+ # the problem here is to attach handlers to loggers\n+ # should we provide a default configuration less open ?\n+ if name is not None:\n+ logger.propagate = False\n+\n # Remove previous handlers\n if logger.hasHandlers():\n for h in list(logger.handlers):\n", "issue": "Interoperability of logging with ignite logger\n## \ud83d\udc1b Bug description\r\n\r\nThis bug is related to logger from module logging. Actually, (logging) handlers are attached to loggers created by user. https://github.com/pytorch/ignite/blob/bef668c152dc86334a8ab09e9ce9368c48e48102/ignite/utils.py#L64-L137\r\n\r\nFrom `logging` documentation (https://docs.python.org/3/howto/logging.html#loggers)\r\n\r\n> Child loggers propagate messages up to the handlers associated with their ancestor loggers. Because of this, it is unnecessary to define and configure handlers for all the loggers an application uses. It is sufficient to configure handlers for a top-level logger and create child loggers as needed. (You can, however, turn off propagation by setting the propagate attribute of a logger to False.)\r\n\r\nThis code shows the problem of propagation to ancestor \r\n\r\n```python\r\n# no ancestor so print is ok\r\nlogger = setup_logger(\"logger\")\r\nlogger.info(\"message 1 from test logger\") \r\n\r\n# logging creates root ancestor of all loggers including one above \r\nlogging.info(\"message from default logging, a root logger is defined !\")\r\n\r\n# root + logger dump...\r\nlogger.info(\"message 2 from test logger\")\r\n```\r\n\r\nResult is\r\n```\r\n> 2020-05-05 09:24:27,583 logger INFO: message 1 from test logger\r\n> 2020-05-05 09:24:27,583 logger INFO: message 2 from test logger\r\n> INFO:logger:message 2 from test logger\r\n```\r\n\r\n## Environment\r\n\r\n - PyTorch Version (e.g., 1.4): 1.5\r\n - Ignite Version (e.g., 0.3.0): 0.4\r\n - OS (e.g., Linux): Linux\r\n - How you installed Ignite (`conda`, `pip`, source): conda\r\n - Python version: 3.7\r\n - Any other relevant information:\r\n\r\n\n", "before_files": [{"content": "import random\nimport collections.abc as collections\nimport logging\nfrom functools import wraps\nfrom typing import Union, Optional, Callable, Any, Type, Tuple\n\nimport torch\nimport torch.distributed as dist\n\n__all__ = [\"convert_tensor\", \"apply_to_tensor\", \"apply_to_type\", \"to_onehot\", \"setup_logger\", \"one_rank_only\"]\n\n\ndef convert_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes],\n device: Optional[Union[str, torch.device]] = None,\n non_blocking: bool = False,\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Move tensors to relevant device.\"\"\"\n\n def _func(tensor: torch.Tensor) -> torch.Tensor:\n return tensor.to(device=device, non_blocking=non_blocking) if device is not None else tensor\n\n return apply_to_tensor(input_, _func)\n\n\ndef apply_to_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes], func: Callable\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a tensor or mapping, or sequence of tensors.\n \"\"\"\n return apply_to_type(input_, torch.Tensor, func)\n\n\ndef apply_to_type(\n input_: Union[Any, collections.Sequence, collections.Mapping, str, bytes],\n input_type: Union[Type, Tuple[Type[Any], Any]],\n func: Callable,\n) -> Union[Any, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a object of `input_type` or mapping, or sequence of objects of `input_type`.\n \"\"\"\n if isinstance(input_, input_type):\n return func(input_)\n elif isinstance(input_, (str, bytes)):\n return input_\n elif isinstance(input_, collections.Mapping):\n return type(input_)({k: apply_to_type(sample, input_type, func) for k, sample in input_.items()})\n elif isinstance(input_, tuple) and hasattr(input_, \"_fields\"): # namedtuple\n return type(input_)(*(apply_to_type(sample, input_type, func) for sample in input_))\n elif isinstance(input_, collections.Sequence):\n return type(input_)([apply_to_type(sample, input_type, func) for sample in input_])\n else:\n raise TypeError((\"input must contain {}, dicts or lists; found {}\".format(input_type, type(input_))))\n\n\ndef to_onehot(indices: torch.Tensor, num_classes: int) -> torch.Tensor:\n \"\"\"Convert a tensor of indices of any shape `(N, ...)` to a\n tensor of one-hot indicators of shape `(N, num_classes, ...) and of type uint8. Output's device is equal to the\n input's device`.\n \"\"\"\n onehot = torch.zeros(indices.shape[0], num_classes, *indices.shape[1:], dtype=torch.uint8, device=indices.device)\n return onehot.scatter_(1, indices.unsqueeze(1), 1)\n\n\ndef setup_logger(\n name: Optional[str] = None,\n level: int = logging.INFO,\n format: str = \"%(asctime)s %(name)s %(levelname)s: %(message)s\",\n filepath: Optional[str] = None,\n distributed_rank: Optional[int] = None,\n) -> logging.Logger:\n \"\"\"Setups logger: name, level, format etc.\n\n Args:\n name (str, optional): new name for the logger. If None, the standard logger is used.\n level (int): logging level, e.g. CRITICAL, ERROR, WARNING, INFO, DEBUG\n format (str): logging format. By default, `%(asctime)s %(name)s %(levelname)s: %(message)s`\n filepath (str, optional): Optional logging file path. If not None, logs are written to the file.\n distributed_rank (int, optional): Optional, rank in distributed configuration to avoid logger setup for workers.\n If None, distributed_rank is initialized to the rank of process.\n\n Returns:\n logging.Logger\n\n For example, to improve logs readability when training with a trainer and evaluator:\n\n .. code-block:: python\n\n from ignite.utils import setup_logger\n\n trainer = ...\n evaluator = ...\n\n trainer.logger = setup_logger(\"trainer\")\n evaluator.logger = setup_logger(\"evaluator\")\n\n trainer.run(data, max_epochs=10)\n\n # Logs will look like\n # 2020-01-21 12:46:07,356 trainer INFO: Engine run starting with max_epochs=5.\n # 2020-01-21 12:46:07,358 trainer INFO: Epoch[1] Complete. Time taken: 00:5:23\n # 2020-01-21 12:46:07,358 evaluator INFO: Engine run starting with max_epochs=1.\n # 2020-01-21 12:46:07,358 evaluator INFO: Epoch[1] Complete. Time taken: 00:01:02\n # ...\n\n \"\"\"\n logger = logging.getLogger(name)\n\n # Remove previous handlers\n if logger.hasHandlers():\n for h in list(logger.handlers):\n logger.removeHandler(h)\n\n formatter = logging.Formatter(format)\n\n if distributed_rank is None:\n if dist.is_available() and dist.is_initialized():\n distributed_rank = dist.get_rank()\n else:\n distributed_rank = 0\n\n if distributed_rank > 0:\n logger.addHandler(logging.NullHandler())\n else:\n logger.setLevel(level)\n\n ch = logging.StreamHandler()\n ch.setLevel(level)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n\n if filepath is not None:\n fh = logging.FileHandler(filepath)\n fh.setLevel(level)\n fh.setFormatter(formatter)\n logger.addHandler(fh)\n\n return logger\n\n\ndef manual_seed(seed: int) -> None:\n \"\"\"Setup random state from a seed for `torch`, `random` and optionally `numpy` (if can be imported).\n\n Args:\n seed (int): Random state seed\n\n \"\"\"\n random.seed(seed)\n torch.manual_seed(seed)\n try:\n import numpy as np\n\n np.random.seed(seed)\n except ImportError:\n pass\n\n\ndef one_rank_only(rank: int = 0, barrier: bool = False):\n \"\"\"Decorator to filter handlers wrt a rank number\n\n Args:\n rank (int): rank number of the handler (default: 0).\n barrier (bool): synchronisation with a barrier (default: False).\n\n .. code-block:: python\n\n engine = ...\n\n @engine.on(...)\n @one_rank_only() # means @one_rank_only(rank=0)\n def some_handler(_):\n ...\n\n @engine.on(...)\n @one_rank_only(rank=1)\n def some_handler(_):\n ...\n \"\"\"\n\n def _one_rank_only(func):\n @wraps(func)\n def wrapper(*args, **kwargs):\n ret = None\n if dist.get_rank() == rank:\n ret = func(*args, **kwargs)\n if barrier:\n dist.barrier()\n return ret\n\n return wrapper\n\n return _one_rank_only\n", "path": "ignite/utils.py"}], "after_files": [{"content": "import random\nimport collections.abc as collections\nimport logging\nfrom functools import wraps\nfrom typing import Union, Optional, Callable, Any, Type, Tuple\n\nimport torch\nimport torch.distributed as dist\n\n__all__ = [\"convert_tensor\", \"apply_to_tensor\", \"apply_to_type\", \"to_onehot\", \"setup_logger\", \"one_rank_only\"]\n\n\ndef convert_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes],\n device: Optional[Union[str, torch.device]] = None,\n non_blocking: bool = False,\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Move tensors to relevant device.\"\"\"\n\n def _func(tensor: torch.Tensor) -> torch.Tensor:\n return tensor.to(device=device, non_blocking=non_blocking) if device is not None else tensor\n\n return apply_to_tensor(input_, _func)\n\n\ndef apply_to_tensor(\n input_: Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes], func: Callable\n) -> Union[torch.Tensor, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a tensor or mapping, or sequence of tensors.\n \"\"\"\n return apply_to_type(input_, torch.Tensor, func)\n\n\ndef apply_to_type(\n input_: Union[Any, collections.Sequence, collections.Mapping, str, bytes],\n input_type: Union[Type, Tuple[Type[Any], Any]],\n func: Callable,\n) -> Union[Any, collections.Sequence, collections.Mapping, str, bytes]:\n \"\"\"Apply a function on a object of `input_type` or mapping, or sequence of objects of `input_type`.\n \"\"\"\n if isinstance(input_, input_type):\n return func(input_)\n elif isinstance(input_, (str, bytes)):\n return input_\n elif isinstance(input_, collections.Mapping):\n return type(input_)({k: apply_to_type(sample, input_type, func) for k, sample in input_.items()})\n elif isinstance(input_, tuple) and hasattr(input_, \"_fields\"): # namedtuple\n return type(input_)(*(apply_to_type(sample, input_type, func) for sample in input_))\n elif isinstance(input_, collections.Sequence):\n return type(input_)([apply_to_type(sample, input_type, func) for sample in input_])\n else:\n raise TypeError((\"input must contain {}, dicts or lists; found {}\".format(input_type, type(input_))))\n\n\ndef to_onehot(indices: torch.Tensor, num_classes: int) -> torch.Tensor:\n \"\"\"Convert a tensor of indices of any shape `(N, ...)` to a\n tensor of one-hot indicators of shape `(N, num_classes, ...) and of type uint8. Output's device is equal to the\n input's device`.\n \"\"\"\n onehot = torch.zeros(indices.shape[0], num_classes, *indices.shape[1:], dtype=torch.uint8, device=indices.device)\n return onehot.scatter_(1, indices.unsqueeze(1), 1)\n\n\ndef setup_logger(\n name: Optional[str] = None,\n level: int = logging.INFO,\n format: str = \"%(asctime)s %(name)s %(levelname)s: %(message)s\",\n filepath: Optional[str] = None,\n distributed_rank: Optional[int] = None,\n) -> logging.Logger:\n \"\"\"Setups logger: name, level, format etc.\n\n Args:\n name (str, optional): new name for the logger. If None, the standard logger is used.\n level (int): logging level, e.g. CRITICAL, ERROR, WARNING, INFO, DEBUG\n format (str): logging format. By default, `%(asctime)s %(name)s %(levelname)s: %(message)s`\n filepath (str, optional): Optional logging file path. If not None, logs are written to the file.\n distributed_rank (int, optional): Optional, rank in distributed configuration to avoid logger setup for workers.\n If None, distributed_rank is initialized to the rank of process.\n\n Returns:\n logging.Logger\n\n For example, to improve logs readability when training with a trainer and evaluator:\n\n .. code-block:: python\n\n from ignite.utils import setup_logger\n\n trainer = ...\n evaluator = ...\n\n trainer.logger = setup_logger(\"trainer\")\n evaluator.logger = setup_logger(\"evaluator\")\n\n trainer.run(data, max_epochs=10)\n\n # Logs will look like\n # 2020-01-21 12:46:07,356 trainer INFO: Engine run starting with max_epochs=5.\n # 2020-01-21 12:46:07,358 trainer INFO: Epoch[1] Complete. Time taken: 00:5:23\n # 2020-01-21 12:46:07,358 evaluator INFO: Engine run starting with max_epochs=1.\n # 2020-01-21 12:46:07,358 evaluator INFO: Epoch[1] Complete. Time taken: 00:01:02\n # ...\n\n \"\"\"\n logger = logging.getLogger(name)\n\n # don't propagate to ancestors\n # the problem here is to attach handlers to loggers\n # should we provide a default configuration less open ?\n if name is not None:\n logger.propagate = False\n\n # Remove previous handlers\n if logger.hasHandlers():\n for h in list(logger.handlers):\n logger.removeHandler(h)\n\n formatter = logging.Formatter(format)\n\n if distributed_rank is None:\n if dist.is_available() and dist.is_initialized():\n distributed_rank = dist.get_rank()\n else:\n distributed_rank = 0\n\n if distributed_rank > 0:\n logger.addHandler(logging.NullHandler())\n else:\n logger.setLevel(level)\n\n ch = logging.StreamHandler()\n ch.setLevel(level)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n\n if filepath is not None:\n fh = logging.FileHandler(filepath)\n fh.setLevel(level)\n fh.setFormatter(formatter)\n logger.addHandler(fh)\n\n return logger\n\n\ndef manual_seed(seed: int) -> None:\n \"\"\"Setup random state from a seed for `torch`, `random` and optionally `numpy` (if can be imported).\n\n Args:\n seed (int): Random state seed\n\n \"\"\"\n random.seed(seed)\n torch.manual_seed(seed)\n try:\n import numpy as np\n\n np.random.seed(seed)\n except ImportError:\n pass\n\n\ndef one_rank_only(rank: int = 0, barrier: bool = False):\n \"\"\"Decorator to filter handlers wrt a rank number\n\n Args:\n rank (int): rank number of the handler (default: 0).\n barrier (bool): synchronisation with a barrier (default: False).\n\n .. code-block:: python\n\n engine = ...\n\n @engine.on(...)\n @one_rank_only() # means @one_rank_only(rank=0)\n def some_handler(_):\n ...\n\n @engine.on(...)\n @one_rank_only(rank=1)\n def some_handler(_):\n ...\n \"\"\"\n\n def _one_rank_only(func):\n @wraps(func)\n def wrapper(*args, **kwargs):\n ret = None\n if dist.get_rank() == rank:\n ret = func(*args, **kwargs)\n if barrier:\n dist.barrier()\n return ret\n\n return wrapper\n\n return _one_rank_only\n", "path": "ignite/utils.py"}]}
| 2,756 | 125 |
gh_patches_debug_29915
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-398
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: confusion matrix chart displays wrong output
To reproduce: https://www.kaggle.com/itay94/notebook05f499eb19

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/checks/performance/confusion_matrix_report.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """The confusion_matrix_report check module."""
12 import numpy as np
13 import sklearn
14 from sklearn.base import BaseEstimator
15
16 import plotly.figure_factory as ff
17 from deepchecks import CheckResult, Dataset
18 from deepchecks.base.check import SingleDatasetBaseCheck
19 from deepchecks.utils.metrics import ModelType, task_type_validation
20
21
22 __all__ = ['ConfusionMatrixReport']
23
24
25 class ConfusionMatrixReport(SingleDatasetBaseCheck):
26 """Calculate the confusion matrix of the model on the given dataset."""
27
28 def run(self, dataset: Dataset, model: BaseEstimator) -> CheckResult:
29 """Run check.
30
31 Args:
32 model (BaseEstimator): A scikit-learn-compatible fitted estimator instance
33 dataset: a Dataset object
34
35 Returns:
36 CheckResult: value is numpy array of the confusion matrix, displays the confusion matrix
37
38 Raises:
39 DeepchecksValueError: If the object is not a Dataset instance with a label
40 """
41 return self._confusion_matrix_report(dataset, model)
42
43 def _confusion_matrix_report(self, dataset: Dataset, model):
44 Dataset.validate_dataset(dataset)
45 dataset.validate_label()
46 task_type_validation(model, dataset, [ModelType.MULTICLASS, ModelType.BINARY])
47
48 label = dataset.label_name
49 ds_x = dataset.data[dataset.features]
50 ds_y = dataset.data[label]
51 y_pred = model.predict(ds_x)
52
53 confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
54
55 labels = [str(val) for val in np.unique(ds_y)]
56 fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')
57 fig.update_layout(width=600, height=600)
58 fig.update_xaxes(title='Predicted Value')
59 fig.update_yaxes(title='True value', autorange='reversed')
60 fig['data'][0]['showscale'] = True
61 fig['layout']['xaxis']['side'] = 'bottom'
62
63 return CheckResult(confusion_matrix, display=fig)
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/checks/performance/confusion_matrix_report.py b/deepchecks/checks/performance/confusion_matrix_report.py
--- a/deepchecks/checks/performance/confusion_matrix_report.py
+++ b/deepchecks/checks/performance/confusion_matrix_report.py
@@ -9,11 +9,10 @@
# ----------------------------------------------------------------------------
#
"""The confusion_matrix_report check module."""
-import numpy as np
import sklearn
from sklearn.base import BaseEstimator
-import plotly.figure_factory as ff
+import plotly.express as px
from deepchecks import CheckResult, Dataset
from deepchecks.base.check import SingleDatasetBaseCheck
from deepchecks.utils.metrics import ModelType, task_type_validation
@@ -49,15 +48,12 @@
ds_x = dataset.data[dataset.features]
ds_y = dataset.data[label]
y_pred = model.predict(ds_x)
-
confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)
- labels = [str(val) for val in np.unique(ds_y)]
- fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')
+ # Figure
+ fig = px.imshow(confusion_matrix, x=dataset.classes, y=dataset.classes, text_auto=True)
fig.update_layout(width=600, height=600)
- fig.update_xaxes(title='Predicted Value')
- fig.update_yaxes(title='True value', autorange='reversed')
- fig['data'][0]['showscale'] = True
- fig['layout']['xaxis']['side'] = 'bottom'
+ fig.update_xaxes(title='Predicted Value', type='category')
+ fig.update_yaxes(title='True value', type='category')
return CheckResult(confusion_matrix, display=fig)
|
{"golden_diff": "diff --git a/deepchecks/checks/performance/confusion_matrix_report.py b/deepchecks/checks/performance/confusion_matrix_report.py\n--- a/deepchecks/checks/performance/confusion_matrix_report.py\n+++ b/deepchecks/checks/performance/confusion_matrix_report.py\n@@ -9,11 +9,10 @@\n # ----------------------------------------------------------------------------\n #\n \"\"\"The confusion_matrix_report check module.\"\"\"\n-import numpy as np\n import sklearn\n from sklearn.base import BaseEstimator\n \n-import plotly.figure_factory as ff\n+import plotly.express as px\n from deepchecks import CheckResult, Dataset\n from deepchecks.base.check import SingleDatasetBaseCheck\n from deepchecks.utils.metrics import ModelType, task_type_validation\n@@ -49,15 +48,12 @@\n ds_x = dataset.data[dataset.features]\n ds_y = dataset.data[label]\n y_pred = model.predict(ds_x)\n-\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n \n- labels = [str(val) for val in np.unique(ds_y)]\n- fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')\n+ # Figure\n+ fig = px.imshow(confusion_matrix, x=dataset.classes, y=dataset.classes, text_auto=True)\n fig.update_layout(width=600, height=600)\n- fig.update_xaxes(title='Predicted Value')\n- fig.update_yaxes(title='True value', autorange='reversed')\n- fig['data'][0]['showscale'] = True\n- fig['layout']['xaxis']['side'] = 'bottom'\n+ fig.update_xaxes(title='Predicted Value', type='category')\n+ fig.update_yaxes(title='True value', type='category')\n \n return CheckResult(confusion_matrix, display=fig)\n", "issue": "BUG: confusion matrix chart displays wrong output\nTo reproduce: https://www.kaggle.com/itay94/notebook05f499eb19\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The confusion_matrix_report check module.\"\"\"\nimport numpy as np\nimport sklearn\nfrom sklearn.base import BaseEstimator\n\nimport plotly.figure_factory as ff\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import SingleDatasetBaseCheck\nfrom deepchecks.utils.metrics import ModelType, task_type_validation\n\n\n__all__ = ['ConfusionMatrixReport']\n\n\nclass ConfusionMatrixReport(SingleDatasetBaseCheck):\n \"\"\"Calculate the confusion matrix of the model on the given dataset.\"\"\"\n\n def run(self, dataset: Dataset, model: BaseEstimator) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance\n dataset: a Dataset object\n\n Returns:\n CheckResult: value is numpy array of the confusion matrix, displays the confusion matrix\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance with a label\n \"\"\"\n return self._confusion_matrix_report(dataset, model)\n\n def _confusion_matrix_report(self, dataset: Dataset, model):\n Dataset.validate_dataset(dataset)\n dataset.validate_label()\n task_type_validation(model, dataset, [ModelType.MULTICLASS, ModelType.BINARY])\n\n label = dataset.label_name\n ds_x = dataset.data[dataset.features]\n ds_y = dataset.data[label]\n y_pred = model.predict(ds_x)\n\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n\n labels = [str(val) for val in np.unique(ds_y)]\n fig = ff.create_annotated_heatmap(confusion_matrix, x=labels, y=labels, colorscale='Viridis')\n fig.update_layout(width=600, height=600)\n fig.update_xaxes(title='Predicted Value')\n fig.update_yaxes(title='True value', autorange='reversed')\n fig['data'][0]['showscale'] = True\n fig['layout']['xaxis']['side'] = 'bottom'\n\n return CheckResult(confusion_matrix, display=fig)\n", "path": "deepchecks/checks/performance/confusion_matrix_report.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"The confusion_matrix_report check module.\"\"\"\nimport sklearn\nfrom sklearn.base import BaseEstimator\n\nimport plotly.express as px\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import SingleDatasetBaseCheck\nfrom deepchecks.utils.metrics import ModelType, task_type_validation\n\n\n__all__ = ['ConfusionMatrixReport']\n\n\nclass ConfusionMatrixReport(SingleDatasetBaseCheck):\n \"\"\"Calculate the confusion matrix of the model on the given dataset.\"\"\"\n\n def run(self, dataset: Dataset, model: BaseEstimator) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance\n dataset: a Dataset object\n\n Returns:\n CheckResult: value is numpy array of the confusion matrix, displays the confusion matrix\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance with a label\n \"\"\"\n return self._confusion_matrix_report(dataset, model)\n\n def _confusion_matrix_report(self, dataset: Dataset, model):\n Dataset.validate_dataset(dataset)\n dataset.validate_label()\n task_type_validation(model, dataset, [ModelType.MULTICLASS, ModelType.BINARY])\n\n label = dataset.label_name\n ds_x = dataset.data[dataset.features]\n ds_y = dataset.data[label]\n y_pred = model.predict(ds_x)\n confusion_matrix = sklearn.metrics.confusion_matrix(ds_y, y_pred)\n\n # Figure\n fig = px.imshow(confusion_matrix, x=dataset.classes, y=dataset.classes, text_auto=True)\n fig.update_layout(width=600, height=600)\n fig.update_xaxes(title='Predicted Value', type='category')\n fig.update_yaxes(title='True value', type='category')\n\n return CheckResult(confusion_matrix, display=fig)\n", "path": "deepchecks/checks/performance/confusion_matrix_report.py"}]}
| 1,020 | 399 |
gh_patches_debug_42763
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1002
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add events to track embeds usage
Add events to track embeds usage
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/handlers/embed.py`
Content:
```
1 import json
2
3 from funcy import project
4 from flask import render_template, request
5 from flask_login import login_required, current_user
6 from flask_restful import abort
7
8 from redash import models, settings
9 from redash import serializers
10 from redash.utils import json_dumps
11 from redash.handlers import routes
12 from redash.handlers.base import org_scoped_rule
13 from redash.permissions import require_access, view_only
14 from authentication import current_org
15
16
17 @routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])
18 @login_required
19 def embed(query_id, visualization_id, org_slug=None):
20 # TODO: add event for embed access
21 query = models.Query.get_by_id_and_org(query_id, current_org)
22 require_access(query.groups, current_user, view_only)
23 vis = query.visualizations.where(models.Visualization.id == visualization_id).first()
24 qr = {}
25
26 if vis is not None:
27 vis = vis.to_dict()
28 qr = query.latest_query_data
29 if qr is None:
30 abort(400, message="No Results for this query")
31 else:
32 qr = qr.to_dict()
33 else:
34 abort(404, message="Visualization not found.")
35
36 client_config = {}
37 client_config.update(settings.COMMON_CLIENT_CONFIG)
38
39 qr = project(qr, ('data', 'id', 'retrieved_at'))
40 vis = project(vis, ('description', 'name', 'id', 'options', 'query', 'type', 'updated_at'))
41 vis['query'] = project(vis['query'], ('created_at', 'description', 'name', 'id', 'latest_query_data_id', 'name', 'updated_at'))
42
43 return render_template("embed.html",
44 client_config=json_dumps(client_config),
45 visualization=json_dumps(vis),
46 query_result=json_dumps(qr))
47
48
49 @routes.route(org_scoped_rule('/public/dashboards/<token>'), methods=['GET'])
50 @login_required
51 def public_dashboard(token, org_slug=None):
52 # TODO: verify object is a dashboard?
53 if not isinstance(current_user, models.ApiUser):
54 api_key = models.ApiKey.get_by_api_key(token)
55 dashboard = api_key.object
56 else:
57 dashboard = current_user.object
58
59 user = {
60 'permissions': [],
61 'apiKey': current_user.id
62 }
63
64 headers = {
65 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'
66 }
67
68 response = render_template("public.html",
69 headless='embed' in request.args,
70 user=json.dumps(user),
71 seed_data=json_dumps({
72 'dashboard': serializers.public_dashboard(dashboard)
73 }),
74 client_config=json.dumps(settings.COMMON_CLIENT_CONFIG))
75
76 return response, 200, headers
77
```
Path: `redash/handlers/base.py`
Content:
```
1 import time
2 from flask import request, Blueprint
3 from flask_restful import Resource, abort
4 from flask_login import current_user, login_required
5 from peewee import DoesNotExist
6
7 from redash import settings
8 from redash.tasks import record_event
9 from redash.models import ApiUser
10 from redash.authentication import current_org
11
12 routes = Blueprint('redash', __name__, template_folder=settings.fix_assets_path('templates'))
13
14
15 class BaseResource(Resource):
16 decorators = [login_required]
17
18 def __init__(self, *args, **kwargs):
19 super(BaseResource, self).__init__(*args, **kwargs)
20 self._user = None
21
22 def dispatch_request(self, *args, **kwargs):
23 kwargs.pop('org_slug', None)
24
25 return super(BaseResource, self).dispatch_request(*args, **kwargs)
26
27 @property
28 def current_user(self):
29 return current_user._get_current_object()
30
31 @property
32 def current_org(self):
33 return current_org._get_current_object()
34
35 def record_event(self, options):
36 if isinstance(self.current_user, ApiUser):
37 options.update({
38 'api_key': self.current_user.name,
39 'org_id': self.current_org.id
40 })
41 else:
42 options.update({
43 'user_id': self.current_user.id,
44 'org_id': self.current_org.id
45 })
46
47 options.update({
48 'user_agent': request.user_agent.string,
49 'ip': request.remote_addr
50 })
51
52 if 'timestamp' not in options:
53 options['timestamp'] = int(time.time())
54
55 record_event.delay(options)
56
57
58 def require_fields(req, fields):
59 for f in fields:
60 if f not in req:
61 abort(400)
62
63
64 def get_object_or_404(fn, *args, **kwargs):
65 try:
66 return fn(*args, **kwargs)
67 except DoesNotExist:
68 abort(404)
69
70
71 def org_scoped_rule(rule):
72 if settings.MULTI_ORG:
73 return "/<org_slug:org_slug>{}".format(rule)
74
75 return rule
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/handlers/base.py b/redash/handlers/base.py
--- a/redash/handlers/base.py
+++ b/redash/handlers/base.py
@@ -5,7 +5,7 @@
from peewee import DoesNotExist
from redash import settings
-from redash.tasks import record_event
+from redash.tasks import record_event as record_event_task
from redash.models import ApiUser
from redash.authentication import current_org
@@ -33,26 +33,30 @@
return current_org._get_current_object()
def record_event(self, options):
- if isinstance(self.current_user, ApiUser):
- options.update({
- 'api_key': self.current_user.name,
- 'org_id': self.current_org.id
- })
- else:
- options.update({
- 'user_id': self.current_user.id,
- 'org_id': self.current_org.id
- })
+ record_event(self.current_org, self.current_user, options)
+
+def record_event(org, user, options):
+ if isinstance(user, ApiUser):
+ options.update({
+ 'api_key': user.name,
+ 'org_id': org.id
+ })
+ else:
options.update({
- 'user_agent': request.user_agent.string,
- 'ip': request.remote_addr
+ 'user_id': user.id,
+ 'org_id': org.id
})
- if 'timestamp' not in options:
- options['timestamp'] = int(time.time())
+ options.update({
+ 'user_agent': request.user_agent.string,
+ 'ip': request.remote_addr
+ })
+
+ if 'timestamp' not in options:
+ options['timestamp'] = int(time.time())
- record_event.delay(options)
+ record_event_task.delay(options)
def require_fields(req, fields):
diff --git a/redash/handlers/embed.py b/redash/handlers/embed.py
--- a/redash/handlers/embed.py
+++ b/redash/handlers/embed.py
@@ -9,7 +9,7 @@
from redash import serializers
from redash.utils import json_dumps
from redash.handlers import routes
-from redash.handlers.base import org_scoped_rule
+from redash.handlers.base import org_scoped_rule, record_event
from redash.permissions import require_access, view_only
from authentication import current_org
@@ -17,7 +17,6 @@
@routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])
@login_required
def embed(query_id, visualization_id, org_slug=None):
- # TODO: add event for embed access
query = models.Query.get_by_id_and_org(query_id, current_org)
require_access(query.groups, current_user, view_only)
vis = query.visualizations.where(models.Visualization.id == visualization_id).first()
@@ -33,6 +32,15 @@
else:
abort(404, message="Visualization not found.")
+ record_event(current_org, current_user, {
+ 'action': 'view',
+ 'object_id': visualization_id,
+ 'object_type': 'visualization',
+ 'query_id': query_id,
+ 'embed': True,
+ 'referer': request.headers.get('Referer')
+ })
+
client_config = {}
client_config.update(settings.COMMON_CLIENT_CONFIG)
@@ -65,6 +73,15 @@
'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'
}
+ record_event(current_org, current_user, {
+ 'action': 'view',
+ 'object_id': dashboard.id,
+ 'object_type': 'dashboard',
+ 'public': True,
+ 'headless': 'embed' in request.args,
+ 'referer': request.headers.get('Referer')
+ })
+
response = render_template("public.html",
headless='embed' in request.args,
user=json.dumps(user),
|
{"golden_diff": "diff --git a/redash/handlers/base.py b/redash/handlers/base.py\n--- a/redash/handlers/base.py\n+++ b/redash/handlers/base.py\n@@ -5,7 +5,7 @@\n from peewee import DoesNotExist\n \n from redash import settings\n-from redash.tasks import record_event\n+from redash.tasks import record_event as record_event_task\n from redash.models import ApiUser\n from redash.authentication import current_org\n \n@@ -33,26 +33,30 @@\n return current_org._get_current_object()\n \n def record_event(self, options):\n- if isinstance(self.current_user, ApiUser):\n- options.update({\n- 'api_key': self.current_user.name,\n- 'org_id': self.current_org.id\n- })\n- else:\n- options.update({\n- 'user_id': self.current_user.id,\n- 'org_id': self.current_org.id\n- })\n+ record_event(self.current_org, self.current_user, options)\n \n+\n+def record_event(org, user, options):\n+ if isinstance(user, ApiUser):\n+ options.update({\n+ 'api_key': user.name,\n+ 'org_id': org.id\n+ })\n+ else:\n options.update({\n- 'user_agent': request.user_agent.string,\n- 'ip': request.remote_addr\n+ 'user_id': user.id,\n+ 'org_id': org.id\n })\n \n- if 'timestamp' not in options:\n- options['timestamp'] = int(time.time())\n+ options.update({\n+ 'user_agent': request.user_agent.string,\n+ 'ip': request.remote_addr\n+ })\n+\n+ if 'timestamp' not in options:\n+ options['timestamp'] = int(time.time())\n \n- record_event.delay(options)\n+ record_event_task.delay(options)\n \n \n def require_fields(req, fields):\ndiff --git a/redash/handlers/embed.py b/redash/handlers/embed.py\n--- a/redash/handlers/embed.py\n+++ b/redash/handlers/embed.py\n@@ -9,7 +9,7 @@\n from redash import serializers\n from redash.utils import json_dumps\n from redash.handlers import routes\n-from redash.handlers.base import org_scoped_rule\n+from redash.handlers.base import org_scoped_rule, record_event\n from redash.permissions import require_access, view_only\n from authentication import current_org\n \n@@ -17,7 +17,6 @@\n @routes.route(org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])\n @login_required\n def embed(query_id, visualization_id, org_slug=None):\n- # TODO: add event for embed access\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.groups, current_user, view_only)\n vis = query.visualizations.where(models.Visualization.id == visualization_id).first()\n@@ -33,6 +32,15 @@\n else:\n abort(404, message=\"Visualization not found.\")\n \n+ record_event(current_org, current_user, {\n+ 'action': 'view',\n+ 'object_id': visualization_id,\n+ 'object_type': 'visualization',\n+ 'query_id': query_id,\n+ 'embed': True,\n+ 'referer': request.headers.get('Referer')\n+ })\n+\n client_config = {}\n client_config.update(settings.COMMON_CLIENT_CONFIG)\n \n@@ -65,6 +73,15 @@\n 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'\n }\n \n+ record_event(current_org, current_user, {\n+ 'action': 'view',\n+ 'object_id': dashboard.id,\n+ 'object_type': 'dashboard',\n+ 'public': True,\n+ 'headless': 'embed' in request.args,\n+ 'referer': request.headers.get('Referer')\n+ })\n+\n response = render_template(\"public.html\",\n headless='embed' in request.args,\n user=json.dumps(user),\n", "issue": "Add events to track embeds usage\n\nAdd events to track embeds usage\n\n", "before_files": [{"content": "import json\n\nfrom funcy import project\nfrom flask import render_template, request\nfrom flask_login import login_required, current_user\nfrom flask_restful import abort\n\nfrom redash import models, settings\nfrom redash import serializers\nfrom redash.utils import json_dumps\nfrom redash.handlers import routes\nfrom redash.handlers.base import org_scoped_rule\nfrom redash.permissions import require_access, view_only\nfrom authentication import current_org\n\n\[email protected](org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])\n@login_required\ndef embed(query_id, visualization_id, org_slug=None):\n # TODO: add event for embed access\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.groups, current_user, view_only)\n vis = query.visualizations.where(models.Visualization.id == visualization_id).first()\n qr = {}\n\n if vis is not None:\n vis = vis.to_dict()\n qr = query.latest_query_data\n if qr is None:\n abort(400, message=\"No Results for this query\")\n else:\n qr = qr.to_dict()\n else:\n abort(404, message=\"Visualization not found.\")\n\n client_config = {}\n client_config.update(settings.COMMON_CLIENT_CONFIG)\n\n qr = project(qr, ('data', 'id', 'retrieved_at'))\n vis = project(vis, ('description', 'name', 'id', 'options', 'query', 'type', 'updated_at'))\n vis['query'] = project(vis['query'], ('created_at', 'description', 'name', 'id', 'latest_query_data_id', 'name', 'updated_at'))\n\n return render_template(\"embed.html\",\n client_config=json_dumps(client_config),\n visualization=json_dumps(vis),\n query_result=json_dumps(qr))\n\n\[email protected](org_scoped_rule('/public/dashboards/<token>'), methods=['GET'])\n@login_required\ndef public_dashboard(token, org_slug=None):\n # TODO: verify object is a dashboard?\n if not isinstance(current_user, models.ApiUser):\n api_key = models.ApiKey.get_by_api_key(token)\n dashboard = api_key.object\n else:\n dashboard = current_user.object\n\n user = {\n 'permissions': [],\n 'apiKey': current_user.id\n }\n\n headers = {\n 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'\n }\n\n response = render_template(\"public.html\",\n headless='embed' in request.args,\n user=json.dumps(user),\n seed_data=json_dumps({\n 'dashboard': serializers.public_dashboard(dashboard)\n }),\n client_config=json.dumps(settings.COMMON_CLIENT_CONFIG))\n\n return response, 200, headers\n", "path": "redash/handlers/embed.py"}, {"content": "import time\nfrom flask import request, Blueprint\nfrom flask_restful import Resource, abort\nfrom flask_login import current_user, login_required\nfrom peewee import DoesNotExist\n\nfrom redash import settings\nfrom redash.tasks import record_event\nfrom redash.models import ApiUser\nfrom redash.authentication import current_org\n\nroutes = Blueprint('redash', __name__, template_folder=settings.fix_assets_path('templates'))\n\n\nclass BaseResource(Resource):\n decorators = [login_required]\n\n def __init__(self, *args, **kwargs):\n super(BaseResource, self).__init__(*args, **kwargs)\n self._user = None\n\n def dispatch_request(self, *args, **kwargs):\n kwargs.pop('org_slug', None)\n\n return super(BaseResource, self).dispatch_request(*args, **kwargs)\n\n @property\n def current_user(self):\n return current_user._get_current_object()\n\n @property\n def current_org(self):\n return current_org._get_current_object()\n\n def record_event(self, options):\n if isinstance(self.current_user, ApiUser):\n options.update({\n 'api_key': self.current_user.name,\n 'org_id': self.current_org.id\n })\n else:\n options.update({\n 'user_id': self.current_user.id,\n 'org_id': self.current_org.id\n })\n\n options.update({\n 'user_agent': request.user_agent.string,\n 'ip': request.remote_addr\n })\n\n if 'timestamp' not in options:\n options['timestamp'] = int(time.time())\n\n record_event.delay(options)\n\n\ndef require_fields(req, fields):\n for f in fields:\n if f not in req:\n abort(400)\n\n\ndef get_object_or_404(fn, *args, **kwargs):\n try:\n return fn(*args, **kwargs)\n except DoesNotExist:\n abort(404)\n\n\ndef org_scoped_rule(rule):\n if settings.MULTI_ORG:\n return \"/<org_slug:org_slug>{}\".format(rule)\n\n return rule\n", "path": "redash/handlers/base.py"}], "after_files": [{"content": "import json\n\nfrom funcy import project\nfrom flask import render_template, request\nfrom flask_login import login_required, current_user\nfrom flask_restful import abort\n\nfrom redash import models, settings\nfrom redash import serializers\nfrom redash.utils import json_dumps\nfrom redash.handlers import routes\nfrom redash.handlers.base import org_scoped_rule, record_event\nfrom redash.permissions import require_access, view_only\nfrom authentication import current_org\n\n\[email protected](org_scoped_rule('/embed/query/<query_id>/visualization/<visualization_id>'), methods=['GET'])\n@login_required\ndef embed(query_id, visualization_id, org_slug=None):\n query = models.Query.get_by_id_and_org(query_id, current_org)\n require_access(query.groups, current_user, view_only)\n vis = query.visualizations.where(models.Visualization.id == visualization_id).first()\n qr = {}\n\n if vis is not None:\n vis = vis.to_dict()\n qr = query.latest_query_data\n if qr is None:\n abort(400, message=\"No Results for this query\")\n else:\n qr = qr.to_dict()\n else:\n abort(404, message=\"Visualization not found.\")\n\n record_event(current_org, current_user, {\n 'action': 'view',\n 'object_id': visualization_id,\n 'object_type': 'visualization',\n 'query_id': query_id,\n 'embed': True,\n 'referer': request.headers.get('Referer')\n })\n\n client_config = {}\n client_config.update(settings.COMMON_CLIENT_CONFIG)\n\n qr = project(qr, ('data', 'id', 'retrieved_at'))\n vis = project(vis, ('description', 'name', 'id', 'options', 'query', 'type', 'updated_at'))\n vis['query'] = project(vis['query'], ('created_at', 'description', 'name', 'id', 'latest_query_data_id', 'name', 'updated_at'))\n\n return render_template(\"embed.html\",\n client_config=json_dumps(client_config),\n visualization=json_dumps(vis),\n query_result=json_dumps(qr))\n\n\[email protected](org_scoped_rule('/public/dashboards/<token>'), methods=['GET'])\n@login_required\ndef public_dashboard(token, org_slug=None):\n # TODO: verify object is a dashboard?\n if not isinstance(current_user, models.ApiUser):\n api_key = models.ApiKey.get_by_api_key(token)\n dashboard = api_key.object\n else:\n dashboard = current_user.object\n\n user = {\n 'permissions': [],\n 'apiKey': current_user.id\n }\n\n headers = {\n 'Cache-Control': 'no-cache, no-store, max-age=0, must-revalidate'\n }\n\n record_event(current_org, current_user, {\n 'action': 'view',\n 'object_id': dashboard.id,\n 'object_type': 'dashboard',\n 'public': True,\n 'headless': 'embed' in request.args,\n 'referer': request.headers.get('Referer')\n })\n\n response = render_template(\"public.html\",\n headless='embed' in request.args,\n user=json.dumps(user),\n seed_data=json_dumps({\n 'dashboard': serializers.public_dashboard(dashboard)\n }),\n client_config=json.dumps(settings.COMMON_CLIENT_CONFIG))\n\n return response, 200, headers\n", "path": "redash/handlers/embed.py"}, {"content": "import time\nfrom flask import request, Blueprint\nfrom flask_restful import Resource, abort\nfrom flask_login import current_user, login_required\nfrom peewee import DoesNotExist\n\nfrom redash import settings\nfrom redash.tasks import record_event as record_event_task\nfrom redash.models import ApiUser\nfrom redash.authentication import current_org\n\nroutes = Blueprint('redash', __name__, template_folder=settings.fix_assets_path('templates'))\n\n\nclass BaseResource(Resource):\n decorators = [login_required]\n\n def __init__(self, *args, **kwargs):\n super(BaseResource, self).__init__(*args, **kwargs)\n self._user = None\n\n def dispatch_request(self, *args, **kwargs):\n kwargs.pop('org_slug', None)\n\n return super(BaseResource, self).dispatch_request(*args, **kwargs)\n\n @property\n def current_user(self):\n return current_user._get_current_object()\n\n @property\n def current_org(self):\n return current_org._get_current_object()\n\n def record_event(self, options):\n record_event(self.current_org, self.current_user, options)\n\n\ndef record_event(org, user, options):\n if isinstance(user, ApiUser):\n options.update({\n 'api_key': user.name,\n 'org_id': org.id\n })\n else:\n options.update({\n 'user_id': user.id,\n 'org_id': org.id\n })\n\n options.update({\n 'user_agent': request.user_agent.string,\n 'ip': request.remote_addr\n })\n\n if 'timestamp' not in options:\n options['timestamp'] = int(time.time())\n\n record_event_task.delay(options)\n\n\ndef require_fields(req, fields):\n for f in fields:\n if f not in req:\n abort(400)\n\n\ndef get_object_or_404(fn, *args, **kwargs):\n try:\n return fn(*args, **kwargs)\n except DoesNotExist:\n abort(404)\n\n\ndef org_scoped_rule(rule):\n if settings.MULTI_ORG:\n return \"/<org_slug:org_slug>{}\".format(rule)\n\n return rule\n", "path": "redash/handlers/base.py"}]}
| 1,634 | 886 |
gh_patches_debug_23847
|
rasdani/github-patches
|
git_diff
|
AppDaemon__appdaemon-1661
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve packaging system
The `requirements.txt` file is used in a bit confusing way. It it usual practice for this file to contain all the dependencies present in the project virtualenv, created using `pip freeze > requirements.txt`, so that the virtualenv can be easily re-created by any developer locally using `pip install -r requirements.txt.`
But this file is also used as the `install_requires` inside `setup.py`, creating a bit of a conflict.
If one installs the appdaemon locally with `pip install .`, then run `pip freeze > requirements.txt`, the `requirements.txt` file is modified, since all the transitive dependencies are also loaded, as is expected. So the question is: shouldn't the declaration of the project dependencies be moved in a more appropriate place, separate from `requirements.txt`?
## Proposed solution
I propose to more crealry declare the project dependencies, by upgrading the way we use the Python packaging system.
At the moment the package is created from the `setup.py`, read by `setuptools` when building the package.
The way to package applications has changed a lot over the years. Nowadays if one were to follow the official [Python packaging guide](https://packaging.python.org/en/latest/tutorials/packaging-projects/), the recommended setup is to use a `pyproject.toml` to describe all the metadata of the project, including the build tool and the project dependencies.
I suggest we move from the current `setup.py` to a more modern and "standard" solution, by migrating to a `pyproject.toml` file to contain all the project dependencies.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 from setuptools import setup, find_packages
5
6 from appdaemon.version import __version__
7
8 # sudo apt-get install python3-aiohttp-dbg
9
10 with open("requirements.txt") as f:
11 install_requires = [x for x in f.read().split("\n") if x]
12
13 with open("README.md") as f:
14 long_description = f.read()
15
16 setup(
17 name="appdaemon",
18 version=__version__,
19 description="Apps for the Home Assistant home automation package.",
20 long_description=long_description,
21 long_description_content_type="text/markdown",
22 author="Andrew I Cockburn",
23 author_email="[email protected]",
24 url="https://github.com/home-assistant/appdaemon.git",
25 packages=find_packages(exclude=["contrib", "docs", "tests*"]),
26 include_package_data=True,
27 install_requires=install_requires,
28 license="Apache License 2.0",
29 python_requires=">=3.7",
30 zip_safe=False,
31 keywords=["appdaemon", "home", "automation"],
32 entry_points={"console_scripts": ["appdaemon = appdaemon.__main__:main"]},
33 classifiers=[
34 "Development Status :: 5 - Production/Stable",
35 "Intended Audience :: Developers",
36 "License :: OSI Approved :: Apache Software License",
37 "Natural Language :: English",
38 "Programming Language :: Python :: 3.7",
39 "Programming Language :: Python :: 3.8",
40 "Programming Language :: Python :: 3.9",
41 "Programming Language :: Python :: 3.10",
42 "Topic :: Home Automation",
43 ],
44 )
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
deleted file mode 100755
--- a/setup.py
+++ /dev/null
@@ -1,44 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-
-from setuptools import setup, find_packages
-
-from appdaemon.version import __version__
-
-# sudo apt-get install python3-aiohttp-dbg
-
-with open("requirements.txt") as f:
- install_requires = [x for x in f.read().split("\n") if x]
-
-with open("README.md") as f:
- long_description = f.read()
-
-setup(
- name="appdaemon",
- version=__version__,
- description="Apps for the Home Assistant home automation package.",
- long_description=long_description,
- long_description_content_type="text/markdown",
- author="Andrew I Cockburn",
- author_email="[email protected]",
- url="https://github.com/home-assistant/appdaemon.git",
- packages=find_packages(exclude=["contrib", "docs", "tests*"]),
- include_package_data=True,
- install_requires=install_requires,
- license="Apache License 2.0",
- python_requires=">=3.7",
- zip_safe=False,
- keywords=["appdaemon", "home", "automation"],
- entry_points={"console_scripts": ["appdaemon = appdaemon.__main__:main"]},
- classifiers=[
- "Development Status :: 5 - Production/Stable",
- "Intended Audience :: Developers",
- "License :: OSI Approved :: Apache Software License",
- "Natural Language :: English",
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
- "Programming Language :: Python :: 3.9",
- "Programming Language :: Python :: 3.10",
- "Topic :: Home Automation",
- ],
-)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\ndeleted file mode 100755\n--- a/setup.py\n+++ /dev/null\n@@ -1,44 +0,0 @@\n-#!/usr/bin/env python\n-# -*- coding: utf-8 -*-\n-\n-from setuptools import setup, find_packages\n-\n-from appdaemon.version import __version__\n-\n-# sudo apt-get install python3-aiohttp-dbg\n-\n-with open(\"requirements.txt\") as f:\n- install_requires = [x for x in f.read().split(\"\\n\") if x]\n-\n-with open(\"README.md\") as f:\n- long_description = f.read()\n-\n-setup(\n- name=\"appdaemon\",\n- version=__version__,\n- description=\"Apps for the Home Assistant home automation package.\",\n- long_description=long_description,\n- long_description_content_type=\"text/markdown\",\n- author=\"Andrew I Cockburn\",\n- author_email=\"[email protected]\",\n- url=\"https://github.com/home-assistant/appdaemon.git\",\n- packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests*\"]),\n- include_package_data=True,\n- install_requires=install_requires,\n- license=\"Apache License 2.0\",\n- python_requires=\">=3.7\",\n- zip_safe=False,\n- keywords=[\"appdaemon\", \"home\", \"automation\"],\n- entry_points={\"console_scripts\": [\"appdaemon = appdaemon.__main__:main\"]},\n- classifiers=[\n- \"Development Status :: 5 - Production/Stable\",\n- \"Intended Audience :: Developers\",\n- \"License :: OSI Approved :: Apache Software License\",\n- \"Natural Language :: English\",\n- \"Programming Language :: Python :: 3.7\",\n- \"Programming Language :: Python :: 3.8\",\n- \"Programming Language :: Python :: 3.9\",\n- \"Programming Language :: Python :: 3.10\",\n- \"Topic :: Home Automation\",\n- ],\n-)\n", "issue": "Improve packaging system\nThe `requirements.txt` file is used in a bit confusing way. It it usual practice for this file to contain all the dependencies present in the project virtualenv, created using `pip freeze > requirements.txt`, so that the virtualenv can be easily re-created by any developer locally using `pip install -r requirements.txt.`\r\nBut this file is also used as the `install_requires` inside `setup.py`, creating a bit of a conflict.\r\nIf one installs the appdaemon locally with `pip install .`, then run `pip freeze > requirements.txt`, the `requirements.txt` file is modified, since all the transitive dependencies are also loaded, as is expected. So the question is: shouldn't the declaration of the project dependencies be moved in a more appropriate place, separate from `requirements.txt`?\r\n\r\n## Proposed solution\r\nI propose to more crealry declare the project dependencies, by upgrading the way we use the Python packaging system.\r\nAt the moment the package is created from the `setup.py`, read by `setuptools` when building the package.\r\nThe way to package applications has changed a lot over the years. Nowadays if one were to follow the official [Python packaging guide](https://packaging.python.org/en/latest/tutorials/packaging-projects/), the recommended setup is to use a `pyproject.toml` to describe all the metadata of the project, including the build tool and the project dependencies.\r\nI suggest we move from the current `setup.py` to a more modern and \"standard\" solution, by migrating to a `pyproject.toml` file to contain all the project dependencies.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom setuptools import setup, find_packages\n\nfrom appdaemon.version import __version__\n\n# sudo apt-get install python3-aiohttp-dbg\n\nwith open(\"requirements.txt\") as f:\n install_requires = [x for x in f.read().split(\"\\n\") if x]\n\nwith open(\"README.md\") as f:\n long_description = f.read()\n\nsetup(\n name=\"appdaemon\",\n version=__version__,\n description=\"Apps for the Home Assistant home automation package.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"Andrew I Cockburn\",\n author_email=\"[email protected]\",\n url=\"https://github.com/home-assistant/appdaemon.git\",\n packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests*\"]),\n include_package_data=True,\n install_requires=install_requires,\n license=\"Apache License 2.0\",\n python_requires=\">=3.7\",\n zip_safe=False,\n keywords=[\"appdaemon\", \"home\", \"automation\"],\n entry_points={\"console_scripts\": [\"appdaemon = appdaemon.__main__:main\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Home Automation\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": null, "path": "setup.py"}]}
| 1,025 | 427 |
gh_patches_debug_6209
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-3021
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
A suspicious user trying to log in results in a 500
https://app.getsentry.com/gratipay/gratipay-com/group/32039756/
<bountysource-plugin>
---
Want to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).
</bountysource-plugin>
A suspicious user trying to log in results in a 500
https://app.getsentry.com/gratipay/gratipay-com/group/32039756/
<bountysource-plugin>
---
Want to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).
</bountysource-plugin>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gratipay/security/user.py`
Content:
```
1
2 from datetime import timedelta
3 import uuid
4
5 from aspen.utils import utcnow
6 from gratipay.models.participant import Participant
7 from gratipay.utils import set_cookie
8
9
10 SESSION = b'session'
11 SESSION_REFRESH = timedelta(hours=1)
12 SESSION_TIMEOUT = timedelta(hours=6)
13
14
15 class User(object):
16 """Represent a user of our website.
17 """
18
19 participant = None
20
21
22 # Constructors
23 # ============
24
25 @classmethod
26 def from_session_token(cls, token):
27 """Find a participant based on token and return a User.
28 """
29 self = cls()
30 self.participant = Participant.from_session_token(token)
31 return self
32
33 @classmethod
34 def from_api_key(cls, api_key):
35 """Find a participant based on token and return a User.
36 """
37 self = cls()
38 self.participant = Participant.from_api_key(api_key)
39 return self
40
41 @classmethod
42 def from_username(cls, username):
43 """Find a participant based on username and return a User.
44 """
45 self = cls()
46 self.participant = Participant.from_username(username)
47 return self
48
49 def __str__(self):
50 if self.participant is None:
51 out = '<Anonymous>'
52 else:
53 out = '<User: %s>' % self.participant.username
54 return out
55 __repr__ = __str__
56
57
58 # Authentication Helpers
59 # ======================
60
61 def sign_in(self, cookies):
62 """Start a new session for the user.
63 """
64 token = uuid.uuid4().hex
65 expires = utcnow() + SESSION_TIMEOUT
66 self.participant.update_session(token, expires)
67 set_cookie(cookies, SESSION, token, expires)
68
69 def keep_signed_in(self, cookies):
70 """Extend the user's current session.
71 """
72 new_expires = utcnow() + SESSION_TIMEOUT
73 if new_expires - self.participant.session_expires > SESSION_REFRESH:
74 self.participant.set_session_expires(new_expires)
75 token = self.participant.session_token
76 set_cookie(cookies, SESSION, token, expires=new_expires)
77
78 def sign_out(self, cookies):
79 """End the user's current session.
80 """
81 self.participant.update_session(None, None)
82 self.participant = None
83 set_cookie(cookies, SESSION, '')
84
85
86 # Roles
87 # =====
88
89 @property
90 def ADMIN(self):
91 return not self.ANON and self.participant.is_admin
92
93 @property
94 def ANON(self):
95 return self.participant is None or self.participant.is_suspicious is True
96 # Append "is True" here because otherwise Python will return the result
97 # of evaluating the right side of the or expression, which can be None.
98
99 def get_highest_role(self, owner):
100 """Return a string representing the highest role this user has.
101
102 :param string owner: the username of the owner of the resource we're
103 concerned with, or None
104
105 """
106 def is_owner():
107 if self.participant is not None:
108 if owner is not None:
109 if self.participant.username == owner:
110 return True
111 return False
112
113 if self.ADMIN:
114 return 'admin'
115 elif is_owner():
116 return 'owner'
117 elif not self.ANON:
118 return 'authenticated'
119 else:
120 return 'anonymous'
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gratipay/security/user.py b/gratipay/security/user.py
--- a/gratipay/security/user.py
+++ b/gratipay/security/user.py
@@ -92,9 +92,7 @@
@property
def ANON(self):
- return self.participant is None or self.participant.is_suspicious is True
- # Append "is True" here because otherwise Python will return the result
- # of evaluating the right side of the or expression, which can be None.
+ return self.participant is None
def get_highest_role(self, owner):
"""Return a string representing the highest role this user has.
|
{"golden_diff": "diff --git a/gratipay/security/user.py b/gratipay/security/user.py\n--- a/gratipay/security/user.py\n+++ b/gratipay/security/user.py\n@@ -92,9 +92,7 @@\n \n @property\n def ANON(self):\n- return self.participant is None or self.participant.is_suspicious is True\n- # Append \"is True\" here because otherwise Python will return the result\n- # of evaluating the right side of the or expression, which can be None.\n+ return self.participant is None\n \n def get_highest_role(self, owner):\n \"\"\"Return a string representing the highest role this user has.\n", "issue": "A suspicious user trying to log in results in a 500\nhttps://app.getsentry.com/gratipay/gratipay-com/group/32039756/\n\n<bountysource-plugin>\n\n---\n\nWant to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).\n</bountysource-plugin>\n\nA suspicious user trying to log in results in a 500\nhttps://app.getsentry.com/gratipay/gratipay-com/group/32039756/\n\n<bountysource-plugin>\n\n---\n\nWant to back this issue? **[Place a bounty on it!](https://www.bountysource.com/issues/4727299-a-suspicious-user-trying-to-log-in-results-in-a-500?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F85909&utm_medium=issues&utm_source=github).\n</bountysource-plugin>\n\n", "before_files": [{"content": "\nfrom datetime import timedelta\nimport uuid\n\nfrom aspen.utils import utcnow\nfrom gratipay.models.participant import Participant\nfrom gratipay.utils import set_cookie\n\n\nSESSION = b'session'\nSESSION_REFRESH = timedelta(hours=1)\nSESSION_TIMEOUT = timedelta(hours=6)\n\n\nclass User(object):\n \"\"\"Represent a user of our website.\n \"\"\"\n\n participant = None\n\n\n # Constructors\n # ============\n\n @classmethod\n def from_session_token(cls, token):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_session_token(token)\n return self\n\n @classmethod\n def from_api_key(cls, api_key):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_api_key(api_key)\n return self\n\n @classmethod\n def from_username(cls, username):\n \"\"\"Find a participant based on username and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_username(username)\n return self\n\n def __str__(self):\n if self.participant is None:\n out = '<Anonymous>'\n else:\n out = '<User: %s>' % self.participant.username\n return out\n __repr__ = __str__\n\n\n # Authentication Helpers\n # ======================\n\n def sign_in(self, cookies):\n \"\"\"Start a new session for the user.\n \"\"\"\n token = uuid.uuid4().hex\n expires = utcnow() + SESSION_TIMEOUT\n self.participant.update_session(token, expires)\n set_cookie(cookies, SESSION, token, expires)\n\n def keep_signed_in(self, cookies):\n \"\"\"Extend the user's current session.\n \"\"\"\n new_expires = utcnow() + SESSION_TIMEOUT\n if new_expires - self.participant.session_expires > SESSION_REFRESH:\n self.participant.set_session_expires(new_expires)\n token = self.participant.session_token\n set_cookie(cookies, SESSION, token, expires=new_expires)\n\n def sign_out(self, cookies):\n \"\"\"End the user's current session.\n \"\"\"\n self.participant.update_session(None, None)\n self.participant = None\n set_cookie(cookies, SESSION, '')\n\n\n # Roles\n # =====\n\n @property\n def ADMIN(self):\n return not self.ANON and self.participant.is_admin\n\n @property\n def ANON(self):\n return self.participant is None or self.participant.is_suspicious is True\n # Append \"is True\" here because otherwise Python will return the result\n # of evaluating the right side of the or expression, which can be None.\n\n def get_highest_role(self, owner):\n \"\"\"Return a string representing the highest role this user has.\n\n :param string owner: the username of the owner of the resource we're\n concerned with, or None\n\n \"\"\"\n def is_owner():\n if self.participant is not None:\n if owner is not None:\n if self.participant.username == owner:\n return True\n return False\n\n if self.ADMIN:\n return 'admin'\n elif is_owner():\n return 'owner'\n elif not self.ANON:\n return 'authenticated'\n else:\n return 'anonymous'\n", "path": "gratipay/security/user.py"}], "after_files": [{"content": "\nfrom datetime import timedelta\nimport uuid\n\nfrom aspen.utils import utcnow\nfrom gratipay.models.participant import Participant\nfrom gratipay.utils import set_cookie\n\n\nSESSION = b'session'\nSESSION_REFRESH = timedelta(hours=1)\nSESSION_TIMEOUT = timedelta(hours=6)\n\n\nclass User(object):\n \"\"\"Represent a user of our website.\n \"\"\"\n\n participant = None\n\n\n # Constructors\n # ============\n\n @classmethod\n def from_session_token(cls, token):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_session_token(token)\n return self\n\n @classmethod\n def from_api_key(cls, api_key):\n \"\"\"Find a participant based on token and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_api_key(api_key)\n return self\n\n @classmethod\n def from_username(cls, username):\n \"\"\"Find a participant based on username and return a User.\n \"\"\"\n self = cls()\n self.participant = Participant.from_username(username)\n return self\n\n def __str__(self):\n if self.participant is None:\n out = '<Anonymous>'\n else:\n out = '<User: %s>' % self.participant.username\n return out\n __repr__ = __str__\n\n\n # Authentication Helpers\n # ======================\n\n def sign_in(self, cookies):\n \"\"\"Start a new session for the user.\n \"\"\"\n token = uuid.uuid4().hex\n expires = utcnow() + SESSION_TIMEOUT\n self.participant.update_session(token, expires)\n set_cookie(cookies, SESSION, token, expires)\n\n def keep_signed_in(self, cookies):\n \"\"\"Extend the user's current session.\n \"\"\"\n new_expires = utcnow() + SESSION_TIMEOUT\n if new_expires - self.participant.session_expires > SESSION_REFRESH:\n self.participant.set_session_expires(new_expires)\n token = self.participant.session_token\n set_cookie(cookies, SESSION, token, expires=new_expires)\n\n def sign_out(self, cookies):\n \"\"\"End the user's current session.\n \"\"\"\n self.participant.update_session(None, None)\n self.participant = None\n set_cookie(cookies, SESSION, '')\n\n\n # Roles\n # =====\n\n @property\n def ADMIN(self):\n return not self.ANON and self.participant.is_admin\n\n @property\n def ANON(self):\n return self.participant is None\n\n def get_highest_role(self, owner):\n \"\"\"Return a string representing the highest role this user has.\n\n :param string owner: the username of the owner of the resource we're\n concerned with, or None\n\n \"\"\"\n def is_owner():\n if self.participant is not None:\n if owner is not None:\n if self.participant.username == owner:\n return True\n return False\n\n if self.ADMIN:\n return 'admin'\n elif is_owner():\n return 'owner'\n elif not self.ANON:\n return 'authenticated'\n else:\n return 'anonymous'\n", "path": "gratipay/security/user.py"}]}
| 1,586 | 145 |
gh_patches_debug_31859
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-1142
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
docs: dropdown menu on main no longer working
try selecting a version here: https://mne.tools/mne-bids/dev/index.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/conf.py`
Content:
```
1 """Configure details for documentation with sphinx."""
2 import os
3 import sys
4 from datetime import date
5
6 import sphinx_gallery # noqa: F401
7 from sphinx_gallery.sorting import ExampleTitleSortKey
8
9 import mne_bids
10
11
12 # If extensions (or modules to document with autodoc) are in another directory,
13 # add these directories to sys.path here. If the directory is relative to the
14 # documentation root, use os.path.abspath to make it absolute, like shown here.
15 curdir = os.path.dirname(__file__)
16 sys.path.append(os.path.abspath(os.path.join(curdir, '..', 'mne_bids')))
17 sys.path.append(os.path.abspath(os.path.join(curdir, 'sphinxext')))
18
19
20 # -- General configuration ------------------------------------------------
21
22 # If your documentation needs a minimal Sphinx version, state it here.
23 #
24 # needs_sphinx = '1.0'
25
26 # Add any Sphinx extension module names here, as strings. They can be
27 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
28 # ones.
29 extensions = [
30 'sphinx.ext.githubpages',
31 'sphinx.ext.autodoc',
32 'sphinx.ext.mathjax',
33 'sphinx.ext.viewcode',
34 'sphinx.ext.autosummary',
35 'sphinx.ext.doctest',
36 'sphinx.ext.intersphinx',
37 'sphinx_gallery.gen_gallery',
38 'numpydoc',
39 'sphinx_copybutton',
40 'gen_cli', # custom extension, see ./sphinxext/gen_cli.py
41 'gh_substitutions', # custom extension, see ./sphinxext/gh_substitutions.py
42 ]
43
44 # configure sphinx-copybutton
45 copybutton_prompt_text = r">>> |\.\.\. |\$ "
46 copybutton_prompt_is_regexp = True
47
48 # configure numpydoc
49 numpydoc_xref_param_type = True
50 numpydoc_class_members_toctree = False
51 numpydoc_attributes_as_param_list = True
52 numpydoc_xref_aliases = {
53 'BIDSPath': ':class:`BIDSPath <mne_bids.BIDSPath>`',
54 'path-like': ':term:`path-like <mne:path-like>`',
55 'array-like': ':term:`array_like <numpy:array_like>`',
56 'int': ':class:`int <python:int>`',
57 'bool': ':class:`bool <python:bool>`',
58 'float': ':class:`float <python:float>`',
59 'list': ':class:`list <python:list>`',
60 'tuple': ':class:`tuple <python:tuple>`',
61 'NibabelImageObject': 'nibabel.spatialimages.SpatialImage',
62 }
63 numpydoc_xref_ignore = {
64 # words
65 'instance', 'instances', 'of'
66 }
67
68
69 # generate autosummary even if no references
70 autosummary_generate = True
71 autodoc_default_options = {'inherited-members': None}
72 default_role = 'autolink' # XXX silently allows bad syntax, someone should fix
73
74 # configure linkcheck
75 # https://sphinx-doc.org/en/master/usage/configuration.html?#options-for-the-linkcheck-builder
76 linkcheck_retries = 2
77 linkcheck_rate_limit_timeout = 15.0
78 linkcheck_ignore = [
79 r'https://www.researchgate.net/profile/.*',
80 ]
81
82 # The suffix(es) of source filenames.
83 # You can specify multiple suffix as a list of string:
84 #
85 # source_suffix = ['.rst', '.md']
86 source_suffix = '.rst'
87
88 # The master toctree document.
89 master_doc = 'index'
90
91 # General information about the project.
92 project = u'MNE-BIDS'
93 td = date.today()
94 copyright = u'2017-%s, MNE Developers. Last updated on %s' % (td.year,
95 td.isoformat())
96
97 author = u'MNE Developers'
98
99 # The version info for the project you're documenting, acts as replacement for
100 # |version| and |release|, also used in various other places throughout the
101 # built documents.
102 #
103 # The short X.Y version.
104 version = mne_bids.__version__
105 # The full version, including alpha/beta/rc tags.
106 release = version
107
108 # List of patterns, relative to source directory, that match files and
109 # directories to ignore when looking for source files.
110 # This patterns also effect to html_static_path and html_extra_path
111 exclude_patterns = ['auto_examples/index.rst', '_build', 'Thumbs.db',
112 '.DS_Store']
113
114 # HTML options (e.g., theme)
115 html_show_sourcelink = False
116 html_copy_source = False
117
118 html_theme = 'pydata_sphinx_theme'
119
120 # Add any paths that contain templates here, relative to this directory.
121 templates_path = ['_templates']
122 html_static_path = ['_static']
123 html_css_files = ['style.css']
124
125 # Theme options are theme-specific and customize the look and feel of a theme
126 # further. For a list of options available for each theme, see the
127 # documentation.
128 html_theme_options = {
129 'icon_links': [
130 dict(name='GitHub',
131 url='https://github.com/mne-tools/mne-bids',
132 icon='fab fa-github-square'),
133 dict(name='Discourse',
134 url='https://mne.discourse.group/tags/mne-bids',
135 icon='fab fa-discourse'),
136 ],
137 'icon_links_label': 'Quick Links', # for screen reader
138 'use_edit_page_button': False,
139 'navigation_with_keys': False,
140 'show_toc_level': 1,
141 'navbar_end': ['version-switcher', 'navbar-icon-links'],
142 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),
143 }
144
145 html_context = {
146 'versions_dropdown': {
147 'dev': 'v0.13 (devel)',
148 'stable': 'v0.12 (stable)',
149 'v0.11': 'v0.11',
150 'v0.10': 'v0.10',
151 'v0.9': 'v0.9',
152 'v0.8': 'v0.8',
153 'v0.7': 'v0.7',
154 'v0.6': 'v0.6',
155 'v0.5': 'v0.5',
156 'v0.4': 'v0.4',
157 'v0.3': 'v0.3',
158 'v0.2': 'v0.2',
159 'v0.1': 'v0.1',
160 },
161 }
162
163 html_sidebars = {}
164
165 # Example configuration for intersphinx: refer to the Python standard library.
166 intersphinx_mapping = {
167 'python': ('https://docs.python.org/3', None),
168 'mne': ('https://mne.tools/dev', None),
169 'mne-gui-addons': ('https://mne.tools/mne-gui-addons', None),
170 'numpy': ('https://numpy.org/devdocs', None),
171 'scipy': ('https://scipy.github.io/devdocs', None),
172 'matplotlib': ('https://matplotlib.org', None),
173 'nilearn': ('http://nilearn.github.io/stable', None),
174 'pandas': ('https://pandas.pydata.org/pandas-docs/dev', None),
175 'nibabel': ('https://nipy.org/nibabel', None),
176 }
177 intersphinx_timeout = 5
178
179 # Resolve binder filepath_prefix. From the docs:
180 # "A prefix to append to the filepath in the Binder links. You should use this
181 # if you will store your built documentation in a sub-folder of a repository,
182 # instead of in the root."
183 # we will store dev docs in a `dev` subdirectory and all other docs in a
184 # directory "v" + version_str. E.g., "v0.3"
185 if 'dev' in version:
186 filepath_prefix = 'dev'
187 else:
188 filepath_prefix = 'v{}'.format(version)
189
190 sphinx_gallery_conf = {
191 'doc_module': 'mne_bids',
192 'reference_url': {
193 'mne_bids': None,
194 },
195 'backreferences_dir': 'generated',
196 'examples_dirs': '../examples',
197 'within_subsection_order': ExampleTitleSortKey,
198 'gallery_dirs': 'auto_examples',
199 'filename_pattern': '^((?!sgskip).)*$',
200 'binder': {
201 # Required keys
202 'org': 'mne-tools',
203 'repo': 'mne-bids',
204 'branch': 'gh-pages', # noqa: E501 Can be any branch, tag, or commit hash. Use a branch that hosts your docs.
205 'binderhub_url': 'https://mybinder.org', # noqa: E501 Any URL of a binderhub deployment. Must be full URL (e.g. https://mybinder.org).
206 'filepath_prefix': filepath_prefix, # noqa: E501 A prefix to prepend to any filepaths in Binder links.
207 'dependencies': [
208 '../test_requirements.txt',
209 './requirements.txt',
210 ],
211 }
212 }
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -21,7 +21,7 @@
# If your documentation needs a minimal Sphinx version, state it here.
#
-# needs_sphinx = '1.0'
+needs_sphinx = '2.0'
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
@@ -125,6 +125,7 @@
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
+switcher_version_match = "dev" if "dev" in release else version
html_theme_options = {
'icon_links': [
dict(name='GitHub',
@@ -138,26 +139,17 @@
'use_edit_page_button': False,
'navigation_with_keys': False,
'show_toc_level': 1,
- 'navbar_end': ['version-switcher', 'navbar-icon-links'],
+ 'navbar_end': ['theme-switcher', 'version-switcher', 'navbar-icon-links'],
'analytics': dict(google_analytics_id='G-C8SH9E98QC'),
+ "switcher": {
+ "json_url": "https://raw.githubusercontent.com/mne-tools/mne-bids/main/doc/_static/versions.json", # noqa: E501
+ "version_match": switcher_version_match,
+ },
}
html_context = {
- 'versions_dropdown': {
- 'dev': 'v0.13 (devel)',
- 'stable': 'v0.12 (stable)',
- 'v0.11': 'v0.11',
- 'v0.10': 'v0.10',
- 'v0.9': 'v0.9',
- 'v0.8': 'v0.8',
- 'v0.7': 'v0.7',
- 'v0.6': 'v0.6',
- 'v0.5': 'v0.5',
- 'v0.4': 'v0.4',
- 'v0.3': 'v0.3',
- 'v0.2': 'v0.2',
- 'v0.1': 'v0.1',
- },
+ "default_mode": "auto",
+ "doc_path": "doc",
}
html_sidebars = {}
|
{"golden_diff": "diff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -21,7 +21,7 @@\n \n # If your documentation needs a minimal Sphinx version, state it here.\n #\n-# needs_sphinx = '1.0'\n+needs_sphinx = '2.0'\n \n # Add any Sphinx extension module names here, as strings. They can be\n # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n@@ -125,6 +125,7 @@\n # Theme options are theme-specific and customize the look and feel of a theme\n # further. For a list of options available for each theme, see the\n # documentation.\n+switcher_version_match = \"dev\" if \"dev\" in release else version\n html_theme_options = {\n 'icon_links': [\n dict(name='GitHub',\n@@ -138,26 +139,17 @@\n 'use_edit_page_button': False,\n 'navigation_with_keys': False,\n 'show_toc_level': 1,\n- 'navbar_end': ['version-switcher', 'navbar-icon-links'],\n+ 'navbar_end': ['theme-switcher', 'version-switcher', 'navbar-icon-links'],\n 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),\n+ \"switcher\": {\n+ \"json_url\": \"https://raw.githubusercontent.com/mne-tools/mne-bids/main/doc/_static/versions.json\", # noqa: E501\n+ \"version_match\": switcher_version_match,\n+ },\n }\n \n html_context = {\n- 'versions_dropdown': {\n- 'dev': 'v0.13 (devel)',\n- 'stable': 'v0.12 (stable)',\n- 'v0.11': 'v0.11',\n- 'v0.10': 'v0.10',\n- 'v0.9': 'v0.9',\n- 'v0.8': 'v0.8',\n- 'v0.7': 'v0.7',\n- 'v0.6': 'v0.6',\n- 'v0.5': 'v0.5',\n- 'v0.4': 'v0.4',\n- 'v0.3': 'v0.3',\n- 'v0.2': 'v0.2',\n- 'v0.1': 'v0.1',\n- },\n+ \"default_mode\": \"auto\",\n+ \"doc_path\": \"doc\",\n }\n \n html_sidebars = {}\n", "issue": "docs: dropdown menu on main no longer working\ntry selecting a version here: https://mne.tools/mne-bids/dev/index.html\n", "before_files": [{"content": "\"\"\"Configure details for documentation with sphinx.\"\"\"\nimport os\nimport sys\nfrom datetime import date\n\nimport sphinx_gallery # noqa: F401\nfrom sphinx_gallery.sorting import ExampleTitleSortKey\n\nimport mne_bids\n\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\ncurdir = os.path.dirname(__file__)\nsys.path.append(os.path.abspath(os.path.join(curdir, '..', 'mne_bids')))\nsys.path.append(os.path.abspath(os.path.join(curdir, 'sphinxext')))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.githubpages',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx_gallery.gen_gallery',\n 'numpydoc',\n 'sphinx_copybutton',\n 'gen_cli', # custom extension, see ./sphinxext/gen_cli.py\n 'gh_substitutions', # custom extension, see ./sphinxext/gh_substitutions.py\n]\n\n# configure sphinx-copybutton\ncopybutton_prompt_text = r\">>> |\\.\\.\\. |\\$ \"\ncopybutton_prompt_is_regexp = True\n\n# configure numpydoc\nnumpydoc_xref_param_type = True\nnumpydoc_class_members_toctree = False\nnumpydoc_attributes_as_param_list = True\nnumpydoc_xref_aliases = {\n 'BIDSPath': ':class:`BIDSPath <mne_bids.BIDSPath>`',\n 'path-like': ':term:`path-like <mne:path-like>`',\n 'array-like': ':term:`array_like <numpy:array_like>`',\n 'int': ':class:`int <python:int>`',\n 'bool': ':class:`bool <python:bool>`',\n 'float': ':class:`float <python:float>`',\n 'list': ':class:`list <python:list>`',\n 'tuple': ':class:`tuple <python:tuple>`',\n 'NibabelImageObject': 'nibabel.spatialimages.SpatialImage',\n}\nnumpydoc_xref_ignore = {\n # words\n 'instance', 'instances', 'of'\n}\n\n\n# generate autosummary even if no references\nautosummary_generate = True\nautodoc_default_options = {'inherited-members': None}\ndefault_role = 'autolink' # XXX silently allows bad syntax, someone should fix\n\n# configure linkcheck\n# https://sphinx-doc.org/en/master/usage/configuration.html?#options-for-the-linkcheck-builder\nlinkcheck_retries = 2\nlinkcheck_rate_limit_timeout = 15.0\nlinkcheck_ignore = [\n r'https://www.researchgate.net/profile/.*',\n]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'MNE-BIDS'\ntd = date.today()\ncopyright = u'2017-%s, MNE Developers. Last updated on %s' % (td.year,\n td.isoformat())\n\nauthor = u'MNE Developers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = mne_bids.__version__\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['auto_examples/index.rst', '_build', 'Thumbs.db',\n '.DS_Store']\n\n# HTML options (e.g., theme)\nhtml_show_sourcelink = False\nhtml_copy_source = False\n\nhtml_theme = 'pydata_sphinx_theme'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\nhtml_static_path = ['_static']\nhtml_css_files = ['style.css']\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n 'icon_links': [\n dict(name='GitHub',\n url='https://github.com/mne-tools/mne-bids',\n icon='fab fa-github-square'),\n dict(name='Discourse',\n url='https://mne.discourse.group/tags/mne-bids',\n icon='fab fa-discourse'),\n ],\n 'icon_links_label': 'Quick Links', # for screen reader\n 'use_edit_page_button': False,\n 'navigation_with_keys': False,\n 'show_toc_level': 1,\n 'navbar_end': ['version-switcher', 'navbar-icon-links'],\n 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),\n}\n\nhtml_context = {\n 'versions_dropdown': {\n 'dev': 'v0.13 (devel)',\n 'stable': 'v0.12 (stable)',\n 'v0.11': 'v0.11',\n 'v0.10': 'v0.10',\n 'v0.9': 'v0.9',\n 'v0.8': 'v0.8',\n 'v0.7': 'v0.7',\n 'v0.6': 'v0.6',\n 'v0.5': 'v0.5',\n 'v0.4': 'v0.4',\n 'v0.3': 'v0.3',\n 'v0.2': 'v0.2',\n 'v0.1': 'v0.1',\n },\n}\n\nhtml_sidebars = {}\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n 'mne': ('https://mne.tools/dev', None),\n 'mne-gui-addons': ('https://mne.tools/mne-gui-addons', None),\n 'numpy': ('https://numpy.org/devdocs', None),\n 'scipy': ('https://scipy.github.io/devdocs', None),\n 'matplotlib': ('https://matplotlib.org', None),\n 'nilearn': ('http://nilearn.github.io/stable', None),\n 'pandas': ('https://pandas.pydata.org/pandas-docs/dev', None),\n 'nibabel': ('https://nipy.org/nibabel', None),\n}\nintersphinx_timeout = 5\n\n# Resolve binder filepath_prefix. From the docs:\n# \"A prefix to append to the filepath in the Binder links. You should use this\n# if you will store your built documentation in a sub-folder of a repository,\n# instead of in the root.\"\n# we will store dev docs in a `dev` subdirectory and all other docs in a\n# directory \"v\" + version_str. E.g., \"v0.3\"\nif 'dev' in version:\n filepath_prefix = 'dev'\nelse:\n filepath_prefix = 'v{}'.format(version)\n\nsphinx_gallery_conf = {\n 'doc_module': 'mne_bids',\n 'reference_url': {\n 'mne_bids': None,\n },\n 'backreferences_dir': 'generated',\n 'examples_dirs': '../examples',\n 'within_subsection_order': ExampleTitleSortKey,\n 'gallery_dirs': 'auto_examples',\n 'filename_pattern': '^((?!sgskip).)*$',\n 'binder': {\n # Required keys\n 'org': 'mne-tools',\n 'repo': 'mne-bids',\n 'branch': 'gh-pages', # noqa: E501 Can be any branch, tag, or commit hash. Use a branch that hosts your docs.\n 'binderhub_url': 'https://mybinder.org', # noqa: E501 Any URL of a binderhub deployment. Must be full URL (e.g. https://mybinder.org).\n 'filepath_prefix': filepath_prefix, # noqa: E501 A prefix to prepend to any filepaths in Binder links.\n 'dependencies': [\n '../test_requirements.txt',\n './requirements.txt',\n ],\n }\n}\n", "path": "doc/conf.py"}], "after_files": [{"content": "\"\"\"Configure details for documentation with sphinx.\"\"\"\nimport os\nimport sys\nfrom datetime import date\n\nimport sphinx_gallery # noqa: F401\nfrom sphinx_gallery.sorting import ExampleTitleSortKey\n\nimport mne_bids\n\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\ncurdir = os.path.dirname(__file__)\nsys.path.append(os.path.abspath(os.path.join(curdir, '..', 'mne_bids')))\nsys.path.append(os.path.abspath(os.path.join(curdir, 'sphinxext')))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\nneeds_sphinx = '2.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.githubpages',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx_gallery.gen_gallery',\n 'numpydoc',\n 'sphinx_copybutton',\n 'gen_cli', # custom extension, see ./sphinxext/gen_cli.py\n 'gh_substitutions', # custom extension, see ./sphinxext/gh_substitutions.py\n]\n\n# configure sphinx-copybutton\ncopybutton_prompt_text = r\">>> |\\.\\.\\. |\\$ \"\ncopybutton_prompt_is_regexp = True\n\n# configure numpydoc\nnumpydoc_xref_param_type = True\nnumpydoc_class_members_toctree = False\nnumpydoc_attributes_as_param_list = True\nnumpydoc_xref_aliases = {\n 'BIDSPath': ':class:`BIDSPath <mne_bids.BIDSPath>`',\n 'path-like': ':term:`path-like <mne:path-like>`',\n 'array-like': ':term:`array_like <numpy:array_like>`',\n 'int': ':class:`int <python:int>`',\n 'bool': ':class:`bool <python:bool>`',\n 'float': ':class:`float <python:float>`',\n 'list': ':class:`list <python:list>`',\n 'tuple': ':class:`tuple <python:tuple>`',\n 'NibabelImageObject': 'nibabel.spatialimages.SpatialImage',\n}\nnumpydoc_xref_ignore = {\n # words\n 'instance', 'instances', 'of'\n}\n\n\n# generate autosummary even if no references\nautosummary_generate = True\nautodoc_default_options = {'inherited-members': None}\ndefault_role = 'autolink' # XXX silently allows bad syntax, someone should fix\n\n# configure linkcheck\n# https://sphinx-doc.org/en/master/usage/configuration.html?#options-for-the-linkcheck-builder\nlinkcheck_retries = 2\nlinkcheck_rate_limit_timeout = 15.0\nlinkcheck_ignore = [\n r'https://www.researchgate.net/profile/.*',\n]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'MNE-BIDS'\ntd = date.today()\ncopyright = u'2017-%s, MNE Developers. Last updated on %s' % (td.year,\n td.isoformat())\n\nauthor = u'MNE Developers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = mne_bids.__version__\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['auto_examples/index.rst', '_build', 'Thumbs.db',\n '.DS_Store']\n\n# HTML options (e.g., theme)\nhtml_show_sourcelink = False\nhtml_copy_source = False\n\nhtml_theme = 'pydata_sphinx_theme'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\nhtml_static_path = ['_static']\nhtml_css_files = ['style.css']\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nswitcher_version_match = \"dev\" if \"dev\" in release else version\nhtml_theme_options = {\n 'icon_links': [\n dict(name='GitHub',\n url='https://github.com/mne-tools/mne-bids',\n icon='fab fa-github-square'),\n dict(name='Discourse',\n url='https://mne.discourse.group/tags/mne-bids',\n icon='fab fa-discourse'),\n ],\n 'icon_links_label': 'Quick Links', # for screen reader\n 'use_edit_page_button': False,\n 'navigation_with_keys': False,\n 'show_toc_level': 1,\n 'navbar_end': ['theme-switcher', 'version-switcher', 'navbar-icon-links'],\n 'analytics': dict(google_analytics_id='G-C8SH9E98QC'),\n \"switcher\": {\n \"json_url\": \"https://raw.githubusercontent.com/mne-tools/mne-bids/main/doc/_static/versions.json\", # noqa: E501\n \"version_match\": switcher_version_match,\n },\n}\n\nhtml_context = {\n \"default_mode\": \"auto\",\n \"doc_path\": \"doc\",\n}\n\nhtml_sidebars = {}\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n 'mne': ('https://mne.tools/dev', None),\n 'mne-gui-addons': ('https://mne.tools/mne-gui-addons', None),\n 'numpy': ('https://numpy.org/devdocs', None),\n 'scipy': ('https://scipy.github.io/devdocs', None),\n 'matplotlib': ('https://matplotlib.org', None),\n 'nilearn': ('http://nilearn.github.io/stable', None),\n 'pandas': ('https://pandas.pydata.org/pandas-docs/dev', None),\n 'nibabel': ('https://nipy.org/nibabel', None),\n}\nintersphinx_timeout = 5\n\n# Resolve binder filepath_prefix. From the docs:\n# \"A prefix to append to the filepath in the Binder links. You should use this\n# if you will store your built documentation in a sub-folder of a repository,\n# instead of in the root.\"\n# we will store dev docs in a `dev` subdirectory and all other docs in a\n# directory \"v\" + version_str. E.g., \"v0.3\"\nif 'dev' in version:\n filepath_prefix = 'dev'\nelse:\n filepath_prefix = 'v{}'.format(version)\n\nsphinx_gallery_conf = {\n 'doc_module': 'mne_bids',\n 'reference_url': {\n 'mne_bids': None,\n },\n 'backreferences_dir': 'generated',\n 'examples_dirs': '../examples',\n 'within_subsection_order': ExampleTitleSortKey,\n 'gallery_dirs': 'auto_examples',\n 'filename_pattern': '^((?!sgskip).)*$',\n 'binder': {\n # Required keys\n 'org': 'mne-tools',\n 'repo': 'mne-bids',\n 'branch': 'gh-pages', # noqa: E501 Can be any branch, tag, or commit hash. Use a branch that hosts your docs.\n 'binderhub_url': 'https://mybinder.org', # noqa: E501 Any URL of a binderhub deployment. Must be full URL (e.g. https://mybinder.org).\n 'filepath_prefix': filepath_prefix, # noqa: E501 A prefix to prepend to any filepaths in Binder links.\n 'dependencies': [\n '../test_requirements.txt',\n './requirements.txt',\n ],\n }\n}\n", "path": "doc/conf.py"}]}
| 2,774 | 578 |
gh_patches_debug_2497
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1047
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Windows agent connection error
agent version: 4.4
OS: Windows 2008 Standard, SP2.
case: https://datadog.desk.com/agent/case/11902
- log snippet:
> 2014-06-24 13:45:04 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/intake?api_key=#################',error=gaierror(11001, 'getaddrinfo failed'),headers={},reason='Unknown',request=<tornado.httpclient.HTTPRequest object at 0x01212170>,request_time=0.018000125885009766,time_info={})
>
> 2014-06-24 13:45:04 Eastern Daylight Time | WARNING | transaction(transaction.pyc:213) | Transaction 4 in error (5 errors), it will be replayed after 2014-06-24 13:46:34
>
> 2014-06-24 13:45:05 Eastern Daylight Time | INFO | win32.agent(agent.pyc:91) | pup has died. Restarting...
>
> 2014-06-24 13:45:05 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/api/v1/series/?api_key=################',error=gaierror(11001, 'getaddrinfo failed`
- able to TCP connection (80 and 443) to app.datadoghq.com
EDIT:
> telnet app.datadoghq.com 80
> telnet app.datadoghq.com 443
- from agent python shell:
> print socket.getaddrinfo('app.datadoghq.com',443)
> Traceback (most recent call last):
> File "shell.py", line 13, in shell
> File "<string>", line 1, in <module>
> gaierror: [Errno 11001] getaddrinfo failed
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import platform
2 import sys
3 from config import get_version
4 from jmxfetch import JMX_FETCH_JAR_NAME
5
6 try:
7 from setuptools import setup, find_packages
8
9 # required to build the cython extensions
10 from distutils.extension import Extension #pylint: disable=no-name-in-module
11
12 except ImportError:
13 from ez_setup import use_setuptools
14 use_setuptools()
15 from setuptools import setup, find_packages
16
17 # Extra arguments to pass to the setup function
18 extra_args = {}
19
20 # Prereqs of the build. Won't get installed when deploying the egg.
21 setup_requires = [
22 ]
23
24 # Prereqs of the install. Will install when deploying the egg.
25 install_requires=[
26 ]
27
28 if sys.platform == 'win32':
29 from glob import glob
30 import py2exe
31 install_requires.extend([
32 'tornado==3.0.1',
33 'pywin32==217',
34 'wmi==1.4.9',
35 'simplejson==2.6.1',
36 'mysql-python==1.2.3',
37 'pymongo==2.3',
38 'pg8000',
39 'python-memcached==1.48',
40 'adodbapi'
41 'elementtree',
42 'pycurl',
43 'pymysql',
44 'psutil',
45 'redis',
46 'requests',
47 'httplib2==0.9',
48 ])
49
50 # Modules to force-include in the exe
51 include_modules = [
52 # 3p
53 'win32service',
54 'win32serviceutil',
55 'win32event',
56 'simplejson',
57 'adodbapi',
58 'elementtree.ElementTree',
59 'pycurl',
60 'tornado.curl_httpclient',
61 'pymongo',
62 'pymysql',
63 'psutil',
64 'pg8000',
65 'redis',
66 'requests',
67
68 # agent
69 'checks.services_checks',
70 'httplib2',
71
72 # pup
73 'pup',
74 'pup.pup',
75 'tornado.websocket',
76 'tornado.web',
77 'tornado.ioloop',
78 ]
79
80 class Target(object):
81 def __init__(self, **kw):
82 self.__dict__.update(kw)
83 self.version = get_version()
84 self.company_name = 'Datadog, Inc.'
85 self.copyright = 'Copyright 2013 Datadog, Inc.'
86 self.cmdline_style = 'pywin32'
87
88 agent_svc = Target(name='Datadog Agent', modules='win32.agent', dest_base='ddagent')
89
90 extra_args = {
91 'options': {
92 'py2exe': {
93 'includes': ','.join(include_modules),
94 'optimize': 0,
95 'compressed': True,
96 'bundle_files': 3,
97 },
98 },
99 'console': ['win32\shell.py'],
100 'service': [agent_svc],
101 'windows': [{'script': 'win32\gui.py',
102 'dest_base': "agent-manager",
103 'uac_info': "requireAdministrator", # The manager needs to be administrator to stop/start the service
104 'icon_resources': [(1, r"packaging\datadog-agent\win32\install_files\dd_agent_win_256.ico")],
105 }],
106 'data_files': [
107 ("Microsoft.VC90.CRT", glob(r'C:\Python27\redist\*.*')),
108 ('pup', glob('pup/pup.html')),
109 ('pup', glob('pup/status.html')),
110 ('pup/static', glob('pup/static/*.*')),
111 ('jmxfetch', glob('checks/libs/%s' % JMX_FETCH_JAR_NAME)),
112 ],
113 }
114
115 setup(
116 name='datadog-agent',
117 version=get_version(),
118 description="DevOps' best friend",
119 author='DataDog',
120 author_email='[email protected]',
121 url='http://www.datadoghq.com',
122 install_requires=install_requires,
123 setup_requires=setup_requires,
124 packages=find_packages(exclude=['ez_setup']),
125 include_package_data=True,
126 test_suite='nose.collector',
127 zip_safe=False,
128 **extra_args
129 )
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -94,6 +94,7 @@
'optimize': 0,
'compressed': True,
'bundle_files': 3,
+ 'dll_excludes': [ "IPHLPAPI.DLL", "NSI.dll", "WINNSI.DLL", "WTSAPI32.dll"],
},
},
'console': ['win32\shell.py'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -94,6 +94,7 @@\n 'optimize': 0,\n 'compressed': True,\n 'bundle_files': 3,\n+ 'dll_excludes': [ \"IPHLPAPI.DLL\", \"NSI.dll\", \"WINNSI.DLL\", \"WTSAPI32.dll\"],\n },\n },\n 'console': ['win32\\shell.py'],\n", "issue": "Windows agent connection error\nagent version: 4.4\nOS: Windows 2008 Standard, SP2.\ncase: https://datadog.desk.com/agent/case/11902\n- log snippet:\n\n> 2014-06-24 13:45:04 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/intake?api_key=#################',error=gaierror(11001, 'getaddrinfo failed'),headers={},reason='Unknown',request=<tornado.httpclient.HTTPRequest object at 0x01212170>,request_time=0.018000125885009766,time_info={})\n> \n> 2014-06-24 13:45:04 Eastern Daylight Time | WARNING | transaction(transaction.pyc:213) | Transaction 4 in error (5 errors), it will be replayed after 2014-06-24 13:46:34\n> \n> 2014-06-24 13:45:05 Eastern Daylight Time | INFO | win32.agent(agent.pyc:91) | pup has died. Restarting...\n> \n> 2014-06-24 13:45:05 Eastern Daylight Time | ERROR | forwarder(ddagent.pyc:240) | Response: HTTPResponse(_body=None,buffer=None,code=599,effective_url='https://app.datadoghq.com/api/v1/series/?api_key=################',error=gaierror(11001, 'getaddrinfo failed`\n- able to TCP connection (80 and 443) to app.datadoghq.com\n EDIT:\n \n > telnet app.datadoghq.com 80\n > telnet app.datadoghq.com 443\n- from agent python shell:\n \n > print socket.getaddrinfo('app.datadoghq.com',443)\n > Traceback (most recent call last):\n > File \"shell.py\", line 13, in shell\n > File \"<string>\", line 1, in <module>\n > gaierror: [Errno 11001] getaddrinfo failed\n\n", "before_files": [{"content": "import platform\nimport sys\nfrom config import get_version\nfrom jmxfetch import JMX_FETCH_JAR_NAME\n\ntry:\n from setuptools import setup, find_packages\n\n # required to build the cython extensions\n from distutils.extension import Extension #pylint: disable=no-name-in-module\n\nexcept ImportError:\n from ez_setup import use_setuptools\n use_setuptools()\n from setuptools import setup, find_packages\n\n# Extra arguments to pass to the setup function\nextra_args = {}\n\n# Prereqs of the build. Won't get installed when deploying the egg.\nsetup_requires = [\n]\n\n# Prereqs of the install. Will install when deploying the egg.\ninstall_requires=[\n]\n\nif sys.platform == 'win32':\n from glob import glob\n import py2exe\n install_requires.extend([\n 'tornado==3.0.1',\n 'pywin32==217',\n 'wmi==1.4.9',\n 'simplejson==2.6.1',\n 'mysql-python==1.2.3',\n 'pymongo==2.3',\n 'pg8000',\n 'python-memcached==1.48',\n 'adodbapi'\n 'elementtree',\n 'pycurl',\n 'pymysql',\n 'psutil',\n 'redis',\n 'requests',\n 'httplib2==0.9',\n ])\n\n # Modules to force-include in the exe\n include_modules = [\n # 3p\n 'win32service',\n 'win32serviceutil',\n 'win32event',\n 'simplejson',\n 'adodbapi',\n 'elementtree.ElementTree',\n 'pycurl',\n 'tornado.curl_httpclient',\n 'pymongo',\n 'pymysql',\n 'psutil',\n 'pg8000',\n 'redis',\n 'requests',\n\n # agent\n 'checks.services_checks',\n 'httplib2',\n\n # pup\n 'pup',\n 'pup.pup',\n 'tornado.websocket',\n 'tornado.web',\n 'tornado.ioloop',\n ]\n\n class Target(object):\n def __init__(self, **kw):\n self.__dict__.update(kw) \n self.version = get_version()\n self.company_name = 'Datadog, Inc.'\n self.copyright = 'Copyright 2013 Datadog, Inc.'\n self.cmdline_style = 'pywin32'\n\n agent_svc = Target(name='Datadog Agent', modules='win32.agent', dest_base='ddagent')\n\n extra_args = {\n 'options': {\n 'py2exe': {\n 'includes': ','.join(include_modules),\n 'optimize': 0,\n 'compressed': True,\n 'bundle_files': 3,\n },\n },\n 'console': ['win32\\shell.py'],\n 'service': [agent_svc],\n 'windows': [{'script': 'win32\\gui.py',\n 'dest_base': \"agent-manager\",\n 'uac_info': \"requireAdministrator\", # The manager needs to be administrator to stop/start the service\n 'icon_resources': [(1, r\"packaging\\datadog-agent\\win32\\install_files\\dd_agent_win_256.ico\")],\n }],\n 'data_files': [\n (\"Microsoft.VC90.CRT\", glob(r'C:\\Python27\\redist\\*.*')),\n ('pup', glob('pup/pup.html')),\n ('pup', glob('pup/status.html')),\n ('pup/static', glob('pup/static/*.*')),\n ('jmxfetch', glob('checks/libs/%s' % JMX_FETCH_JAR_NAME)),\n ],\n }\n\nsetup(\n name='datadog-agent',\n version=get_version(),\n description=\"DevOps' best friend\",\n author='DataDog',\n author_email='[email protected]',\n url='http://www.datadoghq.com',\n install_requires=install_requires,\n setup_requires=setup_requires,\n packages=find_packages(exclude=['ez_setup']),\n include_package_data=True,\n test_suite='nose.collector',\n zip_safe=False,\n **extra_args\n)\n", "path": "setup.py"}], "after_files": [{"content": "import platform\nimport sys\nfrom config import *\nfrom jmxfetch import JMX_FETCH_JAR_NAME\n\ntry:\n from setuptools import setup, find_packages\n\n # required to build the cython extensions\n from distutils.extension import Extension #pylint: disable=no-name-in-module\n\nexcept ImportError:\n from ez_setup import use_setuptools\n use_setuptools()\n from setuptools import setup, find_packages\n\n# Extra arguments to pass to the setup function\nextra_args = {}\n\n# Prereqs of the build. Won't get installed when deploying the egg.\nsetup_requires = [\n]\n\n# Prereqs of the install. Will install when deploying the egg.\ninstall_requires=[\n]\n\nif sys.platform == 'win32':\n from glob import glob\n import py2exe\n install_requires.extend([\n 'tornado==3.0.1',\n 'pywin32==217',\n 'wmi==1.4.9',\n 'simplejson==2.6.1',\n 'mysql-python==1.2.3',\n 'pymongo==2.3',\n 'pg8000',\n 'python-memcached==1.48',\n 'adodbapi'\n 'elementtree',\n 'pycurl',\n 'pymysql',\n 'psutil',\n 'redis',\n 'requests',\n 'httplib2==0.9',\n ])\n\n # Modules to force-include in the exe\n include_modules = [\n # 3p\n 'win32service',\n 'win32serviceutil',\n 'win32event',\n 'simplejson',\n 'adodbapi',\n 'elementtree.ElementTree',\n 'pycurl',\n 'tornado.curl_httpclient',\n 'pymongo',\n 'pymysql',\n 'psutil',\n 'pg8000',\n 'redis',\n 'requests',\n\n # agent\n 'checks.services_checks',\n 'httplib2',\n\n # pup\n 'pup',\n 'pup.pup',\n 'tornado.websocket',\n 'tornado.web',\n 'tornado.ioloop',\n ]\n\n class Target(object):\n def __init__(self, **kw):\n self.__dict__.update(kw) \n self.version = get_version()\n self.company_name = 'Datadog, Inc.'\n self.copyright = 'Copyright 2013 Datadog, Inc.'\n self.cmdline_style = 'pywin32'\n\n agent_svc = Target(name='Datadog Agent', modules='win32.agent', dest_base='ddagent')\n\n extra_args = {\n 'options': {\n 'py2exe': {\n 'includes': ','.join(include_modules),\n 'optimize': 0,\n 'compressed': True,\n 'bundle_files': 3,\n 'dll_excludes': [ \"IPHLPAPI.DLL\", \"NSI.dll\", \"WINNSI.DLL\", \"WTSAPI32.dll\"],\n },\n },\n 'console': ['win32\\shell.py'],\n 'service': [agent_svc],\n 'windows': [{'script': 'win32\\gui.py',\n 'dest_base': \"agent-manager\",\n 'uac_info': \"requireAdministrator\", # The manager needs to be administrator to stop/start the service\n 'icon_resources': [(1, r\"packaging\\datadog-agent\\win32\\install_files\\dd_agent_win_256.ico\")],\n }],\n 'data_files': [\n (\"Microsoft.VC90.CRT\", glob(r'C:\\Python27\\redist\\*.*')),\n ('pup', glob('pup/pup.html')),\n ('pup', glob('pup/status.html')),\n ('pup/static', glob('pup/static/*.*')),\n ('jmxfetch', glob('checks/libs/%s' % JMX_FETCH_JAR_NAME)),\n ],\n }\n\nsetup(\n name='datadog-agent',\n version=get_version(),\n description=\"DevOps' best friend\",\n author='DataDog',\n author_email='[email protected]',\n url='http://www.datadoghq.com',\n install_requires=install_requires,\n setup_requires=setup_requires,\n packages=find_packages(exclude=['ez_setup']),\n include_package_data=True,\n test_suite='nose.collector',\n zip_safe=False,\n **extra_args\n)\n", "path": "setup.py"}]}
| 2,032 | 106 |
gh_patches_debug_14055
|
rasdani/github-patches
|
git_diff
|
spack__spack-12932
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Installation issue: py-adios
### Steps to reproduce the issue
```console
$ spack install -j 64 py-adios ^[email protected]:
```
The result is lots of errors like:
```adios_mpi.cpp:47080:21: error: 'PyThreadState' {aka 'struct _ts'} has no member named 'exc_type'; did you mean 'curexc_type'?```
And similar.
### Platform and user environment
```commandline
$ uname -a
Linux quokka1.ccs.ornl.gov 4.14.0-115.el7a.aarch64 #1 SMP Tue Sep 25 12:32:51 EDT 2018 aarch64 aarch64 aarch64 GNU/Linux
```
### Additional information
py-adios includes a file (adios_mpi.cpp) which was generated using Cython 0.28.2. This version of Cython generates code that won't compile against the Python 3.7 C API. (This was fixed in the 0.29 release.) The Adios developers have been notified (https://github.com/ornladios/ADIOS/issues/202).
I think the workaround is to add a ```depends_on()``` line for python <=3.6.x. If/when the issue is fixed in Adios, we can add a ```when``` clause to the dependency. I'll issue a pull request shortly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/py-adios/package.py`
Content:
```
1 # Copyright 2013-2019 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class PyAdios(PythonPackage):
10 """NumPy bindings of ADIOS1"""
11
12 homepage = "https://www.olcf.ornl.gov/center-projects/adios/"
13 url = "https://github.com/ornladios/ADIOS/archive/v1.12.0.tar.gz"
14 git = "https://github.com/ornladios/ADIOS.git"
15
16 maintainers = ['ax3l']
17
18 version('develop', branch='master')
19 version('1.13.0', '68af36b821debbdf4748b20320a990ce')
20 version('1.12.0', '84a1c71b6698009224f6f748c5257fc9')
21 version('1.11.1', '5639bfc235e50bf17ba9dafb14ea4185')
22 version('1.11.0', '5eead5b2ccf962f5e6d5f254d29d5238')
23 version('1.10.0', 'eff450a4c0130479417cfd63186957f3')
24 version('1.9.0', '310ff02388bbaa2b1c1710ee970b5678')
25
26 variant('mpi', default=True,
27 description='Enable MPI support')
28
29 for v in ['1.9.0', '1.10.0', '1.11.0', '1.11.1', '1.12.0', '1.13.0',
30 'develop']:
31 depends_on('adios@{0} ~mpi'.format(v),
32 when='@{0} ~mpi'.format(v),
33 type=['build', 'link', 'run'])
34 depends_on('adios@{0} +mpi'.format(v),
35 when='@{0} +mpi'.format(v),
36 type=['build', 'link', 'run'])
37
38 depends_on('py-numpy', type=['build', 'run'])
39 depends_on('mpi', when='+mpi')
40 depends_on('py-mpi4py', type=['run'], when='+mpi')
41 depends_on('py-cython', type=['build'])
42
43 phases = ['build_clib', 'install']
44 build_directory = 'wrappers/numpy'
45
46 def setup_file(self):
47 """Returns the name of the setup file to use."""
48 if '+mpi' in self.spec:
49 return 'setup_mpi.py'
50 else:
51 return 'setup.py'
52
53 def build_clib(self, spec, prefix):
54 # calls: make [MPI=y] python
55 args = ''
56 if '+mpi' in self.spec:
57 args = 'MPI=y '
58 args += 'python'
59 with working_dir(self.build_directory):
60 make(args)
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/py-adios/package.py b/var/spack/repos/builtin/packages/py-adios/package.py
--- a/var/spack/repos/builtin/packages/py-adios/package.py
+++ b/var/spack/repos/builtin/packages/py-adios/package.py
@@ -35,6 +35,14 @@
when='@{0} +mpi'.format(v),
type=['build', 'link', 'run'])
+ # NOTE: this dependency is a work-around for a bug in Adios itself.
+ # Specifically, Adios uses code that was generated by Cython 0.28.2.
+ # This code won't compile against the Python 3.7 C API.
+ # See https://github.com/ornladios/ADIOS/issues/202 and
+ # the first entry under "Bug Fixes" at
+ # https://github.com/cython/cython/blob/0.29.x/CHANGES.rst
+ depends_on('python@:3.6')
+
depends_on('py-numpy', type=['build', 'run'])
depends_on('mpi', when='+mpi')
depends_on('py-mpi4py', type=['run'], when='+mpi')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/py-adios/package.py b/var/spack/repos/builtin/packages/py-adios/package.py\n--- a/var/spack/repos/builtin/packages/py-adios/package.py\n+++ b/var/spack/repos/builtin/packages/py-adios/package.py\n@@ -35,6 +35,14 @@\n when='@{0} +mpi'.format(v),\n type=['build', 'link', 'run'])\n \n+ # NOTE: this dependency is a work-around for a bug in Adios itself.\n+ # Specifically, Adios uses code that was generated by Cython 0.28.2.\n+ # This code won't compile against the Python 3.7 C API.\n+ # See https://github.com/ornladios/ADIOS/issues/202 and\n+ # the first entry under \"Bug Fixes\" at\n+ # https://github.com/cython/cython/blob/0.29.x/CHANGES.rst\n+ depends_on('python@:3.6')\n+\n depends_on('py-numpy', type=['build', 'run'])\n depends_on('mpi', when='+mpi')\n depends_on('py-mpi4py', type=['run'], when='+mpi')\n", "issue": "Installation issue: py-adios\n### Steps to reproduce the issue\r\n```console\r\n$ spack install -j 64 py-adios ^[email protected]:\r\n```\r\n\r\nThe result is lots of errors like:\r\n```adios_mpi.cpp:47080:21: error: 'PyThreadState' {aka 'struct _ts'} has no member named 'exc_type'; did you mean 'curexc_type'?```\r\n\r\nAnd similar.\r\n\r\n### Platform and user environment\r\n```commandline\r\n$ uname -a\r\nLinux quokka1.ccs.ornl.gov 4.14.0-115.el7a.aarch64 #1 SMP Tue Sep 25 12:32:51 EDT 2018 aarch64 aarch64 aarch64 GNU/Linux\r\n``` \r\n\r\n### Additional information\r\npy-adios includes a file (adios_mpi.cpp) which was generated using Cython 0.28.2. This version of Cython generates code that won't compile against the Python 3.7 C API. (This was fixed in the 0.29 release.) The Adios developers have been notified (https://github.com/ornladios/ADIOS/issues/202).\r\n\r\nI think the workaround is to add a ```depends_on()``` line for python <=3.6.x. If/when the issue is fixed in Adios, we can add a ```when``` clause to the dependency. I'll issue a pull request shortly.\r\n\n", "before_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass PyAdios(PythonPackage):\n \"\"\"NumPy bindings of ADIOS1\"\"\"\n\n homepage = \"https://www.olcf.ornl.gov/center-projects/adios/\"\n url = \"https://github.com/ornladios/ADIOS/archive/v1.12.0.tar.gz\"\n git = \"https://github.com/ornladios/ADIOS.git\"\n\n maintainers = ['ax3l']\n\n version('develop', branch='master')\n version('1.13.0', '68af36b821debbdf4748b20320a990ce')\n version('1.12.0', '84a1c71b6698009224f6f748c5257fc9')\n version('1.11.1', '5639bfc235e50bf17ba9dafb14ea4185')\n version('1.11.0', '5eead5b2ccf962f5e6d5f254d29d5238')\n version('1.10.0', 'eff450a4c0130479417cfd63186957f3')\n version('1.9.0', '310ff02388bbaa2b1c1710ee970b5678')\n\n variant('mpi', default=True,\n description='Enable MPI support')\n\n for v in ['1.9.0', '1.10.0', '1.11.0', '1.11.1', '1.12.0', '1.13.0',\n 'develop']:\n depends_on('adios@{0} ~mpi'.format(v),\n when='@{0} ~mpi'.format(v),\n type=['build', 'link', 'run'])\n depends_on('adios@{0} +mpi'.format(v),\n when='@{0} +mpi'.format(v),\n type=['build', 'link', 'run'])\n\n depends_on('py-numpy', type=['build', 'run'])\n depends_on('mpi', when='+mpi')\n depends_on('py-mpi4py', type=['run'], when='+mpi')\n depends_on('py-cython', type=['build'])\n\n phases = ['build_clib', 'install']\n build_directory = 'wrappers/numpy'\n\n def setup_file(self):\n \"\"\"Returns the name of the setup file to use.\"\"\"\n if '+mpi' in self.spec:\n return 'setup_mpi.py'\n else:\n return 'setup.py'\n\n def build_clib(self, spec, prefix):\n # calls: make [MPI=y] python\n args = ''\n if '+mpi' in self.spec:\n args = 'MPI=y '\n args += 'python'\n with working_dir(self.build_directory):\n make(args)\n", "path": "var/spack/repos/builtin/packages/py-adios/package.py"}], "after_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass PyAdios(PythonPackage):\n \"\"\"NumPy bindings of ADIOS1\"\"\"\n\n homepage = \"https://www.olcf.ornl.gov/center-projects/adios/\"\n url = \"https://github.com/ornladios/ADIOS/archive/v1.12.0.tar.gz\"\n git = \"https://github.com/ornladios/ADIOS.git\"\n\n maintainers = ['ax3l']\n\n version('develop', branch='master')\n version('1.13.0', '68af36b821debbdf4748b20320a990ce')\n version('1.12.0', '84a1c71b6698009224f6f748c5257fc9')\n version('1.11.1', '5639bfc235e50bf17ba9dafb14ea4185')\n version('1.11.0', '5eead5b2ccf962f5e6d5f254d29d5238')\n version('1.10.0', 'eff450a4c0130479417cfd63186957f3')\n version('1.9.0', '310ff02388bbaa2b1c1710ee970b5678')\n\n variant('mpi', default=True,\n description='Enable MPI support')\n\n for v in ['1.9.0', '1.10.0', '1.11.0', '1.11.1', '1.12.0', '1.13.0',\n 'develop']:\n depends_on('adios@{0} ~mpi'.format(v),\n when='@{0} ~mpi'.format(v),\n type=['build', 'link', 'run'])\n depends_on('adios@{0} +mpi'.format(v),\n when='@{0} +mpi'.format(v),\n type=['build', 'link', 'run'])\n\n # NOTE: this dependency is a work-around for a bug in Adios itself.\n # Specifically, Adios uses code that was generated by Cython 0.28.2.\n # This code won't compile against the Python 3.7 C API.\n # See https://github.com/ornladios/ADIOS/issues/202 and\n # the first entry under \"Bug Fixes\" at\n # https://github.com/cython/cython/blob/0.29.x/CHANGES.rst\n depends_on('python@:3.6')\n\n depends_on('py-numpy', type=['build', 'run'])\n depends_on('mpi', when='+mpi')\n depends_on('py-mpi4py', type=['run'], when='+mpi')\n depends_on('py-cython', type=['build'])\n\n phases = ['build_clib', 'install']\n build_directory = 'wrappers/numpy'\n\n def setup_file(self):\n \"\"\"Returns the name of the setup file to use.\"\"\"\n if '+mpi' in self.spec:\n return 'setup_mpi.py'\n else:\n return 'setup.py'\n\n def build_clib(self, spec, prefix):\n # calls: make [MPI=y] python\n args = ''\n if '+mpi' in self.spec:\n args = 'MPI=y '\n args += 'python'\n with working_dir(self.build_directory):\n make(args)\n", "path": "var/spack/repos/builtin/packages/py-adios/package.py"}]}
| 1,459 | 278 |
gh_patches_debug_24511
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-468
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sound.length always returns 0
The `sound.length` function is implemented to always return 0 on both `gstreamer` and `pygame` incarnations of the audio library. Yet it's documented to return the length of the sound...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kivy/core/audio/audio_gstreamer.py`
Content:
```
1 '''
2 AudioGstreamer: implementation of Sound with GStreamer
3 '''
4
5 try:
6 import pygst
7 if not hasattr(pygst, '_gst_already_checked'):
8 pygst.require('0.10')
9 pygst._gst_already_checked = True
10 import gst
11 except:
12 raise
13
14 from . import Sound, SoundLoader
15 import os
16 import sys
17 from kivy.logger import Logger
18
19 # install the gobject iteration
20 from kivy.support import install_gobject_iteration
21 install_gobject_iteration()
22
23
24 class SoundGstreamer(Sound):
25
26 @staticmethod
27 def extensions():
28 return ('wav', 'ogg', 'mp3', )
29
30 def __init__(self, **kwargs):
31 self._data = None
32 super(SoundGstreamer, self).__init__(**kwargs)
33
34 def __del__(self):
35 if self._data is not None:
36 self._data.set_state(gst.STATE_NULL)
37
38 def _on_gst_message(self, bus, message):
39 t = message.type
40 if t == gst.MESSAGE_EOS:
41 self._data.set_state(gst.STATE_NULL)
42 self.stop()
43 elif t == gst.MESSAGE_ERROR:
44 self._data.set_state(gst.STATE_NULL)
45 err, debug = message.parse_error()
46 Logger.error('AudioGstreamer: %s' % err)
47 Logger.debug(str(debug))
48 self.stop()
49
50 def play(self):
51 if not self._data:
52 return
53 self._data.set_state(gst.STATE_PLAYING)
54 super(SoundGstreamer, self).play()
55
56 def stop(self):
57 if not self._data:
58 return
59 self._data.set_state(gst.STATE_NULL)
60 super(SoundGstreamer, self).stop()
61
62 def load(self):
63 self.unload()
64 fn = self.filename
65 if fn is None:
66 return
67
68 slash = ''
69 if sys.platform in ('win32', 'cygwin'):
70 slash = '/'
71
72 if fn[0] == '/':
73 filepath = 'file://' + slash + fn
74 else:
75 filepath = 'file://' + slash + os.path.join(os.getcwd(), fn)
76
77 self._data = gst.element_factory_make('playbin2', 'player')
78 fakesink = gst.element_factory_make('fakesink', 'fakesink')
79 self._data.set_property('video-sink', fakesink)
80 bus = self._data.get_bus()
81 bus.add_signal_watch()
82 bus.connect('message', self._on_gst_message)
83
84 self._data.set_property('uri', filepath)
85 self._data.set_state(gst.STATE_READY)
86
87 def unload(self):
88 self.stop()
89 self._data = None
90
91 def seek(self, position):
92 if self._data is None:
93 return
94 self._data.seek_simple(gst.FORMAT_TIME, gst.SEEK_FLAG_SKIP,
95 position / 1000000000.)
96
97 def _get_volume(self):
98 if self._data is not None:
99 self._volume = self._data.get_property('volume')
100 return super(SoundGstreamer, self)._get_volume()
101
102 def _set_volume(self, volume):
103 if self._data is not None:
104 self._data.set_property('volume', volume)
105 return super(SoundGstreamer, self)._set_volume(volume)
106
107 SoundLoader.register(SoundGstreamer)
108
```
Path: `kivy/core/audio/audio_pygame.py`
Content:
```
1 '''
2 AudioPygame: implementation of Sound with Pygame
3 '''
4
5 __all__ = ('SoundPygame', )
6
7 from kivy.clock import Clock
8 from kivy.utils import platform
9 from . import Sound, SoundLoader
10
11 try:
12 if platform() == 'android':
13 mixer = __import__('android_mixer')
14 else:
15 mixer = __import__('pygame.mixer', fromlist='.')
16 except:
17 raise
18
19 # init pygame sound
20 mixer.pre_init(44100, -16, 2, 1024)
21 mixer.init()
22 mixer.set_num_channels(32)
23
24
25 class SoundPygame(Sound):
26
27 # XXX we don't set __slots__ here, to automaticly add
28 # a dictionnary. We need that to be able to use weakref for
29 # SoundPygame object. Otherwise, it failed with:
30 # TypeError: cannot create weak reference to 'SoundPygame' object
31 # We use our clock in play() method.
32 # __slots__ = ('_data', '_channel')
33 @staticmethod
34 def extensions():
35 return ('wav', 'ogg', )
36
37 def __init__(self, **kwargs):
38 self._data = None
39 self._channel = None
40 super(SoundPygame, self).__init__(**kwargs)
41
42 def _check_play(self, dt):
43 if self._channel is None:
44 return False
45 if self._channel.get_busy():
46 return
47 self.stop()
48 return False
49
50 def play(self):
51 if not self._data:
52 return
53 self._channel = self._data.play()
54 # schedule event to check if the sound is still playing or not
55 Clock.schedule_interval(self._check_play, 0.1)
56 super(SoundPygame, self).play()
57
58 def stop(self):
59 if not self._data:
60 return
61 self._data.stop()
62 # ensure we don't have anymore the callback
63 Clock.unschedule(self._check_play)
64 self._channel = None
65 super(SoundPygame, self).stop()
66
67 def load(self):
68 self.unload()
69 if self.filename is None:
70 return
71 self._data = mixer.Sound(self.filename)
72
73 def unload(self):
74 self.stop()
75 self._data = None
76
77 def seek(self, position):
78 # Unable to seek in pygame...
79 pass
80
81 def _get_volume(self):
82 if self._data is not None:
83 self._volume = self._data.get_volume()
84 return super(SoundPygame, self)._get_volume()
85
86 def _set_volume(self, volume):
87 if self._data is not None:
88 self._data.set_volume(volume)
89 return super(SoundPygame, self)._set_volume(volume)
90
91 SoundLoader.register(SoundPygame)
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kivy/core/audio/audio_gstreamer.py b/kivy/core/audio/audio_gstreamer.py
--- a/kivy/core/audio/audio_gstreamer.py
+++ b/kivy/core/audio/audio_gstreamer.py
@@ -104,4 +104,20 @@
self._data.set_property('volume', volume)
return super(SoundGstreamer, self)._set_volume(volume)
+ def _get_length(self):
+ if self._data is not None:
+ if self._data.get_state()[1] != gst.STATE_PLAYING:
+ volume_before = self._data.get_property('volume')
+ self._data.set_property('volume', 0)
+ self._data.set_state(gst.STATE_PLAYING)
+ try:
+ self._data.get_state()
+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.
+ finally:
+ self._data.set_state(gst.STATE_NULL)
+ self._data.set_property('volume', volume_before)
+ else:
+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.
+ return super(SoundGstreamer, self)._get_length()
+
SoundLoader.register(SoundGstreamer)
diff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py
--- a/kivy/core/audio/audio_pygame.py
+++ b/kivy/core/audio/audio_pygame.py
@@ -88,4 +88,9 @@
self._data.set_volume(volume)
return super(SoundPygame, self)._set_volume(volume)
+ def _get_length(self):
+ if self._data is not None:
+ return self._data.get_length()
+ return super(SoundPygame, self)._get_length()
+
SoundLoader.register(SoundPygame)
|
{"golden_diff": "diff --git a/kivy/core/audio/audio_gstreamer.py b/kivy/core/audio/audio_gstreamer.py\n--- a/kivy/core/audio/audio_gstreamer.py\n+++ b/kivy/core/audio/audio_gstreamer.py\n@@ -104,4 +104,20 @@\n self._data.set_property('volume', volume)\n return super(SoundGstreamer, self)._set_volume(volume)\n \n+ def _get_length(self):\n+ if self._data is not None:\n+ if self._data.get_state()[1] != gst.STATE_PLAYING:\n+ volume_before = self._data.get_property('volume')\n+ self._data.set_property('volume', 0)\n+ self._data.set_state(gst.STATE_PLAYING)\n+ try:\n+ self._data.get_state()\n+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n+ finally:\n+ self._data.set_state(gst.STATE_NULL)\n+ self._data.set_property('volume', volume_before)\n+ else:\n+ return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n+ return super(SoundGstreamer, self)._get_length()\n+\n SoundLoader.register(SoundGstreamer)\ndiff --git a/kivy/core/audio/audio_pygame.py b/kivy/core/audio/audio_pygame.py\n--- a/kivy/core/audio/audio_pygame.py\n+++ b/kivy/core/audio/audio_pygame.py\n@@ -88,4 +88,9 @@\n self._data.set_volume(volume)\n return super(SoundPygame, self)._set_volume(volume)\n \n+ def _get_length(self):\n+ if self._data is not None:\n+ return self._data.get_length()\n+ return super(SoundPygame, self)._get_length()\n+\n SoundLoader.register(SoundPygame)\n", "issue": "sound.length always returns 0\nThe `sound.length` function is implemented to always return 0 on both `gstreamer` and `pygame` incarnations of the audio library. Yet it's documented to return the length of the sound...\n\n", "before_files": [{"content": "'''\nAudioGstreamer: implementation of Sound with GStreamer\n'''\n\ntry:\n import pygst\n if not hasattr(pygst, '_gst_already_checked'):\n pygst.require('0.10')\n pygst._gst_already_checked = True\n import gst\nexcept:\n raise\n\nfrom . import Sound, SoundLoader\nimport os\nimport sys\nfrom kivy.logger import Logger\n\n# install the gobject iteration\nfrom kivy.support import install_gobject_iteration\ninstall_gobject_iteration()\n\n\nclass SoundGstreamer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', )\n\n def __init__(self, **kwargs):\n self._data = None\n super(SoundGstreamer, self).__init__(**kwargs)\n\n def __del__(self):\n if self._data is not None:\n self._data.set_state(gst.STATE_NULL)\n\n def _on_gst_message(self, bus, message):\n t = message.type\n if t == gst.MESSAGE_EOS:\n self._data.set_state(gst.STATE_NULL)\n self.stop()\n elif t == gst.MESSAGE_ERROR:\n self._data.set_state(gst.STATE_NULL)\n err, debug = message.parse_error()\n Logger.error('AudioGstreamer: %s' % err)\n Logger.debug(str(debug))\n self.stop()\n\n def play(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_PLAYING)\n super(SoundGstreamer, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_NULL)\n super(SoundGstreamer, self).stop()\n\n def load(self):\n self.unload()\n fn = self.filename\n if fn is None:\n return\n\n slash = ''\n if sys.platform in ('win32', 'cygwin'):\n slash = '/'\n\n if fn[0] == '/':\n filepath = 'file://' + slash + fn\n else:\n filepath = 'file://' + slash + os.path.join(os.getcwd(), fn)\n\n self._data = gst.element_factory_make('playbin2', 'player')\n fakesink = gst.element_factory_make('fakesink', 'fakesink')\n self._data.set_property('video-sink', fakesink)\n bus = self._data.get_bus()\n bus.add_signal_watch()\n bus.connect('message', self._on_gst_message)\n\n self._data.set_property('uri', filepath)\n self._data.set_state(gst.STATE_READY)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if self._data is None:\n return\n self._data.seek_simple(gst.FORMAT_TIME, gst.SEEK_FLAG_SKIP,\n position / 1000000000.)\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_property('volume')\n return super(SoundGstreamer, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_property('volume', volume)\n return super(SoundGstreamer, self)._set_volume(volume)\n\nSoundLoader.register(SoundGstreamer)\n", "path": "kivy/core/audio/audio_gstreamer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform\nfrom . import Sound, SoundLoader\n\ntry:\n if platform() == 'android':\n mixer = __import__('android_mixer')\n else:\n mixer = __import__('pygame.mixer', fromlist='.')\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automaticly add\n # a dictionnary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n @staticmethod\n def extensions():\n return ('wav', 'ogg', )\n\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._channel = self._data.play()\n # schedule event to check if the sound is still playing or not\n Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n Clock.unschedule(self._check_play)\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.filename is None:\n return\n self._data = mixer.Sound(self.filename)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n # Unable to seek in pygame...\n pass\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_volume()\n return super(SoundPygame, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n return super(SoundPygame, self)._set_volume(volume)\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}], "after_files": [{"content": "'''\nAudioGstreamer: implementation of Sound with GStreamer\n'''\n\ntry:\n import pygst\n if not hasattr(pygst, '_gst_already_checked'):\n pygst.require('0.10')\n pygst._gst_already_checked = True\n import gst\nexcept:\n raise\n\nfrom . import Sound, SoundLoader\nimport os\nimport sys\nfrom kivy.logger import Logger\n\n# install the gobject iteration\nfrom kivy.support import install_gobject_iteration\ninstall_gobject_iteration()\n\n\nclass SoundGstreamer(Sound):\n\n @staticmethod\n def extensions():\n return ('wav', 'ogg', 'mp3', )\n\n def __init__(self, **kwargs):\n self._data = None\n super(SoundGstreamer, self).__init__(**kwargs)\n\n def __del__(self):\n if self._data is not None:\n self._data.set_state(gst.STATE_NULL)\n\n def _on_gst_message(self, bus, message):\n t = message.type\n if t == gst.MESSAGE_EOS:\n self._data.set_state(gst.STATE_NULL)\n self.stop()\n elif t == gst.MESSAGE_ERROR:\n self._data.set_state(gst.STATE_NULL)\n err, debug = message.parse_error()\n Logger.error('AudioGstreamer: %s' % err)\n Logger.debug(str(debug))\n self.stop()\n\n def play(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_PLAYING)\n super(SoundGstreamer, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.set_state(gst.STATE_NULL)\n super(SoundGstreamer, self).stop()\n\n def load(self):\n self.unload()\n fn = self.filename\n if fn is None:\n return\n\n slash = ''\n if sys.platform in ('win32', 'cygwin'):\n slash = '/'\n\n if fn[0] == '/':\n filepath = 'file://' + slash + fn\n else:\n filepath = 'file://' + slash + os.path.join(os.getcwd(), fn)\n\n self._data = gst.element_factory_make('playbin2', 'player')\n fakesink = gst.element_factory_make('fakesink', 'fakesink')\n self._data.set_property('video-sink', fakesink)\n bus = self._data.get_bus()\n bus.add_signal_watch()\n bus.connect('message', self._on_gst_message)\n\n self._data.set_property('uri', filepath)\n self._data.set_state(gst.STATE_READY)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n if self._data is None:\n return\n self._data.seek_simple(gst.FORMAT_TIME, gst.SEEK_FLAG_SKIP,\n position / 1000000000.)\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_property('volume')\n return super(SoundGstreamer, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_property('volume', volume)\n return super(SoundGstreamer, self)._set_volume(volume)\n\n def _get_length(self):\n if self._data is not None:\n if self._data.get_state()[1] != gst.STATE_PLAYING:\n volume_before = self._data.get_property('volume')\n self._data.set_property('volume', 0)\n self._data.set_state(gst.STATE_PLAYING)\n try:\n self._data.get_state()\n return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n finally:\n self._data.set_state(gst.STATE_NULL)\n self._data.set_property('volume', volume_before)\n else:\n return self._data.query_duration(gst.Format(gst.FORMAT_TIME))[0] / 1000000000.\n return super(SoundGstreamer, self)._get_length()\n\nSoundLoader.register(SoundGstreamer)\n", "path": "kivy/core/audio/audio_gstreamer.py"}, {"content": "'''\nAudioPygame: implementation of Sound with Pygame\n'''\n\n__all__ = ('SoundPygame', )\n\nfrom kivy.clock import Clock\nfrom kivy.utils import platform\nfrom . import Sound, SoundLoader\n\ntry:\n if platform() == 'android':\n mixer = __import__('android_mixer')\n else:\n mixer = __import__('pygame.mixer', fromlist='.')\nexcept:\n raise\n\n# init pygame sound\nmixer.pre_init(44100, -16, 2, 1024)\nmixer.init()\nmixer.set_num_channels(32)\n\n\nclass SoundPygame(Sound):\n\n # XXX we don't set __slots__ here, to automaticly add\n # a dictionnary. We need that to be able to use weakref for\n # SoundPygame object. Otherwise, it failed with:\n # TypeError: cannot create weak reference to 'SoundPygame' object\n # We use our clock in play() method.\n # __slots__ = ('_data', '_channel')\n @staticmethod\n def extensions():\n return ('wav', 'ogg', )\n\n def __init__(self, **kwargs):\n self._data = None\n self._channel = None\n super(SoundPygame, self).__init__(**kwargs)\n\n def _check_play(self, dt):\n if self._channel is None:\n return False\n if self._channel.get_busy():\n return\n self.stop()\n return False\n\n def play(self):\n if not self._data:\n return\n self._channel = self._data.play()\n # schedule event to check if the sound is still playing or not\n Clock.schedule_interval(self._check_play, 0.1)\n super(SoundPygame, self).play()\n\n def stop(self):\n if not self._data:\n return\n self._data.stop()\n # ensure we don't have anymore the callback\n Clock.unschedule(self._check_play)\n self._channel = None\n super(SoundPygame, self).stop()\n\n def load(self):\n self.unload()\n if self.filename is None:\n return\n self._data = mixer.Sound(self.filename)\n\n def unload(self):\n self.stop()\n self._data = None\n\n def seek(self, position):\n # Unable to seek in pygame...\n pass\n\n def _get_volume(self):\n if self._data is not None:\n self._volume = self._data.get_volume()\n return super(SoundPygame, self)._get_volume()\n\n def _set_volume(self, volume):\n if self._data is not None:\n self._data.set_volume(volume)\n return super(SoundPygame, self)._set_volume(volume)\n\n def _get_length(self):\n if self._data is not None:\n return self._data.get_length()\n return super(SoundPygame, self)._get_length()\n\nSoundLoader.register(SoundPygame)\n", "path": "kivy/core/audio/audio_pygame.py"}]}
| 2,072 | 427 |
gh_patches_debug_22564
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2064
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug with `geth_poa_middleware` in the case of non-existing blocks
* Version: 5.20.1
* Python: 3.7.2
* OS: linux
`pip freeze` output:
```
aiohttp==3.7.4.post0
async-timeout==3.0.1
attrs==20.3.0
base58==2.1.0
bitarray==1.2.2
certifi==2020.12.5
chardet==4.0.0
cytoolz==0.11.0
docutils==0.17.1
eth-abi==2.1.1
eth-account==0.5.4
eth-hash==0.3.1
eth-keyfile==0.5.1
eth-keys==0.3.3
eth-rlp==0.2.1
eth-typing==2.2.2
eth-utils==1.10.0
flock==0.1
hexbytes==0.2.1
idna==2.10
importlib-metadata==4.0.1
ipfshttpclient==0.7.0
jsonschema==3.2.0
lockfile==0.12.2
lru-dict==1.1.7
multiaddr==0.0.9
multidict==5.1.0
netaddr==0.8.0
parsimonious==0.8.1
protobuf==3.15.8
pycryptodome==3.10.1
pyrsistent==0.17.3
python-daemon==2.3.0
PyYAML==5.4.1
requests==2.25.1
rlp==2.0.1
six==1.15.0
toolz==0.11.1
typing-extensions==3.7.4.3
urllib3==1.26.4
varint==1.0.2
web3==5.20.1
websockets==9.1
yarl==1.6.3
zipp==3.4.1
```
### What was wrong?
The poa middleware formatters are applied to block contents even in the case when block is not found and `None` returned instead.
Reproducing:
```python
from eth_typing import URI
from web3 import Web3
from web3.middleware import geth_poa_middleware
from web3.providers.auto import load_provider_from_uri
w3 = Web3(load_provider_from_uri(URI('wss://rinkeby.infura.io/ws/v3/__project_id_here__'))) # please update the endpoint url
w3.middleware_onion.inject(geth_poa_middleware, layer=0)
print(w3.eth.get_block(200000000))
```
Expecting `web3.exceptions.BlockNotFound` to be risen.
Instead, got:
```
Traceback (most recent call last):
File "./bin/feed-query", line 85, in <module>
main()
File "./bin/feed-query", line 39, in main
print(w3.eth.get_block(200000000))
File "/venv/lib/python3.7/site-packages/web3/module.py", line 58, in caller
result = w3.manager.request_blocking(method_str, params, error_formatters)
File "/venv/lib/python3.7/site-packages/web3/manager.py", line 154, in request_blocking
response = self._make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/manager.py", line 133, in _make_request
return request_func(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/middleware/gas_price_strategy.py", line 34, in middleware
return make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "/venv/lib/python3.7/site-packages/web3/middleware/attrdict.py", line 33, in middleware
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 74, in apply_formatters
response = make_request(method, formatted_params)
File "/venv/lib/python3.7/site-packages/web3/middleware/normalize_errors.py", line 25, in middleware
result = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/web3/middleware/formatting.py", line 83, in apply_formatters
formatter(response["result"]),
File "cytoolz/functoolz.pyx", line 503, in cytoolz.functoolz.Compose.__call__
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/venv/lib/python3.7/site-packages/eth_utils/functional.py", line 45, in inner
return callback(fn(*args, **kwargs))
File "/venv/lib/python3.7/site-packages/eth_utils/applicators.py", line 126, in apply_key_map
set(value.keys())
AttributeError: 'NoneType' object has no attribute 'keys'
```
### How can it be fixed?
A simple monkey-patch that works for me:
```
def _geth_poa_middleware():
from web3.middleware.geth_poa import geth_poa_cleanup
from web3.middleware import construct_formatting_middleware
from web3.types import RPCEndpoint
def m(value):
# eth_getBlock* may return None
return None if value is None else geth_poa_cleanup(value)
return construct_formatting_middleware(
result_formatters={
RPCEndpoint("eth_getBlockByHash"): m,
RPCEndpoint("eth_getBlockByNumber"): m,
},
)
```
Could be easily incorporated into `web3.middleware.geth_poa` IMO.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/middleware/geth_poa.py`
Content:
```
1 from eth_utils.curried import (
2 apply_formatters_to_dict,
3 apply_key_map,
4 )
5 from eth_utils.toolz import (
6 compose,
7 )
8 from hexbytes import (
9 HexBytes,
10 )
11
12 from web3.middleware.formatting import (
13 construct_formatting_middleware,
14 )
15 from web3.types import (
16 RPCEndpoint,
17 )
18
19 remap_geth_poa_fields = apply_key_map({
20 'extraData': 'proofOfAuthorityData',
21 })
22
23 pythonic_geth_poa = apply_formatters_to_dict({
24 'proofOfAuthorityData': HexBytes,
25 })
26
27 geth_poa_cleanup = compose(pythonic_geth_poa, remap_geth_poa_fields)
28
29 geth_poa_middleware = construct_formatting_middleware(
30 result_formatters={
31 RPCEndpoint("eth_getBlockByHash"): geth_poa_cleanup,
32 RPCEndpoint("eth_getBlockByNumber"): geth_poa_cleanup,
33 },
34 )
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web3/middleware/geth_poa.py b/web3/middleware/geth_poa.py
--- a/web3/middleware/geth_poa.py
+++ b/web3/middleware/geth_poa.py
@@ -1,20 +1,25 @@
from eth_utils.curried import (
+ apply_formatter_if,
apply_formatters_to_dict,
apply_key_map,
+ is_null,
)
from eth_utils.toolz import (
+ complement,
compose,
)
from hexbytes import (
HexBytes,
)
+from web3._utils.rpc_abi import (
+ RPC,
+)
from web3.middleware.formatting import (
construct_formatting_middleware,
)
-from web3.types import (
- RPCEndpoint,
-)
+
+is_not_null = complement(is_null)
remap_geth_poa_fields = apply_key_map({
'extraData': 'proofOfAuthorityData',
@@ -28,7 +33,7 @@
geth_poa_middleware = construct_formatting_middleware(
result_formatters={
- RPCEndpoint("eth_getBlockByHash"): geth_poa_cleanup,
- RPCEndpoint("eth_getBlockByNumber"): geth_poa_cleanup,
+ RPC.eth_getBlockByHash: apply_formatter_if(is_not_null, geth_poa_cleanup),
+ RPC.eth_getBlockByNumber: apply_formatter_if(is_not_null, geth_poa_cleanup),
},
)
|
{"golden_diff": "diff --git a/web3/middleware/geth_poa.py b/web3/middleware/geth_poa.py\n--- a/web3/middleware/geth_poa.py\n+++ b/web3/middleware/geth_poa.py\n@@ -1,20 +1,25 @@\n from eth_utils.curried import (\n+ apply_formatter_if,\n apply_formatters_to_dict,\n apply_key_map,\n+ is_null,\n )\n from eth_utils.toolz import (\n+ complement,\n compose,\n )\n from hexbytes import (\n HexBytes,\n )\n \n+from web3._utils.rpc_abi import (\n+ RPC,\n+)\n from web3.middleware.formatting import (\n construct_formatting_middleware,\n )\n-from web3.types import (\n- RPCEndpoint,\n-)\n+\n+is_not_null = complement(is_null)\n \n remap_geth_poa_fields = apply_key_map({\n 'extraData': 'proofOfAuthorityData',\n@@ -28,7 +33,7 @@\n \n geth_poa_middleware = construct_formatting_middleware(\n result_formatters={\n- RPCEndpoint(\"eth_getBlockByHash\"): geth_poa_cleanup,\n- RPCEndpoint(\"eth_getBlockByNumber\"): geth_poa_cleanup,\n+ RPC.eth_getBlockByHash: apply_formatter_if(is_not_null, geth_poa_cleanup),\n+ RPC.eth_getBlockByNumber: apply_formatter_if(is_not_null, geth_poa_cleanup),\n },\n )\n", "issue": "Bug with `geth_poa_middleware` in the case of non-existing blocks\n* Version: 5.20.1\r\n* Python: 3.7.2\r\n* OS: linux\r\n\r\n`pip freeze` output:\r\n\r\n```\r\naiohttp==3.7.4.post0\r\nasync-timeout==3.0.1\r\nattrs==20.3.0\r\nbase58==2.1.0\r\nbitarray==1.2.2\r\ncertifi==2020.12.5\r\nchardet==4.0.0\r\ncytoolz==0.11.0\r\ndocutils==0.17.1\r\neth-abi==2.1.1\r\neth-account==0.5.4\r\neth-hash==0.3.1\r\neth-keyfile==0.5.1\r\neth-keys==0.3.3\r\neth-rlp==0.2.1\r\neth-typing==2.2.2\r\neth-utils==1.10.0\r\nflock==0.1\r\nhexbytes==0.2.1\r\nidna==2.10\r\nimportlib-metadata==4.0.1\r\nipfshttpclient==0.7.0\r\njsonschema==3.2.0\r\nlockfile==0.12.2\r\nlru-dict==1.1.7\r\nmultiaddr==0.0.9\r\nmultidict==5.1.0\r\nnetaddr==0.8.0\r\nparsimonious==0.8.1\r\nprotobuf==3.15.8\r\npycryptodome==3.10.1\r\npyrsistent==0.17.3\r\npython-daemon==2.3.0\r\nPyYAML==5.4.1\r\nrequests==2.25.1\r\nrlp==2.0.1\r\nsix==1.15.0\r\ntoolz==0.11.1\r\ntyping-extensions==3.7.4.3\r\nurllib3==1.26.4\r\nvarint==1.0.2\r\nweb3==5.20.1\r\nwebsockets==9.1\r\nyarl==1.6.3\r\nzipp==3.4.1\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\nThe poa middleware formatters are applied to block contents even in the case when block is not found and `None` returned instead.\r\n\r\nReproducing:\r\n\r\n```python\r\nfrom eth_typing import URI\r\nfrom web3 import Web3\r\nfrom web3.middleware import geth_poa_middleware\r\nfrom web3.providers.auto import load_provider_from_uri\r\n\r\nw3 = Web3(load_provider_from_uri(URI('wss://rinkeby.infura.io/ws/v3/__project_id_here__'))) # please update the endpoint url\r\nw3.middleware_onion.inject(geth_poa_middleware, layer=0)\r\nprint(w3.eth.get_block(200000000))\r\n```\r\n\r\nExpecting `web3.exceptions.BlockNotFound` to be risen.\r\n\r\nInstead, got:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"./bin/feed-query\", line 85, in <module>\r\n main()\r\n File \"./bin/feed-query\", line 39, in main\r\n print(w3.eth.get_block(200000000))\r\n File \"/venv/lib/python3.7/site-packages/web3/module.py\", line 58, in caller\r\n result = w3.manager.request_blocking(method_str, params, error_formatters)\r\n File \"/venv/lib/python3.7/site-packages/web3/manager.py\", line 154, in request_blocking\r\n response = self._make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/manager.py\", line 133, in _make_request\r\n return request_func(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/gas_price_strategy.py\", line 34, in middleware\r\n return make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/attrdict.py\", line 33, in middleware\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 74, in apply_formatters\r\n response = make_request(method, formatted_params)\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/normalize_errors.py\", line 25, in middleware\r\n result = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/web3/middleware/formatting.py\", line 83, in apply_formatters\r\n formatter(response[\"result\"]),\r\n File \"cytoolz/functoolz.pyx\", line 503, in cytoolz.functoolz.Compose.__call__\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/venv/lib/python3.7/site-packages/eth_utils/functional.py\", line 45, in inner\r\n return callback(fn(*args, **kwargs))\r\n File \"/venv/lib/python3.7/site-packages/eth_utils/applicators.py\", line 126, in apply_key_map\r\n set(value.keys())\r\nAttributeError: 'NoneType' object has no attribute 'keys'\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nA simple monkey-patch that works for me:\r\n\r\n```\r\ndef _geth_poa_middleware():\r\n from web3.middleware.geth_poa import geth_poa_cleanup\r\n from web3.middleware import construct_formatting_middleware\r\n from web3.types import RPCEndpoint\r\n\r\n def m(value):\r\n # eth_getBlock* may return None\r\n return None if value is None else geth_poa_cleanup(value)\r\n\r\n return construct_formatting_middleware(\r\n result_formatters={\r\n RPCEndpoint(\"eth_getBlockByHash\"): m,\r\n RPCEndpoint(\"eth_getBlockByNumber\"): m,\r\n },\r\n )\r\n```\r\n\r\nCould be easily incorporated into `web3.middleware.geth_poa` IMO.\r\n\n", "before_files": [{"content": "from eth_utils.curried import (\n apply_formatters_to_dict,\n apply_key_map,\n)\nfrom eth_utils.toolz import (\n compose,\n)\nfrom hexbytes import (\n HexBytes,\n)\n\nfrom web3.middleware.formatting import (\n construct_formatting_middleware,\n)\nfrom web3.types import (\n RPCEndpoint,\n)\n\nremap_geth_poa_fields = apply_key_map({\n 'extraData': 'proofOfAuthorityData',\n})\n\npythonic_geth_poa = apply_formatters_to_dict({\n 'proofOfAuthorityData': HexBytes,\n})\n\ngeth_poa_cleanup = compose(pythonic_geth_poa, remap_geth_poa_fields)\n\ngeth_poa_middleware = construct_formatting_middleware(\n result_formatters={\n RPCEndpoint(\"eth_getBlockByHash\"): geth_poa_cleanup,\n RPCEndpoint(\"eth_getBlockByNumber\"): geth_poa_cleanup,\n },\n)\n", "path": "web3/middleware/geth_poa.py"}], "after_files": [{"content": "from eth_utils.curried import (\n apply_formatter_if,\n apply_formatters_to_dict,\n apply_key_map,\n is_null,\n)\nfrom eth_utils.toolz import (\n complement,\n compose,\n)\nfrom hexbytes import (\n HexBytes,\n)\n\nfrom web3._utils.rpc_abi import (\n RPC,\n)\nfrom web3.middleware.formatting import (\n construct_formatting_middleware,\n)\n\nis_not_null = complement(is_null)\n\nremap_geth_poa_fields = apply_key_map({\n 'extraData': 'proofOfAuthorityData',\n})\n\npythonic_geth_poa = apply_formatters_to_dict({\n 'proofOfAuthorityData': HexBytes,\n})\n\ngeth_poa_cleanup = compose(pythonic_geth_poa, remap_geth_poa_fields)\n\ngeth_poa_middleware = construct_formatting_middleware(\n result_formatters={\n RPC.eth_getBlockByHash: apply_formatter_if(is_not_null, geth_poa_cleanup),\n RPC.eth_getBlockByNumber: apply_formatter_if(is_not_null, geth_poa_cleanup),\n },\n)\n", "path": "web3/middleware/geth_poa.py"}]}
| 2,225 | 315 |
gh_patches_debug_26161
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1984
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting workers more than 1
If I set `workers=2` when starting KFServer, it always kills the 2nd worker with the following error message
```
Traceback (most recent call last):
File "/usr/lib/python3.8/asyncio/selector_events.py", line 261, in _add_reader
key = self._selector.get_key(fd)
File "/usr/lib/python3.8/selectors.py", line 192, in get_key
raise KeyError("{!r} is not registered".format(fileobj)) from None
KeyError: '6 is not registered'
[I 210811 10:50:57 kfserver:151] Registering model: test
[I 210811 10:50:57 kfserver:121] Setting asyncio max_workers as 12
[I 210811 10:50:57 kfserver:128] Listening on port 8080
[I 210811 10:50:57 kfserver:130] Will fork 2 workers
[I 210811 10:50:57 process:123] Starting 2 processes
[E 210811 10:50:57 __main__:51] fail to load model test from dir /home/swapnesh/test/test_files/. exception type <class 'FileExistsError'>, exception msg: [Errno 17] File exists
[I 210811 10:50:58 process:163] child 1 (pid 5829) exited normally
```
Why can't I set more than 1 worker when max is 12?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kserve/kserve/model_server.py`
Content:
```
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import logging
17 from typing import List, Optional, Dict, Union
18 import tornado.ioloop
19 import tornado.web
20 import tornado.httpserver
21 import tornado.log
22 import asyncio
23 from tornado import concurrent
24
25 from .utils import utils
26
27 import kserve.handlers as handlers
28 from kserve import Model
29 from kserve.model_repository import ModelRepository
30 from ray.serve.api import Deployment, RayServeHandle
31 from ray import serve
32
33 DEFAULT_HTTP_PORT = 8080
34 DEFAULT_GRPC_PORT = 8081
35 DEFAULT_MAX_BUFFER_SIZE = 104857600
36
37 parser = argparse.ArgumentParser(add_help=False)
38 parser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,
39 help='The HTTP Port listened to by the model server.')
40 parser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,
41 help='The GRPC Port listened to by the model server.')
42 parser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,
43 help='The max buffer size for tornado.')
44 parser.add_argument('--workers', default=1, type=int,
45 help='The number of works to fork')
46 parser.add_argument('--max_asyncio_workers', default=None, type=int,
47 help='Max number of asyncio workers to spawn')
48
49 args, _ = parser.parse_known_args()
50
51 tornado.log.enable_pretty_logging()
52
53
54 class ModelServer:
55 def __init__(self, http_port: int = args.http_port,
56 grpc_port: int = args.grpc_port,
57 max_buffer_size: int = args.max_buffer_size,
58 workers: int = args.workers,
59 max_asyncio_workers: int = args.max_asyncio_workers,
60 registered_models: ModelRepository = ModelRepository()):
61 self.registered_models = registered_models
62 self.http_port = http_port
63 self.grpc_port = grpc_port
64 self.max_buffer_size = max_buffer_size
65 self.workers = workers
66 self.max_asyncio_workers = max_asyncio_workers
67 self._http_server: Optional[tornado.httpserver.HTTPServer] = None
68
69 def create_application(self):
70 return tornado.web.Application([
71 # Server Liveness API returns 200 if server is alive.
72 (r"/", handlers.LivenessHandler),
73 (r"/v2/health/live", handlers.LivenessHandler),
74 (r"/v1/models",
75 handlers.ListHandler, dict(models=self.registered_models)),
76 (r"/v2/models",
77 handlers.ListHandler, dict(models=self.registered_models)),
78 # Model Health API returns 200 if model is ready to serve.
79 (r"/v1/models/([a-zA-Z0-9_-]+)",
80 handlers.HealthHandler, dict(models=self.registered_models)),
81 (r"/v2/models/([a-zA-Z0-9_-]+)/status",
82 handlers.HealthHandler, dict(models=self.registered_models)),
83 (r"/v1/models/([a-zA-Z0-9_-]+):predict",
84 handlers.PredictHandler, dict(models=self.registered_models)),
85 (r"/v2/models/([a-zA-Z0-9_-]+)/infer",
86 handlers.PredictHandler, dict(models=self.registered_models)),
87 (r"/v1/models/([a-zA-Z0-9_-]+):explain",
88 handlers.ExplainHandler, dict(models=self.registered_models)),
89 (r"/v2/models/([a-zA-Z0-9_-]+)/explain",
90 handlers.ExplainHandler, dict(models=self.registered_models)),
91 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/load",
92 handlers.LoadHandler, dict(models=self.registered_models)),
93 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/unload",
94 handlers.UnloadHandler, dict(models=self.registered_models)),
95 ], default_handler_class=handlers.NotFoundHandler)
96
97 def start(self, models: Union[List[Model], Dict[str, Deployment]], nest_asyncio: bool = False):
98 if isinstance(models, list):
99 for model in models:
100 if isinstance(model, Model):
101 self.register_model(model)
102 else:
103 raise RuntimeError("Model type should be Model")
104 elif isinstance(models, dict):
105 if all([isinstance(v, Deployment) for v in models.values()]):
106 serve.start(detached=True, http_options={"host": "0.0.0.0", "port": 9071})
107 for key in models:
108 models[key].deploy()
109 handle = models[key].get_handle()
110 self.register_model_handle(key, handle)
111 else:
112 raise RuntimeError("Model type should be RayServe Deployment")
113 else:
114 raise RuntimeError("Unknown model collection types")
115
116 if self.max_asyncio_workers is None:
117 # formula as suggest in https://bugs.python.org/issue35279
118 self.max_asyncio_workers = min(32, utils.cpu_count()+4)
119
120 logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
121 asyncio.get_event_loop().set_default_executor(
122 concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
123
124 self._http_server = tornado.httpserver.HTTPServer(
125 self.create_application(), max_buffer_size=self.max_buffer_size)
126
127 logging.info("Listening on port %s", self.http_port)
128 self._http_server.bind(self.http_port)
129 logging.info("Will fork %d workers", self.workers)
130 self._http_server.start(self.workers)
131
132 # Need to start the IOLoop after workers have been started
133 # https://github.com/tornadoweb/tornado/issues/2426
134 # The nest_asyncio package needs to be installed by the downstream module
135 if nest_asyncio:
136 import nest_asyncio
137 nest_asyncio.apply()
138
139 tornado.ioloop.IOLoop.current().start()
140
141 def register_model_handle(self, name: str, model_handle: RayServeHandle):
142 self.registered_models.update_handle(name, model_handle)
143 logging.info("Registering model handle: %s", name)
144
145 def register_model(self, model: Model):
146 if not model.name:
147 raise Exception(
148 "Failed to register model, model.name must be provided.")
149 self.registered_models.update(model)
150 logging.info("Registering model: %s", model.name)
151
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/kserve/kserve/model_server.py b/python/kserve/kserve/model_server.py
--- a/python/kserve/kserve/model_server.py
+++ b/python/kserve/kserve/model_server.py
@@ -117,10 +117,6 @@
# formula as suggest in https://bugs.python.org/issue35279
self.max_asyncio_workers = min(32, utils.cpu_count()+4)
- logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
- asyncio.get_event_loop().set_default_executor(
- concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
-
self._http_server = tornado.httpserver.HTTPServer(
self.create_application(), max_buffer_size=self.max_buffer_size)
@@ -129,6 +125,10 @@
logging.info("Will fork %d workers", self.workers)
self._http_server.start(self.workers)
+ logging.info(f"Setting max asyncio worker threads as {self.max_asyncio_workers}")
+ asyncio.get_event_loop().set_default_executor(
+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
+
# Need to start the IOLoop after workers have been started
# https://github.com/tornadoweb/tornado/issues/2426
# The nest_asyncio package needs to be installed by the downstream module
|
{"golden_diff": "diff --git a/python/kserve/kserve/model_server.py b/python/kserve/kserve/model_server.py\n--- a/python/kserve/kserve/model_server.py\n+++ b/python/kserve/kserve/model_server.py\n@@ -117,10 +117,6 @@\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n \n- logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n- asyncio.get_event_loop().set_default_executor(\n- concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n-\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n \n@@ -129,6 +125,10 @@\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n \n+ logging.info(f\"Setting max asyncio worker threads as {self.max_asyncio_workers}\")\n+ asyncio.get_event_loop().set_default_executor(\n+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n+\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n", "issue": "Setting workers more than 1\nIf I set `workers=2` when starting KFServer, it always kills the 2nd worker with the following error message\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.8/asyncio/selector_events.py\", line 261, in _add_reader\r\n key = self._selector.get_key(fd)\r\n File \"/usr/lib/python3.8/selectors.py\", line 192, in get_key\r\n raise KeyError(\"{!r} is not registered\".format(fileobj)) from None\r\nKeyError: '6 is not registered'\r\n\r\n[I 210811 10:50:57 kfserver:151] Registering model: test\r\n[I 210811 10:50:57 kfserver:121] Setting asyncio max_workers as 12\r\n[I 210811 10:50:57 kfserver:128] Listening on port 8080\r\n[I 210811 10:50:57 kfserver:130] Will fork 2 workers\r\n[I 210811 10:50:57 process:123] Starting 2 processes\r\n[E 210811 10:50:57 __main__:51] fail to load model test from dir /home/swapnesh/test/test_files/. exception type <class 'FileExistsError'>, exception msg: [Errno 17] File exists\r\n[I 210811 10:50:58 process:163] child 1 (pid 5829) exited normally\r\n```\r\n\r\nWhy can't I set more than 1 worker when max is 12?\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nfrom typing import List, Optional, Dict, Union\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\nimport asyncio\nfrom tornado import concurrent\n\nfrom .utils import utils\n\nimport kserve.handlers as handlers\nfrom kserve import Model\nfrom kserve.model_repository import ModelRepository\nfrom ray.serve.api import Deployment, RayServeHandle\nfrom ray import serve\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nparser.add_argument('--max_asyncio_workers', default=None, type=int,\n help='Max number of asyncio workers to spawn')\n\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass ModelServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: ModelRepository = ModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", handlers.LivenessHandler),\n (r\"/v2/health/live\", handlers.LivenessHandler),\n (r\"/v1/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n handlers.LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n handlers.UnloadHandler, dict(models=self.registered_models)),\n ], default_handler_class=handlers.NotFoundHandler)\n\n def start(self, models: Union[List[Model], Dict[str, Deployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, Model):\n self.register_model(model)\n else:\n raise RuntimeError(\"Model type should be Model\")\n elif isinstance(models, dict):\n if all([isinstance(v, Deployment) for v in models.values()]):\n serve.start(detached=True, http_options={\"host\": \"0.0.0.0\", \"port\": 9071})\n for key in models:\n models[key].deploy()\n handle = models[key].get_handle()\n self.register_model_handle(key, handle)\n else:\n raise RuntimeError(\"Model type should be RayServe Deployment\")\n else:\n raise RuntimeError(\"Unknown model collection types\")\n\n if self.max_asyncio_workers is None:\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n\n logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n asyncio.get_event_loop().set_default_executor(\n concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model_handle(self, name: str, model_handle: RayServeHandle):\n self.registered_models.update_handle(name, model_handle)\n logging.info(\"Registering model handle: %s\", name)\n\n def register_model(self, model: Model):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n", "path": "python/kserve/kserve/model_server.py"}], "after_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nfrom typing import List, Optional, Dict, Union\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\nimport asyncio\nfrom tornado import concurrent\n\nfrom .utils import utils\n\nimport kserve.handlers as handlers\nfrom kserve import Model\nfrom kserve.model_repository import ModelRepository\nfrom ray.serve.api import Deployment, RayServeHandle\nfrom ray import serve\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nparser.add_argument('--max_asyncio_workers', default=None, type=int,\n help='Max number of asyncio workers to spawn')\n\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass ModelServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: ModelRepository = ModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", handlers.LivenessHandler),\n (r\"/v2/health/live\", handlers.LivenessHandler),\n (r\"/v1/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n handlers.ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n handlers.HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n handlers.PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n handlers.ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n handlers.LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n handlers.UnloadHandler, dict(models=self.registered_models)),\n ], default_handler_class=handlers.NotFoundHandler)\n\n def start(self, models: Union[List[Model], Dict[str, Deployment]], nest_asyncio: bool = False):\n if isinstance(models, list):\n for model in models:\n if isinstance(model, Model):\n self.register_model(model)\n else:\n raise RuntimeError(\"Model type should be Model\")\n elif isinstance(models, dict):\n if all([isinstance(v, Deployment) for v in models.values()]):\n serve.start(detached=True, http_options={\"host\": \"0.0.0.0\", \"port\": 9071})\n for key in models:\n models[key].deploy()\n handle = models[key].get_handle()\n self.register_model_handle(key, handle)\n else:\n raise RuntimeError(\"Model type should be RayServe Deployment\")\n else:\n raise RuntimeError(\"Unknown model collection types\")\n\n if self.max_asyncio_workers is None:\n # formula as suggest in https://bugs.python.org/issue35279\n self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n logging.info(f\"Setting max asyncio worker threads as {self.max_asyncio_workers}\")\n asyncio.get_event_loop().set_default_executor(\n concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model_handle(self, name: str, model_handle: RayServeHandle):\n self.registered_models.update_handle(name, model_handle)\n logging.info(\"Registering model handle: %s\", name)\n\n def register_model(self, model: Model):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n", "path": "python/kserve/kserve/model_server.py"}]}
| 2,489 | 306 |
gh_patches_debug_17029
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-3446
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
模型预测出错 TypeError: predict() got an unexpected keyword argument 'auc_roc'
### 问题确认 Search before asking
- [X] 我已经查询[历史issue](https://github.com/PaddlePaddle/PaddleSeg/issues)(包括open与closed),没有发现相似的bug。I have searched the [open and closed issues](https://github.com/PaddlePaddle/PaddleSeg/issues) and found no similar bug report.
### Bug描述 Describe the Bug
我在训练完unet之后,想用模型预测去查看输出的图片
python tools/predict.py \
--config configs/unet/unet_drive_128x128_40k.yml \
--model_path output/drive/best_model/model.pdparams \
--image_path data/DRIVE/images/training/21.png \
--save_dir output/drive/result
然后就报出这个错误。经过查阅,我发现auc_roc在drive.yml里的
test_config:
auc_roc: True
报错文本如下
W0728 08:50:13.112543 40846 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.4, Runtime API Version: 10.2
W0728 08:50:13.112588 40846 gpu_resources.cc:149] device: 0, cuDNN Version: 8.2.
2023-07-28 08:50:15 [INFO] The number of images: 1
Traceback (most recent call last):
File "/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py", line 145, in <module>
main(args)
File "/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py", line 140, in main
**test_config)
TypeError: predict() got an unexpected keyword argument 'auc_roc'
### 复现环境 Environment
platform: Linux-5.4.0-84-generic-x86_64-with-debian-buster-sid
Python: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.2.r11.2/compiler.29558016_0
cudnn: 8.2
GPUs used: 1
CUDA_VISIBLE_DEVICES: 7
GPU: ['GPU 0: Tesla T4', 'GPU 1: Tesla T4', 'GPU 2: Tesla T4', 'GPU 3: Tesla T4', 'GPU 4: Tesla T4', 'GPU 5: Tesla T4', 'GPU 6: Tesla T4', 'GPU 7: Tesla T4']
GCC: gcc (GCC) 8.2.0
PaddleSeg: 2.8.0
PaddlePaddle: 2.5.0
OpenCV: 4.5.5
### Bug描述确认 Bug description confirmation
- [X] 我确认已经提供了Bug复现步骤、代码改动说明、以及环境信息,确认问题是可以复现的。I confirm that the bug replication steps, code change instructions, and environment information have been provided, and the problem can be reproduced.
### 是否愿意提交PR? Are you willing to submit a PR?
- [X] 我愿意提交PR!I'd like to help by submitting a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/predict.py`
Content:
```
1 # Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import os
17
18 import paddle
19
20 from paddleseg.cvlibs import manager, Config, SegBuilder
21 from paddleseg.utils import get_sys_env, logger, get_image_list, utils
22 from paddleseg.core import predict
23 from paddleseg.transforms import Compose
24
25
26 def parse_args():
27 parser = argparse.ArgumentParser(description='Model prediction')
28
29 # Common params
30 parser.add_argument("--config", help="The path of config file.", type=str)
31 parser.add_argument(
32 '--model_path',
33 help='The path of trained weights for prediction.',
34 type=str)
35 parser.add_argument(
36 '--image_path',
37 help='The image to predict, which can be a path of image, or a file list containing image paths, or a directory including images',
38 type=str)
39 parser.add_argument(
40 '--save_dir',
41 help='The directory for saving the predicted results.',
42 type=str,
43 default='./output/result')
44 parser.add_argument(
45 '--device',
46 help='Set the device place for predicting model.',
47 default='gpu',
48 choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],
49 type=str)
50 parser.add_argument(
51 '--device_id',
52 help='Set the device id for predicting model.',
53 default=0,
54 type=int)
55
56 # Data augment params
57 parser.add_argument(
58 '--aug_pred',
59 help='Whether to use mulit-scales and flip augment for prediction',
60 action='store_true')
61 parser.add_argument(
62 '--scales',
63 nargs='+',
64 help='Scales for augment, e.g., `--scales 0.75 1.0 1.25`.',
65 type=float,
66 default=1.0)
67 parser.add_argument(
68 '--flip_horizontal',
69 help='Whether to use flip horizontally augment',
70 action='store_true')
71 parser.add_argument(
72 '--flip_vertical',
73 help='Whether to use flip vertically augment',
74 action='store_true')
75
76 # Sliding window evaluation params
77 parser.add_argument(
78 '--is_slide',
79 help='Whether to predict images in sliding window method',
80 action='store_true')
81 parser.add_argument(
82 '--crop_size',
83 nargs=2,
84 help='The crop size of sliding window, the first is width and the second is height.'
85 'For example, `--crop_size 512 512`',
86 type=int)
87 parser.add_argument(
88 '--stride',
89 nargs=2,
90 help='The stride of sliding window, the first is width and the second is height.'
91 'For example, `--stride 512 512`',
92 type=int)
93
94 # Custom color map
95 parser.add_argument(
96 '--custom_color',
97 nargs='+',
98 help='Save images with a custom color map. Default: None, use paddleseg\'s default color map.',
99 type=int)
100
101 return parser.parse_args()
102
103
104 def merge_test_config(cfg, args):
105 test_config = cfg.test_config
106 if 'aug_eval' in test_config:
107 test_config.pop('aug_eval')
108 if args.aug_pred:
109 test_config['aug_pred'] = args.aug_pred
110 test_config['scales'] = args.scales
111 test_config['flip_horizontal'] = args.flip_horizontal
112 test_config['flip_vertical'] = args.flip_vertical
113 if args.is_slide:
114 test_config['is_slide'] = args.is_slide
115 test_config['crop_size'] = args.crop_size
116 test_config['stride'] = args.stride
117 if args.custom_color:
118 test_config['custom_color'] = args.custom_color
119 return test_config
120
121
122 def main(args):
123 assert args.config is not None, \
124 'No configuration file specified, please set --config'
125 cfg = Config(args.config)
126 builder = SegBuilder(cfg)
127 test_config = merge_test_config(cfg, args)
128
129 utils.show_env_info()
130 utils.show_cfg_info(cfg)
131 if args.device != 'cpu':
132 device = f"{args.device}:{args.device_id}"
133 else:
134 device = args.device
135 utils.set_device(device)
136
137 model = builder.model
138 transforms = Compose(builder.val_transforms)
139 image_list, image_dir = get_image_list(args.image_path)
140 logger.info('The number of images: {}'.format(len(image_list)))
141
142 predict(
143 model,
144 model_path=args.model_path,
145 transforms=transforms,
146 image_list=image_list,
147 image_dir=image_dir,
148 save_dir=args.save_dir,
149 **test_config)
150
151
152 if __name__ == '__main__':
153 args = parse_args()
154 main(args)
155
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/predict.py b/tools/predict.py
--- a/tools/predict.py
+++ b/tools/predict.py
@@ -17,10 +17,10 @@
import paddle
-from paddleseg.cvlibs import manager, Config, SegBuilder
-from paddleseg.utils import get_sys_env, logger, get_image_list, utils
from paddleseg.core import predict
+from paddleseg.cvlibs import Config, SegBuilder, manager
from paddleseg.transforms import Compose
+from paddleseg.utils import get_image_list, get_sys_env, logger, utils
def parse_args():
@@ -105,6 +105,8 @@
test_config = cfg.test_config
if 'aug_eval' in test_config:
test_config.pop('aug_eval')
+ if 'auc_roc' in test_config:
+ test_config.pop('auc_roc')
if args.aug_pred:
test_config['aug_pred'] = args.aug_pred
test_config['scales'] = args.scales
|
{"golden_diff": "diff --git a/tools/predict.py b/tools/predict.py\n--- a/tools/predict.py\n+++ b/tools/predict.py\n@@ -17,10 +17,10 @@\n \n import paddle\n \n-from paddleseg.cvlibs import manager, Config, SegBuilder\n-from paddleseg.utils import get_sys_env, logger, get_image_list, utils\n from paddleseg.core import predict\n+from paddleseg.cvlibs import Config, SegBuilder, manager\n from paddleseg.transforms import Compose\n+from paddleseg.utils import get_image_list, get_sys_env, logger, utils\n \n \n def parse_args():\n@@ -105,6 +105,8 @@\n test_config = cfg.test_config\n if 'aug_eval' in test_config:\n test_config.pop('aug_eval')\n+ if 'auc_roc' in test_config:\n+ test_config.pop('auc_roc')\n if args.aug_pred:\n test_config['aug_pred'] = args.aug_pred\n test_config['scales'] = args.scales\n", "issue": "\u6a21\u578b\u9884\u6d4b\u51fa\u9519 TypeError: predict() got an unexpected keyword argument 'auc_roc'\n### \u95ee\u9898\u786e\u8ba4 Search before asking\n\n- [X] \u6211\u5df2\u7ecf\u67e5\u8be2[\u5386\u53f2issue](https://github.com/PaddlePaddle/PaddleSeg/issues)(\u5305\u62ecopen\u4e0eclosed)\uff0c\u6ca1\u6709\u53d1\u73b0\u76f8\u4f3c\u7684bug\u3002I have searched the [open and closed issues](https://github.com/PaddlePaddle/PaddleSeg/issues) and found no similar bug report.\n\n\n### Bug\u63cf\u8ff0 Describe the Bug\n\n\u6211\u5728\u8bad\u7ec3\u5b8cunet\u4e4b\u540e\uff0c\u60f3\u7528\u6a21\u578b\u9884\u6d4b\u53bb\u67e5\u770b\u8f93\u51fa\u7684\u56fe\u7247\r\npython tools/predict.py \\\r\n --config configs/unet/unet_drive_128x128_40k.yml \\\r\n --model_path output/drive/best_model/model.pdparams \\\r\n --image_path data/DRIVE/images/training/21.png \\\r\n --save_dir output/drive/result\r\n\u7136\u540e\u5c31\u62a5\u51fa\u8fd9\u4e2a\u9519\u8bef\u3002\u7ecf\u8fc7\u67e5\u9605\uff0c\u6211\u53d1\u73b0auc_roc\u5728drive.yml\u91cc\u7684\r\ntest_config:\r\n auc_roc: True\r\n\r\n\r\n\u62a5\u9519\u6587\u672c\u5982\u4e0b\r\nW0728 08:50:13.112543 40846 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.4, Runtime API Version: 10.2\r\nW0728 08:50:13.112588 40846 gpu_resources.cc:149] device: 0, cuDNN Version: 8.2.\r\n2023-07-28 08:50:15 [INFO]\tThe number of images: 1\r\nTraceback (most recent call last):\r\n File \"/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py\", line 145, in <module>\r\n main(args)\r\n File \"/root/distil-unet1/PaddleSeg-release-2.8/tools/predict.py\", line 140, in main\r\n **test_config)\r\nTypeError: predict() got an unexpected keyword argument 'auc_roc'\n\n### \u590d\u73b0\u73af\u5883 Environment\n\nplatform: Linux-5.4.0-84-generic-x86_64-with-debian-buster-sid\r\nPython: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0]\r\nPaddle compiled with cuda: True\r\nNVCC: Build cuda_11.2.r11.2/compiler.29558016_0\r\ncudnn: 8.2\r\nGPUs used: 1\r\nCUDA_VISIBLE_DEVICES: 7\r\nGPU: ['GPU 0: Tesla T4', 'GPU 1: Tesla T4', 'GPU 2: Tesla T4', 'GPU 3: Tesla T4', 'GPU 4: Tesla T4', 'GPU 5: Tesla T4', 'GPU 6: Tesla T4', 'GPU 7: Tesla T4']\r\nGCC: gcc (GCC) 8.2.0\r\nPaddleSeg: 2.8.0\r\nPaddlePaddle: 2.5.0\r\nOpenCV: 4.5.5\r\n\n\n### Bug\u63cf\u8ff0\u786e\u8ba4 Bug description confirmation\n\n- [X] \u6211\u786e\u8ba4\u5df2\u7ecf\u63d0\u4f9b\u4e86Bug\u590d\u73b0\u6b65\u9aa4\u3001\u4ee3\u7801\u6539\u52a8\u8bf4\u660e\u3001\u4ee5\u53ca\u73af\u5883\u4fe1\u606f\uff0c\u786e\u8ba4\u95ee\u9898\u662f\u53ef\u4ee5\u590d\u73b0\u7684\u3002I confirm that the bug replication steps, code change instructions, and environment information have been provided, and the problem can be reproduced.\n\n\n### \u662f\u5426\u613f\u610f\u63d0\u4ea4PR\uff1f Are you willing to submit a PR?\n\n- [X] \u6211\u613f\u610f\u63d0\u4ea4PR\uff01I'd like to help by submitting a PR!\n", "before_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport os\n\nimport paddle\n\nfrom paddleseg.cvlibs import manager, Config, SegBuilder\nfrom paddleseg.utils import get_sys_env, logger, get_image_list, utils\nfrom paddleseg.core import predict\nfrom paddleseg.transforms import Compose\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Model prediction')\n\n # Common params\n parser.add_argument(\"--config\", help=\"The path of config file.\", type=str)\n parser.add_argument(\n '--model_path',\n help='The path of trained weights for prediction.',\n type=str)\n parser.add_argument(\n '--image_path',\n help='The image to predict, which can be a path of image, or a file list containing image paths, or a directory including images',\n type=str)\n parser.add_argument(\n '--save_dir',\n help='The directory for saving the predicted results.',\n type=str,\n default='./output/result')\n parser.add_argument(\n '--device',\n help='Set the device place for predicting model.',\n default='gpu',\n choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],\n type=str)\n parser.add_argument(\n '--device_id',\n help='Set the device id for predicting model.',\n default=0,\n type=int)\n\n # Data augment params\n parser.add_argument(\n '--aug_pred',\n help='Whether to use mulit-scales and flip augment for prediction',\n action='store_true')\n parser.add_argument(\n '--scales',\n nargs='+',\n help='Scales for augment, e.g., `--scales 0.75 1.0 1.25`.',\n type=float,\n default=1.0)\n parser.add_argument(\n '--flip_horizontal',\n help='Whether to use flip horizontally augment',\n action='store_true')\n parser.add_argument(\n '--flip_vertical',\n help='Whether to use flip vertically augment',\n action='store_true')\n\n # Sliding window evaluation params\n parser.add_argument(\n '--is_slide',\n help='Whether to predict images in sliding window method',\n action='store_true')\n parser.add_argument(\n '--crop_size',\n nargs=2,\n help='The crop size of sliding window, the first is width and the second is height.'\n 'For example, `--crop_size 512 512`',\n type=int)\n parser.add_argument(\n '--stride',\n nargs=2,\n help='The stride of sliding window, the first is width and the second is height.'\n 'For example, `--stride 512 512`',\n type=int)\n\n # Custom color map\n parser.add_argument(\n '--custom_color',\n nargs='+',\n help='Save images with a custom color map. Default: None, use paddleseg\\'s default color map.',\n type=int)\n\n return parser.parse_args()\n\n\ndef merge_test_config(cfg, args):\n test_config = cfg.test_config\n if 'aug_eval' in test_config:\n test_config.pop('aug_eval')\n if args.aug_pred:\n test_config['aug_pred'] = args.aug_pred\n test_config['scales'] = args.scales\n test_config['flip_horizontal'] = args.flip_horizontal\n test_config['flip_vertical'] = args.flip_vertical\n if args.is_slide:\n test_config['is_slide'] = args.is_slide\n test_config['crop_size'] = args.crop_size\n test_config['stride'] = args.stride\n if args.custom_color:\n test_config['custom_color'] = args.custom_color\n return test_config\n\n\ndef main(args):\n assert args.config is not None, \\\n 'No configuration file specified, please set --config'\n cfg = Config(args.config)\n builder = SegBuilder(cfg)\n test_config = merge_test_config(cfg, args)\n\n utils.show_env_info()\n utils.show_cfg_info(cfg)\n if args.device != 'cpu':\n device = f\"{args.device}:{args.device_id}\"\n else:\n device = args.device\n utils.set_device(device)\n\n model = builder.model\n transforms = Compose(builder.val_transforms)\n image_list, image_dir = get_image_list(args.image_path)\n logger.info('The number of images: {}'.format(len(image_list)))\n\n predict(\n model,\n model_path=args.model_path,\n transforms=transforms,\n image_list=image_list,\n image_dir=image_dir,\n save_dir=args.save_dir,\n **test_config)\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "tools/predict.py"}], "after_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport os\n\nimport paddle\n\nfrom paddleseg.core import predict\nfrom paddleseg.cvlibs import Config, SegBuilder, manager\nfrom paddleseg.transforms import Compose\nfrom paddleseg.utils import get_image_list, get_sys_env, logger, utils\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Model prediction')\n\n # Common params\n parser.add_argument(\"--config\", help=\"The path of config file.\", type=str)\n parser.add_argument(\n '--model_path',\n help='The path of trained weights for prediction.',\n type=str)\n parser.add_argument(\n '--image_path',\n help='The image to predict, which can be a path of image, or a file list containing image paths, or a directory including images',\n type=str)\n parser.add_argument(\n '--save_dir',\n help='The directory for saving the predicted results.',\n type=str,\n default='./output/result')\n parser.add_argument(\n '--device',\n help='Set the device place for predicting model.',\n default='gpu',\n choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],\n type=str)\n parser.add_argument(\n '--device_id',\n help='Set the device id for predicting model.',\n default=0,\n type=int)\n\n # Data augment params\n parser.add_argument(\n '--aug_pred',\n help='Whether to use mulit-scales and flip augment for prediction',\n action='store_true')\n parser.add_argument(\n '--scales',\n nargs='+',\n help='Scales for augment, e.g., `--scales 0.75 1.0 1.25`.',\n type=float,\n default=1.0)\n parser.add_argument(\n '--flip_horizontal',\n help='Whether to use flip horizontally augment',\n action='store_true')\n parser.add_argument(\n '--flip_vertical',\n help='Whether to use flip vertically augment',\n action='store_true')\n\n # Sliding window evaluation params\n parser.add_argument(\n '--is_slide',\n help='Whether to predict images in sliding window method',\n action='store_true')\n parser.add_argument(\n '--crop_size',\n nargs=2,\n help='The crop size of sliding window, the first is width and the second is height.'\n 'For example, `--crop_size 512 512`',\n type=int)\n parser.add_argument(\n '--stride',\n nargs=2,\n help='The stride of sliding window, the first is width and the second is height.'\n 'For example, `--stride 512 512`',\n type=int)\n\n # Custom color map\n parser.add_argument(\n '--custom_color',\n nargs='+',\n help='Save images with a custom color map. Default: None, use paddleseg\\'s default color map.',\n type=int)\n\n return parser.parse_args()\n\n\ndef merge_test_config(cfg, args):\n test_config = cfg.test_config\n if 'aug_eval' in test_config:\n test_config.pop('aug_eval')\n if 'auc_roc' in test_config:\n test_config.pop('auc_roc')\n if args.aug_pred:\n test_config['aug_pred'] = args.aug_pred\n test_config['scales'] = args.scales\n test_config['flip_horizontal'] = args.flip_horizontal\n test_config['flip_vertical'] = args.flip_vertical\n if args.is_slide:\n test_config['is_slide'] = args.is_slide\n test_config['crop_size'] = args.crop_size\n test_config['stride'] = args.stride\n if args.custom_color:\n test_config['custom_color'] = args.custom_color\n return test_config\n\n\ndef main(args):\n assert args.config is not None, \\\n 'No configuration file specified, please set --config'\n cfg = Config(args.config)\n builder = SegBuilder(cfg)\n test_config = merge_test_config(cfg, args)\n\n utils.show_env_info()\n utils.show_cfg_info(cfg)\n if args.device != 'cpu':\n device = f\"{args.device}:{args.device_id}\"\n else:\n device = args.device\n utils.set_device(device)\n\n model = builder.model\n transforms = Compose(builder.val_transforms)\n image_list, image_dir = get_image_list(args.image_path)\n logger.info('The number of images: {}'.format(len(image_list)))\n\n predict(\n model,\n model_path=args.model_path,\n transforms=transforms,\n image_list=image_list,\n image_dir=image_dir,\n save_dir=args.save_dir,\n **test_config)\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "tools/predict.py"}]}
| 2,566 | 222 |
gh_patches_debug_11980
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1659
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update elasticsearch-dsl to 5.1.0
There's a new version of [elasticsearch-dsl](https://pypi.python.org/pypi/elasticsearch-dsl) available.
You are currently using **5.0.0**. I have updated it to **5.1.0**
These links might come in handy: <a href="http://pypi.python.org/pypi/elasticsearch-dsl">PyPI</a> | <a href="https://pyup.io/changelogs/elasticsearch-dsl/">Changelog</a> | <a href="https://github.com/elasticsearch/elasticsearch-dsl-py">Repo</a>
### Changelog
>
>### 5.1.0
>------------------
> * Renamed ``Result`` and ``ResultMeta`` to ``Hit`` and ``HitMeta`` respectively
> * ``Response`` now stores ``Search`` which it gets as first arg to ``__init__``
> * aggregation results are now wrapped in classes and properly deserialized
> * ``Date`` fields now allow for numerical timestamps in the java format (in millis)
> * Added API documentation
> * replaced generated classes with manually created
*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*
Happy merging! 🤖
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/search.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import urllib.parse
14
15 import certifi
16 import elasticsearch
17 import venusian
18
19 from elasticsearch_dsl import Index
20
21
22 def doc_type(cls):
23 def callback(scanner, _name, item):
24 types_ = scanner.config.registry.setdefault("search.doc_types", set())
25 types_.add(item)
26
27 venusian.attach(cls, callback)
28
29 return cls
30
31
32 def get_index(name, doc_types, *, using, shards=1, replicas=0, interval="1s"):
33 index = Index(name, using=using)
34 for doc_type in doc_types:
35 index.doc_type(doc_type)
36 index.settings(
37 number_of_shards=shards,
38 number_of_replicas=replicas,
39 refresh_interval=interval,
40 )
41 return index
42
43
44 def es(request):
45 client = request.registry["elasticsearch.client"]
46 doc_types = request.registry.get("search.doc_types", set())
47 index_name = request.registry["elasticsearch.index"]
48 index = get_index(
49 index_name,
50 doc_types,
51 using=client,
52 shards=request.registry.get("elasticsearch.shards", 1),
53 replicas=request.registry.get("elasticsearch.replicas", 0),
54 )
55 return index.search()
56
57
58 def includeme(config):
59 p = urllib.parse.urlparse(config.registry.settings["elasticsearch.url"])
60 qs = urllib.parse.parse_qs(p.query)
61 config.registry["elasticsearch.client"] = elasticsearch.Elasticsearch(
62 [urllib.parse.urlunparse(p[:2] + ("",) * 4)],
63 verify_certs=True,
64 ca_certs=certifi.where(),
65 timeout=30,
66 retry_on_timeout=True,
67 )
68 config.registry["elasticsearch.index"] = p.path.strip("/")
69 config.registry["elasticsearch.shards"] = int(qs.get("shards", ["1"])[0])
70 config.registry["elasticsearch.replicas"] = \
71 int(qs.get("replicas", ["0"])[0])
72 config.add_request_method(es, name="es", reify=True)
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/search.py b/warehouse/search.py
--- a/warehouse/search.py
+++ b/warehouse/search.py
@@ -16,7 +16,7 @@
import elasticsearch
import venusian
-from elasticsearch_dsl import Index
+from elasticsearch_dsl import Index, serializer
def doc_type(cls):
@@ -64,6 +64,7 @@
ca_certs=certifi.where(),
timeout=30,
retry_on_timeout=True,
+ serializer=serializer.serializer,
)
config.registry["elasticsearch.index"] = p.path.strip("/")
config.registry["elasticsearch.shards"] = int(qs.get("shards", ["1"])[0])
|
{"golden_diff": "diff --git a/warehouse/search.py b/warehouse/search.py\n--- a/warehouse/search.py\n+++ b/warehouse/search.py\n@@ -16,7 +16,7 @@\n import elasticsearch\n import venusian\n \n-from elasticsearch_dsl import Index\n+from elasticsearch_dsl import Index, serializer\n \n \n def doc_type(cls):\n@@ -64,6 +64,7 @@\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n+ serializer=serializer.serializer,\n )\n config.registry[\"elasticsearch.index\"] = p.path.strip(\"/\")\n config.registry[\"elasticsearch.shards\"] = int(qs.get(\"shards\", [\"1\"])[0])\n", "issue": "Update elasticsearch-dsl to 5.1.0\n\nThere's a new version of [elasticsearch-dsl](https://pypi.python.org/pypi/elasticsearch-dsl) available.\nYou are currently using **5.0.0**. I have updated it to **5.1.0**\n\n\n\nThese links might come in handy: <a href=\"http://pypi.python.org/pypi/elasticsearch-dsl\">PyPI</a> | <a href=\"https://pyup.io/changelogs/elasticsearch-dsl/\">Changelog</a> | <a href=\"https://github.com/elasticsearch/elasticsearch-dsl-py\">Repo</a> \n\n\n\n### Changelog\n> \n>### 5.1.0\n\n>------------------\n> * Renamed ``Result`` and ``ResultMeta`` to ``Hit`` and ``HitMeta`` respectively\n> * ``Response`` now stores ``Search`` which it gets as first arg to ``__init__``\n> * aggregation results are now wrapped in classes and properly deserialized\n> * ``Date`` fields now allow for numerical timestamps in the java format (in millis)\n> * Added API documentation\n> * replaced generated classes with manually created\n\n\n\n\n\n\n\n*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*\n\nHappy merging! \ud83e\udd16\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.parse\n\nimport certifi\nimport elasticsearch\nimport venusian\n\nfrom elasticsearch_dsl import Index\n\n\ndef doc_type(cls):\n def callback(scanner, _name, item):\n types_ = scanner.config.registry.setdefault(\"search.doc_types\", set())\n types_.add(item)\n\n venusian.attach(cls, callback)\n\n return cls\n\n\ndef get_index(name, doc_types, *, using, shards=1, replicas=0, interval=\"1s\"):\n index = Index(name, using=using)\n for doc_type in doc_types:\n index.doc_type(doc_type)\n index.settings(\n number_of_shards=shards,\n number_of_replicas=replicas,\n refresh_interval=interval,\n )\n return index\n\n\ndef es(request):\n client = request.registry[\"elasticsearch.client\"]\n doc_types = request.registry.get(\"search.doc_types\", set())\n index_name = request.registry[\"elasticsearch.index\"]\n index = get_index(\n index_name,\n doc_types,\n using=client,\n shards=request.registry.get(\"elasticsearch.shards\", 1),\n replicas=request.registry.get(\"elasticsearch.replicas\", 0),\n )\n return index.search()\n\n\ndef includeme(config):\n p = urllib.parse.urlparse(config.registry.settings[\"elasticsearch.url\"])\n qs = urllib.parse.parse_qs(p.query)\n config.registry[\"elasticsearch.client\"] = elasticsearch.Elasticsearch(\n [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n verify_certs=True,\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n )\n config.registry[\"elasticsearch.index\"] = p.path.strip(\"/\")\n config.registry[\"elasticsearch.shards\"] = int(qs.get(\"shards\", [\"1\"])[0])\n config.registry[\"elasticsearch.replicas\"] = \\\n int(qs.get(\"replicas\", [\"0\"])[0])\n config.add_request_method(es, name=\"es\", reify=True)\n", "path": "warehouse/search.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.parse\n\nimport certifi\nimport elasticsearch\nimport venusian\n\nfrom elasticsearch_dsl import Index, serializer\n\n\ndef doc_type(cls):\n def callback(scanner, _name, item):\n types_ = scanner.config.registry.setdefault(\"search.doc_types\", set())\n types_.add(item)\n\n venusian.attach(cls, callback)\n\n return cls\n\n\ndef get_index(name, doc_types, *, using, shards=1, replicas=0, interval=\"1s\"):\n index = Index(name, using=using)\n for doc_type in doc_types:\n index.doc_type(doc_type)\n index.settings(\n number_of_shards=shards,\n number_of_replicas=replicas,\n refresh_interval=interval,\n )\n return index\n\n\ndef es(request):\n client = request.registry[\"elasticsearch.client\"]\n doc_types = request.registry.get(\"search.doc_types\", set())\n index_name = request.registry[\"elasticsearch.index\"]\n index = get_index(\n index_name,\n doc_types,\n using=client,\n shards=request.registry.get(\"elasticsearch.shards\", 1),\n replicas=request.registry.get(\"elasticsearch.replicas\", 0),\n )\n return index.search()\n\n\ndef includeme(config):\n p = urllib.parse.urlparse(config.registry.settings[\"elasticsearch.url\"])\n qs = urllib.parse.parse_qs(p.query)\n config.registry[\"elasticsearch.client\"] = elasticsearch.Elasticsearch(\n [urllib.parse.urlunparse(p[:2] + (\"\",) * 4)],\n verify_certs=True,\n ca_certs=certifi.where(),\n timeout=30,\n retry_on_timeout=True,\n serializer=serializer.serializer,\n )\n config.registry[\"elasticsearch.index\"] = p.path.strip(\"/\")\n config.registry[\"elasticsearch.shards\"] = int(qs.get(\"shards\", [\"1\"])[0])\n config.registry[\"elasticsearch.replicas\"] = \\\n int(qs.get(\"replicas\", [\"0\"])[0])\n config.add_request_method(es, name=\"es\", reify=True)\n", "path": "warehouse/search.py"}]}
| 1,228 | 153 |
gh_patches_debug_38640
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-tf-545
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possible error when training on a finite dataset with multiple GPU
When the total number of batches is not a multiple of the number of replicas (finite dataset), the training can stop with an error because some replicas receive an empty batch.
This error can happen on master, or on v2.2.0 when TensorFlow fails to use batch splitting approach to feed the replicas.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opennmt/training.py`
Content:
```
1 """Training related classes and functions."""
2
3 import collections
4 import os
5 import time
6 import six
7
8 import tensorflow as tf
9
10 from opennmt.data import dataset as dataset_util
11 from opennmt.optimizers import utils as optimizer_util
12 from opennmt.utils import misc
13
14
15 class Trainer(object):
16 """Model trainer."""
17
18 def __init__(self, checkpoint, devices=None, mixed_precision=False):
19 """Initializes the trainer.
20
21 Args:
22 checkpoint: A :class:`opennmt.utils.checkpoint.Checkpoint` instance.
23 devices: List of device strings to use for training.
24 mixed_precision: Whether mixed precision is enabled or not.
25 """
26 if checkpoint.optimizer is None:
27 raise ValueError("No optimizer is defined")
28 if not devices:
29 devices = misc.get_devices(count=1) # Train with 1 device by default.
30 self._checkpoint = checkpoint
31 self._mixed_precision = mixed_precision
32 self._model = checkpoint.model
33 self._optimizer = checkpoint.optimizer
34 self._strategy = tf.distribute.MirroredStrategy(devices=devices)
35 self._summary_writer = tf.summary.create_file_writer(checkpoint.model_dir)
36
37 def __call__(self,
38 dataset,
39 max_step=None,
40 accum_steps=1,
41 report_steps=100,
42 save_steps=5000,
43 evaluator=None,
44 eval_steps=5000,
45 export_on_best=None):
46 """Runs the training.
47
48 Args:
49 dataset: A training dataset.
50 max_step: The final training step.
51 accum_steps: The number of gradient accumulation steps.
52 report_steps: Report status every this many steps.
53 save_steps: Save a checkpoint every this many steps.
54 evaluator: A :class:`opennmt.evaluation.Evaluator` instance to call for
55 evaluation.
56 eval_steps: Evaluate every this many steps.
57 export_on_best: Export a SavedModel when this evaluation metric has the
58 best value so far.
59 """
60 if max_step is not None and self._optimizer.iterations.numpy() >= max_step:
61 tf.get_logger().warning("Model already reached max_step = %d. Exiting.", max_step)
62 return
63 if evaluator is not None and evaluator.should_stop():
64 tf.get_logger().warning("Early stopping conditions are already met. Exiting.")
65 return
66
67 with self._strategy.scope():
68 self._model.create_variables(optimizer=self._optimizer)
69 variables = self._model.trainable_variables
70 base_dataset = dataset
71 # We prefer not to use experimental_distribute_dataset here because it
72 # sometimes fails to split the batches (noticed with tokens batch type).
73 # We also assume for now that we are training with a single worker
74 # otherwise we would need to correctly shard the input dataset.
75 dataset = self._strategy.experimental_distribute_datasets_from_function(
76 lambda _: base_dataset)
77 gradient_accumulator = optimizer_util.GradientAccumulator()
78
79 if self._mixed_precision:
80 optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(
81 self._optimizer, "dynamic")
82 else:
83 optimizer = self._optimizer
84
85 def _accumulate_gradients(source, target):
86 outputs, _ = self._model(
87 source,
88 labels=target,
89 training=True,
90 step=self._optimizer.iterations)
91 loss = self._model.compute_loss(outputs, target, training=True)
92 if isinstance(loss, tuple):
93 training_loss = loss[0] / loss[1]
94 reported_loss = loss[0] / loss[2]
95 else:
96 training_loss, reported_loss = loss, loss
97 training_loss = self._model.regularize_loss(training_loss, variables=variables)
98 gradients = optimizer.get_gradients(training_loss, variables)
99 gradient_accumulator(gradients)
100 tf.summary.scalar("gradients/global_norm", tf.linalg.global_norm(gradients))
101 num_words = {}
102 if "length" in source:
103 num_words["source"] = tf.reduce_sum(source["length"])
104 if "length" in target:
105 num_words["target"] = tf.reduce_sum(target["length"])
106 return reported_loss, num_words
107
108 def _apply_gradients():
109 grads_and_vars = []
110 for gradient, variable in zip(gradient_accumulator.gradients, variables):
111 # optimizer.apply_gradients will sum the gradients accross replicas.
112 scaled_gradient = gradient / (self._strategy.num_replicas_in_sync * accum_steps)
113 grads_and_vars.append((scaled_gradient, variable))
114 optimizer.apply_gradients(grads_and_vars)
115 gradient_accumulator.reset()
116
117 @dataset_util.function_on_next(dataset)
118 def _forward(next_fn):
119 tf.summary.experimental.set_step(self._optimizer.iterations)
120 should_record_summaries = tf.logical_and(
121 tf.equal(self._optimizer.iterations % report_steps, 0),
122 tf.equal(gradient_accumulator.step, 0))
123 with tf.summary.record_if(should_record_summaries):
124 with self._strategy.scope():
125 per_replica_source, per_replica_target = next_fn()
126 per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
127 _accumulate_gradients, args=(per_replica_source, per_replica_target))
128
129 # TODO: these reductions could be delayed until _step is called.
130 loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
131 num_words = {
132 k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
133 for k, v in six.iteritems(per_replica_words)}
134 return loss, num_words
135
136 @tf.function
137 def _step():
138 with self._strategy.scope():
139 self._strategy.experimental_run_v2(_apply_gradients)
140
141 accum_num_words = collections.defaultdict(int)
142 last_report_time = time.time()
143 last_step = 0
144
145 with self._summary_writer.as_default():
146 if self._optimizer.iterations.numpy() == 0:
147 self._checkpoint.save(0)
148 self._model.visualize(self._checkpoint.model_dir)
149
150 for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
151 if tf.math.is_nan(loss):
152 raise RuntimeError("Model diverged with loss = NaN.")
153 if i == 0 or (i + 1) % accum_steps == 0:
154 _step()
155
156 for key, value in six.iteritems(num_words):
157 accum_num_words[key] += value.numpy()
158 step = self._optimizer.iterations.numpy()
159 if step == last_step:
160 continue # Do not process same step twice.
161 last_step = step
162 if step % report_steps == 0:
163 last_report_time = _report_training_status(
164 step,
165 loss,
166 self._optimizer.learning_rate,
167 accum_num_words,
168 last_report_time)
169 if save_steps is not None and step % save_steps == 0:
170 self._checkpoint.save(step)
171 if evaluator is not None and eval_steps is not None and step % eval_steps == 0:
172 self._evaluate(evaluator, step, export_on_best=export_on_best)
173 if evaluator.should_stop():
174 tf.get_logger().warning("Early stopping conditions are met. Exiting.")
175 break
176 if step == max_step:
177 break
178
179 if evaluator is not None and step != evaluator.last_evaluated_step:
180 self._evaluate(evaluator, step, export_on_best=export_on_best)
181 self._checkpoint.save(step)
182
183 def _evaluate(self, evaluator, step, export_on_best=None):
184 metrics = evaluator(step)
185 if export_on_best is not None and evaluator.is_best(export_on_best):
186 export_dir = os.path.join(self._checkpoint.model_dir, "export", str(step))
187 tf.get_logger().info("Exporting SavedModel to %s (best %s so far: %f)",
188 export_dir, export_on_best, metrics[export_on_best])
189 self._model.export(export_dir)
190
191
192 def _report_training_status(step, loss, learning_rate, accum_num_words, last_report_time):
193 tf.summary.experimental.set_step(step)
194 new_report_time = time.time()
195 words_per_sec_fmt = []
196 for key, value in six.iteritems(accum_num_words):
197 avg = int(value / (new_report_time - last_report_time))
198 accum_num_words[key] = 0
199 tf.summary.scalar(
200 "words_per_sec/%s" % key,
201 avg,
202 description="%s words per second" % key.capitalize())
203 fmt = "%s words/s = %d" % (key, avg)
204 words_per_sec_fmt.append(fmt)
205 words_per_sec_fmt = sorted(words_per_sec_fmt)
206 if isinstance(learning_rate, tf.optimizers.schedules.LearningRateSchedule):
207 learning_rate = learning_rate(step)
208 tf.get_logger().info(
209 "Step = %d ; %s ; Learning rate = %f ; Loss = %f",
210 step,
211 ", ".join(words_per_sec_fmt),
212 learning_rate,
213 loss)
214 tf.summary.scalar("loss", loss, description="Training loss")
215 tf.summary.scalar("optim/learning_rate", learning_rate, description="Learning rate")
216 return new_report_time
217
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opennmt/training.py b/opennmt/training.py
--- a/opennmt/training.py
+++ b/opennmt/training.py
@@ -123,15 +123,40 @@
with tf.summary.record_if(should_record_summaries):
with self._strategy.scope():
per_replica_source, per_replica_target = next_fn()
- per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
- _accumulate_gradients, args=(per_replica_source, per_replica_target))
- # TODO: these reductions could be delayed until _step is called.
- loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
- num_words = {
- k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
- for k, v in six.iteritems(per_replica_words)}
- return loss, num_words
+ def _run():
+ per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(
+ _accumulate_gradients, args=(per_replica_source, per_replica_target))
+
+ # TODO: these reductions could be delayed until _step is called.
+ loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)
+ num_words = {
+ k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)
+ for k, v in six.iteritems(per_replica_words)}
+ return loss, num_words, False
+
+ def _skip():
+ loss = tf.constant(0, dtype=tf.float32)
+ num_words = {}
+ if "length" in per_replica_source:
+ num_words["source"] = tf.constant(0, dtype=tf.int32)
+ if "length" in per_replica_target:
+ num_words["target"] = tf.constant(0, dtype=tf.int32)
+ return loss, num_words, True
+
+ # We verify here that each replica receives a non empty batch. If not,
+ # we skip this iteration. This typically happens at the last iteration
+ # when training on a finite dataset.
+ # TODO: is there a simpler way to handle this case?
+ per_replica_non_empty_batch = self._strategy.experimental_run_v2(
+ lambda tensor: tf.math.count_nonzero(tf.shape(tensor)[0]),
+ args=(tf.nest.flatten(per_replica_source)[0],))
+ non_empty_batch_count = self._strategy.reduce(
+ tf.distribute.ReduceOp.SUM, per_replica_non_empty_batch, None)
+ return tf.cond(
+ tf.math.equal(non_empty_batch_count, self._strategy.num_replicas_in_sync),
+ true_fn=_run,
+ false_fn=_skip)
@tf.function
def _step():
@@ -147,7 +172,12 @@
self._checkpoint.save(0)
self._model.visualize(self._checkpoint.model_dir)
- for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
+ for i, (loss, num_words, skipped) in enumerate(_forward()): # pylint: disable=no-value-for-parameter
+ if skipped:
+ # We assume only the last partial batch can possibly be skipped.
+ tf.get_logger().warning("Batch %d is partial, i.e. some training replicas "
+ "received an empty batch as input. Skipping.", i + 1)
+ break
if tf.math.is_nan(loss):
raise RuntimeError("Model diverged with loss = NaN.")
if i == 0 or (i + 1) % accum_steps == 0:
|
{"golden_diff": "diff --git a/opennmt/training.py b/opennmt/training.py\n--- a/opennmt/training.py\n+++ b/opennmt/training.py\n@@ -123,15 +123,40 @@\n with tf.summary.record_if(should_record_summaries):\n with self._strategy.scope():\n per_replica_source, per_replica_target = next_fn()\n- per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n- _accumulate_gradients, args=(per_replica_source, per_replica_target))\n \n- # TODO: these reductions could be delayed until _step is called.\n- loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n- num_words = {\n- k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n- for k, v in six.iteritems(per_replica_words)}\n- return loss, num_words\n+ def _run():\n+ per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n+ _accumulate_gradients, args=(per_replica_source, per_replica_target))\n+\n+ # TODO: these reductions could be delayed until _step is called.\n+ loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n+ num_words = {\n+ k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n+ for k, v in six.iteritems(per_replica_words)}\n+ return loss, num_words, False\n+\n+ def _skip():\n+ loss = tf.constant(0, dtype=tf.float32)\n+ num_words = {}\n+ if \"length\" in per_replica_source:\n+ num_words[\"source\"] = tf.constant(0, dtype=tf.int32)\n+ if \"length\" in per_replica_target:\n+ num_words[\"target\"] = tf.constant(0, dtype=tf.int32)\n+ return loss, num_words, True\n+\n+ # We verify here that each replica receives a non empty batch. If not,\n+ # we skip this iteration. This typically happens at the last iteration\n+ # when training on a finite dataset.\n+ # TODO: is there a simpler way to handle this case?\n+ per_replica_non_empty_batch = self._strategy.experimental_run_v2(\n+ lambda tensor: tf.math.count_nonzero(tf.shape(tensor)[0]),\n+ args=(tf.nest.flatten(per_replica_source)[0],))\n+ non_empty_batch_count = self._strategy.reduce(\n+ tf.distribute.ReduceOp.SUM, per_replica_non_empty_batch, None)\n+ return tf.cond(\n+ tf.math.equal(non_empty_batch_count, self._strategy.num_replicas_in_sync),\n+ true_fn=_run,\n+ false_fn=_skip)\n \n @tf.function\n def _step():\n@@ -147,7 +172,12 @@\n self._checkpoint.save(0)\n self._model.visualize(self._checkpoint.model_dir)\n \n- for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n+ for i, (loss, num_words, skipped) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n+ if skipped:\n+ # We assume only the last partial batch can possibly be skipped.\n+ tf.get_logger().warning(\"Batch %d is partial, i.e. some training replicas \"\n+ \"received an empty batch as input. Skipping.\", i + 1)\n+ break\n if tf.math.is_nan(loss):\n raise RuntimeError(\"Model diverged with loss = NaN.\")\n if i == 0 or (i + 1) % accum_steps == 0:\n", "issue": "Possible error when training on a finite dataset with multiple GPU\nWhen the total number of batches is not a multiple of the number of replicas (finite dataset), the training can stop with an error because some replicas receive an empty batch.\r\n\r\nThis error can happen on master, or on v2.2.0 when TensorFlow fails to use batch splitting approach to feed the replicas.\n", "before_files": [{"content": "\"\"\"Training related classes and functions.\"\"\"\n\nimport collections\nimport os\nimport time\nimport six\n\nimport tensorflow as tf\n\nfrom opennmt.data import dataset as dataset_util\nfrom opennmt.optimizers import utils as optimizer_util\nfrom opennmt.utils import misc\n\n\nclass Trainer(object):\n \"\"\"Model trainer.\"\"\"\n\n def __init__(self, checkpoint, devices=None, mixed_precision=False):\n \"\"\"Initializes the trainer.\n\n Args:\n checkpoint: A :class:`opennmt.utils.checkpoint.Checkpoint` instance.\n devices: List of device strings to use for training.\n mixed_precision: Whether mixed precision is enabled or not.\n \"\"\"\n if checkpoint.optimizer is None:\n raise ValueError(\"No optimizer is defined\")\n if not devices:\n devices = misc.get_devices(count=1) # Train with 1 device by default.\n self._checkpoint = checkpoint\n self._mixed_precision = mixed_precision\n self._model = checkpoint.model\n self._optimizer = checkpoint.optimizer\n self._strategy = tf.distribute.MirroredStrategy(devices=devices)\n self._summary_writer = tf.summary.create_file_writer(checkpoint.model_dir)\n\n def __call__(self,\n dataset,\n max_step=None,\n accum_steps=1,\n report_steps=100,\n save_steps=5000,\n evaluator=None,\n eval_steps=5000,\n export_on_best=None):\n \"\"\"Runs the training.\n\n Args:\n dataset: A training dataset.\n max_step: The final training step.\n accum_steps: The number of gradient accumulation steps.\n report_steps: Report status every this many steps.\n save_steps: Save a checkpoint every this many steps.\n evaluator: A :class:`opennmt.evaluation.Evaluator` instance to call for\n evaluation.\n eval_steps: Evaluate every this many steps.\n export_on_best: Export a SavedModel when this evaluation metric has the\n best value so far.\n \"\"\"\n if max_step is not None and self._optimizer.iterations.numpy() >= max_step:\n tf.get_logger().warning(\"Model already reached max_step = %d. Exiting.\", max_step)\n return\n if evaluator is not None and evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are already met. Exiting.\")\n return\n\n with self._strategy.scope():\n self._model.create_variables(optimizer=self._optimizer)\n variables = self._model.trainable_variables\n base_dataset = dataset\n # We prefer not to use experimental_distribute_dataset here because it\n # sometimes fails to split the batches (noticed with tokens batch type).\n # We also assume for now that we are training with a single worker\n # otherwise we would need to correctly shard the input dataset.\n dataset = self._strategy.experimental_distribute_datasets_from_function(\n lambda _: base_dataset)\n gradient_accumulator = optimizer_util.GradientAccumulator()\n\n if self._mixed_precision:\n optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(\n self._optimizer, \"dynamic\")\n else:\n optimizer = self._optimizer\n\n def _accumulate_gradients(source, target):\n outputs, _ = self._model(\n source,\n labels=target,\n training=True,\n step=self._optimizer.iterations)\n loss = self._model.compute_loss(outputs, target, training=True)\n if isinstance(loss, tuple):\n training_loss = loss[0] / loss[1]\n reported_loss = loss[0] / loss[2]\n else:\n training_loss, reported_loss = loss, loss\n training_loss = self._model.regularize_loss(training_loss, variables=variables)\n gradients = optimizer.get_gradients(training_loss, variables)\n gradient_accumulator(gradients)\n tf.summary.scalar(\"gradients/global_norm\", tf.linalg.global_norm(gradients))\n num_words = {}\n if \"length\" in source:\n num_words[\"source\"] = tf.reduce_sum(source[\"length\"])\n if \"length\" in target:\n num_words[\"target\"] = tf.reduce_sum(target[\"length\"])\n return reported_loss, num_words\n\n def _apply_gradients():\n grads_and_vars = []\n for gradient, variable in zip(gradient_accumulator.gradients, variables):\n # optimizer.apply_gradients will sum the gradients accross replicas.\n scaled_gradient = gradient / (self._strategy.num_replicas_in_sync * accum_steps)\n grads_and_vars.append((scaled_gradient, variable))\n optimizer.apply_gradients(grads_and_vars)\n gradient_accumulator.reset()\n\n @dataset_util.function_on_next(dataset)\n def _forward(next_fn):\n tf.summary.experimental.set_step(self._optimizer.iterations)\n should_record_summaries = tf.logical_and(\n tf.equal(self._optimizer.iterations % report_steps, 0),\n tf.equal(gradient_accumulator.step, 0))\n with tf.summary.record_if(should_record_summaries):\n with self._strategy.scope():\n per_replica_source, per_replica_target = next_fn()\n per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n _accumulate_gradients, args=(per_replica_source, per_replica_target))\n\n # TODO: these reductions could be delayed until _step is called.\n loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n num_words = {\n k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n for k, v in six.iteritems(per_replica_words)}\n return loss, num_words\n\n @tf.function\n def _step():\n with self._strategy.scope():\n self._strategy.experimental_run_v2(_apply_gradients)\n\n accum_num_words = collections.defaultdict(int)\n last_report_time = time.time()\n last_step = 0\n\n with self._summary_writer.as_default():\n if self._optimizer.iterations.numpy() == 0:\n self._checkpoint.save(0)\n self._model.visualize(self._checkpoint.model_dir)\n\n for i, (loss, num_words) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n if tf.math.is_nan(loss):\n raise RuntimeError(\"Model diverged with loss = NaN.\")\n if i == 0 or (i + 1) % accum_steps == 0:\n _step()\n\n for key, value in six.iteritems(num_words):\n accum_num_words[key] += value.numpy()\n step = self._optimizer.iterations.numpy()\n if step == last_step:\n continue # Do not process same step twice.\n last_step = step\n if step % report_steps == 0:\n last_report_time = _report_training_status(\n step,\n loss,\n self._optimizer.learning_rate,\n accum_num_words,\n last_report_time)\n if save_steps is not None and step % save_steps == 0:\n self._checkpoint.save(step)\n if evaluator is not None and eval_steps is not None and step % eval_steps == 0:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n if evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are met. Exiting.\")\n break\n if step == max_step:\n break\n\n if evaluator is not None and step != evaluator.last_evaluated_step:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n self._checkpoint.save(step)\n\n def _evaluate(self, evaluator, step, export_on_best=None):\n metrics = evaluator(step)\n if export_on_best is not None and evaluator.is_best(export_on_best):\n export_dir = os.path.join(self._checkpoint.model_dir, \"export\", str(step))\n tf.get_logger().info(\"Exporting SavedModel to %s (best %s so far: %f)\",\n export_dir, export_on_best, metrics[export_on_best])\n self._model.export(export_dir)\n\n\ndef _report_training_status(step, loss, learning_rate, accum_num_words, last_report_time):\n tf.summary.experimental.set_step(step)\n new_report_time = time.time()\n words_per_sec_fmt = []\n for key, value in six.iteritems(accum_num_words):\n avg = int(value / (new_report_time - last_report_time))\n accum_num_words[key] = 0\n tf.summary.scalar(\n \"words_per_sec/%s\" % key,\n avg,\n description=\"%s words per second\" % key.capitalize())\n fmt = \"%s words/s = %d\" % (key, avg)\n words_per_sec_fmt.append(fmt)\n words_per_sec_fmt = sorted(words_per_sec_fmt)\n if isinstance(learning_rate, tf.optimizers.schedules.LearningRateSchedule):\n learning_rate = learning_rate(step)\n tf.get_logger().info(\n \"Step = %d ; %s ; Learning rate = %f ; Loss = %f\",\n step,\n \", \".join(words_per_sec_fmt),\n learning_rate,\n loss)\n tf.summary.scalar(\"loss\", loss, description=\"Training loss\")\n tf.summary.scalar(\"optim/learning_rate\", learning_rate, description=\"Learning rate\")\n return new_report_time\n", "path": "opennmt/training.py"}], "after_files": [{"content": "\"\"\"Training related classes and functions.\"\"\"\n\nimport collections\nimport os\nimport time\nimport six\n\nimport tensorflow as tf\n\nfrom opennmt.data import dataset as dataset_util\nfrom opennmt.optimizers import utils as optimizer_util\nfrom opennmt.utils import misc\n\n\nclass Trainer(object):\n \"\"\"Model trainer.\"\"\"\n\n def __init__(self, checkpoint, devices=None, mixed_precision=False):\n \"\"\"Initializes the trainer.\n\n Args:\n checkpoint: A :class:`opennmt.utils.checkpoint.Checkpoint` instance.\n devices: List of device strings to use for training.\n mixed_precision: Whether mixed precision is enabled or not.\n \"\"\"\n if checkpoint.optimizer is None:\n raise ValueError(\"No optimizer is defined\")\n if not devices:\n devices = misc.get_devices(count=1) # Train with 1 device by default.\n self._checkpoint = checkpoint\n self._mixed_precision = mixed_precision\n self._model = checkpoint.model\n self._optimizer = checkpoint.optimizer\n self._strategy = tf.distribute.MirroredStrategy(devices=devices)\n self._summary_writer = tf.summary.create_file_writer(checkpoint.model_dir)\n\n def __call__(self,\n dataset,\n max_step=None,\n accum_steps=1,\n report_steps=100,\n save_steps=5000,\n evaluator=None,\n eval_steps=5000,\n export_on_best=None):\n \"\"\"Runs the training.\n\n Args:\n dataset: A training dataset.\n max_step: The final training step.\n accum_steps: The number of gradient accumulation steps.\n report_steps: Report status every this many steps.\n save_steps: Save a checkpoint every this many steps.\n evaluator: A :class:`opennmt.evaluation.Evaluator` instance to call for\n evaluation.\n eval_steps: Evaluate every this many steps.\n export_on_best: Export a SavedModel when this evaluation metric has the\n best value so far.\n \"\"\"\n if max_step is not None and self._optimizer.iterations.numpy() >= max_step:\n tf.get_logger().warning(\"Model already reached max_step = %d. Exiting.\", max_step)\n return\n if evaluator is not None and evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are already met. Exiting.\")\n return\n\n with self._strategy.scope():\n self._model.create_variables(optimizer=self._optimizer)\n variables = self._model.trainable_variables\n base_dataset = dataset\n # We prefer not to use experimental_distribute_dataset here because it\n # sometimes fails to split the batches (noticed with tokens batch type).\n # We also assume for now that we are training with a single worker\n # otherwise we would need to correctly shard the input dataset.\n dataset = self._strategy.experimental_distribute_datasets_from_function(\n lambda _: base_dataset)\n gradient_accumulator = optimizer_util.GradientAccumulator()\n\n if self._mixed_precision:\n optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(\n self._optimizer, \"dynamic\")\n else:\n optimizer = self._optimizer\n\n def _accumulate_gradients(source, target):\n outputs, _ = self._model(\n source,\n labels=target,\n training=True,\n step=self._optimizer.iterations)\n loss = self._model.compute_loss(outputs, target, training=True)\n if isinstance(loss, tuple):\n training_loss = loss[0] / loss[1]\n reported_loss = loss[0] / loss[2]\n else:\n training_loss, reported_loss = loss, loss\n training_loss = self._model.regularize_loss(training_loss, variables=variables)\n gradients = optimizer.get_gradients(training_loss, variables)\n gradient_accumulator(gradients)\n tf.summary.scalar(\"gradients/global_norm\", tf.linalg.global_norm(gradients))\n num_words = {}\n if \"length\" in source:\n num_words[\"source\"] = tf.reduce_sum(source[\"length\"])\n if \"length\" in target:\n num_words[\"target\"] = tf.reduce_sum(target[\"length\"])\n return reported_loss, num_words\n\n def _apply_gradients():\n grads_and_vars = []\n for gradient, variable in zip(gradient_accumulator.gradients, variables):\n # optimizer.apply_gradients will sum the gradients accross replicas.\n scaled_gradient = gradient / (self._strategy.num_replicas_in_sync * accum_steps)\n grads_and_vars.append((scaled_gradient, variable))\n optimizer.apply_gradients(grads_and_vars)\n gradient_accumulator.reset()\n\n @dataset_util.function_on_next(dataset)\n def _forward(next_fn):\n tf.summary.experimental.set_step(self._optimizer.iterations)\n should_record_summaries = tf.logical_and(\n tf.equal(self._optimizer.iterations % report_steps, 0),\n tf.equal(gradient_accumulator.step, 0))\n with tf.summary.record_if(should_record_summaries):\n with self._strategy.scope():\n per_replica_source, per_replica_target = next_fn()\n\n def _run():\n per_replica_loss, per_replica_words = self._strategy.experimental_run_v2(\n _accumulate_gradients, args=(per_replica_source, per_replica_target))\n\n # TODO: these reductions could be delayed until _step is called.\n loss = self._strategy.reduce(tf.distribute.ReduceOp.MEAN, per_replica_loss, None)\n num_words = {\n k:self._strategy.reduce(tf.distribute.ReduceOp.SUM, v, None)\n for k, v in six.iteritems(per_replica_words)}\n return loss, num_words, False\n\n def _skip():\n loss = tf.constant(0, dtype=tf.float32)\n num_words = {}\n if \"length\" in per_replica_source:\n num_words[\"source\"] = tf.constant(0, dtype=tf.int32)\n if \"length\" in per_replica_target:\n num_words[\"target\"] = tf.constant(0, dtype=tf.int32)\n return loss, num_words, True\n\n # We verify here that each replica receives a non empty batch. If not,\n # we skip this iteration. This typically happens at the last iteration\n # when training on a finite dataset.\n # TODO: is there a simpler way to handle this case?\n per_replica_non_empty_batch = self._strategy.experimental_run_v2(\n lambda tensor: tf.math.count_nonzero(tf.shape(tensor)[0]),\n args=(tf.nest.flatten(per_replica_source)[0],))\n non_empty_batch_count = self._strategy.reduce(\n tf.distribute.ReduceOp.SUM, per_replica_non_empty_batch, None)\n return tf.cond(\n tf.math.equal(non_empty_batch_count, self._strategy.num_replicas_in_sync),\n true_fn=_run,\n false_fn=_skip)\n\n @tf.function\n def _step():\n with self._strategy.scope():\n self._strategy.experimental_run_v2(_apply_gradients)\n\n accum_num_words = collections.defaultdict(int)\n last_report_time = time.time()\n last_step = 0\n\n with self._summary_writer.as_default():\n if self._optimizer.iterations.numpy() == 0:\n self._checkpoint.save(0)\n self._model.visualize(self._checkpoint.model_dir)\n\n for i, (loss, num_words, skipped) in enumerate(_forward()): # pylint: disable=no-value-for-parameter\n if skipped:\n # We assume only the last partial batch can possibly be skipped.\n tf.get_logger().warning(\"Batch %d is partial, i.e. some training replicas \"\n \"received an empty batch as input. Skipping.\", i + 1)\n break\n if tf.math.is_nan(loss):\n raise RuntimeError(\"Model diverged with loss = NaN.\")\n if i == 0 or (i + 1) % accum_steps == 0:\n _step()\n\n for key, value in six.iteritems(num_words):\n accum_num_words[key] += value.numpy()\n step = self._optimizer.iterations.numpy()\n if step == last_step:\n continue # Do not process same step twice.\n last_step = step\n if step % report_steps == 0:\n last_report_time = _report_training_status(\n step,\n loss,\n self._optimizer.learning_rate,\n accum_num_words,\n last_report_time)\n if save_steps is not None and step % save_steps == 0:\n self._checkpoint.save(step)\n if evaluator is not None and eval_steps is not None and step % eval_steps == 0:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n if evaluator.should_stop():\n tf.get_logger().warning(\"Early stopping conditions are met. Exiting.\")\n break\n if step == max_step:\n break\n\n if evaluator is not None and step != evaluator.last_evaluated_step:\n self._evaluate(evaluator, step, export_on_best=export_on_best)\n self._checkpoint.save(step)\n\n def _evaluate(self, evaluator, step, export_on_best=None):\n metrics = evaluator(step)\n if export_on_best is not None and evaluator.is_best(export_on_best):\n export_dir = os.path.join(self._checkpoint.model_dir, \"export\", str(step))\n tf.get_logger().info(\"Exporting SavedModel to %s (best %s so far: %f)\",\n export_dir, export_on_best, metrics[export_on_best])\n self._model.export(export_dir)\n\n\ndef _report_training_status(step, loss, learning_rate, accum_num_words, last_report_time):\n tf.summary.experimental.set_step(step)\n new_report_time = time.time()\n words_per_sec_fmt = []\n for key, value in six.iteritems(accum_num_words):\n avg = int(value / (new_report_time - last_report_time))\n accum_num_words[key] = 0\n tf.summary.scalar(\n \"words_per_sec/%s\" % key,\n avg,\n description=\"%s words per second\" % key.capitalize())\n fmt = \"%s words/s = %d\" % (key, avg)\n words_per_sec_fmt.append(fmt)\n words_per_sec_fmt = sorted(words_per_sec_fmt)\n if isinstance(learning_rate, tf.optimizers.schedules.LearningRateSchedule):\n learning_rate = learning_rate(step)\n tf.get_logger().info(\n \"Step = %d ; %s ; Learning rate = %f ; Loss = %f\",\n step,\n \", \".join(words_per_sec_fmt),\n learning_rate,\n loss)\n tf.summary.scalar(\"loss\", loss, description=\"Training loss\")\n tf.summary.scalar(\"optim/learning_rate\", learning_rate, description=\"Learning rate\")\n return new_report_time\n", "path": "opennmt/training.py"}]}
| 2,822 | 832 |
gh_patches_debug_638
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2278
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.150
On the docket:
+ [x] Add support for Pip 23.3.1. #2276
+ [x] Support .egg-info dist metadata. #2264
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.149"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.149"
+__version__ = "2.1.150"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.149\"\n+__version__ = \"2.1.150\"\n", "issue": "Release 2.1.150\nOn the docket:\r\n+ [x] Add support for Pip 23.3.1. #2276\r\n+ [x] Support .egg-info dist metadata. #2264\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.149\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.150\"\n", "path": "pex/version.py"}]}
| 362 | 98 |
gh_patches_debug_2529
|
rasdani/github-patches
|
git_diff
|
systemd__mkosi-1847
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tput smam breaks build
Using latest on Debian Sid.
```
‣ Running finalize script…
‣ Creating tar archive /home/ander/Desktop/mkosi/tools/mkosi.workspace/.mkosi-tmp9zitpbja/staging/image.tar…
‣ /home/ander/Desktop/mkosi/tools/mkosi.output/image size is 1016.1M, consumes 1016.1M.
‣ "tput smam" returned non-zero exit code 1.
make: *** [Makefile:13: build] Error 1
```
`tput` in Debian do not understand `smam`?
```
$ tput smam; echo $?
1
```
Introduced in e651b88.
Ugly workaround:
```
$ ln -s /usr/bin/true ~/.local/bin/tput
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkosi/__main__.py`
Content:
```
1 # SPDX-License-Identifier: LGPL-2.1+
2 # PYTHON_ARGCOMPLETE_OK
3
4 import contextlib
5 import logging
6 import shutil
7 import subprocess
8 import sys
9 from collections.abc import Iterator
10
11 from mkosi import run_verb
12 from mkosi.config import MkosiConfigParser
13 from mkosi.log import ARG_DEBUG, log_setup
14 from mkosi.run import ensure_exc_info, run
15
16
17 @contextlib.contextmanager
18 def propagate_failed_return() -> Iterator[None]:
19 try:
20 yield
21 except SystemExit as e:
22 if ARG_DEBUG.get():
23 sys.excepthook(*ensure_exc_info())
24
25 sys.exit(e.code)
26 except KeyboardInterrupt:
27 if ARG_DEBUG.get():
28 sys.excepthook(*ensure_exc_info())
29 else:
30 logging.error("Interrupted")
31
32 sys.exit(1)
33 except subprocess.CalledProcessError as e:
34 # Failures from qemu, ssh and systemd-nspawn are expected and we won't log stacktraces for those.
35 if ARG_DEBUG.get() and e.cmd and e.cmd[0] not in ("qemu", "ssh", "systemd-nspawn"):
36 sys.excepthook(*ensure_exc_info())
37
38 # We always log when subprocess.CalledProcessError is raised, so we don't log again here.
39 sys.exit(e.returncode)
40
41
42 @propagate_failed_return()
43 def main() -> None:
44 log_setup()
45 args, presets = MkosiConfigParser().parse()
46
47 if ARG_DEBUG.get():
48 logging.getLogger().setLevel(logging.DEBUG)
49
50 try:
51 run_verb(args, presets)
52 finally:
53 if sys.stderr.isatty() and shutil.which("tput"):
54 run(["tput", "cnorm"])
55 run(["tput", "smam"])
56
57
58 if __name__ == "__main__":
59 main()
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkosi/__main__.py b/mkosi/__main__.py
--- a/mkosi/__main__.py
+++ b/mkosi/__main__.py
@@ -51,8 +51,8 @@
run_verb(args, presets)
finally:
if sys.stderr.isatty() and shutil.which("tput"):
- run(["tput", "cnorm"])
- run(["tput", "smam"])
+ run(["tput", "cnorm"], check=False)
+ run(["tput", "smam"], check=False)
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/mkosi/__main__.py b/mkosi/__main__.py\n--- a/mkosi/__main__.py\n+++ b/mkosi/__main__.py\n@@ -51,8 +51,8 @@\n run_verb(args, presets)\n finally:\n if sys.stderr.isatty() and shutil.which(\"tput\"):\n- run([\"tput\", \"cnorm\"])\n- run([\"tput\", \"smam\"])\n+ run([\"tput\", \"cnorm\"], check=False)\n+ run([\"tput\", \"smam\"], check=False)\n \n \n if __name__ == \"__main__\":\n", "issue": "tput smam breaks build\nUsing latest on Debian Sid.\r\n\r\n```\r\n\u2023 Running finalize script\u2026\r\n\u2023 Creating tar archive /home/ander/Desktop/mkosi/tools/mkosi.workspace/.mkosi-tmp9zitpbja/staging/image.tar\u2026\r\n\u2023 /home/ander/Desktop/mkosi/tools/mkosi.output/image size is 1016.1M, consumes 1016.1M.\r\n\u2023 \"tput smam\" returned non-zero exit code 1.\r\nmake: *** [Makefile:13: build] Error 1\r\n```\r\n\r\n`tput` in Debian do not understand `smam`?\r\n\r\n```\r\n$ tput smam; echo $?\r\n1\r\n```\r\n\r\nIntroduced in e651b88.\r\n\r\nUgly workaround:\r\n```\r\n$ ln -s /usr/bin/true ~/.local/bin/tput\r\n```\n", "before_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\n# PYTHON_ARGCOMPLETE_OK\n\nimport contextlib\nimport logging\nimport shutil\nimport subprocess\nimport sys\nfrom collections.abc import Iterator\n\nfrom mkosi import run_verb\nfrom mkosi.config import MkosiConfigParser\nfrom mkosi.log import ARG_DEBUG, log_setup\nfrom mkosi.run import ensure_exc_info, run\n\n\[email protected]\ndef propagate_failed_return() -> Iterator[None]:\n try:\n yield\n except SystemExit as e:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n\n sys.exit(e.code)\n except KeyboardInterrupt:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n else:\n logging.error(\"Interrupted\")\n\n sys.exit(1)\n except subprocess.CalledProcessError as e:\n # Failures from qemu, ssh and systemd-nspawn are expected and we won't log stacktraces for those.\n if ARG_DEBUG.get() and e.cmd and e.cmd[0] not in (\"qemu\", \"ssh\", \"systemd-nspawn\"):\n sys.excepthook(*ensure_exc_info())\n\n # We always log when subprocess.CalledProcessError is raised, so we don't log again here.\n sys.exit(e.returncode)\n\n\n@propagate_failed_return()\ndef main() -> None:\n log_setup()\n args, presets = MkosiConfigParser().parse()\n\n if ARG_DEBUG.get():\n logging.getLogger().setLevel(logging.DEBUG)\n\n try:\n run_verb(args, presets)\n finally:\n if sys.stderr.isatty() and shutil.which(\"tput\"):\n run([\"tput\", \"cnorm\"])\n run([\"tput\", \"smam\"])\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mkosi/__main__.py"}], "after_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\n# PYTHON_ARGCOMPLETE_OK\n\nimport contextlib\nimport logging\nimport shutil\nimport subprocess\nimport sys\nfrom collections.abc import Iterator\n\nfrom mkosi import run_verb\nfrom mkosi.config import MkosiConfigParser\nfrom mkosi.log import ARG_DEBUG, log_setup\nfrom mkosi.run import ensure_exc_info, run\n\n\[email protected]\ndef propagate_failed_return() -> Iterator[None]:\n try:\n yield\n except SystemExit as e:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n\n sys.exit(e.code)\n except KeyboardInterrupt:\n if ARG_DEBUG.get():\n sys.excepthook(*ensure_exc_info())\n else:\n logging.error(\"Interrupted\")\n\n sys.exit(1)\n except subprocess.CalledProcessError as e:\n # Failures from qemu, ssh and systemd-nspawn are expected and we won't log stacktraces for those.\n if ARG_DEBUG.get() and e.cmd and e.cmd[0] not in (\"qemu\", \"ssh\", \"systemd-nspawn\"):\n sys.excepthook(*ensure_exc_info())\n\n # We always log when subprocess.CalledProcessError is raised, so we don't log again here.\n sys.exit(e.returncode)\n\n\n@propagate_failed_return()\ndef main() -> None:\n log_setup()\n args, presets = MkosiConfigParser().parse()\n\n if ARG_DEBUG.get():\n logging.getLogger().setLevel(logging.DEBUG)\n\n try:\n run_verb(args, presets)\n finally:\n if sys.stderr.isatty() and shutil.which(\"tput\"):\n run([\"tput\", \"cnorm\"], check=False)\n run([\"tput\", \"smam\"], check=False)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mkosi/__main__.py"}]}
| 948 | 136 |
gh_patches_debug_24881
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-228
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug Report: six should be a required install for pyhf
# Description
While looking at Issue #223 I tried to reproduce it in the [python:3.6.6 Docker image](https://hub.docker.com/_/python/). However, after installing pyhf from PyPI and trying to run the example @lukasheinrich made in #223
```
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
# Expected Behavior
The example should work from any install of pyhf
# Actual Behavior
I came across a new error:
```python-traceback
Traceback (most recent call last):
File "/usr/local/bin/pyhf", line 7, in <module>
from pyhf.commandline import pyhf
File "/usr/local/lib/python3.6/site-packages/pyhf/__init__.py", line 55, in <module>
from .pdf import Model
File "/usr/local/lib/python3.6/site-packages/pyhf/pdf.py", line 7, in <module>
from . import modifiers
File "/usr/local/lib/python3.6/site-packages/pyhf/modifiers/__init__.py", line 1, in <module>
from six import string_types
ModuleNotFoundError: No module named 'six'
```
As the traceback tells us, `six` is not a [required installation library](https://github.com/diana-hep/pyhf/blob/master/setup.py#L11-L15) for pyhf at the moment, yet is [used in `modifiers`](https://github.com/diana-hep/pyhf/blob/master/pyhf/modifiers/__init__.py#L1).
# Steps to Reproduce
```
docker pull python:3.6.6
docker run --rm -it python:3.6.6 /bin/bash
cd root
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
If one then does
```
pip install six
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
then the error in Issue #223 is recovered.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
Bug Repot: basic functionality not working in non-develop pip installs
# Description
`jsonschema` is always imported in pdf.py so it must be a hard dependency unless we choose to make validation optional
# Expected Behavior
this should work for any install of `pyhf`
```
pip install pyhf
cat << 'EOF' | pyhf cls
{
"channels": [
{
"name": "channel1",
"samples": [
{"name": "sig", "data": [ 5.0], "modifiers": [{"name": "mu","data": null, "type": "normfactor"}]},
{"name": "bkg", "data": [50.0], "modifiers": []}
]
}
],
"data": {"channel1": [51.0] },
"toplvl": {
"measurements": [
{"config": {"poi": "mu"}, "name": "HelloWorld"}
]
}
}
EOF
```
# Actual Behavior
```
ImportError: No module named jsonschema
```
# Steps to Reproduce
install pyhf without any extras -- run above example
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 setup(
3 name = 'pyhf',
4 version = '0.0.15',
5 description = '(partial) pure python histfactory implementation',
6 url = '',
7 author = 'Lukas Heinrich',
8 author_email = '[email protected]',
9 packages = find_packages(),
10 include_package_data = True,
11 install_requires = [
12 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us
13 'scipy',
14 'click>=6.0', # for console scripts,
15 'tqdm', # for readxml
16 ],
17 extras_require = {
18 'xmlimport': [
19 'uproot',
20 ],
21 'torch': [
22 'torch>=0.4.0'
23 ],
24 'mxnet':[
25 'mxnet>=1.0.0',
26 'requests<2.19.0,>=2.18.4',
27 'numpy<1.15.0,>=1.8.2',
28 'requests<2.19.0,>=2.18.4',
29 ],
30 'tensorflow':[
31 'tensorflow==1.10.0',
32 'numpy<=1.14.5,>=1.13.3',
33 'setuptools<=39.1.0',
34 ],
35 'develop': [
36 'pyflakes',
37 'pytest>=3.5.1',
38 'pytest-cov>=2.5.1',
39 'pytest-benchmark[histogram]',
40 'pytest-console-scripts',
41 'python-coveralls',
42 'coverage==4.0.3', # coveralls
43 'matplotlib',
44 'jupyter',
45 'uproot',
46 'papermill',
47 'graphviz',
48 'sphinx',
49 'sphinxcontrib-bibtex',
50 'sphinxcontrib-napoleon',
51 'sphinx_rtd_theme',
52 'nbsphinx',
53 'jsonpatch',
54 'jsonschema==v3.0.0a2' # alpha-release for draft 6
55 ]
56 },
57 entry_points = {
58 'console_scripts': ['pyhf=pyhf.commandline:pyhf']
59 },
60 dependency_links = [
61 ]
62 )
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -13,6 +13,8 @@
'scipy',
'click>=6.0', # for console scripts,
'tqdm', # for readxml
+ 'six', # for modifiers
+ 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
],
extras_require = {
'xmlimport': [
@@ -28,7 +30,7 @@
'requests<2.19.0,>=2.18.4',
],
'tensorflow':[
- 'tensorflow==1.10.0',
+ 'tensorflow>=1.10.0',
'numpy<=1.14.5,>=1.13.3',
'setuptools<=39.1.0',
],
@@ -39,7 +41,7 @@
'pytest-benchmark[histogram]',
'pytest-console-scripts',
'python-coveralls',
- 'coverage==4.0.3', # coveralls
+ 'coverage>=4.0', # coveralls
'matplotlib',
'jupyter',
'uproot',
@@ -50,8 +52,7 @@
'sphinxcontrib-napoleon',
'sphinx_rtd_theme',
'nbsphinx',
- 'jsonpatch',
- 'jsonschema==v3.0.0a2' # alpha-release for draft 6
+ 'jsonpatch'
]
},
entry_points = {
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -13,6 +13,8 @@\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n+ 'six', # for modifiers\n+ 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n ],\n extras_require = {\n 'xmlimport': [\n@@ -28,7 +30,7 @@\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n- 'tensorflow==1.10.0',\n+ 'tensorflow>=1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n@@ -39,7 +41,7 @@\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n- 'coverage==4.0.3', # coveralls\n+ 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n@@ -50,8 +52,7 @@\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n- 'jsonpatch',\n- 'jsonschema==v3.0.0a2' # alpha-release for draft 6\n+ 'jsonpatch'\n ]\n },\n entry_points = {\n", "issue": "Bug Report: six should be a required install for pyhf\n# Description\r\n\r\nWhile looking at Issue #223 I tried to reproduce it in the [python:3.6.6 Docker image](https://hub.docker.com/_/python/). However, after installing pyhf from PyPI and trying to run the example @lukasheinrich made in #223 \r\n```\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\n# Expected Behavior\r\n\r\nThe example should work from any install of pyhf\r\n\r\n# Actual Behavior\r\n\r\nI came across a new error:\r\n\r\n```python-traceback\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/pyhf\", line 7, in <module>\r\n from pyhf.commandline import pyhf\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/__init__.py\", line 55, in <module>\r\n from .pdf import Model\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/pdf.py\", line 7, in <module>\r\n from . import modifiers\r\n File \"/usr/local/lib/python3.6/site-packages/pyhf/modifiers/__init__.py\", line 1, in <module>\r\n from six import string_types\r\nModuleNotFoundError: No module named 'six'\r\n```\r\n\r\nAs the traceback tells us, `six` is not a [required installation library](https://github.com/diana-hep/pyhf/blob/master/setup.py#L11-L15) for pyhf at the moment, yet is [used in `modifiers`](https://github.com/diana-hep/pyhf/blob/master/pyhf/modifiers/__init__.py#L1).\r\n\r\n# Steps to Reproduce\r\n\r\n```\r\ndocker pull python:3.6.6\r\ndocker run --rm -it python:3.6.6 /bin/bash\r\ncd root\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\nIf one then does\r\n```\r\npip install six\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n\r\nthen the error in Issue #223 is recovered.\r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\nBug Repot: basic functionality not working in non-develop pip installs \n# Description\r\n\r\n`jsonschema` is always imported in pdf.py so it must be a hard dependency unless we choose to make validation optional\r\n\r\n\r\n# Expected Behavior\r\n\r\nthis should work for any install of `pyhf`\r\n```\r\npip install pyhf\r\ncat << 'EOF' | pyhf cls\r\n{\r\n \"channels\": [\r\n {\r\n \"name\": \"channel1\", \r\n \"samples\": [\r\n {\"name\": \"sig\", \"data\": [ 5.0], \"modifiers\": [{\"name\": \"mu\",\"data\": null, \"type\": \"normfactor\"}]}, \r\n {\"name\": \"bkg\", \"data\": [50.0], \"modifiers\": []}\r\n ]\r\n }\r\n ], \r\n \"data\": {\"channel1\": [51.0] }, \r\n \"toplvl\": {\r\n \"measurements\": [\r\n {\"config\": {\"poi\": \"mu\"}, \"name\": \"HelloWorld\"}\r\n ]\r\n }\r\n}\r\nEOF\r\n```\r\n# Actual Behavior\r\n\r\n```\r\nImportError: No module named jsonschema\r\n```\r\n\r\n# Steps to Reproduce\r\n\r\ninstall pyhf without any extras -- run above example\r\n\r\n# Checklist\r\n\r\n- [x] Run `git fetch` to get the most up to date version of `master`\r\n- [x] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nsetup(\n name = 'pyhf',\n version = '0.0.15',\n description = '(partial) pure python histfactory implementation',\n url = '',\n author = 'Lukas Heinrich',\n author_email = '[email protected]',\n packages = find_packages(),\n include_package_data = True,\n install_requires = [\n 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n ],\n extras_require = {\n 'xmlimport': [\n 'uproot',\n ],\n 'torch': [\n 'torch>=0.4.0'\n ],\n 'mxnet':[\n 'mxnet>=1.0.0',\n 'requests<2.19.0,>=2.18.4',\n 'numpy<1.15.0,>=1.8.2',\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n 'tensorflow==1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n 'develop': [\n 'pyflakes',\n 'pytest>=3.5.1',\n 'pytest-cov>=2.5.1',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage==4.0.3', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n 'papermill',\n 'graphviz',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'jsonpatch',\n 'jsonschema==v3.0.0a2' # alpha-release for draft 6\n ]\n },\n entry_points = {\n 'console_scripts': ['pyhf=pyhf.commandline:pyhf']\n },\n dependency_links = [\n ]\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nsetup(\n name = 'pyhf',\n version = '0.0.15',\n description = '(partial) pure python histfactory implementation',\n url = '',\n author = 'Lukas Heinrich',\n author_email = '[email protected]',\n packages = find_packages(),\n include_package_data = True,\n install_requires = [\n 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n ],\n extras_require = {\n 'xmlimport': [\n 'uproot',\n ],\n 'torch': [\n 'torch>=0.4.0'\n ],\n 'mxnet':[\n 'mxnet>=1.0.0',\n 'requests<2.19.0,>=2.18.4',\n 'numpy<1.15.0,>=1.8.2',\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n 'tensorflow>=1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n 'develop': [\n 'pyflakes',\n 'pytest>=3.5.1',\n 'pytest-cov>=2.5.1',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n 'papermill',\n 'graphviz',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'jsonpatch'\n ]\n },\n entry_points = {\n 'console_scripts': ['pyhf=pyhf.commandline:pyhf']\n },\n dependency_links = [\n ]\n)\n", "path": "setup.py"}]}
| 2,167 | 365 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.