
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_27764
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-4025
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
motherless extractor - test 0 fails
```
$ python ~/projects/youtube-dl/test/test_download.py TestDownload.test_Motherless
[Motherless] AC3FFE1: Downloading webpage
[info] Writing video description metadata as JSON to: AC3FFE1.info.json
[debug] Invoking downloader on 'http://s17.motherlessmedia.com/dev386/0/572/287/0572287847.mp4/5cb6d38eccba71d7f6bb2ef260997c3d/544A96C0.mp4'
[download] Destination: AC3FFE1.mp4
[download] 100% of 10.00KiB in 00:00
F
======================================================================
FAIL: test_Motherless (__main__.TestDownload)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/crabman/projects/youtube-dl/test/test_download.py", line 170, in test_template
self.assertTrue(os.path.exists(tc_filename), msg='Missing file ' + tc_filename)
AssertionError: False is not true : Missing file AC3FFE1.flv
----------------------------------------------------------------------
Ran 1 test in 1.690s
FAILED (failures=1)
```
Apparently that video's page no longer give you flv, but instead gives you mp4 file. I am not sure why it happened. Maybe motherless doesn't serve flv files anymore, maybe it still does for some videos - I don't know.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/motherless.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import datetime
4 import re
5
6 from .common import InfoExtractor
7 from ..utils import (
8 int_or_none,
9 unified_strdate,
10 )
11
12
13 class MotherlessIE(InfoExtractor):
14 _VALID_URL = r'http://(?:www\.)?motherless\.com/(?P<id>[A-Z0-9]+)'
15 _TESTS = [
16 {
17 'url': 'http://motherless.com/AC3FFE1',
18 'md5': '5527fef81d2e529215dad3c2d744a7d9',
19 'info_dict': {
20 'id': 'AC3FFE1',
21 'ext': 'flv',
22 'title': 'Fucked in the ass while playing PS3',
23 'categories': ['Gaming', 'anal', 'reluctant', 'rough', 'Wife'],
24 'upload_date': '20100913',
25 'uploader_id': 'famouslyfuckedup',
26 'thumbnail': 're:http://.*\.jpg',
27 'age_limit': 18,
28 }
29 },
30 {
31 'url': 'http://motherless.com/532291B',
32 'md5': 'bc59a6b47d1f958e61fbd38a4d31b131',
33 'info_dict': {
34 'id': '532291B',
35 'ext': 'mp4',
36 'title': 'Amazing girl playing the omegle game, PERFECT!',
37 'categories': ['Amateur', 'webcam', 'omegle', 'pink', 'young', 'masturbate', 'teen', 'game', 'hairy'],
38 'upload_date': '20140622',
39 'uploader_id': 'Sulivana7x',
40 'thumbnail': 're:http://.*\.jpg',
41 'age_limit': 18,
42 }
43 }
44 ]
45
46 def _real_extract(self,url):
47 mobj = re.match(self._VALID_URL, url)
48 video_id = mobj.group('id')
49
50 webpage = self._download_webpage(url, video_id)
51
52 title = self._html_search_regex(r'id="view-upload-title">\s+([^<]+)<', webpage, 'title')
53
54 video_url = self._html_search_regex(r'setup\(\{\s+"file".+: "([^"]+)",', webpage, 'video_url')
55 age_limit = self._rta_search(webpage)
56
57 view_count = self._html_search_regex(r'<strong>Views</strong>\s+([^<]+)<', webpage, 'view_count')
58
59 upload_date = self._html_search_regex(r'<strong>Uploaded</strong>\s+([^<]+)<', webpage, 'upload_date')
60 if 'Ago' in upload_date:
61 days = int(re.search(r'([0-9]+)', upload_date).group(1))
62 upload_date = (datetime.datetime.now() - datetime.timedelta(days=days)).strftime('%Y%m%d')
63 else:
64 upload_date = unified_strdate(upload_date)
65
66 like_count = self._html_search_regex(r'<strong>Favorited</strong>\s+([^<]+)<', webpage, 'like_count')
67
68 comment_count = webpage.count('class="media-comment-contents"')
69 uploader_id = self._html_search_regex(r'"thumb-member-username">\s+<a href="/m/([^"]+)"', webpage, 'uploader_id')
70
71 categories = self._html_search_meta('keywords', webpage)
72 if categories:
73 categories = [cat.strip() for cat in categories.split(',')]
74
75 return {
76 'id': video_id,
77 'title': title,
78 'upload_date': upload_date,
79 'uploader_id': uploader_id,
80 'thumbnail': self._og_search_thumbnail(webpage),
81 'categories': categories,
82 'view_count': int_or_none(view_count.replace(',', '')),
83 'like_count': int_or_none(like_count.replace(',', '')),
84 'comment_count': comment_count,
85 'age_limit': age_limit,
86 'url': video_url,
87 }
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/motherless.py b/youtube_dl/extractor/motherless.py
--- a/youtube_dl/extractor/motherless.py
+++ b/youtube_dl/extractor/motherless.py
@@ -11,14 +11,14 @@
class MotherlessIE(InfoExtractor):
- _VALID_URL = r'http://(?:www\.)?motherless\.com/(?P<id>[A-Z0-9]+)'
+ _VALID_URL = r'http://(?:www\.)?motherless\.com/(?:g/[a-z0-9_]+/)?(?P<id>[A-Z0-9]+)'
_TESTS = [
{
'url': 'http://motherless.com/AC3FFE1',
- 'md5': '5527fef81d2e529215dad3c2d744a7d9',
+ 'md5': '310f62e325a9fafe64f68c0bccb6e75f',
'info_dict': {
'id': 'AC3FFE1',
- 'ext': 'flv',
+ 'ext': 'mp4',
'title': 'Fucked in the ass while playing PS3',
'categories': ['Gaming', 'anal', 'reluctant', 'rough', 'Wife'],
'upload_date': '20100913',
@@ -40,6 +40,20 @@
'thumbnail': 're:http://.*\.jpg',
'age_limit': 18,
}
+ },
+ {
+ 'url': 'http://motherless.com/g/cosplay/633979F',
+ 'md5': '0b2a43f447a49c3e649c93ad1fafa4a0',
+ 'info_dict': {
+ 'id': '633979F',
+ 'ext': 'mp4',
+ 'title': 'Turtlette',
+ 'categories': ['superheroine heroine superher'],
+ 'upload_date': '20140827',
+ 'uploader_id': 'shade0230',
+ 'thumbnail': 're:http://.*\.jpg',
+ 'age_limit': 18,
+ }
}
]
|
{"golden_diff": "diff --git a/youtube_dl/extractor/motherless.py b/youtube_dl/extractor/motherless.py\n--- a/youtube_dl/extractor/motherless.py\n+++ b/youtube_dl/extractor/motherless.py\n@@ -11,14 +11,14 @@\n \n \n class MotherlessIE(InfoExtractor):\n- _VALID_URL = r'http://(?:www\\.)?motherless\\.com/(?P<id>[A-Z0-9]+)'\n+ _VALID_URL = r'http://(?:www\\.)?motherless\\.com/(?:g/[a-z0-9_]+/)?(?P<id>[A-Z0-9]+)'\n _TESTS = [\n {\n 'url': 'http://motherless.com/AC3FFE1',\n- 'md5': '5527fef81d2e529215dad3c2d744a7d9',\n+ 'md5': '310f62e325a9fafe64f68c0bccb6e75f',\n 'info_dict': {\n 'id': 'AC3FFE1',\n- 'ext': 'flv',\n+ 'ext': 'mp4',\n 'title': 'Fucked in the ass while playing PS3',\n 'categories': ['Gaming', 'anal', 'reluctant', 'rough', 'Wife'],\n 'upload_date': '20100913',\n@@ -40,6 +40,20 @@\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n+ },\n+ {\n+ 'url': 'http://motherless.com/g/cosplay/633979F',\n+ 'md5': '0b2a43f447a49c3e649c93ad1fafa4a0',\n+ 'info_dict': {\n+ 'id': '633979F',\n+ 'ext': 'mp4',\n+ 'title': 'Turtlette',\n+ 'categories': ['superheroine heroine superher'],\n+ 'upload_date': '20140827',\n+ 'uploader_id': 'shade0230',\n+ 'thumbnail': 're:http://.*\\.jpg',\n+ 'age_limit': 18,\n+ }\n }\n ]\n", "issue": "motherless extractor - test 0 fails\n```\n$ python ~/projects/youtube-dl/test/test_download.py TestDownload.test_Motherless\n[Motherless] AC3FFE1: Downloading webpage\n[info] Writing video description metadata as JSON to: AC3FFE1.info.json\n[debug] Invoking downloader on 'http://s17.motherlessmedia.com/dev386/0/572/287/0572287847.mp4/5cb6d38eccba71d7f6bb2ef260997c3d/544A96C0.mp4'\n[download] Destination: AC3FFE1.mp4\n[download] 100% of 10.00KiB in 00:00\nF\n======================================================================\nFAIL: test_Motherless (__main__.TestDownload)\n----------------------------------------------------------------------\nTraceback (most recent call last):\nFile \"/home/crabman/projects/youtube-dl/test/test_download.py\", line 170, in test_template\n self.assertTrue(os.path.exists(tc_filename), msg='Missing file ' + tc_filename)\nAssertionError: False is not true : Missing file AC3FFE1.flv\n\n----------------------------------------------------------------------\nRan 1 test in 1.690s\n\nFAILED (failures=1)\n```\n\nApparently that video's page no longer give you flv, but instead gives you mp4 file. I am not sure why it happened. Maybe motherless doesn't serve flv files anymore, maybe it still does for some videos - I don't know.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport datetime\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n unified_strdate,\n)\n\n\nclass MotherlessIE(InfoExtractor):\n _VALID_URL = r'http://(?:www\\.)?motherless\\.com/(?P<id>[A-Z0-9]+)'\n _TESTS = [\n {\n 'url': 'http://motherless.com/AC3FFE1',\n 'md5': '5527fef81d2e529215dad3c2d744a7d9',\n 'info_dict': {\n 'id': 'AC3FFE1',\n 'ext': 'flv',\n 'title': 'Fucked in the ass while playing PS3',\n 'categories': ['Gaming', 'anal', 'reluctant', 'rough', 'Wife'],\n 'upload_date': '20100913',\n 'uploader_id': 'famouslyfuckedup',\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n },\n {\n 'url': 'http://motherless.com/532291B',\n 'md5': 'bc59a6b47d1f958e61fbd38a4d31b131',\n 'info_dict': {\n 'id': '532291B',\n 'ext': 'mp4',\n 'title': 'Amazing girl playing the omegle game, PERFECT!',\n 'categories': ['Amateur', 'webcam', 'omegle', 'pink', 'young', 'masturbate', 'teen', 'game', 'hairy'],\n 'upload_date': '20140622',\n 'uploader_id': 'Sulivana7x',\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n }\n ]\n\n def _real_extract(self,url):\n mobj = re.match(self._VALID_URL, url)\n video_id = mobj.group('id')\n\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_regex(r'id=\"view-upload-title\">\\s+([^<]+)<', webpage, 'title')\n \n video_url = self._html_search_regex(r'setup\\(\\{\\s+\"file\".+: \"([^\"]+)\",', webpage, 'video_url')\n age_limit = self._rta_search(webpage)\n\n view_count = self._html_search_regex(r'<strong>Views</strong>\\s+([^<]+)<', webpage, 'view_count')\n \n upload_date = self._html_search_regex(r'<strong>Uploaded</strong>\\s+([^<]+)<', webpage, 'upload_date')\n if 'Ago' in upload_date:\n days = int(re.search(r'([0-9]+)', upload_date).group(1))\n upload_date = (datetime.datetime.now() - datetime.timedelta(days=days)).strftime('%Y%m%d')\n else:\n upload_date = unified_strdate(upload_date)\n\n like_count = self._html_search_regex(r'<strong>Favorited</strong>\\s+([^<]+)<', webpage, 'like_count')\n\n comment_count = webpage.count('class=\"media-comment-contents\"')\n uploader_id = self._html_search_regex(r'\"thumb-member-username\">\\s+<a href=\"/m/([^\"]+)\"', webpage, 'uploader_id')\n\n categories = self._html_search_meta('keywords', webpage)\n if categories:\n categories = [cat.strip() for cat in categories.split(',')]\n\n return {\n 'id': video_id,\n 'title': title,\n 'upload_date': upload_date,\n 'uploader_id': uploader_id,\n 'thumbnail': self._og_search_thumbnail(webpage),\n 'categories': categories,\n 'view_count': int_or_none(view_count.replace(',', '')),\n 'like_count': int_or_none(like_count.replace(',', '')),\n 'comment_count': comment_count,\n 'age_limit': age_limit,\n 'url': video_url,\n }\n", "path": "youtube_dl/extractor/motherless.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport datetime\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n unified_strdate,\n)\n\n\nclass MotherlessIE(InfoExtractor):\n _VALID_URL = r'http://(?:www\\.)?motherless\\.com/(?:g/[a-z0-9_]+/)?(?P<id>[A-Z0-9]+)'\n _TESTS = [\n {\n 'url': 'http://motherless.com/AC3FFE1',\n 'md5': '310f62e325a9fafe64f68c0bccb6e75f',\n 'info_dict': {\n 'id': 'AC3FFE1',\n 'ext': 'mp4',\n 'title': 'Fucked in the ass while playing PS3',\n 'categories': ['Gaming', 'anal', 'reluctant', 'rough', 'Wife'],\n 'upload_date': '20100913',\n 'uploader_id': 'famouslyfuckedup',\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n },\n {\n 'url': 'http://motherless.com/532291B',\n 'md5': 'bc59a6b47d1f958e61fbd38a4d31b131',\n 'info_dict': {\n 'id': '532291B',\n 'ext': 'mp4',\n 'title': 'Amazing girl playing the omegle game, PERFECT!',\n 'categories': ['Amateur', 'webcam', 'omegle', 'pink', 'young', 'masturbate', 'teen', 'game', 'hairy'],\n 'upload_date': '20140622',\n 'uploader_id': 'Sulivana7x',\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n },\n {\n 'url': 'http://motherless.com/g/cosplay/633979F',\n 'md5': '0b2a43f447a49c3e649c93ad1fafa4a0',\n 'info_dict': {\n 'id': '633979F',\n 'ext': 'mp4',\n 'title': 'Turtlette',\n 'categories': ['superheroine heroine superher'],\n 'upload_date': '20140827',\n 'uploader_id': 'shade0230',\n 'thumbnail': 're:http://.*\\.jpg',\n 'age_limit': 18,\n }\n }\n ]\n\n def _real_extract(self,url):\n mobj = re.match(self._VALID_URL, url)\n video_id = mobj.group('id')\n\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_regex(r'id=\"view-upload-title\">\\s+([^<]+)<', webpage, 'title')\n \n video_url = self._html_search_regex(r'setup\\(\\{\\s+\"file\".+: \"([^\"]+)\",', webpage, 'video_url')\n age_limit = self._rta_search(webpage)\n\n view_count = self._html_search_regex(r'<strong>Views</strong>\\s+([^<]+)<', webpage, 'view_count')\n \n upload_date = self._html_search_regex(r'<strong>Uploaded</strong>\\s+([^<]+)<', webpage, 'upload_date')\n if 'Ago' in upload_date:\n days = int(re.search(r'([0-9]+)', upload_date).group(1))\n upload_date = (datetime.datetime.now() - datetime.timedelta(days=days)).strftime('%Y%m%d')\n else:\n upload_date = unified_strdate(upload_date)\n\n like_count = self._html_search_regex(r'<strong>Favorited</strong>\\s+([^<]+)<', webpage, 'like_count')\n\n comment_count = webpage.count('class=\"media-comment-contents\"')\n uploader_id = self._html_search_regex(r'\"thumb-member-username\">\\s+<a href=\"/m/([^\"]+)\"', webpage, 'uploader_id')\n\n categories = self._html_search_meta('keywords', webpage)\n if categories:\n categories = [cat.strip() for cat in categories.split(',')]\n\n return {\n 'id': video_id,\n 'title': title,\n 'upload_date': upload_date,\n 'uploader_id': uploader_id,\n 'thumbnail': self._og_search_thumbnail(webpage),\n 'categories': categories,\n 'view_count': int_or_none(view_count.replace(',', '')),\n 'like_count': int_or_none(like_count.replace(',', '')),\n 'comment_count': comment_count,\n 'age_limit': age_limit,\n 'url': video_url,\n }\n", "path": "youtube_dl/extractor/motherless.py"}]}
| 1,688 | 547 |
gh_patches_debug_41421
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-8984
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] m4/1.4.19: Runtime assertion windows pops up on MSVC in Debug mode
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **m4/1.4.19**
* Operating System+version: **Windows 10**
* Compiler+version: **MSVC 2017, 2019 in DEBUG**
* Conan version: **conan 1.44.0**
* Python version: **Python 3.9.5**
I have a recipe that depends on bison. 3.7.6 gives me parse errors, so I keep it at 3.7.1. I had pinned the exact bison/3.7.1 recipe and all worked well. I am trying to update my dependencies, so I tried the newest bison/3.7.1 revision, and I am now getting an assertion popup in m4.
I have tried various combinations to see if I could pinpoint what changed. My conclusion is that it's the move from m4/1.4.18 to m4/1.4.19 (I have tried the newest recipe revision of m4/1.4.18 and it worked, and the only m4/1.4.19 available fails).
```python
# Latest bison/3.7.1 with m4/1.4.18
#self.build_requires("bison/3.7.1#dcffa3dd9204cb79ac7ca09a7f19bb8b") # Works
# First bison/3.7.1 with m4/1.4.19
self.build_requires("bison/3.7.1#47f49e709ddb9f8e055471c4e3c4e67d"): # Fails
# Latest bison/3.7.1
#self.build_requires("bison/3.7.1#ad29e804e82c8b6d58765096676b5a5e") # Fails
```
<img width="886" alt="Screen Shot 2022-01-14 at 13 35 01" src="https://user-images.githubusercontent.com/5479063/149528919-eff87be5-e7cc-4924-bb52-e67246e3cf1f.png">
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
[settings]
arch=x86_64
arch_build=x86_64
build_type=Debug
compiler=Visual Studio
compiler.runtime=MDd
compiler.version=16
os=Windows
os_build=Windows
[options]
[build_requires]
[env]
```
### Steps to reproduce (Include if Applicable)
```
git clone [email protected]:NREL/conan-openstudio-ruby.git
git checkout update_ruby_installer_and_remotes
'C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\Build\vcvarsall.bat' x64
conan create . openstudio_ruby/2.7.2@nrel/testing -b missing -b openstudio_ruby -s build_type=Debug
```
### Logs (Include/Attach if Applicable)
Example of a failed run: https://github.com/NREL/conan-openstudio-ruby/runs/4787415523?check_suite_focus=true
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/m4/all/conanfile.py`
Content:
```
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 from contextlib import contextmanager
3 import functools
4 import os
5
6 required_conan_version = ">=1.33.0"
7
8
9 class M4Conan(ConanFile):
10 name = "m4"
11 description = "GNU M4 is an implementation of the traditional Unix macro processor"
12 topics = ("macro", "preprocessor")
13 homepage = "https://www.gnu.org/software/m4/"
14 url = "https://github.com/conan-io/conan-center-index"
15 license = "GPL-3.0-only"
16 settings = "os", "arch", "compiler", "build_type"
17
18 exports_sources = "patches/*.patch",
19
20 @property
21 def _source_subfolder(self):
22 return "source_subfolder"
23
24 @property
25 def _settings_build(self):
26 return getattr(self, "settings_build", self.settings)
27
28 @property
29 def _is_msvc(self):
30 return self.settings.compiler == "Visual Studio"
31
32 def build_requirements(self):
33 if self._settings_build.os == "Windows" and not tools.get_env("CONAN_BASH_PATH"):
34 self.build_requires("msys2/cci.latest")
35
36 def package_id(self):
37 del self.info.settings.compiler
38
39 def source(self):
40 tools.get(**self.conan_data["sources"][self.version],
41 destination=self._source_subfolder, strip_root=True)
42
43 @functools.lru_cache(1)
44 def _configure_autotools(self):
45 conf_args = []
46 autotools = AutoToolsBuildEnvironment(self, win_bash=self._settings_build.os == "Windows")
47 build_canonical_name = None
48 host_canonical_name = None
49 if self.settings.compiler == "Visual Studio":
50 # The somewhat older configure script of m4 does not understand the canonical names of Visual Studio
51 build_canonical_name = False
52 host_canonical_name = False
53 autotools.flags.append("-FS")
54 # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug
55 # Visual Studio does not support the %n format flag:
56 # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions
57 # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,
58 # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.
59 conf_args.extend(["gl_cv_func_printf_directive_n=no", "gl_cv_func_snprintf_directive_n=no", "gl_cv_func_snprintf_directive_n=no"])
60 if self.settings.build_type in ("Debug", "RelWithDebInfo"):
61 autotools.link_flags.append("-PDB")
62 elif self.settings.compiler == "clang":
63 if tools.Version(self.version) < "1.4.19":
64 autotools.flags.extend(["-rtlib=compiler-rt", "-Wno-unused-command-line-argument"])
65 autotools.configure(args=conf_args, configure_dir=self._source_subfolder, build=build_canonical_name, host=host_canonical_name)
66 return autotools
67
68 @contextmanager
69 def _build_context(self):
70 if self.settings.compiler == "Visual Studio":
71 with tools.vcvars(self.settings):
72 env = {
73 "AR": "{}/build-aux/ar-lib lib".format(tools.unix_path(self._source_subfolder)),
74 "CC": "cl -nologo",
75 "CXX": "cl -nologo",
76 "LD": "link",
77 "NM": "dumpbin -symbols",
78 "OBJDUMP": ":",
79 "RANLIB": ":",
80 "STRIP": ":",
81 }
82 with tools.environment_append(env):
83 yield
84 else:
85 yield
86
87 def _patch_sources(self):
88 for patch in self.conan_data.get("patches", {}).get(self.version, []):
89 tools.patch(**patch)
90
91 def build(self):
92 self._patch_sources()
93 with self._build_context():
94 autotools = self._configure_autotools()
95 autotools.make()
96 if tools.get_env("CONAN_RUN_TESTS", False):
97 self.output.info("Running m4 checks...")
98 with tools.chdir("tests"):
99 autotools.make(target="check")
100
101 def package(self):
102 self.copy("COPYING", src=self._source_subfolder, dst="licenses")
103 with self._build_context():
104 autotools = self._configure_autotools()
105 autotools.install()
106 tools.rmdir(os.path.join(self.package_folder, "share"))
107
108 def package_info(self):
109 self.cpp_info.libdirs = []
110
111 bin_path = os.path.join(self.package_folder, "bin")
112 self.output.info("Appending PATH environment variable: {}".format(bin_path))
113 self.env_info.PATH.append(bin_path)
114
115 bin_ext = ".exe" if self.settings.os == "Windows" else ""
116 m4_bin = os.path.join(self.package_folder, "bin", "m4{}".format(bin_ext)).replace("\\", "/")
117
118 # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path
119 self.output.info("Setting M4 environment variable: {}".format(m4_bin))
120 self.env_info.M4 = m4_bin
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/m4/all/conanfile.py b/recipes/m4/all/conanfile.py
--- a/recipes/m4/all/conanfile.py
+++ b/recipes/m4/all/conanfile.py
@@ -27,7 +27,7 @@
@property
def _is_msvc(self):
- return self.settings.compiler == "Visual Studio"
+ return self.settings.compiler == "Visual Studio" or self.settings.compiler == "msvc"
def build_requirements(self):
if self._settings_build.os == "Windows" and not tools.get_env("CONAN_BASH_PATH"):
@@ -46,7 +46,7 @@
autotools = AutoToolsBuildEnvironment(self, win_bash=self._settings_build.os == "Windows")
build_canonical_name = None
host_canonical_name = None
- if self.settings.compiler == "Visual Studio":
+ if self._is_msvc:
# The somewhat older configure script of m4 does not understand the canonical names of Visual Studio
build_canonical_name = False
host_canonical_name = False
@@ -62,14 +62,18 @@
elif self.settings.compiler == "clang":
if tools.Version(self.version) < "1.4.19":
autotools.flags.extend(["-rtlib=compiler-rt", "-Wno-unused-command-line-argument"])
+ if self.settings.os == 'Windows':
+ conf_args.extend(["ac_cv_func__set_invalid_parameter_handler=yes"])
+
autotools.configure(args=conf_args, configure_dir=self._source_subfolder, build=build_canonical_name, host=host_canonical_name)
return autotools
@contextmanager
def _build_context(self):
- if self.settings.compiler == "Visual Studio":
+ env = {"PATH": [os.path.abspath(self._source_subfolder)]}
+ if self._is_msvc:
with tools.vcvars(self.settings):
- env = {
+ env.update({
"AR": "{}/build-aux/ar-lib lib".format(tools.unix_path(self._source_subfolder)),
"CC": "cl -nologo",
"CXX": "cl -nologo",
@@ -78,17 +82,22 @@
"OBJDUMP": ":",
"RANLIB": ":",
"STRIP": ":",
- }
+ })
with tools.environment_append(env):
yield
else:
- yield
+ with tools.environment_append(env):
+ yield
def _patch_sources(self):
for patch in self.conan_data.get("patches", {}).get(self.version, []):
tools.patch(**patch)
def build(self):
+ with tools.chdir(self._source_subfolder):
+ tools.save("help2man", '#!/usr/bin/env bash\n:')
+ if os.name == 'posix':
+ os.chmod("help2man", os.stat("help2man").st_mode | 0o111)
self._patch_sources()
with self._build_context():
autotools = self._configure_autotools()
|
{"golden_diff": "diff --git a/recipes/m4/all/conanfile.py b/recipes/m4/all/conanfile.py\n--- a/recipes/m4/all/conanfile.py\n+++ b/recipes/m4/all/conanfile.py\n@@ -27,7 +27,7 @@\n \n @property\n def _is_msvc(self):\n- return self.settings.compiler == \"Visual Studio\"\n+ return self.settings.compiler == \"Visual Studio\" or self.settings.compiler == \"msvc\"\n \n def build_requirements(self):\n if self._settings_build.os == \"Windows\" and not tools.get_env(\"CONAN_BASH_PATH\"):\n@@ -46,7 +46,7 @@\n autotools = AutoToolsBuildEnvironment(self, win_bash=self._settings_build.os == \"Windows\")\n build_canonical_name = None\n host_canonical_name = None\n- if self.settings.compiler == \"Visual Studio\":\n+ if self._is_msvc:\n # The somewhat older configure script of m4 does not understand the canonical names of Visual Studio\n build_canonical_name = False\n host_canonical_name = False\n@@ -62,14 +62,18 @@\n elif self.settings.compiler == \"clang\":\n if tools.Version(self.version) < \"1.4.19\":\n autotools.flags.extend([\"-rtlib=compiler-rt\", \"-Wno-unused-command-line-argument\"])\n+ if self.settings.os == 'Windows':\n+ conf_args.extend([\"ac_cv_func__set_invalid_parameter_handler=yes\"])\n+\n autotools.configure(args=conf_args, configure_dir=self._source_subfolder, build=build_canonical_name, host=host_canonical_name)\n return autotools\n \n @contextmanager\n def _build_context(self):\n- if self.settings.compiler == \"Visual Studio\":\n+ env = {\"PATH\": [os.path.abspath(self._source_subfolder)]}\n+ if self._is_msvc:\n with tools.vcvars(self.settings):\n- env = {\n+ env.update({\n \"AR\": \"{}/build-aux/ar-lib lib\".format(tools.unix_path(self._source_subfolder)),\n \"CC\": \"cl -nologo\",\n \"CXX\": \"cl -nologo\",\n@@ -78,17 +82,22 @@\n \"OBJDUMP\": \":\",\n \"RANLIB\": \":\",\n \"STRIP\": \":\",\n- }\n+ })\n with tools.environment_append(env):\n yield\n else:\n- yield\n+ with tools.environment_append(env):\n+ yield\n \n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n \n def build(self):\n+ with tools.chdir(self._source_subfolder):\n+ tools.save(\"help2man\", '#!/usr/bin/env bash\\n:')\n+ if os.name == 'posix':\n+ os.chmod(\"help2man\", os.stat(\"help2man\").st_mode | 0o111)\n self._patch_sources()\n with self._build_context():\n autotools = self._configure_autotools()\n", "issue": "[package] m4/1.4.19: Runtime assertion windows pops up on MSVC in Debug mode\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **m4/1.4.19**\r\n * Operating System+version: **Windows 10**\r\n * Compiler+version: **MSVC 2017, 2019 in DEBUG**\r\n * Conan version: **conan 1.44.0**\r\n * Python version: **Python 3.9.5**\r\n\r\nI have a recipe that depends on bison. 3.7.6 gives me parse errors, so I keep it at 3.7.1. I had pinned the exact bison/3.7.1 recipe and all worked well. I am trying to update my dependencies, so I tried the newest bison/3.7.1 revision, and I am now getting an assertion popup in m4.\r\n\r\nI have tried various combinations to see if I could pinpoint what changed. My conclusion is that it's the move from m4/1.4.18 to m4/1.4.19 (I have tried the newest recipe revision of m4/1.4.18 and it worked, and the only m4/1.4.19 available fails).\r\n\r\n```python\r\n # Latest bison/3.7.1 with m4/1.4.18\r\n #self.build_requires(\"bison/3.7.1#dcffa3dd9204cb79ac7ca09a7f19bb8b\") # Works\r\n\r\n # First bison/3.7.1 with m4/1.4.19\r\n self.build_requires(\"bison/3.7.1#47f49e709ddb9f8e055471c4e3c4e67d\"): # Fails\r\n\r\n # Latest bison/3.7.1\r\n #self.build_requires(\"bison/3.7.1#ad29e804e82c8b6d58765096676b5a5e\") # Fails\r\n```\r\n\r\n<img width=\"886\" alt=\"Screen Shot 2022-01-14 at 13 35 01\" src=\"https://user-images.githubusercontent.com/5479063/149528919-eff87be5-e7cc-4924-bb52-e67246e3cf1f.png\">\r\n\r\n\r\n\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n\r\n```\r\n[settings]\r\narch=x86_64\r\narch_build=x86_64\r\nbuild_type=Debug\r\ncompiler=Visual Studio\r\ncompiler.runtime=MDd\r\ncompiler.version=16\r\nos=Windows\r\nos_build=Windows\r\n[options]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n\r\n```\r\ngit clone [email protected]:NREL/conan-openstudio-ruby.git\r\ngit checkout update_ruby_installer_and_remotes\r\n\r\n'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Auxiliary\\Build\\vcvarsall.bat' x64\r\n\r\nconan create . openstudio_ruby/2.7.2@nrel/testing -b missing -b openstudio_ruby -s build_type=Debug\r\n```\r\n\r\n### Logs (Include/Attach if Applicable)\r\n\r\nExample of a failed run: https://github.com/NREL/conan-openstudio-ruby/runs/4787415523?check_suite_focus=true\r\n\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport functools\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\n\nclass M4Conan(ConanFile):\n name = \"m4\"\n description = \"GNU M4 is an implementation of the traditional Unix macro processor\"\n topics = (\"macro\", \"preprocessor\")\n homepage = \"https://www.gnu.org/software/m4/\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"GPL-3.0-only\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n exports_sources = \"patches/*.patch\",\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _settings_build(self):\n return getattr(self, \"settings_build\", self.settings)\n\n @property\n def _is_msvc(self):\n return self.settings.compiler == \"Visual Studio\"\n\n def build_requirements(self):\n if self._settings_build.os == \"Windows\" and not tools.get_env(\"CONAN_BASH_PATH\"):\n self.build_requires(\"msys2/cci.latest\")\n\n def package_id(self):\n del self.info.settings.compiler\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n @functools.lru_cache(1)\n def _configure_autotools(self):\n conf_args = []\n autotools = AutoToolsBuildEnvironment(self, win_bash=self._settings_build.os == \"Windows\")\n build_canonical_name = None\n host_canonical_name = None\n if self.settings.compiler == \"Visual Studio\":\n # The somewhat older configure script of m4 does not understand the canonical names of Visual Studio\n build_canonical_name = False\n host_canonical_name = False\n autotools.flags.append(\"-FS\")\n # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug\n # Visual Studio does not support the %n format flag:\n # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions\n # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,\n # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.\n conf_args.extend([\"gl_cv_func_printf_directive_n=no\", \"gl_cv_func_snprintf_directive_n=no\", \"gl_cv_func_snprintf_directive_n=no\"])\n if self.settings.build_type in (\"Debug\", \"RelWithDebInfo\"):\n autotools.link_flags.append(\"-PDB\")\n elif self.settings.compiler == \"clang\":\n if tools.Version(self.version) < \"1.4.19\":\n autotools.flags.extend([\"-rtlib=compiler-rt\", \"-Wno-unused-command-line-argument\"])\n autotools.configure(args=conf_args, configure_dir=self._source_subfolder, build=build_canonical_name, host=host_canonical_name)\n return autotools\n\n @contextmanager\n def _build_context(self):\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n env = {\n \"AR\": \"{}/build-aux/ar-lib lib\".format(tools.unix_path(self._source_subfolder)),\n \"CC\": \"cl -nologo\",\n \"CXX\": \"cl -nologo\",\n \"LD\": \"link\",\n \"NM\": \"dumpbin -symbols\",\n \"OBJDUMP\": \":\",\n \"RANLIB\": \":\",\n \"STRIP\": \":\",\n }\n with tools.environment_append(env):\n yield\n else:\n yield\n\n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n if tools.get_env(\"CONAN_RUN_TESTS\", False):\n self.output.info(\"Running m4 checks...\")\n with tools.chdir(\"tests\"):\n autotools.make(target=\"check\")\n\n def package(self):\n self.copy(\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n\n def package_info(self):\n self.cpp_info.libdirs = []\n\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bin_path))\n self.env_info.PATH.append(bin_path)\n\n bin_ext = \".exe\" if self.settings.os == \"Windows\" else \"\"\n m4_bin = os.path.join(self.package_folder, \"bin\", \"m4{}\".format(bin_ext)).replace(\"\\\\\", \"/\")\n\n # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path\n self.output.info(\"Setting M4 environment variable: {}\".format(m4_bin))\n self.env_info.M4 = m4_bin\n", "path": "recipes/m4/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport functools\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\n\nclass M4Conan(ConanFile):\n name = \"m4\"\n description = \"GNU M4 is an implementation of the traditional Unix macro processor\"\n topics = (\"macro\", \"preprocessor\")\n homepage = \"https://www.gnu.org/software/m4/\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"GPL-3.0-only\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n exports_sources = \"patches/*.patch\",\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _settings_build(self):\n return getattr(self, \"settings_build\", self.settings)\n\n @property\n def _is_msvc(self):\n return self.settings.compiler == \"Visual Studio\" or self.settings.compiler == \"msvc\"\n\n def build_requirements(self):\n if self._settings_build.os == \"Windows\" and not tools.get_env(\"CONAN_BASH_PATH\"):\n self.build_requires(\"msys2/cci.latest\")\n\n def package_id(self):\n del self.info.settings.compiler\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n @functools.lru_cache(1)\n def _configure_autotools(self):\n conf_args = []\n autotools = AutoToolsBuildEnvironment(self, win_bash=self._settings_build.os == \"Windows\")\n build_canonical_name = None\n host_canonical_name = None\n if self._is_msvc:\n # The somewhat older configure script of m4 does not understand the canonical names of Visual Studio\n build_canonical_name = False\n host_canonical_name = False\n autotools.flags.append(\"-FS\")\n # Avoid a `Assertion Failed Dialog Box` during configure with build_type=Debug\n # Visual Studio does not support the %n format flag:\n # https://docs.microsoft.com/en-us/cpp/c-runtime-library/format-specification-syntax-printf-and-wprintf-functions\n # Because the %n format is inherently insecure, it is disabled by default. If %n is encountered in a format string,\n # the invalid parameter handler is invoked, as described in Parameter Validation. To enable %n support, see _set_printf_count_output.\n conf_args.extend([\"gl_cv_func_printf_directive_n=no\", \"gl_cv_func_snprintf_directive_n=no\", \"gl_cv_func_snprintf_directive_n=no\"])\n if self.settings.build_type in (\"Debug\", \"RelWithDebInfo\"):\n autotools.link_flags.append(\"-PDB\")\n elif self.settings.compiler == \"clang\":\n if tools.Version(self.version) < \"1.4.19\":\n autotools.flags.extend([\"-rtlib=compiler-rt\", \"-Wno-unused-command-line-argument\"])\n if self.settings.os == 'Windows':\n conf_args.extend([\"ac_cv_func__set_invalid_parameter_handler=yes\"])\n\n autotools.configure(args=conf_args, configure_dir=self._source_subfolder, build=build_canonical_name, host=host_canonical_name)\n return autotools\n\n @contextmanager\n def _build_context(self):\n env = {\"PATH\": [os.path.abspath(self._source_subfolder)]}\n if self._is_msvc:\n with tools.vcvars(self.settings):\n env.update({\n \"AR\": \"{}/build-aux/ar-lib lib\".format(tools.unix_path(self._source_subfolder)),\n \"CC\": \"cl -nologo\",\n \"CXX\": \"cl -nologo\",\n \"LD\": \"link\",\n \"NM\": \"dumpbin -symbols\",\n \"OBJDUMP\": \":\",\n \"RANLIB\": \":\",\n \"STRIP\": \":\",\n })\n with tools.environment_append(env):\n yield\n else:\n with tools.environment_append(env):\n yield\n\n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def build(self):\n with tools.chdir(self._source_subfolder):\n tools.save(\"help2man\", '#!/usr/bin/env bash\\n:')\n if os.name == 'posix':\n os.chmod(\"help2man\", os.stat(\"help2man\").st_mode | 0o111)\n self._patch_sources()\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n if tools.get_env(\"CONAN_RUN_TESTS\", False):\n self.output.info(\"Running m4 checks...\")\n with tools.chdir(\"tests\"):\n autotools.make(target=\"check\")\n\n def package(self):\n self.copy(\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n\n def package_info(self):\n self.cpp_info.libdirs = []\n\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bin_path))\n self.env_info.PATH.append(bin_path)\n\n bin_ext = \".exe\" if self.settings.os == \"Windows\" else \"\"\n m4_bin = os.path.join(self.package_folder, \"bin\", \"m4{}\".format(bin_ext)).replace(\"\\\\\", \"/\")\n\n # M4 environment variable is used by a lot of scripts as a way to override a hard-coded embedded m4 path\n self.output.info(\"Setting M4 environment variable: {}\".format(m4_bin))\n self.env_info.M4 = m4_bin\n", "path": "recipes/m4/all/conanfile.py"}]}
| 2,514 | 685 |
gh_patches_debug_6929
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-803
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
read_pem_file doesn't support certificate chains
Something like this should fix the issue:
```diff
def read_pem_file(file_obj):
cert = b""
for line in file_obj:
if line.startswith(b"-----BEGIN CERTIFICATE-----"):
break
for line in file_obj:
- if not line.startswith(b"-----END CERTIFICATE-----"):
- cert += line.strip()
+ if line.startswith(b"-----END CERTIFICATE-----"):
+ break
+ cert += line.strip()
return base64.b64decode(cert)
```
read_pem_file doesn't support certificate chains
Something like this should fix the issue:
```diff
def read_pem_file(file_obj):
cert = b""
for line in file_obj:
if line.startswith(b"-----BEGIN CERTIFICATE-----"):
break
for line in file_obj:
- if not line.startswith(b"-----END CERTIFICATE-----"):
- cert += line.strip()
+ if line.startswith(b"-----END CERTIFICATE-----"):
+ break
+ cert += line.strip()
return base64.b64decode(cert)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/utils/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31 import base64
32 import os
33 import re
34 from functools import partial
35
36 from elasticapm.conf import constants
37 from elasticapm.utils import compat, encoding
38
39 try:
40 from functools import partialmethod
41
42 partial_types = (partial, partialmethod)
43 except ImportError:
44 # Python 2
45 partial_types = (partial,)
46
47
48 default_ports = {"https": 443, "http": 80, "postgresql": 5432, "mysql": 3306, "mssql": 1433}
49
50
51 def varmap(func, var, context=None, name=None):
52 """
53 Executes ``func(key_name, value)`` on all values,
54 recursively discovering dict and list scoped
55 values.
56 """
57 if context is None:
58 context = set()
59 objid = id(var)
60 if objid in context:
61 return func(name, "<...>")
62 context.add(objid)
63 if isinstance(var, dict):
64 ret = func(name, dict((k, varmap(func, v, context, k)) for k, v in compat.iteritems(var)))
65 elif isinstance(var, (list, tuple)):
66 ret = func(name, [varmap(func, f, context, name) for f in var])
67 else:
68 ret = func(name, var)
69 context.remove(objid)
70 return ret
71
72
73 def get_name_from_func(func):
74 # partials don't have `__module__` or `__name__`, so we use the values from the "inner" function
75 if isinstance(func, partial_types):
76 return "partial({})".format(get_name_from_func(func.func))
77 elif hasattr(func, "_partialmethod") and hasattr(func._partialmethod, "func"):
78 return "partial({})".format(get_name_from_func(func._partialmethod.func))
79
80 module = func.__module__
81
82 if hasattr(func, "__name__"):
83 view_name = func.__name__
84 else: # Fall back if there's no __name__
85 view_name = func.__class__.__name__
86
87 return "{0}.{1}".format(module, view_name)
88
89
90 def build_name_with_http_method_prefix(name, request):
91 return " ".join((request.method, name)) if name else name
92
93
94 def is_master_process():
95 # currently only recognizes uwsgi master process
96 try:
97 import uwsgi
98
99 return os.getpid() == uwsgi.masterpid()
100 except ImportError:
101 return False
102
103
104 def get_url_dict(url):
105 parse_result = compat.urlparse.urlparse(url)
106
107 url_dict = {
108 "full": encoding.keyword_field(url),
109 "protocol": parse_result.scheme + ":",
110 "hostname": encoding.keyword_field(parse_result.hostname),
111 "pathname": encoding.keyword_field(parse_result.path),
112 }
113
114 port = None if parse_result.port is None else str(parse_result.port)
115
116 if port:
117 url_dict["port"] = port
118 if parse_result.query:
119 url_dict["search"] = encoding.keyword_field("?" + parse_result.query)
120 return url_dict
121
122
123 def sanitize_url(url):
124 if "@" not in url:
125 return url
126 parts = compat.urlparse.urlparse(url)
127 return url.replace("%s:%s" % (parts.username, parts.password), "%s:%s" % (parts.username, constants.MASK))
128
129
130 def get_host_from_url(url):
131 parsed_url = compat.urlparse.urlparse(url)
132 host = parsed_url.hostname or " "
133
134 if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:
135 host += ":" + str(parsed_url.port)
136
137 return host
138
139
140 def url_to_destination(url, service_type="external"):
141 parts = compat.urlparse.urlsplit(url)
142 hostname = parts.hostname
143 # preserve brackets for IPv6 URLs
144 if "://[" in url:
145 hostname = "[%s]" % hostname
146 try:
147 port = parts.port
148 except ValueError:
149 # Malformed port, just use None rather than raising an exception
150 port = None
151 default_port = default_ports.get(parts.scheme, None)
152 name = "%s://%s" % (parts.scheme, hostname)
153 resource = hostname
154 if not port and parts.scheme in default_ports:
155 port = default_ports[parts.scheme]
156 if port:
157 if port != default_port:
158 name += ":%d" % port
159 resource += ":%d" % port
160 return {"service": {"name": name, "resource": resource, "type": service_type}}
161
162
163 def read_pem_file(file_obj):
164 cert = b""
165 for line in file_obj:
166 if line.startswith(b"-----BEGIN CERTIFICATE-----"):
167 break
168 for line in file_obj:
169 if not line.startswith(b"-----END CERTIFICATE-----"):
170 cert += line.strip()
171 return base64.b64decode(cert)
172
173
174 def starmatch_to_regex(pattern):
175 i, n = 0, len(pattern)
176 res = []
177 while i < n:
178 c = pattern[i]
179 i = i + 1
180 if c == "*":
181 res.append(".*")
182 else:
183 res.append(re.escape(c))
184 return re.compile(r"(?:%s)\Z" % "".join(res), re.IGNORECASE | re.DOTALL)
185
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py
--- a/elasticapm/utils/__init__.py
+++ b/elasticapm/utils/__init__.py
@@ -165,9 +165,11 @@
for line in file_obj:
if line.startswith(b"-----BEGIN CERTIFICATE-----"):
break
+ # scan until we find the first END CERTIFICATE marker
for line in file_obj:
- if not line.startswith(b"-----END CERTIFICATE-----"):
- cert += line.strip()
+ if line.startswith(b"-----END CERTIFICATE-----"):
+ break
+ cert += line.strip()
return base64.b64decode(cert)
|
{"golden_diff": "diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py\n--- a/elasticapm/utils/__init__.py\n+++ b/elasticapm/utils/__init__.py\n@@ -165,9 +165,11 @@\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n+ # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n- if not line.startswith(b\"-----END CERTIFICATE-----\"):\n- cert += line.strip()\n+ if line.startswith(b\"-----END CERTIFICATE-----\"):\n+ break\n+ cert += line.strip()\n return base64.b64decode(cert)\n", "issue": "read_pem_file doesn't support certificate chains\nSomething like this should fix the issue:\r\n```diff\r\n def read_pem_file(file_obj):\r\n cert = b\"\"\r\n for line in file_obj:\r\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\r\n break\r\n for line in file_obj:\r\n- if not line.startswith(b\"-----END CERTIFICATE-----\"):\r\n- cert += line.strip()\r\n+ if line.startswith(b\"-----END CERTIFICATE-----\"):\r\n+ break\r\n+ cert += line.strip()\r\n return base64.b64decode(cert)\r\n```\nread_pem_file doesn't support certificate chains\nSomething like this should fix the issue:\r\n```diff\r\n def read_pem_file(file_obj):\r\n cert = b\"\"\r\n for line in file_obj:\r\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\r\n break\r\n for line in file_obj:\r\n- if not line.startswith(b\"-----END CERTIFICATE-----\"):\r\n- cert += line.strip()\r\n+ if line.startswith(b\"-----END CERTIFICATE-----\"):\r\n+ break\r\n+ cert += line.strip()\r\n return base64.b64decode(cert)\r\n```\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nfrom functools import partial\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import compat, encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\")\n context.add(objid)\n if isinstance(var, dict):\n ret = func(name, dict((k, varmap(func, v, context, k)) for k, v in compat.iteritems(var)))\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name) for f in var])\n else:\n ret = func(name, var)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func):\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process():\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url):\n parse_result = compat.urlparse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url):\n if \"@\" not in url:\n return url\n parts = compat.urlparse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url):\n parsed_url = compat.urlparse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination(url, service_type=\"external\"):\n parts = compat.urlparse.urlsplit(url)\n hostname = parts.hostname\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return {\"service\": {\"name\": name, \"resource\": resource, \"type\": service_type}}\n\n\ndef read_pem_file(file_obj):\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n for line in file_obj:\n if not line.startswith(b\"-----END CERTIFICATE-----\"):\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern):\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), re.IGNORECASE | re.DOTALL)\n", "path": "elasticapm/utils/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nfrom functools import partial\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import compat, encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\")\n context.add(objid)\n if isinstance(var, dict):\n ret = func(name, dict((k, varmap(func, v, context, k)) for k, v in compat.iteritems(var)))\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name) for f in var])\n else:\n ret = func(name, var)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func):\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process():\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url):\n parse_result = compat.urlparse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url):\n if \"@\" not in url:\n return url\n parts = compat.urlparse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url):\n parsed_url = compat.urlparse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination(url, service_type=\"external\"):\n parts = compat.urlparse.urlsplit(url)\n hostname = parts.hostname\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return {\"service\": {\"name\": name, \"resource\": resource, \"type\": service_type}}\n\n\ndef read_pem_file(file_obj):\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n if line.startswith(b\"-----END CERTIFICATE-----\"):\n break\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern):\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), re.IGNORECASE | re.DOTALL)\n", "path": "elasticapm/utils/__init__.py"}]}
| 2,436 | 162 |
gh_patches_debug_34488
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5785
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.huya: 403 Client Error: Forbidden for url
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
streamlink 6.5.1
### Description
please forgive me, my english so bad and it's hard to understand all these rules, im newbie inpython, I don’t know, this has already been asked and I read the answer that this is not a streamlink problem, but maybe you can help me
### Debug log
```text
C:\Users\matebeats>streamlink.exe https://www.huya.com/sbwfz best
[cli][info] Found matching plugin huya for URL https://www.huya.com/sbwfz
[cli][info] Available streams: source_hw (worst, best)
[cli][info] Opening stream: source_hw (http)
[cli][info] Starting player: D:\matebeats\soft\media\VLC\vlc.exe
[cli][error] Try 1/1: Could not open stream <HTTPStream ['http', 'https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct']> (Could not open stream: Unable to open URL: https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct (403 Client Error: Forbidden for url: https://7b232e9a7ece13f936b4e19cb1594132.livehwc3.cn/hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?cdn_redirect_domain=14769ccad573a2388a716f2ade587c96.livehwc3.cn&cdn_redirect=true&wsTime=65a9468d&ctype=huya_live&fs=bgct&policy=6&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&wsSecret=79ab95ca0c616135da585dba0e2373ef&cdn_redirect_tag=1705592487))
error: Could not open stream <HTTPStream ['http', 'https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct']>, tried 1 times, exiting
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/huya.py`
Content:
```
1 """
2 $description Chinese live-streaming platform for live video game broadcasts and individual live streams.
3 $url huya.com
4 $type live
5 $metadata id
6 $metadata author
7 $metadata title
8 """
9
10 import base64
11 import logging
12 import re
13 from html import unescape as html_unescape
14 from typing import Dict
15
16 from streamlink.plugin import Plugin, pluginmatcher
17 from streamlink.plugin.api import validate
18 from streamlink.stream.http import HTTPStream
19 from streamlink.utils.url import update_scheme
20
21
22 log = logging.getLogger(__name__)
23
24
25 @pluginmatcher(re.compile(
26 r"https?://(?:www\.)?huya\.com/(?P<channel>[^/]+)",
27 ))
28 class Huya(Plugin):
29 QUALITY_WEIGHTS: Dict[str, int] = {}
30
31 @classmethod
32 def stream_weight(cls, key):
33 weight = cls.QUALITY_WEIGHTS.get(key)
34 if weight:
35 return weight, "huya"
36
37 return super().stream_weight(key)
38
39 def _get_streams(self):
40 data = self.session.http.get(self.url, schema=validate.Schema(
41 validate.parse_html(),
42 validate.xml_xpath_string(".//script[contains(text(),'var hyPlayerConfig = {')][1]/text()"),
43 validate.none_or_all(
44 re.compile(r"""(?P<q>"?)stream(?P=q)\s*:\s*(?:"(?P<base64>.+?)"|(?P<json>\{.+?})\s*}\s*;)"""),
45 ),
46 validate.none_or_all(
47 validate.any(
48 validate.all(
49 validate.get("base64"),
50 str,
51 validate.transform(base64.b64decode),
52 ),
53 validate.all(
54 validate.get("json"),
55 str,
56 ),
57 ),
58 validate.parse_json(),
59 {
60 "data": [{
61 "gameLiveInfo": {
62 "liveId": str,
63 "nick": str,
64 "roomName": str,
65 },
66 "gameStreamInfoList": [validate.all(
67 {
68 "sCdnType": str,
69 "iPCPriorityRate": int,
70 "sStreamName": str,
71 "sFlvUrl": str,
72 "sFlvUrlSuffix": str,
73 "sFlvAntiCode": validate.all(str, validate.transform(html_unescape)),
74 },
75 validate.union_get(
76 "sCdnType",
77 "iPCPriorityRate",
78 "sStreamName",
79 "sFlvUrl",
80 "sFlvUrlSuffix",
81 "sFlvAntiCode",
82 )),
83 ],
84 }],
85 },
86 validate.get(("data", 0)),
87 validate.union_get(
88 ("gameLiveInfo", "liveId"),
89 ("gameLiveInfo", "nick"),
90 ("gameLiveInfo", "roomName"),
91 "gameStreamInfoList",
92 ),
93 ),
94 ))
95 if not data:
96 return
97
98 self.id, self.author, self.title, streamdata = data
99
100 for cdntype, priority, streamname, flvurl, suffix, anticode in streamdata:
101 url = update_scheme("https://", f"{flvurl}/{streamname}.{suffix}?{anticode}")
102 if self.session.http.head(url, raise_for_status=False).status_code >= 400:
103 continue
104
105 name = f"source_{cdntype.lower()}"
106 self.QUALITY_WEIGHTS[name] = priority
107 yield name, HTTPStream(self.session, url)
108
109 log.debug(f"QUALITY_WEIGHTS: {self.QUALITY_WEIGHTS!r}")
110
111
112 __plugin__ = Huya
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py
--- a/src/streamlink/plugins/huya.py
+++ b/src/streamlink/plugins/huya.py
@@ -12,22 +12,28 @@
import re
from html import unescape as html_unescape
from typing import Dict
+from urllib.parse import parse_qsl
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
from streamlink.stream.http import HTTPStream
-from streamlink.utils.url import update_scheme
+from streamlink.utils.url import update_qsd, update_scheme
log = logging.getLogger(__name__)
@pluginmatcher(re.compile(
- r"https?://(?:www\.)?huya\.com/(?P<channel>[^/]+)",
+ r"https?://(?:www\.)?huya\.com/(?P<channel>[^/?]+)",
))
class Huya(Plugin):
QUALITY_WEIGHTS: Dict[str, int] = {}
+ _QUALITY_WEIGHTS_OVERRIDE = {
+ "source_hy": -1000, # SSLCertVerificationError
+ }
+ _STREAM_URL_QUERYSTRING_PARAMS = "wsSecret", "wsTime"
+
@classmethod
def stream_weight(cls, key):
weight = cls.QUALITY_WEIGHTS.get(key)
@@ -97,13 +103,18 @@
self.id, self.author, self.title, streamdata = data
+ self.session.http.headers.update({
+ "Origin": "https://www.huya.com",
+ "Referer": "https://www.huya.com/",
+ })
+
for cdntype, priority, streamname, flvurl, suffix, anticode in streamdata:
- url = update_scheme("https://", f"{flvurl}/{streamname}.{suffix}?{anticode}")
- if self.session.http.head(url, raise_for_status=False).status_code >= 400:
- continue
+ qs = {k: v for k, v in dict(parse_qsl(anticode)).items() if k in self._STREAM_URL_QUERYSTRING_PARAMS}
+ url = update_scheme("https://", f"{flvurl}/{streamname}.{suffix}")
+ url = update_qsd(url, qs)
name = f"source_{cdntype.lower()}"
- self.QUALITY_WEIGHTS[name] = priority
+ self.QUALITY_WEIGHTS[name] = self._QUALITY_WEIGHTS_OVERRIDE.get(name, priority)
yield name, HTTPStream(self.session, url)
log.debug(f"QUALITY_WEIGHTS: {self.QUALITY_WEIGHTS!r}")
|
{"golden_diff": "diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py\n--- a/src/streamlink/plugins/huya.py\n+++ b/src/streamlink/plugins/huya.py\n@@ -12,22 +12,28 @@\n import re\n from html import unescape as html_unescape\n from typing import Dict\n+from urllib.parse import parse_qsl\n \n from streamlink.plugin import Plugin, pluginmatcher\n from streamlink.plugin.api import validate\n from streamlink.stream.http import HTTPStream\n-from streamlink.utils.url import update_scheme\n+from streamlink.utils.url import update_qsd, update_scheme\n \n \n log = logging.getLogger(__name__)\n \n \n @pluginmatcher(re.compile(\n- r\"https?://(?:www\\.)?huya\\.com/(?P<channel>[^/]+)\",\n+ r\"https?://(?:www\\.)?huya\\.com/(?P<channel>[^/?]+)\",\n ))\n class Huya(Plugin):\n QUALITY_WEIGHTS: Dict[str, int] = {}\n \n+ _QUALITY_WEIGHTS_OVERRIDE = {\n+ \"source_hy\": -1000, # SSLCertVerificationError\n+ }\n+ _STREAM_URL_QUERYSTRING_PARAMS = \"wsSecret\", \"wsTime\"\n+\n @classmethod\n def stream_weight(cls, key):\n weight = cls.QUALITY_WEIGHTS.get(key)\n@@ -97,13 +103,18 @@\n \n self.id, self.author, self.title, streamdata = data\n \n+ self.session.http.headers.update({\n+ \"Origin\": \"https://www.huya.com\",\n+ \"Referer\": \"https://www.huya.com/\",\n+ })\n+\n for cdntype, priority, streamname, flvurl, suffix, anticode in streamdata:\n- url = update_scheme(\"https://\", f\"{flvurl}/{streamname}.{suffix}?{anticode}\")\n- if self.session.http.head(url, raise_for_status=False).status_code >= 400:\n- continue\n+ qs = {k: v for k, v in dict(parse_qsl(anticode)).items() if k in self._STREAM_URL_QUERYSTRING_PARAMS}\n+ url = update_scheme(\"https://\", f\"{flvurl}/{streamname}.{suffix}\")\n+ url = update_qsd(url, qs)\n \n name = f\"source_{cdntype.lower()}\"\n- self.QUALITY_WEIGHTS[name] = priority\n+ self.QUALITY_WEIGHTS[name] = self._QUALITY_WEIGHTS_OVERRIDE.get(name, priority)\n yield name, HTTPStream(self.session, url)\n \n log.debug(f\"QUALITY_WEIGHTS: {self.QUALITY_WEIGHTS!r}\")\n", "issue": "plugins.huya: 403 Client Error: Forbidden for url\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nstreamlink 6.5.1\n\n### Description\n\nplease forgive me, my english so bad and it's hard to understand all these rules, im newbie inpython, I don\u2019t know, this has already been asked and I read the answer that this is not a streamlink problem, but maybe you can help me\r\n\r\n\n\n### Debug log\n\n```text\nC:\\Users\\matebeats>streamlink.exe https://www.huya.com/sbwfz best\r\n[cli][info] Found matching plugin huya for URL https://www.huya.com/sbwfz\r\n[cli][info] Available streams: source_hw (worst, best)\r\n[cli][info] Opening stream: source_hw (http)\r\n[cli][info] Starting player: D:\\matebeats\\soft\\media\\VLC\\vlc.exe\r\n[cli][error] Try 1/1: Could not open stream <HTTPStream ['http', 'https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct']> (Could not open stream: Unable to open URL: https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct (403 Client Error: Forbidden for url: https://7b232e9a7ece13f936b4e19cb1594132.livehwc3.cn/hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?cdn_redirect_domain=14769ccad573a2388a716f2ade587c96.livehwc3.cn&cdn_redirect=true&wsTime=65a9468d&ctype=huya_live&fs=bgct&policy=6&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&wsSecret=79ab95ca0c616135da585dba0e2373ef&cdn_redirect_tag=1705592487))\r\nerror: Could not open stream <HTTPStream ['http', 'https://hw.flv.huya.com/src/70165683-70165683-301359313786503168-140454822-10057-A-0-1.flv?wsSecret=79ab95ca0c616135da585dba0e2373ef&wsTime=65a9468d&fm=RFdxOEJjSjNoNkRKdDZUWV8kMF8kMV8kMl8kMw%3D%3D&ctype=huya_live&fs=bgct']>, tried 1 times, exiting\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Chinese live-streaming platform for live video game broadcasts and individual live streams.\n$url huya.com\n$type live\n$metadata id\n$metadata author\n$metadata title\n\"\"\"\n\nimport base64\nimport logging\nimport re\nfrom html import unescape as html_unescape\nfrom typing import Dict\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.http import HTTPStream\nfrom streamlink.utils.url import update_scheme\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?huya\\.com/(?P<channel>[^/]+)\",\n))\nclass Huya(Plugin):\n QUALITY_WEIGHTS: Dict[str, int] = {}\n\n @classmethod\n def stream_weight(cls, key):\n weight = cls.QUALITY_WEIGHTS.get(key)\n if weight:\n return weight, \"huya\"\n\n return super().stream_weight(key)\n\n def _get_streams(self):\n data = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//script[contains(text(),'var hyPlayerConfig = {')][1]/text()\"),\n validate.none_or_all(\n re.compile(r\"\"\"(?P<q>\"?)stream(?P=q)\\s*:\\s*(?:\"(?P<base64>.+?)\"|(?P<json>\\{.+?})\\s*}\\s*;)\"\"\"),\n ),\n validate.none_or_all(\n validate.any(\n validate.all(\n validate.get(\"base64\"),\n str,\n validate.transform(base64.b64decode),\n ),\n validate.all(\n validate.get(\"json\"),\n str,\n ),\n ),\n validate.parse_json(),\n {\n \"data\": [{\n \"gameLiveInfo\": {\n \"liveId\": str,\n \"nick\": str,\n \"roomName\": str,\n },\n \"gameStreamInfoList\": [validate.all(\n {\n \"sCdnType\": str,\n \"iPCPriorityRate\": int,\n \"sStreamName\": str,\n \"sFlvUrl\": str,\n \"sFlvUrlSuffix\": str,\n \"sFlvAntiCode\": validate.all(str, validate.transform(html_unescape)),\n },\n validate.union_get(\n \"sCdnType\",\n \"iPCPriorityRate\",\n \"sStreamName\",\n \"sFlvUrl\",\n \"sFlvUrlSuffix\",\n \"sFlvAntiCode\",\n )),\n ],\n }],\n },\n validate.get((\"data\", 0)),\n validate.union_get(\n (\"gameLiveInfo\", \"liveId\"),\n (\"gameLiveInfo\", \"nick\"),\n (\"gameLiveInfo\", \"roomName\"),\n \"gameStreamInfoList\",\n ),\n ),\n ))\n if not data:\n return\n\n self.id, self.author, self.title, streamdata = data\n\n for cdntype, priority, streamname, flvurl, suffix, anticode in streamdata:\n url = update_scheme(\"https://\", f\"{flvurl}/{streamname}.{suffix}?{anticode}\")\n if self.session.http.head(url, raise_for_status=False).status_code >= 400:\n continue\n\n name = f\"source_{cdntype.lower()}\"\n self.QUALITY_WEIGHTS[name] = priority\n yield name, HTTPStream(self.session, url)\n\n log.debug(f\"QUALITY_WEIGHTS: {self.QUALITY_WEIGHTS!r}\")\n\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}], "after_files": [{"content": "\"\"\"\n$description Chinese live-streaming platform for live video game broadcasts and individual live streams.\n$url huya.com\n$type live\n$metadata id\n$metadata author\n$metadata title\n\"\"\"\n\nimport base64\nimport logging\nimport re\nfrom html import unescape as html_unescape\nfrom typing import Dict\nfrom urllib.parse import parse_qsl\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.http import HTTPStream\nfrom streamlink.utils.url import update_qsd, update_scheme\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?huya\\.com/(?P<channel>[^/?]+)\",\n))\nclass Huya(Plugin):\n QUALITY_WEIGHTS: Dict[str, int] = {}\n\n _QUALITY_WEIGHTS_OVERRIDE = {\n \"source_hy\": -1000, # SSLCertVerificationError\n }\n _STREAM_URL_QUERYSTRING_PARAMS = \"wsSecret\", \"wsTime\"\n\n @classmethod\n def stream_weight(cls, key):\n weight = cls.QUALITY_WEIGHTS.get(key)\n if weight:\n return weight, \"huya\"\n\n return super().stream_weight(key)\n\n def _get_streams(self):\n data = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//script[contains(text(),'var hyPlayerConfig = {')][1]/text()\"),\n validate.none_or_all(\n re.compile(r\"\"\"(?P<q>\"?)stream(?P=q)\\s*:\\s*(?:\"(?P<base64>.+?)\"|(?P<json>\\{.+?})\\s*}\\s*;)\"\"\"),\n ),\n validate.none_or_all(\n validate.any(\n validate.all(\n validate.get(\"base64\"),\n str,\n validate.transform(base64.b64decode),\n ),\n validate.all(\n validate.get(\"json\"),\n str,\n ),\n ),\n validate.parse_json(),\n {\n \"data\": [{\n \"gameLiveInfo\": {\n \"liveId\": str,\n \"nick\": str,\n \"roomName\": str,\n },\n \"gameStreamInfoList\": [validate.all(\n {\n \"sCdnType\": str,\n \"iPCPriorityRate\": int,\n \"sStreamName\": str,\n \"sFlvUrl\": str,\n \"sFlvUrlSuffix\": str,\n \"sFlvAntiCode\": validate.all(str, validate.transform(html_unescape)),\n },\n validate.union_get(\n \"sCdnType\",\n \"iPCPriorityRate\",\n \"sStreamName\",\n \"sFlvUrl\",\n \"sFlvUrlSuffix\",\n \"sFlvAntiCode\",\n )),\n ],\n }],\n },\n validate.get((\"data\", 0)),\n validate.union_get(\n (\"gameLiveInfo\", \"liveId\"),\n (\"gameLiveInfo\", \"nick\"),\n (\"gameLiveInfo\", \"roomName\"),\n \"gameStreamInfoList\",\n ),\n ),\n ))\n if not data:\n return\n\n self.id, self.author, self.title, streamdata = data\n\n self.session.http.headers.update({\n \"Origin\": \"https://www.huya.com\",\n \"Referer\": \"https://www.huya.com/\",\n })\n\n for cdntype, priority, streamname, flvurl, suffix, anticode in streamdata:\n qs = {k: v for k, v in dict(parse_qsl(anticode)).items() if k in self._STREAM_URL_QUERYSTRING_PARAMS}\n url = update_scheme(\"https://\", f\"{flvurl}/{streamname}.{suffix}\")\n url = update_qsd(url, qs)\n\n name = f\"source_{cdntype.lower()}\"\n self.QUALITY_WEIGHTS[name] = self._QUALITY_WEIGHTS_OVERRIDE.get(name, priority)\n yield name, HTTPStream(self.session, url)\n\n log.debug(f\"QUALITY_WEIGHTS: {self.QUALITY_WEIGHTS!r}\")\n\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}]}
| 2,424 | 582 |
gh_patches_debug_41285
|
rasdani/github-patches
|
git_diff
|
boto__botocore-939
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feature request: Add ability to ignore params in stubber
It would be nice if the stubber had a solution for being able to ignore randomly generated values in the input. For example:
- idempotency tokens
- statement ids
And really anything that typically is a random value.
There's a few ways I can think of to accomplish this. In `mock`, you can use `mock.ANY` to indicate that you don't care about the value. In the CLI we have an `ignore_params` for `assert_params_for_cmd`, though this only works for top level params (which typically is sufficient).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `botocore/stub.py`
Content:
```
1 # Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"). You
4 # may not use this file except in compliance with the License. A copy of
5 # the License is located at
6 #
7 # http://aws.amazon.com/apache2.0/
8 #
9 # or in the "license" file accompanying this file. This file is
10 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific
12 # language governing permissions and limitations under the License.
13 import copy
14 from collections import deque
15 from pprint import pformat
16
17 from botocore.validate import validate_parameters
18 from botocore.exceptions import ParamValidationError, \
19 StubResponseError, StubAssertionError
20 from botocore.vendored.requests.models import Response
21
22
23 class Stubber(object):
24 """
25 This class will allow you to stub out requests so you don't have to hit
26 an endpoint to write tests. Responses are returned first in, first out.
27 If operations are called out of order, or are called with no remaining
28 queued responses, an error will be raised.
29
30 **Example:**
31 ::
32 import datetime
33 import botocore.session
34 from botocore.stub import Stubber
35
36
37 s3 = botocore.session.get_session().create_client('s3')
38 stubber = Stubber(s3)
39
40 response = {
41 'IsTruncated': False,
42 'Name': 'test-bucket',
43 'MaxKeys': 1000, 'Prefix': '',
44 'Contents': [{
45 'Key': 'test.txt',
46 'ETag': '"abc123"',
47 'StorageClass': 'STANDARD',
48 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),
49 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},
50 'Size': 14814
51 }],
52 'EncodingType': 'url',
53 'ResponseMetadata': {
54 'RequestId': 'abc123',
55 'HTTPStatusCode': 200,
56 'HostId': 'abc123'
57 },
58 'Marker': ''
59 }
60
61 expected_params = {'Bucket': 'test-bucket'}
62
63 stubber.add_response('list_objects', response, expected_params)
64 stubber.activate()
65
66 service_response = s3.list_objects(Bucket='test-bucket')
67 assert service_response == response
68
69
70 This class can also be called as a context manager, which will handle
71 activation / deactivation for you.
72
73 **Example:**
74 ::
75 import datetime
76 import botocore.session
77 from botocore.stub import Stubber
78
79
80 s3 = botocore.session.get_session().create_client('s3')
81
82 response = {
83 "Owner": {
84 "ID": "foo",
85 "DisplayName": "bar"
86 },
87 "Buckets": [{
88 "CreationDate": datetime.datetime(2016, 1, 20, 22, 9),
89 "Name": "baz"
90 }]
91 }
92
93
94 with Stubber(s3) as stubber:
95 stubber.add_response('list_buckets', response, {})
96 service_response = s3.list_buckets()
97
98 assert service_response == response
99 """
100 def __init__(self, client):
101 """
102 :param client: The client to add your stubs to.
103 """
104 self.client = client
105 self._event_id = 'boto_stubber'
106 self._expected_params_event_id = 'boto_stubber_expected_params'
107 self._queue = deque()
108
109 def __enter__(self):
110 self.activate()
111 return self
112
113 def __exit__(self, exception_type, exception_value, traceback):
114 self.deactivate()
115
116 def activate(self):
117 """
118 Activates the stubber on the client
119 """
120 self.client.meta.events.register_first(
121 'before-parameter-build.*.*',
122 self._assert_expected_params,
123 unique_id=self._expected_params_event_id)
124 self.client.meta.events.register(
125 'before-call.*.*',
126 self._get_response_handler,
127 unique_id=self._event_id)
128
129 def deactivate(self):
130 """
131 Deactivates the stubber on the client
132 """
133 self.client.meta.events.unregister(
134 'before-parameter-build.*.*',
135 self._assert_expected_params,
136 unique_id=self._expected_params_event_id)
137 self.client.meta.events.unregister(
138 'before-call.*.*',
139 self._get_response_handler,
140 unique_id=self._event_id)
141
142 def add_response(self, method, service_response, expected_params=None):
143 """
144 Adds a service response to the response queue. This will be validated
145 against the service model to ensure correctness. It should be noted,
146 however, that while missing attributes are often considered correct,
147 your code may not function properly if you leave them out. Therefore
148 you should always fill in every value you see in a typical response for
149 your particular request.
150
151 :param method: The name of the client method to stub.
152 :type method: str
153
154 :param service_response: A dict response stub. Provided parameters will
155 be validated against the service model.
156 :type service_response: dict
157
158 :param expected_params: A dictionary of the expected parameters to
159 be called for the provided service response. The parameters match
160 the names of keyword arguments passed to that client call. If
161 any of the parameters differ a ``StubResponseError`` is thrown.
162 """
163 self._add_response(method, service_response, expected_params)
164
165 def _add_response(self, method, service_response, expected_params):
166 if not hasattr(self.client, method):
167 raise ValueError(
168 "Client %s does not have method: %s"
169 % (self.client.meta.service_model.service_name, method))
170
171 # Create a successful http response
172 http_response = Response()
173 http_response.status_code = 200
174 http_response.reason = 'OK'
175
176 operation_name = self.client.meta.method_to_api_mapping.get(method)
177 self._validate_response(operation_name, service_response)
178
179 # Add the service_response to the queue for returning responses
180 response = {
181 'operation_name': operation_name,
182 'response': (http_response, service_response),
183 'expected_params': expected_params
184 }
185 self._queue.append(response)
186
187 def add_client_error(self, method, service_error_code='',
188 service_message='', http_status_code=400,
189 service_error_meta=None):
190 """
191 Adds a ``ClientError`` to the response queue.
192
193 :param method: The name of the service method to return the error on.
194 :type method: str
195
196 :param service_error_code: The service error code to return,
197 e.g. ``NoSuchBucket``
198 :type service_error_code: str
199
200 :param service_message: The service message to return, e.g.
201 'The specified bucket does not exist.'
202 :type service_message: str
203
204 :param http_status_code: The HTTP status code to return, e.g. 404, etc
205 :type http_status_code: int
206
207 :param service_error_meta: Additional keys to be added to the
208 service Error
209 :type service_error_meta: dict
210 """
211 http_response = Response()
212 http_response.status_code = http_status_code
213
214 # We don't look to the model to build this because the caller would
215 # need to know the details of what the HTTP body would need to
216 # look like.
217 parsed_response = {
218 'ResponseMetadata': {'HTTPStatusCode': http_status_code},
219 'Error': {
220 'Message': service_message,
221 'Code': service_error_code
222 }
223 }
224
225 if service_error_meta is not None:
226 parsed_response['Error'].update(service_error_meta)
227
228 operation_name = self.client.meta.method_to_api_mapping.get(method)
229 # Note that we do not allow for expected_params while
230 # adding errors into the queue yet.
231 response = {
232 'operation_name': operation_name,
233 'response': (http_response, parsed_response),
234 'expected_params': None
235 }
236 self._queue.append(response)
237
238 def assert_no_pending_responses(self):
239 """
240 Asserts that all expected calls were made.
241 """
242 remaining = len(self._queue)
243 if remaining != 0:
244 raise AssertionError(
245 "%d responses remaining in queue." % remaining)
246
247 def _assert_expected_call_order(self, model, params):
248 if not self._queue:
249 raise StubResponseError(
250 operation_name=model.name,
251 reason=('Unexpected API Call: called with parameters:\n%s' %
252 pformat(params)))
253
254 name = self._queue[0]['operation_name']
255 if name != model.name:
256 raise StubResponseError(
257 operation_name=model.name,
258 reason='Operation mismatch: found response for %s.' % name)
259
260 def _get_response_handler(self, model, params, **kwargs):
261 self._assert_expected_call_order(model, params)
262 # Pop off the entire response once everything has been validated
263 return self._queue.popleft()['response']
264
265 def _assert_expected_params(self, model, params, **kwargs):
266 self._assert_expected_call_order(model, params)
267 expected_params = self._queue[0]['expected_params']
268 if expected_params is not None and params != expected_params:
269 raise StubAssertionError(
270 operation_name=model.name,
271 reason='Expected parameters:\n%s,\nbut received:\n%s' % (
272 pformat(expected_params), pformat(params)))
273
274 def _validate_response(self, operation_name, service_response):
275 service_model = self.client.meta.service_model
276 operation_model = service_model.operation_model(operation_name)
277 output_shape = operation_model.output_shape
278
279 # Remove ResponseMetadata so that the validator doesn't attempt to
280 # perform validation on it.
281 response = service_response
282 if 'ResponseMetadata' in response:
283 response = copy.copy(service_response)
284 del response['ResponseMetadata']
285
286 if output_shape is not None:
287 validate_parameters(response, output_shape)
288 elif response:
289 # If the output shape is None, that means the response should be
290 # empty apart from ResponseMetadata
291 raise ParamValidationError(
292 report=(
293 "Service response should only contain ResponseMetadata."))
294
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/botocore/stub.py b/botocore/stub.py
--- a/botocore/stub.py
+++ b/botocore/stub.py
@@ -20,6 +20,9 @@
from botocore.vendored.requests.models import Response
+ANY = object()
+
+
class Stubber(object):
"""
This class will allow you to stub out requests so you don't have to hit
@@ -96,6 +99,50 @@
service_response = s3.list_buckets()
assert service_response == response
+
+
+ If you have an input paramter that is a randomly generated value, or you
+ otherwise don't care about its value, you can use stub.ANY to ignore it in
+ validation.
+
+ **Example:**
+ ::
+ import datetime
+ import botocore.session
+ from botocore.stub import Stubber, ANY
+
+
+ s3 = botocore.session.get_session().create_client('s3')
+ stubber = Stubber(s3)
+
+ response = {
+ 'IsTruncated': False,
+ 'Name': 'test-bucket',
+ 'MaxKeys': 1000, 'Prefix': '',
+ 'Contents': [{
+ 'Key': 'test.txt',
+ 'ETag': '"abc123"',
+ 'StorageClass': 'STANDARD',
+ 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),
+ 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},
+ 'Size': 14814
+ }],
+ 'EncodingType': 'url',
+ 'ResponseMetadata': {
+ 'RequestId': 'abc123',
+ 'HTTPStatusCode': 200,
+ 'HostId': 'abc123'
+ },
+ 'Marker': ''
+ }
+
+ expected_params = {'Bucket': ANY}
+ stubber.add_response('list_objects', response, expected_params)
+
+ with stubber:
+ service_response = s3.list_objects(Bucket='test-bucket')
+
+ assert service_response == response
"""
def __init__(self, client):
"""
@@ -159,6 +206,8 @@
be called for the provided service response. The parameters match
the names of keyword arguments passed to that client call. If
any of the parameters differ a ``StubResponseError`` is thrown.
+ You can use stub.ANY to indicate a particular parameter to ignore
+ in validation. stub.ANY is only valid for top level params.
"""
self._add_response(method, service_response, expected_params)
@@ -265,7 +314,22 @@
def _assert_expected_params(self, model, params, **kwargs):
self._assert_expected_call_order(model, params)
expected_params = self._queue[0]['expected_params']
- if expected_params is not None and params != expected_params:
+ if expected_params is None:
+ return
+
+ # Validate the parameters are equal
+ for param, value in expected_params.items():
+ if value is ANY:
+ continue
+ elif param not in params or \
+ expected_params[param] != params[param]:
+ raise StubAssertionError(
+ operation_name=model.name,
+ reason='Expected parameters:\n%s,\nbut received:\n%s' % (
+ pformat(expected_params), pformat(params)))
+
+ # Ensure there are no extra params hanging around
+ if expected_params.keys() != params.keys():
raise StubAssertionError(
operation_name=model.name,
reason='Expected parameters:\n%s,\nbut received:\n%s' % (
|
{"golden_diff": "diff --git a/botocore/stub.py b/botocore/stub.py\n--- a/botocore/stub.py\n+++ b/botocore/stub.py\n@@ -20,6 +20,9 @@\n from botocore.vendored.requests.models import Response\n \n \n+ANY = object()\n+\n+\n class Stubber(object):\n \"\"\"\n This class will allow you to stub out requests so you don't have to hit\n@@ -96,6 +99,50 @@\n service_response = s3.list_buckets()\n \n assert service_response == response\n+\n+\n+ If you have an input paramter that is a randomly generated value, or you\n+ otherwise don't care about its value, you can use stub.ANY to ignore it in\n+ validation.\n+\n+ **Example:**\n+ ::\n+ import datetime\n+ import botocore.session\n+ from botocore.stub import Stubber, ANY\n+\n+\n+ s3 = botocore.session.get_session().create_client('s3')\n+ stubber = Stubber(s3)\n+\n+ response = {\n+ 'IsTruncated': False,\n+ 'Name': 'test-bucket',\n+ 'MaxKeys': 1000, 'Prefix': '',\n+ 'Contents': [{\n+ 'Key': 'test.txt',\n+ 'ETag': '\"abc123\"',\n+ 'StorageClass': 'STANDARD',\n+ 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),\n+ 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},\n+ 'Size': 14814\n+ }],\n+ 'EncodingType': 'url',\n+ 'ResponseMetadata': {\n+ 'RequestId': 'abc123',\n+ 'HTTPStatusCode': 200,\n+ 'HostId': 'abc123'\n+ },\n+ 'Marker': ''\n+ }\n+\n+ expected_params = {'Bucket': ANY}\n+ stubber.add_response('list_objects', response, expected_params)\n+\n+ with stubber:\n+ service_response = s3.list_objects(Bucket='test-bucket')\n+\n+ assert service_response == response\n \"\"\"\n def __init__(self, client):\n \"\"\"\n@@ -159,6 +206,8 @@\n be called for the provided service response. The parameters match\n the names of keyword arguments passed to that client call. If\n any of the parameters differ a ``StubResponseError`` is thrown.\n+ You can use stub.ANY to indicate a particular parameter to ignore\n+ in validation. stub.ANY is only valid for top level params.\n \"\"\"\n self._add_response(method, service_response, expected_params)\n \n@@ -265,7 +314,22 @@\n def _assert_expected_params(self, model, params, **kwargs):\n self._assert_expected_call_order(model, params)\n expected_params = self._queue[0]['expected_params']\n- if expected_params is not None and params != expected_params:\n+ if expected_params is None:\n+ return\n+\n+ # Validate the parameters are equal\n+ for param, value in expected_params.items():\n+ if value is ANY:\n+ continue\n+ elif param not in params or \\\n+ expected_params[param] != params[param]:\n+ raise StubAssertionError(\n+ operation_name=model.name,\n+ reason='Expected parameters:\\n%s,\\nbut received:\\n%s' % (\n+ pformat(expected_params), pformat(params)))\n+\n+ # Ensure there are no extra params hanging around\n+ if expected_params.keys() != params.keys():\n raise StubAssertionError(\n operation_name=model.name,\n reason='Expected parameters:\\n%s,\\nbut received:\\n%s' % (\n", "issue": "Feature request: Add ability to ignore params in stubber\nIt would be nice if the stubber had a solution for being able to ignore randomly generated values in the input. For example:\n- idempotency tokens\n- statement ids\n\nAnd really anything that typically is a random value. \n\nThere's a few ways I can think of to accomplish this. In `mock`, you can use `mock.ANY` to indicate that you don't care about the value. In the CLI we have an `ignore_params` for `assert_params_for_cmd`, though this only works for top level params (which typically is sufficient).\n\n", "before_files": [{"content": "# Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport copy\nfrom collections import deque\nfrom pprint import pformat\n\nfrom botocore.validate import validate_parameters\nfrom botocore.exceptions import ParamValidationError, \\\n StubResponseError, StubAssertionError\nfrom botocore.vendored.requests.models import Response\n\n\nclass Stubber(object):\n \"\"\"\n This class will allow you to stub out requests so you don't have to hit\n an endpoint to write tests. Responses are returned first in, first out.\n If operations are called out of order, or are called with no remaining\n queued responses, an error will be raised.\n\n **Example:**\n ::\n import datetime\n import botocore.session\n from botocore.stub import Stubber\n\n\n s3 = botocore.session.get_session().create_client('s3')\n stubber = Stubber(s3)\n\n response = {\n 'IsTruncated': False,\n 'Name': 'test-bucket',\n 'MaxKeys': 1000, 'Prefix': '',\n 'Contents': [{\n 'Key': 'test.txt',\n 'ETag': '\"abc123\"',\n 'StorageClass': 'STANDARD',\n 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),\n 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},\n 'Size': 14814\n }],\n 'EncodingType': 'url',\n 'ResponseMetadata': {\n 'RequestId': 'abc123',\n 'HTTPStatusCode': 200,\n 'HostId': 'abc123'\n },\n 'Marker': ''\n }\n\n expected_params = {'Bucket': 'test-bucket'}\n\n stubber.add_response('list_objects', response, expected_params)\n stubber.activate()\n\n service_response = s3.list_objects(Bucket='test-bucket')\n assert service_response == response\n\n\n This class can also be called as a context manager, which will handle\n activation / deactivation for you.\n\n **Example:**\n ::\n import datetime\n import botocore.session\n from botocore.stub import Stubber\n\n\n s3 = botocore.session.get_session().create_client('s3')\n\n response = {\n \"Owner\": {\n \"ID\": \"foo\",\n \"DisplayName\": \"bar\"\n },\n \"Buckets\": [{\n \"CreationDate\": datetime.datetime(2016, 1, 20, 22, 9),\n \"Name\": \"baz\"\n }]\n }\n\n\n with Stubber(s3) as stubber:\n stubber.add_response('list_buckets', response, {})\n service_response = s3.list_buckets()\n\n assert service_response == response\n \"\"\"\n def __init__(self, client):\n \"\"\"\n :param client: The client to add your stubs to.\n \"\"\"\n self.client = client\n self._event_id = 'boto_stubber'\n self._expected_params_event_id = 'boto_stubber_expected_params'\n self._queue = deque()\n\n def __enter__(self):\n self.activate()\n return self\n\n def __exit__(self, exception_type, exception_value, traceback):\n self.deactivate()\n\n def activate(self):\n \"\"\"\n Activates the stubber on the client\n \"\"\"\n self.client.meta.events.register_first(\n 'before-parameter-build.*.*',\n self._assert_expected_params,\n unique_id=self._expected_params_event_id)\n self.client.meta.events.register(\n 'before-call.*.*',\n self._get_response_handler,\n unique_id=self._event_id)\n\n def deactivate(self):\n \"\"\"\n Deactivates the stubber on the client\n \"\"\"\n self.client.meta.events.unregister(\n 'before-parameter-build.*.*',\n self._assert_expected_params,\n unique_id=self._expected_params_event_id)\n self.client.meta.events.unregister(\n 'before-call.*.*',\n self._get_response_handler,\n unique_id=self._event_id)\n\n def add_response(self, method, service_response, expected_params=None):\n \"\"\"\n Adds a service response to the response queue. This will be validated\n against the service model to ensure correctness. It should be noted,\n however, that while missing attributes are often considered correct,\n your code may not function properly if you leave them out. Therefore\n you should always fill in every value you see in a typical response for\n your particular request.\n\n :param method: The name of the client method to stub.\n :type method: str\n\n :param service_response: A dict response stub. Provided parameters will\n be validated against the service model.\n :type service_response: dict\n\n :param expected_params: A dictionary of the expected parameters to\n be called for the provided service response. The parameters match\n the names of keyword arguments passed to that client call. If\n any of the parameters differ a ``StubResponseError`` is thrown.\n \"\"\"\n self._add_response(method, service_response, expected_params)\n\n def _add_response(self, method, service_response, expected_params):\n if not hasattr(self.client, method):\n raise ValueError(\n \"Client %s does not have method: %s\"\n % (self.client.meta.service_model.service_name, method))\n\n # Create a successful http response\n http_response = Response()\n http_response.status_code = 200\n http_response.reason = 'OK'\n\n operation_name = self.client.meta.method_to_api_mapping.get(method)\n self._validate_response(operation_name, service_response)\n\n # Add the service_response to the queue for returning responses\n response = {\n 'operation_name': operation_name,\n 'response': (http_response, service_response),\n 'expected_params': expected_params\n }\n self._queue.append(response)\n\n def add_client_error(self, method, service_error_code='',\n service_message='', http_status_code=400,\n service_error_meta=None):\n \"\"\"\n Adds a ``ClientError`` to the response queue.\n\n :param method: The name of the service method to return the error on.\n :type method: str\n\n :param service_error_code: The service error code to return,\n e.g. ``NoSuchBucket``\n :type service_error_code: str\n\n :param service_message: The service message to return, e.g.\n 'The specified bucket does not exist.'\n :type service_message: str\n\n :param http_status_code: The HTTP status code to return, e.g. 404, etc\n :type http_status_code: int\n\n :param service_error_meta: Additional keys to be added to the\n service Error\n :type service_error_meta: dict\n \"\"\"\n http_response = Response()\n http_response.status_code = http_status_code\n\n # We don't look to the model to build this because the caller would\n # need to know the details of what the HTTP body would need to\n # look like.\n parsed_response = {\n 'ResponseMetadata': {'HTTPStatusCode': http_status_code},\n 'Error': {\n 'Message': service_message,\n 'Code': service_error_code\n }\n }\n\n if service_error_meta is not None:\n parsed_response['Error'].update(service_error_meta)\n\n operation_name = self.client.meta.method_to_api_mapping.get(method)\n # Note that we do not allow for expected_params while\n # adding errors into the queue yet.\n response = {\n 'operation_name': operation_name,\n 'response': (http_response, parsed_response),\n 'expected_params': None\n }\n self._queue.append(response)\n\n def assert_no_pending_responses(self):\n \"\"\"\n Asserts that all expected calls were made.\n \"\"\"\n remaining = len(self._queue)\n if remaining != 0:\n raise AssertionError(\n \"%d responses remaining in queue.\" % remaining)\n\n def _assert_expected_call_order(self, model, params):\n if not self._queue:\n raise StubResponseError(\n operation_name=model.name,\n reason=('Unexpected API Call: called with parameters:\\n%s' %\n pformat(params)))\n\n name = self._queue[0]['operation_name']\n if name != model.name:\n raise StubResponseError(\n operation_name=model.name,\n reason='Operation mismatch: found response for %s.' % name)\n\n def _get_response_handler(self, model, params, **kwargs):\n self._assert_expected_call_order(model, params)\n # Pop off the entire response once everything has been validated\n return self._queue.popleft()['response']\n\n def _assert_expected_params(self, model, params, **kwargs):\n self._assert_expected_call_order(model, params)\n expected_params = self._queue[0]['expected_params']\n if expected_params is not None and params != expected_params:\n raise StubAssertionError(\n operation_name=model.name,\n reason='Expected parameters:\\n%s,\\nbut received:\\n%s' % (\n pformat(expected_params), pformat(params)))\n\n def _validate_response(self, operation_name, service_response):\n service_model = self.client.meta.service_model\n operation_model = service_model.operation_model(operation_name)\n output_shape = operation_model.output_shape\n\n # Remove ResponseMetadata so that the validator doesn't attempt to\n # perform validation on it.\n response = service_response\n if 'ResponseMetadata' in response:\n response = copy.copy(service_response)\n del response['ResponseMetadata']\n\n if output_shape is not None:\n validate_parameters(response, output_shape)\n elif response:\n # If the output shape is None, that means the response should be\n # empty apart from ResponseMetadata\n raise ParamValidationError(\n report=(\n \"Service response should only contain ResponseMetadata.\"))\n", "path": "botocore/stub.py"}], "after_files": [{"content": "# Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"). You\n# may not use this file except in compliance with the License. A copy of\n# the License is located at\n#\n# http://aws.amazon.com/apache2.0/\n#\n# or in the \"license\" file accompanying this file. This file is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific\n# language governing permissions and limitations under the License.\nimport copy\nfrom collections import deque\nfrom pprint import pformat\n\nfrom botocore.validate import validate_parameters\nfrom botocore.exceptions import ParamValidationError, \\\n StubResponseError, StubAssertionError\nfrom botocore.vendored.requests.models import Response\n\n\nANY = object()\n\n\nclass Stubber(object):\n \"\"\"\n This class will allow you to stub out requests so you don't have to hit\n an endpoint to write tests. Responses are returned first in, first out.\n If operations are called out of order, or are called with no remaining\n queued responses, an error will be raised.\n\n **Example:**\n ::\n import datetime\n import botocore.session\n from botocore.stub import Stubber\n\n\n s3 = botocore.session.get_session().create_client('s3')\n stubber = Stubber(s3)\n\n response = {\n 'IsTruncated': False,\n 'Name': 'test-bucket',\n 'MaxKeys': 1000, 'Prefix': '',\n 'Contents': [{\n 'Key': 'test.txt',\n 'ETag': '\"abc123\"',\n 'StorageClass': 'STANDARD',\n 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),\n 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},\n 'Size': 14814\n }],\n 'EncodingType': 'url',\n 'ResponseMetadata': {\n 'RequestId': 'abc123',\n 'HTTPStatusCode': 200,\n 'HostId': 'abc123'\n },\n 'Marker': ''\n }\n\n expected_params = {'Bucket': 'test-bucket'}\n\n stubber.add_response('list_objects', response, expected_params)\n stubber.activate()\n\n service_response = s3.list_objects(Bucket='test-bucket')\n assert service_response == response\n\n\n This class can also be called as a context manager, which will handle\n activation / deactivation for you.\n\n **Example:**\n ::\n import datetime\n import botocore.session\n from botocore.stub import Stubber\n\n\n s3 = botocore.session.get_session().create_client('s3')\n\n response = {\n \"Owner\": {\n \"ID\": \"foo\",\n \"DisplayName\": \"bar\"\n },\n \"Buckets\": [{\n \"CreationDate\": datetime.datetime(2016, 1, 20, 22, 9),\n \"Name\": \"baz\"\n }]\n }\n\n\n with Stubber(s3) as stubber:\n stubber.add_response('list_buckets', response, {})\n service_response = s3.list_buckets()\n\n assert service_response == response\n\n\n If you have an input paramter that is a randomly generated value, or you\n otherwise don't care about its value, you can use stub.ANY to ignore it in\n validation.\n\n **Example:**\n ::\n import datetime\n import botocore.session\n from botocore.stub import Stubber, ANY\n\n\n s3 = botocore.session.get_session().create_client('s3')\n stubber = Stubber(s3)\n\n response = {\n 'IsTruncated': False,\n 'Name': 'test-bucket',\n 'MaxKeys': 1000, 'Prefix': '',\n 'Contents': [{\n 'Key': 'test.txt',\n 'ETag': '\"abc123\"',\n 'StorageClass': 'STANDARD',\n 'LastModified': datetime.datetime(2016, 1, 20, 22, 9),\n 'Owner': {'ID': 'abc123', 'DisplayName': 'myname'},\n 'Size': 14814\n }],\n 'EncodingType': 'url',\n 'ResponseMetadata': {\n 'RequestId': 'abc123',\n 'HTTPStatusCode': 200,\n 'HostId': 'abc123'\n },\n 'Marker': ''\n }\n\n expected_params = {'Bucket': ANY}\n stubber.add_response('list_objects', response, expected_params)\n\n with stubber:\n service_response = s3.list_objects(Bucket='test-bucket')\n\n assert service_response == response\n \"\"\"\n def __init__(self, client):\n \"\"\"\n :param client: The client to add your stubs to.\n \"\"\"\n self.client = client\n self._event_id = 'boto_stubber'\n self._expected_params_event_id = 'boto_stubber_expected_params'\n self._queue = deque()\n\n def __enter__(self):\n self.activate()\n return self\n\n def __exit__(self, exception_type, exception_value, traceback):\n self.deactivate()\n\n def activate(self):\n \"\"\"\n Activates the stubber on the client\n \"\"\"\n self.client.meta.events.register_first(\n 'before-parameter-build.*.*',\n self._assert_expected_params,\n unique_id=self._expected_params_event_id)\n self.client.meta.events.register(\n 'before-call.*.*',\n self._get_response_handler,\n unique_id=self._event_id)\n\n def deactivate(self):\n \"\"\"\n Deactivates the stubber on the client\n \"\"\"\n self.client.meta.events.unregister(\n 'before-parameter-build.*.*',\n self._assert_expected_params,\n unique_id=self._expected_params_event_id)\n self.client.meta.events.unregister(\n 'before-call.*.*',\n self._get_response_handler,\n unique_id=self._event_id)\n\n def add_response(self, method, service_response, expected_params=None):\n \"\"\"\n Adds a service response to the response queue. This will be validated\n against the service model to ensure correctness. It should be noted,\n however, that while missing attributes are often considered correct,\n your code may not function properly if you leave them out. Therefore\n you should always fill in every value you see in a typical response for\n your particular request.\n\n :param method: The name of the client method to stub.\n :type method: str\n\n :param service_response: A dict response stub. Provided parameters will\n be validated against the service model.\n :type service_response: dict\n\n :param expected_params: A dictionary of the expected parameters to\n be called for the provided service response. The parameters match\n the names of keyword arguments passed to that client call. If\n any of the parameters differ a ``StubResponseError`` is thrown.\n You can use stub.ANY to indicate a particular parameter to ignore\n in validation. stub.ANY is only valid for top level params.\n \"\"\"\n self._add_response(method, service_response, expected_params)\n\n def _add_response(self, method, service_response, expected_params):\n if not hasattr(self.client, method):\n raise ValueError(\n \"Client %s does not have method: %s\"\n % (self.client.meta.service_model.service_name, method))\n\n # Create a successful http response\n http_response = Response()\n http_response.status_code = 200\n http_response.reason = 'OK'\n\n operation_name = self.client.meta.method_to_api_mapping.get(method)\n self._validate_response(operation_name, service_response)\n\n # Add the service_response to the queue for returning responses\n response = {\n 'operation_name': operation_name,\n 'response': (http_response, service_response),\n 'expected_params': expected_params\n }\n self._queue.append(response)\n\n def add_client_error(self, method, service_error_code='',\n service_message='', http_status_code=400,\n service_error_meta=None):\n \"\"\"\n Adds a ``ClientError`` to the response queue.\n\n :param method: The name of the service method to return the error on.\n :type method: str\n\n :param service_error_code: The service error code to return,\n e.g. ``NoSuchBucket``\n :type service_error_code: str\n\n :param service_message: The service message to return, e.g.\n 'The specified bucket does not exist.'\n :type service_message: str\n\n :param http_status_code: The HTTP status code to return, e.g. 404, etc\n :type http_status_code: int\n\n :param service_error_meta: Additional keys to be added to the\n service Error\n :type service_error_meta: dict\n \"\"\"\n http_response = Response()\n http_response.status_code = http_status_code\n\n # We don't look to the model to build this because the caller would\n # need to know the details of what the HTTP body would need to\n # look like.\n parsed_response = {\n 'ResponseMetadata': {'HTTPStatusCode': http_status_code},\n 'Error': {\n 'Message': service_message,\n 'Code': service_error_code\n }\n }\n\n if service_error_meta is not None:\n parsed_response['Error'].update(service_error_meta)\n\n operation_name = self.client.meta.method_to_api_mapping.get(method)\n # Note that we do not allow for expected_params while\n # adding errors into the queue yet.\n response = {\n 'operation_name': operation_name,\n 'response': (http_response, parsed_response),\n 'expected_params': None\n }\n self._queue.append(response)\n\n def assert_no_pending_responses(self):\n \"\"\"\n Asserts that all expected calls were made.\n \"\"\"\n remaining = len(self._queue)\n if remaining != 0:\n raise AssertionError(\n \"%d responses remaining in queue.\" % remaining)\n\n def _assert_expected_call_order(self, model, params):\n if not self._queue:\n raise StubResponseError(\n operation_name=model.name,\n reason=('Unexpected API Call: called with parameters:\\n%s' %\n pformat(params)))\n\n name = self._queue[0]['operation_name']\n if name != model.name:\n raise StubResponseError(\n operation_name=model.name,\n reason='Operation mismatch: found response for %s.' % name)\n\n def _get_response_handler(self, model, params, **kwargs):\n self._assert_expected_call_order(model, params)\n # Pop off the entire response once everything has been validated\n return self._queue.popleft()['response']\n\n def _assert_expected_params(self, model, params, **kwargs):\n self._assert_expected_call_order(model, params)\n expected_params = self._queue[0]['expected_params']\n if expected_params is None:\n return\n\n # Validate the parameters are equal\n for param, value in expected_params.items():\n if value is ANY:\n continue\n elif param not in params or \\\n expected_params[param] != params[param]:\n raise StubAssertionError(\n operation_name=model.name,\n reason='Expected parameters:\\n%s,\\nbut received:\\n%s' % (\n pformat(expected_params), pformat(params)))\n\n # Ensure there are no extra params hanging around\n if expected_params.keys() != params.keys():\n raise StubAssertionError(\n operation_name=model.name,\n reason='Expected parameters:\\n%s,\\nbut received:\\n%s' % (\n pformat(expected_params), pformat(params)))\n\n def _validate_response(self, operation_name, service_response):\n service_model = self.client.meta.service_model\n operation_model = service_model.operation_model(operation_name)\n output_shape = operation_model.output_shape\n\n # Remove ResponseMetadata so that the validator doesn't attempt to\n # perform validation on it.\n response = service_response\n if 'ResponseMetadata' in response:\n response = copy.copy(service_response)\n del response['ResponseMetadata']\n\n if output_shape is not None:\n validate_parameters(response, output_shape)\n elif response:\n # If the output shape is None, that means the response should be\n # empty apart from ResponseMetadata\n raise ParamValidationError(\n report=(\n \"Service response should only contain ResponseMetadata.\"))\n", "path": "botocore/stub.py"}]}
| 3,419 | 847 |
gh_patches_debug_33163
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-2487
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use of KerberosClient with webhdfs
Currently webhdfs uses InsecureClient by default. However, the hdfs package also has an KerberosClient which can be used to do authenticated requests.
Our hdfs system uses Kerberos and I would like it if KerberosClient is added as an option.
The KerberosClient does not need any additional settings (as far as I can test). And thus only an additional parameter is needed: `use_kerberos_client`.
Are you willing to accept a pull request for this?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `luigi/contrib/hdfs/webhdfs_client.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2015 VNG Corporation
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 #
17
18 """
19 A luigi file system client that wraps around the hdfs-library (a webhdfs
20 client)
21
22 This is a sensible fast alternative to snakebite. In particular for python3
23 users, where snakebite is not supported at the time of writing (dec 2015).
24
25 Note. This wrapper client is not feature complete yet. As with most software
26 the authors only implement the features they need. If you need to wrap more of
27 the file system operations, please do and contribute back.
28 """
29
30
31 from luigi.contrib.hdfs import config as hdfs_config
32 from luigi.contrib.hdfs import abstract_client as hdfs_abstract_client
33 import luigi.contrib.target
34 import logging
35 import os
36 import warnings
37
38 logger = logging.getLogger('luigi-interface')
39
40
41 class webhdfs(luigi.Config):
42 port = luigi.IntParameter(default=50070,
43 description='Port for webhdfs')
44 user = luigi.Parameter(default='', description='Defaults to $USER envvar',
45 config_path=dict(section='hdfs', name='user'))
46
47
48 class WebHdfsClient(hdfs_abstract_client.HdfsFileSystem):
49 """
50 A webhdfs that tries to confirm to luigis interface for file existence.
51
52 The library is using `this api
53 <https://hdfscli.readthedocs.io/en/latest/api.html>`__.
54 """
55
56 def __init__(self, host=None, port=None, user=None):
57 self.host = host or hdfs_config.hdfs().namenode_host
58 self.port = port or webhdfs().port
59 self.user = user or webhdfs().user or os.environ['USER']
60
61 @property
62 def url(self):
63 # the hdfs package allows it to specify multiple namenodes by passing a string containing
64 # multiple namenodes separated by ';'
65 hosts = self.host.split(";")
66 urls = ['http://' + host + ':' + str(self.port) for host in hosts]
67 return ";".join(urls)
68
69 @property
70 def client(self):
71 # A naive benchmark showed that 1000 existence checks took 2.5 secs
72 # when not recreating the client, and 4.0 secs when recreating it. So
73 # not urgent to memoize it. Note that it *might* be issues with process
74 # forking and whatnot (as the one in the snakebite client) if we
75 # memoize it too trivially.
76 import hdfs
77 return hdfs.InsecureClient(url=self.url, user=self.user)
78
79 def walk(self, path, depth=1):
80 return self.client.walk(path, depth=depth)
81
82 def exists(self, path):
83 """
84 Returns true if the path exists and false otherwise.
85 """
86 import hdfs
87 try:
88 self.client.status(path)
89 return True
90 except hdfs.util.HdfsError as e:
91 if str(e).startswith('File does not exist: '):
92 return False
93 else:
94 raise e
95
96 def upload(self, hdfs_path, local_path, overwrite=False):
97 return self.client.upload(hdfs_path, local_path, overwrite=overwrite)
98
99 def download(self, hdfs_path, local_path, overwrite=False, n_threads=-1):
100 return self.client.download(hdfs_path, local_path, overwrite=overwrite,
101 n_threads=n_threads)
102
103 def remove(self, hdfs_path, recursive=True, skip_trash=False):
104 assert skip_trash # Yes, you need to explicitly say skip_trash=True
105 return self.client.delete(hdfs_path, recursive=recursive)
106
107 def read(self, hdfs_path, offset=0, length=None, buffer_size=None,
108 chunk_size=1024, buffer_char=None):
109 return self.client.read(hdfs_path, offset=offset, length=length,
110 buffer_size=buffer_size, chunk_size=chunk_size,
111 buffer_char=buffer_char)
112
113 def move(self, path, dest):
114 parts = dest.rstrip('/').split('/')
115 if len(parts) > 1:
116 dir_path = '/'.join(parts[0:-1])
117 if not self.exists(dir_path):
118 self.mkdir(dir_path, parents=True)
119 self.client.rename(path, dest)
120
121 def mkdir(self, path, parents=True, mode=0o755, raise_if_exists=False):
122 """
123 Has no returnvalue (just like WebHDFS)
124 """
125 if not parents or raise_if_exists:
126 warnings.warn('webhdfs mkdir: parents/raise_if_exists not implemented')
127 permission = int(oct(mode)[2:]) # Convert from int(decimal) to int(octal)
128 self.client.makedirs(path, permission=permission)
129
130 def chmod(self, path, permissions, recursive=False):
131 """
132 Raise a NotImplementedError exception.
133 """
134 raise NotImplementedError("Webhdfs in luigi doesn't implement chmod")
135
136 def chown(self, path, owner, group, recursive=False):
137 """
138 Raise a NotImplementedError exception.
139 """
140 raise NotImplementedError("Webhdfs in luigi doesn't implement chown")
141
142 def count(self, path):
143 """
144 Raise a NotImplementedError exception.
145 """
146 raise NotImplementedError("Webhdfs in luigi doesn't implement count")
147
148 def copy(self, path, destination):
149 """
150 Raise a NotImplementedError exception.
151 """
152 raise NotImplementedError("Webhdfs in luigi doesn't implement copy")
153
154 def put(self, local_path, destination):
155 """
156 Restricted version of upload
157 """
158 self.upload(local_path, destination)
159
160 def get(self, path, local_destination):
161 """
162 Restricted version of download
163 """
164 self.download(path, local_destination)
165
166 def listdir(self, path, ignore_directories=False, ignore_files=False,
167 include_size=False, include_type=False, include_time=False,
168 recursive=False):
169 assert not recursive
170 return self.client.list(path, status=False)
171
172 def touchz(self, path):
173 """
174 To touchz using the web hdfs "write" cmd.
175 """
176 self.client.write(path, data='', overwrite=False)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/luigi/contrib/hdfs/webhdfs_client.py b/luigi/contrib/hdfs/webhdfs_client.py
--- a/luigi/contrib/hdfs/webhdfs_client.py
+++ b/luigi/contrib/hdfs/webhdfs_client.py
@@ -43,6 +43,8 @@
description='Port for webhdfs')
user = luigi.Parameter(default='', description='Defaults to $USER envvar',
config_path=dict(section='hdfs', name='user'))
+ client_type = luigi.ChoiceParameter(var_type=str, choices=['insecure', 'kerberos'],
+ default='insecure', description='Type of hdfs client to use.')
class WebHdfsClient(hdfs_abstract_client.HdfsFileSystem):
@@ -53,10 +55,11 @@
<https://hdfscli.readthedocs.io/en/latest/api.html>`__.
"""
- def __init__(self, host=None, port=None, user=None):
+ def __init__(self, host=None, port=None, user=None, client_type=None):
self.host = host or hdfs_config.hdfs().namenode_host
self.port = port or webhdfs().port
self.user = user or webhdfs().user or os.environ['USER']
+ self.client_type = client_type or webhdfs().client_type
@property
def url(self):
@@ -73,8 +76,12 @@
# not urgent to memoize it. Note that it *might* be issues with process
# forking and whatnot (as the one in the snakebite client) if we
# memoize it too trivially.
- import hdfs
- return hdfs.InsecureClient(url=self.url, user=self.user)
+ if self.client_type == 'kerberos':
+ from hdfs.ext.kerberos import KerberosClient
+ return KerberosClient(url=self.url)
+ else:
+ import hdfs
+ return hdfs.InsecureClient(url=self.url, user=self.user)
def walk(self, path, depth=1):
return self.client.walk(path, depth=depth)
|
{"golden_diff": "diff --git a/luigi/contrib/hdfs/webhdfs_client.py b/luigi/contrib/hdfs/webhdfs_client.py\n--- a/luigi/contrib/hdfs/webhdfs_client.py\n+++ b/luigi/contrib/hdfs/webhdfs_client.py\n@@ -43,6 +43,8 @@\n description='Port for webhdfs')\n user = luigi.Parameter(default='', description='Defaults to $USER envvar',\n config_path=dict(section='hdfs', name='user'))\n+ client_type = luigi.ChoiceParameter(var_type=str, choices=['insecure', 'kerberos'],\n+ default='insecure', description='Type of hdfs client to use.')\n \n \n class WebHdfsClient(hdfs_abstract_client.HdfsFileSystem):\n@@ -53,10 +55,11 @@\n <https://hdfscli.readthedocs.io/en/latest/api.html>`__.\n \"\"\"\n \n- def __init__(self, host=None, port=None, user=None):\n+ def __init__(self, host=None, port=None, user=None, client_type=None):\n self.host = host or hdfs_config.hdfs().namenode_host\n self.port = port or webhdfs().port\n self.user = user or webhdfs().user or os.environ['USER']\n+ self.client_type = client_type or webhdfs().client_type\n \n @property\n def url(self):\n@@ -73,8 +76,12 @@\n # not urgent to memoize it. Note that it *might* be issues with process\n # forking and whatnot (as the one in the snakebite client) if we\n # memoize it too trivially.\n- import hdfs\n- return hdfs.InsecureClient(url=self.url, user=self.user)\n+ if self.client_type == 'kerberos':\n+ from hdfs.ext.kerberos import KerberosClient\n+ return KerberosClient(url=self.url)\n+ else:\n+ import hdfs\n+ return hdfs.InsecureClient(url=self.url, user=self.user)\n \n def walk(self, path, depth=1):\n return self.client.walk(path, depth=depth)\n", "issue": "Use of KerberosClient with webhdfs\nCurrently webhdfs uses InsecureClient by default. However, the hdfs package also has an KerberosClient which can be used to do authenticated requests. \r\n\r\nOur hdfs system uses Kerberos and I would like it if KerberosClient is added as an option. \r\n\r\nThe KerberosClient does not need any additional settings (as far as I can test). And thus only an additional parameter is needed: `use_kerberos_client`. \r\n\r\nAre you willing to accept a pull request for this? \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2015 VNG Corporation\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nA luigi file system client that wraps around the hdfs-library (a webhdfs\nclient)\n\nThis is a sensible fast alternative to snakebite. In particular for python3\nusers, where snakebite is not supported at the time of writing (dec 2015).\n\nNote. This wrapper client is not feature complete yet. As with most software\nthe authors only implement the features they need. If you need to wrap more of\nthe file system operations, please do and contribute back.\n\"\"\"\n\n\nfrom luigi.contrib.hdfs import config as hdfs_config\nfrom luigi.contrib.hdfs import abstract_client as hdfs_abstract_client\nimport luigi.contrib.target\nimport logging\nimport os\nimport warnings\n\nlogger = logging.getLogger('luigi-interface')\n\n\nclass webhdfs(luigi.Config):\n port = luigi.IntParameter(default=50070,\n description='Port for webhdfs')\n user = luigi.Parameter(default='', description='Defaults to $USER envvar',\n config_path=dict(section='hdfs', name='user'))\n\n\nclass WebHdfsClient(hdfs_abstract_client.HdfsFileSystem):\n \"\"\"\n A webhdfs that tries to confirm to luigis interface for file existence.\n\n The library is using `this api\n <https://hdfscli.readthedocs.io/en/latest/api.html>`__.\n \"\"\"\n\n def __init__(self, host=None, port=None, user=None):\n self.host = host or hdfs_config.hdfs().namenode_host\n self.port = port or webhdfs().port\n self.user = user or webhdfs().user or os.environ['USER']\n\n @property\n def url(self):\n # the hdfs package allows it to specify multiple namenodes by passing a string containing\n # multiple namenodes separated by ';'\n hosts = self.host.split(\";\")\n urls = ['http://' + host + ':' + str(self.port) for host in hosts]\n return \";\".join(urls)\n\n @property\n def client(self):\n # A naive benchmark showed that 1000 existence checks took 2.5 secs\n # when not recreating the client, and 4.0 secs when recreating it. So\n # not urgent to memoize it. Note that it *might* be issues with process\n # forking and whatnot (as the one in the snakebite client) if we\n # memoize it too trivially.\n import hdfs\n return hdfs.InsecureClient(url=self.url, user=self.user)\n\n def walk(self, path, depth=1):\n return self.client.walk(path, depth=depth)\n\n def exists(self, path):\n \"\"\"\n Returns true if the path exists and false otherwise.\n \"\"\"\n import hdfs\n try:\n self.client.status(path)\n return True\n except hdfs.util.HdfsError as e:\n if str(e).startswith('File does not exist: '):\n return False\n else:\n raise e\n\n def upload(self, hdfs_path, local_path, overwrite=False):\n return self.client.upload(hdfs_path, local_path, overwrite=overwrite)\n\n def download(self, hdfs_path, local_path, overwrite=False, n_threads=-1):\n return self.client.download(hdfs_path, local_path, overwrite=overwrite,\n n_threads=n_threads)\n\n def remove(self, hdfs_path, recursive=True, skip_trash=False):\n assert skip_trash # Yes, you need to explicitly say skip_trash=True\n return self.client.delete(hdfs_path, recursive=recursive)\n\n def read(self, hdfs_path, offset=0, length=None, buffer_size=None,\n chunk_size=1024, buffer_char=None):\n return self.client.read(hdfs_path, offset=offset, length=length,\n buffer_size=buffer_size, chunk_size=chunk_size,\n buffer_char=buffer_char)\n\n def move(self, path, dest):\n parts = dest.rstrip('/').split('/')\n if len(parts) > 1:\n dir_path = '/'.join(parts[0:-1])\n if not self.exists(dir_path):\n self.mkdir(dir_path, parents=True)\n self.client.rename(path, dest)\n\n def mkdir(self, path, parents=True, mode=0o755, raise_if_exists=False):\n \"\"\"\n Has no returnvalue (just like WebHDFS)\n \"\"\"\n if not parents or raise_if_exists:\n warnings.warn('webhdfs mkdir: parents/raise_if_exists not implemented')\n permission = int(oct(mode)[2:]) # Convert from int(decimal) to int(octal)\n self.client.makedirs(path, permission=permission)\n\n def chmod(self, path, permissions, recursive=False):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement chmod\")\n\n def chown(self, path, owner, group, recursive=False):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement chown\")\n\n def count(self, path):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement count\")\n\n def copy(self, path, destination):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement copy\")\n\n def put(self, local_path, destination):\n \"\"\"\n Restricted version of upload\n \"\"\"\n self.upload(local_path, destination)\n\n def get(self, path, local_destination):\n \"\"\"\n Restricted version of download\n \"\"\"\n self.download(path, local_destination)\n\n def listdir(self, path, ignore_directories=False, ignore_files=False,\n include_size=False, include_type=False, include_time=False,\n recursive=False):\n assert not recursive\n return self.client.list(path, status=False)\n\n def touchz(self, path):\n \"\"\"\n To touchz using the web hdfs \"write\" cmd.\n \"\"\"\n self.client.write(path, data='', overwrite=False)\n", "path": "luigi/contrib/hdfs/webhdfs_client.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2015 VNG Corporation\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nA luigi file system client that wraps around the hdfs-library (a webhdfs\nclient)\n\nThis is a sensible fast alternative to snakebite. In particular for python3\nusers, where snakebite is not supported at the time of writing (dec 2015).\n\nNote. This wrapper client is not feature complete yet. As with most software\nthe authors only implement the features they need. If you need to wrap more of\nthe file system operations, please do and contribute back.\n\"\"\"\n\n\nfrom luigi.contrib.hdfs import config as hdfs_config\nfrom luigi.contrib.hdfs import abstract_client as hdfs_abstract_client\nimport luigi.contrib.target\nimport logging\nimport os\nimport warnings\n\nlogger = logging.getLogger('luigi-interface')\n\n\nclass webhdfs(luigi.Config):\n port = luigi.IntParameter(default=50070,\n description='Port for webhdfs')\n user = luigi.Parameter(default='', description='Defaults to $USER envvar',\n config_path=dict(section='hdfs', name='user'))\n client_type = luigi.ChoiceParameter(var_type=str, choices=['insecure', 'kerberos'],\n default='insecure', description='Type of hdfs client to use.')\n\n\nclass WebHdfsClient(hdfs_abstract_client.HdfsFileSystem):\n \"\"\"\n A webhdfs that tries to confirm to luigis interface for file existence.\n\n The library is using `this api\n <https://hdfscli.readthedocs.io/en/latest/api.html>`__.\n \"\"\"\n\n def __init__(self, host=None, port=None, user=None, client_type=None):\n self.host = host or hdfs_config.hdfs().namenode_host\n self.port = port or webhdfs().port\n self.user = user or webhdfs().user or os.environ['USER']\n self.client_type = client_type or webhdfs().client_type\n\n @property\n def url(self):\n # the hdfs package allows it to specify multiple namenodes by passing a string containing\n # multiple namenodes separated by ';'\n hosts = self.host.split(\";\")\n urls = ['http://' + host + ':' + str(self.port) for host in hosts]\n return \";\".join(urls)\n\n @property\n def client(self):\n # A naive benchmark showed that 1000 existence checks took 2.5 secs\n # when not recreating the client, and 4.0 secs when recreating it. So\n # not urgent to memoize it. Note that it *might* be issues with process\n # forking and whatnot (as the one in the snakebite client) if we\n # memoize it too trivially.\n if self.client_type == 'kerberos':\n from hdfs.ext.kerberos import KerberosClient\n return KerberosClient(url=self.url)\n else:\n import hdfs\n return hdfs.InsecureClient(url=self.url, user=self.user)\n\n def walk(self, path, depth=1):\n return self.client.walk(path, depth=depth)\n\n def exists(self, path):\n \"\"\"\n Returns true if the path exists and false otherwise.\n \"\"\"\n import hdfs\n try:\n self.client.status(path)\n return True\n except hdfs.util.HdfsError as e:\n if str(e).startswith('File does not exist: '):\n return False\n else:\n raise e\n\n def upload(self, hdfs_path, local_path, overwrite=False):\n return self.client.upload(hdfs_path, local_path, overwrite=overwrite)\n\n def download(self, hdfs_path, local_path, overwrite=False, n_threads=-1):\n return self.client.download(hdfs_path, local_path, overwrite=overwrite,\n n_threads=n_threads)\n\n def remove(self, hdfs_path, recursive=True, skip_trash=False):\n assert skip_trash # Yes, you need to explicitly say skip_trash=True\n return self.client.delete(hdfs_path, recursive=recursive)\n\n def read(self, hdfs_path, offset=0, length=None, buffer_size=None,\n chunk_size=1024, buffer_char=None):\n return self.client.read(hdfs_path, offset=offset, length=length,\n buffer_size=buffer_size, chunk_size=chunk_size,\n buffer_char=buffer_char)\n\n def move(self, path, dest):\n parts = dest.rstrip('/').split('/')\n if len(parts) > 1:\n dir_path = '/'.join(parts[0:-1])\n if not self.exists(dir_path):\n self.mkdir(dir_path, parents=True)\n self.client.rename(path, dest)\n\n def mkdir(self, path, parents=True, mode=0o755, raise_if_exists=False):\n \"\"\"\n Has no returnvalue (just like WebHDFS)\n \"\"\"\n if not parents or raise_if_exists:\n warnings.warn('webhdfs mkdir: parents/raise_if_exists not implemented')\n permission = int(oct(mode)[2:]) # Convert from int(decimal) to int(octal)\n self.client.makedirs(path, permission=permission)\n\n def chmod(self, path, permissions, recursive=False):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement chmod\")\n\n def chown(self, path, owner, group, recursive=False):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement chown\")\n\n def count(self, path):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement count\")\n\n def copy(self, path, destination):\n \"\"\"\n Raise a NotImplementedError exception.\n \"\"\"\n raise NotImplementedError(\"Webhdfs in luigi doesn't implement copy\")\n\n def put(self, local_path, destination):\n \"\"\"\n Restricted version of upload\n \"\"\"\n self.upload(local_path, destination)\n\n def get(self, path, local_destination):\n \"\"\"\n Restricted version of download\n \"\"\"\n self.download(path, local_destination)\n\n def listdir(self, path, ignore_directories=False, ignore_files=False,\n include_size=False, include_type=False, include_time=False,\n recursive=False):\n assert not recursive\n return self.client.list(path, status=False)\n\n def touchz(self, path):\n \"\"\"\n To touchz using the web hdfs \"write\" cmd.\n \"\"\"\n self.client.write(path, data='', overwrite=False)\n", "path": "luigi/contrib/hdfs/webhdfs_client.py"}]}
| 2,247 | 477 |
gh_patches_debug_14166
|
rasdani/github-patches
|
git_diff
|
tiangolo__fastapi-454
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add support for Pydantic's dataclasses
**Describe the question**
I am using a pydantic.dataclasses.dataclass as a response_model of my fast api route.
```
from fastapi import FastAPI
from pydantic.dataclasses import dataclass
@dataclass
class Foo:
bar: int
app = FastAPI()
@app.get('/foo', response_model=Foo)
def get_bar() -> Foo:
return Foo(bar=1)
```
**To Reproduce**
Steps to reproduce the behavior:
1. Create a file **app.py** with the above code.
2. Start the app: `uvicorn app:app`
3. Open the browser and go to **localhost:8000/foo**
4. See error:
```
pydantic.error_wrappers.ValidationError: 1 validation error
response
__init__() got an unexpected keyword argument '__initialised__' (type=type_error)
```
**Expected behavior**
No validation error and serialized json does not contain any keys `__initialised__`.
**Environment:**
- OS: Linux
- FastAPI Version 0.25.0
- Python version 3.7.3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fastapi/utils.py`
Content:
```
1 import re
2 from typing import Any, Dict, List, Sequence, Set, Type, cast
3
4 from fastapi import routing
5 from fastapi.openapi.constants import REF_PREFIX
6 from pydantic import BaseConfig, BaseModel, Schema, create_model
7 from pydantic.fields import Field
8 from pydantic.schema import get_flat_models_from_fields, model_process_schema
9 from pydantic.utils import lenient_issubclass
10 from starlette.routing import BaseRoute
11
12
13 def get_flat_models_from_routes(routes: Sequence[BaseRoute]) -> Set[Type[BaseModel]]:
14 body_fields_from_routes: List[Field] = []
15 responses_from_routes: List[Field] = []
16 for route in routes:
17 if getattr(route, "include_in_schema", None) and isinstance(
18 route, routing.APIRoute
19 ):
20 if route.body_field:
21 assert isinstance(
22 route.body_field, Field
23 ), "A request body must be a Pydantic Field"
24 body_fields_from_routes.append(route.body_field)
25 if route.response_field:
26 responses_from_routes.append(route.response_field)
27 if route.response_fields:
28 responses_from_routes.extend(route.response_fields.values())
29 flat_models = get_flat_models_from_fields(
30 body_fields_from_routes + responses_from_routes, known_models=set()
31 )
32 return flat_models
33
34
35 def get_model_definitions(
36 *, flat_models: Set[Type[BaseModel]], model_name_map: Dict[Type[BaseModel], str]
37 ) -> Dict[str, Any]:
38 definitions: Dict[str, Dict] = {}
39 for model in flat_models:
40 m_schema, m_definitions, m_nested_models = model_process_schema(
41 model, model_name_map=model_name_map, ref_prefix=REF_PREFIX
42 )
43 definitions.update(m_definitions)
44 model_name = model_name_map[model]
45 definitions[model_name] = m_schema
46 return definitions
47
48
49 def get_path_param_names(path: str) -> Set[str]:
50 return {item.strip("{}") for item in re.findall("{[^}]*}", path)}
51
52
53 def create_cloned_field(field: Field) -> Field:
54 original_type = field.type_
55 use_type = original_type
56 if lenient_issubclass(original_type, BaseModel):
57 original_type = cast(Type[BaseModel], original_type)
58 use_type = create_model( # type: ignore
59 original_type.__name__,
60 __config__=original_type.__config__,
61 __validators__=original_type.__validators__,
62 )
63 for f in original_type.__fields__.values():
64 use_type.__fields__[f.name] = f
65 new_field = Field(
66 name=field.name,
67 type_=use_type,
68 class_validators={},
69 default=None,
70 required=False,
71 model_config=BaseConfig,
72 schema=Schema(None),
73 )
74 new_field.has_alias = field.has_alias
75 new_field.alias = field.alias
76 new_field.class_validators = field.class_validators
77 new_field.default = field.default
78 new_field.required = field.required
79 new_field.model_config = field.model_config
80 new_field.schema = field.schema
81 new_field.allow_none = field.allow_none
82 new_field.validate_always = field.validate_always
83 if field.sub_fields:
84 new_field.sub_fields = [
85 create_cloned_field(sub_field) for sub_field in field.sub_fields
86 ]
87 if field.key_field:
88 new_field.key_field = create_cloned_field(field.key_field)
89 new_field.validators = field.validators
90 new_field.whole_pre_validators = field.whole_pre_validators
91 new_field.whole_post_validators = field.whole_post_validators
92 new_field.parse_json = field.parse_json
93 new_field.shape = field.shape
94 new_field._populate_validators()
95 return new_field
96
97
98 def generate_operation_id_for_path(*, name: str, path: str, method: str) -> str:
99 operation_id = name + path
100 operation_id = operation_id.replace("{", "_").replace("}", "_").replace("/", "_")
101 operation_id = operation_id + "_" + method.lower()
102 return operation_id
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -1,4 +1,5 @@
import re
+from dataclasses import is_dataclass
from typing import Any, Dict, List, Sequence, Set, Type, cast
from fastapi import routing
@@ -52,6 +53,8 @@
def create_cloned_field(field: Field) -> Field:
original_type = field.type_
+ if is_dataclass(original_type) and hasattr(original_type, "__pydantic_model__"):
+ original_type = original_type.__pydantic_model__ # type: ignore
use_type = original_type
if lenient_issubclass(original_type, BaseModel):
original_type = cast(Type[BaseModel], original_type)
|
{"golden_diff": "diff --git a/fastapi/utils.py b/fastapi/utils.py\n--- a/fastapi/utils.py\n+++ b/fastapi/utils.py\n@@ -1,4 +1,5 @@\n import re\n+from dataclasses import is_dataclass\n from typing import Any, Dict, List, Sequence, Set, Type, cast\n \n from fastapi import routing\n@@ -52,6 +53,8 @@\n \n def create_cloned_field(field: Field) -> Field:\n original_type = field.type_\n+ if is_dataclass(original_type) and hasattr(original_type, \"__pydantic_model__\"):\n+ original_type = original_type.__pydantic_model__ # type: ignore\n use_type = original_type\n if lenient_issubclass(original_type, BaseModel):\n original_type = cast(Type[BaseModel], original_type)\n", "issue": "Add support for Pydantic's dataclasses\n**Describe the question**\r\nI am using a pydantic.dataclasses.dataclass as a response_model of my fast api route.\r\n\r\n\r\n```\r\nfrom fastapi import FastAPI\r\nfrom pydantic.dataclasses import dataclass\r\n\r\n\r\n@dataclass\r\nclass Foo:\r\n bar: int\r\n\r\napp = FastAPI()\r\n\r\[email protected]('/foo', response_model=Foo)\r\ndef get_bar() -> Foo:\r\n return Foo(bar=1)\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Create a file **app.py** with the above code.\r\n2. Start the app: `uvicorn app:app`\r\n3. Open the browser and go to **localhost:8000/foo**\r\n4. See error: \r\n```\r\npydantic.error_wrappers.ValidationError: 1 validation error\r\nresponse\r\n __init__() got an unexpected keyword argument '__initialised__' (type=type_error)\r\n```\r\n\r\n**Expected behavior**\r\nNo validation error and serialized json does not contain any keys `__initialised__`.\r\n\r\n\r\n**Environment:**\r\n - OS: Linux\r\n - FastAPI Version 0.25.0\r\n- Python version 3.7.3\r\n\n", "before_files": [{"content": "import re\nfrom typing import Any, Dict, List, Sequence, Set, Type, cast\n\nfrom fastapi import routing\nfrom fastapi.openapi.constants import REF_PREFIX\nfrom pydantic import BaseConfig, BaseModel, Schema, create_model\nfrom pydantic.fields import Field\nfrom pydantic.schema import get_flat_models_from_fields, model_process_schema\nfrom pydantic.utils import lenient_issubclass\nfrom starlette.routing import BaseRoute\n\n\ndef get_flat_models_from_routes(routes: Sequence[BaseRoute]) -> Set[Type[BaseModel]]:\n body_fields_from_routes: List[Field] = []\n responses_from_routes: List[Field] = []\n for route in routes:\n if getattr(route, \"include_in_schema\", None) and isinstance(\n route, routing.APIRoute\n ):\n if route.body_field:\n assert isinstance(\n route.body_field, Field\n ), \"A request body must be a Pydantic Field\"\n body_fields_from_routes.append(route.body_field)\n if route.response_field:\n responses_from_routes.append(route.response_field)\n if route.response_fields:\n responses_from_routes.extend(route.response_fields.values())\n flat_models = get_flat_models_from_fields(\n body_fields_from_routes + responses_from_routes, known_models=set()\n )\n return flat_models\n\n\ndef get_model_definitions(\n *, flat_models: Set[Type[BaseModel]], model_name_map: Dict[Type[BaseModel], str]\n) -> Dict[str, Any]:\n definitions: Dict[str, Dict] = {}\n for model in flat_models:\n m_schema, m_definitions, m_nested_models = model_process_schema(\n model, model_name_map=model_name_map, ref_prefix=REF_PREFIX\n )\n definitions.update(m_definitions)\n model_name = model_name_map[model]\n definitions[model_name] = m_schema\n return definitions\n\n\ndef get_path_param_names(path: str) -> Set[str]:\n return {item.strip(\"{}\") for item in re.findall(\"{[^}]*}\", path)}\n\n\ndef create_cloned_field(field: Field) -> Field:\n original_type = field.type_\n use_type = original_type\n if lenient_issubclass(original_type, BaseModel):\n original_type = cast(Type[BaseModel], original_type)\n use_type = create_model( # type: ignore\n original_type.__name__,\n __config__=original_type.__config__,\n __validators__=original_type.__validators__,\n )\n for f in original_type.__fields__.values():\n use_type.__fields__[f.name] = f\n new_field = Field(\n name=field.name,\n type_=use_type,\n class_validators={},\n default=None,\n required=False,\n model_config=BaseConfig,\n schema=Schema(None),\n )\n new_field.has_alias = field.has_alias\n new_field.alias = field.alias\n new_field.class_validators = field.class_validators\n new_field.default = field.default\n new_field.required = field.required\n new_field.model_config = field.model_config\n new_field.schema = field.schema\n new_field.allow_none = field.allow_none\n new_field.validate_always = field.validate_always\n if field.sub_fields:\n new_field.sub_fields = [\n create_cloned_field(sub_field) for sub_field in field.sub_fields\n ]\n if field.key_field:\n new_field.key_field = create_cloned_field(field.key_field)\n new_field.validators = field.validators\n new_field.whole_pre_validators = field.whole_pre_validators\n new_field.whole_post_validators = field.whole_post_validators\n new_field.parse_json = field.parse_json\n new_field.shape = field.shape\n new_field._populate_validators()\n return new_field\n\n\ndef generate_operation_id_for_path(*, name: str, path: str, method: str) -> str:\n operation_id = name + path\n operation_id = operation_id.replace(\"{\", \"_\").replace(\"}\", \"_\").replace(\"/\", \"_\")\n operation_id = operation_id + \"_\" + method.lower()\n return operation_id\n", "path": "fastapi/utils.py"}], "after_files": [{"content": "import re\nfrom dataclasses import is_dataclass\nfrom typing import Any, Dict, List, Sequence, Set, Type, cast\n\nfrom fastapi import routing\nfrom fastapi.openapi.constants import REF_PREFIX\nfrom pydantic import BaseConfig, BaseModel, Schema, create_model\nfrom pydantic.fields import Field\nfrom pydantic.schema import get_flat_models_from_fields, model_process_schema\nfrom pydantic.utils import lenient_issubclass\nfrom starlette.routing import BaseRoute\n\n\ndef get_flat_models_from_routes(routes: Sequence[BaseRoute]) -> Set[Type[BaseModel]]:\n body_fields_from_routes: List[Field] = []\n responses_from_routes: List[Field] = []\n for route in routes:\n if getattr(route, \"include_in_schema\", None) and isinstance(\n route, routing.APIRoute\n ):\n if route.body_field:\n assert isinstance(\n route.body_field, Field\n ), \"A request body must be a Pydantic Field\"\n body_fields_from_routes.append(route.body_field)\n if route.response_field:\n responses_from_routes.append(route.response_field)\n if route.response_fields:\n responses_from_routes.extend(route.response_fields.values())\n flat_models = get_flat_models_from_fields(\n body_fields_from_routes + responses_from_routes, known_models=set()\n )\n return flat_models\n\n\ndef get_model_definitions(\n *, flat_models: Set[Type[BaseModel]], model_name_map: Dict[Type[BaseModel], str]\n) -> Dict[str, Any]:\n definitions: Dict[str, Dict] = {}\n for model in flat_models:\n m_schema, m_definitions, m_nested_models = model_process_schema(\n model, model_name_map=model_name_map, ref_prefix=REF_PREFIX\n )\n definitions.update(m_definitions)\n model_name = model_name_map[model]\n definitions[model_name] = m_schema\n return definitions\n\n\ndef get_path_param_names(path: str) -> Set[str]:\n return {item.strip(\"{}\") for item in re.findall(\"{[^}]*}\", path)}\n\n\ndef create_cloned_field(field: Field) -> Field:\n original_type = field.type_\n if is_dataclass(original_type) and hasattr(original_type, \"__pydantic_model__\"):\n original_type = original_type.__pydantic_model__ # type: ignore\n use_type = original_type\n if lenient_issubclass(original_type, BaseModel):\n original_type = cast(Type[BaseModel], original_type)\n use_type = create_model( # type: ignore\n original_type.__name__,\n __config__=original_type.__config__,\n __validators__=original_type.__validators__,\n )\n for f in original_type.__fields__.values():\n use_type.__fields__[f.name] = f\n new_field = Field(\n name=field.name,\n type_=use_type,\n class_validators={},\n default=None,\n required=False,\n model_config=BaseConfig,\n schema=Schema(None),\n )\n new_field.has_alias = field.has_alias\n new_field.alias = field.alias\n new_field.class_validators = field.class_validators\n new_field.default = field.default\n new_field.required = field.required\n new_field.model_config = field.model_config\n new_field.schema = field.schema\n new_field.allow_none = field.allow_none\n new_field.validate_always = field.validate_always\n if field.sub_fields:\n new_field.sub_fields = [\n create_cloned_field(sub_field) for sub_field in field.sub_fields\n ]\n if field.key_field:\n new_field.key_field = create_cloned_field(field.key_field)\n new_field.validators = field.validators\n new_field.whole_pre_validators = field.whole_pre_validators\n new_field.whole_post_validators = field.whole_post_validators\n new_field.parse_json = field.parse_json\n new_field.shape = field.shape\n new_field._populate_validators()\n return new_field\n\n\ndef generate_operation_id_for_path(*, name: str, path: str, method: str) -> str:\n operation_id = name + path\n operation_id = operation_id.replace(\"{\", \"_\").replace(\"}\", \"_\").replace(\"/\", \"_\")\n operation_id = operation_id + \"_\" + method.lower()\n return operation_id\n", "path": "fastapi/utils.py"}]}
| 1,582 | 178 |
gh_patches_debug_3231
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-2784
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate and remove `skimage.novice`
`skimage.novice` was built by and for Software Carpentry. I've recently learned that it is no longer being used, so I don't see much use for it remaining in the package.
If someone feels excited about turning it into a new package, please do so.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/novice/__init__.py`
Content:
```
1 """
2 skimage.novice
3 ==============
4 A special Python image submodule for beginners.
5
6 Description
7 -----------
8 ``skimage.novice`` provides a simple image manipulation interface for
9 beginners. It allows for easy loading, manipulating, and saving of image
10 files.
11
12 This module is primarily intended for teaching and differs significantly from
13 the normal, array-oriented image functions used by scikit-image.
14
15 .. note::
16
17 This module uses the Cartesian coordinate system, where the origin is at
18 the lower-left corner instead of the upper-right and the order is x, y
19 instead of row, column.
20
21
22 Examples
23 --------
24 We can create a Picture object open opening an image file:
25
26 >>> from skimage import novice
27 >>> from skimage import data
28 >>> picture = novice.open(data.data_dir + '/chelsea.png')
29
30 We can display pictures (after running this command, close the window to access the prompt again):
31
32 >>> picture.show() # doctest: +SKIP
33
34 Pictures know their format:
35
36 >>> picture.format
37 'png'
38
39 ... and where they came from:
40
41 >>> picture.path.endswith('chelsea.png')
42 True
43
44 ... and their size:
45
46 >>> picture.size
47 (451, 300)
48 >>> picture.width
49 451
50
51 As a reminder, we can preview the picture with our earlier command:
52
53 >>> picture.show() # doctest: +SKIP
54
55 Changing `size` resizes the picture.
56
57 >>> picture.size = (45, 30)
58
59 We can preview the changes we made to the picture with the ``compare`` command:
60
61 >>> picture.compare() # doctest: +SKIP
62
63 You can iterate over pixels, which have RGB values between 0 and 255,
64 and know their location in the picture.
65
66 >>> for pixel in picture:
67 ... if (pixel.red > 128) and (pixel.x < picture.width):
68 ... pixel.red = pixel.red / 2
69
70 Pictures know if they've been modified from the original file
71
72 >>> picture.modified
73 True
74 >>> print(picture.path)
75 None
76
77 Pictures can be indexed like arrays
78
79 >>> picture[0:20, 0:20] = (0, 0, 0)
80
81 Saving the picture updates the path attribute, format, and modified state.
82
83 >>> picture.save('save-demo.jpg')
84 >>> picture.path.endswith('save-demo.jpg')
85 True
86 >>> picture.format
87 'jpeg'
88 >>> picture.modified
89 False
90
91 An image can also be restored to its original state after modification:
92
93 >>> picture[0:20, 0:20] = (0, 0, 0)
94 >>> picture.compare() # doctest: +SKIP
95 >>> picture.reset()
96 >>> picture.compare() # doctest: +SKIP
97
98 """
99 from ._novice import Picture, open, colors, color_dict
100
101
102 __all__ = ['Picture', 'open', 'colors', 'color_dict']
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/skimage/novice/__init__.py b/skimage/novice/__init__.py
--- a/skimage/novice/__init__.py
+++ b/skimage/novice/__init__.py
@@ -96,7 +96,11 @@
>>> picture.compare() # doctest: +SKIP
"""
+import warnings
from ._novice import Picture, open, colors, color_dict
+warnings.warn("This module was deprecated in version 0.14. "
+ "It will be removed in 0.16.")
+
__all__ = ['Picture', 'open', 'colors', 'color_dict']
|
{"golden_diff": "diff --git a/skimage/novice/__init__.py b/skimage/novice/__init__.py\n--- a/skimage/novice/__init__.py\n+++ b/skimage/novice/__init__.py\n@@ -96,7 +96,11 @@\n >>> picture.compare() # doctest: +SKIP\n \n \"\"\"\n+import warnings\n from ._novice import Picture, open, colors, color_dict\n \n \n+warnings.warn(\"This module was deprecated in version 0.14. \"\n+ \"It will be removed in 0.16.\")\n+\n __all__ = ['Picture', 'open', 'colors', 'color_dict']\n", "issue": "Deprecate and remove `skimage.novice`\n`skimage.novice` was built by and for Software Carpentry. I've recently learned that it is no longer being used, so I don't see much use for it remaining in the package.\r\n\r\nIf someone feels excited about turning it into a new package, please do so.\n", "before_files": [{"content": "\"\"\"\nskimage.novice\n==============\nA special Python image submodule for beginners.\n\nDescription\n-----------\n``skimage.novice`` provides a simple image manipulation interface for\nbeginners. It allows for easy loading, manipulating, and saving of image\nfiles.\n\nThis module is primarily intended for teaching and differs significantly from\nthe normal, array-oriented image functions used by scikit-image.\n\n.. note::\n\n This module uses the Cartesian coordinate system, where the origin is at\n the lower-left corner instead of the upper-right and the order is x, y\n instead of row, column.\n\n\nExamples\n--------\nWe can create a Picture object open opening an image file:\n\n>>> from skimage import novice\n>>> from skimage import data\n>>> picture = novice.open(data.data_dir + '/chelsea.png')\n\nWe can display pictures (after running this command, close the window to access the prompt again):\n\n>>> picture.show() # doctest: +SKIP\n\nPictures know their format:\n\n>>> picture.format\n'png'\n\n... and where they came from:\n\n>>> picture.path.endswith('chelsea.png')\nTrue\n\n... and their size:\n\n>>> picture.size\n(451, 300)\n>>> picture.width\n451\n\nAs a reminder, we can preview the picture with our earlier command:\n\n>>> picture.show() # doctest: +SKIP\n\nChanging `size` resizes the picture.\n\n>>> picture.size = (45, 30)\n\nWe can preview the changes we made to the picture with the ``compare`` command:\n\n>>> picture.compare() # doctest: +SKIP\n\nYou can iterate over pixels, which have RGB values between 0 and 255,\nand know their location in the picture.\n\n>>> for pixel in picture:\n... if (pixel.red > 128) and (pixel.x < picture.width):\n... pixel.red = pixel.red / 2\n\nPictures know if they've been modified from the original file\n\n>>> picture.modified\nTrue\n>>> print(picture.path)\nNone\n\nPictures can be indexed like arrays\n\n>>> picture[0:20, 0:20] = (0, 0, 0)\n\nSaving the picture updates the path attribute, format, and modified state.\n\n>>> picture.save('save-demo.jpg')\n>>> picture.path.endswith('save-demo.jpg')\nTrue\n>>> picture.format\n'jpeg'\n>>> picture.modified\nFalse\n\nAn image can also be restored to its original state after modification:\n\n>>> picture[0:20, 0:20] = (0, 0, 0)\n>>> picture.compare() # doctest: +SKIP\n>>> picture.reset()\n>>> picture.compare() # doctest: +SKIP\n\n\"\"\"\nfrom ._novice import Picture, open, colors, color_dict\n\n\n__all__ = ['Picture', 'open', 'colors', 'color_dict']\n", "path": "skimage/novice/__init__.py"}], "after_files": [{"content": "\"\"\"\nskimage.novice\n==============\nA special Python image submodule for beginners.\n\nDescription\n-----------\n``skimage.novice`` provides a simple image manipulation interface for\nbeginners. It allows for easy loading, manipulating, and saving of image\nfiles.\n\nThis module is primarily intended for teaching and differs significantly from\nthe normal, array-oriented image functions used by scikit-image.\n\n.. note::\n\n This module uses the Cartesian coordinate system, where the origin is at\n the lower-left corner instead of the upper-right and the order is x, y\n instead of row, column.\n\n\nExamples\n--------\nWe can create a Picture object open opening an image file:\n\n>>> from skimage import novice\n>>> from skimage import data\n>>> picture = novice.open(data.data_dir + '/chelsea.png')\n\nWe can display pictures (after running this command, close the window to access the prompt again):\n\n>>> picture.show() # doctest: +SKIP\n\nPictures know their format:\n\n>>> picture.format\n'png'\n\n... and where they came from:\n\n>>> picture.path.endswith('chelsea.png')\nTrue\n\n... and their size:\n\n>>> picture.size\n(451, 300)\n>>> picture.width\n451\n\nAs a reminder, we can preview the picture with our earlier command:\n\n>>> picture.show() # doctest: +SKIP\n\nChanging `size` resizes the picture.\n\n>>> picture.size = (45, 30)\n\nWe can preview the changes we made to the picture with the ``compare`` command:\n\n>>> picture.compare() # doctest: +SKIP\n\nYou can iterate over pixels, which have RGB values between 0 and 255,\nand know their location in the picture.\n\n>>> for pixel in picture:\n... if (pixel.red > 128) and (pixel.x < picture.width):\n... pixel.red = pixel.red / 2\n\nPictures know if they've been modified from the original file\n\n>>> picture.modified\nTrue\n>>> print(picture.path)\nNone\n\nPictures can be indexed like arrays\n\n>>> picture[0:20, 0:20] = (0, 0, 0)\n\nSaving the picture updates the path attribute, format, and modified state.\n\n>>> picture.save('save-demo.jpg')\n>>> picture.path.endswith('save-demo.jpg')\nTrue\n>>> picture.format\n'jpeg'\n>>> picture.modified\nFalse\n\nAn image can also be restored to its original state after modification:\n\n>>> picture[0:20, 0:20] = (0, 0, 0)\n>>> picture.compare() # doctest: +SKIP\n>>> picture.reset()\n>>> picture.compare() # doctest: +SKIP\n\n\"\"\"\nimport warnings\nfrom ._novice import Picture, open, colors, color_dict\n\n\nwarnings.warn(\"This module was deprecated in version 0.14. \"\n \"It will be removed in 0.16.\")\n\n__all__ = ['Picture', 'open', 'colors', 'color_dict']\n", "path": "skimage/novice/__init__.py"}]}
| 1,160 | 146 |
gh_patches_debug_4553
|
rasdani/github-patches
|
git_diff
|
geopandas__geopandas-591
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[cython] GeoSeries.reindex has wrong filling logic
```
In [2]: s = GeoSeries([Point(1,1), Point(2,2)])
In [3]: s.reindex([0,1,2])
Out[3]: I am densified (3 elements)
0 POINT (1 1)
1 POINT (2 2)
2 POINT (2 2)
dtype: object
```
while this should be `Point(1 1), Point(2 2), None`
The reason for this is because the `indexer` that is passed to `GeometryBlock.take_nd` (and currently thus `GeometryArray.take`) has the form of `array([ 0, 1, -1])`:
```
> /home/joris/scipy/geopandas/geopandas/_block.py(129)take_nd()
-> new_values = self.values[indexer]
(Pdb) l
127 # TODO implement take_nd on GeometryArray
128 # new_values = self.values.take_nd(indexer, fill_value=fill_value)
129 -> new_values = self.values[indexer]
130
(Pdb) indexer
array([ 0, 1, -1])
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geopandas/_block.py`
Content:
```
1 from __future__ import absolute_import, division, print_function
2
3 import numpy as np
4
5 from pandas.core.internals import Block, NonConsolidatableMixIn
6 from pandas.core.common import is_null_slice
7 from shapely.geometry.base import geom_factory, BaseGeometry
8
9 from .vectorized import GeometryArray, to_shapely, concat
10
11
12 class GeometryBlock(NonConsolidatableMixIn, Block):
13 """ implement a geometry block with uint pointers to C objects
14 as underlying data"""
15 __slots__ = ()
16
17 @property
18 def _holder(self):
19 return GeometryArray
20
21 def __init__(self, values, placement, ndim=2, **kwargs):
22
23 if not isinstance(values, self._holder):
24 raise TypeError("values must be a GeometryArray object")
25
26 super(GeometryBlock, self).__init__(values, placement=placement,
27 ndim=ndim, **kwargs)
28
29 @property
30 def _box_func(self):
31 # TODO does not seems to be used at the moment (from the examples) ?
32 print("I am boxed")
33 return geom_factory
34
35 # @property
36 # def _na_value(self):
37 # return None
38 #
39 # @property
40 # def fill_value(self):
41 # return tslib.iNaT
42
43 # TODO
44 # def copy(self, deep=True, mgr=None):
45 # """ copy constructor """
46 # values = self.values
47 # if deep:
48 # values = values.copy(deep=True)
49 # return self.make_block_same_class(values)
50
51 def external_values(self):
52 """ we internally represent the data as a DatetimeIndex, but for
53 external compat with ndarray, export as a ndarray of Timestamps
54 """
55 #return np.asarray(self.values)
56 print("I am densified (external_values, {} elements)".format(len(self)))
57 return self.values.to_dense()
58
59 def formatting_values(self, dtype=None):
60 """ return an internal format, currently just the ndarray
61 this should be the pure internal API format
62 """
63 return self.to_dense()
64
65 def to_dense(self):
66 print("I am densified ({} elements)".format(len(self)))
67 return self.values.to_dense().view()
68
69 def _getitem(self, key):
70 values = self.values[key]
71 return GeometryBlock(values, placement=slice(0, len(values), 1),
72 ndim=1)
73
74 # TODO is this needed?
75 # def get_values(self, dtype=None):
76 # """
77 # return object dtype as boxed values, as shapely objects
78 # """
79 # if is_object_dtype(dtype):
80 # return lib.map_infer(self.values.ravel(),
81 # self._box_func).reshape(self.values.shape)
82 # return self.values
83
84 def to_native_types(self, slicer=None, na_rep=None, date_format=None,
85 quoting=None, **kwargs):
86 """ convert to our native types format, slicing if desired """
87
88 values = self.values
89 if slicer is not None:
90 values = values[slicer]
91
92 values = to_shapely(values.data)
93
94 return np.atleast_2d(values)
95
96 # TODO needed for what?
97 def _can_hold_element(self, element):
98 # if is_list_like(element):
99 # element = np.array(element)
100 # return element.dtype == _NS_DTYPE or element.dtype == np.int64
101 return isinstance(element, BaseGeometry)
102
103 def _slice(self, slicer):
104 """ return a slice of my values """
105 if isinstance(slicer, tuple):
106 col, loc = slicer
107 if not is_null_slice(col) and col != 0:
108 raise IndexError("{0} only contains one item".format(self))
109 return self.values[loc]
110 return self.values[slicer]
111
112 def take_nd(self, indexer, axis=0, new_mgr_locs=None, fill_tuple=None):
113 """
114 Take values according to indexer and return them as a block.bb
115 """
116 if fill_tuple is None:
117 fill_value = None
118 else:
119 fill_value = fill_tuple[0]
120
121 # axis doesn't matter; we are really a single-dim object
122 # but are passed the axis depending on the calling routing
123 # if its REALLY axis 0, then this will be a reindex and not a take
124
125 # TODO implement take_nd on GeometryArray
126 # new_values = self.values.take_nd(indexer, fill_value=fill_value)
127 new_values = self.values[indexer]
128
129 # if we are a 1-dim object, then always place at 0
130 if self.ndim == 1:
131 new_mgr_locs = [0]
132 else:
133 if new_mgr_locs is None:
134 new_mgr_locs = self.mgr_locs
135
136 return self.make_block_same_class(new_values, new_mgr_locs)
137
138 def eval(self, func, other, raise_on_error=True, try_cast=False,
139 mgr=None):
140 if func.__name__ == 'eq':
141 super(GeometryBlock, self).eval(
142 func, other, raise_on_error=raise_on_error, try_cast=try_cast,
143 mgr=mgr)
144 raise TypeError("{} not supported on geometry blocks".format(func.__name__))
145
146
147 def _astype(self, dtype, copy=False, errors='raise', values=None,
148 klass=None, mgr=None):
149 """
150 Coerce to the new type (if copy=True, return a new copy)
151 raise on an except if raise == True
152 """
153
154 if dtype == np.object_:
155 values = self.to_dense()
156 elif dtype == str:
157 values = np.array(list(map(str, self.to_dense())))
158 else:
159 if errors == 'raise':
160 raise TypeError('cannot astype geometries')
161 else:
162 values = self.to_dense()
163
164 if copy:
165 values = values.copy()
166
167 return self.make_block(values)
168
169 # def should_store(self, value):
170 # return (issubclass(value.dtype.type, np.uint64)
171 # and value.dtype == self.dtype)
172
173 def set(self, locs, values, check=False):
174 """
175 Modify Block in-place with new item value
176
177 Returns
178 -------
179 None
180 """
181 if values.dtype != self.dtype:
182 # Workaround for numpy 1.6 bug
183 if isinstance(values, BaseGeometry):
184 values = values.__geom__
185 else:
186 raise ValueError()
187
188 self.values[locs] = values
189
190 def concat_same_type(self, to_concat, placement=None):
191 """
192 Concatenate list of single blocks of the same type.
193 """
194 values = concat([blk.values for blk in to_concat])
195 return self.make_block_same_class(
196 values, placement=placement or slice(0, len(values), 1))
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geopandas/_block.py b/geopandas/_block.py
--- a/geopandas/_block.py
+++ b/geopandas/_block.py
@@ -124,7 +124,7 @@
# TODO implement take_nd on GeometryArray
# new_values = self.values.take_nd(indexer, fill_value=fill_value)
- new_values = self.values[indexer]
+ new_values = self.values.take(indexer)
# if we are a 1-dim object, then always place at 0
if self.ndim == 1:
|
{"golden_diff": "diff --git a/geopandas/_block.py b/geopandas/_block.py\n--- a/geopandas/_block.py\n+++ b/geopandas/_block.py\n@@ -124,7 +124,7 @@\n \n # TODO implement take_nd on GeometryArray\n # new_values = self.values.take_nd(indexer, fill_value=fill_value)\n- new_values = self.values[indexer]\n+ new_values = self.values.take(indexer)\n \n # if we are a 1-dim object, then always place at 0\n if self.ndim == 1:\n", "issue": "[cython] GeoSeries.reindex has wrong filling logic\n```\r\nIn [2]: s = GeoSeries([Point(1,1), Point(2,2)])\r\n\r\nIn [3]: s.reindex([0,1,2])\r\nOut[3]: I am densified (3 elements)\r\n\r\n0 POINT (1 1)\r\n1 POINT (2 2)\r\n2 POINT (2 2)\r\ndtype: object\r\n```\r\n\r\nwhile this should be `Point(1 1), Point(2 2), None`\r\n\r\nThe reason for this is because the `indexer` that is passed to `GeometryBlock.take_nd` (and currently thus `GeometryArray.take`) has the form of `array([ 0, 1, -1])`:\r\n\r\n```\r\n> /home/joris/scipy/geopandas/geopandas/_block.py(129)take_nd()\r\n-> new_values = self.values[indexer]\r\n(Pdb) l\r\n127 \t # TODO implement take_nd on GeometryArray\r\n128 \t # new_values = self.values.take_nd(indexer, fill_value=fill_value)\r\n129 ->\t new_values = self.values[indexer]\r\n130 \t\r\n\r\n(Pdb) indexer\r\narray([ 0, 1, -1])\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport numpy as np\n\nfrom pandas.core.internals import Block, NonConsolidatableMixIn\nfrom pandas.core.common import is_null_slice\nfrom shapely.geometry.base import geom_factory, BaseGeometry\n\nfrom .vectorized import GeometryArray, to_shapely, concat\n\n\nclass GeometryBlock(NonConsolidatableMixIn, Block):\n \"\"\" implement a geometry block with uint pointers to C objects\n as underlying data\"\"\"\n __slots__ = ()\n\n @property\n def _holder(self):\n return GeometryArray\n\n def __init__(self, values, placement, ndim=2, **kwargs):\n\n if not isinstance(values, self._holder):\n raise TypeError(\"values must be a GeometryArray object\")\n\n super(GeometryBlock, self).__init__(values, placement=placement,\n ndim=ndim, **kwargs)\n\n @property\n def _box_func(self):\n # TODO does not seems to be used at the moment (from the examples) ?\n print(\"I am boxed\")\n return geom_factory\n\n # @property\n # def _na_value(self):\n # return None\n #\n # @property\n # def fill_value(self):\n # return tslib.iNaT\n\n # TODO\n # def copy(self, deep=True, mgr=None):\n # \"\"\" copy constructor \"\"\"\n # values = self.values\n # if deep:\n # values = values.copy(deep=True)\n # return self.make_block_same_class(values)\n\n def external_values(self):\n \"\"\" we internally represent the data as a DatetimeIndex, but for\n external compat with ndarray, export as a ndarray of Timestamps\n \"\"\"\n #return np.asarray(self.values)\n print(\"I am densified (external_values, {} elements)\".format(len(self)))\n return self.values.to_dense()\n\n def formatting_values(self, dtype=None):\n \"\"\" return an internal format, currently just the ndarray\n this should be the pure internal API format\n \"\"\"\n return self.to_dense()\n\n def to_dense(self):\n print(\"I am densified ({} elements)\".format(len(self)))\n return self.values.to_dense().view()\n\n def _getitem(self, key):\n values = self.values[key]\n return GeometryBlock(values, placement=slice(0, len(values), 1),\n ndim=1)\n\n # TODO is this needed?\n # def get_values(self, dtype=None):\n # \"\"\"\n # return object dtype as boxed values, as shapely objects\n # \"\"\"\n # if is_object_dtype(dtype):\n # return lib.map_infer(self.values.ravel(),\n # self._box_func).reshape(self.values.shape)\n # return self.values\n\n def to_native_types(self, slicer=None, na_rep=None, date_format=None,\n quoting=None, **kwargs):\n \"\"\" convert to our native types format, slicing if desired \"\"\"\n\n values = self.values\n if slicer is not None:\n values = values[slicer]\n\n values = to_shapely(values.data)\n\n return np.atleast_2d(values)\n\n # TODO needed for what?\n def _can_hold_element(self, element):\n # if is_list_like(element):\n # element = np.array(element)\n # return element.dtype == _NS_DTYPE or element.dtype == np.int64\n return isinstance(element, BaseGeometry)\n\n def _slice(self, slicer):\n \"\"\" return a slice of my values \"\"\"\n if isinstance(slicer, tuple):\n col, loc = slicer\n if not is_null_slice(col) and col != 0:\n raise IndexError(\"{0} only contains one item\".format(self))\n return self.values[loc]\n return self.values[slicer]\n\n def take_nd(self, indexer, axis=0, new_mgr_locs=None, fill_tuple=None):\n \"\"\"\n Take values according to indexer and return them as a block.bb\n \"\"\"\n if fill_tuple is None:\n fill_value = None\n else:\n fill_value = fill_tuple[0]\n\n # axis doesn't matter; we are really a single-dim object\n # but are passed the axis depending on the calling routing\n # if its REALLY axis 0, then this will be a reindex and not a take\n\n # TODO implement take_nd on GeometryArray\n # new_values = self.values.take_nd(indexer, fill_value=fill_value)\n new_values = self.values[indexer]\n\n # if we are a 1-dim object, then always place at 0\n if self.ndim == 1:\n new_mgr_locs = [0]\n else:\n if new_mgr_locs is None:\n new_mgr_locs = self.mgr_locs\n\n return self.make_block_same_class(new_values, new_mgr_locs)\n\n def eval(self, func, other, raise_on_error=True, try_cast=False,\n mgr=None):\n if func.__name__ == 'eq':\n super(GeometryBlock, self).eval(\n func, other, raise_on_error=raise_on_error, try_cast=try_cast,\n mgr=mgr)\n raise TypeError(\"{} not supported on geometry blocks\".format(func.__name__))\n\n\n def _astype(self, dtype, copy=False, errors='raise', values=None,\n klass=None, mgr=None):\n \"\"\"\n Coerce to the new type (if copy=True, return a new copy)\n raise on an except if raise == True\n \"\"\"\n\n if dtype == np.object_:\n values = self.to_dense()\n elif dtype == str:\n values = np.array(list(map(str, self.to_dense())))\n else:\n if errors == 'raise':\n raise TypeError('cannot astype geometries')\n else:\n values = self.to_dense()\n\n if copy:\n values = values.copy()\n\n return self.make_block(values)\n\n # def should_store(self, value):\n # return (issubclass(value.dtype.type, np.uint64)\n # and value.dtype == self.dtype)\n\n def set(self, locs, values, check=False):\n \"\"\"\n Modify Block in-place with new item value\n\n Returns\n -------\n None\n \"\"\"\n if values.dtype != self.dtype:\n # Workaround for numpy 1.6 bug\n if isinstance(values, BaseGeometry):\n values = values.__geom__\n else:\n raise ValueError()\n\n self.values[locs] = values\n\n def concat_same_type(self, to_concat, placement=None):\n \"\"\"\n Concatenate list of single blocks of the same type.\n \"\"\"\n values = concat([blk.values for blk in to_concat])\n return self.make_block_same_class(\n values, placement=placement or slice(0, len(values), 1))\n", "path": "geopandas/_block.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport numpy as np\n\nfrom pandas.core.internals import Block, NonConsolidatableMixIn\nfrom pandas.core.common import is_null_slice\nfrom shapely.geometry.base import geom_factory, BaseGeometry\n\nfrom .vectorized import GeometryArray, to_shapely, concat\n\n\nclass GeometryBlock(NonConsolidatableMixIn, Block):\n \"\"\" implement a geometry block with uint pointers to C objects\n as underlying data\"\"\"\n __slots__ = ()\n\n @property\n def _holder(self):\n return GeometryArray\n\n def __init__(self, values, placement, ndim=2, **kwargs):\n\n if not isinstance(values, self._holder):\n raise TypeError(\"values must be a GeometryArray object\")\n\n super(GeometryBlock, self).__init__(values, placement=placement,\n ndim=ndim, **kwargs)\n\n @property\n def _box_func(self):\n # TODO does not seems to be used at the moment (from the examples) ?\n print(\"I am boxed\")\n return geom_factory\n\n # @property\n # def _na_value(self):\n # return None\n #\n # @property\n # def fill_value(self):\n # return tslib.iNaT\n\n # TODO\n # def copy(self, deep=True, mgr=None):\n # \"\"\" copy constructor \"\"\"\n # values = self.values\n # if deep:\n # values = values.copy(deep=True)\n # return self.make_block_same_class(values)\n\n def external_values(self):\n \"\"\" we internally represent the data as a DatetimeIndex, but for\n external compat with ndarray, export as a ndarray of Timestamps\n \"\"\"\n #return np.asarray(self.values)\n print(\"I am densified (external_values, {} elements)\".format(len(self)))\n return self.values.to_dense()\n\n def formatting_values(self, dtype=None):\n \"\"\" return an internal format, currently just the ndarray\n this should be the pure internal API format\n \"\"\"\n return self.to_dense()\n\n def to_dense(self):\n print(\"I am densified ({} elements)\".format(len(self)))\n return self.values.to_dense().view()\n\n def _getitem(self, key):\n values = self.values[key]\n return GeometryBlock(values, placement=slice(0, len(values), 1),\n ndim=1)\n\n # TODO is this needed?\n # def get_values(self, dtype=None):\n # \"\"\"\n # return object dtype as boxed values, as shapely objects\n # \"\"\"\n # if is_object_dtype(dtype):\n # return lib.map_infer(self.values.ravel(),\n # self._box_func).reshape(self.values.shape)\n # return self.values\n\n def to_native_types(self, slicer=None, na_rep=None, date_format=None,\n quoting=None, **kwargs):\n \"\"\" convert to our native types format, slicing if desired \"\"\"\n\n values = self.values\n if slicer is not None:\n values = values[slicer]\n\n values = to_shapely(values.data)\n\n return np.atleast_2d(values)\n\n # TODO needed for what?\n def _can_hold_element(self, element):\n # if is_list_like(element):\n # element = np.array(element)\n # return element.dtype == _NS_DTYPE or element.dtype == np.int64\n return isinstance(element, BaseGeometry)\n\n def _slice(self, slicer):\n \"\"\" return a slice of my values \"\"\"\n if isinstance(slicer, tuple):\n col, loc = slicer\n if not is_null_slice(col) and col != 0:\n raise IndexError(\"{0} only contains one item\".format(self))\n return self.values[loc]\n return self.values[slicer]\n\n def take_nd(self, indexer, axis=0, new_mgr_locs=None, fill_tuple=None):\n \"\"\"\n Take values according to indexer and return them as a block.bb\n \"\"\"\n if fill_tuple is None:\n fill_value = None\n else:\n fill_value = fill_tuple[0]\n\n # axis doesn't matter; we are really a single-dim object\n # but are passed the axis depending on the calling routing\n # if its REALLY axis 0, then this will be a reindex and not a take\n\n # TODO implement take_nd on GeometryArray\n # new_values = self.values.take_nd(indexer, fill_value=fill_value)\n new_values = self.values.take(indexer)\n\n # if we are a 1-dim object, then always place at 0\n if self.ndim == 1:\n new_mgr_locs = [0]\n else:\n if new_mgr_locs is None:\n new_mgr_locs = self.mgr_locs\n\n return self.make_block_same_class(new_values, new_mgr_locs)\n\n def eval(self, func, other, raise_on_error=True, try_cast=False,\n mgr=None):\n if func.__name__ == 'eq':\n super(GeometryBlock, self).eval(\n func, other, raise_on_error=raise_on_error, try_cast=try_cast,\n mgr=mgr)\n raise TypeError(\"{} not supported on geometry blocks\".format(func.__name__))\n\n\n def _astype(self, dtype, copy=False, errors='raise', values=None,\n klass=None, mgr=None):\n \"\"\"\n Coerce to the new type (if copy=True, return a new copy)\n raise on an except if raise == True\n \"\"\"\n\n if dtype == np.object_:\n values = self.to_dense()\n elif dtype == str:\n values = np.array(list(map(str, self.to_dense())))\n else:\n if errors == 'raise':\n raise TypeError('cannot astype geometries')\n else:\n values = self.to_dense()\n\n if copy:\n values = values.copy()\n\n return self.make_block(values)\n\n # def should_store(self, value):\n # return (issubclass(value.dtype.type, np.uint64)\n # and value.dtype == self.dtype)\n\n def set(self, locs, values, check=False):\n \"\"\"\n Modify Block in-place with new item value\n\n Returns\n -------\n None\n \"\"\"\n if values.dtype != self.dtype:\n # Workaround for numpy 1.6 bug\n if isinstance(values, BaseGeometry):\n values = values.__geom__\n else:\n raise ValueError()\n\n self.values[locs] = values\n\n def concat_same_type(self, to_concat, placement=None):\n \"\"\"\n Concatenate list of single blocks of the same type.\n \"\"\"\n values = concat([blk.values for blk in to_concat])\n return self.make_block_same_class(\n values, placement=placement or slice(0, len(values), 1))\n", "path": "geopandas/_block.py"}]}
| 2,497 | 128 |
gh_patches_debug_21859
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1540
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add readthedocs documentation for pika instrumentation
Part of [1491](https://github.com/open-telemetry/opentelemetry-python-contrib/issues/1491)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """
15 Instrument `pika` to trace RabbitMQ applications.
16
17 Usage
18 -----
19
20 * Start broker backend
21
22 .. code-block:: python
23
24 docker run -p 5672:5672 rabbitmq
25
26 * Run instrumented task
27
28 .. code-block:: python
29
30 import pika
31 from opentelemetry.instrumentation.pika import PikaInstrumentor
32
33 PikaInstrumentor().instrument()
34
35 connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))
36 channel = connection.channel()
37 channel.queue_declare(queue='hello')
38 channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')
39
40 * PikaInstrumentor also supports instrumentation of a single channel
41
42 .. code-block:: python
43
44 import pika
45 from opentelemetry.instrumentation.pika import PikaInstrumentor
46
47 connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))
48 channel = connection.channel()
49 channel.queue_declare(queue='hello')
50
51 pika_instrumentation = PikaInstrumentor()
52 pika_instrumentation.instrument_channel(channel=channel)
53
54
55 channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')
56
57 pika_instrumentation.uninstrument_channel(channel=channel)
58
59 * PikaInstrumentor also supports instrumentation without creating an object, and receiving a tracer_provider
60
61 .. code-block:: python
62
63 PikaInstrumentor.instrument_channel(channel, tracer_provider=tracer_provider)
64
65 * PikaInstrumentor also supports instrumenting with hooks that will be called when producing or consuming a message.
66 The hooks should be of type `Callable[[Span, bytes, BasicProperties], None]`
67 where the first parameter is the span, the second parameter is the message body
68 and the third parameter is the message properties
69
70 .. code-block:: python
71
72 def publish_hook(span: Span, body: bytes, properties: BasicProperties):
73 span.set_attribute("messaging.payload", body.decode())
74
75 def consume_hook(span: Span, body: bytes, properties: BasicProperties):
76 span.set_attribute("messaging.id", properties.message_id)
77
78 PikaInstrumentor.instrument_channel(channel, publish_hook=publish_hook, consume_hook=consume_hook)
79
80 API
81 ---
82 """
83 # pylint: disable=import-error
84
85 from .pika_instrumentor import PikaInstrumentor
86 from .version import __version__
87
88 __all__ = ["PikaInstrumentor", "__version__"]
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py b/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
"""
-Instrument `pika` to trace RabbitMQ applications.
+Instrument pika to trace RabbitMQ applications.
Usage
-----
@@ -63,7 +63,7 @@
PikaInstrumentor.instrument_channel(channel, tracer_provider=tracer_provider)
* PikaInstrumentor also supports instrumenting with hooks that will be called when producing or consuming a message.
- The hooks should be of type `Callable[[Span, bytes, BasicProperties], None]`
+ The hooks should be of type "Callable[[Span, bytes, BasicProperties], None]"
where the first parameter is the span, the second parameter is the message body
and the third parameter is the message properties
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py b/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py\n@@ -12,7 +12,7 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \"\"\"\n-Instrument `pika` to trace RabbitMQ applications.\n+Instrument pika to trace RabbitMQ applications.\n \n Usage\n -----\n@@ -63,7 +63,7 @@\n PikaInstrumentor.instrument_channel(channel, tracer_provider=tracer_provider)\n \n * PikaInstrumentor also supports instrumenting with hooks that will be called when producing or consuming a message.\n- The hooks should be of type `Callable[[Span, bytes, BasicProperties], None]`\n+ The hooks should be of type \"Callable[[Span, bytes, BasicProperties], None]\"\n where the first parameter is the span, the second parameter is the message body\n and the third parameter is the message properties\n", "issue": "Add readthedocs documentation for pika instrumentation\nPart of [1491](https://github.com/open-telemetry/opentelemetry-python-contrib/issues/1491)\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nInstrument `pika` to trace RabbitMQ applications.\n\nUsage\n-----\n\n* Start broker backend\n\n.. code-block:: python\n\n docker run -p 5672:5672 rabbitmq\n\n* Run instrumented task\n\n.. code-block:: python\n\n import pika\n from opentelemetry.instrumentation.pika import PikaInstrumentor\n\n PikaInstrumentor().instrument()\n\n connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))\n channel = connection.channel()\n channel.queue_declare(queue='hello')\n channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')\n\n* PikaInstrumentor also supports instrumentation of a single channel\n\n.. code-block:: python\n\n import pika\n from opentelemetry.instrumentation.pika import PikaInstrumentor\n\n connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))\n channel = connection.channel()\n channel.queue_declare(queue='hello')\n\n pika_instrumentation = PikaInstrumentor()\n pika_instrumentation.instrument_channel(channel=channel)\n\n\n channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')\n\n pika_instrumentation.uninstrument_channel(channel=channel)\n\n* PikaInstrumentor also supports instrumentation without creating an object, and receiving a tracer_provider\n\n.. code-block:: python\n\n PikaInstrumentor.instrument_channel(channel, tracer_provider=tracer_provider)\n\n* PikaInstrumentor also supports instrumenting with hooks that will be called when producing or consuming a message.\n The hooks should be of type `Callable[[Span, bytes, BasicProperties], None]`\n where the first parameter is the span, the second parameter is the message body\n and the third parameter is the message properties\n\n.. code-block:: python\n\n def publish_hook(span: Span, body: bytes, properties: BasicProperties):\n span.set_attribute(\"messaging.payload\", body.decode())\n\n def consume_hook(span: Span, body: bytes, properties: BasicProperties):\n span.set_attribute(\"messaging.id\", properties.message_id)\n\n PikaInstrumentor.instrument_channel(channel, publish_hook=publish_hook, consume_hook=consume_hook)\n\nAPI\n---\n\"\"\"\n# pylint: disable=import-error\n\nfrom .pika_instrumentor import PikaInstrumentor\nfrom .version import __version__\n\n__all__ = [\"PikaInstrumentor\", \"__version__\"]\n", "path": "instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nInstrument pika to trace RabbitMQ applications.\n\nUsage\n-----\n\n* Start broker backend\n\n.. code-block:: python\n\n docker run -p 5672:5672 rabbitmq\n\n* Run instrumented task\n\n.. code-block:: python\n\n import pika\n from opentelemetry.instrumentation.pika import PikaInstrumentor\n\n PikaInstrumentor().instrument()\n\n connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))\n channel = connection.channel()\n channel.queue_declare(queue='hello')\n channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')\n\n* PikaInstrumentor also supports instrumentation of a single channel\n\n.. code-block:: python\n\n import pika\n from opentelemetry.instrumentation.pika import PikaInstrumentor\n\n connection = pika.BlockingConnection(pika.URLParameters('amqp://localhost'))\n channel = connection.channel()\n channel.queue_declare(queue='hello')\n\n pika_instrumentation = PikaInstrumentor()\n pika_instrumentation.instrument_channel(channel=channel)\n\n\n channel.basic_publish(exchange='', routing_key='hello', body=b'Hello World!')\n\n pika_instrumentation.uninstrument_channel(channel=channel)\n\n* PikaInstrumentor also supports instrumentation without creating an object, and receiving a tracer_provider\n\n.. code-block:: python\n\n PikaInstrumentor.instrument_channel(channel, tracer_provider=tracer_provider)\n\n* PikaInstrumentor also supports instrumenting with hooks that will be called when producing or consuming a message.\n The hooks should be of type \"Callable[[Span, bytes, BasicProperties], None]\"\n where the first parameter is the span, the second parameter is the message body\n and the third parameter is the message properties\n\n.. code-block:: python\n\n def publish_hook(span: Span, body: bytes, properties: BasicProperties):\n span.set_attribute(\"messaging.payload\", body.decode())\n\n def consume_hook(span: Span, body: bytes, properties: BasicProperties):\n span.set_attribute(\"messaging.id\", properties.message_id)\n\n PikaInstrumentor.instrument_channel(channel, publish_hook=publish_hook, consume_hook=consume_hook)\n\nAPI\n---\n\"\"\"\n# pylint: disable=import-error\n\nfrom .pika_instrumentor import PikaInstrumentor\nfrom .version import __version__\n\n__all__ = [\"PikaInstrumentor\", \"__version__\"]\n", "path": "instrumentation/opentelemetry-instrumentation-pika/src/opentelemetry/instrumentation/pika/__init__.py"}]}
| 1,142 | 283 |
gh_patches_debug_15296
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1748
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/contrib/pydantic.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Generic, TypeVar
4
5 from pydantic import BaseModel
6
7 from litestar.dto.factory.abc import AbstractDTOFactory
8 from litestar.dto.factory.field import DTO_FIELD_META_KEY, DTOField
9 from litestar.dto.factory.types import FieldDefinition
10 from litestar.dto.factory.utils import get_model_type_hints
11 from litestar.types.empty import Empty
12 from litestar.utils.helpers import get_fully_qualified_class_name
13
14 if TYPE_CHECKING:
15 from typing import Any, ClassVar, Collection, Generator
16
17 from pydantic.fields import ModelField
18
19 from litestar.typing import ParsedType
20
21 __all__ = ("PydanticDTO",)
22
23 T = TypeVar("T", bound="BaseModel | Collection[BaseModel]")
24
25
26 class PydanticDTO(AbstractDTOFactory[T], Generic[T]):
27 """Support for domain modelling with Pydantic."""
28
29 __slots__ = ()
30
31 model_type: ClassVar[type[BaseModel]]
32
33 @classmethod
34 def generate_field_definitions(cls, model_type: type[BaseModel]) -> Generator[FieldDefinition, None, None]:
35 for key, parsed_type in get_model_type_hints(model_type).items():
36 model_field = model_type.__fields__[key]
37
38 dto_field: DTOField | None = model_field.field_info.extra.get(DTO_FIELD_META_KEY)
39
40 def determine_default(_parsed_type: ParsedType, _model_field: ModelField) -> Any:
41 if (
42 _model_field.default is Ellipsis
43 or _model_field.default_factory is not None
44 or (_model_field.default is None and not _parsed_type.is_optional)
45 ):
46 return Empty
47
48 return _model_field.default
49
50 field_def = FieldDefinition(
51 name=key,
52 default=determine_default(parsed_type, model_field),
53 parsed_type=parsed_type,
54 default_factory=model_field.default_factory or Empty,
55 dto_field=dto_field,
56 unique_model_name=get_fully_qualified_class_name(model_type),
57 )
58
59 yield field_def
60
61 @classmethod
62 def detect_nested_field(cls, parsed_type: ParsedType) -> bool:
63 return parsed_type.is_subclass_of(BaseModel)
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/litestar/contrib/pydantic.py b/litestar/contrib/pydantic.py
--- a/litestar/contrib/pydantic.py
+++ b/litestar/contrib/pydantic.py
@@ -32,9 +32,10 @@
@classmethod
def generate_field_definitions(cls, model_type: type[BaseModel]) -> Generator[FieldDefinition, None, None]:
- for key, parsed_type in get_model_type_hints(model_type).items():
+ model_parsed_types = get_model_type_hints(model_type)
+ for key, model_field in model_type.__fields__.items():
+ parsed_type = model_parsed_types[key]
model_field = model_type.__fields__[key]
-
dto_field: DTOField | None = model_field.field_info.extra.get(DTO_FIELD_META_KEY)
def determine_default(_parsed_type: ParsedType, _model_field: ModelField) -> Any:
|
{"golden_diff": "diff --git a/litestar/contrib/pydantic.py b/litestar/contrib/pydantic.py\n--- a/litestar/contrib/pydantic.py\n+++ b/litestar/contrib/pydantic.py\n@@ -32,9 +32,10 @@\n \n @classmethod\n def generate_field_definitions(cls, model_type: type[BaseModel]) -> Generator[FieldDefinition, None, None]:\n- for key, parsed_type in get_model_type_hints(model_type).items():\n+ model_parsed_types = get_model_type_hints(model_type)\n+ for key, model_field in model_type.__fields__.items():\n+ parsed_type = model_parsed_types[key]\n model_field = model_type.__fields__[key]\n-\n dto_field: DTOField | None = model_field.field_info.extra.get(DTO_FIELD_META_KEY)\n \n def determine_default(_parsed_type: ParsedType, _model_field: ModelField) -> Any:\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Generic, TypeVar\n\nfrom pydantic import BaseModel\n\nfrom litestar.dto.factory.abc import AbstractDTOFactory\nfrom litestar.dto.factory.field import DTO_FIELD_META_KEY, DTOField\nfrom litestar.dto.factory.types import FieldDefinition\nfrom litestar.dto.factory.utils import get_model_type_hints\nfrom litestar.types.empty import Empty\nfrom litestar.utils.helpers import get_fully_qualified_class_name\n\nif TYPE_CHECKING:\n from typing import Any, ClassVar, Collection, Generator\n\n from pydantic.fields import ModelField\n\n from litestar.typing import ParsedType\n\n__all__ = (\"PydanticDTO\",)\n\nT = TypeVar(\"T\", bound=\"BaseModel | Collection[BaseModel]\")\n\n\nclass PydanticDTO(AbstractDTOFactory[T], Generic[T]):\n \"\"\"Support for domain modelling with Pydantic.\"\"\"\n\n __slots__ = ()\n\n model_type: ClassVar[type[BaseModel]]\n\n @classmethod\n def generate_field_definitions(cls, model_type: type[BaseModel]) -> Generator[FieldDefinition, None, None]:\n for key, parsed_type in get_model_type_hints(model_type).items():\n model_field = model_type.__fields__[key]\n\n dto_field: DTOField | None = model_field.field_info.extra.get(DTO_FIELD_META_KEY)\n\n def determine_default(_parsed_type: ParsedType, _model_field: ModelField) -> Any:\n if (\n _model_field.default is Ellipsis\n or _model_field.default_factory is not None\n or (_model_field.default is None and not _parsed_type.is_optional)\n ):\n return Empty\n\n return _model_field.default\n\n field_def = FieldDefinition(\n name=key,\n default=determine_default(parsed_type, model_field),\n parsed_type=parsed_type,\n default_factory=model_field.default_factory or Empty,\n dto_field=dto_field,\n unique_model_name=get_fully_qualified_class_name(model_type),\n )\n\n yield field_def\n\n @classmethod\n def detect_nested_field(cls, parsed_type: ParsedType) -> bool:\n return parsed_type.is_subclass_of(BaseModel)\n", "path": "litestar/contrib/pydantic.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Generic, TypeVar\n\nfrom pydantic import BaseModel\n\nfrom litestar.dto.factory.abc import AbstractDTOFactory\nfrom litestar.dto.factory.field import DTO_FIELD_META_KEY, DTOField\nfrom litestar.dto.factory.types import FieldDefinition\nfrom litestar.dto.factory.utils import get_model_type_hints\nfrom litestar.types.empty import Empty\nfrom litestar.utils.helpers import get_fully_qualified_class_name\n\nif TYPE_CHECKING:\n from typing import Any, ClassVar, Collection, Generator\n\n from pydantic.fields import ModelField\n\n from litestar.typing import ParsedType\n\n__all__ = (\"PydanticDTO\",)\n\nT = TypeVar(\"T\", bound=\"BaseModel | Collection[BaseModel]\")\n\n\nclass PydanticDTO(AbstractDTOFactory[T], Generic[T]):\n \"\"\"Support for domain modelling with Pydantic.\"\"\"\n\n __slots__ = ()\n\n model_type: ClassVar[type[BaseModel]]\n\n @classmethod\n def generate_field_definitions(cls, model_type: type[BaseModel]) -> Generator[FieldDefinition, None, None]:\n model_parsed_types = get_model_type_hints(model_type)\n for key, model_field in model_type.__fields__.items():\n parsed_type = model_parsed_types[key]\n model_field = model_type.__fields__[key]\n dto_field: DTOField | None = model_field.field_info.extra.get(DTO_FIELD_META_KEY)\n\n def determine_default(_parsed_type: ParsedType, _model_field: ModelField) -> Any:\n if (\n _model_field.default is Ellipsis\n or _model_field.default_factory is not None\n or (_model_field.default is None and not _parsed_type.is_optional)\n ):\n return Empty\n\n return _model_field.default\n\n field_def = FieldDefinition(\n name=key,\n default=determine_default(parsed_type, model_field),\n parsed_type=parsed_type,\n default_factory=model_field.default_factory or Empty,\n dto_field=dto_field,\n unique_model_name=get_fully_qualified_class_name(model_type),\n )\n\n yield field_def\n\n @classmethod\n def detect_nested_field(cls, parsed_type: ParsedType) -> bool:\n return parsed_type.is_subclass_of(BaseModel)\n", "path": "litestar/contrib/pydantic.py"}]}
| 1,024 | 204 |
gh_patches_debug_37771
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-2757
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Components on multiple objects duplicates objects in all_models
This can causes models to be initialized more than once, which causes errors. Need to protect on both the python and JS sides.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/embed.py`
Content:
```
1 ''' This module provides functions for embedding Bokeh plots in various
2 different ways.
3
4 There are a number of different combinations of options when embedding
5 Bokeh plots. The data for the plot can be contained in the document,
6 or on a Bokeh server, or in a sidecar JavaScript file. Likewise, BokehJS
7 may be inlined in the document, or loaded from CDN or a Bokeh server.
8
9 The functions in ``bokeh.embed`` provide functionality to embed in all
10 these different cases.
11
12 '''
13
14 from __future__ import absolute_import
15
16 from warnings import warn
17 import uuid
18
19 from .protocol import serialize_json
20 from .resources import Resources
21 from .templates import (
22 AUTOLOAD, AUTOLOAD_SERVER, AUTOLOAD_STATIC, FILE,
23 NOTEBOOK_DIV, PLOT_DIV, PLOT_JS, PLOT_SCRIPT, RESOURCES
24 )
25 from .util.string import encode_utf8
26
27 from .plot_object import PlotObject
28 from collections import Sequence
29 from six import string_types
30
31 def _wrap_in_function(code):
32 # Indent and wrap Bokeh function def around
33 code = "\n".join([ " " + line for line in code.split("\n") ])
34 return 'Bokeh.$(function() {\n%s\n});' % code
35
36
37 def components(plot_objects, resources=None):
38 ''' Return HTML components to embed a Bokeh plot.
39
40 The data for the plot is stored directly in the returned HTML.
41
42 .. note:: The returned components assume that BokehJS resources
43 are **already loaded**.
44
45 Args:
46 plot_objects (PlotObject|list|dict|tuple) :
47 The |components| function takes either a single PlotObject, a list/tuple of
48 PlotObjects, or a dictionary of keys and PlotObjects. Each returns
49 a corresponding data structure of script and div pairs.
50
51 The following illustrates how different input types correlate to outputs:
52
53 components(plot)
54 #=> (script, plot_div)
55
56 components((plot_1, plot_2))
57 #=> (script, (plot_1_div, plot_2_div))
58
59 components({"Plot 1": plot_1, "Plot 2": plot_2})
60 #=> (script, {"Plot 1": plot_1_div, "Plot 2": plot_2_div})
61
62 An example can be found in examples/embed/embed_multiple.py
63
64 resources : Deprecated argument
65
66 Returns:
67 (script, div[s]): UTF-8 encoded
68 '''
69 from .document import Document
70 if isinstance(plot_objects, (PlotObject, Document)):
71 plot_objects = [plot_objects]
72 if resources is not None:
73 warn('Because the ``resources`` argument is no longer needed, '
74 'it is deprecated and will be removed in'
75 'a future version.', DeprecationWarning, stacklevel=2)
76 all_models = []
77 plots = []
78 if isinstance(plot_objects, Sequence) and all(isinstance(x, (PlotObject, Document)) for x in plot_objects):
79 divs = []
80 for idx, plot_object in enumerate(plot_objects):
81 elementid = str(uuid.uuid4())
82 _append_plot(all_models, plots, plot_object, elementid)
83 divs = _append_div(elementid, divs)
84 if len(divs) == 1:
85 divs = divs[0]
86 else:
87 divs = tuple(divs)
88 return _component_pair(all_models, plots, divs)
89 elif isinstance(plot_objects, dict) and \
90 all(isinstance(x, string_types) for x in plot_objects.keys()) and \
91 all(isinstance(x, (PlotObject, Document)) for x in plot_objects.values()):
92 divs = {}
93 for key in plot_objects.keys():
94 elementid = str(uuid.uuid4())
95 _append_plot(all_models, plots, plot_objects[key], elementid)
96 divs = _append_div(elementid, divs, key)
97 return _component_pair(all_models, plots, divs)
98 else:
99 raise ValueError('Input must be a PlotObject, a Sequence of PlotObjects, or a mapping of string to PlotObjects')
100
101 def _component_pair(all_models, plots, divs):
102 js = PLOT_JS.render(
103 all_models = serialize_json(all_models),
104 plots = plots
105 )
106 script = PLOT_SCRIPT.render(
107 plot_js = _wrap_in_function(js),
108 )
109 return encode_utf8(script), divs
110
111 def _append_plot(all_models, plots, plot_object, elementid):
112 ref = plot_object.ref
113 all_models.extend(plot_object.dump())
114 plots.append({
115 'modelid': ref["id"],
116 'elementid': '#' + elementid,
117 'modeltype': ref["type"]
118 })
119
120 def _append_div(elementid, divs=None, key=None):
121 div = PLOT_DIV.render(
122 elementid = elementid
123 )
124 if isinstance(divs, list):
125 divs.append(encode_utf8(div))
126 return divs
127 elif isinstance(divs, dict):
128 divs[key] = encode_utf8(div)
129 return divs
130 else:
131 return encode_utf8(div)
132
133 def notebook_div(plot_object):
134 ''' Return HTML for a div that will display a Bokeh plot in an
135 IPython Notebook
136
137 The data for the plot is stored directly in the returned HTML.
138
139 Args:
140 plot_object (PlotObject) : Bokeh object to render
141 typically a Plot or PlotContext
142
143 Returns:
144 div : UTF-8 encoded HTML text
145
146 .. note::
147 Assumes ``bokeh.load_notebook()`` or the equivalent has already
148 been executed.
149
150 '''
151 ref = plot_object.ref
152 elementid = str(uuid.uuid4())
153
154 plots = [{
155 'modelid': ref["id"],
156 'elementid': '#' + elementid,
157 'modeltype': ref["type"]
158 }]
159
160 js = PLOT_JS.render(
161 all_models = serialize_json(plot_object.dump()),
162 plots = plots
163 )
164 script = PLOT_SCRIPT.render(
165 plot_js = _wrap_in_function(js),
166 )
167 div = PLOT_DIV.render(elementid=elementid)
168 html = NOTEBOOK_DIV.render(
169 plot_script = script,
170 plot_div = div,
171 )
172 return encode_utf8(html)
173
174
175 def file_html(plot_object, resources, title, template=FILE, template_variables=None):
176 ''' Return an HTML document that embeds a Bokeh plot.
177
178 The data for the plot is stored directly in the returned HTML.
179
180 Args:
181 plot_object (PlotObject) : Bokeh object to render
182 typically a Plot or PlotContext
183 resources (Resources) : a resource configuration for BokehJS assets
184 title (str) : a title for the HTML document ``<title>`` tags
185 template (Template, optional) : HTML document template (default: FILE)
186 A Jinja2 Template, see bokeh.templates.FILE for the required
187 template parameters
188 template_variables (dict, optional) : variables to be used in the Jinja2
189 template. If used, the following variable names will be overwritten:
190 title, plot_resources, plot_script, plot_div
191
192 Returns:
193 html : standalone HTML document with embedded plot
194
195 '''
196 from .document import Document
197 if not isinstance(plot_object, (PlotObject, Document)):
198 raise ValueError('plot_object must be a single PlotObject')
199
200 plot_resources = RESOURCES.render(
201 js_raw = resources.js_raw,
202 css_raw = resources.css_raw,
203 js_files = resources.js_files,
204 css_files = resources.css_files,
205 )
206 script, div = components(plot_object)
207 template_variables_full = \
208 template_variables.copy() if template_variables is not None else {}
209 template_variables_full.update(
210 {
211 'title': title,
212 'plot_resources': plot_resources,
213 'plot_script': script,
214 'plot_div': div,
215 }
216 )
217 html = template.render(template_variables_full)
218 return encode_utf8(html)
219
220
221 def autoload_static(plot_object, resources, script_path):
222 ''' Return JavaScript code and a script tag that can be used to embed
223 Bokeh Plots.
224
225 The data for the plot is stored directly in the returned JavaScript code.
226
227 Args:
228 plot_object (PlotObject) :
229 resources (Resources) :
230 script_path (str) :
231
232 Returns:
233 (js, tag) :
234 JavaScript code to be saved at ``script_path`` and a ``<script>``
235 tag to load it
236
237 Raises:
238 ValueError
239
240 '''
241 if resources.mode == 'inline':
242 raise ValueError("autoload_static() requires non-inline resources")
243
244 if resources.dev:
245 raise ValueError("autoload_static() only works with non-dev resources")
246
247 elementid = str(uuid.uuid4())
248
249 js = AUTOLOAD.render(
250 all_models = serialize_json(plot_object.dump()),
251 js_url = resources.js_files[0],
252 css_files = resources.css_files,
253 elementid = elementid,
254 )
255
256 tag = AUTOLOAD_STATIC.render(
257 src_path = script_path,
258 elementid = elementid,
259 modelid = plot_object._id,
260 modeltype = plot_object.__view_model__,
261 loglevel = resources.log_level,
262 )
263
264 return encode_utf8(js), encode_utf8(tag)
265
266
267 def autoload_server(plot_object, session, public=False):
268 ''' Return a script tag that can be used to embed Bokeh Plots from
269 a Bokeh Server.
270
271 The data for the plot is stored on the Bokeh Server.
272
273 Args:
274 plot_object (PlotObject) :
275 session (Session) :
276
277 Returns:
278 tag :
279 a ``<script>`` tag that will execute an autoload script
280 loaded from the Bokeh Server
281
282 '''
283 elementid = str(uuid.uuid4())
284 resources = Resources(root_url=session.root_url, mode="server")
285 tag = AUTOLOAD_SERVER.render(
286 src_path = resources._autoload_path(elementid),
287 elementid = elementid,
288 modelid = plot_object._id,
289 root_url = resources.root_url,
290 docid = session.docid,
291 docapikey = session.apikey,
292 loglevel = resources.log_level,
293 public = public
294 )
295
296 return encode_utf8(tag)
297
```
Path: `examples/plotting/file/ajax_source_realtime.py`
Content:
```
1 import numpy as np
2
3 from bokeh.plotting import figure, show, output_file
4 from bokeh.models.sources import AjaxDataSource
5
6 output_file("ajax_source_realtime.html", title="ajax_source_realtime.py example")
7 source = AjaxDataSource(data_url='http://localhost:5050/data', mode="append",
8 if_modified=True, polling_interval=1000, max_size=125)
9 p = figure()
10 p.line('x', 'y', source=source)
11 show(p)
12
13 import time
14 from threading import Thread
15 from collections import namedtuple, deque
16
17 Entry = namedtuple('Entry', ['x', 'y', 'creation'])
18
19 entries = deque(maxlen=120)
20
21 def gen_entry():
22 global entries
23 x = 0
24 while True:
25 last_entry = Entry(x, np.sin(x*np.pi/10), time.time())
26 entries.append(last_entry)
27 print("Entry generated: %s" % str(last_entry))
28 x += 1
29 if x > entries.maxlen and x % 10 == 0:
30 time.sleep(2)
31
32 t = Thread(target=gen_entry)
33 t.daemon = True
34 t.start()
35
36 import json
37 from flask import Flask, Response, request
38 from bokeh.server.crossdomain import crossdomain
39
40 app = Flask(__name__)
41
42 @app.route('/data', methods=['GET', 'OPTIONS'])
43 @crossdomain(origin="*", methods=['GET', 'POST'])
44 def hello_world():
45 global entries
46 try:
47 modified_since = float(request.headers.get('If-Modified-Since'))
48 except TypeError:
49 modified_since = 0
50
51 new_entries = [e for e in entries if e.creation > modified_since]
52 js = json.dumps({'x':[e.x for e in new_entries], 'y':[e.y for e in new_entries]})
53 resp = Response(js, status=200, mimetype='application/json')
54
55 if new_entries:
56 resp.headers['Last-Modified'] = new_entries[-1].creation
57 elif modified_since:
58 resp.headers['Last-Modified'] = modified_since
59
60 return resp
61
62 if __name__ == "__main__":
63 app.run(port=5050)
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/embed.py b/bokeh/embed.py
--- a/bokeh/embed.py
+++ b/bokeh/embed.py
@@ -73,7 +73,7 @@
warn('Because the ``resources`` argument is no longer needed, '
'it is deprecated and will be removed in'
'a future version.', DeprecationWarning, stacklevel=2)
- all_models = []
+ all_models = dict()
plots = []
if isinstance(plot_objects, Sequence) and all(isinstance(x, (PlotObject, Document)) for x in plot_objects):
divs = []
@@ -85,7 +85,7 @@
divs = divs[0]
else:
divs = tuple(divs)
- return _component_pair(all_models, plots, divs)
+ return _component_pair(list(all_models.values()), plots, divs)
elif isinstance(plot_objects, dict) and \
all(isinstance(x, string_types) for x in plot_objects.keys()) and \
all(isinstance(x, (PlotObject, Document)) for x in plot_objects.values()):
@@ -94,7 +94,7 @@
elementid = str(uuid.uuid4())
_append_plot(all_models, plots, plot_objects[key], elementid)
divs = _append_div(elementid, divs, key)
- return _component_pair(all_models, plots, divs)
+ return _component_pair(list(all_models.values()), plots, divs)
else:
raise ValueError('Input must be a PlotObject, a Sequence of PlotObjects, or a mapping of string to PlotObjects')
@@ -110,7 +110,8 @@
def _append_plot(all_models, plots, plot_object, elementid):
ref = plot_object.ref
- all_models.extend(plot_object.dump())
+ for item in plot_object.dump():
+ all_models[item['id']] = item
plots.append({
'modelid': ref["id"],
'elementid': '#' + elementid,
diff --git a/examples/plotting/file/ajax_source_realtime.py b/examples/plotting/file/ajax_source_realtime.py
--- a/examples/plotting/file/ajax_source_realtime.py
+++ b/examples/plotting/file/ajax_source_realtime.py
@@ -24,7 +24,6 @@
while True:
last_entry = Entry(x, np.sin(x*np.pi/10), time.time())
entries.append(last_entry)
- print("Entry generated: %s" % str(last_entry))
x += 1
if x > entries.maxlen and x % 10 == 0:
time.sleep(2)
|
{"golden_diff": "diff --git a/bokeh/embed.py b/bokeh/embed.py\n--- a/bokeh/embed.py\n+++ b/bokeh/embed.py\n@@ -73,7 +73,7 @@\n warn('Because the ``resources`` argument is no longer needed, '\n 'it is deprecated and will be removed in'\n 'a future version.', DeprecationWarning, stacklevel=2)\n- all_models = []\n+ all_models = dict()\n plots = []\n if isinstance(plot_objects, Sequence) and all(isinstance(x, (PlotObject, Document)) for x in plot_objects):\n divs = []\n@@ -85,7 +85,7 @@\n divs = divs[0]\n else:\n divs = tuple(divs)\n- return _component_pair(all_models, plots, divs)\n+ return _component_pair(list(all_models.values()), plots, divs)\n elif isinstance(plot_objects, dict) and \\\n all(isinstance(x, string_types) for x in plot_objects.keys()) and \\\n all(isinstance(x, (PlotObject, Document)) for x in plot_objects.values()):\n@@ -94,7 +94,7 @@\n elementid = str(uuid.uuid4())\n _append_plot(all_models, plots, plot_objects[key], elementid)\n divs = _append_div(elementid, divs, key)\n- return _component_pair(all_models, plots, divs)\n+ return _component_pair(list(all_models.values()), plots, divs)\n else:\n raise ValueError('Input must be a PlotObject, a Sequence of PlotObjects, or a mapping of string to PlotObjects')\n \n@@ -110,7 +110,8 @@\n \n def _append_plot(all_models, plots, plot_object, elementid):\n ref = plot_object.ref\n- all_models.extend(plot_object.dump())\n+ for item in plot_object.dump():\n+ all_models[item['id']] = item\n plots.append({\n 'modelid': ref[\"id\"],\n 'elementid': '#' + elementid,\ndiff --git a/examples/plotting/file/ajax_source_realtime.py b/examples/plotting/file/ajax_source_realtime.py\n--- a/examples/plotting/file/ajax_source_realtime.py\n+++ b/examples/plotting/file/ajax_source_realtime.py\n@@ -24,7 +24,6 @@\n while True:\n last_entry = Entry(x, np.sin(x*np.pi/10), time.time())\n entries.append(last_entry)\n- print(\"Entry generated: %s\" % str(last_entry))\n x += 1\n if x > entries.maxlen and x % 10 == 0:\n time.sleep(2)\n", "issue": "Components on multiple objects duplicates objects in all_models\nThis can causes models to be initialized more than once, which causes errors. Need to protect on both the python and JS sides. \n\n", "before_files": [{"content": "''' This module provides functions for embedding Bokeh plots in various\ndifferent ways.\n\nThere are a number of different combinations of options when embedding\nBokeh plots. The data for the plot can be contained in the document,\nor on a Bokeh server, or in a sidecar JavaScript file. Likewise, BokehJS\nmay be inlined in the document, or loaded from CDN or a Bokeh server.\n\nThe functions in ``bokeh.embed`` provide functionality to embed in all\nthese different cases.\n\n'''\n\nfrom __future__ import absolute_import\n\nfrom warnings import warn\nimport uuid\n\nfrom .protocol import serialize_json\nfrom .resources import Resources\nfrom .templates import (\n AUTOLOAD, AUTOLOAD_SERVER, AUTOLOAD_STATIC, FILE,\n NOTEBOOK_DIV, PLOT_DIV, PLOT_JS, PLOT_SCRIPT, RESOURCES\n)\nfrom .util.string import encode_utf8\n\nfrom .plot_object import PlotObject\nfrom collections import Sequence\nfrom six import string_types\n\ndef _wrap_in_function(code):\n # Indent and wrap Bokeh function def around\n code = \"\\n\".join([ \" \" + line for line in code.split(\"\\n\") ])\n return 'Bokeh.$(function() {\\n%s\\n});' % code\n\n\ndef components(plot_objects, resources=None):\n ''' Return HTML components to embed a Bokeh plot.\n\n The data for the plot is stored directly in the returned HTML.\n\n .. note:: The returned components assume that BokehJS resources\n are **already loaded**.\n\n Args:\n plot_objects (PlotObject|list|dict|tuple) :\n The |components| function takes either a single PlotObject, a list/tuple of\n PlotObjects, or a dictionary of keys and PlotObjects. Each returns\n a corresponding data structure of script and div pairs.\n\n The following illustrates how different input types correlate to outputs:\n\n components(plot)\n #=> (script, plot_div)\n\n components((plot_1, plot_2))\n #=> (script, (plot_1_div, plot_2_div))\n\n components({\"Plot 1\": plot_1, \"Plot 2\": plot_2})\n #=> (script, {\"Plot 1\": plot_1_div, \"Plot 2\": plot_2_div})\n\n An example can be found in examples/embed/embed_multiple.py\n\n resources : Deprecated argument\n\n Returns:\n (script, div[s]): UTF-8 encoded\n '''\n from .document import Document\n if isinstance(plot_objects, (PlotObject, Document)):\n plot_objects = [plot_objects]\n if resources is not None:\n warn('Because the ``resources`` argument is no longer needed, '\n 'it is deprecated and will be removed in'\n 'a future version.', DeprecationWarning, stacklevel=2)\n all_models = []\n plots = []\n if isinstance(plot_objects, Sequence) and all(isinstance(x, (PlotObject, Document)) for x in plot_objects):\n divs = []\n for idx, plot_object in enumerate(plot_objects):\n elementid = str(uuid.uuid4())\n _append_plot(all_models, plots, plot_object, elementid)\n divs = _append_div(elementid, divs)\n if len(divs) == 1:\n divs = divs[0]\n else:\n divs = tuple(divs)\n return _component_pair(all_models, plots, divs)\n elif isinstance(plot_objects, dict) and \\\n all(isinstance(x, string_types) for x in plot_objects.keys()) and \\\n all(isinstance(x, (PlotObject, Document)) for x in plot_objects.values()):\n divs = {}\n for key in plot_objects.keys():\n elementid = str(uuid.uuid4())\n _append_plot(all_models, plots, plot_objects[key], elementid)\n divs = _append_div(elementid, divs, key)\n return _component_pair(all_models, plots, divs)\n else:\n raise ValueError('Input must be a PlotObject, a Sequence of PlotObjects, or a mapping of string to PlotObjects')\n\ndef _component_pair(all_models, plots, divs):\n js = PLOT_JS.render(\n all_models = serialize_json(all_models),\n plots = plots\n )\n script = PLOT_SCRIPT.render(\n plot_js = _wrap_in_function(js),\n )\n return encode_utf8(script), divs\n\ndef _append_plot(all_models, plots, plot_object, elementid):\n ref = plot_object.ref\n all_models.extend(plot_object.dump())\n plots.append({\n 'modelid': ref[\"id\"],\n 'elementid': '#' + elementid,\n 'modeltype': ref[\"type\"]\n })\n\ndef _append_div(elementid, divs=None, key=None):\n div = PLOT_DIV.render(\n elementid = elementid\n )\n if isinstance(divs, list):\n divs.append(encode_utf8(div))\n return divs\n elif isinstance(divs, dict):\n divs[key] = encode_utf8(div)\n return divs\n else:\n return encode_utf8(div)\n\ndef notebook_div(plot_object):\n ''' Return HTML for a div that will display a Bokeh plot in an\n IPython Notebook\n\n The data for the plot is stored directly in the returned HTML.\n\n Args:\n plot_object (PlotObject) : Bokeh object to render\n typically a Plot or PlotContext\n\n Returns:\n div : UTF-8 encoded HTML text\n\n .. note::\n Assumes ``bokeh.load_notebook()`` or the equivalent has already\n been executed.\n\n '''\n ref = plot_object.ref\n elementid = str(uuid.uuid4())\n\n plots = [{\n 'modelid': ref[\"id\"],\n 'elementid': '#' + elementid,\n 'modeltype': ref[\"type\"]\n }]\n\n js = PLOT_JS.render(\n all_models = serialize_json(plot_object.dump()),\n plots = plots\n )\n script = PLOT_SCRIPT.render(\n plot_js = _wrap_in_function(js),\n )\n div = PLOT_DIV.render(elementid=elementid)\n html = NOTEBOOK_DIV.render(\n plot_script = script,\n plot_div = div,\n )\n return encode_utf8(html)\n\n\ndef file_html(plot_object, resources, title, template=FILE, template_variables=None):\n ''' Return an HTML document that embeds a Bokeh plot.\n\n The data for the plot is stored directly in the returned HTML.\n\n Args:\n plot_object (PlotObject) : Bokeh object to render\n typically a Plot or PlotContext\n resources (Resources) : a resource configuration for BokehJS assets\n title (str) : a title for the HTML document ``<title>`` tags\n template (Template, optional) : HTML document template (default: FILE)\n A Jinja2 Template, see bokeh.templates.FILE for the required\n template parameters\n template_variables (dict, optional) : variables to be used in the Jinja2\n template. If used, the following variable names will be overwritten:\n title, plot_resources, plot_script, plot_div\n\n Returns:\n html : standalone HTML document with embedded plot\n\n '''\n from .document import Document\n if not isinstance(plot_object, (PlotObject, Document)):\n raise ValueError('plot_object must be a single PlotObject')\n\n plot_resources = RESOURCES.render(\n js_raw = resources.js_raw,\n css_raw = resources.css_raw,\n js_files = resources.js_files,\n css_files = resources.css_files,\n )\n script, div = components(plot_object)\n template_variables_full = \\\n template_variables.copy() if template_variables is not None else {}\n template_variables_full.update(\n {\n 'title': title,\n 'plot_resources': plot_resources,\n 'plot_script': script,\n 'plot_div': div,\n }\n )\n html = template.render(template_variables_full)\n return encode_utf8(html)\n\n\ndef autoload_static(plot_object, resources, script_path):\n ''' Return JavaScript code and a script tag that can be used to embed\n Bokeh Plots.\n\n The data for the plot is stored directly in the returned JavaScript code.\n\n Args:\n plot_object (PlotObject) :\n resources (Resources) :\n script_path (str) :\n\n Returns:\n (js, tag) :\n JavaScript code to be saved at ``script_path`` and a ``<script>``\n tag to load it\n\n Raises:\n ValueError\n\n '''\n if resources.mode == 'inline':\n raise ValueError(\"autoload_static() requires non-inline resources\")\n\n if resources.dev:\n raise ValueError(\"autoload_static() only works with non-dev resources\")\n\n elementid = str(uuid.uuid4())\n\n js = AUTOLOAD.render(\n all_models = serialize_json(plot_object.dump()),\n js_url = resources.js_files[0],\n css_files = resources.css_files,\n elementid = elementid,\n )\n\n tag = AUTOLOAD_STATIC.render(\n src_path = script_path,\n elementid = elementid,\n modelid = plot_object._id,\n modeltype = plot_object.__view_model__,\n loglevel = resources.log_level,\n )\n\n return encode_utf8(js), encode_utf8(tag)\n\n\ndef autoload_server(plot_object, session, public=False):\n ''' Return a script tag that can be used to embed Bokeh Plots from\n a Bokeh Server.\n\n The data for the plot is stored on the Bokeh Server.\n\n Args:\n plot_object (PlotObject) :\n session (Session) :\n\n Returns:\n tag :\n a ``<script>`` tag that will execute an autoload script\n loaded from the Bokeh Server\n\n '''\n elementid = str(uuid.uuid4())\n resources = Resources(root_url=session.root_url, mode=\"server\")\n tag = AUTOLOAD_SERVER.render(\n src_path = resources._autoload_path(elementid),\n elementid = elementid,\n modelid = plot_object._id,\n root_url = resources.root_url,\n docid = session.docid,\n docapikey = session.apikey,\n loglevel = resources.log_level,\n public = public\n )\n\n return encode_utf8(tag)\n", "path": "bokeh/embed.py"}, {"content": "import numpy as np\n\nfrom bokeh.plotting import figure, show, output_file\nfrom bokeh.models.sources import AjaxDataSource\n\noutput_file(\"ajax_source_realtime.html\", title=\"ajax_source_realtime.py example\")\nsource = AjaxDataSource(data_url='http://localhost:5050/data', mode=\"append\",\n if_modified=True, polling_interval=1000, max_size=125)\np = figure()\np.line('x', 'y', source=source)\nshow(p)\n\nimport time\nfrom threading import Thread\nfrom collections import namedtuple, deque\n\nEntry = namedtuple('Entry', ['x', 'y', 'creation'])\n\nentries = deque(maxlen=120)\n\ndef gen_entry():\n global entries\n x = 0\n while True:\n last_entry = Entry(x, np.sin(x*np.pi/10), time.time())\n entries.append(last_entry)\n print(\"Entry generated: %s\" % str(last_entry))\n x += 1\n if x > entries.maxlen and x % 10 == 0:\n time.sleep(2)\n\nt = Thread(target=gen_entry)\nt.daemon = True\nt.start()\n\nimport json\nfrom flask import Flask, Response, request\nfrom bokeh.server.crossdomain import crossdomain\n\napp = Flask(__name__)\n\[email protected]('/data', methods=['GET', 'OPTIONS'])\n@crossdomain(origin=\"*\", methods=['GET', 'POST'])\ndef hello_world():\n global entries\n try:\n modified_since = float(request.headers.get('If-Modified-Since'))\n except TypeError:\n modified_since = 0\n\n new_entries = [e for e in entries if e.creation > modified_since]\n js = json.dumps({'x':[e.x for e in new_entries], 'y':[e.y for e in new_entries]})\n resp = Response(js, status=200, mimetype='application/json')\n\n if new_entries:\n resp.headers['Last-Modified'] = new_entries[-1].creation\n elif modified_since:\n resp.headers['Last-Modified'] = modified_since\n\n return resp\n\nif __name__ == \"__main__\":\n app.run(port=5050)\n", "path": "examples/plotting/file/ajax_source_realtime.py"}], "after_files": [{"content": "''' This module provides functions for embedding Bokeh plots in various\ndifferent ways.\n\nThere are a number of different combinations of options when embedding\nBokeh plots. The data for the plot can be contained in the document,\nor on a Bokeh server, or in a sidecar JavaScript file. Likewise, BokehJS\nmay be inlined in the document, or loaded from CDN or a Bokeh server.\n\nThe functions in ``bokeh.embed`` provide functionality to embed in all\nthese different cases.\n\n'''\n\nfrom __future__ import absolute_import\n\nfrom warnings import warn\nimport uuid\n\nfrom .protocol import serialize_json\nfrom .resources import Resources\nfrom .templates import (\n AUTOLOAD, AUTOLOAD_SERVER, AUTOLOAD_STATIC, FILE,\n NOTEBOOK_DIV, PLOT_DIV, PLOT_JS, PLOT_SCRIPT, RESOURCES\n)\nfrom .util.string import encode_utf8\n\nfrom .plot_object import PlotObject\nfrom collections import Sequence\nfrom six import string_types\n\ndef _wrap_in_function(code):\n # Indent and wrap Bokeh function def around\n code = \"\\n\".join([ \" \" + line for line in code.split(\"\\n\") ])\n return 'Bokeh.$(function() {\\n%s\\n});' % code\n\n\ndef components(plot_objects, resources=None):\n ''' Return HTML components to embed a Bokeh plot.\n\n The data for the plot is stored directly in the returned HTML.\n\n .. note:: The returned components assume that BokehJS resources\n are **already loaded**.\n\n Args:\n plot_objects (PlotObject|list|dict|tuple) :\n The |components| function takes either a single PlotObject, a list/tuple of\n PlotObjects, or a dictionary of keys and PlotObjects. Each returns\n a corresponding data structure of script and div pairs.\n\n The following illustrates how different input types correlate to outputs:\n\n components(plot)\n #=> (script, plot_div)\n\n components((plot_1, plot_2))\n #=> (script, (plot_1_div, plot_2_div))\n\n components({\"Plot 1\": plot_1, \"Plot 2\": plot_2})\n #=> (script, {\"Plot 1\": plot_1_div, \"Plot 2\": plot_2_div})\n\n An example can be found in examples/embed/embed_multiple.py\n\n resources : Deprecated argument\n\n Returns:\n (script, div[s]): UTF-8 encoded\n '''\n from .document import Document\n if isinstance(plot_objects, (PlotObject, Document)):\n plot_objects = [plot_objects]\n if resources is not None:\n warn('Because the ``resources`` argument is no longer needed, '\n 'it is deprecated and will be removed in'\n 'a future version.', DeprecationWarning, stacklevel=2)\n all_models = dict()\n plots = []\n if isinstance(plot_objects, Sequence) and all(isinstance(x, (PlotObject, Document)) for x in plot_objects):\n divs = []\n for idx, plot_object in enumerate(plot_objects):\n elementid = str(uuid.uuid4())\n _append_plot(all_models, plots, plot_object, elementid)\n divs = _append_div(elementid, divs)\n if len(divs) == 1:\n divs = divs[0]\n else:\n divs = tuple(divs)\n return _component_pair(list(all_models.values()), plots, divs)\n elif isinstance(plot_objects, dict) and \\\n all(isinstance(x, string_types) for x in plot_objects.keys()) and \\\n all(isinstance(x, (PlotObject, Document)) for x in plot_objects.values()):\n divs = {}\n for key in plot_objects.keys():\n elementid = str(uuid.uuid4())\n _append_plot(all_models, plots, plot_objects[key], elementid)\n divs = _append_div(elementid, divs, key)\n return _component_pair(list(all_models.values()), plots, divs)\n else:\n raise ValueError('Input must be a PlotObject, a Sequence of PlotObjects, or a mapping of string to PlotObjects')\n\ndef _component_pair(all_models, plots, divs):\n js = PLOT_JS.render(\n all_models = serialize_json(all_models),\n plots = plots\n )\n script = PLOT_SCRIPT.render(\n plot_js = _wrap_in_function(js),\n )\n return encode_utf8(script), divs\n\ndef _append_plot(all_models, plots, plot_object, elementid):\n ref = plot_object.ref\n for item in plot_object.dump():\n all_models[item['id']] = item\n plots.append({\n 'modelid': ref[\"id\"],\n 'elementid': '#' + elementid,\n 'modeltype': ref[\"type\"]\n })\n\ndef _append_div(elementid, divs=None, key=None):\n div = PLOT_DIV.render(\n elementid = elementid\n )\n if isinstance(divs, list):\n divs.append(encode_utf8(div))\n return divs\n elif isinstance(divs, dict):\n divs[key] = encode_utf8(div)\n return divs\n else:\n return encode_utf8(div)\n\ndef notebook_div(plot_object):\n ''' Return HTML for a div that will display a Bokeh plot in an\n IPython Notebook\n\n The data for the plot is stored directly in the returned HTML.\n\n Args:\n plot_object (PlotObject) : Bokeh object to render\n typically a Plot or PlotContext\n\n Returns:\n div : UTF-8 encoded HTML text\n\n .. note::\n Assumes ``bokeh.load_notebook()`` or the equivalent has already\n been executed.\n\n '''\n ref = plot_object.ref\n elementid = str(uuid.uuid4())\n\n plots = [{\n 'modelid': ref[\"id\"],\n 'elementid': '#' + elementid,\n 'modeltype': ref[\"type\"]\n }]\n\n js = PLOT_JS.render(\n all_models = serialize_json(plot_object.dump()),\n plots = plots\n )\n script = PLOT_SCRIPT.render(\n plot_js = _wrap_in_function(js),\n )\n div = PLOT_DIV.render(elementid=elementid)\n html = NOTEBOOK_DIV.render(\n plot_script = script,\n plot_div = div,\n )\n return encode_utf8(html)\n\n\ndef file_html(plot_object, resources, title, template=FILE, template_variables=None):\n ''' Return an HTML document that embeds a Bokeh plot.\n\n The data for the plot is stored directly in the returned HTML.\n\n Args:\n plot_object (PlotObject) : Bokeh object to render\n typically a Plot or PlotContext\n resources (Resources) : a resource configuration for BokehJS assets\n title (str) : a title for the HTML document ``<title>`` tags\n template (Template, optional) : HTML document template (default: FILE)\n A Jinja2 Template, see bokeh.templates.FILE for the required\n template parameters\n template_variables (dict, optional) : variables to be used in the Jinja2\n template. If used, the following variable names will be overwritten:\n title, plot_resources, plot_script, plot_div\n\n Returns:\n html : standalone HTML document with embedded plot\n\n '''\n from .document import Document\n if not isinstance(plot_object, (PlotObject, Document)):\n raise ValueError('plot_object must be a single PlotObject')\n\n plot_resources = RESOURCES.render(\n js_raw = resources.js_raw,\n css_raw = resources.css_raw,\n js_files = resources.js_files,\n css_files = resources.css_files,\n )\n script, div = components(plot_object)\n template_variables_full = \\\n template_variables.copy() if template_variables is not None else {}\n template_variables_full.update(\n {\n 'title': title,\n 'plot_resources': plot_resources,\n 'plot_script': script,\n 'plot_div': div,\n }\n )\n html = template.render(template_variables_full)\n return encode_utf8(html)\n\n\ndef autoload_static(plot_object, resources, script_path):\n ''' Return JavaScript code and a script tag that can be used to embed\n Bokeh Plots.\n\n The data for the plot is stored directly in the returned JavaScript code.\n\n Args:\n plot_object (PlotObject) :\n resources (Resources) :\n script_path (str) :\n\n Returns:\n (js, tag) :\n JavaScript code to be saved at ``script_path`` and a ``<script>``\n tag to load it\n\n Raises:\n ValueError\n\n '''\n if resources.mode == 'inline':\n raise ValueError(\"autoload_static() requires non-inline resources\")\n\n if resources.dev:\n raise ValueError(\"autoload_static() only works with non-dev resources\")\n\n elementid = str(uuid.uuid4())\n\n js = AUTOLOAD.render(\n all_models = serialize_json(plot_object.dump()),\n js_url = resources.js_files[0],\n css_files = resources.css_files,\n elementid = elementid,\n )\n\n tag = AUTOLOAD_STATIC.render(\n src_path = script_path,\n elementid = elementid,\n modelid = plot_object._id,\n modeltype = plot_object.__view_model__,\n loglevel = resources.log_level,\n )\n\n return encode_utf8(js), encode_utf8(tag)\n\n\ndef autoload_server(plot_object, session, public=False):\n ''' Return a script tag that can be used to embed Bokeh Plots from\n a Bokeh Server.\n\n The data for the plot is stored on the Bokeh Server.\n\n Args:\n plot_object (PlotObject) :\n session (Session) :\n\n Returns:\n tag :\n a ``<script>`` tag that will execute an autoload script\n loaded from the Bokeh Server\n\n '''\n elementid = str(uuid.uuid4())\n resources = Resources(root_url=session.root_url, mode=\"server\")\n tag = AUTOLOAD_SERVER.render(\n src_path = resources._autoload_path(elementid),\n elementid = elementid,\n modelid = plot_object._id,\n root_url = resources.root_url,\n docid = session.docid,\n docapikey = session.apikey,\n loglevel = resources.log_level,\n public = public\n )\n\n return encode_utf8(tag)\n", "path": "bokeh/embed.py"}, {"content": "import numpy as np\n\nfrom bokeh.plotting import figure, show, output_file\nfrom bokeh.models.sources import AjaxDataSource\n\noutput_file(\"ajax_source_realtime.html\", title=\"ajax_source_realtime.py example\")\nsource = AjaxDataSource(data_url='http://localhost:5050/data', mode=\"append\",\n if_modified=True, polling_interval=1000, max_size=125)\np = figure()\np.line('x', 'y', source=source)\nshow(p)\n\nimport time\nfrom threading import Thread\nfrom collections import namedtuple, deque\n\nEntry = namedtuple('Entry', ['x', 'y', 'creation'])\n\nentries = deque(maxlen=120)\n\ndef gen_entry():\n global entries\n x = 0\n while True:\n last_entry = Entry(x, np.sin(x*np.pi/10), time.time())\n entries.append(last_entry)\n x += 1\n if x > entries.maxlen and x % 10 == 0:\n time.sleep(2)\n\nt = Thread(target=gen_entry)\nt.daemon = True\nt.start()\n\nimport json\nfrom flask import Flask, Response, request\nfrom bokeh.server.crossdomain import crossdomain\n\napp = Flask(__name__)\n\[email protected]('/data', methods=['GET', 'OPTIONS'])\n@crossdomain(origin=\"*\", methods=['GET', 'POST'])\ndef hello_world():\n global entries\n try:\n modified_since = float(request.headers.get('If-Modified-Since'))\n except TypeError:\n modified_since = 0\n\n new_entries = [e for e in entries if e.creation > modified_since]\n js = json.dumps({'x':[e.x for e in new_entries], 'y':[e.y for e in new_entries]})\n resp = Response(js, status=200, mimetype='application/json')\n\n if new_entries:\n resp.headers['Last-Modified'] = new_entries[-1].creation\n elif modified_since:\n resp.headers['Last-Modified'] = modified_since\n\n return resp\n\nif __name__ == \"__main__\":\n app.run(port=5050)\n", "path": "examples/plotting/file/ajax_source_realtime.py"}]}
| 3,897 | 578 |
gh_patches_debug_8389
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-95
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make creating a Signer from a JSON keyfile easier.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/auth/crypt.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Cryptography helpers for verifying and signing messages.
16
17 Uses the ``rsa``, ``pyasn1`` and ``pyasn1_modules`` packages
18 to parse PEM files storing PKCS#1 or PKCS#8 keys as well as
19 certificates. There is no support for p12 files.
20
21 The simplest way to verify signatures is using :func:`verify_signature`::
22
23 cert = open('certs.pem').read()
24 valid = crypt.verify_signature(message, signature, cert)
25
26 If you're going to verify many messages with the same certificate, you can use
27 :class:`Verifier`::
28
29 cert = open('certs.pem').read()
30 verifier = crypt.Verifier.from_string(cert)
31 valid = verifier.verify(message, signature)
32
33
34 To sign messages use :class:`Signer` with a private key::
35
36 private_key = open('private_key.pem').read()
37 signer = crypt.Signer(private_key)
38 signature = signer.sign(message)
39
40 """
41
42 from pyasn1.codec.der import decoder
43 from pyasn1_modules import pem
44 from pyasn1_modules.rfc2459 import Certificate
45 from pyasn1_modules.rfc5208 import PrivateKeyInfo
46 import rsa
47 import six
48
49 from google.auth import _helpers
50
51 _POW2 = (128, 64, 32, 16, 8, 4, 2, 1)
52 _CERTIFICATE_MARKER = b'-----BEGIN CERTIFICATE-----'
53 _PKCS1_MARKER = ('-----BEGIN RSA PRIVATE KEY-----',
54 '-----END RSA PRIVATE KEY-----')
55 _PKCS8_MARKER = ('-----BEGIN PRIVATE KEY-----',
56 '-----END PRIVATE KEY-----')
57 _PKCS8_SPEC = PrivateKeyInfo()
58
59
60 def _bit_list_to_bytes(bit_list):
61 """Converts an iterable of 1s and 0s to bytes.
62
63 Combines the list 8 at a time, treating each group of 8 bits
64 as a single byte.
65
66 Args:
67 bit_list (Sequence): Sequence of 1s and 0s.
68
69 Returns:
70 bytes: The decoded bytes.
71 """
72 num_bits = len(bit_list)
73 byte_vals = bytearray()
74 for start in six.moves.xrange(0, num_bits, 8):
75 curr_bits = bit_list[start:start + 8]
76 char_val = sum(val * digit
77 for val, digit in six.moves.zip(_POW2, curr_bits))
78 byte_vals.append(char_val)
79 return bytes(byte_vals)
80
81
82 class Verifier(object):
83 """This object is used to verify cryptographic signatures.
84
85 Args:
86 public_key (rsa.key.PublicKey): The public key used to verify
87 signatures.
88 """
89
90 def __init__(self, public_key):
91 self._pubkey = public_key
92
93 def verify(self, message, signature):
94 """Verifies a message against a cryptographic signature.
95
96 Args:
97 message (Union[str, bytes]): The message to verify.
98 signature (Union[str, bytes]): The cryptography signature to check.
99
100 Returns:
101 bool: True if message was signed by the private key associated
102 with the public key that this object was constructed with.
103 """
104 message = _helpers.to_bytes(message)
105 try:
106 return rsa.pkcs1.verify(message, signature, self._pubkey)
107 except (ValueError, rsa.pkcs1.VerificationError):
108 return False
109
110 @classmethod
111 def from_string(cls, public_key):
112 """Construct an Verifier instance from a public key or public
113 certificate string.
114
115 Args:
116 public_key (Union[str, bytes]): The public key in PEM format or the
117 x509 public key certificate.
118
119 Returns:
120 Verifier: The constructed verifier.
121
122 Raises:
123 ValueError: If the public_key can't be parsed.
124 """
125 public_key = _helpers.to_bytes(public_key)
126 is_x509_cert = _CERTIFICATE_MARKER in public_key
127
128 # If this is a certificate, extract the public key info.
129 if is_x509_cert:
130 der = rsa.pem.load_pem(public_key, 'CERTIFICATE')
131 asn1_cert, remaining = decoder.decode(der, asn1Spec=Certificate())
132 if remaining != b'':
133 raise ValueError('Unused bytes', remaining)
134
135 cert_info = asn1_cert['tbsCertificate']['subjectPublicKeyInfo']
136 key_bytes = _bit_list_to_bytes(cert_info['subjectPublicKey'])
137 pubkey = rsa.PublicKey.load_pkcs1(key_bytes, 'DER')
138 else:
139 pubkey = rsa.PublicKey.load_pkcs1(public_key, 'PEM')
140 return cls(pubkey)
141
142
143 def verify_signature(message, signature, certs):
144 """Verify a cryptographic signature.
145
146 Checks that the provided ``signature`` was generated from ``bytes`` using
147 the private key associated with the ``cert``.
148
149 Args:
150 message (Union[str, bytes]): The plaintext message.
151 signature (Union[str, bytes]): The cryptographic signature to check.
152 certs (Union[Sequence, str, bytes]): The certificate or certificates
153 to use to check the signature.
154
155 Returns:
156 bool: True if the signature is valid, otherwise False.
157 """
158 if isinstance(certs, (six.text_type, six.binary_type)):
159 certs = [certs]
160
161 for cert in certs:
162 verifier = Verifier.from_string(cert)
163 if verifier.verify(message, signature):
164 return True
165 return False
166
167
168 class Signer(object):
169 """Signs messages with a private key.
170
171 Args:
172 private_key (rsa.key.PrivateKey): The private key to sign with.
173 key_id (str): Optional key ID used to identify this private key. This
174 can be useful to associate the private key with its associated
175 public key or certificate.
176 """
177
178 def __init__(self, private_key, key_id=None):
179 self._key = private_key
180 self.key_id = key_id
181
182 def sign(self, message):
183 """Signs a message.
184
185 Args:
186 message (Union[str, bytes]): The message to be signed.
187
188 Returns:
189 bytes: The signature of the message for the given key.
190 """
191 message = _helpers.to_bytes(message)
192 return rsa.pkcs1.sign(message, self._key, 'SHA-256')
193
194 @classmethod
195 def from_string(cls, key, key_id=None):
196 """Construct an Signer instance from a private key in PEM format.
197
198 Args:
199 key (str): Private key in PEM format.
200 key_id (str): An optional key id used to identify the private key.
201
202 Returns:
203 Signer: The constructed signer.
204
205 Raises:
206 ValueError: If the key cannot be parsed as PKCS#1 or PKCS#8 in
207 PEM format.
208 """
209 key = _helpers.from_bytes(key) # PEM expects str in Python 3
210 marker_id, key_bytes = pem.readPemBlocksFromFile(
211 six.StringIO(key), _PKCS1_MARKER, _PKCS8_MARKER)
212
213 # Key is in pkcs1 format.
214 if marker_id == 0:
215 private_key = rsa.key.PrivateKey.load_pkcs1(
216 key_bytes, format='DER')
217 # Key is in pkcs8.
218 elif marker_id == 1:
219 key_info, remaining = decoder.decode(
220 key_bytes, asn1Spec=_PKCS8_SPEC)
221 if remaining != b'':
222 raise ValueError('Unused bytes', remaining)
223 private_key_info = key_info.getComponentByName('privateKey')
224 private_key = rsa.key.PrivateKey.load_pkcs1(
225 private_key_info.asOctets(), format='DER')
226 else:
227 raise ValueError('No key could be detected.')
228
229 return cls(private_key, key_id=key_id)
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/auth/crypt.py b/google/auth/crypt.py
--- a/google/auth/crypt.py
+++ b/google/auth/crypt.py
@@ -227,3 +227,18 @@
raise ValueError('No key could be detected.')
return cls(private_key, key_id=key_id)
+
+ @classmethod
+ def from_service_account_file(cls, filename):
+ """Creates a Signer instance from a service account .json file
+ in Google format.
+
+ Args:
+ filename (str): The path to the service account .json file.
+
+ Returns:
+ Signer: The constructed signer.
+ """
+ from google.auth import _service_account_info
+ _, signer = _service_account_info.from_filename(filename)
+ return signer
|
{"golden_diff": "diff --git a/google/auth/crypt.py b/google/auth/crypt.py\n--- a/google/auth/crypt.py\n+++ b/google/auth/crypt.py\n@@ -227,3 +227,18 @@\n raise ValueError('No key could be detected.')\n \n return cls(private_key, key_id=key_id)\n+\n+ @classmethod\n+ def from_service_account_file(cls, filename):\n+ \"\"\"Creates a Signer instance from a service account .json file\n+ in Google format.\n+\n+ Args:\n+ filename (str): The path to the service account .json file.\n+\n+ Returns:\n+ Signer: The constructed signer.\n+ \"\"\"\n+ from google.auth import _service_account_info\n+ _, signer = _service_account_info.from_filename(filename)\n+ return signer\n", "issue": "Make creating a Signer from a JSON keyfile easier.\n\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Cryptography helpers for verifying and signing messages.\n\nUses the ``rsa``, ``pyasn1`` and ``pyasn1_modules`` packages\nto parse PEM files storing PKCS#1 or PKCS#8 keys as well as\ncertificates. There is no support for p12 files.\n\nThe simplest way to verify signatures is using :func:`verify_signature`::\n\n cert = open('certs.pem').read()\n valid = crypt.verify_signature(message, signature, cert)\n\nIf you're going to verify many messages with the same certificate, you can use\n:class:`Verifier`::\n\n cert = open('certs.pem').read()\n verifier = crypt.Verifier.from_string(cert)\n valid = verifier.verify(message, signature)\n\n\nTo sign messages use :class:`Signer` with a private key::\n\n private_key = open('private_key.pem').read()\n signer = crypt.Signer(private_key)\n signature = signer.sign(message)\n\n\"\"\"\n\nfrom pyasn1.codec.der import decoder\nfrom pyasn1_modules import pem\nfrom pyasn1_modules.rfc2459 import Certificate\nfrom pyasn1_modules.rfc5208 import PrivateKeyInfo\nimport rsa\nimport six\n\nfrom google.auth import _helpers\n\n_POW2 = (128, 64, 32, 16, 8, 4, 2, 1)\n_CERTIFICATE_MARKER = b'-----BEGIN CERTIFICATE-----'\n_PKCS1_MARKER = ('-----BEGIN RSA PRIVATE KEY-----',\n '-----END RSA PRIVATE KEY-----')\n_PKCS8_MARKER = ('-----BEGIN PRIVATE KEY-----',\n '-----END PRIVATE KEY-----')\n_PKCS8_SPEC = PrivateKeyInfo()\n\n\ndef _bit_list_to_bytes(bit_list):\n \"\"\"Converts an iterable of 1s and 0s to bytes.\n\n Combines the list 8 at a time, treating each group of 8 bits\n as a single byte.\n\n Args:\n bit_list (Sequence): Sequence of 1s and 0s.\n\n Returns:\n bytes: The decoded bytes.\n \"\"\"\n num_bits = len(bit_list)\n byte_vals = bytearray()\n for start in six.moves.xrange(0, num_bits, 8):\n curr_bits = bit_list[start:start + 8]\n char_val = sum(val * digit\n for val, digit in six.moves.zip(_POW2, curr_bits))\n byte_vals.append(char_val)\n return bytes(byte_vals)\n\n\nclass Verifier(object):\n \"\"\"This object is used to verify cryptographic signatures.\n\n Args:\n public_key (rsa.key.PublicKey): The public key used to verify\n signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n def verify(self, message, signature):\n \"\"\"Verifies a message against a cryptographic signature.\n\n Args:\n message (Union[str, bytes]): The message to verify.\n signature (Union[str, bytes]): The cryptography signature to check.\n\n Returns:\n bool: True if message was signed by the private key associated\n with the public key that this object was constructed with.\n \"\"\"\n message = _helpers.to_bytes(message)\n try:\n return rsa.pkcs1.verify(message, signature, self._pubkey)\n except (ValueError, rsa.pkcs1.VerificationError):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public_key can't be parsed.\n \"\"\"\n public_key = _helpers.to_bytes(public_key)\n is_x509_cert = _CERTIFICATE_MARKER in public_key\n\n # If this is a certificate, extract the public key info.\n if is_x509_cert:\n der = rsa.pem.load_pem(public_key, 'CERTIFICATE')\n asn1_cert, remaining = decoder.decode(der, asn1Spec=Certificate())\n if remaining != b'':\n raise ValueError('Unused bytes', remaining)\n\n cert_info = asn1_cert['tbsCertificate']['subjectPublicKeyInfo']\n key_bytes = _bit_list_to_bytes(cert_info['subjectPublicKey'])\n pubkey = rsa.PublicKey.load_pkcs1(key_bytes, 'DER')\n else:\n pubkey = rsa.PublicKey.load_pkcs1(public_key, 'PEM')\n return cls(pubkey)\n\n\ndef verify_signature(message, signature, certs):\n \"\"\"Verify a cryptographic signature.\n\n Checks that the provided ``signature`` was generated from ``bytes`` using\n the private key associated with the ``cert``.\n\n Args:\n message (Union[str, bytes]): The plaintext message.\n signature (Union[str, bytes]): The cryptographic signature to check.\n certs (Union[Sequence, str, bytes]): The certificate or certificates\n to use to check the signature.\n\n Returns:\n bool: True if the signature is valid, otherwise False.\n \"\"\"\n if isinstance(certs, (six.text_type, six.binary_type)):\n certs = [certs]\n\n for cert in certs:\n verifier = Verifier.from_string(cert)\n if verifier.verify(message, signature):\n return True\n return False\n\n\nclass Signer(object):\n \"\"\"Signs messages with a private key.\n\n Args:\n private_key (rsa.key.PrivateKey): The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self.key_id = key_id\n\n def sign(self, message):\n \"\"\"Signs a message.\n\n Args:\n message (Union[str, bytes]): The message to be signed.\n\n Returns:\n bytes: The signature of the message for the given key.\n \"\"\"\n message = _helpers.to_bytes(message)\n return rsa.pkcs1.sign(message, self._key, 'SHA-256')\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct an Signer instance from a private key in PEM format.\n\n Args:\n key (str): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n Signer: The constructed signer.\n\n Raises:\n ValueError: If the key cannot be parsed as PKCS#1 or PKCS#8 in\n PEM format.\n \"\"\"\n key = _helpers.from_bytes(key) # PEM expects str in Python 3\n marker_id, key_bytes = pem.readPemBlocksFromFile(\n six.StringIO(key), _PKCS1_MARKER, _PKCS8_MARKER)\n\n # Key is in pkcs1 format.\n if marker_id == 0:\n private_key = rsa.key.PrivateKey.load_pkcs1(\n key_bytes, format='DER')\n # Key is in pkcs8.\n elif marker_id == 1:\n key_info, remaining = decoder.decode(\n key_bytes, asn1Spec=_PKCS8_SPEC)\n if remaining != b'':\n raise ValueError('Unused bytes', remaining)\n private_key_info = key_info.getComponentByName('privateKey')\n private_key = rsa.key.PrivateKey.load_pkcs1(\n private_key_info.asOctets(), format='DER')\n else:\n raise ValueError('No key could be detected.')\n\n return cls(private_key, key_id=key_id)\n", "path": "google/auth/crypt.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Cryptography helpers for verifying and signing messages.\n\nUses the ``rsa``, ``pyasn1`` and ``pyasn1_modules`` packages\nto parse PEM files storing PKCS#1 or PKCS#8 keys as well as\ncertificates. There is no support for p12 files.\n\nThe simplest way to verify signatures is using :func:`verify_signature`::\n\n cert = open('certs.pem').read()\n valid = crypt.verify_signature(message, signature, cert)\n\nIf you're going to verify many messages with the same certificate, you can use\n:class:`Verifier`::\n\n cert = open('certs.pem').read()\n verifier = crypt.Verifier.from_string(cert)\n valid = verifier.verify(message, signature)\n\n\nTo sign messages use :class:`Signer` with a private key::\n\n private_key = open('private_key.pem').read()\n signer = crypt.Signer(private_key)\n signature = signer.sign(message)\n\n\"\"\"\n\nfrom pyasn1.codec.der import decoder\nfrom pyasn1_modules import pem\nfrom pyasn1_modules.rfc2459 import Certificate\nfrom pyasn1_modules.rfc5208 import PrivateKeyInfo\nimport rsa\nimport six\n\nfrom google.auth import _helpers\n\n_POW2 = (128, 64, 32, 16, 8, 4, 2, 1)\n_CERTIFICATE_MARKER = b'-----BEGIN CERTIFICATE-----'\n_PKCS1_MARKER = ('-----BEGIN RSA PRIVATE KEY-----',\n '-----END RSA PRIVATE KEY-----')\n_PKCS8_MARKER = ('-----BEGIN PRIVATE KEY-----',\n '-----END PRIVATE KEY-----')\n_PKCS8_SPEC = PrivateKeyInfo()\n\n\ndef _bit_list_to_bytes(bit_list):\n \"\"\"Converts an iterable of 1s and 0s to bytes.\n\n Combines the list 8 at a time, treating each group of 8 bits\n as a single byte.\n\n Args:\n bit_list (Sequence): Sequence of 1s and 0s.\n\n Returns:\n bytes: The decoded bytes.\n \"\"\"\n num_bits = len(bit_list)\n byte_vals = bytearray()\n for start in six.moves.xrange(0, num_bits, 8):\n curr_bits = bit_list[start:start + 8]\n char_val = sum(val * digit\n for val, digit in six.moves.zip(_POW2, curr_bits))\n byte_vals.append(char_val)\n return bytes(byte_vals)\n\n\nclass Verifier(object):\n \"\"\"This object is used to verify cryptographic signatures.\n\n Args:\n public_key (rsa.key.PublicKey): The public key used to verify\n signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n def verify(self, message, signature):\n \"\"\"Verifies a message against a cryptographic signature.\n\n Args:\n message (Union[str, bytes]): The message to verify.\n signature (Union[str, bytes]): The cryptography signature to check.\n\n Returns:\n bool: True if message was signed by the private key associated\n with the public key that this object was constructed with.\n \"\"\"\n message = _helpers.to_bytes(message)\n try:\n return rsa.pkcs1.verify(message, signature, self._pubkey)\n except (ValueError, rsa.pkcs1.VerificationError):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public_key can't be parsed.\n \"\"\"\n public_key = _helpers.to_bytes(public_key)\n is_x509_cert = _CERTIFICATE_MARKER in public_key\n\n # If this is a certificate, extract the public key info.\n if is_x509_cert:\n der = rsa.pem.load_pem(public_key, 'CERTIFICATE')\n asn1_cert, remaining = decoder.decode(der, asn1Spec=Certificate())\n if remaining != b'':\n raise ValueError('Unused bytes', remaining)\n\n cert_info = asn1_cert['tbsCertificate']['subjectPublicKeyInfo']\n key_bytes = _bit_list_to_bytes(cert_info['subjectPublicKey'])\n pubkey = rsa.PublicKey.load_pkcs1(key_bytes, 'DER')\n else:\n pubkey = rsa.PublicKey.load_pkcs1(public_key, 'PEM')\n return cls(pubkey)\n\n\ndef verify_signature(message, signature, certs):\n \"\"\"Verify a cryptographic signature.\n\n Checks that the provided ``signature`` was generated from ``bytes`` using\n the private key associated with the ``cert``.\n\n Args:\n message (Union[str, bytes]): The plaintext message.\n signature (Union[str, bytes]): The cryptographic signature to check.\n certs (Union[Sequence, str, bytes]): The certificate or certificates\n to use to check the signature.\n\n Returns:\n bool: True if the signature is valid, otherwise False.\n \"\"\"\n if isinstance(certs, (six.text_type, six.binary_type)):\n certs = [certs]\n\n for cert in certs:\n verifier = Verifier.from_string(cert)\n if verifier.verify(message, signature):\n return True\n return False\n\n\nclass Signer(object):\n \"\"\"Signs messages with a private key.\n\n Args:\n private_key (rsa.key.PrivateKey): The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self.key_id = key_id\n\n def sign(self, message):\n \"\"\"Signs a message.\n\n Args:\n message (Union[str, bytes]): The message to be signed.\n\n Returns:\n bytes: The signature of the message for the given key.\n \"\"\"\n message = _helpers.to_bytes(message)\n return rsa.pkcs1.sign(message, self._key, 'SHA-256')\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct an Signer instance from a private key in PEM format.\n\n Args:\n key (str): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n Signer: The constructed signer.\n\n Raises:\n ValueError: If the key cannot be parsed as PKCS#1 or PKCS#8 in\n PEM format.\n \"\"\"\n key = _helpers.from_bytes(key) # PEM expects str in Python 3\n marker_id, key_bytes = pem.readPemBlocksFromFile(\n six.StringIO(key), _PKCS1_MARKER, _PKCS8_MARKER)\n\n # Key is in pkcs1 format.\n if marker_id == 0:\n private_key = rsa.key.PrivateKey.load_pkcs1(\n key_bytes, format='DER')\n # Key is in pkcs8.\n elif marker_id == 1:\n key_info, remaining = decoder.decode(\n key_bytes, asn1Spec=_PKCS8_SPEC)\n if remaining != b'':\n raise ValueError('Unused bytes', remaining)\n private_key_info = key_info.getComponentByName('privateKey')\n private_key = rsa.key.PrivateKey.load_pkcs1(\n private_key_info.asOctets(), format='DER')\n else:\n raise ValueError('No key could be detected.')\n\n return cls(private_key, key_id=key_id)\n\n @classmethod\n def from_service_account_file(cls, filename):\n \"\"\"Creates a Signer instance from a service account .json file\n in Google format.\n\n Args:\n filename (str): The path to the service account .json file.\n\n Returns:\n Signer: The constructed signer.\n \"\"\"\n from google.auth import _service_account_info\n _, signer = _service_account_info.from_filename(filename)\n return signer\n", "path": "google/auth/crypt.py"}]}
| 2,658 | 175 |
gh_patches_debug_23893
|
rasdani/github-patches
|
git_diff
|
vispy__vispy-2179
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update volume_plane.py to allow timer to be stopped
I noticed the volume_plane.py has keyboard handling for moving the plane through the volume, but it doesn't allow you to stop the animation so these events don't actually mean much.
@alisterburt do you have time to fix this? Tradition is to use the spacebar (`" "`) to toggle the timer start/stop
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/scene/volume_plane.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # -----------------------------------------------------------------------------
3 # Copyright (c) Vispy Development Team. All Rights Reserved.
4 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
5 # -----------------------------------------------------------------------------
6 # vispy: gallery 10:200:5
7 """
8 Rendering Planes through 3D Data
9 ================================
10
11 Controls:
12 * 1 - toggle between volume rendering methods
13 * 2 - toggle between volume rendering modes ('volume', 'plane')
14 * [] - shift plane along plane normal
15 * {} - decrease/increase plane thickness
16
17 * x/y/z/o - set plane normal along x/y/z or [1,1,1] oblique axis
18 """
19 import sys
20
21 import numpy as np
22
23 from vispy import app, scene, io
24 from vispy.visuals.transforms import STTransform
25
26 # Read volume
27 vol = np.load(io.load_data_file('volume/stent.npz'))['arr_0']
28
29 # Prepare canvas
30 canvas = scene.SceneCanvas(keys='interactive', show=True)
31 view = canvas.central_widget.add_view()
32
33 # Create the volume visual for plane rendering
34 plane = scene.visuals.Volume(
35 vol,
36 parent=view.scene,
37 raycasting_mode='plane',
38 method='mip',
39 plane_thickness=3.0,
40 plane_position=(128, 60, 64),
41 plane_normal=(1, 0, 0),
42 )
43
44 volume = scene.visuals.Volume(
45 vol,
46 parent=view.scene,
47 raycasting_mode='volume',
48 method='mip',
49 )
50 volume.set_gl_state('additive')
51 volume.opacity = 0.25
52
53 # Create a camera
54 cam = scene.cameras.TurntableCamera(
55 parent=view.scene, fov=60.0, azimuth=-42.0, elevation=30.0
56 )
57 view.camera = cam
58
59 # Create an XYZAxis visual
60 axis = scene.visuals.XYZAxis(parent=view)
61 s = STTransform(translate=(50, 50), scale=(50, 50, 50, 1))
62 affine = s.as_matrix()
63 axis.transform = affine
64
65
66 def update_axis_visual():
67 """Sync XYZAxis visual with camera angles"""
68 axis.transform.reset()
69
70 axis.transform.rotate(cam.roll, (0, 0, 1))
71 axis.transform.rotate(cam.elevation, (1, 0, 0))
72 axis.transform.rotate(cam.azimuth, (0, 1, 0))
73 axis.transform.scale((50, 50, 0.001))
74 axis.transform.translate((50., 50.))
75
76 axis.update()
77
78
79 update_axis_visual()
80
81
82 @canvas.events.mouse_move.connect
83 def on_mouse_move(event):
84 if event.button == 1 and event.is_dragging:
85 update_axis_visual()
86
87
88 # Implement key presses
89 @canvas.events.key_press.connect
90 def on_key_press(event):
91 if event.text == '1':
92 methods = ['mip', 'average']
93 method = methods[(methods.index(plane.method) + 1) % 2]
94 print("Volume render method: %s" % method)
95 plane.method = method
96 elif event.text == '2':
97 modes = ['volume', 'plane']
98 if plane.raycasting_mode == modes[0]:
99 plane.raycasting_mode = modes[1]
100 print(modes[1])
101 else:
102 plane.raycasting_mode = modes[0]
103 print(modes[0])
104 elif event.text != '' and event.text in '{}':
105 t = -1 if event.text == '{' else 1
106 plane.plane_thickness += t
107 plane.plane_thickness += t
108 print(f"plane thickness: {plane.plane_thickness}")
109 elif event.text != '' and event.text in '[]':
110 shift = plane.plane_normal / np.linalg.norm(plane.plane_normal)
111 if event.text == '[':
112 plane.plane_position -= 2 * shift
113 elif event.text == ']':
114 plane.plane_position += 2 * shift
115 print(f"plane position: {plane.plane_position}")
116
117 elif event.text == 'x':
118 plane.plane_normal = [0, 0, 1]
119 elif event.text == 'y':
120 plane.plane_normal = [0, 1, 0]
121 elif event.text == 'z':
122 plane.plane_normal = [1, 0, 0]
123 elif event.text == 'o':
124 plane.plane_normal = [1, 1, 1]
125
126
127 def move_plane(event):
128 z_pos = plane.plane_position[0]
129 if z_pos < 32:
130 plane.plane_position = plane.plane_position + [1, 0, 0]
131 elif 32 < z_pos <= 220:
132 plane.plane_position = plane.plane_position - [1, 0, 0]
133 else:
134 plane.plane_position = (220, 64, 64)
135
136
137 timer = app.Timer('auto', connect=move_plane, start=True)
138
139 if __name__ == '__main__':
140 canvas.show()
141 print(__doc__)
142 if sys.flags.interactive == 0:
143 plane.plane_position = (220, 64, 64)
144 app.run()
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/scene/volume_plane.py b/examples/scene/volume_plane.py
--- a/examples/scene/volume_plane.py
+++ b/examples/scene/volume_plane.py
@@ -13,6 +13,7 @@
* 2 - toggle between volume rendering modes ('volume', 'plane')
* [] - shift plane along plane normal
* {} - decrease/increase plane thickness
+* Spacebar - stop/start animation
* x/y/z/o - set plane normal along x/y/z or [1,1,1] oblique axis
"""
@@ -113,7 +114,6 @@
elif event.text == ']':
plane.plane_position += 2 * shift
print(f"plane position: {plane.plane_position}")
-
elif event.text == 'x':
plane.plane_normal = [0, 0, 1]
elif event.text == 'y':
@@ -122,6 +122,11 @@
plane.plane_normal = [1, 0, 0]
elif event.text == 'o':
plane.plane_normal = [1, 1, 1]
+ elif event.text == ' ':
+ if timer.running:
+ timer.stop()
+ else:
+ timer.start()
def move_plane(event):
|
{"golden_diff": "diff --git a/examples/scene/volume_plane.py b/examples/scene/volume_plane.py\n--- a/examples/scene/volume_plane.py\n+++ b/examples/scene/volume_plane.py\n@@ -13,6 +13,7 @@\n * 2 - toggle between volume rendering modes ('volume', 'plane')\n * [] - shift plane along plane normal\n * {} - decrease/increase plane thickness\n+* Spacebar - stop/start animation\n \n * x/y/z/o - set plane normal along x/y/z or [1,1,1] oblique axis\n \"\"\"\n@@ -113,7 +114,6 @@\n elif event.text == ']':\n plane.plane_position += 2 * shift\n print(f\"plane position: {plane.plane_position}\")\n-\n elif event.text == 'x':\n plane.plane_normal = [0, 0, 1]\n elif event.text == 'y':\n@@ -122,6 +122,11 @@\n plane.plane_normal = [1, 0, 0]\n elif event.text == 'o':\n plane.plane_normal = [1, 1, 1]\n+ elif event.text == ' ':\n+ if timer.running:\n+ timer.stop()\n+ else:\n+ timer.start()\n \n \n def move_plane(event):\n", "issue": "Update volume_plane.py to allow timer to be stopped\nI noticed the volume_plane.py has keyboard handling for moving the plane through the volume, but it doesn't allow you to stop the animation so these events don't actually mean much.\r\n\r\n@alisterburt do you have time to fix this? Tradition is to use the spacebar (`\" \"`) to toggle the timer start/stop\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# -----------------------------------------------------------------------------\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n# -----------------------------------------------------------------------------\n# vispy: gallery 10:200:5\n\"\"\"\nRendering Planes through 3D Data\n================================\n\nControls:\n* 1 - toggle between volume rendering methods\n* 2 - toggle between volume rendering modes ('volume', 'plane')\n* [] - shift plane along plane normal\n* {} - decrease/increase plane thickness\n\n* x/y/z/o - set plane normal along x/y/z or [1,1,1] oblique axis\n\"\"\"\nimport sys\n\nimport numpy as np\n\nfrom vispy import app, scene, io\nfrom vispy.visuals.transforms import STTransform\n\n# Read volume\nvol = np.load(io.load_data_file('volume/stent.npz'))['arr_0']\n\n# Prepare canvas\ncanvas = scene.SceneCanvas(keys='interactive', show=True)\nview = canvas.central_widget.add_view()\n\n# Create the volume visual for plane rendering\nplane = scene.visuals.Volume(\n vol,\n parent=view.scene,\n raycasting_mode='plane',\n method='mip',\n plane_thickness=3.0,\n plane_position=(128, 60, 64),\n plane_normal=(1, 0, 0),\n)\n\nvolume = scene.visuals.Volume(\n vol,\n parent=view.scene,\n raycasting_mode='volume',\n method='mip',\n)\nvolume.set_gl_state('additive')\nvolume.opacity = 0.25\n\n# Create a camera\ncam = scene.cameras.TurntableCamera(\n parent=view.scene, fov=60.0, azimuth=-42.0, elevation=30.0\n)\nview.camera = cam\n\n# Create an XYZAxis visual\naxis = scene.visuals.XYZAxis(parent=view)\ns = STTransform(translate=(50, 50), scale=(50, 50, 50, 1))\naffine = s.as_matrix()\naxis.transform = affine\n\n\ndef update_axis_visual():\n \"\"\"Sync XYZAxis visual with camera angles\"\"\"\n axis.transform.reset()\n\n axis.transform.rotate(cam.roll, (0, 0, 1))\n axis.transform.rotate(cam.elevation, (1, 0, 0))\n axis.transform.rotate(cam.azimuth, (0, 1, 0))\n axis.transform.scale((50, 50, 0.001))\n axis.transform.translate((50., 50.))\n\n axis.update()\n\n\nupdate_axis_visual()\n\n\[email protected]_move.connect\ndef on_mouse_move(event):\n if event.button == 1 and event.is_dragging:\n update_axis_visual()\n\n\n# Implement key presses\[email protected]_press.connect\ndef on_key_press(event):\n if event.text == '1':\n methods = ['mip', 'average']\n method = methods[(methods.index(plane.method) + 1) % 2]\n print(\"Volume render method: %s\" % method)\n plane.method = method\n elif event.text == '2':\n modes = ['volume', 'plane']\n if plane.raycasting_mode == modes[0]:\n plane.raycasting_mode = modes[1]\n print(modes[1])\n else:\n plane.raycasting_mode = modes[0]\n print(modes[0])\n elif event.text != '' and event.text in '{}':\n t = -1 if event.text == '{' else 1\n plane.plane_thickness += t\n plane.plane_thickness += t\n print(f\"plane thickness: {plane.plane_thickness}\")\n elif event.text != '' and event.text in '[]':\n shift = plane.plane_normal / np.linalg.norm(plane.plane_normal)\n if event.text == '[':\n plane.plane_position -= 2 * shift\n elif event.text == ']':\n plane.plane_position += 2 * shift\n print(f\"plane position: {plane.plane_position}\")\n\n elif event.text == 'x':\n plane.plane_normal = [0, 0, 1]\n elif event.text == 'y':\n plane.plane_normal = [0, 1, 0]\n elif event.text == 'z':\n plane.plane_normal = [1, 0, 0]\n elif event.text == 'o':\n plane.plane_normal = [1, 1, 1]\n\n\ndef move_plane(event):\n z_pos = plane.plane_position[0]\n if z_pos < 32:\n plane.plane_position = plane.plane_position + [1, 0, 0]\n elif 32 < z_pos <= 220:\n plane.plane_position = plane.plane_position - [1, 0, 0]\n else:\n plane.plane_position = (220, 64, 64)\n\n\ntimer = app.Timer('auto', connect=move_plane, start=True)\n\nif __name__ == '__main__':\n canvas.show()\n print(__doc__)\n if sys.flags.interactive == 0:\n plane.plane_position = (220, 64, 64)\n app.run()\n", "path": "examples/scene/volume_plane.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# -----------------------------------------------------------------------------\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n# -----------------------------------------------------------------------------\n# vispy: gallery 10:200:5\n\"\"\"\nRendering Planes through 3D Data\n================================\n\nControls:\n* 1 - toggle between volume rendering methods\n* 2 - toggle between volume rendering modes ('volume', 'plane')\n* [] - shift plane along plane normal\n* {} - decrease/increase plane thickness\n* Spacebar - stop/start animation\n\n* x/y/z/o - set plane normal along x/y/z or [1,1,1] oblique axis\n\"\"\"\nimport sys\n\nimport numpy as np\n\nfrom vispy import app, scene, io\nfrom vispy.visuals.transforms import STTransform\n\n# Read volume\nvol = np.load(io.load_data_file('volume/stent.npz'))['arr_0']\n\n# Prepare canvas\ncanvas = scene.SceneCanvas(keys='interactive', show=True)\nview = canvas.central_widget.add_view()\n\n# Create the volume visual for plane rendering\nplane = scene.visuals.Volume(\n vol,\n parent=view.scene,\n raycasting_mode='plane',\n method='mip',\n plane_thickness=3.0,\n plane_position=(128, 60, 64),\n plane_normal=(1, 0, 0),\n)\n\nvolume = scene.visuals.Volume(\n vol,\n parent=view.scene,\n raycasting_mode='volume',\n method='mip',\n)\nvolume.set_gl_state('additive')\nvolume.opacity = 0.25\n\n# Create a camera\ncam = scene.cameras.TurntableCamera(\n parent=view.scene, fov=60.0, azimuth=-42.0, elevation=30.0\n)\nview.camera = cam\n\n# Create an XYZAxis visual\naxis = scene.visuals.XYZAxis(parent=view)\ns = STTransform(translate=(50, 50), scale=(50, 50, 50, 1))\naffine = s.as_matrix()\naxis.transform = affine\n\n\ndef update_axis_visual():\n \"\"\"Sync XYZAxis visual with camera angles\"\"\"\n axis.transform.reset()\n\n axis.transform.rotate(cam.roll, (0, 0, 1))\n axis.transform.rotate(cam.elevation, (1, 0, 0))\n axis.transform.rotate(cam.azimuth, (0, 1, 0))\n axis.transform.scale((50, 50, 0.001))\n axis.transform.translate((50., 50.))\n\n axis.update()\n\n\nupdate_axis_visual()\n\n\[email protected]_move.connect\ndef on_mouse_move(event):\n if event.button == 1 and event.is_dragging:\n update_axis_visual()\n\n\n# Implement key presses\[email protected]_press.connect\ndef on_key_press(event):\n if event.text == '1':\n methods = ['mip', 'average']\n method = methods[(methods.index(plane.method) + 1) % 2]\n print(\"Volume render method: %s\" % method)\n plane.method = method\n elif event.text == '2':\n modes = ['volume', 'plane']\n if plane.raycasting_mode == modes[0]:\n plane.raycasting_mode = modes[1]\n print(modes[1])\n else:\n plane.raycasting_mode = modes[0]\n print(modes[0])\n elif event.text != '' and event.text in '{}':\n t = -1 if event.text == '{' else 1\n plane.plane_thickness += t\n plane.plane_thickness += t\n print(f\"plane thickness: {plane.plane_thickness}\")\n elif event.text != '' and event.text in '[]':\n shift = plane.plane_normal / np.linalg.norm(plane.plane_normal)\n if event.text == '[':\n plane.plane_position -= 2 * shift\n elif event.text == ']':\n plane.plane_position += 2 * shift\n print(f\"plane position: {plane.plane_position}\")\n elif event.text == 'x':\n plane.plane_normal = [0, 0, 1]\n elif event.text == 'y':\n plane.plane_normal = [0, 1, 0]\n elif event.text == 'z':\n plane.plane_normal = [1, 0, 0]\n elif event.text == 'o':\n plane.plane_normal = [1, 1, 1]\n elif event.text == ' ':\n if timer.running:\n timer.stop()\n else:\n timer.start()\n\n\ndef move_plane(event):\n z_pos = plane.plane_position[0]\n if z_pos < 32:\n plane.plane_position = plane.plane_position + [1, 0, 0]\n elif 32 < z_pos <= 220:\n plane.plane_position = plane.plane_position - [1, 0, 0]\n else:\n plane.plane_position = (220, 64, 64)\n\n\ntimer = app.Timer('auto', connect=move_plane, start=True)\n\nif __name__ == '__main__':\n canvas.show()\n print(__doc__)\n if sys.flags.interactive == 0:\n plane.plane_position = (220, 64, 64)\n app.run()\n", "path": "examples/scene/volume_plane.py"}]}
| 1,813 | 286 |
gh_patches_debug_34571
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-5080
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
config: add --list to list all variables and their values
Something that would be handy for us during debugging and for users. Same as `git config --list`. Useful to avoid confusion such as in https://github.com/iterative/dvc/issues/4970
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/command/config.py`
Content:
```
1 import argparse
2 import logging
3
4 from dvc.command.base import CmdBaseNoRepo, append_doc_link
5 from dvc.config import Config, ConfigError
6
7 logger = logging.getLogger(__name__)
8
9
10 class CmdConfig(CmdBaseNoRepo):
11 def __init__(self, args):
12 super().__init__(args)
13
14 self.config = Config(validate=False)
15
16 def run(self):
17 section, opt = self.args.name.lower().strip().split(".", 1)
18
19 if self.args.value is None and not self.args.unset:
20 conf = self.config.load_one(self.args.level)
21 self._check(conf, section, opt)
22 logger.info(conf[section][opt])
23 return 0
24
25 with self.config.edit(self.args.level) as conf:
26 if self.args.unset:
27 self._check(conf, section, opt)
28 del conf[section][opt]
29 else:
30 self._check(conf, section)
31 conf[section][opt] = self.args.value
32
33 if self.args.name == "cache.type":
34 logger.warning(
35 "You have changed the 'cache.type' option. This doesn't update"
36 " any existing workspace file links, but it can be done with:"
37 "\n dvc checkout --relink"
38 )
39
40 return 0
41
42 def _check(self, conf, section, opt=None):
43 if section not in conf:
44 msg = "section {} doesn't exist"
45 raise ConfigError(msg.format(self.args.name))
46
47 if opt and opt not in conf[section]:
48 msg = "option {} doesn't exist"
49 raise ConfigError(msg.format(self.args.name))
50
51
52 parent_config_parser = argparse.ArgumentParser(add_help=False)
53 level_group = parent_config_parser.add_mutually_exclusive_group()
54 level_group.add_argument(
55 "--global",
56 dest="level",
57 action="store_const",
58 const="global",
59 help="Use global config.",
60 )
61 level_group.add_argument(
62 "--system",
63 dest="level",
64 action="store_const",
65 const="system",
66 help="Use system config.",
67 )
68 level_group.add_argument(
69 "--local",
70 dest="level",
71 action="store_const",
72 const="local",
73 help="Use local config.",
74 )
75 parent_config_parser.set_defaults(level="repo")
76
77
78 def add_parser(subparsers, parent_parser):
79 CONFIG_HELP = "Get or set config options."
80
81 config_parser = subparsers.add_parser(
82 "config",
83 parents=[parent_config_parser, parent_parser],
84 description=append_doc_link(CONFIG_HELP, "config"),
85 help=CONFIG_HELP,
86 formatter_class=argparse.RawDescriptionHelpFormatter,
87 )
88 config_parser.add_argument(
89 "-u",
90 "--unset",
91 default=False,
92 action="store_true",
93 help="Unset option.",
94 )
95 config_parser.add_argument("name", help="Option name.")
96 config_parser.add_argument("value", nargs="?", help="Option value.")
97 config_parser.set_defaults(func=CmdConfig)
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/command/config.py b/dvc/command/config.py
--- a/dvc/command/config.py
+++ b/dvc/command/config.py
@@ -3,6 +3,7 @@
from dvc.command.base import CmdBaseNoRepo, append_doc_link
from dvc.config import Config, ConfigError
+from dvc.utils.flatten import flatten
logger = logging.getLogger(__name__)
@@ -14,6 +15,22 @@
self.config = Config(validate=False)
def run(self):
+ if self.args.list:
+ if any((self.args.name, self.args.value, self.args.unset)):
+ logger.error(
+ "-l/--list can't be used together with any of these "
+ "options: -u/--unset, name, value"
+ )
+ return 1
+
+ conf = self.config.load_one(self.args.level)
+ logger.info("\n".join(self._format_config(conf)))
+ return 0
+
+ if self.args.name is None:
+ logger.error("name argument is required")
+ return 1
+
section, opt = self.args.name.lower().strip().split(".", 1)
if self.args.value is None and not self.args.unset:
@@ -48,6 +65,11 @@
msg = "option {} doesn't exist"
raise ConfigError(msg.format(self.args.name))
+ @staticmethod
+ def _format_config(config):
+ for key, value in flatten(config).items():
+ yield f"{key}={value}"
+
parent_config_parser = argparse.ArgumentParser(add_help=False)
level_group = parent_config_parser.add_mutually_exclusive_group()
@@ -92,6 +114,13 @@
action="store_true",
help="Unset option.",
)
- config_parser.add_argument("name", help="Option name.")
+ config_parser.add_argument("name", nargs="?", help="Option name.")
config_parser.add_argument("value", nargs="?", help="Option value.")
+ config_parser.add_argument(
+ "-l",
+ "--list",
+ default=False,
+ action="store_true",
+ help="list all defined config values",
+ )
config_parser.set_defaults(func=CmdConfig)
|
{"golden_diff": "diff --git a/dvc/command/config.py b/dvc/command/config.py\n--- a/dvc/command/config.py\n+++ b/dvc/command/config.py\n@@ -3,6 +3,7 @@\n \n from dvc.command.base import CmdBaseNoRepo, append_doc_link\n from dvc.config import Config, ConfigError\n+from dvc.utils.flatten import flatten\n \n logger = logging.getLogger(__name__)\n \n@@ -14,6 +15,22 @@\n self.config = Config(validate=False)\n \n def run(self):\n+ if self.args.list:\n+ if any((self.args.name, self.args.value, self.args.unset)):\n+ logger.error(\n+ \"-l/--list can't be used together with any of these \"\n+ \"options: -u/--unset, name, value\"\n+ )\n+ return 1\n+\n+ conf = self.config.load_one(self.args.level)\n+ logger.info(\"\\n\".join(self._format_config(conf)))\n+ return 0\n+\n+ if self.args.name is None:\n+ logger.error(\"name argument is required\")\n+ return 1\n+\n section, opt = self.args.name.lower().strip().split(\".\", 1)\n \n if self.args.value is None and not self.args.unset:\n@@ -48,6 +65,11 @@\n msg = \"option {} doesn't exist\"\n raise ConfigError(msg.format(self.args.name))\n \n+ @staticmethod\n+ def _format_config(config):\n+ for key, value in flatten(config).items():\n+ yield f\"{key}={value}\"\n+\n \n parent_config_parser = argparse.ArgumentParser(add_help=False)\n level_group = parent_config_parser.add_mutually_exclusive_group()\n@@ -92,6 +114,13 @@\n action=\"store_true\",\n help=\"Unset option.\",\n )\n- config_parser.add_argument(\"name\", help=\"Option name.\")\n+ config_parser.add_argument(\"name\", nargs=\"?\", help=\"Option name.\")\n config_parser.add_argument(\"value\", nargs=\"?\", help=\"Option value.\")\n+ config_parser.add_argument(\n+ \"-l\",\n+ \"--list\",\n+ default=False,\n+ action=\"store_true\",\n+ help=\"list all defined config values\",\n+ )\n config_parser.set_defaults(func=CmdConfig)\n", "issue": "config: add --list to list all variables and their values\nSomething that would be handy for us during debugging and for users. Same as `git config --list`. Useful to avoid confusion such as in https://github.com/iterative/dvc/issues/4970\n", "before_files": [{"content": "import argparse\nimport logging\n\nfrom dvc.command.base import CmdBaseNoRepo, append_doc_link\nfrom dvc.config import Config, ConfigError\n\nlogger = logging.getLogger(__name__)\n\n\nclass CmdConfig(CmdBaseNoRepo):\n def __init__(self, args):\n super().__init__(args)\n\n self.config = Config(validate=False)\n\n def run(self):\n section, opt = self.args.name.lower().strip().split(\".\", 1)\n\n if self.args.value is None and not self.args.unset:\n conf = self.config.load_one(self.args.level)\n self._check(conf, section, opt)\n logger.info(conf[section][opt])\n return 0\n\n with self.config.edit(self.args.level) as conf:\n if self.args.unset:\n self._check(conf, section, opt)\n del conf[section][opt]\n else:\n self._check(conf, section)\n conf[section][opt] = self.args.value\n\n if self.args.name == \"cache.type\":\n logger.warning(\n \"You have changed the 'cache.type' option. This doesn't update\"\n \" any existing workspace file links, but it can be done with:\"\n \"\\n dvc checkout --relink\"\n )\n\n return 0\n\n def _check(self, conf, section, opt=None):\n if section not in conf:\n msg = \"section {} doesn't exist\"\n raise ConfigError(msg.format(self.args.name))\n\n if opt and opt not in conf[section]:\n msg = \"option {} doesn't exist\"\n raise ConfigError(msg.format(self.args.name))\n\n\nparent_config_parser = argparse.ArgumentParser(add_help=False)\nlevel_group = parent_config_parser.add_mutually_exclusive_group()\nlevel_group.add_argument(\n \"--global\",\n dest=\"level\",\n action=\"store_const\",\n const=\"global\",\n help=\"Use global config.\",\n)\nlevel_group.add_argument(\n \"--system\",\n dest=\"level\",\n action=\"store_const\",\n const=\"system\",\n help=\"Use system config.\",\n)\nlevel_group.add_argument(\n \"--local\",\n dest=\"level\",\n action=\"store_const\",\n const=\"local\",\n help=\"Use local config.\",\n)\nparent_config_parser.set_defaults(level=\"repo\")\n\n\ndef add_parser(subparsers, parent_parser):\n CONFIG_HELP = \"Get or set config options.\"\n\n config_parser = subparsers.add_parser(\n \"config\",\n parents=[parent_config_parser, parent_parser],\n description=append_doc_link(CONFIG_HELP, \"config\"),\n help=CONFIG_HELP,\n formatter_class=argparse.RawDescriptionHelpFormatter,\n )\n config_parser.add_argument(\n \"-u\",\n \"--unset\",\n default=False,\n action=\"store_true\",\n help=\"Unset option.\",\n )\n config_parser.add_argument(\"name\", help=\"Option name.\")\n config_parser.add_argument(\"value\", nargs=\"?\", help=\"Option value.\")\n config_parser.set_defaults(func=CmdConfig)\n", "path": "dvc/command/config.py"}], "after_files": [{"content": "import argparse\nimport logging\n\nfrom dvc.command.base import CmdBaseNoRepo, append_doc_link\nfrom dvc.config import Config, ConfigError\nfrom dvc.utils.flatten import flatten\n\nlogger = logging.getLogger(__name__)\n\n\nclass CmdConfig(CmdBaseNoRepo):\n def __init__(self, args):\n super().__init__(args)\n\n self.config = Config(validate=False)\n\n def run(self):\n if self.args.list:\n if any((self.args.name, self.args.value, self.args.unset)):\n logger.error(\n \"-l/--list can't be used together with any of these \"\n \"options: -u/--unset, name, value\"\n )\n return 1\n\n conf = self.config.load_one(self.args.level)\n logger.info(\"\\n\".join(self._format_config(conf)))\n return 0\n\n if self.args.name is None:\n logger.error(\"name argument is required\")\n return 1\n\n section, opt = self.args.name.lower().strip().split(\".\", 1)\n\n if self.args.value is None and not self.args.unset:\n conf = self.config.load_one(self.args.level)\n self._check(conf, section, opt)\n logger.info(conf[section][opt])\n return 0\n\n with self.config.edit(self.args.level) as conf:\n if self.args.unset:\n self._check(conf, section, opt)\n del conf[section][opt]\n else:\n self._check(conf, section)\n conf[section][opt] = self.args.value\n\n if self.args.name == \"cache.type\":\n logger.warning(\n \"You have changed the 'cache.type' option. This doesn't update\"\n \" any existing workspace file links, but it can be done with:\"\n \"\\n dvc checkout --relink\"\n )\n\n return 0\n\n def _check(self, conf, section, opt=None):\n if section not in conf:\n msg = \"section {} doesn't exist\"\n raise ConfigError(msg.format(self.args.name))\n\n if opt and opt not in conf[section]:\n msg = \"option {} doesn't exist\"\n raise ConfigError(msg.format(self.args.name))\n\n @staticmethod\n def _format_config(config):\n for key, value in flatten(config).items():\n yield f\"{key}={value}\"\n\n\nparent_config_parser = argparse.ArgumentParser(add_help=False)\nlevel_group = parent_config_parser.add_mutually_exclusive_group()\nlevel_group.add_argument(\n \"--global\",\n dest=\"level\",\n action=\"store_const\",\n const=\"global\",\n help=\"Use global config.\",\n)\nlevel_group.add_argument(\n \"--system\",\n dest=\"level\",\n action=\"store_const\",\n const=\"system\",\n help=\"Use system config.\",\n)\nlevel_group.add_argument(\n \"--local\",\n dest=\"level\",\n action=\"store_const\",\n const=\"local\",\n help=\"Use local config.\",\n)\nparent_config_parser.set_defaults(level=\"repo\")\n\n\ndef add_parser(subparsers, parent_parser):\n CONFIG_HELP = \"Get or set config options.\"\n\n config_parser = subparsers.add_parser(\n \"config\",\n parents=[parent_config_parser, parent_parser],\n description=append_doc_link(CONFIG_HELP, \"config\"),\n help=CONFIG_HELP,\n formatter_class=argparse.RawDescriptionHelpFormatter,\n )\n config_parser.add_argument(\n \"-u\",\n \"--unset\",\n default=False,\n action=\"store_true\",\n help=\"Unset option.\",\n )\n config_parser.add_argument(\"name\", nargs=\"?\", help=\"Option name.\")\n config_parser.add_argument(\"value\", nargs=\"?\", help=\"Option value.\")\n config_parser.add_argument(\n \"-l\",\n \"--list\",\n default=False,\n action=\"store_true\",\n help=\"list all defined config values\",\n )\n config_parser.set_defaults(func=CmdConfig)\n", "path": "dvc/command/config.py"}]}
| 1,130 | 495 |
gh_patches_debug_32189
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1475
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PS needs to init wrap initializer when embedding exists
For a PS that does not have non-embedding parameters, it needs to initialize wrap optimizer if embedding layer exists.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/ps/servicer.py`
Content:
```
1 import threading
2
3 from google.protobuf import empty_pb2
4
5 from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
6 from elasticdl.python.common.tensor import (
7 Tensor,
8 emplace_tensor_pb_from_ndarray,
9 serialize_tensor,
10 )
11 from elasticdl.python.master.optimizer_wrapper import OptimizerWrapper
12
13
14 class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
15 """PS service implementation"""
16
17 def __init__(
18 self,
19 parameters,
20 grads_to_wait,
21 optimizer,
22 lr_staleness_modulation=False,
23 use_async=False,
24 evaluation_steps=0,
25 master_channel=None,
26 ):
27 if master_channel is None:
28 self._master_stub = None
29 else:
30 self._master_stub = elasticdl_pb2_grpc.MasterStub(master_channel)
31
32 self._parameters = parameters
33 self._grads_to_wait = grads_to_wait
34 self._optimizer = optimizer
35 self._lr_staleness_modulation = lr_staleness_modulation
36 self._use_async = use_async
37 self._eval_steps = evaluation_steps
38 self._version_lock = threading.Lock()
39 self._lock = threading.Lock()
40
41 self._grads_n = 0
42 self._grads_buffer = {}
43
44 def pull_variable(self, request, _):
45 """
46 Response with all non-embedding parameters if initialized.
47 """
48 res = elasticdl_pb2.PullVariableResponse()
49 if not self._parameters.init_status:
50 res.model_init_status = False
51 return res
52
53 # Only sync-SGD needs lock
54 # TODO: use a read-write lock to support multiple concurrent reads
55 if not self._use_async:
56 self._lock.acquire()
57 res.model.version = self._parameters.version
58 for name, var in self._parameters.non_embedding_params.items():
59 emplace_tensor_pb_from_ndarray(
60 res.model.param, var.numpy(), name=name
61 )
62 if not self._use_async:
63 self._lock.release()
64 res.model_init_status = True
65 return res
66
67 def pull_embedding_vector(self, request, _):
68 ret = elasticdl_pb2.Tensor()
69 if not request.ids:
70 return ret
71 embedding_vectors = self._parameters.get_embedding_param(
72 request.name, request.ids
73 )
74 tensor = Tensor(values=embedding_vectors)
75 serialize_tensor(tensor, ret)
76 return ret
77
78 def push_model(self, request, _):
79 with self._lock:
80 accepted = self._parameters.init_from_model_pb(request)
81 if accepted and self._parameters.has_embedding_params():
82 self.wrap_optimizer()
83 self._parameters.create_slot_params(
84 self._optimizer.allowed_slot_names,
85 self._optimizer.slot_initial_value,
86 )
87 return empty_pb2.Empty()
88
89 def push_embedding_info(self, request, _):
90 with self._lock:
91 self._parameters.init_embedding_params(
92 request.embedding_table_info
93 )
94 return empty_pb2.Empty()
95
96 def push_gradient(self, request, _):
97 res = elasticdl_pb2.PushGradientResponse()
98 if self._use_async:
99 grad_vars = []
100 for pb in request.gradients:
101 grad = Tensor.from_tensor_pb(pb)
102 self._parameters.check_grad(grad)
103 name = grad.name
104 var = self._parameters.get_non_embedding_param(name)
105 grad = grad.to_tf_tensor()
106 if var is None:
107 grad_vars.append((grad, name))
108 else:
109 grad_vars.append((grad, var))
110
111 self._optimizer.apply_gradients(grad_vars)
112 with self._version_lock:
113 self._parameters.version += 1
114 version = self._parameters.version
115 self._report_version_if_needed(version)
116
117 res.accepted = True
118 res.model_version = self._parameters.version
119 return res
120 else:
121 if request.model_version != self._parameters.version:
122 res.accepted = False
123 res.model_version = self._parameters.version
124 return res
125
126 with self._lock:
127 for pb in request.gradients:
128 grad = Tensor.from_tensor_pb(pb)
129 self._parameters.check_grad(grad)
130 if grad.name in self._grads_buffer:
131 self._grads_buffer[grad.name] = (
132 self._grads_buffer[grad.name] + grad
133 )
134 else:
135 self._grads_buffer[grad.name] = grad
136
137 self._grads_n += 1
138 res.accepted = True
139
140 updated_version = False
141 version = self._parameters.version
142 if self._grads_n == self._grads_to_wait:
143 grad_vars = []
144 for name, grad in self._grads_buffer.items():
145 # Dense gradients are averaged,
146 # while sparse gradients are summed
147 if not grad.is_indexed_slices():
148 grad.values = grad.values / self._grads_to_wait
149 var = self._parameters.get_non_embedding_param(name)
150 grad = grad.to_tf_tensor()
151 if var is None:
152 grad_vars.append((grad, name))
153 else:
154 grad_vars.append((grad, var))
155
156 self._optimizer.apply_gradients(grad_vars)
157 self._grads_n = 0
158 self._grads_buffer.clear()
159 self._parameters.version += 1
160 version = self._parameters.version
161 updated_version = True
162
163 if updated_version:
164 self._report_version_if_needed(version)
165 res.model_version = version
166 return res
167
168 def wrap_optimizer(self):
169 # TODO(yunjian.lmh): refine these arguments when we don't need
170 # to support using Redis as distributed KV storage.
171 embedding_dims = {}
172 for table in self._parameters.embedding_params.values():
173 embedding_dims[table.name] = table.dim
174 embedding_service_endpoint = None
175
176 def lookup_embedding_func(keys):
177 embeddings = []
178 for key in keys:
179 arrs = key.split("-")
180 layer_name = "-".join(arrs[:-1])
181 id = int(arrs[-1])
182 embedding = self._parameters.get_embedding_param(
183 layer_name, [id]
184 )
185 embeddings.append(embedding.flatten())
186 return embeddings, []
187
188 def update_embedding_func(keys, values):
189 for key, value in zip(keys, values):
190 arrs = key.split("-")
191 layer_name = "-".join(arrs[:-1])
192 id = int(arrs[-1])
193 self._parameters.set_embedding_param(layer_name, [id], [value])
194
195 self._optimizer = OptimizerWrapper(
196 self._optimizer,
197 embedding_service_endpoint,
198 embedding_dims,
199 self._use_async,
200 lookup_embedding_func,
201 update_embedding_func,
202 )
203
204 def _report_version_if_needed(self, version):
205 if self._eval_steps and version % self._eval_steps == 0:
206 self._report_version(version)
207
208 def _report_version(self, version):
209 req = elasticdl_pb2.ReportVersionRequest()
210 req.model_version = version
211 self._master_stub.ReportVersion(req)
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py
--- a/elasticdl/python/ps/servicer.py
+++ b/elasticdl/python/ps/servicer.py
@@ -37,6 +37,7 @@
self._eval_steps = evaluation_steps
self._version_lock = threading.Lock()
self._lock = threading.Lock()
+ self._use_wrap_opt = False
self._grads_n = 0
self._grads_buffer = {}
@@ -79,11 +80,7 @@
with self._lock:
accepted = self._parameters.init_from_model_pb(request)
if accepted and self._parameters.has_embedding_params():
- self.wrap_optimizer()
- self._parameters.create_slot_params(
- self._optimizer.allowed_slot_names,
- self._optimizer.slot_initial_value,
- )
+ self.wrap_optimizer_and_set_slot()
return empty_pb2.Empty()
def push_embedding_info(self, request, _):
@@ -91,6 +88,7 @@
self._parameters.init_embedding_params(
request.embedding_table_info
)
+ self.wrap_optimizer_and_set_slot()
return empty_pb2.Empty()
def push_gradient(self, request, _):
@@ -209,3 +207,12 @@
req = elasticdl_pb2.ReportVersionRequest()
req.model_version = version
self._master_stub.ReportVersion(req)
+
+ def wrap_optimizer_and_set_slot(self):
+ if not self._use_wrap_opt:
+ self.wrap_optimizer()
+ self._parameters.create_slot_params(
+ self._optimizer.allowed_slot_names,
+ self._optimizer.slot_initial_value,
+ )
+ self._use_wrap_opt = True
|
{"golden_diff": "diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py\n--- a/elasticdl/python/ps/servicer.py\n+++ b/elasticdl/python/ps/servicer.py\n@@ -37,6 +37,7 @@\n self._eval_steps = evaluation_steps\n self._version_lock = threading.Lock()\n self._lock = threading.Lock()\n+ self._use_wrap_opt = False\n \n self._grads_n = 0\n self._grads_buffer = {}\n@@ -79,11 +80,7 @@\n with self._lock:\n accepted = self._parameters.init_from_model_pb(request)\n if accepted and self._parameters.has_embedding_params():\n- self.wrap_optimizer()\n- self._parameters.create_slot_params(\n- self._optimizer.allowed_slot_names,\n- self._optimizer.slot_initial_value,\n- )\n+ self.wrap_optimizer_and_set_slot()\n return empty_pb2.Empty()\n \n def push_embedding_info(self, request, _):\n@@ -91,6 +88,7 @@\n self._parameters.init_embedding_params(\n request.embedding_table_info\n )\n+ self.wrap_optimizer_and_set_slot()\n return empty_pb2.Empty()\n \n def push_gradient(self, request, _):\n@@ -209,3 +207,12 @@\n req = elasticdl_pb2.ReportVersionRequest()\n req.model_version = version\n self._master_stub.ReportVersion(req)\n+\n+ def wrap_optimizer_and_set_slot(self):\n+ if not self._use_wrap_opt:\n+ self.wrap_optimizer()\n+ self._parameters.create_slot_params(\n+ self._optimizer.allowed_slot_names,\n+ self._optimizer.slot_initial_value,\n+ )\n+ self._use_wrap_opt = True\n", "issue": "PS needs to init wrap initializer when embedding exists\nFor a PS that does not have non-embedding parameters, it needs to initialize wrap optimizer if embedding layer exists.\n", "before_files": [{"content": "import threading\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\nfrom elasticdl.python.common.tensor import (\n Tensor,\n emplace_tensor_pb_from_ndarray,\n serialize_tensor,\n)\nfrom elasticdl.python.master.optimizer_wrapper import OptimizerWrapper\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n evaluation_steps=0,\n master_channel=None,\n ):\n if master_channel is None:\n self._master_stub = None\n else:\n self._master_stub = elasticdl_pb2_grpc.MasterStub(master_channel)\n\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._eval_steps = evaluation_steps\n self._version_lock = threading.Lock()\n self._lock = threading.Lock()\n\n self._grads_n = 0\n self._grads_buffer = {}\n\n def pull_variable(self, request, _):\n \"\"\"\n Response with all non-embedding parameters if initialized.\n \"\"\"\n res = elasticdl_pb2.PullVariableResponse()\n if not self._parameters.init_status:\n res.model_init_status = False\n return res\n\n # Only sync-SGD needs lock\n # TODO: use a read-write lock to support multiple concurrent reads\n if not self._use_async:\n self._lock.acquire()\n res.model.version = self._parameters.version\n for name, var in self._parameters.non_embedding_params.items():\n emplace_tensor_pb_from_ndarray(\n res.model.param, var.numpy(), name=name\n )\n if not self._use_async:\n self._lock.release()\n res.model_init_status = True\n return res\n\n def pull_embedding_vector(self, request, _):\n ret = elasticdl_pb2.Tensor()\n if not request.ids:\n return ret\n embedding_vectors = self._parameters.get_embedding_param(\n request.name, request.ids\n )\n tensor = Tensor(values=embedding_vectors)\n serialize_tensor(tensor, ret)\n return ret\n\n def push_model(self, request, _):\n with self._lock:\n accepted = self._parameters.init_from_model_pb(request)\n if accepted and self._parameters.has_embedding_params():\n self.wrap_optimizer()\n self._parameters.create_slot_params(\n self._optimizer.allowed_slot_names,\n self._optimizer.slot_initial_value,\n )\n return empty_pb2.Empty()\n\n def push_embedding_info(self, request, _):\n with self._lock:\n self._parameters.init_embedding_params(\n request.embedding_table_info\n )\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n res = elasticdl_pb2.PushGradientResponse()\n if self._use_async:\n grad_vars = []\n for pb in request.gradients:\n grad = Tensor.from_tensor_pb(pb)\n self._parameters.check_grad(grad)\n name = grad.name\n var = self._parameters.get_non_embedding_param(name)\n grad = grad.to_tf_tensor()\n if var is None:\n grad_vars.append((grad, name))\n else:\n grad_vars.append((grad, var))\n\n self._optimizer.apply_gradients(grad_vars)\n with self._version_lock:\n self._parameters.version += 1\n version = self._parameters.version\n self._report_version_if_needed(version)\n\n res.accepted = True\n res.model_version = self._parameters.version\n return res\n else:\n if request.model_version != self._parameters.version:\n res.accepted = False\n res.model_version = self._parameters.version\n return res\n\n with self._lock:\n for pb in request.gradients:\n grad = Tensor.from_tensor_pb(pb)\n self._parameters.check_grad(grad)\n if grad.name in self._grads_buffer:\n self._grads_buffer[grad.name] = (\n self._grads_buffer[grad.name] + grad\n )\n else:\n self._grads_buffer[grad.name] = grad\n\n self._grads_n += 1\n res.accepted = True\n\n updated_version = False\n version = self._parameters.version\n if self._grads_n == self._grads_to_wait:\n grad_vars = []\n for name, grad in self._grads_buffer.items():\n # Dense gradients are averaged,\n # while sparse gradients are summed\n if not grad.is_indexed_slices():\n grad.values = grad.values / self._grads_to_wait\n var = self._parameters.get_non_embedding_param(name)\n grad = grad.to_tf_tensor()\n if var is None:\n grad_vars.append((grad, name))\n else:\n grad_vars.append((grad, var))\n\n self._optimizer.apply_gradients(grad_vars)\n self._grads_n = 0\n self._grads_buffer.clear()\n self._parameters.version += 1\n version = self._parameters.version\n updated_version = True\n\n if updated_version:\n self._report_version_if_needed(version)\n res.model_version = version\n return res\n\n def wrap_optimizer(self):\n # TODO(yunjian.lmh): refine these arguments when we don't need\n # to support using Redis as distributed KV storage.\n embedding_dims = {}\n for table in self._parameters.embedding_params.values():\n embedding_dims[table.name] = table.dim\n embedding_service_endpoint = None\n\n def lookup_embedding_func(keys):\n embeddings = []\n for key in keys:\n arrs = key.split(\"-\")\n layer_name = \"-\".join(arrs[:-1])\n id = int(arrs[-1])\n embedding = self._parameters.get_embedding_param(\n layer_name, [id]\n )\n embeddings.append(embedding.flatten())\n return embeddings, []\n\n def update_embedding_func(keys, values):\n for key, value in zip(keys, values):\n arrs = key.split(\"-\")\n layer_name = \"-\".join(arrs[:-1])\n id = int(arrs[-1])\n self._parameters.set_embedding_param(layer_name, [id], [value])\n\n self._optimizer = OptimizerWrapper(\n self._optimizer,\n embedding_service_endpoint,\n embedding_dims,\n self._use_async,\n lookup_embedding_func,\n update_embedding_func,\n )\n\n def _report_version_if_needed(self, version):\n if self._eval_steps and version % self._eval_steps == 0:\n self._report_version(version)\n\n def _report_version(self, version):\n req = elasticdl_pb2.ReportVersionRequest()\n req.model_version = version\n self._master_stub.ReportVersion(req)\n", "path": "elasticdl/python/ps/servicer.py"}], "after_files": [{"content": "import threading\n\nfrom google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\nfrom elasticdl.python.common.tensor import (\n Tensor,\n emplace_tensor_pb_from_ndarray,\n serialize_tensor,\n)\nfrom elasticdl.python.master.optimizer_wrapper import OptimizerWrapper\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n evaluation_steps=0,\n master_channel=None,\n ):\n if master_channel is None:\n self._master_stub = None\n else:\n self._master_stub = elasticdl_pb2_grpc.MasterStub(master_channel)\n\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._eval_steps = evaluation_steps\n self._version_lock = threading.Lock()\n self._lock = threading.Lock()\n self._use_wrap_opt = False\n\n self._grads_n = 0\n self._grads_buffer = {}\n\n def pull_variable(self, request, _):\n \"\"\"\n Response with all non-embedding parameters if initialized.\n \"\"\"\n res = elasticdl_pb2.PullVariableResponse()\n if not self._parameters.init_status:\n res.model_init_status = False\n return res\n\n # Only sync-SGD needs lock\n # TODO: use a read-write lock to support multiple concurrent reads\n if not self._use_async:\n self._lock.acquire()\n res.model.version = self._parameters.version\n for name, var in self._parameters.non_embedding_params.items():\n emplace_tensor_pb_from_ndarray(\n res.model.param, var.numpy(), name=name\n )\n if not self._use_async:\n self._lock.release()\n res.model_init_status = True\n return res\n\n def pull_embedding_vector(self, request, _):\n ret = elasticdl_pb2.Tensor()\n if not request.ids:\n return ret\n embedding_vectors = self._parameters.get_embedding_param(\n request.name, request.ids\n )\n tensor = Tensor(values=embedding_vectors)\n serialize_tensor(tensor, ret)\n return ret\n\n def push_model(self, request, _):\n with self._lock:\n accepted = self._parameters.init_from_model_pb(request)\n if accepted and self._parameters.has_embedding_params():\n self.wrap_optimizer_and_set_slot()\n return empty_pb2.Empty()\n\n def push_embedding_info(self, request, _):\n with self._lock:\n self._parameters.init_embedding_params(\n request.embedding_table_info\n )\n self.wrap_optimizer_and_set_slot()\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n res = elasticdl_pb2.PushGradientResponse()\n if self._use_async:\n grad_vars = []\n for pb in request.gradients:\n grad = Tensor.from_tensor_pb(pb)\n self._parameters.check_grad(grad)\n name = grad.name\n var = self._parameters.get_non_embedding_param(name)\n grad = grad.to_tf_tensor()\n if var is None:\n grad_vars.append((grad, name))\n else:\n grad_vars.append((grad, var))\n\n self._optimizer.apply_gradients(grad_vars)\n with self._version_lock:\n self._parameters.version += 1\n version = self._parameters.version\n self._report_version_if_needed(version)\n\n res.accepted = True\n res.model_version = self._parameters.version\n return res\n else:\n if request.model_version != self._parameters.version:\n res.accepted = False\n res.model_version = self._parameters.version\n return res\n\n with self._lock:\n for pb in request.gradients:\n grad = Tensor.from_tensor_pb(pb)\n self._parameters.check_grad(grad)\n if grad.name in self._grads_buffer:\n self._grads_buffer[grad.name] = (\n self._grads_buffer[grad.name] + grad\n )\n else:\n self._grads_buffer[grad.name] = grad\n\n self._grads_n += 1\n res.accepted = True\n\n updated_version = False\n version = self._parameters.version\n if self._grads_n == self._grads_to_wait:\n grad_vars = []\n for name, grad in self._grads_buffer.items():\n # Dense gradients are averaged,\n # while sparse gradients are summed\n if not grad.is_indexed_slices():\n grad.values = grad.values / self._grads_to_wait\n var = self._parameters.get_non_embedding_param(name)\n grad = grad.to_tf_tensor()\n if var is None:\n grad_vars.append((grad, name))\n else:\n grad_vars.append((grad, var))\n\n self._optimizer.apply_gradients(grad_vars)\n self._grads_n = 0\n self._grads_buffer.clear()\n self._parameters.version += 1\n version = self._parameters.version\n updated_version = True\n\n if updated_version:\n self._report_version_if_needed(version)\n res.model_version = version\n return res\n\n def wrap_optimizer(self):\n # TODO(yunjian.lmh): refine these arguments when we don't need\n # to support using Redis as distributed KV storage.\n embedding_dims = {}\n for table in self._parameters.embedding_params.values():\n embedding_dims[table.name] = table.dim\n embedding_service_endpoint = None\n\n def lookup_embedding_func(keys):\n embeddings = []\n for key in keys:\n arrs = key.split(\"-\")\n layer_name = \"-\".join(arrs[:-1])\n id = int(arrs[-1])\n embedding = self._parameters.get_embedding_param(\n layer_name, [id]\n )\n embeddings.append(embedding.flatten())\n return embeddings, []\n\n def update_embedding_func(keys, values):\n for key, value in zip(keys, values):\n arrs = key.split(\"-\")\n layer_name = \"-\".join(arrs[:-1])\n id = int(arrs[-1])\n self._parameters.set_embedding_param(layer_name, [id], [value])\n\n self._optimizer = OptimizerWrapper(\n self._optimizer,\n embedding_service_endpoint,\n embedding_dims,\n self._use_async,\n lookup_embedding_func,\n update_embedding_func,\n )\n\n def _report_version_if_needed(self, version):\n if self._eval_steps and version % self._eval_steps == 0:\n self._report_version(version)\n\n def _report_version(self, version):\n req = elasticdl_pb2.ReportVersionRequest()\n req.model_version = version\n self._master_stub.ReportVersion(req)\n\n def wrap_optimizer_and_set_slot(self):\n if not self._use_wrap_opt:\n self.wrap_optimizer()\n self._parameters.create_slot_params(\n self._optimizer.allowed_slot_names,\n self._optimizer.slot_initial_value,\n )\n self._use_wrap_opt = True\n", "path": "elasticdl/python/ps/servicer.py"}]}
| 2,310 | 388 |
gh_patches_debug_13566
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-5250
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Docs builds for GridInteractionLayer and XebResultDict are broken
**Description of the issue**
Currently we cannot run the `build_api_docs.py` and build the API docs for `GridInteractionLayer` or `XebResultDict`.
**How to reproduce the issue**
```
diff --git a/dev_tools/docs/build_api_docs.py b/dev_tools/docs/build_api_docs.py
index e3f0c79a..076a4acc 100644
--- a/dev_tools/docs/build_api_docs.py
+++ b/dev_tools/docs/build_api_docs.py
@@ -95,6 +95,11 @@ def generate_cirq():
site_path=FLAGS.site_path,
callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
extra_docs=_doc.RECORDED_CONST_DOCS,
+ private_map={
+ # Opt to not build docs for these paths for now since they error.
+ "cirq.experiments": ["CrossEntropyResultDict", "GridInteractionLayer"],
+ "cirq.experiments.random_quantum_circuit_generation": ["GridInteractionLayer"],
+ },
)
```
Removing the `private_map` entry in `build_api_docs.py` above and then running the build script gives:
```
Traceback (most recent call last):
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py", line 546, in write_docs
page_info = docs_for_object.docs_for_object(
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/docs_for_object.py", line 89, in docs_for_object
page_info.docs_for_object(parser_config)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/base_page.py", line 164, in docs_for_object
self.collect_docs(parser_config)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py", line 384, in collect_docs
self._add_member(member_info, defining_class, parser_config)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py", line 337, in _add_member
self._add_method(member_info, defining_class, parser_config)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py", line 277, in _add_method
signature = signature_lib.generate_signature(
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py", line 589, in generate_signature
return_annotation_source) = extract_fn(func)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py", line 624, in _extract_class_defaults_and_annotations
ast_visitor.extract(cls)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py", line 140, in extract
super().extract(cls)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py", line 58, in extract
obj_source = textwrap.dedent(inspect.getsource(obj))
File "/usr/lib/python3.9/inspect.py", line 1024, in getsource
lines, lnum = getsourcelines(object)
File "/usr/lib/python3.9/inspect.py", line 1006, in getsourcelines
lines, lnum = findsource(object)
File "/usr/lib/python3.9/inspect.py", line 851, in findsource
raise OSError('could not find class definition')
OSError: could not find class definition
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py", line 220, in <module>
app.run(main)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/absl/app.py", line 312, in run
_run_main(main, args)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/absl/app.py", line 258, in _run_main
sys.exit(main(argv))
File "/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py", line 79, in main
generate_cirq()
File "/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py", line 106, in generate_cirq
doc_generator.build(output_dir=FLAGS.output_dir)
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py", line 847, in build
write_docs(
File "/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py", line 559, in write_docs
raise ValueError(
ValueError: Failed to generate docs for symbol: `cirq.experiments.GridInteractionLayer`
```
**Cirq version**
```
0.15.0dev
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dev_tools/docs/build_api_docs.py`
Content:
```
1 # Copyright 2021 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Tool to generate external api_docs for Cirq.
16
17 In order to publish to our site, devsite runs two jobs for us: stable and nightly.
18 The stable one downloads the latest cirq release from pypi and uses that to generate the reference
19 API docs.
20 The nightly one downloads the latest cirq pre-release (pip install cirq --pre) and uses that to
21 generate the "nightly diff".
22
23 This script needs to cater for both of these cases.
24 """
25
26 import os
27 import types
28
29 import networkx
30 from absl import app
31 from absl import flags
32 from tensorflow_docs.api_generator import doc_controls
33 from tensorflow_docs.api_generator import generate_lib
34 from tensorflow_docs.api_generator import public_api
35
36 import cirq
37 import cirq_aqt
38 import cirq_google
39 import cirq_ionq
40 import cirq_pasqal
41 import cirq_rigetti
42 import cirq_web
43
44 from cirq import _doc
45
46 flags.DEFINE_string("output_dir", "docs/api_docs", "Where to output the docs")
47
48 flags.DEFINE_string(
49 "code_url_prefix",
50 "https://github.com/quantumlib/Cirq/blob/master",
51 "The url prefix for links to code.",
52 )
53
54 flags.DEFINE_bool("search_hints", True, "Include metadata search hints in the generated files")
55
56 flags.DEFINE_string("site_path", "reference/python", "Path prefix in the _toc.yaml")
57
58 FLAGS = flags.FLAGS
59
60
61 def filter_unwanted_inherited_methods(path, parent, children):
62 """Filter the unwanted inherited methods.
63
64 CircuitDag inherits a lot of methods from `networkx.DiGraph` and `Graph`.
65 This filter removes these, as it creates a lot of noise in the API docs.
66 """
67 if parent.__name__ != "CircuitDag":
68 return children
69
70 filtered_children = []
71 for name, obj in children:
72 if isinstance(obj, types.FunctionType):
73 if obj.__module__.startswith('cirq'):
74 filtered_children.append((name, obj))
75 return filtered_children
76
77
78 def main(unused_argv):
79 generate_cirq()
80 generate_cirq_google()
81 generate_cirq_aqt()
82 generate_cirq_ionq()
83 generate_cirq_pasqal()
84 generate_cirq_rigetti()
85 generate_cirq_web()
86
87
88 def generate_cirq():
89 doc_generator = generate_lib.DocGenerator(
90 root_title="Cirq",
91 py_modules=[("cirq", cirq)],
92 base_dir=os.path.dirname(cirq.__file__),
93 code_url_prefix=FLAGS.code_url_prefix + "/cirq-core/cirq",
94 search_hints=FLAGS.search_hints,
95 site_path=FLAGS.site_path,
96 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
97 extra_docs=_doc.RECORDED_CONST_DOCS,
98 private_map={
99 # Opt to not build docs for these paths for now since they error.
100 "cirq.experiments": ["CrossEntropyResultDict", "GridInteractionLayer"],
101 "cirq.experiments.random_quantum_circuit_generation": ["GridInteractionLayer"],
102 },
103 )
104 doc_controls.decorate_all_class_attributes(
105 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
106 )
107 doc_generator.build(output_dir=FLAGS.output_dir)
108
109
110 def generate_cirq_aqt():
111 doc_generator = generate_lib.DocGenerator(
112 root_title="Cirq-aqt",
113 py_modules=[("cirq_aqt", cirq_aqt)],
114 base_dir=os.path.dirname(cirq_aqt.__file__),
115 code_url_prefix=FLAGS.code_url_prefix + "/cirq-aqt/cirq_aqt",
116 search_hints=FLAGS.search_hints,
117 site_path=FLAGS.site_path,
118 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
119 extra_docs=_doc.RECORDED_CONST_DOCS,
120 )
121 doc_controls.decorate_all_class_attributes(
122 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
123 )
124
125 doc_generator.build(output_dir=FLAGS.output_dir)
126
127
128 def generate_cirq_ionq():
129 doc_generator = generate_lib.DocGenerator(
130 root_title="Cirq_ionq",
131 py_modules=[("cirq_ionq", cirq_ionq)],
132 base_dir=os.path.dirname(cirq_ionq.__file__),
133 code_url_prefix=FLAGS.code_url_prefix + "/cirq-ionq/cirq_ionq",
134 search_hints=FLAGS.search_hints,
135 site_path=FLAGS.site_path,
136 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
137 extra_docs=_doc.RECORDED_CONST_DOCS,
138 )
139 doc_controls.decorate_all_class_attributes(
140 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
141 )
142
143 doc_generator.build(output_dir=FLAGS.output_dir)
144
145
146 def generate_cirq_pasqal():
147 doc_generator = generate_lib.DocGenerator(
148 root_title="Cirq-pasqal",
149 py_modules=[("cirq_pasqal", cirq_pasqal)],
150 base_dir=os.path.dirname(cirq_pasqal.__file__),
151 code_url_prefix=FLAGS.code_url_prefix + "/cirq-pasqal/cirq_pasqal",
152 search_hints=FLAGS.search_hints,
153 site_path=FLAGS.site_path,
154 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
155 extra_docs=_doc.RECORDED_CONST_DOCS,
156 )
157 doc_controls.decorate_all_class_attributes(
158 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
159 )
160
161 doc_generator.build(output_dir=FLAGS.output_dir)
162
163
164 def generate_cirq_rigetti():
165 doc_generator = generate_lib.DocGenerator(
166 root_title="Cirq_rigetti",
167 py_modules=[("cirq_rigetti", cirq_rigetti)],
168 base_dir=os.path.dirname(cirq_rigetti.__file__),
169 code_url_prefix=FLAGS.code_url_prefix + "/cirq-rigetti/cirq_rigetti",
170 search_hints=FLAGS.search_hints,
171 site_path=FLAGS.site_path,
172 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
173 extra_docs=_doc.RECORDED_CONST_DOCS,
174 )
175 doc_controls.decorate_all_class_attributes(
176 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
177 )
178
179 doc_generator.build(output_dir=FLAGS.output_dir)
180
181
182 def generate_cirq_google():
183 doc_generator = generate_lib.DocGenerator(
184 root_title="Cirq-google",
185 py_modules=[("cirq_google", cirq_google)],
186 base_dir=os.path.dirname(cirq_google.__file__),
187 code_url_prefix=FLAGS.code_url_prefix + "/cirq-google/cirq_google",
188 search_hints=FLAGS.search_hints,
189 site_path=FLAGS.site_path,
190 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
191 private_map={
192 # Opt to not build docs for these paths for now since they error.
193 "cirq_google.cloud.quantum.QuantumEngineServiceClient": ["enums"],
194 "cirq_google.cloud.quantum_v1alpha1.QuantumEngineServiceClient": ["enums"],
195 "cirq_google.api": ["v1"],
196 },
197 extra_docs=_doc.RECORDED_CONST_DOCS,
198 )
199 doc_generator.build(output_dir=FLAGS.output_dir)
200
201
202 def generate_cirq_web():
203 doc_generator = generate_lib.DocGenerator(
204 root_title="Cirq_web",
205 py_modules=[("cirq_web", cirq_web)],
206 base_dir=os.path.dirname(cirq_web.__file__),
207 code_url_prefix=FLAGS.code_url_prefix + "/cirq-web/cirq_web",
208 search_hints=FLAGS.search_hints,
209 site_path=FLAGS.site_path,
210 callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
211 extra_docs=_doc.RECORDED_CONST_DOCS,
212 )
213 doc_controls.decorate_all_class_attributes(
214 doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
215 )
216
217 doc_generator.build(output_dir=FLAGS.output_dir)
218
219
220 if __name__ == "__main__":
221 app.run(main)
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dev_tools/docs/build_api_docs.py b/dev_tools/docs/build_api_docs.py
--- a/dev_tools/docs/build_api_docs.py
+++ b/dev_tools/docs/build_api_docs.py
@@ -95,11 +95,6 @@
site_path=FLAGS.site_path,
callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],
extra_docs=_doc.RECORDED_CONST_DOCS,
- private_map={
- # Opt to not build docs for these paths for now since they error.
- "cirq.experiments": ["CrossEntropyResultDict", "GridInteractionLayer"],
- "cirq.experiments.random_quantum_circuit_generation": ["GridInteractionLayer"],
- },
)
doc_controls.decorate_all_class_attributes(
doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]
|
{"golden_diff": "diff --git a/dev_tools/docs/build_api_docs.py b/dev_tools/docs/build_api_docs.py\n--- a/dev_tools/docs/build_api_docs.py\n+++ b/dev_tools/docs/build_api_docs.py\n@@ -95,11 +95,6 @@\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n- private_map={\n- # Opt to not build docs for these paths for now since they error.\n- \"cirq.experiments\": [\"CrossEntropyResultDict\", \"GridInteractionLayer\"],\n- \"cirq.experiments.random_quantum_circuit_generation\": [\"GridInteractionLayer\"],\n- },\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n", "issue": "Docs builds for GridInteractionLayer and XebResultDict are broken\n**Description of the issue**\r\nCurrently we cannot run the `build_api_docs.py` and build the API docs for `GridInteractionLayer` or `XebResultDict`.\r\n\r\n**How to reproduce the issue**\r\n\r\n```\r\ndiff --git a/dev_tools/docs/build_api_docs.py b/dev_tools/docs/build_api_docs.py\r\nindex e3f0c79a..076a4acc 100644\r\n--- a/dev_tools/docs/build_api_docs.py\r\n+++ b/dev_tools/docs/build_api_docs.py\r\n@@ -95,6 +95,11 @@ def generate_cirq():\r\n site_path=FLAGS.site_path,\r\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\r\n extra_docs=_doc.RECORDED_CONST_DOCS,\r\n+ private_map={\r\n+ # Opt to not build docs for these paths for now since they error.\r\n+ \"cirq.experiments\": [\"CrossEntropyResultDict\", \"GridInteractionLayer\"],\r\n+ \"cirq.experiments.random_quantum_circuit_generation\": [\"GridInteractionLayer\"],\r\n+ },\r\n )\r\n```\r\nRemoving the `private_map` entry in `build_api_docs.py` above and then running the build script gives:\r\n\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py\", line 546, in write_docs\r\n page_info = docs_for_object.docs_for_object(\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/docs_for_object.py\", line 89, in docs_for_object\r\n page_info.docs_for_object(parser_config)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/base_page.py\", line 164, in docs_for_object\r\n self.collect_docs(parser_config)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py\", line 384, in collect_docs\r\n self._add_member(member_info, defining_class, parser_config)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py\", line 337, in _add_member\r\n self._add_method(member_info, defining_class, parser_config)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/pretty_docs/class_page.py\", line 277, in _add_method\r\n signature = signature_lib.generate_signature(\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py\", line 589, in generate_signature\r\n return_annotation_source) = extract_fn(func)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py\", line 624, in _extract_class_defaults_and_annotations\r\n ast_visitor.extract(cls)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py\", line 140, in extract\r\n super().extract(cls)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/signature.py\", line 58, in extract\r\n obj_source = textwrap.dedent(inspect.getsource(obj))\r\n File \"/usr/lib/python3.9/inspect.py\", line 1024, in getsource\r\n lines, lnum = getsourcelines(object)\r\n File \"/usr/lib/python3.9/inspect.py\", line 1006, in getsourcelines\r\n lines, lnum = findsource(object)\r\n File \"/usr/lib/python3.9/inspect.py\", line 851, in findsource\r\n raise OSError('could not find class definition')\r\nOSError: could not find class definition\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py\", line 220, in <module>\r\n app.run(main)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/absl/app.py\", line 312, in run\r\n _run_main(main, args)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/absl/app.py\", line 258, in _run_main\r\n sys.exit(main(argv))\r\n File \"/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py\", line 79, in main\r\n generate_cirq()\r\n File \"/home/mbbrough/Desktop/Cirq/dev_tools/docs/build_api_docs.py\", line 106, in generate_cirq\r\n doc_generator.build(output_dir=FLAGS.output_dir)\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py\", line 847, in build\r\n write_docs(\r\n File \"/home/mbbrough/Desktop/cirq_env/lib/python3.9/site-packages/tensorflow_docs/api_generator/generate_lib.py\", line 559, in write_docs\r\n raise ValueError(\r\nValueError: Failed to generate docs for symbol: `cirq.experiments.GridInteractionLayer`\r\n```\r\n\r\n**Cirq version**\r\n```\r\n0.15.0dev\r\n```\r\n\r\n\n", "before_files": [{"content": "# Copyright 2021 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Tool to generate external api_docs for Cirq.\n\nIn order to publish to our site, devsite runs two jobs for us: stable and nightly.\nThe stable one downloads the latest cirq release from pypi and uses that to generate the reference\nAPI docs.\nThe nightly one downloads the latest cirq pre-release (pip install cirq --pre) and uses that to\ngenerate the \"nightly diff\".\n\nThis script needs to cater for both of these cases.\n\"\"\"\n\nimport os\nimport types\n\nimport networkx\nfrom absl import app\nfrom absl import flags\nfrom tensorflow_docs.api_generator import doc_controls\nfrom tensorflow_docs.api_generator import generate_lib\nfrom tensorflow_docs.api_generator import public_api\n\nimport cirq\nimport cirq_aqt\nimport cirq_google\nimport cirq_ionq\nimport cirq_pasqal\nimport cirq_rigetti\nimport cirq_web\n\nfrom cirq import _doc\n\nflags.DEFINE_string(\"output_dir\", \"docs/api_docs\", \"Where to output the docs\")\n\nflags.DEFINE_string(\n \"code_url_prefix\",\n \"https://github.com/quantumlib/Cirq/blob/master\",\n \"The url prefix for links to code.\",\n)\n\nflags.DEFINE_bool(\"search_hints\", True, \"Include metadata search hints in the generated files\")\n\nflags.DEFINE_string(\"site_path\", \"reference/python\", \"Path prefix in the _toc.yaml\")\n\nFLAGS = flags.FLAGS\n\n\ndef filter_unwanted_inherited_methods(path, parent, children):\n \"\"\"Filter the unwanted inherited methods.\n\n CircuitDag inherits a lot of methods from `networkx.DiGraph` and `Graph`.\n This filter removes these, as it creates a lot of noise in the API docs.\n \"\"\"\n if parent.__name__ != \"CircuitDag\":\n return children\n\n filtered_children = []\n for name, obj in children:\n if isinstance(obj, types.FunctionType):\n if obj.__module__.startswith('cirq'):\n filtered_children.append((name, obj))\n return filtered_children\n\n\ndef main(unused_argv):\n generate_cirq()\n generate_cirq_google()\n generate_cirq_aqt()\n generate_cirq_ionq()\n generate_cirq_pasqal()\n generate_cirq_rigetti()\n generate_cirq_web()\n\n\ndef generate_cirq():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq\",\n py_modules=[(\"cirq\", cirq)],\n base_dir=os.path.dirname(cirq.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-core/cirq\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n private_map={\n # Opt to not build docs for these paths for now since they error.\n \"cirq.experiments\": [\"CrossEntropyResultDict\", \"GridInteractionLayer\"],\n \"cirq.experiments.random_quantum_circuit_generation\": [\"GridInteractionLayer\"],\n },\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_aqt():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-aqt\",\n py_modules=[(\"cirq_aqt\", cirq_aqt)],\n base_dir=os.path.dirname(cirq_aqt.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-aqt/cirq_aqt\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_ionq():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_ionq\",\n py_modules=[(\"cirq_ionq\", cirq_ionq)],\n base_dir=os.path.dirname(cirq_ionq.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-ionq/cirq_ionq\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_pasqal():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-pasqal\",\n py_modules=[(\"cirq_pasqal\", cirq_pasqal)],\n base_dir=os.path.dirname(cirq_pasqal.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-pasqal/cirq_pasqal\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_rigetti():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_rigetti\",\n py_modules=[(\"cirq_rigetti\", cirq_rigetti)],\n base_dir=os.path.dirname(cirq_rigetti.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-rigetti/cirq_rigetti\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_google():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-google\",\n py_modules=[(\"cirq_google\", cirq_google)],\n base_dir=os.path.dirname(cirq_google.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-google/cirq_google\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n private_map={\n # Opt to not build docs for these paths for now since they error.\n \"cirq_google.cloud.quantum.QuantumEngineServiceClient\": [\"enums\"],\n \"cirq_google.cloud.quantum_v1alpha1.QuantumEngineServiceClient\": [\"enums\"],\n \"cirq_google.api\": [\"v1\"],\n },\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_web():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_web\",\n py_modules=[(\"cirq_web\", cirq_web)],\n base_dir=os.path.dirname(cirq_web.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-web/cirq_web\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\nif __name__ == \"__main__\":\n app.run(main)\n", "path": "dev_tools/docs/build_api_docs.py"}], "after_files": [{"content": "# Copyright 2021 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Tool to generate external api_docs for Cirq.\n\nIn order to publish to our site, devsite runs two jobs for us: stable and nightly.\nThe stable one downloads the latest cirq release from pypi and uses that to generate the reference\nAPI docs.\nThe nightly one downloads the latest cirq pre-release (pip install cirq --pre) and uses that to\ngenerate the \"nightly diff\".\n\nThis script needs to cater for both of these cases.\n\"\"\"\n\nimport os\nimport types\n\nimport networkx\nfrom absl import app\nfrom absl import flags\nfrom tensorflow_docs.api_generator import doc_controls\nfrom tensorflow_docs.api_generator import generate_lib\nfrom tensorflow_docs.api_generator import public_api\n\nimport cirq\nimport cirq_aqt\nimport cirq_google\nimport cirq_ionq\nimport cirq_pasqal\nimport cirq_rigetti\nimport cirq_web\n\nfrom cirq import _doc\n\nflags.DEFINE_string(\"output_dir\", \"docs/api_docs\", \"Where to output the docs\")\n\nflags.DEFINE_string(\n \"code_url_prefix\",\n \"https://github.com/quantumlib/Cirq/blob/master\",\n \"The url prefix for links to code.\",\n)\n\nflags.DEFINE_bool(\"search_hints\", True, \"Include metadata search hints in the generated files\")\n\nflags.DEFINE_string(\"site_path\", \"reference/python\", \"Path prefix in the _toc.yaml\")\n\nFLAGS = flags.FLAGS\n\n\ndef filter_unwanted_inherited_methods(path, parent, children):\n \"\"\"Filter the unwanted inherited methods.\n\n CircuitDag inherits a lot of methods from `networkx.DiGraph` and `Graph`.\n This filter removes these, as it creates a lot of noise in the API docs.\n \"\"\"\n if parent.__name__ != \"CircuitDag\":\n return children\n\n filtered_children = []\n for name, obj in children:\n if isinstance(obj, types.FunctionType):\n if obj.__module__.startswith('cirq'):\n filtered_children.append((name, obj))\n return filtered_children\n\n\ndef main(unused_argv):\n generate_cirq()\n generate_cirq_google()\n generate_cirq_aqt()\n generate_cirq_ionq()\n generate_cirq_pasqal()\n generate_cirq_rigetti()\n generate_cirq_web()\n\n\ndef generate_cirq():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq\",\n py_modules=[(\"cirq\", cirq)],\n base_dir=os.path.dirname(cirq.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-core/cirq\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_aqt():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-aqt\",\n py_modules=[(\"cirq_aqt\", cirq_aqt)],\n base_dir=os.path.dirname(cirq_aqt.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-aqt/cirq_aqt\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_ionq():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_ionq\",\n py_modules=[(\"cirq_ionq\", cirq_ionq)],\n base_dir=os.path.dirname(cirq_ionq.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-ionq/cirq_ionq\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_pasqal():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-pasqal\",\n py_modules=[(\"cirq_pasqal\", cirq_pasqal)],\n base_dir=os.path.dirname(cirq_pasqal.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-pasqal/cirq_pasqal\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_rigetti():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_rigetti\",\n py_modules=[(\"cirq_rigetti\", cirq_rigetti)],\n base_dir=os.path.dirname(cirq_rigetti.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-rigetti/cirq_rigetti\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_google():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq-google\",\n py_modules=[(\"cirq_google\", cirq_google)],\n base_dir=os.path.dirname(cirq_google.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-google/cirq_google\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n private_map={\n # Opt to not build docs for these paths for now since they error.\n \"cirq_google.cloud.quantum.QuantumEngineServiceClient\": [\"enums\"],\n \"cirq_google.cloud.quantum_v1alpha1.QuantumEngineServiceClient\": [\"enums\"],\n \"cirq_google.api\": [\"v1\"],\n },\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\ndef generate_cirq_web():\n doc_generator = generate_lib.DocGenerator(\n root_title=\"Cirq_web\",\n py_modules=[(\"cirq_web\", cirq_web)],\n base_dir=os.path.dirname(cirq_web.__file__),\n code_url_prefix=FLAGS.code_url_prefix + \"/cirq-web/cirq_web\",\n search_hints=FLAGS.search_hints,\n site_path=FLAGS.site_path,\n callbacks=[public_api.local_definitions_filter, filter_unwanted_inherited_methods],\n extra_docs=_doc.RECORDED_CONST_DOCS,\n )\n doc_controls.decorate_all_class_attributes(\n doc_controls.do_not_doc_inheritable, networkx.DiGraph, skip=[]\n )\n\n doc_generator.build(output_dir=FLAGS.output_dir)\n\n\nif __name__ == \"__main__\":\n app.run(main)\n", "path": "dev_tools/docs/build_api_docs.py"}]}
| 3,938 | 179 |
gh_patches_debug_13391
|
rasdani/github-patches
|
git_diff
|
getmoto__moto-433
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CloudFormation's GetTemplate response is inaccurate
The GetTemplate function returns through `boto` the following format:
``` python
>>> import boto.cloudformation
>>> cf = boto.cloudformation.connect_to_region('us-east-1')
>>> cf.get_template('<my-stack-id>')
{u'GetTemplateResponse': {u'GetTemplateResult': {u'TemplateBody': u'{"Resources": "<RESOURCES HERE>"}', u'ResponseMetadata': {u'RequestId': u'aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee'}}}
```
But moto returns just the template body... Moto's source: https://github.com/spulec/moto/blob/1dcfcbca5711ac50f9c3314b8a7e8812e3025156/moto/cloudformation/responses.py#L87-L91
AWS Docs: http://docs.aws.amazon.com/AWSCloudFormation/latest/APIReference/API_GetTemplate.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `moto/cloudformation/responses.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import json
4 from six.moves.urllib.parse import urlparse
5
6 from moto.core.responses import BaseResponse
7 from moto.s3 import s3_backend
8 from .models import cloudformation_backends
9
10
11 class CloudFormationResponse(BaseResponse):
12
13 @property
14 def cloudformation_backend(self):
15 return cloudformation_backends[self.region]
16
17 def _get_stack_from_s3_url(self, template_url):
18 template_url_parts = urlparse(template_url)
19 bucket_name = template_url_parts.netloc.split(".")[0]
20 key_name = template_url_parts.path.lstrip("/")
21
22 key = s3_backend.get_key(bucket_name, key_name)
23 return key.value.decode("utf-8")
24
25 def create_stack(self):
26 stack_name = self._get_param('StackName')
27 stack_body = self._get_param('TemplateBody')
28 template_url = self._get_param('TemplateURL')
29 parameters_list = self._get_list_prefix("Parameters.member")
30 tags = dict((item['key'], item['value']) for item in self._get_list_prefix("Tags.member"))
31
32 # Hack dict-comprehension
33 parameters = dict([
34 (parameter['parameter_key'], parameter['parameter_value'])
35 for parameter
36 in parameters_list
37 ])
38 if template_url:
39 stack_body = self._get_stack_from_s3_url(template_url)
40 stack_notification_arns = self._get_multi_param('NotificationARNs.member')
41
42 stack = self.cloudformation_backend.create_stack(
43 name=stack_name,
44 template=stack_body,
45 parameters=parameters,
46 region_name=self.region,
47 notification_arns=stack_notification_arns,
48 tags=tags,
49 )
50 stack_body = {
51 'CreateStackResponse': {
52 'CreateStackResult': {
53 'StackId': stack.stack_id,
54 }
55 }
56 }
57 return json.dumps(stack_body)
58
59 def describe_stacks(self):
60 stack_name_or_id = None
61 if self._get_param('StackName'):
62 stack_name_or_id = self.querystring.get('StackName')[0]
63 stacks = self.cloudformation_backend.describe_stacks(stack_name_or_id)
64
65 template = self.response_template(DESCRIBE_STACKS_TEMPLATE)
66 return template.render(stacks=stacks)
67
68 def describe_stack_resources(self):
69 stack_name = self._get_param('StackName')
70 stack = self.cloudformation_backend.get_stack(stack_name)
71
72 template = self.response_template(DESCRIBE_STACKS_RESOURCES_RESPONSE)
73 return template.render(stack=stack)
74
75 def list_stacks(self):
76 stacks = self.cloudformation_backend.list_stacks()
77 template = self.response_template(LIST_STACKS_RESPONSE)
78 return template.render(stacks=stacks)
79
80 def list_stack_resources(self):
81 stack_name_or_id = self._get_param('StackName')
82 resources = self.cloudformation_backend.list_stack_resources(stack_name_or_id)
83
84 template = self.response_template(LIST_STACKS_RESOURCES_RESPONSE)
85 return template.render(resources=resources)
86
87 def get_template(self):
88 name_or_stack_id = self.querystring.get('StackName')[0]
89
90 stack = self.cloudformation_backend.get_stack(name_or_stack_id)
91 return stack.template
92
93 def update_stack(self):
94 stack_name = self._get_param('StackName')
95 stack_body = self._get_param('TemplateBody')
96
97 stack = self.cloudformation_backend.update_stack(
98 name=stack_name,
99 template=stack_body,
100 )
101 stack_body = {
102 'UpdateStackResponse': {
103 'UpdateStackResult': {
104 'StackId': stack.name,
105 }
106 }
107 }
108 return json.dumps(stack_body)
109
110 def delete_stack(self):
111 name_or_stack_id = self.querystring.get('StackName')[0]
112
113 self.cloudformation_backend.delete_stack(name_or_stack_id)
114 return json.dumps({
115 'DeleteStackResponse': {
116 'DeleteStackResult': {},
117 }
118 })
119
120
121 DESCRIBE_STACKS_TEMPLATE = """<DescribeStacksResult>
122 <Stacks>
123 {% for stack in stacks %}
124 <member>
125 <StackName>{{ stack.name }}</StackName>
126 <StackId>{{ stack.stack_id }}</StackId>
127 <CreationTime>2010-07-27T22:28:28Z</CreationTime>
128 <StackStatus>{{ stack.status }}</StackStatus>
129 {% if stack.notification_arns %}
130 <NotificationARNs>
131 {% for notification_arn in stack.notification_arns %}
132 <member>{{ notification_arn }}</member>
133 {% endfor %}
134 </NotificationARNs>
135 {% else %}
136 <NotificationARNs/>
137 {% endif %}
138 <DisableRollback>false</DisableRollback>
139 <Outputs>
140 {% for output in stack.stack_outputs %}
141 <member>
142 <OutputKey>{{ output.key }}</OutputKey>
143 <OutputValue>{{ output.value }}</OutputValue>
144 </member>
145 {% endfor %}
146 </Outputs>
147 <Parameters>
148 {% for param_name, param_value in stack.stack_parameters.items() %}
149 <member>
150 <ParameterKey>{{ param_name }}</ParameterKey>
151 <ParameterValue>{{ param_value }}</ParameterValue>
152 </member>
153 {% endfor %}
154 </Parameters>
155 <Tags>
156 {% for tag_key, tag_value in stack.tags.items() %}
157 <member>
158 <Key>{{ tag_key }}</Key>
159 <Value>{{ tag_value }}</Value>
160 </member>
161 {% endfor %}
162 </Tags>
163 </member>
164 {% endfor %}
165 </Stacks>
166 </DescribeStacksResult>"""
167
168
169 LIST_STACKS_RESPONSE = """<ListStacksResponse>
170 <ListStacksResult>
171 <StackSummaries>
172 {% for stack in stacks %}
173 <member>
174 <StackId>{{ stack.stack_id }}</StackId>
175 <StackStatus>{{ stack.status }}</StackStatus>
176 <StackName>{{ stack.name }}</StackName>
177 <CreationTime>2011-05-23T15:47:44Z</CreationTime>
178 <TemplateDescription>{{ stack.description }}</TemplateDescription>
179 </member>
180 {% endfor %}
181 </StackSummaries>
182 </ListStacksResult>
183 </ListStacksResponse>"""
184
185
186 DESCRIBE_STACKS_RESOURCES_RESPONSE = """<DescribeStackResourcesResult>
187 <StackResources>
188 {% for resource in stack.stack_resources %}
189 <member>
190 <StackId>{{ stack.stack_id }}</StackId>
191 <StackName>{{ stack.name }}</StackName>
192 <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>
193 <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>
194 <ResourceType>{{ resource.type }}</ResourceType>
195 <Timestamp>2010-07-27T22:27:28Z</Timestamp>
196 <ResourceStatus>{{ stack.status }}</ResourceStatus>
197 </member>
198 {% endfor %}
199 </StackResources>
200 </DescribeStackResourcesResult>"""
201
202
203 LIST_STACKS_RESOURCES_RESPONSE = """<ListStackResourcesResponse>
204 <ListStackResourcesResult>
205 <StackResourceSummaries>
206 {% for resource in resources %}
207 <member>
208 <ResourceStatus>CREATE_COMPLETE</ResourceStatus>
209 <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>
210 <LastUpdatedTimestamp>2011-06-21T20:15:58Z</LastUpdatedTimestamp>
211 <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>
212 <ResourceType>{{ resource.type }}</ResourceType>
213 </member>
214 {% endfor %}
215 </StackResourceSummaries>
216 </ListStackResourcesResult>
217 <ResponseMetadata>
218 <RequestId>2d06e36c-ac1d-11e0-a958-f9382b6eb86b</RequestId>
219 </ResponseMetadata>
220 </ListStackResourcesResponse>"""
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/moto/cloudformation/responses.py b/moto/cloudformation/responses.py
--- a/moto/cloudformation/responses.py
+++ b/moto/cloudformation/responses.py
@@ -86,9 +86,19 @@
def get_template(self):
name_or_stack_id = self.querystring.get('StackName')[0]
-
stack = self.cloudformation_backend.get_stack(name_or_stack_id)
- return stack.template
+
+ response = {
+ "GetTemplateResponse": {
+ "GetTemplateResult": {
+ "TemplateBody": stack.template,
+ "ResponseMetadata": {
+ "RequestId": "2d06e36c-ac1d-11e0-a958-f9382b6eb86bEXAMPLE"
+ }
+ }
+ }
+ }
+ return json.dumps(response)
def update_stack(self):
stack_name = self._get_param('StackName')
|
{"golden_diff": "diff --git a/moto/cloudformation/responses.py b/moto/cloudformation/responses.py\n--- a/moto/cloudformation/responses.py\n+++ b/moto/cloudformation/responses.py\n@@ -86,9 +86,19 @@\n \n def get_template(self):\n name_or_stack_id = self.querystring.get('StackName')[0]\n-\n stack = self.cloudformation_backend.get_stack(name_or_stack_id)\n- return stack.template\n+\n+ response = {\n+ \"GetTemplateResponse\": {\n+ \"GetTemplateResult\": {\n+ \"TemplateBody\": stack.template,\n+ \"ResponseMetadata\": {\n+ \"RequestId\": \"2d06e36c-ac1d-11e0-a958-f9382b6eb86bEXAMPLE\"\n+ }\n+ }\n+ }\n+ }\n+ return json.dumps(response)\n \n def update_stack(self):\n stack_name = self._get_param('StackName')\n", "issue": "CloudFormation's GetTemplate response is inaccurate\nThe GetTemplate function returns through `boto` the following format:\n\n``` python\n>>> import boto.cloudformation\n>>> cf = boto.cloudformation.connect_to_region('us-east-1')\n>>> cf.get_template('<my-stack-id>')\n{u'GetTemplateResponse': {u'GetTemplateResult': {u'TemplateBody': u'{\"Resources\": \"<RESOURCES HERE>\"}', u'ResponseMetadata': {u'RequestId': u'aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee'}}}\n```\n\nBut moto returns just the template body... Moto's source: https://github.com/spulec/moto/blob/1dcfcbca5711ac50f9c3314b8a7e8812e3025156/moto/cloudformation/responses.py#L87-L91\n\nAWS Docs: http://docs.aws.amazon.com/AWSCloudFormation/latest/APIReference/API_GetTemplate.html\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport json\nfrom six.moves.urllib.parse import urlparse\n\nfrom moto.core.responses import BaseResponse\nfrom moto.s3 import s3_backend\nfrom .models import cloudformation_backends\n\n\nclass CloudFormationResponse(BaseResponse):\n\n @property\n def cloudformation_backend(self):\n return cloudformation_backends[self.region]\n\n def _get_stack_from_s3_url(self, template_url):\n template_url_parts = urlparse(template_url)\n bucket_name = template_url_parts.netloc.split(\".\")[0]\n key_name = template_url_parts.path.lstrip(\"/\")\n\n key = s3_backend.get_key(bucket_name, key_name)\n return key.value.decode(\"utf-8\")\n\n def create_stack(self):\n stack_name = self._get_param('StackName')\n stack_body = self._get_param('TemplateBody')\n template_url = self._get_param('TemplateURL')\n parameters_list = self._get_list_prefix(\"Parameters.member\")\n tags = dict((item['key'], item['value']) for item in self._get_list_prefix(\"Tags.member\"))\n\n # Hack dict-comprehension\n parameters = dict([\n (parameter['parameter_key'], parameter['parameter_value'])\n for parameter\n in parameters_list\n ])\n if template_url:\n stack_body = self._get_stack_from_s3_url(template_url)\n stack_notification_arns = self._get_multi_param('NotificationARNs.member')\n\n stack = self.cloudformation_backend.create_stack(\n name=stack_name,\n template=stack_body,\n parameters=parameters,\n region_name=self.region,\n notification_arns=stack_notification_arns,\n tags=tags,\n )\n stack_body = {\n 'CreateStackResponse': {\n 'CreateStackResult': {\n 'StackId': stack.stack_id,\n }\n }\n }\n return json.dumps(stack_body)\n\n def describe_stacks(self):\n stack_name_or_id = None\n if self._get_param('StackName'):\n stack_name_or_id = self.querystring.get('StackName')[0]\n stacks = self.cloudformation_backend.describe_stacks(stack_name_or_id)\n\n template = self.response_template(DESCRIBE_STACKS_TEMPLATE)\n return template.render(stacks=stacks)\n\n def describe_stack_resources(self):\n stack_name = self._get_param('StackName')\n stack = self.cloudformation_backend.get_stack(stack_name)\n\n template = self.response_template(DESCRIBE_STACKS_RESOURCES_RESPONSE)\n return template.render(stack=stack)\n\n def list_stacks(self):\n stacks = self.cloudformation_backend.list_stacks()\n template = self.response_template(LIST_STACKS_RESPONSE)\n return template.render(stacks=stacks)\n\n def list_stack_resources(self):\n stack_name_or_id = self._get_param('StackName')\n resources = self.cloudformation_backend.list_stack_resources(stack_name_or_id)\n\n template = self.response_template(LIST_STACKS_RESOURCES_RESPONSE)\n return template.render(resources=resources)\n\n def get_template(self):\n name_or_stack_id = self.querystring.get('StackName')[0]\n\n stack = self.cloudformation_backend.get_stack(name_or_stack_id)\n return stack.template\n\n def update_stack(self):\n stack_name = self._get_param('StackName')\n stack_body = self._get_param('TemplateBody')\n\n stack = self.cloudformation_backend.update_stack(\n name=stack_name,\n template=stack_body,\n )\n stack_body = {\n 'UpdateStackResponse': {\n 'UpdateStackResult': {\n 'StackId': stack.name,\n }\n }\n }\n return json.dumps(stack_body)\n\n def delete_stack(self):\n name_or_stack_id = self.querystring.get('StackName')[0]\n\n self.cloudformation_backend.delete_stack(name_or_stack_id)\n return json.dumps({\n 'DeleteStackResponse': {\n 'DeleteStackResult': {},\n }\n })\n\n\nDESCRIBE_STACKS_TEMPLATE = \"\"\"<DescribeStacksResult>\n <Stacks>\n {% for stack in stacks %}\n <member>\n <StackName>{{ stack.name }}</StackName>\n <StackId>{{ stack.stack_id }}</StackId>\n <CreationTime>2010-07-27T22:28:28Z</CreationTime>\n <StackStatus>{{ stack.status }}</StackStatus>\n {% if stack.notification_arns %}\n <NotificationARNs>\n {% for notification_arn in stack.notification_arns %}\n <member>{{ notification_arn }}</member>\n {% endfor %}\n </NotificationARNs>\n {% else %}\n <NotificationARNs/>\n {% endif %}\n <DisableRollback>false</DisableRollback>\n <Outputs>\n {% for output in stack.stack_outputs %}\n <member>\n <OutputKey>{{ output.key }}</OutputKey>\n <OutputValue>{{ output.value }}</OutputValue>\n </member>\n {% endfor %}\n </Outputs>\n <Parameters>\n {% for param_name, param_value in stack.stack_parameters.items() %}\n <member>\n <ParameterKey>{{ param_name }}</ParameterKey>\n <ParameterValue>{{ param_value }}</ParameterValue>\n </member>\n {% endfor %}\n </Parameters>\n <Tags>\n {% for tag_key, tag_value in stack.tags.items() %}\n <member>\n <Key>{{ tag_key }}</Key>\n <Value>{{ tag_value }}</Value>\n </member>\n {% endfor %}\n </Tags>\n </member>\n {% endfor %}\n </Stacks>\n</DescribeStacksResult>\"\"\"\n\n\nLIST_STACKS_RESPONSE = \"\"\"<ListStacksResponse>\n <ListStacksResult>\n <StackSummaries>\n {% for stack in stacks %}\n <member>\n <StackId>{{ stack.stack_id }}</StackId>\n <StackStatus>{{ stack.status }}</StackStatus>\n <StackName>{{ stack.name }}</StackName>\n <CreationTime>2011-05-23T15:47:44Z</CreationTime>\n <TemplateDescription>{{ stack.description }}</TemplateDescription>\n </member>\n {% endfor %}\n </StackSummaries>\n </ListStacksResult>\n</ListStacksResponse>\"\"\"\n\n\nDESCRIBE_STACKS_RESOURCES_RESPONSE = \"\"\"<DescribeStackResourcesResult>\n <StackResources>\n {% for resource in stack.stack_resources %}\n <member>\n <StackId>{{ stack.stack_id }}</StackId>\n <StackName>{{ stack.name }}</StackName>\n <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>\n <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>\n <ResourceType>{{ resource.type }}</ResourceType>\n <Timestamp>2010-07-27T22:27:28Z</Timestamp>\n <ResourceStatus>{{ stack.status }}</ResourceStatus>\n </member>\n {% endfor %}\n </StackResources>\n</DescribeStackResourcesResult>\"\"\"\n\n\nLIST_STACKS_RESOURCES_RESPONSE = \"\"\"<ListStackResourcesResponse>\n <ListStackResourcesResult>\n <StackResourceSummaries>\n {% for resource in resources %}\n <member>\n <ResourceStatus>CREATE_COMPLETE</ResourceStatus>\n <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>\n <LastUpdatedTimestamp>2011-06-21T20:15:58Z</LastUpdatedTimestamp>\n <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>\n <ResourceType>{{ resource.type }}</ResourceType>\n </member>\n {% endfor %}\n </StackResourceSummaries>\n </ListStackResourcesResult>\n <ResponseMetadata>\n <RequestId>2d06e36c-ac1d-11e0-a958-f9382b6eb86b</RequestId>\n </ResponseMetadata>\n</ListStackResourcesResponse>\"\"\"\n", "path": "moto/cloudformation/responses.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport json\nfrom six.moves.urllib.parse import urlparse\n\nfrom moto.core.responses import BaseResponse\nfrom moto.s3 import s3_backend\nfrom .models import cloudformation_backends\n\n\nclass CloudFormationResponse(BaseResponse):\n\n @property\n def cloudformation_backend(self):\n return cloudformation_backends[self.region]\n\n def _get_stack_from_s3_url(self, template_url):\n template_url_parts = urlparse(template_url)\n bucket_name = template_url_parts.netloc.split(\".\")[0]\n key_name = template_url_parts.path.lstrip(\"/\")\n\n key = s3_backend.get_key(bucket_name, key_name)\n return key.value.decode(\"utf-8\")\n\n def create_stack(self):\n stack_name = self._get_param('StackName')\n stack_body = self._get_param('TemplateBody')\n template_url = self._get_param('TemplateURL')\n parameters_list = self._get_list_prefix(\"Parameters.member\")\n tags = dict((item['key'], item['value']) for item in self._get_list_prefix(\"Tags.member\"))\n\n # Hack dict-comprehension\n parameters = dict([\n (parameter['parameter_key'], parameter['parameter_value'])\n for parameter\n in parameters_list\n ])\n if template_url:\n stack_body = self._get_stack_from_s3_url(template_url)\n stack_notification_arns = self._get_multi_param('NotificationARNs.member')\n\n stack = self.cloudformation_backend.create_stack(\n name=stack_name,\n template=stack_body,\n parameters=parameters,\n region_name=self.region,\n notification_arns=stack_notification_arns,\n tags=tags,\n )\n stack_body = {\n 'CreateStackResponse': {\n 'CreateStackResult': {\n 'StackId': stack.stack_id,\n }\n }\n }\n return json.dumps(stack_body)\n\n def describe_stacks(self):\n stack_name_or_id = None\n if self._get_param('StackName'):\n stack_name_or_id = self.querystring.get('StackName')[0]\n stacks = self.cloudformation_backend.describe_stacks(stack_name_or_id)\n\n template = self.response_template(DESCRIBE_STACKS_TEMPLATE)\n return template.render(stacks=stacks)\n\n def describe_stack_resources(self):\n stack_name = self._get_param('StackName')\n stack = self.cloudformation_backend.get_stack(stack_name)\n\n template = self.response_template(DESCRIBE_STACKS_RESOURCES_RESPONSE)\n return template.render(stack=stack)\n\n def list_stacks(self):\n stacks = self.cloudformation_backend.list_stacks()\n template = self.response_template(LIST_STACKS_RESPONSE)\n return template.render(stacks=stacks)\n\n def list_stack_resources(self):\n stack_name_or_id = self._get_param('StackName')\n resources = self.cloudformation_backend.list_stack_resources(stack_name_or_id)\n\n template = self.response_template(LIST_STACKS_RESOURCES_RESPONSE)\n return template.render(resources=resources)\n\n def get_template(self):\n name_or_stack_id = self.querystring.get('StackName')[0]\n stack = self.cloudformation_backend.get_stack(name_or_stack_id)\n\n response = {\n \"GetTemplateResponse\": {\n \"GetTemplateResult\": {\n \"TemplateBody\": stack.template,\n \"ResponseMetadata\": {\n \"RequestId\": \"2d06e36c-ac1d-11e0-a958-f9382b6eb86bEXAMPLE\"\n }\n }\n }\n }\n return json.dumps(response)\n\n def update_stack(self):\n stack_name = self._get_param('StackName')\n stack_body = self._get_param('TemplateBody')\n\n stack = self.cloudformation_backend.update_stack(\n name=stack_name,\n template=stack_body,\n )\n stack_body = {\n 'UpdateStackResponse': {\n 'UpdateStackResult': {\n 'StackId': stack.name,\n }\n }\n }\n return json.dumps(stack_body)\n\n def delete_stack(self):\n name_or_stack_id = self.querystring.get('StackName')[0]\n\n self.cloudformation_backend.delete_stack(name_or_stack_id)\n return json.dumps({\n 'DeleteStackResponse': {\n 'DeleteStackResult': {},\n }\n })\n\n\nDESCRIBE_STACKS_TEMPLATE = \"\"\"<DescribeStacksResult>\n <Stacks>\n {% for stack in stacks %}\n <member>\n <StackName>{{ stack.name }}</StackName>\n <StackId>{{ stack.stack_id }}</StackId>\n <CreationTime>2010-07-27T22:28:28Z</CreationTime>\n <StackStatus>{{ stack.status }}</StackStatus>\n {% if stack.notification_arns %}\n <NotificationARNs>\n {% for notification_arn in stack.notification_arns %}\n <member>{{ notification_arn }}</member>\n {% endfor %}\n </NotificationARNs>\n {% else %}\n <NotificationARNs/>\n {% endif %}\n <DisableRollback>false</DisableRollback>\n <Outputs>\n {% for output in stack.stack_outputs %}\n <member>\n <OutputKey>{{ output.key }}</OutputKey>\n <OutputValue>{{ output.value }}</OutputValue>\n </member>\n {% endfor %}\n </Outputs>\n <Parameters>\n {% for param_name, param_value in stack.stack_parameters.items() %}\n <member>\n <ParameterKey>{{ param_name }}</ParameterKey>\n <ParameterValue>{{ param_value }}</ParameterValue>\n </member>\n {% endfor %}\n </Parameters>\n <Tags>\n {% for tag_key, tag_value in stack.tags.items() %}\n <member>\n <Key>{{ tag_key }}</Key>\n <Value>{{ tag_value }}</Value>\n </member>\n {% endfor %}\n </Tags>\n </member>\n {% endfor %}\n </Stacks>\n</DescribeStacksResult>\"\"\"\n\n\nLIST_STACKS_RESPONSE = \"\"\"<ListStacksResponse>\n <ListStacksResult>\n <StackSummaries>\n {% for stack in stacks %}\n <member>\n <StackId>{{ stack.stack_id }}</StackId>\n <StackStatus>{{ stack.status }}</StackStatus>\n <StackName>{{ stack.name }}</StackName>\n <CreationTime>2011-05-23T15:47:44Z</CreationTime>\n <TemplateDescription>{{ stack.description }}</TemplateDescription>\n </member>\n {% endfor %}\n </StackSummaries>\n </ListStacksResult>\n</ListStacksResponse>\"\"\"\n\n\nDESCRIBE_STACKS_RESOURCES_RESPONSE = \"\"\"<DescribeStackResourcesResult>\n <StackResources>\n {% for resource in stack.stack_resources %}\n <member>\n <StackId>{{ stack.stack_id }}</StackId>\n <StackName>{{ stack.name }}</StackName>\n <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>\n <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>\n <ResourceType>{{ resource.type }}</ResourceType>\n <Timestamp>2010-07-27T22:27:28Z</Timestamp>\n <ResourceStatus>{{ stack.status }}</ResourceStatus>\n </member>\n {% endfor %}\n </StackResources>\n</DescribeStackResourcesResult>\"\"\"\n\n\nLIST_STACKS_RESOURCES_RESPONSE = \"\"\"<ListStackResourcesResponse>\n <ListStackResourcesResult>\n <StackResourceSummaries>\n {% for resource in resources %}\n <member>\n <ResourceStatus>CREATE_COMPLETE</ResourceStatus>\n <LogicalResourceId>{{ resource.logical_resource_id }}</LogicalResourceId>\n <LastUpdatedTimestamp>2011-06-21T20:15:58Z</LastUpdatedTimestamp>\n <PhysicalResourceId>{{ resource.physical_resource_id }}</PhysicalResourceId>\n <ResourceType>{{ resource.type }}</ResourceType>\n </member>\n {% endfor %}\n </StackResourceSummaries>\n </ListStackResourcesResult>\n <ResponseMetadata>\n <RequestId>2d06e36c-ac1d-11e0-a958-f9382b6eb86b</RequestId>\n </ResponseMetadata>\n</ListStackResourcesResponse>\"\"\"\n", "path": "moto/cloudformation/responses.py"}]}
| 2,711 | 212 |
gh_patches_debug_30600
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-4827
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TypeError: global_add_pool() missing 1 required positional argument: 'batch'
### 🐛 Describe the bug
The documentation of `global_add_pool ` states that the batch parameter is optional, however I get this error ```TypeError: global_add_pool() missing 1 required positional argument: 'batch'``` when I don't pass a value for the batch.
Here is a snippet of code to reproduce the bug:
```Python
import torch
from torch_geometric.nn import global_add_pool
x = torch.zeros(4,5)
z = global_add_pool(x)
```
I think the origin of the issue is the absence of a default value for the batch parameter in the definition of `global_add_pool`.
And the same bug happens when using `global_mean_pool` or `global_max_pool`.
### Environment
* PyG version: 2.0.5
* PyTorch version: 1.11.0
* OS: Fedora release 35
* Python version: 3.9
* CUDA/cuDNN version: 11.3
* How you installed PyTorch and PyG (`conda`, `pip`, source): Poetry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/nn/glob/glob.py`
Content:
```
1 from typing import List, Optional, Union
2
3 import torch
4 from torch import Tensor
5 from torch_scatter import scatter
6
7
8 def global_add_pool(x: Tensor, batch: Optional[Tensor],
9 size: Optional[int] = None) -> Tensor:
10 r"""Returns batch-wise graph-level-outputs by adding node features
11 across the node dimension, so that for a single graph
12 :math:`\mathcal{G}_i` its output is computed by
13
14 .. math::
15 \mathbf{r}_i = \sum_{n=1}^{N_i} \mathbf{x}_n
16
17 Args:
18 x (Tensor): Node feature matrix
19 :math:`\mathbf{X} \in \mathbb{R}^{(N_1 + \ldots + N_B) \times F}`.
20 batch (LongTensor, optional): Batch vector
21 :math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns each
22 node to a specific example.
23 size (int, optional): Batch-size :math:`B`.
24 Automatically calculated if not given. (default: :obj:`None`)
25 """
26 if batch is None:
27 return x.sum(dim=0, keepdim=True)
28 size = int(batch.max().item() + 1) if size is None else size
29 return scatter(x, batch, dim=0, dim_size=size, reduce='add')
30
31
32 def global_mean_pool(x: Tensor, batch: Optional[Tensor],
33 size: Optional[int] = None) -> Tensor:
34 r"""Returns batch-wise graph-level-outputs by averaging node features
35 across the node dimension, so that for a single graph
36 :math:`\mathcal{G}_i` its output is computed by
37
38 .. math::
39 \mathbf{r}_i = \frac{1}{N_i} \sum_{n=1}^{N_i} \mathbf{x}_n
40
41 Args:
42 x (Tensor): Node feature matrix
43 :math:`\mathbf{X} \in \mathbb{R}^{(N_1 + \ldots + N_B) \times F}`.
44 batch (LongTensor, optional): Batch vector
45 :math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns each
46 node to a specific example.
47 size (int, optional): Batch-size :math:`B`.
48 Automatically calculated if not given. (default: :obj:`None`)
49 """
50 if batch is None:
51 return x.mean(dim=0, keepdim=True)
52 size = int(batch.max().item() + 1) if size is None else size
53 return scatter(x, batch, dim=0, dim_size=size, reduce='mean')
54
55
56 def global_max_pool(x: Tensor, batch: Optional[Tensor],
57 size: Optional[int] = None) -> Tensor:
58 r"""Returns batch-wise graph-level-outputs by taking the channel-wise
59 maximum across the node dimension, so that for a single graph
60 :math:`\mathcal{G}_i` its output is computed by
61
62 .. math::
63 \mathbf{r}_i = \mathrm{max}_{n=1}^{N_i} \, \mathbf{x}_n
64
65 Args:
66 x (Tensor): Node feature matrix
67 :math:`\mathbf{X} \in \mathbb{R}^{(N_1 + \ldots + N_B) \times F}`.
68 batch (LongTensor, optional): Batch vector
69 :math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns each
70 node to a specific example.
71 size (int, optional): Batch-size :math:`B`.
72 Automatically calculated if not given. (default: :obj:`None`)
73 """
74 if batch is None:
75 return x.max(dim=0, keepdim=True)[0]
76 size = int(batch.max().item() + 1) if size is None else size
77 return scatter(x, batch, dim=0, dim_size=size, reduce='max')
78
79
80 class GlobalPooling(torch.nn.Module):
81 r"""A global pooling module that wraps the usage of
82 :meth:`~torch_geometric.nn.glob.global_add_pool`,
83 :meth:`~torch_geometric.nn.glob.global_mean_pool` and
84 :meth:`~torch_geometric.nn.glob.global_max_pool` into a single module.
85
86 Args:
87 aggr (string or List[str]): The aggregation scheme to use
88 (:obj:`"add"`, :obj:`"mean"`, :obj:`"max"`).
89 If given as a list, will make use of multiple aggregations in which
90 different outputs will get concatenated in the last dimension.
91 """
92 def __init__(self, aggr: Union[str, List[str]]):
93 super().__init__()
94
95 self.aggrs = [aggr] if isinstance(aggr, str) else aggr
96
97 assert len(self.aggrs) > 0
98 assert len(set(self.aggrs) | {'sum', 'add', 'mean', 'max'}) == 4
99
100 def forward(self, x: Tensor, batch: Optional[Tensor],
101 size: Optional[int] = None) -> Tensor:
102 """"""
103 xs: List[Tensor] = []
104
105 for aggr in self.aggrs:
106 if aggr == 'sum' or aggr == 'add':
107 xs.append(global_add_pool(x, batch, size))
108 elif aggr == 'mean':
109 xs.append(global_mean_pool(x, batch, size))
110 elif aggr == 'max':
111 xs.append(global_max_pool(x, batch, size))
112
113 return xs[0] if len(xs) == 1 else torch.cat(xs, dim=-1)
114
115 def __repr__(self) -> str:
116 aggr = self.aggrs[0] if len(self.aggrs) == 1 else self.aggrs
117 return f'{self.__class__.__name__}(aggr={aggr})'
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/nn/glob/glob.py b/torch_geometric/nn/glob/glob.py
--- a/torch_geometric/nn/glob/glob.py
+++ b/torch_geometric/nn/glob/glob.py
@@ -24,9 +24,9 @@
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.sum(dim=0, keepdim=True)
+ return x.sum(dim=-2, keepdim=x.dim() == 2)
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='add')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='add')
def global_mean_pool(x: Tensor, batch: Optional[Tensor],
@@ -48,9 +48,9 @@
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.mean(dim=0, keepdim=True)
+ return x.mean(dim=-2, keepdim=x.dim() == 2)
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='mean')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='mean')
def global_max_pool(x: Tensor, batch: Optional[Tensor],
@@ -72,9 +72,9 @@
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.max(dim=0, keepdim=True)[0]
+ return x.max(dim=-2, keepdim=x.dim() == 2)[0]
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='max')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='max')
class GlobalPooling(torch.nn.Module):
|
{"golden_diff": "diff --git a/torch_geometric/nn/glob/glob.py b/torch_geometric/nn/glob/glob.py\n--- a/torch_geometric/nn/glob/glob.py\n+++ b/torch_geometric/nn/glob/glob.py\n@@ -24,9 +24,9 @@\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n- return x.sum(dim=0, keepdim=True)\n+ return x.sum(dim=-2, keepdim=x.dim() == 2)\n size = int(batch.max().item() + 1) if size is None else size\n- return scatter(x, batch, dim=0, dim_size=size, reduce='add')\n+ return scatter(x, batch, dim=-2, dim_size=size, reduce='add')\n \n \n def global_mean_pool(x: Tensor, batch: Optional[Tensor],\n@@ -48,9 +48,9 @@\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n- return x.mean(dim=0, keepdim=True)\n+ return x.mean(dim=-2, keepdim=x.dim() == 2)\n size = int(batch.max().item() + 1) if size is None else size\n- return scatter(x, batch, dim=0, dim_size=size, reduce='mean')\n+ return scatter(x, batch, dim=-2, dim_size=size, reduce='mean')\n \n \n def global_max_pool(x: Tensor, batch: Optional[Tensor],\n@@ -72,9 +72,9 @@\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n- return x.max(dim=0, keepdim=True)[0]\n+ return x.max(dim=-2, keepdim=x.dim() == 2)[0]\n size = int(batch.max().item() + 1) if size is None else size\n- return scatter(x, batch, dim=0, dim_size=size, reduce='max')\n+ return scatter(x, batch, dim=-2, dim_size=size, reduce='max')\n \n \n class GlobalPooling(torch.nn.Module):\n", "issue": "TypeError: global_add_pool() missing 1 required positional argument: 'batch'\n### \ud83d\udc1b Describe the bug\n\nThe documentation of `global_add_pool ` states that the batch parameter is optional, however I get this error ```TypeError: global_add_pool() missing 1 required positional argument: 'batch'``` when I don't pass a value for the batch. \r\n\r\nHere is a snippet of code to reproduce the bug:\r\n```Python\r\nimport torch\r\nfrom torch_geometric.nn import global_add_pool\r\nx = torch.zeros(4,5)\r\nz = global_add_pool(x)\r\n```\r\n\r\nI think the origin of the issue is the absence of a default value for the batch parameter in the definition of `global_add_pool`.\r\nAnd the same bug happens when using `global_mean_pool` or `global_max_pool`.\n\n### Environment\n\n* PyG version: 2.0.5\r\n* PyTorch version: 1.11.0\r\n* OS: Fedora release 35\r\n* Python version: 3.9\r\n* CUDA/cuDNN version: 11.3\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): Poetry\r\n\n", "before_files": [{"content": "from typing import List, Optional, Union\n\nimport torch\nfrom torch import Tensor\nfrom torch_scatter import scatter\n\n\ndef global_add_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by adding node features\n across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\sum_{n=1}^{N_i} \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.sum(dim=0, keepdim=True)\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=0, dim_size=size, reduce='add')\n\n\ndef global_mean_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by averaging node features\n across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\frac{1}{N_i} \\sum_{n=1}^{N_i} \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.mean(dim=0, keepdim=True)\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=0, dim_size=size, reduce='mean')\n\n\ndef global_max_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by taking the channel-wise\n maximum across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\mathrm{max}_{n=1}^{N_i} \\, \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.max(dim=0, keepdim=True)[0]\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=0, dim_size=size, reduce='max')\n\n\nclass GlobalPooling(torch.nn.Module):\n r\"\"\"A global pooling module that wraps the usage of\n :meth:`~torch_geometric.nn.glob.global_add_pool`,\n :meth:`~torch_geometric.nn.glob.global_mean_pool` and\n :meth:`~torch_geometric.nn.glob.global_max_pool` into a single module.\n\n Args:\n aggr (string or List[str]): The aggregation scheme to use\n (:obj:`\"add\"`, :obj:`\"mean\"`, :obj:`\"max\"`).\n If given as a list, will make use of multiple aggregations in which\n different outputs will get concatenated in the last dimension.\n \"\"\"\n def __init__(self, aggr: Union[str, List[str]]):\n super().__init__()\n\n self.aggrs = [aggr] if isinstance(aggr, str) else aggr\n\n assert len(self.aggrs) > 0\n assert len(set(self.aggrs) | {'sum', 'add', 'mean', 'max'}) == 4\n\n def forward(self, x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n \"\"\"\"\"\"\n xs: List[Tensor] = []\n\n for aggr in self.aggrs:\n if aggr == 'sum' or aggr == 'add':\n xs.append(global_add_pool(x, batch, size))\n elif aggr == 'mean':\n xs.append(global_mean_pool(x, batch, size))\n elif aggr == 'max':\n xs.append(global_max_pool(x, batch, size))\n\n return xs[0] if len(xs) == 1 else torch.cat(xs, dim=-1)\n\n def __repr__(self) -> str:\n aggr = self.aggrs[0] if len(self.aggrs) == 1 else self.aggrs\n return f'{self.__class__.__name__}(aggr={aggr})'\n", "path": "torch_geometric/nn/glob/glob.py"}], "after_files": [{"content": "from typing import List, Optional, Union\n\nimport torch\nfrom torch import Tensor\nfrom torch_scatter import scatter\n\n\ndef global_add_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by adding node features\n across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\sum_{n=1}^{N_i} \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.sum(dim=-2, keepdim=x.dim() == 2)\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=-2, dim_size=size, reduce='add')\n\n\ndef global_mean_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by averaging node features\n across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\frac{1}{N_i} \\sum_{n=1}^{N_i} \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.mean(dim=-2, keepdim=x.dim() == 2)\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=-2, dim_size=size, reduce='mean')\n\n\ndef global_max_pool(x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n r\"\"\"Returns batch-wise graph-level-outputs by taking the channel-wise\n maximum across the node dimension, so that for a single graph\n :math:`\\mathcal{G}_i` its output is computed by\n\n .. math::\n \\mathbf{r}_i = \\mathrm{max}_{n=1}^{N_i} \\, \\mathbf{x}_n\n\n Args:\n x (Tensor): Node feature matrix\n :math:`\\mathbf{X} \\in \\mathbb{R}^{(N_1 + \\ldots + N_B) \\times F}`.\n batch (LongTensor, optional): Batch vector\n :math:`\\mathbf{b} \\in {\\{ 0, \\ldots, B-1\\}}^N`, which assigns each\n node to a specific example.\n size (int, optional): Batch-size :math:`B`.\n Automatically calculated if not given. (default: :obj:`None`)\n \"\"\"\n if batch is None:\n return x.max(dim=-2, keepdim=x.dim() == 2)[0]\n size = int(batch.max().item() + 1) if size is None else size\n return scatter(x, batch, dim=-2, dim_size=size, reduce='max')\n\n\nclass GlobalPooling(torch.nn.Module):\n r\"\"\"A global pooling module that wraps the usage of\n :meth:`~torch_geometric.nn.glob.global_add_pool`,\n :meth:`~torch_geometric.nn.glob.global_mean_pool` and\n :meth:`~torch_geometric.nn.glob.global_max_pool` into a single module.\n\n Args:\n aggr (string or List[str]): The aggregation scheme to use\n (:obj:`\"add\"`, :obj:`\"mean\"`, :obj:`\"max\"`).\n If given as a list, will make use of multiple aggregations in which\n different outputs will get concatenated in the last dimension.\n \"\"\"\n def __init__(self, aggr: Union[str, List[str]]):\n super().__init__()\n\n self.aggrs = [aggr] if isinstance(aggr, str) else aggr\n\n assert len(self.aggrs) > 0\n assert len(set(self.aggrs) | {'sum', 'add', 'mean', 'max'}) == 4\n\n def forward(self, x: Tensor, batch: Optional[Tensor],\n size: Optional[int] = None) -> Tensor:\n \"\"\"\"\"\"\n xs: List[Tensor] = []\n\n for aggr in self.aggrs:\n if aggr == 'sum' or aggr == 'add':\n xs.append(global_add_pool(x, batch, size))\n elif aggr == 'mean':\n xs.append(global_mean_pool(x, batch, size))\n elif aggr == 'max':\n xs.append(global_max_pool(x, batch, size))\n\n return xs[0] if len(xs) == 1 else torch.cat(xs, dim=-1)\n\n def __repr__(self) -> str:\n aggr = self.aggrs[0] if len(self.aggrs) == 1 else self.aggrs\n return f'{self.__class__.__name__}(aggr={aggr})'\n", "path": "torch_geometric/nn/glob/glob.py"}]}
| 2,101 | 476 |
gh_patches_debug_29621
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-1186
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Lambda Environment variable name validation
Lambda Env variables names are limited to `[a-zA-Z][a-zA-Z0-9_]+`. There is also a set of variable names that are reserved. Currently tropo does not validate the names.
I can provide a PR for that soon.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `troposphere/awslambda.py`
Content:
```
1 from . import AWSObject, AWSProperty, Join, Tags
2 from .validators import positive_integer
3
4 MEMORY_VALUES = [x for x in range(128, 3009, 64)]
5
6
7 def validate_memory_size(memory_value):
8 """ Validate memory size for Lambda Function
9 :param memory_value: The memory size specified in the Function
10 :return: The provided memory size if it is valid
11 """
12 memory_value = int(positive_integer(memory_value))
13 if memory_value not in MEMORY_VALUES:
14 raise ValueError("Lambda Function memory size must be one of:\n %s" %
15 ", ".join(str(mb) for mb in MEMORY_VALUES))
16 return memory_value
17
18
19 class Code(AWSProperty):
20 props = {
21 'S3Bucket': (basestring, False),
22 'S3Key': (basestring, False),
23 'S3ObjectVersion': (basestring, False),
24 'ZipFile': (basestring, False)
25 }
26
27 @staticmethod
28 def check_zip_file(zip_file):
29 maxlength = 4096
30 toolong = (
31 "ZipFile length cannot exceed %d characters. For larger "
32 "source use S3Bucket/S3Key properties instead. "
33 "Current length: %d"
34 )
35
36 if zip_file is None:
37 return
38
39 if isinstance(zip_file, basestring):
40 z_length = len(zip_file)
41 if z_length > maxlength:
42 raise ValueError(toolong % (maxlength, z_length))
43 return
44
45 if isinstance(zip_file, Join):
46 # This code tries to combine the length of all the strings in a
47 # join. If a part is not a string, we do not count it (length 0).
48 delimiter, values = zip_file.data['Fn::Join']
49
50 # Return if there are no values to join
51 if not values or len(values) <= 0:
52 return
53
54 # Get the length of the delimiter
55 if isinstance(delimiter, basestring):
56 d_length = len(delimiter)
57 else:
58 d_length = 0
59
60 # Get the length of each value that will be joined
61 v_lengths = [len(v) for v in values if isinstance(v, basestring)]
62
63 # Add all the lengths together
64 z_length = sum(v_lengths)
65 z_length += (len(values)-1) * d_length
66
67 if z_length > maxlength:
68 raise ValueError(toolong % (maxlength, z_length))
69 return
70
71 def validate(self):
72 zip_file = self.properties.get('ZipFile')
73 s3_bucket = self.properties.get('S3Bucket')
74 s3_key = self.properties.get('S3Key')
75 s3_object_version = self.properties.get('S3ObjectVersion')
76
77 if zip_file and s3_bucket:
78 raise ValueError("You can't specify both 'S3Bucket' and 'ZipFile'")
79 if zip_file and s3_key:
80 raise ValueError("You can't specify both 'S3Key' and 'ZipFile'")
81 if zip_file and s3_object_version:
82 raise ValueError(
83 "You can't specify both 'S3ObjectVersion' and 'ZipFile'"
84 )
85 Code.check_zip_file(zip_file)
86 if not zip_file and not (s3_bucket and s3_key):
87 raise ValueError(
88 "You must specify a bucket location (both the 'S3Bucket' and "
89 "'S3Key' properties) or the 'ZipFile' property"
90 )
91
92
93 class VPCConfig(AWSProperty):
94
95 props = {
96 'SecurityGroupIds': (list, True),
97 'SubnetIds': (list, True),
98 }
99
100
101 class EventSourceMapping(AWSObject):
102 resource_type = "AWS::Lambda::EventSourceMapping"
103
104 props = {
105 'BatchSize': (positive_integer, False),
106 'Enabled': (bool, False),
107 'EventSourceArn': (basestring, True),
108 'FunctionName': (basestring, True),
109 'StartingPosition': (basestring, False),
110 }
111
112
113 class DeadLetterConfig(AWSProperty):
114
115 props = {
116 'TargetArn': (basestring, False),
117 }
118
119
120 class Environment(AWSProperty):
121
122 props = {
123 'Variables': (dict, True),
124 }
125
126
127 class TracingConfig(AWSProperty):
128
129 props = {
130 'Mode': (basestring, False),
131 }
132
133
134 class Function(AWSObject):
135 resource_type = "AWS::Lambda::Function"
136
137 props = {
138 'Code': (Code, True),
139 'Description': (basestring, False),
140 'DeadLetterConfig': (DeadLetterConfig, False),
141 'Environment': (Environment, False),
142 'FunctionName': (basestring, False),
143 'Handler': (basestring, True),
144 'KmsKeyArn': (basestring, False),
145 'MemorySize': (validate_memory_size, False),
146 'ReservedConcurrentExecutions': (positive_integer, False),
147 'Role': (basestring, True),
148 'Runtime': (basestring, True),
149 'Tags': (Tags, False),
150 'Timeout': (positive_integer, False),
151 'TracingConfig': (TracingConfig, False),
152 'VpcConfig': (VPCConfig, False),
153 }
154
155
156 class Permission(AWSObject):
157 resource_type = "AWS::Lambda::Permission"
158
159 props = {
160 'Action': (basestring, True),
161 'EventSourceToken': (basestring, False),
162 'FunctionName': (basestring, True),
163 'Principal': (basestring, True),
164 'SourceAccount': (basestring, False),
165 'SourceArn': (basestring, False),
166 }
167
168
169 class VersionWeight(AWSProperty):
170
171 props = {
172 'FunctionVersion': (basestring, True),
173 'FunctionWeight': (float, True),
174 }
175
176
177 class AliasRoutingConfiguration(AWSProperty):
178
179 props = {
180 'AdditionalVersionWeights': ([VersionWeight], True),
181 }
182
183
184 class Alias(AWSObject):
185 resource_type = "AWS::Lambda::Alias"
186
187 props = {
188 'Description': (basestring, False),
189 'FunctionName': (basestring, True),
190 'FunctionVersion': (basestring, True),
191 'Name': (basestring, True),
192 'RoutingConfig': (AliasRoutingConfiguration, False),
193 }
194
195
196 class Version(AWSObject):
197 resource_type = "AWS::Lambda::Version"
198
199 props = {
200 'CodeSha256': (basestring, False),
201 'Description': (basestring, False),
202 'FunctionName': (basestring, True),
203 }
204
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py
--- a/troposphere/awslambda.py
+++ b/troposphere/awslambda.py
@@ -1,7 +1,33 @@
+import re
from . import AWSObject, AWSProperty, Join, Tags
from .validators import positive_integer
MEMORY_VALUES = [x for x in range(128, 3009, 64)]
+RESERVED_ENVIRONMENT_VARIABLES = [
+ 'AWS_ACCESS_KEY',
+ 'AWS_ACCESS_KEY_ID',
+ 'AWS_DEFAULT_REGION',
+ 'AWS_EXECUTION_ENV',
+ 'AWS_LAMBDA_FUNCTION_MEMORY_SIZE',
+ 'AWS_LAMBDA_FUNCTION_NAME',
+ 'AWS_LAMBDA_FUNCTION_VERSION',
+ 'AWS_LAMBDA_LOG_GROUP_NAME',
+ 'AWS_LAMBDA_LOG_STREAM_NAME',
+ 'AWS_REGION',
+ 'AWS_SECRET_ACCESS_KEY',
+ 'AWS_SECRET_KEY',
+ 'AWS_SECURITY_TOKEN',
+ 'AWS_SESSION_TOKEN',
+ 'LAMBDA_RUNTIME_DIR',
+ 'LAMBDA_TASK_ROOT',
+ 'LANG',
+ 'LD_LIBRARY_PATH',
+ 'NODE_PATH',
+ 'PATH',
+ 'PYTHONPATH',
+ 'TZ'
+]
+ENVIRONMENT_VARIABLES_NAME_PATTERN = r'[a-zA-Z][a-zA-Z0-9_]+'
def validate_memory_size(memory_value):
@@ -16,6 +42,18 @@
return memory_value
+def validate_variables_name(variables):
+ for name in variables:
+ if name in RESERVED_ENVIRONMENT_VARIABLES:
+ raise ValueError("Lambda Function environment variables names"
+ " can't be none of:\n %s" %
+ ", ".join(RESERVED_ENVIRONMENT_VARIABLES))
+ elif not re.match(ENVIRONMENT_VARIABLES_NAME_PATTERN, name):
+ raise ValueError("Invalid environment variable name: %s" % name)
+
+ return variables
+
+
class Code(AWSProperty):
props = {
'S3Bucket': (basestring, False),
@@ -120,7 +158,7 @@
class Environment(AWSProperty):
props = {
- 'Variables': (dict, True),
+ 'Variables': (validate_variables_name, True),
}
|
{"golden_diff": "diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py\n--- a/troposphere/awslambda.py\n+++ b/troposphere/awslambda.py\n@@ -1,7 +1,33 @@\n+import re\n from . import AWSObject, AWSProperty, Join, Tags\n from .validators import positive_integer\n \n MEMORY_VALUES = [x for x in range(128, 3009, 64)]\n+RESERVED_ENVIRONMENT_VARIABLES = [\n+ 'AWS_ACCESS_KEY',\n+ 'AWS_ACCESS_KEY_ID',\n+ 'AWS_DEFAULT_REGION',\n+ 'AWS_EXECUTION_ENV',\n+ 'AWS_LAMBDA_FUNCTION_MEMORY_SIZE',\n+ 'AWS_LAMBDA_FUNCTION_NAME',\n+ 'AWS_LAMBDA_FUNCTION_VERSION',\n+ 'AWS_LAMBDA_LOG_GROUP_NAME',\n+ 'AWS_LAMBDA_LOG_STREAM_NAME',\n+ 'AWS_REGION',\n+ 'AWS_SECRET_ACCESS_KEY',\n+ 'AWS_SECRET_KEY',\n+ 'AWS_SECURITY_TOKEN',\n+ 'AWS_SESSION_TOKEN',\n+ 'LAMBDA_RUNTIME_DIR',\n+ 'LAMBDA_TASK_ROOT',\n+ 'LANG',\n+ 'LD_LIBRARY_PATH',\n+ 'NODE_PATH',\n+ 'PATH',\n+ 'PYTHONPATH',\n+ 'TZ'\n+]\n+ENVIRONMENT_VARIABLES_NAME_PATTERN = r'[a-zA-Z][a-zA-Z0-9_]+'\n \n \n def validate_memory_size(memory_value):\n@@ -16,6 +42,18 @@\n return memory_value\n \n \n+def validate_variables_name(variables):\n+ for name in variables:\n+ if name in RESERVED_ENVIRONMENT_VARIABLES:\n+ raise ValueError(\"Lambda Function environment variables names\"\n+ \" can't be none of:\\n %s\" %\n+ \", \".join(RESERVED_ENVIRONMENT_VARIABLES))\n+ elif not re.match(ENVIRONMENT_VARIABLES_NAME_PATTERN, name):\n+ raise ValueError(\"Invalid environment variable name: %s\" % name)\n+\n+ return variables\n+\n+\n class Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n@@ -120,7 +158,7 @@\n class Environment(AWSProperty):\n \n props = {\n- 'Variables': (dict, True),\n+ 'Variables': (validate_variables_name, True),\n }\n", "issue": "Add Lambda Environment variable name validation\nLambda Env variables names are limited to `[a-zA-Z][a-zA-Z0-9_]+`. There is also a set of variable names that are reserved. Currently tropo does not validate the names. \r\n\r\nI can provide a PR for that soon.\n", "before_files": [{"content": "from . import AWSObject, AWSProperty, Join, Tags\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 3009, 64)]\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n @staticmethod\n def check_zip_file(zip_file):\n maxlength = 4096\n toolong = (\n \"ZipFile length cannot exceed %d characters. For larger \"\n \"source use S3Bucket/S3Key properties instead. \"\n \"Current length: %d\"\n )\n\n if zip_file is None:\n return\n\n if isinstance(zip_file, basestring):\n z_length = len(zip_file)\n if z_length > maxlength:\n raise ValueError(toolong % (maxlength, z_length))\n return\n\n if isinstance(zip_file, Join):\n # This code tries to combine the length of all the strings in a\n # join. If a part is not a string, we do not count it (length 0).\n delimiter, values = zip_file.data['Fn::Join']\n\n # Return if there are no values to join\n if not values or len(values) <= 0:\n return\n\n # Get the length of the delimiter\n if isinstance(delimiter, basestring):\n d_length = len(delimiter)\n else:\n d_length = 0\n\n # Get the length of each value that will be joined\n v_lengths = [len(v) for v in values if isinstance(v, basestring)]\n\n # Add all the lengths together\n z_length = sum(v_lengths)\n z_length += (len(values)-1) * d_length\n\n if z_length > maxlength:\n raise ValueError(toolong % (maxlength, z_length))\n return\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('S3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n Code.check_zip_file(zip_file)\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, False),\n }\n\n\nclass DeadLetterConfig(AWSProperty):\n\n props = {\n 'TargetArn': (basestring, False),\n }\n\n\nclass Environment(AWSProperty):\n\n props = {\n 'Variables': (dict, True),\n }\n\n\nclass TracingConfig(AWSProperty):\n\n props = {\n 'Mode': (basestring, False),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'DeadLetterConfig': (DeadLetterConfig, False),\n 'Environment': (Environment, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'KmsKeyArn': (basestring, False),\n 'MemorySize': (validate_memory_size, False),\n 'ReservedConcurrentExecutions': (positive_integer, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Tags': (Tags, False),\n 'Timeout': (positive_integer, False),\n 'TracingConfig': (TracingConfig, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'EventSourceToken': (basestring, False),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass VersionWeight(AWSProperty):\n\n props = {\n 'FunctionVersion': (basestring, True),\n 'FunctionWeight': (float, True),\n }\n\n\nclass AliasRoutingConfiguration(AWSProperty):\n\n props = {\n 'AdditionalVersionWeights': ([VersionWeight], True),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n 'RoutingConfig': (AliasRoutingConfiguration, False),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}], "after_files": [{"content": "import re\nfrom . import AWSObject, AWSProperty, Join, Tags\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 3009, 64)]\nRESERVED_ENVIRONMENT_VARIABLES = [\n 'AWS_ACCESS_KEY',\n 'AWS_ACCESS_KEY_ID',\n 'AWS_DEFAULT_REGION',\n 'AWS_EXECUTION_ENV',\n 'AWS_LAMBDA_FUNCTION_MEMORY_SIZE',\n 'AWS_LAMBDA_FUNCTION_NAME',\n 'AWS_LAMBDA_FUNCTION_VERSION',\n 'AWS_LAMBDA_LOG_GROUP_NAME',\n 'AWS_LAMBDA_LOG_STREAM_NAME',\n 'AWS_REGION',\n 'AWS_SECRET_ACCESS_KEY',\n 'AWS_SECRET_KEY',\n 'AWS_SECURITY_TOKEN',\n 'AWS_SESSION_TOKEN',\n 'LAMBDA_RUNTIME_DIR',\n 'LAMBDA_TASK_ROOT',\n 'LANG',\n 'LD_LIBRARY_PATH',\n 'NODE_PATH',\n 'PATH',\n 'PYTHONPATH',\n 'TZ'\n]\nENVIRONMENT_VARIABLES_NAME_PATTERN = r'[a-zA-Z][a-zA-Z0-9_]+'\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\ndef validate_variables_name(variables):\n for name in variables:\n if name in RESERVED_ENVIRONMENT_VARIABLES:\n raise ValueError(\"Lambda Function environment variables names\"\n \" can't be none of:\\n %s\" %\n \", \".join(RESERVED_ENVIRONMENT_VARIABLES))\n elif not re.match(ENVIRONMENT_VARIABLES_NAME_PATTERN, name):\n raise ValueError(\"Invalid environment variable name: %s\" % name)\n\n return variables\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n @staticmethod\n def check_zip_file(zip_file):\n maxlength = 4096\n toolong = (\n \"ZipFile length cannot exceed %d characters. For larger \"\n \"source use S3Bucket/S3Key properties instead. \"\n \"Current length: %d\"\n )\n\n if zip_file is None:\n return\n\n if isinstance(zip_file, basestring):\n z_length = len(zip_file)\n if z_length > maxlength:\n raise ValueError(toolong % (maxlength, z_length))\n return\n\n if isinstance(zip_file, Join):\n # This code tries to combine the length of all the strings in a\n # join. If a part is not a string, we do not count it (length 0).\n delimiter, values = zip_file.data['Fn::Join']\n\n # Return if there are no values to join\n if not values or len(values) <= 0:\n return\n\n # Get the length of the delimiter\n if isinstance(delimiter, basestring):\n d_length = len(delimiter)\n else:\n d_length = 0\n\n # Get the length of each value that will be joined\n v_lengths = [len(v) for v in values if isinstance(v, basestring)]\n\n # Add all the lengths together\n z_length = sum(v_lengths)\n z_length += (len(values)-1) * d_length\n\n if z_length > maxlength:\n raise ValueError(toolong % (maxlength, z_length))\n return\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('S3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n Code.check_zip_file(zip_file)\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, False),\n }\n\n\nclass DeadLetterConfig(AWSProperty):\n\n props = {\n 'TargetArn': (basestring, False),\n }\n\n\nclass Environment(AWSProperty):\n\n props = {\n 'Variables': (validate_variables_name, True),\n }\n\n\nclass TracingConfig(AWSProperty):\n\n props = {\n 'Mode': (basestring, False),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'DeadLetterConfig': (DeadLetterConfig, False),\n 'Environment': (Environment, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'KmsKeyArn': (basestring, False),\n 'MemorySize': (validate_memory_size, False),\n 'ReservedConcurrentExecutions': (positive_integer, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Tags': (Tags, False),\n 'Timeout': (positive_integer, False),\n 'TracingConfig': (TracingConfig, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'EventSourceToken': (basestring, False),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass VersionWeight(AWSProperty):\n\n props = {\n 'FunctionVersion': (basestring, True),\n 'FunctionWeight': (float, True),\n }\n\n\nclass AliasRoutingConfiguration(AWSProperty):\n\n props = {\n 'AdditionalVersionWeights': ([VersionWeight], True),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n 'RoutingConfig': (AliasRoutingConfiguration, False),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}]}
| 2,267 | 509 |
gh_patches_debug_50333
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-7741
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Russian translation
The Russian Translation is at [100% on Weblate](https://hosted.weblate.org/languages/ru/pypa/) so I think it should be added to the localization footer.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/i18n/__init__.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import functools
14
15 from babel.core import Locale
16 from pyramid import viewderivers
17 from pyramid.i18n import TranslationStringFactory, default_locale_negotiator
18 from pyramid.threadlocal import get_current_request
19
20 from warehouse.cache.http import add_vary
21
22 # Taken from:
23 # https://github.com/django/django/blob/master/django/conf/locale/__init__.py
24 KNOWN_LOCALES = {
25 "en": "English", # English
26 "es": "español", # Spanish
27 "fr": "français", # French
28 "ja": "日本語", # Japanese
29 "pt_BR": "Português Brasileiro", # Brazilian Portugeuse
30 "uk": "Українська", # Ukrainian
31 "el": "Ελληνικά", # Greek
32 "de": "Deutsch", # German
33 "zh_Hans": "简体中文", # Simplified Chinese
34 }
35
36 LOCALE_ATTR = "_LOCALE_"
37
38 _translation_factory = TranslationStringFactory("messages")
39
40
41 class LazyString:
42 def __init__(self, fn, *args, **kwargs):
43 self.fn = fn
44 self.args = args
45 self.mapping = kwargs.get("mapping", {})
46 self.kwargs = kwargs
47
48 def __json__(self, request):
49 return str(self)
50
51 def __mod__(self, new_mapping):
52 mapping = self.mapping.copy()
53 mapping.update(new_mapping)
54 return LazyString(self.fn, *self.args, mapping=new_mapping, **self.kwargs)
55
56 def __str__(self):
57 return self.fn(*self.args, **self.kwargs)
58
59
60 def _locale(request):
61 """
62 Computes a babel.core:Locale() object for this request.
63 """
64 return Locale.parse(request.locale_name, sep="_")
65
66
67 def _negotiate_locale(request):
68 locale_name = getattr(request, LOCALE_ATTR, None)
69 if locale_name is not None:
70 return locale_name
71
72 locale_name = request.params.get(LOCALE_ATTR)
73 if locale_name is not None:
74 return locale_name
75
76 locale_name = request.cookies.get(LOCALE_ATTR)
77 if locale_name is not None:
78 return locale_name
79
80 if not request.accept_language:
81 return default_locale_negotiator(request)
82
83 return request.accept_language.best_match(
84 tuple(KNOWN_LOCALES.keys()), default_match=default_locale_negotiator(request)
85 )
86
87
88 def localize(message, **kwargs):
89 def _localize(message, **kwargs):
90 request = get_current_request()
91 return request.localizer.translate(_translation_factory(message, **kwargs))
92
93 return LazyString(_localize, message, **kwargs)
94
95
96 class InvalidLocalizer:
97 def _fail(self):
98 raise RuntimeError("Cannot use localizer without has_translations=True")
99
100 @property
101 def locale_name(self):
102 self._fail()
103
104 def pluralize(self, *args, **kwargs):
105 self._fail()
106
107 def translate(self, *args, **kwargs):
108 self._fail()
109
110
111 def translated_view(view, info):
112 if info.options.get("has_translations"):
113 # If this page can be translated, then we'll add a Vary: PyPI-Locale
114 # Vary header.
115 # Note: This will give weird results if hitting PyPI directly instead of through
116 # the Fastly VCL which sets PyPI-Locale.
117 return add_vary("PyPI-Locale")(view)
118 elif info.exception_only:
119 return view
120 else:
121 # If we're not using translations on this view, then we'll wrap the view
122 # with a wrapper that just ensures that the localizer cannot be used.
123 @functools.wraps(view)
124 def wrapped(context, request):
125 # This whole method is a little bit of an odd duck, we want to make
126 # sure that we don't actually *access* request.localizer, because
127 # doing so triggers the machinery to create a new localizer. So
128 # instead we will dig into the request object __dict__ to
129 # effectively do the same thing, just without triggering an access
130 # on request.localizer.
131
132 # Save the original session so that we can restore it once the
133 # inner views have been called.
134 nothing = object()
135 original_localizer = request.__dict__.get("localizer", nothing)
136
137 # This particular view hasn't been set to allow access to the
138 # translations, so we'll just assign an InvalidLocalizer to
139 # request.localizer
140 request.__dict__["localizer"] = InvalidLocalizer()
141
142 try:
143 # Invoke the real view
144 return view(context, request)
145 finally:
146 # Restore the original session so that things like
147 # pyramid_debugtoolbar can access it.
148 if original_localizer is nothing:
149 del request.__dict__["localizer"]
150 else:
151 request.__dict__["localizer"] = original_localizer
152
153 return wrapped
154
155
156 translated_view.options = {"has_translations"}
157
158
159 def includeme(config):
160 # Add the request attributes
161 config.add_request_method(_locale, name="locale", reify=True)
162
163 # Register our translation directory.
164 config.add_translation_dirs("warehouse:locale/")
165
166 config.set_locale_negotiator(_negotiate_locale)
167
168 # Register our i18n/l10n filters for Jinja2
169 filters = config.get_settings().setdefault("jinja2.filters", {})
170 filters.setdefault("format_date", "warehouse.i18n.filters:format_date")
171 filters.setdefault("format_datetime", "warehouse.i18n.filters:format_datetime")
172 filters.setdefault(
173 "format_rfc822_datetime", "warehouse.i18n.filters:format_rfc822_datetime"
174 )
175 filters.setdefault("format_number", "warehouse.i18n.filters:format_number")
176
177 jglobals = config.get_settings().setdefault("jinja2.globals", {})
178 jglobals.setdefault("KNOWN_LOCALES", "warehouse.i18n:KNOWN_LOCALES")
179
180 config.add_view_deriver(
181 translated_view, over="rendered_view", under=viewderivers.INGRESS
182 )
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/i18n/__init__.py b/warehouse/i18n/__init__.py
--- a/warehouse/i18n/__init__.py
+++ b/warehouse/i18n/__init__.py
@@ -31,6 +31,7 @@
"el": "Ελληνικά", # Greek
"de": "Deutsch", # German
"zh_Hans": "简体中文", # Simplified Chinese
+ "ru": "Русский", # Russian
}
LOCALE_ATTR = "_LOCALE_"
|
{"golden_diff": "diff --git a/warehouse/i18n/__init__.py b/warehouse/i18n/__init__.py\n--- a/warehouse/i18n/__init__.py\n+++ b/warehouse/i18n/__init__.py\n@@ -31,6 +31,7 @@\n \"el\": \"\u0395\u03bb\u03bb\u03b7\u03bd\u03b9\u03ba\u03ac\", # Greek\n \"de\": \"Deutsch\", # German\n \"zh_Hans\": \"\u7b80\u4f53\u4e2d\u6587\", # Simplified Chinese\n+ \"ru\": \"\u0420\u0443\u0441\u0441\u043a\u0438\u0439\", # Russian\n }\n \n LOCALE_ATTR = \"_LOCALE_\"\n", "issue": "Add Russian translation\nThe Russian Translation is at [100% on Weblate](https://hosted.weblate.org/languages/ru/pypa/) so I think it should be added to the localization footer.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\n\nfrom babel.core import Locale\nfrom pyramid import viewderivers\nfrom pyramid.i18n import TranslationStringFactory, default_locale_negotiator\nfrom pyramid.threadlocal import get_current_request\n\nfrom warehouse.cache.http import add_vary\n\n# Taken from:\n# https://github.com/django/django/blob/master/django/conf/locale/__init__.py\nKNOWN_LOCALES = {\n \"en\": \"English\", # English\n \"es\": \"espa\u00f1ol\", # Spanish\n \"fr\": \"fran\u00e7ais\", # French\n \"ja\": \"\u65e5\u672c\u8a9e\", # Japanese\n \"pt_BR\": \"Portugu\u00eas Brasileiro\", # Brazilian Portugeuse\n \"uk\": \"\u0423\u043a\u0440\u0430\u0457\u043d\u0441\u044c\u043a\u0430\", # Ukrainian\n \"el\": \"\u0395\u03bb\u03bb\u03b7\u03bd\u03b9\u03ba\u03ac\", # Greek\n \"de\": \"Deutsch\", # German\n \"zh_Hans\": \"\u7b80\u4f53\u4e2d\u6587\", # Simplified Chinese\n}\n\nLOCALE_ATTR = \"_LOCALE_\"\n\n_translation_factory = TranslationStringFactory(\"messages\")\n\n\nclass LazyString:\n def __init__(self, fn, *args, **kwargs):\n self.fn = fn\n self.args = args\n self.mapping = kwargs.get(\"mapping\", {})\n self.kwargs = kwargs\n\n def __json__(self, request):\n return str(self)\n\n def __mod__(self, new_mapping):\n mapping = self.mapping.copy()\n mapping.update(new_mapping)\n return LazyString(self.fn, *self.args, mapping=new_mapping, **self.kwargs)\n\n def __str__(self):\n return self.fn(*self.args, **self.kwargs)\n\n\ndef _locale(request):\n \"\"\"\n Computes a babel.core:Locale() object for this request.\n \"\"\"\n return Locale.parse(request.locale_name, sep=\"_\")\n\n\ndef _negotiate_locale(request):\n locale_name = getattr(request, LOCALE_ATTR, None)\n if locale_name is not None:\n return locale_name\n\n locale_name = request.params.get(LOCALE_ATTR)\n if locale_name is not None:\n return locale_name\n\n locale_name = request.cookies.get(LOCALE_ATTR)\n if locale_name is not None:\n return locale_name\n\n if not request.accept_language:\n return default_locale_negotiator(request)\n\n return request.accept_language.best_match(\n tuple(KNOWN_LOCALES.keys()), default_match=default_locale_negotiator(request)\n )\n\n\ndef localize(message, **kwargs):\n def _localize(message, **kwargs):\n request = get_current_request()\n return request.localizer.translate(_translation_factory(message, **kwargs))\n\n return LazyString(_localize, message, **kwargs)\n\n\nclass InvalidLocalizer:\n def _fail(self):\n raise RuntimeError(\"Cannot use localizer without has_translations=True\")\n\n @property\n def locale_name(self):\n self._fail()\n\n def pluralize(self, *args, **kwargs):\n self._fail()\n\n def translate(self, *args, **kwargs):\n self._fail()\n\n\ndef translated_view(view, info):\n if info.options.get(\"has_translations\"):\n # If this page can be translated, then we'll add a Vary: PyPI-Locale\n # Vary header.\n # Note: This will give weird results if hitting PyPI directly instead of through\n # the Fastly VCL which sets PyPI-Locale.\n return add_vary(\"PyPI-Locale\")(view)\n elif info.exception_only:\n return view\n else:\n # If we're not using translations on this view, then we'll wrap the view\n # with a wrapper that just ensures that the localizer cannot be used.\n @functools.wraps(view)\n def wrapped(context, request):\n # This whole method is a little bit of an odd duck, we want to make\n # sure that we don't actually *access* request.localizer, because\n # doing so triggers the machinery to create a new localizer. So\n # instead we will dig into the request object __dict__ to\n # effectively do the same thing, just without triggering an access\n # on request.localizer.\n\n # Save the original session so that we can restore it once the\n # inner views have been called.\n nothing = object()\n original_localizer = request.__dict__.get(\"localizer\", nothing)\n\n # This particular view hasn't been set to allow access to the\n # translations, so we'll just assign an InvalidLocalizer to\n # request.localizer\n request.__dict__[\"localizer\"] = InvalidLocalizer()\n\n try:\n # Invoke the real view\n return view(context, request)\n finally:\n # Restore the original session so that things like\n # pyramid_debugtoolbar can access it.\n if original_localizer is nothing:\n del request.__dict__[\"localizer\"]\n else:\n request.__dict__[\"localizer\"] = original_localizer\n\n return wrapped\n\n\ntranslated_view.options = {\"has_translations\"}\n\n\ndef includeme(config):\n # Add the request attributes\n config.add_request_method(_locale, name=\"locale\", reify=True)\n\n # Register our translation directory.\n config.add_translation_dirs(\"warehouse:locale/\")\n\n config.set_locale_negotiator(_negotiate_locale)\n\n # Register our i18n/l10n filters for Jinja2\n filters = config.get_settings().setdefault(\"jinja2.filters\", {})\n filters.setdefault(\"format_date\", \"warehouse.i18n.filters:format_date\")\n filters.setdefault(\"format_datetime\", \"warehouse.i18n.filters:format_datetime\")\n filters.setdefault(\n \"format_rfc822_datetime\", \"warehouse.i18n.filters:format_rfc822_datetime\"\n )\n filters.setdefault(\"format_number\", \"warehouse.i18n.filters:format_number\")\n\n jglobals = config.get_settings().setdefault(\"jinja2.globals\", {})\n jglobals.setdefault(\"KNOWN_LOCALES\", \"warehouse.i18n:KNOWN_LOCALES\")\n\n config.add_view_deriver(\n translated_view, over=\"rendered_view\", under=viewderivers.INGRESS\n )\n", "path": "warehouse/i18n/__init__.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\n\nfrom babel.core import Locale\nfrom pyramid import viewderivers\nfrom pyramid.i18n import TranslationStringFactory, default_locale_negotiator\nfrom pyramid.threadlocal import get_current_request\n\nfrom warehouse.cache.http import add_vary\n\n# Taken from:\n# https://github.com/django/django/blob/master/django/conf/locale/__init__.py\nKNOWN_LOCALES = {\n \"en\": \"English\", # English\n \"es\": \"espa\u00f1ol\", # Spanish\n \"fr\": \"fran\u00e7ais\", # French\n \"ja\": \"\u65e5\u672c\u8a9e\", # Japanese\n \"pt_BR\": \"Portugu\u00eas Brasileiro\", # Brazilian Portugeuse\n \"uk\": \"\u0423\u043a\u0440\u0430\u0457\u043d\u0441\u044c\u043a\u0430\", # Ukrainian\n \"el\": \"\u0395\u03bb\u03bb\u03b7\u03bd\u03b9\u03ba\u03ac\", # Greek\n \"de\": \"Deutsch\", # German\n \"zh_Hans\": \"\u7b80\u4f53\u4e2d\u6587\", # Simplified Chinese\n \"ru\": \"\u0420\u0443\u0441\u0441\u043a\u0438\u0439\", # Russian\n}\n\nLOCALE_ATTR = \"_LOCALE_\"\n\n_translation_factory = TranslationStringFactory(\"messages\")\n\n\nclass LazyString:\n def __init__(self, fn, *args, **kwargs):\n self.fn = fn\n self.args = args\n self.mapping = kwargs.get(\"mapping\", {})\n self.kwargs = kwargs\n\n def __json__(self, request):\n return str(self)\n\n def __mod__(self, new_mapping):\n mapping = self.mapping.copy()\n mapping.update(new_mapping)\n return LazyString(self.fn, *self.args, mapping=new_mapping, **self.kwargs)\n\n def __str__(self):\n return self.fn(*self.args, **self.kwargs)\n\n\ndef _locale(request):\n \"\"\"\n Computes a babel.core:Locale() object for this request.\n \"\"\"\n return Locale.parse(request.locale_name, sep=\"_\")\n\n\ndef _negotiate_locale(request):\n locale_name = getattr(request, LOCALE_ATTR, None)\n if locale_name is not None:\n return locale_name\n\n locale_name = request.params.get(LOCALE_ATTR)\n if locale_name is not None:\n return locale_name\n\n locale_name = request.cookies.get(LOCALE_ATTR)\n if locale_name is not None:\n return locale_name\n\n if not request.accept_language:\n return default_locale_negotiator(request)\n\n return request.accept_language.best_match(\n tuple(KNOWN_LOCALES.keys()), default_match=default_locale_negotiator(request)\n )\n\n\ndef localize(message, **kwargs):\n def _localize(message, **kwargs):\n request = get_current_request()\n return request.localizer.translate(_translation_factory(message, **kwargs))\n\n return LazyString(_localize, message, **kwargs)\n\n\nclass InvalidLocalizer:\n def _fail(self):\n raise RuntimeError(\"Cannot use localizer without has_translations=True\")\n\n @property\n def locale_name(self):\n self._fail()\n\n def pluralize(self, *args, **kwargs):\n self._fail()\n\n def translate(self, *args, **kwargs):\n self._fail()\n\n\ndef translated_view(view, info):\n if info.options.get(\"has_translations\"):\n # If this page can be translated, then we'll add a Vary: PyPI-Locale\n # Vary header.\n # Note: This will give weird results if hitting PyPI directly instead of through\n # the Fastly VCL which sets PyPI-Locale.\n return add_vary(\"PyPI-Locale\")(view)\n elif info.exception_only:\n return view\n else:\n # If we're not using translations on this view, then we'll wrap the view\n # with a wrapper that just ensures that the localizer cannot be used.\n @functools.wraps(view)\n def wrapped(context, request):\n # This whole method is a little bit of an odd duck, we want to make\n # sure that we don't actually *access* request.localizer, because\n # doing so triggers the machinery to create a new localizer. So\n # instead we will dig into the request object __dict__ to\n # effectively do the same thing, just without triggering an access\n # on request.localizer.\n\n # Save the original session so that we can restore it once the\n # inner views have been called.\n nothing = object()\n original_localizer = request.__dict__.get(\"localizer\", nothing)\n\n # This particular view hasn't been set to allow access to the\n # translations, so we'll just assign an InvalidLocalizer to\n # request.localizer\n request.__dict__[\"localizer\"] = InvalidLocalizer()\n\n try:\n # Invoke the real view\n return view(context, request)\n finally:\n # Restore the original session so that things like\n # pyramid_debugtoolbar can access it.\n if original_localizer is nothing:\n del request.__dict__[\"localizer\"]\n else:\n request.__dict__[\"localizer\"] = original_localizer\n\n return wrapped\n\n\ntranslated_view.options = {\"has_translations\"}\n\n\ndef includeme(config):\n # Add the request attributes\n config.add_request_method(_locale, name=\"locale\", reify=True)\n\n # Register our translation directory.\n config.add_translation_dirs(\"warehouse:locale/\")\n\n config.set_locale_negotiator(_negotiate_locale)\n\n # Register our i18n/l10n filters for Jinja2\n filters = config.get_settings().setdefault(\"jinja2.filters\", {})\n filters.setdefault(\"format_date\", \"warehouse.i18n.filters:format_date\")\n filters.setdefault(\"format_datetime\", \"warehouse.i18n.filters:format_datetime\")\n filters.setdefault(\n \"format_rfc822_datetime\", \"warehouse.i18n.filters:format_rfc822_datetime\"\n )\n filters.setdefault(\"format_number\", \"warehouse.i18n.filters:format_number\")\n\n jglobals = config.get_settings().setdefault(\"jinja2.globals\", {})\n jglobals.setdefault(\"KNOWN_LOCALES\", \"warehouse.i18n:KNOWN_LOCALES\")\n\n config.add_view_deriver(\n translated_view, over=\"rendered_view\", under=viewderivers.INGRESS\n )\n", "path": "warehouse/i18n/__init__.py"}]}
| 2,222 | 136 |
gh_patches_debug_2847
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-1278
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Type selectors can't contain a number
It seems that type selectors can't handle types that have a number in their name. For example this:
```python
from textual.app import App, ComposeResult
from textual.widgets import Label
class H1( Label ):
pass
class NumberError( App[ None ] ):
CSS = """
H1 {
text-style: bold;
color: yellow;
background: red;
}
"""
def compose( self ) -> ComposeResult:
yield H1( "This is a very important heading" )
if __name__ == "__main__":
NumberError().run()
```
throws this error:
```
Error in stylesheet:
/Users/davep/develop/python/textual-sandbox/not_all_types.py:NumberError:1:5
╭───────────────────────────────────────────────────────────────────────────────────────────╮
│ ❱ 1 │ │
│ 2 │ H1 { │
│ 3 │ │ text-style: bold; │
╰───────────────────────────────────────────────────────────────────────────────────────────╯
• Expected one of 'combinator child', 'comment start', 'declaration set start', 'new
selector', 'pseudo class', 'selector', 'selector class', 'selector id', 'selector
universal', or 'whitespace'.
• Did you forget a semicolon at the end of a line?
```
whereas this works fine:
```python
from textual.app import App, ComposeResult
from textual.widgets import Label
class HOne( Label ):
pass
class NumberError( App[ None ] ):
CSS = """
HOne {
text-style: bold;
color: yellow;
background: red;
}
"""
def compose( self ) -> ComposeResult:
yield HOne( "This is a very important heading" )
if __name__ == "__main__":
NumberError().run()
```
as does, of course, this:
```python
from textual.app import App, ComposeResult
from textual.widgets import Label
class H1( Label ):
pass
class NumberError( App[ None ] ):
CSS = """
Label {
text-style: bold;
color: yellow;
background: red;
}
"""
def compose( self ) -> ComposeResult:
yield H1( "This is a very important heading" )
if __name__ == "__main__":
NumberError().run()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/textual/css/tokenize.py`
Content:
```
1 from __future__ import annotations
2
3 import re
4 from pathlib import PurePath
5 from typing import Iterable
6
7 from textual.css.tokenizer import Expect, Tokenizer, Token
8
9 PERCENT = r"-?\d+\.?\d*%"
10 DECIMAL = r"-?\d+\.?\d*"
11 COMMA = r"\s*,\s*"
12 OPEN_BRACE = r"\(\s*"
13 CLOSE_BRACE = r"\s*\)"
14
15 HEX_COLOR = r"\#[0-9a-fA-F]{8}|\#[0-9a-fA-F]{6}|\#[0-9a-fA-F]{4}|\#[0-9a-fA-F]{3}"
16 RGB_COLOR = rf"rgb{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}|rgba{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}"
17 HSL_COLOR = rf"hsl{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{CLOSE_BRACE}|hsla{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{COMMA}{DECIMAL}{CLOSE_BRACE}"
18
19 COMMENT_START = r"\/\*"
20 SCALAR = rf"{DECIMAL}(?:fr|%|w|h|vw|vh)"
21 DURATION = r"\d+\.?\d*(?:ms|s)"
22 NUMBER = r"\-?\d+\.?\d*"
23 COLOR = rf"{HEX_COLOR}|{RGB_COLOR}|{HSL_COLOR}"
24 KEY_VALUE = r"[a-zA-Z_-][a-zA-Z0-9_-]*=[0-9a-zA-Z_\-\/]+"
25 TOKEN = "[a-zA-Z][a-zA-Z0-9_-]*"
26 STRING = r"\".*?\""
27 VARIABLE_REF = r"\$[a-zA-Z0-9_\-]+"
28
29 IDENTIFIER = r"[a-zA-Z_\-][a-zA-Z0-9_\-]*"
30
31 # Values permitted in variable and rule declarations.
32 DECLARATION_VALUES = {
33 "scalar": SCALAR,
34 "duration": DURATION,
35 "number": NUMBER,
36 "color": COLOR,
37 "key_value": KEY_VALUE,
38 "token": TOKEN,
39 "string": STRING,
40 "variable_ref": VARIABLE_REF,
41 }
42
43 # The tokenizers "expectation" while at the root/highest level of scope
44 # in the CSS file. At this level we might expect to see selectors, comments,
45 # variable definitions etc.
46 expect_root_scope = Expect(
47 whitespace=r"\s+",
48 comment_start=COMMENT_START,
49 selector_start_id=r"\#" + IDENTIFIER,
50 selector_start_class=r"\." + IDENTIFIER,
51 selector_start_universal=r"\*",
52 selector_start=r"[a-zA-Z_\-]+",
53 variable_name=rf"{VARIABLE_REF}:",
54 ).expect_eof(True)
55
56 # After a variable declaration e.g. "$warning-text: TOKENS;"
57 # for tokenizing variable value ------^~~~~~~^
58 expect_variable_name_continue = Expect(
59 variable_value_end=r"\n|;",
60 whitespace=r"\s+",
61 comment_start=COMMENT_START,
62 **DECLARATION_VALUES,
63 ).expect_eof(True)
64
65 expect_comment_end = Expect(
66 comment_end=re.escape("*/"),
67 )
68
69 # After we come across a selector in CSS e.g. ".my-class", we may
70 # find other selectors, pseudo-classes... e.g. ".my-class :hover"
71 expect_selector_continue = Expect(
72 whitespace=r"\s+",
73 comment_start=COMMENT_START,
74 pseudo_class=r"\:[a-zA-Z_-]+",
75 selector_id=r"\#[a-zA-Z_\-][a-zA-Z0-9_\-]*",
76 selector_class=r"\.[a-zA-Z_\-][a-zA-Z0-9_\-]*",
77 selector_universal=r"\*",
78 selector=r"[a-zA-Z_\-]+",
79 combinator_child=">",
80 new_selector=r",",
81 declaration_set_start=r"\{",
82 )
83
84 # A rule declaration e.g. "text: red;"
85 # ^---^
86 expect_declaration = Expect(
87 whitespace=r"\s+",
88 comment_start=COMMENT_START,
89 declaration_name=r"[a-zA-Z_\-]+\:",
90 declaration_set_end=r"\}",
91 )
92
93 expect_declaration_solo = Expect(
94 whitespace=r"\s+",
95 comment_start=COMMENT_START,
96 declaration_name=r"[a-zA-Z_\-]+\:",
97 declaration_set_end=r"\}",
98 ).expect_eof(True)
99
100 # The value(s)/content from a rule declaration e.g. "text: red;"
101 # ^---^
102 expect_declaration_content = Expect(
103 declaration_end=r";",
104 whitespace=r"\s+",
105 comment_start=COMMENT_START,
106 **DECLARATION_VALUES,
107 important=r"\!important",
108 comma=",",
109 declaration_set_end=r"\}",
110 )
111
112 expect_declaration_content_solo = Expect(
113 declaration_end=r";",
114 whitespace=r"\s+",
115 comment_start=COMMENT_START,
116 **DECLARATION_VALUES,
117 important=r"\!important",
118 comma=",",
119 declaration_set_end=r"\}",
120 ).expect_eof(True)
121
122
123 class TokenizerState:
124 """State machine for the tokenizer.
125
126 Attributes:
127 EXPECT: The initial expectation of the tokenizer. Since we start tokenizing
128 at the root scope, we might expect to see either a variable or selector, for example.
129 STATE_MAP: Maps token names to Expects, defines the sets of valid tokens
130 that we'd expect to see next, given the current token. For example, if
131 we've just processed a variable declaration name, we next expect to see
132 the value of that variable.
133 """
134
135 EXPECT = expect_root_scope
136 STATE_MAP = {
137 "variable_name": expect_variable_name_continue,
138 "variable_value_end": expect_root_scope,
139 "selector_start": expect_selector_continue,
140 "selector_start_id": expect_selector_continue,
141 "selector_start_class": expect_selector_continue,
142 "selector_start_universal": expect_selector_continue,
143 "selector_id": expect_selector_continue,
144 "selector_class": expect_selector_continue,
145 "selector_universal": expect_selector_continue,
146 "declaration_set_start": expect_declaration,
147 "declaration_name": expect_declaration_content,
148 "declaration_end": expect_declaration,
149 "declaration_set_end": expect_root_scope,
150 }
151
152 def __call__(self, code: str, path: str | PurePath) -> Iterable[Token]:
153 tokenizer = Tokenizer(code, path=path)
154 expect = self.EXPECT
155 get_token = tokenizer.get_token
156 get_state = self.STATE_MAP.get
157 while True:
158 token = get_token(expect)
159 name = token.name
160 if name == "comment_start":
161 tokenizer.skip_to(expect_comment_end)
162 continue
163 elif name == "eof":
164 break
165 expect = get_state(name, expect)
166 yield token
167
168
169 class DeclarationTokenizerState(TokenizerState):
170 EXPECT = expect_declaration_solo
171 STATE_MAP = {
172 "declaration_name": expect_declaration_content,
173 "declaration_end": expect_declaration_solo,
174 }
175
176
177 class ValueTokenizerState(TokenizerState):
178 EXPECT = expect_declaration_content_solo
179
180
181 tokenize = TokenizerState()
182 tokenize_declarations = DeclarationTokenizerState()
183 tokenize_value = ValueTokenizerState()
184
185
186 def tokenize_values(values: dict[str, str]) -> dict[str, list[Token]]:
187 """Tokens the values in a dict of strings.
188
189 Args:
190 values (dict[str, str]): A mapping of CSS variable name on to a value, to be
191 added to the CSS context.
192
193 Returns:
194 dict[str, list[Token]]: A mapping of name on to a list of tokens,
195 """
196 value_tokens = {
197 name: list(tokenize_value(value, "__name__")) for name, value in values.items()
198 }
199 return value_tokens
200
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/textual/css/tokenize.py b/src/textual/css/tokenize.py
--- a/src/textual/css/tokenize.py
+++ b/src/textual/css/tokenize.py
@@ -49,7 +49,7 @@
selector_start_id=r"\#" + IDENTIFIER,
selector_start_class=r"\." + IDENTIFIER,
selector_start_universal=r"\*",
- selector_start=r"[a-zA-Z_\-]+",
+ selector_start=IDENTIFIER,
variable_name=rf"{VARIABLE_REF}:",
).expect_eof(True)
|
{"golden_diff": "diff --git a/src/textual/css/tokenize.py b/src/textual/css/tokenize.py\n--- a/src/textual/css/tokenize.py\n+++ b/src/textual/css/tokenize.py\n@@ -49,7 +49,7 @@\n selector_start_id=r\"\\#\" + IDENTIFIER,\n selector_start_class=r\"\\.\" + IDENTIFIER,\n selector_start_universal=r\"\\*\",\n- selector_start=r\"[a-zA-Z_\\-]+\",\n+ selector_start=IDENTIFIER,\n variable_name=rf\"{VARIABLE_REF}:\",\n ).expect_eof(True)\n", "issue": "Type selectors can't contain a number\nIt seems that type selectors can't handle types that have a number in their name. For example this:\r\n\r\n```python\r\nfrom textual.app import App, ComposeResult\r\nfrom textual.widgets import Label\r\n\r\nclass H1( Label ):\r\n pass\r\n\r\nclass NumberError( App[ None ] ):\r\n\r\n CSS = \"\"\"\r\n H1 {\r\n text-style: bold;\r\n color: yellow;\r\n background: red;\r\n }\r\n \"\"\"\r\n def compose( self ) -> ComposeResult:\r\n yield H1( \"This is a very important heading\" )\r\n\r\nif __name__ == \"__main__\":\r\n NumberError().run()\r\n```\r\n\r\nthrows this error:\r\n\r\n```\r\nError in stylesheet:\r\n /Users/davep/develop/python/textual-sandbox/not_all_types.py:NumberError:1:5\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 \u2771 1 \u2502 \u2502\r\n\u2502 2 \u2502 H1 { \u2502\r\n\u2502 3 \u2502 \u2502 text-style: bold; \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\n \u2022 Expected one of 'combinator child', 'comment start', 'declaration set start', 'new\r\n selector', 'pseudo class', 'selector', 'selector class', 'selector id', 'selector\r\n universal', or 'whitespace'.\r\n \u2022 Did you forget a semicolon at the end of a line?\r\n```\r\n\r\nwhereas this works fine:\r\n\r\n```python\r\nfrom textual.app import App, ComposeResult\r\nfrom textual.widgets import Label\r\n\r\nclass HOne( Label ):\r\n pass\r\n\r\nclass NumberError( App[ None ] ):\r\n\r\n CSS = \"\"\"\r\n HOne {\r\n text-style: bold;\r\n color: yellow;\r\n background: red;\r\n }\r\n \"\"\"\r\n def compose( self ) -> ComposeResult:\r\n yield HOne( \"This is a very important heading\" )\r\n\r\nif __name__ == \"__main__\":\r\n NumberError().run()\r\n```\r\n\r\nas does, of course, this:\r\n\r\n```python\r\nfrom textual.app import App, ComposeResult\r\nfrom textual.widgets import Label\r\n\r\nclass H1( Label ):\r\n pass\r\n\r\nclass NumberError( App[ None ] ):\r\n\r\n CSS = \"\"\"\r\n Label {\r\n text-style: bold;\r\n color: yellow;\r\n background: red;\r\n }\r\n \"\"\"\r\n def compose( self ) -> ComposeResult:\r\n yield H1( \"This is a very important heading\" )\r\n\r\nif __name__ == \"__main__\":\r\n NumberError().run()\r\n```\n", "before_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom pathlib import PurePath\nfrom typing import Iterable\n\nfrom textual.css.tokenizer import Expect, Tokenizer, Token\n\nPERCENT = r\"-?\\d+\\.?\\d*%\"\nDECIMAL = r\"-?\\d+\\.?\\d*\"\nCOMMA = r\"\\s*,\\s*\"\nOPEN_BRACE = r\"\\(\\s*\"\nCLOSE_BRACE = r\"\\s*\\)\"\n\nHEX_COLOR = r\"\\#[0-9a-fA-F]{8}|\\#[0-9a-fA-F]{6}|\\#[0-9a-fA-F]{4}|\\#[0-9a-fA-F]{3}\"\nRGB_COLOR = rf\"rgb{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}|rgba{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}\"\nHSL_COLOR = rf\"hsl{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{CLOSE_BRACE}|hsla{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{COMMA}{DECIMAL}{CLOSE_BRACE}\"\n\nCOMMENT_START = r\"\\/\\*\"\nSCALAR = rf\"{DECIMAL}(?:fr|%|w|h|vw|vh)\"\nDURATION = r\"\\d+\\.?\\d*(?:ms|s)\"\nNUMBER = r\"\\-?\\d+\\.?\\d*\"\nCOLOR = rf\"{HEX_COLOR}|{RGB_COLOR}|{HSL_COLOR}\"\nKEY_VALUE = r\"[a-zA-Z_-][a-zA-Z0-9_-]*=[0-9a-zA-Z_\\-\\/]+\"\nTOKEN = \"[a-zA-Z][a-zA-Z0-9_-]*\"\nSTRING = r\"\\\".*?\\\"\"\nVARIABLE_REF = r\"\\$[a-zA-Z0-9_\\-]+\"\n\nIDENTIFIER = r\"[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\"\n\n# Values permitted in variable and rule declarations.\nDECLARATION_VALUES = {\n \"scalar\": SCALAR,\n \"duration\": DURATION,\n \"number\": NUMBER,\n \"color\": COLOR,\n \"key_value\": KEY_VALUE,\n \"token\": TOKEN,\n \"string\": STRING,\n \"variable_ref\": VARIABLE_REF,\n}\n\n# The tokenizers \"expectation\" while at the root/highest level of scope\n# in the CSS file. At this level we might expect to see selectors, comments,\n# variable definitions etc.\nexpect_root_scope = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n selector_start_id=r\"\\#\" + IDENTIFIER,\n selector_start_class=r\"\\.\" + IDENTIFIER,\n selector_start_universal=r\"\\*\",\n selector_start=r\"[a-zA-Z_\\-]+\",\n variable_name=rf\"{VARIABLE_REF}:\",\n).expect_eof(True)\n\n# After a variable declaration e.g. \"$warning-text: TOKENS;\"\n# for tokenizing variable value ------^~~~~~~^\nexpect_variable_name_continue = Expect(\n variable_value_end=r\"\\n|;\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n).expect_eof(True)\n\nexpect_comment_end = Expect(\n comment_end=re.escape(\"*/\"),\n)\n\n# After we come across a selector in CSS e.g. \".my-class\", we may\n# find other selectors, pseudo-classes... e.g. \".my-class :hover\"\nexpect_selector_continue = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n pseudo_class=r\"\\:[a-zA-Z_-]+\",\n selector_id=r\"\\#[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\",\n selector_class=r\"\\.[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\",\n selector_universal=r\"\\*\",\n selector=r\"[a-zA-Z_\\-]+\",\n combinator_child=\">\",\n new_selector=r\",\",\n declaration_set_start=r\"\\{\",\n)\n\n# A rule declaration e.g. \"text: red;\"\n# ^---^\nexpect_declaration = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n declaration_name=r\"[a-zA-Z_\\-]+\\:\",\n declaration_set_end=r\"\\}\",\n)\n\nexpect_declaration_solo = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n declaration_name=r\"[a-zA-Z_\\-]+\\:\",\n declaration_set_end=r\"\\}\",\n).expect_eof(True)\n\n# The value(s)/content from a rule declaration e.g. \"text: red;\"\n# ^---^\nexpect_declaration_content = Expect(\n declaration_end=r\";\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n important=r\"\\!important\",\n comma=\",\",\n declaration_set_end=r\"\\}\",\n)\n\nexpect_declaration_content_solo = Expect(\n declaration_end=r\";\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n important=r\"\\!important\",\n comma=\",\",\n declaration_set_end=r\"\\}\",\n).expect_eof(True)\n\n\nclass TokenizerState:\n \"\"\"State machine for the tokenizer.\n\n Attributes:\n EXPECT: The initial expectation of the tokenizer. Since we start tokenizing\n at the root scope, we might expect to see either a variable or selector, for example.\n STATE_MAP: Maps token names to Expects, defines the sets of valid tokens\n that we'd expect to see next, given the current token. For example, if\n we've just processed a variable declaration name, we next expect to see\n the value of that variable.\n \"\"\"\n\n EXPECT = expect_root_scope\n STATE_MAP = {\n \"variable_name\": expect_variable_name_continue,\n \"variable_value_end\": expect_root_scope,\n \"selector_start\": expect_selector_continue,\n \"selector_start_id\": expect_selector_continue,\n \"selector_start_class\": expect_selector_continue,\n \"selector_start_universal\": expect_selector_continue,\n \"selector_id\": expect_selector_continue,\n \"selector_class\": expect_selector_continue,\n \"selector_universal\": expect_selector_continue,\n \"declaration_set_start\": expect_declaration,\n \"declaration_name\": expect_declaration_content,\n \"declaration_end\": expect_declaration,\n \"declaration_set_end\": expect_root_scope,\n }\n\n def __call__(self, code: str, path: str | PurePath) -> Iterable[Token]:\n tokenizer = Tokenizer(code, path=path)\n expect = self.EXPECT\n get_token = tokenizer.get_token\n get_state = self.STATE_MAP.get\n while True:\n token = get_token(expect)\n name = token.name\n if name == \"comment_start\":\n tokenizer.skip_to(expect_comment_end)\n continue\n elif name == \"eof\":\n break\n expect = get_state(name, expect)\n yield token\n\n\nclass DeclarationTokenizerState(TokenizerState):\n EXPECT = expect_declaration_solo\n STATE_MAP = {\n \"declaration_name\": expect_declaration_content,\n \"declaration_end\": expect_declaration_solo,\n }\n\n\nclass ValueTokenizerState(TokenizerState):\n EXPECT = expect_declaration_content_solo\n\n\ntokenize = TokenizerState()\ntokenize_declarations = DeclarationTokenizerState()\ntokenize_value = ValueTokenizerState()\n\n\ndef tokenize_values(values: dict[str, str]) -> dict[str, list[Token]]:\n \"\"\"Tokens the values in a dict of strings.\n\n Args:\n values (dict[str, str]): A mapping of CSS variable name on to a value, to be\n added to the CSS context.\n\n Returns:\n dict[str, list[Token]]: A mapping of name on to a list of tokens,\n \"\"\"\n value_tokens = {\n name: list(tokenize_value(value, \"__name__\")) for name, value in values.items()\n }\n return value_tokens\n", "path": "src/textual/css/tokenize.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom pathlib import PurePath\nfrom typing import Iterable\n\nfrom textual.css.tokenizer import Expect, Tokenizer, Token\n\nPERCENT = r\"-?\\d+\\.?\\d*%\"\nDECIMAL = r\"-?\\d+\\.?\\d*\"\nCOMMA = r\"\\s*,\\s*\"\nOPEN_BRACE = r\"\\(\\s*\"\nCLOSE_BRACE = r\"\\s*\\)\"\n\nHEX_COLOR = r\"\\#[0-9a-fA-F]{8}|\\#[0-9a-fA-F]{6}|\\#[0-9a-fA-F]{4}|\\#[0-9a-fA-F]{3}\"\nRGB_COLOR = rf\"rgb{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}|rgba{OPEN_BRACE}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{COMMA}{DECIMAL}{CLOSE_BRACE}\"\nHSL_COLOR = rf\"hsl{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{CLOSE_BRACE}|hsla{OPEN_BRACE}{DECIMAL}{COMMA}{PERCENT}{COMMA}{PERCENT}{COMMA}{DECIMAL}{CLOSE_BRACE}\"\n\nCOMMENT_START = r\"\\/\\*\"\nSCALAR = rf\"{DECIMAL}(?:fr|%|w|h|vw|vh)\"\nDURATION = r\"\\d+\\.?\\d*(?:ms|s)\"\nNUMBER = r\"\\-?\\d+\\.?\\d*\"\nCOLOR = rf\"{HEX_COLOR}|{RGB_COLOR}|{HSL_COLOR}\"\nKEY_VALUE = r\"[a-zA-Z_-][a-zA-Z0-9_-]*=[0-9a-zA-Z_\\-\\/]+\"\nTOKEN = \"[a-zA-Z][a-zA-Z0-9_-]*\"\nSTRING = r\"\\\".*?\\\"\"\nVARIABLE_REF = r\"\\$[a-zA-Z0-9_\\-]+\"\n\nIDENTIFIER = r\"[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\"\n\n# Values permitted in variable and rule declarations.\nDECLARATION_VALUES = {\n \"scalar\": SCALAR,\n \"duration\": DURATION,\n \"number\": NUMBER,\n \"color\": COLOR,\n \"key_value\": KEY_VALUE,\n \"token\": TOKEN,\n \"string\": STRING,\n \"variable_ref\": VARIABLE_REF,\n}\n\n# The tokenizers \"expectation\" while at the root/highest level of scope\n# in the CSS file. At this level we might expect to see selectors, comments,\n# variable definitions etc.\nexpect_root_scope = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n selector_start_id=r\"\\#\" + IDENTIFIER,\n selector_start_class=r\"\\.\" + IDENTIFIER,\n selector_start_universal=r\"\\*\",\n selector_start=IDENTIFIER,\n variable_name=rf\"{VARIABLE_REF}:\",\n).expect_eof(True)\n\n# After a variable declaration e.g. \"$warning-text: TOKENS;\"\n# for tokenizing variable value ------^~~~~~~^\nexpect_variable_name_continue = Expect(\n variable_value_end=r\"\\n|;\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n).expect_eof(True)\n\nexpect_comment_end = Expect(\n comment_end=re.escape(\"*/\"),\n)\n\n# After we come across a selector in CSS e.g. \".my-class\", we may\n# find other selectors, pseudo-classes... e.g. \".my-class :hover\"\nexpect_selector_continue = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n pseudo_class=r\"\\:[a-zA-Z_-]+\",\n selector_id=r\"\\#[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\",\n selector_class=r\"\\.[a-zA-Z_\\-][a-zA-Z0-9_\\-]*\",\n selector_universal=r\"\\*\",\n selector=r\"[a-zA-Z_\\-]+\",\n combinator_child=\">\",\n new_selector=r\",\",\n declaration_set_start=r\"\\{\",\n)\n\n# A rule declaration e.g. \"text: red;\"\n# ^---^\nexpect_declaration = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n declaration_name=r\"[a-zA-Z_\\-]+\\:\",\n declaration_set_end=r\"\\}\",\n)\n\nexpect_declaration_solo = Expect(\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n declaration_name=r\"[a-zA-Z_\\-]+\\:\",\n declaration_set_end=r\"\\}\",\n).expect_eof(True)\n\n# The value(s)/content from a rule declaration e.g. \"text: red;\"\n# ^---^\nexpect_declaration_content = Expect(\n declaration_end=r\";\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n important=r\"\\!important\",\n comma=\",\",\n declaration_set_end=r\"\\}\",\n)\n\nexpect_declaration_content_solo = Expect(\n declaration_end=r\";\",\n whitespace=r\"\\s+\",\n comment_start=COMMENT_START,\n **DECLARATION_VALUES,\n important=r\"\\!important\",\n comma=\",\",\n declaration_set_end=r\"\\}\",\n).expect_eof(True)\n\n\nclass TokenizerState:\n \"\"\"State machine for the tokenizer.\n\n Attributes:\n EXPECT: The initial expectation of the tokenizer. Since we start tokenizing\n at the root scope, we might expect to see either a variable or selector, for example.\n STATE_MAP: Maps token names to Expects, defines the sets of valid tokens\n that we'd expect to see next, given the current token. For example, if\n we've just processed a variable declaration name, we next expect to see\n the value of that variable.\n \"\"\"\n\n EXPECT = expect_root_scope\n STATE_MAP = {\n \"variable_name\": expect_variable_name_continue,\n \"variable_value_end\": expect_root_scope,\n \"selector_start\": expect_selector_continue,\n \"selector_start_id\": expect_selector_continue,\n \"selector_start_class\": expect_selector_continue,\n \"selector_start_universal\": expect_selector_continue,\n \"selector_id\": expect_selector_continue,\n \"selector_class\": expect_selector_continue,\n \"selector_universal\": expect_selector_continue,\n \"declaration_set_start\": expect_declaration,\n \"declaration_name\": expect_declaration_content,\n \"declaration_end\": expect_declaration,\n \"declaration_set_end\": expect_root_scope,\n }\n\n def __call__(self, code: str, path: str | PurePath) -> Iterable[Token]:\n tokenizer = Tokenizer(code, path=path)\n expect = self.EXPECT\n get_token = tokenizer.get_token\n get_state = self.STATE_MAP.get\n while True:\n token = get_token(expect)\n name = token.name\n if name == \"comment_start\":\n tokenizer.skip_to(expect_comment_end)\n continue\n elif name == \"eof\":\n break\n expect = get_state(name, expect)\n yield token\n\n\nclass DeclarationTokenizerState(TokenizerState):\n EXPECT = expect_declaration_solo\n STATE_MAP = {\n \"declaration_name\": expect_declaration_content,\n \"declaration_end\": expect_declaration_solo,\n }\n\n\nclass ValueTokenizerState(TokenizerState):\n EXPECT = expect_declaration_content_solo\n\n\ntokenize = TokenizerState()\ntokenize_declarations = DeclarationTokenizerState()\ntokenize_value = ValueTokenizerState()\n\n\ndef tokenize_values(values: dict[str, str]) -> dict[str, list[Token]]:\n \"\"\"Tokens the values in a dict of strings.\n\n Args:\n values (dict[str, str]): A mapping of CSS variable name on to a value, to be\n added to the CSS context.\n\n Returns:\n dict[str, list[Token]]: A mapping of name on to a list of tokens,\n \"\"\"\n value_tokens = {\n name: list(tokenize_value(value, \"__name__\")) for name, value in values.items()\n }\n return value_tokens\n", "path": "src/textual/css/tokenize.py"}]}
| 2,981 | 120 |
gh_patches_debug_48261
|
rasdani/github-patches
|
git_diff
|
systemd__mkosi-2307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`RepositoryKeyCheck` is not respected for Deb-based distros
Hey there!
The man page suggests that the `Distribution.RepositoryKeyCheck` configuration option is not used for DNF-based distros yet (which would imply to me that it is used for other distributions). When looking at the code, however, it seems that it is only used for `pacman`, `zypper`, and `dnf` (i.e. DNF-based distros, too). Furthermore, it seems that the input is not respected for Deb-based distros. When trying to build an Ubuntu image without making the public key available to the build environment and with setting the `RepositoryKeyCheck` option to `false`, I receive the following error:
```console
‣ Installing Ubuntu
Get:1 http://archive.ubuntu.com/ubuntu jammy InRelease [270 kB]
Get:2 http://security.ubuntu.com/ubuntu jammy-security InRelease [110 kB]
Err:2 http://security.ubuntu.com/ubuntu jammy-security InRelease
The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
Get:3 http://archive.ubuntu.com/ubuntu jammy-updates InRelease [119 kB]
Err:1 http://archive.ubuntu.com/ubuntu jammy InRelease
The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
Err:3 http://archive.ubuntu.com/ubuntu jammy-updates InRelease
The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
Reading package lists... Done
W: GPG error: http://security.ubuntu.com/ubuntu jammy-security InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
E: The repository 'http://security.ubuntu.com/ubuntu jammy-security InRelease' is not signed.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.
W: GPG error: http://archive.ubuntu.com/ubuntu jammy InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
E: The repository 'http://archive.ubuntu.com/ubuntu jammy InRelease' is not signed.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.
W: GPG error: http://archive.ubuntu.com/ubuntu jammy-updates InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C
E: The repository 'http://archive.ubuntu.com/ubuntu jammy-updates InRelease' is not signed.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.
```
When the public key is supplied via `mkosi.skeleton`, the build succeeds.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkosi/installer/apt.py`
Content:
```
1 # SPDX-License-Identifier: LGPL-2.1+
2 import textwrap
3 from collections.abc import Sequence
4
5 from mkosi.context import Context
6 from mkosi.installer import finalize_package_manager_mounts
7 from mkosi.mounts import finalize_ephemeral_source_mounts
8 from mkosi.run import find_binary, run
9 from mkosi.sandbox import apivfs_cmd
10 from mkosi.types import PathString
11 from mkosi.util import sort_packages, umask
12
13
14 def setup_apt(context: Context, repos: Sequence[str]) -> None:
15 (context.pkgmngr / "etc/apt").mkdir(exist_ok=True, parents=True)
16 (context.pkgmngr / "etc/apt/apt.conf.d").mkdir(exist_ok=True, parents=True)
17 (context.pkgmngr / "etc/apt/preferences.d").mkdir(exist_ok=True, parents=True)
18 (context.pkgmngr / "etc/apt/sources.list.d").mkdir(exist_ok=True, parents=True)
19
20 # TODO: Drop once apt 2.5.4 is widely available.
21 with umask(~0o755):
22 (context.root / "var/lib/dpkg").mkdir(parents=True, exist_ok=True)
23 (context.root / "var/lib/dpkg/status").touch()
24
25 (context.cache_dir / "lib/apt").mkdir(exist_ok=True, parents=True)
26 (context.cache_dir / "cache/apt").mkdir(exist_ok=True, parents=True)
27
28 # We have a special apt.conf outside of pkgmngr dir that only configures "Dir::Etc" that we pass to APT_CONFIG to
29 # tell apt it should read config files from /etc/apt in case this is overridden by distributions. This is required
30 # because apt parses CLI configuration options after parsing its configuration files and as such we can't use CLI
31 # options to tell apt where to look for configuration files.
32 config = context.workspace / "apt.conf"
33 if not config.exists():
34 config.write_text(
35 textwrap.dedent(
36 """\
37 Dir::Etc "etc/apt";
38 """
39 )
40 )
41
42 sources = context.pkgmngr / "etc/apt/sources.list"
43 if not sources.exists():
44 with sources.open("w") as f:
45 for repo in repos:
46 f.write(f"{repo}\n")
47
48
49 def apt_cmd(context: Context, command: str) -> list[PathString]:
50 debarch = context.config.distribution.architecture(context.config.architecture)
51
52 cmdline: list[PathString] = [
53 "env",
54 f"APT_CONFIG={context.workspace / 'apt.conf'}",
55 "DEBIAN_FRONTEND=noninteractive",
56 "DEBCONF_INTERACTIVE_SEEN=true",
57 "INITRD=No",
58 command,
59 "-o", f"APT::Architecture={debarch}",
60 "-o", f"APT::Architectures={debarch}",
61 "-o", f"APT::Install-Recommends={str(context.config.with_recommends).lower()}",
62 "-o", "APT::Immediate-Configure=off",
63 "-o", "APT::Get::Assume-Yes=true",
64 "-o", "APT::Get::AutomaticRemove=true",
65 "-o", "APT::Get::Allow-Change-Held-Packages=true",
66 "-o", "APT::Get::Allow-Remove-Essential=true",
67 "-o", "APT::Sandbox::User=root",
68 "-o", "Dir::Cache=/var/cache/apt",
69 "-o", "Dir::State=/var/lib/apt",
70 "-o", f"Dir::State::Status={context.root / 'var/lib/dpkg/status'}",
71 "-o", f"Dir::Log={context.workspace}",
72 "-o", f"Dir::Bin::DPkg={find_binary('dpkg', root=context.config.tools())}",
73 "-o", "Debug::NoLocking=true",
74 "-o", f"DPkg::Options::=--root={context.root}",
75 "-o", "DPkg::Options::=--force-unsafe-io",
76 "-o", "DPkg::Options::=--force-architecture",
77 "-o", "DPkg::Options::=--force-depends",
78 "-o", "DPkg::Options::=--no-debsig",
79 "-o", "DPkg::Use-Pty=false",
80 "-o", "DPkg::Install::Recursive::Minimum=1000",
81 "-o", "pkgCacheGen::ForceEssential=,",
82 ]
83
84 if not context.config.with_docs:
85 cmdline += [
86 "-o", "DPkg::Options::=--path-exclude=/usr/share/doc/*",
87 "-o", "DPkg::Options::=--path-include=/usr/share/doc/*/copyright",
88 "-o", "DPkg::Options::=--path-exclude=/usr/share/man/*",
89 "-o", "DPkg::Options::=--path-exclude=/usr/share/groff/*",
90 "-o", "DPkg::Options::=--path-exclude=/usr/share/info/*",
91 ]
92
93 return cmdline
94
95
96 def invoke_apt(
97 context: Context,
98 command: str,
99 operation: str,
100 packages: Sequence[str] = (),
101 *,
102 apivfs: bool = True,
103 mounts: Sequence[PathString] = (),
104 ) -> None:
105 with finalize_ephemeral_source_mounts(context.config) as sources:
106 run(
107 apt_cmd(context, command) + [operation, *sort_packages(packages)],
108 sandbox=(
109 context.sandbox(
110 network=True,
111 options=[
112 "--bind", context.root, context.root,
113 *finalize_package_manager_mounts(context),
114 *sources,
115 *mounts,
116 "--chdir", "/work/src",
117 ],
118 ) + (apivfs_cmd(context.root) if apivfs else [])
119 ),
120 env=context.config.environment,
121 )
122
123
124 def createrepo_apt(context: Context) -> None:
125 with (context.packages / "Packages").open("wb") as f:
126 run(["dpkg-scanpackages", context.packages],
127 stdout=f, sandbox=context.sandbox(options=["--ro-bind", context.packages, context.packages]))
128
129 (context.pkgmngr / "etc/apt/sources.list.d").mkdir(parents=True, exist_ok=True)
130 (context.pkgmngr / "etc/apt/sources.list.d/mkosi-packages.sources").write_text(
131 f"""\
132 Enabled: yes
133 Types: deb
134 URIs: file:///work/packages
135 Suites: {context.config.release}
136 Components: main
137 Trusted: yes
138 """
139 )
140
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkosi/installer/apt.py b/mkosi/installer/apt.py
--- a/mkosi/installer/apt.py
+++ b/mkosi/installer/apt.py
@@ -81,6 +81,13 @@
"-o", "pkgCacheGen::ForceEssential=,",
]
+ if not context.config.repository_key_check:
+ cmdline += [
+ "-o", "Acquire::AllowInsecureRepositories=true",
+ "-o", "Acquire::AllowDowngradeToInsecureRepositories=true",
+ "-o", "APT::Get::AllowUnauthenticated=true",
+ ]
+
if not context.config.with_docs:
cmdline += [
"-o", "DPkg::Options::=--path-exclude=/usr/share/doc/*",
|
{"golden_diff": "diff --git a/mkosi/installer/apt.py b/mkosi/installer/apt.py\n--- a/mkosi/installer/apt.py\n+++ b/mkosi/installer/apt.py\n@@ -81,6 +81,13 @@\n \"-o\", \"pkgCacheGen::ForceEssential=,\",\n ]\n \n+ if not context.config.repository_key_check:\n+ cmdline += [\n+ \"-o\", \"Acquire::AllowInsecureRepositories=true\",\n+ \"-o\", \"Acquire::AllowDowngradeToInsecureRepositories=true\",\n+ \"-o\", \"APT::Get::AllowUnauthenticated=true\",\n+ ]\n+\n if not context.config.with_docs:\n cmdline += [\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/doc/*\",\n", "issue": "`RepositoryKeyCheck` is not respected for Deb-based distros\nHey there!\r\n\r\nThe man page suggests that the `Distribution.RepositoryKeyCheck` configuration option is not used for DNF-based distros yet (which would imply to me that it is used for other distributions). When looking at the code, however, it seems that it is only used for `pacman`, `zypper`, and `dnf` (i.e. DNF-based distros, too). Furthermore, it seems that the input is not respected for Deb-based distros. When trying to build an Ubuntu image without making the public key available to the build environment and with setting the `RepositoryKeyCheck` option to `false`, I receive the following error:\r\n\r\n```console\r\n\u2023 Installing Ubuntu\r\nGet:1 http://archive.ubuntu.com/ubuntu jammy InRelease [270 kB]\r\nGet:2 http://security.ubuntu.com/ubuntu jammy-security InRelease [110 kB]\r\nErr:2 http://security.ubuntu.com/ubuntu jammy-security InRelease \r\n The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nGet:3 http://archive.ubuntu.com/ubuntu jammy-updates InRelease [119 kB]\r\nErr:1 http://archive.ubuntu.com/ubuntu jammy InRelease\r\n The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nErr:3 http://archive.ubuntu.com/ubuntu jammy-updates InRelease\r\n The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nReading package lists... Done\r\nW: GPG error: http://security.ubuntu.com/ubuntu jammy-security InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nE: The repository 'http://security.ubuntu.com/ubuntu jammy-security InRelease' is not signed.\r\nN: Updating from such a repository can't be done securely, and is therefore disabled by default.\r\nN: See apt-secure(8) manpage for repository creation and user configuration details.\r\nW: GPG error: http://archive.ubuntu.com/ubuntu jammy InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nE: The repository 'http://archive.ubuntu.com/ubuntu jammy InRelease' is not signed.\r\nN: Updating from such a repository can't be done securely, and is therefore disabled by default.\r\nN: See apt-secure(8) manpage for repository creation and user configuration details.\r\nW: GPG error: http://archive.ubuntu.com/ubuntu jammy-updates InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 871920D1991BC93C\r\nE: The repository 'http://archive.ubuntu.com/ubuntu jammy-updates InRelease' is not signed.\r\nN: Updating from such a repository can't be done securely, and is therefore disabled by default.\r\nN: See apt-secure(8) manpage for repository creation and user configuration details.\r\n```\r\n\r\nWhen the public key is supplied via `mkosi.skeleton`, the build succeeds.\n", "before_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\nimport textwrap\nfrom collections.abc import Sequence\n\nfrom mkosi.context import Context\nfrom mkosi.installer import finalize_package_manager_mounts\nfrom mkosi.mounts import finalize_ephemeral_source_mounts\nfrom mkosi.run import find_binary, run\nfrom mkosi.sandbox import apivfs_cmd\nfrom mkosi.types import PathString\nfrom mkosi.util import sort_packages, umask\n\n\ndef setup_apt(context: Context, repos: Sequence[str]) -> None:\n (context.pkgmngr / \"etc/apt\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/apt.conf.d\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/preferences.d\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/sources.list.d\").mkdir(exist_ok=True, parents=True)\n\n # TODO: Drop once apt 2.5.4 is widely available.\n with umask(~0o755):\n (context.root / \"var/lib/dpkg\").mkdir(parents=True, exist_ok=True)\n (context.root / \"var/lib/dpkg/status\").touch()\n\n (context.cache_dir / \"lib/apt\").mkdir(exist_ok=True, parents=True)\n (context.cache_dir / \"cache/apt\").mkdir(exist_ok=True, parents=True)\n\n # We have a special apt.conf outside of pkgmngr dir that only configures \"Dir::Etc\" that we pass to APT_CONFIG to\n # tell apt it should read config files from /etc/apt in case this is overridden by distributions. This is required\n # because apt parses CLI configuration options after parsing its configuration files and as such we can't use CLI\n # options to tell apt where to look for configuration files.\n config = context.workspace / \"apt.conf\"\n if not config.exists():\n config.write_text(\n textwrap.dedent(\n \"\"\"\\\n Dir::Etc \"etc/apt\";\n \"\"\"\n )\n )\n\n sources = context.pkgmngr / \"etc/apt/sources.list\"\n if not sources.exists():\n with sources.open(\"w\") as f:\n for repo in repos:\n f.write(f\"{repo}\\n\")\n\n\ndef apt_cmd(context: Context, command: str) -> list[PathString]:\n debarch = context.config.distribution.architecture(context.config.architecture)\n\n cmdline: list[PathString] = [\n \"env\",\n f\"APT_CONFIG={context.workspace / 'apt.conf'}\",\n \"DEBIAN_FRONTEND=noninteractive\",\n \"DEBCONF_INTERACTIVE_SEEN=true\",\n \"INITRD=No\",\n command,\n \"-o\", f\"APT::Architecture={debarch}\",\n \"-o\", f\"APT::Architectures={debarch}\",\n \"-o\", f\"APT::Install-Recommends={str(context.config.with_recommends).lower()}\",\n \"-o\", \"APT::Immediate-Configure=off\",\n \"-o\", \"APT::Get::Assume-Yes=true\",\n \"-o\", \"APT::Get::AutomaticRemove=true\",\n \"-o\", \"APT::Get::Allow-Change-Held-Packages=true\",\n \"-o\", \"APT::Get::Allow-Remove-Essential=true\",\n \"-o\", \"APT::Sandbox::User=root\",\n \"-o\", \"Dir::Cache=/var/cache/apt\",\n \"-o\", \"Dir::State=/var/lib/apt\",\n \"-o\", f\"Dir::State::Status={context.root / 'var/lib/dpkg/status'}\",\n \"-o\", f\"Dir::Log={context.workspace}\",\n \"-o\", f\"Dir::Bin::DPkg={find_binary('dpkg', root=context.config.tools())}\",\n \"-o\", \"Debug::NoLocking=true\",\n \"-o\", f\"DPkg::Options::=--root={context.root}\",\n \"-o\", \"DPkg::Options::=--force-unsafe-io\",\n \"-o\", \"DPkg::Options::=--force-architecture\",\n \"-o\", \"DPkg::Options::=--force-depends\",\n \"-o\", \"DPkg::Options::=--no-debsig\",\n \"-o\", \"DPkg::Use-Pty=false\",\n \"-o\", \"DPkg::Install::Recursive::Minimum=1000\",\n \"-o\", \"pkgCacheGen::ForceEssential=,\",\n ]\n\n if not context.config.with_docs:\n cmdline += [\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/doc/*\",\n \"-o\", \"DPkg::Options::=--path-include=/usr/share/doc/*/copyright\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/man/*\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/groff/*\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/info/*\",\n ]\n\n return cmdline\n\n\ndef invoke_apt(\n context: Context,\n command: str,\n operation: str,\n packages: Sequence[str] = (),\n *,\n apivfs: bool = True,\n mounts: Sequence[PathString] = (),\n) -> None:\n with finalize_ephemeral_source_mounts(context.config) as sources:\n run(\n apt_cmd(context, command) + [operation, *sort_packages(packages)],\n sandbox=(\n context.sandbox(\n network=True,\n options=[\n \"--bind\", context.root, context.root,\n *finalize_package_manager_mounts(context),\n *sources,\n *mounts,\n \"--chdir\", \"/work/src\",\n ],\n ) + (apivfs_cmd(context.root) if apivfs else [])\n ),\n env=context.config.environment,\n )\n\n\ndef createrepo_apt(context: Context) -> None:\n with (context.packages / \"Packages\").open(\"wb\") as f:\n run([\"dpkg-scanpackages\", context.packages],\n stdout=f, sandbox=context.sandbox(options=[\"--ro-bind\", context.packages, context.packages]))\n\n (context.pkgmngr / \"etc/apt/sources.list.d\").mkdir(parents=True, exist_ok=True)\n (context.pkgmngr / \"etc/apt/sources.list.d/mkosi-packages.sources\").write_text(\n f\"\"\"\\\n Enabled: yes\n Types: deb\n URIs: file:///work/packages\n Suites: {context.config.release}\n Components: main\n Trusted: yes\n \"\"\"\n )\n", "path": "mkosi/installer/apt.py"}], "after_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\nimport textwrap\nfrom collections.abc import Sequence\n\nfrom mkosi.context import Context\nfrom mkosi.installer import finalize_package_manager_mounts\nfrom mkosi.mounts import finalize_ephemeral_source_mounts\nfrom mkosi.run import find_binary, run\nfrom mkosi.sandbox import apivfs_cmd\nfrom mkosi.types import PathString\nfrom mkosi.util import sort_packages, umask\n\n\ndef setup_apt(context: Context, repos: Sequence[str]) -> None:\n (context.pkgmngr / \"etc/apt\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/apt.conf.d\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/preferences.d\").mkdir(exist_ok=True, parents=True)\n (context.pkgmngr / \"etc/apt/sources.list.d\").mkdir(exist_ok=True, parents=True)\n\n # TODO: Drop once apt 2.5.4 is widely available.\n with umask(~0o755):\n (context.root / \"var/lib/dpkg\").mkdir(parents=True, exist_ok=True)\n (context.root / \"var/lib/dpkg/status\").touch()\n\n (context.cache_dir / \"lib/apt\").mkdir(exist_ok=True, parents=True)\n (context.cache_dir / \"cache/apt\").mkdir(exist_ok=True, parents=True)\n\n # We have a special apt.conf outside of pkgmngr dir that only configures \"Dir::Etc\" that we pass to APT_CONFIG to\n # tell apt it should read config files from /etc/apt in case this is overridden by distributions. This is required\n # because apt parses CLI configuration options after parsing its configuration files and as such we can't use CLI\n # options to tell apt where to look for configuration files.\n config = context.workspace / \"apt.conf\"\n if not config.exists():\n config.write_text(\n textwrap.dedent(\n \"\"\"\\\n Dir::Etc \"etc/apt\";\n \"\"\"\n )\n )\n\n sources = context.pkgmngr / \"etc/apt/sources.list\"\n if not sources.exists():\n with sources.open(\"w\") as f:\n for repo in repos:\n f.write(f\"{repo}\\n\")\n\n\ndef apt_cmd(context: Context, command: str) -> list[PathString]:\n debarch = context.config.distribution.architecture(context.config.architecture)\n\n cmdline: list[PathString] = [\n \"env\",\n f\"APT_CONFIG={context.workspace / 'apt.conf'}\",\n \"DEBIAN_FRONTEND=noninteractive\",\n \"DEBCONF_INTERACTIVE_SEEN=true\",\n \"INITRD=No\",\n command,\n \"-o\", f\"APT::Architecture={debarch}\",\n \"-o\", f\"APT::Architectures={debarch}\",\n \"-o\", f\"APT::Install-Recommends={str(context.config.with_recommends).lower()}\",\n \"-o\", \"APT::Immediate-Configure=off\",\n \"-o\", \"APT::Get::Assume-Yes=true\",\n \"-o\", \"APT::Get::AutomaticRemove=true\",\n \"-o\", \"APT::Get::Allow-Change-Held-Packages=true\",\n \"-o\", \"APT::Get::Allow-Remove-Essential=true\",\n \"-o\", \"APT::Sandbox::User=root\",\n \"-o\", \"Dir::Cache=/var/cache/apt\",\n \"-o\", \"Dir::State=/var/lib/apt\",\n \"-o\", f\"Dir::State::Status={context.root / 'var/lib/dpkg/status'}\",\n \"-o\", f\"Dir::Log={context.workspace}\",\n \"-o\", f\"Dir::Bin::DPkg={find_binary('dpkg', root=context.config.tools())}\",\n \"-o\", \"Debug::NoLocking=true\",\n \"-o\", f\"DPkg::Options::=--root={context.root}\",\n \"-o\", \"DPkg::Options::=--force-unsafe-io\",\n \"-o\", \"DPkg::Options::=--force-architecture\",\n \"-o\", \"DPkg::Options::=--force-depends\",\n \"-o\", \"DPkg::Options::=--no-debsig\",\n \"-o\", \"DPkg::Use-Pty=false\",\n \"-o\", \"DPkg::Install::Recursive::Minimum=1000\",\n \"-o\", \"pkgCacheGen::ForceEssential=,\",\n ]\n\n if not context.config.repository_key_check:\n cmdline += [\n \"-o\", \"Acquire::AllowInsecureRepositories=true\",\n \"-o\", \"Acquire::AllowDowngradeToInsecureRepositories=true\",\n \"-o\", \"APT::Get::AllowUnauthenticated=true\",\n ]\n\n if not context.config.with_docs:\n cmdline += [\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/doc/*\",\n \"-o\", \"DPkg::Options::=--path-include=/usr/share/doc/*/copyright\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/man/*\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/groff/*\",\n \"-o\", \"DPkg::Options::=--path-exclude=/usr/share/info/*\",\n ]\n\n return cmdline\n\n\ndef invoke_apt(\n context: Context,\n command: str,\n operation: str,\n packages: Sequence[str] = (),\n *,\n apivfs: bool = True,\n mounts: Sequence[PathString] = (),\n) -> None:\n with finalize_ephemeral_source_mounts(context.config) as sources:\n run(\n apt_cmd(context, command) + [operation, *sort_packages(packages)],\n sandbox=(\n context.sandbox(\n network=True,\n options=[\n \"--bind\", context.root, context.root,\n *finalize_package_manager_mounts(context),\n *sources,\n *mounts,\n \"--chdir\", \"/work/src\",\n ],\n ) + (apivfs_cmd(context.root) if apivfs else [])\n ),\n env=context.config.environment,\n )\n\n\ndef createrepo_apt(context: Context) -> None:\n with (context.packages / \"Packages\").open(\"wb\") as f:\n run([\"dpkg-scanpackages\", context.packages],\n stdout=f, sandbox=context.sandbox(options=[\"--ro-bind\", context.packages, context.packages]))\n\n (context.pkgmngr / \"etc/apt/sources.list.d\").mkdir(parents=True, exist_ok=True)\n (context.pkgmngr / \"etc/apt/sources.list.d/mkosi-packages.sources\").write_text(\n f\"\"\"\\\n Enabled: yes\n Types: deb\n URIs: file:///work/packages\n Suites: {context.config.release}\n Components: main\n Trusted: yes\n \"\"\"\n )\n", "path": "mkosi/installer/apt.py"}]}
| 2,742 | 171 |
gh_patches_debug_26903
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-6139
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use WebSocket.ping to keep connections alive across proxies
I am accessing a remote IPython Notebook and need to use a proxy (Squid/SOCKS) for internet access.
As long as I am running cells everything works fine, but after one minute of inactivity the proxy seems to close the connection, resulting in the following Firefox console log:
```
The connection to wss://example.org/kernels/$uuid/shell was interrupted while the page
was loading. @ https://example.org/static/js/kernel.js
```
The websocket connection is reestablished immediately (and interrupted again after one minute), but running cells does not work anymore until I manually restart the kernel.
```
ipython --version
0.13.1.rc2
```
Sending any message via each websocket (shell+iopub) will avoid interruption. This is a quick and _dirty_ client side workaround:
```
from IPython.core.display import HTML
HTML('''<script>
var keepalive_timer;
function keep_connection_alive() {
IPython.notebook.kernel.execute();
keepalive_timer = setTimeout('keep_connection_alive()', 55000);
}
keep_connection_alive();
</script>''')
```
WebSocket has ping and pong frames for keep-alive, tornado has a ping() function to send such a frame. Could the ping function be called somewhere in the kernel code to keep alive connections even via proxy?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/html/base/zmqhandlers.py`
Content:
```
1 """Tornado handlers for WebSocket <-> ZMQ sockets."""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 import json
7
8 try:
9 from urllib.parse import urlparse # Py 3
10 except ImportError:
11 from urlparse import urlparse # Py 2
12
13 try:
14 from http.cookies import SimpleCookie # Py 3
15 except ImportError:
16 from Cookie import SimpleCookie # Py 2
17 import logging
18
19 import tornado
20 from tornado import web
21 from tornado import websocket
22
23 from IPython.kernel.zmq.session import Session
24 from IPython.utils.jsonutil import date_default
25 from IPython.utils.py3compat import PY3, cast_unicode
26
27 from .handlers import IPythonHandler
28
29
30 class ZMQStreamHandler(websocket.WebSocketHandler):
31
32 def check_origin(self, origin):
33 """Check Origin == Host or Access-Control-Allow-Origin.
34
35 Tornado >= 4 calls this method automatically, raising 403 if it returns False.
36 We call it explicitly in `open` on Tornado < 4.
37 """
38 if self.allow_origin == '*':
39 return True
40
41 host = self.request.headers.get("Host")
42
43 # If no header is provided, assume we can't verify origin
44 if(origin is None or host is None):
45 return False
46
47 host_origin = "{0}://{1}".format(self.request.protocol, host)
48
49 # OK if origin matches host
50 if origin == host_origin:
51 return True
52
53 # Check CORS headers
54 if self.allow_origin:
55 return self.allow_origin == origin
56 elif self.allow_origin_pat:
57 return bool(self.allow_origin_pat.match(origin))
58 else:
59 # No CORS headers deny the request
60 return False
61
62 def clear_cookie(self, *args, **kwargs):
63 """meaningless for websockets"""
64 pass
65
66 def _reserialize_reply(self, msg_list):
67 """Reserialize a reply message using JSON.
68
69 This takes the msg list from the ZMQ socket, unserializes it using
70 self.session and then serializes the result using JSON. This method
71 should be used by self._on_zmq_reply to build messages that can
72 be sent back to the browser.
73 """
74 idents, msg_list = self.session.feed_identities(msg_list)
75 msg = self.session.unserialize(msg_list)
76 try:
77 msg['header'].pop('date')
78 except KeyError:
79 pass
80 try:
81 msg['parent_header'].pop('date')
82 except KeyError:
83 pass
84 msg.pop('buffers')
85 return json.dumps(msg, default=date_default)
86
87 def _on_zmq_reply(self, msg_list):
88 # Sometimes this gets triggered when the on_close method is scheduled in the
89 # eventloop but hasn't been called.
90 if self.stream.closed(): return
91 try:
92 msg = self._reserialize_reply(msg_list)
93 except Exception:
94 self.log.critical("Malformed message: %r" % msg_list, exc_info=True)
95 else:
96 self.write_message(msg)
97
98 def allow_draft76(self):
99 """Allow draft 76, until browsers such as Safari update to RFC 6455.
100
101 This has been disabled by default in tornado in release 2.2.0, and
102 support will be removed in later versions.
103 """
104 return True
105
106
107 class AuthenticatedZMQStreamHandler(ZMQStreamHandler, IPythonHandler):
108 def set_default_headers(self):
109 """Undo the set_default_headers in IPythonHandler
110
111 which doesn't make sense for websockets
112 """
113 pass
114
115 def open(self, kernel_id):
116 self.kernel_id = cast_unicode(kernel_id, 'ascii')
117 # Check to see that origin matches host directly, including ports
118 # Tornado 4 already does CORS checking
119 if tornado.version_info[0] < 4:
120 if not self.check_origin(self.get_origin()):
121 self.log.warn("Cross Origin WebSocket Attempt from %s", self.get_origin())
122 raise web.HTTPError(403)
123
124 self.session = Session(config=self.config)
125 self.save_on_message = self.on_message
126 self.on_message = self.on_first_message
127
128 def _inject_cookie_message(self, msg):
129 """Inject the first message, which is the document cookie,
130 for authentication."""
131 if not PY3 and isinstance(msg, unicode):
132 # Cookie constructor doesn't accept unicode strings
133 # under Python 2.x for some reason
134 msg = msg.encode('utf8', 'replace')
135 try:
136 identity, msg = msg.split(':', 1)
137 self.session.session = cast_unicode(identity, 'ascii')
138 except Exception:
139 logging.error("First ws message didn't have the form 'identity:[cookie]' - %r", msg)
140
141 try:
142 self.request._cookies = SimpleCookie(msg)
143 except:
144 self.log.warn("couldn't parse cookie string: %s",msg, exc_info=True)
145
146 def on_first_message(self, msg):
147 self._inject_cookie_message(msg)
148 if self.get_current_user() is None:
149 self.log.warn("Couldn't authenticate WebSocket connection")
150 raise web.HTTPError(403)
151 self.on_message = self.save_on_message
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/html/base/zmqhandlers.py b/IPython/html/base/zmqhandlers.py
--- a/IPython/html/base/zmqhandlers.py
+++ b/IPython/html/base/zmqhandlers.py
@@ -17,6 +17,7 @@
import logging
import tornado
+from tornado import ioloop
from tornado import web
from tornado import websocket
@@ -103,8 +104,12 @@
"""
return True
+# ping interval for keeping websockets alive (30 seconds)
+WS_PING_INTERVAL = 30000
class AuthenticatedZMQStreamHandler(ZMQStreamHandler, IPythonHandler):
+ ping_callback = None
+
def set_default_headers(self):
"""Undo the set_default_headers in IPythonHandler
@@ -124,6 +129,16 @@
self.session = Session(config=self.config)
self.save_on_message = self.on_message
self.on_message = self.on_first_message
+ self.ping_callback = ioloop.PeriodicCallback(self.send_ping, WS_PING_INTERVAL)
+ self.ping_callback.start()
+
+ def send_ping(self):
+ """send a ping to keep the websocket alive"""
+ if self.stream.closed() and self.ping_callback is not None:
+ self.ping_callback.stop()
+ return
+
+ self.ping(b'')
def _inject_cookie_message(self, msg):
"""Inject the first message, which is the document cookie,
|
{"golden_diff": "diff --git a/IPython/html/base/zmqhandlers.py b/IPython/html/base/zmqhandlers.py\n--- a/IPython/html/base/zmqhandlers.py\n+++ b/IPython/html/base/zmqhandlers.py\n@@ -17,6 +17,7 @@\n import logging\n \n import tornado\n+from tornado import ioloop\n from tornado import web\n from tornado import websocket\n \n@@ -103,8 +104,12 @@\n \"\"\"\n return True\n \n+# ping interval for keeping websockets alive (30 seconds)\n+WS_PING_INTERVAL = 30000\n \n class AuthenticatedZMQStreamHandler(ZMQStreamHandler, IPythonHandler):\n+ ping_callback = None\n+\n def set_default_headers(self):\n \"\"\"Undo the set_default_headers in IPythonHandler\n \n@@ -124,6 +129,16 @@\n self.session = Session(config=self.config)\n self.save_on_message = self.on_message\n self.on_message = self.on_first_message\n+ self.ping_callback = ioloop.PeriodicCallback(self.send_ping, WS_PING_INTERVAL)\n+ self.ping_callback.start()\n+\n+ def send_ping(self):\n+ \"\"\"send a ping to keep the websocket alive\"\"\"\n+ if self.stream.closed() and self.ping_callback is not None:\n+ self.ping_callback.stop()\n+ return\n+\n+ self.ping(b'')\n \n def _inject_cookie_message(self, msg):\n \"\"\"Inject the first message, which is the document cookie,\n", "issue": "Use WebSocket.ping to keep connections alive across proxies\nI am accessing a remote IPython Notebook and need to use a proxy (Squid/SOCKS) for internet access.\nAs long as I am running cells everything works fine, but after one minute of inactivity the proxy seems to close the connection, resulting in the following Firefox console log:\n\n```\nThe connection to wss://example.org/kernels/$uuid/shell was interrupted while the page \nwas loading. @ https://example.org/static/js/kernel.js\n```\n\nThe websocket connection is reestablished immediately (and interrupted again after one minute), but running cells does not work anymore until I manually restart the kernel.\n\n```\nipython --version\n0.13.1.rc2\n```\n\nSending any message via each websocket (shell+iopub) will avoid interruption. This is a quick and _dirty_ client side workaround:\n\n```\nfrom IPython.core.display import HTML\nHTML('''<script>\nvar keepalive_timer;\nfunction keep_connection_alive() {\n IPython.notebook.kernel.execute();\n keepalive_timer = setTimeout('keep_connection_alive()', 55000);\n}\nkeep_connection_alive();\n</script>''')\n```\n\nWebSocket has ping and pong frames for keep-alive, tornado has a ping() function to send such a frame. Could the ping function be called somewhere in the kernel code to keep alive connections even via proxy?\n\n", "before_files": [{"content": "\"\"\"Tornado handlers for WebSocket <-> ZMQ sockets.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\ntry:\n from urllib.parse import urlparse # Py 3\nexcept ImportError:\n from urlparse import urlparse # Py 2\n\ntry:\n from http.cookies import SimpleCookie # Py 3\nexcept ImportError:\n from Cookie import SimpleCookie # Py 2\nimport logging\n\nimport tornado\nfrom tornado import web\nfrom tornado import websocket\n\nfrom IPython.kernel.zmq.session import Session\nfrom IPython.utils.jsonutil import date_default\nfrom IPython.utils.py3compat import PY3, cast_unicode\n\nfrom .handlers import IPythonHandler\n\n\nclass ZMQStreamHandler(websocket.WebSocketHandler):\n \n def check_origin(self, origin):\n \"\"\"Check Origin == Host or Access-Control-Allow-Origin.\n \n Tornado >= 4 calls this method automatically, raising 403 if it returns False.\n We call it explicitly in `open` on Tornado < 4.\n \"\"\"\n if self.allow_origin == '*':\n return True\n\n host = self.request.headers.get(\"Host\")\n\n # If no header is provided, assume we can't verify origin\n if(origin is None or host is None):\n return False\n \n host_origin = \"{0}://{1}\".format(self.request.protocol, host)\n \n # OK if origin matches host\n if origin == host_origin:\n return True\n \n # Check CORS headers\n if self.allow_origin:\n return self.allow_origin == origin\n elif self.allow_origin_pat:\n return bool(self.allow_origin_pat.match(origin))\n else:\n # No CORS headers deny the request\n return False\n\n def clear_cookie(self, *args, **kwargs):\n \"\"\"meaningless for websockets\"\"\"\n pass\n\n def _reserialize_reply(self, msg_list):\n \"\"\"Reserialize a reply message using JSON.\n\n This takes the msg list from the ZMQ socket, unserializes it using\n self.session and then serializes the result using JSON. This method\n should be used by self._on_zmq_reply to build messages that can\n be sent back to the browser.\n \"\"\"\n idents, msg_list = self.session.feed_identities(msg_list)\n msg = self.session.unserialize(msg_list)\n try:\n msg['header'].pop('date')\n except KeyError:\n pass\n try:\n msg['parent_header'].pop('date')\n except KeyError:\n pass\n msg.pop('buffers')\n return json.dumps(msg, default=date_default)\n\n def _on_zmq_reply(self, msg_list):\n # Sometimes this gets triggered when the on_close method is scheduled in the\n # eventloop but hasn't been called.\n if self.stream.closed(): return\n try:\n msg = self._reserialize_reply(msg_list)\n except Exception:\n self.log.critical(\"Malformed message: %r\" % msg_list, exc_info=True)\n else:\n self.write_message(msg)\n\n def allow_draft76(self):\n \"\"\"Allow draft 76, until browsers such as Safari update to RFC 6455.\n \n This has been disabled by default in tornado in release 2.2.0, and\n support will be removed in later versions.\n \"\"\"\n return True\n\n\nclass AuthenticatedZMQStreamHandler(ZMQStreamHandler, IPythonHandler):\n def set_default_headers(self):\n \"\"\"Undo the set_default_headers in IPythonHandler\n \n which doesn't make sense for websockets\n \"\"\"\n pass\n\n def open(self, kernel_id):\n self.kernel_id = cast_unicode(kernel_id, 'ascii')\n # Check to see that origin matches host directly, including ports\n # Tornado 4 already does CORS checking\n if tornado.version_info[0] < 4:\n if not self.check_origin(self.get_origin()):\n self.log.warn(\"Cross Origin WebSocket Attempt from %s\", self.get_origin())\n raise web.HTTPError(403)\n\n self.session = Session(config=self.config)\n self.save_on_message = self.on_message\n self.on_message = self.on_first_message\n\n def _inject_cookie_message(self, msg):\n \"\"\"Inject the first message, which is the document cookie,\n for authentication.\"\"\"\n if not PY3 and isinstance(msg, unicode):\n # Cookie constructor doesn't accept unicode strings\n # under Python 2.x for some reason\n msg = msg.encode('utf8', 'replace')\n try:\n identity, msg = msg.split(':', 1)\n self.session.session = cast_unicode(identity, 'ascii')\n except Exception:\n logging.error(\"First ws message didn't have the form 'identity:[cookie]' - %r\", msg)\n \n try:\n self.request._cookies = SimpleCookie(msg)\n except:\n self.log.warn(\"couldn't parse cookie string: %s\",msg, exc_info=True)\n\n def on_first_message(self, msg):\n self._inject_cookie_message(msg)\n if self.get_current_user() is None:\n self.log.warn(\"Couldn't authenticate WebSocket connection\")\n raise web.HTTPError(403)\n self.on_message = self.save_on_message\n", "path": "IPython/html/base/zmqhandlers.py"}], "after_files": [{"content": "\"\"\"Tornado handlers for WebSocket <-> ZMQ sockets.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\ntry:\n from urllib.parse import urlparse # Py 3\nexcept ImportError:\n from urlparse import urlparse # Py 2\n\ntry:\n from http.cookies import SimpleCookie # Py 3\nexcept ImportError:\n from Cookie import SimpleCookie # Py 2\nimport logging\n\nimport tornado\nfrom tornado import ioloop\nfrom tornado import web\nfrom tornado import websocket\n\nfrom IPython.kernel.zmq.session import Session\nfrom IPython.utils.jsonutil import date_default\nfrom IPython.utils.py3compat import PY3, cast_unicode\n\nfrom .handlers import IPythonHandler\n\n\nclass ZMQStreamHandler(websocket.WebSocketHandler):\n \n def check_origin(self, origin):\n \"\"\"Check Origin == Host or Access-Control-Allow-Origin.\n \n Tornado >= 4 calls this method automatically, raising 403 if it returns False.\n We call it explicitly in `open` on Tornado < 4.\n \"\"\"\n if self.allow_origin == '*':\n return True\n\n host = self.request.headers.get(\"Host\")\n\n # If no header is provided, assume we can't verify origin\n if(origin is None or host is None):\n return False\n \n host_origin = \"{0}://{1}\".format(self.request.protocol, host)\n \n # OK if origin matches host\n if origin == host_origin:\n return True\n \n # Check CORS headers\n if self.allow_origin:\n return self.allow_origin == origin\n elif self.allow_origin_pat:\n return bool(self.allow_origin_pat.match(origin))\n else:\n # No CORS headers deny the request\n return False\n\n def clear_cookie(self, *args, **kwargs):\n \"\"\"meaningless for websockets\"\"\"\n pass\n\n def _reserialize_reply(self, msg_list):\n \"\"\"Reserialize a reply message using JSON.\n\n This takes the msg list from the ZMQ socket, unserializes it using\n self.session and then serializes the result using JSON. This method\n should be used by self._on_zmq_reply to build messages that can\n be sent back to the browser.\n \"\"\"\n idents, msg_list = self.session.feed_identities(msg_list)\n msg = self.session.unserialize(msg_list)\n try:\n msg['header'].pop('date')\n except KeyError:\n pass\n try:\n msg['parent_header'].pop('date')\n except KeyError:\n pass\n msg.pop('buffers')\n return json.dumps(msg, default=date_default)\n\n def _on_zmq_reply(self, msg_list):\n # Sometimes this gets triggered when the on_close method is scheduled in the\n # eventloop but hasn't been called.\n if self.stream.closed(): return\n try:\n msg = self._reserialize_reply(msg_list)\n except Exception:\n self.log.critical(\"Malformed message: %r\" % msg_list, exc_info=True)\n else:\n self.write_message(msg)\n\n def allow_draft76(self):\n \"\"\"Allow draft 76, until browsers such as Safari update to RFC 6455.\n \n This has been disabled by default in tornado in release 2.2.0, and\n support will be removed in later versions.\n \"\"\"\n return True\n\n# ping interval for keeping websockets alive (30 seconds)\nWS_PING_INTERVAL = 30000\n\nclass AuthenticatedZMQStreamHandler(ZMQStreamHandler, IPythonHandler):\n ping_callback = None\n\n def set_default_headers(self):\n \"\"\"Undo the set_default_headers in IPythonHandler\n \n which doesn't make sense for websockets\n \"\"\"\n pass\n\n def open(self, kernel_id):\n self.kernel_id = cast_unicode(kernel_id, 'ascii')\n # Check to see that origin matches host directly, including ports\n # Tornado 4 already does CORS checking\n if tornado.version_info[0] < 4:\n if not self.check_origin(self.get_origin()):\n self.log.warn(\"Cross Origin WebSocket Attempt from %s\", self.get_origin())\n raise web.HTTPError(403)\n\n self.session = Session(config=self.config)\n self.save_on_message = self.on_message\n self.on_message = self.on_first_message\n self.ping_callback = ioloop.PeriodicCallback(self.send_ping, WS_PING_INTERVAL)\n self.ping_callback.start()\n\n def send_ping(self):\n \"\"\"send a ping to keep the websocket alive\"\"\"\n if self.stream.closed() and self.ping_callback is not None:\n self.ping_callback.stop()\n return\n\n self.ping(b'')\n\n def _inject_cookie_message(self, msg):\n \"\"\"Inject the first message, which is the document cookie,\n for authentication.\"\"\"\n if not PY3 and isinstance(msg, unicode):\n # Cookie constructor doesn't accept unicode strings\n # under Python 2.x for some reason\n msg = msg.encode('utf8', 'replace')\n try:\n identity, msg = msg.split(':', 1)\n self.session.session = cast_unicode(identity, 'ascii')\n except Exception:\n logging.error(\"First ws message didn't have the form 'identity:[cookie]' - %r\", msg)\n \n try:\n self.request._cookies = SimpleCookie(msg)\n except:\n self.log.warn(\"couldn't parse cookie string: %s\",msg, exc_info=True)\n\n def on_first_message(self, msg):\n self._inject_cookie_message(msg)\n if self.get_current_user() is None:\n self.log.warn(\"Couldn't authenticate WebSocket connection\")\n raise web.HTTPError(403)\n self.on_message = self.save_on_message\n", "path": "IPython/html/base/zmqhandlers.py"}]}
| 2,023 | 322 |
gh_patches_debug_2257
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-204
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Numbers should be safe characters in file names
If the attachment for the "Exercise with attachment" is named for example "2.zip", the name for that file will be just ".zip" in the database because numbers are not considered as safe characters:
https://github.com/Aalto-LeTech/a-plus/blob/a86bf/lib/helpers.py#L62
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/helpers.py`
Content:
```
1 from django.conf import settings
2 from random import choice
3 from PIL import Image
4 import string
5 import urllib
6
7
8 def extract_form_errors(form):
9 """
10 Extracts Django form errors to a list of error messages.
11 """
12 errors = []
13 for field in form.errors:
14 for err in form.errors[field]:
15 errors.append("%s: %s" % (field, err))
16 return errors
17
18
19 def get_random_string(length=32):
20 """
21 This function creates a random string with a given length.
22 The strings consist of upper and lower case letters and numbers.
23
24 @param length: the length of the randomized string, defaults to 32
25 @return: a random string containing lower and upper case letters and digits
26 """
27
28 # Use all letters and numbers in the identifier
29 choices = string.ascii_letters + string.digits
30
31 return ''.join([choice(choices) for _ in range(length)])
32
33
34 def query_dict_to_list_of_tuples(query_dict):
35 """
36 This helper function creates a list of tuples with the values
37 from a QueryDict object. In a QueryDict the same key can have
38 several values, which is not possible with a typical dict nor a JSON
39 object. The resulting list will be similar to [(key1, value1), (key2, value2)].
40
41 @param query_dict: a QueryDict object
42 @return: a list of tuples with the same keys and values as in the given QueryDict
43 """
44 list_of_tuples = []
45 for key in query_dict:
46 for val in query_dict.getlist(key):
47 list_of_tuples.append((key, val))
48 return list_of_tuples
49
50
51 def update_url_params(url, params):
52 delimiter = "&" if "?" in url else "?"
53 return url + delimiter + urllib.parse.urlencode(params)
54
55
56 def has_same_domain(url1, url2):
57 uri1 = urllib.parse.urlparse(url1)
58 uri2 = urllib.parse.urlparse(url2)
59 return uri1.netloc == uri2.netloc
60
61
62 FILENAME_CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-"
63
64 def safe_file_name(name):
65 safename = "".join(c for c in name if c in FILENAME_CHARS)
66 if safename[0] == "-":
67 return "_" + safename[1:80]
68 return safename[:80]
69
70
71 def resize_image(path, max_size):
72 image = Image.open(path)
73 image.thumbnail(max_size, Image.ANTIALIAS)
74 image.save(path)
75
76
77 def roman_numeral(number):
78 numbers = [1000,900,500,400,100,90,50,40,10,9,5,4,1];
79 letters = ["M","CM","D","CD","C","XC","L","XL","X","IX","V","IV","I"];
80 roman = ""
81 for i in range(len(numbers)):
82 while number >= numbers[i]:
83 roman += letters[i]
84 number -= numbers[i]
85 return roman
86
87
88 def settings_text(request, key):
89 def get(name):
90 if hasattr(settings, name):
91 return getattr(settings, name)
92 return None
93 return get('{}_{}'.format(key, request.LANGUAGE_CODE.upper())) or get(key)
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/helpers.py b/lib/helpers.py
--- a/lib/helpers.py
+++ b/lib/helpers.py
@@ -59,7 +59,7 @@
return uri1.netloc == uri2.netloc
-FILENAME_CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-"
+FILENAME_CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-0123456789"
def safe_file_name(name):
safename = "".join(c for c in name if c in FILENAME_CHARS)
|
{"golden_diff": "diff --git a/lib/helpers.py b/lib/helpers.py\n--- a/lib/helpers.py\n+++ b/lib/helpers.py\n@@ -59,7 +59,7 @@\n return uri1.netloc == uri2.netloc\n \n \n-FILENAME_CHARS = \"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-\"\n+FILENAME_CHARS = \"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-0123456789\"\n \n def safe_file_name(name):\n safename = \"\".join(c for c in name if c in FILENAME_CHARS)\n", "issue": "Numbers should be safe characters in file names\nIf the attachment for the \"Exercise with attachment\" is named for example \"2.zip\", the name for that file will be just \".zip\" in the database because numbers are not considered as safe characters:\n\nhttps://github.com/Aalto-LeTech/a-plus/blob/a86bf/lib/helpers.py#L62\n\n", "before_files": [{"content": "from django.conf import settings\nfrom random import choice\nfrom PIL import Image\nimport string\nimport urllib\n\n\ndef extract_form_errors(form):\n \"\"\"\n Extracts Django form errors to a list of error messages.\n \"\"\"\n errors = []\n for field in form.errors:\n for err in form.errors[field]:\n errors.append(\"%s: %s\" % (field, err))\n return errors\n\n\ndef get_random_string(length=32):\n \"\"\"\n This function creates a random string with a given length.\n The strings consist of upper and lower case letters and numbers.\n\n @param length: the length of the randomized string, defaults to 32\n @return: a random string containing lower and upper case letters and digits\n \"\"\"\n\n # Use all letters and numbers in the identifier\n choices = string.ascii_letters + string.digits\n\n return ''.join([choice(choices) for _ in range(length)])\n\n\ndef query_dict_to_list_of_tuples(query_dict):\n \"\"\"\n This helper function creates a list of tuples with the values\n from a QueryDict object. In a QueryDict the same key can have\n several values, which is not possible with a typical dict nor a JSON\n object. The resulting list will be similar to [(key1, value1), (key2, value2)].\n\n @param query_dict: a QueryDict object\n @return: a list of tuples with the same keys and values as in the given QueryDict\n \"\"\"\n list_of_tuples = []\n for key in query_dict:\n for val in query_dict.getlist(key):\n list_of_tuples.append((key, val))\n return list_of_tuples\n\n\ndef update_url_params(url, params):\n delimiter = \"&\" if \"?\" in url else \"?\"\n return url + delimiter + urllib.parse.urlencode(params)\n\n\ndef has_same_domain(url1, url2):\n uri1 = urllib.parse.urlparse(url1)\n uri2 = urllib.parse.urlparse(url2)\n return uri1.netloc == uri2.netloc\n\n\nFILENAME_CHARS = \"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-\"\n\ndef safe_file_name(name):\n safename = \"\".join(c for c in name if c in FILENAME_CHARS)\n if safename[0] == \"-\":\n return \"_\" + safename[1:80]\n return safename[:80]\n\n\ndef resize_image(path, max_size):\n image = Image.open(path)\n image.thumbnail(max_size, Image.ANTIALIAS)\n image.save(path)\n\n\ndef roman_numeral(number):\n numbers = [1000,900,500,400,100,90,50,40,10,9,5,4,1];\n letters = [\"M\",\"CM\",\"D\",\"CD\",\"C\",\"XC\",\"L\",\"XL\",\"X\",\"IX\",\"V\",\"IV\",\"I\"];\n roman = \"\"\n for i in range(len(numbers)):\n while number >= numbers[i]:\n roman += letters[i]\n number -= numbers[i]\n return roman\n\n\ndef settings_text(request, key):\n def get(name):\n if hasattr(settings, name):\n return getattr(settings, name)\n return None\n return get('{}_{}'.format(key, request.LANGUAGE_CODE.upper())) or get(key)\n", "path": "lib/helpers.py"}], "after_files": [{"content": "from django.conf import settings\nfrom random import choice\nfrom PIL import Image\nimport string\nimport urllib\n\n\ndef extract_form_errors(form):\n \"\"\"\n Extracts Django form errors to a list of error messages.\n \"\"\"\n errors = []\n for field in form.errors:\n for err in form.errors[field]:\n errors.append(\"%s: %s\" % (field, err))\n return errors\n\n\ndef get_random_string(length=32):\n \"\"\"\n This function creates a random string with a given length.\n The strings consist of upper and lower case letters and numbers.\n\n @param length: the length of the randomized string, defaults to 32\n @return: a random string containing lower and upper case letters and digits\n \"\"\"\n\n # Use all letters and numbers in the identifier\n choices = string.ascii_letters + string.digits\n\n return ''.join([choice(choices) for _ in range(length)])\n\n\ndef query_dict_to_list_of_tuples(query_dict):\n \"\"\"\n This helper function creates a list of tuples with the values\n from a QueryDict object. In a QueryDict the same key can have\n several values, which is not possible with a typical dict nor a JSON\n object. The resulting list will be similar to [(key1, value1), (key2, value2)].\n\n @param query_dict: a QueryDict object\n @return: a list of tuples with the same keys and values as in the given QueryDict\n \"\"\"\n list_of_tuples = []\n for key in query_dict:\n for val in query_dict.getlist(key):\n list_of_tuples.append((key, val))\n return list_of_tuples\n\n\ndef update_url_params(url, params):\n delimiter = \"&\" if \"?\" in url else \"?\"\n return url + delimiter + urllib.parse.urlencode(params)\n\n\ndef has_same_domain(url1, url2):\n uri1 = urllib.parse.urlparse(url1)\n uri2 = urllib.parse.urlparse(url2)\n return uri1.netloc == uri2.netloc\n\n\nFILENAME_CHARS = \"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._-0123456789\"\n\ndef safe_file_name(name):\n safename = \"\".join(c for c in name if c in FILENAME_CHARS)\n if safename[0] == \"-\":\n return \"_\" + safename[1:80]\n return safename[:80]\n\n\ndef resize_image(path, max_size):\n image = Image.open(path)\n image.thumbnail(max_size, Image.ANTIALIAS)\n image.save(path)\n\n\ndef roman_numeral(number):\n numbers = [1000,900,500,400,100,90,50,40,10,9,5,4,1];\n letters = [\"M\",\"CM\",\"D\",\"CD\",\"C\",\"XC\",\"L\",\"XL\",\"X\",\"IX\",\"V\",\"IV\",\"I\"];\n roman = \"\"\n for i in range(len(numbers)):\n while number >= numbers[i]:\n roman += letters[i]\n number -= numbers[i]\n return roman\n\n\ndef settings_text(request, key):\n def get(name):\n if hasattr(settings, name):\n return getattr(settings, name)\n return None\n return get('{}_{}'.format(key, request.LANGUAGE_CODE.upper())) or get(key)\n", "path": "lib/helpers.py"}]}
| 1,216 | 104 |
gh_patches_debug_10343
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-3671
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Copying items not work correctly with list values
> > item = Item()
> > item['some_field'] = []
> >
> > c_item = Item(item)
> > c_item['some_field'].append(1)
> >
> > print item['some_field'], c_item['some_field']
> > [1] [1]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/item.py`
Content:
```
1 """
2 Scrapy Item
3
4 See documentation in docs/topics/item.rst
5 """
6
7 from pprint import pformat
8 from collections import MutableMapping
9
10 from abc import ABCMeta
11 import six
12
13 from scrapy.utils.trackref import object_ref
14
15
16 class BaseItem(object_ref):
17 """Base class for all scraped items."""
18 pass
19
20
21 class Field(dict):
22 """Container of field metadata"""
23
24
25 class ItemMeta(ABCMeta):
26
27 def __new__(mcs, class_name, bases, attrs):
28 classcell = attrs.pop('__classcell__', None)
29 new_bases = tuple(base._class for base in bases if hasattr(base, '_class'))
30 _class = super(ItemMeta, mcs).__new__(mcs, 'x_' + class_name, new_bases, attrs)
31
32 fields = getattr(_class, 'fields', {})
33 new_attrs = {}
34 for n in dir(_class):
35 v = getattr(_class, n)
36 if isinstance(v, Field):
37 fields[n] = v
38 elif n in attrs:
39 new_attrs[n] = attrs[n]
40
41 new_attrs['fields'] = fields
42 new_attrs['_class'] = _class
43 if classcell is not None:
44 new_attrs['__classcell__'] = classcell
45 return super(ItemMeta, mcs).__new__(mcs, class_name, bases, new_attrs)
46
47
48 class DictItem(MutableMapping, BaseItem):
49
50 fields = {}
51
52 def __init__(self, *args, **kwargs):
53 self._values = {}
54 if args or kwargs: # avoid creating dict for most common case
55 for k, v in six.iteritems(dict(*args, **kwargs)):
56 self[k] = v
57
58 def __getitem__(self, key):
59 return self._values[key]
60
61 def __setitem__(self, key, value):
62 if key in self.fields:
63 self._values[key] = value
64 else:
65 raise KeyError("%s does not support field: %s" %
66 (self.__class__.__name__, key))
67
68 def __delitem__(self, key):
69 del self._values[key]
70
71 def __getattr__(self, name):
72 if name in self.fields:
73 raise AttributeError("Use item[%r] to get field value" % name)
74 raise AttributeError(name)
75
76 def __setattr__(self, name, value):
77 if not name.startswith('_'):
78 raise AttributeError("Use item[%r] = %r to set field value" %
79 (name, value))
80 super(DictItem, self).__setattr__(name, value)
81
82 def __len__(self):
83 return len(self._values)
84
85 def __iter__(self):
86 return iter(self._values)
87
88 __hash__ = BaseItem.__hash__
89
90 def keys(self):
91 return self._values.keys()
92
93 def __repr__(self):
94 return pformat(dict(self))
95
96 def copy(self):
97 return self.__class__(self)
98
99
100 @six.add_metaclass(ItemMeta)
101 class Item(DictItem):
102 pass
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/item.py b/scrapy/item.py
--- a/scrapy/item.py
+++ b/scrapy/item.py
@@ -6,6 +6,7 @@
from pprint import pformat
from collections import MutableMapping
+from copy import deepcopy
from abc import ABCMeta
import six
@@ -96,6 +97,13 @@
def copy(self):
return self.__class__(self)
+ def deepcopy(self):
+ """Return a `deep copy`_ of this item.
+
+ .. _deep copy: https://docs.python.org/library/copy.html#copy.deepcopy
+ """
+ return deepcopy(self)
+
@six.add_metaclass(ItemMeta)
class Item(DictItem):
|
{"golden_diff": "diff --git a/scrapy/item.py b/scrapy/item.py\n--- a/scrapy/item.py\n+++ b/scrapy/item.py\n@@ -6,6 +6,7 @@\n \n from pprint import pformat\n from collections import MutableMapping\n+from copy import deepcopy\n \n from abc import ABCMeta\n import six\n@@ -96,6 +97,13 @@\n def copy(self):\n return self.__class__(self)\n \n+ def deepcopy(self):\n+ \"\"\"Return a `deep copy`_ of this item.\n+\n+ .. _deep copy: https://docs.python.org/library/copy.html#copy.deepcopy\n+ \"\"\"\n+ return deepcopy(self)\n+\n \n @six.add_metaclass(ItemMeta)\n class Item(DictItem):\n", "issue": "Copying items not work correctly with list values\n> > item = Item()\n> > item['some_field'] = []\n> > \n> > c_item = Item(item)\n> > c_item['some_field'].append(1)\n> > \n> > print item['some_field'], c_item['some_field']\n> > [1] [1]\n\n", "before_files": [{"content": "\"\"\"\nScrapy Item\n\nSee documentation in docs/topics/item.rst\n\"\"\"\n\nfrom pprint import pformat\nfrom collections import MutableMapping\n\nfrom abc import ABCMeta\nimport six\n\nfrom scrapy.utils.trackref import object_ref\n\n\nclass BaseItem(object_ref):\n \"\"\"Base class for all scraped items.\"\"\"\n pass\n\n\nclass Field(dict):\n \"\"\"Container of field metadata\"\"\"\n\n\nclass ItemMeta(ABCMeta):\n\n def __new__(mcs, class_name, bases, attrs):\n classcell = attrs.pop('__classcell__', None)\n new_bases = tuple(base._class for base in bases if hasattr(base, '_class'))\n _class = super(ItemMeta, mcs).__new__(mcs, 'x_' + class_name, new_bases, attrs)\n\n fields = getattr(_class, 'fields', {})\n new_attrs = {}\n for n in dir(_class):\n v = getattr(_class, n)\n if isinstance(v, Field):\n fields[n] = v\n elif n in attrs:\n new_attrs[n] = attrs[n]\n\n new_attrs['fields'] = fields\n new_attrs['_class'] = _class\n if classcell is not None:\n new_attrs['__classcell__'] = classcell\n return super(ItemMeta, mcs).__new__(mcs, class_name, bases, new_attrs)\n\n\nclass DictItem(MutableMapping, BaseItem):\n\n fields = {}\n\n def __init__(self, *args, **kwargs):\n self._values = {}\n if args or kwargs: # avoid creating dict for most common case\n for k, v in six.iteritems(dict(*args, **kwargs)):\n self[k] = v\n\n def __getitem__(self, key):\n return self._values[key]\n\n def __setitem__(self, key, value):\n if key in self.fields:\n self._values[key] = value\n else:\n raise KeyError(\"%s does not support field: %s\" %\n (self.__class__.__name__, key))\n\n def __delitem__(self, key):\n del self._values[key]\n\n def __getattr__(self, name):\n if name in self.fields:\n raise AttributeError(\"Use item[%r] to get field value\" % name)\n raise AttributeError(name)\n\n def __setattr__(self, name, value):\n if not name.startswith('_'):\n raise AttributeError(\"Use item[%r] = %r to set field value\" %\n (name, value))\n super(DictItem, self).__setattr__(name, value)\n\n def __len__(self):\n return len(self._values)\n\n def __iter__(self):\n return iter(self._values)\n\n __hash__ = BaseItem.__hash__\n\n def keys(self):\n return self._values.keys()\n\n def __repr__(self):\n return pformat(dict(self))\n\n def copy(self):\n return self.__class__(self)\n\n\[email protected]_metaclass(ItemMeta)\nclass Item(DictItem):\n pass\n", "path": "scrapy/item.py"}], "after_files": [{"content": "\"\"\"\nScrapy Item\n\nSee documentation in docs/topics/item.rst\n\"\"\"\n\nfrom pprint import pformat\nfrom collections import MutableMapping\nfrom copy import deepcopy\n\nfrom abc import ABCMeta\nimport six\n\nfrom scrapy.utils.trackref import object_ref\n\n\nclass BaseItem(object_ref):\n \"\"\"Base class for all scraped items.\"\"\"\n pass\n\n\nclass Field(dict):\n \"\"\"Container of field metadata\"\"\"\n\n\nclass ItemMeta(ABCMeta):\n\n def __new__(mcs, class_name, bases, attrs):\n classcell = attrs.pop('__classcell__', None)\n new_bases = tuple(base._class for base in bases if hasattr(base, '_class'))\n _class = super(ItemMeta, mcs).__new__(mcs, 'x_' + class_name, new_bases, attrs)\n\n fields = getattr(_class, 'fields', {})\n new_attrs = {}\n for n in dir(_class):\n v = getattr(_class, n)\n if isinstance(v, Field):\n fields[n] = v\n elif n in attrs:\n new_attrs[n] = attrs[n]\n\n new_attrs['fields'] = fields\n new_attrs['_class'] = _class\n if classcell is not None:\n new_attrs['__classcell__'] = classcell\n return super(ItemMeta, mcs).__new__(mcs, class_name, bases, new_attrs)\n\n\nclass DictItem(MutableMapping, BaseItem):\n\n fields = {}\n\n def __init__(self, *args, **kwargs):\n self._values = {}\n if args or kwargs: # avoid creating dict for most common case\n for k, v in six.iteritems(dict(*args, **kwargs)):\n self[k] = v\n\n def __getitem__(self, key):\n return self._values[key]\n\n def __setitem__(self, key, value):\n if key in self.fields:\n self._values[key] = value\n else:\n raise KeyError(\"%s does not support field: %s\" %\n (self.__class__.__name__, key))\n\n def __delitem__(self, key):\n del self._values[key]\n\n def __getattr__(self, name):\n if name in self.fields:\n raise AttributeError(\"Use item[%r] to get field value\" % name)\n raise AttributeError(name)\n\n def __setattr__(self, name, value):\n if not name.startswith('_'):\n raise AttributeError(\"Use item[%r] = %r to set field value\" %\n (name, value))\n super(DictItem, self).__setattr__(name, value)\n\n def __len__(self):\n return len(self._values)\n\n def __iter__(self):\n return iter(self._values)\n\n __hash__ = BaseItem.__hash__\n\n def keys(self):\n return self._values.keys()\n\n def __repr__(self):\n return pformat(dict(self))\n\n def copy(self):\n return self.__class__(self)\n\n def deepcopy(self):\n \"\"\"Return a `deep copy`_ of this item.\n\n .. _deep copy: https://docs.python.org/library/copy.html#copy.deepcopy\n \"\"\"\n return deepcopy(self)\n\n\[email protected]_metaclass(ItemMeta)\nclass Item(DictItem):\n pass\n", "path": "scrapy/item.py"}]}
| 1,187 | 159 |
gh_patches_debug_26731
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-3497
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clipboard implementation leads to wrong logs when choosing sdl2 or gtk3
https://gist.github.com/anonymous/1dfd55b91a319b2e1393
Courtesy Dessant for reporting.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kivy/core/clipboard/__init__.py`
Content:
```
1 '''
2 Clipboard
3 =========
4
5 Core class for accessing the Clipboard. If we are not able to access the
6 system clipboard, a fake one will be used.
7
8 Usage example::
9
10 >>> from kivy.core.clipboard import Clipboard
11 >>> Clipboard.get_types()
12 ['TIMESTAMP', 'TARGETS', 'MULTIPLE', 'SAVE_TARGETS', 'UTF8_STRING',
13 'COMPOUND_TEXT', 'TEXT', 'STRING', 'text/plain;charset=utf-8',
14 'text/plain']
15 >>> Clipboard.get('TEXT')
16 'Hello World'
17 >>> Clipboard.put('Great', 'UTF8_STRING')
18 >>> Clipboard.get_types()
19 ['UTF8_STRING']
20 >>> Clipboard.get('UTF8_STRING')
21 'Great'
22
23 .. note:: The main implementation relies on Pygame and works well with
24 text/strings. Anything else might not work the same on all platforms.
25 '''
26
27 __all__ = ('ClipboardBase', 'Clipboard')
28
29 from kivy import Logger
30 from kivy.core import core_select_lib
31 from kivy.utils import platform
32 from kivy.setupconfig import USE_SDL2
33
34
35 class ClipboardBase(object):
36
37 def get(self, mimetype):
38 '''Get the current data in clipboard, using the mimetype if possible.
39 You not use this method directly. Use :meth:`paste` instead.
40 '''
41 return None
42
43 def put(self, data, mimetype):
44 '''Put data on the clipboard, and attach a mimetype.
45 You should not use this method directly. Use :meth:`copy` instead.
46 '''
47 pass
48
49 def get_types(self):
50 '''Return a list of supported mimetypes
51 '''
52 return []
53
54 def _ensure_clipboard(self):
55 ''' Ensure that the clipboard has been properly initialised.
56 '''
57
58 if hasattr(self, '_clip_mime_type'):
59 return
60
61 if platform == 'win':
62 self._clip_mime_type = 'text/plain;charset=utf-8'
63 # windows clipboard uses a utf-16 little endian encoding
64 self._encoding = 'utf-16-le'
65 elif platform == 'linux':
66 self._clip_mime_type = 'text/plain;charset=utf-8'
67 self._encoding = 'utf-8'
68 else:
69 self._clip_mime_type = 'text/plain'
70 self._encoding = 'utf-8'
71
72 def copy(self, data=''):
73 ''' Copy the value provided in argument `data` into current clipboard.
74 If data is not of type string it will be converted to string.
75
76 .. versionadded:: 1.9.0
77
78 '''
79 if data:
80 self._copy(data)
81
82 def paste(self):
83 ''' Get text from the system clipboard and return it a usable string.
84
85 .. versionadded:: 1.9.0
86
87 '''
88 return self._paste()
89
90 def _copy(self, data):
91 # explicitly terminate strings with a null character
92 # so as to avoid putting spurious data after the end.
93 # MS windows issue.
94 self._ensure_clipboard()
95 if not isinstance(data, bytes):
96 data = data.encode(self._encoding)
97 if platform == 'win':
98 data += b'\x00'
99 self.put(data, self._clip_mime_type)
100
101 def _paste(self):
102 self._ensure_clipboard()
103 _clip_types = Clipboard.get_types()
104
105 mime_type = self._clip_mime_type
106 if mime_type not in _clip_types:
107 mime_type = 'text/plain'
108
109 data = self.get(mime_type)
110 if data is not None:
111 # decode only if we don't have unicode
112 # we would still need to decode from utf-16 (windows)
113 # data is of type bytes in PY3
114 if isinstance(data, bytes):
115 data = data.decode(self._encoding, 'ignore')
116 # remove null strings mostly a windows issue
117 data = data.replace(u'\x00', u'')
118 return data
119 return u''
120
121
122 # load clipboard implementation
123 _clipboards = []
124 if platform == 'android':
125 _clipboards.append(
126 ('android', 'clipboard_android', 'ClipboardAndroid'))
127 elif platform == 'macosx':
128 _clipboards.append(
129 ('nspaste', 'clipboard_nspaste', 'ClipboardNSPaste'))
130 elif platform == 'win':
131 _clipboards.append(
132 ('winctypes', 'clipboard_winctypes', 'ClipboardWindows'))
133 elif platform == 'linux':
134 _clipboards.append(
135 ('dbusklipper', 'clipboard_dbusklipper', 'ClipboardDbusKlipper'))
136 _clipboards.append(
137 ('gtk3', 'clipboard_gtk3', 'ClipboardGtk3'))
138 _clipboards.append(
139 ('xclip', 'clipboard_xclip', 'ClipboardXclip'))
140 _clipboards.append(
141 ('xsel', 'clipboard_xsel', 'ClipboardXsel'))
142
143 if USE_SDL2:
144 _clipboards.append(
145 ('sdl2', 'clipboard_sdl2', 'ClipboardSDL2'))
146 else:
147 _clipboards.append(
148 ('pygame', 'clipboard_pygame', 'ClipboardPygame'))
149
150 _clipboards.append(
151 ('dummy', 'clipboard_dummy', 'ClipboardDummy'))
152
153 Clipboard = core_select_lib('clipboard', _clipboards, True)
154 CutBuffer = None
155
156 if platform == 'linux':
157 _cutbuffers = [
158 ('xclip', 'clipboard_xclip', 'ClipboardXclip'),
159 ('xsel', 'clipboard_xsel', 'ClipboardXsel'),
160 ]
161
162 if Clipboard.__class__.__name__ in (c[2] for c in _cutbuffers):
163 CutBuffer = Clipboard
164 else:
165 CutBuffer = core_select_lib('clipboard', _cutbuffers, True)
166
167 if CutBuffer:
168 Logger.info('CutBuffer: cut buffer support enabled')
169
```
Path: `kivy/core/__init__.py`
Content:
```
1 '''
2 Core Abstraction
3 ================
4
5 This module defines the abstraction layers for our core providers and their
6 implementations. For further information, please refer to
7 :ref:`architecture` and the :ref:`providers` section of the documentation.
8
9 In most cases, you shouldn't directly use a library that's already covered
10 by the core abstraction. Always try to use our providers first.
11 In case we are missing a feature or method, please let us know by
12 opening a new Bug report instead of relying on your library.
13
14 .. warning::
15 These are **not** widgets! These are just abstractions of the respective
16 functionality. For example, you cannot add a core image to your window.
17 You have to use the image **widget** class instead. If you're really
18 looking for widgets, please refer to :mod:`kivy.uix` instead.
19 '''
20
21
22 import os
23 import sys
24 import traceback
25 import kivy
26 from kivy.logger import Logger
27
28
29 class CoreCriticalException(Exception):
30 pass
31
32
33 def core_select_lib(category, llist, create_instance=False, base='kivy.core'):
34 if 'KIVY_DOC' in os.environ:
35 return
36 category = category.lower()
37 libs_ignored = []
38 errs = []
39 for option, modulename, classname in llist:
40 try:
41 # module activated in config ?
42 try:
43 if option not in kivy.kivy_options[category]:
44 libs_ignored.append(modulename)
45 Logger.debug(
46 '{0}: Provider <{1}> ignored by config'.format(
47 category.capitalize(), option))
48 continue
49 except KeyError:
50 pass
51
52 # import module
53 mod = __import__(name='{2}.{0}.{1}'.format(
54 category, modulename, base),
55 globals=globals(),
56 locals=locals(),
57 fromlist=[modulename], level=0)
58 cls = mod.__getattribute__(classname)
59
60 # ok !
61 Logger.info('{0}: Provider: {1}{2}'.format(
62 category.capitalize(), option,
63 '({0} ignored)'.format(libs_ignored) if libs_ignored else ''))
64 if create_instance:
65 cls = cls()
66 return cls
67
68 except ImportError as e:
69 errs.append((option, e, sys.exc_info()[2]))
70 libs_ignored.append(modulename)
71 Logger.debug('{0}: Ignored <{1}> (import error)'.format(
72 category.capitalize(), option))
73 Logger.trace('', exc_info=e)
74
75 except CoreCriticalException as e:
76 errs.append((option, e, sys.exc_info()[2]))
77 Logger.error('{0}: Unable to use {1}'.format(
78 category.capitalize(), option))
79 Logger.error(
80 '{0}: The module raised an important error: {1!r}'.format(
81 category.capitalize(), e.message))
82 raise
83
84 except Exception as e:
85 errs.append((option, e, sys.exc_info()[2]))
86 libs_ignored.append(modulename)
87 Logger.trace('{0}: Unable to use {1}'.format(
88 category.capitalize(), option, category))
89 Logger.trace('', exc_info=e)
90
91 err = '\n'.join(['{} - {}: {}\n{}'.format(opt, e.__class__.__name__, e,
92 ''.join(traceback.format_tb(tb))) for opt, e, tb in errs])
93 Logger.critical(
94 '{0}: Unable to find any valuable {0} provider at all!\n{1}'.format(
95 category.capitalize(), err))
96
97
98 def core_register_libs(category, libs, base='kivy.core'):
99 if 'KIVY_DOC' in os.environ:
100 return
101 category = category.lower()
102 kivy_options = kivy.kivy_options[category]
103 libs_loadable = {}
104 libs_ignored = []
105
106 for option, lib in libs:
107 # module activated in config ?
108 if option not in kivy_options:
109 Logger.debug('{0}: option <{1}> ignored by config'.format(
110 category.capitalize(), option))
111 libs_ignored.append(lib)
112 continue
113 libs_loadable[option] = lib
114
115 libs_loaded = []
116 for item in kivy_options:
117 try:
118 # import module
119 try:
120 lib = libs_loadable[item]
121 except KeyError:
122 continue
123 __import__(name='{2}.{0}.{1}'.format(category, lib, base),
124 globals=globals(),
125 locals=locals(),
126 fromlist=[lib],
127 level=0)
128
129 libs_loaded.append(lib)
130
131 except Exception as e:
132 Logger.trace('{0}: Unable to use <{1}> as loader!'.format(
133 category.capitalize(), option))
134 Logger.trace('', exc_info=e)
135 libs_ignored.append(lib)
136
137 Logger.info('{0}: Providers: {1} {2}'.format(
138 category.capitalize(),
139 ', '.join(libs_loaded),
140 '({0} ignored)'.format(
141 ', '.join(libs_ignored)) if libs_ignored else ''))
142 return libs_loaded
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kivy/core/__init__.py b/kivy/core/__init__.py
--- a/kivy/core/__init__.py
+++ b/kivy/core/__init__.py
@@ -30,10 +30,11 @@
pass
-def core_select_lib(category, llist, create_instance=False, base='kivy.core'):
+def core_select_lib(category, llist, create_instance=False, base='kivy.core', basemodule=None):
if 'KIVY_DOC' in os.environ:
return
category = category.lower()
+ basemodule = basemodule or category
libs_ignored = []
errs = []
for option, modulename, classname in llist:
@@ -51,7 +52,7 @@
# import module
mod = __import__(name='{2}.{0}.{1}'.format(
- category, modulename, base),
+ basemodule, modulename, base),
globals=globals(),
locals=locals(),
fromlist=[modulename], level=0)
diff --git a/kivy/core/clipboard/__init__.py b/kivy/core/clipboard/__init__.py
--- a/kivy/core/clipboard/__init__.py
+++ b/kivy/core/clipboard/__init__.py
@@ -162,7 +162,7 @@
if Clipboard.__class__.__name__ in (c[2] for c in _cutbuffers):
CutBuffer = Clipboard
else:
- CutBuffer = core_select_lib('clipboard', _cutbuffers, True)
+ CutBuffer = core_select_lib('cutbuffer', _cutbuffers, True, basemodule='clipboard')
if CutBuffer:
Logger.info('CutBuffer: cut buffer support enabled')
|
{"golden_diff": "diff --git a/kivy/core/__init__.py b/kivy/core/__init__.py\n--- a/kivy/core/__init__.py\n+++ b/kivy/core/__init__.py\n@@ -30,10 +30,11 @@\n pass\n \n \n-def core_select_lib(category, llist, create_instance=False, base='kivy.core'):\n+def core_select_lib(category, llist, create_instance=False, base='kivy.core', basemodule=None):\n if 'KIVY_DOC' in os.environ:\n return\n category = category.lower()\n+ basemodule = basemodule or category\n libs_ignored = []\n errs = []\n for option, modulename, classname in llist:\n@@ -51,7 +52,7 @@\n \n # import module\n mod = __import__(name='{2}.{0}.{1}'.format(\n- category, modulename, base),\n+ basemodule, modulename, base),\n globals=globals(),\n locals=locals(),\n fromlist=[modulename], level=0)\ndiff --git a/kivy/core/clipboard/__init__.py b/kivy/core/clipboard/__init__.py\n--- a/kivy/core/clipboard/__init__.py\n+++ b/kivy/core/clipboard/__init__.py\n@@ -162,7 +162,7 @@\n if Clipboard.__class__.__name__ in (c[2] for c in _cutbuffers):\n CutBuffer = Clipboard\n else:\n- CutBuffer = core_select_lib('clipboard', _cutbuffers, True)\n+ CutBuffer = core_select_lib('cutbuffer', _cutbuffers, True, basemodule='clipboard')\n \n if CutBuffer:\n Logger.info('CutBuffer: cut buffer support enabled')\n", "issue": "Clipboard implementation leads to wrong logs when choosing sdl2 or gtk3\nhttps://gist.github.com/anonymous/1dfd55b91a319b2e1393\nCourtesy Dessant for reporting.\n\n", "before_files": [{"content": "'''\nClipboard\n=========\n\nCore class for accessing the Clipboard. If we are not able to access the\nsystem clipboard, a fake one will be used.\n\nUsage example::\n\n >>> from kivy.core.clipboard import Clipboard\n >>> Clipboard.get_types()\n ['TIMESTAMP', 'TARGETS', 'MULTIPLE', 'SAVE_TARGETS', 'UTF8_STRING',\n 'COMPOUND_TEXT', 'TEXT', 'STRING', 'text/plain;charset=utf-8',\n 'text/plain']\n >>> Clipboard.get('TEXT')\n 'Hello World'\n >>> Clipboard.put('Great', 'UTF8_STRING')\n >>> Clipboard.get_types()\n ['UTF8_STRING']\n >>> Clipboard.get('UTF8_STRING')\n 'Great'\n\n.. note:: The main implementation relies on Pygame and works well with\n text/strings. Anything else might not work the same on all platforms.\n'''\n\n__all__ = ('ClipboardBase', 'Clipboard')\n\nfrom kivy import Logger\nfrom kivy.core import core_select_lib\nfrom kivy.utils import platform\nfrom kivy.setupconfig import USE_SDL2\n\n\nclass ClipboardBase(object):\n\n def get(self, mimetype):\n '''Get the current data in clipboard, using the mimetype if possible.\n You not use this method directly. Use :meth:`paste` instead.\n '''\n return None\n\n def put(self, data, mimetype):\n '''Put data on the clipboard, and attach a mimetype.\n You should not use this method directly. Use :meth:`copy` instead.\n '''\n pass\n\n def get_types(self):\n '''Return a list of supported mimetypes\n '''\n return []\n\n def _ensure_clipboard(self):\n ''' Ensure that the clipboard has been properly initialised.\n '''\n\n if hasattr(self, '_clip_mime_type'):\n return\n\n if platform == 'win':\n self._clip_mime_type = 'text/plain;charset=utf-8'\n # windows clipboard uses a utf-16 little endian encoding\n self._encoding = 'utf-16-le'\n elif platform == 'linux':\n self._clip_mime_type = 'text/plain;charset=utf-8'\n self._encoding = 'utf-8'\n else:\n self._clip_mime_type = 'text/plain'\n self._encoding = 'utf-8'\n\n def copy(self, data=''):\n ''' Copy the value provided in argument `data` into current clipboard.\n If data is not of type string it will be converted to string.\n\n .. versionadded:: 1.9.0\n\n '''\n if data:\n self._copy(data)\n\n def paste(self):\n ''' Get text from the system clipboard and return it a usable string.\n\n .. versionadded:: 1.9.0\n\n '''\n return self._paste()\n\n def _copy(self, data):\n # explicitly terminate strings with a null character\n # so as to avoid putting spurious data after the end.\n # MS windows issue.\n self._ensure_clipboard()\n if not isinstance(data, bytes):\n data = data.encode(self._encoding)\n if platform == 'win':\n data += b'\\x00'\n self.put(data, self._clip_mime_type)\n\n def _paste(self):\n self._ensure_clipboard()\n _clip_types = Clipboard.get_types()\n\n mime_type = self._clip_mime_type\n if mime_type not in _clip_types:\n mime_type = 'text/plain'\n\n data = self.get(mime_type)\n if data is not None:\n # decode only if we don't have unicode\n # we would still need to decode from utf-16 (windows)\n # data is of type bytes in PY3\n if isinstance(data, bytes):\n data = data.decode(self._encoding, 'ignore')\n # remove null strings mostly a windows issue\n data = data.replace(u'\\x00', u'')\n return data\n return u''\n\n\n# load clipboard implementation\n_clipboards = []\nif platform == 'android':\n _clipboards.append(\n ('android', 'clipboard_android', 'ClipboardAndroid'))\nelif platform == 'macosx':\n _clipboards.append(\n ('nspaste', 'clipboard_nspaste', 'ClipboardNSPaste'))\nelif platform == 'win':\n _clipboards.append(\n ('winctypes', 'clipboard_winctypes', 'ClipboardWindows'))\nelif platform == 'linux':\n _clipboards.append(\n ('dbusklipper', 'clipboard_dbusklipper', 'ClipboardDbusKlipper'))\n _clipboards.append(\n ('gtk3', 'clipboard_gtk3', 'ClipboardGtk3'))\n _clipboards.append(\n ('xclip', 'clipboard_xclip', 'ClipboardXclip'))\n _clipboards.append(\n ('xsel', 'clipboard_xsel', 'ClipboardXsel'))\n\nif USE_SDL2:\n _clipboards.append(\n ('sdl2', 'clipboard_sdl2', 'ClipboardSDL2'))\nelse:\n _clipboards.append(\n ('pygame', 'clipboard_pygame', 'ClipboardPygame'))\n\n_clipboards.append(\n ('dummy', 'clipboard_dummy', 'ClipboardDummy'))\n\nClipboard = core_select_lib('clipboard', _clipboards, True)\nCutBuffer = None\n\nif platform == 'linux':\n _cutbuffers = [\n ('xclip', 'clipboard_xclip', 'ClipboardXclip'),\n ('xsel', 'clipboard_xsel', 'ClipboardXsel'),\n ]\n\n if Clipboard.__class__.__name__ in (c[2] for c in _cutbuffers):\n CutBuffer = Clipboard\n else:\n CutBuffer = core_select_lib('clipboard', _cutbuffers, True)\n\n if CutBuffer:\n Logger.info('CutBuffer: cut buffer support enabled')\n", "path": "kivy/core/clipboard/__init__.py"}, {"content": "'''\nCore Abstraction\n================\n\nThis module defines the abstraction layers for our core providers and their\nimplementations. For further information, please refer to\n:ref:`architecture` and the :ref:`providers` section of the documentation.\n\nIn most cases, you shouldn't directly use a library that's already covered\nby the core abstraction. Always try to use our providers first.\nIn case we are missing a feature or method, please let us know by\nopening a new Bug report instead of relying on your library.\n\n.. warning::\n These are **not** widgets! These are just abstractions of the respective\n functionality. For example, you cannot add a core image to your window.\n You have to use the image **widget** class instead. If you're really\n looking for widgets, please refer to :mod:`kivy.uix` instead.\n'''\n\n\nimport os\nimport sys\nimport traceback\nimport kivy\nfrom kivy.logger import Logger\n\n\nclass CoreCriticalException(Exception):\n pass\n\n\ndef core_select_lib(category, llist, create_instance=False, base='kivy.core'):\n if 'KIVY_DOC' in os.environ:\n return\n category = category.lower()\n libs_ignored = []\n errs = []\n for option, modulename, classname in llist:\n try:\n # module activated in config ?\n try:\n if option not in kivy.kivy_options[category]:\n libs_ignored.append(modulename)\n Logger.debug(\n '{0}: Provider <{1}> ignored by config'.format(\n category.capitalize(), option))\n continue\n except KeyError:\n pass\n\n # import module\n mod = __import__(name='{2}.{0}.{1}'.format(\n category, modulename, base),\n globals=globals(),\n locals=locals(),\n fromlist=[modulename], level=0)\n cls = mod.__getattribute__(classname)\n\n # ok !\n Logger.info('{0}: Provider: {1}{2}'.format(\n category.capitalize(), option,\n '({0} ignored)'.format(libs_ignored) if libs_ignored else ''))\n if create_instance:\n cls = cls()\n return cls\n\n except ImportError as e:\n errs.append((option, e, sys.exc_info()[2]))\n libs_ignored.append(modulename)\n Logger.debug('{0}: Ignored <{1}> (import error)'.format(\n category.capitalize(), option))\n Logger.trace('', exc_info=e)\n\n except CoreCriticalException as e:\n errs.append((option, e, sys.exc_info()[2]))\n Logger.error('{0}: Unable to use {1}'.format(\n category.capitalize(), option))\n Logger.error(\n '{0}: The module raised an important error: {1!r}'.format(\n category.capitalize(), e.message))\n raise\n\n except Exception as e:\n errs.append((option, e, sys.exc_info()[2]))\n libs_ignored.append(modulename)\n Logger.trace('{0}: Unable to use {1}'.format(\n category.capitalize(), option, category))\n Logger.trace('', exc_info=e)\n\n err = '\\n'.join(['{} - {}: {}\\n{}'.format(opt, e.__class__.__name__, e,\n ''.join(traceback.format_tb(tb))) for opt, e, tb in errs])\n Logger.critical(\n '{0}: Unable to find any valuable {0} provider at all!\\n{1}'.format(\n category.capitalize(), err))\n\n\ndef core_register_libs(category, libs, base='kivy.core'):\n if 'KIVY_DOC' in os.environ:\n return\n category = category.lower()\n kivy_options = kivy.kivy_options[category]\n libs_loadable = {}\n libs_ignored = []\n\n for option, lib in libs:\n # module activated in config ?\n if option not in kivy_options:\n Logger.debug('{0}: option <{1}> ignored by config'.format(\n category.capitalize(), option))\n libs_ignored.append(lib)\n continue\n libs_loadable[option] = lib\n\n libs_loaded = []\n for item in kivy_options:\n try:\n # import module\n try:\n lib = libs_loadable[item]\n except KeyError:\n continue\n __import__(name='{2}.{0}.{1}'.format(category, lib, base),\n globals=globals(),\n locals=locals(),\n fromlist=[lib],\n level=0)\n\n libs_loaded.append(lib)\n\n except Exception as e:\n Logger.trace('{0}: Unable to use <{1}> as loader!'.format(\n category.capitalize(), option))\n Logger.trace('', exc_info=e)\n libs_ignored.append(lib)\n\n Logger.info('{0}: Providers: {1} {2}'.format(\n category.capitalize(),\n ', '.join(libs_loaded),\n '({0} ignored)'.format(\n ', '.join(libs_ignored)) if libs_ignored else ''))\n return libs_loaded\n", "path": "kivy/core/__init__.py"}], "after_files": [{"content": "'''\nClipboard\n=========\n\nCore class for accessing the Clipboard. If we are not able to access the\nsystem clipboard, a fake one will be used.\n\nUsage example::\n\n >>> from kivy.core.clipboard import Clipboard\n >>> Clipboard.get_types()\n ['TIMESTAMP', 'TARGETS', 'MULTIPLE', 'SAVE_TARGETS', 'UTF8_STRING',\n 'COMPOUND_TEXT', 'TEXT', 'STRING', 'text/plain;charset=utf-8',\n 'text/plain']\n >>> Clipboard.get('TEXT')\n 'Hello World'\n >>> Clipboard.put('Great', 'UTF8_STRING')\n >>> Clipboard.get_types()\n ['UTF8_STRING']\n >>> Clipboard.get('UTF8_STRING')\n 'Great'\n\n.. note:: The main implementation relies on Pygame and works well with\n text/strings. Anything else might not work the same on all platforms.\n'''\n\n__all__ = ('ClipboardBase', 'Clipboard')\n\nfrom kivy import Logger\nfrom kivy.core import core_select_lib\nfrom kivy.utils import platform\nfrom kivy.setupconfig import USE_SDL2\n\n\nclass ClipboardBase(object):\n\n def get(self, mimetype):\n '''Get the current data in clipboard, using the mimetype if possible.\n You not use this method directly. Use :meth:`paste` instead.\n '''\n return None\n\n def put(self, data, mimetype):\n '''Put data on the clipboard, and attach a mimetype.\n You should not use this method directly. Use :meth:`copy` instead.\n '''\n pass\n\n def get_types(self):\n '''Return a list of supported mimetypes\n '''\n return []\n\n def _ensure_clipboard(self):\n ''' Ensure that the clipboard has been properly initialised.\n '''\n\n if hasattr(self, '_clip_mime_type'):\n return\n\n if platform == 'win':\n self._clip_mime_type = 'text/plain;charset=utf-8'\n # windows clipboard uses a utf-16 little endian encoding\n self._encoding = 'utf-16-le'\n elif platform == 'linux':\n self._clip_mime_type = 'text/plain;charset=utf-8'\n self._encoding = 'utf-8'\n else:\n self._clip_mime_type = 'text/plain'\n self._encoding = 'utf-8'\n\n def copy(self, data=''):\n ''' Copy the value provided in argument `data` into current clipboard.\n If data is not of type string it will be converted to string.\n\n .. versionadded:: 1.9.0\n\n '''\n if data:\n self._copy(data)\n\n def paste(self):\n ''' Get text from the system clipboard and return it a usable string.\n\n .. versionadded:: 1.9.0\n\n '''\n return self._paste()\n\n def _copy(self, data):\n # explicitly terminate strings with a null character\n # so as to avoid putting spurious data after the end.\n # MS windows issue.\n self._ensure_clipboard()\n if not isinstance(data, bytes):\n data = data.encode(self._encoding)\n if platform == 'win':\n data += b'\\x00'\n self.put(data, self._clip_mime_type)\n\n def _paste(self):\n self._ensure_clipboard()\n _clip_types = Clipboard.get_types()\n\n mime_type = self._clip_mime_type\n if mime_type not in _clip_types:\n mime_type = 'text/plain'\n\n data = self.get(mime_type)\n if data is not None:\n # decode only if we don't have unicode\n # we would still need to decode from utf-16 (windows)\n # data is of type bytes in PY3\n if isinstance(data, bytes):\n data = data.decode(self._encoding, 'ignore')\n # remove null strings mostly a windows issue\n data = data.replace(u'\\x00', u'')\n return data\n return u''\n\n\n# load clipboard implementation\n_clipboards = []\nif platform == 'android':\n _clipboards.append(\n ('android', 'clipboard_android', 'ClipboardAndroid'))\nelif platform == 'macosx':\n _clipboards.append(\n ('nspaste', 'clipboard_nspaste', 'ClipboardNSPaste'))\nelif platform == 'win':\n _clipboards.append(\n ('winctypes', 'clipboard_winctypes', 'ClipboardWindows'))\nelif platform == 'linux':\n _clipboards.append(\n ('dbusklipper', 'clipboard_dbusklipper', 'ClipboardDbusKlipper'))\n _clipboards.append(\n ('gtk3', 'clipboard_gtk3', 'ClipboardGtk3'))\n _clipboards.append(\n ('xclip', 'clipboard_xclip', 'ClipboardXclip'))\n _clipboards.append(\n ('xsel', 'clipboard_xsel', 'ClipboardXsel'))\n\nif USE_SDL2:\n _clipboards.append(\n ('sdl2', 'clipboard_sdl2', 'ClipboardSDL2'))\nelse:\n _clipboards.append(\n ('pygame', 'clipboard_pygame', 'ClipboardPygame'))\n\n_clipboards.append(\n ('dummy', 'clipboard_dummy', 'ClipboardDummy'))\n\nClipboard = core_select_lib('clipboard', _clipboards, True)\nCutBuffer = None\n\nif platform == 'linux':\n _cutbuffers = [\n ('xclip', 'clipboard_xclip', 'ClipboardXclip'),\n ('xsel', 'clipboard_xsel', 'ClipboardXsel'),\n ]\n\n if Clipboard.__class__.__name__ in (c[2] for c in _cutbuffers):\n CutBuffer = Clipboard\n else:\n CutBuffer = core_select_lib('cutbuffer', _cutbuffers, True, basemodule='clipboard')\n\n if CutBuffer:\n Logger.info('CutBuffer: cut buffer support enabled')\n", "path": "kivy/core/clipboard/__init__.py"}, {"content": "'''\nCore Abstraction\n================\n\nThis module defines the abstraction layers for our core providers and their\nimplementations. For further information, please refer to\n:ref:`architecture` and the :ref:`providers` section of the documentation.\n\nIn most cases, you shouldn't directly use a library that's already covered\nby the core abstraction. Always try to use our providers first.\nIn case we are missing a feature or method, please let us know by\nopening a new Bug report instead of relying on your library.\n\n.. warning::\n These are **not** widgets! These are just abstractions of the respective\n functionality. For example, you cannot add a core image to your window.\n You have to use the image **widget** class instead. If you're really\n looking for widgets, please refer to :mod:`kivy.uix` instead.\n'''\n\n\nimport os\nimport sys\nimport traceback\nimport kivy\nfrom kivy.logger import Logger\n\n\nclass CoreCriticalException(Exception):\n pass\n\n\ndef core_select_lib(category, llist, create_instance=False, base='kivy.core', basemodule=None):\n if 'KIVY_DOC' in os.environ:\n return\n category = category.lower()\n basemodule = basemodule or category\n libs_ignored = []\n errs = []\n for option, modulename, classname in llist:\n try:\n # module activated in config ?\n try:\n if option not in kivy.kivy_options[category]:\n libs_ignored.append(modulename)\n Logger.debug(\n '{0}: Provider <{1}> ignored by config'.format(\n category.capitalize(), option))\n continue\n except KeyError:\n pass\n\n # import module\n mod = __import__(name='{2}.{0}.{1}'.format(\n basemodule, modulename, base),\n globals=globals(),\n locals=locals(),\n fromlist=[modulename], level=0)\n cls = mod.__getattribute__(classname)\n\n # ok !\n Logger.info('{0}: Provider: {1}{2}'.format(\n category.capitalize(), option,\n '({0} ignored)'.format(libs_ignored) if libs_ignored else ''))\n if create_instance:\n cls = cls()\n return cls\n\n except ImportError as e:\n errs.append((option, e, sys.exc_info()[2]))\n libs_ignored.append(modulename)\n Logger.debug('{0}: Ignored <{1}> (import error)'.format(\n category.capitalize(), option))\n Logger.trace('', exc_info=e)\n\n except CoreCriticalException as e:\n errs.append((option, e, sys.exc_info()[2]))\n Logger.error('{0}: Unable to use {1}'.format(\n category.capitalize(), option))\n Logger.error(\n '{0}: The module raised an important error: {1!r}'.format(\n category.capitalize(), e.message))\n raise\n\n except Exception as e:\n errs.append((option, e, sys.exc_info()[2]))\n libs_ignored.append(modulename)\n Logger.trace('{0}: Unable to use {1}'.format(\n category.capitalize(), option, category))\n Logger.trace('', exc_info=e)\n\n err = '\\n'.join(['{} - {}: {}\\n{}'.format(opt, e.__class__.__name__, e,\n ''.join(traceback.format_tb(tb))) for opt, e, tb in errs])\n Logger.critical(\n '{0}: Unable to find any valuable {0} provider at all!\\n{1}'.format(\n category.capitalize(), err))\n\n\ndef core_register_libs(category, libs, base='kivy.core'):\n if 'KIVY_DOC' in os.environ:\n return\n category = category.lower()\n kivy_options = kivy.kivy_options[category]\n libs_loadable = {}\n libs_ignored = []\n\n for option, lib in libs:\n # module activated in config ?\n if option not in kivy_options:\n Logger.debug('{0}: option <{1}> ignored by config'.format(\n category.capitalize(), option))\n libs_ignored.append(lib)\n continue\n libs_loadable[option] = lib\n\n libs_loaded = []\n for item in kivy_options:\n try:\n # import module\n try:\n lib = libs_loadable[item]\n except KeyError:\n continue\n __import__(name='{2}.{0}.{1}'.format(category, lib, base),\n globals=globals(),\n locals=locals(),\n fromlist=[lib],\n level=0)\n\n libs_loaded.append(lib)\n\n except Exception as e:\n Logger.trace('{0}: Unable to use <{1}> as loader!'.format(\n category.capitalize(), option))\n Logger.trace('', exc_info=e)\n libs_ignored.append(lib)\n\n Logger.info('{0}: Providers: {1} {2}'.format(\n category.capitalize(),\n ', '.join(libs_loaded),\n '({0} ignored)'.format(\n ', '.join(libs_ignored)) if libs_ignored else ''))\n return libs_loaded\n", "path": "kivy/core/__init__.py"}]}
| 3,360 | 387 |
gh_patches_debug_24337
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-258
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Faker should provide company VAT numbers
It would be nice if faker could provide company VAT numbers. More information about VAT codes is in Wikipedia: https://en.wikipedia.org/wiki/VAT_identification_number
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/company/fi_FI/__init__.py`
Content:
```
1 from __future__ import unicode_literals
2 from .. import Provider as CompanyProvider
3
4
5 class Provider(CompanyProvider):
6 formats = (
7 '{{last_name}} {{company_suffix}}',
8 '{{last_name}} {{last_name}} {{company_suffix}}',
9 '{{last_name}} {{last_name}} {{company_suffix}}',
10 '{{last_name}}'
11 )
12
13 company_suffixes = (
14 'As Oy', 'Tmi', 'Oy', 'Oyj', 'Ky', 'Osk', 'ry'
15 )
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/company/fi_FI/__init__.py b/faker/providers/company/fi_FI/__init__.py
--- a/faker/providers/company/fi_FI/__init__.py
+++ b/faker/providers/company/fi_FI/__init__.py
@@ -13,3 +13,41 @@
company_suffixes = (
'As Oy', 'Tmi', 'Oy', 'Oyj', 'Ky', 'Osk', 'ry'
)
+
+ def company_business_id(self):
+ """
+ Returns Finnish company Business Identity Code (y-tunnus).
+ Format is 8 digits - e.g. FI99999999,[8] last digit is a check
+ digit utilizing MOD 11-2. The first digit is zero for some old
+ organizations. This function provides current codes starting with
+ non-zero.
+ """
+ def calculate_checksum(number):
+ """Calculate the checksum using mod 11,2 method"""
+ factors = [7, 9, 10, 5, 8, 4, 2]
+ sum = 0
+ for x, y in zip(number, factors):
+ sum = sum + int(x) * y
+ if sum % 11 == 0:
+ return '0'
+ else:
+ return str(11 - sum % 11)
+
+ first_digit = str(self.random_digit_not_null())
+ body = first_digit + self.bothify(self.random_element(('######',)))
+ cs = calculate_checksum(body)
+ return (body + '-' + str(cs))
+
+ def company_vat(self):
+ """
+ Returns Finnish VAT identification number (Arvonlisaveronumero).
+ This can be calculated from company business identity code by
+ adding prefix "FI" and removing dash before checksum.
+ """
+ def convert_to_vat(business_id):
+ """
+ Convert business id to VATIN
+ """
+ return 'FI' + business_id.replace('-', '')
+
+ return convert_to_vat(self.company_business_id())
|
{"golden_diff": "diff --git a/faker/providers/company/fi_FI/__init__.py b/faker/providers/company/fi_FI/__init__.py\n--- a/faker/providers/company/fi_FI/__init__.py\n+++ b/faker/providers/company/fi_FI/__init__.py\n@@ -13,3 +13,41 @@\n company_suffixes = (\n 'As Oy', 'Tmi', 'Oy', 'Oyj', 'Ky', 'Osk', 'ry'\n )\n+\n+ def company_business_id(self):\n+ \"\"\"\n+ Returns Finnish company Business Identity Code (y-tunnus).\n+ Format is 8 digits - e.g. FI99999999,[8] last digit is a check\n+ digit utilizing MOD 11-2. The first digit is zero for some old\n+ organizations. This function provides current codes starting with\n+ non-zero.\n+ \"\"\"\n+ def calculate_checksum(number):\n+ \"\"\"Calculate the checksum using mod 11,2 method\"\"\"\n+ factors = [7, 9, 10, 5, 8, 4, 2]\n+ sum = 0\n+ for x, y in zip(number, factors):\n+ sum = sum + int(x) * y\n+ if sum % 11 == 0:\n+ return '0'\n+ else:\n+ return str(11 - sum % 11)\n+\n+ first_digit = str(self.random_digit_not_null())\n+ body = first_digit + self.bothify(self.random_element(('######',)))\n+ cs = calculate_checksum(body)\n+ return (body + '-' + str(cs))\n+\n+ def company_vat(self):\n+ \"\"\"\n+ Returns Finnish VAT identification number (Arvonlisaveronumero).\n+ This can be calculated from company business identity code by\n+ adding prefix \"FI\" and removing dash before checksum.\n+ \"\"\"\n+ def convert_to_vat(business_id):\n+ \"\"\"\n+ Convert business id to VATIN\n+ \"\"\"\n+ return 'FI' + business_id.replace('-', '')\n+\n+ return convert_to_vat(self.company_business_id())\n", "issue": "Faker should provide company VAT numbers\nIt would be nice if faker could provide company VAT numbers. More information about VAT codes is in Wikipedia: https://en.wikipedia.org/wiki/VAT_identification_number\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom .. import Provider as CompanyProvider\n\n\nclass Provider(CompanyProvider):\n formats = (\n '{{last_name}} {{company_suffix}}',\n '{{last_name}} {{last_name}} {{company_suffix}}',\n '{{last_name}} {{last_name}} {{company_suffix}}',\n '{{last_name}}'\n )\n\n company_suffixes = (\n 'As Oy', 'Tmi', 'Oy', 'Oyj', 'Ky', 'Osk', 'ry'\n )\n", "path": "faker/providers/company/fi_FI/__init__.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom .. import Provider as CompanyProvider\n\n\nclass Provider(CompanyProvider):\n formats = (\n '{{last_name}} {{company_suffix}}',\n '{{last_name}} {{last_name}} {{company_suffix}}',\n '{{last_name}} {{last_name}} {{company_suffix}}',\n '{{last_name}}'\n )\n\n company_suffixes = (\n 'As Oy', 'Tmi', 'Oy', 'Oyj', 'Ky', 'Osk', 'ry'\n )\n\n def company_business_id(self):\n \"\"\"\n Returns Finnish company Business Identity Code (y-tunnus).\n Format is 8 digits - e.g. FI99999999,[8] last digit is a check\n digit utilizing MOD 11-2. The first digit is zero for some old\n organizations. This function provides current codes starting with\n non-zero.\n \"\"\"\n def calculate_checksum(number):\n \"\"\"Calculate the checksum using mod 11,2 method\"\"\"\n factors = [7, 9, 10, 5, 8, 4, 2]\n sum = 0\n for x, y in zip(number, factors):\n sum = sum + int(x) * y\n if sum % 11 == 0:\n return '0'\n else:\n return str(11 - sum % 11)\n\n first_digit = str(self.random_digit_not_null())\n body = first_digit + self.bothify(self.random_element(('######',)))\n cs = calculate_checksum(body)\n return (body + '-' + str(cs))\n\n def company_vat(self):\n \"\"\"\n Returns Finnish VAT identification number (Arvonlisaveronumero).\n This can be calculated from company business identity code by\n adding prefix \"FI\" and removing dash before checksum.\n \"\"\"\n def convert_to_vat(business_id):\n \"\"\"\n Convert business id to VATIN\n \"\"\"\n return 'FI' + business_id.replace('-', '')\n\n return convert_to_vat(self.company_business_id())\n", "path": "faker/providers/company/fi_FI/__init__.py"}]}
| 441 | 478 |
gh_patches_debug_33818
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-2742
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
target() cannot be called outside a hypothesis test
I have a test `assert_allclose_phase` which checks whether two arrays are almost equal modulo one. When running under `hypothesis`, this seems like a sensible place to put `target`, albeit with a(n optional?) `name` argument in case I want to call it twice in the same test. Unfortunately if I do so then I can't use the same function in non-`hypothesis` tests:
```
E hypothesis.errors.InvalidArgument: Calling target() outside of a test is invalid.
```
My current workaround is to call `target` only if `name` is provided, but this clutters simple tests that wouldn't need a `name`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/control.py`
Content:
```
1 # This file is part of Hypothesis, which may be found at
2 # https://github.com/HypothesisWorks/hypothesis/
3 #
4 # Most of this work is copyright (C) 2013-2021 David R. MacIver
5 # ([email protected]), but it contains contributions by others. See
6 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
7 # consult the git log if you need to determine who owns an individual
8 # contribution.
9 #
10 # This Source Code Form is subject to the terms of the Mozilla Public License,
11 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
12 # obtain one at https://mozilla.org/MPL/2.0/.
13 #
14 # END HEADER
15
16 import math
17 import traceback
18 from typing import NoReturn, Union
19
20 from hypothesis import Verbosity, settings
21 from hypothesis.errors import CleanupFailed, InvalidArgument, UnsatisfiedAssumption
22 from hypothesis.internal.conjecture.data import ConjectureData
23 from hypothesis.internal.reflection import deprecated_posargs
24 from hypothesis.internal.validation import check_type
25 from hypothesis.reporting import report, verbose_report
26 from hypothesis.utils.dynamicvariables import DynamicVariable
27
28
29 def reject() -> NoReturn:
30 raise UnsatisfiedAssumption()
31
32
33 def assume(condition: object) -> bool:
34 """Calling ``assume`` is like an :ref:`assert <python:assert>` that marks
35 the example as bad, rather than failing the test.
36
37 This allows you to specify properties that you *assume* will be
38 true, and let Hypothesis try to avoid similar examples in future.
39 """
40 if not condition:
41 raise UnsatisfiedAssumption()
42 return True
43
44
45 _current_build_context = DynamicVariable(None)
46
47
48 def current_build_context():
49 context = _current_build_context.value
50 if context is None:
51 raise InvalidArgument("No build context registered")
52 return context
53
54
55 class BuildContext:
56 def __init__(self, data, is_final=False, close_on_capture=True):
57 assert isinstance(data, ConjectureData)
58 self.data = data
59 self.tasks = []
60 self.is_final = is_final
61 self.close_on_capture = close_on_capture
62 self.close_on_del = False
63
64 def __enter__(self):
65 self.assign_variable = _current_build_context.with_value(self)
66 self.assign_variable.__enter__()
67 return self
68
69 def __exit__(self, exc_type, exc_value, tb):
70 self.assign_variable.__exit__(exc_type, exc_value, tb)
71 if self.close() and exc_type is None:
72 raise CleanupFailed()
73
74 def close(self):
75 any_failed = False
76 for task in self.tasks:
77 try:
78 task()
79 except BaseException:
80 any_failed = True
81 report(traceback.format_exc())
82 return any_failed
83
84
85 def cleanup(teardown):
86 """Register a function to be called when the current test has finished
87 executing. Any exceptions thrown in teardown will be printed but not
88 rethrown.
89
90 Inside a test this isn't very interesting, because you can just use
91 a finally block, but note that you can use this inside map, flatmap,
92 etc. in order to e.g. insist that a value is closed at the end.
93 """
94 context = _current_build_context.value
95 if context is None:
96 raise InvalidArgument("Cannot register cleanup outside of build context")
97 context.tasks.append(teardown)
98
99
100 def should_note():
101 context = _current_build_context.value
102 if context is None:
103 raise InvalidArgument("Cannot make notes outside of a test")
104 return context.is_final or settings.default.verbosity >= Verbosity.verbose
105
106
107 def note(value: str) -> None:
108 """Report this value in the final execution."""
109 if should_note():
110 report(value)
111
112
113 def event(value: str) -> None:
114 """Record an event that occurred this test. Statistics on number of test
115 runs with each event will be reported at the end if you run Hypothesis in
116 statistics reporting mode.
117
118 Events should be strings or convertible to them.
119 """
120 context = _current_build_context.value
121 if context is None:
122 raise InvalidArgument("Cannot make record events outside of a test")
123
124 context.data.note_event(value)
125
126
127 @deprecated_posargs
128 def target(observation: Union[int, float], *, label: str = "") -> None:
129 """Calling this function with an ``int`` or ``float`` observation gives it feedback
130 with which to guide our search for inputs that will cause an error, in
131 addition to all the usual heuristics. Observations must always be finite.
132
133 Hypothesis will try to maximize the observed value over several examples;
134 almost any metric will work so long as it makes sense to increase it.
135 For example, ``-abs(error)`` is a metric that increases as ``error``
136 approaches zero.
137
138 Example metrics:
139
140 - Number of elements in a collection, or tasks in a queue
141 - Mean or maximum runtime of a task (or both, if you use ``label``)
142 - Compression ratio for data (perhaps per-algorithm or per-level)
143 - Number of steps taken by a state machine
144
145 The optional ``label`` argument can be used to distinguish between
146 and therefore separately optimise distinct observations, such as the
147 mean and standard deviation of a dataset. It is an error to call
148 ``target()`` with any label more than once per test case.
149
150 .. note::
151 **The more examples you run, the better this technique works.**
152
153 As a rule of thumb, the targeting effect is noticeable above
154 :obj:`max_examples=1000 <hypothesis.settings.max_examples>`,
155 and immediately obvious by around ten thousand examples
156 *per label* used by your test.
157
158 .. note::
159 ``hypothesis.target`` is considered experimental, and may be radically
160 changed or even removed in a future version. If you find it useful,
161 please let us know so we can share and build on that success!
162
163 :ref:`statistics` include the best score seen for each label,
164 which can help avoid `the threshold problem
165 <https://hypothesis.works/articles/threshold-problem/>`__ when the minimal
166 example shrinks right down to the threshold of failure (:issue:`2180`).
167 """
168 check_type((int, float), observation, "observation")
169 if not math.isfinite(observation):
170 raise InvalidArgument("observation=%r must be a finite float." % observation)
171 check_type(str, label, "label")
172
173 context = _current_build_context.value
174 if context is None:
175 raise InvalidArgument("Calling target() outside of a test is invalid.")
176 verbose_report("Saw target(observation=%r, label=%r)" % (observation, label))
177
178 if label in context.data.target_observations:
179 raise InvalidArgument(
180 "Calling target(%r, label=%r) would overwrite target(%r, label=%r)"
181 % (observation, label, context.data.target_observations[label], label)
182 )
183 else:
184 context.data.target_observations[label] = observation
185
```
Path: `hypothesis-python/src/hypothesis/__init__.py`
Content:
```
1 # This file is part of Hypothesis, which may be found at
2 # https://github.com/HypothesisWorks/hypothesis/
3 #
4 # Most of this work is copyright (C) 2013-2021 David R. MacIver
5 # ([email protected]), but it contains contributions by others. See
6 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
7 # consult the git log if you need to determine who owns an individual
8 # contribution.
9 #
10 # This Source Code Form is subject to the terms of the Mozilla Public License,
11 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
12 # obtain one at https://mozilla.org/MPL/2.0/.
13 #
14 # END HEADER
15
16 """Hypothesis is a library for writing unit tests which are parametrized by
17 some source of data.
18
19 It verifies your code against a wide range of input and minimizes any
20 failing examples it finds.
21 """
22
23 import hypothesis._error_if_old # noqa # imported for side-effect of nice error
24 from hypothesis._settings import HealthCheck, Phase, Verbosity, settings
25 from hypothesis.control import assume, event, note, reject, target
26 from hypothesis.core import example, find, given, reproduce_failure, seed
27 from hypothesis.entry_points import run
28 from hypothesis.internal.entropy import register_random
29 from hypothesis.utils.conventions import infer
30 from hypothesis.version import __version__, __version_info__
31
32 __all__ = [
33 "settings",
34 "Verbosity",
35 "HealthCheck",
36 "Phase",
37 "assume",
38 "reject",
39 "seed",
40 "given",
41 "reproduce_failure",
42 "find",
43 "example",
44 "note",
45 "event",
46 "infer",
47 "register_random",
48 "target",
49 "__version__",
50 "__version_info__",
51 ]
52
53 run()
54 del run
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/__init__.py b/hypothesis-python/src/hypothesis/__init__.py
--- a/hypothesis-python/src/hypothesis/__init__.py
+++ b/hypothesis-python/src/hypothesis/__init__.py
@@ -22,7 +22,14 @@
import hypothesis._error_if_old # noqa # imported for side-effect of nice error
from hypothesis._settings import HealthCheck, Phase, Verbosity, settings
-from hypothesis.control import assume, event, note, reject, target
+from hypothesis.control import (
+ assume,
+ currently_in_test_context,
+ event,
+ note,
+ reject,
+ target,
+)
from hypothesis.core import example, find, given, reproduce_failure, seed
from hypothesis.entry_points import run
from hypothesis.internal.entropy import register_random
@@ -30,21 +37,22 @@
from hypothesis.version import __version__, __version_info__
__all__ = [
- "settings",
- "Verbosity",
"HealthCheck",
"Phase",
+ "Verbosity",
"assume",
- "reject",
- "seed",
- "given",
- "reproduce_failure",
- "find",
- "example",
- "note",
+ "currently_in_test_context",
"event",
+ "example",
+ "find",
+ "given",
"infer",
+ "note",
"register_random",
+ "reject",
+ "reproduce_failure",
+ "seed",
+ "settings",
"target",
"__version__",
"__version_info__",
diff --git a/hypothesis-python/src/hypothesis/control.py b/hypothesis-python/src/hypothesis/control.py
--- a/hypothesis-python/src/hypothesis/control.py
+++ b/hypothesis-python/src/hypothesis/control.py
@@ -45,6 +45,18 @@
_current_build_context = DynamicVariable(None)
+def currently_in_test_context() -> bool:
+ """Return ``True`` if the calling code is currently running inside an
+ :func:`@given <hypothesis.given>` or :doc:`stateful <stateful>` test,
+ ``False`` otherwise.
+
+ This is useful for third-party integrations and assertion helpers which
+ may be called from traditional or property-based tests, but can only use
+ :func:`~hypothesis.assume` or :func:`~hypothesis.target` in the latter case.
+ """
+ return _current_build_context.value is not None
+
+
def current_build_context():
context = _current_build_context.value
if context is None:
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/__init__.py b/hypothesis-python/src/hypothesis/__init__.py\n--- a/hypothesis-python/src/hypothesis/__init__.py\n+++ b/hypothesis-python/src/hypothesis/__init__.py\n@@ -22,7 +22,14 @@\n \n import hypothesis._error_if_old # noqa # imported for side-effect of nice error\n from hypothesis._settings import HealthCheck, Phase, Verbosity, settings\n-from hypothesis.control import assume, event, note, reject, target\n+from hypothesis.control import (\n+ assume,\n+ currently_in_test_context,\n+ event,\n+ note,\n+ reject,\n+ target,\n+)\n from hypothesis.core import example, find, given, reproduce_failure, seed\n from hypothesis.entry_points import run\n from hypothesis.internal.entropy import register_random\n@@ -30,21 +37,22 @@\n from hypothesis.version import __version__, __version_info__\n \n __all__ = [\n- \"settings\",\n- \"Verbosity\",\n \"HealthCheck\",\n \"Phase\",\n+ \"Verbosity\",\n \"assume\",\n- \"reject\",\n- \"seed\",\n- \"given\",\n- \"reproduce_failure\",\n- \"find\",\n- \"example\",\n- \"note\",\n+ \"currently_in_test_context\",\n \"event\",\n+ \"example\",\n+ \"find\",\n+ \"given\",\n \"infer\",\n+ \"note\",\n \"register_random\",\n+ \"reject\",\n+ \"reproduce_failure\",\n+ \"seed\",\n+ \"settings\",\n \"target\",\n \"__version__\",\n \"__version_info__\",\ndiff --git a/hypothesis-python/src/hypothesis/control.py b/hypothesis-python/src/hypothesis/control.py\n--- a/hypothesis-python/src/hypothesis/control.py\n+++ b/hypothesis-python/src/hypothesis/control.py\n@@ -45,6 +45,18 @@\n _current_build_context = DynamicVariable(None)\n \n \n+def currently_in_test_context() -> bool:\n+ \"\"\"Return ``True`` if the calling code is currently running inside an\n+ :func:`@given <hypothesis.given>` or :doc:`stateful <stateful>` test,\n+ ``False`` otherwise.\n+\n+ This is useful for third-party integrations and assertion helpers which\n+ may be called from traditional or property-based tests, but can only use\n+ :func:`~hypothesis.assume` or :func:`~hypothesis.target` in the latter case.\n+ \"\"\"\n+ return _current_build_context.value is not None\n+\n+\n def current_build_context():\n context = _current_build_context.value\n if context is None:\n", "issue": "target() cannot be called outside a hypothesis test\nI have a test `assert_allclose_phase` which checks whether two arrays are almost equal modulo one. When running under `hypothesis`, this seems like a sensible place to put `target`, albeit with a(n optional?) `name` argument in case I want to call it twice in the same test. Unfortunately if I do so then I can't use the same function in non-`hypothesis` tests:\r\n\r\n```\r\nE hypothesis.errors.InvalidArgument: Calling target() outside of a test is invalid.\r\n```\r\n\r\nMy current workaround is to call `target` only if `name` is provided, but this clutters simple tests that wouldn't need a `name`.\n", "before_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nimport math\nimport traceback\nfrom typing import NoReturn, Union\n\nfrom hypothesis import Verbosity, settings\nfrom hypothesis.errors import CleanupFailed, InvalidArgument, UnsatisfiedAssumption\nfrom hypothesis.internal.conjecture.data import ConjectureData\nfrom hypothesis.internal.reflection import deprecated_posargs\nfrom hypothesis.internal.validation import check_type\nfrom hypothesis.reporting import report, verbose_report\nfrom hypothesis.utils.dynamicvariables import DynamicVariable\n\n\ndef reject() -> NoReturn:\n raise UnsatisfiedAssumption()\n\n\ndef assume(condition: object) -> bool:\n \"\"\"Calling ``assume`` is like an :ref:`assert <python:assert>` that marks\n the example as bad, rather than failing the test.\n\n This allows you to specify properties that you *assume* will be\n true, and let Hypothesis try to avoid similar examples in future.\n \"\"\"\n if not condition:\n raise UnsatisfiedAssumption()\n return True\n\n\n_current_build_context = DynamicVariable(None)\n\n\ndef current_build_context():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"No build context registered\")\n return context\n\n\nclass BuildContext:\n def __init__(self, data, is_final=False, close_on_capture=True):\n assert isinstance(data, ConjectureData)\n self.data = data\n self.tasks = []\n self.is_final = is_final\n self.close_on_capture = close_on_capture\n self.close_on_del = False\n\n def __enter__(self):\n self.assign_variable = _current_build_context.with_value(self)\n self.assign_variable.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n self.assign_variable.__exit__(exc_type, exc_value, tb)\n if self.close() and exc_type is None:\n raise CleanupFailed()\n\n def close(self):\n any_failed = False\n for task in self.tasks:\n try:\n task()\n except BaseException:\n any_failed = True\n report(traceback.format_exc())\n return any_failed\n\n\ndef cleanup(teardown):\n \"\"\"Register a function to be called when the current test has finished\n executing. Any exceptions thrown in teardown will be printed but not\n rethrown.\n\n Inside a test this isn't very interesting, because you can just use\n a finally block, but note that you can use this inside map, flatmap,\n etc. in order to e.g. insist that a value is closed at the end.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot register cleanup outside of build context\")\n context.tasks.append(teardown)\n\n\ndef should_note():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot make notes outside of a test\")\n return context.is_final or settings.default.verbosity >= Verbosity.verbose\n\n\ndef note(value: str) -> None:\n \"\"\"Report this value in the final execution.\"\"\"\n if should_note():\n report(value)\n\n\ndef event(value: str) -> None:\n \"\"\"Record an event that occurred this test. Statistics on number of test\n runs with each event will be reported at the end if you run Hypothesis in\n statistics reporting mode.\n\n Events should be strings or convertible to them.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot make record events outside of a test\")\n\n context.data.note_event(value)\n\n\n@deprecated_posargs\ndef target(observation: Union[int, float], *, label: str = \"\") -> None:\n \"\"\"Calling this function with an ``int`` or ``float`` observation gives it feedback\n with which to guide our search for inputs that will cause an error, in\n addition to all the usual heuristics. Observations must always be finite.\n\n Hypothesis will try to maximize the observed value over several examples;\n almost any metric will work so long as it makes sense to increase it.\n For example, ``-abs(error)`` is a metric that increases as ``error``\n approaches zero.\n\n Example metrics:\n\n - Number of elements in a collection, or tasks in a queue\n - Mean or maximum runtime of a task (or both, if you use ``label``)\n - Compression ratio for data (perhaps per-algorithm or per-level)\n - Number of steps taken by a state machine\n\n The optional ``label`` argument can be used to distinguish between\n and therefore separately optimise distinct observations, such as the\n mean and standard deviation of a dataset. It is an error to call\n ``target()`` with any label more than once per test case.\n\n .. note::\n **The more examples you run, the better this technique works.**\n\n As a rule of thumb, the targeting effect is noticeable above\n :obj:`max_examples=1000 <hypothesis.settings.max_examples>`,\n and immediately obvious by around ten thousand examples\n *per label* used by your test.\n\n .. note::\n ``hypothesis.target`` is considered experimental, and may be radically\n changed or even removed in a future version. If you find it useful,\n please let us know so we can share and build on that success!\n\n :ref:`statistics` include the best score seen for each label,\n which can help avoid `the threshold problem\n <https://hypothesis.works/articles/threshold-problem/>`__ when the minimal\n example shrinks right down to the threshold of failure (:issue:`2180`).\n \"\"\"\n check_type((int, float), observation, \"observation\")\n if not math.isfinite(observation):\n raise InvalidArgument(\"observation=%r must be a finite float.\" % observation)\n check_type(str, label, \"label\")\n\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Calling target() outside of a test is invalid.\")\n verbose_report(\"Saw target(observation=%r, label=%r)\" % (observation, label))\n\n if label in context.data.target_observations:\n raise InvalidArgument(\n \"Calling target(%r, label=%r) would overwrite target(%r, label=%r)\"\n % (observation, label, context.data.target_observations[label], label)\n )\n else:\n context.data.target_observations[label] = observation\n", "path": "hypothesis-python/src/hypothesis/control.py"}, {"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\n\"\"\"Hypothesis is a library for writing unit tests which are parametrized by\nsome source of data.\n\nIt verifies your code against a wide range of input and minimizes any\nfailing examples it finds.\n\"\"\"\n\nimport hypothesis._error_if_old # noqa # imported for side-effect of nice error\nfrom hypothesis._settings import HealthCheck, Phase, Verbosity, settings\nfrom hypothesis.control import assume, event, note, reject, target\nfrom hypothesis.core import example, find, given, reproduce_failure, seed\nfrom hypothesis.entry_points import run\nfrom hypothesis.internal.entropy import register_random\nfrom hypothesis.utils.conventions import infer\nfrom hypothesis.version import __version__, __version_info__\n\n__all__ = [\n \"settings\",\n \"Verbosity\",\n \"HealthCheck\",\n \"Phase\",\n \"assume\",\n \"reject\",\n \"seed\",\n \"given\",\n \"reproduce_failure\",\n \"find\",\n \"example\",\n \"note\",\n \"event\",\n \"infer\",\n \"register_random\",\n \"target\",\n \"__version__\",\n \"__version_info__\",\n]\n\nrun()\ndel run\n", "path": "hypothesis-python/src/hypothesis/__init__.py"}], "after_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nimport math\nimport traceback\nfrom typing import NoReturn, Union\n\nfrom hypothesis import Verbosity, settings\nfrom hypothesis.errors import CleanupFailed, InvalidArgument, UnsatisfiedAssumption\nfrom hypothesis.internal.conjecture.data import ConjectureData\nfrom hypothesis.internal.reflection import deprecated_posargs\nfrom hypothesis.internal.validation import check_type\nfrom hypothesis.reporting import report, verbose_report\nfrom hypothesis.utils.dynamicvariables import DynamicVariable\n\n\ndef reject() -> NoReturn:\n raise UnsatisfiedAssumption()\n\n\ndef assume(condition: object) -> bool:\n \"\"\"Calling ``assume`` is like an :ref:`assert <python:assert>` that marks\n the example as bad, rather than failing the test.\n\n This allows you to specify properties that you *assume* will be\n true, and let Hypothesis try to avoid similar examples in future.\n \"\"\"\n if not condition:\n raise UnsatisfiedAssumption()\n return True\n\n\n_current_build_context = DynamicVariable(None)\n\n\ndef currently_in_test_context() -> bool:\n \"\"\"Return ``True`` if the calling code is currently running inside an\n :func:`@given <hypothesis.given>` or :doc:`stateful <stateful>` test,\n ``False`` otherwise.\n\n This is useful for third-party integrations and assertion helpers which\n may be called from traditional or property-based tests, but can only use\n :func:`~hypothesis.assume` or :func:`~hypothesis.target` in the latter case.\n \"\"\"\n return _current_build_context.value is not None\n\n\ndef current_build_context():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"No build context registered\")\n return context\n\n\nclass BuildContext:\n def __init__(self, data, is_final=False, close_on_capture=True):\n assert isinstance(data, ConjectureData)\n self.data = data\n self.tasks = []\n self.is_final = is_final\n self.close_on_capture = close_on_capture\n self.close_on_del = False\n\n def __enter__(self):\n self.assign_variable = _current_build_context.with_value(self)\n self.assign_variable.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_value, tb):\n self.assign_variable.__exit__(exc_type, exc_value, tb)\n if self.close() and exc_type is None:\n raise CleanupFailed()\n\n def close(self):\n any_failed = False\n for task in self.tasks:\n try:\n task()\n except BaseException:\n any_failed = True\n report(traceback.format_exc())\n return any_failed\n\n\ndef cleanup(teardown):\n \"\"\"Register a function to be called when the current test has finished\n executing. Any exceptions thrown in teardown will be printed but not\n rethrown.\n\n Inside a test this isn't very interesting, because you can just use\n a finally block, but note that you can use this inside map, flatmap,\n etc. in order to e.g. insist that a value is closed at the end.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot register cleanup outside of build context\")\n context.tasks.append(teardown)\n\n\ndef should_note():\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot make notes outside of a test\")\n return context.is_final or settings.default.verbosity >= Verbosity.verbose\n\n\ndef note(value: str) -> None:\n \"\"\"Report this value in the final execution.\"\"\"\n if should_note():\n report(value)\n\n\ndef event(value: str) -> None:\n \"\"\"Record an event that occurred this test. Statistics on number of test\n runs with each event will be reported at the end if you run Hypothesis in\n statistics reporting mode.\n\n Events should be strings or convertible to them.\n \"\"\"\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Cannot make record events outside of a test\")\n\n context.data.note_event(value)\n\n\n@deprecated_posargs\ndef target(observation: Union[int, float], *, label: str = \"\") -> None:\n \"\"\"Calling this function with an ``int`` or ``float`` observation gives it feedback\n with which to guide our search for inputs that will cause an error, in\n addition to all the usual heuristics. Observations must always be finite.\n\n Hypothesis will try to maximize the observed value over several examples;\n almost any metric will work so long as it makes sense to increase it.\n For example, ``-abs(error)`` is a metric that increases as ``error``\n approaches zero.\n\n Example metrics:\n\n - Number of elements in a collection, or tasks in a queue\n - Mean or maximum runtime of a task (or both, if you use ``label``)\n - Compression ratio for data (perhaps per-algorithm or per-level)\n - Number of steps taken by a state machine\n\n The optional ``label`` argument can be used to distinguish between\n and therefore separately optimise distinct observations, such as the\n mean and standard deviation of a dataset. It is an error to call\n ``target()`` with any label more than once per test case.\n\n .. note::\n **The more examples you run, the better this technique works.**\n\n As a rule of thumb, the targeting effect is noticeable above\n :obj:`max_examples=1000 <hypothesis.settings.max_examples>`,\n and immediately obvious by around ten thousand examples\n *per label* used by your test.\n\n .. note::\n ``hypothesis.target`` is considered experimental, and may be radically\n changed or even removed in a future version. If you find it useful,\n please let us know so we can share and build on that success!\n\n :ref:`statistics` include the best score seen for each label,\n which can help avoid `the threshold problem\n <https://hypothesis.works/articles/threshold-problem/>`__ when the minimal\n example shrinks right down to the threshold of failure (:issue:`2180`).\n \"\"\"\n check_type((int, float), observation, \"observation\")\n if not math.isfinite(observation):\n raise InvalidArgument(\"observation=%r must be a finite float.\" % observation)\n check_type(str, label, \"label\")\n\n context = _current_build_context.value\n if context is None:\n raise InvalidArgument(\"Calling target() outside of a test is invalid.\")\n verbose_report(\"Saw target(observation=%r, label=%r)\" % (observation, label))\n\n if label in context.data.target_observations:\n raise InvalidArgument(\n \"Calling target(%r, label=%r) would overwrite target(%r, label=%r)\"\n % (observation, label, context.data.target_observations[label], label)\n )\n else:\n context.data.target_observations[label] = observation\n", "path": "hypothesis-python/src/hypothesis/control.py"}, {"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2021 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\n\"\"\"Hypothesis is a library for writing unit tests which are parametrized by\nsome source of data.\n\nIt verifies your code against a wide range of input and minimizes any\nfailing examples it finds.\n\"\"\"\n\nimport hypothesis._error_if_old # noqa # imported for side-effect of nice error\nfrom hypothesis._settings import HealthCheck, Phase, Verbosity, settings\nfrom hypothesis.control import (\n assume,\n currently_in_test_context,\n event,\n note,\n reject,\n target,\n)\nfrom hypothesis.core import example, find, given, reproduce_failure, seed\nfrom hypothesis.entry_points import run\nfrom hypothesis.internal.entropy import register_random\nfrom hypothesis.utils.conventions import infer\nfrom hypothesis.version import __version__, __version_info__\n\n__all__ = [\n \"HealthCheck\",\n \"Phase\",\n \"Verbosity\",\n \"assume\",\n \"currently_in_test_context\",\n \"event\",\n \"example\",\n \"find\",\n \"given\",\n \"infer\",\n \"note\",\n \"register_random\",\n \"reject\",\n \"reproduce_failure\",\n \"seed\",\n \"settings\",\n \"target\",\n \"__version__\",\n \"__version_info__\",\n]\n\nrun()\ndel run\n", "path": "hypothesis-python/src/hypothesis/__init__.py"}]}
| 2,949 | 594 |
gh_patches_debug_61685
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1432
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
gmail.co.uk isn't a valid free email domain in the UK
* Faker version: 6.6.2
* OS: macOS 11.2.3
When generating a free email address, I got a result with the domain `gmail.co.uk`. From the source code, this list of free UK email domains was copied from the PHP version of Faker, which is now archived.
According to [this Google support thread](https://support.google.com/mail/thread/4572636?hl=en) (albeit not necessarily from someone with the authority to speak on behalf of Google), there is no such domain.
### Steps to reproduce
1. Configure Faker with the `en_UK` locale.
1. Generate free emails by calling `fake.free_email()` repeatedly
1. Observe that some of them end in `gmail.co.uk`
### Expected behavior
Email addresses should not have `gmail.co.uk` as a domain.
### Actual behavior
As a replacement, maybe include Hotmail's successor, `outlook.com`? It's not UK specific, but I don't know anything about the state of free UK email providers.
gmail.co.uk isn't a valid free email domain in the UK
* Faker version: 6.6.2
* OS: macOS 11.2.3
When generating a free email address, I got a result with the domain `gmail.co.uk`. From the source code, this list of free UK email domains was copied from the PHP version of Faker, which is now archived.
According to [this Google support thread](https://support.google.com/mail/thread/4572636?hl=en) (albeit not necessarily from someone with the authority to speak on behalf of Google), there is no such domain.
### Steps to reproduce
1. Configure Faker with the `en_UK` locale.
1. Generate free emails by calling `fake.free_email()` repeatedly
1. Observe that some of them end in `gmail.co.uk`
### Expected behavior
Email addresses should not have `gmail.co.uk` as a domain.
### Actual behavior
As a replacement, maybe include Hotmail's successor, `outlook.com`? It's not UK specific, but I don't know anything about the state of free UK email providers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/internet/en_GB/__init__.py`
Content:
```
1 from .. import Provider as InternetProvider
2
3
4 class Provider(InternetProvider):
5 # Data taken from
6 # https://github.com/fzaninotto/Faker/blob/master/src/Faker/Provider/en_GB/Internet.php
7
8 free_email_domains = (
9 'gmail.com',
10 'yahoo.com',
11 'hotmail.com',
12 'gmail.co.uk',
13 'yahoo.co.uk',
14 'hotmail.co.uk',
15 )
16
17 tlds = ('com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org', 'co.uk')
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/internet/en_GB/__init__.py b/faker/providers/internet/en_GB/__init__.py
--- a/faker/providers/internet/en_GB/__init__.py
+++ b/faker/providers/internet/en_GB/__init__.py
@@ -9,9 +9,9 @@
'gmail.com',
'yahoo.com',
'hotmail.com',
- 'gmail.co.uk',
'yahoo.co.uk',
'hotmail.co.uk',
+ 'outlook.com',
)
tlds = ('com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org', 'co.uk')
|
{"golden_diff": "diff --git a/faker/providers/internet/en_GB/__init__.py b/faker/providers/internet/en_GB/__init__.py\n--- a/faker/providers/internet/en_GB/__init__.py\n+++ b/faker/providers/internet/en_GB/__init__.py\n@@ -9,9 +9,9 @@\n 'gmail.com',\n 'yahoo.com',\n 'hotmail.com',\n- 'gmail.co.uk',\n 'yahoo.co.uk',\n 'hotmail.co.uk',\n+ 'outlook.com',\n )\n \n tlds = ('com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org', 'co.uk')\n", "issue": "gmail.co.uk isn't a valid free email domain in the UK\n* Faker version: 6.6.2\r\n* OS: macOS 11.2.3\r\n\r\nWhen generating a free email address, I got a result with the domain `gmail.co.uk`. From the source code, this list of free UK email domains was copied from the PHP version of Faker, which is now archived. \r\n\r\nAccording to [this Google support thread](https://support.google.com/mail/thread/4572636?hl=en) (albeit not necessarily from someone with the authority to speak on behalf of Google), there is no such domain.\r\n\r\n### Steps to reproduce\r\n\r\n1. Configure Faker with the `en_UK` locale.\r\n1. Generate free emails by calling `fake.free_email()` repeatedly\r\n1. Observe that some of them end in `gmail.co.uk`\r\n\r\n### Expected behavior\r\nEmail addresses should not have `gmail.co.uk` as a domain.\r\n\r\n### Actual behavior\r\nAs a replacement, maybe include Hotmail's successor, `outlook.com`? It's not UK specific, but I don't know anything about the state of free UK email providers.\ngmail.co.uk isn't a valid free email domain in the UK\n* Faker version: 6.6.2\r\n* OS: macOS 11.2.3\r\n\r\nWhen generating a free email address, I got a result with the domain `gmail.co.uk`. From the source code, this list of free UK email domains was copied from the PHP version of Faker, which is now archived. \r\n\r\nAccording to [this Google support thread](https://support.google.com/mail/thread/4572636?hl=en) (albeit not necessarily from someone with the authority to speak on behalf of Google), there is no such domain.\r\n\r\n### Steps to reproduce\r\n\r\n1. Configure Faker with the `en_UK` locale.\r\n1. Generate free emails by calling `fake.free_email()` repeatedly\r\n1. Observe that some of them end in `gmail.co.uk`\r\n\r\n### Expected behavior\r\nEmail addresses should not have `gmail.co.uk` as a domain.\r\n\r\n### Actual behavior\r\nAs a replacement, maybe include Hotmail's successor, `outlook.com`? It's not UK specific, but I don't know anything about the state of free UK email providers.\n", "before_files": [{"content": "from .. import Provider as InternetProvider\n\n\nclass Provider(InternetProvider):\n # Data taken from\n # https://github.com/fzaninotto/Faker/blob/master/src/Faker/Provider/en_GB/Internet.php\n\n free_email_domains = (\n 'gmail.com',\n 'yahoo.com',\n 'hotmail.com',\n 'gmail.co.uk',\n 'yahoo.co.uk',\n 'hotmail.co.uk',\n )\n\n tlds = ('com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org', 'co.uk')\n", "path": "faker/providers/internet/en_GB/__init__.py"}], "after_files": [{"content": "from .. import Provider as InternetProvider\n\n\nclass Provider(InternetProvider):\n # Data taken from\n # https://github.com/fzaninotto/Faker/blob/master/src/Faker/Provider/en_GB/Internet.php\n\n free_email_domains = (\n 'gmail.com',\n 'yahoo.com',\n 'hotmail.com',\n 'yahoo.co.uk',\n 'hotmail.co.uk',\n 'outlook.com',\n )\n\n tlds = ('com', 'com', 'com', 'com', 'com', 'com', 'biz', 'info', 'net', 'org', 'co.uk')\n", "path": "faker/providers/internet/en_GB/__init__.py"}]}
| 903 | 148 |
gh_patches_debug_18301
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-3362
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Groups cannot be listed using JSON IPC
Using the JSON serialization format in the IPC and trying to list groups yields exception
```
Object of type set is not JSON serializable
NoneType: None
```
in the qtile logs and causes a `IPCError: Unable to decode json data` in the client end.
Reproduce with:
```python
from libqtile.command.client import (
InteractiveCommandClient,
Client,
find_sockfile,
IPCCommandInterface,
)
c = InteractiveCommandClient(
command=IPCCommandInterface(
Client(find_sockfile(), is_json=True)
)
)
c.groups()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/ipc.py`
Content:
```
1 # Copyright (c) 2008, Aldo Cortesi. All rights reserved.
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a copy
4 # of this software and associated documentation files (the "Software"), to deal
5 # in the Software without restriction, including without limitation the rights
6 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
7 # copies of the Software, and to permit persons to whom the Software is
8 # furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
16 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
18 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
19 # SOFTWARE.
20
21 """
22 A simple IPC mechanism for communicating between two local processes. We
23 use marshal to serialize data - this means that both client and server must
24 run the same Python version, and that clients must be trusted (as
25 un-marshalling untrusted data can result in arbitrary code execution).
26 """
27
28 from __future__ import annotations
29
30 import asyncio
31 import fcntl
32 import json
33 import marshal
34 import os.path
35 import socket
36 import struct
37 from typing import Any
38
39 from libqtile.log_utils import logger
40 from libqtile.utils import get_cache_dir
41
42 HDRFORMAT = "!L"
43 HDRLEN = struct.calcsize(HDRFORMAT)
44
45 SOCKBASE = "qtilesocket.%s"
46
47
48 class IPCError(Exception):
49 pass
50
51
52 def find_sockfile(display: str = None):
53 """
54 Finds the appropriate socket file for the given display.
55
56 If unspecified, the socket file is determined as follows:
57
58 - If WAYLAND_DISPLAY is set, use it.
59 - else if DISPLAY is set, use that.
60 - else check for the existence of a socket file for WAYLAND_DISPLAY=wayland-0
61 and if it exists, use it.
62 - else check for the existence of a socket file for DISPLAY=:0
63 and if it exists, use it.
64 - else raise an IPCError.
65
66 """
67 cache_directory = get_cache_dir()
68
69 if display:
70 return os.path.join(cache_directory, SOCKBASE % display)
71
72 display = os.environ.get("WAYLAND_DISPLAY")
73 if display:
74 return os.path.join(cache_directory, SOCKBASE % display)
75
76 display = os.environ.get("DISPLAY")
77 if display:
78 return os.path.join(cache_directory, SOCKBASE % display)
79
80 sockfile = os.path.join(cache_directory, SOCKBASE % "wayland-0")
81 if os.path.exists(sockfile):
82 return sockfile
83
84 sockfile = os.path.join(cache_directory, SOCKBASE % ":0")
85 if os.path.exists(sockfile):
86 return sockfile
87
88 raise IPCError("Could not find socket file.")
89
90
91 class _IPC:
92 """A helper class to handle properly packing and unpacking messages"""
93
94 @staticmethod
95 def unpack(data: bytes, *, is_json: bool | None = None) -> tuple[Any, bool]:
96 """Unpack the incoming message
97
98 Parameters
99 ----------
100 data: bytes
101 The incoming message to unpack
102 is_json: bool | None
103 If the message should be unpacked as json. By default, try to
104 unpack json and fallback gracefully to marshalled bytes.
105
106 Returns
107 -------
108 tuple[Any, bool]
109 A tuple of the unpacked object and a boolean denoting if the
110 message was deserialized using json. If True, the return message
111 should be packed as json.
112 """
113 if is_json is None or is_json:
114 try:
115 return json.loads(data.decode()), True
116 except ValueError as e:
117 if is_json:
118 raise IPCError("Unable to decode json data") from e
119
120 try:
121 assert len(data) >= HDRLEN
122 size = struct.unpack(HDRFORMAT, data[:HDRLEN])[0]
123 assert size >= len(data[HDRLEN:])
124 return marshal.loads(data[HDRLEN : HDRLEN + size]), False
125 except AssertionError as e:
126 raise IPCError("error reading reply! (probably the socket was disconnected)") from e
127
128 @staticmethod
129 def pack(msg: Any, *, is_json: bool = False) -> bytes:
130 """Pack the object into a message to pass"""
131 if is_json:
132 json_obj = json.dumps(msg)
133 return json_obj.encode()
134
135 msg_bytes = marshal.dumps(msg)
136 size = struct.pack(HDRFORMAT, len(msg_bytes))
137 return size + msg_bytes
138
139
140 class Client:
141 def __init__(self, socket_path: str, is_json=False) -> None:
142 """Create a new IPC client
143
144 Parameters
145 ----------
146 socket_path: str
147 The file path to the file that is used to open the connection to
148 the running IPC server.
149 is_json: bool
150 Pack and unpack messages as json
151 """
152 self.socket_path = socket_path
153 self.is_json = is_json
154
155 def call(self, data: Any) -> Any:
156 return self.send(data)
157
158 def send(self, msg: Any) -> Any:
159 """Send the message and return the response from the server
160
161 If any exception is raised by the server, that will propogate out of
162 this call.
163 """
164 return asyncio.run(self.async_send(msg))
165
166 async def async_send(self, msg: Any) -> Any:
167 """Send the message to the server
168
169 Connect to the server, then pack and send the message to the server,
170 then wait for and return the response from the server.
171 """
172 try:
173 reader, writer = await asyncio.wait_for(
174 asyncio.open_unix_connection(path=self.socket_path), timeout=3
175 )
176 except (ConnectionRefusedError, FileNotFoundError):
177 raise IPCError("Could not open {}".format(self.socket_path))
178
179 try:
180 send_data = _IPC.pack(msg, is_json=self.is_json)
181 writer.write(send_data)
182 writer.write_eof()
183
184 read_data = await asyncio.wait_for(reader.read(), timeout=10)
185 except asyncio.TimeoutError:
186 raise IPCError("Server not responding")
187 finally:
188 # see the note in Server._server_callback()
189 writer.close()
190 await writer.wait_closed()
191
192 data, _ = _IPC.unpack(read_data, is_json=self.is_json)
193
194 return data
195
196
197 class Server:
198 def __init__(self, socket_path: str, handler) -> None:
199 self.socket_path = socket_path
200 self.handler = handler
201 self.server = None # type: asyncio.AbstractServer | None
202
203 if os.path.exists(socket_path):
204 os.unlink(socket_path)
205
206 self.sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM, 0)
207 flags = fcntl.fcntl(self.sock.fileno(), fcntl.F_GETFD)
208 fcntl.fcntl(self.sock.fileno(), fcntl.F_SETFD, flags | fcntl.FD_CLOEXEC)
209 self.sock.bind(self.socket_path)
210
211 async def _server_callback(
212 self, reader: asyncio.StreamReader, writer: asyncio.StreamWriter
213 ) -> None:
214 """Callback when a connection is made to the server
215
216 Read the data sent from the client, execute the requested command, and
217 send the reply back to the client.
218 """
219 try:
220 logger.debug("Connection made to server")
221 data = await reader.read()
222 logger.debug("EOF received by server")
223
224 req, is_json = _IPC.unpack(data)
225 except IPCError:
226 logger.warning("Invalid data received, closing connection")
227 else:
228 rep = self.handler(req)
229
230 result = _IPC.pack(rep, is_json=is_json)
231
232 logger.debug("Sending result on receive EOF")
233 writer.write(result)
234 logger.debug("Closing connection on receive EOF")
235 writer.write_eof()
236 finally:
237 writer.close()
238 await writer.wait_closed()
239
240 async def __aenter__(self) -> "Server":
241 """Start and return the server"""
242 await self.start()
243 return self
244
245 async def __aexit__(self, _exc_type, _exc_value, _tb) -> None:
246 """Close and shutdown the server"""
247 await self.close()
248
249 async def start(self) -> None:
250 """Start the server"""
251 assert self.server is None
252
253 logger.debug("Starting server")
254 server_coroutine = asyncio.start_unix_server(self._server_callback, sock=self.sock)
255 self.server = await server_coroutine
256
257 async def close(self) -> None:
258 """Close and shutdown the server"""
259 assert self.server is not None
260
261 logger.debug("Stopping server on close")
262 self.server.close()
263 await self.server.wait_closed()
264
265 self.server = None
266
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/ipc.py b/libqtile/ipc.py
--- a/libqtile/ipc.py
+++ b/libqtile/ipc.py
@@ -129,13 +129,20 @@
def pack(msg: Any, *, is_json: bool = False) -> bytes:
"""Pack the object into a message to pass"""
if is_json:
- json_obj = json.dumps(msg)
+ json_obj = json.dumps(msg, default=_IPC._json_encoder)
return json_obj.encode()
msg_bytes = marshal.dumps(msg)
size = struct.pack(HDRFORMAT, len(msg_bytes))
return size + msg_bytes
+ @staticmethod
+ def _json_encoder(field: Any) -> Any:
+ """Convert non-serializable types to ones understood by stdlib json module"""
+ if isinstance(field, set):
+ return list(field)
+ raise ValueError(f"Tried to JSON serialize unsupported type {type(field)}: {field}")
+
class Client:
def __init__(self, socket_path: str, is_json=False) -> None:
|
{"golden_diff": "diff --git a/libqtile/ipc.py b/libqtile/ipc.py\n--- a/libqtile/ipc.py\n+++ b/libqtile/ipc.py\n@@ -129,13 +129,20 @@\n def pack(msg: Any, *, is_json: bool = False) -> bytes:\n \"\"\"Pack the object into a message to pass\"\"\"\n if is_json:\n- json_obj = json.dumps(msg)\n+ json_obj = json.dumps(msg, default=_IPC._json_encoder)\n return json_obj.encode()\n \n msg_bytes = marshal.dumps(msg)\n size = struct.pack(HDRFORMAT, len(msg_bytes))\n return size + msg_bytes\n \n+ @staticmethod\n+ def _json_encoder(field: Any) -> Any:\n+ \"\"\"Convert non-serializable types to ones understood by stdlib json module\"\"\"\n+ if isinstance(field, set):\n+ return list(field)\n+ raise ValueError(f\"Tried to JSON serialize unsupported type {type(field)}: {field}\")\n+\n \n class Client:\n def __init__(self, socket_path: str, is_json=False) -> None:\n", "issue": "Groups cannot be listed using JSON IPC\nUsing the JSON serialization format in the IPC and trying to list groups yields exception \r\n```\r\nObject of type set is not JSON serializable\r\nNoneType: None\r\n```\r\nin the qtile logs and causes a `IPCError: Unable to decode json data` in the client end.\r\n\r\nReproduce with:\r\n```python\r\nfrom libqtile.command.client import (\r\n InteractiveCommandClient,\r\n Client,\r\n find_sockfile,\r\n IPCCommandInterface,\r\n)\r\nc = InteractiveCommandClient(\r\n command=IPCCommandInterface(\r\n Client(find_sockfile(), is_json=True)\r\n )\r\n)\r\nc.groups()\r\n```\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) 2008, Aldo Cortesi. All rights reserved.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\"\"\"\n A simple IPC mechanism for communicating between two local processes. We\n use marshal to serialize data - this means that both client and server must\n run the same Python version, and that clients must be trusted (as\n un-marshalling untrusted data can result in arbitrary code execution).\n\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport fcntl\nimport json\nimport marshal\nimport os.path\nimport socket\nimport struct\nfrom typing import Any\n\nfrom libqtile.log_utils import logger\nfrom libqtile.utils import get_cache_dir\n\nHDRFORMAT = \"!L\"\nHDRLEN = struct.calcsize(HDRFORMAT)\n\nSOCKBASE = \"qtilesocket.%s\"\n\n\nclass IPCError(Exception):\n pass\n\n\ndef find_sockfile(display: str = None):\n \"\"\"\n Finds the appropriate socket file for the given display.\n\n If unspecified, the socket file is determined as follows:\n\n - If WAYLAND_DISPLAY is set, use it.\n - else if DISPLAY is set, use that.\n - else check for the existence of a socket file for WAYLAND_DISPLAY=wayland-0\n and if it exists, use it.\n - else check for the existence of a socket file for DISPLAY=:0\n and if it exists, use it.\n - else raise an IPCError.\n\n \"\"\"\n cache_directory = get_cache_dir()\n\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n display = os.environ.get(\"WAYLAND_DISPLAY\")\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n display = os.environ.get(\"DISPLAY\")\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n sockfile = os.path.join(cache_directory, SOCKBASE % \"wayland-0\")\n if os.path.exists(sockfile):\n return sockfile\n\n sockfile = os.path.join(cache_directory, SOCKBASE % \":0\")\n if os.path.exists(sockfile):\n return sockfile\n\n raise IPCError(\"Could not find socket file.\")\n\n\nclass _IPC:\n \"\"\"A helper class to handle properly packing and unpacking messages\"\"\"\n\n @staticmethod\n def unpack(data: bytes, *, is_json: bool | None = None) -> tuple[Any, bool]:\n \"\"\"Unpack the incoming message\n\n Parameters\n ----------\n data: bytes\n The incoming message to unpack\n is_json: bool | None\n If the message should be unpacked as json. By default, try to\n unpack json and fallback gracefully to marshalled bytes.\n\n Returns\n -------\n tuple[Any, bool]\n A tuple of the unpacked object and a boolean denoting if the\n message was deserialized using json. If True, the return message\n should be packed as json.\n \"\"\"\n if is_json is None or is_json:\n try:\n return json.loads(data.decode()), True\n except ValueError as e:\n if is_json:\n raise IPCError(\"Unable to decode json data\") from e\n\n try:\n assert len(data) >= HDRLEN\n size = struct.unpack(HDRFORMAT, data[:HDRLEN])[0]\n assert size >= len(data[HDRLEN:])\n return marshal.loads(data[HDRLEN : HDRLEN + size]), False\n except AssertionError as e:\n raise IPCError(\"error reading reply! (probably the socket was disconnected)\") from e\n\n @staticmethod\n def pack(msg: Any, *, is_json: bool = False) -> bytes:\n \"\"\"Pack the object into a message to pass\"\"\"\n if is_json:\n json_obj = json.dumps(msg)\n return json_obj.encode()\n\n msg_bytes = marshal.dumps(msg)\n size = struct.pack(HDRFORMAT, len(msg_bytes))\n return size + msg_bytes\n\n\nclass Client:\n def __init__(self, socket_path: str, is_json=False) -> None:\n \"\"\"Create a new IPC client\n\n Parameters\n ----------\n socket_path: str\n The file path to the file that is used to open the connection to\n the running IPC server.\n is_json: bool\n Pack and unpack messages as json\n \"\"\"\n self.socket_path = socket_path\n self.is_json = is_json\n\n def call(self, data: Any) -> Any:\n return self.send(data)\n\n def send(self, msg: Any) -> Any:\n \"\"\"Send the message and return the response from the server\n\n If any exception is raised by the server, that will propogate out of\n this call.\n \"\"\"\n return asyncio.run(self.async_send(msg))\n\n async def async_send(self, msg: Any) -> Any:\n \"\"\"Send the message to the server\n\n Connect to the server, then pack and send the message to the server,\n then wait for and return the response from the server.\n \"\"\"\n try:\n reader, writer = await asyncio.wait_for(\n asyncio.open_unix_connection(path=self.socket_path), timeout=3\n )\n except (ConnectionRefusedError, FileNotFoundError):\n raise IPCError(\"Could not open {}\".format(self.socket_path))\n\n try:\n send_data = _IPC.pack(msg, is_json=self.is_json)\n writer.write(send_data)\n writer.write_eof()\n\n read_data = await asyncio.wait_for(reader.read(), timeout=10)\n except asyncio.TimeoutError:\n raise IPCError(\"Server not responding\")\n finally:\n # see the note in Server._server_callback()\n writer.close()\n await writer.wait_closed()\n\n data, _ = _IPC.unpack(read_data, is_json=self.is_json)\n\n return data\n\n\nclass Server:\n def __init__(self, socket_path: str, handler) -> None:\n self.socket_path = socket_path\n self.handler = handler\n self.server = None # type: asyncio.AbstractServer | None\n\n if os.path.exists(socket_path):\n os.unlink(socket_path)\n\n self.sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM, 0)\n flags = fcntl.fcntl(self.sock.fileno(), fcntl.F_GETFD)\n fcntl.fcntl(self.sock.fileno(), fcntl.F_SETFD, flags | fcntl.FD_CLOEXEC)\n self.sock.bind(self.socket_path)\n\n async def _server_callback(\n self, reader: asyncio.StreamReader, writer: asyncio.StreamWriter\n ) -> None:\n \"\"\"Callback when a connection is made to the server\n\n Read the data sent from the client, execute the requested command, and\n send the reply back to the client.\n \"\"\"\n try:\n logger.debug(\"Connection made to server\")\n data = await reader.read()\n logger.debug(\"EOF received by server\")\n\n req, is_json = _IPC.unpack(data)\n except IPCError:\n logger.warning(\"Invalid data received, closing connection\")\n else:\n rep = self.handler(req)\n\n result = _IPC.pack(rep, is_json=is_json)\n\n logger.debug(\"Sending result on receive EOF\")\n writer.write(result)\n logger.debug(\"Closing connection on receive EOF\")\n writer.write_eof()\n finally:\n writer.close()\n await writer.wait_closed()\n\n async def __aenter__(self) -> \"Server\":\n \"\"\"Start and return the server\"\"\"\n await self.start()\n return self\n\n async def __aexit__(self, _exc_type, _exc_value, _tb) -> None:\n \"\"\"Close and shutdown the server\"\"\"\n await self.close()\n\n async def start(self) -> None:\n \"\"\"Start the server\"\"\"\n assert self.server is None\n\n logger.debug(\"Starting server\")\n server_coroutine = asyncio.start_unix_server(self._server_callback, sock=self.sock)\n self.server = await server_coroutine\n\n async def close(self) -> None:\n \"\"\"Close and shutdown the server\"\"\"\n assert self.server is not None\n\n logger.debug(\"Stopping server on close\")\n self.server.close()\n await self.server.wait_closed()\n\n self.server = None\n", "path": "libqtile/ipc.py"}], "after_files": [{"content": "# Copyright (c) 2008, Aldo Cortesi. All rights reserved.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\"\"\"\n A simple IPC mechanism for communicating between two local processes. We\n use marshal to serialize data - this means that both client and server must\n run the same Python version, and that clients must be trusted (as\n un-marshalling untrusted data can result in arbitrary code execution).\n\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport fcntl\nimport json\nimport marshal\nimport os.path\nimport socket\nimport struct\nfrom typing import Any\n\nfrom libqtile.log_utils import logger\nfrom libqtile.utils import get_cache_dir\n\nHDRFORMAT = \"!L\"\nHDRLEN = struct.calcsize(HDRFORMAT)\n\nSOCKBASE = \"qtilesocket.%s\"\n\n\nclass IPCError(Exception):\n pass\n\n\ndef find_sockfile(display: str = None):\n \"\"\"\n Finds the appropriate socket file for the given display.\n\n If unspecified, the socket file is determined as follows:\n\n - If WAYLAND_DISPLAY is set, use it.\n - else if DISPLAY is set, use that.\n - else check for the existence of a socket file for WAYLAND_DISPLAY=wayland-0\n and if it exists, use it.\n - else check for the existence of a socket file for DISPLAY=:0\n and if it exists, use it.\n - else raise an IPCError.\n\n \"\"\"\n cache_directory = get_cache_dir()\n\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n display = os.environ.get(\"WAYLAND_DISPLAY\")\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n display = os.environ.get(\"DISPLAY\")\n if display:\n return os.path.join(cache_directory, SOCKBASE % display)\n\n sockfile = os.path.join(cache_directory, SOCKBASE % \"wayland-0\")\n if os.path.exists(sockfile):\n return sockfile\n\n sockfile = os.path.join(cache_directory, SOCKBASE % \":0\")\n if os.path.exists(sockfile):\n return sockfile\n\n raise IPCError(\"Could not find socket file.\")\n\n\nclass _IPC:\n \"\"\"A helper class to handle properly packing and unpacking messages\"\"\"\n\n @staticmethod\n def unpack(data: bytes, *, is_json: bool | None = None) -> tuple[Any, bool]:\n \"\"\"Unpack the incoming message\n\n Parameters\n ----------\n data: bytes\n The incoming message to unpack\n is_json: bool | None\n If the message should be unpacked as json. By default, try to\n unpack json and fallback gracefully to marshalled bytes.\n\n Returns\n -------\n tuple[Any, bool]\n A tuple of the unpacked object and a boolean denoting if the\n message was deserialized using json. If True, the return message\n should be packed as json.\n \"\"\"\n if is_json is None or is_json:\n try:\n return json.loads(data.decode()), True\n except ValueError as e:\n if is_json:\n raise IPCError(\"Unable to decode json data\") from e\n\n try:\n assert len(data) >= HDRLEN\n size = struct.unpack(HDRFORMAT, data[:HDRLEN])[0]\n assert size >= len(data[HDRLEN:])\n return marshal.loads(data[HDRLEN : HDRLEN + size]), False\n except AssertionError as e:\n raise IPCError(\"error reading reply! (probably the socket was disconnected)\") from e\n\n @staticmethod\n def pack(msg: Any, *, is_json: bool = False) -> bytes:\n \"\"\"Pack the object into a message to pass\"\"\"\n if is_json:\n json_obj = json.dumps(msg, default=_IPC._json_encoder)\n return json_obj.encode()\n\n msg_bytes = marshal.dumps(msg)\n size = struct.pack(HDRFORMAT, len(msg_bytes))\n return size + msg_bytes\n\n @staticmethod\n def _json_encoder(field: Any) -> Any:\n \"\"\"Convert non-serializable types to ones understood by stdlib json module\"\"\"\n if isinstance(field, set):\n return list(field)\n raise ValueError(f\"Tried to JSON serialize unsupported type {type(field)}: {field}\")\n\n\nclass Client:\n def __init__(self, socket_path: str, is_json=False) -> None:\n \"\"\"Create a new IPC client\n\n Parameters\n ----------\n socket_path: str\n The file path to the file that is used to open the connection to\n the running IPC server.\n is_json: bool\n Pack and unpack messages as json\n \"\"\"\n self.socket_path = socket_path\n self.is_json = is_json\n\n def call(self, data: Any) -> Any:\n return self.send(data)\n\n def send(self, msg: Any) -> Any:\n \"\"\"Send the message and return the response from the server\n\n If any exception is raised by the server, that will propogate out of\n this call.\n \"\"\"\n return asyncio.run(self.async_send(msg))\n\n async def async_send(self, msg: Any) -> Any:\n \"\"\"Send the message to the server\n\n Connect to the server, then pack and send the message to the server,\n then wait for and return the response from the server.\n \"\"\"\n try:\n reader, writer = await asyncio.wait_for(\n asyncio.open_unix_connection(path=self.socket_path), timeout=3\n )\n except (ConnectionRefusedError, FileNotFoundError):\n raise IPCError(\"Could not open {}\".format(self.socket_path))\n\n try:\n send_data = _IPC.pack(msg, is_json=self.is_json)\n writer.write(send_data)\n writer.write_eof()\n\n read_data = await asyncio.wait_for(reader.read(), timeout=10)\n except asyncio.TimeoutError:\n raise IPCError(\"Server not responding\")\n finally:\n # see the note in Server._server_callback()\n writer.close()\n await writer.wait_closed()\n\n data, _ = _IPC.unpack(read_data, is_json=self.is_json)\n\n return data\n\n\nclass Server:\n def __init__(self, socket_path: str, handler) -> None:\n self.socket_path = socket_path\n self.handler = handler\n self.server = None # type: asyncio.AbstractServer | None\n\n if os.path.exists(socket_path):\n os.unlink(socket_path)\n\n self.sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM, 0)\n flags = fcntl.fcntl(self.sock.fileno(), fcntl.F_GETFD)\n fcntl.fcntl(self.sock.fileno(), fcntl.F_SETFD, flags | fcntl.FD_CLOEXEC)\n self.sock.bind(self.socket_path)\n\n async def _server_callback(\n self, reader: asyncio.StreamReader, writer: asyncio.StreamWriter\n ) -> None:\n \"\"\"Callback when a connection is made to the server\n\n Read the data sent from the client, execute the requested command, and\n send the reply back to the client.\n \"\"\"\n try:\n logger.debug(\"Connection made to server\")\n data = await reader.read()\n logger.debug(\"EOF received by server\")\n\n req, is_json = _IPC.unpack(data)\n except IPCError:\n logger.warning(\"Invalid data received, closing connection\")\n else:\n rep = self.handler(req)\n\n result = _IPC.pack(rep, is_json=is_json)\n\n logger.debug(\"Sending result on receive EOF\")\n writer.write(result)\n logger.debug(\"Closing connection on receive EOF\")\n writer.write_eof()\n finally:\n writer.close()\n await writer.wait_closed()\n\n async def __aenter__(self) -> \"Server\":\n \"\"\"Start and return the server\"\"\"\n await self.start()\n return self\n\n async def __aexit__(self, _exc_type, _exc_value, _tb) -> None:\n \"\"\"Close and shutdown the server\"\"\"\n await self.close()\n\n async def start(self) -> None:\n \"\"\"Start the server\"\"\"\n assert self.server is None\n\n logger.debug(\"Starting server\")\n server_coroutine = asyncio.start_unix_server(self._server_callback, sock=self.sock)\n self.server = await server_coroutine\n\n async def close(self) -> None:\n \"\"\"Close and shutdown the server\"\"\"\n assert self.server is not None\n\n logger.debug(\"Stopping server on close\")\n self.server.close()\n await self.server.wait_closed()\n\n self.server = None\n", "path": "libqtile/ipc.py"}]}
| 3,043 | 240 |
gh_patches_debug_15260
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate `pcre` language
Now that pygrep (#630) is a much more portable alternative, pcre is unnecessary and should be deprecated.
A deprecation warning should be issued when loading a configuration containing `language: pcre` and should point the consumer in the right direction to correcting it (either by suggesting a pull request, or by indicating they should modify their `local` configuration).
The `pcre` language will likely be removed in `pre-commit==2.0.0`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/commands/run.py`
Content:
```
1 from __future__ import print_function
2 from __future__ import unicode_literals
3
4 import logging
5 import os
6 import re
7 import subprocess
8 import sys
9
10 from identify.identify import tags_from_path
11
12 from pre_commit import color
13 from pre_commit import git
14 from pre_commit import output
15 from pre_commit.output import get_hook_message
16 from pre_commit.staged_files_only import staged_files_only
17 from pre_commit.util import cmd_output
18 from pre_commit.util import memoize_by_cwd
19 from pre_commit.util import noop_context
20
21
22 logger = logging.getLogger('pre_commit')
23
24
25 tags_from_path = memoize_by_cwd(tags_from_path)
26
27
28 def _get_skips(environ):
29 skips = environ.get('SKIP', '')
30 return {skip.strip() for skip in skips.split(',') if skip.strip()}
31
32
33 def _hook_msg_start(hook, verbose):
34 return '{}{}'.format(
35 '[{}] '.format(hook['id']) if verbose else '', hook['name'],
36 )
37
38
39 def _filter_by_include_exclude(filenames, include, exclude):
40 include_re, exclude_re = re.compile(include), re.compile(exclude)
41 return {
42 filename for filename in filenames
43 if (
44 include_re.search(filename) and
45 not exclude_re.search(filename) and
46 os.path.lexists(filename)
47 )
48 }
49
50
51 def _filter_by_types(filenames, types, exclude_types):
52 types, exclude_types = frozenset(types), frozenset(exclude_types)
53 ret = []
54 for filename in filenames:
55 tags = tags_from_path(filename)
56 if tags >= types and not tags & exclude_types:
57 ret.append(filename)
58 return tuple(ret)
59
60
61 SKIPPED = 'Skipped'
62 NO_FILES = '(no files to check)'
63
64
65 def _run_single_hook(filenames, hook, repo, args, skips, cols):
66 include, exclude = hook['files'], hook['exclude']
67 filenames = _filter_by_include_exclude(filenames, include, exclude)
68 types, exclude_types = hook['types'], hook['exclude_types']
69 filenames = _filter_by_types(filenames, types, exclude_types)
70 if hook['id'] in skips:
71 output.write(get_hook_message(
72 _hook_msg_start(hook, args.verbose),
73 end_msg=SKIPPED,
74 end_color=color.YELLOW,
75 use_color=args.color,
76 cols=cols,
77 ))
78 return 0
79 elif not filenames and not hook['always_run']:
80 output.write(get_hook_message(
81 _hook_msg_start(hook, args.verbose),
82 postfix=NO_FILES,
83 end_msg=SKIPPED,
84 end_color=color.TURQUOISE,
85 use_color=args.color,
86 cols=cols,
87 ))
88 return 0
89
90 # Print the hook and the dots first in case the hook takes hella long to
91 # run.
92 output.write(get_hook_message(
93 _hook_msg_start(hook, args.verbose), end_len=6, cols=cols,
94 ))
95 sys.stdout.flush()
96
97 diff_before = cmd_output(
98 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,
99 )
100 retcode, stdout, stderr = repo.run_hook(
101 hook, tuple(filenames) if hook['pass_filenames'] else (),
102 )
103 diff_after = cmd_output(
104 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,
105 )
106
107 file_modifications = diff_before != diff_after
108
109 # If the hook makes changes, fail the commit
110 if file_modifications:
111 retcode = 1
112
113 if retcode:
114 retcode = 1
115 print_color = color.RED
116 pass_fail = 'Failed'
117 else:
118 retcode = 0
119 print_color = color.GREEN
120 pass_fail = 'Passed'
121
122 output.write_line(color.format_color(pass_fail, print_color, args.color))
123
124 if (stdout or stderr or file_modifications) and (retcode or args.verbose):
125 output.write_line('hookid: {}\n'.format(hook['id']))
126
127 # Print a message if failing due to file modifications
128 if file_modifications:
129 output.write('Files were modified by this hook.')
130
131 if stdout or stderr:
132 output.write_line(' Additional output:')
133
134 output.write_line()
135
136 for out in (stdout, stderr):
137 assert type(out) is bytes, type(out)
138 if out.strip():
139 output.write_line(out.strip(), logfile_name=hook['log_file'])
140 output.write_line()
141
142 return retcode
143
144
145 def _compute_cols(hooks, verbose):
146 """Compute the number of columns to display hook messages. The widest
147 that will be displayed is in the no files skipped case:
148
149 Hook name...(no files to check) Skipped
150
151 or in the verbose case
152
153 Hook name [hookid]...(no files to check) Skipped
154 """
155 if hooks:
156 name_len = max(len(_hook_msg_start(hook, verbose)) for hook in hooks)
157 else:
158 name_len = 0
159
160 cols = name_len + 3 + len(NO_FILES) + 1 + len(SKIPPED)
161 return max(cols, 80)
162
163
164 def _all_filenames(args):
165 if args.origin and args.source:
166 return git.get_changed_files(args.origin, args.source)
167 elif args.hook_stage == 'commit-msg':
168 return (args.commit_msg_filename,)
169 elif args.files:
170 return args.files
171 elif args.all_files:
172 return git.get_all_files()
173 elif git.is_in_merge_conflict():
174 return git.get_conflicted_files()
175 else:
176 return git.get_staged_files()
177
178
179 def _run_hooks(config, repo_hooks, args, environ):
180 """Actually run the hooks."""
181 skips = _get_skips(environ)
182 cols = _compute_cols([hook for _, hook in repo_hooks], args.verbose)
183 filenames = _all_filenames(args)
184 filenames = _filter_by_include_exclude(filenames, '', config['exclude'])
185 retval = 0
186 for repo, hook in repo_hooks:
187 retval |= _run_single_hook(filenames, hook, repo, args, skips, cols)
188 if retval and config['fail_fast']:
189 break
190 if (
191 retval and
192 args.show_diff_on_failure and
193 subprocess.call(('git', 'diff', '--quiet', '--no-ext-diff')) != 0
194 ):
195 print('All changes made by hooks:')
196 subprocess.call(('git', '--no-pager', 'diff', '--no-ext-diff'))
197 return retval
198
199
200 def _has_unmerged_paths():
201 _, stdout, _ = cmd_output('git', 'ls-files', '--unmerged')
202 return bool(stdout.strip())
203
204
205 def _has_unstaged_config(runner):
206 retcode, _, _ = cmd_output(
207 'git', 'diff', '--no-ext-diff', '--exit-code', runner.config_file_path,
208 retcode=None,
209 )
210 # be explicit, other git errors don't mean it has an unstaged config.
211 return retcode == 1
212
213
214 def run(runner, args, environ=os.environ):
215 no_stash = args.all_files or bool(args.files)
216
217 # Check if we have unresolved merge conflict files and fail fast.
218 if _has_unmerged_paths():
219 logger.error('Unmerged files. Resolve before committing.')
220 return 1
221 if bool(args.source) != bool(args.origin):
222 logger.error('Specify both --origin and --source.')
223 return 1
224 if _has_unstaged_config(runner) and not no_stash:
225 logger.error(
226 'Your pre-commit configuration is unstaged.\n'
227 '`git add {}` to fix this.'.format(runner.config_file),
228 )
229 return 1
230
231 # Expose origin / source as environment variables for hooks to consume
232 if args.origin and args.source:
233 environ['PRE_COMMIT_ORIGIN'] = args.origin
234 environ['PRE_COMMIT_SOURCE'] = args.source
235
236 if no_stash:
237 ctx = noop_context()
238 else:
239 ctx = staged_files_only(runner.store.directory)
240
241 with ctx:
242 repo_hooks = []
243 for repo in runner.repositories:
244 for _, hook in repo.hooks:
245 if (
246 (not args.hook or hook['id'] == args.hook) and
247 not hook['stages'] or args.hook_stage in hook['stages']
248 ):
249 repo_hooks.append((repo, hook))
250
251 if args.hook and not repo_hooks:
252 output.write_line('No hook with id `{}`'.format(args.hook))
253 return 1
254
255 for repo in {repo for repo, _ in repo_hooks}:
256 repo.require_installed()
257
258 return _run_hooks(runner.config, repo_hooks, args, environ)
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/commands/run.py b/pre_commit/commands/run.py
--- a/pre_commit/commands/run.py
+++ b/pre_commit/commands/run.py
@@ -67,6 +67,15 @@
filenames = _filter_by_include_exclude(filenames, include, exclude)
types, exclude_types = hook['types'], hook['exclude_types']
filenames = _filter_by_types(filenames, types, exclude_types)
+
+ if hook['language'] == 'pcre':
+ logger.warning(
+ '`{}` (from {}) uses the deprecated pcre language.\n'
+ 'The pcre language is scheduled for removal in pre-commit 2.x.\n'
+ 'The pygrep language is a more portable (and usually drop-in) '
+ 'replacement.'.format(hook['id'], repo.repo_config['repo']),
+ )
+
if hook['id'] in skips:
output.write(get_hook_message(
_hook_msg_start(hook, args.verbose),
|
{"golden_diff": "diff --git a/pre_commit/commands/run.py b/pre_commit/commands/run.py\n--- a/pre_commit/commands/run.py\n+++ b/pre_commit/commands/run.py\n@@ -67,6 +67,15 @@\n filenames = _filter_by_include_exclude(filenames, include, exclude)\n types, exclude_types = hook['types'], hook['exclude_types']\n filenames = _filter_by_types(filenames, types, exclude_types)\n+\n+ if hook['language'] == 'pcre':\n+ logger.warning(\n+ '`{}` (from {}) uses the deprecated pcre language.\\n'\n+ 'The pcre language is scheduled for removal in pre-commit 2.x.\\n'\n+ 'The pygrep language is a more portable (and usually drop-in) '\n+ 'replacement.'.format(hook['id'], repo.repo_config['repo']),\n+ )\n+\n if hook['id'] in skips:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n", "issue": "Deprecate `pcre` language\nNow that pygrep (#630) is a much more portable alternative, pcre is unnecessary and should be deprecated.\r\n\r\nA deprecation warning should be issued when loading a configuration containing `language: pcre` and should point the consumer in the right direction to correcting it (either by suggesting a pull request, or by indicating they should modify their `local` configuration).\r\n\r\nThe `pcre` language will likely be removed in `pre-commit==2.0.0`\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\nimport re\nimport subprocess\nimport sys\n\nfrom identify.identify import tags_from_path\n\nfrom pre_commit import color\nfrom pre_commit import git\nfrom pre_commit import output\nfrom pre_commit.output import get_hook_message\nfrom pre_commit.staged_files_only import staged_files_only\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import memoize_by_cwd\nfrom pre_commit.util import noop_context\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ntags_from_path = memoize_by_cwd(tags_from_path)\n\n\ndef _get_skips(environ):\n skips = environ.get('SKIP', '')\n return {skip.strip() for skip in skips.split(',') if skip.strip()}\n\n\ndef _hook_msg_start(hook, verbose):\n return '{}{}'.format(\n '[{}] '.format(hook['id']) if verbose else '', hook['name'],\n )\n\n\ndef _filter_by_include_exclude(filenames, include, exclude):\n include_re, exclude_re = re.compile(include), re.compile(exclude)\n return {\n filename for filename in filenames\n if (\n include_re.search(filename) and\n not exclude_re.search(filename) and\n os.path.lexists(filename)\n )\n }\n\n\ndef _filter_by_types(filenames, types, exclude_types):\n types, exclude_types = frozenset(types), frozenset(exclude_types)\n ret = []\n for filename in filenames:\n tags = tags_from_path(filename)\n if tags >= types and not tags & exclude_types:\n ret.append(filename)\n return tuple(ret)\n\n\nSKIPPED = 'Skipped'\nNO_FILES = '(no files to check)'\n\n\ndef _run_single_hook(filenames, hook, repo, args, skips, cols):\n include, exclude = hook['files'], hook['exclude']\n filenames = _filter_by_include_exclude(filenames, include, exclude)\n types, exclude_types = hook['types'], hook['exclude_types']\n filenames = _filter_by_types(filenames, types, exclude_types)\n if hook['id'] in skips:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n end_msg=SKIPPED,\n end_color=color.YELLOW,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n elif not filenames and not hook['always_run']:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n postfix=NO_FILES,\n end_msg=SKIPPED,\n end_color=color.TURQUOISE,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n\n # Print the hook and the dots first in case the hook takes hella long to\n # run.\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose), end_len=6, cols=cols,\n ))\n sys.stdout.flush()\n\n diff_before = cmd_output(\n 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,\n )\n retcode, stdout, stderr = repo.run_hook(\n hook, tuple(filenames) if hook['pass_filenames'] else (),\n )\n diff_after = cmd_output(\n 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,\n )\n\n file_modifications = diff_before != diff_after\n\n # If the hook makes changes, fail the commit\n if file_modifications:\n retcode = 1\n\n if retcode:\n retcode = 1\n print_color = color.RED\n pass_fail = 'Failed'\n else:\n retcode = 0\n print_color = color.GREEN\n pass_fail = 'Passed'\n\n output.write_line(color.format_color(pass_fail, print_color, args.color))\n\n if (stdout or stderr or file_modifications) and (retcode or args.verbose):\n output.write_line('hookid: {}\\n'.format(hook['id']))\n\n # Print a message if failing due to file modifications\n if file_modifications:\n output.write('Files were modified by this hook.')\n\n if stdout or stderr:\n output.write_line(' Additional output:')\n\n output.write_line()\n\n for out in (stdout, stderr):\n assert type(out) is bytes, type(out)\n if out.strip():\n output.write_line(out.strip(), logfile_name=hook['log_file'])\n output.write_line()\n\n return retcode\n\n\ndef _compute_cols(hooks, verbose):\n \"\"\"Compute the number of columns to display hook messages. The widest\n that will be displayed is in the no files skipped case:\n\n Hook name...(no files to check) Skipped\n\n or in the verbose case\n\n Hook name [hookid]...(no files to check) Skipped\n \"\"\"\n if hooks:\n name_len = max(len(_hook_msg_start(hook, verbose)) for hook in hooks)\n else:\n name_len = 0\n\n cols = name_len + 3 + len(NO_FILES) + 1 + len(SKIPPED)\n return max(cols, 80)\n\n\ndef _all_filenames(args):\n if args.origin and args.source:\n return git.get_changed_files(args.origin, args.source)\n elif args.hook_stage == 'commit-msg':\n return (args.commit_msg_filename,)\n elif args.files:\n return args.files\n elif args.all_files:\n return git.get_all_files()\n elif git.is_in_merge_conflict():\n return git.get_conflicted_files()\n else:\n return git.get_staged_files()\n\n\ndef _run_hooks(config, repo_hooks, args, environ):\n \"\"\"Actually run the hooks.\"\"\"\n skips = _get_skips(environ)\n cols = _compute_cols([hook for _, hook in repo_hooks], args.verbose)\n filenames = _all_filenames(args)\n filenames = _filter_by_include_exclude(filenames, '', config['exclude'])\n retval = 0\n for repo, hook in repo_hooks:\n retval |= _run_single_hook(filenames, hook, repo, args, skips, cols)\n if retval and config['fail_fast']:\n break\n if (\n retval and\n args.show_diff_on_failure and\n subprocess.call(('git', 'diff', '--quiet', '--no-ext-diff')) != 0\n ):\n print('All changes made by hooks:')\n subprocess.call(('git', '--no-pager', 'diff', '--no-ext-diff'))\n return retval\n\n\ndef _has_unmerged_paths():\n _, stdout, _ = cmd_output('git', 'ls-files', '--unmerged')\n return bool(stdout.strip())\n\n\ndef _has_unstaged_config(runner):\n retcode, _, _ = cmd_output(\n 'git', 'diff', '--no-ext-diff', '--exit-code', runner.config_file_path,\n retcode=None,\n )\n # be explicit, other git errors don't mean it has an unstaged config.\n return retcode == 1\n\n\ndef run(runner, args, environ=os.environ):\n no_stash = args.all_files or bool(args.files)\n\n # Check if we have unresolved merge conflict files and fail fast.\n if _has_unmerged_paths():\n logger.error('Unmerged files. Resolve before committing.')\n return 1\n if bool(args.source) != bool(args.origin):\n logger.error('Specify both --origin and --source.')\n return 1\n if _has_unstaged_config(runner) and not no_stash:\n logger.error(\n 'Your pre-commit configuration is unstaged.\\n'\n '`git add {}` to fix this.'.format(runner.config_file),\n )\n return 1\n\n # Expose origin / source as environment variables for hooks to consume\n if args.origin and args.source:\n environ['PRE_COMMIT_ORIGIN'] = args.origin\n environ['PRE_COMMIT_SOURCE'] = args.source\n\n if no_stash:\n ctx = noop_context()\n else:\n ctx = staged_files_only(runner.store.directory)\n\n with ctx:\n repo_hooks = []\n for repo in runner.repositories:\n for _, hook in repo.hooks:\n if (\n (not args.hook or hook['id'] == args.hook) and\n not hook['stages'] or args.hook_stage in hook['stages']\n ):\n repo_hooks.append((repo, hook))\n\n if args.hook and not repo_hooks:\n output.write_line('No hook with id `{}`'.format(args.hook))\n return 1\n\n for repo in {repo for repo, _ in repo_hooks}:\n repo.require_installed()\n\n return _run_hooks(runner.config, repo_hooks, args, environ)\n", "path": "pre_commit/commands/run.py"}], "after_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\nimport re\nimport subprocess\nimport sys\n\nfrom identify.identify import tags_from_path\n\nfrom pre_commit import color\nfrom pre_commit import git\nfrom pre_commit import output\nfrom pre_commit.output import get_hook_message\nfrom pre_commit.staged_files_only import staged_files_only\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import memoize_by_cwd\nfrom pre_commit.util import noop_context\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ntags_from_path = memoize_by_cwd(tags_from_path)\n\n\ndef _get_skips(environ):\n skips = environ.get('SKIP', '')\n return {skip.strip() for skip in skips.split(',') if skip.strip()}\n\n\ndef _hook_msg_start(hook, verbose):\n return '{}{}'.format(\n '[{}] '.format(hook['id']) if verbose else '', hook['name'],\n )\n\n\ndef _filter_by_include_exclude(filenames, include, exclude):\n include_re, exclude_re = re.compile(include), re.compile(exclude)\n return {\n filename for filename in filenames\n if (\n include_re.search(filename) and\n not exclude_re.search(filename) and\n os.path.lexists(filename)\n )\n }\n\n\ndef _filter_by_types(filenames, types, exclude_types):\n types, exclude_types = frozenset(types), frozenset(exclude_types)\n ret = []\n for filename in filenames:\n tags = tags_from_path(filename)\n if tags >= types and not tags & exclude_types:\n ret.append(filename)\n return tuple(ret)\n\n\nSKIPPED = 'Skipped'\nNO_FILES = '(no files to check)'\n\n\ndef _run_single_hook(filenames, hook, repo, args, skips, cols):\n include, exclude = hook['files'], hook['exclude']\n filenames = _filter_by_include_exclude(filenames, include, exclude)\n types, exclude_types = hook['types'], hook['exclude_types']\n filenames = _filter_by_types(filenames, types, exclude_types)\n\n if hook['language'] == 'pcre':\n logger.warning(\n '`{}` (from {}) uses the deprecated pcre language.\\n'\n 'The pcre language is scheduled for removal in pre-commit 2.x.\\n'\n 'The pygrep language is a more portable (and usually drop-in) '\n 'replacement.'.format(hook['id'], repo.repo_config['repo']),\n )\n\n if hook['id'] in skips:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n end_msg=SKIPPED,\n end_color=color.YELLOW,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n elif not filenames and not hook['always_run']:\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose),\n postfix=NO_FILES,\n end_msg=SKIPPED,\n end_color=color.TURQUOISE,\n use_color=args.color,\n cols=cols,\n ))\n return 0\n\n # Print the hook and the dots first in case the hook takes hella long to\n # run.\n output.write(get_hook_message(\n _hook_msg_start(hook, args.verbose), end_len=6, cols=cols,\n ))\n sys.stdout.flush()\n\n diff_before = cmd_output(\n 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,\n )\n retcode, stdout, stderr = repo.run_hook(\n hook, tuple(filenames) if hook['pass_filenames'] else (),\n )\n diff_after = cmd_output(\n 'git', 'diff', '--no-ext-diff', retcode=None, encoding=None,\n )\n\n file_modifications = diff_before != diff_after\n\n # If the hook makes changes, fail the commit\n if file_modifications:\n retcode = 1\n\n if retcode:\n retcode = 1\n print_color = color.RED\n pass_fail = 'Failed'\n else:\n retcode = 0\n print_color = color.GREEN\n pass_fail = 'Passed'\n\n output.write_line(color.format_color(pass_fail, print_color, args.color))\n\n if (stdout or stderr or file_modifications) and (retcode or args.verbose):\n output.write_line('hookid: {}\\n'.format(hook['id']))\n\n # Print a message if failing due to file modifications\n if file_modifications:\n output.write('Files were modified by this hook.')\n\n if stdout or stderr:\n output.write_line(' Additional output:')\n\n output.write_line()\n\n for out in (stdout, stderr):\n assert type(out) is bytes, type(out)\n if out.strip():\n output.write_line(out.strip(), logfile_name=hook['log_file'])\n output.write_line()\n\n return retcode\n\n\ndef _compute_cols(hooks, verbose):\n \"\"\"Compute the number of columns to display hook messages. The widest\n that will be displayed is in the no files skipped case:\n\n Hook name...(no files to check) Skipped\n\n or in the verbose case\n\n Hook name [hookid]...(no files to check) Skipped\n \"\"\"\n if hooks:\n name_len = max(len(_hook_msg_start(hook, verbose)) for hook in hooks)\n else:\n name_len = 0\n\n cols = name_len + 3 + len(NO_FILES) + 1 + len(SKIPPED)\n return max(cols, 80)\n\n\ndef _all_filenames(args):\n if args.origin and args.source:\n return git.get_changed_files(args.origin, args.source)\n elif args.hook_stage == 'commit-msg':\n return (args.commit_msg_filename,)\n elif args.files:\n return args.files\n elif args.all_files:\n return git.get_all_files()\n elif git.is_in_merge_conflict():\n return git.get_conflicted_files()\n else:\n return git.get_staged_files()\n\n\ndef _run_hooks(config, repo_hooks, args, environ):\n \"\"\"Actually run the hooks.\"\"\"\n skips = _get_skips(environ)\n cols = _compute_cols([hook for _, hook in repo_hooks], args.verbose)\n filenames = _all_filenames(args)\n filenames = _filter_by_include_exclude(filenames, '', config['exclude'])\n retval = 0\n for repo, hook in repo_hooks:\n retval |= _run_single_hook(filenames, hook, repo, args, skips, cols)\n if retval and config['fail_fast']:\n break\n if (\n retval and\n args.show_diff_on_failure and\n subprocess.call(('git', 'diff', '--quiet', '--no-ext-diff')) != 0\n ):\n print('All changes made by hooks:')\n subprocess.call(('git', '--no-pager', 'diff', '--no-ext-diff'))\n return retval\n\n\ndef _has_unmerged_paths():\n _, stdout, _ = cmd_output('git', 'ls-files', '--unmerged')\n return bool(stdout.strip())\n\n\ndef _has_unstaged_config(runner):\n retcode, _, _ = cmd_output(\n 'git', 'diff', '--no-ext-diff', '--exit-code', runner.config_file_path,\n retcode=None,\n )\n # be explicit, other git errors don't mean it has an unstaged config.\n return retcode == 1\n\n\ndef run(runner, args, environ=os.environ):\n no_stash = args.all_files or bool(args.files)\n\n # Check if we have unresolved merge conflict files and fail fast.\n if _has_unmerged_paths():\n logger.error('Unmerged files. Resolve before committing.')\n return 1\n if bool(args.source) != bool(args.origin):\n logger.error('Specify both --origin and --source.')\n return 1\n if _has_unstaged_config(runner) and not no_stash:\n logger.error(\n 'Your pre-commit configuration is unstaged.\\n'\n '`git add {}` to fix this.'.format(runner.config_file),\n )\n return 1\n\n # Expose origin / source as environment variables for hooks to consume\n if args.origin and args.source:\n environ['PRE_COMMIT_ORIGIN'] = args.origin\n environ['PRE_COMMIT_SOURCE'] = args.source\n\n if no_stash:\n ctx = noop_context()\n else:\n ctx = staged_files_only(runner.store.directory)\n\n with ctx:\n repo_hooks = []\n for repo in runner.repositories:\n for _, hook in repo.hooks:\n if (\n (not args.hook or hook['id'] == args.hook) and\n not hook['stages'] or args.hook_stage in hook['stages']\n ):\n repo_hooks.append((repo, hook))\n\n if args.hook and not repo_hooks:\n output.write_line('No hook with id `{}`'.format(args.hook))\n return 1\n\n for repo in {repo for repo, _ in repo_hooks}:\n repo.require_installed()\n\n return _run_hooks(runner.config, repo_hooks, args, environ)\n", "path": "pre_commit/commands/run.py"}]}
| 2,925 | 215 |
gh_patches_debug_60838
|
rasdani/github-patches
|
git_diff
|
docarray__docarray-60
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fix: fix tags type after pydantic model
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docarray/document/pydantic_model.py`
Content:
```
1 from typing import Optional, List, Dict, Any, TYPE_CHECKING, Union
2
3 from pydantic import BaseModel, validator
4
5 from ..math.ndarray import to_list
6
7 if TYPE_CHECKING:
8 from ..types import ArrayType
9
10 _ProtoValueType = Optional[Union[str, bool, float]]
11 _StructValueType = Union[
12 _ProtoValueType, List[_ProtoValueType], Dict[str, _ProtoValueType]
13 ]
14
15
16 def _convert_ndarray_to_list(v: 'ArrayType'):
17 if v is not None:
18 return to_list(v)
19
20
21 class PydanticDocument(BaseModel):
22 id: str
23 parent_id: Optional[str]
24 granularity: Optional[int]
25 adjacency: Optional[int]
26 blob: Optional[bytes]
27 tensor: Optional[Any]
28 mime_type: Optional[str]
29 text: Optional[str]
30 weight: Optional[float]
31 uri: Optional[str]
32 tags: Optional[Dict[str, '_StructValueType']]
33 offset: Optional[float]
34 location: Optional[List[float]]
35 embedding: Optional[Any]
36 modality: Optional[str]
37 evaluations: Optional[Dict[str, Dict[str, '_StructValueType']]]
38 scores: Optional[Dict[str, Dict[str, '_StructValueType']]]
39 chunks: Optional[List['PydanticDocument']]
40 matches: Optional[List['PydanticDocument']]
41
42 _tensor2list = validator('tensor', allow_reuse=True)(_convert_ndarray_to_list)
43 _embedding2list = validator('embedding', allow_reuse=True)(_convert_ndarray_to_list)
44
45
46 PydanticDocument.update_forward_refs()
47
48 PydanticDocumentArray = List[PydanticDocument]
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docarray/document/pydantic_model.py b/docarray/document/pydantic_model.py
--- a/docarray/document/pydantic_model.py
+++ b/docarray/document/pydantic_model.py
@@ -7,7 +7,8 @@
if TYPE_CHECKING:
from ..types import ArrayType
-_ProtoValueType = Optional[Union[str, bool, float]]
+# this order must be preserved: https://pydantic-docs.helpmanual.io/usage/types/#unions
+_ProtoValueType = Optional[Union[bool, float, str]]
_StructValueType = Union[
_ProtoValueType, List[_ProtoValueType], Dict[str, _ProtoValueType]
]
|
{"golden_diff": "diff --git a/docarray/document/pydantic_model.py b/docarray/document/pydantic_model.py\n--- a/docarray/document/pydantic_model.py\n+++ b/docarray/document/pydantic_model.py\n@@ -7,7 +7,8 @@\n if TYPE_CHECKING:\n from ..types import ArrayType\n \n-_ProtoValueType = Optional[Union[str, bool, float]]\n+# this order must be preserved: https://pydantic-docs.helpmanual.io/usage/types/#unions\n+_ProtoValueType = Optional[Union[bool, float, str]]\n _StructValueType = Union[\n _ProtoValueType, List[_ProtoValueType], Dict[str, _ProtoValueType]\n ]\n", "issue": "fix: fix tags type after pydantic model\n\n", "before_files": [{"content": "from typing import Optional, List, Dict, Any, TYPE_CHECKING, Union\n\nfrom pydantic import BaseModel, validator\n\nfrom ..math.ndarray import to_list\n\nif TYPE_CHECKING:\n from ..types import ArrayType\n\n_ProtoValueType = Optional[Union[str, bool, float]]\n_StructValueType = Union[\n _ProtoValueType, List[_ProtoValueType], Dict[str, _ProtoValueType]\n]\n\n\ndef _convert_ndarray_to_list(v: 'ArrayType'):\n if v is not None:\n return to_list(v)\n\n\nclass PydanticDocument(BaseModel):\n id: str\n parent_id: Optional[str]\n granularity: Optional[int]\n adjacency: Optional[int]\n blob: Optional[bytes]\n tensor: Optional[Any]\n mime_type: Optional[str]\n text: Optional[str]\n weight: Optional[float]\n uri: Optional[str]\n tags: Optional[Dict[str, '_StructValueType']]\n offset: Optional[float]\n location: Optional[List[float]]\n embedding: Optional[Any]\n modality: Optional[str]\n evaluations: Optional[Dict[str, Dict[str, '_StructValueType']]]\n scores: Optional[Dict[str, Dict[str, '_StructValueType']]]\n chunks: Optional[List['PydanticDocument']]\n matches: Optional[List['PydanticDocument']]\n\n _tensor2list = validator('tensor', allow_reuse=True)(_convert_ndarray_to_list)\n _embedding2list = validator('embedding', allow_reuse=True)(_convert_ndarray_to_list)\n\n\nPydanticDocument.update_forward_refs()\n\nPydanticDocumentArray = List[PydanticDocument]\n", "path": "docarray/document/pydantic_model.py"}], "after_files": [{"content": "from typing import Optional, List, Dict, Any, TYPE_CHECKING, Union\n\nfrom pydantic import BaseModel, validator\n\nfrom ..math.ndarray import to_list\n\nif TYPE_CHECKING:\n from ..types import ArrayType\n\n# this order must be preserved: https://pydantic-docs.helpmanual.io/usage/types/#unions\n_ProtoValueType = Optional[Union[bool, float, str]]\n_StructValueType = Union[\n _ProtoValueType, List[_ProtoValueType], Dict[str, _ProtoValueType]\n]\n\n\ndef _convert_ndarray_to_list(v: 'ArrayType'):\n if v is not None:\n return to_list(v)\n\n\nclass PydanticDocument(BaseModel):\n id: str\n parent_id: Optional[str]\n granularity: Optional[int]\n adjacency: Optional[int]\n blob: Optional[bytes]\n tensor: Optional[Any]\n mime_type: Optional[str]\n text: Optional[str]\n weight: Optional[float]\n uri: Optional[str]\n tags: Optional[Dict[str, '_StructValueType']]\n offset: Optional[float]\n location: Optional[List[float]]\n embedding: Optional[Any]\n modality: Optional[str]\n evaluations: Optional[Dict[str, Dict[str, '_StructValueType']]]\n scores: Optional[Dict[str, Dict[str, '_StructValueType']]]\n chunks: Optional[List['PydanticDocument']]\n matches: Optional[List['PydanticDocument']]\n\n _tensor2list = validator('tensor', allow_reuse=True)(_convert_ndarray_to_list)\n _embedding2list = validator('embedding', allow_reuse=True)(_convert_ndarray_to_list)\n\n\nPydanticDocument.update_forward_refs()\n\nPydanticDocumentArray = List[PydanticDocument]\n", "path": "docarray/document/pydantic_model.py"}]}
| 706 | 142 |
gh_patches_debug_32437
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-292
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow querying `ChainInfo` by `shortName`
@rmeissner add use case
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/chains/urls.py`
Content:
```
1 from django.urls import path
2
3 from chains.views import ChainsDetailView, ChainsListView
4
5 app_name = "chains"
6
7 urlpatterns = [
8 path("", ChainsListView.as_view(), name="list"),
9 path("<pk>/", ChainsDetailView.as_view(), name="detail"),
10 ]
11
```
Path: `src/chains/views.py`
Content:
```
1 from rest_framework import filters
2 from rest_framework.generics import ListAPIView, RetrieveAPIView
3 from rest_framework.pagination import LimitOffsetPagination
4
5 from .models import Chain
6 from .serializers import ChainSerializer
7
8
9 class ChainsListView(ListAPIView):
10 serializer_class = ChainSerializer
11 pagination_class = LimitOffsetPagination
12 pagination_class.max_limit = 100
13 pagination_class.default_limit = 10
14 queryset = Chain.objects.all()
15 filter_backends = [filters.OrderingFilter]
16 ordering_fields = ["relevance", "name"]
17 ordering = [
18 "relevance",
19 "name",
20 ]
21
22
23 class ChainsDetailView(RetrieveAPIView):
24 serializer_class = ChainSerializer
25 queryset = Chain.objects.all()
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/chains/urls.py b/src/chains/urls.py
--- a/src/chains/urls.py
+++ b/src/chains/urls.py
@@ -1,10 +1,15 @@
from django.urls import path
-from chains.views import ChainsDetailView, ChainsListView
+from chains.views import ChainsDetailView, ChainsDetailViewByShortName, ChainsListView
app_name = "chains"
urlpatterns = [
path("", ChainsListView.as_view(), name="list"),
- path("<pk>/", ChainsDetailView.as_view(), name="detail"),
+ path("<int:pk>/", ChainsDetailView.as_view(), name="detail"),
+ path(
+ "<str:short_name>/",
+ ChainsDetailViewByShortName.as_view(),
+ name="detail_by_short_name",
+ ),
]
diff --git a/src/chains/views.py b/src/chains/views.py
--- a/src/chains/views.py
+++ b/src/chains/views.py
@@ -1,6 +1,11 @@
+from typing import Any
+
+from drf_yasg.utils import swagger_auto_schema
from rest_framework import filters
from rest_framework.generics import ListAPIView, RetrieveAPIView
from rest_framework.pagination import LimitOffsetPagination
+from rest_framework.request import Request
+from rest_framework.response import Response
from .models import Chain
from .serializers import ChainSerializer
@@ -23,3 +28,22 @@
class ChainsDetailView(RetrieveAPIView):
serializer_class = ChainSerializer
queryset = Chain.objects.all()
+
+ @swagger_auto_schema(
+ operation_id="Get chain by id"
+ ) # type: ignore[misc] # Untyped decorator makes function "get" untyped
+ def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:
+ return super().get(request, *args, **kwargs)
+
+
+class ChainsDetailViewByShortName(RetrieveAPIView):
+ lookup_field = "short_name"
+ serializer_class = ChainSerializer
+ queryset = Chain.objects.all()
+
+ @swagger_auto_schema(
+ operation_id="Get chain by shortName",
+ operation_description="Warning: `shortNames` may contain characters that need to be URL encoded (i.e.: whitespaces)", # noqa E501
+ ) # type: ignore[misc] # Untyped decorator makes function "get" untyped
+ def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:
+ return super().get(request, *args, **kwargs)
|
{"golden_diff": "diff --git a/src/chains/urls.py b/src/chains/urls.py\n--- a/src/chains/urls.py\n+++ b/src/chains/urls.py\n@@ -1,10 +1,15 @@\n from django.urls import path\n \n-from chains.views import ChainsDetailView, ChainsListView\n+from chains.views import ChainsDetailView, ChainsDetailViewByShortName, ChainsListView\n \n app_name = \"chains\"\n \n urlpatterns = [\n path(\"\", ChainsListView.as_view(), name=\"list\"),\n- path(\"<pk>/\", ChainsDetailView.as_view(), name=\"detail\"),\n+ path(\"<int:pk>/\", ChainsDetailView.as_view(), name=\"detail\"),\n+ path(\n+ \"<str:short_name>/\",\n+ ChainsDetailViewByShortName.as_view(),\n+ name=\"detail_by_short_name\",\n+ ),\n ]\ndiff --git a/src/chains/views.py b/src/chains/views.py\n--- a/src/chains/views.py\n+++ b/src/chains/views.py\n@@ -1,6 +1,11 @@\n+from typing import Any\n+\n+from drf_yasg.utils import swagger_auto_schema\n from rest_framework import filters\n from rest_framework.generics import ListAPIView, RetrieveAPIView\n from rest_framework.pagination import LimitOffsetPagination\n+from rest_framework.request import Request\n+from rest_framework.response import Response\n \n from .models import Chain\n from .serializers import ChainSerializer\n@@ -23,3 +28,22 @@\n class ChainsDetailView(RetrieveAPIView):\n serializer_class = ChainSerializer\n queryset = Chain.objects.all()\n+\n+ @swagger_auto_schema(\n+ operation_id=\"Get chain by id\"\n+ ) # type: ignore[misc] # Untyped decorator makes function \"get\" untyped\n+ def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n+ return super().get(request, *args, **kwargs)\n+\n+\n+class ChainsDetailViewByShortName(RetrieveAPIView):\n+ lookup_field = \"short_name\"\n+ serializer_class = ChainSerializer\n+ queryset = Chain.objects.all()\n+\n+ @swagger_auto_schema(\n+ operation_id=\"Get chain by shortName\",\n+ operation_description=\"Warning: `shortNames` may contain characters that need to be URL encoded (i.e.: whitespaces)\", # noqa E501\n+ ) # type: ignore[misc] # Untyped decorator makes function \"get\" untyped\n+ def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n+ return super().get(request, *args, **kwargs)\n", "issue": "Allow querying `ChainInfo` by `shortName`\n@rmeissner add use case\n", "before_files": [{"content": "from django.urls import path\n\nfrom chains.views import ChainsDetailView, ChainsListView\n\napp_name = \"chains\"\n\nurlpatterns = [\n path(\"\", ChainsListView.as_view(), name=\"list\"),\n path(\"<pk>/\", ChainsDetailView.as_view(), name=\"detail\"),\n]\n", "path": "src/chains/urls.py"}, {"content": "from rest_framework import filters\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView\nfrom rest_framework.pagination import LimitOffsetPagination\n\nfrom .models import Chain\nfrom .serializers import ChainSerializer\n\n\nclass ChainsListView(ListAPIView):\n serializer_class = ChainSerializer\n pagination_class = LimitOffsetPagination\n pagination_class.max_limit = 100\n pagination_class.default_limit = 10\n queryset = Chain.objects.all()\n filter_backends = [filters.OrderingFilter]\n ordering_fields = [\"relevance\", \"name\"]\n ordering = [\n \"relevance\",\n \"name\",\n ]\n\n\nclass ChainsDetailView(RetrieveAPIView):\n serializer_class = ChainSerializer\n queryset = Chain.objects.all()\n", "path": "src/chains/views.py"}], "after_files": [{"content": "from django.urls import path\n\nfrom chains.views import ChainsDetailView, ChainsDetailViewByShortName, ChainsListView\n\napp_name = \"chains\"\n\nurlpatterns = [\n path(\"\", ChainsListView.as_view(), name=\"list\"),\n path(\"<int:pk>/\", ChainsDetailView.as_view(), name=\"detail\"),\n path(\n \"<str:short_name>/\",\n ChainsDetailViewByShortName.as_view(),\n name=\"detail_by_short_name\",\n ),\n]\n", "path": "src/chains/urls.py"}, {"content": "from typing import Any\n\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework import filters\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView\nfrom rest_framework.pagination import LimitOffsetPagination\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom .models import Chain\nfrom .serializers import ChainSerializer\n\n\nclass ChainsListView(ListAPIView):\n serializer_class = ChainSerializer\n pagination_class = LimitOffsetPagination\n pagination_class.max_limit = 100\n pagination_class.default_limit = 10\n queryset = Chain.objects.all()\n filter_backends = [filters.OrderingFilter]\n ordering_fields = [\"relevance\", \"name\"]\n ordering = [\n \"relevance\",\n \"name\",\n ]\n\n\nclass ChainsDetailView(RetrieveAPIView):\n serializer_class = ChainSerializer\n queryset = Chain.objects.all()\n\n @swagger_auto_schema(\n operation_id=\"Get chain by id\"\n ) # type: ignore[misc] # Untyped decorator makes function \"get\" untyped\n def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n return super().get(request, *args, **kwargs)\n\n\nclass ChainsDetailViewByShortName(RetrieveAPIView):\n lookup_field = \"short_name\"\n serializer_class = ChainSerializer\n queryset = Chain.objects.all()\n\n @swagger_auto_schema(\n operation_id=\"Get chain by shortName\",\n operation_description=\"Warning: `shortNames` may contain characters that need to be URL encoded (i.e.: whitespaces)\", # noqa E501\n ) # type: ignore[misc] # Untyped decorator makes function \"get\" untyped\n def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n return super().get(request, *args, **kwargs)\n", "path": "src/chains/views.py"}]}
| 562 | 558 |
gh_patches_debug_21696
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-2921
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add layer argument to `score_genes()`/`score_genes_cell_cycle()`
### What kind of feature would you like to request?
Additional function parameters / changed functionality / changed defaults?
### Please describe your wishes
These functions are some of the few to still not have this argument. Would also help with #2909.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scanpy/tools/_score_genes.py`
Content:
```
1 """Calculate scores based on the expression of gene lists."""
2
3 from __future__ import annotations
4
5 from typing import TYPE_CHECKING
6
7 import numpy as np
8 import pandas as pd
9 from scipy.sparse import issparse
10
11 from scanpy._utils import _check_use_raw, is_backed_type
12
13 from .. import logging as logg
14 from .._compat import old_positionals
15 from ..get import _get_obs_rep
16
17 if TYPE_CHECKING:
18 from collections.abc import Sequence
19 from typing import Literal
20
21 from anndata import AnnData
22 from numpy.typing import DTypeLike, NDArray
23 from scipy.sparse import csc_matrix, csr_matrix
24
25 from .._utils import AnyRandom
26
27
28 def _sparse_nanmean(
29 X: csr_matrix | csc_matrix, axis: Literal[0, 1]
30 ) -> NDArray[np.float64]:
31 """
32 np.nanmean equivalent for sparse matrices
33 """
34 if not issparse(X):
35 raise TypeError("X must be a sparse matrix")
36
37 # count the number of nan elements per row/column (dep. on axis)
38 Z = X.copy()
39 Z.data = np.isnan(Z.data)
40 Z.eliminate_zeros()
41 n_elements = Z.shape[axis] - Z.sum(axis)
42
43 # set the nans to 0, so that a normal .sum() works
44 Y = X.copy()
45 Y.data[np.isnan(Y.data)] = 0
46 Y.eliminate_zeros()
47
48 # the average
49 s = Y.sum(axis, dtype="float64") # float64 for score_genes function compatibility)
50 m = s / n_elements
51
52 return m
53
54
55 @old_positionals(
56 "ctrl_size", "gene_pool", "n_bins", "score_name", "random_state", "copy", "use_raw"
57 )
58 def score_genes(
59 adata: AnnData,
60 gene_list: Sequence[str] | pd.Index[str],
61 *,
62 ctrl_size: int = 50,
63 gene_pool: Sequence[str] | pd.Index[str] | None = None,
64 n_bins: int = 25,
65 score_name: str = "score",
66 random_state: AnyRandom = 0,
67 copy: bool = False,
68 use_raw: bool | None = None,
69 ) -> AnnData | None:
70 """\
71 Score a set of genes :cite:p:`Satija2015`.
72
73 The score is the average expression of a set of genes subtracted with the
74 average expression of a reference set of genes. The reference set is
75 randomly sampled from the `gene_pool` for each binned expression value.
76
77 This reproduces the approach in Seurat :cite:p:`Satija2015` and has been implemented
78 for Scanpy by Davide Cittaro.
79
80 Parameters
81 ----------
82 adata
83 The annotated data matrix.
84 gene_list
85 The list of gene names used for score calculation.
86 ctrl_size
87 Number of reference genes to be sampled from each bin. If `len(gene_list)` is not too
88 low, you can set `ctrl_size=len(gene_list)`.
89 gene_pool
90 Genes for sampling the reference set. Default is all genes.
91 n_bins
92 Number of expression level bins for sampling.
93 score_name
94 Name of the field to be added in `.obs`.
95 random_state
96 The random seed for sampling.
97 copy
98 Copy `adata` or modify it inplace.
99 use_raw
100 Whether to use `raw` attribute of `adata`. Defaults to `True` if `.raw` is present.
101
102 .. versionchanged:: 1.4.5
103 Default value changed from `False` to `None`.
104
105 Returns
106 -------
107 Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following field:
108
109 `adata.obs[score_name]` : :class:`numpy.ndarray` (dtype `float`)
110 Scores of each cell.
111
112 Examples
113 --------
114 See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.
115 """
116 start = logg.info(f"computing score {score_name!r}")
117 adata = adata.copy() if copy else adata
118 use_raw = _check_use_raw(adata, use_raw)
119 if is_backed_type(adata.X) and not use_raw:
120 raise NotImplementedError(
121 f"score_genes is not implemented for matrices of type {type(adata.X)}"
122 )
123
124 if random_state is not None:
125 np.random.seed(random_state)
126
127 var_names = adata.raw.var_names if use_raw else adata.var_names
128 gene_list = pd.Index([gene_list] if isinstance(gene_list, str) else gene_list)
129 genes_to_ignore = gene_list.difference(var_names, sort=False) # first get missing
130 gene_list = gene_list.intersection(var_names) # then restrict to present
131 if len(genes_to_ignore) > 0:
132 logg.warning(f"genes are not in var_names and ignored: {genes_to_ignore}")
133 if len(gene_list) == 0:
134 raise ValueError("No valid genes were passed for scoring.")
135
136 if gene_pool is None:
137 gene_pool = pd.Index(var_names, dtype="string")
138 else:
139 gene_pool = pd.Index(gene_pool, dtype="string").intersection(var_names)
140 if len(gene_pool) == 0:
141 raise ValueError("No valid genes were passed for reference set.")
142
143 # Trying here to match the Seurat approach in scoring cells.
144 # Basically we need to compare genes against random genes in a matched
145 # interval of expression.
146
147 def get_subset(genes: pd.Index[str]):
148 x = _get_obs_rep(adata, use_raw=use_raw)
149 if len(genes) == len(var_names):
150 return x
151 idx = var_names.get_indexer(genes)
152 return x[:, idx]
153
154 # average expression of genes
155 obs_avg = pd.Series(_nan_means(get_subset(gene_pool), axis=0), index=gene_pool)
156 # Sometimes (and I don’t know how) missing data may be there, with NaNs for missing entries
157 obs_avg = obs_avg[np.isfinite(obs_avg)]
158
159 n_items = int(np.round(len(obs_avg) / (n_bins - 1)))
160 obs_cut = obs_avg.rank(method="min") // n_items
161 control_genes = pd.Index([], dtype="string")
162
163 # now pick `ctrl_size` genes from every cut
164 for cut in np.unique(obs_cut.loc[gene_list]):
165 r_genes: pd.Index[str] = obs_cut[obs_cut == cut].index
166 if ctrl_size < len(r_genes):
167 r_genes = r_genes.to_series().sample(ctrl_size).index
168 control_genes = control_genes.union(r_genes.difference(gene_list))
169
170 means_list, means_control = (
171 _nan_means(get_subset(genes), axis=1, dtype="float64")
172 for genes in (gene_list, control_genes)
173 )
174 score = means_list - means_control
175
176 adata.obs[score_name] = pd.Series(
177 np.array(score).ravel(), index=adata.obs_names, dtype="float64"
178 )
179
180 logg.info(
181 " finished",
182 time=start,
183 deep=(
184 "added\n"
185 f" {score_name!r}, score of gene set (adata.obs).\n"
186 f" {len(control_genes)} total control genes are used."
187 ),
188 )
189 return adata if copy else None
190
191
192 def _nan_means(
193 x, *, axis: Literal[0, 1], dtype: DTypeLike | None = None
194 ) -> NDArray[np.float64]:
195 if issparse(x):
196 return np.array(_sparse_nanmean(x, axis=axis)).flatten()
197 return np.nanmean(x, axis=axis, dtype=dtype)
198
199
200 @old_positionals("s_genes", "g2m_genes", "copy")
201 def score_genes_cell_cycle(
202 adata: AnnData,
203 *,
204 s_genes: Sequence[str],
205 g2m_genes: Sequence[str],
206 copy: bool = False,
207 **kwargs,
208 ) -> AnnData | None:
209 """\
210 Score cell cycle genes :cite:p:`Satija2015`.
211
212 Given two lists of genes associated to S phase and G2M phase, calculates
213 scores and assigns a cell cycle phase (G1, S or G2M). See
214 :func:`~scanpy.tl.score_genes` for more explanation.
215
216 Parameters
217 ----------
218 adata
219 The annotated data matrix.
220 s_genes
221 List of genes associated with S phase.
222 g2m_genes
223 List of genes associated with G2M phase.
224 copy
225 Copy `adata` or modify it inplace.
226 **kwargs
227 Are passed to :func:`~scanpy.tl.score_genes`. `ctrl_size` is not
228 possible, as it's set as `min(len(s_genes), len(g2m_genes))`.
229
230 Returns
231 -------
232 Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following fields:
233
234 `adata.obs['S_score']` : :class:`pandas.Series` (dtype `object`)
235 The score for S phase for each cell.
236 `adata.obs['G2M_score']` : :class:`pandas.Series` (dtype `object`)
237 The score for G2M phase for each cell.
238 `adata.obs['phase']` : :class:`pandas.Series` (dtype `object`)
239 The cell cycle phase (`S`, `G2M` or `G1`) for each cell.
240
241 See also
242 --------
243 score_genes
244
245 Examples
246 --------
247 See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.
248 """
249 logg.info("calculating cell cycle phase")
250
251 adata = adata.copy() if copy else adata
252 ctrl_size = min(len(s_genes), len(g2m_genes))
253 for genes, name in [(s_genes, "S_score"), (g2m_genes, "G2M_score")]:
254 score_genes(adata, genes, score_name=name, ctrl_size=ctrl_size, **kwargs)
255 scores = adata.obs[["S_score", "G2M_score"]]
256
257 # default phase is S
258 phase = pd.Series("S", index=scores.index)
259
260 # if G2M is higher than S, it's G2M
261 phase[scores["G2M_score"] > scores["S_score"]] = "G2M"
262
263 # if all scores are negative, it's G1...
264 phase[np.all(scores < 0, axis=1)] = "G1"
265
266 adata.obs["phase"] = phase
267 logg.hint(" 'phase', cell cycle phase (adata.obs)")
268 return adata if copy else None
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scanpy/tools/_score_genes.py b/scanpy/tools/_score_genes.py
--- a/scanpy/tools/_score_genes.py
+++ b/scanpy/tools/_score_genes.py
@@ -66,6 +66,7 @@
random_state: AnyRandom = 0,
copy: bool = False,
use_raw: bool | None = None,
+ layer: str | None = None,
) -> AnnData | None:
"""\
Score a set of genes :cite:p:`Satija2015`.
@@ -101,6 +102,8 @@
.. versionchanged:: 1.4.5
Default value changed from `False` to `None`.
+ layer
+ Key from `adata.layers` whose value will be used to perform tests on.
Returns
-------
@@ -145,7 +148,7 @@
# interval of expression.
def get_subset(genes: pd.Index[str]):
- x = _get_obs_rep(adata, use_raw=use_raw)
+ x = _get_obs_rep(adata, use_raw=use_raw, layer=layer)
if len(genes) == len(var_names):
return x
idx = var_names.get_indexer(genes)
|
{"golden_diff": "diff --git a/scanpy/tools/_score_genes.py b/scanpy/tools/_score_genes.py\n--- a/scanpy/tools/_score_genes.py\n+++ b/scanpy/tools/_score_genes.py\n@@ -66,6 +66,7 @@\n random_state: AnyRandom = 0,\n copy: bool = False,\n use_raw: bool | None = None,\n+ layer: str | None = None,\n ) -> AnnData | None:\n \"\"\"\\\n Score a set of genes :cite:p:`Satija2015`.\n@@ -101,6 +102,8 @@\n \n .. versionchanged:: 1.4.5\n Default value changed from `False` to `None`.\n+ layer\n+ Key from `adata.layers` whose value will be used to perform tests on.\n \n Returns\n -------\n@@ -145,7 +148,7 @@\n # interval of expression.\n \n def get_subset(genes: pd.Index[str]):\n- x = _get_obs_rep(adata, use_raw=use_raw)\n+ x = _get_obs_rep(adata, use_raw=use_raw, layer=layer)\n if len(genes) == len(var_names):\n return x\n idx = var_names.get_indexer(genes)\n", "issue": "Add layer argument to `score_genes()`/`score_genes_cell_cycle()`\n### What kind of feature would you like to request?\n\nAdditional function parameters / changed functionality / changed defaults?\n\n### Please describe your wishes\n\nThese functions are some of the few to still not have this argument. Would also help with #2909.\n", "before_files": [{"content": "\"\"\"Calculate scores based on the expression of gene lists.\"\"\"\n\nfrom __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nimport numpy as np\nimport pandas as pd\nfrom scipy.sparse import issparse\n\nfrom scanpy._utils import _check_use_raw, is_backed_type\n\nfrom .. import logging as logg\nfrom .._compat import old_positionals\nfrom ..get import _get_obs_rep\n\nif TYPE_CHECKING:\n from collections.abc import Sequence\n from typing import Literal\n\n from anndata import AnnData\n from numpy.typing import DTypeLike, NDArray\n from scipy.sparse import csc_matrix, csr_matrix\n\n from .._utils import AnyRandom\n\n\ndef _sparse_nanmean(\n X: csr_matrix | csc_matrix, axis: Literal[0, 1]\n) -> NDArray[np.float64]:\n \"\"\"\n np.nanmean equivalent for sparse matrices\n \"\"\"\n if not issparse(X):\n raise TypeError(\"X must be a sparse matrix\")\n\n # count the number of nan elements per row/column (dep. on axis)\n Z = X.copy()\n Z.data = np.isnan(Z.data)\n Z.eliminate_zeros()\n n_elements = Z.shape[axis] - Z.sum(axis)\n\n # set the nans to 0, so that a normal .sum() works\n Y = X.copy()\n Y.data[np.isnan(Y.data)] = 0\n Y.eliminate_zeros()\n\n # the average\n s = Y.sum(axis, dtype=\"float64\") # float64 for score_genes function compatibility)\n m = s / n_elements\n\n return m\n\n\n@old_positionals(\n \"ctrl_size\", \"gene_pool\", \"n_bins\", \"score_name\", \"random_state\", \"copy\", \"use_raw\"\n)\ndef score_genes(\n adata: AnnData,\n gene_list: Sequence[str] | pd.Index[str],\n *,\n ctrl_size: int = 50,\n gene_pool: Sequence[str] | pd.Index[str] | None = None,\n n_bins: int = 25,\n score_name: str = \"score\",\n random_state: AnyRandom = 0,\n copy: bool = False,\n use_raw: bool | None = None,\n) -> AnnData | None:\n \"\"\"\\\n Score a set of genes :cite:p:`Satija2015`.\n\n The score is the average expression of a set of genes subtracted with the\n average expression of a reference set of genes. The reference set is\n randomly sampled from the `gene_pool` for each binned expression value.\n\n This reproduces the approach in Seurat :cite:p:`Satija2015` and has been implemented\n for Scanpy by Davide Cittaro.\n\n Parameters\n ----------\n adata\n The annotated data matrix.\n gene_list\n The list of gene names used for score calculation.\n ctrl_size\n Number of reference genes to be sampled from each bin. If `len(gene_list)` is not too\n low, you can set `ctrl_size=len(gene_list)`.\n gene_pool\n Genes for sampling the reference set. Default is all genes.\n n_bins\n Number of expression level bins for sampling.\n score_name\n Name of the field to be added in `.obs`.\n random_state\n The random seed for sampling.\n copy\n Copy `adata` or modify it inplace.\n use_raw\n Whether to use `raw` attribute of `adata`. Defaults to `True` if `.raw` is present.\n\n .. versionchanged:: 1.4.5\n Default value changed from `False` to `None`.\n\n Returns\n -------\n Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following field:\n\n `adata.obs[score_name]` : :class:`numpy.ndarray` (dtype `float`)\n Scores of each cell.\n\n Examples\n --------\n See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.\n \"\"\"\n start = logg.info(f\"computing score {score_name!r}\")\n adata = adata.copy() if copy else adata\n use_raw = _check_use_raw(adata, use_raw)\n if is_backed_type(adata.X) and not use_raw:\n raise NotImplementedError(\n f\"score_genes is not implemented for matrices of type {type(adata.X)}\"\n )\n\n if random_state is not None:\n np.random.seed(random_state)\n\n var_names = adata.raw.var_names if use_raw else adata.var_names\n gene_list = pd.Index([gene_list] if isinstance(gene_list, str) else gene_list)\n genes_to_ignore = gene_list.difference(var_names, sort=False) # first get missing\n gene_list = gene_list.intersection(var_names) # then restrict to present\n if len(genes_to_ignore) > 0:\n logg.warning(f\"genes are not in var_names and ignored: {genes_to_ignore}\")\n if len(gene_list) == 0:\n raise ValueError(\"No valid genes were passed for scoring.\")\n\n if gene_pool is None:\n gene_pool = pd.Index(var_names, dtype=\"string\")\n else:\n gene_pool = pd.Index(gene_pool, dtype=\"string\").intersection(var_names)\n if len(gene_pool) == 0:\n raise ValueError(\"No valid genes were passed for reference set.\")\n\n # Trying here to match the Seurat approach in scoring cells.\n # Basically we need to compare genes against random genes in a matched\n # interval of expression.\n\n def get_subset(genes: pd.Index[str]):\n x = _get_obs_rep(adata, use_raw=use_raw)\n if len(genes) == len(var_names):\n return x\n idx = var_names.get_indexer(genes)\n return x[:, idx]\n\n # average expression of genes\n obs_avg = pd.Series(_nan_means(get_subset(gene_pool), axis=0), index=gene_pool)\n # Sometimes (and I don\u2019t know how) missing data may be there, with NaNs for missing entries\n obs_avg = obs_avg[np.isfinite(obs_avg)]\n\n n_items = int(np.round(len(obs_avg) / (n_bins - 1)))\n obs_cut = obs_avg.rank(method=\"min\") // n_items\n control_genes = pd.Index([], dtype=\"string\")\n\n # now pick `ctrl_size` genes from every cut\n for cut in np.unique(obs_cut.loc[gene_list]):\n r_genes: pd.Index[str] = obs_cut[obs_cut == cut].index\n if ctrl_size < len(r_genes):\n r_genes = r_genes.to_series().sample(ctrl_size).index\n control_genes = control_genes.union(r_genes.difference(gene_list))\n\n means_list, means_control = (\n _nan_means(get_subset(genes), axis=1, dtype=\"float64\")\n for genes in (gene_list, control_genes)\n )\n score = means_list - means_control\n\n adata.obs[score_name] = pd.Series(\n np.array(score).ravel(), index=adata.obs_names, dtype=\"float64\"\n )\n\n logg.info(\n \" finished\",\n time=start,\n deep=(\n \"added\\n\"\n f\" {score_name!r}, score of gene set (adata.obs).\\n\"\n f\" {len(control_genes)} total control genes are used.\"\n ),\n )\n return adata if copy else None\n\n\ndef _nan_means(\n x, *, axis: Literal[0, 1], dtype: DTypeLike | None = None\n) -> NDArray[np.float64]:\n if issparse(x):\n return np.array(_sparse_nanmean(x, axis=axis)).flatten()\n return np.nanmean(x, axis=axis, dtype=dtype)\n\n\n@old_positionals(\"s_genes\", \"g2m_genes\", \"copy\")\ndef score_genes_cell_cycle(\n adata: AnnData,\n *,\n s_genes: Sequence[str],\n g2m_genes: Sequence[str],\n copy: bool = False,\n **kwargs,\n) -> AnnData | None:\n \"\"\"\\\n Score cell cycle genes :cite:p:`Satija2015`.\n\n Given two lists of genes associated to S phase and G2M phase, calculates\n scores and assigns a cell cycle phase (G1, S or G2M). See\n :func:`~scanpy.tl.score_genes` for more explanation.\n\n Parameters\n ----------\n adata\n The annotated data matrix.\n s_genes\n List of genes associated with S phase.\n g2m_genes\n List of genes associated with G2M phase.\n copy\n Copy `adata` or modify it inplace.\n **kwargs\n Are passed to :func:`~scanpy.tl.score_genes`. `ctrl_size` is not\n possible, as it's set as `min(len(s_genes), len(g2m_genes))`.\n\n Returns\n -------\n Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following fields:\n\n `adata.obs['S_score']` : :class:`pandas.Series` (dtype `object`)\n The score for S phase for each cell.\n `adata.obs['G2M_score']` : :class:`pandas.Series` (dtype `object`)\n The score for G2M phase for each cell.\n `adata.obs['phase']` : :class:`pandas.Series` (dtype `object`)\n The cell cycle phase (`S`, `G2M` or `G1`) for each cell.\n\n See also\n --------\n score_genes\n\n Examples\n --------\n See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.\n \"\"\"\n logg.info(\"calculating cell cycle phase\")\n\n adata = adata.copy() if copy else adata\n ctrl_size = min(len(s_genes), len(g2m_genes))\n for genes, name in [(s_genes, \"S_score\"), (g2m_genes, \"G2M_score\")]:\n score_genes(adata, genes, score_name=name, ctrl_size=ctrl_size, **kwargs)\n scores = adata.obs[[\"S_score\", \"G2M_score\"]]\n\n # default phase is S\n phase = pd.Series(\"S\", index=scores.index)\n\n # if G2M is higher than S, it's G2M\n phase[scores[\"G2M_score\"] > scores[\"S_score\"]] = \"G2M\"\n\n # if all scores are negative, it's G1...\n phase[np.all(scores < 0, axis=1)] = \"G1\"\n\n adata.obs[\"phase\"] = phase\n logg.hint(\" 'phase', cell cycle phase (adata.obs)\")\n return adata if copy else None\n", "path": "scanpy/tools/_score_genes.py"}], "after_files": [{"content": "\"\"\"Calculate scores based on the expression of gene lists.\"\"\"\n\nfrom __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nimport numpy as np\nimport pandas as pd\nfrom scipy.sparse import issparse\n\nfrom scanpy._utils import _check_use_raw, is_backed_type\n\nfrom .. import logging as logg\nfrom .._compat import old_positionals\nfrom ..get import _get_obs_rep\n\nif TYPE_CHECKING:\n from collections.abc import Sequence\n from typing import Literal\n\n from anndata import AnnData\n from numpy.typing import DTypeLike, NDArray\n from scipy.sparse import csc_matrix, csr_matrix\n\n from .._utils import AnyRandom\n\n\ndef _sparse_nanmean(\n X: csr_matrix | csc_matrix, axis: Literal[0, 1]\n) -> NDArray[np.float64]:\n \"\"\"\n np.nanmean equivalent for sparse matrices\n \"\"\"\n if not issparse(X):\n raise TypeError(\"X must be a sparse matrix\")\n\n # count the number of nan elements per row/column (dep. on axis)\n Z = X.copy()\n Z.data = np.isnan(Z.data)\n Z.eliminate_zeros()\n n_elements = Z.shape[axis] - Z.sum(axis)\n\n # set the nans to 0, so that a normal .sum() works\n Y = X.copy()\n Y.data[np.isnan(Y.data)] = 0\n Y.eliminate_zeros()\n\n # the average\n s = Y.sum(axis, dtype=\"float64\") # float64 for score_genes function compatibility)\n m = s / n_elements\n\n return m\n\n\n@old_positionals(\n \"ctrl_size\", \"gene_pool\", \"n_bins\", \"score_name\", \"random_state\", \"copy\", \"use_raw\"\n)\ndef score_genes(\n adata: AnnData,\n gene_list: Sequence[str] | pd.Index[str],\n *,\n ctrl_size: int = 50,\n gene_pool: Sequence[str] | pd.Index[str] | None = None,\n n_bins: int = 25,\n score_name: str = \"score\",\n random_state: AnyRandom = 0,\n copy: bool = False,\n use_raw: bool | None = None,\n layer: str | None = None,\n) -> AnnData | None:\n \"\"\"\\\n Score a set of genes :cite:p:`Satija2015`.\n\n The score is the average expression of a set of genes subtracted with the\n average expression of a reference set of genes. The reference set is\n randomly sampled from the `gene_pool` for each binned expression value.\n\n This reproduces the approach in Seurat :cite:p:`Satija2015` and has been implemented\n for Scanpy by Davide Cittaro.\n\n Parameters\n ----------\n adata\n The annotated data matrix.\n gene_list\n The list of gene names used for score calculation.\n ctrl_size\n Number of reference genes to be sampled from each bin. If `len(gene_list)` is not too\n low, you can set `ctrl_size=len(gene_list)`.\n gene_pool\n Genes for sampling the reference set. Default is all genes.\n n_bins\n Number of expression level bins for sampling.\n score_name\n Name of the field to be added in `.obs`.\n random_state\n The random seed for sampling.\n copy\n Copy `adata` or modify it inplace.\n use_raw\n Whether to use `raw` attribute of `adata`. Defaults to `True` if `.raw` is present.\n\n .. versionchanged:: 1.4.5\n Default value changed from `False` to `None`.\n layer\n Key from `adata.layers` whose value will be used to perform tests on.\n\n Returns\n -------\n Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following field:\n\n `adata.obs[score_name]` : :class:`numpy.ndarray` (dtype `float`)\n Scores of each cell.\n\n Examples\n --------\n See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.\n \"\"\"\n start = logg.info(f\"computing score {score_name!r}\")\n adata = adata.copy() if copy else adata\n use_raw = _check_use_raw(adata, use_raw)\n if is_backed_type(adata.X) and not use_raw:\n raise NotImplementedError(\n f\"score_genes is not implemented for matrices of type {type(adata.X)}\"\n )\n\n if random_state is not None:\n np.random.seed(random_state)\n\n var_names = adata.raw.var_names if use_raw else adata.var_names\n gene_list = pd.Index([gene_list] if isinstance(gene_list, str) else gene_list)\n genes_to_ignore = gene_list.difference(var_names, sort=False) # first get missing\n gene_list = gene_list.intersection(var_names) # then restrict to present\n if len(genes_to_ignore) > 0:\n logg.warning(f\"genes are not in var_names and ignored: {genes_to_ignore}\")\n if len(gene_list) == 0:\n raise ValueError(\"No valid genes were passed for scoring.\")\n\n if gene_pool is None:\n gene_pool = pd.Index(var_names, dtype=\"string\")\n else:\n gene_pool = pd.Index(gene_pool, dtype=\"string\").intersection(var_names)\n if len(gene_pool) == 0:\n raise ValueError(\"No valid genes were passed for reference set.\")\n\n # Trying here to match the Seurat approach in scoring cells.\n # Basically we need to compare genes against random genes in a matched\n # interval of expression.\n\n def get_subset(genes: pd.Index[str]):\n x = _get_obs_rep(adata, use_raw=use_raw, layer=layer)\n if len(genes) == len(var_names):\n return x\n idx = var_names.get_indexer(genes)\n return x[:, idx]\n\n # average expression of genes\n obs_avg = pd.Series(_nan_means(get_subset(gene_pool), axis=0), index=gene_pool)\n # Sometimes (and I don\u2019t know how) missing data may be there, with NaNs for missing entries\n obs_avg = obs_avg[np.isfinite(obs_avg)]\n\n n_items = int(np.round(len(obs_avg) / (n_bins - 1)))\n obs_cut = obs_avg.rank(method=\"min\") // n_items\n control_genes = pd.Index([], dtype=\"string\")\n\n # now pick `ctrl_size` genes from every cut\n for cut in np.unique(obs_cut.loc[gene_list]):\n r_genes: pd.Index[str] = obs_cut[obs_cut == cut].index\n if ctrl_size < len(r_genes):\n r_genes = r_genes.to_series().sample(ctrl_size).index\n control_genes = control_genes.union(r_genes.difference(gene_list))\n\n means_list, means_control = (\n _nan_means(get_subset(genes), axis=1, dtype=\"float64\")\n for genes in (gene_list, control_genes)\n )\n score = means_list - means_control\n\n adata.obs[score_name] = pd.Series(\n np.array(score).ravel(), index=adata.obs_names, dtype=\"float64\"\n )\n\n logg.info(\n \" finished\",\n time=start,\n deep=(\n \"added\\n\"\n f\" {score_name!r}, score of gene set (adata.obs).\\n\"\n f\" {len(control_genes)} total control genes are used.\"\n ),\n )\n return adata if copy else None\n\n\ndef _nan_means(\n x, *, axis: Literal[0, 1], dtype: DTypeLike | None = None\n) -> NDArray[np.float64]:\n if issparse(x):\n return np.array(_sparse_nanmean(x, axis=axis)).flatten()\n return np.nanmean(x, axis=axis, dtype=dtype)\n\n\n@old_positionals(\"s_genes\", \"g2m_genes\", \"copy\")\ndef score_genes_cell_cycle(\n adata: AnnData,\n *,\n s_genes: Sequence[str],\n g2m_genes: Sequence[str],\n copy: bool = False,\n **kwargs,\n) -> AnnData | None:\n \"\"\"\\\n Score cell cycle genes :cite:p:`Satija2015`.\n\n Given two lists of genes associated to S phase and G2M phase, calculates\n scores and assigns a cell cycle phase (G1, S or G2M). See\n :func:`~scanpy.tl.score_genes` for more explanation.\n\n Parameters\n ----------\n adata\n The annotated data matrix.\n s_genes\n List of genes associated with S phase.\n g2m_genes\n List of genes associated with G2M phase.\n copy\n Copy `adata` or modify it inplace.\n **kwargs\n Are passed to :func:`~scanpy.tl.score_genes`. `ctrl_size` is not\n possible, as it's set as `min(len(s_genes), len(g2m_genes))`.\n\n Returns\n -------\n Returns `None` if `copy=False`, else returns an `AnnData` object. Sets the following fields:\n\n `adata.obs['S_score']` : :class:`pandas.Series` (dtype `object`)\n The score for S phase for each cell.\n `adata.obs['G2M_score']` : :class:`pandas.Series` (dtype `object`)\n The score for G2M phase for each cell.\n `adata.obs['phase']` : :class:`pandas.Series` (dtype `object`)\n The cell cycle phase (`S`, `G2M` or `G1`) for each cell.\n\n See also\n --------\n score_genes\n\n Examples\n --------\n See this `notebook <https://github.com/scverse/scanpy_usage/tree/master/180209_cell_cycle>`__.\n \"\"\"\n logg.info(\"calculating cell cycle phase\")\n\n adata = adata.copy() if copy else adata\n ctrl_size = min(len(s_genes), len(g2m_genes))\n for genes, name in [(s_genes, \"S_score\"), (g2m_genes, \"G2M_score\")]:\n score_genes(adata, genes, score_name=name, ctrl_size=ctrl_size, **kwargs)\n scores = adata.obs[[\"S_score\", \"G2M_score\"]]\n\n # default phase is S\n phase = pd.Series(\"S\", index=scores.index)\n\n # if G2M is higher than S, it's G2M\n phase[scores[\"G2M_score\"] > scores[\"S_score\"]] = \"G2M\"\n\n # if all scores are negative, it's G1...\n phase[np.all(scores < 0, axis=1)] = \"G1\"\n\n adata.obs[\"phase\"] = phase\n logg.hint(\" 'phase', cell cycle phase (adata.obs)\")\n return adata if copy else None\n", "path": "scanpy/tools/_score_genes.py"}]}
| 3,430 | 283 |
gh_patches_debug_2542
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-1508
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Access media library from Challenge UI
Accessing the media library from the challenge UI is a useful idea if you're using images in the challenge interface. Saves some clicks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/admin/pages.py`
Content:
```
1 from flask import render_template, request
2
3 from CTFd.admin import admin
4 from CTFd.models import Pages
5 from CTFd.schemas.pages import PageSchema
6 from CTFd.utils import markdown
7 from CTFd.utils.config.pages import build_html
8 from CTFd.utils.decorators import admins_only
9
10
11 @admin.route("/admin/pages")
12 @admins_only
13 def pages_listing():
14 pages = Pages.query.all()
15 return render_template("admin/pages.html", pages=pages)
16
17
18 @admin.route("/admin/pages/new")
19 @admins_only
20 def pages_new():
21 return render_template("admin/editor.html")
22
23
24 @admin.route("/admin/pages/preview", methods=["POST"])
25 @admins_only
26 def pages_preview():
27 data = request.form.to_dict()
28 schema = PageSchema()
29 page = schema.load(data)
30 return render_template("page.html", content=build_html(page.data["content"]))
31
32
33 @admin.route("/admin/pages/<int:page_id>")
34 @admins_only
35 def pages_detail(page_id):
36 page = Pages.query.filter_by(id=page_id).first_or_404()
37 page_op = request.args.get("operation")
38
39 if request.method == "GET" and page_op == "preview":
40 return render_template("page.html", content=markdown(page.content))
41
42 if request.method == "GET" and page_op == "create":
43 return render_template("admin/editor.html")
44
45 return render_template("admin/editor.html", page=page)
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/admin/pages.py b/CTFd/admin/pages.py
--- a/CTFd/admin/pages.py
+++ b/CTFd/admin/pages.py
@@ -27,7 +27,7 @@
data = request.form.to_dict()
schema = PageSchema()
page = schema.load(data)
- return render_template("page.html", content=build_html(page.data["content"]))
+ return render_template("page.html", content=build_html(page.data.content))
@admin.route("/admin/pages/<int:page_id>")
|
{"golden_diff": "diff --git a/CTFd/admin/pages.py b/CTFd/admin/pages.py\n--- a/CTFd/admin/pages.py\n+++ b/CTFd/admin/pages.py\n@@ -27,7 +27,7 @@\n data = request.form.to_dict()\n schema = PageSchema()\n page = schema.load(data)\n- return render_template(\"page.html\", content=build_html(page.data[\"content\"]))\n+ return render_template(\"page.html\", content=build_html(page.data.content))\n \n \n @admin.route(\"/admin/pages/<int:page_id>\")\n", "issue": "Access media library from Challenge UI\nAccessing the media library from the challenge UI is a useful idea if you're using images in the challenge interface. Saves some clicks. \n", "before_files": [{"content": "from flask import render_template, request\n\nfrom CTFd.admin import admin\nfrom CTFd.models import Pages\nfrom CTFd.schemas.pages import PageSchema\nfrom CTFd.utils import markdown\nfrom CTFd.utils.config.pages import build_html\nfrom CTFd.utils.decorators import admins_only\n\n\[email protected](\"/admin/pages\")\n@admins_only\ndef pages_listing():\n pages = Pages.query.all()\n return render_template(\"admin/pages.html\", pages=pages)\n\n\[email protected](\"/admin/pages/new\")\n@admins_only\ndef pages_new():\n return render_template(\"admin/editor.html\")\n\n\[email protected](\"/admin/pages/preview\", methods=[\"POST\"])\n@admins_only\ndef pages_preview():\n data = request.form.to_dict()\n schema = PageSchema()\n page = schema.load(data)\n return render_template(\"page.html\", content=build_html(page.data[\"content\"]))\n\n\[email protected](\"/admin/pages/<int:page_id>\")\n@admins_only\ndef pages_detail(page_id):\n page = Pages.query.filter_by(id=page_id).first_or_404()\n page_op = request.args.get(\"operation\")\n\n if request.method == \"GET\" and page_op == \"preview\":\n return render_template(\"page.html\", content=markdown(page.content))\n\n if request.method == \"GET\" and page_op == \"create\":\n return render_template(\"admin/editor.html\")\n\n return render_template(\"admin/editor.html\", page=page)\n", "path": "CTFd/admin/pages.py"}], "after_files": [{"content": "from flask import render_template, request\n\nfrom CTFd.admin import admin\nfrom CTFd.models import Pages\nfrom CTFd.schemas.pages import PageSchema\nfrom CTFd.utils import markdown\nfrom CTFd.utils.config.pages import build_html\nfrom CTFd.utils.decorators import admins_only\n\n\[email protected](\"/admin/pages\")\n@admins_only\ndef pages_listing():\n pages = Pages.query.all()\n return render_template(\"admin/pages.html\", pages=pages)\n\n\[email protected](\"/admin/pages/new\")\n@admins_only\ndef pages_new():\n return render_template(\"admin/editor.html\")\n\n\[email protected](\"/admin/pages/preview\", methods=[\"POST\"])\n@admins_only\ndef pages_preview():\n data = request.form.to_dict()\n schema = PageSchema()\n page = schema.load(data)\n return render_template(\"page.html\", content=build_html(page.data.content))\n\n\[email protected](\"/admin/pages/<int:page_id>\")\n@admins_only\ndef pages_detail(page_id):\n page = Pages.query.filter_by(id=page_id).first_or_404()\n page_op = request.args.get(\"operation\")\n\n if request.method == \"GET\" and page_op == \"preview\":\n return render_template(\"page.html\", content=markdown(page.content))\n\n if request.method == \"GET\" and page_op == \"create\":\n return render_template(\"admin/editor.html\")\n\n return render_template(\"admin/editor.html\", page=page)\n", "path": "CTFd/admin/pages.py"}]}
| 689 | 117 |
gh_patches_debug_39796
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-851
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error title should default to HTTP status
When the title is set to `None`, `HTTPError` should default to simply reusing the description passed in with the code in the `status` argument, i.e.:
``` py
self.title = status_code[4:]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `falcon/http_error.py`
Content:
```
1 # Copyright 2013 by Rackspace Hosting, Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """HTTPError exception class."""
16
17 import json
18 import xml.etree.ElementTree as et
19
20 try:
21 from collections import OrderedDict
22 except ImportError:
23 OrderedDict = dict
24
25 from falcon.util import uri
26
27
28 class HTTPError(Exception):
29 """Represents a generic HTTP error.
30
31 Raise this or a child class to have Falcon automagically return pretty
32 error responses (with an appropriate HTTP status code) to the client
33 when something goes wrong.
34
35 Attributes:
36 status (str): HTTP status line, e.g. '748 Confounded by Ponies'.
37 has_representation (bool): Read-only property that determines
38 whether error details will be serialized when composing
39 the HTTP response. In ``HTTPError`` this property always
40 returns ``True``, but child classes may override it
41 in order to return ``False`` when an empty HTTP body is desired.
42 See also the ``falcon.http_error.NoRepresentation`` mixin.
43 title (str): Error title to send to the client. Will be ``None`` if
44 the error should result in an HTTP response with an empty body.
45 description (str): Description of the error to send to the client.
46 headers (dict): Extra headers to add to the response.
47 link (str): An href that the client can provide to the user for
48 getting help.
49 code (int): An internal application code that a user can reference when
50 requesting support for the error.
51
52 Args:
53 status (str): HTTP status code and text, such as "400 Bad Request"
54
55 Keyword Args:
56 title (str): Human-friendly error title (default ``None``).
57 description (str): Human-friendly description of the error, along with
58 a helpful suggestion or two (default ``None``).
59 headers (dict or list): A ``dict`` of header names and values
60 to set, or a ``list`` of (*name*, *value*) tuples. Both *name* and
61 *value* must be of type ``str`` or ``StringType``, and only
62 character values 0x00 through 0xFF may be used on platforms that
63 use wide characters.
64
65 Note:
66 The Content-Type header, if present, will be overridden. If
67 you wish to return custom error messages, you can create
68 your own HTTP error class, and install an error handler
69 to convert it into an appropriate HTTP response for the
70 client
71
72 Note:
73 Falcon can process a list of ``tuple`` slightly faster
74 than a ``dict``.
75
76 headers (dict): Extra headers to return in the
77 response to the client (default ``None``).
78 href (str): A URL someone can visit to find out more information
79 (default ``None``). Unicode characters are percent-encoded.
80 href_text (str): If href is given, use this as the friendly
81 title/description for the link (defaults to "API documentation
82 for this error").
83 code (int): An internal code that customers can reference in their
84 support request or to help them when searching for knowledge
85 base articles related to this error (default ``None``).
86 """
87
88 __slots__ = (
89 'status',
90 'title',
91 'description',
92 'headers',
93 'link',
94 'code',
95 )
96
97 def __init__(self, status, title=None, description=None, headers=None,
98 href=None, href_text=None, code=None):
99 self.status = status
100 self.title = title
101 self.description = description
102 self.headers = headers
103 self.code = code
104
105 if href:
106 link = self.link = OrderedDict()
107 link['text'] = (href_text or 'Documentation related to this error')
108 link['href'] = uri.encode(href)
109 link['rel'] = 'help'
110 else:
111 self.link = None
112
113 @property
114 def has_representation(self):
115 return True
116
117 def to_dict(self, obj_type=dict):
118 """Returns a basic dictionary representing the error.
119
120 This method can be useful when serializing the error to hash-like
121 media types, such as YAML, JSON, and MessagePack.
122
123 Args:
124 obj_type: A dict-like type that will be used to store the
125 error information (default ``dict``).
126
127 Returns:
128 A dictionary populated with the error's title, description, etc.
129
130 """
131
132 assert self.has_representation
133
134 obj = obj_type()
135
136 if self.title is not None:
137 obj['title'] = self.title
138
139 if self.description is not None:
140 obj['description'] = self.description
141
142 if self.code is not None:
143 obj['code'] = self.code
144
145 if self.link is not None:
146 obj['link'] = self.link
147
148 return obj
149
150 def to_json(self):
151 """Returns a pretty-printed JSON representation of the error.
152
153 Returns:
154 A JSON document for the error.
155
156 """
157
158 obj = self.to_dict(OrderedDict)
159 return json.dumps(obj, indent=4, separators=(',', ': '),
160 ensure_ascii=False)
161
162 def to_xml(self):
163 """Returns an XML-encoded representation of the error.
164
165 Returns:
166 An XML document for the error.
167
168 """
169
170 assert self.has_representation
171
172 error_element = et.Element('error')
173
174 if self.title is not None:
175 et.SubElement(error_element, 'title').text = self.title
176
177 if self.description is not None:
178 et.SubElement(error_element, 'description').text = self.description
179
180 if self.code is not None:
181 et.SubElement(error_element, 'code').text = str(self.code)
182
183 if self.link is not None:
184 link_element = et.SubElement(error_element, 'link')
185
186 for key in ('text', 'href', 'rel'):
187 et.SubElement(link_element, key).text = self.link[key]
188
189 return (b'<?xml version="1.0" encoding="UTF-8"?>' +
190 et.tostring(error_element, encoding='utf-8'))
191
192
193 class NoRepresentation(object):
194 """Mixin for ``HTTPError`` child classes that have no representation.
195
196 This class can be mixed in when inheriting from ``HTTPError``, in order
197 to override the `has_representation` property such that it always
198 returns ``False``. This, in turn, will cause Falcon to return an empty
199 response body to the client.
200
201 You can use this mixin when defining errors that either should not have
202 a body (as dictated by HTTP standards or common practice), or in the
203 case that a detailed error response may leak information to an attacker.
204
205 Note:
206 This mixin class must appear before ``HTTPError`` in the base class
207 list when defining the child; otherwise, it will not override the
208 `has_representation` property as expected.
209
210 """
211
212 @property
213 def has_representation(self):
214 return False
215
216
217 class OptionalRepresentation(object):
218 """Mixin for ``HTTPError`` child classes that may have a representation.
219
220 This class can be mixed in when inheriting from ``HTTPError`` in order
221 to override the `has_representation` property, such that it will
222 return ``False`` when the error instance has no description
223 (i.e., the `description` kwarg was not set).
224
225 You can use this mixin when defining errors that do not include
226 a body in the HTTP response by default, serializing details only when
227 the web developer provides a description of the error.
228
229 Note:
230 This mixin class must appear before ``HTTPError`` in the base class
231 list when defining the child; otherwise, it will not override the
232 `has_representation` property as expected.
233
234 """
235 @property
236 def has_representation(self):
237 return super(OptionalRepresentation, self).description is not None
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/falcon/http_error.py b/falcon/http_error.py
--- a/falcon/http_error.py
+++ b/falcon/http_error.py
@@ -40,8 +40,7 @@
returns ``True``, but child classes may override it
in order to return ``False`` when an empty HTTP body is desired.
See also the ``falcon.http_error.NoRepresentation`` mixin.
- title (str): Error title to send to the client. Will be ``None`` if
- the error should result in an HTTP response with an empty body.
+ title (str): Error title to send to the client.
description (str): Description of the error to send to the client.
headers (dict): Extra headers to add to the response.
link (str): An href that the client can provide to the user for
@@ -53,7 +52,8 @@
status (str): HTTP status code and text, such as "400 Bad Request"
Keyword Args:
- title (str): Human-friendly error title (default ``None``).
+ title (str): Human-friendly error title. If not provided, defaults
+ to the HTTP status line as determined by the ``status`` argument.
description (str): Human-friendly description of the error, along with
a helpful suggestion or two (default ``None``).
headers (dict or list): A ``dict`` of header names and values
@@ -97,7 +97,13 @@
def __init__(self, status, title=None, description=None, headers=None,
href=None, href_text=None, code=None):
self.status = status
- self.title = title
+
+ # TODO(kgriffs): HTTP/2 does away with the "reason phrase". Eventually
+ # we'll probably switch over to making everything code-based to more
+ # easily support HTTP/2. When that happens, should we continue to
+ # include the reason phrase in the title?
+ self.title = title or status
+
self.description = description
self.headers = headers
self.code = code
@@ -133,8 +139,7 @@
obj = obj_type()
- if self.title is not None:
- obj['title'] = self.title
+ obj['title'] = self.title
if self.description is not None:
obj['description'] = self.description
@@ -171,8 +176,7 @@
error_element = et.Element('error')
- if self.title is not None:
- et.SubElement(error_element, 'title').text = self.title
+ et.SubElement(error_element, 'title').text = self.title
if self.description is not None:
et.SubElement(error_element, 'description').text = self.description
|
{"golden_diff": "diff --git a/falcon/http_error.py b/falcon/http_error.py\n--- a/falcon/http_error.py\n+++ b/falcon/http_error.py\n@@ -40,8 +40,7 @@\n returns ``True``, but child classes may override it\n in order to return ``False`` when an empty HTTP body is desired.\n See also the ``falcon.http_error.NoRepresentation`` mixin.\n- title (str): Error title to send to the client. Will be ``None`` if\n- the error should result in an HTTP response with an empty body.\n+ title (str): Error title to send to the client.\n description (str): Description of the error to send to the client.\n headers (dict): Extra headers to add to the response.\n link (str): An href that the client can provide to the user for\n@@ -53,7 +52,8 @@\n status (str): HTTP status code and text, such as \"400 Bad Request\"\n \n Keyword Args:\n- title (str): Human-friendly error title (default ``None``).\n+ title (str): Human-friendly error title. If not provided, defaults\n+ to the HTTP status line as determined by the ``status`` argument.\n description (str): Human-friendly description of the error, along with\n a helpful suggestion or two (default ``None``).\n headers (dict or list): A ``dict`` of header names and values\n@@ -97,7 +97,13 @@\n def __init__(self, status, title=None, description=None, headers=None,\n href=None, href_text=None, code=None):\n self.status = status\n- self.title = title\n+\n+ # TODO(kgriffs): HTTP/2 does away with the \"reason phrase\". Eventually\n+ # we'll probably switch over to making everything code-based to more\n+ # easily support HTTP/2. When that happens, should we continue to\n+ # include the reason phrase in the title?\n+ self.title = title or status\n+\n self.description = description\n self.headers = headers\n self.code = code\n@@ -133,8 +139,7 @@\n \n obj = obj_type()\n \n- if self.title is not None:\n- obj['title'] = self.title\n+ obj['title'] = self.title\n \n if self.description is not None:\n obj['description'] = self.description\n@@ -171,8 +176,7 @@\n \n error_element = et.Element('error')\n \n- if self.title is not None:\n- et.SubElement(error_element, 'title').text = self.title\n+ et.SubElement(error_element, 'title').text = self.title\n \n if self.description is not None:\n et.SubElement(error_element, 'description').text = self.description\n", "issue": "Error title should default to HTTP status\nWhen the title is set to `None`, `HTTPError` should default to simply reusing the description passed in with the code in the `status` argument, i.e.: \n\n``` py\nself.title = status_code[4:]\n```\n\n", "before_files": [{"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"HTTPError exception class.\"\"\"\n\nimport json\nimport xml.etree.ElementTree as et\n\ntry:\n from collections import OrderedDict\nexcept ImportError:\n OrderedDict = dict\n\nfrom falcon.util import uri\n\n\nclass HTTPError(Exception):\n \"\"\"Represents a generic HTTP error.\n\n Raise this or a child class to have Falcon automagically return pretty\n error responses (with an appropriate HTTP status code) to the client\n when something goes wrong.\n\n Attributes:\n status (str): HTTP status line, e.g. '748 Confounded by Ponies'.\n has_representation (bool): Read-only property that determines\n whether error details will be serialized when composing\n the HTTP response. In ``HTTPError`` this property always\n returns ``True``, but child classes may override it\n in order to return ``False`` when an empty HTTP body is desired.\n See also the ``falcon.http_error.NoRepresentation`` mixin.\n title (str): Error title to send to the client. Will be ``None`` if\n the error should result in an HTTP response with an empty body.\n description (str): Description of the error to send to the client.\n headers (dict): Extra headers to add to the response.\n link (str): An href that the client can provide to the user for\n getting help.\n code (int): An internal application code that a user can reference when\n requesting support for the error.\n\n Args:\n status (str): HTTP status code and text, such as \"400 Bad Request\"\n\n Keyword Args:\n title (str): Human-friendly error title (default ``None``).\n description (str): Human-friendly description of the error, along with\n a helpful suggestion or two (default ``None``).\n headers (dict or list): A ``dict`` of header names and values\n to set, or a ``list`` of (*name*, *value*) tuples. Both *name* and\n *value* must be of type ``str`` or ``StringType``, and only\n character values 0x00 through 0xFF may be used on platforms that\n use wide characters.\n\n Note:\n The Content-Type header, if present, will be overridden. If\n you wish to return custom error messages, you can create\n your own HTTP error class, and install an error handler\n to convert it into an appropriate HTTP response for the\n client\n\n Note:\n Falcon can process a list of ``tuple`` slightly faster\n than a ``dict``.\n\n headers (dict): Extra headers to return in the\n response to the client (default ``None``).\n href (str): A URL someone can visit to find out more information\n (default ``None``). Unicode characters are percent-encoded.\n href_text (str): If href is given, use this as the friendly\n title/description for the link (defaults to \"API documentation\n for this error\").\n code (int): An internal code that customers can reference in their\n support request or to help them when searching for knowledge\n base articles related to this error (default ``None``).\n \"\"\"\n\n __slots__ = (\n 'status',\n 'title',\n 'description',\n 'headers',\n 'link',\n 'code',\n )\n\n def __init__(self, status, title=None, description=None, headers=None,\n href=None, href_text=None, code=None):\n self.status = status\n self.title = title\n self.description = description\n self.headers = headers\n self.code = code\n\n if href:\n link = self.link = OrderedDict()\n link['text'] = (href_text or 'Documentation related to this error')\n link['href'] = uri.encode(href)\n link['rel'] = 'help'\n else:\n self.link = None\n\n @property\n def has_representation(self):\n return True\n\n def to_dict(self, obj_type=dict):\n \"\"\"Returns a basic dictionary representing the error.\n\n This method can be useful when serializing the error to hash-like\n media types, such as YAML, JSON, and MessagePack.\n\n Args:\n obj_type: A dict-like type that will be used to store the\n error information (default ``dict``).\n\n Returns:\n A dictionary populated with the error's title, description, etc.\n\n \"\"\"\n\n assert self.has_representation\n\n obj = obj_type()\n\n if self.title is not None:\n obj['title'] = self.title\n\n if self.description is not None:\n obj['description'] = self.description\n\n if self.code is not None:\n obj['code'] = self.code\n\n if self.link is not None:\n obj['link'] = self.link\n\n return obj\n\n def to_json(self):\n \"\"\"Returns a pretty-printed JSON representation of the error.\n\n Returns:\n A JSON document for the error.\n\n \"\"\"\n\n obj = self.to_dict(OrderedDict)\n return json.dumps(obj, indent=4, separators=(',', ': '),\n ensure_ascii=False)\n\n def to_xml(self):\n \"\"\"Returns an XML-encoded representation of the error.\n\n Returns:\n An XML document for the error.\n\n \"\"\"\n\n assert self.has_representation\n\n error_element = et.Element('error')\n\n if self.title is not None:\n et.SubElement(error_element, 'title').text = self.title\n\n if self.description is not None:\n et.SubElement(error_element, 'description').text = self.description\n\n if self.code is not None:\n et.SubElement(error_element, 'code').text = str(self.code)\n\n if self.link is not None:\n link_element = et.SubElement(error_element, 'link')\n\n for key in ('text', 'href', 'rel'):\n et.SubElement(link_element, key).text = self.link[key]\n\n return (b'<?xml version=\"1.0\" encoding=\"UTF-8\"?>' +\n et.tostring(error_element, encoding='utf-8'))\n\n\nclass NoRepresentation(object):\n \"\"\"Mixin for ``HTTPError`` child classes that have no representation.\n\n This class can be mixed in when inheriting from ``HTTPError``, in order\n to override the `has_representation` property such that it always\n returns ``False``. This, in turn, will cause Falcon to return an empty\n response body to the client.\n\n You can use this mixin when defining errors that either should not have\n a body (as dictated by HTTP standards or common practice), or in the\n case that a detailed error response may leak information to an attacker.\n\n Note:\n This mixin class must appear before ``HTTPError`` in the base class\n list when defining the child; otherwise, it will not override the\n `has_representation` property as expected.\n\n \"\"\"\n\n @property\n def has_representation(self):\n return False\n\n\nclass OptionalRepresentation(object):\n \"\"\"Mixin for ``HTTPError`` child classes that may have a representation.\n\n This class can be mixed in when inheriting from ``HTTPError`` in order\n to override the `has_representation` property, such that it will\n return ``False`` when the error instance has no description\n (i.e., the `description` kwarg was not set).\n\n You can use this mixin when defining errors that do not include\n a body in the HTTP response by default, serializing details only when\n the web developer provides a description of the error.\n\n Note:\n This mixin class must appear before ``HTTPError`` in the base class\n list when defining the child; otherwise, it will not override the\n `has_representation` property as expected.\n\n \"\"\"\n @property\n def has_representation(self):\n return super(OptionalRepresentation, self).description is not None\n", "path": "falcon/http_error.py"}], "after_files": [{"content": "# Copyright 2013 by Rackspace Hosting, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"HTTPError exception class.\"\"\"\n\nimport json\nimport xml.etree.ElementTree as et\n\ntry:\n from collections import OrderedDict\nexcept ImportError:\n OrderedDict = dict\n\nfrom falcon.util import uri\n\n\nclass HTTPError(Exception):\n \"\"\"Represents a generic HTTP error.\n\n Raise this or a child class to have Falcon automagically return pretty\n error responses (with an appropriate HTTP status code) to the client\n when something goes wrong.\n\n Attributes:\n status (str): HTTP status line, e.g. '748 Confounded by Ponies'.\n has_representation (bool): Read-only property that determines\n whether error details will be serialized when composing\n the HTTP response. In ``HTTPError`` this property always\n returns ``True``, but child classes may override it\n in order to return ``False`` when an empty HTTP body is desired.\n See also the ``falcon.http_error.NoRepresentation`` mixin.\n title (str): Error title to send to the client.\n description (str): Description of the error to send to the client.\n headers (dict): Extra headers to add to the response.\n link (str): An href that the client can provide to the user for\n getting help.\n code (int): An internal application code that a user can reference when\n requesting support for the error.\n\n Args:\n status (str): HTTP status code and text, such as \"400 Bad Request\"\n\n Keyword Args:\n title (str): Human-friendly error title. If not provided, defaults\n to the HTTP status line as determined by the ``status`` argument.\n description (str): Human-friendly description of the error, along with\n a helpful suggestion or two (default ``None``).\n headers (dict or list): A ``dict`` of header names and values\n to set, or a ``list`` of (*name*, *value*) tuples. Both *name* and\n *value* must be of type ``str`` or ``StringType``, and only\n character values 0x00 through 0xFF may be used on platforms that\n use wide characters.\n\n Note:\n The Content-Type header, if present, will be overridden. If\n you wish to return custom error messages, you can create\n your own HTTP error class, and install an error handler\n to convert it into an appropriate HTTP response for the\n client\n\n Note:\n Falcon can process a list of ``tuple`` slightly faster\n than a ``dict``.\n\n headers (dict): Extra headers to return in the\n response to the client (default ``None``).\n href (str): A URL someone can visit to find out more information\n (default ``None``). Unicode characters are percent-encoded.\n href_text (str): If href is given, use this as the friendly\n title/description for the link (defaults to \"API documentation\n for this error\").\n code (int): An internal code that customers can reference in their\n support request or to help them when searching for knowledge\n base articles related to this error (default ``None``).\n \"\"\"\n\n __slots__ = (\n 'status',\n 'title',\n 'description',\n 'headers',\n 'link',\n 'code',\n )\n\n def __init__(self, status, title=None, description=None, headers=None,\n href=None, href_text=None, code=None):\n self.status = status\n\n # TODO(kgriffs): HTTP/2 does away with the \"reason phrase\". Eventually\n # we'll probably switch over to making everything code-based to more\n # easily support HTTP/2. When that happens, should we continue to\n # include the reason phrase in the title?\n self.title = title or status\n\n self.description = description\n self.headers = headers\n self.code = code\n\n if href:\n link = self.link = OrderedDict()\n link['text'] = (href_text or 'Documentation related to this error')\n link['href'] = uri.encode(href)\n link['rel'] = 'help'\n else:\n self.link = None\n\n @property\n def has_representation(self):\n return True\n\n def to_dict(self, obj_type=dict):\n \"\"\"Returns a basic dictionary representing the error.\n\n This method can be useful when serializing the error to hash-like\n media types, such as YAML, JSON, and MessagePack.\n\n Args:\n obj_type: A dict-like type that will be used to store the\n error information (default ``dict``).\n\n Returns:\n A dictionary populated with the error's title, description, etc.\n\n \"\"\"\n\n assert self.has_representation\n\n obj = obj_type()\n\n obj['title'] = self.title\n\n if self.description is not None:\n obj['description'] = self.description\n\n if self.code is not None:\n obj['code'] = self.code\n\n if self.link is not None:\n obj['link'] = self.link\n\n return obj\n\n def to_json(self):\n \"\"\"Returns a pretty-printed JSON representation of the error.\n\n Returns:\n A JSON document for the error.\n\n \"\"\"\n\n obj = self.to_dict(OrderedDict)\n return json.dumps(obj, indent=4, separators=(',', ': '),\n ensure_ascii=False)\n\n def to_xml(self):\n \"\"\"Returns an XML-encoded representation of the error.\n\n Returns:\n An XML document for the error.\n\n \"\"\"\n\n assert self.has_representation\n\n error_element = et.Element('error')\n\n et.SubElement(error_element, 'title').text = self.title\n\n if self.description is not None:\n et.SubElement(error_element, 'description').text = self.description\n\n if self.code is not None:\n et.SubElement(error_element, 'code').text = str(self.code)\n\n if self.link is not None:\n link_element = et.SubElement(error_element, 'link')\n\n for key in ('text', 'href', 'rel'):\n et.SubElement(link_element, key).text = self.link[key]\n\n return (b'<?xml version=\"1.0\" encoding=\"UTF-8\"?>' +\n et.tostring(error_element, encoding='utf-8'))\n\n\nclass NoRepresentation(object):\n \"\"\"Mixin for ``HTTPError`` child classes that have no representation.\n\n This class can be mixed in when inheriting from ``HTTPError``, in order\n to override the `has_representation` property such that it always\n returns ``False``. This, in turn, will cause Falcon to return an empty\n response body to the client.\n\n You can use this mixin when defining errors that either should not have\n a body (as dictated by HTTP standards or common practice), or in the\n case that a detailed error response may leak information to an attacker.\n\n Note:\n This mixin class must appear before ``HTTPError`` in the base class\n list when defining the child; otherwise, it will not override the\n `has_representation` property as expected.\n\n \"\"\"\n\n @property\n def has_representation(self):\n return False\n\n\nclass OptionalRepresentation(object):\n \"\"\"Mixin for ``HTTPError`` child classes that may have a representation.\n\n This class can be mixed in when inheriting from ``HTTPError`` in order\n to override the `has_representation` property, such that it will\n return ``False`` when the error instance has no description\n (i.e., the `description` kwarg was not set).\n\n You can use this mixin when defining errors that do not include\n a body in the HTTP response by default, serializing details only when\n the web developer provides a description of the error.\n\n Note:\n This mixin class must appear before ``HTTPError`` in the base class\n list when defining the child; otherwise, it will not override the\n `has_representation` property as expected.\n\n \"\"\"\n @property\n def has_representation(self):\n return super(OptionalRepresentation, self).description is not None\n", "path": "falcon/http_error.py"}]}
| 2,754 | 618 |
gh_patches_debug_41102
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1857
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add docs references to plot_energy docstring
Add links to the related functions and classes to all the places where they are mentioned in the [plot_energy](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_energy.html) docstring.
## Sample PR:
You can see https://github.com/arviz-devs/arviz/pull/1816 for the function, `plot_autocorr`.
> ⚠️ Always create a new branch for changes. Don't make any changes to the `main` branch.
## Source File
Source file: https://github.com/arviz-devs/arviz/blob/main/arviz/plots/energyplot.py
## How to add links
Add the links in the docstring of doc. You can also check the docstring by going to the `[source]`.
* Add links to the ArviZ functions and classes using [Cross-referencing with Sphinx](https://docs.readthedocs.io/en/stable/guides/cross-referencing-with-sphinx.html).
* Add links to the xarray functions and classes using [Intersphinx](https://docs.readthedocs.io/en/stable/guides/intersphinx.html).
* Add the rest of the external links using this [syntax](https://sublime-and-sphinx-guide.readthedocs.io/en/latest/references.html#links-to-external-web-pages).
## `backend_kwargs`, `plot_kwargs` and `fill_kwargs`
For adding `backend_kwargs` as they have been added in #1816, see [Adding backend_kwargs guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-backend_kwargs). Follow the same process for `fill_kwargs` and `plot_kwargs`.
## See also section
Add the following functions in the "See also" section:
1. [bfmi](https://arviz-devs.github.io/arviz/api/generated/arviz.bfmi.html)
See [Adding "see also" section](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-see-also-section) for more details.
## Checking the preview of docs
For checking the preview of docs, you don't need t set up the project on your local machine. Just follow the [checking the preview guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#how-to-check-the-preview-of-docs).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/plots/energyplot.py`
Content:
```
1 """Plot energy transition distribution in HMC inference."""
2 import warnings
3
4 from ..data import convert_to_dataset
5 from ..rcparams import rcParams
6 from .plot_utils import get_plotting_function
7
8
9 def plot_energy(
10 data,
11 kind=None,
12 bfmi=True,
13 figsize=None,
14 legend=True,
15 fill_alpha=(1, 0.75),
16 fill_color=("C0", "C5"),
17 bw="experimental",
18 textsize=None,
19 fill_kwargs=None,
20 plot_kwargs=None,
21 ax=None,
22 backend=None,
23 backend_kwargs=None,
24 show=None,
25 ):
26 """Plot energy transition distribution and marginal energy distribution in HMC algorithms.
27
28 This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.
29
30 Parameters
31 ----------
32 data : xarray dataset, or object that can be converted (must represent
33 `sample_stats` and have an `energy` variable)
34 kind : str
35 Type of plot to display {"kde", "hist")
36 bfmi : bool
37 If True add to the plot the value of the estimated Bayesian fraction of missing information
38 figsize : tuple
39 Figure size. If None it will be defined automatically.
40 legend : bool
41 Flag for plotting legend (defaults to True)
42 fill_alpha : tuple of floats
43 Alpha blending value for the shaded area under the curve, between 0
44 (no shade) and 1 (opaque). Defaults to (1, .75)
45 fill_color : tuple of valid matplotlib color
46 Color for Marginal energy distribution and Energy transition distribution.
47 Defaults to ('C0', 'C5')
48 bw: float or str, optional
49 If numeric, indicates the bandwidth and must be positive.
50 If str, indicates the method to estimate the bandwidth and must be
51 one of "scott", "silverman", "isj" or "experimental". Defaults to "experimental"
52 Only works if `kind='kde'`
53 textsize: float
54 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
55 on figsize.
56 fill_kwargs : dicts, optional
57 Additional keywords passed to `arviz.plot_kde` (to control the shade)
58 plot_kwargs : dicts, optional
59 Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')
60 ax: axes, optional
61 Matplotlib axes or bokeh figures.
62 backend: str, optional
63 Select plotting backend {"matplotlib","bokeh"}. Default "matplotlib".
64 backend_kwargs: bool, optional
65 These are kwargs specific to the backend being used. For additional documentation
66 check the plotting method of the backend.
67 show : bool, optional
68 Call backend show function.
69
70 Returns
71 -------
72 axes : matplotlib axes or bokeh figures
73
74 Examples
75 --------
76 Plot a default energy plot
77
78 .. plot::
79 :context: close-figs
80
81 >>> import arviz as az
82 >>> data = az.load_arviz_data('centered_eight')
83 >>> az.plot_energy(data)
84
85 Represent energy plot via histograms
86
87 .. plot::
88 :context: close-figs
89
90 >>> az.plot_energy(data, kind='hist')
91
92 """
93 energy = convert_to_dataset(data, group="sample_stats").energy.values
94
95 if kind == "histogram":
96 warnings.warn(
97 "kind histogram will be deprecated in a future release. Use `hist` "
98 "or set rcParam `plot.density_kind` to `hist`",
99 FutureWarning,
100 )
101 kind = "hist"
102
103 if kind is None:
104 kind = rcParams["plot.density_kind"]
105
106 plot_energy_kwargs = dict(
107 ax=ax,
108 energy=energy,
109 kind=kind,
110 bfmi=bfmi,
111 figsize=figsize,
112 textsize=textsize,
113 fill_alpha=fill_alpha,
114 fill_color=fill_color,
115 fill_kwargs=fill_kwargs,
116 plot_kwargs=plot_kwargs,
117 bw=bw,
118 legend=legend,
119 backend_kwargs=backend_kwargs,
120 show=show,
121 )
122
123 if backend is None:
124 backend = rcParams["plot.backend"]
125 backend = backend.lower()
126
127 # TODO: Add backend kwargs
128 plot = get_plotting_function("plot_energy", "energyplot", backend)
129 ax = plot(**plot_energy_kwargs)
130 return ax
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py
--- a/arviz/plots/energyplot.py
+++ b/arviz/plots/energyplot.py
@@ -29,41 +29,44 @@
Parameters
----------
- data : xarray dataset, or object that can be converted (must represent
- `sample_stats` and have an `energy` variable)
+ data : obj
+ :class:`xarray.Dataset`, or any object that can be converted (must represent
+ ``sample_stats`` and have an ``energy`` variable).
kind : str
- Type of plot to display {"kde", "hist")
+ Type of plot to display ("kde", "hist").
bfmi : bool
If True add to the plot the value of the estimated Bayesian fraction of missing information
figsize : tuple
Figure size. If None it will be defined automatically.
legend : bool
- Flag for plotting legend (defaults to True)
+ Flag for plotting legend. Defaults to True.
fill_alpha : tuple of floats
Alpha blending value for the shaded area under the curve, between 0
- (no shade) and 1 (opaque). Defaults to (1, .75)
+ (no shade) and 1 (opaque). Defaults to (1, .75).
fill_color : tuple of valid matplotlib color
Color for Marginal energy distribution and Energy transition distribution.
- Defaults to ('C0', 'C5')
+ Defaults to ('C0', 'C5').
bw: float or str, optional
If numeric, indicates the bandwidth and must be positive.
If str, indicates the method to estimate the bandwidth and must be
- one of "scott", "silverman", "isj" or "experimental". Defaults to "experimental"
- Only works if `kind='kde'`
+ one of "scott", "silverman", "isj" or "experimental". Defaults to "experimental".
+ Only works if ``kind='kde'``.
textsize: float
Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
on figsize.
fill_kwargs : dicts, optional
- Additional keywords passed to `arviz.plot_kde` (to control the shade)
+ Additional keywords passed to :func:`arviz.plot_kde` (to control the shade).
plot_kwargs : dicts, optional
- Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')
+ Additional keywords passed to :func:`arviz.plot_kde` or :func:`matplotlib.pyplot.hist`
+ (if ``type='hist'``).
ax: axes, optional
- Matplotlib axes or bokeh figures.
+ :class:`matplotlib.axes.Axes` or :class:`bokeh.plotting.Figure`.
backend: str, optional
- Select plotting backend {"matplotlib","bokeh"}. Default "matplotlib".
+ Select plotting backend {"matplotlib", "bokeh"}. Defaults to "matplotlib".
backend_kwargs: bool, optional
- These are kwargs specific to the backend being used. For additional documentation
- check the plotting method of the backend.
+ These are kwargs specific to the backend being used, passed to
+ :func:`matplotlib.pyplot.subplots` or
+ :func:`bokeh.plotting.figure`.
show : bool, optional
Call backend show function.
@@ -71,6 +74,10 @@
-------
axes : matplotlib axes or bokeh figures
+ See Also
+ --------
+ bfmi : Calculate the estimated Bayesian fraction of missing information (BFMI).
+
Examples
--------
Plot a default energy plot
|
{"golden_diff": "diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py\n--- a/arviz/plots/energyplot.py\n+++ b/arviz/plots/energyplot.py\n@@ -29,41 +29,44 @@\n \n Parameters\n ----------\n- data : xarray dataset, or object that can be converted (must represent\n- `sample_stats` and have an `energy` variable)\n+ data : obj\n+ :class:`xarray.Dataset`, or any object that can be converted (must represent\n+ ``sample_stats`` and have an ``energy`` variable).\n kind : str\n- Type of plot to display {\"kde\", \"hist\")\n+ Type of plot to display (\"kde\", \"hist\").\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n- Flag for plotting legend (defaults to True)\n+ Flag for plotting legend. Defaults to True.\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n- (no shade) and 1 (opaque). Defaults to (1, .75)\n+ (no shade) and 1 (opaque). Defaults to (1, .75).\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n- Defaults to ('C0', 'C5')\n+ Defaults to ('C0', 'C5').\n bw: float or str, optional\n If numeric, indicates the bandwidth and must be positive.\n If str, indicates the method to estimate the bandwidth and must be\n- one of \"scott\", \"silverman\", \"isj\" or \"experimental\". Defaults to \"experimental\"\n- Only works if `kind='kde'`\n+ one of \"scott\", \"silverman\", \"isj\" or \"experimental\". Defaults to \"experimental\".\n+ Only works if ``kind='kde'``.\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n- Additional keywords passed to `arviz.plot_kde` (to control the shade)\n+ Additional keywords passed to :func:`arviz.plot_kde` (to control the shade).\n plot_kwargs : dicts, optional\n- Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')\n+ Additional keywords passed to :func:`arviz.plot_kde` or :func:`matplotlib.pyplot.hist`\n+ (if ``type='hist'``).\n ax: axes, optional\n- Matplotlib axes or bokeh figures.\n+ :class:`matplotlib.axes.Axes` or :class:`bokeh.plotting.Figure`.\n backend: str, optional\n- Select plotting backend {\"matplotlib\",\"bokeh\"}. Default \"matplotlib\".\n+ Select plotting backend {\"matplotlib\", \"bokeh\"}. Defaults to \"matplotlib\".\n backend_kwargs: bool, optional\n- These are kwargs specific to the backend being used. For additional documentation\n- check the plotting method of the backend.\n+ These are kwargs specific to the backend being used, passed to\n+ :func:`matplotlib.pyplot.subplots` or\n+ :func:`bokeh.plotting.figure`.\n show : bool, optional\n Call backend show function.\n \n@@ -71,6 +74,10 @@\n -------\n axes : matplotlib axes or bokeh figures\n \n+ See Also\n+ --------\n+ bfmi : Calculate the estimated Bayesian fraction of missing information (BFMI).\n+\n Examples\n --------\n Plot a default energy plot\n", "issue": "Add docs references to plot_energy docstring\nAdd links to the related functions and classes to all the places where they are mentioned in the [plot_energy](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_energy.html) docstring.\r\n\r\n## Sample PR:\r\nYou can see https://github.com/arviz-devs/arviz/pull/1816 for the function, `plot_autocorr`. \r\n> \u26a0\ufe0f Always create a new branch for changes. Don't make any changes to the `main` branch. \r\n\r\n\r\n## Source File\r\nSource file: https://github.com/arviz-devs/arviz/blob/main/arviz/plots/energyplot.py\r\n\r\n## How to add links\r\nAdd the links in the docstring of doc. You can also check the docstring by going to the `[source]`. \r\n\r\n* Add links to the ArviZ functions and classes using [Cross-referencing with Sphinx](https://docs.readthedocs.io/en/stable/guides/cross-referencing-with-sphinx.html).\r\n* Add links to the xarray functions and classes using [Intersphinx](https://docs.readthedocs.io/en/stable/guides/intersphinx.html).\r\n* Add the rest of the external links using this [syntax](https://sublime-and-sphinx-guide.readthedocs.io/en/latest/references.html#links-to-external-web-pages).\r\n\r\n## `backend_kwargs`, `plot_kwargs` and `fill_kwargs`\r\nFor adding `backend_kwargs` as they have been added in #1816, see [Adding backend_kwargs guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-backend_kwargs). Follow the same process for `fill_kwargs` and `plot_kwargs`.\r\n\r\n## See also section\r\nAdd the following functions in the \"See also\" section:\r\n1. [bfmi](https://arviz-devs.github.io/arviz/api/generated/arviz.bfmi.html)\r\n\r\n\r\nSee [Adding \"see also\" section](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-see-also-section) for more details. \r\n\r\n## Checking the preview of docs\r\nFor checking the preview of docs, you don't need t set up the project on your local machine. Just follow the [checking the preview guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#how-to-check-the-preview-of-docs). \n", "before_files": [{"content": "\"\"\"Plot energy transition distribution in HMC inference.\"\"\"\nimport warnings\n\nfrom ..data import convert_to_dataset\nfrom ..rcparams import rcParams\nfrom .plot_utils import get_plotting_function\n\n\ndef plot_energy(\n data,\n kind=None,\n bfmi=True,\n figsize=None,\n legend=True,\n fill_alpha=(1, 0.75),\n fill_color=(\"C0\", \"C5\"),\n bw=\"experimental\",\n textsize=None,\n fill_kwargs=None,\n plot_kwargs=None,\n ax=None,\n backend=None,\n backend_kwargs=None,\n show=None,\n):\n \"\"\"Plot energy transition distribution and marginal energy distribution in HMC algorithms.\n\n This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.\n\n Parameters\n ----------\n data : xarray dataset, or object that can be converted (must represent\n `sample_stats` and have an `energy` variable)\n kind : str\n Type of plot to display {\"kde\", \"hist\")\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n Flag for plotting legend (defaults to True)\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n (no shade) and 1 (opaque). Defaults to (1, .75)\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n Defaults to ('C0', 'C5')\n bw: float or str, optional\n If numeric, indicates the bandwidth and must be positive.\n If str, indicates the method to estimate the bandwidth and must be\n one of \"scott\", \"silverman\", \"isj\" or \"experimental\". Defaults to \"experimental\"\n Only works if `kind='kde'`\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` (to control the shade)\n plot_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')\n ax: axes, optional\n Matplotlib axes or bokeh figures.\n backend: str, optional\n Select plotting backend {\"matplotlib\",\"bokeh\"}. Default \"matplotlib\".\n backend_kwargs: bool, optional\n These are kwargs specific to the backend being used. For additional documentation\n check the plotting method of the backend.\n show : bool, optional\n Call backend show function.\n\n Returns\n -------\n axes : matplotlib axes or bokeh figures\n\n Examples\n --------\n Plot a default energy plot\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> data = az.load_arviz_data('centered_eight')\n >>> az.plot_energy(data)\n\n Represent energy plot via histograms\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_energy(data, kind='hist')\n\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n\n if kind == \"histogram\":\n warnings.warn(\n \"kind histogram will be deprecated in a future release. Use `hist` \"\n \"or set rcParam `plot.density_kind` to `hist`\",\n FutureWarning,\n )\n kind = \"hist\"\n\n if kind is None:\n kind = rcParams[\"plot.density_kind\"]\n\n plot_energy_kwargs = dict(\n ax=ax,\n energy=energy,\n kind=kind,\n bfmi=bfmi,\n figsize=figsize,\n textsize=textsize,\n fill_alpha=fill_alpha,\n fill_color=fill_color,\n fill_kwargs=fill_kwargs,\n plot_kwargs=plot_kwargs,\n bw=bw,\n legend=legend,\n backend_kwargs=backend_kwargs,\n show=show,\n )\n\n if backend is None:\n backend = rcParams[\"plot.backend\"]\n backend = backend.lower()\n\n # TODO: Add backend kwargs\n plot = get_plotting_function(\"plot_energy\", \"energyplot\", backend)\n ax = plot(**plot_energy_kwargs)\n return ax\n", "path": "arviz/plots/energyplot.py"}], "after_files": [{"content": "\"\"\"Plot energy transition distribution in HMC inference.\"\"\"\nimport warnings\n\nfrom ..data import convert_to_dataset\nfrom ..rcparams import rcParams\nfrom .plot_utils import get_plotting_function\n\n\ndef plot_energy(\n data,\n kind=None,\n bfmi=True,\n figsize=None,\n legend=True,\n fill_alpha=(1, 0.75),\n fill_color=(\"C0\", \"C5\"),\n bw=\"experimental\",\n textsize=None,\n fill_kwargs=None,\n plot_kwargs=None,\n ax=None,\n backend=None,\n backend_kwargs=None,\n show=None,\n):\n \"\"\"Plot energy transition distribution and marginal energy distribution in HMC algorithms.\n\n This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.\n\n Parameters\n ----------\n data : obj\n :class:`xarray.Dataset`, or any object that can be converted (must represent\n ``sample_stats`` and have an ``energy`` variable).\n kind : str\n Type of plot to display (\"kde\", \"hist\").\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n Flag for plotting legend. Defaults to True.\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n (no shade) and 1 (opaque). Defaults to (1, .75).\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n Defaults to ('C0', 'C5').\n bw: float or str, optional\n If numeric, indicates the bandwidth and must be positive.\n If str, indicates the method to estimate the bandwidth and must be\n one of \"scott\", \"silverman\", \"isj\" or \"experimental\". Defaults to \"experimental\".\n Only works if ``kind='kde'``.\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n Additional keywords passed to :func:`arviz.plot_kde` (to control the shade).\n plot_kwargs : dicts, optional\n Additional keywords passed to :func:`arviz.plot_kde` or :func:`matplotlib.pyplot.hist`\n (if ``type='hist'``).\n ax: axes, optional\n :class:`matplotlib.axes.Axes` or :class:`bokeh.plotting.Figure`.\n backend: str, optional\n Select plotting backend {\"matplotlib\", \"bokeh\"}. Defaults to \"matplotlib\".\n backend_kwargs: bool, optional\n These are kwargs specific to the backend being used, passed to\n :func:`matplotlib.pyplot.subplots` or\n :func:`bokeh.plotting.figure`.\n show : bool, optional\n Call backend show function.\n\n Returns\n -------\n axes : matplotlib axes or bokeh figures\n\n See Also\n --------\n bfmi : Calculate the estimated Bayesian fraction of missing information (BFMI).\n\n Examples\n --------\n Plot a default energy plot\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> data = az.load_arviz_data('centered_eight')\n >>> az.plot_energy(data)\n\n Represent energy plot via histograms\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_energy(data, kind='hist')\n\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n\n if kind == \"histogram\":\n warnings.warn(\n \"kind histogram will be deprecated in a future release. Use `hist` \"\n \"or set rcParam `plot.density_kind` to `hist`\",\n FutureWarning,\n )\n kind = \"hist\"\n\n if kind is None:\n kind = rcParams[\"plot.density_kind\"]\n\n plot_energy_kwargs = dict(\n ax=ax,\n energy=energy,\n kind=kind,\n bfmi=bfmi,\n figsize=figsize,\n textsize=textsize,\n fill_alpha=fill_alpha,\n fill_color=fill_color,\n fill_kwargs=fill_kwargs,\n plot_kwargs=plot_kwargs,\n bw=bw,\n legend=legend,\n backend_kwargs=backend_kwargs,\n show=show,\n )\n\n if backend is None:\n backend = rcParams[\"plot.backend\"]\n backend = backend.lower()\n\n # TODO: Add backend kwargs\n plot = get_plotting_function(\"plot_energy\", \"energyplot\", backend)\n ax = plot(**plot_energy_kwargs)\n return ax\n", "path": "arviz/plots/energyplot.py"}]}
| 2,030 | 832 |
gh_patches_debug_23181
|
rasdani/github-patches
|
git_diff
|
v7labs__darwin-py-372
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
darwin-py 0.7.11 causing `MissingConfig` issues
When I try using 0.7.11, I am getting an error when I run `dataset.pull`
It appears to be something with the release.py `download_zip` code passing config.yaml. I checked my .darwin folder and I don't see a config.yaml so I'm sure that's why it's causing an issue, but not sure where that is supposed to come from.
Here's a reproducible version you should be able to use
```
import darwin; print(darwin.__version__)
from darwin.client import Client
API_KEY = *your_key_here*
client = Client.from_api_key(API_KEY)
datasets={d.name:d for d in client.list_remote_datasets()}
dataset=datasets["kevin-tmp"]
release = dataset.get_release()
dataset.pull(release=release)
```
stack trace in 0.7.11:
```
---------------------------------------------------------------------------
MissingConfig Traceback (most recent call last)
/tmp/ipykernel_277/279924910.py in <module>
10
11 release = dataset.get_release()
---> 12 dataset.pull(release=release)
/opt/conda/lib/python3.7/site-packages/darwin/dataset/remote_dataset.py in pull(self, release, blocking, multi_threaded, only_annotations, force_replace, remove_extra, subset_filter_annotations_function, subset_folder_name, use_folders, video_frames)
309 tmp_dir = Path(tmp_dir_str)
310 # Download the release from Darwin
--> 311 zip_file_path = release.download_zip(tmp_dir / "dataset.zip")
312 with zipfile.ZipFile(zip_file_path) as z:
313 # Extract annotations
/opt/conda/lib/python3.7/site-packages/darwin/dataset/release.py in download_zip(self, path)
195
196 config_path: Path = Path.home() / ".darwin" / "config.yaml"
--> 197 client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)
198
199 data: Response = client.fetch_binary(self.url)
/opt/conda/lib/python3.7/site-packages/darwin/client.py in from_config(cls, config_path, team_slug)
836 """
837 if not config_path.exists():
--> 838 raise MissingConfig()
839 config = Config(config_path)
840
MissingConfig:
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `darwin/version/__init__.py`
Content:
```
1 __version__ = "0.7.11"
2
```
Path: `darwin/dataset/release.py`
Content:
```
1 import datetime
2 from pathlib import Path
3 from typing import Any, Dict, Optional
4
5 from darwin.dataset.identifier import DatasetIdentifier
6 from requests import Response
7
8
9 class Release:
10 """
11 Represents a release/export. Releases created this way can only contain items with 'completed'
12 status.
13
14 Parameters
15 ----------
16 dataset_slug : str
17 The slug of the dataset.
18 team_slug : str
19 the slug of the team.
20 version : str
21 The version of the ``Release``.
22 name : str
23 The name of the ``Release``.
24 url : Optional[str]
25 The full url used to download the ``Release``.
26 export_date : datetime.datetime
27 The ``datetime`` of when this release was created.
28 image_count : Optional[int]
29 Number of images in this ``Release``.
30 class_count : Optional[int]
31 Number of distinct classes in this ``Release``.
32 available : bool
33 If this ``Release`` is downloadable or not.
34 latest : bool
35 If this ``Release`` is the latest one or not.
36 format : str
37 Format for the file of this ``Release`` should it be downloaded.
38
39 Attributes
40 ----------
41 dataset_slug : str
42 The slug of the dataset.
43 team_slug : str
44 the slug of the team.
45 version : str
46 The version of the ``Release``.
47 name : str
48 The name of the ``Release``.
49 url : Optional[str]
50 The full url used to download the ``Release``.
51 export_date : datetime.datetime
52 The ``datetime`` of when this release was created.
53 image_count : Optional[int]
54 Number of images in this ``Release``.
55 class_count : Optional[int]
56 Number of distinct classes in this ``Release``.
57 available : bool
58 If this ``Release`` is downloadable or not.
59 latest : bool
60 If this ``Release`` is the latest one or not.
61 format : str
62 Format for the file of this ``Release`` should it be downloaded.
63 """
64
65 def __init__(
66 self,
67 dataset_slug: str,
68 team_slug: str,
69 version: str,
70 name: str,
71 url: Optional[str],
72 export_date: datetime.datetime,
73 image_count: Optional[int],
74 class_count: Optional[int],
75 available: bool,
76 latest: bool,
77 format: str,
78 ):
79 self.dataset_slug = dataset_slug
80 self.team_slug = team_slug
81 self.version = version
82 self.name = name
83 self.url = url
84 self.export_date = export_date
85 self.image_count = image_count
86 self.class_count = class_count
87 self.available = available
88 self.latest = latest
89 self.format = format
90
91 @classmethod
92 def parse_json(cls, dataset_slug: str, team_slug: str, payload: Dict[str, Any]) -> "Release":
93 """
94 Given a json, parses it into a ``Release`` object instance.
95
96 Parameters
97 ----------
98 dataset_slug : str
99 The slug of the dataset this ``Release`` belongs to.
100 team_slug : str
101 The slug of the team this ``Release``'s dataset belongs to.
102 payload : Dict[str, Any]
103 A Dictionary with the ``Release`` information. It must have a minimal format similar to:
104
105 .. code-block:: javascript
106 {
107 "version": "a_version",
108 "name": "a_name"
109 }
110
111 If no ``format`` key is found in ``payload``, the default will be ``json``.
112
113 Optional ``payload`` has no ``download_url`` key, then ``url``, ``available``,
114 ``image_count``, ``class_count`` and ``latest`` will default to either ``None`` or
115 ``False`` depending on the type.
116
117 A more complete format for this parameter would be similar to:
118
119 .. code-block:: javascript
120 {
121 "version": "a_version",
122 "name": "a_name",
123 "metadata": {
124 "num_images": 1,
125 "annotation_classes": []
126 },
127 "download_url": "http://www.some_url_here.com",
128 "latest": false,
129 "format": "a_format"
130 }
131
132 Returns
133 -------
134 Release
135 A ``Release`` created from the given payload.
136 """
137 try:
138 export_date: datetime.datetime = datetime.datetime.strptime(payload["inserted_at"], "%Y-%m-%dT%H:%M:%S%z")
139 except ValueError:
140 # For python version older than 3.7
141 export_date = datetime.datetime.strptime(payload["inserted_at"], "%Y-%m-%dT%H:%M:%SZ")
142
143 if payload["download_url"] is None:
144 return cls(
145 dataset_slug=dataset_slug,
146 team_slug=team_slug,
147 version=payload["version"],
148 name=payload["name"],
149 export_date=export_date,
150 url=None,
151 available=False,
152 image_count=None,
153 class_count=None,
154 latest=False,
155 format=payload.get("format", "json"),
156 )
157
158 return cls(
159 dataset_slug=dataset_slug,
160 team_slug=team_slug,
161 version=payload["version"],
162 name=payload["name"],
163 image_count=payload["metadata"]["num_images"],
164 class_count=len(payload["metadata"]["annotation_classes"]),
165 export_date=export_date,
166 url=payload["download_url"],
167 available=True,
168 latest=payload["latest"],
169 format=payload.get("format", "json"),
170 )
171
172 def download_zip(self, path: Path) -> Path:
173 """
174 Downloads the release content into a zip file located by the given path.
175
176 Parameters
177 ----------
178 path : Path
179 The path where the zip file will be located.
180
181 Returns
182 --------
183 Path
184 Same ``Path`` as provided in the parameters.
185
186 Raises
187 ------
188 ValueError
189 If this ``Release`` object does not have a specified url.
190 """
191 if not self.url:
192 raise ValueError("Release must have a valid url to download the zip.")
193
194 from darwin.client import Client
195
196 config_path: Path = Path.home() / ".darwin" / "config.yaml"
197 client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)
198
199 data: Response = client.fetch_binary(self.url)
200 with open(path, "wb") as download_file:
201 for chunk in data.iter_content(chunk_size=8192):
202 download_file.write(chunk)
203
204 return path
205
206 @property
207 def identifier(self) -> DatasetIdentifier:
208 """DatasetIdentifier : The ``DatasetIdentifier`` for this ``Release``."""
209 return DatasetIdentifier(team_slug=self.team_slug, dataset_slug=self.dataset_slug, version=self.name)
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/darwin/dataset/release.py b/darwin/dataset/release.py
--- a/darwin/dataset/release.py
+++ b/darwin/dataset/release.py
@@ -1,9 +1,10 @@
import datetime
+import shutil
from pathlib import Path
from typing import Any, Dict, Optional
+import requests
from darwin.dataset.identifier import DatasetIdentifier
-from requests import Response
class Release:
@@ -191,15 +192,9 @@
if not self.url:
raise ValueError("Release must have a valid url to download the zip.")
- from darwin.client import Client
-
- config_path: Path = Path.home() / ".darwin" / "config.yaml"
- client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)
-
- data: Response = client.fetch_binary(self.url)
- with open(path, "wb") as download_file:
- for chunk in data.iter_content(chunk_size=8192):
- download_file.write(chunk)
+ with requests.get(self.url, stream=True) as response:
+ with open(path, "wb") as download_file:
+ shutil.copyfileobj(response.raw, download_file)
return path
diff --git a/darwin/version/__init__.py b/darwin/version/__init__.py
--- a/darwin/version/__init__.py
+++ b/darwin/version/__init__.py
@@ -1 +1 @@
-__version__ = "0.7.11"
+__version__ = "0.7.12"
|
{"golden_diff": "diff --git a/darwin/dataset/release.py b/darwin/dataset/release.py\n--- a/darwin/dataset/release.py\n+++ b/darwin/dataset/release.py\n@@ -1,9 +1,10 @@\n import datetime\n+import shutil\n from pathlib import Path\n from typing import Any, Dict, Optional\n \n+import requests\n from darwin.dataset.identifier import DatasetIdentifier\n-from requests import Response\n \n \n class Release:\n@@ -191,15 +192,9 @@\n if not self.url:\n raise ValueError(\"Release must have a valid url to download the zip.\")\n \n- from darwin.client import Client\n-\n- config_path: Path = Path.home() / \".darwin\" / \"config.yaml\"\n- client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)\n-\n- data: Response = client.fetch_binary(self.url)\n- with open(path, \"wb\") as download_file:\n- for chunk in data.iter_content(chunk_size=8192):\n- download_file.write(chunk)\n+ with requests.get(self.url, stream=True) as response:\n+ with open(path, \"wb\") as download_file:\n+ shutil.copyfileobj(response.raw, download_file)\n \n return path\n \ndiff --git a/darwin/version/__init__.py b/darwin/version/__init__.py\n--- a/darwin/version/__init__.py\n+++ b/darwin/version/__init__.py\n@@ -1 +1 @@\n-__version__ = \"0.7.11\"\n+__version__ = \"0.7.12\"\n", "issue": "darwin-py 0.7.11 causing `MissingConfig` issues\nWhen I try using 0.7.11, I am getting an error when I run `dataset.pull`\r\n\r\nIt appears to be something with the release.py `download_zip` code passing config.yaml. I checked my .darwin folder and I don't see a config.yaml so I'm sure that's why it's causing an issue, but not sure where that is supposed to come from. \r\n\r\nHere's a reproducible version you should be able to use\r\n```\r\nimport darwin; print(darwin.__version__)\r\nfrom darwin.client import Client\r\n\r\nAPI_KEY = *your_key_here*\r\nclient = Client.from_api_key(API_KEY)\r\n\r\ndatasets={d.name:d for d in client.list_remote_datasets()}\r\ndataset=datasets[\"kevin-tmp\"]\r\n\r\nrelease = dataset.get_release()\r\ndataset.pull(release=release)\r\n```\r\n\r\nstack trace in 0.7.11: \r\n```\r\n---------------------------------------------------------------------------\r\nMissingConfig Traceback (most recent call last)\r\n/tmp/ipykernel_277/279924910.py in <module>\r\n 10 \r\n 11 release = dataset.get_release()\r\n---> 12 dataset.pull(release=release)\r\n\r\n/opt/conda/lib/python3.7/site-packages/darwin/dataset/remote_dataset.py in pull(self, release, blocking, multi_threaded, only_annotations, force_replace, remove_extra, subset_filter_annotations_function, subset_folder_name, use_folders, video_frames)\r\n 309 tmp_dir = Path(tmp_dir_str)\r\n 310 # Download the release from Darwin\r\n--> 311 zip_file_path = release.download_zip(tmp_dir / \"dataset.zip\")\r\n 312 with zipfile.ZipFile(zip_file_path) as z:\r\n 313 # Extract annotations\r\n\r\n/opt/conda/lib/python3.7/site-packages/darwin/dataset/release.py in download_zip(self, path)\r\n 195 \r\n 196 config_path: Path = Path.home() / \".darwin\" / \"config.yaml\"\r\n--> 197 client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)\r\n 198 \r\n 199 data: Response = client.fetch_binary(self.url)\r\n\r\n/opt/conda/lib/python3.7/site-packages/darwin/client.py in from_config(cls, config_path, team_slug)\r\n 836 \"\"\"\r\n 837 if not config_path.exists():\r\n--> 838 raise MissingConfig()\r\n 839 config = Config(config_path)\r\n 840 \r\n\r\nMissingConfig:\r\n```\n", "before_files": [{"content": "__version__ = \"0.7.11\"\n", "path": "darwin/version/__init__.py"}, {"content": "import datetime\nfrom pathlib import Path\nfrom typing import Any, Dict, Optional\n\nfrom darwin.dataset.identifier import DatasetIdentifier\nfrom requests import Response\n\n\nclass Release:\n \"\"\"\n Represents a release/export. Releases created this way can only contain items with 'completed'\n status.\n\n Parameters\n ----------\n dataset_slug : str\n The slug of the dataset.\n team_slug : str\n the slug of the team.\n version : str\n The version of the ``Release``.\n name : str\n The name of the ``Release``.\n url : Optional[str]\n The full url used to download the ``Release``.\n export_date : datetime.datetime\n The ``datetime`` of when this release was created.\n image_count : Optional[int]\n Number of images in this ``Release``.\n class_count : Optional[int]\n Number of distinct classes in this ``Release``.\n available : bool\n If this ``Release`` is downloadable or not.\n latest : bool\n If this ``Release`` is the latest one or not.\n format : str\n Format for the file of this ``Release`` should it be downloaded.\n\n Attributes\n ----------\n dataset_slug : str\n The slug of the dataset.\n team_slug : str\n the slug of the team.\n version : str\n The version of the ``Release``.\n name : str\n The name of the ``Release``.\n url : Optional[str]\n The full url used to download the ``Release``.\n export_date : datetime.datetime\n The ``datetime`` of when this release was created.\n image_count : Optional[int]\n Number of images in this ``Release``.\n class_count : Optional[int]\n Number of distinct classes in this ``Release``.\n available : bool\n If this ``Release`` is downloadable or not.\n latest : bool\n If this ``Release`` is the latest one or not.\n format : str\n Format for the file of this ``Release`` should it be downloaded.\n \"\"\"\n\n def __init__(\n self,\n dataset_slug: str,\n team_slug: str,\n version: str,\n name: str,\n url: Optional[str],\n export_date: datetime.datetime,\n image_count: Optional[int],\n class_count: Optional[int],\n available: bool,\n latest: bool,\n format: str,\n ):\n self.dataset_slug = dataset_slug\n self.team_slug = team_slug\n self.version = version\n self.name = name\n self.url = url\n self.export_date = export_date\n self.image_count = image_count\n self.class_count = class_count\n self.available = available\n self.latest = latest\n self.format = format\n\n @classmethod\n def parse_json(cls, dataset_slug: str, team_slug: str, payload: Dict[str, Any]) -> \"Release\":\n \"\"\"\n Given a json, parses it into a ``Release`` object instance.\n\n Parameters\n ----------\n dataset_slug : str\n The slug of the dataset this ``Release`` belongs to.\n team_slug : str\n The slug of the team this ``Release``'s dataset belongs to.\n payload : Dict[str, Any]\n A Dictionary with the ``Release`` information. It must have a minimal format similar to:\n\n .. code-block:: javascript\n {\n \"version\": \"a_version\",\n \"name\": \"a_name\"\n }\n\n If no ``format`` key is found in ``payload``, the default will be ``json``.\n\n Optional ``payload`` has no ``download_url`` key, then ``url``, ``available``,\n ``image_count``, ``class_count`` and ``latest`` will default to either ``None`` or\n ``False`` depending on the type.\n\n A more complete format for this parameter would be similar to:\n\n .. code-block:: javascript\n {\n \"version\": \"a_version\",\n \"name\": \"a_name\",\n \"metadata\": {\n \"num_images\": 1,\n \"annotation_classes\": []\n },\n \"download_url\": \"http://www.some_url_here.com\",\n \"latest\": false,\n \"format\": \"a_format\"\n }\n\n Returns\n -------\n Release\n A ``Release`` created from the given payload.\n \"\"\"\n try:\n export_date: datetime.datetime = datetime.datetime.strptime(payload[\"inserted_at\"], \"%Y-%m-%dT%H:%M:%S%z\")\n except ValueError:\n # For python version older than 3.7\n export_date = datetime.datetime.strptime(payload[\"inserted_at\"], \"%Y-%m-%dT%H:%M:%SZ\")\n\n if payload[\"download_url\"] is None:\n return cls(\n dataset_slug=dataset_slug,\n team_slug=team_slug,\n version=payload[\"version\"],\n name=payload[\"name\"],\n export_date=export_date,\n url=None,\n available=False,\n image_count=None,\n class_count=None,\n latest=False,\n format=payload.get(\"format\", \"json\"),\n )\n\n return cls(\n dataset_slug=dataset_slug,\n team_slug=team_slug,\n version=payload[\"version\"],\n name=payload[\"name\"],\n image_count=payload[\"metadata\"][\"num_images\"],\n class_count=len(payload[\"metadata\"][\"annotation_classes\"]),\n export_date=export_date,\n url=payload[\"download_url\"],\n available=True,\n latest=payload[\"latest\"],\n format=payload.get(\"format\", \"json\"),\n )\n\n def download_zip(self, path: Path) -> Path:\n \"\"\"\n Downloads the release content into a zip file located by the given path.\n\n Parameters\n ----------\n path : Path\n The path where the zip file will be located.\n\n Returns\n --------\n Path\n Same ``Path`` as provided in the parameters.\n\n Raises\n ------\n ValueError\n If this ``Release`` object does not have a specified url.\n \"\"\"\n if not self.url:\n raise ValueError(\"Release must have a valid url to download the zip.\")\n\n from darwin.client import Client\n\n config_path: Path = Path.home() / \".darwin\" / \"config.yaml\"\n client: Client = Client.from_config(config_path=config_path, team_slug=self.team_slug)\n\n data: Response = client.fetch_binary(self.url)\n with open(path, \"wb\") as download_file:\n for chunk in data.iter_content(chunk_size=8192):\n download_file.write(chunk)\n\n return path\n\n @property\n def identifier(self) -> DatasetIdentifier:\n \"\"\"DatasetIdentifier : The ``DatasetIdentifier`` for this ``Release``.\"\"\"\n return DatasetIdentifier(team_slug=self.team_slug, dataset_slug=self.dataset_slug, version=self.name)\n", "path": "darwin/dataset/release.py"}], "after_files": [{"content": "__version__ = \"0.7.12\"\n", "path": "darwin/version/__init__.py"}, {"content": "import datetime\nimport shutil\nfrom pathlib import Path\nfrom typing import Any, Dict, Optional\n\nimport requests\nfrom darwin.dataset.identifier import DatasetIdentifier\n\n\nclass Release:\n \"\"\"\n Represents a release/export. Releases created this way can only contain items with 'completed'\n status.\n\n Parameters\n ----------\n dataset_slug : str\n The slug of the dataset.\n team_slug : str\n the slug of the team.\n version : str\n The version of the ``Release``.\n name : str\n The name of the ``Release``.\n url : Optional[str]\n The full url used to download the ``Release``.\n export_date : datetime.datetime\n The ``datetime`` of when this release was created.\n image_count : Optional[int]\n Number of images in this ``Release``.\n class_count : Optional[int]\n Number of distinct classes in this ``Release``.\n available : bool\n If this ``Release`` is downloadable or not.\n latest : bool\n If this ``Release`` is the latest one or not.\n format : str\n Format for the file of this ``Release`` should it be downloaded.\n\n Attributes\n ----------\n dataset_slug : str\n The slug of the dataset.\n team_slug : str\n the slug of the team.\n version : str\n The version of the ``Release``.\n name : str\n The name of the ``Release``.\n url : Optional[str]\n The full url used to download the ``Release``.\n export_date : datetime.datetime\n The ``datetime`` of when this release was created.\n image_count : Optional[int]\n Number of images in this ``Release``.\n class_count : Optional[int]\n Number of distinct classes in this ``Release``.\n available : bool\n If this ``Release`` is downloadable or not.\n latest : bool\n If this ``Release`` is the latest one or not.\n format : str\n Format for the file of this ``Release`` should it be downloaded.\n \"\"\"\n\n def __init__(\n self,\n dataset_slug: str,\n team_slug: str,\n version: str,\n name: str,\n url: Optional[str],\n export_date: datetime.datetime,\n image_count: Optional[int],\n class_count: Optional[int],\n available: bool,\n latest: bool,\n format: str,\n ):\n self.dataset_slug = dataset_slug\n self.team_slug = team_slug\n self.version = version\n self.name = name\n self.url = url\n self.export_date = export_date\n self.image_count = image_count\n self.class_count = class_count\n self.available = available\n self.latest = latest\n self.format = format\n\n @classmethod\n def parse_json(cls, dataset_slug: str, team_slug: str, payload: Dict[str, Any]) -> \"Release\":\n \"\"\"\n Given a json, parses it into a ``Release`` object instance.\n\n Parameters\n ----------\n dataset_slug : str\n The slug of the dataset this ``Release`` belongs to.\n team_slug : str\n The slug of the team this ``Release``'s dataset belongs to.\n payload : Dict[str, Any]\n A Dictionary with the ``Release`` information. It must have a minimal format similar to:\n\n .. code-block:: javascript\n {\n \"version\": \"a_version\",\n \"name\": \"a_name\"\n }\n\n If no ``format`` key is found in ``payload``, the default will be ``json``.\n\n Optional ``payload`` has no ``download_url`` key, then ``url``, ``available``,\n ``image_count``, ``class_count`` and ``latest`` will default to either ``None`` or\n ``False`` depending on the type.\n\n A more complete format for this parameter would be similar to:\n\n .. code-block:: javascript\n {\n \"version\": \"a_version\",\n \"name\": \"a_name\",\n \"metadata\": {\n \"num_images\": 1,\n \"annotation_classes\": []\n },\n \"download_url\": \"http://www.some_url_here.com\",\n \"latest\": false,\n \"format\": \"a_format\"\n }\n\n Returns\n -------\n Release\n A ``Release`` created from the given payload.\n \"\"\"\n try:\n export_date: datetime.datetime = datetime.datetime.strptime(payload[\"inserted_at\"], \"%Y-%m-%dT%H:%M:%S%z\")\n except ValueError:\n # For python version older than 3.7\n export_date = datetime.datetime.strptime(payload[\"inserted_at\"], \"%Y-%m-%dT%H:%M:%SZ\")\n\n if payload[\"download_url\"] is None:\n return cls(\n dataset_slug=dataset_slug,\n team_slug=team_slug,\n version=payload[\"version\"],\n name=payload[\"name\"],\n export_date=export_date,\n url=None,\n available=False,\n image_count=None,\n class_count=None,\n latest=False,\n format=payload.get(\"format\", \"json\"),\n )\n\n return cls(\n dataset_slug=dataset_slug,\n team_slug=team_slug,\n version=payload[\"version\"],\n name=payload[\"name\"],\n image_count=payload[\"metadata\"][\"num_images\"],\n class_count=len(payload[\"metadata\"][\"annotation_classes\"]),\n export_date=export_date,\n url=payload[\"download_url\"],\n available=True,\n latest=payload[\"latest\"],\n format=payload.get(\"format\", \"json\"),\n )\n\n def download_zip(self, path: Path) -> Path:\n \"\"\"\n Downloads the release content into a zip file located by the given path.\n\n Parameters\n ----------\n path : Path\n The path where the zip file will be located.\n\n Returns\n --------\n Path\n Same ``Path`` as provided in the parameters.\n\n Raises\n ------\n ValueError\n If this ``Release`` object does not have a specified url.\n \"\"\"\n if not self.url:\n raise ValueError(\"Release must have a valid url to download the zip.\")\n\n with requests.get(self.url, stream=True) as response:\n with open(path, \"wb\") as download_file:\n shutil.copyfileobj(response.raw, download_file)\n\n return path\n\n @property\n def identifier(self) -> DatasetIdentifier:\n \"\"\"DatasetIdentifier : The ``DatasetIdentifier`` for this ``Release``.\"\"\"\n return DatasetIdentifier(team_slug=self.team_slug, dataset_slug=self.dataset_slug, version=self.name)\n", "path": "darwin/dataset/release.py"}]}
| 2,829 | 349 |
gh_patches_debug_37212
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-15
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
在 nonebot-test 前端调试时无法让 Bot 说出 <test>
nonebot.load_builtin_plugins() 后,在 nonebot-test 前端向 Bot 发送 /say <test>
Bot 未发送任何消息,且 nonebot2 控制台返回:
```
[ERROR] nonebot_test | Tag "<test>" does not corespond to any known ansi directive, make sure you did not misspelled it (or prepend '\' to escape it)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nonebot/utils.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3
4 import json
5 import asyncio
6 import dataclasses
7 from functools import wraps, partial
8
9 from nonebot.typing import Any, Callable, Awaitable, overrides
10
11
12 def run_sync(func: Callable[..., Any]) -> Callable[..., Awaitable[Any]]:
13 """
14 :说明:
15 一个用于包装 sync function 为 async function 的装饰器
16 :参数:
17 * ``func: Callable[..., Any]``: 被装饰的同步函数
18 :返回:
19 - ``Callable[..., Awaitable[Any]]``
20 """
21
22 @wraps(func)
23 async def _wrapper(*args: Any, **kwargs: Any) -> Any:
24 loop = asyncio.get_running_loop()
25 pfunc = partial(func, *args, **kwargs)
26 result = await loop.run_in_executor(None, pfunc)
27 return result
28
29 return _wrapper
30
31
32 class DataclassEncoder(json.JSONEncoder):
33 """
34 :说明:
35 在JSON序列化 ``Message`` (List[Dataclass]) 时使用的 ``JSONEncoder``
36 """
37
38 @overrides(json.JSONEncoder)
39 def default(self, o):
40 if dataclasses.is_dataclass(o):
41 return dataclasses.asdict(o)
42 return super().default(o)
43
```
Path: `nonebot/__init__.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3
4 import importlib
5 from nonebot.typing import Bot, Dict, Type, Union, Driver, Optional, NoReturn
6
7 _driver: Optional[Driver] = None
8
9
10 def get_driver() -> Union[NoReturn, Driver]:
11 """
12 :说明:
13
14 获取全局 Driver 对象。可用于在计划任务的回调中获取当前 Driver 对象。
15
16 :返回:
17
18 * ``Driver``: 全局 Driver 对象
19
20 :异常:
21
22 * ``ValueError``: 全局 Driver 对象尚未初始化 (nonebot.init 尚未调用)
23
24 :用法:
25
26 .. code-block:: python
27
28 driver = nonebot.get_driver()
29
30 """
31 if _driver is None:
32 raise ValueError("NoneBot has not been initialized.")
33 return _driver
34
35
36 def get_app():
37 """
38 :说明:
39
40 获取全局 Driver 对应 Server App 对象。
41
42 :返回:
43
44 * ``Any``: Server App 对象
45
46 :异常:
47
48 * ``ValueError``: 全局 Driver 对象尚未初始化 (nonebot.init 尚未调用)
49
50 :用法:
51
52 .. code-block:: python
53
54 app = nonebot.get_app()
55
56 """
57 driver = get_driver()
58 return driver.server_app
59
60
61 def get_asgi():
62 """
63 :说明:
64
65 获取全局 Driver 对应 Asgi 对象。
66
67 :返回:
68
69 * ``Any``: Asgi 对象
70
71 :异常:
72
73 * ``ValueError``: 全局 Driver 对象尚未初始化 (nonebot.init 尚未调用)
74
75 :用法:
76
77 .. code-block:: python
78
79 asgi = nonebot.get_asgi()
80
81 """
82 driver = get_driver()
83 return driver.asgi
84
85
86 def get_bots() -> Union[NoReturn, Dict[str, Bot]]:
87 """
88 :说明:
89
90 获取所有通过 ws 连接 NoneBot 的 Bot 对象。
91
92 :返回:
93
94 * ``Dict[str, Bot]``: 一个以字符串 ID 为键,Bot 对象为值的字典
95
96 :异常:
97
98 * ``ValueError``: 全局 Driver 对象尚未初始化 (nonebot.init 尚未调用)
99
100 :用法:
101
102 .. code-block:: python
103
104 bots = nonebot.get_bots()
105
106 """
107 driver = get_driver()
108 return driver.bots
109
110
111 from nonebot.sched import scheduler
112 from nonebot.config import Env, Config
113 from nonebot.log import logger, default_filter
114 from nonebot.adapters.cqhttp import Bot as CQBot
115
116 try:
117 import nonebot_test
118 except ImportError:
119 nonebot_test = None
120
121
122 def init(*, _env_file: Optional[str] = None, **kwargs):
123 """
124 :说明:
125
126 初始化 NoneBot 以及 全局 Driver 对象。
127
128 NoneBot 将会从 .env 文件中读取环境信息,并使用相应的 env 文件配置。
129
130 你也可以传入自定义的 _env_file 来指定 NoneBot 从该文件读取配置。
131
132 :参数:
133
134 * ``_env_file: Optional[str]``: 配置文件名,默认从 .env.{env_name} 中读取配置
135 * ``**kwargs``: 任意变量,将会存储到 Config 对象里
136
137 :返回:
138
139 - ``None``
140
141 :用法:
142
143 .. code-block:: python
144
145 nonebot.init(database=Database(...))
146
147 """
148 global _driver
149 if not _driver:
150 logger.info("NoneBot is initializing...")
151 env = Env()
152 logger.opt(
153 colors=True).info(f"Current <y><b>Env: {env.environment}</b></y>")
154 config = Config(**kwargs,
155 _env_file=_env_file or f".env.{env.environment}")
156
157 default_filter.level = "DEBUG" if config.debug else "INFO"
158 logger.opt(
159 colors=True).debug(f"Loaded <y><b>Config</b></y>: {config.dict()}")
160
161 DriverClass: Type[Driver] = getattr(
162 importlib.import_module(config.driver), "Driver")
163 _driver = DriverClass(env, config)
164
165 # register build-in adapters
166 _driver.register_adapter("cqhttp", CQBot)
167
168 # load nonebot test frontend if debug
169 if config.debug and nonebot_test:
170 logger.debug("Loading nonebot test frontend...")
171 nonebot_test.init()
172
173 if scheduler:
174 _driver.on_startup(_start_scheduler)
175
176
177 def run(host: Optional[str] = None,
178 port: Optional[int] = None,
179 *args,
180 **kwargs):
181 """
182 :说明:
183
184 启动 NoneBot,即运行全局 Driver 对象。
185
186 :参数:
187
188 * ``host: Optional[str]``: 主机名/IP,若不传入则使用配置文件中指定的值
189 * ``port: Optional[int]``: 端口,若不传入则使用配置文件中指定的值
190 * ``*args``: 传入 Driver.run 的位置参数
191 * ``**kwargs``: 传入 Driver.run 的命名参数
192
193 :返回:
194
195 - ``None``
196
197 :用法:
198
199 .. code-block:: python
200
201 nonebot.run(host="127.0.0.1", port=8080)
202
203 """
204 logger.info("Running NoneBot...")
205 get_driver().run(host, port, *args, **kwargs)
206
207
208 async def _start_scheduler():
209 if scheduler and not scheduler.running:
210 scheduler.configure(_driver.config.apscheduler_config)
211 scheduler.start()
212 logger.opt(colors=True).info("<y>Scheduler Started</y>")
213
214
215 from nonebot.plugin import on_message, on_notice, on_request, on_metaevent
216 from nonebot.plugin import on_startswith, on_endswith, on_command, on_regex, CommandGroup
217 from nonebot.plugin import load_plugin, load_plugins, load_builtin_plugins, get_loaded_plugins
218
```
Path: `nonebot/message.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3
4 import asyncio
5 from datetime import datetime
6
7 from nonebot.log import logger
8 from nonebot.rule import TrieRule
9 from nonebot.matcher import matchers
10 from nonebot.typing import Set, Type, Union, NoReturn
11 from nonebot.typing import Bot, Event, Matcher, PreProcessor
12 from nonebot.exception import IgnoredException, ExpiredException
13 from nonebot.exception import StopPropagation, _ExceptionContainer
14
15 _event_preprocessors: Set[PreProcessor] = set()
16
17
18 def event_preprocessor(func: PreProcessor) -> PreProcessor:
19 _event_preprocessors.add(func)
20 return func
21
22
23 async def _run_matcher(Matcher: Type[Matcher], bot: Bot, event: Event,
24 state: dict) -> Union[None, NoReturn]:
25 if Matcher.expire_time and datetime.now() > Matcher.expire_time:
26 raise _ExceptionContainer([ExpiredException])
27
28 try:
29 if not await Matcher.check_perm(
30 bot, event) or not await Matcher.check_rule(bot, event, state):
31 return
32 except Exception as e:
33 logger.opt(colors=True, exception=e).error(
34 f"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>")
35 return
36
37 logger.info(f"Event will be handled by {Matcher}")
38
39 matcher = Matcher()
40 # TODO: BeforeMatcherRun
41 try:
42 logger.debug(f"Running matcher {matcher}")
43 await matcher.run(bot, event, state)
44 except Exception as e:
45 logger.opt(colors=True, exception=e).error(
46 f"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>"
47 )
48
49 exceptions = []
50 if Matcher.temp:
51 exceptions.append(ExpiredException)
52 if Matcher.block:
53 exceptions.append(StopPropagation)
54 if exceptions:
55 raise _ExceptionContainer(exceptions)
56
57
58 async def handle_event(bot: Bot, event: Event):
59 log_msg = f"<m>{bot.type.upper()} </m>| {event.self_id} [{event.name}]: "
60 if event.type == "message":
61 log_msg += f"Message {event.id} from "
62 log_msg += str(event.user_id)
63 if event.detail_type == "group":
64 log_msg += f"@[群:{event.group_id}]:"
65
66 log_msg += ' "' + "".join(
67 map(lambda x: str(x) if x.type == "text" else f"<le>{x!s}</le>",
68 event.message)) + '"' # type: ignore
69 elif event.type == "notice":
70 log_msg += f"Notice {event.raw_event}"
71 elif event.type == "request":
72 log_msg += f"Request {event.raw_event}"
73 elif event.type == "meta_event":
74 log_msg += f"MetaEvent {event.raw_event}"
75 logger.opt(colors=True).info(log_msg)
76
77 coros = []
78 state = {}
79 for preprocessor in _event_preprocessors:
80 coros.append(preprocessor(bot, event, state))
81 if coros:
82 try:
83 logger.debug("Running PreProcessors...")
84 await asyncio.gather(*coros)
85 except IgnoredException:
86 logger.opt(
87 colors=True).info(f"Event {event.name} is <b>ignored</b>")
88 return
89
90 # Trie Match
91 _, _ = TrieRule.get_value(bot, event, state)
92
93 break_flag = False
94 for priority in sorted(matchers.keys()):
95 if break_flag:
96 break
97
98 pending_tasks = [
99 _run_matcher(matcher, bot, event, state.copy())
100 for matcher in matchers[priority]
101 ]
102
103 logger.debug(f"Checking for matchers in priority {priority}...")
104 results = await asyncio.gather(*pending_tasks, return_exceptions=True)
105
106 i = 0
107 for index, result in enumerate(results):
108 if isinstance(result, _ExceptionContainer):
109 e_list = result.exceptions
110 if StopPropagation in e_list:
111 if not break_flag:
112 break_flag = True
113 logger.debug("Stop event propagation")
114 if ExpiredException in e_list:
115 logger.debug(
116 f"Matcher {matchers[priority][index - i]} will be removed."
117 )
118 del matchers[priority][index - i]
119 i += 1
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nonebot/__init__.py b/nonebot/__init__.py
--- a/nonebot/__init__.py
+++ b/nonebot/__init__.py
@@ -109,6 +109,7 @@
from nonebot.sched import scheduler
+from nonebot.utils import escape_tag
from nonebot.config import Env, Config
from nonebot.log import logger, default_filter
from nonebot.adapters.cqhttp import Bot as CQBot
@@ -155,8 +156,8 @@
_env_file=_env_file or f".env.{env.environment}")
default_filter.level = "DEBUG" if config.debug else "INFO"
- logger.opt(
- colors=True).debug(f"Loaded <y><b>Config</b></y>: {config.dict()}")
+ logger.opt(colors=True).debug(
+ f"Loaded <y><b>Config</b></y>: {escape_tag(str(config.dict()))}")
DriverClass: Type[Driver] = getattr(
importlib.import_module(config.driver), "Driver")
diff --git a/nonebot/message.py b/nonebot/message.py
--- a/nonebot/message.py
+++ b/nonebot/message.py
@@ -6,6 +6,7 @@
from nonebot.log import logger
from nonebot.rule import TrieRule
+from nonebot.utils import escape_tag
from nonebot.matcher import matchers
from nonebot.typing import Set, Type, Union, NoReturn
from nonebot.typing import Bot, Event, Matcher, PreProcessor
@@ -64,7 +65,9 @@
log_msg += f"@[群:{event.group_id}]:"
log_msg += ' "' + "".join(
- map(lambda x: str(x) if x.type == "text" else f"<le>{x!s}</le>",
+ map(
+ lambda x: escape_tag(str(x))
+ if x.type == "text" else f"<le>{escape_tag(str(x))}</le>",
event.message)) + '"' # type: ignore
elif event.type == "notice":
log_msg += f"Notice {event.raw_event}"
diff --git a/nonebot/utils.py b/nonebot/utils.py
--- a/nonebot/utils.py
+++ b/nonebot/utils.py
@@ -1,6 +1,7 @@
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
+import re
import json
import asyncio
import dataclasses
@@ -9,6 +10,10 @@
from nonebot.typing import Any, Callable, Awaitable, overrides
+def escape_tag(s: str) -> str:
+ return re.sub(r"</?((?:[fb]g\s)?[^<>\s]*)>", r"\\\g<0>", s)
+
+
def run_sync(func: Callable[..., Any]) -> Callable[..., Awaitable[Any]]:
"""
:说明:
|
{"golden_diff": "diff --git a/nonebot/__init__.py b/nonebot/__init__.py\n--- a/nonebot/__init__.py\n+++ b/nonebot/__init__.py\n@@ -109,6 +109,7 @@\n \n \n from nonebot.sched import scheduler\n+from nonebot.utils import escape_tag\n from nonebot.config import Env, Config\n from nonebot.log import logger, default_filter\n from nonebot.adapters.cqhttp import Bot as CQBot\n@@ -155,8 +156,8 @@\n _env_file=_env_file or f\".env.{env.environment}\")\n \n default_filter.level = \"DEBUG\" if config.debug else \"INFO\"\n- logger.opt(\n- colors=True).debug(f\"Loaded <y><b>Config</b></y>: {config.dict()}\")\n+ logger.opt(colors=True).debug(\n+ f\"Loaded <y><b>Config</b></y>: {escape_tag(str(config.dict()))}\")\n \n DriverClass: Type[Driver] = getattr(\n importlib.import_module(config.driver), \"Driver\")\ndiff --git a/nonebot/message.py b/nonebot/message.py\n--- a/nonebot/message.py\n+++ b/nonebot/message.py\n@@ -6,6 +6,7 @@\n \n from nonebot.log import logger\n from nonebot.rule import TrieRule\n+from nonebot.utils import escape_tag\n from nonebot.matcher import matchers\n from nonebot.typing import Set, Type, Union, NoReturn\n from nonebot.typing import Bot, Event, Matcher, PreProcessor\n@@ -64,7 +65,9 @@\n log_msg += f\"@[\u7fa4:{event.group_id}]:\"\n \n log_msg += ' \"' + \"\".join(\n- map(lambda x: str(x) if x.type == \"text\" else f\"<le>{x!s}</le>\",\n+ map(\n+ lambda x: escape_tag(str(x))\n+ if x.type == \"text\" else f\"<le>{escape_tag(str(x))}</le>\",\n event.message)) + '\"' # type: ignore\n elif event.type == \"notice\":\n log_msg += f\"Notice {event.raw_event}\"\ndiff --git a/nonebot/utils.py b/nonebot/utils.py\n--- a/nonebot/utils.py\n+++ b/nonebot/utils.py\n@@ -1,6 +1,7 @@\n #!/usr/bin/env python3\n # -*- coding: utf-8 -*-\n \n+import re\n import json\n import asyncio\n import dataclasses\n@@ -9,6 +10,10 @@\n from nonebot.typing import Any, Callable, Awaitable, overrides\n \n \n+def escape_tag(s: str) -> str:\n+ return re.sub(r\"</?((?:[fb]g\\s)?[^<>\\s]*)>\", r\"\\\\\\g<0>\", s)\n+\n+\n def run_sync(func: Callable[..., Any]) -> Callable[..., Awaitable[Any]]:\n \"\"\"\n :\u8bf4\u660e:\n", "issue": "\u5728 nonebot-test \u524d\u7aef\u8c03\u8bd5\u65f6\u65e0\u6cd5\u8ba9 Bot \u8bf4\u51fa <test>\nnonebot.load_builtin_plugins() \u540e\uff0c\u5728 nonebot-test \u524d\u7aef\u5411 Bot \u53d1\u9001 /say <test> \r\n\r\nBot \u672a\u53d1\u9001\u4efb\u4f55\u6d88\u606f\uff0c\u4e14 nonebot2 \u63a7\u5236\u53f0\u8fd4\u56de\uff1a\r\n\r\n```\r\n[ERROR] nonebot_test | Tag \"<test>\" does not corespond to any known ansi directive, make sure you did not misspelled it (or prepend '\\' to escape it)\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport json\nimport asyncio\nimport dataclasses\nfrom functools import wraps, partial\n\nfrom nonebot.typing import Any, Callable, Awaitable, overrides\n\n\ndef run_sync(func: Callable[..., Any]) -> Callable[..., Awaitable[Any]]:\n \"\"\"\n :\u8bf4\u660e:\n \u4e00\u4e2a\u7528\u4e8e\u5305\u88c5 sync function \u4e3a async function \u7684\u88c5\u9970\u5668\n :\u53c2\u6570:\n * ``func: Callable[..., Any]``: \u88ab\u88c5\u9970\u7684\u540c\u6b65\u51fd\u6570\n :\u8fd4\u56de:\n - ``Callable[..., Awaitable[Any]]``\n \"\"\"\n\n @wraps(func)\n async def _wrapper(*args: Any, **kwargs: Any) -> Any:\n loop = asyncio.get_running_loop()\n pfunc = partial(func, *args, **kwargs)\n result = await loop.run_in_executor(None, pfunc)\n return result\n\n return _wrapper\n\n\nclass DataclassEncoder(json.JSONEncoder):\n \"\"\"\n :\u8bf4\u660e:\n \u5728JSON\u5e8f\u5217\u5316 ``Message`` (List[Dataclass]) \u65f6\u4f7f\u7528\u7684 ``JSONEncoder``\n \"\"\"\n\n @overrides(json.JSONEncoder)\n def default(self, o):\n if dataclasses.is_dataclass(o):\n return dataclasses.asdict(o)\n return super().default(o)\n", "path": "nonebot/utils.py"}, {"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport importlib\nfrom nonebot.typing import Bot, Dict, Type, Union, Driver, Optional, NoReturn\n\n_driver: Optional[Driver] = None\n\n\ndef get_driver() -> Union[NoReturn, Driver]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u8c61\u3002\u53ef\u7528\u4e8e\u5728\u8ba1\u5212\u4efb\u52a1\u7684\u56de\u8c03\u4e2d\u83b7\u53d6\u5f53\u524d Driver \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Driver``: \u5168\u5c40 Driver \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n driver = nonebot.get_driver()\n\n \"\"\"\n if _driver is None:\n raise ValueError(\"NoneBot has not been initialized.\")\n return _driver\n\n\ndef get_app():\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u5e94 Server App \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Any``: Server App \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n app = nonebot.get_app()\n\n \"\"\"\n driver = get_driver()\n return driver.server_app\n\n\ndef get_asgi():\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u5e94 Asgi \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Any``: Asgi \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n asgi = nonebot.get_asgi()\n\n \"\"\"\n driver = get_driver()\n return driver.asgi\n\n\ndef get_bots() -> Union[NoReturn, Dict[str, Bot]]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u6240\u6709\u901a\u8fc7 ws \u8fde\u63a5 NoneBot \u7684 Bot \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Dict[str, Bot]``: \u4e00\u4e2a\u4ee5\u5b57\u7b26\u4e32 ID \u4e3a\u952e\uff0cBot \u5bf9\u8c61\u4e3a\u503c\u7684\u5b57\u5178\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n bots = nonebot.get_bots()\n\n \"\"\"\n driver = get_driver()\n return driver.bots\n\n\nfrom nonebot.sched import scheduler\nfrom nonebot.config import Env, Config\nfrom nonebot.log import logger, default_filter\nfrom nonebot.adapters.cqhttp import Bot as CQBot\n\ntry:\n import nonebot_test\nexcept ImportError:\n nonebot_test = None\n\n\ndef init(*, _env_file: Optional[str] = None, **kwargs):\n \"\"\"\n :\u8bf4\u660e:\n\n \u521d\u59cb\u5316 NoneBot \u4ee5\u53ca \u5168\u5c40 Driver \u5bf9\u8c61\u3002\n\n NoneBot \u5c06\u4f1a\u4ece .env \u6587\u4ef6\u4e2d\u8bfb\u53d6\u73af\u5883\u4fe1\u606f\uff0c\u5e76\u4f7f\u7528\u76f8\u5e94\u7684 env \u6587\u4ef6\u914d\u7f6e\u3002\n\n \u4f60\u4e5f\u53ef\u4ee5\u4f20\u5165\u81ea\u5b9a\u4e49\u7684 _env_file \u6765\u6307\u5b9a NoneBot \u4ece\u8be5\u6587\u4ef6\u8bfb\u53d6\u914d\u7f6e\u3002\n\n :\u53c2\u6570:\n\n * ``_env_file: Optional[str]``: \u914d\u7f6e\u6587\u4ef6\u540d\uff0c\u9ed8\u8ba4\u4ece .env.{env_name} \u4e2d\u8bfb\u53d6\u914d\u7f6e\n * ``**kwargs``: \u4efb\u610f\u53d8\u91cf\uff0c\u5c06\u4f1a\u5b58\u50a8\u5230 Config \u5bf9\u8c61\u91cc\n\n :\u8fd4\u56de:\n\n - ``None``\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n nonebot.init(database=Database(...))\n\n \"\"\"\n global _driver\n if not _driver:\n logger.info(\"NoneBot is initializing...\")\n env = Env()\n logger.opt(\n colors=True).info(f\"Current <y><b>Env: {env.environment}</b></y>\")\n config = Config(**kwargs,\n _env_file=_env_file or f\".env.{env.environment}\")\n\n default_filter.level = \"DEBUG\" if config.debug else \"INFO\"\n logger.opt(\n colors=True).debug(f\"Loaded <y><b>Config</b></y>: {config.dict()}\")\n\n DriverClass: Type[Driver] = getattr(\n importlib.import_module(config.driver), \"Driver\")\n _driver = DriverClass(env, config)\n\n # register build-in adapters\n _driver.register_adapter(\"cqhttp\", CQBot)\n\n # load nonebot test frontend if debug\n if config.debug and nonebot_test:\n logger.debug(\"Loading nonebot test frontend...\")\n nonebot_test.init()\n\n if scheduler:\n _driver.on_startup(_start_scheduler)\n\n\ndef run(host: Optional[str] = None,\n port: Optional[int] = None,\n *args,\n **kwargs):\n \"\"\"\n :\u8bf4\u660e:\n\n \u542f\u52a8 NoneBot\uff0c\u5373\u8fd0\u884c\u5168\u5c40 Driver \u5bf9\u8c61\u3002\n\n :\u53c2\u6570:\n\n * ``host: Optional[str]``: \u4e3b\u673a\u540d\uff0fIP\uff0c\u82e5\u4e0d\u4f20\u5165\u5219\u4f7f\u7528\u914d\u7f6e\u6587\u4ef6\u4e2d\u6307\u5b9a\u7684\u503c\n * ``port: Optional[int]``: \u7aef\u53e3\uff0c\u82e5\u4e0d\u4f20\u5165\u5219\u4f7f\u7528\u914d\u7f6e\u6587\u4ef6\u4e2d\u6307\u5b9a\u7684\u503c\n * ``*args``: \u4f20\u5165 Driver.run \u7684\u4f4d\u7f6e\u53c2\u6570\n * ``**kwargs``: \u4f20\u5165 Driver.run \u7684\u547d\u540d\u53c2\u6570\n\n :\u8fd4\u56de:\n\n - ``None``\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n nonebot.run(host=\"127.0.0.1\", port=8080)\n\n \"\"\"\n logger.info(\"Running NoneBot...\")\n get_driver().run(host, port, *args, **kwargs)\n\n\nasync def _start_scheduler():\n if scheduler and not scheduler.running:\n scheduler.configure(_driver.config.apscheduler_config)\n scheduler.start()\n logger.opt(colors=True).info(\"<y>Scheduler Started</y>\")\n\n\nfrom nonebot.plugin import on_message, on_notice, on_request, on_metaevent\nfrom nonebot.plugin import on_startswith, on_endswith, on_command, on_regex, CommandGroup\nfrom nonebot.plugin import load_plugin, load_plugins, load_builtin_plugins, get_loaded_plugins\n", "path": "nonebot/__init__.py"}, {"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport asyncio\nfrom datetime import datetime\n\nfrom nonebot.log import logger\nfrom nonebot.rule import TrieRule\nfrom nonebot.matcher import matchers\nfrom nonebot.typing import Set, Type, Union, NoReturn\nfrom nonebot.typing import Bot, Event, Matcher, PreProcessor\nfrom nonebot.exception import IgnoredException, ExpiredException\nfrom nonebot.exception import StopPropagation, _ExceptionContainer\n\n_event_preprocessors: Set[PreProcessor] = set()\n\n\ndef event_preprocessor(func: PreProcessor) -> PreProcessor:\n _event_preprocessors.add(func)\n return func\n\n\nasync def _run_matcher(Matcher: Type[Matcher], bot: Bot, event: Event,\n state: dict) -> Union[None, NoReturn]:\n if Matcher.expire_time and datetime.now() > Matcher.expire_time:\n raise _ExceptionContainer([ExpiredException])\n\n try:\n if not await Matcher.check_perm(\n bot, event) or not await Matcher.check_rule(bot, event, state):\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>\")\n return\n\n logger.info(f\"Event will be handled by {Matcher}\")\n\n matcher = Matcher()\n # TODO: BeforeMatcherRun\n try:\n logger.debug(f\"Running matcher {matcher}\")\n await matcher.run(bot, event, state)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>\"\n )\n\n exceptions = []\n if Matcher.temp:\n exceptions.append(ExpiredException)\n if Matcher.block:\n exceptions.append(StopPropagation)\n if exceptions:\n raise _ExceptionContainer(exceptions)\n\n\nasync def handle_event(bot: Bot, event: Event):\n log_msg = f\"<m>{bot.type.upper()} </m>| {event.self_id} [{event.name}]: \"\n if event.type == \"message\":\n log_msg += f\"Message {event.id} from \"\n log_msg += str(event.user_id)\n if event.detail_type == \"group\":\n log_msg += f\"@[\u7fa4:{event.group_id}]:\"\n\n log_msg += ' \"' + \"\".join(\n map(lambda x: str(x) if x.type == \"text\" else f\"<le>{x!s}</le>\",\n event.message)) + '\"' # type: ignore\n elif event.type == \"notice\":\n log_msg += f\"Notice {event.raw_event}\"\n elif event.type == \"request\":\n log_msg += f\"Request {event.raw_event}\"\n elif event.type == \"meta_event\":\n log_msg += f\"MetaEvent {event.raw_event}\"\n logger.opt(colors=True).info(log_msg)\n\n coros = []\n state = {}\n for preprocessor in _event_preprocessors:\n coros.append(preprocessor(bot, event, state))\n if coros:\n try:\n logger.debug(\"Running PreProcessors...\")\n await asyncio.gather(*coros)\n except IgnoredException:\n logger.opt(\n colors=True).info(f\"Event {event.name} is <b>ignored</b>\")\n return\n\n # Trie Match\n _, _ = TrieRule.get_value(bot, event, state)\n\n break_flag = False\n for priority in sorted(matchers.keys()):\n if break_flag:\n break\n\n pending_tasks = [\n _run_matcher(matcher, bot, event, state.copy())\n for matcher in matchers[priority]\n ]\n\n logger.debug(f\"Checking for matchers in priority {priority}...\")\n results = await asyncio.gather(*pending_tasks, return_exceptions=True)\n\n i = 0\n for index, result in enumerate(results):\n if isinstance(result, _ExceptionContainer):\n e_list = result.exceptions\n if StopPropagation in e_list:\n if not break_flag:\n break_flag = True\n logger.debug(\"Stop event propagation\")\n if ExpiredException in e_list:\n logger.debug(\n f\"Matcher {matchers[priority][index - i]} will be removed.\"\n )\n del matchers[priority][index - i]\n i += 1\n", "path": "nonebot/message.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport re\nimport json\nimport asyncio\nimport dataclasses\nfrom functools import wraps, partial\n\nfrom nonebot.typing import Any, Callable, Awaitable, overrides\n\n\ndef escape_tag(s: str) -> str:\n return re.sub(r\"</?((?:[fb]g\\s)?[^<>\\s]*)>\", r\"\\\\\\g<0>\", s)\n\n\ndef run_sync(func: Callable[..., Any]) -> Callable[..., Awaitable[Any]]:\n \"\"\"\n :\u8bf4\u660e:\n \u4e00\u4e2a\u7528\u4e8e\u5305\u88c5 sync function \u4e3a async function \u7684\u88c5\u9970\u5668\n :\u53c2\u6570:\n * ``func: Callable[..., Any]``: \u88ab\u88c5\u9970\u7684\u540c\u6b65\u51fd\u6570\n :\u8fd4\u56de:\n - ``Callable[..., Awaitable[Any]]``\n \"\"\"\n\n @wraps(func)\n async def _wrapper(*args: Any, **kwargs: Any) -> Any:\n loop = asyncio.get_running_loop()\n pfunc = partial(func, *args, **kwargs)\n result = await loop.run_in_executor(None, pfunc)\n return result\n\n return _wrapper\n\n\nclass DataclassEncoder(json.JSONEncoder):\n \"\"\"\n :\u8bf4\u660e:\n \u5728JSON\u5e8f\u5217\u5316 ``Message`` (List[Dataclass]) \u65f6\u4f7f\u7528\u7684 ``JSONEncoder``\n \"\"\"\n\n @overrides(json.JSONEncoder)\n def default(self, o):\n if dataclasses.is_dataclass(o):\n return dataclasses.asdict(o)\n return super().default(o)\n", "path": "nonebot/utils.py"}, {"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport importlib\nfrom nonebot.typing import Bot, Dict, Type, Union, Driver, Optional, NoReturn\n\n_driver: Optional[Driver] = None\n\n\ndef get_driver() -> Union[NoReturn, Driver]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u8c61\u3002\u53ef\u7528\u4e8e\u5728\u8ba1\u5212\u4efb\u52a1\u7684\u56de\u8c03\u4e2d\u83b7\u53d6\u5f53\u524d Driver \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Driver``: \u5168\u5c40 Driver \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n driver = nonebot.get_driver()\n\n \"\"\"\n if _driver is None:\n raise ValueError(\"NoneBot has not been initialized.\")\n return _driver\n\n\ndef get_app():\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u5e94 Server App \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Any``: Server App \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n app = nonebot.get_app()\n\n \"\"\"\n driver = get_driver()\n return driver.server_app\n\n\ndef get_asgi():\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u5168\u5c40 Driver \u5bf9\u5e94 Asgi \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Any``: Asgi \u5bf9\u8c61\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n asgi = nonebot.get_asgi()\n\n \"\"\"\n driver = get_driver()\n return driver.asgi\n\n\ndef get_bots() -> Union[NoReturn, Dict[str, Bot]]:\n \"\"\"\n :\u8bf4\u660e:\n\n \u83b7\u53d6\u6240\u6709\u901a\u8fc7 ws \u8fde\u63a5 NoneBot \u7684 Bot \u5bf9\u8c61\u3002\n\n :\u8fd4\u56de:\n\n * ``Dict[str, Bot]``: \u4e00\u4e2a\u4ee5\u5b57\u7b26\u4e32 ID \u4e3a\u952e\uff0cBot \u5bf9\u8c61\u4e3a\u503c\u7684\u5b57\u5178\n\n :\u5f02\u5e38:\n\n * ``ValueError``: \u5168\u5c40 Driver \u5bf9\u8c61\u5c1a\u672a\u521d\u59cb\u5316 (nonebot.init \u5c1a\u672a\u8c03\u7528)\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n bots = nonebot.get_bots()\n\n \"\"\"\n driver = get_driver()\n return driver.bots\n\n\nfrom nonebot.sched import scheduler\nfrom nonebot.utils import escape_tag\nfrom nonebot.config import Env, Config\nfrom nonebot.log import logger, default_filter\nfrom nonebot.adapters.cqhttp import Bot as CQBot\n\ntry:\n import nonebot_test\nexcept ImportError:\n nonebot_test = None\n\n\ndef init(*, _env_file: Optional[str] = None, **kwargs):\n \"\"\"\n :\u8bf4\u660e:\n\n \u521d\u59cb\u5316 NoneBot \u4ee5\u53ca \u5168\u5c40 Driver \u5bf9\u8c61\u3002\n\n NoneBot \u5c06\u4f1a\u4ece .env \u6587\u4ef6\u4e2d\u8bfb\u53d6\u73af\u5883\u4fe1\u606f\uff0c\u5e76\u4f7f\u7528\u76f8\u5e94\u7684 env \u6587\u4ef6\u914d\u7f6e\u3002\n\n \u4f60\u4e5f\u53ef\u4ee5\u4f20\u5165\u81ea\u5b9a\u4e49\u7684 _env_file \u6765\u6307\u5b9a NoneBot \u4ece\u8be5\u6587\u4ef6\u8bfb\u53d6\u914d\u7f6e\u3002\n\n :\u53c2\u6570:\n\n * ``_env_file: Optional[str]``: \u914d\u7f6e\u6587\u4ef6\u540d\uff0c\u9ed8\u8ba4\u4ece .env.{env_name} \u4e2d\u8bfb\u53d6\u914d\u7f6e\n * ``**kwargs``: \u4efb\u610f\u53d8\u91cf\uff0c\u5c06\u4f1a\u5b58\u50a8\u5230 Config \u5bf9\u8c61\u91cc\n\n :\u8fd4\u56de:\n\n - ``None``\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n nonebot.init(database=Database(...))\n\n \"\"\"\n global _driver\n if not _driver:\n logger.info(\"NoneBot is initializing...\")\n env = Env()\n logger.opt(\n colors=True).info(f\"Current <y><b>Env: {env.environment}</b></y>\")\n config = Config(**kwargs,\n _env_file=_env_file or f\".env.{env.environment}\")\n\n default_filter.level = \"DEBUG\" if config.debug else \"INFO\"\n logger.opt(colors=True).debug(\n f\"Loaded <y><b>Config</b></y>: {escape_tag(str(config.dict()))}\")\n\n DriverClass: Type[Driver] = getattr(\n importlib.import_module(config.driver), \"Driver\")\n _driver = DriverClass(env, config)\n\n # register build-in adapters\n _driver.register_adapter(\"cqhttp\", CQBot)\n\n # load nonebot test frontend if debug\n if config.debug and nonebot_test:\n logger.debug(\"Loading nonebot test frontend...\")\n nonebot_test.init()\n\n if scheduler:\n _driver.on_startup(_start_scheduler)\n\n\ndef run(host: Optional[str] = None,\n port: Optional[int] = None,\n *args,\n **kwargs):\n \"\"\"\n :\u8bf4\u660e:\n\n \u542f\u52a8 NoneBot\uff0c\u5373\u8fd0\u884c\u5168\u5c40 Driver \u5bf9\u8c61\u3002\n\n :\u53c2\u6570:\n\n * ``host: Optional[str]``: \u4e3b\u673a\u540d\uff0fIP\uff0c\u82e5\u4e0d\u4f20\u5165\u5219\u4f7f\u7528\u914d\u7f6e\u6587\u4ef6\u4e2d\u6307\u5b9a\u7684\u503c\n * ``port: Optional[int]``: \u7aef\u53e3\uff0c\u82e5\u4e0d\u4f20\u5165\u5219\u4f7f\u7528\u914d\u7f6e\u6587\u4ef6\u4e2d\u6307\u5b9a\u7684\u503c\n * ``*args``: \u4f20\u5165 Driver.run \u7684\u4f4d\u7f6e\u53c2\u6570\n * ``**kwargs``: \u4f20\u5165 Driver.run \u7684\u547d\u540d\u53c2\u6570\n\n :\u8fd4\u56de:\n\n - ``None``\n\n :\u7528\u6cd5:\n\n .. code-block:: python\n\n nonebot.run(host=\"127.0.0.1\", port=8080)\n\n \"\"\"\n logger.info(\"Running NoneBot...\")\n get_driver().run(host, port, *args, **kwargs)\n\n\nasync def _start_scheduler():\n if scheduler and not scheduler.running:\n scheduler.configure(_driver.config.apscheduler_config)\n scheduler.start()\n logger.opt(colors=True).info(\"<y>Scheduler Started</y>\")\n\n\nfrom nonebot.plugin import on_message, on_notice, on_request, on_metaevent\nfrom nonebot.plugin import on_startswith, on_endswith, on_command, on_regex, CommandGroup\nfrom nonebot.plugin import load_plugin, load_plugins, load_builtin_plugins, get_loaded_plugins\n", "path": "nonebot/__init__.py"}, {"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport asyncio\nfrom datetime import datetime\n\nfrom nonebot.log import logger\nfrom nonebot.rule import TrieRule\nfrom nonebot.utils import escape_tag\nfrom nonebot.matcher import matchers\nfrom nonebot.typing import Set, Type, Union, NoReturn\nfrom nonebot.typing import Bot, Event, Matcher, PreProcessor\nfrom nonebot.exception import IgnoredException, ExpiredException\nfrom nonebot.exception import StopPropagation, _ExceptionContainer\n\n_event_preprocessors: Set[PreProcessor] = set()\n\n\ndef event_preprocessor(func: PreProcessor) -> PreProcessor:\n _event_preprocessors.add(func)\n return func\n\n\nasync def _run_matcher(Matcher: Type[Matcher], bot: Bot, event: Event,\n state: dict) -> Union[None, NoReturn]:\n if Matcher.expire_time and datetime.now() > Matcher.expire_time:\n raise _ExceptionContainer([ExpiredException])\n\n try:\n if not await Matcher.check_perm(\n bot, event) or not await Matcher.check_rule(bot, event, state):\n return\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Rule check failed for {Matcher}.</bg #f8bbd0></r>\")\n return\n\n logger.info(f\"Event will be handled by {Matcher}\")\n\n matcher = Matcher()\n # TODO: BeforeMatcherRun\n try:\n logger.debug(f\"Running matcher {matcher}\")\n await matcher.run(bot, event, state)\n except Exception as e:\n logger.opt(colors=True, exception=e).error(\n f\"<r><bg #f8bbd0>Running matcher {matcher} failed.</bg #f8bbd0></r>\"\n )\n\n exceptions = []\n if Matcher.temp:\n exceptions.append(ExpiredException)\n if Matcher.block:\n exceptions.append(StopPropagation)\n if exceptions:\n raise _ExceptionContainer(exceptions)\n\n\nasync def handle_event(bot: Bot, event: Event):\n log_msg = f\"<m>{bot.type.upper()} </m>| {event.self_id} [{event.name}]: \"\n if event.type == \"message\":\n log_msg += f\"Message {event.id} from \"\n log_msg += str(event.user_id)\n if event.detail_type == \"group\":\n log_msg += f\"@[\u7fa4:{event.group_id}]:\"\n\n log_msg += ' \"' + \"\".join(\n map(\n lambda x: escape_tag(str(x))\n if x.type == \"text\" else f\"<le>{escape_tag(str(x))}</le>\",\n event.message)) + '\"' # type: ignore\n elif event.type == \"notice\":\n log_msg += f\"Notice {event.raw_event}\"\n elif event.type == \"request\":\n log_msg += f\"Request {event.raw_event}\"\n elif event.type == \"meta_event\":\n log_msg += f\"MetaEvent {event.raw_event}\"\n logger.opt(colors=True).info(log_msg)\n\n coros = []\n state = {}\n for preprocessor in _event_preprocessors:\n coros.append(preprocessor(bot, event, state))\n if coros:\n try:\n logger.debug(\"Running PreProcessors...\")\n await asyncio.gather(*coros)\n except IgnoredException:\n logger.opt(\n colors=True).info(f\"Event {event.name} is <b>ignored</b>\")\n return\n\n # Trie Match\n _, _ = TrieRule.get_value(bot, event, state)\n\n break_flag = False\n for priority in sorted(matchers.keys()):\n if break_flag:\n break\n\n pending_tasks = [\n _run_matcher(matcher, bot, event, state.copy())\n for matcher in matchers[priority]\n ]\n\n logger.debug(f\"Checking for matchers in priority {priority}...\")\n results = await asyncio.gather(*pending_tasks, return_exceptions=True)\n\n i = 0\n for index, result in enumerate(results):\n if isinstance(result, _ExceptionContainer):\n e_list = result.exceptions\n if StopPropagation in e_list:\n if not break_flag:\n break_flag = True\n logger.debug(\"Stop event propagation\")\n if ExpiredException in e_list:\n logger.debug(\n f\"Matcher {matchers[priority][index - i]} will be removed.\"\n )\n del matchers[priority][index - i]\n i += 1\n", "path": "nonebot/message.py"}]}
| 3,849 | 641 |
gh_patches_debug_63640
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-3224
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Notitications was not showing followers, now it's not showing anything and the notification page shows "System error"
**Describe the bug**
The notification page is not working. When I see that there's a new notification (with a number close to the bell icon), I click on it. Then I get "System error"
<img width="672" alt="Screenshot 2024-01-05 at 10 30 20" src="https://github.com/bookwyrm-social/bookwyrm/assets/6791923/4cd46e03-6b50-4679-b8a0-61fdb50570a8">
<img width="456" alt="Screenshot 2024-01-05 at 10 30 08" src="https://github.com/bookwyrm-social/bookwyrm/assets/6791923/2130a984-9ed1-4a77-92b3-9dd63fa9c41f">
**Instance**
https://books.babb.no
**Additional context**
Before this happened, the notifications for new following requests were not showing on the list of notifications. A follow request would trigger the update on the number of new notifications, but the notification itself wasn't showing on the list of notifications
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/templatetags/utilities.py`
Content:
```
1 """ template filters for really common utilities """
2 import os
3 import re
4 from uuid import uuid4
5 from urllib.parse import urlparse
6 from django import template
7 from django.utils.safestring import mark_safe
8 from django.utils.translation import gettext_lazy as _
9 from django.templatetags.static import static
10
11 from bookwyrm.models import User
12 from bookwyrm.settings import INSTANCE_ACTOR_USERNAME
13
14 register = template.Library()
15
16
17 @register.filter(name="uuid")
18 def get_uuid(identifier):
19 """for avoiding clashing ids when there are many forms"""
20 return f"{identifier}{uuid4()}"
21
22
23 @register.simple_tag(takes_context=False)
24 def join(*args):
25 """concatenate an arbitrary set of values"""
26 return "_".join(str(a) for a in args)
27
28
29 @register.filter(name="username")
30 def get_user_identifier(user):
31 """use localname for local users, username for remote"""
32 return user.localname if user.localname else user.username
33
34
35 @register.filter(name="user_from_remote_id")
36 def get_user_identifier_from_remote_id(remote_id):
37 """get the local user id from their remote id"""
38 user = User.objects.get(remote_id=remote_id)
39 return user if user else None
40
41
42 @register.filter(name="book_title")
43 def get_title(book, too_short=5):
44 """display the subtitle if the title is short"""
45 if not book:
46 return ""
47 title = book.title
48 if len(title) <= too_short and book.subtitle:
49 title = _("%(title)s: %(subtitle)s") % {
50 "title": title,
51 "subtitle": book.subtitle,
52 }
53 return title
54
55
56 @register.simple_tag(takes_context=False)
57 def comparison_bool(str1, str2, reverse=False):
58 """idk why I need to write a tag for this, it returns a bool"""
59 if reverse:
60 return str1 != str2
61 return str1 == str2
62
63
64 @register.filter(is_safe=True)
65 def truncatepath(value, arg):
66 """Truncate a path by removing all directories except the first and truncating"""
67 path = os.path.normpath(value.name)
68 path_list = path.split(os.sep)
69 try:
70 length = int(arg)
71 except ValueError: # invalid literal for int()
72 return path_list[-1] # Fail silently.
73 return f"{path_list[0]}/…{path_list[-1][-length:]}"
74
75
76 @register.simple_tag(takes_context=False)
77 def get_book_cover_thumbnail(book, size="medium", ext="jpg"):
78 """Returns a book thumbnail at the specified size and extension,
79 with fallback if needed"""
80 if size == "":
81 size = "medium"
82 try:
83 cover_thumbnail = getattr(book, f"cover_bw_book_{size}_{ext}")
84 return cover_thumbnail.url
85 except OSError:
86 return static("images/no_cover.jpg")
87
88
89 @register.filter(name="get_isni_bio")
90 def get_isni_bio(existing, author):
91 """Returns the isni bio string if an existing author has an isni listed"""
92 auth_isni = re.sub(r"\D", "", str(author.isni))
93 if len(existing) == 0:
94 return ""
95 for value in existing:
96 if hasattr(value, "bio") and auth_isni == re.sub(r"\D", "", str(value.isni)):
97 return mark_safe(f"Author of <em>{value.bio}</em>")
98
99 return ""
100
101
102 # pylint: disable=unused-argument
103 @register.filter(name="get_isni", needs_autoescape=True)
104 def get_isni(existing, author, autoescape=True):
105 """Returns the isni ID if an existing author has an ISNI listing"""
106 auth_isni = re.sub(r"\D", "", str(author.isni))
107 if len(existing) == 0:
108 return ""
109 for value in existing:
110 if hasattr(value, "isni") and auth_isni == re.sub(r"\D", "", str(value.isni)):
111 isni = value.isni
112 return mark_safe(
113 f'<input type="text" name="isni-for-{author.id}" value="{isni}" hidden>'
114 )
115 return ""
116
117
118 @register.simple_tag(takes_context=False)
119 def id_to_username(user_id):
120 """given an arbitrary remote id, return the username"""
121 if user_id:
122 url = urlparse(user_id)
123 domain = url.netloc
124 parts = url.path.split("/")
125 name = parts[-1]
126 value = f"{name}@{domain}"
127
128 return value
129
130
131 @register.filter(name="get_file_size")
132 def get_file_size(file):
133 """display the size of a file in human readable terms"""
134
135 try:
136 raw_size = os.stat(file.path).st_size
137 if raw_size < 1024:
138 return f"{raw_size} bytes"
139 if raw_size < 1024**2:
140 return f"{raw_size/1024:.2f} KB"
141 if raw_size < 1024**3:
142 return f"{raw_size/1024**2:.2f} MB"
143 return f"{raw_size/1024**3:.2f} GB"
144 except Exception: # pylint: disable=broad-except
145 return ""
146
147
148 @register.filter(name="get_user_permission")
149 def get_user_permission(user):
150 """given a user, return their permission level"""
151
152 return user.groups.first() or "User"
153
154
155 @register.filter(name="is_instance_admin")
156 def is_instance_admin(localname):
157 """Returns a boolean indicating whether the user is the instance admin account"""
158 return localname == INSTANCE_ACTOR_USERNAME
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/templatetags/utilities.py b/bookwyrm/templatetags/utilities.py
--- a/bookwyrm/templatetags/utilities.py
+++ b/bookwyrm/templatetags/utilities.py
@@ -125,7 +125,8 @@
name = parts[-1]
value = f"{name}@{domain}"
- return value
+ return value
+ return "a new user account"
@register.filter(name="get_file_size")
|
{"golden_diff": "diff --git a/bookwyrm/templatetags/utilities.py b/bookwyrm/templatetags/utilities.py\n--- a/bookwyrm/templatetags/utilities.py\n+++ b/bookwyrm/templatetags/utilities.py\n@@ -125,7 +125,8 @@\n name = parts[-1]\n value = f\"{name}@{domain}\"\n \n- return value\n+ return value\n+ return \"a new user account\"\n \n \n @register.filter(name=\"get_file_size\")\n", "issue": "Notitications was not showing followers, now it's not showing anything and the notification page shows \"System error\"\n**Describe the bug**\r\nThe notification page is not working. When I see that there's a new notification (with a number close to the bell icon), I click on it. Then I get \"System error\" \r\n<img width=\"672\" alt=\"Screenshot 2024-01-05 at 10 30 20\" src=\"https://github.com/bookwyrm-social/bookwyrm/assets/6791923/4cd46e03-6b50-4679-b8a0-61fdb50570a8\">\r\n<img width=\"456\" alt=\"Screenshot 2024-01-05 at 10 30 08\" src=\"https://github.com/bookwyrm-social/bookwyrm/assets/6791923/2130a984-9ed1-4a77-92b3-9dd63fa9c41f\">\r\n\r\n**Instance**\r\n\r\nhttps://books.babb.no\r\n\r\n**Additional context**\r\nBefore this happened, the notifications for new following requests were not showing on the list of notifications. A follow request would trigger the update on the number of new notifications, but the notification itself wasn't showing on the list of notifications\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\" template filters for really common utilities \"\"\"\nimport os\nimport re\nfrom uuid import uuid4\nfrom urllib.parse import urlparse\nfrom django import template\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import gettext_lazy as _\nfrom django.templatetags.static import static\n\nfrom bookwyrm.models import User\nfrom bookwyrm.settings import INSTANCE_ACTOR_USERNAME\n\nregister = template.Library()\n\n\[email protected](name=\"uuid\")\ndef get_uuid(identifier):\n \"\"\"for avoiding clashing ids when there are many forms\"\"\"\n return f\"{identifier}{uuid4()}\"\n\n\[email protected]_tag(takes_context=False)\ndef join(*args):\n \"\"\"concatenate an arbitrary set of values\"\"\"\n return \"_\".join(str(a) for a in args)\n\n\[email protected](name=\"username\")\ndef get_user_identifier(user):\n \"\"\"use localname for local users, username for remote\"\"\"\n return user.localname if user.localname else user.username\n\n\[email protected](name=\"user_from_remote_id\")\ndef get_user_identifier_from_remote_id(remote_id):\n \"\"\"get the local user id from their remote id\"\"\"\n user = User.objects.get(remote_id=remote_id)\n return user if user else None\n\n\[email protected](name=\"book_title\")\ndef get_title(book, too_short=5):\n \"\"\"display the subtitle if the title is short\"\"\"\n if not book:\n return \"\"\n title = book.title\n if len(title) <= too_short and book.subtitle:\n title = _(\"%(title)s: %(subtitle)s\") % {\n \"title\": title,\n \"subtitle\": book.subtitle,\n }\n return title\n\n\[email protected]_tag(takes_context=False)\ndef comparison_bool(str1, str2, reverse=False):\n \"\"\"idk why I need to write a tag for this, it returns a bool\"\"\"\n if reverse:\n return str1 != str2\n return str1 == str2\n\n\[email protected](is_safe=True)\ndef truncatepath(value, arg):\n \"\"\"Truncate a path by removing all directories except the first and truncating\"\"\"\n path = os.path.normpath(value.name)\n path_list = path.split(os.sep)\n try:\n length = int(arg)\n except ValueError: # invalid literal for int()\n return path_list[-1] # Fail silently.\n return f\"{path_list[0]}/\u2026{path_list[-1][-length:]}\"\n\n\[email protected]_tag(takes_context=False)\ndef get_book_cover_thumbnail(book, size=\"medium\", ext=\"jpg\"):\n \"\"\"Returns a book thumbnail at the specified size and extension,\n with fallback if needed\"\"\"\n if size == \"\":\n size = \"medium\"\n try:\n cover_thumbnail = getattr(book, f\"cover_bw_book_{size}_{ext}\")\n return cover_thumbnail.url\n except OSError:\n return static(\"images/no_cover.jpg\")\n\n\[email protected](name=\"get_isni_bio\")\ndef get_isni_bio(existing, author):\n \"\"\"Returns the isni bio string if an existing author has an isni listed\"\"\"\n auth_isni = re.sub(r\"\\D\", \"\", str(author.isni))\n if len(existing) == 0:\n return \"\"\n for value in existing:\n if hasattr(value, \"bio\") and auth_isni == re.sub(r\"\\D\", \"\", str(value.isni)):\n return mark_safe(f\"Author of <em>{value.bio}</em>\")\n\n return \"\"\n\n\n# pylint: disable=unused-argument\[email protected](name=\"get_isni\", needs_autoescape=True)\ndef get_isni(existing, author, autoescape=True):\n \"\"\"Returns the isni ID if an existing author has an ISNI listing\"\"\"\n auth_isni = re.sub(r\"\\D\", \"\", str(author.isni))\n if len(existing) == 0:\n return \"\"\n for value in existing:\n if hasattr(value, \"isni\") and auth_isni == re.sub(r\"\\D\", \"\", str(value.isni)):\n isni = value.isni\n return mark_safe(\n f'<input type=\"text\" name=\"isni-for-{author.id}\" value=\"{isni}\" hidden>'\n )\n return \"\"\n\n\[email protected]_tag(takes_context=False)\ndef id_to_username(user_id):\n \"\"\"given an arbitrary remote id, return the username\"\"\"\n if user_id:\n url = urlparse(user_id)\n domain = url.netloc\n parts = url.path.split(\"/\")\n name = parts[-1]\n value = f\"{name}@{domain}\"\n\n return value\n\n\[email protected](name=\"get_file_size\")\ndef get_file_size(file):\n \"\"\"display the size of a file in human readable terms\"\"\"\n\n try:\n raw_size = os.stat(file.path).st_size\n if raw_size < 1024:\n return f\"{raw_size} bytes\"\n if raw_size < 1024**2:\n return f\"{raw_size/1024:.2f} KB\"\n if raw_size < 1024**3:\n return f\"{raw_size/1024**2:.2f} MB\"\n return f\"{raw_size/1024**3:.2f} GB\"\n except Exception: # pylint: disable=broad-except\n return \"\"\n\n\[email protected](name=\"get_user_permission\")\ndef get_user_permission(user):\n \"\"\"given a user, return their permission level\"\"\"\n\n return user.groups.first() or \"User\"\n\n\[email protected](name=\"is_instance_admin\")\ndef is_instance_admin(localname):\n \"\"\"Returns a boolean indicating whether the user is the instance admin account\"\"\"\n return localname == INSTANCE_ACTOR_USERNAME\n", "path": "bookwyrm/templatetags/utilities.py"}], "after_files": [{"content": "\"\"\" template filters for really common utilities \"\"\"\nimport os\nimport re\nfrom uuid import uuid4\nfrom urllib.parse import urlparse\nfrom django import template\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import gettext_lazy as _\nfrom django.templatetags.static import static\n\nfrom bookwyrm.models import User\nfrom bookwyrm.settings import INSTANCE_ACTOR_USERNAME\n\nregister = template.Library()\n\n\[email protected](name=\"uuid\")\ndef get_uuid(identifier):\n \"\"\"for avoiding clashing ids when there are many forms\"\"\"\n return f\"{identifier}{uuid4()}\"\n\n\[email protected]_tag(takes_context=False)\ndef join(*args):\n \"\"\"concatenate an arbitrary set of values\"\"\"\n return \"_\".join(str(a) for a in args)\n\n\[email protected](name=\"username\")\ndef get_user_identifier(user):\n \"\"\"use localname for local users, username for remote\"\"\"\n return user.localname if user.localname else user.username\n\n\[email protected](name=\"user_from_remote_id\")\ndef get_user_identifier_from_remote_id(remote_id):\n \"\"\"get the local user id from their remote id\"\"\"\n user = User.objects.get(remote_id=remote_id)\n return user if user else None\n\n\[email protected](name=\"book_title\")\ndef get_title(book, too_short=5):\n \"\"\"display the subtitle if the title is short\"\"\"\n if not book:\n return \"\"\n title = book.title\n if len(title) <= too_short and book.subtitle:\n title = _(\"%(title)s: %(subtitle)s\") % {\n \"title\": title,\n \"subtitle\": book.subtitle,\n }\n return title\n\n\[email protected]_tag(takes_context=False)\ndef comparison_bool(str1, str2, reverse=False):\n \"\"\"idk why I need to write a tag for this, it returns a bool\"\"\"\n if reverse:\n return str1 != str2\n return str1 == str2\n\n\[email protected](is_safe=True)\ndef truncatepath(value, arg):\n \"\"\"Truncate a path by removing all directories except the first and truncating\"\"\"\n path = os.path.normpath(value.name)\n path_list = path.split(os.sep)\n try:\n length = int(arg)\n except ValueError: # invalid literal for int()\n return path_list[-1] # Fail silently.\n return f\"{path_list[0]}/\u2026{path_list[-1][-length:]}\"\n\n\[email protected]_tag(takes_context=False)\ndef get_book_cover_thumbnail(book, size=\"medium\", ext=\"jpg\"):\n \"\"\"Returns a book thumbnail at the specified size and extension,\n with fallback if needed\"\"\"\n if size == \"\":\n size = \"medium\"\n try:\n cover_thumbnail = getattr(book, f\"cover_bw_book_{size}_{ext}\")\n return cover_thumbnail.url\n except OSError:\n return static(\"images/no_cover.jpg\")\n\n\[email protected](name=\"get_isni_bio\")\ndef get_isni_bio(existing, author):\n \"\"\"Returns the isni bio string if an existing author has an isni listed\"\"\"\n auth_isni = re.sub(r\"\\D\", \"\", str(author.isni))\n if len(existing) == 0:\n return \"\"\n for value in existing:\n if hasattr(value, \"bio\") and auth_isni == re.sub(r\"\\D\", \"\", str(value.isni)):\n return mark_safe(f\"Author of <em>{value.bio}</em>\")\n\n return \"\"\n\n\n# pylint: disable=unused-argument\[email protected](name=\"get_isni\", needs_autoescape=True)\ndef get_isni(existing, author, autoescape=True):\n \"\"\"Returns the isni ID if an existing author has an ISNI listing\"\"\"\n auth_isni = re.sub(r\"\\D\", \"\", str(author.isni))\n if len(existing) == 0:\n return \"\"\n for value in existing:\n if hasattr(value, \"isni\") and auth_isni == re.sub(r\"\\D\", \"\", str(value.isni)):\n isni = value.isni\n return mark_safe(\n f'<input type=\"text\" name=\"isni-for-{author.id}\" value=\"{isni}\" hidden>'\n )\n return \"\"\n\n\[email protected]_tag(takes_context=False)\ndef id_to_username(user_id):\n \"\"\"given an arbitrary remote id, return the username\"\"\"\n if user_id:\n url = urlparse(user_id)\n domain = url.netloc\n parts = url.path.split(\"/\")\n name = parts[-1]\n value = f\"{name}@{domain}\"\n\n return value\n return \"a new user account\"\n\n\[email protected](name=\"get_file_size\")\ndef get_file_size(file):\n \"\"\"display the size of a file in human readable terms\"\"\"\n\n try:\n raw_size = os.stat(file.path).st_size\n if raw_size < 1024:\n return f\"{raw_size} bytes\"\n if raw_size < 1024**2:\n return f\"{raw_size/1024:.2f} KB\"\n if raw_size < 1024**3:\n return f\"{raw_size/1024**2:.2f} MB\"\n return f\"{raw_size/1024**3:.2f} GB\"\n except Exception: # pylint: disable=broad-except\n return \"\"\n\n\[email protected](name=\"get_user_permission\")\ndef get_user_permission(user):\n \"\"\"given a user, return their permission level\"\"\"\n\n return user.groups.first() or \"User\"\n\n\[email protected](name=\"is_instance_admin\")\ndef is_instance_admin(localname):\n \"\"\"Returns a boolean indicating whether the user is the instance admin account\"\"\"\n return localname == INSTANCE_ACTOR_USERNAME\n", "path": "bookwyrm/templatetags/utilities.py"}]}
| 2,151 | 117 |
gh_patches_debug_25524
|
rasdani/github-patches
|
git_diff
|
ciudadanointeligente__votainteligente-portal-electoral-462
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Paso 3 que te aparezca el resultado de la pregunta del paso 2
<!---
@huboard:{"order":0.21846582396300857,"milestone_order":237}
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `popular_proposal/views.py`
Content:
```
1 from django.views.generic.edit import FormView, UpdateView
2 from popular_proposal.forms import (ProposalForm,
3 SubscriptionForm,
4 get_form_list,
5 AreaForm,
6 UpdateProposalForm,
7 ProposalFilterForm,
8 )
9 from django.core.urlresolvers import reverse
10 from django.shortcuts import get_object_or_404
11 from popolo.models import Area
12 from django.utils.decorators import method_decorator
13 from django.contrib.auth.decorators import login_required
14 from django.views.generic.base import TemplateView
15 from django.views.generic.detail import DetailView
16 from popular_proposal.models import (PopularProposal,
17 ProposalTemporaryData,
18 ProposalLike)
19 from django.shortcuts import render_to_response
20 from formtools.wizard.views import SessionWizardView
21 from collections import OrderedDict
22 from django.views.generic import View
23 from django.http import JsonResponse, HttpResponseNotFound
24 from django_filters.views import FilterView
25 from django.views.generic.list import ListView
26 from popular_proposal.forms import ProposalAreaFilterForm
27 from popular_proposal.filters import ProposalAreaFilter
28
29
30 class ProposalCreationView(FormView):
31 template_name = 'popular_proposal/create.html'
32 form_class = ProposalForm
33
34 @method_decorator(login_required)
35 def dispatch(self, *args, **kwargs):
36 self.area = get_object_or_404(Area, id=self.kwargs['slug'])
37 return super(ProposalCreationView, self).dispatch(*args, **kwargs)
38
39 def get_context_data(self, **kwargs):
40 kwargs = super(ProposalCreationView, self).get_context_data(**kwargs)
41 kwargs['area'] = self.area
42 return kwargs
43
44 def get_form_kwargs(self):
45 kwargs = super(ProposalCreationView, self).get_form_kwargs()
46 kwargs['proposer'] = self.request.user
47 kwargs['area'] = self.area
48 return kwargs
49
50 def form_valid(self, form):
51 form.save()
52 return super(ProposalCreationView, self).form_valid(form)
53
54 def get_success_url(self):
55 return reverse('popular_proposals:thanks', kwargs={'pk': self.area.id})
56
57
58 class ThanksForProposingView(TemplateView):
59 template_name = 'popular_proposal/thanks.html'
60
61 def dispatch(self, *args, **kwargs):
62 self.area = get_object_or_404(Area, id=self.kwargs['pk'])
63 return super(ThanksForProposingView, self).dispatch(*args, **kwargs)
64
65 def get_context_data(self, **kwargs):
66 kwargs = super(ThanksForProposingView, self).get_context_data(**kwargs)
67 kwargs['area'] = self.area
68 return kwargs
69
70
71 class SubscriptionView(FormView):
72 template_name = 'popular_proposal/new_subscription.html'
73 form_class = SubscriptionForm
74
75 @method_decorator(login_required)
76 def dispatch(self, *args, **kwargs):
77 self.proposal = get_object_or_404(PopularProposal, id=self.kwargs['pk'])
78 return super(SubscriptionView, self).dispatch(*args, **kwargs)
79
80 def get_form_kwargs(self):
81 kwargs = super(SubscriptionView, self).get_form_kwargs()
82 kwargs['user'] = self.request.user
83 kwargs['proposal'] = self.proposal
84 return kwargs
85
86 def get_context_data(self, **kwargs):
87 kwargs = super(SubscriptionView, self).get_context_data(**kwargs)
88 kwargs['proposal'] = self.proposal
89 return kwargs
90
91 def get_success_url(self):
92 return reverse('area', kwargs={'slug': self.proposal.area.id})
93
94 def form_valid(self, form):
95 form.subscribe()
96 return super(SubscriptionView, self).form_valid(form)
97
98
99 class HomeView(FilterView):
100 model = PopularProposal
101 template_name = 'popular_proposal/home.html'
102 layout = 'base.html'
103
104 def get_queryset(self):
105 qs = super(HomeView, self).get_queryset()
106 return qs
107
108 def get_context_data(self, **kwargs):
109 context = super(HomeView, self).get_context_data(**kwargs)
110 initial = self.request.GET
111 context['form'] = ProposalFilterForm(initial=initial)
112 context['layout'] = self.layout
113 return context
114
115 def get_context_object_name(self, object_list):
116 return 'popular_proposals'
117
118
119 class PopularProposalDetailView(DetailView):
120 model = PopularProposal
121 template_name = 'popular_proposal/detail.html'
122 context_object_name = 'popular_proposal'
123 layout = 'base.html'
124
125 def get_context_data(self, *args, **kwargs):
126 context = super(PopularProposalDetailView, self).get_context_data(*args, **kwargs)
127 context['layout'] = self.layout
128 return context
129
130
131 wizard_form_list = get_form_list()
132
133
134 class ProposalWizardBase(SessionWizardView):
135 form_list = wizard_form_list
136 template_name = 'popular_proposal/wizard/form_step.html'
137
138 def get_template_names(self):
139 form = self.get_form(step=self.steps.current)
140 template_name = getattr(form, 'template', self.template_name)
141 return template_name
142
143 def get_previous_forms(self):
144 return []
145
146 def get_form_list(self):
147 form_list = OrderedDict()
148 previous_forms = self.get_previous_forms()
149 my_list = previous_forms + get_form_list(user=self.request.user)
150 counter = 0
151 for form_class in my_list:
152 form_list[str(counter)] = form_class
153 counter += 1
154 self.form_list = form_list
155 return form_list
156
157
158 class ProposalWizard(ProposalWizardBase):
159 @method_decorator(login_required)
160 def dispatch(self, request, *args, **kwargs):
161 self.area = get_object_or_404(Area, id=self.kwargs['slug'])
162
163 return super(ProposalWizard, self).dispatch(request, *args, **kwargs)
164
165 def done(self, form_list, **kwargs):
166 data = {}
167 [data.update(form.cleaned_data) for form in form_list]
168 t_data = ProposalTemporaryData.objects.create(proposer=self.request.user,
169 area=self.area,
170 data=data)
171 t_data.notify_new()
172 return render_to_response('popular_proposal/wizard/done.html', {
173 'proposal': t_data,
174 'area': self.area
175 })
176
177 def get_context_data(self, form, **kwargs):
178 context = super(ProposalWizard, self).get_context_data(form, **kwargs)
179 context['area'] = self.area
180 context['preview_data'] = self.get_all_cleaned_data()
181 return context
182
183
184 full_wizard_form_list = [AreaForm, ] + wizard_form_list
185
186
187 class ProposalWizardFull(ProposalWizardBase):
188 form_list = full_wizard_form_list
189 template_name = 'popular_proposal/wizard/form_step.html'
190
191 @method_decorator(login_required)
192 def dispatch(self, request, *args, **kwargs):
193 return super(ProposalWizardFull, self).dispatch(request,
194 *args,
195 **kwargs)
196
197 def get_previous_forms(self):
198 return [AreaForm, ]
199
200 def done(self, form_list, **kwargs):
201 data = {}
202 [data.update(form.cleaned_data) for form in form_list]
203 area = data['area']
204 temporary_data = ProposalTemporaryData.objects.create(proposer=self.request.user,
205 area=area,
206 data=data)
207 return render_to_response('popular_proposal/wizard/done.html', {
208 'proposal': temporary_data,
209 'area': area
210 })
211
212
213 class PopularProposalUpdateView(UpdateView):
214 form_class = UpdateProposalForm
215 template_name = 'popular_proposal/update.html'
216 model = PopularProposal
217 context_object_name = 'popular_proposal'
218
219 @method_decorator(login_required)
220 def dispatch(self, request, *args, **kwargs):
221 return super(PopularProposalUpdateView, self).dispatch(request,
222 *args,
223 **kwargs)
224
225 def get_queryset(self):
226 qs = super(PopularProposalUpdateView, self).get_queryset()
227 qs = qs.filter(proposer=self.request.user)
228 return qs
229
230
231 class UnlikeProposalView(View):
232 def dispatch(self, request, *args, **kwargs):
233 if not self.request.user.is_authenticated():
234 return HttpResponseNotFound()
235 self.pk = self.kwargs.pop('pk')
236 self.like = get_object_or_404(ProposalLike,
237 pk=self.pk,
238 user=self.request.user)
239 return super(UnlikeProposalView, self).dispatch(request,
240 *args,
241 **kwargs)
242
243 def post(self, request, **kwargs):
244 self.like.delete()
245 return JsonResponse({'deleted_item': self.pk})
246
247
248 class ProposalsPerArea(ListView):
249 model = PopularProposal
250 layout = 'base.html'
251 template_name = 'popular_proposal/area.html'
252 context_object_name = 'popular_proposals'
253
254 def dispatch(self, request, *args, **kwargs):
255 self.area = get_object_or_404(Area, id=self.kwargs['slug'])
256 return super(ProposalsPerArea, self).dispatch(request, *args, **kwargs)
257
258 def get_context_data(self):
259 context = super(ProposalsPerArea, self).get_context_data()
260 context['layout'] = self.layout
261 initial = self.request.GET or None
262 context['form'] = ProposalAreaFilterForm(area=self.area,
263 initial=initial)
264 return context
265
266 def get_queryset(self):
267 kwargs = {'data': self.request.GET or None,
268 'area': self.area
269 }
270 filterset = ProposalAreaFilter(**kwargs)
271 return filterset
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/popular_proposal/views.py b/popular_proposal/views.py
--- a/popular_proposal/views.py
+++ b/popular_proposal/views.py
@@ -170,7 +170,7 @@
data=data)
t_data.notify_new()
return render_to_response('popular_proposal/wizard/done.html', {
- 'proposal': t_data,
+ 'popular_proposal': t_data,
'area': self.area
})
@@ -205,10 +205,19 @@
area=area,
data=data)
return render_to_response('popular_proposal/wizard/done.html', {
- 'proposal': temporary_data,
+ 'popular_proposal': temporary_data,
'area': area
})
+ def get_context_data(self, *args, **kwargs):
+ context = super(ProposalWizardFull, self).get_context_data(*args, **kwargs)
+ data = self.get_all_cleaned_data()
+ if 'area' in data:
+ context['area'] = data['area']
+ context['preview_data'] = self.get_all_cleaned_data()
+
+ return context
+
class PopularProposalUpdateView(UpdateView):
form_class = UpdateProposalForm
|
{"golden_diff": "diff --git a/popular_proposal/views.py b/popular_proposal/views.py\n--- a/popular_proposal/views.py\n+++ b/popular_proposal/views.py\n@@ -170,7 +170,7 @@\n data=data)\n t_data.notify_new()\n return render_to_response('popular_proposal/wizard/done.html', {\n- 'proposal': t_data,\n+ 'popular_proposal': t_data,\n 'area': self.area\n })\n \n@@ -205,10 +205,19 @@\n area=area,\n data=data)\n return render_to_response('popular_proposal/wizard/done.html', {\n- 'proposal': temporary_data,\n+ 'popular_proposal': temporary_data,\n 'area': area\n })\n \n+ def get_context_data(self, *args, **kwargs):\n+ context = super(ProposalWizardFull, self).get_context_data(*args, **kwargs)\n+ data = self.get_all_cleaned_data()\n+ if 'area' in data:\n+ context['area'] = data['area']\n+ context['preview_data'] = self.get_all_cleaned_data()\n+ \n+ return context\n+\n \n class PopularProposalUpdateView(UpdateView):\n form_class = UpdateProposalForm\n", "issue": "Paso 3 que te aparezca el resultado de la pregunta del paso 2\n<!---\n@huboard:{\"order\":0.21846582396300857,\"milestone_order\":237}\n-->\n\n", "before_files": [{"content": "from django.views.generic.edit import FormView, UpdateView\nfrom popular_proposal.forms import (ProposalForm,\n SubscriptionForm,\n get_form_list,\n AreaForm,\n UpdateProposalForm,\n ProposalFilterForm,\n )\nfrom django.core.urlresolvers import reverse\nfrom django.shortcuts import get_object_or_404\nfrom popolo.models import Area\nfrom django.utils.decorators import method_decorator\nfrom django.contrib.auth.decorators import login_required\nfrom django.views.generic.base import TemplateView\nfrom django.views.generic.detail import DetailView\nfrom popular_proposal.models import (PopularProposal,\n ProposalTemporaryData,\n ProposalLike)\nfrom django.shortcuts import render_to_response\nfrom formtools.wizard.views import SessionWizardView\nfrom collections import OrderedDict\nfrom django.views.generic import View\nfrom django.http import JsonResponse, HttpResponseNotFound\nfrom django_filters.views import FilterView\nfrom django.views.generic.list import ListView\nfrom popular_proposal.forms import ProposalAreaFilterForm\nfrom popular_proposal.filters import ProposalAreaFilter\n\n\nclass ProposalCreationView(FormView):\n template_name = 'popular_proposal/create.html'\n form_class = ProposalForm\n\n @method_decorator(login_required)\n def dispatch(self, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n return super(ProposalCreationView, self).dispatch(*args, **kwargs)\n\n def get_context_data(self, **kwargs):\n kwargs = super(ProposalCreationView, self).get_context_data(**kwargs)\n kwargs['area'] = self.area\n return kwargs\n\n def get_form_kwargs(self):\n kwargs = super(ProposalCreationView, self).get_form_kwargs()\n kwargs['proposer'] = self.request.user\n kwargs['area'] = self.area\n return kwargs\n\n def form_valid(self, form):\n form.save()\n return super(ProposalCreationView, self).form_valid(form)\n\n def get_success_url(self):\n return reverse('popular_proposals:thanks', kwargs={'pk': self.area.id})\n\n\nclass ThanksForProposingView(TemplateView):\n template_name = 'popular_proposal/thanks.html'\n\n def dispatch(self, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['pk'])\n return super(ThanksForProposingView, self).dispatch(*args, **kwargs)\n\n def get_context_data(self, **kwargs):\n kwargs = super(ThanksForProposingView, self).get_context_data(**kwargs)\n kwargs['area'] = self.area\n return kwargs\n\n\nclass SubscriptionView(FormView):\n template_name = 'popular_proposal/new_subscription.html'\n form_class = SubscriptionForm\n\n @method_decorator(login_required)\n def dispatch(self, *args, **kwargs):\n self.proposal = get_object_or_404(PopularProposal, id=self.kwargs['pk'])\n return super(SubscriptionView, self).dispatch(*args, **kwargs)\n\n def get_form_kwargs(self):\n kwargs = super(SubscriptionView, self).get_form_kwargs()\n kwargs['user'] = self.request.user\n kwargs['proposal'] = self.proposal\n return kwargs\n\n def get_context_data(self, **kwargs):\n kwargs = super(SubscriptionView, self).get_context_data(**kwargs)\n kwargs['proposal'] = self.proposal\n return kwargs\n\n def get_success_url(self):\n return reverse('area', kwargs={'slug': self.proposal.area.id})\n\n def form_valid(self, form):\n form.subscribe()\n return super(SubscriptionView, self).form_valid(form)\n\n\nclass HomeView(FilterView):\n model = PopularProposal\n template_name = 'popular_proposal/home.html'\n layout = 'base.html'\n\n def get_queryset(self):\n qs = super(HomeView, self).get_queryset()\n return qs\n\n def get_context_data(self, **kwargs):\n context = super(HomeView, self).get_context_data(**kwargs)\n initial = self.request.GET\n context['form'] = ProposalFilterForm(initial=initial)\n context['layout'] = self.layout\n return context\n\n def get_context_object_name(self, object_list):\n return 'popular_proposals'\n\n\nclass PopularProposalDetailView(DetailView):\n model = PopularProposal\n template_name = 'popular_proposal/detail.html'\n context_object_name = 'popular_proposal'\n layout = 'base.html'\n\n def get_context_data(self, *args, **kwargs):\n context = super(PopularProposalDetailView, self).get_context_data(*args, **kwargs)\n context['layout'] = self.layout\n return context\n\n\nwizard_form_list = get_form_list()\n\n\nclass ProposalWizardBase(SessionWizardView):\n form_list = wizard_form_list\n template_name = 'popular_proposal/wizard/form_step.html'\n\n def get_template_names(self):\n form = self.get_form(step=self.steps.current)\n template_name = getattr(form, 'template', self.template_name)\n return template_name\n\n def get_previous_forms(self):\n return []\n\n def get_form_list(self):\n form_list = OrderedDict()\n previous_forms = self.get_previous_forms()\n my_list = previous_forms + get_form_list(user=self.request.user)\n counter = 0\n for form_class in my_list:\n form_list[str(counter)] = form_class\n counter += 1\n self.form_list = form_list\n return form_list\n\n\nclass ProposalWizard(ProposalWizardBase):\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n\n return super(ProposalWizard, self).dispatch(request, *args, **kwargs)\n\n def done(self, form_list, **kwargs):\n data = {}\n [data.update(form.cleaned_data) for form in form_list]\n t_data = ProposalTemporaryData.objects.create(proposer=self.request.user,\n area=self.area,\n data=data)\n t_data.notify_new()\n return render_to_response('popular_proposal/wizard/done.html', {\n 'proposal': t_data,\n 'area': self.area\n })\n\n def get_context_data(self, form, **kwargs):\n context = super(ProposalWizard, self).get_context_data(form, **kwargs)\n context['area'] = self.area\n context['preview_data'] = self.get_all_cleaned_data()\n return context\n\n\nfull_wizard_form_list = [AreaForm, ] + wizard_form_list\n\n\nclass ProposalWizardFull(ProposalWizardBase):\n form_list = full_wizard_form_list\n template_name = 'popular_proposal/wizard/form_step.html'\n\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n return super(ProposalWizardFull, self).dispatch(request,\n *args,\n **kwargs)\n\n def get_previous_forms(self):\n return [AreaForm, ]\n\n def done(self, form_list, **kwargs):\n data = {}\n [data.update(form.cleaned_data) for form in form_list]\n area = data['area']\n temporary_data = ProposalTemporaryData.objects.create(proposer=self.request.user,\n area=area,\n data=data)\n return render_to_response('popular_proposal/wizard/done.html', {\n 'proposal': temporary_data,\n 'area': area\n })\n\n\nclass PopularProposalUpdateView(UpdateView):\n form_class = UpdateProposalForm\n template_name = 'popular_proposal/update.html'\n model = PopularProposal\n context_object_name = 'popular_proposal'\n\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n return super(PopularProposalUpdateView, self).dispatch(request,\n *args,\n **kwargs)\n\n def get_queryset(self):\n qs = super(PopularProposalUpdateView, self).get_queryset()\n qs = qs.filter(proposer=self.request.user)\n return qs\n\n\nclass UnlikeProposalView(View):\n def dispatch(self, request, *args, **kwargs):\n if not self.request.user.is_authenticated():\n return HttpResponseNotFound()\n self.pk = self.kwargs.pop('pk')\n self.like = get_object_or_404(ProposalLike,\n pk=self.pk,\n user=self.request.user)\n return super(UnlikeProposalView, self).dispatch(request,\n *args,\n **kwargs)\n\n def post(self, request, **kwargs):\n self.like.delete()\n return JsonResponse({'deleted_item': self.pk})\n\n\nclass ProposalsPerArea(ListView):\n model = PopularProposal\n layout = 'base.html'\n template_name = 'popular_proposal/area.html'\n context_object_name = 'popular_proposals'\n\n def dispatch(self, request, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n return super(ProposalsPerArea, self).dispatch(request, *args, **kwargs)\n\n def get_context_data(self):\n context = super(ProposalsPerArea, self).get_context_data()\n context['layout'] = self.layout\n initial = self.request.GET or None\n context['form'] = ProposalAreaFilterForm(area=self.area,\n initial=initial)\n return context\n\n def get_queryset(self):\n kwargs = {'data': self.request.GET or None,\n 'area': self.area\n }\n filterset = ProposalAreaFilter(**kwargs)\n return filterset", "path": "popular_proposal/views.py"}], "after_files": [{"content": "from django.views.generic.edit import FormView, UpdateView\nfrom popular_proposal.forms import (ProposalForm,\n SubscriptionForm,\n get_form_list,\n AreaForm,\n UpdateProposalForm,\n ProposalFilterForm,\n )\nfrom django.core.urlresolvers import reverse\nfrom django.shortcuts import get_object_or_404\nfrom popolo.models import Area\nfrom django.utils.decorators import method_decorator\nfrom django.contrib.auth.decorators import login_required\nfrom django.views.generic.base import TemplateView\nfrom django.views.generic.detail import DetailView\nfrom popular_proposal.models import (PopularProposal,\n ProposalTemporaryData,\n ProposalLike)\nfrom django.shortcuts import render_to_response\nfrom formtools.wizard.views import SessionWizardView\nfrom collections import OrderedDict\nfrom django.views.generic import View\nfrom django.http import JsonResponse, HttpResponseNotFound\nfrom django_filters.views import FilterView\nfrom django.views.generic.list import ListView\nfrom popular_proposal.forms import ProposalAreaFilterForm\nfrom popular_proposal.filters import ProposalAreaFilter\n\n\nclass ProposalCreationView(FormView):\n template_name = 'popular_proposal/create.html'\n form_class = ProposalForm\n\n @method_decorator(login_required)\n def dispatch(self, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n return super(ProposalCreationView, self).dispatch(*args, **kwargs)\n\n def get_context_data(self, **kwargs):\n kwargs = super(ProposalCreationView, self).get_context_data(**kwargs)\n kwargs['area'] = self.area\n return kwargs\n\n def get_form_kwargs(self):\n kwargs = super(ProposalCreationView, self).get_form_kwargs()\n kwargs['proposer'] = self.request.user\n kwargs['area'] = self.area\n return kwargs\n\n def form_valid(self, form):\n form.save()\n return super(ProposalCreationView, self).form_valid(form)\n\n def get_success_url(self):\n return reverse('popular_proposals:thanks', kwargs={'pk': self.area.id})\n\n\nclass ThanksForProposingView(TemplateView):\n template_name = 'popular_proposal/thanks.html'\n\n def dispatch(self, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['pk'])\n return super(ThanksForProposingView, self).dispatch(*args, **kwargs)\n\n def get_context_data(self, **kwargs):\n kwargs = super(ThanksForProposingView, self).get_context_data(**kwargs)\n kwargs['area'] = self.area\n return kwargs\n\n\nclass SubscriptionView(FormView):\n template_name = 'popular_proposal/new_subscription.html'\n form_class = SubscriptionForm\n\n @method_decorator(login_required)\n def dispatch(self, *args, **kwargs):\n self.proposal = get_object_or_404(PopularProposal, id=self.kwargs['pk'])\n return super(SubscriptionView, self).dispatch(*args, **kwargs)\n\n def get_form_kwargs(self):\n kwargs = super(SubscriptionView, self).get_form_kwargs()\n kwargs['user'] = self.request.user\n kwargs['proposal'] = self.proposal\n return kwargs\n\n def get_context_data(self, **kwargs):\n kwargs = super(SubscriptionView, self).get_context_data(**kwargs)\n kwargs['proposal'] = self.proposal\n return kwargs\n\n def get_success_url(self):\n return reverse('area', kwargs={'slug': self.proposal.area.id})\n\n def form_valid(self, form):\n form.subscribe()\n return super(SubscriptionView, self).form_valid(form)\n\n\nclass HomeView(FilterView):\n model = PopularProposal\n template_name = 'popular_proposal/home.html'\n layout = 'base.html'\n\n def get_queryset(self):\n qs = super(HomeView, self).get_queryset()\n return qs\n\n def get_context_data(self, **kwargs):\n context = super(HomeView, self).get_context_data(**kwargs)\n initial = self.request.GET\n context['form'] = ProposalFilterForm(initial=initial)\n context['layout'] = self.layout\n return context\n\n def get_context_object_name(self, object_list):\n return 'popular_proposals'\n\n\nclass PopularProposalDetailView(DetailView):\n model = PopularProposal\n template_name = 'popular_proposal/detail.html'\n context_object_name = 'popular_proposal'\n layout = 'base.html'\n\n def get_context_data(self, *args, **kwargs):\n context = super(PopularProposalDetailView, self).get_context_data(*args, **kwargs)\n context['layout'] = self.layout\n return context\n\n\nwizard_form_list = get_form_list()\n\n\nclass ProposalWizardBase(SessionWizardView):\n form_list = wizard_form_list\n template_name = 'popular_proposal/wizard/form_step.html'\n\n def get_template_names(self):\n form = self.get_form(step=self.steps.current)\n template_name = getattr(form, 'template', self.template_name)\n return template_name\n\n def get_previous_forms(self):\n return []\n\n def get_form_list(self):\n form_list = OrderedDict()\n previous_forms = self.get_previous_forms()\n my_list = previous_forms + get_form_list(user=self.request.user)\n counter = 0\n for form_class in my_list:\n form_list[str(counter)] = form_class\n counter += 1\n self.form_list = form_list\n return form_list\n\n\nclass ProposalWizard(ProposalWizardBase):\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n\n return super(ProposalWizard, self).dispatch(request, *args, **kwargs)\n\n def done(self, form_list, **kwargs):\n data = {}\n [data.update(form.cleaned_data) for form in form_list]\n t_data = ProposalTemporaryData.objects.create(proposer=self.request.user,\n area=self.area,\n data=data)\n t_data.notify_new()\n return render_to_response('popular_proposal/wizard/done.html', {\n 'popular_proposal': t_data,\n 'area': self.area\n })\n\n def get_context_data(self, form, **kwargs):\n context = super(ProposalWizard, self).get_context_data(form, **kwargs)\n context['area'] = self.area\n context['preview_data'] = self.get_all_cleaned_data()\n return context\n\n\nfull_wizard_form_list = [AreaForm, ] + wizard_form_list\n\n\nclass ProposalWizardFull(ProposalWizardBase):\n form_list = full_wizard_form_list\n template_name = 'popular_proposal/wizard/form_step.html'\n\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n return super(ProposalWizardFull, self).dispatch(request,\n *args,\n **kwargs)\n\n def get_previous_forms(self):\n return [AreaForm, ]\n\n def done(self, form_list, **kwargs):\n data = {}\n [data.update(form.cleaned_data) for form in form_list]\n area = data['area']\n temporary_data = ProposalTemporaryData.objects.create(proposer=self.request.user,\n area=area,\n data=data)\n return render_to_response('popular_proposal/wizard/done.html', {\n 'popular_proposal': temporary_data,\n 'area': area\n })\n\n def get_context_data(self, *args, **kwargs):\n context = super(ProposalWizardFull, self).get_context_data(*args, **kwargs)\n data = self.get_all_cleaned_data()\n if 'area' in data:\n context['area'] = data['area']\n context['preview_data'] = self.get_all_cleaned_data()\n \n return context\n\n\nclass PopularProposalUpdateView(UpdateView):\n form_class = UpdateProposalForm\n template_name = 'popular_proposal/update.html'\n model = PopularProposal\n context_object_name = 'popular_proposal'\n\n @method_decorator(login_required)\n def dispatch(self, request, *args, **kwargs):\n return super(PopularProposalUpdateView, self).dispatch(request,\n *args,\n **kwargs)\n\n def get_queryset(self):\n qs = super(PopularProposalUpdateView, self).get_queryset()\n qs = qs.filter(proposer=self.request.user)\n return qs\n\n\nclass UnlikeProposalView(View):\n def dispatch(self, request, *args, **kwargs):\n if not self.request.user.is_authenticated():\n return HttpResponseNotFound()\n self.pk = self.kwargs.pop('pk')\n self.like = get_object_or_404(ProposalLike,\n pk=self.pk,\n user=self.request.user)\n return super(UnlikeProposalView, self).dispatch(request,\n *args,\n **kwargs)\n\n def post(self, request, **kwargs):\n self.like.delete()\n return JsonResponse({'deleted_item': self.pk})\n\n\nclass ProposalsPerArea(ListView):\n model = PopularProposal\n layout = 'base.html'\n template_name = 'popular_proposal/area.html'\n context_object_name = 'popular_proposals'\n\n def dispatch(self, request, *args, **kwargs):\n self.area = get_object_or_404(Area, id=self.kwargs['slug'])\n return super(ProposalsPerArea, self).dispatch(request, *args, **kwargs)\n\n def get_context_data(self):\n context = super(ProposalsPerArea, self).get_context_data()\n context['layout'] = self.layout\n initial = self.request.GET or None\n context['form'] = ProposalAreaFilterForm(area=self.area,\n initial=initial)\n return context\n\n def get_queryset(self):\n kwargs = {'data': self.request.GET or None,\n 'area': self.area\n }\n filterset = ProposalAreaFilter(**kwargs)\n return filterset", "path": "popular_proposal/views.py"}]}
| 3,064 | 279 |
gh_patches_debug_16361
|
rasdani/github-patches
|
git_diff
|
benoitc__gunicorn-3083
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Version 21.0.1 or higher breaks with python 3.5
I am currently running an older application with Python 3.5, and I encountered an error when attempting to update the Gunicorn version to the latest one:
```
NameError: name 'ModuleNotFoundError' is not defined
```
After some investigation, I realized that the 'ModuleNotFoundError' is only available for Python 3.6 or higher. My suspicion is that this bug was introduced in [this commit](https://github.com/benoitc/gunicorn/commit/f628dd9730f965b1917397ea1846c68844b1fe7a).
As a result, it seems that Gunicorn is not fully compatible with Python 3.5
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -
2 #
3 # This file is part of gunicorn released under the MIT license.
4 # See the NOTICE for more information.
5
6 import os
7 import sys
8
9 from setuptools import setup, find_packages
10 from setuptools.command.test import test as TestCommand
11
12 from gunicorn import __version__
13
14
15 CLASSIFIERS = [
16 'Development Status :: 5 - Production/Stable',
17 'Environment :: Other Environment',
18 'Intended Audience :: Developers',
19 'License :: OSI Approved :: MIT License',
20 'Operating System :: MacOS :: MacOS X',
21 'Operating System :: POSIX',
22 'Programming Language :: Python',
23 'Programming Language :: Python :: 3',
24 'Programming Language :: Python :: 3.5',
25 'Programming Language :: Python :: 3.6',
26 'Programming Language :: Python :: 3.7',
27 'Programming Language :: Python :: 3.8',
28 'Programming Language :: Python :: 3.9',
29 'Programming Language :: Python :: 3.10',
30 'Programming Language :: Python :: 3.11',
31 'Programming Language :: Python :: 3 :: Only',
32 'Programming Language :: Python :: Implementation :: CPython',
33 'Programming Language :: Python :: Implementation :: PyPy',
34 'Topic :: Internet',
35 'Topic :: Utilities',
36 'Topic :: Software Development :: Libraries :: Python Modules',
37 'Topic :: Internet :: WWW/HTTP',
38 'Topic :: Internet :: WWW/HTTP :: WSGI',
39 'Topic :: Internet :: WWW/HTTP :: WSGI :: Server',
40 'Topic :: Internet :: WWW/HTTP :: Dynamic Content']
41
42 # read long description
43 with open(os.path.join(os.path.dirname(__file__), 'README.rst')) as f:
44 long_description = f.read()
45
46 # read dev requirements
47 fname = os.path.join(os.path.dirname(__file__), 'requirements_test.txt')
48 with open(fname) as f:
49 tests_require = [l.strip() for l in f.readlines()]
50
51 class PyTestCommand(TestCommand):
52 user_options = [
53 ("cov", None, "measure coverage")
54 ]
55
56 def initialize_options(self):
57 TestCommand.initialize_options(self)
58 self.cov = None
59
60 def finalize_options(self):
61 TestCommand.finalize_options(self)
62 self.test_args = ['tests']
63 if self.cov:
64 self.test_args += ['--cov', 'gunicorn']
65 self.test_suite = True
66
67 def run_tests(self):
68 import pytest
69 errno = pytest.main(self.test_args)
70 sys.exit(errno)
71
72
73 install_requires = [
74 'importlib_metadata; python_version<"3.8"',
75 'packaging',
76 ]
77
78 extras_require = {
79 'gevent': ['gevent>=1.4.0'],
80 'eventlet': ['eventlet>=0.24.1'],
81 'tornado': ['tornado>=0.2'],
82 'gthread': [],
83 'setproctitle': ['setproctitle'],
84 }
85
86 setup(
87 name='gunicorn',
88 version=__version__,
89
90 description='WSGI HTTP Server for UNIX',
91 long_description=long_description,
92 author='Benoit Chesneau',
93 author_email='[email protected]',
94 license='MIT',
95 url='https://gunicorn.org',
96 project_urls={
97 'Documentation': 'https://docs.gunicorn.org',
98 'Homepage': 'https://gunicorn.org',
99 'Issue tracker': 'https://github.com/benoitc/gunicorn/issues',
100 'Source code': 'https://github.com/benoitc/gunicorn',
101 },
102
103 python_requires='>=3.5',
104 install_requires=install_requires,
105 classifiers=CLASSIFIERS,
106 zip_safe=False,
107 packages=find_packages(exclude=['examples', 'tests']),
108 include_package_data=True,
109
110 tests_require=tests_require,
111 cmdclass={'test': PyTestCommand},
112
113 entry_points="""
114 [console_scripts]
115 gunicorn=gunicorn.app.wsgiapp:run
116
117 [paste.server_runner]
118 main=gunicorn.app.pasterapp:serve
119 """,
120 extras_require=extras_require,
121 )
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,8 +21,6 @@
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
- 'Programming Language :: Python :: 3.5',
- 'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: 3.9',
@@ -100,7 +98,7 @@
'Source code': 'https://github.com/benoitc/gunicorn',
},
- python_requires='>=3.5',
+ python_requires='>=3.7',
install_requires=install_requires,
classifiers=CLASSIFIERS,
zip_safe=False,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,8 +21,6 @@\n 'Operating System :: POSIX',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n- 'Programming Language :: Python :: 3.5',\n- 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n@@ -100,7 +98,7 @@\n 'Source code': 'https://github.com/benoitc/gunicorn',\n },\n \n- python_requires='>=3.5',\n+ python_requires='>=3.7',\n install_requires=install_requires,\n classifiers=CLASSIFIERS,\n zip_safe=False,\n", "issue": "Version 21.0.1 or higher breaks with python 3.5\nI am currently running an older application with Python 3.5, and I encountered an error when attempting to update the Gunicorn version to the latest one:\r\n\r\n```\r\nNameError: name 'ModuleNotFoundError' is not defined\r\n```\r\n\r\nAfter some investigation, I realized that the 'ModuleNotFoundError' is only available for Python 3.6 or higher. My suspicion is that this bug was introduced in [this commit](https://github.com/benoitc/gunicorn/commit/f628dd9730f965b1917397ea1846c68844b1fe7a).\r\n\r\nAs a result, it seems that Gunicorn is not fully compatible with Python 3.5\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\nfrom setuptools.command.test import test as TestCommand\n\nfrom gunicorn import __version__\n\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Other Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Programming Language :: Python :: 3 :: Only',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Internet',\n 'Topic :: Utilities',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Internet :: WWW/HTTP :: WSGI',\n 'Topic :: Internet :: WWW/HTTP :: WSGI :: Server',\n 'Topic :: Internet :: WWW/HTTP :: Dynamic Content']\n\n# read long description\nwith open(os.path.join(os.path.dirname(__file__), 'README.rst')) as f:\n long_description = f.read()\n\n# read dev requirements\nfname = os.path.join(os.path.dirname(__file__), 'requirements_test.txt')\nwith open(fname) as f:\n tests_require = [l.strip() for l in f.readlines()]\n\nclass PyTestCommand(TestCommand):\n user_options = [\n (\"cov\", None, \"measure coverage\")\n ]\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.cov = None\n\n def finalize_options(self):\n TestCommand.finalize_options(self)\n self.test_args = ['tests']\n if self.cov:\n self.test_args += ['--cov', 'gunicorn']\n self.test_suite = True\n\n def run_tests(self):\n import pytest\n errno = pytest.main(self.test_args)\n sys.exit(errno)\n\n\ninstall_requires = [\n 'importlib_metadata; python_version<\"3.8\"',\n 'packaging',\n]\n\nextras_require = {\n 'gevent': ['gevent>=1.4.0'],\n 'eventlet': ['eventlet>=0.24.1'],\n 'tornado': ['tornado>=0.2'],\n 'gthread': [],\n 'setproctitle': ['setproctitle'],\n}\n\nsetup(\n name='gunicorn',\n version=__version__,\n\n description='WSGI HTTP Server for UNIX',\n long_description=long_description,\n author='Benoit Chesneau',\n author_email='[email protected]',\n license='MIT',\n url='https://gunicorn.org',\n project_urls={\n 'Documentation': 'https://docs.gunicorn.org',\n 'Homepage': 'https://gunicorn.org',\n 'Issue tracker': 'https://github.com/benoitc/gunicorn/issues',\n 'Source code': 'https://github.com/benoitc/gunicorn',\n },\n\n python_requires='>=3.5',\n install_requires=install_requires,\n classifiers=CLASSIFIERS,\n zip_safe=False,\n packages=find_packages(exclude=['examples', 'tests']),\n include_package_data=True,\n\n tests_require=tests_require,\n cmdclass={'test': PyTestCommand},\n\n entry_points=\"\"\"\n [console_scripts]\n gunicorn=gunicorn.app.wsgiapp:run\n\n [paste.server_runner]\n main=gunicorn.app.pasterapp:serve\n \"\"\",\n extras_require=extras_require,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\nfrom setuptools.command.test import test as TestCommand\n\nfrom gunicorn import __version__\n\n\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Other Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Programming Language :: Python :: 3 :: Only',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Internet',\n 'Topic :: Utilities',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Internet :: WWW/HTTP :: WSGI',\n 'Topic :: Internet :: WWW/HTTP :: WSGI :: Server',\n 'Topic :: Internet :: WWW/HTTP :: Dynamic Content']\n\n# read long description\nwith open(os.path.join(os.path.dirname(__file__), 'README.rst')) as f:\n long_description = f.read()\n\n# read dev requirements\nfname = os.path.join(os.path.dirname(__file__), 'requirements_test.txt')\nwith open(fname) as f:\n tests_require = [l.strip() for l in f.readlines()]\n\nclass PyTestCommand(TestCommand):\n user_options = [\n (\"cov\", None, \"measure coverage\")\n ]\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.cov = None\n\n def finalize_options(self):\n TestCommand.finalize_options(self)\n self.test_args = ['tests']\n if self.cov:\n self.test_args += ['--cov', 'gunicorn']\n self.test_suite = True\n\n def run_tests(self):\n import pytest\n errno = pytest.main(self.test_args)\n sys.exit(errno)\n\n\ninstall_requires = [\n 'importlib_metadata; python_version<\"3.8\"',\n 'packaging',\n]\n\nextras_require = {\n 'gevent': ['gevent>=1.4.0'],\n 'eventlet': ['eventlet>=0.24.1'],\n 'tornado': ['tornado>=0.2'],\n 'gthread': [],\n 'setproctitle': ['setproctitle'],\n}\n\nsetup(\n name='gunicorn',\n version=__version__,\n\n description='WSGI HTTP Server for UNIX',\n long_description=long_description,\n author='Benoit Chesneau',\n author_email='[email protected]',\n license='MIT',\n url='https://gunicorn.org',\n project_urls={\n 'Documentation': 'https://docs.gunicorn.org',\n 'Homepage': 'https://gunicorn.org',\n 'Issue tracker': 'https://github.com/benoitc/gunicorn/issues',\n 'Source code': 'https://github.com/benoitc/gunicorn',\n },\n\n python_requires='>=3.7',\n install_requires=install_requires,\n classifiers=CLASSIFIERS,\n zip_safe=False,\n packages=find_packages(exclude=['examples', 'tests']),\n include_package_data=True,\n\n tests_require=tests_require,\n cmdclass={'test': PyTestCommand},\n\n entry_points=\"\"\"\n [console_scripts]\n gunicorn=gunicorn.app.wsgiapp:run\n\n [paste.server_runner]\n main=gunicorn.app.pasterapp:serve\n \"\"\",\n extras_require=extras_require,\n)\n", "path": "setup.py"}]}
| 1,568 | 190 |
gh_patches_debug_26238
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-2787
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support (non-legacy) SQL nested data types
`STRUCT<t>` and `ARRAY<t>` seem to be the types.
See #2342. h/t to @c0b for filing.
---
From #2585: [Sample app that reproduces this](https://github.com/GoogleCloudPlatform/python-docs-samples/blob/176f161cae3d4f01b01456a6e403faf6645414a1/bigquery/cloud-client/simple_app.py)
Stacktrace:
``` python
Traceback (most recent call last):
File "simple_app.py", line 57, in <module>
query_shakespeare()
File "simple_app.py", line 47, in query_shakespeare
page_token=page_token)
File "lib/python2.7/site-packages/google/cloud/bigquery/query.py", line 401, in fetch_data
rows_data = _rows_from_json(response.get('rows', ()), self.schema)
File "lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py", line 98, in _rows_from_json
for item in cell['v']])
File "lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py", line 61, in _record_from_json
for subfield, cell in zip(field.fields, value['f']):
KeyError: 'f'
```
---
Stepping into the debugger:
``` python
ipdb> value
{u'v': {u'f': [{u'v': u'hamlet'}, {u'v': u'5318'}]}}
ipdb> field.__dict__
{'field_type': u'RECORD', 'description': None, 'name': u'title', 'fields': [<google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227550>, <google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227690>], 'mode': u'REPEATED'}
```
(Added by @dhermes)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bigquery/google/cloud/bigquery/_helpers.py`
Content:
```
1 # Copyright 2015 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Shared helper functions for BigQuery API classes."""
16
17 from google.cloud._helpers import _datetime_from_microseconds
18 from google.cloud._helpers import _date_from_iso8601_date
19
20
21 def _not_null(value, field):
22 """Check whether 'value' should be coerced to 'field' type."""
23 return value is not None or field.mode != 'NULLABLE'
24
25
26 def _int_from_json(value, field):
27 """Coerce 'value' to an int, if set or not nullable."""
28 if _not_null(value, field):
29 return int(value)
30
31
32 def _float_from_json(value, field):
33 """Coerce 'value' to a float, if set or not nullable."""
34 if _not_null(value, field):
35 return float(value)
36
37
38 def _bool_from_json(value, field):
39 """Coerce 'value' to a bool, if set or not nullable."""
40 if _not_null(value, field):
41 return value.lower() in ['t', 'true', '1']
42
43
44 def _datetime_from_json(value, field):
45 """Coerce 'value' to a datetime, if set or not nullable."""
46 if _not_null(value, field):
47 # value will be a float in seconds, to microsecond precision, in UTC.
48 return _datetime_from_microseconds(1e6 * float(value))
49
50
51 def _date_from_json(value, field):
52 """Coerce 'value' to a datetime date, if set or not nullable"""
53 if _not_null(value, field):
54 return _date_from_iso8601_date(value)
55
56
57 def _record_from_json(value, field):
58 """Coerce 'value' to a mapping, if set or not nullable."""
59 if _not_null(value, field):
60 record = {}
61 for subfield, cell in zip(field.fields, value['f']):
62 converter = _CELLDATA_FROM_JSON[subfield.field_type]
63 if field.mode == 'REPEATED':
64 value = [converter(item, subfield) for item in cell['v']]
65 else:
66 value = converter(cell['v'], subfield)
67 record[subfield.name] = value
68 return record
69
70
71 def _string_from_json(value, _):
72 """NOOP string -> string coercion"""
73 return value
74
75
76 _CELLDATA_FROM_JSON = {
77 'INTEGER': _int_from_json,
78 'INT64': _int_from_json,
79 'FLOAT': _float_from_json,
80 'FLOAT64': _float_from_json,
81 'BOOLEAN': _bool_from_json,
82 'BOOL': _bool_from_json,
83 'TIMESTAMP': _datetime_from_json,
84 'DATE': _date_from_json,
85 'RECORD': _record_from_json,
86 'STRING': _string_from_json,
87 }
88
89
90 def _row_from_json(row, schema):
91 """Convert JSON row data to row with appropriate types.
92
93 :type row: dict
94 :param row: A JSON response row to be converted.
95
96 :type schema: tuple
97 :param schema: A tuple of
98 :class:`~google.cloud.bigquery.schema.SchemaField`.
99
100 :rtype: tuple
101 :returns: A tuple of data converted to native types.
102 """
103 row_data = []
104 for field, cell in zip(schema, row['f']):
105 converter = _CELLDATA_FROM_JSON[field.field_type]
106 if field.mode == 'REPEATED':
107 row_data.append([converter(item, field)
108 for item in cell['v']])
109 else:
110 row_data.append(converter(cell['v'], field))
111
112 return tuple(row_data)
113
114
115 def _rows_from_json(rows, schema):
116 """Convert JSON row data to rows with appropriate types."""
117 return [_row_from_json(row, schema) for row in rows]
118
119
120 class _ConfigurationProperty(object):
121 """Base property implementation.
122
123 Values will be stored on a `_configuration` helper attribute of the
124 property's job instance.
125
126 :type name: str
127 :param name: name of the property
128 """
129
130 def __init__(self, name):
131 self.name = name
132 self._backing_name = '_%s' % (self.name,)
133
134 def __get__(self, instance, owner):
135 """Descriptor protocal: accesstor"""
136 if instance is None:
137 return self
138 return getattr(instance._configuration, self._backing_name)
139
140 def _validate(self, value):
141 """Subclasses override to impose validation policy."""
142 pass
143
144 def __set__(self, instance, value):
145 """Descriptor protocal: mutator"""
146 self._validate(value)
147 setattr(instance._configuration, self._backing_name, value)
148
149 def __delete__(self, instance):
150 """Descriptor protocal: deleter"""
151 delattr(instance._configuration, self._backing_name)
152
153
154 class _TypedProperty(_ConfigurationProperty):
155 """Property implementation: validates based on value type.
156
157 :type name: str
158 :param name: name of the property
159
160 :type property_type: type or sequence of types
161 :param property_type: type to be validated
162 """
163 def __init__(self, name, property_type):
164 super(_TypedProperty, self).__init__(name)
165 self.property_type = property_type
166
167 def _validate(self, value):
168 """Ensure that 'value' is of the appropriate type.
169
170 :raises: ValueError on a type mismatch.
171 """
172 if not isinstance(value, self.property_type):
173 raise ValueError('Required type: %s' % (self.property_type,))
174
175
176 class _EnumProperty(_ConfigurationProperty):
177 """Pseudo-enumeration class.
178
179 Subclasses must define ``ALLOWED`` as a class-level constant: it must
180 be a sequence of strings.
181
182 :type name: str
183 :param name: name of the property.
184 """
185 def _validate(self, value):
186 """Check that ``value`` is one of the allowed values.
187
188 :raises: ValueError if value is not allowed.
189 """
190 if value not in self.ALLOWED:
191 raise ValueError('Pass one of: %s' ', '.join(self.ALLOWED))
192
193
194 class UDFResource(object):
195 """Describe a single user-defined function (UDF) resource.
196
197 :type udf_type: str
198 :param udf_type: the type of the resource ('inlineCode' or 'resourceUri')
199
200 :type value: str
201 :param value: the inline code or resource URI.
202
203 See
204 https://cloud.google.com/bigquery/user-defined-functions#api
205 """
206 def __init__(self, udf_type, value):
207 self.udf_type = udf_type
208 self.value = value
209
210 def __eq__(self, other):
211 return(
212 self.udf_type == other.udf_type and
213 self.value == other.value)
214
215
216 class UDFResourcesProperty(object):
217 """Custom property type, holding :class:`UDFResource` instances."""
218
219 def __get__(self, instance, owner):
220 """Descriptor protocol: accessor"""
221 if instance is None:
222 return self
223 return list(instance._udf_resources)
224
225 def __set__(self, instance, value):
226 """Descriptor protocol: mutator"""
227 if not all(isinstance(u, UDFResource) for u in value):
228 raise ValueError("udf items must be UDFResource")
229 instance._udf_resources = tuple(value)
230
231
232 def _build_udf_resources(resources):
233 """
234 :type resources: sequence of :class:`UDFResource`
235 :param resources: fields to be appended.
236
237 :rtype: mapping
238 :returns: a mapping describing userDefinedFunctionResources for the query.
239 """
240 udfs = []
241 for resource in resources:
242 udf = {resource.udf_type: resource.value}
243 udfs.append(udf)
244 return udfs
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bigquery/google/cloud/bigquery/_helpers.py b/bigquery/google/cloud/bigquery/_helpers.py
--- a/bigquery/google/cloud/bigquery/_helpers.py
+++ b/bigquery/google/cloud/bigquery/_helpers.py
@@ -58,10 +58,11 @@
"""Coerce 'value' to a mapping, if set or not nullable."""
if _not_null(value, field):
record = {}
- for subfield, cell in zip(field.fields, value['f']):
+ record_iter = zip(field.fields, value['f'])
+ for subfield, cell in record_iter:
converter = _CELLDATA_FROM_JSON[subfield.field_type]
- if field.mode == 'REPEATED':
- value = [converter(item, subfield) for item in cell['v']]
+ if subfield.mode == 'REPEATED':
+ value = [converter(item['v'], subfield) for item in cell['v']]
else:
value = converter(cell['v'], subfield)
record[subfield.name] = value
@@ -103,7 +104,7 @@
for field, cell in zip(schema, row['f']):
converter = _CELLDATA_FROM_JSON[field.field_type]
if field.mode == 'REPEATED':
- row_data.append([converter(item, field)
+ row_data.append([converter(item['v'], field)
for item in cell['v']])
else:
row_data.append(converter(cell['v'], field))
|
{"golden_diff": "diff --git a/bigquery/google/cloud/bigquery/_helpers.py b/bigquery/google/cloud/bigquery/_helpers.py\n--- a/bigquery/google/cloud/bigquery/_helpers.py\n+++ b/bigquery/google/cloud/bigquery/_helpers.py\n@@ -58,10 +58,11 @@\n \"\"\"Coerce 'value' to a mapping, if set or not nullable.\"\"\"\n if _not_null(value, field):\n record = {}\n- for subfield, cell in zip(field.fields, value['f']):\n+ record_iter = zip(field.fields, value['f'])\n+ for subfield, cell in record_iter:\n converter = _CELLDATA_FROM_JSON[subfield.field_type]\n- if field.mode == 'REPEATED':\n- value = [converter(item, subfield) for item in cell['v']]\n+ if subfield.mode == 'REPEATED':\n+ value = [converter(item['v'], subfield) for item in cell['v']]\n else:\n value = converter(cell['v'], subfield)\n record[subfield.name] = value\n@@ -103,7 +104,7 @@\n for field, cell in zip(schema, row['f']):\n converter = _CELLDATA_FROM_JSON[field.field_type]\n if field.mode == 'REPEATED':\n- row_data.append([converter(item, field)\n+ row_data.append([converter(item['v'], field)\n for item in cell['v']])\n else:\n row_data.append(converter(cell['v'], field))\n", "issue": "Support (non-legacy) SQL nested data types\n`STRUCT<t>` and `ARRAY<t>` seem to be the types.\n\nSee #2342. h/t to @c0b for filing.\n\n---\n\nFrom #2585: [Sample app that reproduces this](https://github.com/GoogleCloudPlatform/python-docs-samples/blob/176f161cae3d4f01b01456a6e403faf6645414a1/bigquery/cloud-client/simple_app.py)\n\nStacktrace:\n\n``` python\nTraceback (most recent call last):\n File \"simple_app.py\", line 57, in <module>\n query_shakespeare()\n File \"simple_app.py\", line 47, in query_shakespeare\n page_token=page_token)\n File \"lib/python2.7/site-packages/google/cloud/bigquery/query.py\", line 401, in fetch_data\n rows_data = _rows_from_json(response.get('rows', ()), self.schema)\n File \"lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py\", line 98, in _rows_from_json\n for item in cell['v']])\n File \"lib/python2.7/site-packages/google/cloud/bigquery/_helpers.py\", line 61, in _record_from_json\n for subfield, cell in zip(field.fields, value['f']):\nKeyError: 'f'\n```\n\n---\n\nStepping into the debugger:\n\n``` python\nipdb> value\n{u'v': {u'f': [{u'v': u'hamlet'}, {u'v': u'5318'}]}}\nipdb> field.__dict__\n{'field_type': u'RECORD', 'description': None, 'name': u'title', 'fields': [<google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227550>, <google.cloud.bigquery.schema.SchemaField object at 0x7f4ba9227690>], 'mode': u'REPEATED'}\n```\n\n(Added by @dhermes)\n\n", "before_files": [{"content": "# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for BigQuery API classes.\"\"\"\n\nfrom google.cloud._helpers import _datetime_from_microseconds\nfrom google.cloud._helpers import _date_from_iso8601_date\n\n\ndef _not_null(value, field):\n \"\"\"Check whether 'value' should be coerced to 'field' type.\"\"\"\n return value is not None or field.mode != 'NULLABLE'\n\n\ndef _int_from_json(value, field):\n \"\"\"Coerce 'value' to an int, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return int(value)\n\n\ndef _float_from_json(value, field):\n \"\"\"Coerce 'value' to a float, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return float(value)\n\n\ndef _bool_from_json(value, field):\n \"\"\"Coerce 'value' to a bool, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return value.lower() in ['t', 'true', '1']\n\n\ndef _datetime_from_json(value, field):\n \"\"\"Coerce 'value' to a datetime, if set or not nullable.\"\"\"\n if _not_null(value, field):\n # value will be a float in seconds, to microsecond precision, in UTC.\n return _datetime_from_microseconds(1e6 * float(value))\n\n\ndef _date_from_json(value, field):\n \"\"\"Coerce 'value' to a datetime date, if set or not nullable\"\"\"\n if _not_null(value, field):\n return _date_from_iso8601_date(value)\n\n\ndef _record_from_json(value, field):\n \"\"\"Coerce 'value' to a mapping, if set or not nullable.\"\"\"\n if _not_null(value, field):\n record = {}\n for subfield, cell in zip(field.fields, value['f']):\n converter = _CELLDATA_FROM_JSON[subfield.field_type]\n if field.mode == 'REPEATED':\n value = [converter(item, subfield) for item in cell['v']]\n else:\n value = converter(cell['v'], subfield)\n record[subfield.name] = value\n return record\n\n\ndef _string_from_json(value, _):\n \"\"\"NOOP string -> string coercion\"\"\"\n return value\n\n\n_CELLDATA_FROM_JSON = {\n 'INTEGER': _int_from_json,\n 'INT64': _int_from_json,\n 'FLOAT': _float_from_json,\n 'FLOAT64': _float_from_json,\n 'BOOLEAN': _bool_from_json,\n 'BOOL': _bool_from_json,\n 'TIMESTAMP': _datetime_from_json,\n 'DATE': _date_from_json,\n 'RECORD': _record_from_json,\n 'STRING': _string_from_json,\n}\n\n\ndef _row_from_json(row, schema):\n \"\"\"Convert JSON row data to row with appropriate types.\n\n :type row: dict\n :param row: A JSON response row to be converted.\n\n :type schema: tuple\n :param schema: A tuple of\n :class:`~google.cloud.bigquery.schema.SchemaField`.\n\n :rtype: tuple\n :returns: A tuple of data converted to native types.\n \"\"\"\n row_data = []\n for field, cell in zip(schema, row['f']):\n converter = _CELLDATA_FROM_JSON[field.field_type]\n if field.mode == 'REPEATED':\n row_data.append([converter(item, field)\n for item in cell['v']])\n else:\n row_data.append(converter(cell['v'], field))\n\n return tuple(row_data)\n\n\ndef _rows_from_json(rows, schema):\n \"\"\"Convert JSON row data to rows with appropriate types.\"\"\"\n return [_row_from_json(row, schema) for row in rows]\n\n\nclass _ConfigurationProperty(object):\n \"\"\"Base property implementation.\n\n Values will be stored on a `_configuration` helper attribute of the\n property's job instance.\n\n :type name: str\n :param name: name of the property\n \"\"\"\n\n def __init__(self, name):\n self.name = name\n self._backing_name = '_%s' % (self.name,)\n\n def __get__(self, instance, owner):\n \"\"\"Descriptor protocal: accesstor\"\"\"\n if instance is None:\n return self\n return getattr(instance._configuration, self._backing_name)\n\n def _validate(self, value):\n \"\"\"Subclasses override to impose validation policy.\"\"\"\n pass\n\n def __set__(self, instance, value):\n \"\"\"Descriptor protocal: mutator\"\"\"\n self._validate(value)\n setattr(instance._configuration, self._backing_name, value)\n\n def __delete__(self, instance):\n \"\"\"Descriptor protocal: deleter\"\"\"\n delattr(instance._configuration, self._backing_name)\n\n\nclass _TypedProperty(_ConfigurationProperty):\n \"\"\"Property implementation: validates based on value type.\n\n :type name: str\n :param name: name of the property\n\n :type property_type: type or sequence of types\n :param property_type: type to be validated\n \"\"\"\n def __init__(self, name, property_type):\n super(_TypedProperty, self).__init__(name)\n self.property_type = property_type\n\n def _validate(self, value):\n \"\"\"Ensure that 'value' is of the appropriate type.\n\n :raises: ValueError on a type mismatch.\n \"\"\"\n if not isinstance(value, self.property_type):\n raise ValueError('Required type: %s' % (self.property_type,))\n\n\nclass _EnumProperty(_ConfigurationProperty):\n \"\"\"Pseudo-enumeration class.\n\n Subclasses must define ``ALLOWED`` as a class-level constant: it must\n be a sequence of strings.\n\n :type name: str\n :param name: name of the property.\n \"\"\"\n def _validate(self, value):\n \"\"\"Check that ``value`` is one of the allowed values.\n\n :raises: ValueError if value is not allowed.\n \"\"\"\n if value not in self.ALLOWED:\n raise ValueError('Pass one of: %s' ', '.join(self.ALLOWED))\n\n\nclass UDFResource(object):\n \"\"\"Describe a single user-defined function (UDF) resource.\n\n :type udf_type: str\n :param udf_type: the type of the resource ('inlineCode' or 'resourceUri')\n\n :type value: str\n :param value: the inline code or resource URI.\n\n See\n https://cloud.google.com/bigquery/user-defined-functions#api\n \"\"\"\n def __init__(self, udf_type, value):\n self.udf_type = udf_type\n self.value = value\n\n def __eq__(self, other):\n return(\n self.udf_type == other.udf_type and\n self.value == other.value)\n\n\nclass UDFResourcesProperty(object):\n \"\"\"Custom property type, holding :class:`UDFResource` instances.\"\"\"\n\n def __get__(self, instance, owner):\n \"\"\"Descriptor protocol: accessor\"\"\"\n if instance is None:\n return self\n return list(instance._udf_resources)\n\n def __set__(self, instance, value):\n \"\"\"Descriptor protocol: mutator\"\"\"\n if not all(isinstance(u, UDFResource) for u in value):\n raise ValueError(\"udf items must be UDFResource\")\n instance._udf_resources = tuple(value)\n\n\ndef _build_udf_resources(resources):\n \"\"\"\n :type resources: sequence of :class:`UDFResource`\n :param resources: fields to be appended.\n\n :rtype: mapping\n :returns: a mapping describing userDefinedFunctionResources for the query.\n \"\"\"\n udfs = []\n for resource in resources:\n udf = {resource.udf_type: resource.value}\n udfs.append(udf)\n return udfs\n", "path": "bigquery/google/cloud/bigquery/_helpers.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for BigQuery API classes.\"\"\"\n\nfrom google.cloud._helpers import _datetime_from_microseconds\nfrom google.cloud._helpers import _date_from_iso8601_date\n\n\ndef _not_null(value, field):\n \"\"\"Check whether 'value' should be coerced to 'field' type.\"\"\"\n return value is not None or field.mode != 'NULLABLE'\n\n\ndef _int_from_json(value, field):\n \"\"\"Coerce 'value' to an int, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return int(value)\n\n\ndef _float_from_json(value, field):\n \"\"\"Coerce 'value' to a float, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return float(value)\n\n\ndef _bool_from_json(value, field):\n \"\"\"Coerce 'value' to a bool, if set or not nullable.\"\"\"\n if _not_null(value, field):\n return value.lower() in ['t', 'true', '1']\n\n\ndef _datetime_from_json(value, field):\n \"\"\"Coerce 'value' to a datetime, if set or not nullable.\"\"\"\n if _not_null(value, field):\n # value will be a float in seconds, to microsecond precision, in UTC.\n return _datetime_from_microseconds(1e6 * float(value))\n\n\ndef _date_from_json(value, field):\n \"\"\"Coerce 'value' to a datetime date, if set or not nullable\"\"\"\n if _not_null(value, field):\n return _date_from_iso8601_date(value)\n\n\ndef _record_from_json(value, field):\n \"\"\"Coerce 'value' to a mapping, if set or not nullable.\"\"\"\n if _not_null(value, field):\n record = {}\n record_iter = zip(field.fields, value['f'])\n for subfield, cell in record_iter:\n converter = _CELLDATA_FROM_JSON[subfield.field_type]\n if subfield.mode == 'REPEATED':\n value = [converter(item['v'], subfield) for item in cell['v']]\n else:\n value = converter(cell['v'], subfield)\n record[subfield.name] = value\n return record\n\n\ndef _string_from_json(value, _):\n \"\"\"NOOP string -> string coercion\"\"\"\n return value\n\n\n_CELLDATA_FROM_JSON = {\n 'INTEGER': _int_from_json,\n 'INT64': _int_from_json,\n 'FLOAT': _float_from_json,\n 'FLOAT64': _float_from_json,\n 'BOOLEAN': _bool_from_json,\n 'TIMESTAMP': _datetime_from_json,\n 'DATE': _date_from_json,\n 'RECORD': _record_from_json,\n 'STRING': _string_from_json,\n}\n\n\ndef _row_from_json(row, schema):\n \"\"\"Convert JSON row data to row with appropriate types.\n\n :type row: dict\n :param row: A JSON response row to be converted.\n\n :type schema: tuple\n :param schema: A tuple of\n :class:`~google.cloud.bigquery.schema.SchemaField`.\n\n :rtype: tuple\n :returns: A tuple of data converted to native types.\n \"\"\"\n row_data = []\n for field, cell in zip(schema, row['f']):\n converter = _CELLDATA_FROM_JSON[field.field_type]\n if field.mode == 'REPEATED':\n row_data.append([converter(item['v'], field)\n for item in cell['v']])\n else:\n row_data.append(converter(cell['v'], field))\n\n return tuple(row_data)\n\n\ndef _rows_from_json(rows, schema):\n \"\"\"Convert JSON row data to rows with appropriate types.\"\"\"\n return [_row_from_json(row, schema) for row in rows]\n\n\nclass _ConfigurationProperty(object):\n \"\"\"Base property implementation.\n\n Values will be stored on a `_configuration` helper attribute of the\n property's job instance.\n\n :type name: str\n :param name: name of the property\n \"\"\"\n\n def __init__(self, name):\n self.name = name\n self._backing_name = '_%s' % (self.name,)\n\n def __get__(self, instance, owner):\n \"\"\"Descriptor protocal: accesstor\"\"\"\n if instance is None:\n return self\n return getattr(instance._configuration, self._backing_name)\n\n def _validate(self, value):\n \"\"\"Subclasses override to impose validation policy.\"\"\"\n pass\n\n def __set__(self, instance, value):\n \"\"\"Descriptor protocal: mutator\"\"\"\n self._validate(value)\n setattr(instance._configuration, self._backing_name, value)\n\n def __delete__(self, instance):\n \"\"\"Descriptor protocal: deleter\"\"\"\n delattr(instance._configuration, self._backing_name)\n\n\nclass _TypedProperty(_ConfigurationProperty):\n \"\"\"Property implementation: validates based on value type.\n\n :type name: str\n :param name: name of the property\n\n :type property_type: type or sequence of types\n :param property_type: type to be validated\n \"\"\"\n def __init__(self, name, property_type):\n super(_TypedProperty, self).__init__(name)\n self.property_type = property_type\n\n def _validate(self, value):\n \"\"\"Ensure that 'value' is of the appropriate type.\n\n :raises: ValueError on a type mismatch.\n \"\"\"\n if not isinstance(value, self.property_type):\n raise ValueError('Required type: %s' % (self.property_type,))\n\n\nclass _EnumProperty(_ConfigurationProperty):\n \"\"\"Pseudo-enumeration class.\n\n Subclasses must define ``ALLOWED`` as a class-level constant: it must\n be a sequence of strings.\n\n :type name: str\n :param name: name of the property.\n \"\"\"\n def _validate(self, value):\n \"\"\"Check that ``value`` is one of the allowed values.\n\n :raises: ValueError if value is not allowed.\n \"\"\"\n if value not in self.ALLOWED:\n raise ValueError('Pass one of: %s' ', '.join(self.ALLOWED))\n\n\nclass UDFResource(object):\n \"\"\"Describe a single user-defined function (UDF) resource.\n\n :type udf_type: str\n :param udf_type: the type of the resource ('inlineCode' or 'resourceUri')\n\n :type value: str\n :param value: the inline code or resource URI.\n\n See\n https://cloud.google.com/bigquery/user-defined-functions#api\n \"\"\"\n def __init__(self, udf_type, value):\n self.udf_type = udf_type\n self.value = value\n\n def __eq__(self, other):\n return(\n self.udf_type == other.udf_type and\n self.value == other.value)\n\n\nclass UDFResourcesProperty(object):\n \"\"\"Custom property type, holding :class:`UDFResource` instances.\"\"\"\n\n def __get__(self, instance, owner):\n \"\"\"Descriptor protocol: accessor\"\"\"\n if instance is None:\n return self\n return list(instance._udf_resources)\n\n def __set__(self, instance, value):\n \"\"\"Descriptor protocol: mutator\"\"\"\n if not all(isinstance(u, UDFResource) for u in value):\n raise ValueError(\"udf items must be UDFResource\")\n instance._udf_resources = tuple(value)\n\n\ndef _build_udf_resources(resources):\n \"\"\"\n :type resources: sequence of :class:`UDFResource`\n :param resources: fields to be appended.\n\n :rtype: mapping\n :returns: a mapping describing userDefinedFunctionResources for the query.\n \"\"\"\n udfs = []\n for resource in resources:\n udf = {resource.udf_type: resource.value}\n udfs.append(udf)\n return udfs\n", "path": "bigquery/google/cloud/bigquery/_helpers.py"}]}
| 3,181 | 325 |
gh_patches_debug_4870
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-1809
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NiftiMasker with target_affine throws exception.
I am using the NifitiMasker in a sklearn pipeline. Everythings works fine until i try to reshape the images:
`nifti_masker = NiftiMasker(target_affine=np.eye(3)*3)`
The error i got was:
`File "/anaconda3/envs/toolbox/lib/python3.6/site-packages/nilearn/masking.py", line 62, in _load_mask_img
% values)
ValueError: Given mask is not made of 2 values: [-0.0000000e+00 1.4012985e-45 2.8025969e-45 ... 5.1444152e-15
5.3116801e-15 1.0000000e+00]. Cannot interpret as true or false`
I unsing nilearn version 0.4.2 .
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nilearn/input_data/nifti_masker.py`
Content:
```
1 """
2 Transformer used to apply basic transformations on MRI data.
3 """
4 # Author: Gael Varoquaux, Alexandre Abraham
5 # License: simplified BSD
6
7 from copy import copy as copy_object
8
9 from sklearn.externals.joblib import Memory
10
11 from .base_masker import BaseMasker, filter_and_extract
12 from .. import _utils
13 from .. import image
14 from .. import masking
15 from .._utils import CacheMixin
16 from .._utils.class_inspect import get_params
17 from .._utils.niimg_conversions import _check_same_fov
18
19
20 class _ExtractionFunctor(object):
21 func_name = 'nifti_masker_extractor'
22
23 def __init__(self, mask_img_):
24 self.mask_img_ = mask_img_
25
26 def __call__(self, imgs):
27 return(masking.apply_mask(imgs, self.mask_img_,
28 dtype=imgs.get_data_dtype()), imgs.affine)
29
30
31 def filter_and_mask(imgs, mask_img_, parameters,
32 memory_level=0, memory=Memory(cachedir=None),
33 verbose=0,
34 confounds=None,
35 copy=True,
36 dtype=None):
37 imgs = _utils.check_niimg(imgs, atleast_4d=True, ensure_ndim=4)
38
39 # Check whether resampling is truly necessary. If so, crop mask
40 # as small as possible in order to speed up the process
41
42 if not _check_same_fov(imgs, mask_img_):
43 parameters = copy_object(parameters)
44 # now we can crop
45 mask_img_ = image.crop_img(mask_img_, copy=False)
46 parameters['target_shape'] = mask_img_.shape
47 parameters['target_affine'] = mask_img_.affine
48
49 data, affine = filter_and_extract(imgs, _ExtractionFunctor(mask_img_),
50 parameters,
51 memory_level=memory_level,
52 memory=memory,
53 verbose=verbose,
54 confounds=confounds, copy=copy,
55 dtype=dtype)
56
57 # For _later_: missing value removal or imputing of missing data
58 # (i.e. we want to get rid of NaNs, if smoothing must be done
59 # earlier)
60 # Optionally: 'doctor_nan', remove voxels with NaNs, other option
61 # for later: some form of imputation
62 return data
63
64
65 class NiftiMasker(BaseMasker, CacheMixin):
66 """Applying a mask to extract time-series from Niimg-like objects.
67
68 NiftiMasker is useful when preprocessing (detrending, standardization,
69 resampling, etc.) of in-mask voxels is necessary. Use case: working with
70 time series of resting-state or task maps.
71
72 Parameters
73 ----------
74 mask_img : Niimg-like object, optional
75 See http://nilearn.github.io/manipulating_images/input_output.html
76 Mask for the data. If not given, a mask is computed in the fit step.
77 Optional parameters (mask_args and mask_strategy) can be set to
78 fine tune the mask extraction.
79
80 sessions : numpy array, optional
81 Add a session level to the preprocessing. Each session will be
82 detrended independently. Must be a 1D array of n_samples elements.
83
84 smoothing_fwhm : float, optional
85 If smoothing_fwhm is not None, it gives the full-width half maximum in
86 millimeters of the spatial smoothing to apply to the signal.
87
88 standardize : boolean, optional
89 If standardize is True, the time-series are centered and normed:
90 their mean is put to 0 and their variance to 1 in the time dimension.
91
92 detrend : boolean, optional
93 This parameter is passed to signal.clean. Please see the related
94 documentation for details
95
96 low_pass: None or float, optional
97 This parameter is passed to signal.clean. Please see the related
98 documentation for details
99
100 high_pass: None or float, optional
101 This parameter is passed to signal.clean. Please see the related
102 documentation for details
103
104 t_r : float, optional
105 This parameter is passed to signal.clean. Please see the related
106 documentation for details
107
108 target_affine : 3x3 or 4x4 matrix, optional
109 This parameter is passed to image.resample_img. Please see the
110 related documentation for details.
111
112 target_shape : 3-tuple of integers, optional
113 This parameter is passed to image.resample_img. Please see the
114 related documentation for details.
115
116 mask_strategy: {'background', 'epi' or 'template'}, optional
117 The strategy used to compute the mask: use 'background' if your
118 images present a clear homogeneous background, 'epi' if they
119 are raw EPI images, or you could use 'template' which will
120 extract the gray matter part of your data by resampling the MNI152
121 brain mask for your data's field of view.
122 Depending on this value, the mask will be computed from
123 masking.compute_background_mask, masking.compute_epi_mask or
124 masking.compute_gray_matter_mask. Default is 'background'.
125
126 mask_args : dict, optional
127 If mask is None, these are additional parameters passed to
128 masking.compute_background_mask or masking.compute_epi_mask
129 to fine-tune mask computation. Please see the related documentation
130 for details.
131
132 sample_mask : Any type compatible with numpy-array indexing
133 Masks the niimgs along time/fourth dimension. This complements
134 3D masking by the mask_img argument. This masking step is applied
135 before data preprocessing at the beginning of NiftiMasker.transform.
136 This is useful to perform data subselection as part of a scikit-learn
137 pipeline.
138
139 `dtype: {dtype, "auto"}
140 Data type toward which the data should be converted. If "auto", the
141 data will be converted to int32 if dtype is discrete and float32 if it
142 is continuous.
143
144 memory : instance of joblib.Memory or string
145 Used to cache the masking process.
146 By default, no caching is done. If a string is given, it is the
147 path to the caching directory.
148
149 memory_level : integer, optional
150 Rough estimator of the amount of memory used by caching. Higher value
151 means more memory for caching.
152
153 verbose : integer, optional
154 Indicate the level of verbosity. By default, nothing is printed
155
156 Attributes
157 ----------
158 `mask_img_` : nibabel.Nifti1Image
159 The mask of the data, or the computed one.
160
161 `affine_` : 4x4 numpy array
162 Affine of the transformed image.
163
164 See also
165 --------
166 nilearn.masking.compute_background_mask
167 nilearn.masking.compute_epi_mask
168 nilearn.image.resample_img
169 nilearn.masking.apply_mask
170 nilearn.signal.clean
171 """
172
173 def __init__(self, mask_img=None, sessions=None, smoothing_fwhm=None,
174 standardize=False, detrend=False,
175 low_pass=None, high_pass=None, t_r=None,
176 target_affine=None, target_shape=None,
177 mask_strategy='background',
178 mask_args=None, sample_mask=None, dtype=None,
179 memory_level=1, memory=Memory(cachedir=None),
180 verbose=0
181 ):
182 # Mask is provided or computed
183 self.mask_img = mask_img
184
185 self.sessions = sessions
186 self.smoothing_fwhm = smoothing_fwhm
187 self.standardize = standardize
188 self.detrend = detrend
189 self.low_pass = low_pass
190 self.high_pass = high_pass
191 self.t_r = t_r
192 self.target_affine = target_affine
193 self.target_shape = target_shape
194 self.mask_strategy = mask_strategy
195 self.mask_args = mask_args
196 self.sample_mask = sample_mask
197 self.dtype = dtype
198
199 self.memory = memory
200 self.memory_level = memory_level
201 self.verbose = verbose
202
203 self._shelving = False
204
205 def _check_fitted(self):
206 if not hasattr(self, 'mask_img_'):
207 raise ValueError('It seems that %s has not been fitted. '
208 'You must call fit() before calling transform().'
209 % self.__class__.__name__)
210
211 def fit(self, imgs=None, y=None):
212 """Compute the mask corresponding to the data
213
214 Parameters
215 ----------
216 imgs: list of Niimg-like objects
217 See http://nilearn.github.io/manipulating_images/input_output.html
218 Data on which the mask must be calculated. If this is a list,
219 the affine is considered the same for all.
220 """
221 # y=None is for scikit-learn compatibility (unused here).
222
223 # Load data (if filenames are given, load them)
224 if self.verbose > 0:
225 print("[%s.fit] Loading data from %s" % (
226 self.__class__.__name__,
227 _utils._repr_niimgs(imgs)[:200]))
228
229 # Compute the mask if not given by the user
230 if self.mask_img is None:
231 mask_args = (self.mask_args if self.mask_args is not None
232 else {})
233 if self.mask_strategy == 'background':
234 compute_mask = masking.compute_background_mask
235 elif self.mask_strategy == 'epi':
236 compute_mask = masking.compute_epi_mask
237 elif self.mask_strategy == 'template':
238 compute_mask = masking.compute_gray_matter_mask
239 else:
240 raise ValueError("Unknown value of mask_strategy '%s'. "
241 "Acceptable values are 'background', "
242 "'epi' and 'template'." % self.mask_strategy)
243 if self.verbose > 0:
244 print("[%s.fit] Computing the mask" % self.__class__.__name__)
245 self.mask_img_ = self._cache(compute_mask, ignore=['verbose'])(
246 imgs, verbose=max(0, self.verbose - 1), **mask_args)
247 else:
248 self.mask_img_ = _utils.check_niimg_3d(self.mask_img)
249
250 # If resampling is requested, resample also the mask
251 # Resampling: allows the user to change the affine, the shape or both
252 if self.verbose > 0:
253 print("[%s.fit] Resampling mask" % self.__class__.__name__)
254 self.mask_img_ = self._cache(image.resample_img)(
255 self.mask_img_,
256 target_affine=self.target_affine,
257 target_shape=self.target_shape,
258 copy=False)
259 if self.target_affine is not None:
260 self.affine_ = self.target_affine
261 else:
262 self.affine_ = self.mask_img_.affine
263 # Load data in memory
264 self.mask_img_.get_data()
265 if self.verbose > 10:
266 print("[%s.fit] Finished fit" % self.__class__.__name__)
267 return self
268
269 def transform_single_imgs(self, imgs, confounds=None, copy=True):
270 """Apply mask, spatial and temporal preprocessing
271
272 Parameters
273 ----------
274 imgs: 3D/4D Niimg-like object
275 See http://nilearn.github.io/manipulating_images/input_output.html
276 Images to process. It must boil down to a 4D image with scans
277 number as last dimension.
278
279 confounds: CSV file or array-like, optional
280 This parameter is passed to signal.clean. Please see the related
281 documentation for details.
282 shape: (number of scans, number of confounds)
283
284 Returns
285 -------
286 region_signals: 2D numpy.ndarray
287 Signal for each voxel inside the mask.
288 shape: (number of scans, number of voxels)
289 """
290
291 # Ignore the mask-computing params: they are not useful and will
292 # just invalid the cache for no good reason
293 # target_shape and target_affine are conveyed implicitly in mask_img
294 params = get_params(self.__class__, self,
295 ignore=['mask_img', 'mask_args', 'mask_strategy'])
296
297 data = self._cache(filter_and_mask,
298 ignore=['verbose', 'memory', 'memory_level',
299 'copy'],
300 shelve=self._shelving)(
301 imgs, self.mask_img_, params,
302 memory_level=self.memory_level,
303 memory=self.memory,
304 verbose=self.verbose,
305 confounds=confounds,
306 copy=copy,
307 dtype=self.dtype
308 )
309
310 return data
311
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nilearn/input_data/nifti_masker.py b/nilearn/input_data/nifti_masker.py
--- a/nilearn/input_data/nifti_masker.py
+++ b/nilearn/input_data/nifti_masker.py
@@ -255,7 +255,7 @@
self.mask_img_,
target_affine=self.target_affine,
target_shape=self.target_shape,
- copy=False)
+ copy=False, interpolation='nearest')
if self.target_affine is not None:
self.affine_ = self.target_affine
else:
|
{"golden_diff": "diff --git a/nilearn/input_data/nifti_masker.py b/nilearn/input_data/nifti_masker.py\n--- a/nilearn/input_data/nifti_masker.py\n+++ b/nilearn/input_data/nifti_masker.py\n@@ -255,7 +255,7 @@\n self.mask_img_,\n target_affine=self.target_affine,\n target_shape=self.target_shape,\n- copy=False)\n+ copy=False, interpolation='nearest')\n if self.target_affine is not None:\n self.affine_ = self.target_affine\n else:\n", "issue": "NiftiMasker with target_affine throws exception.\nI am using the NifitiMasker in a sklearn pipeline. Everythings works fine until i try to reshape the images:\r\n\r\n`nifti_masker = NiftiMasker(target_affine=np.eye(3)*3)`\r\n\r\nThe error i got was:\r\n\r\n`File \"/anaconda3/envs/toolbox/lib/python3.6/site-packages/nilearn/masking.py\", line 62, in _load_mask_img\r\n % values)\r\nValueError: Given mask is not made of 2 values: [-0.0000000e+00 1.4012985e-45 2.8025969e-45 ... 5.1444152e-15\r\n 5.3116801e-15 1.0000000e+00]. Cannot interpret as true or false`\r\n\r\nI unsing nilearn version 0.4.2 .\n", "before_files": [{"content": "\"\"\"\nTransformer used to apply basic transformations on MRI data.\n\"\"\"\n# Author: Gael Varoquaux, Alexandre Abraham\n# License: simplified BSD\n\nfrom copy import copy as copy_object\n\nfrom sklearn.externals.joblib import Memory\n\nfrom .base_masker import BaseMasker, filter_and_extract\nfrom .. import _utils\nfrom .. import image\nfrom .. import masking\nfrom .._utils import CacheMixin\nfrom .._utils.class_inspect import get_params\nfrom .._utils.niimg_conversions import _check_same_fov\n\n\nclass _ExtractionFunctor(object):\n func_name = 'nifti_masker_extractor'\n\n def __init__(self, mask_img_):\n self.mask_img_ = mask_img_\n\n def __call__(self, imgs):\n return(masking.apply_mask(imgs, self.mask_img_,\n dtype=imgs.get_data_dtype()), imgs.affine)\n\n\ndef filter_and_mask(imgs, mask_img_, parameters,\n memory_level=0, memory=Memory(cachedir=None),\n verbose=0,\n confounds=None,\n copy=True,\n dtype=None):\n imgs = _utils.check_niimg(imgs, atleast_4d=True, ensure_ndim=4)\n\n # Check whether resampling is truly necessary. If so, crop mask\n # as small as possible in order to speed up the process\n\n if not _check_same_fov(imgs, mask_img_):\n parameters = copy_object(parameters)\n # now we can crop\n mask_img_ = image.crop_img(mask_img_, copy=False)\n parameters['target_shape'] = mask_img_.shape\n parameters['target_affine'] = mask_img_.affine\n\n data, affine = filter_and_extract(imgs, _ExtractionFunctor(mask_img_),\n parameters,\n memory_level=memory_level,\n memory=memory,\n verbose=verbose,\n confounds=confounds, copy=copy,\n dtype=dtype)\n\n # For _later_: missing value removal or imputing of missing data\n # (i.e. we want to get rid of NaNs, if smoothing must be done\n # earlier)\n # Optionally: 'doctor_nan', remove voxels with NaNs, other option\n # for later: some form of imputation\n return data\n\n\nclass NiftiMasker(BaseMasker, CacheMixin):\n \"\"\"Applying a mask to extract time-series from Niimg-like objects.\n\n NiftiMasker is useful when preprocessing (detrending, standardization,\n resampling, etc.) of in-mask voxels is necessary. Use case: working with\n time series of resting-state or task maps.\n\n Parameters\n ----------\n mask_img : Niimg-like object, optional\n See http://nilearn.github.io/manipulating_images/input_output.html\n Mask for the data. If not given, a mask is computed in the fit step.\n Optional parameters (mask_args and mask_strategy) can be set to\n fine tune the mask extraction.\n\n sessions : numpy array, optional\n Add a session level to the preprocessing. Each session will be\n detrended independently. Must be a 1D array of n_samples elements.\n\n smoothing_fwhm : float, optional\n If smoothing_fwhm is not None, it gives the full-width half maximum in\n millimeters of the spatial smoothing to apply to the signal.\n\n standardize : boolean, optional\n If standardize is True, the time-series are centered and normed:\n their mean is put to 0 and their variance to 1 in the time dimension.\n\n detrend : boolean, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n low_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n high_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n t_r : float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n target_affine : 3x3 or 4x4 matrix, optional\n This parameter is passed to image.resample_img. Please see the\n related documentation for details.\n\n target_shape : 3-tuple of integers, optional\n This parameter is passed to image.resample_img. Please see the\n related documentation for details.\n\n mask_strategy: {'background', 'epi' or 'template'}, optional\n The strategy used to compute the mask: use 'background' if your\n images present a clear homogeneous background, 'epi' if they\n are raw EPI images, or you could use 'template' which will\n extract the gray matter part of your data by resampling the MNI152\n brain mask for your data's field of view.\n Depending on this value, the mask will be computed from\n masking.compute_background_mask, masking.compute_epi_mask or\n masking.compute_gray_matter_mask. Default is 'background'.\n\n mask_args : dict, optional\n If mask is None, these are additional parameters passed to\n masking.compute_background_mask or masking.compute_epi_mask\n to fine-tune mask computation. Please see the related documentation\n for details.\n\n sample_mask : Any type compatible with numpy-array indexing\n Masks the niimgs along time/fourth dimension. This complements\n 3D masking by the mask_img argument. This masking step is applied\n before data preprocessing at the beginning of NiftiMasker.transform.\n This is useful to perform data subselection as part of a scikit-learn\n pipeline.\n\n `dtype: {dtype, \"auto\"}\n Data type toward which the data should be converted. If \"auto\", the\n data will be converted to int32 if dtype is discrete and float32 if it\n is continuous.\n\n memory : instance of joblib.Memory or string\n Used to cache the masking process.\n By default, no caching is done. If a string is given, it is the\n path to the caching directory.\n\n memory_level : integer, optional\n Rough estimator of the amount of memory used by caching. Higher value\n means more memory for caching.\n\n verbose : integer, optional\n Indicate the level of verbosity. By default, nothing is printed\n\n Attributes\n ----------\n `mask_img_` : nibabel.Nifti1Image\n The mask of the data, or the computed one.\n\n `affine_` : 4x4 numpy array\n Affine of the transformed image.\n\n See also\n --------\n nilearn.masking.compute_background_mask\n nilearn.masking.compute_epi_mask\n nilearn.image.resample_img\n nilearn.masking.apply_mask\n nilearn.signal.clean\n \"\"\"\n\n def __init__(self, mask_img=None, sessions=None, smoothing_fwhm=None,\n standardize=False, detrend=False,\n low_pass=None, high_pass=None, t_r=None,\n target_affine=None, target_shape=None,\n mask_strategy='background',\n mask_args=None, sample_mask=None, dtype=None,\n memory_level=1, memory=Memory(cachedir=None),\n verbose=0\n ):\n # Mask is provided or computed\n self.mask_img = mask_img\n\n self.sessions = sessions\n self.smoothing_fwhm = smoothing_fwhm\n self.standardize = standardize\n self.detrend = detrend\n self.low_pass = low_pass\n self.high_pass = high_pass\n self.t_r = t_r\n self.target_affine = target_affine\n self.target_shape = target_shape\n self.mask_strategy = mask_strategy\n self.mask_args = mask_args\n self.sample_mask = sample_mask\n self.dtype = dtype\n\n self.memory = memory\n self.memory_level = memory_level\n self.verbose = verbose\n\n self._shelving = False\n\n def _check_fitted(self):\n if not hasattr(self, 'mask_img_'):\n raise ValueError('It seems that %s has not been fitted. '\n 'You must call fit() before calling transform().'\n % self.__class__.__name__)\n\n def fit(self, imgs=None, y=None):\n \"\"\"Compute the mask corresponding to the data\n\n Parameters\n ----------\n imgs: list of Niimg-like objects\n See http://nilearn.github.io/manipulating_images/input_output.html\n Data on which the mask must be calculated. If this is a list,\n the affine is considered the same for all.\n \"\"\"\n # y=None is for scikit-learn compatibility (unused here).\n\n # Load data (if filenames are given, load them)\n if self.verbose > 0:\n print(\"[%s.fit] Loading data from %s\" % (\n self.__class__.__name__,\n _utils._repr_niimgs(imgs)[:200]))\n\n # Compute the mask if not given by the user\n if self.mask_img is None:\n mask_args = (self.mask_args if self.mask_args is not None\n else {})\n if self.mask_strategy == 'background':\n compute_mask = masking.compute_background_mask\n elif self.mask_strategy == 'epi':\n compute_mask = masking.compute_epi_mask\n elif self.mask_strategy == 'template':\n compute_mask = masking.compute_gray_matter_mask\n else:\n raise ValueError(\"Unknown value of mask_strategy '%s'. \"\n \"Acceptable values are 'background', \"\n \"'epi' and 'template'.\" % self.mask_strategy)\n if self.verbose > 0:\n print(\"[%s.fit] Computing the mask\" % self.__class__.__name__)\n self.mask_img_ = self._cache(compute_mask, ignore=['verbose'])(\n imgs, verbose=max(0, self.verbose - 1), **mask_args)\n else:\n self.mask_img_ = _utils.check_niimg_3d(self.mask_img)\n\n # If resampling is requested, resample also the mask\n # Resampling: allows the user to change the affine, the shape or both\n if self.verbose > 0:\n print(\"[%s.fit] Resampling mask\" % self.__class__.__name__)\n self.mask_img_ = self._cache(image.resample_img)(\n self.mask_img_,\n target_affine=self.target_affine,\n target_shape=self.target_shape,\n copy=False)\n if self.target_affine is not None:\n self.affine_ = self.target_affine\n else:\n self.affine_ = self.mask_img_.affine\n # Load data in memory\n self.mask_img_.get_data()\n if self.verbose > 10:\n print(\"[%s.fit] Finished fit\" % self.__class__.__name__)\n return self\n\n def transform_single_imgs(self, imgs, confounds=None, copy=True):\n \"\"\"Apply mask, spatial and temporal preprocessing\n\n Parameters\n ----------\n imgs: 3D/4D Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Images to process. It must boil down to a 4D image with scans\n number as last dimension.\n\n confounds: CSV file or array-like, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details.\n shape: (number of scans, number of confounds)\n\n Returns\n -------\n region_signals: 2D numpy.ndarray\n Signal for each voxel inside the mask.\n shape: (number of scans, number of voxels)\n \"\"\"\n\n # Ignore the mask-computing params: they are not useful and will\n # just invalid the cache for no good reason\n # target_shape and target_affine are conveyed implicitly in mask_img\n params = get_params(self.__class__, self,\n ignore=['mask_img', 'mask_args', 'mask_strategy'])\n\n data = self._cache(filter_and_mask,\n ignore=['verbose', 'memory', 'memory_level',\n 'copy'],\n shelve=self._shelving)(\n imgs, self.mask_img_, params,\n memory_level=self.memory_level,\n memory=self.memory,\n verbose=self.verbose,\n confounds=confounds,\n copy=copy,\n dtype=self.dtype\n )\n\n return data\n", "path": "nilearn/input_data/nifti_masker.py"}], "after_files": [{"content": "\"\"\"\nTransformer used to apply basic transformations on MRI data.\n\"\"\"\n# Author: Gael Varoquaux, Alexandre Abraham\n# License: simplified BSD\n\nfrom copy import copy as copy_object\n\nfrom sklearn.externals.joblib import Memory\n\nfrom .base_masker import BaseMasker, filter_and_extract\nfrom .. import _utils\nfrom .. import image\nfrom .. import masking\nfrom .._utils import CacheMixin\nfrom .._utils.class_inspect import get_params\nfrom .._utils.niimg_conversions import _check_same_fov\n\n\nclass _ExtractionFunctor(object):\n func_name = 'nifti_masker_extractor'\n\n def __init__(self, mask_img_):\n self.mask_img_ = mask_img_\n\n def __call__(self, imgs):\n return(masking.apply_mask(imgs, self.mask_img_,\n dtype=imgs.get_data_dtype()), imgs.affine)\n\n\ndef filter_and_mask(imgs, mask_img_, parameters,\n memory_level=0, memory=Memory(cachedir=None),\n verbose=0,\n confounds=None,\n copy=True,\n dtype=None):\n imgs = _utils.check_niimg(imgs, atleast_4d=True, ensure_ndim=4)\n\n # Check whether resampling is truly necessary. If so, crop mask\n # as small as possible in order to speed up the process\n\n if not _check_same_fov(imgs, mask_img_):\n parameters = copy_object(parameters)\n # now we can crop\n mask_img_ = image.crop_img(mask_img_, copy=False)\n parameters['target_shape'] = mask_img_.shape\n parameters['target_affine'] = mask_img_.affine\n\n data, affine = filter_and_extract(imgs, _ExtractionFunctor(mask_img_),\n parameters,\n memory_level=memory_level,\n memory=memory,\n verbose=verbose,\n confounds=confounds, copy=copy,\n dtype=dtype)\n\n # For _later_: missing value removal or imputing of missing data\n # (i.e. we want to get rid of NaNs, if smoothing must be done\n # earlier)\n # Optionally: 'doctor_nan', remove voxels with NaNs, other option\n # for later: some form of imputation\n return data\n\n\nclass NiftiMasker(BaseMasker, CacheMixin):\n \"\"\"Applying a mask to extract time-series from Niimg-like objects.\n\n NiftiMasker is useful when preprocessing (detrending, standardization,\n resampling, etc.) of in-mask voxels is necessary. Use case: working with\n time series of resting-state or task maps.\n\n Parameters\n ----------\n mask_img : Niimg-like object, optional\n See http://nilearn.github.io/manipulating_images/input_output.html\n Mask for the data. If not given, a mask is computed in the fit step.\n Optional parameters (mask_args and mask_strategy) can be set to\n fine tune the mask extraction.\n\n sessions : numpy array, optional\n Add a session level to the preprocessing. Each session will be\n detrended independently. Must be a 1D array of n_samples elements.\n\n smoothing_fwhm : float, optional\n If smoothing_fwhm is not None, it gives the full-width half maximum in\n millimeters of the spatial smoothing to apply to the signal.\n\n standardize : boolean, optional\n If standardize is True, the time-series are centered and normed:\n their mean is put to 0 and their variance to 1 in the time dimension.\n\n detrend : boolean, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n low_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n high_pass: None or float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n t_r : float, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details\n\n target_affine : 3x3 or 4x4 matrix, optional\n This parameter is passed to image.resample_img. Please see the\n related documentation for details.\n\n target_shape : 3-tuple of integers, optional\n This parameter is passed to image.resample_img. Please see the\n related documentation for details.\n\n mask_strategy: {'background', 'epi' or 'template'}, optional\n The strategy used to compute the mask: use 'background' if your\n images present a clear homogeneous background, 'epi' if they\n are raw EPI images, or you could use 'template' which will\n extract the gray matter part of your data by resampling the MNI152\n brain mask for your data's field of view.\n Depending on this value, the mask will be computed from\n masking.compute_background_mask, masking.compute_epi_mask or\n masking.compute_gray_matter_mask. Default is 'background'.\n\n mask_args : dict, optional\n If mask is None, these are additional parameters passed to\n masking.compute_background_mask or masking.compute_epi_mask\n to fine-tune mask computation. Please see the related documentation\n for details.\n\n sample_mask : Any type compatible with numpy-array indexing\n Masks the niimgs along time/fourth dimension. This complements\n 3D masking by the mask_img argument. This masking step is applied\n before data preprocessing at the beginning of NiftiMasker.transform.\n This is useful to perform data subselection as part of a scikit-learn\n pipeline.\n\n `dtype: {dtype, \"auto\"}\n Data type toward which the data should be converted. If \"auto\", the\n data will be converted to int32 if dtype is discrete and float32 if it\n is continuous.\n\n memory : instance of joblib.Memory or string\n Used to cache the masking process.\n By default, no caching is done. If a string is given, it is the\n path to the caching directory.\n\n memory_level : integer, optional\n Rough estimator of the amount of memory used by caching. Higher value\n means more memory for caching.\n\n verbose : integer, optional\n Indicate the level of verbosity. By default, nothing is printed\n\n Attributes\n ----------\n `mask_img_` : nibabel.Nifti1Image\n The mask of the data, or the computed one.\n\n `affine_` : 4x4 numpy array\n Affine of the transformed image.\n\n See also\n --------\n nilearn.masking.compute_background_mask\n nilearn.masking.compute_epi_mask\n nilearn.image.resample_img\n nilearn.masking.apply_mask\n nilearn.signal.clean\n \"\"\"\n\n def __init__(self, mask_img=None, sessions=None, smoothing_fwhm=None,\n standardize=False, detrend=False,\n low_pass=None, high_pass=None, t_r=None,\n target_affine=None, target_shape=None,\n mask_strategy='background',\n mask_args=None, sample_mask=None, dtype=None,\n memory_level=1, memory=Memory(cachedir=None),\n verbose=0\n ):\n # Mask is provided or computed\n self.mask_img = mask_img\n\n self.sessions = sessions\n self.smoothing_fwhm = smoothing_fwhm\n self.standardize = standardize\n self.detrend = detrend\n self.low_pass = low_pass\n self.high_pass = high_pass\n self.t_r = t_r\n self.target_affine = target_affine\n self.target_shape = target_shape\n self.mask_strategy = mask_strategy\n self.mask_args = mask_args\n self.sample_mask = sample_mask\n self.dtype = dtype\n\n self.memory = memory\n self.memory_level = memory_level\n self.verbose = verbose\n\n self._shelving = False\n\n def _check_fitted(self):\n if not hasattr(self, 'mask_img_'):\n raise ValueError('It seems that %s has not been fitted. '\n 'You must call fit() before calling transform().'\n % self.__class__.__name__)\n\n def fit(self, imgs=None, y=None):\n \"\"\"Compute the mask corresponding to the data\n\n Parameters\n ----------\n imgs: list of Niimg-like objects\n See http://nilearn.github.io/manipulating_images/input_output.html\n Data on which the mask must be calculated. If this is a list,\n the affine is considered the same for all.\n \"\"\"\n # y=None is for scikit-learn compatibility (unused here).\n\n # Load data (if filenames are given, load them)\n if self.verbose > 0:\n print(\"[%s.fit] Loading data from %s\" % (\n self.__class__.__name__,\n _utils._repr_niimgs(imgs)[:200]))\n\n # Compute the mask if not given by the user\n if self.mask_img is None:\n mask_args = (self.mask_args if self.mask_args is not None\n else {})\n if self.mask_strategy == 'background':\n compute_mask = masking.compute_background_mask\n elif self.mask_strategy == 'epi':\n compute_mask = masking.compute_epi_mask\n elif self.mask_strategy == 'template':\n compute_mask = masking.compute_gray_matter_mask\n else:\n raise ValueError(\"Unknown value of mask_strategy '%s'. \"\n \"Acceptable values are 'background', \"\n \"'epi' and 'template'.\" % self.mask_strategy)\n if self.verbose > 0:\n print(\"[%s.fit] Computing the mask\" % self.__class__.__name__)\n self.mask_img_ = self._cache(compute_mask, ignore=['verbose'])(\n imgs, verbose=max(0, self.verbose - 1), **mask_args)\n else:\n self.mask_img_ = _utils.check_niimg_3d(self.mask_img)\n\n # If resampling is requested, resample also the mask\n # Resampling: allows the user to change the affine, the shape or both\n if self.verbose > 0:\n print(\"[%s.fit] Resampling mask\" % self.__class__.__name__)\n self.mask_img_ = self._cache(image.resample_img)(\n self.mask_img_,\n target_affine=self.target_affine,\n target_shape=self.target_shape,\n copy=False, interpolation='nearest')\n if self.target_affine is not None:\n self.affine_ = self.target_affine\n else:\n self.affine_ = self.mask_img_.affine\n # Load data in memory\n self.mask_img_.get_data()\n if self.verbose > 10:\n print(\"[%s.fit] Finished fit\" % self.__class__.__name__)\n return self\n\n def transform_single_imgs(self, imgs, confounds=None, copy=True):\n \"\"\"Apply mask, spatial and temporal preprocessing\n\n Parameters\n ----------\n imgs: 3D/4D Niimg-like object\n See http://nilearn.github.io/manipulating_images/input_output.html\n Images to process. It must boil down to a 4D image with scans\n number as last dimension.\n\n confounds: CSV file or array-like, optional\n This parameter is passed to signal.clean. Please see the related\n documentation for details.\n shape: (number of scans, number of confounds)\n\n Returns\n -------\n region_signals: 2D numpy.ndarray\n Signal for each voxel inside the mask.\n shape: (number of scans, number of voxels)\n \"\"\"\n\n # Ignore the mask-computing params: they are not useful and will\n # just invalid the cache for no good reason\n # target_shape and target_affine are conveyed implicitly in mask_img\n params = get_params(self.__class__, self,\n ignore=['mask_img', 'mask_args', 'mask_strategy'])\n\n data = self._cache(filter_and_mask,\n ignore=['verbose', 'memory', 'memory_level',\n 'copy'],\n shelve=self._shelving)(\n imgs, self.mask_img_, params,\n memory_level=self.memory_level,\n memory=self.memory,\n verbose=self.verbose,\n confounds=confounds,\n copy=copy,\n dtype=self.dtype\n )\n\n return data\n", "path": "nilearn/input_data/nifti_masker.py"}]}
| 4,010 | 130 |
gh_patches_debug_18991
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-547
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
import_verified field missing in table resource
## Description
<!-- A clear and concise description of what the bug is. -->
The Table API does not include the `import_verified` field.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The frontend needs the `import_verified` field to figure out which tables to show in preview mode and which tables to show normally.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/serializers.py`
Content:
```
1 import requests
2
3 from django.urls import reverse
4 from rest_framework import serializers
5 from rest_framework.exceptions import ValidationError
6
7 from mathesar.models import Table, Schema, DataFile, Database, Constraint
8
9
10 SUPPORTED_URL_CONTENT_TYPES = {'text/csv', 'text/plain'}
11
12
13 class NestedTableSerializer(serializers.HyperlinkedModelSerializer):
14 url = serializers.SerializerMethodField()
15
16 class Meta:
17 model = Table
18 fields = ['id', 'name', 'url']
19
20 def get_url(self, obj):
21 request = self.context['request']
22 return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))
23
24
25 class ModelNameField(serializers.CharField):
26 """
27 De-serializes the request field as a string, but serializes the response field as
28 `model.name`. Required to support passing and returing a model name from the
29 endpoint, while also storing the model as a related field.
30 """
31 def to_representation(self, value):
32 return value.name
33
34
35 class SchemaSerializer(serializers.HyperlinkedModelSerializer):
36 tables = NestedTableSerializer(many=True, read_only=True)
37 name = serializers.CharField()
38 database = ModelNameField(max_length=128)
39
40 class Meta:
41 model = Schema
42 fields = ['id', 'name', 'tables', 'database', 'has_dependencies']
43
44
45 class TypeOptionSerializer(serializers.Serializer):
46 precision = serializers.IntegerField(required=False)
47 scale = serializers.IntegerField(required=False)
48
49
50 class SimpleColumnSerializer(serializers.Serializer):
51 name = serializers.CharField()
52 type = serializers.CharField(source='plain_type')
53 type_options = TypeOptionSerializer(required=False)
54
55
56 class ColumnSerializer(SimpleColumnSerializer):
57 index = serializers.IntegerField(source='column_index', read_only=True)
58 nullable = serializers.BooleanField(default=True)
59 primary_key = serializers.BooleanField(default=False)
60 valid_target_types = serializers.ListField(read_only=True)
61
62
63 class TableSerializer(serializers.ModelSerializer):
64 columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')
65 records_url = serializers.SerializerMethodField()
66 constraints_url = serializers.SerializerMethodField()
67 columns_url = serializers.SerializerMethodField()
68 name = serializers.CharField(required=False, allow_blank=True, default='')
69 data_files = serializers.PrimaryKeyRelatedField(
70 required=False, many=True, queryset=DataFile.objects.all()
71 )
72
73 class Meta:
74 model = Table
75 fields = ['id', 'name', 'schema', 'created_at', 'updated_at',
76 'columns', 'records_url', 'constraints_url', 'columns_url', 'data_files', 'has_dependencies']
77
78 def get_records_url(self, obj):
79 if isinstance(obj, Table):
80 # Only get records if we are serializing an existing table
81 request = self.context['request']
82 return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))
83 else:
84 return None
85
86 def get_constraints_url(self, obj):
87 if isinstance(obj, Table):
88 # Only get constraints if we are serializing an existing table
89 request = self.context['request']
90 return request.build_absolute_uri(reverse('table-constraint-list', kwargs={'table_pk': obj.pk}))
91 else:
92 return None
93
94 def get_columns_url(self, obj):
95 if isinstance(obj, Table):
96 # Only get columns if we are serializing an existing table
97 request = self.context['request']
98 return request.build_absolute_uri(reverse('table-column-list', kwargs={'table_pk': obj.pk}))
99 else:
100 return None
101
102 def validate_data_files(self, data_files):
103 if data_files and len(data_files) > 1:
104 raise ValidationError('Multiple data files are unsupported.')
105 return data_files
106
107
108 class RecordSerializer(serializers.BaseSerializer):
109 def to_representation(self, instance):
110 return instance._asdict()
111
112
113 class TablePreviewSerializer(serializers.Serializer):
114 name = serializers.CharField(required=False)
115 columns = SimpleColumnSerializer(many=True)
116
117
118 class RecordListParameterSerializer(serializers.Serializer):
119 filters = serializers.JSONField(required=False, default=[])
120 order_by = serializers.JSONField(required=False, default=[])
121 group_count_by = serializers.JSONField(required=False, default=[])
122
123
124 class DatabaseSerializer(serializers.ModelSerializer):
125 supported_types = serializers.ListField(child=serializers.CharField())
126
127 class Meta:
128 model = Database
129 fields = ['id', 'name', 'deleted', 'supported_types']
130 read_only_fields = ['id', 'name', 'deleted', 'supported_types']
131
132
133 class DataFileSerializer(serializers.ModelSerializer):
134 user = serializers.PrimaryKeyRelatedField(
135 default=serializers.CurrentUserDefault(), read_only=True
136 )
137 header = serializers.BooleanField(default=True)
138 paste = serializers.CharField(required=False, trim_whitespace=False)
139 url = serializers.URLField(required=False)
140
141 class Meta:
142 model = DataFile
143 fields = [
144 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter',
145 'escapechar', 'quotechar', 'paste', 'url', 'created_from'
146 ]
147 extra_kwargs = {
148 'file': {'required': False},
149 'delimiter': {'trim_whitespace': False},
150 'escapechar': {'trim_whitespace': False},
151 'quotechar': {'trim_whitespace': False}
152 }
153 # We only currently support importing to a new table, so setting a table via API is invalid.
154 # User should be set automatically, not submitted via the API.
155 read_only_fields = ['user', 'table_imported_to', 'created_from']
156 write_only_fields = ['paste', 'url']
157
158 def save(self, **kwargs):
159 """
160 Set user to current user while saving the data file.
161 """
162 current_user = self.fields['user'].get_default()
163 if current_user.is_authenticated:
164 kwargs['user'] = current_user
165 return super().save(**kwargs)
166
167 def validate(self, data):
168 if not self.partial:
169 # Only perform validation on source files when we're not partial
170 source_fields = ['file', 'paste', 'url']
171 present_fields = [field for field in source_fields if field in data]
172 if len(present_fields) > 1:
173 raise ValidationError(
174 f'Multiple source fields passed: {present_fields}.'
175 f' Only one of {source_fields} should be specified.'
176 )
177 elif len(present_fields) == 0:
178 raise ValidationError(
179 f'One of {source_fields} should be specified.'
180 )
181 return data
182
183 def validate_url(self, url):
184 try:
185 response = requests.head(url, allow_redirects=True)
186 except requests.exceptions.ConnectionError:
187 raise ValidationError('URL cannot be reached.')
188
189 content_type = response.headers.get('content-type')
190 if content_type not in SUPPORTED_URL_CONTENT_TYPES:
191 raise ValidationError(f"URL resource '{content_type}' not a valid type.")
192 return url
193
194
195 class ConstraintSerializer(serializers.ModelSerializer):
196 name = serializers.CharField(required=False)
197 type = serializers.CharField()
198 columns = serializers.ListField()
199
200 class Meta:
201 model = Constraint
202 fields = ['id', 'name', 'type', 'columns']
203
```
Path: `mathesar/imports/csv.py`
Content:
```
1 from io import TextIOWrapper
2
3 import clevercsv as csv
4
5 from mathesar.database.base import create_mathesar_engine
6 from mathesar.models import Table
7 from db import tables, records
8 from mathesar.errors import InvalidTableError
9
10 ALLOWED_DELIMITERS = ",\t:| "
11 SAMPLE_SIZE = 20000
12 CHECK_ROWS = 10
13
14
15 def check_dialect(file, dialect):
16 """
17 Checks to see if we can parse the given file with the given dialect
18
19 Parses the first CHECK_ROWS rows. Checks to see if any have formatting issues (as
20 indicated by parse_row), or if any have a differing number of columns.
21
22 Args:
23 file: _io.TextIOWrapper object, an already opened file
24 dialect: csv.Dialect object, the dialect we are validating
25
26 Returns:
27 bool: False if any error that would cause SQL errors were found, otherwise True
28 """
29 prev_num_columns = None
30 row_gen = csv.read.reader(file, dialect)
31 for _ in range(CHECK_ROWS):
32 try:
33 row = next(row_gen)
34 except StopIteration:
35 # If less than CHECK_ROWS rows in file, stop early
36 break
37
38 num_columns = len(row)
39 if prev_num_columns is None:
40 prev_num_columns = num_columns
41 elif prev_num_columns != num_columns:
42 return False
43 return True
44
45
46 def get_sv_dialect(file):
47 """
48 Given a *sv file, generate a dialect to parse it.
49
50 Args:
51 file: _io.TextIOWrapper object, an already opened file
52
53 Returns:
54 dialect: csv.Dialect object, the dialect to parse the file
55
56 Raises:
57 InvalidTableError: If the generated dialect was unable to parse the file
58 """
59 dialect = csv.detect.Detector().detect(file.read(SAMPLE_SIZE),
60 delimiters=ALLOWED_DELIMITERS)
61 if dialect is None:
62 raise InvalidTableError
63
64 file.seek(0)
65 if check_dialect(file, dialect):
66 file.seek(0)
67 return dialect
68 else:
69 raise InvalidTableError
70
71
72 def get_sv_reader(file, header, dialect=None):
73 file = TextIOWrapper(file, encoding="utf-8-sig")
74 if dialect:
75 reader = csv.DictReader(file, dialect=dialect)
76 else:
77 reader = csv.DictReader(file)
78 if not header:
79 reader.fieldnames = [
80 f"column_{i}" for i in range(len(reader.fieldnames))
81 ]
82 file.seek(0)
83 return reader
84
85
86 def create_db_table_from_data_file(data_file, name, schema):
87 engine = create_mathesar_engine(schema.database.name)
88 sv_filename = data_file.file.path
89 header = data_file.header
90 dialect = csv.dialect.SimpleDialect(data_file.delimiter, data_file.quotechar,
91 data_file.escapechar)
92 with open(sv_filename, 'rb') as sv_file:
93 sv_reader = get_sv_reader(sv_file, header, dialect=dialect)
94 column_names = sv_reader.fieldnames
95 table = tables.create_string_column_table(
96 name=name,
97 schema=schema.name,
98 column_names=column_names,
99 engine=engine
100 )
101 records.create_records_from_csv(
102 table,
103 engine,
104 sv_filename,
105 column_names,
106 header,
107 delimiter=dialect.delimiter,
108 escape=dialect.escapechar,
109 quote=dialect.quotechar,
110 )
111 return table
112
113
114 def create_table_from_csv(data_file, name, schema):
115 engine = create_mathesar_engine(schema.database.name)
116 db_table = create_db_table_from_data_file(
117 data_file, name, schema
118 )
119 db_table_oid = tables.get_oid_from_table(db_table.name, db_table.schema, engine)
120 table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema)
121 data_file.table_imported_to = table
122 data_file.save()
123 return table
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mathesar/imports/csv.py b/mathesar/imports/csv.py
--- a/mathesar/imports/csv.py
+++ b/mathesar/imports/csv.py
@@ -117,7 +117,7 @@
data_file, name, schema
)
db_table_oid = tables.get_oid_from_table(db_table.name, db_table.schema, engine)
- table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema)
+ table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema, import_verified=False)
data_file.table_imported_to = table
data_file.save()
return table
diff --git a/mathesar/serializers.py b/mathesar/serializers.py
--- a/mathesar/serializers.py
+++ b/mathesar/serializers.py
@@ -72,7 +72,7 @@
class Meta:
model = Table
- fields = ['id', 'name', 'schema', 'created_at', 'updated_at',
+ fields = ['id', 'name', 'schema', 'created_at', 'updated_at', 'import_verified',
'columns', 'records_url', 'constraints_url', 'columns_url', 'data_files', 'has_dependencies']
def get_records_url(self, obj):
|
{"golden_diff": "diff --git a/mathesar/imports/csv.py b/mathesar/imports/csv.py\n--- a/mathesar/imports/csv.py\n+++ b/mathesar/imports/csv.py\n@@ -117,7 +117,7 @@\n data_file, name, schema\n )\n db_table_oid = tables.get_oid_from_table(db_table.name, db_table.schema, engine)\n- table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema)\n+ table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema, import_verified=False)\n data_file.table_imported_to = table\n data_file.save()\n return table\ndiff --git a/mathesar/serializers.py b/mathesar/serializers.py\n--- a/mathesar/serializers.py\n+++ b/mathesar/serializers.py\n@@ -72,7 +72,7 @@\n \n class Meta:\n model = Table\n- fields = ['id', 'name', 'schema', 'created_at', 'updated_at',\n+ fields = ['id', 'name', 'schema', 'created_at', 'updated_at', 'import_verified',\n 'columns', 'records_url', 'constraints_url', 'columns_url', 'data_files', 'has_dependencies']\n \n def get_records_url(self, obj):\n", "issue": "import_verified field missing in table resource\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe Table API does not include the `import_verified` field.\r\n\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe frontend needs the `import_verified` field to figure out which tables to show in preview mode and which tables to show normally.\n", "before_files": [{"content": "import requests\n\nfrom django.urls import reverse\nfrom rest_framework import serializers\nfrom rest_framework.exceptions import ValidationError\n\nfrom mathesar.models import Table, Schema, DataFile, Database, Constraint\n\n\nSUPPORTED_URL_CONTENT_TYPES = {'text/csv', 'text/plain'}\n\n\nclass NestedTableSerializer(serializers.HyperlinkedModelSerializer):\n url = serializers.SerializerMethodField()\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'url']\n\n def get_url(self, obj):\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))\n\n\nclass ModelNameField(serializers.CharField):\n \"\"\"\n De-serializes the request field as a string, but serializes the response field as\n `model.name`. Required to support passing and returing a model name from the\n endpoint, while also storing the model as a related field.\n \"\"\"\n def to_representation(self, value):\n return value.name\n\n\nclass SchemaSerializer(serializers.HyperlinkedModelSerializer):\n tables = NestedTableSerializer(many=True, read_only=True)\n name = serializers.CharField()\n database = ModelNameField(max_length=128)\n\n class Meta:\n model = Schema\n fields = ['id', 'name', 'tables', 'database', 'has_dependencies']\n\n\nclass TypeOptionSerializer(serializers.Serializer):\n precision = serializers.IntegerField(required=False)\n scale = serializers.IntegerField(required=False)\n\n\nclass SimpleColumnSerializer(serializers.Serializer):\n name = serializers.CharField()\n type = serializers.CharField(source='plain_type')\n type_options = TypeOptionSerializer(required=False)\n\n\nclass ColumnSerializer(SimpleColumnSerializer):\n index = serializers.IntegerField(source='column_index', read_only=True)\n nullable = serializers.BooleanField(default=True)\n primary_key = serializers.BooleanField(default=False)\n valid_target_types = serializers.ListField(read_only=True)\n\n\nclass TableSerializer(serializers.ModelSerializer):\n columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')\n records_url = serializers.SerializerMethodField()\n constraints_url = serializers.SerializerMethodField()\n columns_url = serializers.SerializerMethodField()\n name = serializers.CharField(required=False, allow_blank=True, default='')\n data_files = serializers.PrimaryKeyRelatedField(\n required=False, many=True, queryset=DataFile.objects.all()\n )\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'schema', 'created_at', 'updated_at',\n 'columns', 'records_url', 'constraints_url', 'columns_url', 'data_files', 'has_dependencies']\n\n def get_records_url(self, obj):\n if isinstance(obj, Table):\n # Only get records if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def get_constraints_url(self, obj):\n if isinstance(obj, Table):\n # Only get constraints if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-constraint-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def get_columns_url(self, obj):\n if isinstance(obj, Table):\n # Only get columns if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-column-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def validate_data_files(self, data_files):\n if data_files and len(data_files) > 1:\n raise ValidationError('Multiple data files are unsupported.')\n return data_files\n\n\nclass RecordSerializer(serializers.BaseSerializer):\n def to_representation(self, instance):\n return instance._asdict()\n\n\nclass TablePreviewSerializer(serializers.Serializer):\n name = serializers.CharField(required=False)\n columns = SimpleColumnSerializer(many=True)\n\n\nclass RecordListParameterSerializer(serializers.Serializer):\n filters = serializers.JSONField(required=False, default=[])\n order_by = serializers.JSONField(required=False, default=[])\n group_count_by = serializers.JSONField(required=False, default=[])\n\n\nclass DatabaseSerializer(serializers.ModelSerializer):\n supported_types = serializers.ListField(child=serializers.CharField())\n\n class Meta:\n model = Database\n fields = ['id', 'name', 'deleted', 'supported_types']\n read_only_fields = ['id', 'name', 'deleted', 'supported_types']\n\n\nclass DataFileSerializer(serializers.ModelSerializer):\n user = serializers.PrimaryKeyRelatedField(\n default=serializers.CurrentUserDefault(), read_only=True\n )\n header = serializers.BooleanField(default=True)\n paste = serializers.CharField(required=False, trim_whitespace=False)\n url = serializers.URLField(required=False)\n\n class Meta:\n model = DataFile\n fields = [\n 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter',\n 'escapechar', 'quotechar', 'paste', 'url', 'created_from'\n ]\n extra_kwargs = {\n 'file': {'required': False},\n 'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n 'quotechar': {'trim_whitespace': False}\n }\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['user', 'table_imported_to', 'created_from']\n write_only_fields = ['paste', 'url']\n\n def save(self, **kwargs):\n \"\"\"\n Set user to current user while saving the data file.\n \"\"\"\n current_user = self.fields['user'].get_default()\n if current_user.is_authenticated:\n kwargs['user'] = current_user\n return super().save(**kwargs)\n\n def validate(self, data):\n if not self.partial:\n # Only perform validation on source files when we're not partial\n source_fields = ['file', 'paste', 'url']\n present_fields = [field for field in source_fields if field in data]\n if len(present_fields) > 1:\n raise ValidationError(\n f'Multiple source fields passed: {present_fields}.'\n f' Only one of {source_fields} should be specified.'\n )\n elif len(present_fields) == 0:\n raise ValidationError(\n f'One of {source_fields} should be specified.'\n )\n return data\n\n def validate_url(self, url):\n try:\n response = requests.head(url, allow_redirects=True)\n except requests.exceptions.ConnectionError:\n raise ValidationError('URL cannot be reached.')\n\n content_type = response.headers.get('content-type')\n if content_type not in SUPPORTED_URL_CONTENT_TYPES:\n raise ValidationError(f\"URL resource '{content_type}' not a valid type.\")\n return url\n\n\nclass ConstraintSerializer(serializers.ModelSerializer):\n name = serializers.CharField(required=False)\n type = serializers.CharField()\n columns = serializers.ListField()\n\n class Meta:\n model = Constraint\n fields = ['id', 'name', 'type', 'columns']\n", "path": "mathesar/serializers.py"}, {"content": "from io import TextIOWrapper\n\nimport clevercsv as csv\n\nfrom mathesar.database.base import create_mathesar_engine\nfrom mathesar.models import Table\nfrom db import tables, records\nfrom mathesar.errors import InvalidTableError\n\nALLOWED_DELIMITERS = \",\\t:| \"\nSAMPLE_SIZE = 20000\nCHECK_ROWS = 10\n\n\ndef check_dialect(file, dialect):\n \"\"\"\n Checks to see if we can parse the given file with the given dialect\n\n Parses the first CHECK_ROWS rows. Checks to see if any have formatting issues (as\n indicated by parse_row), or if any have a differing number of columns.\n\n Args:\n file: _io.TextIOWrapper object, an already opened file\n dialect: csv.Dialect object, the dialect we are validating\n\n Returns:\n bool: False if any error that would cause SQL errors were found, otherwise True\n \"\"\"\n prev_num_columns = None\n row_gen = csv.read.reader(file, dialect)\n for _ in range(CHECK_ROWS):\n try:\n row = next(row_gen)\n except StopIteration:\n # If less than CHECK_ROWS rows in file, stop early\n break\n\n num_columns = len(row)\n if prev_num_columns is None:\n prev_num_columns = num_columns\n elif prev_num_columns != num_columns:\n return False\n return True\n\n\ndef get_sv_dialect(file):\n \"\"\"\n Given a *sv file, generate a dialect to parse it.\n\n Args:\n file: _io.TextIOWrapper object, an already opened file\n\n Returns:\n dialect: csv.Dialect object, the dialect to parse the file\n\n Raises:\n InvalidTableError: If the generated dialect was unable to parse the file\n \"\"\"\n dialect = csv.detect.Detector().detect(file.read(SAMPLE_SIZE),\n delimiters=ALLOWED_DELIMITERS)\n if dialect is None:\n raise InvalidTableError\n\n file.seek(0)\n if check_dialect(file, dialect):\n file.seek(0)\n return dialect\n else:\n raise InvalidTableError\n\n\ndef get_sv_reader(file, header, dialect=None):\n file = TextIOWrapper(file, encoding=\"utf-8-sig\")\n if dialect:\n reader = csv.DictReader(file, dialect=dialect)\n else:\n reader = csv.DictReader(file)\n if not header:\n reader.fieldnames = [\n f\"column_{i}\" for i in range(len(reader.fieldnames))\n ]\n file.seek(0)\n return reader\n\n\ndef create_db_table_from_data_file(data_file, name, schema):\n engine = create_mathesar_engine(schema.database.name)\n sv_filename = data_file.file.path\n header = data_file.header\n dialect = csv.dialect.SimpleDialect(data_file.delimiter, data_file.quotechar,\n data_file.escapechar)\n with open(sv_filename, 'rb') as sv_file:\n sv_reader = get_sv_reader(sv_file, header, dialect=dialect)\n column_names = sv_reader.fieldnames\n table = tables.create_string_column_table(\n name=name,\n schema=schema.name,\n column_names=column_names,\n engine=engine\n )\n records.create_records_from_csv(\n table,\n engine,\n sv_filename,\n column_names,\n header,\n delimiter=dialect.delimiter,\n escape=dialect.escapechar,\n quote=dialect.quotechar,\n )\n return table\n\n\ndef create_table_from_csv(data_file, name, schema):\n engine = create_mathesar_engine(schema.database.name)\n db_table = create_db_table_from_data_file(\n data_file, name, schema\n )\n db_table_oid = tables.get_oid_from_table(db_table.name, db_table.schema, engine)\n table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema)\n data_file.table_imported_to = table\n data_file.save()\n return table\n", "path": "mathesar/imports/csv.py"}], "after_files": [{"content": "import requests\n\nfrom django.urls import reverse\nfrom rest_framework import serializers\nfrom rest_framework.exceptions import ValidationError\n\nfrom mathesar.models import Table, Schema, DataFile, Database, Constraint\n\n\nSUPPORTED_URL_CONTENT_TYPES = {'text/csv', 'text/plain'}\n\n\nclass NestedTableSerializer(serializers.HyperlinkedModelSerializer):\n url = serializers.SerializerMethodField()\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'url']\n\n def get_url(self, obj):\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))\n\n\nclass ModelNameField(serializers.CharField):\n \"\"\"\n De-serializes the request field as a string, but serializes the response field as\n `model.name`. Required to support passing and returing a model name from the\n endpoint, while also storing the model as a related field.\n \"\"\"\n def to_representation(self, value):\n return value.name\n\n\nclass SchemaSerializer(serializers.HyperlinkedModelSerializer):\n tables = NestedTableSerializer(many=True, read_only=True)\n name = serializers.CharField()\n database = ModelNameField(max_length=128)\n\n class Meta:\n model = Schema\n fields = ['id', 'name', 'tables', 'database', 'has_dependencies']\n\n\nclass TypeOptionSerializer(serializers.Serializer):\n precision = serializers.IntegerField(required=False)\n scale = serializers.IntegerField(required=False)\n\n\nclass SimpleColumnSerializer(serializers.Serializer):\n name = serializers.CharField()\n type = serializers.CharField(source='plain_type')\n type_options = TypeOptionSerializer(required=False)\n\n\nclass ColumnSerializer(SimpleColumnSerializer):\n index = serializers.IntegerField(source='column_index', read_only=True)\n nullable = serializers.BooleanField(default=True)\n primary_key = serializers.BooleanField(default=False)\n valid_target_types = serializers.ListField(read_only=True)\n\n\nclass TableSerializer(serializers.ModelSerializer):\n columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')\n records_url = serializers.SerializerMethodField()\n constraints_url = serializers.SerializerMethodField()\n columns_url = serializers.SerializerMethodField()\n name = serializers.CharField(required=False, allow_blank=True, default='')\n data_files = serializers.PrimaryKeyRelatedField(\n required=False, many=True, queryset=DataFile.objects.all()\n )\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'schema', 'created_at', 'updated_at', 'import_verified',\n 'columns', 'records_url', 'constraints_url', 'columns_url', 'data_files', 'has_dependencies']\n\n def get_records_url(self, obj):\n if isinstance(obj, Table):\n # Only get records if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def get_constraints_url(self, obj):\n if isinstance(obj, Table):\n # Only get constraints if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-constraint-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def get_columns_url(self, obj):\n if isinstance(obj, Table):\n # Only get columns if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-column-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n def validate_data_files(self, data_files):\n if data_files and len(data_files) > 1:\n raise ValidationError('Multiple data files are unsupported.')\n return data_files\n\n\nclass RecordSerializer(serializers.BaseSerializer):\n def to_representation(self, instance):\n return instance._asdict()\n\n\nclass TablePreviewSerializer(serializers.Serializer):\n name = serializers.CharField(required=False)\n columns = SimpleColumnSerializer(many=True)\n\n\nclass RecordListParameterSerializer(serializers.Serializer):\n filters = serializers.JSONField(required=False, default=[])\n order_by = serializers.JSONField(required=False, default=[])\n group_count_by = serializers.JSONField(required=False, default=[])\n\n\nclass DatabaseSerializer(serializers.ModelSerializer):\n supported_types = serializers.ListField(child=serializers.CharField())\n\n class Meta:\n model = Database\n fields = ['id', 'name', 'deleted', 'supported_types']\n read_only_fields = ['id', 'name', 'deleted', 'supported_types']\n\n\nclass DataFileSerializer(serializers.ModelSerializer):\n user = serializers.PrimaryKeyRelatedField(\n default=serializers.CurrentUserDefault(), read_only=True\n )\n header = serializers.BooleanField(default=True)\n paste = serializers.CharField(required=False, trim_whitespace=False)\n url = serializers.URLField(required=False)\n\n class Meta:\n model = DataFile\n fields = [\n 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter',\n 'escapechar', 'quotechar', 'paste', 'url', 'created_from'\n ]\n extra_kwargs = {\n 'file': {'required': False},\n 'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n 'quotechar': {'trim_whitespace': False}\n }\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['user', 'table_imported_to', 'created_from']\n write_only_fields = ['paste', 'url']\n\n def save(self, **kwargs):\n \"\"\"\n Set user to current user while saving the data file.\n \"\"\"\n current_user = self.fields['user'].get_default()\n if current_user.is_authenticated:\n kwargs['user'] = current_user\n return super().save(**kwargs)\n\n def validate(self, data):\n if not self.partial:\n # Only perform validation on source files when we're not partial\n source_fields = ['file', 'paste', 'url']\n present_fields = [field for field in source_fields if field in data]\n if len(present_fields) > 1:\n raise ValidationError(\n f'Multiple source fields passed: {present_fields}.'\n f' Only one of {source_fields} should be specified.'\n )\n elif len(present_fields) == 0:\n raise ValidationError(\n f'One of {source_fields} should be specified.'\n )\n return data\n\n def validate_url(self, url):\n try:\n response = requests.head(url, allow_redirects=True)\n except requests.exceptions.ConnectionError:\n raise ValidationError('URL cannot be reached.')\n\n content_type = response.headers.get('content-type')\n if content_type not in SUPPORTED_URL_CONTENT_TYPES:\n raise ValidationError(f\"URL resource '{content_type}' not a valid type.\")\n return url\n\n\nclass ConstraintSerializer(serializers.ModelSerializer):\n name = serializers.CharField(required=False)\n type = serializers.CharField()\n columns = serializers.ListField()\n\n class Meta:\n model = Constraint\n fields = ['id', 'name', 'type', 'columns']\n", "path": "mathesar/serializers.py"}, {"content": "from io import TextIOWrapper\n\nimport clevercsv as csv\n\nfrom mathesar.database.base import create_mathesar_engine\nfrom mathesar.models import Table\nfrom db import tables, records\nfrom mathesar.errors import InvalidTableError\n\nALLOWED_DELIMITERS = \",\\t:| \"\nSAMPLE_SIZE = 20000\nCHECK_ROWS = 10\n\n\ndef check_dialect(file, dialect):\n \"\"\"\n Checks to see if we can parse the given file with the given dialect\n\n Parses the first CHECK_ROWS rows. Checks to see if any have formatting issues (as\n indicated by parse_row), or if any have a differing number of columns.\n\n Args:\n file: _io.TextIOWrapper object, an already opened file\n dialect: csv.Dialect object, the dialect we are validating\n\n Returns:\n bool: False if any error that would cause SQL errors were found, otherwise True\n \"\"\"\n prev_num_columns = None\n row_gen = csv.read.reader(file, dialect)\n for _ in range(CHECK_ROWS):\n try:\n row = next(row_gen)\n except StopIteration:\n # If less than CHECK_ROWS rows in file, stop early\n break\n\n num_columns = len(row)\n if prev_num_columns is None:\n prev_num_columns = num_columns\n elif prev_num_columns != num_columns:\n return False\n return True\n\n\ndef get_sv_dialect(file):\n \"\"\"\n Given a *sv file, generate a dialect to parse it.\n\n Args:\n file: _io.TextIOWrapper object, an already opened file\n\n Returns:\n dialect: csv.Dialect object, the dialect to parse the file\n\n Raises:\n InvalidTableError: If the generated dialect was unable to parse the file\n \"\"\"\n dialect = csv.detect.Detector().detect(file.read(SAMPLE_SIZE),\n delimiters=ALLOWED_DELIMITERS)\n if dialect is None:\n raise InvalidTableError\n\n file.seek(0)\n if check_dialect(file, dialect):\n file.seek(0)\n return dialect\n else:\n raise InvalidTableError\n\n\ndef get_sv_reader(file, header, dialect=None):\n file = TextIOWrapper(file, encoding=\"utf-8-sig\")\n if dialect:\n reader = csv.DictReader(file, dialect=dialect)\n else:\n reader = csv.DictReader(file)\n if not header:\n reader.fieldnames = [\n f\"column_{i}\" for i in range(len(reader.fieldnames))\n ]\n file.seek(0)\n return reader\n\n\ndef create_db_table_from_data_file(data_file, name, schema):\n engine = create_mathesar_engine(schema.database.name)\n sv_filename = data_file.file.path\n header = data_file.header\n dialect = csv.dialect.SimpleDialect(data_file.delimiter, data_file.quotechar,\n data_file.escapechar)\n with open(sv_filename, 'rb') as sv_file:\n sv_reader = get_sv_reader(sv_file, header, dialect=dialect)\n column_names = sv_reader.fieldnames\n table = tables.create_string_column_table(\n name=name,\n schema=schema.name,\n column_names=column_names,\n engine=engine\n )\n records.create_records_from_csv(\n table,\n engine,\n sv_filename,\n column_names,\n header,\n delimiter=dialect.delimiter,\n escape=dialect.escapechar,\n quote=dialect.quotechar,\n )\n return table\n\n\ndef create_table_from_csv(data_file, name, schema):\n engine = create_mathesar_engine(schema.database.name)\n db_table = create_db_table_from_data_file(\n data_file, name, schema\n )\n db_table_oid = tables.get_oid_from_table(db_table.name, db_table.schema, engine)\n table, _ = Table.objects.get_or_create(oid=db_table_oid, schema=schema, import_verified=False)\n data_file.table_imported_to = table\n data_file.save()\n return table\n", "path": "mathesar/imports/csv.py"}]}
| 3,488 | 283 |
gh_patches_debug_5581
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-6644
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The DependencyMixin is being deprecated.
### Summary
When I use the module to blacklist a kernel module, a warning appears.
### Issue Type
Bug Report
### Component Name
kernel_blacklist
### Ansible Version
```console (paste below)
$ansible --version
ansible [core 2.15.0]
config file = None
configured module search path = ['/home/bandura/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /home/bandura/.local/lib/python3.9/site-packages/ansible
ansible collection location = /home/bandura/.ansible/collections:/usr/share/ansible/collections
executable location = /home/bandura/.local/bin/ansible
python version = 3.9.2 (default, Feb 28 2021, 17:03:44) [GCC 10.2.1 20210110] (/usr/bin/python3)
jinja version = 3.1.2
libyaml = True
```
### Community.general Version
```console (paste below)
$ansible-galaxy collection list community.general
# /home/bandura/.local/lib/python3.9/site-packages/ansible_collections
Collection Version
----------------- -------
community.general 7.0.1
```
### Configuration
```console (paste below)
$ansible-config dump --only-changed
CONFIG_FILE() = None
```
### OS / Environment
Debian 11-based
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
- name: Blacklist old kernel module
become: true
community.general.kernel_blacklist:
name: x_tables
```
### Expected Results
No warning
### Actual Results
Works, but with warning.
```console (paste below)
TASK [install-nftables : Blacklist old IPv4 kernel module] *********************
[DEPRECATION WARNING]: The DependencyMixin is being deprecated. Modules should
use community.general.plugins.module_utils.deps instead. This feature will be
removed from community.general in version 9.0.0. Deprecation warnings can be
disabled by setting deprecation_warnings=False in ansible.cfg.
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/module_utils/mh/mixins/deps.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # (c) 2020, Alexei Znamensky <[email protected]>
3 # Copyright (c) 2020, Ansible Project
4 # Simplified BSD License (see LICENSES/BSD-2-Clause.txt or https://opensource.org/licenses/BSD-2-Clause)
5 # SPDX-License-Identifier: BSD-2-Clause
6
7 from __future__ import absolute_import, division, print_function
8 __metaclass__ = type
9
10 import traceback
11
12 from ansible_collections.community.general.plugins.module_utils.mh.base import ModuleHelperBase
13 from ansible_collections.community.general.plugins.module_utils.mh.deco import module_fails_on_exception
14
15
16 class DependencyCtxMgr(object):
17 def __init__(self, name, msg=None):
18 self.name = name
19 self.msg = msg
20 self.has_it = False
21 self.exc_type = None
22 self.exc_val = None
23 self.exc_tb = None
24
25 def __enter__(self):
26 return self
27
28 def __exit__(self, exc_type, exc_val, exc_tb):
29 self.has_it = exc_type is None
30 self.exc_type = exc_type
31 self.exc_val = exc_val
32 self.exc_tb = exc_tb
33 return not self.has_it
34
35 @property
36 def text(self):
37 return self.msg or str(self.exc_val)
38
39
40 class DependencyMixin(ModuleHelperBase):
41 """
42 THIS CLASS IS BEING DEPRECATED.
43 See the deprecation notice in ``DependencyMixin.fail_on_missing_deps()`` below.
44
45 Mixin for mapping module options to running a CLI command with its arguments.
46 """
47 _dependencies = []
48
49 @classmethod
50 def dependency(cls, name, msg):
51 cls._dependencies.append(DependencyCtxMgr(name, msg))
52 return cls._dependencies[-1]
53
54 def fail_on_missing_deps(self):
55 self.module.deprecate(
56 'The DependencyMixin is being deprecated. '
57 'Modules should use community.general.plugins.module_utils.deps instead.',
58 version='9.0.0',
59 collection_name='community.general',
60 )
61 for d in self._dependencies:
62 if not d.has_it:
63 self.module.fail_json(changed=False,
64 exception="\n".join(traceback.format_exception(d.exc_type, d.exc_val, d.exc_tb)),
65 msg=d.text,
66 **self.output)
67
68 @module_fails_on_exception
69 def run(self):
70 self.fail_on_missing_deps()
71 super(DependencyMixin, self).run()
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/module_utils/mh/mixins/deps.py b/plugins/module_utils/mh/mixins/deps.py
--- a/plugins/module_utils/mh/mixins/deps.py
+++ b/plugins/module_utils/mh/mixins/deps.py
@@ -52,6 +52,8 @@
return cls._dependencies[-1]
def fail_on_missing_deps(self):
+ if not self._dependencies:
+ return
self.module.deprecate(
'The DependencyMixin is being deprecated. '
'Modules should use community.general.plugins.module_utils.deps instead.',
|
{"golden_diff": "diff --git a/plugins/module_utils/mh/mixins/deps.py b/plugins/module_utils/mh/mixins/deps.py\n--- a/plugins/module_utils/mh/mixins/deps.py\n+++ b/plugins/module_utils/mh/mixins/deps.py\n@@ -52,6 +52,8 @@\n return cls._dependencies[-1]\n \n def fail_on_missing_deps(self):\n+ if not self._dependencies:\n+ return\n self.module.deprecate(\n 'The DependencyMixin is being deprecated. '\n 'Modules should use community.general.plugins.module_utils.deps instead.',\n", "issue": "The DependencyMixin is being deprecated.\n### Summary\r\n\r\nWhen I use the module to blacklist a kernel module, a warning appears.\r\n\r\n### Issue Type\r\n\r\nBug Report\r\n\r\n### Component Name\r\n\r\nkernel_blacklist\r\n\r\n### Ansible Version\r\n\r\n```console (paste below)\r\n$ansible --version\r\nansible [core 2.15.0]\r\n config file = None\r\n configured module search path = ['/home/bandura/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /home/bandura/.local/lib/python3.9/site-packages/ansible\r\n ansible collection location = /home/bandura/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /home/bandura/.local/bin/ansible\r\n python version = 3.9.2 (default, Feb 28 2021, 17:03:44) [GCC 10.2.1 20210110] (/usr/bin/python3)\r\n jinja version = 3.1.2\r\n libyaml = True\r\n```\r\n\r\n\r\n### Community.general Version\r\n\r\n```console (paste below)\r\n$ansible-galaxy collection list community.general\r\n\r\n# /home/bandura/.local/lib/python3.9/site-packages/ansible_collections\r\nCollection Version\r\n----------------- -------\r\ncommunity.general 7.0.1\r\n```\r\n\r\n\r\n### Configuration\r\n\r\n```console (paste below)\r\n$ansible-config dump --only-changed\r\nCONFIG_FILE() = None\r\n```\r\n\r\n\r\n### OS / Environment\r\n\r\nDebian 11-based\r\n\r\n### Steps to Reproduce\r\n\r\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n- name: Blacklist old kernel module\r\n become: true\r\n community.general.kernel_blacklist:\r\n name: x_tables\r\n```\r\n\r\n\r\n### Expected Results\r\n\r\nNo warning\r\n\r\n### Actual Results\r\n\r\nWorks, but with warning.\r\n```console (paste below)\r\nTASK [install-nftables : Blacklist old IPv4 kernel module] *********************\r\n[DEPRECATION WARNING]: The DependencyMixin is being deprecated. Modules should \r\nuse community.general.plugins.module_utils.deps instead. This feature will be \r\nremoved from community.general in version 9.0.0. Deprecation warnings can be \r\ndisabled by setting deprecation_warnings=False in ansible.cfg.\r\n```\r\n\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# (c) 2020, Alexei Znamensky <[email protected]>\n# Copyright (c) 2020, Ansible Project\n# Simplified BSD License (see LICENSES/BSD-2-Clause.txt or https://opensource.org/licenses/BSD-2-Clause)\n# SPDX-License-Identifier: BSD-2-Clause\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nimport traceback\n\nfrom ansible_collections.community.general.plugins.module_utils.mh.base import ModuleHelperBase\nfrom ansible_collections.community.general.plugins.module_utils.mh.deco import module_fails_on_exception\n\n\nclass DependencyCtxMgr(object):\n def __init__(self, name, msg=None):\n self.name = name\n self.msg = msg\n self.has_it = False\n self.exc_type = None\n self.exc_val = None\n self.exc_tb = None\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.has_it = exc_type is None\n self.exc_type = exc_type\n self.exc_val = exc_val\n self.exc_tb = exc_tb\n return not self.has_it\n\n @property\n def text(self):\n return self.msg or str(self.exc_val)\n\n\nclass DependencyMixin(ModuleHelperBase):\n \"\"\"\n THIS CLASS IS BEING DEPRECATED.\n See the deprecation notice in ``DependencyMixin.fail_on_missing_deps()`` below.\n\n Mixin for mapping module options to running a CLI command with its arguments.\n \"\"\"\n _dependencies = []\n\n @classmethod\n def dependency(cls, name, msg):\n cls._dependencies.append(DependencyCtxMgr(name, msg))\n return cls._dependencies[-1]\n\n def fail_on_missing_deps(self):\n self.module.deprecate(\n 'The DependencyMixin is being deprecated. '\n 'Modules should use community.general.plugins.module_utils.deps instead.',\n version='9.0.0',\n collection_name='community.general',\n )\n for d in self._dependencies:\n if not d.has_it:\n self.module.fail_json(changed=False,\n exception=\"\\n\".join(traceback.format_exception(d.exc_type, d.exc_val, d.exc_tb)),\n msg=d.text,\n **self.output)\n\n @module_fails_on_exception\n def run(self):\n self.fail_on_missing_deps()\n super(DependencyMixin, self).run()\n", "path": "plugins/module_utils/mh/mixins/deps.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# (c) 2020, Alexei Znamensky <[email protected]>\n# Copyright (c) 2020, Ansible Project\n# Simplified BSD License (see LICENSES/BSD-2-Clause.txt or https://opensource.org/licenses/BSD-2-Clause)\n# SPDX-License-Identifier: BSD-2-Clause\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nimport traceback\n\nfrom ansible_collections.community.general.plugins.module_utils.mh.base import ModuleHelperBase\nfrom ansible_collections.community.general.plugins.module_utils.mh.deco import module_fails_on_exception\n\n\nclass DependencyCtxMgr(object):\n def __init__(self, name, msg=None):\n self.name = name\n self.msg = msg\n self.has_it = False\n self.exc_type = None\n self.exc_val = None\n self.exc_tb = None\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.has_it = exc_type is None\n self.exc_type = exc_type\n self.exc_val = exc_val\n self.exc_tb = exc_tb\n return not self.has_it\n\n @property\n def text(self):\n return self.msg or str(self.exc_val)\n\n\nclass DependencyMixin(ModuleHelperBase):\n \"\"\"\n THIS CLASS IS BEING DEPRECATED.\n See the deprecation notice in ``DependencyMixin.fail_on_missing_deps()`` below.\n\n Mixin for mapping module options to running a CLI command with its arguments.\n \"\"\"\n _dependencies = []\n\n @classmethod\n def dependency(cls, name, msg):\n cls._dependencies.append(DependencyCtxMgr(name, msg))\n return cls._dependencies[-1]\n\n def fail_on_missing_deps(self):\n if not self._dependencies:\n return\n self.module.deprecate(\n 'The DependencyMixin is being deprecated. '\n 'Modules should use community.general.plugins.module_utils.deps instead.',\n version='9.0.0',\n collection_name='community.general',\n )\n for d in self._dependencies:\n if not d.has_it:\n self.module.fail_json(changed=False,\n exception=\"\\n\".join(traceback.format_exception(d.exc_type, d.exc_val, d.exc_tb)),\n msg=d.text,\n **self.output)\n\n @module_fails_on_exception\n def run(self):\n self.fail_on_missing_deps()\n super(DependencyMixin, self).run()\n", "path": "plugins/module_utils/mh/mixins/deps.py"}]}
| 1,445 | 128 |
gh_patches_debug_26570
|
rasdani/github-patches
|
git_diff
|
dmlc__dgl-5742
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[GraphBolt] New Storage API : create_heterograph_from_shared_memory
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/dgl/graphbolt/graph_storage/csc_sampling_graph.py`
Content:
```
1 """CSC format sampling graph."""
2 # pylint: disable= invalid-name
3 import os
4 import tarfile
5 import tempfile
6 from typing import Dict, Optional, Tuple
7
8 import torch
9
10
11 class GraphMetadata:
12 r"""Class for metadata of csc sampling graph."""
13
14 def __init__(
15 self,
16 node_type_to_id: Dict[str, int],
17 edge_type_to_id: Dict[Tuple[str, str, str], int],
18 ):
19 """Initialize the GraphMetadata object.
20
21 Parameters
22 ----------
23 node_type_to_id : Dict[str, int]
24 Dictionary from node types to node type IDs.
25 edge_type_to_id : Dict[Tuple[str, str, str], int]
26 Dictionary from edge types to edge type IDs.
27
28 Raises
29 ------
30 AssertionError
31 If any of the assertions fail.
32 """
33
34 node_types = list(node_type_to_id.keys())
35 edge_types = list(edge_type_to_id.keys())
36 node_type_ids = list(node_type_to_id.values())
37 edge_type_ids = list(edge_type_to_id.values())
38
39 # Validate node_type_to_id.
40 assert all(
41 isinstance(x, str) for x in node_types
42 ), "Node type name should be string."
43 assert all(
44 isinstance(x, int) for x in node_type_ids
45 ), "Node type id should be int."
46 assert len(node_type_ids) == len(
47 set(node_type_ids)
48 ), "Multiple node types shoud not be mapped to a same id."
49 # Validate edge_type_to_id.
50 for edge_type in edge_types:
51 src, edge, dst = edge_type
52 assert isinstance(edge, str), "Edge type name should be string."
53 assert (
54 src in node_types
55 ), f"Unrecognized node type {src} in edge type {edge_type}"
56 assert (
57 dst in node_types
58 ), f"Unrecognized node type {dst} in edge type {edge_type}"
59 assert all(
60 isinstance(x, int) for x in edge_type_ids
61 ), "Edge type id should be int."
62 assert len(edge_type_ids) == len(
63 set(edge_type_ids)
64 ), "Multiple edge types shoud not be mapped to a same id."
65
66 self.node_type_to_id = node_type_to_id
67 self.edge_type_to_id = edge_type_to_id
68
69
70 class CSCSamplingGraph:
71 r"""Class for CSC sampling graph."""
72
73 def __repr__(self):
74 return _csc_sampling_graph_str(self)
75
76 def __init__(
77 self, c_csc_graph: torch.ScriptObject, metadata: Optional[GraphMetadata]
78 ):
79 self._c_csc_graph = c_csc_graph
80 self._metadata = metadata
81
82 @property
83 def num_nodes(self) -> int:
84 """Returns the number of nodes in the graph.
85
86 Returns
87 -------
88 int
89 The number of rows in the dense format.
90 """
91 return self._c_csc_graph.num_nodes()
92
93 @property
94 def num_edges(self) -> int:
95 """Returns the number of edges in the graph.
96
97 Returns
98 -------
99 int
100 The number of edges in the graph.
101 """
102 return self._c_csc_graph.num_edges()
103
104 @property
105 def csc_indptr(self) -> torch.tensor:
106 """Returns the indices pointer in the CSC graph.
107
108 Returns
109 -------
110 torch.tensor
111 The indices pointer in the CSC graph. An integer tensor with
112 shape `(num_nodes+1,)`.
113 """
114 return self._c_csc_graph.csc_indptr()
115
116 @property
117 def indices(self) -> torch.tensor:
118 """Returns the indices in the CSC graph.
119
120 Returns
121 -------
122 torch.tensor
123 The indices in the CSC graph. An integer tensor with shape
124 `(num_edges,)`.
125
126 Notes
127 -------
128 It is assumed that edges of each node are already sorted by edge type
129 ids.
130 """
131 return self._c_csc_graph.indices()
132
133 @property
134 def node_type_offset(self) -> Optional[torch.Tensor]:
135 """Returns the node type offset tensor if present.
136
137 Returns
138 -------
139 torch.Tensor or None
140 If present, returns a 1D integer tensor of shape
141 `(num_node_types + 1,)`. The tensor is in ascending order as nodes
142 of the same type have continuous IDs, and larger node IDs are
143 paired with larger node type IDs. The first value is 0 and last
144 value is the number of nodes. And nodes with IDs between
145 `node_type_offset_[i]~node_type_offset_[i+1]` are of type id 'i'.
146
147 """
148 return self._c_csc_graph.node_type_offset()
149
150 @property
151 def type_per_edge(self) -> Optional[torch.Tensor]:
152 """Returns the edge type tensor if present.
153
154 Returns
155 -------
156 torch.Tensor or None
157 If present, returns a 1D integer tensor of shape (num_edges,)
158 containing the type of each edge in the graph.
159 """
160 return self._c_csc_graph.type_per_edge()
161
162 @property
163 def metadata(self) -> Optional[GraphMetadata]:
164 """Returns the metadata of the graph.
165
166 Returns
167 -------
168 GraphMetadata or None
169 If present, returns the metadata of the graph.
170 """
171 return self._metadata
172
173 def in_subgraph(self, nodes: torch.Tensor) -> torch.ScriptObject:
174 """Return the subgraph induced on the inbound edges of the given nodes.
175
176 An in subgraph is equivalent to creating a new graph using the incoming
177 edges of the given nodes.
178
179 Parameters
180 ----------
181 nodes : torch.Tensor
182 The nodes to form the subgraph which are type agnostic.
183
184 Returns
185 -------
186 SampledSubgraph
187 The in subgraph.
188 """
189 # Ensure nodes is 1-D tensor.
190 assert nodes.dim() == 1, "Nodes should be 1-D tensor."
191 # Ensure that there are no duplicate nodes.
192 assert len(torch.unique(nodes)) == len(
193 nodes
194 ), "Nodes cannot have duplicate values."
195 return self._c_csc_graph.in_subgraph(nodes)
196
197
198 def from_csc(
199 csc_indptr: torch.Tensor,
200 indices: torch.Tensor,
201 node_type_offset: Optional[torch.tensor] = None,
202 type_per_edge: Optional[torch.tensor] = None,
203 metadata: Optional[GraphMetadata] = None,
204 ) -> CSCSamplingGraph:
205 """Create a CSCSamplingGraph object from a CSC representation.
206
207 Parameters
208 ----------
209 csc_indptr : torch.Tensor
210 Pointer to the start of each row in the `indices`. An integer tensor
211 with shape `(num_nodes+1,)`.
212 indices : torch.Tensor
213 Column indices of the non-zero elements in the CSC graph. An integer
214 tensor with shape `(num_edges,)`.
215 node_type_offset : Optional[torch.tensor], optional
216 Offset of node types in the graph, by default None.
217 type_per_edge : Optional[torch.tensor], optional
218 Type ids of each edge in the graph, by default None.
219 metadata: Optional[GraphMetadata], optional
220 Metadata of the graph, by default None.
221 Returns
222 -------
223 CSCSamplingGraph
224 The created CSCSamplingGraph object.
225
226 Examples
227 --------
228 >>> ntypes = {'n1': 0, 'n2': 1, 'n3': 2}
229 >>> etypes = {('n1', 'e1', 'n2'): 0, ('n1', 'e2', 'n3'): 1}
230 >>> metadata = graphbolt.GraphMetadata(ntypes, etypes)
231 >>> csc_indptr = torch.tensor([0, 2, 5, 7])
232 >>> indices = torch.tensor([1, 3, 0, 1, 2, 0, 3])
233 >>> node_type_offset = torch.tensor([0, 1, 2, 3])
234 >>> type_per_edge = torch.tensor([0, 1, 0, 1, 1, 0, 0])
235 >>> graph = graphbolt.from_csc(csc_indptr, indices, node_type_offset, \
236 >>> type_per_edge, metadata)
237 >>> print(graph)
238 CSCSamplingGraph(csc_indptr=tensor([0, 2, 5, 7]),
239 indices=tensor([1, 3, 0, 1, 2, 0, 3]),
240 num_nodes=3, num_edges=7)
241 """
242 if metadata and metadata.node_type_to_id and node_type_offset is not None:
243 assert len(metadata.node_type_to_id) + 1 == node_type_offset.size(
244 0
245 ), "node_type_offset length should be |ntypes| + 1."
246 return CSCSamplingGraph(
247 torch.ops.graphbolt.from_csc(
248 csc_indptr, indices, node_type_offset, type_per_edge
249 ),
250 metadata,
251 )
252
253
254 def _csc_sampling_graph_str(graph: CSCSamplingGraph) -> str:
255 """Internal function for converting a csc sampling graph to string
256 representation.
257 """
258 csc_indptr_str = str(graph.csc_indptr)
259 indices_str = str(graph.indices)
260 meta_str = f"num_nodes={graph.num_nodes}, num_edges={graph.num_edges}"
261 prefix = f"{type(graph).__name__}("
262
263 def _add_indent(_str, indent):
264 lines = _str.split("\n")
265 lines = [lines[0]] + [" " * indent + line for line in lines[1:]]
266 return "\n".join(lines)
267
268 final_str = (
269 "csc_indptr="
270 + _add_indent(csc_indptr_str, len("csc_indptr="))
271 + ",\n"
272 + "indices="
273 + _add_indent(indices_str, len("indices="))
274 + ",\n"
275 + meta_str
276 + ")"
277 )
278
279 final_str = prefix + _add_indent(final_str, len(prefix))
280 return final_str
281
282
283 def load_csc_sampling_graph(filename):
284 """Load CSCSamplingGraph from tar file."""
285 with tempfile.TemporaryDirectory() as temp_dir:
286 with tarfile.open(filename, "r") as archive:
287 archive.extractall(temp_dir)
288 graph_filename = os.path.join(temp_dir, "csc_sampling_graph.pt")
289 metadata_filename = os.path.join(temp_dir, "metadata.pt")
290 return CSCSamplingGraph(
291 torch.ops.graphbolt.load_csc_sampling_graph(graph_filename),
292 torch.load(metadata_filename),
293 )
294
295
296 def save_csc_sampling_graph(graph, filename):
297 """Save CSCSamplingGraph to tar file."""
298 with tempfile.TemporaryDirectory() as temp_dir:
299 graph_filename = os.path.join(temp_dir, "csc_sampling_graph.pt")
300 torch.ops.graphbolt.save_csc_sampling_graph(
301 graph._c_csc_graph, graph_filename
302 )
303 metadata_filename = os.path.join(temp_dir, "metadata.pt")
304 torch.save(graph.metadata, metadata_filename)
305 with tarfile.open(filename, "w") as archive:
306 archive.add(
307 graph_filename, arcname=os.path.basename(graph_filename)
308 )
309 archive.add(
310 metadata_filename, arcname=os.path.basename(metadata_filename)
311 )
312 print(f"CSCSamplingGraph has been saved to {filename}.")
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py b/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py
--- a/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py
+++ b/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py
@@ -194,6 +194,24 @@
), "Nodes cannot have duplicate values."
return self._c_csc_graph.in_subgraph(nodes)
+ def copy_to_shared_memory(self, shared_memory_name: str):
+ """Copy the graph to shared memory.
+
+ Parameters
+ ----------
+ shared_memory_name : str
+ Name of the shared memory.
+
+ Returns
+ -------
+ CSCSamplingGraph
+ The copied CSCSamplingGraph object on shared memory.
+ """
+ return CSCSamplingGraph(
+ self._c_csc_graph.copy_to_shared_memory(shared_memory_name),
+ self._metadata,
+ )
+
def from_csc(
csc_indptr: torch.Tensor,
@@ -251,6 +269,28 @@
)
+def load_from_shared_memory(
+ shared_memory_name: str,
+ metadata: Optional[GraphMetadata] = None,
+) -> CSCSamplingGraph:
+ """Load a CSCSamplingGraph object from shared memory.
+
+ Parameters
+ ----------
+ shared_memory_name : str
+ Name of the shared memory.
+
+ Returns
+ -------
+ CSCSamplingGraph
+ The loaded CSCSamplingGraph object on shared memory.
+ """
+ return CSCSamplingGraph(
+ torch.ops.graphbolt.load_from_shared_memory(shared_memory_name),
+ metadata,
+ )
+
+
def _csc_sampling_graph_str(graph: CSCSamplingGraph) -> str:
"""Internal function for converting a csc sampling graph to string
representation.
|
{"golden_diff": "diff --git a/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py b/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py\n--- a/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py\n+++ b/python/dgl/graphbolt/graph_storage/csc_sampling_graph.py\n@@ -194,6 +194,24 @@\n ), \"Nodes cannot have duplicate values.\"\n return self._c_csc_graph.in_subgraph(nodes)\n \n+ def copy_to_shared_memory(self, shared_memory_name: str):\n+ \"\"\"Copy the graph to shared memory.\n+\n+ Parameters\n+ ----------\n+ shared_memory_name : str\n+ Name of the shared memory.\n+\n+ Returns\n+ -------\n+ CSCSamplingGraph\n+ The copied CSCSamplingGraph object on shared memory.\n+ \"\"\"\n+ return CSCSamplingGraph(\n+ self._c_csc_graph.copy_to_shared_memory(shared_memory_name),\n+ self._metadata,\n+ )\n+\n \n def from_csc(\n csc_indptr: torch.Tensor,\n@@ -251,6 +269,28 @@\n )\n \n \n+def load_from_shared_memory(\n+ shared_memory_name: str,\n+ metadata: Optional[GraphMetadata] = None,\n+) -> CSCSamplingGraph:\n+ \"\"\"Load a CSCSamplingGraph object from shared memory.\n+\n+ Parameters\n+ ----------\n+ shared_memory_name : str\n+ Name of the shared memory.\n+\n+ Returns\n+ -------\n+ CSCSamplingGraph\n+ The loaded CSCSamplingGraph object on shared memory.\n+ \"\"\"\n+ return CSCSamplingGraph(\n+ torch.ops.graphbolt.load_from_shared_memory(shared_memory_name),\n+ metadata,\n+ )\n+\n+\n def _csc_sampling_graph_str(graph: CSCSamplingGraph) -> str:\n \"\"\"Internal function for converting a csc sampling graph to string\n representation.\n", "issue": "[GraphBolt] New Storage API : create_heterograph_from_shared_memory\n\n", "before_files": [{"content": "\"\"\"CSC format sampling graph.\"\"\"\n# pylint: disable= invalid-name\nimport os\nimport tarfile\nimport tempfile\nfrom typing import Dict, Optional, Tuple\n\nimport torch\n\n\nclass GraphMetadata:\n r\"\"\"Class for metadata of csc sampling graph.\"\"\"\n\n def __init__(\n self,\n node_type_to_id: Dict[str, int],\n edge_type_to_id: Dict[Tuple[str, str, str], int],\n ):\n \"\"\"Initialize the GraphMetadata object.\n\n Parameters\n ----------\n node_type_to_id : Dict[str, int]\n Dictionary from node types to node type IDs.\n edge_type_to_id : Dict[Tuple[str, str, str], int]\n Dictionary from edge types to edge type IDs.\n\n Raises\n ------\n AssertionError\n If any of the assertions fail.\n \"\"\"\n\n node_types = list(node_type_to_id.keys())\n edge_types = list(edge_type_to_id.keys())\n node_type_ids = list(node_type_to_id.values())\n edge_type_ids = list(edge_type_to_id.values())\n\n # Validate node_type_to_id.\n assert all(\n isinstance(x, str) for x in node_types\n ), \"Node type name should be string.\"\n assert all(\n isinstance(x, int) for x in node_type_ids\n ), \"Node type id should be int.\"\n assert len(node_type_ids) == len(\n set(node_type_ids)\n ), \"Multiple node types shoud not be mapped to a same id.\"\n # Validate edge_type_to_id.\n for edge_type in edge_types:\n src, edge, dst = edge_type\n assert isinstance(edge, str), \"Edge type name should be string.\"\n assert (\n src in node_types\n ), f\"Unrecognized node type {src} in edge type {edge_type}\"\n assert (\n dst in node_types\n ), f\"Unrecognized node type {dst} in edge type {edge_type}\"\n assert all(\n isinstance(x, int) for x in edge_type_ids\n ), \"Edge type id should be int.\"\n assert len(edge_type_ids) == len(\n set(edge_type_ids)\n ), \"Multiple edge types shoud not be mapped to a same id.\"\n\n self.node_type_to_id = node_type_to_id\n self.edge_type_to_id = edge_type_to_id\n\n\nclass CSCSamplingGraph:\n r\"\"\"Class for CSC sampling graph.\"\"\"\n\n def __repr__(self):\n return _csc_sampling_graph_str(self)\n\n def __init__(\n self, c_csc_graph: torch.ScriptObject, metadata: Optional[GraphMetadata]\n ):\n self._c_csc_graph = c_csc_graph\n self._metadata = metadata\n\n @property\n def num_nodes(self) -> int:\n \"\"\"Returns the number of nodes in the graph.\n\n Returns\n -------\n int\n The number of rows in the dense format.\n \"\"\"\n return self._c_csc_graph.num_nodes()\n\n @property\n def num_edges(self) -> int:\n \"\"\"Returns the number of edges in the graph.\n\n Returns\n -------\n int\n The number of edges in the graph.\n \"\"\"\n return self._c_csc_graph.num_edges()\n\n @property\n def csc_indptr(self) -> torch.tensor:\n \"\"\"Returns the indices pointer in the CSC graph.\n\n Returns\n -------\n torch.tensor\n The indices pointer in the CSC graph. An integer tensor with\n shape `(num_nodes+1,)`.\n \"\"\"\n return self._c_csc_graph.csc_indptr()\n\n @property\n def indices(self) -> torch.tensor:\n \"\"\"Returns the indices in the CSC graph.\n\n Returns\n -------\n torch.tensor\n The indices in the CSC graph. An integer tensor with shape\n `(num_edges,)`.\n\n Notes\n -------\n It is assumed that edges of each node are already sorted by edge type\n ids.\n \"\"\"\n return self._c_csc_graph.indices()\n\n @property\n def node_type_offset(self) -> Optional[torch.Tensor]:\n \"\"\"Returns the node type offset tensor if present.\n\n Returns\n -------\n torch.Tensor or None\n If present, returns a 1D integer tensor of shape\n `(num_node_types + 1,)`. The tensor is in ascending order as nodes\n of the same type have continuous IDs, and larger node IDs are\n paired with larger node type IDs. The first value is 0 and last\n value is the number of nodes. And nodes with IDs between\n `node_type_offset_[i]~node_type_offset_[i+1]` are of type id 'i'.\n\n \"\"\"\n return self._c_csc_graph.node_type_offset()\n\n @property\n def type_per_edge(self) -> Optional[torch.Tensor]:\n \"\"\"Returns the edge type tensor if present.\n\n Returns\n -------\n torch.Tensor or None\n If present, returns a 1D integer tensor of shape (num_edges,)\n containing the type of each edge in the graph.\n \"\"\"\n return self._c_csc_graph.type_per_edge()\n\n @property\n def metadata(self) -> Optional[GraphMetadata]:\n \"\"\"Returns the metadata of the graph.\n\n Returns\n -------\n GraphMetadata or None\n If present, returns the metadata of the graph.\n \"\"\"\n return self._metadata\n\n def in_subgraph(self, nodes: torch.Tensor) -> torch.ScriptObject:\n \"\"\"Return the subgraph induced on the inbound edges of the given nodes.\n\n An in subgraph is equivalent to creating a new graph using the incoming\n edges of the given nodes.\n\n Parameters\n ----------\n nodes : torch.Tensor\n The nodes to form the subgraph which are type agnostic.\n\n Returns\n -------\n SampledSubgraph\n The in subgraph.\n \"\"\"\n # Ensure nodes is 1-D tensor.\n assert nodes.dim() == 1, \"Nodes should be 1-D tensor.\"\n # Ensure that there are no duplicate nodes.\n assert len(torch.unique(nodes)) == len(\n nodes\n ), \"Nodes cannot have duplicate values.\"\n return self._c_csc_graph.in_subgraph(nodes)\n\n\ndef from_csc(\n csc_indptr: torch.Tensor,\n indices: torch.Tensor,\n node_type_offset: Optional[torch.tensor] = None,\n type_per_edge: Optional[torch.tensor] = None,\n metadata: Optional[GraphMetadata] = None,\n) -> CSCSamplingGraph:\n \"\"\"Create a CSCSamplingGraph object from a CSC representation.\n\n Parameters\n ----------\n csc_indptr : torch.Tensor\n Pointer to the start of each row in the `indices`. An integer tensor\n with shape `(num_nodes+1,)`.\n indices : torch.Tensor\n Column indices of the non-zero elements in the CSC graph. An integer\n tensor with shape `(num_edges,)`.\n node_type_offset : Optional[torch.tensor], optional\n Offset of node types in the graph, by default None.\n type_per_edge : Optional[torch.tensor], optional\n Type ids of each edge in the graph, by default None.\n metadata: Optional[GraphMetadata], optional\n Metadata of the graph, by default None.\n Returns\n -------\n CSCSamplingGraph\n The created CSCSamplingGraph object.\n\n Examples\n --------\n >>> ntypes = {'n1': 0, 'n2': 1, 'n3': 2}\n >>> etypes = {('n1', 'e1', 'n2'): 0, ('n1', 'e2', 'n3'): 1}\n >>> metadata = graphbolt.GraphMetadata(ntypes, etypes)\n >>> csc_indptr = torch.tensor([0, 2, 5, 7])\n >>> indices = torch.tensor([1, 3, 0, 1, 2, 0, 3])\n >>> node_type_offset = torch.tensor([0, 1, 2, 3])\n >>> type_per_edge = torch.tensor([0, 1, 0, 1, 1, 0, 0])\n >>> graph = graphbolt.from_csc(csc_indptr, indices, node_type_offset, \\\n >>> type_per_edge, metadata)\n >>> print(graph)\n CSCSamplingGraph(csc_indptr=tensor([0, 2, 5, 7]),\n indices=tensor([1, 3, 0, 1, 2, 0, 3]),\n num_nodes=3, num_edges=7)\n \"\"\"\n if metadata and metadata.node_type_to_id and node_type_offset is not None:\n assert len(metadata.node_type_to_id) + 1 == node_type_offset.size(\n 0\n ), \"node_type_offset length should be |ntypes| + 1.\"\n return CSCSamplingGraph(\n torch.ops.graphbolt.from_csc(\n csc_indptr, indices, node_type_offset, type_per_edge\n ),\n metadata,\n )\n\n\ndef _csc_sampling_graph_str(graph: CSCSamplingGraph) -> str:\n \"\"\"Internal function for converting a csc sampling graph to string\n representation.\n \"\"\"\n csc_indptr_str = str(graph.csc_indptr)\n indices_str = str(graph.indices)\n meta_str = f\"num_nodes={graph.num_nodes}, num_edges={graph.num_edges}\"\n prefix = f\"{type(graph).__name__}(\"\n\n def _add_indent(_str, indent):\n lines = _str.split(\"\\n\")\n lines = [lines[0]] + [\" \" * indent + line for line in lines[1:]]\n return \"\\n\".join(lines)\n\n final_str = (\n \"csc_indptr=\"\n + _add_indent(csc_indptr_str, len(\"csc_indptr=\"))\n + \",\\n\"\n + \"indices=\"\n + _add_indent(indices_str, len(\"indices=\"))\n + \",\\n\"\n + meta_str\n + \")\"\n )\n\n final_str = prefix + _add_indent(final_str, len(prefix))\n return final_str\n\n\ndef load_csc_sampling_graph(filename):\n \"\"\"Load CSCSamplingGraph from tar file.\"\"\"\n with tempfile.TemporaryDirectory() as temp_dir:\n with tarfile.open(filename, \"r\") as archive:\n archive.extractall(temp_dir)\n graph_filename = os.path.join(temp_dir, \"csc_sampling_graph.pt\")\n metadata_filename = os.path.join(temp_dir, \"metadata.pt\")\n return CSCSamplingGraph(\n torch.ops.graphbolt.load_csc_sampling_graph(graph_filename),\n torch.load(metadata_filename),\n )\n\n\ndef save_csc_sampling_graph(graph, filename):\n \"\"\"Save CSCSamplingGraph to tar file.\"\"\"\n with tempfile.TemporaryDirectory() as temp_dir:\n graph_filename = os.path.join(temp_dir, \"csc_sampling_graph.pt\")\n torch.ops.graphbolt.save_csc_sampling_graph(\n graph._c_csc_graph, graph_filename\n )\n metadata_filename = os.path.join(temp_dir, \"metadata.pt\")\n torch.save(graph.metadata, metadata_filename)\n with tarfile.open(filename, \"w\") as archive:\n archive.add(\n graph_filename, arcname=os.path.basename(graph_filename)\n )\n archive.add(\n metadata_filename, arcname=os.path.basename(metadata_filename)\n )\n print(f\"CSCSamplingGraph has been saved to {filename}.\")\n", "path": "python/dgl/graphbolt/graph_storage/csc_sampling_graph.py"}], "after_files": [{"content": "\"\"\"CSC format sampling graph.\"\"\"\n# pylint: disable= invalid-name\nimport os\nimport tarfile\nimport tempfile\nfrom typing import Dict, Optional, Tuple\n\nimport torch\n\n\nclass GraphMetadata:\n r\"\"\"Class for metadata of csc sampling graph.\"\"\"\n\n def __init__(\n self,\n node_type_to_id: Dict[str, int],\n edge_type_to_id: Dict[Tuple[str, str, str], int],\n ):\n \"\"\"Initialize the GraphMetadata object.\n\n Parameters\n ----------\n node_type_to_id : Dict[str, int]\n Dictionary from node types to node type IDs.\n edge_type_to_id : Dict[Tuple[str, str, str], int]\n Dictionary from edge types to edge type IDs.\n\n Raises\n ------\n AssertionError\n If any of the assertions fail.\n \"\"\"\n\n node_types = list(node_type_to_id.keys())\n edge_types = list(edge_type_to_id.keys())\n node_type_ids = list(node_type_to_id.values())\n edge_type_ids = list(edge_type_to_id.values())\n\n # Validate node_type_to_id.\n assert all(\n isinstance(x, str) for x in node_types\n ), \"Node type name should be string.\"\n assert all(\n isinstance(x, int) for x in node_type_ids\n ), \"Node type id should be int.\"\n assert len(node_type_ids) == len(\n set(node_type_ids)\n ), \"Multiple node types shoud not be mapped to a same id.\"\n # Validate edge_type_to_id.\n for edge_type in edge_types:\n src, edge, dst = edge_type\n assert isinstance(edge, str), \"Edge type name should be string.\"\n assert (\n src in node_types\n ), f\"Unrecognized node type {src} in edge type {edge_type}\"\n assert (\n dst in node_types\n ), f\"Unrecognized node type {dst} in edge type {edge_type}\"\n assert all(\n isinstance(x, int) for x in edge_type_ids\n ), \"Edge type id should be int.\"\n assert len(edge_type_ids) == len(\n set(edge_type_ids)\n ), \"Multiple edge types shoud not be mapped to a same id.\"\n\n self.node_type_to_id = node_type_to_id\n self.edge_type_to_id = edge_type_to_id\n\n\nclass CSCSamplingGraph:\n r\"\"\"Class for CSC sampling graph.\"\"\"\n\n def __repr__(self):\n return _csc_sampling_graph_str(self)\n\n def __init__(\n self, c_csc_graph: torch.ScriptObject, metadata: Optional[GraphMetadata]\n ):\n self._c_csc_graph = c_csc_graph\n self._metadata = metadata\n\n @property\n def num_nodes(self) -> int:\n \"\"\"Returns the number of nodes in the graph.\n\n Returns\n -------\n int\n The number of rows in the dense format.\n \"\"\"\n return self._c_csc_graph.num_nodes()\n\n @property\n def num_edges(self) -> int:\n \"\"\"Returns the number of edges in the graph.\n\n Returns\n -------\n int\n The number of edges in the graph.\n \"\"\"\n return self._c_csc_graph.num_edges()\n\n @property\n def csc_indptr(self) -> torch.tensor:\n \"\"\"Returns the indices pointer in the CSC graph.\n\n Returns\n -------\n torch.tensor\n The indices pointer in the CSC graph. An integer tensor with\n shape `(num_nodes+1,)`.\n \"\"\"\n return self._c_csc_graph.csc_indptr()\n\n @property\n def indices(self) -> torch.tensor:\n \"\"\"Returns the indices in the CSC graph.\n\n Returns\n -------\n torch.tensor\n The indices in the CSC graph. An integer tensor with shape\n `(num_edges,)`.\n\n Notes\n -------\n It is assumed that edges of each node are already sorted by edge type\n ids.\n \"\"\"\n return self._c_csc_graph.indices()\n\n @property\n def node_type_offset(self) -> Optional[torch.Tensor]:\n \"\"\"Returns the node type offset tensor if present.\n\n Returns\n -------\n torch.Tensor or None\n If present, returns a 1D integer tensor of shape\n `(num_node_types + 1,)`. The tensor is in ascending order as nodes\n of the same type have continuous IDs, and larger node IDs are\n paired with larger node type IDs. The first value is 0 and last\n value is the number of nodes. And nodes with IDs between\n `node_type_offset_[i]~node_type_offset_[i+1]` are of type id 'i'.\n\n \"\"\"\n return self._c_csc_graph.node_type_offset()\n\n @property\n def type_per_edge(self) -> Optional[torch.Tensor]:\n \"\"\"Returns the edge type tensor if present.\n\n Returns\n -------\n torch.Tensor or None\n If present, returns a 1D integer tensor of shape (num_edges,)\n containing the type of each edge in the graph.\n \"\"\"\n return self._c_csc_graph.type_per_edge()\n\n @property\n def metadata(self) -> Optional[GraphMetadata]:\n \"\"\"Returns the metadata of the graph.\n\n Returns\n -------\n GraphMetadata or None\n If present, returns the metadata of the graph.\n \"\"\"\n return self._metadata\n\n def in_subgraph(self, nodes: torch.Tensor) -> torch.ScriptObject:\n \"\"\"Return the subgraph induced on the inbound edges of the given nodes.\n\n An in subgraph is equivalent to creating a new graph using the incoming\n edges of the given nodes.\n\n Parameters\n ----------\n nodes : torch.Tensor\n The nodes to form the subgraph which are type agnostic.\n\n Returns\n -------\n SampledSubgraph\n The in subgraph.\n \"\"\"\n # Ensure nodes is 1-D tensor.\n assert nodes.dim() == 1, \"Nodes should be 1-D tensor.\"\n # Ensure that there are no duplicate nodes.\n assert len(torch.unique(nodes)) == len(\n nodes\n ), \"Nodes cannot have duplicate values.\"\n return self._c_csc_graph.in_subgraph(nodes)\n\n def copy_to_shared_memory(self, shared_memory_name: str):\n \"\"\"Copy the graph to shared memory.\n\n Parameters\n ----------\n shared_memory_name : str\n Name of the shared memory.\n\n Returns\n -------\n CSCSamplingGraph\n The copied CSCSamplingGraph object on shared memory.\n \"\"\"\n return CSCSamplingGraph(\n self._c_csc_graph.copy_to_shared_memory(shared_memory_name),\n self._metadata,\n )\n\n\ndef from_csc(\n csc_indptr: torch.Tensor,\n indices: torch.Tensor,\n node_type_offset: Optional[torch.tensor] = None,\n type_per_edge: Optional[torch.tensor] = None,\n metadata: Optional[GraphMetadata] = None,\n) -> CSCSamplingGraph:\n \"\"\"Create a CSCSamplingGraph object from a CSC representation.\n\n Parameters\n ----------\n csc_indptr : torch.Tensor\n Pointer to the start of each row in the `indices`. An integer tensor\n with shape `(num_nodes+1,)`.\n indices : torch.Tensor\n Column indices of the non-zero elements in the CSC graph. An integer\n tensor with shape `(num_edges,)`.\n node_type_offset : Optional[torch.tensor], optional\n Offset of node types in the graph, by default None.\n type_per_edge : Optional[torch.tensor], optional\n Type ids of each edge in the graph, by default None.\n metadata: Optional[GraphMetadata], optional\n Metadata of the graph, by default None.\n Returns\n -------\n CSCSamplingGraph\n The created CSCSamplingGraph object.\n\n Examples\n --------\n >>> ntypes = {'n1': 0, 'n2': 1, 'n3': 2}\n >>> etypes = {('n1', 'e1', 'n2'): 0, ('n1', 'e2', 'n3'): 1}\n >>> metadata = graphbolt.GraphMetadata(ntypes, etypes)\n >>> csc_indptr = torch.tensor([0, 2, 5, 7])\n >>> indices = torch.tensor([1, 3, 0, 1, 2, 0, 3])\n >>> node_type_offset = torch.tensor([0, 1, 2, 3])\n >>> type_per_edge = torch.tensor([0, 1, 0, 1, 1, 0, 0])\n >>> graph = graphbolt.from_csc(csc_indptr, indices, node_type_offset, \\\n >>> type_per_edge, metadata)\n >>> print(graph)\n CSCSamplingGraph(csc_indptr=tensor([0, 2, 5, 7]),\n indices=tensor([1, 3, 0, 1, 2, 0, 3]),\n num_nodes=3, num_edges=7)\n \"\"\"\n if metadata and metadata.node_type_to_id and node_type_offset is not None:\n assert len(metadata.node_type_to_id) + 1 == node_type_offset.size(\n 0\n ), \"node_type_offset length should be |ntypes| + 1.\"\n return CSCSamplingGraph(\n torch.ops.graphbolt.from_csc(\n csc_indptr, indices, node_type_offset, type_per_edge\n ),\n metadata,\n )\n\n\ndef load_from_shared_memory(\n shared_memory_name: str,\n metadata: Optional[GraphMetadata] = None,\n) -> CSCSamplingGraph:\n \"\"\"Load a CSCSamplingGraph object from shared memory.\n\n Parameters\n ----------\n shared_memory_name : str\n Name of the shared memory.\n\n Returns\n -------\n CSCSamplingGraph\n The loaded CSCSamplingGraph object on shared memory.\n \"\"\"\n return CSCSamplingGraph(\n torch.ops.graphbolt.load_from_shared_memory(shared_memory_name),\n metadata,\n )\n\n\ndef _csc_sampling_graph_str(graph: CSCSamplingGraph) -> str:\n \"\"\"Internal function for converting a csc sampling graph to string\n representation.\n \"\"\"\n csc_indptr_str = str(graph.csc_indptr)\n indices_str = str(graph.indices)\n meta_str = f\"num_nodes={graph.num_nodes}, num_edges={graph.num_edges}\"\n prefix = f\"{type(graph).__name__}(\"\n\n def _add_indent(_str, indent):\n lines = _str.split(\"\\n\")\n lines = [lines[0]] + [\" \" * indent + line for line in lines[1:]]\n return \"\\n\".join(lines)\n\n final_str = (\n \"csc_indptr=\"\n + _add_indent(csc_indptr_str, len(\"csc_indptr=\"))\n + \",\\n\"\n + \"indices=\"\n + _add_indent(indices_str, len(\"indices=\"))\n + \",\\n\"\n + meta_str\n + \")\"\n )\n\n final_str = prefix + _add_indent(final_str, len(prefix))\n return final_str\n\n\ndef load_csc_sampling_graph(filename):\n \"\"\"Load CSCSamplingGraph from tar file.\"\"\"\n with tempfile.TemporaryDirectory() as temp_dir:\n with tarfile.open(filename, \"r\") as archive:\n archive.extractall(temp_dir)\n graph_filename = os.path.join(temp_dir, \"csc_sampling_graph.pt\")\n metadata_filename = os.path.join(temp_dir, \"metadata.pt\")\n return CSCSamplingGraph(\n torch.ops.graphbolt.load_csc_sampling_graph(graph_filename),\n torch.load(metadata_filename),\n )\n\n\ndef save_csc_sampling_graph(graph, filename):\n \"\"\"Save CSCSamplingGraph to tar file.\"\"\"\n with tempfile.TemporaryDirectory() as temp_dir:\n graph_filename = os.path.join(temp_dir, \"csc_sampling_graph.pt\")\n torch.ops.graphbolt.save_csc_sampling_graph(\n graph._c_csc_graph, graph_filename\n )\n metadata_filename = os.path.join(temp_dir, \"metadata.pt\")\n torch.save(graph.metadata, metadata_filename)\n with tarfile.open(filename, \"w\") as archive:\n archive.add(\n graph_filename, arcname=os.path.basename(graph_filename)\n )\n archive.add(\n metadata_filename, arcname=os.path.basename(metadata_filename)\n )\n print(f\"CSCSamplingGraph has been saved to {filename}.\")\n", "path": "python/dgl/graphbolt/graph_storage/csc_sampling_graph.py"}]}
| 3,560 | 404 |
gh_patches_debug_42165
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1978
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Enabling reverse stack growth
**Is your feature request related to a problem? Please describe.**
In GEF it is possible to visualize the stack growth in reverse (i.e., upper addresses go to higher positions). This is possible by setting up the context.grow_stack_down parameter.
**Describe the solution you'd like**
It would be very nice to have the equivalent functionality in Pwndbg (or if there is already, make it more accessible).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/commands/telescope.py`
Content:
```
1 """
2 Prints out pointer chains starting at some address in memory.
3
4 Generally used to print out the stack or register values.
5 """
6
7 from __future__ import annotations
8
9 import argparse
10 import collections
11 import math
12 from typing import DefaultDict
13
14 import pwndbg.chain
15 import pwndbg.color.telescope as T
16 import pwndbg.commands
17 import pwndbg.gdblib.arch
18 import pwndbg.gdblib.config
19 import pwndbg.gdblib.memory
20 import pwndbg.gdblib.regs
21 import pwndbg.gdblib.typeinfo
22 from pwndbg.color import theme
23 from pwndbg.commands import CommandCategory
24
25 telescope_lines = pwndbg.gdblib.config.add_param(
26 "telescope-lines", 8, "number of lines to printed by the telescope command"
27 )
28 skip_repeating_values = pwndbg.gdblib.config.add_param(
29 "telescope-skip-repeating-val",
30 True,
31 "whether to skip repeating values of the telescope command",
32 )
33 skip_repeating_values_minimum = pwndbg.gdblib.config.add_param(
34 "telescope-skip-repeating-val-minimum",
35 3,
36 "minimum amount of repeated values before skipping lines",
37 )
38 print_framepointer_offset = pwndbg.gdblib.config.add_param(
39 "telescope-framepointer-offset",
40 True,
41 "print offset to framepointer for each address, if sufficiently small",
42 )
43
44 offset_separator = theme.add_param(
45 "telescope-offset-separator", "│", "offset separator of the telescope command"
46 )
47 offset_delimiter = theme.add_param(
48 "telescope-offset-delimiter", ":", "offset delimiter of the telescope command"
49 )
50 repeating_marker = theme.add_param(
51 "telescope-repeating-marker", "... ↓", "repeating values marker of the telescope command"
52 )
53
54
55 parser = argparse.ArgumentParser(
56 description="Recursively dereferences pointers starting at the specified address."
57 )
58 parser.add_argument(
59 "-r",
60 "--reverse",
61 dest="reverse",
62 action="store_true",
63 default=False,
64 help="Show <count> previous addresses instead of next ones",
65 )
66
67 parser.add_argument(
68 "-f",
69 "--frame",
70 dest="frame",
71 action="store_true",
72 default=False,
73 help="Show the stack frame, from rsp to rbp",
74 )
75
76 parser.add_argument(
77 "address", nargs="?", default="$sp", type=int, help="The address to telescope at."
78 )
79
80 parser.add_argument(
81 "count", nargs="?", default=telescope_lines, type=int, help="The number of lines to show."
82 )
83
84
85 @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.MEMORY)
86 @pwndbg.commands.OnlyWhenRunning
87 def telescope(address=None, count=telescope_lines, to_string=False, reverse=False, frame=False):
88 """
89 Recursively dereferences pointers starting at the specified address
90 ($sp by default)
91 """
92 ptrsize = pwndbg.gdblib.typeinfo.ptrsize
93 if telescope.repeat:
94 address = telescope.last_address + ptrsize
95 telescope.offset += 1
96 else:
97 telescope.offset = 0
98
99 address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask
100 input_address = address
101 count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask
102 delimiter = T.delimiter(offset_delimiter)
103 separator = T.separator(offset_separator)
104
105 # Allow invocation of "telescope 20" to dump 20 bytes at the stack pointer
106 if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):
107 count = address
108 address = pwndbg.gdblib.regs.sp
109
110 # Allow invocation of telescope -r to dump previous addresses
111 if reverse:
112 address -= (count - 1) * ptrsize
113
114 # Allow invocation of telescope -f (--frame) to dump all addresses in a frame
115 if frame:
116 sp = pwndbg.gdblib.regs.sp
117 bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]
118 if sp > bp:
119 print("Cannot display stack frame because base pointer is below stack pointer")
120 return
121
122 for page in pwndbg.gdblib.vmmap.get():
123 if sp in page and bp not in page:
124 print(
125 "Cannot display stack frame because base pointer is not on the same page with stack pointer"
126 )
127 return
128
129 address = sp
130 count = int((bp - sp) / ptrsize) + 1
131
132 # Allow invocation of "telescope a b" to dump all bytes from A to B
133 if int(address) <= int(count):
134 # adjust count if it is an address. use ceil division as count is number of
135 # ptrsize values and we don't want to strip out a value if dest is unaligned
136 count -= address
137 count = max(math.ceil(count / ptrsize), 1)
138
139 # Map of address to register string
140 reg_values: DefaultDict[int, list[str]] = collections.defaultdict(lambda: [])
141 for reg in pwndbg.gdblib.regs.common:
142 reg_values[pwndbg.gdblib.regs[reg]].append(reg)
143
144 start = address
145 stop = address + (count * ptrsize)
146 step = ptrsize
147
148 # Find all registers which show up in the trace, map address to regs
149 regs: dict[int, str] = {}
150 for i in range(start, stop, step):
151 values = list(reg_values[i])
152
153 # Find all regs that point to somewhere in the current ptrsize step
154 for width in range(1, pwndbg.gdblib.arch.ptrsize):
155 values.extend("%s-%i" % (r, width) for r in reg_values[i + width])
156
157 regs[i] = " ".join(values)
158
159 # Find the longest set of register information (length of string), used for padding
160 if regs:
161 longest_regs = max(map(len, regs.values()))
162 else:
163 longest_regs = 0
164
165 # Print everything out
166 result = []
167 last = None
168 collapse_buffer: list[str] = []
169 skipped_padding = (
170 2
171 + len(offset_delimiter)
172 + 4
173 + len(offset_separator)
174 + 1
175 + longest_regs
176 + 1
177 - len(repeating_marker)
178 )
179
180 # Collapse repeating values exceeding minimum delta.
181 def collapse_repeating_values() -> None:
182 # The first line was already printed, hence increment by 1
183 if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:
184 result.append(
185 T.repeating_marker(
186 "%s%s%i skipped"
187 % (repeating_marker, " " * skipped_padding, len(collapse_buffer))
188 )
189 )
190 else:
191 result.extend(collapse_buffer)
192 collapse_buffer.clear()
193
194 bp = None
195 if print_framepointer_offset and pwndbg.gdblib.regs.frame is not None:
196 # regs.frame can be None on aarch64
197 bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]
198
199 for i, addr in enumerate(range(start, stop, step)):
200 if not pwndbg.gdblib.memory.peek(addr):
201 collapse_repeating_values()
202 result.append("<Could not read memory at %#x>" % addr)
203 break
204
205 line = T.offset(
206 "%02x%s%04x%s"
207 % (
208 i + telescope.offset,
209 delimiter,
210 addr - start + (telescope.offset * ptrsize),
211 separator,
212 )
213 ) + " ".join(
214 (
215 regs_or_frame_offset(addr, bp, regs, longest_regs),
216 pwndbg.chain.format(addr),
217 )
218 )
219
220 # Buffer repeating values.
221 if skip_repeating_values:
222 value = pwndbg.gdblib.memory.pvoid(addr)
223 if last == value and addr != input_address:
224 collapse_buffer.append(line)
225 continue
226 collapse_repeating_values()
227 last = value
228
229 result.append(line)
230
231 collapse_repeating_values()
232 telescope.offset += i
233 telescope.last_address = addr
234
235 if not to_string:
236 print("\n".join(result))
237
238 return result
239
240
241 def regs_or_frame_offset(addr: int, bp: int | None, regs: dict[int, str], longest_regs: int) -> str:
242 # bp only set if print_framepointer_offset=True
243 # len(regs[addr]) == 1 if no registers pointer to address
244 if bp is None or len(regs[addr]) > 1 or not -0xFFF <= addr - bp <= 0xFFF:
245 return " " + T.register(regs[addr].ljust(longest_regs))
246 else:
247 # If offset to frame pointer as hex fits in hex 3 digits, print it
248 return ("%+04x" % (addr - bp)).ljust(longest_regs + 1)
249
250
251 parser = argparse.ArgumentParser(
252 description="Dereferences on stack data with specified count and offset."
253 )
254 parser.add_argument(
255 "-f",
256 "--frame",
257 dest="frame",
258 action="store_true",
259 default=False,
260 help="Show the stack frame, from rsp to rbp",
261 )
262 parser.add_argument("count", nargs="?", default=8, type=int, help="number of element to dump")
263 parser.add_argument(
264 "offset",
265 nargs="?",
266 default=0,
267 type=int,
268 help="Element offset from $sp (support negative offset)",
269 )
270
271
272 @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.STACK)
273 @pwndbg.commands.OnlyWhenRunning
274 def stack(count, offset, frame) -> None:
275 ptrsize = pwndbg.gdblib.typeinfo.ptrsize
276 telescope.repeat = stack.repeat
277 telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame)
278
279
280 parser = argparse.ArgumentParser(
281 description="Dereferences on stack data, printing the entire stack frame with specified count and offset ."
282 )
283 parser.add_argument("count", nargs="?", default=8, type=int, help="number of element to dump")
284 parser.add_argument(
285 "offset",
286 nargs="?",
287 default=0,
288 type=int,
289 help="Element offset from $sp (support negative offset)",
290 )
291
292
293 @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.STACK)
294 @pwndbg.commands.OnlyWhenRunning
295 def stackf(count, offset) -> None:
296 ptrsize = pwndbg.gdblib.typeinfo.ptrsize
297 telescope.repeat = stack.repeat
298 telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=True)
299
300
301 telescope.last_address = 0
302 telescope.offset = 0
303
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/commands/telescope.py b/pwndbg/commands/telescope.py
--- a/pwndbg/commands/telescope.py
+++ b/pwndbg/commands/telescope.py
@@ -73,6 +73,16 @@
help="Show the stack frame, from rsp to rbp",
)
+parser.add_argument(
+ "-i",
+ "--inverse",
+ dest="inverse",
+ action="store_true",
+ default=False,
+ help="Show the stack reverse growth",
+)
+
+
parser.add_argument(
"address", nargs="?", default="$sp", type=int, help="The address to telescope at."
)
@@ -84,7 +94,9 @@
@pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.MEMORY)
@pwndbg.commands.OnlyWhenRunning
-def telescope(address=None, count=telescope_lines, to_string=False, reverse=False, frame=False):
+def telescope(
+ address=None, count=telescope_lines, to_string=False, reverse=False, frame=False, inverse=False
+):
"""
Recursively dereferences pointers starting at the specified address
($sp by default)
@@ -141,9 +153,14 @@
for reg in pwndbg.gdblib.regs.common:
reg_values[pwndbg.gdblib.regs[reg]].append(reg)
- start = address
- stop = address + (count * ptrsize)
- step = ptrsize
+ if not inverse:
+ start = address
+ stop = address + (count * ptrsize)
+ step = ptrsize
+ else:
+ start = address + ((count - 1) * ptrsize)
+ stop = address - ptrsize
+ step = -1 * ptrsize
# Find all registers which show up in the trace, map address to regs
regs: dict[int, str] = {}
@@ -201,13 +218,18 @@
collapse_repeating_values()
result.append("<Could not read memory at %#x>" % addr)
break
-
+ if inverse:
+ line_offset = addr - (stop + ptrsize) + (telescope.offset * ptrsize)
+ idx_offset = int((start - stop - ptrsize) / ptrsize) - (i + telescope.offset)
+ else:
+ line_offset = addr - start + (telescope.offset * ptrsize)
+ idx_offset = i + telescope.offset
line = T.offset(
"%02x%s%04x%s"
% (
- i + telescope.offset,
+ idx_offset,
delimiter,
- addr - start + (telescope.offset * ptrsize),
+ line_offset,
separator,
)
) + " ".join(
@@ -259,6 +281,16 @@
default=False,
help="Show the stack frame, from rsp to rbp",
)
+
+parser.add_argument(
+ "-i",
+ "--inverse",
+ dest="inverse",
+ action="store_true",
+ default=False,
+ help="Show reverse stack growth",
+)
+
parser.add_argument("count", nargs="?", default=8, type=int, help="number of element to dump")
parser.add_argument(
"offset",
@@ -271,10 +303,12 @@
@pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.STACK)
@pwndbg.commands.OnlyWhenRunning
-def stack(count, offset, frame) -> None:
+def stack(count, offset, frame, inverse) -> None:
ptrsize = pwndbg.gdblib.typeinfo.ptrsize
telescope.repeat = stack.repeat
- telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame)
+ telescope(
+ address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame, inverse=inverse
+ )
parser = argparse.ArgumentParser(
|
{"golden_diff": "diff --git a/pwndbg/commands/telescope.py b/pwndbg/commands/telescope.py\n--- a/pwndbg/commands/telescope.py\n+++ b/pwndbg/commands/telescope.py\n@@ -73,6 +73,16 @@\n help=\"Show the stack frame, from rsp to rbp\",\n )\n \n+parser.add_argument(\n+ \"-i\",\n+ \"--inverse\",\n+ dest=\"inverse\",\n+ action=\"store_true\",\n+ default=False,\n+ help=\"Show the stack reverse growth\",\n+)\n+\n+\n parser.add_argument(\n \"address\", nargs=\"?\", default=\"$sp\", type=int, help=\"The address to telescope at.\"\n )\n@@ -84,7 +94,9 @@\n \n @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.MEMORY)\n @pwndbg.commands.OnlyWhenRunning\n-def telescope(address=None, count=telescope_lines, to_string=False, reverse=False, frame=False):\n+def telescope(\n+ address=None, count=telescope_lines, to_string=False, reverse=False, frame=False, inverse=False\n+):\n \"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n@@ -141,9 +153,14 @@\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n \n- start = address\n- stop = address + (count * ptrsize)\n- step = ptrsize\n+ if not inverse:\n+ start = address\n+ stop = address + (count * ptrsize)\n+ step = ptrsize\n+ else:\n+ start = address + ((count - 1) * ptrsize)\n+ stop = address - ptrsize\n+ step = -1 * ptrsize\n \n # Find all registers which show up in the trace, map address to regs\n regs: dict[int, str] = {}\n@@ -201,13 +218,18 @@\n collapse_repeating_values()\n result.append(\"<Could not read memory at %#x>\" % addr)\n break\n-\n+ if inverse:\n+ line_offset = addr - (stop + ptrsize) + (telescope.offset * ptrsize)\n+ idx_offset = int((start - stop - ptrsize) / ptrsize) - (i + telescope.offset)\n+ else:\n+ line_offset = addr - start + (telescope.offset * ptrsize)\n+ idx_offset = i + telescope.offset\n line = T.offset(\n \"%02x%s%04x%s\"\n % (\n- i + telescope.offset,\n+ idx_offset,\n delimiter,\n- addr - start + (telescope.offset * ptrsize),\n+ line_offset,\n separator,\n )\n ) + \" \".join(\n@@ -259,6 +281,16 @@\n default=False,\n help=\"Show the stack frame, from rsp to rbp\",\n )\n+\n+parser.add_argument(\n+ \"-i\",\n+ \"--inverse\",\n+ dest=\"inverse\",\n+ action=\"store_true\",\n+ default=False,\n+ help=\"Show reverse stack growth\",\n+)\n+\n parser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\n parser.add_argument(\n \"offset\",\n@@ -271,10 +303,12 @@\n \n @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.STACK)\n @pwndbg.commands.OnlyWhenRunning\n-def stack(count, offset, frame) -> None:\n+def stack(count, offset, frame, inverse) -> None:\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n- telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame)\n+ telescope(\n+ address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame, inverse=inverse\n+ )\n \n \n parser = argparse.ArgumentParser(\n", "issue": "Enabling reverse stack growth\n**Is your feature request related to a problem? Please describe.**\r\nIn GEF it is possible to visualize the stack growth in reverse (i.e., upper addresses go to higher positions). This is possible by setting up the context.grow_stack_down parameter.\r\n\r\n**Describe the solution you'd like**\r\nIt would be very nice to have the equivalent functionality in Pwndbg (or if there is already, make it more accessible).\n", "before_files": [{"content": "\"\"\"\nPrints out pointer chains starting at some address in memory.\n\nGenerally used to print out the stack or register values.\n\"\"\"\n\nfrom __future__ import annotations\n\nimport argparse\nimport collections\nimport math\nfrom typing import DefaultDict\n\nimport pwndbg.chain\nimport pwndbg.color.telescope as T\nimport pwndbg.commands\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.config\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.regs\nimport pwndbg.gdblib.typeinfo\nfrom pwndbg.color import theme\nfrom pwndbg.commands import CommandCategory\n\ntelescope_lines = pwndbg.gdblib.config.add_param(\n \"telescope-lines\", 8, \"number of lines to printed by the telescope command\"\n)\nskip_repeating_values = pwndbg.gdblib.config.add_param(\n \"telescope-skip-repeating-val\",\n True,\n \"whether to skip repeating values of the telescope command\",\n)\nskip_repeating_values_minimum = pwndbg.gdblib.config.add_param(\n \"telescope-skip-repeating-val-minimum\",\n 3,\n \"minimum amount of repeated values before skipping lines\",\n)\nprint_framepointer_offset = pwndbg.gdblib.config.add_param(\n \"telescope-framepointer-offset\",\n True,\n \"print offset to framepointer for each address, if sufficiently small\",\n)\n\noffset_separator = theme.add_param(\n \"telescope-offset-separator\", \"\u2502\", \"offset separator of the telescope command\"\n)\noffset_delimiter = theme.add_param(\n \"telescope-offset-delimiter\", \":\", \"offset delimiter of the telescope command\"\n)\nrepeating_marker = theme.add_param(\n \"telescope-repeating-marker\", \"... \u2193\", \"repeating values marker of the telescope command\"\n)\n\n\nparser = argparse.ArgumentParser(\n description=\"Recursively dereferences pointers starting at the specified address.\"\n)\nparser.add_argument(\n \"-r\",\n \"--reverse\",\n dest=\"reverse\",\n action=\"store_true\",\n default=False,\n help=\"Show <count> previous addresses instead of next ones\",\n)\n\nparser.add_argument(\n \"-f\",\n \"--frame\",\n dest=\"frame\",\n action=\"store_true\",\n default=False,\n help=\"Show the stack frame, from rsp to rbp\",\n)\n\nparser.add_argument(\n \"address\", nargs=\"?\", default=\"$sp\", type=int, help=\"The address to telescope at.\"\n)\n\nparser.add_argument(\n \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n)\n\n\[email protected](parser, category=CommandCategory.MEMORY)\[email protected]\ndef telescope(address=None, count=telescope_lines, to_string=False, reverse=False, frame=False):\n \"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n if telescope.repeat:\n address = telescope.last_address + ptrsize\n telescope.offset += 1\n else:\n telescope.offset = 0\n\n address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask\n input_address = address\n count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask\n delimiter = T.delimiter(offset_delimiter)\n separator = T.separator(offset_separator)\n\n # Allow invocation of \"telescope 20\" to dump 20 bytes at the stack pointer\n if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):\n count = address\n address = pwndbg.gdblib.regs.sp\n\n # Allow invocation of telescope -r to dump previous addresses\n if reverse:\n address -= (count - 1) * ptrsize\n\n # Allow invocation of telescope -f (--frame) to dump all addresses in a frame\n if frame:\n sp = pwndbg.gdblib.regs.sp\n bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]\n if sp > bp:\n print(\"Cannot display stack frame because base pointer is below stack pointer\")\n return\n\n for page in pwndbg.gdblib.vmmap.get():\n if sp in page and bp not in page:\n print(\n \"Cannot display stack frame because base pointer is not on the same page with stack pointer\"\n )\n return\n\n address = sp\n count = int((bp - sp) / ptrsize) + 1\n\n # Allow invocation of \"telescope a b\" to dump all bytes from A to B\n if int(address) <= int(count):\n # adjust count if it is an address. use ceil division as count is number of\n # ptrsize values and we don't want to strip out a value if dest is unaligned\n count -= address\n count = max(math.ceil(count / ptrsize), 1)\n\n # Map of address to register string\n reg_values: DefaultDict[int, list[str]] = collections.defaultdict(lambda: [])\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n\n start = address\n stop = address + (count * ptrsize)\n step = ptrsize\n\n # Find all registers which show up in the trace, map address to regs\n regs: dict[int, str] = {}\n for i in range(start, stop, step):\n values = list(reg_values[i])\n\n # Find all regs that point to somewhere in the current ptrsize step\n for width in range(1, pwndbg.gdblib.arch.ptrsize):\n values.extend(\"%s-%i\" % (r, width) for r in reg_values[i + width])\n\n regs[i] = \" \".join(values)\n\n # Find the longest set of register information (length of string), used for padding\n if regs:\n longest_regs = max(map(len, regs.values()))\n else:\n longest_regs = 0\n\n # Print everything out\n result = []\n last = None\n collapse_buffer: list[str] = []\n skipped_padding = (\n 2\n + len(offset_delimiter)\n + 4\n + len(offset_separator)\n + 1\n + longest_regs\n + 1\n - len(repeating_marker)\n )\n\n # Collapse repeating values exceeding minimum delta.\n def collapse_repeating_values() -> None:\n # The first line was already printed, hence increment by 1\n if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:\n result.append(\n T.repeating_marker(\n \"%s%s%i skipped\"\n % (repeating_marker, \" \" * skipped_padding, len(collapse_buffer))\n )\n )\n else:\n result.extend(collapse_buffer)\n collapse_buffer.clear()\n\n bp = None\n if print_framepointer_offset and pwndbg.gdblib.regs.frame is not None:\n # regs.frame can be None on aarch64\n bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]\n\n for i, addr in enumerate(range(start, stop, step)):\n if not pwndbg.gdblib.memory.peek(addr):\n collapse_repeating_values()\n result.append(\"<Could not read memory at %#x>\" % addr)\n break\n\n line = T.offset(\n \"%02x%s%04x%s\"\n % (\n i + telescope.offset,\n delimiter,\n addr - start + (telescope.offset * ptrsize),\n separator,\n )\n ) + \" \".join(\n (\n regs_or_frame_offset(addr, bp, regs, longest_regs),\n pwndbg.chain.format(addr),\n )\n )\n\n # Buffer repeating values.\n if skip_repeating_values:\n value = pwndbg.gdblib.memory.pvoid(addr)\n if last == value and addr != input_address:\n collapse_buffer.append(line)\n continue\n collapse_repeating_values()\n last = value\n\n result.append(line)\n\n collapse_repeating_values()\n telescope.offset += i\n telescope.last_address = addr\n\n if not to_string:\n print(\"\\n\".join(result))\n\n return result\n\n\ndef regs_or_frame_offset(addr: int, bp: int | None, regs: dict[int, str], longest_regs: int) -> str:\n # bp only set if print_framepointer_offset=True\n # len(regs[addr]) == 1 if no registers pointer to address\n if bp is None or len(regs[addr]) > 1 or not -0xFFF <= addr - bp <= 0xFFF:\n return \" \" + T.register(regs[addr].ljust(longest_regs))\n else:\n # If offset to frame pointer as hex fits in hex 3 digits, print it\n return (\"%+04x\" % (addr - bp)).ljust(longest_regs + 1)\n\n\nparser = argparse.ArgumentParser(\n description=\"Dereferences on stack data with specified count and offset.\"\n)\nparser.add_argument(\n \"-f\",\n \"--frame\",\n dest=\"frame\",\n action=\"store_true\",\n default=False,\n help=\"Show the stack frame, from rsp to rbp\",\n)\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser, category=CommandCategory.STACK)\[email protected]\ndef stack(count, offset, frame) -> None:\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame)\n\n\nparser = argparse.ArgumentParser(\n description=\"Dereferences on stack data, printing the entire stack frame with specified count and offset .\"\n)\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser, category=CommandCategory.STACK)\[email protected]\ndef stackf(count, offset) -> None:\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=True)\n\n\ntelescope.last_address = 0\ntelescope.offset = 0\n", "path": "pwndbg/commands/telescope.py"}], "after_files": [{"content": "\"\"\"\nPrints out pointer chains starting at some address in memory.\n\nGenerally used to print out the stack or register values.\n\"\"\"\n\nfrom __future__ import annotations\n\nimport argparse\nimport collections\nimport math\nfrom typing import DefaultDict\n\nimport pwndbg.chain\nimport pwndbg.color.telescope as T\nimport pwndbg.commands\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.config\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.regs\nimport pwndbg.gdblib.typeinfo\nfrom pwndbg.color import theme\nfrom pwndbg.commands import CommandCategory\n\ntelescope_lines = pwndbg.gdblib.config.add_param(\n \"telescope-lines\", 8, \"number of lines to printed by the telescope command\"\n)\nskip_repeating_values = pwndbg.gdblib.config.add_param(\n \"telescope-skip-repeating-val\",\n True,\n \"whether to skip repeating values of the telescope command\",\n)\nskip_repeating_values_minimum = pwndbg.gdblib.config.add_param(\n \"telescope-skip-repeating-val-minimum\",\n 3,\n \"minimum amount of repeated values before skipping lines\",\n)\nprint_framepointer_offset = pwndbg.gdblib.config.add_param(\n \"telescope-framepointer-offset\",\n True,\n \"print offset to framepointer for each address, if sufficiently small\",\n)\n\noffset_separator = theme.add_param(\n \"telescope-offset-separator\", \"\u2502\", \"offset separator of the telescope command\"\n)\noffset_delimiter = theme.add_param(\n \"telescope-offset-delimiter\", \":\", \"offset delimiter of the telescope command\"\n)\nrepeating_marker = theme.add_param(\n \"telescope-repeating-marker\", \"... \u2193\", \"repeating values marker of the telescope command\"\n)\n\n\nparser = argparse.ArgumentParser(\n description=\"Recursively dereferences pointers starting at the specified address.\"\n)\nparser.add_argument(\n \"-r\",\n \"--reverse\",\n dest=\"reverse\",\n action=\"store_true\",\n default=False,\n help=\"Show <count> previous addresses instead of next ones\",\n)\n\nparser.add_argument(\n \"-f\",\n \"--frame\",\n dest=\"frame\",\n action=\"store_true\",\n default=False,\n help=\"Show the stack frame, from rsp to rbp\",\n)\n\nparser.add_argument(\n \"-i\",\n \"--inverse\",\n dest=\"inverse\",\n action=\"store_true\",\n default=False,\n help=\"Show the stack reverse growth\",\n)\n\n\nparser.add_argument(\n \"address\", nargs=\"?\", default=\"$sp\", type=int, help=\"The address to telescope at.\"\n)\n\nparser.add_argument(\n \"count\", nargs=\"?\", default=telescope_lines, type=int, help=\"The number of lines to show.\"\n)\n\n\[email protected](parser, category=CommandCategory.MEMORY)\[email protected]\ndef telescope(\n address=None, count=telescope_lines, to_string=False, reverse=False, frame=False, inverse=False\n):\n \"\"\"\n Recursively dereferences pointers starting at the specified address\n ($sp by default)\n \"\"\"\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n if telescope.repeat:\n address = telescope.last_address + ptrsize\n telescope.offset += 1\n else:\n telescope.offset = 0\n\n address = int(address if address else pwndbg.gdblib.regs.sp) & pwndbg.gdblib.arch.ptrmask\n input_address = address\n count = max(int(count), 1) & pwndbg.gdblib.arch.ptrmask\n delimiter = T.delimiter(offset_delimiter)\n separator = T.separator(offset_separator)\n\n # Allow invocation of \"telescope 20\" to dump 20 bytes at the stack pointer\n if address < pwndbg.gdblib.memory.MMAP_MIN_ADDR and not pwndbg.gdblib.memory.peek(address):\n count = address\n address = pwndbg.gdblib.regs.sp\n\n # Allow invocation of telescope -r to dump previous addresses\n if reverse:\n address -= (count - 1) * ptrsize\n\n # Allow invocation of telescope -f (--frame) to dump all addresses in a frame\n if frame:\n sp = pwndbg.gdblib.regs.sp\n bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]\n if sp > bp:\n print(\"Cannot display stack frame because base pointer is below stack pointer\")\n return\n\n for page in pwndbg.gdblib.vmmap.get():\n if sp in page and bp not in page:\n print(\n \"Cannot display stack frame because base pointer is not on the same page with stack pointer\"\n )\n return\n\n address = sp\n count = int((bp - sp) / ptrsize) + 1\n\n # Allow invocation of \"telescope a b\" to dump all bytes from A to B\n if int(address) <= int(count):\n # adjust count if it is an address. use ceil division as count is number of\n # ptrsize values and we don't want to strip out a value if dest is unaligned\n count -= address\n count = max(math.ceil(count / ptrsize), 1)\n\n # Map of address to register string\n reg_values: DefaultDict[int, list[str]] = collections.defaultdict(lambda: [])\n for reg in pwndbg.gdblib.regs.common:\n reg_values[pwndbg.gdblib.regs[reg]].append(reg)\n\n if not inverse:\n start = address\n stop = address + (count * ptrsize)\n step = ptrsize\n else:\n start = address + ((count - 1) * ptrsize)\n stop = address - ptrsize\n step = -1 * ptrsize\n\n # Find all registers which show up in the trace, map address to regs\n regs: dict[int, str] = {}\n for i in range(start, stop, step):\n values = list(reg_values[i])\n\n # Find all regs that point to somewhere in the current ptrsize step\n for width in range(1, pwndbg.gdblib.arch.ptrsize):\n values.extend(\"%s-%i\" % (r, width) for r in reg_values[i + width])\n\n regs[i] = \" \".join(values)\n\n # Find the longest set of register information (length of string), used for padding\n if regs:\n longest_regs = max(map(len, regs.values()))\n else:\n longest_regs = 0\n\n # Print everything out\n result = []\n last = None\n collapse_buffer: list[str] = []\n skipped_padding = (\n 2\n + len(offset_delimiter)\n + 4\n + len(offset_separator)\n + 1\n + longest_regs\n + 1\n - len(repeating_marker)\n )\n\n # Collapse repeating values exceeding minimum delta.\n def collapse_repeating_values() -> None:\n # The first line was already printed, hence increment by 1\n if collapse_buffer and len(collapse_buffer) + 1 >= skip_repeating_values_minimum:\n result.append(\n T.repeating_marker(\n \"%s%s%i skipped\"\n % (repeating_marker, \" \" * skipped_padding, len(collapse_buffer))\n )\n )\n else:\n result.extend(collapse_buffer)\n collapse_buffer.clear()\n\n bp = None\n if print_framepointer_offset and pwndbg.gdblib.regs.frame is not None:\n # regs.frame can be None on aarch64\n bp = pwndbg.gdblib.regs[pwndbg.gdblib.regs.frame]\n\n for i, addr in enumerate(range(start, stop, step)):\n if not pwndbg.gdblib.memory.peek(addr):\n collapse_repeating_values()\n result.append(\"<Could not read memory at %#x>\" % addr)\n break\n if inverse:\n line_offset = addr - (stop + ptrsize) + (telescope.offset * ptrsize)\n idx_offset = int((start - stop - ptrsize) / ptrsize) - (i + telescope.offset)\n else:\n line_offset = addr - start + (telescope.offset * ptrsize)\n idx_offset = i + telescope.offset\n line = T.offset(\n \"%02x%s%04x%s\"\n % (\n idx_offset,\n delimiter,\n line_offset,\n separator,\n )\n ) + \" \".join(\n (\n regs_or_frame_offset(addr, bp, regs, longest_regs),\n pwndbg.chain.format(addr),\n )\n )\n\n # Buffer repeating values.\n if skip_repeating_values:\n value = pwndbg.gdblib.memory.pvoid(addr)\n if last == value and addr != input_address:\n collapse_buffer.append(line)\n continue\n collapse_repeating_values()\n last = value\n\n result.append(line)\n\n collapse_repeating_values()\n telescope.offset += i\n telescope.last_address = addr\n\n if not to_string:\n print(\"\\n\".join(result))\n\n return result\n\n\ndef regs_or_frame_offset(addr: int, bp: int | None, regs: dict[int, str], longest_regs: int) -> str:\n # bp only set if print_framepointer_offset=True\n # len(regs[addr]) == 1 if no registers pointer to address\n if bp is None or len(regs[addr]) > 1 or not -0xFFF <= addr - bp <= 0xFFF:\n return \" \" + T.register(regs[addr].ljust(longest_regs))\n else:\n # If offset to frame pointer as hex fits in hex 3 digits, print it\n return (\"%+04x\" % (addr - bp)).ljust(longest_regs + 1)\n\n\nparser = argparse.ArgumentParser(\n description=\"Dereferences on stack data with specified count and offset.\"\n)\nparser.add_argument(\n \"-f\",\n \"--frame\",\n dest=\"frame\",\n action=\"store_true\",\n default=False,\n help=\"Show the stack frame, from rsp to rbp\",\n)\n\nparser.add_argument(\n \"-i\",\n \"--inverse\",\n dest=\"inverse\",\n action=\"store_true\",\n default=False,\n help=\"Show reverse stack growth\",\n)\n\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser, category=CommandCategory.STACK)\[email protected]\ndef stack(count, offset, frame, inverse) -> None:\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(\n address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=frame, inverse=inverse\n )\n\n\nparser = argparse.ArgumentParser(\n description=\"Dereferences on stack data, printing the entire stack frame with specified count and offset .\"\n)\nparser.add_argument(\"count\", nargs=\"?\", default=8, type=int, help=\"number of element to dump\")\nparser.add_argument(\n \"offset\",\n nargs=\"?\",\n default=0,\n type=int,\n help=\"Element offset from $sp (support negative offset)\",\n)\n\n\[email protected](parser, category=CommandCategory.STACK)\[email protected]\ndef stackf(count, offset) -> None:\n ptrsize = pwndbg.gdblib.typeinfo.ptrsize\n telescope.repeat = stack.repeat\n telescope(address=pwndbg.gdblib.regs.sp + offset * ptrsize, count=count, frame=True)\n\n\ntelescope.last_address = 0\ntelescope.offset = 0\n", "path": "pwndbg/commands/telescope.py"}]}
| 3,528 | 894 |
gh_patches_debug_23120
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1457
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dataminimization breaks editing user profiles
### Describe the bug
I cannot edit the profiles and user information of users whose data has been minimized.
### How to reproduce
Steps to reproduce the behaviour:
1. View member information with missing data fields (due to minimization)
2. Try to edit a value (e.g. email address)
3. Save form
4. Form cannot be saved because of data inconsistency errors
### Expected behaviour
Edits in incomplete profiles can still happen even though information is missing
### Screenshots
<img width="526" alt="image" src="https://user-images.githubusercontent.com/1576660/90406160-0cf79800-e0a5-11ea-8072-e8e311c58b75.png">
### Additional context
I was trying to change someones email address, so they could reset their password and renew their membership
Dataminimization breaks editing user profiles
### Describe the bug
I cannot edit the profiles and user information of users whose data has been minimized.
### How to reproduce
Steps to reproduce the behaviour:
1. View member information with missing data fields (due to minimization)
2. Try to edit a value (e.g. email address)
3. Save form
4. Form cannot be saved because of data inconsistency errors
### Expected behaviour
Edits in incomplete profiles can still happen even though information is missing
### Screenshots
<img width="526" alt="image" src="https://user-images.githubusercontent.com/1576660/90406160-0cf79800-e0a5-11ea-8072-e8e311c58b75.png">
### Additional context
I was trying to change someones email address, so they could reset their password and renew their membership
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/members/services.py`
Content:
```
1 """Services defined in the members package"""
2 from datetime import date
3 from typing import Callable, List, Dict, Any
4
5 from django.conf import settings
6 from django.db.models import Q, Count
7 from django.utils import timezone
8 from django.utils.translation import gettext
9
10 from members import emails
11 from members.models import Membership, Member
12 from utils.snippets import datetime_to_lectureyear
13
14
15 def _member_group_memberships(
16 member: Member, condition: Callable[[Membership], bool]
17 ) -> Dict[str, Any]:
18 """
19 Determines the group membership of a user based on a condition
20 :return: Object with group memberships
21 """
22 memberships = member.membergroupmembership_set.all()
23 data = {}
24
25 for membership in memberships:
26 if not condition(membership):
27 continue
28 period = {
29 "since": membership.since,
30 "until": membership.until,
31 "chair": membership.chair,
32 }
33
34 if hasattr(membership.group, "board"):
35 period["role"] = membership.role
36
37 if membership.until is None and hasattr(membership.group, "board"):
38 period["until"] = membership.group.board.until
39
40 name = membership.group.name
41 if data.get(name):
42 data[name]["periods"].append(period)
43 if data[name]["earliest"] > period["since"]:
44 data[name]["earliest"] = period["since"]
45 if period["until"] is None or (
46 data[name]["latest"] is not None
47 and data[name]["latest"] < period["until"]
48 ):
49 data[name]["latest"] = period["until"]
50 data[name]["periods"].sort(key=lambda x: x["since"])
51 else:
52 data[name] = {
53 "pk": membership.group.pk,
54 "active": membership.group.active,
55 "name": name,
56 "periods": [period],
57 "url": settings.BASE_URL + membership.group.get_absolute_url(),
58 "earliest": period["since"],
59 "latest": period["until"],
60 }
61 return data
62
63
64 def member_achievements(member) -> List:
65 """
66 Derives a list of achievements of a member
67 Committee and board memberships + mentorships
68 """
69 achievements = _member_group_memberships(
70 member,
71 lambda membership: (
72 hasattr(membership.group, "board") or hasattr(membership.group, "committee")
73 ),
74 )
75
76 mentor_years = member.mentorship_set.all()
77 for mentor_year in mentor_years:
78 name = "Mentor in {}".format(mentor_year.year)
79 # Ensure mentorships appear last but are sorted
80 earliest = date.today()
81 earliest = earliest.replace(year=earliest.year + mentor_year.year)
82 if not achievements.get(name):
83 achievements[name] = {
84 "name": name,
85 "earliest": earliest,
86 }
87 return sorted(achievements.values(), key=lambda x: x["earliest"])
88
89
90 def member_societies(member) -> List:
91 """
92 Derives a list of societies a member was part of
93 """
94 societies = _member_group_memberships(
95 member, lambda membership: (hasattr(membership.group, "society"))
96 )
97 return sorted(societies.values(), key=lambda x: x["earliest"])
98
99
100 def gen_stats_member_type() -> Dict[str, int]:
101 """
102 Generate a dictionary where every key is a member type with
103 the value being the number of current members of that type
104 """
105
106 data = {}
107 for key, display in Membership.MEMBERSHIP_TYPES:
108 data[str(display)] = (
109 Membership.objects.filter(since__lte=date.today())
110 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
111 .filter(type=key)
112 .count()
113 )
114 return data
115
116
117 def gen_stats_year() -> Dict[str, Dict[str, int]]:
118 """
119 Generate list with 6 entries, where each entry represents the total amount
120 of Thalia members in a year. The sixth element contains all the multi-year
121 students.
122 """
123 stats_year = {}
124 current_year = datetime_to_lectureyear(date.today())
125
126 for i in range(5):
127 new = {}
128 for key, _ in Membership.MEMBERSHIP_TYPES:
129 new[key] = (
130 Membership.objects.filter(user__profile__starting_year=current_year - i)
131 .filter(since__lte=date.today())
132 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
133 .filter(type=key)
134 .count()
135 )
136 stats_year[str(current_year - i)] = new
137
138 # Add multi year members
139 new = {}
140 for key, _ in Membership.MEMBERSHIP_TYPES:
141 new[key] = (
142 Membership.objects.filter(user__profile__starting_year__lt=current_year - 4)
143 .filter(since__lte=date.today())
144 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
145 .filter(type=key)
146 .count()
147 )
148 stats_year[str(gettext("Older"))] = new
149
150 return stats_year
151
152
153 def verify_email_change(change_request) -> None:
154 """
155 Mark the email change request as verified
156
157 :param change_request: the email change request
158 """
159 change_request.verified = True
160 change_request.save()
161
162 process_email_change(change_request)
163
164
165 def confirm_email_change(change_request) -> None:
166 """
167 Mark the email change request as verified
168
169 :param change_request: the email change request
170 """
171 change_request.confirmed = True
172 change_request.save()
173
174 process_email_change(change_request)
175
176
177 def process_email_change(change_request) -> None:
178 """
179 Change the user's email address if the request was completed and
180 send the completion email
181
182 :param change_request: the email change request
183 """
184 if not change_request.completed:
185 return
186
187 member = change_request.member
188 member.email = change_request.email
189 member.save()
190
191 emails.send_email_change_completion_message(change_request)
192
193
194 def execute_data_minimisation(dry_run=False, members=None) -> List[Member]:
195 """
196 Clean the profiles of members/users of whom the last membership ended
197 at least 31 days ago
198
199 :param dry_run: does not really remove data if True
200 :param members: queryset of members to process, optional
201 :return: list of processed members
202 """
203 if not members:
204 members = Member.objects
205 members = (
206 members.annotate(membership_count=Count("membership"))
207 .exclude(
208 (
209 Q(membership__until__isnull=True)
210 | Q(membership__until__gt=timezone.now().date())
211 )
212 & Q(membership_count__gt=0)
213 )
214 .distinct()
215 .prefetch_related("membership_set", "profile")
216 )
217 deletion_period = timezone.now().date() - timezone.timedelta(days=31)
218 processed_members = []
219 for member in members:
220 if (
221 member.latest_membership is None
222 or member.latest_membership.until <= deletion_period
223 ):
224 processed_members.append(member)
225 profile = member.profile
226 profile.student_number = None
227 profile.phone_number = None
228 profile.address_street = None
229 profile.address_street2 = None
230 profile.address_postal_code = None
231 profile.address_city = None
232 profile.address_country = None
233 profile.birthday = None
234 profile.emergency_contact_phone_number = None
235 profile.emergency_contact = None
236 member.bank_accounts.all().delete()
237 if not dry_run:
238 profile.save()
239
240 return processed_members
241
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/members/services.py b/website/members/services.py
--- a/website/members/services.py
+++ b/website/members/services.py
@@ -1,5 +1,5 @@
"""Services defined in the members package"""
-from datetime import date
+from datetime import date, datetime
from typing import Callable, List, Dict, Any
from django.conf import settings
@@ -225,12 +225,12 @@
profile = member.profile
profile.student_number = None
profile.phone_number = None
- profile.address_street = None
+ profile.address_street = "<removed> 1"
profile.address_street2 = None
- profile.address_postal_code = None
- profile.address_city = None
- profile.address_country = None
- profile.birthday = None
+ profile.address_postal_code = "<removed>"
+ profile.address_city = "<removed>"
+ profile.address_country = "NL"
+ profile.birthday = datetime(1900, 1, 1)
profile.emergency_contact_phone_number = None
profile.emergency_contact = None
member.bank_accounts.all().delete()
|
{"golden_diff": "diff --git a/website/members/services.py b/website/members/services.py\n--- a/website/members/services.py\n+++ b/website/members/services.py\n@@ -1,5 +1,5 @@\n \"\"\"Services defined in the members package\"\"\"\n-from datetime import date\n+from datetime import date, datetime\n from typing import Callable, List, Dict, Any\n \n from django.conf import settings\n@@ -225,12 +225,12 @@\n profile = member.profile\n profile.student_number = None\n profile.phone_number = None\n- profile.address_street = None\n+ profile.address_street = \"<removed> 1\"\n profile.address_street2 = None\n- profile.address_postal_code = None\n- profile.address_city = None\n- profile.address_country = None\n- profile.birthday = None\n+ profile.address_postal_code = \"<removed>\"\n+ profile.address_city = \"<removed>\"\n+ profile.address_country = \"NL\"\n+ profile.birthday = datetime(1900, 1, 1)\n profile.emergency_contact_phone_number = None\n profile.emergency_contact = None\n member.bank_accounts.all().delete()\n", "issue": "Dataminimization breaks editing user profiles\n### Describe the bug\r\nI cannot edit the profiles and user information of users whose data has been minimized. \r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. View member information with missing data fields (due to minimization)\r\n2. Try to edit a value (e.g. email address)\r\n3. Save form\r\n4. Form cannot be saved because of data inconsistency errors\r\n\r\n### Expected behaviour\r\nEdits in incomplete profiles can still happen even though information is missing\r\n\r\n### Screenshots\r\n<img width=\"526\" alt=\"image\" src=\"https://user-images.githubusercontent.com/1576660/90406160-0cf79800-e0a5-11ea-8072-e8e311c58b75.png\">\r\n\r\n\r\n### Additional context\r\nI was trying to change someones email address, so they could reset their password and renew their membership\r\n\nDataminimization breaks editing user profiles\n### Describe the bug\r\nI cannot edit the profiles and user information of users whose data has been minimized. \r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. View member information with missing data fields (due to minimization)\r\n2. Try to edit a value (e.g. email address)\r\n3. Save form\r\n4. Form cannot be saved because of data inconsistency errors\r\n\r\n### Expected behaviour\r\nEdits in incomplete profiles can still happen even though information is missing\r\n\r\n### Screenshots\r\n<img width=\"526\" alt=\"image\" src=\"https://user-images.githubusercontent.com/1576660/90406160-0cf79800-e0a5-11ea-8072-e8e311c58b75.png\">\r\n\r\n\r\n### Additional context\r\nI was trying to change someones email address, so they could reset their password and renew their membership\r\n\n", "before_files": [{"content": "\"\"\"Services defined in the members package\"\"\"\nfrom datetime import date\nfrom typing import Callable, List, Dict, Any\n\nfrom django.conf import settings\nfrom django.db.models import Q, Count\nfrom django.utils import timezone\nfrom django.utils.translation import gettext\n\nfrom members import emails\nfrom members.models import Membership, Member\nfrom utils.snippets import datetime_to_lectureyear\n\n\ndef _member_group_memberships(\n member: Member, condition: Callable[[Membership], bool]\n) -> Dict[str, Any]:\n \"\"\"\n Determines the group membership of a user based on a condition\n :return: Object with group memberships\n \"\"\"\n memberships = member.membergroupmembership_set.all()\n data = {}\n\n for membership in memberships:\n if not condition(membership):\n continue\n period = {\n \"since\": membership.since,\n \"until\": membership.until,\n \"chair\": membership.chair,\n }\n\n if hasattr(membership.group, \"board\"):\n period[\"role\"] = membership.role\n\n if membership.until is None and hasattr(membership.group, \"board\"):\n period[\"until\"] = membership.group.board.until\n\n name = membership.group.name\n if data.get(name):\n data[name][\"periods\"].append(period)\n if data[name][\"earliest\"] > period[\"since\"]:\n data[name][\"earliest\"] = period[\"since\"]\n if period[\"until\"] is None or (\n data[name][\"latest\"] is not None\n and data[name][\"latest\"] < period[\"until\"]\n ):\n data[name][\"latest\"] = period[\"until\"]\n data[name][\"periods\"].sort(key=lambda x: x[\"since\"])\n else:\n data[name] = {\n \"pk\": membership.group.pk,\n \"active\": membership.group.active,\n \"name\": name,\n \"periods\": [period],\n \"url\": settings.BASE_URL + membership.group.get_absolute_url(),\n \"earliest\": period[\"since\"],\n \"latest\": period[\"until\"],\n }\n return data\n\n\ndef member_achievements(member) -> List:\n \"\"\"\n Derives a list of achievements of a member\n Committee and board memberships + mentorships\n \"\"\"\n achievements = _member_group_memberships(\n member,\n lambda membership: (\n hasattr(membership.group, \"board\") or hasattr(membership.group, \"committee\")\n ),\n )\n\n mentor_years = member.mentorship_set.all()\n for mentor_year in mentor_years:\n name = \"Mentor in {}\".format(mentor_year.year)\n # Ensure mentorships appear last but are sorted\n earliest = date.today()\n earliest = earliest.replace(year=earliest.year + mentor_year.year)\n if not achievements.get(name):\n achievements[name] = {\n \"name\": name,\n \"earliest\": earliest,\n }\n return sorted(achievements.values(), key=lambda x: x[\"earliest\"])\n\n\ndef member_societies(member) -> List:\n \"\"\"\n Derives a list of societies a member was part of\n \"\"\"\n societies = _member_group_memberships(\n member, lambda membership: (hasattr(membership.group, \"society\"))\n )\n return sorted(societies.values(), key=lambda x: x[\"earliest\"])\n\n\ndef gen_stats_member_type() -> Dict[str, int]:\n \"\"\"\n Generate a dictionary where every key is a member type with\n the value being the number of current members of that type\n \"\"\"\n\n data = {}\n for key, display in Membership.MEMBERSHIP_TYPES:\n data[str(display)] = (\n Membership.objects.filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n return data\n\n\ndef gen_stats_year() -> Dict[str, Dict[str, int]]:\n \"\"\"\n Generate list with 6 entries, where each entry represents the total amount\n of Thalia members in a year. The sixth element contains all the multi-year\n students.\n \"\"\"\n stats_year = {}\n current_year = datetime_to_lectureyear(date.today())\n\n for i in range(5):\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year=current_year - i)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(current_year - i)] = new\n\n # Add multi year members\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year__lt=current_year - 4)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(gettext(\"Older\"))] = new\n\n return stats_year\n\n\ndef verify_email_change(change_request) -> None:\n \"\"\"\n Mark the email change request as verified\n\n :param change_request: the email change request\n \"\"\"\n change_request.verified = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef confirm_email_change(change_request) -> None:\n \"\"\"\n Mark the email change request as verified\n\n :param change_request: the email change request\n \"\"\"\n change_request.confirmed = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef process_email_change(change_request) -> None:\n \"\"\"\n Change the user's email address if the request was completed and\n send the completion email\n\n :param change_request: the email change request\n \"\"\"\n if not change_request.completed:\n return\n\n member = change_request.member\n member.email = change_request.email\n member.save()\n\n emails.send_email_change_completion_message(change_request)\n\n\ndef execute_data_minimisation(dry_run=False, members=None) -> List[Member]:\n \"\"\"\n Clean the profiles of members/users of whom the last membership ended\n at least 31 days ago\n\n :param dry_run: does not really remove data if True\n :param members: queryset of members to process, optional\n :return: list of processed members\n \"\"\"\n if not members:\n members = Member.objects\n members = (\n members.annotate(membership_count=Count(\"membership\"))\n .exclude(\n (\n Q(membership__until__isnull=True)\n | Q(membership__until__gt=timezone.now().date())\n )\n & Q(membership_count__gt=0)\n )\n .distinct()\n .prefetch_related(\"membership_set\", \"profile\")\n )\n deletion_period = timezone.now().date() - timezone.timedelta(days=31)\n processed_members = []\n for member in members:\n if (\n member.latest_membership is None\n or member.latest_membership.until <= deletion_period\n ):\n processed_members.append(member)\n profile = member.profile\n profile.student_number = None\n profile.phone_number = None\n profile.address_street = None\n profile.address_street2 = None\n profile.address_postal_code = None\n profile.address_city = None\n profile.address_country = None\n profile.birthday = None\n profile.emergency_contact_phone_number = None\n profile.emergency_contact = None\n member.bank_accounts.all().delete()\n if not dry_run:\n profile.save()\n\n return processed_members\n", "path": "website/members/services.py"}], "after_files": [{"content": "\"\"\"Services defined in the members package\"\"\"\nfrom datetime import date, datetime\nfrom typing import Callable, List, Dict, Any\n\nfrom django.conf import settings\nfrom django.db.models import Q, Count\nfrom django.utils import timezone\nfrom django.utils.translation import gettext\n\nfrom members import emails\nfrom members.models import Membership, Member\nfrom utils.snippets import datetime_to_lectureyear\n\n\ndef _member_group_memberships(\n member: Member, condition: Callable[[Membership], bool]\n) -> Dict[str, Any]:\n \"\"\"\n Determines the group membership of a user based on a condition\n :return: Object with group memberships\n \"\"\"\n memberships = member.membergroupmembership_set.all()\n data = {}\n\n for membership in memberships:\n if not condition(membership):\n continue\n period = {\n \"since\": membership.since,\n \"until\": membership.until,\n \"chair\": membership.chair,\n }\n\n if hasattr(membership.group, \"board\"):\n period[\"role\"] = membership.role\n\n if membership.until is None and hasattr(membership.group, \"board\"):\n period[\"until\"] = membership.group.board.until\n\n name = membership.group.name\n if data.get(name):\n data[name][\"periods\"].append(period)\n if data[name][\"earliest\"] > period[\"since\"]:\n data[name][\"earliest\"] = period[\"since\"]\n if period[\"until\"] is None or (\n data[name][\"latest\"] is not None\n and data[name][\"latest\"] < period[\"until\"]\n ):\n data[name][\"latest\"] = period[\"until\"]\n data[name][\"periods\"].sort(key=lambda x: x[\"since\"])\n else:\n data[name] = {\n \"pk\": membership.group.pk,\n \"active\": membership.group.active,\n \"name\": name,\n \"periods\": [period],\n \"url\": settings.BASE_URL + membership.group.get_absolute_url(),\n \"earliest\": period[\"since\"],\n \"latest\": period[\"until\"],\n }\n return data\n\n\ndef member_achievements(member) -> List:\n \"\"\"\n Derives a list of achievements of a member\n Committee and board memberships + mentorships\n \"\"\"\n achievements = _member_group_memberships(\n member,\n lambda membership: (\n hasattr(membership.group, \"board\") or hasattr(membership.group, \"committee\")\n ),\n )\n\n mentor_years = member.mentorship_set.all()\n for mentor_year in mentor_years:\n name = \"Mentor in {}\".format(mentor_year.year)\n # Ensure mentorships appear last but are sorted\n earliest = date.today()\n earliest = earliest.replace(year=earliest.year + mentor_year.year)\n if not achievements.get(name):\n achievements[name] = {\n \"name\": name,\n \"earliest\": earliest,\n }\n return sorted(achievements.values(), key=lambda x: x[\"earliest\"])\n\n\ndef member_societies(member) -> List:\n \"\"\"\n Derives a list of societies a member was part of\n \"\"\"\n societies = _member_group_memberships(\n member, lambda membership: (hasattr(membership.group, \"society\"))\n )\n return sorted(societies.values(), key=lambda x: x[\"earliest\"])\n\n\ndef gen_stats_member_type() -> Dict[str, int]:\n \"\"\"\n Generate a dictionary where every key is a member type with\n the value being the number of current members of that type\n \"\"\"\n\n data = {}\n for key, display in Membership.MEMBERSHIP_TYPES:\n data[str(display)] = (\n Membership.objects.filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n return data\n\n\ndef gen_stats_year() -> Dict[str, Dict[str, int]]:\n \"\"\"\n Generate list with 6 entries, where each entry represents the total amount\n of Thalia members in a year. The sixth element contains all the multi-year\n students.\n \"\"\"\n stats_year = {}\n current_year = datetime_to_lectureyear(date.today())\n\n for i in range(5):\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year=current_year - i)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(current_year - i)] = new\n\n # Add multi year members\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year__lt=current_year - 4)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(gettext(\"Older\"))] = new\n\n return stats_year\n\n\ndef verify_email_change(change_request) -> None:\n \"\"\"\n Mark the email change request as verified\n\n :param change_request: the email change request\n \"\"\"\n change_request.verified = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef confirm_email_change(change_request) -> None:\n \"\"\"\n Mark the email change request as verified\n\n :param change_request: the email change request\n \"\"\"\n change_request.confirmed = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef process_email_change(change_request) -> None:\n \"\"\"\n Change the user's email address if the request was completed and\n send the completion email\n\n :param change_request: the email change request\n \"\"\"\n if not change_request.completed:\n return\n\n member = change_request.member\n member.email = change_request.email\n member.save()\n\n emails.send_email_change_completion_message(change_request)\n\n\ndef execute_data_minimisation(dry_run=False, members=None) -> List[Member]:\n \"\"\"\n Clean the profiles of members/users of whom the last membership ended\n at least 31 days ago\n\n :param dry_run: does not really remove data if True\n :param members: queryset of members to process, optional\n :return: list of processed members\n \"\"\"\n if not members:\n members = Member.objects\n members = (\n members.annotate(membership_count=Count(\"membership\"))\n .exclude(\n (\n Q(membership__until__isnull=True)\n | Q(membership__until__gt=timezone.now().date())\n )\n & Q(membership_count__gt=0)\n )\n .distinct()\n .prefetch_related(\"membership_set\", \"profile\")\n )\n deletion_period = timezone.now().date() - timezone.timedelta(days=31)\n processed_members = []\n for member in members:\n if (\n member.latest_membership is None\n or member.latest_membership.until <= deletion_period\n ):\n processed_members.append(member)\n profile = member.profile\n profile.student_number = None\n profile.phone_number = None\n profile.address_street = \"<removed> 1\"\n profile.address_street2 = None\n profile.address_postal_code = \"<removed>\"\n profile.address_city = \"<removed>\"\n profile.address_country = \"NL\"\n profile.birthday = datetime(1900, 1, 1)\n profile.emergency_contact_phone_number = None\n profile.emergency_contact = None\n member.bank_accounts.all().delete()\n if not dry_run:\n profile.save()\n\n return processed_members\n", "path": "website/members/services.py"}]}
| 2,930 | 256 |
gh_patches_debug_24855
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-9182
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sorts/random_normal_distribution_quicksort.py has no tests
### Repository commit
3
### Python version (python --version)
Python 3.11.5
### Dependencies version (pip freeze)
Numpy
### Expected behavior
Tests.
### Actual behavior
No tests.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sorts/random_normal_distribution_quicksort.py`
Content:
```
1 from random import randint
2 from tempfile import TemporaryFile
3
4 import numpy as np
5
6
7 def _in_place_quick_sort(a, start, end):
8 count = 0
9 if start < end:
10 pivot = randint(start, end)
11 temp = a[end]
12 a[end] = a[pivot]
13 a[pivot] = temp
14
15 p, count = _in_place_partition(a, start, end)
16 count += _in_place_quick_sort(a, start, p - 1)
17 count += _in_place_quick_sort(a, p + 1, end)
18 return count
19
20
21 def _in_place_partition(a, start, end):
22 count = 0
23 pivot = randint(start, end)
24 temp = a[end]
25 a[end] = a[pivot]
26 a[pivot] = temp
27 new_pivot_index = start - 1
28 for index in range(start, end):
29 count += 1
30 if a[index] < a[end]: # check if current val is less than pivot value
31 new_pivot_index = new_pivot_index + 1
32 temp = a[new_pivot_index]
33 a[new_pivot_index] = a[index]
34 a[index] = temp
35
36 temp = a[new_pivot_index + 1]
37 a[new_pivot_index + 1] = a[end]
38 a[end] = temp
39 return new_pivot_index + 1, count
40
41
42 outfile = TemporaryFile()
43 p = 100 # 1000 elements are to be sorted
44
45
46 mu, sigma = 0, 1 # mean and standard deviation
47 X = np.random.normal(mu, sigma, p)
48 np.save(outfile, X)
49 print("The array is")
50 print(X)
51
52
53 outfile.seek(0) # using the same array
54 M = np.load(outfile)
55 r = len(M) - 1
56 z = _in_place_quick_sort(M, 0, r)
57
58 print(
59 "No of Comparisons for 100 elements selected from a standard normal distribution"
60 "is :"
61 )
62 print(z)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sorts/random_normal_distribution_quicksort.py b/sorts/random_normal_distribution_quicksort.py
deleted file mode 100644
--- a/sorts/random_normal_distribution_quicksort.py
+++ /dev/null
@@ -1,62 +0,0 @@
-from random import randint
-from tempfile import TemporaryFile
-
-import numpy as np
-
-
-def _in_place_quick_sort(a, start, end):
- count = 0
- if start < end:
- pivot = randint(start, end)
- temp = a[end]
- a[end] = a[pivot]
- a[pivot] = temp
-
- p, count = _in_place_partition(a, start, end)
- count += _in_place_quick_sort(a, start, p - 1)
- count += _in_place_quick_sort(a, p + 1, end)
- return count
-
-
-def _in_place_partition(a, start, end):
- count = 0
- pivot = randint(start, end)
- temp = a[end]
- a[end] = a[pivot]
- a[pivot] = temp
- new_pivot_index = start - 1
- for index in range(start, end):
- count += 1
- if a[index] < a[end]: # check if current val is less than pivot value
- new_pivot_index = new_pivot_index + 1
- temp = a[new_pivot_index]
- a[new_pivot_index] = a[index]
- a[index] = temp
-
- temp = a[new_pivot_index + 1]
- a[new_pivot_index + 1] = a[end]
- a[end] = temp
- return new_pivot_index + 1, count
-
-
-outfile = TemporaryFile()
-p = 100 # 1000 elements are to be sorted
-
-
-mu, sigma = 0, 1 # mean and standard deviation
-X = np.random.normal(mu, sigma, p)
-np.save(outfile, X)
-print("The array is")
-print(X)
-
-
-outfile.seek(0) # using the same array
-M = np.load(outfile)
-r = len(M) - 1
-z = _in_place_quick_sort(M, 0, r)
-
-print(
- "No of Comparisons for 100 elements selected from a standard normal distribution"
- "is :"
-)
-print(z)
|
{"golden_diff": "diff --git a/sorts/random_normal_distribution_quicksort.py b/sorts/random_normal_distribution_quicksort.py\ndeleted file mode 100644\n--- a/sorts/random_normal_distribution_quicksort.py\n+++ /dev/null\n@@ -1,62 +0,0 @@\n-from random import randint\n-from tempfile import TemporaryFile\n-\n-import numpy as np\n-\n-\n-def _in_place_quick_sort(a, start, end):\n- count = 0\n- if start < end:\n- pivot = randint(start, end)\n- temp = a[end]\n- a[end] = a[pivot]\n- a[pivot] = temp\n-\n- p, count = _in_place_partition(a, start, end)\n- count += _in_place_quick_sort(a, start, p - 1)\n- count += _in_place_quick_sort(a, p + 1, end)\n- return count\n-\n-\n-def _in_place_partition(a, start, end):\n- count = 0\n- pivot = randint(start, end)\n- temp = a[end]\n- a[end] = a[pivot]\n- a[pivot] = temp\n- new_pivot_index = start - 1\n- for index in range(start, end):\n- count += 1\n- if a[index] < a[end]: # check if current val is less than pivot value\n- new_pivot_index = new_pivot_index + 1\n- temp = a[new_pivot_index]\n- a[new_pivot_index] = a[index]\n- a[index] = temp\n-\n- temp = a[new_pivot_index + 1]\n- a[new_pivot_index + 1] = a[end]\n- a[end] = temp\n- return new_pivot_index + 1, count\n-\n-\n-outfile = TemporaryFile()\n-p = 100 # 1000 elements are to be sorted\n-\n-\n-mu, sigma = 0, 1 # mean and standard deviation\n-X = np.random.normal(mu, sigma, p)\n-np.save(outfile, X)\n-print(\"The array is\")\n-print(X)\n-\n-\n-outfile.seek(0) # using the same array\n-M = np.load(outfile)\n-r = len(M) - 1\n-z = _in_place_quick_sort(M, 0, r)\n-\n-print(\n- \"No of Comparisons for 100 elements selected from a standard normal distribution\"\n- \"is :\"\n-)\n-print(z)\n", "issue": "sorts/random_normal_distribution_quicksort.py has no tests\n### Repository commit\n\n3\n\n### Python version (python --version)\n\nPython 3.11.5\n\n### Dependencies version (pip freeze)\n\nNumpy\n\n### Expected behavior\n\nTests.\n\n### Actual behavior\n\nNo tests.\n", "before_files": [{"content": "from random import randint\nfrom tempfile import TemporaryFile\n\nimport numpy as np\n\n\ndef _in_place_quick_sort(a, start, end):\n count = 0\n if start < end:\n pivot = randint(start, end)\n temp = a[end]\n a[end] = a[pivot]\n a[pivot] = temp\n\n p, count = _in_place_partition(a, start, end)\n count += _in_place_quick_sort(a, start, p - 1)\n count += _in_place_quick_sort(a, p + 1, end)\n return count\n\n\ndef _in_place_partition(a, start, end):\n count = 0\n pivot = randint(start, end)\n temp = a[end]\n a[end] = a[pivot]\n a[pivot] = temp\n new_pivot_index = start - 1\n for index in range(start, end):\n count += 1\n if a[index] < a[end]: # check if current val is less than pivot value\n new_pivot_index = new_pivot_index + 1\n temp = a[new_pivot_index]\n a[new_pivot_index] = a[index]\n a[index] = temp\n\n temp = a[new_pivot_index + 1]\n a[new_pivot_index + 1] = a[end]\n a[end] = temp\n return new_pivot_index + 1, count\n\n\noutfile = TemporaryFile()\np = 100 # 1000 elements are to be sorted\n\n\nmu, sigma = 0, 1 # mean and standard deviation\nX = np.random.normal(mu, sigma, p)\nnp.save(outfile, X)\nprint(\"The array is\")\nprint(X)\n\n\noutfile.seek(0) # using the same array\nM = np.load(outfile)\nr = len(M) - 1\nz = _in_place_quick_sort(M, 0, r)\n\nprint(\n \"No of Comparisons for 100 elements selected from a standard normal distribution\"\n \"is :\"\n)\nprint(z)\n", "path": "sorts/random_normal_distribution_quicksort.py"}], "after_files": [{"content": null, "path": "sorts/random_normal_distribution_quicksort.py"}]}
| 895 | 553 |
gh_patches_debug_16321
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tag fallback bypasses the bot's DM restrictions
When a user issues a command that does not exist, we fall back to trying to match it as a tag name. This means that a message containing `!f-strings`, which is not a command in itself, will result in the bot sending the contents of the `f-strings` tag. This is a great feature, but it currently does not respect the DM-restriction we've put in place: Members should only be able to issue commands in public channels, not a DM conversation with the bot.
The [current code responsible for the tag fallback](https://github.com/python-discord/bot/blob/master/bot/cogs/error_handler.py#L73) only checks if the user is not issuing the pseudo-command in checkpoint. The global checks that prevent commands from being issued in DMs are [defined in the security cog](https://github.com/python-discord/bot/blob/master/bot/cogs/security.py).
#### Bot response after command in DM

#### Bot response after tag in DM
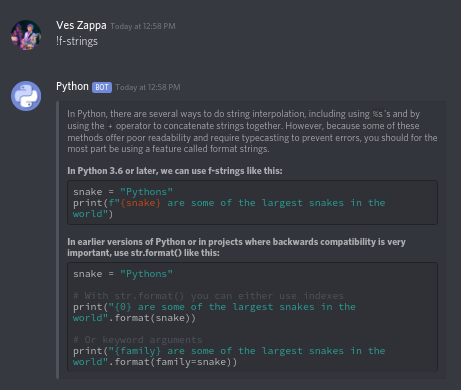
Tag fallback bypasses the bot's DM restrictions
When a user issues a command that does not exist, we fall back to trying to match it as a tag name. This means that a message containing `!f-strings`, which is not a command in itself, will result in the bot sending the contents of the `f-strings` tag. This is a great feature, but it currently does not respect the DM-restriction we've put in place: Members should only be able to issue commands in public channels, not a DM conversation with the bot.
The [current code responsible for the tag fallback](https://github.com/python-discord/bot/blob/master/bot/cogs/error_handler.py#L73) only checks if the user is not issuing the pseudo-command in checkpoint. The global checks that prevent commands from being issued in DMs are [defined in the security cog](https://github.com/python-discord/bot/blob/master/bot/cogs/security.py).
#### Bot response after command in DM

#### Bot response after tag in DM

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/cogs/error_handler.py`
Content:
```
1 import contextlib
2 import logging
3
4 from discord.ext.commands import (
5 BadArgument,
6 BotMissingPermissions,
7 CheckFailure,
8 CommandError,
9 CommandInvokeError,
10 CommandNotFound,
11 CommandOnCooldown,
12 DisabledCommand,
13 MissingPermissions,
14 NoPrivateMessage,
15 UserInputError,
16 )
17 from discord.ext.commands import Bot, Cog, Context
18
19 from bot.api import ResponseCodeError
20 from bot.constants import Channels
21 from bot.decorators import InChannelCheckFailure
22
23 log = logging.getLogger(__name__)
24
25
26 class ErrorHandler(Cog):
27 """Handles errors emitted from commands."""
28
29 def __init__(self, bot: Bot):
30 self.bot = bot
31
32 @Cog.listener()
33 async def on_command_error(self, ctx: Context, e: CommandError) -> None:
34 """
35 Provide generic command error handling.
36
37 Error handling is deferred to any local error handler, if present.
38
39 Error handling emits a single error response, prioritized as follows:
40 1. If the name fails to match a command but matches a tag, the tag is invoked
41 2. Send a BadArgument error message to the invoking context & invoke the command's help
42 3. Send a UserInputError error message to the invoking context & invoke the command's help
43 4. Send a NoPrivateMessage error message to the invoking context
44 5. Send a BotMissingPermissions error message to the invoking context
45 6. Log a MissingPermissions error, no message is sent
46 7. Send a InChannelCheckFailure error message to the invoking context
47 8. Log CheckFailure, CommandOnCooldown, and DisabledCommand errors, no message is sent
48 9. For CommandInvokeErrors, response is based on the type of error:
49 * 404: Error message is sent to the invoking context
50 * 400: Log the resopnse JSON, no message is sent
51 * 500 <= status <= 600: Error message is sent to the invoking context
52 10. Otherwise, handling is deferred to `handle_unexpected_error`
53 """
54 command = ctx.command
55 parent = None
56
57 if command is not None:
58 parent = command.parent
59
60 # Retrieve the help command for the invoked command.
61 if parent and command:
62 help_command = (self.bot.get_command("help"), parent.name, command.name)
63 elif command:
64 help_command = (self.bot.get_command("help"), command.name)
65 else:
66 help_command = (self.bot.get_command("help"),)
67
68 if hasattr(e, "handled"):
69 log.trace(f"Command {command} had its error already handled locally; ignoring.")
70 return
71
72 # Try to look for a tag with the command's name if the command isn't found.
73 if isinstance(e, CommandNotFound) and not hasattr(ctx, "invoked_from_error_handler"):
74 if not ctx.channel.id == Channels.verification:
75 tags_get_command = self.bot.get_command("tags get")
76 ctx.invoked_from_error_handler = True
77
78 # Return to not raise the exception
79 with contextlib.suppress(ResponseCodeError):
80 await ctx.invoke(tags_get_command, tag_name=ctx.invoked_with)
81 return
82 elif isinstance(e, BadArgument):
83 await ctx.send(f"Bad argument: {e}\n")
84 await ctx.invoke(*help_command)
85 elif isinstance(e, UserInputError):
86 await ctx.send("Something about your input seems off. Check the arguments:")
87 await ctx.invoke(*help_command)
88 log.debug(
89 f"Command {command} invoked by {ctx.message.author} with error "
90 f"{e.__class__.__name__}: {e}"
91 )
92 elif isinstance(e, NoPrivateMessage):
93 await ctx.send("Sorry, this command can't be used in a private message!")
94 elif isinstance(e, BotMissingPermissions):
95 await ctx.send(f"Sorry, it looks like I don't have the permissions I need to do that.")
96 log.warning(
97 f"The bot is missing permissions to execute command {command}: {e.missing_perms}"
98 )
99 elif isinstance(e, MissingPermissions):
100 log.debug(
101 f"{ctx.message.author} is missing permissions to invoke command {command}: "
102 f"{e.missing_perms}"
103 )
104 elif isinstance(e, InChannelCheckFailure):
105 await ctx.send(e)
106 elif isinstance(e, (CheckFailure, CommandOnCooldown, DisabledCommand)):
107 log.debug(
108 f"Command {command} invoked by {ctx.message.author} with error "
109 f"{e.__class__.__name__}: {e}"
110 )
111 elif isinstance(e, CommandInvokeError):
112 if isinstance(e.original, ResponseCodeError):
113 status = e.original.response.status
114
115 if status == 404:
116 await ctx.send("There does not seem to be anything matching your query.")
117 elif status == 400:
118 content = await e.original.response.json()
119 log.debug(f"API responded with 400 for command {command}: %r.", content)
120 await ctx.send("According to the API, your request is malformed.")
121 elif 500 <= status < 600:
122 await ctx.send("Sorry, there seems to be an internal issue with the API.")
123 log.warning(f"API responded with {status} for command {command}")
124 else:
125 await ctx.send(f"Got an unexpected status code from the API (`{status}`).")
126 log.warning(f"Unexpected API response for command {command}: {status}")
127 else:
128 await self.handle_unexpected_error(ctx, e.original)
129 else:
130 await self.handle_unexpected_error(ctx, e)
131
132 @staticmethod
133 async def handle_unexpected_error(ctx: Context, e: CommandError) -> None:
134 """Generic handler for errors without an explicit handler."""
135 await ctx.send(
136 f"Sorry, an unexpected error occurred. Please let us know!\n\n"
137 f"```{e.__class__.__name__}: {e}```"
138 )
139 log.error(
140 f"Error executing command invoked by {ctx.message.author}: {ctx.message.content}"
141 )
142 raise e
143
144
145 def setup(bot: Bot) -> None:
146 """Error handler cog load."""
147 bot.add_cog(ErrorHandler(bot))
148 log.info("Cog loaded: Events")
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/cogs/error_handler.py b/bot/cogs/error_handler.py
--- a/bot/cogs/error_handler.py
+++ b/bot/cogs/error_handler.py
@@ -75,6 +75,16 @@
tags_get_command = self.bot.get_command("tags get")
ctx.invoked_from_error_handler = True
+ log_msg = "Cancelling attempt to fall back to a tag due to failed checks."
+ try:
+ if not await tags_get_command.can_run(ctx):
+ log.debug(log_msg)
+ return
+ except CommandError as tag_error:
+ log.debug(log_msg)
+ await self.on_command_error(ctx, tag_error)
+ return
+
# Return to not raise the exception
with contextlib.suppress(ResponseCodeError):
await ctx.invoke(tags_get_command, tag_name=ctx.invoked_with)
|
{"golden_diff": "diff --git a/bot/cogs/error_handler.py b/bot/cogs/error_handler.py\n--- a/bot/cogs/error_handler.py\n+++ b/bot/cogs/error_handler.py\n@@ -75,6 +75,16 @@\n tags_get_command = self.bot.get_command(\"tags get\")\n ctx.invoked_from_error_handler = True\n \n+ log_msg = \"Cancelling attempt to fall back to a tag due to failed checks.\"\n+ try:\n+ if not await tags_get_command.can_run(ctx):\n+ log.debug(log_msg)\n+ return\n+ except CommandError as tag_error:\n+ log.debug(log_msg)\n+ await self.on_command_error(ctx, tag_error)\n+ return\n+\n # Return to not raise the exception\n with contextlib.suppress(ResponseCodeError):\n await ctx.invoke(tags_get_command, tag_name=ctx.invoked_with)\n", "issue": "Tag fallback bypasses the bot's DM restrictions\nWhen a user issues a command that does not exist, we fall back to trying to match it as a tag name. This means that a message containing `!f-strings`, which is not a command in itself, will result in the bot sending the contents of the `f-strings` tag. This is a great feature, but it currently does not respect the DM-restriction we've put in place: Members should only be able to issue commands in public channels, not a DM conversation with the bot.\r\n\r\nThe [current code responsible for the tag fallback](https://github.com/python-discord/bot/blob/master/bot/cogs/error_handler.py#L73) only checks if the user is not issuing the pseudo-command in checkpoint. The global checks that prevent commands from being issued in DMs are [defined in the security cog](https://github.com/python-discord/bot/blob/master/bot/cogs/security.py).\r\n\r\n#### Bot response after command in DM\r\n\r\n\r\n\r\n#### Bot response after tag in DM\r\n\r\n\r\n\nTag fallback bypasses the bot's DM restrictions\nWhen a user issues a command that does not exist, we fall back to trying to match it as a tag name. This means that a message containing `!f-strings`, which is not a command in itself, will result in the bot sending the contents of the `f-strings` tag. This is a great feature, but it currently does not respect the DM-restriction we've put in place: Members should only be able to issue commands in public channels, not a DM conversation with the bot.\r\n\r\nThe [current code responsible for the tag fallback](https://github.com/python-discord/bot/blob/master/bot/cogs/error_handler.py#L73) only checks if the user is not issuing the pseudo-command in checkpoint. The global checks that prevent commands from being issued in DMs are [defined in the security cog](https://github.com/python-discord/bot/blob/master/bot/cogs/security.py).\r\n\r\n#### Bot response after command in DM\r\n\r\n\r\n\r\n#### Bot response after tag in DM\r\n\r\n\r\n\n", "before_files": [{"content": "import contextlib\nimport logging\n\nfrom discord.ext.commands import (\n BadArgument,\n BotMissingPermissions,\n CheckFailure,\n CommandError,\n CommandInvokeError,\n CommandNotFound,\n CommandOnCooldown,\n DisabledCommand,\n MissingPermissions,\n NoPrivateMessage,\n UserInputError,\n)\nfrom discord.ext.commands import Bot, Cog, Context\n\nfrom bot.api import ResponseCodeError\nfrom bot.constants import Channels\nfrom bot.decorators import InChannelCheckFailure\n\nlog = logging.getLogger(__name__)\n\n\nclass ErrorHandler(Cog):\n \"\"\"Handles errors emitted from commands.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n @Cog.listener()\n async def on_command_error(self, ctx: Context, e: CommandError) -> None:\n \"\"\"\n Provide generic command error handling.\n\n Error handling is deferred to any local error handler, if present.\n\n Error handling emits a single error response, prioritized as follows:\n 1. If the name fails to match a command but matches a tag, the tag is invoked\n 2. Send a BadArgument error message to the invoking context & invoke the command's help\n 3. Send a UserInputError error message to the invoking context & invoke the command's help\n 4. Send a NoPrivateMessage error message to the invoking context\n 5. Send a BotMissingPermissions error message to the invoking context\n 6. Log a MissingPermissions error, no message is sent\n 7. Send a InChannelCheckFailure error message to the invoking context\n 8. Log CheckFailure, CommandOnCooldown, and DisabledCommand errors, no message is sent\n 9. For CommandInvokeErrors, response is based on the type of error:\n * 404: Error message is sent to the invoking context\n * 400: Log the resopnse JSON, no message is sent\n * 500 <= status <= 600: Error message is sent to the invoking context\n 10. Otherwise, handling is deferred to `handle_unexpected_error`\n \"\"\"\n command = ctx.command\n parent = None\n\n if command is not None:\n parent = command.parent\n\n # Retrieve the help command for the invoked command.\n if parent and command:\n help_command = (self.bot.get_command(\"help\"), parent.name, command.name)\n elif command:\n help_command = (self.bot.get_command(\"help\"), command.name)\n else:\n help_command = (self.bot.get_command(\"help\"),)\n\n if hasattr(e, \"handled\"):\n log.trace(f\"Command {command} had its error already handled locally; ignoring.\")\n return\n\n # Try to look for a tag with the command's name if the command isn't found.\n if isinstance(e, CommandNotFound) and not hasattr(ctx, \"invoked_from_error_handler\"):\n if not ctx.channel.id == Channels.verification:\n tags_get_command = self.bot.get_command(\"tags get\")\n ctx.invoked_from_error_handler = True\n\n # Return to not raise the exception\n with contextlib.suppress(ResponseCodeError):\n await ctx.invoke(tags_get_command, tag_name=ctx.invoked_with)\n return\n elif isinstance(e, BadArgument):\n await ctx.send(f\"Bad argument: {e}\\n\")\n await ctx.invoke(*help_command)\n elif isinstance(e, UserInputError):\n await ctx.send(\"Something about your input seems off. Check the arguments:\")\n await ctx.invoke(*help_command)\n log.debug(\n f\"Command {command} invoked by {ctx.message.author} with error \"\n f\"{e.__class__.__name__}: {e}\"\n )\n elif isinstance(e, NoPrivateMessage):\n await ctx.send(\"Sorry, this command can't be used in a private message!\")\n elif isinstance(e, BotMissingPermissions):\n await ctx.send(f\"Sorry, it looks like I don't have the permissions I need to do that.\")\n log.warning(\n f\"The bot is missing permissions to execute command {command}: {e.missing_perms}\"\n )\n elif isinstance(e, MissingPermissions):\n log.debug(\n f\"{ctx.message.author} is missing permissions to invoke command {command}: \"\n f\"{e.missing_perms}\"\n )\n elif isinstance(e, InChannelCheckFailure):\n await ctx.send(e)\n elif isinstance(e, (CheckFailure, CommandOnCooldown, DisabledCommand)):\n log.debug(\n f\"Command {command} invoked by {ctx.message.author} with error \"\n f\"{e.__class__.__name__}: {e}\"\n )\n elif isinstance(e, CommandInvokeError):\n if isinstance(e.original, ResponseCodeError):\n status = e.original.response.status\n\n if status == 404:\n await ctx.send(\"There does not seem to be anything matching your query.\")\n elif status == 400:\n content = await e.original.response.json()\n log.debug(f\"API responded with 400 for command {command}: %r.\", content)\n await ctx.send(\"According to the API, your request is malformed.\")\n elif 500 <= status < 600:\n await ctx.send(\"Sorry, there seems to be an internal issue with the API.\")\n log.warning(f\"API responded with {status} for command {command}\")\n else:\n await ctx.send(f\"Got an unexpected status code from the API (`{status}`).\")\n log.warning(f\"Unexpected API response for command {command}: {status}\")\n else:\n await self.handle_unexpected_error(ctx, e.original)\n else:\n await self.handle_unexpected_error(ctx, e)\n\n @staticmethod\n async def handle_unexpected_error(ctx: Context, e: CommandError) -> None:\n \"\"\"Generic handler for errors without an explicit handler.\"\"\"\n await ctx.send(\n f\"Sorry, an unexpected error occurred. Please let us know!\\n\\n\"\n f\"```{e.__class__.__name__}: {e}```\"\n )\n log.error(\n f\"Error executing command invoked by {ctx.message.author}: {ctx.message.content}\"\n )\n raise e\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Error handler cog load.\"\"\"\n bot.add_cog(ErrorHandler(bot))\n log.info(\"Cog loaded: Events\")\n", "path": "bot/cogs/error_handler.py"}], "after_files": [{"content": "import contextlib\nimport logging\n\nfrom discord.ext.commands import (\n BadArgument,\n BotMissingPermissions,\n CheckFailure,\n CommandError,\n CommandInvokeError,\n CommandNotFound,\n CommandOnCooldown,\n DisabledCommand,\n MissingPermissions,\n NoPrivateMessage,\n UserInputError,\n)\nfrom discord.ext.commands import Bot, Cog, Context\n\nfrom bot.api import ResponseCodeError\nfrom bot.constants import Channels\nfrom bot.decorators import InChannelCheckFailure\n\nlog = logging.getLogger(__name__)\n\n\nclass ErrorHandler(Cog):\n \"\"\"Handles errors emitted from commands.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n @Cog.listener()\n async def on_command_error(self, ctx: Context, e: CommandError) -> None:\n \"\"\"\n Provide generic command error handling.\n\n Error handling is deferred to any local error handler, if present.\n\n Error handling emits a single error response, prioritized as follows:\n 1. If the name fails to match a command but matches a tag, the tag is invoked\n 2. Send a BadArgument error message to the invoking context & invoke the command's help\n 3. Send a UserInputError error message to the invoking context & invoke the command's help\n 4. Send a NoPrivateMessage error message to the invoking context\n 5. Send a BotMissingPermissions error message to the invoking context\n 6. Log a MissingPermissions error, no message is sent\n 7. Send a InChannelCheckFailure error message to the invoking context\n 8. Log CheckFailure, CommandOnCooldown, and DisabledCommand errors, no message is sent\n 9. For CommandInvokeErrors, response is based on the type of error:\n * 404: Error message is sent to the invoking context\n * 400: Log the resopnse JSON, no message is sent\n * 500 <= status <= 600: Error message is sent to the invoking context\n 10. Otherwise, handling is deferred to `handle_unexpected_error`\n \"\"\"\n command = ctx.command\n parent = None\n\n if command is not None:\n parent = command.parent\n\n # Retrieve the help command for the invoked command.\n if parent and command:\n help_command = (self.bot.get_command(\"help\"), parent.name, command.name)\n elif command:\n help_command = (self.bot.get_command(\"help\"), command.name)\n else:\n help_command = (self.bot.get_command(\"help\"),)\n\n if hasattr(e, \"handled\"):\n log.trace(f\"Command {command} had its error already handled locally; ignoring.\")\n return\n\n # Try to look for a tag with the command's name if the command isn't found.\n if isinstance(e, CommandNotFound) and not hasattr(ctx, \"invoked_from_error_handler\"):\n if not ctx.channel.id == Channels.verification:\n tags_get_command = self.bot.get_command(\"tags get\")\n ctx.invoked_from_error_handler = True\n\n log_msg = \"Cancelling attempt to fall back to a tag due to failed checks.\"\n try:\n if not await tags_get_command.can_run(ctx):\n log.debug(log_msg)\n return\n except CommandError as tag_error:\n log.debug(log_msg)\n await self.on_command_error(ctx, tag_error)\n return\n\n # Return to not raise the exception\n with contextlib.suppress(ResponseCodeError):\n await ctx.invoke(tags_get_command, tag_name=ctx.invoked_with)\n return\n elif isinstance(e, BadArgument):\n await ctx.send(f\"Bad argument: {e}\\n\")\n await ctx.invoke(*help_command)\n elif isinstance(e, UserInputError):\n await ctx.send(\"Something about your input seems off. Check the arguments:\")\n await ctx.invoke(*help_command)\n log.debug(\n f\"Command {command} invoked by {ctx.message.author} with error \"\n f\"{e.__class__.__name__}: {e}\"\n )\n elif isinstance(e, NoPrivateMessage):\n await ctx.send(\"Sorry, this command can't be used in a private message!\")\n elif isinstance(e, BotMissingPermissions):\n await ctx.send(f\"Sorry, it looks like I don't have the permissions I need to do that.\")\n log.warning(\n f\"The bot is missing permissions to execute command {command}: {e.missing_perms}\"\n )\n elif isinstance(e, MissingPermissions):\n log.debug(\n f\"{ctx.message.author} is missing permissions to invoke command {command}: \"\n f\"{e.missing_perms}\"\n )\n elif isinstance(e, InChannelCheckFailure):\n await ctx.send(e)\n elif isinstance(e, (CheckFailure, CommandOnCooldown, DisabledCommand)):\n log.debug(\n f\"Command {command} invoked by {ctx.message.author} with error \"\n f\"{e.__class__.__name__}: {e}\"\n )\n elif isinstance(e, CommandInvokeError):\n if isinstance(e.original, ResponseCodeError):\n status = e.original.response.status\n\n if status == 404:\n await ctx.send(\"There does not seem to be anything matching your query.\")\n elif status == 400:\n content = await e.original.response.json()\n log.debug(f\"API responded with 400 for command {command}: %r.\", content)\n await ctx.send(\"According to the API, your request is malformed.\")\n elif 500 <= status < 600:\n await ctx.send(\"Sorry, there seems to be an internal issue with the API.\")\n log.warning(f\"API responded with {status} for command {command}\")\n else:\n await ctx.send(f\"Got an unexpected status code from the API (`{status}`).\")\n log.warning(f\"Unexpected API response for command {command}: {status}\")\n else:\n await self.handle_unexpected_error(ctx, e.original)\n else:\n await self.handle_unexpected_error(ctx, e)\n\n @staticmethod\n async def handle_unexpected_error(ctx: Context, e: CommandError) -> None:\n \"\"\"Generic handler for errors without an explicit handler.\"\"\"\n await ctx.send(\n f\"Sorry, an unexpected error occurred. Please let us know!\\n\\n\"\n f\"```{e.__class__.__name__}: {e}```\"\n )\n log.error(\n f\"Error executing command invoked by {ctx.message.author}: {ctx.message.content}\"\n )\n raise e\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Error handler cog load.\"\"\"\n bot.add_cog(ErrorHandler(bot))\n log.info(\"Cog loaded: Events\")\n", "path": "bot/cogs/error_handler.py"}]}
| 2,635 | 192 |
gh_patches_debug_9195
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-4015
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Redirect loop when requesting missing package
**Describe the bug**
When I `curl -v https://pypi.org/pypi/bogus/1.0.0/json` with an invalid package/version combination, I get put in an infinite redirect loop. If the package/version combination is correct, then the data is served as expected.
I noticed this because the `license_finder` gem just now started having issues when looking for my team's internal (non-PyPi) packages. Previously, it hadn't complained.
**Expected behavior**
For an invalid package/version combination, I'd expect a 404 (or whatever the previous behavior was).
**To Reproduce**
`curl -v https://pypi.org/pypi/bogus/1.0.0/json`, note that the `Location` header leads you to the same URL.
**My Platform**
Pretty sure my platform isn't relevant. I've reproduced the problem both from my personal internet connection as well as within AWS.
**Additional context**
Adding @dstufft @di as suggested on IRC.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/routes.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13
14 def includeme(config):
15 # We need to get the value of the Warehouse and Forklift domains, we'll use
16 # these to segregate the Warehouse routes from the Forklift routes until
17 # Forklift is properly split out into it's own project.
18 warehouse = config.get_settings().get("warehouse.domain")
19 files_url = config.get_settings()["files.url"]
20
21 # Simple Route for health checks.
22 config.add_route("health", "/_health/")
23
24 # Internal route to make it easier to force a particular status for
25 # debugging HTTPException templates.
26 config.add_route("force-status", "/_force-status/{status:[45]\d\d}/")
27
28 # Basic global routes
29 config.add_route("index", "/", domain=warehouse)
30 config.add_route("robots.txt", "/robots.txt", domain=warehouse)
31 config.add_route("opensearch.xml", "/opensearch.xml", domain=warehouse)
32 config.add_route("index.sitemap.xml", "/sitemap.xml", domain=warehouse)
33 config.add_route(
34 "bucket.sitemap.xml",
35 "/{bucket}.sitemap.xml",
36 domain=warehouse,
37 )
38
39 # Some static, template driven pages
40 config.add_template_view("help", "/help/", "pages/help.html")
41 config.add_template_view("security", "/security/", "pages/security.html")
42 config.add_template_view(
43 "sponsors",
44 "/sponsors/",
45 # Use the full resource path here to make it able to be overridden by
46 # pypi-theme.
47 "warehouse:templates/pages/sponsors.html",
48 )
49
50 # Our legal policies
51 config.add_policy("terms-of-use", "terms.md")
52
53 # HTML Snippets for including into other pages.
54 config.add_route(
55 "includes.current-user-indicator",
56 "/_includes/current-user-indicator/",
57 domain=warehouse,
58 )
59 config.add_route(
60 "includes.flash-messages",
61 "/_includes/flash-messages/",
62 domain=warehouse,
63 )
64 config.add_route(
65 "includes.current-user-profile-callout",
66 "/_includes/current-user-profile-callout/{username}",
67 factory="warehouse.accounts.models:UserFactory",
68 traverse="/{username}",
69 domain=warehouse,
70 )
71 config.add_route(
72 "includes.edit-project-button",
73 "/_includes/edit-project-button/{project_name}",
74 factory="warehouse.packaging.models:ProjectFactory",
75 traverse="/{project_name}",
76 domain=warehouse,
77 )
78 config.add_route(
79 "includes.profile-actions",
80 "/_includes/profile-actions/{username}",
81 factory="warehouse.accounts.models:UserFactory",
82 traverse="/{username}",
83 domain=warehouse,
84 )
85
86 # Classifier Routes
87 config.add_route("classifiers", "/classifiers/", domain=warehouse)
88
89 # Search Routes
90 config.add_route("search", "/search/", domain=warehouse)
91
92 # Accounts
93 config.add_route(
94 "accounts.profile",
95 "/user/{username}/",
96 factory="warehouse.accounts.models:UserFactory",
97 traverse="/{username}",
98 domain=warehouse,
99 )
100 config.add_route("accounts.login", "/account/login/", domain=warehouse)
101 config.add_route("accounts.logout", "/account/logout/", domain=warehouse)
102 config.add_route(
103 "accounts.register",
104 "/account/register/",
105 domain=warehouse,
106 )
107 config.add_route(
108 "accounts.request-password-reset",
109 "/account/request-password-reset/",
110 domain=warehouse,
111 )
112 config.add_route(
113 "accounts.reset-password",
114 "/account/reset-password/",
115 domain=warehouse,
116 )
117 config.add_route(
118 "accounts.verify-email",
119 "/account/verify-email/",
120 domain=warehouse,
121 )
122
123 # Management (views for logged-in users)
124 config.add_route("manage.account", "/manage/account/", domain=warehouse)
125 config.add_route("manage.projects", "/manage/projects/", domain=warehouse)
126 config.add_route(
127 "manage.project.settings",
128 "/manage/project/{project_name}/settings/",
129 factory="warehouse.packaging.models:ProjectFactory",
130 traverse="/{project_name}",
131 domain=warehouse,
132 )
133 config.add_route(
134 "manage.project.delete_project",
135 "/manage/project/{project_name}/delete_project/",
136 factory="warehouse.packaging.models:ProjectFactory",
137 traverse="/{project_name}",
138 domain=warehouse,
139 )
140 config.add_route(
141 "manage.project.destroy_docs",
142 "/manage/project/{project_name}/delete_project_docs/",
143 factory="warehouse.packaging.models:ProjectFactory",
144 traverse="/{project_name}",
145 domain=warehouse,
146 )
147 config.add_route(
148 "manage.project.releases",
149 "/manage/project/{project_name}/releases/",
150 factory="warehouse.packaging.models:ProjectFactory",
151 traverse="/{project_name}",
152 domain=warehouse,
153 )
154 config.add_route(
155 "manage.project.release",
156 "/manage/project/{project_name}/release/{version}/",
157 factory="warehouse.packaging.models:ProjectFactory",
158 traverse="/{project_name}/{version}",
159 domain=warehouse,
160 )
161 config.add_route(
162 "manage.project.roles",
163 "/manage/project/{project_name}/collaboration/",
164 factory="warehouse.packaging.models:ProjectFactory",
165 traverse="/{project_name}",
166 domain=warehouse,
167 )
168 config.add_route(
169 "manage.project.change_role",
170 "/manage/project/{project_name}/collaboration/change/",
171 factory="warehouse.packaging.models:ProjectFactory",
172 traverse="/{project_name}",
173 domain=warehouse,
174 )
175 config.add_route(
176 "manage.project.delete_role",
177 "/manage/project/{project_name}/collaboration/delete/",
178 factory="warehouse.packaging.models:ProjectFactory",
179 traverse="/{project_name}",
180 domain=warehouse,
181 )
182 config.add_route(
183 "manage.project.documentation",
184 "/manage/project/{project_name}/documentation/",
185 factory="warehouse.packaging.models:ProjectFactory",
186 traverse="/{project_name}",
187 domain=warehouse,
188 )
189 config.add_route(
190 "manage.project.history",
191 "/manage/project/{project_name}/history/",
192 factory="warehouse.packaging.models:ProjectFactory",
193 traverse="/{project_name}",
194 domain=warehouse,
195 )
196
197 # Packaging
198 config.add_redirect('/p/{name}/', '/project/{name}/', domain=warehouse)
199 config.add_route(
200 "packaging.project",
201 "/project/{name}/",
202 factory="warehouse.packaging.models:ProjectFactory",
203 traverse="/{name}",
204 domain=warehouse,
205 )
206 config.add_route(
207 "packaging.release",
208 "/project/{name}/{version}/",
209 factory="warehouse.packaging.models:ProjectFactory",
210 traverse="/{name}/{version}",
211 domain=warehouse,
212 )
213 config.add_route("packaging.file", files_url)
214
215 # SES Webhooks
216 config.add_route("ses.hook", "/_/ses-hook/", domain=warehouse)
217
218 # RSS
219 config.add_route("rss.updates", "/rss/updates.xml", domain=warehouse)
220 config.add_route("rss.packages", "/rss/packages.xml", domain=warehouse)
221
222 # Legacy URLs
223 config.add_route("legacy.api.simple.index", "/simple/", domain=warehouse)
224 config.add_route(
225 "legacy.api.simple.detail",
226 "/simple/{name}/",
227 factory="warehouse.packaging.models:ProjectFactory",
228 traverse="/{name}/",
229 read_only=True,
230 domain=warehouse,
231 )
232 config.add_route(
233 "legacy.api.json.project",
234 "/pypi/{name}/json",
235 factory="warehouse.packaging.models:ProjectFactory",
236 traverse="/{name}",
237 read_only=True,
238 domain=warehouse,
239 )
240 config.add_route(
241 "legacy.api.json.release",
242 "/pypi/{name}/{version}/json",
243 factory="warehouse.packaging.models:ProjectFactory",
244 traverse="/{name}/{version}",
245 read_only=True,
246 domain=warehouse,
247 )
248
249 # Legacy Action URLs
250 # TODO: We should probably add Warehouse routes for these that just error
251 # and direct people to use upload.pypi.io
252 config.add_pypi_action_route(
253 "legacy.api.pypi.file_upload",
254 "file_upload",
255 domain=warehouse,
256 )
257 config.add_pypi_action_route(
258 "legacy.api.pypi.submit",
259 "submit",
260 domain=warehouse,
261 )
262 config.add_pypi_action_route(
263 "legacy.api.pypi.submit_pkg_info",
264 "submit_pkg_info",
265 domain=warehouse,
266 )
267 config.add_pypi_action_route(
268 "legacy.api.pypi.doc_upload",
269 "doc_upload",
270 domain=warehouse,
271 )
272 config.add_pypi_action_route(
273 "legacy.api.pypi.doap",
274 "doap",
275 domain=warehouse,
276 )
277 config.add_pypi_action_route(
278 "legacy.api.pypi.list_classifiers",
279 "list_classifiers",
280 domain=warehouse,
281 )
282 config.add_pypi_action_route(
283 'legacy.api.pypi.search',
284 'search',
285 domain=warehouse,
286 )
287 config.add_pypi_action_route(
288 'legacy.api.pypi.browse',
289 'browse',
290 domain=warehouse,
291 )
292 config.add_pypi_action_route(
293 'legacy.api.pypi.files',
294 'files',
295 domain=warehouse,
296 )
297 config.add_pypi_action_route(
298 'legacy.api.pypi.display',
299 'display',
300 domain=warehouse,
301 )
302
303 # Legacy XMLRPC
304 config.add_xmlrpc_endpoint(
305 "pypi",
306 pattern="/pypi",
307 header="Content-Type:text/xml",
308 domain=warehouse,
309 )
310 config.add_xmlrpc_endpoint(
311 "pypi_slash",
312 pattern="/pypi/",
313 header="Content-Type:text/xml",
314 domain=warehouse,
315 )
316 config.add_xmlrpc_endpoint(
317 "RPC2",
318 pattern="/RPC2",
319 header="Content-Type:text/xml",
320 domain=warehouse,
321 )
322
323 # Legacy Documentation
324 config.add_route("legacy.docs", config.registry.settings["docs.url"])
325
326 # Legacy Redirects
327 config.add_redirect("/pypi/{name}/", "/project/{name}/", domain=warehouse)
328 config.add_redirect(
329 "/pypi/{name}/{version}/json/",
330 "/pypi/{name}/{version}/json",
331 domain=warehouse,
332 )
333 config.add_redirect(
334 "/pypi/{name}/json/",
335 "/pypi/{name}/json",
336 domain=warehouse,
337 )
338
339 config.add_redirect(
340 "/pypi/{name}/{version}/",
341 "/project/{name}/{version}/",
342 domain=warehouse,
343 )
344 config.add_redirect("/packages/{path:.*}", files_url, domain=warehouse)
345
346 # Legacy Action Redirects
347 config.add_pypi_action_redirect(
348 "rss",
349 "/rss/updates.xml",
350 domain=warehouse,
351 )
352 config.add_pypi_action_redirect(
353 "packages_rss",
354 "/rss/packages.xml",
355 domain=warehouse,
356 )
357
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/routes.py b/warehouse/routes.py
--- a/warehouse/routes.py
+++ b/warehouse/routes.py
@@ -325,17 +325,6 @@
# Legacy Redirects
config.add_redirect("/pypi/{name}/", "/project/{name}/", domain=warehouse)
- config.add_redirect(
- "/pypi/{name}/{version}/json/",
- "/pypi/{name}/{version}/json",
- domain=warehouse,
- )
- config.add_redirect(
- "/pypi/{name}/json/",
- "/pypi/{name}/json",
- domain=warehouse,
- )
-
config.add_redirect(
"/pypi/{name}/{version}/",
"/project/{name}/{version}/",
|
{"golden_diff": "diff --git a/warehouse/routes.py b/warehouse/routes.py\n--- a/warehouse/routes.py\n+++ b/warehouse/routes.py\n@@ -325,17 +325,6 @@\n \n # Legacy Redirects\n config.add_redirect(\"/pypi/{name}/\", \"/project/{name}/\", domain=warehouse)\n- config.add_redirect(\n- \"/pypi/{name}/{version}/json/\",\n- \"/pypi/{name}/{version}/json\",\n- domain=warehouse,\n- )\n- config.add_redirect(\n- \"/pypi/{name}/json/\",\n- \"/pypi/{name}/json\",\n- domain=warehouse,\n- )\n-\n config.add_redirect(\n \"/pypi/{name}/{version}/\",\n \"/project/{name}/{version}/\",\n", "issue": "Redirect loop when requesting missing package\n**Describe the bug**\r\nWhen I `curl -v https://pypi.org/pypi/bogus/1.0.0/json` with an invalid package/version combination, I get put in an infinite redirect loop. If the package/version combination is correct, then the data is served as expected.\r\n\r\nI noticed this because the `license_finder` gem just now started having issues when looking for my team's internal (non-PyPi) packages. Previously, it hadn't complained.\r\n\r\n**Expected behavior**\r\nFor an invalid package/version combination, I'd expect a 404 (or whatever the previous behavior was).\r\n\r\n**To Reproduce**\r\n`curl -v https://pypi.org/pypi/bogus/1.0.0/json`, note that the `Location` header leads you to the same URL.\r\n\r\n**My Platform**\r\nPretty sure my platform isn't relevant. I've reproduced the problem both from my personal internet connection as well as within AWS.\r\n\r\n**Additional context**\r\nAdding @dstufft @di as suggested on IRC.\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef includeme(config):\n # We need to get the value of the Warehouse and Forklift domains, we'll use\n # these to segregate the Warehouse routes from the Forklift routes until\n # Forklift is properly split out into it's own project.\n warehouse = config.get_settings().get(\"warehouse.domain\")\n files_url = config.get_settings()[\"files.url\"]\n\n # Simple Route for health checks.\n config.add_route(\"health\", \"/_health/\")\n\n # Internal route to make it easier to force a particular status for\n # debugging HTTPException templates.\n config.add_route(\"force-status\", \"/_force-status/{status:[45]\\d\\d}/\")\n\n # Basic global routes\n config.add_route(\"index\", \"/\", domain=warehouse)\n config.add_route(\"robots.txt\", \"/robots.txt\", domain=warehouse)\n config.add_route(\"opensearch.xml\", \"/opensearch.xml\", domain=warehouse)\n config.add_route(\"index.sitemap.xml\", \"/sitemap.xml\", domain=warehouse)\n config.add_route(\n \"bucket.sitemap.xml\",\n \"/{bucket}.sitemap.xml\",\n domain=warehouse,\n )\n\n # Some static, template driven pages\n config.add_template_view(\"help\", \"/help/\", \"pages/help.html\")\n config.add_template_view(\"security\", \"/security/\", \"pages/security.html\")\n config.add_template_view(\n \"sponsors\",\n \"/sponsors/\",\n # Use the full resource path here to make it able to be overridden by\n # pypi-theme.\n \"warehouse:templates/pages/sponsors.html\",\n )\n\n # Our legal policies\n config.add_policy(\"terms-of-use\", \"terms.md\")\n\n # HTML Snippets for including into other pages.\n config.add_route(\n \"includes.current-user-indicator\",\n \"/_includes/current-user-indicator/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.flash-messages\",\n \"/_includes/flash-messages/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.current-user-profile-callout\",\n \"/_includes/current-user-profile-callout/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.edit-project-button\",\n \"/_includes/edit-project-button/{project_name}\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.profile-actions\",\n \"/_includes/profile-actions/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n\n # Classifier Routes\n config.add_route(\"classifiers\", \"/classifiers/\", domain=warehouse)\n\n # Search Routes\n config.add_route(\"search\", \"/search/\", domain=warehouse)\n\n # Accounts\n config.add_route(\n \"accounts.profile\",\n \"/user/{username}/\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\"accounts.login\", \"/account/login/\", domain=warehouse)\n config.add_route(\"accounts.logout\", \"/account/logout/\", domain=warehouse)\n config.add_route(\n \"accounts.register\",\n \"/account/register/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.request-password-reset\",\n \"/account/request-password-reset/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.reset-password\",\n \"/account/reset-password/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.verify-email\",\n \"/account/verify-email/\",\n domain=warehouse,\n )\n\n # Management (views for logged-in users)\n config.add_route(\"manage.account\", \"/manage/account/\", domain=warehouse)\n config.add_route(\"manage.projects\", \"/manage/projects/\", domain=warehouse)\n config.add_route(\n \"manage.project.settings\",\n \"/manage/project/{project_name}/settings/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_project\",\n \"/manage/project/{project_name}/delete_project/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.destroy_docs\",\n \"/manage/project/{project_name}/delete_project_docs/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.releases\",\n \"/manage/project/{project_name}/releases/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.release\",\n \"/manage/project/{project_name}/release/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.roles\",\n \"/manage/project/{project_name}/collaboration/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.change_role\",\n \"/manage/project/{project_name}/collaboration/change/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_role\",\n \"/manage/project/{project_name}/collaboration/delete/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.documentation\",\n \"/manage/project/{project_name}/documentation/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.history\",\n \"/manage/project/{project_name}/history/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n\n # Packaging\n config.add_redirect('/p/{name}/', '/project/{name}/', domain=warehouse)\n config.add_route(\n \"packaging.project\",\n \"/project/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n domain=warehouse,\n )\n config.add_route(\n \"packaging.release\",\n \"/project/{name}/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\"packaging.file\", files_url)\n\n # SES Webhooks\n config.add_route(\"ses.hook\", \"/_/ses-hook/\", domain=warehouse)\n\n # RSS\n config.add_route(\"rss.updates\", \"/rss/updates.xml\", domain=warehouse)\n config.add_route(\"rss.packages\", \"/rss/packages.xml\", domain=warehouse)\n\n # Legacy URLs\n config.add_route(\"legacy.api.simple.index\", \"/simple/\", domain=warehouse)\n config.add_route(\n \"legacy.api.simple.detail\",\n \"/simple/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.project\",\n \"/pypi/{name}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.release\",\n \"/pypi/{name}/{version}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n read_only=True,\n domain=warehouse,\n )\n\n # Legacy Action URLs\n # TODO: We should probably add Warehouse routes for these that just error\n # and direct people to use upload.pypi.io\n config.add_pypi_action_route(\n \"legacy.api.pypi.file_upload\",\n \"file_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit\",\n \"submit\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit_pkg_info\",\n \"submit_pkg_info\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doc_upload\",\n \"doc_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doap\",\n \"doap\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.list_classifiers\",\n \"list_classifiers\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.search',\n 'search',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.browse',\n 'browse',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.files',\n 'files',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.display',\n 'display',\n domain=warehouse,\n )\n\n # Legacy XMLRPC\n config.add_xmlrpc_endpoint(\n \"pypi\",\n pattern=\"/pypi\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n config.add_xmlrpc_endpoint(\n \"pypi_slash\",\n pattern=\"/pypi/\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n config.add_xmlrpc_endpoint(\n \"RPC2\",\n pattern=\"/RPC2\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n\n # Legacy Documentation\n config.add_route(\"legacy.docs\", config.registry.settings[\"docs.url\"])\n\n # Legacy Redirects\n config.add_redirect(\"/pypi/{name}/\", \"/project/{name}/\", domain=warehouse)\n config.add_redirect(\n \"/pypi/{name}/{version}/json/\",\n \"/pypi/{name}/{version}/json\",\n domain=warehouse,\n )\n config.add_redirect(\n \"/pypi/{name}/json/\",\n \"/pypi/{name}/json\",\n domain=warehouse,\n )\n\n config.add_redirect(\n \"/pypi/{name}/{version}/\",\n \"/project/{name}/{version}/\",\n domain=warehouse,\n )\n config.add_redirect(\"/packages/{path:.*}\", files_url, domain=warehouse)\n\n # Legacy Action Redirects\n config.add_pypi_action_redirect(\n \"rss\",\n \"/rss/updates.xml\",\n domain=warehouse,\n )\n config.add_pypi_action_redirect(\n \"packages_rss\",\n \"/rss/packages.xml\",\n domain=warehouse,\n )\n", "path": "warehouse/routes.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef includeme(config):\n # We need to get the value of the Warehouse and Forklift domains, we'll use\n # these to segregate the Warehouse routes from the Forklift routes until\n # Forklift is properly split out into it's own project.\n warehouse = config.get_settings().get(\"warehouse.domain\")\n files_url = config.get_settings()[\"files.url\"]\n\n # Simple Route for health checks.\n config.add_route(\"health\", \"/_health/\")\n\n # Internal route to make it easier to force a particular status for\n # debugging HTTPException templates.\n config.add_route(\"force-status\", \"/_force-status/{status:[45]\\d\\d}/\")\n\n # Basic global routes\n config.add_route(\"index\", \"/\", domain=warehouse)\n config.add_route(\"robots.txt\", \"/robots.txt\", domain=warehouse)\n config.add_route(\"opensearch.xml\", \"/opensearch.xml\", domain=warehouse)\n config.add_route(\"index.sitemap.xml\", \"/sitemap.xml\", domain=warehouse)\n config.add_route(\n \"bucket.sitemap.xml\",\n \"/{bucket}.sitemap.xml\",\n domain=warehouse,\n )\n\n # Some static, template driven pages\n config.add_template_view(\"help\", \"/help/\", \"pages/help.html\")\n config.add_template_view(\"security\", \"/security/\", \"pages/security.html\")\n config.add_template_view(\n \"sponsors\",\n \"/sponsors/\",\n # Use the full resource path here to make it able to be overridden by\n # pypi-theme.\n \"warehouse:templates/pages/sponsors.html\",\n )\n\n # Our legal policies\n config.add_policy(\"terms-of-use\", \"terms.md\")\n\n # HTML Snippets for including into other pages.\n config.add_route(\n \"includes.current-user-indicator\",\n \"/_includes/current-user-indicator/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.flash-messages\",\n \"/_includes/flash-messages/\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.current-user-profile-callout\",\n \"/_includes/current-user-profile-callout/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.edit-project-button\",\n \"/_includes/edit-project-button/{project_name}\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"includes.profile-actions\",\n \"/_includes/profile-actions/{username}\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n\n # Classifier Routes\n config.add_route(\"classifiers\", \"/classifiers/\", domain=warehouse)\n\n # Search Routes\n config.add_route(\"search\", \"/search/\", domain=warehouse)\n\n # Accounts\n config.add_route(\n \"accounts.profile\",\n \"/user/{username}/\",\n factory=\"warehouse.accounts.models:UserFactory\",\n traverse=\"/{username}\",\n domain=warehouse,\n )\n config.add_route(\"accounts.login\", \"/account/login/\", domain=warehouse)\n config.add_route(\"accounts.logout\", \"/account/logout/\", domain=warehouse)\n config.add_route(\n \"accounts.register\",\n \"/account/register/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.request-password-reset\",\n \"/account/request-password-reset/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.reset-password\",\n \"/account/reset-password/\",\n domain=warehouse,\n )\n config.add_route(\n \"accounts.verify-email\",\n \"/account/verify-email/\",\n domain=warehouse,\n )\n\n # Management (views for logged-in users)\n config.add_route(\"manage.account\", \"/manage/account/\", domain=warehouse)\n config.add_route(\"manage.projects\", \"/manage/projects/\", domain=warehouse)\n config.add_route(\n \"manage.project.settings\",\n \"/manage/project/{project_name}/settings/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_project\",\n \"/manage/project/{project_name}/delete_project/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.destroy_docs\",\n \"/manage/project/{project_name}/delete_project_docs/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.releases\",\n \"/manage/project/{project_name}/releases/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.release\",\n \"/manage/project/{project_name}/release/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.roles\",\n \"/manage/project/{project_name}/collaboration/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.change_role\",\n \"/manage/project/{project_name}/collaboration/change/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.delete_role\",\n \"/manage/project/{project_name}/collaboration/delete/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.documentation\",\n \"/manage/project/{project_name}/documentation/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n config.add_route(\n \"manage.project.history\",\n \"/manage/project/{project_name}/history/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{project_name}\",\n domain=warehouse,\n )\n\n # Packaging\n config.add_redirect('/p/{name}/', '/project/{name}/', domain=warehouse)\n config.add_route(\n \"packaging.project\",\n \"/project/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n domain=warehouse,\n )\n config.add_route(\n \"packaging.release\",\n \"/project/{name}/{version}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n domain=warehouse,\n )\n config.add_route(\"packaging.file\", files_url)\n\n # SES Webhooks\n config.add_route(\"ses.hook\", \"/_/ses-hook/\", domain=warehouse)\n\n # RSS\n config.add_route(\"rss.updates\", \"/rss/updates.xml\", domain=warehouse)\n config.add_route(\"rss.packages\", \"/rss/packages.xml\", domain=warehouse)\n\n # Legacy URLs\n config.add_route(\"legacy.api.simple.index\", \"/simple/\", domain=warehouse)\n config.add_route(\n \"legacy.api.simple.detail\",\n \"/simple/{name}/\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.project\",\n \"/pypi/{name}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}\",\n read_only=True,\n domain=warehouse,\n )\n config.add_route(\n \"legacy.api.json.release\",\n \"/pypi/{name}/{version}/json\",\n factory=\"warehouse.packaging.models:ProjectFactory\",\n traverse=\"/{name}/{version}\",\n read_only=True,\n domain=warehouse,\n )\n\n # Legacy Action URLs\n # TODO: We should probably add Warehouse routes for these that just error\n # and direct people to use upload.pypi.io\n config.add_pypi_action_route(\n \"legacy.api.pypi.file_upload\",\n \"file_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit\",\n \"submit\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.submit_pkg_info\",\n \"submit_pkg_info\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doc_upload\",\n \"doc_upload\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.doap\",\n \"doap\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n \"legacy.api.pypi.list_classifiers\",\n \"list_classifiers\",\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.search',\n 'search',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.browse',\n 'browse',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.files',\n 'files',\n domain=warehouse,\n )\n config.add_pypi_action_route(\n 'legacy.api.pypi.display',\n 'display',\n domain=warehouse,\n )\n\n # Legacy XMLRPC\n config.add_xmlrpc_endpoint(\n \"pypi\",\n pattern=\"/pypi\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n config.add_xmlrpc_endpoint(\n \"pypi_slash\",\n pattern=\"/pypi/\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n config.add_xmlrpc_endpoint(\n \"RPC2\",\n pattern=\"/RPC2\",\n header=\"Content-Type:text/xml\",\n domain=warehouse,\n )\n\n # Legacy Documentation\n config.add_route(\"legacy.docs\", config.registry.settings[\"docs.url\"])\n\n # Legacy Redirects\n config.add_redirect(\"/pypi/{name}/\", \"/project/{name}/\", domain=warehouse)\n config.add_redirect(\n \"/pypi/{name}/{version}/\",\n \"/project/{name}/{version}/\",\n domain=warehouse,\n )\n config.add_redirect(\"/packages/{path:.*}\", files_url, domain=warehouse)\n\n # Legacy Action Redirects\n config.add_pypi_action_redirect(\n \"rss\",\n \"/rss/updates.xml\",\n domain=warehouse,\n )\n config.add_pypi_action_redirect(\n \"packages_rss\",\n \"/rss/packages.xml\",\n domain=warehouse,\n )\n", "path": "warehouse/routes.py"}]}
| 3,886 | 170 |
gh_patches_debug_3739
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-7642
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Cloud CLI schedule help has same text for describe and list
### Meltano Version
2.18.0
### Python Version
3.10
### Bug scope
CLI (options, error messages, logging, etc.)
### Operating System
Mac M1
### Description
```
❯ meltano-cloud schedule --help
Usage: meltano-cloud schedule [OPTIONS] COMMAND [ARGS]...
Interact with Meltano Cloud project schedules.
Options:
--deployment TEXT The name of the Meltano Cloud deployment the schedule
belongs to.
--schedule TEXT The name of a schedule within the specified deployment.
--help Show this message and exit.
Commands:
describe List Meltano Cloud schedules.
disable Disable a Meltano Cloud schedule.
enable Enable a Meltano Cloud schedule.
list List Meltano Cloud schedules.
```
`describe` and `list` say the same thing
### Code
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cloud-cli/meltano/cloud/cli/schedule.py`
Content:
```
1 """Meltano Cloud `schedules` command."""
2
3 from __future__ import annotations
4
5 import itertools as it
6 import json
7 import typing as t
8 from datetime import datetime, timedelta, timezone
9 from http import HTTPStatus
10
11 import click
12 import tabulate
13 from croniter import croniter, croniter_range
14
15 from meltano.cloud.api.client import MeltanoCloudClient, MeltanoCloudError
16 from meltano.cloud.cli.base import pass_context, run_async, shared_option
17
18 if t.TYPE_CHECKING:
19 from meltano.cloud.api.config import MeltanoCloudConfig
20 from meltano.cloud.api.types import CloudProjectSchedule
21 from meltano.cloud.cli.base import MeltanoCloudCLIContext
22
23 MAX_PAGE_SIZE = 250
24
25
26 class SchedulesCloudClient(MeltanoCloudClient):
27 """A Meltano Cloud client with extensions for schedules."""
28
29 async def set_schedule_enabled(
30 self,
31 *,
32 deployment_name: str,
33 schedule_name: str,
34 enabled: bool,
35 ):
36 """Use PUT to update the enabled state of a Meltano Cloud project schedule.
37
38 Args:
39 deployment: The name of the deployment the schedule belongs to.
40 schedule: The name of the schedule to enable/disable.
41 enabled: Whether the schedule should be enabled.
42
43 Raises:
44 MeltanoCloudError: The Meltano Cloud API responded with an error.
45 """
46 async with self.authenticated():
47 try:
48 await self._json_request(
49 "PUT",
50 "/".join(
51 (
52 "/schedules/v1",
53 f"{self.config.tenant_resource_key}",
54 f"{self.config.internal_project_id}",
55 deployment_name,
56 schedule_name,
57 "enabled",
58 ),
59 ),
60 json=enabled,
61 )
62 except MeltanoCloudError as ex:
63 if ex.response.status == HTTPStatus.NOT_FOUND:
64 ex.response.reason = (
65 f"Unable to find schedule named {schedule_name!r} "
66 f"within a deployment named {deployment_name!r}"
67 )
68 raise MeltanoCloudError(ex.response) from ex
69 raise
70
71 async def get_schedule(
72 self,
73 *,
74 deployment_name: str,
75 schedule_name: str,
76 ):
77 """Use GET to get a Meltano Cloud project schedule.
78
79 Args:
80 deployment_name: The name of the deployment the schedule belongs to.
81 schedule_name: The name of the schedule.
82
83 Raises:
84 MeltanoCloudError: The Meltano Cloud API responded with an error.
85 """
86 async with self.authenticated():
87 try:
88 return await self._json_request(
89 "GET",
90 "/".join(
91 (
92 "/schedules/v1",
93 self.config.tenant_resource_key,
94 self.config.internal_project_id,
95 deployment_name,
96 schedule_name,
97 ),
98 ),
99 )
100 except MeltanoCloudError as ex:
101 if ex.response.status == HTTPStatus.NOT_FOUND:
102 ex.response.reason = (
103 f"Unable to find schedule named {schedule_name!r} "
104 f"within a deployment named {deployment_name!r}"
105 )
106 raise MeltanoCloudError(ex.response) from ex
107 raise
108
109 async def get_schedules(
110 self,
111 *,
112 deployment_name: str | None = None,
113 page_size: int | None = None,
114 page_token: str | None = None,
115 ):
116 """Use GET to get Meltano Cloud project schedules.
117
118 Args:
119 deployment_name: The name of the deployment the schedule belongs to.
120 page_size: The number of items to request per page.
121 page_token: The page token.
122 """
123 params: dict[str, t.Any] = {
124 "page_size": page_size,
125 "page_token": page_token,
126 }
127
128 path = [
129 "/schedules/v1",
130 self.config.tenant_resource_key,
131 self.config.internal_project_id,
132 ]
133 if deployment_name is not None:
134 path.append(deployment_name)
135
136 async with self.authenticated():
137 return await self._json_request(
138 "GET",
139 "/".join(path),
140 params=self.clean_params(params),
141 )
142
143
144 async def _set_enabled_state(
145 *,
146 config: MeltanoCloudConfig,
147 deployment_name: str | None,
148 schedule_name: str | None,
149 enabled: bool,
150 ):
151 if schedule_name is None:
152 raise click.UsageError("Missing option '--schedule'")
153 if deployment_name is None:
154 raise click.UsageError("Missing option '--deployment'")
155 async with SchedulesCloudClient(config=config) as client:
156 await client.set_schedule_enabled(
157 deployment_name=deployment_name,
158 schedule_name=schedule_name,
159 enabled=enabled,
160 )
161
162
163 deployment_option = shared_option(
164 "--deployment",
165 help="The name of the Meltano Cloud deployment the schedule belongs to.",
166 )
167
168 schedule_option = shared_option(
169 "--schedule",
170 help="The name of a schedule within the specified deployment.",
171 )
172
173
174 @click.group("schedule")
175 @deployment_option
176 @schedule_option
177 def schedule_group() -> None:
178 """Interact with Meltano Cloud project schedules."""
179
180
181 @schedule_group.command("enable")
182 @deployment_option
183 @schedule_option
184 @pass_context
185 @run_async
186 async def enable(context: MeltanoCloudCLIContext) -> None:
187 """Enable a Meltano Cloud schedule."""
188 await _set_enabled_state(
189 config=context.config,
190 deployment_name=context.deployment,
191 schedule_name=context.schedule,
192 enabled=True,
193 )
194
195
196 @schedule_group.command("disable")
197 @deployment_option
198 @schedule_option
199 @pass_context
200 @run_async
201 async def disable(context: MeltanoCloudCLIContext) -> None:
202 """Disable a Meltano Cloud schedule."""
203 await _set_enabled_state(
204 config=context.config,
205 deployment_name=context.deployment,
206 schedule_name=context.schedule,
207 enabled=False,
208 )
209
210
211 async def _get_schedule(
212 config: MeltanoCloudConfig,
213 deployment_name: str | None,
214 schedule_name: str | None,
215 ) -> CloudProjectSchedule:
216 if schedule_name is None:
217 raise click.UsageError("Missing option '--schedule'")
218 if deployment_name is None:
219 raise click.UsageError("Missing option '--deployment'")
220 async with SchedulesCloudClient(config=config) as client:
221 return await client.get_schedule(
222 deployment_name=deployment_name,
223 schedule_name=schedule_name,
224 )
225
226
227 async def _get_schedules(
228 config: MeltanoCloudConfig,
229 deployment_name: str | None,
230 limit: int,
231 ) -> list[CloudProjectSchedule]:
232 page_token = None
233 page_size = min(limit, MAX_PAGE_SIZE)
234 results: list[CloudProjectSchedule] = []
235
236 async with SchedulesCloudClient(config=config) as client:
237 while True:
238 response = await client.get_schedules(
239 deployment_name=deployment_name,
240 page_size=page_size,
241 page_token=page_token,
242 )
243
244 results.extend(response["results"])
245
246 if response["pagination"] and len(results) < limit:
247 page_token = response["pagination"]["next_page_token"]
248 else:
249 break
250
251 return results[:limit]
252
253
254 def _next_n_runs(n: int, cron_expr: str) -> tuple[datetime, ...]:
255 now = datetime.now(timezone.utc)
256 return tuple(it.islice(croniter(cron_expr, now, ret_type=datetime), n))
257
258
259 timedelta_year = timedelta(days=365) # noqa: WPS432
260
261
262 def _approx_daily_freq(
263 cron_expr: str,
264 sample_period: timedelta = timedelta_year,
265 num_digits_precision: int = 1,
266 ) -> str:
267 now = datetime.now(timezone.utc)
268 num_runs = sum(1 for _ in croniter_range(now, now + sample_period, cron_expr))
269 freq = round(num_runs / sample_period.days, num_digits_precision)
270 return "< 1" if freq < 1 else str(freq)
271
272
273 def _process_table_row(
274 schedule: CloudProjectSchedule,
275 ) -> tuple[str, str, str, str, bool]:
276 return (
277 schedule["deployment_name"],
278 schedule["schedule_name"],
279 schedule["interval"],
280 _approx_daily_freq(schedule["interval"]),
281 schedule["enabled"],
282 )
283
284
285 def _format_schedules_table(
286 schedules: list[CloudProjectSchedule],
287 table_format: str,
288 ) -> str:
289 """Format the schedules as a table.
290
291 Args:
292 schedules: The schedules to format.
293
294 Returns:
295 The formatted schedules.
296 """
297 return tabulate.tabulate(
298 [_process_table_row(schedule) for schedule in schedules],
299 headers=(
300 "Deployment",
301 "Schedule",
302 "Interval",
303 "Runs / Day",
304 "Enabled",
305 ),
306 tablefmt=table_format,
307 floatfmt=".1f",
308 # To avoid a tabulate bug (IndexError), only set colalign if there are schedules
309 colalign=("left", "left", "left", "right", "left") if schedules else (),
310 )
311
312
313 schedule_list_formatters = {
314 "json": lambda schedules: json.dumps(schedules, indent=2),
315 "markdown": lambda schedules: _format_schedules_table(
316 schedules,
317 table_format="github",
318 ),
319 "terminal": lambda schedules: _format_schedules_table(
320 schedules,
321 table_format="rounded_outline",
322 ),
323 }
324
325
326 @schedule_group.command("list")
327 @deployment_option
328 @click.option(
329 "--limit",
330 required=False,
331 type=int,
332 default=10,
333 help="The maximum number of schedules to display.",
334 )
335 @click.option(
336 "--format",
337 "output_format",
338 required=False,
339 default="terminal",
340 type=click.Choice(("terminal", "markdown", "json")),
341 help="The output format to use.",
342 )
343 @pass_context
344 @run_async
345 async def list_schedules(
346 context: MeltanoCloudCLIContext,
347 output_format: str,
348 limit: int,
349 ) -> None:
350 """List Meltano Cloud schedules."""
351 click.echo(
352 schedule_list_formatters[output_format](
353 await _get_schedules(
354 config=context.config,
355 deployment_name=context.deployment,
356 limit=limit,
357 ),
358 ),
359 )
360
361
362 @schedule_group.command("describe")
363 @deployment_option
364 @schedule_option
365 @click.option(
366 "--only-upcoming",
367 is_flag=True,
368 help="Only list upcoming scheduled run start datetimes",
369 )
370 @click.option(
371 "--num-upcoming",
372 type=int,
373 default=10,
374 help="The number of upcoming scheduled run start datetimes to list",
375 )
376 @pass_context
377 @run_async
378 async def describe_schedule(
379 context: MeltanoCloudCLIContext,
380 only_upcoming: bool,
381 num_upcoming: int,
382 ) -> None:
383 """List Meltano Cloud schedules."""
384 schedule = await _get_schedule(
385 config=context.config,
386 deployment_name=context.deployment,
387 schedule_name=context.schedule,
388 )
389
390 if not only_upcoming:
391 click.echo(
392 f"Deployment name: {schedule['deployment_name']}\n"
393 f"Schedule name: {schedule['schedule_name']}\n"
394 f"Interval: {schedule['interval']}\n"
395 f"Enabled: {schedule['enabled']}",
396 )
397 if schedule["enabled"]:
398 click.echo(
399 "\nApproximate starting date and time (UTC) of "
400 f"next {num_upcoming} scheduled runs:",
401 )
402 if schedule["enabled"]:
403 for dt in _next_n_runs(num_upcoming, schedule["interval"]):
404 click.echo(dt.strftime("%Y-%m-%d %H:%M"))
405
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cloud-cli/meltano/cloud/cli/schedule.py b/src/cloud-cli/meltano/cloud/cli/schedule.py
--- a/src/cloud-cli/meltano/cloud/cli/schedule.py
+++ b/src/cloud-cli/meltano/cloud/cli/schedule.py
@@ -380,7 +380,7 @@
only_upcoming: bool,
num_upcoming: int,
) -> None:
- """List Meltano Cloud schedules."""
+ """Describe a Meltano Cloud schedules & list upcoming scheduled runs."""
schedule = await _get_schedule(
config=context.config,
deployment_name=context.deployment,
|
{"golden_diff": "diff --git a/src/cloud-cli/meltano/cloud/cli/schedule.py b/src/cloud-cli/meltano/cloud/cli/schedule.py\n--- a/src/cloud-cli/meltano/cloud/cli/schedule.py\n+++ b/src/cloud-cli/meltano/cloud/cli/schedule.py\n@@ -380,7 +380,7 @@\n only_upcoming: bool,\n num_upcoming: int,\n ) -> None:\n- \"\"\"List Meltano Cloud schedules.\"\"\"\n+ \"\"\"Describe a Meltano Cloud schedules & list upcoming scheduled runs.\"\"\"\n schedule = await _get_schedule(\n config=context.config,\n deployment_name=context.deployment,\n", "issue": "bug: Cloud CLI schedule help has same text for describe and list\n### Meltano Version\n\n2.18.0\n\n### Python Version\n\n3.10\n\n### Bug scope\n\nCLI (options, error messages, logging, etc.)\n\n### Operating System\n\nMac M1\n\n### Description\n\n```\r\n\u276f meltano-cloud schedule --help\r\nUsage: meltano-cloud schedule [OPTIONS] COMMAND [ARGS]...\r\n\r\n Interact with Meltano Cloud project schedules.\r\n\r\nOptions:\r\n --deployment TEXT The name of the Meltano Cloud deployment the schedule\r\n belongs to.\r\n --schedule TEXT The name of a schedule within the specified deployment.\r\n --help Show this message and exit.\r\n\r\nCommands:\r\n describe List Meltano Cloud schedules.\r\n disable Disable a Meltano Cloud schedule.\r\n enable Enable a Meltano Cloud schedule.\r\n list List Meltano Cloud schedules.\r\n```\r\n\r\n`describe` and `list` say the same thing\n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Meltano Cloud `schedules` command.\"\"\"\n\nfrom __future__ import annotations\n\nimport itertools as it\nimport json\nimport typing as t\nfrom datetime import datetime, timedelta, timezone\nfrom http import HTTPStatus\n\nimport click\nimport tabulate\nfrom croniter import croniter, croniter_range\n\nfrom meltano.cloud.api.client import MeltanoCloudClient, MeltanoCloudError\nfrom meltano.cloud.cli.base import pass_context, run_async, shared_option\n\nif t.TYPE_CHECKING:\n from meltano.cloud.api.config import MeltanoCloudConfig\n from meltano.cloud.api.types import CloudProjectSchedule\n from meltano.cloud.cli.base import MeltanoCloudCLIContext\n\nMAX_PAGE_SIZE = 250\n\n\nclass SchedulesCloudClient(MeltanoCloudClient):\n \"\"\"A Meltano Cloud client with extensions for schedules.\"\"\"\n\n async def set_schedule_enabled(\n self,\n *,\n deployment_name: str,\n schedule_name: str,\n enabled: bool,\n ):\n \"\"\"Use PUT to update the enabled state of a Meltano Cloud project schedule.\n\n Args:\n deployment: The name of the deployment the schedule belongs to.\n schedule: The name of the schedule to enable/disable.\n enabled: Whether the schedule should be enabled.\n\n Raises:\n MeltanoCloudError: The Meltano Cloud API responded with an error.\n \"\"\"\n async with self.authenticated():\n try:\n await self._json_request(\n \"PUT\",\n \"/\".join(\n (\n \"/schedules/v1\",\n f\"{self.config.tenant_resource_key}\",\n f\"{self.config.internal_project_id}\",\n deployment_name,\n schedule_name,\n \"enabled\",\n ),\n ),\n json=enabled,\n )\n except MeltanoCloudError as ex:\n if ex.response.status == HTTPStatus.NOT_FOUND:\n ex.response.reason = (\n f\"Unable to find schedule named {schedule_name!r} \"\n f\"within a deployment named {deployment_name!r}\"\n )\n raise MeltanoCloudError(ex.response) from ex\n raise\n\n async def get_schedule(\n self,\n *,\n deployment_name: str,\n schedule_name: str,\n ):\n \"\"\"Use GET to get a Meltano Cloud project schedule.\n\n Args:\n deployment_name: The name of the deployment the schedule belongs to.\n schedule_name: The name of the schedule.\n\n Raises:\n MeltanoCloudError: The Meltano Cloud API responded with an error.\n \"\"\"\n async with self.authenticated():\n try:\n return await self._json_request(\n \"GET\",\n \"/\".join(\n (\n \"/schedules/v1\",\n self.config.tenant_resource_key,\n self.config.internal_project_id,\n deployment_name,\n schedule_name,\n ),\n ),\n )\n except MeltanoCloudError as ex:\n if ex.response.status == HTTPStatus.NOT_FOUND:\n ex.response.reason = (\n f\"Unable to find schedule named {schedule_name!r} \"\n f\"within a deployment named {deployment_name!r}\"\n )\n raise MeltanoCloudError(ex.response) from ex\n raise\n\n async def get_schedules(\n self,\n *,\n deployment_name: str | None = None,\n page_size: int | None = None,\n page_token: str | None = None,\n ):\n \"\"\"Use GET to get Meltano Cloud project schedules.\n\n Args:\n deployment_name: The name of the deployment the schedule belongs to.\n page_size: The number of items to request per page.\n page_token: The page token.\n \"\"\"\n params: dict[str, t.Any] = {\n \"page_size\": page_size,\n \"page_token\": page_token,\n }\n\n path = [\n \"/schedules/v1\",\n self.config.tenant_resource_key,\n self.config.internal_project_id,\n ]\n if deployment_name is not None:\n path.append(deployment_name)\n\n async with self.authenticated():\n return await self._json_request(\n \"GET\",\n \"/\".join(path),\n params=self.clean_params(params),\n )\n\n\nasync def _set_enabled_state(\n *,\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n schedule_name: str | None,\n enabled: bool,\n):\n if schedule_name is None:\n raise click.UsageError(\"Missing option '--schedule'\")\n if deployment_name is None:\n raise click.UsageError(\"Missing option '--deployment'\")\n async with SchedulesCloudClient(config=config) as client:\n await client.set_schedule_enabled(\n deployment_name=deployment_name,\n schedule_name=schedule_name,\n enabled=enabled,\n )\n\n\ndeployment_option = shared_option(\n \"--deployment\",\n help=\"The name of the Meltano Cloud deployment the schedule belongs to.\",\n)\n\nschedule_option = shared_option(\n \"--schedule\",\n help=\"The name of a schedule within the specified deployment.\",\n)\n\n\[email protected](\"schedule\")\n@deployment_option\n@schedule_option\ndef schedule_group() -> None:\n \"\"\"Interact with Meltano Cloud project schedules.\"\"\"\n\n\n@schedule_group.command(\"enable\")\n@deployment_option\n@schedule_option\n@pass_context\n@run_async\nasync def enable(context: MeltanoCloudCLIContext) -> None:\n \"\"\"Enable a Meltano Cloud schedule.\"\"\"\n await _set_enabled_state(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n enabled=True,\n )\n\n\n@schedule_group.command(\"disable\")\n@deployment_option\n@schedule_option\n@pass_context\n@run_async\nasync def disable(context: MeltanoCloudCLIContext) -> None:\n \"\"\"Disable a Meltano Cloud schedule.\"\"\"\n await _set_enabled_state(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n enabled=False,\n )\n\n\nasync def _get_schedule(\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n schedule_name: str | None,\n) -> CloudProjectSchedule:\n if schedule_name is None:\n raise click.UsageError(\"Missing option '--schedule'\")\n if deployment_name is None:\n raise click.UsageError(\"Missing option '--deployment'\")\n async with SchedulesCloudClient(config=config) as client:\n return await client.get_schedule(\n deployment_name=deployment_name,\n schedule_name=schedule_name,\n )\n\n\nasync def _get_schedules(\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n limit: int,\n) -> list[CloudProjectSchedule]:\n page_token = None\n page_size = min(limit, MAX_PAGE_SIZE)\n results: list[CloudProjectSchedule] = []\n\n async with SchedulesCloudClient(config=config) as client:\n while True:\n response = await client.get_schedules(\n deployment_name=deployment_name,\n page_size=page_size,\n page_token=page_token,\n )\n\n results.extend(response[\"results\"])\n\n if response[\"pagination\"] and len(results) < limit:\n page_token = response[\"pagination\"][\"next_page_token\"]\n else:\n break\n\n return results[:limit]\n\n\ndef _next_n_runs(n: int, cron_expr: str) -> tuple[datetime, ...]:\n now = datetime.now(timezone.utc)\n return tuple(it.islice(croniter(cron_expr, now, ret_type=datetime), n))\n\n\ntimedelta_year = timedelta(days=365) # noqa: WPS432\n\n\ndef _approx_daily_freq(\n cron_expr: str,\n sample_period: timedelta = timedelta_year,\n num_digits_precision: int = 1,\n) -> str:\n now = datetime.now(timezone.utc)\n num_runs = sum(1 for _ in croniter_range(now, now + sample_period, cron_expr))\n freq = round(num_runs / sample_period.days, num_digits_precision)\n return \"< 1\" if freq < 1 else str(freq)\n\n\ndef _process_table_row(\n schedule: CloudProjectSchedule,\n) -> tuple[str, str, str, str, bool]:\n return (\n schedule[\"deployment_name\"],\n schedule[\"schedule_name\"],\n schedule[\"interval\"],\n _approx_daily_freq(schedule[\"interval\"]),\n schedule[\"enabled\"],\n )\n\n\ndef _format_schedules_table(\n schedules: list[CloudProjectSchedule],\n table_format: str,\n) -> str:\n \"\"\"Format the schedules as a table.\n\n Args:\n schedules: The schedules to format.\n\n Returns:\n The formatted schedules.\n \"\"\"\n return tabulate.tabulate(\n [_process_table_row(schedule) for schedule in schedules],\n headers=(\n \"Deployment\",\n \"Schedule\",\n \"Interval\",\n \"Runs / Day\",\n \"Enabled\",\n ),\n tablefmt=table_format,\n floatfmt=\".1f\",\n # To avoid a tabulate bug (IndexError), only set colalign if there are schedules\n colalign=(\"left\", \"left\", \"left\", \"right\", \"left\") if schedules else (),\n )\n\n\nschedule_list_formatters = {\n \"json\": lambda schedules: json.dumps(schedules, indent=2),\n \"markdown\": lambda schedules: _format_schedules_table(\n schedules,\n table_format=\"github\",\n ),\n \"terminal\": lambda schedules: _format_schedules_table(\n schedules,\n table_format=\"rounded_outline\",\n ),\n}\n\n\n@schedule_group.command(\"list\")\n@deployment_option\[email protected](\n \"--limit\",\n required=False,\n type=int,\n default=10,\n help=\"The maximum number of schedules to display.\",\n)\[email protected](\n \"--format\",\n \"output_format\",\n required=False,\n default=\"terminal\",\n type=click.Choice((\"terminal\", \"markdown\", \"json\")),\n help=\"The output format to use.\",\n)\n@pass_context\n@run_async\nasync def list_schedules(\n context: MeltanoCloudCLIContext,\n output_format: str,\n limit: int,\n) -> None:\n \"\"\"List Meltano Cloud schedules.\"\"\"\n click.echo(\n schedule_list_formatters[output_format](\n await _get_schedules(\n config=context.config,\n deployment_name=context.deployment,\n limit=limit,\n ),\n ),\n )\n\n\n@schedule_group.command(\"describe\")\n@deployment_option\n@schedule_option\[email protected](\n \"--only-upcoming\",\n is_flag=True,\n help=\"Only list upcoming scheduled run start datetimes\",\n)\[email protected](\n \"--num-upcoming\",\n type=int,\n default=10,\n help=\"The number of upcoming scheduled run start datetimes to list\",\n)\n@pass_context\n@run_async\nasync def describe_schedule(\n context: MeltanoCloudCLIContext,\n only_upcoming: bool,\n num_upcoming: int,\n) -> None:\n \"\"\"List Meltano Cloud schedules.\"\"\"\n schedule = await _get_schedule(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n )\n\n if not only_upcoming:\n click.echo(\n f\"Deployment name: {schedule['deployment_name']}\\n\"\n f\"Schedule name: {schedule['schedule_name']}\\n\"\n f\"Interval: {schedule['interval']}\\n\"\n f\"Enabled: {schedule['enabled']}\",\n )\n if schedule[\"enabled\"]:\n click.echo(\n \"\\nApproximate starting date and time (UTC) of \"\n f\"next {num_upcoming} scheduled runs:\",\n )\n if schedule[\"enabled\"]:\n for dt in _next_n_runs(num_upcoming, schedule[\"interval\"]):\n click.echo(dt.strftime(\"%Y-%m-%d %H:%M\"))\n", "path": "src/cloud-cli/meltano/cloud/cli/schedule.py"}], "after_files": [{"content": "\"\"\"Meltano Cloud `schedules` command.\"\"\"\n\nfrom __future__ import annotations\n\nimport itertools as it\nimport json\nimport typing as t\nfrom datetime import datetime, timedelta, timezone\nfrom http import HTTPStatus\n\nimport click\nimport tabulate\nfrom croniter import croniter, croniter_range\n\nfrom meltano.cloud.api.client import MeltanoCloudClient, MeltanoCloudError\nfrom meltano.cloud.cli.base import pass_context, run_async, shared_option\n\nif t.TYPE_CHECKING:\n from meltano.cloud.api.config import MeltanoCloudConfig\n from meltano.cloud.api.types import CloudProjectSchedule\n from meltano.cloud.cli.base import MeltanoCloudCLIContext\n\nMAX_PAGE_SIZE = 250\n\n\nclass SchedulesCloudClient(MeltanoCloudClient):\n \"\"\"A Meltano Cloud client with extensions for schedules.\"\"\"\n\n async def set_schedule_enabled(\n self,\n *,\n deployment_name: str,\n schedule_name: str,\n enabled: bool,\n ):\n \"\"\"Use PUT to update the enabled state of a Meltano Cloud project schedule.\n\n Args:\n deployment: The name of the deployment the schedule belongs to.\n schedule: The name of the schedule to enable/disable.\n enabled: Whether the schedule should be enabled.\n\n Raises:\n MeltanoCloudError: The Meltano Cloud API responded with an error.\n \"\"\"\n async with self.authenticated():\n try:\n await self._json_request(\n \"PUT\",\n \"/\".join(\n (\n \"/schedules/v1\",\n f\"{self.config.tenant_resource_key}\",\n f\"{self.config.internal_project_id}\",\n deployment_name,\n schedule_name,\n \"enabled\",\n ),\n ),\n json=enabled,\n )\n except MeltanoCloudError as ex:\n if ex.response.status == HTTPStatus.NOT_FOUND:\n ex.response.reason = (\n f\"Unable to find schedule named {schedule_name!r} \"\n f\"within a deployment named {deployment_name!r}\"\n )\n raise MeltanoCloudError(ex.response) from ex\n raise\n\n async def get_schedule(\n self,\n *,\n deployment_name: str,\n schedule_name: str,\n ):\n \"\"\"Use GET to get a Meltano Cloud project schedule.\n\n Args:\n deployment_name: The name of the deployment the schedule belongs to.\n schedule_name: The name of the schedule.\n\n Raises:\n MeltanoCloudError: The Meltano Cloud API responded with an error.\n \"\"\"\n async with self.authenticated():\n try:\n return await self._json_request(\n \"GET\",\n \"/\".join(\n (\n \"/schedules/v1\",\n self.config.tenant_resource_key,\n self.config.internal_project_id,\n deployment_name,\n schedule_name,\n ),\n ),\n )\n except MeltanoCloudError as ex:\n if ex.response.status == HTTPStatus.NOT_FOUND:\n ex.response.reason = (\n f\"Unable to find schedule named {schedule_name!r} \"\n f\"within a deployment named {deployment_name!r}\"\n )\n raise MeltanoCloudError(ex.response) from ex\n raise\n\n async def get_schedules(\n self,\n *,\n deployment_name: str | None = None,\n page_size: int | None = None,\n page_token: str | None = None,\n ):\n \"\"\"Use GET to get Meltano Cloud project schedules.\n\n Args:\n deployment_name: The name of the deployment the schedule belongs to.\n page_size: The number of items to request per page.\n page_token: The page token.\n \"\"\"\n params: dict[str, t.Any] = {\n \"page_size\": page_size,\n \"page_token\": page_token,\n }\n\n path = [\n \"/schedules/v1\",\n self.config.tenant_resource_key,\n self.config.internal_project_id,\n ]\n if deployment_name is not None:\n path.append(deployment_name)\n\n async with self.authenticated():\n return await self._json_request(\n \"GET\",\n \"/\".join(path),\n params=self.clean_params(params),\n )\n\n\nasync def _set_enabled_state(\n *,\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n schedule_name: str | None,\n enabled: bool,\n):\n if schedule_name is None:\n raise click.UsageError(\"Missing option '--schedule'\")\n if deployment_name is None:\n raise click.UsageError(\"Missing option '--deployment'\")\n async with SchedulesCloudClient(config=config) as client:\n await client.set_schedule_enabled(\n deployment_name=deployment_name,\n schedule_name=schedule_name,\n enabled=enabled,\n )\n\n\ndeployment_option = shared_option(\n \"--deployment\",\n help=\"The name of the Meltano Cloud deployment the schedule belongs to.\",\n)\n\nschedule_option = shared_option(\n \"--schedule\",\n help=\"The name of a schedule within the specified deployment.\",\n)\n\n\[email protected](\"schedule\")\n@deployment_option\n@schedule_option\ndef schedule_group() -> None:\n \"\"\"Interact with Meltano Cloud project schedules.\"\"\"\n\n\n@schedule_group.command(\"enable\")\n@deployment_option\n@schedule_option\n@pass_context\n@run_async\nasync def enable(context: MeltanoCloudCLIContext) -> None:\n \"\"\"Enable a Meltano Cloud schedule.\"\"\"\n await _set_enabled_state(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n enabled=True,\n )\n\n\n@schedule_group.command(\"disable\")\n@deployment_option\n@schedule_option\n@pass_context\n@run_async\nasync def disable(context: MeltanoCloudCLIContext) -> None:\n \"\"\"Disable a Meltano Cloud schedule.\"\"\"\n await _set_enabled_state(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n enabled=False,\n )\n\n\nasync def _get_schedule(\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n schedule_name: str | None,\n) -> CloudProjectSchedule:\n if schedule_name is None:\n raise click.UsageError(\"Missing option '--schedule'\")\n if deployment_name is None:\n raise click.UsageError(\"Missing option '--deployment'\")\n async with SchedulesCloudClient(config=config) as client:\n return await client.get_schedule(\n deployment_name=deployment_name,\n schedule_name=schedule_name,\n )\n\n\nasync def _get_schedules(\n config: MeltanoCloudConfig,\n deployment_name: str | None,\n limit: int,\n) -> list[CloudProjectSchedule]:\n page_token = None\n page_size = min(limit, MAX_PAGE_SIZE)\n results: list[CloudProjectSchedule] = []\n\n async with SchedulesCloudClient(config=config) as client:\n while True:\n response = await client.get_schedules(\n deployment_name=deployment_name,\n page_size=page_size,\n page_token=page_token,\n )\n\n results.extend(response[\"results\"])\n\n if response[\"pagination\"] and len(results) < limit:\n page_token = response[\"pagination\"][\"next_page_token\"]\n else:\n break\n\n return results[:limit]\n\n\ndef _next_n_runs(n: int, cron_expr: str) -> tuple[datetime, ...]:\n now = datetime.now(timezone.utc)\n return tuple(it.islice(croniter(cron_expr, now, ret_type=datetime), n))\n\n\ntimedelta_year = timedelta(days=365) # noqa: WPS432\n\n\ndef _approx_daily_freq(\n cron_expr: str,\n sample_period: timedelta = timedelta_year,\n num_digits_precision: int = 1,\n) -> str:\n now = datetime.now(timezone.utc)\n num_runs = sum(1 for _ in croniter_range(now, now + sample_period, cron_expr))\n freq = round(num_runs / sample_period.days, num_digits_precision)\n return \"< 1\" if freq < 1 else str(freq)\n\n\ndef _process_table_row(\n schedule: CloudProjectSchedule,\n) -> tuple[str, str, str, str, bool]:\n return (\n schedule[\"deployment_name\"],\n schedule[\"schedule_name\"],\n schedule[\"interval\"],\n _approx_daily_freq(schedule[\"interval\"]),\n schedule[\"enabled\"],\n )\n\n\ndef _format_schedules_table(\n schedules: list[CloudProjectSchedule],\n table_format: str,\n) -> str:\n \"\"\"Format the schedules as a table.\n\n Args:\n schedules: The schedules to format.\n\n Returns:\n The formatted schedules.\n \"\"\"\n return tabulate.tabulate(\n [_process_table_row(schedule) for schedule in schedules],\n headers=(\n \"Deployment\",\n \"Schedule\",\n \"Interval\",\n \"Runs / Day\",\n \"Enabled\",\n ),\n tablefmt=table_format,\n floatfmt=\".1f\",\n # To avoid a tabulate bug (IndexError), only set colalign if there are schedules\n colalign=(\"left\", \"left\", \"left\", \"right\", \"left\") if schedules else (),\n )\n\n\nschedule_list_formatters = {\n \"json\": lambda schedules: json.dumps(schedules, indent=2),\n \"markdown\": lambda schedules: _format_schedules_table(\n schedules,\n table_format=\"github\",\n ),\n \"terminal\": lambda schedules: _format_schedules_table(\n schedules,\n table_format=\"rounded_outline\",\n ),\n}\n\n\n@schedule_group.command(\"list\")\n@deployment_option\[email protected](\n \"--limit\",\n required=False,\n type=int,\n default=10,\n help=\"The maximum number of schedules to display.\",\n)\[email protected](\n \"--format\",\n \"output_format\",\n required=False,\n default=\"terminal\",\n type=click.Choice((\"terminal\", \"markdown\", \"json\")),\n help=\"The output format to use.\",\n)\n@pass_context\n@run_async\nasync def list_schedules(\n context: MeltanoCloudCLIContext,\n output_format: str,\n limit: int,\n) -> None:\n \"\"\"List Meltano Cloud schedules.\"\"\"\n click.echo(\n schedule_list_formatters[output_format](\n await _get_schedules(\n config=context.config,\n deployment_name=context.deployment,\n limit=limit,\n ),\n ),\n )\n\n\n@schedule_group.command(\"describe\")\n@deployment_option\n@schedule_option\[email protected](\n \"--only-upcoming\",\n is_flag=True,\n help=\"Only list upcoming scheduled run start datetimes\",\n)\[email protected](\n \"--num-upcoming\",\n type=int,\n default=10,\n help=\"The number of upcoming scheduled run start datetimes to list\",\n)\n@pass_context\n@run_async\nasync def describe_schedule(\n context: MeltanoCloudCLIContext,\n only_upcoming: bool,\n num_upcoming: int,\n) -> None:\n \"\"\"Describe a Meltano Cloud schedules & list upcoming scheduled runs.\"\"\"\n schedule = await _get_schedule(\n config=context.config,\n deployment_name=context.deployment,\n schedule_name=context.schedule,\n )\n\n if not only_upcoming:\n click.echo(\n f\"Deployment name: {schedule['deployment_name']}\\n\"\n f\"Schedule name: {schedule['schedule_name']}\\n\"\n f\"Interval: {schedule['interval']}\\n\"\n f\"Enabled: {schedule['enabled']}\",\n )\n if schedule[\"enabled\"]:\n click.echo(\n \"\\nApproximate starting date and time (UTC) of \"\n f\"next {num_upcoming} scheduled runs:\",\n )\n if schedule[\"enabled\"]:\n for dt in _next_n_runs(num_upcoming, schedule[\"interval\"]):\n click.echo(dt.strftime(\"%Y-%m-%d %H:%M\"))\n", "path": "src/cloud-cli/meltano/cloud/cli/schedule.py"}]}
| 4,084 | 134 |
gh_patches_debug_26006
|
rasdani/github-patches
|
git_diff
|
napari__napari-1229
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Icons not loading with napari 0.3.0
## 🐛 Bug
When trying to start napari, the interface loads, but all icons are absent.
## To Reproduce
Steps to reproduce the behavior:
`python -m napari`
In the console
```
WARNING: DirectWrite: CreateFontFaceFromHDC() failed (Indicates an error in an input file such as a font file.) for QFontDef(Family="8514oem", pointsize=12, pixelsize=20, styleHint=5, weight=50, stretch=100, hintingPreference=0) LOGFONT("8514oem", lfWidth=0, lfHeight=-20) dpi=144
WARNING: Cannot open file ':/themes/dark/right_arrow.svg', because: No such file or directory
WARNING: Cannot open file ':/themes/dark/right_arrow.svg', because: No such file or directory
WARNING: Cannot open file ':/themes/dark/delete_shape.svg', because: No such file or directory
... and so on for all the other icon files
```
## Expected behavior
The icons should load
## Environment
```
napari: 0.3.0
Platform: Windows-10-10.0.18362-SP0
Python: 3.7.6 | packaged by conda-forge | (default, Mar 23 2020, 22:22:21) [MSC v.1916 64 bit (AMD64)]
Qt: 5.12.5
PyQt5: 5.12.3
NumPy: 1.18.1
SciPy: 1.3.1
Dask: 2.13.0
VisPy: 0.6.4
GL version: 4.6.0 NVIDIA 441.22
MAX_TEXTURE_SIZE: 32768
Plugins:
- napari-plugin-engine: 0.1.4
- svg: 0.1.2
```
I got the same issue on another Windows installation, but not on OS X (where I also have an older QT version than officially required by napari)
Need consensus on options for delivering icons & resources
## ❓ Question
As shown in #1209, it looks like the strategy of building icons after installation is not going to work in every case. Even though I tried to put in three levels of "fallback" behavior, in case of permissions errors and stuff, I think it's probably safer to ship a default resources file that is checked into source (or built just prior to uploading our package to PyPI)...
This brings us back to cross pyside/pyqt resource compatibility and compatibility of resources built with various rcc versions. I just tested a crapload of combinations of `_qt_resources.py` files built with various versions of `pyside2-rcc` or `pyrcc5`, and tested them on various installs of napari using pyside2 and qt5 installed with both pip and conda.
## tldr;
resources built with the `pyrcc5` binary from `pyqt5` have much broader compatibility than those built with `pyside2-rcc`. So if we pre-build using the latest `pyrcc5`, we should be able to expect it to be supported on all version of pyside2 and pyqt5 available on either pip or conda. (that is not the case with `pyside2-rcc`)
<details>
<summary>exact combinations I tested</summary>
## resources generated with pyside2-rcc v5.14.2 (from pip)
### using pip to install pyside2/pyqt5
>PySide2==5.11.2 -> 'Shiboken.ObjectType' object is not iterable
>PySide2==5.12.6 -> 'Shiboken.ObjectType' object is not iterable
>PySide2==5.13.2 -> 'Shiboken.ObjectType' object is not iterable
PySide2==5.14.0 -> **works**
PySide2==5.14.2.1 -> **works**
(PyQt5 < 5.11.3 -> uninstallable on pip due to sip)
PyQt5==5.11.3 -> no icons
PyQt5==5.12.3 -> no icons
PyQt5==5.13.2 -> **works**
PyQt5==5.14.2 -> **works**
### using conda to install pyside2/pyqt5
pyside2=5.12.4.py37h9cca949_0 conda-forge -> no icons
pyside2=5.13.2.py37ha8f7116_2 conda-forge -> no icons
pyqt=5.9.2.py37h2a560b1_4 conda-forge -> no icons
pyqt=5.12.3.py37ha62fc16_3 conda-forge -> no icons
## resources generated with pyrcc5 v5.14.2 (from pip)
### using pip to install pyside2/pyqt5
PySide2==5.14.2.1 -> **works**
PyQt5==5.11.3 -> **works**
PyQt5==5.12.3 -> **works**
PyQt5==5.13.2 -> **works**
PyQt5==5.14.2 -> **works**
### using conda to install pyside2/pyqt5
pyside2=5.12.4.py37h9cca949_0 conda-forge -> **works**
pyside2=5.13.2.py37ha8f7116_2 conda-forge -> **works**
pyqt=5.9.2.py37h2a560b1_4 conda-forge -> **works**
pyqt=5.12.3.py37ha62fc16_3 conda-forge -> **works**
</details>
### question for @napari/core-devs
I think we should bundle resources built with `pyrcc5`, rather than building them after install. (though end-users could still be able to rebuild icons using `python -m napari.resources.build_icons`). How best to do this?
- Just have someone manually build it and check it into source whenever it needs updating? making sure they are building with `pyrcc5` instead of `pyside2-rcc` (testing for this is possible)...
- not check into source, and have it built on github actions prior to deployment, by installing `pyqt5` prior to running `setup.py`. This is made complicated by the fact that we actually check to see which backend is installed when writing our requirements. So we'd basically have to pip install pyqt5, build the icons, uninstall, pip install pyside2, run setup.py... 🙄
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `napari/resources/build_icons.py`
Content:
```
1 """Utility script to generate copies of icons with colors based
2 on our themes. Neccessary workaround because qt does not allow
3 for styling svg elements using qss
4 """
5
6 import os
7 import re
8 import shutil
9 from subprocess import check_call, CalledProcessError
10 from typing import Dict, List, Tuple
11
12 from ..utils.theme import palettes as _palettes
13
14 RESOURCES_DIR = os.path.abspath(os.path.dirname(__file__))
15 SVGPATH = os.path.join(RESOURCES_DIR, 'icons')
16
17 svg_tag_open = re.compile(r'(<svg[^>]*>)')
18
19
20 def themify_icons(
21 dest_dir: str,
22 svg_path: str = SVGPATH,
23 palettes: Dict[str, Dict[str, str]] = _palettes,
24 color_lookup: Dict[str, str] = None,
25 ) -> List[str]:
26 """Create a new "themed" SVG file, for every SVG file in ``svg_path``.
27
28 Parameters
29 ----------
30 dest_dir : str
31 The directory in which to write all of the themed icons. Individual
32 themes will be in subdirectories named after each theme.
33 svg_path : str, optional
34 The folder to look in for SVG files, by default will search in a folder
35 named ``icons`` in the same directory as this file.
36 palettes : dict, optional
37 A mapping of ``theme_name: theme_dict``, where ``theme_dict`` is a
38 mapping of color classes to rgb strings. By default will uses palettes
39 from :const:`napari.resources.utils.theme.palettes`.
40 color_lookup : dict, optional
41 A mapping of icon name to color class. If the icon name is not in the
42 color_lookup, it's color class will be ``"icon"``.
43
44 Returns
45 -------
46 files : list of str
47 a list of generaged SVG filepaths (each relative to dest_dir)
48 """
49
50 color_lookup = color_lookup or {
51 'visibility': 'text',
52 'visibility_off': 'highlight',
53 'menu': 'highlight',
54 'drop_down': 'secondary',
55 'plus': 'secondary',
56 'minus': 'secondary',
57 'properties_contract': 'secondary',
58 'properties_expand': 'secondary',
59 }
60 icon_names = [
61 i.replace('.svg', '')
62 for i in os.listdir(SVGPATH)
63 if i.endswith('.svg')
64 ]
65
66 svg_style_insert = r"""<style type="text/css">
67 path{fill:{{ color }}}
68 polygon{fill:{{ color }}}
69 circle{fill:{{ color }}}
70 rect{fill:{{ color }}}
71 </style>"""
72
73 files = []
74 for theme_name, palette in palettes.items():
75 palette_dir = os.path.join(dest_dir, theme_name)
76 os.makedirs(palette_dir, exist_ok=True)
77 for icon_name in icon_names:
78 svg_name = icon_name + '.svg'
79 new_file = os.path.join(palette_dir, svg_name)
80 color = color_lookup.get(icon_name, 'icon')
81 css = svg_style_insert.replace('{{ color }}', palette[color])
82 with open(os.path.join(SVGPATH, svg_name), 'r') as fr:
83 contents = fr.read()
84 with open(new_file, 'w') as fw:
85 # use regex to find the svg tag and insert css right after
86 # (the '\\1' syntax includes the matched tag in the output)
87 fw.write(svg_tag_open.sub(f'\\1{css}', contents))
88 files.append(os.path.join(theme_name, svg_name))
89 return files
90
91
92 def build_resources_qrc(
93 dest_dir: str, overwrite: bool = False
94 ) -> Tuple[str, str]:
95 """Create a res.qrc file for all icons generated by ``themify_icons``.
96
97 Parameters
98 ----------
99 dest_dir : str
100 The directory in which to write create the output file. Themed SVG
101 icons will also be written to ``dest_dir/themes``.
102 overwrite : bool
103 Whether to force rebuilding of the icons and res.qrc file, by default
104 False
105
106 Returns
107 -------
108 tuple
109 2-tuple of (path-to-qrc.res, path-to-theme-directory).
110 """
111 qrc_path = os.path.join(dest_dir, 'res.qrc')
112 theme_dir = os.path.join(dest_dir, 'themes')
113 if os.path.exists(qrc_path) and (not overwrite):
114 return qrc_path, theme_dir
115
116 qrc_string = """
117 <!DOCTYPE RCC>
118 <RCC version="1.0">
119 <qresource>
120 """
121 for filename in themify_icons(theme_dir):
122 qrc_string += f'\n <file>themes/{filename}</file>'
123
124 qrc_string += """
125 </qresource>
126 </RCC>
127 """
128
129 with open(qrc_path, 'w') as f:
130 f.write(qrc_string)
131
132 return qrc_path, theme_dir
133
134
135 def build_pyqt_resources(out_path: str, overwrite: bool = False) -> str:
136 """Build a res.qrc file from icons and convert for python usage.
137
138 calls :func:`build_resources` and then converts using ``pyside2-rcc`` or
139 ``pyrcc5`` depending on which is installed in the environment.
140 Finally, cleans up autogenerated icon.svgs and res.qrc file after _qt.py
141 file is generated
142
143 References
144 ----------
145 https://doc.qt.io/qt-5/resources.html
146
147 Parameters
148 ----------
149 out_path : str
150 Path to write the python resource file.
151 overwrite : bool, optional
152 Whether to force rebuilding of the output file, by default False
153
154 Returns
155 -------
156 out_path : str
157 Path to the python resource file. Import this file to make the SVGs
158 and other resources available to Qt stylesheets.
159 """
160
161 if os.path.exists(out_path) and not overwrite:
162 return out_path
163
164 # build the resource file to the same path
165 qrc_path, theme_dir = build_resources_qrc(
166 os.path.dirname(out_path), overwrite=overwrite
167 )
168
169 # then convert it to a python file
170 try:
171 check_call(['pyrcc5', '-o', out_path, qrc_path])
172 except (FileNotFoundError, CalledProcessError):
173 check_call(['pyside2-rcc', '-o', out_path, qrc_path])
174
175 # make sure we import from qtpy
176 with open(out_path, "rt") as fin:
177 data = fin.read()
178 data = data.replace('PySide2', 'qtpy').replace('PyQt5', 'qtpy')
179 with open(out_path, "wt") as fin:
180 fin.write(data)
181
182 # cleanup.
183 # we do this here because pip uninstall napari would not collect these
184 # and the final `out_path.py` contains all the necessary bytes info
185 shutil.rmtree(theme_dir, ignore_errors=True)
186 try:
187 os.remove(qrc_path)
188 except Exception:
189 pass
190 return out_path
191
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/napari/resources/build_icons.py b/napari/resources/build_icons.py
--- a/napari/resources/build_icons.py
+++ b/napari/resources/build_icons.py
@@ -6,7 +6,7 @@
import os
import re
import shutil
-from subprocess import check_call, CalledProcessError
+from subprocess import check_call
from typing import Dict, List, Tuple
from ..utils.theme import palettes as _palettes
@@ -167,10 +167,24 @@
)
# then convert it to a python file
- try:
- check_call(['pyrcc5', '-o', out_path, qrc_path])
- except (FileNotFoundError, CalledProcessError):
- check_call(['pyside2-rcc', '-o', out_path, qrc_path])
+ # this looks a little funny, but rather than pick the exact binary to try
+ # once, we use this try/catch loop because
+ # 1. we always want to use pyrcc5 if it's available, regardless of API
+ # 2. it will sometimes, (if not always) be named pyrcc5.bat on windows...
+ # 3. only then do we try pyside2-rcc
+ # see https://github.com/napari/napari/issues/1221 for background
+ for binary in ('pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'):
+ try:
+ check_call([binary, '-o', out_path, qrc_path])
+ except FileNotFoundError:
+ continue
+ break
+ else:
+ raise FileNotFoundError(
+ "Unable to find an executable to build Qt resources (icons).\n"
+ "Tried: 'pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'.\n"
+ "Please open issue at https://github.com/napari/napari/issues/."
+ )
# make sure we import from qtpy
with open(out_path, "rt") as fin:
|
{"golden_diff": "diff --git a/napari/resources/build_icons.py b/napari/resources/build_icons.py\n--- a/napari/resources/build_icons.py\n+++ b/napari/resources/build_icons.py\n@@ -6,7 +6,7 @@\n import os\n import re\n import shutil\n-from subprocess import check_call, CalledProcessError\n+from subprocess import check_call\n from typing import Dict, List, Tuple\n \n from ..utils.theme import palettes as _palettes\n@@ -167,10 +167,24 @@\n )\n \n # then convert it to a python file\n- try:\n- check_call(['pyrcc5', '-o', out_path, qrc_path])\n- except (FileNotFoundError, CalledProcessError):\n- check_call(['pyside2-rcc', '-o', out_path, qrc_path])\n+ # this looks a little funny, but rather than pick the exact binary to try\n+ # once, we use this try/catch loop because\n+ # 1. we always want to use pyrcc5 if it's available, regardless of API\n+ # 2. it will sometimes, (if not always) be named pyrcc5.bat on windows...\n+ # 3. only then do we try pyside2-rcc\n+ # see https://github.com/napari/napari/issues/1221 for background\n+ for binary in ('pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'):\n+ try:\n+ check_call([binary, '-o', out_path, qrc_path])\n+ except FileNotFoundError:\n+ continue\n+ break\n+ else:\n+ raise FileNotFoundError(\n+ \"Unable to find an executable to build Qt resources (icons).\\n\"\n+ \"Tried: 'pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'.\\n\"\n+ \"Please open issue at https://github.com/napari/napari/issues/.\"\n+ )\n \n # make sure we import from qtpy\n with open(out_path, \"rt\") as fin:\n", "issue": "Icons not loading with napari 0.3.0\n## \ud83d\udc1b Bug\r\n\r\nWhen trying to start napari, the interface loads, but all icons are absent.\r\n\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n`python -m napari`\r\n\r\nIn the console\r\n```\r\nWARNING: DirectWrite: CreateFontFaceFromHDC() failed (Indicates an error in an input file such as a font file.) for QFontDef(Family=\"8514oem\", pointsize=12, pixelsize=20, styleHint=5, weight=50, stretch=100, hintingPreference=0) LOGFONT(\"8514oem\", lfWidth=0, lfHeight=-20) dpi=144\r\nWARNING: Cannot open file ':/themes/dark/right_arrow.svg', because: No such file or directory\r\nWARNING: Cannot open file ':/themes/dark/right_arrow.svg', because: No such file or directory\r\nWARNING: Cannot open file ':/themes/dark/delete_shape.svg', because: No such file or directory\r\n... and so on for all the other icon files\r\n```\r\n\r\n## Expected behavior\r\n\r\nThe icons should load\r\n## Environment\r\n```\r\nnapari: 0.3.0\r\nPlatform: Windows-10-10.0.18362-SP0\r\nPython: 3.7.6 | packaged by conda-forge | (default, Mar 23 2020, 22:22:21) [MSC v.1916 64 bit (AMD64)]\r\nQt: 5.12.5\r\nPyQt5: 5.12.3\r\nNumPy: 1.18.1\r\nSciPy: 1.3.1\r\nDask: 2.13.0\r\nVisPy: 0.6.4\r\n\r\nGL version: 4.6.0 NVIDIA 441.22\r\nMAX_TEXTURE_SIZE: 32768\r\n\r\nPlugins:\r\n- napari-plugin-engine: 0.1.4\r\n- svg: 0.1.2\r\n```\r\nI got the same issue on another Windows installation, but not on OS X (where I also have an older QT version than officially required by napari)\r\n\nNeed consensus on options for delivering icons & resources\n## \u2753 Question\r\n\r\nAs shown in #1209, it looks like the strategy of building icons after installation is not going to work in every case. Even though I tried to put in three levels of \"fallback\" behavior, in case of permissions errors and stuff, I think it's probably safer to ship a default resources file that is checked into source (or built just prior to uploading our package to PyPI)... \r\n\r\nThis brings us back to cross pyside/pyqt resource compatibility and compatibility of resources built with various rcc versions. I just tested a crapload of combinations of `_qt_resources.py` files built with various versions of `pyside2-rcc` or `pyrcc5`, and tested them on various installs of napari using pyside2 and qt5 installed with both pip and conda.\r\n\r\n## tldr;\r\nresources built with the `pyrcc5` binary from `pyqt5` have much broader compatibility than those built with `pyside2-rcc`. So if we pre-build using the latest `pyrcc5`, we should be able to expect it to be supported on all version of pyside2 and pyqt5 available on either pip or conda. (that is not the case with `pyside2-rcc`)\r\n\r\n<details>\r\n<summary>exact combinations I tested</summary>\r\n\r\n## resources generated with pyside2-rcc v5.14.2 (from pip)\r\n\r\n### using pip to install pyside2/pyqt5\r\n\r\n>PySide2==5.11.2 -> 'Shiboken.ObjectType' object is not iterable\r\n>PySide2==5.12.6 -> 'Shiboken.ObjectType' object is not iterable\r\n>PySide2==5.13.2 -> 'Shiboken.ObjectType' object is not iterable\r\n\r\nPySide2==5.14.0 -> **works**\r\nPySide2==5.14.2.1 -> **works**\r\n\r\n(PyQt5 < 5.11.3 -> uninstallable on pip due to sip)\r\nPyQt5==5.11.3 -> no icons\r\nPyQt5==5.12.3 -> no icons\r\nPyQt5==5.13.2 -> **works**\r\nPyQt5==5.14.2 -> **works**\r\n\r\n### using conda to install pyside2/pyqt5\r\n\r\npyside2=5.12.4.py37h9cca949_0 conda-forge -> no icons\r\npyside2=5.13.2.py37ha8f7116_2 conda-forge -> no icons\r\npyqt=5.9.2.py37h2a560b1_4 conda-forge -> no icons\r\npyqt=5.12.3.py37ha62fc16_3 conda-forge -> no icons\r\n\r\n## resources generated with pyrcc5 v5.14.2 (from pip)\r\n\r\n### using pip to install pyside2/pyqt5\r\n\r\nPySide2==5.14.2.1 -> **works**\r\nPyQt5==5.11.3 -> **works**\r\nPyQt5==5.12.3 -> **works**\r\nPyQt5==5.13.2 -> **works**\r\nPyQt5==5.14.2 -> **works**\r\n\r\n### using conda to install pyside2/pyqt5\r\n\r\npyside2=5.12.4.py37h9cca949_0 conda-forge -> **works**\r\npyside2=5.13.2.py37ha8f7116_2 conda-forge -> **works**\r\npyqt=5.9.2.py37h2a560b1_4 conda-forge -> **works**\r\npyqt=5.12.3.py37ha62fc16_3 conda-forge -> **works**\r\n\r\n</details>\r\n\r\n### question for @napari/core-devs \r\nI think we should bundle resources built with `pyrcc5`, rather than building them after install. (though end-users could still be able to rebuild icons using `python -m napari.resources.build_icons`). How best to do this?\r\n- Just have someone manually build it and check it into source whenever it needs updating? making sure they are building with `pyrcc5` instead of `pyside2-rcc` (testing for this is possible)... \r\n- not check into source, and have it built on github actions prior to deployment, by installing `pyqt5` prior to running `setup.py`. This is made complicated by the fact that we actually check to see which backend is installed when writing our requirements. So we'd basically have to pip install pyqt5, build the icons, uninstall, pip install pyside2, run setup.py... \ud83d\ude44\n", "before_files": [{"content": "\"\"\"Utility script to generate copies of icons with colors based\non our themes. Neccessary workaround because qt does not allow\nfor styling svg elements using qss\n\"\"\"\n\nimport os\nimport re\nimport shutil\nfrom subprocess import check_call, CalledProcessError\nfrom typing import Dict, List, Tuple\n\nfrom ..utils.theme import palettes as _palettes\n\nRESOURCES_DIR = os.path.abspath(os.path.dirname(__file__))\nSVGPATH = os.path.join(RESOURCES_DIR, 'icons')\n\nsvg_tag_open = re.compile(r'(<svg[^>]*>)')\n\n\ndef themify_icons(\n dest_dir: str,\n svg_path: str = SVGPATH,\n palettes: Dict[str, Dict[str, str]] = _palettes,\n color_lookup: Dict[str, str] = None,\n) -> List[str]:\n \"\"\"Create a new \"themed\" SVG file, for every SVG file in ``svg_path``.\n\n Parameters\n ----------\n dest_dir : str\n The directory in which to write all of the themed icons. Individual\n themes will be in subdirectories named after each theme.\n svg_path : str, optional\n The folder to look in for SVG files, by default will search in a folder\n named ``icons`` in the same directory as this file.\n palettes : dict, optional\n A mapping of ``theme_name: theme_dict``, where ``theme_dict`` is a\n mapping of color classes to rgb strings. By default will uses palettes\n from :const:`napari.resources.utils.theme.palettes`.\n color_lookup : dict, optional\n A mapping of icon name to color class. If the icon name is not in the\n color_lookup, it's color class will be ``\"icon\"``.\n\n Returns\n -------\n files : list of str\n a list of generaged SVG filepaths (each relative to dest_dir)\n \"\"\"\n\n color_lookup = color_lookup or {\n 'visibility': 'text',\n 'visibility_off': 'highlight',\n 'menu': 'highlight',\n 'drop_down': 'secondary',\n 'plus': 'secondary',\n 'minus': 'secondary',\n 'properties_contract': 'secondary',\n 'properties_expand': 'secondary',\n }\n icon_names = [\n i.replace('.svg', '')\n for i in os.listdir(SVGPATH)\n if i.endswith('.svg')\n ]\n\n svg_style_insert = r\"\"\"<style type=\"text/css\">\n path{fill:{{ color }}}\n polygon{fill:{{ color }}}\n circle{fill:{{ color }}}\n rect{fill:{{ color }}}\n </style>\"\"\"\n\n files = []\n for theme_name, palette in palettes.items():\n palette_dir = os.path.join(dest_dir, theme_name)\n os.makedirs(palette_dir, exist_ok=True)\n for icon_name in icon_names:\n svg_name = icon_name + '.svg'\n new_file = os.path.join(palette_dir, svg_name)\n color = color_lookup.get(icon_name, 'icon')\n css = svg_style_insert.replace('{{ color }}', palette[color])\n with open(os.path.join(SVGPATH, svg_name), 'r') as fr:\n contents = fr.read()\n with open(new_file, 'w') as fw:\n # use regex to find the svg tag and insert css right after\n # (the '\\\\1' syntax includes the matched tag in the output)\n fw.write(svg_tag_open.sub(f'\\\\1{css}', contents))\n files.append(os.path.join(theme_name, svg_name))\n return files\n\n\ndef build_resources_qrc(\n dest_dir: str, overwrite: bool = False\n) -> Tuple[str, str]:\n \"\"\"Create a res.qrc file for all icons generated by ``themify_icons``.\n\n Parameters\n ----------\n dest_dir : str\n The directory in which to write create the output file. Themed SVG\n icons will also be written to ``dest_dir/themes``.\n overwrite : bool\n Whether to force rebuilding of the icons and res.qrc file, by default\n False\n\n Returns\n -------\n tuple\n 2-tuple of (path-to-qrc.res, path-to-theme-directory).\n \"\"\"\n qrc_path = os.path.join(dest_dir, 'res.qrc')\n theme_dir = os.path.join(dest_dir, 'themes')\n if os.path.exists(qrc_path) and (not overwrite):\n return qrc_path, theme_dir\n\n qrc_string = \"\"\"\n <!DOCTYPE RCC>\n <RCC version=\"1.0\">\n <qresource>\n \"\"\"\n for filename in themify_icons(theme_dir):\n qrc_string += f'\\n <file>themes/{filename}</file>'\n\n qrc_string += \"\"\"\n </qresource>\n </RCC>\n \"\"\"\n\n with open(qrc_path, 'w') as f:\n f.write(qrc_string)\n\n return qrc_path, theme_dir\n\n\ndef build_pyqt_resources(out_path: str, overwrite: bool = False) -> str:\n \"\"\"Build a res.qrc file from icons and convert for python usage.\n\n calls :func:`build_resources` and then converts using ``pyside2-rcc`` or\n ``pyrcc5`` depending on which is installed in the environment.\n Finally, cleans up autogenerated icon.svgs and res.qrc file after _qt.py\n file is generated\n\n References\n ----------\n https://doc.qt.io/qt-5/resources.html\n\n Parameters\n ----------\n out_path : str\n Path to write the python resource file.\n overwrite : bool, optional\n Whether to force rebuilding of the output file, by default False\n\n Returns\n -------\n out_path : str\n Path to the python resource file. Import this file to make the SVGs\n and other resources available to Qt stylesheets.\n \"\"\"\n\n if os.path.exists(out_path) and not overwrite:\n return out_path\n\n # build the resource file to the same path\n qrc_path, theme_dir = build_resources_qrc(\n os.path.dirname(out_path), overwrite=overwrite\n )\n\n # then convert it to a python file\n try:\n check_call(['pyrcc5', '-o', out_path, qrc_path])\n except (FileNotFoundError, CalledProcessError):\n check_call(['pyside2-rcc', '-o', out_path, qrc_path])\n\n # make sure we import from qtpy\n with open(out_path, \"rt\") as fin:\n data = fin.read()\n data = data.replace('PySide2', 'qtpy').replace('PyQt5', 'qtpy')\n with open(out_path, \"wt\") as fin:\n fin.write(data)\n\n # cleanup.\n # we do this here because pip uninstall napari would not collect these\n # and the final `out_path.py` contains all the necessary bytes info\n shutil.rmtree(theme_dir, ignore_errors=True)\n try:\n os.remove(qrc_path)\n except Exception:\n pass\n return out_path\n", "path": "napari/resources/build_icons.py"}], "after_files": [{"content": "\"\"\"Utility script to generate copies of icons with colors based\non our themes. Neccessary workaround because qt does not allow\nfor styling svg elements using qss\n\"\"\"\n\nimport os\nimport re\nimport shutil\nfrom subprocess import check_call\nfrom typing import Dict, List, Tuple\n\nfrom ..utils.theme import palettes as _palettes\n\nRESOURCES_DIR = os.path.abspath(os.path.dirname(__file__))\nSVGPATH = os.path.join(RESOURCES_DIR, 'icons')\n\nsvg_tag_open = re.compile(r'(<svg[^>]*>)')\n\n\ndef themify_icons(\n dest_dir: str,\n svg_path: str = SVGPATH,\n palettes: Dict[str, Dict[str, str]] = _palettes,\n color_lookup: Dict[str, str] = None,\n) -> List[str]:\n \"\"\"Create a new \"themed\" SVG file, for every SVG file in ``svg_path``.\n\n Parameters\n ----------\n dest_dir : str\n The directory in which to write all of the themed icons. Individual\n themes will be in subdirectories named after each theme.\n svg_path : str, optional\n The folder to look in for SVG files, by default will search in a folder\n named ``icons`` in the same directory as this file.\n palettes : dict, optional\n A mapping of ``theme_name: theme_dict``, where ``theme_dict`` is a\n mapping of color classes to rgb strings. By default will uses palettes\n from :const:`napari.resources.utils.theme.palettes`.\n color_lookup : dict, optional\n A mapping of icon name to color class. If the icon name is not in the\n color_lookup, it's color class will be ``\"icon\"``.\n\n Returns\n -------\n files : list of str\n a list of generaged SVG filepaths (each relative to dest_dir)\n \"\"\"\n\n color_lookup = color_lookup or {\n 'visibility': 'text',\n 'visibility_off': 'highlight',\n 'menu': 'highlight',\n 'drop_down': 'secondary',\n 'plus': 'secondary',\n 'minus': 'secondary',\n 'properties_contract': 'secondary',\n 'properties_expand': 'secondary',\n }\n icon_names = [\n i.replace('.svg', '')\n for i in os.listdir(SVGPATH)\n if i.endswith('.svg')\n ]\n\n svg_style_insert = r\"\"\"<style type=\"text/css\">\n path{fill:{{ color }}}\n polygon{fill:{{ color }}}\n circle{fill:{{ color }}}\n rect{fill:{{ color }}}\n </style>\"\"\"\n\n files = []\n for theme_name, palette in palettes.items():\n palette_dir = os.path.join(dest_dir, theme_name)\n os.makedirs(palette_dir, exist_ok=True)\n for icon_name in icon_names:\n svg_name = icon_name + '.svg'\n new_file = os.path.join(palette_dir, svg_name)\n color = color_lookup.get(icon_name, 'icon')\n css = svg_style_insert.replace('{{ color }}', palette[color])\n with open(os.path.join(SVGPATH, svg_name), 'r') as fr:\n contents = fr.read()\n with open(new_file, 'w') as fw:\n # use regex to find the svg tag and insert css right after\n # (the '\\\\1' syntax includes the matched tag in the output)\n fw.write(svg_tag_open.sub(f'\\\\1{css}', contents))\n files.append(os.path.join(theme_name, svg_name))\n return files\n\n\ndef build_resources_qrc(\n dest_dir: str, overwrite: bool = False\n) -> Tuple[str, str]:\n \"\"\"Create a res.qrc file for all icons generated by ``themify_icons``.\n\n Parameters\n ----------\n dest_dir : str\n The directory in which to write create the output file. Themed SVG\n icons will also be written to ``dest_dir/themes``.\n overwrite : bool\n Whether to force rebuilding of the icons and res.qrc file, by default\n False\n\n Returns\n -------\n tuple\n 2-tuple of (path-to-qrc.res, path-to-theme-directory).\n \"\"\"\n qrc_path = os.path.join(dest_dir, 'res.qrc')\n theme_dir = os.path.join(dest_dir, 'themes')\n if os.path.exists(qrc_path) and (not overwrite):\n return qrc_path, theme_dir\n\n qrc_string = \"\"\"\n <!DOCTYPE RCC>\n <RCC version=\"1.0\">\n <qresource>\n \"\"\"\n for filename in themify_icons(theme_dir):\n qrc_string += f'\\n <file>themes/{filename}</file>'\n\n qrc_string += \"\"\"\n </qresource>\n </RCC>\n \"\"\"\n\n with open(qrc_path, 'w') as f:\n f.write(qrc_string)\n\n return qrc_path, theme_dir\n\n\ndef build_pyqt_resources(out_path: str, overwrite: bool = False) -> str:\n \"\"\"Build a res.qrc file from icons and convert for python usage.\n\n calls :func:`build_resources` and then converts using ``pyside2-rcc`` or\n ``pyrcc5`` depending on which is installed in the environment.\n Finally, cleans up autogenerated icon.svgs and res.qrc file after _qt.py\n file is generated\n\n References\n ----------\n https://doc.qt.io/qt-5/resources.html\n\n Parameters\n ----------\n out_path : str\n Path to write the python resource file.\n overwrite : bool, optional\n Whether to force rebuilding of the output file, by default False\n\n Returns\n -------\n out_path : str\n Path to the python resource file. Import this file to make the SVGs\n and other resources available to Qt stylesheets.\n \"\"\"\n\n if os.path.exists(out_path) and not overwrite:\n return out_path\n\n # build the resource file to the same path\n qrc_path, theme_dir = build_resources_qrc(\n os.path.dirname(out_path), overwrite=overwrite\n )\n\n # then convert it to a python file\n # this looks a little funny, but rather than pick the exact binary to try\n # once, we use this try/catch loop because\n # 1. we always want to use pyrcc5 if it's available, regardless of API\n # 2. it will sometimes, (if not always) be named pyrcc5.bat on windows...\n # 3. only then do we try pyside2-rcc\n # see https://github.com/napari/napari/issues/1221 for background\n for binary in ('pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'):\n try:\n check_call([binary, '-o', out_path, qrc_path])\n except FileNotFoundError:\n continue\n break\n else:\n raise FileNotFoundError(\n \"Unable to find an executable to build Qt resources (icons).\\n\"\n \"Tried: 'pyrcc5.bat', 'pyrcc5', 'pyside2-rcc'.\\n\"\n \"Please open issue at https://github.com/napari/napari/issues/.\"\n )\n\n # make sure we import from qtpy\n with open(out_path, \"rt\") as fin:\n data = fin.read()\n data = data.replace('PySide2', 'qtpy').replace('PyQt5', 'qtpy')\n with open(out_path, \"wt\") as fin:\n fin.write(data)\n\n # cleanup.\n # we do this here because pip uninstall napari would not collect these\n # and the final `out_path.py` contains all the necessary bytes info\n shutil.rmtree(theme_dir, ignore_errors=True)\n try:\n os.remove(qrc_path)\n except Exception:\n pass\n return out_path\n", "path": "napari/resources/build_icons.py"}]}
| 3,889 | 468 |
gh_patches_debug_35931
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-1132
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New debugger displays warnings about `speeds using cython not found`
@DonJayamanne commented on [Mon Jan 28 2019](https://github.com/Microsoft/vscode-python/issues/4190)
Old version of PTVSD didn't display this warning, new version of PTVDS does.
Here's the old version:
<img width="924" alt="screen shot 2019-01-28 at 4 46 12 pm" src="https://user-images.githubusercontent.com/1948812/51876152-732e9580-231c-11e9-950c-2daf36348496.png">
Here's the output from the new version:
<img width="924" alt="screen shot 2019-01-28 at 4 46 54 pm" src="https://user-images.githubusercontent.com/1948812/51876162-7aee3a00-231c-11e9-926e-edc7c3a7991d.png">
I consider this a P1 as we're displaying warnings that we didn't (removed) in previous versions. This will end up confusing users.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py`
Content:
```
1 import os
2 import sys
3
4 from _pydevd_bundle.pydevd_constants import IS_PYCHARM
5
6 IS_PY36_OR_GREATER = sys.version_info >= (3, 6)
7
8 frame_eval_func = None
9 stop_frame_eval = None
10 dummy_trace_dispatch = None
11 show_frame_eval_warning = False
12 clear_thread_local_info = None
13
14 # "NO" means we should not use frame evaluation, 'YES' we should use it (and fail if not there) and unspecified uses if possible.
15 use_frame_eval = os.environ.get('PYDEVD_USE_FRAME_EVAL', None)
16
17 if use_frame_eval == 'NO':
18 pass
19
20 elif use_frame_eval == 'YES':
21 # Fail if unable to use
22 from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info
23
24 elif use_frame_eval is None:
25 # Try to use if possible
26 if IS_PY36_OR_GREATER:
27 try:
28 from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info
29 except ImportError:
30 from _pydev_bundle.pydev_monkey import log_error_once
31
32 dirname = os.path.dirname(os.path.dirname(__file__))
33 if not IS_PYCHARM:
34 log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
35 sys.executable, os.path.join(dirname, 'setup_cython.py')))
36 else:
37 show_frame_eval_warning = True
38
39 else:
40 raise RuntimeError('Unexpected value for PYDEVD_USE_FRAME_EVAL: %s (accepted: YES, NO)' % (use_frame_eval,))
41
```
Path: `src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py`
Content:
```
1 # Defines which version of the trace_dispatch we'll use.
2 # Should give warning only here if cython is not available but supported.
3
4 import os
5 import sys
6 from _pydevd_bundle.pydevd_constants import CYTHON_SUPPORTED
7
8
9 use_cython = os.getenv('PYDEVD_USE_CYTHON', None)
10 dirname = os.path.dirname(os.path.dirname(__file__))
11 # Do not show incorrect warning for .egg files for Remote debugger
12 if not CYTHON_SUPPORTED or dirname.endswith('.egg'):
13 # Do not try to import cython extensions if cython isn't supported
14 use_cython = 'NO'
15
16
17 def delete_old_compiled_extensions():
18 import _pydevd_bundle_ext
19 cython_extensions_dir = os.path.dirname(os.path.dirname(_pydevd_bundle_ext.__file__))
20 _pydevd_bundle_ext_dir = os.path.dirname(_pydevd_bundle_ext.__file__)
21 _pydevd_frame_eval_ext_dir = os.path.join(cython_extensions_dir, '_pydevd_frame_eval_ext')
22 try:
23 import shutil
24 for file in os.listdir(_pydevd_bundle_ext_dir):
25 if file.startswith("pydevd") and file.endswith(".so"):
26 os.remove(os.path.join(_pydevd_bundle_ext_dir, file))
27 for file in os.listdir(_pydevd_frame_eval_ext_dir):
28 if file.startswith("pydevd") and file.endswith(".so"):
29 os.remove(os.path.join(_pydevd_frame_eval_ext_dir, file))
30 build_dir = os.path.join(cython_extensions_dir, "build")
31 if os.path.exists(build_dir):
32 shutil.rmtree(os.path.join(cython_extensions_dir, "build"))
33 except OSError:
34 from _pydev_bundle.pydev_monkey import log_error_once
35 log_error_once("warning: failed to delete old cython speedups. Please delete all *.so files from the directories "
36 "\"%s\" and \"%s\"" % (_pydevd_bundle_ext_dir, _pydevd_frame_eval_ext_dir))
37
38
39 if use_cython == 'YES':
40 # We must import the cython version if forcing cython
41 from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func
42
43 elif use_cython == 'NO':
44 # Use the regular version if not forcing cython
45 from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport
46
47 elif use_cython is None:
48 # Regular: use fallback if not found and give message to user
49 try:
50 from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func
51
52 # This version number is always available
53 from _pydevd_bundle.pydevd_additional_thread_info_regular import version as regular_version
54 # This version number from the already compiled cython extension
55 from _pydevd_bundle.pydevd_cython_wrapper import version as cython_version
56 if cython_version != regular_version:
57 delete_old_compiled_extensions()
58 raise ImportError()
59
60 except ImportError:
61 from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport
62 from _pydev_bundle.pydev_monkey import log_error_once
63
64 log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
65 sys.executable, os.path.join(dirname, 'setup_cython.py')))
66
67 else:
68 raise RuntimeError('Unexpected value for PYDEVD_USE_CYTHON: %s (accepted: YES, NO)' % (use_cython,))
69
70
71
```
Path: `src/ptvsd/_vendored/force_pydevd.py`
Content:
```
1 from importlib import import_module
2 import warnings
3
4 from . import check_modules, prefix_matcher, preimport, vendored
5
6
7 # Ensure that pydevd is our vendored copy.
8 _unvendored, _ = check_modules('pydevd',
9 prefix_matcher('pydev', '_pydev'))
10 if _unvendored:
11 _unvendored = sorted(_unvendored.values())
12 msg = 'incompatible copy of pydevd already imported'
13 #raise ImportError(msg)
14 warnings.warn(msg + ':\n {}'.format('\n '.join(_unvendored)))
15
16
17 # Constants must be set before importing any other pydevd module
18 # # due to heavy use of "from" in them.
19 with vendored('pydevd'):
20 pydevd_constants = import_module('_pydevd_bundle.pydevd_constants')
21 # Disable this, since we aren't packaging the Cython modules at the moment.
22 pydevd_constants.CYTHON_SUPPORTED = False
23 # We limit representation size in our representation provider when needed.
24 pydevd_constants.MAXIMUM_VARIABLE_REPRESENTATION_SIZE = 2**32
25
26
27 # Now make sure all the top-level modules and packages in pydevd are
28 # loaded. Any pydevd modules that aren't loaded at this point, will
29 # be loaded using their parent package's __path__ (i.e. one of the
30 # following).
31 preimport('pydevd', [
32 '_pydev_bundle',
33 '_pydev_imps',
34 '_pydev_runfiles',
35 '_pydevd_bundle',
36 '_pydevd_frame_eval',
37 'pydev_ipython',
38 'pydevd_concurrency_analyser',
39 'pydevd_plugins',
40 'pydevd',
41 ])
42
43 # When pydevd is imported it sets the breakpoint behavior, but it needs to be
44 # overridden because the pydevd version will connect to the remote debugger by
45 # default, but without using the ptvsd protocol (so, we need to use the ptvsd
46 # API to handle things as expected by the debug adapter).
47 import pydevd # noqa
48 import ptvsd # noqa
49
50
51 def ptvsd_breakpointhook():
52 ptvsd.break_into_debugger()
53
54
55 pydevd.install_breakpointhook(ptvsd_breakpointhook)
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/ptvsd/_vendored/force_pydevd.py b/src/ptvsd/_vendored/force_pydevd.py
--- a/src/ptvsd/_vendored/force_pydevd.py
+++ b/src/ptvsd/_vendored/force_pydevd.py
@@ -18,7 +18,7 @@
# # due to heavy use of "from" in them.
with vendored('pydevd'):
pydevd_constants = import_module('_pydevd_bundle.pydevd_constants')
-# Disable this, since we aren't packaging the Cython modules at the moment.
+# TODO: figure out what the appropriate setting is to work for both wheels and sdist.
pydevd_constants.CYTHON_SUPPORTED = False
# We limit representation size in our representation provider when needed.
pydevd_constants.MAXIMUM_VARIABLE_REPRESENTATION_SIZE = 2**32
diff --git a/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py b/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py
--- a/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py
+++ b/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py
@@ -59,10 +59,11 @@
except ImportError:
from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport
- from _pydev_bundle.pydev_monkey import log_error_once
+ #from _pydev_bundle.pydev_monkey import log_error_once
- log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
- sys.executable, os.path.join(dirname, 'setup_cython.py')))
+ #log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
+ # sys.executable, os.path.join(dirname, 'setup_cython.py')))
+ pass
else:
raise RuntimeError('Unexpected value for PYDEVD_USE_CYTHON: %s (accepted: YES, NO)' % (use_cython,))
diff --git a/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py b/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py
--- a/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py
+++ b/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py
@@ -31,8 +31,9 @@
dirname = os.path.dirname(os.path.dirname(__file__))
if not IS_PYCHARM:
- log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
- sys.executable, os.path.join(dirname, 'setup_cython.py')))
+ #log_error_once("warning: Debugger speedups using cython not found. Run '\"%s\" \"%s\" build_ext --inplace' to build." % (
+ # sys.executable, os.path.join(dirname, 'setup_cython.py')))
+ pass
else:
show_frame_eval_warning = True
|
{"golden_diff": "diff --git a/src/ptvsd/_vendored/force_pydevd.py b/src/ptvsd/_vendored/force_pydevd.py\n--- a/src/ptvsd/_vendored/force_pydevd.py\n+++ b/src/ptvsd/_vendored/force_pydevd.py\n@@ -18,7 +18,7 @@\n # # due to heavy use of \"from\" in them.\n with vendored('pydevd'):\n pydevd_constants = import_module('_pydevd_bundle.pydevd_constants')\n-# Disable this, since we aren't packaging the Cython modules at the moment.\n+# TODO: figure out what the appropriate setting is to work for both wheels and sdist.\n pydevd_constants.CYTHON_SUPPORTED = False\n # We limit representation size in our representation provider when needed.\n pydevd_constants.MAXIMUM_VARIABLE_REPRESENTATION_SIZE = 2**32\ndiff --git a/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py b/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py\n--- a/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py\n+++ b/src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py\n@@ -59,10 +59,11 @@\n \n except ImportError:\n from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport\n- from _pydev_bundle.pydev_monkey import log_error_once\n+ #from _pydev_bundle.pydev_monkey import log_error_once\n \n- log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n- sys.executable, os.path.join(dirname, 'setup_cython.py')))\n+ #log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n+ # sys.executable, os.path.join(dirname, 'setup_cython.py')))\n+ pass\n \n else:\n raise RuntimeError('Unexpected value for PYDEVD_USE_CYTHON: %s (accepted: YES, NO)' % (use_cython,))\ndiff --git a/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py b/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py\n--- a/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py\n+++ b/src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py\n@@ -31,8 +31,9 @@\n \n dirname = os.path.dirname(os.path.dirname(__file__))\n if not IS_PYCHARM:\n- log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n- sys.executable, os.path.join(dirname, 'setup_cython.py')))\n+ #log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n+ # sys.executable, os.path.join(dirname, 'setup_cython.py')))\n+ pass\n else:\n show_frame_eval_warning = True\n", "issue": "New debugger displays warnings about `speeds using cython not found`\n@DonJayamanne commented on [Mon Jan 28 2019](https://github.com/Microsoft/vscode-python/issues/4190)\r\n\r\nOld version of PTVSD didn't display this warning, new version of PTVDS does.\r\n\r\nHere's the old version:\r\n<img width=\"924\" alt=\"screen shot 2019-01-28 at 4 46 12 pm\" src=\"https://user-images.githubusercontent.com/1948812/51876152-732e9580-231c-11e9-950c-2daf36348496.png\">\r\n\r\nHere's the output from the new version:\r\n<img width=\"924\" alt=\"screen shot 2019-01-28 at 4 46 54 pm\" src=\"https://user-images.githubusercontent.com/1948812/51876162-7aee3a00-231c-11e9-926e-edc7c3a7991d.png\">\r\n\r\n\r\nI consider this a P1 as we're displaying warnings that we didn't (removed) in previous versions. This will end up confusing users.\r\n\r\n\n", "before_files": [{"content": "import os\nimport sys\n\nfrom _pydevd_bundle.pydevd_constants import IS_PYCHARM\n\nIS_PY36_OR_GREATER = sys.version_info >= (3, 6)\n\nframe_eval_func = None\nstop_frame_eval = None\ndummy_trace_dispatch = None\nshow_frame_eval_warning = False\nclear_thread_local_info = None\n\n# \"NO\" means we should not use frame evaluation, 'YES' we should use it (and fail if not there) and unspecified uses if possible.\nuse_frame_eval = os.environ.get('PYDEVD_USE_FRAME_EVAL', None)\n\nif use_frame_eval == 'NO':\n pass\n\nelif use_frame_eval == 'YES':\n # Fail if unable to use\n from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info\n\nelif use_frame_eval is None:\n # Try to use if possible\n if IS_PY36_OR_GREATER:\n try:\n from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info\n except ImportError:\n from _pydev_bundle.pydev_monkey import log_error_once\n\n dirname = os.path.dirname(os.path.dirname(__file__))\n if not IS_PYCHARM:\n log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n sys.executable, os.path.join(dirname, 'setup_cython.py')))\n else:\n show_frame_eval_warning = True\n\nelse:\n raise RuntimeError('Unexpected value for PYDEVD_USE_FRAME_EVAL: %s (accepted: YES, NO)' % (use_frame_eval,))\n", "path": "src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py"}, {"content": "# Defines which version of the trace_dispatch we'll use.\n# Should give warning only here if cython is not available but supported.\n\nimport os\nimport sys\nfrom _pydevd_bundle.pydevd_constants import CYTHON_SUPPORTED\n\n\nuse_cython = os.getenv('PYDEVD_USE_CYTHON', None)\ndirname = os.path.dirname(os.path.dirname(__file__))\n# Do not show incorrect warning for .egg files for Remote debugger\nif not CYTHON_SUPPORTED or dirname.endswith('.egg'):\n # Do not try to import cython extensions if cython isn't supported\n use_cython = 'NO'\n\n\ndef delete_old_compiled_extensions():\n import _pydevd_bundle_ext\n cython_extensions_dir = os.path.dirname(os.path.dirname(_pydevd_bundle_ext.__file__))\n _pydevd_bundle_ext_dir = os.path.dirname(_pydevd_bundle_ext.__file__)\n _pydevd_frame_eval_ext_dir = os.path.join(cython_extensions_dir, '_pydevd_frame_eval_ext')\n try:\n import shutil\n for file in os.listdir(_pydevd_bundle_ext_dir):\n if file.startswith(\"pydevd\") and file.endswith(\".so\"):\n os.remove(os.path.join(_pydevd_bundle_ext_dir, file))\n for file in os.listdir(_pydevd_frame_eval_ext_dir):\n if file.startswith(\"pydevd\") and file.endswith(\".so\"):\n os.remove(os.path.join(_pydevd_frame_eval_ext_dir, file))\n build_dir = os.path.join(cython_extensions_dir, \"build\")\n if os.path.exists(build_dir):\n shutil.rmtree(os.path.join(cython_extensions_dir, \"build\"))\n except OSError:\n from _pydev_bundle.pydev_monkey import log_error_once\n log_error_once(\"warning: failed to delete old cython speedups. Please delete all *.so files from the directories \"\n \"\\\"%s\\\" and \\\"%s\\\"\" % (_pydevd_bundle_ext_dir, _pydevd_frame_eval_ext_dir))\n\n\nif use_cython == 'YES':\n # We must import the cython version if forcing cython\n from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func\n\nelif use_cython == 'NO':\n # Use the regular version if not forcing cython\n from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport\n\nelif use_cython is None:\n # Regular: use fallback if not found and give message to user\n try:\n from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func\n\n # This version number is always available\n from _pydevd_bundle.pydevd_additional_thread_info_regular import version as regular_version\n # This version number from the already compiled cython extension\n from _pydevd_bundle.pydevd_cython_wrapper import version as cython_version\n if cython_version != regular_version:\n delete_old_compiled_extensions()\n raise ImportError()\n\n except ImportError:\n from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport\n from _pydev_bundle.pydev_monkey import log_error_once\n\n log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n sys.executable, os.path.join(dirname, 'setup_cython.py')))\n\nelse:\n raise RuntimeError('Unexpected value for PYDEVD_USE_CYTHON: %s (accepted: YES, NO)' % (use_cython,))\n\n\n", "path": "src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py"}, {"content": "from importlib import import_module\nimport warnings\n\nfrom . import check_modules, prefix_matcher, preimport, vendored\n\n\n# Ensure that pydevd is our vendored copy.\n_unvendored, _ = check_modules('pydevd',\n prefix_matcher('pydev', '_pydev'))\nif _unvendored:\n _unvendored = sorted(_unvendored.values())\n msg = 'incompatible copy of pydevd already imported'\n #raise ImportError(msg)\n warnings.warn(msg + ':\\n {}'.format('\\n '.join(_unvendored)))\n\n\n# Constants must be set before importing any other pydevd module\n# # due to heavy use of \"from\" in them.\nwith vendored('pydevd'):\n pydevd_constants = import_module('_pydevd_bundle.pydevd_constants')\n# Disable this, since we aren't packaging the Cython modules at the moment.\npydevd_constants.CYTHON_SUPPORTED = False\n# We limit representation size in our representation provider when needed.\npydevd_constants.MAXIMUM_VARIABLE_REPRESENTATION_SIZE = 2**32\n\n\n# Now make sure all the top-level modules and packages in pydevd are\n# loaded. Any pydevd modules that aren't loaded at this point, will\n# be loaded using their parent package's __path__ (i.e. one of the\n# following).\npreimport('pydevd', [\n '_pydev_bundle',\n '_pydev_imps',\n '_pydev_runfiles',\n '_pydevd_bundle',\n '_pydevd_frame_eval',\n 'pydev_ipython',\n 'pydevd_concurrency_analyser',\n 'pydevd_plugins',\n 'pydevd',\n])\n\n# When pydevd is imported it sets the breakpoint behavior, but it needs to be\n# overridden because the pydevd version will connect to the remote debugger by\n# default, but without using the ptvsd protocol (so, we need to use the ptvsd\n# API to handle things as expected by the debug adapter).\nimport pydevd # noqa\nimport ptvsd # noqa\n\n\ndef ptvsd_breakpointhook():\n ptvsd.break_into_debugger()\n\n\npydevd.install_breakpointhook(ptvsd_breakpointhook)\n", "path": "src/ptvsd/_vendored/force_pydevd.py"}], "after_files": [{"content": "import os\nimport sys\n\nfrom _pydevd_bundle.pydevd_constants import IS_PYCHARM\n\nIS_PY36_OR_GREATER = sys.version_info >= (3, 6)\n\nframe_eval_func = None\nstop_frame_eval = None\ndummy_trace_dispatch = None\nshow_frame_eval_warning = False\nclear_thread_local_info = None\n\n# \"NO\" means we should not use frame evaluation, 'YES' we should use it (and fail if not there) and unspecified uses if possible.\nuse_frame_eval = os.environ.get('PYDEVD_USE_FRAME_EVAL', None)\n\nif use_frame_eval == 'NO':\n pass\n\nelif use_frame_eval == 'YES':\n # Fail if unable to use\n from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info\n\nelif use_frame_eval is None:\n # Try to use if possible\n if IS_PY36_OR_GREATER:\n try:\n from _pydevd_frame_eval.pydevd_frame_eval_cython_wrapper import frame_eval_func, stop_frame_eval, dummy_trace_dispatch, clear_thread_local_info\n except ImportError:\n from _pydev_bundle.pydev_monkey import log_error_once\n\n dirname = os.path.dirname(os.path.dirname(__file__))\n if not IS_PYCHARM:\n #log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n # sys.executable, os.path.join(dirname, 'setup_cython.py')))\n pass\n else:\n show_frame_eval_warning = True\n\nelse:\n raise RuntimeError('Unexpected value for PYDEVD_USE_FRAME_EVAL: %s (accepted: YES, NO)' % (use_frame_eval,))\n", "path": "src/ptvsd/_vendored/pydevd/_pydevd_frame_eval/pydevd_frame_eval_main.py"}, {"content": "# Defines which version of the trace_dispatch we'll use.\n# Should give warning only here if cython is not available but supported.\n\nimport os\nimport sys\nfrom _pydevd_bundle.pydevd_constants import CYTHON_SUPPORTED\n\n\nuse_cython = os.getenv('PYDEVD_USE_CYTHON', None)\ndirname = os.path.dirname(os.path.dirname(__file__))\n# Do not show incorrect warning for .egg files for Remote debugger\nif not CYTHON_SUPPORTED or dirname.endswith('.egg'):\n # Do not try to import cython extensions if cython isn't supported\n use_cython = 'NO'\n\n\ndef delete_old_compiled_extensions():\n import _pydevd_bundle_ext\n cython_extensions_dir = os.path.dirname(os.path.dirname(_pydevd_bundle_ext.__file__))\n _pydevd_bundle_ext_dir = os.path.dirname(_pydevd_bundle_ext.__file__)\n _pydevd_frame_eval_ext_dir = os.path.join(cython_extensions_dir, '_pydevd_frame_eval_ext')\n try:\n import shutil\n for file in os.listdir(_pydevd_bundle_ext_dir):\n if file.startswith(\"pydevd\") and file.endswith(\".so\"):\n os.remove(os.path.join(_pydevd_bundle_ext_dir, file))\n for file in os.listdir(_pydevd_frame_eval_ext_dir):\n if file.startswith(\"pydevd\") and file.endswith(\".so\"):\n os.remove(os.path.join(_pydevd_frame_eval_ext_dir, file))\n build_dir = os.path.join(cython_extensions_dir, \"build\")\n if os.path.exists(build_dir):\n shutil.rmtree(os.path.join(cython_extensions_dir, \"build\"))\n except OSError:\n from _pydev_bundle.pydev_monkey import log_error_once\n log_error_once(\"warning: failed to delete old cython speedups. Please delete all *.so files from the directories \"\n \"\\\"%s\\\" and \\\"%s\\\"\" % (_pydevd_bundle_ext_dir, _pydevd_frame_eval_ext_dir))\n\n\nif use_cython == 'YES':\n # We must import the cython version if forcing cython\n from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func\n\nelif use_cython == 'NO':\n # Use the regular version if not forcing cython\n from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport\n\nelif use_cython is None:\n # Regular: use fallback if not found and give message to user\n try:\n from _pydevd_bundle.pydevd_cython_wrapper import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func\n\n # This version number is always available\n from _pydevd_bundle.pydevd_additional_thread_info_regular import version as regular_version\n # This version number from the already compiled cython extension\n from _pydevd_bundle.pydevd_cython_wrapper import version as cython_version\n if cython_version != regular_version:\n delete_old_compiled_extensions()\n raise ImportError()\n\n except ImportError:\n from _pydevd_bundle.pydevd_trace_dispatch_regular import trace_dispatch, global_cache_skips, global_cache_frame_skips, fix_top_level_trace_and_get_trace_func # @UnusedImport\n #from _pydev_bundle.pydev_monkey import log_error_once\n\n #log_error_once(\"warning: Debugger speedups using cython not found. Run '\\\"%s\\\" \\\"%s\\\" build_ext --inplace' to build.\" % (\n # sys.executable, os.path.join(dirname, 'setup_cython.py')))\n pass\n\nelse:\n raise RuntimeError('Unexpected value for PYDEVD_USE_CYTHON: %s (accepted: YES, NO)' % (use_cython,))\n\n\n", "path": "src/ptvsd/_vendored/pydevd/_pydevd_bundle/pydevd_trace_dispatch.py"}, {"content": "from importlib import import_module\nimport warnings\n\nfrom . import check_modules, prefix_matcher, preimport, vendored\n\n\n# Ensure that pydevd is our vendored copy.\n_unvendored, _ = check_modules('pydevd',\n prefix_matcher('pydev', '_pydev'))\nif _unvendored:\n _unvendored = sorted(_unvendored.values())\n msg = 'incompatible copy of pydevd already imported'\n #raise ImportError(msg)\n warnings.warn(msg + ':\\n {}'.format('\\n '.join(_unvendored)))\n\n\n# Constants must be set before importing any other pydevd module\n# # due to heavy use of \"from\" in them.\nwith vendored('pydevd'):\n pydevd_constants = import_module('_pydevd_bundle.pydevd_constants')\n# TODO: figure out what the appropriate setting is to work for both wheels and sdist.\npydevd_constants.CYTHON_SUPPORTED = False\n# We limit representation size in our representation provider when needed.\npydevd_constants.MAXIMUM_VARIABLE_REPRESENTATION_SIZE = 2**32\n\n\n# Now make sure all the top-level modules and packages in pydevd are\n# loaded. Any pydevd modules that aren't loaded at this point, will\n# be loaded using their parent package's __path__ (i.e. one of the\n# following).\npreimport('pydevd', [\n '_pydev_bundle',\n '_pydev_imps',\n '_pydev_runfiles',\n '_pydevd_bundle',\n '_pydevd_frame_eval',\n 'pydev_ipython',\n 'pydevd_concurrency_analyser',\n 'pydevd_plugins',\n 'pydevd',\n])\n\n# When pydevd is imported it sets the breakpoint behavior, but it needs to be\n# overridden because the pydevd version will connect to the remote debugger by\n# default, but without using the ptvsd protocol (so, we need to use the ptvsd\n# API to handle things as expected by the debug adapter).\nimport pydevd # noqa\nimport ptvsd # noqa\n\n\ndef ptvsd_breakpointhook():\n ptvsd.break_into_debugger()\n\n\npydevd.install_breakpointhook(ptvsd_breakpointhook)\n", "path": "src/ptvsd/_vendored/force_pydevd.py"}]}
| 2,686 | 812 |
gh_patches_debug_25968
|
rasdani/github-patches
|
git_diff
|
sopel-irc__sopel-1092
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
web: broken header behavior
Yes, I know its deprecated, I'm going to fix it anyways.
headers bleed between web requests because we're using `update` on `default_headers`.
``` python
web.get('http://google.com/')
# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat)
web.get('http://google.com/', headers={'some-header': 'value'})
# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat), some-header: value
web.get('http://google.com/')
# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat), some-header: value
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sopel/web.py`
Content:
```
1 # coding=utf-8
2 """
3 *Availability: 3+, depreacted in 6.2.0*
4
5 The web class contains essential web-related functions for interaction with web
6 applications or websites in your modules. It supports HTTP GET, HTTP POST and
7 HTTP HEAD.
8 """
9 # Copyright © 2008, Sean B. Palmer, inamidst.com
10 # Copyright © 2009, Michael Yanovich <[email protected]>
11 # Copyright © 2012, Dimitri Molenaars, Tyrope.nl.
12 # Copyright © 2012-2013, Elad Alfassa, <[email protected]>
13 # Licensed under the Eiffel Forum License 2.
14
15 from __future__ import unicode_literals, absolute_import, print_function, division
16
17 import re
18 import sys
19 import urllib
20 import os.path
21 import requests
22
23 from sopel import __version__
24 from sopel.tools import deprecated
25
26 if sys.version_info.major < 3:
27 import httplib
28 from htmlentitydefs import name2codepoint
29 from urlparse import urlparse
30 from urlparse import urlunparse
31 else:
32 import http.client as httplib
33 from html.entities import name2codepoint
34 from urllib.parse import urlparse
35 from urllib.parse import urlunparse
36 unichr = chr
37 unicode = str
38
39 try:
40 import ssl
41 if not hasattr(ssl, 'match_hostname'):
42 # Attempt to import ssl_match_hostname from python-backports
43 import backports.ssl_match_hostname
44 ssl.match_hostname = backports.ssl_match_hostname.match_hostname
45 ssl.CertificateError = backports.ssl_match_hostname.CertificateError
46 has_ssl = True
47 except ImportError:
48 has_ssl = False
49
50 USER_AGENT = 'Sopel/{} (http://sopel.chat)'.format(__version__)
51 default_headers = {'User-Agent': USER_AGENT}
52 ca_certs = None # Will be overriden when config loads. This is for an edge case.
53
54
55 class MockHttpResponse(httplib.HTTPResponse):
56 "Mock HTTPResponse with data that comes from requests."
57 def __init__(self, response):
58 self.headers = response.headers
59 self.status = response.status_code
60 self.reason = response.reason
61 self.close = response.close
62 self.read = response.raw.read
63 self.url = response.url
64
65 def geturl(self):
66 return self.url
67
68
69 # HTTP GET
70 @deprecated
71 def get(uri, timeout=20, headers=None, return_headers=False,
72 limit_bytes=None, verify_ssl=True, dont_decode=False):
73 """Execute an HTTP GET query on `uri`, and return the result. Deprecated.
74
75 `timeout` is an optional argument, which represents how much time we should
76 wait before throwing a timeout exception. It defaults to 20, but can be set
77 to higher values if you are communicating with a slow web application.
78 `headers` is a dict of HTTP headers to send with the request. If
79 `return_headers` is True, return a tuple of (bytes, headers)
80
81 `limit_bytes` is ignored.
82
83 """
84 if not uri.startswith('http'):
85 uri = "http://" + uri
86 if headers is None:
87 headers = default_headers
88 else:
89 headers = default_headers.update(headers)
90 u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)
91 bytes = u.content
92 u.close()
93 headers = u.headers
94 if not dont_decode:
95 bytes = u.text
96 if not return_headers:
97 return bytes
98 else:
99 headers['_http_status'] = u.status_code
100 return (bytes, headers)
101
102
103 # Get HTTP headers
104 @deprecated
105 def head(uri, timeout=20, headers=None, verify_ssl=True):
106 """Execute an HTTP GET query on `uri`, and return the headers. Deprecated.
107
108 `timeout` is an optional argument, which represents how much time we should
109 wait before throwing a timeout exception. It defaults to 20, but can be set
110 to higher values if you are communicating with a slow web application.
111
112 """
113 if not uri.startswith('http'):
114 uri = "http://" + uri
115 if headers is None:
116 headers = default_headers
117 else:
118 headers = default_headers.update(headers)
119 u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)
120 info = u.headers
121 u.close()
122 return info
123
124
125 # HTTP POST
126 @deprecated
127 def post(uri, query, limit_bytes=None, timeout=20, verify_ssl=True, return_headers=False):
128 """Execute an HTTP POST query. Deprecated.
129
130 `uri` is the target URI, and `query` is the POST data. `headers` is a dict
131 of HTTP headers to send with the request.
132
133 `limit_bytes` is ignored.
134
135 """
136 if not uri.startswith('http'):
137 uri = "http://" + uri
138 u = requests.post(uri, timeout=timeout, verify=verify_ssl, data=query)
139 bytes = u.raw.read(limit_bytes)
140 headers = u.headers
141 u.close()
142 if not return_headers:
143 return bytes
144 else:
145 headers['_http_status'] = u.status_code
146 return (bytes, headers)
147
148 r_entity = re.compile(r'&([^;\s]+);')
149
150
151 def entity(match):
152 value = match.group(1).lower()
153 if value.startswith('#x'):
154 return unichr(int(value[2:], 16))
155 elif value.startswith('#'):
156 return unichr(int(value[1:]))
157 elif value in name2codepoint:
158 return unichr(name2codepoint[value])
159 return '[' + value + ']'
160
161
162 def decode(html):
163 return r_entity.sub(entity, html)
164
165
166 # For internal use in web.py, (modules can use this if they need a urllib
167 # object they can execute read() on) Both handles redirects and makes sure
168 # input URI is UTF-8
169 @deprecated
170 def get_urllib_object(uri, timeout, headers=None, verify_ssl=True, data=None):
171 """Return an HTTPResponse object for `uri` and `timeout` and `headers`. Deprecated
172
173 """
174
175 if headers is None:
176 headers = default_headers
177 else:
178 headers = default_headers.update(headers)
179 if data is not None:
180 response = requests.post(uri, timeout=timeout, verify=verify_ssl,
181 data=data, headers=headers)
182 else:
183 response = requests.get(uri, timeout=timeout, verify=verify_ssl,
184 headers=headers)
185 return MockHttpResponse(response)
186
187
188 # Identical to urllib2.quote
189 def quote(string, safe='/'):
190 """Like urllib2.quote but handles unicode properly."""
191 if sys.version_info.major < 3:
192 if isinstance(string, unicode):
193 string = string.encode('utf8')
194 string = urllib.quote(string, safe.encode('utf8'))
195 else:
196 string = urllib.parse.quote(str(string), safe)
197 return string
198
199
200 def quote_query(string):
201 """Quotes the query parameters."""
202 parsed = urlparse(string)
203 string = string.replace(parsed.query, quote(parsed.query, "/=&"), 1)
204 return string
205
206
207 # Functions for international domain name magic
208
209 def urlencode_non_ascii(b):
210 regex = '[\x80-\xFF]'
211 if sys.version_info.major > 2:
212 regex = b'[\x80-\xFF]'
213 return re.sub(regex, lambda c: '%%%02x' % ord(c.group(0)), b)
214
215
216 def iri_to_uri(iri):
217 parts = urlparse(iri)
218 parts_seq = (part.encode('idna') if parti == 1 else urlencode_non_ascii(part.encode('utf-8')) for parti, part in enumerate(parts))
219 if sys.version_info.major > 2:
220 parts_seq = list(parts_seq)
221
222 parsed = urlunparse(parts_seq)
223 if sys.version_info.major > 2:
224 return parsed.decode()
225 else:
226 return parsed
227
228
229 if sys.version_info.major < 3:
230 urlencode = urllib.urlencode
231 else:
232 urlencode = urllib.parse.urlencode
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sopel/web.py b/sopel/web.py
--- a/sopel/web.py
+++ b/sopel/web.py
@@ -86,7 +86,8 @@
if headers is None:
headers = default_headers
else:
- headers = default_headers.update(headers)
+ tmp = default_headers.copy()
+ headers = tmp.update(headers)
u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)
bytes = u.content
u.close()
@@ -115,7 +116,8 @@
if headers is None:
headers = default_headers
else:
- headers = default_headers.update(headers)
+ tmp = default_headers.copy()
+ headers = tmp.update(headers)
u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)
info = u.headers
u.close()
@@ -175,7 +177,8 @@
if headers is None:
headers = default_headers
else:
- headers = default_headers.update(headers)
+ tmp = default_headers.copy()
+ headers = tmp.update(headers)
if data is not None:
response = requests.post(uri, timeout=timeout, verify=verify_ssl,
data=data, headers=headers)
|
{"golden_diff": "diff --git a/sopel/web.py b/sopel/web.py\n--- a/sopel/web.py\n+++ b/sopel/web.py\n@@ -86,7 +86,8 @@\n if headers is None:\n headers = default_headers\n else:\n- headers = default_headers.update(headers)\n+ tmp = default_headers.copy()\n+ headers = tmp.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n bytes = u.content\n u.close()\n@@ -115,7 +116,8 @@\n if headers is None:\n headers = default_headers\n else:\n- headers = default_headers.update(headers)\n+ tmp = default_headers.copy()\n+ headers = tmp.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n info = u.headers\n u.close()\n@@ -175,7 +177,8 @@\n if headers is None:\n headers = default_headers\n else:\n- headers = default_headers.update(headers)\n+ tmp = default_headers.copy()\n+ headers = tmp.update(headers)\n if data is not None:\n response = requests.post(uri, timeout=timeout, verify=verify_ssl,\n data=data, headers=headers)\n", "issue": "web: broken header behavior\nYes, I know its deprecated, I'm going to fix it anyways.\n\nheaders bleed between web requests because we're using `update` on `default_headers`.\n\n``` python\nweb.get('http://google.com/')\n# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat)\nweb.get('http://google.com/', headers={'some-header': 'value'})\n# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat), some-header: value\nweb.get('http://google.com/')\n# Headers: User-Agent: Sopel/6.3.1 (http://sopel.chat), some-header: value\n```\n\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\n*Availability: 3+, depreacted in 6.2.0*\n\nThe web class contains essential web-related functions for interaction with web\napplications or websites in your modules. It supports HTTP GET, HTTP POST and\nHTTP HEAD.\n\"\"\"\n# Copyright \u00a9 2008, Sean B. Palmer, inamidst.com\n# Copyright \u00a9 2009, Michael Yanovich <[email protected]>\n# Copyright \u00a9 2012, Dimitri Molenaars, Tyrope.nl.\n# Copyright \u00a9 2012-2013, Elad Alfassa, <[email protected]>\n# Licensed under the Eiffel Forum License 2.\n\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\nimport sys\nimport urllib\nimport os.path\nimport requests\n\nfrom sopel import __version__\nfrom sopel.tools import deprecated\n\nif sys.version_info.major < 3:\n import httplib\n from htmlentitydefs import name2codepoint\n from urlparse import urlparse\n from urlparse import urlunparse\nelse:\n import http.client as httplib\n from html.entities import name2codepoint\n from urllib.parse import urlparse\n from urllib.parse import urlunparse\n unichr = chr\n unicode = str\n\ntry:\n import ssl\n if not hasattr(ssl, 'match_hostname'):\n # Attempt to import ssl_match_hostname from python-backports\n import backports.ssl_match_hostname\n ssl.match_hostname = backports.ssl_match_hostname.match_hostname\n ssl.CertificateError = backports.ssl_match_hostname.CertificateError\n has_ssl = True\nexcept ImportError:\n has_ssl = False\n\nUSER_AGENT = 'Sopel/{} (http://sopel.chat)'.format(__version__)\ndefault_headers = {'User-Agent': USER_AGENT}\nca_certs = None # Will be overriden when config loads. This is for an edge case.\n\n\nclass MockHttpResponse(httplib.HTTPResponse):\n \"Mock HTTPResponse with data that comes from requests.\"\n def __init__(self, response):\n self.headers = response.headers\n self.status = response.status_code\n self.reason = response.reason\n self.close = response.close\n self.read = response.raw.read\n self.url = response.url\n\n def geturl(self):\n return self.url\n\n\n# HTTP GET\n@deprecated\ndef get(uri, timeout=20, headers=None, return_headers=False,\n limit_bytes=None, verify_ssl=True, dont_decode=False):\n \"\"\"Execute an HTTP GET query on `uri`, and return the result. Deprecated.\n\n `timeout` is an optional argument, which represents how much time we should\n wait before throwing a timeout exception. It defaults to 20, but can be set\n to higher values if you are communicating with a slow web application.\n `headers` is a dict of HTTP headers to send with the request. If\n `return_headers` is True, return a tuple of (bytes, headers)\n\n `limit_bytes` is ignored.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n if headers is None:\n headers = default_headers\n else:\n headers = default_headers.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n bytes = u.content\n u.close()\n headers = u.headers\n if not dont_decode:\n bytes = u.text\n if not return_headers:\n return bytes\n else:\n headers['_http_status'] = u.status_code\n return (bytes, headers)\n\n\n# Get HTTP headers\n@deprecated\ndef head(uri, timeout=20, headers=None, verify_ssl=True):\n \"\"\"Execute an HTTP GET query on `uri`, and return the headers. Deprecated.\n\n `timeout` is an optional argument, which represents how much time we should\n wait before throwing a timeout exception. It defaults to 20, but can be set\n to higher values if you are communicating with a slow web application.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n if headers is None:\n headers = default_headers\n else:\n headers = default_headers.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n info = u.headers\n u.close()\n return info\n\n\n# HTTP POST\n@deprecated\ndef post(uri, query, limit_bytes=None, timeout=20, verify_ssl=True, return_headers=False):\n \"\"\"Execute an HTTP POST query. Deprecated.\n\n `uri` is the target URI, and `query` is the POST data. `headers` is a dict\n of HTTP headers to send with the request.\n\n `limit_bytes` is ignored.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n u = requests.post(uri, timeout=timeout, verify=verify_ssl, data=query)\n bytes = u.raw.read(limit_bytes)\n headers = u.headers\n u.close()\n if not return_headers:\n return bytes\n else:\n headers['_http_status'] = u.status_code\n return (bytes, headers)\n\nr_entity = re.compile(r'&([^;\\s]+);')\n\n\ndef entity(match):\n value = match.group(1).lower()\n if value.startswith('#x'):\n return unichr(int(value[2:], 16))\n elif value.startswith('#'):\n return unichr(int(value[1:]))\n elif value in name2codepoint:\n return unichr(name2codepoint[value])\n return '[' + value + ']'\n\n\ndef decode(html):\n return r_entity.sub(entity, html)\n\n\n# For internal use in web.py, (modules can use this if they need a urllib\n# object they can execute read() on) Both handles redirects and makes sure\n# input URI is UTF-8\n@deprecated\ndef get_urllib_object(uri, timeout, headers=None, verify_ssl=True, data=None):\n \"\"\"Return an HTTPResponse object for `uri` and `timeout` and `headers`. Deprecated\n\n \"\"\"\n\n if headers is None:\n headers = default_headers\n else:\n headers = default_headers.update(headers)\n if data is not None:\n response = requests.post(uri, timeout=timeout, verify=verify_ssl,\n data=data, headers=headers)\n else:\n response = requests.get(uri, timeout=timeout, verify=verify_ssl,\n headers=headers)\n return MockHttpResponse(response)\n\n\n# Identical to urllib2.quote\ndef quote(string, safe='/'):\n \"\"\"Like urllib2.quote but handles unicode properly.\"\"\"\n if sys.version_info.major < 3:\n if isinstance(string, unicode):\n string = string.encode('utf8')\n string = urllib.quote(string, safe.encode('utf8'))\n else:\n string = urllib.parse.quote(str(string), safe)\n return string\n\n\ndef quote_query(string):\n \"\"\"Quotes the query parameters.\"\"\"\n parsed = urlparse(string)\n string = string.replace(parsed.query, quote(parsed.query, \"/=&\"), 1)\n return string\n\n\n# Functions for international domain name magic\n\ndef urlencode_non_ascii(b):\n regex = '[\\x80-\\xFF]'\n if sys.version_info.major > 2:\n regex = b'[\\x80-\\xFF]'\n return re.sub(regex, lambda c: '%%%02x' % ord(c.group(0)), b)\n\n\ndef iri_to_uri(iri):\n parts = urlparse(iri)\n parts_seq = (part.encode('idna') if parti == 1 else urlencode_non_ascii(part.encode('utf-8')) for parti, part in enumerate(parts))\n if sys.version_info.major > 2:\n parts_seq = list(parts_seq)\n\n parsed = urlunparse(parts_seq)\n if sys.version_info.major > 2:\n return parsed.decode()\n else:\n return parsed\n\n\nif sys.version_info.major < 3:\n urlencode = urllib.urlencode\nelse:\n urlencode = urllib.parse.urlencode\n", "path": "sopel/web.py"}], "after_files": [{"content": "# coding=utf-8\n\"\"\"\n*Availability: 3+, depreacted in 6.2.0*\n\nThe web class contains essential web-related functions for interaction with web\napplications or websites in your modules. It supports HTTP GET, HTTP POST and\nHTTP HEAD.\n\"\"\"\n# Copyright \u00a9 2008, Sean B. Palmer, inamidst.com\n# Copyright \u00a9 2009, Michael Yanovich <[email protected]>\n# Copyright \u00a9 2012, Dimitri Molenaars, Tyrope.nl.\n# Copyright \u00a9 2012-2013, Elad Alfassa, <[email protected]>\n# Licensed under the Eiffel Forum License 2.\n\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\nimport sys\nimport urllib\nimport os.path\nimport requests\n\nfrom sopel import __version__\nfrom sopel.tools import deprecated\n\nif sys.version_info.major < 3:\n import httplib\n from htmlentitydefs import name2codepoint\n from urlparse import urlparse\n from urlparse import urlunparse\nelse:\n import http.client as httplib\n from html.entities import name2codepoint\n from urllib.parse import urlparse\n from urllib.parse import urlunparse\n unichr = chr\n unicode = str\n\ntry:\n import ssl\n if not hasattr(ssl, 'match_hostname'):\n # Attempt to import ssl_match_hostname from python-backports\n import backports.ssl_match_hostname\n ssl.match_hostname = backports.ssl_match_hostname.match_hostname\n ssl.CertificateError = backports.ssl_match_hostname.CertificateError\n has_ssl = True\nexcept ImportError:\n has_ssl = False\n\nUSER_AGENT = 'Sopel/{} (http://sopel.chat)'.format(__version__)\ndefault_headers = {'User-Agent': USER_AGENT}\nca_certs = None # Will be overriden when config loads. This is for an edge case.\n\n\nclass MockHttpResponse(httplib.HTTPResponse):\n \"Mock HTTPResponse with data that comes from requests.\"\n def __init__(self, response):\n self.headers = response.headers\n self.status = response.status_code\n self.reason = response.reason\n self.close = response.close\n self.read = response.raw.read\n self.url = response.url\n\n def geturl(self):\n return self.url\n\n\n# HTTP GET\n@deprecated\ndef get(uri, timeout=20, headers=None, return_headers=False,\n limit_bytes=None, verify_ssl=True, dont_decode=False):\n \"\"\"Execute an HTTP GET query on `uri`, and return the result. Deprecated.\n\n `timeout` is an optional argument, which represents how much time we should\n wait before throwing a timeout exception. It defaults to 20, but can be set\n to higher values if you are communicating with a slow web application.\n `headers` is a dict of HTTP headers to send with the request. If\n `return_headers` is True, return a tuple of (bytes, headers)\n\n `limit_bytes` is ignored.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n if headers is None:\n headers = default_headers\n else:\n tmp = default_headers.copy()\n headers = tmp.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n bytes = u.content\n u.close()\n headers = u.headers\n if not dont_decode:\n bytes = u.text\n if not return_headers:\n return bytes\n else:\n headers['_http_status'] = u.status_code\n return (bytes, headers)\n\n\n# Get HTTP headers\n@deprecated\ndef head(uri, timeout=20, headers=None, verify_ssl=True):\n \"\"\"Execute an HTTP GET query on `uri`, and return the headers. Deprecated.\n\n `timeout` is an optional argument, which represents how much time we should\n wait before throwing a timeout exception. It defaults to 20, but can be set\n to higher values if you are communicating with a slow web application.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n if headers is None:\n headers = default_headers\n else:\n tmp = default_headers.copy()\n headers = tmp.update(headers)\n u = requests.get(uri, timeout=timeout, headers=headers, verify=verify_ssl)\n info = u.headers\n u.close()\n return info\n\n\n# HTTP POST\n@deprecated\ndef post(uri, query, limit_bytes=None, timeout=20, verify_ssl=True, return_headers=False):\n \"\"\"Execute an HTTP POST query. Deprecated.\n\n `uri` is the target URI, and `query` is the POST data. `headers` is a dict\n of HTTP headers to send with the request.\n\n `limit_bytes` is ignored.\n\n \"\"\"\n if not uri.startswith('http'):\n uri = \"http://\" + uri\n u = requests.post(uri, timeout=timeout, verify=verify_ssl, data=query)\n bytes = u.raw.read(limit_bytes)\n headers = u.headers\n u.close()\n if not return_headers:\n return bytes\n else:\n headers['_http_status'] = u.status_code\n return (bytes, headers)\n\nr_entity = re.compile(r'&([^;\\s]+);')\n\n\ndef entity(match):\n value = match.group(1).lower()\n if value.startswith('#x'):\n return unichr(int(value[2:], 16))\n elif value.startswith('#'):\n return unichr(int(value[1:]))\n elif value in name2codepoint:\n return unichr(name2codepoint[value])\n return '[' + value + ']'\n\n\ndef decode(html):\n return r_entity.sub(entity, html)\n\n\n# For internal use in web.py, (modules can use this if they need a urllib\n# object they can execute read() on) Both handles redirects and makes sure\n# input URI is UTF-8\n@deprecated\ndef get_urllib_object(uri, timeout, headers=None, verify_ssl=True, data=None):\n \"\"\"Return an HTTPResponse object for `uri` and `timeout` and `headers`. Deprecated\n\n \"\"\"\n\n if headers is None:\n headers = default_headers\n else:\n tmp = default_headers.copy()\n headers = tmp.update(headers)\n if data is not None:\n response = requests.post(uri, timeout=timeout, verify=verify_ssl,\n data=data, headers=headers)\n else:\n response = requests.get(uri, timeout=timeout, verify=verify_ssl,\n headers=headers)\n return MockHttpResponse(response)\n\n\n# Identical to urllib2.quote\ndef quote(string, safe='/'):\n \"\"\"Like urllib2.quote but handles unicode properly.\"\"\"\n if sys.version_info.major < 3:\n if isinstance(string, unicode):\n string = string.encode('utf8')\n string = urllib.quote(string, safe.encode('utf8'))\n else:\n string = urllib.parse.quote(str(string), safe)\n return string\n\n\ndef quote_query(string):\n \"\"\"Quotes the query parameters.\"\"\"\n parsed = urlparse(string)\n string = string.replace(parsed.query, quote(parsed.query, \"/=&\"), 1)\n return string\n\n\n# Functions for international domain name magic\n\ndef urlencode_non_ascii(b):\n regex = '[\\x80-\\xFF]'\n if sys.version_info.major > 2:\n regex = b'[\\x80-\\xFF]'\n return re.sub(regex, lambda c: '%%%02x' % ord(c.group(0)), b)\n\n\ndef iri_to_uri(iri):\n parts = urlparse(iri)\n parts_seq = (part.encode('idna') if parti == 1 else urlencode_non_ascii(part.encode('utf-8')) for parti, part in enumerate(parts))\n if sys.version_info.major > 2:\n parts_seq = list(parts_seq)\n\n parsed = urlunparse(parts_seq)\n if sys.version_info.major > 2:\n return parsed.decode()\n else:\n return parsed\n\n\nif sys.version_info.major < 3:\n urlencode = urllib.urlencode\nelse:\n urlencode = urllib.parse.urlencode\n", "path": "sopel/web.py"}]}
| 2,767 | 280 |
gh_patches_debug_29697
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-736
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[2.3.0-RC1] --config file parsing regressions
When specifying a config file generated from /var/log/archinstall/user_configuration.json to attempt to retry the same installation, I ran into hardware related import errors until I dropped gfx_driver from the config file, and then once I did, the installer was prompting me to re-enter a lot of entries (not imported properly), even though they seemed to be in the configuration file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `archinstall/__init__.py`
Content:
```
1 """Arch Linux installer - guided, templates etc."""
2 import urllib.error
3 import urllib.parse
4 import urllib.request
5 from argparse import ArgumentParser
6
7 from .lib.disk import *
8 from .lib.exceptions import *
9 from .lib.general import *
10 from .lib.hardware import *
11 from .lib.installer import __packages__, Installer
12 from .lib.locale_helpers import *
13 from .lib.luks import *
14 from .lib.mirrors import *
15 from .lib.networking import *
16 from .lib.output import *
17 from .lib.packages import *
18 from .lib.profiles import *
19 from .lib.services import *
20 from .lib.storage import *
21 from .lib.systemd import *
22 from .lib.user_interaction import *
23
24 parser = ArgumentParser()
25
26 __version__ = "2.3.0.dev0"
27 storage['__version__'] = __version__
28
29
30 def initialize_arguments():
31 config = {}
32 parser.add_argument("--config", nargs="?", help="JSON configuration file or URL")
33 parser.add_argument("--creds", nargs="?", help="JSON credentials configuration file")
34 parser.add_argument("--silent", action="store_true",
35 help="WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored")
36 parser.add_argument("--dry-run", action="store_true",
37 help="Generates a configuration file and then exits instead of performing an installation")
38 parser.add_argument("--script", default="guided", nargs="?", help="Script to run for installation", type=str)
39 args, unknowns = parser.parse_known_args()
40 if args.config is not None:
41 try:
42 # First, let's check if this is a URL scheme instead of a filename
43 parsed_url = urllib.parse.urlparse(args.config)
44
45 if not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.
46 with open(args.config) as file:
47 config = json.load(file)
48 else: # Attempt to load the configuration from the URL.
49 with urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:
50 config = json.loads(response.read())
51 except Exception as e:
52 print(e)
53 if args.creds is not None:
54 with open(args.creds) as file:
55 config.update(json.load(file))
56 # Installation can't be silent if config is not passed
57 config["silent"] = args.silent
58 for arg in unknowns:
59 if '--' == arg[:2]:
60 if '=' in arg:
61 key, val = [x.strip() for x in arg[2:].split('=', 1)]
62 else:
63 key, val = arg[2:], True
64 config[key] = val
65 config["script"] = args.script
66 if args.dry_run is not None:
67 config["dry-run"] = args.dry_run
68 return config
69
70
71 arguments = initialize_arguments()
72 storage['arguments'] = arguments
73 if arguments.get('debug'):
74 log(f"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!", fg="red", level=logging.WARNING)
75 if arguments.get('mount-point'):
76 storage['MOUNT_POINT'] = arguments['mount-point']
77
78 from .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony
79
80 if arguments.get('plugin', None):
81 load_plugin(arguments['plugin'])
82
83 # TODO: Learn the dark arts of argparse... (I summon thee dark spawn of cPython)
84
85
86 def run_as_a_module():
87 """
88 Since we're running this as a 'python -m archinstall' module OR
89 a nuitka3 compiled version of the project.
90 This function and the file __main__ acts as a entry point.
91 """
92
93 # Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.
94 storage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))
95 try:
96 script = Script(arguments.get('script', None))
97 except ProfileNotFound as err:
98 print(f"Couldn't find file: {err}")
99 sys.exit(1)
100
101 os.chdir(os.path.abspath(os.path.dirname(__file__)))
102
103 # Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.
104 storage['PROFILE_PATH'].pop()
105 script.execute()
106
```
Path: `archinstall/lib/systemd.py`
Content:
```
1 import logging
2 import time
3 from .exceptions import SysCallError
4 from .general import SysCommand, SysCommandWorker, locate_binary
5 from .installer import Installer
6 from .output import log
7 from .storage import storage
8
9
10 class Ini:
11 def __init__(self, *args, **kwargs):
12 """
13 Limited INI handler for now.
14 Supports multiple keywords through dictionary list items.
15 """
16 self.kwargs = kwargs
17
18 def __str__(self):
19 result = ''
20 first_row_done = False
21 for top_level in self.kwargs:
22 if first_row_done:
23 result += f"\n[{top_level}]\n"
24 else:
25 result += f"[{top_level}]\n"
26 first_row_done = True
27
28 for key, val in self.kwargs[top_level].items():
29 if type(val) == list:
30 for item in val:
31 result += f"{key}={item}\n"
32 else:
33 result += f"{key}={val}\n"
34
35 return result
36
37
38 class Systemd(Ini):
39 """
40 Placeholder class to do systemd specific setups.
41 """
42
43
44 class Networkd(Systemd):
45 """
46 Placeholder class to do systemd-network specific setups.
47 """
48
49
50 class Boot:
51 def __init__(self, installation: Installer):
52 self.instance = installation
53 self.container_name = 'archinstall'
54 self.session = None
55 self.ready = False
56
57 def __enter__(self):
58 if (existing_session := storage.get('active_boot', None)) and existing_session.instance != self.instance:
59 raise KeyError("Archinstall only supports booting up one instance, and a active session is already active and it is not this one.")
60
61 if existing_session:
62 self.session = existing_session.session
63 self.ready = existing_session.ready
64 else:
65 self.session = SysCommandWorker([
66 '/usr/bin/systemd-nspawn',
67 '-D', self.instance.target,
68 '--timezone=off',
69 '-b',
70 '--no-pager',
71 '--machine', self.container_name
72 ])
73 # '-P' or --console=pipe could help us not having to do a bunch of os.write() calls, but instead use pipes (stdin, stdout and stderr) as usual.
74
75 if not self.ready:
76 while self.session.is_alive():
77 if b' login:' in self.session:
78 self.ready = True
79 break
80
81 storage['active_boot'] = self
82 return self
83
84 def __exit__(self, *args, **kwargs):
85 # b''.join(sys_command('sync')) # No need to, since the underlying fs() object will call sync.
86 # TODO: https://stackoverflow.com/questions/28157929/how-to-safely-handle-an-exception-inside-a-context-manager
87
88 if len(args) >= 2 and args[1]:
89 log(args[1], level=logging.ERROR, fg='red')
90 log(f"The error above occured in a temporary boot-up of the installation {self.instance}", level=logging.ERROR, fg="red")
91
92 shutdown = SysCommand(f'systemd-run --machine={self.container_name} --pty /bin/bash -c "shutdown now"')
93 while self.session.is_alive():
94 time.sleep(0.25)
95
96 if shutdown.exit_code == 0:
97 storage['active_boot'] = None
98 else:
99 raise SysCallError(f"Could not shut down temporary boot of {self.instance}", level=logging.ERROR, fg="red")
100
101 def __iter__(self):
102 if self.session:
103 for value in self.session:
104 yield value
105
106 def __contains__(self, key: bytes):
107 if self.session is None:
108 return False
109
110 return key in self.session
111
112 def is_alive(self):
113 if self.session is None:
114 return False
115
116 return self.session.is_alive()
117
118 def SysCommand(self, cmd: list, *args, **kwargs):
119 if cmd[0][0] != '/' and cmd[0][:2] != './':
120 # This check is also done in SysCommand & SysCommandWorker.
121 # However, that check is done for `machinectl` and not for our chroot command.
122 # So this wrapper for SysCommand will do this additionally.
123
124 cmd[0] = locate_binary(cmd[0])
125
126 return SysCommand(["systemd-run", f"--machine={self.container_name}", "--pty", *cmd], *args, **kwargs)
127
128 def SysCommandWorker(self, cmd: list, *args, **kwargs):
129 if cmd[0][0] != '/' and cmd[0][:2] != './':
130 cmd[0] = locate_binary(cmd[0])
131
132 return SysCommandWorker(["systemd-run", f"--machine={self.container_name}", "--pty", *cmd], *args, **kwargs)
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/archinstall/__init__.py b/archinstall/__init__.py
--- a/archinstall/__init__.py
+++ b/archinstall/__init__.py
@@ -49,12 +49,15 @@
with urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:
config = json.loads(response.read())
except Exception as e:
- print(e)
+ raise ValueError(f"Could not load --config because: {e}")
+
if args.creds is not None:
with open(args.creds) as file:
config.update(json.load(file))
+
# Installation can't be silent if config is not passed
config["silent"] = args.silent
+
for arg in unknowns:
if '--' == arg[:2]:
if '=' in arg:
@@ -62,9 +65,12 @@
else:
key, val = arg[2:], True
config[key] = val
+
config["script"] = args.script
+
if args.dry_run is not None:
config["dry-run"] = args.dry_run
+
return config
diff --git a/archinstall/lib/systemd.py b/archinstall/lib/systemd.py
--- a/archinstall/lib/systemd.py
+++ b/archinstall/lib/systemd.py
@@ -96,7 +96,7 @@
if shutdown.exit_code == 0:
storage['active_boot'] = None
else:
- raise SysCallError(f"Could not shut down temporary boot of {self.instance}", level=logging.ERROR, fg="red")
+ raise SysCallError(f"Could not shut down temporary boot of {self.instance}: {shutdown}", exit_code=shutdown.exit_code)
def __iter__(self):
if self.session:
|
{"golden_diff": "diff --git a/archinstall/__init__.py b/archinstall/__init__.py\n--- a/archinstall/__init__.py\n+++ b/archinstall/__init__.py\n@@ -49,12 +49,15 @@\n \t\t\t\twith urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:\n \t\t\t\t\tconfig = json.loads(response.read())\n \t\texcept Exception as e:\n-\t\t\tprint(e)\n+\t\t\traise ValueError(f\"Could not load --config because: {e}\")\n+\t\n \t\tif args.creds is not None:\n \t\t\twith open(args.creds) as file:\n \t\t\t\tconfig.update(json.load(file))\n+\t\n \t\t# Installation can't be silent if config is not passed\n \t\tconfig[\"silent\"] = args.silent\n+\t\n \tfor arg in unknowns:\n \t\tif '--' == arg[:2]:\n \t\t\tif '=' in arg:\n@@ -62,9 +65,12 @@\n \t\t\telse:\n \t\t\t\tkey, val = arg[2:], True\n \t\t\tconfig[key] = val\n+\t\n \tconfig[\"script\"] = args.script\n+\t\n \tif args.dry_run is not None:\n \t\tconfig[\"dry-run\"] = args.dry_run\n+\n \treturn config\n \n \ndiff --git a/archinstall/lib/systemd.py b/archinstall/lib/systemd.py\n--- a/archinstall/lib/systemd.py\n+++ b/archinstall/lib/systemd.py\n@@ -96,7 +96,7 @@\n \t\tif shutdown.exit_code == 0:\n \t\t\tstorage['active_boot'] = None\n \t\telse:\n-\t\t\traise SysCallError(f\"Could not shut down temporary boot of {self.instance}\", level=logging.ERROR, fg=\"red\")\n+\t\t\traise SysCallError(f\"Could not shut down temporary boot of {self.instance}: {shutdown}\", exit_code=shutdown.exit_code)\n \n \tdef __iter__(self):\n \t\tif self.session:\n", "issue": "[2.3.0-RC1] --config file parsing regressions\nWhen specifying a config file generated from /var/log/archinstall/user_configuration.json to attempt to retry the same installation, I ran into hardware related import errors until I dropped gfx_driver from the config file, and then once I did, the installer was prompting me to re-enter a lot of entries (not imported properly), even though they seemed to be in the configuration file.\n", "before_files": [{"content": "\"\"\"Arch Linux installer - guided, templates etc.\"\"\"\nimport urllib.error\nimport urllib.parse\nimport urllib.request\nfrom argparse import ArgumentParser\n\nfrom .lib.disk import *\nfrom .lib.exceptions import *\nfrom .lib.general import *\nfrom .lib.hardware import *\nfrom .lib.installer import __packages__, Installer\nfrom .lib.locale_helpers import *\nfrom .lib.luks import *\nfrom .lib.mirrors import *\nfrom .lib.networking import *\nfrom .lib.output import *\nfrom .lib.packages import *\nfrom .lib.profiles import *\nfrom .lib.services import *\nfrom .lib.storage import *\nfrom .lib.systemd import *\nfrom .lib.user_interaction import *\n\nparser = ArgumentParser()\n\n__version__ = \"2.3.0.dev0\"\nstorage['__version__'] = __version__\n\n\ndef initialize_arguments():\n\tconfig = {}\n\tparser.add_argument(\"--config\", nargs=\"?\", help=\"JSON configuration file or URL\")\n\tparser.add_argument(\"--creds\", nargs=\"?\", help=\"JSON credentials configuration file\")\n\tparser.add_argument(\"--silent\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored\")\n\tparser.add_argument(\"--dry-run\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"Generates a configuration file and then exits instead of performing an installation\")\n\tparser.add_argument(\"--script\", default=\"guided\", nargs=\"?\", help=\"Script to run for installation\", type=str)\n\targs, unknowns = parser.parse_known_args()\n\tif args.config is not None:\n\t\ttry:\n\t\t\t# First, let's check if this is a URL scheme instead of a filename\n\t\t\tparsed_url = urllib.parse.urlparse(args.config)\n\n\t\t\tif not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.\n\t\t\t\twith open(args.config) as file:\n\t\t\t\t\tconfig = json.load(file)\n\t\t\telse: # Attempt to load the configuration from the URL.\n\t\t\t\twith urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:\n\t\t\t\t\tconfig = json.loads(response.read())\n\t\texcept Exception as e:\n\t\t\tprint(e)\n\t\tif args.creds is not None:\n\t\t\twith open(args.creds) as file:\n\t\t\t\tconfig.update(json.load(file))\n\t\t# Installation can't be silent if config is not passed\n\t\tconfig[\"silent\"] = args.silent\n\tfor arg in unknowns:\n\t\tif '--' == arg[:2]:\n\t\t\tif '=' in arg:\n\t\t\t\tkey, val = [x.strip() for x in arg[2:].split('=', 1)]\n\t\t\telse:\n\t\t\t\tkey, val = arg[2:], True\n\t\t\tconfig[key] = val\n\tconfig[\"script\"] = args.script\n\tif args.dry_run is not None:\n\t\tconfig[\"dry-run\"] = args.dry_run\n\treturn config\n\n\narguments = initialize_arguments()\nstorage['arguments'] = arguments\nif arguments.get('debug'):\n\tlog(f\"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!\", fg=\"red\", level=logging.WARNING)\nif arguments.get('mount-point'):\n\tstorage['MOUNT_POINT'] = arguments['mount-point']\n\nfrom .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony\n\nif arguments.get('plugin', None):\n\tload_plugin(arguments['plugin'])\n\n# TODO: Learn the dark arts of argparse... (I summon thee dark spawn of cPython)\n\n\ndef run_as_a_module():\n\t\"\"\"\n\tSince we're running this as a 'python -m archinstall' module OR\n\ta nuitka3 compiled version of the project.\n\tThis function and the file __main__ acts as a entry point.\n\t\"\"\"\n\n\t# Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.\n\tstorage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))\n\ttry:\n\t\tscript = Script(arguments.get('script', None))\n\texcept ProfileNotFound as err:\n\t\tprint(f\"Couldn't find file: {err}\")\n\t\tsys.exit(1)\n\n\tos.chdir(os.path.abspath(os.path.dirname(__file__)))\n\n\t# Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.\n\tstorage['PROFILE_PATH'].pop()\n\tscript.execute()\n", "path": "archinstall/__init__.py"}, {"content": "import logging\nimport time\nfrom .exceptions import SysCallError\nfrom .general import SysCommand, SysCommandWorker, locate_binary\nfrom .installer import Installer\nfrom .output import log\nfrom .storage import storage\n\n\nclass Ini:\n\tdef __init__(self, *args, **kwargs):\n\t\t\"\"\"\n\t\tLimited INI handler for now.\n\t\tSupports multiple keywords through dictionary list items.\n\t\t\"\"\"\n\t\tself.kwargs = kwargs\n\n\tdef __str__(self):\n\t\tresult = ''\n\t\tfirst_row_done = False\n\t\tfor top_level in self.kwargs:\n\t\t\tif first_row_done:\n\t\t\t\tresult += f\"\\n[{top_level}]\\n\"\n\t\t\telse:\n\t\t\t\tresult += f\"[{top_level}]\\n\"\n\t\t\t\tfirst_row_done = True\n\n\t\t\tfor key, val in self.kwargs[top_level].items():\n\t\t\t\tif type(val) == list:\n\t\t\t\t\tfor item in val:\n\t\t\t\t\t\tresult += f\"{key}={item}\\n\"\n\t\t\t\telse:\n\t\t\t\t\tresult += f\"{key}={val}\\n\"\n\n\t\treturn result\n\n\nclass Systemd(Ini):\n\t\"\"\"\n\tPlaceholder class to do systemd specific setups.\n\t\"\"\"\n\n\nclass Networkd(Systemd):\n\t\"\"\"\n\tPlaceholder class to do systemd-network specific setups.\n\t\"\"\"\n\n\nclass Boot:\n\tdef __init__(self, installation: Installer):\n\t\tself.instance = installation\n\t\tself.container_name = 'archinstall'\n\t\tself.session = None\n\t\tself.ready = False\n\n\tdef __enter__(self):\n\t\tif (existing_session := storage.get('active_boot', None)) and existing_session.instance != self.instance:\n\t\t\traise KeyError(\"Archinstall only supports booting up one instance, and a active session is already active and it is not this one.\")\n\n\t\tif existing_session:\n\t\t\tself.session = existing_session.session\n\t\t\tself.ready = existing_session.ready\n\t\telse:\n\t\t\tself.session = SysCommandWorker([\n\t\t\t\t'/usr/bin/systemd-nspawn',\n\t\t\t\t'-D', self.instance.target,\n\t\t\t\t'--timezone=off',\n\t\t\t\t'-b',\n\t\t\t\t'--no-pager',\n\t\t\t\t'--machine', self.container_name\n\t\t\t])\n\t\t\t# '-P' or --console=pipe could help us not having to do a bunch of os.write() calls, but instead use pipes (stdin, stdout and stderr) as usual.\n\n\t\tif not self.ready:\n\t\t\twhile self.session.is_alive():\n\t\t\t\tif b' login:' in self.session:\n\t\t\t\t\tself.ready = True\n\t\t\t\t\tbreak\n\n\t\tstorage['active_boot'] = self\n\t\treturn self\n\n\tdef __exit__(self, *args, **kwargs):\n\t\t# b''.join(sys_command('sync')) # No need to, since the underlying fs() object will call sync.\n\t\t# TODO: https://stackoverflow.com/questions/28157929/how-to-safely-handle-an-exception-inside-a-context-manager\n\n\t\tif len(args) >= 2 and args[1]:\n\t\t\tlog(args[1], level=logging.ERROR, fg='red')\n\t\t\tlog(f\"The error above occured in a temporary boot-up of the installation {self.instance}\", level=logging.ERROR, fg=\"red\")\n\n\t\tshutdown = SysCommand(f'systemd-run --machine={self.container_name} --pty /bin/bash -c \"shutdown now\"')\n\t\twhile self.session.is_alive():\n\t\t\ttime.sleep(0.25)\n\n\t\tif shutdown.exit_code == 0:\n\t\t\tstorage['active_boot'] = None\n\t\telse:\n\t\t\traise SysCallError(f\"Could not shut down temporary boot of {self.instance}\", level=logging.ERROR, fg=\"red\")\n\n\tdef __iter__(self):\n\t\tif self.session:\n\t\t\tfor value in self.session:\n\t\t\t\tyield value\n\n\tdef __contains__(self, key: bytes):\n\t\tif self.session is None:\n\t\t\treturn False\n\n\t\treturn key in self.session\n\n\tdef is_alive(self):\n\t\tif self.session is None:\n\t\t\treturn False\n\n\t\treturn self.session.is_alive()\n\n\tdef SysCommand(self, cmd: list, *args, **kwargs):\n\t\tif cmd[0][0] != '/' and cmd[0][:2] != './':\n\t\t\t# This check is also done in SysCommand & SysCommandWorker.\n\t\t\t# However, that check is done for `machinectl` and not for our chroot command.\n\t\t\t# So this wrapper for SysCommand will do this additionally.\n\n\t\t\tcmd[0] = locate_binary(cmd[0])\n\n\t\treturn SysCommand([\"systemd-run\", f\"--machine={self.container_name}\", \"--pty\", *cmd], *args, **kwargs)\n\n\tdef SysCommandWorker(self, cmd: list, *args, **kwargs):\n\t\tif cmd[0][0] != '/' and cmd[0][:2] != './':\n\t\t\tcmd[0] = locate_binary(cmd[0])\n\n\t\treturn SysCommandWorker([\"systemd-run\", f\"--machine={self.container_name}\", \"--pty\", *cmd], *args, **kwargs)\n", "path": "archinstall/lib/systemd.py"}], "after_files": [{"content": "\"\"\"Arch Linux installer - guided, templates etc.\"\"\"\nimport urllib.error\nimport urllib.parse\nimport urllib.request\nfrom argparse import ArgumentParser\n\nfrom .lib.disk import *\nfrom .lib.exceptions import *\nfrom .lib.general import *\nfrom .lib.hardware import *\nfrom .lib.installer import __packages__, Installer\nfrom .lib.locale_helpers import *\nfrom .lib.luks import *\nfrom .lib.mirrors import *\nfrom .lib.networking import *\nfrom .lib.output import *\nfrom .lib.packages import *\nfrom .lib.profiles import *\nfrom .lib.services import *\nfrom .lib.storage import *\nfrom .lib.systemd import *\nfrom .lib.user_interaction import *\n\nparser = ArgumentParser()\n\n__version__ = \"2.3.0.dev0\"\nstorage['__version__'] = __version__\n\n\ndef initialize_arguments():\n\tconfig = {}\n\tparser.add_argument(\"--config\", nargs=\"?\", help=\"JSON configuration file or URL\")\n\tparser.add_argument(\"--creds\", nargs=\"?\", help=\"JSON credentials configuration file\")\n\tparser.add_argument(\"--silent\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"WARNING: Disables all prompts for input and confirmation. If no configuration is provided, this is ignored\")\n\tparser.add_argument(\"--dry-run\", action=\"store_true\",\n\t\t\t\t\t\thelp=\"Generates a configuration file and then exits instead of performing an installation\")\n\tparser.add_argument(\"--script\", default=\"guided\", nargs=\"?\", help=\"Script to run for installation\", type=str)\n\targs, unknowns = parser.parse_known_args()\n\tif args.config is not None:\n\t\ttry:\n\t\t\t# First, let's check if this is a URL scheme instead of a filename\n\t\t\tparsed_url = urllib.parse.urlparse(args.config)\n\n\t\t\tif not parsed_url.scheme: # The Profile was not a direct match on a remote URL, it must be a local file.\n\t\t\t\twith open(args.config) as file:\n\t\t\t\t\tconfig = json.load(file)\n\t\t\telse: # Attempt to load the configuration from the URL.\n\t\t\t\twith urllib.request.urlopen(urllib.request.Request(args.config, headers={'User-Agent': 'ArchInstall'})) as response:\n\t\t\t\t\tconfig = json.loads(response.read())\n\t\texcept Exception as e:\n\t\t\traise ValueError(f\"Could not load --config because: {e}\")\n\t\n\t\tif args.creds is not None:\n\t\t\twith open(args.creds) as file:\n\t\t\t\tconfig.update(json.load(file))\n\t\n\t\t# Installation can't be silent if config is not passed\n\t\tconfig[\"silent\"] = args.silent\n\t\n\tfor arg in unknowns:\n\t\tif '--' == arg[:2]:\n\t\t\tif '=' in arg:\n\t\t\t\tkey, val = [x.strip() for x in arg[2:].split('=', 1)]\n\t\t\telse:\n\t\t\t\tkey, val = arg[2:], True\n\t\t\tconfig[key] = val\n\t\n\tconfig[\"script\"] = args.script\n\t\n\tif args.dry_run is not None:\n\t\tconfig[\"dry-run\"] = args.dry_run\n\n\treturn config\n\n\narguments = initialize_arguments()\nstorage['arguments'] = arguments\nif arguments.get('debug'):\n\tlog(f\"Warning: --debug mode will write certain credentials to {storage['LOG_PATH']}/{storage['LOG_FILE']}!\", fg=\"red\", level=logging.WARNING)\nif arguments.get('mount-point'):\n\tstorage['MOUNT_POINT'] = arguments['mount-point']\n\nfrom .lib.plugins import plugins, load_plugin # This initiates the plugin loading ceremony\n\nif arguments.get('plugin', None):\n\tload_plugin(arguments['plugin'])\n\n# TODO: Learn the dark arts of argparse... (I summon thee dark spawn of cPython)\n\n\ndef run_as_a_module():\n\t\"\"\"\n\tSince we're running this as a 'python -m archinstall' module OR\n\ta nuitka3 compiled version of the project.\n\tThis function and the file __main__ acts as a entry point.\n\t\"\"\"\n\n\t# Add another path for finding profiles, so that list_profiles() in Script() can find guided.py, unattended.py etc.\n\tstorage['PROFILE_PATH'].append(os.path.abspath(f'{os.path.dirname(__file__)}/examples'))\n\ttry:\n\t\tscript = Script(arguments.get('script', None))\n\texcept ProfileNotFound as err:\n\t\tprint(f\"Couldn't find file: {err}\")\n\t\tsys.exit(1)\n\n\tos.chdir(os.path.abspath(os.path.dirname(__file__)))\n\n\t# Remove the example directory from the PROFILE_PATH, to avoid guided.py etc shows up in user input questions.\n\tstorage['PROFILE_PATH'].pop()\n\tscript.execute()\n", "path": "archinstall/__init__.py"}, {"content": "import logging\nimport time\nfrom .exceptions import SysCallError\nfrom .general import SysCommand, SysCommandWorker, locate_binary\nfrom .installer import Installer\nfrom .output import log\nfrom .storage import storage\n\n\nclass Ini:\n\tdef __init__(self, *args, **kwargs):\n\t\t\"\"\"\n\t\tLimited INI handler for now.\n\t\tSupports multiple keywords through dictionary list items.\n\t\t\"\"\"\n\t\tself.kwargs = kwargs\n\n\tdef __str__(self):\n\t\tresult = ''\n\t\tfirst_row_done = False\n\t\tfor top_level in self.kwargs:\n\t\t\tif first_row_done:\n\t\t\t\tresult += f\"\\n[{top_level}]\\n\"\n\t\t\telse:\n\t\t\t\tresult += f\"[{top_level}]\\n\"\n\t\t\t\tfirst_row_done = True\n\n\t\t\tfor key, val in self.kwargs[top_level].items():\n\t\t\t\tif type(val) == list:\n\t\t\t\t\tfor item in val:\n\t\t\t\t\t\tresult += f\"{key}={item}\\n\"\n\t\t\t\telse:\n\t\t\t\t\tresult += f\"{key}={val}\\n\"\n\n\t\treturn result\n\n\nclass Systemd(Ini):\n\t\"\"\"\n\tPlaceholder class to do systemd specific setups.\n\t\"\"\"\n\n\nclass Networkd(Systemd):\n\t\"\"\"\n\tPlaceholder class to do systemd-network specific setups.\n\t\"\"\"\n\n\nclass Boot:\n\tdef __init__(self, installation: Installer):\n\t\tself.instance = installation\n\t\tself.container_name = 'archinstall'\n\t\tself.session = None\n\t\tself.ready = False\n\n\tdef __enter__(self):\n\t\tif (existing_session := storage.get('active_boot', None)) and existing_session.instance != self.instance:\n\t\t\traise KeyError(\"Archinstall only supports booting up one instance, and a active session is already active and it is not this one.\")\n\n\t\tif existing_session:\n\t\t\tself.session = existing_session.session\n\t\t\tself.ready = existing_session.ready\n\t\telse:\n\t\t\tself.session = SysCommandWorker([\n\t\t\t\t'/usr/bin/systemd-nspawn',\n\t\t\t\t'-D', self.instance.target,\n\t\t\t\t'--timezone=off',\n\t\t\t\t'-b',\n\t\t\t\t'--no-pager',\n\t\t\t\t'--machine', self.container_name\n\t\t\t])\n\t\t\t# '-P' or --console=pipe could help us not having to do a bunch of os.write() calls, but instead use pipes (stdin, stdout and stderr) as usual.\n\n\t\tif not self.ready:\n\t\t\twhile self.session.is_alive():\n\t\t\t\tif b' login:' in self.session:\n\t\t\t\t\tself.ready = True\n\t\t\t\t\tbreak\n\n\t\tstorage['active_boot'] = self\n\t\treturn self\n\n\tdef __exit__(self, *args, **kwargs):\n\t\t# b''.join(sys_command('sync')) # No need to, since the underlying fs() object will call sync.\n\t\t# TODO: https://stackoverflow.com/questions/28157929/how-to-safely-handle-an-exception-inside-a-context-manager\n\n\t\tif len(args) >= 2 and args[1]:\n\t\t\tlog(args[1], level=logging.ERROR, fg='red')\n\t\t\tlog(f\"The error above occured in a temporary boot-up of the installation {self.instance}\", level=logging.ERROR, fg=\"red\")\n\n\t\tshutdown = SysCommand(f'systemd-run --machine={self.container_name} --pty /bin/bash -c \"shutdown now\"')\n\t\twhile self.session.is_alive():\n\t\t\ttime.sleep(0.25)\n\n\t\tif shutdown.exit_code == 0:\n\t\t\tstorage['active_boot'] = None\n\t\telse:\n\t\t\traise SysCallError(f\"Could not shut down temporary boot of {self.instance}: {shutdown}\", exit_code=shutdown.exit_code)\n\n\tdef __iter__(self):\n\t\tif self.session:\n\t\t\tfor value in self.session:\n\t\t\t\tyield value\n\n\tdef __contains__(self, key: bytes):\n\t\tif self.session is None:\n\t\t\treturn False\n\n\t\treturn key in self.session\n\n\tdef is_alive(self):\n\t\tif self.session is None:\n\t\t\treturn False\n\n\t\treturn self.session.is_alive()\n\n\tdef SysCommand(self, cmd: list, *args, **kwargs):\n\t\tif cmd[0][0] != '/' and cmd[0][:2] != './':\n\t\t\t# This check is also done in SysCommand & SysCommandWorker.\n\t\t\t# However, that check is done for `machinectl` and not for our chroot command.\n\t\t\t# So this wrapper for SysCommand will do this additionally.\n\n\t\t\tcmd[0] = locate_binary(cmd[0])\n\n\t\treturn SysCommand([\"systemd-run\", f\"--machine={self.container_name}\", \"--pty\", *cmd], *args, **kwargs)\n\n\tdef SysCommandWorker(self, cmd: list, *args, **kwargs):\n\t\tif cmd[0][0] != '/' and cmd[0][:2] != './':\n\t\t\tcmd[0] = locate_binary(cmd[0])\n\n\t\treturn SysCommandWorker([\"systemd-run\", f\"--machine={self.container_name}\", \"--pty\", *cmd], *args, **kwargs)\n", "path": "archinstall/lib/systemd.py"}]}
| 2,880 | 402 |
gh_patches_debug_4174
|
rasdani/github-patches
|
git_diff
|
aimhubio__aim-2577
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Detection of Jax Arrays Breaks on Jax=0.4.*
The detection for jax arrays here https://github.com/aimhubio/aim/blob/285a09fefbf25d418e00bc305e9a1357d6343d3c/aim/sdk/num_utils.py#L66 is broken in Jax 0.4.* since `DeviceArray` was renamed to `Array`. The simple fix to support the prior/current version would be to check for either `DeviceArray` or `Array`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aim/sdk/num_utils.py`
Content:
```
1 def get_inst_type_str(inst):
2 """
3 Get instance type and class type full names
4 """
5 obj_name = obj_module = obj_cls_name = obj_cls_module = ''
6
7 if hasattr(inst, '__name__'):
8 obj_name = inst.__name__
9 if hasattr(inst, '__module__'):
10 obj_module = inst.__module__
11 if hasattr(inst, '__class__'):
12 if hasattr(inst.__class__, '__name__'):
13 obj_cls_name = inst.__class__.__name__
14 if hasattr(inst.__class__, '__module__'):
15 obj_cls_module = inst.__class__.__module__
16
17 obj_full = '{}.{}'.format(obj_name, obj_module)
18 obj_cls_full = '{}.{}'.format(obj_cls_name, obj_cls_module)
19
20 return obj_full, obj_cls_full
21
22
23 def get_inst_base_types(inst):
24 """
25 Get instance and it's base classes types
26 """
27 bases_types = []
28 for b in inst.__class__.__bases__:
29 b_type, b_cls_type = get_inst_type_str(b)
30 bases_types.append(b_type)
31 bases_types.append(b_cls_type)
32 return bases_types
33
34
35 def inst_has_typename(inst, types):
36 """
37 Return `True` if the instance is created from class
38 which has base that matches passed `types`
39 """
40 inst_type, inst_cls_type = get_inst_type_str(inst)
41 inst_types = [inst_type, inst_cls_type] + get_inst_base_types(inst)
42
43 for i in inst_types:
44 found = True
45 for t in types:
46 if i.find(t) == -1:
47 found = False
48 break
49 if found:
50 return True
51
52 return False
53
54
55 def is_pytorch_tensor(inst):
56 """
57 Check whether `inst` is instance of pytorch tensor
58 """
59 return inst_has_typename(inst, ['torch', 'Tensor'])
60
61
62 def is_tf_tensor(inst):
63 return inst_has_typename(inst, ['tensorflow', 'Tensor'])
64
65
66 def is_jax_device_array(inst):
67 """
68 Check whether `inst` is instance of jax device array
69 """
70 return inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray'])
71
72
73 def is_numpy_array(inst):
74 """
75 Check whether `inst` is instance of numpy array
76 """
77 return inst_has_typename(inst, ['numpy', 'ndarray'])
78
79
80 def is_numpy_number(inst):
81 """
82 Check whether `inst` is numpy number
83 """
84
85 return inst_has_typename(inst, ['numpy'])
86
87
88 def is_py_number(value):
89 return isinstance(value, (int, float))
90
91
92 def is_number(value):
93 """
94 Checks if the given value is a number
95 """
96 if is_py_number(value):
97 return True
98
99 if is_numpy_array(value):
100 return True
101
102 if is_numpy_number(value):
103 return True
104
105 if is_jax_device_array(value):
106 return True
107
108 if is_pytorch_tensor(value):
109 return True
110
111 if is_tf_tensor(value):
112 return True
113
114 return False
115
116
117 def convert_to_py_number(value) -> object:
118 """
119 Converts numpy objects or tensors to python number types
120 """
121 if isinstance(value, int):
122 return int(value)
123
124 if isinstance(value, float):
125 return float(value)
126
127 if is_numpy_array(value):
128 return value.item()
129
130 if is_numpy_number(value):
131 return value.item()
132
133 if is_jax_device_array(value):
134 return value.item()
135
136 if is_pytorch_tensor(value):
137 return value.item()
138
139 if is_tf_tensor(value):
140 return value.numpy().item()
141
142 raise ValueError('not a number')
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/aim/sdk/num_utils.py b/aim/sdk/num_utils.py
--- a/aim/sdk/num_utils.py
+++ b/aim/sdk/num_utils.py
@@ -67,7 +67,11 @@
"""
Check whether `inst` is instance of jax device array
"""
- return inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray'])
+ if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'Array']):
+ return True
+ if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray']):
+ return True
+ return False
def is_numpy_array(inst):
|
{"golden_diff": "diff --git a/aim/sdk/num_utils.py b/aim/sdk/num_utils.py\n--- a/aim/sdk/num_utils.py\n+++ b/aim/sdk/num_utils.py\n@@ -67,7 +67,11 @@\n \"\"\"\n Check whether `inst` is instance of jax device array\n \"\"\"\n- return inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray'])\n+ if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'Array']):\n+ return True\n+ if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray']):\n+ return True\n+ return False\n \n \n def is_numpy_array(inst):\n", "issue": "Detection of Jax Arrays Breaks on Jax=0.4.*\nThe detection for jax arrays here https://github.com/aimhubio/aim/blob/285a09fefbf25d418e00bc305e9a1357d6343d3c/aim/sdk/num_utils.py#L66 is broken in Jax 0.4.* since `DeviceArray` was renamed to `Array`. The simple fix to support the prior/current version would be to check for either `DeviceArray` or `Array`\n", "before_files": [{"content": "def get_inst_type_str(inst):\n \"\"\"\n Get instance type and class type full names\n \"\"\"\n obj_name = obj_module = obj_cls_name = obj_cls_module = ''\n\n if hasattr(inst, '__name__'):\n obj_name = inst.__name__\n if hasattr(inst, '__module__'):\n obj_module = inst.__module__\n if hasattr(inst, '__class__'):\n if hasattr(inst.__class__, '__name__'):\n obj_cls_name = inst.__class__.__name__\n if hasattr(inst.__class__, '__module__'):\n obj_cls_module = inst.__class__.__module__\n\n obj_full = '{}.{}'.format(obj_name, obj_module)\n obj_cls_full = '{}.{}'.format(obj_cls_name, obj_cls_module)\n\n return obj_full, obj_cls_full\n\n\ndef get_inst_base_types(inst):\n \"\"\"\n Get instance and it's base classes types\n \"\"\"\n bases_types = []\n for b in inst.__class__.__bases__:\n b_type, b_cls_type = get_inst_type_str(b)\n bases_types.append(b_type)\n bases_types.append(b_cls_type)\n return bases_types\n\n\ndef inst_has_typename(inst, types):\n \"\"\"\n Return `True` if the instance is created from class\n which has base that matches passed `types`\n \"\"\"\n inst_type, inst_cls_type = get_inst_type_str(inst)\n inst_types = [inst_type, inst_cls_type] + get_inst_base_types(inst)\n\n for i in inst_types:\n found = True\n for t in types:\n if i.find(t) == -1:\n found = False\n break\n if found:\n return True\n\n return False\n\n\ndef is_pytorch_tensor(inst):\n \"\"\"\n Check whether `inst` is instance of pytorch tensor\n \"\"\"\n return inst_has_typename(inst, ['torch', 'Tensor'])\n\n\ndef is_tf_tensor(inst):\n return inst_has_typename(inst, ['tensorflow', 'Tensor'])\n\n\ndef is_jax_device_array(inst):\n \"\"\"\n Check whether `inst` is instance of jax device array\n \"\"\"\n return inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray'])\n\n\ndef is_numpy_array(inst):\n \"\"\"\n Check whether `inst` is instance of numpy array\n \"\"\"\n return inst_has_typename(inst, ['numpy', 'ndarray'])\n\n\ndef is_numpy_number(inst):\n \"\"\"\n Check whether `inst` is numpy number\n \"\"\"\n\n return inst_has_typename(inst, ['numpy'])\n\n\ndef is_py_number(value):\n return isinstance(value, (int, float))\n\n\ndef is_number(value):\n \"\"\"\n Checks if the given value is a number\n \"\"\"\n if is_py_number(value):\n return True\n\n if is_numpy_array(value):\n return True\n\n if is_numpy_number(value):\n return True\n\n if is_jax_device_array(value):\n return True\n\n if is_pytorch_tensor(value):\n return True\n\n if is_tf_tensor(value):\n return True\n\n return False\n\n\ndef convert_to_py_number(value) -> object:\n \"\"\"\n Converts numpy objects or tensors to python number types\n \"\"\"\n if isinstance(value, int):\n return int(value)\n\n if isinstance(value, float):\n return float(value)\n\n if is_numpy_array(value):\n return value.item()\n\n if is_numpy_number(value):\n return value.item()\n\n if is_jax_device_array(value):\n return value.item()\n\n if is_pytorch_tensor(value):\n return value.item()\n\n if is_tf_tensor(value):\n return value.numpy().item()\n\n raise ValueError('not a number')\n", "path": "aim/sdk/num_utils.py"}], "after_files": [{"content": "def get_inst_type_str(inst):\n \"\"\"\n Get instance type and class type full names\n \"\"\"\n obj_name = obj_module = obj_cls_name = obj_cls_module = ''\n\n if hasattr(inst, '__name__'):\n obj_name = inst.__name__\n if hasattr(inst, '__module__'):\n obj_module = inst.__module__\n if hasattr(inst, '__class__'):\n if hasattr(inst.__class__, '__name__'):\n obj_cls_name = inst.__class__.__name__\n if hasattr(inst.__class__, '__module__'):\n obj_cls_module = inst.__class__.__module__\n\n obj_full = '{}.{}'.format(obj_name, obj_module)\n obj_cls_full = '{}.{}'.format(obj_cls_name, obj_cls_module)\n\n return obj_full, obj_cls_full\n\n\ndef get_inst_base_types(inst):\n \"\"\"\n Get instance and it's base classes types\n \"\"\"\n bases_types = []\n for b in inst.__class__.__bases__:\n b_type, b_cls_type = get_inst_type_str(b)\n bases_types.append(b_type)\n bases_types.append(b_cls_type)\n return bases_types\n\n\ndef inst_has_typename(inst, types):\n \"\"\"\n Return `True` if the instance is created from class\n which has base that matches passed `types`\n \"\"\"\n inst_type, inst_cls_type = get_inst_type_str(inst)\n inst_types = [inst_type, inst_cls_type] + get_inst_base_types(inst)\n\n for i in inst_types:\n found = True\n for t in types:\n if i.find(t) == -1:\n found = False\n break\n if found:\n return True\n\n return False\n\n\ndef is_pytorch_tensor(inst):\n \"\"\"\n Check whether `inst` is instance of pytorch tensor\n \"\"\"\n return inst_has_typename(inst, ['torch', 'Tensor'])\n\n\ndef is_tf_tensor(inst):\n return inst_has_typename(inst, ['tensorflow', 'Tensor'])\n\n\ndef is_jax_device_array(inst):\n \"\"\"\n Check whether `inst` is instance of jax device array\n \"\"\"\n if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'Array']):\n return True\n if inst_has_typename(inst, ['jaxlib', 'xla_extension', 'DeviceArray']):\n return True\n return False\n\n\ndef is_numpy_array(inst):\n \"\"\"\n Check whether `inst` is instance of numpy array\n \"\"\"\n return inst_has_typename(inst, ['numpy', 'ndarray'])\n\n\ndef is_numpy_number(inst):\n \"\"\"\n Check whether `inst` is numpy number\n \"\"\"\n\n return inst_has_typename(inst, ['numpy'])\n\n\ndef is_py_number(value):\n return isinstance(value, (int, float))\n\n\ndef is_number(value):\n \"\"\"\n Checks if the given value is a number\n \"\"\"\n if is_py_number(value):\n return True\n\n if is_numpy_array(value):\n return True\n\n if is_numpy_number(value):\n return True\n\n if is_jax_device_array(value):\n return True\n\n if is_pytorch_tensor(value):\n return True\n\n if is_tf_tensor(value):\n return True\n\n return False\n\n\ndef convert_to_py_number(value) -> object:\n \"\"\"\n Converts numpy objects or tensors to python number types\n \"\"\"\n if isinstance(value, int):\n return int(value)\n\n if isinstance(value, float):\n return float(value)\n\n if is_numpy_array(value):\n return value.item()\n\n if is_numpy_number(value):\n return value.item()\n\n if is_jax_device_array(value):\n return value.item()\n\n if is_pytorch_tensor(value):\n return value.item()\n\n if is_tf_tensor(value):\n return value.numpy().item()\n\n raise ValueError('not a number')\n", "path": "aim/sdk/num_utils.py"}]}
| 1,500 | 158 |
gh_patches_debug_19053
|
rasdani/github-patches
|
git_diff
|
SciTools__cartopy-582
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: 'LineString' object has no attribute 'exterior'
Running the first example from #13 prints this (snipped) traceback:
```
File ".../matplotlib/transforms.py", line 2227, in transform_path_non_affine
return self._a.transform_path_non_affine(path)
File ".../Cartopy-0.12.x-py2.7-linux-x86_64.egg/cartopy/mpl/geoaxes.py", line 169, in transform_path_non_affine
getattr(self, 'force_path_ccw', False))
File ".../Cartopy-0.12.x-py2.7-linux-x86_64.egg/cartopy/mpl/patch.py", line 226, in path_to_geos
if force_ccw and not geom.exterior.is_ccw:
AttributeError: 'LineString' object has no attribute 'exterior'
```
I'm not sure if this can be triggered by other (i.e., not otherwise known to be broken) usage.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/cartopy/mpl/patch.py`
Content:
```
1 # (C) British Crown Copyright 2011 - 2014, Met Office
2 #
3 # This file is part of cartopy.
4 #
5 # cartopy is free software: you can redistribute it and/or modify it under
6 # the terms of the GNU Lesser General Public License as published by the
7 # Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # cartopy is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU Lesser General Public License for more details.
14 #
15 # You should have received a copy of the GNU Lesser General Public License
16 # along with cartopy. If not, see <http://www.gnu.org/licenses/>.
17 """
18 Provides shapely geometry <-> matplotlib path support.
19
20
21 See also `Shapely Geometric Objects <see_also_shapely>`_
22 and `Matplotlib Path API <http://matplotlib.org/api/path_api.html>`_.
23
24 .. see_also_shapely:
25 http://toblerity.github.com/shapely/manual.html#geometric-objects
26
27 """
28
29 from __future__ import (absolute_import, division, print_function)
30
31 import numpy as np
32 import matplotlib.path
33 from matplotlib.path import Path
34 import shapely
35 from shapely.geometry.collection import GeometryCollection
36 from shapely.geometry.linestring import LineString
37 from shapely.geometry.point import Point
38 from shapely.geometry.polygon import Polygon
39 from shapely.geometry.multilinestring import MultiLineString
40 from shapely.geometry.multipoint import MultiPoint
41 from shapely.geometry.multipolygon import MultiPolygon
42
43
44 def geos_to_path(shape):
45 """
46 Creates a list of :class:`matplotlib.path.Path` objects that describe
47 a shape.
48
49 Args:
50
51 * shape
52 A list, tuple or single instance of any of the following
53 types: :class:`shapely.geometry.point.Point`,
54 :class:`shapely.geometry.linestring.LineString`,
55 :class:`shapely.geometry.polygon.Polygon`,
56 :class:`shapely.geometry.multipoint.MultiPoint`,
57 :class:`shapely.geometry.multipolygon.MultiPolygon`,
58 :class:`shapely.geometry.multilinestring.MultiLineString`,
59 :class:`shapely.geometry.collection.GeometryCollection`,
60 or any type with a _as_mpl_path() method.
61
62 Returns:
63 A list of :class:`matplotlib.path.Path` objects.
64
65 """
66 if isinstance(shape, (list, tuple)):
67 paths = []
68 for shp in shape:
69 paths.extend(geos_to_path(shp))
70 return paths
71
72 if isinstance(shape, (LineString, Point)):
73 return [Path(np.vstack(shape.xy).T)]
74 elif isinstance(shape, Polygon):
75 def poly_codes(poly):
76 codes = np.ones(len(poly.xy[0])) * Path.LINETO
77 codes[0] = Path.MOVETO
78 return codes
79 if shape.is_empty:
80 return []
81 vertices = np.concatenate([np.array(shape.exterior.xy)] +
82 [np.array(ring.xy) for ring in
83 shape.interiors], 1).T
84 codes = np.concatenate([poly_codes(shape.exterior)] +
85 [poly_codes(ring) for ring in shape.interiors])
86 return [Path(vertices, codes)]
87 elif isinstance(shape, (MultiPolygon, GeometryCollection, MultiLineString,
88 MultiPoint)):
89 paths = []
90 for geom in shape.geoms:
91 paths.extend(geos_to_path(geom))
92 return paths
93 elif hasattr(shape, '_as_mpl_path'):
94 vertices, codes = shape._as_mpl_path()
95 return [Path(vertices, codes)]
96 else:
97 raise ValueError('Unsupported shape type {}.'.format(type(shape)))
98
99
100 def path_segments(path, transform=None, remove_nans=False, clip=None,
101 quantize=False, simplify=False, curves=False,
102 stroke_width=1.0, snap=False):
103 """
104 Creates an array of vertices and a corresponding array of codes from a
105 :class:`matplotlib.path.Path`.
106
107 Args:
108
109 * path
110 A :class:`matplotlib.path.Path` instance.
111
112 Kwargs:
113 See :func:`matplotlib.path.iter_segments` for details of the keyword
114 arguments.
115
116 Returns:
117 A (vertices, codes) tuple, where vertices is a numpy array of
118 coordinates, and codes is a numpy array of matplotlib path codes.
119 See :class:`matplotlib.path.Path` for information on the types of
120 codes and their meanings.
121
122 """
123 # XXX assigned to avoid a ValueError inside the mpl C code...
124 a = transform, remove_nans, clip, quantize, simplify, curves
125
126 # Series of cleanups and conversions to the path e.g. it
127 # can convert curved segments to line segments.
128 vertices, codes = matplotlib.path.cleanup_path(path, transform,
129 remove_nans, clip,
130 snap, stroke_width,
131 simplify, curves)
132
133 # Remove the final vertex (with code 0)
134 return vertices[:-1, :], codes[:-1]
135
136
137 # Matplotlib v1.3+ deprecates the use of matplotlib.path.cleanup_path. Instead
138 # there is a method on a Path instance to simplify this.
139 if hasattr(matplotlib.path.Path, 'cleaned'):
140 _path_segments_doc = path_segments.__doc__
141
142 def path_segments(path, **kwargs):
143 pth = path.cleaned(**kwargs)
144 return pth.vertices[:-1, :], pth.codes[:-1]
145
146 path_segments.__doc__ = _path_segments_doc
147
148
149 def path_to_geos(path, force_ccw=False):
150 """
151 Creates a list of Shapely geometric objects from a
152 :class:`matplotlib.path.Path`.
153
154 Args:
155
156 * path
157 A :class:`matplotlib.path.Path` instance.
158
159 Kwargs:
160
161 * force_ccw
162 Boolean flag determining whether the path can be inverted to enforce
163 ccw.
164
165 Returns:
166 A list of :class:`shapely.geometry.polygon.Polygon`,
167 :class:`shapely.geometry.linestring.LineString` and/or
168 :class:`shapely.geometry.multilinestring.MultiLineString` instances.
169
170 """
171 # Convert path into numpy array of vertices (and associated codes)
172 path_verts, path_codes = path_segments(path, curves=False)
173
174 # Split into subarrays such that each subarray consists of connected
175 # line segments based on the start of each one being marked by a
176 # matplotlib MOVETO code.
177 verts_split_inds = np.where(path_codes == Path.MOVETO)[0]
178 verts_split = np.split(path_verts, verts_split_inds)
179 codes_split = np.split(path_codes, verts_split_inds)
180
181 # Iterate through the vertices generating a list of
182 # (external_geom, [internal_polygons]) tuples.
183 collection = []
184 for path_verts, path_codes in zip(verts_split, codes_split):
185 if len(path_verts) == 0:
186 continue
187
188 # XXX A path can be given which does not end with close poly, in that
189 # situation, we have to guess?
190 # XXX Implement a point
191 if (path_verts.shape[0] > 2 and
192 (path_codes[-1] == Path.CLOSEPOLY or
193 all(path_verts[0, :] == path_verts[-1, :]))):
194 if path_codes[-1] == Path.CLOSEPOLY:
195 geom = Polygon(path_verts[:-1, :])
196 else:
197 geom = Polygon(path_verts)
198 else:
199 geom = LineString(path_verts)
200
201 # If geom is a Polygon and is contained within the last geom in
202 # collection, add it to its list of internal polygons, otherwise
203 # simple append it as a new external geom.
204 if geom.is_empty:
205 pass
206 elif (len(collection) > 0 and
207 isinstance(collection[-1][0], Polygon) and
208 isinstance(geom, Polygon) and
209 collection[-1][0].contains(geom.exterior)):
210 collection[-1][1].append(geom.exterior)
211 else:
212 collection.append((geom, []))
213
214 # Convert each (external_geom, [internal_polygons]) pair into a
215 # a shapely Polygon that encapsulates the internal polygons, if the
216 # external geom is a LineSting leave it alone.
217 geom_collection = []
218 for external_geom, internal_polys in collection:
219 if internal_polys:
220 # XXX worry about islands within lakes
221 geom = Polygon(external_geom.exterior, internal_polys)
222 else:
223 geom = external_geom
224
225 # Correctly orientate the polygon (ccw)
226 if force_ccw and not geom.exterior.is_ccw:
227 geom = shapely.geometry.polygon.orient(geom)
228
229 geom_collection.append(geom)
230
231 # If the geom_collection only contains LineStrings combine them
232 # into a single MultiLinestring.
233 if geom_collection and all(isinstance(geom, LineString) for
234 geom in geom_collection):
235 geom_collection = [MultiLineString(geom_collection)]
236
237 # Remove any zero area Polygons
238 not_zero_poly = lambda geom: ((isinstance(geom, Polygon) and
239 not geom._is_empty and geom.area != 0) or
240 not isinstance(geom, Polygon))
241 result = list(filter(not_zero_poly, geom_collection))
242
243 return result
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/cartopy/mpl/patch.py b/lib/cartopy/mpl/patch.py
--- a/lib/cartopy/mpl/patch.py
+++ b/lib/cartopy/mpl/patch.py
@@ -213,7 +213,7 @@
# Convert each (external_geom, [internal_polygons]) pair into a
# a shapely Polygon that encapsulates the internal polygons, if the
- # external geom is a LineSting leave it alone.
+ # external geom is a LineString leave it alone.
geom_collection = []
for external_geom, internal_polys in collection:
if internal_polys:
@@ -223,8 +223,9 @@
geom = external_geom
# Correctly orientate the polygon (ccw)
- if force_ccw and not geom.exterior.is_ccw:
- geom = shapely.geometry.polygon.orient(geom)
+ if isinstance(geom, Polygon):
+ if force_ccw and not geom.exterior.is_ccw:
+ geom = shapely.geometry.polygon.orient(geom)
geom_collection.append(geom)
|
{"golden_diff": "diff --git a/lib/cartopy/mpl/patch.py b/lib/cartopy/mpl/patch.py\n--- a/lib/cartopy/mpl/patch.py\n+++ b/lib/cartopy/mpl/patch.py\n@@ -213,7 +213,7 @@\n \n # Convert each (external_geom, [internal_polygons]) pair into a\n # a shapely Polygon that encapsulates the internal polygons, if the\n- # external geom is a LineSting leave it alone.\n+ # external geom is a LineString leave it alone.\n geom_collection = []\n for external_geom, internal_polys in collection:\n if internal_polys:\n@@ -223,8 +223,9 @@\n geom = external_geom\n \n # Correctly orientate the polygon (ccw)\n- if force_ccw and not geom.exterior.is_ccw:\n- geom = shapely.geometry.polygon.orient(geom)\n+ if isinstance(geom, Polygon):\n+ if force_ccw and not geom.exterior.is_ccw:\n+ geom = shapely.geometry.polygon.orient(geom)\n \n geom_collection.append(geom)\n", "issue": "AttributeError: 'LineString' object has no attribute 'exterior'\nRunning the first example from #13 prints this (snipped) traceback:\n\n```\n File \".../matplotlib/transforms.py\", line 2227, in transform_path_non_affine\n return self._a.transform_path_non_affine(path)\n File \".../Cartopy-0.12.x-py2.7-linux-x86_64.egg/cartopy/mpl/geoaxes.py\", line 169, in transform_path_non_affine\n getattr(self, 'force_path_ccw', False))\n File \".../Cartopy-0.12.x-py2.7-linux-x86_64.egg/cartopy/mpl/patch.py\", line 226, in path_to_geos\n if force_ccw and not geom.exterior.is_ccw:\nAttributeError: 'LineString' object has no attribute 'exterior'\n```\n\nI'm not sure if this can be triggered by other (i.e., not otherwise known to be broken) usage.\n\n", "before_files": [{"content": "# (C) British Crown Copyright 2011 - 2014, Met Office\n#\n# This file is part of cartopy.\n#\n# cartopy is free software: you can redistribute it and/or modify it under\n# the terms of the GNU Lesser General Public License as published by the\n# Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# cartopy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public License\n# along with cartopy. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\nProvides shapely geometry <-> matplotlib path support.\n\n\nSee also `Shapely Geometric Objects <see_also_shapely>`_\nand `Matplotlib Path API <http://matplotlib.org/api/path_api.html>`_.\n\n.. see_also_shapely:\n http://toblerity.github.com/shapely/manual.html#geometric-objects\n\n\"\"\"\n\nfrom __future__ import (absolute_import, division, print_function)\n\nimport numpy as np\nimport matplotlib.path\nfrom matplotlib.path import Path\nimport shapely\nfrom shapely.geometry.collection import GeometryCollection\nfrom shapely.geometry.linestring import LineString\nfrom shapely.geometry.point import Point\nfrom shapely.geometry.polygon import Polygon\nfrom shapely.geometry.multilinestring import MultiLineString\nfrom shapely.geometry.multipoint import MultiPoint\nfrom shapely.geometry.multipolygon import MultiPolygon\n\n\ndef geos_to_path(shape):\n \"\"\"\n Creates a list of :class:`matplotlib.path.Path` objects that describe\n a shape.\n\n Args:\n\n * shape\n A list, tuple or single instance of any of the following\n types: :class:`shapely.geometry.point.Point`,\n :class:`shapely.geometry.linestring.LineString`,\n :class:`shapely.geometry.polygon.Polygon`,\n :class:`shapely.geometry.multipoint.MultiPoint`,\n :class:`shapely.geometry.multipolygon.MultiPolygon`,\n :class:`shapely.geometry.multilinestring.MultiLineString`,\n :class:`shapely.geometry.collection.GeometryCollection`,\n or any type with a _as_mpl_path() method.\n\n Returns:\n A list of :class:`matplotlib.path.Path` objects.\n\n \"\"\"\n if isinstance(shape, (list, tuple)):\n paths = []\n for shp in shape:\n paths.extend(geos_to_path(shp))\n return paths\n\n if isinstance(shape, (LineString, Point)):\n return [Path(np.vstack(shape.xy).T)]\n elif isinstance(shape, Polygon):\n def poly_codes(poly):\n codes = np.ones(len(poly.xy[0])) * Path.LINETO\n codes[0] = Path.MOVETO\n return codes\n if shape.is_empty:\n return []\n vertices = np.concatenate([np.array(shape.exterior.xy)] +\n [np.array(ring.xy) for ring in\n shape.interiors], 1).T\n codes = np.concatenate([poly_codes(shape.exterior)] +\n [poly_codes(ring) for ring in shape.interiors])\n return [Path(vertices, codes)]\n elif isinstance(shape, (MultiPolygon, GeometryCollection, MultiLineString,\n MultiPoint)):\n paths = []\n for geom in shape.geoms:\n paths.extend(geos_to_path(geom))\n return paths\n elif hasattr(shape, '_as_mpl_path'):\n vertices, codes = shape._as_mpl_path()\n return [Path(vertices, codes)]\n else:\n raise ValueError('Unsupported shape type {}.'.format(type(shape)))\n\n\ndef path_segments(path, transform=None, remove_nans=False, clip=None,\n quantize=False, simplify=False, curves=False,\n stroke_width=1.0, snap=False):\n \"\"\"\n Creates an array of vertices and a corresponding array of codes from a\n :class:`matplotlib.path.Path`.\n\n Args:\n\n * path\n A :class:`matplotlib.path.Path` instance.\n\n Kwargs:\n See :func:`matplotlib.path.iter_segments` for details of the keyword\n arguments.\n\n Returns:\n A (vertices, codes) tuple, where vertices is a numpy array of\n coordinates, and codes is a numpy array of matplotlib path codes.\n See :class:`matplotlib.path.Path` for information on the types of\n codes and their meanings.\n\n \"\"\"\n # XXX assigned to avoid a ValueError inside the mpl C code...\n a = transform, remove_nans, clip, quantize, simplify, curves\n\n # Series of cleanups and conversions to the path e.g. it\n # can convert curved segments to line segments.\n vertices, codes = matplotlib.path.cleanup_path(path, transform,\n remove_nans, clip,\n snap, stroke_width,\n simplify, curves)\n\n # Remove the final vertex (with code 0)\n return vertices[:-1, :], codes[:-1]\n\n\n# Matplotlib v1.3+ deprecates the use of matplotlib.path.cleanup_path. Instead\n# there is a method on a Path instance to simplify this.\nif hasattr(matplotlib.path.Path, 'cleaned'):\n _path_segments_doc = path_segments.__doc__\n\n def path_segments(path, **kwargs):\n pth = path.cleaned(**kwargs)\n return pth.vertices[:-1, :], pth.codes[:-1]\n\n path_segments.__doc__ = _path_segments_doc\n\n\ndef path_to_geos(path, force_ccw=False):\n \"\"\"\n Creates a list of Shapely geometric objects from a\n :class:`matplotlib.path.Path`.\n\n Args:\n\n * path\n A :class:`matplotlib.path.Path` instance.\n\n Kwargs:\n\n * force_ccw\n Boolean flag determining whether the path can be inverted to enforce\n ccw.\n\n Returns:\n A list of :class:`shapely.geometry.polygon.Polygon`,\n :class:`shapely.geometry.linestring.LineString` and/or\n :class:`shapely.geometry.multilinestring.MultiLineString` instances.\n\n \"\"\"\n # Convert path into numpy array of vertices (and associated codes)\n path_verts, path_codes = path_segments(path, curves=False)\n\n # Split into subarrays such that each subarray consists of connected\n # line segments based on the start of each one being marked by a\n # matplotlib MOVETO code.\n verts_split_inds = np.where(path_codes == Path.MOVETO)[0]\n verts_split = np.split(path_verts, verts_split_inds)\n codes_split = np.split(path_codes, verts_split_inds)\n\n # Iterate through the vertices generating a list of\n # (external_geom, [internal_polygons]) tuples.\n collection = []\n for path_verts, path_codes in zip(verts_split, codes_split):\n if len(path_verts) == 0:\n continue\n\n # XXX A path can be given which does not end with close poly, in that\n # situation, we have to guess?\n # XXX Implement a point\n if (path_verts.shape[0] > 2 and\n (path_codes[-1] == Path.CLOSEPOLY or\n all(path_verts[0, :] == path_verts[-1, :]))):\n if path_codes[-1] == Path.CLOSEPOLY:\n geom = Polygon(path_verts[:-1, :])\n else:\n geom = Polygon(path_verts)\n else:\n geom = LineString(path_verts)\n\n # If geom is a Polygon and is contained within the last geom in\n # collection, add it to its list of internal polygons, otherwise\n # simple append it as a new external geom.\n if geom.is_empty:\n pass\n elif (len(collection) > 0 and\n isinstance(collection[-1][0], Polygon) and\n isinstance(geom, Polygon) and\n collection[-1][0].contains(geom.exterior)):\n collection[-1][1].append(geom.exterior)\n else:\n collection.append((geom, []))\n\n # Convert each (external_geom, [internal_polygons]) pair into a\n # a shapely Polygon that encapsulates the internal polygons, if the\n # external geom is a LineSting leave it alone.\n geom_collection = []\n for external_geom, internal_polys in collection:\n if internal_polys:\n # XXX worry about islands within lakes\n geom = Polygon(external_geom.exterior, internal_polys)\n else:\n geom = external_geom\n\n # Correctly orientate the polygon (ccw)\n if force_ccw and not geom.exterior.is_ccw:\n geom = shapely.geometry.polygon.orient(geom)\n\n geom_collection.append(geom)\n\n # If the geom_collection only contains LineStrings combine them\n # into a single MultiLinestring.\n if geom_collection and all(isinstance(geom, LineString) for\n geom in geom_collection):\n geom_collection = [MultiLineString(geom_collection)]\n\n # Remove any zero area Polygons\n not_zero_poly = lambda geom: ((isinstance(geom, Polygon) and\n not geom._is_empty and geom.area != 0) or\n not isinstance(geom, Polygon))\n result = list(filter(not_zero_poly, geom_collection))\n\n return result\n", "path": "lib/cartopy/mpl/patch.py"}], "after_files": [{"content": "# (C) British Crown Copyright 2011 - 2014, Met Office\n#\n# This file is part of cartopy.\n#\n# cartopy is free software: you can redistribute it and/or modify it under\n# the terms of the GNU Lesser General Public License as published by the\n# Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# cartopy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public License\n# along with cartopy. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\nProvides shapely geometry <-> matplotlib path support.\n\n\nSee also `Shapely Geometric Objects <see_also_shapely>`_\nand `Matplotlib Path API <http://matplotlib.org/api/path_api.html>`_.\n\n.. see_also_shapely:\n http://toblerity.github.com/shapely/manual.html#geometric-objects\n\n\"\"\"\n\nfrom __future__ import (absolute_import, division, print_function)\n\nimport numpy as np\nimport matplotlib.path\nfrom matplotlib.path import Path\nimport shapely\nfrom shapely.geometry.collection import GeometryCollection\nfrom shapely.geometry.linestring import LineString\nfrom shapely.geometry.point import Point\nfrom shapely.geometry.polygon import Polygon\nfrom shapely.geometry.multilinestring import MultiLineString\nfrom shapely.geometry.multipoint import MultiPoint\nfrom shapely.geometry.multipolygon import MultiPolygon\n\n\ndef geos_to_path(shape):\n \"\"\"\n Creates a list of :class:`matplotlib.path.Path` objects that describe\n a shape.\n\n Args:\n\n * shape\n A list, tuple or single instance of any of the following\n types: :class:`shapely.geometry.point.Point`,\n :class:`shapely.geometry.linestring.LineString`,\n :class:`shapely.geometry.polygon.Polygon`,\n :class:`shapely.geometry.multipoint.MultiPoint`,\n :class:`shapely.geometry.multipolygon.MultiPolygon`,\n :class:`shapely.geometry.multilinestring.MultiLineString`,\n :class:`shapely.geometry.collection.GeometryCollection`,\n or any type with a _as_mpl_path() method.\n\n Returns:\n A list of :class:`matplotlib.path.Path` objects.\n\n \"\"\"\n if isinstance(shape, (list, tuple)):\n paths = []\n for shp in shape:\n paths.extend(geos_to_path(shp))\n return paths\n\n if isinstance(shape, (LineString, Point)):\n return [Path(np.vstack(shape.xy).T)]\n elif isinstance(shape, Polygon):\n def poly_codes(poly):\n codes = np.ones(len(poly.xy[0])) * Path.LINETO\n codes[0] = Path.MOVETO\n return codes\n if shape.is_empty:\n return []\n vertices = np.concatenate([np.array(shape.exterior.xy)] +\n [np.array(ring.xy) for ring in\n shape.interiors], 1).T\n codes = np.concatenate([poly_codes(shape.exterior)] +\n [poly_codes(ring) for ring in shape.interiors])\n return [Path(vertices, codes)]\n elif isinstance(shape, (MultiPolygon, GeometryCollection, MultiLineString,\n MultiPoint)):\n paths = []\n for geom in shape.geoms:\n paths.extend(geos_to_path(geom))\n return paths\n elif hasattr(shape, '_as_mpl_path'):\n vertices, codes = shape._as_mpl_path()\n return [Path(vertices, codes)]\n else:\n raise ValueError('Unsupported shape type {}.'.format(type(shape)))\n\n\ndef path_segments(path, transform=None, remove_nans=False, clip=None,\n quantize=False, simplify=False, curves=False,\n stroke_width=1.0, snap=False):\n \"\"\"\n Creates an array of vertices and a corresponding array of codes from a\n :class:`matplotlib.path.Path`.\n\n Args:\n\n * path\n A :class:`matplotlib.path.Path` instance.\n\n Kwargs:\n See :func:`matplotlib.path.iter_segments` for details of the keyword\n arguments.\n\n Returns:\n A (vertices, codes) tuple, where vertices is a numpy array of\n coordinates, and codes is a numpy array of matplotlib path codes.\n See :class:`matplotlib.path.Path` for information on the types of\n codes and their meanings.\n\n \"\"\"\n # XXX assigned to avoid a ValueError inside the mpl C code...\n a = transform, remove_nans, clip, quantize, simplify, curves\n\n # Series of cleanups and conversions to the path e.g. it\n # can convert curved segments to line segments.\n vertices, codes = matplotlib.path.cleanup_path(path, transform,\n remove_nans, clip,\n snap, stroke_width,\n simplify, curves)\n\n # Remove the final vertex (with code 0)\n return vertices[:-1, :], codes[:-1]\n\n\n# Matplotlib v1.3+ deprecates the use of matplotlib.path.cleanup_path. Instead\n# there is a method on a Path instance to simplify this.\nif hasattr(matplotlib.path.Path, 'cleaned'):\n _path_segments_doc = path_segments.__doc__\n\n def path_segments(path, **kwargs):\n pth = path.cleaned(**kwargs)\n return pth.vertices[:-1, :], pth.codes[:-1]\n\n path_segments.__doc__ = _path_segments_doc\n\n\ndef path_to_geos(path, force_ccw=False):\n \"\"\"\n Creates a list of Shapely geometric objects from a\n :class:`matplotlib.path.Path`.\n\n Args:\n\n * path\n A :class:`matplotlib.path.Path` instance.\n\n Kwargs:\n\n * force_ccw\n Boolean flag determining whether the path can be inverted to enforce\n ccw.\n\n Returns:\n A list of :class:`shapely.geometry.polygon.Polygon`,\n :class:`shapely.geometry.linestring.LineString` and/or\n :class:`shapely.geometry.multilinestring.MultiLineString` instances.\n\n \"\"\"\n # Convert path into numpy array of vertices (and associated codes)\n path_verts, path_codes = path_segments(path, curves=False)\n\n # Split into subarrays such that each subarray consists of connected\n # line segments based on the start of each one being marked by a\n # matplotlib MOVETO code.\n verts_split_inds = np.where(path_codes == Path.MOVETO)[0]\n verts_split = np.split(path_verts, verts_split_inds)\n codes_split = np.split(path_codes, verts_split_inds)\n\n # Iterate through the vertices generating a list of\n # (external_geom, [internal_polygons]) tuples.\n collection = []\n for path_verts, path_codes in zip(verts_split, codes_split):\n if len(path_verts) == 0:\n continue\n\n # XXX A path can be given which does not end with close poly, in that\n # situation, we have to guess?\n # XXX Implement a point\n if (path_verts.shape[0] > 2 and\n (path_codes[-1] == Path.CLOSEPOLY or\n all(path_verts[0, :] == path_verts[-1, :]))):\n if path_codes[-1] == Path.CLOSEPOLY:\n geom = Polygon(path_verts[:-1, :])\n else:\n geom = Polygon(path_verts)\n else:\n geom = LineString(path_verts)\n\n # If geom is a Polygon and is contained within the last geom in\n # collection, add it to its list of internal polygons, otherwise\n # simple append it as a new external geom.\n if geom.is_empty:\n pass\n elif (len(collection) > 0 and\n isinstance(collection[-1][0], Polygon) and\n isinstance(geom, Polygon) and\n collection[-1][0].contains(geom.exterior)):\n collection[-1][1].append(geom.exterior)\n else:\n collection.append((geom, []))\n\n # Convert each (external_geom, [internal_polygons]) pair into a\n # a shapely Polygon that encapsulates the internal polygons, if the\n # external geom is a LineString leave it alone.\n geom_collection = []\n for external_geom, internal_polys in collection:\n if internal_polys:\n # XXX worry about islands within lakes\n geom = Polygon(external_geom.exterior, internal_polys)\n else:\n geom = external_geom\n\n # Correctly orientate the polygon (ccw)\n if isinstance(geom, Polygon):\n if force_ccw and not geom.exterior.is_ccw:\n geom = shapely.geometry.polygon.orient(geom)\n\n geom_collection.append(geom)\n\n # If the geom_collection only contains LineStrings combine them\n # into a single MultiLinestring.\n if geom_collection and all(isinstance(geom, LineString) for\n geom in geom_collection):\n geom_collection = [MultiLineString(geom_collection)]\n\n # Remove any zero area Polygons\n not_zero_poly = lambda geom: ((isinstance(geom, Polygon) and\n not geom._is_empty and geom.area != 0) or\n not isinstance(geom, Polygon))\n result = list(filter(not_zero_poly, geom_collection))\n\n return result\n", "path": "lib/cartopy/mpl/patch.py"}]}
| 3,170 | 251 |
gh_patches_debug_12355
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
datastore: default to empty dataset
When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending "s~" to dataset ids as that is not always a valid operation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gcloud/datastore/key.py`
Content:
```
1 """Create / interact with gcloud datastore keys."""
2
3 import copy
4 from itertools import izip
5
6 from gcloud.datastore import datastore_v1_pb2 as datastore_pb
7 from gcloud.datastore.dataset import Dataset
8
9
10 class Key(object):
11 """An immutable representation of a datastore Key.
12
13 .. automethod:: __init__
14 """
15
16 def __init__(self, dataset=None, namespace=None, path=None):
17 """Constructor / initializer for a key.
18
19 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
20 :param dataset: A dataset instance for the key.
21
22 :type namespace: :class:`str`
23 :param namespace: A namespace identifier for the key.
24
25 :type path: sequence of dicts
26 :param path: Each dict must have keys 'kind' (a string) and optionally
27 'name' (a string) or 'id' (an integer).
28 """
29 self._dataset = dataset
30 self._namespace = namespace
31 self._path = path or [{'kind': ''}]
32
33 def _clone(self):
34 """Duplicates the Key.
35
36 We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`
37 because it holds a reference an authenticated connection,
38 which we don't want to lose.
39
40 :rtype: :class:`gcloud.datastore.key.Key`
41 :returns: a new `Key` instance
42 """
43 clone = copy.deepcopy(self)
44 clone._dataset = self._dataset # Make a shallow copy of the Dataset.
45 return clone
46
47 @classmethod
48 def from_protobuf(cls, pb, dataset=None):
49 """Factory method for creating a key based on a protobuf.
50
51 The protobuf should be one returned from the Cloud Datastore
52 Protobuf API.
53
54 :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`
55 :param pb: The Protobuf representing the key.
56
57 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
58 :param dataset: A dataset instance. If not passed, defaults to an
59 instance whose ID is derived from pb.
60
61 :rtype: :class:`gcloud.datastore.key.Key`
62 :returns: a new `Key` instance
63 """
64 path = []
65 for element in pb.path_element:
66 element_dict = {'kind': element.kind}
67
68 if element.HasField('id'):
69 element_dict['id'] = element.id
70
71 # This is safe: we expect proto objects returned will only have
72 # one of `name` or `id` set.
73 if element.HasField('name'):
74 element_dict['name'] = element.name
75
76 path.append(element_dict)
77
78 if not dataset:
79 dataset = Dataset(id=pb.partition_id.dataset_id)
80 namespace = pb.partition_id.namespace
81 else:
82 namespace = None
83
84 return cls(dataset, namespace, path)
85
86 def to_protobuf(self):
87 """Return a protobuf corresponding to the key.
88
89 :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`
90 :returns: The Protobuf representing the key.
91 """
92 key = datastore_pb.Key()
93
94 # Technically a dataset is required to do anything with the key,
95 # but we shouldn't throw a cryptic error if one isn't provided
96 # in the initializer.
97 if self.dataset():
98 dataset_id = self.dataset().id()
99 if dataset_id:
100 key.partition_id.dataset_id = dataset_id
101
102 if self._namespace:
103 key.partition_id.namespace = self._namespace
104
105 for item in self.path():
106 element = key.path_element.add()
107 if 'kind' in item:
108 element.kind = item['kind']
109 if 'id' in item:
110 element.id = item['id']
111 if 'name' in item:
112 element.name = item['name']
113
114 return key
115
116 @classmethod
117 def from_path(cls, *args, **kwargs):
118 """Factory method for creating a key based on a path.
119
120 :type args: :class:`tuple`
121 :param args: sequence of even length, where the first of each pair is a
122 string representing the 'kind' of the path element, and
123 the second of the pair is either a string (for the path
124 element's name) or an integer (for its id).
125
126 :type kwargs: :class:`dict`
127 :param kwargs: Other named parameters which can be passed to
128 :func:`Key.__init__`.
129
130 :rtype: :class:`gcloud.datastore.key.Key`
131 :returns: a new :class:`Key` instance
132 """
133 if len(args) % 2:
134 raise ValueError('Must pass an even number of args.')
135
136 path = []
137 items = iter(args)
138
139 for kind, id_or_name in izip(items, items):
140 entry = {'kind': kind}
141 if isinstance(id_or_name, basestring):
142 entry['name'] = id_or_name
143 else:
144 entry['id'] = id_or_name
145 path.append(entry)
146
147 kwargs['path'] = path
148 return cls(**kwargs)
149
150 def is_partial(self):
151 """Boolean test: is the key fully mapped onto a backend entity?
152
153 :rtype: :class:`bool`
154 :returns: True if the last element of the key's path does not have
155 an 'id' or a 'name'.
156 """
157 return self.id_or_name() is None
158
159 def dataset(self, dataset=None):
160 """Dataset setter / getter.
161
162 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
163 :param dataset: A dataset instance for the key.
164
165 :rtype: :class:`Key` (for setter); or
166 :class:`gcloud.datastore.dataset.Dataset` (for getter)
167 :returns: a new key, cloned from self., with the given dataset
168 (setter); or self's dataset (getter).
169 """
170 if dataset:
171 clone = self._clone()
172 clone._dataset = dataset
173 return clone
174 else:
175 return self._dataset
176
177 def namespace(self, namespace=None):
178 """Namespace setter / getter.
179
180 :type namespace: :class:`str`
181 :param namespace: A namespace identifier for the key.
182
183 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
184 :returns: a new key, cloned from self., with the given namespace
185 (setter); or self's namespace (getter).
186 """
187 if namespace:
188 clone = self._clone()
189 clone._namespace = namespace
190 return clone
191 else:
192 return self._namespace
193
194 def path(self, path=None):
195 """Path setter / getter.
196
197 :type path: sequence of dicts
198 :param path: Each dict must have keys 'kind' (a string) and optionally
199 'name' (a string) or 'id' (an integer).
200
201 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
202 :returns: a new key, cloned from self., with the given path (setter);
203 or self's path (getter).
204 """
205 if path:
206 clone = self._clone()
207 clone._path = path
208 return clone
209 else:
210 return self._path
211
212 def kind(self, kind=None):
213 """Kind setter / getter. Based on the last element of path.
214
215 :type kind: :class:`str`
216 :param kind: The new kind for the key.
217
218 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
219 :returns: a new key, cloned from self., with the given kind (setter);
220 or self's kind (getter).
221 """
222 if kind:
223 clone = self._clone()
224 clone._path[-1]['kind'] = kind
225 return clone
226 elif self.path():
227 return self._path[-1]['kind']
228
229 def id(self, id_to_set=None):
230 """ID setter / getter. Based on the last element of path.
231
232 :type id_to_set: :class:`int`
233 :param id_to_set: The new ID for the key.
234
235 :rtype: :class:`Key` (for setter); or :class:`int` (for getter)
236 :returns: a new key, cloned from self., with the given id (setter);
237 or self's id (getter).
238 """
239 if id_to_set:
240 clone = self._clone()
241 clone._path[-1]['id'] = id_to_set
242 return clone
243 elif self.path():
244 return self._path[-1].get('id')
245
246 def name(self, name=None):
247 """Name setter / getter. Based on the last element of path.
248
249 :type kind: :class:`str`
250 :param kind: The new name for the key.
251
252 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
253 :returns: a new key, cloned from self., with the given name (setter);
254 or self's name (getter).
255 """
256 if name:
257 clone = self._clone()
258 clone._path[-1]['name'] = name
259 return clone
260 elif self.path():
261 return self._path[-1].get('name')
262
263 def id_or_name(self):
264 """Getter. Based on the last element of path.
265
266 :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')
267 :returns: True if the last element of the key's path has either an 'id'
268 or a 'name'.
269 """
270 return self.id() or self.name()
271
272 def parent(self):
273 """Getter: return a new key for the next highest element in path.
274
275 :rtype: :class:`gcloud.datastore.key.Key`
276 :returns: a new `Key` instance, whose path consists of all but the last
277 element of self's path. If self has only one path element,
278 return None.
279 """
280 if len(self._path) <= 1:
281 return None
282 return self.path(self.path()[:-1])
283
284 def __repr__(self):
285 return '<Key%s>' % self.path()
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gcloud/datastore/key.py b/gcloud/datastore/key.py
--- a/gcloud/datastore/key.py
+++ b/gcloud/datastore/key.py
@@ -95,8 +95,13 @@
# but we shouldn't throw a cryptic error if one isn't provided
# in the initializer.
if self.dataset():
+ # Apparently 's~' is a prefix for High-Replication and is necessary
+ # here. Another valid preflix is 'e~' indicating EU datacenters.
dataset_id = self.dataset().id()
if dataset_id:
+ if dataset_id[:2] not in ['s~', 'e~']:
+ dataset_id = 's~' + dataset_id
+
key.partition_id.dataset_id = dataset_id
if self._namespace:
|
{"golden_diff": "diff --git a/gcloud/datastore/key.py b/gcloud/datastore/key.py\n--- a/gcloud/datastore/key.py\n+++ b/gcloud/datastore/key.py\n@@ -95,8 +95,13 @@\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n+ # Apparently 's~' is a prefix for High-Replication and is necessary\n+ # here. Another valid preflix is 'e~' indicating EU datacenters.\n dataset_id = self.dataset().id()\n if dataset_id:\n+ if dataset_id[:2] not in ['s~', 'e~']:\n+ dataset_id = 's~' + dataset_id\n+\n key.partition_id.dataset_id = dataset_id\n \n if self._namespace:\n", "issue": "datastore: default to empty dataset\nWhen working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation.\n\n", "before_files": [{"content": "\"\"\"Create / interact with gcloud datastore keys.\"\"\"\n\nimport copy\nfrom itertools import izip\n\nfrom gcloud.datastore import datastore_v1_pb2 as datastore_pb\nfrom gcloud.datastore.dataset import Dataset\n\n\nclass Key(object):\n \"\"\"An immutable representation of a datastore Key.\n\n .. automethod:: __init__\n \"\"\"\n\n def __init__(self, dataset=None, namespace=None, path=None):\n \"\"\"Constructor / initializer for a key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n \"\"\"\n self._dataset = dataset\n self._namespace = namespace\n self._path = path or [{'kind': ''}]\n\n def _clone(self):\n \"\"\"Duplicates the Key.\n\n We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`\n because it holds a reference an authenticated connection,\n which we don't want to lose.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n clone = copy.deepcopy(self)\n clone._dataset = self._dataset # Make a shallow copy of the Dataset.\n return clone\n\n @classmethod\n def from_protobuf(cls, pb, dataset=None):\n \"\"\"Factory method for creating a key based on a protobuf.\n\n The protobuf should be one returned from the Cloud Datastore\n Protobuf API.\n\n :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :param pb: The Protobuf representing the key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance. If not passed, defaults to an\n instance whose ID is derived from pb.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n path = []\n for element in pb.path_element:\n element_dict = {'kind': element.kind}\n\n if element.HasField('id'):\n element_dict['id'] = element.id\n\n # This is safe: we expect proto objects returned will only have\n # one of `name` or `id` set.\n if element.HasField('name'):\n element_dict['name'] = element.name\n\n path.append(element_dict)\n\n if not dataset:\n dataset = Dataset(id=pb.partition_id.dataset_id)\n namespace = pb.partition_id.namespace\n else:\n namespace = None\n\n return cls(dataset, namespace, path)\n\n def to_protobuf(self):\n \"\"\"Return a protobuf corresponding to the key.\n\n :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :returns: The Protobuf representing the key.\n \"\"\"\n key = datastore_pb.Key()\n\n # Technically a dataset is required to do anything with the key,\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n dataset_id = self.dataset().id()\n if dataset_id:\n key.partition_id.dataset_id = dataset_id\n\n if self._namespace:\n key.partition_id.namespace = self._namespace\n\n for item in self.path():\n element = key.path_element.add()\n if 'kind' in item:\n element.kind = item['kind']\n if 'id' in item:\n element.id = item['id']\n if 'name' in item:\n element.name = item['name']\n\n return key\n\n @classmethod\n def from_path(cls, *args, **kwargs):\n \"\"\"Factory method for creating a key based on a path.\n\n :type args: :class:`tuple`\n :param args: sequence of even length, where the first of each pair is a\n string representing the 'kind' of the path element, and\n the second of the pair is either a string (for the path\n element's name) or an integer (for its id).\n\n :type kwargs: :class:`dict`\n :param kwargs: Other named parameters which can be passed to\n :func:`Key.__init__`.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new :class:`Key` instance\n \"\"\"\n if len(args) % 2:\n raise ValueError('Must pass an even number of args.')\n\n path = []\n items = iter(args)\n\n for kind, id_or_name in izip(items, items):\n entry = {'kind': kind}\n if isinstance(id_or_name, basestring):\n entry['name'] = id_or_name\n else:\n entry['id'] = id_or_name\n path.append(entry)\n\n kwargs['path'] = path\n return cls(**kwargs)\n\n def is_partial(self):\n \"\"\"Boolean test: is the key fully mapped onto a backend entity?\n\n :rtype: :class:`bool`\n :returns: True if the last element of the key's path does not have\n an 'id' or a 'name'.\n \"\"\"\n return self.id_or_name() is None\n\n def dataset(self, dataset=None):\n \"\"\"Dataset setter / getter.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :rtype: :class:`Key` (for setter); or\n :class:`gcloud.datastore.dataset.Dataset` (for getter)\n :returns: a new key, cloned from self., with the given dataset\n (setter); or self's dataset (getter).\n \"\"\"\n if dataset:\n clone = self._clone()\n clone._dataset = dataset\n return clone\n else:\n return self._dataset\n\n def namespace(self, namespace=None):\n \"\"\"Namespace setter / getter.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given namespace\n (setter); or self's namespace (getter).\n \"\"\"\n if namespace:\n clone = self._clone()\n clone._namespace = namespace\n return clone\n else:\n return self._namespace\n\n def path(self, path=None):\n \"\"\"Path setter / getter.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given path (setter);\n or self's path (getter).\n \"\"\"\n if path:\n clone = self._clone()\n clone._path = path\n return clone\n else:\n return self._path\n\n def kind(self, kind=None):\n \"\"\"Kind setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new kind for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given kind (setter);\n or self's kind (getter).\n \"\"\"\n if kind:\n clone = self._clone()\n clone._path[-1]['kind'] = kind\n return clone\n elif self.path():\n return self._path[-1]['kind']\n\n def id(self, id_to_set=None):\n \"\"\"ID setter / getter. Based on the last element of path.\n\n :type id_to_set: :class:`int`\n :param id_to_set: The new ID for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`int` (for getter)\n :returns: a new key, cloned from self., with the given id (setter);\n or self's id (getter).\n \"\"\"\n if id_to_set:\n clone = self._clone()\n clone._path[-1]['id'] = id_to_set\n return clone\n elif self.path():\n return self._path[-1].get('id')\n\n def name(self, name=None):\n \"\"\"Name setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new name for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given name (setter);\n or self's name (getter).\n \"\"\"\n if name:\n clone = self._clone()\n clone._path[-1]['name'] = name\n return clone\n elif self.path():\n return self._path[-1].get('name')\n\n def id_or_name(self):\n \"\"\"Getter. Based on the last element of path.\n\n :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')\n :returns: True if the last element of the key's path has either an 'id'\n or a 'name'.\n \"\"\"\n return self.id() or self.name()\n\n def parent(self):\n \"\"\"Getter: return a new key for the next highest element in path.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance, whose path consists of all but the last\n element of self's path. If self has only one path element,\n return None.\n \"\"\"\n if len(self._path) <= 1:\n return None\n return self.path(self.path()[:-1])\n\n def __repr__(self):\n return '<Key%s>' % self.path()\n", "path": "gcloud/datastore/key.py"}], "after_files": [{"content": "\"\"\"Create / interact with gcloud datastore keys.\"\"\"\n\nimport copy\nfrom itertools import izip\n\nfrom gcloud.datastore import datastore_v1_pb2 as datastore_pb\nfrom gcloud.datastore.dataset import Dataset\n\n\nclass Key(object):\n \"\"\"An immutable representation of a datastore Key.\n\n .. automethod:: __init__\n \"\"\"\n\n def __init__(self, dataset=None, namespace=None, path=None):\n \"\"\"Constructor / initializer for a key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n \"\"\"\n self._dataset = dataset\n self._namespace = namespace\n self._path = path or [{'kind': ''}]\n\n def _clone(self):\n \"\"\"Duplicates the Key.\n\n We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`\n because it holds a reference an authenticated connection,\n which we don't want to lose.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n clone = copy.deepcopy(self)\n clone._dataset = self._dataset # Make a shallow copy of the Dataset.\n return clone\n\n @classmethod\n def from_protobuf(cls, pb, dataset=None):\n \"\"\"Factory method for creating a key based on a protobuf.\n\n The protobuf should be one returned from the Cloud Datastore\n Protobuf API.\n\n :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :param pb: The Protobuf representing the key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance. If not passed, defaults to an\n instance whose ID is derived from pb.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n path = []\n for element in pb.path_element:\n element_dict = {'kind': element.kind}\n\n if element.HasField('id'):\n element_dict['id'] = element.id\n\n # This is safe: we expect proto objects returned will only have\n # one of `name` or `id` set.\n if element.HasField('name'):\n element_dict['name'] = element.name\n\n path.append(element_dict)\n\n if not dataset:\n dataset = Dataset(id=pb.partition_id.dataset_id)\n namespace = pb.partition_id.namespace\n else:\n namespace = None\n\n return cls(dataset, namespace, path)\n\n def to_protobuf(self):\n \"\"\"Return a protobuf corresponding to the key.\n\n :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :returns: The Protobuf representing the key.\n \"\"\"\n key = datastore_pb.Key()\n\n # Technically a dataset is required to do anything with the key,\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n # Apparently 's~' is a prefix for High-Replication and is necessary\n # here. Another valid preflix is 'e~' indicating EU datacenters.\n dataset_id = self.dataset().id()\n if dataset_id:\n if dataset_id[:2] not in ['s~', 'e~']:\n dataset_id = 's~' + dataset_id\n\n key.partition_id.dataset_id = dataset_id\n\n if self._namespace:\n key.partition_id.namespace = self._namespace\n\n for item in self.path():\n element = key.path_element.add()\n if 'kind' in item:\n element.kind = item['kind']\n if 'id' in item:\n element.id = item['id']\n if 'name' in item:\n element.name = item['name']\n\n return key\n\n @classmethod\n def from_path(cls, *args, **kwargs):\n \"\"\"Factory method for creating a key based on a path.\n\n :type args: :class:`tuple`\n :param args: sequence of even length, where the first of each pair is a\n string representing the 'kind' of the path element, and\n the second of the pair is either a string (for the path\n element's name) or an integer (for its id).\n\n :type kwargs: :class:`dict`\n :param kwargs: Other named parameters which can be passed to\n :func:`Key.__init__`.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new :class:`Key` instance\n \"\"\"\n if len(args) % 2:\n raise ValueError('Must pass an even number of args.')\n\n path = []\n items = iter(args)\n\n for kind, id_or_name in izip(items, items):\n entry = {'kind': kind}\n if isinstance(id_or_name, basestring):\n entry['name'] = id_or_name\n else:\n entry['id'] = id_or_name\n path.append(entry)\n\n kwargs['path'] = path\n return cls(**kwargs)\n\n def is_partial(self):\n \"\"\"Boolean test: is the key fully mapped onto a backend entity?\n\n :rtype: :class:`bool`\n :returns: True if the last element of the key's path does not have\n an 'id' or a 'name'.\n \"\"\"\n return self.id_or_name() is None\n\n def dataset(self, dataset=None):\n \"\"\"Dataset setter / getter.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :rtype: :class:`Key` (for setter); or\n :class:`gcloud.datastore.dataset.Dataset` (for getter)\n :returns: a new key, cloned from self., with the given dataset\n (setter); or self's dataset (getter).\n \"\"\"\n if dataset:\n clone = self._clone()\n clone._dataset = dataset\n return clone\n else:\n return self._dataset\n\n def namespace(self, namespace=None):\n \"\"\"Namespace setter / getter.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given namespace\n (setter); or self's namespace (getter).\n \"\"\"\n if namespace:\n clone = self._clone()\n clone._namespace = namespace\n return clone\n else:\n return self._namespace\n\n def path(self, path=None):\n \"\"\"Path setter / getter.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given path (setter);\n or self's path (getter).\n \"\"\"\n if path:\n clone = self._clone()\n clone._path = path\n return clone\n else:\n return self._path\n\n def kind(self, kind=None):\n \"\"\"Kind setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new kind for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given kind (setter);\n or self's kind (getter).\n \"\"\"\n if kind:\n clone = self._clone()\n clone._path[-1]['kind'] = kind\n return clone\n elif self.path():\n return self._path[-1]['kind']\n\n def id(self, id_to_set=None):\n \"\"\"ID setter / getter. Based on the last element of path.\n\n :type id_to_set: :class:`int`\n :param id_to_set: The new ID for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`int` (for getter)\n :returns: a new key, cloned from self., with the given id (setter);\n or self's id (getter).\n \"\"\"\n if id_to_set:\n clone = self._clone()\n clone._path[-1]['id'] = id_to_set\n return clone\n elif self.path():\n return self._path[-1].get('id')\n\n def name(self, name=None):\n \"\"\"Name setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new name for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given name (setter);\n or self's name (getter).\n \"\"\"\n if name:\n clone = self._clone()\n clone._path[-1]['name'] = name\n return clone\n elif self.path():\n return self._path[-1].get('name')\n\n def id_or_name(self):\n \"\"\"Getter. Based on the last element of path.\n\n :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')\n :returns: True if the last element of the key's path has either an 'id'\n or a 'name'.\n \"\"\"\n return self.id() or self.name()\n\n def parent(self):\n \"\"\"Getter: return a new key for the next highest element in path.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance, whose path consists of all but the last\n element of self's path. If self has only one path element,\n return None.\n \"\"\"\n if len(self._path) <= 1:\n return None\n return self.path(self.path()[:-1])\n\n def __repr__(self):\n return '<Key%s>' % self.path()\n", "path": "gcloud/datastore/key.py"}]}
| 3,303 | 178 |
gh_patches_debug_683
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-1726
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pytest fails due to missing dependency
Reproduction:
Activate virtualenv and execute `pytest`
Expected result:
Tests are run
Actual result:
```(env) :~/git/werkzeug[master ?]🙂 pytest
========================= test session starts ==========================
platform darwin -- Python 3.6.8, pytest-5.3.2, py-1.8.0, pluggy-0.13.0
rootdir: /Users/latham/git/werkzeug, inifile: setup.cfg, testpaths: tests
plugins: mock-1.11.2, cov-2.8.1
collected 563 items / 1 error / 562 selected
================================ ERRORS ================================
_________________ ERROR collecting tests/test_debug.py _________________
tests/test_debug.py:372: in <module>
@pytest.mark.timeout(2)
../../Library/Python/3.6/lib/python/site-packages/_pytest/mark/structures.py:327: in __getattr__
PytestUnknownMarkWarning,
E pytest.PytestUnknownMarkWarning: Unknown pytest.mark.timeout - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html
!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!
=========================== 1 error in 1.60s ===========================```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import io
2 import re
3
4 from setuptools import find_packages
5 from setuptools import setup
6
7 with io.open("README.rst", "rt", encoding="utf8") as f:
8 readme = f.read()
9
10 with io.open("src/werkzeug/__init__.py", "rt", encoding="utf8") as f:
11 version = re.search(r'__version__ = "(.*?)"', f.read(), re.M).group(1)
12
13 setup(
14 name="Werkzeug",
15 version=version,
16 url="https://palletsprojects.com/p/werkzeug/",
17 project_urls={
18 "Documentation": "https://werkzeug.palletsprojects.com/",
19 "Code": "https://github.com/pallets/werkzeug",
20 "Issue tracker": "https://github.com/pallets/werkzeug/issues",
21 },
22 license="BSD-3-Clause",
23 author="Armin Ronacher",
24 author_email="[email protected]",
25 maintainer="Pallets",
26 maintainer_email="[email protected]",
27 description="The comprehensive WSGI web application library.",
28 long_description=readme,
29 classifiers=[
30 "Development Status :: 5 - Production/Stable",
31 "Environment :: Web Environment",
32 "Intended Audience :: Developers",
33 "License :: OSI Approved :: BSD License",
34 "Operating System :: OS Independent",
35 "Programming Language :: Python",
36 "Programming Language :: Python :: 2",
37 "Programming Language :: Python :: 2.7",
38 "Programming Language :: Python :: 3",
39 "Programming Language :: Python :: 3.5",
40 "Programming Language :: Python :: 3.6",
41 "Programming Language :: Python :: 3.7",
42 "Programming Language :: Python :: 3.8",
43 "Programming Language :: Python :: Implementation :: CPython",
44 "Programming Language :: Python :: Implementation :: PyPy",
45 "Topic :: Internet :: WWW/HTTP :: Dynamic Content",
46 "Topic :: Internet :: WWW/HTTP :: WSGI",
47 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
48 "Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware",
49 "Topic :: Software Development :: Libraries :: Application Frameworks",
50 "Topic :: Software Development :: Libraries :: Python Modules",
51 ],
52 packages=find_packages("src"),
53 package_dir={"": "src"},
54 include_package_data=True,
55 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*",
56 extras_require={
57 "watchdog": ["watchdog"],
58 "dev": [
59 "pytest",
60 "coverage",
61 "tox",
62 "sphinx",
63 "pallets-sphinx-themes",
64 "sphinx-issues",
65 ],
66 },
67 )
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -57,6 +57,7 @@
"watchdog": ["watchdog"],
"dev": [
"pytest",
+ "pytest-timeout",
"coverage",
"tox",
"sphinx",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -57,6 +57,7 @@\n \"watchdog\": [\"watchdog\"],\n \"dev\": [\n \"pytest\",\n+ \"pytest-timeout\",\n \"coverage\",\n \"tox\",\n \"sphinx\",\n", "issue": "Pytest fails due to missing dependency\nReproduction:\r\n\r\nActivate virtualenv and execute `pytest` \r\n\r\nExpected result:\r\nTests are run\r\n\r\nActual result:\r\n```(env) :~/git/werkzeug[master ?]\ud83d\ude42 pytest\r\n========================= test session starts ==========================\r\nplatform darwin -- Python 3.6.8, pytest-5.3.2, py-1.8.0, pluggy-0.13.0\r\nrootdir: /Users/latham/git/werkzeug, inifile: setup.cfg, testpaths: tests\r\nplugins: mock-1.11.2, cov-2.8.1\r\ncollected 563 items / 1 error / 562 selected \r\n\r\n================================ ERRORS ================================\r\n_________________ ERROR collecting tests/test_debug.py _________________\r\ntests/test_debug.py:372: in <module>\r\n @pytest.mark.timeout(2)\r\n../../Library/Python/3.6/lib/python/site-packages/_pytest/mark/structures.py:327: in __getattr__\r\n PytestUnknownMarkWarning,\r\nE pytest.PytestUnknownMarkWarning: Unknown pytest.mark.timeout - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/latest/mark.html\r\n!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!\r\n=========================== 1 error in 1.60s ===========================```\r\n\n", "before_files": [{"content": "import io\nimport re\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nwith io.open(\"README.rst\", \"rt\", encoding=\"utf8\") as f:\n readme = f.read()\n\nwith io.open(\"src/werkzeug/__init__.py\", \"rt\", encoding=\"utf8\") as f:\n version = re.search(r'__version__ = \"(.*?)\"', f.read(), re.M).group(1)\n\nsetup(\n name=\"Werkzeug\",\n version=version,\n url=\"https://palletsprojects.com/p/werkzeug/\",\n project_urls={\n \"Documentation\": \"https://werkzeug.palletsprojects.com/\",\n \"Code\": \"https://github.com/pallets/werkzeug\",\n \"Issue tracker\": \"https://github.com/pallets/werkzeug/issues\",\n },\n license=\"BSD-3-Clause\",\n author=\"Armin Ronacher\",\n author_email=\"[email protected]\",\n maintainer=\"Pallets\",\n maintainer_email=\"[email protected]\",\n description=\"The comprehensive WSGI web application library.\",\n long_description=readme,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware\",\n \"Topic :: Software Development :: Libraries :: Application Frameworks\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n extras_require={\n \"watchdog\": [\"watchdog\"],\n \"dev\": [\n \"pytest\",\n \"coverage\",\n \"tox\",\n \"sphinx\",\n \"pallets-sphinx-themes\",\n \"sphinx-issues\",\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import io\nimport re\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nwith io.open(\"README.rst\", \"rt\", encoding=\"utf8\") as f:\n readme = f.read()\n\nwith io.open(\"src/werkzeug/__init__.py\", \"rt\", encoding=\"utf8\") as f:\n version = re.search(r'__version__ = \"(.*?)\"', f.read(), re.M).group(1)\n\nsetup(\n name=\"Werkzeug\",\n version=version,\n url=\"https://palletsprojects.com/p/werkzeug/\",\n project_urls={\n \"Documentation\": \"https://werkzeug.palletsprojects.com/\",\n \"Code\": \"https://github.com/pallets/werkzeug\",\n \"Issue tracker\": \"https://github.com/pallets/werkzeug/issues\",\n },\n license=\"BSD-3-Clause\",\n author=\"Armin Ronacher\",\n author_email=\"[email protected]\",\n maintainer=\"Pallets\",\n maintainer_email=\"[email protected]\",\n description=\"The comprehensive WSGI web application library.\",\n long_description=readme,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware\",\n \"Topic :: Software Development :: Libraries :: Application Frameworks\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n extras_require={\n \"watchdog\": [\"watchdog\"],\n \"dev\": [\n \"pytest\",\n \"pytest-timeout\",\n \"coverage\",\n \"tox\",\n \"sphinx\",\n \"pallets-sphinx-themes\",\n \"sphinx-issues\",\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,298 | 71 |
gh_patches_debug_17286
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-6761
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Depend on josepy>=1.1.0 in setup.py files
Where we depend on `josepy`, I think we should depend on `josepy>=1.1.0`.
The reason for this is when older versions of `josepy` are used with `cryptography>=2.0`, users hit https://github.com/certbot/josepy/issues/13. Really, we'd like logic like "if cryptography>=2.0 is the version being used, depend on josepy>=1.1.0", but I'm not even sure logic like this is possible and if it is, it complicates things significantly.
A small bump to the version requirements in new versions of acme, certbot, etc. for another package of ours shouldn't be a problem at all and avoids this complexity.
Depend on josepy>=1.1.0 in setup.py files
Where we depend on `josepy`, I think we should depend on `josepy>=1.1.0`.
The reason for this is when older versions of `josepy` are used with `cryptography>=2.0`, users hit https://github.com/certbot/josepy/issues/13. Really, we'd like logic like "if cryptography>=2.0 is the version being used, depend on josepy>=1.1.0", but I'm not even sure logic like this is possible and if it is, it complicates things significantly.
A small bump to the version requirements in new versions of acme, certbot, etc. for another package of ours shouldn't be a problem at all and avoids this complexity.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import codecs
2 import os
3 import re
4
5 from setuptools import find_packages, setup
6
7 # Workaround for http://bugs.python.org/issue8876, see
8 # http://bugs.python.org/issue8876#msg208792
9 # This can be removed when using Python 2.7.9 or later:
10 # https://hg.python.org/cpython/raw-file/v2.7.9/Misc/NEWS
11 if os.path.abspath(__file__).split(os.path.sep)[1] == 'vagrant':
12 del os.link
13
14
15 def read_file(filename, encoding='utf8'):
16 """Read unicode from given file."""
17 with codecs.open(filename, encoding=encoding) as fd:
18 return fd.read()
19
20
21 here = os.path.abspath(os.path.dirname(__file__))
22
23 # read version number (and other metadata) from package init
24 init_fn = os.path.join(here, 'certbot', '__init__.py')
25 meta = dict(re.findall(r"""__([a-z]+)__ = '([^']+)""", read_file(init_fn)))
26
27 readme = read_file(os.path.join(here, 'README.rst'))
28 version = meta['version']
29
30 # This package relies on PyOpenSSL, requests, and six, however, it isn't
31 # specified here to avoid masking the more specific request requirements in
32 # acme. See https://github.com/pypa/pip/issues/988 for more info.
33 install_requires = [
34 'acme>=0.29.0',
35 # We technically need ConfigArgParse 0.10.0 for Python 2.6 support, but
36 # saying so here causes a runtime error against our temporary fork of 0.9.3
37 # in which we added 2.6 support (see #2243), so we relax the requirement.
38 'ConfigArgParse>=0.9.3',
39 'configobj',
40 'cryptography>=1.2.3', # load_pem_x509_certificate
41 'josepy',
42 'mock',
43 'parsedatetime>=1.3', # Calendar.parseDT
44 'pyrfc3339',
45 'pytz',
46 'setuptools',
47 'zope.component',
48 'zope.interface',
49 ]
50
51 dev_extras = [
52 # Pin astroid==1.3.5, pylint==1.4.2 as a workaround for #289
53 'astroid==1.3.5',
54 'coverage',
55 'ipdb',
56 'pytest',
57 'pytest-cov',
58 'pytest-xdist',
59 'pylint==1.4.2', # upstream #248
60 'tox',
61 'twine',
62 'wheel',
63 ]
64
65 dev3_extras = [
66 'mypy',
67 'typing', # for python3.4
68 ]
69
70 docs_extras = [
71 # If you have Sphinx<1.5.1, you need docutils<0.13.1
72 # https://github.com/sphinx-doc/sphinx/issues/3212
73 'repoze.sphinx.autointerface',
74 'Sphinx>=1.2', # Annotation support
75 'sphinx_rtd_theme',
76 ]
77
78 setup(
79 name='certbot',
80 version=version,
81 description="ACME client",
82 long_description=readme,
83 url='https://github.com/letsencrypt/letsencrypt',
84 author="Certbot Project",
85 author_email='[email protected]',
86 license='Apache License 2.0',
87 python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
88 classifiers=[
89 'Development Status :: 5 - Production/Stable',
90 'Environment :: Console',
91 'Environment :: Console :: Curses',
92 'Intended Audience :: System Administrators',
93 'License :: OSI Approved :: Apache Software License',
94 'Operating System :: POSIX :: Linux',
95 'Programming Language :: Python',
96 'Programming Language :: Python :: 2',
97 'Programming Language :: Python :: 2.7',
98 'Programming Language :: Python :: 3',
99 'Programming Language :: Python :: 3.4',
100 'Programming Language :: Python :: 3.5',
101 'Programming Language :: Python :: 3.6',
102 'Programming Language :: Python :: 3.7',
103 'Topic :: Internet :: WWW/HTTP',
104 'Topic :: Security',
105 'Topic :: System :: Installation/Setup',
106 'Topic :: System :: Networking',
107 'Topic :: System :: Systems Administration',
108 'Topic :: Utilities',
109 ],
110
111 packages=find_packages(exclude=['docs', 'examples', 'tests', 'venv']),
112 include_package_data=True,
113
114 install_requires=install_requires,
115 extras_require={
116 'dev': dev_extras,
117 'dev3': dev3_extras,
118 'docs': docs_extras,
119 },
120
121 # to test all packages run "python setup.py test -s
122 # {acme,certbot_apache,certbot_nginx}"
123 test_suite='certbot',
124
125 entry_points={
126 'console_scripts': [
127 'certbot = certbot.main:main',
128 ],
129 'certbot.plugins': [
130 'manual = certbot.plugins.manual:Authenticator',
131 'null = certbot.plugins.null:Installer',
132 'standalone = certbot.plugins.standalone:Authenticator',
133 'webroot = certbot.plugins.webroot:Authenticator',
134 ],
135 },
136 )
137
```
Path: `acme/setup.py`
Content:
```
1 from setuptools import setup
2 from setuptools import find_packages
3 from setuptools.command.test import test as TestCommand
4 import sys
5
6 version = '0.32.0.dev0'
7
8 # Please update tox.ini when modifying dependency version requirements
9 install_requires = [
10 # load_pem_private/public_key (>=0.6)
11 # rsa_recover_prime_factors (>=0.8)
12 'cryptography>=1.2.3',
13 # formerly known as acme.jose:
14 'josepy>=1.0.0',
15 # Connection.set_tlsext_host_name (>=0.13)
16 'mock',
17 'PyOpenSSL>=0.13.1',
18 'pyrfc3339',
19 'pytz',
20 'requests[security]>=2.6.0', # security extras added in 2.4.1
21 'requests-toolbelt>=0.3.0',
22 'setuptools',
23 'six>=1.9.0', # needed for python_2_unicode_compatible
24 ]
25
26 dev_extras = [
27 'pytest',
28 'pytest-xdist',
29 'tox',
30 ]
31
32 docs_extras = [
33 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags
34 'sphinx_rtd_theme',
35 ]
36
37 class PyTest(TestCommand):
38 user_options = []
39
40 def initialize_options(self):
41 TestCommand.initialize_options(self)
42 self.pytest_args = ''
43
44 def run_tests(self):
45 import shlex
46 # import here, cause outside the eggs aren't loaded
47 import pytest
48 errno = pytest.main(shlex.split(self.pytest_args))
49 sys.exit(errno)
50
51 setup(
52 name='acme',
53 version=version,
54 description='ACME protocol implementation in Python',
55 url='https://github.com/letsencrypt/letsencrypt',
56 author="Certbot Project",
57 author_email='[email protected]',
58 license='Apache License 2.0',
59 python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
60 classifiers=[
61 'Development Status :: 5 - Production/Stable',
62 'Intended Audience :: Developers',
63 'License :: OSI Approved :: Apache Software License',
64 'Programming Language :: Python',
65 'Programming Language :: Python :: 2',
66 'Programming Language :: Python :: 2.7',
67 'Programming Language :: Python :: 3',
68 'Programming Language :: Python :: 3.4',
69 'Programming Language :: Python :: 3.5',
70 'Programming Language :: Python :: 3.6',
71 'Programming Language :: Python :: 3.7',
72 'Topic :: Internet :: WWW/HTTP',
73 'Topic :: Security',
74 ],
75
76 packages=find_packages(),
77 include_package_data=True,
78 install_requires=install_requires,
79 extras_require={
80 'dev': dev_extras,
81 'docs': docs_extras,
82 },
83 tests_require=["pytest"],
84 test_suite='acme',
85 cmdclass={"test": PyTest},
86 )
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/acme/setup.py b/acme/setup.py
--- a/acme/setup.py
+++ b/acme/setup.py
@@ -11,7 +11,9 @@
# rsa_recover_prime_factors (>=0.8)
'cryptography>=1.2.3',
# formerly known as acme.jose:
- 'josepy>=1.0.0',
+ # 1.1.0+ is required to avoid the warnings described at
+ # https://github.com/certbot/josepy/issues/13.
+ 'josepy>=1.1.0',
# Connection.set_tlsext_host_name (>=0.13)
'mock',
'PyOpenSSL>=0.13.1',
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -38,7 +38,9 @@
'ConfigArgParse>=0.9.3',
'configobj',
'cryptography>=1.2.3', # load_pem_x509_certificate
- 'josepy',
+ # 1.1.0+ is required to avoid the warnings described at
+ # https://github.com/certbot/josepy/issues/13.
+ 'josepy>=1.1.0',
'mock',
'parsedatetime>=1.3', # Calendar.parseDT
'pyrfc3339',
|
{"golden_diff": "diff --git a/acme/setup.py b/acme/setup.py\n--- a/acme/setup.py\n+++ b/acme/setup.py\n@@ -11,7 +11,9 @@\n # rsa_recover_prime_factors (>=0.8)\n 'cryptography>=1.2.3',\n # formerly known as acme.jose:\n- 'josepy>=1.0.0',\n+ # 1.1.0+ is required to avoid the warnings described at\n+ # https://github.com/certbot/josepy/issues/13.\n+ 'josepy>=1.1.0',\n # Connection.set_tlsext_host_name (>=0.13)\n 'mock',\n 'PyOpenSSL>=0.13.1',\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -38,7 +38,9 @@\n 'ConfigArgParse>=0.9.3',\n 'configobj',\n 'cryptography>=1.2.3', # load_pem_x509_certificate\n- 'josepy',\n+ # 1.1.0+ is required to avoid the warnings described at\n+ # https://github.com/certbot/josepy/issues/13.\n+ 'josepy>=1.1.0',\n 'mock',\n 'parsedatetime>=1.3', # Calendar.parseDT\n 'pyrfc3339',\n", "issue": "Depend on josepy>=1.1.0 in setup.py files\nWhere we depend on `josepy`, I think we should depend on `josepy>=1.1.0`.\r\n\r\nThe reason for this is when older versions of `josepy` are used with `cryptography>=2.0`, users hit https://github.com/certbot/josepy/issues/13. Really, we'd like logic like \"if cryptography>=2.0 is the version being used, depend on josepy>=1.1.0\", but I'm not even sure logic like this is possible and if it is, it complicates things significantly.\r\n\r\nA small bump to the version requirements in new versions of acme, certbot, etc. for another package of ours shouldn't be a problem at all and avoids this complexity.\nDepend on josepy>=1.1.0 in setup.py files\nWhere we depend on `josepy`, I think we should depend on `josepy>=1.1.0`.\r\n\r\nThe reason for this is when older versions of `josepy` are used with `cryptography>=2.0`, users hit https://github.com/certbot/josepy/issues/13. Really, we'd like logic like \"if cryptography>=2.0 is the version being used, depend on josepy>=1.1.0\", but I'm not even sure logic like this is possible and if it is, it complicates things significantly.\r\n\r\nA small bump to the version requirements in new versions of acme, certbot, etc. for another package of ours shouldn't be a problem at all and avoids this complexity.\n", "before_files": [{"content": "import codecs\nimport os\nimport re\n\nfrom setuptools import find_packages, setup\n\n# Workaround for http://bugs.python.org/issue8876, see\n# http://bugs.python.org/issue8876#msg208792\n# This can be removed when using Python 2.7.9 or later:\n# https://hg.python.org/cpython/raw-file/v2.7.9/Misc/NEWS\nif os.path.abspath(__file__).split(os.path.sep)[1] == 'vagrant':\n del os.link\n\n\ndef read_file(filename, encoding='utf8'):\n \"\"\"Read unicode from given file.\"\"\"\n with codecs.open(filename, encoding=encoding) as fd:\n return fd.read()\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n# read version number (and other metadata) from package init\ninit_fn = os.path.join(here, 'certbot', '__init__.py')\nmeta = dict(re.findall(r\"\"\"__([a-z]+)__ = '([^']+)\"\"\", read_file(init_fn)))\n\nreadme = read_file(os.path.join(here, 'README.rst'))\nversion = meta['version']\n\n# This package relies on PyOpenSSL, requests, and six, however, it isn't\n# specified here to avoid masking the more specific request requirements in\n# acme. See https://github.com/pypa/pip/issues/988 for more info.\ninstall_requires = [\n 'acme>=0.29.0',\n # We technically need ConfigArgParse 0.10.0 for Python 2.6 support, but\n # saying so here causes a runtime error against our temporary fork of 0.9.3\n # in which we added 2.6 support (see #2243), so we relax the requirement.\n 'ConfigArgParse>=0.9.3',\n 'configobj',\n 'cryptography>=1.2.3', # load_pem_x509_certificate\n 'josepy',\n 'mock',\n 'parsedatetime>=1.3', # Calendar.parseDT\n 'pyrfc3339',\n 'pytz',\n 'setuptools',\n 'zope.component',\n 'zope.interface',\n]\n\ndev_extras = [\n # Pin astroid==1.3.5, pylint==1.4.2 as a workaround for #289\n 'astroid==1.3.5',\n 'coverage',\n 'ipdb',\n 'pytest',\n 'pytest-cov',\n 'pytest-xdist',\n 'pylint==1.4.2', # upstream #248\n 'tox',\n 'twine',\n 'wheel',\n]\n\ndev3_extras = [\n 'mypy',\n 'typing', # for python3.4\n]\n\ndocs_extras = [\n # If you have Sphinx<1.5.1, you need docutils<0.13.1\n # https://github.com/sphinx-doc/sphinx/issues/3212\n 'repoze.sphinx.autointerface',\n 'Sphinx>=1.2', # Annotation support\n 'sphinx_rtd_theme',\n]\n\nsetup(\n name='certbot',\n version=version,\n description=\"ACME client\",\n long_description=readme,\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n 'Topic :: System :: Installation/Setup',\n 'Topic :: System :: Networking',\n 'Topic :: System :: Systems Administration',\n 'Topic :: Utilities',\n ],\n\n packages=find_packages(exclude=['docs', 'examples', 'tests', 'venv']),\n include_package_data=True,\n\n install_requires=install_requires,\n extras_require={\n 'dev': dev_extras,\n 'dev3': dev3_extras,\n 'docs': docs_extras,\n },\n\n # to test all packages run \"python setup.py test -s\n # {acme,certbot_apache,certbot_nginx}\"\n test_suite='certbot',\n\n entry_points={\n 'console_scripts': [\n 'certbot = certbot.main:main',\n ],\n 'certbot.plugins': [\n 'manual = certbot.plugins.manual:Authenticator',\n 'null = certbot.plugins.null:Installer',\n 'standalone = certbot.plugins.standalone:Authenticator',\n 'webroot = certbot.plugins.webroot:Authenticator',\n ],\n },\n)\n", "path": "setup.py"}, {"content": "from setuptools import setup\nfrom setuptools import find_packages\nfrom setuptools.command.test import test as TestCommand\nimport sys\n\nversion = '0.32.0.dev0'\n\n# Please update tox.ini when modifying dependency version requirements\ninstall_requires = [\n # load_pem_private/public_key (>=0.6)\n # rsa_recover_prime_factors (>=0.8)\n 'cryptography>=1.2.3',\n # formerly known as acme.jose:\n 'josepy>=1.0.0',\n # Connection.set_tlsext_host_name (>=0.13)\n 'mock',\n 'PyOpenSSL>=0.13.1',\n 'pyrfc3339',\n 'pytz',\n 'requests[security]>=2.6.0', # security extras added in 2.4.1\n 'requests-toolbelt>=0.3.0',\n 'setuptools',\n 'six>=1.9.0', # needed for python_2_unicode_compatible\n]\n\ndev_extras = [\n 'pytest',\n 'pytest-xdist',\n 'tox',\n]\n\ndocs_extras = [\n 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags\n 'sphinx_rtd_theme',\n]\n\nclass PyTest(TestCommand):\n user_options = []\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.pytest_args = ''\n\n def run_tests(self):\n import shlex\n # import here, cause outside the eggs aren't loaded\n import pytest\n errno = pytest.main(shlex.split(self.pytest_args))\n sys.exit(errno)\n\nsetup(\n name='acme',\n version=version,\n description='ACME protocol implementation in Python',\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n ],\n\n packages=find_packages(),\n include_package_data=True,\n install_requires=install_requires,\n extras_require={\n 'dev': dev_extras,\n 'docs': docs_extras,\n },\n tests_require=[\"pytest\"],\n test_suite='acme',\n cmdclass={\"test\": PyTest},\n)\n", "path": "acme/setup.py"}], "after_files": [{"content": "import codecs\nimport os\nimport re\n\nfrom setuptools import find_packages, setup\n\n# Workaround for http://bugs.python.org/issue8876, see\n# http://bugs.python.org/issue8876#msg208792\n# This can be removed when using Python 2.7.9 or later:\n# https://hg.python.org/cpython/raw-file/v2.7.9/Misc/NEWS\nif os.path.abspath(__file__).split(os.path.sep)[1] == 'vagrant':\n del os.link\n\n\ndef read_file(filename, encoding='utf8'):\n \"\"\"Read unicode from given file.\"\"\"\n with codecs.open(filename, encoding=encoding) as fd:\n return fd.read()\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n# read version number (and other metadata) from package init\ninit_fn = os.path.join(here, 'certbot', '__init__.py')\nmeta = dict(re.findall(r\"\"\"__([a-z]+)__ = '([^']+)\"\"\", read_file(init_fn)))\n\nreadme = read_file(os.path.join(here, 'README.rst'))\nversion = meta['version']\n\n# This package relies on PyOpenSSL, requests, and six, however, it isn't\n# specified here to avoid masking the more specific request requirements in\n# acme. See https://github.com/pypa/pip/issues/988 for more info.\ninstall_requires = [\n 'acme>=0.29.0',\n # We technically need ConfigArgParse 0.10.0 for Python 2.6 support, but\n # saying so here causes a runtime error against our temporary fork of 0.9.3\n # in which we added 2.6 support (see #2243), so we relax the requirement.\n 'ConfigArgParse>=0.9.3',\n 'configobj',\n 'cryptography>=1.2.3', # load_pem_x509_certificate\n # 1.1.0+ is required to avoid the warnings described at\n # https://github.com/certbot/josepy/issues/13.\n 'josepy>=1.1.0',\n 'mock',\n 'parsedatetime>=1.3', # Calendar.parseDT\n 'pyrfc3339',\n 'pytz',\n 'setuptools',\n 'zope.component',\n 'zope.interface',\n]\n\ndev_extras = [\n # Pin astroid==1.3.5, pylint==1.4.2 as a workaround for #289\n 'astroid==1.3.5',\n 'coverage',\n 'ipdb',\n 'pytest',\n 'pytest-cov',\n 'pytest-xdist',\n 'pylint==1.4.2', # upstream #248\n 'tox',\n 'twine',\n 'wheel',\n]\n\ndev3_extras = [\n 'mypy',\n 'typing', # for python3.4\n]\n\ndocs_extras = [\n # If you have Sphinx<1.5.1, you need docutils<0.13.1\n # https://github.com/sphinx-doc/sphinx/issues/3212\n 'repoze.sphinx.autointerface',\n 'Sphinx>=1.2', # Annotation support\n 'sphinx_rtd_theme',\n]\n\nsetup(\n name='certbot',\n version=version,\n description=\"ACME client\",\n long_description=readme,\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n 'Topic :: System :: Installation/Setup',\n 'Topic :: System :: Networking',\n 'Topic :: System :: Systems Administration',\n 'Topic :: Utilities',\n ],\n\n packages=find_packages(exclude=['docs', 'examples', 'tests', 'venv']),\n include_package_data=True,\n\n install_requires=install_requires,\n extras_require={\n 'dev': dev_extras,\n 'dev3': dev3_extras,\n 'docs': docs_extras,\n },\n\n # to test all packages run \"python setup.py test -s\n # {acme,certbot_apache,certbot_nginx}\"\n test_suite='certbot',\n\n entry_points={\n 'console_scripts': [\n 'certbot = certbot.main:main',\n ],\n 'certbot.plugins': [\n 'manual = certbot.plugins.manual:Authenticator',\n 'null = certbot.plugins.null:Installer',\n 'standalone = certbot.plugins.standalone:Authenticator',\n 'webroot = certbot.plugins.webroot:Authenticator',\n ],\n },\n)\n", "path": "setup.py"}, {"content": "from setuptools import setup\nfrom setuptools import find_packages\nfrom setuptools.command.test import test as TestCommand\nimport sys\n\nversion = '0.32.0.dev0'\n\n# Please update tox.ini when modifying dependency version requirements\ninstall_requires = [\n # load_pem_private/public_key (>=0.6)\n # rsa_recover_prime_factors (>=0.8)\n 'cryptography>=1.2.3',\n # formerly known as acme.jose:\n # 1.1.0+ is required to avoid the warnings described at\n # https://github.com/certbot/josepy/issues/13.\n 'josepy>=1.1.0',\n # Connection.set_tlsext_host_name (>=0.13)\n 'mock',\n 'PyOpenSSL>=0.13.1',\n 'pyrfc3339',\n 'pytz',\n 'requests[security]>=2.6.0', # security extras added in 2.4.1\n 'requests-toolbelt>=0.3.0',\n 'setuptools',\n 'six>=1.9.0', # needed for python_2_unicode_compatible\n]\n\ndev_extras = [\n 'pytest',\n 'pytest-xdist',\n 'tox',\n]\n\ndocs_extras = [\n 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags\n 'sphinx_rtd_theme',\n]\n\nclass PyTest(TestCommand):\n user_options = []\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.pytest_args = ''\n\n def run_tests(self):\n import shlex\n # import here, cause outside the eggs aren't loaded\n import pytest\n errno = pytest.main(shlex.split(self.pytest_args))\n sys.exit(errno)\n\nsetup(\n name='acme',\n version=version,\n description='ACME protocol implementation in Python',\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n ],\n\n packages=find_packages(),\n include_package_data=True,\n install_requires=install_requires,\n extras_require={\n 'dev': dev_extras,\n 'docs': docs_extras,\n },\n tests_require=[\"pytest\"],\n test_suite='acme',\n cmdclass={\"test\": PyTest},\n)\n", "path": "acme/setup.py"}]}
| 2,946 | 327 |
gh_patches_debug_2224
|
rasdani/github-patches
|
git_diff
|
google__TensorNetwork-608
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some doc links to github yield error
The "Edit on GitHub" links in the top right of some doc pages yield 404 errors when followed, for example [tn.Node](https://tensornetwork.readthedocs.io/en/latest/stubs/tensornetwork.Node.html) and [tn.contractors.optimal](https://tensornetwork.readthedocs.io/en/latest/stubs/tensornetwork.contractors.optimal.html#tensornetwork.contractors.optimal).
The links at the top of list pages work, for example [common functions](https://tensornetwork.readthedocs.io/en/latest/network.html) and [contractors](https://tensornetwork.readthedocs.io/en/latest/contractors.html).
Possibly those are meant to be links to edit the doc pages themselves, rather than the source code?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # http://www.sphinx-doc.org/en/master/config
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 import os
14 import sys
15 sys.path.insert(0, os.path.abspath('../'))
16
17 # -- Project information -----------------------------------------------------
18
19 project = 'TensorNetwork'
20 copyright = '2019, The TensorNetwork Authors'
21 author = 'The TensorNetwork Authors'
22
23 # -- General configuration ---------------------------------------------------
24
25 # Add any Sphinx extension module names here, as strings. They can be
26 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
27 # ones.
28 extensions = [
29 'sphinx.ext.autodoc',
30 'sphinx.ext.napoleon',
31 'sphinx.ext.autosummary',
32 ]
33
34 # Add any paths that contain templates here, relative to this directory.
35 templates_path = ['_templates']
36
37 # The master toctree document.
38 master_doc = 'index'
39
40 # List of patterns, relative to source directory, that match files and
41 # directories to ignore when looking for source files.
42 # This pattern also affects html_static_path and html_extra_path.
43 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
44
45 autosummary_generate = True
46 napolean_use_rtype = False
47 # -- Options for HTML output -------------------------------------------------
48
49 # The theme to use for HTML and HTML Help pages. See the documentation for
50 # a list of builtin themes.
51 #
52 html_theme = 'sphinx_rtd_theme'
53 html_theme_options = {
54 'logo_only': True,
55 }
56 html_logo = '_static/tensornetwork_logo.jpg'
57 master_doc = 'index'
58 default_role = 'py:obj'
59 autodoc_default_flags = ['members']
60 autosummary_generate = True
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -43,6 +43,7 @@
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
autosummary_generate = True
+autosummary_generate_overwrite = False
napolean_use_rtype = False
# -- Options for HTML output -------------------------------------------------
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -43,6 +43,7 @@\n exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n \n autosummary_generate = True\n+autosummary_generate_overwrite = False\n napolean_use_rtype = False\n # -- Options for HTML output -------------------------------------------------\n", "issue": "Some doc links to github yield error\nThe \"Edit on GitHub\" links in the top right of some doc pages yield 404 errors when followed, for example [tn.Node](https://tensornetwork.readthedocs.io/en/latest/stubs/tensornetwork.Node.html) and [tn.contractors.optimal](https://tensornetwork.readthedocs.io/en/latest/stubs/tensornetwork.contractors.optimal.html#tensornetwork.contractors.optimal).\r\n\r\nThe links at the top of list pages work, for example [common functions](https://tensornetwork.readthedocs.io/en/latest/network.html) and [contractors](https://tensornetwork.readthedocs.io/en/latest/contractors.html).\r\n\r\nPossibly those are meant to be links to edit the doc pages themselves, rather than the source code?\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- Project information -----------------------------------------------------\n\nproject = 'TensorNetwork'\ncopyright = '2019, The TensorNetwork Authors'\nauthor = 'The TensorNetwork Authors'\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.autosummary',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\nautosummary_generate = True\nnapolean_use_rtype = False\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'logo_only': True,\n}\nhtml_logo = '_static/tensornetwork_logo.jpg'\nmaster_doc = 'index'\ndefault_role = 'py:obj'\nautodoc_default_flags = ['members']\nautosummary_generate = True\n", "path": "docs/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- Project information -----------------------------------------------------\n\nproject = 'TensorNetwork'\ncopyright = '2019, The TensorNetwork Authors'\nauthor = 'The TensorNetwork Authors'\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.autosummary',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\nautosummary_generate = True\nautosummary_generate_overwrite = False\nnapolean_use_rtype = False\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'logo_only': True,\n}\nhtml_logo = '_static/tensornetwork_logo.jpg'\nmaster_doc = 'index'\ndefault_role = 'py:obj'\nautodoc_default_flags = ['members']\nautosummary_generate = True\n", "path": "docs/conf.py"}]}
| 988 | 86 |
gh_patches_debug_66225
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-1605
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JavaScript negative timestamp are not supported
# Bug
When parsing a JavaScript positive timestamp (number of milliseconds since EPOCH), pydantic parses it properly. However, for a negative JavaScript timestamp (before 1st January 1970), a `date value out of range` error is thrown.
```
File "pydantic/main.py", line 447, in pydantic.main.BaseModel.parse_obj
File "pydantic/main.py", line 336, in pydantic.main.BaseModel.__init__
File "pydantic/main.py", line 887, in pydantic.main.validate_model
File "pydantic/fields.py", line 549, in pydantic.fields.ModelField.validate
File "pydantic/fields.py", line 704, in pydantic.fields.ModelField._validate_singleton
File "pydantic/fields.py", line 711, in pydantic.fields.ModelField._apply_validators
File "pydantic/class_validators.py", line 313, in pydantic.class_validators._generic_validator_basic.lambda11
File "pydantic/datetime_parse.py", line 169, in pydantic.datetime_parse.parse_datetime
File "pydantic/datetime_parse.py", line 80, in pydantic.datetime_parse.from_unix_seconds
OverflowError: date value out of range
```
## Version
Output of `python -c "import pydantic.utils; print(pydantic.utils.version_info())"`:
```
pydantic version: 1.5.1
pydantic compiled: True
install path: /Users/thibaud/Documents/Programmation/Scopyleft/Terrapeutes/aposto-server/venv/lib/python3.7/site-packages/pydantic
python version: 3.7.3 (default, Mar 6 2020, 22:34:30) [Clang 11.0.3 (clang-1103.0.32.29)]
platform: Darwin-19.5.0-x86_64-i386-64bit
optional deps. installed: ['typing-extensions', 'email-validator']
```
## Code example
The following code raises the describe error (while it would correctly work with `{ "jsTimestamp": 1118102400000 }`).
```py
from datetime import datetime
from pydantic import BaseModel
class MyModel(BaseModel):
jsTimestamp: datetime
MyModel.parse_obj({ "jsTimestamp": -1118102400000 })
```
## Possible solution
A solution would be to update the `from_unix_seconds` function in _datetime_parse.py_ to compare `seconds` with `MS_WATERSHED` as absolute value.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pydantic/datetime_parse.py`
Content:
```
1 """
2 Functions to parse datetime objects.
3
4 We're using regular expressions rather than time.strptime because:
5 - They provide both validation and parsing.
6 - They're more flexible for datetimes.
7 - The date/datetime/time constructors produce friendlier error messages.
8
9 Stolen from https://raw.githubusercontent.com/django/django/master/django/utils/dateparse.py at
10 9718fa2e8abe430c3526a9278dd976443d4ae3c6
11
12 Changed to:
13 * use standard python datetime types not django.utils.timezone
14 * raise ValueError when regex doesn't match rather than returning None
15 * support parsing unix timestamps for dates and datetimes
16 """
17 import re
18 from datetime import date, datetime, time, timedelta, timezone
19 from typing import Dict, Union
20
21 from . import errors
22
23 date_re = re.compile(r'(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})$')
24
25 time_re = re.compile(
26 r'(?P<hour>\d{1,2}):(?P<minute>\d{1,2})(?::(?P<second>\d{1,2})(?:\.(?P<microsecond>\d{1,6})\d{0,6})?)?'
27 )
28
29 datetime_re = re.compile(
30 r'(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})'
31 r'[T ](?P<hour>\d{1,2}):(?P<minute>\d{1,2})'
32 r'(?::(?P<second>\d{1,2})(?:\.(?P<microsecond>\d{1,6})\d{0,6})?)?'
33 r'(?P<tzinfo>Z|[+-]\d{2}(?::?\d{2})?)?$'
34 )
35
36 standard_duration_re = re.compile(
37 r'^'
38 r'(?:(?P<days>-?\d+) (days?, )?)?'
39 r'((?:(?P<hours>-?\d+):)(?=\d+:\d+))?'
40 r'(?:(?P<minutes>-?\d+):)?'
41 r'(?P<seconds>-?\d+)'
42 r'(?:\.(?P<microseconds>\d{1,6})\d{0,6})?'
43 r'$'
44 )
45
46 # Support the sections of ISO 8601 date representation that are accepted by timedelta
47 iso8601_duration_re = re.compile(
48 r'^(?P<sign>[-+]?)'
49 r'P'
50 r'(?:(?P<days>\d+(.\d+)?)D)?'
51 r'(?:T'
52 r'(?:(?P<hours>\d+(.\d+)?)H)?'
53 r'(?:(?P<minutes>\d+(.\d+)?)M)?'
54 r'(?:(?P<seconds>\d+(.\d+)?)S)?'
55 r')?'
56 r'$'
57 )
58
59 EPOCH = datetime(1970, 1, 1)
60 # if greater than this, the number is in ms, if less than or equal it's in seconds
61 # (in seconds this is 11th October 2603, in ms it's 20th August 1970)
62 MS_WATERSHED = int(2e10)
63 StrBytesIntFloat = Union[str, bytes, int, float]
64
65
66 def get_numeric(value: StrBytesIntFloat, native_expected_type: str) -> Union[None, int, float]:
67 if isinstance(value, (int, float)):
68 return value
69 try:
70 return float(value)
71 except ValueError:
72 return None
73 except TypeError:
74 raise TypeError(f'invalid type; expected {native_expected_type}, string, bytes, int or float')
75
76
77 def from_unix_seconds(seconds: Union[int, float]) -> datetime:
78 while seconds > MS_WATERSHED:
79 seconds /= 1000
80 dt = EPOCH + timedelta(seconds=seconds)
81 return dt.replace(tzinfo=timezone.utc)
82
83
84 def parse_date(value: Union[date, StrBytesIntFloat]) -> date:
85 """
86 Parse a date/int/float/string and return a datetime.date.
87
88 Raise ValueError if the input is well formatted but not a valid date.
89 Raise ValueError if the input isn't well formatted.
90 """
91 if isinstance(value, date):
92 if isinstance(value, datetime):
93 return value.date()
94 else:
95 return value
96
97 number = get_numeric(value, 'date')
98 if number is not None:
99 return from_unix_seconds(number).date()
100
101 if isinstance(value, bytes):
102 value = value.decode()
103
104 match = date_re.match(value) # type: ignore
105 if match is None:
106 raise errors.DateError()
107
108 kw = {k: int(v) for k, v in match.groupdict().items()}
109
110 try:
111 return date(**kw)
112 except ValueError:
113 raise errors.DateError()
114
115
116 def parse_time(value: Union[time, StrBytesIntFloat]) -> time:
117 """
118 Parse a time/string and return a datetime.time.
119
120 This function doesn't support time zone offsets.
121
122 Raise ValueError if the input is well formatted but not a valid time.
123 Raise ValueError if the input isn't well formatted, in particular if it contains an offset.
124 """
125 if isinstance(value, time):
126 return value
127
128 number = get_numeric(value, 'time')
129 if number is not None:
130 if number >= 86400:
131 # doesn't make sense since the time time loop back around to 0
132 raise errors.TimeError()
133 return (datetime.min + timedelta(seconds=number)).time()
134
135 if isinstance(value, bytes):
136 value = value.decode()
137
138 match = time_re.match(value) # type: ignore
139 if match is None:
140 raise errors.TimeError()
141
142 kw = match.groupdict()
143 if kw['microsecond']:
144 kw['microsecond'] = kw['microsecond'].ljust(6, '0')
145
146 kw_ = {k: int(v) for k, v in kw.items() if v is not None}
147
148 try:
149 return time(**kw_) # type: ignore
150 except ValueError:
151 raise errors.TimeError()
152
153
154 def parse_datetime(value: Union[datetime, StrBytesIntFloat]) -> datetime:
155 """
156 Parse a datetime/int/float/string and return a datetime.datetime.
157
158 This function supports time zone offsets. When the input contains one,
159 the output uses a timezone with a fixed offset from UTC.
160
161 Raise ValueError if the input is well formatted but not a valid datetime.
162 Raise ValueError if the input isn't well formatted.
163 """
164 if isinstance(value, datetime):
165 return value
166
167 number = get_numeric(value, 'datetime')
168 if number is not None:
169 return from_unix_seconds(number)
170
171 if isinstance(value, bytes):
172 value = value.decode()
173
174 match = datetime_re.match(value) # type: ignore
175 if match is None:
176 raise errors.DateTimeError()
177
178 kw = match.groupdict()
179 if kw['microsecond']:
180 kw['microsecond'] = kw['microsecond'].ljust(6, '0')
181
182 tzinfo_str = kw.pop('tzinfo')
183 if tzinfo_str == 'Z':
184 tzinfo = timezone.utc
185 elif tzinfo_str is not None:
186 offset_mins = int(tzinfo_str[-2:]) if len(tzinfo_str) > 3 else 0
187 offset = 60 * int(tzinfo_str[1:3]) + offset_mins
188 if tzinfo_str[0] == '-':
189 offset = -offset
190 tzinfo = timezone(timedelta(minutes=offset))
191 else:
192 tzinfo = None
193
194 kw_: Dict[str, Union[int, timezone]] = {k: int(v) for k, v in kw.items() if v is not None}
195 kw_['tzinfo'] = tzinfo
196
197 try:
198 return datetime(**kw_) # type: ignore
199 except ValueError:
200 raise errors.DateTimeError()
201
202
203 def parse_duration(value: StrBytesIntFloat) -> timedelta:
204 """
205 Parse a duration int/float/string and return a datetime.timedelta.
206
207 The preferred format for durations in Django is '%d %H:%M:%S.%f'.
208
209 Also supports ISO 8601 representation.
210 """
211 if isinstance(value, timedelta):
212 return value
213
214 if isinstance(value, (int, float)):
215 # bellow code requires a string
216 value = str(value)
217 elif isinstance(value, bytes):
218 value = value.decode()
219
220 try:
221 match = standard_duration_re.match(value) or iso8601_duration_re.match(value)
222 except TypeError:
223 raise TypeError('invalid type; expected timedelta, string, bytes, int or float')
224
225 if not match:
226 raise errors.DurationError()
227
228 kw = match.groupdict()
229 sign = -1 if kw.pop('sign', '+') == '-' else 1
230 if kw.get('microseconds'):
231 kw['microseconds'] = kw['microseconds'].ljust(6, '0')
232
233 if kw.get('seconds') and kw.get('microseconds') and kw['seconds'].startswith('-'):
234 kw['microseconds'] = '-' + kw['microseconds']
235
236 kw_ = {k: float(v) for k, v in kw.items() if v is not None}
237
238 return sign * timedelta(**kw_) # type: ignore
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pydantic/datetime_parse.py b/pydantic/datetime_parse.py
--- a/pydantic/datetime_parse.py
+++ b/pydantic/datetime_parse.py
@@ -75,7 +75,7 @@
def from_unix_seconds(seconds: Union[int, float]) -> datetime:
- while seconds > MS_WATERSHED:
+ while abs(seconds) > MS_WATERSHED:
seconds /= 1000
dt = EPOCH + timedelta(seconds=seconds)
return dt.replace(tzinfo=timezone.utc)
|
{"golden_diff": "diff --git a/pydantic/datetime_parse.py b/pydantic/datetime_parse.py\n--- a/pydantic/datetime_parse.py\n+++ b/pydantic/datetime_parse.py\n@@ -75,7 +75,7 @@\n \n \n def from_unix_seconds(seconds: Union[int, float]) -> datetime:\n- while seconds > MS_WATERSHED:\n+ while abs(seconds) > MS_WATERSHED:\n seconds /= 1000\n dt = EPOCH + timedelta(seconds=seconds)\n return dt.replace(tzinfo=timezone.utc)\n", "issue": "JavaScript negative timestamp are not supported\n# Bug\r\n\r\nWhen parsing a JavaScript positive timestamp (number of milliseconds since EPOCH), pydantic parses it properly. However, for a negative JavaScript timestamp (before 1st January 1970), a `date value out of range` error is thrown.\r\n\r\n```\r\n File \"pydantic/main.py\", line 447, in pydantic.main.BaseModel.parse_obj\r\n File \"pydantic/main.py\", line 336, in pydantic.main.BaseModel.__init__\r\n File \"pydantic/main.py\", line 887, in pydantic.main.validate_model\r\n File \"pydantic/fields.py\", line 549, in pydantic.fields.ModelField.validate\r\n File \"pydantic/fields.py\", line 704, in pydantic.fields.ModelField._validate_singleton\r\n File \"pydantic/fields.py\", line 711, in pydantic.fields.ModelField._apply_validators\r\n File \"pydantic/class_validators.py\", line 313, in pydantic.class_validators._generic_validator_basic.lambda11\r\n File \"pydantic/datetime_parse.py\", line 169, in pydantic.datetime_parse.parse_datetime\r\n File \"pydantic/datetime_parse.py\", line 80, in pydantic.datetime_parse.from_unix_seconds\r\nOverflowError: date value out of range\r\n```\r\n\r\n## Version\r\n\r\nOutput of `python -c \"import pydantic.utils; print(pydantic.utils.version_info())\"`:\r\n```\r\n pydantic version: 1.5.1\r\n pydantic compiled: True\r\n install path: /Users/thibaud/Documents/Programmation/Scopyleft/Terrapeutes/aposto-server/venv/lib/python3.7/site-packages/pydantic\r\n python version: 3.7.3 (default, Mar 6 2020, 22:34:30) [Clang 11.0.3 (clang-1103.0.32.29)]\r\n platform: Darwin-19.5.0-x86_64-i386-64bit\r\n optional deps. installed: ['typing-extensions', 'email-validator']\r\n```\r\n\r\n## Code example\r\n\r\nThe following code raises the describe error (while it would correctly work with `{ \"jsTimestamp\": 1118102400000 }`).\r\n\r\n```py\r\nfrom datetime import datetime\r\n\r\nfrom pydantic import BaseModel\r\n\r\n\r\nclass MyModel(BaseModel):\r\n jsTimestamp: datetime\r\n\r\nMyModel.parse_obj({ \"jsTimestamp\": -1118102400000 })\r\n```\r\n\r\n## Possible solution\r\n\r\nA solution would be to update the `from_unix_seconds` function in _datetime_parse.py_ to compare `seconds` with `MS_WATERSHED` as absolute value.\n", "before_files": [{"content": "\"\"\"\nFunctions to parse datetime objects.\n\nWe're using regular expressions rather than time.strptime because:\n- They provide both validation and parsing.\n- They're more flexible for datetimes.\n- The date/datetime/time constructors produce friendlier error messages.\n\nStolen from https://raw.githubusercontent.com/django/django/master/django/utils/dateparse.py at\n9718fa2e8abe430c3526a9278dd976443d4ae3c6\n\nChanged to:\n* use standard python datetime types not django.utils.timezone\n* raise ValueError when regex doesn't match rather than returning None\n* support parsing unix timestamps for dates and datetimes\n\"\"\"\nimport re\nfrom datetime import date, datetime, time, timedelta, timezone\nfrom typing import Dict, Union\n\nfrom . import errors\n\ndate_re = re.compile(r'(?P<year>\\d{4})-(?P<month>\\d{1,2})-(?P<day>\\d{1,2})$')\n\ntime_re = re.compile(\n r'(?P<hour>\\d{1,2}):(?P<minute>\\d{1,2})(?::(?P<second>\\d{1,2})(?:\\.(?P<microsecond>\\d{1,6})\\d{0,6})?)?'\n)\n\ndatetime_re = re.compile(\n r'(?P<year>\\d{4})-(?P<month>\\d{1,2})-(?P<day>\\d{1,2})'\n r'[T ](?P<hour>\\d{1,2}):(?P<minute>\\d{1,2})'\n r'(?::(?P<second>\\d{1,2})(?:\\.(?P<microsecond>\\d{1,6})\\d{0,6})?)?'\n r'(?P<tzinfo>Z|[+-]\\d{2}(?::?\\d{2})?)?$'\n)\n\nstandard_duration_re = re.compile(\n r'^'\n r'(?:(?P<days>-?\\d+) (days?, )?)?'\n r'((?:(?P<hours>-?\\d+):)(?=\\d+:\\d+))?'\n r'(?:(?P<minutes>-?\\d+):)?'\n r'(?P<seconds>-?\\d+)'\n r'(?:\\.(?P<microseconds>\\d{1,6})\\d{0,6})?'\n r'$'\n)\n\n# Support the sections of ISO 8601 date representation that are accepted by timedelta\niso8601_duration_re = re.compile(\n r'^(?P<sign>[-+]?)'\n r'P'\n r'(?:(?P<days>\\d+(.\\d+)?)D)?'\n r'(?:T'\n r'(?:(?P<hours>\\d+(.\\d+)?)H)?'\n r'(?:(?P<minutes>\\d+(.\\d+)?)M)?'\n r'(?:(?P<seconds>\\d+(.\\d+)?)S)?'\n r')?'\n r'$'\n)\n\nEPOCH = datetime(1970, 1, 1)\n# if greater than this, the number is in ms, if less than or equal it's in seconds\n# (in seconds this is 11th October 2603, in ms it's 20th August 1970)\nMS_WATERSHED = int(2e10)\nStrBytesIntFloat = Union[str, bytes, int, float]\n\n\ndef get_numeric(value: StrBytesIntFloat, native_expected_type: str) -> Union[None, int, float]:\n if isinstance(value, (int, float)):\n return value\n try:\n return float(value)\n except ValueError:\n return None\n except TypeError:\n raise TypeError(f'invalid type; expected {native_expected_type}, string, bytes, int or float')\n\n\ndef from_unix_seconds(seconds: Union[int, float]) -> datetime:\n while seconds > MS_WATERSHED:\n seconds /= 1000\n dt = EPOCH + timedelta(seconds=seconds)\n return dt.replace(tzinfo=timezone.utc)\n\n\ndef parse_date(value: Union[date, StrBytesIntFloat]) -> date:\n \"\"\"\n Parse a date/int/float/string and return a datetime.date.\n\n Raise ValueError if the input is well formatted but not a valid date.\n Raise ValueError if the input isn't well formatted.\n \"\"\"\n if isinstance(value, date):\n if isinstance(value, datetime):\n return value.date()\n else:\n return value\n\n number = get_numeric(value, 'date')\n if number is not None:\n return from_unix_seconds(number).date()\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = date_re.match(value) # type: ignore\n if match is None:\n raise errors.DateError()\n\n kw = {k: int(v) for k, v in match.groupdict().items()}\n\n try:\n return date(**kw)\n except ValueError:\n raise errors.DateError()\n\n\ndef parse_time(value: Union[time, StrBytesIntFloat]) -> time:\n \"\"\"\n Parse a time/string and return a datetime.time.\n\n This function doesn't support time zone offsets.\n\n Raise ValueError if the input is well formatted but not a valid time.\n Raise ValueError if the input isn't well formatted, in particular if it contains an offset.\n \"\"\"\n if isinstance(value, time):\n return value\n\n number = get_numeric(value, 'time')\n if number is not None:\n if number >= 86400:\n # doesn't make sense since the time time loop back around to 0\n raise errors.TimeError()\n return (datetime.min + timedelta(seconds=number)).time()\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = time_re.match(value) # type: ignore\n if match is None:\n raise errors.TimeError()\n\n kw = match.groupdict()\n if kw['microsecond']:\n kw['microsecond'] = kw['microsecond'].ljust(6, '0')\n\n kw_ = {k: int(v) for k, v in kw.items() if v is not None}\n\n try:\n return time(**kw_) # type: ignore\n except ValueError:\n raise errors.TimeError()\n\n\ndef parse_datetime(value: Union[datetime, StrBytesIntFloat]) -> datetime:\n \"\"\"\n Parse a datetime/int/float/string and return a datetime.datetime.\n\n This function supports time zone offsets. When the input contains one,\n the output uses a timezone with a fixed offset from UTC.\n\n Raise ValueError if the input is well formatted but not a valid datetime.\n Raise ValueError if the input isn't well formatted.\n \"\"\"\n if isinstance(value, datetime):\n return value\n\n number = get_numeric(value, 'datetime')\n if number is not None:\n return from_unix_seconds(number)\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = datetime_re.match(value) # type: ignore\n if match is None:\n raise errors.DateTimeError()\n\n kw = match.groupdict()\n if kw['microsecond']:\n kw['microsecond'] = kw['microsecond'].ljust(6, '0')\n\n tzinfo_str = kw.pop('tzinfo')\n if tzinfo_str == 'Z':\n tzinfo = timezone.utc\n elif tzinfo_str is not None:\n offset_mins = int(tzinfo_str[-2:]) if len(tzinfo_str) > 3 else 0\n offset = 60 * int(tzinfo_str[1:3]) + offset_mins\n if tzinfo_str[0] == '-':\n offset = -offset\n tzinfo = timezone(timedelta(minutes=offset))\n else:\n tzinfo = None\n\n kw_: Dict[str, Union[int, timezone]] = {k: int(v) for k, v in kw.items() if v is not None}\n kw_['tzinfo'] = tzinfo\n\n try:\n return datetime(**kw_) # type: ignore\n except ValueError:\n raise errors.DateTimeError()\n\n\ndef parse_duration(value: StrBytesIntFloat) -> timedelta:\n \"\"\"\n Parse a duration int/float/string and return a datetime.timedelta.\n\n The preferred format for durations in Django is '%d %H:%M:%S.%f'.\n\n Also supports ISO 8601 representation.\n \"\"\"\n if isinstance(value, timedelta):\n return value\n\n if isinstance(value, (int, float)):\n # bellow code requires a string\n value = str(value)\n elif isinstance(value, bytes):\n value = value.decode()\n\n try:\n match = standard_duration_re.match(value) or iso8601_duration_re.match(value)\n except TypeError:\n raise TypeError('invalid type; expected timedelta, string, bytes, int or float')\n\n if not match:\n raise errors.DurationError()\n\n kw = match.groupdict()\n sign = -1 if kw.pop('sign', '+') == '-' else 1\n if kw.get('microseconds'):\n kw['microseconds'] = kw['microseconds'].ljust(6, '0')\n\n if kw.get('seconds') and kw.get('microseconds') and kw['seconds'].startswith('-'):\n kw['microseconds'] = '-' + kw['microseconds']\n\n kw_ = {k: float(v) for k, v in kw.items() if v is not None}\n\n return sign * timedelta(**kw_) # type: ignore\n", "path": "pydantic/datetime_parse.py"}], "after_files": [{"content": "\"\"\"\nFunctions to parse datetime objects.\n\nWe're using regular expressions rather than time.strptime because:\n- They provide both validation and parsing.\n- They're more flexible for datetimes.\n- The date/datetime/time constructors produce friendlier error messages.\n\nStolen from https://raw.githubusercontent.com/django/django/master/django/utils/dateparse.py at\n9718fa2e8abe430c3526a9278dd976443d4ae3c6\n\nChanged to:\n* use standard python datetime types not django.utils.timezone\n* raise ValueError when regex doesn't match rather than returning None\n* support parsing unix timestamps for dates and datetimes\n\"\"\"\nimport re\nfrom datetime import date, datetime, time, timedelta, timezone\nfrom typing import Dict, Union\n\nfrom . import errors\n\ndate_re = re.compile(r'(?P<year>\\d{4})-(?P<month>\\d{1,2})-(?P<day>\\d{1,2})$')\n\ntime_re = re.compile(\n r'(?P<hour>\\d{1,2}):(?P<minute>\\d{1,2})(?::(?P<second>\\d{1,2})(?:\\.(?P<microsecond>\\d{1,6})\\d{0,6})?)?'\n)\n\ndatetime_re = re.compile(\n r'(?P<year>\\d{4})-(?P<month>\\d{1,2})-(?P<day>\\d{1,2})'\n r'[T ](?P<hour>\\d{1,2}):(?P<minute>\\d{1,2})'\n r'(?::(?P<second>\\d{1,2})(?:\\.(?P<microsecond>\\d{1,6})\\d{0,6})?)?'\n r'(?P<tzinfo>Z|[+-]\\d{2}(?::?\\d{2})?)?$'\n)\n\nstandard_duration_re = re.compile(\n r'^'\n r'(?:(?P<days>-?\\d+) (days?, )?)?'\n r'((?:(?P<hours>-?\\d+):)(?=\\d+:\\d+))?'\n r'(?:(?P<minutes>-?\\d+):)?'\n r'(?P<seconds>-?\\d+)'\n r'(?:\\.(?P<microseconds>\\d{1,6})\\d{0,6})?'\n r'$'\n)\n\n# Support the sections of ISO 8601 date representation that are accepted by timedelta\niso8601_duration_re = re.compile(\n r'^(?P<sign>[-+]?)'\n r'P'\n r'(?:(?P<days>\\d+(.\\d+)?)D)?'\n r'(?:T'\n r'(?:(?P<hours>\\d+(.\\d+)?)H)?'\n r'(?:(?P<minutes>\\d+(.\\d+)?)M)?'\n r'(?:(?P<seconds>\\d+(.\\d+)?)S)?'\n r')?'\n r'$'\n)\n\nEPOCH = datetime(1970, 1, 1)\n# if greater than this, the number is in ms, if less than or equal it's in seconds\n# (in seconds this is 11th October 2603, in ms it's 20th August 1970)\nMS_WATERSHED = int(2e10)\nStrBytesIntFloat = Union[str, bytes, int, float]\n\n\ndef get_numeric(value: StrBytesIntFloat, native_expected_type: str) -> Union[None, int, float]:\n if isinstance(value, (int, float)):\n return value\n try:\n return float(value)\n except ValueError:\n return None\n except TypeError:\n raise TypeError(f'invalid type; expected {native_expected_type}, string, bytes, int or float')\n\n\ndef from_unix_seconds(seconds: Union[int, float]) -> datetime:\n while abs(seconds) > MS_WATERSHED:\n seconds /= 1000\n dt = EPOCH + timedelta(seconds=seconds)\n return dt.replace(tzinfo=timezone.utc)\n\n\ndef parse_date(value: Union[date, StrBytesIntFloat]) -> date:\n \"\"\"\n Parse a date/int/float/string and return a datetime.date.\n\n Raise ValueError if the input is well formatted but not a valid date.\n Raise ValueError if the input isn't well formatted.\n \"\"\"\n if isinstance(value, date):\n if isinstance(value, datetime):\n return value.date()\n else:\n return value\n\n number = get_numeric(value, 'date')\n if number is not None:\n return from_unix_seconds(number).date()\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = date_re.match(value) # type: ignore\n if match is None:\n raise errors.DateError()\n\n kw = {k: int(v) for k, v in match.groupdict().items()}\n\n try:\n return date(**kw)\n except ValueError:\n raise errors.DateError()\n\n\ndef parse_time(value: Union[time, StrBytesIntFloat]) -> time:\n \"\"\"\n Parse a time/string and return a datetime.time.\n\n This function doesn't support time zone offsets.\n\n Raise ValueError if the input is well formatted but not a valid time.\n Raise ValueError if the input isn't well formatted, in particular if it contains an offset.\n \"\"\"\n if isinstance(value, time):\n return value\n\n number = get_numeric(value, 'time')\n if number is not None:\n if number >= 86400:\n # doesn't make sense since the time time loop back around to 0\n raise errors.TimeError()\n return (datetime.min + timedelta(seconds=number)).time()\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = time_re.match(value) # type: ignore\n if match is None:\n raise errors.TimeError()\n\n kw = match.groupdict()\n if kw['microsecond']:\n kw['microsecond'] = kw['microsecond'].ljust(6, '0')\n\n kw_ = {k: int(v) for k, v in kw.items() if v is not None}\n\n try:\n return time(**kw_) # type: ignore\n except ValueError:\n raise errors.TimeError()\n\n\ndef parse_datetime(value: Union[datetime, StrBytesIntFloat]) -> datetime:\n \"\"\"\n Parse a datetime/int/float/string and return a datetime.datetime.\n\n This function supports time zone offsets. When the input contains one,\n the output uses a timezone with a fixed offset from UTC.\n\n Raise ValueError if the input is well formatted but not a valid datetime.\n Raise ValueError if the input isn't well formatted.\n \"\"\"\n if isinstance(value, datetime):\n return value\n\n number = get_numeric(value, 'datetime')\n if number is not None:\n return from_unix_seconds(number)\n\n if isinstance(value, bytes):\n value = value.decode()\n\n match = datetime_re.match(value) # type: ignore\n if match is None:\n raise errors.DateTimeError()\n\n kw = match.groupdict()\n if kw['microsecond']:\n kw['microsecond'] = kw['microsecond'].ljust(6, '0')\n\n tzinfo_str = kw.pop('tzinfo')\n if tzinfo_str == 'Z':\n tzinfo = timezone.utc\n elif tzinfo_str is not None:\n offset_mins = int(tzinfo_str[-2:]) if len(tzinfo_str) > 3 else 0\n offset = 60 * int(tzinfo_str[1:3]) + offset_mins\n if tzinfo_str[0] == '-':\n offset = -offset\n tzinfo = timezone(timedelta(minutes=offset))\n else:\n tzinfo = None\n\n kw_: Dict[str, Union[int, timezone]] = {k: int(v) for k, v in kw.items() if v is not None}\n kw_['tzinfo'] = tzinfo\n\n try:\n return datetime(**kw_) # type: ignore\n except ValueError:\n raise errors.DateTimeError()\n\n\ndef parse_duration(value: StrBytesIntFloat) -> timedelta:\n \"\"\"\n Parse a duration int/float/string and return a datetime.timedelta.\n\n The preferred format for durations in Django is '%d %H:%M:%S.%f'.\n\n Also supports ISO 8601 representation.\n \"\"\"\n if isinstance(value, timedelta):\n return value\n\n if isinstance(value, (int, float)):\n # bellow code requires a string\n value = str(value)\n elif isinstance(value, bytes):\n value = value.decode()\n\n try:\n match = standard_duration_re.match(value) or iso8601_duration_re.match(value)\n except TypeError:\n raise TypeError('invalid type; expected timedelta, string, bytes, int or float')\n\n if not match:\n raise errors.DurationError()\n\n kw = match.groupdict()\n sign = -1 if kw.pop('sign', '+') == '-' else 1\n if kw.get('microseconds'):\n kw['microseconds'] = kw['microseconds'].ljust(6, '0')\n\n if kw.get('seconds') and kw.get('microseconds') and kw['seconds'].startswith('-'):\n kw['microseconds'] = '-' + kw['microseconds']\n\n kw_ = {k: float(v) for k, v in kw.items() if v is not None}\n\n return sign * timedelta(**kw_) # type: ignore\n", "path": "pydantic/datetime_parse.py"}]}
| 3,621 | 124 |
gh_patches_debug_13468
|
rasdani/github-patches
|
git_diff
|
doccano__doccano-163
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot use the same shortcut and label name in different projects
The issue is the following:
1. I create Project A.
2. Import some annotated data to the project - set of labels is automatically created as a result (let's say, Label 1, Label 2, Label 3)
3. I edit these labels - provide a shortcut and color
4. I create Project B and import another portion of dataset (with the same set of labels)
5. I try to replicate setting of Project A (assign the same shortcuts, colors and label names to labels), which gives me an error:
`You cannot use same label name or shortcut key.`
It seems not very convenient that we cannot create labels with the same shortcut and label name in different project. I wonder if it was made intentionally or it is a bug.
Thank you very much for a great tool.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/server/serializers.py`
Content:
```
1 from django.contrib.auth import get_user_model
2 from rest_framework import serializers
3 from rest_polymorphic.serializers import PolymorphicSerializer
4 from rest_framework.exceptions import ValidationError
5
6
7 from .models import Label, Project, Document
8 from .models import TextClassificationProject, SequenceLabelingProject, Seq2seqProject
9 from .models import DocumentAnnotation, SequenceAnnotation, Seq2seqAnnotation
10
11
12 class UserSerializer(serializers.ModelSerializer):
13
14 class Meta:
15 model = get_user_model()
16 fields = ('id', 'username', 'first_name', 'last_name', 'email', 'is_superuser')
17
18
19 class LabelSerializer(serializers.ModelSerializer):
20
21 def validate(self, attrs):
22 if 'prefix_key' not in attrs and 'suffix_key' not in attrs:
23 return super().validate(attrs)
24
25 prefix_key = attrs['prefix_key']
26 suffix_key = attrs['suffix_key']
27
28 # In the case of user don't set any shortcut key.
29 if prefix_key is None and suffix_key is None:
30 return super().validate(attrs)
31
32 # Don't allow shortcut key not to have a suffix key.
33 if prefix_key and not suffix_key:
34 raise ValidationError('Shortcut key may not have a suffix key.')
35
36 # Don't allow to save same shortcut key when prefix_key is null.
37 if Label.objects.filter(suffix_key=suffix_key,
38 prefix_key__isnull=True).exists():
39 raise ValidationError('Duplicate key.')
40 return super().validate(attrs)
41
42 class Meta:
43 model = Label
44 fields = ('id', 'text', 'prefix_key', 'suffix_key', 'background_color', 'text_color')
45
46
47 class DocumentSerializer(serializers.ModelSerializer):
48 annotations = serializers.SerializerMethodField()
49
50 def get_annotations(self, instance):
51 request = self.context.get('request')
52 project = instance.project
53 model = project.get_annotation_class()
54 serializer = project.get_annotation_serializer()
55 annotations = model.objects.filter(document=instance.id)
56 if request:
57 annotations = annotations.filter(user=request.user)
58 serializer = serializer(annotations, many=True)
59 return serializer.data
60
61 class Meta:
62 model = Document
63 fields = ('id', 'text', 'annotations', 'meta')
64
65
66 class ProjectSerializer(serializers.ModelSerializer):
67
68 class Meta:
69 model = Project
70 fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')
71 read_only_fields = ('image', 'updated_at')
72
73
74 class TextClassificationProjectSerializer(serializers.ModelSerializer):
75
76 class Meta:
77 model = TextClassificationProject
78 fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')
79 read_only_fields = ('image', 'updated_at', 'users')
80
81
82 class SequenceLabelingProjectSerializer(serializers.ModelSerializer):
83
84 class Meta:
85 model = SequenceLabelingProject
86 fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')
87 read_only_fields = ('image', 'updated_at', 'users')
88
89
90 class Seq2seqProjectSerializer(serializers.ModelSerializer):
91
92 class Meta:
93 model = Seq2seqProject
94 fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')
95 read_only_fields = ('image', 'updated_at', 'users')
96
97
98 class ProjectPolymorphicSerializer(PolymorphicSerializer):
99 model_serializer_mapping = {
100 Project: ProjectSerializer,
101 TextClassificationProject: TextClassificationProjectSerializer,
102 SequenceLabelingProject: SequenceLabelingProjectSerializer,
103 Seq2seqProject: Seq2seqProjectSerializer
104 }
105
106
107 class ProjectFilteredPrimaryKeyRelatedField(serializers.PrimaryKeyRelatedField):
108
109 def get_queryset(self):
110 view = self.context.get('view', None)
111 request = self.context.get('request', None)
112 queryset = super(ProjectFilteredPrimaryKeyRelatedField, self).get_queryset()
113 if not request or not queryset or not view:
114 return None
115 return queryset.filter(project=view.kwargs['project_id'])
116
117
118 class DocumentAnnotationSerializer(serializers.ModelSerializer):
119 # label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())
120 label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())
121 document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())
122
123 class Meta:
124 model = DocumentAnnotation
125 fields = ('id', 'prob', 'label', 'user', 'document')
126 read_only_fields = ('user', )
127
128
129 class SequenceAnnotationSerializer(serializers.ModelSerializer):
130 #label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())
131 label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())
132 document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())
133
134 class Meta:
135 model = SequenceAnnotation
136 fields = ('id', 'prob', 'label', 'start_offset', 'end_offset', 'user', 'document')
137 read_only_fields = ('user',)
138
139
140 class Seq2seqAnnotationSerializer(serializers.ModelSerializer):
141 document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())
142
143 class Meta:
144 model = Seq2seqAnnotation
145 fields = ('id', 'text', 'user', 'document')
146 read_only_fields = ('user',)
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/server/serializers.py b/app/server/serializers.py
--- a/app/server/serializers.py
+++ b/app/server/serializers.py
@@ -34,8 +34,11 @@
raise ValidationError('Shortcut key may not have a suffix key.')
# Don't allow to save same shortcut key when prefix_key is null.
+ context = self.context['request'].parser_context
+ project_id = context['kwargs'].get('project_id')
if Label.objects.filter(suffix_key=suffix_key,
- prefix_key__isnull=True).exists():
+ prefix_key__isnull=True,
+ project=project_id).exists():
raise ValidationError('Duplicate key.')
return super().validate(attrs)
|
{"golden_diff": "diff --git a/app/server/serializers.py b/app/server/serializers.py\n--- a/app/server/serializers.py\n+++ b/app/server/serializers.py\n@@ -34,8 +34,11 @@\n raise ValidationError('Shortcut key may not have a suffix key.')\n \n # Don't allow to save same shortcut key when prefix_key is null.\n+ context = self.context['request'].parser_context\n+ project_id = context['kwargs'].get('project_id')\n if Label.objects.filter(suffix_key=suffix_key,\n- prefix_key__isnull=True).exists():\n+ prefix_key__isnull=True,\n+ project=project_id).exists():\n raise ValidationError('Duplicate key.')\n return super().validate(attrs)\n", "issue": "Cannot use the same shortcut and label name in different projects\nThe issue is the following:\r\n\r\n1. I create Project A.\r\n2. Import some annotated data to the project - set of labels is automatically created as a result (let's say, Label 1, Label 2, Label 3)\r\n3. I edit these labels - provide a shortcut and color\r\n4. I create Project B and import another portion of dataset (with the same set of labels)\r\n5. I try to replicate setting of Project A (assign the same shortcuts, colors and label names to labels), which gives me an error:\r\n`You cannot use same label name or shortcut key.`\r\n\r\nIt seems not very convenient that we cannot create labels with the same shortcut and label name in different project. I wonder if it was made intentionally or it is a bug.\r\n\r\nThank you very much for a great tool.\n", "before_files": [{"content": "from django.contrib.auth import get_user_model\nfrom rest_framework import serializers\nfrom rest_polymorphic.serializers import PolymorphicSerializer\nfrom rest_framework.exceptions import ValidationError\n\n\nfrom .models import Label, Project, Document\nfrom .models import TextClassificationProject, SequenceLabelingProject, Seq2seqProject\nfrom .models import DocumentAnnotation, SequenceAnnotation, Seq2seqAnnotation\n\n\nclass UserSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = get_user_model()\n fields = ('id', 'username', 'first_name', 'last_name', 'email', 'is_superuser')\n\n\nclass LabelSerializer(serializers.ModelSerializer):\n\n def validate(self, attrs):\n if 'prefix_key' not in attrs and 'suffix_key' not in attrs:\n return super().validate(attrs)\n\n prefix_key = attrs['prefix_key']\n suffix_key = attrs['suffix_key']\n\n # In the case of user don't set any shortcut key.\n if prefix_key is None and suffix_key is None:\n return super().validate(attrs)\n\n # Don't allow shortcut key not to have a suffix key.\n if prefix_key and not suffix_key:\n raise ValidationError('Shortcut key may not have a suffix key.')\n\n # Don't allow to save same shortcut key when prefix_key is null.\n if Label.objects.filter(suffix_key=suffix_key,\n prefix_key__isnull=True).exists():\n raise ValidationError('Duplicate key.')\n return super().validate(attrs)\n\n class Meta:\n model = Label\n fields = ('id', 'text', 'prefix_key', 'suffix_key', 'background_color', 'text_color')\n\n\nclass DocumentSerializer(serializers.ModelSerializer):\n annotations = serializers.SerializerMethodField()\n\n def get_annotations(self, instance):\n request = self.context.get('request')\n project = instance.project\n model = project.get_annotation_class()\n serializer = project.get_annotation_serializer()\n annotations = model.objects.filter(document=instance.id)\n if request:\n annotations = annotations.filter(user=request.user)\n serializer = serializer(annotations, many=True)\n return serializer.data\n\n class Meta:\n model = Document\n fields = ('id', 'text', 'annotations', 'meta')\n\n\nclass ProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Project\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at')\n\n\nclass TextClassificationProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = TextClassificationProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass SequenceLabelingProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = SequenceLabelingProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass Seq2seqProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Seq2seqProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass ProjectPolymorphicSerializer(PolymorphicSerializer):\n model_serializer_mapping = {\n Project: ProjectSerializer,\n TextClassificationProject: TextClassificationProjectSerializer,\n SequenceLabelingProject: SequenceLabelingProjectSerializer,\n Seq2seqProject: Seq2seqProjectSerializer\n }\n\n\nclass ProjectFilteredPrimaryKeyRelatedField(serializers.PrimaryKeyRelatedField):\n\n def get_queryset(self):\n view = self.context.get('view', None)\n request = self.context.get('request', None)\n queryset = super(ProjectFilteredPrimaryKeyRelatedField, self).get_queryset()\n if not request or not queryset or not view:\n return None\n return queryset.filter(project=view.kwargs['project_id'])\n\n\nclass DocumentAnnotationSerializer(serializers.ModelSerializer):\n # label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())\n label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = DocumentAnnotation\n fields = ('id', 'prob', 'label', 'user', 'document')\n read_only_fields = ('user', )\n\n\nclass SequenceAnnotationSerializer(serializers.ModelSerializer):\n #label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())\n label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = SequenceAnnotation\n fields = ('id', 'prob', 'label', 'start_offset', 'end_offset', 'user', 'document')\n read_only_fields = ('user',)\n\n\nclass Seq2seqAnnotationSerializer(serializers.ModelSerializer):\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = Seq2seqAnnotation\n fields = ('id', 'text', 'user', 'document')\n read_only_fields = ('user',)\n", "path": "app/server/serializers.py"}], "after_files": [{"content": "from django.contrib.auth import get_user_model\nfrom rest_framework import serializers\nfrom rest_polymorphic.serializers import PolymorphicSerializer\nfrom rest_framework.exceptions import ValidationError\n\n\nfrom .models import Label, Project, Document\nfrom .models import TextClassificationProject, SequenceLabelingProject, Seq2seqProject\nfrom .models import DocumentAnnotation, SequenceAnnotation, Seq2seqAnnotation\n\n\nclass UserSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = get_user_model()\n fields = ('id', 'username', 'first_name', 'last_name', 'email', 'is_superuser')\n\n\nclass LabelSerializer(serializers.ModelSerializer):\n\n def validate(self, attrs):\n if 'prefix_key' not in attrs and 'suffix_key' not in attrs:\n return super().validate(attrs)\n\n prefix_key = attrs['prefix_key']\n suffix_key = attrs['suffix_key']\n\n # In the case of user don't set any shortcut key.\n if prefix_key is None and suffix_key is None:\n return super().validate(attrs)\n\n # Don't allow shortcut key not to have a suffix key.\n if prefix_key and not suffix_key:\n raise ValidationError('Shortcut key may not have a suffix key.')\n\n # Don't allow to save same shortcut key when prefix_key is null.\n context = self.context['request'].parser_context\n project_id = context['kwargs'].get('project_id')\n if Label.objects.filter(suffix_key=suffix_key,\n prefix_key__isnull=True,\n project=project_id).exists():\n raise ValidationError('Duplicate key.')\n return super().validate(attrs)\n\n class Meta:\n model = Label\n fields = ('id', 'text', 'prefix_key', 'suffix_key', 'background_color', 'text_color')\n\n\nclass DocumentSerializer(serializers.ModelSerializer):\n annotations = serializers.SerializerMethodField()\n\n def get_annotations(self, instance):\n request = self.context.get('request')\n project = instance.project\n model = project.get_annotation_class()\n serializer = project.get_annotation_serializer()\n annotations = model.objects.filter(document=instance.id)\n if request:\n annotations = annotations.filter(user=request.user)\n serializer = serializer(annotations, many=True)\n return serializer.data\n\n class Meta:\n model = Document\n fields = ('id', 'text', 'annotations', 'meta')\n\n\nclass ProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Project\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at')\n\n\nclass TextClassificationProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = TextClassificationProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass SequenceLabelingProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = SequenceLabelingProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass Seq2seqProjectSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Seq2seqProject\n fields = ('id', 'name', 'description', 'guideline', 'users', 'project_type', 'image', 'updated_at')\n read_only_fields = ('image', 'updated_at', 'users')\n\n\nclass ProjectPolymorphicSerializer(PolymorphicSerializer):\n model_serializer_mapping = {\n Project: ProjectSerializer,\n TextClassificationProject: TextClassificationProjectSerializer,\n SequenceLabelingProject: SequenceLabelingProjectSerializer,\n Seq2seqProject: Seq2seqProjectSerializer\n }\n\n\nclass ProjectFilteredPrimaryKeyRelatedField(serializers.PrimaryKeyRelatedField):\n\n def get_queryset(self):\n view = self.context.get('view', None)\n request = self.context.get('request', None)\n queryset = super(ProjectFilteredPrimaryKeyRelatedField, self).get_queryset()\n if not request or not queryset or not view:\n return None\n return queryset.filter(project=view.kwargs['project_id'])\n\n\nclass DocumentAnnotationSerializer(serializers.ModelSerializer):\n # label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())\n label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = DocumentAnnotation\n fields = ('id', 'prob', 'label', 'user', 'document')\n read_only_fields = ('user', )\n\n\nclass SequenceAnnotationSerializer(serializers.ModelSerializer):\n #label = ProjectFilteredPrimaryKeyRelatedField(queryset=Label.objects.all())\n label = serializers.PrimaryKeyRelatedField(queryset=Label.objects.all())\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = SequenceAnnotation\n fields = ('id', 'prob', 'label', 'start_offset', 'end_offset', 'user', 'document')\n read_only_fields = ('user',)\n\n\nclass Seq2seqAnnotationSerializer(serializers.ModelSerializer):\n document = serializers.PrimaryKeyRelatedField(queryset=Document.objects.all())\n\n class Meta:\n model = Seq2seqAnnotation\n fields = ('id', 'text', 'user', 'document')\n read_only_fields = ('user',)\n", "path": "app/server/serializers.py"}]}
| 1,893 | 159 |
gh_patches_debug_1019
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-2561
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Document the CI
DOCUMENT ALL THE THINGS
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/net/jsoc/attrs.py`
Content:
```
1 from __future__ import absolute_import
2
3 from sunpy.net.attr import AttrWalker, AttrAnd, AttrOr
4 from sunpy.net.vso.attrs import _VSOSimpleAttr
5 from sunpy.net.vso.attrs import Time, Wavelength
6
7
8 __all__ = ['Series', 'Protocol', 'Notify', 'Compression', 'Segment']
9
10
11 class Series(_VSOSimpleAttr):
12 """
13 The JSOC Series to Download.
14
15 See `this<http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`
16 for a list of series'.
17 """
18 pass
19
20
21 class Segment(_VSOSimpleAttr):
22 """
23 Segments choose which files to download when there are more than
24 one present for each record e.g. 'image'
25 """
26 pass
27
28
29 class Protocol(_VSOSimpleAttr):
30 """
31 The type of download to request one of
32 ("FITS", "JPEG", "MPG", "MP4", or "as-is").
33 Only FITS is supported, the others will require extra keywords.
34 """
35 pass
36
37
38 class Notify(_VSOSimpleAttr):
39 """
40 An email address to get a notification to when JSOC has staged your request
41 """
42
43 def __init__(self, value):
44 super(Notify, self).__init__(value)
45 if value.find('@') == -1:
46 raise ValueError("Notify attribute must contain an '@' symbol "
47 "to be a valid email address")
48 self.value = value
49
50
51 class Compression(_VSOSimpleAttr):
52 """
53 Compression format for requested files.
54
55 'rice' or None, download FITS files with RICE compression.
56 """
57 pass
58
59
60 walker = AttrWalker()
61
62
63 @walker.add_creator(AttrAnd, _VSOSimpleAttr, Time)
64 def _create(wlk, query):
65
66 map_ = {}
67 wlk.apply(query, map_)
68 return [map_]
69
70
71 @walker.add_applier(AttrAnd)
72 def _apply(wlk, query, imap):
73
74 for iattr in query.attrs:
75 wlk.apply(iattr, imap)
76
77
78 @walker.add_applier(_VSOSimpleAttr)
79 def _apply1(wlk, query, imap):
80
81 imap[query.__class__.__name__.lower()] = query.value
82
83
84 @walker.add_applier(Time)
85 def _apply2(wlk, query, imap):
86 imap['start_time'] = query.start
87 imap['end_time'] = query.end
88
89
90 @walker.add_applier(Wavelength)
91 def _apply_wave(wlk, query, imap):
92 if query.min != query.max:
93 raise ValueError(
94 "For JSOC queries Wavelength.min must equal Wavelength.max")
95
96 imap[query.__class__.__name__.lower()] = query.min
97
98
99 @walker.add_creator(AttrOr)
100 def _create1(wlk, query):
101
102 qblocks = []
103 for iattr in query.attrs:
104 qblocks.extend(wlk.create(iattr))
105
106 return qblocks
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sunpy/net/jsoc/attrs.py b/sunpy/net/jsoc/attrs.py
--- a/sunpy/net/jsoc/attrs.py
+++ b/sunpy/net/jsoc/attrs.py
@@ -12,8 +12,7 @@
"""
The JSOC Series to Download.
- See `this<http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`
- for a list of series'.
+ This is the list of `Series <http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`.
"""
pass
|
{"golden_diff": "diff --git a/sunpy/net/jsoc/attrs.py b/sunpy/net/jsoc/attrs.py\n--- a/sunpy/net/jsoc/attrs.py\n+++ b/sunpy/net/jsoc/attrs.py\n@@ -12,8 +12,7 @@\n \"\"\"\n The JSOC Series to Download.\n \n- See `this<http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`\n- for a list of series'.\n+ This is the list of `Series <http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`.\n \"\"\"\n pass\n", "issue": "Document the CI\nDOCUMENT ALL THE THINGS\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom sunpy.net.attr import AttrWalker, AttrAnd, AttrOr\nfrom sunpy.net.vso.attrs import _VSOSimpleAttr\nfrom sunpy.net.vso.attrs import Time, Wavelength\n\n\n__all__ = ['Series', 'Protocol', 'Notify', 'Compression', 'Segment']\n\n\nclass Series(_VSOSimpleAttr):\n \"\"\"\n The JSOC Series to Download.\n\n See `this<http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`\n for a list of series'.\n \"\"\"\n pass\n\n\nclass Segment(_VSOSimpleAttr):\n \"\"\"\n Segments choose which files to download when there are more than\n one present for each record e.g. 'image'\n \"\"\"\n pass\n\n\nclass Protocol(_VSOSimpleAttr):\n \"\"\"\n The type of download to request one of\n (\"FITS\", \"JPEG\", \"MPG\", \"MP4\", or \"as-is\").\n Only FITS is supported, the others will require extra keywords.\n \"\"\"\n pass\n\n\nclass Notify(_VSOSimpleAttr):\n \"\"\"\n An email address to get a notification to when JSOC has staged your request\n \"\"\"\n\n def __init__(self, value):\n super(Notify, self).__init__(value)\n if value.find('@') == -1:\n raise ValueError(\"Notify attribute must contain an '@' symbol \"\n \"to be a valid email address\")\n self.value = value\n\n\nclass Compression(_VSOSimpleAttr):\n \"\"\"\n Compression format for requested files.\n\n 'rice' or None, download FITS files with RICE compression.\n \"\"\"\n pass\n\n\nwalker = AttrWalker()\n\n\[email protected]_creator(AttrAnd, _VSOSimpleAttr, Time)\ndef _create(wlk, query):\n\n map_ = {}\n wlk.apply(query, map_)\n return [map_]\n\n\[email protected]_applier(AttrAnd)\ndef _apply(wlk, query, imap):\n\n for iattr in query.attrs:\n wlk.apply(iattr, imap)\n\n\[email protected]_applier(_VSOSimpleAttr)\ndef _apply1(wlk, query, imap):\n\n imap[query.__class__.__name__.lower()] = query.value\n\n\[email protected]_applier(Time)\ndef _apply2(wlk, query, imap):\n imap['start_time'] = query.start\n imap['end_time'] = query.end\n\n\[email protected]_applier(Wavelength)\ndef _apply_wave(wlk, query, imap):\n if query.min != query.max:\n raise ValueError(\n \"For JSOC queries Wavelength.min must equal Wavelength.max\")\n\n imap[query.__class__.__name__.lower()] = query.min\n\n\[email protected]_creator(AttrOr)\ndef _create1(wlk, query):\n\n qblocks = []\n for iattr in query.attrs:\n qblocks.extend(wlk.create(iattr))\n\n return qblocks\n", "path": "sunpy/net/jsoc/attrs.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nfrom sunpy.net.attr import AttrWalker, AttrAnd, AttrOr\nfrom sunpy.net.vso.attrs import _VSOSimpleAttr\nfrom sunpy.net.vso.attrs import Time, Wavelength\n\n\n__all__ = ['Series', 'Protocol', 'Notify', 'Compression', 'Segment']\n\n\nclass Series(_VSOSimpleAttr):\n \"\"\"\n The JSOC Series to Download.\n\n This is the list of `Series <http://jsoc.stanford.edu/JsocSeries_DataProducts_map.html>_`.\n \"\"\"\n pass\n\n\nclass Segment(_VSOSimpleAttr):\n \"\"\"\n Segments choose which files to download when there are more than\n one present for each record e.g. 'image'\n \"\"\"\n pass\n\n\nclass Protocol(_VSOSimpleAttr):\n \"\"\"\n The type of download to request one of\n (\"FITS\", \"JPEG\", \"MPG\", \"MP4\", or \"as-is\").\n Only FITS is supported, the others will require extra keywords.\n \"\"\"\n pass\n\n\nclass Notify(_VSOSimpleAttr):\n \"\"\"\n An email address to get a notification to when JSOC has staged your request\n \"\"\"\n\n def __init__(self, value):\n super(Notify, self).__init__(value)\n if value.find('@') == -1:\n raise ValueError(\"Notify attribute must contain an '@' symbol \"\n \"to be a valid email address\")\n self.value = value\n\n\nclass Compression(_VSOSimpleAttr):\n \"\"\"\n Compression format for requested files.\n\n 'rice' or None, download FITS files with RICE compression.\n \"\"\"\n pass\n\n\nwalker = AttrWalker()\n\n\[email protected]_creator(AttrAnd, _VSOSimpleAttr, Time)\ndef _create(wlk, query):\n\n map_ = {}\n wlk.apply(query, map_)\n return [map_]\n\n\[email protected]_applier(AttrAnd)\ndef _apply(wlk, query, imap):\n\n for iattr in query.attrs:\n wlk.apply(iattr, imap)\n\n\[email protected]_applier(_VSOSimpleAttr)\ndef _apply1(wlk, query, imap):\n\n imap[query.__class__.__name__.lower()] = query.value\n\n\[email protected]_applier(Time)\ndef _apply2(wlk, query, imap):\n imap['start_time'] = query.start\n imap['end_time'] = query.end\n\n\[email protected]_applier(Wavelength)\ndef _apply_wave(wlk, query, imap):\n if query.min != query.max:\n raise ValueError(\n \"For JSOC queries Wavelength.min must equal Wavelength.max\")\n\n imap[query.__class__.__name__.lower()] = query.min\n\n\[email protected]_creator(AttrOr)\ndef _create1(wlk, query):\n\n qblocks = []\n for iattr in query.attrs:\n qblocks.extend(wlk.create(iattr))\n\n return qblocks\n", "path": "sunpy/net/jsoc/attrs.py"}]}
| 1,133 | 134 |
gh_patches_debug_21587
|
rasdani/github-patches
|
git_diff
|
plotly__dash-744
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
merge pytest fixtures
the scope of the issue is to merge and restructure the pytest fixtures in https://github.com/plotly/pytest-dash into dash. It might include few integration tests rewrite with the new fixtures and python state `assert`, but all tests rewrite is out of the scope of this issue.
Note: all fixtures will be available for pytest as plugin thanks to the `pytest11` entry point by `pip install dash`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import io
2 from setuptools import setup, find_packages
3
4 main_ns = {}
5 exec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used
6
7 setup(
8 name='dash',
9 version=main_ns['__version__'],
10 author='chris p',
11 author_email='[email protected]',
12 packages=find_packages(exclude=['tests*']),
13 include_package_data=True,
14 license='MIT',
15 description=('A Python framework for building reactive web-apps. '
16 'Developed by Plotly.'),
17 long_description=io.open('README.md', encoding='utf-8').read(),
18 long_description_content_type='text/markdown',
19 install_requires=[
20 'Flask>=0.12',
21 'flask-compress',
22 'plotly',
23 'dash_renderer==0.24.0',
24 'dash-core-components==0.48.0',
25 'dash-html-components==0.16.0',
26 'dash-table==3.7.0'
27 ],
28 entry_points={
29 'console_scripts': [
30 'dash-generate-components ='
31 ' dash.development.component_generator:cli'
32 ]
33 },
34 url='https://plot.ly/dash',
35 classifiers=[
36 'Development Status :: 5 - Production/Stable',
37 'Environment :: Web Environment',
38 'Framework :: Flask',
39 'Intended Audience :: Developers',
40 'Intended Audience :: Education',
41 'Intended Audience :: Financial and Insurance Industry',
42 'Intended Audience :: Healthcare Industry',
43 'Intended Audience :: Manufacturing',
44 'Intended Audience :: Science/Research',
45 'License :: OSI Approved :: MIT License',
46 'Programming Language :: Python',
47 'Programming Language :: Python :: 2',
48 'Programming Language :: Python :: 2.7',
49 'Programming Language :: Python :: 3',
50 'Programming Language :: Python :: 3.3',
51 'Programming Language :: Python :: 3.4',
52 'Programming Language :: Python :: 3.5',
53 'Programming Language :: Python :: 3.6',
54 'Programming Language :: Python :: 3.7',
55 'Topic :: Database :: Front-Ends',
56 'Topic :: Office/Business :: Financial :: Spreadsheet',
57 'Topic :: Scientific/Engineering :: Visualization',
58 'Topic :: Software Development :: Libraries :: Application Frameworks',
59 'Topic :: Software Development :: Widget Sets'
60 ]
61 )
62
```
Path: `dash-renderer/version.py`
Content:
```
1 __version__ = '0.23.0'
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dash-renderer/version.py b/dash-renderer/version.py
--- a/dash-renderer/version.py
+++ b/dash-renderer/version.py
@@ -1 +1 @@
-__version__ = '0.23.0'
+__version__ = '0.24.0'
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,8 +12,10 @@
packages=find_packages(exclude=['tests*']),
include_package_data=True,
license='MIT',
- description=('A Python framework for building reactive web-apps. '
- 'Developed by Plotly.'),
+ description=(
+ 'A Python framework for building reactive web-apps. '
+ 'Developed by Plotly.'
+ ),
long_description=io.open('README.md', encoding='utf-8').read(),
long_description_content_type='text/markdown',
install_requires=[
@@ -29,7 +31,10 @@
'console_scripts': [
'dash-generate-components ='
' dash.development.component_generator:cli'
- ]
+ ],
+ 'pytest11': [
+ 'dash = dash.testing.plugin'
+ ],
},
url='https://plot.ly/dash',
classifiers=[
|
{"golden_diff": "diff --git a/dash-renderer/version.py b/dash-renderer/version.py\n--- a/dash-renderer/version.py\n+++ b/dash-renderer/version.py\n@@ -1 +1 @@\n-__version__ = '0.23.0'\n+__version__ = '0.24.0'\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -12,8 +12,10 @@\n packages=find_packages(exclude=['tests*']),\n include_package_data=True,\n license='MIT',\n- description=('A Python framework for building reactive web-apps. '\n- 'Developed by Plotly.'),\n+ description=(\n+ 'A Python framework for building reactive web-apps. '\n+ 'Developed by Plotly.'\n+ ),\n long_description=io.open('README.md', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n install_requires=[\n@@ -29,7 +31,10 @@\n 'console_scripts': [\n 'dash-generate-components ='\n ' dash.development.component_generator:cli'\n- ]\n+ ],\n+ 'pytest11': [\n+ 'dash = dash.testing.plugin'\n+ ],\n },\n url='https://plot.ly/dash',\n classifiers=[\n", "issue": "merge pytest fixtures\nthe scope of the issue is to merge and restructure the pytest fixtures in https://github.com/plotly/pytest-dash into dash. It might include few integration tests rewrite with the new fixtures and python state `assert`, but all tests rewrite is out of the scope of this issue. \r\n\r\nNote: all fixtures will be available for pytest as plugin thanks to the `pytest11` entry point by `pip install dash`. \n", "before_files": [{"content": "import io\nfrom setuptools import setup, find_packages\n\nmain_ns = {}\nexec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used\n\nsetup(\n name='dash',\n version=main_ns['__version__'],\n author='chris p',\n author_email='[email protected]',\n packages=find_packages(exclude=['tests*']),\n include_package_data=True,\n license='MIT',\n description=('A Python framework for building reactive web-apps. '\n 'Developed by Plotly.'),\n long_description=io.open('README.md', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n install_requires=[\n 'Flask>=0.12',\n 'flask-compress',\n 'plotly',\n 'dash_renderer==0.24.0',\n 'dash-core-components==0.48.0',\n 'dash-html-components==0.16.0',\n 'dash-table==3.7.0'\n ],\n entry_points={\n 'console_scripts': [\n 'dash-generate-components ='\n ' dash.development.component_generator:cli'\n ]\n },\n url='https://plot.ly/dash',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Flask',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Financial and Insurance Industry',\n 'Intended Audience :: Healthcare Industry',\n 'Intended Audience :: Manufacturing',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Widget Sets'\n ]\n)\n", "path": "setup.py"}, {"content": "__version__ = '0.23.0'\n", "path": "dash-renderer/version.py"}], "after_files": [{"content": "import io\nfrom setuptools import setup, find_packages\n\nmain_ns = {}\nexec(open('dash/version.py').read(), main_ns) # pylint: disable=exec-used\n\nsetup(\n name='dash',\n version=main_ns['__version__'],\n author='chris p',\n author_email='[email protected]',\n packages=find_packages(exclude=['tests*']),\n include_package_data=True,\n license='MIT',\n description=(\n 'A Python framework for building reactive web-apps. '\n 'Developed by Plotly.'\n ),\n long_description=io.open('README.md', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n install_requires=[\n 'Flask>=0.12',\n 'flask-compress',\n 'plotly',\n 'dash_renderer==0.24.0',\n 'dash-core-components==0.48.0',\n 'dash-html-components==0.16.0',\n 'dash-table==3.7.0'\n ],\n entry_points={\n 'console_scripts': [\n 'dash-generate-components ='\n ' dash.development.component_generator:cli'\n ],\n 'pytest11': [\n 'dash = dash.testing.plugin'\n ],\n },\n url='https://plot.ly/dash',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Web Environment',\n 'Framework :: Flask',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Financial and Insurance Industry',\n 'Intended Audience :: Healthcare Industry',\n 'Intended Audience :: Manufacturing',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Widget Sets'\n ]\n)\n", "path": "setup.py"}, {"content": "__version__ = '0.24.0'\n", "path": "dash-renderer/version.py"}]}
| 1,005 | 286 |
gh_patches_debug_23701
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-905
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplify emoji code
This pull requests contains the squashed changes from #894 (thanks
@bakonydraco!) and provides some simplifications so that we have a base set of
features to work with and can subsequently make additions or modifications as
necessary.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `praw/models/reddit/emoji.py`
Content:
```
1 """Provide the Emoji class."""
2 import os
3
4 from ...const import API_PATH
5 from ...exceptions import ClientException
6 from .base import RedditBase
7
8
9 class Emoji(RedditBase):
10 """An individual Emoji object."""
11
12 __hash__ = RedditBase.__hash__
13 STR_FIELD = 'name'
14
15 def __init__(self, reddit, subreddit, name, _data=None):
16 """Construct an instance of the Emoji object."""
17 self.name = name
18 self.subreddit = subreddit
19 super(Emoji, self).__init__(reddit, _data)
20
21 def _fetch(self):
22 for emoji in self.subreddit.emoji:
23 if emoji.name.lower() == self.name.lower():
24 self.__dict__.update(emoji.__dict__)
25 self._fetched = True
26 return
27 raise ClientException('/r/{} does not have the emoji {}'
28 .format(self.subreddit, self.name))
29
30 def delete(self):
31 """Delete an emoji from this subreddit by Emoji.
32
33 To delete ``'test'`` as an emoji on the subreddit ``'praw_test'`` try:
34
35 .. code:: python
36
37 reddit.subreddit('praw_test').emoji['test'].delete()
38
39 """
40 url = API_PATH['emoji_delete'].format(
41 emoji_name=self.name, subreddit=self.subreddit)
42 self._reddit.request('DELETE', url)
43
44
45 class SubredditEmoji(RedditBase):
46 """Provides a set of functions to a Subreddit for emoji."""
47
48 __hash__ = RedditBase.__hash__
49
50 def __getitem__(self, name):
51 """Lazily return the Emoji for the subreddit named ``name``.
52
53 :param name: The name of the emoji
54
55 This method is to be used to fetch a specific emoji url, like so:
56
57 .. code:: python
58
59 emoji = reddit.subreddit('praw_test').emoji['test']
60 print(emoji)
61
62 """
63 return Emoji(self._reddit, self.subreddit, name)
64
65 def __init__(self, subreddit):
66 """Create a SubredditEmoji instance.
67
68 :param subreddit: The subreddit whose emoji are affected.
69
70 """
71 self.subreddit = subreddit
72 super(SubredditEmoji, self).__init__(subreddit._reddit, None)
73
74 def __iter__(self):
75 """Return a list of Emoji for the subreddit.
76
77 This method is to be used to discover all emoji for a subreddit:
78
79 .. code:: python
80
81 for emoji in reddit.subreddit('praw_test').emoji:
82 print(emoji)
83
84 """
85 response = self.subreddit._reddit.get(
86 API_PATH['emoji_list'].format(subreddit=self.subreddit))
87 for emoji_name, emoji_data in \
88 response[self.subreddit.fullname].items():
89 yield Emoji(self._reddit, self.subreddit, emoji_name,
90 _data=emoji_data)
91
92 def add(self, name, image_path):
93 """Add an emoji to this subreddit.
94
95 :param name: The name of the emoji
96 :param image_path: A path to a jpeg or png image.
97 :returns: The Emoji added.
98
99 To add ``'test'`` to the subreddit ``'praw_test'`` try:
100
101 .. code:: python
102
103 reddit.subreddit('praw_test').emoji.add('test','test.png')
104
105 """
106 data = {'filepath': os.path.basename(image_path),
107 'mimetype': 'image/jpeg'}
108 if image_path.lower().endswith('.png'):
109 data['mimetype'] = 'image/png'
110 url = API_PATH['emoji_lease'].format(subreddit=self.subreddit)
111
112 # until we learn otherwise, assume this request always succeeds
113 upload_lease = self._reddit.post(url, data=data)['s3UploadLease']
114 upload_data = {item['name']: item['value']
115 for item in upload_lease['fields']}
116 upload_url = 'https:{}'.format(upload_lease['action'])
117
118 with open(image_path, 'rb') as image:
119 response = self._reddit._core._requestor._http.post(
120 upload_url, data=upload_data, files={'file': image})
121 response.raise_for_status()
122
123 url = API_PATH['emoji_upload'].format(
124 subreddit=self.subreddit)
125 self._reddit.post(url,
126 data={'name': name, 's3_key': upload_data['key']})
127 return Emoji(self._reddit, self.subreddit, name)
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/praw/models/reddit/emoji.py b/praw/models/reddit/emoji.py
--- a/praw/models/reddit/emoji.py
+++ b/praw/models/reddit/emoji.py
@@ -9,9 +9,20 @@
class Emoji(RedditBase):
"""An individual Emoji object."""
- __hash__ = RedditBase.__hash__
STR_FIELD = 'name'
+ def __eq__(self, other):
+ """Return whether the other instance equals the current."""
+ if isinstance(other, str):
+ return other == str(self)
+ return (isinstance(other, self.__class__) and
+ str(self) == str(other) and other.subreddit == self.subreddit)
+
+ def __hash__(self):
+ """Return the hash of the current instance."""
+ return (hash(self.__class__.__name__) ^ hash(str(self)) ^
+ hash(self.subreddit))
+
def __init__(self, reddit, subreddit, name, _data=None):
"""Construct an instance of the Emoji object."""
self.name = name
@@ -20,7 +31,7 @@
def _fetch(self):
for emoji in self.subreddit.emoji:
- if emoji.name.lower() == self.name.lower():
+ if emoji.name == self.name:
self.__dict__.update(emoji.__dict__)
self._fetched = True
return
|
{"golden_diff": "diff --git a/praw/models/reddit/emoji.py b/praw/models/reddit/emoji.py\n--- a/praw/models/reddit/emoji.py\n+++ b/praw/models/reddit/emoji.py\n@@ -9,9 +9,20 @@\n class Emoji(RedditBase):\n \"\"\"An individual Emoji object.\"\"\"\n \n- __hash__ = RedditBase.__hash__\n STR_FIELD = 'name'\n \n+ def __eq__(self, other):\n+ \"\"\"Return whether the other instance equals the current.\"\"\"\n+ if isinstance(other, str):\n+ return other == str(self)\n+ return (isinstance(other, self.__class__) and\n+ str(self) == str(other) and other.subreddit == self.subreddit)\n+\n+ def __hash__(self):\n+ \"\"\"Return the hash of the current instance.\"\"\"\n+ return (hash(self.__class__.__name__) ^ hash(str(self)) ^\n+ hash(self.subreddit))\n+\n def __init__(self, reddit, subreddit, name, _data=None):\n \"\"\"Construct an instance of the Emoji object.\"\"\"\n self.name = name\n@@ -20,7 +31,7 @@\n \n def _fetch(self):\n for emoji in self.subreddit.emoji:\n- if emoji.name.lower() == self.name.lower():\n+ if emoji.name == self.name:\n self.__dict__.update(emoji.__dict__)\n self._fetched = True\n return\n", "issue": "Simplify emoji code\nThis pull requests contains the squashed changes from #894 (thanks\n@bakonydraco!) and provides some simplifications so that we have a base set of\nfeatures to work with and can subsequently make additions or modifications as\nnecessary.\n", "before_files": [{"content": "\"\"\"Provide the Emoji class.\"\"\"\nimport os\n\nfrom ...const import API_PATH\nfrom ...exceptions import ClientException\nfrom .base import RedditBase\n\n\nclass Emoji(RedditBase):\n \"\"\"An individual Emoji object.\"\"\"\n\n __hash__ = RedditBase.__hash__\n STR_FIELD = 'name'\n\n def __init__(self, reddit, subreddit, name, _data=None):\n \"\"\"Construct an instance of the Emoji object.\"\"\"\n self.name = name\n self.subreddit = subreddit\n super(Emoji, self).__init__(reddit, _data)\n\n def _fetch(self):\n for emoji in self.subreddit.emoji:\n if emoji.name.lower() == self.name.lower():\n self.__dict__.update(emoji.__dict__)\n self._fetched = True\n return\n raise ClientException('/r/{} does not have the emoji {}'\n .format(self.subreddit, self.name))\n\n def delete(self):\n \"\"\"Delete an emoji from this subreddit by Emoji.\n\n To delete ``'test'`` as an emoji on the subreddit ``'praw_test'`` try:\n\n .. code:: python\n\n reddit.subreddit('praw_test').emoji['test'].delete()\n\n \"\"\"\n url = API_PATH['emoji_delete'].format(\n emoji_name=self.name, subreddit=self.subreddit)\n self._reddit.request('DELETE', url)\n\n\nclass SubredditEmoji(RedditBase):\n \"\"\"Provides a set of functions to a Subreddit for emoji.\"\"\"\n\n __hash__ = RedditBase.__hash__\n\n def __getitem__(self, name):\n \"\"\"Lazily return the Emoji for the subreddit named ``name``.\n\n :param name: The name of the emoji\n\n This method is to be used to fetch a specific emoji url, like so:\n\n .. code:: python\n\n emoji = reddit.subreddit('praw_test').emoji['test']\n print(emoji)\n\n \"\"\"\n return Emoji(self._reddit, self.subreddit, name)\n\n def __init__(self, subreddit):\n \"\"\"Create a SubredditEmoji instance.\n\n :param subreddit: The subreddit whose emoji are affected.\n\n \"\"\"\n self.subreddit = subreddit\n super(SubredditEmoji, self).__init__(subreddit._reddit, None)\n\n def __iter__(self):\n \"\"\"Return a list of Emoji for the subreddit.\n\n This method is to be used to discover all emoji for a subreddit:\n\n .. code:: python\n\n for emoji in reddit.subreddit('praw_test').emoji:\n print(emoji)\n\n \"\"\"\n response = self.subreddit._reddit.get(\n API_PATH['emoji_list'].format(subreddit=self.subreddit))\n for emoji_name, emoji_data in \\\n response[self.subreddit.fullname].items():\n yield Emoji(self._reddit, self.subreddit, emoji_name,\n _data=emoji_data)\n\n def add(self, name, image_path):\n \"\"\"Add an emoji to this subreddit.\n\n :param name: The name of the emoji\n :param image_path: A path to a jpeg or png image.\n :returns: The Emoji added.\n\n To add ``'test'`` to the subreddit ``'praw_test'`` try:\n\n .. code:: python\n\n reddit.subreddit('praw_test').emoji.add('test','test.png')\n\n \"\"\"\n data = {'filepath': os.path.basename(image_path),\n 'mimetype': 'image/jpeg'}\n if image_path.lower().endswith('.png'):\n data['mimetype'] = 'image/png'\n url = API_PATH['emoji_lease'].format(subreddit=self.subreddit)\n\n # until we learn otherwise, assume this request always succeeds\n upload_lease = self._reddit.post(url, data=data)['s3UploadLease']\n upload_data = {item['name']: item['value']\n for item in upload_lease['fields']}\n upload_url = 'https:{}'.format(upload_lease['action'])\n\n with open(image_path, 'rb') as image:\n response = self._reddit._core._requestor._http.post(\n upload_url, data=upload_data, files={'file': image})\n response.raise_for_status()\n\n url = API_PATH['emoji_upload'].format(\n subreddit=self.subreddit)\n self._reddit.post(url,\n data={'name': name, 's3_key': upload_data['key']})\n return Emoji(self._reddit, self.subreddit, name)\n", "path": "praw/models/reddit/emoji.py"}], "after_files": [{"content": "\"\"\"Provide the Emoji class.\"\"\"\nimport os\n\nfrom ...const import API_PATH\nfrom ...exceptions import ClientException\nfrom .base import RedditBase\n\n\nclass Emoji(RedditBase):\n \"\"\"An individual Emoji object.\"\"\"\n\n STR_FIELD = 'name'\n\n def __eq__(self, other):\n \"\"\"Return whether the other instance equals the current.\"\"\"\n if isinstance(other, str):\n return other == str(self)\n return (isinstance(other, self.__class__) and\n str(self) == str(other) and other.subreddit == self.subreddit)\n\n def __hash__(self):\n \"\"\"Return the hash of the current instance.\"\"\"\n return (hash(self.__class__.__name__) ^ hash(str(self)) ^\n hash(self.subreddit))\n\n def __init__(self, reddit, subreddit, name, _data=None):\n \"\"\"Construct an instance of the Emoji object.\"\"\"\n self.name = name\n self.subreddit = subreddit\n super(Emoji, self).__init__(reddit, _data)\n\n def _fetch(self):\n for emoji in self.subreddit.emoji:\n if emoji.name == self.name:\n self.__dict__.update(emoji.__dict__)\n self._fetched = True\n return\n raise ClientException('/r/{} does not have the emoji {}'\n .format(self.subreddit, self.name))\n\n def delete(self):\n \"\"\"Delete an emoji from this subreddit by Emoji.\n\n To delete ``'test'`` as an emoji on the subreddit ``'praw_test'`` try:\n\n .. code:: python\n\n reddit.subreddit('praw_test').emoji['test'].delete()\n\n \"\"\"\n url = API_PATH['emoji_delete'].format(\n emoji_name=self.name, subreddit=self.subreddit)\n self._reddit.request('DELETE', url)\n\n\nclass SubredditEmoji(RedditBase):\n \"\"\"Provides a set of functions to a Subreddit for emoji.\"\"\"\n\n __hash__ = RedditBase.__hash__\n\n def __getitem__(self, name):\n \"\"\"Lazily return the Emoji for the subreddit named ``name``.\n\n :param name: The name of the emoji\n\n This method is to be used to fetch a specific emoji url, like so:\n\n .. code:: python\n\n emoji = reddit.subreddit('praw_test').emoji['test']\n print(emoji)\n\n \"\"\"\n return Emoji(self._reddit, self.subreddit, name)\n\n def __init__(self, subreddit):\n \"\"\"Create a SubredditEmoji instance.\n\n :param subreddit: The subreddit whose emoji are affected.\n\n \"\"\"\n self.subreddit = subreddit\n super(SubredditEmoji, self).__init__(subreddit._reddit, None)\n\n def __iter__(self):\n \"\"\"Return a list of Emoji for the subreddit.\n\n This method is to be used to discover all emoji for a subreddit:\n\n .. code:: python\n\n for emoji in reddit.subreddit('praw_test').emoji:\n print(emoji)\n\n \"\"\"\n response = self.subreddit._reddit.get(\n API_PATH['emoji_list'].format(subreddit=self.subreddit))\n for emoji_name, emoji_data in \\\n response[self.subreddit.fullname].items():\n yield Emoji(self._reddit, self.subreddit, emoji_name,\n _data=emoji_data)\n\n def add(self, name, image_path):\n \"\"\"Add an emoji to this subreddit.\n\n :param name: The name of the emoji\n :param image_path: A path to a jpeg or png image.\n :returns: The Emoji added.\n\n To add ``'test'`` to the subreddit ``'praw_test'`` try:\n\n .. code:: python\n\n reddit.subreddit('praw_test').emoji.add('test','test.png')\n\n \"\"\"\n data = {'filepath': os.path.basename(image_path),\n 'mimetype': 'image/jpeg'}\n if image_path.lower().endswith('.png'):\n data['mimetype'] = 'image/png'\n url = API_PATH['emoji_lease'].format(subreddit=self.subreddit)\n\n # until we learn otherwise, assume this request always succeeds\n upload_lease = self._reddit.post(url, data=data)['s3UploadLease']\n upload_data = {item['name']: item['value']\n for item in upload_lease['fields']}\n upload_url = 'https:{}'.format(upload_lease['action'])\n\n with open(image_path, 'rb') as image:\n response = self._reddit._core._requestor._http.post(\n upload_url, data=upload_data, files={'file': image})\n response.raise_for_status()\n\n url = API_PATH['emoji_upload'].format(\n subreddit=self.subreddit)\n self._reddit.post(url,\n data={'name': name, 's3_key': upload_data['key']})\n return Emoji(self._reddit, self.subreddit, name)\n", "path": "praw/models/reddit/emoji.py"}]}
| 1,553 | 309 |
gh_patches_debug_20203
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-583
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rewrite Docs with Low-Level Building Blocks: Python API
# Rewrite Docs with Low-Level Building Blocks: Main Concepts
The [Python API](https://docs.lightly.ai/lightly.html) pages still contain mid- and high-level building blocks.
- [x] Remove the documentation for the mid-level building blocks
- [x] Remove the documentation for the high-level building blocks
Related to #493.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightly/__init__.py`
Content:
```
1 """Lightly is a computer vision framework for self-supervised learning.
2
3 With Lightly you can train deep learning models using
4 self-supervision. This means, that you don't require
5 any labels to train a model. Lightly has been built
6 to help you understand and work with large unlabeled datasets.
7 It is built on top of PyTorch and therefore fully compatible
8 with other frameworks such as Fast.ai.
9
10 The framework is structured into the following modules:
11
12 - **api**:
13
14 The lightly.api module handles communication with the Lightly web-app.
15
16 - **cli**:
17
18 The lightly.cli module provides a command-line interface for training
19 self-supervised models and embedding images. Furthermore, the command-line
20 tool can be used to upload and download images from/to the Lightly web-app.
21
22 - **core**:
23
24 The lightly.core module offers one-liners for simple self-supervised learning.
25
26 - **data**:
27
28 The lightly.data module provides a dataset wrapper and collate functions. The
29 collate functions are in charge of the data augmentations which are crucial for
30 self-supervised learning.
31
32 - **embedding**:
33
34 The lightly.embedding module combines the self-supervised models with a dataloader,
35 optimizer, and loss function to provide a simple pytorch-lightning trainable.
36
37 - **loss**:
38
39 The lightly.loss module contains implementations of popular self-supervised training
40 loss functions.
41
42 - **models**:
43
44 The lightly.models module holds the implementation of the ResNet as well as self-
45 supervised methods. Currently implements:
46
47 - SimCLR
48
49 - MoCo
50
51 - SimSiam
52
53 - Barlow Twins
54
55 - BYOL
56
57 - NNCLR
58
59 - **transforms**:
60
61 The lightly.transforms module implements custom data transforms. Currently implements:
62
63 - Gaussian Blur
64
65 - Random Rotation
66
67 - Random Solarization
68
69 - **utils**:
70
71 The lightly.utils package provides global utility methods.
72 The io module contains utility to save and load embeddings in a format which is
73 understood by the Lightly library.
74
75 """
76
77 # Copyright (c) 2020. Lightly AG and its affiliates.
78 # All Rights Reserved
79
80 __name__ = 'lightly'
81 __version__ = '1.1.22'
82
83 import os
84
85 try:
86 # See (https://github.com/PyTorchLightning/pytorch-lightning)
87 # This variable is injected in the __builtins__ by the build
88 # process. It used to enable importing subpackages of skimage when
89 # the binaries are not built
90 __LIGHTLY_SETUP__
91 except NameError:
92 __LIGHTLY_SETUP__ = False
93
94
95 if __LIGHTLY_SETUP__:
96 # setting up lightly
97 msg = f'Partial import of {__name__}=={__version__} during build process.'
98 print(msg)
99 else:
100 # see if prefetch_generator is available
101 try:
102 import prefetch_generator
103 except ImportError:
104 _prefetch_generator_available = False
105 else:
106 _prefetch_generator_available = True
107
108 def _is_prefetch_generator_available():
109 return _prefetch_generator_available
110
111 from lightly.core import *
112 from lightly import active_learning
113 from lightly import api
114 from lightly import data
115 from lightly import embedding
116 from lightly import loss
117 from lightly import models
118 from lightly import openapi_generated
119 from lightly import transforms
120 from lightly import utils
121
122 from lightly.api.version_checking import do_version_check
123
124 if os.getenv('LIGHTLY_DID_VERSION_CHECK', 'False') == 'False':
125 os.environ['LIGHTLY_DID_VERSION_CHECK'] = 'True'
126
127 try:
128 do_version_check(current_version=__version__)
129 except Exception as e:
130 pass
131
132
133
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightly/__init__.py b/lightly/__init__.py
--- a/lightly/__init__.py
+++ b/lightly/__init__.py
@@ -29,11 +29,6 @@
collate functions are in charge of the data augmentations which are crucial for
self-supervised learning.
-- **embedding**:
-
- The lightly.embedding module combines the self-supervised models with a dataloader,
- optimizer, and loss function to provide a simple pytorch-lightning trainable.
-
- **loss**:
The lightly.loss module contains implementations of popular self-supervised training
@@ -41,20 +36,22 @@
- **models**:
- The lightly.models module holds the implementation of the ResNet as well as self-
- supervised methods. Currently implements:
-
- - SimCLR
-
- - MoCo
-
- - SimSiam
+ The lightly.models module holds the implementation of the ResNet as well as heads
+ for self-supervised methods. It currently implements the heads of:
- Barlow Twins
- BYOL
-
+
+ - MoCo
+
- NNCLR
+
+ - SimCLR
+
+ - SimSiam
+
+ - SwaV
- **transforms**:
|
{"golden_diff": "diff --git a/lightly/__init__.py b/lightly/__init__.py\n--- a/lightly/__init__.py\n+++ b/lightly/__init__.py\n@@ -29,11 +29,6 @@\n collate functions are in charge of the data augmentations which are crucial for\n self-supervised learning.\n \n-- **embedding**:\n-\n- The lightly.embedding module combines the self-supervised models with a dataloader,\n- optimizer, and loss function to provide a simple pytorch-lightning trainable.\n-\n - **loss**:\n \n The lightly.loss module contains implementations of popular self-supervised training\n@@ -41,20 +36,22 @@\n \n - **models**:\n \n- The lightly.models module holds the implementation of the ResNet as well as self-\n- supervised methods. Currently implements:\n-\n- - SimCLR\n-\n- - MoCo\n-\n- - SimSiam\n+ The lightly.models module holds the implementation of the ResNet as well as heads\n+ for self-supervised methods. It currently implements the heads of:\n \n - Barlow Twins\n \n - BYOL\n-\n+ \n+ - MoCo\n+ \n - NNCLR\n+ \n+ - SimCLR\n+ \n+ - SimSiam\n+ \n+ - SwaV\n \n - **transforms**:\n", "issue": "Rewrite Docs with Low-Level Building Blocks: Python API\n# Rewrite Docs with Low-Level Building Blocks: Main Concepts\r\n\r\nThe [Python API](https://docs.lightly.ai/lightly.html) pages still contain mid- and high-level building blocks.\r\n\r\n- [x] Remove the documentation for the mid-level building blocks\r\n- [x] Remove the documentation for the high-level building blocks\r\n\r\nRelated to #493.\n", "before_files": [{"content": "\"\"\"Lightly is a computer vision framework for self-supervised learning.\n\nWith Lightly you can train deep learning models using\nself-supervision. This means, that you don't require\nany labels to train a model. Lightly has been built\nto help you understand and work with large unlabeled datasets.\nIt is built on top of PyTorch and therefore fully compatible \nwith other frameworks such as Fast.ai.\n\nThe framework is structured into the following modules:\n\n- **api**: \n\n The lightly.api module handles communication with the Lightly web-app.\n\n- **cli**:\n\n The lightly.cli module provides a command-line interface for training \n self-supervised models and embedding images. Furthermore, the command-line\n tool can be used to upload and download images from/to the Lightly web-app.\n\n- **core**:\n\n The lightly.core module offers one-liners for simple self-supervised learning.\n\n- **data**:\n\n The lightly.data module provides a dataset wrapper and collate functions. The\n collate functions are in charge of the data augmentations which are crucial for\n self-supervised learning.\n\n- **embedding**:\n\n The lightly.embedding module combines the self-supervised models with a dataloader,\n optimizer, and loss function to provide a simple pytorch-lightning trainable.\n\n- **loss**:\n\n The lightly.loss module contains implementations of popular self-supervised training\n loss functions.\n\n- **models**:\n\n The lightly.models module holds the implementation of the ResNet as well as self-\n supervised methods. Currently implements:\n\n - SimCLR\n\n - MoCo\n\n - SimSiam\n\n - Barlow Twins\n\n - BYOL\n\n - NNCLR\n\n- **transforms**:\n\n The lightly.transforms module implements custom data transforms. Currently implements:\n\n - Gaussian Blur\n\n - Random Rotation\n\n - Random Solarization\n\n- **utils**:\n\n The lightly.utils package provides global utility methods.\n The io module contains utility to save and load embeddings in a format which is\n understood by the Lightly library.\n\n\"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\n__name__ = 'lightly'\n__version__ = '1.1.22'\n\nimport os\n\ntry:\n # See (https://github.com/PyTorchLightning/pytorch-lightning)\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __LIGHTLY_SETUP__\nexcept NameError:\n __LIGHTLY_SETUP__ = False\n\n\nif __LIGHTLY_SETUP__:\n # setting up lightly\n msg = f'Partial import of {__name__}=={__version__} during build process.' \n print(msg)\nelse:\n # see if prefetch_generator is available\n try:\n import prefetch_generator\n except ImportError:\n _prefetch_generator_available = False\n else:\n _prefetch_generator_available = True\n\n def _is_prefetch_generator_available():\n return _prefetch_generator_available\n\n from lightly.core import *\n from lightly import active_learning\n from lightly import api\n from lightly import data\n from lightly import embedding\n from lightly import loss\n from lightly import models\n from lightly import openapi_generated\n from lightly import transforms\n from lightly import utils\n \n from lightly.api.version_checking import do_version_check\n\n if os.getenv('LIGHTLY_DID_VERSION_CHECK', 'False') == 'False':\n os.environ['LIGHTLY_DID_VERSION_CHECK'] = 'True'\n\n try:\n do_version_check(current_version=__version__)\n except Exception as e:\n pass\n\n\n\n", "path": "lightly/__init__.py"}], "after_files": [{"content": "\"\"\"Lightly is a computer vision framework for self-supervised learning.\n\nWith Lightly you can train deep learning models using\nself-supervision. This means, that you don't require\nany labels to train a model. Lightly has been built\nto help you understand and work with large unlabeled datasets.\nIt is built on top of PyTorch and therefore fully compatible \nwith other frameworks such as Fast.ai.\n\nThe framework is structured into the following modules:\n\n- **api**: \n\n The lightly.api module handles communication with the Lightly web-app.\n\n- **cli**:\n\n The lightly.cli module provides a command-line interface for training \n self-supervised models and embedding images. Furthermore, the command-line\n tool can be used to upload and download images from/to the Lightly web-app.\n\n- **core**:\n\n The lightly.core module offers one-liners for simple self-supervised learning.\n\n- **data**:\n\n The lightly.data module provides a dataset wrapper and collate functions. The\n collate functions are in charge of the data augmentations which are crucial for\n self-supervised learning.\n\n- **loss**:\n\n The lightly.loss module contains implementations of popular self-supervised training\n loss functions.\n\n- **models**:\n\n The lightly.models module holds the implementation of the ResNet as well as heads\n for self-supervised methods. It currently implements the heads of:\n\n - Barlow Twins\n\n - BYOL\n \n - MoCo\n \n - NNCLR\n \n - SimCLR\n \n - SimSiam\n \n - SwaV\n\n- **transforms**:\n\n The lightly.transforms module implements custom data transforms. Currently implements:\n\n - Gaussian Blur\n\n - Random Rotation\n\n - Random Solarization\n\n- **utils**:\n\n The lightly.utils package provides global utility methods.\n The io module contains utility to save and load embeddings in a format which is\n understood by the Lightly library.\n\n\"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\n__name__ = 'lightly'\n__version__ = '1.1.22'\n\nimport os\n\ntry:\n # See (https://github.com/PyTorchLightning/pytorch-lightning)\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __LIGHTLY_SETUP__\nexcept NameError:\n __LIGHTLY_SETUP__ = False\n\n\nif __LIGHTLY_SETUP__:\n # setting up lightly\n msg = f'Partial import of {__name__}=={__version__} during build process.' \n print(msg)\nelse:\n # see if prefetch_generator is available\n try:\n import prefetch_generator\n except ImportError:\n _prefetch_generator_available = False\n else:\n _prefetch_generator_available = True\n\n def _is_prefetch_generator_available():\n return _prefetch_generator_available\n\n from lightly.core import *\n from lightly import active_learning\n from lightly import api\n from lightly import data\n from lightly import embedding\n from lightly import loss\n from lightly import models\n from lightly import openapi_generated\n from lightly import transforms\n from lightly import utils\n \n from lightly.api.version_checking import do_version_check\n\n if os.getenv('LIGHTLY_DID_VERSION_CHECK', 'False') == 'False':\n os.environ['LIGHTLY_DID_VERSION_CHECK'] = 'True'\n\n try:\n do_version_check(current_version=__version__)\n except Exception as e:\n pass\n\n\n\n", "path": "lightly/__init__.py"}]}
| 1,465 | 296 |
gh_patches_debug_22491
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-617
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Redesign manim-example blocks
At the very least the blocks should be easier to distinguish from each other.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/manim_directive.py`
Content:
```
1 r"""
2 A directive for including Manim videos in a Sphinx document
3 ===========================================================
4
5 When rendering the HTML documentation, the ``.. manim::`` directive
6 implemented here allows to include rendered videos.
7
8 Its basic usage that allows processing **inline content**
9 looks as follows::
10
11 .. manim:: MyScene
12
13 class MyScene(Scene):
14 def construct(self):
15 ...
16
17 It is required to pass the name of the class representing the
18 scene to be rendered to the directive.
19
20 As a second application, the directive can also be used to
21 render scenes that are defined within doctests, for example::
22
23 .. manim:: DirectiveDoctestExample
24 :ref_classes: Dot
25
26 >>> dot = Dot(color=RED)
27 >>> dot.color
28 <Color #fc6255>
29 >>> class DirectiveDoctestExample(Scene):
30 ... def construct(self):
31 ... self.play(ShowCreation(dot))
32
33
34 Options
35 -------
36
37 Options can be passed as follows::
38
39 .. manim:: <Class name>
40 :<option name>: <value>
41
42 The following configuration options are supported by the
43 directive:
44
45 hide_source
46 If this flag is present without argument,
47 the source code is not displayed above the rendered video.
48
49 quality : {'low', 'medium', 'high', 'fourk'}
50 Controls render quality of the video, in analogy to
51 the corresponding command line flags.
52
53 save_as_gif
54 If this flag is present without argument,
55 the scene is rendered as a gif.
56
57 save_last_frame
58 If this flag is present without argument,
59 an image representing the last frame of the scene will
60 be rendered and displayed, instead of a video.
61
62 ref_classes
63 A list of classes, separated by spaces, that is
64 rendered in a reference block after the source code.
65
66 ref_functions
67 A list of functions and methods, separated by spaces,
68 that is rendered in a reference block after the source code.
69
70 """
71 from docutils.parsers.rst import directives, Directive
72
73 import jinja2
74 import os
75 from os.path import relpath
76 from typing import List
77
78 import shutil
79
80 classnamedict = {}
81
82
83 def process_name_list(option_input: str, reference_type: str) -> List[str]:
84 r"""Reformats a string of space separated class names
85 as a list of strings containing valid Sphinx references.
86
87 TESTS
88 -----
89
90 ::
91
92 >>> process_name_list("Tex TexTemplate", "class")
93 [":class:`~.Tex`", ":class:`~.TexTemplate`"]
94 >>> process_name_list("Scene.play Mobject.rotate", "func")
95 [":func:`~.Scene.play`", ":func:`~.Mobject.rotate`"]
96 """
97 return [f":{reference_type}:`~.{name}`" for name in option_input.split()]
98
99
100 class ManimDirective(Directive):
101 r"""The manim directive, rendering videos while building
102 the documentation.
103
104 See the module docstring for documentation.
105 """
106 has_content = True
107 required_arguments = 1
108 optional_arguments = 0
109 option_spec = {
110 "hide_source": bool,
111 "quality": lambda arg: directives.choice(
112 arg, ("low", "medium", "high", "fourk")
113 ),
114 "save_as_gif": bool,
115 "save_last_frame": bool,
116 "ref_classes": lambda arg: process_name_list(arg, "class"),
117 "ref_functions": lambda arg: process_name_list(arg, "func"),
118 }
119 final_argument_whitespace = True
120
121 def run(self):
122 from manim import config
123
124 global classnamedict
125
126 clsname = self.arguments[0]
127 if clsname not in classnamedict:
128 classnamedict[clsname] = 1
129 else:
130 classnamedict[clsname] += 1
131
132 hide_source = "hide_source" in self.options
133 save_as_gif = "save_as_gif" in self.options
134 save_last_frame = "save_last_frame" in self.options
135 assert not (save_as_gif and save_last_frame)
136 if "ref_classes" in self.options or "ref_functions" in self.options:
137 ref_classes = self.options.get("ref_classes", [])
138 ref_functions = self.options.get("ref_functions", [])
139 ref_content = ref_classes + ref_functions
140 ref_block = f"""
141 .. admonition:: Example References
142 :class: example-reference
143
144 {' '.join(ref_content)}"""
145 else:
146 ref_block = ""
147
148 frame_rate = 30
149 pixel_height = 480
150 pixel_width = 854
151
152 if "quality" in self.options:
153 quality = self.options["quality"]
154 if quality == "low":
155 pixel_height = 480
156 pixel_width = 854
157 frame_rate = 15
158 elif quality == "medium":
159 pixel_height = 720
160 pixel_width = 1280
161 frame_rate = 30
162 elif quality == "high":
163 pixel_height = 1440
164 pixel_width = 2560
165 frame_rate = 60
166 elif quality == "fourk":
167 pixel_height = 2160
168 pixel_width = 3840
169 frame_rate = 60
170
171 qualitydir = f"{pixel_height}p{frame_rate}"
172
173 state_machine = self.state_machine
174 document = state_machine.document
175
176 source_file_name = document.attributes["source"]
177 source_rel_name = relpath(source_file_name, setup.confdir)
178 source_rel_dir = os.path.dirname(source_rel_name)
179 while source_rel_dir.startswith(os.path.sep):
180 source_rel_dir = source_rel_dir[1:]
181
182 dest_dir = os.path.abspath(
183 os.path.join(setup.app.builder.outdir, source_rel_dir)
184 )
185 if not os.path.exists(dest_dir):
186 os.makedirs(dest_dir)
187
188 source_block = [
189 ".. code-block:: python",
190 "",
191 *[" " + line for line in self.content],
192 ]
193 source_block = "\n".join(source_block)
194
195 media_dir = os.path.join(setup.confdir, "media")
196 if not os.path.exists(media_dir):
197 os.mkdir(media_dir)
198 images_dir = os.path.join(media_dir, "images")
199 if not os.path.exists(images_dir):
200 os.mkdir(images_dir)
201 tex_dir = os.path.join(media_dir, "tex")
202 if not os.path.exists(tex_dir):
203 os.mkdir(tex_dir)
204 text_dir = os.path.join(media_dir, "text")
205 if not os.path.exists(text_dir):
206 os.mkdir(text_dir)
207 video_dir = os.path.join(media_dir, "videos")
208 output_file = f"{clsname}-{classnamedict[clsname]}"
209
210 file_writer_config_code = [
211 f'config["frame_rate"] = {frame_rate}',
212 f'config["pixel_height"] = {pixel_height}',
213 f'config["pixel_width"] = {pixel_width}',
214 f'file_writer_config["media_dir"] = r"{media_dir}"',
215 f'file_writer_config["images_dir"] = r"{images_dir}"',
216 f'file_writer_config["tex_dir"] = r"{tex_dir}"',
217 f'file_writer_config["text_dir"] = r"{text_dir}"',
218 f'file_writer_config["video_dir"] = r"{video_dir}"',
219 f'file_writer_config["save_last_frame"] = {save_last_frame}',
220 f'file_writer_config["save_as_gif"] = {save_as_gif}',
221 f'file_writer_config["output_file"] = r"{output_file}"',
222 ]
223
224 user_code = self.content
225 if user_code[0].startswith(">>> "): # check whether block comes from doctest
226 user_code = [
227 line[4:] for line in user_code if line.startswith((">>> ", "... "))
228 ]
229
230 code = [
231 "from manim import *",
232 *file_writer_config_code,
233 *user_code,
234 f"{clsname}().render()",
235 ]
236 exec("\n".join(code), globals())
237
238 # copy video file to output directory
239 if not (save_as_gif or save_last_frame):
240 filename = f"{output_file}.mp4"
241 filesrc = os.path.join(video_dir, qualitydir, filename)
242 destfile = os.path.join(dest_dir, filename)
243 shutil.copyfile(filesrc, destfile)
244 elif save_as_gif:
245 filename = f"{output_file}.gif"
246 filesrc = os.path.join(video_dir, qualitydir, filename)
247 elif save_last_frame:
248 filename = f"{output_file}.png"
249 filesrc = os.path.join(images_dir, filename)
250 else:
251 raise ValueError("Invalid combination of render flags received.")
252
253 rendered_template = jinja2.Template(TEMPLATE).render(
254 hide_source=hide_source,
255 filesrc_rel=os.path.relpath(filesrc, setup.confdir),
256 output_file=output_file,
257 save_last_frame=save_last_frame,
258 save_as_gif=save_as_gif,
259 source_block=source_block,
260 ref_block=ref_block,
261 )
262 state_machine.insert_input(
263 rendered_template.split("\n"), source=document.attributes["source"]
264 )
265
266 return []
267
268
269 def setup(app):
270 import manim
271
272 setup.app = app
273 setup.config = app.config
274 setup.confdir = app.confdir
275 app.add_directive("manim", ManimDirective)
276
277 metadata = {"parallel_read_safe": False, "parallel_write_safe": True}
278 return metadata
279
280
281 TEMPLATE = r"""
282 {% if not hide_source %}
283 .. raw:: html
284
285 <div class="manim-example">
286
287 {{ source_block }}
288 {{ ref_block }}
289 {% endif %}
290
291 {% if not (save_as_gif or save_last_frame) %}
292 .. raw:: html
293
294 <video class="manim-video" controls loop autoplay src="./{{ output_file }}.mp4"></video>
295 {% elif save_as_gif %}
296 .. image:: /{{ filesrc_rel }}
297 :align: center
298 {% elif save_last_frame %}
299 .. image:: /{{ filesrc_rel }}
300 :align: center
301 {% endif %}
302
303 {% if not hide_source %}
304 .. raw:: html
305
306 </div>
307 {% endif %}
308 """
309
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/manim_directive.py b/docs/source/manim_directive.py
--- a/docs/source/manim_directive.py
+++ b/docs/source/manim_directive.py
@@ -251,6 +251,7 @@
raise ValueError("Invalid combination of render flags received.")
rendered_template = jinja2.Template(TEMPLATE).render(
+ clsname=clsname,
hide_source=hide_source,
filesrc_rel=os.path.relpath(filesrc, setup.confdir),
output_file=output_file,
@@ -284,8 +285,6 @@
<div class="manim-example">
-{{ source_block }}
-{{ ref_block }}
{% endif %}
{% if not (save_as_gif or save_last_frame) %}
@@ -299,10 +298,16 @@
.. image:: /{{ filesrc_rel }}
:align: center
{% endif %}
-
{% if not hide_source %}
.. raw:: html
- </div>
+ <div class="example-header">{{ clsname }}</div>
+
+{{ source_block }}
+{{ ref_block }}
{% endif %}
+
+.. raw:: html
+
+ </div>
"""
|
{"golden_diff": "diff --git a/docs/source/manim_directive.py b/docs/source/manim_directive.py\n--- a/docs/source/manim_directive.py\n+++ b/docs/source/manim_directive.py\n@@ -251,6 +251,7 @@\n raise ValueError(\"Invalid combination of render flags received.\")\n \n rendered_template = jinja2.Template(TEMPLATE).render(\n+ clsname=clsname,\n hide_source=hide_source,\n filesrc_rel=os.path.relpath(filesrc, setup.confdir),\n output_file=output_file,\n@@ -284,8 +285,6 @@\n \n <div class=\"manim-example\">\n \n-{{ source_block }}\n-{{ ref_block }}\n {% endif %}\n \n {% if not (save_as_gif or save_last_frame) %}\n@@ -299,10 +298,16 @@\n .. image:: /{{ filesrc_rel }}\n :align: center\n {% endif %}\n-\n {% if not hide_source %}\n .. raw:: html\n \n- </div>\n+ <div class=\"example-header\">{{ clsname }}</div>\n+\n+{{ source_block }}\n+{{ ref_block }}\n {% endif %}\n+\n+.. raw:: html\n+\n+ </div>\n \"\"\"\n", "issue": "Redesign manim-example blocks\nAt the very least the blocks should be easier to distinguish from each other.\n", "before_files": [{"content": "r\"\"\"\nA directive for including Manim videos in a Sphinx document\n===========================================================\n\nWhen rendering the HTML documentation, the ``.. manim::`` directive\nimplemented here allows to include rendered videos.\n\nIts basic usage that allows processing **inline content**\nlooks as follows::\n\n .. manim:: MyScene\n\n class MyScene(Scene):\n def construct(self):\n ...\n\nIt is required to pass the name of the class representing the\nscene to be rendered to the directive.\n\nAs a second application, the directive can also be used to\nrender scenes that are defined within doctests, for example::\n\n .. manim:: DirectiveDoctestExample\n :ref_classes: Dot\n\n >>> dot = Dot(color=RED)\n >>> dot.color\n <Color #fc6255>\n >>> class DirectiveDoctestExample(Scene):\n ... def construct(self):\n ... self.play(ShowCreation(dot))\n\n\nOptions\n-------\n\nOptions can be passed as follows::\n\n .. manim:: <Class name>\n :<option name>: <value>\n\nThe following configuration options are supported by the\ndirective:\n\n hide_source\n If this flag is present without argument,\n the source code is not displayed above the rendered video.\n\n quality : {'low', 'medium', 'high', 'fourk'}\n Controls render quality of the video, in analogy to\n the corresponding command line flags.\n\n save_as_gif\n If this flag is present without argument,\n the scene is rendered as a gif.\n\n save_last_frame\n If this flag is present without argument,\n an image representing the last frame of the scene will\n be rendered and displayed, instead of a video.\n\n ref_classes\n A list of classes, separated by spaces, that is\n rendered in a reference block after the source code.\n\n ref_functions\n A list of functions and methods, separated by spaces,\n that is rendered in a reference block after the source code.\n\n\"\"\"\nfrom docutils.parsers.rst import directives, Directive\n\nimport jinja2\nimport os\nfrom os.path import relpath\nfrom typing import List\n\nimport shutil\n\nclassnamedict = {}\n\n\ndef process_name_list(option_input: str, reference_type: str) -> List[str]:\n r\"\"\"Reformats a string of space separated class names\n as a list of strings containing valid Sphinx references.\n\n TESTS\n -----\n\n ::\n\n >>> process_name_list(\"Tex TexTemplate\", \"class\")\n [\":class:`~.Tex`\", \":class:`~.TexTemplate`\"]\n >>> process_name_list(\"Scene.play Mobject.rotate\", \"func\")\n [\":func:`~.Scene.play`\", \":func:`~.Mobject.rotate`\"]\n \"\"\"\n return [f\":{reference_type}:`~.{name}`\" for name in option_input.split()]\n\n\nclass ManimDirective(Directive):\n r\"\"\"The manim directive, rendering videos while building\n the documentation.\n\n See the module docstring for documentation.\n \"\"\"\n has_content = True\n required_arguments = 1\n optional_arguments = 0\n option_spec = {\n \"hide_source\": bool,\n \"quality\": lambda arg: directives.choice(\n arg, (\"low\", \"medium\", \"high\", \"fourk\")\n ),\n \"save_as_gif\": bool,\n \"save_last_frame\": bool,\n \"ref_classes\": lambda arg: process_name_list(arg, \"class\"),\n \"ref_functions\": lambda arg: process_name_list(arg, \"func\"),\n }\n final_argument_whitespace = True\n\n def run(self):\n from manim import config\n\n global classnamedict\n\n clsname = self.arguments[0]\n if clsname not in classnamedict:\n classnamedict[clsname] = 1\n else:\n classnamedict[clsname] += 1\n\n hide_source = \"hide_source\" in self.options\n save_as_gif = \"save_as_gif\" in self.options\n save_last_frame = \"save_last_frame\" in self.options\n assert not (save_as_gif and save_last_frame)\n if \"ref_classes\" in self.options or \"ref_functions\" in self.options:\n ref_classes = self.options.get(\"ref_classes\", [])\n ref_functions = self.options.get(\"ref_functions\", [])\n ref_content = ref_classes + ref_functions\n ref_block = f\"\"\"\n.. admonition:: Example References\n :class: example-reference\n\n {' '.join(ref_content)}\"\"\"\n else:\n ref_block = \"\"\n\n frame_rate = 30\n pixel_height = 480\n pixel_width = 854\n\n if \"quality\" in self.options:\n quality = self.options[\"quality\"]\n if quality == \"low\":\n pixel_height = 480\n pixel_width = 854\n frame_rate = 15\n elif quality == \"medium\":\n pixel_height = 720\n pixel_width = 1280\n frame_rate = 30\n elif quality == \"high\":\n pixel_height = 1440\n pixel_width = 2560\n frame_rate = 60\n elif quality == \"fourk\":\n pixel_height = 2160\n pixel_width = 3840\n frame_rate = 60\n\n qualitydir = f\"{pixel_height}p{frame_rate}\"\n\n state_machine = self.state_machine\n document = state_machine.document\n\n source_file_name = document.attributes[\"source\"]\n source_rel_name = relpath(source_file_name, setup.confdir)\n source_rel_dir = os.path.dirname(source_rel_name)\n while source_rel_dir.startswith(os.path.sep):\n source_rel_dir = source_rel_dir[1:]\n\n dest_dir = os.path.abspath(\n os.path.join(setup.app.builder.outdir, source_rel_dir)\n )\n if not os.path.exists(dest_dir):\n os.makedirs(dest_dir)\n\n source_block = [\n \".. code-block:: python\",\n \"\",\n *[\" \" + line for line in self.content],\n ]\n source_block = \"\\n\".join(source_block)\n\n media_dir = os.path.join(setup.confdir, \"media\")\n if not os.path.exists(media_dir):\n os.mkdir(media_dir)\n images_dir = os.path.join(media_dir, \"images\")\n if not os.path.exists(images_dir):\n os.mkdir(images_dir)\n tex_dir = os.path.join(media_dir, \"tex\")\n if not os.path.exists(tex_dir):\n os.mkdir(tex_dir)\n text_dir = os.path.join(media_dir, \"text\")\n if not os.path.exists(text_dir):\n os.mkdir(text_dir)\n video_dir = os.path.join(media_dir, \"videos\")\n output_file = f\"{clsname}-{classnamedict[clsname]}\"\n\n file_writer_config_code = [\n f'config[\"frame_rate\"] = {frame_rate}',\n f'config[\"pixel_height\"] = {pixel_height}',\n f'config[\"pixel_width\"] = {pixel_width}',\n f'file_writer_config[\"media_dir\"] = r\"{media_dir}\"',\n f'file_writer_config[\"images_dir\"] = r\"{images_dir}\"',\n f'file_writer_config[\"tex_dir\"] = r\"{tex_dir}\"',\n f'file_writer_config[\"text_dir\"] = r\"{text_dir}\"',\n f'file_writer_config[\"video_dir\"] = r\"{video_dir}\"',\n f'file_writer_config[\"save_last_frame\"] = {save_last_frame}',\n f'file_writer_config[\"save_as_gif\"] = {save_as_gif}',\n f'file_writer_config[\"output_file\"] = r\"{output_file}\"',\n ]\n\n user_code = self.content\n if user_code[0].startswith(\">>> \"): # check whether block comes from doctest\n user_code = [\n line[4:] for line in user_code if line.startswith((\">>> \", \"... \"))\n ]\n\n code = [\n \"from manim import *\",\n *file_writer_config_code,\n *user_code,\n f\"{clsname}().render()\",\n ]\n exec(\"\\n\".join(code), globals())\n\n # copy video file to output directory\n if not (save_as_gif or save_last_frame):\n filename = f\"{output_file}.mp4\"\n filesrc = os.path.join(video_dir, qualitydir, filename)\n destfile = os.path.join(dest_dir, filename)\n shutil.copyfile(filesrc, destfile)\n elif save_as_gif:\n filename = f\"{output_file}.gif\"\n filesrc = os.path.join(video_dir, qualitydir, filename)\n elif save_last_frame:\n filename = f\"{output_file}.png\"\n filesrc = os.path.join(images_dir, filename)\n else:\n raise ValueError(\"Invalid combination of render flags received.\")\n\n rendered_template = jinja2.Template(TEMPLATE).render(\n hide_source=hide_source,\n filesrc_rel=os.path.relpath(filesrc, setup.confdir),\n output_file=output_file,\n save_last_frame=save_last_frame,\n save_as_gif=save_as_gif,\n source_block=source_block,\n ref_block=ref_block,\n )\n state_machine.insert_input(\n rendered_template.split(\"\\n\"), source=document.attributes[\"source\"]\n )\n\n return []\n\n\ndef setup(app):\n import manim\n\n setup.app = app\n setup.config = app.config\n setup.confdir = app.confdir\n app.add_directive(\"manim\", ManimDirective)\n\n metadata = {\"parallel_read_safe\": False, \"parallel_write_safe\": True}\n return metadata\n\n\nTEMPLATE = r\"\"\"\n{% if not hide_source %}\n.. raw:: html\n\n <div class=\"manim-example\">\n\n{{ source_block }}\n{{ ref_block }}\n{% endif %}\n\n{% if not (save_as_gif or save_last_frame) %}\n.. raw:: html\n\n <video class=\"manim-video\" controls loop autoplay src=\"./{{ output_file }}.mp4\"></video>\n{% elif save_as_gif %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n{% elif save_last_frame %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n{% endif %}\n\n{% if not hide_source %}\n.. raw:: html\n\n </div>\n{% endif %}\n\"\"\"\n", "path": "docs/source/manim_directive.py"}], "after_files": [{"content": "r\"\"\"\nA directive for including Manim videos in a Sphinx document\n===========================================================\n\nWhen rendering the HTML documentation, the ``.. manim::`` directive\nimplemented here allows to include rendered videos.\n\nIts basic usage that allows processing **inline content**\nlooks as follows::\n\n .. manim:: MyScene\n\n class MyScene(Scene):\n def construct(self):\n ...\n\nIt is required to pass the name of the class representing the\nscene to be rendered to the directive.\n\nAs a second application, the directive can also be used to\nrender scenes that are defined within doctests, for example::\n\n .. manim:: DirectiveDoctestExample\n :ref_classes: Dot\n\n >>> dot = Dot(color=RED)\n >>> dot.color\n <Color #fc6255>\n >>> class DirectiveDoctestExample(Scene):\n ... def construct(self):\n ... self.play(ShowCreation(dot))\n\n\nOptions\n-------\n\nOptions can be passed as follows::\n\n .. manim:: <Class name>\n :<option name>: <value>\n\nThe following configuration options are supported by the\ndirective:\n\n hide_source\n If this flag is present without argument,\n the source code is not displayed above the rendered video.\n\n quality : {'low', 'medium', 'high', 'fourk'}\n Controls render quality of the video, in analogy to\n the corresponding command line flags.\n\n save_as_gif\n If this flag is present without argument,\n the scene is rendered as a gif.\n\n save_last_frame\n If this flag is present without argument,\n an image representing the last frame of the scene will\n be rendered and displayed, instead of a video.\n\n ref_classes\n A list of classes, separated by spaces, that is\n rendered in a reference block after the source code.\n\n ref_functions\n A list of functions and methods, separated by spaces,\n that is rendered in a reference block after the source code.\n\n\"\"\"\nfrom docutils.parsers.rst import directives, Directive\n\nimport jinja2\nimport os\nfrom os.path import relpath\nfrom typing import List\n\nimport shutil\n\nclassnamedict = {}\n\n\ndef process_name_list(option_input: str, reference_type: str) -> List[str]:\n r\"\"\"Reformats a string of space separated class names\n as a list of strings containing valid Sphinx references.\n\n TESTS\n -----\n\n ::\n\n >>> process_name_list(\"Tex TexTemplate\", \"class\")\n [\":class:`~.Tex`\", \":class:`~.TexTemplate`\"]\n >>> process_name_list(\"Scene.play Mobject.rotate\", \"func\")\n [\":func:`~.Scene.play`\", \":func:`~.Mobject.rotate`\"]\n \"\"\"\n return [f\":{reference_type}:`~.{name}`\" for name in option_input.split()]\n\n\nclass ManimDirective(Directive):\n r\"\"\"The manim directive, rendering videos while building\n the documentation.\n\n See the module docstring for documentation.\n \"\"\"\n has_content = True\n required_arguments = 1\n optional_arguments = 0\n option_spec = {\n \"hide_source\": bool,\n \"quality\": lambda arg: directives.choice(\n arg, (\"low\", \"medium\", \"high\", \"fourk\")\n ),\n \"save_as_gif\": bool,\n \"save_last_frame\": bool,\n \"ref_classes\": lambda arg: process_name_list(arg, \"class\"),\n \"ref_functions\": lambda arg: process_name_list(arg, \"func\"),\n }\n final_argument_whitespace = True\n\n def run(self):\n from manim import config\n\n global classnamedict\n\n clsname = self.arguments[0]\n if clsname not in classnamedict:\n classnamedict[clsname] = 1\n else:\n classnamedict[clsname] += 1\n\n hide_source = \"hide_source\" in self.options\n save_as_gif = \"save_as_gif\" in self.options\n save_last_frame = \"save_last_frame\" in self.options\n assert not (save_as_gif and save_last_frame)\n if \"ref_classes\" in self.options or \"ref_functions\" in self.options:\n ref_classes = self.options.get(\"ref_classes\", [])\n ref_functions = self.options.get(\"ref_functions\", [])\n ref_content = ref_classes + ref_functions\n ref_block = f\"\"\"\n.. admonition:: Example References\n :class: example-reference\n\n {' '.join(ref_content)}\"\"\"\n else:\n ref_block = \"\"\n\n frame_rate = 30\n pixel_height = 480\n pixel_width = 854\n\n if \"quality\" in self.options:\n quality = self.options[\"quality\"]\n if quality == \"low\":\n pixel_height = 480\n pixel_width = 854\n frame_rate = 15\n elif quality == \"medium\":\n pixel_height = 720\n pixel_width = 1280\n frame_rate = 30\n elif quality == \"high\":\n pixel_height = 1440\n pixel_width = 2560\n frame_rate = 60\n elif quality == \"fourk\":\n pixel_height = 2160\n pixel_width = 3840\n frame_rate = 60\n\n qualitydir = f\"{pixel_height}p{frame_rate}\"\n\n state_machine = self.state_machine\n document = state_machine.document\n\n source_file_name = document.attributes[\"source\"]\n source_rel_name = relpath(source_file_name, setup.confdir)\n source_rel_dir = os.path.dirname(source_rel_name)\n while source_rel_dir.startswith(os.path.sep):\n source_rel_dir = source_rel_dir[1:]\n\n dest_dir = os.path.abspath(\n os.path.join(setup.app.builder.outdir, source_rel_dir)\n )\n if not os.path.exists(dest_dir):\n os.makedirs(dest_dir)\n\n source_block = [\n \".. code-block:: python\",\n \"\",\n *[\" \" + line for line in self.content],\n ]\n source_block = \"\\n\".join(source_block)\n\n media_dir = os.path.join(setup.confdir, \"media\")\n if not os.path.exists(media_dir):\n os.mkdir(media_dir)\n images_dir = os.path.join(media_dir, \"images\")\n if not os.path.exists(images_dir):\n os.mkdir(images_dir)\n tex_dir = os.path.join(media_dir, \"tex\")\n if not os.path.exists(tex_dir):\n os.mkdir(tex_dir)\n text_dir = os.path.join(media_dir, \"text\")\n if not os.path.exists(text_dir):\n os.mkdir(text_dir)\n video_dir = os.path.join(media_dir, \"videos\")\n output_file = f\"{clsname}-{classnamedict[clsname]}\"\n\n file_writer_config_code = [\n f'config[\"frame_rate\"] = {frame_rate}',\n f'config[\"pixel_height\"] = {pixel_height}',\n f'config[\"pixel_width\"] = {pixel_width}',\n f'file_writer_config[\"media_dir\"] = r\"{media_dir}\"',\n f'file_writer_config[\"images_dir\"] = r\"{images_dir}\"',\n f'file_writer_config[\"tex_dir\"] = r\"{tex_dir}\"',\n f'file_writer_config[\"text_dir\"] = r\"{text_dir}\"',\n f'file_writer_config[\"video_dir\"] = r\"{video_dir}\"',\n f'file_writer_config[\"save_last_frame\"] = {save_last_frame}',\n f'file_writer_config[\"save_as_gif\"] = {save_as_gif}',\n f'file_writer_config[\"output_file\"] = r\"{output_file}\"',\n ]\n\n user_code = self.content\n if user_code[0].startswith(\">>> \"): # check whether block comes from doctest\n user_code = [\n line[4:] for line in user_code if line.startswith((\">>> \", \"... \"))\n ]\n\n code = [\n \"from manim import *\",\n *file_writer_config_code,\n *user_code,\n f\"{clsname}().render()\",\n ]\n exec(\"\\n\".join(code), globals())\n\n # copy video file to output directory\n if not (save_as_gif or save_last_frame):\n filename = f\"{output_file}.mp4\"\n filesrc = os.path.join(video_dir, qualitydir, filename)\n destfile = os.path.join(dest_dir, filename)\n shutil.copyfile(filesrc, destfile)\n elif save_as_gif:\n filename = f\"{output_file}.gif\"\n filesrc = os.path.join(video_dir, qualitydir, filename)\n elif save_last_frame:\n filename = f\"{output_file}.png\"\n filesrc = os.path.join(images_dir, filename)\n else:\n raise ValueError(\"Invalid combination of render flags received.\")\n\n rendered_template = jinja2.Template(TEMPLATE).render(\n clsname=clsname,\n hide_source=hide_source,\n filesrc_rel=os.path.relpath(filesrc, setup.confdir),\n output_file=output_file,\n save_last_frame=save_last_frame,\n save_as_gif=save_as_gif,\n source_block=source_block,\n ref_block=ref_block,\n )\n state_machine.insert_input(\n rendered_template.split(\"\\n\"), source=document.attributes[\"source\"]\n )\n\n return []\n\n\ndef setup(app):\n import manim\n\n setup.app = app\n setup.config = app.config\n setup.confdir = app.confdir\n app.add_directive(\"manim\", ManimDirective)\n\n metadata = {\"parallel_read_safe\": False, \"parallel_write_safe\": True}\n return metadata\n\n\nTEMPLATE = r\"\"\"\n{% if not hide_source %}\n.. raw:: html\n\n <div class=\"manim-example\">\n\n{% endif %}\n\n{% if not (save_as_gif or save_last_frame) %}\n.. raw:: html\n\n <video class=\"manim-video\" controls loop autoplay src=\"./{{ output_file }}.mp4\"></video>\n{% elif save_as_gif %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n{% elif save_last_frame %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n{% endif %}\n{% if not hide_source %}\n.. raw:: html\n\n <div class=\"example-header\">{{ clsname }}</div>\n\n{{ source_block }}\n{{ ref_block }}\n{% endif %}\n\n.. raw:: html\n\n </div>\n\"\"\"\n", "path": "docs/source/manim_directive.py"}]}
| 3,336 | 261 |
gh_patches_debug_35788
|
rasdani/github-patches
|
git_diff
|
pypa__pip-5419
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip version check file doesn't honor cache-dir
- Pip version: 7.1.0
- Python version: 2.7.6
- Operating System: Fedora 22
My pip config looks like:
```
[dev@machine ~] $ cat ~/.config/pip/pip.conf
[global]
cache-dir=/ssd/dev/.pip/cache
```
Whenever I try to install any package, it caches the wheels in the `cache-dir` as specified above. However, the pip-version check is performed and the file `selfcheck.json` and it's lock file is placed in the directory: `$HOME/.cache/pip/` , which should have been inside the `cache-dir` as specified above.
I get around this problem by specifying the following in the pip config (but it's not a very good solution):
```
disable-pip-version-check=true
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pip/_internal/utils/outdated.py`
Content:
```
1 from __future__ import absolute_import
2
3 import datetime
4 import json
5 import logging
6 import os.path
7 import sys
8
9 from pip._vendor import lockfile
10 from pip._vendor.packaging import version as packaging_version
11
12 from pip._internal.compat import WINDOWS
13 from pip._internal.index import PackageFinder
14 from pip._internal.locations import USER_CACHE_DIR, running_under_virtualenv
15 from pip._internal.utils.filesystem import check_path_owner
16 from pip._internal.utils.misc import ensure_dir, get_installed_version
17
18 SELFCHECK_DATE_FMT = "%Y-%m-%dT%H:%M:%SZ"
19
20
21 logger = logging.getLogger(__name__)
22
23
24 class VirtualenvSelfCheckState(object):
25 def __init__(self):
26 self.statefile_path = os.path.join(sys.prefix, "pip-selfcheck.json")
27
28 # Load the existing state
29 try:
30 with open(self.statefile_path) as statefile:
31 self.state = json.load(statefile)
32 except (IOError, ValueError):
33 self.state = {}
34
35 def save(self, pypi_version, current_time):
36 # Attempt to write out our version check file
37 with open(self.statefile_path, "w") as statefile:
38 json.dump(
39 {
40 "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
41 "pypi_version": pypi_version,
42 },
43 statefile,
44 sort_keys=True,
45 separators=(",", ":")
46 )
47
48
49 class GlobalSelfCheckState(object):
50 def __init__(self):
51 self.statefile_path = os.path.join(USER_CACHE_DIR, "selfcheck.json")
52
53 # Load the existing state
54 try:
55 with open(self.statefile_path) as statefile:
56 self.state = json.load(statefile)[sys.prefix]
57 except (IOError, ValueError, KeyError):
58 self.state = {}
59
60 def save(self, pypi_version, current_time):
61 # Check to make sure that we own the directory
62 if not check_path_owner(os.path.dirname(self.statefile_path)):
63 return
64
65 # Now that we've ensured the directory is owned by this user, we'll go
66 # ahead and make sure that all our directories are created.
67 ensure_dir(os.path.dirname(self.statefile_path))
68
69 # Attempt to write out our version check file
70 with lockfile.LockFile(self.statefile_path):
71 if os.path.exists(self.statefile_path):
72 with open(self.statefile_path) as statefile:
73 state = json.load(statefile)
74 else:
75 state = {}
76
77 state[sys.prefix] = {
78 "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
79 "pypi_version": pypi_version,
80 }
81
82 with open(self.statefile_path, "w") as statefile:
83 json.dump(state, statefile, sort_keys=True,
84 separators=(",", ":"))
85
86
87 def load_selfcheck_statefile():
88 if running_under_virtualenv():
89 return VirtualenvSelfCheckState()
90 else:
91 return GlobalSelfCheckState()
92
93
94 def pip_version_check(session, options):
95 """Check for an update for pip.
96
97 Limit the frequency of checks to once per week. State is stored either in
98 the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix
99 of the pip script path.
100 """
101 installed_version = get_installed_version("pip")
102 if not installed_version:
103 return
104
105 pip_version = packaging_version.parse(installed_version)
106 pypi_version = None
107
108 try:
109 state = load_selfcheck_statefile()
110
111 current_time = datetime.datetime.utcnow()
112 # Determine if we need to refresh the state
113 if "last_check" in state.state and "pypi_version" in state.state:
114 last_check = datetime.datetime.strptime(
115 state.state["last_check"],
116 SELFCHECK_DATE_FMT
117 )
118 if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:
119 pypi_version = state.state["pypi_version"]
120
121 # Refresh the version if we need to or just see if we need to warn
122 if pypi_version is None:
123 # Lets use PackageFinder to see what the latest pip version is
124 finder = PackageFinder(
125 find_links=options.find_links,
126 index_urls=[options.index_url] + options.extra_index_urls,
127 allow_all_prereleases=False, # Explicitly set to False
128 trusted_hosts=options.trusted_hosts,
129 process_dependency_links=options.process_dependency_links,
130 session=session,
131 )
132 all_candidates = finder.find_all_candidates("pip")
133 if not all_candidates:
134 return
135 pypi_version = str(
136 max(all_candidates, key=lambda c: c.version).version
137 )
138
139 # save that we've performed a check
140 state.save(pypi_version, current_time)
141
142 remote_version = packaging_version.parse(pypi_version)
143
144 # Determine if our pypi_version is older
145 if (pip_version < remote_version and
146 pip_version.base_version != remote_version.base_version):
147 # Advise "python -m pip" on Windows to avoid issues
148 # with overwriting pip.exe.
149 if WINDOWS:
150 pip_cmd = "python -m pip"
151 else:
152 pip_cmd = "pip"
153 logger.warning(
154 "You are using pip version %s, however version %s is "
155 "available.\nYou should consider upgrading via the "
156 "'%s install --upgrade pip' command.",
157 pip_version, pypi_version, pip_cmd
158 )
159 except Exception:
160 logger.debug(
161 "There was an error checking the latest version of pip",
162 exc_info=True,
163 )
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pip/_internal/utils/outdated.py b/src/pip/_internal/utils/outdated.py
--- a/src/pip/_internal/utils/outdated.py
+++ b/src/pip/_internal/utils/outdated.py
@@ -11,7 +11,6 @@
from pip._internal.compat import WINDOWS
from pip._internal.index import PackageFinder
-from pip._internal.locations import USER_CACHE_DIR, running_under_virtualenv
from pip._internal.utils.filesystem import check_path_owner
from pip._internal.utils.misc import ensure_dir, get_installed_version
@@ -21,34 +20,9 @@
logger = logging.getLogger(__name__)
-class VirtualenvSelfCheckState(object):
- def __init__(self):
- self.statefile_path = os.path.join(sys.prefix, "pip-selfcheck.json")
-
- # Load the existing state
- try:
- with open(self.statefile_path) as statefile:
- self.state = json.load(statefile)
- except (IOError, ValueError):
- self.state = {}
-
- def save(self, pypi_version, current_time):
- # Attempt to write out our version check file
- with open(self.statefile_path, "w") as statefile:
- json.dump(
- {
- "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
- "pypi_version": pypi_version,
- },
- statefile,
- sort_keys=True,
- separators=(",", ":")
- )
-
-
-class GlobalSelfCheckState(object):
- def __init__(self):
- self.statefile_path = os.path.join(USER_CACHE_DIR, "selfcheck.json")
+class SelfCheckState(object):
+ def __init__(self, cache_dir):
+ self.statefile_path = os.path.join(cache_dir, "selfcheck.json")
# Load the existing state
try:
@@ -84,13 +58,6 @@
separators=(",", ":"))
-def load_selfcheck_statefile():
- if running_under_virtualenv():
- return VirtualenvSelfCheckState()
- else:
- return GlobalSelfCheckState()
-
-
def pip_version_check(session, options):
"""Check for an update for pip.
@@ -106,7 +73,7 @@
pypi_version = None
try:
- state = load_selfcheck_statefile()
+ state = SelfCheckState(cache_dir=options.cache_dir)
current_time = datetime.datetime.utcnow()
# Determine if we need to refresh the state
|
{"golden_diff": "diff --git a/src/pip/_internal/utils/outdated.py b/src/pip/_internal/utils/outdated.py\n--- a/src/pip/_internal/utils/outdated.py\n+++ b/src/pip/_internal/utils/outdated.py\n@@ -11,7 +11,6 @@\n \n from pip._internal.compat import WINDOWS\n from pip._internal.index import PackageFinder\n-from pip._internal.locations import USER_CACHE_DIR, running_under_virtualenv\n from pip._internal.utils.filesystem import check_path_owner\n from pip._internal.utils.misc import ensure_dir, get_installed_version\n \n@@ -21,34 +20,9 @@\n logger = logging.getLogger(__name__)\n \n \n-class VirtualenvSelfCheckState(object):\n- def __init__(self):\n- self.statefile_path = os.path.join(sys.prefix, \"pip-selfcheck.json\")\n-\n- # Load the existing state\n- try:\n- with open(self.statefile_path) as statefile:\n- self.state = json.load(statefile)\n- except (IOError, ValueError):\n- self.state = {}\n-\n- def save(self, pypi_version, current_time):\n- # Attempt to write out our version check file\n- with open(self.statefile_path, \"w\") as statefile:\n- json.dump(\n- {\n- \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n- \"pypi_version\": pypi_version,\n- },\n- statefile,\n- sort_keys=True,\n- separators=(\",\", \":\")\n- )\n-\n-\n-class GlobalSelfCheckState(object):\n- def __init__(self):\n- self.statefile_path = os.path.join(USER_CACHE_DIR, \"selfcheck.json\")\n+class SelfCheckState(object):\n+ def __init__(self, cache_dir):\n+ self.statefile_path = os.path.join(cache_dir, \"selfcheck.json\")\n \n # Load the existing state\n try:\n@@ -84,13 +58,6 @@\n separators=(\",\", \":\"))\n \n \n-def load_selfcheck_statefile():\n- if running_under_virtualenv():\n- return VirtualenvSelfCheckState()\n- else:\n- return GlobalSelfCheckState()\n-\n-\n def pip_version_check(session, options):\n \"\"\"Check for an update for pip.\n \n@@ -106,7 +73,7 @@\n pypi_version = None\n \n try:\n- state = load_selfcheck_statefile()\n+ state = SelfCheckState(cache_dir=options.cache_dir)\n \n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n", "issue": "pip version check file doesn't honor cache-dir\n- Pip version: 7.1.0\n- Python version: 2.7.6\n- Operating System: Fedora 22\n\nMy pip config looks like:\n\n```\n[dev@machine ~] $ cat ~/.config/pip/pip.conf \n[global]\ncache-dir=/ssd/dev/.pip/cache\n```\n\nWhenever I try to install any package, it caches the wheels in the `cache-dir` as specified above. However, the pip-version check is performed and the file `selfcheck.json` and it's lock file is placed in the directory: `$HOME/.cache/pip/` , which should have been inside the `cache-dir` as specified above.\n\nI get around this problem by specifying the following in the pip config (but it's not a very good solution):\n\n```\ndisable-pip-version-check=true\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import lockfile\nfrom pip._vendor.packaging import version as packaging_version\n\nfrom pip._internal.compat import WINDOWS\nfrom pip._internal.index import PackageFinder\nfrom pip._internal.locations import USER_CACHE_DIR, running_under_virtualenv\nfrom pip._internal.utils.filesystem import check_path_owner\nfrom pip._internal.utils.misc import ensure_dir, get_installed_version\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass VirtualenvSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(sys.prefix, \"pip-selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)\n except (IOError, ValueError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Attempt to write out our version check file\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(\n {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n },\n statefile,\n sort_keys=True,\n separators=(\",\", \":\")\n )\n\n\nclass GlobalSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(USER_CACHE_DIR, \"selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)[sys.prefix]\n except (IOError, ValueError, KeyError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n # Attempt to write out our version check file\n with lockfile.LockFile(self.statefile_path):\n if os.path.exists(self.statefile_path):\n with open(self.statefile_path) as statefile:\n state = json.load(statefile)\n else:\n state = {}\n\n state[sys.prefix] = {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(state, statefile, sort_keys=True,\n separators=(\",\", \":\"))\n\n\ndef load_selfcheck_statefile():\n if running_under_virtualenv():\n return VirtualenvSelfCheckState()\n else:\n return GlobalSelfCheckState()\n\n\ndef pip_version_check(session, options):\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n installed_version = get_installed_version(\"pip\")\n if not installed_version:\n return\n\n pip_version = packaging_version.parse(installed_version)\n pypi_version = None\n\n try:\n state = load_selfcheck_statefile()\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n # Lets use PackageFinder to see what the latest pip version is\n finder = PackageFinder(\n find_links=options.find_links,\n index_urls=[options.index_url] + options.extra_index_urls,\n allow_all_prereleases=False, # Explicitly set to False\n trusted_hosts=options.trusted_hosts,\n process_dependency_links=options.process_dependency_links,\n session=session,\n )\n all_candidates = finder.find_all_candidates(\"pip\")\n if not all_candidates:\n return\n pypi_version = str(\n max(all_candidates, key=lambda c: c.version).version\n )\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n remote_version = packaging_version.parse(pypi_version)\n\n # Determine if our pypi_version is older\n if (pip_version < remote_version and\n pip_version.base_version != remote_version.base_version):\n # Advise \"python -m pip\" on Windows to avoid issues\n # with overwriting pip.exe.\n if WINDOWS:\n pip_cmd = \"python -m pip\"\n else:\n pip_cmd = \"pip\"\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'%s install --upgrade pip' command.\",\n pip_version, pypi_version, pip_cmd\n )\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "src/pip/_internal/utils/outdated.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import lockfile\nfrom pip._vendor.packaging import version as packaging_version\n\nfrom pip._internal.compat import WINDOWS\nfrom pip._internal.index import PackageFinder\nfrom pip._internal.utils.filesystem import check_path_owner\nfrom pip._internal.utils.misc import ensure_dir, get_installed_version\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass SelfCheckState(object):\n def __init__(self, cache_dir):\n self.statefile_path = os.path.join(cache_dir, \"selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)[sys.prefix]\n except (IOError, ValueError, KeyError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n # Attempt to write out our version check file\n with lockfile.LockFile(self.statefile_path):\n if os.path.exists(self.statefile_path):\n with open(self.statefile_path) as statefile:\n state = json.load(statefile)\n else:\n state = {}\n\n state[sys.prefix] = {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(state, statefile, sort_keys=True,\n separators=(\",\", \":\"))\n\n\ndef pip_version_check(session, options):\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n installed_version = get_installed_version(\"pip\")\n if not installed_version:\n return\n\n pip_version = packaging_version.parse(installed_version)\n pypi_version = None\n\n try:\n state = SelfCheckState(cache_dir=options.cache_dir)\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if (current_time - last_check).total_seconds() < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n # Lets use PackageFinder to see what the latest pip version is\n finder = PackageFinder(\n find_links=options.find_links,\n index_urls=[options.index_url] + options.extra_index_urls,\n allow_all_prereleases=False, # Explicitly set to False\n trusted_hosts=options.trusted_hosts,\n process_dependency_links=options.process_dependency_links,\n session=session,\n )\n all_candidates = finder.find_all_candidates(\"pip\")\n if not all_candidates:\n return\n pypi_version = str(\n max(all_candidates, key=lambda c: c.version).version\n )\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n remote_version = packaging_version.parse(pypi_version)\n\n # Determine if our pypi_version is older\n if (pip_version < remote_version and\n pip_version.base_version != remote_version.base_version):\n # Advise \"python -m pip\" on Windows to avoid issues\n # with overwriting pip.exe.\n if WINDOWS:\n pip_cmd = \"python -m pip\"\n else:\n pip_cmd = \"pip\"\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'%s install --upgrade pip' command.\",\n pip_version, pypi_version, pip_cmd\n )\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "src/pip/_internal/utils/outdated.py"}]}
| 2,036 | 552 |
gh_patches_debug_7085
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-471
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Importing ABC directly from collections module was removed in Python 3.9
Since the project is Python 3 only importing from collections.abc will resolve the issue. I will raise a PR.
https://github.com/marshmallow-code/webargs/blob/1b34470908cb54862b7aeb578f794ac3285cdf38/src/webargs/pyramidparser.py#L141
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/webargs/pyramidparser.py`
Content:
```
1 """Pyramid request argument parsing.
2
3 Example usage: ::
4
5 from wsgiref.simple_server import make_server
6 from pyramid.config import Configurator
7 from pyramid.response import Response
8 from marshmallow import fields
9 from webargs.pyramidparser import use_args
10
11 hello_args = {
12 'name': fields.Str(missing='World')
13 }
14
15 @use_args(hello_args)
16 def hello_world(request, args):
17 return Response('Hello ' + args['name'])
18
19 if __name__ == '__main__':
20 config = Configurator()
21 config.add_route('hello', '/')
22 config.add_view(hello_world, route_name='hello')
23 app = config.make_wsgi_app()
24 server = make_server('0.0.0.0', 6543, app)
25 server.serve_forever()
26 """
27 import collections
28 import functools
29
30 from webob.multidict import MultiDict
31 from pyramid.httpexceptions import exception_response
32
33 from webargs import core
34 from webargs.core import json
35 from webargs.multidictproxy import MultiDictProxy
36
37
38 def is_json_request(req):
39 return core.is_json(req.headers.get("content-type"))
40
41
42 class PyramidParser(core.Parser):
43 """Pyramid request argument parser."""
44
45 __location_map__ = dict(
46 matchdict="load_matchdict",
47 path="load_matchdict",
48 **core.Parser.__location_map__,
49 )
50
51 def _raw_load_json(self, req):
52 """Return a json payload from the request for the core parser's load_json
53
54 Checks the input mimetype and may return 'missing' if the mimetype is
55 non-json, even if the request body is parseable as json."""
56 if not is_json_request(req):
57 return core.missing
58
59 return core.parse_json(req.body, req.charset)
60
61 def load_querystring(self, req, schema):
62 """Return query params from the request as a MultiDictProxy."""
63 return MultiDictProxy(req.GET, schema)
64
65 def load_form(self, req, schema):
66 """Return form values from the request as a MultiDictProxy."""
67 return MultiDictProxy(req.POST, schema)
68
69 def load_cookies(self, req, schema):
70 """Return cookies from the request as a MultiDictProxy."""
71 return MultiDictProxy(req.cookies, schema)
72
73 def load_headers(self, req, schema):
74 """Return headers from the request as a MultiDictProxy."""
75 return MultiDictProxy(req.headers, schema)
76
77 def load_files(self, req, schema):
78 """Return files from the request as a MultiDictProxy."""
79 files = ((k, v) for k, v in req.POST.items() if hasattr(v, "file"))
80 return MultiDictProxy(MultiDict(files), schema)
81
82 def load_matchdict(self, req, schema):
83 """Return the request's ``matchdict`` as a MultiDictProxy."""
84 return MultiDictProxy(req.matchdict, schema)
85
86 def handle_error(self, error, req, schema, error_status_code, error_headers):
87 """Handles errors during parsing. Aborts the current HTTP request and
88 responds with a 400 error.
89 """
90 status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS
91 response = exception_response(
92 status_code,
93 detail=str(error),
94 headers=error_headers,
95 content_type="application/json",
96 )
97 body = json.dumps(error.messages)
98 response.body = body.encode("utf-8") if isinstance(body, str) else body
99 raise response
100
101 def _handle_invalid_json_error(self, error, req, *args, **kwargs):
102 messages = {"json": ["Invalid JSON body."]}
103 response = exception_response(
104 400, detail=str(messages), content_type="application/json"
105 )
106 body = json.dumps(messages)
107 response.body = body.encode("utf-8") if isinstance(body, str) else body
108 raise response
109
110 def use_args(
111 self,
112 argmap,
113 req=None,
114 location=core.Parser.DEFAULT_LOCATION,
115 as_kwargs=False,
116 validate=None,
117 error_status_code=None,
118 error_headers=None,
119 ):
120 """Decorator that injects parsed arguments into a view callable.
121 Supports the *Class-based View* pattern where `request` is saved as an instance
122 attribute on a view class.
123
124 :param dict argmap: Either a `marshmallow.Schema`, a `dict`
125 of argname -> `marshmallow.fields.Field` pairs, or a callable
126 which accepts a request and returns a `marshmallow.Schema`.
127 :param req: The request object to parse. Pulled off of the view by default.
128 :param str location: Where on the request to load values.
129 :param bool as_kwargs: Whether to insert arguments as keyword arguments.
130 :param callable validate: Validation function that receives the dictionary
131 of parsed arguments. If the function returns ``False``, the parser
132 will raise a :exc:`ValidationError`.
133 :param int error_status_code: Status code passed to error handler functions when
134 a `ValidationError` is raised.
135 :param dict error_headers: Headers passed to error handler functions when a
136 a `ValidationError` is raised.
137 """
138 location = location or self.location
139 # Optimization: If argmap is passed as a dictionary, we only need
140 # to generate a Schema once
141 if isinstance(argmap, collections.Mapping):
142 argmap = core.dict2schema(argmap, self.schema_class)()
143
144 def decorator(func):
145 @functools.wraps(func)
146 def wrapper(obj, *args, **kwargs):
147 # The first argument is either `self` or `request`
148 try: # get self.request
149 request = req or obj.request
150 except AttributeError: # first arg is request
151 request = obj
152 # NOTE: At this point, argmap may be a Schema, callable, or dict
153 parsed_args = self.parse(
154 argmap,
155 req=request,
156 location=location,
157 validate=validate,
158 error_status_code=error_status_code,
159 error_headers=error_headers,
160 )
161 if as_kwargs:
162 kwargs.update(parsed_args)
163 return func(obj, *args, **kwargs)
164 else:
165 return func(obj, parsed_args, *args, **kwargs)
166
167 wrapper.__wrapped__ = func
168 return wrapper
169
170 return decorator
171
172
173 parser = PyramidParser()
174 use_args = parser.use_args
175 use_kwargs = parser.use_kwargs
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/webargs/pyramidparser.py b/src/webargs/pyramidparser.py
--- a/src/webargs/pyramidparser.py
+++ b/src/webargs/pyramidparser.py
@@ -138,7 +138,7 @@
location = location or self.location
# Optimization: If argmap is passed as a dictionary, we only need
# to generate a Schema once
- if isinstance(argmap, collections.Mapping):
+ if isinstance(argmap, collections.abc.Mapping):
argmap = core.dict2schema(argmap, self.schema_class)()
def decorator(func):
|
{"golden_diff": "diff --git a/src/webargs/pyramidparser.py b/src/webargs/pyramidparser.py\n--- a/src/webargs/pyramidparser.py\n+++ b/src/webargs/pyramidparser.py\n@@ -138,7 +138,7 @@\n location = location or self.location\n # Optimization: If argmap is passed as a dictionary, we only need\n # to generate a Schema once\n- if isinstance(argmap, collections.Mapping):\n+ if isinstance(argmap, collections.abc.Mapping):\n argmap = core.dict2schema(argmap, self.schema_class)()\n \n def decorator(func):\n", "issue": "Importing ABC directly from collections module was removed in Python 3.9\nSince the project is Python 3 only importing from collections.abc will resolve the issue. I will raise a PR.\r\n\r\nhttps://github.com/marshmallow-code/webargs/blob/1b34470908cb54862b7aeb578f794ac3285cdf38/src/webargs/pyramidparser.py#L141\n", "before_files": [{"content": "\"\"\"Pyramid request argument parsing.\n\nExample usage: ::\n\n from wsgiref.simple_server import make_server\n from pyramid.config import Configurator\n from pyramid.response import Response\n from marshmallow import fields\n from webargs.pyramidparser import use_args\n\n hello_args = {\n 'name': fields.Str(missing='World')\n }\n\n @use_args(hello_args)\n def hello_world(request, args):\n return Response('Hello ' + args['name'])\n\n if __name__ == '__main__':\n config = Configurator()\n config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n\"\"\"\nimport collections\nimport functools\n\nfrom webob.multidict import MultiDict\nfrom pyramid.httpexceptions import exception_response\n\nfrom webargs import core\nfrom webargs.core import json\nfrom webargs.multidictproxy import MultiDictProxy\n\n\ndef is_json_request(req):\n return core.is_json(req.headers.get(\"content-type\"))\n\n\nclass PyramidParser(core.Parser):\n \"\"\"Pyramid request argument parser.\"\"\"\n\n __location_map__ = dict(\n matchdict=\"load_matchdict\",\n path=\"load_matchdict\",\n **core.Parser.__location_map__,\n )\n\n def _raw_load_json(self, req):\n \"\"\"Return a json payload from the request for the core parser's load_json\n\n Checks the input mimetype and may return 'missing' if the mimetype is\n non-json, even if the request body is parseable as json.\"\"\"\n if not is_json_request(req):\n return core.missing\n\n return core.parse_json(req.body, req.charset)\n\n def load_querystring(self, req, schema):\n \"\"\"Return query params from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.GET, schema)\n\n def load_form(self, req, schema):\n \"\"\"Return form values from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.POST, schema)\n\n def load_cookies(self, req, schema):\n \"\"\"Return cookies from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.cookies, schema)\n\n def load_headers(self, req, schema):\n \"\"\"Return headers from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.headers, schema)\n\n def load_files(self, req, schema):\n \"\"\"Return files from the request as a MultiDictProxy.\"\"\"\n files = ((k, v) for k, v in req.POST.items() if hasattr(v, \"file\"))\n return MultiDictProxy(MultiDict(files), schema)\n\n def load_matchdict(self, req, schema):\n \"\"\"Return the request's ``matchdict`` as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.matchdict, schema)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 400 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n response = exception_response(\n status_code,\n detail=str(error),\n headers=error_headers,\n content_type=\"application/json\",\n )\n body = json.dumps(error.messages)\n response.body = body.encode(\"utf-8\") if isinstance(body, str) else body\n raise response\n\n def _handle_invalid_json_error(self, error, req, *args, **kwargs):\n messages = {\"json\": [\"Invalid JSON body.\"]}\n response = exception_response(\n 400, detail=str(messages), content_type=\"application/json\"\n )\n body = json.dumps(messages)\n response.body = body.encode(\"utf-8\") if isinstance(body, str) else body\n raise response\n\n def use_args(\n self,\n argmap,\n req=None,\n location=core.Parser.DEFAULT_LOCATION,\n as_kwargs=False,\n validate=None,\n error_status_code=None,\n error_headers=None,\n ):\n \"\"\"Decorator that injects parsed arguments into a view callable.\n Supports the *Class-based View* pattern where `request` is saved as an instance\n attribute on a view class.\n\n :param dict argmap: Either a `marshmallow.Schema`, a `dict`\n of argname -> `marshmallow.fields.Field` pairs, or a callable\n which accepts a request and returns a `marshmallow.Schema`.\n :param req: The request object to parse. Pulled off of the view by default.\n :param str location: Where on the request to load values.\n :param bool as_kwargs: Whether to insert arguments as keyword arguments.\n :param callable validate: Validation function that receives the dictionary\n of parsed arguments. If the function returns ``False``, the parser\n will raise a :exc:`ValidationError`.\n :param int error_status_code: Status code passed to error handler functions when\n a `ValidationError` is raised.\n :param dict error_headers: Headers passed to error handler functions when a\n a `ValidationError` is raised.\n \"\"\"\n location = location or self.location\n # Optimization: If argmap is passed as a dictionary, we only need\n # to generate a Schema once\n if isinstance(argmap, collections.Mapping):\n argmap = core.dict2schema(argmap, self.schema_class)()\n\n def decorator(func):\n @functools.wraps(func)\n def wrapper(obj, *args, **kwargs):\n # The first argument is either `self` or `request`\n try: # get self.request\n request = req or obj.request\n except AttributeError: # first arg is request\n request = obj\n # NOTE: At this point, argmap may be a Schema, callable, or dict\n parsed_args = self.parse(\n argmap,\n req=request,\n location=location,\n validate=validate,\n error_status_code=error_status_code,\n error_headers=error_headers,\n )\n if as_kwargs:\n kwargs.update(parsed_args)\n return func(obj, *args, **kwargs)\n else:\n return func(obj, parsed_args, *args, **kwargs)\n\n wrapper.__wrapped__ = func\n return wrapper\n\n return decorator\n\n\nparser = PyramidParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "src/webargs/pyramidparser.py"}], "after_files": [{"content": "\"\"\"Pyramid request argument parsing.\n\nExample usage: ::\n\n from wsgiref.simple_server import make_server\n from pyramid.config import Configurator\n from pyramid.response import Response\n from marshmallow import fields\n from webargs.pyramidparser import use_args\n\n hello_args = {\n 'name': fields.Str(missing='World')\n }\n\n @use_args(hello_args)\n def hello_world(request, args):\n return Response('Hello ' + args['name'])\n\n if __name__ == '__main__':\n config = Configurator()\n config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n\"\"\"\nimport collections\nimport functools\n\nfrom webob.multidict import MultiDict\nfrom pyramid.httpexceptions import exception_response\n\nfrom webargs import core\nfrom webargs.core import json\nfrom webargs.multidictproxy import MultiDictProxy\n\n\ndef is_json_request(req):\n return core.is_json(req.headers.get(\"content-type\"))\n\n\nclass PyramidParser(core.Parser):\n \"\"\"Pyramid request argument parser.\"\"\"\n\n __location_map__ = dict(\n matchdict=\"load_matchdict\",\n path=\"load_matchdict\",\n **core.Parser.__location_map__,\n )\n\n def _raw_load_json(self, req):\n \"\"\"Return a json payload from the request for the core parser's load_json\n\n Checks the input mimetype and may return 'missing' if the mimetype is\n non-json, even if the request body is parseable as json.\"\"\"\n if not is_json_request(req):\n return core.missing\n\n return core.parse_json(req.body, req.charset)\n\n def load_querystring(self, req, schema):\n \"\"\"Return query params from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.GET, schema)\n\n def load_form(self, req, schema):\n \"\"\"Return form values from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.POST, schema)\n\n def load_cookies(self, req, schema):\n \"\"\"Return cookies from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.cookies, schema)\n\n def load_headers(self, req, schema):\n \"\"\"Return headers from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.headers, schema)\n\n def load_files(self, req, schema):\n \"\"\"Return files from the request as a MultiDictProxy.\"\"\"\n files = ((k, v) for k, v in req.POST.items() if hasattr(v, \"file\"))\n return MultiDictProxy(MultiDict(files), schema)\n\n def load_matchdict(self, req, schema):\n \"\"\"Return the request's ``matchdict`` as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.matchdict, schema)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 400 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n response = exception_response(\n status_code,\n detail=str(error),\n headers=error_headers,\n content_type=\"application/json\",\n )\n body = json.dumps(error.messages)\n response.body = body.encode(\"utf-8\") if isinstance(body, str) else body\n raise response\n\n def _handle_invalid_json_error(self, error, req, *args, **kwargs):\n messages = {\"json\": [\"Invalid JSON body.\"]}\n response = exception_response(\n 400, detail=str(messages), content_type=\"application/json\"\n )\n body = json.dumps(messages)\n response.body = body.encode(\"utf-8\") if isinstance(body, str) else body\n raise response\n\n def use_args(\n self,\n argmap,\n req=None,\n location=core.Parser.DEFAULT_LOCATION,\n as_kwargs=False,\n validate=None,\n error_status_code=None,\n error_headers=None,\n ):\n \"\"\"Decorator that injects parsed arguments into a view callable.\n Supports the *Class-based View* pattern where `request` is saved as an instance\n attribute on a view class.\n\n :param dict argmap: Either a `marshmallow.Schema`, a `dict`\n of argname -> `marshmallow.fields.Field` pairs, or a callable\n which accepts a request and returns a `marshmallow.Schema`.\n :param req: The request object to parse. Pulled off of the view by default.\n :param str location: Where on the request to load values.\n :param bool as_kwargs: Whether to insert arguments as keyword arguments.\n :param callable validate: Validation function that receives the dictionary\n of parsed arguments. If the function returns ``False``, the parser\n will raise a :exc:`ValidationError`.\n :param int error_status_code: Status code passed to error handler functions when\n a `ValidationError` is raised.\n :param dict error_headers: Headers passed to error handler functions when a\n a `ValidationError` is raised.\n \"\"\"\n location = location or self.location\n # Optimization: If argmap is passed as a dictionary, we only need\n # to generate a Schema once\n if isinstance(argmap, collections.abc.Mapping):\n argmap = core.dict2schema(argmap, self.schema_class)()\n\n def decorator(func):\n @functools.wraps(func)\n def wrapper(obj, *args, **kwargs):\n # The first argument is either `self` or `request`\n try: # get self.request\n request = req or obj.request\n except AttributeError: # first arg is request\n request = obj\n # NOTE: At this point, argmap may be a Schema, callable, or dict\n parsed_args = self.parse(\n argmap,\n req=request,\n location=location,\n validate=validate,\n error_status_code=error_status_code,\n error_headers=error_headers,\n )\n if as_kwargs:\n kwargs.update(parsed_args)\n return func(obj, *args, **kwargs)\n else:\n return func(obj, parsed_args, *args, **kwargs)\n\n wrapper.__wrapped__ = func\n return wrapper\n\n return decorator\n\n\nparser = PyramidParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "src/webargs/pyramidparser.py"}]}
| 2,162 | 131 |
gh_patches_debug_2060
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-4453
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Stop backing up lavalink logs
Lavalink logs are host specific, stop backing them up.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redbot/core/utils/_internal_utils.py`
Content:
```
1 from __future__ import annotations
2
3 import asyncio
4 import collections.abc
5 import json
6 import logging
7 import os
8 import re
9 import shutil
10 import tarfile
11 from datetime import datetime
12 from pathlib import Path
13 from typing import (
14 AsyncIterator,
15 Awaitable,
16 Callable,
17 Iterator,
18 List,
19 Optional,
20 Union,
21 TYPE_CHECKING,
22 Tuple,
23 )
24
25 import aiohttp
26 import discord
27 import pkg_resources
28 from fuzzywuzzy import fuzz, process
29 from redbot import VersionInfo
30
31 from redbot.core import data_manager
32 from redbot.core.utils.chat_formatting import box
33
34 if TYPE_CHECKING:
35 from redbot.core.bot import Red
36 from redbot.core.commands import Command, Context
37
38 main_log = logging.getLogger("red")
39
40 __all__ = (
41 "safe_delete",
42 "fuzzy_command_search",
43 "format_fuzzy_results",
44 "create_backup",
45 "send_to_owners_with_preprocessor",
46 "send_to_owners_with_prefix_replaced",
47 "expected_version",
48 "fetch_latest_red_version_info",
49 )
50
51
52 def safe_delete(pth: Path):
53 if pth.exists():
54 for root, dirs, files in os.walk(str(pth)):
55 os.chmod(root, 0o700)
56
57 for d in dirs:
58 os.chmod(os.path.join(root, d), 0o700)
59
60 for f in files:
61 os.chmod(os.path.join(root, f), 0o700)
62
63 shutil.rmtree(str(pth), ignore_errors=True)
64
65
66 def _fuzzy_log_filter(record):
67 return record.funcName != "extractWithoutOrder"
68
69
70 logging.getLogger().addFilter(_fuzzy_log_filter)
71
72
73 async def fuzzy_command_search(
74 ctx: Context,
75 term: Optional[str] = None,
76 *,
77 commands: Optional[Union[AsyncIterator[Command], Iterator[Command]]] = None,
78 min_score: int = 80,
79 ) -> Optional[List[Command]]:
80 """Search for commands which are similar in name to the one invoked.
81
82 Returns a maximum of 5 commands which must all be at least matched
83 greater than ``min_score``.
84
85 Parameters
86 ----------
87 ctx : `commands.Context <redbot.core.commands.Context>`
88 The command invocation context.
89 term : Optional[str]
90 The name of the invoked command. If ``None``,
91 `Context.invoked_with` will be used instead.
92 commands : Optional[Union[AsyncIterator[commands.Command], Iterator[commands.Command]]]
93 The commands available to choose from when doing a fuzzy match.
94 When omitted, `Bot.walk_commands` will be used instead.
95 min_score : int
96 The minimum score for matched commands to reach. Defaults to 80.
97
98 Returns
99 -------
100 Optional[List[`commands.Command <redbot.core.commands.Command>`]]
101 A list of commands which were fuzzily matched with the invoked
102 command.
103
104 """
105 if ctx.guild is not None:
106 enabled = await ctx.bot._config.guild(ctx.guild).fuzzy()
107 else:
108 enabled = await ctx.bot._config.fuzzy()
109
110 if not enabled:
111 return None
112
113 if term is None:
114 term = ctx.invoked_with
115
116 # If the term is an alias or CC, we don't want to send a supplementary fuzzy search.
117 alias_cog = ctx.bot.get_cog("Alias")
118 if alias_cog is not None:
119 alias = await alias_cog._aliases.get_alias(ctx.guild, term)
120
121 if alias:
122 return None
123 customcom_cog = ctx.bot.get_cog("CustomCommands")
124 if customcom_cog is not None:
125 cmd_obj = customcom_cog.commandobj
126
127 try:
128 await cmd_obj.get(ctx.message, term)
129 except:
130 pass
131 else:
132 return None
133
134 if commands is None:
135 choices = set(ctx.bot.walk_commands())
136 elif isinstance(commands, collections.abc.AsyncIterator):
137 choices = {c async for c in commands}
138 else:
139 choices = set(commands)
140
141 # Do the scoring. `extracted` is a list of tuples in the form `(command, score)`
142 extracted = process.extract(term, choices, limit=5, scorer=fuzz.QRatio)
143 if not extracted:
144 return None
145
146 # Filter through the fuzzy-matched commands.
147 matched_commands = []
148 for command, score in extracted:
149 if score < min_score:
150 # Since the list is in decreasing order of score, we can exit early.
151 break
152 if await command.can_see(ctx):
153 matched_commands.append(command)
154
155 return matched_commands
156
157
158 async def format_fuzzy_results(
159 ctx: Context, matched_commands: List[Command], *, embed: Optional[bool] = None
160 ) -> Union[str, discord.Embed]:
161 """Format the result of a fuzzy command search.
162
163 Parameters
164 ----------
165 ctx : `commands.Context <redbot.core.commands.Context>`
166 The context in which this result is being displayed.
167 matched_commands : List[`commands.Command <redbot.core.commands.Command>`]
168 A list of commands which have been matched by the fuzzy search, sorted
169 in order of decreasing similarity.
170 embed : bool
171 Whether or not the result should be an embed. If set to ``None``, this
172 will default to the result of `ctx.embed_requested`.
173
174 Returns
175 -------
176 Union[str, discord.Embed]
177 The formatted results.
178
179 """
180 if embed is not False and (embed is True or await ctx.embed_requested()):
181 lines = []
182 for cmd in matched_commands:
183 short_doc = cmd.format_shortdoc_for_context(ctx)
184 lines.append(f"**{ctx.clean_prefix}{cmd.qualified_name}** {short_doc}")
185 return discord.Embed(
186 title="Perhaps you wanted one of these?",
187 colour=await ctx.embed_colour(),
188 description="\n".join(lines),
189 )
190 else:
191 lines = []
192 for cmd in matched_commands:
193 short_doc = cmd.format_shortdoc_for_context(ctx)
194 lines.append(f"{ctx.clean_prefix}{cmd.qualified_name} -- {short_doc}")
195 return "Perhaps you wanted one of these? " + box("\n".join(lines), lang="vhdl")
196
197
198 async def create_backup(dest: Path = Path.home()) -> Optional[Path]:
199 data_path = Path(data_manager.core_data_path().parent)
200 if not data_path.exists():
201 return None
202
203 dest.mkdir(parents=True, exist_ok=True)
204 timestr = datetime.utcnow().strftime("%Y-%m-%dT%H-%M-%S")
205 backup_fpath = dest / f"redv3_{data_manager.instance_name}_{timestr}.tar.gz"
206
207 to_backup = []
208 exclusions = [
209 "__pycache__",
210 "Lavalink.jar",
211 os.path.join("Downloader", "lib"),
212 os.path.join("CogManager", "cogs"),
213 os.path.join("RepoManager", "repos"),
214 ]
215
216 # Avoiding circular imports
217 from ...cogs.downloader.repo_manager import RepoManager
218
219 repo_mgr = RepoManager()
220 await repo_mgr.initialize()
221 repo_output = []
222 for repo in repo_mgr.repos:
223 repo_output.append({"url": repo.url, "name": repo.name, "branch": repo.branch})
224 repos_file = data_path / "cogs" / "RepoManager" / "repos.json"
225 with repos_file.open("w") as fs:
226 json.dump(repo_output, fs, indent=4)
227 instance_file = data_path / "instance.json"
228 with instance_file.open("w") as fs:
229 json.dump({data_manager.instance_name: data_manager.basic_config}, fs, indent=4)
230 for f in data_path.glob("**/*"):
231 if not any(ex in str(f) for ex in exclusions) and f.is_file():
232 to_backup.append(f)
233
234 with tarfile.open(str(backup_fpath), "w:gz") as tar:
235 for f in to_backup:
236 tar.add(str(f), arcname=str(f.relative_to(data_path)), recursive=False)
237 return backup_fpath
238
239
240 # this might be worth moving to `bot.send_to_owners` at later date
241
242
243 async def send_to_owners_with_preprocessor(
244 bot: Red,
245 content: str,
246 *,
247 content_preprocessor: Optional[
248 Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]
249 ] = None,
250 **kwargs,
251 ):
252 """
253 This sends something to all owners and their configured extra destinations.
254
255 This acts the same as `Red.send_to_owners`, with
256 one added keyword argument as detailed below in *Other Parameters*.
257
258 Other Parameters
259 ----------------
260 content_preprocessor: Optional[Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]]
261 Optional async function that takes
262 bot object, owner notification destination and message content
263 and returns the content that should be sent to given location.
264 """
265 destinations = await bot.get_owner_notification_destinations()
266
267 async def wrapped_send(bot, location, content=None, preprocessor=None, **kwargs):
268 try:
269 if preprocessor is not None:
270 content = await preprocessor(bot, location, content)
271 await location.send(content, **kwargs)
272 except Exception as _exc:
273 main_log.error(
274 "I could not send an owner notification to %s (%s)",
275 location,
276 location.id,
277 exc_info=_exc,
278 )
279
280 sends = [wrapped_send(bot, d, content, content_preprocessor, **kwargs) for d in destinations]
281 await asyncio.gather(*sends)
282
283
284 async def send_to_owners_with_prefix_replaced(bot: Red, content: str, **kwargs):
285 """
286 This sends something to all owners and their configured extra destinations.
287
288 This acts the same as `Red.send_to_owners`, with one addition - `[p]` in ``content`` argument
289 is replaced with a clean prefix for each specific destination.
290 """
291
292 async def preprocessor(bot: Red, destination: discord.abc.Messageable, content: str) -> str:
293 prefixes = await bot.get_valid_prefixes(getattr(destination, "guild", None))
294 prefix = re.sub(
295 rf"<@!?{bot.user.id}>", f"@{bot.user.name}".replace("\\", r"\\"), prefixes[0]
296 )
297 return content.replace("[p]", prefix)
298
299 await send_to_owners_with_preprocessor(bot, content, content_preprocessor=preprocessor)
300
301
302 def expected_version(current: str, expected: str) -> bool:
303 # `pkg_resources` needs a regular requirement string, so "x" serves as requirement's name here
304 return current in pkg_resources.Requirement.parse(f"x{expected}")
305
306
307 async def fetch_latest_red_version_info() -> Tuple[Optional[VersionInfo], Optional[str]]:
308 try:
309 async with aiohttp.ClientSession() as session:
310 async with session.get("https://pypi.org/pypi/Red-DiscordBot/json") as r:
311 data = await r.json()
312 except (aiohttp.ClientError, asyncio.TimeoutError):
313 return None, None
314 else:
315 release = VersionInfo.from_str(data["info"]["version"])
316 required_python = data["info"]["requires_python"]
317
318 return release, required_python
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redbot/core/utils/_internal_utils.py b/redbot/core/utils/_internal_utils.py
--- a/redbot/core/utils/_internal_utils.py
+++ b/redbot/core/utils/_internal_utils.py
@@ -211,6 +211,7 @@
os.path.join("Downloader", "lib"),
os.path.join("CogManager", "cogs"),
os.path.join("RepoManager", "repos"),
+ os.path.join("Audio", "logs"),
]
# Avoiding circular imports
|
{"golden_diff": "diff --git a/redbot/core/utils/_internal_utils.py b/redbot/core/utils/_internal_utils.py\n--- a/redbot/core/utils/_internal_utils.py\n+++ b/redbot/core/utils/_internal_utils.py\n@@ -211,6 +211,7 @@\n os.path.join(\"Downloader\", \"lib\"),\n os.path.join(\"CogManager\", \"cogs\"),\n os.path.join(\"RepoManager\", \"repos\"),\n+ os.path.join(\"Audio\", \"logs\"),\n ]\n \n # Avoiding circular imports\n", "issue": "Stop backing up lavalink logs\nLavalink logs are host specific, stop backing them up.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport asyncio\nimport collections.abc\nimport json\nimport logging\nimport os\nimport re\nimport shutil\nimport tarfile\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import (\n AsyncIterator,\n Awaitable,\n Callable,\n Iterator,\n List,\n Optional,\n Union,\n TYPE_CHECKING,\n Tuple,\n)\n\nimport aiohttp\nimport discord\nimport pkg_resources\nfrom fuzzywuzzy import fuzz, process\nfrom redbot import VersionInfo\n\nfrom redbot.core import data_manager\nfrom redbot.core.utils.chat_formatting import box\n\nif TYPE_CHECKING:\n from redbot.core.bot import Red\n from redbot.core.commands import Command, Context\n\nmain_log = logging.getLogger(\"red\")\n\n__all__ = (\n \"safe_delete\",\n \"fuzzy_command_search\",\n \"format_fuzzy_results\",\n \"create_backup\",\n \"send_to_owners_with_preprocessor\",\n \"send_to_owners_with_prefix_replaced\",\n \"expected_version\",\n \"fetch_latest_red_version_info\",\n)\n\n\ndef safe_delete(pth: Path):\n if pth.exists():\n for root, dirs, files in os.walk(str(pth)):\n os.chmod(root, 0o700)\n\n for d in dirs:\n os.chmod(os.path.join(root, d), 0o700)\n\n for f in files:\n os.chmod(os.path.join(root, f), 0o700)\n\n shutil.rmtree(str(pth), ignore_errors=True)\n\n\ndef _fuzzy_log_filter(record):\n return record.funcName != \"extractWithoutOrder\"\n\n\nlogging.getLogger().addFilter(_fuzzy_log_filter)\n\n\nasync def fuzzy_command_search(\n ctx: Context,\n term: Optional[str] = None,\n *,\n commands: Optional[Union[AsyncIterator[Command], Iterator[Command]]] = None,\n min_score: int = 80,\n) -> Optional[List[Command]]:\n \"\"\"Search for commands which are similar in name to the one invoked.\n\n Returns a maximum of 5 commands which must all be at least matched\n greater than ``min_score``.\n\n Parameters\n ----------\n ctx : `commands.Context <redbot.core.commands.Context>`\n The command invocation context.\n term : Optional[str]\n The name of the invoked command. If ``None``,\n `Context.invoked_with` will be used instead.\n commands : Optional[Union[AsyncIterator[commands.Command], Iterator[commands.Command]]]\n The commands available to choose from when doing a fuzzy match.\n When omitted, `Bot.walk_commands` will be used instead.\n min_score : int\n The minimum score for matched commands to reach. Defaults to 80.\n\n Returns\n -------\n Optional[List[`commands.Command <redbot.core.commands.Command>`]]\n A list of commands which were fuzzily matched with the invoked\n command.\n\n \"\"\"\n if ctx.guild is not None:\n enabled = await ctx.bot._config.guild(ctx.guild).fuzzy()\n else:\n enabled = await ctx.bot._config.fuzzy()\n\n if not enabled:\n return None\n\n if term is None:\n term = ctx.invoked_with\n\n # If the term is an alias or CC, we don't want to send a supplementary fuzzy search.\n alias_cog = ctx.bot.get_cog(\"Alias\")\n if alias_cog is not None:\n alias = await alias_cog._aliases.get_alias(ctx.guild, term)\n\n if alias:\n return None\n customcom_cog = ctx.bot.get_cog(\"CustomCommands\")\n if customcom_cog is not None:\n cmd_obj = customcom_cog.commandobj\n\n try:\n await cmd_obj.get(ctx.message, term)\n except:\n pass\n else:\n return None\n\n if commands is None:\n choices = set(ctx.bot.walk_commands())\n elif isinstance(commands, collections.abc.AsyncIterator):\n choices = {c async for c in commands}\n else:\n choices = set(commands)\n\n # Do the scoring. `extracted` is a list of tuples in the form `(command, score)`\n extracted = process.extract(term, choices, limit=5, scorer=fuzz.QRatio)\n if not extracted:\n return None\n\n # Filter through the fuzzy-matched commands.\n matched_commands = []\n for command, score in extracted:\n if score < min_score:\n # Since the list is in decreasing order of score, we can exit early.\n break\n if await command.can_see(ctx):\n matched_commands.append(command)\n\n return matched_commands\n\n\nasync def format_fuzzy_results(\n ctx: Context, matched_commands: List[Command], *, embed: Optional[bool] = None\n) -> Union[str, discord.Embed]:\n \"\"\"Format the result of a fuzzy command search.\n\n Parameters\n ----------\n ctx : `commands.Context <redbot.core.commands.Context>`\n The context in which this result is being displayed.\n matched_commands : List[`commands.Command <redbot.core.commands.Command>`]\n A list of commands which have been matched by the fuzzy search, sorted\n in order of decreasing similarity.\n embed : bool\n Whether or not the result should be an embed. If set to ``None``, this\n will default to the result of `ctx.embed_requested`.\n\n Returns\n -------\n Union[str, discord.Embed]\n The formatted results.\n\n \"\"\"\n if embed is not False and (embed is True or await ctx.embed_requested()):\n lines = []\n for cmd in matched_commands:\n short_doc = cmd.format_shortdoc_for_context(ctx)\n lines.append(f\"**{ctx.clean_prefix}{cmd.qualified_name}** {short_doc}\")\n return discord.Embed(\n title=\"Perhaps you wanted one of these?\",\n colour=await ctx.embed_colour(),\n description=\"\\n\".join(lines),\n )\n else:\n lines = []\n for cmd in matched_commands:\n short_doc = cmd.format_shortdoc_for_context(ctx)\n lines.append(f\"{ctx.clean_prefix}{cmd.qualified_name} -- {short_doc}\")\n return \"Perhaps you wanted one of these? \" + box(\"\\n\".join(lines), lang=\"vhdl\")\n\n\nasync def create_backup(dest: Path = Path.home()) -> Optional[Path]:\n data_path = Path(data_manager.core_data_path().parent)\n if not data_path.exists():\n return None\n\n dest.mkdir(parents=True, exist_ok=True)\n timestr = datetime.utcnow().strftime(\"%Y-%m-%dT%H-%M-%S\")\n backup_fpath = dest / f\"redv3_{data_manager.instance_name}_{timestr}.tar.gz\"\n\n to_backup = []\n exclusions = [\n \"__pycache__\",\n \"Lavalink.jar\",\n os.path.join(\"Downloader\", \"lib\"),\n os.path.join(\"CogManager\", \"cogs\"),\n os.path.join(\"RepoManager\", \"repos\"),\n ]\n\n # Avoiding circular imports\n from ...cogs.downloader.repo_manager import RepoManager\n\n repo_mgr = RepoManager()\n await repo_mgr.initialize()\n repo_output = []\n for repo in repo_mgr.repos:\n repo_output.append({\"url\": repo.url, \"name\": repo.name, \"branch\": repo.branch})\n repos_file = data_path / \"cogs\" / \"RepoManager\" / \"repos.json\"\n with repos_file.open(\"w\") as fs:\n json.dump(repo_output, fs, indent=4)\n instance_file = data_path / \"instance.json\"\n with instance_file.open(\"w\") as fs:\n json.dump({data_manager.instance_name: data_manager.basic_config}, fs, indent=4)\n for f in data_path.glob(\"**/*\"):\n if not any(ex in str(f) for ex in exclusions) and f.is_file():\n to_backup.append(f)\n\n with tarfile.open(str(backup_fpath), \"w:gz\") as tar:\n for f in to_backup:\n tar.add(str(f), arcname=str(f.relative_to(data_path)), recursive=False)\n return backup_fpath\n\n\n# this might be worth moving to `bot.send_to_owners` at later date\n\n\nasync def send_to_owners_with_preprocessor(\n bot: Red,\n content: str,\n *,\n content_preprocessor: Optional[\n Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]\n ] = None,\n **kwargs,\n):\n \"\"\"\n This sends something to all owners and their configured extra destinations.\n\n This acts the same as `Red.send_to_owners`, with\n one added keyword argument as detailed below in *Other Parameters*.\n\n Other Parameters\n ----------------\n content_preprocessor: Optional[Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]]\n Optional async function that takes\n bot object, owner notification destination and message content\n and returns the content that should be sent to given location.\n \"\"\"\n destinations = await bot.get_owner_notification_destinations()\n\n async def wrapped_send(bot, location, content=None, preprocessor=None, **kwargs):\n try:\n if preprocessor is not None:\n content = await preprocessor(bot, location, content)\n await location.send(content, **kwargs)\n except Exception as _exc:\n main_log.error(\n \"I could not send an owner notification to %s (%s)\",\n location,\n location.id,\n exc_info=_exc,\n )\n\n sends = [wrapped_send(bot, d, content, content_preprocessor, **kwargs) for d in destinations]\n await asyncio.gather(*sends)\n\n\nasync def send_to_owners_with_prefix_replaced(bot: Red, content: str, **kwargs):\n \"\"\"\n This sends something to all owners and their configured extra destinations.\n\n This acts the same as `Red.send_to_owners`, with one addition - `[p]` in ``content`` argument\n is replaced with a clean prefix for each specific destination.\n \"\"\"\n\n async def preprocessor(bot: Red, destination: discord.abc.Messageable, content: str) -> str:\n prefixes = await bot.get_valid_prefixes(getattr(destination, \"guild\", None))\n prefix = re.sub(\n rf\"<@!?{bot.user.id}>\", f\"@{bot.user.name}\".replace(\"\\\\\", r\"\\\\\"), prefixes[0]\n )\n return content.replace(\"[p]\", prefix)\n\n await send_to_owners_with_preprocessor(bot, content, content_preprocessor=preprocessor)\n\n\ndef expected_version(current: str, expected: str) -> bool:\n # `pkg_resources` needs a regular requirement string, so \"x\" serves as requirement's name here\n return current in pkg_resources.Requirement.parse(f\"x{expected}\")\n\n\nasync def fetch_latest_red_version_info() -> Tuple[Optional[VersionInfo], Optional[str]]:\n try:\n async with aiohttp.ClientSession() as session:\n async with session.get(\"https://pypi.org/pypi/Red-DiscordBot/json\") as r:\n data = await r.json()\n except (aiohttp.ClientError, asyncio.TimeoutError):\n return None, None\n else:\n release = VersionInfo.from_str(data[\"info\"][\"version\"])\n required_python = data[\"info\"][\"requires_python\"]\n\n return release, required_python\n", "path": "redbot/core/utils/_internal_utils.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport asyncio\nimport collections.abc\nimport json\nimport logging\nimport os\nimport re\nimport shutil\nimport tarfile\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import (\n AsyncIterator,\n Awaitable,\n Callable,\n Iterator,\n List,\n Optional,\n Union,\n TYPE_CHECKING,\n Tuple,\n)\n\nimport aiohttp\nimport discord\nimport pkg_resources\nfrom fuzzywuzzy import fuzz, process\nfrom redbot import VersionInfo\n\nfrom redbot.core import data_manager\nfrom redbot.core.utils.chat_formatting import box\n\nif TYPE_CHECKING:\n from redbot.core.bot import Red\n from redbot.core.commands import Command, Context\n\nmain_log = logging.getLogger(\"red\")\n\n__all__ = (\n \"safe_delete\",\n \"fuzzy_command_search\",\n \"format_fuzzy_results\",\n \"create_backup\",\n \"send_to_owners_with_preprocessor\",\n \"send_to_owners_with_prefix_replaced\",\n \"expected_version\",\n \"fetch_latest_red_version_info\",\n)\n\n\ndef safe_delete(pth: Path):\n if pth.exists():\n for root, dirs, files in os.walk(str(pth)):\n os.chmod(root, 0o700)\n\n for d in dirs:\n os.chmod(os.path.join(root, d), 0o700)\n\n for f in files:\n os.chmod(os.path.join(root, f), 0o700)\n\n shutil.rmtree(str(pth), ignore_errors=True)\n\n\ndef _fuzzy_log_filter(record):\n return record.funcName != \"extractWithoutOrder\"\n\n\nlogging.getLogger().addFilter(_fuzzy_log_filter)\n\n\nasync def fuzzy_command_search(\n ctx: Context,\n term: Optional[str] = None,\n *,\n commands: Optional[Union[AsyncIterator[Command], Iterator[Command]]] = None,\n min_score: int = 80,\n) -> Optional[List[Command]]:\n \"\"\"Search for commands which are similar in name to the one invoked.\n\n Returns a maximum of 5 commands which must all be at least matched\n greater than ``min_score``.\n\n Parameters\n ----------\n ctx : `commands.Context <redbot.core.commands.Context>`\n The command invocation context.\n term : Optional[str]\n The name of the invoked command. If ``None``,\n `Context.invoked_with` will be used instead.\n commands : Optional[Union[AsyncIterator[commands.Command], Iterator[commands.Command]]]\n The commands available to choose from when doing a fuzzy match.\n When omitted, `Bot.walk_commands` will be used instead.\n min_score : int\n The minimum score for matched commands to reach. Defaults to 80.\n\n Returns\n -------\n Optional[List[`commands.Command <redbot.core.commands.Command>`]]\n A list of commands which were fuzzily matched with the invoked\n command.\n\n \"\"\"\n if ctx.guild is not None:\n enabled = await ctx.bot._config.guild(ctx.guild).fuzzy()\n else:\n enabled = await ctx.bot._config.fuzzy()\n\n if not enabled:\n return None\n\n if term is None:\n term = ctx.invoked_with\n\n # If the term is an alias or CC, we don't want to send a supplementary fuzzy search.\n alias_cog = ctx.bot.get_cog(\"Alias\")\n if alias_cog is not None:\n alias = await alias_cog._aliases.get_alias(ctx.guild, term)\n\n if alias:\n return None\n customcom_cog = ctx.bot.get_cog(\"CustomCommands\")\n if customcom_cog is not None:\n cmd_obj = customcom_cog.commandobj\n\n try:\n await cmd_obj.get(ctx.message, term)\n except:\n pass\n else:\n return None\n\n if commands is None:\n choices = set(ctx.bot.walk_commands())\n elif isinstance(commands, collections.abc.AsyncIterator):\n choices = {c async for c in commands}\n else:\n choices = set(commands)\n\n # Do the scoring. `extracted` is a list of tuples in the form `(command, score)`\n extracted = process.extract(term, choices, limit=5, scorer=fuzz.QRatio)\n if not extracted:\n return None\n\n # Filter through the fuzzy-matched commands.\n matched_commands = []\n for command, score in extracted:\n if score < min_score:\n # Since the list is in decreasing order of score, we can exit early.\n break\n if await command.can_see(ctx):\n matched_commands.append(command)\n\n return matched_commands\n\n\nasync def format_fuzzy_results(\n ctx: Context, matched_commands: List[Command], *, embed: Optional[bool] = None\n) -> Union[str, discord.Embed]:\n \"\"\"Format the result of a fuzzy command search.\n\n Parameters\n ----------\n ctx : `commands.Context <redbot.core.commands.Context>`\n The context in which this result is being displayed.\n matched_commands : List[`commands.Command <redbot.core.commands.Command>`]\n A list of commands which have been matched by the fuzzy search, sorted\n in order of decreasing similarity.\n embed : bool\n Whether or not the result should be an embed. If set to ``None``, this\n will default to the result of `ctx.embed_requested`.\n\n Returns\n -------\n Union[str, discord.Embed]\n The formatted results.\n\n \"\"\"\n if embed is not False and (embed is True or await ctx.embed_requested()):\n lines = []\n for cmd in matched_commands:\n short_doc = cmd.format_shortdoc_for_context(ctx)\n lines.append(f\"**{ctx.clean_prefix}{cmd.qualified_name}** {short_doc}\")\n return discord.Embed(\n title=\"Perhaps you wanted one of these?\",\n colour=await ctx.embed_colour(),\n description=\"\\n\".join(lines),\n )\n else:\n lines = []\n for cmd in matched_commands:\n short_doc = cmd.format_shortdoc_for_context(ctx)\n lines.append(f\"{ctx.clean_prefix}{cmd.qualified_name} -- {short_doc}\")\n return \"Perhaps you wanted one of these? \" + box(\"\\n\".join(lines), lang=\"vhdl\")\n\n\nasync def create_backup(dest: Path = Path.home()) -> Optional[Path]:\n data_path = Path(data_manager.core_data_path().parent)\n if not data_path.exists():\n return None\n\n dest.mkdir(parents=True, exist_ok=True)\n timestr = datetime.utcnow().strftime(\"%Y-%m-%dT%H-%M-%S\")\n backup_fpath = dest / f\"redv3_{data_manager.instance_name}_{timestr}.tar.gz\"\n\n to_backup = []\n exclusions = [\n \"__pycache__\",\n \"Lavalink.jar\",\n os.path.join(\"Downloader\", \"lib\"),\n os.path.join(\"CogManager\", \"cogs\"),\n os.path.join(\"RepoManager\", \"repos\"),\n os.path.join(\"Audio\", \"logs\"),\n ]\n\n # Avoiding circular imports\n from ...cogs.downloader.repo_manager import RepoManager\n\n repo_mgr = RepoManager()\n await repo_mgr.initialize()\n repo_output = []\n for repo in repo_mgr.repos:\n repo_output.append({\"url\": repo.url, \"name\": repo.name, \"branch\": repo.branch})\n repos_file = data_path / \"cogs\" / \"RepoManager\" / \"repos.json\"\n with repos_file.open(\"w\") as fs:\n json.dump(repo_output, fs, indent=4)\n instance_file = data_path / \"instance.json\"\n with instance_file.open(\"w\") as fs:\n json.dump({data_manager.instance_name: data_manager.basic_config}, fs, indent=4)\n for f in data_path.glob(\"**/*\"):\n if not any(ex in str(f) for ex in exclusions) and f.is_file():\n to_backup.append(f)\n\n with tarfile.open(str(backup_fpath), \"w:gz\") as tar:\n for f in to_backup:\n tar.add(str(f), arcname=str(f.relative_to(data_path)), recursive=False)\n return backup_fpath\n\n\n# this might be worth moving to `bot.send_to_owners` at later date\n\n\nasync def send_to_owners_with_preprocessor(\n bot: Red,\n content: str,\n *,\n content_preprocessor: Optional[\n Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]\n ] = None,\n **kwargs,\n):\n \"\"\"\n This sends something to all owners and their configured extra destinations.\n\n This acts the same as `Red.send_to_owners`, with\n one added keyword argument as detailed below in *Other Parameters*.\n\n Other Parameters\n ----------------\n content_preprocessor: Optional[Callable[[Red, discord.abc.Messageable, str], Awaitable[str]]]\n Optional async function that takes\n bot object, owner notification destination and message content\n and returns the content that should be sent to given location.\n \"\"\"\n destinations = await bot.get_owner_notification_destinations()\n\n async def wrapped_send(bot, location, content=None, preprocessor=None, **kwargs):\n try:\n if preprocessor is not None:\n content = await preprocessor(bot, location, content)\n await location.send(content, **kwargs)\n except Exception as _exc:\n main_log.error(\n \"I could not send an owner notification to %s (%s)\",\n location,\n location.id,\n exc_info=_exc,\n )\n\n sends = [wrapped_send(bot, d, content, content_preprocessor, **kwargs) for d in destinations]\n await asyncio.gather(*sends)\n\n\nasync def send_to_owners_with_prefix_replaced(bot: Red, content: str, **kwargs):\n \"\"\"\n This sends something to all owners and their configured extra destinations.\n\n This acts the same as `Red.send_to_owners`, with one addition - `[p]` in ``content`` argument\n is replaced with a clean prefix for each specific destination.\n \"\"\"\n\n async def preprocessor(bot: Red, destination: discord.abc.Messageable, content: str) -> str:\n prefixes = await bot.get_valid_prefixes(getattr(destination, \"guild\", None))\n prefix = re.sub(\n rf\"<@!?{bot.user.id}>\", f\"@{bot.user.name}\".replace(\"\\\\\", r\"\\\\\"), prefixes[0]\n )\n return content.replace(\"[p]\", prefix)\n\n await send_to_owners_with_preprocessor(bot, content, content_preprocessor=preprocessor)\n\n\ndef expected_version(current: str, expected: str) -> bool:\n # `pkg_resources` needs a regular requirement string, so \"x\" serves as requirement's name here\n return current in pkg_resources.Requirement.parse(f\"x{expected}\")\n\n\nasync def fetch_latest_red_version_info() -> Tuple[Optional[VersionInfo], Optional[str]]:\n try:\n async with aiohttp.ClientSession() as session:\n async with session.get(\"https://pypi.org/pypi/Red-DiscordBot/json\") as r:\n data = await r.json()\n except (aiohttp.ClientError, asyncio.TimeoutError):\n return None, None\n else:\n release = VersionInfo.from_str(data[\"info\"][\"version\"])\n required_python = data[\"info\"][\"requires_python\"]\n\n return release, required_python\n", "path": "redbot/core/utils/_internal_utils.py"}]}
| 3,568 | 112 |
gh_patches_debug_19443
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1122
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[META 388] Collect Azure App Service cloud metadata
Implement https://github.com/elastic/apm/issues/388
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/utils/cloud.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 import json
32 import os
33 import socket
34
35 import urllib3
36
37
38 def aws_metadata():
39 """
40 Fetch AWS metadata from the local metadata server. If metadata server is
41 not found, return an empty dictionary
42 """
43 http = urllib3.PoolManager()
44
45 try:
46 # This will throw an error if the metadata server isn't available,
47 # and will be quiet in the logs, unlike urllib3
48 socket.create_connection(("169.254.169.254", 80), 0.1)
49
50 try:
51 # This whole block is almost unnecessary. IMDSv1 will be supported
52 # indefinitely, so the only time this block is needed is if a
53 # security-conscious user has set the metadata service to require
54 # IMDSv2. Thus, the very expansive try:except: coverage.
55
56 # TODO: should we have a config option to completely disable IMDSv2 to reduce overhead?
57 ttl_header = {"X-aws-ec2-metadata-token-ttl-seconds": "300"}
58 token_url = "http://169.254.169.254/latest/api/token"
59 token_request = http.request("PUT", token_url, headers=ttl_header, timeout=1.0, retries=False)
60 token = token_request.data.decode("utf-8")
61 aws_token_header = {"X-aws-ec2-metadata-token": token} if token else {}
62 except Exception:
63 aws_token_header = {}
64 metadata = json.loads(
65 http.request(
66 "GET",
67 "http://169.254.169.254/latest/dynamic/instance-identity/document",
68 headers=aws_token_header,
69 timeout=1.0,
70 retries=False,
71 ).data.decode("utf-8")
72 )
73
74 return {
75 "account": {"id": metadata["accountId"]},
76 "instance": {"id": metadata["instanceId"]},
77 "availability_zone": metadata["availabilityZone"],
78 "machine": {"type": metadata["instanceType"]},
79 "provider": "aws",
80 "region": metadata["region"],
81 }
82
83 except Exception:
84 # Not on an AWS box
85 return {}
86
87
88 def gcp_metadata():
89 """
90 Fetch GCP metadata from the local metadata server. If metadata server is
91 not found, return an empty dictionary
92 """
93 headers = {"Metadata-Flavor": "Google"}
94 http = urllib3.PoolManager()
95
96 try:
97 # This will throw an error if the metadata server isn't available,
98 # and will be quiet in the logs, unlike urllib3
99 socket.getaddrinfo("metadata.google.internal", 80, 0, socket.SOCK_STREAM)
100
101 metadata = json.loads(
102 http.request(
103 "GET",
104 "http://metadata.google.internal/computeMetadata/v1/?recursive=true",
105 headers=headers,
106 timeout=1.0,
107 retries=False,
108 ).data.decode("utf-8")
109 )
110
111 availability_zone = os.path.split(metadata["instance"]["zone"])[1]
112
113 return {
114 "provider": "gcp",
115 "instance": {"id": str(metadata["instance"]["id"]), "name": metadata["instance"]["name"]},
116 "project": {"id": str(metadata["project"]["numericProjectId"]), "name": metadata["project"]["projectId"]},
117 "availability_zone": availability_zone,
118 "region": availability_zone.rsplit("-", 1)[0],
119 "machine": {"type": metadata["instance"]["machineType"].split("/")[-1]},
120 }
121
122 except Exception:
123 # Not on a gcp box
124 return {}
125
126
127 def azure_metadata():
128 """
129 Fetch Azure metadata from the local metadata server. If metadata server is
130 not found, return an empty dictionary
131 """
132 headers = {"Metadata": "true"}
133 http = urllib3.PoolManager()
134
135 try:
136 # This will throw an error if the metadata server isn't available,
137 # and will be quiet in the logs, unlike urllib3
138 socket.create_connection(("169.254.169.254", 80), 0.1)
139
140 # Can't use newest metadata service version, as it's not guaranteed
141 # to be available in all regions
142 metadata = json.loads(
143 http.request(
144 "GET",
145 "http://169.254.169.254/metadata/instance/compute?api-version=2019-08-15",
146 headers=headers,
147 timeout=1.0,
148 retries=False,
149 ).data.decode("utf-8")
150 )
151
152 ret = {
153 "account": {"id": metadata["subscriptionId"]},
154 "instance": {"id": metadata["vmId"], "name": metadata["name"]},
155 "project": {"name": metadata["resourceGroupName"]},
156 "availability_zone": metadata["zone"],
157 "machine": {"type": metadata["vmSize"]},
158 "provider": "azure",
159 "region": metadata["location"],
160 }
161
162 if not ret["availability_zone"]:
163 ret.pop("availability_zone")
164 return ret
165
166 except Exception:
167 # Not on an Azure box
168 return {}
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/utils/cloud.py b/elasticapm/utils/cloud.py
--- a/elasticapm/utils/cloud.py
+++ b/elasticapm/utils/cloud.py
@@ -164,5 +164,30 @@
return ret
except Exception:
- # Not on an Azure box
+ # Not on an Azure box, maybe an azure app service?
+ return azure_app_service_metadata()
+
+
+def azure_app_service_metadata():
+ ret = {"provider": "azure"}
+ website_owner_name = os.environ.get("WEBSITE_OWNER_NAME")
+ website_instance_id = os.environ.get("WEBSITE_INSTANCE_ID")
+ website_site_name = os.environ.get("WEBSITE_SITE_NAME")
+ website_resource_group = os.environ.get("WEBSITE_RESOURCE_GROUP")
+ if not all((website_owner_name, website_instance_id, website_site_name, website_resource_group)):
+ return {}
+ # Format of website_owner_name: {subscription id}+{app service plan resource group}-{region}webspace{.*}
+ if "+" not in website_owner_name:
+ return {}
+ try:
+ account_id, website_owner_name = website_owner_name.split("+")
+ ret["account"] = {"id": account_id}
+ region, _ = website_owner_name.split("webspace")
+ ret["region"] = region.rsplit("-", 1)[1]
+ except Exception:
return {}
+
+ ret["instance"] = {"id": website_instance_id, "name": website_site_name}
+ ret["project"] = {"name": website_resource_group}
+
+ return ret
|
{"golden_diff": "diff --git a/elasticapm/utils/cloud.py b/elasticapm/utils/cloud.py\n--- a/elasticapm/utils/cloud.py\n+++ b/elasticapm/utils/cloud.py\n@@ -164,5 +164,30 @@\n return ret\n \n except Exception:\n- # Not on an Azure box\n+ # Not on an Azure box, maybe an azure app service?\n+ return azure_app_service_metadata()\n+\n+\n+def azure_app_service_metadata():\n+ ret = {\"provider\": \"azure\"}\n+ website_owner_name = os.environ.get(\"WEBSITE_OWNER_NAME\")\n+ website_instance_id = os.environ.get(\"WEBSITE_INSTANCE_ID\")\n+ website_site_name = os.environ.get(\"WEBSITE_SITE_NAME\")\n+ website_resource_group = os.environ.get(\"WEBSITE_RESOURCE_GROUP\")\n+ if not all((website_owner_name, website_instance_id, website_site_name, website_resource_group)):\n+ return {}\n+ # Format of website_owner_name: {subscription id}+{app service plan resource group}-{region}webspace{.*}\n+ if \"+\" not in website_owner_name:\n+ return {}\n+ try:\n+ account_id, website_owner_name = website_owner_name.split(\"+\")\n+ ret[\"account\"] = {\"id\": account_id}\n+ region, _ = website_owner_name.split(\"webspace\")\n+ ret[\"region\"] = region.rsplit(\"-\", 1)[1]\n+ except Exception:\n return {}\n+\n+ ret[\"instance\"] = {\"id\": website_instance_id, \"name\": website_site_name}\n+ ret[\"project\"] = {\"name\": website_resource_group}\n+\n+ return ret\n", "issue": "[META 388] Collect Azure App Service cloud metadata\nImplement https://github.com/elastic/apm/issues/388\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport json\nimport os\nimport socket\n\nimport urllib3\n\n\ndef aws_metadata():\n \"\"\"\n Fetch AWS metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.create_connection((\"169.254.169.254\", 80), 0.1)\n\n try:\n # This whole block is almost unnecessary. IMDSv1 will be supported\n # indefinitely, so the only time this block is needed is if a\n # security-conscious user has set the metadata service to require\n # IMDSv2. Thus, the very expansive try:except: coverage.\n\n # TODO: should we have a config option to completely disable IMDSv2 to reduce overhead?\n ttl_header = {\"X-aws-ec2-metadata-token-ttl-seconds\": \"300\"}\n token_url = \"http://169.254.169.254/latest/api/token\"\n token_request = http.request(\"PUT\", token_url, headers=ttl_header, timeout=1.0, retries=False)\n token = token_request.data.decode(\"utf-8\")\n aws_token_header = {\"X-aws-ec2-metadata-token\": token} if token else {}\n except Exception:\n aws_token_header = {}\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://169.254.169.254/latest/dynamic/instance-identity/document\",\n headers=aws_token_header,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n return {\n \"account\": {\"id\": metadata[\"accountId\"]},\n \"instance\": {\"id\": metadata[\"instanceId\"]},\n \"availability_zone\": metadata[\"availabilityZone\"],\n \"machine\": {\"type\": metadata[\"instanceType\"]},\n \"provider\": \"aws\",\n \"region\": metadata[\"region\"],\n }\n\n except Exception:\n # Not on an AWS box\n return {}\n\n\ndef gcp_metadata():\n \"\"\"\n Fetch GCP metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n headers = {\"Metadata-Flavor\": \"Google\"}\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.getaddrinfo(\"metadata.google.internal\", 80, 0, socket.SOCK_STREAM)\n\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://metadata.google.internal/computeMetadata/v1/?recursive=true\",\n headers=headers,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n availability_zone = os.path.split(metadata[\"instance\"][\"zone\"])[1]\n\n return {\n \"provider\": \"gcp\",\n \"instance\": {\"id\": str(metadata[\"instance\"][\"id\"]), \"name\": metadata[\"instance\"][\"name\"]},\n \"project\": {\"id\": str(metadata[\"project\"][\"numericProjectId\"]), \"name\": metadata[\"project\"][\"projectId\"]},\n \"availability_zone\": availability_zone,\n \"region\": availability_zone.rsplit(\"-\", 1)[0],\n \"machine\": {\"type\": metadata[\"instance\"][\"machineType\"].split(\"/\")[-1]},\n }\n\n except Exception:\n # Not on a gcp box\n return {}\n\n\ndef azure_metadata():\n \"\"\"\n Fetch Azure metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n headers = {\"Metadata\": \"true\"}\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.create_connection((\"169.254.169.254\", 80), 0.1)\n\n # Can't use newest metadata service version, as it's not guaranteed\n # to be available in all regions\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://169.254.169.254/metadata/instance/compute?api-version=2019-08-15\",\n headers=headers,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n ret = {\n \"account\": {\"id\": metadata[\"subscriptionId\"]},\n \"instance\": {\"id\": metadata[\"vmId\"], \"name\": metadata[\"name\"]},\n \"project\": {\"name\": metadata[\"resourceGroupName\"]},\n \"availability_zone\": metadata[\"zone\"],\n \"machine\": {\"type\": metadata[\"vmSize\"]},\n \"provider\": \"azure\",\n \"region\": metadata[\"location\"],\n }\n\n if not ret[\"availability_zone\"]:\n ret.pop(\"availability_zone\")\n return ret\n\n except Exception:\n # Not on an Azure box\n return {}\n", "path": "elasticapm/utils/cloud.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport json\nimport os\nimport socket\n\nimport urllib3\n\n\ndef aws_metadata():\n \"\"\"\n Fetch AWS metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.create_connection((\"169.254.169.254\", 80), 0.1)\n\n try:\n # This whole block is almost unnecessary. IMDSv1 will be supported\n # indefinitely, so the only time this block is needed is if a\n # security-conscious user has set the metadata service to require\n # IMDSv2. Thus, the very expansive try:except: coverage.\n\n # TODO: should we have a config option to completely disable IMDSv2 to reduce overhead?\n ttl_header = {\"X-aws-ec2-metadata-token-ttl-seconds\": \"300\"}\n token_url = \"http://169.254.169.254/latest/api/token\"\n token_request = http.request(\"PUT\", token_url, headers=ttl_header, timeout=1.0, retries=False)\n token = token_request.data.decode(\"utf-8\")\n aws_token_header = {\"X-aws-ec2-metadata-token\": token} if token else {}\n except Exception:\n aws_token_header = {}\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://169.254.169.254/latest/dynamic/instance-identity/document\",\n headers=aws_token_header,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n return {\n \"account\": {\"id\": metadata[\"accountId\"]},\n \"instance\": {\"id\": metadata[\"instanceId\"]},\n \"availability_zone\": metadata[\"availabilityZone\"],\n \"machine\": {\"type\": metadata[\"instanceType\"]},\n \"provider\": \"aws\",\n \"region\": metadata[\"region\"],\n }\n\n except Exception:\n # Not on an AWS box\n return {}\n\n\ndef gcp_metadata():\n \"\"\"\n Fetch GCP metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n headers = {\"Metadata-Flavor\": \"Google\"}\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.getaddrinfo(\"metadata.google.internal\", 80, 0, socket.SOCK_STREAM)\n\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://metadata.google.internal/computeMetadata/v1/?recursive=true\",\n headers=headers,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n availability_zone = os.path.split(metadata[\"instance\"][\"zone\"])[1]\n\n return {\n \"provider\": \"gcp\",\n \"instance\": {\"id\": str(metadata[\"instance\"][\"id\"]), \"name\": metadata[\"instance\"][\"name\"]},\n \"project\": {\"id\": str(metadata[\"project\"][\"numericProjectId\"]), \"name\": metadata[\"project\"][\"projectId\"]},\n \"availability_zone\": availability_zone,\n \"region\": availability_zone.rsplit(\"-\", 1)[0],\n \"machine\": {\"type\": metadata[\"instance\"][\"machineType\"].split(\"/\")[-1]},\n }\n\n except Exception:\n # Not on a gcp box\n return {}\n\n\ndef azure_metadata():\n \"\"\"\n Fetch Azure metadata from the local metadata server. If metadata server is\n not found, return an empty dictionary\n \"\"\"\n headers = {\"Metadata\": \"true\"}\n http = urllib3.PoolManager()\n\n try:\n # This will throw an error if the metadata server isn't available,\n # and will be quiet in the logs, unlike urllib3\n socket.create_connection((\"169.254.169.254\", 80), 0.1)\n\n # Can't use newest metadata service version, as it's not guaranteed\n # to be available in all regions\n metadata = json.loads(\n http.request(\n \"GET\",\n \"http://169.254.169.254/metadata/instance/compute?api-version=2019-08-15\",\n headers=headers,\n timeout=1.0,\n retries=False,\n ).data.decode(\"utf-8\")\n )\n\n ret = {\n \"account\": {\"id\": metadata[\"subscriptionId\"]},\n \"instance\": {\"id\": metadata[\"vmId\"], \"name\": metadata[\"name\"]},\n \"project\": {\"name\": metadata[\"resourceGroupName\"]},\n \"availability_zone\": metadata[\"zone\"],\n \"machine\": {\"type\": metadata[\"vmSize\"]},\n \"provider\": \"azure\",\n \"region\": metadata[\"location\"],\n }\n\n if not ret[\"availability_zone\"]:\n ret.pop(\"availability_zone\")\n return ret\n\n except Exception:\n # Not on an Azure box, maybe an azure app service?\n return azure_app_service_metadata()\n\n\ndef azure_app_service_metadata():\n ret = {\"provider\": \"azure\"}\n website_owner_name = os.environ.get(\"WEBSITE_OWNER_NAME\")\n website_instance_id = os.environ.get(\"WEBSITE_INSTANCE_ID\")\n website_site_name = os.environ.get(\"WEBSITE_SITE_NAME\")\n website_resource_group = os.environ.get(\"WEBSITE_RESOURCE_GROUP\")\n if not all((website_owner_name, website_instance_id, website_site_name, website_resource_group)):\n return {}\n # Format of website_owner_name: {subscription id}+{app service plan resource group}-{region}webspace{.*}\n if \"+\" not in website_owner_name:\n return {}\n try:\n account_id, website_owner_name = website_owner_name.split(\"+\")\n ret[\"account\"] = {\"id\": account_id}\n region, _ = website_owner_name.split(\"webspace\")\n ret[\"region\"] = region.rsplit(\"-\", 1)[1]\n except Exception:\n return {}\n\n ret[\"instance\"] = {\"id\": website_instance_id, \"name\": website_site_name}\n ret[\"project\"] = {\"name\": website_resource_group}\n\n return ret\n", "path": "elasticapm/utils/cloud.py"}]}
| 2,162 | 354 |
gh_patches_debug_34833
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-4051
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Traductions sur le "hover" des filtres
# Résumé
Dans l'interface, tout les filtres qui utilisent le widget `OneLineRangeWidget` ne sont pas traduit.
# Reproduction
- Passé geotrek admin en anglais
- Remplir certains filtres (ceux avec min / max)
- Fermer la fenêtre des filtres
- Placer la souris sur le bouton `Filter`
On pourra observer certains éléments traduits et d'autre non.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geotrek/common/filters/__init__.py`
Content:
```
1 from django.utils.translation import gettext_lazy as _
2 from django_filters import ModelMultipleChoiceFilter, RangeFilter
3 from mapentity.filters import MapEntityFilterSet
4
5 from geotrek.common.filters.fields import ComaSeparatedMultipleModelChoiceField, OneLineRangeField
6 from geotrek.common.models import HDViewPoint
7
8
9 class ComaSeparatedMultipleModelChoiceFilter(ModelMultipleChoiceFilter):
10 field_class = ComaSeparatedMultipleModelChoiceField
11
12
13 class OptionalRangeFilter(RangeFilter):
14 field_class = OneLineRangeField
15
16 def __init__(self, *args, **kwargs):
17 super().__init__(*args, **kwargs)
18 self.field.fields[0].label = _('min %s') % self.field.label
19 self.field.fields[1].label = _('max %s') % self.field.label
20
21
22 class RightFilter(ModelMultipleChoiceFilter):
23 model = None
24 queryset = None
25
26 def __init__(self, *args, **kwargs):
27 kwargs.setdefault('queryset', self.get_queryset())
28 super().__init__(*args, **kwargs)
29 self.field.widget.attrs['class'] = self.field.widget.attrs.get('class', '') + 'right-filter'
30 self.field.widget.renderer = None
31
32 def get_queryset(self, request=None):
33 if self.queryset is not None:
34 return self.queryset
35 return self.model.objects.all()
36
37
38 class HDViewPointFilterSet(MapEntityFilterSet):
39
40 class Meta(MapEntityFilterSet.Meta):
41 model = HDViewPoint
42 fields = ['title']
43
```
Path: `geotrek/maintenance/filters.py`
Content:
```
1 from django.db.models import Q
2 from django.conf import settings
3 from django.contrib.gis.geos import GeometryCollection
4 from django.utils.translation import gettext_lazy as _
5 from django_filters import ChoiceFilter, MultipleChoiceFilter, DateFromToRangeFilter, ModelMultipleChoiceFilter
6
7 from mapentity.filters import PolygonFilter, PythonPolygonFilter
8
9 from geotrek.altimetry.filters import AltimetryPointFilterSet
10 from geotrek.authent.filters import StructureRelatedFilterSet
11 from geotrek.common.filters import OptionalRangeFilter, RightFilter
12 from geotrek.common.widgets import OneLineRangeWidget
13 from geotrek.zoning.filters import (IntersectionFilterCity, IntersectionFilterDistrict,
14 IntersectionFilterRestrictedArea, IntersectionFilterRestrictedAreaType,
15 ZoningFilterSet)
16 from geotrek.zoning.models import City, District, RestrictedArea, RestrictedAreaType
17
18 from .models import Intervention, Project, Contractor
19
20
21 class BboxInterventionFilterMixin:
22 def filter(self, qs, value):
23 if value:
24 value = value.transform(settings.SRID, clone=True)
25 return super().filter(qs, [value, ])
26 else:
27 return qs
28
29
30 class PolygonInterventionFilterMixin:
31 def get_geom(self, value):
32 return value
33
34 def filter(self, qs, values):
35 if not values:
36 return qs
37 geom_intersect = GeometryCollection([self.get_geom(value) for value in values])
38 interventions = []
39 for element in qs:
40 if element.target:
41 if not element.target.geom or element.target.geom.intersects(geom_intersect):
42 interventions.append(element.pk)
43 elif element.target_type:
44 interventions.append(element.pk)
45
46 qs = qs.filter(pk__in=interventions).existing()
47 return qs
48
49
50 class PolygonProjectFilterMixin(PolygonInterventionFilterMixin):
51 def get_geom(self, value):
52 return value.geom
53
54 def filter(self, qs, values):
55 if not values:
56 return qs
57 interventions = Intervention.objects.all()
58 return qs.filter(interventions__in=super().filter(interventions, values).values_list('id', flat=True))
59
60
61 class InterventionIntersectionFilterRestrictedAreaType(PolygonInterventionFilterMixin,
62 IntersectionFilterRestrictedAreaType):
63
64 def get_geom(self, value):
65 return value.geom
66
67 def filter(self, qs, values):
68 restricted_areas = RestrictedArea.objects.filter(area_type__in=values)
69 if not restricted_areas and values:
70 return qs.none()
71 return super().filter(qs, list(restricted_areas))
72
73
74 class InterventionIntersectionFilterRestrictedArea(PolygonInterventionFilterMixin,
75 IntersectionFilterRestrictedArea):
76 def get_geom(self, value):
77 return value.geom
78
79
80 class InterventionIntersectionFilterCity(PolygonInterventionFilterMixin,
81 IntersectionFilterCity):
82 def get_geom(self, value):
83 return value.geom
84
85
86 class InterventionIntersectionFilterDistrict(PolygonInterventionFilterMixin,
87 IntersectionFilterDistrict):
88 def get_geom(self, value):
89 return value.geom
90
91
92 class PolygonTopologyFilter(BboxInterventionFilterMixin, PolygonInterventionFilterMixin, PolygonFilter):
93 pass
94
95
96 class ProjectIntersectionFilterCity(PolygonProjectFilterMixin, RightFilter):
97 model = City
98
99
100 class ProjectIntersectionFilterDistrict(PolygonProjectFilterMixin, RightFilter):
101 model = District
102
103
104 class ProjectIntersectionFilterRestrictedArea(PolygonProjectFilterMixin, RightFilter):
105 model = RestrictedArea
106
107
108 class ProjectIntersectionFilterRestrictedAreaType(PolygonProjectFilterMixin, RightFilter):
109 model = RestrictedAreaType
110
111 def filter(self, qs, values):
112 restricted_areas = RestrictedArea.objects.filter(area_type__in=values)
113 if not restricted_areas and values:
114 return qs.none()
115 return super().filter(qs, list(restricted_areas)).distinct()
116
117
118 class AltimetryInterventionFilterSet(AltimetryPointFilterSet):
119 length_3d = OptionalRangeFilter(field_name='length', label=_('length 3d'))
120 ascent = OptionalRangeFilter(label=_('ascent'))
121 descent = OptionalRangeFilter(label=_('descent'))
122 slope = OptionalRangeFilter(label=_('slope'))
123
124
125 class CustomDateFromToRangeFilter(DateFromToRangeFilter):
126 def __init__(self, *args, **kwargs):
127 super(DateFromToRangeFilter, self).__init__(*args, **kwargs)
128 self.field.fields[0].label = _('min %s') % self.field.label
129 self.field.fields[1].label = _('max %s') % self.field.label
130
131
132 class InterventionFilterSet(AltimetryInterventionFilterSet, ZoningFilterSet, StructureRelatedFilterSet):
133 ON_CHOICES = (('infrastructure', _("Infrastructure")), ('signage', _("Signage")), ('blade', _("Blade")),
134 ('topology', _("Path")), ('trek', _("Trek")), ('poi', _("POI")), ('service', _("Service")),
135 ('trail', _("Trail")))
136
137 if 'geotrek.outdoor' in settings.INSTALLED_APPS:
138 ON_CHOICES += (('course', _("Outdoor Course")), ('site', _("Outdoor Site")),)
139
140 bbox = PolygonTopologyFilter(lookup_expr='intersects')
141 begin_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by begin date range')},), label=_('begin date'))
142 end_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by end date range')},), label=_('end date'))
143 year = MultipleChoiceFilter(choices=lambda: Intervention.objects.year_choices(),
144 method='filter_year', label=_("Year"))
145 on = ChoiceFilter(field_name='target_type__model', choices=ON_CHOICES, label=_("On"), empty_label=_("On"))
146 area_type = InterventionIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), required=False,
147 lookup_expr='intersects')
148 area = InterventionIntersectionFilterRestrictedArea(label=_('Restricted area'), required=False,
149 lookup_expr='intersects')
150 city = InterventionIntersectionFilterCity(label=_('City'), required=False, lookup_expr='intersects')
151 district = InterventionIntersectionFilterDistrict(label=_('District'), required=False, lookup_expr='intersects')
152
153 class Meta(StructureRelatedFilterSet.Meta):
154 model = Intervention
155 fields = StructureRelatedFilterSet.Meta.fields + [
156 'status', 'type', 'stake', 'subcontracting', 'project', 'contractors', 'on',
157 ]
158
159 def filter_year(self, qs, name, values):
160 conditions = Q()
161 for value in values:
162 # Filter only with precise begin year
163 conditions |= Q(begin_date__year=value, end_date__isnull=True)
164 # Filter year between begin and end date
165 conditions |= Q(begin_date__year__lte=value, end_date__year__gte=value)
166 return qs.filter(conditions)
167
168
169 class ProjectFilterSet(StructureRelatedFilterSet):
170 bbox = PythonPolygonFilter(field_name='geom')
171 year = MultipleChoiceFilter(
172 label=_("Year of activity"), method='filter_year',
173 choices=lambda: Project.objects.year_choices()
174 )
175 city = ProjectIntersectionFilterCity(label=_('City'), lookup_expr='intersects', required=False)
176 district = ProjectIntersectionFilterDistrict(label=_('District'), lookup_expr='intersects', required=False)
177 area_type = ProjectIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), lookup_expr='intersects', required=False)
178 area = ProjectIntersectionFilterRestrictedArea(label=_('Restricted area'), lookup_expr='intersects', required=False)
179 contractors = ModelMultipleChoiceFilter(label=_("Intervention contractors"), queryset=Contractor.objects.all(), method='filter_contractors')
180
181 class Meta(StructureRelatedFilterSet.Meta):
182 model = Project
183 fields = StructureRelatedFilterSet.Meta.fields + [
184 'year', 'type', 'domain', 'contractors', 'project_owner',
185 'project_manager', 'founders'
186 ]
187
188 def filter_contractors(self, qs, name, values):
189 q = Q()
190 if values:
191 q |= Q(contractors__in=values)
192 q |= Q(interventions__contractors__in=values)
193 return qs.filter(q)
194
195 def filter_year(self, qs, name, values):
196 q = Q()
197 for value in values:
198 q |= Q(begin_year__lte=value, end_year__gte=value)
199 return qs.filter(q)
200
201 def __init__(self, *args, **kwargs):
202 super().__init__(*args, **kwargs)
203 self.form.fields['year'].choices = Project.objects.year_choices()
204
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geotrek/common/filters/__init__.py b/geotrek/common/filters/__init__.py
--- a/geotrek/common/filters/__init__.py
+++ b/geotrek/common/filters/__init__.py
@@ -1,3 +1,4 @@
+from django.utils.text import format_lazy
from django.utils.translation import gettext_lazy as _
from django_filters import ModelMultipleChoiceFilter, RangeFilter
from mapentity.filters import MapEntityFilterSet
@@ -15,8 +16,8 @@
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
- self.field.fields[0].label = _('min %s') % self.field.label
- self.field.fields[1].label = _('max %s') % self.field.label
+ self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)
+ self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)
class RightFilter(ModelMultipleChoiceFilter):
diff --git a/geotrek/maintenance/filters.py b/geotrek/maintenance/filters.py
--- a/geotrek/maintenance/filters.py
+++ b/geotrek/maintenance/filters.py
@@ -2,6 +2,7 @@
from django.conf import settings
from django.contrib.gis.geos import GeometryCollection
from django.utils.translation import gettext_lazy as _
+from django.utils.text import format_lazy
from django_filters import ChoiceFilter, MultipleChoiceFilter, DateFromToRangeFilter, ModelMultipleChoiceFilter
from mapentity.filters import PolygonFilter, PythonPolygonFilter
@@ -125,8 +126,8 @@
class CustomDateFromToRangeFilter(DateFromToRangeFilter):
def __init__(self, *args, **kwargs):
super(DateFromToRangeFilter, self).__init__(*args, **kwargs)
- self.field.fields[0].label = _('min %s') % self.field.label
- self.field.fields[1].label = _('max %s') % self.field.label
+ self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)
+ self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)
class InterventionFilterSet(AltimetryInterventionFilterSet, ZoningFilterSet, StructureRelatedFilterSet):
|
{"golden_diff": "diff --git a/geotrek/common/filters/__init__.py b/geotrek/common/filters/__init__.py\n--- a/geotrek/common/filters/__init__.py\n+++ b/geotrek/common/filters/__init__.py\n@@ -1,3 +1,4 @@\n+from django.utils.text import format_lazy\n from django.utils.translation import gettext_lazy as _\n from django_filters import ModelMultipleChoiceFilter, RangeFilter\n from mapentity.filters import MapEntityFilterSet\n@@ -15,8 +16,8 @@\n \n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n- self.field.fields[0].label = _('min %s') % self.field.label\n- self.field.fields[1].label = _('max %s') % self.field.label\n+ self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)\n+ self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)\n \n \n class RightFilter(ModelMultipleChoiceFilter):\ndiff --git a/geotrek/maintenance/filters.py b/geotrek/maintenance/filters.py\n--- a/geotrek/maintenance/filters.py\n+++ b/geotrek/maintenance/filters.py\n@@ -2,6 +2,7 @@\n from django.conf import settings\n from django.contrib.gis.geos import GeometryCollection\n from django.utils.translation import gettext_lazy as _\n+from django.utils.text import format_lazy\n from django_filters import ChoiceFilter, MultipleChoiceFilter, DateFromToRangeFilter, ModelMultipleChoiceFilter\n \n from mapentity.filters import PolygonFilter, PythonPolygonFilter\n@@ -125,8 +126,8 @@\n class CustomDateFromToRangeFilter(DateFromToRangeFilter):\n def __init__(self, *args, **kwargs):\n super(DateFromToRangeFilter, self).__init__(*args, **kwargs)\n- self.field.fields[0].label = _('min %s') % self.field.label\n- self.field.fields[1].label = _('max %s') % self.field.label\n+ self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)\n+ self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)\n \n \n class InterventionFilterSet(AltimetryInterventionFilterSet, ZoningFilterSet, StructureRelatedFilterSet):\n", "issue": "Traductions sur le \"hover\" des filtres\n# R\u00e9sum\u00e9\r\n\r\nDans l'interface, tout les filtres qui utilisent le widget `OneLineRangeWidget` ne sont pas traduit.\r\n\r\n# Reproduction\r\n\r\n- Pass\u00e9 geotrek admin en anglais\r\n- Remplir certains filtres (ceux avec min / max)\r\n- Fermer la fen\u00eatre des filtres\r\n- Placer la souris sur le bouton `Filter`\r\n\r\nOn pourra observer certains \u00e9l\u00e9ments traduits et d'autre non.\n", "before_files": [{"content": "from django.utils.translation import gettext_lazy as _\nfrom django_filters import ModelMultipleChoiceFilter, RangeFilter\nfrom mapentity.filters import MapEntityFilterSet\n\nfrom geotrek.common.filters.fields import ComaSeparatedMultipleModelChoiceField, OneLineRangeField\nfrom geotrek.common.models import HDViewPoint\n\n\nclass ComaSeparatedMultipleModelChoiceFilter(ModelMultipleChoiceFilter):\n field_class = ComaSeparatedMultipleModelChoiceField\n\n\nclass OptionalRangeFilter(RangeFilter):\n field_class = OneLineRangeField\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.field.fields[0].label = _('min %s') % self.field.label\n self.field.fields[1].label = _('max %s') % self.field.label\n\n\nclass RightFilter(ModelMultipleChoiceFilter):\n model = None\n queryset = None\n\n def __init__(self, *args, **kwargs):\n kwargs.setdefault('queryset', self.get_queryset())\n super().__init__(*args, **kwargs)\n self.field.widget.attrs['class'] = self.field.widget.attrs.get('class', '') + 'right-filter'\n self.field.widget.renderer = None\n\n def get_queryset(self, request=None):\n if self.queryset is not None:\n return self.queryset\n return self.model.objects.all()\n\n\nclass HDViewPointFilterSet(MapEntityFilterSet):\n\n class Meta(MapEntityFilterSet.Meta):\n model = HDViewPoint\n fields = ['title']\n", "path": "geotrek/common/filters/__init__.py"}, {"content": "from django.db.models import Q\nfrom django.conf import settings\nfrom django.contrib.gis.geos import GeometryCollection\nfrom django.utils.translation import gettext_lazy as _\nfrom django_filters import ChoiceFilter, MultipleChoiceFilter, DateFromToRangeFilter, ModelMultipleChoiceFilter\n\nfrom mapentity.filters import PolygonFilter, PythonPolygonFilter\n\nfrom geotrek.altimetry.filters import AltimetryPointFilterSet\nfrom geotrek.authent.filters import StructureRelatedFilterSet\nfrom geotrek.common.filters import OptionalRangeFilter, RightFilter\nfrom geotrek.common.widgets import OneLineRangeWidget\nfrom geotrek.zoning.filters import (IntersectionFilterCity, IntersectionFilterDistrict,\n IntersectionFilterRestrictedArea, IntersectionFilterRestrictedAreaType,\n ZoningFilterSet)\nfrom geotrek.zoning.models import City, District, RestrictedArea, RestrictedAreaType\n\nfrom .models import Intervention, Project, Contractor\n\n\nclass BboxInterventionFilterMixin:\n def filter(self, qs, value):\n if value:\n value = value.transform(settings.SRID, clone=True)\n return super().filter(qs, [value, ])\n else:\n return qs\n\n\nclass PolygonInterventionFilterMixin:\n def get_geom(self, value):\n return value\n\n def filter(self, qs, values):\n if not values:\n return qs\n geom_intersect = GeometryCollection([self.get_geom(value) for value in values])\n interventions = []\n for element in qs:\n if element.target:\n if not element.target.geom or element.target.geom.intersects(geom_intersect):\n interventions.append(element.pk)\n elif element.target_type:\n interventions.append(element.pk)\n\n qs = qs.filter(pk__in=interventions).existing()\n return qs\n\n\nclass PolygonProjectFilterMixin(PolygonInterventionFilterMixin):\n def get_geom(self, value):\n return value.geom\n\n def filter(self, qs, values):\n if not values:\n return qs\n interventions = Intervention.objects.all()\n return qs.filter(interventions__in=super().filter(interventions, values).values_list('id', flat=True))\n\n\nclass InterventionIntersectionFilterRestrictedAreaType(PolygonInterventionFilterMixin,\n IntersectionFilterRestrictedAreaType):\n\n def get_geom(self, value):\n return value.geom\n\n def filter(self, qs, values):\n restricted_areas = RestrictedArea.objects.filter(area_type__in=values)\n if not restricted_areas and values:\n return qs.none()\n return super().filter(qs, list(restricted_areas))\n\n\nclass InterventionIntersectionFilterRestrictedArea(PolygonInterventionFilterMixin,\n IntersectionFilterRestrictedArea):\n def get_geom(self, value):\n return value.geom\n\n\nclass InterventionIntersectionFilterCity(PolygonInterventionFilterMixin,\n IntersectionFilterCity):\n def get_geom(self, value):\n return value.geom\n\n\nclass InterventionIntersectionFilterDistrict(PolygonInterventionFilterMixin,\n IntersectionFilterDistrict):\n def get_geom(self, value):\n return value.geom\n\n\nclass PolygonTopologyFilter(BboxInterventionFilterMixin, PolygonInterventionFilterMixin, PolygonFilter):\n pass\n\n\nclass ProjectIntersectionFilterCity(PolygonProjectFilterMixin, RightFilter):\n model = City\n\n\nclass ProjectIntersectionFilterDistrict(PolygonProjectFilterMixin, RightFilter):\n model = District\n\n\nclass ProjectIntersectionFilterRestrictedArea(PolygonProjectFilterMixin, RightFilter):\n model = RestrictedArea\n\n\nclass ProjectIntersectionFilterRestrictedAreaType(PolygonProjectFilterMixin, RightFilter):\n model = RestrictedAreaType\n\n def filter(self, qs, values):\n restricted_areas = RestrictedArea.objects.filter(area_type__in=values)\n if not restricted_areas and values:\n return qs.none()\n return super().filter(qs, list(restricted_areas)).distinct()\n\n\nclass AltimetryInterventionFilterSet(AltimetryPointFilterSet):\n length_3d = OptionalRangeFilter(field_name='length', label=_('length 3d'))\n ascent = OptionalRangeFilter(label=_('ascent'))\n descent = OptionalRangeFilter(label=_('descent'))\n slope = OptionalRangeFilter(label=_('slope'))\n\n\nclass CustomDateFromToRangeFilter(DateFromToRangeFilter):\n def __init__(self, *args, **kwargs):\n super(DateFromToRangeFilter, self).__init__(*args, **kwargs)\n self.field.fields[0].label = _('min %s') % self.field.label\n self.field.fields[1].label = _('max %s') % self.field.label\n\n\nclass InterventionFilterSet(AltimetryInterventionFilterSet, ZoningFilterSet, StructureRelatedFilterSet):\n ON_CHOICES = (('infrastructure', _(\"Infrastructure\")), ('signage', _(\"Signage\")), ('blade', _(\"Blade\")),\n ('topology', _(\"Path\")), ('trek', _(\"Trek\")), ('poi', _(\"POI\")), ('service', _(\"Service\")),\n ('trail', _(\"Trail\")))\n\n if 'geotrek.outdoor' in settings.INSTALLED_APPS:\n ON_CHOICES += (('course', _(\"Outdoor Course\")), ('site', _(\"Outdoor Site\")),)\n\n bbox = PolygonTopologyFilter(lookup_expr='intersects')\n begin_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by begin date range')},), label=_('begin date'))\n end_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by end date range')},), label=_('end date'))\n year = MultipleChoiceFilter(choices=lambda: Intervention.objects.year_choices(),\n method='filter_year', label=_(\"Year\"))\n on = ChoiceFilter(field_name='target_type__model', choices=ON_CHOICES, label=_(\"On\"), empty_label=_(\"On\"))\n area_type = InterventionIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), required=False,\n lookup_expr='intersects')\n area = InterventionIntersectionFilterRestrictedArea(label=_('Restricted area'), required=False,\n lookup_expr='intersects')\n city = InterventionIntersectionFilterCity(label=_('City'), required=False, lookup_expr='intersects')\n district = InterventionIntersectionFilterDistrict(label=_('District'), required=False, lookup_expr='intersects')\n\n class Meta(StructureRelatedFilterSet.Meta):\n model = Intervention\n fields = StructureRelatedFilterSet.Meta.fields + [\n 'status', 'type', 'stake', 'subcontracting', 'project', 'contractors', 'on',\n ]\n\n def filter_year(self, qs, name, values):\n conditions = Q()\n for value in values:\n # Filter only with precise begin year\n conditions |= Q(begin_date__year=value, end_date__isnull=True)\n # Filter year between begin and end date\n conditions |= Q(begin_date__year__lte=value, end_date__year__gte=value)\n return qs.filter(conditions)\n\n\nclass ProjectFilterSet(StructureRelatedFilterSet):\n bbox = PythonPolygonFilter(field_name='geom')\n year = MultipleChoiceFilter(\n label=_(\"Year of activity\"), method='filter_year',\n choices=lambda: Project.objects.year_choices()\n )\n city = ProjectIntersectionFilterCity(label=_('City'), lookup_expr='intersects', required=False)\n district = ProjectIntersectionFilterDistrict(label=_('District'), lookup_expr='intersects', required=False)\n area_type = ProjectIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), lookup_expr='intersects', required=False)\n area = ProjectIntersectionFilterRestrictedArea(label=_('Restricted area'), lookup_expr='intersects', required=False)\n contractors = ModelMultipleChoiceFilter(label=_(\"Intervention contractors\"), queryset=Contractor.objects.all(), method='filter_contractors')\n\n class Meta(StructureRelatedFilterSet.Meta):\n model = Project\n fields = StructureRelatedFilterSet.Meta.fields + [\n 'year', 'type', 'domain', 'contractors', 'project_owner',\n 'project_manager', 'founders'\n ]\n\n def filter_contractors(self, qs, name, values):\n q = Q()\n if values:\n q |= Q(contractors__in=values)\n q |= Q(interventions__contractors__in=values)\n return qs.filter(q)\n\n def filter_year(self, qs, name, values):\n q = Q()\n for value in values:\n q |= Q(begin_year__lte=value, end_year__gte=value)\n return qs.filter(q)\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.form.fields['year'].choices = Project.objects.year_choices()\n", "path": "geotrek/maintenance/filters.py"}], "after_files": [{"content": "from django.utils.text import format_lazy\nfrom django.utils.translation import gettext_lazy as _\nfrom django_filters import ModelMultipleChoiceFilter, RangeFilter\nfrom mapentity.filters import MapEntityFilterSet\n\nfrom geotrek.common.filters.fields import ComaSeparatedMultipleModelChoiceField, OneLineRangeField\nfrom geotrek.common.models import HDViewPoint\n\n\nclass ComaSeparatedMultipleModelChoiceFilter(ModelMultipleChoiceFilter):\n field_class = ComaSeparatedMultipleModelChoiceField\n\n\nclass OptionalRangeFilter(RangeFilter):\n field_class = OneLineRangeField\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)\n self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)\n\n\nclass RightFilter(ModelMultipleChoiceFilter):\n model = None\n queryset = None\n\n def __init__(self, *args, **kwargs):\n kwargs.setdefault('queryset', self.get_queryset())\n super().__init__(*args, **kwargs)\n self.field.widget.attrs['class'] = self.field.widget.attrs.get('class', '') + 'right-filter'\n self.field.widget.renderer = None\n\n def get_queryset(self, request=None):\n if self.queryset is not None:\n return self.queryset\n return self.model.objects.all()\n\n\nclass HDViewPointFilterSet(MapEntityFilterSet):\n\n class Meta(MapEntityFilterSet.Meta):\n model = HDViewPoint\n fields = ['title']\n", "path": "geotrek/common/filters/__init__.py"}, {"content": "from django.db.models import Q\nfrom django.conf import settings\nfrom django.contrib.gis.geos import GeometryCollection\nfrom django.utils.translation import gettext_lazy as _\nfrom django.utils.text import format_lazy\nfrom django_filters import ChoiceFilter, MultipleChoiceFilter, DateFromToRangeFilter, ModelMultipleChoiceFilter\n\nfrom mapentity.filters import PolygonFilter, PythonPolygonFilter\n\nfrom geotrek.altimetry.filters import AltimetryPointFilterSet\nfrom geotrek.authent.filters import StructureRelatedFilterSet\nfrom geotrek.common.filters import OptionalRangeFilter, RightFilter\nfrom geotrek.common.widgets import OneLineRangeWidget\nfrom geotrek.zoning.filters import (IntersectionFilterCity, IntersectionFilterDistrict,\n IntersectionFilterRestrictedArea, IntersectionFilterRestrictedAreaType,\n ZoningFilterSet)\nfrom geotrek.zoning.models import City, District, RestrictedArea, RestrictedAreaType\n\nfrom .models import Intervention, Project, Contractor\n\n\nclass BboxInterventionFilterMixin:\n def filter(self, qs, value):\n if value:\n value = value.transform(settings.SRID, clone=True)\n return super().filter(qs, [value, ])\n else:\n return qs\n\n\nclass PolygonInterventionFilterMixin:\n def get_geom(self, value):\n return value\n\n def filter(self, qs, values):\n if not values:\n return qs\n geom_intersect = GeometryCollection([self.get_geom(value) for value in values])\n interventions = []\n for element in qs:\n if element.target:\n if not element.target.geom or element.target.geom.intersects(geom_intersect):\n interventions.append(element.pk)\n elif element.target_type:\n interventions.append(element.pk)\n\n qs = qs.filter(pk__in=interventions).existing()\n return qs\n\n\nclass PolygonProjectFilterMixin(PolygonInterventionFilterMixin):\n def get_geom(self, value):\n return value.geom\n\n def filter(self, qs, values):\n if not values:\n return qs\n interventions = Intervention.objects.all()\n return qs.filter(interventions__in=super().filter(interventions, values).values_list('id', flat=True))\n\n\nclass InterventionIntersectionFilterRestrictedAreaType(PolygonInterventionFilterMixin,\n IntersectionFilterRestrictedAreaType):\n\n def get_geom(self, value):\n return value.geom\n\n def filter(self, qs, values):\n restricted_areas = RestrictedArea.objects.filter(area_type__in=values)\n if not restricted_areas and values:\n return qs.none()\n return super().filter(qs, list(restricted_areas))\n\n\nclass InterventionIntersectionFilterRestrictedArea(PolygonInterventionFilterMixin,\n IntersectionFilterRestrictedArea):\n def get_geom(self, value):\n return value.geom\n\n\nclass InterventionIntersectionFilterCity(PolygonInterventionFilterMixin,\n IntersectionFilterCity):\n def get_geom(self, value):\n return value.geom\n\n\nclass InterventionIntersectionFilterDistrict(PolygonInterventionFilterMixin,\n IntersectionFilterDistrict):\n def get_geom(self, value):\n return value.geom\n\n\nclass PolygonTopologyFilter(BboxInterventionFilterMixin, PolygonInterventionFilterMixin, PolygonFilter):\n pass\n\n\nclass ProjectIntersectionFilterCity(PolygonProjectFilterMixin, RightFilter):\n model = City\n\n\nclass ProjectIntersectionFilterDistrict(PolygonProjectFilterMixin, RightFilter):\n model = District\n\n\nclass ProjectIntersectionFilterRestrictedArea(PolygonProjectFilterMixin, RightFilter):\n model = RestrictedArea\n\n\nclass ProjectIntersectionFilterRestrictedAreaType(PolygonProjectFilterMixin, RightFilter):\n model = RestrictedAreaType\n\n def filter(self, qs, values):\n restricted_areas = RestrictedArea.objects.filter(area_type__in=values)\n if not restricted_areas and values:\n return qs.none()\n return super().filter(qs, list(restricted_areas)).distinct()\n\n\nclass AltimetryInterventionFilterSet(AltimetryPointFilterSet):\n length_3d = OptionalRangeFilter(field_name='length', label=_('length 3d'))\n ascent = OptionalRangeFilter(label=_('ascent'))\n descent = OptionalRangeFilter(label=_('descent'))\n slope = OptionalRangeFilter(label=_('slope'))\n\n\nclass CustomDateFromToRangeFilter(DateFromToRangeFilter):\n def __init__(self, *args, **kwargs):\n super(DateFromToRangeFilter, self).__init__(*args, **kwargs)\n self.field.fields[0].label = format_lazy('{min} {label}', min=_('min'), label=self.field.label)\n self.field.fields[1].label = format_lazy('{max} {label}', max=_('max'), label=self.field.label)\n\n\nclass InterventionFilterSet(AltimetryInterventionFilterSet, ZoningFilterSet, StructureRelatedFilterSet):\n ON_CHOICES = (('infrastructure', _(\"Infrastructure\")), ('signage', _(\"Signage\")), ('blade', _(\"Blade\")),\n ('topology', _(\"Path\")), ('trek', _(\"Trek\")), ('poi', _(\"POI\")), ('service', _(\"Service\")),\n ('trail', _(\"Trail\")))\n\n if 'geotrek.outdoor' in settings.INSTALLED_APPS:\n ON_CHOICES += (('course', _(\"Outdoor Course\")), ('site', _(\"Outdoor Site\")),)\n\n bbox = PolygonTopologyFilter(lookup_expr='intersects')\n begin_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by begin date range')},), label=_('begin date'))\n end_date = CustomDateFromToRangeFilter(widget=OneLineRangeWidget(attrs={'type': 'text', 'class': 'minmax-field', 'title': _('Filter by end date range')},), label=_('end date'))\n year = MultipleChoiceFilter(choices=lambda: Intervention.objects.year_choices(),\n method='filter_year', label=_(\"Year\"))\n on = ChoiceFilter(field_name='target_type__model', choices=ON_CHOICES, label=_(\"On\"), empty_label=_(\"On\"))\n area_type = InterventionIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), required=False,\n lookup_expr='intersects')\n area = InterventionIntersectionFilterRestrictedArea(label=_('Restricted area'), required=False,\n lookup_expr='intersects')\n city = InterventionIntersectionFilterCity(label=_('City'), required=False, lookup_expr='intersects')\n district = InterventionIntersectionFilterDistrict(label=_('District'), required=False, lookup_expr='intersects')\n\n class Meta(StructureRelatedFilterSet.Meta):\n model = Intervention\n fields = StructureRelatedFilterSet.Meta.fields + [\n 'status', 'type', 'stake', 'subcontracting', 'project', 'contractors', 'on',\n ]\n\n def filter_year(self, qs, name, values):\n conditions = Q()\n for value in values:\n # Filter only with precise begin year\n conditions |= Q(begin_date__year=value, end_date__isnull=True)\n # Filter year between begin and end date\n conditions |= Q(begin_date__year__lte=value, end_date__year__gte=value)\n return qs.filter(conditions)\n\n\nclass ProjectFilterSet(StructureRelatedFilterSet):\n bbox = PythonPolygonFilter(field_name='geom')\n year = MultipleChoiceFilter(\n label=_(\"Year of activity\"), method='filter_year',\n choices=lambda: Project.objects.year_choices()\n )\n city = ProjectIntersectionFilterCity(label=_('City'), lookup_expr='intersects', required=False)\n district = ProjectIntersectionFilterDistrict(label=_('District'), lookup_expr='intersects', required=False)\n area_type = ProjectIntersectionFilterRestrictedAreaType(label=_('Restricted area type'), lookup_expr='intersects', required=False)\n area = ProjectIntersectionFilterRestrictedArea(label=_('Restricted area'), lookup_expr='intersects', required=False)\n contractors = ModelMultipleChoiceFilter(label=_(\"Intervention contractors\"), queryset=Contractor.objects.all(), method='filter_contractors')\n\n class Meta(StructureRelatedFilterSet.Meta):\n model = Project\n fields = StructureRelatedFilterSet.Meta.fields + [\n 'year', 'type', 'domain', 'contractors', 'project_owner',\n 'project_manager', 'founders'\n ]\n\n def filter_contractors(self, qs, name, values):\n q = Q()\n if values:\n q |= Q(contractors__in=values)\n q |= Q(interventions__contractors__in=values)\n return qs.filter(q)\n\n def filter_year(self, qs, name, values):\n q = Q()\n for value in values:\n q |= Q(begin_year__lte=value, end_year__gte=value)\n return qs.filter(q)\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.form.fields['year'].choices = Project.objects.year_choices()\n", "path": "geotrek/maintenance/filters.py"}]}
| 3,131 | 539 |
gh_patches_debug_40041
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-6496
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[request] celero/2.8.0
### Package Details
* Package Name/Version: **celero/2.8.0**
* Changelog: **https://github.com/DigitalInBlue/Celero/releases/tag/v2.8.0**
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/celero/all/conanfile.py`
Content:
```
1 import os
2
3 from conans import ConanFile, CMake, tools
4 from conans.errors import ConanInvalidConfiguration
5
6 required_conan_version = ">=1.28.0"
7
8 class CeleroConan(ConanFile):
9 name = "celero"
10 description = "C++ Benchmarking Library"
11 license = "Apache-2.0"
12 topics = ("conan", "celero", "benchmark", "benchmark-tests", "measurements", "microbenchmarks")
13 homepage = "https://github.com/DigitalInBlue/Celero"
14 url = "https://github.com/conan-io/conan-center-index"
15 exports_sources = ["CMakeLists.txt", "patches/**"]
16 generators = "cmake"
17 settings = "os", "arch", "compiler", "build_type"
18 options = {"shared": [True, False], "fPIC": [True, False]}
19 default_options = {"shared": False, "fPIC": True}
20
21 _cmake = None
22
23 @property
24 def _source_subfolder(self):
25 return "source_subfolder"
26
27 def config_options(self):
28 if self.settings.os == "Windows":
29 del self.options.fPIC
30
31 @property
32 def _compilers_minimum_version(self):
33 return {
34 "gcc": "6",
35 "Visual Studio": "14",
36 "clang": "3.4",
37 "apple-clang": "5.1",
38 }
39
40 def configure(self):
41 if self.options.shared:
42 del self.options.fPIC
43 if self.settings.compiler.cppstd:
44 tools.check_min_cppstd(self, 14)
45 minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)
46 if not minimum_version:
47 self.output.warn("celero requires C++14. Your compiler is unknown. Assuming it supports C++14.")
48 elif tools.Version(self.settings.compiler.version) < minimum_version:
49 raise ConanInvalidConfiguration("celero requires C++14, which your compiler does not support.")
50
51 def source(self):
52 tools.get(**self.conan_data["sources"][self.version])
53 os.rename("Celero-" + self.version, self._source_subfolder)
54
55 def _configure_cmake(self):
56 if self._cmake:
57 return self._cmake
58 self._cmake = CMake(self)
59 self._cmake.definitions["CELERO_COMPILE_DYNAMIC_LIBRARIES"] = self.options.shared
60 self._cmake.definitions["CELERO_COMPILE_PIC"] = self.options.get_safe("fPIC", True)
61 self._cmake.definitions["CELERO_ENABLE_EXPERIMENTS"] = False
62 self._cmake.definitions["CELERO_ENABLE_FOLDERS"] = False
63 self._cmake.definitions["CELERO_ENABLE_TESTS"] = False
64 self._cmake.definitions["CELERO_TREAT_WARNINGS_AS_ERRORS"] = False
65 self._cmake.configure()
66 return self._cmake
67
68 def build(self):
69 for patch in self.conan_data.get("patches", {}).get(self.version, []):
70 tools.patch(**patch)
71 cmake = self._configure_cmake()
72 cmake.build()
73
74 def package(self):
75 self.copy("license.txt", dst="licenses", src=self._source_subfolder)
76 cmake = self._configure_cmake()
77 cmake.install()
78 tools.rmdir(os.path.join(self.package_folder, "share"))
79
80 def package_info(self):
81 # FIXME: official CMake target is exported without namespace
82 self.cpp_info.filenames["cmake_find_package"] = "Celero"
83 self.cpp_info.filenames["cmake_find_package_multi"] = "Celero"
84 self.cpp_info.names["cmake_find_package"] = "celero"
85 self.cpp_info.names["cmake_find_package_multi"] = "celero"
86 self.cpp_info.libs = tools.collect_libs(self)
87 if not self.options.shared:
88 self.cpp_info.defines = ["CELERO_STATIC"]
89 if self.settings.os == "Linux":
90 self.cpp_info.system_libs = ["pthread"]
91 elif self.settings.os == "Windows":
92 self.cpp_info.system_libs = ["powrprof", "psapi"]
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/celero/all/conanfile.py b/recipes/celero/all/conanfile.py
--- a/recipes/celero/all/conanfile.py
+++ b/recipes/celero/all/conanfile.py
@@ -1,9 +1,9 @@
import os
-
+import textwrap
from conans import ConanFile, CMake, tools
from conans.errors import ConanInvalidConfiguration
-required_conan_version = ">=1.28.0"
+required_conan_version = ">=1.33.0"
class CeleroConan(ConanFile):
name = "celero"
@@ -49,8 +49,7 @@
raise ConanInvalidConfiguration("celero requires C++14, which your compiler does not support.")
def source(self):
- tools.get(**self.conan_data["sources"][self.version])
- os.rename("Celero-" + self.version, self._source_subfolder)
+ tools.get(**self.conan_data["sources"][self.version], strip_root=True, destination=self._source_subfolder)
def _configure_cmake(self):
if self._cmake:
@@ -76,17 +75,44 @@
cmake = self._configure_cmake()
cmake.install()
tools.rmdir(os.path.join(self.package_folder, "share"))
+ self._create_cmake_module_alias_targets(
+ os.path.join(self.package_folder, self._module_file_rel_path),
+ {"celero": "celero::celero"}
+ )
+
+ @staticmethod
+ def _create_cmake_module_alias_targets(module_file, targets):
+ content = ""
+ for alias, aliased in targets.items():
+ content += textwrap.dedent("""\
+ if(TARGET {aliased} AND NOT TARGET {alias})
+ add_library({alias} INTERFACE IMPORTED)
+ set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})
+ endif()
+ """.format(alias=alias, aliased=aliased))
+ tools.save(module_file, content)
+
+ @property
+ def _module_subfolder(self):
+ return os.path.join("lib", "cmake")
+
+ @property
+ def _module_file_rel_path(self):
+ return os.path.join(self._module_subfolder,
+ "conan-official-{}-targets.cmake".format(self.name))
def package_info(self):
- # FIXME: official CMake target is exported without namespace
self.cpp_info.filenames["cmake_find_package"] = "Celero"
self.cpp_info.filenames["cmake_find_package_multi"] = "Celero"
self.cpp_info.names["cmake_find_package"] = "celero"
self.cpp_info.names["cmake_find_package_multi"] = "celero"
self.cpp_info.libs = tools.collect_libs(self)
+ self.cpp_info.builddirs.append(self._module_subfolder)
+ self.cpp_info.build_modules["cmake_find_package"] = [self._module_file_rel_path]
+ self.cpp_info.build_modules["cmake_find_package_multi"] = [self._module_file_rel_path]
if not self.options.shared:
self.cpp_info.defines = ["CELERO_STATIC"]
- if self.settings.os == "Linux":
+ if self.settings.os in ("FreeBSD", "Linux"):
self.cpp_info.system_libs = ["pthread"]
elif self.settings.os == "Windows":
self.cpp_info.system_libs = ["powrprof", "psapi"]
|
{"golden_diff": "diff --git a/recipes/celero/all/conanfile.py b/recipes/celero/all/conanfile.py\n--- a/recipes/celero/all/conanfile.py\n+++ b/recipes/celero/all/conanfile.py\n@@ -1,9 +1,9 @@\n import os\n-\n+import textwrap\n from conans import ConanFile, CMake, tools\n from conans.errors import ConanInvalidConfiguration\n \n-required_conan_version = \">=1.28.0\"\n+required_conan_version = \">=1.33.0\"\n \n class CeleroConan(ConanFile):\n name = \"celero\"\n@@ -49,8 +49,7 @@\n raise ConanInvalidConfiguration(\"celero requires C++14, which your compiler does not support.\")\n \n def source(self):\n- tools.get(**self.conan_data[\"sources\"][self.version])\n- os.rename(\"Celero-\" + self.version, self._source_subfolder)\n+ tools.get(**self.conan_data[\"sources\"][self.version], strip_root=True, destination=self._source_subfolder)\n \n def _configure_cmake(self):\n if self._cmake:\n@@ -76,17 +75,44 @@\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n+ self._create_cmake_module_alias_targets(\n+ os.path.join(self.package_folder, self._module_file_rel_path),\n+ {\"celero\": \"celero::celero\"}\n+ )\n+\n+ @staticmethod\n+ def _create_cmake_module_alias_targets(module_file, targets):\n+ content = \"\"\n+ for alias, aliased in targets.items():\n+ content += textwrap.dedent(\"\"\"\\\n+ if(TARGET {aliased} AND NOT TARGET {alias})\n+ add_library({alias} INTERFACE IMPORTED)\n+ set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})\n+ endif()\n+ \"\"\".format(alias=alias, aliased=aliased))\n+ tools.save(module_file, content)\n+\n+ @property\n+ def _module_subfolder(self):\n+ return os.path.join(\"lib\", \"cmake\")\n+\n+ @property\n+ def _module_file_rel_path(self):\n+ return os.path.join(self._module_subfolder,\n+ \"conan-official-{}-targets.cmake\".format(self.name))\n \n def package_info(self):\n- # FIXME: official CMake target is exported without namespace\n self.cpp_info.filenames[\"cmake_find_package\"] = \"Celero\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"Celero\"\n self.cpp_info.names[\"cmake_find_package\"] = \"celero\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"celero\"\n self.cpp_info.libs = tools.collect_libs(self)\n+ self.cpp_info.builddirs.append(self._module_subfolder)\n+ self.cpp_info.build_modules[\"cmake_find_package\"] = [self._module_file_rel_path]\n+ self.cpp_info.build_modules[\"cmake_find_package_multi\"] = [self._module_file_rel_path]\n if not self.options.shared:\n self.cpp_info.defines = [\"CELERO_STATIC\"]\n- if self.settings.os == \"Linux\":\n+ if self.settings.os in (\"FreeBSD\", \"Linux\"):\n self.cpp_info.system_libs = [\"pthread\"]\n elif self.settings.os == \"Windows\":\n self.cpp_info.system_libs = [\"powrprof\", \"psapi\"]\n", "issue": "[request] celero/2.8.0\n### Package Details\r\n * Package Name/Version: **celero/2.8.0**\r\n * Changelog: **https://github.com/DigitalInBlue/Celero/releases/tag/v2.8.0**\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\r\n\n", "before_files": [{"content": "import os\n\nfrom conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\nrequired_conan_version = \">=1.28.0\"\n\nclass CeleroConan(ConanFile):\n name = \"celero\"\n description = \"C++ Benchmarking Library\"\n license = \"Apache-2.0\"\n topics = (\"conan\", \"celero\", \"benchmark\", \"benchmark-tests\", \"measurements\", \"microbenchmarks\")\n homepage = \"https://github.com/DigitalInBlue/Celero\"\n url = \"https://github.com/conan-io/conan-center-index\"\n exports_sources = [\"CMakeLists.txt\", \"patches/**\"]\n generators = \"cmake\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n @property\n def _compilers_minimum_version(self):\n return {\n \"gcc\": \"6\",\n \"Visual Studio\": \"14\",\n \"clang\": \"3.4\",\n \"apple-clang\": \"5.1\",\n }\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, 14)\n minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)\n if not minimum_version:\n self.output.warn(\"celero requires C++14. Your compiler is unknown. Assuming it supports C++14.\")\n elif tools.Version(self.settings.compiler.version) < minimum_version:\n raise ConanInvalidConfiguration(\"celero requires C++14, which your compiler does not support.\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"Celero-\" + self.version, self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"CELERO_COMPILE_DYNAMIC_LIBRARIES\"] = self.options.shared\n self._cmake.definitions[\"CELERO_COMPILE_PIC\"] = self.options.get_safe(\"fPIC\", True)\n self._cmake.definitions[\"CELERO_ENABLE_EXPERIMENTS\"] = False\n self._cmake.definitions[\"CELERO_ENABLE_FOLDERS\"] = False\n self._cmake.definitions[\"CELERO_ENABLE_TESTS\"] = False\n self._cmake.definitions[\"CELERO_TREAT_WARNINGS_AS_ERRORS\"] = False\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"license.txt\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n\n def package_info(self):\n # FIXME: official CMake target is exported without namespace\n self.cpp_info.filenames[\"cmake_find_package\"] = \"Celero\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"Celero\"\n self.cpp_info.names[\"cmake_find_package\"] = \"celero\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"celero\"\n self.cpp_info.libs = tools.collect_libs(self)\n if not self.options.shared:\n self.cpp_info.defines = [\"CELERO_STATIC\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs = [\"pthread\"]\n elif self.settings.os == \"Windows\":\n self.cpp_info.system_libs = [\"powrprof\", \"psapi\"]\n", "path": "recipes/celero/all/conanfile.py"}], "after_files": [{"content": "import os\nimport textwrap\nfrom conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\nrequired_conan_version = \">=1.33.0\"\n\nclass CeleroConan(ConanFile):\n name = \"celero\"\n description = \"C++ Benchmarking Library\"\n license = \"Apache-2.0\"\n topics = (\"conan\", \"celero\", \"benchmark\", \"benchmark-tests\", \"measurements\", \"microbenchmarks\")\n homepage = \"https://github.com/DigitalInBlue/Celero\"\n url = \"https://github.com/conan-io/conan-center-index\"\n exports_sources = [\"CMakeLists.txt\", \"patches/**\"]\n generators = \"cmake\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n @property\n def _compilers_minimum_version(self):\n return {\n \"gcc\": \"6\",\n \"Visual Studio\": \"14\",\n \"clang\": \"3.4\",\n \"apple-clang\": \"5.1\",\n }\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, 14)\n minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)\n if not minimum_version:\n self.output.warn(\"celero requires C++14. Your compiler is unknown. Assuming it supports C++14.\")\n elif tools.Version(self.settings.compiler.version) < minimum_version:\n raise ConanInvalidConfiguration(\"celero requires C++14, which your compiler does not support.\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version], strip_root=True, destination=self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"CELERO_COMPILE_DYNAMIC_LIBRARIES\"] = self.options.shared\n self._cmake.definitions[\"CELERO_COMPILE_PIC\"] = self.options.get_safe(\"fPIC\", True)\n self._cmake.definitions[\"CELERO_ENABLE_EXPERIMENTS\"] = False\n self._cmake.definitions[\"CELERO_ENABLE_FOLDERS\"] = False\n self._cmake.definitions[\"CELERO_ENABLE_TESTS\"] = False\n self._cmake.definitions[\"CELERO_TREAT_WARNINGS_AS_ERRORS\"] = False\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"license.txt\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n self._create_cmake_module_alias_targets(\n os.path.join(self.package_folder, self._module_file_rel_path),\n {\"celero\": \"celero::celero\"}\n )\n\n @staticmethod\n def _create_cmake_module_alias_targets(module_file, targets):\n content = \"\"\n for alias, aliased in targets.items():\n content += textwrap.dedent(\"\"\"\\\n if(TARGET {aliased} AND NOT TARGET {alias})\n add_library({alias} INTERFACE IMPORTED)\n set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})\n endif()\n \"\"\".format(alias=alias, aliased=aliased))\n tools.save(module_file, content)\n\n @property\n def _module_subfolder(self):\n return os.path.join(\"lib\", \"cmake\")\n\n @property\n def _module_file_rel_path(self):\n return os.path.join(self._module_subfolder,\n \"conan-official-{}-targets.cmake\".format(self.name))\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"Celero\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"Celero\"\n self.cpp_info.names[\"cmake_find_package\"] = \"celero\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"celero\"\n self.cpp_info.libs = tools.collect_libs(self)\n self.cpp_info.builddirs.append(self._module_subfolder)\n self.cpp_info.build_modules[\"cmake_find_package\"] = [self._module_file_rel_path]\n self.cpp_info.build_modules[\"cmake_find_package_multi\"] = [self._module_file_rel_path]\n if not self.options.shared:\n self.cpp_info.defines = [\"CELERO_STATIC\"]\n if self.settings.os in (\"FreeBSD\", \"Linux\"):\n self.cpp_info.system_libs = [\"pthread\"]\n elif self.settings.os == \"Windows\":\n self.cpp_info.system_libs = [\"powrprof\", \"psapi\"]\n", "path": "recipes/celero/all/conanfile.py"}]}
| 1,426 | 773 |
gh_patches_debug_1916
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-23
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Set port numbers in docker compose via environment variables
To provide more flexibility when setting up the ports for a given environment, we should not use static ports in `docker-compose`. Instead those ports should be extracted to the `.env` file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/config/gunicorn.py`
Content:
```
1 import multiprocessing
2 import os
3 from distutils.util import strtobool
4
5 bind = f"0.0.0.0:{os.getenv('PORT', '8000')}"
6 accesslog = "-"
7
8 workers = int(os.getenv("WEB_CONCURRENCY", multiprocessing.cpu_count() * 2))
9 threads = int(os.getenv("PYTHON_MAX_THREADS", 1))
10
11 reload = bool(strtobool(os.getenv("WEB_RELOAD", "false")))
12
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/config/gunicorn.py b/src/config/gunicorn.py
--- a/src/config/gunicorn.py
+++ b/src/config/gunicorn.py
@@ -2,7 +2,7 @@
import os
from distutils.util import strtobool
-bind = f"0.0.0.0:{os.getenv('PORT', '8000')}"
+bind = f"0.0.0.0:{os.getenv('GUNICORN_BIND_PORT', '8000')}"
accesslog = "-"
workers = int(os.getenv("WEB_CONCURRENCY", multiprocessing.cpu_count() * 2))
|
{"golden_diff": "diff --git a/src/config/gunicorn.py b/src/config/gunicorn.py\n--- a/src/config/gunicorn.py\n+++ b/src/config/gunicorn.py\n@@ -2,7 +2,7 @@\n import os\n from distutils.util import strtobool\n \n-bind = f\"0.0.0.0:{os.getenv('PORT', '8000')}\"\n+bind = f\"0.0.0.0:{os.getenv('GUNICORN_BIND_PORT', '8000')}\"\n accesslog = \"-\"\n \n workers = int(os.getenv(\"WEB_CONCURRENCY\", multiprocessing.cpu_count() * 2))\n", "issue": "Set port numbers in docker compose via environment variables\nTo provide more flexibility when setting up the ports for a given environment, we should not use static ports in `docker-compose`. Instead those ports should be extracted to the `.env` file.\n", "before_files": [{"content": "import multiprocessing\nimport os\nfrom distutils.util import strtobool\n\nbind = f\"0.0.0.0:{os.getenv('PORT', '8000')}\"\naccesslog = \"-\"\n\nworkers = int(os.getenv(\"WEB_CONCURRENCY\", multiprocessing.cpu_count() * 2))\nthreads = int(os.getenv(\"PYTHON_MAX_THREADS\", 1))\n\nreload = bool(strtobool(os.getenv(\"WEB_RELOAD\", \"false\")))\n", "path": "src/config/gunicorn.py"}], "after_files": [{"content": "import multiprocessing\nimport os\nfrom distutils.util import strtobool\n\nbind = f\"0.0.0.0:{os.getenv('GUNICORN_BIND_PORT', '8000')}\"\naccesslog = \"-\"\n\nworkers = int(os.getenv(\"WEB_CONCURRENCY\", multiprocessing.cpu_count() * 2))\nthreads = int(os.getenv(\"PYTHON_MAX_THREADS\", 1))\n\nreload = bool(strtobool(os.getenv(\"WEB_RELOAD\", \"false\")))\n", "path": "src/config/gunicorn.py"}]}
| 417 | 132 |
gh_patches_debug_33340
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-627
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
multivariate normal density cannot handle vectors as it claims
It seems that if `x` and `mu` are vectors, the call to `tf.matrix_triangular_solve` would fail (as `d = x - mu` is rank 1). Worse, if `x` and `mu` are of different dimensionality (e.g. one a row, one a column vector) broadcasting happens and fails silently.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpflow/models/gpr.py`
Content:
```
1 # Copyright 2016 James Hensman, Valentine Svensson, alexggmatthews, fujiisoup
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from __future__ import absolute_import
17 import tensorflow as tf
18
19 from .. import likelihoods
20 from .. import settings
21
22 from ..params import DataHolder
23 from ..decors import params_as_tensors
24 from ..decors import name_scope
25 from ..densities import multivariate_normal
26
27 from .model import GPModel
28
29
30 class GPR(GPModel):
31 """
32 Gaussian Process Regression.
33
34 This is a vanilla implementation of GP regression with a Gaussian
35 likelihood. Multiple columns of Y are treated independently.
36
37 The log likelihood i this models is sometimes referred to as the 'marginal log likelihood', and is given by
38
39 .. math::
40
41 \\log p(\\mathbf y \\,|\\, \\mathbf f) = \\mathcal N\\left(\\mathbf y\,|\, 0, \\mathbf K + \\sigma_n \\mathbf I\\right)
42 """
43 def __init__(self, X, Y, kern, mean_function=None, **kwargs):
44 """
45 X is a data matrix, size N x D
46 Y is a data matrix, size N x R
47 kern, mean_function are appropriate GPflow objects
48 """
49 likelihood = likelihoods.Gaussian()
50 X = DataHolder(X)
51 Y = DataHolder(Y)
52 GPModel.__init__(self, X, Y, kern, likelihood, mean_function, **kwargs)
53
54 @name_scope('likelihood')
55 @params_as_tensors
56 def _build_likelihood(self):
57 """
58 Construct a tensorflow function to compute the likelihood.
59
60 \log p(Y | theta).
61
62 """
63 K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance
64 L = tf.cholesky(K)
65 m = self.mean_function(self.X)
66
67 return multivariate_normal(self.Y, m, L)
68
69 @name_scope('predict')
70 @params_as_tensors
71 def _build_predict(self, Xnew, full_cov=False):
72 """
73 Xnew is a data matrix, point at which we want to predict
74
75 This method computes
76
77 p(F* | Y )
78
79 where F* are points on the GP at Xnew, Y are noisy observations at X.
80
81 """
82 Kx = self.kern.K(self.X, Xnew)
83 K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance
84 L = tf.cholesky(K)
85 A = tf.matrix_triangular_solve(L, Kx, lower=True)
86 V = tf.matrix_triangular_solve(L, self.Y - self.mean_function(self.X))
87 fmean = tf.matmul(A, V, transpose_a=True) + self.mean_function(Xnew)
88 if full_cov:
89 fvar = self.kern.K(Xnew) - tf.matmul(A, A, transpose_a=True)
90 shape = tf.stack([1, 1, tf.shape(self.Y)[1]])
91 fvar = tf.tile(tf.expand_dims(fvar, 2), shape)
92 else:
93 fvar = self.kern.Kdiag(Xnew) - tf.reduce_sum(tf.square(A), 0)
94 fvar = tf.tile(tf.reshape(fvar, (-1, 1)), [1, tf.shape(self.Y)[1]])
95 return fmean, fvar
96
```
Path: `gpflow/densities.py`
Content:
```
1 # Copyright 2016 James Hensman, alexggmatthews
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import tensorflow as tf
17 import numpy as np
18
19
20 from . import settings
21
22
23 def gaussian(x, mu, var):
24 return -0.5 * (np.log(2 * np.pi) + tf.log(var) + tf.square(mu-x)/var)
25
26
27 def lognormal(x, mu, var):
28 lnx = tf.log(x)
29 return gaussian(lnx, mu, var) - lnx
30
31
32 def bernoulli(p, y):
33 return tf.log(tf.where(tf.equal(y, 1), p, 1-p))
34
35
36 def poisson(lamb, y):
37 return y * tf.log(lamb) - lamb - tf.lgamma(y + 1.)
38
39
40 def exponential(lamb, y):
41 return - y/lamb - tf.log(lamb)
42
43
44 def gamma(shape, scale, x):
45 return -shape * tf.log(scale) - tf.lgamma(shape)\
46 + (shape - 1.) * tf.log(x) - x / scale
47
48
49 def student_t(x, mean, scale, deg_free):
50 const = tf.lgamma(tf.cast((deg_free + 1.) * 0.5, settings.float_type))\
51 - tf.lgamma(tf.cast(deg_free * 0.5, settings.float_type))\
52 - 0.5*(tf.log(tf.square(scale)) + tf.cast(tf.log(deg_free), settings.float_type)
53 + np.log(np.pi))
54 const = tf.cast(const, settings.float_type)
55 return const - 0.5*(deg_free + 1.) * \
56 tf.log(1. + (1. / deg_free) * (tf.square((x - mean) / scale)))
57
58
59 def beta(alpha, beta, y):
60 # need to clip y, since log of 0 is nan...
61 y = tf.clip_by_value(y, 1e-6, 1-1e-6)
62 return (alpha - 1.) * tf.log(y) + (beta - 1.) * tf.log(1. - y) \
63 + tf.lgamma(alpha + beta)\
64 - tf.lgamma(alpha)\
65 - tf.lgamma(beta)
66
67
68 def laplace(mu, sigma, y):
69 return - tf.abs(mu - y) / sigma - tf.log(2. * sigma)
70
71
72 def multivariate_normal(x, mu, L):
73 """
74 L is the Cholesky decomposition of the covariance.
75
76 x and mu are either vectors (ndim=1) or matrices. In the matrix case, we
77 assume independence over the *columns*: the number of rows must match the
78 size of L.
79 """
80 d = x - mu
81 alpha = tf.matrix_triangular_solve(L, d, lower=True)
82 num_col = 1 if tf.rank(x) == 1 else tf.shape(x)[1]
83 num_col = tf.cast(num_col, settings.float_type)
84 num_dims = tf.cast(tf.shape(x)[0], settings.float_type)
85 ret = - 0.5 * num_dims * num_col * np.log(2 * np.pi)
86 ret += - num_col * tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))
87 ret += - 0.5 * tf.reduce_sum(tf.square(alpha))
88 return ret
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gpflow/densities.py b/gpflow/densities.py
--- a/gpflow/densities.py
+++ b/gpflow/densities.py
@@ -71,18 +71,25 @@
def multivariate_normal(x, mu, L):
"""
- L is the Cholesky decomposition of the covariance.
-
- x and mu are either vectors (ndim=1) or matrices. In the matrix case, we
- assume independence over the *columns*: the number of rows must match the
- size of L.
+ Computes the log-density of a multivariate normal.
+ :param x : D or DxN sample(s) for which we want the density
+ :param mu : D or DxN mean(s) of the normal distribution
+ :param L : DxD Cholesky decomposition of the covariance matrix
+ :return p : N vector of log densities for each of the N x's and/or mu's
+
+ x and mu are either vectors or matrices. If both are vectors ((N,) or (N,1)):
+ p[0] = log pdf(x) where x ~ N(mu, LL^T)
+ If at least one is a matrix, we assume independence over the *columns*:
+ the number of rows must match the size of L. Broadcasting behaviour:
+ p[n] = log pdf of:
+ x[n] ~ N(mu, LL^T) or x ~ N(mu[n], LL^T) or x[n] ~ N(mu[n], LL^T)
"""
+ x = tf.cond(tf.rank(x) < 2, lambda: x[:, None], lambda: x)
+ mu = tf.cond(tf.rank(mu) < 2, lambda: mu[:, None], lambda: mu)
d = x - mu
alpha = tf.matrix_triangular_solve(L, d, lower=True)
- num_col = 1 if tf.rank(x) == 1 else tf.shape(x)[1]
- num_col = tf.cast(num_col, settings.float_type)
- num_dims = tf.cast(tf.shape(x)[0], settings.float_type)
- ret = - 0.5 * num_dims * num_col * np.log(2 * np.pi)
- ret += - num_col * tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))
- ret += - 0.5 * tf.reduce_sum(tf.square(alpha))
- return ret
+ num_dims = tf.cast(tf.shape(d)[0], L.dtype)
+ p = - 0.5 * tf.reduce_sum(tf.square(alpha), 0)
+ p -= 0.5 * num_dims * np.log(2 * np.pi)
+ p -= tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))
+ return p
diff --git a/gpflow/models/gpr.py b/gpflow/models/gpr.py
--- a/gpflow/models/gpr.py
+++ b/gpflow/models/gpr.py
@@ -63,8 +63,9 @@
K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance
L = tf.cholesky(K)
m = self.mean_function(self.X)
+ logpdf = multivariate_normal(self.Y, m, L) # (R,) log-likelihoods for each independent dimension of Y
- return multivariate_normal(self.Y, m, L)
+ return tf.reduce_sum(logpdf)
@name_scope('predict')
@params_as_tensors
|
{"golden_diff": "diff --git a/gpflow/densities.py b/gpflow/densities.py\n--- a/gpflow/densities.py\n+++ b/gpflow/densities.py\n@@ -71,18 +71,25 @@\n \n def multivariate_normal(x, mu, L):\n \"\"\"\n- L is the Cholesky decomposition of the covariance.\n-\n- x and mu are either vectors (ndim=1) or matrices. In the matrix case, we\n- assume independence over the *columns*: the number of rows must match the\n- size of L.\n+ Computes the log-density of a multivariate normal.\n+ :param x : D or DxN sample(s) for which we want the density\n+ :param mu : D or DxN mean(s) of the normal distribution\n+ :param L : DxD Cholesky decomposition of the covariance matrix\n+ :return p : N vector of log densities for each of the N x's and/or mu's\n+\n+ x and mu are either vectors or matrices. If both are vectors ((N,) or (N,1)):\n+ p[0] = log pdf(x) where x ~ N(mu, LL^T)\n+ If at least one is a matrix, we assume independence over the *columns*:\n+ the number of rows must match the size of L. Broadcasting behaviour:\n+ p[n] = log pdf of:\n+ x[n] ~ N(mu, LL^T) or x ~ N(mu[n], LL^T) or x[n] ~ N(mu[n], LL^T)\n \"\"\"\n+ x = tf.cond(tf.rank(x) < 2, lambda: x[:, None], lambda: x)\n+ mu = tf.cond(tf.rank(mu) < 2, lambda: mu[:, None], lambda: mu)\n d = x - mu\n alpha = tf.matrix_triangular_solve(L, d, lower=True)\n- num_col = 1 if tf.rank(x) == 1 else tf.shape(x)[1]\n- num_col = tf.cast(num_col, settings.float_type)\n- num_dims = tf.cast(tf.shape(x)[0], settings.float_type)\n- ret = - 0.5 * num_dims * num_col * np.log(2 * np.pi)\n- ret += - num_col * tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))\n- ret += - 0.5 * tf.reduce_sum(tf.square(alpha))\n- return ret\n+ num_dims = tf.cast(tf.shape(d)[0], L.dtype)\n+ p = - 0.5 * tf.reduce_sum(tf.square(alpha), 0)\n+ p -= 0.5 * num_dims * np.log(2 * np.pi)\n+ p -= tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))\n+ return p\ndiff --git a/gpflow/models/gpr.py b/gpflow/models/gpr.py\n--- a/gpflow/models/gpr.py\n+++ b/gpflow/models/gpr.py\n@@ -63,8 +63,9 @@\n K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance\n L = tf.cholesky(K)\n m = self.mean_function(self.X)\n+ logpdf = multivariate_normal(self.Y, m, L) # (R,) log-likelihoods for each independent dimension of Y\n \n- return multivariate_normal(self.Y, m, L)\n+ return tf.reduce_sum(logpdf)\n \n @name_scope('predict')\n @params_as_tensors\n", "issue": "multivariate normal density cannot handle vectors as it claims\nIt seems that if `x` and `mu` are vectors, the call to `tf.matrix_triangular_solve` would fail (as `d = x - mu` is rank 1). Worse, if `x` and `mu` are of different dimensionality (e.g. one a row, one a column vector) broadcasting happens and fails silently.\n", "before_files": [{"content": "# Copyright 2016 James Hensman, Valentine Svensson, alexggmatthews, fujiisoup\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom __future__ import absolute_import\nimport tensorflow as tf\n\nfrom .. import likelihoods\nfrom .. import settings\n\nfrom ..params import DataHolder\nfrom ..decors import params_as_tensors\nfrom ..decors import name_scope\nfrom ..densities import multivariate_normal\n\nfrom .model import GPModel\n\n\nclass GPR(GPModel):\n \"\"\"\n Gaussian Process Regression.\n\n This is a vanilla implementation of GP regression with a Gaussian\n likelihood. Multiple columns of Y are treated independently.\n\n The log likelihood i this models is sometimes referred to as the 'marginal log likelihood', and is given by\n\n .. math::\n\n \\\\log p(\\\\mathbf y \\\\,|\\\\, \\\\mathbf f) = \\\\mathcal N\\\\left(\\\\mathbf y\\,|\\, 0, \\\\mathbf K + \\\\sigma_n \\\\mathbf I\\\\right)\n \"\"\"\n def __init__(self, X, Y, kern, mean_function=None, **kwargs):\n \"\"\"\n X is a data matrix, size N x D\n Y is a data matrix, size N x R\n kern, mean_function are appropriate GPflow objects\n \"\"\"\n likelihood = likelihoods.Gaussian()\n X = DataHolder(X)\n Y = DataHolder(Y)\n GPModel.__init__(self, X, Y, kern, likelihood, mean_function, **kwargs)\n\n @name_scope('likelihood')\n @params_as_tensors\n def _build_likelihood(self):\n \"\"\"\n Construct a tensorflow function to compute the likelihood.\n\n \\log p(Y | theta).\n\n \"\"\"\n K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance\n L = tf.cholesky(K)\n m = self.mean_function(self.X)\n\n return multivariate_normal(self.Y, m, L)\n\n @name_scope('predict')\n @params_as_tensors\n def _build_predict(self, Xnew, full_cov=False):\n \"\"\"\n Xnew is a data matrix, point at which we want to predict\n\n This method computes\n\n p(F* | Y )\n\n where F* are points on the GP at Xnew, Y are noisy observations at X.\n\n \"\"\"\n Kx = self.kern.K(self.X, Xnew)\n K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance\n L = tf.cholesky(K)\n A = tf.matrix_triangular_solve(L, Kx, lower=True)\n V = tf.matrix_triangular_solve(L, self.Y - self.mean_function(self.X))\n fmean = tf.matmul(A, V, transpose_a=True) + self.mean_function(Xnew)\n if full_cov:\n fvar = self.kern.K(Xnew) - tf.matmul(A, A, transpose_a=True)\n shape = tf.stack([1, 1, tf.shape(self.Y)[1]])\n fvar = tf.tile(tf.expand_dims(fvar, 2), shape)\n else:\n fvar = self.kern.Kdiag(Xnew) - tf.reduce_sum(tf.square(A), 0)\n fvar = tf.tile(tf.reshape(fvar, (-1, 1)), [1, tf.shape(self.Y)[1]])\n return fmean, fvar\n", "path": "gpflow/models/gpr.py"}, {"content": "# Copyright 2016 James Hensman, alexggmatthews\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport tensorflow as tf\nimport numpy as np\n\n\nfrom . import settings\n\n\ndef gaussian(x, mu, var):\n return -0.5 * (np.log(2 * np.pi) + tf.log(var) + tf.square(mu-x)/var)\n\n\ndef lognormal(x, mu, var):\n lnx = tf.log(x)\n return gaussian(lnx, mu, var) - lnx\n\n\ndef bernoulli(p, y):\n return tf.log(tf.where(tf.equal(y, 1), p, 1-p))\n\n\ndef poisson(lamb, y):\n return y * tf.log(lamb) - lamb - tf.lgamma(y + 1.)\n\n\ndef exponential(lamb, y):\n return - y/lamb - tf.log(lamb)\n\n\ndef gamma(shape, scale, x):\n return -shape * tf.log(scale) - tf.lgamma(shape)\\\n + (shape - 1.) * tf.log(x) - x / scale\n\n\ndef student_t(x, mean, scale, deg_free):\n const = tf.lgamma(tf.cast((deg_free + 1.) * 0.5, settings.float_type))\\\n - tf.lgamma(tf.cast(deg_free * 0.5, settings.float_type))\\\n - 0.5*(tf.log(tf.square(scale)) + tf.cast(tf.log(deg_free), settings.float_type)\n + np.log(np.pi))\n const = tf.cast(const, settings.float_type)\n return const - 0.5*(deg_free + 1.) * \\\n tf.log(1. + (1. / deg_free) * (tf.square((x - mean) / scale)))\n\n\ndef beta(alpha, beta, y):\n # need to clip y, since log of 0 is nan...\n y = tf.clip_by_value(y, 1e-6, 1-1e-6)\n return (alpha - 1.) * tf.log(y) + (beta - 1.) * tf.log(1. - y) \\\n + tf.lgamma(alpha + beta)\\\n - tf.lgamma(alpha)\\\n - tf.lgamma(beta)\n\n\ndef laplace(mu, sigma, y):\n return - tf.abs(mu - y) / sigma - tf.log(2. * sigma)\n\n\ndef multivariate_normal(x, mu, L):\n \"\"\"\n L is the Cholesky decomposition of the covariance.\n\n x and mu are either vectors (ndim=1) or matrices. In the matrix case, we\n assume independence over the *columns*: the number of rows must match the\n size of L.\n \"\"\"\n d = x - mu\n alpha = tf.matrix_triangular_solve(L, d, lower=True)\n num_col = 1 if tf.rank(x) == 1 else tf.shape(x)[1]\n num_col = tf.cast(num_col, settings.float_type)\n num_dims = tf.cast(tf.shape(x)[0], settings.float_type)\n ret = - 0.5 * num_dims * num_col * np.log(2 * np.pi)\n ret += - num_col * tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))\n ret += - 0.5 * tf.reduce_sum(tf.square(alpha))\n return ret\n", "path": "gpflow/densities.py"}], "after_files": [{"content": "# Copyright 2016 James Hensman, Valentine Svensson, alexggmatthews, fujiisoup\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom __future__ import absolute_import\nimport tensorflow as tf\n\nfrom .. import likelihoods\nfrom .. import settings\n\nfrom ..params import DataHolder\nfrom ..decors import params_as_tensors\nfrom ..decors import name_scope\nfrom ..densities import multivariate_normal\n\nfrom .model import GPModel\n\n\nclass GPR(GPModel):\n \"\"\"\n Gaussian Process Regression.\n\n This is a vanilla implementation of GP regression with a Gaussian\n likelihood. Multiple columns of Y are treated independently.\n\n The log likelihood i this models is sometimes referred to as the 'marginal log likelihood', and is given by\n\n .. math::\n\n \\\\log p(\\\\mathbf y \\\\,|\\\\, \\\\mathbf f) = \\\\mathcal N\\\\left(\\\\mathbf y\\,|\\, 0, \\\\mathbf K + \\\\sigma_n \\\\mathbf I\\\\right)\n \"\"\"\n def __init__(self, X, Y, kern, mean_function=None, **kwargs):\n \"\"\"\n X is a data matrix, size N x D\n Y is a data matrix, size N x R\n kern, mean_function are appropriate GPflow objects\n \"\"\"\n likelihood = likelihoods.Gaussian()\n X = DataHolder(X)\n Y = DataHolder(Y)\n GPModel.__init__(self, X, Y, kern, likelihood, mean_function, **kwargs)\n\n @name_scope('likelihood')\n @params_as_tensors\n def _build_likelihood(self):\n \"\"\"\n Construct a tensorflow function to compute the likelihood.\n\n \\log p(Y | theta).\n\n \"\"\"\n K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance\n L = tf.cholesky(K)\n m = self.mean_function(self.X)\n logpdf = multivariate_normal(self.Y, m, L) # (R,) log-likelihoods for each independent dimension of Y\n\n return tf.reduce_sum(logpdf)\n\n @name_scope('predict')\n @params_as_tensors\n def _build_predict(self, Xnew, full_cov=False):\n \"\"\"\n Xnew is a data matrix, point at which we want to predict\n\n This method computes\n\n p(F* | Y )\n\n where F* are points on the GP at Xnew, Y are noisy observations at X.\n\n \"\"\"\n Kx = self.kern.K(self.X, Xnew)\n K = self.kern.K(self.X) + tf.eye(tf.shape(self.X)[0], dtype=settings.float_type) * self.likelihood.variance\n L = tf.cholesky(K)\n A = tf.matrix_triangular_solve(L, Kx, lower=True)\n V = tf.matrix_triangular_solve(L, self.Y - self.mean_function(self.X))\n fmean = tf.matmul(A, V, transpose_a=True) + self.mean_function(Xnew)\n if full_cov:\n fvar = self.kern.K(Xnew) - tf.matmul(A, A, transpose_a=True)\n shape = tf.stack([1, 1, tf.shape(self.Y)[1]])\n fvar = tf.tile(tf.expand_dims(fvar, 2), shape)\n else:\n fvar = self.kern.Kdiag(Xnew) - tf.reduce_sum(tf.square(A), 0)\n fvar = tf.tile(tf.reshape(fvar, (-1, 1)), [1, tf.shape(self.Y)[1]])\n return fmean, fvar\n", "path": "gpflow/models/gpr.py"}, {"content": "# Copyright 2016 James Hensman, alexggmatthews\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport tensorflow as tf\nimport numpy as np\n\n\nfrom . import settings\n\n\ndef gaussian(x, mu, var):\n return -0.5 * (np.log(2 * np.pi) + tf.log(var) + tf.square(mu-x)/var)\n\n\ndef lognormal(x, mu, var):\n lnx = tf.log(x)\n return gaussian(lnx, mu, var) - lnx\n\n\ndef bernoulli(p, y):\n return tf.log(tf.where(tf.equal(y, 1), p, 1-p))\n\n\ndef poisson(lamb, y):\n return y * tf.log(lamb) - lamb - tf.lgamma(y + 1.)\n\n\ndef exponential(lamb, y):\n return - y/lamb - tf.log(lamb)\n\n\ndef gamma(shape, scale, x):\n return -shape * tf.log(scale) - tf.lgamma(shape)\\\n + (shape - 1.) * tf.log(x) - x / scale\n\n\ndef student_t(x, mean, scale, deg_free):\n const = tf.lgamma(tf.cast((deg_free + 1.) * 0.5, settings.float_type))\\\n - tf.lgamma(tf.cast(deg_free * 0.5, settings.float_type))\\\n - 0.5*(tf.log(tf.square(scale)) + tf.cast(tf.log(deg_free), settings.float_type)\n + np.log(np.pi))\n const = tf.cast(const, settings.float_type)\n return const - 0.5*(deg_free + 1.) * \\\n tf.log(1. + (1. / deg_free) * (tf.square((x - mean) / scale)))\n\n\ndef beta(alpha, beta, y):\n # need to clip y, since log of 0 is nan...\n y = tf.clip_by_value(y, 1e-6, 1-1e-6)\n return (alpha - 1.) * tf.log(y) + (beta - 1.) * tf.log(1. - y) \\\n + tf.lgamma(alpha + beta)\\\n - tf.lgamma(alpha)\\\n - tf.lgamma(beta)\n\n\ndef laplace(mu, sigma, y):\n return - tf.abs(mu - y) / sigma - tf.log(2. * sigma)\n\n\ndef multivariate_normal(x, mu, L):\n \"\"\"\n Computes the log-density of a multivariate normal.\n :param x : D or DxN sample(s) for which we want the density\n :param mu : D or DxN mean(s) of the normal distribution\n :param L : DxD Cholesky decomposition of the covariance matrix\n :return p : N vector of log densities for each of the N x's and/or mu's\n\n x and mu are either vectors or matrices. If both are vectors ((N,) or (N,1)):\n p[0] = log pdf(x) where x ~ N(mu, LL^T)\n If at least one is a matrix, we assume independence over the *columns*:\n the number of rows must match the size of L. Broadcasting behaviour:\n p[n] = log pdf of:\n x[n] ~ N(mu, LL^T) or x ~ N(mu[n], LL^T) or x[n] ~ N(mu[n], LL^T)\n \"\"\"\n x = tf.cond(tf.rank(x) < 2, lambda: x[:, None], lambda: x)\n mu = tf.cond(tf.rank(mu) < 2, lambda: mu[:, None], lambda: mu)\n d = x - mu\n alpha = tf.matrix_triangular_solve(L, d, lower=True)\n num_dims = tf.cast(tf.shape(d)[0], L.dtype)\n p = - 0.5 * tf.reduce_sum(tf.square(alpha), 0)\n p -= 0.5 * num_dims * np.log(2 * np.pi)\n p -= tf.reduce_sum(tf.log(tf.matrix_diag_part(L)))\n return p\n", "path": "gpflow/densities.py"}]}
| 2,424 | 787 |
gh_patches_debug_18452
|
rasdani/github-patches
|
git_diff
|
conda__conda-build-2443
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
metapackage does not seem to accept channel arguments, but fails if depenencies are in non-default channel
example:
```
conda metapackage acme-unified 1.1 --build-number 0 --dependencies "uvcdat ==2.10" "cibots ==0.2" "cdp ==1.0.3" "output_viewer ==1.2.2" "netCDF4 ==1.2.7" "xarray ==0.9.5" "dask ==0.14.3" "bottleneck ==1.0.6" "lxml ==3.7.3" "nco ==4.6.7" "sympy ==1.0" "pyproj ==1.9.5.1" "pytest ==3.0.7" "shapely ==1.5.17" "cartopy ==0.15.1" pyevtk progressbar scitools
```
fails with:
```
> conda metapackage acme-unified 1.1 --build-number 0 --dependencies "uvcdat ==2.10" "cibots ==0.2" "cdp ==1.0.3" "output_viewer ==1.2.2" "netCDF4 ==1.2.7" "xarray ==0.9.5" "dask ==0.14.3" "bottleneck ==1.0.6" "lxml ==3.7.3" "nco ==4.6.7" "sympy ==1.0" "pyproj ==1.9.5.1" "pytest ==3.0.7" "shapely ==1.5.17" "cartopy ==0.15.1" pyevtk progressbar scitools
Attempting to finalize metadata for acme-unified
INFO:conda_build.metadata:Attempting to finalize metadata for acme-unified
BUILD START: [u'acme-unified-1.1-hdfe7718_0.tar.bz2']
Leaving build/test directories:
Work: ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/work
Test: ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/test_tmp
Leaving build/test environments:
Test: source activate ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_p
Build: source activate ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_plac
Traceback (most recent call last):
File "/home/doutriaux1/anaconda2/bin/conda-metapackage", line 6, in <module>
sys.exit(conda_build.cli.main_metapackage.main())
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/cli/main_metapackage.py", line 118, in main
return execute(sys.argv[1:])
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/cli/main_metapackage.py", line 114, in execute
api.create_metapackage(**args.__dict__)
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/api.py", line 347, in create_metapackage
license_name=license_name, summary=summary, config=config)
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/metapackage.py", line 29, in create_metapackage
return build(m, config=config, need_source_download=False)
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/api.py", line 184, in build
need_source_download=need_source_download, config=config, variants=variants)
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/build.py", line 1633, in build_tree
notest=notest,
File "/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/build.py", line 980, in build
raise e
conda_build.exceptions.DependencyNeedsBuildingError: Unsatisfiable dependencies for platform linux-64: set(['netCDF4', 'output_viewer', 'cartopy', 'uvcdat', 'cdp', 'nco', 'cibots', 'bottleneck', 'scitools', 'pyevtk', 'shapely'])
```
On a linux system using latest conda and conda-build
originally at:
https://github.com/conda/conda/issues/5720#issuecomment-335941008
putting channels in conda defaults works, but it is a persistent thing which is annoying.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_build/cli/main_metapackage.py`
Content:
```
1 # (c) Continuum Analytics, Inc. / http://continuum.io
2 # All Rights Reserved
3 #
4 # conda is distributed under the terms of the BSD 3-clause license.
5 # Consult LICENSE.txt or http://opensource.org/licenses/BSD-3-Clause.
6
7 from __future__ import absolute_import, division, print_function
8
9 import argparse
10 import logging
11 import sys
12
13 from conda_build.conda_interface import binstar_upload
14 from conda_build.conda_interface import ArgumentParser
15 from conda_build import api
16
17 logging.basicConfig(level=logging.INFO)
18
19
20 def parse_args(args):
21 p = ArgumentParser(
22 description='''
23 Tool for building conda metapackages. A metapackage is a package with no
24 files, only metadata. They are typically used to collect several packages
25 together into a single package via dependencies.
26
27 NOTE: Metapackages can also be created by creating a recipe with the necessary
28 metadata in the meta.yaml, but a metapackage can be created entirely from the
29 command line with the conda metapackage command.
30 ''',
31 )
32
33 p.add_argument(
34 "--no-anaconda-upload",
35 action="store_false",
36 help="Do not ask to upload the package to anaconda.org.",
37 dest='anaconda_upload',
38 default=binstar_upload,
39 )
40 p.add_argument(
41 "--no-binstar-upload",
42 action="store_false",
43 help=argparse.SUPPRESS,
44 dest='anaconda_upload',
45 default=binstar_upload,
46 )
47 p.add_argument(
48 '--token',
49 help="Token to pass through to anaconda upload"
50 )
51 p.add_argument(
52 '--user',
53 help="User/organization to upload packages to on anaconda.org"
54 )
55 p.add_argument(
56 "name",
57 help="Name of the created package.",
58 )
59 p.add_argument(
60 "version",
61 help="Version of the created package.",
62 )
63 p.add_argument(
64 "--build-number",
65 type=int,
66 default=0,
67 help="Build number for the package (default is 0).",
68 )
69 p.add_argument(
70 "--build-string",
71 default=None,
72 help="Build string for the package (default is automatically generated).",
73 )
74 p.add_argument(
75 "--dependencies", "-d",
76 nargs='*',
77 default=(),
78 help="""The dependencies of the package. To specify a version restriction for a
79 dependency, wrap the dependency in quotes, like 'package >=2.0'.""",
80 )
81 p.add_argument(
82 "--home",
83 help="The homepage for the metapackage.",
84
85 )
86 p.add_argument(
87 "--license",
88 help="The license of the metapackage.",
89 dest='license_name'
90 )
91 p.add_argument(
92 "--summary",
93 help="""Summary of the package. Pass this in as a string on the command
94 line, like --summary 'A metapackage for X'. It is recommended to use
95 single quotes if you are not doing variable substitution to avoid
96 interpretation of special characters.""",
97 )
98 p.add_argument(
99 "--entry-points",
100 nargs='*',
101 default=(),
102 help="""Python entry points to create automatically. They should use the same
103 syntax as in the meta.yaml of a recipe, e.g., --entry-points
104 bsdiff4=bsdiff4.cli:main_bsdiff4 will create an entry point called
105 bsdiff4 that calls bsdiff4.cli.main_bsdiff4(). """,
106 )
107
108 args = p.parse_args(args)
109 return p, args
110
111
112 def execute(args):
113 _, args = parse_args(args)
114 api.create_metapackage(**args.__dict__)
115
116
117 def main():
118 return execute(sys.argv[1:])
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_build/cli/main_metapackage.py b/conda_build/cli/main_metapackage.py
--- a/conda_build/cli/main_metapackage.py
+++ b/conda_build/cli/main_metapackage.py
@@ -12,6 +12,7 @@
from conda_build.conda_interface import binstar_upload
from conda_build.conda_interface import ArgumentParser
+from conda_build.conda_interface import add_parser_channels
from conda_build import api
logging.basicConfig(level=logging.INFO)
@@ -105,13 +106,15 @@
bsdiff4 that calls bsdiff4.cli.main_bsdiff4(). """,
)
+ add_parser_channels(p)
args = p.parse_args(args)
return p, args
def execute(args):
_, args = parse_args(args)
- api.create_metapackage(**args.__dict__)
+ channel_urls = args.__dict__.get('channel') or args.__dict__.get('channels') or ()
+ api.create_metapackage(channel_urls=channel_urls, **args.__dict__)
def main():
|
{"golden_diff": "diff --git a/conda_build/cli/main_metapackage.py b/conda_build/cli/main_metapackage.py\n--- a/conda_build/cli/main_metapackage.py\n+++ b/conda_build/cli/main_metapackage.py\n@@ -12,6 +12,7 @@\n \n from conda_build.conda_interface import binstar_upload\n from conda_build.conda_interface import ArgumentParser\n+from conda_build.conda_interface import add_parser_channels\n from conda_build import api\n \n logging.basicConfig(level=logging.INFO)\n@@ -105,13 +106,15 @@\n bsdiff4 that calls bsdiff4.cli.main_bsdiff4(). \"\"\",\n )\n \n+ add_parser_channels(p)\n args = p.parse_args(args)\n return p, args\n \n \n def execute(args):\n _, args = parse_args(args)\n- api.create_metapackage(**args.__dict__)\n+ channel_urls = args.__dict__.get('channel') or args.__dict__.get('channels') or ()\n+ api.create_metapackage(channel_urls=channel_urls, **args.__dict__)\n \n \n def main():\n", "issue": "metapackage does not seem to accept channel arguments, but fails if depenencies are in non-default channel\nexample:\r\n\r\n```\r\nconda metapackage acme-unified 1.1 --build-number 0 --dependencies \"uvcdat ==2.10\" \"cibots ==0.2\" \"cdp ==1.0.3\" \"output_viewer ==1.2.2\" \"netCDF4 ==1.2.7\" \"xarray ==0.9.5\" \"dask ==0.14.3\" \"bottleneck ==1.0.6\" \"lxml ==3.7.3\" \"nco ==4.6.7\" \"sympy ==1.0\" \"pyproj ==1.9.5.1\" \"pytest ==3.0.7\" \"shapely ==1.5.17\" \"cartopy ==0.15.1\" pyevtk progressbar scitools\r\n```\r\nfails with:\r\n\r\n```\r\n> conda metapackage acme-unified 1.1 --build-number 0 --dependencies \"uvcdat ==2.10\" \"cibots ==0.2\" \"cdp ==1.0.3\" \"output_viewer ==1.2.2\" \"netCDF4 ==1.2.7\" \"xarray ==0.9.5\" \"dask ==0.14.3\" \"bottleneck ==1.0.6\" \"lxml ==3.7.3\" \"nco ==4.6.7\" \"sympy ==1.0\" \"pyproj ==1.9.5.1\" \"pytest ==3.0.7\" \"shapely ==1.5.17\" \"cartopy ==0.15.1\" pyevtk progressbar scitools\r\nAttempting to finalize metadata for acme-unified\r\nINFO:conda_build.metadata:Attempting to finalize metadata for acme-unified\r\nBUILD START: [u'acme-unified-1.1-hdfe7718_0.tar.bz2']\r\n\r\nLeaving build/test directories:\r\n Work:\t ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/work \r\n Test:\t ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/test_tmp \r\nLeaving build/test environments:\r\n Test:\tsource activate ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_p \r\n Build:\tsource activate ../../home/doutriaux1/anaconda2/conda-bld/acme-unified_1500932469544/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_plac \r\n\r\n\r\nTraceback (most recent call last):\r\n File \"/home/doutriaux1/anaconda2/bin/conda-metapackage\", line 6, in <module>\r\n sys.exit(conda_build.cli.main_metapackage.main())\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/cli/main_metapackage.py\", line 118, in main\r\n return execute(sys.argv[1:])\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/cli/main_metapackage.py\", line 114, in execute\r\n api.create_metapackage(**args.__dict__)\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/api.py\", line 347, in create_metapackage\r\n license_name=license_name, summary=summary, config=config)\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/metapackage.py\", line 29, in create_metapackage\r\n return build(m, config=config, need_source_download=False)\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/api.py\", line 184, in build\r\n need_source_download=need_source_download, config=config, variants=variants)\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/build.py\", line 1633, in build_tree\r\n notest=notest,\r\n File \"/home/doutriaux1/anaconda2/lib/python2.7/site-packages/conda_build/build.py\", line 980, in build\r\n raise e\r\nconda_build.exceptions.DependencyNeedsBuildingError: Unsatisfiable dependencies for platform linux-64: set(['netCDF4', 'output_viewer', 'cartopy', 'uvcdat', 'cdp', 'nco', 'cibots', 'bottleneck', 'scitools', 'pyevtk', 'shapely'])\r\n```\r\n\r\nOn a linux system using latest conda and conda-build\r\n\r\noriginally at:\r\nhttps://github.com/conda/conda/issues/5720#issuecomment-335941008\r\n\r\nputting channels in conda defaults works, but it is a persistent thing which is annoying.\n", "before_files": [{"content": "# (c) Continuum Analytics, Inc. / http://continuum.io\n# All Rights Reserved\n#\n# conda is distributed under the terms of the BSD 3-clause license.\n# Consult LICENSE.txt or http://opensource.org/licenses/BSD-3-Clause.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport argparse\nimport logging\nimport sys\n\nfrom conda_build.conda_interface import binstar_upload\nfrom conda_build.conda_interface import ArgumentParser\nfrom conda_build import api\n\nlogging.basicConfig(level=logging.INFO)\n\n\ndef parse_args(args):\n p = ArgumentParser(\n description='''\nTool for building conda metapackages. A metapackage is a package with no\nfiles, only metadata. They are typically used to collect several packages\ntogether into a single package via dependencies.\n\nNOTE: Metapackages can also be created by creating a recipe with the necessary\nmetadata in the meta.yaml, but a metapackage can be created entirely from the\ncommand line with the conda metapackage command.\n''',\n )\n\n p.add_argument(\n \"--no-anaconda-upload\",\n action=\"store_false\",\n help=\"Do not ask to upload the package to anaconda.org.\",\n dest='anaconda_upload',\n default=binstar_upload,\n )\n p.add_argument(\n \"--no-binstar-upload\",\n action=\"store_false\",\n help=argparse.SUPPRESS,\n dest='anaconda_upload',\n default=binstar_upload,\n )\n p.add_argument(\n '--token',\n help=\"Token to pass through to anaconda upload\"\n )\n p.add_argument(\n '--user',\n help=\"User/organization to upload packages to on anaconda.org\"\n )\n p.add_argument(\n \"name\",\n help=\"Name of the created package.\",\n )\n p.add_argument(\n \"version\",\n help=\"Version of the created package.\",\n )\n p.add_argument(\n \"--build-number\",\n type=int,\n default=0,\n help=\"Build number for the package (default is 0).\",\n )\n p.add_argument(\n \"--build-string\",\n default=None,\n help=\"Build string for the package (default is automatically generated).\",\n )\n p.add_argument(\n \"--dependencies\", \"-d\",\n nargs='*',\n default=(),\n help=\"\"\"The dependencies of the package. To specify a version restriction for a\n dependency, wrap the dependency in quotes, like 'package >=2.0'.\"\"\",\n )\n p.add_argument(\n \"--home\",\n help=\"The homepage for the metapackage.\",\n\n )\n p.add_argument(\n \"--license\",\n help=\"The license of the metapackage.\",\n dest='license_name'\n )\n p.add_argument(\n \"--summary\",\n help=\"\"\"Summary of the package. Pass this in as a string on the command\n line, like --summary 'A metapackage for X'. It is recommended to use\n single quotes if you are not doing variable substitution to avoid\n interpretation of special characters.\"\"\",\n )\n p.add_argument(\n \"--entry-points\",\n nargs='*',\n default=(),\n help=\"\"\"Python entry points to create automatically. They should use the same\n syntax as in the meta.yaml of a recipe, e.g., --entry-points\n bsdiff4=bsdiff4.cli:main_bsdiff4 will create an entry point called\n bsdiff4 that calls bsdiff4.cli.main_bsdiff4(). \"\"\",\n )\n\n args = p.parse_args(args)\n return p, args\n\n\ndef execute(args):\n _, args = parse_args(args)\n api.create_metapackage(**args.__dict__)\n\n\ndef main():\n return execute(sys.argv[1:])\n", "path": "conda_build/cli/main_metapackage.py"}], "after_files": [{"content": "# (c) Continuum Analytics, Inc. / http://continuum.io\n# All Rights Reserved\n#\n# conda is distributed under the terms of the BSD 3-clause license.\n# Consult LICENSE.txt or http://opensource.org/licenses/BSD-3-Clause.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport argparse\nimport logging\nimport sys\n\nfrom conda_build.conda_interface import binstar_upload\nfrom conda_build.conda_interface import ArgumentParser\nfrom conda_build.conda_interface import add_parser_channels\nfrom conda_build import api\n\nlogging.basicConfig(level=logging.INFO)\n\n\ndef parse_args(args):\n p = ArgumentParser(\n description='''\nTool for building conda metapackages. A metapackage is a package with no\nfiles, only metadata. They are typically used to collect several packages\ntogether into a single package via dependencies.\n\nNOTE: Metapackages can also be created by creating a recipe with the necessary\nmetadata in the meta.yaml, but a metapackage can be created entirely from the\ncommand line with the conda metapackage command.\n''',\n )\n\n p.add_argument(\n \"--no-anaconda-upload\",\n action=\"store_false\",\n help=\"Do not ask to upload the package to anaconda.org.\",\n dest='anaconda_upload',\n default=binstar_upload,\n )\n p.add_argument(\n \"--no-binstar-upload\",\n action=\"store_false\",\n help=argparse.SUPPRESS,\n dest='anaconda_upload',\n default=binstar_upload,\n )\n p.add_argument(\n '--token',\n help=\"Token to pass through to anaconda upload\"\n )\n p.add_argument(\n '--user',\n help=\"User/organization to upload packages to on anaconda.org\"\n )\n p.add_argument(\n \"name\",\n help=\"Name of the created package.\",\n )\n p.add_argument(\n \"version\",\n help=\"Version of the created package.\",\n )\n p.add_argument(\n \"--build-number\",\n type=int,\n default=0,\n help=\"Build number for the package (default is 0).\",\n )\n p.add_argument(\n \"--build-string\",\n default=None,\n help=\"Build string for the package (default is automatically generated).\",\n )\n p.add_argument(\n \"--dependencies\", \"-d\",\n nargs='*',\n default=(),\n help=\"\"\"The dependencies of the package. To specify a version restriction for a\n dependency, wrap the dependency in quotes, like 'package >=2.0'.\"\"\",\n )\n p.add_argument(\n \"--home\",\n help=\"The homepage for the metapackage.\",\n\n )\n p.add_argument(\n \"--license\",\n help=\"The license of the metapackage.\",\n dest='license_name'\n )\n p.add_argument(\n \"--summary\",\n help=\"\"\"Summary of the package. Pass this in as a string on the command\n line, like --summary 'A metapackage for X'. It is recommended to use\n single quotes if you are not doing variable substitution to avoid\n interpretation of special characters.\"\"\",\n )\n p.add_argument(\n \"--entry-points\",\n nargs='*',\n default=(),\n help=\"\"\"Python entry points to create automatically. They should use the same\n syntax as in the meta.yaml of a recipe, e.g., --entry-points\n bsdiff4=bsdiff4.cli:main_bsdiff4 will create an entry point called\n bsdiff4 that calls bsdiff4.cli.main_bsdiff4(). \"\"\",\n )\n\n add_parser_channels(p)\n args = p.parse_args(args)\n return p, args\n\n\ndef execute(args):\n _, args = parse_args(args)\n channel_urls = args.__dict__.get('channel') or args.__dict__.get('channels') or ()\n api.create_metapackage(channel_urls=channel_urls, **args.__dict__)\n\n\ndef main():\n return execute(sys.argv[1:])\n", "path": "conda_build/cli/main_metapackage.py"}]}
| 2,557 | 242 |
gh_patches_debug_35252
|
rasdani/github-patches
|
git_diff
|
pytorch__text-1525
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a `max_words` argument to `build_vocab_from_iterator`
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
[Link to the docs](https://pytorch.org/text/stable/vocab.html?highlight=build%20vocab#torchtext.vocab.build_vocab_from_iterator)
I believe it would be beneficial to limit the number of words you want in your vocabulary with an argument like `max_words`, e.g.:
```
vocab = build_vocab_from_iterator(yield_tokens_batch(file_path), specials=["<unk>"], max_words=50000)
```
**Motivation**
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
This allows a controllable-sized `nn.Embedding`, with rare words being mapped to `<unk>`. Otherwise, it would not be practical to use `build_vocab_from_iterator` for larger datasets.
**Alternatives**
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
Keras and Huggingface's tokenizers would be viable alternatives, but do not nicely integrate with the torchtext ecosystem.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchtext/vocab/vocab_factory.py`
Content:
```
1 from .vocab import Vocab
2 from typing import Dict, Iterable, Optional, List
3 from collections import Counter, OrderedDict
4 from torchtext._torchtext import (
5 Vocab as VocabPybind,
6 )
7
8
9 def vocab(ordered_dict: Dict, min_freq: int = 1,
10 specials: Optional[List[str]] = None,
11 special_first: bool = True) -> Vocab:
12 r"""Factory method for creating a vocab object which maps tokens to indices.
13
14 Note that the ordering in which key value pairs were inserted in the `ordered_dict` will be respected when building the vocab.
15 Therefore if sorting by token frequency is important to the user, the `ordered_dict` should be created in a way to reflect this.
16
17 Args:
18 ordered_dict: Ordered Dictionary mapping tokens to their corresponding occurance frequencies.
19 min_freq: The minimum frequency needed to include a token in the vocabulary.
20 specials: Special symbols to add. The order of supplied tokens will be preserved.
21 special_first: Indicates whether to insert symbols at the beginning or at the end.
22
23 Returns:
24 torchtext.vocab.Vocab: A `Vocab` object
25
26 Examples:
27 >>> from torchtext.vocab import vocab
28 >>> from collections import Counter, OrderedDict
29 >>> counter = Counter(["a", "a", "b", "b", "b"])
30 >>> sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True)
31 >>> ordered_dict = OrderedDict(sorted_by_freq_tuples)
32 >>> v1 = vocab(ordered_dict)
33 >>> print(v1['a']) #prints 1
34 >>> print(v1['out of vocab']) #raise RuntimeError since default index is not set
35 >>> tokens = ['e', 'd', 'c', 'b', 'a']
36 >>> #adding <unk> token and default index
37 >>> unk_token = '<unk>'
38 >>> default_index = -1
39 >>> v2 = vocab(OrderedDict([(token, 1) for token in tokens]), specials=[unk_token])
40 >>> v2.set_default_index(default_index)
41 >>> print(v2['<unk>']) #prints 0
42 >>> print(v2['out of vocab']) #prints -1
43 >>> #make default index same as index of unk_token
44 >>> v2.set_default_index(v2[unk_token])
45 >>> v2['out of vocab'] is v2[unk_token] #prints True
46 """
47 specials = specials or []
48 for token in specials:
49 ordered_dict.pop(token, None)
50
51 tokens = []
52 for token, freq in ordered_dict.items():
53 if freq >= min_freq:
54 tokens.append(token)
55
56 if special_first:
57 tokens[0:0] = specials
58 else:
59 tokens.extend(specials)
60
61 return Vocab(VocabPybind(tokens, None))
62
63
64 def build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True) -> Vocab:
65 """
66 Build a Vocab from an iterator.
67
68 Args:
69 iterator: Iterator used to build Vocab. Must yield list or iterator of tokens.
70 min_freq: The minimum frequency needed to include a token in the vocabulary.
71 specials: Special symbols to add. The order of supplied tokens will be preserved.
72 special_first: Indicates whether to insert symbols at the beginning or at the end.
73
74
75 Returns:
76 torchtext.vocab.Vocab: A `Vocab` object
77
78 Examples:
79 >>> #generating vocab from text file
80 >>> import io
81 >>> from torchtext.vocab import build_vocab_from_iterator
82 >>> def yield_tokens(file_path):
83 >>> with io.open(file_path, encoding = 'utf-8') as f:
84 >>> for line in f:
85 >>> yield line.strip().split()
86 >>> vocab = build_vocab_from_iterator(yield_tokens_batch(file_path), specials=["<unk>"])
87 """
88
89 counter = Counter()
90 for tokens in iterator:
91 counter.update(tokens)
92
93 sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[0])
94 sorted_by_freq_tuples.sort(key=lambda x: x[1], reverse=True)
95 ordered_dict = OrderedDict(sorted_by_freq_tuples)
96
97 word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials or [],
98 special_first=special_first)
99 return word_vocab
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchtext/vocab/vocab_factory.py b/torchtext/vocab/vocab_factory.py
--- a/torchtext/vocab/vocab_factory.py
+++ b/torchtext/vocab/vocab_factory.py
@@ -49,6 +49,7 @@
ordered_dict.pop(token, None)
tokens = []
+ # Save room for special tokens
for token, freq in ordered_dict.items():
if freq >= min_freq:
tokens.append(token)
@@ -61,7 +62,7 @@
return Vocab(VocabPybind(tokens, None))
-def build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True) -> Vocab:
+def build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True, max_tokens: Optional[int] = None) -> Vocab:
"""
Build a Vocab from an iterator.
@@ -70,6 +71,7 @@
min_freq: The minimum frequency needed to include a token in the vocabulary.
specials: Special symbols to add. The order of supplied tokens will be preserved.
special_first: Indicates whether to insert symbols at the beginning or at the end.
+ max_tokens: If provided, creates the vocab from the `max_tokens - len(specials)` most frequent tokens.
Returns:
@@ -90,10 +92,16 @@
for tokens in iterator:
counter.update(tokens)
- sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[0])
- sorted_by_freq_tuples.sort(key=lambda x: x[1], reverse=True)
- ordered_dict = OrderedDict(sorted_by_freq_tuples)
+ specials = specials or []
+
+ # First sort by descending frequency, then lexicographically
+ sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: (-x[1], x[0]))
+
+ if max_tokens is None:
+ ordered_dict = OrderedDict(sorted_by_freq_tuples)
+ else:
+ assert len(specials) < max_tokens, "len(specials) >= max_tokens, so the vocab will be entirely special tokens."
+ ordered_dict = OrderedDict(sorted_by_freq_tuples[:max_tokens - len(specials)])
- word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials or [],
- special_first=special_first)
+ word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials, special_first=special_first)
return word_vocab
|
{"golden_diff": "diff --git a/torchtext/vocab/vocab_factory.py b/torchtext/vocab/vocab_factory.py\n--- a/torchtext/vocab/vocab_factory.py\n+++ b/torchtext/vocab/vocab_factory.py\n@@ -49,6 +49,7 @@\n ordered_dict.pop(token, None)\n \n tokens = []\n+ # Save room for special tokens\n for token, freq in ordered_dict.items():\n if freq >= min_freq:\n tokens.append(token)\n@@ -61,7 +62,7 @@\n return Vocab(VocabPybind(tokens, None))\n \n \n-def build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True) -> Vocab:\n+def build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True, max_tokens: Optional[int] = None) -> Vocab:\n \"\"\"\n Build a Vocab from an iterator.\n \n@@ -70,6 +71,7 @@\n min_freq: The minimum frequency needed to include a token in the vocabulary.\n specials: Special symbols to add. The order of supplied tokens will be preserved.\n special_first: Indicates whether to insert symbols at the beginning or at the end.\n+ max_tokens: If provided, creates the vocab from the `max_tokens - len(specials)` most frequent tokens.\n \n \n Returns:\n@@ -90,10 +92,16 @@\n for tokens in iterator:\n counter.update(tokens)\n \n- sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[0])\n- sorted_by_freq_tuples.sort(key=lambda x: x[1], reverse=True)\n- ordered_dict = OrderedDict(sorted_by_freq_tuples)\n+ specials = specials or []\n+\n+ # First sort by descending frequency, then lexicographically\n+ sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: (-x[1], x[0]))\n+\n+ if max_tokens is None:\n+ ordered_dict = OrderedDict(sorted_by_freq_tuples)\n+ else:\n+ assert len(specials) < max_tokens, \"len(specials) >= max_tokens, so the vocab will be entirely special tokens.\"\n+ ordered_dict = OrderedDict(sorted_by_freq_tuples[:max_tokens - len(specials)])\n \n- word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials or [],\n- special_first=special_first)\n+ word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials, special_first=special_first)\n return word_vocab\n", "issue": "Add a `max_words` argument to `build_vocab_from_iterator`\n## \ud83d\ude80 Feature\r\n<!-- A clear and concise description of the feature proposal -->\r\n\r\n[Link to the docs](https://pytorch.org/text/stable/vocab.html?highlight=build%20vocab#torchtext.vocab.build_vocab_from_iterator)\r\n\r\nI believe it would be beneficial to limit the number of words you want in your vocabulary with an argument like `max_words`, e.g.:\r\n```\r\nvocab = build_vocab_from_iterator(yield_tokens_batch(file_path), specials=[\"<unk>\"], max_words=50000)\r\n```\r\n\r\n**Motivation**\r\n\r\n<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->\r\n\r\n\r\nThis allows a controllable-sized `nn.Embedding`, with rare words being mapped to `<unk>`. Otherwise, it would not be practical to use `build_vocab_from_iterator` for larger datasets.\r\n\r\n\r\n**Alternatives**\r\n\r\n<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->\r\n\r\nKeras and Huggingface's tokenizers would be viable alternatives, but do not nicely integrate with the torchtext ecosystem.\r\n\r\n\n", "before_files": [{"content": "from .vocab import Vocab\nfrom typing import Dict, Iterable, Optional, List\nfrom collections import Counter, OrderedDict\nfrom torchtext._torchtext import (\n Vocab as VocabPybind,\n)\n\n\ndef vocab(ordered_dict: Dict, min_freq: int = 1,\n specials: Optional[List[str]] = None,\n special_first: bool = True) -> Vocab:\n r\"\"\"Factory method for creating a vocab object which maps tokens to indices.\n\n Note that the ordering in which key value pairs were inserted in the `ordered_dict` will be respected when building the vocab.\n Therefore if sorting by token frequency is important to the user, the `ordered_dict` should be created in a way to reflect this.\n\n Args:\n ordered_dict: Ordered Dictionary mapping tokens to their corresponding occurance frequencies.\n min_freq: The minimum frequency needed to include a token in the vocabulary.\n specials: Special symbols to add. The order of supplied tokens will be preserved.\n special_first: Indicates whether to insert symbols at the beginning or at the end.\n\n Returns:\n torchtext.vocab.Vocab: A `Vocab` object\n\n Examples:\n >>> from torchtext.vocab import vocab\n >>> from collections import Counter, OrderedDict\n >>> counter = Counter([\"a\", \"a\", \"b\", \"b\", \"b\"])\n >>> sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True)\n >>> ordered_dict = OrderedDict(sorted_by_freq_tuples)\n >>> v1 = vocab(ordered_dict)\n >>> print(v1['a']) #prints 1\n >>> print(v1['out of vocab']) #raise RuntimeError since default index is not set\n >>> tokens = ['e', 'd', 'c', 'b', 'a']\n >>> #adding <unk> token and default index\n >>> unk_token = '<unk>'\n >>> default_index = -1\n >>> v2 = vocab(OrderedDict([(token, 1) for token in tokens]), specials=[unk_token])\n >>> v2.set_default_index(default_index)\n >>> print(v2['<unk>']) #prints 0\n >>> print(v2['out of vocab']) #prints -1\n >>> #make default index same as index of unk_token\n >>> v2.set_default_index(v2[unk_token])\n >>> v2['out of vocab'] is v2[unk_token] #prints True\n \"\"\"\n specials = specials or []\n for token in specials:\n ordered_dict.pop(token, None)\n\n tokens = []\n for token, freq in ordered_dict.items():\n if freq >= min_freq:\n tokens.append(token)\n\n if special_first:\n tokens[0:0] = specials\n else:\n tokens.extend(specials)\n\n return Vocab(VocabPybind(tokens, None))\n\n\ndef build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True) -> Vocab:\n \"\"\"\n Build a Vocab from an iterator.\n\n Args:\n iterator: Iterator used to build Vocab. Must yield list or iterator of tokens.\n min_freq: The minimum frequency needed to include a token in the vocabulary.\n specials: Special symbols to add. The order of supplied tokens will be preserved.\n special_first: Indicates whether to insert symbols at the beginning or at the end.\n\n\n Returns:\n torchtext.vocab.Vocab: A `Vocab` object\n\n Examples:\n >>> #generating vocab from text file\n >>> import io\n >>> from torchtext.vocab import build_vocab_from_iterator\n >>> def yield_tokens(file_path):\n >>> with io.open(file_path, encoding = 'utf-8') as f:\n >>> for line in f:\n >>> yield line.strip().split()\n >>> vocab = build_vocab_from_iterator(yield_tokens_batch(file_path), specials=[\"<unk>\"])\n \"\"\"\n\n counter = Counter()\n for tokens in iterator:\n counter.update(tokens)\n\n sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[0])\n sorted_by_freq_tuples.sort(key=lambda x: x[1], reverse=True)\n ordered_dict = OrderedDict(sorted_by_freq_tuples)\n\n word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials or [],\n special_first=special_first)\n return word_vocab\n", "path": "torchtext/vocab/vocab_factory.py"}], "after_files": [{"content": "from .vocab import Vocab\nfrom typing import Dict, Iterable, Optional, List\nfrom collections import Counter, OrderedDict\nfrom torchtext._torchtext import (\n Vocab as VocabPybind,\n)\n\n\ndef vocab(ordered_dict: Dict, min_freq: int = 1,\n specials: Optional[List[str]] = None,\n special_first: bool = True) -> Vocab:\n r\"\"\"Factory method for creating a vocab object which maps tokens to indices.\n\n Note that the ordering in which key value pairs were inserted in the `ordered_dict` will be respected when building the vocab.\n Therefore if sorting by token frequency is important to the user, the `ordered_dict` should be created in a way to reflect this.\n\n Args:\n ordered_dict: Ordered Dictionary mapping tokens to their corresponding occurance frequencies.\n min_freq: The minimum frequency needed to include a token in the vocabulary.\n specials: Special symbols to add. The order of supplied tokens will be preserved.\n special_first: Indicates whether to insert symbols at the beginning or at the end.\n\n Returns:\n torchtext.vocab.Vocab: A `Vocab` object\n\n Examples:\n >>> from torchtext.vocab import vocab\n >>> from collections import Counter, OrderedDict\n >>> counter = Counter([\"a\", \"a\", \"b\", \"b\", \"b\"])\n >>> sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True)\n >>> ordered_dict = OrderedDict(sorted_by_freq_tuples)\n >>> v1 = vocab(ordered_dict)\n >>> print(v1['a']) #prints 1\n >>> print(v1['out of vocab']) #raise RuntimeError since default index is not set\n >>> tokens = ['e', 'd', 'c', 'b', 'a']\n >>> #adding <unk> token and default index\n >>> unk_token = '<unk>'\n >>> default_index = -1\n >>> v2 = vocab(OrderedDict([(token, 1) for token in tokens]), specials=[unk_token])\n >>> v2.set_default_index(default_index)\n >>> print(v2['<unk>']) #prints 0\n >>> print(v2['out of vocab']) #prints -1\n >>> #make default index same as index of unk_token\n >>> v2.set_default_index(v2[unk_token])\n >>> v2['out of vocab'] is v2[unk_token] #prints True\n \"\"\"\n specials = specials or []\n for token in specials:\n ordered_dict.pop(token, None)\n\n tokens = []\n # Save room for special tokens\n for token, freq in ordered_dict.items():\n if freq >= min_freq:\n tokens.append(token)\n\n if special_first:\n tokens[0:0] = specials\n else:\n tokens.extend(specials)\n\n return Vocab(VocabPybind(tokens, None))\n\n\ndef build_vocab_from_iterator(iterator: Iterable, min_freq: int = 1, specials: Optional[List[str]] = None, special_first: bool = True, max_tokens: Optional[int] = None) -> Vocab:\n \"\"\"\n Build a Vocab from an iterator.\n\n Args:\n iterator: Iterator used to build Vocab. Must yield list or iterator of tokens.\n min_freq: The minimum frequency needed to include a token in the vocabulary.\n specials: Special symbols to add. The order of supplied tokens will be preserved.\n special_first: Indicates whether to insert symbols at the beginning or at the end.\n max_tokens: If provided, creates the vocab from the `max_tokens - len(specials)` most frequent tokens.\n\n\n Returns:\n torchtext.vocab.Vocab: A `Vocab` object\n\n Examples:\n >>> #generating vocab from text file\n >>> import io\n >>> from torchtext.vocab import build_vocab_from_iterator\n >>> def yield_tokens(file_path):\n >>> with io.open(file_path, encoding = 'utf-8') as f:\n >>> for line in f:\n >>> yield line.strip().split()\n >>> vocab = build_vocab_from_iterator(yield_tokens_batch(file_path), specials=[\"<unk>\"])\n \"\"\"\n\n counter = Counter()\n for tokens in iterator:\n counter.update(tokens)\n\n specials = specials or []\n\n # First sort by descending frequency, then lexicographically\n sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: (-x[1], x[0]))\n\n if max_tokens is None:\n ordered_dict = OrderedDict(sorted_by_freq_tuples)\n else:\n assert len(specials) < max_tokens, \"len(specials) >= max_tokens, so the vocab will be entirely special tokens.\"\n ordered_dict = OrderedDict(sorted_by_freq_tuples[:max_tokens - len(specials)])\n\n word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials, special_first=special_first)\n return word_vocab\n", "path": "torchtext/vocab/vocab_factory.py"}]}
| 1,661 | 572 |
gh_patches_debug_20842
|
rasdani/github-patches
|
git_diff
|
napari__napari-2398
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Settings manager may need to handle edge case where loaded data is None
## 🐛 Bug
Looks like the settings manager `_load` method may need to handle the case where `safe_load` returns `None`. I don't yet have a reproducible example... but I'm working on some stuff that is crashing napari a lot :joy:, so maybe settings aren't getting written correctly at close? and during one of my runs I got this traceback:
```pytb
File "/Users/talley/Desktop/t.py", line 45, in <module>
import napari
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/__init__.py", line 22, in <module>
from ._event_loop import gui_qt, run
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_event_loop.py", line 2, in <module>
from ._qt.qt_event_loop import gui_qt, run
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_qt/__init__.py", line 41, in <module>
from .qt_main_window import Window
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_qt/qt_main_window.py", line 30, in <module>
from ..utils.settings import SETTINGS
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/__init__.py", line 5, in <module>
from ._manager import SETTINGS
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py", line 177, in <module>
SETTINGS = SettingsManager()
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py", line 66, in __init__
self._load()
File "/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py", line 115, in _load
for section, model_data in data.items():
AttributeError: 'NoneType' object has no attribute 'items'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `napari/utils/settings/_manager.py`
Content:
```
1 """Settings management.
2 """
3
4 import os
5 from pathlib import Path
6
7 from appdirs import user_config_dir
8 from pydantic import ValidationError
9 from yaml import safe_dump, safe_load
10
11 from ._defaults import CORE_SETTINGS, ApplicationSettings, PluginSettings
12
13
14 class SettingsManager:
15 """
16 Napari settings manager using evented SettingsModels.
17
18 This provides the presistence layer for the application settings.
19
20 Parameters
21 ----------
22 config_path : str, optional
23 Provide the base folder to store napari configuration. Default is None,
24 which will point to user config provided by `appdirs`.
25 save_to_disk : bool, optional
26 Persist settings on disk. Default is True.
27
28 Notes
29 -----
30 The settings manager will create a new user configuration folder which is
31 provided by `appdirs` in a cross platform manner. On the first startup a
32 new configuration file will be created using the default values defined by
33 the `CORE_SETTINGS` models.
34
35 If a configuration file is found in the specified location, it will be
36 loaded by the `_load` method. On configuration load the following checks
37 are performed:
38
39 - If invalid sections are found, these will be removed from the file.
40 - If invalid keys are found within a valid section, these will be removed
41 from the file.
42 - If invalid values are found within valid sections and valid keys, these
43 will be replaced by the default value provided by `CORE_SETTINGS`
44 models.
45 """
46
47 _FILENAME = "settings.yaml"
48 _APPNAME = "Napari"
49 _APPAUTHOR = "Napari"
50 application: ApplicationSettings
51 plugin: PluginSettings
52
53 def __init__(self, config_path: str = None, save_to_disk: bool = True):
54 self._config_path = (
55 Path(user_config_dir(self._APPNAME, self._APPAUTHOR))
56 if config_path is None
57 else Path(config_path)
58 )
59 self._save_to_disk = save_to_disk
60 self._settings = {}
61 self._defaults = {}
62 self._models = {}
63 self._plugins = []
64
65 if not self._config_path.is_dir():
66 os.makedirs(self._config_path)
67
68 self._load()
69
70 def __getattr__(self, attr):
71 if attr in self._settings:
72 return self._settings[attr]
73
74 def __dir__(self):
75 """Add setting keys to make tab completion works."""
76 return super().__dir__() + list(self._settings)
77
78 @staticmethod
79 def _get_section_name(settings) -> str:
80 """
81 Return the normalized name of a section based on its config title.
82 """
83 section = settings.Config.title.replace(" ", "_").lower()
84 if section.endswith("_settings"):
85 section = section.replace("_settings", "")
86
87 return section
88
89 def _to_dict(self) -> dict:
90 """Convert the settings to a dictionary."""
91 data = {}
92 for section, model in self._settings.items():
93 data[section] = model.dict()
94
95 return data
96
97 def _save(self):
98 """Save configuration to disk."""
99 if self._save_to_disk:
100 path = self.path / self._FILENAME
101 with open(path, "w") as fh:
102 fh.write(safe_dump(self._to_dict()))
103
104 def _load(self):
105 """Read configuration from disk."""
106 path = self.path / self._FILENAME
107 for plugin in CORE_SETTINGS:
108 section = self._get_section_name(plugin)
109 self._defaults[section] = plugin()
110 self._models[section] = plugin
111
112 if path.is_file():
113 with open(path) as fh:
114 data = safe_load(fh.read())
115
116 # Check with models
117 for section, model_data in data.items():
118 try:
119 model = self._models[section](**model_data)
120 model.events.connect(lambda x: self._save())
121 self._settings[section] = model
122 except KeyError:
123 pass
124 except ValidationError as e:
125 # Handle extra fields
126 model_data_replace = {}
127 for error in e.errors():
128 # Grab the first error entry
129 item = error["loc"][0]
130 try:
131 model_data_replace[item] = getattr(
132 self._defaults[section], item
133 )
134 except AttributeError:
135 model_data.pop(item)
136
137 model_data.update(model_data_replace)
138 model = self._models[section](**model_data)
139 model.events.connect(lambda x: self._save())
140 self._settings[section] = model
141 else:
142 self._settings = self._defaults
143
144 self._save()
145
146 @property
147 def path(self):
148 return self._config_path
149
150 def reset(self):
151 """Reset settings to default values."""
152 for section in self._settings:
153 self._settings[section] = self._models[section]()
154
155 self._save()
156
157 def schemas(self) -> dict:
158 """Return the json schema for each of the settings model."""
159 schemas = {}
160 for section, settings in self._settings.items():
161 schemas[section] = {
162 "json_schema": settings.schema_json(),
163 "model": settings,
164 }
165
166 return schemas
167
168 def register_plugin(self, plugin):
169 """Register plugin settings with the settings manager.
170
171 Parameters
172 ----------
173 plugin:
174 The napari plugin that may or may not provide settings.
175 """
176 self._plugins.append(plugin)
177
178
179 SETTINGS = SettingsManager()
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/napari/utils/settings/_manager.py b/napari/utils/settings/_manager.py
--- a/napari/utils/settings/_manager.py
+++ b/napari/utils/settings/_manager.py
@@ -108,10 +108,11 @@
section = self._get_section_name(plugin)
self._defaults[section] = plugin()
self._models[section] = plugin
+ self._settings[section] = plugin()
if path.is_file():
with open(path) as fh:
- data = safe_load(fh.read())
+ data = safe_load(fh.read()) or {}
# Check with models
for section, model_data in data.items():
@@ -138,8 +139,6 @@
model = self._models[section](**model_data)
model.events.connect(lambda x: self._save())
self._settings[section] = model
- else:
- self._settings = self._defaults
self._save()
|
{"golden_diff": "diff --git a/napari/utils/settings/_manager.py b/napari/utils/settings/_manager.py\n--- a/napari/utils/settings/_manager.py\n+++ b/napari/utils/settings/_manager.py\n@@ -108,10 +108,11 @@\n section = self._get_section_name(plugin)\n self._defaults[section] = plugin()\n self._models[section] = plugin\n+ self._settings[section] = plugin()\n \n if path.is_file():\n with open(path) as fh:\n- data = safe_load(fh.read())\n+ data = safe_load(fh.read()) or {}\n \n # Check with models\n for section, model_data in data.items():\n@@ -138,8 +139,6 @@\n model = self._models[section](**model_data)\n model.events.connect(lambda x: self._save())\n self._settings[section] = model\n- else:\n- self._settings = self._defaults\n \n self._save()\n", "issue": "Settings manager may need to handle edge case where loaded data is None\n## \ud83d\udc1b Bug\r\nLooks like the settings manager `_load` method may need to handle the case where `safe_load` returns `None`. I don't yet have a reproducible example... but I'm working on some stuff that is crashing napari a lot :joy:, so maybe settings aren't getting written correctly at close? and during one of my runs I got this traceback:\r\n\r\n```pytb\r\n File \"/Users/talley/Desktop/t.py\", line 45, in <module>\r\n import napari\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/__init__.py\", line 22, in <module>\r\n from ._event_loop import gui_qt, run\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_event_loop.py\", line 2, in <module>\r\n from ._qt.qt_event_loop import gui_qt, run\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_qt/__init__.py\", line 41, in <module>\r\n from .qt_main_window import Window\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/_qt/qt_main_window.py\", line 30, in <module>\r\n from ..utils.settings import SETTINGS\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/__init__.py\", line 5, in <module>\r\n from ._manager import SETTINGS\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py\", line 177, in <module>\r\n SETTINGS = SettingsManager()\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py\", line 66, in __init__\r\n self._load()\r\n File \"/Users/talley/Dropbox (HMS)/Python/forks/napari/napari/utils/settings/_manager.py\", line 115, in _load\r\n for section, model_data in data.items():\r\nAttributeError: 'NoneType' object has no attribute 'items'\r\n```\n", "before_files": [{"content": "\"\"\"Settings management.\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom appdirs import user_config_dir\nfrom pydantic import ValidationError\nfrom yaml import safe_dump, safe_load\n\nfrom ._defaults import CORE_SETTINGS, ApplicationSettings, PluginSettings\n\n\nclass SettingsManager:\n \"\"\"\n Napari settings manager using evented SettingsModels.\n\n This provides the presistence layer for the application settings.\n\n Parameters\n ----------\n config_path : str, optional\n Provide the base folder to store napari configuration. Default is None,\n which will point to user config provided by `appdirs`.\n save_to_disk : bool, optional\n Persist settings on disk. Default is True.\n\n Notes\n -----\n The settings manager will create a new user configuration folder which is\n provided by `appdirs` in a cross platform manner. On the first startup a\n new configuration file will be created using the default values defined by\n the `CORE_SETTINGS` models.\n\n If a configuration file is found in the specified location, it will be\n loaded by the `_load` method. On configuration load the following checks\n are performed:\n\n - If invalid sections are found, these will be removed from the file.\n - If invalid keys are found within a valid section, these will be removed\n from the file.\n - If invalid values are found within valid sections and valid keys, these\n will be replaced by the default value provided by `CORE_SETTINGS`\n models.\n \"\"\"\n\n _FILENAME = \"settings.yaml\"\n _APPNAME = \"Napari\"\n _APPAUTHOR = \"Napari\"\n application: ApplicationSettings\n plugin: PluginSettings\n\n def __init__(self, config_path: str = None, save_to_disk: bool = True):\n self._config_path = (\n Path(user_config_dir(self._APPNAME, self._APPAUTHOR))\n if config_path is None\n else Path(config_path)\n )\n self._save_to_disk = save_to_disk\n self._settings = {}\n self._defaults = {}\n self._models = {}\n self._plugins = []\n\n if not self._config_path.is_dir():\n os.makedirs(self._config_path)\n\n self._load()\n\n def __getattr__(self, attr):\n if attr in self._settings:\n return self._settings[attr]\n\n def __dir__(self):\n \"\"\"Add setting keys to make tab completion works.\"\"\"\n return super().__dir__() + list(self._settings)\n\n @staticmethod\n def _get_section_name(settings) -> str:\n \"\"\"\n Return the normalized name of a section based on its config title.\n \"\"\"\n section = settings.Config.title.replace(\" \", \"_\").lower()\n if section.endswith(\"_settings\"):\n section = section.replace(\"_settings\", \"\")\n\n return section\n\n def _to_dict(self) -> dict:\n \"\"\"Convert the settings to a dictionary.\"\"\"\n data = {}\n for section, model in self._settings.items():\n data[section] = model.dict()\n\n return data\n\n def _save(self):\n \"\"\"Save configuration to disk.\"\"\"\n if self._save_to_disk:\n path = self.path / self._FILENAME\n with open(path, \"w\") as fh:\n fh.write(safe_dump(self._to_dict()))\n\n def _load(self):\n \"\"\"Read configuration from disk.\"\"\"\n path = self.path / self._FILENAME\n for plugin in CORE_SETTINGS:\n section = self._get_section_name(plugin)\n self._defaults[section] = plugin()\n self._models[section] = plugin\n\n if path.is_file():\n with open(path) as fh:\n data = safe_load(fh.read())\n\n # Check with models\n for section, model_data in data.items():\n try:\n model = self._models[section](**model_data)\n model.events.connect(lambda x: self._save())\n self._settings[section] = model\n except KeyError:\n pass\n except ValidationError as e:\n # Handle extra fields\n model_data_replace = {}\n for error in e.errors():\n # Grab the first error entry\n item = error[\"loc\"][0]\n try:\n model_data_replace[item] = getattr(\n self._defaults[section], item\n )\n except AttributeError:\n model_data.pop(item)\n\n model_data.update(model_data_replace)\n model = self._models[section](**model_data)\n model.events.connect(lambda x: self._save())\n self._settings[section] = model\n else:\n self._settings = self._defaults\n\n self._save()\n\n @property\n def path(self):\n return self._config_path\n\n def reset(self):\n \"\"\"Reset settings to default values.\"\"\"\n for section in self._settings:\n self._settings[section] = self._models[section]()\n\n self._save()\n\n def schemas(self) -> dict:\n \"\"\"Return the json schema for each of the settings model.\"\"\"\n schemas = {}\n for section, settings in self._settings.items():\n schemas[section] = {\n \"json_schema\": settings.schema_json(),\n \"model\": settings,\n }\n\n return schemas\n\n def register_plugin(self, plugin):\n \"\"\"Register plugin settings with the settings manager.\n\n Parameters\n ----------\n plugin:\n The napari plugin that may or may not provide settings.\n \"\"\"\n self._plugins.append(plugin)\n\n\nSETTINGS = SettingsManager()\n", "path": "napari/utils/settings/_manager.py"}], "after_files": [{"content": "\"\"\"Settings management.\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom appdirs import user_config_dir\nfrom pydantic import ValidationError\nfrom yaml import safe_dump, safe_load\n\nfrom ._defaults import CORE_SETTINGS, ApplicationSettings, PluginSettings\n\n\nclass SettingsManager:\n \"\"\"\n Napari settings manager using evented SettingsModels.\n\n This provides the presistence layer for the application settings.\n\n Parameters\n ----------\n config_path : str, optional\n Provide the base folder to store napari configuration. Default is None,\n which will point to user config provided by `appdirs`.\n save_to_disk : bool, optional\n Persist settings on disk. Default is True.\n\n Notes\n -----\n The settings manager will create a new user configuration folder which is\n provided by `appdirs` in a cross platform manner. On the first startup a\n new configuration file will be created using the default values defined by\n the `CORE_SETTINGS` models.\n\n If a configuration file is found in the specified location, it will be\n loaded by the `_load` method. On configuration load the following checks\n are performed:\n\n - If invalid sections are found, these will be removed from the file.\n - If invalid keys are found within a valid section, these will be removed\n from the file.\n - If invalid values are found within valid sections and valid keys, these\n will be replaced by the default value provided by `CORE_SETTINGS`\n models.\n \"\"\"\n\n _FILENAME = \"settings.yaml\"\n _APPNAME = \"Napari\"\n _APPAUTHOR = \"Napari\"\n application: ApplicationSettings\n plugin: PluginSettings\n\n def __init__(self, config_path: str = None, save_to_disk: bool = True):\n self._config_path = (\n Path(user_config_dir(self._APPNAME, self._APPAUTHOR))\n if config_path is None\n else Path(config_path)\n )\n self._save_to_disk = save_to_disk\n self._settings = {}\n self._defaults = {}\n self._models = {}\n self._plugins = []\n\n if not self._config_path.is_dir():\n os.makedirs(self._config_path)\n\n self._load()\n\n def __getattr__(self, attr):\n if attr in self._settings:\n return self._settings[attr]\n\n def __dir__(self):\n \"\"\"Add setting keys to make tab completion works.\"\"\"\n return super().__dir__() + list(self._settings)\n\n @staticmethod\n def _get_section_name(settings) -> str:\n \"\"\"\n Return the normalized name of a section based on its config title.\n \"\"\"\n section = settings.Config.title.replace(\" \", \"_\").lower()\n if section.endswith(\"_settings\"):\n section = section.replace(\"_settings\", \"\")\n\n return section\n\n def _to_dict(self) -> dict:\n \"\"\"Convert the settings to a dictionary.\"\"\"\n data = {}\n for section, model in self._settings.items():\n data[section] = model.dict()\n\n return data\n\n def _save(self):\n \"\"\"Save configuration to disk.\"\"\"\n if self._save_to_disk:\n path = self.path / self._FILENAME\n with open(path, \"w\") as fh:\n fh.write(safe_dump(self._to_dict()))\n\n def _load(self):\n \"\"\"Read configuration from disk.\"\"\"\n path = self.path / self._FILENAME\n for plugin in CORE_SETTINGS:\n section = self._get_section_name(plugin)\n self._defaults[section] = plugin()\n self._models[section] = plugin\n self._settings[section] = plugin()\n\n if path.is_file():\n with open(path) as fh:\n data = safe_load(fh.read()) or {}\n\n # Check with models\n for section, model_data in data.items():\n try:\n model = self._models[section](**model_data)\n model.events.connect(lambda x: self._save())\n self._settings[section] = model\n except KeyError:\n pass\n except ValidationError as e:\n # Handle extra fields\n model_data_replace = {}\n for error in e.errors():\n # Grab the first error entry\n item = error[\"loc\"][0]\n try:\n model_data_replace[item] = getattr(\n self._defaults[section], item\n )\n except AttributeError:\n model_data.pop(item)\n\n model_data.update(model_data_replace)\n model = self._models[section](**model_data)\n model.events.connect(lambda x: self._save())\n self._settings[section] = model\n\n self._save()\n\n @property\n def path(self):\n return self._config_path\n\n def reset(self):\n \"\"\"Reset settings to default values.\"\"\"\n for section in self._settings:\n self._settings[section] = self._models[section]()\n\n self._save()\n\n def schemas(self) -> dict:\n \"\"\"Return the json schema for each of the settings model.\"\"\"\n schemas = {}\n for section, settings in self._settings.items():\n schemas[section] = {\n \"json_schema\": settings.schema_json(),\n \"model\": settings,\n }\n\n return schemas\n\n def register_plugin(self, plugin):\n \"\"\"Register plugin settings with the settings manager.\n\n Parameters\n ----------\n plugin:\n The napari plugin that may or may not provide settings.\n \"\"\"\n self._plugins.append(plugin)\n\n\nSETTINGS = SettingsManager()\n", "path": "napari/utils/settings/_manager.py"}]}
| 2,362 | 215 |
gh_patches_debug_11496
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-9498
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting external methods should throw errors when the method does not exist
### What I'm trying to achieve
I'm setting an external method that does not exist
### Steps to reproduce the problem
I base64 encoded `app:1234:some-id` that was never a real id external method id:
<img width="1440" alt="image" src="https://user-images.githubusercontent.com/2566928/154252619-496c1b91-ca79-4fe8-bc1d-abcd0cbb743c.png">
There is no error, but the delivery method is still null.
### What I expected to happen
I would expect an error response, rather than noop.
### Screenshots and logs
<!-- If applicable, add screenshots to help explain your problem. -->
**System information**
<!-- Provide the version of Saleor or whether you're using it from the `main` branch. If using Saleor Dashboard or Storefront, provide their versions too. -->
Saleor version:
- [ ] dev (current main)
- [ ] 3.0
- [ ] 2.11
- [ ] 2.10
Operating system:
- [ ] Windows
- [ ] Linux
- [ ] MacOS
- [ ] Other
Setting external methods should throw errors when the method does not exist
### What I'm trying to achieve
I'm setting an external method that does not exist
### Steps to reproduce the problem
I base64 encoded `app:1234:some-id` that was never a real id external method id:
<img width="1440" alt="image" src="https://user-images.githubusercontent.com/2566928/154252619-496c1b91-ca79-4fe8-bc1d-abcd0cbb743c.png">
There is no error, but the delivery method is still null.
### What I expected to happen
I would expect an error response, rather than noop.
### Screenshots and logs
<!-- If applicable, add screenshots to help explain your problem. -->
**System information**
<!-- Provide the version of Saleor or whether you're using it from the `main` branch. If using Saleor Dashboard or Storefront, provide their versions too. -->
Saleor version:
- [ ] dev (current main)
- [ ] 3.0
- [ ] 2.11
- [ ] 2.10
Operating system:
- [ ] Windows
- [ ] Linux
- [ ] MacOS
- [ ] Other
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/checkout/mutations/checkout_delivery_method_update.py`
Content:
```
1 from typing import Optional
2
3 import graphene
4 from django.core.exceptions import ValidationError
5
6 from ....checkout.error_codes import CheckoutErrorCode
7 from ....checkout.fetch import fetch_checkout_info, fetch_checkout_lines
8 from ....checkout.utils import (
9 delete_external_shipping_id,
10 is_shipping_required,
11 recalculate_checkout_discount,
12 set_external_shipping_id,
13 )
14 from ....plugins.webhook.utils import APP_ID_PREFIX
15 from ....shipping import interface as shipping_interface
16 from ....shipping import models as shipping_models
17 from ....shipping.utils import convert_to_shipping_method_data
18 from ....warehouse import models as warehouse_models
19 from ...core.descriptions import ADDED_IN_31, PREVIEW_FEATURE
20 from ...core.mutations import BaseMutation
21 from ...core.scalars import UUID
22 from ...core.types import CheckoutError
23 from ...core.utils import from_global_id_or_error
24 from ...shipping.types import ShippingMethod
25 from ...warehouse.types import Warehouse
26 from ..types import Checkout
27 from .utils import ERROR_DOES_NOT_SHIP, clean_delivery_method, get_checkout_by_token
28
29
30 class CheckoutDeliveryMethodUpdate(BaseMutation):
31 checkout = graphene.Field(Checkout, description="An updated checkout.")
32
33 class Arguments:
34 token = UUID(description="Checkout token.", required=False)
35 delivery_method_id = graphene.ID(
36 description="Delivery Method ID (`Warehouse` ID or `ShippingMethod` ID).",
37 required=False,
38 )
39
40 class Meta:
41 description = (
42 f"{ADDED_IN_31} Updates the delivery method "
43 f"(shipping method or pick up point) of the checkout. {PREVIEW_FEATURE}"
44 )
45 error_type_class = CheckoutError
46
47 @classmethod
48 def perform_on_shipping_method(
49 cls, info, shipping_method_id, checkout_info, lines, checkout, manager
50 ):
51 shipping_method = cls.get_node_or_error(
52 info,
53 shipping_method_id,
54 only_type=ShippingMethod,
55 field="delivery_method_id",
56 qs=shipping_models.ShippingMethod.objects.prefetch_related(
57 "postal_code_rules"
58 ),
59 )
60
61 delivery_method = convert_to_shipping_method_data(
62 shipping_method,
63 shipping_models.ShippingMethodChannelListing.objects.filter(
64 shipping_method=shipping_method,
65 channel=checkout_info.channel,
66 ).first(),
67 )
68 cls._check_delivery_method(
69 checkout_info, lines, shipping_method=delivery_method, collection_point=None
70 )
71
72 cls._update_delivery_method(
73 manager,
74 checkout,
75 shipping_method=shipping_method,
76 external_shipping_method=None,
77 collection_point=None,
78 )
79 recalculate_checkout_discount(
80 manager, checkout_info, lines, info.context.discounts
81 )
82 return CheckoutDeliveryMethodUpdate(checkout=checkout)
83
84 @classmethod
85 def perform_on_external_shipping_method(
86 cls, info, shipping_method_id, checkout_info, lines, checkout, manager
87 ):
88 delivery_method = manager.get_shipping_method(
89 checkout=checkout,
90 channel_slug=checkout.channel.slug,
91 shipping_method_id=shipping_method_id,
92 )
93
94 cls._check_delivery_method(
95 checkout_info, lines, shipping_method=delivery_method, collection_point=None
96 )
97
98 cls._update_delivery_method(
99 manager,
100 checkout,
101 shipping_method=None,
102 external_shipping_method=delivery_method,
103 collection_point=None,
104 )
105 recalculate_checkout_discount(
106 manager, checkout_info, lines, info.context.discounts
107 )
108 return CheckoutDeliveryMethodUpdate(checkout=checkout)
109
110 @classmethod
111 def perform_on_collection_point(
112 cls, info, collection_point_id, checkout_info, lines, checkout, manager
113 ):
114 collection_point = cls.get_node_or_error(
115 info,
116 collection_point_id,
117 only_type=Warehouse,
118 field="delivery_method_id",
119 qs=warehouse_models.Warehouse.objects.select_related("address"),
120 )
121 cls._check_delivery_method(
122 checkout_info,
123 lines,
124 shipping_method=None,
125 collection_point=collection_point,
126 )
127 cls._update_delivery_method(
128 manager,
129 checkout,
130 shipping_method=None,
131 external_shipping_method=None,
132 collection_point=collection_point,
133 )
134 return CheckoutDeliveryMethodUpdate(checkout=checkout)
135
136 @staticmethod
137 def _check_delivery_method(
138 checkout_info,
139 lines,
140 *,
141 shipping_method: Optional[shipping_interface.ShippingMethodData],
142 collection_point: Optional[Warehouse]
143 ) -> None:
144 delivery_method = shipping_method
145 error_msg = "This shipping method is not applicable."
146
147 if collection_point is not None:
148 delivery_method = collection_point
149 error_msg = "This pick up point is not applicable."
150
151 delivery_method_is_valid = clean_delivery_method(
152 checkout_info=checkout_info, lines=lines, method=delivery_method
153 )
154 if not delivery_method_is_valid:
155 raise ValidationError(
156 {
157 "delivery_method_id": ValidationError(
158 error_msg,
159 code=CheckoutErrorCode.DELIVERY_METHOD_NOT_APPLICABLE.value,
160 )
161 }
162 )
163
164 @staticmethod
165 def _update_delivery_method(
166 manager,
167 checkout: Checkout,
168 *,
169 shipping_method: Optional[ShippingMethod],
170 external_shipping_method: Optional[shipping_interface.ShippingMethodData],
171 collection_point: Optional[Warehouse]
172 ) -> None:
173 if external_shipping_method:
174 set_external_shipping_id(
175 checkout=checkout, app_shipping_id=external_shipping_method.id
176 )
177 else:
178 delete_external_shipping_id(checkout=checkout)
179 checkout.shipping_method = shipping_method
180 checkout.collection_point = collection_point
181 checkout.save(
182 update_fields=[
183 "private_metadata",
184 "shipping_method",
185 "collection_point",
186 "last_change",
187 ]
188 )
189 manager.checkout_updated(checkout)
190
191 @staticmethod
192 def _resolve_delivery_method_type(id_) -> Optional[str]:
193 if id_ is None:
194 return None
195
196 possible_types = ("Warehouse", "ShippingMethod", APP_ID_PREFIX)
197 type_, id_ = from_global_id_or_error(id_)
198 str_type = str(type_)
199
200 if str_type not in possible_types:
201 raise ValidationError(
202 {
203 "delivery_method_id": ValidationError(
204 "ID does not belong to Warehouse or ShippingMethod",
205 code=CheckoutErrorCode.INVALID.value,
206 )
207 }
208 )
209
210 return str_type
211
212 @classmethod
213 def perform_mutation(
214 cls,
215 _,
216 info,
217 token,
218 delivery_method_id=None,
219 ):
220
221 checkout = get_checkout_by_token(token)
222
223 manager = info.context.plugins
224 lines, unavailable_variant_pks = fetch_checkout_lines(checkout)
225 if unavailable_variant_pks:
226 not_available_variants_ids = {
227 graphene.Node.to_global_id("ProductVariant", pk)
228 for pk in unavailable_variant_pks
229 }
230 raise ValidationError(
231 {
232 "lines": ValidationError(
233 "Some of the checkout lines variants are unavailable.",
234 code=CheckoutErrorCode.UNAVAILABLE_VARIANT_IN_CHANNEL.value,
235 params={"variants": not_available_variants_ids},
236 )
237 }
238 )
239
240 if not is_shipping_required(lines):
241 raise ValidationError(
242 {
243 "delivery_method": ValidationError(
244 ERROR_DOES_NOT_SHIP,
245 code=CheckoutErrorCode.SHIPPING_NOT_REQUIRED,
246 )
247 }
248 )
249 type_name = cls._resolve_delivery_method_type(delivery_method_id)
250
251 checkout_info = fetch_checkout_info(
252 checkout, lines, info.context.discounts, manager
253 )
254 if type_name == "Warehouse":
255 return cls.perform_on_collection_point(
256 info, delivery_method_id, checkout_info, lines, checkout, manager
257 )
258 if type_name == "ShippingMethod":
259 return cls.perform_on_shipping_method(
260 info, delivery_method_id, checkout_info, lines, checkout, manager
261 )
262 return cls.perform_on_external_shipping_method(
263 info, delivery_method_id, checkout_info, lines, checkout, manager
264 )
265
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py b/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py
--- a/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py
+++ b/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py
@@ -91,6 +91,16 @@
shipping_method_id=shipping_method_id,
)
+ if delivery_method is None and shipping_method_id:
+ raise ValidationError(
+ {
+ "delivery_method_id": ValidationError(
+ f"Couldn't resolve to a node: ${shipping_method_id}",
+ code=CheckoutErrorCode.NOT_FOUND,
+ )
+ }
+ )
+
cls._check_delivery_method(
checkout_info, lines, shipping_method=delivery_method, collection_point=None
)
|
{"golden_diff": "diff --git a/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py b/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py\n--- a/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py\n+++ b/saleor/graphql/checkout/mutations/checkout_delivery_method_update.py\n@@ -91,6 +91,16 @@\n shipping_method_id=shipping_method_id,\n )\n \n+ if delivery_method is None and shipping_method_id:\n+ raise ValidationError(\n+ {\n+ \"delivery_method_id\": ValidationError(\n+ f\"Couldn't resolve to a node: ${shipping_method_id}\",\n+ code=CheckoutErrorCode.NOT_FOUND,\n+ )\n+ }\n+ )\n+\n cls._check_delivery_method(\n checkout_info, lines, shipping_method=delivery_method, collection_point=None\n )\n", "issue": "Setting external methods should throw errors when the method does not exist\n### What I'm trying to achieve\r\nI'm setting an external method that does not exist\r\n\r\n### Steps to reproduce the problem\r\nI base64 encoded `app:1234:some-id` that was never a real id external method id:\r\n\r\n<img width=\"1440\" alt=\"image\" src=\"https://user-images.githubusercontent.com/2566928/154252619-496c1b91-ca79-4fe8-bc1d-abcd0cbb743c.png\">\r\n\r\nThere is no error, but the delivery method is still null.\r\n\r\n\r\n### What I expected to happen\r\nI would expect an error response, rather than noop.\r\n\r\n### Screenshots and logs\r\n<!-- If applicable, add screenshots to help explain your problem. -->\r\n\r\n**System information**\r\n<!-- Provide the version of Saleor or whether you're using it from the `main` branch. If using Saleor Dashboard or Storefront, provide their versions too. -->\r\nSaleor version:\r\n- [ ] dev (current main)\r\n- [ ] 3.0\r\n- [ ] 2.11\r\n- [ ] 2.10\r\n\r\nOperating system:\r\n- [ ] Windows\r\n- [ ] Linux\r\n- [ ] MacOS\r\n- [ ] Other\r\n\nSetting external methods should throw errors when the method does not exist\n### What I'm trying to achieve\r\nI'm setting an external method that does not exist\r\n\r\n### Steps to reproduce the problem\r\nI base64 encoded `app:1234:some-id` that was never a real id external method id:\r\n\r\n<img width=\"1440\" alt=\"image\" src=\"https://user-images.githubusercontent.com/2566928/154252619-496c1b91-ca79-4fe8-bc1d-abcd0cbb743c.png\">\r\n\r\nThere is no error, but the delivery method is still null.\r\n\r\n\r\n### What I expected to happen\r\nI would expect an error response, rather than noop.\r\n\r\n### Screenshots and logs\r\n<!-- If applicable, add screenshots to help explain your problem. -->\r\n\r\n**System information**\r\n<!-- Provide the version of Saleor or whether you're using it from the `main` branch. If using Saleor Dashboard or Storefront, provide their versions too. -->\r\nSaleor version:\r\n- [ ] dev (current main)\r\n- [ ] 3.0\r\n- [ ] 2.11\r\n- [ ] 2.10\r\n\r\nOperating system:\r\n- [ ] Windows\r\n- [ ] Linux\r\n- [ ] MacOS\r\n- [ ] Other\r\n\n", "before_files": [{"content": "from typing import Optional\n\nimport graphene\nfrom django.core.exceptions import ValidationError\n\nfrom ....checkout.error_codes import CheckoutErrorCode\nfrom ....checkout.fetch import fetch_checkout_info, fetch_checkout_lines\nfrom ....checkout.utils import (\n delete_external_shipping_id,\n is_shipping_required,\n recalculate_checkout_discount,\n set_external_shipping_id,\n)\nfrom ....plugins.webhook.utils import APP_ID_PREFIX\nfrom ....shipping import interface as shipping_interface\nfrom ....shipping import models as shipping_models\nfrom ....shipping.utils import convert_to_shipping_method_data\nfrom ....warehouse import models as warehouse_models\nfrom ...core.descriptions import ADDED_IN_31, PREVIEW_FEATURE\nfrom ...core.mutations import BaseMutation\nfrom ...core.scalars import UUID\nfrom ...core.types import CheckoutError\nfrom ...core.utils import from_global_id_or_error\nfrom ...shipping.types import ShippingMethod\nfrom ...warehouse.types import Warehouse\nfrom ..types import Checkout\nfrom .utils import ERROR_DOES_NOT_SHIP, clean_delivery_method, get_checkout_by_token\n\n\nclass CheckoutDeliveryMethodUpdate(BaseMutation):\n checkout = graphene.Field(Checkout, description=\"An updated checkout.\")\n\n class Arguments:\n token = UUID(description=\"Checkout token.\", required=False)\n delivery_method_id = graphene.ID(\n description=\"Delivery Method ID (`Warehouse` ID or `ShippingMethod` ID).\",\n required=False,\n )\n\n class Meta:\n description = (\n f\"{ADDED_IN_31} Updates the delivery method \"\n f\"(shipping method or pick up point) of the checkout. {PREVIEW_FEATURE}\"\n )\n error_type_class = CheckoutError\n\n @classmethod\n def perform_on_shipping_method(\n cls, info, shipping_method_id, checkout_info, lines, checkout, manager\n ):\n shipping_method = cls.get_node_or_error(\n info,\n shipping_method_id,\n only_type=ShippingMethod,\n field=\"delivery_method_id\",\n qs=shipping_models.ShippingMethod.objects.prefetch_related(\n \"postal_code_rules\"\n ),\n )\n\n delivery_method = convert_to_shipping_method_data(\n shipping_method,\n shipping_models.ShippingMethodChannelListing.objects.filter(\n shipping_method=shipping_method,\n channel=checkout_info.channel,\n ).first(),\n )\n cls._check_delivery_method(\n checkout_info, lines, shipping_method=delivery_method, collection_point=None\n )\n\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=shipping_method,\n external_shipping_method=None,\n collection_point=None,\n )\n recalculate_checkout_discount(\n manager, checkout_info, lines, info.context.discounts\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @classmethod\n def perform_on_external_shipping_method(\n cls, info, shipping_method_id, checkout_info, lines, checkout, manager\n ):\n delivery_method = manager.get_shipping_method(\n checkout=checkout,\n channel_slug=checkout.channel.slug,\n shipping_method_id=shipping_method_id,\n )\n\n cls._check_delivery_method(\n checkout_info, lines, shipping_method=delivery_method, collection_point=None\n )\n\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=None,\n external_shipping_method=delivery_method,\n collection_point=None,\n )\n recalculate_checkout_discount(\n manager, checkout_info, lines, info.context.discounts\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @classmethod\n def perform_on_collection_point(\n cls, info, collection_point_id, checkout_info, lines, checkout, manager\n ):\n collection_point = cls.get_node_or_error(\n info,\n collection_point_id,\n only_type=Warehouse,\n field=\"delivery_method_id\",\n qs=warehouse_models.Warehouse.objects.select_related(\"address\"),\n )\n cls._check_delivery_method(\n checkout_info,\n lines,\n shipping_method=None,\n collection_point=collection_point,\n )\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=None,\n external_shipping_method=None,\n collection_point=collection_point,\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @staticmethod\n def _check_delivery_method(\n checkout_info,\n lines,\n *,\n shipping_method: Optional[shipping_interface.ShippingMethodData],\n collection_point: Optional[Warehouse]\n ) -> None:\n delivery_method = shipping_method\n error_msg = \"This shipping method is not applicable.\"\n\n if collection_point is not None:\n delivery_method = collection_point\n error_msg = \"This pick up point is not applicable.\"\n\n delivery_method_is_valid = clean_delivery_method(\n checkout_info=checkout_info, lines=lines, method=delivery_method\n )\n if not delivery_method_is_valid:\n raise ValidationError(\n {\n \"delivery_method_id\": ValidationError(\n error_msg,\n code=CheckoutErrorCode.DELIVERY_METHOD_NOT_APPLICABLE.value,\n )\n }\n )\n\n @staticmethod\n def _update_delivery_method(\n manager,\n checkout: Checkout,\n *,\n shipping_method: Optional[ShippingMethod],\n external_shipping_method: Optional[shipping_interface.ShippingMethodData],\n collection_point: Optional[Warehouse]\n ) -> None:\n if external_shipping_method:\n set_external_shipping_id(\n checkout=checkout, app_shipping_id=external_shipping_method.id\n )\n else:\n delete_external_shipping_id(checkout=checkout)\n checkout.shipping_method = shipping_method\n checkout.collection_point = collection_point\n checkout.save(\n update_fields=[\n \"private_metadata\",\n \"shipping_method\",\n \"collection_point\",\n \"last_change\",\n ]\n )\n manager.checkout_updated(checkout)\n\n @staticmethod\n def _resolve_delivery_method_type(id_) -> Optional[str]:\n if id_ is None:\n return None\n\n possible_types = (\"Warehouse\", \"ShippingMethod\", APP_ID_PREFIX)\n type_, id_ = from_global_id_or_error(id_)\n str_type = str(type_)\n\n if str_type not in possible_types:\n raise ValidationError(\n {\n \"delivery_method_id\": ValidationError(\n \"ID does not belong to Warehouse or ShippingMethod\",\n code=CheckoutErrorCode.INVALID.value,\n )\n }\n )\n\n return str_type\n\n @classmethod\n def perform_mutation(\n cls,\n _,\n info,\n token,\n delivery_method_id=None,\n ):\n\n checkout = get_checkout_by_token(token)\n\n manager = info.context.plugins\n lines, unavailable_variant_pks = fetch_checkout_lines(checkout)\n if unavailable_variant_pks:\n not_available_variants_ids = {\n graphene.Node.to_global_id(\"ProductVariant\", pk)\n for pk in unavailable_variant_pks\n }\n raise ValidationError(\n {\n \"lines\": ValidationError(\n \"Some of the checkout lines variants are unavailable.\",\n code=CheckoutErrorCode.UNAVAILABLE_VARIANT_IN_CHANNEL.value,\n params={\"variants\": not_available_variants_ids},\n )\n }\n )\n\n if not is_shipping_required(lines):\n raise ValidationError(\n {\n \"delivery_method\": ValidationError(\n ERROR_DOES_NOT_SHIP,\n code=CheckoutErrorCode.SHIPPING_NOT_REQUIRED,\n )\n }\n )\n type_name = cls._resolve_delivery_method_type(delivery_method_id)\n\n checkout_info = fetch_checkout_info(\n checkout, lines, info.context.discounts, manager\n )\n if type_name == \"Warehouse\":\n return cls.perform_on_collection_point(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n if type_name == \"ShippingMethod\":\n return cls.perform_on_shipping_method(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n return cls.perform_on_external_shipping_method(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n", "path": "saleor/graphql/checkout/mutations/checkout_delivery_method_update.py"}], "after_files": [{"content": "from typing import Optional\n\nimport graphene\nfrom django.core.exceptions import ValidationError\n\nfrom ....checkout.error_codes import CheckoutErrorCode\nfrom ....checkout.fetch import fetch_checkout_info, fetch_checkout_lines\nfrom ....checkout.utils import (\n delete_external_shipping_id,\n is_shipping_required,\n recalculate_checkout_discount,\n set_external_shipping_id,\n)\nfrom ....plugins.webhook.utils import APP_ID_PREFIX\nfrom ....shipping import interface as shipping_interface\nfrom ....shipping import models as shipping_models\nfrom ....shipping.utils import convert_to_shipping_method_data\nfrom ....warehouse import models as warehouse_models\nfrom ...core.descriptions import ADDED_IN_31, PREVIEW_FEATURE\nfrom ...core.mutations import BaseMutation\nfrom ...core.scalars import UUID\nfrom ...core.types import CheckoutError\nfrom ...core.utils import from_global_id_or_error\nfrom ...shipping.types import ShippingMethod\nfrom ...warehouse.types import Warehouse\nfrom ..types import Checkout\nfrom .utils import ERROR_DOES_NOT_SHIP, clean_delivery_method, get_checkout_by_token\n\n\nclass CheckoutDeliveryMethodUpdate(BaseMutation):\n checkout = graphene.Field(Checkout, description=\"An updated checkout.\")\n\n class Arguments:\n token = UUID(description=\"Checkout token.\", required=False)\n delivery_method_id = graphene.ID(\n description=\"Delivery Method ID (`Warehouse` ID or `ShippingMethod` ID).\",\n required=False,\n )\n\n class Meta:\n description = (\n f\"{ADDED_IN_31} Updates the delivery method \"\n f\"(shipping method or pick up point) of the checkout. {PREVIEW_FEATURE}\"\n )\n error_type_class = CheckoutError\n\n @classmethod\n def perform_on_shipping_method(\n cls, info, shipping_method_id, checkout_info, lines, checkout, manager\n ):\n shipping_method = cls.get_node_or_error(\n info,\n shipping_method_id,\n only_type=ShippingMethod,\n field=\"delivery_method_id\",\n qs=shipping_models.ShippingMethod.objects.prefetch_related(\n \"postal_code_rules\"\n ),\n )\n\n delivery_method = convert_to_shipping_method_data(\n shipping_method,\n shipping_models.ShippingMethodChannelListing.objects.filter(\n shipping_method=shipping_method,\n channel=checkout_info.channel,\n ).first(),\n )\n cls._check_delivery_method(\n checkout_info, lines, shipping_method=delivery_method, collection_point=None\n )\n\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=shipping_method,\n external_shipping_method=None,\n collection_point=None,\n )\n recalculate_checkout_discount(\n manager, checkout_info, lines, info.context.discounts\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @classmethod\n def perform_on_external_shipping_method(\n cls, info, shipping_method_id, checkout_info, lines, checkout, manager\n ):\n delivery_method = manager.get_shipping_method(\n checkout=checkout,\n channel_slug=checkout.channel.slug,\n shipping_method_id=shipping_method_id,\n )\n\n if delivery_method is None and shipping_method_id:\n raise ValidationError(\n {\n \"delivery_method_id\": ValidationError(\n f\"Couldn't resolve to a node: ${shipping_method_id}\",\n code=CheckoutErrorCode.NOT_FOUND,\n )\n }\n )\n\n cls._check_delivery_method(\n checkout_info, lines, shipping_method=delivery_method, collection_point=None\n )\n\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=None,\n external_shipping_method=delivery_method,\n collection_point=None,\n )\n recalculate_checkout_discount(\n manager, checkout_info, lines, info.context.discounts\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @classmethod\n def perform_on_collection_point(\n cls, info, collection_point_id, checkout_info, lines, checkout, manager\n ):\n collection_point = cls.get_node_or_error(\n info,\n collection_point_id,\n only_type=Warehouse,\n field=\"delivery_method_id\",\n qs=warehouse_models.Warehouse.objects.select_related(\"address\"),\n )\n cls._check_delivery_method(\n checkout_info,\n lines,\n shipping_method=None,\n collection_point=collection_point,\n )\n cls._update_delivery_method(\n manager,\n checkout,\n shipping_method=None,\n external_shipping_method=None,\n collection_point=collection_point,\n )\n return CheckoutDeliveryMethodUpdate(checkout=checkout)\n\n @staticmethod\n def _check_delivery_method(\n checkout_info,\n lines,\n *,\n shipping_method: Optional[shipping_interface.ShippingMethodData],\n collection_point: Optional[Warehouse]\n ) -> None:\n delivery_method = shipping_method\n error_msg = \"This shipping method is not applicable.\"\n\n if collection_point is not None:\n delivery_method = collection_point\n error_msg = \"This pick up point is not applicable.\"\n\n delivery_method_is_valid = clean_delivery_method(\n checkout_info=checkout_info, lines=lines, method=delivery_method\n )\n if not delivery_method_is_valid:\n raise ValidationError(\n {\n \"delivery_method_id\": ValidationError(\n error_msg,\n code=CheckoutErrorCode.DELIVERY_METHOD_NOT_APPLICABLE.value,\n )\n }\n )\n\n @staticmethod\n def _update_delivery_method(\n manager,\n checkout: Checkout,\n *,\n shipping_method: Optional[ShippingMethod],\n external_shipping_method: Optional[shipping_interface.ShippingMethodData],\n collection_point: Optional[Warehouse]\n ) -> None:\n if external_shipping_method:\n set_external_shipping_id(\n checkout=checkout, app_shipping_id=external_shipping_method.id\n )\n else:\n delete_external_shipping_id(checkout=checkout)\n checkout.shipping_method = shipping_method\n checkout.collection_point = collection_point\n checkout.save(\n update_fields=[\n \"private_metadata\",\n \"shipping_method\",\n \"collection_point\",\n \"last_change\",\n ]\n )\n manager.checkout_updated(checkout)\n\n @staticmethod\n def _resolve_delivery_method_type(id_) -> Optional[str]:\n if id_ is None:\n return None\n\n possible_types = (\"Warehouse\", \"ShippingMethod\", APP_ID_PREFIX)\n type_, id_ = from_global_id_or_error(id_)\n str_type = str(type_)\n\n if str_type not in possible_types:\n raise ValidationError(\n {\n \"delivery_method_id\": ValidationError(\n \"ID does not belong to Warehouse or ShippingMethod\",\n code=CheckoutErrorCode.INVALID.value,\n )\n }\n )\n\n return str_type\n\n @classmethod\n def perform_mutation(\n cls,\n _,\n info,\n token,\n delivery_method_id=None,\n ):\n\n checkout = get_checkout_by_token(token)\n\n manager = info.context.plugins\n lines, unavailable_variant_pks = fetch_checkout_lines(checkout)\n if unavailable_variant_pks:\n not_available_variants_ids = {\n graphene.Node.to_global_id(\"ProductVariant\", pk)\n for pk in unavailable_variant_pks\n }\n raise ValidationError(\n {\n \"lines\": ValidationError(\n \"Some of the checkout lines variants are unavailable.\",\n code=CheckoutErrorCode.UNAVAILABLE_VARIANT_IN_CHANNEL.value,\n params={\"variants\": not_available_variants_ids},\n )\n }\n )\n\n if not is_shipping_required(lines):\n raise ValidationError(\n {\n \"delivery_method\": ValidationError(\n ERROR_DOES_NOT_SHIP,\n code=CheckoutErrorCode.SHIPPING_NOT_REQUIRED,\n )\n }\n )\n type_name = cls._resolve_delivery_method_type(delivery_method_id)\n\n checkout_info = fetch_checkout_info(\n checkout, lines, info.context.discounts, manager\n )\n if type_name == \"Warehouse\":\n return cls.perform_on_collection_point(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n if type_name == \"ShippingMethod\":\n return cls.perform_on_shipping_method(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n return cls.perform_on_external_shipping_method(\n info, delivery_method_id, checkout_info, lines, checkout, manager\n )\n", "path": "saleor/graphql/checkout/mutations/checkout_delivery_method_update.py"}]}
| 3,178 | 182 |
gh_patches_debug_30437
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-4261
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Docker container's /tmp doesn't get automatically cleaned
## Problem Definition
PyInstaller extracts the files in /tmp every time the backend starts
In the docker container /tmp is never cleaned which results in an ever-increasing size on every application restart
## TODO
- [ ] Add /tmp cleanup on start
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packaging/docker/entrypoint.py`
Content:
```
1 #!/usr/bin/python3
2 import json
3 import logging
4 import os
5 import subprocess
6 import time
7 from pathlib import Path
8 from typing import Dict, Optional, Any, List
9
10 logger = logging.getLogger('monitor')
11 logging.basicConfig(level=logging.DEBUG)
12
13 DEFAULT_LOG_LEVEL = 'critical'
14
15
16 def load_config_from_file() -> Optional[Dict[str, Any]]:
17 config_file = Path('/config/rotki_config.json')
18 if not config_file.exists():
19 logger.info('no config file provided')
20 return None
21
22 with open(config_file) as file:
23 try:
24 data = json.load(file)
25 return data
26 except json.JSONDecodeError as e:
27 logger.error(e)
28 return None
29
30
31 def load_config_from_env() -> Dict[str, Any]:
32 loglevel = os.environ.get('LOGLEVEL')
33 logfromothermodules = os.environ.get('LOGFROMOTHERMODDULES')
34 sleep_secs = os.environ.get('SLEEP_SECS')
35 max_size_in_mb_all_logs = os.environ.get('MAX_SIZE_IN_MB_ALL_LOGS')
36 max_logfiles_num = os.environ.get('MAX_LOGFILES_NUM')
37
38 return {
39 'loglevel': loglevel,
40 'logfromothermodules': logfromothermodules,
41 'sleep_secs': sleep_secs,
42 'max_logfiles_num': max_logfiles_num,
43 'max_size_in_mb_all_logs': max_size_in_mb_all_logs,
44 }
45
46
47 def load_config() -> List[str]:
48 env_config = load_config_from_env()
49 file_config = load_config_from_file()
50
51 logger.info('loading config from env')
52
53 loglevel = env_config.get('loglevel')
54 log_from_other_modules = env_config.get('logfromothermodules')
55 sleep_secs = env_config.get('sleep_secs')
56 max_logfiles_num = env_config.get('max_logfiles_num')
57 max_size_in_mb_all_logs = env_config.get('max_size_in_mb_all_logs')
58
59 if file_config is not None:
60 logger.info('loading config from file')
61
62 if file_config.get('loglevel') is not None:
63 loglevel = file_config.get('loglevel')
64
65 if file_config.get('logfromothermodules') is not None:
66 log_from_other_modules = file_config.get('logfromothermodules')
67
68 if file_config.get('sleep-secs') is not None:
69 sleep_secs = file_config.get('sleep-secs')
70
71 if file_config.get('max_logfiles_num') is not None:
72 max_logfiles_num = file_config.get('max_logfiles_num')
73
74 if file_config.get('max_size_in_mb_all_logs') is not None:
75 max_size_in_mb_all_logs = file_config.get('max_size_in_mb_all_logs')
76
77 args = [
78 '--data-dir',
79 '/data',
80 '--logfile',
81 '/logs/rotki.log',
82 '--loglevel',
83 loglevel if loglevel is not None else DEFAULT_LOG_LEVEL,
84 ]
85
86 if log_from_other_modules is True:
87 args.append('--logfromothermodules')
88
89 if sleep_secs is not None:
90 args.append('--sleep-secs')
91 args.append(str(sleep_secs))
92
93 if max_logfiles_num is not None:
94 args.append('--max-logfiles-num')
95 args.append(str(max_logfiles_num))
96
97 if max_size_in_mb_all_logs is not None:
98 args.append('--max-size-in-mb-all-logs')
99 args.append(str(max_size_in_mb_all_logs))
100
101 return args
102
103
104 base_args = [
105 '/usr/sbin/rotki',
106 '--rest-api-port',
107 '4242',
108 '--websockets-api-port',
109 '4243',
110 '--api-cors',
111 'http://localhost:*/*,app://.',
112 '--api-host',
113 '0.0.0.0',
114 ]
115
116 config_args = load_config()
117 cmd = base_args + config_args
118
119 logger.info('starting rotki backend')
120
121 rotki = subprocess.Popen(cmd)
122
123 if rotki.returncode == 1:
124 logger.error('Failed to start rotki')
125 exit(1)
126
127 logger.info('starting nginx')
128
129 nginx = subprocess.Popen('nginx -g "daemon off;"', shell=True)
130
131 if nginx.returncode == 1:
132 logger.error('Failed to start nginx')
133 exit(1)
134
135 while True:
136 time.sleep(60)
137
138 if rotki.poll() is not None:
139 logger.error('rotki has terminated exiting')
140 exit(1)
141
142 if nginx.poll() is not None:
143 logger.error('nginx was not running')
144 exit(1)
145
146 logger.info('OK: processes still running')
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packaging/docker/entrypoint.py b/packaging/docker/entrypoint.py
--- a/packaging/docker/entrypoint.py
+++ b/packaging/docker/entrypoint.py
@@ -2,10 +2,12 @@
import json
import logging
import os
+import shutil
import subprocess
import time
+from datetime import datetime, timedelta
from pathlib import Path
-from typing import Dict, Optional, Any, List
+from typing import Any, Dict, List, Optional
logger = logging.getLogger('monitor')
logging.basicConfig(level=logging.DEBUG)
@@ -13,6 +15,41 @@
DEFAULT_LOG_LEVEL = 'critical'
+def can_delete(file: Path, cutoff: int) -> bool:
+ return int(os.stat(file).st_mtime) <= cutoff or file.name.startswith('_MEI')
+
+
+def cleanup_tmp() -> None:
+ logger.info('Preparing to cleanup tmp directory')
+ tmp_dir = Path('/tmp/').glob('*')
+ cache_cutoff = datetime.today() - timedelta(hours=6)
+ cutoff_epoch = int(cache_cutoff.strftime("%s"))
+ to_delete = filter(lambda x: can_delete(x, cutoff_epoch), tmp_dir)
+
+ deleted = 0
+ skipped = 0
+
+ for item in to_delete:
+ path = Path(item)
+ if path.is_file():
+ try:
+ path.unlink()
+ deleted += 1
+ continue
+ except PermissionError:
+ skipped += 1
+ continue
+
+ try:
+ shutil.rmtree(item)
+ deleted += 1
+ except OSError:
+ skipped += 1
+ continue
+
+ logger.info(f'Deleted {deleted} files or directories, skipped {skipped} from /tmp')
+
+
def load_config_from_file() -> Optional[Dict[str, Any]]:
config_file = Path('/config/rotki_config.json')
if not config_file.exists():
@@ -101,6 +138,8 @@
return args
+cleanup_tmp()
+
base_args = [
'/usr/sbin/rotki',
'--rest-api-port',
|
{"golden_diff": "diff --git a/packaging/docker/entrypoint.py b/packaging/docker/entrypoint.py\n--- a/packaging/docker/entrypoint.py\n+++ b/packaging/docker/entrypoint.py\n@@ -2,10 +2,12 @@\n import json\n import logging\n import os\n+import shutil\n import subprocess\n import time\n+from datetime import datetime, timedelta\n from pathlib import Path\n-from typing import Dict, Optional, Any, List\n+from typing import Any, Dict, List, Optional\n \n logger = logging.getLogger('monitor')\n logging.basicConfig(level=logging.DEBUG)\n@@ -13,6 +15,41 @@\n DEFAULT_LOG_LEVEL = 'critical'\n \n \n+def can_delete(file: Path, cutoff: int) -> bool:\n+ return int(os.stat(file).st_mtime) <= cutoff or file.name.startswith('_MEI')\n+\n+\n+def cleanup_tmp() -> None:\n+ logger.info('Preparing to cleanup tmp directory')\n+ tmp_dir = Path('/tmp/').glob('*')\n+ cache_cutoff = datetime.today() - timedelta(hours=6)\n+ cutoff_epoch = int(cache_cutoff.strftime(\"%s\"))\n+ to_delete = filter(lambda x: can_delete(x, cutoff_epoch), tmp_dir)\n+\n+ deleted = 0\n+ skipped = 0\n+\n+ for item in to_delete:\n+ path = Path(item)\n+ if path.is_file():\n+ try:\n+ path.unlink()\n+ deleted += 1\n+ continue\n+ except PermissionError:\n+ skipped += 1\n+ continue\n+\n+ try:\n+ shutil.rmtree(item)\n+ deleted += 1\n+ except OSError:\n+ skipped += 1\n+ continue\n+\n+ logger.info(f'Deleted {deleted} files or directories, skipped {skipped} from /tmp')\n+\n+\n def load_config_from_file() -> Optional[Dict[str, Any]]:\n config_file = Path('/config/rotki_config.json')\n if not config_file.exists():\n@@ -101,6 +138,8 @@\n return args\n \n \n+cleanup_tmp()\n+\n base_args = [\n '/usr/sbin/rotki',\n '--rest-api-port',\n", "issue": "Docker container's /tmp doesn't get automatically cleaned\n## Problem Definition\r\n\r\nPyInstaller extracts the files in /tmp every time the backend starts\r\nIn the docker container /tmp is never cleaned which results in an ever-increasing size on every application restart\r\n\r\n## TODO\r\n\r\n- [ ] Add /tmp cleanup on start\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/python3\nimport json\nimport logging\nimport os\nimport subprocess\nimport time\nfrom pathlib import Path\nfrom typing import Dict, Optional, Any, List\n\nlogger = logging.getLogger('monitor')\nlogging.basicConfig(level=logging.DEBUG)\n\nDEFAULT_LOG_LEVEL = 'critical'\n\n\ndef load_config_from_file() -> Optional[Dict[str, Any]]:\n config_file = Path('/config/rotki_config.json')\n if not config_file.exists():\n logger.info('no config file provided')\n return None\n\n with open(config_file) as file:\n try:\n data = json.load(file)\n return data\n except json.JSONDecodeError as e:\n logger.error(e)\n return None\n\n\ndef load_config_from_env() -> Dict[str, Any]:\n loglevel = os.environ.get('LOGLEVEL')\n logfromothermodules = os.environ.get('LOGFROMOTHERMODDULES')\n sleep_secs = os.environ.get('SLEEP_SECS')\n max_size_in_mb_all_logs = os.environ.get('MAX_SIZE_IN_MB_ALL_LOGS')\n max_logfiles_num = os.environ.get('MAX_LOGFILES_NUM')\n\n return {\n 'loglevel': loglevel,\n 'logfromothermodules': logfromothermodules,\n 'sleep_secs': sleep_secs,\n 'max_logfiles_num': max_logfiles_num,\n 'max_size_in_mb_all_logs': max_size_in_mb_all_logs,\n }\n\n\ndef load_config() -> List[str]:\n env_config = load_config_from_env()\n file_config = load_config_from_file()\n\n logger.info('loading config from env')\n\n loglevel = env_config.get('loglevel')\n log_from_other_modules = env_config.get('logfromothermodules')\n sleep_secs = env_config.get('sleep_secs')\n max_logfiles_num = env_config.get('max_logfiles_num')\n max_size_in_mb_all_logs = env_config.get('max_size_in_mb_all_logs')\n\n if file_config is not None:\n logger.info('loading config from file')\n\n if file_config.get('loglevel') is not None:\n loglevel = file_config.get('loglevel')\n\n if file_config.get('logfromothermodules') is not None:\n log_from_other_modules = file_config.get('logfromothermodules')\n\n if file_config.get('sleep-secs') is not None:\n sleep_secs = file_config.get('sleep-secs')\n\n if file_config.get('max_logfiles_num') is not None:\n max_logfiles_num = file_config.get('max_logfiles_num')\n\n if file_config.get('max_size_in_mb_all_logs') is not None:\n max_size_in_mb_all_logs = file_config.get('max_size_in_mb_all_logs')\n\n args = [\n '--data-dir',\n '/data',\n '--logfile',\n '/logs/rotki.log',\n '--loglevel',\n loglevel if loglevel is not None else DEFAULT_LOG_LEVEL,\n ]\n\n if log_from_other_modules is True:\n args.append('--logfromothermodules')\n\n if sleep_secs is not None:\n args.append('--sleep-secs')\n args.append(str(sleep_secs))\n\n if max_logfiles_num is not None:\n args.append('--max-logfiles-num')\n args.append(str(max_logfiles_num))\n\n if max_size_in_mb_all_logs is not None:\n args.append('--max-size-in-mb-all-logs')\n args.append(str(max_size_in_mb_all_logs))\n\n return args\n\n\nbase_args = [\n '/usr/sbin/rotki',\n '--rest-api-port',\n '4242',\n '--websockets-api-port',\n '4243',\n '--api-cors',\n 'http://localhost:*/*,app://.',\n '--api-host',\n '0.0.0.0',\n]\n\nconfig_args = load_config()\ncmd = base_args + config_args\n\nlogger.info('starting rotki backend')\n\nrotki = subprocess.Popen(cmd)\n\nif rotki.returncode == 1:\n logger.error('Failed to start rotki')\n exit(1)\n\nlogger.info('starting nginx')\n\nnginx = subprocess.Popen('nginx -g \"daemon off;\"', shell=True)\n\nif nginx.returncode == 1:\n logger.error('Failed to start nginx')\n exit(1)\n\nwhile True:\n time.sleep(60)\n\n if rotki.poll() is not None:\n logger.error('rotki has terminated exiting')\n exit(1)\n\n if nginx.poll() is not None:\n logger.error('nginx was not running')\n exit(1)\n\n logger.info('OK: processes still running')\n", "path": "packaging/docker/entrypoint.py"}], "after_files": [{"content": "#!/usr/bin/python3\nimport json\nimport logging\nimport os\nimport shutil\nimport subprocess\nimport time\nfrom datetime import datetime, timedelta\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Optional\n\nlogger = logging.getLogger('monitor')\nlogging.basicConfig(level=logging.DEBUG)\n\nDEFAULT_LOG_LEVEL = 'critical'\n\n\ndef can_delete(file: Path, cutoff: int) -> bool:\n return int(os.stat(file).st_mtime) <= cutoff or file.name.startswith('_MEI')\n\n\ndef cleanup_tmp() -> None:\n logger.info('Preparing to cleanup tmp directory')\n tmp_dir = Path('/tmp/').glob('*')\n cache_cutoff = datetime.today() - timedelta(hours=6)\n cutoff_epoch = int(cache_cutoff.strftime(\"%s\"))\n to_delete = filter(lambda x: can_delete(x, cutoff_epoch), tmp_dir)\n\n deleted = 0\n skipped = 0\n\n for item in to_delete:\n path = Path(item)\n if path.is_file():\n try:\n path.unlink()\n deleted += 1\n continue\n except PermissionError:\n skipped += 1\n continue\n\n try:\n shutil.rmtree(item)\n deleted += 1\n except OSError:\n skipped += 1\n continue\n\n logger.info(f'Deleted {deleted} files or directories, skipped {skipped} from /tmp')\n\n\ndef load_config_from_file() -> Optional[Dict[str, Any]]:\n config_file = Path('/config/rotki_config.json')\n if not config_file.exists():\n logger.info('no config file provided')\n return None\n\n with open(config_file) as file:\n try:\n data = json.load(file)\n return data\n except json.JSONDecodeError as e:\n logger.error(e)\n return None\n\n\ndef load_config_from_env() -> Dict[str, Any]:\n loglevel = os.environ.get('LOGLEVEL')\n logfromothermodules = os.environ.get('LOGFROMOTHERMODDULES')\n sleep_secs = os.environ.get('SLEEP_SECS')\n max_size_in_mb_all_logs = os.environ.get('MAX_SIZE_IN_MB_ALL_LOGS')\n max_logfiles_num = os.environ.get('MAX_LOGFILES_NUM')\n\n return {\n 'loglevel': loglevel,\n 'logfromothermodules': logfromothermodules,\n 'sleep_secs': sleep_secs,\n 'max_logfiles_num': max_logfiles_num,\n 'max_size_in_mb_all_logs': max_size_in_mb_all_logs,\n }\n\n\ndef load_config() -> List[str]:\n env_config = load_config_from_env()\n file_config = load_config_from_file()\n\n logger.info('loading config from env')\n\n loglevel = env_config.get('loglevel')\n log_from_other_modules = env_config.get('logfromothermodules')\n sleep_secs = env_config.get('sleep_secs')\n max_logfiles_num = env_config.get('max_logfiles_num')\n max_size_in_mb_all_logs = env_config.get('max_size_in_mb_all_logs')\n\n if file_config is not None:\n logger.info('loading config from file')\n\n if file_config.get('loglevel') is not None:\n loglevel = file_config.get('loglevel')\n\n if file_config.get('logfromothermodules') is not None:\n log_from_other_modules = file_config.get('logfromothermodules')\n\n if file_config.get('sleep-secs') is not None:\n sleep_secs = file_config.get('sleep-secs')\n\n if file_config.get('max_logfiles_num') is not None:\n max_logfiles_num = file_config.get('max_logfiles_num')\n\n if file_config.get('max_size_in_mb_all_logs') is not None:\n max_size_in_mb_all_logs = file_config.get('max_size_in_mb_all_logs')\n\n args = [\n '--data-dir',\n '/data',\n '--logfile',\n '/logs/rotki.log',\n '--loglevel',\n loglevel if loglevel is not None else DEFAULT_LOG_LEVEL,\n ]\n\n if log_from_other_modules is True:\n args.append('--logfromothermodules')\n\n if sleep_secs is not None:\n args.append('--sleep-secs')\n args.append(str(sleep_secs))\n\n if max_logfiles_num is not None:\n args.append('--max-logfiles-num')\n args.append(str(max_logfiles_num))\n\n if max_size_in_mb_all_logs is not None:\n args.append('--max-size-in-mb-all-logs')\n args.append(str(max_size_in_mb_all_logs))\n\n return args\n\n\ncleanup_tmp()\n\nbase_args = [\n '/usr/sbin/rotki',\n '--rest-api-port',\n '4242',\n '--websockets-api-port',\n '4243',\n '--api-cors',\n 'http://localhost:*/*,app://.',\n '--api-host',\n '0.0.0.0',\n]\n\nconfig_args = load_config()\ncmd = base_args + config_args\n\nlogger.info('starting rotki backend')\n\nrotki = subprocess.Popen(cmd)\n\nif rotki.returncode == 1:\n logger.error('Failed to start rotki')\n exit(1)\n\nlogger.info('starting nginx')\n\nnginx = subprocess.Popen('nginx -g \"daemon off;\"', shell=True)\n\nif nginx.returncode == 1:\n logger.error('Failed to start nginx')\n exit(1)\n\nwhile True:\n time.sleep(60)\n\n if rotki.poll() is not None:\n logger.error('rotki has terminated exiting')\n exit(1)\n\n if nginx.poll() is not None:\n logger.error('nginx was not running')\n exit(1)\n\n logger.info('OK: processes still running')\n", "path": "packaging/docker/entrypoint.py"}]}
| 1,656 | 472 |
gh_patches_debug_105
|
rasdani/github-patches
|
git_diff
|
celery__celery-3671
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Request on_timeout should ignore soft time limit exception
When Request.on_timeout receive a soft timeout from billiard, it does the same as if it was receiving a hard time limit exception. This is ran by the controller.
But the task may catch this exception and eg. return (this is what soft timeout are for).
This cause:
1. the result to be saved once as an exception by the controller (on_timeout) and another time with the result returned by the task
2. the task status to be passed to failure and to success on the same manner
3. if the task is participating to a chord, the chord result counter (at least with redis) is incremented twice (instead of once), making the chord to return prematurely and eventually loose tasks…
1, 2 and 3 can leads of course to strange race conditions…
## Steps to reproduce (Illustration)
with the program in test_timeout.py:
```python
import time
import celery
app = celery.Celery('test_timeout')
app.conf.update(
result_backend="redis://localhost/0",
broker_url="amqp://celery:celery@localhost:5672/host",
)
@app.task(soft_time_limit=1)
def test():
try:
time.sleep(2)
except Exception:
return 1
@app.task()
def add(args):
print("### adding", args)
return sum(args)
@app.task()
def on_error(context, exception, traceback, **kwargs):
print("### on_error: ", exception)
if __name__ == "__main__":
result = celery.chord([test.s().set(link_error=on_error.s()), test.s().set(link_error=on_error.s())])(add.s())
result.get()
```
start a worker and the program:
```
$ celery -A test_timeout worker -l WARNING
$ python3 test_timeout.py
```
## Expected behavior
add method is called with `[1, 1]` as argument and test_timeout.py return normally
## Actual behavior
The test_timeout.py fails, with
```
celery.backends.base.ChordError: Callback error: ChordError("Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)",
```
On the worker side, the **on_error is called but the add method as well !**
```
[2017-11-29 23:07:25,538: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[15109e05-da43-449f-9081-85d839ac0ef2]
[2017-11-29 23:07:25,546: WARNING/MainProcess] ### on_error:
[2017-11-29 23:07:25,546: WARNING/MainProcess] SoftTimeLimitExceeded(True,)
[2017-11-29 23:07:25,547: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[38f3f7f2-4a89-4318-8ee9-36a987f73757]
[2017-11-29 23:07:25,553: ERROR/MainProcess] Chord callback for 'ef6d7a38-d1b4-40ad-b937-ffa84e40bb23' raised: ChordError("Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)",)
Traceback (most recent call last):
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 290, in on_chord_part_return
callback.delay([unpack(tup, decode) for tup in resl])
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 290, in <listcomp>
callback.delay([unpack(tup, decode) for tup in resl])
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 243, in _unpack_chord_result
raise ChordError('Dependency {0} raised {1!r}'.format(tid, retval))
celery.exceptions.ChordError: Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)
[2017-11-29 23:07:25,565: WARNING/MainProcess] ### on_error:
[2017-11-29 23:07:25,565: WARNING/MainProcess] SoftTimeLimitExceeded(True,)
[2017-11-29 23:07:27,262: WARNING/PoolWorker-2] ### adding
[2017-11-29 23:07:27,264: WARNING/PoolWorker-2] [1, 1]
```
Of course, on purpose did I choose to call the test.s() twice, to show that the count in the chord continues. In fact:
- the chord result is incremented twice by the error of soft time limit
- the chord result is again incremented twice by the correct returning of `test` task
## Conclusion
Request.on_timeout should not process soft time limit exception.
here is a quick monkey patch (correction of celery is trivial)
```python
def patch_celery_request_on_timeout():
from celery.worker import request
orig = request.Request.on_timeout
def patched_on_timeout(self, soft, timeout):
if not soft:
orig(self, soft, timeout)
request.Request.on_timeout = patched_on_timeout
patch_celery_request_on_timeout()
```
## version info
software -> celery:4.1.0 (latentcall) kombu:4.0.2 py:3.4.3
billiard:3.5.0.2 py-amqp:2.1.4
platform -> system:Linux arch:64bit, ELF imp:CPython
loader -> celery.loaders.app.AppLoader
settings -> transport:amqp results:redis://10.0.3.253/0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/next-steps/proj/tasks.py`
Content:
```
1 from __future__ import absolute_import, unicode_literals
2 from . import app
3
4
5 @app.task
6 def add(x, y):
7 return x + y
8
9
10 @app.task
11 def mul(x, y):
12 return x * y
13
14
15 @app.task
16 def xsum(numbers):
17 return sum(numbers)
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/next-steps/proj/tasks.py b/examples/next-steps/proj/tasks.py
--- a/examples/next-steps/proj/tasks.py
+++ b/examples/next-steps/proj/tasks.py
@@ -1,5 +1,5 @@
from __future__ import absolute_import, unicode_literals
-from . import app
+from .celery import app
@app.task
|
{"golden_diff": "diff --git a/examples/next-steps/proj/tasks.py b/examples/next-steps/proj/tasks.py\n--- a/examples/next-steps/proj/tasks.py\n+++ b/examples/next-steps/proj/tasks.py\n@@ -1,5 +1,5 @@\n from __future__ import absolute_import, unicode_literals\n-from . import app\n+from .celery import app\n \n \n @app.task\n", "issue": "Request on_timeout should ignore soft time limit exception\nWhen Request.on_timeout receive a soft timeout from billiard, it does the same as if it was receiving a hard time limit exception. This is ran by the controller.\r\n\r\nBut the task may catch this exception and eg. return (this is what soft timeout are for).\r\n\r\nThis cause:\r\n1. the result to be saved once as an exception by the controller (on_timeout) and another time with the result returned by the task\r\n2. the task status to be passed to failure and to success on the same manner\r\n3. if the task is participating to a chord, the chord result counter (at least with redis) is incremented twice (instead of once), making the chord to return prematurely and eventually loose tasks\u2026\r\n\r\n1, 2 and 3 can leads of course to strange race conditions\u2026\r\n\r\n## Steps to reproduce (Illustration)\r\n\r\nwith the program in test_timeout.py:\r\n\r\n```python\r\nimport time\r\nimport celery\r\n\r\n\r\napp = celery.Celery('test_timeout')\r\napp.conf.update(\r\n result_backend=\"redis://localhost/0\",\r\n broker_url=\"amqp://celery:celery@localhost:5672/host\",\r\n)\r\n\r\[email protected](soft_time_limit=1)\r\ndef test():\r\n try:\r\n time.sleep(2)\r\n except Exception:\r\n return 1\r\n\r\[email protected]()\r\ndef add(args):\r\n print(\"### adding\", args)\r\n return sum(args)\r\n\r\[email protected]()\r\ndef on_error(context, exception, traceback, **kwargs):\r\n print(\"### on_error:\u00a0\", exception)\r\n\r\nif __name__ == \"__main__\":\r\n result = celery.chord([test.s().set(link_error=on_error.s()), test.s().set(link_error=on_error.s())])(add.s())\r\n result.get()\r\n```\r\n\r\nstart a worker and the program:\r\n\r\n```\r\n$ celery -A test_timeout worker -l WARNING\r\n$ python3 test_timeout.py\r\n```\r\n\r\n## Expected behavior\r\n\r\nadd method is called with `[1, 1]` as argument and test_timeout.py return normally\r\n\r\n## Actual behavior\r\n\r\nThe test_timeout.py fails, with\r\n```\r\ncelery.backends.base.ChordError: Callback error: ChordError(\"Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\",\r\n```\r\nOn the worker side, the **on_error is called but the add method as well !**\r\n\r\n```\r\n[2017-11-29 23:07:25,538: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[15109e05-da43-449f-9081-85d839ac0ef2]\r\n[2017-11-29 23:07:25,546: WARNING/MainProcess] ### on_error:\r\n[2017-11-29 23:07:25,546: WARNING/MainProcess] SoftTimeLimitExceeded(True,)\r\n[2017-11-29 23:07:25,547: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[38f3f7f2-4a89-4318-8ee9-36a987f73757]\r\n[2017-11-29 23:07:25,553: ERROR/MainProcess] Chord callback for 'ef6d7a38-d1b4-40ad-b937-ffa84e40bb23' raised: ChordError(\"Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\",)\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 290, in on_chord_part_return\r\n callback.delay([unpack(tup, decode) for tup in resl])\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 290, in <listcomp>\r\n callback.delay([unpack(tup, decode) for tup in resl])\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 243, in _unpack_chord_result\r\n raise ChordError('Dependency {0} raised {1!r}'.format(tid, retval))\r\ncelery.exceptions.ChordError: Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\r\n[2017-11-29 23:07:25,565: WARNING/MainProcess] ### on_error:\r\n[2017-11-29 23:07:25,565: WARNING/MainProcess] SoftTimeLimitExceeded(True,)\r\n[2017-11-29 23:07:27,262: WARNING/PoolWorker-2] ### adding\r\n[2017-11-29 23:07:27,264: WARNING/PoolWorker-2] [1, 1]\r\n```\r\n\r\nOf course, on purpose did I choose to call the test.s() twice, to show that the count in the chord continues. In fact:\r\n- the chord result is incremented twice by the error of soft time limit\r\n- the chord result is again incremented twice by the correct returning of `test` task\r\n\r\n## Conclusion\r\n\r\nRequest.on_timeout should not process soft time limit exception. \r\n\r\nhere is a quick monkey patch (correction of celery is trivial)\r\n\r\n```python\r\ndef patch_celery_request_on_timeout():\r\n from celery.worker import request\r\n orig = request.Request.on_timeout\r\n def patched_on_timeout(self, soft, timeout):\r\n if not soft:\r\n orig(self, soft, timeout)\r\n request.Request.on_timeout = patched_on_timeout\r\npatch_celery_request_on_timeout()\r\n```\r\n\r\n\r\n\r\n## version info\r\n\r\nsoftware -> celery:4.1.0 (latentcall) kombu:4.0.2 py:3.4.3\r\n billiard:3.5.0.2 py-amqp:2.1.4\r\nplatform -> system:Linux arch:64bit, ELF imp:CPython\r\nloader -> celery.loaders.app.AppLoader\r\nsettings -> transport:amqp results:redis://10.0.3.253/0\r\n\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\nfrom . import app\n\n\[email protected]\ndef add(x, y):\n return x + y\n\n\[email protected]\ndef mul(x, y):\n return x * y\n\n\[email protected]\ndef xsum(numbers):\n return sum(numbers)\n", "path": "examples/next-steps/proj/tasks.py"}], "after_files": [{"content": "from __future__ import absolute_import, unicode_literals\nfrom .celery import app\n\n\[email protected]\ndef add(x, y):\n return x + y\n\n\[email protected]\ndef mul(x, y):\n return x * y\n\n\[email protected]\ndef xsum(numbers):\n return sum(numbers)\n", "path": "examples/next-steps/proj/tasks.py"}]}
| 1,858 | 87 |
gh_patches_debug_4098
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-4745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
apache2_module fails for php7.0 on Ubuntu Xenial
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
apache2_module
##### ANSIBLE VERSION
<!--- Paste verbatim output from “ansible --version” between quotes below -->
```
ansible 2.2.0 (devel 982db58aff) last updated 2016/09/08 11:50:49 (GMT +100)
lib/ansible/modules/core: (detached HEAD db38f0c876) last updated 2016/09/08 13:03:40 (GMT +100)
lib/ansible/modules/extras: (detached HEAD 8bfdcfcab2) last updated 2016/09/08 11:51:00 (GMT +100)
config file = /home/rowan/.ansible.cfg
configured module search path = Default w/o overrides
```
##### CONFIGURATION
N/A
##### OS / ENVIRONMENT
N/A
##### SUMMARY
Ubuntu Xenial lists the php7.0 module as php7_module when running apache2ctl -M this breaks the regexp checking if the module is enabled.
I've made a work around here https://github.com/rwky/ansible-modules-core/commit/00ad6ef035a10dac7c84b7b68f04b00a739b104b but I didn't make a PR since I expect it may break other distros/versions.
Not entirely sure what the best solution to this is.
##### STEPS TO REPRODUCE
Run apache2_module with name=php7.0 state=present on a xenial server.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web_infrastructure/apache2_module.py`
Content:
```
1 #!/usr/bin/python
2 #coding: utf-8 -*-
3
4 # (c) 2013-2014, Christian Berendt <[email protected]>
5 #
6 # This module is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This software is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this software. If not, see <http://www.gnu.org/licenses/>.
18
19 DOCUMENTATION = '''
20 ---
21 module: apache2_module
22 version_added: 1.6
23 author: "Christian Berendt (@berendt)"
24 short_description: enables/disables a module of the Apache2 webserver
25 description:
26 - Enables or disables a specified module of the Apache2 webserver.
27 options:
28 name:
29 description:
30 - name of the module to enable/disable
31 required: true
32 force:
33 description:
34 - force disabling of default modules and override Debian warnings
35 required: false
36 choices: ['yes', 'no']
37 default: no
38 version_added: "2.1"
39 state:
40 description:
41 - indicate the desired state of the resource
42 choices: ['present', 'absent']
43 default: present
44
45 requirements: ["a2enmod","a2dismod"]
46 '''
47
48 EXAMPLES = '''
49 # enables the Apache2 module "wsgi"
50 - apache2_module: state=present name=wsgi
51
52 # disables the Apache2 module "wsgi"
53 - apache2_module: state=absent name=wsgi
54 '''
55
56 import re
57
58 def _run_threaded(module):
59 control_binary = _get_ctl_binary(module)
60
61 result, stdout, stderr = module.run_command("%s -V" % control_binary)
62
63 if re.search(r'threaded:[ ]*yes', stdout):
64 return True
65 else:
66 return False
67
68 def _get_ctl_binary(module):
69 for command in ['apache2ctl', 'apachectl']:
70 ctl_binary = module.get_bin_path(command)
71 if ctl_binary is not None:
72 return ctl_binary
73
74 module.fail_json(
75 msg="None of httpd, apachectl or apach2ctl found. At least one apache control binary is necessary.")
76
77 def _module_is_enabled(module):
78 control_binary = _get_ctl_binary(module)
79 name = module.params['name']
80
81 result, stdout, stderr = module.run_command("%s -M" % control_binary)
82
83 if result != 0:
84 module.fail_json(msg="Error executing %s: %s" % (control_binary, stderr))
85
86 if re.search(r' ' + name + r'_module', stdout):
87 return True
88 else:
89 return False
90
91 def _set_state(module, state):
92 name = module.params['name']
93 force = module.params['force']
94
95 want_enabled = state == 'present'
96 state_string = {'present': 'enabled', 'absent': 'disabled'}[state]
97 a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]
98 success_msg = "Module %s %s" % (name, state_string)
99
100 if _module_is_enabled(module) != want_enabled:
101 if module.check_mode:
102 module.exit_json(changed = True, result = success_msg)
103
104 a2mod_binary = module.get_bin_path(a2mod_binary)
105 if a2mod_binary is None:
106 module.fail_json(msg="%s not found. Perhaps this system does not use %s to manage apache" % (a2mod_binary, a2mod_binary))
107
108 if not want_enabled and force:
109 # force exists only for a2dismod on debian
110 a2mod_binary += ' -f'
111
112 result, stdout, stderr = module.run_command("%s %s" % (a2mod_binary, name))
113
114 if _module_is_enabled(module) == want_enabled:
115 module.exit_json(changed = True, result = success_msg)
116 else:
117 module.fail_json(msg="Failed to set module %s to %s: %s" % (name, state_string, stdout), rc=result, stdout=stdout, stderr=stderr)
118 else:
119 module.exit_json(changed = False, result = success_msg)
120
121 def main():
122 module = AnsibleModule(
123 argument_spec = dict(
124 name = dict(required=True),
125 force = dict(required=False, type='bool', default=False),
126 state = dict(default='present', choices=['absent', 'present'])
127 ),
128 supports_check_mode = True,
129 )
130
131 name = module.params['name']
132 if name == 'cgi' and _run_threaded(module):
133 module.fail_json(msg="Your MPM seems to be threaded. No automatic actions on module %s possible." % name)
134
135 if module.params['state'] in ['present', 'absent']:
136 _set_state(module, module.params['state'])
137
138 # import module snippets
139 from ansible.module_utils.basic import *
140 if __name__ == '__main__':
141 main()
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py
--- a/web_infrastructure/apache2_module.py
+++ b/web_infrastructure/apache2_module.py
@@ -80,6 +80,12 @@
result, stdout, stderr = module.run_command("%s -M" % control_binary)
+ """
+ Work around for Ubuntu Xenial listing php7_module as php7.0
+ """
+ if name == "php7.0":
+ name = "php7"
+
if result != 0:
module.fail_json(msg="Error executing %s: %s" % (control_binary, stderr))
|
{"golden_diff": "diff --git a/web_infrastructure/apache2_module.py b/web_infrastructure/apache2_module.py\n--- a/web_infrastructure/apache2_module.py\n+++ b/web_infrastructure/apache2_module.py\n@@ -80,6 +80,12 @@\n \n result, stdout, stderr = module.run_command(\"%s -M\" % control_binary)\n \n+ \"\"\"\n+ Work around for Ubuntu Xenial listing php7_module as php7.0\n+ \"\"\"\n+ if name == \"php7.0\":\n+ name = \"php7\"\n+\n if result != 0:\n module.fail_json(msg=\"Error executing %s: %s\" % (control_binary, stderr))\n", "issue": "apache2_module fails for php7.0 on Ubuntu Xenial\n##### ISSUE TYPE\n- Bug Report\n##### COMPONENT NAME\n\napache2_module\n##### ANSIBLE VERSION\n\n<!--- Paste verbatim output from \u201cansible --version\u201d between quotes below -->\n\n```\nansible 2.2.0 (devel 982db58aff) last updated 2016/09/08 11:50:49 (GMT +100)\n lib/ansible/modules/core: (detached HEAD db38f0c876) last updated 2016/09/08 13:03:40 (GMT +100)\n lib/ansible/modules/extras: (detached HEAD 8bfdcfcab2) last updated 2016/09/08 11:51:00 (GMT +100)\n config file = /home/rowan/.ansible.cfg\n configured module search path = Default w/o overrides\n```\n##### CONFIGURATION\n\nN/A\n##### OS / ENVIRONMENT\n\nN/A\n##### SUMMARY\n\nUbuntu Xenial lists the php7.0 module as php7_module when running apache2ctl -M this breaks the regexp checking if the module is enabled.\n\nI've made a work around here https://github.com/rwky/ansible-modules-core/commit/00ad6ef035a10dac7c84b7b68f04b00a739b104b but I didn't make a PR since I expect it may break other distros/versions.\n\nNot entirely sure what the best solution to this is.\n##### STEPS TO REPRODUCE\n\nRun apache2_module with name=php7.0 state=present on a xenial server.\n\n", "before_files": [{"content": "#!/usr/bin/python\n#coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nversion_added: 1.6\nauthor: \"Christian Berendt (@berendt)\"\nshort_description: enables/disables a module of the Apache2 webserver\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n description:\n - name of the module to enable/disable\n required: true\n force:\n description:\n - force disabling of default modules and override Debian warnings\n required: false\n choices: ['yes', 'no']\n default: no\n version_added: \"2.1\"\n state:\n description:\n - indicate the desired state of the resource\n choices: ['present', 'absent']\n default: present\n\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n# enables the Apache2 module \"wsgi\"\n- apache2_module: state=present name=wsgi\n\n# disables the Apache2 module \"wsgi\"\n- apache2_module: state=absent name=wsgi\n'''\n\nimport re\n\ndef _run_threaded(module):\n control_binary = _get_ctl_binary(module)\n\n result, stdout, stderr = module.run_command(\"%s -V\" % control_binary)\n\n if re.search(r'threaded:[ ]*yes', stdout):\n return True\n else:\n return False\n\ndef _get_ctl_binary(module):\n for command in ['apache2ctl', 'apachectl']:\n ctl_binary = module.get_bin_path(command)\n if ctl_binary is not None:\n return ctl_binary\n\n module.fail_json(\n msg=\"None of httpd, apachectl or apach2ctl found. At least one apache control binary is necessary.\")\n\ndef _module_is_enabled(module):\n control_binary = _get_ctl_binary(module)\n name = module.params['name']\n\n result, stdout, stderr = module.run_command(\"%s -M\" % control_binary)\n\n if result != 0:\n module.fail_json(msg=\"Error executing %s: %s\" % (control_binary, stderr))\n\n if re.search(r' ' + name + r'_module', stdout):\n return True\n else:\n return False\n\ndef _set_state(module, state):\n name = module.params['name']\n force = module.params['force']\n\n want_enabled = state == 'present'\n state_string = {'present': 'enabled', 'absent': 'disabled'}[state]\n a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]\n success_msg = \"Module %s %s\" % (name, state_string)\n\n if _module_is_enabled(module) != want_enabled:\n if module.check_mode:\n module.exit_json(changed = True, result = success_msg)\n\n a2mod_binary = module.get_bin_path(a2mod_binary)\n if a2mod_binary is None:\n module.fail_json(msg=\"%s not found. Perhaps this system does not use %s to manage apache\" % (a2mod_binary, a2mod_binary))\n\n if not want_enabled and force:\n # force exists only for a2dismod on debian\n a2mod_binary += ' -f'\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2mod_binary, name))\n\n if _module_is_enabled(module) == want_enabled:\n module.exit_json(changed = True, result = success_msg)\n else:\n module.fail_json(msg=\"Failed to set module %s to %s: %s\" % (name, state_string, stdout), rc=result, stdout=stdout, stderr=stderr)\n else:\n module.exit_json(changed = False, result = success_msg)\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n force = dict(required=False, type='bool', default=False),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n supports_check_mode = True,\n )\n\n name = module.params['name']\n if name == 'cgi' and _run_threaded(module):\n module.fail_json(msg=\"Your MPM seems to be threaded. No automatic actions on module %s possible.\" % name)\n\n if module.params['state'] in ['present', 'absent']:\n _set_state(module, module.params['state'])\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nif __name__ == '__main__':\n main()\n", "path": "web_infrastructure/apache2_module.py"}], "after_files": [{"content": "#!/usr/bin/python\n#coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nversion_added: 1.6\nauthor: \"Christian Berendt (@berendt)\"\nshort_description: enables/disables a module of the Apache2 webserver\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n description:\n - name of the module to enable/disable\n required: true\n force:\n description:\n - force disabling of default modules and override Debian warnings\n required: false\n choices: ['yes', 'no']\n default: no\n version_added: \"2.1\"\n state:\n description:\n - indicate the desired state of the resource\n choices: ['present', 'absent']\n default: present\n\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n# enables the Apache2 module \"wsgi\"\n- apache2_module: state=present name=wsgi\n\n# disables the Apache2 module \"wsgi\"\n- apache2_module: state=absent name=wsgi\n'''\n\nimport re\n\ndef _run_threaded(module):\n control_binary = _get_ctl_binary(module)\n\n result, stdout, stderr = module.run_command(\"%s -V\" % control_binary)\n\n if re.search(r'threaded:[ ]*yes', stdout):\n return True\n else:\n return False\n\ndef _get_ctl_binary(module):\n for command in ['apache2ctl', 'apachectl']:\n ctl_binary = module.get_bin_path(command)\n if ctl_binary is not None:\n return ctl_binary\n\n module.fail_json(\n msg=\"None of httpd, apachectl or apach2ctl found. At least one apache control binary is necessary.\")\n\ndef _module_is_enabled(module):\n control_binary = _get_ctl_binary(module)\n name = module.params['name']\n\n result, stdout, stderr = module.run_command(\"%s -M\" % control_binary)\n\n \"\"\"\n Work around for Ubuntu Xenial listing php7_module as php7.0\n \"\"\"\n if name == \"php7.0\":\n name = \"php7\"\n\n if result != 0:\n module.fail_json(msg=\"Error executing %s: %s\" % (control_binary, stderr))\n\n if re.search(r' ' + name + r'_module', stdout):\n return True\n else:\n return False\n\ndef _set_state(module, state):\n name = module.params['name']\n force = module.params['force']\n\n want_enabled = state == 'present'\n state_string = {'present': 'enabled', 'absent': 'disabled'}[state]\n a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]\n success_msg = \"Module %s %s\" % (name, state_string)\n\n if _module_is_enabled(module) != want_enabled:\n if module.check_mode:\n module.exit_json(changed = True, result = success_msg)\n\n a2mod_binary = module.get_bin_path(a2mod_binary)\n if a2mod_binary is None:\n module.fail_json(msg=\"%s not found. Perhaps this system does not use %s to manage apache\" % (a2mod_binary, a2mod_binary))\n\n if not want_enabled and force:\n # force exists only for a2dismod on debian\n a2mod_binary += ' -f'\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2mod_binary, name))\n\n if _module_is_enabled(module) == want_enabled:\n module.exit_json(changed = True, result = success_msg)\n else:\n module.fail_json(msg=\"Failed to set module %s to %s: %s\" % (name, state_string, stdout), rc=result, stdout=stdout, stderr=stderr)\n else:\n module.exit_json(changed = False, result = success_msg)\n\ndef main():\n module = AnsibleModule(\n argument_spec = dict(\n name = dict(required=True),\n force = dict(required=False, type='bool', default=False),\n state = dict(default='present', choices=['absent', 'present'])\n ),\n supports_check_mode = True,\n )\n\n name = module.params['name']\n if name == 'cgi' and _run_threaded(module):\n module.fail_json(msg=\"Your MPM seems to be threaded. No automatic actions on module %s possible.\" % name)\n\n if module.params['state'] in ['present', 'absent']:\n _set_state(module, module.params['state'])\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nif __name__ == '__main__':\n main()\n", "path": "web_infrastructure/apache2_module.py"}]}
| 2,144 | 146 |
gh_patches_debug_13328
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-7452
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
icinga2_host - ip should not be required
### Summary
Hi all,
as one can see in https://icinga.com/docs/icinga-2/latest/doc/09-object-types/#host the address variable is not mandatory, so IP should be optional in the plugin, too.
### Issue Type
Bug Report
### Component Name
icinga2_host
### Ansible Version
```console (paste below)
$ ansible --version
2.11.4
```
### Community.general Version
```console (paste below)
$ ansible-galaxy collection list community.general
5.5.0
```
### Configuration
```console (paste below)
```
### OS / Environment
Ubuntu 22.04
### Steps to Reproduce
Try to create a host without given an IP
### Expected Results
Address is optionally
### Actual Results
Address is mandatory
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/modules/icinga2_host.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # This module is proudly sponsored by CGI (www.cgi.com) and
5 # KPN (www.kpn.com).
6 # Copyright (c) Ansible project
7 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
8 # SPDX-License-Identifier: GPL-3.0-or-later
9
10 from __future__ import absolute_import, division, print_function
11 __metaclass__ = type
12
13
14 DOCUMENTATION = '''
15 ---
16 module: icinga2_host
17 short_description: Manage a host in Icinga2
18 description:
19 - "Add or remove a host to Icinga2 through the API."
20 - "See U(https://www.icinga.com/docs/icinga2/latest/doc/12-icinga2-api/)"
21 author: "Jurgen Brand (@t794104)"
22 attributes:
23 check_mode:
24 support: full
25 diff_mode:
26 support: none
27 options:
28 url:
29 type: str
30 description:
31 - HTTP, HTTPS, or FTP URL in the form (http|https|ftp)://[user[:pass]]@host.domain[:port]/path
32 use_proxy:
33 description:
34 - If V(false), it will not use a proxy, even if one is defined in
35 an environment variable on the target hosts.
36 type: bool
37 default: true
38 validate_certs:
39 description:
40 - If V(false), SSL certificates will not be validated. This should only be used
41 on personally controlled sites using self-signed certificates.
42 type: bool
43 default: true
44 url_username:
45 type: str
46 description:
47 - The username for use in HTTP basic authentication.
48 - This parameter can be used without O(url_password) for sites that allow empty passwords.
49 url_password:
50 type: str
51 description:
52 - The password for use in HTTP basic authentication.
53 - If the O(url_username) parameter is not specified, the O(url_password) parameter will not be used.
54 force_basic_auth:
55 description:
56 - httplib2, the library used by the uri module only sends authentication information when a webservice
57 responds to an initial request with a 401 status. Since some basic auth services do not properly
58 send a 401, logins will fail. This option forces the sending of the Basic authentication header
59 upon initial request.
60 type: bool
61 default: false
62 client_cert:
63 type: path
64 description:
65 - PEM formatted certificate chain file to be used for SSL client
66 authentication. This file can also include the key as well, and if
67 the key is included, O(client_key) is not required.
68 client_key:
69 type: path
70 description:
71 - PEM formatted file that contains your private key to be used for SSL
72 client authentication. If O(client_cert) contains both the certificate
73 and key, this option is not required.
74 state:
75 type: str
76 description:
77 - Apply feature state.
78 choices: [ "present", "absent" ]
79 default: present
80 name:
81 type: str
82 description:
83 - Name used to create / delete the host. This does not need to be the FQDN, but does needs to be unique.
84 required: true
85 aliases: [host]
86 zone:
87 type: str
88 description:
89 - The zone from where this host should be polled.
90 template:
91 type: str
92 description:
93 - The template used to define the host.
94 - Template cannot be modified after object creation.
95 check_command:
96 type: str
97 description:
98 - The command used to check if the host is alive.
99 default: "hostalive"
100 display_name:
101 type: str
102 description:
103 - The name used to display the host.
104 - If not specified, it defaults to the value of the O(name) parameter.
105 ip:
106 type: str
107 description:
108 - The IP address of the host.
109 required: true
110 variables:
111 type: dict
112 description:
113 - Dictionary of variables.
114 extends_documentation_fragment:
115 - ansible.builtin.url
116 - community.general.attributes
117 '''
118
119 EXAMPLES = '''
120 - name: Add host to icinga
121 community.general.icinga2_host:
122 url: "https://icinga2.example.com"
123 url_username: "ansible"
124 url_password: "a_secret"
125 state: present
126 name: "{{ ansible_fqdn }}"
127 ip: "{{ ansible_default_ipv4.address }}"
128 variables:
129 foo: "bar"
130 delegate_to: 127.0.0.1
131 '''
132
133 RETURN = '''
134 name:
135 description: The name used to create, modify or delete the host
136 type: str
137 returned: always
138 data:
139 description: The data structure used for create, modify or delete of the host
140 type: dict
141 returned: always
142 '''
143
144 import json
145
146 from ansible.module_utils.basic import AnsibleModule
147 from ansible.module_utils.urls import fetch_url, url_argument_spec
148
149
150 # ===========================================
151 # Icinga2 API class
152 #
153 class icinga2_api:
154 module = None
155
156 def __init__(self, module):
157 self.module = module
158
159 def call_url(self, path, data='', method='GET'):
160 headers = {
161 'Accept': 'application/json',
162 'X-HTTP-Method-Override': method,
163 }
164 url = self.module.params.get("url") + "/" + path
165 rsp, info = fetch_url(module=self.module, url=url, data=data, headers=headers, method=method, use_proxy=self.module.params['use_proxy'])
166 body = ''
167 if rsp:
168 body = json.loads(rsp.read())
169 if info['status'] >= 400:
170 body = info['body']
171 return {'code': info['status'], 'data': body}
172
173 def check_connection(self):
174 ret = self.call_url('v1/status')
175 if ret['code'] == 200:
176 return True
177 return False
178
179 def exists(self, hostname):
180 data = {
181 "filter": "match(\"" + hostname + "\", host.name)",
182 }
183 ret = self.call_url(
184 path="v1/objects/hosts",
185 data=self.module.jsonify(data)
186 )
187 if ret['code'] == 200:
188 if len(ret['data']['results']) == 1:
189 return True
190 return False
191
192 def create(self, hostname, data):
193 ret = self.call_url(
194 path="v1/objects/hosts/" + hostname,
195 data=self.module.jsonify(data),
196 method="PUT"
197 )
198 return ret
199
200 def delete(self, hostname):
201 data = {"cascade": 1}
202 ret = self.call_url(
203 path="v1/objects/hosts/" + hostname,
204 data=self.module.jsonify(data),
205 method="DELETE"
206 )
207 return ret
208
209 def modify(self, hostname, data):
210 ret = self.call_url(
211 path="v1/objects/hosts/" + hostname,
212 data=self.module.jsonify(data),
213 method="POST"
214 )
215 return ret
216
217 def diff(self, hostname, data):
218 ret = self.call_url(
219 path="v1/objects/hosts/" + hostname,
220 method="GET"
221 )
222 changed = False
223 ic_data = ret['data']['results'][0]
224 for key in data['attrs']:
225 if key not in ic_data['attrs'].keys():
226 changed = True
227 elif data['attrs'][key] != ic_data['attrs'][key]:
228 changed = True
229 return changed
230
231
232 # ===========================================
233 # Module execution.
234 #
235 def main():
236 # use the predefined argument spec for url
237 argument_spec = url_argument_spec()
238 # add our own arguments
239 argument_spec.update(
240 state=dict(default="present", choices=["absent", "present"]),
241 name=dict(required=True, aliases=['host']),
242 zone=dict(),
243 template=dict(default=None),
244 check_command=dict(default="hostalive"),
245 display_name=dict(default=None),
246 ip=dict(required=True),
247 variables=dict(type='dict', default=None),
248 )
249
250 # Define the main module
251 module = AnsibleModule(
252 argument_spec=argument_spec,
253 supports_check_mode=True
254 )
255
256 state = module.params["state"]
257 name = module.params["name"]
258 zone = module.params["zone"]
259 template = []
260 if module.params["template"]:
261 template = [module.params["template"]]
262 check_command = module.params["check_command"]
263 ip = module.params["ip"]
264 display_name = module.params["display_name"]
265 if not display_name:
266 display_name = name
267 variables = module.params["variables"]
268
269 try:
270 icinga = icinga2_api(module=module)
271 icinga.check_connection()
272 except Exception as e:
273 module.fail_json(msg="unable to connect to Icinga. Exception message: %s" % (e))
274
275 data = {
276 'templates': template,
277 'attrs': {
278 'address': ip,
279 'display_name': display_name,
280 'check_command': check_command,
281 'zone': zone,
282 'vars.made_by': "ansible"
283 }
284 }
285
286 for key, value in variables.items():
287 data['attrs']['vars.' + key] = value
288
289 changed = False
290 if icinga.exists(name):
291 if state == "absent":
292 if module.check_mode:
293 module.exit_json(changed=True, name=name, data=data)
294 else:
295 try:
296 ret = icinga.delete(name)
297 if ret['code'] == 200:
298 changed = True
299 else:
300 module.fail_json(msg="bad return code (%s) deleting host: '%s'" % (ret['code'], ret['data']))
301 except Exception as e:
302 module.fail_json(msg="exception deleting host: " + str(e))
303
304 elif icinga.diff(name, data):
305 if module.check_mode:
306 module.exit_json(changed=False, name=name, data=data)
307
308 # Template attribute is not allowed in modification
309 del data['templates']
310
311 ret = icinga.modify(name, data)
312
313 if ret['code'] == 200:
314 changed = True
315 else:
316 module.fail_json(msg="bad return code (%s) modifying host: '%s'" % (ret['code'], ret['data']))
317
318 else:
319 if state == "present":
320 if module.check_mode:
321 changed = True
322 else:
323 try:
324 ret = icinga.create(name, data)
325 if ret['code'] == 200:
326 changed = True
327 else:
328 module.fail_json(msg="bad return code (%s) creating host: '%s'" % (ret['code'], ret['data']))
329 except Exception as e:
330 module.fail_json(msg="exception creating host: " + str(e))
331
332 module.exit_json(changed=changed, name=name, data=data)
333
334
335 # import module snippets
336 if __name__ == '__main__':
337 main()
338
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/modules/icinga2_host.py b/plugins/modules/icinga2_host.py
--- a/plugins/modules/icinga2_host.py
+++ b/plugins/modules/icinga2_host.py
@@ -106,7 +106,7 @@
type: str
description:
- The IP address of the host.
- required: true
+ - This is no longer required since community.general 8.0.0.
variables:
type: dict
description:
@@ -243,7 +243,7 @@
template=dict(default=None),
check_command=dict(default="hostalive"),
display_name=dict(default=None),
- ip=dict(required=True),
+ ip=dict(),
variables=dict(type='dict', default=None),
)
|
{"golden_diff": "diff --git a/plugins/modules/icinga2_host.py b/plugins/modules/icinga2_host.py\n--- a/plugins/modules/icinga2_host.py\n+++ b/plugins/modules/icinga2_host.py\n@@ -106,7 +106,7 @@\n type: str\n description:\n - The IP address of the host.\n- required: true\n+ - This is no longer required since community.general 8.0.0.\n variables:\n type: dict\n description:\n@@ -243,7 +243,7 @@\n template=dict(default=None),\n check_command=dict(default=\"hostalive\"),\n display_name=dict(default=None),\n- ip=dict(required=True),\n+ ip=dict(),\n variables=dict(type='dict', default=None),\n )\n", "issue": "icinga2_host - ip should not be required\n### Summary\r\n\r\nHi all,\r\nas one can see in https://icinga.com/docs/icinga-2/latest/doc/09-object-types/#host the address variable is not mandatory, so IP should be optional in the plugin, too.\r\n\r\n\r\n### Issue Type\r\n\r\nBug Report\r\n\r\n### Component Name\r\n\r\nicinga2_host\r\n\r\n### Ansible Version\r\n\r\n```console (paste below)\r\n$ ansible --version\r\n2.11.4\r\n```\r\n\r\n\r\n### Community.general Version\r\n\r\n```console (paste below)\r\n$ ansible-galaxy collection list community.general\r\n5.5.0\r\n```\r\n\r\n\r\n### Configuration\r\n\r\n```console (paste below)\r\n\r\n```\r\n\r\n\r\n### OS / Environment\r\n\r\nUbuntu 22.04\r\n\r\n### Steps to Reproduce\r\nTry to create a host without given an IP\r\n\r\n\r\n### Expected Results\r\n\r\nAddress is optionally\r\n\r\n### Actual Results\r\n\r\nAddress is mandatory\r\n\r\n\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# This module is proudly sponsored by CGI (www.cgi.com) and\n# KPN (www.kpn.com).\n# Copyright (c) Ansible project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: icinga2_host\nshort_description: Manage a host in Icinga2\ndescription:\n - \"Add or remove a host to Icinga2 through the API.\"\n - \"See U(https://www.icinga.com/docs/icinga2/latest/doc/12-icinga2-api/)\"\nauthor: \"Jurgen Brand (@t794104)\"\nattributes:\n check_mode:\n support: full\n diff_mode:\n support: none\noptions:\n url:\n type: str\n description:\n - HTTP, HTTPS, or FTP URL in the form (http|https|ftp)://[user[:pass]]@host.domain[:port]/path\n use_proxy:\n description:\n - If V(false), it will not use a proxy, even if one is defined in\n an environment variable on the target hosts.\n type: bool\n default: true\n validate_certs:\n description:\n - If V(false), SSL certificates will not be validated. This should only be used\n on personally controlled sites using self-signed certificates.\n type: bool\n default: true\n url_username:\n type: str\n description:\n - The username for use in HTTP basic authentication.\n - This parameter can be used without O(url_password) for sites that allow empty passwords.\n url_password:\n type: str\n description:\n - The password for use in HTTP basic authentication.\n - If the O(url_username) parameter is not specified, the O(url_password) parameter will not be used.\n force_basic_auth:\n description:\n - httplib2, the library used by the uri module only sends authentication information when a webservice\n responds to an initial request with a 401 status. Since some basic auth services do not properly\n send a 401, logins will fail. This option forces the sending of the Basic authentication header\n upon initial request.\n type: bool\n default: false\n client_cert:\n type: path\n description:\n - PEM formatted certificate chain file to be used for SSL client\n authentication. This file can also include the key as well, and if\n the key is included, O(client_key) is not required.\n client_key:\n type: path\n description:\n - PEM formatted file that contains your private key to be used for SSL\n client authentication. If O(client_cert) contains both the certificate\n and key, this option is not required.\n state:\n type: str\n description:\n - Apply feature state.\n choices: [ \"present\", \"absent\" ]\n default: present\n name:\n type: str\n description:\n - Name used to create / delete the host. This does not need to be the FQDN, but does needs to be unique.\n required: true\n aliases: [host]\n zone:\n type: str\n description:\n - The zone from where this host should be polled.\n template:\n type: str\n description:\n - The template used to define the host.\n - Template cannot be modified after object creation.\n check_command:\n type: str\n description:\n - The command used to check if the host is alive.\n default: \"hostalive\"\n display_name:\n type: str\n description:\n - The name used to display the host.\n - If not specified, it defaults to the value of the O(name) parameter.\n ip:\n type: str\n description:\n - The IP address of the host.\n required: true\n variables:\n type: dict\n description:\n - Dictionary of variables.\nextends_documentation_fragment:\n - ansible.builtin.url\n - community.general.attributes\n'''\n\nEXAMPLES = '''\n- name: Add host to icinga\n community.general.icinga2_host:\n url: \"https://icinga2.example.com\"\n url_username: \"ansible\"\n url_password: \"a_secret\"\n state: present\n name: \"{{ ansible_fqdn }}\"\n ip: \"{{ ansible_default_ipv4.address }}\"\n variables:\n foo: \"bar\"\n delegate_to: 127.0.0.1\n'''\n\nRETURN = '''\nname:\n description: The name used to create, modify or delete the host\n type: str\n returned: always\ndata:\n description: The data structure used for create, modify or delete of the host\n type: dict\n returned: always\n'''\n\nimport json\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils.urls import fetch_url, url_argument_spec\n\n\n# ===========================================\n# Icinga2 API class\n#\nclass icinga2_api:\n module = None\n\n def __init__(self, module):\n self.module = module\n\n def call_url(self, path, data='', method='GET'):\n headers = {\n 'Accept': 'application/json',\n 'X-HTTP-Method-Override': method,\n }\n url = self.module.params.get(\"url\") + \"/\" + path\n rsp, info = fetch_url(module=self.module, url=url, data=data, headers=headers, method=method, use_proxy=self.module.params['use_proxy'])\n body = ''\n if rsp:\n body = json.loads(rsp.read())\n if info['status'] >= 400:\n body = info['body']\n return {'code': info['status'], 'data': body}\n\n def check_connection(self):\n ret = self.call_url('v1/status')\n if ret['code'] == 200:\n return True\n return False\n\n def exists(self, hostname):\n data = {\n \"filter\": \"match(\\\"\" + hostname + \"\\\", host.name)\",\n }\n ret = self.call_url(\n path=\"v1/objects/hosts\",\n data=self.module.jsonify(data)\n )\n if ret['code'] == 200:\n if len(ret['data']['results']) == 1:\n return True\n return False\n\n def create(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"PUT\"\n )\n return ret\n\n def delete(self, hostname):\n data = {\"cascade\": 1}\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"DELETE\"\n )\n return ret\n\n def modify(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"POST\"\n )\n return ret\n\n def diff(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n method=\"GET\"\n )\n changed = False\n ic_data = ret['data']['results'][0]\n for key in data['attrs']:\n if key not in ic_data['attrs'].keys():\n changed = True\n elif data['attrs'][key] != ic_data['attrs'][key]:\n changed = True\n return changed\n\n\n# ===========================================\n# Module execution.\n#\ndef main():\n # use the predefined argument spec for url\n argument_spec = url_argument_spec()\n # add our own arguments\n argument_spec.update(\n state=dict(default=\"present\", choices=[\"absent\", \"present\"]),\n name=dict(required=True, aliases=['host']),\n zone=dict(),\n template=dict(default=None),\n check_command=dict(default=\"hostalive\"),\n display_name=dict(default=None),\n ip=dict(required=True),\n variables=dict(type='dict', default=None),\n )\n\n # Define the main module\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True\n )\n\n state = module.params[\"state\"]\n name = module.params[\"name\"]\n zone = module.params[\"zone\"]\n template = []\n if module.params[\"template\"]:\n template = [module.params[\"template\"]]\n check_command = module.params[\"check_command\"]\n ip = module.params[\"ip\"]\n display_name = module.params[\"display_name\"]\n if not display_name:\n display_name = name\n variables = module.params[\"variables\"]\n\n try:\n icinga = icinga2_api(module=module)\n icinga.check_connection()\n except Exception as e:\n module.fail_json(msg=\"unable to connect to Icinga. Exception message: %s\" % (e))\n\n data = {\n 'templates': template,\n 'attrs': {\n 'address': ip,\n 'display_name': display_name,\n 'check_command': check_command,\n 'zone': zone,\n 'vars.made_by': \"ansible\"\n }\n }\n\n for key, value in variables.items():\n data['attrs']['vars.' + key] = value\n\n changed = False\n if icinga.exists(name):\n if state == \"absent\":\n if module.check_mode:\n module.exit_json(changed=True, name=name, data=data)\n else:\n try:\n ret = icinga.delete(name)\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) deleting host: '%s'\" % (ret['code'], ret['data']))\n except Exception as e:\n module.fail_json(msg=\"exception deleting host: \" + str(e))\n\n elif icinga.diff(name, data):\n if module.check_mode:\n module.exit_json(changed=False, name=name, data=data)\n\n # Template attribute is not allowed in modification\n del data['templates']\n\n ret = icinga.modify(name, data)\n\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) modifying host: '%s'\" % (ret['code'], ret['data']))\n\n else:\n if state == \"present\":\n if module.check_mode:\n changed = True\n else:\n try:\n ret = icinga.create(name, data)\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) creating host: '%s'\" % (ret['code'], ret['data']))\n except Exception as e:\n module.fail_json(msg=\"exception creating host: \" + str(e))\n\n module.exit_json(changed=changed, name=name, data=data)\n\n\n# import module snippets\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/icinga2_host.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# This module is proudly sponsored by CGI (www.cgi.com) and\n# KPN (www.kpn.com).\n# Copyright (c) Ansible project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: icinga2_host\nshort_description: Manage a host in Icinga2\ndescription:\n - \"Add or remove a host to Icinga2 through the API.\"\n - \"See U(https://www.icinga.com/docs/icinga2/latest/doc/12-icinga2-api/)\"\nauthor: \"Jurgen Brand (@t794104)\"\nattributes:\n check_mode:\n support: full\n diff_mode:\n support: none\noptions:\n url:\n type: str\n description:\n - HTTP, HTTPS, or FTP URL in the form (http|https|ftp)://[user[:pass]]@host.domain[:port]/path\n use_proxy:\n description:\n - If V(false), it will not use a proxy, even if one is defined in\n an environment variable on the target hosts.\n type: bool\n default: true\n validate_certs:\n description:\n - If V(false), SSL certificates will not be validated. This should only be used\n on personally controlled sites using self-signed certificates.\n type: bool\n default: true\n url_username:\n type: str\n description:\n - The username for use in HTTP basic authentication.\n - This parameter can be used without O(url_password) for sites that allow empty passwords.\n url_password:\n type: str\n description:\n - The password for use in HTTP basic authentication.\n - If the O(url_username) parameter is not specified, the O(url_password) parameter will not be used.\n force_basic_auth:\n description:\n - httplib2, the library used by the uri module only sends authentication information when a webservice\n responds to an initial request with a 401 status. Since some basic auth services do not properly\n send a 401, logins will fail. This option forces the sending of the Basic authentication header\n upon initial request.\n type: bool\n default: false\n client_cert:\n type: path\n description:\n - PEM formatted certificate chain file to be used for SSL client\n authentication. This file can also include the key as well, and if\n the key is included, O(client_key) is not required.\n client_key:\n type: path\n description:\n - PEM formatted file that contains your private key to be used for SSL\n client authentication. If O(client_cert) contains both the certificate\n and key, this option is not required.\n state:\n type: str\n description:\n - Apply feature state.\n choices: [ \"present\", \"absent\" ]\n default: present\n name:\n type: str\n description:\n - Name used to create / delete the host. This does not need to be the FQDN, but does needs to be unique.\n required: true\n aliases: [host]\n zone:\n type: str\n description:\n - The zone from where this host should be polled.\n template:\n type: str\n description:\n - The template used to define the host.\n - Template cannot be modified after object creation.\n check_command:\n type: str\n description:\n - The command used to check if the host is alive.\n default: \"hostalive\"\n display_name:\n type: str\n description:\n - The name used to display the host.\n - If not specified, it defaults to the value of the O(name) parameter.\n ip:\n type: str\n description:\n - The IP address of the host.\n - This is no longer required since community.general 8.0.0.\n variables:\n type: dict\n description:\n - Dictionary of variables.\nextends_documentation_fragment:\n - ansible.builtin.url\n - community.general.attributes\n'''\n\nEXAMPLES = '''\n- name: Add host to icinga\n community.general.icinga2_host:\n url: \"https://icinga2.example.com\"\n url_username: \"ansible\"\n url_password: \"a_secret\"\n state: present\n name: \"{{ ansible_fqdn }}\"\n ip: \"{{ ansible_default_ipv4.address }}\"\n variables:\n foo: \"bar\"\n delegate_to: 127.0.0.1\n'''\n\nRETURN = '''\nname:\n description: The name used to create, modify or delete the host\n type: str\n returned: always\ndata:\n description: The data structure used for create, modify or delete of the host\n type: dict\n returned: always\n'''\n\nimport json\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils.urls import fetch_url, url_argument_spec\n\n\n# ===========================================\n# Icinga2 API class\n#\nclass icinga2_api:\n module = None\n\n def __init__(self, module):\n self.module = module\n\n def call_url(self, path, data='', method='GET'):\n headers = {\n 'Accept': 'application/json',\n 'X-HTTP-Method-Override': method,\n }\n url = self.module.params.get(\"url\") + \"/\" + path\n rsp, info = fetch_url(module=self.module, url=url, data=data, headers=headers, method=method, use_proxy=self.module.params['use_proxy'])\n body = ''\n if rsp:\n body = json.loads(rsp.read())\n if info['status'] >= 400:\n body = info['body']\n return {'code': info['status'], 'data': body}\n\n def check_connection(self):\n ret = self.call_url('v1/status')\n if ret['code'] == 200:\n return True\n return False\n\n def exists(self, hostname):\n data = {\n \"filter\": \"match(\\\"\" + hostname + \"\\\", host.name)\",\n }\n ret = self.call_url(\n path=\"v1/objects/hosts\",\n data=self.module.jsonify(data)\n )\n if ret['code'] == 200:\n if len(ret['data']['results']) == 1:\n return True\n return False\n\n def create(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"PUT\"\n )\n return ret\n\n def delete(self, hostname):\n data = {\"cascade\": 1}\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"DELETE\"\n )\n return ret\n\n def modify(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n data=self.module.jsonify(data),\n method=\"POST\"\n )\n return ret\n\n def diff(self, hostname, data):\n ret = self.call_url(\n path=\"v1/objects/hosts/\" + hostname,\n method=\"GET\"\n )\n changed = False\n ic_data = ret['data']['results'][0]\n for key in data['attrs']:\n if key not in ic_data['attrs'].keys():\n changed = True\n elif data['attrs'][key] != ic_data['attrs'][key]:\n changed = True\n return changed\n\n\n# ===========================================\n# Module execution.\n#\ndef main():\n # use the predefined argument spec for url\n argument_spec = url_argument_spec()\n # add our own arguments\n argument_spec.update(\n state=dict(default=\"present\", choices=[\"absent\", \"present\"]),\n name=dict(required=True, aliases=['host']),\n zone=dict(),\n template=dict(default=None),\n check_command=dict(default=\"hostalive\"),\n display_name=dict(default=None),\n ip=dict(),\n variables=dict(type='dict', default=None),\n )\n\n # Define the main module\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True\n )\n\n state = module.params[\"state\"]\n name = module.params[\"name\"]\n zone = module.params[\"zone\"]\n template = []\n if module.params[\"template\"]:\n template = [module.params[\"template\"]]\n check_command = module.params[\"check_command\"]\n ip = module.params[\"ip\"]\n display_name = module.params[\"display_name\"]\n if not display_name:\n display_name = name\n variables = module.params[\"variables\"]\n\n try:\n icinga = icinga2_api(module=module)\n icinga.check_connection()\n except Exception as e:\n module.fail_json(msg=\"unable to connect to Icinga. Exception message: %s\" % (e))\n\n data = {\n 'templates': template,\n 'attrs': {\n 'address': ip,\n 'display_name': display_name,\n 'check_command': check_command,\n 'zone': zone,\n 'vars.made_by': \"ansible\"\n }\n }\n\n for key, value in variables.items():\n data['attrs']['vars.' + key] = value\n\n changed = False\n if icinga.exists(name):\n if state == \"absent\":\n if module.check_mode:\n module.exit_json(changed=True, name=name, data=data)\n else:\n try:\n ret = icinga.delete(name)\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) deleting host: '%s'\" % (ret['code'], ret['data']))\n except Exception as e:\n module.fail_json(msg=\"exception deleting host: \" + str(e))\n\n elif icinga.diff(name, data):\n if module.check_mode:\n module.exit_json(changed=False, name=name, data=data)\n\n # Template attribute is not allowed in modification\n del data['templates']\n\n ret = icinga.modify(name, data)\n\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) modifying host: '%s'\" % (ret['code'], ret['data']))\n\n else:\n if state == \"present\":\n if module.check_mode:\n changed = True\n else:\n try:\n ret = icinga.create(name, data)\n if ret['code'] == 200:\n changed = True\n else:\n module.fail_json(msg=\"bad return code (%s) creating host: '%s'\" % (ret['code'], ret['data']))\n except Exception as e:\n module.fail_json(msg=\"exception creating host: \" + str(e))\n\n module.exit_json(changed=changed, name=name, data=data)\n\n\n# import module snippets\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/icinga2_host.py"}]}
| 3,798 | 170 |
gh_patches_debug_29139
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-19038
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add "Privacy and security" section to personal Settings menu
Some personal settings are hard to find right now, and some settings pages have too many different kinds of settings. We should make the settings easier to navigate by splitting "Your account" into two sections:
1. **Profile** (1st on the list). We can try removing all the section headers and see if it's OK or confusing.
Settings (in order): Full name, Profile picture, "Deactivate account" button, everything currently under **Your account > Profile** (custom fields).
I'm not entirely sure about the "Deactivate account" button placement; we can play with it.
2. **Privacy and security** (2nd on the list)
Settings (in order):
a. **User settings**: Email, password, role
b. **Presence** (currently under **Notifications**)
c. **API key**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zerver/lib/markdown/help_relative_links.py`
Content:
```
1 import re
2 from typing import Any, List, Match, Optional
3
4 from markdown import Markdown
5 from markdown.extensions import Extension
6 from markdown.preprocessors import Preprocessor
7
8 # There is a lot of duplicated code between this file and
9 # help_settings_links.py. So if you're making a change here consider making
10 # it there as well.
11
12 REGEXP = re.compile(r"\{relative\|(?P<link_type>.*?)\|(?P<key>.*?)\}")
13
14 gear_info = {
15 # The pattern is key: [name, link]
16 # key is from REGEXP: `{relative|gear|key}`
17 # name is what the item is called in the gear menu: `Select **name**.`
18 # link is used for relative links: `Select [name](link).`
19 "manage-streams": ["Manage streams", "/#streams/subscribed"],
20 "settings": ["Settings", "/#settings/your-account"],
21 "manage-organization": ["Manage organization", "/#organization/organization-profile"],
22 "integrations": ["Integrations", "/integrations"],
23 "stats": ["Usage statistics", "/stats"],
24 "plans": ["Plans and pricing", "/plans"],
25 "billing": ["Billing", "/billing"],
26 "invite": ["Invite users", "/#invite"],
27 }
28
29 gear_instructions = """
30 1. From your desktop, click on the **gear**
31 (<i class="fa fa-cog"></i>) in the upper right corner.
32
33 1. Select {item}.
34 """
35
36
37 def gear_handle_match(key: str) -> str:
38 if relative_help_links:
39 item = f"[{gear_info[key][0]}]({gear_info[key][1]})"
40 else:
41 item = f"**{gear_info[key][0]}**"
42 return gear_instructions.format(item=item)
43
44
45 stream_info = {
46 "all": ["All streams", "/#streams/all"],
47 "subscribed": ["Your streams", "/#streams/subscribed"],
48 }
49
50 stream_instructions_no_link = """
51 1. From your desktop, click on the **gear**
52 (<i class="fa fa-cog"></i>) in the upper right corner.
53
54 1. Click **Manage streams**.
55 """
56
57
58 def stream_handle_match(key: str) -> str:
59 if relative_help_links:
60 return f"1. Go to [{stream_info[key][0]}]({stream_info[key][1]})."
61 if key == "all":
62 return stream_instructions_no_link + "\n\n1. Click **All streams** in the upper left."
63 return stream_instructions_no_link
64
65
66 LINK_TYPE_HANDLERS = {
67 "gear": gear_handle_match,
68 "stream": stream_handle_match,
69 }
70
71
72 class RelativeLinksHelpExtension(Extension):
73 def extendMarkdown(self, md: Markdown) -> None:
74 """Add RelativeLinksHelpExtension to the Markdown instance."""
75 md.registerExtension(self)
76 md.preprocessors.register(RelativeLinks(), "help_relative_links", 520)
77
78
79 relative_help_links: Optional[bool] = None
80
81
82 def set_relative_help_links(value: bool) -> None:
83 global relative_help_links
84 relative_help_links = value
85
86
87 class RelativeLinks(Preprocessor):
88 def run(self, lines: List[str]) -> List[str]:
89 done = False
90 while not done:
91 for line in lines:
92 loc = lines.index(line)
93 match = REGEXP.search(line)
94
95 if match:
96 text = [self.handleMatch(match)]
97 # The line that contains the directive to include the macro
98 # may be preceded or followed by text or tags, in that case
99 # we need to make sure that any preceding or following text
100 # stays the same.
101 line_split = REGEXP.split(line, maxsplit=0)
102 preceding = line_split[0]
103 following = line_split[-1]
104 text = [preceding, *text, following]
105 lines = lines[:loc] + text + lines[loc + 1 :]
106 break
107 else:
108 done = True
109 return lines
110
111 def handleMatch(self, match: Match[str]) -> str:
112 return LINK_TYPE_HANDLERS[match.group("link_type")](match.group("key"))
113
114
115 def makeExtension(*args: Any, **kwargs: Any) -> RelativeLinksHelpExtension:
116 return RelativeLinksHelpExtension(*args, **kwargs)
117
```
Path: `zerver/lib/markdown/help_settings_links.py`
Content:
```
1 import re
2 from typing import Any, List, Match, Optional
3
4 from markdown import Markdown
5 from markdown.extensions import Extension
6 from markdown.preprocessors import Preprocessor
7
8 # There is a lot of duplicated code between this file and
9 # help_relative_links.py. So if you're making a change here consider making
10 # it there as well.
11
12 REGEXP = re.compile(r"\{settings_tab\|(?P<setting_identifier>.*?)\}")
13
14 link_mapping = {
15 # a mapping from the setting identifier that is the same as the final URL
16 # breadcrumb to that setting to the name of its setting type, the setting
17 # name as it appears in the user interface, and a relative link that can
18 # be used to get to that setting
19 "your-account": ["Settings", "Your account", "/#settings/your-account"],
20 "display-settings": ["Settings", "Display settings", "/#settings/display-settings"],
21 "notifications": ["Settings", "Notifications", "/#settings/notifications"],
22 "your-bots": ["Settings", "Your bots", "/#settings/your-bots"],
23 "alert-words": ["Settings", "Alert words", "/#settings/alert-words"],
24 "uploaded-files": ["Settings", "Uploaded files", "/#settings/uploaded-files"],
25 "muted-topics": ["Settings", "Muted topics", "/#settings/muted-topics"],
26 "muted-users": ["Settings", "Muted users", "/#settings/muted-users"],
27 "organization-profile": [
28 "Manage organization",
29 "Organization profile",
30 "/#organization/organization-profile",
31 ],
32 "organization-settings": [
33 "Manage organization",
34 "Organization settings",
35 "/#organization/organization-settings",
36 ],
37 "organization-permissions": [
38 "Manage organization",
39 "Organization permissions",
40 "/#organization/organization-permissions",
41 ],
42 "emoji-settings": ["Manage organization", "Custom emoji", "/#organization/emoji-settings"],
43 "auth-methods": [
44 "Manage organization",
45 "Authentication methods",
46 "/#organization/auth-methods",
47 ],
48 "user-groups-admin": ["Manage organization", "User groups", "/#organization/user-groups-admin"],
49 "user-list-admin": ["Manage organization", "Users", "/#organization/user-list-admin"],
50 "deactivated-users-admin": [
51 "Manage organization",
52 "Deactivated users",
53 "/#organization/deactivated-users-admin",
54 ],
55 "bot-list-admin": ["Manage organization", "Bots", "/#organization/bot-list-admin"],
56 "default-streams-list": [
57 "Manage organization",
58 "Default streams",
59 "/#organization/default-streams-list",
60 ],
61 "linkifier-settings": [
62 "Manage organization",
63 "Linkifiers",
64 "/#organization/linkifier-settings",
65 ],
66 "playground-settings": [
67 "Manage organization",
68 "Code playgrounds",
69 "/#organization/playground-settings",
70 ],
71 "profile-field-settings": [
72 "Manage organization",
73 "Custom profile fields",
74 "/#organization/profile-field-settings",
75 ],
76 "invites-list-admin": [
77 "Manage organization",
78 "Invitations",
79 "/#organization/invites-list-admin",
80 ],
81 "data-exports-admin": [
82 "Manage organization",
83 "Data exports",
84 "/#organization/data-exports-admin",
85 ],
86 }
87
88 settings_markdown = """
89 1. From your desktop, click on the **gear**
90 (<i class="fa fa-cog"></i>) in the upper right corner.
91
92 1. Select **{setting_type_name}**.
93
94 1. On the left, click {setting_reference}.
95 """
96
97
98 class SettingHelpExtension(Extension):
99 def extendMarkdown(self, md: Markdown) -> None:
100 """Add SettingHelpExtension to the Markdown instance."""
101 md.registerExtension(self)
102 md.preprocessors.register(Setting(), "setting", 515)
103
104
105 relative_settings_links: Optional[bool] = None
106
107
108 def set_relative_settings_links(value: bool) -> None:
109 global relative_settings_links
110 relative_settings_links = value
111
112
113 class Setting(Preprocessor):
114 def run(self, lines: List[str]) -> List[str]:
115 done = False
116 while not done:
117 for line in lines:
118 loc = lines.index(line)
119 match = REGEXP.search(line)
120
121 if match:
122 text = [self.handleMatch(match)]
123 # The line that contains the directive to include the macro
124 # may be preceded or followed by text or tags, in that case
125 # we need to make sure that any preceding or following text
126 # stays the same.
127 line_split = REGEXP.split(line, maxsplit=0)
128 preceding = line_split[0]
129 following = line_split[-1]
130 text = [preceding, *text, following]
131 lines = lines[:loc] + text + lines[loc + 1 :]
132 break
133 else:
134 done = True
135 return lines
136
137 def handleMatch(self, match: Match[str]) -> str:
138 setting_identifier = match.group("setting_identifier")
139 setting_type_name = link_mapping[setting_identifier][0]
140 setting_name = link_mapping[setting_identifier][1]
141 setting_link = link_mapping[setting_identifier][2]
142 if relative_settings_links:
143 return f"1. Go to [{setting_name}]({setting_link})."
144 return settings_markdown.format(
145 setting_type_name=setting_type_name,
146 setting_reference=f"**{setting_name}**",
147 )
148
149
150 def makeExtension(*args: Any, **kwargs: Any) -> SettingHelpExtension:
151 return SettingHelpExtension(*args, **kwargs)
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zerver/lib/markdown/help_relative_links.py b/zerver/lib/markdown/help_relative_links.py
--- a/zerver/lib/markdown/help_relative_links.py
+++ b/zerver/lib/markdown/help_relative_links.py
@@ -17,7 +17,7 @@
# name is what the item is called in the gear menu: `Select **name**.`
# link is used for relative links: `Select [name](link).`
"manage-streams": ["Manage streams", "/#streams/subscribed"],
- "settings": ["Settings", "/#settings/your-account"],
+ "settings": ["Settings", "/#settings/profile"],
"manage-organization": ["Manage organization", "/#organization/organization-profile"],
"integrations": ["Integrations", "/integrations"],
"stats": ["Usage statistics", "/stats"],
diff --git a/zerver/lib/markdown/help_settings_links.py b/zerver/lib/markdown/help_settings_links.py
--- a/zerver/lib/markdown/help_settings_links.py
+++ b/zerver/lib/markdown/help_settings_links.py
@@ -16,7 +16,8 @@
# breadcrumb to that setting to the name of its setting type, the setting
# name as it appears in the user interface, and a relative link that can
# be used to get to that setting
- "your-account": ["Settings", "Your account", "/#settings/your-account"],
+ "profile": ["Settings", "Profile", "/#settings/profile"],
+ "account-and-privacy": ["Settings", "Account & privacy", "/#settings/account-and-privacy"],
"display-settings": ["Settings", "Display settings", "/#settings/display-settings"],
"notifications": ["Settings", "Notifications", "/#settings/notifications"],
"your-bots": ["Settings", "Your bots", "/#settings/your-bots"],
|
{"golden_diff": "diff --git a/zerver/lib/markdown/help_relative_links.py b/zerver/lib/markdown/help_relative_links.py\n--- a/zerver/lib/markdown/help_relative_links.py\n+++ b/zerver/lib/markdown/help_relative_links.py\n@@ -17,7 +17,7 @@\n # name is what the item is called in the gear menu: `Select **name**.`\n # link is used for relative links: `Select [name](link).`\n \"manage-streams\": [\"Manage streams\", \"/#streams/subscribed\"],\n- \"settings\": [\"Settings\", \"/#settings/your-account\"],\n+ \"settings\": [\"Settings\", \"/#settings/profile\"],\n \"manage-organization\": [\"Manage organization\", \"/#organization/organization-profile\"],\n \"integrations\": [\"Integrations\", \"/integrations\"],\n \"stats\": [\"Usage statistics\", \"/stats\"],\ndiff --git a/zerver/lib/markdown/help_settings_links.py b/zerver/lib/markdown/help_settings_links.py\n--- a/zerver/lib/markdown/help_settings_links.py\n+++ b/zerver/lib/markdown/help_settings_links.py\n@@ -16,7 +16,8 @@\n # breadcrumb to that setting to the name of its setting type, the setting\n # name as it appears in the user interface, and a relative link that can\n # be used to get to that setting\n- \"your-account\": [\"Settings\", \"Your account\", \"/#settings/your-account\"],\n+ \"profile\": [\"Settings\", \"Profile\", \"/#settings/profile\"],\n+ \"account-and-privacy\": [\"Settings\", \"Account & privacy\", \"/#settings/account-and-privacy\"],\n \"display-settings\": [\"Settings\", \"Display settings\", \"/#settings/display-settings\"],\n \"notifications\": [\"Settings\", \"Notifications\", \"/#settings/notifications\"],\n \"your-bots\": [\"Settings\", \"Your bots\", \"/#settings/your-bots\"],\n", "issue": "Add \"Privacy and security\" section to personal Settings menu \nSome personal settings are hard to find right now, and some settings pages have too many different kinds of settings. We should make the settings easier to navigate by splitting \"Your account\" into two sections:\r\n\r\n1. **Profile** (1st on the list). We can try removing all the section headers and see if it's OK or confusing.\r\nSettings (in order): Full name, Profile picture, \"Deactivate account\" button, everything currently under **Your account > Profile** (custom fields).\r\n\r\nI'm not entirely sure about the \"Deactivate account\" button placement; we can play with it.\r\n\r\n2. **Privacy and security** (2nd on the list) \r\nSettings (in order):\r\n a. **User settings**: Email, password, role\r\n b. **Presence** (currently under **Notifications**)\r\n c. **API key**\r\n\r\n\n", "before_files": [{"content": "import re\nfrom typing import Any, List, Match, Optional\n\nfrom markdown import Markdown\nfrom markdown.extensions import Extension\nfrom markdown.preprocessors import Preprocessor\n\n# There is a lot of duplicated code between this file and\n# help_settings_links.py. So if you're making a change here consider making\n# it there as well.\n\nREGEXP = re.compile(r\"\\{relative\\|(?P<link_type>.*?)\\|(?P<key>.*?)\\}\")\n\ngear_info = {\n # The pattern is key: [name, link]\n # key is from REGEXP: `{relative|gear|key}`\n # name is what the item is called in the gear menu: `Select **name**.`\n # link is used for relative links: `Select [name](link).`\n \"manage-streams\": [\"Manage streams\", \"/#streams/subscribed\"],\n \"settings\": [\"Settings\", \"/#settings/your-account\"],\n \"manage-organization\": [\"Manage organization\", \"/#organization/organization-profile\"],\n \"integrations\": [\"Integrations\", \"/integrations\"],\n \"stats\": [\"Usage statistics\", \"/stats\"],\n \"plans\": [\"Plans and pricing\", \"/plans\"],\n \"billing\": [\"Billing\", \"/billing\"],\n \"invite\": [\"Invite users\", \"/#invite\"],\n}\n\ngear_instructions = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Select {item}.\n\"\"\"\n\n\ndef gear_handle_match(key: str) -> str:\n if relative_help_links:\n item = f\"[{gear_info[key][0]}]({gear_info[key][1]})\"\n else:\n item = f\"**{gear_info[key][0]}**\"\n return gear_instructions.format(item=item)\n\n\nstream_info = {\n \"all\": [\"All streams\", \"/#streams/all\"],\n \"subscribed\": [\"Your streams\", \"/#streams/subscribed\"],\n}\n\nstream_instructions_no_link = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Click **Manage streams**.\n\"\"\"\n\n\ndef stream_handle_match(key: str) -> str:\n if relative_help_links:\n return f\"1. Go to [{stream_info[key][0]}]({stream_info[key][1]}).\"\n if key == \"all\":\n return stream_instructions_no_link + \"\\n\\n1. Click **All streams** in the upper left.\"\n return stream_instructions_no_link\n\n\nLINK_TYPE_HANDLERS = {\n \"gear\": gear_handle_match,\n \"stream\": stream_handle_match,\n}\n\n\nclass RelativeLinksHelpExtension(Extension):\n def extendMarkdown(self, md: Markdown) -> None:\n \"\"\"Add RelativeLinksHelpExtension to the Markdown instance.\"\"\"\n md.registerExtension(self)\n md.preprocessors.register(RelativeLinks(), \"help_relative_links\", 520)\n\n\nrelative_help_links: Optional[bool] = None\n\n\ndef set_relative_help_links(value: bool) -> None:\n global relative_help_links\n relative_help_links = value\n\n\nclass RelativeLinks(Preprocessor):\n def run(self, lines: List[str]) -> List[str]:\n done = False\n while not done:\n for line in lines:\n loc = lines.index(line)\n match = REGEXP.search(line)\n\n if match:\n text = [self.handleMatch(match)]\n # The line that contains the directive to include the macro\n # may be preceded or followed by text or tags, in that case\n # we need to make sure that any preceding or following text\n # stays the same.\n line_split = REGEXP.split(line, maxsplit=0)\n preceding = line_split[0]\n following = line_split[-1]\n text = [preceding, *text, following]\n lines = lines[:loc] + text + lines[loc + 1 :]\n break\n else:\n done = True\n return lines\n\n def handleMatch(self, match: Match[str]) -> str:\n return LINK_TYPE_HANDLERS[match.group(\"link_type\")](match.group(\"key\"))\n\n\ndef makeExtension(*args: Any, **kwargs: Any) -> RelativeLinksHelpExtension:\n return RelativeLinksHelpExtension(*args, **kwargs)\n", "path": "zerver/lib/markdown/help_relative_links.py"}, {"content": "import re\nfrom typing import Any, List, Match, Optional\n\nfrom markdown import Markdown\nfrom markdown.extensions import Extension\nfrom markdown.preprocessors import Preprocessor\n\n# There is a lot of duplicated code between this file and\n# help_relative_links.py. So if you're making a change here consider making\n# it there as well.\n\nREGEXP = re.compile(r\"\\{settings_tab\\|(?P<setting_identifier>.*?)\\}\")\n\nlink_mapping = {\n # a mapping from the setting identifier that is the same as the final URL\n # breadcrumb to that setting to the name of its setting type, the setting\n # name as it appears in the user interface, and a relative link that can\n # be used to get to that setting\n \"your-account\": [\"Settings\", \"Your account\", \"/#settings/your-account\"],\n \"display-settings\": [\"Settings\", \"Display settings\", \"/#settings/display-settings\"],\n \"notifications\": [\"Settings\", \"Notifications\", \"/#settings/notifications\"],\n \"your-bots\": [\"Settings\", \"Your bots\", \"/#settings/your-bots\"],\n \"alert-words\": [\"Settings\", \"Alert words\", \"/#settings/alert-words\"],\n \"uploaded-files\": [\"Settings\", \"Uploaded files\", \"/#settings/uploaded-files\"],\n \"muted-topics\": [\"Settings\", \"Muted topics\", \"/#settings/muted-topics\"],\n \"muted-users\": [\"Settings\", \"Muted users\", \"/#settings/muted-users\"],\n \"organization-profile\": [\n \"Manage organization\",\n \"Organization profile\",\n \"/#organization/organization-profile\",\n ],\n \"organization-settings\": [\n \"Manage organization\",\n \"Organization settings\",\n \"/#organization/organization-settings\",\n ],\n \"organization-permissions\": [\n \"Manage organization\",\n \"Organization permissions\",\n \"/#organization/organization-permissions\",\n ],\n \"emoji-settings\": [\"Manage organization\", \"Custom emoji\", \"/#organization/emoji-settings\"],\n \"auth-methods\": [\n \"Manage organization\",\n \"Authentication methods\",\n \"/#organization/auth-methods\",\n ],\n \"user-groups-admin\": [\"Manage organization\", \"User groups\", \"/#organization/user-groups-admin\"],\n \"user-list-admin\": [\"Manage organization\", \"Users\", \"/#organization/user-list-admin\"],\n \"deactivated-users-admin\": [\n \"Manage organization\",\n \"Deactivated users\",\n \"/#organization/deactivated-users-admin\",\n ],\n \"bot-list-admin\": [\"Manage organization\", \"Bots\", \"/#organization/bot-list-admin\"],\n \"default-streams-list\": [\n \"Manage organization\",\n \"Default streams\",\n \"/#organization/default-streams-list\",\n ],\n \"linkifier-settings\": [\n \"Manage organization\",\n \"Linkifiers\",\n \"/#organization/linkifier-settings\",\n ],\n \"playground-settings\": [\n \"Manage organization\",\n \"Code playgrounds\",\n \"/#organization/playground-settings\",\n ],\n \"profile-field-settings\": [\n \"Manage organization\",\n \"Custom profile fields\",\n \"/#organization/profile-field-settings\",\n ],\n \"invites-list-admin\": [\n \"Manage organization\",\n \"Invitations\",\n \"/#organization/invites-list-admin\",\n ],\n \"data-exports-admin\": [\n \"Manage organization\",\n \"Data exports\",\n \"/#organization/data-exports-admin\",\n ],\n}\n\nsettings_markdown = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Select **{setting_type_name}**.\n\n1. On the left, click {setting_reference}.\n\"\"\"\n\n\nclass SettingHelpExtension(Extension):\n def extendMarkdown(self, md: Markdown) -> None:\n \"\"\"Add SettingHelpExtension to the Markdown instance.\"\"\"\n md.registerExtension(self)\n md.preprocessors.register(Setting(), \"setting\", 515)\n\n\nrelative_settings_links: Optional[bool] = None\n\n\ndef set_relative_settings_links(value: bool) -> None:\n global relative_settings_links\n relative_settings_links = value\n\n\nclass Setting(Preprocessor):\n def run(self, lines: List[str]) -> List[str]:\n done = False\n while not done:\n for line in lines:\n loc = lines.index(line)\n match = REGEXP.search(line)\n\n if match:\n text = [self.handleMatch(match)]\n # The line that contains the directive to include the macro\n # may be preceded or followed by text or tags, in that case\n # we need to make sure that any preceding or following text\n # stays the same.\n line_split = REGEXP.split(line, maxsplit=0)\n preceding = line_split[0]\n following = line_split[-1]\n text = [preceding, *text, following]\n lines = lines[:loc] + text + lines[loc + 1 :]\n break\n else:\n done = True\n return lines\n\n def handleMatch(self, match: Match[str]) -> str:\n setting_identifier = match.group(\"setting_identifier\")\n setting_type_name = link_mapping[setting_identifier][0]\n setting_name = link_mapping[setting_identifier][1]\n setting_link = link_mapping[setting_identifier][2]\n if relative_settings_links:\n return f\"1. Go to [{setting_name}]({setting_link}).\"\n return settings_markdown.format(\n setting_type_name=setting_type_name,\n setting_reference=f\"**{setting_name}**\",\n )\n\n\ndef makeExtension(*args: Any, **kwargs: Any) -> SettingHelpExtension:\n return SettingHelpExtension(*args, **kwargs)\n", "path": "zerver/lib/markdown/help_settings_links.py"}], "after_files": [{"content": "import re\nfrom typing import Any, List, Match, Optional\n\nfrom markdown import Markdown\nfrom markdown.extensions import Extension\nfrom markdown.preprocessors import Preprocessor\n\n# There is a lot of duplicated code between this file and\n# help_settings_links.py. So if you're making a change here consider making\n# it there as well.\n\nREGEXP = re.compile(r\"\\{relative\\|(?P<link_type>.*?)\\|(?P<key>.*?)\\}\")\n\ngear_info = {\n # The pattern is key: [name, link]\n # key is from REGEXP: `{relative|gear|key}`\n # name is what the item is called in the gear menu: `Select **name**.`\n # link is used for relative links: `Select [name](link).`\n \"manage-streams\": [\"Manage streams\", \"/#streams/subscribed\"],\n \"settings\": [\"Settings\", \"/#settings/profile\"],\n \"manage-organization\": [\"Manage organization\", \"/#organization/organization-profile\"],\n \"integrations\": [\"Integrations\", \"/integrations\"],\n \"stats\": [\"Usage statistics\", \"/stats\"],\n \"plans\": [\"Plans and pricing\", \"/plans\"],\n \"billing\": [\"Billing\", \"/billing\"],\n \"invite\": [\"Invite users\", \"/#invite\"],\n}\n\ngear_instructions = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Select {item}.\n\"\"\"\n\n\ndef gear_handle_match(key: str) -> str:\n if relative_help_links:\n item = f\"[{gear_info[key][0]}]({gear_info[key][1]})\"\n else:\n item = f\"**{gear_info[key][0]}**\"\n return gear_instructions.format(item=item)\n\n\nstream_info = {\n \"all\": [\"All streams\", \"/#streams/all\"],\n \"subscribed\": [\"Your streams\", \"/#streams/subscribed\"],\n}\n\nstream_instructions_no_link = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Click **Manage streams**.\n\"\"\"\n\n\ndef stream_handle_match(key: str) -> str:\n if relative_help_links:\n return f\"1. Go to [{stream_info[key][0]}]({stream_info[key][1]}).\"\n if key == \"all\":\n return stream_instructions_no_link + \"\\n\\n1. Click **All streams** in the upper left.\"\n return stream_instructions_no_link\n\n\nLINK_TYPE_HANDLERS = {\n \"gear\": gear_handle_match,\n \"stream\": stream_handle_match,\n}\n\n\nclass RelativeLinksHelpExtension(Extension):\n def extendMarkdown(self, md: Markdown) -> None:\n \"\"\"Add RelativeLinksHelpExtension to the Markdown instance.\"\"\"\n md.registerExtension(self)\n md.preprocessors.register(RelativeLinks(), \"help_relative_links\", 520)\n\n\nrelative_help_links: Optional[bool] = None\n\n\ndef set_relative_help_links(value: bool) -> None:\n global relative_help_links\n relative_help_links = value\n\n\nclass RelativeLinks(Preprocessor):\n def run(self, lines: List[str]) -> List[str]:\n done = False\n while not done:\n for line in lines:\n loc = lines.index(line)\n match = REGEXP.search(line)\n\n if match:\n text = [self.handleMatch(match)]\n # The line that contains the directive to include the macro\n # may be preceded or followed by text or tags, in that case\n # we need to make sure that any preceding or following text\n # stays the same.\n line_split = REGEXP.split(line, maxsplit=0)\n preceding = line_split[0]\n following = line_split[-1]\n text = [preceding, *text, following]\n lines = lines[:loc] + text + lines[loc + 1 :]\n break\n else:\n done = True\n return lines\n\n def handleMatch(self, match: Match[str]) -> str:\n return LINK_TYPE_HANDLERS[match.group(\"link_type\")](match.group(\"key\"))\n\n\ndef makeExtension(*args: Any, **kwargs: Any) -> RelativeLinksHelpExtension:\n return RelativeLinksHelpExtension(*args, **kwargs)\n", "path": "zerver/lib/markdown/help_relative_links.py"}, {"content": "import re\nfrom typing import Any, List, Match, Optional\n\nfrom markdown import Markdown\nfrom markdown.extensions import Extension\nfrom markdown.preprocessors import Preprocessor\n\n# There is a lot of duplicated code between this file and\n# help_relative_links.py. So if you're making a change here consider making\n# it there as well.\n\nREGEXP = re.compile(r\"\\{settings_tab\\|(?P<setting_identifier>.*?)\\}\")\n\nlink_mapping = {\n # a mapping from the setting identifier that is the same as the final URL\n # breadcrumb to that setting to the name of its setting type, the setting\n # name as it appears in the user interface, and a relative link that can\n # be used to get to that setting\n \"profile\": [\"Settings\", \"Profile\", \"/#settings/profile\"],\n \"account-and-privacy\": [\"Settings\", \"Account & privacy\", \"/#settings/account-and-privacy\"],\n \"display-settings\": [\"Settings\", \"Display settings\", \"/#settings/display-settings\"],\n \"notifications\": [\"Settings\", \"Notifications\", \"/#settings/notifications\"],\n \"your-bots\": [\"Settings\", \"Your bots\", \"/#settings/your-bots\"],\n \"alert-words\": [\"Settings\", \"Alert words\", \"/#settings/alert-words\"],\n \"uploaded-files\": [\"Settings\", \"Uploaded files\", \"/#settings/uploaded-files\"],\n \"muted-topics\": [\"Settings\", \"Muted topics\", \"/#settings/muted-topics\"],\n \"muted-users\": [\"Settings\", \"Muted users\", \"/#settings/muted-users\"],\n \"organization-profile\": [\n \"Manage organization\",\n \"Organization profile\",\n \"/#organization/organization-profile\",\n ],\n \"organization-settings\": [\n \"Manage organization\",\n \"Organization settings\",\n \"/#organization/organization-settings\",\n ],\n \"organization-permissions\": [\n \"Manage organization\",\n \"Organization permissions\",\n \"/#organization/organization-permissions\",\n ],\n \"emoji-settings\": [\"Manage organization\", \"Custom emoji\", \"/#organization/emoji-settings\"],\n \"auth-methods\": [\n \"Manage organization\",\n \"Authentication methods\",\n \"/#organization/auth-methods\",\n ],\n \"user-groups-admin\": [\"Manage organization\", \"User groups\", \"/#organization/user-groups-admin\"],\n \"user-list-admin\": [\"Manage organization\", \"Users\", \"/#organization/user-list-admin\"],\n \"deactivated-users-admin\": [\n \"Manage organization\",\n \"Deactivated users\",\n \"/#organization/deactivated-users-admin\",\n ],\n \"bot-list-admin\": [\"Manage organization\", \"Bots\", \"/#organization/bot-list-admin\"],\n \"default-streams-list\": [\n \"Manage organization\",\n \"Default streams\",\n \"/#organization/default-streams-list\",\n ],\n \"linkifier-settings\": [\n \"Manage organization\",\n \"Linkifiers\",\n \"/#organization/linkifier-settings\",\n ],\n \"playground-settings\": [\n \"Manage organization\",\n \"Code playgrounds\",\n \"/#organization/playground-settings\",\n ],\n \"profile-field-settings\": [\n \"Manage organization\",\n \"Custom profile fields\",\n \"/#organization/profile-field-settings\",\n ],\n \"invites-list-admin\": [\n \"Manage organization\",\n \"Invitations\",\n \"/#organization/invites-list-admin\",\n ],\n \"data-exports-admin\": [\n \"Manage organization\",\n \"Data exports\",\n \"/#organization/data-exports-admin\",\n ],\n}\n\nsettings_markdown = \"\"\"\n1. From your desktop, click on the **gear**\n (<i class=\"fa fa-cog\"></i>) in the upper right corner.\n\n1. Select **{setting_type_name}**.\n\n1. On the left, click {setting_reference}.\n\"\"\"\n\n\nclass SettingHelpExtension(Extension):\n def extendMarkdown(self, md: Markdown) -> None:\n \"\"\"Add SettingHelpExtension to the Markdown instance.\"\"\"\n md.registerExtension(self)\n md.preprocessors.register(Setting(), \"setting\", 515)\n\n\nrelative_settings_links: Optional[bool] = None\n\n\ndef set_relative_settings_links(value: bool) -> None:\n global relative_settings_links\n relative_settings_links = value\n\n\nclass Setting(Preprocessor):\n def run(self, lines: List[str]) -> List[str]:\n done = False\n while not done:\n for line in lines:\n loc = lines.index(line)\n match = REGEXP.search(line)\n\n if match:\n text = [self.handleMatch(match)]\n # The line that contains the directive to include the macro\n # may be preceded or followed by text or tags, in that case\n # we need to make sure that any preceding or following text\n # stays the same.\n line_split = REGEXP.split(line, maxsplit=0)\n preceding = line_split[0]\n following = line_split[-1]\n text = [preceding, *text, following]\n lines = lines[:loc] + text + lines[loc + 1 :]\n break\n else:\n done = True\n return lines\n\n def handleMatch(self, match: Match[str]) -> str:\n setting_identifier = match.group(\"setting_identifier\")\n setting_type_name = link_mapping[setting_identifier][0]\n setting_name = link_mapping[setting_identifier][1]\n setting_link = link_mapping[setting_identifier][2]\n if relative_settings_links:\n return f\"1. Go to [{setting_name}]({setting_link}).\"\n return settings_markdown.format(\n setting_type_name=setting_type_name,\n setting_reference=f\"**{setting_name}**\",\n )\n\n\ndef makeExtension(*args: Any, **kwargs: Any) -> SettingHelpExtension:\n return SettingHelpExtension(*args, **kwargs)\n", "path": "zerver/lib/markdown/help_settings_links.py"}]}
| 3,204 | 404 |
gh_patches_debug_42171
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5620
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/shardformer/shard/shard_config.py`
Content:
```
1 import warnings
2 from dataclasses import dataclass, field
3 from typing import Any, Dict, Optional
4
5 import torch.distributed as dist
6 from torch.distributed import ProcessGroup
7
8 from colossalai.pipeline.stage_manager import PipelineStageManager
9
10 from .grad_ckpt_config import GradientCheckpointConfig
11
12 __all__ = ["ShardConfig"]
13 SUPPORT_SP_MODE = ["split_gather", "ring", "all_to_all"]
14
15
16 @dataclass
17 class ShardConfig:
18 r"""
19 The config for sharding the huggingface model
20
21 Args:
22 tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.
23 pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.
24 enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.
25 enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.
26 enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.
27 enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.
28 enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.
29 enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.
30 gradient_checkpoint_config (Optional[GradientCheckpointConfig]): The gradient checkpoint config. Defaults to None.
31 enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.
32 """
33 tensor_parallel_process_group: Optional[ProcessGroup] = None
34 sequence_parallel_process_group: Optional[ProcessGroup] = None
35 pipeline_stage_manager: Optional[PipelineStageManager] = None
36 enable_tensor_parallelism: bool = True
37 enable_all_optimization: bool = False
38 enable_fused_normalization: bool = False
39 enable_flash_attention: bool = False
40 enable_jit_fused: bool = False
41 enable_sequence_parallelism: bool = False
42 sequence_parallelism_mode: str = None
43 enable_sequence_overlap: bool = False
44 parallel_output: bool = True
45 make_vocab_size_divisible_by: int = 64
46 gradient_checkpoint_config: Optional[GradientCheckpointConfig] = None
47 extra_kwargs: Dict[str, Any] = field(default_factory=dict)
48 # pipeline_parallel_size: int
49 # data_parallel_size: int
50 # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
51
52 @property
53 def tensor_parallel_size(self):
54 return self._tensor_parallel_size
55
56 @property
57 def sequence_parallel_size(self):
58 return self._sequence_parallel_size
59
60 def __post_init__(self):
61 # turn on all optimization if all_optimization is set to True
62 if self.enable_all_optimization:
63 self._turn_on_all_optimization()
64
65 if self.enable_sequence_parallelism:
66 self.sequence_parallelism_mode = (
67 "split_gather" if self.sequence_parallelism_mode is None else self.sequence_parallelism_mode
68 )
69 assert (
70 self.sequence_parallelism_mode in SUPPORT_SP_MODE
71 ), f"Sequence parallelism mode {self.sequence_parallelism_mode} is not in the supported list {SUPPORT_SP_MODE}"
72 if self.sequence_parallelism_mode in ["split_gather", "ring"]:
73 assert (
74 self.enable_tensor_parallelism
75 ), f"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is True"
76 elif self.sequence_parallelism_mode in ["all_to_all"]:
77 assert (
78 not self.enable_tensor_parallelism
79 ), f"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is False"
80 if self.enable_sequence_overlap:
81 self.enable_sequence_overlap = False
82 warnings.warn(
83 f"The enable_sequence_overlap flag will be ignored in sequence parallelism mode {self.sequence_parallelism_mode}"
84 )
85 else:
86 if self.sequence_parallelism_mode:
87 self.sequence_parallelism_mode = None
88 warnings.warn(
89 f"The sequence_parallelism_mode will be ignored when enable_sequence_parallelism is False"
90 )
91 assert (
92 not self.enable_sequence_overlap
93 ), f"enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True"
94
95 # get the tensor parallel size
96 if not self.enable_tensor_parallelism:
97 self._tensor_parallel_size = 1
98 else:
99 self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)
100
101 # get the sequence parallel size
102 if not self.enable_sequence_parallelism:
103 self._sequence_parallel_size = 1
104 else:
105 self._sequence_parallel_size = dist.get_world_size(self.sequence_parallel_process_group)
106
107 def _turn_on_all_optimization(self):
108 """
109 Turn on all optimization.
110 """
111 # you can add all the optimization flag here
112 self.enable_fused_normalization = True
113 self.enable_flash_attention = True
114 self.enable_jit_fused = True
115 # This can cause non-in-place param sharding when used without ZeRO.
116 # It may also slow down training when seq len is small. Plz enable manually.
117 # self.enable_sequence_parallelism = True
118 # self.enable_sequence_overlap = True
119
120 def _infer(self):
121 """
122 Set default params for inference.
123 """
124 # assert self.pipeline_stage_manager is None, "pipeline parallelism is not supported in inference for now"
125
```
Path: `colossalai/shardformer/shard/grad_ckpt_config.py`
Content:
```
1 from dataclasses import dataclass
2 from typing import List, Optional
3
4
5 @dataclass
6 class GradientCheckpointConfig:
7 gradient_checkpointing_ratio: float = 0.0
8
9 def get_num_ckpt_layers(self, num_layers: int) -> int:
10 return int(self.gradient_checkpointing_ratio * num_layers)
11
12
13 @dataclass
14 class PipelineGradientCheckpointConfig(GradientCheckpointConfig):
15 r"""
16 The pipeline gradient config is designed to provide more flexibility for users to control gradient checkpoint in pipeline parallelism.
17 Combined with PipelineStageManager.set_distribution_config, user can fully control the distribution of layers and checkpointed layers in pipeline parallelism.
18 Refer to https://github.com/hpcaitech/ColossalAI/issues/5509 for more details.
19
20 It provides the following features:
21 1. `gradient_checkpointing_ratio`: This is used to control gradient checkpointing more precisely, e.g., set 50% of the layers to use gradient checkpointing.
22 2. Customize # ckpt layers assigned to each stage. This takes precedence over `gradient_checkpointing_ratio`.
23
24 """
25 """
26 Args:
27 gradient_checkpointing_ratio (Optional[float]): The ratio of gradient checkpointing. It can only be used in pipeline parallelism. Defaults to None.
28 num_stages (Optional[int]): Number of stages in the pipeline. Defaults to None. For sanity check.
29 num_model_chunks (Optional[int]): Number of model chunks (1F1B or Interleaved). Defaults to None. For sanity check.
30 num_model_layers (Optional[int]): Number of model layers. Defaults to None. For sanity check.
31 num_ckpt_layers_per_stage (Optional[List[int]]): Number of checkpointed layers for each stage. Defaults to None.
32
33 Example 1:
34 num_stages = 8
35 num_layers = 80
36 num_model_chunks = 1
37 num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]
38 num_ckpt_layers_per_stage = [4, 4, 2, 2, 0, 0, 0, 0]
39
40 Example 2:
41 num_stages = 4
42 num_layers = 80
43 num_model_chunks = 2
44 num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]
45 # device 0 holds num_layers_per_stage[0] and num_layers_per_stage[4] layers
46 ...
47
48 """
49 num_stages: Optional[int] = None
50 num_model_chunks: Optional[int] = None
51 num_model_layers: Optional[int] = None
52 num_ckpt_layers_per_stage: Optional[List[int]] = None
53
54 def __post_init__(self):
55 if self._enable_gradient_checkpointing_ratio:
56 if not (0 <= self.gradient_checkpointing_ratio <= 1):
57 raise ValueError("gradient_checkpointing_ratio should be in 0% to 100%")
58
59 if self._enable_customized_ckpt_layers_per_stage:
60 assert (
61 self.num_stages is not None and self.num_model_chunks is not None and self.num_model_layers is not None
62 )
63 assert len(self.num_ckpt_layers_per_stage) == self.num_stages * self.num_model_chunks
64 assert all(
65 [0 <= num_ckpt_layers < self.num_model_layers for num_ckpt_layers in self.num_ckpt_layers_per_stage]
66 )
67 self.gradient_checkpointing_ratio = sum(self.num_ckpt_layers_per_stage) / self.num_model_layers
68
69 @property
70 def _enable_gradient_checkpointing_ratio(self) -> bool:
71 return self.gradient_checkpointing_ratio is not None
72
73 @property
74 def _enable_customized_ckpt_layers_per_stage(self) -> bool:
75 return self.num_ckpt_layers_per_stage is not None
76
77 def get_num_ckpt_layers(self, stage: int, num_layers: int, model_chunk_id: int = 0) -> int:
78 if not self._enable_gradient_checkpointing_ratio and not self._enable_customized_ckpt_layers_per_stage:
79 raise RuntimeError("No checkpointed layers information is provided")
80
81 if self._enable_customized_ckpt_layers_per_stage:
82 assert stage <= self.num_stages and model_chunk_id <= self.num_model_chunks
83 num_ckpt_layers = self.num_ckpt_layers_per_stage[stage + model_chunk_id * self.num_stages]
84 assert num_ckpt_layers <= num_layers
85 return num_ckpt_layers
86 else:
87 return int(self.gradient_checkpointing_ratio * num_layers)
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/shardformer/shard/grad_ckpt_config.py b/colossalai/shardformer/shard/grad_ckpt_config.py
--- a/colossalai/shardformer/shard/grad_ckpt_config.py
+++ b/colossalai/shardformer/shard/grad_ckpt_config.py
@@ -22,6 +22,7 @@
2. Customize # ckpt layers assigned to each stage. This takes precedence over `gradient_checkpointing_ratio`.
"""
+
"""
Args:
gradient_checkpointing_ratio (Optional[float]): The ratio of gradient checkpointing. It can only be used in pipeline parallelism. Defaults to None.
@@ -49,6 +50,7 @@
num_stages: Optional[int] = None
num_model_chunks: Optional[int] = None
num_model_layers: Optional[int] = None
+ num_layers_per_stage: Optional[List[int]] = None
num_ckpt_layers_per_stage: Optional[List[int]] = None
def __post_init__(self):
@@ -70,6 +72,10 @@
def _enable_gradient_checkpointing_ratio(self) -> bool:
return self.gradient_checkpointing_ratio is not None
+ @property
+ def _customize_num_layers_per_stage(self) -> bool:
+ return self.num_layers_per_stage is not None and self.num_model_layers is not None
+
@property
def _enable_customized_ckpt_layers_per_stage(self) -> bool:
return self.num_ckpt_layers_per_stage is not None
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -7,7 +7,7 @@
from colossalai.pipeline.stage_manager import PipelineStageManager
-from .grad_ckpt_config import GradientCheckpointConfig
+from .grad_ckpt_config import GradientCheckpointConfig, PipelineGradientCheckpointConfig
__all__ = ["ShardConfig"]
SUPPORT_SP_MODE = ["split_gather", "ring", "all_to_all"]
@@ -30,6 +30,7 @@
gradient_checkpoint_config (Optional[GradientCheckpointConfig]): The gradient checkpoint config. Defaults to None.
enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.
"""
+
tensor_parallel_process_group: Optional[ProcessGroup] = None
sequence_parallel_process_group: Optional[ProcessGroup] = None
pipeline_stage_manager: Optional[PipelineStageManager] = None
@@ -104,6 +105,16 @@
else:
self._sequence_parallel_size = dist.get_world_size(self.sequence_parallel_process_group)
+ if (
+ self.pipeline_stage_manager is not None
+ and isinstance(self.gradient_checkpoint_config, PipelineGradientCheckpointConfig)
+ and self.gradient_checkpoint_config._customize_num_layers_per_stage
+ ):
+ self.pipeline_stage_manager.set_distribution_config(
+ self.gradient_checkpoint_config.num_model_layers,
+ self.gradient_checkpoint_config.num_layers_per_stage,
+ )
+
def _turn_on_all_optimization(self):
"""
Turn on all optimization.
|
{"golden_diff": "diff --git a/colossalai/shardformer/shard/grad_ckpt_config.py b/colossalai/shardformer/shard/grad_ckpt_config.py\n--- a/colossalai/shardformer/shard/grad_ckpt_config.py\n+++ b/colossalai/shardformer/shard/grad_ckpt_config.py\n@@ -22,6 +22,7 @@\n 2. Customize # ckpt layers assigned to each stage. This takes precedence over `gradient_checkpointing_ratio`.\n \n \"\"\"\n+\n \"\"\"\n Args:\n gradient_checkpointing_ratio (Optional[float]): The ratio of gradient checkpointing. It can only be used in pipeline parallelism. Defaults to None.\n@@ -49,6 +50,7 @@\n num_stages: Optional[int] = None\n num_model_chunks: Optional[int] = None\n num_model_layers: Optional[int] = None\n+ num_layers_per_stage: Optional[List[int]] = None\n num_ckpt_layers_per_stage: Optional[List[int]] = None\n \n def __post_init__(self):\n@@ -70,6 +72,10 @@\n def _enable_gradient_checkpointing_ratio(self) -> bool:\n return self.gradient_checkpointing_ratio is not None\n \n+ @property\n+ def _customize_num_layers_per_stage(self) -> bool:\n+ return self.num_layers_per_stage is not None and self.num_model_layers is not None\n+\n @property\n def _enable_customized_ckpt_layers_per_stage(self) -> bool:\n return self.num_ckpt_layers_per_stage is not None\ndiff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py\n--- a/colossalai/shardformer/shard/shard_config.py\n+++ b/colossalai/shardformer/shard/shard_config.py\n@@ -7,7 +7,7 @@\n \n from colossalai.pipeline.stage_manager import PipelineStageManager\n \n-from .grad_ckpt_config import GradientCheckpointConfig\n+from .grad_ckpt_config import GradientCheckpointConfig, PipelineGradientCheckpointConfig\n \n __all__ = [\"ShardConfig\"]\n SUPPORT_SP_MODE = [\"split_gather\", \"ring\", \"all_to_all\"]\n@@ -30,6 +30,7 @@\n gradient_checkpoint_config (Optional[GradientCheckpointConfig]): The gradient checkpoint config. Defaults to None.\n enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.\n \"\"\"\n+\n tensor_parallel_process_group: Optional[ProcessGroup] = None\n sequence_parallel_process_group: Optional[ProcessGroup] = None\n pipeline_stage_manager: Optional[PipelineStageManager] = None\n@@ -104,6 +105,16 @@\n else:\n self._sequence_parallel_size = dist.get_world_size(self.sequence_parallel_process_group)\n \n+ if (\n+ self.pipeline_stage_manager is not None\n+ and isinstance(self.gradient_checkpoint_config, PipelineGradientCheckpointConfig)\n+ and self.gradient_checkpoint_config._customize_num_layers_per_stage\n+ ):\n+ self.pipeline_stage_manager.set_distribution_config(\n+ self.gradient_checkpoint_config.num_model_layers,\n+ self.gradient_checkpoint_config.num_layers_per_stage,\n+ )\n+\n def _turn_on_all_optimization(self):\n \"\"\"\n Turn on all optimization.\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import warnings\nfrom dataclasses import dataclass, field\nfrom typing import Any, Dict, Optional\n\nimport torch.distributed as dist\nfrom torch.distributed import ProcessGroup\n\nfrom colossalai.pipeline.stage_manager import PipelineStageManager\n\nfrom .grad_ckpt_config import GradientCheckpointConfig\n\n__all__ = [\"ShardConfig\"]\nSUPPORT_SP_MODE = [\"split_gather\", \"ring\", \"all_to_all\"]\n\n\n@dataclass\nclass ShardConfig:\n r\"\"\"\n The config for sharding the huggingface model\n\n Args:\n tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.\n pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.\n enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.\n enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.\n enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.\n enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.\n enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.\n enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.\n gradient_checkpoint_config (Optional[GradientCheckpointConfig]): The gradient checkpoint config. Defaults to None.\n enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.\n \"\"\"\n tensor_parallel_process_group: Optional[ProcessGroup] = None\n sequence_parallel_process_group: Optional[ProcessGroup] = None\n pipeline_stage_manager: Optional[PipelineStageManager] = None\n enable_tensor_parallelism: bool = True\n enable_all_optimization: bool = False\n enable_fused_normalization: bool = False\n enable_flash_attention: bool = False\n enable_jit_fused: bool = False\n enable_sequence_parallelism: bool = False\n sequence_parallelism_mode: str = None\n enable_sequence_overlap: bool = False\n parallel_output: bool = True\n make_vocab_size_divisible_by: int = 64\n gradient_checkpoint_config: Optional[GradientCheckpointConfig] = None\n extra_kwargs: Dict[str, Any] = field(default_factory=dict)\n # pipeline_parallel_size: int\n # data_parallel_size: int\n # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']\n\n @property\n def tensor_parallel_size(self):\n return self._tensor_parallel_size\n\n @property\n def sequence_parallel_size(self):\n return self._sequence_parallel_size\n\n def __post_init__(self):\n # turn on all optimization if all_optimization is set to True\n if self.enable_all_optimization:\n self._turn_on_all_optimization()\n\n if self.enable_sequence_parallelism:\n self.sequence_parallelism_mode = (\n \"split_gather\" if self.sequence_parallelism_mode is None else self.sequence_parallelism_mode\n )\n assert (\n self.sequence_parallelism_mode in SUPPORT_SP_MODE\n ), f\"Sequence parallelism mode {self.sequence_parallelism_mode} is not in the supported list {SUPPORT_SP_MODE}\"\n if self.sequence_parallelism_mode in [\"split_gather\", \"ring\"]:\n assert (\n self.enable_tensor_parallelism\n ), f\"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is True\"\n elif self.sequence_parallelism_mode in [\"all_to_all\"]:\n assert (\n not self.enable_tensor_parallelism\n ), f\"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is False\"\n if self.enable_sequence_overlap:\n self.enable_sequence_overlap = False\n warnings.warn(\n f\"The enable_sequence_overlap flag will be ignored in sequence parallelism mode {self.sequence_parallelism_mode}\"\n )\n else:\n if self.sequence_parallelism_mode:\n self.sequence_parallelism_mode = None\n warnings.warn(\n f\"The sequence_parallelism_mode will be ignored when enable_sequence_parallelism is False\"\n )\n assert (\n not self.enable_sequence_overlap\n ), f\"enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True\"\n\n # get the tensor parallel size\n if not self.enable_tensor_parallelism:\n self._tensor_parallel_size = 1\n else:\n self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)\n\n # get the sequence parallel size\n if not self.enable_sequence_parallelism:\n self._sequence_parallel_size = 1\n else:\n self._sequence_parallel_size = dist.get_world_size(self.sequence_parallel_process_group)\n\n def _turn_on_all_optimization(self):\n \"\"\"\n Turn on all optimization.\n \"\"\"\n # you can add all the optimization flag here\n self.enable_fused_normalization = True\n self.enable_flash_attention = True\n self.enable_jit_fused = True\n # This can cause non-in-place param sharding when used without ZeRO.\n # It may also slow down training when seq len is small. Plz enable manually.\n # self.enable_sequence_parallelism = True\n # self.enable_sequence_overlap = True\n\n def _infer(self):\n \"\"\"\n Set default params for inference.\n \"\"\"\n # assert self.pipeline_stage_manager is None, \"pipeline parallelism is not supported in inference for now\"\n", "path": "colossalai/shardformer/shard/shard_config.py"}, {"content": "from dataclasses import dataclass\nfrom typing import List, Optional\n\n\n@dataclass\nclass GradientCheckpointConfig:\n gradient_checkpointing_ratio: float = 0.0\n\n def get_num_ckpt_layers(self, num_layers: int) -> int:\n return int(self.gradient_checkpointing_ratio * num_layers)\n\n\n@dataclass\nclass PipelineGradientCheckpointConfig(GradientCheckpointConfig):\n r\"\"\"\n The pipeline gradient config is designed to provide more flexibility for users to control gradient checkpoint in pipeline parallelism.\n Combined with PipelineStageManager.set_distribution_config, user can fully control the distribution of layers and checkpointed layers in pipeline parallelism.\n Refer to https://github.com/hpcaitech/ColossalAI/issues/5509 for more details.\n\n It provides the following features:\n 1. `gradient_checkpointing_ratio`: This is used to control gradient checkpointing more precisely, e.g., set 50% of the layers to use gradient checkpointing.\n 2. Customize # ckpt layers assigned to each stage. This takes precedence over `gradient_checkpointing_ratio`.\n\n \"\"\"\n \"\"\"\n Args:\n gradient_checkpointing_ratio (Optional[float]): The ratio of gradient checkpointing. It can only be used in pipeline parallelism. Defaults to None.\n num_stages (Optional[int]): Number of stages in the pipeline. Defaults to None. For sanity check.\n num_model_chunks (Optional[int]): Number of model chunks (1F1B or Interleaved). Defaults to None. For sanity check.\n num_model_layers (Optional[int]): Number of model layers. Defaults to None. For sanity check.\n num_ckpt_layers_per_stage (Optional[List[int]]): Number of checkpointed layers for each stage. Defaults to None.\n\n Example 1:\n num_stages = 8\n num_layers = 80\n num_model_chunks = 1\n num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]\n num_ckpt_layers_per_stage = [4, 4, 2, 2, 0, 0, 0, 0]\n\n Example 2:\n num_stages = 4\n num_layers = 80\n num_model_chunks = 2\n num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]\n # device 0 holds num_layers_per_stage[0] and num_layers_per_stage[4] layers\n ...\n\n \"\"\"\n num_stages: Optional[int] = None\n num_model_chunks: Optional[int] = None\n num_model_layers: Optional[int] = None\n num_ckpt_layers_per_stage: Optional[List[int]] = None\n\n def __post_init__(self):\n if self._enable_gradient_checkpointing_ratio:\n if not (0 <= self.gradient_checkpointing_ratio <= 1):\n raise ValueError(\"gradient_checkpointing_ratio should be in 0% to 100%\")\n\n if self._enable_customized_ckpt_layers_per_stage:\n assert (\n self.num_stages is not None and self.num_model_chunks is not None and self.num_model_layers is not None\n )\n assert len(self.num_ckpt_layers_per_stage) == self.num_stages * self.num_model_chunks\n assert all(\n [0 <= num_ckpt_layers < self.num_model_layers for num_ckpt_layers in self.num_ckpt_layers_per_stage]\n )\n self.gradient_checkpointing_ratio = sum(self.num_ckpt_layers_per_stage) / self.num_model_layers\n\n @property\n def _enable_gradient_checkpointing_ratio(self) -> bool:\n return self.gradient_checkpointing_ratio is not None\n\n @property\n def _enable_customized_ckpt_layers_per_stage(self) -> bool:\n return self.num_ckpt_layers_per_stage is not None\n\n def get_num_ckpt_layers(self, stage: int, num_layers: int, model_chunk_id: int = 0) -> int:\n if not self._enable_gradient_checkpointing_ratio and not self._enable_customized_ckpt_layers_per_stage:\n raise RuntimeError(\"No checkpointed layers information is provided\")\n\n if self._enable_customized_ckpt_layers_per_stage:\n assert stage <= self.num_stages and model_chunk_id <= self.num_model_chunks\n num_ckpt_layers = self.num_ckpt_layers_per_stage[stage + model_chunk_id * self.num_stages]\n assert num_ckpt_layers <= num_layers\n return num_ckpt_layers\n else:\n return int(self.gradient_checkpointing_ratio * num_layers)\n", "path": "colossalai/shardformer/shard/grad_ckpt_config.py"}], "after_files": [{"content": "import warnings\nfrom dataclasses import dataclass, field\nfrom typing import Any, Dict, Optional\n\nimport torch.distributed as dist\nfrom torch.distributed import ProcessGroup\n\nfrom colossalai.pipeline.stage_manager import PipelineStageManager\n\nfrom .grad_ckpt_config import GradientCheckpointConfig, PipelineGradientCheckpointConfig\n\n__all__ = [\"ShardConfig\"]\nSUPPORT_SP_MODE = [\"split_gather\", \"ring\", \"all_to_all\"]\n\n\n@dataclass\nclass ShardConfig:\n r\"\"\"\n The config for sharding the huggingface model\n\n Args:\n tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.\n pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.\n enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.\n enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.\n enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.\n enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.\n enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.\n enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.\n gradient_checkpoint_config (Optional[GradientCheckpointConfig]): The gradient checkpoint config. Defaults to None.\n enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.\n \"\"\"\n\n tensor_parallel_process_group: Optional[ProcessGroup] = None\n sequence_parallel_process_group: Optional[ProcessGroup] = None\n pipeline_stage_manager: Optional[PipelineStageManager] = None\n enable_tensor_parallelism: bool = True\n enable_all_optimization: bool = False\n enable_fused_normalization: bool = False\n enable_flash_attention: bool = False\n enable_jit_fused: bool = False\n enable_sequence_parallelism: bool = False\n sequence_parallelism_mode: str = None\n enable_sequence_overlap: bool = False\n parallel_output: bool = True\n make_vocab_size_divisible_by: int = 64\n gradient_checkpoint_config: Optional[GradientCheckpointConfig] = None\n extra_kwargs: Dict[str, Any] = field(default_factory=dict)\n # pipeline_parallel_size: int\n # data_parallel_size: int\n # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']\n\n @property\n def tensor_parallel_size(self):\n return self._tensor_parallel_size\n\n @property\n def sequence_parallel_size(self):\n return self._sequence_parallel_size\n\n def __post_init__(self):\n # turn on all optimization if all_optimization is set to True\n if self.enable_all_optimization:\n self._turn_on_all_optimization()\n\n if self.enable_sequence_parallelism:\n self.sequence_parallelism_mode = (\n \"split_gather\" if self.sequence_parallelism_mode is None else self.sequence_parallelism_mode\n )\n assert (\n self.sequence_parallelism_mode in SUPPORT_SP_MODE\n ), f\"Sequence parallelism mode {self.sequence_parallelism_mode} is not in the supported list {SUPPORT_SP_MODE}\"\n if self.sequence_parallelism_mode in [\"split_gather\", \"ring\"]:\n assert (\n self.enable_tensor_parallelism\n ), f\"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is True\"\n elif self.sequence_parallelism_mode in [\"all_to_all\"]:\n assert (\n not self.enable_tensor_parallelism\n ), f\"sequence parallelism mode {self.sequence_parallelism_mode} can only be used when enable_tensor_parallelism is False\"\n if self.enable_sequence_overlap:\n self.enable_sequence_overlap = False\n warnings.warn(\n f\"The enable_sequence_overlap flag will be ignored in sequence parallelism mode {self.sequence_parallelism_mode}\"\n )\n else:\n if self.sequence_parallelism_mode:\n self.sequence_parallelism_mode = None\n warnings.warn(\n f\"The sequence_parallelism_mode will be ignored when enable_sequence_parallelism is False\"\n )\n assert (\n not self.enable_sequence_overlap\n ), f\"enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True\"\n\n # get the tensor parallel size\n if not self.enable_tensor_parallelism:\n self._tensor_parallel_size = 1\n else:\n self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)\n\n # get the sequence parallel size\n if not self.enable_sequence_parallelism:\n self._sequence_parallel_size = 1\n else:\n self._sequence_parallel_size = dist.get_world_size(self.sequence_parallel_process_group)\n\n if (\n self.pipeline_stage_manager is not None\n and isinstance(self.gradient_checkpoint_config, PipelineGradientCheckpointConfig)\n and self.gradient_checkpoint_config._customize_num_layers_per_stage\n ):\n self.pipeline_stage_manager.set_distribution_config(\n self.gradient_checkpoint_config.num_model_layers,\n self.gradient_checkpoint_config.num_layers_per_stage,\n )\n\n def _turn_on_all_optimization(self):\n \"\"\"\n Turn on all optimization.\n \"\"\"\n # you can add all the optimization flag here\n self.enable_fused_normalization = True\n self.enable_flash_attention = True\n self.enable_jit_fused = True\n # This can cause non-in-place param sharding when used without ZeRO.\n # It may also slow down training when seq len is small. Plz enable manually.\n # self.enable_sequence_parallelism = True\n # self.enable_sequence_overlap = True\n\n def _infer(self):\n \"\"\"\n Set default params for inference.\n \"\"\"\n # assert self.pipeline_stage_manager is None, \"pipeline parallelism is not supported in inference for now\"\n", "path": "colossalai/shardformer/shard/shard_config.py"}, {"content": "from dataclasses import dataclass\nfrom typing import List, Optional\n\n\n@dataclass\nclass GradientCheckpointConfig:\n gradient_checkpointing_ratio: float = 0.0\n\n def get_num_ckpt_layers(self, num_layers: int) -> int:\n return int(self.gradient_checkpointing_ratio * num_layers)\n\n\n@dataclass\nclass PipelineGradientCheckpointConfig(GradientCheckpointConfig):\n r\"\"\"\n The pipeline gradient config is designed to provide more flexibility for users to control gradient checkpoint in pipeline parallelism.\n Combined with PipelineStageManager.set_distribution_config, user can fully control the distribution of layers and checkpointed layers in pipeline parallelism.\n Refer to https://github.com/hpcaitech/ColossalAI/issues/5509 for more details.\n\n It provides the following features:\n 1. `gradient_checkpointing_ratio`: This is used to control gradient checkpointing more precisely, e.g., set 50% of the layers to use gradient checkpointing.\n 2. Customize # ckpt layers assigned to each stage. This takes precedence over `gradient_checkpointing_ratio`.\n\n \"\"\"\n\n \"\"\"\n Args:\n gradient_checkpointing_ratio (Optional[float]): The ratio of gradient checkpointing. It can only be used in pipeline parallelism. Defaults to None.\n num_stages (Optional[int]): Number of stages in the pipeline. Defaults to None. For sanity check.\n num_model_chunks (Optional[int]): Number of model chunks (1F1B or Interleaved). Defaults to None. For sanity check.\n num_model_layers (Optional[int]): Number of model layers. Defaults to None. For sanity check.\n num_ckpt_layers_per_stage (Optional[List[int]]): Number of checkpointed layers for each stage. Defaults to None.\n\n Example 1:\n num_stages = 8\n num_layers = 80\n num_model_chunks = 1\n num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]\n num_ckpt_layers_per_stage = [4, 4, 2, 2, 0, 0, 0, 0]\n\n Example 2:\n num_stages = 4\n num_layers = 80\n num_model_chunks = 2\n num_layers_per_stage = [9, 9, 9, 10, 11, 10, 11, 11]\n # device 0 holds num_layers_per_stage[0] and num_layers_per_stage[4] layers\n ...\n\n \"\"\"\n num_stages: Optional[int] = None\n num_model_chunks: Optional[int] = None\n num_model_layers: Optional[int] = None\n num_layers_per_stage: Optional[List[int]] = None\n num_ckpt_layers_per_stage: Optional[List[int]] = None\n\n def __post_init__(self):\n if self._enable_gradient_checkpointing_ratio:\n if not (0 <= self.gradient_checkpointing_ratio <= 1):\n raise ValueError(\"gradient_checkpointing_ratio should be in 0% to 100%\")\n\n if self._enable_customized_ckpt_layers_per_stage:\n assert (\n self.num_stages is not None and self.num_model_chunks is not None and self.num_model_layers is not None\n )\n assert len(self.num_ckpt_layers_per_stage) == self.num_stages * self.num_model_chunks\n assert all(\n [0 <= num_ckpt_layers < self.num_model_layers for num_ckpt_layers in self.num_ckpt_layers_per_stage]\n )\n self.gradient_checkpointing_ratio = sum(self.num_ckpt_layers_per_stage) / self.num_model_layers\n\n @property\n def _enable_gradient_checkpointing_ratio(self) -> bool:\n return self.gradient_checkpointing_ratio is not None\n\n @property\n def _customize_num_layers_per_stage(self) -> bool:\n return self.num_layers_per_stage is not None and self.num_model_layers is not None\n\n @property\n def _enable_customized_ckpt_layers_per_stage(self) -> bool:\n return self.num_ckpt_layers_per_stage is not None\n\n def get_num_ckpt_layers(self, stage: int, num_layers: int, model_chunk_id: int = 0) -> int:\n if not self._enable_gradient_checkpointing_ratio and not self._enable_customized_ckpt_layers_per_stage:\n raise RuntimeError(\"No checkpointed layers information is provided\")\n\n if self._enable_customized_ckpt_layers_per_stage:\n assert stage <= self.num_stages and model_chunk_id <= self.num_model_chunks\n num_ckpt_layers = self.num_ckpt_layers_per_stage[stage + model_chunk_id * self.num_stages]\n assert num_ckpt_layers <= num_layers\n return num_ckpt_layers\n else:\n return int(self.gradient_checkpointing_ratio * num_layers)\n", "path": "colossalai/shardformer/shard/grad_ckpt_config.py"}]}
| 3,026 | 735 |
gh_patches_debug_31975
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-535
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some pcx images are displayed incorrectly
Hi everyone!
I'm trying to use pcx images extracted from an old game (Might and Magic VI, the game has 2D UI over the 3D environment. This 2D UI is composed by various internal formats and pcx files.)
The problem is that one of these pcx is displayed incorrecly by pillow, while being displayed correctly by EyeOfGnome (gdk-pixbuf) image viewer.
Another pcx is displayed correctly by pillow!
What do I mean by incorrectly? The bad image has a kind of "red shift" of pixels colors. the left border is a bit red. It' like a "3D-ified" image, it's a bit blurry and the whole is a bit darker.
I opened the pcx files with an hex editor and the main difference I spotted in the pcx-header is that the wrong one has the "48 byte palette" field completely empty. while the other one has some data in it. But it shoudn't be a problem because other viewers display it correctly.
I simply use this code
img = Image.open(pcxfilename)
img.show()
this archive contains the pcx files https://db.tt/td291VTh
gdk-pixbuf decoding of pcx is a bit more complex than the pillow one:
gdk-pixbuf/io-pcx.c VS libImaging/PcxDecode.c
thanks for any help!

Some pcx images are displayed incorrectly
Hi everyone!
I'm trying to use pcx images extracted from an old game (Might and Magic VI, the game has 2D UI over the 3D environment. This 2D UI is composed by various internal formats and pcx files.)
The problem is that one of these pcx is displayed incorrecly by pillow, while being displayed correctly by EyeOfGnome (gdk-pixbuf) image viewer.
Another pcx is displayed correctly by pillow!
What do I mean by incorrectly? The bad image has a kind of "red shift" of pixels colors. the left border is a bit red. It' like a "3D-ified" image, it's a bit blurry and the whole is a bit darker.
I opened the pcx files with an hex editor and the main difference I spotted in the pcx-header is that the wrong one has the "48 byte palette" field completely empty. while the other one has some data in it. But it shoudn't be a problem because other viewers display it correctly.
I simply use this code
img = Image.open(pcxfilename)
img.show()
this archive contains the pcx files https://db.tt/td291VTh
gdk-pixbuf decoding of pcx is a bit more complex than the pillow one:
gdk-pixbuf/io-pcx.c VS libImaging/PcxDecode.c
thanks for any help!

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PIL/PcxImagePlugin.py`
Content:
```
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # PCX file handling
6 #
7 # This format was originally used by ZSoft's popular PaintBrush
8 # program for the IBM PC. It is also supported by many MS-DOS and
9 # Windows applications, including the Windows PaintBrush program in
10 # Windows 3.
11 #
12 # history:
13 # 1995-09-01 fl Created
14 # 1996-05-20 fl Fixed RGB support
15 # 1997-01-03 fl Fixed 2-bit and 4-bit support
16 # 1999-02-03 fl Fixed 8-bit support (broken in 1.0b1)
17 # 1999-02-07 fl Added write support
18 # 2002-06-09 fl Made 2-bit and 4-bit support a bit more robust
19 # 2002-07-30 fl Seek from to current position, not beginning of file
20 # 2003-06-03 fl Extract DPI settings (info["dpi"])
21 #
22 # Copyright (c) 1997-2003 by Secret Labs AB.
23 # Copyright (c) 1995-2003 by Fredrik Lundh.
24 #
25 # See the README file for information on usage and redistribution.
26 #
27
28 __version__ = "0.6"
29
30 from PIL import Image, ImageFile, ImagePalette, _binary
31
32 i8 = _binary.i8
33 i16 = _binary.i16le
34 o8 = _binary.o8
35
36 def _accept(prefix):
37 return i8(prefix[0]) == 10 and i8(prefix[1]) in [0, 2, 3, 5]
38
39 ##
40 # Image plugin for Paintbrush images.
41
42 class PcxImageFile(ImageFile.ImageFile):
43
44 format = "PCX"
45 format_description = "Paintbrush"
46
47 def _open(self):
48
49 # header
50 s = self.fp.read(128)
51 if not _accept(s):
52 raise SyntaxError("not a PCX file")
53
54 # image
55 bbox = i16(s,4), i16(s,6), i16(s,8)+1, i16(s,10)+1
56 if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:
57 raise SyntaxError("bad PCX image size")
58
59 # format
60 version = i8(s[1])
61 bits = i8(s[3])
62 planes = i8(s[65])
63 stride = i16(s,66)
64
65 self.info["dpi"] = i16(s,12), i16(s,14)
66
67 if bits == 1 and planes == 1:
68 mode = rawmode = "1"
69
70 elif bits == 1 and planes in (2, 4):
71 mode = "P"
72 rawmode = "P;%dL" % planes
73 self.palette = ImagePalette.raw("RGB", s[16:64])
74
75 elif version == 5 and bits == 8 and planes == 1:
76 mode = rawmode = "L"
77 # FIXME: hey, this doesn't work with the incremental loader !!!
78 self.fp.seek(-769, 2)
79 s = self.fp.read(769)
80 if len(s) == 769 and i8(s[0]) == 12:
81 # check if the palette is linear greyscale
82 for i in range(256):
83 if s[i*3+1:i*3+4] != o8(i)*3:
84 mode = rawmode = "P"
85 break
86 if mode == "P":
87 self.palette = ImagePalette.raw("RGB", s[1:])
88 self.fp.seek(128)
89
90 elif version == 5 and bits == 8 and planes == 3:
91 mode = "RGB"
92 rawmode = "RGB;L"
93
94 else:
95 raise IOError("unknown PCX mode")
96
97 self.mode = mode
98 self.size = bbox[2]-bbox[0], bbox[3]-bbox[1]
99
100 bbox = (0, 0) + self.size
101
102 self.tile = [("pcx", bbox, self.fp.tell(), (rawmode, planes * stride))]
103
104 # --------------------------------------------------------------------
105 # save PCX files
106
107 SAVE = {
108 # mode: (version, bits, planes, raw mode)
109 "1": (2, 1, 1, "1"),
110 "L": (5, 8, 1, "L"),
111 "P": (5, 8, 1, "P"),
112 "RGB": (5, 8, 3, "RGB;L"),
113 }
114
115 o16 = _binary.o16le
116
117 def _save(im, fp, filename, check=0):
118
119 try:
120 version, bits, planes, rawmode = SAVE[im.mode]
121 except KeyError:
122 raise ValueError("Cannot save %s images as PCX" % im.mode)
123
124 if check:
125 return check
126
127 # bytes per plane
128 stride = (im.size[0] * bits + 7) // 8
129
130 # under windows, we could determine the current screen size with
131 # "Image.core.display_mode()[1]", but I think that's overkill...
132
133 screen = im.size
134
135 dpi = 100, 100
136
137 # PCX header
138 fp.write(
139 o8(10) + o8(version) + o8(1) + o8(bits) + o16(0) +
140 o16(0) + o16(im.size[0]-1) + o16(im.size[1]-1) + o16(dpi[0]) +
141 o16(dpi[1]) + b"\0"*24 + b"\xFF"*24 + b"\0" + o8(planes) +
142 o16(stride) + o16(1) + o16(screen[0]) + o16(screen[1]) +
143 b"\0"*54
144 )
145
146 assert fp.tell() == 128
147
148 ImageFile._save(im, fp, [("pcx", (0,0)+im.size, 0,
149 (rawmode, bits*planes))])
150
151 if im.mode == "P":
152 # colour palette
153 fp.write(o8(12))
154 fp.write(im.im.getpalette("RGB", "RGB")) # 768 bytes
155 elif im.mode == "L":
156 # greyscale palette
157 fp.write(o8(12))
158 for i in range(256):
159 fp.write(o8(i)*3)
160
161 # --------------------------------------------------------------------
162 # registry
163
164 Image.register_open("PCX", PcxImageFile, _accept)
165 Image.register_save("PCX", _save)
166
167 Image.register_extension("PCX", ".pcx")
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PIL/PcxImagePlugin.py b/PIL/PcxImagePlugin.py
--- a/PIL/PcxImagePlugin.py
+++ b/PIL/PcxImagePlugin.py
@@ -55,12 +55,18 @@
bbox = i16(s,4), i16(s,6), i16(s,8)+1, i16(s,10)+1
if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:
raise SyntaxError("bad PCX image size")
+ if Image.DEBUG:
+ print ("BBox: %s %s %s %s" % bbox)
+
# format
version = i8(s[1])
bits = i8(s[3])
planes = i8(s[65])
stride = i16(s,66)
+ if Image.DEBUG:
+ print ("PCX version %s, bits %s, planes %s, stride %s" %
+ (version, bits, planes, stride))
self.info["dpi"] = i16(s,12), i16(s,14)
@@ -98,7 +104,9 @@
self.size = bbox[2]-bbox[0], bbox[3]-bbox[1]
bbox = (0, 0) + self.size
-
+ if Image.DEBUG:
+ print ("size: %sx%s" % self.size)
+
self.tile = [("pcx", bbox, self.fp.tell(), (rawmode, planes * stride))]
# --------------------------------------------------------------------
@@ -126,6 +134,16 @@
# bytes per plane
stride = (im.size[0] * bits + 7) // 8
+ # stride should be even
+ stride = stride + (stride % 2)
+ # Stride needs to be kept in sync with the PcxEncode.c version.
+ # Ideally it should be passed in in the state, but the bytes value
+ # gets overwritten.
+
+
+ if Image.DEBUG:
+ print ("PcxImagePlugin._save: xwidth: %d, bits: %d, stride: %d" % (
+ im.size[0], bits, stride))
# under windows, we could determine the current screen size with
# "Image.core.display_mode()[1]", but I think that's overkill...
|
{"golden_diff": "diff --git a/PIL/PcxImagePlugin.py b/PIL/PcxImagePlugin.py\n--- a/PIL/PcxImagePlugin.py\n+++ b/PIL/PcxImagePlugin.py\n@@ -55,12 +55,18 @@\n bbox = i16(s,4), i16(s,6), i16(s,8)+1, i16(s,10)+1\n if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:\n raise SyntaxError(\"bad PCX image size\")\n+ if Image.DEBUG:\n+ print (\"BBox: %s %s %s %s\" % bbox)\n+\n \n # format\n version = i8(s[1])\n bits = i8(s[3])\n planes = i8(s[65])\n stride = i16(s,66)\n+ if Image.DEBUG:\n+ print (\"PCX version %s, bits %s, planes %s, stride %s\" %\n+ (version, bits, planes, stride))\n \n self.info[\"dpi\"] = i16(s,12), i16(s,14)\n \n@@ -98,7 +104,9 @@\n self.size = bbox[2]-bbox[0], bbox[3]-bbox[1]\n \n bbox = (0, 0) + self.size\n-\n+ if Image.DEBUG:\n+ print (\"size: %sx%s\" % self.size)\n+ \n self.tile = [(\"pcx\", bbox, self.fp.tell(), (rawmode, planes * stride))]\n \n # --------------------------------------------------------------------\n@@ -126,6 +134,16 @@\n \n # bytes per plane\n stride = (im.size[0] * bits + 7) // 8\n+ # stride should be even\n+ stride = stride + (stride % 2)\n+ # Stride needs to be kept in sync with the PcxEncode.c version.\n+ # Ideally it should be passed in in the state, but the bytes value\n+ # gets overwritten. \n+\n+\n+ if Image.DEBUG:\n+ print (\"PcxImagePlugin._save: xwidth: %d, bits: %d, stride: %d\" % (\n+ im.size[0], bits, stride))\n \n # under windows, we could determine the current screen size with\n # \"Image.core.display_mode()[1]\", but I think that's overkill...\n", "issue": "Some pcx images are displayed incorrectly\nHi everyone!\nI'm trying to use pcx images extracted from an old game (Might and Magic VI, the game has 2D UI over the 3D environment. This 2D UI is composed by various internal formats and pcx files.)\n\nThe problem is that one of these pcx is displayed incorrecly by pillow, while being displayed correctly by EyeOfGnome (gdk-pixbuf) image viewer.\nAnother pcx is displayed correctly by pillow!\n\nWhat do I mean by incorrectly? The bad image has a kind of \"red shift\" of pixels colors. the left border is a bit red. It' like a \"3D-ified\" image, it's a bit blurry and the whole is a bit darker.\n\nI opened the pcx files with an hex editor and the main difference I spotted in the pcx-header is that the wrong one has the \"48 byte palette\" field completely empty. while the other one has some data in it. But it shoudn't be a problem because other viewers display it correctly.\n\nI simply use this code\nimg = Image.open(pcxfilename)\nimg.show()\n\nthis archive contains the pcx files https://db.tt/td291VTh\n\ngdk-pixbuf decoding of pcx is a bit more complex than the pillow one:\ngdk-pixbuf/io-pcx.c VS libImaging/PcxDecode.c\n\nthanks for any help!\n\n\n\nSome pcx images are displayed incorrectly\nHi everyone!\nI'm trying to use pcx images extracted from an old game (Might and Magic VI, the game has 2D UI over the 3D environment. This 2D UI is composed by various internal formats and pcx files.)\n\nThe problem is that one of these pcx is displayed incorrecly by pillow, while being displayed correctly by EyeOfGnome (gdk-pixbuf) image viewer.\nAnother pcx is displayed correctly by pillow!\n\nWhat do I mean by incorrectly? The bad image has a kind of \"red shift\" of pixels colors. the left border is a bit red. It' like a \"3D-ified\" image, it's a bit blurry and the whole is a bit darker.\n\nI opened the pcx files with an hex editor and the main difference I spotted in the pcx-header is that the wrong one has the \"48 byte palette\" field completely empty. while the other one has some data in it. But it shoudn't be a problem because other viewers display it correctly.\n\nI simply use this code\nimg = Image.open(pcxfilename)\nimg.show()\n\nthis archive contains the pcx files https://db.tt/td291VTh\n\ngdk-pixbuf decoding of pcx is a bit more complex than the pillow one:\ngdk-pixbuf/io-pcx.c VS libImaging/PcxDecode.c\n\nthanks for any help!\n\n\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# PCX file handling\n#\n# This format was originally used by ZSoft's popular PaintBrush\n# program for the IBM PC. It is also supported by many MS-DOS and\n# Windows applications, including the Windows PaintBrush program in\n# Windows 3.\n#\n# history:\n# 1995-09-01 fl Created\n# 1996-05-20 fl Fixed RGB support\n# 1997-01-03 fl Fixed 2-bit and 4-bit support\n# 1999-02-03 fl Fixed 8-bit support (broken in 1.0b1)\n# 1999-02-07 fl Added write support\n# 2002-06-09 fl Made 2-bit and 4-bit support a bit more robust\n# 2002-07-30 fl Seek from to current position, not beginning of file\n# 2003-06-03 fl Extract DPI settings (info[\"dpi\"])\n#\n# Copyright (c) 1997-2003 by Secret Labs AB.\n# Copyright (c) 1995-2003 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n__version__ = \"0.6\"\n\nfrom PIL import Image, ImageFile, ImagePalette, _binary\n\ni8 = _binary.i8\ni16 = _binary.i16le\no8 = _binary.o8\n\ndef _accept(prefix):\n return i8(prefix[0]) == 10 and i8(prefix[1]) in [0, 2, 3, 5]\n\n##\n# Image plugin for Paintbrush images.\n\nclass PcxImageFile(ImageFile.ImageFile):\n\n format = \"PCX\"\n format_description = \"Paintbrush\"\n\n def _open(self):\n\n # header\n s = self.fp.read(128)\n if not _accept(s):\n raise SyntaxError(\"not a PCX file\")\n\n # image\n bbox = i16(s,4), i16(s,6), i16(s,8)+1, i16(s,10)+1\n if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:\n raise SyntaxError(\"bad PCX image size\")\n\n # format\n version = i8(s[1])\n bits = i8(s[3])\n planes = i8(s[65])\n stride = i16(s,66)\n\n self.info[\"dpi\"] = i16(s,12), i16(s,14)\n\n if bits == 1 and planes == 1:\n mode = rawmode = \"1\"\n\n elif bits == 1 and planes in (2, 4):\n mode = \"P\"\n rawmode = \"P;%dL\" % planes\n self.palette = ImagePalette.raw(\"RGB\", s[16:64])\n\n elif version == 5 and bits == 8 and planes == 1:\n mode = rawmode = \"L\"\n # FIXME: hey, this doesn't work with the incremental loader !!!\n self.fp.seek(-769, 2)\n s = self.fp.read(769)\n if len(s) == 769 and i8(s[0]) == 12:\n # check if the palette is linear greyscale\n for i in range(256):\n if s[i*3+1:i*3+4] != o8(i)*3:\n mode = rawmode = \"P\"\n break\n if mode == \"P\":\n self.palette = ImagePalette.raw(\"RGB\", s[1:])\n self.fp.seek(128)\n\n elif version == 5 and bits == 8 and planes == 3:\n mode = \"RGB\"\n rawmode = \"RGB;L\"\n\n else:\n raise IOError(\"unknown PCX mode\")\n\n self.mode = mode\n self.size = bbox[2]-bbox[0], bbox[3]-bbox[1]\n\n bbox = (0, 0) + self.size\n\n self.tile = [(\"pcx\", bbox, self.fp.tell(), (rawmode, planes * stride))]\n\n# --------------------------------------------------------------------\n# save PCX files\n\nSAVE = {\n # mode: (version, bits, planes, raw mode)\n \"1\": (2, 1, 1, \"1\"),\n \"L\": (5, 8, 1, \"L\"),\n \"P\": (5, 8, 1, \"P\"),\n \"RGB\": (5, 8, 3, \"RGB;L\"),\n}\n\no16 = _binary.o16le\n\ndef _save(im, fp, filename, check=0):\n\n try:\n version, bits, planes, rawmode = SAVE[im.mode]\n except KeyError:\n raise ValueError(\"Cannot save %s images as PCX\" % im.mode)\n\n if check:\n return check\n\n # bytes per plane\n stride = (im.size[0] * bits + 7) // 8\n\n # under windows, we could determine the current screen size with\n # \"Image.core.display_mode()[1]\", but I think that's overkill...\n\n screen = im.size\n\n dpi = 100, 100\n\n # PCX header\n fp.write(\n o8(10) + o8(version) + o8(1) + o8(bits) + o16(0) +\n o16(0) + o16(im.size[0]-1) + o16(im.size[1]-1) + o16(dpi[0]) +\n o16(dpi[1]) + b\"\\0\"*24 + b\"\\xFF\"*24 + b\"\\0\" + o8(planes) +\n o16(stride) + o16(1) + o16(screen[0]) + o16(screen[1]) +\n b\"\\0\"*54\n )\n\n assert fp.tell() == 128\n\n ImageFile._save(im, fp, [(\"pcx\", (0,0)+im.size, 0,\n (rawmode, bits*planes))])\n\n if im.mode == \"P\":\n # colour palette\n fp.write(o8(12))\n fp.write(im.im.getpalette(\"RGB\", \"RGB\")) # 768 bytes\n elif im.mode == \"L\":\n # greyscale palette\n fp.write(o8(12))\n for i in range(256):\n fp.write(o8(i)*3)\n\n# --------------------------------------------------------------------\n# registry\n\nImage.register_open(\"PCX\", PcxImageFile, _accept)\nImage.register_save(\"PCX\", _save)\n\nImage.register_extension(\"PCX\", \".pcx\")\n", "path": "PIL/PcxImagePlugin.py"}], "after_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# PCX file handling\n#\n# This format was originally used by ZSoft's popular PaintBrush\n# program for the IBM PC. It is also supported by many MS-DOS and\n# Windows applications, including the Windows PaintBrush program in\n# Windows 3.\n#\n# history:\n# 1995-09-01 fl Created\n# 1996-05-20 fl Fixed RGB support\n# 1997-01-03 fl Fixed 2-bit and 4-bit support\n# 1999-02-03 fl Fixed 8-bit support (broken in 1.0b1)\n# 1999-02-07 fl Added write support\n# 2002-06-09 fl Made 2-bit and 4-bit support a bit more robust\n# 2002-07-30 fl Seek from to current position, not beginning of file\n# 2003-06-03 fl Extract DPI settings (info[\"dpi\"])\n#\n# Copyright (c) 1997-2003 by Secret Labs AB.\n# Copyright (c) 1995-2003 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n__version__ = \"0.6\"\n\nfrom PIL import Image, ImageFile, ImagePalette, _binary\n\ni8 = _binary.i8\ni16 = _binary.i16le\no8 = _binary.o8\n\ndef _accept(prefix):\n return i8(prefix[0]) == 10 and i8(prefix[1]) in [0, 2, 3, 5]\n\n##\n# Image plugin for Paintbrush images.\n\nclass PcxImageFile(ImageFile.ImageFile):\n\n format = \"PCX\"\n format_description = \"Paintbrush\"\n\n def _open(self):\n\n # header\n s = self.fp.read(128)\n if not _accept(s):\n raise SyntaxError(\"not a PCX file\")\n\n # image\n bbox = i16(s,4), i16(s,6), i16(s,8)+1, i16(s,10)+1\n if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:\n raise SyntaxError(\"bad PCX image size\")\n if Image.DEBUG:\n print (\"BBox: %s %s %s %s\" % bbox)\n\n\n # format\n version = i8(s[1])\n bits = i8(s[3])\n planes = i8(s[65])\n stride = i16(s,66)\n if Image.DEBUG:\n print (\"PCX version %s, bits %s, planes %s, stride %s\" %\n (version, bits, planes, stride))\n\n self.info[\"dpi\"] = i16(s,12), i16(s,14)\n\n if bits == 1 and planes == 1:\n mode = rawmode = \"1\"\n\n elif bits == 1 and planes in (2, 4):\n mode = \"P\"\n rawmode = \"P;%dL\" % planes\n self.palette = ImagePalette.raw(\"RGB\", s[16:64])\n\n elif version == 5 and bits == 8 and planes == 1:\n mode = rawmode = \"L\"\n # FIXME: hey, this doesn't work with the incremental loader !!!\n self.fp.seek(-769, 2)\n s = self.fp.read(769)\n if len(s) == 769 and i8(s[0]) == 12:\n # check if the palette is linear greyscale\n for i in range(256):\n if s[i*3+1:i*3+4] != o8(i)*3:\n mode = rawmode = \"P\"\n break\n if mode == \"P\":\n self.palette = ImagePalette.raw(\"RGB\", s[1:])\n self.fp.seek(128)\n\n elif version == 5 and bits == 8 and planes == 3:\n mode = \"RGB\"\n rawmode = \"RGB;L\"\n\n else:\n raise IOError(\"unknown PCX mode\")\n\n self.mode = mode\n self.size = bbox[2]-bbox[0], bbox[3]-bbox[1]\n\n bbox = (0, 0) + self.size\n if Image.DEBUG:\n print (\"size: %sx%s\" % self.size)\n \n self.tile = [(\"pcx\", bbox, self.fp.tell(), (rawmode, planes * stride))]\n\n# --------------------------------------------------------------------\n# save PCX files\n\nSAVE = {\n # mode: (version, bits, planes, raw mode)\n \"1\": (2, 1, 1, \"1\"),\n \"L\": (5, 8, 1, \"L\"),\n \"P\": (5, 8, 1, \"P\"),\n \"RGB\": (5, 8, 3, \"RGB;L\"),\n}\n\no16 = _binary.o16le\n\ndef _save(im, fp, filename, check=0):\n\n try:\n version, bits, planes, rawmode = SAVE[im.mode]\n except KeyError:\n raise ValueError(\"Cannot save %s images as PCX\" % im.mode)\n\n if check:\n return check\n\n # bytes per plane\n stride = (im.size[0] * bits + 7) // 8\n # stride should be even\n stride = stride + (stride % 2)\n # Stride needs to be kept in sync with the PcxEncode.c version.\n # Ideally it should be passed in in the state, but the bytes value\n # gets overwritten. \n\n\n if Image.DEBUG:\n print (\"PcxImagePlugin._save: xwidth: %d, bits: %d, stride: %d\" % (\n im.size[0], bits, stride))\n\n # under windows, we could determine the current screen size with\n # \"Image.core.display_mode()[1]\", but I think that's overkill...\n\n screen = im.size\n\n dpi = 100, 100\n\n # PCX header\n fp.write(\n o8(10) + o8(version) + o8(1) + o8(bits) + o16(0) +\n o16(0) + o16(im.size[0]-1) + o16(im.size[1]-1) + o16(dpi[0]) +\n o16(dpi[1]) + b\"\\0\"*24 + b\"\\xFF\"*24 + b\"\\0\" + o8(planes) +\n o16(stride) + o16(1) + o16(screen[0]) + o16(screen[1]) +\n b\"\\0\"*54\n )\n\n assert fp.tell() == 128\n\n ImageFile._save(im, fp, [(\"pcx\", (0,0)+im.size, 0,\n (rawmode, bits*planes))])\n\n if im.mode == \"P\":\n # colour palette\n fp.write(o8(12))\n fp.write(im.im.getpalette(\"RGB\", \"RGB\")) # 768 bytes\n elif im.mode == \"L\":\n # greyscale palette\n fp.write(o8(12))\n for i in range(256):\n fp.write(o8(i)*3)\n\n# --------------------------------------------------------------------\n# registry\n\nImage.register_open(\"PCX\", PcxImageFile, _accept)\nImage.register_save(\"PCX\", _save)\n\nImage.register_extension(\"PCX\", \".pcx\")\n", "path": "PIL/PcxImagePlugin.py"}]}
| 2,945 | 539 |
gh_patches_debug_32429
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-1117
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
access log format is invalid when using gunicorn worker
It seems you have to pass in `--access-logformat='%a %l %u %t "%r" %s %b "%{Referrer}i" "%{User-Agent}i"'` to gunicorn for logging to work, they default format from gunicorn is `"%(h)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s"` which doesn't work with aiohttp
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aiohttp/worker.py`
Content:
```
1 """Async gunicorn worker for aiohttp.web"""
2
3 import asyncio
4 import os
5 import signal
6 import ssl
7 import sys
8
9 import gunicorn.workers.base as base
10
11 from aiohttp.helpers import ensure_future
12
13 __all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')
14
15
16 class GunicornWebWorker(base.Worker):
17
18 def __init__(self, *args, **kw): # pragma: no cover
19 super().__init__(*args, **kw)
20
21 self.servers = {}
22 self.exit_code = 0
23
24 def init_process(self):
25 # create new event_loop after fork
26 asyncio.get_event_loop().close()
27
28 self.loop = asyncio.new_event_loop()
29 asyncio.set_event_loop(self.loop)
30
31 super().init_process()
32
33 def run(self):
34 self.loop.run_until_complete(self.wsgi.startup())
35 self._runner = ensure_future(self._run(), loop=self.loop)
36
37 try:
38 self.loop.run_until_complete(self._runner)
39 finally:
40 self.loop.close()
41
42 sys.exit(self.exit_code)
43
44 def make_handler(self, app):
45 return app.make_handler(
46 logger=self.log,
47 debug=self.cfg.debug,
48 timeout=self.cfg.timeout,
49 keep_alive=self.cfg.keepalive,
50 access_log=self.log.access_log,
51 access_log_format=self.cfg.access_log_format)
52
53 @asyncio.coroutine
54 def close(self):
55 if self.servers:
56 servers = self.servers
57 self.servers = None
58
59 # stop accepting connections
60 for server, handler in servers.items():
61 self.log.info("Stopping server: %s, connections: %s",
62 self.pid, len(handler.connections))
63 server.close()
64 yield from server.wait_closed()
65
66 # send on_shutdown event
67 yield from self.wsgi.shutdown()
68
69 # stop alive connections
70 tasks = [
71 handler.finish_connections(
72 timeout=self.cfg.graceful_timeout / 100 * 95)
73 for handler in servers.values()]
74 yield from asyncio.gather(*tasks, loop=self.loop)
75
76 # cleanup application
77 yield from self.wsgi.cleanup()
78
79 @asyncio.coroutine
80 def _run(self):
81
82 ctx = self._create_ssl_context(self.cfg) if self.cfg.is_ssl else None
83
84 for sock in self.sockets:
85 handler = self.make_handler(self.wsgi)
86 srv = yield from self.loop.create_server(handler, sock=sock.sock,
87 ssl=ctx)
88 self.servers[srv] = handler
89
90 # If our parent changed then we shut down.
91 pid = os.getpid()
92 try:
93 while self.alive:
94 self.notify()
95
96 cnt = sum(handler.requests_count
97 for handler in self.servers.values())
98 if self.cfg.max_requests and cnt > self.cfg.max_requests:
99 self.alive = False
100 self.log.info("Max requests, shutting down: %s", self)
101
102 elif pid == os.getpid() and self.ppid != os.getppid():
103 self.alive = False
104 self.log.info("Parent changed, shutting down: %s", self)
105 else:
106 yield from asyncio.sleep(1.0, loop=self.loop)
107
108 except BaseException:
109 pass
110
111 yield from self.close()
112
113 def init_signals(self):
114 # Set up signals through the event loop API.
115
116 self.loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,
117 signal.SIGQUIT, None)
118
119 self.loop.add_signal_handler(signal.SIGTERM, self.handle_exit,
120 signal.SIGTERM, None)
121
122 self.loop.add_signal_handler(signal.SIGINT, self.handle_quit,
123 signal.SIGINT, None)
124
125 self.loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,
126 signal.SIGWINCH, None)
127
128 self.loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,
129 signal.SIGUSR1, None)
130
131 self.loop.add_signal_handler(signal.SIGABRT, self.handle_abort,
132 signal.SIGABRT, None)
133
134 # Don't let SIGTERM and SIGUSR1 disturb active requests
135 # by interrupting system calls
136 signal.siginterrupt(signal.SIGTERM, False)
137 signal.siginterrupt(signal.SIGUSR1, False)
138
139 def handle_quit(self, sig, frame):
140 self.alive = False
141
142 def handle_abort(self, sig, frame):
143 self.alive = False
144 self.exit_code = 1
145
146 @staticmethod
147 def _create_ssl_context(cfg):
148 """ Creates SSLContext instance for usage in asyncio.create_server.
149
150 See ssl.SSLSocket.__init__ for more details.
151 """
152 ctx = ssl.SSLContext(cfg.ssl_version)
153 ctx.load_cert_chain(cfg.certfile, cfg.keyfile)
154 ctx.verify_mode = cfg.cert_reqs
155 if cfg.ca_certs:
156 ctx.load_verify_locations(cfg.ca_certs)
157 if cfg.ciphers:
158 ctx.set_ciphers(cfg.ciphers)
159 return ctx
160
161
162 class GunicornUVLoopWebWorker(GunicornWebWorker):
163
164 def init_process(self):
165 import uvloop
166
167 # Close any existing event loop before setting a
168 # new policy.
169 asyncio.get_event_loop().close()
170
171 # Setup uvloop policy, so that every
172 # asyncio.get_event_loop() will create an instance
173 # of uvloop event loop.
174 asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
175
176 super().init_process()
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/aiohttp/worker.py b/aiohttp/worker.py
--- a/aiohttp/worker.py
+++ b/aiohttp/worker.py
@@ -2,19 +2,24 @@
import asyncio
import os
+import re
import signal
import ssl
import sys
import gunicorn.workers.base as base
-from aiohttp.helpers import ensure_future
+from gunicorn.config import AccessLogFormat as GunicornAccessLogFormat
+from aiohttp.helpers import AccessLogger, ensure_future
__all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')
class GunicornWebWorker(base.Worker):
+ DEFAULT_AIOHTTP_LOG_FORMAT = AccessLogger.LOG_FORMAT
+ DEFAULT_GUNICORN_LOG_FORMAT = GunicornAccessLogFormat.default
+
def __init__(self, *args, **kw): # pragma: no cover
super().__init__(*args, **kw)
@@ -48,7 +53,8 @@
timeout=self.cfg.timeout,
keep_alive=self.cfg.keepalive,
access_log=self.log.access_log,
- access_log_format=self.cfg.access_log_format)
+ access_log_format=self._get_valid_log_format(
+ self.cfg.access_log_format))
@asyncio.coroutine
def close(self):
@@ -158,6 +164,20 @@
ctx.set_ciphers(cfg.ciphers)
return ctx
+ def _get_valid_log_format(self, source_format):
+ if source_format == self.DEFAULT_GUNICORN_LOG_FORMAT:
+ return self.DEFAULT_AIOHTTP_LOG_FORMAT
+ elif re.search(r'%\([^\)]+\)', source_format):
+ raise ValueError(
+ "Gunicorn's style options in form of `%(name)s` are not "
+ "supported for the log formatting. Please use aiohttp's "
+ "format specification to configure access log formatting: "
+ "http://aiohttp.readthedocs.io/en/stable/logging.html"
+ "#format-specification"
+ )
+ else:
+ return source_format
+
class GunicornUVLoopWebWorker(GunicornWebWorker):
|
{"golden_diff": "diff --git a/aiohttp/worker.py b/aiohttp/worker.py\n--- a/aiohttp/worker.py\n+++ b/aiohttp/worker.py\n@@ -2,19 +2,24 @@\n \n import asyncio\n import os\n+import re\n import signal\n import ssl\n import sys\n \n import gunicorn.workers.base as base\n \n-from aiohttp.helpers import ensure_future\n+from gunicorn.config import AccessLogFormat as GunicornAccessLogFormat\n+from aiohttp.helpers import AccessLogger, ensure_future\n \n __all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')\n \n \n class GunicornWebWorker(base.Worker):\n \n+ DEFAULT_AIOHTTP_LOG_FORMAT = AccessLogger.LOG_FORMAT\n+ DEFAULT_GUNICORN_LOG_FORMAT = GunicornAccessLogFormat.default\n+\n def __init__(self, *args, **kw): # pragma: no cover\n super().__init__(*args, **kw)\n \n@@ -48,7 +53,8 @@\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n- access_log_format=self.cfg.access_log_format)\n+ access_log_format=self._get_valid_log_format(\n+ self.cfg.access_log_format))\n \n @asyncio.coroutine\n def close(self):\n@@ -158,6 +164,20 @@\n ctx.set_ciphers(cfg.ciphers)\n return ctx\n \n+ def _get_valid_log_format(self, source_format):\n+ if source_format == self.DEFAULT_GUNICORN_LOG_FORMAT:\n+ return self.DEFAULT_AIOHTTP_LOG_FORMAT\n+ elif re.search(r'%\\([^\\)]+\\)', source_format):\n+ raise ValueError(\n+ \"Gunicorn's style options in form of `%(name)s` are not \"\n+ \"supported for the log formatting. Please use aiohttp's \"\n+ \"format specification to configure access log formatting: \"\n+ \"http://aiohttp.readthedocs.io/en/stable/logging.html\"\n+ \"#format-specification\"\n+ )\n+ else:\n+ return source_format\n+\n \n class GunicornUVLoopWebWorker(GunicornWebWorker):\n", "issue": "access log format is invalid when using gunicorn worker\nIt seems you have to pass in `--access-logformat='%a %l %u %t \"%r\" %s %b \"%{Referrer}i\" \"%{User-Agent}i\"'` to gunicorn for logging to work, they default format from gunicorn is `\"%(h)s %(l)s %(u)s %(t)s \"%(r)s\" %(s)s %(b)s \"%(f)s\" \"%(a)s\"` which doesn't work with aiohttp\n\n", "before_files": [{"content": "\"\"\"Async gunicorn worker for aiohttp.web\"\"\"\n\nimport asyncio\nimport os\nimport signal\nimport ssl\nimport sys\n\nimport gunicorn.workers.base as base\n\nfrom aiohttp.helpers import ensure_future\n\n__all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')\n\n\nclass GunicornWebWorker(base.Worker):\n\n def __init__(self, *args, **kw): # pragma: no cover\n super().__init__(*args, **kw)\n\n self.servers = {}\n self.exit_code = 0\n\n def init_process(self):\n # create new event_loop after fork\n asyncio.get_event_loop().close()\n\n self.loop = asyncio.new_event_loop()\n asyncio.set_event_loop(self.loop)\n\n super().init_process()\n\n def run(self):\n self.loop.run_until_complete(self.wsgi.startup())\n self._runner = ensure_future(self._run(), loop=self.loop)\n\n try:\n self.loop.run_until_complete(self._runner)\n finally:\n self.loop.close()\n\n sys.exit(self.exit_code)\n\n def make_handler(self, app):\n return app.make_handler(\n logger=self.log,\n debug=self.cfg.debug,\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self.cfg.access_log_format)\n\n @asyncio.coroutine\n def close(self):\n if self.servers:\n servers = self.servers\n self.servers = None\n\n # stop accepting connections\n for server, handler in servers.items():\n self.log.info(\"Stopping server: %s, connections: %s\",\n self.pid, len(handler.connections))\n server.close()\n yield from server.wait_closed()\n\n # send on_shutdown event\n yield from self.wsgi.shutdown()\n\n # stop alive connections\n tasks = [\n handler.finish_connections(\n timeout=self.cfg.graceful_timeout / 100 * 95)\n for handler in servers.values()]\n yield from asyncio.gather(*tasks, loop=self.loop)\n\n # cleanup application\n yield from self.wsgi.cleanup()\n\n @asyncio.coroutine\n def _run(self):\n\n ctx = self._create_ssl_context(self.cfg) if self.cfg.is_ssl else None\n\n for sock in self.sockets:\n handler = self.make_handler(self.wsgi)\n srv = yield from self.loop.create_server(handler, sock=sock.sock,\n ssl=ctx)\n self.servers[srv] = handler\n\n # If our parent changed then we shut down.\n pid = os.getpid()\n try:\n while self.alive:\n self.notify()\n\n cnt = sum(handler.requests_count\n for handler in self.servers.values())\n if self.cfg.max_requests and cnt > self.cfg.max_requests:\n self.alive = False\n self.log.info(\"Max requests, shutting down: %s\", self)\n\n elif pid == os.getpid() and self.ppid != os.getppid():\n self.alive = False\n self.log.info(\"Parent changed, shutting down: %s\", self)\n else:\n yield from asyncio.sleep(1.0, loop=self.loop)\n\n except BaseException:\n pass\n\n yield from self.close()\n\n def init_signals(self):\n # Set up signals through the event loop API.\n\n self.loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,\n signal.SIGQUIT, None)\n\n self.loop.add_signal_handler(signal.SIGTERM, self.handle_exit,\n signal.SIGTERM, None)\n\n self.loop.add_signal_handler(signal.SIGINT, self.handle_quit,\n signal.SIGINT, None)\n\n self.loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,\n signal.SIGWINCH, None)\n\n self.loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,\n signal.SIGUSR1, None)\n\n self.loop.add_signal_handler(signal.SIGABRT, self.handle_abort,\n signal.SIGABRT, None)\n\n # Don't let SIGTERM and SIGUSR1 disturb active requests\n # by interrupting system calls\n signal.siginterrupt(signal.SIGTERM, False)\n signal.siginterrupt(signal.SIGUSR1, False)\n\n def handle_quit(self, sig, frame):\n self.alive = False\n\n def handle_abort(self, sig, frame):\n self.alive = False\n self.exit_code = 1\n\n @staticmethod\n def _create_ssl_context(cfg):\n \"\"\" Creates SSLContext instance for usage in asyncio.create_server.\n\n See ssl.SSLSocket.__init__ for more details.\n \"\"\"\n ctx = ssl.SSLContext(cfg.ssl_version)\n ctx.load_cert_chain(cfg.certfile, cfg.keyfile)\n ctx.verify_mode = cfg.cert_reqs\n if cfg.ca_certs:\n ctx.load_verify_locations(cfg.ca_certs)\n if cfg.ciphers:\n ctx.set_ciphers(cfg.ciphers)\n return ctx\n\n\nclass GunicornUVLoopWebWorker(GunicornWebWorker):\n\n def init_process(self):\n import uvloop\n\n # Close any existing event loop before setting a\n # new policy.\n asyncio.get_event_loop().close()\n\n # Setup uvloop policy, so that every\n # asyncio.get_event_loop() will create an instance\n # of uvloop event loop.\n asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())\n\n super().init_process()\n", "path": "aiohttp/worker.py"}], "after_files": [{"content": "\"\"\"Async gunicorn worker for aiohttp.web\"\"\"\n\nimport asyncio\nimport os\nimport re\nimport signal\nimport ssl\nimport sys\n\nimport gunicorn.workers.base as base\n\nfrom gunicorn.config import AccessLogFormat as GunicornAccessLogFormat\nfrom aiohttp.helpers import AccessLogger, ensure_future\n\n__all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')\n\n\nclass GunicornWebWorker(base.Worker):\n\n DEFAULT_AIOHTTP_LOG_FORMAT = AccessLogger.LOG_FORMAT\n DEFAULT_GUNICORN_LOG_FORMAT = GunicornAccessLogFormat.default\n\n def __init__(self, *args, **kw): # pragma: no cover\n super().__init__(*args, **kw)\n\n self.servers = {}\n self.exit_code = 0\n\n def init_process(self):\n # create new event_loop after fork\n asyncio.get_event_loop().close()\n\n self.loop = asyncio.new_event_loop()\n asyncio.set_event_loop(self.loop)\n\n super().init_process()\n\n def run(self):\n self.loop.run_until_complete(self.wsgi.startup())\n self._runner = ensure_future(self._run(), loop=self.loop)\n\n try:\n self.loop.run_until_complete(self._runner)\n finally:\n self.loop.close()\n\n sys.exit(self.exit_code)\n\n def make_handler(self, app):\n return app.make_handler(\n logger=self.log,\n debug=self.cfg.debug,\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self._get_valid_log_format(\n self.cfg.access_log_format))\n\n @asyncio.coroutine\n def close(self):\n if self.servers:\n servers = self.servers\n self.servers = None\n\n # stop accepting connections\n for server, handler in servers.items():\n self.log.info(\"Stopping server: %s, connections: %s\",\n self.pid, len(handler.connections))\n server.close()\n yield from server.wait_closed()\n\n # send on_shutdown event\n yield from self.wsgi.shutdown()\n\n # stop alive connections\n tasks = [\n handler.finish_connections(\n timeout=self.cfg.graceful_timeout / 100 * 95)\n for handler in servers.values()]\n yield from asyncio.gather(*tasks, loop=self.loop)\n\n # cleanup application\n yield from self.wsgi.cleanup()\n\n @asyncio.coroutine\n def _run(self):\n\n ctx = self._create_ssl_context(self.cfg) if self.cfg.is_ssl else None\n\n for sock in self.sockets:\n handler = self.make_handler(self.wsgi)\n srv = yield from self.loop.create_server(handler, sock=sock.sock,\n ssl=ctx)\n self.servers[srv] = handler\n\n # If our parent changed then we shut down.\n pid = os.getpid()\n try:\n while self.alive:\n self.notify()\n\n cnt = sum(handler.requests_count\n for handler in self.servers.values())\n if self.cfg.max_requests and cnt > self.cfg.max_requests:\n self.alive = False\n self.log.info(\"Max requests, shutting down: %s\", self)\n\n elif pid == os.getpid() and self.ppid != os.getppid():\n self.alive = False\n self.log.info(\"Parent changed, shutting down: %s\", self)\n else:\n yield from asyncio.sleep(1.0, loop=self.loop)\n\n except BaseException:\n pass\n\n yield from self.close()\n\n def init_signals(self):\n # Set up signals through the event loop API.\n\n self.loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,\n signal.SIGQUIT, None)\n\n self.loop.add_signal_handler(signal.SIGTERM, self.handle_exit,\n signal.SIGTERM, None)\n\n self.loop.add_signal_handler(signal.SIGINT, self.handle_quit,\n signal.SIGINT, None)\n\n self.loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,\n signal.SIGWINCH, None)\n\n self.loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,\n signal.SIGUSR1, None)\n\n self.loop.add_signal_handler(signal.SIGABRT, self.handle_abort,\n signal.SIGABRT, None)\n\n # Don't let SIGTERM and SIGUSR1 disturb active requests\n # by interrupting system calls\n signal.siginterrupt(signal.SIGTERM, False)\n signal.siginterrupt(signal.SIGUSR1, False)\n\n def handle_quit(self, sig, frame):\n self.alive = False\n\n def handle_abort(self, sig, frame):\n self.alive = False\n self.exit_code = 1\n\n @staticmethod\n def _create_ssl_context(cfg):\n \"\"\" Creates SSLContext instance for usage in asyncio.create_server.\n\n See ssl.SSLSocket.__init__ for more details.\n \"\"\"\n ctx = ssl.SSLContext(cfg.ssl_version)\n ctx.load_cert_chain(cfg.certfile, cfg.keyfile)\n ctx.verify_mode = cfg.cert_reqs\n if cfg.ca_certs:\n ctx.load_verify_locations(cfg.ca_certs)\n if cfg.ciphers:\n ctx.set_ciphers(cfg.ciphers)\n return ctx\n\n def _get_valid_log_format(self, source_format):\n if source_format == self.DEFAULT_GUNICORN_LOG_FORMAT:\n return self.DEFAULT_AIOHTTP_LOG_FORMAT\n elif re.search(r'%\\([^\\)]+\\)', source_format):\n raise ValueError(\n \"Gunicorn's style options in form of `%(name)s` are not \"\n \"supported for the log formatting. Please use aiohttp's \"\n \"format specification to configure access log formatting: \"\n \"http://aiohttp.readthedocs.io/en/stable/logging.html\"\n \"#format-specification\"\n )\n else:\n return source_format\n\n\nclass GunicornUVLoopWebWorker(GunicornWebWorker):\n\n def init_process(self):\n import uvloop\n\n # Close any existing event loop before setting a\n # new policy.\n asyncio.get_event_loop().close()\n\n # Setup uvloop policy, so that every\n # asyncio.get_event_loop() will create an instance\n # of uvloop event loop.\n asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())\n\n super().init_process()\n", "path": "aiohttp/worker.py"}]}
| 1,955 | 469 |
gh_patches_debug_4839
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-261
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Half installed AioHttpIntegration causes aiohttp to crash
If I call:
```python
sentry_sdk.integrations.setup_integrations(
[sentry_sdk.integrations.aiohttp.AioHttpIntegration()])
```
after `sentry_sdk.init()` the `_handle` method of `aiohttp.web.Application` gets replaced but the integration does not get registered in the client. This causes the replaced `_handle` ro run into a codepath where there as a `await` missing. This gives an exception in every request:
```
ERROR:aiohttp.server:Unhandled exception
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/aiohttp/web_protocol.py", line 447, in start
await resp.prepare(request)
AttributeError: 'coroutine' object has no attribute 'prepare'
/usr/local/lib/python3.7/site-packages/xxx/base.py:151: RuntimeWarning: coroutine 'Application._handle' was never awaited
self._loop.run_forever()
```
This will not get logged to sentry at all, because the `aiohttp.server` logger gets ignored by (half-)installing the integration (see #259).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/integrations/aiohttp.py`
Content:
```
1 import sys
2 import weakref
3
4 from sentry_sdk._compat import reraise
5 from sentry_sdk.hub import Hub
6 from sentry_sdk.integrations import Integration
7 from sentry_sdk.integrations.logging import ignore_logger
8 from sentry_sdk.integrations._wsgi_common import _filter_headers
9 from sentry_sdk.utils import capture_internal_exceptions, event_from_exception
10
11 import asyncio
12 from aiohttp.web import Application, HTTPException
13
14
15 class AioHttpIntegration(Integration):
16 identifier = "aiohttp"
17
18 @staticmethod
19 def setup_once():
20 if sys.version_info < (3, 7):
21 # We better have contextvars or we're going to leak state between
22 # requests.
23 raise RuntimeError(
24 "The aiohttp integration for Sentry requires Python 3.7+"
25 )
26
27 ignore_logger("aiohttp.server")
28
29 old_handle = Application._handle
30
31 async def sentry_app_handle(self, request, *args, **kwargs):
32 async def inner():
33 hub = Hub.current
34 if hub.get_integration(AioHttpIntegration) is None:
35 return old_handle(self, request, *args, **kwargs)
36
37 weak_request = weakref.ref(request)
38
39 with Hub(Hub.current) as hub:
40 with hub.configure_scope() as scope:
41 scope.add_event_processor(_make_request_processor(weak_request))
42
43 try:
44 response = await old_handle(self, request)
45 except HTTPException:
46 raise
47 except Exception:
48 reraise(*_capture_exception(hub))
49
50 return response
51
52 return await asyncio.create_task(inner())
53
54 Application._handle = sentry_app_handle
55
56
57 def _make_request_processor(weak_request):
58 def aiohttp_processor(event, hint):
59 request = weak_request()
60 if request is None:
61 return event
62
63 with capture_internal_exceptions():
64 # TODO: Figure out what to do with request body. Methods on request
65 # are async, but event processors are not.
66
67 request_info = event.setdefault("request", {})
68
69 request_info["url"] = "%s://%s%s" % (
70 request.scheme,
71 request.host,
72 request.path,
73 )
74
75 request_info["query_string"] = request.query_string
76 request_info["method"] = request.method
77 request_info["env"] = {"REMOTE_ADDR": request.remote}
78 request_info["headers"] = _filter_headers(dict(request.headers))
79
80 return event
81
82 return aiohttp_processor
83
84
85 def _capture_exception(hub):
86 exc_info = sys.exc_info()
87 event, hint = event_from_exception(
88 exc_info,
89 client_options=hub.client.options,
90 mechanism={"type": "aiohttp", "handled": False},
91 )
92 hub.capture_event(event, hint=hint)
93 return exc_info
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/integrations/aiohttp.py b/sentry_sdk/integrations/aiohttp.py
--- a/sentry_sdk/integrations/aiohttp.py
+++ b/sentry_sdk/integrations/aiohttp.py
@@ -32,7 +32,7 @@
async def inner():
hub = Hub.current
if hub.get_integration(AioHttpIntegration) is None:
- return old_handle(self, request, *args, **kwargs)
+ return await old_handle(self, request, *args, **kwargs)
weak_request = weakref.ref(request)
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/aiohttp.py b/sentry_sdk/integrations/aiohttp.py\n--- a/sentry_sdk/integrations/aiohttp.py\n+++ b/sentry_sdk/integrations/aiohttp.py\n@@ -32,7 +32,7 @@\n async def inner():\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n- return old_handle(self, request, *args, **kwargs)\n+ return await old_handle(self, request, *args, **kwargs)\n \n weak_request = weakref.ref(request)\n", "issue": "Half installed AioHttpIntegration causes aiohttp to crash\nIf I call:\r\n```python\r\nsentry_sdk.integrations.setup_integrations(\r\n [sentry_sdk.integrations.aiohttp.AioHttpIntegration()])\r\n```\r\nafter `sentry_sdk.init()` the `_handle` method of `aiohttp.web.Application` gets replaced but the integration does not get registered in the client. This causes the replaced `_handle` ro run into a codepath where there as a `await` missing. This gives an exception in every request:\r\n```\r\nERROR:aiohttp.server:Unhandled exception \r\nTraceback (most recent call last): \r\n File \"/usr/local/lib/python3.7/site-packages/aiohttp/web_protocol.py\", line 447, in start \r\n await resp.prepare(request) \r\nAttributeError: 'coroutine' object has no attribute 'prepare' \r\n/usr/local/lib/python3.7/site-packages/xxx/base.py:151: RuntimeWarning: coroutine 'Application._handle' was never awaited \r\n self._loop.run_forever() \r\n```\r\n\r\nThis will not get logged to sentry at all, because the `aiohttp.server` logger gets ignored by (half-)installing the integration (see #259).\n", "before_files": [{"content": "import sys\nimport weakref\n\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.integrations.logging import ignore_logger\nfrom sentry_sdk.integrations._wsgi_common import _filter_headers\nfrom sentry_sdk.utils import capture_internal_exceptions, event_from_exception\n\nimport asyncio\nfrom aiohttp.web import Application, HTTPException\n\n\nclass AioHttpIntegration(Integration):\n identifier = \"aiohttp\"\n\n @staticmethod\n def setup_once():\n if sys.version_info < (3, 7):\n # We better have contextvars or we're going to leak state between\n # requests.\n raise RuntimeError(\n \"The aiohttp integration for Sentry requires Python 3.7+\"\n )\n\n ignore_logger(\"aiohttp.server\")\n\n old_handle = Application._handle\n\n async def sentry_app_handle(self, request, *args, **kwargs):\n async def inner():\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return old_handle(self, request, *args, **kwargs)\n\n weak_request = weakref.ref(request)\n\n with Hub(Hub.current) as hub:\n with hub.configure_scope() as scope:\n scope.add_event_processor(_make_request_processor(weak_request))\n\n try:\n response = await old_handle(self, request)\n except HTTPException:\n raise\n except Exception:\n reraise(*_capture_exception(hub))\n\n return response\n\n return await asyncio.create_task(inner())\n\n Application._handle = sentry_app_handle\n\n\ndef _make_request_processor(weak_request):\n def aiohttp_processor(event, hint):\n request = weak_request()\n if request is None:\n return event\n\n with capture_internal_exceptions():\n # TODO: Figure out what to do with request body. Methods on request\n # are async, but event processors are not.\n\n request_info = event.setdefault(\"request\", {})\n\n request_info[\"url\"] = \"%s://%s%s\" % (\n request.scheme,\n request.host,\n request.path,\n )\n\n request_info[\"query_string\"] = request.query_string\n request_info[\"method\"] = request.method\n request_info[\"env\"] = {\"REMOTE_ADDR\": request.remote}\n request_info[\"headers\"] = _filter_headers(dict(request.headers))\n\n return event\n\n return aiohttp_processor\n\n\ndef _capture_exception(hub):\n exc_info = sys.exc_info()\n event, hint = event_from_exception(\n exc_info,\n client_options=hub.client.options,\n mechanism={\"type\": \"aiohttp\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n return exc_info\n", "path": "sentry_sdk/integrations/aiohttp.py"}], "after_files": [{"content": "import sys\nimport weakref\n\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.integrations.logging import ignore_logger\nfrom sentry_sdk.integrations._wsgi_common import _filter_headers\nfrom sentry_sdk.utils import capture_internal_exceptions, event_from_exception\n\nimport asyncio\nfrom aiohttp.web import Application, HTTPException\n\n\nclass AioHttpIntegration(Integration):\n identifier = \"aiohttp\"\n\n @staticmethod\n def setup_once():\n if sys.version_info < (3, 7):\n # We better have contextvars or we're going to leak state between\n # requests.\n raise RuntimeError(\n \"The aiohttp integration for Sentry requires Python 3.7+\"\n )\n\n ignore_logger(\"aiohttp.server\")\n\n old_handle = Application._handle\n\n async def sentry_app_handle(self, request, *args, **kwargs):\n async def inner():\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return await old_handle(self, request, *args, **kwargs)\n\n weak_request = weakref.ref(request)\n\n with Hub(Hub.current) as hub:\n with hub.configure_scope() as scope:\n scope.add_event_processor(_make_request_processor(weak_request))\n\n try:\n response = await old_handle(self, request)\n except HTTPException:\n raise\n except Exception:\n reraise(*_capture_exception(hub))\n\n return response\n\n return await asyncio.create_task(inner())\n\n Application._handle = sentry_app_handle\n\n\ndef _make_request_processor(weak_request):\n def aiohttp_processor(event, hint):\n request = weak_request()\n if request is None:\n return event\n\n with capture_internal_exceptions():\n # TODO: Figure out what to do with request body. Methods on request\n # are async, but event processors are not.\n\n request_info = event.setdefault(\"request\", {})\n\n request_info[\"url\"] = \"%s://%s%s\" % (\n request.scheme,\n request.host,\n request.path,\n )\n\n request_info[\"query_string\"] = request.query_string\n request_info[\"method\"] = request.method\n request_info[\"env\"] = {\"REMOTE_ADDR\": request.remote}\n request_info[\"headers\"] = _filter_headers(dict(request.headers))\n\n return event\n\n return aiohttp_processor\n\n\ndef _capture_exception(hub):\n exc_info = sys.exc_info()\n event, hint = event_from_exception(\n exc_info,\n client_options=hub.client.options,\n mechanism={\"type\": \"aiohttp\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n return exc_info\n", "path": "sentry_sdk/integrations/aiohttp.py"}]}
| 1,317 | 129 |
gh_patches_debug_744
|
rasdani/github-patches
|
git_diff
|
LMFDB__lmfdb-5795
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Half integeral weight page visible on prod
https://www.lmfdb.org/ModularForm/GL2/Q/holomorphic/half/ should redirect to beta, but it doesn't since the whitelist thinks it's inside CMFs.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lmfdb/half_integral_weight_forms/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 from lmfdb.app import app
4 from lmfdb.logger import make_logger
5 from flask import Blueprint
6
7 hiwf_page = Blueprint("hiwf", __name__, template_folder='templates', static_folder="static")
8 hiwf_logger = make_logger(hiwf_page)
9
10
11 @hiwf_page.context_processor
12 def body_class():
13 return {'body_class': 'hiwf'}
14
15 from . import half_integral_form
16 assert half_integral_form
17
18 app.register_blueprint(hiwf_page, url_prefix="/ModularForm/GL2/Q/holomorphic/half")
19
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lmfdb/half_integral_weight_forms/__init__.py b/lmfdb/half_integral_weight_forms/__init__.py
--- a/lmfdb/half_integral_weight_forms/__init__.py
+++ b/lmfdb/half_integral_weight_forms/__init__.py
@@ -15,4 +15,4 @@
from . import half_integral_form
assert half_integral_form
-app.register_blueprint(hiwf_page, url_prefix="/ModularForm/GL2/Q/holomorphic/half")
+app.register_blueprint(hiwf_page, url_prefix="/ModularForm/GL2/Q/holomorphic_half")
|
{"golden_diff": "diff --git a/lmfdb/half_integral_weight_forms/__init__.py b/lmfdb/half_integral_weight_forms/__init__.py\n--- a/lmfdb/half_integral_weight_forms/__init__.py\n+++ b/lmfdb/half_integral_weight_forms/__init__.py\n@@ -15,4 +15,4 @@\n from . import half_integral_form\n assert half_integral_form\n \n-app.register_blueprint(hiwf_page, url_prefix=\"/ModularForm/GL2/Q/holomorphic/half\")\n+app.register_blueprint(hiwf_page, url_prefix=\"/ModularForm/GL2/Q/holomorphic_half\")\n", "issue": "Half integeral weight page visible on prod\nhttps://www.lmfdb.org/ModularForm/GL2/Q/holomorphic/half/ should redirect to beta, but it doesn't since the whitelist thinks it's inside CMFs.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom lmfdb.app import app\nfrom lmfdb.logger import make_logger\nfrom flask import Blueprint\n\nhiwf_page = Blueprint(\"hiwf\", __name__, template_folder='templates', static_folder=\"static\")\nhiwf_logger = make_logger(hiwf_page)\n\n\n@hiwf_page.context_processor\ndef body_class():\n return {'body_class': 'hiwf'}\n\nfrom . import half_integral_form\nassert half_integral_form\n\napp.register_blueprint(hiwf_page, url_prefix=\"/ModularForm/GL2/Q/holomorphic/half\")\n", "path": "lmfdb/half_integral_weight_forms/__init__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom lmfdb.app import app\nfrom lmfdb.logger import make_logger\nfrom flask import Blueprint\n\nhiwf_page = Blueprint(\"hiwf\", __name__, template_folder='templates', static_folder=\"static\")\nhiwf_logger = make_logger(hiwf_page)\n\n\n@hiwf_page.context_processor\ndef body_class():\n return {'body_class': 'hiwf'}\n\nfrom . import half_integral_form\nassert half_integral_form\n\napp.register_blueprint(hiwf_page, url_prefix=\"/ModularForm/GL2/Q/holomorphic_half\")\n", "path": "lmfdb/half_integral_weight_forms/__init__.py"}]}
| 467 | 130 |
gh_patches_debug_29078
|
rasdani/github-patches
|
git_diff
|
mindee__doctr-848
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[datasets] Targets are modified inplace
### Bug description
**Targets** are being changed when iterating over some dataset more than one time.
The reason is storing targets in self.data, and changing them in the `__getitem__` ***in place*** using `pre_transforms`, etc.
```python
# _AbstractDataset
def __getitem__(
self,
index: int
) -> Tuple[Any, Any]:
# Read image
img, target = self._read_sample(index)
# Pre-transforms (format conversion at run-time etc.)
if self._pre_transforms is not None:
img, target = self._pre_transforms(img, target)
if self.img_transforms is not None:
# typing issue cf. https://github.com/python/mypy/issues/5485
img = self.img_transforms(img) # type: ignore[call-arg]
if self.sample_transforms is not None:
img, target = self.sample_transforms(img, target)
return img, target
```
This can be fixed by copying target in the `_read_sample`
```python
# AbstractDataset
def _read_sample(self, index: int) -> Tuple[tf.Tensor, Any]:
img_name, target = self.data[index]
# Read image
img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)
return img, target
```
**OR** returning a copy of the target in all transform methods.
```python
def convert_target_to_relative(img: ImageTensor, target: Dict[str, Any]) -> Tuple[ImageTensor, Dict[str, Any]]:
target['boxes'] = convert_to_relative_coords(target['boxes'], get_img_shape(img))
return img, target
```
### Code snippet to reproduce the bug
```python
def process_image(train_example):
img, target = train_example
img_numpy = img.numpy() * 255
for example in target['boxes']:
print(example)
unnormalized_example = [int(example[0]*img.shape[1]), int(example[1]*img.shape[0]),
int(example[2]*img.shape[1]), int(example[3]*img.shape[0])]
cv2.rectangle(img=img_numpy,
pt1=(unnormalized_example[0], unnormalized_example[1]),
pt2=(unnormalized_example[2], unnormalized_example[3]),
color=(0, 0, 255), thickness=2)
return img_numpy
train_set = SROIE(train=True, download=True)
for i in range(2):
for j, example in enumerate(train_set):
if j == 0:
print(f"{i} ____")
img_n = process_image(example)
```
P.S. Sorry for not a pretty code style. This snippet is just for an example :)
### Error traceback
~changed target box coordinates
### Environment
.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doctr/datasets/datasets/tensorflow.py`
Content:
```
1 # Copyright (C) 2021-2022, Mindee.
2
3 # This program is licensed under the Apache License version 2.
4 # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
5
6 import os
7 from typing import Any, List, Tuple
8
9 import tensorflow as tf
10
11 from doctr.io import read_img_as_tensor
12
13 from .base import _AbstractDataset, _VisionDataset
14
15 __all__ = ['AbstractDataset', 'VisionDataset']
16
17
18 class AbstractDataset(_AbstractDataset):
19
20 def _read_sample(self, index: int) -> Tuple[tf.Tensor, Any]:
21 img_name, target = self.data[index]
22 # Read image
23 img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)
24
25 return img, target
26
27 @staticmethod
28 def collate_fn(samples: List[Tuple[tf.Tensor, Any]]) -> Tuple[tf.Tensor, List[Any]]:
29
30 images, targets = zip(*samples)
31 images = tf.stack(images, axis=0)
32
33 return images, list(targets)
34
35
36 class VisionDataset(AbstractDataset, _VisionDataset):
37 pass
38
```
Path: `doctr/datasets/datasets/pytorch.py`
Content:
```
1 # Copyright (C) 2021-2022, Mindee.
2
3 # This program is licensed under the Apache License version 2.
4 # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
5
6 import os
7 from typing import Any, List, Tuple
8
9 import torch
10
11 from doctr.io import read_img_as_tensor
12
13 from .base import _AbstractDataset, _VisionDataset
14
15 __all__ = ['AbstractDataset', 'VisionDataset']
16
17
18 class AbstractDataset(_AbstractDataset):
19
20 def _read_sample(self, index: int) -> Tuple[torch.Tensor, Any]:
21 img_name, target = self.data[index]
22 # Read image
23 img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=torch.float32)
24
25 return img, target
26
27 @staticmethod
28 def collate_fn(samples: List[Tuple[torch.Tensor, Any]]) -> Tuple[torch.Tensor, List[Any]]:
29
30 images, targets = zip(*samples)
31 images = torch.stack(images, dim=0)
32
33 return images, list(targets)
34
35
36 class VisionDataset(AbstractDataset, _VisionDataset):
37 pass
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doctr/datasets/datasets/pytorch.py b/doctr/datasets/datasets/pytorch.py
--- a/doctr/datasets/datasets/pytorch.py
+++ b/doctr/datasets/datasets/pytorch.py
@@ -4,6 +4,7 @@
# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
import os
+from copy import deepcopy
from typing import Any, List, Tuple
import torch
@@ -22,7 +23,7 @@
# Read image
img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=torch.float32)
- return img, target
+ return img, deepcopy(target)
@staticmethod
def collate_fn(samples: List[Tuple[torch.Tensor, Any]]) -> Tuple[torch.Tensor, List[Any]]:
diff --git a/doctr/datasets/datasets/tensorflow.py b/doctr/datasets/datasets/tensorflow.py
--- a/doctr/datasets/datasets/tensorflow.py
+++ b/doctr/datasets/datasets/tensorflow.py
@@ -4,6 +4,7 @@
# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.
import os
+from copy import deepcopy
from typing import Any, List, Tuple
import tensorflow as tf
@@ -22,7 +23,7 @@
# Read image
img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)
- return img, target
+ return img, deepcopy(target)
@staticmethod
def collate_fn(samples: List[Tuple[tf.Tensor, Any]]) -> Tuple[tf.Tensor, List[Any]]:
|
{"golden_diff": "diff --git a/doctr/datasets/datasets/pytorch.py b/doctr/datasets/datasets/pytorch.py\n--- a/doctr/datasets/datasets/pytorch.py\n+++ b/doctr/datasets/datasets/pytorch.py\n@@ -4,6 +4,7 @@\n # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n \n import os\n+from copy import deepcopy\n from typing import Any, List, Tuple\n \n import torch\n@@ -22,7 +23,7 @@\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=torch.float32)\n \n- return img, target\n+ return img, deepcopy(target)\n \n @staticmethod\n def collate_fn(samples: List[Tuple[torch.Tensor, Any]]) -> Tuple[torch.Tensor, List[Any]]:\ndiff --git a/doctr/datasets/datasets/tensorflow.py b/doctr/datasets/datasets/tensorflow.py\n--- a/doctr/datasets/datasets/tensorflow.py\n+++ b/doctr/datasets/datasets/tensorflow.py\n@@ -4,6 +4,7 @@\n # See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n \n import os\n+from copy import deepcopy\n from typing import Any, List, Tuple\n \n import tensorflow as tf\n@@ -22,7 +23,7 @@\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)\n \n- return img, target\n+ return img, deepcopy(target)\n \n @staticmethod\n def collate_fn(samples: List[Tuple[tf.Tensor, Any]]) -> Tuple[tf.Tensor, List[Any]]:\n", "issue": "[datasets] Targets are modified inplace\n### Bug description\n\n**Targets** are being changed when iterating over some dataset more than one time.\r\nThe reason is storing targets in self.data, and changing them in the `__getitem__` ***in place*** using `pre_transforms`, etc.\r\n```python\r\n# _AbstractDataset\r\ndef __getitem__(\r\n self,\r\n index: int\r\n ) -> Tuple[Any, Any]:\r\n\r\n # Read image\r\n img, target = self._read_sample(index)\r\n # Pre-transforms (format conversion at run-time etc.)\r\n if self._pre_transforms is not None:\r\n img, target = self._pre_transforms(img, target)\r\n\r\n if self.img_transforms is not None:\r\n # typing issue cf. https://github.com/python/mypy/issues/5485\r\n img = self.img_transforms(img) # type: ignore[call-arg]\r\n\r\n if self.sample_transforms is not None:\r\n img, target = self.sample_transforms(img, target)\r\n\r\n return img, target\r\n```\r\n\r\nThis can be fixed by copying target in the `_read_sample` \r\n```python\r\n# AbstractDataset\r\ndef _read_sample(self, index: int) -> Tuple[tf.Tensor, Any]:\r\n img_name, target = self.data[index]\r\n # Read image\r\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)\r\n\r\n return img, target\r\n```\r\n\r\n**OR** returning a copy of the target in all transform methods.\r\n```python\r\ndef convert_target_to_relative(img: ImageTensor, target: Dict[str, Any]) -> Tuple[ImageTensor, Dict[str, Any]]:\r\n\r\n target['boxes'] = convert_to_relative_coords(target['boxes'], get_img_shape(img))\r\n return img, target\r\n```\r\n\n\n### Code snippet to reproduce the bug\n\n```python\r\ndef process_image(train_example):\r\n img, target = train_example\r\n img_numpy = img.numpy() * 255\r\n for example in target['boxes']:\r\n print(example)\r\n unnormalized_example = [int(example[0]*img.shape[1]), int(example[1]*img.shape[0]),\r\n int(example[2]*img.shape[1]), int(example[3]*img.shape[0])]\r\n cv2.rectangle(img=img_numpy,\r\n pt1=(unnormalized_example[0], unnormalized_example[1]),\r\n pt2=(unnormalized_example[2], unnormalized_example[3]),\r\n color=(0, 0, 255), thickness=2)\r\n return img_numpy \r\n\r\n\r\ntrain_set = SROIE(train=True, download=True)\r\n\r\nfor i in range(2):\r\n for j, example in enumerate(train_set):\r\n if j == 0: \r\n print(f\"{i} ____\")\r\n img_n = process_image(example)\r\n```\r\n\r\nP.S. Sorry for not a pretty code style. This snippet is just for an example :) \n\n### Error traceback\n\n~changed target box coordinates\n\n### Environment\n\n.\n", "before_files": [{"content": "# Copyright (C) 2021-2022, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport os\nfrom typing import Any, List, Tuple\n\nimport tensorflow as tf\n\nfrom doctr.io import read_img_as_tensor\n\nfrom .base import _AbstractDataset, _VisionDataset\n\n__all__ = ['AbstractDataset', 'VisionDataset']\n\n\nclass AbstractDataset(_AbstractDataset):\n\n def _read_sample(self, index: int) -> Tuple[tf.Tensor, Any]:\n img_name, target = self.data[index]\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)\n\n return img, target\n\n @staticmethod\n def collate_fn(samples: List[Tuple[tf.Tensor, Any]]) -> Tuple[tf.Tensor, List[Any]]:\n\n images, targets = zip(*samples)\n images = tf.stack(images, axis=0)\n\n return images, list(targets)\n\n\nclass VisionDataset(AbstractDataset, _VisionDataset):\n pass\n", "path": "doctr/datasets/datasets/tensorflow.py"}, {"content": "# Copyright (C) 2021-2022, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport os\nfrom typing import Any, List, Tuple\n\nimport torch\n\nfrom doctr.io import read_img_as_tensor\n\nfrom .base import _AbstractDataset, _VisionDataset\n\n__all__ = ['AbstractDataset', 'VisionDataset']\n\n\nclass AbstractDataset(_AbstractDataset):\n\n def _read_sample(self, index: int) -> Tuple[torch.Tensor, Any]:\n img_name, target = self.data[index]\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=torch.float32)\n\n return img, target\n\n @staticmethod\n def collate_fn(samples: List[Tuple[torch.Tensor, Any]]) -> Tuple[torch.Tensor, List[Any]]:\n\n images, targets = zip(*samples)\n images = torch.stack(images, dim=0)\n\n return images, list(targets)\n\n\nclass VisionDataset(AbstractDataset, _VisionDataset):\n pass\n", "path": "doctr/datasets/datasets/pytorch.py"}], "after_files": [{"content": "# Copyright (C) 2021-2022, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport os\nfrom copy import deepcopy\nfrom typing import Any, List, Tuple\n\nimport tensorflow as tf\n\nfrom doctr.io import read_img_as_tensor\n\nfrom .base import _AbstractDataset, _VisionDataset\n\n__all__ = ['AbstractDataset', 'VisionDataset']\n\n\nclass AbstractDataset(_AbstractDataset):\n\n def _read_sample(self, index: int) -> Tuple[tf.Tensor, Any]:\n img_name, target = self.data[index]\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=tf.float32)\n\n return img, deepcopy(target)\n\n @staticmethod\n def collate_fn(samples: List[Tuple[tf.Tensor, Any]]) -> Tuple[tf.Tensor, List[Any]]:\n\n images, targets = zip(*samples)\n images = tf.stack(images, axis=0)\n\n return images, list(targets)\n\n\nclass VisionDataset(AbstractDataset, _VisionDataset):\n pass\n", "path": "doctr/datasets/datasets/tensorflow.py"}, {"content": "# Copyright (C) 2021-2022, Mindee.\n\n# This program is licensed under the Apache License version 2.\n# See LICENSE or go to <https://www.apache.org/licenses/LICENSE-2.0.txt> for full license details.\n\nimport os\nfrom copy import deepcopy\nfrom typing import Any, List, Tuple\n\nimport torch\n\nfrom doctr.io import read_img_as_tensor\n\nfrom .base import _AbstractDataset, _VisionDataset\n\n__all__ = ['AbstractDataset', 'VisionDataset']\n\n\nclass AbstractDataset(_AbstractDataset):\n\n def _read_sample(self, index: int) -> Tuple[torch.Tensor, Any]:\n img_name, target = self.data[index]\n # Read image\n img = read_img_as_tensor(os.path.join(self.root, img_name), dtype=torch.float32)\n\n return img, deepcopy(target)\n\n @staticmethod\n def collate_fn(samples: List[Tuple[torch.Tensor, Any]]) -> Tuple[torch.Tensor, List[Any]]:\n\n images, targets = zip(*samples)\n images = torch.stack(images, dim=0)\n\n return images, list(targets)\n\n\nclass VisionDataset(AbstractDataset, _VisionDataset):\n pass\n", "path": "doctr/datasets/datasets/pytorch.py"}]}
| 1,572 | 386 |
gh_patches_debug_24256
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-228
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add center cropping
**Is your feature request related to a problem? Please describe.**
We do not have any mechanism to perform cropping, which is important for certain DL training problems.
**Describe the solution you'd like**
Expose the [cropping functionality in TorchIO](https://torchio.readthedocs.io/transforms/preprocessing.html?highlight=crop#torchio.transforms.Crop) as a preprocessing mechanism.
**Describe alternatives you've considered**
N.A.
**Additional context**
Requested by @Geeks-Sid for SBU-TIL.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `GANDLF/data/preprocessing/__init__.py`
Content:
```
1 from .crop_zero_planes import CropExternalZeroplanes
2 from .non_zero_normalize import NonZeroNormalizeOnMaskedRegion
3 from .threshold_and_clip import (
4 threshold_transform,
5 clip_transform,
6 )
7 from .normalize_rgb import (
8 normalize_by_val_transform,
9 normalize_imagenet_transform,
10 normalize_standardize_transform,
11 normalize_div_by_255_transform,
12 )
13
14 from torchio.transforms import (
15 ZNormalization,
16 ToCanonical,
17 )
18
19
20 def positive_voxel_mask(image):
21 return image > 0
22
23
24 def nonzero_voxel_mask(image):
25 return image != 0
26
27
28 def to_canonical_transform(parameters):
29 return ToCanonical()
30
31
32 # defining dict for pre-processing - key is the string and the value is the transform object
33 global_preprocessing_dict = {
34 "to_canonical": to_canonical_transform,
35 "threshold": threshold_transform,
36 "clip": clip_transform,
37 "clamp": clip_transform,
38 "crop_external_zero_planes": CropExternalZeroplanes,
39 "normalize_by_val": normalize_by_val_transform,
40 "normalize_imagenet": normalize_imagenet_transform,
41 "normalize_standardize": normalize_standardize_transform,
42 "normalize_div_by_255": normalize_div_by_255_transform,
43 "normalize": ZNormalization(),
44 "normalize_positive": ZNormalization(masking_method=positive_voxel_mask),
45 "normalize_nonZero": ZNormalization(masking_method=nonzero_voxel_mask),
46 "normalize_nonZero_masked": NonZeroNormalizeOnMaskedRegion(),
47 }
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/GANDLF/data/preprocessing/__init__.py b/GANDLF/data/preprocessing/__init__.py
--- a/GANDLF/data/preprocessing/__init__.py
+++ b/GANDLF/data/preprocessing/__init__.py
@@ -14,6 +14,8 @@
from torchio.transforms import (
ZNormalization,
ToCanonical,
+ Crop,
+ CropOrPad,
)
@@ -29,6 +31,14 @@
return ToCanonical()
+def crop_transform(patch_size):
+ return Crop(patch_size)
+
+
+def centercrop_transform(patch_size):
+ return CropOrPad(target_shape=patch_size)
+
+
# defining dict for pre-processing - key is the string and the value is the transform object
global_preprocessing_dict = {
"to_canonical": to_canonical_transform,
@@ -36,6 +46,8 @@
"clip": clip_transform,
"clamp": clip_transform,
"crop_external_zero_planes": CropExternalZeroplanes,
+ "crop": crop_transform,
+ "centercrop": centercrop_transform,
"normalize_by_val": normalize_by_val_transform,
"normalize_imagenet": normalize_imagenet_transform,
"normalize_standardize": normalize_standardize_transform,
|
{"golden_diff": "diff --git a/GANDLF/data/preprocessing/__init__.py b/GANDLF/data/preprocessing/__init__.py\n--- a/GANDLF/data/preprocessing/__init__.py\n+++ b/GANDLF/data/preprocessing/__init__.py\n@@ -14,6 +14,8 @@\n from torchio.transforms import (\n ZNormalization,\n ToCanonical,\n+ Crop,\n+ CropOrPad,\n )\n \n \n@@ -29,6 +31,14 @@\n return ToCanonical()\n \n \n+def crop_transform(patch_size):\n+ return Crop(patch_size)\n+\n+\n+def centercrop_transform(patch_size):\n+ return CropOrPad(target_shape=patch_size)\n+\n+\n # defining dict for pre-processing - key is the string and the value is the transform object\n global_preprocessing_dict = {\n \"to_canonical\": to_canonical_transform,\n@@ -36,6 +46,8 @@\n \"clip\": clip_transform,\n \"clamp\": clip_transform,\n \"crop_external_zero_planes\": CropExternalZeroplanes,\n+ \"crop\": crop_transform,\n+ \"centercrop\": centercrop_transform,\n \"normalize_by_val\": normalize_by_val_transform,\n \"normalize_imagenet\": normalize_imagenet_transform,\n \"normalize_standardize\": normalize_standardize_transform,\n", "issue": "Add center cropping\n**Is your feature request related to a problem? Please describe.**\r\nWe do not have any mechanism to perform cropping, which is important for certain DL training problems.\r\n\r\n**Describe the solution you'd like**\r\nExpose the [cropping functionality in TorchIO](https://torchio.readthedocs.io/transforms/preprocessing.html?highlight=crop#torchio.transforms.Crop) as a preprocessing mechanism.\r\n\r\n**Describe alternatives you've considered**\r\nN.A.\r\n\r\n**Additional context**\r\nRequested by @Geeks-Sid for SBU-TIL.\r\n\n", "before_files": [{"content": "from .crop_zero_planes import CropExternalZeroplanes\nfrom .non_zero_normalize import NonZeroNormalizeOnMaskedRegion\nfrom .threshold_and_clip import (\n threshold_transform,\n clip_transform,\n)\nfrom .normalize_rgb import (\n normalize_by_val_transform,\n normalize_imagenet_transform,\n normalize_standardize_transform,\n normalize_div_by_255_transform,\n)\n\nfrom torchio.transforms import (\n ZNormalization,\n ToCanonical,\n)\n\n\ndef positive_voxel_mask(image):\n return image > 0\n\n\ndef nonzero_voxel_mask(image):\n return image != 0\n\n\ndef to_canonical_transform(parameters):\n return ToCanonical()\n\n\n# defining dict for pre-processing - key is the string and the value is the transform object\nglobal_preprocessing_dict = {\n \"to_canonical\": to_canonical_transform,\n \"threshold\": threshold_transform,\n \"clip\": clip_transform,\n \"clamp\": clip_transform,\n \"crop_external_zero_planes\": CropExternalZeroplanes,\n \"normalize_by_val\": normalize_by_val_transform,\n \"normalize_imagenet\": normalize_imagenet_transform,\n \"normalize_standardize\": normalize_standardize_transform,\n \"normalize_div_by_255\": normalize_div_by_255_transform,\n \"normalize\": ZNormalization(),\n \"normalize_positive\": ZNormalization(masking_method=positive_voxel_mask),\n \"normalize_nonZero\": ZNormalization(masking_method=nonzero_voxel_mask),\n \"normalize_nonZero_masked\": NonZeroNormalizeOnMaskedRegion(),\n}\n", "path": "GANDLF/data/preprocessing/__init__.py"}], "after_files": [{"content": "from .crop_zero_planes import CropExternalZeroplanes\nfrom .non_zero_normalize import NonZeroNormalizeOnMaskedRegion\nfrom .threshold_and_clip import (\n threshold_transform,\n clip_transform,\n)\nfrom .normalize_rgb import (\n normalize_by_val_transform,\n normalize_imagenet_transform,\n normalize_standardize_transform,\n normalize_div_by_255_transform,\n)\n\nfrom torchio.transforms import (\n ZNormalization,\n ToCanonical,\n Crop,\n CropOrPad,\n)\n\n\ndef positive_voxel_mask(image):\n return image > 0\n\n\ndef nonzero_voxel_mask(image):\n return image != 0\n\n\ndef to_canonical_transform(parameters):\n return ToCanonical()\n\n\ndef crop_transform(patch_size):\n return Crop(patch_size)\n\n\ndef centercrop_transform(patch_size):\n return CropOrPad(target_shape=patch_size)\n\n\n# defining dict for pre-processing - key is the string and the value is the transform object\nglobal_preprocessing_dict = {\n \"to_canonical\": to_canonical_transform,\n \"threshold\": threshold_transform,\n \"clip\": clip_transform,\n \"clamp\": clip_transform,\n \"crop_external_zero_planes\": CropExternalZeroplanes,\n \"crop\": crop_transform,\n \"centercrop\": centercrop_transform,\n \"normalize_by_val\": normalize_by_val_transform,\n \"normalize_imagenet\": normalize_imagenet_transform,\n \"normalize_standardize\": normalize_standardize_transform,\n \"normalize_div_by_255\": normalize_div_by_255_transform,\n \"normalize\": ZNormalization(),\n \"normalize_positive\": ZNormalization(masking_method=positive_voxel_mask),\n \"normalize_nonZero\": ZNormalization(masking_method=nonzero_voxel_mask),\n \"normalize_nonZero_masked\": NonZeroNormalizeOnMaskedRegion(),\n}\n", "path": "GANDLF/data/preprocessing/__init__.py"}]}
| 790 | 277 |
gh_patches_debug_23874
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6798
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Static type checking (mypy) CI job failing
### Meltano Version
N/A
### Python Version
NA
### Bug scope
Other
### Operating System
N/A
### Description
Example from `main`: https://github.com/meltano/meltano/actions/runs/3129670243/jobs/5079038959
```
nox > Running session mypy
nox > Creating virtual environment (virtualenv) using python3.9 in .nox/mypy
nox > poetry build --format=wheel --no-ansi
nox > pip uninstall --yes file:///home/runner/work/meltano/meltano/dist/meltano-2.7.0-py3-none-any.whl
nox > poetry export --format=requirements.txt --dev --extras=infra --extras=mssql --extras=repl --without-hashes
The `--dev` option is deprecated, use the `--with dev` notation instead.
nox > python -m pip install --constraint=.nox/mypy/tmp/requirements.txt file:///home/runner/work/meltano/meltano/dist/meltano-2.7.0-py3-none-any.whl
nox > python -m pip install --constraint=.nox/mypy/tmp/requirements.txt mypy sqlalchemy2-stubs types-requests
nox > mypy src/meltano
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: error: Variable "f4c225a9492f_create_dedicated_job_state_table.SystemModel" is not valid as a type
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: error: Invalid base class "SystemModel"
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:69: error: Need type annotation for "completed_state" (hint: "completed_state: Dict[<type>, <type>] = ...")
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:70: error: Need type annotation for "partial_state" (hint: "partial_state: Dict[<type>, <type>] = ...")
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:274: error: "object" has no attribute "query"
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: error: Variable "f4c225a9492f_create_dedicated_job_state_table.SystemModel" is not valid as a type
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: error: Invalid base class "SystemModel"
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:340: error: Need type annotation for "completed_state" (hint: "completed_state: Dict[<type>, <type>] = ...")
src/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:341: error: Need type annotation for "partial_state" (hint: "partial_state: Dict[<type>, <type>] = ...")
src/meltano/core/job_state.py:19: error: Variable "meltano.core.models.SystemModel" is not valid as a type
src/meltano/core/job_state.py:19: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases
src/meltano/core/job_state.py:19: error: Invalid base class "SystemModel"
Found 11 errors in 2 files (checked 203 source files)
nox > Command mypy src/meltano failed with exit code 1
nox > Session mypy failed.
Error: Process completed with exit code 1.
```
### Code
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `noxfile.py`
Content:
```
1 """Nox configuration."""
2
3 from __future__ import annotations
4
5 import os
6 import sys
7 from pathlib import Path
8 from random import randint
9 from textwrap import dedent
10
11 try:
12 from nox_poetry import Session
13 from nox_poetry import session as nox_session
14 except ImportError:
15 message = f"""\
16 Nox failed to import the 'nox-poetry' package.
17 Please install it using the following command:
18 {sys.executable} -m pip install nox-poetry"""
19 raise SystemExit(dedent(message)) from None
20
21
22 package = "meltano"
23 python_versions = ["3.10", "3.9", "3.8", "3.7"]
24 main_python_version = "3.9"
25 locations = "src", "tests", "noxfile.py"
26
27
28 @nox_session(python=python_versions)
29 def tests(session: Session) -> None:
30 """Execute pytest tests and compute coverage.
31
32 Args:
33 session: Nox session.
34 """
35 backend_db = os.environ.get("PYTEST_BACKEND", "sqlite")
36
37 if backend_db == "mssql":
38 session.install(".[mssql]")
39 else:
40 session.install(".")
41
42 session.install(
43 "freezegun",
44 "mock",
45 "pytest",
46 "pytest-asyncio",
47 "pytest-cov",
48 "pytest-docker",
49 "pytest-order",
50 "pytest-randomly",
51 "pytest-xdist",
52 "requests-mock",
53 )
54
55 try:
56 session.run(
57 "pytest",
58 f"--randomly-seed={randint(0, 2**32-1)}", # noqa: S311, WPS432
59 *session.posargs,
60 env={"NOX_CURRENT_SESSION": "tests"},
61 )
62 finally:
63 if session.interactive:
64 session.notify("coverage", posargs=[])
65
66
67 @nox_session(python=main_python_version)
68 def coverage(session: Session) -> None:
69 """Upload coverage data.
70
71 Args:
72 session: Nox session.
73 """
74 args = session.posargs or ["report"]
75
76 session.install("coverage[toml]")
77
78 if not session.posargs and any(Path().glob(".coverage.*")):
79 session.run("coverage", "combine")
80
81 session.run("coverage", *args)
82
83
84 @nox_session(python=main_python_version)
85 def mypy(session: Session) -> None:
86 """Run mypy type checking.
87
88 Args:
89 session: Nox session.
90 """
91 args = session.posargs or ["src/meltano"]
92
93 session.install(".")
94 session.install(
95 "mypy",
96 "sqlalchemy2-stubs",
97 "types-requests",
98 )
99 session.run("mypy", *args)
100
```
Path: `src/meltano/core/job_state.py`
Content:
```
1 """Defines JobState model class."""
2 from __future__ import annotations
3
4 from datetime import datetime
5 from typing import Any
6
7 from sqlalchemy import Column, types
8 from sqlalchemy.ext.mutable import MutableDict
9 from sqlalchemy.orm import Session
10
11 from meltano.core.job import JobFinder, Payload
12 from meltano.core.models import SystemModel
13 from meltano.core.sqlalchemy import JSONEncodedDict
14 from meltano.core.utils import merge
15
16 SINGER_STATE_KEY = "singer_state"
17
18
19 class JobState(SystemModel):
20 """Model class that represents the current state of a given job.
21
22 Modified during `meltano elt` or `meltano run` runs whenever a
23 STATE message is emitted by a Singer target. Also written and read
24 by `meltano state` CLI invocations. Only holds the _current_ state
25 for a given job_name. Full job run history is held by the Job model.
26 """
27
28 __tablename__ = "state"
29 job_name = Column(types.String, unique=True, primary_key=True, nullable=False)
30
31 updated_at = Column(types.DATETIME, onupdate=datetime.now)
32
33 partial_state = Column(MutableDict.as_mutable(JSONEncodedDict))
34 completed_state = Column(MutableDict.as_mutable(JSONEncodedDict))
35
36 @classmethod
37 def from_job_history(cls, session: Session, job_name: str):
38 """Build JobState from job run history.
39
40 Args:
41 session: the session to use in finding job history
42 job_name: the name of the job to build JobState for
43
44 Returns:
45 JobState built from job run history
46 """
47 completed_state: dict[Any, Any] = {}
48 partial_state: dict[Any, Any] = {}
49 incomplete_since = None
50 finder = JobFinder(job_name)
51
52 # Get the state for the most recent completed job.
53 # Do not consider dummy jobs create via add_state.
54 state_job = finder.latest_with_payload(session, flags=Payload.STATE)
55 if state_job:
56 incomplete_since = state_job.ended_at
57 if SINGER_STATE_KEY in state_job.payload:
58 merge(state_job.payload, partial_state)
59
60 # If there have been any incomplete jobs since the most recent completed jobs,
61 # merge the state emitted by those jobs into the state for the most recent
62 # completed job. If there are no completed jobs, get the full history of
63 # incomplete jobs and use the most recent state emitted per stream
64 incomplete_state_jobs = finder.with_payload(
65 session, flags=Payload.INCOMPLETE_STATE, since=incomplete_since
66 )
67 for incomplete_state_job in incomplete_state_jobs:
68 if SINGER_STATE_KEY in incomplete_state_job.payload:
69 partial_state = merge(incomplete_state_job.payload, partial_state)
70
71 return cls(
72 job_name=job_name,
73 partial_state=partial_state,
74 completed_state=completed_state,
75 )
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -88,7 +88,7 @@
Args:
session: Nox session.
"""
- args = session.posargs or ["src/meltano"]
+ args = session.posargs or ["src/meltano", "--exclude", "src/meltano/migrations/"]
session.install(".")
session.install(
diff --git a/src/meltano/core/job_state.py b/src/meltano/core/job_state.py
--- a/src/meltano/core/job_state.py
+++ b/src/meltano/core/job_state.py
@@ -6,7 +6,7 @@
from sqlalchemy import Column, types
from sqlalchemy.ext.mutable import MutableDict
-from sqlalchemy.orm import Session
+from sqlalchemy.orm import Mapped, Session
from meltano.core.job import JobFinder, Payload
from meltano.core.models import SystemModel
@@ -30,8 +30,8 @@
updated_at = Column(types.DATETIME, onupdate=datetime.now)
- partial_state = Column(MutableDict.as_mutable(JSONEncodedDict))
- completed_state = Column(MutableDict.as_mutable(JSONEncodedDict))
+ partial_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))
+ completed_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))
@classmethod
def from_job_history(cls, session: Session, job_name: str):
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -88,7 +88,7 @@\n Args:\n session: Nox session.\n \"\"\"\n- args = session.posargs or [\"src/meltano\"]\n+ args = session.posargs or [\"src/meltano\", \"--exclude\", \"src/meltano/migrations/\"]\n \n session.install(\".\")\n session.install(\ndiff --git a/src/meltano/core/job_state.py b/src/meltano/core/job_state.py\n--- a/src/meltano/core/job_state.py\n+++ b/src/meltano/core/job_state.py\n@@ -6,7 +6,7 @@\n \n from sqlalchemy import Column, types\n from sqlalchemy.ext.mutable import MutableDict\n-from sqlalchemy.orm import Session\n+from sqlalchemy.orm import Mapped, Session\n \n from meltano.core.job import JobFinder, Payload\n from meltano.core.models import SystemModel\n@@ -30,8 +30,8 @@\n \n updated_at = Column(types.DATETIME, onupdate=datetime.now)\n \n- partial_state = Column(MutableDict.as_mutable(JSONEncodedDict))\n- completed_state = Column(MutableDict.as_mutable(JSONEncodedDict))\n+ partial_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))\n+ completed_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))\n \n @classmethod\n def from_job_history(cls, session: Session, job_name: str):\n", "issue": "bug: Static type checking (mypy) CI job failing\n### Meltano Version\n\nN/A\n\n### Python Version\n\nNA\n\n### Bug scope\n\nOther\n\n### Operating System\n\nN/A\n\n### Description\n\nExample from `main`: https://github.com/meltano/meltano/actions/runs/3129670243/jobs/5079038959\r\n\r\n```\r\nnox > Running session mypy\r\nnox > Creating virtual environment (virtualenv) using python3.9 in .nox/mypy\r\nnox > poetry build --format=wheel --no-ansi\r\nnox > pip uninstall --yes file:///home/runner/work/meltano/meltano/dist/meltano-2.7.0-py3-none-any.whl\r\nnox > poetry export --format=requirements.txt --dev --extras=infra --extras=mssql --extras=repl --without-hashes\r\nThe `--dev` option is deprecated, use the `--with dev` notation instead.\r\nnox > python -m pip install --constraint=.nox/mypy/tmp/requirements.txt file:///home/runner/work/meltano/meltano/dist/meltano-2.7.0-py3-none-any.whl\r\nnox > python -m pip install --constraint=.nox/mypy/tmp/requirements.txt mypy sqlalchemy2-stubs types-requests\r\nnox > mypy src/meltano\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: error: Variable \"f4c225a9492f_create_dedicated_job_state_table.SystemModel\" is not valid as a type\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:39: error: Invalid base class \"SystemModel\"\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:69: error: Need type annotation for \"completed_state\" (hint: \"completed_state: Dict[<type>, <type>] = ...\")\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:70: error: Need type annotation for \"partial_state\" (hint: \"partial_state: Dict[<type>, <type>] = ...\")\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:274: error: \"object\" has no attribute \"query\"\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: error: Variable \"f4c225a9492f_create_dedicated_job_state_table.SystemModel\" is not valid as a type\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:307: error: Invalid base class \"SystemModel\"\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:340: error: Need type annotation for \"completed_state\" (hint: \"completed_state: Dict[<type>, <type>] = ...\")\r\nsrc/meltano/migrations/versions/f4c225a9492f_create_dedicated_job_state_table.py:341: error: Need type annotation for \"partial_state\" (hint: \"partial_state: Dict[<type>, <type>] = ...\")\r\nsrc/meltano/core/job_state.py:19: error: Variable \"meltano.core.models.SystemModel\" is not valid as a type\r\nsrc/meltano/core/job_state.py:19: note: See https://mypy.readthedocs.io/en/stable/common_issues.html#variables-vs-type-aliases\r\nsrc/meltano/core/job_state.py:19: error: Invalid base class \"SystemModel\"\r\nFound 11 errors in 2 files (checked 203 source files)\r\nnox > Command mypy src/meltano failed with exit code 1\r\nnox > Session mypy failed.\r\nError: Process completed with exit code 1.\r\n```\n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Nox configuration.\"\"\"\n\nfrom __future__ import annotations\n\nimport os\nimport sys\nfrom pathlib import Path\nfrom random import randint\nfrom textwrap import dedent\n\ntry:\n from nox_poetry import Session\n from nox_poetry import session as nox_session\nexcept ImportError:\n message = f\"\"\"\\\n Nox failed to import the 'nox-poetry' package.\n Please install it using the following command:\n {sys.executable} -m pip install nox-poetry\"\"\"\n raise SystemExit(dedent(message)) from None\n\n\npackage = \"meltano\"\npython_versions = [\"3.10\", \"3.9\", \"3.8\", \"3.7\"]\nmain_python_version = \"3.9\"\nlocations = \"src\", \"tests\", \"noxfile.py\"\n\n\n@nox_session(python=python_versions)\ndef tests(session: Session) -> None:\n \"\"\"Execute pytest tests and compute coverage.\n\n Args:\n session: Nox session.\n \"\"\"\n backend_db = os.environ.get(\"PYTEST_BACKEND\", \"sqlite\")\n\n if backend_db == \"mssql\":\n session.install(\".[mssql]\")\n else:\n session.install(\".\")\n\n session.install(\n \"freezegun\",\n \"mock\",\n \"pytest\",\n \"pytest-asyncio\",\n \"pytest-cov\",\n \"pytest-docker\",\n \"pytest-order\",\n \"pytest-randomly\",\n \"pytest-xdist\",\n \"requests-mock\",\n )\n\n try:\n session.run(\n \"pytest\",\n f\"--randomly-seed={randint(0, 2**32-1)}\", # noqa: S311, WPS432\n *session.posargs,\n env={\"NOX_CURRENT_SESSION\": \"tests\"},\n )\n finally:\n if session.interactive:\n session.notify(\"coverage\", posargs=[])\n\n\n@nox_session(python=main_python_version)\ndef coverage(session: Session) -> None:\n \"\"\"Upload coverage data.\n\n Args:\n session: Nox session.\n \"\"\"\n args = session.posargs or [\"report\"]\n\n session.install(\"coverage[toml]\")\n\n if not session.posargs and any(Path().glob(\".coverage.*\")):\n session.run(\"coverage\", \"combine\")\n\n session.run(\"coverage\", *args)\n\n\n@nox_session(python=main_python_version)\ndef mypy(session: Session) -> None:\n \"\"\"Run mypy type checking.\n\n Args:\n session: Nox session.\n \"\"\"\n args = session.posargs or [\"src/meltano\"]\n\n session.install(\".\")\n session.install(\n \"mypy\",\n \"sqlalchemy2-stubs\",\n \"types-requests\",\n )\n session.run(\"mypy\", *args)\n", "path": "noxfile.py"}, {"content": "\"\"\"Defines JobState model class.\"\"\"\nfrom __future__ import annotations\n\nfrom datetime import datetime\nfrom typing import Any\n\nfrom sqlalchemy import Column, types\nfrom sqlalchemy.ext.mutable import MutableDict\nfrom sqlalchemy.orm import Session\n\nfrom meltano.core.job import JobFinder, Payload\nfrom meltano.core.models import SystemModel\nfrom meltano.core.sqlalchemy import JSONEncodedDict\nfrom meltano.core.utils import merge\n\nSINGER_STATE_KEY = \"singer_state\"\n\n\nclass JobState(SystemModel):\n \"\"\"Model class that represents the current state of a given job.\n\n Modified during `meltano elt` or `meltano run` runs whenever a\n STATE message is emitted by a Singer target. Also written and read\n by `meltano state` CLI invocations. Only holds the _current_ state\n for a given job_name. Full job run history is held by the Job model.\n \"\"\"\n\n __tablename__ = \"state\"\n job_name = Column(types.String, unique=True, primary_key=True, nullable=False)\n\n updated_at = Column(types.DATETIME, onupdate=datetime.now)\n\n partial_state = Column(MutableDict.as_mutable(JSONEncodedDict))\n completed_state = Column(MutableDict.as_mutable(JSONEncodedDict))\n\n @classmethod\n def from_job_history(cls, session: Session, job_name: str):\n \"\"\"Build JobState from job run history.\n\n Args:\n session: the session to use in finding job history\n job_name: the name of the job to build JobState for\n\n Returns:\n JobState built from job run history\n \"\"\"\n completed_state: dict[Any, Any] = {}\n partial_state: dict[Any, Any] = {}\n incomplete_since = None\n finder = JobFinder(job_name)\n\n # Get the state for the most recent completed job.\n # Do not consider dummy jobs create via add_state.\n state_job = finder.latest_with_payload(session, flags=Payload.STATE)\n if state_job:\n incomplete_since = state_job.ended_at\n if SINGER_STATE_KEY in state_job.payload:\n merge(state_job.payload, partial_state)\n\n # If there have been any incomplete jobs since the most recent completed jobs,\n # merge the state emitted by those jobs into the state for the most recent\n # completed job. If there are no completed jobs, get the full history of\n # incomplete jobs and use the most recent state emitted per stream\n incomplete_state_jobs = finder.with_payload(\n session, flags=Payload.INCOMPLETE_STATE, since=incomplete_since\n )\n for incomplete_state_job in incomplete_state_jobs:\n if SINGER_STATE_KEY in incomplete_state_job.payload:\n partial_state = merge(incomplete_state_job.payload, partial_state)\n\n return cls(\n job_name=job_name,\n partial_state=partial_state,\n completed_state=completed_state,\n )\n", "path": "src/meltano/core/job_state.py"}], "after_files": [{"content": "\"\"\"Nox configuration.\"\"\"\n\nfrom __future__ import annotations\n\nimport os\nimport sys\nfrom pathlib import Path\nfrom random import randint\nfrom textwrap import dedent\n\ntry:\n from nox_poetry import Session\n from nox_poetry import session as nox_session\nexcept ImportError:\n message = f\"\"\"\\\n Nox failed to import the 'nox-poetry' package.\n Please install it using the following command:\n {sys.executable} -m pip install nox-poetry\"\"\"\n raise SystemExit(dedent(message)) from None\n\n\npackage = \"meltano\"\npython_versions = [\"3.10\", \"3.9\", \"3.8\", \"3.7\"]\nmain_python_version = \"3.9\"\nlocations = \"src\", \"tests\", \"noxfile.py\"\n\n\n@nox_session(python=python_versions)\ndef tests(session: Session) -> None:\n \"\"\"Execute pytest tests and compute coverage.\n\n Args:\n session: Nox session.\n \"\"\"\n backend_db = os.environ.get(\"PYTEST_BACKEND\", \"sqlite\")\n\n if backend_db == \"mssql\":\n session.install(\".[mssql]\")\n else:\n session.install(\".\")\n\n session.install(\n \"freezegun\",\n \"mock\",\n \"pytest\",\n \"pytest-asyncio\",\n \"pytest-cov\",\n \"pytest-docker\",\n \"pytest-order\",\n \"pytest-randomly\",\n \"pytest-xdist\",\n \"requests-mock\",\n )\n\n try:\n session.run(\n \"pytest\",\n f\"--randomly-seed={randint(0, 2**32-1)}\", # noqa: S311, WPS432\n *session.posargs,\n env={\"NOX_CURRENT_SESSION\": \"tests\"},\n )\n finally:\n if session.interactive:\n session.notify(\"coverage\", posargs=[])\n\n\n@nox_session(python=main_python_version)\ndef coverage(session: Session) -> None:\n \"\"\"Upload coverage data.\n\n Args:\n session: Nox session.\n \"\"\"\n args = session.posargs or [\"report\"]\n\n session.install(\"coverage[toml]\")\n\n if not session.posargs and any(Path().glob(\".coverage.*\")):\n session.run(\"coverage\", \"combine\")\n\n session.run(\"coverage\", *args)\n\n\n@nox_session(python=main_python_version)\ndef mypy(session: Session) -> None:\n \"\"\"Run mypy type checking.\n\n Args:\n session: Nox session.\n \"\"\"\n args = session.posargs or [\"src/meltano\", \"--exclude\", \"src/meltano/migrations/\"]\n\n session.install(\".\")\n session.install(\n \"mypy\",\n \"sqlalchemy2-stubs\",\n \"types-requests\",\n )\n session.run(\"mypy\", *args)\n", "path": "noxfile.py"}, {"content": "\"\"\"Defines JobState model class.\"\"\"\nfrom __future__ import annotations\n\nfrom datetime import datetime\nfrom typing import Any\n\nfrom sqlalchemy import Column, types\nfrom sqlalchemy.ext.mutable import MutableDict\nfrom sqlalchemy.orm import Mapped, Session\n\nfrom meltano.core.job import JobFinder, Payload\nfrom meltano.core.models import SystemModel\nfrom meltano.core.sqlalchemy import JSONEncodedDict\nfrom meltano.core.utils import merge\n\nSINGER_STATE_KEY = \"singer_state\"\n\n\nclass JobState(SystemModel):\n \"\"\"Model class that represents the current state of a given job.\n\n Modified during `meltano elt` or `meltano run` runs whenever a\n STATE message is emitted by a Singer target. Also written and read\n by `meltano state` CLI invocations. Only holds the _current_ state\n for a given job_name. Full job run history is held by the Job model.\n \"\"\"\n\n __tablename__ = \"state\"\n job_name = Column(types.String, unique=True, primary_key=True, nullable=False)\n\n updated_at = Column(types.DATETIME, onupdate=datetime.now)\n\n partial_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))\n completed_state: Mapped[Any] = Column(MutableDict.as_mutable(JSONEncodedDict))\n\n @classmethod\n def from_job_history(cls, session: Session, job_name: str):\n \"\"\"Build JobState from job run history.\n\n Args:\n session: the session to use in finding job history\n job_name: the name of the job to build JobState for\n\n Returns:\n JobState built from job run history\n \"\"\"\n completed_state: dict[Any, Any] = {}\n partial_state: dict[Any, Any] = {}\n incomplete_since = None\n finder = JobFinder(job_name)\n\n # Get the state for the most recent completed job.\n # Do not consider dummy jobs create via add_state.\n state_job = finder.latest_with_payload(session, flags=Payload.STATE)\n if state_job:\n incomplete_since = state_job.ended_at\n if SINGER_STATE_KEY in state_job.payload:\n merge(state_job.payload, partial_state)\n\n # If there have been any incomplete jobs since the most recent completed jobs,\n # merge the state emitted by those jobs into the state for the most recent\n # completed job. If there are no completed jobs, get the full history of\n # incomplete jobs and use the most recent state emitted per stream\n incomplete_state_jobs = finder.with_payload(\n session, flags=Payload.INCOMPLETE_STATE, since=incomplete_since\n )\n for incomplete_state_job in incomplete_state_jobs:\n if SINGER_STATE_KEY in incomplete_state_job.payload:\n partial_state = merge(incomplete_state_job.payload, partial_state)\n\n return cls(\n job_name=job_name,\n partial_state=partial_state,\n completed_state=completed_state,\n )\n", "path": "src/meltano/core/job_state.py"}]}
| 2,883 | 332 |
gh_patches_debug_31454
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-18885
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Permissions and warning for custom emoji overriding unicode emoji
Only administrators/owners should be able to override unicode emoji
1. If an administrator attempts to override a unicode emoji with a custom emoji, they should get a warning. #16937 attempts to fix this, but it is currently not working in production.
We should also shorten the warning message and avoid referring to "unicode" to avoid confusing non-technical users:
>**Override built-in emoji?**
> Uploading a custom emoji with the name **<name>** will override the built-in **<name>** emoji. Continue?
2. If a non-administrator attempts to override an emoji, show an error in the same style as the error for overriding custom emoji (screenshot below). Text: "Failed: An emoji with this name already exists. Only administrators can override built-in emoji."
Error for overriding custom emoji:
<img width="531" alt="Screen Shot 2021-06-15 at 2 30 38 PM" src="https://user-images.githubusercontent.com/2090066/122126418-915e9880-cde6-11eb-86f6-0a4338478739.png">
Related issue: #18269
[Related CZO thread](https://chat.zulip.org/#narrow/stream/2-general/topic/ok.20emoji)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zerver/views/realm_emoji.py`
Content:
```
1 from django.conf import settings
2 from django.http import HttpRequest, HttpResponse
3 from django.utils.translation import gettext as _
4
5 from zerver.decorator import require_member_or_admin
6 from zerver.lib.actions import check_add_realm_emoji, do_remove_realm_emoji
7 from zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name
8 from zerver.lib.request import REQ, JsonableError, has_request_variables
9 from zerver.lib.response import json_success
10 from zerver.models import RealmEmoji, UserProfile
11
12
13 def list_emoji(request: HttpRequest, user_profile: UserProfile) -> HttpResponse:
14
15 # We don't call check_emoji_admin here because the list of realm
16 # emoji is public.
17 return json_success({"emoji": user_profile.realm.get_emoji()})
18
19
20 @require_member_or_admin
21 @has_request_variables
22 def upload_emoji(
23 request: HttpRequest, user_profile: UserProfile, emoji_name: str = REQ(path_only=True)
24 ) -> HttpResponse:
25 emoji_name = emoji_name.strip().replace(" ", "_")
26 check_valid_emoji_name(emoji_name)
27 check_emoji_admin(user_profile)
28 if RealmEmoji.objects.filter(
29 realm=user_profile.realm, name=emoji_name, deactivated=False
30 ).exists():
31 raise JsonableError(_("A custom emoji with this name already exists."))
32 if len(request.FILES) != 1:
33 raise JsonableError(_("You must upload exactly one file."))
34 emoji_file = list(request.FILES.values())[0]
35 if (settings.MAX_EMOJI_FILE_SIZE_MIB * 1024 * 1024) < emoji_file.size:
36 raise JsonableError(
37 _("Uploaded file is larger than the allowed limit of {} MiB").format(
38 settings.MAX_EMOJI_FILE_SIZE_MIB,
39 )
40 )
41
42 realm_emoji = check_add_realm_emoji(user_profile.realm, emoji_name, user_profile, emoji_file)
43 if realm_emoji is None:
44 raise JsonableError(_("Image file upload failed."))
45 return json_success()
46
47
48 def delete_emoji(request: HttpRequest, user_profile: UserProfile, emoji_name: str) -> HttpResponse:
49 if not RealmEmoji.objects.filter(
50 realm=user_profile.realm, name=emoji_name, deactivated=False
51 ).exists():
52 raise JsonableError(_("Emoji '{}' does not exist").format(emoji_name))
53 check_emoji_admin(user_profile, emoji_name)
54 do_remove_realm_emoji(user_profile.realm, emoji_name)
55 return json_success()
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zerver/views/realm_emoji.py b/zerver/views/realm_emoji.py
--- a/zerver/views/realm_emoji.py
+++ b/zerver/views/realm_emoji.py
@@ -4,7 +4,7 @@
from zerver.decorator import require_member_or_admin
from zerver.lib.actions import check_add_realm_emoji, do_remove_realm_emoji
-from zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name
+from zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name, name_to_codepoint
from zerver.lib.request import REQ, JsonableError, has_request_variables
from zerver.lib.response import json_success
from zerver.models import RealmEmoji, UserProfile
@@ -23,6 +23,7 @@
request: HttpRequest, user_profile: UserProfile, emoji_name: str = REQ(path_only=True)
) -> HttpResponse:
emoji_name = emoji_name.strip().replace(" ", "_")
+ valid_built_in_emoji = name_to_codepoint.keys()
check_valid_emoji_name(emoji_name)
check_emoji_admin(user_profile)
if RealmEmoji.objects.filter(
@@ -31,6 +32,9 @@
raise JsonableError(_("A custom emoji with this name already exists."))
if len(request.FILES) != 1:
raise JsonableError(_("You must upload exactly one file."))
+ if emoji_name in valid_built_in_emoji:
+ if not user_profile.is_realm_admin:
+ raise JsonableError(_("Only administrators can override built-in emoji."))
emoji_file = list(request.FILES.values())[0]
if (settings.MAX_EMOJI_FILE_SIZE_MIB * 1024 * 1024) < emoji_file.size:
raise JsonableError(
|
{"golden_diff": "diff --git a/zerver/views/realm_emoji.py b/zerver/views/realm_emoji.py\n--- a/zerver/views/realm_emoji.py\n+++ b/zerver/views/realm_emoji.py\n@@ -4,7 +4,7 @@\n \n from zerver.decorator import require_member_or_admin\n from zerver.lib.actions import check_add_realm_emoji, do_remove_realm_emoji\n-from zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name\n+from zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name, name_to_codepoint\n from zerver.lib.request import REQ, JsonableError, has_request_variables\n from zerver.lib.response import json_success\n from zerver.models import RealmEmoji, UserProfile\n@@ -23,6 +23,7 @@\n request: HttpRequest, user_profile: UserProfile, emoji_name: str = REQ(path_only=True)\n ) -> HttpResponse:\n emoji_name = emoji_name.strip().replace(\" \", \"_\")\n+ valid_built_in_emoji = name_to_codepoint.keys()\n check_valid_emoji_name(emoji_name)\n check_emoji_admin(user_profile)\n if RealmEmoji.objects.filter(\n@@ -31,6 +32,9 @@\n raise JsonableError(_(\"A custom emoji with this name already exists.\"))\n if len(request.FILES) != 1:\n raise JsonableError(_(\"You must upload exactly one file.\"))\n+ if emoji_name in valid_built_in_emoji:\n+ if not user_profile.is_realm_admin:\n+ raise JsonableError(_(\"Only administrators can override built-in emoji.\"))\n emoji_file = list(request.FILES.values())[0]\n if (settings.MAX_EMOJI_FILE_SIZE_MIB * 1024 * 1024) < emoji_file.size:\n raise JsonableError(\n", "issue": "Permissions and warning for custom emoji overriding unicode emoji\nOnly administrators/owners should be able to override unicode emoji\r\n\r\n1. If an administrator attempts to override a unicode emoji with a custom emoji, they should get a warning. #16937 attempts to fix this, but it is currently not working in production.\r\n\r\nWe should also shorten the warning message and avoid referring to \"unicode\" to avoid confusing non-technical users:\r\n>**Override built-in emoji?**\r\n> Uploading a custom emoji with the name **<name>** will override the built-in **<name>** emoji. Continue?\r\n\r\n2. If a non-administrator attempts to override an emoji, show an error in the same style as the error for overriding custom emoji (screenshot below). Text: \"Failed: An emoji with this name already exists. Only administrators can override built-in emoji.\"\r\n\r\nError for overriding custom emoji:\r\n<img width=\"531\" alt=\"Screen Shot 2021-06-15 at 2 30 38 PM\" src=\"https://user-images.githubusercontent.com/2090066/122126418-915e9880-cde6-11eb-86f6-0a4338478739.png\">\r\n\r\nRelated issue: #18269\r\n[Related CZO thread](https://chat.zulip.org/#narrow/stream/2-general/topic/ok.20emoji)\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.http import HttpRequest, HttpResponse\nfrom django.utils.translation import gettext as _\n\nfrom zerver.decorator import require_member_or_admin\nfrom zerver.lib.actions import check_add_realm_emoji, do_remove_realm_emoji\nfrom zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name\nfrom zerver.lib.request import REQ, JsonableError, has_request_variables\nfrom zerver.lib.response import json_success\nfrom zerver.models import RealmEmoji, UserProfile\n\n\ndef list_emoji(request: HttpRequest, user_profile: UserProfile) -> HttpResponse:\n\n # We don't call check_emoji_admin here because the list of realm\n # emoji is public.\n return json_success({\"emoji\": user_profile.realm.get_emoji()})\n\n\n@require_member_or_admin\n@has_request_variables\ndef upload_emoji(\n request: HttpRequest, user_profile: UserProfile, emoji_name: str = REQ(path_only=True)\n) -> HttpResponse:\n emoji_name = emoji_name.strip().replace(\" \", \"_\")\n check_valid_emoji_name(emoji_name)\n check_emoji_admin(user_profile)\n if RealmEmoji.objects.filter(\n realm=user_profile.realm, name=emoji_name, deactivated=False\n ).exists():\n raise JsonableError(_(\"A custom emoji with this name already exists.\"))\n if len(request.FILES) != 1:\n raise JsonableError(_(\"You must upload exactly one file.\"))\n emoji_file = list(request.FILES.values())[0]\n if (settings.MAX_EMOJI_FILE_SIZE_MIB * 1024 * 1024) < emoji_file.size:\n raise JsonableError(\n _(\"Uploaded file is larger than the allowed limit of {} MiB\").format(\n settings.MAX_EMOJI_FILE_SIZE_MIB,\n )\n )\n\n realm_emoji = check_add_realm_emoji(user_profile.realm, emoji_name, user_profile, emoji_file)\n if realm_emoji is None:\n raise JsonableError(_(\"Image file upload failed.\"))\n return json_success()\n\n\ndef delete_emoji(request: HttpRequest, user_profile: UserProfile, emoji_name: str) -> HttpResponse:\n if not RealmEmoji.objects.filter(\n realm=user_profile.realm, name=emoji_name, deactivated=False\n ).exists():\n raise JsonableError(_(\"Emoji '{}' does not exist\").format(emoji_name))\n check_emoji_admin(user_profile, emoji_name)\n do_remove_realm_emoji(user_profile.realm, emoji_name)\n return json_success()\n", "path": "zerver/views/realm_emoji.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.http import HttpRequest, HttpResponse\nfrom django.utils.translation import gettext as _\n\nfrom zerver.decorator import require_member_or_admin\nfrom zerver.lib.actions import check_add_realm_emoji, do_remove_realm_emoji\nfrom zerver.lib.emoji import check_emoji_admin, check_valid_emoji_name, name_to_codepoint\nfrom zerver.lib.request import REQ, JsonableError, has_request_variables\nfrom zerver.lib.response import json_success\nfrom zerver.models import RealmEmoji, UserProfile\n\n\ndef list_emoji(request: HttpRequest, user_profile: UserProfile) -> HttpResponse:\n\n # We don't call check_emoji_admin here because the list of realm\n # emoji is public.\n return json_success({\"emoji\": user_profile.realm.get_emoji()})\n\n\n@require_member_or_admin\n@has_request_variables\ndef upload_emoji(\n request: HttpRequest, user_profile: UserProfile, emoji_name: str = REQ(path_only=True)\n) -> HttpResponse:\n emoji_name = emoji_name.strip().replace(\" \", \"_\")\n valid_built_in_emoji = name_to_codepoint.keys()\n check_valid_emoji_name(emoji_name)\n check_emoji_admin(user_profile)\n if RealmEmoji.objects.filter(\n realm=user_profile.realm, name=emoji_name, deactivated=False\n ).exists():\n raise JsonableError(_(\"A custom emoji with this name already exists.\"))\n if len(request.FILES) != 1:\n raise JsonableError(_(\"You must upload exactly one file.\"))\n if emoji_name in valid_built_in_emoji:\n if not user_profile.is_realm_admin:\n raise JsonableError(_(\"Only administrators can override built-in emoji.\"))\n emoji_file = list(request.FILES.values())[0]\n if (settings.MAX_EMOJI_FILE_SIZE_MIB * 1024 * 1024) < emoji_file.size:\n raise JsonableError(\n _(\"Uploaded file is larger than the allowed limit of {} MiB\").format(\n settings.MAX_EMOJI_FILE_SIZE_MIB,\n )\n )\n\n realm_emoji = check_add_realm_emoji(user_profile.realm, emoji_name, user_profile, emoji_file)\n if realm_emoji is None:\n raise JsonableError(_(\"Image file upload failed.\"))\n return json_success()\n\n\ndef delete_emoji(request: HttpRequest, user_profile: UserProfile, emoji_name: str) -> HttpResponse:\n if not RealmEmoji.objects.filter(\n realm=user_profile.realm, name=emoji_name, deactivated=False\n ).exists():\n raise JsonableError(_(\"Emoji '{}' does not exist\").format(emoji_name))\n check_emoji_admin(user_profile, emoji_name)\n do_remove_realm_emoji(user_profile.realm, emoji_name)\n return json_success()\n", "path": "zerver/views/realm_emoji.py"}]}
| 1,209 | 391 |
gh_patches_debug_28335
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-881
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Viewer: LabelPainter overlay does not update with new loaded image
Reproduce: open the Watershed demo, then load another image of a different `shape`. The overlay won't cover the entire image, and when watershed is called there will be a shape mismatch.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/viewer/plugins/labelplugin.py`
Content:
```
1 import numpy as np
2
3 from .base import Plugin
4 from ..widgets import ComboBox, Slider
5 from ..canvastools import PaintTool
6
7
8 __all__ = ['LabelPainter']
9
10
11 rad2deg = 180 / np.pi
12
13
14 class LabelPainter(Plugin):
15 name = 'LabelPainter'
16
17 def __init__(self, max_radius=20, **kwargs):
18 super(LabelPainter, self).__init__(**kwargs)
19
20 # These widgets adjust plugin properties instead of an image filter.
21 self._radius_widget = Slider('radius', low=1, high=max_radius,
22 value=5, value_type='int', ptype='plugin')
23 labels = [str(i) for i in range(6)]
24 labels[0] = 'Erase'
25 self._label_widget = ComboBox('label', labels, ptype='plugin')
26 self.add_widget(self._radius_widget)
27 self.add_widget(self._label_widget)
28
29 print(self.help())
30
31 def help(self):
32 helpstr = ("Label painter",
33 "Hold left-mouse button and paint on canvas.")
34 return '\n'.join(helpstr)
35
36 def attach(self, image_viewer):
37 super(LabelPainter, self).attach(image_viewer)
38
39 image = image_viewer.original_image
40 self.paint_tool = PaintTool(self.image_viewer.ax, image.shape,
41 on_enter=self.on_enter)
42 self.paint_tool.radius = self.radius
43 self.paint_tool.label = self._label_widget.index = 1
44 self.artists.append(self.paint_tool)
45
46 def on_enter(self, overlay):
47 pass
48
49 @property
50 def radius(self):
51 return self._radius_widget.val
52
53 @radius.setter
54 def radius(self, val):
55 self.paint_tool.radius = val
56
57 @property
58 def label(self):
59 return self._label_widget.val
60
61 @label.setter
62 def label(self, val):
63 self.paint_tool.label = val
64
```
Path: `skimage/viewer/canvastools/painttool.py`
Content:
```
1 import numpy as np
2 import matplotlib.pyplot as plt
3 import matplotlib.colors as mcolors
4 LABELS_CMAP = mcolors.ListedColormap(['white', 'red', 'dodgerblue', 'gold',
5 'greenyellow', 'blueviolet'])
6
7 from skimage.viewer.canvastools.base import CanvasToolBase
8
9
10 __all__ = ['PaintTool']
11
12
13 class PaintTool(CanvasToolBase):
14 """Widget for painting on top of a plot.
15
16 Parameters
17 ----------
18 ax : :class:`matplotlib.axes.Axes`
19 Matplotlib axes where tool is displayed.
20 overlay_shape : shape tuple
21 2D shape tuple used to initialize overlay image.
22 alpha : float (between [0, 1])
23 Opacity of overlay
24 on_move : function
25 Function called whenever a control handle is moved.
26 This function must accept the end points of line as the only argument.
27 on_release : function
28 Function called whenever the control handle is released.
29 on_enter : function
30 Function called whenever the "enter" key is pressed.
31 rect_props : dict
32 Properties for :class:`matplotlib.patches.Rectangle`. This class
33 redefines defaults in :class:`matplotlib.widgets.RectangleSelector`.
34
35 Attributes
36 ----------
37 overlay : array
38 Overlay of painted labels displayed on top of image.
39 label : int
40 Current paint color.
41 """
42 def __init__(self, ax, overlay_shape, radius=5, alpha=0.3, on_move=None,
43 on_release=None, on_enter=None, rect_props=None):
44 super(PaintTool, self).__init__(ax, on_move=on_move, on_enter=on_enter,
45 on_release=on_release)
46
47 props = dict(edgecolor='r', facecolor='0.7', alpha=0.5, animated=True)
48 props.update(rect_props if rect_props is not None else {})
49
50 self.alpha = alpha
51 self.cmap = LABELS_CMAP
52 self._overlay_plot = None
53 self._shape = overlay_shape
54 self.overlay = np.zeros(overlay_shape, dtype='uint8')
55
56 self._cursor = plt.Rectangle((0, 0), 0, 0, **props)
57 self._cursor.set_visible(False)
58 self.ax.add_patch(self._cursor)
59
60 # `label` and `radius` can only be set after initializing `_cursor`
61 self.label = 1
62 self.radius = radius
63
64 # Note that the order is important: Redraw cursor *after* overlay
65 self._artists = [self._overlay_plot, self._cursor]
66
67 self.connect_event('button_press_event', self.on_mouse_press)
68 self.connect_event('button_release_event', self.on_mouse_release)
69 self.connect_event('motion_notify_event', self.on_move)
70
71 @property
72 def label(self):
73 return self._label
74
75 @label.setter
76 def label(self, value):
77 if value >= self.cmap.N:
78 raise ValueError('Maximum label value = %s' % len(self.cmap - 1))
79 self._label = value
80 self._cursor.set_edgecolor(self.cmap(value))
81
82 @property
83 def radius(self):
84 return self._radius
85
86 @radius.setter
87 def radius(self, r):
88 self._radius = r
89 self._width = 2 * r + 1
90 self._cursor.set_width(self._width)
91 self._cursor.set_height(self._width)
92 self.window = CenteredWindow(r, self._shape)
93
94 @property
95 def overlay(self):
96 return self._overlay
97
98 @overlay.setter
99 def overlay(self, image):
100 self._overlay = image
101 if image is None:
102 self.ax.images.remove(self._overlay_plot)
103 self._overlay_plot = None
104 elif self._overlay_plot is None:
105 props = dict(cmap=self.cmap, alpha=self.alpha,
106 norm=mcolors.no_norm(), animated=True)
107 self._overlay_plot = self.ax.imshow(image, **props)
108 else:
109 self._overlay_plot.set_data(image)
110 self.redraw()
111
112 def _on_key_press(self, event):
113 if event.key == 'enter':
114 self.callback_on_enter(self.geometry)
115 self.redraw()
116
117 def on_mouse_press(self, event):
118 if event.button != 1 or not self.ax.in_axes(event):
119 return
120 self.update_cursor(event.xdata, event.ydata)
121 self.update_overlay(event.xdata, event.ydata)
122
123 def on_mouse_release(self, event):
124 if event.button != 1:
125 return
126 self.callback_on_release(self.geometry)
127
128 def on_move(self, event):
129 if not self.ax.in_axes(event):
130 self._cursor.set_visible(False)
131 self.redraw() # make sure cursor is not visible
132 return
133 self._cursor.set_visible(True)
134
135 self.update_cursor(event.xdata, event.ydata)
136 if event.button != 1:
137 self.redraw() # update cursor position
138 return
139 self.update_overlay(event.xdata, event.ydata)
140 self.callback_on_move(self.geometry)
141
142 def update_overlay(self, x, y):
143 overlay = self.overlay
144 overlay[self.window.at(y, x)] = self.label
145 # Note that overlay calls `redraw`
146 self.overlay = overlay
147
148 def update_cursor(self, x, y):
149 x = x - self.radius - 1
150 y = y - self.radius - 1
151 self._cursor.set_xy((x, y))
152
153 @property
154 def geometry(self):
155 return self.overlay
156
157
158 class CenteredWindow(object):
159 """Window that create slices numpy arrays over 2D windows.
160
161 Examples
162 --------
163 >>> a = np.arange(16).reshape(4, 4)
164 >>> w = CenteredWindow(1, a.shape)
165 >>> a[w.at(1, 1)]
166 array([[ 0, 1, 2],
167 [ 4, 5, 6],
168 [ 8, 9, 10]])
169 >>> a[w.at(0, 0)]
170 array([[0, 1],
171 [4, 5]])
172 >>> a[w.at(4, 3)]
173 array([[14, 15]])
174 """
175 def __init__(self, radius, array_shape):
176 self.radius = radius
177 self.array_shape = array_shape
178
179 def at(self, row, col):
180 h, w = self.array_shape
181 r = self.radius
182 xmin = max(0, col - r)
183 xmax = min(w, col + r + 1)
184 ymin = max(0, row - r)
185 ymax = min(h, row + r + 1)
186 return [slice(ymin, ymax), slice(xmin, xmax)]
187
188
189 if __name__ == '__main__':
190 np.testing.rundocs()
191 from skimage import data
192
193 image = data.camera()
194
195 f, ax = plt.subplots()
196 ax.imshow(image, interpolation='nearest')
197 paint_tool = PaintTool(ax, image.shape)
198 plt.show()
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/skimage/viewer/canvastools/painttool.py b/skimage/viewer/canvastools/painttool.py
--- a/skimage/viewer/canvastools/painttool.py
+++ b/skimage/viewer/canvastools/painttool.py
@@ -50,8 +50,7 @@
self.alpha = alpha
self.cmap = LABELS_CMAP
self._overlay_plot = None
- self._shape = overlay_shape
- self.overlay = np.zeros(overlay_shape, dtype='uint8')
+ self.shape = overlay_shape
self._cursor = plt.Rectangle((0, 0), 0, 0, **props)
self._cursor.set_visible(False)
@@ -109,6 +108,19 @@
self._overlay_plot.set_data(image)
self.redraw()
+ @property
+ def shape(self):
+ return self._shape
+
+ @shape.setter
+ def shape(self, shape):
+ self._shape = shape
+ if not self._overlay_plot is None:
+ self._overlay_plot.set_extent((-0.5, shape[1] + 0.5,
+ shape[0] + 0.5, -0.5))
+ self.radius = self._radius
+ self.overlay = np.zeros(shape, dtype='uint8')
+
def _on_key_press(self, event):
if event.key == 'enter':
self.callback_on_enter(self.geometry)
diff --git a/skimage/viewer/plugins/labelplugin.py b/skimage/viewer/plugins/labelplugin.py
--- a/skimage/viewer/plugins/labelplugin.py
+++ b/skimage/viewer/plugins/labelplugin.py
@@ -43,6 +43,10 @@
self.paint_tool.label = self._label_widget.index = 1
self.artists.append(self.paint_tool)
+ def _on_new_image(self, image):
+ """Update plugin for new images."""
+ self.paint_tool.shape = image.shape
+
def on_enter(self, overlay):
pass
|
{"golden_diff": "diff --git a/skimage/viewer/canvastools/painttool.py b/skimage/viewer/canvastools/painttool.py\n--- a/skimage/viewer/canvastools/painttool.py\n+++ b/skimage/viewer/canvastools/painttool.py\n@@ -50,8 +50,7 @@\n self.alpha = alpha\n self.cmap = LABELS_CMAP\n self._overlay_plot = None\n- self._shape = overlay_shape\n- self.overlay = np.zeros(overlay_shape, dtype='uint8')\n+ self.shape = overlay_shape\n \n self._cursor = plt.Rectangle((0, 0), 0, 0, **props)\n self._cursor.set_visible(False)\n@@ -109,6 +108,19 @@\n self._overlay_plot.set_data(image)\n self.redraw()\n \n+ @property\n+ def shape(self):\n+ return self._shape\n+\n+ @shape.setter\n+ def shape(self, shape):\n+ self._shape = shape\n+ if not self._overlay_plot is None:\n+ self._overlay_plot.set_extent((-0.5, shape[1] + 0.5,\n+ shape[0] + 0.5, -0.5))\n+ self.radius = self._radius\n+ self.overlay = np.zeros(shape, dtype='uint8')\n+\n def _on_key_press(self, event):\n if event.key == 'enter':\n self.callback_on_enter(self.geometry)\ndiff --git a/skimage/viewer/plugins/labelplugin.py b/skimage/viewer/plugins/labelplugin.py\n--- a/skimage/viewer/plugins/labelplugin.py\n+++ b/skimage/viewer/plugins/labelplugin.py\n@@ -43,6 +43,10 @@\n self.paint_tool.label = self._label_widget.index = 1\n self.artists.append(self.paint_tool)\n \n+ def _on_new_image(self, image):\n+ \"\"\"Update plugin for new images.\"\"\"\n+ self.paint_tool.shape = image.shape\n+\n def on_enter(self, overlay):\n pass\n", "issue": "Viewer: LabelPainter overlay does not update with new loaded image\nReproduce: open the Watershed demo, then load another image of a different `shape`. The overlay won't cover the entire image, and when watershed is called there will be a shape mismatch.\n\n", "before_files": [{"content": "import numpy as np\n\nfrom .base import Plugin\nfrom ..widgets import ComboBox, Slider\nfrom ..canvastools import PaintTool\n\n\n__all__ = ['LabelPainter']\n\n\nrad2deg = 180 / np.pi\n\n\nclass LabelPainter(Plugin):\n name = 'LabelPainter'\n\n def __init__(self, max_radius=20, **kwargs):\n super(LabelPainter, self).__init__(**kwargs)\n\n # These widgets adjust plugin properties instead of an image filter.\n self._radius_widget = Slider('radius', low=1, high=max_radius,\n value=5, value_type='int', ptype='plugin')\n labels = [str(i) for i in range(6)]\n labels[0] = 'Erase'\n self._label_widget = ComboBox('label', labels, ptype='plugin')\n self.add_widget(self._radius_widget)\n self.add_widget(self._label_widget)\n\n print(self.help())\n\n def help(self):\n helpstr = (\"Label painter\",\n \"Hold left-mouse button and paint on canvas.\")\n return '\\n'.join(helpstr)\n\n def attach(self, image_viewer):\n super(LabelPainter, self).attach(image_viewer)\n\n image = image_viewer.original_image\n self.paint_tool = PaintTool(self.image_viewer.ax, image.shape,\n on_enter=self.on_enter)\n self.paint_tool.radius = self.radius\n self.paint_tool.label = self._label_widget.index = 1\n self.artists.append(self.paint_tool)\n\n def on_enter(self, overlay):\n pass\n\n @property\n def radius(self):\n return self._radius_widget.val\n\n @radius.setter\n def radius(self, val):\n self.paint_tool.radius = val\n\n @property\n def label(self):\n return self._label_widget.val\n\n @label.setter\n def label(self, val):\n self.paint_tool.label = val\n", "path": "skimage/viewer/plugins/labelplugin.py"}, {"content": "import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.colors as mcolors\nLABELS_CMAP = mcolors.ListedColormap(['white', 'red', 'dodgerblue', 'gold',\n 'greenyellow', 'blueviolet'])\n\nfrom skimage.viewer.canvastools.base import CanvasToolBase\n\n\n__all__ = ['PaintTool']\n\n\nclass PaintTool(CanvasToolBase):\n \"\"\"Widget for painting on top of a plot.\n\n Parameters\n ----------\n ax : :class:`matplotlib.axes.Axes`\n Matplotlib axes where tool is displayed.\n overlay_shape : shape tuple\n 2D shape tuple used to initialize overlay image.\n alpha : float (between [0, 1])\n Opacity of overlay\n on_move : function\n Function called whenever a control handle is moved.\n This function must accept the end points of line as the only argument.\n on_release : function\n Function called whenever the control handle is released.\n on_enter : function\n Function called whenever the \"enter\" key is pressed.\n rect_props : dict\n Properties for :class:`matplotlib.patches.Rectangle`. This class\n redefines defaults in :class:`matplotlib.widgets.RectangleSelector`.\n\n Attributes\n ----------\n overlay : array\n Overlay of painted labels displayed on top of image.\n label : int\n Current paint color.\n \"\"\"\n def __init__(self, ax, overlay_shape, radius=5, alpha=0.3, on_move=None,\n on_release=None, on_enter=None, rect_props=None):\n super(PaintTool, self).__init__(ax, on_move=on_move, on_enter=on_enter,\n on_release=on_release)\n\n props = dict(edgecolor='r', facecolor='0.7', alpha=0.5, animated=True)\n props.update(rect_props if rect_props is not None else {})\n\n self.alpha = alpha\n self.cmap = LABELS_CMAP\n self._overlay_plot = None\n self._shape = overlay_shape\n self.overlay = np.zeros(overlay_shape, dtype='uint8')\n\n self._cursor = plt.Rectangle((0, 0), 0, 0, **props)\n self._cursor.set_visible(False)\n self.ax.add_patch(self._cursor)\n\n # `label` and `radius` can only be set after initializing `_cursor`\n self.label = 1\n self.radius = radius\n\n # Note that the order is important: Redraw cursor *after* overlay\n self._artists = [self._overlay_plot, self._cursor]\n\n self.connect_event('button_press_event', self.on_mouse_press)\n self.connect_event('button_release_event', self.on_mouse_release)\n self.connect_event('motion_notify_event', self.on_move)\n\n @property\n def label(self):\n return self._label\n\n @label.setter\n def label(self, value):\n if value >= self.cmap.N:\n raise ValueError('Maximum label value = %s' % len(self.cmap - 1))\n self._label = value\n self._cursor.set_edgecolor(self.cmap(value))\n\n @property\n def radius(self):\n return self._radius\n\n @radius.setter\n def radius(self, r):\n self._radius = r\n self._width = 2 * r + 1\n self._cursor.set_width(self._width)\n self._cursor.set_height(self._width)\n self.window = CenteredWindow(r, self._shape)\n\n @property\n def overlay(self):\n return self._overlay\n\n @overlay.setter\n def overlay(self, image):\n self._overlay = image\n if image is None:\n self.ax.images.remove(self._overlay_plot)\n self._overlay_plot = None\n elif self._overlay_plot is None:\n props = dict(cmap=self.cmap, alpha=self.alpha,\n norm=mcolors.no_norm(), animated=True)\n self._overlay_plot = self.ax.imshow(image, **props)\n else:\n self._overlay_plot.set_data(image)\n self.redraw()\n\n def _on_key_press(self, event):\n if event.key == 'enter':\n self.callback_on_enter(self.geometry)\n self.redraw()\n\n def on_mouse_press(self, event):\n if event.button != 1 or not self.ax.in_axes(event):\n return\n self.update_cursor(event.xdata, event.ydata)\n self.update_overlay(event.xdata, event.ydata)\n\n def on_mouse_release(self, event):\n if event.button != 1:\n return\n self.callback_on_release(self.geometry)\n\n def on_move(self, event):\n if not self.ax.in_axes(event):\n self._cursor.set_visible(False)\n self.redraw() # make sure cursor is not visible\n return\n self._cursor.set_visible(True)\n\n self.update_cursor(event.xdata, event.ydata)\n if event.button != 1:\n self.redraw() # update cursor position\n return\n self.update_overlay(event.xdata, event.ydata)\n self.callback_on_move(self.geometry)\n\n def update_overlay(self, x, y):\n overlay = self.overlay\n overlay[self.window.at(y, x)] = self.label\n # Note that overlay calls `redraw`\n self.overlay = overlay\n\n def update_cursor(self, x, y):\n x = x - self.radius - 1\n y = y - self.radius - 1\n self._cursor.set_xy((x, y))\n\n @property\n def geometry(self):\n return self.overlay\n\n\nclass CenteredWindow(object):\n \"\"\"Window that create slices numpy arrays over 2D windows.\n\n Examples\n --------\n >>> a = np.arange(16).reshape(4, 4)\n >>> w = CenteredWindow(1, a.shape)\n >>> a[w.at(1, 1)]\n array([[ 0, 1, 2],\n [ 4, 5, 6],\n [ 8, 9, 10]])\n >>> a[w.at(0, 0)]\n array([[0, 1],\n [4, 5]])\n >>> a[w.at(4, 3)]\n array([[14, 15]])\n \"\"\"\n def __init__(self, radius, array_shape):\n self.radius = radius\n self.array_shape = array_shape\n\n def at(self, row, col):\n h, w = self.array_shape\n r = self.radius\n xmin = max(0, col - r)\n xmax = min(w, col + r + 1)\n ymin = max(0, row - r)\n ymax = min(h, row + r + 1)\n return [slice(ymin, ymax), slice(xmin, xmax)]\n\n\nif __name__ == '__main__':\n np.testing.rundocs()\n from skimage import data\n\n image = data.camera()\n\n f, ax = plt.subplots()\n ax.imshow(image, interpolation='nearest')\n paint_tool = PaintTool(ax, image.shape)\n plt.show()\n", "path": "skimage/viewer/canvastools/painttool.py"}], "after_files": [{"content": "import numpy as np\n\nfrom .base import Plugin\nfrom ..widgets import ComboBox, Slider\nfrom ..canvastools import PaintTool\n\n\n__all__ = ['LabelPainter']\n\n\nrad2deg = 180 / np.pi\n\n\nclass LabelPainter(Plugin):\n name = 'LabelPainter'\n\n def __init__(self, max_radius=20, **kwargs):\n super(LabelPainter, self).__init__(**kwargs)\n\n # These widgets adjust plugin properties instead of an image filter.\n self._radius_widget = Slider('radius', low=1, high=max_radius,\n value=5, value_type='int', ptype='plugin')\n labels = [str(i) for i in range(6)]\n labels[0] = 'Erase'\n self._label_widget = ComboBox('label', labels, ptype='plugin')\n self.add_widget(self._radius_widget)\n self.add_widget(self._label_widget)\n\n print(self.help())\n\n def help(self):\n helpstr = (\"Label painter\",\n \"Hold left-mouse button and paint on canvas.\")\n return '\\n'.join(helpstr)\n\n def attach(self, image_viewer):\n super(LabelPainter, self).attach(image_viewer)\n\n image = image_viewer.original_image\n self.paint_tool = PaintTool(self.image_viewer.ax, image.shape,\n on_enter=self.on_enter)\n self.paint_tool.radius = self.radius\n self.paint_tool.label = self._label_widget.index = 1\n self.artists.append(self.paint_tool)\n\n def _on_new_image(self, image):\n \"\"\"Update plugin for new images.\"\"\"\n self.paint_tool.shape = image.shape\n\n def on_enter(self, overlay):\n pass\n\n @property\n def radius(self):\n return self._radius_widget.val\n\n @radius.setter\n def radius(self, val):\n self.paint_tool.radius = val\n\n @property\n def label(self):\n return self._label_widget.val\n\n @label.setter\n def label(self, val):\n self.paint_tool.label = val\n", "path": "skimage/viewer/plugins/labelplugin.py"}, {"content": "import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.colors as mcolors\nLABELS_CMAP = mcolors.ListedColormap(['white', 'red', 'dodgerblue', 'gold',\n 'greenyellow', 'blueviolet'])\n\nfrom skimage.viewer.canvastools.base import CanvasToolBase\n\n\n__all__ = ['PaintTool']\n\n\nclass PaintTool(CanvasToolBase):\n \"\"\"Widget for painting on top of a plot.\n\n Parameters\n ----------\n ax : :class:`matplotlib.axes.Axes`\n Matplotlib axes where tool is displayed.\n overlay_shape : shape tuple\n 2D shape tuple used to initialize overlay image.\n alpha : float (between [0, 1])\n Opacity of overlay\n on_move : function\n Function called whenever a control handle is moved.\n This function must accept the end points of line as the only argument.\n on_release : function\n Function called whenever the control handle is released.\n on_enter : function\n Function called whenever the \"enter\" key is pressed.\n rect_props : dict\n Properties for :class:`matplotlib.patches.Rectangle`. This class\n redefines defaults in :class:`matplotlib.widgets.RectangleSelector`.\n\n Attributes\n ----------\n overlay : array\n Overlay of painted labels displayed on top of image.\n label : int\n Current paint color.\n \"\"\"\n def __init__(self, ax, overlay_shape, radius=5, alpha=0.3, on_move=None,\n on_release=None, on_enter=None, rect_props=None):\n super(PaintTool, self).__init__(ax, on_move=on_move, on_enter=on_enter,\n on_release=on_release)\n\n props = dict(edgecolor='r', facecolor='0.7', alpha=0.5, animated=True)\n props.update(rect_props if rect_props is not None else {})\n\n self.alpha = alpha\n self.cmap = LABELS_CMAP\n self._overlay_plot = None\n self.shape = overlay_shape\n\n self._cursor = plt.Rectangle((0, 0), 0, 0, **props)\n self._cursor.set_visible(False)\n self.ax.add_patch(self._cursor)\n\n # `label` and `radius` can only be set after initializing `_cursor`\n self.label = 1\n self.radius = radius\n\n # Note that the order is important: Redraw cursor *after* overlay\n self._artists = [self._overlay_plot, self._cursor]\n\n self.connect_event('button_press_event', self.on_mouse_press)\n self.connect_event('button_release_event', self.on_mouse_release)\n self.connect_event('motion_notify_event', self.on_move)\n\n @property\n def label(self):\n return self._label\n\n @label.setter\n def label(self, value):\n if value >= self.cmap.N:\n raise ValueError('Maximum label value = %s' % len(self.cmap - 1))\n self._label = value\n self._cursor.set_edgecolor(self.cmap(value))\n\n @property\n def radius(self):\n return self._radius\n\n @radius.setter\n def radius(self, r):\n self._radius = r\n self._width = 2 * r + 1\n self._cursor.set_width(self._width)\n self._cursor.set_height(self._width)\n self.window = CenteredWindow(r, self._shape)\n\n @property\n def overlay(self):\n return self._overlay\n\n @overlay.setter\n def overlay(self, image):\n self._overlay = image\n if image is None:\n self.ax.images.remove(self._overlay_plot)\n self._overlay_plot = None\n elif self._overlay_plot is None:\n props = dict(cmap=self.cmap, alpha=self.alpha,\n norm=mcolors.no_norm(), animated=True)\n self._overlay_plot = self.ax.imshow(image, **props)\n else:\n self._overlay_plot.set_data(image)\n self.redraw()\n\n @property\n def shape(self):\n return self._shape\n\n @shape.setter\n def shape(self, shape):\n self._shape = shape\n if not self._overlay_plot is None:\n self._overlay_plot.set_extent((-0.5, shape[1] + 0.5,\n shape[0] + 0.5, -0.5))\n self.radius = self._radius\n self.overlay = np.zeros(shape, dtype='uint8')\n\n def _on_key_press(self, event):\n if event.key == 'enter':\n self.callback_on_enter(self.geometry)\n self.redraw()\n\n def on_mouse_press(self, event):\n if event.button != 1 or not self.ax.in_axes(event):\n return\n self.update_cursor(event.xdata, event.ydata)\n self.update_overlay(event.xdata, event.ydata)\n\n def on_mouse_release(self, event):\n if event.button != 1:\n return\n self.callback_on_release(self.geometry)\n\n def on_move(self, event):\n if not self.ax.in_axes(event):\n self._cursor.set_visible(False)\n self.redraw() # make sure cursor is not visible\n return\n self._cursor.set_visible(True)\n\n self.update_cursor(event.xdata, event.ydata)\n if event.button != 1:\n self.redraw() # update cursor position\n return\n self.update_overlay(event.xdata, event.ydata)\n self.callback_on_move(self.geometry)\n\n def update_overlay(self, x, y):\n overlay = self.overlay\n overlay[self.window.at(y, x)] = self.label\n # Note that overlay calls `redraw`\n self.overlay = overlay\n\n def update_cursor(self, x, y):\n x = x - self.radius - 1\n y = y - self.radius - 1\n self._cursor.set_xy((x, y))\n\n @property\n def geometry(self):\n return self.overlay\n\n\nclass CenteredWindow(object):\n \"\"\"Window that create slices numpy arrays over 2D windows.\n\n Examples\n --------\n >>> a = np.arange(16).reshape(4, 4)\n >>> w = CenteredWindow(1, a.shape)\n >>> a[w.at(1, 1)]\n array([[ 0, 1, 2],\n [ 4, 5, 6],\n [ 8, 9, 10]])\n >>> a[w.at(0, 0)]\n array([[0, 1],\n [4, 5]])\n >>> a[w.at(4, 3)]\n array([[14, 15]])\n \"\"\"\n def __init__(self, radius, array_shape):\n self.radius = radius\n self.array_shape = array_shape\n\n def at(self, row, col):\n h, w = self.array_shape\n r = self.radius\n xmin = max(0, col - r)\n xmax = min(w, col + r + 1)\n ymin = max(0, row - r)\n ymax = min(h, row + r + 1)\n return [slice(ymin, ymax), slice(xmin, xmax)]\n\n\nif __name__ == '__main__':\n np.testing.rundocs()\n from skimage import data\n\n image = data.camera()\n\n f, ax = plt.subplots()\n ax.imshow(image, interpolation='nearest')\n paint_tool = PaintTool(ax, image.shape)\n plt.show()\n", "path": "skimage/viewer/canvastools/painttool.py"}]}
| 2,903 | 471 |
gh_patches_debug_14158
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-834
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: `geocentroid` coordiantes should divide distance
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #832
- [x] whatsnew entry
```latex
\left\{\begin{matrix}
d_i &=& D(P(\bar{x}_n, \bar{y}_n), P(x_i,y_i)) \\
\bar{x}_0 &=& \frac{\sum w_i x_i}{\sum w_i} \\
\bar{y}_0 &=& \frac{\sum w_i y_i}{\sum w_i} \\
\bar{x}_{n+1} &=& \frac{\sum w_i x_i / d_i}{\sum w_i / d_i} \\
\bar{y}_{n+1} &=& \frac{\sum w_i y_i / d_i}{\sum w_i / d_i} \\
\end{matrix}\right.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/geoseries/geocentroid.py`
Content:
```
1 import geopandas as gpd
2 import numpy as np
3 import pandas as pd
4 from shapely import Point
5
6 from dtoolkit.geoaccessor.geoseries.geodistance import geodistance
7 from dtoolkit.geoaccessor.geoseries.xy import xy
8 from dtoolkit.geoaccessor.register import register_geoseries_method
9
10
11 @register_geoseries_method
12 def geocentroid(
13 s: gpd.GeoSeries,
14 /,
15 weights: pd.Series = None,
16 max_iter: int = 300,
17 tol: float = 1e-5,
18 ) -> Point:
19 r"""
20 Return the centroid of all points via the center of gravity method.
21
22 .. math::
23
24 \left\{\begin{matrix}
25 d_i &=& D(P(\bar{x}_n, \bar{y}_n), P(x_i, y_i)) \\
26 \bar{x}_0 &=& \frac{\sum w_i x_i}{\sum w_i} \\
27 \bar{y}_0 &=& \frac{\sum w_i y_i}{\sum w_i} \\
28 \bar{x}_{n+1} &=& \frac{\sum w_i x_i / d_i}{\sum w_i / d_i} \\
29 \bar{y}_{n+1} &=& \frac{\sum w_i y_i / d_i}{\sum w_i / d_i} \\
30 \end{matrix}\right.
31
32 Parameters
33 ----------
34 weights : Hashable or 1d array-like, optional
35 - None : All weights will be set to 1.
36 - Hashable : Only for DataFrame, the column name.
37 - 1d array-like : The weights of each point.
38
39 max_iter : int, default 300
40 Maximum number of iterations to perform.
41
42 tol : float, default 1e-5
43 Tolerance for convergence.
44
45 Returns
46 -------
47 Point
48
49 See Also
50 --------
51 geopandas.GeoSeries.centroid
52 dtoolkit.geoaccessor.geoseries.geocentroid
53 dtoolkit.geoaccessor.geodataframe.geocentroid
54
55 Examples
56 --------
57 >>> import dtoolkit.geoaccessor
58 >>> import geopandas as gpd
59 >>> from shapely import Point
60 >>> df = gpd.GeoDataFrame(
61 ... {
62 ... "weights": [1, 2, 3],
63 ... "geometry": [Point(100, 32), Point(120, 50), Point(122, 55)],
64 ... },
65 ... crs=4326,
66 ... )
67 >>> df
68 weights geometry
69 0 1 POINT (100.00000 32.00000)
70 1 2 POINT (120.00000 50.00000)
71 2 3 POINT (122.00000 55.00000)
72 >>> df.geocentroid()
73 <POINT (120 50)>
74
75 Set weights for each point.
76
77 >>> df.geocentroid("weights")
78 <POINT (121.999 54.998)>
79 >>> df.geocentroid([1, 2, 3])
80 <POINT (121.999 54.998)>
81 """
82
83 weights = np.asarray(weights) if weights is not None else 1
84 coord = xy(s)
85 X = coord.mean()
86 for _ in range(max_iter):
87 dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)
88 Xt = coord.mul(dis, axis=0).sum() / dis.sum()
89
90 if ((X - Xt).abs() <= tol).all():
91 X = Xt
92 break
93
94 X = Xt
95
96 return Point(*X.tolist())
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py
--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py
+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py
@@ -75,14 +75,14 @@
Set weights for each point.
>>> df.geocentroid("weights")
- <POINT (121.999 54.998)>
+ <POINT (121.999 54.999)>
>>> df.geocentroid([1, 2, 3])
- <POINT (121.999 54.998)>
+ <POINT (121.999 54.999)>
"""
weights = np.asarray(weights) if weights is not None else 1
coord = xy(s)
- X = coord.mean()
+ X = coord.mul(weights, axis=0).mean()
for _ in range(max_iter):
dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)
Xt = coord.mul(dis, axis=0).sum() / dis.sum()
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py\n+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n@@ -75,14 +75,14 @@\n Set weights for each point.\n \n >>> df.geocentroid(\"weights\")\n- <POINT (121.999 54.998)>\n+ <POINT (121.999 54.999)>\n >>> df.geocentroid([1, 2, 3])\n- <POINT (121.999 54.998)>\n+ <POINT (121.999 54.999)>\n \"\"\"\n \n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n- X = coord.mean()\n+ X = coord.mul(weights, axis=0).mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n", "issue": "BUG: `geocentroid` coordiantes should divide distance\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #832\r\n- [x] whatsnew entry\r\n\r\n```latex\r\n \\left\\{\\begin{matrix}\r\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i,y_i)) \\\\\r\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\r\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\r\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\r\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\r\n \\end{matrix}\\right.\r\n```\n", "before_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n r\"\"\"\n Return the centroid of all points via the center of gravity method.\n\n .. math::\n\n \\left\\{\\begin{matrix}\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n \\end{matrix}\\right.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-5\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (120 50)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (121.999 54.998)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (121.999 54.998)>\n \"\"\"\n\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(*X.tolist())\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}], "after_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n r\"\"\"\n Return the centroid of all points via the center of gravity method.\n\n .. math::\n\n \\left\\{\\begin{matrix}\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n \\end{matrix}\\right.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-5\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (120 50)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (121.999 54.999)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (121.999 54.999)>\n \"\"\"\n\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mul(weights, axis=0).mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(*X.tolist())\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}]}
| 1,711 | 296 |
gh_patches_debug_37513
|
rasdani/github-patches
|
git_diff
|
doccano__doccano-1529
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ModuleNotFoundError: No module named 'fcntl'
How to reproduce the behaviour
---------
After downloading doccano and trying to start it via `doccano init` I get the following message:
```
doccano init
Traceback (most recent call last):
File "C:\Users\\AppData\Local\Programs\Python\Python39\Scripts\doccano-script.py", line 33, in <module>
sys.exit(load_entry_point('doccano==1.4.1', 'console_scripts', 'doccano')())
File "C:\Users\\AppData\Local\Programs\Python\Python39\Scripts\doccano-script.py", line 25, in importlib_load_entry_point
return next(matches).load()
File "c:\users\\appdata\local\programs\python\python39\lib\importlib\metadata.py", line 77, in load
module = import_module(match.group('module'))
File "c:\users\\appdata\local\programs\python\python39\lib\importlib\__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 790, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "c:\users\\appdata\local\programs\python\python39\lib\site-packages\backend\cli.py", line 7, in <module>
import gunicorn.app.base
File "c:\users\\appdata\local\programs\python\python39\lib\site-packages\gunicorn\app\base.py", line 11, in <module>
from gunicorn import util
File "c:\users\\appdata\local\programs\python\python39\lib\site-packages\gunicorn\util.py", line 8, in <module>
import fcntl
ModuleNotFoundError: No module named 'fcntl'
```
Your Environment
---------
* Operating System: Windows 10 1909
* Python Version Used: 3.9.4
* When you install doccano: 17.06.2021
* How did you install doccano (Heroku button etc): `pip install doccano`
Own Research:
----------
Apparently Windows doesn''t support `fcntl`. Therefore nobody that uses Windows can install doccano via pip.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 import io
4 import os
5
6 from setuptools import find_packages, setup
7
8 NAME = 'doccano'
9 DESCRIPTION = 'doccano, text annotation tool for machine learning practitioners'
10 URL = 'https://github.com/doccano/doccano'
11 EMAIL = '[email protected]'
12 AUTHOR = 'Hironsan'
13 LICENSE = 'MIT'
14
15 here = os.path.abspath(os.path.dirname(__file__))
16 with io.open(os.path.join(here, 'README.md'), encoding='utf-8') as f:
17 long_description = '\n' + f.read()
18
19 required = [
20 'apache-libcloud>=3.2.0',
21 'colour>=0.1.5',
22 'conllu>=4.2.2',
23 'dj-database-url>=0.5.0',
24 'django-cors-headers>=3.5.0',
25 'django-filter>=2.4.0',
26 'django-rest-polymorphic>=0.1.9',
27 'djangorestframework-csv>=2.1.0',
28 'djangorestframework-xml>=2.0.0',
29 'drf-yasg>=1.20.0',
30 'environs>=9.2.0',
31 'furl>=2.1.0',
32 'pyexcel>=0.6.6',
33 'pyexcel-xlsx>=0.6.0',
34 'python-jose>=3.2.0',
35 'seqeval>=1.2.2',
36 'social-auth-app-django>=4.0.0',
37 'whitenoise>=5.2.0',
38 'auto-labeling-pipeline>=0.1.12',
39 'celery>=5.0.5',
40 'dj-rest-auth>=2.1.4',
41 'django-celery-results>=2.0.1',
42 'django-drf-filepond>=0.3.0',
43 'sqlalchemy>=1.4.7',
44 'gunicorn>=20.1.0',
45 ]
46
47 setup(
48 name=NAME,
49 use_scm_version=True,
50 setup_requires=['setuptools_scm'],
51 description=DESCRIPTION,
52 long_description=long_description,
53 long_description_content_type='text/markdown',
54 author=AUTHOR,
55 author_email=EMAIL,
56 url=URL,
57 packages=find_packages(exclude=('*.tests',)),
58 entry_points={
59 'console_scripts': [
60 'doccano = backend.cli:main'
61 ]
62 },
63 install_requires=required,
64 extras_require={
65 'postgresql': ['psycopg2-binary>=2.8.6'],
66 'mssql': ['django-mssql-backend>=2.8.1'],
67 },
68 include_package_data=True,
69 license=LICENSE,
70 classifiers=[
71 'License :: OSI Approved :: MIT License',
72 'Programming Language :: Python',
73 'Programming Language :: Python :: 3.6',
74 'Programming Language :: Python :: 3.7',
75 'Programming Language :: Python :: 3.8',
76 'Programming Language :: Python :: Implementation :: CPython',
77 'Programming Language :: Python :: Implementation :: PyPy'
78 ],
79 )
80
```
Path: `backend/cli.py`
Content:
```
1 import argparse
2 import multiprocessing
3 import os
4 import subprocess
5 import sys
6
7 import gunicorn.app.base
8 import gunicorn.util
9
10 from .app.celery import app
11
12 base = os.path.abspath(os.path.dirname(__file__))
13 manage_path = os.path.join(base, 'manage.py')
14 parser = argparse.ArgumentParser(description='doccano, text annotation for machine learning practitioners.')
15
16
17 def number_of_workers():
18 return (multiprocessing.cpu_count() * 2) + 1
19
20
21 class StandaloneApplication(gunicorn.app.base.BaseApplication):
22
23 def __init__(self, options=None):
24 self.options = options or {}
25 super().__init__()
26
27 def load_config(self):
28 config = {key: value for key, value in self.options.items()
29 if key in self.cfg.settings and value is not None}
30 for key, value in config.items():
31 self.cfg.set(key.lower(), value)
32
33 def load(self):
34 sys.path.append(base)
35 return gunicorn.util.import_app('app.wsgi')
36
37
38 def command_db_init(args):
39 print('Setup Database.')
40 subprocess.call([sys.executable, manage_path, 'wait_for_db'], shell=False)
41 subprocess.call([sys.executable, manage_path, 'migrate'], shell=False)
42 subprocess.call([sys.executable, manage_path, 'create_roles'], shell=False)
43
44
45 def command_user_create(args):
46 print('Create admin user.')
47 subprocess.call([sys.executable, manage_path, 'create_admin',
48 '--username', args.username,
49 '--password', args.password,
50 '--email', args.email,
51 '--noinput'], shell=False)
52
53
54 def command_run_webserver(args):
55 print(f'Starting server with port {args.port}.')
56 options = {
57 'bind': '%s:%s' % ('0.0.0.0', args.port),
58 'workers': number_of_workers(),
59 'chdir': base
60 }
61 StandaloneApplication(options).run()
62
63
64 def command_run_task_queue(args):
65 print('Starting task queue.')
66 app.worker_main(
67 argv=[
68 '--app=app',
69 '--workdir={}'.format(base),
70 'worker',
71 '--loglevel=info',
72 '--concurrency={}'.format(args.concurrency),
73 ]
74 )
75
76
77 def command_help(args):
78 print(parser.parse_args([args.command, '--help']))
79
80
81 def main():
82 # Create a command line parser.
83 subparsers = parser.add_subparsers()
84
85 # Create a parser for db initialization.
86 parser_init = subparsers.add_parser('init', help='see `init -h`')
87
88 parser_init.set_defaults(handler=command_db_init)
89
90 # Create a parser for user creation.
91 parser_create_user = subparsers.add_parser('createuser', help='see `createuser -h`')
92 parser_create_user.add_argument('--username', type=str, default='admin', help='admin username')
93 parser_create_user.add_argument('--password', type=str, default='password', help='admin password')
94 parser_create_user.add_argument('--email', type=str, default='[email protected]', help='admin email')
95 parser_create_user.set_defaults(handler=command_user_create)
96
97 # Create a parser for web server.
98 parser_server = subparsers.add_parser('webserver', help='see `webserver -h`')
99 parser_server.add_argument('--port', type=int, default=8000, help='port number')
100 parser_server.set_defaults(handler=command_run_webserver)
101
102 # Create a parser for task queue.
103 parser_queue = subparsers.add_parser('task', help='see `task -h`')
104 parser_queue.add_argument('--concurrency', type=int, default=2, help='concurrency')
105 parser_queue.set_defaults(handler=command_run_task_queue)
106
107 # Create a parser for help.
108 parser_help = subparsers.add_parser('help', help='see `help -h`')
109 parser_help.add_argument('command', help='command name which help is shown')
110 parser_help.set_defaults(handler=command_help)
111
112 # Dispatch handler.
113 args = parser.parse_args()
114 if hasattr(args, 'handler'):
115 args.handler(args)
116 else:
117 # If specified unknown command, show help.
118 parser.print_help()
119
120
121 if __name__ == '__main__':
122 main()
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/cli.py b/backend/cli.py
--- a/backend/cli.py
+++ b/backend/cli.py
@@ -1,15 +1,13 @@
import argparse
import multiprocessing
import os
+import platform
import subprocess
import sys
-import gunicorn.app.base
-import gunicorn.util
-
from .app.celery import app
-
base = os.path.abspath(os.path.dirname(__file__))
+sys.path.append(base)
manage_path = os.path.join(base, 'manage.py')
parser = argparse.ArgumentParser(description='doccano, text annotation for machine learning practitioners.')
@@ -18,21 +16,37 @@
return (multiprocessing.cpu_count() * 2) + 1
-class StandaloneApplication(gunicorn.app.base.BaseApplication):
+def run_on_nix(args):
+ import gunicorn.app.base
+ import gunicorn.util
+
+ class StandaloneApplication(gunicorn.app.base.BaseApplication):
- def __init__(self, options=None):
- self.options = options or {}
- super().__init__()
+ def __init__(self, options=None):
+ self.options = options or {}
+ super().__init__()
- def load_config(self):
- config = {key: value for key, value in self.options.items()
- if key in self.cfg.settings and value is not None}
- for key, value in config.items():
- self.cfg.set(key.lower(), value)
+ def load_config(self):
+ config = {key: value for key, value in self.options.items()
+ if key in self.cfg.settings and value is not None}
+ for key, value in config.items():
+ self.cfg.set(key.lower(), value)
- def load(self):
- sys.path.append(base)
- return gunicorn.util.import_app('app.wsgi')
+ def load(self):
+ return gunicorn.util.import_app('app.wsgi')
+
+ options = {
+ 'bind': '%s:%s' % ('0.0.0.0', args.port),
+ 'workers': number_of_workers(),
+ 'chdir': base
+ }
+ StandaloneApplication(options).run()
+
+
+def run_on_windows(args):
+ from waitress import serve
+ from app.wsgi import application
+ serve(application, port=args.port)
def command_db_init(args):
@@ -53,12 +67,10 @@
def command_run_webserver(args):
print(f'Starting server with port {args.port}.')
- options = {
- 'bind': '%s:%s' % ('0.0.0.0', args.port),
- 'workers': number_of_workers(),
- 'chdir': base
- }
- StandaloneApplication(options).run()
+ if platform.system() == 'Windows':
+ run_on_windows(args)
+ else:
+ run_on_nix(args)
def command_run_task_queue(args):
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,6 +42,7 @@
'django-drf-filepond>=0.3.0',
'sqlalchemy>=1.4.7',
'gunicorn>=20.1.0',
+ 'waitress>=2.0.0',
]
setup(
|
{"golden_diff": "diff --git a/backend/cli.py b/backend/cli.py\n--- a/backend/cli.py\n+++ b/backend/cli.py\n@@ -1,15 +1,13 @@\n import argparse\n import multiprocessing\n import os\n+import platform\n import subprocess\n import sys\n \n-import gunicorn.app.base\n-import gunicorn.util\n-\n from .app.celery import app\n-\n base = os.path.abspath(os.path.dirname(__file__))\n+sys.path.append(base)\n manage_path = os.path.join(base, 'manage.py')\n parser = argparse.ArgumentParser(description='doccano, text annotation for machine learning practitioners.')\n \n@@ -18,21 +16,37 @@\n return (multiprocessing.cpu_count() * 2) + 1\n \n \n-class StandaloneApplication(gunicorn.app.base.BaseApplication):\n+def run_on_nix(args):\n+ import gunicorn.app.base\n+ import gunicorn.util\n+\n+ class StandaloneApplication(gunicorn.app.base.BaseApplication):\n \n- def __init__(self, options=None):\n- self.options = options or {}\n- super().__init__()\n+ def __init__(self, options=None):\n+ self.options = options or {}\n+ super().__init__()\n \n- def load_config(self):\n- config = {key: value for key, value in self.options.items()\n- if key in self.cfg.settings and value is not None}\n- for key, value in config.items():\n- self.cfg.set(key.lower(), value)\n+ def load_config(self):\n+ config = {key: value for key, value in self.options.items()\n+ if key in self.cfg.settings and value is not None}\n+ for key, value in config.items():\n+ self.cfg.set(key.lower(), value)\n \n- def load(self):\n- sys.path.append(base)\n- return gunicorn.util.import_app('app.wsgi')\n+ def load(self):\n+ return gunicorn.util.import_app('app.wsgi')\n+\n+ options = {\n+ 'bind': '%s:%s' % ('0.0.0.0', args.port),\n+ 'workers': number_of_workers(),\n+ 'chdir': base\n+ }\n+ StandaloneApplication(options).run()\n+\n+\n+def run_on_windows(args):\n+ from waitress import serve\n+ from app.wsgi import application\n+ serve(application, port=args.port)\n \n \n def command_db_init(args):\n@@ -53,12 +67,10 @@\n \n def command_run_webserver(args):\n print(f'Starting server with port {args.port}.')\n- options = {\n- 'bind': '%s:%s' % ('0.0.0.0', args.port),\n- 'workers': number_of_workers(),\n- 'chdir': base\n- }\n- StandaloneApplication(options).run()\n+ if platform.system() == 'Windows':\n+ run_on_windows(args)\n+ else:\n+ run_on_nix(args)\n \n \n def command_run_task_queue(args):\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,6 +42,7 @@\n 'django-drf-filepond>=0.3.0',\n 'sqlalchemy>=1.4.7',\n 'gunicorn>=20.1.0',\n+ 'waitress>=2.0.0',\n ]\n \n setup(\n", "issue": "ModuleNotFoundError: No module named 'fcntl'\nHow to reproduce the behaviour\r\n---------\r\nAfter downloading doccano and trying to start it via `doccano init` I get the following message:\r\n\r\n```\r\ndoccano init\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\\\AppData\\Local\\Programs\\Python\\Python39\\Scripts\\doccano-script.py\", line 33, in <module>\r\n sys.exit(load_entry_point('doccano==1.4.1', 'console_scripts', 'doccano')())\r\n File \"C:\\Users\\\\AppData\\Local\\Programs\\Python\\Python39\\Scripts\\doccano-script.py\", line 25, in importlib_load_entry_point\r\n return next(matches).load()\r\n File \"c:\\users\\\\appdata\\local\\programs\\python\\python39\\lib\\importlib\\metadata.py\", line 77, in load\r\n module = import_module(match.group('module'))\r\n File \"c:\\users\\\\appdata\\local\\programs\\python\\python39\\lib\\importlib\\__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 1030, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1007, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 986, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 680, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 790, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 228, in _call_with_frames_removed\r\n File \"c:\\users\\\\appdata\\local\\programs\\python\\python39\\lib\\site-packages\\backend\\cli.py\", line 7, in <module>\r\n import gunicorn.app.base\r\n File \"c:\\users\\\\appdata\\local\\programs\\python\\python39\\lib\\site-packages\\gunicorn\\app\\base.py\", line 11, in <module>\r\n from gunicorn import util\r\n File \"c:\\users\\\\appdata\\local\\programs\\python\\python39\\lib\\site-packages\\gunicorn\\util.py\", line 8, in <module>\r\n import fcntl\r\nModuleNotFoundError: No module named 'fcntl' \r\n```\r\n\r\nYour Environment\r\n---------\r\n* Operating System: Windows 10 1909\r\n* Python Version Used: 3.9.4\r\n* When you install doccano: 17.06.2021\r\n* How did you install doccano (Heroku button etc): `pip install doccano`\r\n\r\nOwn Research:\r\n----------\r\nApparently Windows doesn''t support `fcntl`. Therefore nobody that uses Windows can install doccano via pip.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport io\nimport os\n\nfrom setuptools import find_packages, setup\n\nNAME = 'doccano'\nDESCRIPTION = 'doccano, text annotation tool for machine learning practitioners'\nURL = 'https://github.com/doccano/doccano'\nEMAIL = '[email protected]'\nAUTHOR = 'Hironsan'\nLICENSE = 'MIT'\n\nhere = os.path.abspath(os.path.dirname(__file__))\nwith io.open(os.path.join(here, 'README.md'), encoding='utf-8') as f:\n long_description = '\\n' + f.read()\n\nrequired = [\n 'apache-libcloud>=3.2.0',\n 'colour>=0.1.5',\n 'conllu>=4.2.2',\n 'dj-database-url>=0.5.0',\n 'django-cors-headers>=3.5.0',\n 'django-filter>=2.4.0',\n 'django-rest-polymorphic>=0.1.9',\n 'djangorestframework-csv>=2.1.0',\n 'djangorestframework-xml>=2.0.0',\n 'drf-yasg>=1.20.0',\n 'environs>=9.2.0',\n 'furl>=2.1.0',\n 'pyexcel>=0.6.6',\n 'pyexcel-xlsx>=0.6.0',\n 'python-jose>=3.2.0',\n 'seqeval>=1.2.2',\n 'social-auth-app-django>=4.0.0',\n 'whitenoise>=5.2.0',\n 'auto-labeling-pipeline>=0.1.12',\n 'celery>=5.0.5',\n 'dj-rest-auth>=2.1.4',\n 'django-celery-results>=2.0.1',\n 'django-drf-filepond>=0.3.0',\n 'sqlalchemy>=1.4.7',\n 'gunicorn>=20.1.0',\n]\n\nsetup(\n name=NAME,\n use_scm_version=True,\n setup_requires=['setuptools_scm'],\n description=DESCRIPTION,\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=AUTHOR,\n author_email=EMAIL,\n url=URL,\n packages=find_packages(exclude=('*.tests',)),\n entry_points={\n 'console_scripts': [\n 'doccano = backend.cli:main'\n ]\n },\n install_requires=required,\n extras_require={\n 'postgresql': ['psycopg2-binary>=2.8.6'],\n 'mssql': ['django-mssql-backend>=2.8.1'],\n },\n include_package_data=True,\n license=LICENSE,\n classifiers=[\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy'\n ],\n)\n", "path": "setup.py"}, {"content": "import argparse\nimport multiprocessing\nimport os\nimport subprocess\nimport sys\n\nimport gunicorn.app.base\nimport gunicorn.util\n\nfrom .app.celery import app\n\nbase = os.path.abspath(os.path.dirname(__file__))\nmanage_path = os.path.join(base, 'manage.py')\nparser = argparse.ArgumentParser(description='doccano, text annotation for machine learning practitioners.')\n\n\ndef number_of_workers():\n return (multiprocessing.cpu_count() * 2) + 1\n\n\nclass StandaloneApplication(gunicorn.app.base.BaseApplication):\n\n def __init__(self, options=None):\n self.options = options or {}\n super().__init__()\n\n def load_config(self):\n config = {key: value for key, value in self.options.items()\n if key in self.cfg.settings and value is not None}\n for key, value in config.items():\n self.cfg.set(key.lower(), value)\n\n def load(self):\n sys.path.append(base)\n return gunicorn.util.import_app('app.wsgi')\n\n\ndef command_db_init(args):\n print('Setup Database.')\n subprocess.call([sys.executable, manage_path, 'wait_for_db'], shell=False)\n subprocess.call([sys.executable, manage_path, 'migrate'], shell=False)\n subprocess.call([sys.executable, manage_path, 'create_roles'], shell=False)\n\n\ndef command_user_create(args):\n print('Create admin user.')\n subprocess.call([sys.executable, manage_path, 'create_admin',\n '--username', args.username,\n '--password', args.password,\n '--email', args.email,\n '--noinput'], shell=False)\n\n\ndef command_run_webserver(args):\n print(f'Starting server with port {args.port}.')\n options = {\n 'bind': '%s:%s' % ('0.0.0.0', args.port),\n 'workers': number_of_workers(),\n 'chdir': base\n }\n StandaloneApplication(options).run()\n\n\ndef command_run_task_queue(args):\n print('Starting task queue.')\n app.worker_main(\n argv=[\n '--app=app',\n '--workdir={}'.format(base),\n 'worker',\n '--loglevel=info',\n '--concurrency={}'.format(args.concurrency),\n ]\n )\n\n\ndef command_help(args):\n print(parser.parse_args([args.command, '--help']))\n\n\ndef main():\n # Create a command line parser.\n subparsers = parser.add_subparsers()\n\n # Create a parser for db initialization.\n parser_init = subparsers.add_parser('init', help='see `init -h`')\n\n parser_init.set_defaults(handler=command_db_init)\n\n # Create a parser for user creation.\n parser_create_user = subparsers.add_parser('createuser', help='see `createuser -h`')\n parser_create_user.add_argument('--username', type=str, default='admin', help='admin username')\n parser_create_user.add_argument('--password', type=str, default='password', help='admin password')\n parser_create_user.add_argument('--email', type=str, default='[email protected]', help='admin email')\n parser_create_user.set_defaults(handler=command_user_create)\n\n # Create a parser for web server.\n parser_server = subparsers.add_parser('webserver', help='see `webserver -h`')\n parser_server.add_argument('--port', type=int, default=8000, help='port number')\n parser_server.set_defaults(handler=command_run_webserver)\n\n # Create a parser for task queue.\n parser_queue = subparsers.add_parser('task', help='see `task -h`')\n parser_queue.add_argument('--concurrency', type=int, default=2, help='concurrency')\n parser_queue.set_defaults(handler=command_run_task_queue)\n\n # Create a parser for help.\n parser_help = subparsers.add_parser('help', help='see `help -h`')\n parser_help.add_argument('command', help='command name which help is shown')\n parser_help.set_defaults(handler=command_help)\n\n # Dispatch handler.\n args = parser.parse_args()\n if hasattr(args, 'handler'):\n args.handler(args)\n else:\n # If specified unknown command, show help.\n parser.print_help()\n\n\nif __name__ == '__main__':\n main()\n", "path": "backend/cli.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport io\nimport os\n\nfrom setuptools import find_packages, setup\n\nNAME = 'doccano'\nDESCRIPTION = 'doccano, text annotation tool for machine learning practitioners'\nURL = 'https://github.com/doccano/doccano'\nEMAIL = '[email protected]'\nAUTHOR = 'Hironsan'\nLICENSE = 'MIT'\n\nhere = os.path.abspath(os.path.dirname(__file__))\nwith io.open(os.path.join(here, 'README.md'), encoding='utf-8') as f:\n long_description = '\\n' + f.read()\n\nrequired = [\n 'apache-libcloud>=3.2.0',\n 'colour>=0.1.5',\n 'conllu>=4.2.2',\n 'dj-database-url>=0.5.0',\n 'django-cors-headers>=3.5.0',\n 'django-filter>=2.4.0',\n 'django-rest-polymorphic>=0.1.9',\n 'djangorestframework-csv>=2.1.0',\n 'djangorestframework-xml>=2.0.0',\n 'drf-yasg>=1.20.0',\n 'environs>=9.2.0',\n 'furl>=2.1.0',\n 'pyexcel>=0.6.6',\n 'pyexcel-xlsx>=0.6.0',\n 'python-jose>=3.2.0',\n 'seqeval>=1.2.2',\n 'social-auth-app-django>=4.0.0',\n 'whitenoise>=5.2.0',\n 'auto-labeling-pipeline>=0.1.12',\n 'celery>=5.0.5',\n 'dj-rest-auth>=2.1.4',\n 'django-celery-results>=2.0.1',\n 'django-drf-filepond>=0.3.0',\n 'sqlalchemy>=1.4.7',\n 'gunicorn>=20.1.0',\n 'waitress>=2.0.0',\n]\n\nsetup(\n name=NAME,\n use_scm_version=True,\n setup_requires=['setuptools_scm'],\n description=DESCRIPTION,\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=AUTHOR,\n author_email=EMAIL,\n url=URL,\n packages=find_packages(exclude=('*.tests',)),\n entry_points={\n 'console_scripts': [\n 'doccano = backend.cli:main'\n ]\n },\n install_requires=required,\n extras_require={\n 'postgresql': ['psycopg2-binary>=2.8.6'],\n 'mssql': ['django-mssql-backend>=2.8.1'],\n },\n include_package_data=True,\n license=LICENSE,\n classifiers=[\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy'\n ],\n)\n", "path": "setup.py"}, {"content": "import argparse\nimport multiprocessing\nimport os\nimport platform\nimport subprocess\nimport sys\n\nfrom .app.celery import app\nbase = os.path.abspath(os.path.dirname(__file__))\nsys.path.append(base)\nmanage_path = os.path.join(base, 'manage.py')\nparser = argparse.ArgumentParser(description='doccano, text annotation for machine learning practitioners.')\n\n\ndef number_of_workers():\n return (multiprocessing.cpu_count() * 2) + 1\n\n\ndef run_on_nix(args):\n import gunicorn.app.base\n import gunicorn.util\n\n class StandaloneApplication(gunicorn.app.base.BaseApplication):\n\n def __init__(self, options=None):\n self.options = options or {}\n super().__init__()\n\n def load_config(self):\n config = {key: value for key, value in self.options.items()\n if key in self.cfg.settings and value is not None}\n for key, value in config.items():\n self.cfg.set(key.lower(), value)\n\n def load(self):\n return gunicorn.util.import_app('app.wsgi')\n\n options = {\n 'bind': '%s:%s' % ('0.0.0.0', args.port),\n 'workers': number_of_workers(),\n 'chdir': base\n }\n StandaloneApplication(options).run()\n\n\ndef run_on_windows(args):\n from waitress import serve\n from app.wsgi import application\n serve(application, port=args.port)\n\n\ndef command_db_init(args):\n print('Setup Database.')\n subprocess.call([sys.executable, manage_path, 'wait_for_db'], shell=False)\n subprocess.call([sys.executable, manage_path, 'migrate'], shell=False)\n subprocess.call([sys.executable, manage_path, 'create_roles'], shell=False)\n\n\ndef command_user_create(args):\n print('Create admin user.')\n subprocess.call([sys.executable, manage_path, 'create_admin',\n '--username', args.username,\n '--password', args.password,\n '--email', args.email,\n '--noinput'], shell=False)\n\n\ndef command_run_webserver(args):\n print(f'Starting server with port {args.port}.')\n if platform.system() == 'Windows':\n run_on_windows(args)\n else:\n run_on_nix(args)\n\n\ndef command_run_task_queue(args):\n print('Starting task queue.')\n app.worker_main(\n argv=[\n '--app=app',\n '--workdir={}'.format(base),\n 'worker',\n '--loglevel=info',\n '--concurrency={}'.format(args.concurrency),\n ]\n )\n\n\ndef command_help(args):\n print(parser.parse_args([args.command, '--help']))\n\n\ndef main():\n # Create a command line parser.\n subparsers = parser.add_subparsers()\n\n # Create a parser for db initialization.\n parser_init = subparsers.add_parser('init', help='see `init -h`')\n\n parser_init.set_defaults(handler=command_db_init)\n\n # Create a parser for user creation.\n parser_create_user = subparsers.add_parser('createuser', help='see `createuser -h`')\n parser_create_user.add_argument('--username', type=str, default='admin', help='admin username')\n parser_create_user.add_argument('--password', type=str, default='password', help='admin password')\n parser_create_user.add_argument('--email', type=str, default='[email protected]', help='admin email')\n parser_create_user.set_defaults(handler=command_user_create)\n\n # Create a parser for web server.\n parser_server = subparsers.add_parser('webserver', help='see `webserver -h`')\n parser_server.add_argument('--port', type=int, default=8000, help='port number')\n parser_server.set_defaults(handler=command_run_webserver)\n\n # Create a parser for task queue.\n parser_queue = subparsers.add_parser('task', help='see `task -h`')\n parser_queue.add_argument('--concurrency', type=int, default=2, help='concurrency')\n parser_queue.set_defaults(handler=command_run_task_queue)\n\n # Create a parser for help.\n parser_help = subparsers.add_parser('help', help='see `help -h`')\n parser_help.add_argument('command', help='command name which help is shown')\n parser_help.set_defaults(handler=command_help)\n\n # Dispatch handler.\n args = parser.parse_args()\n if hasattr(args, 'handler'):\n args.handler(args)\n else:\n # If specified unknown command, show help.\n parser.print_help()\n\n\nif __name__ == '__main__':\n main()\n", "path": "backend/cli.py"}]}
| 2,938 | 731 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.