
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_5807
|
rasdani/github-patches
|
git_diff
|
scikit-hep__awkward-970
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doubly jagged workaround broken in awkward 1.4.0rc2
There was a quick fix (made for KM3NeT data 😄) for doubly jagged arrays which were discussed here https://github.com/scikit-hep/uproot4/issues/90 and the it uses the `akward._io` submodule which is not accessible anymore directly (`AttributeError`) in `1.4.0rc2`.
See here:
https://github.com/scikit-hep/awkward-1.0/blob/main/src/awkward/_connect/_uproot.py#L35
I am not sure what the desired fix is, to import `_io` in `_connect/_uproot.py` or if this fix is now covered by further developments, so I thought I ask first before I do a PR 😉
Here is the full MWE (needs `pip install km3net-testdata`, I am not sure if this test
```python
>>> import uproot
>>> uproot.__version__
'4.0.7'
>>> import awkward as ak
>>> ak.__version__
'1.4.0rc2'
>>> from km3net_testdata import data_path
>>> f = uproot.open(data_path("offline/mcv5.11r2.gsg_muonCChigherE-CC_50-5000GeV.km3_AAv1.jterbr00004695.jchain.aanet.498.root"))
>>> f["E/Evt/trks/trks.rec_stages"].array()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-80472509fad7> in <module>
----> 1 f["E/Evt/trks/trks.rec_stages"].array()
~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in array(self, interpretation, entry_start, entry_stop, decompression_executor, interpretation_executor, array_cache, library)
2076 ranges_or_baskets.append((branch, basket_num, range_or_basket))
2077
-> 2078 _ranges_or_baskets_to_arrays(
2079 self,
2080 ranges_or_baskets,
~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in _ranges_or_baskets_to_arrays(hasbranches, ranges_or_baskets, branchid_interpretation, entry_start, entry_stop, decompression_executor, interpretation_executor, library, arrays, update_ranges_or_baskets)
3476
3477 elif isinstance(obj, tuple) and len(obj) == 3:
-> 3478 uproot.source.futures.delayed_raise(*obj)
3479
3480 else:
~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/source/futures.py in delayed_raise(exception_class, exception_value, traceback)
44 exec("raise exception_class, exception_value, traceback")
45 else:
---> 46 raise exception_value.with_traceback(traceback)
47
48
~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in basket_to_array(basket)
3420 basket_arrays = branchid_arrays[branch.cache_key]
3421
-> 3422 basket_arrays[basket.basket_num] = interpretation.basket_array(
3423 basket.data,
3424 basket.byte_offsets,
~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/interpretation/objects.py in basket_array(self, data, byte_offsets, basket, branch, context, cursor_offset, library)
151 "cursor_offset": cursor_offset,
152 }
--> 153 output = awkward._connect._uproot.basket_array(
154 form, data, byte_offsets, extra
155 )
~/Dev/km3io/venv/lib/python3.9/site-packages/awkward/_connect/_uproot.py in basket_array(form, data, byte_offsets, extra)
36 # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done
37
---> 38 return ak._io.uproot_issue_90(
39 form,
40 ak.layout.NumpyArray(data),
AttributeError: module 'awkward' has no attribute '_io'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/awkward/_connect/_uproot.py`
Content:
```
1 # BSD 3-Clause License; see https://github.com/scikit-hep/awkward-1.0/blob/main/LICENSE
2
3 from __future__ import absolute_import
4
5 import json
6
7 # don't import awkward._connect._uproot in awkward/__init__.py!
8 import uproot
9
10 import awkward as ak
11
12
13 def can_optimize(interpretation, form):
14 if isinstance(interpretation, uproot.interpretation.objects.AsObjects):
15 jsonform = json.loads(form.tojson(verbose=True))
16 if (
17 jsonform["class"] == "ListOffsetArray64"
18 and jsonform["parameters"].get("uproot")
19 == {"as": "array", "header": True, "speedbump": False}
20 and jsonform["content"]["class"] == "ListOffsetArray64"
21 and jsonform["content"]["parameters"].get("uproot")
22 == {"as": "vector", "header": False}
23 and jsonform["content"]["content"]["class"] == "NumpyArray"
24 and jsonform["content"]["content"]["inner_shape"] == []
25 and (
26 jsonform["content"]["content"].get("primitive") == "float64"
27 or jsonform["content"]["content"].get("primitive") == "int32"
28 )
29 ):
30 return True
31
32 return False
33
34
35 def basket_array(form, data, byte_offsets, extra):
36 # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done
37
38 return ak._io.uproot_issue_90(
39 form,
40 ak.layout.NumpyArray(data),
41 ak.layout.Index32(byte_offsets),
42 )
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/awkward/_connect/_uproot.py b/src/awkward/_connect/_uproot.py
--- a/src/awkward/_connect/_uproot.py
+++ b/src/awkward/_connect/_uproot.py
@@ -33,9 +33,11 @@
def basket_array(form, data, byte_offsets, extra):
+ import awkward._io
+
# FIXME: uproot_issue_90 is just a placeholder, to show how it would be done
- return ak._io.uproot_issue_90(
+ return awkward._io.uproot_issue_90(
form,
ak.layout.NumpyArray(data),
ak.layout.Index32(byte_offsets),
|
{"golden_diff": "diff --git a/src/awkward/_connect/_uproot.py b/src/awkward/_connect/_uproot.py\n--- a/src/awkward/_connect/_uproot.py\n+++ b/src/awkward/_connect/_uproot.py\n@@ -33,9 +33,11 @@\n \n \n def basket_array(form, data, byte_offsets, extra):\n+ import awkward._io\n+\n # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done\n \n- return ak._io.uproot_issue_90(\n+ return awkward._io.uproot_issue_90(\n form,\n ak.layout.NumpyArray(data),\n ak.layout.Index32(byte_offsets),\n", "issue": "Doubly jagged workaround broken in awkward 1.4.0rc2\nThere was a quick fix (made for KM3NeT data \ud83d\ude04) for doubly jagged arrays which were discussed here https://github.com/scikit-hep/uproot4/issues/90 and the it uses the `akward._io` submodule which is not accessible anymore directly (`AttributeError`) in `1.4.0rc2`.\r\n\r\nSee here:\r\n\r\nhttps://github.com/scikit-hep/awkward-1.0/blob/main/src/awkward/_connect/_uproot.py#L35\r\n\r\nI am not sure what the desired fix is, to import `_io` in `_connect/_uproot.py` or if this fix is now covered by further developments, so I thought I ask first before I do a PR \ud83d\ude09 \r\n\r\nHere is the full MWE (needs `pip install km3net-testdata`, I am not sure if this test\r\n\r\n```python\r\n>>> import uproot\r\n\r\n>>> uproot.__version__\r\n'4.0.7'\r\n\r\n>>> import awkward as ak\r\n\r\n>>> ak.__version__\r\n'1.4.0rc2'\r\n\r\n>>> from km3net_testdata import data_path\r\n\r\n>>> f = uproot.open(data_path(\"offline/mcv5.11r2.gsg_muonCChigherE-CC_50-5000GeV.km3_AAv1.jterbr00004695.jchain.aanet.498.root\"))\r\n\r\n>>> f[\"E/Evt/trks/trks.rec_stages\"].array()\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-18-80472509fad7> in <module>\r\n----> 1 f[\"E/Evt/trks/trks.rec_stages\"].array()\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in array(self, interpretation, entry_start, entry_stop, decompression_executor, interpretation_executor, array_cache, library)\r\n 2076 ranges_or_baskets.append((branch, basket_num, range_or_basket))\r\n 2077\r\n-> 2078 _ranges_or_baskets_to_arrays(\r\n 2079 self,\r\n 2080 ranges_or_baskets,\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in _ranges_or_baskets_to_arrays(hasbranches, ranges_or_baskets, branchid_interpretation, entry_start, entry_stop, decompression_executor, interpretation_executor, library, arrays, update_ranges_or_baskets)\r\n 3476\r\n 3477 elif isinstance(obj, tuple) and len(obj) == 3:\r\n-> 3478 uproot.source.futures.delayed_raise(*obj)\r\n 3479\r\n 3480 else:\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/source/futures.py in delayed_raise(exception_class, exception_value, traceback)\r\n 44 exec(\"raise exception_class, exception_value, traceback\")\r\n 45 else:\r\n---> 46 raise exception_value.with_traceback(traceback)\r\n 47\r\n 48\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/behaviors/TBranch.py in basket_to_array(basket)\r\n 3420 basket_arrays = branchid_arrays[branch.cache_key]\r\n 3421\r\n-> 3422 basket_arrays[basket.basket_num] = interpretation.basket_array(\r\n 3423 basket.data,\r\n 3424 basket.byte_offsets,\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/uproot/interpretation/objects.py in basket_array(self, data, byte_offsets, basket, branch, context, cursor_offset, library)\r\n 151 \"cursor_offset\": cursor_offset,\r\n 152 }\r\n--> 153 output = awkward._connect._uproot.basket_array(\r\n 154 form, data, byte_offsets, extra\r\n 155 )\r\n\r\n~/Dev/km3io/venv/lib/python3.9/site-packages/awkward/_connect/_uproot.py in basket_array(form, data, byte_offsets, extra)\r\n 36 # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done\r\n 37\r\n---> 38 return ak._io.uproot_issue_90(\r\n 39 form,\r\n 40 ak.layout.NumpyArray(data),\r\n\r\nAttributeError: module 'awkward' has no attribute '_io'\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License; see https://github.com/scikit-hep/awkward-1.0/blob/main/LICENSE\n\nfrom __future__ import absolute_import\n\nimport json\n\n# don't import awkward._connect._uproot in awkward/__init__.py!\nimport uproot\n\nimport awkward as ak\n\n\ndef can_optimize(interpretation, form):\n if isinstance(interpretation, uproot.interpretation.objects.AsObjects):\n jsonform = json.loads(form.tojson(verbose=True))\n if (\n jsonform[\"class\"] == \"ListOffsetArray64\"\n and jsonform[\"parameters\"].get(\"uproot\")\n == {\"as\": \"array\", \"header\": True, \"speedbump\": False}\n and jsonform[\"content\"][\"class\"] == \"ListOffsetArray64\"\n and jsonform[\"content\"][\"parameters\"].get(\"uproot\")\n == {\"as\": \"vector\", \"header\": False}\n and jsonform[\"content\"][\"content\"][\"class\"] == \"NumpyArray\"\n and jsonform[\"content\"][\"content\"][\"inner_shape\"] == []\n and (\n jsonform[\"content\"][\"content\"].get(\"primitive\") == \"float64\"\n or jsonform[\"content\"][\"content\"].get(\"primitive\") == \"int32\"\n )\n ):\n return True\n\n return False\n\n\ndef basket_array(form, data, byte_offsets, extra):\n # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done\n\n return ak._io.uproot_issue_90(\n form,\n ak.layout.NumpyArray(data),\n ak.layout.Index32(byte_offsets),\n )\n", "path": "src/awkward/_connect/_uproot.py"}], "after_files": [{"content": "# BSD 3-Clause License; see https://github.com/scikit-hep/awkward-1.0/blob/main/LICENSE\n\nfrom __future__ import absolute_import\n\nimport json\n\n# don't import awkward._connect._uproot in awkward/__init__.py!\nimport uproot\n\nimport awkward as ak\n\n\ndef can_optimize(interpretation, form):\n if isinstance(interpretation, uproot.interpretation.objects.AsObjects):\n jsonform = json.loads(form.tojson(verbose=True))\n if (\n jsonform[\"class\"] == \"ListOffsetArray64\"\n and jsonform[\"parameters\"].get(\"uproot\")\n == {\"as\": \"array\", \"header\": True, \"speedbump\": False}\n and jsonform[\"content\"][\"class\"] == \"ListOffsetArray64\"\n and jsonform[\"content\"][\"parameters\"].get(\"uproot\")\n == {\"as\": \"vector\", \"header\": False}\n and jsonform[\"content\"][\"content\"][\"class\"] == \"NumpyArray\"\n and jsonform[\"content\"][\"content\"][\"inner_shape\"] == []\n and (\n jsonform[\"content\"][\"content\"].get(\"primitive\") == \"float64\"\n or jsonform[\"content\"][\"content\"].get(\"primitive\") == \"int32\"\n )\n ):\n return True\n\n return False\n\n\ndef basket_array(form, data, byte_offsets, extra):\n import awkward._io\n\n # FIXME: uproot_issue_90 is just a placeholder, to show how it would be done\n\n return awkward._io.uproot_issue_90(\n form,\n ak.layout.NumpyArray(data),\n ak.layout.Index32(byte_offsets),\n )\n", "path": "src/awkward/_connect/_uproot.py"}]}
| 1,739 | 155 |
gh_patches_debug_25846
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-1591
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Could not parse docx document
### Description
I can't upload a docx document after updating to the latest release candidate.
### Steps to reproduce
1. Update paperless-ngx to 1.9.0-rc1 (ghcr.io/paperless-ngx/paperless-ngx:beta)
2. Upload a docx-document and an error occurs "_`Error while consuming document khms-immoconsult_20170924_2.docx: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'`_"
### Webserver logs
```bash
2022-09-14 05:45:14,789] [INFO] [paperless.consumer] Consuming khms-immoconsult_20170924_2.docx
[2022-09-14 05:45:14,791] [DEBUG] [paperless.consumer] Detected mime type: application/vnd.openxmlformats-officedocument.wordprocessingml.document
[2022-09-14 05:45:14,795] [DEBUG] [paperless.consumer] Parser: TikaDocumentParser
[2022-09-14 05:45:14,800] [DEBUG] [paperless.consumer] Parsing khms-immoconsult_20170924_2.docx...
[2022-09-14 05:45:14,801] [INFO] [paperless.parsing.tika] Sending /tmp/paperless/paperless-upload-iwgwe9h0 to Tika server
[2022-09-14 05:45:14,802] [DEBUG] [paperless.parsing.tika] Deleting directory /tmp/paperless/paperless-86t5km9q
[2022-09-14 05:45:14,806] [ERROR] [paperless.consumer] Error while consuming document khms-immoconsult_20170924_2.docx: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'
Traceback (most recent call last):
File "/usr/src/paperless/src/paperless_tika/parsers.py", line 55, in parse
parsed = parser.from_file(document_path, tika_server)
File "/usr/local/lib/python3.9/site-packages/tika/parser.py", line 40, in from_file
output = parse1(service, filename, serverEndpoint, headers=headers, config_path=config_path, requestOptions=requestOptions)
File "/usr/local/lib/python3.9/site-packages/tika/tika.py", line 327, in parse1
path, file_type = getRemoteFile(urlOrPath, TikaFilesPath)
File "/usr/local/lib/python3.9/site-packages/tika/tika.py", line 762, in getRemoteFile
urlp = urlparse(urlOrPath)
File "/usr/local/lib/python3.9/urllib/parse.py", line 392, in urlparse
url, scheme, _coerce_result = _coerce_args(url, scheme)
File "/usr/local/lib/python3.9/urllib/parse.py", line 128, in _coerce_args
return _decode_args(args) + (_encode_result,)
File "/usr/local/lib/python3.9/urllib/parse.py", line 112, in _decode_args
return tuple(x.decode(encoding, errors) if x else '' for x in args)
File "/usr/local/lib/python3.9/urllib/parse.py", line 112, in <genexpr>
return tuple(x.decode(encoding, errors) if x else '' for x in args)
AttributeError: 'PosixPath' object has no attribute 'decode'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/src/paperless/src/documents/consumer.py", line 320, in try_consume_file
document_parser.parse(self.path, mime_type, self.filename)
File "/usr/src/paperless/src/paperless_tika/parsers.py", line 57, in parse
raise ParseError(
documents.parsers.ParseError: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'
```
### Paperless-ngx version
1.9.0-rc1
### Host OS
Ubuntu 22.04 LTS
### Installation method
Docker - official image
### Browser
Google Chrome
### Configuration changes
_No response_
### Other
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/paperless_tika/parsers.py`
Content:
```
1 import os
2
3 import dateutil.parser
4 import requests
5 from django.conf import settings
6 from documents.parsers import DocumentParser
7 from documents.parsers import make_thumbnail_from_pdf
8 from documents.parsers import ParseError
9 from tika import parser
10
11
12 class TikaDocumentParser(DocumentParser):
13 """
14 This parser sends documents to a local tika server
15 """
16
17 logging_name = "paperless.parsing.tika"
18
19 def get_thumbnail(self, document_path, mime_type, file_name=None):
20 if not self.archive_path:
21 self.archive_path = self.convert_to_pdf(document_path, file_name)
22
23 return make_thumbnail_from_pdf(
24 self.archive_path,
25 self.tempdir,
26 self.logging_group,
27 )
28
29 def extract_metadata(self, document_path, mime_type):
30 tika_server = settings.TIKA_ENDPOINT
31 try:
32 parsed = parser.from_file(document_path, tika_server)
33 except Exception as e:
34 self.log(
35 "warning",
36 f"Error while fetching document metadata for " f"{document_path}: {e}",
37 )
38 return []
39
40 return [
41 {
42 "namespace": "",
43 "prefix": "",
44 "key": key,
45 "value": parsed["metadata"][key],
46 }
47 for key in parsed["metadata"]
48 ]
49
50 def parse(self, document_path, mime_type, file_name=None):
51 self.log("info", f"Sending {document_path} to Tika server")
52 tika_server = settings.TIKA_ENDPOINT
53
54 try:
55 parsed = parser.from_file(document_path, tika_server)
56 except Exception as err:
57 raise ParseError(
58 f"Could not parse {document_path} with tika server at "
59 f"{tika_server}: {err}",
60 ) from err
61
62 self.text = parsed["content"].strip()
63
64 try:
65 self.date = dateutil.parser.isoparse(parsed["metadata"]["Creation-Date"])
66 except Exception as e:
67 self.log(
68 "warning",
69 f"Unable to extract date for document " f"{document_path}: {e}",
70 )
71
72 self.archive_path = self.convert_to_pdf(document_path, file_name)
73
74 def convert_to_pdf(self, document_path, file_name):
75 pdf_path = os.path.join(self.tempdir, "convert.pdf")
76 gotenberg_server = settings.TIKA_GOTENBERG_ENDPOINT
77 url = gotenberg_server + "/forms/libreoffice/convert"
78
79 self.log("info", f"Converting {document_path} to PDF as {pdf_path}")
80 with open(document_path, "rb") as document_handle:
81 files = {
82 "files": (
83 file_name or os.path.basename(document_path),
84 document_handle,
85 ),
86 }
87 headers = {}
88
89 try:
90 response = requests.post(url, files=files, headers=headers)
91 response.raise_for_status() # ensure we notice bad responses
92 except Exception as err:
93 raise ParseError(
94 f"Error while converting document to PDF: {err}",
95 ) from err
96
97 with open(pdf_path, "wb") as file:
98 file.write(response.content)
99 file.close()
100
101 return pdf_path
102
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/paperless_tika/parsers.py b/src/paperless_tika/parsers.py
--- a/src/paperless_tika/parsers.py
+++ b/src/paperless_tika/parsers.py
@@ -1,4 +1,5 @@
import os
+from pathlib import Path
import dateutil.parser
import requests
@@ -28,6 +29,11 @@
def extract_metadata(self, document_path, mime_type):
tika_server = settings.TIKA_ENDPOINT
+
+ # tika does not support a PathLike, only strings
+ # ensure this is a string
+ document_path = str(document_path)
+
try:
parsed = parser.from_file(document_path, tika_server)
except Exception as e:
@@ -47,10 +53,14 @@
for key in parsed["metadata"]
]
- def parse(self, document_path, mime_type, file_name=None):
+ def parse(self, document_path: Path, mime_type, file_name=None):
self.log("info", f"Sending {document_path} to Tika server")
tika_server = settings.TIKA_ENDPOINT
+ # tika does not support a PathLike, only strings
+ # ensure this is a string
+ document_path = str(document_path)
+
try:
parsed = parser.from_file(document_path, tika_server)
except Exception as err:
|
{"golden_diff": "diff --git a/src/paperless_tika/parsers.py b/src/paperless_tika/parsers.py\n--- a/src/paperless_tika/parsers.py\n+++ b/src/paperless_tika/parsers.py\n@@ -1,4 +1,5 @@\n import os\n+from pathlib import Path\n \n import dateutil.parser\n import requests\n@@ -28,6 +29,11 @@\n \n def extract_metadata(self, document_path, mime_type):\n tika_server = settings.TIKA_ENDPOINT\n+\n+ # tika does not support a PathLike, only strings\n+ # ensure this is a string\n+ document_path = str(document_path)\n+\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as e:\n@@ -47,10 +53,14 @@\n for key in parsed[\"metadata\"]\n ]\n \n- def parse(self, document_path, mime_type, file_name=None):\n+ def parse(self, document_path: Path, mime_type, file_name=None):\n self.log(\"info\", f\"Sending {document_path} to Tika server\")\n tika_server = settings.TIKA_ENDPOINT\n \n+ # tika does not support a PathLike, only strings\n+ # ensure this is a string\n+ document_path = str(document_path)\n+\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as err:\n", "issue": "[BUG] Could not parse docx document\n### Description\n\nI can't upload a docx document after updating to the latest release candidate.\n\n### Steps to reproduce\n\n1. Update paperless-ngx to 1.9.0-rc1 (ghcr.io/paperless-ngx/paperless-ngx:beta)\r\n2. Upload a docx-document and an error occurs \"_`Error while consuming document khms-immoconsult_20170924_2.docx: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'`_\"\n\n### Webserver logs\n\n```bash\n2022-09-14 05:45:14,789] [INFO] [paperless.consumer] Consuming khms-immoconsult_20170924_2.docx\r\n\r\n[2022-09-14 05:45:14,791] [DEBUG] [paperless.consumer] Detected mime type: application/vnd.openxmlformats-officedocument.wordprocessingml.document\r\n\r\n[2022-09-14 05:45:14,795] [DEBUG] [paperless.consumer] Parser: TikaDocumentParser\r\n\r\n[2022-09-14 05:45:14,800] [DEBUG] [paperless.consumer] Parsing khms-immoconsult_20170924_2.docx...\r\n\r\n[2022-09-14 05:45:14,801] [INFO] [paperless.parsing.tika] Sending /tmp/paperless/paperless-upload-iwgwe9h0 to Tika server\r\n\r\n[2022-09-14 05:45:14,802] [DEBUG] [paperless.parsing.tika] Deleting directory /tmp/paperless/paperless-86t5km9q\r\n\r\n[2022-09-14 05:45:14,806] [ERROR] [paperless.consumer] Error while consuming document khms-immoconsult_20170924_2.docx: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'\r\n\r\nTraceback (most recent call last):\r\n\r\n File \"/usr/src/paperless/src/paperless_tika/parsers.py\", line 55, in parse\r\n\r\n parsed = parser.from_file(document_path, tika_server)\r\n\r\n File \"/usr/local/lib/python3.9/site-packages/tika/parser.py\", line 40, in from_file\r\n\r\n output = parse1(service, filename, serverEndpoint, headers=headers, config_path=config_path, requestOptions=requestOptions)\r\n\r\n File \"/usr/local/lib/python3.9/site-packages/tika/tika.py\", line 327, in parse1\r\n\r\n path, file_type = getRemoteFile(urlOrPath, TikaFilesPath)\r\n\r\n File \"/usr/local/lib/python3.9/site-packages/tika/tika.py\", line 762, in getRemoteFile\r\n\r\n urlp = urlparse(urlOrPath)\r\n\r\n File \"/usr/local/lib/python3.9/urllib/parse.py\", line 392, in urlparse\r\n\r\n url, scheme, _coerce_result = _coerce_args(url, scheme)\r\n\r\n File \"/usr/local/lib/python3.9/urllib/parse.py\", line 128, in _coerce_args\r\n\r\n return _decode_args(args) + (_encode_result,)\r\n\r\n File \"/usr/local/lib/python3.9/urllib/parse.py\", line 112, in _decode_args\r\n\r\n return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n\r\n File \"/usr/local/lib/python3.9/urllib/parse.py\", line 112, in <genexpr>\r\n\r\n return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n\r\nAttributeError: 'PosixPath' object has no attribute 'decode'\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 320, in try_consume_file\r\n\r\n document_parser.parse(self.path, mime_type, self.filename)\r\n\r\n File \"/usr/src/paperless/src/paperless_tika/parsers.py\", line 57, in parse\r\n\r\n raise ParseError(\r\n\r\ndocuments.parsers.ParseError: Could not parse /tmp/paperless/paperless-upload-iwgwe9h0 with tika server at http://tika:9998: 'PosixPath' object has no attribute 'decode'\n```\n\n\n### Paperless-ngx version\n\n1.9.0-rc1\n\n### Host OS\n\nUbuntu 22.04 LTS\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\nGoogle Chrome\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n", "before_files": [{"content": "import os\n\nimport dateutil.parser\nimport requests\nfrom django.conf import settings\nfrom documents.parsers import DocumentParser\nfrom documents.parsers import make_thumbnail_from_pdf\nfrom documents.parsers import ParseError\nfrom tika import parser\n\n\nclass TikaDocumentParser(DocumentParser):\n \"\"\"\n This parser sends documents to a local tika server\n \"\"\"\n\n logging_name = \"paperless.parsing.tika\"\n\n def get_thumbnail(self, document_path, mime_type, file_name=None):\n if not self.archive_path:\n self.archive_path = self.convert_to_pdf(document_path, file_name)\n\n return make_thumbnail_from_pdf(\n self.archive_path,\n self.tempdir,\n self.logging_group,\n )\n\n def extract_metadata(self, document_path, mime_type):\n tika_server = settings.TIKA_ENDPOINT\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as e:\n self.log(\n \"warning\",\n f\"Error while fetching document metadata for \" f\"{document_path}: {e}\",\n )\n return []\n\n return [\n {\n \"namespace\": \"\",\n \"prefix\": \"\",\n \"key\": key,\n \"value\": parsed[\"metadata\"][key],\n }\n for key in parsed[\"metadata\"]\n ]\n\n def parse(self, document_path, mime_type, file_name=None):\n self.log(\"info\", f\"Sending {document_path} to Tika server\")\n tika_server = settings.TIKA_ENDPOINT\n\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as err:\n raise ParseError(\n f\"Could not parse {document_path} with tika server at \"\n f\"{tika_server}: {err}\",\n ) from err\n\n self.text = parsed[\"content\"].strip()\n\n try:\n self.date = dateutil.parser.isoparse(parsed[\"metadata\"][\"Creation-Date\"])\n except Exception as e:\n self.log(\n \"warning\",\n f\"Unable to extract date for document \" f\"{document_path}: {e}\",\n )\n\n self.archive_path = self.convert_to_pdf(document_path, file_name)\n\n def convert_to_pdf(self, document_path, file_name):\n pdf_path = os.path.join(self.tempdir, \"convert.pdf\")\n gotenberg_server = settings.TIKA_GOTENBERG_ENDPOINT\n url = gotenberg_server + \"/forms/libreoffice/convert\"\n\n self.log(\"info\", f\"Converting {document_path} to PDF as {pdf_path}\")\n with open(document_path, \"rb\") as document_handle:\n files = {\n \"files\": (\n file_name or os.path.basename(document_path),\n document_handle,\n ),\n }\n headers = {}\n\n try:\n response = requests.post(url, files=files, headers=headers)\n response.raise_for_status() # ensure we notice bad responses\n except Exception as err:\n raise ParseError(\n f\"Error while converting document to PDF: {err}\",\n ) from err\n\n with open(pdf_path, \"wb\") as file:\n file.write(response.content)\n file.close()\n\n return pdf_path\n", "path": "src/paperless_tika/parsers.py"}], "after_files": [{"content": "import os\nfrom pathlib import Path\n\nimport dateutil.parser\nimport requests\nfrom django.conf import settings\nfrom documents.parsers import DocumentParser\nfrom documents.parsers import make_thumbnail_from_pdf\nfrom documents.parsers import ParseError\nfrom tika import parser\n\n\nclass TikaDocumentParser(DocumentParser):\n \"\"\"\n This parser sends documents to a local tika server\n \"\"\"\n\n logging_name = \"paperless.parsing.tika\"\n\n def get_thumbnail(self, document_path, mime_type, file_name=None):\n if not self.archive_path:\n self.archive_path = self.convert_to_pdf(document_path, file_name)\n\n return make_thumbnail_from_pdf(\n self.archive_path,\n self.tempdir,\n self.logging_group,\n )\n\n def extract_metadata(self, document_path, mime_type):\n tika_server = settings.TIKA_ENDPOINT\n\n # tika does not support a PathLike, only strings\n # ensure this is a string\n document_path = str(document_path)\n\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as e:\n self.log(\n \"warning\",\n f\"Error while fetching document metadata for \" f\"{document_path}: {e}\",\n )\n return []\n\n return [\n {\n \"namespace\": \"\",\n \"prefix\": \"\",\n \"key\": key,\n \"value\": parsed[\"metadata\"][key],\n }\n for key in parsed[\"metadata\"]\n ]\n\n def parse(self, document_path: Path, mime_type, file_name=None):\n self.log(\"info\", f\"Sending {document_path} to Tika server\")\n tika_server = settings.TIKA_ENDPOINT\n\n # tika does not support a PathLike, only strings\n # ensure this is a string\n document_path = str(document_path)\n\n try:\n parsed = parser.from_file(document_path, tika_server)\n except Exception as err:\n raise ParseError(\n f\"Could not parse {document_path} with tika server at \"\n f\"{tika_server}: {err}\",\n ) from err\n\n self.text = parsed[\"content\"].strip()\n\n try:\n self.date = dateutil.parser.isoparse(parsed[\"metadata\"][\"Creation-Date\"])\n except Exception as e:\n self.log(\n \"warning\",\n f\"Unable to extract date for document \" f\"{document_path}: {e}\",\n )\n\n self.archive_path = self.convert_to_pdf(document_path, file_name)\n\n def convert_to_pdf(self, document_path, file_name):\n pdf_path = os.path.join(self.tempdir, \"convert.pdf\")\n gotenberg_server = settings.TIKA_GOTENBERG_ENDPOINT\n url = gotenberg_server + \"/forms/libreoffice/convert\"\n\n self.log(\"info\", f\"Converting {document_path} to PDF as {pdf_path}\")\n with open(document_path, \"rb\") as document_handle:\n files = {\n \"files\": (\n file_name or os.path.basename(document_path),\n document_handle,\n ),\n }\n headers = {}\n\n try:\n response = requests.post(url, files=files, headers=headers)\n response.raise_for_status() # ensure we notice bad responses\n except Exception as err:\n raise ParseError(\n f\"Error while converting document to PDF: {err}\",\n ) from err\n\n with open(pdf_path, \"wb\") as file:\n file.write(response.content)\n file.close()\n\n return pdf_path\n", "path": "src/paperless_tika/parsers.py"}]}
| 2,280 | 313 |
gh_patches_debug_30613
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-2729
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Erreurs 404 non générées sur certaines pages
Certaines pages devraient générées des erreurs 404 au lieu d'afficher le contenu des pages.
J'ai découvert ce bug en voulant corriger des erreurs dans les liens sur la page des CGU, un oubli de mailto produit actuellement un lien vers http://zestedesavoir.com/pages/cgu/[email protected] qui affiche la page des CGU. Or une erreur 404 devrait être générée. Peu importe la suite de l'URL cela fonctionne et ce pour plusieurs pages...
Il manque un `$` à la fin de certaines expressions régulières dans zds/pages/urls.py.
De plus le fichier urls.py importe pages.views mais ne l'utilise à aucun moment.
Du coup je me demande si je supprime l'import de views (ligne 5) ou bien si j'utilise par exemple `views.about` au lieu de `'zds.pages.views.about'` ?
Je veux bien bien me charger de faire une PR pour corriger ces bugs :)
EDIT: Je n'arrive pas à m'assigner à cette issue (comme suggéré par CONTRIBUTING.md), problèmes de droits ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/pages/urls.py`
Content:
```
1 # coding: utf-8
2
3 from django.conf.urls import patterns, url
4
5 from . import views
6
7
8 urlpatterns = patterns('',
9
10 url(r'^apropos/$', 'zds.pages.views.about'),
11 url(r'^association/$', 'zds.pages.views.association'),
12 url(r'^contact/', 'zds.pages.views.contact'),
13 url(r'^cgu/', 'zds.pages.views.eula'),
14 url(r'^alertes/', 'zds.pages.views.alerts'),
15 url(r'^cookies/', 'zds.pages.views.cookies'),
16 url(r'^association/inscription/$', 'zds.pages.views.assoc_subscribe'),
17
18 url(r'^$', 'zds.pages.views.index'),
19 )
20
```
Path: `zds/search/urls.py`
Content:
```
1 # coding: utf-8
2
3 from django.conf.urls import patterns, url
4
5 from . import views
6 from haystack.views import search_view_factory
7 from zds.search.views import CustomSearchView
8 from zds.search.forms import CustomSearchForm
9
10 urlpatterns = patterns('haystack.views',
11 url(r'^$', search_view_factory(
12 view_class=CustomSearchView,
13 template='search/search.html',
14 form_class=CustomSearchForm
15 ), name='haystack_search'))
16
17 urlpatterns += patterns('',
18 url(r'^opensearch.xml', 'zds.search.views.opensearch')
19 )
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/pages/urls.py b/zds/pages/urls.py
--- a/zds/pages/urls.py
+++ b/zds/pages/urls.py
@@ -2,17 +2,15 @@
from django.conf.urls import patterns, url
-from . import views
-
urlpatterns = patterns('',
url(r'^apropos/$', 'zds.pages.views.about'),
url(r'^association/$', 'zds.pages.views.association'),
- url(r'^contact/', 'zds.pages.views.contact'),
- url(r'^cgu/', 'zds.pages.views.eula'),
- url(r'^alertes/', 'zds.pages.views.alerts'),
- url(r'^cookies/', 'zds.pages.views.cookies'),
+ url(r'^contact/$', 'zds.pages.views.contact'),
+ url(r'^cgu/$', 'zds.pages.views.eula'),
+ url(r'^alertes/$', 'zds.pages.views.alerts'),
+ url(r'^cookies/$', 'zds.pages.views.cookies'),
url(r'^association/inscription/$', 'zds.pages.views.assoc_subscribe'),
url(r'^$', 'zds.pages.views.index'),
diff --git a/zds/search/urls.py b/zds/search/urls.py
--- a/zds/search/urls.py
+++ b/zds/search/urls.py
@@ -2,7 +2,6 @@
from django.conf.urls import patterns, url
-from . import views
from haystack.views import search_view_factory
from zds.search.views import CustomSearchView
from zds.search.forms import CustomSearchForm
@@ -15,5 +14,5 @@
), name='haystack_search'))
urlpatterns += patterns('',
- url(r'^opensearch.xml', 'zds.search.views.opensearch')
+ url(r'^opensearch\.xml$', 'zds.search.views.opensearch')
)
|
{"golden_diff": "diff --git a/zds/pages/urls.py b/zds/pages/urls.py\n--- a/zds/pages/urls.py\n+++ b/zds/pages/urls.py\n@@ -2,17 +2,15 @@\n \n from django.conf.urls import patterns, url\n \n-from . import views\n-\n \n urlpatterns = patterns('',\n \n url(r'^apropos/$', 'zds.pages.views.about'),\n url(r'^association/$', 'zds.pages.views.association'),\n- url(r'^contact/', 'zds.pages.views.contact'),\n- url(r'^cgu/', 'zds.pages.views.eula'),\n- url(r'^alertes/', 'zds.pages.views.alerts'),\n- url(r'^cookies/', 'zds.pages.views.cookies'),\n+ url(r'^contact/$', 'zds.pages.views.contact'),\n+ url(r'^cgu/$', 'zds.pages.views.eula'),\n+ url(r'^alertes/$', 'zds.pages.views.alerts'),\n+ url(r'^cookies/$', 'zds.pages.views.cookies'),\n url(r'^association/inscription/$', 'zds.pages.views.assoc_subscribe'),\n \n url(r'^$', 'zds.pages.views.index'),\ndiff --git a/zds/search/urls.py b/zds/search/urls.py\n--- a/zds/search/urls.py\n+++ b/zds/search/urls.py\n@@ -2,7 +2,6 @@\n \n from django.conf.urls import patterns, url\n \n-from . import views\n from haystack.views import search_view_factory\n from zds.search.views import CustomSearchView\n from zds.search.forms import CustomSearchForm\n@@ -15,5 +14,5 @@\n ), name='haystack_search'))\n \n urlpatterns += patterns('',\n- url(r'^opensearch.xml', 'zds.search.views.opensearch')\n+ url(r'^opensearch\\.xml$', 'zds.search.views.opensearch')\n )\n", "issue": "Erreurs 404 non g\u00e9n\u00e9r\u00e9es sur certaines pages\nCertaines pages devraient g\u00e9n\u00e9r\u00e9es des erreurs 404 au lieu d'afficher le contenu des pages.\nJ'ai d\u00e9couvert ce bug en voulant corriger des erreurs dans les liens sur la page des CGU, un oubli de mailto produit actuellement un lien vers http://zestedesavoir.com/pages/cgu/[email protected] qui affiche la page des CGU. Or une erreur 404 devrait \u00eatre g\u00e9n\u00e9r\u00e9e. Peu importe la suite de l'URL cela fonctionne et ce pour plusieurs pages...\nIl manque un `$` \u00e0 la fin de certaines expressions r\u00e9guli\u00e8res dans zds/pages/urls.py.\n\nDe plus le fichier urls.py importe pages.views mais ne l'utilise \u00e0 aucun moment.\nDu coup je me demande si je supprime l'import de views (ligne 5) ou bien si j'utilise par exemple `views.about` au lieu de `'zds.pages.views.about'` ?\n\nJe veux bien bien me charger de faire une PR pour corriger ces bugs :)\n\nEDIT: Je n'arrive pas \u00e0 m'assigner \u00e0 cette issue (comme sugg\u00e9r\u00e9 par CONTRIBUTING.md), probl\u00e8mes de droits ?\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom django.conf.urls import patterns, url\n\nfrom . import views\n\n\nurlpatterns = patterns('',\n\n url(r'^apropos/$', 'zds.pages.views.about'),\n url(r'^association/$', 'zds.pages.views.association'),\n url(r'^contact/', 'zds.pages.views.contact'),\n url(r'^cgu/', 'zds.pages.views.eula'),\n url(r'^alertes/', 'zds.pages.views.alerts'),\n url(r'^cookies/', 'zds.pages.views.cookies'),\n url(r'^association/inscription/$', 'zds.pages.views.assoc_subscribe'),\n\n url(r'^$', 'zds.pages.views.index'),\n )\n", "path": "zds/pages/urls.py"}, {"content": "# coding: utf-8\n\nfrom django.conf.urls import patterns, url\n\nfrom . import views\nfrom haystack.views import search_view_factory\nfrom zds.search.views import CustomSearchView\nfrom zds.search.forms import CustomSearchForm\n\nurlpatterns = patterns('haystack.views',\n url(r'^$', search_view_factory(\n view_class=CustomSearchView,\n template='search/search.html',\n form_class=CustomSearchForm\n ), name='haystack_search'))\n\nurlpatterns += patterns('',\n url(r'^opensearch.xml', 'zds.search.views.opensearch')\n )\n", "path": "zds/search/urls.py"}], "after_files": [{"content": "# coding: utf-8\n\nfrom django.conf.urls import patterns, url\n\n\nurlpatterns = patterns('',\n\n url(r'^apropos/$', 'zds.pages.views.about'),\n url(r'^association/$', 'zds.pages.views.association'),\n url(r'^contact/$', 'zds.pages.views.contact'),\n url(r'^cgu/$', 'zds.pages.views.eula'),\n url(r'^alertes/$', 'zds.pages.views.alerts'),\n url(r'^cookies/$', 'zds.pages.views.cookies'),\n url(r'^association/inscription/$', 'zds.pages.views.assoc_subscribe'),\n\n url(r'^$', 'zds.pages.views.index'),\n )\n", "path": "zds/pages/urls.py"}, {"content": "# coding: utf-8\n\nfrom django.conf.urls import patterns, url\n\nfrom haystack.views import search_view_factory\nfrom zds.search.views import CustomSearchView\nfrom zds.search.forms import CustomSearchForm\n\nurlpatterns = patterns('haystack.views',\n url(r'^$', search_view_factory(\n view_class=CustomSearchView,\n template='search/search.html',\n form_class=CustomSearchForm\n ), name='haystack_search'))\n\nurlpatterns += patterns('',\n url(r'^opensearch\\.xml$', 'zds.search.views.opensearch')\n )\n", "path": "zds/search/urls.py"}]}
| 886 | 405 |
gh_patches_debug_912
|
rasdani/github-patches
|
git_diff
|
AUTOMATIC1111__stable-diffusion-webui-60
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FileNotFoundError after new update
Getting a FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\Users\\admin\\stable-diffusion-webui\\scripts' after the new update.
Not exactly good at all the coding stuff, using it just fine yesterday but I downloaded the repo instead of git clone, for the sake of easier update I started a new installation by git cloning into user folder and the installation went well but ran into this while launching through webui.py.
Python 3.10.6
venv C:\Users\admin\stable-diffusion-webui\venv\Scripts\Python.exe
Launching webui.py...
Loading model from C:\Users\admin\stable-diffusion-webui\model.ckpt
Global Step: 470000
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Traceback (most recent call last):
File "C:\Users\admin\stable-diffusion-webui\webui.py", line 135, in <module>
modules.scripts.load_scripts(os.path.join(script_path, "scripts"))
File "C:\Users\admin\stable-diffusion-webui\modules\scripts.py", line 32, in load_scripts
for filename in os.listdir(basedir):
FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\Users\\admin\\stable-diffusion-webui\\scripts'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `modules/scripts.py`
Content:
```
1 import os
2 import sys
3 import traceback
4
5 import modules.ui as ui
6 import gradio as gr
7
8 from modules.processing import StableDiffusionProcessing
9
10 class Script:
11 filename = None
12 args_from = None
13 args_to = None
14
15 def title(self):
16 raise NotImplementedError()
17
18 def ui(self, is_img2img):
19 pass
20
21 def run(self, *args):
22 raise NotImplementedError()
23
24 def describe(self):
25 return ""
26
27
28 scripts = []
29
30
31 def load_scripts(basedir):
32 for filename in os.listdir(basedir):
33 path = os.path.join(basedir, filename)
34
35 if not os.path.isfile(path):
36 continue
37
38 with open(path, "r", encoding="utf8") as file:
39 text = file.read()
40
41 from types import ModuleType
42 compiled = compile(text, path, 'exec')
43 module = ModuleType(filename)
44 exec(compiled, module.__dict__)
45
46 for key, script_class in module.__dict__.items():
47 if type(script_class) == type and issubclass(script_class, Script):
48 obj = script_class()
49 obj.filename = path
50
51 scripts.append(obj)
52
53
54 def wrap_call(func, filename, funcname, *args, default=None, **kwargs):
55 try:
56 res = func(*args, **kwargs)
57 return res
58 except Exception:
59 print(f"Error calling: {filename}/{funcname}", file=sys.stderr)
60 print(traceback.format_exc(), file=sys.stderr)
61
62 return default
63
64
65 def setup_ui(is_img2img):
66 titles = [wrap_call(script.title, script.filename, "title") or f"{script.filename} [error]" for script in scripts]
67
68 dropdown = gr.Dropdown(label="Script", choices=["None"] + titles, value="None", type="index")
69
70 inputs = [dropdown]
71
72 for script in scripts:
73 script.args_from = len(inputs)
74 controls = script.ui(is_img2img)
75
76 for control in controls:
77 control.visible = False
78
79 inputs += controls
80 script.args_to = len(inputs)
81
82 def select_script(index):
83 if index > 0:
84 script = scripts[index-1]
85 args_from = script.args_from
86 args_to = script.args_to
87 else:
88 args_from = 0
89 args_to = 0
90
91 return [ui.gr_show(True if i == 0 else args_from <= i < args_to) for i in range(len(inputs))]
92
93 dropdown.change(
94 fn=select_script,
95 inputs=[dropdown],
96 outputs=inputs
97 )
98
99 return inputs
100
101
102 def run(p: StableDiffusionProcessing, *args):
103 script_index = args[0] - 1
104
105 if script_index < 0 or script_index >= len(scripts):
106 return None
107
108 script = scripts[script_index]
109
110 script_args = args[script.args_from:script.args_to]
111 processed = script.run(p, *script_args)
112
113 return processed
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/modules/scripts.py b/modules/scripts.py
--- a/modules/scripts.py
+++ b/modules/scripts.py
@@ -29,6 +29,9 @@
def load_scripts(basedir):
+ if not os.path.exists(basedir):
+ return
+
for filename in os.listdir(basedir):
path = os.path.join(basedir, filename)
|
{"golden_diff": "diff --git a/modules/scripts.py b/modules/scripts.py\n--- a/modules/scripts.py\n+++ b/modules/scripts.py\n@@ -29,6 +29,9 @@\n \r\n \r\n def load_scripts(basedir):\r\n+ if not os.path.exists(basedir):\r\n+ return\r\n+\r\n for filename in os.listdir(basedir):\r\n path = os.path.join(basedir, filename)\n", "issue": "FileNotFoundError after new update\nGetting a FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\\\Users\\\\admin\\\\stable-diffusion-webui\\\\scripts' after the new update. \r\n\r\nNot exactly good at all the coding stuff, using it just fine yesterday but I downloaded the repo instead of git clone, for the sake of easier update I started a new installation by git cloning into user folder and the installation went well but ran into this while launching through webui.py.\r\n\r\nPython 3.10.6\r\nvenv C:\\Users\\admin\\stable-diffusion-webui\\venv\\Scripts\\Python.exe\r\nLaunching webui.py...\r\nLoading model from C:\\Users\\admin\\stable-diffusion-webui\\model.ckpt\r\nGlobal Step: 470000\r\nLatentDiffusion: Running in eps-prediction mode\r\nDiffusionWrapper has 859.52 M params.\r\nmaking attention of type 'vanilla' with 512 in_channels\r\nWorking with z of shape (1, 4, 32, 32) = 4096 dimensions.\r\nmaking attention of type 'vanilla' with 512 in_channels\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\admin\\stable-diffusion-webui\\webui.py\", line 135, in <module>\r\n modules.scripts.load_scripts(os.path.join(script_path, \"scripts\"))\r\n File \"C:\\Users\\admin\\stable-diffusion-webui\\modules\\scripts.py\", line 32, in load_scripts\r\n for filename in os.listdir(basedir):\r\nFileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\\\Users\\\\admin\\\\stable-diffusion-webui\\\\scripts'\n", "before_files": [{"content": "import os\r\nimport sys\r\nimport traceback\r\n\r\nimport modules.ui as ui\r\nimport gradio as gr\r\n\r\nfrom modules.processing import StableDiffusionProcessing\r\n\r\nclass Script:\r\n filename = None\r\n args_from = None\r\n args_to = None\r\n\r\n def title(self):\r\n raise NotImplementedError()\r\n\r\n def ui(self, is_img2img):\r\n pass\r\n\r\n def run(self, *args):\r\n raise NotImplementedError()\r\n\r\n def describe(self):\r\n return \"\"\r\n\r\n\r\nscripts = []\r\n\r\n\r\ndef load_scripts(basedir):\r\n for filename in os.listdir(basedir):\r\n path = os.path.join(basedir, filename)\r\n\r\n if not os.path.isfile(path):\r\n continue\r\n\r\n with open(path, \"r\", encoding=\"utf8\") as file:\r\n text = file.read()\r\n\r\n from types import ModuleType\r\n compiled = compile(text, path, 'exec')\r\n module = ModuleType(filename)\r\n exec(compiled, module.__dict__)\r\n\r\n for key, script_class in module.__dict__.items():\r\n if type(script_class) == type and issubclass(script_class, Script):\r\n obj = script_class()\r\n obj.filename = path\r\n\r\n scripts.append(obj)\r\n\r\n\r\ndef wrap_call(func, filename, funcname, *args, default=None, **kwargs):\r\n try:\r\n res = func(*args, **kwargs)\r\n return res\r\n except Exception:\r\n print(f\"Error calling: {filename}/{funcname}\", file=sys.stderr)\r\n print(traceback.format_exc(), file=sys.stderr)\r\n\r\n return default\r\n\r\n\r\ndef setup_ui(is_img2img):\r\n titles = [wrap_call(script.title, script.filename, \"title\") or f\"{script.filename} [error]\" for script in scripts]\r\n\r\n dropdown = gr.Dropdown(label=\"Script\", choices=[\"None\"] + titles, value=\"None\", type=\"index\")\r\n\r\n inputs = [dropdown]\r\n\r\n for script in scripts:\r\n script.args_from = len(inputs)\r\n controls = script.ui(is_img2img)\r\n\r\n for control in controls:\r\n control.visible = False\r\n\r\n inputs += controls\r\n script.args_to = len(inputs)\r\n\r\n def select_script(index):\r\n if index > 0:\r\n script = scripts[index-1]\r\n args_from = script.args_from\r\n args_to = script.args_to\r\n else:\r\n args_from = 0\r\n args_to = 0\r\n\r\n return [ui.gr_show(True if i == 0 else args_from <= i < args_to) for i in range(len(inputs))]\r\n\r\n dropdown.change(\r\n fn=select_script,\r\n inputs=[dropdown],\r\n outputs=inputs\r\n )\r\n\r\n return inputs\r\n\r\n\r\ndef run(p: StableDiffusionProcessing, *args):\r\n script_index = args[0] - 1\r\n\r\n if script_index < 0 or script_index >= len(scripts):\r\n return None\r\n\r\n script = scripts[script_index]\r\n\r\n script_args = args[script.args_from:script.args_to]\r\n processed = script.run(p, *script_args)\r\n\r\n return processed\r\n", "path": "modules/scripts.py"}], "after_files": [{"content": "import os\r\nimport sys\r\nimport traceback\r\n\r\nimport modules.ui as ui\r\nimport gradio as gr\r\n\r\nfrom modules.processing import StableDiffusionProcessing\r\n\r\nclass Script:\r\n filename = None\r\n args_from = None\r\n args_to = None\r\n\r\n def title(self):\r\n raise NotImplementedError()\r\n\r\n def ui(self, is_img2img):\r\n pass\r\n\r\n def run(self, *args):\r\n raise NotImplementedError()\r\n\r\n def describe(self):\r\n return \"\"\r\n\r\n\r\nscripts = []\r\n\r\n\r\ndef load_scripts(basedir):\r\n if not os.path.exists(basedir):\r\n return\r\n\r\n for filename in os.listdir(basedir):\r\n path = os.path.join(basedir, filename)\r\n\r\n if not os.path.isfile(path):\r\n continue\r\n\r\n with open(path, \"r\", encoding=\"utf8\") as file:\r\n text = file.read()\r\n\r\n from types import ModuleType\r\n compiled = compile(text, path, 'exec')\r\n module = ModuleType(filename)\r\n exec(compiled, module.__dict__)\r\n\r\n for key, script_class in module.__dict__.items():\r\n if type(script_class) == type and issubclass(script_class, Script):\r\n obj = script_class()\r\n obj.filename = path\r\n\r\n scripts.append(obj)\r\n\r\n\r\ndef wrap_call(func, filename, funcname, *args, default=None, **kwargs):\r\n try:\r\n res = func(*args, **kwargs)\r\n return res\r\n except Exception:\r\n print(f\"Error calling: {filename}/{funcname}\", file=sys.stderr)\r\n print(traceback.format_exc(), file=sys.stderr)\r\n\r\n return default\r\n\r\n\r\ndef setup_ui(is_img2img):\r\n titles = [wrap_call(script.title, script.filename, \"title\") or f\"{script.filename} [error]\" for script in scripts]\r\n\r\n dropdown = gr.Dropdown(label=\"Script\", choices=[\"None\"] + titles, value=\"None\", type=\"index\")\r\n\r\n inputs = [dropdown]\r\n\r\n for script in scripts:\r\n script.args_from = len(inputs)\r\n controls = script.ui(is_img2img)\r\n\r\n for control in controls:\r\n control.visible = False\r\n\r\n inputs += controls\r\n script.args_to = len(inputs)\r\n\r\n def select_script(index):\r\n if index > 0:\r\n script = scripts[index-1]\r\n args_from = script.args_from\r\n args_to = script.args_to\r\n else:\r\n args_from = 0\r\n args_to = 0\r\n\r\n return [ui.gr_show(True if i == 0 else args_from <= i < args_to) for i in range(len(inputs))]\r\n\r\n dropdown.change(\r\n fn=select_script,\r\n inputs=[dropdown],\r\n outputs=inputs\r\n )\r\n\r\n return inputs\r\n\r\n\r\ndef run(p: StableDiffusionProcessing, *args):\r\n script_index = args[0] - 1\r\n\r\n if script_index < 0 or script_index >= len(scripts):\r\n return None\r\n\r\n script = scripts[script_index]\r\n\r\n script_args = args[script.args_from:script.args_to]\r\n processed = script.run(p, *script_args)\r\n\r\n return processed\r\n", "path": "modules/scripts.py"}]}
| 1,520 | 83 |
gh_patches_debug_18976
|
rasdani/github-patches
|
git_diff
|
ros2__ros2_documentation-1163
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add the ROS distro version above the fold
With #1150 we have the new versioning tabs which are moderately small and compact, but that makes it hard to tell what version you're looking at. Having a subtitle or other content at the top to know what version you're looking at at the top would be valuable. It could likely go in as a subtitle under ros2_documentation or elsewhere near the top of the left menu.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # rosindex documentation build configuration file, created by
4 # sphinx-quickstart on Tue Oct 2 16:34:57 2018.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19
20 import itertools
21 import os
22 import sys
23 import time
24
25 from docutils.parsers.rst import Directive
26
27 sys.path.append(os.path.abspath('./sphinx-multiversion'))
28
29
30 # The suffix(es) of source filenames.
31 # You can specify multiple suffix as a list of string:
32 #
33 # The master toctree document.
34 master_doc = 'index'
35
36 # The default role
37 default_role = 'any'
38
39 # The set of warnings to suppress.
40 suppress_warnings = ['image.nonlocal_uri']
41
42 # General information about the project.
43 project = 'ros2 documentation'
44 author = 'Open Robotics'
45 copyright = '{}, {}'.format(time.strftime('%Y'), author)
46
47 # The version info for the project you're documenting, acts as replacement for
48 # |version| and |release|, also used in various other places throughout the
49 # built documents.
50 #
51 # The short X.Y version.
52 version = u''
53 # The full version, including alpha/beta/rc tags.
54 release = u''
55
56 # Define the default role to use for links
57 default_role = 'any'
58
59 # The language for content autogenerated by Sphinx. Refer to documentation
60 # for a list of supported languages.
61 #
62 # This is also used if you do content translation via gettext catalogs.
63 # Usually you set "language" from the command line for these cases.
64 language = None
65
66 # List of patterns, relative to source directory, that match files and
67 # directories to ignore when looking for source files.
68 # This patterns also effect to html_static_path and html_extra_path
69 exclude_patterns = ['**/_*.rst']
70
71 # The name of the Pygments (syntax highlighting) style to use.
72 pygments_style = 'sphinx'
73
74 # Add any Sphinx extension module names here, as strings. They can be
75 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
76 extensions = ['sphinx.ext.intersphinx', 'sphinx_tabs.tabs', 'sphinx_multiversion', 'sphinx_rtd_theme']
77
78 # Intersphinx mapping
79
80 intersphinx_mapping = {
81 'catkin_pkg': ('http://docs.ros.org/en/independent/api/catkin_pkg/html', None),
82 'jenkins_tools': ('http://docs.ros.org/en/independent/api/jenkins_tools/html', None),
83 'rosdep': ('http://docs.ros.org/en/independent/api/rosdep/html', None),
84 'rosdistro': ('http://docs.ros.org/en/independent/api/rosdistro/html', None),
85 'rosinstall': ('http://docs.ros.org/en/independent/api/rosinstall/html', None),
86 'rospkg': ('http://docs.ros.org/en/independent/api/rospkg/html', None),
87 'vcstools': ('http://docs.ros.org/en/independent/api/vcstools/html', None)
88 }
89
90 # -- Options for HTML output ----------------------------------------------
91
92 # The theme to use for HTML and HTML Help pages. See the documentation for
93 # a list of builtin themes.
94 #
95 html_theme = 'sphinx_rtd_theme'
96 html_theme_options = {
97 'collapse_navigation': False,
98 'sticky_navigation': True,
99 'navigation_depth': -1,
100 }
101
102 html_context = {
103 'display_github': True,
104 'github_user': 'ros2',
105 'github_repo': 'ros2_documentation',
106 'github_version': 'rolling/source/', # Will be overridden when building multiversion
107 }
108
109 templates_path = [
110 "source/_templates",
111 ]
112
113 # smv_tag_whitelist = None
114
115 smv_branch_whitelist = r'^(rolling|foxy|eloquent|dashing|crystal)$'
116
117
118 smv_released_pattern = r'^refs/(heads|remotes/[^/]+)/(foxy|eloquent|dashing|crystal).*$'
119 smv_remote_whitelist = r'^(origin)$'
120 smv_latest_version = 'foxy'
121
122
123
124 html_favicon = 'favicon.ico'
125
126 # Add any paths that contain custom static files (such as style sheets) here,
127 # relative to this directory. They are copied after the builtin static files,
128 # so a file named "default.css" will overwrite the builtin "default.css".
129 # html_static_path = ['_static']
130
131 # Drop any source link suffix
132 html_sourcelink_suffix = ''
133
134 # -- Options for HTMLHelp output ------------------------------------------
135
136 # Output file base name for HTML help builder.
137 htmlhelp_basename = 'ros2_docsdoc'
138
139 html_baseurl = 'https://docs.ros.org/en'
140
141 class RedirectFrom(Directive):
142
143 has_content = True
144 template_name = 'layout.html'
145 redirections = {}
146
147 @classmethod
148 def register(cls, app):
149 app.connect('html-collect-pages', cls.generate)
150 app.add_directive('redirect-from', cls)
151 return app
152
153 @classmethod
154 def generate(cls, app):
155 from sphinx.builders.html import StandaloneHTMLBuilder
156 if not isinstance(app.builder, StandaloneHTMLBuilder):
157 return
158
159 redirect_html_fragment = """
160 <link rel="canonical" href="{base_url}/{url}" />
161 <meta http-equiv="refresh" content="0; url={url}" />
162 <script>
163 window.location.href = '{url}';
164 </script>
165 """
166 redirections = {
167 os.path.splitext(os.path.relpath(
168 document_path, app.srcdir
169 ))[0]: redirect_urls
170 for document_path, redirect_urls in cls.redirections.items()
171 }
172 redirection_conflict = next((
173 (canon_1, canon_2, redirs_1.intersection(redirs_2))
174 for (canon_1, redirs_1), (canon_2, redirs_2)
175 in itertools.combinations(redirections.items(), 2)
176 if redirs_1.intersection(redirs_2)
177 ), None)
178 if redirection_conflict:
179 canonical_url_1, canonical_url_2 = redirection_conflict[:2]
180 conflicting_redirect_urls = redirection_conflict[-1]
181 raise RuntimeError(
182 'Documents {} and {} define conflicting redirects: {}'.format(
183 canonical_url_1, canonical_url_2, conflicting_redirect_urls
184 )
185 )
186 all_canonical_urls = set(redirections.keys())
187 all_redirect_urls = {
188 redirect_url
189 for redirect_urls in redirections.values()
190 for redirect_url in redirect_urls
191 }
192 conflicting_urls = all_canonical_urls.intersection(all_redirect_urls)
193 if conflicting_urls:
194 raise RuntimeError(
195 'Some redirects conflict with existing documents: {}'.format(
196 conflicting_urls
197 )
198 )
199
200 for canonical_url, redirect_urls in redirections.items():
201 for redirect_url in redirect_urls:
202 context = {
203 'canonical_url': os.path.relpath(
204 canonical_url, redirect_url
205 ),
206 'title': os.path.basename(redirect_url),
207 'metatags': redirect_html_fragment.format(
208 base_url=app.config.html_baseurl,
209 url=app.builder.get_relative_uri(
210 redirect_url, canonical_url
211 )
212 )
213 }
214 yield (redirect_url, context, cls.template_name)
215
216 def run(self):
217 document_path = self.state.document.current_source
218 if document_path not in RedirectFrom.redirections:
219 RedirectFrom.redirections[document_path] = set()
220 RedirectFrom.redirections[document_path].update(self.content)
221 return []
222
223
224 def make_router(origin, destination):
225 def _missing_reference(app, env, node, contnode):
226 from docutils import nodes
227 from docutils.utils import relative_path
228 from sphinx.util import docname_join
229
230 doctarget = docname_join(node['refdoc'], node['reftarget'])
231 if doctarget.startswith(origin):
232 routed_doctarget = doctarget.replace(origin, destination)
233 if routed_doctarget in env.all_docs:
234 newnode = nodes.reference(
235 '', contnode.astext(), internal=True
236 )
237 newnode['refuri'] = app.builder.get_relative_uri(
238 node['refdoc'], routed_doctarget
239 )
240 return newnode
241 return _missing_reference
242
243 def smv_rewrite_baseurl(app, config):
244 # When using Sphinx multiversion, there is no way at initial configuration time
245 # to determine the distribution we are currently targeting (conf.py is read before
246 # external defines are setup, and environment variables aren't passed through to
247 # conf.py). Instead, hook into the 'config-inited' event which is late enough
248 # to rewrite the html_baseurl with the current version.
249 if app.config.smv_current_version != '':
250 app.config.html_baseurl = app.config.html_baseurl + '/' + app.config.smv_current_version
251
252 def github_link_rewrite_branch(app, pagename, templatename, context, doctree):
253 if app.config.smv_current_version != '':
254 context['github_version'] = app.config.smv_current_version + '/source/'
255
256 def setup(app):
257 app.connect('config-inited', smv_rewrite_baseurl)
258 app.connect('html-page-context', github_link_rewrite_branch)
259 RedirectFrom.register(app)
260
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conf.py b/conf.py
--- a/conf.py
+++ b/conf.py
@@ -40,7 +40,7 @@
suppress_warnings = ['image.nonlocal_uri']
# General information about the project.
-project = 'ros2 documentation'
+project = 'ROS 2 documentation'
author = 'Open Robotics'
copyright = '{}, {}'.format(time.strftime('%Y'), author)
@@ -248,6 +248,7 @@
# to rewrite the html_baseurl with the current version.
if app.config.smv_current_version != '':
app.config.html_baseurl = app.config.html_baseurl + '/' + app.config.smv_current_version
+ app.config.project = 'ROS 2 Documentation: ' + app.config.smv_current_version.title()
def github_link_rewrite_branch(app, pagename, templatename, context, doctree):
if app.config.smv_current_version != '':
|
{"golden_diff": "diff --git a/conf.py b/conf.py\n--- a/conf.py\n+++ b/conf.py\n@@ -40,7 +40,7 @@\n suppress_warnings = ['image.nonlocal_uri']\n \n # General information about the project.\n-project = 'ros2 documentation'\n+project = 'ROS 2 documentation'\n author = 'Open Robotics'\n copyright = '{}, {}'.format(time.strftime('%Y'), author)\n \n@@ -248,6 +248,7 @@\n # to rewrite the html_baseurl with the current version.\n if app.config.smv_current_version != '':\n app.config.html_baseurl = app.config.html_baseurl + '/' + app.config.smv_current_version\n+ app.config.project = 'ROS 2 Documentation: ' + app.config.smv_current_version.title()\n \n def github_link_rewrite_branch(app, pagename, templatename, context, doctree):\n if app.config.smv_current_version != '':\n", "issue": "Add the ROS distro version above the fold\nWith #1150 we have the new versioning tabs which are moderately small and compact, but that makes it hard to tell what version you're looking at. Having a subtitle or other content at the top to know what version you're looking at at the top would be valuable. It could likely go in as a subtitle under ros2_documentation or elsewhere near the top of the left menu.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# rosindex documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 2 16:34:57 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n\nimport itertools\nimport os\nimport sys\nimport time\n\nfrom docutils.parsers.rst import Directive\n\nsys.path.append(os.path.abspath('./sphinx-multiversion'))\n\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# The master toctree document.\nmaster_doc = 'index'\n\n# The default role\ndefault_role = 'any'\n\n# The set of warnings to suppress.\nsuppress_warnings = ['image.nonlocal_uri']\n\n# General information about the project.\nproject = 'ros2 documentation'\nauthor = 'Open Robotics'\ncopyright = '{}, {}'.format(time.strftime('%Y'), author)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u''\n# The full version, including alpha/beta/rc tags.\nrelease = u''\n\n# Define the default role to use for links\ndefault_role = 'any'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['**/_*.rst']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\nextensions = ['sphinx.ext.intersphinx', 'sphinx_tabs.tabs', 'sphinx_multiversion', 'sphinx_rtd_theme']\n\n# Intersphinx mapping\n\nintersphinx_mapping = {\n 'catkin_pkg': ('http://docs.ros.org/en/independent/api/catkin_pkg/html', None),\n 'jenkins_tools': ('http://docs.ros.org/en/independent/api/jenkins_tools/html', None),\n 'rosdep': ('http://docs.ros.org/en/independent/api/rosdep/html', None),\n 'rosdistro': ('http://docs.ros.org/en/independent/api/rosdistro/html', None),\n 'rosinstall': ('http://docs.ros.org/en/independent/api/rosinstall/html', None),\n 'rospkg': ('http://docs.ros.org/en/independent/api/rospkg/html', None),\n 'vcstools': ('http://docs.ros.org/en/independent/api/vcstools/html', None)\n}\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'collapse_navigation': False,\n 'sticky_navigation': True,\n 'navigation_depth': -1,\n}\n\nhtml_context = {\n 'display_github': True,\n 'github_user': 'ros2',\n 'github_repo': 'ros2_documentation',\n 'github_version': 'rolling/source/', # Will be overridden when building multiversion\n}\n\ntemplates_path = [\n \"source/_templates\",\n]\n\n# smv_tag_whitelist = None\n\nsmv_branch_whitelist = r'^(rolling|foxy|eloquent|dashing|crystal)$'\n\n\nsmv_released_pattern = r'^refs/(heads|remotes/[^/]+)/(foxy|eloquent|dashing|crystal).*$'\nsmv_remote_whitelist = r'^(origin)$'\nsmv_latest_version = 'foxy'\n\n\n\nhtml_favicon = 'favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Drop any source link suffix\nhtml_sourcelink_suffix = ''\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'ros2_docsdoc'\n\nhtml_baseurl = 'https://docs.ros.org/en'\n\nclass RedirectFrom(Directive):\n\n has_content = True\n template_name = 'layout.html'\n redirections = {}\n\n @classmethod\n def register(cls, app):\n app.connect('html-collect-pages', cls.generate)\n app.add_directive('redirect-from', cls)\n return app\n\n @classmethod\n def generate(cls, app):\n from sphinx.builders.html import StandaloneHTMLBuilder\n if not isinstance(app.builder, StandaloneHTMLBuilder):\n return\n\n redirect_html_fragment = \"\"\"\n <link rel=\"canonical\" href=\"{base_url}/{url}\" />\n <meta http-equiv=\"refresh\" content=\"0; url={url}\" />\n <script>\n window.location.href = '{url}';\n </script>\n \"\"\"\n redirections = {\n os.path.splitext(os.path.relpath(\n document_path, app.srcdir\n ))[0]: redirect_urls\n for document_path, redirect_urls in cls.redirections.items()\n }\n redirection_conflict = next((\n (canon_1, canon_2, redirs_1.intersection(redirs_2))\n for (canon_1, redirs_1), (canon_2, redirs_2)\n in itertools.combinations(redirections.items(), 2)\n if redirs_1.intersection(redirs_2)\n ), None)\n if redirection_conflict:\n canonical_url_1, canonical_url_2 = redirection_conflict[:2]\n conflicting_redirect_urls = redirection_conflict[-1]\n raise RuntimeError(\n 'Documents {} and {} define conflicting redirects: {}'.format(\n canonical_url_1, canonical_url_2, conflicting_redirect_urls\n )\n )\n all_canonical_urls = set(redirections.keys())\n all_redirect_urls = {\n redirect_url\n for redirect_urls in redirections.values()\n for redirect_url in redirect_urls\n }\n conflicting_urls = all_canonical_urls.intersection(all_redirect_urls)\n if conflicting_urls:\n raise RuntimeError(\n 'Some redirects conflict with existing documents: {}'.format(\n conflicting_urls\n )\n )\n\n for canonical_url, redirect_urls in redirections.items():\n for redirect_url in redirect_urls:\n context = {\n 'canonical_url': os.path.relpath(\n canonical_url, redirect_url\n ),\n 'title': os.path.basename(redirect_url),\n 'metatags': redirect_html_fragment.format(\n base_url=app.config.html_baseurl,\n url=app.builder.get_relative_uri(\n redirect_url, canonical_url\n )\n )\n }\n yield (redirect_url, context, cls.template_name)\n\n def run(self):\n document_path = self.state.document.current_source\n if document_path not in RedirectFrom.redirections:\n RedirectFrom.redirections[document_path] = set()\n RedirectFrom.redirections[document_path].update(self.content)\n return []\n\n\ndef make_router(origin, destination):\n def _missing_reference(app, env, node, contnode):\n from docutils import nodes\n from docutils.utils import relative_path\n from sphinx.util import docname_join\n\n doctarget = docname_join(node['refdoc'], node['reftarget'])\n if doctarget.startswith(origin):\n routed_doctarget = doctarget.replace(origin, destination)\n if routed_doctarget in env.all_docs:\n newnode = nodes.reference(\n '', contnode.astext(), internal=True\n )\n newnode['refuri'] = app.builder.get_relative_uri(\n node['refdoc'], routed_doctarget\n )\n return newnode\n return _missing_reference\n\ndef smv_rewrite_baseurl(app, config):\n # When using Sphinx multiversion, there is no way at initial configuration time\n # to determine the distribution we are currently targeting (conf.py is read before\n # external defines are setup, and environment variables aren't passed through to\n # conf.py). Instead, hook into the 'config-inited' event which is late enough\n # to rewrite the html_baseurl with the current version.\n if app.config.smv_current_version != '':\n app.config.html_baseurl = app.config.html_baseurl + '/' + app.config.smv_current_version\n\ndef github_link_rewrite_branch(app, pagename, templatename, context, doctree):\n if app.config.smv_current_version != '':\n context['github_version'] = app.config.smv_current_version + '/source/'\n\ndef setup(app):\n app.connect('config-inited', smv_rewrite_baseurl)\n app.connect('html-page-context', github_link_rewrite_branch)\n RedirectFrom.register(app)\n", "path": "conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# rosindex documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 2 16:34:57 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n\nimport itertools\nimport os\nimport sys\nimport time\n\nfrom docutils.parsers.rst import Directive\n\nsys.path.append(os.path.abspath('./sphinx-multiversion'))\n\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# The master toctree document.\nmaster_doc = 'index'\n\n# The default role\ndefault_role = 'any'\n\n# The set of warnings to suppress.\nsuppress_warnings = ['image.nonlocal_uri']\n\n# General information about the project.\nproject = 'ROS 2 documentation'\nauthor = 'Open Robotics'\ncopyright = '{}, {}'.format(time.strftime('%Y'), author)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u''\n# The full version, including alpha/beta/rc tags.\nrelease = u''\n\n# Define the default role to use for links\ndefault_role = 'any'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['**/_*.rst']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\nextensions = ['sphinx.ext.intersphinx', 'sphinx_tabs.tabs', 'sphinx_multiversion', 'sphinx_rtd_theme']\n\n# Intersphinx mapping\n\nintersphinx_mapping = {\n 'catkin_pkg': ('http://docs.ros.org/en/independent/api/catkin_pkg/html', None),\n 'jenkins_tools': ('http://docs.ros.org/en/independent/api/jenkins_tools/html', None),\n 'rosdep': ('http://docs.ros.org/en/independent/api/rosdep/html', None),\n 'rosdistro': ('http://docs.ros.org/en/independent/api/rosdistro/html', None),\n 'rosinstall': ('http://docs.ros.org/en/independent/api/rosinstall/html', None),\n 'rospkg': ('http://docs.ros.org/en/independent/api/rospkg/html', None),\n 'vcstools': ('http://docs.ros.org/en/independent/api/vcstools/html', None)\n}\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'collapse_navigation': False,\n 'sticky_navigation': True,\n 'navigation_depth': -1,\n}\n\nhtml_context = {\n 'display_github': True,\n 'github_user': 'ros2',\n 'github_repo': 'ros2_documentation',\n 'github_version': 'rolling/source/', # Will be overridden when building multiversion\n}\n\ntemplates_path = [\n \"source/_templates\",\n]\n\n# smv_tag_whitelist = None\n\nsmv_branch_whitelist = r'^(rolling|foxy|eloquent|dashing|crystal)$'\n\n\nsmv_released_pattern = r'^refs/(heads|remotes/[^/]+)/(foxy|eloquent|dashing|crystal).*$'\nsmv_remote_whitelist = r'^(origin)$'\nsmv_latest_version = 'foxy'\n\n\n\nhtml_favicon = 'favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Drop any source link suffix\nhtml_sourcelink_suffix = ''\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'ros2_docsdoc'\n\nhtml_baseurl = 'https://docs.ros.org/en'\n\nclass RedirectFrom(Directive):\n\n has_content = True\n template_name = 'layout.html'\n redirections = {}\n\n @classmethod\n def register(cls, app):\n app.connect('html-collect-pages', cls.generate)\n app.add_directive('redirect-from', cls)\n return app\n\n @classmethod\n def generate(cls, app):\n from sphinx.builders.html import StandaloneHTMLBuilder\n if not isinstance(app.builder, StandaloneHTMLBuilder):\n return\n\n redirect_html_fragment = \"\"\"\n <link rel=\"canonical\" href=\"{base_url}/{url}\" />\n <meta http-equiv=\"refresh\" content=\"0; url={url}\" />\n <script>\n window.location.href = '{url}';\n </script>\n \"\"\"\n redirections = {\n os.path.splitext(os.path.relpath(\n document_path, app.srcdir\n ))[0]: redirect_urls\n for document_path, redirect_urls in cls.redirections.items()\n }\n redirection_conflict = next((\n (canon_1, canon_2, redirs_1.intersection(redirs_2))\n for (canon_1, redirs_1), (canon_2, redirs_2)\n in itertools.combinations(redirections.items(), 2)\n if redirs_1.intersection(redirs_2)\n ), None)\n if redirection_conflict:\n canonical_url_1, canonical_url_2 = redirection_conflict[:2]\n conflicting_redirect_urls = redirection_conflict[-1]\n raise RuntimeError(\n 'Documents {} and {} define conflicting redirects: {}'.format(\n canonical_url_1, canonical_url_2, conflicting_redirect_urls\n )\n )\n all_canonical_urls = set(redirections.keys())\n all_redirect_urls = {\n redirect_url\n for redirect_urls in redirections.values()\n for redirect_url in redirect_urls\n }\n conflicting_urls = all_canonical_urls.intersection(all_redirect_urls)\n if conflicting_urls:\n raise RuntimeError(\n 'Some redirects conflict with existing documents: {}'.format(\n conflicting_urls\n )\n )\n\n for canonical_url, redirect_urls in redirections.items():\n for redirect_url in redirect_urls:\n context = {\n 'canonical_url': os.path.relpath(\n canonical_url, redirect_url\n ),\n 'title': os.path.basename(redirect_url),\n 'metatags': redirect_html_fragment.format(\n base_url=app.config.html_baseurl,\n url=app.builder.get_relative_uri(\n redirect_url, canonical_url\n )\n )\n }\n yield (redirect_url, context, cls.template_name)\n\n def run(self):\n document_path = self.state.document.current_source\n if document_path not in RedirectFrom.redirections:\n RedirectFrom.redirections[document_path] = set()\n RedirectFrom.redirections[document_path].update(self.content)\n return []\n\n\ndef make_router(origin, destination):\n def _missing_reference(app, env, node, contnode):\n from docutils import nodes\n from docutils.utils import relative_path\n from sphinx.util import docname_join\n\n doctarget = docname_join(node['refdoc'], node['reftarget'])\n if doctarget.startswith(origin):\n routed_doctarget = doctarget.replace(origin, destination)\n if routed_doctarget in env.all_docs:\n newnode = nodes.reference(\n '', contnode.astext(), internal=True\n )\n newnode['refuri'] = app.builder.get_relative_uri(\n node['refdoc'], routed_doctarget\n )\n return newnode\n return _missing_reference\n\ndef smv_rewrite_baseurl(app, config):\n # When using Sphinx multiversion, there is no way at initial configuration time\n # to determine the distribution we are currently targeting (conf.py is read before\n # external defines are setup, and environment variables aren't passed through to\n # conf.py). Instead, hook into the 'config-inited' event which is late enough\n # to rewrite the html_baseurl with the current version.\n if app.config.smv_current_version != '':\n app.config.html_baseurl = app.config.html_baseurl + '/' + app.config.smv_current_version\n app.config.project = 'ROS 2 Documentation: ' + app.config.smv_current_version.title()\n\ndef github_link_rewrite_branch(app, pagename, templatename, context, doctree):\n if app.config.smv_current_version != '':\n context['github_version'] = app.config.smv_current_version + '/source/'\n\ndef setup(app):\n app.connect('config-inited', smv_rewrite_baseurl)\n app.connect('html-page-context', github_link_rewrite_branch)\n RedirectFrom.register(app)\n", "path": "conf.py"}]}
| 3,132 | 197 |
gh_patches_debug_12710
|
rasdani/github-patches
|
git_diff
|
autorope__donkeycar-273
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support WIFI network that does not have internet access
REF: https://github.com/wroscoe/donkey/blob/dev/donkeycar/util/web.py
The system determines its IP address using a ping to 8.8.8.8
This approach fails when the WIFI network does not have internet access.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `donkeycar/util/web.py`
Content:
```
1 import socket
2
3 def get_ip_address():
4 ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith("127.")][:1],
5 [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in
6 [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])
7 return ip
8
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/donkeycar/util/web.py b/donkeycar/util/web.py
--- a/donkeycar/util/web.py
+++ b/donkeycar/util/web.py
@@ -1,7 +1,10 @@
import socket
def get_ip_address():
- ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith("127.")][:1],
- [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in
- [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])
- return ip
+ try:
+ ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith("127.")][:1],
+ [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in
+ [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])
+ return ip
+ except OSError: #occurs when cannot connect to '8.8.8.8'
+ return "127.0.0.1" #loopback
\ No newline at end of file
|
{"golden_diff": "diff --git a/donkeycar/util/web.py b/donkeycar/util/web.py\n--- a/donkeycar/util/web.py\n+++ b/donkeycar/util/web.py\n@@ -1,7 +1,10 @@\n import socket\n \n def get_ip_address():\n- ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith(\"127.\")][:1],\n- [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in\n- [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])\n- return ip\n+ try:\n+ ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith(\"127.\")][:1],\n+ [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in\n+ [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])\n+ return ip\n+ except OSError: #occurs when cannot connect to '8.8.8.8' \n+ return \"127.0.0.1\" #loopback\n\\ No newline at end of file\n", "issue": "Support WIFI network that does not have internet access\nREF: https://github.com/wroscoe/donkey/blob/dev/donkeycar/util/web.py\r\n\r\nThe system determines its IP address using a ping to 8.8.8.8\r\nThis approach fails when the WIFI network does not have internet access.\r\n\r\n\r\n\n", "before_files": [{"content": "import socket\n\ndef get_ip_address():\n ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith(\"127.\")][:1],\n [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in\n [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])\n return ip\n", "path": "donkeycar/util/web.py"}], "after_files": [{"content": "import socket\n\ndef get_ip_address():\n try:\n ip = ([l for l in ([ip for ip in socket.gethostbyname_ex(socket.gethostname())[2] if not ip.startswith(\"127.\")][:1],\n [[(s.connect(('8.8.8.8', 53)), s.getsockname()[0], s.close()) for s in\n [socket.socket(socket.AF_INET, socket.SOCK_DGRAM)]][0][1]]) if l][0][0])\n return ip\n except OSError: #occurs when cannot connect to '8.8.8.8' \n return \"127.0.0.1\" #loopback", "path": "donkeycar/util/web.py"}]}
| 439 | 311 |
gh_patches_debug_26766
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-1045
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Capitalization of "S" in "S3://" results in inconsistent behaviors when reading from S3 path
<!--
General questions should be asked on the mailing list [email protected].
Before submitting an issue, please fill out the following form.
-->
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux
- **Modin installed from (source or binary)**: binary
- **Modin version**: 0.7.0
- **Python version**: 3.6.8
- **Exact command to reproduce**:
<!--
You can obtain the Modin version with
python -c "import modin; print(modin.__version__)"
-->
### Describe the problem
<!-- Describe the problem clearly here. -->
Reading data from a S3 path, e.g. `read_csv`, `read_json`, behaves differently based on the capitalization of "S" in the path. See below code example.
### Source code / logs
<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->
```
import pandas as pd
import ray
import modin.pandas as mpd
filepath = "s3://my-bucket/data/traffic.json"
filepath_2 = "s3://my-bucket/data/BikeSharingDaily.csv"
filepath_3 = "S3://my-bucket/data/BikeSharingDaily.csv"
# working
df_native = pd.read_json(filepath, lines=True)
df_native_2 = pd.read_csv(filepath_2)
# not working (FileNotFoundError: [Errno 2] No such file or directory: 's3://my-bucket/data/traffic.json')
df_modin = mpd.read_json(filepath, lines=True)
# working (but it prints, defaulting to pandas implementation)
df_modin_2 = mpd.read_csv(filepath_2)
# working (no additional print)
df_modin_3 = mpd.read_csv(filepath_3)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `modin/engines/base/io/file_reader.py`
Content:
```
1 import os
2 import re
3
4 S3_ADDRESS_REGEX = re.compile("s3://(.*?)/(.*)")
5 NOT_IMPLEMENTED_MESSAGE = "Implement in children classes!"
6
7
8 class FileReader:
9 frame_cls = None
10 frame_partition_cls = None
11 query_compiler_cls = None
12
13 @classmethod
14 def get_path(cls, file_path):
15 if S3_ADDRESS_REGEX.search(file_path):
16 return file_path
17 else:
18 return os.path.abspath(file_path)
19
20 @classmethod
21 def file_open(cls, file_path, mode="rb", compression="infer"):
22 if isinstance(file_path, str):
23 match = S3_ADDRESS_REGEX.search(file_path)
24 if match:
25 import s3fs as S3FS
26 from botocore.exceptions import NoCredentialsError
27
28 s3fs = S3FS.S3FileSystem(anon=False)
29 try:
30 return s3fs.open(file_path)
31 except NoCredentialsError:
32 s3fs = S3FS.S3FileSystem(anon=True)
33 return s3fs.open(file_path)
34 elif compression == "gzip":
35 import gzip
36
37 return gzip.open(file_path, mode=mode)
38 elif compression == "bz2":
39 import bz2
40
41 return bz2.BZ2File(file_path, mode=mode)
42 elif compression == "xz":
43 import lzma
44
45 return lzma.LZMAFile(file_path, mode=mode)
46 elif compression == "zip":
47 import zipfile
48
49 zf = zipfile.ZipFile(file_path, mode=mode.replace("b", ""))
50 if zf.mode == "w":
51 return zf
52 elif zf.mode == "r":
53 zip_names = zf.namelist()
54 if len(zip_names) == 1:
55 f = zf.open(zip_names.pop())
56 return f
57 elif len(zip_names) == 0:
58 raise ValueError(
59 "Zero files found in ZIP file {}".format(file_path)
60 )
61 else:
62 raise ValueError(
63 "Multiple files found in ZIP file."
64 " Only one file per ZIP: {}".format(zip_names)
65 )
66
67 return open(file_path, mode=mode)
68
69 @classmethod
70 def file_size(cls, f):
71 cur_pos = f.tell()
72 f.seek(0, os.SEEK_END)
73 size = f.tell()
74 f.seek(cur_pos, os.SEEK_SET)
75 return size
76
77 @classmethod
78 def file_exists(cls, file_path):
79 if isinstance(file_path, str):
80 match = S3_ADDRESS_REGEX.search(file_path)
81 if match:
82 import s3fs as S3FS
83 from botocore.exceptions import NoCredentialsError
84
85 s3fs = S3FS.S3FileSystem(anon=False)
86 exists = False
87 try:
88 exists = s3fs.exists(file_path) or exists
89 except NoCredentialsError:
90 pass
91 s3fs = S3FS.S3FileSystem(anon=True)
92 return exists or s3fs.exists(file_path)
93 return os.path.exists(file_path)
94
95 @classmethod
96 def deploy(cls, func, args, num_return_vals):
97 raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)
98
99 def parse(self, func, args, num_return_vals):
100 raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)
101
102 @classmethod
103 def materialize(cls, obj_id):
104 raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/modin/engines/base/io/file_reader.py b/modin/engines/base/io/file_reader.py
--- a/modin/engines/base/io/file_reader.py
+++ b/modin/engines/base/io/file_reader.py
@@ -1,7 +1,7 @@
import os
import re
-S3_ADDRESS_REGEX = re.compile("s3://(.*?)/(.*)")
+S3_ADDRESS_REGEX = re.compile("[sS]3://(.*?)/(.*)")
NOT_IMPLEMENTED_MESSAGE = "Implement in children classes!"
@@ -21,7 +21,9 @@
def file_open(cls, file_path, mode="rb", compression="infer"):
if isinstance(file_path, str):
match = S3_ADDRESS_REGEX.search(file_path)
- if match:
+ if match is not None:
+ if file_path[0] == "S":
+ file_path = "{}{}".format("s", file_path[1:])
import s3fs as S3FS
from botocore.exceptions import NoCredentialsError
@@ -78,7 +80,9 @@
def file_exists(cls, file_path):
if isinstance(file_path, str):
match = S3_ADDRESS_REGEX.search(file_path)
- if match:
+ if match is not None:
+ if file_path[0] == "S":
+ file_path = "{}{}".format("s", file_path[1:])
import s3fs as S3FS
from botocore.exceptions import NoCredentialsError
|
{"golden_diff": "diff --git a/modin/engines/base/io/file_reader.py b/modin/engines/base/io/file_reader.py\n--- a/modin/engines/base/io/file_reader.py\n+++ b/modin/engines/base/io/file_reader.py\n@@ -1,7 +1,7 @@\n import os\n import re\n \n-S3_ADDRESS_REGEX = re.compile(\"s3://(.*?)/(.*)\")\n+S3_ADDRESS_REGEX = re.compile(\"[sS]3://(.*?)/(.*)\")\n NOT_IMPLEMENTED_MESSAGE = \"Implement in children classes!\"\n \n \n@@ -21,7 +21,9 @@\n def file_open(cls, file_path, mode=\"rb\", compression=\"infer\"):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n- if match:\n+ if match is not None:\n+ if file_path[0] == \"S\":\n+ file_path = \"{}{}\".format(\"s\", file_path[1:])\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n \n@@ -78,7 +80,9 @@\n def file_exists(cls, file_path):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n- if match:\n+ if match is not None:\n+ if file_path[0] == \"S\":\n+ file_path = \"{}{}\".format(\"s\", file_path[1:])\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n", "issue": "Capitalization of \"S\" in \"S3://\" results in inconsistent behaviors when reading from S3 path\n<!--\r\nGeneral questions should be asked on the mailing list [email protected].\r\n\r\nBefore submitting an issue, please fill out the following form.\r\n-->\r\n\r\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux\r\n- **Modin installed from (source or binary)**: binary\r\n- **Modin version**: 0.7.0\r\n- **Python version**: 3.6.8\r\n- **Exact command to reproduce**: \r\n\r\n<!--\r\nYou can obtain the Modin version with\r\n\r\npython -c \"import modin; print(modin.__version__)\"\r\n-->\r\n\r\n### Describe the problem\r\n<!-- Describe the problem clearly here. -->\r\nReading data from a S3 path, e.g. `read_csv`, `read_json`, behaves differently based on the capitalization of \"S\" in the path. See below code example.\r\n\r\n### Source code / logs\r\n<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->\r\n```\r\nimport pandas as pd\r\nimport ray\r\nimport modin.pandas as mpd\r\n\r\nfilepath = \"s3://my-bucket/data/traffic.json\"\r\nfilepath_2 = \"s3://my-bucket/data/BikeSharingDaily.csv\"\r\nfilepath_3 = \"S3://my-bucket/data/BikeSharingDaily.csv\"\r\n\r\n# working\r\ndf_native = pd.read_json(filepath, lines=True)\r\ndf_native_2 = pd.read_csv(filepath_2)\r\n\r\n# not working (FileNotFoundError: [Errno 2] No such file or directory: 's3://my-bucket/data/traffic.json')\r\ndf_modin = mpd.read_json(filepath, lines=True)\r\n\r\n# working (but it prints, defaulting to pandas implementation)\r\ndf_modin_2 = mpd.read_csv(filepath_2)\r\n\r\n# working (no additional print)\r\ndf_modin_3 = mpd.read_csv(filepath_3)\r\n```\n", "before_files": [{"content": "import os\nimport re\n\nS3_ADDRESS_REGEX = re.compile(\"s3://(.*?)/(.*)\")\nNOT_IMPLEMENTED_MESSAGE = \"Implement in children classes!\"\n\n\nclass FileReader:\n frame_cls = None\n frame_partition_cls = None\n query_compiler_cls = None\n\n @classmethod\n def get_path(cls, file_path):\n if S3_ADDRESS_REGEX.search(file_path):\n return file_path\n else:\n return os.path.abspath(file_path)\n\n @classmethod\n def file_open(cls, file_path, mode=\"rb\", compression=\"infer\"):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n if match:\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n\n s3fs = S3FS.S3FileSystem(anon=False)\n try:\n return s3fs.open(file_path)\n except NoCredentialsError:\n s3fs = S3FS.S3FileSystem(anon=True)\n return s3fs.open(file_path)\n elif compression == \"gzip\":\n import gzip\n\n return gzip.open(file_path, mode=mode)\n elif compression == \"bz2\":\n import bz2\n\n return bz2.BZ2File(file_path, mode=mode)\n elif compression == \"xz\":\n import lzma\n\n return lzma.LZMAFile(file_path, mode=mode)\n elif compression == \"zip\":\n import zipfile\n\n zf = zipfile.ZipFile(file_path, mode=mode.replace(\"b\", \"\"))\n if zf.mode == \"w\":\n return zf\n elif zf.mode == \"r\":\n zip_names = zf.namelist()\n if len(zip_names) == 1:\n f = zf.open(zip_names.pop())\n return f\n elif len(zip_names) == 0:\n raise ValueError(\n \"Zero files found in ZIP file {}\".format(file_path)\n )\n else:\n raise ValueError(\n \"Multiple files found in ZIP file.\"\n \" Only one file per ZIP: {}\".format(zip_names)\n )\n\n return open(file_path, mode=mode)\n\n @classmethod\n def file_size(cls, f):\n cur_pos = f.tell()\n f.seek(0, os.SEEK_END)\n size = f.tell()\n f.seek(cur_pos, os.SEEK_SET)\n return size\n\n @classmethod\n def file_exists(cls, file_path):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n if match:\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n\n s3fs = S3FS.S3FileSystem(anon=False)\n exists = False\n try:\n exists = s3fs.exists(file_path) or exists\n except NoCredentialsError:\n pass\n s3fs = S3FS.S3FileSystem(anon=True)\n return exists or s3fs.exists(file_path)\n return os.path.exists(file_path)\n\n @classmethod\n def deploy(cls, func, args, num_return_vals):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n\n def parse(self, func, args, num_return_vals):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n\n @classmethod\n def materialize(cls, obj_id):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n", "path": "modin/engines/base/io/file_reader.py"}], "after_files": [{"content": "import os\nimport re\n\nS3_ADDRESS_REGEX = re.compile(\"[sS]3://(.*?)/(.*)\")\nNOT_IMPLEMENTED_MESSAGE = \"Implement in children classes!\"\n\n\nclass FileReader:\n frame_cls = None\n frame_partition_cls = None\n query_compiler_cls = None\n\n @classmethod\n def get_path(cls, file_path):\n if S3_ADDRESS_REGEX.search(file_path):\n return file_path\n else:\n return os.path.abspath(file_path)\n\n @classmethod\n def file_open(cls, file_path, mode=\"rb\", compression=\"infer\"):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n if match is not None:\n if file_path[0] == \"S\":\n file_path = \"{}{}\".format(\"s\", file_path[1:])\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n\n s3fs = S3FS.S3FileSystem(anon=False)\n try:\n return s3fs.open(file_path)\n except NoCredentialsError:\n s3fs = S3FS.S3FileSystem(anon=True)\n return s3fs.open(file_path)\n elif compression == \"gzip\":\n import gzip\n\n return gzip.open(file_path, mode=mode)\n elif compression == \"bz2\":\n import bz2\n\n return bz2.BZ2File(file_path, mode=mode)\n elif compression == \"xz\":\n import lzma\n\n return lzma.LZMAFile(file_path, mode=mode)\n elif compression == \"zip\":\n import zipfile\n\n zf = zipfile.ZipFile(file_path, mode=mode.replace(\"b\", \"\"))\n if zf.mode == \"w\":\n return zf\n elif zf.mode == \"r\":\n zip_names = zf.namelist()\n if len(zip_names) == 1:\n f = zf.open(zip_names.pop())\n return f\n elif len(zip_names) == 0:\n raise ValueError(\n \"Zero files found in ZIP file {}\".format(file_path)\n )\n else:\n raise ValueError(\n \"Multiple files found in ZIP file.\"\n \" Only one file per ZIP: {}\".format(zip_names)\n )\n\n return open(file_path, mode=mode)\n\n @classmethod\n def file_size(cls, f):\n cur_pos = f.tell()\n f.seek(0, os.SEEK_END)\n size = f.tell()\n f.seek(cur_pos, os.SEEK_SET)\n return size\n\n @classmethod\n def file_exists(cls, file_path):\n if isinstance(file_path, str):\n match = S3_ADDRESS_REGEX.search(file_path)\n if match is not None:\n if file_path[0] == \"S\":\n file_path = \"{}{}\".format(\"s\", file_path[1:])\n import s3fs as S3FS\n from botocore.exceptions import NoCredentialsError\n\n s3fs = S3FS.S3FileSystem(anon=False)\n exists = False\n try:\n exists = s3fs.exists(file_path) or exists\n except NoCredentialsError:\n pass\n s3fs = S3FS.S3FileSystem(anon=True)\n return exists or s3fs.exists(file_path)\n return os.path.exists(file_path)\n\n @classmethod\n def deploy(cls, func, args, num_return_vals):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n\n def parse(self, func, args, num_return_vals):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n\n @classmethod\n def materialize(cls, obj_id):\n raise NotImplementedError(NOT_IMPLEMENTED_MESSAGE)\n", "path": "modin/engines/base/io/file_reader.py"}]}
| 1,650 | 330 |
gh_patches_debug_35876
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-127
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add testing agains each feat PT version
## 🚀 Feature
Add a conda setup for testing against all PyTorch feature releases such as 1.4, 1.5, 1.6, ...
### Motivation
have better validation if some functions are not supported in old PT versions
### Pitch
<!-- A clear and concise description of what you want to happen. -->
### Alternatives
use CI action with conda setup, probably no need for pull large docker image
### Additional context
take inspiration from past Conda matrix in PL
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `integrations/lightning_models.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import torch
15 from pytorch_lightning import LightningModule
16 from torch.utils.data import Dataset
17
18
19 class RandomDictStringDataset(Dataset):
20
21 def __init__(self, size, length):
22 self.len = length
23 self.data = torch.randn(length, size)
24
25 def __getitem__(self, index):
26 return {"id": str(index), "x": self.data[index]}
27
28 def __len__(self):
29 return self.len
30
31
32 class RandomDataset(Dataset):
33
34 def __init__(self, size, length):
35 self.len = length
36 self.data = torch.randn(length, size)
37
38 def __getitem__(self, index):
39 return self.data[index]
40
41 def __len__(self):
42 return self.len
43
44
45 class BoringModel(LightningModule):
46
47 def __init__(self):
48 """
49 Testing PL Module
50
51 Use as follows:
52 - subclass
53 - modify the behavior for what you want
54
55 class TestModel(BaseTestModel):
56 def training_step(...):
57 # do your own thing
58
59 or:
60
61 model = BaseTestModel()
62 model.training_epoch_end = None
63
64 """
65 super().__init__()
66 self.layer = torch.nn.Linear(32, 2)
67
68 def forward(self, x):
69 return self.layer(x)
70
71 @staticmethod
72 def loss(_, prediction):
73 # An arbitrary loss to have a loss that updates the model weights during `Trainer.fit` calls
74 return torch.nn.functional.mse_loss(prediction, torch.ones_like(prediction))
75
76 def step(self, x):
77 x = self(x)
78 out = torch.nn.functional.mse_loss(x, torch.ones_like(x))
79 return out
80
81 def training_step(self, batch, batch_idx):
82 output = self.layer(batch)
83 loss = self.loss(batch, output)
84 return {"loss": loss}
85
86 def training_step_end(self, training_step_outputs):
87 return training_step_outputs
88
89 def training_epoch_end(self, outputs) -> None:
90 torch.stack([x["loss"] for x in outputs]).mean()
91
92 def validation_step(self, batch, batch_idx):
93 output = self.layer(batch)
94 loss = self.loss(batch, output)
95 return {"x": loss}
96
97 def validation_epoch_end(self, outputs) -> None:
98 torch.stack([x['x'] for x in outputs]).mean()
99
100 def test_step(self, batch, batch_idx):
101 output = self.layer(batch)
102 loss = self.loss(batch, output)
103 return {"y": loss}
104
105 def test_epoch_end(self, outputs) -> None:
106 torch.stack([x["y"] for x in outputs]).mean()
107
108 def configure_optimizers(self):
109 optimizer = torch.optim.SGD(self.layer.parameters(), lr=0.1)
110 lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1)
111 return [optimizer], [lr_scheduler]
112
113 def train_dataloader(self):
114 return torch.utils.data.DataLoader(RandomDataset(32, 64))
115
116 def val_dataloader(self):
117 return torch.utils.data.DataLoader(RandomDataset(32, 64))
118
119 def test_dataloader(self):
120 return torch.utils.data.DataLoader(RandomDataset(32, 64))
121
```
Path: `torchmetrics/utilities/imports.py`
Content:
```
1 from distutils.version import LooseVersion
2
3 import torch
4
5 _TORCH_LOWER_1_4 = LooseVersion(torch.__version__) < LooseVersion("1.4.0")
6 _TORCH_LOWER_1_5 = LooseVersion(torch.__version__) < LooseVersion("1.5.0")
7 _TORCH_LOWER_1_6 = LooseVersion(torch.__version__) < LooseVersion("1.6.0")
8
```
Path: `integrations/__init__.py`
Content:
```
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/integrations/__init__.py b/integrations/__init__.py
--- a/integrations/__init__.py
+++ b/integrations/__init__.py
@@ -0,0 +1,3 @@
+from torchmetrics.utilities.imports import _module_available
+
+_PL_AVAILABLE = _module_available('pytorch_lightning')
diff --git a/integrations/lightning_models.py b/integrations/lightning_models.py
--- a/integrations/lightning_models.py
+++ b/integrations/lightning_models.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+
import torch
from pytorch_lightning import LightningModule
from torch.utils.data import Dataset
diff --git a/torchmetrics/utilities/imports.py b/torchmetrics/utilities/imports.py
--- a/torchmetrics/utilities/imports.py
+++ b/torchmetrics/utilities/imports.py
@@ -1,6 +1,64 @@
+# Copyright The PyTorch Lightning team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
from distutils.version import LooseVersion
+from importlib import import_module
+from importlib.util import find_spec
import torch
+from pkg_resources import DistributionNotFound
+
+
+def _module_available(module_path: str) -> bool:
+ """
+ Check if a path is available in your environment
+
+ >>> _module_available('os')
+ True
+ >>> _module_available('bla.bla')
+ False
+ """
+ try:
+ return find_spec(module_path) is not None
+ except AttributeError:
+ # Python 3.6
+ return False
+ except ModuleNotFoundError:
+ # Python 3.7+
+ return False
+
+
+def _compare_version(package: str, op, version) -> bool:
+ """
+ Compare package version with some requirements
+
+ >>> import operator
+ >>> _compare_version("torch", operator.ge, "0.1")
+ True
+ """
+ try:
+ pkg = import_module(package)
+ except (ModuleNotFoundError, DistributionNotFound):
+ return False
+ try:
+ pkg_version = LooseVersion(pkg.__version__)
+ except AttributeError:
+ return False
+ if not (hasattr(pkg_version, "vstring") and hasattr(pkg_version, "version")):
+ # this is mock by sphinx, so it shall return True ro generate all summaries
+ return True
+ return op(pkg_version, LooseVersion(version))
+
_TORCH_LOWER_1_4 = LooseVersion(torch.__version__) < LooseVersion("1.4.0")
_TORCH_LOWER_1_5 = LooseVersion(torch.__version__) < LooseVersion("1.5.0")
|
{"golden_diff": "diff --git a/integrations/__init__.py b/integrations/__init__.py\n--- a/integrations/__init__.py\n+++ b/integrations/__init__.py\n@@ -0,0 +1,3 @@\n+from torchmetrics.utilities.imports import _module_available\n+\n+_PL_AVAILABLE = _module_available('pytorch_lightning')\ndiff --git a/integrations/lightning_models.py b/integrations/lightning_models.py\n--- a/integrations/lightning_models.py\n+++ b/integrations/lightning_models.py\n@@ -11,6 +11,7 @@\n # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n # See the License for the specific language governing permissions and\n # limitations under the License.\n+\n import torch\n from pytorch_lightning import LightningModule\n from torch.utils.data import Dataset\ndiff --git a/torchmetrics/utilities/imports.py b/torchmetrics/utilities/imports.py\n--- a/torchmetrics/utilities/imports.py\n+++ b/torchmetrics/utilities/imports.py\n@@ -1,6 +1,64 @@\n+# Copyright The PyTorch Lightning team.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n from distutils.version import LooseVersion\n+from importlib import import_module\n+from importlib.util import find_spec\n \n import torch\n+from pkg_resources import DistributionNotFound\n+\n+\n+def _module_available(module_path: str) -> bool:\n+ \"\"\"\n+ Check if a path is available in your environment\n+\n+ >>> _module_available('os')\n+ True\n+ >>> _module_available('bla.bla')\n+ False\n+ \"\"\"\n+ try:\n+ return find_spec(module_path) is not None\n+ except AttributeError:\n+ # Python 3.6\n+ return False\n+ except ModuleNotFoundError:\n+ # Python 3.7+\n+ return False\n+\n+\n+def _compare_version(package: str, op, version) -> bool:\n+ \"\"\"\n+ Compare package version with some requirements\n+\n+ >>> import operator\n+ >>> _compare_version(\"torch\", operator.ge, \"0.1\")\n+ True\n+ \"\"\"\n+ try:\n+ pkg = import_module(package)\n+ except (ModuleNotFoundError, DistributionNotFound):\n+ return False\n+ try:\n+ pkg_version = LooseVersion(pkg.__version__)\n+ except AttributeError:\n+ return False\n+ if not (hasattr(pkg_version, \"vstring\") and hasattr(pkg_version, \"version\")):\n+ # this is mock by sphinx, so it shall return True ro generate all summaries\n+ return True\n+ return op(pkg_version, LooseVersion(version))\n+\n \n _TORCH_LOWER_1_4 = LooseVersion(torch.__version__) < LooseVersion(\"1.4.0\")\n _TORCH_LOWER_1_5 = LooseVersion(torch.__version__) < LooseVersion(\"1.5.0\")\n", "issue": "Add testing agains each feat PT version\n## \ud83d\ude80 Feature\r\n\r\nAdd a conda setup for testing against all PyTorch feature releases such as 1.4, 1.5, 1.6, ...\r\n\r\n### Motivation\r\n\r\nhave better validation if some functions are not supported in old PT versions\r\n\r\n### Pitch\r\n\r\n<!-- A clear and concise description of what you want to happen. -->\r\n\r\n### Alternatives\r\n\r\nuse CI action with conda setup, probably no need for pull large docker image\r\n\r\n### Additional context\r\n\r\ntake inspiration from past Conda matrix in PL\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport torch\nfrom pytorch_lightning import LightningModule\nfrom torch.utils.data import Dataset\n\n\nclass RandomDictStringDataset(Dataset):\n\n def __init__(self, size, length):\n self.len = length\n self.data = torch.randn(length, size)\n\n def __getitem__(self, index):\n return {\"id\": str(index), \"x\": self.data[index]}\n\n def __len__(self):\n return self.len\n\n\nclass RandomDataset(Dataset):\n\n def __init__(self, size, length):\n self.len = length\n self.data = torch.randn(length, size)\n\n def __getitem__(self, index):\n return self.data[index]\n\n def __len__(self):\n return self.len\n\n\nclass BoringModel(LightningModule):\n\n def __init__(self):\n \"\"\"\n Testing PL Module\n\n Use as follows:\n - subclass\n - modify the behavior for what you want\n\n class TestModel(BaseTestModel):\n def training_step(...):\n # do your own thing\n\n or:\n\n model = BaseTestModel()\n model.training_epoch_end = None\n\n \"\"\"\n super().__init__()\n self.layer = torch.nn.Linear(32, 2)\n\n def forward(self, x):\n return self.layer(x)\n\n @staticmethod\n def loss(_, prediction):\n # An arbitrary loss to have a loss that updates the model weights during `Trainer.fit` calls\n return torch.nn.functional.mse_loss(prediction, torch.ones_like(prediction))\n\n def step(self, x):\n x = self(x)\n out = torch.nn.functional.mse_loss(x, torch.ones_like(x))\n return out\n\n def training_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"loss\": loss}\n\n def training_step_end(self, training_step_outputs):\n return training_step_outputs\n\n def training_epoch_end(self, outputs) -> None:\n torch.stack([x[\"loss\"] for x in outputs]).mean()\n\n def validation_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"x\": loss}\n\n def validation_epoch_end(self, outputs) -> None:\n torch.stack([x['x'] for x in outputs]).mean()\n\n def test_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"y\": loss}\n\n def test_epoch_end(self, outputs) -> None:\n torch.stack([x[\"y\"] for x in outputs]).mean()\n\n def configure_optimizers(self):\n optimizer = torch.optim.SGD(self.layer.parameters(), lr=0.1)\n lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1)\n return [optimizer], [lr_scheduler]\n\n def train_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n\n def val_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n\n def test_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n", "path": "integrations/lightning_models.py"}, {"content": "from distutils.version import LooseVersion\n\nimport torch\n\n_TORCH_LOWER_1_4 = LooseVersion(torch.__version__) < LooseVersion(\"1.4.0\")\n_TORCH_LOWER_1_5 = LooseVersion(torch.__version__) < LooseVersion(\"1.5.0\")\n_TORCH_LOWER_1_6 = LooseVersion(torch.__version__) < LooseVersion(\"1.6.0\")\n", "path": "torchmetrics/utilities/imports.py"}, {"content": "", "path": "integrations/__init__.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport torch\nfrom pytorch_lightning import LightningModule\nfrom torch.utils.data import Dataset\n\n\nclass RandomDictStringDataset(Dataset):\n\n def __init__(self, size, length):\n self.len = length\n self.data = torch.randn(length, size)\n\n def __getitem__(self, index):\n return {\"id\": str(index), \"x\": self.data[index]}\n\n def __len__(self):\n return self.len\n\n\nclass RandomDataset(Dataset):\n\n def __init__(self, size, length):\n self.len = length\n self.data = torch.randn(length, size)\n\n def __getitem__(self, index):\n return self.data[index]\n\n def __len__(self):\n return self.len\n\n\nclass BoringModel(LightningModule):\n\n def __init__(self):\n \"\"\"\n Testing PL Module\n\n Use as follows:\n - subclass\n - modify the behavior for what you want\n\n class TestModel(BaseTestModel):\n def training_step(...):\n # do your own thing\n\n or:\n\n model = BaseTestModel()\n model.training_epoch_end = None\n\n \"\"\"\n super().__init__()\n self.layer = torch.nn.Linear(32, 2)\n\n def forward(self, x):\n return self.layer(x)\n\n @staticmethod\n def loss(_, prediction):\n # An arbitrary loss to have a loss that updates the model weights during `Trainer.fit` calls\n return torch.nn.functional.mse_loss(prediction, torch.ones_like(prediction))\n\n def step(self, x):\n x = self(x)\n out = torch.nn.functional.mse_loss(x, torch.ones_like(x))\n return out\n\n def training_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"loss\": loss}\n\n def training_step_end(self, training_step_outputs):\n return training_step_outputs\n\n def training_epoch_end(self, outputs) -> None:\n torch.stack([x[\"loss\"] for x in outputs]).mean()\n\n def validation_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"x\": loss}\n\n def validation_epoch_end(self, outputs) -> None:\n torch.stack([x['x'] for x in outputs]).mean()\n\n def test_step(self, batch, batch_idx):\n output = self.layer(batch)\n loss = self.loss(batch, output)\n return {\"y\": loss}\n\n def test_epoch_end(self, outputs) -> None:\n torch.stack([x[\"y\"] for x in outputs]).mean()\n\n def configure_optimizers(self):\n optimizer = torch.optim.SGD(self.layer.parameters(), lr=0.1)\n lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1)\n return [optimizer], [lr_scheduler]\n\n def train_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n\n def val_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n\n def test_dataloader(self):\n return torch.utils.data.DataLoader(RandomDataset(32, 64))\n", "path": "integrations/lightning_models.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom distutils.version import LooseVersion\nfrom importlib import import_module\nfrom importlib.util import find_spec\n\nimport torch\nfrom pkg_resources import DistributionNotFound\n\n\ndef _module_available(module_path: str) -> bool:\n \"\"\"\n Check if a path is available in your environment\n\n >>> _module_available('os')\n True\n >>> _module_available('bla.bla')\n False\n \"\"\"\n try:\n return find_spec(module_path) is not None\n except AttributeError:\n # Python 3.6\n return False\n except ModuleNotFoundError:\n # Python 3.7+\n return False\n\n\ndef _compare_version(package: str, op, version) -> bool:\n \"\"\"\n Compare package version with some requirements\n\n >>> import operator\n >>> _compare_version(\"torch\", operator.ge, \"0.1\")\n True\n \"\"\"\n try:\n pkg = import_module(package)\n except (ModuleNotFoundError, DistributionNotFound):\n return False\n try:\n pkg_version = LooseVersion(pkg.__version__)\n except AttributeError:\n return False\n if not (hasattr(pkg_version, \"vstring\") and hasattr(pkg_version, \"version\")):\n # this is mock by sphinx, so it shall return True ro generate all summaries\n return True\n return op(pkg_version, LooseVersion(version))\n\n\n_TORCH_LOWER_1_4 = LooseVersion(torch.__version__) < LooseVersion(\"1.4.0\")\n_TORCH_LOWER_1_5 = LooseVersion(torch.__version__) < LooseVersion(\"1.5.0\")\n_TORCH_LOWER_1_6 = LooseVersion(torch.__version__) < LooseVersion(\"1.6.0\")\n", "path": "torchmetrics/utilities/imports.py"}, {"content": "from torchmetrics.utilities.imports import _module_available\n\n_PL_AVAILABLE = _module_available('pytorch_lightning')\n", "path": "integrations/__init__.py"}]}
| 1,593 | 744 |
gh_patches_debug_26374
|
rasdani/github-patches
|
git_diff
|
nextcloud__appstore-697
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
App details are not updated to the latest upload if only pre-releases or nightlies exist
Hi,
I've put a new app on the nextcloud app repo, with what seems to be a correct info.xml, but it doesn't take description categories and screenshot into account,
see there
https://apps.nextcloud.com/apps/carnet
Any ideas why ? Thanks !
App details are not updated to the latest upload if only pre-releases or nightlies exist
Hi,
I've put a new app on the nextcloud app repo, with what seems to be a correct info.xml, but it doesn't take description categories and screenshot into account,
see there
https://apps.nextcloud.com/apps/carnet
Any ideas why ? Thanks !
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nextcloudappstore/api/v1/release/importer.py`
Content:
```
1 from typing import Dict, Any, Set, Tuple # type: ignore
2
3 from django.utils import timezone
4 from django.conf import settings # type: ignore
5 from semantic_version import Version # type: ignore
6
7 from nextcloudappstore.core.facades import any_match
8 from nextcloudappstore.core.models import App, Screenshot, Category, \
9 AppRelease, ShellCommand, License, Database, DatabaseDependency, \
10 PhpExtensionDependency, PhpExtension, AppAuthor
11 from nextcloudappstore.core.versioning import to_spec, to_raw_spec
12
13
14 def none_to_empty_string(value: str) -> str:
15 if value is None:
16 return ''
17 else:
18 return value.strip()
19
20
21 class Importer:
22 def __init__(self, importers: Dict[str, 'Importer'],
23 ignored_fields: Set[str]) -> None:
24 self.importers = importers
25 self.ignored_fields = ignored_fields
26
27 def import_data(self, key: str, value: Any, obj: Any) -> None:
28 obj = self._get_object(key, value, obj)
29 value, obj = self._before_import(key, value, obj)
30 for key, val in value.items():
31 if key not in self.ignored_fields:
32 self.importers[key].import_data(key, val, obj)
33 obj.save()
34
35 def _get_object(self, key: str, value: Any, obj: Any) -> Any:
36 raise NotImplementedError
37
38 def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,
39 Any]:
40 raise NotImplementedError
41
42
43 class ScalarImporter(Importer):
44 def __init__(self) -> None:
45 super().__init__({}, set())
46
47
48 class PhpExtensionImporter(ScalarImporter):
49 def import_data(self, key: str, value: Any, obj: Any) -> None:
50 for ext in value:
51 version_spec = to_spec(ext['php_extension']['min_version'],
52 ext['php_extension']['max_version'])
53 raw_version_spec = to_raw_spec(
54 ext['php_extension']['raw_min_version'],
55 ext['php_extension']['raw_max_version'])
56 extension, created = PhpExtension.objects.get_or_create(
57 id=ext['php_extension']['id'])
58 PhpExtensionDependency.objects.create(
59 version_spec=version_spec,
60 raw_version_spec=raw_version_spec,
61 app_release=obj, php_extension=extension,
62 )
63
64
65 class DatabaseImporter(ScalarImporter):
66 def import_data(self, key: str, value: Any, obj: Any) -> None:
67 for db in value:
68 version_spec = to_spec(db['database']['min_version'],
69 db['database']['max_version'])
70 raw_version_spec = to_raw_spec(db['database']['raw_min_version'],
71 db['database']['raw_max_version'])
72 # all dbs should be known already
73 database = Database.objects.get(id=db['database']['id'])
74 DatabaseDependency.objects.create(
75 version_spec=version_spec,
76 raw_version_spec=raw_version_spec,
77 app_release=obj, database=database,
78 )
79
80
81 class LicenseImporter(ScalarImporter):
82 def import_data(self, key: str, value: Any, obj: Any) -> None:
83 def map_models(data: Dict) -> License:
84 id = data['license']['id']
85 model, created = License.objects.get_or_create(id=id)
86 return model
87
88 obj.licenses.set(list(map(map_models, value)))
89
90
91 class ShellCommandImporter(ScalarImporter):
92 def import_data(self, key: str, value: Any, obj: Any) -> None:
93 def map_commands(data: Dict) -> ShellCommand:
94 name = data['shell_command']['name']
95 command, created = ShellCommand.objects.get_or_create(name=name)
96 return command
97
98 obj.shell_commands.set(list(map(map_commands, value)))
99
100
101 class AuthorImporter(ScalarImporter):
102 def import_data(self, key: str, value: Any, obj: Any) -> None:
103 def map_authors(data: Dict) -> AppAuthor:
104 author = data['author']
105 return AppAuthor.objects.create(
106 name=author['name'],
107 mail=none_to_empty_string(author['mail']),
108 homepage=none_to_empty_string(author['homepage'])
109 )
110
111 obj.authors.set(list(map(map_authors, value)))
112
113
114 class DefaultAttributeImporter(ScalarImporter):
115 def import_data(self, key: str, value: Any, obj: Any) -> None:
116 setattr(obj, key, value)
117
118
119 class StringAttributeImporter(ScalarImporter):
120 def import_data(self, key: str, value: Any, obj: Any) -> None:
121 setattr(obj, key, none_to_empty_string(value))
122
123
124 class ScreenshotsImporter(ScalarImporter):
125 def import_data(self, key: str, value: Any, obj: Any) -> None:
126 def create_screenshot(img: Dict[str, str]) -> Screenshot:
127 return Screenshot.objects.create(
128 url=img['url'], app=obj, ordering=img['ordering'],
129 small_thumbnail=none_to_empty_string(img['small_thumbnail']))
130
131 shots = map(lambda val: create_screenshot(val['screenshot']), value)
132 obj.screenshots.set(list(shots))
133
134
135 class CategoryImporter(ScalarImporter):
136 def import_data(self, key: str, value: Any, obj: Any) -> None:
137 def map_categories(cat: Dict) -> Category:
138 id = cat['category']['id']
139 category, created = Category.objects.get_or_create(id=id)
140 return category
141
142 obj.categories.set(list(map(map_categories, value)))
143
144
145 class L10NImporter(ScalarImporter):
146 def import_data(self, key: str, value: Any, obj: Any) -> None:
147 for lang, translation in value.items():
148 obj.set_current_language(lang)
149 setattr(obj, key, translation.strip())
150 obj.save()
151
152
153 class AppReleaseImporter(Importer):
154 def __init__(self, php_extension_importer: PhpExtensionImporter,
155 database_importer: DatabaseImporter,
156 license_importer: LicenseImporter,
157 shell_command_importer: ShellCommandImporter,
158 string_attribute_importer: StringAttributeImporter,
159 default_attribute_importer: DefaultAttributeImporter,
160 l10n_importer: L10NImporter) -> None:
161 super().__init__({
162 'php_extensions': php_extension_importer,
163 'databases': database_importer,
164 'licenses': license_importer,
165 'php_version_spec': string_attribute_importer,
166 'platform_version_spec': string_attribute_importer,
167 'raw_php_version_spec': string_attribute_importer,
168 'raw_platform_version_spec': string_attribute_importer,
169 'min_int_size': default_attribute_importer,
170 'shell_commands': shell_command_importer,
171 'signature': string_attribute_importer,
172 'download': string_attribute_importer,
173 'changelog': l10n_importer,
174 'is_nightly': default_attribute_importer,
175 }, {
176 'version',
177 'raw_version',
178 'php_min_version',
179 'php_max_version',
180 'raw_php_min_version',
181 'raw_php_max_version',
182 'platform_min_version',
183 'platform_max_version',
184 'raw_platform_min_version',
185 'raw_platform_max_version',
186 })
187
188 def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,
189 Any]:
190 # combine versions into specs
191 value['platform_version_spec'] = to_spec(
192 value['platform_min_version'], value['platform_max_version'])
193 value['php_version_spec'] = to_spec(value['php_min_version'],
194 value['php_max_version'])
195 value['raw_platform_version_spec'] = to_raw_spec(
196 value['raw_platform_min_version'],
197 value['raw_platform_max_version'])
198 value['raw_php_version_spec'] = to_raw_spec(
199 value['raw_php_min_version'],
200 value['raw_php_max_version'])
201 obj.licenses.clear()
202 obj.shell_commands.clear()
203 obj.licenses.clear()
204 obj.php_extensions.clear()
205 obj.databases.clear()
206 obj.signature_digest = settings.CERTIFICATE_DIGEST
207 return value, obj
208
209 def _get_object(self, key: str, value: Any, obj: Any) -> Any:
210 release, created = AppRelease.objects.get_or_create(
211 version=value['version'], app=obj, is_nightly=value['is_nightly']
212 )
213 return release
214
215
216 class AppImporter(Importer):
217 def __init__(self, release_importer: AppReleaseImporter,
218 screenshots_importer: ScreenshotsImporter,
219 attribute_importer: StringAttributeImporter,
220 l10n_importer: L10NImporter,
221 category_importer: CategoryImporter,
222 author_importer: AuthorImporter,
223 default_attribute_importer: DefaultAttributeImporter) -> None:
224 super().__init__({
225 'release': release_importer,
226 'screenshots': screenshots_importer,
227 'user_docs': attribute_importer,
228 'admin_docs': attribute_importer,
229 'website': attribute_importer,
230 'discussion': attribute_importer,
231 'developer_docs': attribute_importer,
232 'issue_tracker': attribute_importer,
233 'certificate': attribute_importer,
234 'name': l10n_importer,
235 'summary': l10n_importer,
236 'description': l10n_importer,
237 'categories': category_importer,
238 'authors': author_importer
239 }, {'id'})
240
241 def _get_object(self, key: str, value: Any, obj: Any) -> Any:
242 # only update app if newest or equal to newest release
243 app, created = App.objects.get_or_create(pk=value['id'])
244 return app
245
246 def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,
247 Any]:
248 obj.last_release = timezone.now()
249
250 if 'is_nightly' not in value['release']:
251 value['release']['is_nightly'] = False
252 if value['release']['is_nightly']:
253 AppRelease.objects.filter(app__id=obj.id, is_nightly=True).delete()
254
255 # only new releases update an app's data
256 if self._should_update_everything(value):
257 # clear all relations
258 obj.screenshots.all().delete()
259 obj.authors.all().delete()
260 obj.categories.clear()
261 for translation in obj.translations.all():
262 translation.delete()
263 else:
264 value = {'id': value['id'], 'release': value['release']}
265
266 return value, obj
267
268 def _should_update_everything(self, value: Any) -> bool:
269 releases = AppRelease.objects.filter(app__id=value['id'])
270
271 # if its the first release it should always set the required initial
272 # data
273 if len(releases) == 0:
274 return True
275
276 current_version = value['release']['version']
277
278 # we do not care about nightlies here so it's fine to just use a
279 # normal semver
280 uploaded_version = Version(current_version)
281 is_prerelease = '-' in current_version
282 is_nightly = value['release']['is_nightly']
283 is_stable = not is_prerelease and not is_nightly
284
285 def is_newer_version(release: Any) -> bool:
286 return uploaded_version >= Version(release.version)
287
288 # the main page should only be updated when stable and new releases
289 # are uploaded
290 is_latest_version = any_match(is_newer_version, releases)
291 return is_latest_version and is_stable
292
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nextcloudappstore/api/v1/release/importer.py b/nextcloudappstore/api/v1/release/importer.py
--- a/nextcloudappstore/api/v1/release/importer.py
+++ b/nextcloudappstore/api/v1/release/importer.py
@@ -273,6 +273,16 @@
if len(releases) == 0:
return True
+ # if the app has no stable releases update everything
+ has_stable_release = False
+ for release in releases:
+ if '-' not in release.version and not release.is_nightly:
+ has_stable_release = True
+ break
+
+ if not has_stable_release:
+ return True
+
current_version = value['release']['version']
# we do not care about nightlies here so it's fine to just use a
@@ -282,10 +292,14 @@
is_nightly = value['release']['is_nightly']
is_stable = not is_prerelease and not is_nightly
+ # let's go out quickly
+ if not is_stable:
+ return False
+
def is_newer_version(release: Any) -> bool:
return uploaded_version >= Version(release.version)
# the main page should only be updated when stable and new releases
# are uploaded
is_latest_version = any_match(is_newer_version, releases)
- return is_latest_version and is_stable
+ return is_latest_version
|
{"golden_diff": "diff --git a/nextcloudappstore/api/v1/release/importer.py b/nextcloudappstore/api/v1/release/importer.py\n--- a/nextcloudappstore/api/v1/release/importer.py\n+++ b/nextcloudappstore/api/v1/release/importer.py\n@@ -273,6 +273,16 @@\n if len(releases) == 0:\n return True\n \n+ # if the app has no stable releases update everything\n+ has_stable_release = False\n+ for release in releases:\n+ if '-' not in release.version and not release.is_nightly:\n+ has_stable_release = True\n+ break\n+\n+ if not has_stable_release:\n+ return True\n+\n current_version = value['release']['version']\n \n # we do not care about nightlies here so it's fine to just use a\n@@ -282,10 +292,14 @@\n is_nightly = value['release']['is_nightly']\n is_stable = not is_prerelease and not is_nightly\n \n+ # let's go out quickly\n+ if not is_stable:\n+ return False\n+\n def is_newer_version(release: Any) -> bool:\n return uploaded_version >= Version(release.version)\n \n # the main page should only be updated when stable and new releases\n # are uploaded\n is_latest_version = any_match(is_newer_version, releases)\n- return is_latest_version and is_stable\n+ return is_latest_version\n", "issue": "App details are not updated to the latest upload if only pre-releases or nightlies exist\nHi, \r\n\r\nI've put a new app on the nextcloud app repo, with what seems to be a correct info.xml, but it doesn't take description categories and screenshot into account, \r\n\r\nsee there\r\n\r\nhttps://apps.nextcloud.com/apps/carnet\r\n\r\nAny ideas why ? Thanks !\nApp details are not updated to the latest upload if only pre-releases or nightlies exist\nHi, \r\n\r\nI've put a new app on the nextcloud app repo, with what seems to be a correct info.xml, but it doesn't take description categories and screenshot into account, \r\n\r\nsee there\r\n\r\nhttps://apps.nextcloud.com/apps/carnet\r\n\r\nAny ideas why ? Thanks !\n", "before_files": [{"content": "from typing import Dict, Any, Set, Tuple # type: ignore\n\nfrom django.utils import timezone\nfrom django.conf import settings # type: ignore\nfrom semantic_version import Version # type: ignore\n\nfrom nextcloudappstore.core.facades import any_match\nfrom nextcloudappstore.core.models import App, Screenshot, Category, \\\n AppRelease, ShellCommand, License, Database, DatabaseDependency, \\\n PhpExtensionDependency, PhpExtension, AppAuthor\nfrom nextcloudappstore.core.versioning import to_spec, to_raw_spec\n\n\ndef none_to_empty_string(value: str) -> str:\n if value is None:\n return ''\n else:\n return value.strip()\n\n\nclass Importer:\n def __init__(self, importers: Dict[str, 'Importer'],\n ignored_fields: Set[str]) -> None:\n self.importers = importers\n self.ignored_fields = ignored_fields\n\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n obj = self._get_object(key, value, obj)\n value, obj = self._before_import(key, value, obj)\n for key, val in value.items():\n if key not in self.ignored_fields:\n self.importers[key].import_data(key, val, obj)\n obj.save()\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n raise NotImplementedError\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n raise NotImplementedError\n\n\nclass ScalarImporter(Importer):\n def __init__(self) -> None:\n super().__init__({}, set())\n\n\nclass PhpExtensionImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for ext in value:\n version_spec = to_spec(ext['php_extension']['min_version'],\n ext['php_extension']['max_version'])\n raw_version_spec = to_raw_spec(\n ext['php_extension']['raw_min_version'],\n ext['php_extension']['raw_max_version'])\n extension, created = PhpExtension.objects.get_or_create(\n id=ext['php_extension']['id'])\n PhpExtensionDependency.objects.create(\n version_spec=version_spec,\n raw_version_spec=raw_version_spec,\n app_release=obj, php_extension=extension,\n )\n\n\nclass DatabaseImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for db in value:\n version_spec = to_spec(db['database']['min_version'],\n db['database']['max_version'])\n raw_version_spec = to_raw_spec(db['database']['raw_min_version'],\n db['database']['raw_max_version'])\n # all dbs should be known already\n database = Database.objects.get(id=db['database']['id'])\n DatabaseDependency.objects.create(\n version_spec=version_spec,\n raw_version_spec=raw_version_spec,\n app_release=obj, database=database,\n )\n\n\nclass LicenseImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_models(data: Dict) -> License:\n id = data['license']['id']\n model, created = License.objects.get_or_create(id=id)\n return model\n\n obj.licenses.set(list(map(map_models, value)))\n\n\nclass ShellCommandImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_commands(data: Dict) -> ShellCommand:\n name = data['shell_command']['name']\n command, created = ShellCommand.objects.get_or_create(name=name)\n return command\n\n obj.shell_commands.set(list(map(map_commands, value)))\n\n\nclass AuthorImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_authors(data: Dict) -> AppAuthor:\n author = data['author']\n return AppAuthor.objects.create(\n name=author['name'],\n mail=none_to_empty_string(author['mail']),\n homepage=none_to_empty_string(author['homepage'])\n )\n\n obj.authors.set(list(map(map_authors, value)))\n\n\nclass DefaultAttributeImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n setattr(obj, key, value)\n\n\nclass StringAttributeImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n setattr(obj, key, none_to_empty_string(value))\n\n\nclass ScreenshotsImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def create_screenshot(img: Dict[str, str]) -> Screenshot:\n return Screenshot.objects.create(\n url=img['url'], app=obj, ordering=img['ordering'],\n small_thumbnail=none_to_empty_string(img['small_thumbnail']))\n\n shots = map(lambda val: create_screenshot(val['screenshot']), value)\n obj.screenshots.set(list(shots))\n\n\nclass CategoryImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_categories(cat: Dict) -> Category:\n id = cat['category']['id']\n category, created = Category.objects.get_or_create(id=id)\n return category\n\n obj.categories.set(list(map(map_categories, value)))\n\n\nclass L10NImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for lang, translation in value.items():\n obj.set_current_language(lang)\n setattr(obj, key, translation.strip())\n obj.save()\n\n\nclass AppReleaseImporter(Importer):\n def __init__(self, php_extension_importer: PhpExtensionImporter,\n database_importer: DatabaseImporter,\n license_importer: LicenseImporter,\n shell_command_importer: ShellCommandImporter,\n string_attribute_importer: StringAttributeImporter,\n default_attribute_importer: DefaultAttributeImporter,\n l10n_importer: L10NImporter) -> None:\n super().__init__({\n 'php_extensions': php_extension_importer,\n 'databases': database_importer,\n 'licenses': license_importer,\n 'php_version_spec': string_attribute_importer,\n 'platform_version_spec': string_attribute_importer,\n 'raw_php_version_spec': string_attribute_importer,\n 'raw_platform_version_spec': string_attribute_importer,\n 'min_int_size': default_attribute_importer,\n 'shell_commands': shell_command_importer,\n 'signature': string_attribute_importer,\n 'download': string_attribute_importer,\n 'changelog': l10n_importer,\n 'is_nightly': default_attribute_importer,\n }, {\n 'version',\n 'raw_version',\n 'php_min_version',\n 'php_max_version',\n 'raw_php_min_version',\n 'raw_php_max_version',\n 'platform_min_version',\n 'platform_max_version',\n 'raw_platform_min_version',\n 'raw_platform_max_version',\n })\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n # combine versions into specs\n value['platform_version_spec'] = to_spec(\n value['platform_min_version'], value['platform_max_version'])\n value['php_version_spec'] = to_spec(value['php_min_version'],\n value['php_max_version'])\n value['raw_platform_version_spec'] = to_raw_spec(\n value['raw_platform_min_version'],\n value['raw_platform_max_version'])\n value['raw_php_version_spec'] = to_raw_spec(\n value['raw_php_min_version'],\n value['raw_php_max_version'])\n obj.licenses.clear()\n obj.shell_commands.clear()\n obj.licenses.clear()\n obj.php_extensions.clear()\n obj.databases.clear()\n obj.signature_digest = settings.CERTIFICATE_DIGEST\n return value, obj\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n release, created = AppRelease.objects.get_or_create(\n version=value['version'], app=obj, is_nightly=value['is_nightly']\n )\n return release\n\n\nclass AppImporter(Importer):\n def __init__(self, release_importer: AppReleaseImporter,\n screenshots_importer: ScreenshotsImporter,\n attribute_importer: StringAttributeImporter,\n l10n_importer: L10NImporter,\n category_importer: CategoryImporter,\n author_importer: AuthorImporter,\n default_attribute_importer: DefaultAttributeImporter) -> None:\n super().__init__({\n 'release': release_importer,\n 'screenshots': screenshots_importer,\n 'user_docs': attribute_importer,\n 'admin_docs': attribute_importer,\n 'website': attribute_importer,\n 'discussion': attribute_importer,\n 'developer_docs': attribute_importer,\n 'issue_tracker': attribute_importer,\n 'certificate': attribute_importer,\n 'name': l10n_importer,\n 'summary': l10n_importer,\n 'description': l10n_importer,\n 'categories': category_importer,\n 'authors': author_importer\n }, {'id'})\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n # only update app if newest or equal to newest release\n app, created = App.objects.get_or_create(pk=value['id'])\n return app\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n obj.last_release = timezone.now()\n\n if 'is_nightly' not in value['release']:\n value['release']['is_nightly'] = False\n if value['release']['is_nightly']:\n AppRelease.objects.filter(app__id=obj.id, is_nightly=True).delete()\n\n # only new releases update an app's data\n if self._should_update_everything(value):\n # clear all relations\n obj.screenshots.all().delete()\n obj.authors.all().delete()\n obj.categories.clear()\n for translation in obj.translations.all():\n translation.delete()\n else:\n value = {'id': value['id'], 'release': value['release']}\n\n return value, obj\n\n def _should_update_everything(self, value: Any) -> bool:\n releases = AppRelease.objects.filter(app__id=value['id'])\n\n # if its the first release it should always set the required initial\n # data\n if len(releases) == 0:\n return True\n\n current_version = value['release']['version']\n\n # we do not care about nightlies here so it's fine to just use a\n # normal semver\n uploaded_version = Version(current_version)\n is_prerelease = '-' in current_version\n is_nightly = value['release']['is_nightly']\n is_stable = not is_prerelease and not is_nightly\n\n def is_newer_version(release: Any) -> bool:\n return uploaded_version >= Version(release.version)\n\n # the main page should only be updated when stable and new releases\n # are uploaded\n is_latest_version = any_match(is_newer_version, releases)\n return is_latest_version and is_stable\n", "path": "nextcloudappstore/api/v1/release/importer.py"}], "after_files": [{"content": "from typing import Dict, Any, Set, Tuple # type: ignore\n\nfrom django.utils import timezone\nfrom django.conf import settings # type: ignore\nfrom semantic_version import Version # type: ignore\n\nfrom nextcloudappstore.core.facades import any_match\nfrom nextcloudappstore.core.models import App, Screenshot, Category, \\\n AppRelease, ShellCommand, License, Database, DatabaseDependency, \\\n PhpExtensionDependency, PhpExtension, AppAuthor\nfrom nextcloudappstore.core.versioning import to_spec, to_raw_spec\n\n\ndef none_to_empty_string(value: str) -> str:\n if value is None:\n return ''\n else:\n return value.strip()\n\n\nclass Importer:\n def __init__(self, importers: Dict[str, 'Importer'],\n ignored_fields: Set[str]) -> None:\n self.importers = importers\n self.ignored_fields = ignored_fields\n\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n obj = self._get_object(key, value, obj)\n value, obj = self._before_import(key, value, obj)\n for key, val in value.items():\n if key not in self.ignored_fields:\n self.importers[key].import_data(key, val, obj)\n obj.save()\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n raise NotImplementedError\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n raise NotImplementedError\n\n\nclass ScalarImporter(Importer):\n def __init__(self) -> None:\n super().__init__({}, set())\n\n\nclass PhpExtensionImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for ext in value:\n version_spec = to_spec(ext['php_extension']['min_version'],\n ext['php_extension']['max_version'])\n raw_version_spec = to_raw_spec(\n ext['php_extension']['raw_min_version'],\n ext['php_extension']['raw_max_version'])\n extension, created = PhpExtension.objects.get_or_create(\n id=ext['php_extension']['id'])\n PhpExtensionDependency.objects.create(\n version_spec=version_spec,\n raw_version_spec=raw_version_spec,\n app_release=obj, php_extension=extension,\n )\n\n\nclass DatabaseImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for db in value:\n version_spec = to_spec(db['database']['min_version'],\n db['database']['max_version'])\n raw_version_spec = to_raw_spec(db['database']['raw_min_version'],\n db['database']['raw_max_version'])\n # all dbs should be known already\n database = Database.objects.get(id=db['database']['id'])\n DatabaseDependency.objects.create(\n version_spec=version_spec,\n raw_version_spec=raw_version_spec,\n app_release=obj, database=database,\n )\n\n\nclass LicenseImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_models(data: Dict) -> License:\n id = data['license']['id']\n model, created = License.objects.get_or_create(id=id)\n return model\n\n obj.licenses.set(list(map(map_models, value)))\n\n\nclass ShellCommandImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_commands(data: Dict) -> ShellCommand:\n name = data['shell_command']['name']\n command, created = ShellCommand.objects.get_or_create(name=name)\n return command\n\n obj.shell_commands.set(list(map(map_commands, value)))\n\n\nclass AuthorImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_authors(data: Dict) -> AppAuthor:\n author = data['author']\n return AppAuthor.objects.create(\n name=author['name'],\n mail=none_to_empty_string(author['mail']),\n homepage=none_to_empty_string(author['homepage'])\n )\n\n obj.authors.set(list(map(map_authors, value)))\n\n\nclass DefaultAttributeImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n setattr(obj, key, value)\n\n\nclass StringAttributeImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n setattr(obj, key, none_to_empty_string(value))\n\n\nclass ScreenshotsImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def create_screenshot(img: Dict[str, str]) -> Screenshot:\n return Screenshot.objects.create(\n url=img['url'], app=obj, ordering=img['ordering'],\n small_thumbnail=none_to_empty_string(img['small_thumbnail']))\n\n shots = map(lambda val: create_screenshot(val['screenshot']), value)\n obj.screenshots.set(list(shots))\n\n\nclass CategoryImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n def map_categories(cat: Dict) -> Category:\n id = cat['category']['id']\n category, created = Category.objects.get_or_create(id=id)\n return category\n\n obj.categories.set(list(map(map_categories, value)))\n\n\nclass L10NImporter(ScalarImporter):\n def import_data(self, key: str, value: Any, obj: Any) -> None:\n for lang, translation in value.items():\n obj.set_current_language(lang)\n setattr(obj, key, translation.strip())\n obj.save()\n\n\nclass AppReleaseImporter(Importer):\n def __init__(self, php_extension_importer: PhpExtensionImporter,\n database_importer: DatabaseImporter,\n license_importer: LicenseImporter,\n shell_command_importer: ShellCommandImporter,\n string_attribute_importer: StringAttributeImporter,\n default_attribute_importer: DefaultAttributeImporter,\n l10n_importer: L10NImporter) -> None:\n super().__init__({\n 'php_extensions': php_extension_importer,\n 'databases': database_importer,\n 'licenses': license_importer,\n 'php_version_spec': string_attribute_importer,\n 'platform_version_spec': string_attribute_importer,\n 'raw_php_version_spec': string_attribute_importer,\n 'raw_platform_version_spec': string_attribute_importer,\n 'min_int_size': default_attribute_importer,\n 'shell_commands': shell_command_importer,\n 'signature': string_attribute_importer,\n 'download': string_attribute_importer,\n 'changelog': l10n_importer,\n 'is_nightly': default_attribute_importer,\n }, {\n 'version',\n 'raw_version',\n 'php_min_version',\n 'php_max_version',\n 'raw_php_min_version',\n 'raw_php_max_version',\n 'platform_min_version',\n 'platform_max_version',\n 'raw_platform_min_version',\n 'raw_platform_max_version',\n })\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n # combine versions into specs\n value['platform_version_spec'] = to_spec(\n value['platform_min_version'], value['platform_max_version'])\n value['php_version_spec'] = to_spec(value['php_min_version'],\n value['php_max_version'])\n value['raw_platform_version_spec'] = to_raw_spec(\n value['raw_platform_min_version'],\n value['raw_platform_max_version'])\n value['raw_php_version_spec'] = to_raw_spec(\n value['raw_php_min_version'],\n value['raw_php_max_version'])\n obj.licenses.clear()\n obj.shell_commands.clear()\n obj.licenses.clear()\n obj.php_extensions.clear()\n obj.databases.clear()\n obj.signature_digest = settings.CERTIFICATE_DIGEST\n return value, obj\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n release, created = AppRelease.objects.get_or_create(\n version=value['version'], app=obj, is_nightly=value['is_nightly']\n )\n return release\n\n\nclass AppImporter(Importer):\n def __init__(self, release_importer: AppReleaseImporter,\n screenshots_importer: ScreenshotsImporter,\n attribute_importer: StringAttributeImporter,\n l10n_importer: L10NImporter,\n category_importer: CategoryImporter,\n author_importer: AuthorImporter,\n default_attribute_importer: DefaultAttributeImporter) -> None:\n super().__init__({\n 'release': release_importer,\n 'screenshots': screenshots_importer,\n 'user_docs': attribute_importer,\n 'admin_docs': attribute_importer,\n 'website': attribute_importer,\n 'discussion': attribute_importer,\n 'developer_docs': attribute_importer,\n 'issue_tracker': attribute_importer,\n 'certificate': attribute_importer,\n 'name': l10n_importer,\n 'summary': l10n_importer,\n 'description': l10n_importer,\n 'categories': category_importer,\n 'authors': author_importer\n }, {'id'})\n\n def _get_object(self, key: str, value: Any, obj: Any) -> Any:\n # only update app if newest or equal to newest release\n app, created = App.objects.get_or_create(pk=value['id'])\n return app\n\n def _before_import(self, key: str, value: Any, obj: Any) -> Tuple[Any,\n Any]:\n obj.last_release = timezone.now()\n\n if 'is_nightly' not in value['release']:\n value['release']['is_nightly'] = False\n if value['release']['is_nightly']:\n AppRelease.objects.filter(app__id=obj.id, is_nightly=True).delete()\n\n # only new releases update an app's data\n if self._should_update_everything(value):\n # clear all relations\n obj.screenshots.all().delete()\n obj.authors.all().delete()\n obj.categories.clear()\n for translation in obj.translations.all():\n translation.delete()\n else:\n value = {'id': value['id'], 'release': value['release']}\n\n return value, obj\n\n def _should_update_everything(self, value: Any) -> bool:\n releases = AppRelease.objects.filter(app__id=value['id'])\n\n # if its the first release it should always set the required initial\n # data\n if len(releases) == 0:\n return True\n\n # if the app has no stable releases update everything\n has_stable_release = False\n for release in releases:\n if '-' not in release.version and not release.is_nightly:\n has_stable_release = True\n break\n\n if not has_stable_release:\n return True\n\n current_version = value['release']['version']\n\n # we do not care about nightlies here so it's fine to just use a\n # normal semver\n uploaded_version = Version(current_version)\n is_prerelease = '-' in current_version\n is_nightly = value['release']['is_nightly']\n is_stable = not is_prerelease and not is_nightly\n\n # let's go out quickly\n if not is_stable:\n return False\n\n def is_newer_version(release: Any) -> bool:\n return uploaded_version >= Version(release.version)\n\n # the main page should only be updated when stable and new releases\n # are uploaded\n is_latest_version = any_match(is_newer_version, releases)\n return is_latest_version\n", "path": "nextcloudappstore/api/v1/release/importer.py"}]}
| 3,652 | 337 |
gh_patches_debug_58686
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-1177
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CUDA errors in NTXentLoss with gloo backend in multi-gpu training
I was wondering if the `gloo` distributed communication package for multi-gpu training is officially supported by lightly. It seems like e.g. NTXentLoss doesn't work with `gloo` (I'm using pytorch lightning): I get CUDA errors, even when setting `gather_distributed = False`.
I can fix the issue when using `gather_distributed = False` by replacing the line
https://github.com/lightly-ai/lightly/blob/master/lightly/loss/ntx_ent_loss.py#L164
by
```python
labels = labels + batch_size * (dist.rank() if gather_distributed else 0)
```
but then of course I can't use `gather_distributed = True` anymore.
Using the `nccl` backend, everything works fine, but `nccl` is not working well on some of our machines, so unfortunately I'm stuck with `gloo`. I think using `gloo` might be too much of an exception to fix the problem for `gather_distributed = True`, but maybe it'd help to just replace the line above and mention somewhere in the documentation that `gather_distributed` is not supported for `gloo`?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightly/loss/ntx_ent_loss.py`
Content:
```
1 """ Contrastive Loss Functions """
2
3 # Copyright (c) 2020. Lightly AG and its affiliates.
4 # All Rights Reserved
5
6 import torch
7 from torch import nn
8
9 from lightly.loss.memory_bank import MemoryBankModule
10 from lightly.utils import dist
11
12
13 class NTXentLoss(MemoryBankModule):
14 """Implementation of the Contrastive Cross Entropy Loss.
15
16 This implementation follows the SimCLR[0] paper. If you enable the memory
17 bank by setting the `memory_bank_size` value > 0 the loss behaves like
18 the one described in the MoCo[1] paper.
19
20 - [0] SimCLR, 2020, https://arxiv.org/abs/2002.05709
21 - [1] MoCo, 2020, https://arxiv.org/abs/1911.05722
22
23 Attributes:
24 temperature:
25 Scale logits by the inverse of the temperature.
26 memory_bank_size:
27 Number of negative samples to store in the memory bank.
28 Use 0 for SimCLR. For MoCo we typically use numbers like 4096 or 65536.
29 gather_distributed:
30 If True then negatives from all gpus are gathered before the
31 loss calculation. This flag has no effect if memory_bank_size > 0.
32
33 Raises:
34 ValueError: If abs(temperature) < 1e-8 to prevent divide by zero.
35
36 Examples:
37
38 >>> # initialize loss function without memory bank
39 >>> loss_fn = NTXentLoss(memory_bank_size=0)
40 >>>
41 >>> # generate two random transforms of images
42 >>> t0 = transforms(images)
43 >>> t1 = transforms(images)
44 >>>
45 >>> # feed through SimCLR or MoCo model
46 >>> batch = torch.cat((t0, t1), dim=0)
47 >>> output = model(batch)
48 >>>
49 >>> # calculate loss
50 >>> loss = loss_fn(output)
51
52 """
53
54 def __init__(
55 self,
56 temperature: float = 0.5,
57 memory_bank_size: int = 0,
58 gather_distributed: bool = False,
59 ):
60 super(NTXentLoss, self).__init__(size=memory_bank_size)
61 self.temperature = temperature
62 self.gather_distributed = gather_distributed
63 self.cross_entropy = nn.CrossEntropyLoss(reduction="mean")
64 self.eps = 1e-8
65
66 if abs(self.temperature) < self.eps:
67 raise ValueError(
68 "Illegal temperature: abs({}) < 1e-8".format(self.temperature)
69 )
70
71 def forward(self, out0: torch.Tensor, out1: torch.Tensor):
72 """Forward pass through Contrastive Cross-Entropy Loss.
73
74 If used with a memory bank, the samples from the memory bank are used
75 as negative examples. Otherwise, within-batch samples are used as
76 negative samples.
77
78 Args:
79 out0:
80 Output projections of the first set of transformed images.
81 Shape: (batch_size, embedding_size)
82 out1:
83 Output projections of the second set of transformed images.
84 Shape: (batch_size, embedding_size)
85
86 Returns:
87 Contrastive Cross Entropy Loss value.
88
89 """
90
91 device = out0.device
92 batch_size, _ = out0.shape
93
94 # normalize the output to length 1
95 out0 = nn.functional.normalize(out0, dim=1)
96 out1 = nn.functional.normalize(out1, dim=1)
97
98 # ask memory bank for negative samples and extend it with out1 if
99 # out1 requires a gradient, otherwise keep the same vectors in the
100 # memory bank (this allows for keeping the memory bank constant e.g.
101 # for evaluating the loss on the test set)
102 # out1: shape: (batch_size, embedding_size)
103 # negatives: shape: (embedding_size, memory_bank_size)
104 out1, negatives = super(NTXentLoss, self).forward(
105 out1, update=out0.requires_grad
106 )
107
108 # We use the cosine similarity, which is a dot product (einsum) here,
109 # as all vectors are already normalized to unit length.
110 # Notation in einsum: n = batch_size, c = embedding_size and k = memory_bank_size.
111
112 if negatives is not None:
113 # use negatives from memory bank
114 negatives = negatives.to(device)
115
116 # sim_pos is of shape (batch_size, 1) and sim_pos[i] denotes the similarity
117 # of the i-th sample in the batch to its positive pair
118 sim_pos = torch.einsum("nc,nc->n", out0, out1).unsqueeze(-1)
119
120 # sim_neg is of shape (batch_size, memory_bank_size) and sim_neg[i,j] denotes the similarity
121 # of the i-th sample to the j-th negative sample
122 sim_neg = torch.einsum("nc,ck->nk", out0, negatives)
123
124 # set the labels to the first "class", i.e. sim_pos,
125 # so that it is maximized in relation to sim_neg
126 logits = torch.cat([sim_pos, sim_neg], dim=1) / self.temperature
127 labels = torch.zeros(logits.shape[0], device=device, dtype=torch.long)
128
129 else:
130 # user other samples from batch as negatives
131 # and create diagonal mask that only selects similarities between
132 # views of the same image
133 if self.gather_distributed and dist.world_size() > 1:
134 # gather hidden representations from other processes
135 out0_large = torch.cat(dist.gather(out0), 0)
136 out1_large = torch.cat(dist.gather(out1), 0)
137 diag_mask = dist.eye_rank(batch_size, device=out0.device)
138 else:
139 # single process
140 out0_large = out0
141 out1_large = out1
142 diag_mask = torch.eye(batch_size, device=out0.device, dtype=torch.bool)
143
144 # calculate similiarities
145 # here n = batch_size and m = batch_size * world_size
146 # the resulting vectors have shape (n, m)
147 logits_00 = torch.einsum("nc,mc->nm", out0, out0_large) / self.temperature
148 logits_01 = torch.einsum("nc,mc->nm", out0, out1_large) / self.temperature
149 logits_10 = torch.einsum("nc,mc->nm", out1, out0_large) / self.temperature
150 logits_11 = torch.einsum("nc,mc->nm", out1, out1_large) / self.temperature
151
152 # remove simliarities between same views of the same image
153 logits_00 = logits_00[~diag_mask].view(batch_size, -1)
154 logits_11 = logits_11[~diag_mask].view(batch_size, -1)
155
156 # concatenate logits
157 # the logits tensor in the end has shape (2*n, 2*m-1)
158 logits_0100 = torch.cat([logits_01, logits_00], dim=1)
159 logits_1011 = torch.cat([logits_10, logits_11], dim=1)
160 logits = torch.cat([logits_0100, logits_1011], dim=0)
161
162 # create labels
163 labels = torch.arange(batch_size, device=device, dtype=torch.long)
164 labels = labels + dist.rank() * batch_size
165 labels = labels.repeat(2)
166
167 loss = self.cross_entropy(logits, labels)
168
169 return loss
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightly/loss/ntx_ent_loss.py b/lightly/loss/ntx_ent_loss.py
--- a/lightly/loss/ntx_ent_loss.py
+++ b/lightly/loss/ntx_ent_loss.py
@@ -161,7 +161,8 @@
# create labels
labels = torch.arange(batch_size, device=device, dtype=torch.long)
- labels = labels + dist.rank() * batch_size
+ if self.gather_distributed:
+ labels = labels + dist.rank() * batch_size
labels = labels.repeat(2)
loss = self.cross_entropy(logits, labels)
|
{"golden_diff": "diff --git a/lightly/loss/ntx_ent_loss.py b/lightly/loss/ntx_ent_loss.py\n--- a/lightly/loss/ntx_ent_loss.py\n+++ b/lightly/loss/ntx_ent_loss.py\n@@ -161,7 +161,8 @@\n \n # create labels\n labels = torch.arange(batch_size, device=device, dtype=torch.long)\n- labels = labels + dist.rank() * batch_size\n+ if self.gather_distributed:\n+ labels = labels + dist.rank() * batch_size\n labels = labels.repeat(2)\n \n loss = self.cross_entropy(logits, labels)\n", "issue": "CUDA errors in NTXentLoss with gloo backend in multi-gpu training \nI was wondering if the `gloo` distributed communication package for multi-gpu training is officially supported by lightly. It seems like e.g. NTXentLoss doesn't work with `gloo` (I'm using pytorch lightning): I get CUDA errors, even when setting `gather_distributed = False`.\r\nI can fix the issue when using `gather_distributed = False` by replacing the line\r\nhttps://github.com/lightly-ai/lightly/blob/master/lightly/loss/ntx_ent_loss.py#L164\r\nby\r\n```python\r\nlabels = labels + batch_size * (dist.rank() if gather_distributed else 0)\r\n```\r\nbut then of course I can't use `gather_distributed = True` anymore. \r\n\r\nUsing the `nccl` backend, everything works fine, but `nccl` is not working well on some of our machines, so unfortunately I'm stuck with `gloo`. I think using `gloo` might be too much of an exception to fix the problem for `gather_distributed = True`, but maybe it'd help to just replace the line above and mention somewhere in the documentation that `gather_distributed` is not supported for `gloo`?\n", "before_files": [{"content": "\"\"\" Contrastive Loss Functions \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nimport torch\nfrom torch import nn\n\nfrom lightly.loss.memory_bank import MemoryBankModule\nfrom lightly.utils import dist\n\n\nclass NTXentLoss(MemoryBankModule):\n \"\"\"Implementation of the Contrastive Cross Entropy Loss.\n\n This implementation follows the SimCLR[0] paper. If you enable the memory\n bank by setting the `memory_bank_size` value > 0 the loss behaves like\n the one described in the MoCo[1] paper.\n\n - [0] SimCLR, 2020, https://arxiv.org/abs/2002.05709\n - [1] MoCo, 2020, https://arxiv.org/abs/1911.05722\n\n Attributes:\n temperature:\n Scale logits by the inverse of the temperature.\n memory_bank_size:\n Number of negative samples to store in the memory bank.\n Use 0 for SimCLR. For MoCo we typically use numbers like 4096 or 65536.\n gather_distributed:\n If True then negatives from all gpus are gathered before the\n loss calculation. This flag has no effect if memory_bank_size > 0.\n\n Raises:\n ValueError: If abs(temperature) < 1e-8 to prevent divide by zero.\n\n Examples:\n\n >>> # initialize loss function without memory bank\n >>> loss_fn = NTXentLoss(memory_bank_size=0)\n >>>\n >>> # generate two random transforms of images\n >>> t0 = transforms(images)\n >>> t1 = transforms(images)\n >>>\n >>> # feed through SimCLR or MoCo model\n >>> batch = torch.cat((t0, t1), dim=0)\n >>> output = model(batch)\n >>>\n >>> # calculate loss\n >>> loss = loss_fn(output)\n\n \"\"\"\n\n def __init__(\n self,\n temperature: float = 0.5,\n memory_bank_size: int = 0,\n gather_distributed: bool = False,\n ):\n super(NTXentLoss, self).__init__(size=memory_bank_size)\n self.temperature = temperature\n self.gather_distributed = gather_distributed\n self.cross_entropy = nn.CrossEntropyLoss(reduction=\"mean\")\n self.eps = 1e-8\n\n if abs(self.temperature) < self.eps:\n raise ValueError(\n \"Illegal temperature: abs({}) < 1e-8\".format(self.temperature)\n )\n\n def forward(self, out0: torch.Tensor, out1: torch.Tensor):\n \"\"\"Forward pass through Contrastive Cross-Entropy Loss.\n\n If used with a memory bank, the samples from the memory bank are used\n as negative examples. Otherwise, within-batch samples are used as\n negative samples.\n\n Args:\n out0:\n Output projections of the first set of transformed images.\n Shape: (batch_size, embedding_size)\n out1:\n Output projections of the second set of transformed images.\n Shape: (batch_size, embedding_size)\n\n Returns:\n Contrastive Cross Entropy Loss value.\n\n \"\"\"\n\n device = out0.device\n batch_size, _ = out0.shape\n\n # normalize the output to length 1\n out0 = nn.functional.normalize(out0, dim=1)\n out1 = nn.functional.normalize(out1, dim=1)\n\n # ask memory bank for negative samples and extend it with out1 if\n # out1 requires a gradient, otherwise keep the same vectors in the\n # memory bank (this allows for keeping the memory bank constant e.g.\n # for evaluating the loss on the test set)\n # out1: shape: (batch_size, embedding_size)\n # negatives: shape: (embedding_size, memory_bank_size)\n out1, negatives = super(NTXentLoss, self).forward(\n out1, update=out0.requires_grad\n )\n\n # We use the cosine similarity, which is a dot product (einsum) here,\n # as all vectors are already normalized to unit length.\n # Notation in einsum: n = batch_size, c = embedding_size and k = memory_bank_size.\n\n if negatives is not None:\n # use negatives from memory bank\n negatives = negatives.to(device)\n\n # sim_pos is of shape (batch_size, 1) and sim_pos[i] denotes the similarity\n # of the i-th sample in the batch to its positive pair\n sim_pos = torch.einsum(\"nc,nc->n\", out0, out1).unsqueeze(-1)\n\n # sim_neg is of shape (batch_size, memory_bank_size) and sim_neg[i,j] denotes the similarity\n # of the i-th sample to the j-th negative sample\n sim_neg = torch.einsum(\"nc,ck->nk\", out0, negatives)\n\n # set the labels to the first \"class\", i.e. sim_pos,\n # so that it is maximized in relation to sim_neg\n logits = torch.cat([sim_pos, sim_neg], dim=1) / self.temperature\n labels = torch.zeros(logits.shape[0], device=device, dtype=torch.long)\n\n else:\n # user other samples from batch as negatives\n # and create diagonal mask that only selects similarities between\n # views of the same image\n if self.gather_distributed and dist.world_size() > 1:\n # gather hidden representations from other processes\n out0_large = torch.cat(dist.gather(out0), 0)\n out1_large = torch.cat(dist.gather(out1), 0)\n diag_mask = dist.eye_rank(batch_size, device=out0.device)\n else:\n # single process\n out0_large = out0\n out1_large = out1\n diag_mask = torch.eye(batch_size, device=out0.device, dtype=torch.bool)\n\n # calculate similiarities\n # here n = batch_size and m = batch_size * world_size\n # the resulting vectors have shape (n, m)\n logits_00 = torch.einsum(\"nc,mc->nm\", out0, out0_large) / self.temperature\n logits_01 = torch.einsum(\"nc,mc->nm\", out0, out1_large) / self.temperature\n logits_10 = torch.einsum(\"nc,mc->nm\", out1, out0_large) / self.temperature\n logits_11 = torch.einsum(\"nc,mc->nm\", out1, out1_large) / self.temperature\n\n # remove simliarities between same views of the same image\n logits_00 = logits_00[~diag_mask].view(batch_size, -1)\n logits_11 = logits_11[~diag_mask].view(batch_size, -1)\n\n # concatenate logits\n # the logits tensor in the end has shape (2*n, 2*m-1)\n logits_0100 = torch.cat([logits_01, logits_00], dim=1)\n logits_1011 = torch.cat([logits_10, logits_11], dim=1)\n logits = torch.cat([logits_0100, logits_1011], dim=0)\n\n # create labels\n labels = torch.arange(batch_size, device=device, dtype=torch.long)\n labels = labels + dist.rank() * batch_size\n labels = labels.repeat(2)\n\n loss = self.cross_entropy(logits, labels)\n\n return loss\n", "path": "lightly/loss/ntx_ent_loss.py"}], "after_files": [{"content": "\"\"\" Contrastive Loss Functions \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nimport torch\nfrom torch import nn\n\nfrom lightly.loss.memory_bank import MemoryBankModule\nfrom lightly.utils import dist\n\n\nclass NTXentLoss(MemoryBankModule):\n \"\"\"Implementation of the Contrastive Cross Entropy Loss.\n\n This implementation follows the SimCLR[0] paper. If you enable the memory\n bank by setting the `memory_bank_size` value > 0 the loss behaves like\n the one described in the MoCo[1] paper.\n\n - [0] SimCLR, 2020, https://arxiv.org/abs/2002.05709\n - [1] MoCo, 2020, https://arxiv.org/abs/1911.05722\n\n Attributes:\n temperature:\n Scale logits by the inverse of the temperature.\n memory_bank_size:\n Number of negative samples to store in the memory bank.\n Use 0 for SimCLR. For MoCo we typically use numbers like 4096 or 65536.\n gather_distributed:\n If True then negatives from all gpus are gathered before the\n loss calculation. This flag has no effect if memory_bank_size > 0.\n\n Raises:\n ValueError: If abs(temperature) < 1e-8 to prevent divide by zero.\n\n Examples:\n\n >>> # initialize loss function without memory bank\n >>> loss_fn = NTXentLoss(memory_bank_size=0)\n >>>\n >>> # generate two random transforms of images\n >>> t0 = transforms(images)\n >>> t1 = transforms(images)\n >>>\n >>> # feed through SimCLR or MoCo model\n >>> batch = torch.cat((t0, t1), dim=0)\n >>> output = model(batch)\n >>>\n >>> # calculate loss\n >>> loss = loss_fn(output)\n\n \"\"\"\n\n def __init__(\n self,\n temperature: float = 0.5,\n memory_bank_size: int = 0,\n gather_distributed: bool = False,\n ):\n super(NTXentLoss, self).__init__(size=memory_bank_size)\n self.temperature = temperature\n self.gather_distributed = gather_distributed\n self.cross_entropy = nn.CrossEntropyLoss(reduction=\"mean\")\n self.eps = 1e-8\n\n if abs(self.temperature) < self.eps:\n raise ValueError(\n \"Illegal temperature: abs({}) < 1e-8\".format(self.temperature)\n )\n\n def forward(self, out0: torch.Tensor, out1: torch.Tensor):\n \"\"\"Forward pass through Contrastive Cross-Entropy Loss.\n\n If used with a memory bank, the samples from the memory bank are used\n as negative examples. Otherwise, within-batch samples are used as\n negative samples.\n\n Args:\n out0:\n Output projections of the first set of transformed images.\n Shape: (batch_size, embedding_size)\n out1:\n Output projections of the second set of transformed images.\n Shape: (batch_size, embedding_size)\n\n Returns:\n Contrastive Cross Entropy Loss value.\n\n \"\"\"\n\n device = out0.device\n batch_size, _ = out0.shape\n\n # normalize the output to length 1\n out0 = nn.functional.normalize(out0, dim=1)\n out1 = nn.functional.normalize(out1, dim=1)\n\n # ask memory bank for negative samples and extend it with out1 if\n # out1 requires a gradient, otherwise keep the same vectors in the\n # memory bank (this allows for keeping the memory bank constant e.g.\n # for evaluating the loss on the test set)\n # out1: shape: (batch_size, embedding_size)\n # negatives: shape: (embedding_size, memory_bank_size)\n out1, negatives = super(NTXentLoss, self).forward(\n out1, update=out0.requires_grad\n )\n\n # We use the cosine similarity, which is a dot product (einsum) here,\n # as all vectors are already normalized to unit length.\n # Notation in einsum: n = batch_size, c = embedding_size and k = memory_bank_size.\n\n if negatives is not None:\n # use negatives from memory bank\n negatives = negatives.to(device)\n\n # sim_pos is of shape (batch_size, 1) and sim_pos[i] denotes the similarity\n # of the i-th sample in the batch to its positive pair\n sim_pos = torch.einsum(\"nc,nc->n\", out0, out1).unsqueeze(-1)\n\n # sim_neg is of shape (batch_size, memory_bank_size) and sim_neg[i,j] denotes the similarity\n # of the i-th sample to the j-th negative sample\n sim_neg = torch.einsum(\"nc,ck->nk\", out0, negatives)\n\n # set the labels to the first \"class\", i.e. sim_pos,\n # so that it is maximized in relation to sim_neg\n logits = torch.cat([sim_pos, sim_neg], dim=1) / self.temperature\n labels = torch.zeros(logits.shape[0], device=device, dtype=torch.long)\n\n else:\n # user other samples from batch as negatives\n # and create diagonal mask that only selects similarities between\n # views of the same image\n if self.gather_distributed and dist.world_size() > 1:\n # gather hidden representations from other processes\n out0_large = torch.cat(dist.gather(out0), 0)\n out1_large = torch.cat(dist.gather(out1), 0)\n diag_mask = dist.eye_rank(batch_size, device=out0.device)\n else:\n # single process\n out0_large = out0\n out1_large = out1\n diag_mask = torch.eye(batch_size, device=out0.device, dtype=torch.bool)\n\n # calculate similiarities\n # here n = batch_size and m = batch_size * world_size\n # the resulting vectors have shape (n, m)\n logits_00 = torch.einsum(\"nc,mc->nm\", out0, out0_large) / self.temperature\n logits_01 = torch.einsum(\"nc,mc->nm\", out0, out1_large) / self.temperature\n logits_10 = torch.einsum(\"nc,mc->nm\", out1, out0_large) / self.temperature\n logits_11 = torch.einsum(\"nc,mc->nm\", out1, out1_large) / self.temperature\n\n # remove simliarities between same views of the same image\n logits_00 = logits_00[~diag_mask].view(batch_size, -1)\n logits_11 = logits_11[~diag_mask].view(batch_size, -1)\n\n # concatenate logits\n # the logits tensor in the end has shape (2*n, 2*m-1)\n logits_0100 = torch.cat([logits_01, logits_00], dim=1)\n logits_1011 = torch.cat([logits_10, logits_11], dim=1)\n logits = torch.cat([logits_0100, logits_1011], dim=0)\n\n # create labels\n labels = torch.arange(batch_size, device=device, dtype=torch.long)\n if self.gather_distributed:\n labels = labels + dist.rank() * batch_size\n labels = labels.repeat(2)\n\n loss = self.cross_entropy(logits, labels)\n\n return loss\n", "path": "lightly/loss/ntx_ent_loss.py"}]}
| 2,606 | 141 |
gh_patches_debug_3999
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-pipeline-743
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: Too many JSON files error
https://mne.discourse.group/t/mne-bids-pipeline-too-many-json-files-error/6436
> This is a MEG dataset which I converted to BIDS format using mne-bids. The json files which appear to cause the trouble are [_beh.json] sidecar files for the behavioural data I saved to the beh/ subfolder like so:
>
> |MNE-BIDS_data/
> |— README
> |— dataset_description.json
> |— participants.json
> |— participants.tsv
> |— sub-01/
> |------ sub-01_scans.tsv
> |------ beh/
> |--------- sub-01_task-main_run-01_beh.json
> |--------- sub-01_task-main_run-01_beh.tsv
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mne_bids_pipeline/steps/init/_02_find_empty_room.py`
Content:
```
1 """Find empty-room data matches."""
2
3 from types import SimpleNamespace
4 from typing import Dict, Optional
5
6 from mne.utils import _pl
7 from mne_bids import BIDSPath
8
9 from ..._config_utils import (
10 get_datatype,
11 get_task,
12 get_sessions,
13 get_subjects,
14 get_runs,
15 )
16 from ..._io import _empty_room_match_path, _write_json
17 from ..._logging import gen_log_kwargs, logger
18 from ..._run import _update_for_splits, failsafe_run, save_logs
19
20
21 def get_input_fnames_find_empty_room(
22 *, subject: str, session: Optional[str], run: Optional[str], cfg: SimpleNamespace
23 ) -> Dict[str, BIDSPath]:
24 """Get paths of files required by filter_data function."""
25 bids_path_in = BIDSPath(
26 subject=subject,
27 run=run,
28 session=session,
29 task=cfg.task,
30 acquisition=cfg.acq,
31 recording=cfg.rec,
32 space=cfg.space,
33 datatype=cfg.datatype,
34 processing=cfg.proc,
35 root=cfg.bids_root,
36 check=False,
37 )
38 in_files: Dict[str, BIDSPath] = dict()
39 in_files[f"raw_run-{run}"] = bids_path_in
40 _update_for_splits(in_files, f"raw_run-{run}", single=True)
41 if hasattr(bids_path_in, "find_matching_sidecar"):
42 in_files["sidecar"] = (
43 bids_path_in.copy()
44 .update(datatype=None)
45 .find_matching_sidecar(extension=".json")
46 )
47 try:
48 fname = bids_path_in.find_empty_room(use_sidecar_only=True)
49 except Exception:
50 fname = None
51 if fname is None and hasattr(bids_path_in, "get_empty_room_candidates"):
52 for ci, path in enumerate(bids_path_in.get_empty_room_candidates()):
53 in_files[f"empty_room_candidate_{ci}"] = path
54 return in_files
55
56
57 @failsafe_run(
58 get_input_fnames=get_input_fnames_find_empty_room,
59 )
60 def find_empty_room(
61 *,
62 cfg: SimpleNamespace,
63 exec_params: SimpleNamespace,
64 subject: str,
65 session: Optional[str],
66 run: Optional[str],
67 in_files: Dict[str, BIDSPath],
68 ) -> Dict[str, BIDSPath]:
69 raw_path = in_files.pop(f"raw_run-{run}")
70 in_files.pop("sidecar", None)
71 try:
72 fname = raw_path.find_empty_room(use_sidecar_only=True)
73 except (FileNotFoundError, AssertionError, ValueError):
74 fname = ""
75 if fname is None:
76 # sidecar is very fast and checking all can be slow (seconds), so only
77 # log when actually looking through files
78 ending = "empty-room files"
79 if len(in_files): # MNE-BIDS < 0.12 missing get_empty_room_candidates
80 ending = f"{len(in_files)} empty-room file{_pl(in_files)}"
81 msg = f"Nearest-date matching {ending}"
82 logger.info(**gen_log_kwargs(message=msg))
83 try:
84 fname = raw_path.find_empty_room()
85 except (
86 ValueError, # non-MEG data
87 AssertionError, # MNE-BIDS check assert exists()
88 FileNotFoundError,
89 ): # MNE-BIDS PR-1080 exists()
90 fname = None
91 in_files.clear() # MNE-BIDS find_empty_room should have looked at all
92 elif fname == "":
93 fname = None # not downloaded, or EEG data
94 elif not fname.fpath.exists():
95 fname = None # path found by sidecar but does not exist
96 out_files = dict()
97 out_files["empty_room_match"] = _empty_room_match_path(raw_path, cfg)
98 _write_json(out_files["empty_room_match"], dict(fname=fname))
99 return out_files
100
101
102 def get_config(
103 *,
104 config,
105 ) -> SimpleNamespace:
106 cfg = SimpleNamespace(
107 proc=config.proc,
108 task=get_task(config),
109 datatype=get_datatype(config),
110 acq=config.acq,
111 rec=config.rec,
112 space=config.space,
113 bids_root=config.bids_root,
114 deriv_root=config.deriv_root,
115 )
116 return cfg
117
118
119 def main(*, config) -> None:
120 """Run find_empty_room."""
121 if not config.process_empty_room:
122 msg = "Skipping, process_empty_room is set to False …"
123 logger.info(**gen_log_kwargs(message=msg, emoji="skip"))
124 return
125 if get_datatype(config) != "meg":
126 msg = "Skipping, empty-room data only relevant for MEG …"
127 logger.info(**gen_log_kwargs(message=msg, emoji="skip"))
128 return
129 # This will be I/O bound if the sidecar is not complete, so let's not run
130 # in parallel.
131 logs = list()
132 for subject in get_subjects(config):
133 if config.use_maxwell_filter:
134 run = config.mf_reference_run
135 else:
136 run = get_runs(config=config, subject=subject)[0]
137 logs.append(
138 find_empty_room(
139 cfg=get_config(
140 config=config,
141 ),
142 exec_params=config.exec_params,
143 subject=subject,
144 session=get_sessions(config)[0],
145 run=run,
146 )
147 )
148 save_logs(config=config, logs=logs)
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mne_bids_pipeline/steps/init/_02_find_empty_room.py b/mne_bids_pipeline/steps/init/_02_find_empty_room.py
--- a/mne_bids_pipeline/steps/init/_02_find_empty_room.py
+++ b/mne_bids_pipeline/steps/init/_02_find_empty_room.py
@@ -41,7 +41,7 @@
if hasattr(bids_path_in, "find_matching_sidecar"):
in_files["sidecar"] = (
bids_path_in.copy()
- .update(datatype=None)
+ .update(datatype=None, suffix="meg")
.find_matching_sidecar(extension=".json")
)
try:
|
{"golden_diff": "diff --git a/mne_bids_pipeline/steps/init/_02_find_empty_room.py b/mne_bids_pipeline/steps/init/_02_find_empty_room.py\n--- a/mne_bids_pipeline/steps/init/_02_find_empty_room.py\n+++ b/mne_bids_pipeline/steps/init/_02_find_empty_room.py\n@@ -41,7 +41,7 @@\n if hasattr(bids_path_in, \"find_matching_sidecar\"):\n in_files[\"sidecar\"] = (\n bids_path_in.copy()\n- .update(datatype=None)\n+ .update(datatype=None, suffix=\"meg\")\n .find_matching_sidecar(extension=\".json\")\n )\n try:\n", "issue": "BUG: Too many JSON files error\nhttps://mne.discourse.group/t/mne-bids-pipeline-too-many-json-files-error/6436\r\n\r\n> This is a MEG dataset which I converted to BIDS format using mne-bids. The json files which appear to cause the trouble are [_beh.json] sidecar files for the behavioural data I saved to the beh/ subfolder like so:\r\n>\r\n> |MNE-BIDS_data/\r\n> |\u2014 README\r\n> |\u2014 dataset_description.json\r\n> |\u2014 participants.json\r\n> |\u2014 participants.tsv\r\n> |\u2014 sub-01/\r\n> |------ sub-01_scans.tsv\r\n> |------ beh/\r\n> |--------- sub-01_task-main_run-01_beh.json\r\n> |--------- sub-01_task-main_run-01_beh.tsv\n", "before_files": [{"content": "\"\"\"Find empty-room data matches.\"\"\"\n\nfrom types import SimpleNamespace\nfrom typing import Dict, Optional\n\nfrom mne.utils import _pl\nfrom mne_bids import BIDSPath\n\nfrom ..._config_utils import (\n get_datatype,\n get_task,\n get_sessions,\n get_subjects,\n get_runs,\n)\nfrom ..._io import _empty_room_match_path, _write_json\nfrom ..._logging import gen_log_kwargs, logger\nfrom ..._run import _update_for_splits, failsafe_run, save_logs\n\n\ndef get_input_fnames_find_empty_room(\n *, subject: str, session: Optional[str], run: Optional[str], cfg: SimpleNamespace\n) -> Dict[str, BIDSPath]:\n \"\"\"Get paths of files required by filter_data function.\"\"\"\n bids_path_in = BIDSPath(\n subject=subject,\n run=run,\n session=session,\n task=cfg.task,\n acquisition=cfg.acq,\n recording=cfg.rec,\n space=cfg.space,\n datatype=cfg.datatype,\n processing=cfg.proc,\n root=cfg.bids_root,\n check=False,\n )\n in_files: Dict[str, BIDSPath] = dict()\n in_files[f\"raw_run-{run}\"] = bids_path_in\n _update_for_splits(in_files, f\"raw_run-{run}\", single=True)\n if hasattr(bids_path_in, \"find_matching_sidecar\"):\n in_files[\"sidecar\"] = (\n bids_path_in.copy()\n .update(datatype=None)\n .find_matching_sidecar(extension=\".json\")\n )\n try:\n fname = bids_path_in.find_empty_room(use_sidecar_only=True)\n except Exception:\n fname = None\n if fname is None and hasattr(bids_path_in, \"get_empty_room_candidates\"):\n for ci, path in enumerate(bids_path_in.get_empty_room_candidates()):\n in_files[f\"empty_room_candidate_{ci}\"] = path\n return in_files\n\n\n@failsafe_run(\n get_input_fnames=get_input_fnames_find_empty_room,\n)\ndef find_empty_room(\n *,\n cfg: SimpleNamespace,\n exec_params: SimpleNamespace,\n subject: str,\n session: Optional[str],\n run: Optional[str],\n in_files: Dict[str, BIDSPath],\n) -> Dict[str, BIDSPath]:\n raw_path = in_files.pop(f\"raw_run-{run}\")\n in_files.pop(\"sidecar\", None)\n try:\n fname = raw_path.find_empty_room(use_sidecar_only=True)\n except (FileNotFoundError, AssertionError, ValueError):\n fname = \"\"\n if fname is None:\n # sidecar is very fast and checking all can be slow (seconds), so only\n # log when actually looking through files\n ending = \"empty-room files\"\n if len(in_files): # MNE-BIDS < 0.12 missing get_empty_room_candidates\n ending = f\"{len(in_files)} empty-room file{_pl(in_files)}\"\n msg = f\"Nearest-date matching {ending}\"\n logger.info(**gen_log_kwargs(message=msg))\n try:\n fname = raw_path.find_empty_room()\n except (\n ValueError, # non-MEG data\n AssertionError, # MNE-BIDS check assert exists()\n FileNotFoundError,\n ): # MNE-BIDS PR-1080 exists()\n fname = None\n in_files.clear() # MNE-BIDS find_empty_room should have looked at all\n elif fname == \"\":\n fname = None # not downloaded, or EEG data\n elif not fname.fpath.exists():\n fname = None # path found by sidecar but does not exist\n out_files = dict()\n out_files[\"empty_room_match\"] = _empty_room_match_path(raw_path, cfg)\n _write_json(out_files[\"empty_room_match\"], dict(fname=fname))\n return out_files\n\n\ndef get_config(\n *,\n config,\n) -> SimpleNamespace:\n cfg = SimpleNamespace(\n proc=config.proc,\n task=get_task(config),\n datatype=get_datatype(config),\n acq=config.acq,\n rec=config.rec,\n space=config.space,\n bids_root=config.bids_root,\n deriv_root=config.deriv_root,\n )\n return cfg\n\n\ndef main(*, config) -> None:\n \"\"\"Run find_empty_room.\"\"\"\n if not config.process_empty_room:\n msg = \"Skipping, process_empty_room is set to False \u2026\"\n logger.info(**gen_log_kwargs(message=msg, emoji=\"skip\"))\n return\n if get_datatype(config) != \"meg\":\n msg = \"Skipping, empty-room data only relevant for MEG \u2026\"\n logger.info(**gen_log_kwargs(message=msg, emoji=\"skip\"))\n return\n # This will be I/O bound if the sidecar is not complete, so let's not run\n # in parallel.\n logs = list()\n for subject in get_subjects(config):\n if config.use_maxwell_filter:\n run = config.mf_reference_run\n else:\n run = get_runs(config=config, subject=subject)[0]\n logs.append(\n find_empty_room(\n cfg=get_config(\n config=config,\n ),\n exec_params=config.exec_params,\n subject=subject,\n session=get_sessions(config)[0],\n run=run,\n )\n )\n save_logs(config=config, logs=logs)\n", "path": "mne_bids_pipeline/steps/init/_02_find_empty_room.py"}], "after_files": [{"content": "\"\"\"Find empty-room data matches.\"\"\"\n\nfrom types import SimpleNamespace\nfrom typing import Dict, Optional\n\nfrom mne.utils import _pl\nfrom mne_bids import BIDSPath\n\nfrom ..._config_utils import (\n get_datatype,\n get_task,\n get_sessions,\n get_subjects,\n get_runs,\n)\nfrom ..._io import _empty_room_match_path, _write_json\nfrom ..._logging import gen_log_kwargs, logger\nfrom ..._run import _update_for_splits, failsafe_run, save_logs\n\n\ndef get_input_fnames_find_empty_room(\n *, subject: str, session: Optional[str], run: Optional[str], cfg: SimpleNamespace\n) -> Dict[str, BIDSPath]:\n \"\"\"Get paths of files required by filter_data function.\"\"\"\n bids_path_in = BIDSPath(\n subject=subject,\n run=run,\n session=session,\n task=cfg.task,\n acquisition=cfg.acq,\n recording=cfg.rec,\n space=cfg.space,\n datatype=cfg.datatype,\n processing=cfg.proc,\n root=cfg.bids_root,\n check=False,\n )\n in_files: Dict[str, BIDSPath] = dict()\n in_files[f\"raw_run-{run}\"] = bids_path_in\n _update_for_splits(in_files, f\"raw_run-{run}\", single=True)\n if hasattr(bids_path_in, \"find_matching_sidecar\"):\n in_files[\"sidecar\"] = (\n bids_path_in.copy()\n .update(datatype=None, suffix=\"meg\")\n .find_matching_sidecar(extension=\".json\")\n )\n try:\n fname = bids_path_in.find_empty_room(use_sidecar_only=True)\n except Exception:\n fname = None\n if fname is None and hasattr(bids_path_in, \"get_empty_room_candidates\"):\n for ci, path in enumerate(bids_path_in.get_empty_room_candidates()):\n in_files[f\"empty_room_candidate_{ci}\"] = path\n return in_files\n\n\n@failsafe_run(\n get_input_fnames=get_input_fnames_find_empty_room,\n)\ndef find_empty_room(\n *,\n cfg: SimpleNamespace,\n exec_params: SimpleNamespace,\n subject: str,\n session: Optional[str],\n run: Optional[str],\n in_files: Dict[str, BIDSPath],\n) -> Dict[str, BIDSPath]:\n raw_path = in_files.pop(f\"raw_run-{run}\")\n in_files.pop(\"sidecar\", None)\n try:\n fname = raw_path.find_empty_room(use_sidecar_only=True)\n except (FileNotFoundError, AssertionError, ValueError):\n fname = \"\"\n if fname is None:\n # sidecar is very fast and checking all can be slow (seconds), so only\n # log when actually looking through files\n ending = \"empty-room files\"\n if len(in_files): # MNE-BIDS < 0.12 missing get_empty_room_candidates\n ending = f\"{len(in_files)} empty-room file{_pl(in_files)}\"\n msg = f\"Nearest-date matching {ending}\"\n logger.info(**gen_log_kwargs(message=msg))\n try:\n fname = raw_path.find_empty_room()\n except (\n ValueError, # non-MEG data\n AssertionError, # MNE-BIDS check assert exists()\n FileNotFoundError,\n ): # MNE-BIDS PR-1080 exists()\n fname = None\n in_files.clear() # MNE-BIDS find_empty_room should have looked at all\n elif fname == \"\":\n fname = None # not downloaded, or EEG data\n elif not fname.fpath.exists():\n fname = None # path found by sidecar but does not exist\n out_files = dict()\n out_files[\"empty_room_match\"] = _empty_room_match_path(raw_path, cfg)\n _write_json(out_files[\"empty_room_match\"], dict(fname=fname))\n return out_files\n\n\ndef get_config(\n *,\n config,\n) -> SimpleNamespace:\n cfg = SimpleNamespace(\n proc=config.proc,\n task=get_task(config),\n datatype=get_datatype(config),\n acq=config.acq,\n rec=config.rec,\n space=config.space,\n bids_root=config.bids_root,\n deriv_root=config.deriv_root,\n )\n return cfg\n\n\ndef main(*, config) -> None:\n \"\"\"Run find_empty_room.\"\"\"\n if not config.process_empty_room:\n msg = \"Skipping, process_empty_room is set to False \u2026\"\n logger.info(**gen_log_kwargs(message=msg, emoji=\"skip\"))\n return\n if get_datatype(config) != \"meg\":\n msg = \"Skipping, empty-room data only relevant for MEG \u2026\"\n logger.info(**gen_log_kwargs(message=msg, emoji=\"skip\"))\n return\n # This will be I/O bound if the sidecar is not complete, so let's not run\n # in parallel.\n logs = list()\n for subject in get_subjects(config):\n if config.use_maxwell_filter:\n run = config.mf_reference_run\n else:\n run = get_runs(config=config, subject=subject)[0]\n logs.append(\n find_empty_room(\n cfg=get_config(\n config=config,\n ),\n exec_params=config.exec_params,\n subject=subject,\n session=get_sessions(config)[0],\n run=run,\n )\n )\n save_logs(config=config, logs=logs)\n", "path": "mne_bids_pipeline/steps/init/_02_find_empty_room.py"}]}
| 1,924 | 148 |
gh_patches_debug_14606
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-5301
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
La comparaison des versions a perdu sa sidebar
## Étapes pour reproduire
- prenez un tuto avec plusieurs éditions
- cliquer sur "comparer les versions"
- sélectionner deux versions
**Comportement observé**
la sidebar n'apparaît pas dans la page de comparaison des versions
**Comportement désiré**
La sidebar est là.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/utils/templatetags/htmldiff.py`
Content:
```
1 from difflib import HtmlDiff
2 from django import template
3 from django.utils.html import format_html
4 from django.utils.safestring import mark_safe
5 from django.utils.translation import ugettext_lazy as _
6
7
8 register = template.Library()
9
10
11 @register.simple_tag
12 def htmldiff(string1, string2):
13
14 try:
15 txt1 = string1.decode('utf-8').splitlines()
16 # string1 is an empty SafeText from template
17 except AttributeError:
18 txt1 = string1.splitlines()
19
20 try:
21 txt2 = string2.decode('utf-8').splitlines()
22 except AttributeError:
23 txt2 = string2.splitlines()
24
25 diff = HtmlDiff(tabsize=4, wrapcolumn=80)
26 result = diff.make_table(txt1, txt2, context=True, numlines=2)
27
28 if 'No Differences Found' in result:
29 return format_html('<p>{}</p>', _('Pas de changements.'))
30 else:
31 return format_html('<div class="diff_delta">{}</div>', mark_safe(result))
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/utils/templatetags/htmldiff.py b/zds/utils/templatetags/htmldiff.py
--- a/zds/utils/templatetags/htmldiff.py
+++ b/zds/utils/templatetags/htmldiff.py
@@ -22,10 +22,12 @@
except AttributeError:
txt2 = string2.splitlines()
- diff = HtmlDiff(tabsize=4, wrapcolumn=80)
+ diff = HtmlDiff(tabsize=4)
result = diff.make_table(txt1, txt2, context=True, numlines=2)
if 'No Differences Found' in result:
return format_html('<p>{}</p>', _('Pas de changements.'))
else:
- return format_html('<div class="diff_delta">{}</div>', mark_safe(result))
+ # the diff.make_table() replaces all spaces by non-breakable ones, which prevent line breaks:
+ r = mark_safe(result.replace('<td nowrap="nowrap">', '<td>').replace(' ', ' '))
+ return format_html('<div class="diff_delta">{}</div>', r)
|
{"golden_diff": "diff --git a/zds/utils/templatetags/htmldiff.py b/zds/utils/templatetags/htmldiff.py\n--- a/zds/utils/templatetags/htmldiff.py\n+++ b/zds/utils/templatetags/htmldiff.py\n@@ -22,10 +22,12 @@\n except AttributeError:\n txt2 = string2.splitlines()\n \n- diff = HtmlDiff(tabsize=4, wrapcolumn=80)\n+ diff = HtmlDiff(tabsize=4)\n result = diff.make_table(txt1, txt2, context=True, numlines=2)\n \n if 'No Differences Found' in result:\n return format_html('<p>{}</p>', _('Pas de changements.'))\n else:\n- return format_html('<div class=\"diff_delta\">{}</div>', mark_safe(result))\n+ # the diff.make_table() replaces all spaces by non-breakable ones, which prevent line breaks:\n+ r = mark_safe(result.replace('<td nowrap=\"nowrap\">', '<td>').replace(' ', ' '))\n+ return format_html('<div class=\"diff_delta\">{}</div>', r)\n", "issue": "La comparaison des versions a perdu sa sidebar\n## \u00c9tapes pour reproduire \r\n\r\n- prenez un tuto avec plusieurs \u00e9ditions\r\n- cliquer sur \"comparer les versions\"\r\n- s\u00e9lectionner deux versions\r\n\r\n**Comportement observ\u00e9**\r\n\r\nla sidebar n'appara\u00eet pas dans la page de comparaison des versions\r\n\r\n**Comportement d\u00e9sir\u00e9**\r\n\r\nLa sidebar est l\u00e0.\n", "before_files": [{"content": "from difflib import HtmlDiff\nfrom django import template\nfrom django.utils.html import format_html\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext_lazy as _\n\n\nregister = template.Library()\n\n\[email protected]_tag\ndef htmldiff(string1, string2):\n\n try:\n txt1 = string1.decode('utf-8').splitlines()\n # string1 is an empty SafeText from template\n except AttributeError:\n txt1 = string1.splitlines()\n\n try:\n txt2 = string2.decode('utf-8').splitlines()\n except AttributeError:\n txt2 = string2.splitlines()\n\n diff = HtmlDiff(tabsize=4, wrapcolumn=80)\n result = diff.make_table(txt1, txt2, context=True, numlines=2)\n\n if 'No Differences Found' in result:\n return format_html('<p>{}</p>', _('Pas de changements.'))\n else:\n return format_html('<div class=\"diff_delta\">{}</div>', mark_safe(result))\n", "path": "zds/utils/templatetags/htmldiff.py"}], "after_files": [{"content": "from difflib import HtmlDiff\nfrom django import template\nfrom django.utils.html import format_html\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext_lazy as _\n\n\nregister = template.Library()\n\n\[email protected]_tag\ndef htmldiff(string1, string2):\n\n try:\n txt1 = string1.decode('utf-8').splitlines()\n # string1 is an empty SafeText from template\n except AttributeError:\n txt1 = string1.splitlines()\n\n try:\n txt2 = string2.decode('utf-8').splitlines()\n except AttributeError:\n txt2 = string2.splitlines()\n\n diff = HtmlDiff(tabsize=4)\n result = diff.make_table(txt1, txt2, context=True, numlines=2)\n\n if 'No Differences Found' in result:\n return format_html('<p>{}</p>', _('Pas de changements.'))\n else:\n # the diff.make_table() replaces all spaces by non-breakable ones, which prevent line breaks:\n r = mark_safe(result.replace('<td nowrap=\"nowrap\">', '<td>').replace(' ', ' '))\n return format_html('<div class=\"diff_delta\">{}</div>', r)\n", "path": "zds/utils/templatetags/htmldiff.py"}]}
| 634 | 252 |
gh_patches_debug_19627
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1910
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Android system file browser cannot be invoked
### Describe the bug
I tried to invoke Android's system file browser UI (SAF) but get following error message:
`No appropriate Activity found to handle this intent.`
### Steps to reproduce
Try following code:
```
from android.content import Intent
intent = Intent(Intent.ACTION_OPEN_DOCUMENT)
intent.addCategory(Intent.CATEGORY_OPENABLE)
intent.setType("*/*")
result = await self.app._impl.intent_result(intent)
```
### Expected behavior
The system file browser should open because under my Android 13, it is definitely there.
With following code, the file browser is shown, but the app doesn't wait for the result:
```
intent = Intent(Intent.ACTION_OPEN_DOCUMENT)
intent.addCategory(Intent.CATEGORY_OPENABLE)
intent.setType("*/*")
result = await self.app._impl.native.startActivityForResult(intent, 1234)
```
I get the error back `object NoneType can't be used in 'await' expression`
### Screenshots
_No response_
### Environment
- Operating System: Android 13
- Python version: 3.11
- Software versions:
- Toga: 0.3.1dev93
### Logs
```
```
### Additional context
The same problem exists with Intent.ACTION_CREATE_DOCUMENT and this Intent also can be invoked directly with startActivityForResult
The problem stems from this code in app.py:
```
if not intent.resolveActivity(self.native.getPackageManager()):
raise RuntimeError("No appropriate Activity found to handle this intent.")
```
This may be a good way to find Activities of standard apps, but it seems to fail in the case of internal Activities like the system file browser.
It might be better to remove this code and instead catch and return exceptions that occur when invoking startActivityForResult unguarded
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `android/src/toga_android/app.py`
Content:
```
1 import asyncio
2
3 from rubicon.java import android_events
4
5 import toga
6 from toga.command import Group
7
8 from .libs.activity import IPythonApp, MainActivity
9 from .libs.android.graphics import Drawable
10 from .libs.android.view import Menu, MenuItem
11 from .window import Window
12
13 # `MainWindow` is defined here in `app.py`, not `window.py`, to mollify the test suite.
14 MainWindow = Window
15
16
17 class TogaApp(IPythonApp):
18 last_intent_requestcode = (
19 -1
20 ) # always increment before using it for invoking new Intents
21 running_intents = {} # dictionary for currently running Intents
22 menuitem_mapping = {} # dictionary for mapping menuitems to commands
23
24 def __init__(self, app):
25 super().__init__()
26 self._impl = app
27 MainActivity.setPythonApp(self)
28 print("Python app launched & stored in Android Activity class")
29
30 def onCreate(self):
31 print("Toga app: onCreate")
32
33 def onStart(self):
34 print("Toga app: onStart")
35
36 def onResume(self):
37 print("Toga app: onResume")
38
39 def onPause(self):
40 print("Toga app: onPause")
41
42 def onStop(self):
43 print("Toga app: onStop")
44
45 def onDestroy(self):
46 print("Toga app: onDestroy")
47
48 def onRestart(self):
49 print("Toga app: onRestart")
50
51 def onActivityResult(self, requestCode, resultCode, resultData):
52 """Callback method, called from MainActivity when an Intent ends.
53
54 :param int requestCode: The integer request code originally supplied to startActivityForResult(),
55 allowing you to identify who this result came from.
56 :param int resultCode: The integer result code returned by the child activity through its setResult().
57 :param Intent resultData: An Intent, which can return result data to the caller (various data can be attached
58 to Intent "extras").
59 """
60 print(
61 f"Toga app: onActivityResult, requestCode={requestCode}, resultData={resultData}"
62 )
63 try:
64 # remove Intent from the list of running Intents,
65 # and set the result of the intent.
66 result_future = self.running_intents.pop(requestCode)
67 result_future.set_result(
68 {"resultCode": resultCode, "resultData": resultData}
69 )
70 except KeyError:
71 print("No intent matching request code {requestCode}")
72
73 def onConfigurationChanged(self, new_config):
74 pass
75
76 def onOptionsItemSelected(self, menuitem):
77 consumed = False
78 try:
79 cmd = self.menuitem_mapping[menuitem.getItemId()]
80 consumed = True
81 if cmd.action is not None:
82 cmd.action(menuitem)
83 except KeyError:
84 print("menu item id not found in menuitem_mapping dictionary!")
85 return consumed
86
87 def onPrepareOptionsMenu(self, menu):
88 menu.clear()
89 itemid = 0
90 menulist = {} # dictionary with all menus
91 self.menuitem_mapping.clear()
92
93 # create option menu
94 for cmd in self._impl.interface.commands:
95 if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:
96 continue
97 if cmd in self._impl.interface.main_window.toolbar:
98 continue # do not show toolbar commands in the option menu (except when overflowing)
99
100 grouppath = cmd.group.path
101 if grouppath[0] != Group.COMMANDS:
102 # only the Commands group (and its subgroups) are supported
103 # other groups should eventually go into the navigation drawer
104 continue
105 if cmd.group.key in menulist:
106 menugroup = menulist[cmd.group.key]
107 else:
108 # create all missing submenus
109 parentmenu = menu
110 for group in grouppath:
111 groupkey = group.key
112 if groupkey in menulist:
113 menugroup = menulist[groupkey]
114 else:
115 if group.text == toga.Group.COMMANDS.text:
116 menulist[groupkey] = menu
117 menugroup = menu
118 else:
119 itemid += 1
120 order = Menu.NONE if group.order is None else group.order
121 menugroup = parentmenu.addSubMenu(
122 Menu.NONE, itemid, order, group.text
123 ) # groupId, itemId, order, title
124 menulist[groupkey] = menugroup
125 parentmenu = menugroup
126 # create menu item
127 itemid += 1
128 order = Menu.NONE if cmd.order is None else cmd.order
129 menuitem = menugroup.add(
130 Menu.NONE, itemid, order, cmd.text
131 ) # groupId, itemId, order, title
132 menuitem.setShowAsActionFlags(MenuItem.SHOW_AS_ACTION_NEVER)
133 menuitem.setEnabled(cmd.enabled)
134 self.menuitem_mapping[
135 itemid
136 ] = cmd # store itemid for use in onOptionsItemSelected
137
138 # create toolbar actions
139 if self._impl.interface.main_window:
140 for cmd in self._impl.interface.main_window.toolbar:
141 if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:
142 continue
143 itemid += 1
144 order = Menu.NONE if cmd.order is None else cmd.order
145 menuitem = menu.add(
146 Menu.NONE, itemid, order, cmd.text
147 ) # groupId, itemId, order, title
148 menuitem.setShowAsActionFlags(
149 MenuItem.SHOW_AS_ACTION_IF_ROOM
150 ) # toolbar button / item in options menu on overflow
151 menuitem.setEnabled(cmd.enabled)
152 if cmd.icon:
153 icon = Drawable.createFromPath(str(cmd.icon._impl.path))
154 if icon:
155 menuitem.setIcon(icon)
156 else:
157 print("Could not create icon: " + str(cmd.icon._impl.path))
158 self.menuitem_mapping[
159 itemid
160 ] = cmd # store itemid for use in onOptionsItemSelected
161
162 return True
163
164 @property
165 def native(self):
166 # We access `MainActivity.singletonThis` freshly each time, rather than
167 # storing a reference in `__init__()`, because it's not safe to use the
168 # same reference over time because `rubicon-java` creates a JNI local
169 # reference.
170 return MainActivity.singletonThis
171
172
173 class App:
174 def __init__(self, interface):
175 self.interface = interface
176 self.interface._impl = self
177 self._listener = None
178
179 self.loop = android_events.AndroidEventLoop()
180
181 @property
182 def native(self):
183 return self._listener.native if self._listener else None
184
185 def create(self):
186 # The `_listener` listens for activity event callbacks. For simplicity,
187 # the app's `.native` is the listener's native Java class.
188 self._listener = TogaApp(self)
189 # Call user code to populate the main window
190 self.interface.startup()
191
192 def open_document(self, fileURL):
193 print("Can't open document %s (yet)" % fileURL)
194
195 def main_loop(self):
196 # In order to support user asyncio code, start the Python/Android cooperative event loop.
197 self.loop.run_forever_cooperatively()
198
199 # On Android, Toga UI integrates automatically into the main Android event loop by virtue
200 # of the Android Activity system.
201 self.create()
202
203 def set_main_window(self, window):
204 pass
205
206 def show_about_dialog(self):
207 self.interface.factory.not_implemented("App.show_about_dialog()")
208
209 def exit(self):
210 pass
211
212 async def intent_result(self, intent):
213 """Calls an Intent and waits for its result.
214
215 A RuntimeError will be raised when the Intent cannot be invoked.
216
217 :param Intent intent: The Intent to call
218 :returns: A Dictionary containing "resultCode" (int) and "resultData" (Intent or None)
219 :rtype: dict
220 """
221 if not intent.resolveActivity(self.native.getPackageManager()):
222 raise RuntimeError("No appropriate Activity found to handle this intent.")
223 self._listener.last_intent_requestcode += 1
224 code = self._listener.last_intent_requestcode
225
226 result_future = asyncio.Future()
227 self._listener.running_intents[code] = result_future
228
229 self.native.startActivityForResult(intent, code)
230 await result_future
231 return result_future.result()
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/android/src/toga_android/app.py b/android/src/toga_android/app.py
--- a/android/src/toga_android/app.py
+++ b/android/src/toga_android/app.py
@@ -218,14 +218,15 @@
:returns: A Dictionary containing "resultCode" (int) and "resultData" (Intent or None)
:rtype: dict
"""
- if not intent.resolveActivity(self.native.getPackageManager()):
- raise RuntimeError("No appropriate Activity found to handle this intent.")
- self._listener.last_intent_requestcode += 1
- code = self._listener.last_intent_requestcode
+ try:
+ self._listener.last_intent_requestcode += 1
+ code = self._listener.last_intent_requestcode
- result_future = asyncio.Future()
- self._listener.running_intents[code] = result_future
+ result_future = asyncio.Future()
+ self._listener.running_intents[code] = result_future
- self.native.startActivityForResult(intent, code)
- await result_future
- return result_future.result()
+ self.native.startActivityForResult(intent, code)
+ await result_future
+ return result_future.result()
+ except AttributeError:
+ raise RuntimeError("No appropriate Activity found to handle this intent.")
|
{"golden_diff": "diff --git a/android/src/toga_android/app.py b/android/src/toga_android/app.py\n--- a/android/src/toga_android/app.py\n+++ b/android/src/toga_android/app.py\n@@ -218,14 +218,15 @@\n :returns: A Dictionary containing \"resultCode\" (int) and \"resultData\" (Intent or None)\n :rtype: dict\n \"\"\"\n- if not intent.resolveActivity(self.native.getPackageManager()):\n- raise RuntimeError(\"No appropriate Activity found to handle this intent.\")\n- self._listener.last_intent_requestcode += 1\n- code = self._listener.last_intent_requestcode\n+ try:\n+ self._listener.last_intent_requestcode += 1\n+ code = self._listener.last_intent_requestcode\n \n- result_future = asyncio.Future()\n- self._listener.running_intents[code] = result_future\n+ result_future = asyncio.Future()\n+ self._listener.running_intents[code] = result_future\n \n- self.native.startActivityForResult(intent, code)\n- await result_future\n- return result_future.result()\n+ self.native.startActivityForResult(intent, code)\n+ await result_future\n+ return result_future.result()\n+ except AttributeError:\n+ raise RuntimeError(\"No appropriate Activity found to handle this intent.\")\n", "issue": "Android system file browser cannot be invoked\n### Describe the bug\r\n\r\nI tried to invoke Android's system file browser UI (SAF) but get following error message:\r\n`No appropriate Activity found to handle this intent.`\r\n\r\n\r\n### Steps to reproduce\r\n\r\nTry following code:\r\n```\r\nfrom android.content import Intent\r\n\r\nintent = Intent(Intent.ACTION_OPEN_DOCUMENT)\r\nintent.addCategory(Intent.CATEGORY_OPENABLE) \r\nintent.setType(\"*/*\")\r\nresult = await self.app._impl.intent_result(intent) \r\n```\r\n\r\n\r\n### Expected behavior\r\n\r\nThe system file browser should open because under my Android 13, it is definitely there.\r\n\r\nWith following code, the file browser is shown, but the app doesn't wait for the result:\r\n```\r\nintent = Intent(Intent.ACTION_OPEN_DOCUMENT)\r\nintent.addCategory(Intent.CATEGORY_OPENABLE) \r\nintent.setType(\"*/*\")\r\nresult = await self.app._impl.native.startActivityForResult(intent, 1234) \r\n```\r\nI get the error back `object NoneType can't be used in 'await' expression`\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Environment\r\n\r\n- Operating System: Android 13\r\n- Python version: 3.11\r\n- Software versions:\r\n - Toga: 0.3.1dev93\r\n \r\n\r\n### Logs\r\n\r\n```\r\n\r\n```\r\n\r\n\r\n### Additional context\r\nThe same problem exists with Intent.ACTION_CREATE_DOCUMENT and this Intent also can be invoked directly with startActivityForResult\r\n\r\nThe problem stems from this code in app.py:\r\n\r\n```\r\nif not intent.resolveActivity(self.native.getPackageManager()):\r\n raise RuntimeError(\"No appropriate Activity found to handle this intent.\")\r\n```\r\nThis may be a good way to find Activities of standard apps, but it seems to fail in the case of internal Activities like the system file browser.\r\n\r\nIt might be better to remove this code and instead catch and return exceptions that occur when invoking startActivityForResult unguarded\n", "before_files": [{"content": "import asyncio\n\nfrom rubicon.java import android_events\n\nimport toga\nfrom toga.command import Group\n\nfrom .libs.activity import IPythonApp, MainActivity\nfrom .libs.android.graphics import Drawable\nfrom .libs.android.view import Menu, MenuItem\nfrom .window import Window\n\n# `MainWindow` is defined here in `app.py`, not `window.py`, to mollify the test suite.\nMainWindow = Window\n\n\nclass TogaApp(IPythonApp):\n last_intent_requestcode = (\n -1\n ) # always increment before using it for invoking new Intents\n running_intents = {} # dictionary for currently running Intents\n menuitem_mapping = {} # dictionary for mapping menuitems to commands\n\n def __init__(self, app):\n super().__init__()\n self._impl = app\n MainActivity.setPythonApp(self)\n print(\"Python app launched & stored in Android Activity class\")\n\n def onCreate(self):\n print(\"Toga app: onCreate\")\n\n def onStart(self):\n print(\"Toga app: onStart\")\n\n def onResume(self):\n print(\"Toga app: onResume\")\n\n def onPause(self):\n print(\"Toga app: onPause\")\n\n def onStop(self):\n print(\"Toga app: onStop\")\n\n def onDestroy(self):\n print(\"Toga app: onDestroy\")\n\n def onRestart(self):\n print(\"Toga app: onRestart\")\n\n def onActivityResult(self, requestCode, resultCode, resultData):\n \"\"\"Callback method, called from MainActivity when an Intent ends.\n\n :param int requestCode: The integer request code originally supplied to startActivityForResult(),\n allowing you to identify who this result came from.\n :param int resultCode: The integer result code returned by the child activity through its setResult().\n :param Intent resultData: An Intent, which can return result data to the caller (various data can be attached\n to Intent \"extras\").\n \"\"\"\n print(\n f\"Toga app: onActivityResult, requestCode={requestCode}, resultData={resultData}\"\n )\n try:\n # remove Intent from the list of running Intents,\n # and set the result of the intent.\n result_future = self.running_intents.pop(requestCode)\n result_future.set_result(\n {\"resultCode\": resultCode, \"resultData\": resultData}\n )\n except KeyError:\n print(\"No intent matching request code {requestCode}\")\n\n def onConfigurationChanged(self, new_config):\n pass\n\n def onOptionsItemSelected(self, menuitem):\n consumed = False\n try:\n cmd = self.menuitem_mapping[menuitem.getItemId()]\n consumed = True\n if cmd.action is not None:\n cmd.action(menuitem)\n except KeyError:\n print(\"menu item id not found in menuitem_mapping dictionary!\")\n return consumed\n\n def onPrepareOptionsMenu(self, menu):\n menu.clear()\n itemid = 0\n menulist = {} # dictionary with all menus\n self.menuitem_mapping.clear()\n\n # create option menu\n for cmd in self._impl.interface.commands:\n if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:\n continue\n if cmd in self._impl.interface.main_window.toolbar:\n continue # do not show toolbar commands in the option menu (except when overflowing)\n\n grouppath = cmd.group.path\n if grouppath[0] != Group.COMMANDS:\n # only the Commands group (and its subgroups) are supported\n # other groups should eventually go into the navigation drawer\n continue\n if cmd.group.key in menulist:\n menugroup = menulist[cmd.group.key]\n else:\n # create all missing submenus\n parentmenu = menu\n for group in grouppath:\n groupkey = group.key\n if groupkey in menulist:\n menugroup = menulist[groupkey]\n else:\n if group.text == toga.Group.COMMANDS.text:\n menulist[groupkey] = menu\n menugroup = menu\n else:\n itemid += 1\n order = Menu.NONE if group.order is None else group.order\n menugroup = parentmenu.addSubMenu(\n Menu.NONE, itemid, order, group.text\n ) # groupId, itemId, order, title\n menulist[groupkey] = menugroup\n parentmenu = menugroup\n # create menu item\n itemid += 1\n order = Menu.NONE if cmd.order is None else cmd.order\n menuitem = menugroup.add(\n Menu.NONE, itemid, order, cmd.text\n ) # groupId, itemId, order, title\n menuitem.setShowAsActionFlags(MenuItem.SHOW_AS_ACTION_NEVER)\n menuitem.setEnabled(cmd.enabled)\n self.menuitem_mapping[\n itemid\n ] = cmd # store itemid for use in onOptionsItemSelected\n\n # create toolbar actions\n if self._impl.interface.main_window:\n for cmd in self._impl.interface.main_window.toolbar:\n if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:\n continue\n itemid += 1\n order = Menu.NONE if cmd.order is None else cmd.order\n menuitem = menu.add(\n Menu.NONE, itemid, order, cmd.text\n ) # groupId, itemId, order, title\n menuitem.setShowAsActionFlags(\n MenuItem.SHOW_AS_ACTION_IF_ROOM\n ) # toolbar button / item in options menu on overflow\n menuitem.setEnabled(cmd.enabled)\n if cmd.icon:\n icon = Drawable.createFromPath(str(cmd.icon._impl.path))\n if icon:\n menuitem.setIcon(icon)\n else:\n print(\"Could not create icon: \" + str(cmd.icon._impl.path))\n self.menuitem_mapping[\n itemid\n ] = cmd # store itemid for use in onOptionsItemSelected\n\n return True\n\n @property\n def native(self):\n # We access `MainActivity.singletonThis` freshly each time, rather than\n # storing a reference in `__init__()`, because it's not safe to use the\n # same reference over time because `rubicon-java` creates a JNI local\n # reference.\n return MainActivity.singletonThis\n\n\nclass App:\n def __init__(self, interface):\n self.interface = interface\n self.interface._impl = self\n self._listener = None\n\n self.loop = android_events.AndroidEventLoop()\n\n @property\n def native(self):\n return self._listener.native if self._listener else None\n\n def create(self):\n # The `_listener` listens for activity event callbacks. For simplicity,\n # the app's `.native` is the listener's native Java class.\n self._listener = TogaApp(self)\n # Call user code to populate the main window\n self.interface.startup()\n\n def open_document(self, fileURL):\n print(\"Can't open document %s (yet)\" % fileURL)\n\n def main_loop(self):\n # In order to support user asyncio code, start the Python/Android cooperative event loop.\n self.loop.run_forever_cooperatively()\n\n # On Android, Toga UI integrates automatically into the main Android event loop by virtue\n # of the Android Activity system.\n self.create()\n\n def set_main_window(self, window):\n pass\n\n def show_about_dialog(self):\n self.interface.factory.not_implemented(\"App.show_about_dialog()\")\n\n def exit(self):\n pass\n\n async def intent_result(self, intent):\n \"\"\"Calls an Intent and waits for its result.\n\n A RuntimeError will be raised when the Intent cannot be invoked.\n\n :param Intent intent: The Intent to call\n :returns: A Dictionary containing \"resultCode\" (int) and \"resultData\" (Intent or None)\n :rtype: dict\n \"\"\"\n if not intent.resolveActivity(self.native.getPackageManager()):\n raise RuntimeError(\"No appropriate Activity found to handle this intent.\")\n self._listener.last_intent_requestcode += 1\n code = self._listener.last_intent_requestcode\n\n result_future = asyncio.Future()\n self._listener.running_intents[code] = result_future\n\n self.native.startActivityForResult(intent, code)\n await result_future\n return result_future.result()\n", "path": "android/src/toga_android/app.py"}], "after_files": [{"content": "import asyncio\n\nfrom rubicon.java import android_events\n\nimport toga\nfrom toga.command import Group\n\nfrom .libs.activity import IPythonApp, MainActivity\nfrom .libs.android.graphics import Drawable\nfrom .libs.android.view import Menu, MenuItem\nfrom .window import Window\n\n# `MainWindow` is defined here in `app.py`, not `window.py`, to mollify the test suite.\nMainWindow = Window\n\n\nclass TogaApp(IPythonApp):\n last_intent_requestcode = (\n -1\n ) # always increment before using it for invoking new Intents\n running_intents = {} # dictionary for currently running Intents\n menuitem_mapping = {} # dictionary for mapping menuitems to commands\n\n def __init__(self, app):\n super().__init__()\n self._impl = app\n MainActivity.setPythonApp(self)\n print(\"Python app launched & stored in Android Activity class\")\n\n def onCreate(self):\n print(\"Toga app: onCreate\")\n\n def onStart(self):\n print(\"Toga app: onStart\")\n\n def onResume(self):\n print(\"Toga app: onResume\")\n\n def onPause(self):\n print(\"Toga app: onPause\")\n\n def onStop(self):\n print(\"Toga app: onStop\")\n\n def onDestroy(self):\n print(\"Toga app: onDestroy\")\n\n def onRestart(self):\n print(\"Toga app: onRestart\")\n\n def onActivityResult(self, requestCode, resultCode, resultData):\n \"\"\"Callback method, called from MainActivity when an Intent ends.\n\n :param int requestCode: The integer request code originally supplied to startActivityForResult(),\n allowing you to identify who this result came from.\n :param int resultCode: The integer result code returned by the child activity through its setResult().\n :param Intent resultData: An Intent, which can return result data to the caller (various data can be attached\n to Intent \"extras\").\n \"\"\"\n print(\n f\"Toga app: onActivityResult, requestCode={requestCode}, resultData={resultData}\"\n )\n try:\n # remove Intent from the list of running Intents,\n # and set the result of the intent.\n result_future = self.running_intents.pop(requestCode)\n result_future.set_result(\n {\"resultCode\": resultCode, \"resultData\": resultData}\n )\n except KeyError:\n print(\"No intent matching request code {requestCode}\")\n\n def onConfigurationChanged(self, new_config):\n pass\n\n def onOptionsItemSelected(self, menuitem):\n consumed = False\n try:\n cmd = self.menuitem_mapping[menuitem.getItemId()]\n consumed = True\n if cmd.action is not None:\n cmd.action(menuitem)\n except KeyError:\n print(\"menu item id not found in menuitem_mapping dictionary!\")\n return consumed\n\n def onPrepareOptionsMenu(self, menu):\n menu.clear()\n itemid = 0\n menulist = {} # dictionary with all menus\n self.menuitem_mapping.clear()\n\n # create option menu\n for cmd in self._impl.interface.commands:\n if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:\n continue\n if cmd in self._impl.interface.main_window.toolbar:\n continue # do not show toolbar commands in the option menu (except when overflowing)\n\n grouppath = cmd.group.path\n if grouppath[0] != Group.COMMANDS:\n # only the Commands group (and its subgroups) are supported\n # other groups should eventually go into the navigation drawer\n continue\n if cmd.group.key in menulist:\n menugroup = menulist[cmd.group.key]\n else:\n # create all missing submenus\n parentmenu = menu\n for group in grouppath:\n groupkey = group.key\n if groupkey in menulist:\n menugroup = menulist[groupkey]\n else:\n if group.text == toga.Group.COMMANDS.text:\n menulist[groupkey] = menu\n menugroup = menu\n else:\n itemid += 1\n order = Menu.NONE if group.order is None else group.order\n menugroup = parentmenu.addSubMenu(\n Menu.NONE, itemid, order, group.text\n ) # groupId, itemId, order, title\n menulist[groupkey] = menugroup\n parentmenu = menugroup\n # create menu item\n itemid += 1\n order = Menu.NONE if cmd.order is None else cmd.order\n menuitem = menugroup.add(\n Menu.NONE, itemid, order, cmd.text\n ) # groupId, itemId, order, title\n menuitem.setShowAsActionFlags(MenuItem.SHOW_AS_ACTION_NEVER)\n menuitem.setEnabled(cmd.enabled)\n self.menuitem_mapping[\n itemid\n ] = cmd # store itemid for use in onOptionsItemSelected\n\n # create toolbar actions\n if self._impl.interface.main_window:\n for cmd in self._impl.interface.main_window.toolbar:\n if cmd == toga.SECTION_BREAK or cmd == toga.GROUP_BREAK:\n continue\n itemid += 1\n order = Menu.NONE if cmd.order is None else cmd.order\n menuitem = menu.add(\n Menu.NONE, itemid, order, cmd.text\n ) # groupId, itemId, order, title\n menuitem.setShowAsActionFlags(\n MenuItem.SHOW_AS_ACTION_IF_ROOM\n ) # toolbar button / item in options menu on overflow\n menuitem.setEnabled(cmd.enabled)\n if cmd.icon:\n icon = Drawable.createFromPath(str(cmd.icon._impl.path))\n if icon:\n menuitem.setIcon(icon)\n else:\n print(\"Could not create icon: \" + str(cmd.icon._impl.path))\n self.menuitem_mapping[\n itemid\n ] = cmd # store itemid for use in onOptionsItemSelected\n\n return True\n\n @property\n def native(self):\n # We access `MainActivity.singletonThis` freshly each time, rather than\n # storing a reference in `__init__()`, because it's not safe to use the\n # same reference over time because `rubicon-java` creates a JNI local\n # reference.\n return MainActivity.singletonThis\n\n\nclass App:\n def __init__(self, interface):\n self.interface = interface\n self.interface._impl = self\n self._listener = None\n\n self.loop = android_events.AndroidEventLoop()\n\n @property\n def native(self):\n return self._listener.native if self._listener else None\n\n def create(self):\n # The `_listener` listens for activity event callbacks. For simplicity,\n # the app's `.native` is the listener's native Java class.\n self._listener = TogaApp(self)\n # Call user code to populate the main window\n self.interface.startup()\n\n def open_document(self, fileURL):\n print(\"Can't open document %s (yet)\" % fileURL)\n\n def main_loop(self):\n # In order to support user asyncio code, start the Python/Android cooperative event loop.\n self.loop.run_forever_cooperatively()\n\n # On Android, Toga UI integrates automatically into the main Android event loop by virtue\n # of the Android Activity system.\n self.create()\n\n def set_main_window(self, window):\n pass\n\n def show_about_dialog(self):\n self.interface.factory.not_implemented(\"App.show_about_dialog()\")\n\n def exit(self):\n pass\n\n async def intent_result(self, intent):\n \"\"\"Calls an Intent and waits for its result.\n\n A RuntimeError will be raised when the Intent cannot be invoked.\n\n :param Intent intent: The Intent to call\n :returns: A Dictionary containing \"resultCode\" (int) and \"resultData\" (Intent or None)\n :rtype: dict\n \"\"\"\n try:\n self._listener.last_intent_requestcode += 1\n code = self._listener.last_intent_requestcode\n\n result_future = asyncio.Future()\n self._listener.running_intents[code] = result_future\n\n self.native.startActivityForResult(intent, code)\n await result_future\n return result_future.result()\n except AttributeError:\n raise RuntimeError(\"No appropriate Activity found to handle this intent.\")\n", "path": "android/src/toga_android/app.py"}]}
| 2,992 | 276 |
gh_patches_debug_19182
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-python-6426
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Why do we have matplotlib < 3.1 in requirements.txt?
@massich can you try if 3.1 works? It would be nice to support the current matplotlib version.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mne/conftest.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Author: Eric Larson <[email protected]>
3 #
4 # License: BSD (3-clause)
5
6 import os.path as op
7 import warnings
8 import pytest
9 # For some unknown reason, on Travis-xenial there are segfaults caused on
10 # the line pytest -> pdb.Pdb.__init__ -> "import readline". Forcing an
11 # import here seems to prevent them (!?). This suggests a potential problem
12 # with some other library stepping on memory where it shouldn't. It only
13 # seems to happen on the Linux runs that install Mayavi. Anectodally,
14 # @larsoner has had problems a couple of years ago where a mayavi import
15 # seemed to corrupt SciPy linalg function results (!), likely due to the
16 # associated VTK import, so this could be another manifestation of that.
17 try:
18 import readline # noqa
19 except Exception:
20 pass
21
22 import numpy as np
23 import mne
24 from mne.datasets import testing
25 from mne.fixes import _get_args
26
27 test_path = testing.data_path(download=False)
28 s_path = op.join(test_path, 'MEG', 'sample')
29 fname_evoked = op.join(s_path, 'sample_audvis_trunc-ave.fif')
30 fname_cov = op.join(s_path, 'sample_audvis_trunc-cov.fif')
31 fname_fwd = op.join(s_path, 'sample_audvis_trunc-meg-eeg-oct-4-fwd.fif')
32
33
34 def pytest_configure(config):
35 """Configure pytest options."""
36 # Markers
37 for marker in ('slowtest', 'ultraslowtest'):
38 config.addinivalue_line('markers', marker)
39
40 # Fixtures
41 for fixture in ('matplotlib_config',):
42 config.addinivalue_line('usefixtures', fixture)
43
44 # Warnings
45 # - Once SciPy updates not to have non-integer and non-tuple errors (1.2.0)
46 # we should remove them from here.
47 # - This list should also be considered alongside reset_warnings in
48 # doc/conf.py.
49 warning_lines = """
50 error::
51 ignore::ImportWarning
52 ignore:the matrix subclass:PendingDeprecationWarning
53 ignore:numpy.dtype size changed:RuntimeWarning
54 ignore:.*HasTraits.trait_.*:DeprecationWarning
55 ignore:.*takes no parameters:DeprecationWarning
56 ignore:joblib not installed:RuntimeWarning
57 ignore:Using a non-tuple sequence for multidimensional indexing:FutureWarning
58 ignore:using a non-integer number instead of an integer will result in an error:DeprecationWarning
59 ignore:Importing from numpy.testing.decorators is deprecated:DeprecationWarning
60 ignore:np.loads is deprecated, use pickle.loads instead:DeprecationWarning
61 ignore:The oldnumeric module will be dropped:DeprecationWarning
62 ignore:Collection picker None could not be converted to float:UserWarning
63 ignore:covariance is not positive-semidefinite:RuntimeWarning
64 ignore:Can only plot ICA components:RuntimeWarning
65 ignore:Matplotlib is building the font cache using fc-list:UserWarning
66 ignore:Using or importing the ABCs from 'collections':DeprecationWarning
67 ignore:`formatargspec` is deprecated:DeprecationWarning
68 # This is only necessary until sklearn updates their wheels for NumPy 1.16
69 ignore:numpy.ufunc size changed:RuntimeWarning
70 ignore:.*mne-realtime.*:DeprecationWarning
71 """ # noqa: E501
72 for warning_line in warning_lines.split('\n'):
73 warning_line = warning_line.strip()
74 if warning_line and not warning_line.startswith('#'):
75 config.addinivalue_line('filterwarnings', warning_line)
76
77
78 @pytest.fixture(scope='session')
79 def matplotlib_config():
80 """Configure matplotlib for viz tests."""
81 import matplotlib
82 # "force" should not really be necessary but should not hurt
83 kwargs = dict()
84 if 'warn' in _get_args(matplotlib.use):
85 kwargs['warn'] = False
86 matplotlib.use('agg', force=True, **kwargs) # don't pop up windows
87 import matplotlib.pyplot as plt
88 assert plt.get_backend() == 'agg'
89 # overwrite some params that can horribly slow down tests that
90 # users might have changed locally (but should not otherwise affect
91 # functionality)
92 plt.ioff()
93 plt.rcParams['figure.dpi'] = 100
94 try:
95 from traits.etsconfig.api import ETSConfig
96 except Exception:
97 pass
98 else:
99 ETSConfig.toolkit = 'qt4'
100 try:
101 with warnings.catch_warnings(record=True): # traits
102 from mayavi import mlab
103 except Exception:
104 pass
105 else:
106 mlab.options.backend = 'test'
107
108
109 @pytest.fixture(scope='function', params=[testing._pytest_param()])
110 def evoked():
111 """Get evoked data."""
112 evoked = mne.read_evokeds(fname_evoked, condition='Left Auditory',
113 baseline=(None, 0))
114 evoked.crop(0, 0.2)
115 return evoked
116
117
118 @pytest.fixture(scope='function', params=[testing._pytest_param()])
119 def noise_cov():
120 """Get a noise cov from the testing dataset."""
121 return mne.read_cov(fname_cov)
122
123
124 @pytest.fixture(scope='function')
125 def bias_params_free(evoked, noise_cov):
126 """Provide inputs for free bias functions."""
127 fwd = mne.read_forward_solution(fname_fwd)
128 return _bias_params(evoked, noise_cov, fwd)
129
130
131 @pytest.fixture(scope='function')
132 def bias_params_fixed(evoked, noise_cov):
133 """Provide inputs for fixed bias functions."""
134 fwd = mne.read_forward_solution(fname_fwd)
135 fwd = mne.convert_forward_solution(fwd, force_fixed=True, surf_ori=True)
136 return _bias_params(evoked, noise_cov, fwd)
137
138
139 def _bias_params(evoked, noise_cov, fwd):
140 evoked.pick_types(meg=True, eeg=True, exclude=())
141 # restrict to limited set of verts (small src here) and one hemi for speed
142 vertices = [fwd['src'][0]['vertno'].copy(), []]
143 stc = mne.SourceEstimate(np.zeros((sum(len(v) for v in vertices), 1)),
144 vertices, 0., 1.)
145 fwd = mne.forward.restrict_forward_to_stc(fwd, stc)
146 assert fwd['sol']['row_names'] == noise_cov['names']
147 assert noise_cov['names'] == evoked.ch_names
148 evoked = mne.EvokedArray(fwd['sol']['data'].copy(), evoked.info)
149 data_cov = noise_cov.copy()
150 data_cov['data'] = np.dot(fwd['sol']['data'], fwd['sol']['data'].T)
151 assert data_cov['data'].shape[0] == len(noise_cov['names'])
152 want = np.arange(fwd['sol']['data'].shape[1])
153 if not mne.forward.is_fixed_orient(fwd):
154 want //= 3
155 return evoked, fwd, noise_cov, data_cov, want
156
157
158 @pytest.fixture(scope="module", params=[
159 "mayavi",
160 "pyvista",
161 ])
162 def backend_name(request):
163 """Get the backend name."""
164 yield request.param
165
166
167 @pytest.yield_fixture
168 def renderer(backend_name):
169 """Yield the 3D backends."""
170 from mne.viz.backends.renderer import _use_test_3d_backend
171 from mne.viz.backends.tests._utils import has_mayavi, has_pyvista
172 if backend_name == 'mayavi':
173 if not has_mayavi():
174 pytest.skip("Test skipped, requires mayavi.")
175 elif backend_name == 'pyvista':
176 if not has_pyvista():
177 pytest.skip("Test skipped, requires pyvista.")
178 with _use_test_3d_backend(backend_name):
179 from mne.viz.backends import renderer
180 yield renderer
181 renderer._close_all()
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mne/conftest.py b/mne/conftest.py
--- a/mne/conftest.py
+++ b/mne/conftest.py
@@ -22,7 +22,6 @@
import numpy as np
import mne
from mne.datasets import testing
-from mne.fixes import _get_args
test_path = testing.data_path(download=False)
s_path = op.join(test_path, 'MEG', 'sample')
@@ -81,9 +80,8 @@
import matplotlib
# "force" should not really be necessary but should not hurt
kwargs = dict()
- if 'warn' in _get_args(matplotlib.use):
- kwargs['warn'] = False
- matplotlib.use('agg', force=True, **kwargs) # don't pop up windows
+ with warnings.catch_warnings(record=True): # ignore warning
+ matplotlib.use('agg', force=True, **kwargs) # don't pop up windows
import matplotlib.pyplot as plt
assert plt.get_backend() == 'agg'
# overwrite some params that can horribly slow down tests that
|
{"golden_diff": "diff --git a/mne/conftest.py b/mne/conftest.py\n--- a/mne/conftest.py\n+++ b/mne/conftest.py\n@@ -22,7 +22,6 @@\n import numpy as np\n import mne\n from mne.datasets import testing\n-from mne.fixes import _get_args\n \n test_path = testing.data_path(download=False)\n s_path = op.join(test_path, 'MEG', 'sample')\n@@ -81,9 +80,8 @@\n import matplotlib\n # \"force\" should not really be necessary but should not hurt\n kwargs = dict()\n- if 'warn' in _get_args(matplotlib.use):\n- kwargs['warn'] = False\n- matplotlib.use('agg', force=True, **kwargs) # don't pop up windows\n+ with warnings.catch_warnings(record=True): # ignore warning\n+ matplotlib.use('agg', force=True, **kwargs) # don't pop up windows\n import matplotlib.pyplot as plt\n assert plt.get_backend() == 'agg'\n # overwrite some params that can horribly slow down tests that\n", "issue": "Why do we have matplotlib < 3.1 in requirements.txt?\n@massich can you try if 3.1 works? It would be nice to support the current matplotlib version.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Author: Eric Larson <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport os.path as op\nimport warnings\nimport pytest\n# For some unknown reason, on Travis-xenial there are segfaults caused on\n# the line pytest -> pdb.Pdb.__init__ -> \"import readline\". Forcing an\n# import here seems to prevent them (!?). This suggests a potential problem\n# with some other library stepping on memory where it shouldn't. It only\n# seems to happen on the Linux runs that install Mayavi. Anectodally,\n# @larsoner has had problems a couple of years ago where a mayavi import\n# seemed to corrupt SciPy linalg function results (!), likely due to the\n# associated VTK import, so this could be another manifestation of that.\ntry:\n import readline # noqa\nexcept Exception:\n pass\n\nimport numpy as np\nimport mne\nfrom mne.datasets import testing\nfrom mne.fixes import _get_args\n\ntest_path = testing.data_path(download=False)\ns_path = op.join(test_path, 'MEG', 'sample')\nfname_evoked = op.join(s_path, 'sample_audvis_trunc-ave.fif')\nfname_cov = op.join(s_path, 'sample_audvis_trunc-cov.fif')\nfname_fwd = op.join(s_path, 'sample_audvis_trunc-meg-eeg-oct-4-fwd.fif')\n\n\ndef pytest_configure(config):\n \"\"\"Configure pytest options.\"\"\"\n # Markers\n for marker in ('slowtest', 'ultraslowtest'):\n config.addinivalue_line('markers', marker)\n\n # Fixtures\n for fixture in ('matplotlib_config',):\n config.addinivalue_line('usefixtures', fixture)\n\n # Warnings\n # - Once SciPy updates not to have non-integer and non-tuple errors (1.2.0)\n # we should remove them from here.\n # - This list should also be considered alongside reset_warnings in\n # doc/conf.py.\n warning_lines = \"\"\"\n error::\n ignore::ImportWarning\n ignore:the matrix subclass:PendingDeprecationWarning\n ignore:numpy.dtype size changed:RuntimeWarning\n ignore:.*HasTraits.trait_.*:DeprecationWarning\n ignore:.*takes no parameters:DeprecationWarning\n ignore:joblib not installed:RuntimeWarning\n ignore:Using a non-tuple sequence for multidimensional indexing:FutureWarning\n ignore:using a non-integer number instead of an integer will result in an error:DeprecationWarning\n ignore:Importing from numpy.testing.decorators is deprecated:DeprecationWarning\n ignore:np.loads is deprecated, use pickle.loads instead:DeprecationWarning\n ignore:The oldnumeric module will be dropped:DeprecationWarning\n ignore:Collection picker None could not be converted to float:UserWarning\n ignore:covariance is not positive-semidefinite:RuntimeWarning\n ignore:Can only plot ICA components:RuntimeWarning\n ignore:Matplotlib is building the font cache using fc-list:UserWarning\n ignore:Using or importing the ABCs from 'collections':DeprecationWarning\n ignore:`formatargspec` is deprecated:DeprecationWarning\n # This is only necessary until sklearn updates their wheels for NumPy 1.16\n ignore:numpy.ufunc size changed:RuntimeWarning\n ignore:.*mne-realtime.*:DeprecationWarning\n \"\"\" # noqa: E501\n for warning_line in warning_lines.split('\\n'):\n warning_line = warning_line.strip()\n if warning_line and not warning_line.startswith('#'):\n config.addinivalue_line('filterwarnings', warning_line)\n\n\[email protected](scope='session')\ndef matplotlib_config():\n \"\"\"Configure matplotlib for viz tests.\"\"\"\n import matplotlib\n # \"force\" should not really be necessary but should not hurt\n kwargs = dict()\n if 'warn' in _get_args(matplotlib.use):\n kwargs['warn'] = False\n matplotlib.use('agg', force=True, **kwargs) # don't pop up windows\n import matplotlib.pyplot as plt\n assert plt.get_backend() == 'agg'\n # overwrite some params that can horribly slow down tests that\n # users might have changed locally (but should not otherwise affect\n # functionality)\n plt.ioff()\n plt.rcParams['figure.dpi'] = 100\n try:\n from traits.etsconfig.api import ETSConfig\n except Exception:\n pass\n else:\n ETSConfig.toolkit = 'qt4'\n try:\n with warnings.catch_warnings(record=True): # traits\n from mayavi import mlab\n except Exception:\n pass\n else:\n mlab.options.backend = 'test'\n\n\[email protected](scope='function', params=[testing._pytest_param()])\ndef evoked():\n \"\"\"Get evoked data.\"\"\"\n evoked = mne.read_evokeds(fname_evoked, condition='Left Auditory',\n baseline=(None, 0))\n evoked.crop(0, 0.2)\n return evoked\n\n\[email protected](scope='function', params=[testing._pytest_param()])\ndef noise_cov():\n \"\"\"Get a noise cov from the testing dataset.\"\"\"\n return mne.read_cov(fname_cov)\n\n\[email protected](scope='function')\ndef bias_params_free(evoked, noise_cov):\n \"\"\"Provide inputs for free bias functions.\"\"\"\n fwd = mne.read_forward_solution(fname_fwd)\n return _bias_params(evoked, noise_cov, fwd)\n\n\[email protected](scope='function')\ndef bias_params_fixed(evoked, noise_cov):\n \"\"\"Provide inputs for fixed bias functions.\"\"\"\n fwd = mne.read_forward_solution(fname_fwd)\n fwd = mne.convert_forward_solution(fwd, force_fixed=True, surf_ori=True)\n return _bias_params(evoked, noise_cov, fwd)\n\n\ndef _bias_params(evoked, noise_cov, fwd):\n evoked.pick_types(meg=True, eeg=True, exclude=())\n # restrict to limited set of verts (small src here) and one hemi for speed\n vertices = [fwd['src'][0]['vertno'].copy(), []]\n stc = mne.SourceEstimate(np.zeros((sum(len(v) for v in vertices), 1)),\n vertices, 0., 1.)\n fwd = mne.forward.restrict_forward_to_stc(fwd, stc)\n assert fwd['sol']['row_names'] == noise_cov['names']\n assert noise_cov['names'] == evoked.ch_names\n evoked = mne.EvokedArray(fwd['sol']['data'].copy(), evoked.info)\n data_cov = noise_cov.copy()\n data_cov['data'] = np.dot(fwd['sol']['data'], fwd['sol']['data'].T)\n assert data_cov['data'].shape[0] == len(noise_cov['names'])\n want = np.arange(fwd['sol']['data'].shape[1])\n if not mne.forward.is_fixed_orient(fwd):\n want //= 3\n return evoked, fwd, noise_cov, data_cov, want\n\n\[email protected](scope=\"module\", params=[\n \"mayavi\",\n \"pyvista\",\n])\ndef backend_name(request):\n \"\"\"Get the backend name.\"\"\"\n yield request.param\n\n\[email protected]_fixture\ndef renderer(backend_name):\n \"\"\"Yield the 3D backends.\"\"\"\n from mne.viz.backends.renderer import _use_test_3d_backend\n from mne.viz.backends.tests._utils import has_mayavi, has_pyvista\n if backend_name == 'mayavi':\n if not has_mayavi():\n pytest.skip(\"Test skipped, requires mayavi.\")\n elif backend_name == 'pyvista':\n if not has_pyvista():\n pytest.skip(\"Test skipped, requires pyvista.\")\n with _use_test_3d_backend(backend_name):\n from mne.viz.backends import renderer\n yield renderer\n renderer._close_all()\n", "path": "mne/conftest.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Author: Eric Larson <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport os.path as op\nimport warnings\nimport pytest\n# For some unknown reason, on Travis-xenial there are segfaults caused on\n# the line pytest -> pdb.Pdb.__init__ -> \"import readline\". Forcing an\n# import here seems to prevent them (!?). This suggests a potential problem\n# with some other library stepping on memory where it shouldn't. It only\n# seems to happen on the Linux runs that install Mayavi. Anectodally,\n# @larsoner has had problems a couple of years ago where a mayavi import\n# seemed to corrupt SciPy linalg function results (!), likely due to the\n# associated VTK import, so this could be another manifestation of that.\ntry:\n import readline # noqa\nexcept Exception:\n pass\n\nimport numpy as np\nimport mne\nfrom mne.datasets import testing\n\ntest_path = testing.data_path(download=False)\ns_path = op.join(test_path, 'MEG', 'sample')\nfname_evoked = op.join(s_path, 'sample_audvis_trunc-ave.fif')\nfname_cov = op.join(s_path, 'sample_audvis_trunc-cov.fif')\nfname_fwd = op.join(s_path, 'sample_audvis_trunc-meg-eeg-oct-4-fwd.fif')\n\n\ndef pytest_configure(config):\n \"\"\"Configure pytest options.\"\"\"\n # Markers\n for marker in ('slowtest', 'ultraslowtest'):\n config.addinivalue_line('markers', marker)\n\n # Fixtures\n for fixture in ('matplotlib_config',):\n config.addinivalue_line('usefixtures', fixture)\n\n # Warnings\n # - Once SciPy updates not to have non-integer and non-tuple errors (1.2.0)\n # we should remove them from here.\n # - This list should also be considered alongside reset_warnings in\n # doc/conf.py.\n warning_lines = \"\"\"\n error::\n ignore::ImportWarning\n ignore:the matrix subclass:PendingDeprecationWarning\n ignore:numpy.dtype size changed:RuntimeWarning\n ignore:.*HasTraits.trait_.*:DeprecationWarning\n ignore:.*takes no parameters:DeprecationWarning\n ignore:joblib not installed:RuntimeWarning\n ignore:Using a non-tuple sequence for multidimensional indexing:FutureWarning\n ignore:using a non-integer number instead of an integer will result in an error:DeprecationWarning\n ignore:Importing from numpy.testing.decorators is deprecated:DeprecationWarning\n ignore:np.loads is deprecated, use pickle.loads instead:DeprecationWarning\n ignore:The oldnumeric module will be dropped:DeprecationWarning\n ignore:Collection picker None could not be converted to float:UserWarning\n ignore:covariance is not positive-semidefinite:RuntimeWarning\n ignore:Can only plot ICA components:RuntimeWarning\n ignore:Matplotlib is building the font cache using fc-list:UserWarning\n ignore:Using or importing the ABCs from 'collections':DeprecationWarning\n ignore:`formatargspec` is deprecated:DeprecationWarning\n # This is only necessary until sklearn updates their wheels for NumPy 1.16\n ignore:numpy.ufunc size changed:RuntimeWarning\n ignore:.*mne-realtime.*:DeprecationWarning\n \"\"\" # noqa: E501\n for warning_line in warning_lines.split('\\n'):\n warning_line = warning_line.strip()\n if warning_line and not warning_line.startswith('#'):\n config.addinivalue_line('filterwarnings', warning_line)\n\n\[email protected](scope='session')\ndef matplotlib_config():\n \"\"\"Configure matplotlib for viz tests.\"\"\"\n import matplotlib\n # \"force\" should not really be necessary but should not hurt\n kwargs = dict()\n with warnings.catch_warnings(record=True): # ignore warning\n matplotlib.use('agg', force=True, **kwargs) # don't pop up windows\n import matplotlib.pyplot as plt\n assert plt.get_backend() == 'agg'\n # overwrite some params that can horribly slow down tests that\n # users might have changed locally (but should not otherwise affect\n # functionality)\n plt.ioff()\n plt.rcParams['figure.dpi'] = 100\n try:\n from traits.etsconfig.api import ETSConfig\n except Exception:\n pass\n else:\n ETSConfig.toolkit = 'qt4'\n try:\n with warnings.catch_warnings(record=True): # traits\n from mayavi import mlab\n except Exception:\n pass\n else:\n mlab.options.backend = 'test'\n\n\[email protected](scope='function', params=[testing._pytest_param()])\ndef evoked():\n \"\"\"Get evoked data.\"\"\"\n evoked = mne.read_evokeds(fname_evoked, condition='Left Auditory',\n baseline=(None, 0))\n evoked.crop(0, 0.2)\n return evoked\n\n\[email protected](scope='function', params=[testing._pytest_param()])\ndef noise_cov():\n \"\"\"Get a noise cov from the testing dataset.\"\"\"\n return mne.read_cov(fname_cov)\n\n\[email protected](scope='function')\ndef bias_params_free(evoked, noise_cov):\n \"\"\"Provide inputs for free bias functions.\"\"\"\n fwd = mne.read_forward_solution(fname_fwd)\n return _bias_params(evoked, noise_cov, fwd)\n\n\[email protected](scope='function')\ndef bias_params_fixed(evoked, noise_cov):\n \"\"\"Provide inputs for fixed bias functions.\"\"\"\n fwd = mne.read_forward_solution(fname_fwd)\n fwd = mne.convert_forward_solution(fwd, force_fixed=True, surf_ori=True)\n return _bias_params(evoked, noise_cov, fwd)\n\n\ndef _bias_params(evoked, noise_cov, fwd):\n evoked.pick_types(meg=True, eeg=True, exclude=())\n # restrict to limited set of verts (small src here) and one hemi for speed\n vertices = [fwd['src'][0]['vertno'].copy(), []]\n stc = mne.SourceEstimate(np.zeros((sum(len(v) for v in vertices), 1)),\n vertices, 0., 1.)\n fwd = mne.forward.restrict_forward_to_stc(fwd, stc)\n assert fwd['sol']['row_names'] == noise_cov['names']\n assert noise_cov['names'] == evoked.ch_names\n evoked = mne.EvokedArray(fwd['sol']['data'].copy(), evoked.info)\n data_cov = noise_cov.copy()\n data_cov['data'] = np.dot(fwd['sol']['data'], fwd['sol']['data'].T)\n assert data_cov['data'].shape[0] == len(noise_cov['names'])\n want = np.arange(fwd['sol']['data'].shape[1])\n if not mne.forward.is_fixed_orient(fwd):\n want //= 3\n return evoked, fwd, noise_cov, data_cov, want\n\n\[email protected](scope=\"module\", params=[\n \"mayavi\",\n \"pyvista\",\n])\ndef backend_name(request):\n \"\"\"Get the backend name.\"\"\"\n yield request.param\n\n\[email protected]_fixture\ndef renderer(backend_name):\n \"\"\"Yield the 3D backends.\"\"\"\n from mne.viz.backends.renderer import _use_test_3d_backend\n from mne.viz.backends.tests._utils import has_mayavi, has_pyvista\n if backend_name == 'mayavi':\n if not has_mayavi():\n pytest.skip(\"Test skipped, requires mayavi.\")\n elif backend_name == 'pyvista':\n if not has_pyvista():\n pytest.skip(\"Test skipped, requires pyvista.\")\n with _use_test_3d_backend(backend_name):\n from mne.viz.backends import renderer\n yield renderer\n renderer._close_all()\n", "path": "mne/conftest.py"}]}
| 2,486 | 243 |
gh_patches_debug_3292
|
rasdani/github-patches
|
git_diff
|
getmoto__moto-2305
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API Gateway generates invalid IDs
Generated IDs in API Gateway resources look like `A-Z601A-Z47201`. They contain `A-Z` instead of letters.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `moto/apigateway/utils.py`
Content:
```
1 from __future__ import unicode_literals
2 import six
3 import random
4
5
6 def create_id():
7 size = 10
8 chars = list(range(10)) + ['A-Z']
9 return ''.join(six.text_type(random.choice(chars)) for x in range(size))
10
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/moto/apigateway/utils.py b/moto/apigateway/utils.py
--- a/moto/apigateway/utils.py
+++ b/moto/apigateway/utils.py
@@ -1,9 +1,10 @@
from __future__ import unicode_literals
import six
import random
+import string
def create_id():
size = 10
- chars = list(range(10)) + ['A-Z']
+ chars = list(range(10)) + list(string.ascii_lowercase)
return ''.join(six.text_type(random.choice(chars)) for x in range(size))
|
{"golden_diff": "diff --git a/moto/apigateway/utils.py b/moto/apigateway/utils.py\n--- a/moto/apigateway/utils.py\n+++ b/moto/apigateway/utils.py\n@@ -1,9 +1,10 @@\n from __future__ import unicode_literals\n import six\n import random\n+import string\n \n \n def create_id():\n size = 10\n- chars = list(range(10)) + ['A-Z']\n+ chars = list(range(10)) + list(string.ascii_lowercase)\n return ''.join(six.text_type(random.choice(chars)) for x in range(size))\n", "issue": "API Gateway generates invalid IDs\nGenerated IDs in API Gateway resources look like `A-Z601A-Z47201`. They contain `A-Z` instead of letters.\n", "before_files": [{"content": "from __future__ import unicode_literals\nimport six\nimport random\n\n\ndef create_id():\n size = 10\n chars = list(range(10)) + ['A-Z']\n return ''.join(six.text_type(random.choice(chars)) for x in range(size))\n", "path": "moto/apigateway/utils.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nimport six\nimport random\nimport string\n\n\ndef create_id():\n size = 10\n chars = list(range(10)) + list(string.ascii_lowercase)\n return ''.join(six.text_type(random.choice(chars)) for x in range(size))\n", "path": "moto/apigateway/utils.py"}]}
| 369 | 130 |
gh_patches_debug_28024
|
rasdani/github-patches
|
git_diff
|
google__flax-1311
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
threading.Condition.notifyAll has been deprecated in favour of notify_all in Python 3.10
### Problem you have encountered:
`threading.Condition.notifyAll` has been deprecated in favour of `notify_all` in Python 3.10. Ref : python/cpython#25174
### What you expected to happen:
use `notify_all` in below places.
```
rg -t py -w 'currentThread|notifyAll|activeCount|isDaemon|setDaemon'
flax/training/prefetch_iterator.py
58: self._cond.notifyAll()
68: self._cond.notifyAll()
80: self._cond.notifyAll()
88: self._cond.notifyAll()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flax/training/prefetch_iterator.py`
Content:
```
1 # Copyright 2021 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utility for constructing an iterator which prefetches data asynchronously.
16 """
17
18 import threading
19 import warnings
20
21
22 class PrefetchIterator:
23 """Wraps an iterator to provide async prefetching.
24
25 DEPRECATION WARNING:
26 TensorFlow datasets no longer require manual prefetching.
27
28 Previously this class was used to make data loading using TensorFlow datasets
29 more efficient. Now TF data handles prefetching with NumPy iterators
30 correctly.
31
32 Example::
33
34 tf_iter = dataset.as_numpy_iterator() # only loads data while calling next
35 tf_iter = PrefetchIterator(tf_iter) # prefetches data in the background
36
37 """
38
39 def __init__(self, data_iter, buffer_size=1):
40 """Construct a PrefetchIterator.
41
42 Args:
43 data_iter: the Iterator that should be prefetched.
44 buffer_size: how many items to prefetch (default: 1).
45 """
46 warnings.warn('PrefetchIterator is deprecated. Use the standard `tf.data`'
47 ' prefetch method instead', DeprecationWarning)
48
49 self._data_iter = data_iter
50 self.buffer_size = buffer_size
51 self._cond = threading.Condition()
52 self._buffer = []
53 self._active = True
54 self._thread = threading.Thread(target=self._prefetch_loop, daemon=True)
55 self._thread.start()
56 self._error = None
57
58 def __iter__(self):
59 return self
60
61 def __next__(self):
62 with self._cond:
63 self._cond.wait_for(lambda: self._buffer or not self._active)
64 if self._buffer:
65 item = self._buffer.pop(0)
66 self._cond.notifyAll()
67 return item
68 if self._error:
69 raise self._error # pylint: disable=raising-bad-type
70 assert not self._active
71 raise StopIteration()
72
73 def close(self):
74 with self._cond:
75 self._active = False
76 self._cond.notifyAll()
77
78 def _prefetch_loop(self):
79 """Prefetch loop that prefetches a tf dataset."""
80 def _predicate():
81 return len(self._buffer) < self.buffer_size or not self._active
82
83 while True:
84 try:
85 item = next(self._data_iter)
86 with self._cond:
87 self._buffer.append(item)
88 self._cond.notifyAll()
89 self._cond.wait_for(_predicate)
90 if not self._active:
91 return
92 except Exception as e: # pylint: disable=broad-except
93 with self._cond:
94 self._error = e
95 self._active = False
96 self._cond.notifyAll()
97 return
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/flax/training/prefetch_iterator.py b/flax/training/prefetch_iterator.py
--- a/flax/training/prefetch_iterator.py
+++ b/flax/training/prefetch_iterator.py
@@ -55,7 +55,7 @@
self._cond.wait_for(lambda: self._buffer or not self._active)
if self._buffer:
item = self._buffer.pop(0)
- self._cond.notifyAll()
+ self._cond.notify_all()
return item
if self._error:
raise self._error # pylint: disable=raising-bad-type
@@ -65,7 +65,7 @@
def close(self):
with self._cond:
self._active = False
- self._cond.notifyAll()
+ self._cond.notify_all()
def _prefetch_loop(self):
"""Prefetch loop that prefetches a tf dataset."""
@@ -77,7 +77,7 @@
item = next(self._data_iter)
with self._cond:
self._buffer.append(item)
- self._cond.notifyAll()
+ self._cond.notify_all()
self._cond.wait_for(_predicate)
if not self._active:
return
@@ -85,5 +85,5 @@
with self._cond:
self._error = e
self._active = False
- self._cond.notifyAll()
+ self._cond.notify_all()
return
|
{"golden_diff": "diff --git a/flax/training/prefetch_iterator.py b/flax/training/prefetch_iterator.py\n--- a/flax/training/prefetch_iterator.py\n+++ b/flax/training/prefetch_iterator.py\n@@ -55,7 +55,7 @@\n self._cond.wait_for(lambda: self._buffer or not self._active)\n if self._buffer:\n item = self._buffer.pop(0)\n- self._cond.notifyAll()\n+ self._cond.notify_all()\n return item\n if self._error:\n raise self._error # pylint: disable=raising-bad-type\n@@ -65,7 +65,7 @@\n def close(self):\n with self._cond:\n self._active = False\n- self._cond.notifyAll()\n+ self._cond.notify_all()\n \n def _prefetch_loop(self):\n \"\"\"Prefetch loop that prefetches a tf dataset.\"\"\"\n@@ -77,7 +77,7 @@\n item = next(self._data_iter)\n with self._cond:\n self._buffer.append(item)\n- self._cond.notifyAll()\n+ self._cond.notify_all()\n self._cond.wait_for(_predicate)\n if not self._active:\n return\n@@ -85,5 +85,5 @@\n with self._cond:\n self._error = e\n self._active = False\n- self._cond.notifyAll()\n+ self._cond.notify_all()\n return\n", "issue": " threading.Condition.notifyAll has been deprecated in favour of notify_all in Python 3.10\n### Problem you have encountered:\r\n\r\n `threading.Condition.notifyAll` has been deprecated in favour of `notify_all` in Python 3.10. Ref : python/cpython#25174\r\n\r\n### What you expected to happen:\r\n\r\nuse `notify_all` in below places.\r\n\r\n```\r\nrg -t py -w 'currentThread|notifyAll|activeCount|isDaemon|setDaemon' \r\nflax/training/prefetch_iterator.py\r\n58: self._cond.notifyAll()\r\n68: self._cond.notifyAll()\r\n80: self._cond.notifyAll()\r\n88: self._cond.notifyAll()\r\n```\n", "before_files": [{"content": "# Copyright 2021 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utility for constructing an iterator which prefetches data asynchronously.\n\"\"\"\n\nimport threading\nimport warnings\n\n\nclass PrefetchIterator:\n \"\"\"Wraps an iterator to provide async prefetching.\n\n DEPRECATION WARNING:\n TensorFlow datasets no longer require manual prefetching.\n\n Previously this class was used to make data loading using TensorFlow datasets\n more efficient. Now TF data handles prefetching with NumPy iterators\n correctly.\n\n Example::\n\n tf_iter = dataset.as_numpy_iterator() # only loads data while calling next\n tf_iter = PrefetchIterator(tf_iter) # prefetches data in the background\n\n \"\"\"\n\n def __init__(self, data_iter, buffer_size=1):\n \"\"\"Construct a PrefetchIterator.\n\n Args:\n data_iter: the Iterator that should be prefetched.\n buffer_size: how many items to prefetch (default: 1).\n \"\"\"\n warnings.warn('PrefetchIterator is deprecated. Use the standard `tf.data`'\n ' prefetch method instead', DeprecationWarning)\n\n self._data_iter = data_iter\n self.buffer_size = buffer_size\n self._cond = threading.Condition()\n self._buffer = []\n self._active = True\n self._thread = threading.Thread(target=self._prefetch_loop, daemon=True)\n self._thread.start()\n self._error = None\n\n def __iter__(self):\n return self\n\n def __next__(self):\n with self._cond:\n self._cond.wait_for(lambda: self._buffer or not self._active)\n if self._buffer:\n item = self._buffer.pop(0)\n self._cond.notifyAll()\n return item\n if self._error:\n raise self._error # pylint: disable=raising-bad-type\n assert not self._active\n raise StopIteration()\n\n def close(self):\n with self._cond:\n self._active = False\n self._cond.notifyAll()\n\n def _prefetch_loop(self):\n \"\"\"Prefetch loop that prefetches a tf dataset.\"\"\"\n def _predicate():\n return len(self._buffer) < self.buffer_size or not self._active\n\n while True:\n try:\n item = next(self._data_iter)\n with self._cond:\n self._buffer.append(item)\n self._cond.notifyAll()\n self._cond.wait_for(_predicate)\n if not self._active:\n return\n except Exception as e: # pylint: disable=broad-except\n with self._cond:\n self._error = e\n self._active = False\n self._cond.notifyAll()\n return\n", "path": "flax/training/prefetch_iterator.py"}], "after_files": [{"content": "# Copyright 2020 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Lint as: python3\n\"\"\"Utility for constructing an iterator which prefetches data asynchronously.\n\"\"\"\n\nimport threading\n\n\nclass PrefetchIterator:\n \"\"\"Wraps an iterator to provide async prefetching.\n\n This class is particularly useful for making data loading using TensorFlow\n more efficient. Currently, the numpy iterator in TensorFlow will not\n automatically prefetch data in the background::\n\n tf_iter = dataset.as_numpy_iterator() # only loads data while calling next\n tf_iter = PrefetchIterator(tf_iter) # prefetches data in the background\n\n \"\"\"\n\n def __init__(self, data_iter, buffer_size=1):\n \"\"\"Construct a PrefetchIterator.\n\n Args:\n data_iter: the Iterator that should be prefetched.\n buffer_size: how many items to prefetch (default: 1).\n \"\"\"\n self._data_iter = data_iter\n self.buffer_size = buffer_size\n self._cond = threading.Condition()\n self._buffer = []\n self._active = True\n self._thread = threading.Thread(target=self._prefetch_loop, daemon=True)\n self._thread.start()\n self._error = None\n\n def __iter__(self):\n return self\n\n def __next__(self):\n with self._cond:\n self._cond.wait_for(lambda: self._buffer or not self._active)\n if self._buffer:\n item = self._buffer.pop(0)\n self._cond.notify_all()\n return item\n if self._error:\n raise self._error # pylint: disable=raising-bad-type\n assert not self._active\n raise StopIteration()\n\n def close(self):\n with self._cond:\n self._active = False\n self._cond.notify_all()\n\n def _prefetch_loop(self):\n \"\"\"Prefetch loop that prefetches a tf dataset.\"\"\"\n def _predicate():\n return len(self._buffer) < self.buffer_size or not self._active\n\n while True:\n try:\n item = next(self._data_iter)\n with self._cond:\n self._buffer.append(item)\n self._cond.notify_all()\n self._cond.wait_for(_predicate)\n if not self._active:\n return\n except Exception as e: # pylint: disable=broad-except\n with self._cond:\n self._error = e\n self._active = False\n self._cond.notify_all()\n return\n", "path": "flax/training/prefetch_iterator.py"}]}
| 1,303 | 322 |
gh_patches_debug_823
|
rasdani/github-patches
|
git_diff
|
angr__angr-1303
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cachetools broke their API
There's a new major version of cachetools (providing LRUCache), 3.0.0. This has caused everything to break. I have pinned our version to `cachetools<3` for the time being, but we should migrate.
My guess is that this is because we were using the `missing` argument to LRUCache (in claripy, specifically), and I am fairly sure the intended replacement is to [implement the `__missing__` method](https://cachetools.readthedocs.io/en/latest/#extending-cache-classes). Unsure if there are more implications, which is why this issue is open under angr instead of claripy.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # pylint: disable=no-name-in-module,import-error,unused-variable
2 import os
3 import sys
4 import subprocess
5 import pkg_resources
6 import shutil
7 import platform
8
9 if bytes is str:
10 raise Exception("""
11
12 =-=-=-=-=-=-=-=-=-=-=-=-= WELCOME TO THE FUTURE! =-=-=-=-=-=-=-=-=-=-=-=-=-=
13
14 angr has transitioned to python 3. Due to the small size of the team behind it,
15 we can't reasonably maintain compatibility between both python 2 and python 3.
16 If you want to continue using the most recent version of angr (you definitely
17 want that, trust us) you should upgrade to python 3. It's like getting your
18 vaccinations. It hurts a little bit initially but in the end it's worth it.
19
20 If you are staying on python 2 and would like to make sure you don't get
21 incompatible versions, make sure your pip is at least version 9.0, and it will
22 use our metadata to implicitly avoid them.
23
24 For more information, see here: https://docs.angr.io/MIGRATION.html
25
26 Good luck!
27 """)
28
29 try:
30 from setuptools import setup
31 from setuptools import find_packages
32 packages = find_packages()
33 except ImportError:
34 from distutils.core import setup
35 packages = [x.strip('./').replace('/','.') for x in os.popen('find -name "__init__.py" | xargs -n1 dirname').read().strip().split('\n')]
36
37 from distutils.util import get_platform
38 from distutils.errors import LibError
39 from distutils.command.build import build as _build
40
41 if sys.platform == 'darwin':
42 library_file = "angr_native.dylib"
43 elif sys.platform in ('win32', 'cygwin'):
44 library_file = "angr_native.dll"
45 else:
46 library_file = "angr_native.so"
47
48 def _build_native():
49 try:
50 import unicorn
51 import pyvex
52 except ImportError:
53 raise LibError("You must install unicorn and pyvex before building angr")
54
55 env = os.environ.copy()
56 env_data = (('UNICORN_INCLUDE_PATH', 'unicorn', 'include'),
57 ('UNICORN_LIB_PATH', 'unicorn', 'lib'),
58 ('UNICORN_LIB_FILE', 'unicorn', 'lib\\unicorn.lib'),
59 ('PYVEX_INCLUDE_PATH', 'pyvex', 'include'),
60 ('PYVEX_LIB_PATH', 'pyvex', 'lib'),
61 ('PYVEX_LIB_FILE', 'pyvex', 'lib\\pyvex.lib'))
62 for var, pkg, fnm in env_data:
63 try:
64 env[var] = pkg_resources.resource_filename(pkg, fnm)
65 except KeyError:
66 pass
67
68 cmd1 = ['nmake', '/f', 'Makefile-win']
69 cmd2 = ['make']
70 for cmd in (cmd1, cmd2):
71 try:
72 if subprocess.call(cmd, cwd='native', env=env) != 0:
73 raise LibError('Unable to build angr_native')
74 break
75 except OSError:
76 continue
77 else:
78 raise LibError('Unable to build angr_native')
79
80 shutil.rmtree('angr/lib', ignore_errors=True)
81 os.mkdir('angr/lib')
82 shutil.copy(os.path.join('native', library_file), 'angr/lib')
83
84 class build(_build):
85 def run(self, *args):
86 self.execute(_build_native, (), msg='Building angr_native')
87 _build.run(self, *args)
88
89 cmdclass = {
90 'build': build,
91 }
92
93 try:
94 from setuptools.command.develop import develop as _develop
95 class develop(_develop):
96 def run(self, *args):
97 self.execute(_build_native, (), msg='Building angr_native')
98 _develop.run(self, *args)
99
100 cmdclass['develop'] = develop
101 except ImportError:
102 pass
103
104 if 'bdist_wheel' in sys.argv and '--plat-name' not in sys.argv:
105 sys.argv.append('--plat-name')
106 name = get_platform()
107 if 'linux' in name:
108 # linux_* platform tags are disallowed because the python ecosystem is fubar
109 # linux builds should be built in the centos 5 vm for maximum compatibility
110 sys.argv.append('manylinux1_' + platform.machine())
111 else:
112 # https://www.python.org/dev/peps/pep-0425/
113 sys.argv.append(name.replace('.', '_').replace('-', '_'))
114
115 setup(
116 name='angr',
117 version='8.18.10.25',
118 python_requires='>=3.5',
119 description='A multi-architecture binary analysis toolkit, with the ability to perform dynamic symbolic execution and various static analyses on binaries',
120 url='https://github.com/angr/angr',
121 packages=packages,
122 install_requires=[
123 'ana',
124 'sortedcontainers',
125 'cachetools<3',
126 'capstone>=3.0.5rc2',
127 'cooldict',
128 'dpkt',
129 'futures; python_version == "2.7"',
130 'mulpyplexer',
131 'networkx>=2.0',
132 'progressbar',
133 'rpyc',
134 'cffi>=1.7.0',
135 'unicorn',
136 'archinfo==8.18.10.25',
137 'claripy==8.18.10.25',
138 'cle==8.18.10.25',
139 'pyvex==8.18.10.25',
140 'ailment==8.18.10.25',
141 'GitPython',
142 'pycparser>=2.18',
143 'itanium_demangler',
144 ],
145 setup_requires=['unicorn', 'pyvex'],
146 cmdclass=cmdclass,
147 include_package_data=True,
148 package_data={
149 'angr': ['lib/*']
150 }
151 )
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -122,7 +122,7 @@
install_requires=[
'ana',
'sortedcontainers',
- 'cachetools<3',
+ 'cachetools',
'capstone>=3.0.5rc2',
'cooldict',
'dpkt',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -122,7 +122,7 @@\n install_requires=[\n 'ana',\n 'sortedcontainers',\n- 'cachetools<3',\n+ 'cachetools',\n 'capstone>=3.0.5rc2',\n 'cooldict',\n 'dpkt',\n", "issue": "Cachetools broke their API\nThere's a new major version of cachetools (providing LRUCache), 3.0.0. This has caused everything to break. I have pinned our version to `cachetools<3` for the time being, but we should migrate.\r\n\r\nMy guess is that this is because we were using the `missing` argument to LRUCache (in claripy, specifically), and I am fairly sure the intended replacement is to [implement the `__missing__` method](https://cachetools.readthedocs.io/en/latest/#extending-cache-classes). Unsure if there are more implications, which is why this issue is open under angr instead of claripy.\n", "before_files": [{"content": "# pylint: disable=no-name-in-module,import-error,unused-variable\nimport os\nimport sys\nimport subprocess\nimport pkg_resources\nimport shutil\nimport platform\n\nif bytes is str:\n raise Exception(\"\"\"\n\n=-=-=-=-=-=-=-=-=-=-=-=-= WELCOME TO THE FUTURE! =-=-=-=-=-=-=-=-=-=-=-=-=-=\n\nangr has transitioned to python 3. Due to the small size of the team behind it,\nwe can't reasonably maintain compatibility between both python 2 and python 3.\nIf you want to continue using the most recent version of angr (you definitely\nwant that, trust us) you should upgrade to python 3. It's like getting your\nvaccinations. It hurts a little bit initially but in the end it's worth it.\n\nIf you are staying on python 2 and would like to make sure you don't get\nincompatible versions, make sure your pip is at least version 9.0, and it will\nuse our metadata to implicitly avoid them.\n\nFor more information, see here: https://docs.angr.io/MIGRATION.html\n\nGood luck!\n\"\"\")\n\ntry:\n from setuptools import setup\n from setuptools import find_packages\n packages = find_packages()\nexcept ImportError:\n from distutils.core import setup\n packages = [x.strip('./').replace('/','.') for x in os.popen('find -name \"__init__.py\" | xargs -n1 dirname').read().strip().split('\\n')]\n\nfrom distutils.util import get_platform\nfrom distutils.errors import LibError\nfrom distutils.command.build import build as _build\n\nif sys.platform == 'darwin':\n library_file = \"angr_native.dylib\"\nelif sys.platform in ('win32', 'cygwin'):\n library_file = \"angr_native.dll\"\nelse:\n library_file = \"angr_native.so\"\n\ndef _build_native():\n try:\n import unicorn\n import pyvex\n except ImportError:\n raise LibError(\"You must install unicorn and pyvex before building angr\")\n\n env = os.environ.copy()\n env_data = (('UNICORN_INCLUDE_PATH', 'unicorn', 'include'),\n ('UNICORN_LIB_PATH', 'unicorn', 'lib'),\n ('UNICORN_LIB_FILE', 'unicorn', 'lib\\\\unicorn.lib'),\n ('PYVEX_INCLUDE_PATH', 'pyvex', 'include'),\n ('PYVEX_LIB_PATH', 'pyvex', 'lib'),\n ('PYVEX_LIB_FILE', 'pyvex', 'lib\\\\pyvex.lib'))\n for var, pkg, fnm in env_data:\n try:\n env[var] = pkg_resources.resource_filename(pkg, fnm)\n except KeyError:\n pass\n\n cmd1 = ['nmake', '/f', 'Makefile-win']\n cmd2 = ['make']\n for cmd in (cmd1, cmd2):\n try:\n if subprocess.call(cmd, cwd='native', env=env) != 0:\n raise LibError('Unable to build angr_native')\n break\n except OSError:\n continue\n else:\n raise LibError('Unable to build angr_native')\n\n shutil.rmtree('angr/lib', ignore_errors=True)\n os.mkdir('angr/lib')\n shutil.copy(os.path.join('native', library_file), 'angr/lib')\n\nclass build(_build):\n def run(self, *args):\n self.execute(_build_native, (), msg='Building angr_native')\n _build.run(self, *args)\n\ncmdclass = {\n 'build': build,\n}\n\ntry:\n from setuptools.command.develop import develop as _develop\n class develop(_develop):\n def run(self, *args):\n self.execute(_build_native, (), msg='Building angr_native')\n _develop.run(self, *args)\n\n cmdclass['develop'] = develop\nexcept ImportError:\n pass\n\nif 'bdist_wheel' in sys.argv and '--plat-name' not in sys.argv:\n sys.argv.append('--plat-name')\n name = get_platform()\n if 'linux' in name:\n # linux_* platform tags are disallowed because the python ecosystem is fubar\n # linux builds should be built in the centos 5 vm for maximum compatibility\n sys.argv.append('manylinux1_' + platform.machine())\n else:\n # https://www.python.org/dev/peps/pep-0425/\n sys.argv.append(name.replace('.', '_').replace('-', '_'))\n\nsetup(\n name='angr',\n version='8.18.10.25',\n python_requires='>=3.5',\n description='A multi-architecture binary analysis toolkit, with the ability to perform dynamic symbolic execution and various static analyses on binaries',\n url='https://github.com/angr/angr',\n packages=packages,\n install_requires=[\n 'ana',\n 'sortedcontainers',\n 'cachetools<3',\n 'capstone>=3.0.5rc2',\n 'cooldict',\n 'dpkt',\n 'futures; python_version == \"2.7\"',\n 'mulpyplexer',\n 'networkx>=2.0',\n 'progressbar',\n 'rpyc',\n 'cffi>=1.7.0',\n 'unicorn',\n 'archinfo==8.18.10.25',\n 'claripy==8.18.10.25',\n 'cle==8.18.10.25',\n 'pyvex==8.18.10.25',\n 'ailment==8.18.10.25',\n 'GitPython',\n 'pycparser>=2.18',\n 'itanium_demangler',\n ],\n setup_requires=['unicorn', 'pyvex'],\n cmdclass=cmdclass,\n include_package_data=True,\n package_data={\n 'angr': ['lib/*']\n }\n)\n", "path": "setup.py"}], "after_files": [{"content": "# pylint: disable=no-name-in-module,import-error,unused-variable\nimport os\nimport sys\nimport subprocess\nimport pkg_resources\nimport shutil\nimport platform\n\nif bytes is str:\n raise Exception(\"\"\"\n\n=-=-=-=-=-=-=-=-=-=-=-=-= WELCOME TO THE FUTURE! =-=-=-=-=-=-=-=-=-=-=-=-=-=\n\nangr has transitioned to python 3. Due to the small size of the team behind it,\nwe can't reasonably maintain compatibility between both python 2 and python 3.\nIf you want to continue using the most recent version of angr (you definitely\nwant that, trust us) you should upgrade to python 3. It's like getting your\nvaccinations. It hurts a little bit initially but in the end it's worth it.\n\nIf you are staying on python 2 and would like to make sure you don't get\nincompatible versions, make sure your pip is at least version 9.0, and it will\nuse our metadata to implicitly avoid them.\n\nFor more information, see here: https://docs.angr.io/MIGRATION.html\n\nGood luck!\n\"\"\")\n\ntry:\n from setuptools import setup\n from setuptools import find_packages\n packages = find_packages()\nexcept ImportError:\n from distutils.core import setup\n packages = [x.strip('./').replace('/','.') for x in os.popen('find -name \"__init__.py\" | xargs -n1 dirname').read().strip().split('\\n')]\n\nfrom distutils.util import get_platform\nfrom distutils.errors import LibError\nfrom distutils.command.build import build as _build\n\nif sys.platform == 'darwin':\n library_file = \"angr_native.dylib\"\nelif sys.platform in ('win32', 'cygwin'):\n library_file = \"angr_native.dll\"\nelse:\n library_file = \"angr_native.so\"\n\ndef _build_native():\n try:\n import unicorn\n import pyvex\n except ImportError:\n raise LibError(\"You must install unicorn and pyvex before building angr\")\n\n env = os.environ.copy()\n env_data = (('UNICORN_INCLUDE_PATH', 'unicorn', 'include'),\n ('UNICORN_LIB_PATH', 'unicorn', 'lib'),\n ('UNICORN_LIB_FILE', 'unicorn', 'lib\\\\unicorn.lib'),\n ('PYVEX_INCLUDE_PATH', 'pyvex', 'include'),\n ('PYVEX_LIB_PATH', 'pyvex', 'lib'),\n ('PYVEX_LIB_FILE', 'pyvex', 'lib\\\\pyvex.lib'))\n for var, pkg, fnm in env_data:\n try:\n env[var] = pkg_resources.resource_filename(pkg, fnm)\n except KeyError:\n pass\n\n cmd1 = ['nmake', '/f', 'Makefile-win']\n cmd2 = ['make']\n for cmd in (cmd1, cmd2):\n try:\n if subprocess.call(cmd, cwd='native', env=env) != 0:\n raise LibError('Unable to build angr_native')\n break\n except OSError:\n continue\n else:\n raise LibError('Unable to build angr_native')\n\n shutil.rmtree('angr/lib', ignore_errors=True)\n os.mkdir('angr/lib')\n shutil.copy(os.path.join('native', library_file), 'angr/lib')\n\nclass build(_build):\n def run(self, *args):\n self.execute(_build_native, (), msg='Building angr_native')\n _build.run(self, *args)\n\ncmdclass = {\n 'build': build,\n}\n\ntry:\n from setuptools.command.develop import develop as _develop\n class develop(_develop):\n def run(self, *args):\n self.execute(_build_native, (), msg='Building angr_native')\n _develop.run(self, *args)\n\n cmdclass['develop'] = develop\nexcept ImportError:\n pass\n\nif 'bdist_wheel' in sys.argv and '--plat-name' not in sys.argv:\n sys.argv.append('--plat-name')\n name = get_platform()\n if 'linux' in name:\n # linux_* platform tags are disallowed because the python ecosystem is fubar\n # linux builds should be built in the centos 5 vm for maximum compatibility\n sys.argv.append('manylinux1_' + platform.machine())\n else:\n # https://www.python.org/dev/peps/pep-0425/\n sys.argv.append(name.replace('.', '_').replace('-', '_'))\n\nsetup(\n name='angr',\n version='8.18.10.25',\n python_requires='>=3.5',\n description='A multi-architecture binary analysis toolkit, with the ability to perform dynamic symbolic execution and various static analyses on binaries',\n url='https://github.com/angr/angr',\n packages=packages,\n install_requires=[\n 'ana',\n 'sortedcontainers',\n 'cachetools',\n 'capstone>=3.0.5rc2',\n 'cooldict',\n 'dpkt',\n 'futures; python_version == \"2.7\"',\n 'mulpyplexer',\n 'networkx>=2.0',\n 'progressbar',\n 'rpyc',\n 'cffi>=1.7.0',\n 'unicorn',\n 'archinfo==8.18.10.25',\n 'claripy==8.18.10.25',\n 'cle==8.18.10.25',\n 'pyvex==8.18.10.25',\n 'ailment==8.18.10.25',\n 'GitPython',\n 'pycparser>=2.18',\n 'itanium_demangler',\n ],\n setup_requires=['unicorn', 'pyvex'],\n cmdclass=cmdclass,\n include_package_data=True,\n package_data={\n 'angr': ['lib/*']\n }\n)\n", "path": "setup.py"}]}
| 2,028 | 89 |
gh_patches_debug_28944
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-3050
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Segfault when iterating on a transform-mapped Vector in a thread
<!-- In the following, please describe your issue in detail! -->
<!-- If some sections do not apply, just remove them. -->
### Short description
Take a Vector, map it with a transform, put it in a _threading_ Thread, iterate, and BOOM.
### Code to reproduce
<!-- Please provide a minimal working example that reproduces the issue in the code block below.
Ideally, this should be a full example someone else could run without additional setup. -->
```python
import pyqtgraph as pg
import threading
def do_it():
xform = pg.SRTTransform3D()
v = xform.map(pg.Vector((0, 0, 0)))
tuple(v)
pg.mkQApp()
threading.Thread(target=do_it).start()
```
### Expected behavior
<!-- What should happen? -->
### Real behavior
<!-- What happens? -->
`SIGSEGV`
### Tested environment(s)
* PyQtGraph version: 0.13.8dev0
* Qt Python binding: PyQt5 5.15.10 Qt 5.15.2
* Python version: 3.11
* NumPy version: 1.26.3
* Operating system: linux
* Installation method: git
### Additional context
Workaround: use a `QThread`, and this isn't an issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/SRTTransform3D.py`
Content:
```
1 from math import atan2, degrees
2
3 import numpy as np
4
5 from . import SRTTransform
6 from .Qt import QtGui
7 from .Transform3D import Transform3D
8 from .Vector import Vector
9
10
11 class SRTTransform3D(Transform3D):
12 """4x4 Transform matrix that can always be represented as a combination of 3 matrices: scale * rotate * translate
13 This transform has no shear; angles are always preserved.
14 """
15 def __init__(self, init=None):
16 Transform3D.__init__(self)
17 self.reset()
18 if init is None:
19 return
20 if init.__class__ is QtGui.QTransform:
21 init = SRTTransform.SRTTransform(init)
22
23 if isinstance(init, dict):
24 self.restoreState(init)
25 elif isinstance(init, SRTTransform3D):
26 self._state = {
27 'pos': Vector(init._state['pos']),
28 'scale': Vector(init._state['scale']),
29 'angle': init._state['angle'],
30 'axis': Vector(init._state['axis']),
31 }
32 self.update()
33 elif isinstance(init, SRTTransform.SRTTransform):
34 self._state = {
35 'pos': Vector(init._state['pos']),
36 'scale': Vector(init._state['scale']),
37 'angle': init._state['angle'],
38 'axis': Vector(0, 0, 1),
39 }
40 self._state['scale'][2] = 1.0
41 self.update()
42 elif isinstance(init, QtGui.QMatrix4x4):
43 self.setFromMatrix(init)
44 else:
45 raise Exception("Cannot build SRTTransform3D from argument type:", type(init))
46
47
48 def getScale(self):
49 return Vector(self._state['scale'])
50
51 def getRotation(self):
52 """Return (angle, axis) of rotation"""
53 return self._state['angle'], Vector(self._state['axis'])
54
55 def getTranslation(self):
56 return Vector(self._state['pos'])
57
58 def reset(self):
59 self._state = {
60 'pos': Vector(0,0,0),
61 'scale': Vector(1,1,1),
62 'angle': 0.0, ## in degrees
63 'axis': (0, 0, 1)
64 }
65 self.update()
66
67 def translate(self, *args):
68 """Adjust the translation of this transform"""
69 t = Vector(*args)
70 self.setTranslate(self._state['pos']+t)
71
72 def setTranslate(self, *args):
73 """Set the translation of this transform"""
74 self._state['pos'] = Vector(*args)
75 self.update()
76
77 def scale(self, *args):
78 """adjust the scale of this transform"""
79 ## try to prevent accidentally setting 0 scale on z axis
80 if len(args) == 1 and hasattr(args[0], '__len__'):
81 args = args[0]
82 if len(args) == 2:
83 args = args + (1,)
84
85 s = Vector(*args)
86 self.setScale(self._state['scale'] * s)
87
88 def setScale(self, *args):
89 """Set the scale of this transform"""
90 if len(args) == 1 and hasattr(args[0], '__len__'):
91 args = args[0]
92 if len(args) == 2:
93 args = args + (1,)
94 self._state['scale'] = Vector(*args)
95 self.update()
96
97 def rotate(self, angle, axis=(0,0,1)):
98 """Adjust the rotation of this transform"""
99 origAxis = self._state['axis']
100 if axis[0] == origAxis[0] and axis[1] == origAxis[1] and axis[2] == origAxis[2]:
101 self.setRotate(self._state['angle'] + angle)
102 else:
103 m = QtGui.QMatrix4x4()
104 m.translate(*self._state['pos'])
105 m.rotate(self._state['angle'], *self._state['axis'])
106 m.rotate(angle, *axis)
107 m.scale(*self._state['scale'])
108 self.setFromMatrix(m)
109
110 def setRotate(self, angle, axis=(0,0,1)):
111 """Set the transformation rotation to angle (in degrees)"""
112
113 self._state['angle'] = angle
114 self._state['axis'] = Vector(axis)
115 self.update()
116
117 def setFromMatrix(self, m):
118 """
119 Set this transform based on the elements of *m*
120 The input matrix must be affine AND have no shear,
121 otherwise the conversion will most likely fail.
122 """
123 import numpy.linalg
124 for i in range(4):
125 self.setRow(i, m.row(i))
126 m = self.matrix().reshape(4,4)
127 ## translation is 4th column
128 self._state['pos'] = m[:3,3]
129
130 ## scale is vector-length of first three columns
131 scale = (m[:3,:3]**2).sum(axis=0)**0.5
132 ## see whether there is an inversion
133 z = np.cross(m[0, :3], m[1, :3])
134 if np.dot(z, m[2, :3]) < 0:
135 scale[1] *= -1 ## doesn't really matter which axis we invert
136 self._state['scale'] = scale
137
138 ## rotation axis is the eigenvector with eigenvalue=1
139 r = m[:3, :3] / scale[np.newaxis, :]
140 try:
141 evals, evecs = numpy.linalg.eig(r)
142 except:
143 print("Rotation matrix: %s" % str(r))
144 print("Scale: %s" % str(scale))
145 print("Original matrix: %s" % str(m))
146 raise
147 eigIndex = np.argwhere(np.abs(evals-1) < 1e-6)
148 if len(eigIndex) < 1:
149 print("eigenvalues: %s" % str(evals))
150 print("eigenvectors: %s" % str(evecs))
151 print("index: %s, %s" % (str(eigIndex), str(evals-1)))
152 raise Exception("Could not determine rotation axis.")
153 axis = evecs[:,eigIndex[0,0]].real
154 axis /= ((axis**2).sum())**0.5
155 self._state['axis'] = axis
156
157 ## trace(r) == 2 cos(angle) + 1, so:
158 cos = (r.trace()-1)*0.5 ## this only gets us abs(angle)
159
160 ## The off-diagonal values can be used to correct the angle ambiguity,
161 ## but we need to figure out which element to use:
162 axisInd = np.argmax(np.abs(axis))
163 rInd,sign = [((1,2), -1), ((0,2), 1), ((0,1), -1)][axisInd]
164
165 ## Then we have r-r.T = sin(angle) * 2 * sign * axis[axisInd];
166 ## solve for sin(angle)
167 sin = (r-r.T)[rInd] / (2. * sign * axis[axisInd])
168
169 ## finally, we get the complete angle from arctan(sin/cos)
170 self._state['angle'] = degrees(atan2(sin, cos))
171 if self._state['angle'] == 0:
172 self._state['axis'] = (0,0,1)
173
174 def as2D(self):
175 """Return a QTransform representing the x,y portion of this transform (if possible)"""
176 return SRTTransform.SRTTransform(self)
177
178 #def __div__(self, t):
179 #"""A / B == B^-1 * A"""
180 #dt = t.inverted()[0] * self
181 #return SRTTransform.SRTTransform(dt)
182
183 #def __mul__(self, t):
184 #return SRTTransform.SRTTransform(QtGui.QTransform.__mul__(self, t))
185
186 def saveState(self):
187 p = self._state['pos']
188 s = self._state['scale']
189 ax = self._state['axis']
190 #if s[0] == 0:
191 #raise Exception('Invalid scale: %s' % str(s))
192 return {
193 'pos': (p[0], p[1], p[2]),
194 'scale': (s[0], s[1], s[2]),
195 'angle': self._state['angle'],
196 'axis': (ax[0], ax[1], ax[2])
197 }
198
199 def restoreState(self, state):
200 self._state['pos'] = Vector(state.get('pos', (0.,0.,0.)))
201 scale = state.get('scale', (1.,1.,1.))
202 scale = tuple(scale) + (1.,) * (3-len(scale))
203 self._state['scale'] = Vector(scale)
204 self._state['angle'] = state.get('angle', 0.)
205 self._state['axis'] = state.get('axis', (0, 0, 1))
206 self.update()
207
208 def update(self):
209 Transform3D.setToIdentity(self)
210 ## modifications to the transform are multiplied on the right, so we need to reverse order here.
211 Transform3D.translate(self, *self._state['pos'])
212 Transform3D.rotate(self, self._state['angle'], *self._state['axis'])
213 Transform3D.scale(self, *self._state['scale'])
214
215 def __repr__(self):
216 return str(self.saveState())
217
218 def matrix(self, nd=3):
219 if nd == 3:
220 return np.array(self.copyDataTo()).reshape(4,4)
221 elif nd == 2:
222 m = np.array(self.copyDataTo()).reshape(4,4)
223 m[2] = m[3]
224 m[:,2] = m[:,3]
225 return m[:3,:3]
226 else:
227 raise Exception("Argument 'nd' must be 2 or 3")
228
229 def __reduce__(self):
230 return SRTTransform3D, (self.saveState(),)
231
```
Path: `pyqtgraph/Transform3D.py`
Content:
```
1 import numpy as np
2
3 from . import functions as fn
4 from .Qt import QtGui
5 from .Vector import Vector
6
7
8 class Transform3D(QtGui.QMatrix4x4):
9 """
10 Extension of QMatrix4x4 with some helpful methods added.
11 """
12 def __init__(self, *args):
13 if len(args) == 1:
14 if isinstance(args[0], (list, tuple, np.ndarray)):
15 args = [x for y in args[0] for x in y]
16 if len(args) != 16:
17 raise TypeError("Single argument to Transform3D must have 16 elements.")
18 elif isinstance(args[0], QtGui.QMatrix4x4):
19 args = list(args[0].copyDataTo())
20
21 QtGui.QMatrix4x4.__init__(self, *args)
22
23 def matrix(self, nd=3):
24 if nd == 3:
25 return np.array(self.copyDataTo()).reshape(4,4)
26 elif nd == 2:
27 m = np.array(self.copyDataTo()).reshape(4,4)
28 m[2] = m[3]
29 m[:,2] = m[:,3]
30 return m[:3,:3]
31 else:
32 raise Exception("Argument 'nd' must be 2 or 3")
33
34 def map(self, obj):
35 """
36 Extends QMatrix4x4.map() to allow mapping (3, ...) arrays of coordinates
37 """
38 if isinstance(obj, np.ndarray) and obj.shape[0] in (2,3):
39 if obj.ndim >= 2:
40 return fn.transformCoordinates(self, obj)
41 elif obj.ndim == 1:
42 v = QtGui.QMatrix4x4.map(self, Vector(obj))
43 return np.array([v.x(), v.y(), v.z()])[:obj.shape[0]]
44 elif isinstance(obj, (list, tuple)):
45 v = QtGui.QMatrix4x4.map(self, Vector(obj))
46 return type(obj)([v.x(), v.y(), v.z()])[:len(obj)]
47 else:
48 return QtGui.QMatrix4x4.map(self, obj)
49
50 def inverted(self):
51 inv, b = QtGui.QMatrix4x4.inverted(self)
52 return Transform3D(inv), b
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyqtgraph/SRTTransform3D.py b/pyqtgraph/SRTTransform3D.py
--- a/pyqtgraph/SRTTransform3D.py
+++ b/pyqtgraph/SRTTransform3D.py
@@ -214,17 +214,6 @@
def __repr__(self):
return str(self.saveState())
-
- def matrix(self, nd=3):
- if nd == 3:
- return np.array(self.copyDataTo()).reshape(4,4)
- elif nd == 2:
- m = np.array(self.copyDataTo()).reshape(4,4)
- m[2] = m[3]
- m[:,2] = m[:,3]
- return m[:3,:3]
- else:
- raise Exception("Argument 'nd' must be 2 or 3")
def __reduce__(self):
return SRTTransform3D, (self.saveState(),)
diff --git a/pyqtgraph/Transform3D.py b/pyqtgraph/Transform3D.py
--- a/pyqtgraph/Transform3D.py
+++ b/pyqtgraph/Transform3D.py
@@ -30,7 +30,7 @@
return m[:3,:3]
else:
raise Exception("Argument 'nd' must be 2 or 3")
-
+
def map(self, obj):
"""
Extends QMatrix4x4.map() to allow mapping (3, ...) arrays of coordinates
@@ -45,8 +45,11 @@
v = QtGui.QMatrix4x4.map(self, Vector(obj))
return type(obj)([v.x(), v.y(), v.z()])[:len(obj)]
else:
- return QtGui.QMatrix4x4.map(self, obj)
-
+ retval = QtGui.QMatrix4x4.map(self, obj)
+ if not isinstance(retval, type(obj)):
+ return type(obj)(retval)
+ return retval
+
def inverted(self):
inv, b = QtGui.QMatrix4x4.inverted(self)
return Transform3D(inv), b
|
{"golden_diff": "diff --git a/pyqtgraph/SRTTransform3D.py b/pyqtgraph/SRTTransform3D.py\n--- a/pyqtgraph/SRTTransform3D.py\n+++ b/pyqtgraph/SRTTransform3D.py\n@@ -214,17 +214,6 @@\n \n def __repr__(self):\n return str(self.saveState())\n- \n- def matrix(self, nd=3):\n- if nd == 3:\n- return np.array(self.copyDataTo()).reshape(4,4)\n- elif nd == 2:\n- m = np.array(self.copyDataTo()).reshape(4,4)\n- m[2] = m[3]\n- m[:,2] = m[:,3]\n- return m[:3,:3]\n- else:\n- raise Exception(\"Argument 'nd' must be 2 or 3\")\n \n def __reduce__(self):\n return SRTTransform3D, (self.saveState(),)\ndiff --git a/pyqtgraph/Transform3D.py b/pyqtgraph/Transform3D.py\n--- a/pyqtgraph/Transform3D.py\n+++ b/pyqtgraph/Transform3D.py\n@@ -30,7 +30,7 @@\n return m[:3,:3]\n else:\n raise Exception(\"Argument 'nd' must be 2 or 3\")\n- \n+\n def map(self, obj):\n \"\"\"\n Extends QMatrix4x4.map() to allow mapping (3, ...) arrays of coordinates\n@@ -45,8 +45,11 @@\n v = QtGui.QMatrix4x4.map(self, Vector(obj))\n return type(obj)([v.x(), v.y(), v.z()])[:len(obj)]\n else:\n- return QtGui.QMatrix4x4.map(self, obj)\n- \n+ retval = QtGui.QMatrix4x4.map(self, obj)\n+ if not isinstance(retval, type(obj)):\n+ return type(obj)(retval)\n+ return retval\n+\n def inverted(self):\n inv, b = QtGui.QMatrix4x4.inverted(self)\n return Transform3D(inv), b\n", "issue": "Segfault when iterating on a transform-mapped Vector in a thread\n<!-- In the following, please describe your issue in detail! -->\r\n<!-- If some sections do not apply, just remove them. -->\r\n\r\n### Short description\r\nTake a Vector, map it with a transform, put it in a _threading_ Thread, iterate, and BOOM.\r\n\r\n### Code to reproduce\r\n<!-- Please provide a minimal working example that reproduces the issue in the code block below.\r\n Ideally, this should be a full example someone else could run without additional setup. -->\r\n\r\n```python\r\nimport pyqtgraph as pg\r\nimport threading\r\n\r\n\r\ndef do_it():\r\n xform = pg.SRTTransform3D()\r\n v = xform.map(pg.Vector((0, 0, 0)))\r\n tuple(v)\r\n\r\n\r\npg.mkQApp()\r\nthreading.Thread(target=do_it).start()\r\n```\r\n\r\n### Expected behavior\r\n<!-- What should happen? -->\r\n\r\n### Real behavior\r\n<!-- What happens? -->\r\n`SIGSEGV`\r\n\r\n### Tested environment(s)\r\n\r\n * PyQtGraph version: 0.13.8dev0\r\n * Qt Python binding: PyQt5 5.15.10 Qt 5.15.2\r\n * Python version: 3.11\r\n * NumPy version: 1.26.3\r\n * Operating system: linux\r\n * Installation method: git\r\n\r\n### Additional context\r\n\r\nWorkaround: use a `QThread`, and this isn't an issue.\n", "before_files": [{"content": "from math import atan2, degrees\n\nimport numpy as np\n\nfrom . import SRTTransform\nfrom .Qt import QtGui\nfrom .Transform3D import Transform3D\nfrom .Vector import Vector\n\n\nclass SRTTransform3D(Transform3D):\n \"\"\"4x4 Transform matrix that can always be represented as a combination of 3 matrices: scale * rotate * translate\n This transform has no shear; angles are always preserved.\n \"\"\"\n def __init__(self, init=None):\n Transform3D.__init__(self)\n self.reset()\n if init is None:\n return\n if init.__class__ is QtGui.QTransform:\n init = SRTTransform.SRTTransform(init)\n \n if isinstance(init, dict):\n self.restoreState(init)\n elif isinstance(init, SRTTransform3D):\n self._state = {\n 'pos': Vector(init._state['pos']),\n 'scale': Vector(init._state['scale']),\n 'angle': init._state['angle'],\n 'axis': Vector(init._state['axis']),\n }\n self.update()\n elif isinstance(init, SRTTransform.SRTTransform):\n self._state = {\n 'pos': Vector(init._state['pos']),\n 'scale': Vector(init._state['scale']),\n 'angle': init._state['angle'],\n 'axis': Vector(0, 0, 1),\n }\n self._state['scale'][2] = 1.0\n self.update()\n elif isinstance(init, QtGui.QMatrix4x4):\n self.setFromMatrix(init)\n else:\n raise Exception(\"Cannot build SRTTransform3D from argument type:\", type(init))\n\n \n def getScale(self):\n return Vector(self._state['scale'])\n \n def getRotation(self):\n \"\"\"Return (angle, axis) of rotation\"\"\"\n return self._state['angle'], Vector(self._state['axis'])\n \n def getTranslation(self):\n return Vector(self._state['pos'])\n \n def reset(self):\n self._state = {\n 'pos': Vector(0,0,0),\n 'scale': Vector(1,1,1),\n 'angle': 0.0, ## in degrees\n 'axis': (0, 0, 1)\n }\n self.update()\n \n def translate(self, *args):\n \"\"\"Adjust the translation of this transform\"\"\"\n t = Vector(*args)\n self.setTranslate(self._state['pos']+t)\n \n def setTranslate(self, *args):\n \"\"\"Set the translation of this transform\"\"\"\n self._state['pos'] = Vector(*args)\n self.update()\n \n def scale(self, *args):\n \"\"\"adjust the scale of this transform\"\"\"\n ## try to prevent accidentally setting 0 scale on z axis\n if len(args) == 1 and hasattr(args[0], '__len__'):\n args = args[0]\n if len(args) == 2:\n args = args + (1,)\n \n s = Vector(*args)\n self.setScale(self._state['scale'] * s)\n \n def setScale(self, *args):\n \"\"\"Set the scale of this transform\"\"\"\n if len(args) == 1 and hasattr(args[0], '__len__'):\n args = args[0]\n if len(args) == 2:\n args = args + (1,)\n self._state['scale'] = Vector(*args)\n self.update()\n \n def rotate(self, angle, axis=(0,0,1)):\n \"\"\"Adjust the rotation of this transform\"\"\"\n origAxis = self._state['axis']\n if axis[0] == origAxis[0] and axis[1] == origAxis[1] and axis[2] == origAxis[2]:\n self.setRotate(self._state['angle'] + angle)\n else:\n m = QtGui.QMatrix4x4()\n m.translate(*self._state['pos'])\n m.rotate(self._state['angle'], *self._state['axis'])\n m.rotate(angle, *axis)\n m.scale(*self._state['scale'])\n self.setFromMatrix(m)\n \n def setRotate(self, angle, axis=(0,0,1)):\n \"\"\"Set the transformation rotation to angle (in degrees)\"\"\"\n \n self._state['angle'] = angle\n self._state['axis'] = Vector(axis)\n self.update()\n \n def setFromMatrix(self, m):\n \"\"\"\n Set this transform based on the elements of *m*\n The input matrix must be affine AND have no shear,\n otherwise the conversion will most likely fail.\n \"\"\"\n import numpy.linalg\n for i in range(4):\n self.setRow(i, m.row(i))\n m = self.matrix().reshape(4,4)\n ## translation is 4th column\n self._state['pos'] = m[:3,3]\n \n ## scale is vector-length of first three columns\n scale = (m[:3,:3]**2).sum(axis=0)**0.5\n ## see whether there is an inversion\n z = np.cross(m[0, :3], m[1, :3])\n if np.dot(z, m[2, :3]) < 0:\n scale[1] *= -1 ## doesn't really matter which axis we invert\n self._state['scale'] = scale\n \n ## rotation axis is the eigenvector with eigenvalue=1\n r = m[:3, :3] / scale[np.newaxis, :]\n try:\n evals, evecs = numpy.linalg.eig(r)\n except:\n print(\"Rotation matrix: %s\" % str(r))\n print(\"Scale: %s\" % str(scale))\n print(\"Original matrix: %s\" % str(m))\n raise\n eigIndex = np.argwhere(np.abs(evals-1) < 1e-6)\n if len(eigIndex) < 1:\n print(\"eigenvalues: %s\" % str(evals))\n print(\"eigenvectors: %s\" % str(evecs))\n print(\"index: %s, %s\" % (str(eigIndex), str(evals-1)))\n raise Exception(\"Could not determine rotation axis.\")\n axis = evecs[:,eigIndex[0,0]].real\n axis /= ((axis**2).sum())**0.5\n self._state['axis'] = axis\n \n ## trace(r) == 2 cos(angle) + 1, so:\n cos = (r.trace()-1)*0.5 ## this only gets us abs(angle)\n \n ## The off-diagonal values can be used to correct the angle ambiguity, \n ## but we need to figure out which element to use:\n axisInd = np.argmax(np.abs(axis))\n rInd,sign = [((1,2), -1), ((0,2), 1), ((0,1), -1)][axisInd]\n \n ## Then we have r-r.T = sin(angle) * 2 * sign * axis[axisInd];\n ## solve for sin(angle)\n sin = (r-r.T)[rInd] / (2. * sign * axis[axisInd])\n \n ## finally, we get the complete angle from arctan(sin/cos)\n self._state['angle'] = degrees(atan2(sin, cos))\n if self._state['angle'] == 0:\n self._state['axis'] = (0,0,1)\n \n def as2D(self):\n \"\"\"Return a QTransform representing the x,y portion of this transform (if possible)\"\"\"\n return SRTTransform.SRTTransform(self)\n\n #def __div__(self, t):\n #\"\"\"A / B == B^-1 * A\"\"\"\n #dt = t.inverted()[0] * self\n #return SRTTransform.SRTTransform(dt)\n \n #def __mul__(self, t):\n #return SRTTransform.SRTTransform(QtGui.QTransform.__mul__(self, t))\n\n def saveState(self):\n p = self._state['pos']\n s = self._state['scale']\n ax = self._state['axis']\n #if s[0] == 0:\n #raise Exception('Invalid scale: %s' % str(s))\n return {\n 'pos': (p[0], p[1], p[2]), \n 'scale': (s[0], s[1], s[2]), \n 'angle': self._state['angle'], \n 'axis': (ax[0], ax[1], ax[2])\n }\n\n def restoreState(self, state):\n self._state['pos'] = Vector(state.get('pos', (0.,0.,0.)))\n scale = state.get('scale', (1.,1.,1.))\n scale = tuple(scale) + (1.,) * (3-len(scale))\n self._state['scale'] = Vector(scale)\n self._state['angle'] = state.get('angle', 0.)\n self._state['axis'] = state.get('axis', (0, 0, 1))\n self.update()\n\n def update(self):\n Transform3D.setToIdentity(self)\n ## modifications to the transform are multiplied on the right, so we need to reverse order here.\n Transform3D.translate(self, *self._state['pos'])\n Transform3D.rotate(self, self._state['angle'], *self._state['axis'])\n Transform3D.scale(self, *self._state['scale'])\n\n def __repr__(self):\n return str(self.saveState())\n \n def matrix(self, nd=3):\n if nd == 3:\n return np.array(self.copyDataTo()).reshape(4,4)\n elif nd == 2:\n m = np.array(self.copyDataTo()).reshape(4,4)\n m[2] = m[3]\n m[:,2] = m[:,3]\n return m[:3,:3]\n else:\n raise Exception(\"Argument 'nd' must be 2 or 3\")\n\n def __reduce__(self):\n return SRTTransform3D, (self.saveState(),)\n", "path": "pyqtgraph/SRTTransform3D.py"}, {"content": "import numpy as np\n\nfrom . import functions as fn\nfrom .Qt import QtGui\nfrom .Vector import Vector\n\n\nclass Transform3D(QtGui.QMatrix4x4):\n \"\"\"\n Extension of QMatrix4x4 with some helpful methods added.\n \"\"\"\n def __init__(self, *args):\n if len(args) == 1:\n if isinstance(args[0], (list, tuple, np.ndarray)):\n args = [x for y in args[0] for x in y]\n if len(args) != 16:\n raise TypeError(\"Single argument to Transform3D must have 16 elements.\")\n elif isinstance(args[0], QtGui.QMatrix4x4):\n args = list(args[0].copyDataTo())\n \n QtGui.QMatrix4x4.__init__(self, *args)\n \n def matrix(self, nd=3):\n if nd == 3:\n return np.array(self.copyDataTo()).reshape(4,4)\n elif nd == 2:\n m = np.array(self.copyDataTo()).reshape(4,4)\n m[2] = m[3]\n m[:,2] = m[:,3]\n return m[:3,:3]\n else:\n raise Exception(\"Argument 'nd' must be 2 or 3\")\n \n def map(self, obj):\n \"\"\"\n Extends QMatrix4x4.map() to allow mapping (3, ...) arrays of coordinates\n \"\"\"\n if isinstance(obj, np.ndarray) and obj.shape[0] in (2,3):\n if obj.ndim >= 2:\n return fn.transformCoordinates(self, obj)\n elif obj.ndim == 1:\n v = QtGui.QMatrix4x4.map(self, Vector(obj))\n return np.array([v.x(), v.y(), v.z()])[:obj.shape[0]]\n elif isinstance(obj, (list, tuple)):\n v = QtGui.QMatrix4x4.map(self, Vector(obj))\n return type(obj)([v.x(), v.y(), v.z()])[:len(obj)]\n else:\n return QtGui.QMatrix4x4.map(self, obj)\n \n def inverted(self):\n inv, b = QtGui.QMatrix4x4.inverted(self)\n return Transform3D(inv), b\n", "path": "pyqtgraph/Transform3D.py"}], "after_files": [{"content": "from math import atan2, degrees\n\nimport numpy as np\n\nfrom . import SRTTransform\nfrom .Qt import QtGui\nfrom .Transform3D import Transform3D\nfrom .Vector import Vector\n\n\nclass SRTTransform3D(Transform3D):\n \"\"\"4x4 Transform matrix that can always be represented as a combination of 3 matrices: scale * rotate * translate\n This transform has no shear; angles are always preserved.\n \"\"\"\n def __init__(self, init=None):\n Transform3D.__init__(self)\n self.reset()\n if init is None:\n return\n if init.__class__ is QtGui.QTransform:\n init = SRTTransform.SRTTransform(init)\n \n if isinstance(init, dict):\n self.restoreState(init)\n elif isinstance(init, SRTTransform3D):\n self._state = {\n 'pos': Vector(init._state['pos']),\n 'scale': Vector(init._state['scale']),\n 'angle': init._state['angle'],\n 'axis': Vector(init._state['axis']),\n }\n self.update()\n elif isinstance(init, SRTTransform.SRTTransform):\n self._state = {\n 'pos': Vector(init._state['pos']),\n 'scale': Vector(init._state['scale']),\n 'angle': init._state['angle'],\n 'axis': Vector(0, 0, 1),\n }\n self._state['scale'][2] = 1.0\n self.update()\n elif isinstance(init, QtGui.QMatrix4x4):\n self.setFromMatrix(init)\n else:\n raise Exception(\"Cannot build SRTTransform3D from argument type:\", type(init))\n\n \n def getScale(self):\n return Vector(self._state['scale'])\n \n def getRotation(self):\n \"\"\"Return (angle, axis) of rotation\"\"\"\n return self._state['angle'], Vector(self._state['axis'])\n \n def getTranslation(self):\n return Vector(self._state['pos'])\n \n def reset(self):\n self._state = {\n 'pos': Vector(0,0,0),\n 'scale': Vector(1,1,1),\n 'angle': 0.0, ## in degrees\n 'axis': (0, 0, 1)\n }\n self.update()\n \n def translate(self, *args):\n \"\"\"Adjust the translation of this transform\"\"\"\n t = Vector(*args)\n self.setTranslate(self._state['pos']+t)\n \n def setTranslate(self, *args):\n \"\"\"Set the translation of this transform\"\"\"\n self._state['pos'] = Vector(*args)\n self.update()\n \n def scale(self, *args):\n \"\"\"adjust the scale of this transform\"\"\"\n ## try to prevent accidentally setting 0 scale on z axis\n if len(args) == 1 and hasattr(args[0], '__len__'):\n args = args[0]\n if len(args) == 2:\n args = args + (1,)\n \n s = Vector(*args)\n self.setScale(self._state['scale'] * s)\n \n def setScale(self, *args):\n \"\"\"Set the scale of this transform\"\"\"\n if len(args) == 1 and hasattr(args[0], '__len__'):\n args = args[0]\n if len(args) == 2:\n args = args + (1,)\n self._state['scale'] = Vector(*args)\n self.update()\n \n def rotate(self, angle, axis=(0,0,1)):\n \"\"\"Adjust the rotation of this transform\"\"\"\n origAxis = self._state['axis']\n if axis[0] == origAxis[0] and axis[1] == origAxis[1] and axis[2] == origAxis[2]:\n self.setRotate(self._state['angle'] + angle)\n else:\n m = QtGui.QMatrix4x4()\n m.translate(*self._state['pos'])\n m.rotate(self._state['angle'], *self._state['axis'])\n m.rotate(angle, *axis)\n m.scale(*self._state['scale'])\n self.setFromMatrix(m)\n \n def setRotate(self, angle, axis=(0,0,1)):\n \"\"\"Set the transformation rotation to angle (in degrees)\"\"\"\n \n self._state['angle'] = angle\n self._state['axis'] = Vector(axis)\n self.update()\n \n def setFromMatrix(self, m):\n \"\"\"\n Set this transform based on the elements of *m*\n The input matrix must be affine AND have no shear,\n otherwise the conversion will most likely fail.\n \"\"\"\n import numpy.linalg\n for i in range(4):\n self.setRow(i, m.row(i))\n m = self.matrix().reshape(4,4)\n ## translation is 4th column\n self._state['pos'] = m[:3,3]\n \n ## scale is vector-length of first three columns\n scale = (m[:3,:3]**2).sum(axis=0)**0.5\n ## see whether there is an inversion\n z = np.cross(m[0, :3], m[1, :3])\n if np.dot(z, m[2, :3]) < 0:\n scale[1] *= -1 ## doesn't really matter which axis we invert\n self._state['scale'] = scale\n \n ## rotation axis is the eigenvector with eigenvalue=1\n r = m[:3, :3] / scale[np.newaxis, :]\n try:\n evals, evecs = numpy.linalg.eig(r)\n except:\n print(\"Rotation matrix: %s\" % str(r))\n print(\"Scale: %s\" % str(scale))\n print(\"Original matrix: %s\" % str(m))\n raise\n eigIndex = np.argwhere(np.abs(evals-1) < 1e-6)\n if len(eigIndex) < 1:\n print(\"eigenvalues: %s\" % str(evals))\n print(\"eigenvectors: %s\" % str(evecs))\n print(\"index: %s, %s\" % (str(eigIndex), str(evals-1)))\n raise Exception(\"Could not determine rotation axis.\")\n axis = evecs[:,eigIndex[0,0]].real\n axis /= ((axis**2).sum())**0.5\n self._state['axis'] = axis\n \n ## trace(r) == 2 cos(angle) + 1, so:\n cos = (r.trace()-1)*0.5 ## this only gets us abs(angle)\n \n ## The off-diagonal values can be used to correct the angle ambiguity, \n ## but we need to figure out which element to use:\n axisInd = np.argmax(np.abs(axis))\n rInd,sign = [((1,2), -1), ((0,2), 1), ((0,1), -1)][axisInd]\n \n ## Then we have r-r.T = sin(angle) * 2 * sign * axis[axisInd];\n ## solve for sin(angle)\n sin = (r-r.T)[rInd] / (2. * sign * axis[axisInd])\n \n ## finally, we get the complete angle from arctan(sin/cos)\n self._state['angle'] = degrees(atan2(sin, cos))\n if self._state['angle'] == 0:\n self._state['axis'] = (0,0,1)\n \n def as2D(self):\n \"\"\"Return a QTransform representing the x,y portion of this transform (if possible)\"\"\"\n return SRTTransform.SRTTransform(self)\n\n #def __div__(self, t):\n #\"\"\"A / B == B^-1 * A\"\"\"\n #dt = t.inverted()[0] * self\n #return SRTTransform.SRTTransform(dt)\n \n #def __mul__(self, t):\n #return SRTTransform.SRTTransform(QtGui.QTransform.__mul__(self, t))\n\n def saveState(self):\n p = self._state['pos']\n s = self._state['scale']\n ax = self._state['axis']\n #if s[0] == 0:\n #raise Exception('Invalid scale: %s' % str(s))\n return {\n 'pos': (p[0], p[1], p[2]), \n 'scale': (s[0], s[1], s[2]), \n 'angle': self._state['angle'], \n 'axis': (ax[0], ax[1], ax[2])\n }\n\n def restoreState(self, state):\n self._state['pos'] = Vector(state.get('pos', (0.,0.,0.)))\n scale = state.get('scale', (1.,1.,1.))\n scale = tuple(scale) + (1.,) * (3-len(scale))\n self._state['scale'] = Vector(scale)\n self._state['angle'] = state.get('angle', 0.)\n self._state['axis'] = state.get('axis', (0, 0, 1))\n self.update()\n\n def update(self):\n Transform3D.setToIdentity(self)\n ## modifications to the transform are multiplied on the right, so we need to reverse order here.\n Transform3D.translate(self, *self._state['pos'])\n Transform3D.rotate(self, self._state['angle'], *self._state['axis'])\n Transform3D.scale(self, *self._state['scale'])\n\n def __repr__(self):\n return str(self.saveState())\n\n def __reduce__(self):\n return SRTTransform3D, (self.saveState(),)\n", "path": "pyqtgraph/SRTTransform3D.py"}, {"content": "import numpy as np\n\nfrom . import functions as fn\nfrom .Qt import QtGui\nfrom .Vector import Vector\n\n\nclass Transform3D(QtGui.QMatrix4x4):\n \"\"\"\n Extension of QMatrix4x4 with some helpful methods added.\n \"\"\"\n def __init__(self, *args):\n if len(args) == 1:\n if isinstance(args[0], (list, tuple, np.ndarray)):\n args = [x for y in args[0] for x in y]\n if len(args) != 16:\n raise TypeError(\"Single argument to Transform3D must have 16 elements.\")\n elif isinstance(args[0], QtGui.QMatrix4x4):\n args = list(args[0].copyDataTo())\n \n QtGui.QMatrix4x4.__init__(self, *args)\n \n def matrix(self, nd=3):\n if nd == 3:\n return np.array(self.copyDataTo()).reshape(4,4)\n elif nd == 2:\n m = np.array(self.copyDataTo()).reshape(4,4)\n m[2] = m[3]\n m[:,2] = m[:,3]\n return m[:3,:3]\n else:\n raise Exception(\"Argument 'nd' must be 2 or 3\")\n\n def map(self, obj):\n \"\"\"\n Extends QMatrix4x4.map() to allow mapping (3, ...) arrays of coordinates\n \"\"\"\n if isinstance(obj, np.ndarray) and obj.shape[0] in (2,3):\n if obj.ndim >= 2:\n return fn.transformCoordinates(self, obj)\n elif obj.ndim == 1:\n v = QtGui.QMatrix4x4.map(self, Vector(obj))\n return np.array([v.x(), v.y(), v.z()])[:obj.shape[0]]\n elif isinstance(obj, (list, tuple)):\n v = QtGui.QMatrix4x4.map(self, Vector(obj))\n return type(obj)([v.x(), v.y(), v.z()])[:len(obj)]\n else:\n retval = QtGui.QMatrix4x4.map(self, obj)\n if not isinstance(retval, type(obj)):\n return type(obj)(retval)\n return retval\n\n def inverted(self):\n inv, b = QtGui.QMatrix4x4.inverted(self)\n return Transform3D(inv), b\n", "path": "pyqtgraph/Transform3D.py"}]}
| 3,936 | 464 |
gh_patches_debug_11730
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-7077
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Search indexing logic called twice after update or create dataset
**CKAN version**
2.10
**Describe the bug**
When updating or creating a dataset, we are indexing the dataset twice in a row, ie the [`index_package()`](https://github.com/ckan/ckan/blob/9f1b5cfaff8c135b589e2ea0275f1286c2e02711/ckan/lib/search/index.py#L108) function gets called twice during the same operation (and of course any `IPackageController.before_index()` hook gets called twice as well.
The root cause is the the obscure code run in the [`DomainObjectModificationExtension`](https://github.com/ckan/ckan/blob/9f1b5cfaff8c135b589e2ea0275f1286c2e02711/ckan/model/modification.py#L27), which considers the same Package object both new and changed at the same time, and fires two separate notification events.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/model/modification.py`
Content:
```
1 # encoding: utf-8
2
3 import logging
4 from typing import Any
5
6 from ckan.lib.search import SearchIndexError
7
8 import ckan.plugins as plugins
9 import ckan.model as model
10
11 log = logging.getLogger(__name__)
12
13 __all__ = ['DomainObjectModificationExtension']
14
15
16 class DomainObjectModificationExtension(plugins.SingletonPlugin):
17 """
18 Notify observers about domain object modifications before commit.
19
20 Observers are other plugins implementing the IDomainObjectModification
21 interface.
22 """
23
24 def before_commit(self, session: Any):
25 self.notify_observers(session, self.notify)
26
27 def notify_observers(self, session: Any, method: Any):
28 session.flush()
29 if not hasattr(session, '_object_cache'):
30 return
31
32 obj_cache = session._object_cache
33 new = obj_cache['new']
34 changed = obj_cache['changed']
35 deleted = obj_cache['deleted']
36
37 for obj in set(new):
38 if isinstance(obj, (model.Package, model.Resource)):
39 method(obj, model.DomainObjectOperation.new)
40 for obj in set(deleted):
41 if isinstance(obj, (model.Package, model.Resource)):
42 method(obj, model.DomainObjectOperation.deleted)
43 for obj in set(changed):
44 if isinstance(obj, model.Resource):
45 method(obj, model.DomainObjectOperation.changed)
46 if getattr(obj, 'url_changed', False):
47 for item in plugins.PluginImplementations(plugins.IResourceUrlChange):
48 item.notify(obj)
49
50 changed_pkgs = set(obj for obj in changed
51 if isinstance(obj, model.Package))
52
53 for obj in new | changed | deleted:
54 if not isinstance(obj, model.Package):
55 try:
56 changed_pkgs.update(obj.related_packages())
57 except AttributeError:
58 continue
59
60 for obj in changed_pkgs:
61 method(obj, model.DomainObjectOperation.changed)
62
63 def notify(self, entity: Any, operation: Any):
64 for observer in plugins.PluginImplementations(
65 plugins.IDomainObjectModification):
66 try:
67 observer.notify(entity, operation)
68 except SearchIndexError as search_error:
69 log.exception(search_error)
70 # Reraise, since it's pretty crucial to ckan if it can't index
71 # a dataset
72 raise
73 except Exception as ex:
74 log.exception(ex)
75 # Don't reraise other exceptions since they are generally of
76 # secondary importance so shouldn't disrupt the commit.
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/model/modification.py b/ckan/model/modification.py
--- a/ckan/model/modification.py
+++ b/ckan/model/modification.py
@@ -47,8 +47,12 @@
for item in plugins.PluginImplementations(plugins.IResourceUrlChange):
item.notify(obj)
- changed_pkgs = set(obj for obj in changed
- if isinstance(obj, model.Package))
+
+ changed_pkgs = set()
+ new_pkg_ids = [obj.id for obj in new if isinstance(obj, model.Package)]
+ for obj in changed:
+ if isinstance(obj, model.Package) and obj.id not in new_pkg_ids:
+ changed_pkgs.add(obj)
for obj in new | changed | deleted:
if not isinstance(obj, model.Package):
|
{"golden_diff": "diff --git a/ckan/model/modification.py b/ckan/model/modification.py\n--- a/ckan/model/modification.py\n+++ b/ckan/model/modification.py\n@@ -47,8 +47,12 @@\n for item in plugins.PluginImplementations(plugins.IResourceUrlChange):\n item.notify(obj)\n \n- changed_pkgs = set(obj for obj in changed\n- if isinstance(obj, model.Package))\n+\n+ changed_pkgs = set()\n+ new_pkg_ids = [obj.id for obj in new if isinstance(obj, model.Package)]\n+ for obj in changed:\n+ if isinstance(obj, model.Package) and obj.id not in new_pkg_ids:\n+ changed_pkgs.add(obj)\n \n for obj in new | changed | deleted:\n if not isinstance(obj, model.Package):\n", "issue": "Search indexing logic called twice after update or create dataset\n**CKAN version**\r\n2.10\r\n\r\n\r\n**Describe the bug**\r\n\r\nWhen updating or creating a dataset, we are indexing the dataset twice in a row, ie the [`index_package()`](https://github.com/ckan/ckan/blob/9f1b5cfaff8c135b589e2ea0275f1286c2e02711/ckan/lib/search/index.py#L108) function gets called twice during the same operation (and of course any `IPackageController.before_index()` hook gets called twice as well.\r\n\r\nThe root cause is the the obscure code run in the [`DomainObjectModificationExtension`](https://github.com/ckan/ckan/blob/9f1b5cfaff8c135b589e2ea0275f1286c2e02711/ckan/model/modification.py#L27), which considers the same Package object both new and changed at the same time, and fires two separate notification events.\n", "before_files": [{"content": "# encoding: utf-8\n\nimport logging\nfrom typing import Any\n\nfrom ckan.lib.search import SearchIndexError\n\nimport ckan.plugins as plugins\nimport ckan.model as model\n\nlog = logging.getLogger(__name__)\n\n__all__ = ['DomainObjectModificationExtension']\n\n\nclass DomainObjectModificationExtension(plugins.SingletonPlugin):\n \"\"\"\n Notify observers about domain object modifications before commit.\n\n Observers are other plugins implementing the IDomainObjectModification\n interface.\n \"\"\"\n\n def before_commit(self, session: Any):\n self.notify_observers(session, self.notify)\n\n def notify_observers(self, session: Any, method: Any):\n session.flush()\n if not hasattr(session, '_object_cache'):\n return\n\n obj_cache = session._object_cache\n new = obj_cache['new']\n changed = obj_cache['changed']\n deleted = obj_cache['deleted']\n\n for obj in set(new):\n if isinstance(obj, (model.Package, model.Resource)):\n method(obj, model.DomainObjectOperation.new)\n for obj in set(deleted):\n if isinstance(obj, (model.Package, model.Resource)):\n method(obj, model.DomainObjectOperation.deleted)\n for obj in set(changed):\n if isinstance(obj, model.Resource):\n method(obj, model.DomainObjectOperation.changed)\n if getattr(obj, 'url_changed', False):\n for item in plugins.PluginImplementations(plugins.IResourceUrlChange):\n item.notify(obj)\n\n changed_pkgs = set(obj for obj in changed\n if isinstance(obj, model.Package))\n\n for obj in new | changed | deleted:\n if not isinstance(obj, model.Package):\n try:\n changed_pkgs.update(obj.related_packages())\n except AttributeError:\n continue\n\n for obj in changed_pkgs:\n method(obj, model.DomainObjectOperation.changed)\n\n def notify(self, entity: Any, operation: Any):\n for observer in plugins.PluginImplementations(\n plugins.IDomainObjectModification):\n try:\n observer.notify(entity, operation)\n except SearchIndexError as search_error:\n log.exception(search_error)\n # Reraise, since it's pretty crucial to ckan if it can't index\n # a dataset\n raise\n except Exception as ex:\n log.exception(ex)\n # Don't reraise other exceptions since they are generally of\n # secondary importance so shouldn't disrupt the commit.\n", "path": "ckan/model/modification.py"}], "after_files": [{"content": "# encoding: utf-8\n\nimport logging\nfrom typing import Any\n\nfrom ckan.lib.search import SearchIndexError\n\nimport ckan.plugins as plugins\nimport ckan.model as model\n\nlog = logging.getLogger(__name__)\n\n__all__ = ['DomainObjectModificationExtension']\n\n\nclass DomainObjectModificationExtension(plugins.SingletonPlugin):\n \"\"\"\n Notify observers about domain object modifications before commit.\n\n Observers are other plugins implementing the IDomainObjectModification\n interface.\n \"\"\"\n\n def before_commit(self, session: Any):\n self.notify_observers(session, self.notify)\n\n def notify_observers(self, session: Any, method: Any):\n session.flush()\n if not hasattr(session, '_object_cache'):\n return\n\n obj_cache = session._object_cache\n new = obj_cache['new']\n changed = obj_cache['changed']\n deleted = obj_cache['deleted']\n\n for obj in set(new):\n if isinstance(obj, (model.Package, model.Resource)):\n method(obj, model.DomainObjectOperation.new)\n for obj in set(deleted):\n if isinstance(obj, (model.Package, model.Resource)):\n method(obj, model.DomainObjectOperation.deleted)\n for obj in set(changed):\n if isinstance(obj, model.Resource):\n method(obj, model.DomainObjectOperation.changed)\n if getattr(obj, 'url_changed', False):\n for item in plugins.PluginImplementations(plugins.IResourceUrlChange):\n item.notify(obj)\n\n\n changed_pkgs = set()\n new_pkg_ids = [obj.id for obj in new if isinstance(obj, model.Package)]\n for obj in changed:\n if isinstance(obj, model.Package) and obj.id not in new_pkg_ids:\n changed_pkgs.add(obj)\n\n for obj in new | changed | deleted:\n if not isinstance(obj, model.Package):\n try:\n changed_pkgs.update(obj.related_packages())\n except AttributeError:\n continue\n\n for obj in changed_pkgs:\n method(obj, model.DomainObjectOperation.changed)\n\n def notify(self, entity: Any, operation: Any):\n for observer in plugins.PluginImplementations(\n plugins.IDomainObjectModification):\n try:\n observer.notify(entity, operation)\n except SearchIndexError as search_error:\n log.exception(search_error)\n # Reraise, since it's pretty crucial to ckan if it can't index\n # a dataset\n raise\n except Exception as ex:\n log.exception(ex)\n # Don't reraise other exceptions since they are generally of\n # secondary importance so shouldn't disrupt the commit.\n", "path": "ckan/model/modification.py"}]}
| 1,151 | 178 |
gh_patches_debug_21020
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1106
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Warning has been seen to appear below OK checks in suite condition table
**Describe the bug**
In a certain case, the condition table has been seen to have a warning appear blow the OK checks
**Expected behavior**
Condition order in the table should be:
Fail with Display
Fail without Display
Warning with Display
Warning without Display
Pass with Display
Pass without Display
Other then that order should conform to order of checks in the check_result.
**Screenshots**
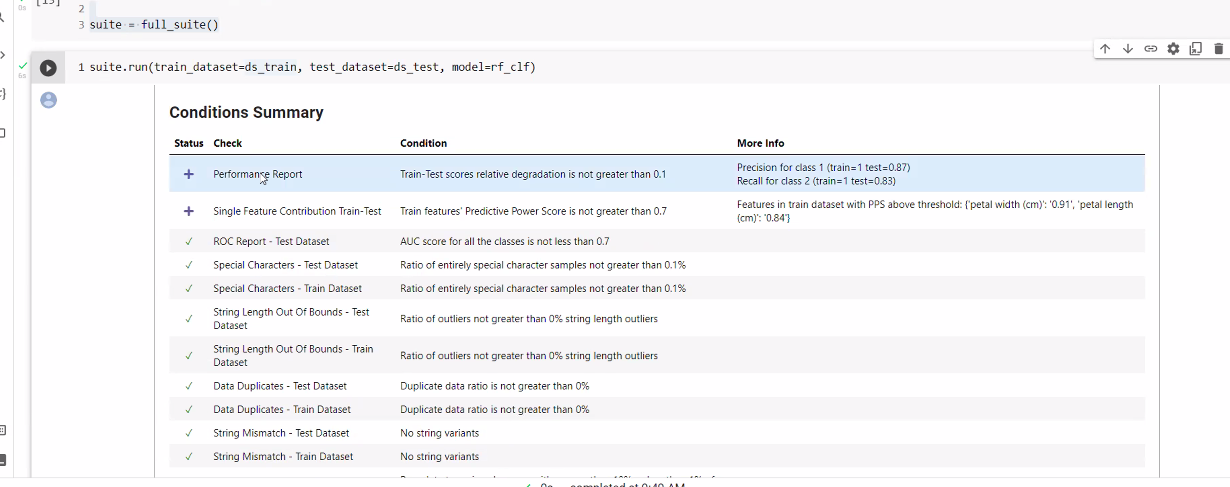

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/core/display_pandas.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Handle displays of pandas objects."""
12 from deepchecks.utils.strings import get_docs_summary, get_ellipsis
13
14 from typing import List, Union, TYPE_CHECKING
15 import warnings
16
17 import pandas as pd
18 from pandas.io.formats.style import Styler
19
20
21 if TYPE_CHECKING:
22 from deepchecks.core.check_result import CheckResult
23
24
25 __all__ = ['dataframe_to_html', 'get_conditions_table']
26
27
28 def dataframe_to_html(df: Union[pd.DataFrame, Styler]):
29 """Convert dataframe to html.
30
31 Parameters
32 ----------
33 df: Union[pd.DataFrame, Styler]
34 Dataframe to convert to html
35
36 Returns
37 -------
38 pd.DataFrame:
39 dataframe with styling
40 """
41 try:
42 if isinstance(df, pd.DataFrame):
43 df_styler = df.style
44 else:
45 df_styler = df
46 # Using deprecated pandas method so hiding the warning
47 with warnings.catch_warnings():
48 warnings.simplefilter(action='ignore', category=FutureWarning)
49 df_styler.set_precision(2)
50
51 table_css_props = [
52 ('text-align', 'left'), # Align everything to the left
53 ('white-space', 'pre-wrap') # Define how to handle white space characters (like \n)
54 ]
55 df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=table_css_props)])
56 return df_styler.render()
57 # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style
58 # attribute, hence we need to display as a regular pd html format.
59 except ValueError:
60 return df.to_html()
61
62
63 def get_conditions_table(check_results: Union['CheckResult', List['CheckResult']],
64 unique_id: str = None, max_info_len: int = 3000, icon_html: bool = True) -> Styler:
65 """Return the conditions table as DataFrame.
66
67 Parameters
68 ----------
69 check_results : Union['CheckResult', List['CheckResult']]
70 check results to show conditions of.
71 unique_id : str
72 the unique id to append for the check names to create links (won't create links if None/empty).
73 max_info_len : int
74 max length of the additional info.
75 icon_html : bool , default: True
76 if to show the html condition result icon or the enum
77 Returns
78 -------
79 pd.Dataframe:
80 the condition table.
81 """
82 if not isinstance(check_results, List):
83 show_check_column = False
84 check_results = [check_results]
85 else:
86 show_check_column = True
87
88 table = []
89 for check_result in check_results:
90 for cond_result in check_result.conditions_results:
91 sort_value = cond_result.priority
92 icon = cond_result.get_icon() if icon_html else cond_result.category.value
93 check_header = check_result.get_header()
94 if unique_id and check_result.have_display():
95 check_id = f'{check_result.check.__class__.__name__}_{unique_id}'
96 link = f'<a href=#{check_id}>{check_header}</a>'
97 else:
98 link = check_header
99 sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top
100 table.append([icon, link, cond_result.name,
101 cond_result.details, sort_value])
102
103 conditions_table = pd.DataFrame(data=table,
104 columns=['Status', 'Check', 'Condition', 'More Info', 'sort'])
105 conditions_table.sort_values(by=['sort'], inplace=True)
106 conditions_table.drop('sort', axis=1, inplace=True)
107 if show_check_column is False:
108 conditions_table.drop('Check', axis=1, inplace=True)
109 conditions_table['More Info'] = conditions_table['More Info'].map(lambda x: get_ellipsis(x, max_info_len))
110 with warnings.catch_warnings():
111 warnings.simplefilter(action='ignore', category=FutureWarning)
112 return conditions_table.style.hide_index()
113
114
115 def get_result_navigation_display(check_results: List['CheckResult'], unique_id: str):
116 """Display the results as a table with links for navigation.
117
118 Parameters
119 ----------
120 check_results : Union['CheckResult', List['CheckResult']]
121 check results to show navigation for.
122 unique_id : str
123 the unique id to append for the check names to create links.
124 Returns
125 -------
126 str
127 html representation of the navigation table.
128 """
129 table = []
130 for check_result in check_results:
131 if check_result.have_display():
132 check_header = check_result.get_header()
133 check_id = f'{check_result.check.__class__.__name__}_{unique_id}'
134 link = f'<a href=#{check_id}>{check_header}</a>'
135 summary = get_docs_summary(check_result.check)
136 table.append([link, summary])
137
138 nav_table = pd.DataFrame(data=table,
139 columns=['Check', 'Summary'])
140 with warnings.catch_warnings():
141 warnings.simplefilter(action='ignore', category=FutureWarning)
142 return dataframe_to_html(nav_table.style.hide_index())
143
```
Path: `deepchecks/utils/typing.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Type definitions."""
12 # pylint: disable=invalid-hash-returned,invalid-name
13 from typing_extensions import Protocol, runtime_checkable
14 from typing import List
15
16
17 __all__ = ['Hashable', 'BasicModel', 'ClassificationModel']
18
19
20 @runtime_checkable
21 class Hashable(Protocol):
22 """Trait for any hashable type that also defines comparison operators."""
23
24 def __hash__(self) -> int: # noqa: D105
25 ...
26
27 def __le__(self, __value) -> bool: # noqa: D105
28 ...
29
30 def __lt__(self, __value) -> bool: # noqa: D105
31 ...
32
33 def __ge__(self, __value) -> bool: # noqa: D105
34 ...
35
36 def __gt__(self, __value) -> bool: # noqa: D105
37 ...
38
39 def __eq__(self, __value) -> bool: # noqa: D105
40 ...
41
42
43 @runtime_checkable
44 class BasicModel(Protocol):
45 """Traits of a model that are necessary for deepchecks."""
46
47 def predict(self, X) -> List[Hashable]:
48 """Predict on given X."""
49 ...
50
51
52 @runtime_checkable
53 class ClassificationModel(BasicModel, Protocol):
54 """Traits of a classification model that are used by deepchecks."""
55
56 def predict_proba(self, X) -> List[Hashable]:
57 """Predict probabilities on given X."""
58 ...
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/core/display_pandas.py b/deepchecks/core/display_pandas.py
--- a/deepchecks/core/display_pandas.py
+++ b/deepchecks/core/display_pandas.py
@@ -96,7 +96,8 @@
link = f'<a href=#{check_id}>{check_header}</a>'
else:
link = check_header
- sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top
+ # if it has no display show on bottom for the category (lower priority)
+ sort_value += 0.1
table.append([icon, link, cond_result.name,
cond_result.details, sort_value])
diff --git a/deepchecks/utils/typing.py b/deepchecks/utils/typing.py
--- a/deepchecks/utils/typing.py
+++ b/deepchecks/utils/typing.py
@@ -46,7 +46,6 @@
def predict(self, X) -> List[Hashable]:
"""Predict on given X."""
- ...
@runtime_checkable
@@ -55,4 +54,3 @@
def predict_proba(self, X) -> List[Hashable]:
"""Predict probabilities on given X."""
- ...
|
{"golden_diff": "diff --git a/deepchecks/core/display_pandas.py b/deepchecks/core/display_pandas.py\n--- a/deepchecks/core/display_pandas.py\n+++ b/deepchecks/core/display_pandas.py\n@@ -96,7 +96,8 @@\n link = f'<a href=#{check_id}>{check_header}</a>'\n else:\n link = check_header\n- sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top\n+ # if it has no display show on bottom for the category (lower priority)\n+ sort_value += 0.1\n table.append([icon, link, cond_result.name,\n cond_result.details, sort_value])\n \ndiff --git a/deepchecks/utils/typing.py b/deepchecks/utils/typing.py\n--- a/deepchecks/utils/typing.py\n+++ b/deepchecks/utils/typing.py\n@@ -46,7 +46,6 @@\n \n def predict(self, X) -> List[Hashable]:\n \"\"\"Predict on given X.\"\"\"\n- ...\n \n \n @runtime_checkable\n@@ -55,4 +54,3 @@\n \n def predict_proba(self, X) -> List[Hashable]:\n \"\"\"Predict probabilities on given X.\"\"\"\n- ...\n", "issue": "[BUG] Warning has been seen to appear below OK checks in suite condition table\n**Describe the bug**\r\nIn a certain case, the condition table has been seen to have a warning appear blow the OK checks\r\n\r\n**Expected behavior**\r\nCondition order in the table should be:\r\nFail with Display\r\nFail without Display\r\nWarning with Display\r\nWarning without Display\r\nPass with Display\r\nPass without Display\r\n\r\nOther then that order should conform to order of checks in the check_result. \r\n\r\n**Screenshots**\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle displays of pandas objects.\"\"\"\nfrom deepchecks.utils.strings import get_docs_summary, get_ellipsis\n\nfrom typing import List, Union, TYPE_CHECKING\nimport warnings\n\nimport pandas as pd\nfrom pandas.io.formats.style import Styler\n\n\nif TYPE_CHECKING:\n from deepchecks.core.check_result import CheckResult\n\n\n__all__ = ['dataframe_to_html', 'get_conditions_table']\n\n\ndef dataframe_to_html(df: Union[pd.DataFrame, Styler]):\n \"\"\"Convert dataframe to html.\n\n Parameters\n ----------\n df: Union[pd.DataFrame, Styler]\n Dataframe to convert to html\n\n Returns\n -------\n pd.DataFrame:\n dataframe with styling\n \"\"\"\n try:\n if isinstance(df, pd.DataFrame):\n df_styler = df.style\n else:\n df_styler = df\n # Using deprecated pandas method so hiding the warning\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n df_styler.set_precision(2)\n\n table_css_props = [\n ('text-align', 'left'), # Align everything to the left\n ('white-space', 'pre-wrap') # Define how to handle white space characters (like \\n)\n ]\n df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=table_css_props)])\n return df_styler.render()\n # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style\n # attribute, hence we need to display as a regular pd html format.\n except ValueError:\n return df.to_html()\n\n\ndef get_conditions_table(check_results: Union['CheckResult', List['CheckResult']],\n unique_id: str = None, max_info_len: int = 3000, icon_html: bool = True) -> Styler:\n \"\"\"Return the conditions table as DataFrame.\n\n Parameters\n ----------\n check_results : Union['CheckResult', List['CheckResult']]\n check results to show conditions of.\n unique_id : str\n the unique id to append for the check names to create links (won't create links if None/empty).\n max_info_len : int\n max length of the additional info.\n icon_html : bool , default: True\n if to show the html condition result icon or the enum\n Returns\n -------\n pd.Dataframe:\n the condition table.\n \"\"\"\n if not isinstance(check_results, List):\n show_check_column = False\n check_results = [check_results]\n else:\n show_check_column = True\n\n table = []\n for check_result in check_results:\n for cond_result in check_result.conditions_results:\n sort_value = cond_result.priority\n icon = cond_result.get_icon() if icon_html else cond_result.category.value\n check_header = check_result.get_header()\n if unique_id and check_result.have_display():\n check_id = f'{check_result.check.__class__.__name__}_{unique_id}'\n link = f'<a href=#{check_id}>{check_header}</a>'\n else:\n link = check_header\n sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top\n table.append([icon, link, cond_result.name,\n cond_result.details, sort_value])\n\n conditions_table = pd.DataFrame(data=table,\n columns=['Status', 'Check', 'Condition', 'More Info', 'sort'])\n conditions_table.sort_values(by=['sort'], inplace=True)\n conditions_table.drop('sort', axis=1, inplace=True)\n if show_check_column is False:\n conditions_table.drop('Check', axis=1, inplace=True)\n conditions_table['More Info'] = conditions_table['More Info'].map(lambda x: get_ellipsis(x, max_info_len))\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n return conditions_table.style.hide_index()\n\n\ndef get_result_navigation_display(check_results: List['CheckResult'], unique_id: str):\n \"\"\"Display the results as a table with links for navigation.\n\n Parameters\n ----------\n check_results : Union['CheckResult', List['CheckResult']]\n check results to show navigation for.\n unique_id : str\n the unique id to append for the check names to create links.\n Returns\n -------\n str\n html representation of the navigation table.\n \"\"\"\n table = []\n for check_result in check_results:\n if check_result.have_display():\n check_header = check_result.get_header()\n check_id = f'{check_result.check.__class__.__name__}_{unique_id}'\n link = f'<a href=#{check_id}>{check_header}</a>'\n summary = get_docs_summary(check_result.check)\n table.append([link, summary])\n\n nav_table = pd.DataFrame(data=table,\n columns=['Check', 'Summary'])\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n return dataframe_to_html(nav_table.style.hide_index())\n", "path": "deepchecks/core/display_pandas.py"}, {"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Type definitions.\"\"\"\n# pylint: disable=invalid-hash-returned,invalid-name\nfrom typing_extensions import Protocol, runtime_checkable\nfrom typing import List\n\n\n__all__ = ['Hashable', 'BasicModel', 'ClassificationModel']\n\n\n@runtime_checkable\nclass Hashable(Protocol):\n \"\"\"Trait for any hashable type that also defines comparison operators.\"\"\"\n\n def __hash__(self) -> int: # noqa: D105\n ...\n\n def __le__(self, __value) -> bool: # noqa: D105\n ...\n\n def __lt__(self, __value) -> bool: # noqa: D105\n ...\n\n def __ge__(self, __value) -> bool: # noqa: D105\n ...\n\n def __gt__(self, __value) -> bool: # noqa: D105\n ...\n\n def __eq__(self, __value) -> bool: # noqa: D105\n ...\n\n\n@runtime_checkable\nclass BasicModel(Protocol):\n \"\"\"Traits of a model that are necessary for deepchecks.\"\"\"\n\n def predict(self, X) -> List[Hashable]:\n \"\"\"Predict on given X.\"\"\"\n ...\n\n\n@runtime_checkable\nclass ClassificationModel(BasicModel, Protocol):\n \"\"\"Traits of a classification model that are used by deepchecks.\"\"\"\n\n def predict_proba(self, X) -> List[Hashable]:\n \"\"\"Predict probabilities on given X.\"\"\"\n ...\n", "path": "deepchecks/utils/typing.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle displays of pandas objects.\"\"\"\nfrom deepchecks.utils.strings import get_docs_summary, get_ellipsis\n\nfrom typing import List, Union, TYPE_CHECKING\nimport warnings\n\nimport pandas as pd\nfrom pandas.io.formats.style import Styler\n\n\nif TYPE_CHECKING:\n from deepchecks.core.check_result import CheckResult\n\n\n__all__ = ['dataframe_to_html', 'get_conditions_table']\n\n\ndef dataframe_to_html(df: Union[pd.DataFrame, Styler]):\n \"\"\"Convert dataframe to html.\n\n Parameters\n ----------\n df: Union[pd.DataFrame, Styler]\n Dataframe to convert to html\n\n Returns\n -------\n pd.DataFrame:\n dataframe with styling\n \"\"\"\n try:\n if isinstance(df, pd.DataFrame):\n df_styler = df.style\n else:\n df_styler = df\n # Using deprecated pandas method so hiding the warning\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n df_styler.set_precision(2)\n\n table_css_props = [\n ('text-align', 'left'), # Align everything to the left\n ('white-space', 'pre-wrap') # Define how to handle white space characters (like \\n)\n ]\n df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=table_css_props)])\n return df_styler.render()\n # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style\n # attribute, hence we need to display as a regular pd html format.\n except ValueError:\n return df.to_html()\n\n\ndef get_conditions_table(check_results: Union['CheckResult', List['CheckResult']],\n unique_id: str = None, max_info_len: int = 3000, icon_html: bool = True) -> Styler:\n \"\"\"Return the conditions table as DataFrame.\n\n Parameters\n ----------\n check_results : Union['CheckResult', List['CheckResult']]\n check results to show conditions of.\n unique_id : str\n the unique id to append for the check names to create links (won't create links if None/empty).\n max_info_len : int\n max length of the additional info.\n icon_html : bool , default: True\n if to show the html condition result icon or the enum\n Returns\n -------\n pd.Dataframe:\n the condition table.\n \"\"\"\n if not isinstance(check_results, List):\n show_check_column = False\n check_results = [check_results]\n else:\n show_check_column = True\n\n table = []\n for check_result in check_results:\n for cond_result in check_result.conditions_results:\n sort_value = cond_result.priority\n icon = cond_result.get_icon() if icon_html else cond_result.category.value\n check_header = check_result.get_header()\n if unique_id and check_result.have_display():\n check_id = f'{check_result.check.__class__.__name__}_{unique_id}'\n link = f'<a href=#{check_id}>{check_header}</a>'\n else:\n link = check_header\n # if it has no display show on bottom for the category (lower priority)\n sort_value += 0.1\n table.append([icon, link, cond_result.name,\n cond_result.details, sort_value])\n\n conditions_table = pd.DataFrame(data=table,\n columns=['Status', 'Check', 'Condition', 'More Info', 'sort'])\n conditions_table.sort_values(by=['sort'], inplace=True)\n conditions_table.drop('sort', axis=1, inplace=True)\n if show_check_column is False:\n conditions_table.drop('Check', axis=1, inplace=True)\n conditions_table['More Info'] = conditions_table['More Info'].map(lambda x: get_ellipsis(x, max_info_len))\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n return conditions_table.style.hide_index()\n\n\ndef get_result_navigation_display(check_results: List['CheckResult'], unique_id: str):\n \"\"\"Display the results as a table with links for navigation.\n\n Parameters\n ----------\n check_results : Union['CheckResult', List['CheckResult']]\n check results to show navigation for.\n unique_id : str\n the unique id to append for the check names to create links.\n Returns\n -------\n str\n html representation of the navigation table.\n \"\"\"\n table = []\n for check_result in check_results:\n if check_result.have_display():\n check_header = check_result.get_header()\n check_id = f'{check_result.check.__class__.__name__}_{unique_id}'\n link = f'<a href=#{check_id}>{check_header}</a>'\n summary = get_docs_summary(check_result.check)\n table.append([link, summary])\n\n nav_table = pd.DataFrame(data=table,\n columns=['Check', 'Summary'])\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n return dataframe_to_html(nav_table.style.hide_index())\n", "path": "deepchecks/core/display_pandas.py"}, {"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Type definitions.\"\"\"\n# pylint: disable=invalid-hash-returned,invalid-name\nfrom typing_extensions import Protocol, runtime_checkable\nfrom typing import List\n\n\n__all__ = ['Hashable', 'BasicModel', 'ClassificationModel']\n\n\n@runtime_checkable\nclass Hashable(Protocol):\n \"\"\"Trait for any hashable type that also defines comparison operators.\"\"\"\n\n def __hash__(self) -> int: # noqa: D105\n ...\n\n def __le__(self, __value) -> bool: # noqa: D105\n ...\n\n def __lt__(self, __value) -> bool: # noqa: D105\n ...\n\n def __ge__(self, __value) -> bool: # noqa: D105\n ...\n\n def __gt__(self, __value) -> bool: # noqa: D105\n ...\n\n def __eq__(self, __value) -> bool: # noqa: D105\n ...\n\n\n@runtime_checkable\nclass BasicModel(Protocol):\n \"\"\"Traits of a model that are necessary for deepchecks.\"\"\"\n\n def predict(self, X) -> List[Hashable]:\n \"\"\"Predict on given X.\"\"\"\n\n\n@runtime_checkable\nclass ClassificationModel(BasicModel, Protocol):\n \"\"\"Traits of a classification model that are used by deepchecks.\"\"\"\n\n def predict_proba(self, X) -> List[Hashable]:\n \"\"\"Predict probabilities on given X.\"\"\"\n", "path": "deepchecks/utils/typing.py"}]}
| 2,542 | 280 |
gh_patches_debug_36676
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-2767
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py`
Content:
```
1 from typing import Optional
2
3 import torch
4 import torch.distributed as dist
5 import torch.nn as nn
6 import torch.optim as optim
7
8 import colossalai
9 from colossalai.nn.optimizer import CPUAdam, HybridAdam
10 from colossalai.nn.parallel import zero_model_wrapper, zero_optim_wrapper
11 from colossalai.tensor import ProcessGroup, ShardSpec
12 from colossalai.utils import get_current_device
13 from colossalai.utils.model.colo_init_context import ColoInitContext
14
15 from .ddp import DDPStrategy
16
17
18 class ColossalAIStrategy(DDPStrategy):
19 """
20 The strategy for training with ColossalAI.
21
22 Args:
23 stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
24 seed(int): The seed for the random number generator.
25 shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
26 placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')
27 If it is “cpu”, parameters, gradients and optimizer states will be offloaded to CPU,
28 If it is “cuda”, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.
29 pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.
30 force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.
31 search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.
32 hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.
33 min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.
34 gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.
35 reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.
36 overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.
37 initial_scale(float): The initial scale for the optimizer.
38 growth_factor(float): The growth factor for the optimizer.
39 backoff_factor(float): The backoff factor for the optimizer.
40 growth_interval(int): The growth interval for the optimizer.
41 hysteresis(int): The hysteresis for the optimizer.
42 min_scale(float): The minimum scale for the optimizer.
43 max_scale(float): The maximum scale for the optimizer.
44 max_norm(float): The maximum norm for the optimizer.
45 norm_type(float): The norm type for the optimizer.
46
47 """
48
49 def __init__(
50 self,
51 stage: int = 3,
52 seed: int = 42,
53 shard_init: bool = True, # only for stage 3
54 placement_policy: str = 'cuda',
55 pin_memory: bool = True, # only for stage 3
56 force_outputs_fp32: bool = False, # only for stage 3
57 search_range_mb: int = 32, # only for stage 3
58 hidden_dim: Optional[int] = None, # only for stage 3
59 min_chunk_size_mb: float = 32, # only for stage 3
60 gpu_margin_mem_ratio: float = 0.0, # only for stage 3
61 reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2
62 overlap_communication: bool = True, # only for stage 1&2
63 initial_scale: float = 2**16,
64 growth_factor: float = 2,
65 backoff_factor: float = 0.5,
66 growth_interval: int = 1000,
67 hysteresis: int = 2,
68 min_scale: float = 1,
69 max_scale: float = 2**32,
70 max_norm: float = 0.0,
71 norm_type: float = 2.0) -> None:
72 super().__init__(seed)
73 assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
74 self.stage = stage
75 self.shard_init = shard_init
76 self.gemini_config = dict(device=get_current_device(),
77 placement_policy=placement_policy,
78 pin_memory=pin_memory,
79 force_outputs_fp32=force_outputs_fp32,
80 strict_ddp_mode=shard_init,
81 search_range_mb=search_range_mb,
82 hidden_dim=hidden_dim,
83 min_chunk_size_mb=min_chunk_size_mb)
84 if stage == 3:
85 self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)
86 else:
87 self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,
88 overlap_communication=overlap_communication,
89 cpu_offload=(placement_policy == 'cpu'))
90 self.optim_kwargs = dict(initial_scale=initial_scale,
91 growth_factor=growth_factor,
92 backoff_factor=backoff_factor,
93 growth_interval=growth_interval,
94 hysteresis=hysteresis,
95 min_scale=min_scale,
96 max_scale=max_scale,
97 max_norm=max_norm,
98 norm_type=norm_type)
99
100 def setup_distributed(self) -> None:
101 colossalai.launch_from_torch({}, seed=self.seed)
102
103 def model_init_context(self):
104 if self.stage == 3:
105 world_size = dist.get_world_size()
106 shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None
107 default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None
108 return ColoInitContext(device=get_current_device(),
109 dtype=torch.half,
110 default_pg=shard_pg,
111 default_dist_spec=default_dist_spec)
112 return super().model_init_context()
113
114 def setup_model(self, model: nn.Module) -> nn.Module:
115 return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
116
117 def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
118 assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'
119 return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)
120
121 def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
122 optimizer.backward(loss)
123
124 def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
125 optimizer.step()
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
--- a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
@@ -1,3 +1,4 @@
+import warnings
from typing import Optional
import torch
@@ -23,6 +24,7 @@
stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
seed(int): The seed for the random number generator.
shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
+ This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.
placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')
If it is “cpu”, parameters, gradients and optimizer states will be offloaded to CPU,
If it is “cuda”, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.
@@ -50,7 +52,7 @@
self,
stage: int = 3,
seed: int = 42,
- shard_init: bool = True, # only for stage 3
+ shard_init: bool = False, # only for stage 3
placement_policy: str = 'cuda',
pin_memory: bool = True, # only for stage 3
force_outputs_fp32: bool = False, # only for stage 3
@@ -72,6 +74,10 @@
super().__init__(seed)
assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
self.stage = stage
+ # TODO(ver217): support shard_init when using from_pretrained()
+ if shard_init:
+ warnings.warn(f'Shard init is not supported yet. Ignore.')
+ shard_init = False
self.shard_init = shard_init
self.gemini_config = dict(device=get_current_device(),
placement_policy=placement_policy,
|
{"golden_diff": "diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n--- a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n+++ b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n@@ -1,3 +1,4 @@\n+import warnings\n from typing import Optional\n \n import torch\n@@ -23,6 +24,7 @@\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n+ This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.\n placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')\n If it is \u201ccpu\u201d, parameters, gradients and optimizer states will be offloaded to CPU,\n If it is \u201ccuda\u201d, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.\n@@ -50,7 +52,7 @@\n self,\n stage: int = 3,\n seed: int = 42,\n- shard_init: bool = True, # only for stage 3\n+ shard_init: bool = False, # only for stage 3\n placement_policy: str = 'cuda',\n pin_memory: bool = True, # only for stage 3\n force_outputs_fp32: bool = False, # only for stage 3\n@@ -72,6 +74,10 @@\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n self.stage = stage\n+ # TODO(ver217): support shard_init when using from_pretrained()\n+ if shard_init:\n+ warnings.warn(f'Shard init is not supported yet. Ignore.')\n+ shard_init = False\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from typing import Optional\n\nimport torch\nimport torch.distributed as dist\nimport torch.nn as nn\nimport torch.optim as optim\n\nimport colossalai\nfrom colossalai.nn.optimizer import CPUAdam, HybridAdam\nfrom colossalai.nn.parallel import zero_model_wrapper, zero_optim_wrapper\nfrom colossalai.tensor import ProcessGroup, ShardSpec\nfrom colossalai.utils import get_current_device\nfrom colossalai.utils.model.colo_init_context import ColoInitContext\n\nfrom .ddp import DDPStrategy\n\n\nclass ColossalAIStrategy(DDPStrategy):\n \"\"\"\n The strategy for training with ColossalAI.\n\n Args:\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')\n If it is \u201ccpu\u201d, parameters, gradients and optimizer states will be offloaded to CPU,\n If it is \u201ccuda\u201d, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.\n pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.\n force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.\n search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.\n hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.\n min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.\n gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.\n reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.\n overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.\n initial_scale(float): The initial scale for the optimizer.\n growth_factor(float): The growth factor for the optimizer.\n backoff_factor(float): The backoff factor for the optimizer.\n growth_interval(int): The growth interval for the optimizer.\n hysteresis(int): The hysteresis for the optimizer.\n min_scale(float): The minimum scale for the optimizer.\n max_scale(float): The maximum scale for the optimizer.\n max_norm(float): The maximum norm for the optimizer.\n norm_type(float): The norm type for the optimizer.\n\n \"\"\"\n\n def __init__(\n self,\n stage: int = 3,\n seed: int = 42,\n shard_init: bool = True, # only for stage 3\n placement_policy: str = 'cuda',\n pin_memory: bool = True, # only for stage 3\n force_outputs_fp32: bool = False, # only for stage 3\n search_range_mb: int = 32, # only for stage 3\n hidden_dim: Optional[int] = None, # only for stage 3\n min_chunk_size_mb: float = 32, # only for stage 3\n gpu_margin_mem_ratio: float = 0.0, # only for stage 3\n reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2\n overlap_communication: bool = True, # only for stage 1&2\n initial_scale: float = 2**16,\n growth_factor: float = 2,\n backoff_factor: float = 0.5,\n growth_interval: int = 1000,\n hysteresis: int = 2,\n min_scale: float = 1,\n max_scale: float = 2**32,\n max_norm: float = 0.0,\n norm_type: float = 2.0) -> None:\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n self.stage = stage\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n pin_memory=pin_memory,\n force_outputs_fp32=force_outputs_fp32,\n strict_ddp_mode=shard_init,\n search_range_mb=search_range_mb,\n hidden_dim=hidden_dim,\n min_chunk_size_mb=min_chunk_size_mb)\n if stage == 3:\n self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)\n else:\n self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,\n overlap_communication=overlap_communication,\n cpu_offload=(placement_policy == 'cpu'))\n self.optim_kwargs = dict(initial_scale=initial_scale,\n growth_factor=growth_factor,\n backoff_factor=backoff_factor,\n growth_interval=growth_interval,\n hysteresis=hysteresis,\n min_scale=min_scale,\n max_scale=max_scale,\n max_norm=max_norm,\n norm_type=norm_type)\n\n def setup_distributed(self) -> None:\n colossalai.launch_from_torch({}, seed=self.seed)\n\n def model_init_context(self):\n if self.stage == 3:\n world_size = dist.get_world_size()\n shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None\n default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None\n return ColoInitContext(device=get_current_device(),\n dtype=torch.half,\n default_pg=shard_pg,\n default_dist_spec=default_dist_spec)\n return super().model_init_context()\n\n def setup_model(self, model: nn.Module) -> nn.Module:\n return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n\n def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:\n assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'\n return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)\n\n def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.backward(loss)\n\n def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.step()\n", "path": "applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py"}], "after_files": [{"content": "import warnings\nfrom typing import Optional\n\nimport torch\nimport torch.distributed as dist\nimport torch.nn as nn\nimport torch.optim as optim\n\nimport colossalai\nfrom colossalai.nn.optimizer import CPUAdam, HybridAdam\nfrom colossalai.nn.parallel import zero_model_wrapper, zero_optim_wrapper\nfrom colossalai.tensor import ProcessGroup, ShardSpec\nfrom colossalai.utils import get_current_device\nfrom colossalai.utils.model.colo_init_context import ColoInitContext\n\nfrom .ddp import DDPStrategy\n\n\nclass ColossalAIStrategy(DDPStrategy):\n \"\"\"\n The strategy for training with ColossalAI.\n\n Args:\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.\n placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')\n If it is \u201ccpu\u201d, parameters, gradients and optimizer states will be offloaded to CPU,\n If it is \u201ccuda\u201d, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.\n pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.\n force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.\n search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.\n hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.\n min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.\n gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.\n reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.\n overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.\n initial_scale(float): The initial scale for the optimizer.\n growth_factor(float): The growth factor for the optimizer.\n backoff_factor(float): The backoff factor for the optimizer.\n growth_interval(int): The growth interval for the optimizer.\n hysteresis(int): The hysteresis for the optimizer.\n min_scale(float): The minimum scale for the optimizer.\n max_scale(float): The maximum scale for the optimizer.\n max_norm(float): The maximum norm for the optimizer.\n norm_type(float): The norm type for the optimizer.\n\n \"\"\"\n\n def __init__(\n self,\n stage: int = 3,\n seed: int = 42,\n shard_init: bool = False, # only for stage 3\n placement_policy: str = 'cuda',\n pin_memory: bool = True, # only for stage 3\n force_outputs_fp32: bool = False, # only for stage 3\n search_range_mb: int = 32, # only for stage 3\n hidden_dim: Optional[int] = None, # only for stage 3\n min_chunk_size_mb: float = 32, # only for stage 3\n gpu_margin_mem_ratio: float = 0.0, # only for stage 3\n reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2\n overlap_communication: bool = True, # only for stage 1&2\n initial_scale: float = 2**16,\n growth_factor: float = 2,\n backoff_factor: float = 0.5,\n growth_interval: int = 1000,\n hysteresis: int = 2,\n min_scale: float = 1,\n max_scale: float = 2**32,\n max_norm: float = 0.0,\n norm_type: float = 2.0) -> None:\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n self.stage = stage\n # TODO(ver217): support shard_init when using from_pretrained()\n if shard_init:\n warnings.warn(f'Shard init is not supported yet. Ignore.')\n shard_init = False\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n pin_memory=pin_memory,\n force_outputs_fp32=force_outputs_fp32,\n strict_ddp_mode=shard_init,\n search_range_mb=search_range_mb,\n hidden_dim=hidden_dim,\n min_chunk_size_mb=min_chunk_size_mb)\n if stage == 3:\n self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)\n else:\n self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,\n overlap_communication=overlap_communication,\n cpu_offload=(placement_policy == 'cpu'))\n self.optim_kwargs = dict(initial_scale=initial_scale,\n growth_factor=growth_factor,\n backoff_factor=backoff_factor,\n growth_interval=growth_interval,\n hysteresis=hysteresis,\n min_scale=min_scale,\n max_scale=max_scale,\n max_norm=max_norm,\n norm_type=norm_type)\n\n def setup_distributed(self) -> None:\n colossalai.launch_from_torch({}, seed=self.seed)\n\n def model_init_context(self):\n if self.stage == 3:\n world_size = dist.get_world_size()\n shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None\n default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None\n return ColoInitContext(device=get_current_device(),\n dtype=torch.half,\n default_pg=shard_pg,\n default_dist_spec=default_dist_spec)\n return super().model_init_context()\n\n def setup_model(self, model: nn.Module) -> nn.Module:\n return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n\n def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:\n assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'\n return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)\n\n def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.backward(loss)\n\n def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.step()\n", "path": "applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py"}]}
| 1,989 | 505 |
gh_patches_debug_2629
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1880
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ImproperlyConfigured: Field name `language` is not valid for model `Profile`.
Sentry Issue: [CONCREXIT-8J](https://sentry.io/organizations/thalia/issues/2580014551/?referrer=github_integration)
```
ImproperlyConfigured: Field name `language` is not valid for model `Profile`.
(14 additional frame(s) were not displayed)
...
File "django/utils/functional.py", line 48, in __get__
res = instance.__dict__[self.name] = self.func(instance)
File "rest_framework/serializers.py", line 349, in fields
for key, value in self.get_fields().items():
File "rest_framework/serializers.py", line 1053, in get_fields
field_class, field_kwargs = self.build_field(
File "rest_framework/serializers.py", line 1199, in build_field
return self.build_unknown_field(field_name, model_class)
File "rest_framework/serializers.py", line 1317, in build_unknown_field
raise ImproperlyConfigured(
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/members/api/v1/serializers.py`
Content:
```
1 """DRF serializers defined by the members package."""
2 from django.templatetags.static import static
3 from rest_framework import serializers
4
5 from members.models import Member, Profile
6 from members.services import member_achievements, member_societies
7 from thaliawebsite.api.services import create_image_thumbnail_dict
8
9
10 class ProfileRetrieveSerializer(serializers.ModelSerializer):
11 """Serializer that renders a member profile."""
12
13 class Meta:
14 model = Profile
15 fields = (
16 "pk",
17 "display_name",
18 "avatar",
19 "profile_description",
20 "birthday",
21 "starting_year",
22 "programme",
23 "website",
24 "membership_type",
25 "achievements",
26 "societies",
27 )
28
29 pk = serializers.SerializerMethodField("_pk")
30 avatar = serializers.SerializerMethodField("_avatar")
31 birthday = serializers.SerializerMethodField("_birthday")
32 membership_type = serializers.SerializerMethodField("_membership_type")
33 achievements = serializers.SerializerMethodField("_achievements")
34 societies = serializers.SerializerMethodField("_societies")
35
36 def _pk(self, instance):
37 return instance.user.pk
38
39 def _birthday(self, instance):
40 if instance.show_birthday:
41 return instance.birthday
42 return None
43
44 def _membership_type(self, instance):
45 membership = instance.user.current_membership
46 if membership:
47 return membership.type
48 return None
49
50 def _achievements(self, instance):
51 return member_achievements(instance.user)
52
53 def _societies(self, instance):
54 return member_societies(instance.user)
55
56 def _avatar(self, instance):
57 placeholder = self.context["request"].build_absolute_uri(
58 static("members/images/default-avatar.jpg")
59 )
60 file = None
61 if instance.photo:
62 file = instance.photo
63 return create_image_thumbnail_dict(
64 self.context["request"], file, placeholder=placeholder, size_large="800x800"
65 )
66
67
68 class MemberListSerializer(serializers.ModelSerializer):
69 """Serializer that renders a list of members."""
70
71 class Meta:
72 model = Member
73 fields = ("pk", "starting_year", "display_name", "membership_type", "avatar")
74
75 display_name = serializers.SerializerMethodField("_display_name")
76 starting_year = serializers.SerializerMethodField("_starting_year")
77 avatar = serializers.SerializerMethodField("_avatar")
78 membership_type = serializers.SerializerMethodField("_membership_type")
79
80 def _display_name(self, instance):
81 return instance.profile.display_name()
82
83 def _starting_year(self, instance):
84 return instance.profile.starting_year
85
86 def _avatar(self, instance):
87 placeholder = self.context["request"].build_absolute_uri(
88 static("members/images/default-avatar.jpg")
89 )
90 file = None
91 if instance.profile.photo:
92 file = instance.profile.photo
93 return create_image_thumbnail_dict(
94 self.context["request"], file, placeholder=placeholder, size_large="800x800"
95 )
96
97 def _membership_type(self, instance):
98 membership = instance.current_membership
99 if membership:
100 return membership.type
101 return None
102
103
104 class ProfileEditSerializer(serializers.ModelSerializer):
105 """Serializer that renders a profile to be edited."""
106
107 class Meta:
108 model = Profile
109 fields = (
110 "pk",
111 "email",
112 "first_name",
113 "last_name",
114 "address_street",
115 "address_street2",
116 "address_postal_code",
117 "address_city",
118 "address_country",
119 "phone_number",
120 "show_birthday",
121 "website",
122 "photo",
123 "emergency_contact",
124 "emergency_contact_phone_number",
125 "profile_description",
126 "nickname",
127 "display_name_preference",
128 "language",
129 "receive_optin",
130 "receive_newsletter",
131 "receive_magazine",
132 "display_name",
133 "avatar",
134 "birthday",
135 "starting_year",
136 "programme",
137 "membership_type",
138 "achievements",
139 "societies",
140 )
141
142 read_only_fields = ("display_name", "starting_year", "programme", "birthday")
143
144 pk = serializers.SerializerMethodField("_pk")
145 email = serializers.SerializerMethodField("_email")
146 first_name = serializers.SerializerMethodField("_first_name")
147 last_name = serializers.SerializerMethodField("_last_name")
148 avatar = serializers.SerializerMethodField("_avatar")
149 membership_type = serializers.SerializerMethodField("_membership_type")
150 achievements = serializers.SerializerMethodField("_achievements")
151 societies = serializers.SerializerMethodField("_societies")
152
153 def _pk(self, instance):
154 return instance.user.pk
155
156 def _email(self, instance):
157 return instance.user.email
158
159 def _first_name(self, instance):
160 return instance.user.first_name
161
162 def _last_name(self, instance):
163 return instance.user.last_name
164
165 def _membership_type(self, instance):
166 membership = instance.user.current_membership
167 if membership:
168 return membership.type
169 return None
170
171 def _achievements(self, instance):
172 return member_achievements(instance.user)
173
174 def _societies(self, instance):
175 return member_societies(instance.user)
176
177 def _avatar(self, instance):
178 placeholder = self.context["request"].build_absolute_uri(
179 static("members/images/default-avatar.jpg")
180 )
181 file = None
182 if instance.photo:
183 file = instance.photo
184 return create_image_thumbnail_dict(
185 self.context["request"], file, placeholder=placeholder, size_large="800x800"
186 )
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/members/api/v1/serializers.py b/website/members/api/v1/serializers.py
--- a/website/members/api/v1/serializers.py
+++ b/website/members/api/v1/serializers.py
@@ -125,7 +125,6 @@
"profile_description",
"nickname",
"display_name_preference",
- "language",
"receive_optin",
"receive_newsletter",
"receive_magazine",
|
{"golden_diff": "diff --git a/website/members/api/v1/serializers.py b/website/members/api/v1/serializers.py\n--- a/website/members/api/v1/serializers.py\n+++ b/website/members/api/v1/serializers.py\n@@ -125,7 +125,6 @@\n \"profile_description\",\n \"nickname\",\n \"display_name_preference\",\n- \"language\",\n \"receive_optin\",\n \"receive_newsletter\",\n \"receive_magazine\",\n", "issue": "ImproperlyConfigured: Field name `language` is not valid for model `Profile`.\nSentry Issue: [CONCREXIT-8J](https://sentry.io/organizations/thalia/issues/2580014551/?referrer=github_integration)\n\n```\nImproperlyConfigured: Field name `language` is not valid for model `Profile`.\n(14 additional frame(s) were not displayed)\n...\n File \"django/utils/functional.py\", line 48, in __get__\n res = instance.__dict__[self.name] = self.func(instance)\n File \"rest_framework/serializers.py\", line 349, in fields\n for key, value in self.get_fields().items():\n File \"rest_framework/serializers.py\", line 1053, in get_fields\n field_class, field_kwargs = self.build_field(\n File \"rest_framework/serializers.py\", line 1199, in build_field\n return self.build_unknown_field(field_name, model_class)\n File \"rest_framework/serializers.py\", line 1317, in build_unknown_field\n raise ImproperlyConfigured(\n```\n", "before_files": [{"content": "\"\"\"DRF serializers defined by the members package.\"\"\"\nfrom django.templatetags.static import static\nfrom rest_framework import serializers\n\nfrom members.models import Member, Profile\nfrom members.services import member_achievements, member_societies\nfrom thaliawebsite.api.services import create_image_thumbnail_dict\n\n\nclass ProfileRetrieveSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a member profile.\"\"\"\n\n class Meta:\n model = Profile\n fields = (\n \"pk\",\n \"display_name\",\n \"avatar\",\n \"profile_description\",\n \"birthday\",\n \"starting_year\",\n \"programme\",\n \"website\",\n \"membership_type\",\n \"achievements\",\n \"societies\",\n )\n\n pk = serializers.SerializerMethodField(\"_pk\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n birthday = serializers.SerializerMethodField(\"_birthday\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n achievements = serializers.SerializerMethodField(\"_achievements\")\n societies = serializers.SerializerMethodField(\"_societies\")\n\n def _pk(self, instance):\n return instance.user.pk\n\n def _birthday(self, instance):\n if instance.show_birthday:\n return instance.birthday\n return None\n\n def _membership_type(self, instance):\n membership = instance.user.current_membership\n if membership:\n return membership.type\n return None\n\n def _achievements(self, instance):\n return member_achievements(instance.user)\n\n def _societies(self, instance):\n return member_societies(instance.user)\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.photo:\n file = instance.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n\nclass MemberListSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a list of members.\"\"\"\n\n class Meta:\n model = Member\n fields = (\"pk\", \"starting_year\", \"display_name\", \"membership_type\", \"avatar\")\n\n display_name = serializers.SerializerMethodField(\"_display_name\")\n starting_year = serializers.SerializerMethodField(\"_starting_year\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n\n def _display_name(self, instance):\n return instance.profile.display_name()\n\n def _starting_year(self, instance):\n return instance.profile.starting_year\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.profile.photo:\n file = instance.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n def _membership_type(self, instance):\n membership = instance.current_membership\n if membership:\n return membership.type\n return None\n\n\nclass ProfileEditSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a profile to be edited.\"\"\"\n\n class Meta:\n model = Profile\n fields = (\n \"pk\",\n \"email\",\n \"first_name\",\n \"last_name\",\n \"address_street\",\n \"address_street2\",\n \"address_postal_code\",\n \"address_city\",\n \"address_country\",\n \"phone_number\",\n \"show_birthday\",\n \"website\",\n \"photo\",\n \"emergency_contact\",\n \"emergency_contact_phone_number\",\n \"profile_description\",\n \"nickname\",\n \"display_name_preference\",\n \"language\",\n \"receive_optin\",\n \"receive_newsletter\",\n \"receive_magazine\",\n \"display_name\",\n \"avatar\",\n \"birthday\",\n \"starting_year\",\n \"programme\",\n \"membership_type\",\n \"achievements\",\n \"societies\",\n )\n\n read_only_fields = (\"display_name\", \"starting_year\", \"programme\", \"birthday\")\n\n pk = serializers.SerializerMethodField(\"_pk\")\n email = serializers.SerializerMethodField(\"_email\")\n first_name = serializers.SerializerMethodField(\"_first_name\")\n last_name = serializers.SerializerMethodField(\"_last_name\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n achievements = serializers.SerializerMethodField(\"_achievements\")\n societies = serializers.SerializerMethodField(\"_societies\")\n\n def _pk(self, instance):\n return instance.user.pk\n\n def _email(self, instance):\n return instance.user.email\n\n def _first_name(self, instance):\n return instance.user.first_name\n\n def _last_name(self, instance):\n return instance.user.last_name\n\n def _membership_type(self, instance):\n membership = instance.user.current_membership\n if membership:\n return membership.type\n return None\n\n def _achievements(self, instance):\n return member_achievements(instance.user)\n\n def _societies(self, instance):\n return member_societies(instance.user)\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.photo:\n file = instance.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n", "path": "website/members/api/v1/serializers.py"}], "after_files": [{"content": "\"\"\"DRF serializers defined by the members package.\"\"\"\nfrom django.templatetags.static import static\nfrom rest_framework import serializers\n\nfrom members.models import Member, Profile\nfrom members.services import member_achievements, member_societies\nfrom thaliawebsite.api.services import create_image_thumbnail_dict\n\n\nclass ProfileRetrieveSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a member profile.\"\"\"\n\n class Meta:\n model = Profile\n fields = (\n \"pk\",\n \"display_name\",\n \"avatar\",\n \"profile_description\",\n \"birthday\",\n \"starting_year\",\n \"programme\",\n \"website\",\n \"membership_type\",\n \"achievements\",\n \"societies\",\n )\n\n pk = serializers.SerializerMethodField(\"_pk\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n birthday = serializers.SerializerMethodField(\"_birthday\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n achievements = serializers.SerializerMethodField(\"_achievements\")\n societies = serializers.SerializerMethodField(\"_societies\")\n\n def _pk(self, instance):\n return instance.user.pk\n\n def _birthday(self, instance):\n if instance.show_birthday:\n return instance.birthday\n return None\n\n def _membership_type(self, instance):\n membership = instance.user.current_membership\n if membership:\n return membership.type\n return None\n\n def _achievements(self, instance):\n return member_achievements(instance.user)\n\n def _societies(self, instance):\n return member_societies(instance.user)\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.photo:\n file = instance.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n\nclass MemberListSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a list of members.\"\"\"\n\n class Meta:\n model = Member\n fields = (\"pk\", \"starting_year\", \"display_name\", \"membership_type\", \"avatar\")\n\n display_name = serializers.SerializerMethodField(\"_display_name\")\n starting_year = serializers.SerializerMethodField(\"_starting_year\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n\n def _display_name(self, instance):\n return instance.profile.display_name()\n\n def _starting_year(self, instance):\n return instance.profile.starting_year\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.profile.photo:\n file = instance.profile.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n\n def _membership_type(self, instance):\n membership = instance.current_membership\n if membership:\n return membership.type\n return None\n\n\nclass ProfileEditSerializer(serializers.ModelSerializer):\n \"\"\"Serializer that renders a profile to be edited.\"\"\"\n\n class Meta:\n model = Profile\n fields = (\n \"pk\",\n \"email\",\n \"first_name\",\n \"last_name\",\n \"address_street\",\n \"address_street2\",\n \"address_postal_code\",\n \"address_city\",\n \"address_country\",\n \"phone_number\",\n \"show_birthday\",\n \"website\",\n \"photo\",\n \"emergency_contact\",\n \"emergency_contact_phone_number\",\n \"profile_description\",\n \"nickname\",\n \"display_name_preference\",\n \"receive_optin\",\n \"receive_newsletter\",\n \"receive_magazine\",\n \"display_name\",\n \"avatar\",\n \"birthday\",\n \"starting_year\",\n \"programme\",\n \"membership_type\",\n \"achievements\",\n \"societies\",\n )\n\n read_only_fields = (\"display_name\", \"starting_year\", \"programme\", \"birthday\")\n\n pk = serializers.SerializerMethodField(\"_pk\")\n email = serializers.SerializerMethodField(\"_email\")\n first_name = serializers.SerializerMethodField(\"_first_name\")\n last_name = serializers.SerializerMethodField(\"_last_name\")\n avatar = serializers.SerializerMethodField(\"_avatar\")\n membership_type = serializers.SerializerMethodField(\"_membership_type\")\n achievements = serializers.SerializerMethodField(\"_achievements\")\n societies = serializers.SerializerMethodField(\"_societies\")\n\n def _pk(self, instance):\n return instance.user.pk\n\n def _email(self, instance):\n return instance.user.email\n\n def _first_name(self, instance):\n return instance.user.first_name\n\n def _last_name(self, instance):\n return instance.user.last_name\n\n def _membership_type(self, instance):\n membership = instance.user.current_membership\n if membership:\n return membership.type\n return None\n\n def _achievements(self, instance):\n return member_achievements(instance.user)\n\n def _societies(self, instance):\n return member_societies(instance.user)\n\n def _avatar(self, instance):\n placeholder = self.context[\"request\"].build_absolute_uri(\n static(\"members/images/default-avatar.jpg\")\n )\n file = None\n if instance.photo:\n file = instance.photo\n return create_image_thumbnail_dict(\n self.context[\"request\"], file, placeholder=placeholder, size_large=\"800x800\"\n )\n", "path": "website/members/api/v1/serializers.py"}]}
| 2,134 | 108 |
gh_patches_debug_50780
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-3745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Explicitly depend on setuptools
Context: #3295
We should explicitly depend on a minimum version of setuptools to get around problems installing our packages if setuptools is too old.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/setup.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 from setuptools import find_packages
18 from setuptools import setup
19
20
21 PACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))
22
23 with open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:
24 README = file_obj.read()
25
26 # NOTE: This is duplicated throughout and we should try to
27 # consolidate.
28 SETUP_BASE = {
29 'author': 'Google Cloud Platform',
30 'author_email': '[email protected]',
31 'scripts': [],
32 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',
33 'license': 'Apache 2.0',
34 'platforms': 'Posix; MacOS X; Windows',
35 'include_package_data': True,
36 'zip_safe': False,
37 'classifiers': [
38 'Development Status :: 4 - Beta',
39 'Intended Audience :: Developers',
40 'License :: OSI Approved :: Apache Software License',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 2',
43 'Programming Language :: Python :: 2.7',
44 'Programming Language :: Python :: 3',
45 'Programming Language :: Python :: 3.4',
46 'Programming Language :: Python :: 3.5',
47 'Programming Language :: Python :: 3.6',
48 'Topic :: Internet',
49 ],
50 }
51
52
53 REQUIREMENTS = [
54 'googleapis-common-protos >= 1.3.4',
55 'protobuf >= 3.0.0',
56 'google-auth >= 0.4.0, < 2.0.0dev',
57 'requests >= 2.4.0, < 3.0.0dev',
58 'six',
59 'tenacity >= 4.0.0, <5.0.0dev'
60 ]
61
62 setup(
63 name='google-cloud-core',
64 version='0.26.0',
65 description='API Client library for Google Cloud: Core Helpers',
66 long_description=README,
67 namespace_packages=[
68 'google',
69 'google.cloud',
70 'google.api',
71 ],
72 packages=find_packages(exclude=('tests*',)),
73 install_requires=REQUIREMENTS,
74 **SETUP_BASE
75 )
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -55,6 +55,7 @@
'protobuf >= 3.0.0',
'google-auth >= 0.4.0, < 2.0.0dev',
'requests >= 2.4.0, < 3.0.0dev',
+ 'setuptools >= 34.0.0',
'six',
'tenacity >= 4.0.0, <5.0.0dev'
]
|
{"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -55,6 +55,7 @@\n 'protobuf >= 3.0.0',\n 'google-auth >= 0.4.0, < 2.0.0dev',\n 'requests >= 2.4.0, < 3.0.0dev',\n+ 'setuptools >= 34.0.0',\n 'six',\n 'tenacity >= 4.0.0, <5.0.0dev'\n ]\n", "issue": "Explicitly depend on setuptools\nContext: #3295\r\n\r\nWe should explicitly depend on a minimum version of setuptools to get around problems installing our packages if setuptools is too old.\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'googleapis-common-protos >= 1.3.4',\n 'protobuf >= 3.0.0',\n 'google-auth >= 0.4.0, < 2.0.0dev',\n 'requests >= 2.4.0, < 3.0.0dev',\n 'six',\n 'tenacity >= 4.0.0, <5.0.0dev'\n]\n\nsetup(\n name='google-cloud-core',\n version='0.26.0',\n description='API Client library for Google Cloud: Core Helpers',\n long_description=README,\n namespace_packages=[\n 'google',\n 'google.cloud',\n 'google.api',\n ],\n packages=find_packages(exclude=('tests*',)),\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "core/setup.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'googleapis-common-protos >= 1.3.4',\n 'protobuf >= 3.0.0',\n 'google-auth >= 0.4.0, < 2.0.0dev',\n 'requests >= 2.4.0, < 3.0.0dev',\n 'setuptools >= 34.0.0',\n 'six',\n 'tenacity >= 4.0.0, <5.0.0dev'\n]\n\nsetup(\n name='google-cloud-core',\n version='0.26.0',\n description='API Client library for Google Cloud: Core Helpers',\n long_description=README,\n namespace_packages=[\n 'google',\n 'google.cloud',\n 'google.api',\n ],\n packages=find_packages(exclude=('tests*',)),\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "core/setup.py"}]}
| 1,034 | 127 |
gh_patches_debug_16165
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6240
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Viewing profile of user with Persona account generates an ISE
**Summary**
It seems that viewing the profile of a user who has a Persona social account triggers an ISE.
**Steps To Reproduce (STR)**
1. Visit https://developer.allizom.org/en-US/profiles/sheppy
2. It will generate a 500 error
3. Visit https://developer.allizom.org/en-US/profiles/escattone
4. Displays fine
**Actual behavior**
Returns 500 (internal server error)
**Expected behavior**
Success display of user's profile page
**Additional context**
This seems to be related to one or more of the account PR's that were merged prior to deploying to stage.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/users/templatetags/jinja_helpers.py`
Content:
```
1 from allauth.account.utils import user_display
2 from allauth.socialaccount import providers
3 from allauth.socialaccount.templatetags.socialaccount import get_providers
4 from allauth.utils import get_request_param
5 from django.conf import settings
6 from django.contrib import admin
7 from django.utils.translation import ugettext
8 from django_jinja import library
9 from honeypot.templatetags.honeypot import render_honeypot_field
10 from jinja2 import contextfunction, escape, Markup
11
12 from kuma.core.templatetags.jinja_helpers import datetimeformat
13 from kuma.core.urlresolvers import reverse
14
15 from ..models import User
16
17
18 @library.global_function
19 def get_avatar_url(user):
20 """
21 Get the user's avatar URL for the first social account provider that has one.
22 Assumes that the user is not anonymous or None.
23 If the user has no avatar for any provider, returns the default avatar.
24 """
25 for account in user.socialaccount_set.order_by('date_joined'):
26 avatar_url = account.get_avatar_url()
27 if avatar_url:
28 return avatar_url
29 return settings.DEFAULT_AVATAR
30
31
32 @library.global_function
33 @contextfunction
34 def ban_links(context, ban_user, banner_user):
35 """Returns a link to ban a user"""
36 links = ''
37 if ban_user.id != banner_user.id and banner_user.has_perm('users.add_userban'):
38 active_ban = ban_user.active_ban
39 url_ban_cleanup = reverse('users.ban_user_and_cleanup',
40 kwargs={'username': ban_user.username})
41 if active_ban:
42 url = reverse('admin:users_userban_change', args=(active_ban.id,))
43 title = ugettext('Banned on %(ban_date)s by %(ban_admin)s.') % {
44 'ban_date': datetimeformat(context, active_ban.date,
45 format='date', output='json'),
46 'ban_admin': active_ban.by,
47 }
48 link = ('<a id="ban_link" href="%s" class="button ban-link" title="%s">%s'
49 '<i aria-hidden="true" class="icon-ban"></i></a>'
50 % (url, title, ugettext('Banned')))
51 link_cleanup = ('<a id="cleanup_link" href="%s" class="button negative ban-link">%s'
52 '<i aria-hidden="true" class="icon-ban"></i></a>'
53 % (url_ban_cleanup, ugettext('Clean Up Revisions')))
54 else:
55 url = reverse('users.ban_user', kwargs={'username': ban_user.username})
56 link = ('<a id="ban_link" href="%s" class="button negative ban-link">%s'
57 '<i aria-hidden="true" class="icon-ban"></i></a>'
58 % (url, ugettext('Ban User')))
59 link_cleanup = ('<a id="cleanup_link" href="%s" class="button negative ban-link">%s'
60 '<i aria-hidden="true" class="icon-ban"></i></a>'
61 % (url_ban_cleanup, ugettext('Ban User & Clean Up')))
62 links = link_cleanup + ' ' + link
63 return Markup(links)
64
65
66 @library.global_function
67 def admin_link(user):
68 """Returns a link to admin a user"""
69 url = reverse('admin:users_user_change', args=(user.id,),
70 current_app=admin.site.name)
71 link = ('<a href="%s" class="button neutral">%s'
72 '<i aria-hidden="true" class="icon-wrench"></i></a>' %
73 (url, ugettext('Admin')))
74 return Markup(link)
75
76
77 @library.filter
78 def public_email(email):
79 """Email address -> publicly displayable email."""
80 return Markup('<span class="email">%s</span>' % unicode_to_html(email))
81
82
83 def unicode_to_html(text):
84 """Turns all unicode into html entities, e.g. E -> E."""
85 return ''.join(['&#%s;' % ord(i) for i in text])
86
87
88 @library.global_function
89 def user_list(users):
90 """Turn a list of users into a list of links to their profiles."""
91 link = '<a href="%s">%s</a>'
92 list = ', '.join([link % (escape(u.get_absolute_url()), escape(u.username))
93 for u in users])
94 return Markup(list)
95
96
97 # Returns a string representation of a user
98 library.global_function(user_display)
99
100 # Returns a list of social authentication providers.
101 library.global_function(get_providers)
102
103
104 @library.global_function
105 @contextfunction
106 def provider_login_url(context, provider_id, **params):
107 """
108 {{ provider_login_url("github", next="/some/url") }}
109 """
110 request = context['request']
111 provider = providers.registry.by_id(provider_id)
112 auth_params = params.get('auth_params', None)
113 scope = params.get('scope', None)
114 process = params.get('process', None)
115 if scope == '':
116 del params['scope']
117 if auth_params == '':
118 del params['auth_params']
119 if 'next' not in params:
120 next = get_request_param(request, 'next')
121 if next:
122 params['next'] = next
123 elif process == 'redirect':
124 params['next'] = request.get_full_path()
125 else:
126 if not params['next']:
127 del params['next']
128 # get the login url and append params as url parameters
129 return Markup(provider.get_login_url(request, **params))
130
131
132 @library.global_function
133 @contextfunction
134 def providers_media_js(context):
135 """
136 {{ providers_media_js() }}
137 """
138 request = context['request']
139 return Markup('\n'.join([p.media_js(request)
140 for p in providers.registry.get_list()]))
141
142
143 @library.global_function
144 def social_accounts(user):
145 """
146 {% set accounts = social_accounts(user) %}
147
148 Then:
149 {{ accounts.twitter }} -- a list of connected Twitter accounts
150 {{ accounts.twitter.0 }} -- the first Twitter account
151 {% if accounts %} -- if there is at least one social account
152 """
153 accounts = {}
154 if not user.is_authenticated:
155 return accounts
156 for account in user.socialaccount_set.all().iterator():
157 providers = accounts.setdefault(account.provider, [])
158 providers.append(account)
159 return accounts
160
161
162 @library.global_function
163 @library.render_with('honeypot/honeypot_field.html')
164 def honeypot_field(field_name=None):
165 return render_honeypot_field(field_name)
166
167
168 @library.global_function
169 def get_primary_email(email_addresses):
170 for email in email_addresses:
171 if email_addresses[email].get('primary'):
172 return email
173
174
175 @library.global_function
176 def is_username_taken(username):
177 """
178 Returns True if a user with the given username exists (case-insentive),
179 otherwise False.
180 """
181 return User.objects.filter(username=username).exists()
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/users/templatetags/jinja_helpers.py b/kuma/users/templatetags/jinja_helpers.py
--- a/kuma/users/templatetags/jinja_helpers.py
+++ b/kuma/users/templatetags/jinja_helpers.py
@@ -18,11 +18,14 @@
@library.global_function
def get_avatar_url(user):
"""
- Get the user's avatar URL for the first social account provider that has one.
- Assumes that the user is not anonymous or None.
- If the user has no avatar for any provider, returns the default avatar.
+ Get the avatar URL of the user's first-joined social account that has one,
+ excluding all Persona social accounts. Assumes that the user is not None or
+ anonymous. If the user has no social account with an avatar, returns the
+ default avatar URL.
"""
- for account in user.socialaccount_set.order_by('date_joined'):
+ for account in (user.socialaccount_set
+ .exclude(provider='persona')
+ .order_by('date_joined')):
avatar_url = account.get_avatar_url()
if avatar_url:
return avatar_url
|
{"golden_diff": "diff --git a/kuma/users/templatetags/jinja_helpers.py b/kuma/users/templatetags/jinja_helpers.py\n--- a/kuma/users/templatetags/jinja_helpers.py\n+++ b/kuma/users/templatetags/jinja_helpers.py\n@@ -18,11 +18,14 @@\n @library.global_function\n def get_avatar_url(user):\n \"\"\"\n- Get the user's avatar URL for the first social account provider that has one.\n- Assumes that the user is not anonymous or None.\n- If the user has no avatar for any provider, returns the default avatar.\n+ Get the avatar URL of the user's first-joined social account that has one,\n+ excluding all Persona social accounts. Assumes that the user is not None or\n+ anonymous. If the user has no social account with an avatar, returns the\n+ default avatar URL.\n \"\"\"\n- for account in user.socialaccount_set.order_by('date_joined'):\n+ for account in (user.socialaccount_set\n+ .exclude(provider='persona')\n+ .order_by('date_joined')):\n avatar_url = account.get_avatar_url()\n if avatar_url:\n return avatar_url\n", "issue": "Viewing profile of user with Persona account generates an ISE\n**Summary**\r\nIt seems that viewing the profile of a user who has a Persona social account triggers an ISE.\r\n\r\n**Steps To Reproduce (STR)**\r\n1. Visit https://developer.allizom.org/en-US/profiles/sheppy\r\n2. It will generate a 500 error\r\n3. Visit https://developer.allizom.org/en-US/profiles/escattone\r\n4. Displays fine\r\n\r\n**Actual behavior**\r\nReturns 500 (internal server error)\r\n\r\n**Expected behavior**\r\nSuccess display of user's profile page\r\n\r\n**Additional context**\r\nThis seems to be related to one or more of the account PR's that were merged prior to deploying to stage.\r\n\n", "before_files": [{"content": "from allauth.account.utils import user_display\nfrom allauth.socialaccount import providers\nfrom allauth.socialaccount.templatetags.socialaccount import get_providers\nfrom allauth.utils import get_request_param\nfrom django.conf import settings\nfrom django.contrib import admin\nfrom django.utils.translation import ugettext\nfrom django_jinja import library\nfrom honeypot.templatetags.honeypot import render_honeypot_field\nfrom jinja2 import contextfunction, escape, Markup\n\nfrom kuma.core.templatetags.jinja_helpers import datetimeformat\nfrom kuma.core.urlresolvers import reverse\n\nfrom ..models import User\n\n\[email protected]_function\ndef get_avatar_url(user):\n \"\"\"\n Get the user's avatar URL for the first social account provider that has one.\n Assumes that the user is not anonymous or None.\n If the user has no avatar for any provider, returns the default avatar.\n \"\"\"\n for account in user.socialaccount_set.order_by('date_joined'):\n avatar_url = account.get_avatar_url()\n if avatar_url:\n return avatar_url\n return settings.DEFAULT_AVATAR\n\n\[email protected]_function\n@contextfunction\ndef ban_links(context, ban_user, banner_user):\n \"\"\"Returns a link to ban a user\"\"\"\n links = ''\n if ban_user.id != banner_user.id and banner_user.has_perm('users.add_userban'):\n active_ban = ban_user.active_ban\n url_ban_cleanup = reverse('users.ban_user_and_cleanup',\n kwargs={'username': ban_user.username})\n if active_ban:\n url = reverse('admin:users_userban_change', args=(active_ban.id,))\n title = ugettext('Banned on %(ban_date)s by %(ban_admin)s.') % {\n 'ban_date': datetimeformat(context, active_ban.date,\n format='date', output='json'),\n 'ban_admin': active_ban.by,\n }\n link = ('<a id=\"ban_link\" href=\"%s\" class=\"button ban-link\" title=\"%s\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url, title, ugettext('Banned')))\n link_cleanup = ('<a id=\"cleanup_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url_ban_cleanup, ugettext('Clean Up Revisions')))\n else:\n url = reverse('users.ban_user', kwargs={'username': ban_user.username})\n link = ('<a id=\"ban_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url, ugettext('Ban User')))\n link_cleanup = ('<a id=\"cleanup_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url_ban_cleanup, ugettext('Ban User & Clean Up')))\n links = link_cleanup + ' ' + link\n return Markup(links)\n\n\[email protected]_function\ndef admin_link(user):\n \"\"\"Returns a link to admin a user\"\"\"\n url = reverse('admin:users_user_change', args=(user.id,),\n current_app=admin.site.name)\n link = ('<a href=\"%s\" class=\"button neutral\">%s'\n '<i aria-hidden=\"true\" class=\"icon-wrench\"></i></a>' %\n (url, ugettext('Admin')))\n return Markup(link)\n\n\[email protected]\ndef public_email(email):\n \"\"\"Email address -> publicly displayable email.\"\"\"\n return Markup('<span class=\"email\">%s</span>' % unicode_to_html(email))\n\n\ndef unicode_to_html(text):\n \"\"\"Turns all unicode into html entities, e.g. E -> E.\"\"\"\n return ''.join(['&#%s;' % ord(i) for i in text])\n\n\[email protected]_function\ndef user_list(users):\n \"\"\"Turn a list of users into a list of links to their profiles.\"\"\"\n link = '<a href=\"%s\">%s</a>'\n list = ', '.join([link % (escape(u.get_absolute_url()), escape(u.username))\n for u in users])\n return Markup(list)\n\n\n# Returns a string representation of a user\nlibrary.global_function(user_display)\n\n# Returns a list of social authentication providers.\nlibrary.global_function(get_providers)\n\n\[email protected]_function\n@contextfunction\ndef provider_login_url(context, provider_id, **params):\n \"\"\"\n {{ provider_login_url(\"github\", next=\"/some/url\") }}\n \"\"\"\n request = context['request']\n provider = providers.registry.by_id(provider_id)\n auth_params = params.get('auth_params', None)\n scope = params.get('scope', None)\n process = params.get('process', None)\n if scope == '':\n del params['scope']\n if auth_params == '':\n del params['auth_params']\n if 'next' not in params:\n next = get_request_param(request, 'next')\n if next:\n params['next'] = next\n elif process == 'redirect':\n params['next'] = request.get_full_path()\n else:\n if not params['next']:\n del params['next']\n # get the login url and append params as url parameters\n return Markup(provider.get_login_url(request, **params))\n\n\[email protected]_function\n@contextfunction\ndef providers_media_js(context):\n \"\"\"\n {{ providers_media_js() }}\n \"\"\"\n request = context['request']\n return Markup('\\n'.join([p.media_js(request)\n for p in providers.registry.get_list()]))\n\n\[email protected]_function\ndef social_accounts(user):\n \"\"\"\n {% set accounts = social_accounts(user) %}\n\n Then:\n {{ accounts.twitter }} -- a list of connected Twitter accounts\n {{ accounts.twitter.0 }} -- the first Twitter account\n {% if accounts %} -- if there is at least one social account\n \"\"\"\n accounts = {}\n if not user.is_authenticated:\n return accounts\n for account in user.socialaccount_set.all().iterator():\n providers = accounts.setdefault(account.provider, [])\n providers.append(account)\n return accounts\n\n\[email protected]_function\[email protected]_with('honeypot/honeypot_field.html')\ndef honeypot_field(field_name=None):\n return render_honeypot_field(field_name)\n\n\[email protected]_function\ndef get_primary_email(email_addresses):\n for email in email_addresses:\n if email_addresses[email].get('primary'):\n return email\n\n\[email protected]_function\ndef is_username_taken(username):\n \"\"\"\n Returns True if a user with the given username exists (case-insentive),\n otherwise False.\n \"\"\"\n return User.objects.filter(username=username).exists()\n", "path": "kuma/users/templatetags/jinja_helpers.py"}], "after_files": [{"content": "from allauth.account.utils import user_display\nfrom allauth.socialaccount import providers\nfrom allauth.socialaccount.templatetags.socialaccount import get_providers\nfrom allauth.utils import get_request_param\nfrom django.conf import settings\nfrom django.contrib import admin\nfrom django.utils.translation import ugettext\nfrom django_jinja import library\nfrom honeypot.templatetags.honeypot import render_honeypot_field\nfrom jinja2 import contextfunction, escape, Markup\n\nfrom kuma.core.templatetags.jinja_helpers import datetimeformat\nfrom kuma.core.urlresolvers import reverse\n\nfrom ..models import User\n\n\[email protected]_function\ndef get_avatar_url(user):\n \"\"\"\n Get the avatar URL of the user's first-joined social account that has one,\n excluding all Persona social accounts. Assumes that the user is not None or\n anonymous. If the user has no social account with an avatar, returns the\n default avatar URL.\n \"\"\"\n for account in (user.socialaccount_set\n .exclude(provider='persona')\n .order_by('date_joined')):\n avatar_url = account.get_avatar_url()\n if avatar_url:\n return avatar_url\n return settings.DEFAULT_AVATAR\n\n\[email protected]_function\n@contextfunction\ndef ban_links(context, ban_user, banner_user):\n \"\"\"Returns a link to ban a user\"\"\"\n links = ''\n if ban_user.id != banner_user.id and banner_user.has_perm('users.add_userban'):\n active_ban = ban_user.active_ban\n url_ban_cleanup = reverse('users.ban_user_and_cleanup',\n kwargs={'username': ban_user.username})\n if active_ban:\n url = reverse('admin:users_userban_change', args=(active_ban.id,))\n title = ugettext('Banned on %(ban_date)s by %(ban_admin)s.') % {\n 'ban_date': datetimeformat(context, active_ban.date,\n format='date', output='json'),\n 'ban_admin': active_ban.by,\n }\n link = ('<a id=\"ban_link\" href=\"%s\" class=\"button ban-link\" title=\"%s\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url, title, ugettext('Banned')))\n link_cleanup = ('<a id=\"cleanup_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url_ban_cleanup, ugettext('Clean Up Revisions')))\n else:\n url = reverse('users.ban_user', kwargs={'username': ban_user.username})\n link = ('<a id=\"ban_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url, ugettext('Ban User')))\n link_cleanup = ('<a id=\"cleanup_link\" href=\"%s\" class=\"button negative ban-link\">%s'\n '<i aria-hidden=\"true\" class=\"icon-ban\"></i></a>'\n % (url_ban_cleanup, ugettext('Ban User & Clean Up')))\n links = link_cleanup + ' ' + link\n return Markup(links)\n\n\[email protected]_function\ndef admin_link(user):\n \"\"\"Returns a link to admin a user\"\"\"\n url = reverse('admin:users_user_change', args=(user.id,),\n current_app=admin.site.name)\n link = ('<a href=\"%s\" class=\"button neutral\">%s'\n '<i aria-hidden=\"true\" class=\"icon-wrench\"></i></a>' %\n (url, ugettext('Admin')))\n return Markup(link)\n\n\[email protected]\ndef public_email(email):\n \"\"\"Email address -> publicly displayable email.\"\"\"\n return Markup('<span class=\"email\">%s</span>' % unicode_to_html(email))\n\n\ndef unicode_to_html(text):\n \"\"\"Turns all unicode into html entities, e.g. E -> E.\"\"\"\n return ''.join(['&#%s;' % ord(i) for i in text])\n\n\[email protected]_function\ndef user_list(users):\n \"\"\"Turn a list of users into a list of links to their profiles.\"\"\"\n link = '<a href=\"%s\">%s</a>'\n list = ', '.join([link % (escape(u.get_absolute_url()), escape(u.username))\n for u in users])\n return Markup(list)\n\n\n# Returns a string representation of a user\nlibrary.global_function(user_display)\n\n# Returns a list of social authentication providers.\nlibrary.global_function(get_providers)\n\n\[email protected]_function\n@contextfunction\ndef provider_login_url(context, provider_id, **params):\n \"\"\"\n {{ provider_login_url(\"github\", next=\"/some/url\") }}\n \"\"\"\n request = context['request']\n provider = providers.registry.by_id(provider_id)\n auth_params = params.get('auth_params', None)\n scope = params.get('scope', None)\n process = params.get('process', None)\n if scope == '':\n del params['scope']\n if auth_params == '':\n del params['auth_params']\n if 'next' not in params:\n next = get_request_param(request, 'next')\n if next:\n params['next'] = next\n elif process == 'redirect':\n params['next'] = request.get_full_path()\n else:\n if not params['next']:\n del params['next']\n # get the login url and append params as url parameters\n return Markup(provider.get_login_url(request, **params))\n\n\[email protected]_function\n@contextfunction\ndef providers_media_js(context):\n \"\"\"\n {{ providers_media_js() }}\n \"\"\"\n request = context['request']\n return Markup('\\n'.join([p.media_js(request)\n for p in providers.registry.get_list()]))\n\n\[email protected]_function\ndef social_accounts(user):\n \"\"\"\n {% set accounts = social_accounts(user) %}\n\n Then:\n {{ accounts.twitter }} -- a list of connected Twitter accounts\n {{ accounts.twitter.0 }} -- the first Twitter account\n {% if accounts %} -- if there is at least one social account\n \"\"\"\n accounts = {}\n if not user.is_authenticated:\n return accounts\n for account in user.socialaccount_set.all().iterator():\n providers = accounts.setdefault(account.provider, [])\n providers.append(account)\n return accounts\n\n\[email protected]_function\[email protected]_with('honeypot/honeypot_field.html')\ndef honeypot_field(field_name=None):\n return render_honeypot_field(field_name)\n\n\[email protected]_function\ndef get_primary_email(email_addresses):\n for email in email_addresses:\n if email_addresses[email].get('primary'):\n return email\n\n\[email protected]_function\ndef is_username_taken(username):\n \"\"\"\n Returns True if a user with the given username exists (case-insentive),\n otherwise False.\n \"\"\"\n return User.objects.filter(username=username).exists()\n", "path": "kuma/users/templatetags/jinja_helpers.py"}]}
| 2,327 | 260 |
gh_patches_debug_28051
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-5226
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove cupyx.allow_synchronize?
`cupyx.allow_synchronize` (#2808) was introduced originally for both unit tests and users who want to notice device synchronization in their own code.
Application in uint tests was dissmissed (#2893) because much more tests were synchronous than I had expected.
Now I doubt the usefulness of this feature for users as well.
It's fundamentally impossible to eliminate false positives and/or false negatives.
If we took a policy for zero false positives, there would be too many false negatives which I think would make this feature useless.
For example, the documentation of [cudaMemcpy](https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html#group__CUDART__MEMORY_1gc263dbe6574220cc776b45438fc351e8) says *"This function exhibits synchronous behavior for most use cases"*. If we took this policy, we wouldn't be able to consider this function synchronous, because no condition is mentioned that would make this function asynchronous.
If we took a policy to allow some false positives, this feature wouldn't be used to detect unexpected synchronization in users' code.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/_core/syncdetect.py`
Content:
```
1 import contextlib
2 import threading
3
4 from cupy import _util
5
6
7 _thread_local = threading.local()
8
9
10 class DeviceSynchronized(RuntimeError):
11 """Raised when device synchronization is detected while disallowed.
12
13 .. seealso:: :func:`cupyx.allow_synchronize`
14
15 """
16
17 def __init__(self, message=None):
18 if message is None:
19 message = 'Device synchronization was detected while disallowed.'
20 super().__init__(message)
21
22
23 def _is_allowed():
24 # Returns whether device synchronization is allowed in the current thread.
25 try:
26 return _thread_local.allowed
27 except AttributeError:
28 _thread_local.allowed = True
29 return True
30
31
32 def _declare_synchronize():
33 # Raises DeviceSynchronized if device synchronization is disallowed in
34 # the current thread.
35 if not _is_allowed():
36 raise DeviceSynchronized()
37
38
39 @contextlib.contextmanager
40 def allow_synchronize(allow):
41 """Allows or disallows device synchronization temporarily in the current \
42 thread.
43
44 If device synchronization is detected, :class:`cupyx.DeviceSynchronized`
45 will be raised.
46
47 Note that there can be false negatives and positives.
48 Device synchronization outside CuPy will not be detected.
49 """
50 _util.experimental('cupyx.allow_synchronize')
51 old = _is_allowed()
52 _thread_local.allowed = allow
53 try:
54 yield
55 finally:
56 _thread_local.allowed = old
57
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupy/_core/syncdetect.py b/cupy/_core/syncdetect.py
--- a/cupy/_core/syncdetect.py
+++ b/cupy/_core/syncdetect.py
@@ -1,7 +1,6 @@
import contextlib
import threading
-
-from cupy import _util
+import warnings
_thread_local = threading.local()
@@ -10,6 +9,11 @@
class DeviceSynchronized(RuntimeError):
"""Raised when device synchronization is detected while disallowed.
+ .. warning::
+
+ This API has been deprecated in CuPy v10 and will be removed in future
+ releases.
+
.. seealso:: :func:`cupyx.allow_synchronize`
"""
@@ -41,13 +45,21 @@
"""Allows or disallows device synchronization temporarily in the current \
thread.
+ .. warning::
+
+ This API has been deprecated in CuPy v10 and will be removed in future
+ releases.
+
If device synchronization is detected, :class:`cupyx.DeviceSynchronized`
will be raised.
Note that there can be false negatives and positives.
Device synchronization outside CuPy will not be detected.
"""
- _util.experimental('cupyx.allow_synchronize')
+ warnings.warn(
+ 'cupyx.allow_synchronize will be removed in future releases as it '
+ 'is not possible to reliably detect synchronizations.')
+
old = _is_allowed()
_thread_local.allowed = allow
try:
|
{"golden_diff": "diff --git a/cupy/_core/syncdetect.py b/cupy/_core/syncdetect.py\n--- a/cupy/_core/syncdetect.py\n+++ b/cupy/_core/syncdetect.py\n@@ -1,7 +1,6 @@\n import contextlib\n import threading\n-\n-from cupy import _util\n+import warnings\n \n \n _thread_local = threading.local()\n@@ -10,6 +9,11 @@\n class DeviceSynchronized(RuntimeError):\n \"\"\"Raised when device synchronization is detected while disallowed.\n \n+ .. warning::\n+\n+ This API has been deprecated in CuPy v10 and will be removed in future\n+ releases.\n+\n .. seealso:: :func:`cupyx.allow_synchronize`\n \n \"\"\"\n@@ -41,13 +45,21 @@\n \"\"\"Allows or disallows device synchronization temporarily in the current \\\n thread.\n \n+ .. warning::\n+\n+ This API has been deprecated in CuPy v10 and will be removed in future\n+ releases.\n+\n If device synchronization is detected, :class:`cupyx.DeviceSynchronized`\n will be raised.\n \n Note that there can be false negatives and positives.\n Device synchronization outside CuPy will not be detected.\n \"\"\"\n- _util.experimental('cupyx.allow_synchronize')\n+ warnings.warn(\n+ 'cupyx.allow_synchronize will be removed in future releases as it '\n+ 'is not possible to reliably detect synchronizations.')\n+\n old = _is_allowed()\n _thread_local.allowed = allow\n try:\n", "issue": "Remove cupyx.allow_synchronize?\n`cupyx.allow_synchronize` (#2808) was introduced originally for both unit tests and users who want to notice device synchronization in their own code.\r\n\r\nApplication in uint tests was dissmissed (#2893) because much more tests were synchronous than I had expected. \r\n\r\nNow I doubt the usefulness of this feature for users as well.\r\nIt's fundamentally impossible to eliminate false positives and/or false negatives.\r\n\r\nIf we took a policy for zero false positives, there would be too many false negatives which I think would make this feature useless.\r\nFor example, the documentation of [cudaMemcpy](https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html#group__CUDART__MEMORY_1gc263dbe6574220cc776b45438fc351e8) says *\"This function exhibits synchronous behavior for most use cases\"*. If we took this policy, we wouldn't be able to consider this function synchronous, because no condition is mentioned that would make this function asynchronous.\r\n\r\nIf we took a policy to allow some false positives, this feature wouldn't be used to detect unexpected synchronization in users' code.\n", "before_files": [{"content": "import contextlib\nimport threading\n\nfrom cupy import _util\n\n\n_thread_local = threading.local()\n\n\nclass DeviceSynchronized(RuntimeError):\n \"\"\"Raised when device synchronization is detected while disallowed.\n\n .. seealso:: :func:`cupyx.allow_synchronize`\n\n \"\"\"\n\n def __init__(self, message=None):\n if message is None:\n message = 'Device synchronization was detected while disallowed.'\n super().__init__(message)\n\n\ndef _is_allowed():\n # Returns whether device synchronization is allowed in the current thread.\n try:\n return _thread_local.allowed\n except AttributeError:\n _thread_local.allowed = True\n return True\n\n\ndef _declare_synchronize():\n # Raises DeviceSynchronized if device synchronization is disallowed in\n # the current thread.\n if not _is_allowed():\n raise DeviceSynchronized()\n\n\[email protected]\ndef allow_synchronize(allow):\n \"\"\"Allows or disallows device synchronization temporarily in the current \\\nthread.\n\n If device synchronization is detected, :class:`cupyx.DeviceSynchronized`\n will be raised.\n\n Note that there can be false negatives and positives.\n Device synchronization outside CuPy will not be detected.\n \"\"\"\n _util.experimental('cupyx.allow_synchronize')\n old = _is_allowed()\n _thread_local.allowed = allow\n try:\n yield\n finally:\n _thread_local.allowed = old\n", "path": "cupy/_core/syncdetect.py"}], "after_files": [{"content": "import contextlib\nimport threading\nimport warnings\n\n\n_thread_local = threading.local()\n\n\nclass DeviceSynchronized(RuntimeError):\n \"\"\"Raised when device synchronization is detected while disallowed.\n\n .. warning::\n\n This API has been deprecated in CuPy v10 and will be removed in future\n releases.\n\n .. seealso:: :func:`cupyx.allow_synchronize`\n\n \"\"\"\n\n def __init__(self, message=None):\n if message is None:\n message = 'Device synchronization was detected while disallowed.'\n super().__init__(message)\n\n\ndef _is_allowed():\n # Returns whether device synchronization is allowed in the current thread.\n try:\n return _thread_local.allowed\n except AttributeError:\n _thread_local.allowed = True\n return True\n\n\ndef _declare_synchronize():\n # Raises DeviceSynchronized if device synchronization is disallowed in\n # the current thread.\n if not _is_allowed():\n raise DeviceSynchronized()\n\n\[email protected]\ndef allow_synchronize(allow):\n \"\"\"Allows or disallows device synchronization temporarily in the current \\\nthread.\n\n .. warning::\n\n This API has been deprecated in CuPy v10 and will be removed in future\n releases.\n\n If device synchronization is detected, :class:`cupyx.DeviceSynchronized`\n will be raised.\n\n Note that there can be false negatives and positives.\n Device synchronization outside CuPy will not be detected.\n \"\"\"\n warnings.warn(\n 'cupyx.allow_synchronize will be removed in future releases as it '\n 'is not possible to reliably detect synchronizations.')\n\n old = _is_allowed()\n _thread_local.allowed = allow\n try:\n yield\n finally:\n _thread_local.allowed = old\n", "path": "cupy/_core/syncdetect.py"}]}
| 928 | 333 |
gh_patches_debug_33243
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-760
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'testing/constraints-*.txt' not used
From #757.
In [`noxfile.py`](https://github.com/googleapis/google-auth-library-python/blob/a9234423cb2b69068fc0d30a5a0ee86a599ab8b7/noxfile.py#L87-L89), the constraints are not being used, which is why the one populated file, [`testing/constraints-3.6.txt](https://github.com/googleapis/google-auth-library-python/blob/master/testing/constraints-3.6.txt) is in an invalid state (multiple entries for `rsa`, maybe more issues).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `noxfile.py`
Content:
```
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import shutil
16 import os
17 import nox
18
19 TEST_DEPENDENCIES = [
20 "flask",
21 "freezegun",
22 "mock",
23 "oauth2client",
24 "pyopenssl",
25 "pytest",
26 "pytest-cov",
27 "pytest-localserver",
28 "pyu2f",
29 "requests",
30 "urllib3",
31 "cryptography",
32 "responses",
33 "grpcio",
34 ]
35
36 ASYNC_DEPENDENCIES = [
37 "pytest-asyncio",
38 "aioresponses",
39 "asynctest",
40 "aiohttp!=3.7.4.post0",
41 ]
42
43 BLACK_VERSION = "black==19.3b0"
44 BLACK_PATHS = [
45 "google",
46 "tests",
47 "tests_async",
48 "noxfile.py",
49 "setup.py",
50 "docs/conf.py",
51 ]
52
53
54 @nox.session(python="3.7")
55 def lint(session):
56 session.install("flake8", "flake8-import-order", "docutils", BLACK_VERSION)
57 session.install(".")
58 session.run("black", "--check", *BLACK_PATHS)
59 session.run(
60 "flake8",
61 "--import-order-style=google",
62 "--application-import-names=google,tests,system_tests",
63 "google",
64 "tests",
65 "tests_async",
66 )
67 session.run(
68 "python", "setup.py", "check", "--metadata", "--restructuredtext", "--strict"
69 )
70
71
72 @nox.session(python="3.8")
73 def blacken(session):
74 """Run black.
75 Format code to uniform standard.
76 The Python version should be consistent with what is
77 supplied in the Python Owlbot postprocessor.
78
79 https://github.com/googleapis/synthtool/blob/master/docker/owlbot/python/Dockerfile
80 """
81 session.install(BLACK_VERSION)
82 session.run("black", *BLACK_PATHS)
83
84
85 @nox.session(python=["3.6", "3.7", "3.8", "3.9"])
86 def unit(session):
87 session.install(*TEST_DEPENDENCIES)
88 session.install(*(ASYNC_DEPENDENCIES))
89 session.install(".")
90 session.run(
91 "pytest",
92 f"--junitxml=unit_{session.python}_sponge_log.xml",
93 "--cov=google.auth",
94 "--cov=google.oauth2",
95 "--cov=tests",
96 "tests",
97 "tests_async",
98 )
99
100
101 @nox.session(python=["2.7"])
102 def unit_prev_versions(session):
103 session.install(".")
104 session.install(*TEST_DEPENDENCIES)
105 session.run(
106 "pytest",
107 f"--junitxml=unit_{session.python}_sponge_log.xml",
108 "--cov=google.auth",
109 "--cov=google.oauth2",
110 "--cov=tests",
111 "tests",
112 )
113
114
115 @nox.session(python="3.7")
116 def cover(session):
117 session.install(*TEST_DEPENDENCIES)
118 session.install(*(ASYNC_DEPENDENCIES))
119 session.install(".")
120 session.run(
121 "pytest",
122 "--cov=google.auth",
123 "--cov=google.oauth2",
124 "--cov=tests",
125 "--cov=tests_async",
126 "--cov-report=",
127 "tests",
128 "tests_async",
129 )
130 session.run("coverage", "report", "--show-missing", "--fail-under=100")
131
132
133 @nox.session(python="3.7")
134 def docgen(session):
135 session.env["SPHINX_APIDOC_OPTIONS"] = "members,inherited-members,show-inheritance"
136 session.install(*TEST_DEPENDENCIES)
137 session.install("sphinx")
138 session.install(".")
139 session.run("rm", "-r", "docs/reference")
140 session.run(
141 "sphinx-apidoc",
142 "--output-dir",
143 "docs/reference",
144 "--separate",
145 "--module-first",
146 "google",
147 )
148
149
150 @nox.session(python="3.7")
151 def docs(session):
152 """Build the docs for this library."""
153
154 session.install("-e", ".[aiohttp]")
155 session.install(
156 "sphinx<3.0.0", "alabaster", "recommonmark", "sphinx-docstring-typing"
157 )
158
159 shutil.rmtree(os.path.join("docs", "_build"), ignore_errors=True)
160 session.run(
161 "sphinx-build",
162 "-T", # show full traceback on exception
163 "-W", # warnings as errors
164 "-N", # no colors
165 "-b",
166 "html",
167 "-d",
168 os.path.join("docs", "_build", "doctrees", ""),
169 os.path.join("docs", ""),
170 os.path.join("docs", "_build", "html", ""),
171 )
172
173
174 @nox.session(python="pypy")
175 def pypy(session):
176 session.install(*TEST_DEPENDENCIES)
177 session.install(*ASYNC_DEPENDENCIES)
178 session.install(".")
179 session.run(
180 "pytest",
181 f"--junitxml=unit_{session.python}_sponge_log.xml",
182 "--cov=google.auth",
183 "--cov=google.oauth2",
184 "--cov=tests",
185 "tests",
186 "tests_async",
187 )
188
```
Path: `setup.py`
Content:
```
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 from setuptools import find_packages
19 from setuptools import setup
20
21
22 DEPENDENCIES = (
23 "cachetools>=2.0.0,<5.0",
24 "pyasn1-modules>=0.2.1",
25 # rsa==4.5 is the last version to support 2.7
26 # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233
27 'rsa<4.6; python_version < "3.6"',
28 'rsa>=3.1.4,<5; python_version >= "3.6"',
29 "setuptools>=40.3.0",
30 "six>=1.9.0",
31 )
32
33 extras = {
34 "aiohttp": [
35 "aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'",
36 "requests >= 2.18.0, < 3.0.0dev",
37 "urllib3 >= 1.0.0, <2.0.0dev",
38 ],
39 "pyopenssl": "pyopenssl>=20.0.0",
40 "reauth": "pyu2f>=0.1.5",
41 }
42
43 with io.open("README.rst", "r") as fh:
44 long_description = fh.read()
45
46 package_root = os.path.abspath(os.path.dirname(__file__))
47
48 version = {}
49 with open(os.path.join(package_root, "google/auth/version.py")) as fp:
50 exec(fp.read(), version)
51 version = version["__version__"]
52
53 setup(
54 name="google-auth",
55 version=version,
56 author="Google Cloud Platform",
57 author_email="[email protected]",
58 description="Google Authentication Library",
59 long_description=long_description,
60 url="https://github.com/googleapis/google-auth-library-python",
61 packages=find_packages(exclude=("tests*", "system_tests*")),
62 namespace_packages=("google",),
63 install_requires=DEPENDENCIES,
64 extras_require=extras,
65 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*",
66 license="Apache 2.0",
67 keywords="google auth oauth client",
68 classifiers=[
69 "Programming Language :: Python :: 2",
70 "Programming Language :: Python :: 2.7",
71 "Programming Language :: Python :: 3",
72 "Programming Language :: Python :: 3.6",
73 "Programming Language :: Python :: 3.7",
74 "Programming Language :: Python :: 3.8",
75 "Programming Language :: Python :: 3.9",
76 "Development Status :: 5 - Production/Stable",
77 "Intended Audience :: Developers",
78 "License :: OSI Approved :: Apache Software License",
79 "Operating System :: POSIX",
80 "Operating System :: Microsoft :: Windows",
81 "Operating System :: MacOS :: MacOS X",
82 "Operating System :: OS Independent",
83 "Topic :: Internet :: WWW/HTTP",
84 ],
85 )
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -12,10 +12,14 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import shutil
import os
+import pathlib
+import shutil
+
import nox
+CURRENT_DIRECTORY = pathlib.Path(__file__).parent.absolute()
+
TEST_DEPENDENCIES = [
"flask",
"freezegun",
@@ -84,15 +88,20 @@
@nox.session(python=["3.6", "3.7", "3.8", "3.9"])
def unit(session):
- session.install(*TEST_DEPENDENCIES)
- session.install(*(ASYNC_DEPENDENCIES))
- session.install(".")
+ constraints_path = str(
+ CURRENT_DIRECTORY / "testing" / f"constraints-{session.python}.txt"
+ )
+ add_constraints = ["-c", constraints_path]
+ session.install(*(TEST_DEPENDENCIES + add_constraints))
+ session.install(*(ASYNC_DEPENDENCIES + add_constraints))
+ session.install(".", *add_constraints)
session.run(
"pytest",
f"--junitxml=unit_{session.python}_sponge_log.xml",
"--cov=google.auth",
"--cov=google.oauth2",
"--cov=tests",
+ "--cov-report=term-missing",
"tests",
"tests_async",
)
@@ -123,7 +132,7 @@
"--cov=google.oauth2",
"--cov=tests",
"--cov=tests_async",
- "--cov-report=",
+ "--cov-report=term-missing",
"tests",
"tests_async",
)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -33,8 +33,7 @@
extras = {
"aiohttp": [
"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'",
- "requests >= 2.18.0, < 3.0.0dev",
- "urllib3 >= 1.0.0, <2.0.0dev",
+ "requests >= 2.20.0, < 3.0.0dev",
],
"pyopenssl": "pyopenssl>=20.0.0",
"reauth": "pyu2f>=0.1.5",
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -12,10 +12,14 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-import shutil\n import os\n+import pathlib\n+import shutil\n+\n import nox\n \n+CURRENT_DIRECTORY = pathlib.Path(__file__).parent.absolute()\n+\n TEST_DEPENDENCIES = [\n \"flask\",\n \"freezegun\",\n@@ -84,15 +88,20 @@\n \n @nox.session(python=[\"3.6\", \"3.7\", \"3.8\", \"3.9\"])\n def unit(session):\n- session.install(*TEST_DEPENDENCIES)\n- session.install(*(ASYNC_DEPENDENCIES))\n- session.install(\".\")\n+ constraints_path = str(\n+ CURRENT_DIRECTORY / \"testing\" / f\"constraints-{session.python}.txt\"\n+ )\n+ add_constraints = [\"-c\", constraints_path]\n+ session.install(*(TEST_DEPENDENCIES + add_constraints))\n+ session.install(*(ASYNC_DEPENDENCIES + add_constraints))\n+ session.install(\".\", *add_constraints)\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n+ \"--cov-report=term-missing\",\n \"tests\",\n \"tests_async\",\n )\n@@ -123,7 +132,7 @@\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"--cov=tests_async\",\n- \"--cov-report=\",\n+ \"--cov-report=term-missing\",\n \"tests\",\n \"tests_async\",\n )\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -33,8 +33,7 @@\n extras = {\n \"aiohttp\": [\n \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\",\n- \"requests >= 2.18.0, < 3.0.0dev\",\n- \"urllib3 >= 1.0.0, <2.0.0dev\",\n+ \"requests >= 2.20.0, < 3.0.0dev\",\n ],\n \"pyopenssl\": \"pyopenssl>=20.0.0\",\n \"reauth\": \"pyu2f>=0.1.5\",\n", "issue": "'testing/constraints-*.txt' not used\nFrom #757.\r\n\r\nIn [`noxfile.py`](https://github.com/googleapis/google-auth-library-python/blob/a9234423cb2b69068fc0d30a5a0ee86a599ab8b7/noxfile.py#L87-L89), the constraints are not being used, which is why the one populated file, [`testing/constraints-3.6.txt](https://github.com/googleapis/google-auth-library-python/blob/master/testing/constraints-3.6.txt) is in an invalid state (multiple entries for `rsa`, maybe more issues).\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport shutil\nimport os\nimport nox\n\nTEST_DEPENDENCIES = [\n \"flask\",\n \"freezegun\",\n \"mock\",\n \"oauth2client\",\n \"pyopenssl\",\n \"pytest\",\n \"pytest-cov\",\n \"pytest-localserver\",\n \"pyu2f\",\n \"requests\",\n \"urllib3\",\n \"cryptography\",\n \"responses\",\n \"grpcio\",\n]\n\nASYNC_DEPENDENCIES = [\n \"pytest-asyncio\",\n \"aioresponses\",\n \"asynctest\",\n \"aiohttp!=3.7.4.post0\",\n]\n\nBLACK_VERSION = \"black==19.3b0\"\nBLACK_PATHS = [\n \"google\",\n \"tests\",\n \"tests_async\",\n \"noxfile.py\",\n \"setup.py\",\n \"docs/conf.py\",\n]\n\n\[email protected](python=\"3.7\")\ndef lint(session):\n session.install(\"flake8\", \"flake8-import-order\", \"docutils\", BLACK_VERSION)\n session.install(\".\")\n session.run(\"black\", \"--check\", *BLACK_PATHS)\n session.run(\n \"flake8\",\n \"--import-order-style=google\",\n \"--application-import-names=google,tests,system_tests\",\n \"google\",\n \"tests\",\n \"tests_async\",\n )\n session.run(\n \"python\", \"setup.py\", \"check\", \"--metadata\", \"--restructuredtext\", \"--strict\"\n )\n\n\[email protected](python=\"3.8\")\ndef blacken(session):\n \"\"\"Run black.\n Format code to uniform standard.\n The Python version should be consistent with what is\n supplied in the Python Owlbot postprocessor.\n\n https://github.com/googleapis/synthtool/blob/master/docker/owlbot/python/Dockerfile\n \"\"\"\n session.install(BLACK_VERSION)\n session.run(\"black\", *BLACK_PATHS)\n\n\[email protected](python=[\"3.6\", \"3.7\", \"3.8\", \"3.9\"])\ndef unit(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(*(ASYNC_DEPENDENCIES))\n session.install(\".\")\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"tests\",\n \"tests_async\",\n )\n\n\[email protected](python=[\"2.7\"])\ndef unit_prev_versions(session):\n session.install(\".\")\n session.install(*TEST_DEPENDENCIES)\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"tests\",\n )\n\n\[email protected](python=\"3.7\")\ndef cover(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(*(ASYNC_DEPENDENCIES))\n session.install(\".\")\n session.run(\n \"pytest\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"--cov=tests_async\",\n \"--cov-report=\",\n \"tests\",\n \"tests_async\",\n )\n session.run(\"coverage\", \"report\", \"--show-missing\", \"--fail-under=100\")\n\n\[email protected](python=\"3.7\")\ndef docgen(session):\n session.env[\"SPHINX_APIDOC_OPTIONS\"] = \"members,inherited-members,show-inheritance\"\n session.install(*TEST_DEPENDENCIES)\n session.install(\"sphinx\")\n session.install(\".\")\n session.run(\"rm\", \"-r\", \"docs/reference\")\n session.run(\n \"sphinx-apidoc\",\n \"--output-dir\",\n \"docs/reference\",\n \"--separate\",\n \"--module-first\",\n \"google\",\n )\n\n\[email protected](python=\"3.7\")\ndef docs(session):\n \"\"\"Build the docs for this library.\"\"\"\n\n session.install(\"-e\", \".[aiohttp]\")\n session.install(\n \"sphinx<3.0.0\", \"alabaster\", \"recommonmark\", \"sphinx-docstring-typing\"\n )\n\n shutil.rmtree(os.path.join(\"docs\", \"_build\"), ignore_errors=True)\n session.run(\n \"sphinx-build\",\n \"-T\", # show full traceback on exception\n \"-W\", # warnings as errors\n \"-N\", # no colors\n \"-b\",\n \"html\",\n \"-d\",\n os.path.join(\"docs\", \"_build\", \"doctrees\", \"\"),\n os.path.join(\"docs\", \"\"),\n os.path.join(\"docs\", \"_build\", \"html\", \"\"),\n )\n\n\[email protected](python=\"pypy\")\ndef pypy(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(*ASYNC_DEPENDENCIES)\n session.install(\".\")\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"tests\",\n \"tests_async\",\n )\n", "path": "noxfile.py"}, {"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nDEPENDENCIES = (\n \"cachetools>=2.0.0,<5.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n 'rsa<4.6; python_version < \"3.6\"',\n 'rsa>=3.1.4,<5; python_version >= \"3.6\"',\n \"setuptools>=40.3.0\",\n \"six>=1.9.0\",\n)\n\nextras = {\n \"aiohttp\": [\n \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n \"urllib3 >= 1.0.0, <2.0.0dev\",\n ],\n \"pyopenssl\": \"pyopenssl>=20.0.0\",\n \"reauth\": \"pyu2f>=0.1.5\",\n}\n\nwith io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nversion = {}\nwith open(os.path.join(package_root, \"google/auth/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\nsetup(\n name=\"google-auth\",\n version=version,\n author=\"Google Cloud Platform\",\n author_email=\"[email protected]\",\n description=\"Google Authentication Library\",\n long_description=long_description,\n url=\"https://github.com/googleapis/google-auth-library-python\",\n packages=find_packages(exclude=(\"tests*\", \"system_tests*\")),\n namespace_packages=(\"google\",),\n install_requires=DEPENDENCIES,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*\",\n license=\"Apache 2.0\",\n keywords=\"google auth oauth client\",\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport pathlib\nimport shutil\n\nimport nox\n\nCURRENT_DIRECTORY = pathlib.Path(__file__).parent.absolute()\n\nTEST_DEPENDENCIES = [\n \"flask\",\n \"freezegun\",\n \"mock\",\n \"oauth2client\",\n \"pyopenssl\",\n \"pytest\",\n \"pytest-cov\",\n \"pytest-localserver\",\n \"pyu2f\",\n \"requests\",\n \"urllib3\",\n \"cryptography\",\n \"responses\",\n \"grpcio\",\n]\n\nASYNC_DEPENDENCIES = [\n \"pytest-asyncio\",\n \"aioresponses\",\n \"asynctest\",\n \"aiohttp!=3.7.4.post0\",\n]\n\nBLACK_VERSION = \"black==19.3b0\"\nBLACK_PATHS = [\n \"google\",\n \"tests\",\n \"tests_async\",\n \"noxfile.py\",\n \"setup.py\",\n \"docs/conf.py\",\n]\n\n\[email protected](python=\"3.7\")\ndef lint(session):\n session.install(\"flake8\", \"flake8-import-order\", \"docutils\", BLACK_VERSION)\n session.install(\".\")\n session.run(\"black\", \"--check\", *BLACK_PATHS)\n session.run(\n \"flake8\",\n \"--import-order-style=google\",\n \"--application-import-names=google,tests,system_tests\",\n \"google\",\n \"tests\",\n \"tests_async\",\n )\n session.run(\n \"python\", \"setup.py\", \"check\", \"--metadata\", \"--restructuredtext\", \"--strict\"\n )\n\n\[email protected](python=\"3.8\")\ndef blacken(session):\n \"\"\"Run black.\n Format code to uniform standard.\n The Python version should be consistent with what is\n supplied in the Python Owlbot postprocessor.\n\n https://github.com/googleapis/synthtool/blob/master/docker/owlbot/python/Dockerfile\n \"\"\"\n session.install(BLACK_VERSION)\n session.run(\"black\", *BLACK_PATHS)\n\n\[email protected](python=[\"3.6\", \"3.7\", \"3.8\", \"3.9\"])\ndef unit(session):\n constraints_path = str(\n CURRENT_DIRECTORY / \"testing\" / f\"constraints-{session.python}.txt\"\n )\n add_constraints = [\"-c\", constraints_path]\n session.install(*(TEST_DEPENDENCIES + add_constraints))\n session.install(*(ASYNC_DEPENDENCIES + add_constraints))\n session.install(\".\", *add_constraints)\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"--cov-report=term-missing\",\n \"tests\",\n \"tests_async\",\n )\n\n\[email protected](python=[\"2.7\"])\ndef unit_prev_versions(session):\n session.install(\".\")\n session.install(*TEST_DEPENDENCIES)\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"tests\",\n )\n\n\[email protected](python=\"3.7\")\ndef cover(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(*(ASYNC_DEPENDENCIES))\n session.install(\".\")\n session.run(\n \"pytest\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"--cov=tests_async\",\n \"--cov-report=term-missing\",\n \"tests\",\n \"tests_async\",\n )\n session.run(\"coverage\", \"report\", \"--show-missing\", \"--fail-under=100\")\n\n\[email protected](python=\"3.7\")\ndef docgen(session):\n session.env[\"SPHINX_APIDOC_OPTIONS\"] = \"members,inherited-members,show-inheritance\"\n session.install(*TEST_DEPENDENCIES)\n session.install(\"sphinx\")\n session.install(\".\")\n session.run(\"rm\", \"-r\", \"docs/reference\")\n session.run(\n \"sphinx-apidoc\",\n \"--output-dir\",\n \"docs/reference\",\n \"--separate\",\n \"--module-first\",\n \"google\",\n )\n\n\[email protected](python=\"3.7\")\ndef docs(session):\n \"\"\"Build the docs for this library.\"\"\"\n\n session.install(\"-e\", \".[aiohttp]\")\n session.install(\n \"sphinx<3.0.0\", \"alabaster\", \"recommonmark\", \"sphinx-docstring-typing\"\n )\n\n shutil.rmtree(os.path.join(\"docs\", \"_build\"), ignore_errors=True)\n session.run(\n \"sphinx-build\",\n \"-T\", # show full traceback on exception\n \"-W\", # warnings as errors\n \"-N\", # no colors\n \"-b\",\n \"html\",\n \"-d\",\n os.path.join(\"docs\", \"_build\", \"doctrees\", \"\"),\n os.path.join(\"docs\", \"\"),\n os.path.join(\"docs\", \"_build\", \"html\", \"\"),\n )\n\n\[email protected](python=\"pypy\")\ndef pypy(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(*ASYNC_DEPENDENCIES)\n session.install(\".\")\n session.run(\n \"pytest\",\n f\"--junitxml=unit_{session.python}_sponge_log.xml\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"tests\",\n \"tests_async\",\n )\n", "path": "noxfile.py"}, {"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nDEPENDENCIES = (\n \"cachetools>=2.0.0,<5.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n 'rsa<4.6; python_version < \"3.6\"',\n 'rsa>=3.1.4,<5; python_version >= \"3.6\"',\n \"setuptools>=40.3.0\",\n \"six>=1.9.0\",\n)\n\nextras = {\n \"aiohttp\": [\n \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\",\n \"requests >= 2.20.0, < 3.0.0dev\",\n ],\n \"pyopenssl\": \"pyopenssl>=20.0.0\",\n \"reauth\": \"pyu2f>=0.1.5\",\n}\n\nwith io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nversion = {}\nwith open(os.path.join(package_root, \"google/auth/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\nsetup(\n name=\"google-auth\",\n version=version,\n author=\"Google Cloud Platform\",\n author_email=\"[email protected]\",\n description=\"Google Authentication Library\",\n long_description=long_description,\n url=\"https://github.com/googleapis/google-auth-library-python\",\n packages=find_packages(exclude=(\"tests*\", \"system_tests*\")),\n namespace_packages=(\"google\",),\n install_requires=DEPENDENCIES,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*\",\n license=\"Apache 2.0\",\n keywords=\"google auth oauth client\",\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}]}
| 3,061 | 556 |
gh_patches_debug_27897
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-4144
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possibly slightly wrong informative pair merging
When merging longer timeframe to a shorter one, the timedelta is added to the date:
https://github.com/freqtrade/freqtrade/blob/f320cb0d7a12e064018967cf049dd6719fff8ddb/freqtrade/strategy/strategy_helper.py#L35
then it merges to the shorter timeframe with these dates..
https://github.com/freqtrade/freqtrade/blob/f320cb0d7a12e064018967cf049dd6719fff8ddb/freqtrade/strategy/strategy_helper.py#L42-L43
So lets say we are merging a `1h` timeframe to a `5m` timeframe and there is a signal `True` at `00:00` on the `1h` timeseries.
With this merge, the signal will appear in the `5m` timeseries also at `00:00`. However the `00:00` candle for the `5m` timeframe is received at `00:05`, that is five minutes later than the time you actually received the `1h` candle, which should have been received at the candle with date `11:55`.
So after merging, the values should be shifted backward (`shift(-1)`)..or the merging dates should be reduced by one unit of timedelta of the shorter timeframe..
```python
informative['date_merge'] = informative["date"] + pd.to_timedelta(minutes_inf, 'm') - pd.to_timedelta(minutes, 'm')
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/strategy/strategy_helper.py`
Content:
```
1 import pandas as pd
2
3 from freqtrade.exchange import timeframe_to_minutes
4
5
6 def merge_informative_pair(dataframe: pd.DataFrame, informative: pd.DataFrame,
7 timeframe: str, timeframe_inf: str, ffill: bool = True) -> pd.DataFrame:
8 """
9 Correctly merge informative samples to the original dataframe, avoiding lookahead bias.
10
11 Since dates are candle open dates, merging a 15m candle that starts at 15:00, and a
12 1h candle that starts at 15:00 will result in all candles to know the close at 16:00
13 which they should not know.
14
15 Moves the date of the informative pair by 1 time interval forward.
16 This way, the 14:00 1h candle is merged to 15:00 15m candle, since the 14:00 1h candle is the
17 last candle that's closed at 15:00, 15:15, 15:30 or 15:45.
18
19 Assuming inf_tf = '1d' - then the resulting columns will be:
20 date_1d, open_1d, high_1d, low_1d, close_1d, rsi_1d
21
22 :param dataframe: Original dataframe
23 :param informative: Informative pair, most likely loaded via dp.get_pair_dataframe
24 :param timeframe: Timeframe of the original pair sample.
25 :param timeframe_inf: Timeframe of the informative pair sample.
26 :param ffill: Forwardfill missing values - optional but usually required
27 """
28
29 minutes_inf = timeframe_to_minutes(timeframe_inf)
30 minutes = timeframe_to_minutes(timeframe)
31 if minutes >= minutes_inf:
32 # No need to forwardshift if the timeframes are identical
33 informative['date_merge'] = informative["date"]
34 else:
35 informative['date_merge'] = informative["date"] + pd.to_timedelta(minutes_inf, 'm')
36
37 # Rename columns to be unique
38 informative.columns = [f"{col}_{timeframe_inf}" for col in informative.columns]
39
40 # Combine the 2 dataframes
41 # all indicators on the informative sample MUST be calculated before this point
42 dataframe = pd.merge(dataframe, informative, left_on='date',
43 right_on=f'date_merge_{timeframe_inf}', how='left')
44 dataframe = dataframe.drop(f'date_merge_{timeframe_inf}', axis=1)
45
46 if ffill:
47 dataframe = dataframe.ffill()
48
49 return dataframe
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/freqtrade/strategy/strategy_helper.py b/freqtrade/strategy/strategy_helper.py
--- a/freqtrade/strategy/strategy_helper.py
+++ b/freqtrade/strategy/strategy_helper.py
@@ -24,15 +24,24 @@
:param timeframe: Timeframe of the original pair sample.
:param timeframe_inf: Timeframe of the informative pair sample.
:param ffill: Forwardfill missing values - optional but usually required
+ :return: Merged dataframe
+ :raise: ValueError if the secondary timeframe is shorter than the dataframe timeframe
"""
minutes_inf = timeframe_to_minutes(timeframe_inf)
minutes = timeframe_to_minutes(timeframe)
- if minutes >= minutes_inf:
+ if minutes == minutes_inf:
# No need to forwardshift if the timeframes are identical
informative['date_merge'] = informative["date"]
+ elif minutes < minutes_inf:
+ # Subtract "small" timeframe so merging is not delayed by 1 small candle
+ # Detailed explanation in https://github.com/freqtrade/freqtrade/issues/4073
+ informative['date_merge'] = (
+ informative["date"] + pd.to_timedelta(minutes_inf, 'm') - pd.to_timedelta(minutes, 'm')
+ )
else:
- informative['date_merge'] = informative["date"] + pd.to_timedelta(minutes_inf, 'm')
+ raise ValueError("Tried to merge a faster timeframe to a slower timeframe."
+ "This would create new rows, and can throw off your regular indicators.")
# Rename columns to be unique
informative.columns = [f"{col}_{timeframe_inf}" for col in informative.columns]
|
{"golden_diff": "diff --git a/freqtrade/strategy/strategy_helper.py b/freqtrade/strategy/strategy_helper.py\n--- a/freqtrade/strategy/strategy_helper.py\n+++ b/freqtrade/strategy/strategy_helper.py\n@@ -24,15 +24,24 @@\n :param timeframe: Timeframe of the original pair sample.\n :param timeframe_inf: Timeframe of the informative pair sample.\n :param ffill: Forwardfill missing values - optional but usually required\n+ :return: Merged dataframe\n+ :raise: ValueError if the secondary timeframe is shorter than the dataframe timeframe\n \"\"\"\n \n minutes_inf = timeframe_to_minutes(timeframe_inf)\n minutes = timeframe_to_minutes(timeframe)\n- if minutes >= minutes_inf:\n+ if minutes == minutes_inf:\n # No need to forwardshift if the timeframes are identical\n informative['date_merge'] = informative[\"date\"]\n+ elif minutes < minutes_inf:\n+ # Subtract \"small\" timeframe so merging is not delayed by 1 small candle\n+ # Detailed explanation in https://github.com/freqtrade/freqtrade/issues/4073\n+ informative['date_merge'] = (\n+ informative[\"date\"] + pd.to_timedelta(minutes_inf, 'm') - pd.to_timedelta(minutes, 'm')\n+ )\n else:\n- informative['date_merge'] = informative[\"date\"] + pd.to_timedelta(minutes_inf, 'm')\n+ raise ValueError(\"Tried to merge a faster timeframe to a slower timeframe.\"\n+ \"This would create new rows, and can throw off your regular indicators.\")\n \n # Rename columns to be unique\n informative.columns = [f\"{col}_{timeframe_inf}\" for col in informative.columns]\n", "issue": "Possibly slightly wrong informative pair merging\nWhen merging longer timeframe to a shorter one, the timedelta is added to the date:\r\nhttps://github.com/freqtrade/freqtrade/blob/f320cb0d7a12e064018967cf049dd6719fff8ddb/freqtrade/strategy/strategy_helper.py#L35\r\n\r\nthen it merges to the shorter timeframe with these dates..\r\nhttps://github.com/freqtrade/freqtrade/blob/f320cb0d7a12e064018967cf049dd6719fff8ddb/freqtrade/strategy/strategy_helper.py#L42-L43\r\n\r\nSo lets say we are merging a `1h` timeframe to a `5m` timeframe and there is a signal `True` at `00:00` on the `1h` timeseries. \r\nWith this merge, the signal will appear in the `5m` timeseries also at `00:00`. However the `00:00` candle for the `5m` timeframe is received at `00:05`, that is five minutes later than the time you actually received the `1h` candle, which should have been received at the candle with date `11:55`. \r\nSo after merging, the values should be shifted backward (`shift(-1)`)..or the merging dates should be reduced by one unit of timedelta of the shorter timeframe..\r\n```python\r\ninformative['date_merge'] = informative[\"date\"] + pd.to_timedelta(minutes_inf, 'm') - pd.to_timedelta(minutes, 'm')\r\n```\n", "before_files": [{"content": "import pandas as pd\n\nfrom freqtrade.exchange import timeframe_to_minutes\n\n\ndef merge_informative_pair(dataframe: pd.DataFrame, informative: pd.DataFrame,\n timeframe: str, timeframe_inf: str, ffill: bool = True) -> pd.DataFrame:\n \"\"\"\n Correctly merge informative samples to the original dataframe, avoiding lookahead bias.\n\n Since dates are candle open dates, merging a 15m candle that starts at 15:00, and a\n 1h candle that starts at 15:00 will result in all candles to know the close at 16:00\n which they should not know.\n\n Moves the date of the informative pair by 1 time interval forward.\n This way, the 14:00 1h candle is merged to 15:00 15m candle, since the 14:00 1h candle is the\n last candle that's closed at 15:00, 15:15, 15:30 or 15:45.\n\n Assuming inf_tf = '1d' - then the resulting columns will be:\n date_1d, open_1d, high_1d, low_1d, close_1d, rsi_1d\n\n :param dataframe: Original dataframe\n :param informative: Informative pair, most likely loaded via dp.get_pair_dataframe\n :param timeframe: Timeframe of the original pair sample.\n :param timeframe_inf: Timeframe of the informative pair sample.\n :param ffill: Forwardfill missing values - optional but usually required\n \"\"\"\n\n minutes_inf = timeframe_to_minutes(timeframe_inf)\n minutes = timeframe_to_minutes(timeframe)\n if minutes >= minutes_inf:\n # No need to forwardshift if the timeframes are identical\n informative['date_merge'] = informative[\"date\"]\n else:\n informative['date_merge'] = informative[\"date\"] + pd.to_timedelta(minutes_inf, 'm')\n\n # Rename columns to be unique\n informative.columns = [f\"{col}_{timeframe_inf}\" for col in informative.columns]\n\n # Combine the 2 dataframes\n # all indicators on the informative sample MUST be calculated before this point\n dataframe = pd.merge(dataframe, informative, left_on='date',\n right_on=f'date_merge_{timeframe_inf}', how='left')\n dataframe = dataframe.drop(f'date_merge_{timeframe_inf}', axis=1)\n\n if ffill:\n dataframe = dataframe.ffill()\n\n return dataframe\n", "path": "freqtrade/strategy/strategy_helper.py"}], "after_files": [{"content": "import pandas as pd\n\nfrom freqtrade.exchange import timeframe_to_minutes\n\n\ndef merge_informative_pair(dataframe: pd.DataFrame, informative: pd.DataFrame,\n timeframe: str, timeframe_inf: str, ffill: bool = True) -> pd.DataFrame:\n \"\"\"\n Correctly merge informative samples to the original dataframe, avoiding lookahead bias.\n\n Since dates are candle open dates, merging a 15m candle that starts at 15:00, and a\n 1h candle that starts at 15:00 will result in all candles to know the close at 16:00\n which they should not know.\n\n Moves the date of the informative pair by 1 time interval forward.\n This way, the 14:00 1h candle is merged to 15:00 15m candle, since the 14:00 1h candle is the\n last candle that's closed at 15:00, 15:15, 15:30 or 15:45.\n\n Assuming inf_tf = '1d' - then the resulting columns will be:\n date_1d, open_1d, high_1d, low_1d, close_1d, rsi_1d\n\n :param dataframe: Original dataframe\n :param informative: Informative pair, most likely loaded via dp.get_pair_dataframe\n :param timeframe: Timeframe of the original pair sample.\n :param timeframe_inf: Timeframe of the informative pair sample.\n :param ffill: Forwardfill missing values - optional but usually required\n :return: Merged dataframe\n :raise: ValueError if the secondary timeframe is shorter than the dataframe timeframe\n \"\"\"\n\n minutes_inf = timeframe_to_minutes(timeframe_inf)\n minutes = timeframe_to_minutes(timeframe)\n if minutes == minutes_inf:\n # No need to forwardshift if the timeframes are identical\n informative['date_merge'] = informative[\"date\"]\n elif minutes < minutes_inf:\n # Subtract \"small\" timeframe so merging is not delayed by 1 small candle\n # Detailed explanation in https://github.com/freqtrade/freqtrade/issues/4073\n informative['date_merge'] = (\n informative[\"date\"] + pd.to_timedelta(minutes_inf, 'm') - pd.to_timedelta(minutes, 'm')\n )\n else:\n raise ValueError(\"Tried to merge a faster timeframe to a slower timeframe.\"\n \"This would create new rows, and can throw off your regular indicators.\")\n\n # Rename columns to be unique\n informative.columns = [f\"{col}_{timeframe_inf}\" for col in informative.columns]\n\n # Combine the 2 dataframes\n # all indicators on the informative sample MUST be calculated before this point\n dataframe = pd.merge(dataframe, informative, left_on='date',\n right_on=f'date_merge_{timeframe_inf}', how='left')\n dataframe = dataframe.drop(f'date_merge_{timeframe_inf}', axis=1)\n\n if ffill:\n dataframe = dataframe.ffill()\n\n return dataframe\n", "path": "freqtrade/strategy/strategy_helper.py"}]}
| 1,269 | 372 |
gh_patches_debug_13394
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-1923
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Command line help text is cut off
## Enhancement proposal
When running `manim --help`, the following output is returned:
```
Manim Community v0.9.0
Usage: manim [OPTIONS] COMMAND [ARGS]...
Animation engine for explanatory math videos
Options:
--version Show version and exit.
--help Show this message and exit.
Commands:
render* Render SCENE(S) from the input FILE.
cfg Manages Manim configuration files.
init Sets up a project in current working directory with default...
new Create a new project or insert a new scene.
plugins Manages Manim plugins.
Made with <3 by Manim Community developers.
```
As you can see, the help text for `init` is cut off, and does not provide sufficient information about what that command does.
## Additional comments
<!-- Add further context that you think might be relevant. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `manim/cli/init/commands.py`
Content:
```
1 """Manim's init subcommand.
2
3 Manim's init subcommand is accessed in the command-line interface via ``manim
4 init``. Here you can specify options, subcommands, and subgroups for the init
5 group.
6
7 """
8 from pathlib import Path
9
10 import click
11
12 from ...constants import CONTEXT_SETTINGS, EPILOG
13 from ...utils.file_ops import copy_template_files
14
15
16 @click.command(
17 context_settings=CONTEXT_SETTINGS,
18 epilog=EPILOG,
19 )
20 def init():
21 """Sets up a project in current working directory with default settings.
22
23 It copies files from templates directory and pastes them in the current working dir.
24
25 The new project is set up with default settings.
26 """
27 cfg = Path("manim.cfg")
28 if cfg.exists():
29 raise FileExistsError(f"\t{cfg} exists\n")
30 else:
31 copy_template_files()
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/manim/cli/init/commands.py b/manim/cli/init/commands.py
--- a/manim/cli/init/commands.py
+++ b/manim/cli/init/commands.py
@@ -16,13 +16,14 @@
@click.command(
context_settings=CONTEXT_SETTINGS,
epilog=EPILOG,
+ short_help="""Sets up a new project in current working directory with default settings.\n
+It copies files from templates directory and pastes them in the current working dir.
+""",
)
def init():
- """Sets up a project in current working directory with default settings.
+ """Sets up a new project in current working directory with default settings.
It copies files from templates directory and pastes them in the current working dir.
-
- The new project is set up with default settings.
"""
cfg = Path("manim.cfg")
if cfg.exists():
|
{"golden_diff": "diff --git a/manim/cli/init/commands.py b/manim/cli/init/commands.py\n--- a/manim/cli/init/commands.py\n+++ b/manim/cli/init/commands.py\n@@ -16,13 +16,14 @@\n @click.command(\n context_settings=CONTEXT_SETTINGS,\n epilog=EPILOG,\n+ short_help=\"\"\"Sets up a new project in current working directory with default settings.\\n\n+It copies files from templates directory and pastes them in the current working dir.\n+\"\"\",\n )\n def init():\n- \"\"\"Sets up a project in current working directory with default settings.\n+ \"\"\"Sets up a new project in current working directory with default settings.\n \n It copies files from templates directory and pastes them in the current working dir.\n-\n- The new project is set up with default settings.\n \"\"\"\n cfg = Path(\"manim.cfg\")\n if cfg.exists():\n", "issue": "Command line help text is cut off\n## Enhancement proposal\r\nWhen running `manim --help`, the following output is returned:\r\n\r\n```\r\nManim Community v0.9.0\r\n\r\nUsage: manim [OPTIONS] COMMAND [ARGS]...\r\n\r\n Animation engine for explanatory math videos\r\n\r\nOptions:\r\n --version Show version and exit.\r\n --help Show this message and exit.\r\n\r\nCommands:\r\n render* Render SCENE(S) from the input FILE.\r\n cfg Manages Manim configuration files.\r\n init Sets up a project in current working directory with default...\r\n new Create a new project or insert a new scene.\r\n plugins Manages Manim plugins.\r\n\r\n Made with <3 by Manim Community developers.\r\n```\r\n\r\nAs you can see, the help text for `init` is cut off, and does not provide sufficient information about what that command does.\r\n## Additional comments\r\n<!-- Add further context that you think might be relevant. -->\r\n\n", "before_files": [{"content": "\"\"\"Manim's init subcommand.\n\nManim's init subcommand is accessed in the command-line interface via ``manim\ninit``. Here you can specify options, subcommands, and subgroups for the init\ngroup.\n\n\"\"\"\nfrom pathlib import Path\n\nimport click\n\nfrom ...constants import CONTEXT_SETTINGS, EPILOG\nfrom ...utils.file_ops import copy_template_files\n\n\[email protected](\n context_settings=CONTEXT_SETTINGS,\n epilog=EPILOG,\n)\ndef init():\n \"\"\"Sets up a project in current working directory with default settings.\n\n It copies files from templates directory and pastes them in the current working dir.\n\n The new project is set up with default settings.\n \"\"\"\n cfg = Path(\"manim.cfg\")\n if cfg.exists():\n raise FileExistsError(f\"\\t{cfg} exists\\n\")\n else:\n copy_template_files()\n", "path": "manim/cli/init/commands.py"}], "after_files": [{"content": "\"\"\"Manim's init subcommand.\n\nManim's init subcommand is accessed in the command-line interface via ``manim\ninit``. Here you can specify options, subcommands, and subgroups for the init\ngroup.\n\n\"\"\"\nfrom pathlib import Path\n\nimport click\n\nfrom ...constants import CONTEXT_SETTINGS, EPILOG\nfrom ...utils.file_ops import copy_template_files\n\n\[email protected](\n context_settings=CONTEXT_SETTINGS,\n epilog=EPILOG,\n short_help=\"\"\"Sets up a new project in current working directory with default settings.\\n\nIt copies files from templates directory and pastes them in the current working dir.\n\"\"\",\n)\ndef init():\n \"\"\"Sets up a new project in current working directory with default settings.\n\n It copies files from templates directory and pastes them in the current working dir.\n \"\"\"\n cfg = Path(\"manim.cfg\")\n if cfg.exists():\n raise FileExistsError(f\"\\t{cfg} exists\\n\")\n else:\n copy_template_files()\n", "path": "manim/cli/init/commands.py"}]}
| 704 | 193 |
gh_patches_debug_10626
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-3216
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
using default_scheduler_url as a mounting point (not root `http://address/mount`) behind proxy not working
<!---
We use GitHub issues mainly for tracking bugs and feature requests.
Questions for how to use luigi can be sent to the mailing list.
Currently, there are no strict procedures or guidelines for submitting issues.
In short, please just use common sense.
Common sense includes this at bare-minimum:
* search for similar issues posted before creating a new issue.
* Use markdown to format all code/logs. Issues which are hard to read
when rendered on GitHub might be closed with a friendly reminder of this.
* If applicable, reading relevant parts of the documentation.
Also, add steps to reproduce the bug, if applicable. Sample code would be nice too :)
For more information on how to submit valuable contributions,
see https://opensource.guide/how-to-contribute/#how-to-submit-a-contribution
-->
I need to mount `luigi` behind a nginx, for example luigi at `http://address/mount`.
For that I configure:
```ini
[core]
default_scheduler_url=http://address/mount
....
```
GUI is ok and works but, CLI not due to url resolution. it happens there https://github.com/spotify/luigi/blob/c13566418c92de3e4d8d33ead4e7c936511afae1/luigi/rpc.py#L54
To understand what happened:
```python
parsed=urlparse('http://address/mount')
url='/api/add_task'
urljoin(parsed.geturl(), url)
# ==> give 'http://address/api/add_task'
# expected http://address/mount/api/add_task
```
What I must do for working - slash at the end of mount point, no slash for url -:
```python
parsed=urlparse('http://address/mount/')
url='api/add_task'
urljoin(parsed.geturl(), url)
# ==> http://address/mount/api/add_task
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `luigi/rpc.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2012-2015 Spotify AB
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 #
17 """
18 Implementation of the REST interface between the workers and the server.
19 rpc.py implements the client side of it, server.py implements the server side.
20 See :doc:`/central_scheduler` for more info.
21 """
22 import abc
23 import os
24 import json
25 import logging
26 import socket
27 import base64
28
29 from urllib.parse import urljoin, urlencode, urlparse
30 from urllib.request import urlopen, Request
31 from urllib.error import URLError
32
33 from tenacity import Retrying, wait_fixed, stop_after_attempt
34 from luigi import configuration
35 from luigi.scheduler import RPC_METHODS
36
37 HAS_UNIX_SOCKET = True
38 HAS_REQUESTS = True
39
40
41 try:
42 import requests_unixsocket as requests
43 except ImportError:
44 HAS_UNIX_SOCKET = False
45 try:
46 import requests
47 except ImportError:
48 HAS_REQUESTS = False
49
50
51 logger = logging.getLogger('luigi-interface') # TODO: 'interface'?
52
53
54 def _urljoin(base, url):
55 """
56 Join relative URLs to base URLs like urllib.parse.urljoin but support
57 arbitrary URIs (esp. 'http+unix://').
58 """
59 parsed = urlparse(base)
60 scheme = parsed.scheme
61 return urlparse(
62 urljoin(parsed._replace(scheme='http').geturl(), url)
63 )._replace(scheme=scheme).geturl()
64
65
66 class RPCError(Exception):
67
68 def __init__(self, message, sub_exception=None):
69 super(RPCError, self).__init__(message)
70 self.sub_exception = sub_exception
71
72
73 class _FetcherInterface(metaclass=abc.ABCMeta):
74 @abc.abstractmethod
75 def fetch(self, full_url, body, timeout):
76 pass
77
78 @abc.abstractmethod
79 def close(self):
80 pass
81
82
83 class URLLibFetcher(_FetcherInterface):
84 raises = (URLError, socket.timeout)
85
86 def _create_request(self, full_url, body=None):
87 # when full_url contains basic auth info, extract it and set the Authorization header
88 url = urlparse(full_url)
89 if url.username:
90 # base64 encoding of username:password
91 auth = base64.b64encode('{}:{}'.format(url.username, url.password or '').encode('utf-8'))
92 auth = auth.decode('utf-8')
93 # update full_url and create a request object with the auth header set
94 full_url = url._replace(netloc=url.netloc.split('@', 1)[-1]).geturl()
95 req = Request(full_url)
96 req.add_header('Authorization', 'Basic {}'.format(auth))
97 else:
98 req = Request(full_url)
99
100 # add the request body
101 if body:
102 req.data = urlencode(body).encode('utf-8')
103
104 return req
105
106 def fetch(self, full_url, body, timeout):
107 req = self._create_request(full_url, body=body)
108 return urlopen(req, timeout=timeout).read().decode('utf-8')
109
110 def close(self):
111 pass
112
113
114 class RequestsFetcher(_FetcherInterface):
115 def __init__(self):
116 from requests import exceptions as requests_exceptions
117 self.raises = requests_exceptions.RequestException
118 self.session = requests.Session()
119 self.process_id = os.getpid()
120
121 def check_pid(self):
122 # if the process id change changed from when the session was created
123 # a new session needs to be setup since requests isn't multiprocessing safe.
124 if os.getpid() != self.process_id:
125 self.session = requests.Session()
126 self.process_id = os.getpid()
127
128 def fetch(self, full_url, body, timeout):
129 self.check_pid()
130 resp = self.session.post(full_url, data=body, timeout=timeout)
131 resp.raise_for_status()
132 return resp.text
133
134 def close(self):
135 self.session.close()
136
137
138 class RemoteScheduler:
139 """
140 Scheduler proxy object. Talks to a RemoteSchedulerResponder.
141 """
142
143 def __init__(self, url='http://localhost:8082/', connect_timeout=None):
144 assert not url.startswith('http+unix://') or HAS_UNIX_SOCKET, (
145 'You need to install requests-unixsocket for Unix socket support.'
146 )
147
148 self._url = url.rstrip('/')
149 config = configuration.get_config()
150
151 if connect_timeout is None:
152 connect_timeout = config.getfloat('core', 'rpc-connect-timeout', 10.0)
153 self._connect_timeout = connect_timeout
154
155 self._rpc_retry_attempts = config.getint('core', 'rpc-retry-attempts', 3)
156 self._rpc_retry_wait = config.getint('core', 'rpc-retry-wait', 30)
157 self._rpc_log_retries = config.getboolean('core', 'rpc-log-retries', True)
158
159 if HAS_REQUESTS:
160 self._fetcher = RequestsFetcher()
161 else:
162 self._fetcher = URLLibFetcher()
163
164 def close(self):
165 self._fetcher.close()
166
167 def _get_retryer(self):
168 def retry_logging(retry_state):
169 if self._rpc_log_retries:
170 logger.warning("Failed connecting to remote scheduler %r", self._url, exc_info=True)
171 logger.info("Retrying attempt %r of %r (max)" % (retry_state.attempt_number + 1, self._rpc_retry_attempts))
172 logger.info("Wait for %d seconds" % self._rpc_retry_wait)
173
174 return Retrying(wait=wait_fixed(self._rpc_retry_wait),
175 stop=stop_after_attempt(self._rpc_retry_attempts),
176 reraise=True,
177 after=retry_logging)
178
179 def _fetch(self, url_suffix, body):
180 full_url = _urljoin(self._url, url_suffix)
181 scheduler_retry = self._get_retryer()
182
183 try:
184 response = scheduler_retry(self._fetcher.fetch, full_url, body, self._connect_timeout)
185 except self._fetcher.raises as e:
186 raise RPCError(
187 "Errors (%d attempts) when connecting to remote scheduler %r" %
188 (self._rpc_retry_attempts, self._url),
189 e
190 )
191 return response
192
193 def _request(self, url, data, attempts=3, allow_null=True):
194 body = {'data': json.dumps(data)}
195
196 for _ in range(attempts):
197 page = self._fetch(url, body)
198 response = json.loads(page)["response"]
199 if allow_null or response is not None:
200 return response
201 raise RPCError("Received null response from remote scheduler %r" % self._url)
202
203
204 for method_name, method in RPC_METHODS.items():
205 setattr(RemoteScheduler, method_name, method)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/luigi/rpc.py b/luigi/rpc.py
--- a/luigi/rpc.py
+++ b/luigi/rpc.py
@@ -55,11 +55,12 @@
"""
Join relative URLs to base URLs like urllib.parse.urljoin but support
arbitrary URIs (esp. 'http+unix://').
+ base part is fixed or mounted point, every url contains full base part.
"""
parsed = urlparse(base)
scheme = parsed.scheme
return urlparse(
- urljoin(parsed._replace(scheme='http').geturl(), url)
+ urljoin(parsed._replace(scheme='http').geturl(), parsed.path + (url if url[0] == '/' else '/' + url))
)._replace(scheme=scheme).geturl()
|
{"golden_diff": "diff --git a/luigi/rpc.py b/luigi/rpc.py\n--- a/luigi/rpc.py\n+++ b/luigi/rpc.py\n@@ -55,11 +55,12 @@\n \"\"\"\n Join relative URLs to base URLs like urllib.parse.urljoin but support\n arbitrary URIs (esp. 'http+unix://').\n+ base part is fixed or mounted point, every url contains full base part.\n \"\"\"\n parsed = urlparse(base)\n scheme = parsed.scheme\n return urlparse(\n- urljoin(parsed._replace(scheme='http').geturl(), url)\n+ urljoin(parsed._replace(scheme='http').geturl(), parsed.path + (url if url[0] == '/' else '/' + url))\n )._replace(scheme=scheme).geturl()\n", "issue": "using default_scheduler_url as a mounting point (not root `http://address/mount`) behind proxy not working\n<!---\r\nWe use GitHub issues mainly for tracking bugs and feature requests.\r\nQuestions for how to use luigi can be sent to the mailing list.\r\n\r\nCurrently, there are no strict procedures or guidelines for submitting issues.\r\nIn short, please just use common sense.\r\n\r\nCommon sense includes this at bare-minimum:\r\n\r\n * search for similar issues posted before creating a new issue.\r\n * Use markdown to format all code/logs. Issues which are hard to read\r\n when rendered on GitHub might be closed with a friendly reminder of this.\r\n * If applicable, reading relevant parts of the documentation.\r\n\r\nAlso, add steps to reproduce the bug, if applicable. Sample code would be nice too :)\r\n\r\nFor more information on how to submit valuable contributions,\r\nsee https://opensource.guide/how-to-contribute/#how-to-submit-a-contribution\r\n-->\r\nI need to mount `luigi` behind a nginx, for example luigi at `http://address/mount`.\r\nFor that I configure:\r\n```ini\r\n[core]\r\ndefault_scheduler_url=http://address/mount\r\n....\r\n```\r\n\r\nGUI is ok and works but, CLI not due to url resolution. it happens there https://github.com/spotify/luigi/blob/c13566418c92de3e4d8d33ead4e7c936511afae1/luigi/rpc.py#L54\r\n\r\nTo understand what happened:\r\n```python\r\nparsed=urlparse('http://address/mount')\r\nurl='/api/add_task'\r\nurljoin(parsed.geturl(), url)\r\n# ==> give 'http://address/api/add_task'\r\n# expected http://address/mount/api/add_task\r\n```\r\nWhat I must do for working - slash at the end of mount point, no slash for url -:\r\n```python\r\nparsed=urlparse('http://address/mount/')\r\nurl='api/add_task'\r\nurljoin(parsed.geturl(), url)\r\n# ==> http://address/mount/api/add_task\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2012-2015 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nImplementation of the REST interface between the workers and the server.\nrpc.py implements the client side of it, server.py implements the server side.\nSee :doc:`/central_scheduler` for more info.\n\"\"\"\nimport abc\nimport os\nimport json\nimport logging\nimport socket\nimport base64\n\nfrom urllib.parse import urljoin, urlencode, urlparse\nfrom urllib.request import urlopen, Request\nfrom urllib.error import URLError\n\nfrom tenacity import Retrying, wait_fixed, stop_after_attempt\nfrom luigi import configuration\nfrom luigi.scheduler import RPC_METHODS\n\nHAS_UNIX_SOCKET = True\nHAS_REQUESTS = True\n\n\ntry:\n import requests_unixsocket as requests\nexcept ImportError:\n HAS_UNIX_SOCKET = False\n try:\n import requests\n except ImportError:\n HAS_REQUESTS = False\n\n\nlogger = logging.getLogger('luigi-interface') # TODO: 'interface'?\n\n\ndef _urljoin(base, url):\n \"\"\"\n Join relative URLs to base URLs like urllib.parse.urljoin but support\n arbitrary URIs (esp. 'http+unix://').\n \"\"\"\n parsed = urlparse(base)\n scheme = parsed.scheme\n return urlparse(\n urljoin(parsed._replace(scheme='http').geturl(), url)\n )._replace(scheme=scheme).geturl()\n\n\nclass RPCError(Exception):\n\n def __init__(self, message, sub_exception=None):\n super(RPCError, self).__init__(message)\n self.sub_exception = sub_exception\n\n\nclass _FetcherInterface(metaclass=abc.ABCMeta):\n @abc.abstractmethod\n def fetch(self, full_url, body, timeout):\n pass\n\n @abc.abstractmethod\n def close(self):\n pass\n\n\nclass URLLibFetcher(_FetcherInterface):\n raises = (URLError, socket.timeout)\n\n def _create_request(self, full_url, body=None):\n # when full_url contains basic auth info, extract it and set the Authorization header\n url = urlparse(full_url)\n if url.username:\n # base64 encoding of username:password\n auth = base64.b64encode('{}:{}'.format(url.username, url.password or '').encode('utf-8'))\n auth = auth.decode('utf-8')\n # update full_url and create a request object with the auth header set\n full_url = url._replace(netloc=url.netloc.split('@', 1)[-1]).geturl()\n req = Request(full_url)\n req.add_header('Authorization', 'Basic {}'.format(auth))\n else:\n req = Request(full_url)\n\n # add the request body\n if body:\n req.data = urlencode(body).encode('utf-8')\n\n return req\n\n def fetch(self, full_url, body, timeout):\n req = self._create_request(full_url, body=body)\n return urlopen(req, timeout=timeout).read().decode('utf-8')\n\n def close(self):\n pass\n\n\nclass RequestsFetcher(_FetcherInterface):\n def __init__(self):\n from requests import exceptions as requests_exceptions\n self.raises = requests_exceptions.RequestException\n self.session = requests.Session()\n self.process_id = os.getpid()\n\n def check_pid(self):\n # if the process id change changed from when the session was created\n # a new session needs to be setup since requests isn't multiprocessing safe.\n if os.getpid() != self.process_id:\n self.session = requests.Session()\n self.process_id = os.getpid()\n\n def fetch(self, full_url, body, timeout):\n self.check_pid()\n resp = self.session.post(full_url, data=body, timeout=timeout)\n resp.raise_for_status()\n return resp.text\n\n def close(self):\n self.session.close()\n\n\nclass RemoteScheduler:\n \"\"\"\n Scheduler proxy object. Talks to a RemoteSchedulerResponder.\n \"\"\"\n\n def __init__(self, url='http://localhost:8082/', connect_timeout=None):\n assert not url.startswith('http+unix://') or HAS_UNIX_SOCKET, (\n 'You need to install requests-unixsocket for Unix socket support.'\n )\n\n self._url = url.rstrip('/')\n config = configuration.get_config()\n\n if connect_timeout is None:\n connect_timeout = config.getfloat('core', 'rpc-connect-timeout', 10.0)\n self._connect_timeout = connect_timeout\n\n self._rpc_retry_attempts = config.getint('core', 'rpc-retry-attempts', 3)\n self._rpc_retry_wait = config.getint('core', 'rpc-retry-wait', 30)\n self._rpc_log_retries = config.getboolean('core', 'rpc-log-retries', True)\n\n if HAS_REQUESTS:\n self._fetcher = RequestsFetcher()\n else:\n self._fetcher = URLLibFetcher()\n\n def close(self):\n self._fetcher.close()\n\n def _get_retryer(self):\n def retry_logging(retry_state):\n if self._rpc_log_retries:\n logger.warning(\"Failed connecting to remote scheduler %r\", self._url, exc_info=True)\n logger.info(\"Retrying attempt %r of %r (max)\" % (retry_state.attempt_number + 1, self._rpc_retry_attempts))\n logger.info(\"Wait for %d seconds\" % self._rpc_retry_wait)\n\n return Retrying(wait=wait_fixed(self._rpc_retry_wait),\n stop=stop_after_attempt(self._rpc_retry_attempts),\n reraise=True,\n after=retry_logging)\n\n def _fetch(self, url_suffix, body):\n full_url = _urljoin(self._url, url_suffix)\n scheduler_retry = self._get_retryer()\n\n try:\n response = scheduler_retry(self._fetcher.fetch, full_url, body, self._connect_timeout)\n except self._fetcher.raises as e:\n raise RPCError(\n \"Errors (%d attempts) when connecting to remote scheduler %r\" %\n (self._rpc_retry_attempts, self._url),\n e\n )\n return response\n\n def _request(self, url, data, attempts=3, allow_null=True):\n body = {'data': json.dumps(data)}\n\n for _ in range(attempts):\n page = self._fetch(url, body)\n response = json.loads(page)[\"response\"]\n if allow_null or response is not None:\n return response\n raise RPCError(\"Received null response from remote scheduler %r\" % self._url)\n\n\nfor method_name, method in RPC_METHODS.items():\n setattr(RemoteScheduler, method_name, method)\n", "path": "luigi/rpc.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2012-2015 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nImplementation of the REST interface between the workers and the server.\nrpc.py implements the client side of it, server.py implements the server side.\nSee :doc:`/central_scheduler` for more info.\n\"\"\"\nimport abc\nimport os\nimport json\nimport logging\nimport socket\nimport base64\n\nfrom urllib.parse import urljoin, urlencode, urlparse\nfrom urllib.request import urlopen, Request\nfrom urllib.error import URLError\n\nfrom tenacity import Retrying, wait_fixed, stop_after_attempt\nfrom luigi import configuration\nfrom luigi.scheduler import RPC_METHODS\n\nHAS_UNIX_SOCKET = True\nHAS_REQUESTS = True\n\n\ntry:\n import requests_unixsocket as requests\nexcept ImportError:\n HAS_UNIX_SOCKET = False\n try:\n import requests\n except ImportError:\n HAS_REQUESTS = False\n\n\nlogger = logging.getLogger('luigi-interface') # TODO: 'interface'?\n\n\ndef _urljoin(base, url):\n \"\"\"\n Join relative URLs to base URLs like urllib.parse.urljoin but support\n arbitrary URIs (esp. 'http+unix://').\n base part is fixed or mounted point, every url contains full base part.\n \"\"\"\n parsed = urlparse(base)\n scheme = parsed.scheme\n return urlparse(\n urljoin(parsed._replace(scheme='http').geturl(), parsed.path + (url if url[0] == '/' else '/' + url))\n )._replace(scheme=scheme).geturl()\n\n\nclass RPCError(Exception):\n\n def __init__(self, message, sub_exception=None):\n super(RPCError, self).__init__(message)\n self.sub_exception = sub_exception\n\n\nclass _FetcherInterface(metaclass=abc.ABCMeta):\n @abc.abstractmethod\n def fetch(self, full_url, body, timeout):\n pass\n\n @abc.abstractmethod\n def close(self):\n pass\n\n\nclass URLLibFetcher(_FetcherInterface):\n raises = (URLError, socket.timeout)\n\n def _create_request(self, full_url, body=None):\n # when full_url contains basic auth info, extract it and set the Authorization header\n url = urlparse(full_url)\n if url.username:\n # base64 encoding of username:password\n auth = base64.b64encode('{}:{}'.format(url.username, url.password or '').encode('utf-8'))\n auth = auth.decode('utf-8')\n # update full_url and create a request object with the auth header set\n full_url = url._replace(netloc=url.netloc.split('@', 1)[-1]).geturl()\n req = Request(full_url)\n req.add_header('Authorization', 'Basic {}'.format(auth))\n else:\n req = Request(full_url)\n\n # add the request body\n if body:\n req.data = urlencode(body).encode('utf-8')\n\n return req\n\n def fetch(self, full_url, body, timeout):\n req = self._create_request(full_url, body=body)\n return urlopen(req, timeout=timeout).read().decode('utf-8')\n\n def close(self):\n pass\n\n\nclass RequestsFetcher(_FetcherInterface):\n def __init__(self):\n from requests import exceptions as requests_exceptions\n self.raises = requests_exceptions.RequestException\n self.session = requests.Session()\n self.process_id = os.getpid()\n\n def check_pid(self):\n # if the process id change changed from when the session was created\n # a new session needs to be setup since requests isn't multiprocessing safe.\n if os.getpid() != self.process_id:\n self.session = requests.Session()\n self.process_id = os.getpid()\n\n def fetch(self, full_url, body, timeout):\n self.check_pid()\n resp = self.session.post(full_url, data=body, timeout=timeout)\n resp.raise_for_status()\n return resp.text\n\n def close(self):\n self.session.close()\n\n\nclass RemoteScheduler:\n \"\"\"\n Scheduler proxy object. Talks to a RemoteSchedulerResponder.\n \"\"\"\n\n def __init__(self, url='http://localhost:8082/', connect_timeout=None):\n assert not url.startswith('http+unix://') or HAS_UNIX_SOCKET, (\n 'You need to install requests-unixsocket for Unix socket support.'\n )\n\n self._url = url.rstrip('/')\n config = configuration.get_config()\n\n if connect_timeout is None:\n connect_timeout = config.getfloat('core', 'rpc-connect-timeout', 10.0)\n self._connect_timeout = connect_timeout\n\n self._rpc_retry_attempts = config.getint('core', 'rpc-retry-attempts', 3)\n self._rpc_retry_wait = config.getint('core', 'rpc-retry-wait', 30)\n self._rpc_log_retries = config.getboolean('core', 'rpc-log-retries', True)\n\n if HAS_REQUESTS:\n self._fetcher = RequestsFetcher()\n else:\n self._fetcher = URLLibFetcher()\n\n def close(self):\n self._fetcher.close()\n\n def _get_retryer(self):\n def retry_logging(retry_state):\n if self._rpc_log_retries:\n logger.warning(\"Failed connecting to remote scheduler %r\", self._url, exc_info=True)\n logger.info(\"Retrying attempt %r of %r (max)\" % (retry_state.attempt_number + 1, self._rpc_retry_attempts))\n logger.info(\"Wait for %d seconds\" % self._rpc_retry_wait)\n\n return Retrying(wait=wait_fixed(self._rpc_retry_wait),\n stop=stop_after_attempt(self._rpc_retry_attempts),\n reraise=True,\n after=retry_logging)\n\n def _fetch(self, url_suffix, body):\n full_url = _urljoin(self._url, url_suffix)\n scheduler_retry = self._get_retryer()\n\n try:\n response = scheduler_retry(self._fetcher.fetch, full_url, body, self._connect_timeout)\n except self._fetcher.raises as e:\n raise RPCError(\n \"Errors (%d attempts) when connecting to remote scheduler %r\" %\n (self._rpc_retry_attempts, self._url),\n e\n )\n return response\n\n def _request(self, url, data, attempts=3, allow_null=True):\n body = {'data': json.dumps(data)}\n\n for _ in range(attempts):\n page = self._fetch(url, body)\n response = json.loads(page)[\"response\"]\n if allow_null or response is not None:\n return response\n raise RPCError(\"Received null response from remote scheduler %r\" % self._url)\n\n\nfor method_name, method in RPC_METHODS.items():\n setattr(RemoteScheduler, method_name, method)\n", "path": "luigi/rpc.py"}]}
| 2,757 | 176 |
gh_patches_debug_24682
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-7975
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
poetry install does not honor `build-system.requires`
<!--
Hi there! Thank you for discovering and submitting an issue.
Before you submit this; let's make sure of a few things.
Please make sure the following boxes are ticked if they are correct.
If not, please try and fulfill these first.
-->
<!-- Checked checkbox should look like this: [x] -->
- [ ] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
<!--
Once those are done, if you're able to fill in the following list with your information,
it'd be very helpful to whoever handles the issue.
-->
- **OS version and name**: Ubuntu 20.04.4
- **Poetry version**: 1.2.0b2
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**:
<details>
<summary>pyproject.toml</summary>
```
[tool.poetry]
name = "meow"
version = "0.1.0"
description = ""
authors = [""]
build = "build.py"
[tool.poetry.dependencies]
python = "^3.9"
SoundFile = "0.10.*"
crcmod = "^1.7"
librosa = ">=0.8.0"
numba = "^0.56.0"
protobuf = "3.14.0"
tensorboard = "^2.10.0"
torchaudio = {version = "=0.12.1+cu113", source="torch"}
torch = {version = "=1.12.1+cu113", source="torch"}
[[tool.poetry.source]]
name = "torch"
url = "https://download.pytorch.org/whl/cu113"
secondary = true
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0", "setuptools>=40.6.0", "wheel", "numpy", "pybind11"]
build-backend = "poetry.core.masonry.api"
```
</details>
## Issue
<!-- Now feel free to write your issue, but please be descriptive! Thanks again 🙌 ❤️ -->
Running `poetry build` with the above `pyproject.toml` does the right thing:
```
Preparing build environment with build-system requirements poetry-core>=1.0.0, setuptools>=40.6.0, wheel, numpy, pybind11
[...snip...]
```
Running `poetry install` fails because it attempts to build the project without installing `build-system.requires` packages.
I would have expected the install command to create an isolated environment, install the build requirements and perform the build in that isolated environment, and then install the produced artifact in my current environment.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/poetry/masonry/builders/editable.py`
Content:
```
1 from __future__ import annotations
2
3 import csv
4 import hashlib
5 import json
6 import os
7
8 from base64 import urlsafe_b64encode
9 from pathlib import Path
10 from typing import TYPE_CHECKING
11
12 from poetry.core.constraints.version import Version
13 from poetry.core.masonry.builders.builder import Builder
14 from poetry.core.masonry.builders.sdist import SdistBuilder
15 from poetry.core.masonry.utils.package_include import PackageInclude
16
17 from poetry.utils._compat import WINDOWS
18 from poetry.utils._compat import decode
19 from poetry.utils.env import build_environment
20 from poetry.utils.helpers import is_dir_writable
21 from poetry.utils.pip import pip_install
22
23
24 if TYPE_CHECKING:
25 from cleo.io.io import IO
26
27 from poetry.poetry import Poetry
28 from poetry.utils.env import Env
29
30 SCRIPT_TEMPLATE = """\
31 #!{python}
32 import sys
33 from {module} import {callable_holder}
34
35 if __name__ == '__main__':
36 sys.exit({callable_}())
37 """
38
39 WINDOWS_CMD_TEMPLATE = """\
40 @echo off\r\n"{python}" "%~dp0\\{script}" %*\r\n
41 """
42
43
44 class EditableBuilder(Builder):
45 def __init__(self, poetry: Poetry, env: Env, io: IO) -> None:
46 self._poetry: Poetry
47 super().__init__(poetry)
48
49 self._env = env
50 self._io = io
51
52 def build(self, target_dir: Path | None = None) -> Path:
53 self._debug(
54 f" - Building package <c1>{self._package.name}</c1> in"
55 " <info>editable</info> mode"
56 )
57
58 if self._package.build_script:
59 if self._package.build_should_generate_setup():
60 self._debug(
61 " - <warning>Falling back on using a <b>setup.py</b></warning>"
62 )
63 self._setup_build()
64 path: Path = self._path
65 return path
66
67 self._run_build_script(self._package.build_script)
68
69 for removed in self._env.site_packages.remove_distribution_files(
70 distribution_name=self._package.name
71 ):
72 self._debug(
73 f" - Removed <c2>{removed.name}</c2> directory from"
74 f" <b>{removed.parent}</b>"
75 )
76
77 added_files = []
78 added_files += self._add_pth()
79 added_files += self._add_scripts()
80 self._add_dist_info(added_files)
81
82 path = self._path
83 return path
84
85 def _run_build_script(self, build_script: str) -> None:
86 with build_environment(poetry=self._poetry, env=self._env, io=self._io) as env:
87 self._debug(f" - Executing build script: <b>{build_script}</b>")
88 env.run("python", str(self._path.joinpath(build_script)), call=True)
89
90 def _setup_build(self) -> None:
91 builder = SdistBuilder(self._poetry)
92 setup = self._path / "setup.py"
93 has_setup = setup.exists()
94
95 if has_setup:
96 self._io.write_error_line(
97 "<warning>A setup.py file already exists. Using it.</warning>"
98 )
99 else:
100 with setup.open("w", encoding="utf-8") as f:
101 f.write(decode(builder.build_setup()))
102
103 try:
104 if self._env.pip_version < Version.from_parts(19, 0):
105 pip_install(self._path, self._env, upgrade=True, editable=True)
106 else:
107 # Temporarily rename pyproject.toml
108 renamed_pyproject = self._poetry.file.path.with_suffix(".tmp")
109 self._poetry.file.path.rename(renamed_pyproject)
110 try:
111 pip_install(self._path, self._env, upgrade=True, editable=True)
112 finally:
113 renamed_pyproject.rename(self._poetry.file.path)
114 finally:
115 if not has_setup:
116 os.remove(setup)
117
118 def _add_pth(self) -> list[Path]:
119 paths = {
120 include.base.resolve().as_posix()
121 for include in self._module.includes
122 if isinstance(include, PackageInclude)
123 and (include.is_module() or include.is_package())
124 }
125
126 content = "".join(decode(path + os.linesep) for path in paths)
127 pth_file = Path(self._module.name).with_suffix(".pth")
128
129 # remove any pre-existing pth files for this package
130 for file in self._env.site_packages.find(path=pth_file, writable_only=True):
131 self._debug(
132 f" - Removing existing <c2>{file.name}</c2> from <b>{file.parent}</b>"
133 f" for {self._poetry.file.path.parent}"
134 )
135 file.unlink(missing_ok=True)
136
137 try:
138 pth_file = self._env.site_packages.write_text(
139 pth_file, content, encoding="utf-8"
140 )
141 self._debug(
142 f" - Adding <c2>{pth_file.name}</c2> to <b>{pth_file.parent}</b> for"
143 f" {self._poetry.file.path.parent}"
144 )
145 return [pth_file]
146 except OSError:
147 # TODO: Replace with PermissionError
148 self._io.write_error_line(
149 f" - Failed to create <c2>{pth_file.name}</c2> for"
150 f" {self._poetry.file.path.parent}"
151 )
152 return []
153
154 def _add_scripts(self) -> list[Path]:
155 added = []
156 entry_points = self.convert_entry_points()
157
158 for scripts_path in self._env.script_dirs:
159 if is_dir_writable(path=scripts_path, create=True):
160 break
161 else:
162 self._io.write_error_line(
163 " - Failed to find a suitable script installation directory for"
164 f" {self._poetry.file.path.parent}"
165 )
166 return []
167
168 scripts = entry_points.get("console_scripts", [])
169 for script in scripts:
170 name, script = script.split(" = ")
171 module, callable_ = script.split(":")
172 callable_holder = callable_.split(".", 1)[0]
173
174 script_file = scripts_path.joinpath(name)
175 self._debug(
176 f" - Adding the <c2>{name}</c2> script to <b>{scripts_path}</b>"
177 )
178 with script_file.open("w", encoding="utf-8") as f:
179 f.write(
180 decode(
181 SCRIPT_TEMPLATE.format(
182 python=self._env.python,
183 module=module,
184 callable_holder=callable_holder,
185 callable_=callable_,
186 )
187 )
188 )
189
190 script_file.chmod(0o755)
191
192 added.append(script_file)
193
194 if WINDOWS:
195 cmd_script = script_file.with_suffix(".cmd")
196 cmd = WINDOWS_CMD_TEMPLATE.format(python=self._env.python, script=name)
197 self._debug(
198 f" - Adding the <c2>{cmd_script.name}</c2> script wrapper to"
199 f" <b>{scripts_path}</b>"
200 )
201
202 with cmd_script.open("w", encoding="utf-8") as f:
203 f.write(decode(cmd))
204
205 added.append(cmd_script)
206
207 return added
208
209 def _add_dist_info(self, added_files: list[Path]) -> None:
210 from poetry.core.masonry.builders.wheel import WheelBuilder
211
212 added_files = added_files[:]
213
214 builder = WheelBuilder(self._poetry)
215 dist_info = self._env.site_packages.mkdir(Path(builder.dist_info))
216
217 self._debug(
218 f" - Adding the <c2>{dist_info.name}</c2> directory to"
219 f" <b>{dist_info.parent}</b>"
220 )
221
222 with dist_info.joinpath("METADATA").open("w", encoding="utf-8") as f:
223 builder._write_metadata_file(f)
224
225 added_files.append(dist_info.joinpath("METADATA"))
226
227 with dist_info.joinpath("INSTALLER").open("w", encoding="utf-8") as f:
228 f.write("poetry")
229
230 added_files.append(dist_info.joinpath("INSTALLER"))
231
232 if self.convert_entry_points():
233 with dist_info.joinpath("entry_points.txt").open(
234 "w", encoding="utf-8"
235 ) as f:
236 builder._write_entry_points(f)
237
238 added_files.append(dist_info.joinpath("entry_points.txt"))
239
240 # write PEP 610 metadata
241 direct_url_json = dist_info.joinpath("direct_url.json")
242 direct_url_json.write_text(
243 json.dumps(
244 {
245 "dir_info": {"editable": True},
246 "url": self._poetry.file.path.parent.absolute().as_uri(),
247 }
248 )
249 )
250 added_files.append(direct_url_json)
251
252 record = dist_info.joinpath("RECORD")
253 with record.open("w", encoding="utf-8", newline="") as f:
254 csv_writer = csv.writer(f)
255 for path in added_files:
256 hash = self._get_file_hash(path)
257 size = path.stat().st_size
258 csv_writer.writerow((path, f"sha256={hash}", size))
259
260 # RECORD itself is recorded with no hash or size
261 csv_writer.writerow((record, "", ""))
262
263 def _get_file_hash(self, filepath: Path) -> str:
264 hashsum = hashlib.sha256()
265 with filepath.open("rb") as src:
266 while True:
267 buf = src.read(1024 * 8)
268 if not buf:
269 break
270 hashsum.update(buf)
271
272 src.seek(0)
273
274 return urlsafe_b64encode(hashsum.digest()).decode("ascii").rstrip("=")
275
276 def _debug(self, msg: str) -> None:
277 if self._io.is_debug():
278 self._io.write_line(msg)
279
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/poetry/masonry/builders/editable.py b/src/poetry/masonry/builders/editable.py
--- a/src/poetry/masonry/builders/editable.py
+++ b/src/poetry/masonry/builders/editable.py
@@ -9,7 +9,6 @@
from pathlib import Path
from typing import TYPE_CHECKING
-from poetry.core.constraints.version import Version
from poetry.core.masonry.builders.builder import Builder
from poetry.core.masonry.builders.sdist import SdistBuilder
from poetry.core.masonry.utils.package_include import PackageInclude
@@ -101,16 +100,7 @@
f.write(decode(builder.build_setup()))
try:
- if self._env.pip_version < Version.from_parts(19, 0):
- pip_install(self._path, self._env, upgrade=True, editable=True)
- else:
- # Temporarily rename pyproject.toml
- renamed_pyproject = self._poetry.file.path.with_suffix(".tmp")
- self._poetry.file.path.rename(renamed_pyproject)
- try:
- pip_install(self._path, self._env, upgrade=True, editable=True)
- finally:
- renamed_pyproject.rename(self._poetry.file.path)
+ pip_install(self._path, self._env, upgrade=True, editable=True)
finally:
if not has_setup:
os.remove(setup)
|
{"golden_diff": "diff --git a/src/poetry/masonry/builders/editable.py b/src/poetry/masonry/builders/editable.py\n--- a/src/poetry/masonry/builders/editable.py\n+++ b/src/poetry/masonry/builders/editable.py\n@@ -9,7 +9,6 @@\n from pathlib import Path\n from typing import TYPE_CHECKING\n \n-from poetry.core.constraints.version import Version\n from poetry.core.masonry.builders.builder import Builder\n from poetry.core.masonry.builders.sdist import SdistBuilder\n from poetry.core.masonry.utils.package_include import PackageInclude\n@@ -101,16 +100,7 @@\n f.write(decode(builder.build_setup()))\n \n try:\n- if self._env.pip_version < Version.from_parts(19, 0):\n- pip_install(self._path, self._env, upgrade=True, editable=True)\n- else:\n- # Temporarily rename pyproject.toml\n- renamed_pyproject = self._poetry.file.path.with_suffix(\".tmp\")\n- self._poetry.file.path.rename(renamed_pyproject)\n- try:\n- pip_install(self._path, self._env, upgrade=True, editable=True)\n- finally:\n- renamed_pyproject.rename(self._poetry.file.path)\n+ pip_install(self._path, self._env, upgrade=True, editable=True)\n finally:\n if not has_setup:\n os.remove(setup)\n", "issue": "poetry install does not honor `build-system.requires`\n<!--\r\n Hi there! Thank you for discovering and submitting an issue.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the following boxes are ticked if they are correct.\r\n If not, please try and fulfill these first.\r\n-->\r\n\r\n<!-- Checked checkbox should look like this: [x] -->\r\n- [ ] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.\r\n- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n<!--\r\n Once those are done, if you're able to fill in the following list with your information,\r\n it'd be very helpful to whoever handles the issue.\r\n-->\r\n\r\n- **OS version and name**: Ubuntu 20.04.4\r\n- **Poetry version**: 1.2.0b2\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**:\r\n<details>\r\n<summary>pyproject.toml</summary>\r\n\r\n```\r\n[tool.poetry]\r\nname = \"meow\"\r\nversion = \"0.1.0\"\r\ndescription = \"\"\r\nauthors = [\"\"]\r\nbuild = \"build.py\"\r\n\r\n[tool.poetry.dependencies]\r\npython = \"^3.9\"\r\nSoundFile = \"0.10.*\"\r\ncrcmod = \"^1.7\"\r\nlibrosa = \">=0.8.0\"\r\nnumba = \"^0.56.0\"\r\nprotobuf = \"3.14.0\"\r\ntensorboard = \"^2.10.0\"\r\ntorchaudio = {version = \"=0.12.1+cu113\", source=\"torch\"}\r\ntorch = {version = \"=1.12.1+cu113\", source=\"torch\"}\r\n\r\n[[tool.poetry.source]]\r\nname = \"torch\"\r\nurl = \"https://download.pytorch.org/whl/cu113\"\r\nsecondary = true\r\n\r\n[tool.poetry.dev-dependencies]\r\n\r\n[build-system]\r\nrequires = [\"poetry-core>=1.0.0\", \"setuptools>=40.6.0\", \"wheel\", \"numpy\", \"pybind11\"]\r\nbuild-backend = \"poetry.core.masonry.api\"\r\n```\r\n\r\n</details>\r\n\r\n## Issue\r\n<!-- Now feel free to write your issue, but please be descriptive! Thanks again \ud83d\ude4c \u2764\ufe0f -->\r\nRunning `poetry build` with the above `pyproject.toml` does the right thing:\r\n```\r\nPreparing build environment with build-system requirements poetry-core>=1.0.0, setuptools>=40.6.0, wheel, numpy, pybind11\r\n[...snip...]\r\n```\r\n\r\nRunning `poetry install` fails because it attempts to build the project without installing `build-system.requires` packages.\r\n\r\nI would have expected the install command to create an isolated environment, install the build requirements and perform the build in that isolated environment, and then install the produced artifact in my current environment.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport csv\nimport hashlib\nimport json\nimport os\n\nfrom base64 import urlsafe_b64encode\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING\n\nfrom poetry.core.constraints.version import Version\nfrom poetry.core.masonry.builders.builder import Builder\nfrom poetry.core.masonry.builders.sdist import SdistBuilder\nfrom poetry.core.masonry.utils.package_include import PackageInclude\n\nfrom poetry.utils._compat import WINDOWS\nfrom poetry.utils._compat import decode\nfrom poetry.utils.env import build_environment\nfrom poetry.utils.helpers import is_dir_writable\nfrom poetry.utils.pip import pip_install\n\n\nif TYPE_CHECKING:\n from cleo.io.io import IO\n\n from poetry.poetry import Poetry\n from poetry.utils.env import Env\n\nSCRIPT_TEMPLATE = \"\"\"\\\n#!{python}\nimport sys\nfrom {module} import {callable_holder}\n\nif __name__ == '__main__':\n sys.exit({callable_}())\n\"\"\"\n\nWINDOWS_CMD_TEMPLATE = \"\"\"\\\n@echo off\\r\\n\"{python}\" \"%~dp0\\\\{script}\" %*\\r\\n\n\"\"\"\n\n\nclass EditableBuilder(Builder):\n def __init__(self, poetry: Poetry, env: Env, io: IO) -> None:\n self._poetry: Poetry\n super().__init__(poetry)\n\n self._env = env\n self._io = io\n\n def build(self, target_dir: Path | None = None) -> Path:\n self._debug(\n f\" - Building package <c1>{self._package.name}</c1> in\"\n \" <info>editable</info> mode\"\n )\n\n if self._package.build_script:\n if self._package.build_should_generate_setup():\n self._debug(\n \" - <warning>Falling back on using a <b>setup.py</b></warning>\"\n )\n self._setup_build()\n path: Path = self._path\n return path\n\n self._run_build_script(self._package.build_script)\n\n for removed in self._env.site_packages.remove_distribution_files(\n distribution_name=self._package.name\n ):\n self._debug(\n f\" - Removed <c2>{removed.name}</c2> directory from\"\n f\" <b>{removed.parent}</b>\"\n )\n\n added_files = []\n added_files += self._add_pth()\n added_files += self._add_scripts()\n self._add_dist_info(added_files)\n\n path = self._path\n return path\n\n def _run_build_script(self, build_script: str) -> None:\n with build_environment(poetry=self._poetry, env=self._env, io=self._io) as env:\n self._debug(f\" - Executing build script: <b>{build_script}</b>\")\n env.run(\"python\", str(self._path.joinpath(build_script)), call=True)\n\n def _setup_build(self) -> None:\n builder = SdistBuilder(self._poetry)\n setup = self._path / \"setup.py\"\n has_setup = setup.exists()\n\n if has_setup:\n self._io.write_error_line(\n \"<warning>A setup.py file already exists. Using it.</warning>\"\n )\n else:\n with setup.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(builder.build_setup()))\n\n try:\n if self._env.pip_version < Version.from_parts(19, 0):\n pip_install(self._path, self._env, upgrade=True, editable=True)\n else:\n # Temporarily rename pyproject.toml\n renamed_pyproject = self._poetry.file.path.with_suffix(\".tmp\")\n self._poetry.file.path.rename(renamed_pyproject)\n try:\n pip_install(self._path, self._env, upgrade=True, editable=True)\n finally:\n renamed_pyproject.rename(self._poetry.file.path)\n finally:\n if not has_setup:\n os.remove(setup)\n\n def _add_pth(self) -> list[Path]:\n paths = {\n include.base.resolve().as_posix()\n for include in self._module.includes\n if isinstance(include, PackageInclude)\n and (include.is_module() or include.is_package())\n }\n\n content = \"\".join(decode(path + os.linesep) for path in paths)\n pth_file = Path(self._module.name).with_suffix(\".pth\")\n\n # remove any pre-existing pth files for this package\n for file in self._env.site_packages.find(path=pth_file, writable_only=True):\n self._debug(\n f\" - Removing existing <c2>{file.name}</c2> from <b>{file.parent}</b>\"\n f\" for {self._poetry.file.path.parent}\"\n )\n file.unlink(missing_ok=True)\n\n try:\n pth_file = self._env.site_packages.write_text(\n pth_file, content, encoding=\"utf-8\"\n )\n self._debug(\n f\" - Adding <c2>{pth_file.name}</c2> to <b>{pth_file.parent}</b> for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return [pth_file]\n except OSError:\n # TODO: Replace with PermissionError\n self._io.write_error_line(\n f\" - Failed to create <c2>{pth_file.name}</c2> for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return []\n\n def _add_scripts(self) -> list[Path]:\n added = []\n entry_points = self.convert_entry_points()\n\n for scripts_path in self._env.script_dirs:\n if is_dir_writable(path=scripts_path, create=True):\n break\n else:\n self._io.write_error_line(\n \" - Failed to find a suitable script installation directory for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return []\n\n scripts = entry_points.get(\"console_scripts\", [])\n for script in scripts:\n name, script = script.split(\" = \")\n module, callable_ = script.split(\":\")\n callable_holder = callable_.split(\".\", 1)[0]\n\n script_file = scripts_path.joinpath(name)\n self._debug(\n f\" - Adding the <c2>{name}</c2> script to <b>{scripts_path}</b>\"\n )\n with script_file.open(\"w\", encoding=\"utf-8\") as f:\n f.write(\n decode(\n SCRIPT_TEMPLATE.format(\n python=self._env.python,\n module=module,\n callable_holder=callable_holder,\n callable_=callable_,\n )\n )\n )\n\n script_file.chmod(0o755)\n\n added.append(script_file)\n\n if WINDOWS:\n cmd_script = script_file.with_suffix(\".cmd\")\n cmd = WINDOWS_CMD_TEMPLATE.format(python=self._env.python, script=name)\n self._debug(\n f\" - Adding the <c2>{cmd_script.name}</c2> script wrapper to\"\n f\" <b>{scripts_path}</b>\"\n )\n\n with cmd_script.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(cmd))\n\n added.append(cmd_script)\n\n return added\n\n def _add_dist_info(self, added_files: list[Path]) -> None:\n from poetry.core.masonry.builders.wheel import WheelBuilder\n\n added_files = added_files[:]\n\n builder = WheelBuilder(self._poetry)\n dist_info = self._env.site_packages.mkdir(Path(builder.dist_info))\n\n self._debug(\n f\" - Adding the <c2>{dist_info.name}</c2> directory to\"\n f\" <b>{dist_info.parent}</b>\"\n )\n\n with dist_info.joinpath(\"METADATA\").open(\"w\", encoding=\"utf-8\") as f:\n builder._write_metadata_file(f)\n\n added_files.append(dist_info.joinpath(\"METADATA\"))\n\n with dist_info.joinpath(\"INSTALLER\").open(\"w\", encoding=\"utf-8\") as f:\n f.write(\"poetry\")\n\n added_files.append(dist_info.joinpath(\"INSTALLER\"))\n\n if self.convert_entry_points():\n with dist_info.joinpath(\"entry_points.txt\").open(\n \"w\", encoding=\"utf-8\"\n ) as f:\n builder._write_entry_points(f)\n\n added_files.append(dist_info.joinpath(\"entry_points.txt\"))\n\n # write PEP 610 metadata\n direct_url_json = dist_info.joinpath(\"direct_url.json\")\n direct_url_json.write_text(\n json.dumps(\n {\n \"dir_info\": {\"editable\": True},\n \"url\": self._poetry.file.path.parent.absolute().as_uri(),\n }\n )\n )\n added_files.append(direct_url_json)\n\n record = dist_info.joinpath(\"RECORD\")\n with record.open(\"w\", encoding=\"utf-8\", newline=\"\") as f:\n csv_writer = csv.writer(f)\n for path in added_files:\n hash = self._get_file_hash(path)\n size = path.stat().st_size\n csv_writer.writerow((path, f\"sha256={hash}\", size))\n\n # RECORD itself is recorded with no hash or size\n csv_writer.writerow((record, \"\", \"\"))\n\n def _get_file_hash(self, filepath: Path) -> str:\n hashsum = hashlib.sha256()\n with filepath.open(\"rb\") as src:\n while True:\n buf = src.read(1024 * 8)\n if not buf:\n break\n hashsum.update(buf)\n\n src.seek(0)\n\n return urlsafe_b64encode(hashsum.digest()).decode(\"ascii\").rstrip(\"=\")\n\n def _debug(self, msg: str) -> None:\n if self._io.is_debug():\n self._io.write_line(msg)\n", "path": "src/poetry/masonry/builders/editable.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport csv\nimport hashlib\nimport json\nimport os\n\nfrom base64 import urlsafe_b64encode\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING\n\nfrom poetry.core.masonry.builders.builder import Builder\nfrom poetry.core.masonry.builders.sdist import SdistBuilder\nfrom poetry.core.masonry.utils.package_include import PackageInclude\n\nfrom poetry.utils._compat import WINDOWS\nfrom poetry.utils._compat import decode\nfrom poetry.utils.env import build_environment\nfrom poetry.utils.helpers import is_dir_writable\nfrom poetry.utils.pip import pip_install\n\n\nif TYPE_CHECKING:\n from cleo.io.io import IO\n\n from poetry.poetry import Poetry\n from poetry.utils.env import Env\n\nSCRIPT_TEMPLATE = \"\"\"\\\n#!{python}\nimport sys\nfrom {module} import {callable_holder}\n\nif __name__ == '__main__':\n sys.exit({callable_}())\n\"\"\"\n\nWINDOWS_CMD_TEMPLATE = \"\"\"\\\n@echo off\\r\\n\"{python}\" \"%~dp0\\\\{script}\" %*\\r\\n\n\"\"\"\n\n\nclass EditableBuilder(Builder):\n def __init__(self, poetry: Poetry, env: Env, io: IO) -> None:\n self._poetry: Poetry\n super().__init__(poetry)\n\n self._env = env\n self._io = io\n\n def build(self, target_dir: Path | None = None) -> Path:\n self._debug(\n f\" - Building package <c1>{self._package.name}</c1> in\"\n \" <info>editable</info> mode\"\n )\n\n if self._package.build_script:\n if self._package.build_should_generate_setup():\n self._debug(\n \" - <warning>Falling back on using a <b>setup.py</b></warning>\"\n )\n self._setup_build()\n path: Path = self._path\n return path\n\n self._run_build_script(self._package.build_script)\n\n for removed in self._env.site_packages.remove_distribution_files(\n distribution_name=self._package.name\n ):\n self._debug(\n f\" - Removed <c2>{removed.name}</c2> directory from\"\n f\" <b>{removed.parent}</b>\"\n )\n\n added_files = []\n added_files += self._add_pth()\n added_files += self._add_scripts()\n self._add_dist_info(added_files)\n\n path = self._path\n return path\n\n def _run_build_script(self, build_script: str) -> None:\n with build_environment(poetry=self._poetry, env=self._env, io=self._io) as env:\n self._debug(f\" - Executing build script: <b>{build_script}</b>\")\n env.run(\"python\", str(self._path.joinpath(build_script)), call=True)\n\n def _setup_build(self) -> None:\n builder = SdistBuilder(self._poetry)\n setup = self._path / \"setup.py\"\n has_setup = setup.exists()\n\n if has_setup:\n self._io.write_error_line(\n \"<warning>A setup.py file already exists. Using it.</warning>\"\n )\n else:\n with setup.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(builder.build_setup()))\n\n try:\n pip_install(self._path, self._env, upgrade=True, editable=True)\n finally:\n if not has_setup:\n os.remove(setup)\n\n def _add_pth(self) -> list[Path]:\n paths = {\n include.base.resolve().as_posix()\n for include in self._module.includes\n if isinstance(include, PackageInclude)\n and (include.is_module() or include.is_package())\n }\n\n content = \"\".join(decode(path + os.linesep) for path in paths)\n pth_file = Path(self._module.name).with_suffix(\".pth\")\n\n # remove any pre-existing pth files for this package\n for file in self._env.site_packages.find(path=pth_file, writable_only=True):\n self._debug(\n f\" - Removing existing <c2>{file.name}</c2> from <b>{file.parent}</b>\"\n f\" for {self._poetry.file.path.parent}\"\n )\n file.unlink(missing_ok=True)\n\n try:\n pth_file = self._env.site_packages.write_text(\n pth_file, content, encoding=\"utf-8\"\n )\n self._debug(\n f\" - Adding <c2>{pth_file.name}</c2> to <b>{pth_file.parent}</b> for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return [pth_file]\n except OSError:\n # TODO: Replace with PermissionError\n self._io.write_error_line(\n f\" - Failed to create <c2>{pth_file.name}</c2> for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return []\n\n def _add_scripts(self) -> list[Path]:\n added = []\n entry_points = self.convert_entry_points()\n\n for scripts_path in self._env.script_dirs:\n if is_dir_writable(path=scripts_path, create=True):\n break\n else:\n self._io.write_error_line(\n \" - Failed to find a suitable script installation directory for\"\n f\" {self._poetry.file.path.parent}\"\n )\n return []\n\n scripts = entry_points.get(\"console_scripts\", [])\n for script in scripts:\n name, script = script.split(\" = \")\n module, callable_ = script.split(\":\")\n callable_holder = callable_.split(\".\", 1)[0]\n\n script_file = scripts_path.joinpath(name)\n self._debug(\n f\" - Adding the <c2>{name}</c2> script to <b>{scripts_path}</b>\"\n )\n with script_file.open(\"w\", encoding=\"utf-8\") as f:\n f.write(\n decode(\n SCRIPT_TEMPLATE.format(\n python=self._env.python,\n module=module,\n callable_holder=callable_holder,\n callable_=callable_,\n )\n )\n )\n\n script_file.chmod(0o755)\n\n added.append(script_file)\n\n if WINDOWS:\n cmd_script = script_file.with_suffix(\".cmd\")\n cmd = WINDOWS_CMD_TEMPLATE.format(python=self._env.python, script=name)\n self._debug(\n f\" - Adding the <c2>{cmd_script.name}</c2> script wrapper to\"\n f\" <b>{scripts_path}</b>\"\n )\n\n with cmd_script.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(cmd))\n\n added.append(cmd_script)\n\n return added\n\n def _add_dist_info(self, added_files: list[Path]) -> None:\n from poetry.core.masonry.builders.wheel import WheelBuilder\n\n added_files = added_files[:]\n\n builder = WheelBuilder(self._poetry)\n dist_info = self._env.site_packages.mkdir(Path(builder.dist_info))\n\n self._debug(\n f\" - Adding the <c2>{dist_info.name}</c2> directory to\"\n f\" <b>{dist_info.parent}</b>\"\n )\n\n with dist_info.joinpath(\"METADATA\").open(\"w\", encoding=\"utf-8\") as f:\n builder._write_metadata_file(f)\n\n added_files.append(dist_info.joinpath(\"METADATA\"))\n\n with dist_info.joinpath(\"INSTALLER\").open(\"w\", encoding=\"utf-8\") as f:\n f.write(\"poetry\")\n\n added_files.append(dist_info.joinpath(\"INSTALLER\"))\n\n if self.convert_entry_points():\n with dist_info.joinpath(\"entry_points.txt\").open(\n \"w\", encoding=\"utf-8\"\n ) as f:\n builder._write_entry_points(f)\n\n added_files.append(dist_info.joinpath(\"entry_points.txt\"))\n\n # write PEP 610 metadata\n direct_url_json = dist_info.joinpath(\"direct_url.json\")\n direct_url_json.write_text(\n json.dumps(\n {\n \"dir_info\": {\"editable\": True},\n \"url\": self._poetry.file.path.parent.absolute().as_uri(),\n }\n )\n )\n added_files.append(direct_url_json)\n\n record = dist_info.joinpath(\"RECORD\")\n with record.open(\"w\", encoding=\"utf-8\", newline=\"\") as f:\n csv_writer = csv.writer(f)\n for path in added_files:\n hash = self._get_file_hash(path)\n size = path.stat().st_size\n csv_writer.writerow((path, f\"sha256={hash}\", size))\n\n # RECORD itself is recorded with no hash or size\n csv_writer.writerow((record, \"\", \"\"))\n\n def _get_file_hash(self, filepath: Path) -> str:\n hashsum = hashlib.sha256()\n with filepath.open(\"rb\") as src:\n while True:\n buf = src.read(1024 * 8)\n if not buf:\n break\n hashsum.update(buf)\n\n src.seek(0)\n\n return urlsafe_b64encode(hashsum.digest()).decode(\"ascii\").rstrip(\"=\")\n\n def _debug(self, msg: str) -> None:\n if self._io.is_debug():\n self._io.write_line(msg)\n", "path": "src/poetry/masonry/builders/editable.py"}]}
| 3,801 | 306 |
gh_patches_debug_27261
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-27396
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Eporner stuck at invoked download
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.07.28. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.
- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.
- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Read bugs section in FAQ: http://yt-dl.org/reporting
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a broken site support issue
- [x] I've verified that I'm running youtube-dl version **2020.07.28**
- [x] I've checked that all provided URLs are alive and playable in a browser
- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped
- [x] I've searched the bugtracker for similar bug reports including closed ones
- [x] I've read bugs section in FAQ
## Verbose log
<!--
Provide the complete verbose output of youtube-dl that clearly demonstrates the problem.
Add the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:
[debug] System config: []
[debug] User config: []
[debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']
[debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251
[debug] youtube-dl version 2020.07.28
[debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2
[debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4
[debug] Proxy map: {}
<more lines>
-->
```
PASTE VERBOSE LOG HERE
```
ubuntu@ip-172-26-9-219:~$ youtube-dl --verbose https://www.eporner.com/hd-porn/HBgBgaViIbY/Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked/
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'--verbose', u'https://www.eporner.com/hd-porn/HBgBgaViIbY/Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked/']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2020.07.28
[debug] Python version 2.7.17 (CPython) - Linux-5.3.0-1032-aws-x86_64-with-Ubuntu-18.04-bionic
[debug] exe versions: none
[debug] Proxy map: {}
[Eporner] Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked: Downloading webpage
[Eporner] Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked: Downloading video JSON
WARNING: unable to extract view count; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
[debug] Default format spec: best/bestvideo+bestaudio
[debug] Invoking downloader on u'https://cache1-ca-cdn.eporner.com/bb6353b496c613f4904fe9760409625d/5f23b8c504f800/2361178-1080p.mp4'
## Description
<!--
Provide an explanation of your issue in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.
If work on your issue requires account credentials please provide them or explain how one can obtain them.
-->
WRITE DESCRIPTION HERE
Can't download any video from eporner it use YouTube extractor not using eporner.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/eporner.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import re
5
6 from .common import InfoExtractor
7 from ..utils import (
8 encode_base_n,
9 ExtractorError,
10 int_or_none,
11 merge_dicts,
12 parse_duration,
13 str_to_int,
14 url_or_none,
15 )
16
17
18 class EpornerIE(InfoExtractor):
19 _VALID_URL = r'https?://(?:www\.)?eporner\.com/(?:hd-porn|embed)/(?P<id>\w+)(?:/(?P<display_id>[\w-]+))?'
20 _TESTS = [{
21 'url': 'http://www.eporner.com/hd-porn/95008/Infamous-Tiffany-Teen-Strip-Tease-Video/',
22 'md5': '39d486f046212d8e1b911c52ab4691f8',
23 'info_dict': {
24 'id': 'qlDUmNsj6VS',
25 'display_id': 'Infamous-Tiffany-Teen-Strip-Tease-Video',
26 'ext': 'mp4',
27 'title': 'Infamous Tiffany Teen Strip Tease Video',
28 'description': 'md5:764f39abf932daafa37485eb46efa152',
29 'timestamp': 1232520922,
30 'upload_date': '20090121',
31 'duration': 1838,
32 'view_count': int,
33 'age_limit': 18,
34 },
35 'params': {
36 'proxy': '127.0.0.1:8118'
37 }
38 }, {
39 # New (May 2016) URL layout
40 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0/Star-Wars-XXX-Parody/',
41 'only_matching': True,
42 }, {
43 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',
44 'only_matching': True,
45 }, {
46 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',
47 'only_matching': True,
48 }]
49
50 def _real_extract(self, url):
51 mobj = re.match(self._VALID_URL, url)
52 video_id = mobj.group('id')
53 display_id = mobj.group('display_id') or video_id
54
55 webpage, urlh = self._download_webpage_handle(url, display_id)
56
57 video_id = self._match_id(urlh.geturl())
58
59 hash = self._search_regex(
60 r'hash\s*:\s*["\']([\da-f]{32})', webpage, 'hash')
61
62 title = self._og_search_title(webpage, default=None) or self._html_search_regex(
63 r'<title>(.+?) - EPORNER', webpage, 'title')
64
65 # Reverse engineered from vjs.js
66 def calc_hash(s):
67 return ''.join((encode_base_n(int(s[lb:lb + 8], 16), 36) for lb in range(0, 32, 8)))
68
69 video = self._download_json(
70 'http://www.eporner.com/xhr/video/%s' % video_id,
71 display_id, note='Downloading video JSON',
72 query={
73 'hash': calc_hash(hash),
74 'device': 'generic',
75 'domain': 'www.eporner.com',
76 'fallback': 'false',
77 })
78
79 if video.get('available') is False:
80 raise ExtractorError(
81 '%s said: %s' % (self.IE_NAME, video['message']), expected=True)
82
83 sources = video['sources']
84
85 formats = []
86 for kind, formats_dict in sources.items():
87 if not isinstance(formats_dict, dict):
88 continue
89 for format_id, format_dict in formats_dict.items():
90 if not isinstance(format_dict, dict):
91 continue
92 src = url_or_none(format_dict.get('src'))
93 if not src or not src.startswith('http'):
94 continue
95 if kind == 'hls':
96 formats.extend(self._extract_m3u8_formats(
97 src, display_id, 'mp4', entry_protocol='m3u8_native',
98 m3u8_id=kind, fatal=False))
99 else:
100 height = int_or_none(self._search_regex(
101 r'(\d+)[pP]', format_id, 'height', default=None))
102 fps = int_or_none(self._search_regex(
103 r'(\d+)fps', format_id, 'fps', default=None))
104
105 formats.append({
106 'url': src,
107 'format_id': format_id,
108 'height': height,
109 'fps': fps,
110 })
111 self._sort_formats(formats)
112
113 json_ld = self._search_json_ld(webpage, display_id, default={})
114
115 duration = parse_duration(self._html_search_meta(
116 'duration', webpage, default=None))
117 view_count = str_to_int(self._search_regex(
118 r'id="cinemaviews">\s*([0-9,]+)\s*<small>views',
119 webpage, 'view count', fatal=False))
120
121 return merge_dicts(json_ld, {
122 'id': video_id,
123 'display_id': display_id,
124 'title': title,
125 'duration': duration,
126 'view_count': view_count,
127 'formats': formats,
128 'age_limit': 18,
129 })
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/eporner.py b/youtube_dl/extractor/eporner.py
--- a/youtube_dl/extractor/eporner.py
+++ b/youtube_dl/extractor/eporner.py
@@ -16,7 +16,7 @@
class EpornerIE(InfoExtractor):
- _VALID_URL = r'https?://(?:www\.)?eporner\.com/(?:hd-porn|embed)/(?P<id>\w+)(?:/(?P<display_id>[\w-]+))?'
+ _VALID_URL = r'https?://(?:www\.)?eporner\.com/(?:(?:hd-porn|embed)/|video-)(?P<id>\w+)(?:/(?P<display_id>[\w-]+))?'
_TESTS = [{
'url': 'http://www.eporner.com/hd-porn/95008/Infamous-Tiffany-Teen-Strip-Tease-Video/',
'md5': '39d486f046212d8e1b911c52ab4691f8',
@@ -45,6 +45,9 @@
}, {
'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',
'only_matching': True,
+ }, {
+ 'url': 'https://www.eporner.com/video-FJsA19J3Y3H/one-of-the-greats/',
+ 'only_matching': True,
}]
def _real_extract(self, url):
@@ -57,7 +60,7 @@
video_id = self._match_id(urlh.geturl())
hash = self._search_regex(
- r'hash\s*:\s*["\']([\da-f]{32})', webpage, 'hash')
+ r'hash\s*[:=]\s*["\']([\da-f]{32})', webpage, 'hash')
title = self._og_search_title(webpage, default=None) or self._html_search_regex(
r'<title>(.+?) - EPORNER', webpage, 'title')
|
{"golden_diff": "diff --git a/youtube_dl/extractor/eporner.py b/youtube_dl/extractor/eporner.py\n--- a/youtube_dl/extractor/eporner.py\n+++ b/youtube_dl/extractor/eporner.py\n@@ -16,7 +16,7 @@\n \n \n class EpornerIE(InfoExtractor):\n- _VALID_URL = r'https?://(?:www\\.)?eporner\\.com/(?:hd-porn|embed)/(?P<id>\\w+)(?:/(?P<display_id>[\\w-]+))?'\n+ _VALID_URL = r'https?://(?:www\\.)?eporner\\.com/(?:(?:hd-porn|embed)/|video-)(?P<id>\\w+)(?:/(?P<display_id>[\\w-]+))?'\n _TESTS = [{\n 'url': 'http://www.eporner.com/hd-porn/95008/Infamous-Tiffany-Teen-Strip-Tease-Video/',\n 'md5': '39d486f046212d8e1b911c52ab4691f8',\n@@ -45,6 +45,9 @@\n }, {\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',\n 'only_matching': True,\n+ }, {\n+ 'url': 'https://www.eporner.com/video-FJsA19J3Y3H/one-of-the-greats/',\n+ 'only_matching': True,\n }]\n \n def _real_extract(self, url):\n@@ -57,7 +60,7 @@\n video_id = self._match_id(urlh.geturl())\n \n hash = self._search_regex(\n- r'hash\\s*:\\s*[\"\\']([\\da-f]{32})', webpage, 'hash')\n+ r'hash\\s*[:=]\\s*[\"\\']([\\da-f]{32})', webpage, 'hash')\n \n title = self._og_search_title(webpage, default=None) or self._html_search_regex(\n r'<title>(.+?) - EPORNER', webpage, 'title')\n", "issue": "Eporner stuck at invoked download\n<!--\r\n\r\n######################################################################\r\n WARNING!\r\n IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE\r\n######################################################################\r\n\r\n-->\r\n\r\n\r\n## Checklist\r\n\r\n<!--\r\nCarefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:\r\n- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.07.28. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.\r\n- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.\r\n- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.\r\n- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.\r\n- Read bugs section in FAQ: http://yt-dl.org/reporting\r\n- Finally, put x into all relevant boxes (like this [x])\r\n-->\r\n\r\n- [x] I'm reporting a broken site support issue\r\n- [x] I've verified that I'm running youtube-dl version **2020.07.28**\r\n- [x] I've checked that all provided URLs are alive and playable in a browser\r\n- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped\r\n- [x] I've searched the bugtracker for similar bug reports including closed ones\r\n- [x] I've read bugs section in FAQ\r\n\r\n\r\n## Verbose log\r\n\r\n\r\n<!--\r\nProvide the complete verbose output of youtube-dl that clearly demonstrates the problem.\r\nAdd the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:\r\n [debug] System config: []\r\n [debug] User config: []\r\n [debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']\r\n [debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251\r\n [debug] youtube-dl version 2020.07.28\r\n [debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2\r\n [debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4\r\n [debug] Proxy map: {}\r\n <more lines>\r\n-->\r\n\r\n```\r\nPASTE VERBOSE LOG HERE\r\n```\r\nubuntu@ip-172-26-9-219:~$ youtube-dl --verbose https://www.eporner.com/hd-porn/HBgBgaViIbY/Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked/\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'--verbose', u'https://www.eporner.com/hd-porn/HBgBgaViIbY/Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked/']\r\n[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2020.07.28\r\n[debug] Python version 2.7.17 (CPython) - Linux-5.3.0-1032-aws-x86_64-with-Ubuntu-18.04-bionic\r\n[debug] exe versions: none\r\n[debug] Proxy map: {}\r\n[Eporner] Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked: Downloading webpage\r\n[Eporner] Busty-Tiny-Teen-With-Angel-Body-Gets-Fucked: Downloading video JSON\r\nWARNING: unable to extract view count; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n[debug] Default format spec: best/bestvideo+bestaudio\r\n[debug] Invoking downloader on u'https://cache1-ca-cdn.eporner.com/bb6353b496c613f4904fe9760409625d/5f23b8c504f800/2361178-1080p.mp4'\r\n\r\n## Description\r\n\r\n<!--\r\nProvide an explanation of your issue in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.\r\nIf work on your issue requires account credentials please provide them or explain how one can obtain them.\r\n-->\r\n\r\nWRITE DESCRIPTION HERE\r\nCan't download any video from eporner it use YouTube extractor not using eporner.py\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n encode_base_n,\n ExtractorError,\n int_or_none,\n merge_dicts,\n parse_duration,\n str_to_int,\n url_or_none,\n)\n\n\nclass EpornerIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?eporner\\.com/(?:hd-porn|embed)/(?P<id>\\w+)(?:/(?P<display_id>[\\w-]+))?'\n _TESTS = [{\n 'url': 'http://www.eporner.com/hd-porn/95008/Infamous-Tiffany-Teen-Strip-Tease-Video/',\n 'md5': '39d486f046212d8e1b911c52ab4691f8',\n 'info_dict': {\n 'id': 'qlDUmNsj6VS',\n 'display_id': 'Infamous-Tiffany-Teen-Strip-Tease-Video',\n 'ext': 'mp4',\n 'title': 'Infamous Tiffany Teen Strip Tease Video',\n 'description': 'md5:764f39abf932daafa37485eb46efa152',\n 'timestamp': 1232520922,\n 'upload_date': '20090121',\n 'duration': 1838,\n 'view_count': int,\n 'age_limit': 18,\n },\n 'params': {\n 'proxy': '127.0.0.1:8118'\n }\n }, {\n # New (May 2016) URL layout\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0/Star-Wars-XXX-Parody/',\n 'only_matching': True,\n }, {\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',\n 'only_matching': True,\n }, {\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n mobj = re.match(self._VALID_URL, url)\n video_id = mobj.group('id')\n display_id = mobj.group('display_id') or video_id\n\n webpage, urlh = self._download_webpage_handle(url, display_id)\n\n video_id = self._match_id(urlh.geturl())\n\n hash = self._search_regex(\n r'hash\\s*:\\s*[\"\\']([\\da-f]{32})', webpage, 'hash')\n\n title = self._og_search_title(webpage, default=None) or self._html_search_regex(\n r'<title>(.+?) - EPORNER', webpage, 'title')\n\n # Reverse engineered from vjs.js\n def calc_hash(s):\n return ''.join((encode_base_n(int(s[lb:lb + 8], 16), 36) for lb in range(0, 32, 8)))\n\n video = self._download_json(\n 'http://www.eporner.com/xhr/video/%s' % video_id,\n display_id, note='Downloading video JSON',\n query={\n 'hash': calc_hash(hash),\n 'device': 'generic',\n 'domain': 'www.eporner.com',\n 'fallback': 'false',\n })\n\n if video.get('available') is False:\n raise ExtractorError(\n '%s said: %s' % (self.IE_NAME, video['message']), expected=True)\n\n sources = video['sources']\n\n formats = []\n for kind, formats_dict in sources.items():\n if not isinstance(formats_dict, dict):\n continue\n for format_id, format_dict in formats_dict.items():\n if not isinstance(format_dict, dict):\n continue\n src = url_or_none(format_dict.get('src'))\n if not src or not src.startswith('http'):\n continue\n if kind == 'hls':\n formats.extend(self._extract_m3u8_formats(\n src, display_id, 'mp4', entry_protocol='m3u8_native',\n m3u8_id=kind, fatal=False))\n else:\n height = int_or_none(self._search_regex(\n r'(\\d+)[pP]', format_id, 'height', default=None))\n fps = int_or_none(self._search_regex(\n r'(\\d+)fps', format_id, 'fps', default=None))\n\n formats.append({\n 'url': src,\n 'format_id': format_id,\n 'height': height,\n 'fps': fps,\n })\n self._sort_formats(formats)\n\n json_ld = self._search_json_ld(webpage, display_id, default={})\n\n duration = parse_duration(self._html_search_meta(\n 'duration', webpage, default=None))\n view_count = str_to_int(self._search_regex(\n r'id=\"cinemaviews\">\\s*([0-9,]+)\\s*<small>views',\n webpage, 'view count', fatal=False))\n\n return merge_dicts(json_ld, {\n 'id': video_id,\n 'display_id': display_id,\n 'title': title,\n 'duration': duration,\n 'view_count': view_count,\n 'formats': formats,\n 'age_limit': 18,\n })\n", "path": "youtube_dl/extractor/eporner.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n encode_base_n,\n ExtractorError,\n int_or_none,\n merge_dicts,\n parse_duration,\n str_to_int,\n url_or_none,\n)\n\n\nclass EpornerIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?eporner\\.com/(?:(?:hd-porn|embed)/|video-)(?P<id>\\w+)(?:/(?P<display_id>[\\w-]+))?'\n _TESTS = [{\n 'url': 'http://www.eporner.com/hd-porn/95008/Infamous-Tiffany-Teen-Strip-Tease-Video/',\n 'md5': '39d486f046212d8e1b911c52ab4691f8',\n 'info_dict': {\n 'id': 'qlDUmNsj6VS',\n 'display_id': 'Infamous-Tiffany-Teen-Strip-Tease-Video',\n 'ext': 'mp4',\n 'title': 'Infamous Tiffany Teen Strip Tease Video',\n 'description': 'md5:764f39abf932daafa37485eb46efa152',\n 'timestamp': 1232520922,\n 'upload_date': '20090121',\n 'duration': 1838,\n 'view_count': int,\n 'age_limit': 18,\n },\n 'params': {\n 'proxy': '127.0.0.1:8118'\n }\n }, {\n # New (May 2016) URL layout\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0/Star-Wars-XXX-Parody/',\n 'only_matching': True,\n }, {\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',\n 'only_matching': True,\n }, {\n 'url': 'http://www.eporner.com/hd-porn/3YRUtzMcWn0',\n 'only_matching': True,\n }, {\n 'url': 'https://www.eporner.com/video-FJsA19J3Y3H/one-of-the-greats/',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n mobj = re.match(self._VALID_URL, url)\n video_id = mobj.group('id')\n display_id = mobj.group('display_id') or video_id\n\n webpage, urlh = self._download_webpage_handle(url, display_id)\n\n video_id = self._match_id(urlh.geturl())\n\n hash = self._search_regex(\n r'hash\\s*[:=]\\s*[\"\\']([\\da-f]{32})', webpage, 'hash')\n\n title = self._og_search_title(webpage, default=None) or self._html_search_regex(\n r'<title>(.+?) - EPORNER', webpage, 'title')\n\n # Reverse engineered from vjs.js\n def calc_hash(s):\n return ''.join((encode_base_n(int(s[lb:lb + 8], 16), 36) for lb in range(0, 32, 8)))\n\n video = self._download_json(\n 'http://www.eporner.com/xhr/video/%s' % video_id,\n display_id, note='Downloading video JSON',\n query={\n 'hash': calc_hash(hash),\n 'device': 'generic',\n 'domain': 'www.eporner.com',\n 'fallback': 'false',\n })\n\n if video.get('available') is False:\n raise ExtractorError(\n '%s said: %s' % (self.IE_NAME, video['message']), expected=True)\n\n sources = video['sources']\n\n formats = []\n for kind, formats_dict in sources.items():\n if not isinstance(formats_dict, dict):\n continue\n for format_id, format_dict in formats_dict.items():\n if not isinstance(format_dict, dict):\n continue\n src = url_or_none(format_dict.get('src'))\n if not src or not src.startswith('http'):\n continue\n if kind == 'hls':\n formats.extend(self._extract_m3u8_formats(\n src, display_id, 'mp4', entry_protocol='m3u8_native',\n m3u8_id=kind, fatal=False))\n else:\n height = int_or_none(self._search_regex(\n r'(\\d+)[pP]', format_id, 'height', default=None))\n fps = int_or_none(self._search_regex(\n r'(\\d+)fps', format_id, 'fps', default=None))\n\n formats.append({\n 'url': src,\n 'format_id': format_id,\n 'height': height,\n 'fps': fps,\n })\n self._sort_formats(formats)\n\n json_ld = self._search_json_ld(webpage, display_id, default={})\n\n duration = parse_duration(self._html_search_meta(\n 'duration', webpage, default=None))\n view_count = str_to_int(self._search_regex(\n r'id=\"cinemaviews\">\\s*([0-9,]+)\\s*<small>views',\n webpage, 'view count', fatal=False))\n\n return merge_dicts(json_ld, {\n 'id': video_id,\n 'display_id': display_id,\n 'title': title,\n 'duration': duration,\n 'view_count': view_count,\n 'formats': formats,\n 'age_limit': 18,\n })\n", "path": "youtube_dl/extractor/eporner.py"}]}
| 2,960 | 493 |
gh_patches_debug_5711
|
rasdani/github-patches
|
git_diff
|
borgbackup__borg-6135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update pypi metadata
master (1.2): alpha -> beta (and keep that at least until 1.2.1)
1.1-maint: definitely beta -> stable
https://pypi.org/classifiers/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # borgbackup - main setup code (see also other setup_*.py files)
2
3 import os
4 import sys
5 from collections import defaultdict
6 from glob import glob
7
8 try:
9 import multiprocessing
10 except ImportError:
11 multiprocessing = None
12
13 from setuptools.command.build_ext import build_ext
14 from setuptools import setup, find_packages, Extension, Command
15 from setuptools.command.sdist import sdist
16
17 try:
18 from Cython.Build import cythonize
19 except ImportError:
20 cythonize = None
21
22 import setup_checksums
23 import setup_compress
24 import setup_crypto
25 import setup_docs
26
27 is_win32 = sys.platform.startswith('win32')
28
29 # How the build process finds the system libs / uses the bundled code:
30 #
31 # 1. it will try to use (system) libs (see 1.1. and 1.2.),
32 # except if you use these env vars to force using the bundled code:
33 # BORG_USE_BUNDLED_XXX undefined --> try using system lib
34 # BORG_USE_BUNDLED_XXX=YES --> use the bundled code
35 # Note: do not use =NO, that is not supported!
36 # 1.1. if BORG_LIBXXX_PREFIX is set, it will use headers and libs from there.
37 # 1.2. if not and pkg-config can locate the lib, the lib located by
38 # pkg-config will be used. We use the pkg-config tool via the pkgconfig
39 # python package, which must be installed before invoking setup.py.
40 # if pkgconfig is not installed, this step is skipped.
41 # 2. if no system lib could be located via 1.1. or 1.2., it will fall back
42 # to using the bundled code.
43
44 # OpenSSL is required as a (system) lib in any case as we do not bundle it.
45 # Thus, only step 1.1. and 1.2. apply to openssl (but not 1. and 2.).
46 # needed: openssl >=1.0.2 or >=1.1.0 (or compatible)
47 system_prefix_openssl = os.environ.get('BORG_OPENSSL_PREFIX')
48
49 # needed: lz4 (>= 1.7.0 / r129)
50 prefer_system_liblz4 = not bool(os.environ.get('BORG_USE_BUNDLED_LZ4'))
51 system_prefix_liblz4 = os.environ.get('BORG_LIBLZ4_PREFIX')
52
53 # needed: zstd (>= 1.3.0)
54 prefer_system_libzstd = not bool(os.environ.get('BORG_USE_BUNDLED_ZSTD'))
55 system_prefix_libzstd = os.environ.get('BORG_LIBZSTD_PREFIX')
56
57 prefer_system_libxxhash = not bool(os.environ.get('BORG_USE_BUNDLED_XXHASH'))
58 system_prefix_libxxhash = os.environ.get('BORG_LIBXXHASH_PREFIX')
59
60 # Number of threads to use for cythonize, not used on windows
61 cpu_threads = multiprocessing.cpu_count() if multiprocessing and multiprocessing.get_start_method() != 'spawn' else None
62
63 # Are we building on ReadTheDocs?
64 on_rtd = os.environ.get('READTHEDOCS')
65
66 install_requires = [
67 # we are rather picky about msgpack versions, because a good working msgpack is
68 # very important for borg, see: https://github.com/borgbackup/borg/issues/3753
69 'msgpack >=0.5.6, <=1.0.3, !=1.0.1',
70 # Please note:
71 # using any other version is not supported by borg development and
72 # any feedback related to issues caused by this will be ignored.
73 'packaging',
74 ]
75
76 # note for package maintainers: if you package borgbackup for distribution,
77 # please (if available) add pyfuse3 (preferably) or llfuse (not maintained any more)
78 # as a *requirement*. "borg mount" needs one of them to work.
79 # if neither is available, do not require it, most of borgbackup will work.
80 extras_require = {
81 'llfuse': [
82 'llfuse >= 1.3.8',
83 ],
84 'pyfuse3': [
85 'pyfuse3 >= 3.1.1',
86 ],
87 'nofuse': [],
88 }
89
90 compress_source = 'src/borg/compress.pyx'
91 crypto_ll_source = 'src/borg/crypto/low_level.pyx'
92 crypto_helpers = 'src/borg/crypto/_crypto_helpers.c'
93 chunker_source = 'src/borg/chunker.pyx'
94 hashindex_source = 'src/borg/hashindex.pyx'
95 item_source = 'src/borg/item.pyx'
96 checksums_source = 'src/borg/algorithms/checksums.pyx'
97 platform_posix_source = 'src/borg/platform/posix.pyx'
98 platform_linux_source = 'src/borg/platform/linux.pyx'
99 platform_syncfilerange_source = 'src/borg/platform/syncfilerange.pyx'
100 platform_darwin_source = 'src/borg/platform/darwin.pyx'
101 platform_freebsd_source = 'src/borg/platform/freebsd.pyx'
102 platform_windows_source = 'src/borg/platform/windows.pyx'
103
104 cython_sources = [
105 compress_source,
106 crypto_ll_source,
107 chunker_source,
108 hashindex_source,
109 item_source,
110 checksums_source,
111
112 platform_posix_source,
113 platform_linux_source,
114 platform_syncfilerange_source,
115 platform_freebsd_source,
116 platform_darwin_source,
117 platform_windows_source,
118 ]
119
120 if cythonize:
121 Sdist = sdist
122 else:
123 class Sdist(sdist):
124 def __init__(self, *args, **kwargs):
125 raise Exception('Cython is required to run sdist')
126
127 cython_c_files = [fn.replace('.pyx', '.c') for fn in cython_sources]
128 if not on_rtd and not all(os.path.exists(path) for path in cython_c_files):
129 raise ImportError('The GIT version of Borg needs Cython. Install Cython or use a released version.')
130
131
132 def rm(file):
133 try:
134 os.unlink(file)
135 print('rm', file)
136 except FileNotFoundError:
137 pass
138
139
140 class Clean(Command):
141 user_options = []
142
143 def initialize_options(self):
144 pass
145
146 def finalize_options(self):
147 pass
148
149 def run(self):
150 for source in cython_sources:
151 genc = source.replace('.pyx', '.c')
152 rm(genc)
153 compiled_glob = source.replace('.pyx', '.cpython*')
154 for compiled in sorted(glob(compiled_glob)):
155 rm(compiled)
156
157
158 cmdclass = {
159 'build_ext': build_ext,
160 'build_usage': setup_docs.build_usage,
161 'build_man': setup_docs.build_man,
162 'sdist': Sdist,
163 'clean2': Clean,
164 }
165
166 ext_modules = []
167 if not on_rtd:
168
169 def members_appended(*ds):
170 result = defaultdict(list)
171 for d in ds:
172 for k, v in d.items():
173 assert isinstance(v, list)
174 result[k].extend(v)
175 return result
176
177 try:
178 import pkgconfig as pc
179 except ImportError:
180 print('Warning: can not import pkgconfig python package.')
181 pc = None
182
183 crypto_ext_kwargs = members_appended(
184 dict(sources=[crypto_ll_source, crypto_helpers]),
185 setup_crypto.crypto_ext_kwargs(pc, system_prefix_openssl),
186 )
187
188 compress_ext_kwargs = members_appended(
189 dict(sources=[compress_source]),
190 setup_compress.lz4_ext_kwargs(pc, prefer_system_liblz4, system_prefix_liblz4),
191 setup_compress.zstd_ext_kwargs(pc, prefer_system_libzstd, system_prefix_libzstd,
192 multithreaded=False, legacy=False),
193 )
194
195 checksums_ext_kwargs = members_appended(
196 dict(sources=[checksums_source]),
197 setup_checksums.xxhash_ext_kwargs(pc, prefer_system_libxxhash, system_prefix_libxxhash),
198 )
199
200 ext_modules += [
201 Extension('borg.crypto.low_level', **crypto_ext_kwargs),
202 Extension('borg.compress', **compress_ext_kwargs),
203 Extension('borg.hashindex', [hashindex_source]),
204 Extension('borg.item', [item_source]),
205 Extension('borg.chunker', [chunker_source]),
206 Extension('borg.algorithms.checksums', **checksums_ext_kwargs),
207 ]
208
209 posix_ext = Extension('borg.platform.posix', [platform_posix_source])
210 linux_ext = Extension('borg.platform.linux', [platform_linux_source], libraries=['acl'])
211 syncfilerange_ext = Extension('borg.platform.syncfilerange', [platform_syncfilerange_source])
212 freebsd_ext = Extension('borg.platform.freebsd', [platform_freebsd_source])
213 darwin_ext = Extension('borg.platform.darwin', [platform_darwin_source])
214 windows_ext = Extension('borg.platform.windows', [platform_windows_source])
215
216 if not is_win32:
217 ext_modules.append(posix_ext)
218 else:
219 ext_modules.append(windows_ext)
220 if sys.platform == 'linux':
221 ext_modules.append(linux_ext)
222 ext_modules.append(syncfilerange_ext)
223 elif sys.platform.startswith('freebsd'):
224 ext_modules.append(freebsd_ext)
225 elif sys.platform == 'darwin':
226 ext_modules.append(darwin_ext)
227
228 # sometimes there's no need to cythonize
229 # this breaks chained commands like 'clean sdist'
230 cythonizing = len(sys.argv) > 1 and sys.argv[1] not in (
231 ('clean', 'clean2', 'egg_info', '--help-commands', '--version')) and '--help' not in sys.argv[1:]
232
233 if cythonize and cythonizing:
234 cython_opts = dict(
235 # default language_level will be '3str' starting from Cython 3.0.0,
236 # but old cython versions (< 0.29) do not know that, thus we use 3 for now.
237 compiler_directives={'language_level': 3},
238 )
239 if not is_win32:
240 # compile .pyx extensions to .c in parallel, does not work on windows
241 cython_opts['nthreads'] = cpu_threads
242
243 # generate C code from Cython for ALL supported platforms, so we have them in the sdist.
244 # the sdist does not require Cython at install time, so we need all as C.
245 cythonize([posix_ext, linux_ext, syncfilerange_ext, freebsd_ext, darwin_ext, windows_ext], **cython_opts)
246 # generate C code from Cython for THIS platform (and for all platform-independent Cython parts).
247 ext_modules = cythonize(ext_modules, **cython_opts)
248
249
250 setup(
251 name='borgbackup',
252 use_scm_version={
253 'write_to': 'src/borg/_version.py',
254 },
255 author='The Borg Collective (see AUTHORS file)',
256 author_email='[email protected]',
257 url='https://borgbackup.readthedocs.io/',
258 description='Deduplicated, encrypted, authenticated and compressed backups',
259 long_description=setup_docs.long_desc_from_readme(),
260 license='BSD',
261 platforms=['Linux', 'MacOS X', 'FreeBSD', 'OpenBSD', 'NetBSD', ],
262 classifiers=[
263 'Development Status :: 3 - Alpha',
264 'Environment :: Console',
265 'Intended Audience :: System Administrators',
266 'License :: OSI Approved :: BSD License',
267 'Operating System :: POSIX :: BSD :: FreeBSD',
268 'Operating System :: POSIX :: BSD :: OpenBSD',
269 'Operating System :: POSIX :: BSD :: NetBSD',
270 'Operating System :: MacOS :: MacOS X',
271 'Operating System :: POSIX :: Linux',
272 'Programming Language :: Python',
273 'Programming Language :: Python :: 3',
274 'Programming Language :: Python :: 3.8',
275 'Programming Language :: Python :: 3.9',
276 'Programming Language :: Python :: 3.10',
277 'Topic :: Security :: Cryptography',
278 'Topic :: System :: Archiving :: Backup',
279 ],
280 packages=find_packages('src'),
281 package_dir={'': 'src'},
282 zip_safe=False,
283 entry_points={
284 'console_scripts': [
285 'borg = borg.archiver:main',
286 'borgfs = borg.archiver:main',
287 ]
288 },
289 # See also the MANIFEST.in file.
290 # We want to install all the files in the package directories...
291 include_package_data=True,
292 # ...except the source files which have been compiled (C extensions):
293 exclude_package_data={
294 '': ['*.c', '*.h', '*.pyx', ],
295 },
296 cmdclass=cmdclass,
297 ext_modules=ext_modules,
298 setup_requires=['setuptools_scm>=1.7'],
299 install_requires=install_requires,
300 extras_require=extras_require,
301 python_requires='>=3.8',
302 )
303
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -260,7 +260,7 @@
license='BSD',
platforms=['Linux', 'MacOS X', 'FreeBSD', 'OpenBSD', 'NetBSD', ],
classifiers=[
- 'Development Status :: 3 - Alpha',
+ 'Development Status :: 4 - Beta',
'Environment :: Console',
'Intended Audience :: System Administrators',
'License :: OSI Approved :: BSD License',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -260,7 +260,7 @@\n license='BSD',\n platforms=['Linux', 'MacOS X', 'FreeBSD', 'OpenBSD', 'NetBSD', ],\n classifiers=[\n- 'Development Status :: 3 - Alpha',\n+ 'Development Status :: 4 - Beta',\n 'Environment :: Console',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: BSD License',\n", "issue": "update pypi metadata\nmaster (1.2): alpha -> beta (and keep that at least until 1.2.1)\r\n\r\n1.1-maint: definitely beta -> stable\r\n\r\nhttps://pypi.org/classifiers/\r\n\n", "before_files": [{"content": "# borgbackup - main setup code (see also other setup_*.py files)\n\nimport os\nimport sys\nfrom collections import defaultdict\nfrom glob import glob\n\ntry:\n import multiprocessing\nexcept ImportError:\n multiprocessing = None\n\nfrom setuptools.command.build_ext import build_ext\nfrom setuptools import setup, find_packages, Extension, Command\nfrom setuptools.command.sdist import sdist\n\ntry:\n from Cython.Build import cythonize\nexcept ImportError:\n cythonize = None\n\nimport setup_checksums\nimport setup_compress\nimport setup_crypto\nimport setup_docs\n\nis_win32 = sys.platform.startswith('win32')\n\n# How the build process finds the system libs / uses the bundled code:\n#\n# 1. it will try to use (system) libs (see 1.1. and 1.2.),\n# except if you use these env vars to force using the bundled code:\n# BORG_USE_BUNDLED_XXX undefined --> try using system lib\n# BORG_USE_BUNDLED_XXX=YES --> use the bundled code\n# Note: do not use =NO, that is not supported!\n# 1.1. if BORG_LIBXXX_PREFIX is set, it will use headers and libs from there.\n# 1.2. if not and pkg-config can locate the lib, the lib located by\n# pkg-config will be used. We use the pkg-config tool via the pkgconfig\n# python package, which must be installed before invoking setup.py.\n# if pkgconfig is not installed, this step is skipped.\n# 2. if no system lib could be located via 1.1. or 1.2., it will fall back\n# to using the bundled code.\n\n# OpenSSL is required as a (system) lib in any case as we do not bundle it.\n# Thus, only step 1.1. and 1.2. apply to openssl (but not 1. and 2.).\n# needed: openssl >=1.0.2 or >=1.1.0 (or compatible)\nsystem_prefix_openssl = os.environ.get('BORG_OPENSSL_PREFIX')\n\n# needed: lz4 (>= 1.7.0 / r129)\nprefer_system_liblz4 = not bool(os.environ.get('BORG_USE_BUNDLED_LZ4'))\nsystem_prefix_liblz4 = os.environ.get('BORG_LIBLZ4_PREFIX')\n\n# needed: zstd (>= 1.3.0)\nprefer_system_libzstd = not bool(os.environ.get('BORG_USE_BUNDLED_ZSTD'))\nsystem_prefix_libzstd = os.environ.get('BORG_LIBZSTD_PREFIX')\n\nprefer_system_libxxhash = not bool(os.environ.get('BORG_USE_BUNDLED_XXHASH'))\nsystem_prefix_libxxhash = os.environ.get('BORG_LIBXXHASH_PREFIX')\n\n# Number of threads to use for cythonize, not used on windows\ncpu_threads = multiprocessing.cpu_count() if multiprocessing and multiprocessing.get_start_method() != 'spawn' else None\n\n# Are we building on ReadTheDocs?\non_rtd = os.environ.get('READTHEDOCS')\n\ninstall_requires = [\n # we are rather picky about msgpack versions, because a good working msgpack is\n # very important for borg, see: https://github.com/borgbackup/borg/issues/3753\n 'msgpack >=0.5.6, <=1.0.3, !=1.0.1',\n # Please note:\n # using any other version is not supported by borg development and\n # any feedback related to issues caused by this will be ignored.\n 'packaging',\n]\n\n# note for package maintainers: if you package borgbackup for distribution,\n# please (if available) add pyfuse3 (preferably) or llfuse (not maintained any more)\n# as a *requirement*. \"borg mount\" needs one of them to work.\n# if neither is available, do not require it, most of borgbackup will work.\nextras_require = {\n 'llfuse': [\n 'llfuse >= 1.3.8',\n ],\n 'pyfuse3': [\n 'pyfuse3 >= 3.1.1',\n ],\n 'nofuse': [],\n}\n\ncompress_source = 'src/borg/compress.pyx'\ncrypto_ll_source = 'src/borg/crypto/low_level.pyx'\ncrypto_helpers = 'src/borg/crypto/_crypto_helpers.c'\nchunker_source = 'src/borg/chunker.pyx'\nhashindex_source = 'src/borg/hashindex.pyx'\nitem_source = 'src/borg/item.pyx'\nchecksums_source = 'src/borg/algorithms/checksums.pyx'\nplatform_posix_source = 'src/borg/platform/posix.pyx'\nplatform_linux_source = 'src/borg/platform/linux.pyx'\nplatform_syncfilerange_source = 'src/borg/platform/syncfilerange.pyx'\nplatform_darwin_source = 'src/borg/platform/darwin.pyx'\nplatform_freebsd_source = 'src/borg/platform/freebsd.pyx'\nplatform_windows_source = 'src/borg/platform/windows.pyx'\n\ncython_sources = [\n compress_source,\n crypto_ll_source,\n chunker_source,\n hashindex_source,\n item_source,\n checksums_source,\n\n platform_posix_source,\n platform_linux_source,\n platform_syncfilerange_source,\n platform_freebsd_source,\n platform_darwin_source,\n platform_windows_source,\n]\n\nif cythonize:\n Sdist = sdist\nelse:\n class Sdist(sdist):\n def __init__(self, *args, **kwargs):\n raise Exception('Cython is required to run sdist')\n\n cython_c_files = [fn.replace('.pyx', '.c') for fn in cython_sources]\n if not on_rtd and not all(os.path.exists(path) for path in cython_c_files):\n raise ImportError('The GIT version of Borg needs Cython. Install Cython or use a released version.')\n\n\ndef rm(file):\n try:\n os.unlink(file)\n print('rm', file)\n except FileNotFoundError:\n pass\n\n\nclass Clean(Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n for source in cython_sources:\n genc = source.replace('.pyx', '.c')\n rm(genc)\n compiled_glob = source.replace('.pyx', '.cpython*')\n for compiled in sorted(glob(compiled_glob)):\n rm(compiled)\n\n\ncmdclass = {\n 'build_ext': build_ext,\n 'build_usage': setup_docs.build_usage,\n 'build_man': setup_docs.build_man,\n 'sdist': Sdist,\n 'clean2': Clean,\n}\n\next_modules = []\nif not on_rtd:\n\n def members_appended(*ds):\n result = defaultdict(list)\n for d in ds:\n for k, v in d.items():\n assert isinstance(v, list)\n result[k].extend(v)\n return result\n\n try:\n import pkgconfig as pc\n except ImportError:\n print('Warning: can not import pkgconfig python package.')\n pc = None\n\n crypto_ext_kwargs = members_appended(\n dict(sources=[crypto_ll_source, crypto_helpers]),\n setup_crypto.crypto_ext_kwargs(pc, system_prefix_openssl),\n )\n\n compress_ext_kwargs = members_appended(\n dict(sources=[compress_source]),\n setup_compress.lz4_ext_kwargs(pc, prefer_system_liblz4, system_prefix_liblz4),\n setup_compress.zstd_ext_kwargs(pc, prefer_system_libzstd, system_prefix_libzstd,\n multithreaded=False, legacy=False),\n )\n\n checksums_ext_kwargs = members_appended(\n dict(sources=[checksums_source]),\n setup_checksums.xxhash_ext_kwargs(pc, prefer_system_libxxhash, system_prefix_libxxhash),\n )\n\n ext_modules += [\n Extension('borg.crypto.low_level', **crypto_ext_kwargs),\n Extension('borg.compress', **compress_ext_kwargs),\n Extension('borg.hashindex', [hashindex_source]),\n Extension('borg.item', [item_source]),\n Extension('borg.chunker', [chunker_source]),\n Extension('borg.algorithms.checksums', **checksums_ext_kwargs),\n ]\n\n posix_ext = Extension('borg.platform.posix', [platform_posix_source])\n linux_ext = Extension('borg.platform.linux', [platform_linux_source], libraries=['acl'])\n syncfilerange_ext = Extension('borg.platform.syncfilerange', [platform_syncfilerange_source])\n freebsd_ext = Extension('borg.platform.freebsd', [platform_freebsd_source])\n darwin_ext = Extension('borg.platform.darwin', [platform_darwin_source])\n windows_ext = Extension('borg.platform.windows', [platform_windows_source])\n\n if not is_win32:\n ext_modules.append(posix_ext)\n else:\n ext_modules.append(windows_ext)\n if sys.platform == 'linux':\n ext_modules.append(linux_ext)\n ext_modules.append(syncfilerange_ext)\n elif sys.platform.startswith('freebsd'):\n ext_modules.append(freebsd_ext)\n elif sys.platform == 'darwin':\n ext_modules.append(darwin_ext)\n\n # sometimes there's no need to cythonize\n # this breaks chained commands like 'clean sdist'\n cythonizing = len(sys.argv) > 1 and sys.argv[1] not in (\n ('clean', 'clean2', 'egg_info', '--help-commands', '--version')) and '--help' not in sys.argv[1:]\n\n if cythonize and cythonizing:\n cython_opts = dict(\n # default language_level will be '3str' starting from Cython 3.0.0,\n # but old cython versions (< 0.29) do not know that, thus we use 3 for now.\n compiler_directives={'language_level': 3},\n )\n if not is_win32:\n # compile .pyx extensions to .c in parallel, does not work on windows\n cython_opts['nthreads'] = cpu_threads\n\n # generate C code from Cython for ALL supported platforms, so we have them in the sdist.\n # the sdist does not require Cython at install time, so we need all as C.\n cythonize([posix_ext, linux_ext, syncfilerange_ext, freebsd_ext, darwin_ext, windows_ext], **cython_opts)\n # generate C code from Cython for THIS platform (and for all platform-independent Cython parts).\n ext_modules = cythonize(ext_modules, **cython_opts)\n\n\nsetup(\n name='borgbackup',\n use_scm_version={\n 'write_to': 'src/borg/_version.py',\n },\n author='The Borg Collective (see AUTHORS file)',\n author_email='[email protected]',\n url='https://borgbackup.readthedocs.io/',\n description='Deduplicated, encrypted, authenticated and compressed backups',\n long_description=setup_docs.long_desc_from_readme(),\n license='BSD',\n platforms=['Linux', 'MacOS X', 'FreeBSD', 'OpenBSD', 'NetBSD', ],\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: POSIX :: BSD :: FreeBSD',\n 'Operating System :: POSIX :: BSD :: OpenBSD',\n 'Operating System :: POSIX :: BSD :: NetBSD',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Topic :: Security :: Cryptography',\n 'Topic :: System :: Archiving :: Backup',\n ],\n packages=find_packages('src'),\n package_dir={'': 'src'},\n zip_safe=False,\n entry_points={\n 'console_scripts': [\n 'borg = borg.archiver:main',\n 'borgfs = borg.archiver:main',\n ]\n },\n # See also the MANIFEST.in file.\n # We want to install all the files in the package directories...\n include_package_data=True,\n # ...except the source files which have been compiled (C extensions):\n exclude_package_data={\n '': ['*.c', '*.h', '*.pyx', ],\n },\n cmdclass=cmdclass,\n ext_modules=ext_modules,\n setup_requires=['setuptools_scm>=1.7'],\n install_requires=install_requires,\n extras_require=extras_require,\n python_requires='>=3.8',\n)\n", "path": "setup.py"}], "after_files": [{"content": "# borgbackup - main setup code (see also other setup_*.py files)\n\nimport os\nimport sys\nfrom collections import defaultdict\nfrom glob import glob\n\ntry:\n import multiprocessing\nexcept ImportError:\n multiprocessing = None\n\nfrom setuptools.command.build_ext import build_ext\nfrom setuptools import setup, find_packages, Extension, Command\nfrom setuptools.command.sdist import sdist\n\ntry:\n from Cython.Build import cythonize\nexcept ImportError:\n cythonize = None\n\nimport setup_checksums\nimport setup_compress\nimport setup_crypto\nimport setup_docs\n\nis_win32 = sys.platform.startswith('win32')\n\n# How the build process finds the system libs / uses the bundled code:\n#\n# 1. it will try to use (system) libs (see 1.1. and 1.2.),\n# except if you use these env vars to force using the bundled code:\n# BORG_USE_BUNDLED_XXX undefined --> try using system lib\n# BORG_USE_BUNDLED_XXX=YES --> use the bundled code\n# Note: do not use =NO, that is not supported!\n# 1.1. if BORG_LIBXXX_PREFIX is set, it will use headers and libs from there.\n# 1.2. if not and pkg-config can locate the lib, the lib located by\n# pkg-config will be used. We use the pkg-config tool via the pkgconfig\n# python package, which must be installed before invoking setup.py.\n# if pkgconfig is not installed, this step is skipped.\n# 2. if no system lib could be located via 1.1. or 1.2., it will fall back\n# to using the bundled code.\n\n# OpenSSL is required as a (system) lib in any case as we do not bundle it.\n# Thus, only step 1.1. and 1.2. apply to openssl (but not 1. and 2.).\n# needed: openssl >=1.0.2 or >=1.1.0 (or compatible)\nsystem_prefix_openssl = os.environ.get('BORG_OPENSSL_PREFIX')\n\n# needed: lz4 (>= 1.7.0 / r129)\nprefer_system_liblz4 = not bool(os.environ.get('BORG_USE_BUNDLED_LZ4'))\nsystem_prefix_liblz4 = os.environ.get('BORG_LIBLZ4_PREFIX')\n\n# needed: zstd (>= 1.3.0)\nprefer_system_libzstd = not bool(os.environ.get('BORG_USE_BUNDLED_ZSTD'))\nsystem_prefix_libzstd = os.environ.get('BORG_LIBZSTD_PREFIX')\n\nprefer_system_libxxhash = not bool(os.environ.get('BORG_USE_BUNDLED_XXHASH'))\nsystem_prefix_libxxhash = os.environ.get('BORG_LIBXXHASH_PREFIX')\n\n# Number of threads to use for cythonize, not used on windows\ncpu_threads = multiprocessing.cpu_count() if multiprocessing and multiprocessing.get_start_method() != 'spawn' else None\n\n# Are we building on ReadTheDocs?\non_rtd = os.environ.get('READTHEDOCS')\n\ninstall_requires = [\n # we are rather picky about msgpack versions, because a good working msgpack is\n # very important for borg, see: https://github.com/borgbackup/borg/issues/3753\n 'msgpack >=0.5.6, <=1.0.3, !=1.0.1',\n # Please note:\n # using any other version is not supported by borg development and\n # any feedback related to issues caused by this will be ignored.\n 'packaging',\n]\n\n# note for package maintainers: if you package borgbackup for distribution,\n# please (if available) add pyfuse3 (preferably) or llfuse (not maintained any more)\n# as a *requirement*. \"borg mount\" needs one of them to work.\n# if neither is available, do not require it, most of borgbackup will work.\nextras_require = {\n 'llfuse': [\n 'llfuse >= 1.3.8',\n ],\n 'pyfuse3': [\n 'pyfuse3 >= 3.1.1',\n ],\n 'nofuse': [],\n}\n\ncompress_source = 'src/borg/compress.pyx'\ncrypto_ll_source = 'src/borg/crypto/low_level.pyx'\ncrypto_helpers = 'src/borg/crypto/_crypto_helpers.c'\nchunker_source = 'src/borg/chunker.pyx'\nhashindex_source = 'src/borg/hashindex.pyx'\nitem_source = 'src/borg/item.pyx'\nchecksums_source = 'src/borg/algorithms/checksums.pyx'\nplatform_posix_source = 'src/borg/platform/posix.pyx'\nplatform_linux_source = 'src/borg/platform/linux.pyx'\nplatform_syncfilerange_source = 'src/borg/platform/syncfilerange.pyx'\nplatform_darwin_source = 'src/borg/platform/darwin.pyx'\nplatform_freebsd_source = 'src/borg/platform/freebsd.pyx'\nplatform_windows_source = 'src/borg/platform/windows.pyx'\n\ncython_sources = [\n compress_source,\n crypto_ll_source,\n chunker_source,\n hashindex_source,\n item_source,\n checksums_source,\n\n platform_posix_source,\n platform_linux_source,\n platform_syncfilerange_source,\n platform_freebsd_source,\n platform_darwin_source,\n platform_windows_source,\n]\n\nif cythonize:\n Sdist = sdist\nelse:\n class Sdist(sdist):\n def __init__(self, *args, **kwargs):\n raise Exception('Cython is required to run sdist')\n\n cython_c_files = [fn.replace('.pyx', '.c') for fn in cython_sources]\n if not on_rtd and not all(os.path.exists(path) for path in cython_c_files):\n raise ImportError('The GIT version of Borg needs Cython. Install Cython or use a released version.')\n\n\ndef rm(file):\n try:\n os.unlink(file)\n print('rm', file)\n except FileNotFoundError:\n pass\n\n\nclass Clean(Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n for source in cython_sources:\n genc = source.replace('.pyx', '.c')\n rm(genc)\n compiled_glob = source.replace('.pyx', '.cpython*')\n for compiled in sorted(glob(compiled_glob)):\n rm(compiled)\n\n\ncmdclass = {\n 'build_ext': build_ext,\n 'build_usage': setup_docs.build_usage,\n 'build_man': setup_docs.build_man,\n 'sdist': Sdist,\n 'clean2': Clean,\n}\n\next_modules = []\nif not on_rtd:\n\n def members_appended(*ds):\n result = defaultdict(list)\n for d in ds:\n for k, v in d.items():\n assert isinstance(v, list)\n result[k].extend(v)\n return result\n\n try:\n import pkgconfig as pc\n except ImportError:\n print('Warning: can not import pkgconfig python package.')\n pc = None\n\n crypto_ext_kwargs = members_appended(\n dict(sources=[crypto_ll_source, crypto_helpers]),\n setup_crypto.crypto_ext_kwargs(pc, system_prefix_openssl),\n )\n\n compress_ext_kwargs = members_appended(\n dict(sources=[compress_source]),\n setup_compress.lz4_ext_kwargs(pc, prefer_system_liblz4, system_prefix_liblz4),\n setup_compress.zstd_ext_kwargs(pc, prefer_system_libzstd, system_prefix_libzstd,\n multithreaded=False, legacy=False),\n )\n\n checksums_ext_kwargs = members_appended(\n dict(sources=[checksums_source]),\n setup_checksums.xxhash_ext_kwargs(pc, prefer_system_libxxhash, system_prefix_libxxhash),\n )\n\n ext_modules += [\n Extension('borg.crypto.low_level', **crypto_ext_kwargs),\n Extension('borg.compress', **compress_ext_kwargs),\n Extension('borg.hashindex', [hashindex_source]),\n Extension('borg.item', [item_source]),\n Extension('borg.chunker', [chunker_source]),\n Extension('borg.algorithms.checksums', **checksums_ext_kwargs),\n ]\n\n posix_ext = Extension('borg.platform.posix', [platform_posix_source])\n linux_ext = Extension('borg.platform.linux', [platform_linux_source], libraries=['acl'])\n syncfilerange_ext = Extension('borg.platform.syncfilerange', [platform_syncfilerange_source])\n freebsd_ext = Extension('borg.platform.freebsd', [platform_freebsd_source])\n darwin_ext = Extension('borg.platform.darwin', [platform_darwin_source])\n windows_ext = Extension('borg.platform.windows', [platform_windows_source])\n\n if not is_win32:\n ext_modules.append(posix_ext)\n else:\n ext_modules.append(windows_ext)\n if sys.platform == 'linux':\n ext_modules.append(linux_ext)\n ext_modules.append(syncfilerange_ext)\n elif sys.platform.startswith('freebsd'):\n ext_modules.append(freebsd_ext)\n elif sys.platform == 'darwin':\n ext_modules.append(darwin_ext)\n\n # sometimes there's no need to cythonize\n # this breaks chained commands like 'clean sdist'\n cythonizing = len(sys.argv) > 1 and sys.argv[1] not in (\n ('clean', 'clean2', 'egg_info', '--help-commands', '--version')) and '--help' not in sys.argv[1:]\n\n if cythonize and cythonizing:\n cython_opts = dict(\n # default language_level will be '3str' starting from Cython 3.0.0,\n # but old cython versions (< 0.29) do not know that, thus we use 3 for now.\n compiler_directives={'language_level': 3},\n )\n if not is_win32:\n # compile .pyx extensions to .c in parallel, does not work on windows\n cython_opts['nthreads'] = cpu_threads\n\n # generate C code from Cython for ALL supported platforms, so we have them in the sdist.\n # the sdist does not require Cython at install time, so we need all as C.\n cythonize([posix_ext, linux_ext, syncfilerange_ext, freebsd_ext, darwin_ext, windows_ext], **cython_opts)\n # generate C code from Cython for THIS platform (and for all platform-independent Cython parts).\n ext_modules = cythonize(ext_modules, **cython_opts)\n\n\nsetup(\n name='borgbackup',\n use_scm_version={\n 'write_to': 'src/borg/_version.py',\n },\n author='The Borg Collective (see AUTHORS file)',\n author_email='[email protected]',\n url='https://borgbackup.readthedocs.io/',\n description='Deduplicated, encrypted, authenticated and compressed backups',\n long_description=setup_docs.long_desc_from_readme(),\n license='BSD',\n platforms=['Linux', 'MacOS X', 'FreeBSD', 'OpenBSD', 'NetBSD', ],\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Environment :: Console',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: POSIX :: BSD :: FreeBSD',\n 'Operating System :: POSIX :: BSD :: OpenBSD',\n 'Operating System :: POSIX :: BSD :: NetBSD',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Topic :: Security :: Cryptography',\n 'Topic :: System :: Archiving :: Backup',\n ],\n packages=find_packages('src'),\n package_dir={'': 'src'},\n zip_safe=False,\n entry_points={\n 'console_scripts': [\n 'borg = borg.archiver:main',\n 'borgfs = borg.archiver:main',\n ]\n },\n # See also the MANIFEST.in file.\n # We want to install all the files in the package directories...\n include_package_data=True,\n # ...except the source files which have been compiled (C extensions):\n exclude_package_data={\n '': ['*.c', '*.h', '*.pyx', ],\n },\n cmdclass=cmdclass,\n ext_modules=ext_modules,\n setup_requires=['setuptools_scm>=1.7'],\n install_requires=install_requires,\n extras_require=extras_require,\n python_requires='>=3.8',\n)\n", "path": "setup.py"}]}
| 3,872 | 113 |
gh_patches_debug_16755
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5299
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tests failing with new Sybil
Sybil 3.0.0 was just released, and at least the following change breaks our tests: `CodeBlockParser has been renamed to PythonCodeBlockParser`
```python-traceback
docs/conftest.py:24: in <module>
CodeBlockParser(future_imports=['print_function']),
E TypeError: __init__() got an unexpected keyword argument 'future_imports'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conftest.py`
Content:
```
1 import os
2 from doctest import ELLIPSIS, NORMALIZE_WHITESPACE
3
4 from scrapy.http.response.html import HtmlResponse
5 from sybil import Sybil
6 from sybil.parsers.codeblock import CodeBlockParser
7 from sybil.parsers.doctest import DocTestParser
8 from sybil.parsers.skip import skip
9
10
11 def load_response(url, filename):
12 input_path = os.path.join(os.path.dirname(__file__), '_tests', filename)
13 with open(input_path, 'rb') as input_file:
14 return HtmlResponse(url, body=input_file.read())
15
16
17 def setup(namespace):
18 namespace['load_response'] = load_response
19
20
21 pytest_collect_file = Sybil(
22 parsers=[
23 DocTestParser(optionflags=ELLIPSIS | NORMALIZE_WHITESPACE),
24 CodeBlockParser(future_imports=['print_function']),
25 skip,
26 ],
27 pattern='*.rst',
28 setup=setup,
29 ).pytest()
30
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conftest.py b/docs/conftest.py
--- a/docs/conftest.py
+++ b/docs/conftest.py
@@ -3,7 +3,11 @@
from scrapy.http.response.html import HtmlResponse
from sybil import Sybil
-from sybil.parsers.codeblock import CodeBlockParser
+try:
+ # >2.0.1
+ from sybil.parsers.codeblock import PythonCodeBlockParser
+except ImportError:
+ from sybil.parsers.codeblock import CodeBlockParser as PythonCodeBlockParser
from sybil.parsers.doctest import DocTestParser
from sybil.parsers.skip import skip
@@ -21,7 +25,7 @@
pytest_collect_file = Sybil(
parsers=[
DocTestParser(optionflags=ELLIPSIS | NORMALIZE_WHITESPACE),
- CodeBlockParser(future_imports=['print_function']),
+ PythonCodeBlockParser(future_imports=['print_function']),
skip,
],
pattern='*.rst',
|
{"golden_diff": "diff --git a/docs/conftest.py b/docs/conftest.py\n--- a/docs/conftest.py\n+++ b/docs/conftest.py\n@@ -3,7 +3,11 @@\n \n from scrapy.http.response.html import HtmlResponse\n from sybil import Sybil\n-from sybil.parsers.codeblock import CodeBlockParser\n+try:\n+ # >2.0.1\n+ from sybil.parsers.codeblock import PythonCodeBlockParser\n+except ImportError:\n+ from sybil.parsers.codeblock import CodeBlockParser as PythonCodeBlockParser\n from sybil.parsers.doctest import DocTestParser\n from sybil.parsers.skip import skip\n \n@@ -21,7 +25,7 @@\n pytest_collect_file = Sybil(\n parsers=[\n DocTestParser(optionflags=ELLIPSIS | NORMALIZE_WHITESPACE),\n- CodeBlockParser(future_imports=['print_function']),\n+ PythonCodeBlockParser(future_imports=['print_function']),\n skip,\n ],\n pattern='*.rst',\n", "issue": "Tests failing with new Sybil\nSybil 3.0.0 was just released, and at least the following change breaks our tests: `CodeBlockParser has been renamed to PythonCodeBlockParser`\r\n\r\n```python-traceback\r\ndocs/conftest.py:24: in <module>\r\n CodeBlockParser(future_imports=['print_function']),\r\nE TypeError: __init__() got an unexpected keyword argument 'future_imports'\r\n```\n", "before_files": [{"content": "import os\nfrom doctest import ELLIPSIS, NORMALIZE_WHITESPACE\n\nfrom scrapy.http.response.html import HtmlResponse\nfrom sybil import Sybil\nfrom sybil.parsers.codeblock import CodeBlockParser\nfrom sybil.parsers.doctest import DocTestParser\nfrom sybil.parsers.skip import skip\n\n\ndef load_response(url, filename):\n input_path = os.path.join(os.path.dirname(__file__), '_tests', filename)\n with open(input_path, 'rb') as input_file:\n return HtmlResponse(url, body=input_file.read())\n\n\ndef setup(namespace):\n namespace['load_response'] = load_response\n\n\npytest_collect_file = Sybil(\n parsers=[\n DocTestParser(optionflags=ELLIPSIS | NORMALIZE_WHITESPACE),\n CodeBlockParser(future_imports=['print_function']),\n skip,\n ],\n pattern='*.rst',\n setup=setup,\n).pytest()\n", "path": "docs/conftest.py"}], "after_files": [{"content": "import os\nfrom doctest import ELLIPSIS, NORMALIZE_WHITESPACE\n\nfrom scrapy.http.response.html import HtmlResponse\nfrom sybil import Sybil\ntry:\n # >2.0.1\n from sybil.parsers.codeblock import PythonCodeBlockParser\nexcept ImportError:\n from sybil.parsers.codeblock import CodeBlockParser as PythonCodeBlockParser\nfrom sybil.parsers.doctest import DocTestParser\nfrom sybil.parsers.skip import skip\n\n\ndef load_response(url, filename):\n input_path = os.path.join(os.path.dirname(__file__), '_tests', filename)\n with open(input_path, 'rb') as input_file:\n return HtmlResponse(url, body=input_file.read())\n\n\ndef setup(namespace):\n namespace['load_response'] = load_response\n\n\npytest_collect_file = Sybil(\n parsers=[\n DocTestParser(optionflags=ELLIPSIS | NORMALIZE_WHITESPACE),\n PythonCodeBlockParser(future_imports=['print_function']),\n skip,\n ],\n pattern='*.rst',\n setup=setup,\n).pytest()\n", "path": "docs/conftest.py"}]}
| 596 | 216 |
gh_patches_debug_40430
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1586
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: portenf_sa_gov_au reporting incorrect dates
### I Have A Problem With:
A specific source
### What's Your Problem
The portenf_sa_gov_au sensor has been reporting incorrectly since it updated itself on 24 December 2023 (I can see this from HA logs). It appears that when there is 1 week or less left in the month "main-month" switches to the coming month and "other-month" becomes the current month.
Because of this, the integration reports the current collection next month and the next collections as in the past (and hides them).
The fix in #1110 by @5ila5 partly addresses the problem but it was not foreseeable to him that EOM would be treated this way. @5ila5 also noted that this might be an issue in that closed issue.
### Source (if relevant)
portenf_sa_gov_au
### Logs
```Shell
Output of test_sources.py:
Testing source portenf_sa_gov_au ...
found 8 entries for Broadview, Regency Road, 565
2024-01-26 : general-waste bin [mdi:trash-can]
2024-01-26 : recycling bin [mdi:recycle]
2023-12-02 : general-waste bin [mdi:trash-can]
2023-12-02 : organics bin [mdi:leaf]
2023-12-09 : general-waste bin [mdi:trash-can]
2023-12-09 : recycling bin [mdi:recycle]
2023-12-16 : general-waste bin [mdi:trash-can]
2023-12-16 : organics bin [mdi:leaf]
found 8 entries for 48 Floriedale Rd
2024-01-26 : general-waste bin [mdi:trash-can]
2024-01-26 : recycling bin [mdi:recycle]
2023-12-02 : general-waste bin [mdi:trash-can]
2023-12-02 : organics bin [mdi:leaf]
2023-12-09 : general-waste bin [mdi:trash-can]
2023-12-09 : recycling bin [mdi:recycle]
2023-12-16 : general-waste bin [mdi:trash-can]
2023-12-16 : organics bin [mdi:leaf]
found 8 entries for 24 Margaret Terrace
2024-01-28 : general-waste bin [mdi:trash-can]
2024-01-28 : organics bin [mdi:leaf]
2023-12-04 : general-waste bin [mdi:trash-can]
2023-12-04 : recycling bin [mdi:recycle]
2023-12-11 : general-waste bin [mdi:trash-can]
2023-12-11 : organics bin [mdi:leaf]
2023-12-18 : general-waste bin [mdi:trash-can]
2023-12-18 : recycling bin [mdi:recycle]
found 8 entries for Addison Road 91 with unit
2024-01-28 : general-waste bin [mdi:trash-can]
2024-01-28 : organics bin [mdi:leaf]
2023-12-04 : general-waste bin [mdi:trash-can]
2023-12-04 : recycling bin [mdi:recycle]
2023-12-11 : general-waste bin [mdi:trash-can]
2023-12-11 : organics bin [mdi:leaf]
2023-12-18 : general-waste bin [mdi:trash-can]
2023-12-18 : recycling bin [mdi:recycle]
```
### Relevant Configuration
_No response_
### Checklist Source Error
- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [X] Checked that the website of your service provider is still working
- [X] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py`
Content:
```
1 import datetime
2 import logging
3 import re
4
5 import requests
6 import urllib3
7 from bs4 import BeautifulSoup
8 from waste_collection_schedule import Collection # type: ignore[attr-defined]
9
10 # With verify=True the POST fails due to a SSLCertVerificationError.
11 # Using verify=False works, but is not ideal. The following links may provide a better way of dealing with this:
12 # https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
13 # https://urllib3.readthedocs.io/en/1.26.x/user-guide.html#ssl
14 # These two lines areused to suppress the InsecureRequestWarning when using verify=False
15 urllib3.disable_warnings()
16
17 TITLE = "Port Adelaide Enfield, South Australia"
18 DESCRIPTION = "Source for City of Port Adelaide Enfield, South Australia."
19 URL = "https://ecouncil.portenf.sa.gov.au/"
20 TEST_CASES = {
21 "Broadview, Regency Road, 565 ": {
22 "suburb": "Broadview",
23 "street": "Regency Road",
24 "house_number": 565,
25 "unit_number": "",
26 },
27 "48 Floriedale Rd ": {
28 "suburb": "Greenacres",
29 "street": "Floriedale Rd",
30 "house_number": "48",
31 },
32 "24 Margaret Terrace": {
33 "suburb": "Rosewater",
34 "street": "Margaret Terrace",
35 "house_number": "24",
36 },
37 "Addison Road 91 with unit": {
38 "suburb": "Rosewater",
39 "street": "Addison Road",
40 "house_number": 91,
41 "unit_number": 2,
42 },
43 }
44
45 ICON_MAP = {
46 "general-waste bin": "mdi:trash-can",
47 "organics bin": "mdi:leaf",
48 "recycling bin": "mdi:recycle",
49 }
50
51 LOGGER = logging.getLogger(__name__)
52
53 API_URL = "https://ecouncil.portenf.sa.gov.au/public/propertywastedates/public.aspx"
54
55
56 class Source:
57 def __init__(
58 self,
59 suburb: str,
60 street: str,
61 house_number: str | int,
62 unit_number: str | int = "",
63 ):
64 self._suburb: str = suburb
65 self._street: str = street
66 self._house_number: str = str(house_number)
67 self._unit_number: str = str(unit_number)
68
69 def __set_args(
70 self, soup: BeautifulSoup, event_taget=None, additional: dict = {}
71 ) -> dict:
72 args = {
73 "ctl00$MainContent$txtSuburb": self._suburb,
74 "ctl00$MainContent$txtStreetName": self._street,
75 "ctl00$MainContent$txtHouseNumber": self._house_number,
76 "ctl00$MainContent$txtUnitNumber": self._unit_number,
77 }
78 if event_taget is not None:
79 args["__EVENTTARGET"] = event_taget
80
81 for hidden_val in soup.find_all("input", {"type": "hidden"}):
82 args[hidden_val["name"]] = hidden_val["value"]
83
84 for key, value in additional.items():
85 args[key] = value
86 return args
87
88 def fetch(self):
89 session = requests.Session()
90
91 # get First page
92 r = session.get(API_URL, verify=False)
93 r.raise_for_status()
94
95 # extractt arguments
96 args = self.__set_args(
97 BeautifulSoup(r.text, "html.parser"),
98 event_taget="ctl00$MainContent$btnSearch",
99 )
100
101 r = session.post(API_URL, data=args)
102 r.raise_for_status()
103
104 # get page to select an address
105 soup = BeautifulSoup(r.text, "html.parser")
106
107 selectable = soup.find_all("a", {"class": "anchor-button small"}, text="Select")
108
109 if len(selectable) == 0:
110 raise ValueError("No address found")
111 selected = selectable[0]
112
113 # If multiple addresses are found, try to find the one that matches the input and warn if there are multiple or none matches
114 if len(selectable) > 1:
115 found = [
116 " ".join(
117 [y.text for y in x.parent.parent.find_all("td")[1].find_all("span")]
118 )
119 for x in selectable
120 ]
121 using_index = 0
122
123 match = False
124
125 for index, entry in enumerate(found):
126 entry = entry.lower().strip().replace(" ", "")
127 if (
128 self._house_number.lower().strip().replace(" ", "") in entry
129 and self._street.lower().strip().replace(" ", "") in entry
130 and self._suburb.lower().strip().replace(" ", "") in entry
131 and self._unit_number.lower().strip().replace(" ", "") in entry
132 ):
133 if match:
134 LOGGER.warning(
135 f"Multiple addresses found, using first one \nfound:{', '.join(found[:10])}{'...' if len(found) >= 10 else ''} \nusing:{found[using_index]}"
136 )
137 break
138 using_index = index
139 match = True
140 if not match:
141 LOGGER.warning(
142 f"no perfect address match found, using:{found[using_index]}"
143 )
144
145 # request first address
146 args = self.__set_args(
147 soup,
148 event_taget="ctl00$MainContent$gvPropertyResults$ctl02$btnSelect",
149 additional={selected["href"].split("'")[1]: ""},
150 )
151 r = session.post(API_URL, data=args)
152 r.raise_for_status()
153
154 soup = BeautifulSoup(r.text, "html.parser")
155 cal_header = soup.find("th", {"class": "header-month"}).find("span").text
156 main_month = cal_header.split("-")[0].strip()
157
158 secondary_month = cal_header.split("-")[1].strip().split(" ")[0]
159 secondary_year = main_year = cal_header.split("-")[1].strip().split(" ")[1]
160
161 # if main month contains a year, set it (maybe happens in december???)
162 if len(main_month.split(" ")) > 1:
163 main_year = main_month.split(" ")[1]
164 main_month = main_month.split(" ")[0]
165
166 entries = []
167
168 calendar = soup.find("table", {"class": "collection-day-calendar"})
169 # Iterate over all days with pickups
170 for pickup in calendar.find_all(
171 "div", {"class": re.compile(r"pickup|next-pickup")}
172 ):
173 parent_td = pickup.parent
174 month = (
175 main_month
176 if "main-month" in parent_td.attrs["class"]
177 else secondary_month
178 )
179 year = (
180 main_year
181 if "main-month" in parent_td.attrs["class"]
182 else secondary_year
183 )
184 day = parent_td.find("div", {"class": "daynumber"}).text
185
186 # Iterate over all pickup container types for this day
187 for container in pickup.find_all("div", {"class": "bin-container"}):
188 container_type = " ".join(container.find("div").attrs["class"])
189 container_icon = ICON_MAP.get(container_type)
190
191 date = datetime.datetime.strptime(
192 f"{year}-{month}-{day}", "%Y-%B-%d"
193 ).date()
194 entries.append(
195 Collection(date=date, t=container_type, icon=container_icon)
196 )
197
198 return entries
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py
@@ -1,6 +1,6 @@
-import datetime
import logging
import re
+from datetime import datetime
import requests
import urllib3
@@ -153,15 +153,28 @@
soup = BeautifulSoup(r.text, "html.parser")
cal_header = soup.find("th", {"class": "header-month"}).find("span").text
- main_month = cal_header.split("-")[0].strip()
-
- secondary_month = cal_header.split("-")[1].strip().split(" ")[0]
- secondary_year = main_year = cal_header.split("-")[1].strip().split(" ")[1]
+ from_month = cal_header.split("-")[0].strip()
+ to_month = cal_header.split("-")[1].strip().split(" ")[0]
+ to_year = from_year = cal_header.split("-")[1].strip().split(" ")[1]
# if main month contains a year, set it (maybe happens in december???)
- if len(main_month.split(" ")) > 1:
- main_year = main_month.split(" ")[1]
- main_month = main_month.split(" ")[0]
+ if len(from_month.split(" ")) > 1:
+ from_year = from_month.split(" ")[1]
+ from_month = from_month.split(" ")[0]
+
+ today_div = soup.find("table", id="cal").find("td", class_="today")
+ print(today_div)
+
+ # if other-month is to_month
+ if (
+ "other-month" in today_div.attrs
+ and datetime.now().strftime("%B") != to_month
+ ):
+ main_month, other_month = from_month, to_month
+ main_year, other_year = from_year, to_year
+ else: # if other-month is from_month
+ main_month, other_month = to_month, from_month
+ main_year, other_year = to_year, from_year
entries = []
@@ -172,15 +185,9 @@
):
parent_td = pickup.parent
month = (
- main_month
- if "main-month" in parent_td.attrs["class"]
- else secondary_month
- )
- year = (
- main_year
- if "main-month" in parent_td.attrs["class"]
- else secondary_year
+ main_month if "main-month" in parent_td.attrs["class"] else other_month
)
+ year = main_year if "main-month" in parent_td.attrs["class"] else other_year
day = parent_td.find("div", {"class": "daynumber"}).text
# Iterate over all pickup container types for this day
@@ -188,9 +195,7 @@
container_type = " ".join(container.find("div").attrs["class"])
container_icon = ICON_MAP.get(container_type)
- date = datetime.datetime.strptime(
- f"{year}-{month}-{day}", "%Y-%B-%d"
- ).date()
+ date = datetime.strptime(f"{year}-{month}-{day}", "%Y-%B-%d").date()
entries.append(
Collection(date=date, t=container_type, icon=container_icon)
)
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py\n@@ -1,6 +1,6 @@\n-import datetime\n import logging\n import re\n+from datetime import datetime\n \n import requests\n import urllib3\n@@ -153,15 +153,28 @@\n \n soup = BeautifulSoup(r.text, \"html.parser\")\n cal_header = soup.find(\"th\", {\"class\": \"header-month\"}).find(\"span\").text\n- main_month = cal_header.split(\"-\")[0].strip()\n-\n- secondary_month = cal_header.split(\"-\")[1].strip().split(\" \")[0]\n- secondary_year = main_year = cal_header.split(\"-\")[1].strip().split(\" \")[1]\n \n+ from_month = cal_header.split(\"-\")[0].strip()\n+ to_month = cal_header.split(\"-\")[1].strip().split(\" \")[0]\n+ to_year = from_year = cal_header.split(\"-\")[1].strip().split(\" \")[1]\n # if main month contains a year, set it (maybe happens in december???)\n- if len(main_month.split(\" \")) > 1:\n- main_year = main_month.split(\" \")[1]\n- main_month = main_month.split(\" \")[0]\n+ if len(from_month.split(\" \")) > 1:\n+ from_year = from_month.split(\" \")[1]\n+ from_month = from_month.split(\" \")[0]\n+\n+ today_div = soup.find(\"table\", id=\"cal\").find(\"td\", class_=\"today\")\n+ print(today_div)\n+\n+ # if other-month is to_month\n+ if (\n+ \"other-month\" in today_div.attrs\n+ and datetime.now().strftime(\"%B\") != to_month\n+ ):\n+ main_month, other_month = from_month, to_month\n+ main_year, other_year = from_year, to_year\n+ else: # if other-month is from_month\n+ main_month, other_month = to_month, from_month\n+ main_year, other_year = to_year, from_year\n \n entries = []\n \n@@ -172,15 +185,9 @@\n ):\n parent_td = pickup.parent\n month = (\n- main_month\n- if \"main-month\" in parent_td.attrs[\"class\"]\n- else secondary_month\n- )\n- year = (\n- main_year\n- if \"main-month\" in parent_td.attrs[\"class\"]\n- else secondary_year\n+ main_month if \"main-month\" in parent_td.attrs[\"class\"] else other_month\n )\n+ year = main_year if \"main-month\" in parent_td.attrs[\"class\"] else other_year\n day = parent_td.find(\"div\", {\"class\": \"daynumber\"}).text\n \n # Iterate over all pickup container types for this day\n@@ -188,9 +195,7 @@\n container_type = \" \".join(container.find(\"div\").attrs[\"class\"])\n container_icon = ICON_MAP.get(container_type)\n \n- date = datetime.datetime.strptime(\n- f\"{year}-{month}-{day}\", \"%Y-%B-%d\"\n- ).date()\n+ date = datetime.strptime(f\"{year}-{month}-{day}\", \"%Y-%B-%d\").date()\n entries.append(\n Collection(date=date, t=container_type, icon=container_icon)\n )\n", "issue": "[Bug]: portenf_sa_gov_au reporting incorrect dates\n### I Have A Problem With:\r\n\r\nA specific source\r\n\r\n### What's Your Problem\r\n\r\nThe portenf_sa_gov_au sensor has been reporting incorrectly since it updated itself on 24 December 2023 (I can see this from HA logs). It appears that when there is 1 week or less left in the month \"main-month\" switches to the coming month and \"other-month\" becomes the current month.\r\n\r\nBecause of this, the integration reports the current collection next month and the next collections as in the past (and hides them).\r\n\r\nThe fix in #1110 by @5ila5 partly addresses the problem but it was not foreseeable to him that EOM would be treated this way. @5ila5 also noted that this might be an issue in that closed issue.\r\n\r\n### Source (if relevant)\r\n\r\nportenf_sa_gov_au\r\n\r\n### Logs\r\n\r\n```Shell\r\nOutput of test_sources.py:\r\n\r\nTesting source portenf_sa_gov_au ...\r\n found 8 entries for Broadview, Regency Road, 565\r\n 2024-01-26 : general-waste bin [mdi:trash-can]\r\n 2024-01-26 : recycling bin [mdi:recycle]\r\n 2023-12-02 : general-waste bin [mdi:trash-can]\r\n 2023-12-02 : organics bin [mdi:leaf]\r\n 2023-12-09 : general-waste bin [mdi:trash-can]\r\n 2023-12-09 : recycling bin [mdi:recycle]\r\n 2023-12-16 : general-waste bin [mdi:trash-can]\r\n 2023-12-16 : organics bin [mdi:leaf]\r\n found 8 entries for 48 Floriedale Rd\r\n 2024-01-26 : general-waste bin [mdi:trash-can]\r\n 2024-01-26 : recycling bin [mdi:recycle]\r\n 2023-12-02 : general-waste bin [mdi:trash-can]\r\n 2023-12-02 : organics bin [mdi:leaf]\r\n 2023-12-09 : general-waste bin [mdi:trash-can]\r\n 2023-12-09 : recycling bin [mdi:recycle]\r\n 2023-12-16 : general-waste bin [mdi:trash-can]\r\n 2023-12-16 : organics bin [mdi:leaf]\r\n found 8 entries for 24 Margaret Terrace\r\n 2024-01-28 : general-waste bin [mdi:trash-can]\r\n 2024-01-28 : organics bin [mdi:leaf]\r\n 2023-12-04 : general-waste bin [mdi:trash-can]\r\n 2023-12-04 : recycling bin [mdi:recycle]\r\n 2023-12-11 : general-waste bin [mdi:trash-can]\r\n 2023-12-11 : organics bin [mdi:leaf]\r\n 2023-12-18 : general-waste bin [mdi:trash-can]\r\n 2023-12-18 : recycling bin [mdi:recycle]\r\n found 8 entries for Addison Road 91 with unit\r\n 2024-01-28 : general-waste bin [mdi:trash-can]\r\n 2024-01-28 : organics bin [mdi:leaf]\r\n 2023-12-04 : general-waste bin [mdi:trash-can]\r\n 2023-12-04 : recycling bin [mdi:recycle]\r\n 2023-12-11 : general-waste bin [mdi:trash-can]\r\n 2023-12-11 : organics bin [mdi:leaf]\r\n 2023-12-18 : general-waste bin [mdi:trash-can]\r\n 2023-12-18 : recycling bin [mdi:recycle]\r\n```\r\n\r\n\r\n### Relevant Configuration\r\n\r\n_No response_\r\n\r\n### Checklist Source Error\r\n\r\n- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\r\n- [X] Checked that the website of your service provider is still working\r\n- [X] Tested my attributes on the service provider website (if possible)\r\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\r\n\r\n### Checklist Sensor Error\r\n\r\n- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\r\n\r\n### Required\r\n\r\n- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\r\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "import datetime\nimport logging\nimport re\n\nimport requests\nimport urllib3\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\n\n# With verify=True the POST fails due to a SSLCertVerificationError.\n# Using verify=False works, but is not ideal. The following links may provide a better way of dealing with this:\n# https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings\n# https://urllib3.readthedocs.io/en/1.26.x/user-guide.html#ssl\n# These two lines areused to suppress the InsecureRequestWarning when using verify=False\nurllib3.disable_warnings()\n\nTITLE = \"Port Adelaide Enfield, South Australia\"\nDESCRIPTION = \"Source for City of Port Adelaide Enfield, South Australia.\"\nURL = \"https://ecouncil.portenf.sa.gov.au/\"\nTEST_CASES = {\n \"Broadview, Regency Road, 565 \": {\n \"suburb\": \"Broadview\",\n \"street\": \"Regency Road\",\n \"house_number\": 565,\n \"unit_number\": \"\",\n },\n \"48 Floriedale Rd \": {\n \"suburb\": \"Greenacres\",\n \"street\": \"Floriedale Rd\",\n \"house_number\": \"48\",\n },\n \"24 Margaret Terrace\": {\n \"suburb\": \"Rosewater\",\n \"street\": \"Margaret Terrace\",\n \"house_number\": \"24\",\n },\n \"Addison Road 91 with unit\": {\n \"suburb\": \"Rosewater\",\n \"street\": \"Addison Road\",\n \"house_number\": 91,\n \"unit_number\": 2,\n },\n}\n\nICON_MAP = {\n \"general-waste bin\": \"mdi:trash-can\",\n \"organics bin\": \"mdi:leaf\",\n \"recycling bin\": \"mdi:recycle\",\n}\n\nLOGGER = logging.getLogger(__name__)\n\nAPI_URL = \"https://ecouncil.portenf.sa.gov.au/public/propertywastedates/public.aspx\"\n\n\nclass Source:\n def __init__(\n self,\n suburb: str,\n street: str,\n house_number: str | int,\n unit_number: str | int = \"\",\n ):\n self._suburb: str = suburb\n self._street: str = street\n self._house_number: str = str(house_number)\n self._unit_number: str = str(unit_number)\n\n def __set_args(\n self, soup: BeautifulSoup, event_taget=None, additional: dict = {}\n ) -> dict:\n args = {\n \"ctl00$MainContent$txtSuburb\": self._suburb,\n \"ctl00$MainContent$txtStreetName\": self._street,\n \"ctl00$MainContent$txtHouseNumber\": self._house_number,\n \"ctl00$MainContent$txtUnitNumber\": self._unit_number,\n }\n if event_taget is not None:\n args[\"__EVENTTARGET\"] = event_taget\n\n for hidden_val in soup.find_all(\"input\", {\"type\": \"hidden\"}):\n args[hidden_val[\"name\"]] = hidden_val[\"value\"]\n\n for key, value in additional.items():\n args[key] = value\n return args\n\n def fetch(self):\n session = requests.Session()\n\n # get First page\n r = session.get(API_URL, verify=False)\n r.raise_for_status()\n\n # extractt arguments\n args = self.__set_args(\n BeautifulSoup(r.text, \"html.parser\"),\n event_taget=\"ctl00$MainContent$btnSearch\",\n )\n\n r = session.post(API_URL, data=args)\n r.raise_for_status()\n\n # get page to select an address\n soup = BeautifulSoup(r.text, \"html.parser\")\n\n selectable = soup.find_all(\"a\", {\"class\": \"anchor-button small\"}, text=\"Select\")\n\n if len(selectable) == 0:\n raise ValueError(\"No address found\")\n selected = selectable[0]\n\n # If multiple addresses are found, try to find the one that matches the input and warn if there are multiple or none matches\n if len(selectable) > 1:\n found = [\n \" \".join(\n [y.text for y in x.parent.parent.find_all(\"td\")[1].find_all(\"span\")]\n )\n for x in selectable\n ]\n using_index = 0\n\n match = False\n\n for index, entry in enumerate(found):\n entry = entry.lower().strip().replace(\" \", \"\")\n if (\n self._house_number.lower().strip().replace(\" \", \"\") in entry\n and self._street.lower().strip().replace(\" \", \"\") in entry\n and self._suburb.lower().strip().replace(\" \", \"\") in entry\n and self._unit_number.lower().strip().replace(\" \", \"\") in entry\n ):\n if match:\n LOGGER.warning(\n f\"Multiple addresses found, using first one \\nfound:{', '.join(found[:10])}{'...' if len(found) >= 10 else ''} \\nusing:{found[using_index]}\"\n )\n break\n using_index = index\n match = True\n if not match:\n LOGGER.warning(\n f\"no perfect address match found, using:{found[using_index]}\"\n )\n\n # request first address\n args = self.__set_args(\n soup,\n event_taget=\"ctl00$MainContent$gvPropertyResults$ctl02$btnSelect\",\n additional={selected[\"href\"].split(\"'\")[1]: \"\"},\n )\n r = session.post(API_URL, data=args)\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n cal_header = soup.find(\"th\", {\"class\": \"header-month\"}).find(\"span\").text\n main_month = cal_header.split(\"-\")[0].strip()\n\n secondary_month = cal_header.split(\"-\")[1].strip().split(\" \")[0]\n secondary_year = main_year = cal_header.split(\"-\")[1].strip().split(\" \")[1]\n\n # if main month contains a year, set it (maybe happens in december???)\n if len(main_month.split(\" \")) > 1:\n main_year = main_month.split(\" \")[1]\n main_month = main_month.split(\" \")[0]\n\n entries = []\n\n calendar = soup.find(\"table\", {\"class\": \"collection-day-calendar\"})\n # Iterate over all days with pickups\n for pickup in calendar.find_all(\n \"div\", {\"class\": re.compile(r\"pickup|next-pickup\")}\n ):\n parent_td = pickup.parent\n month = (\n main_month\n if \"main-month\" in parent_td.attrs[\"class\"]\n else secondary_month\n )\n year = (\n main_year\n if \"main-month\" in parent_td.attrs[\"class\"]\n else secondary_year\n )\n day = parent_td.find(\"div\", {\"class\": \"daynumber\"}).text\n\n # Iterate over all pickup container types for this day\n for container in pickup.find_all(\"div\", {\"class\": \"bin-container\"}):\n container_type = \" \".join(container.find(\"div\").attrs[\"class\"])\n container_icon = ICON_MAP.get(container_type)\n\n date = datetime.datetime.strptime(\n f\"{year}-{month}-{day}\", \"%Y-%B-%d\"\n ).date()\n entries.append(\n Collection(date=date, t=container_type, icon=container_icon)\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py"}], "after_files": [{"content": "import logging\nimport re\nfrom datetime import datetime\n\nimport requests\nimport urllib3\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\n\n# With verify=True the POST fails due to a SSLCertVerificationError.\n# Using verify=False works, but is not ideal. The following links may provide a better way of dealing with this:\n# https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings\n# https://urllib3.readthedocs.io/en/1.26.x/user-guide.html#ssl\n# These two lines areused to suppress the InsecureRequestWarning when using verify=False\nurllib3.disable_warnings()\n\nTITLE = \"Port Adelaide Enfield, South Australia\"\nDESCRIPTION = \"Source for City of Port Adelaide Enfield, South Australia.\"\nURL = \"https://ecouncil.portenf.sa.gov.au/\"\nTEST_CASES = {\n \"Broadview, Regency Road, 565 \": {\n \"suburb\": \"Broadview\",\n \"street\": \"Regency Road\",\n \"house_number\": 565,\n \"unit_number\": \"\",\n },\n \"48 Floriedale Rd \": {\n \"suburb\": \"Greenacres\",\n \"street\": \"Floriedale Rd\",\n \"house_number\": \"48\",\n },\n \"24 Margaret Terrace\": {\n \"suburb\": \"Rosewater\",\n \"street\": \"Margaret Terrace\",\n \"house_number\": \"24\",\n },\n \"Addison Road 91 with unit\": {\n \"suburb\": \"Rosewater\",\n \"street\": \"Addison Road\",\n \"house_number\": 91,\n \"unit_number\": 2,\n },\n}\n\nICON_MAP = {\n \"general-waste bin\": \"mdi:trash-can\",\n \"organics bin\": \"mdi:leaf\",\n \"recycling bin\": \"mdi:recycle\",\n}\n\nLOGGER = logging.getLogger(__name__)\n\nAPI_URL = \"https://ecouncil.portenf.sa.gov.au/public/propertywastedates/public.aspx\"\n\n\nclass Source:\n def __init__(\n self,\n suburb: str,\n street: str,\n house_number: str | int,\n unit_number: str | int = \"\",\n ):\n self._suburb: str = suburb\n self._street: str = street\n self._house_number: str = str(house_number)\n self._unit_number: str = str(unit_number)\n\n def __set_args(\n self, soup: BeautifulSoup, event_taget=None, additional: dict = {}\n ) -> dict:\n args = {\n \"ctl00$MainContent$txtSuburb\": self._suburb,\n \"ctl00$MainContent$txtStreetName\": self._street,\n \"ctl00$MainContent$txtHouseNumber\": self._house_number,\n \"ctl00$MainContent$txtUnitNumber\": self._unit_number,\n }\n if event_taget is not None:\n args[\"__EVENTTARGET\"] = event_taget\n\n for hidden_val in soup.find_all(\"input\", {\"type\": \"hidden\"}):\n args[hidden_val[\"name\"]] = hidden_val[\"value\"]\n\n for key, value in additional.items():\n args[key] = value\n return args\n\n def fetch(self):\n session = requests.Session()\n\n # get First page\n r = session.get(API_URL, verify=False)\n r.raise_for_status()\n\n # extractt arguments\n args = self.__set_args(\n BeautifulSoup(r.text, \"html.parser\"),\n event_taget=\"ctl00$MainContent$btnSearch\",\n )\n\n r = session.post(API_URL, data=args)\n r.raise_for_status()\n\n # get page to select an address\n soup = BeautifulSoup(r.text, \"html.parser\")\n\n selectable = soup.find_all(\"a\", {\"class\": \"anchor-button small\"}, text=\"Select\")\n\n if len(selectable) == 0:\n raise ValueError(\"No address found\")\n selected = selectable[0]\n\n # If multiple addresses are found, try to find the one that matches the input and warn if there are multiple or none matches\n if len(selectable) > 1:\n found = [\n \" \".join(\n [y.text for y in x.parent.parent.find_all(\"td\")[1].find_all(\"span\")]\n )\n for x in selectable\n ]\n using_index = 0\n\n match = False\n\n for index, entry in enumerate(found):\n entry = entry.lower().strip().replace(\" \", \"\")\n if (\n self._house_number.lower().strip().replace(\" \", \"\") in entry\n and self._street.lower().strip().replace(\" \", \"\") in entry\n and self._suburb.lower().strip().replace(\" \", \"\") in entry\n and self._unit_number.lower().strip().replace(\" \", \"\") in entry\n ):\n if match:\n LOGGER.warning(\n f\"Multiple addresses found, using first one \\nfound:{', '.join(found[:10])}{'...' if len(found) >= 10 else ''} \\nusing:{found[using_index]}\"\n )\n break\n using_index = index\n match = True\n if not match:\n LOGGER.warning(\n f\"no perfect address match found, using:{found[using_index]}\"\n )\n\n # request first address\n args = self.__set_args(\n soup,\n event_taget=\"ctl00$MainContent$gvPropertyResults$ctl02$btnSelect\",\n additional={selected[\"href\"].split(\"'\")[1]: \"\"},\n )\n r = session.post(API_URL, data=args)\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n cal_header = soup.find(\"th\", {\"class\": \"header-month\"}).find(\"span\").text\n\n from_month = cal_header.split(\"-\")[0].strip()\n to_month = cal_header.split(\"-\")[1].strip().split(\" \")[0]\n to_year = from_year = cal_header.split(\"-\")[1].strip().split(\" \")[1]\n # if main month contains a year, set it (maybe happens in december???)\n if len(from_month.split(\" \")) > 1:\n from_year = from_month.split(\" \")[1]\n from_month = from_month.split(\" \")[0]\n\n today_div = soup.find(\"table\", id=\"cal\").find(\"td\", class_=\"today\")\n print(today_div)\n\n # if other-month is to_month\n if (\n \"other-month\" in today_div.attrs\n and datetime.now().strftime(\"%B\") != to_month\n ):\n main_month, other_month = from_month, to_month\n main_year, other_year = from_year, to_year\n else: # if other-month is from_month\n main_month, other_month = to_month, from_month\n main_year, other_year = to_year, from_year\n\n entries = []\n\n calendar = soup.find(\"table\", {\"class\": \"collection-day-calendar\"})\n # Iterate over all days with pickups\n for pickup in calendar.find_all(\n \"div\", {\"class\": re.compile(r\"pickup|next-pickup\")}\n ):\n parent_td = pickup.parent\n month = (\n main_month if \"main-month\" in parent_td.attrs[\"class\"] else other_month\n )\n year = main_year if \"main-month\" in parent_td.attrs[\"class\"] else other_year\n day = parent_td.find(\"div\", {\"class\": \"daynumber\"}).text\n\n # Iterate over all pickup container types for this day\n for container in pickup.find_all(\"div\", {\"class\": \"bin-container\"}):\n container_type = \" \".join(container.find(\"div\").attrs[\"class\"])\n container_icon = ICON_MAP.get(container_type)\n\n date = datetime.strptime(f\"{year}-{month}-{day}\", \"%Y-%B-%d\").date()\n entries.append(\n Collection(date=date, t=container_type, icon=container_icon)\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/portenf_sa_gov_au.py"}]}
| 3,588 | 802 |
gh_patches_debug_5396
|
rasdani/github-patches
|
git_diff
|
tensorflow__tfx-1082
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
just a few typos fixed
That Python version check can be removed in a few days when Colab drops Python 2 support.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py`
Content:
```
1 # Lint as: python2, python3
2 # Copyright 2019 Google LLC. All Rights Reserved.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Example pipeline to demonstrate custom TFX component.
16
17 This example consists of standard TFX components as well as a custom TFX
18 component requesting for manual review through Slack.
19
20 This example along with the custom `SlackComponent` will only serve as an
21 example and will not be supported by TFX team.
22
23 This example runs in Kubeflow with Google Cloud services..
24 """
25
26 from __future__ import absolute_import
27 from __future__ import division
28 from __future__ import print_function
29
30 import datetime
31 import os
32
33 from slack_component.component import SlackComponent
34
35 from tfx.components import CsvExampleGen
36 from tfx.components import Evaluator
37 from tfx.components import ExampleValidator
38 from tfx.components import ModelValidator
39 from tfx.components import Pusher
40 from tfx.components import SchemaGen
41 from tfx.components import StatisticsGen
42 from tfx.components import Trainer
43 from tfx.components import Transform
44 from tfx.orchestration import pipeline
45 from tfx.orchestration.kubeflow import kubeflow_dag_runner
46 from tfx.proto import evaluator_pb2
47 from tfx.proto import pusher_pb2
48 from tfx.proto import trainer_pb2
49 from tfx.utils.dsl_utils import csv_input
50
51 # This example assumes that the taxi data is stored in _input_bucket/data/simple
52 # and the taxi utility function is in example/taxi_utils_slack.py.
53 # Feel free to customize this as needed.
54 _input_bucket = 'gs://my-bucket'
55 _output_bucket = 'gs://my-bucket'
56 _taxi_root = __file__
57 _data_root = os.path.join(_input_bucket, 'data', 'simple')
58
59
60 # Python module file to inject customized logic into the TFX components. The
61 # Transform and Trainer both require user-defined functions to run successfully.
62 _taxi_trainer_func = 'example.taxi_utils_slack.trainer_fn'
63 _taxi_transformer_func = 'example.taxi_utils_slack.preprocessing_fn'
64 # Path which can be listened to by the model server. Pusher will output the
65 # trained model here.
66 _serving_model_dir = os.path.join(_taxi_root, 'serving_model/taxi_slack')
67 # Slack channel to push the model notifications to.
68 _slack_channel_id = 'my-channel-id'
69 # Slack token to set up connection.
70 _slack_token = os.environ['SLACK_BOT_TOKEN']
71
72 # Directory and data locations. This example assumes all of the chicago taxi
73 # example code and metadata library is relative to $HOME, but you can store
74 # these files anywhere on your local filesystem.
75 _tfx_root = os.path.join(os.environ['HOME'], '/tfx')
76 _pipeline_name = 'chicago_taxi_slack_kubeflow'
77 _pipeline_root = os.path.join(_input_bucket, _pipeline_name)
78 _log_root = os.path.join(_tfx_root, 'logs')
79
80 # Airflow-specific configs; these will be passed directly to airflow
81 _airflow_config = {
82 'schedule_interval': None,
83 'start_date': datetime.datetime(2019, 1, 1),
84 }
85
86
87 def _create_pipeline():
88 """Implements the chicago taxi pipeline with TFX."""
89 examples = csv_input(_data_root)
90
91 # Brings data into the pipeline or otherwise joins/converts training data.
92 example_gen = CsvExampleGen(input=examples)
93
94 # Computes statistics over data for visualization and example validation.
95 statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])
96
97 # Generates schema based on statistics files.
98 infer_schema = SchemaGen(statistics=statistics_gen.outputs['statistics'])
99
100 # Performs anomaly detection based on statistics and data schema.
101 validate_stats = ExampleValidator(
102 statistics=statistics_gen.outputs['statistics'],
103 schema=infer_schema.outputs['schema'])
104
105 # Performs transformations and feature engineering in training and serving.
106 transform = Transform(
107 examples=example_gen.outputs['examples'],
108 schema=infer_schema.outputs['schema'],
109 preprocessing_fn=_taxi_transformer_func)
110
111 # Uses user-provided Python function that implements a model using TF-Learn.
112 trainer = Trainer(
113 trainer_fn=_taxi_trainer_func,
114 examples=transform.outputs['transformed_examples'],
115 schema=infer_schema.outputs['schema'],
116 transform_graph=transform.outputs['transform_graph'],
117 train_args=trainer_pb2.TrainArgs(num_steps=10000),
118 eval_args=trainer_pb2.EvalArgs(num_steps=5000))
119
120 # Uses TFMA to compute a evaluation statistics over features of a model.
121 model_analyzer = Evaluator(
122 examples=example_gen.outputs['examples'],
123 model_exports=trainer.outputs['model'],
124 feature_slicing_spec=evaluator_pb2.FeatureSlicingSpec(specs=[
125 evaluator_pb2.SingleSlicingSpec(
126 column_for_slicing=['trip_start_hour'])
127 ]))
128
129 # Performs quality validation of a candidate model (compared to a baseline).
130 model_validator = ModelValidator(
131 examples=example_gen.outputs['examples'], model=trainer.outputs['model'])
132
133 # This custom component serves as a bridge between pipeline and human model
134 # reviewers to enable review-and-push workflow in model development cycle. It
135 # utilizes Slack API to send message to user-defined Slack channel with model
136 # URI info and wait for go / no-go decision from the same Slack channel:
137 # * To approve the model, users need to reply the thread sent out by the bot
138 # started by SlackComponent with 'lgtm' or 'approve'.
139 # * To reject the model, users need to reply the thread sent out by the bot
140 # started by SlackComponent with 'decline' or 'reject'.
141 slack_validator = SlackComponent(
142 model=trainer.outputs['model'],
143 model_blessing=model_validator.outputs['blessing'],
144 slack_token=_slack_token,
145 slack_channel_id=_slack_channel_id,
146 timeout_sec=3600,
147 )
148 # Checks whether the model passed the validation steps and pushes the model
149 # to a file destination if check passed.
150 pusher = Pusher(
151 model=trainer.outputs['model'],
152 model_blessing=slack_validator.outputs['slack_blessing'],
153 push_destination=pusher_pb2.PushDestination(
154 filesystem=pusher_pb2.PushDestination.Filesystem(
155 base_directory=_serving_model_dir)))
156
157 return pipeline.Pipeline(
158 pipeline_name=_pipeline_name,
159 pipeline_root=_pipeline_root,
160 components=[
161 example_gen, statistics_gen, infer_schema, validate_stats, transform,
162 trainer, model_analyzer, model_validator, slack_validator, pusher
163 ],
164 enable_cache=True,
165 )
166
167
168 if __name__ == '__main__':
169 # Metadata config. The defaults works work with the installation of
170 # KF Pipelines using Kubeflow. If installing KF Pipelines using the
171 # lightweight deployment option, you may need to override the defaults.
172 metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
173
174 # This pipeline automatically injects the Kubeflow TFX image if the
175 # environment variable 'KUBEFLOW_TFX_IMAGE' is defined. Currently, the tfx
176 # cli tool exports the environment variable to pass to the pipelines.
177 tfx_image = os.environ.get('KUBEFLOW_TFX_IMAGE', None)
178
179 runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
180 kubeflow_metadata_config=metadata_config,
181 # Specify custom docker image to use.
182 tfx_image=tfx_image
183 )
184
185 kubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run(
186 _create_pipeline())
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py b/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py
--- a/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py
+++ b/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py
@@ -145,7 +145,7 @@
slack_channel_id=_slack_channel_id,
timeout_sec=3600,
)
- # Checks whether the model passed the validation steps and pushes the model
+ # Checks whether the model passed the validation steps and pushes the model
# to a file destination if check passed.
pusher = Pusher(
model=trainer.outputs['model'],
|
{"golden_diff": "diff --git a/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py b/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py\n--- a/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py\n+++ b/tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py\n@@ -145,7 +145,7 @@\n slack_channel_id=_slack_channel_id,\n timeout_sec=3600,\n )\n- # Checks whether the model passed the validation steps and pushes the model\n+ # Checks whether the model passed the validation steps and pushes the model\n # to a file destination if check passed.\n pusher = Pusher(\n model=trainer.outputs['model'],\n", "issue": "just a few typos fixed\nThat Python version check can be removed in a few days when Colab drops Python 2 support.\n", "before_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Example pipeline to demonstrate custom TFX component.\n\nThis example consists of standard TFX components as well as a custom TFX\ncomponent requesting for manual review through Slack.\n\nThis example along with the custom `SlackComponent` will only serve as an\nexample and will not be supported by TFX team.\n\nThis example runs in Kubeflow with Google Cloud services..\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport datetime\nimport os\n\nfrom slack_component.component import SlackComponent\n\nfrom tfx.components import CsvExampleGen\nfrom tfx.components import Evaluator\nfrom tfx.components import ExampleValidator\nfrom tfx.components import ModelValidator\nfrom tfx.components import Pusher\nfrom tfx.components import SchemaGen\nfrom tfx.components import StatisticsGen\nfrom tfx.components import Trainer\nfrom tfx.components import Transform\nfrom tfx.orchestration import pipeline\nfrom tfx.orchestration.kubeflow import kubeflow_dag_runner\nfrom tfx.proto import evaluator_pb2\nfrom tfx.proto import pusher_pb2\nfrom tfx.proto import trainer_pb2\nfrom tfx.utils.dsl_utils import csv_input\n\n# This example assumes that the taxi data is stored in _input_bucket/data/simple\n# and the taxi utility function is in example/taxi_utils_slack.py.\n# Feel free to customize this as needed.\n_input_bucket = 'gs://my-bucket'\n_output_bucket = 'gs://my-bucket'\n_taxi_root = __file__\n_data_root = os.path.join(_input_bucket, 'data', 'simple')\n\n\n# Python module file to inject customized logic into the TFX components. The\n# Transform and Trainer both require user-defined functions to run successfully.\n_taxi_trainer_func = 'example.taxi_utils_slack.trainer_fn'\n_taxi_transformer_func = 'example.taxi_utils_slack.preprocessing_fn'\n# Path which can be listened to by the model server. Pusher will output the\n# trained model here.\n_serving_model_dir = os.path.join(_taxi_root, 'serving_model/taxi_slack')\n# Slack channel to push the model notifications to.\n_slack_channel_id = 'my-channel-id'\n# Slack token to set up connection.\n_slack_token = os.environ['SLACK_BOT_TOKEN']\n\n# Directory and data locations. This example assumes all of the chicago taxi\n# example code and metadata library is relative to $HOME, but you can store\n# these files anywhere on your local filesystem.\n_tfx_root = os.path.join(os.environ['HOME'], '/tfx')\n_pipeline_name = 'chicago_taxi_slack_kubeflow'\n_pipeline_root = os.path.join(_input_bucket, _pipeline_name)\n_log_root = os.path.join(_tfx_root, 'logs')\n\n# Airflow-specific configs; these will be passed directly to airflow\n_airflow_config = {\n 'schedule_interval': None,\n 'start_date': datetime.datetime(2019, 1, 1),\n}\n\n\ndef _create_pipeline():\n \"\"\"Implements the chicago taxi pipeline with TFX.\"\"\"\n examples = csv_input(_data_root)\n\n # Brings data into the pipeline or otherwise joins/converts training data.\n example_gen = CsvExampleGen(input=examples)\n\n # Computes statistics over data for visualization and example validation.\n statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])\n\n # Generates schema based on statistics files.\n infer_schema = SchemaGen(statistics=statistics_gen.outputs['statistics'])\n\n # Performs anomaly detection based on statistics and data schema.\n validate_stats = ExampleValidator(\n statistics=statistics_gen.outputs['statistics'],\n schema=infer_schema.outputs['schema'])\n\n # Performs transformations and feature engineering in training and serving.\n transform = Transform(\n examples=example_gen.outputs['examples'],\n schema=infer_schema.outputs['schema'],\n preprocessing_fn=_taxi_transformer_func)\n\n # Uses user-provided Python function that implements a model using TF-Learn.\n trainer = Trainer(\n trainer_fn=_taxi_trainer_func,\n examples=transform.outputs['transformed_examples'],\n schema=infer_schema.outputs['schema'],\n transform_graph=transform.outputs['transform_graph'],\n train_args=trainer_pb2.TrainArgs(num_steps=10000),\n eval_args=trainer_pb2.EvalArgs(num_steps=5000))\n\n # Uses TFMA to compute a evaluation statistics over features of a model.\n model_analyzer = Evaluator(\n examples=example_gen.outputs['examples'],\n model_exports=trainer.outputs['model'],\n feature_slicing_spec=evaluator_pb2.FeatureSlicingSpec(specs=[\n evaluator_pb2.SingleSlicingSpec(\n column_for_slicing=['trip_start_hour'])\n ]))\n\n # Performs quality validation of a candidate model (compared to a baseline).\n model_validator = ModelValidator(\n examples=example_gen.outputs['examples'], model=trainer.outputs['model'])\n\n # This custom component serves as a bridge between pipeline and human model\n # reviewers to enable review-and-push workflow in model development cycle. It\n # utilizes Slack API to send message to user-defined Slack channel with model\n # URI info and wait for go / no-go decision from the same Slack channel:\n # * To approve the model, users need to reply the thread sent out by the bot\n # started by SlackComponent with 'lgtm' or 'approve'.\n # * To reject the model, users need to reply the thread sent out by the bot\n # started by SlackComponent with 'decline' or 'reject'.\n slack_validator = SlackComponent(\n model=trainer.outputs['model'],\n model_blessing=model_validator.outputs['blessing'],\n slack_token=_slack_token,\n slack_channel_id=_slack_channel_id,\n timeout_sec=3600,\n )\n # Checks whether the model passed the validation steps and pushes the model\n # to a file destination if check passed.\n pusher = Pusher(\n model=trainer.outputs['model'],\n model_blessing=slack_validator.outputs['slack_blessing'],\n push_destination=pusher_pb2.PushDestination(\n filesystem=pusher_pb2.PushDestination.Filesystem(\n base_directory=_serving_model_dir)))\n\n return pipeline.Pipeline(\n pipeline_name=_pipeline_name,\n pipeline_root=_pipeline_root,\n components=[\n example_gen, statistics_gen, infer_schema, validate_stats, transform,\n trainer, model_analyzer, model_validator, slack_validator, pusher\n ],\n enable_cache=True,\n )\n\n\nif __name__ == '__main__':\n # Metadata config. The defaults works work with the installation of\n # KF Pipelines using Kubeflow. If installing KF Pipelines using the\n # lightweight deployment option, you may need to override the defaults.\n metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()\n\n # This pipeline automatically injects the Kubeflow TFX image if the\n # environment variable 'KUBEFLOW_TFX_IMAGE' is defined. Currently, the tfx\n # cli tool exports the environment variable to pass to the pipelines.\n tfx_image = os.environ.get('KUBEFLOW_TFX_IMAGE', None)\n\n runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(\n kubeflow_metadata_config=metadata_config,\n # Specify custom docker image to use.\n tfx_image=tfx_image\n )\n\n kubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run(\n _create_pipeline())\n", "path": "tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py"}], "after_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Example pipeline to demonstrate custom TFX component.\n\nThis example consists of standard TFX components as well as a custom TFX\ncomponent requesting for manual review through Slack.\n\nThis example along with the custom `SlackComponent` will only serve as an\nexample and will not be supported by TFX team.\n\nThis example runs in Kubeflow with Google Cloud services..\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport datetime\nimport os\n\nfrom slack_component.component import SlackComponent\n\nfrom tfx.components import CsvExampleGen\nfrom tfx.components import Evaluator\nfrom tfx.components import ExampleValidator\nfrom tfx.components import ModelValidator\nfrom tfx.components import Pusher\nfrom tfx.components import SchemaGen\nfrom tfx.components import StatisticsGen\nfrom tfx.components import Trainer\nfrom tfx.components import Transform\nfrom tfx.orchestration import pipeline\nfrom tfx.orchestration.kubeflow import kubeflow_dag_runner\nfrom tfx.proto import evaluator_pb2\nfrom tfx.proto import pusher_pb2\nfrom tfx.proto import trainer_pb2\nfrom tfx.utils.dsl_utils import csv_input\n\n# This example assumes that the taxi data is stored in _input_bucket/data/simple\n# and the taxi utility function is in example/taxi_utils_slack.py.\n# Feel free to customize this as needed.\n_input_bucket = 'gs://my-bucket'\n_output_bucket = 'gs://my-bucket'\n_taxi_root = __file__\n_data_root = os.path.join(_input_bucket, 'data', 'simple')\n\n\n# Python module file to inject customized logic into the TFX components. The\n# Transform and Trainer both require user-defined functions to run successfully.\n_taxi_trainer_func = 'example.taxi_utils_slack.trainer_fn'\n_taxi_transformer_func = 'example.taxi_utils_slack.preprocessing_fn'\n# Path which can be listened to by the model server. Pusher will output the\n# trained model here.\n_serving_model_dir = os.path.join(_taxi_root, 'serving_model/taxi_slack')\n# Slack channel to push the model notifications to.\n_slack_channel_id = 'my-channel-id'\n# Slack token to set up connection.\n_slack_token = os.environ['SLACK_BOT_TOKEN']\n\n# Directory and data locations. This example assumes all of the chicago taxi\n# example code and metadata library is relative to $HOME, but you can store\n# these files anywhere on your local filesystem.\n_tfx_root = os.path.join(os.environ['HOME'], '/tfx')\n_pipeline_name = 'chicago_taxi_slack_kubeflow'\n_pipeline_root = os.path.join(_input_bucket, _pipeline_name)\n_log_root = os.path.join(_tfx_root, 'logs')\n\n# Airflow-specific configs; these will be passed directly to airflow\n_airflow_config = {\n 'schedule_interval': None,\n 'start_date': datetime.datetime(2019, 1, 1),\n}\n\n\ndef _create_pipeline():\n \"\"\"Implements the chicago taxi pipeline with TFX.\"\"\"\n examples = csv_input(_data_root)\n\n # Brings data into the pipeline or otherwise joins/converts training data.\n example_gen = CsvExampleGen(input=examples)\n\n # Computes statistics over data for visualization and example validation.\n statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])\n\n # Generates schema based on statistics files.\n infer_schema = SchemaGen(statistics=statistics_gen.outputs['statistics'])\n\n # Performs anomaly detection based on statistics and data schema.\n validate_stats = ExampleValidator(\n statistics=statistics_gen.outputs['statistics'],\n schema=infer_schema.outputs['schema'])\n\n # Performs transformations and feature engineering in training and serving.\n transform = Transform(\n examples=example_gen.outputs['examples'],\n schema=infer_schema.outputs['schema'],\n preprocessing_fn=_taxi_transformer_func)\n\n # Uses user-provided Python function that implements a model using TF-Learn.\n trainer = Trainer(\n trainer_fn=_taxi_trainer_func,\n examples=transform.outputs['transformed_examples'],\n schema=infer_schema.outputs['schema'],\n transform_graph=transform.outputs['transform_graph'],\n train_args=trainer_pb2.TrainArgs(num_steps=10000),\n eval_args=trainer_pb2.EvalArgs(num_steps=5000))\n\n # Uses TFMA to compute a evaluation statistics over features of a model.\n model_analyzer = Evaluator(\n examples=example_gen.outputs['examples'],\n model_exports=trainer.outputs['model'],\n feature_slicing_spec=evaluator_pb2.FeatureSlicingSpec(specs=[\n evaluator_pb2.SingleSlicingSpec(\n column_for_slicing=['trip_start_hour'])\n ]))\n\n # Performs quality validation of a candidate model (compared to a baseline).\n model_validator = ModelValidator(\n examples=example_gen.outputs['examples'], model=trainer.outputs['model'])\n\n # This custom component serves as a bridge between pipeline and human model\n # reviewers to enable review-and-push workflow in model development cycle. It\n # utilizes Slack API to send message to user-defined Slack channel with model\n # URI info and wait for go / no-go decision from the same Slack channel:\n # * To approve the model, users need to reply the thread sent out by the bot\n # started by SlackComponent with 'lgtm' or 'approve'.\n # * To reject the model, users need to reply the thread sent out by the bot\n # started by SlackComponent with 'decline' or 'reject'.\n slack_validator = SlackComponent(\n model=trainer.outputs['model'],\n model_blessing=model_validator.outputs['blessing'],\n slack_token=_slack_token,\n slack_channel_id=_slack_channel_id,\n timeout_sec=3600,\n )\n # Checks whether the model passed the validation steps and pushes the model\n # to a file destination if check passed.\n pusher = Pusher(\n model=trainer.outputs['model'],\n model_blessing=slack_validator.outputs['slack_blessing'],\n push_destination=pusher_pb2.PushDestination(\n filesystem=pusher_pb2.PushDestination.Filesystem(\n base_directory=_serving_model_dir)))\n\n return pipeline.Pipeline(\n pipeline_name=_pipeline_name,\n pipeline_root=_pipeline_root,\n components=[\n example_gen, statistics_gen, infer_schema, validate_stats, transform,\n trainer, model_analyzer, model_validator, slack_validator, pusher\n ],\n enable_cache=True,\n )\n\n\nif __name__ == '__main__':\n # Metadata config. The defaults works work with the installation of\n # KF Pipelines using Kubeflow. If installing KF Pipelines using the\n # lightweight deployment option, you may need to override the defaults.\n metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()\n\n # This pipeline automatically injects the Kubeflow TFX image if the\n # environment variable 'KUBEFLOW_TFX_IMAGE' is defined. Currently, the tfx\n # cli tool exports the environment variable to pass to the pipelines.\n tfx_image = os.environ.get('KUBEFLOW_TFX_IMAGE', None)\n\n runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(\n kubeflow_metadata_config=metadata_config,\n # Specify custom docker image to use.\n tfx_image=tfx_image\n )\n\n kubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run(\n _create_pipeline())\n", "path": "tfx/examples/custom_components/slack/example/taxi_pipeline_slack_kubeflow.py"}]}
| 2,548 | 178 |
gh_patches_debug_4388
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-2197
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Build number in -dev versioning
Since we do not have a build number in the -dev version, it may be quite complex to understand which particular version of freqtrade the user runs (especially with that your conda). So if we change user interface I guess it's better for a while to make those changes along with changing the version of both develop and master...
Is it possible to introduce the build number into the -dev versioning, which will change with every merge, as ccxt employs, for example?
It's not necessary for master (2019-8 is completely enough), but for develop changing every day this may be useful since `freqtrade -V` will give particular version info (even when a user has current codebase from github fetched in a dir, but installed an outdated version with that your conda, which is used instead of latest develop from the dir; that's the confusing usecase when it's complicated to find out the actual version of freqtrade that runs at the user site...)
It's not necessary to be an increasing number, it can be a short commit id (merged into develop), for example...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/__init__.py`
Content:
```
1 """ FreqTrade bot """
2 __version__ = '2019.7-dev'
3
4
5 class DependencyException(Exception):
6 """
7 Indicates that an assumed dependency is not met.
8 This could happen when there is currently not enough money on the account.
9 """
10
11
12 class OperationalException(Exception):
13 """
14 Requires manual intervention and will usually stop the bot.
15 This happens when an exchange returns an unexpected error during runtime
16 or given configuration is invalid.
17 """
18
19
20 class InvalidOrderException(Exception):
21 """
22 This is returned when the order is not valid. Example:
23 If stoploss on exchange order is hit, then trying to cancel the order
24 should return this exception.
25 """
26
27
28 class TemporaryError(Exception):
29 """
30 Temporary network or exchange related error.
31 This could happen when an exchange is congested, unavailable, or the user
32 has networking problems. Usually resolves itself after a time.
33 """
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/freqtrade/__init__.py b/freqtrade/__init__.py
--- a/freqtrade/__init__.py
+++ b/freqtrade/__init__.py
@@ -1,5 +1,16 @@
""" FreqTrade bot """
-__version__ = '2019.7-dev'
+__version__ = 'develop'
+
+if __version__ == 'develop':
+
+ try:
+ import subprocess
+ __version__ = 'develop-' + subprocess.check_output(
+ ['git', 'log', '--format="%h"', '-n 1'],
+ stderr=subprocess.DEVNULL).decode("utf-8").rstrip().strip('"')
+ except Exception:
+ # git not available, ignore
+ pass
class DependencyException(Exception):
|
{"golden_diff": "diff --git a/freqtrade/__init__.py b/freqtrade/__init__.py\n--- a/freqtrade/__init__.py\n+++ b/freqtrade/__init__.py\n@@ -1,5 +1,16 @@\n \"\"\" FreqTrade bot \"\"\"\n-__version__ = '2019.7-dev'\n+__version__ = 'develop'\n+\n+if __version__ == 'develop':\n+\n+ try:\n+ import subprocess\n+ __version__ = 'develop-' + subprocess.check_output(\n+ ['git', 'log', '--format=\"%h\"', '-n 1'],\n+ stderr=subprocess.DEVNULL).decode(\"utf-8\").rstrip().strip('\"')\n+ except Exception:\n+ # git not available, ignore\n+ pass\n \n \n class DependencyException(Exception):\n", "issue": "Build number in -dev versioning\nSince we do not have a build number in the -dev version, it may be quite complex to understand which particular version of freqtrade the user runs (especially with that your conda). So if we change user interface I guess it's better for a while to make those changes along with changing the version of both develop and master...\r\n\r\nIs it possible to introduce the build number into the -dev versioning, which will change with every merge, as ccxt employs, for example?\r\n\r\nIt's not necessary for master (2019-8 is completely enough), but for develop changing every day this may be useful since `freqtrade -V` will give particular version info (even when a user has current codebase from github fetched in a dir, but installed an outdated version with that your conda, which is used instead of latest develop from the dir; that's the confusing usecase when it's complicated to find out the actual version of freqtrade that runs at the user site...)\r\n\r\nIt's not necessary to be an increasing number, it can be a short commit id (merged into develop), for example...\r\n\n", "before_files": [{"content": "\"\"\" FreqTrade bot \"\"\"\n__version__ = '2019.7-dev'\n\n\nclass DependencyException(Exception):\n \"\"\"\n Indicates that an assumed dependency is not met.\n This could happen when there is currently not enough money on the account.\n \"\"\"\n\n\nclass OperationalException(Exception):\n \"\"\"\n Requires manual intervention and will usually stop the bot.\n This happens when an exchange returns an unexpected error during runtime\n or given configuration is invalid.\n \"\"\"\n\n\nclass InvalidOrderException(Exception):\n \"\"\"\n This is returned when the order is not valid. Example:\n If stoploss on exchange order is hit, then trying to cancel the order\n should return this exception.\n \"\"\"\n\n\nclass TemporaryError(Exception):\n \"\"\"\n Temporary network or exchange related error.\n This could happen when an exchange is congested, unavailable, or the user\n has networking problems. Usually resolves itself after a time.\n \"\"\"\n", "path": "freqtrade/__init__.py"}], "after_files": [{"content": "\"\"\" FreqTrade bot \"\"\"\n__version__ = 'develop'\n\nif __version__ == 'develop':\n\n try:\n import subprocess\n __version__ = 'develop-' + subprocess.check_output(\n ['git', 'log', '--format=\"%h\"', '-n 1'],\n stderr=subprocess.DEVNULL).decode(\"utf-8\").rstrip().strip('\"')\n except Exception:\n # git not available, ignore\n pass\n\n\nclass DependencyException(Exception):\n \"\"\"\n Indicates that an assumed dependency is not met.\n This could happen when there is currently not enough money on the account.\n \"\"\"\n\n\nclass OperationalException(Exception):\n \"\"\"\n Requires manual intervention and will usually stop the bot.\n This happens when an exchange returns an unexpected error during runtime\n or given configuration is invalid.\n \"\"\"\n\n\nclass InvalidOrderException(Exception):\n \"\"\"\n This is returned when the order is not valid. Example:\n If stoploss on exchange order is hit, then trying to cancel the order\n should return this exception.\n \"\"\"\n\n\nclass TemporaryError(Exception):\n \"\"\"\n Temporary network or exchange related error.\n This could happen when an exchange is congested, unavailable, or the user\n has networking problems. Usually resolves itself after a time.\n \"\"\"\n", "path": "freqtrade/__init__.py"}]}
| 750 | 174 |
gh_patches_debug_1680
|
rasdani/github-patches
|
git_diff
|
vispy__vispy-2592
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
What's the status of GLFW?
I see there's a `glfw` backend, but in `setup.py` it is neither listed as a dependency nor defined as an extra. Is that an oversight or deliberately?
I'm packaging `vispy` for Fedora and with [glfw](https://pypi.org/project/glfw/) added as a dependency, I'm seeing `glfw` listed in the output of `vispy.sys_info()`. Tests using `glsw` as a backend also appear to work fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4 """Vispy setup script.
5
6 Steps to do a new release:
7
8 Preparations:
9 * Test on Windows, Linux, Mac
10 * Make release notes
11 * Update API documentation and other docs that need updating.
12
13 Define the version and release:
14 * tag the tip changeset as version x.x.x; `git tag -a 'vX.Y.Z' -m "Version X.Y.Z"`
15 * push tag to github
16 * verify that azure pipelines complete
17 * verify that `.tar.gz` sdist and binary wheels are available on PyPI
18
19 Announcing:
20 * It can be worth waiting a day for eager users to report critical bugs
21 * Announce in scipy-user, vispy mailing list, twitter (@vispyproject)
22
23 """
24
25 import os
26 import sys
27 from os import path as op
28 from setuptools import setup, find_packages
29
30 import numpy as np
31 from Cython.Build import cythonize
32 from Cython.Distutils import Extension
33
34 name = 'vispy'
35 description = 'Interactive visualization in Python'
36
37 # Special commands for building jupyter notebook extension
38 here = os.path.dirname(os.path.abspath(__file__))
39 node_root = os.path.join(here, 'js')
40 is_repo = os.path.exists(os.path.join(here, '.git'))
41
42 npm_path = os.pathsep.join([
43 os.path.join(node_root, 'node_modules', '.bin'),
44 os.environ.get('PATH', os.defpath),
45 ])
46
47
48 def set_builtin(name, value):
49 if isinstance(__builtins__, dict):
50 __builtins__[name] = value
51 else:
52 setattr(__builtins__, name, value)
53
54
55 extensions = [Extension('vispy.visuals.text._sdf_cpu',
56 sources=[op.join('vispy', 'visuals', 'text', '_sdf_cpu.pyx')],
57 include_dirs=[np.get_include()],
58 cython_directives={"language_level": "3"},
59 define_macros=[("NPY_NO_DEPRECATED_API", "NPY_1_7_API_VERSION")],
60 ),
61 ]
62
63 install_requires = ['numpy', 'freetype-py', 'hsluv', 'kiwisolver', 'packaging']
64 if sys.version_info < (3, 9):
65 install_requires.append("importlib-resources")
66
67 readme = open('README.rst', 'r').read()
68 setup(
69 name=name,
70 use_scm_version={
71 'write_to': 'vispy/version.py',
72 # uses setuptools_scm.version.get_local_dirty_tag (+dirty or empty string)
73 'local_scheme': 'dirty-tag',
74 },
75 author='Vispy contributors',
76 author_email='[email protected]',
77 license='BSD-3-Clause',
78 url='http://vispy.org',
79 download_url='https://pypi.python.org/pypi/vispy',
80 keywords=[
81 'visualization',
82 'OpenGl',
83 'ES',
84 'medical',
85 'imaging',
86 '3D',
87 'plotting',
88 'numpy',
89 'bigdata',
90 'ipython',
91 'jupyter',
92 'widgets',
93 ],
94 description=description,
95 long_description=readme,
96 long_description_content_type='text/x-rst',
97 platforms='any',
98 provides=['vispy'],
99 python_requires='>=3.8',
100 install_requires=install_requires,
101 extras_require={
102 'ipython-static': ['ipython'],
103 'pyglet': ['pyglet>=1.2'],
104 'pyqt5': ['pyqt5'],
105 'pyqt6': ['pyqt6'],
106 'pyside': ['PySide'],
107 'pyside2': ['PySide2'],
108 'pyside6': ['PySide6'],
109 'sdl2': ['PySDL2'],
110 'wx': ['wxPython'],
111 'tk': ['pyopengltk'],
112 'doc': ['pydata-sphinx-theme', 'numpydoc', 'sphinxcontrib-apidoc',
113 'sphinx-gallery', 'myst-parser', 'pillow', 'pytest',
114 'pyopengl'],
115 'io': ['meshio', 'Pillow'],
116 },
117 packages=find_packages(exclude=['make']),
118 ext_modules=cythonize(extensions, language_level=3),
119 package_dir={'vispy': 'vispy'},
120 data_files=[],
121 include_package_data=True,
122 package_data={
123 'vispy': [op.join('io', '_data', '*'),
124 op.join('app', 'tests', 'qt-designer.ui'),
125 op.join('util', 'fonts', 'data', '*.ttf'),
126 ],
127
128 'vispy.glsl': ['*.vert', '*.frag', "*.glsl"],
129 'vispy.glsl.antialias': ['*.vert', '*.frag', "*.glsl"],
130 'vispy.glsl.arrowheads': ['*.vert', '*.frag', "*.glsl"],
131 'vispy.glsl.arrows': ['*.vert', '*.frag', "*.glsl"],
132 'vispy.glsl.collections': ['*.vert', '*.frag', "*.glsl"],
133 'vispy.glsl.colormaps': ['*.vert', '*.frag', "*.glsl"],
134 'vispy.glsl.lines': ['*.vert', '*.frag', "*.glsl"],
135 'vispy.glsl.markers': ['*.vert', '*.frag', "*.glsl"],
136 'vispy.glsl.math': ['*.vert', '*.frag', "*.glsl"],
137 'vispy.glsl.misc': ['*.vert', '*.frag', "*.glsl"],
138 'vispy.glsl.transforms': ['*.vert', '*.frag', "*.glsl"],
139
140 },
141 zip_safe=False,
142 classifiers=[
143 'Development Status :: 3 - Alpha',
144 'Intended Audience :: Science/Research',
145 'Intended Audience :: Education',
146 'Intended Audience :: Developers',
147 'Topic :: Scientific/Engineering :: Visualization',
148 'License :: OSI Approved :: BSD License',
149 'Operating System :: MacOS :: MacOS X',
150 'Operating System :: Microsoft :: Windows',
151 'Operating System :: POSIX',
152 'Programming Language :: Python',
153 'Programming Language :: Python :: 3.8',
154 'Programming Language :: Python :: 3.9',
155 'Programming Language :: Python :: 3.10',
156 'Programming Language :: Python :: 3.11',
157 'Framework :: IPython'
158 ],
159 )
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -106,6 +106,7 @@
'pyside': ['PySide'],
'pyside2': ['PySide2'],
'pyside6': ['PySide6'],
+ 'glfw': ['glfw'],
'sdl2': ['PySDL2'],
'wx': ['wxPython'],
'tk': ['pyopengltk'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -106,6 +106,7 @@\n 'pyside': ['PySide'],\n 'pyside2': ['PySide2'],\n 'pyside6': ['PySide6'],\n+ 'glfw': ['glfw'],\n 'sdl2': ['PySDL2'],\n 'wx': ['wxPython'],\n 'tk': ['pyopengltk'],\n", "issue": "What's the status of GLFW?\nI see there's a `glfw` backend, but in `setup.py` it is neither listed as a dependency nor defined as an extra. Is that an oversight or deliberately?\r\n\r\nI'm packaging `vispy` for Fedora and with [glfw](https://pypi.org/project/glfw/) added as a dependency, I'm seeing `glfw` listed in the output of `vispy.sys_info()`. Tests using `glsw` as a backend also appear to work fine.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\"\"\"Vispy setup script.\n\nSteps to do a new release:\n\nPreparations:\n * Test on Windows, Linux, Mac\n * Make release notes\n * Update API documentation and other docs that need updating.\n\nDefine the version and release:\n * tag the tip changeset as version x.x.x; `git tag -a 'vX.Y.Z' -m \"Version X.Y.Z\"`\n * push tag to github\n * verify that azure pipelines complete\n * verify that `.tar.gz` sdist and binary wheels are available on PyPI\n\nAnnouncing:\n * It can be worth waiting a day for eager users to report critical bugs\n * Announce in scipy-user, vispy mailing list, twitter (@vispyproject)\n\n\"\"\"\n\nimport os\nimport sys\nfrom os import path as op\nfrom setuptools import setup, find_packages\n\nimport numpy as np\nfrom Cython.Build import cythonize\nfrom Cython.Distutils import Extension\n\nname = 'vispy'\ndescription = 'Interactive visualization in Python'\n\n# Special commands for building jupyter notebook extension\nhere = os.path.dirname(os.path.abspath(__file__))\nnode_root = os.path.join(here, 'js')\nis_repo = os.path.exists(os.path.join(here, '.git'))\n\nnpm_path = os.pathsep.join([\n os.path.join(node_root, 'node_modules', '.bin'),\n os.environ.get('PATH', os.defpath),\n])\n\n\ndef set_builtin(name, value):\n if isinstance(__builtins__, dict):\n __builtins__[name] = value\n else:\n setattr(__builtins__, name, value)\n\n\nextensions = [Extension('vispy.visuals.text._sdf_cpu',\n sources=[op.join('vispy', 'visuals', 'text', '_sdf_cpu.pyx')],\n include_dirs=[np.get_include()],\n cython_directives={\"language_level\": \"3\"},\n define_macros=[(\"NPY_NO_DEPRECATED_API\", \"NPY_1_7_API_VERSION\")],\n ),\n ]\n\ninstall_requires = ['numpy', 'freetype-py', 'hsluv', 'kiwisolver', 'packaging']\nif sys.version_info < (3, 9):\n install_requires.append(\"importlib-resources\")\n\nreadme = open('README.rst', 'r').read()\nsetup(\n name=name,\n use_scm_version={\n 'write_to': 'vispy/version.py',\n # uses setuptools_scm.version.get_local_dirty_tag (+dirty or empty string)\n 'local_scheme': 'dirty-tag',\n },\n author='Vispy contributors',\n author_email='[email protected]',\n license='BSD-3-Clause',\n url='http://vispy.org',\n download_url='https://pypi.python.org/pypi/vispy',\n keywords=[\n 'visualization',\n 'OpenGl',\n 'ES',\n 'medical',\n 'imaging',\n '3D',\n 'plotting',\n 'numpy',\n 'bigdata',\n 'ipython',\n 'jupyter',\n 'widgets',\n ],\n description=description,\n long_description=readme,\n long_description_content_type='text/x-rst',\n platforms='any',\n provides=['vispy'],\n python_requires='>=3.8',\n install_requires=install_requires,\n extras_require={\n 'ipython-static': ['ipython'],\n 'pyglet': ['pyglet>=1.2'],\n 'pyqt5': ['pyqt5'],\n 'pyqt6': ['pyqt6'],\n 'pyside': ['PySide'],\n 'pyside2': ['PySide2'],\n 'pyside6': ['PySide6'],\n 'sdl2': ['PySDL2'],\n 'wx': ['wxPython'],\n 'tk': ['pyopengltk'],\n 'doc': ['pydata-sphinx-theme', 'numpydoc', 'sphinxcontrib-apidoc',\n 'sphinx-gallery', 'myst-parser', 'pillow', 'pytest',\n 'pyopengl'],\n 'io': ['meshio', 'Pillow'],\n },\n packages=find_packages(exclude=['make']),\n ext_modules=cythonize(extensions, language_level=3),\n package_dir={'vispy': 'vispy'},\n data_files=[],\n include_package_data=True,\n package_data={\n 'vispy': [op.join('io', '_data', '*'),\n op.join('app', 'tests', 'qt-designer.ui'),\n op.join('util', 'fonts', 'data', '*.ttf'),\n ],\n\n 'vispy.glsl': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.antialias': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.arrowheads': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.arrows': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.collections': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.colormaps': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.lines': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.markers': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.math': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.misc': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.transforms': ['*.vert', '*.frag', \"*.glsl\"],\n\n },\n zip_safe=False,\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Education',\n 'Intended Audience :: Developers',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Framework :: IPython'\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\"\"\"Vispy setup script.\n\nSteps to do a new release:\n\nPreparations:\n * Test on Windows, Linux, Mac\n * Make release notes\n * Update API documentation and other docs that need updating.\n\nDefine the version and release:\n * tag the tip changeset as version x.x.x; `git tag -a 'vX.Y.Z' -m \"Version X.Y.Z\"`\n * push tag to github\n * verify that azure pipelines complete\n * verify that `.tar.gz` sdist and binary wheels are available on PyPI\n\nAnnouncing:\n * It can be worth waiting a day for eager users to report critical bugs\n * Announce in scipy-user, vispy mailing list, twitter (@vispyproject)\n\n\"\"\"\n\nimport os\nimport sys\nfrom os import path as op\nfrom setuptools import setup, find_packages\n\nimport numpy as np\nfrom Cython.Build import cythonize\nfrom Cython.Distutils import Extension\n\nname = 'vispy'\ndescription = 'Interactive visualization in Python'\n\n# Special commands for building jupyter notebook extension\nhere = os.path.dirname(os.path.abspath(__file__))\nnode_root = os.path.join(here, 'js')\nis_repo = os.path.exists(os.path.join(here, '.git'))\n\nnpm_path = os.pathsep.join([\n os.path.join(node_root, 'node_modules', '.bin'),\n os.environ.get('PATH', os.defpath),\n])\n\n\ndef set_builtin(name, value):\n if isinstance(__builtins__, dict):\n __builtins__[name] = value\n else:\n setattr(__builtins__, name, value)\n\n\nextensions = [Extension('vispy.visuals.text._sdf_cpu',\n sources=[op.join('vispy', 'visuals', 'text', '_sdf_cpu.pyx')],\n include_dirs=[np.get_include()],\n cython_directives={\"language_level\": \"3\"},\n define_macros=[(\"NPY_NO_DEPRECATED_API\", \"NPY_1_7_API_VERSION\")],\n ),\n ]\n\ninstall_requires = ['numpy', 'freetype-py', 'hsluv', 'kiwisolver', 'packaging']\nif sys.version_info < (3, 9):\n install_requires.append(\"importlib-resources\")\n\nreadme = open('README.rst', 'r').read()\nsetup(\n name=name,\n use_scm_version={\n 'write_to': 'vispy/version.py',\n # uses setuptools_scm.version.get_local_dirty_tag (+dirty or empty string)\n 'local_scheme': 'dirty-tag',\n },\n author='Vispy contributors',\n author_email='[email protected]',\n license='BSD-3-Clause',\n url='http://vispy.org',\n download_url='https://pypi.python.org/pypi/vispy',\n keywords=[\n 'visualization',\n 'OpenGl',\n 'ES',\n 'medical',\n 'imaging',\n '3D',\n 'plotting',\n 'numpy',\n 'bigdata',\n 'ipython',\n 'jupyter',\n 'widgets',\n ],\n description=description,\n long_description=readme,\n long_description_content_type='text/x-rst',\n platforms='any',\n provides=['vispy'],\n python_requires='>=3.8',\n install_requires=install_requires,\n extras_require={\n 'ipython-static': ['ipython'],\n 'pyglet': ['pyglet>=1.2'],\n 'pyqt5': ['pyqt5'],\n 'pyqt6': ['pyqt6'],\n 'pyside': ['PySide'],\n 'pyside2': ['PySide2'],\n 'pyside6': ['PySide6'],\n 'glfw': ['glfw'],\n 'sdl2': ['PySDL2'],\n 'wx': ['wxPython'],\n 'tk': ['pyopengltk'],\n 'doc': ['pydata-sphinx-theme', 'numpydoc', 'sphinxcontrib-apidoc',\n 'sphinx-gallery', 'myst-parser', 'pillow', 'pytest',\n 'pyopengl'],\n 'io': ['meshio', 'Pillow'],\n },\n packages=find_packages(exclude=['make']),\n ext_modules=cythonize(extensions, language_level=3),\n package_dir={'vispy': 'vispy'},\n data_files=[],\n include_package_data=True,\n package_data={\n 'vispy': [op.join('io', '_data', '*'),\n op.join('app', 'tests', 'qt-designer.ui'),\n op.join('util', 'fonts', 'data', '*.ttf'),\n ],\n\n 'vispy.glsl': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.antialias': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.arrowheads': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.arrows': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.collections': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.colormaps': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.lines': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.markers': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.math': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.misc': ['*.vert', '*.frag', \"*.glsl\"],\n 'vispy.glsl.transforms': ['*.vert', '*.frag', \"*.glsl\"],\n\n },\n zip_safe=False,\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Education',\n 'Intended Audience :: Developers',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Framework :: IPython'\n ],\n)\n", "path": "setup.py"}]}
| 2,129 | 105 |
gh_patches_debug_23613
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-552
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Prepend emojis indicative of success for !eval
Comments on [org-issue-141](https://github.com/python-discord/organisation/issues/141) suggests something quite useful.
Add emojis indicative of success when you use !eval.
- ✅ - if no error.
- ❌ - if exception.
- ❗ - for other cases, as it runs but there's no output



--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/cogs/snekbox.py`
Content:
```
1 import datetime
2 import logging
3 import re
4 import textwrap
5 from signal import Signals
6 from typing import Optional, Tuple
7
8 from discord.ext.commands import Bot, Cog, Context, command, guild_only
9
10 from bot.constants import Channels, Roles, URLs
11 from bot.decorators import in_channel
12 from bot.utils.messages import wait_for_deletion
13
14 log = logging.getLogger(__name__)
15
16 ESCAPE_REGEX = re.compile("[`\u202E\u200B]{3,}")
17 FORMATTED_CODE_REGEX = re.compile(
18 r"^\s*" # any leading whitespace from the beginning of the string
19 r"(?P<delim>(?P<block>```)|``?)" # code delimiter: 1-3 backticks; (?P=block) only matches if it's a block
20 r"(?(block)(?:(?P<lang>[a-z]+)\n)?)" # if we're in a block, match optional language (only letters plus newline)
21 r"(?:[ \t]*\n)*" # any blank (empty or tabs/spaces only) lines before the code
22 r"(?P<code>.*?)" # extract all code inside the markup
23 r"\s*" # any more whitespace before the end of the code markup
24 r"(?P=delim)" # match the exact same delimiter from the start again
25 r"\s*$", # any trailing whitespace until the end of the string
26 re.DOTALL | re.IGNORECASE # "." also matches newlines, case insensitive
27 )
28 RAW_CODE_REGEX = re.compile(
29 r"^(?:[ \t]*\n)*" # any blank (empty or tabs/spaces only) lines before the code
30 r"(?P<code>.*?)" # extract all the rest as code
31 r"\s*$", # any trailing whitespace until the end of the string
32 re.DOTALL # "." also matches newlines
33 )
34
35 MAX_PASTE_LEN = 1000
36 EVAL_ROLES = (Roles.helpers, Roles.moderator, Roles.admin, Roles.owner, Roles.rockstars, Roles.partners)
37
38
39 class Snekbox(Cog):
40 """Safe evaluation of Python code using Snekbox."""
41
42 def __init__(self, bot: Bot):
43 self.bot = bot
44 self.jobs = {}
45
46 async def post_eval(self, code: str) -> dict:
47 """Send a POST request to the Snekbox API to evaluate code and return the results."""
48 url = URLs.snekbox_eval_api
49 data = {"input": code}
50 async with self.bot.http_session.post(url, json=data, raise_for_status=True) as resp:
51 return await resp.json()
52
53 async def upload_output(self, output: str) -> Optional[str]:
54 """Upload the eval output to a paste service and return a URL to it if successful."""
55 log.trace("Uploading full output to paste service...")
56
57 if len(output) > MAX_PASTE_LEN:
58 log.info("Full output is too long to upload")
59 return "too long to upload"
60
61 url = URLs.paste_service.format(key="documents")
62 try:
63 async with self.bot.http_session.post(url, data=output, raise_for_status=True) as resp:
64 data = await resp.json()
65
66 if "key" in data:
67 return URLs.paste_service.format(key=data["key"])
68 except Exception:
69 # 400 (Bad Request) means there are too many characters
70 log.exception("Failed to upload full output to paste service!")
71
72 @staticmethod
73 def prepare_input(code: str) -> str:
74 """Extract code from the Markdown, format it, and insert it into the code template."""
75 match = FORMATTED_CODE_REGEX.fullmatch(code)
76 if match:
77 code, block, lang, delim = match.group("code", "block", "lang", "delim")
78 code = textwrap.dedent(code)
79 if block:
80 info = (f"'{lang}' highlighted" if lang else "plain") + " code block"
81 else:
82 info = f"{delim}-enclosed inline code"
83 log.trace(f"Extracted {info} for evaluation:\n{code}")
84 else:
85 code = textwrap.dedent(RAW_CODE_REGEX.fullmatch(code).group("code"))
86 log.trace(
87 f"Eval message contains unformatted or badly formatted code, "
88 f"stripping whitespace only:\n{code}"
89 )
90
91 return code
92
93 @staticmethod
94 def get_results_message(results: dict) -> Tuple[str, str]:
95 """Return a user-friendly message and error corresponding to the process's return code."""
96 stdout, returncode = results["stdout"], results["returncode"]
97 msg = f"Your eval job has completed with return code {returncode}"
98 error = ""
99
100 if returncode is None:
101 msg = "Your eval job has failed"
102 error = stdout.strip()
103 elif returncode == 128 + Signals.SIGKILL:
104 msg = "Your eval job timed out or ran out of memory"
105 elif returncode == 255:
106 msg = "Your eval job has failed"
107 error = "A fatal NsJail error occurred"
108 else:
109 # Try to append signal's name if one exists
110 try:
111 name = Signals(returncode - 128).name
112 msg = f"{msg} ({name})"
113 except ValueError:
114 pass
115
116 return msg, error
117
118 async def format_output(self, output: str) -> Tuple[str, Optional[str]]:
119 """
120 Format the output and return a tuple of the formatted output and a URL to the full output.
121
122 Prepend each line with a line number. Truncate if there are over 10 lines or 1000 characters
123 and upload the full output to a paste service.
124 """
125 log.trace("Formatting output...")
126
127 output = output.strip(" \n")
128 original_output = output # To be uploaded to a pasting service if needed
129 paste_link = None
130
131 if "<@" in output:
132 output = output.replace("<@", "<@\u200B") # Zero-width space
133
134 if "<!@" in output:
135 output = output.replace("<!@", "<!@\u200B") # Zero-width space
136
137 if ESCAPE_REGEX.findall(output):
138 return "Code block escape attempt detected; will not output result", paste_link
139
140 truncated = False
141 lines = output.count("\n")
142
143 if lines > 0:
144 output = output.split("\n")[:10] # Only first 10 cause the rest is truncated anyway
145 output = (f"{i:03d} | {line}" for i, line in enumerate(output, 1))
146 output = "\n".join(output)
147
148 if lines > 10:
149 truncated = True
150 if len(output) >= 1000:
151 output = f"{output[:1000]}\n... (truncated - too long, too many lines)"
152 else:
153 output = f"{output}\n... (truncated - too many lines)"
154 elif len(output) >= 1000:
155 truncated = True
156 output = f"{output[:1000]}\n... (truncated - too long)"
157
158 if truncated:
159 paste_link = await self.upload_output(original_output)
160
161 output = output.strip()
162 if not output:
163 output = "[No output]"
164
165 return output, paste_link
166
167 @command(name="eval", aliases=("e",))
168 @guild_only()
169 @in_channel(Channels.bot, bypass_roles=EVAL_ROLES)
170 async def eval_command(self, ctx: Context, *, code: str = None) -> None:
171 """
172 Run Python code and get the results.
173
174 This command supports multiple lines of code, including code wrapped inside a formatted code
175 block. We've done our best to make this safe, but do let us know if you manage to find an
176 issue with it!
177 """
178 if ctx.author.id in self.jobs:
179 await ctx.send(
180 f"{ctx.author.mention} You've already got a job running - "
181 "please wait for it to finish!"
182 )
183 return
184
185 if not code: # None or empty string
186 await ctx.invoke(self.bot.get_command("help"), "eval")
187 return
188
189 log.info(f"Received code from {ctx.author} for evaluation:\n{code}")
190
191 self.jobs[ctx.author.id] = datetime.datetime.now()
192 code = self.prepare_input(code)
193
194 try:
195 async with ctx.typing():
196 results = await self.post_eval(code)
197 msg, error = self.get_results_message(results)
198
199 if error:
200 output, paste_link = error, None
201 else:
202 output, paste_link = await self.format_output(results["stdout"])
203
204 msg = f"{ctx.author.mention} {msg}.\n\n```py\n{output}\n```"
205 if paste_link:
206 msg = f"{msg}\nFull output: {paste_link}"
207
208 response = await ctx.send(msg)
209 self.bot.loop.create_task(
210 wait_for_deletion(response, user_ids=(ctx.author.id,), client=ctx.bot)
211 )
212
213 log.info(f"{ctx.author}'s job had a return code of {results['returncode']}")
214 finally:
215 del self.jobs[ctx.author.id]
216
217
218 def setup(bot: Bot) -> None:
219 """Snekbox cog load."""
220 bot.add_cog(Snekbox(bot))
221 log.info("Cog loaded: Snekbox")
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/cogs/snekbox.py b/bot/cogs/snekbox.py
--- a/bot/cogs/snekbox.py
+++ b/bot/cogs/snekbox.py
@@ -115,6 +115,16 @@
return msg, error
+ @staticmethod
+ def get_status_emoji(results: dict) -> str:
+ """Return an emoji corresponding to the status code or lack of output in result."""
+ if not results["stdout"].strip(): # No output
+ return ":warning:"
+ elif results["returncode"] == 0: # No error
+ return ":white_check_mark:"
+ else: # Exception
+ return ":x:"
+
async def format_output(self, output: str) -> Tuple[str, Optional[str]]:
"""
Format the output and return a tuple of the formatted output and a URL to the full output.
@@ -201,7 +211,8 @@
else:
output, paste_link = await self.format_output(results["stdout"])
- msg = f"{ctx.author.mention} {msg}.\n\n```py\n{output}\n```"
+ icon = self.get_status_emoji(results)
+ msg = f"{ctx.author.mention} {icon} {msg}.\n\n```py\n{output}\n```"
if paste_link:
msg = f"{msg}\nFull output: {paste_link}"
|
{"golden_diff": "diff --git a/bot/cogs/snekbox.py b/bot/cogs/snekbox.py\n--- a/bot/cogs/snekbox.py\n+++ b/bot/cogs/snekbox.py\n@@ -115,6 +115,16 @@\n \n return msg, error\n \n+ @staticmethod\n+ def get_status_emoji(results: dict) -> str:\n+ \"\"\"Return an emoji corresponding to the status code or lack of output in result.\"\"\"\n+ if not results[\"stdout\"].strip(): # No output\n+ return \":warning:\"\n+ elif results[\"returncode\"] == 0: # No error\n+ return \":white_check_mark:\"\n+ else: # Exception\n+ return \":x:\"\n+\n async def format_output(self, output: str) -> Tuple[str, Optional[str]]:\n \"\"\"\n Format the output and return a tuple of the formatted output and a URL to the full output.\n@@ -201,7 +211,8 @@\n else:\n output, paste_link = await self.format_output(results[\"stdout\"])\n \n- msg = f\"{ctx.author.mention} {msg}.\\n\\n```py\\n{output}\\n```\"\n+ icon = self.get_status_emoji(results)\n+ msg = f\"{ctx.author.mention} {icon} {msg}.\\n\\n```py\\n{output}\\n```\"\n if paste_link:\n msg = f\"{msg}\\nFull output: {paste_link}\"\n", "issue": "Prepend emojis indicative of success for !eval\nComments on [org-issue-141](https://github.com/python-discord/organisation/issues/141) suggests something quite useful. \r\n\r\nAdd emojis indicative of success when you use !eval. \r\n\r\n- \u2705 - if no error.\r\n- \u274c - if exception.\r\n- \u2757 - for other cases, as it runs but there's no output\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import datetime\nimport logging\nimport re\nimport textwrap\nfrom signal import Signals\nfrom typing import Optional, Tuple\n\nfrom discord.ext.commands import Bot, Cog, Context, command, guild_only\n\nfrom bot.constants import Channels, Roles, URLs\nfrom bot.decorators import in_channel\nfrom bot.utils.messages import wait_for_deletion\n\nlog = logging.getLogger(__name__)\n\nESCAPE_REGEX = re.compile(\"[`\\u202E\\u200B]{3,}\")\nFORMATTED_CODE_REGEX = re.compile(\n r\"^\\s*\" # any leading whitespace from the beginning of the string\n r\"(?P<delim>(?P<block>```)|``?)\" # code delimiter: 1-3 backticks; (?P=block) only matches if it's a block\n r\"(?(block)(?:(?P<lang>[a-z]+)\\n)?)\" # if we're in a block, match optional language (only letters plus newline)\n r\"(?:[ \\t]*\\n)*\" # any blank (empty or tabs/spaces only) lines before the code\n r\"(?P<code>.*?)\" # extract all code inside the markup\n r\"\\s*\" # any more whitespace before the end of the code markup\n r\"(?P=delim)\" # match the exact same delimiter from the start again\n r\"\\s*$\", # any trailing whitespace until the end of the string\n re.DOTALL | re.IGNORECASE # \".\" also matches newlines, case insensitive\n)\nRAW_CODE_REGEX = re.compile(\n r\"^(?:[ \\t]*\\n)*\" # any blank (empty or tabs/spaces only) lines before the code\n r\"(?P<code>.*?)\" # extract all the rest as code\n r\"\\s*$\", # any trailing whitespace until the end of the string\n re.DOTALL # \".\" also matches newlines\n)\n\nMAX_PASTE_LEN = 1000\nEVAL_ROLES = (Roles.helpers, Roles.moderator, Roles.admin, Roles.owner, Roles.rockstars, Roles.partners)\n\n\nclass Snekbox(Cog):\n \"\"\"Safe evaluation of Python code using Snekbox.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.jobs = {}\n\n async def post_eval(self, code: str) -> dict:\n \"\"\"Send a POST request to the Snekbox API to evaluate code and return the results.\"\"\"\n url = URLs.snekbox_eval_api\n data = {\"input\": code}\n async with self.bot.http_session.post(url, json=data, raise_for_status=True) as resp:\n return await resp.json()\n\n async def upload_output(self, output: str) -> Optional[str]:\n \"\"\"Upload the eval output to a paste service and return a URL to it if successful.\"\"\"\n log.trace(\"Uploading full output to paste service...\")\n\n if len(output) > MAX_PASTE_LEN:\n log.info(\"Full output is too long to upload\")\n return \"too long to upload\"\n\n url = URLs.paste_service.format(key=\"documents\")\n try:\n async with self.bot.http_session.post(url, data=output, raise_for_status=True) as resp:\n data = await resp.json()\n\n if \"key\" in data:\n return URLs.paste_service.format(key=data[\"key\"])\n except Exception:\n # 400 (Bad Request) means there are too many characters\n log.exception(\"Failed to upload full output to paste service!\")\n\n @staticmethod\n def prepare_input(code: str) -> str:\n \"\"\"Extract code from the Markdown, format it, and insert it into the code template.\"\"\"\n match = FORMATTED_CODE_REGEX.fullmatch(code)\n if match:\n code, block, lang, delim = match.group(\"code\", \"block\", \"lang\", \"delim\")\n code = textwrap.dedent(code)\n if block:\n info = (f\"'{lang}' highlighted\" if lang else \"plain\") + \" code block\"\n else:\n info = f\"{delim}-enclosed inline code\"\n log.trace(f\"Extracted {info} for evaluation:\\n{code}\")\n else:\n code = textwrap.dedent(RAW_CODE_REGEX.fullmatch(code).group(\"code\"))\n log.trace(\n f\"Eval message contains unformatted or badly formatted code, \"\n f\"stripping whitespace only:\\n{code}\"\n )\n\n return code\n\n @staticmethod\n def get_results_message(results: dict) -> Tuple[str, str]:\n \"\"\"Return a user-friendly message and error corresponding to the process's return code.\"\"\"\n stdout, returncode = results[\"stdout\"], results[\"returncode\"]\n msg = f\"Your eval job has completed with return code {returncode}\"\n error = \"\"\n\n if returncode is None:\n msg = \"Your eval job has failed\"\n error = stdout.strip()\n elif returncode == 128 + Signals.SIGKILL:\n msg = \"Your eval job timed out or ran out of memory\"\n elif returncode == 255:\n msg = \"Your eval job has failed\"\n error = \"A fatal NsJail error occurred\"\n else:\n # Try to append signal's name if one exists\n try:\n name = Signals(returncode - 128).name\n msg = f\"{msg} ({name})\"\n except ValueError:\n pass\n\n return msg, error\n\n async def format_output(self, output: str) -> Tuple[str, Optional[str]]:\n \"\"\"\n Format the output and return a tuple of the formatted output and a URL to the full output.\n\n Prepend each line with a line number. Truncate if there are over 10 lines or 1000 characters\n and upload the full output to a paste service.\n \"\"\"\n log.trace(\"Formatting output...\")\n\n output = output.strip(\" \\n\")\n original_output = output # To be uploaded to a pasting service if needed\n paste_link = None\n\n if \"<@\" in output:\n output = output.replace(\"<@\", \"<@\\u200B\") # Zero-width space\n\n if \"<!@\" in output:\n output = output.replace(\"<!@\", \"<!@\\u200B\") # Zero-width space\n\n if ESCAPE_REGEX.findall(output):\n return \"Code block escape attempt detected; will not output result\", paste_link\n\n truncated = False\n lines = output.count(\"\\n\")\n\n if lines > 0:\n output = output.split(\"\\n\")[:10] # Only first 10 cause the rest is truncated anyway\n output = (f\"{i:03d} | {line}\" for i, line in enumerate(output, 1))\n output = \"\\n\".join(output)\n\n if lines > 10:\n truncated = True\n if len(output) >= 1000:\n output = f\"{output[:1000]}\\n... (truncated - too long, too many lines)\"\n else:\n output = f\"{output}\\n... (truncated - too many lines)\"\n elif len(output) >= 1000:\n truncated = True\n output = f\"{output[:1000]}\\n... (truncated - too long)\"\n\n if truncated:\n paste_link = await self.upload_output(original_output)\n\n output = output.strip()\n if not output:\n output = \"[No output]\"\n\n return output, paste_link\n\n @command(name=\"eval\", aliases=(\"e\",))\n @guild_only()\n @in_channel(Channels.bot, bypass_roles=EVAL_ROLES)\n async def eval_command(self, ctx: Context, *, code: str = None) -> None:\n \"\"\"\n Run Python code and get the results.\n\n This command supports multiple lines of code, including code wrapped inside a formatted code\n block. We've done our best to make this safe, but do let us know if you manage to find an\n issue with it!\n \"\"\"\n if ctx.author.id in self.jobs:\n await ctx.send(\n f\"{ctx.author.mention} You've already got a job running - \"\n \"please wait for it to finish!\"\n )\n return\n\n if not code: # None or empty string\n await ctx.invoke(self.bot.get_command(\"help\"), \"eval\")\n return\n\n log.info(f\"Received code from {ctx.author} for evaluation:\\n{code}\")\n\n self.jobs[ctx.author.id] = datetime.datetime.now()\n code = self.prepare_input(code)\n\n try:\n async with ctx.typing():\n results = await self.post_eval(code)\n msg, error = self.get_results_message(results)\n\n if error:\n output, paste_link = error, None\n else:\n output, paste_link = await self.format_output(results[\"stdout\"])\n\n msg = f\"{ctx.author.mention} {msg}.\\n\\n```py\\n{output}\\n```\"\n if paste_link:\n msg = f\"{msg}\\nFull output: {paste_link}\"\n\n response = await ctx.send(msg)\n self.bot.loop.create_task(\n wait_for_deletion(response, user_ids=(ctx.author.id,), client=ctx.bot)\n )\n\n log.info(f\"{ctx.author}'s job had a return code of {results['returncode']}\")\n finally:\n del self.jobs[ctx.author.id]\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Snekbox cog load.\"\"\"\n bot.add_cog(Snekbox(bot))\n log.info(\"Cog loaded: Snekbox\")\n", "path": "bot/cogs/snekbox.py"}], "after_files": [{"content": "import datetime\nimport logging\nimport re\nimport textwrap\nfrom signal import Signals\nfrom typing import Optional, Tuple\n\nfrom discord.ext.commands import Bot, Cog, Context, command, guild_only\n\nfrom bot.constants import Channels, Roles, URLs\nfrom bot.decorators import in_channel\nfrom bot.utils.messages import wait_for_deletion\n\nlog = logging.getLogger(__name__)\n\nESCAPE_REGEX = re.compile(\"[`\\u202E\\u200B]{3,}\")\nFORMATTED_CODE_REGEX = re.compile(\n r\"^\\s*\" # any leading whitespace from the beginning of the string\n r\"(?P<delim>(?P<block>```)|``?)\" # code delimiter: 1-3 backticks; (?P=block) only matches if it's a block\n r\"(?(block)(?:(?P<lang>[a-z]+)\\n)?)\" # if we're in a block, match optional language (only letters plus newline)\n r\"(?:[ \\t]*\\n)*\" # any blank (empty or tabs/spaces only) lines before the code\n r\"(?P<code>.*?)\" # extract all code inside the markup\n r\"\\s*\" # any more whitespace before the end of the code markup\n r\"(?P=delim)\" # match the exact same delimiter from the start again\n r\"\\s*$\", # any trailing whitespace until the end of the string\n re.DOTALL | re.IGNORECASE # \".\" also matches newlines, case insensitive\n)\nRAW_CODE_REGEX = re.compile(\n r\"^(?:[ \\t]*\\n)*\" # any blank (empty or tabs/spaces only) lines before the code\n r\"(?P<code>.*?)\" # extract all the rest as code\n r\"\\s*$\", # any trailing whitespace until the end of the string\n re.DOTALL # \".\" also matches newlines\n)\n\nMAX_PASTE_LEN = 1000\nEVAL_ROLES = (Roles.helpers, Roles.moderator, Roles.admin, Roles.owner, Roles.rockstars, Roles.partners)\n\n\nclass Snekbox(Cog):\n \"\"\"Safe evaluation of Python code using Snekbox.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.jobs = {}\n\n async def post_eval(self, code: str) -> dict:\n \"\"\"Send a POST request to the Snekbox API to evaluate code and return the results.\"\"\"\n url = URLs.snekbox_eval_api\n data = {\"input\": code}\n async with self.bot.http_session.post(url, json=data, raise_for_status=True) as resp:\n return await resp.json()\n\n async def upload_output(self, output: str) -> Optional[str]:\n \"\"\"Upload the eval output to a paste service and return a URL to it if successful.\"\"\"\n log.trace(\"Uploading full output to paste service...\")\n\n if len(output) > MAX_PASTE_LEN:\n log.info(\"Full output is too long to upload\")\n return \"too long to upload\"\n\n url = URLs.paste_service.format(key=\"documents\")\n try:\n async with self.bot.http_session.post(url, data=output, raise_for_status=True) as resp:\n data = await resp.json()\n\n if \"key\" in data:\n return URLs.paste_service.format(key=data[\"key\"])\n except Exception:\n # 400 (Bad Request) means there are too many characters\n log.exception(\"Failed to upload full output to paste service!\")\n\n @staticmethod\n def prepare_input(code: str) -> str:\n \"\"\"Extract code from the Markdown, format it, and insert it into the code template.\"\"\"\n match = FORMATTED_CODE_REGEX.fullmatch(code)\n if match:\n code, block, lang, delim = match.group(\"code\", \"block\", \"lang\", \"delim\")\n code = textwrap.dedent(code)\n if block:\n info = (f\"'{lang}' highlighted\" if lang else \"plain\") + \" code block\"\n else:\n info = f\"{delim}-enclosed inline code\"\n log.trace(f\"Extracted {info} for evaluation:\\n{code}\")\n else:\n code = textwrap.dedent(RAW_CODE_REGEX.fullmatch(code).group(\"code\"))\n log.trace(\n f\"Eval message contains unformatted or badly formatted code, \"\n f\"stripping whitespace only:\\n{code}\"\n )\n\n return code\n\n @staticmethod\n def get_results_message(results: dict) -> Tuple[str, str]:\n \"\"\"Return a user-friendly message and error corresponding to the process's return code.\"\"\"\n stdout, returncode = results[\"stdout\"], results[\"returncode\"]\n msg = f\"Your eval job has completed with return code {returncode}\"\n error = \"\"\n\n if returncode is None:\n msg = \"Your eval job has failed\"\n error = stdout.strip()\n elif returncode == 128 + Signals.SIGKILL:\n msg = \"Your eval job timed out or ran out of memory\"\n elif returncode == 255:\n msg = \"Your eval job has failed\"\n error = \"A fatal NsJail error occurred\"\n else:\n # Try to append signal's name if one exists\n try:\n name = Signals(returncode - 128).name\n msg = f\"{msg} ({name})\"\n except ValueError:\n pass\n\n return msg, error\n\n @staticmethod\n def get_status_emoji(results: dict) -> str:\n \"\"\"Return an emoji corresponding to the status code or lack of output in result.\"\"\"\n if not results[\"stdout\"].strip(): # No output\n return \":warning:\"\n elif results[\"returncode\"] == 0: # No error\n return \":white_check_mark:\"\n else: # Exception\n return \":x:\"\n\n async def format_output(self, output: str) -> Tuple[str, Optional[str]]:\n \"\"\"\n Format the output and return a tuple of the formatted output and a URL to the full output.\n\n Prepend each line with a line number. Truncate if there are over 10 lines or 1000 characters\n and upload the full output to a paste service.\n \"\"\"\n log.trace(\"Formatting output...\")\n\n output = output.strip(\" \\n\")\n original_output = output # To be uploaded to a pasting service if needed\n paste_link = None\n\n if \"<@\" in output:\n output = output.replace(\"<@\", \"<@\\u200B\") # Zero-width space\n\n if \"<!@\" in output:\n output = output.replace(\"<!@\", \"<!@\\u200B\") # Zero-width space\n\n if ESCAPE_REGEX.findall(output):\n return \"Code block escape attempt detected; will not output result\", paste_link\n\n truncated = False\n lines = output.count(\"\\n\")\n\n if lines > 0:\n output = output.split(\"\\n\")[:10] # Only first 10 cause the rest is truncated anyway\n output = (f\"{i:03d} | {line}\" for i, line in enumerate(output, 1))\n output = \"\\n\".join(output)\n\n if lines > 10:\n truncated = True\n if len(output) >= 1000:\n output = f\"{output[:1000]}\\n... (truncated - too long, too many lines)\"\n else:\n output = f\"{output}\\n... (truncated - too many lines)\"\n elif len(output) >= 1000:\n truncated = True\n output = f\"{output[:1000]}\\n... (truncated - too long)\"\n\n if truncated:\n paste_link = await self.upload_output(original_output)\n\n output = output.strip()\n if not output:\n output = \"[No output]\"\n\n return output, paste_link\n\n @command(name=\"eval\", aliases=(\"e\",))\n @guild_only()\n @in_channel(Channels.bot, bypass_roles=EVAL_ROLES)\n async def eval_command(self, ctx: Context, *, code: str = None) -> None:\n \"\"\"\n Run Python code and get the results.\n\n This command supports multiple lines of code, including code wrapped inside a formatted code\n block. We've done our best to make this safe, but do let us know if you manage to find an\n issue with it!\n \"\"\"\n if ctx.author.id in self.jobs:\n await ctx.send(\n f\"{ctx.author.mention} You've already got a job running - \"\n \"please wait for it to finish!\"\n )\n return\n\n if not code: # None or empty string\n await ctx.invoke(self.bot.get_command(\"help\"), \"eval\")\n return\n\n log.info(f\"Received code from {ctx.author} for evaluation:\\n{code}\")\n\n self.jobs[ctx.author.id] = datetime.datetime.now()\n code = self.prepare_input(code)\n\n try:\n async with ctx.typing():\n results = await self.post_eval(code)\n msg, error = self.get_results_message(results)\n\n if error:\n output, paste_link = error, None\n else:\n output, paste_link = await self.format_output(results[\"stdout\"])\n\n icon = self.get_status_emoji(results)\n msg = f\"{ctx.author.mention} {icon} {msg}.\\n\\n```py\\n{output}\\n```\"\n if paste_link:\n msg = f\"{msg}\\nFull output: {paste_link}\"\n\n response = await ctx.send(msg)\n self.bot.loop.create_task(\n wait_for_deletion(response, user_ids=(ctx.author.id,), client=ctx.bot)\n )\n\n log.info(f\"{ctx.author}'s job had a return code of {results['returncode']}\")\n finally:\n del self.jobs[ctx.author.id]\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Snekbox cog load.\"\"\"\n bot.add_cog(Snekbox(bot))\n log.info(\"Cog loaded: Snekbox\")\n", "path": "bot/cogs/snekbox.py"}]}
| 3,137 | 322 |
gh_patches_debug_13454
|
rasdani/github-patches
|
git_diff
|
psychopy__psychopy-773
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Overlapping recordings problem
I am having a problem with mic.record and mic.stop - I am currently on psychopy 1.81.00, but I have had the same problem in earlier versions. I have written some code which records until the participant hits a key, or until a time-limit is reached. I am getting occasional truncated recordings or zero-length recordings - these occur when I test the code myself, so it's not just the participants being trigger-happy. I think the problem occurs when the timer on some past recording runs out, it stops the current recording. So say you set a recording running with a limit of 10 seconds, send a mic.stop() after 5 seconds, then start a new recording, that new recording will be stopped after 5 seconds, when the timer on the original recording runs out - it doesn't seem to be quite as neat as that in practice, which is confusing, but you can see this in action with something like the following little program. How often to occurs depends on how unlucky you are, but if you run through the for loop 10-15 times you will get some truncated recordings.
from psychopy import microphone,core,event, visual
def recording(window,trialNum,mic):
print('recording ' + str(trialNum))
mic.reset()
instructionText = visual.TextStim(window, text='Count to five, then press space',color="black",pos=(0,0.0),wrapWidth=2)
instructionText.draw()
window.flip()
mic.record(7,block=False,filename=str(trialNum)+'.wav') #start recording
event.waitKeys(maxWait='inf', keyList=['space']) #wait for a space from participant
core.wait(0.1) #so you can hear the click of the spacebar
window.flip()
mic.stop() #stop the mic
core.wait(0.1) #to get a flicker between screens
# set up mic and window
microphone.switchOn(sampleRate=44100)
mic = microphone.AudioCapture()
myWin = visual.Window((800,600), allowGUI=True,color='white')
for t in range(100): #shouldn't need to do as many as 100 to get some truncated recordings!
recording(myWin,t,mic)
microphone.switchOff()
core.quit()
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `psychopy/app/builder/components/microphone.py`
Content:
```
1 # Part of the PsychoPy library
2 # Copyright (C) 2014 Jonathan Peirce
3 # Distributed under the terms of the GNU General Public License (GPL).
4
5 # Author: Jeremy R. Gray, 2012
6
7 from _base import *
8 from os import path
9 from psychopy.app.builder import components #for getInitVals()
10
11 thisFolder = path.abspath(path.dirname(__file__))#the absolute path to the folder containing this path
12 iconFile = path.join(thisFolder,'microphone.png')
13 tooltip = _translate('Microphone: basic sound capture (fixed onset & duration), okay for spoken words')
14
15 _localized = {'stereo': _translate('Stereo')}
16
17 class MicrophoneComponent(BaseComponent):
18 """An event class for capturing short sound stimuli"""
19 categories = ['Responses']
20 def __init__(self, exp, parentName, name='mic_1',
21 startType='time (s)', startVal=0.0,
22 stopType='duration (s)', stopVal=2.0, startEstim='', durationEstim='',
23 stereo=False
24 ):
25 super(MicrophoneComponent, self).__init__(exp, parentName, name=name,
26 startType=startType, startVal=startVal,
27 stopType=stopType, stopVal=stopVal,
28 startEstim=startEstim, durationEstim=durationEstim)
29 self.type='Microphone'
30 self.url="http://www.psychopy.org/builder/components/microphone.html"
31 self.exp.requirePsychopyLibs(['microphone'])
32 #params
33 self.params['stereo']=Param(stereo, valType='bool',
34 hint=_translate("Record two channels (stereo) or one (mono, smaller file)"),
35 label=_localized['stereo'])
36 self.params['stopType'].allowedVals = ['duration (s)']
37 self.params['stopType'].hint = _translate('The duration of the recording in seconds; blank = 0 sec')
38 def writeStartCode(self,buff):
39 # filename should have date_time, so filename_wav should be unique
40 buff.writeIndented("wavDirName = filename + '_wav'\n")
41 buff.writeIndented("if not os.path.isdir(wavDirName):\n" +
42 " os.makedirs(wavDirName) # to hold .wav files\n")
43 def writeRoutineStartCode(self,buff):
44 inits = components.getInitVals(self.params)
45 buff.writeIndented("%s = microphone.AdvAudioCapture(name='%s', saveDir=wavDirName, stereo=%s)\n" %(
46 inits['name'], inits['name'], inits['stereo']))
47 def writeFrameCode(self,buff):
48 """Write the code that will be called every frame"""
49 duration = "%s" % self.params['stopVal'] # type is code
50 if not len(duration):
51 duration = "0"
52 # starting condition:
53 buff.writeIndented("\n")
54 buff.writeIndented("# *%s* updates\n" %(self.params['name']))
55 self.writeStartTestCode(buff) # writes an if statement
56 buff.writeIndented("%(name)s.status = STARTED\n" %(self.params))
57 buff.writeIndented("%s.record(sec=%s, block=False) # start the recording thread\n" %
58 (self.params['name'], duration))
59 buff.setIndentLevel(-1, relative=True) # ends the if statement
60 buff.writeIndented("\n")
61 # these lines handle both normal end of rec thread, and user .stop():
62 buff.writeIndented("if %(name)s.status == STARTED and not %(name)s.recorder.running:\n" % self.params)
63 buff.writeIndented(" %s.status = FINISHED\n" % self.params['name'])
64 def writeRoutineEndCode(self,buff):
65 #some shortcuts
66 name = self.params['name']
67 if len(self.exp.flow._loopList):
68 currLoop = self.exp.flow._loopList[-1] #last (outer-most) loop
69 else:
70 currLoop = self.exp._expHandler
71
72 #write the actual code
73 buff.writeIndented("# check responses\n" %self.params)
74 buff.writeIndented("if not %(name)s.savedFile:\n"%self.params)
75 buff.writeIndented(" %(name)s.savedFile = None\n" %(self.params))
76 buff.writeIndented("# store data for %s (%s)\n" %(currLoop.params['name'], currLoop.type))
77
78 #always add saved file name
79 buff.writeIndented("%s.addData('%s.filename', %s.savedFile)\n" % (currLoop.params['name'],name,name))
80 if currLoop.params['name'].val == self.exp._expHandler.name:
81 buff.writeIndented("%s.nextEntry()\n" % self.exp._expHandler.name)
82 # best not to do loudness / rms or other processing here
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/psychopy/app/builder/components/microphone.py b/psychopy/app/builder/components/microphone.py
--- a/psychopy/app/builder/components/microphone.py
+++ b/psychopy/app/builder/components/microphone.py
@@ -70,7 +70,8 @@
currLoop = self.exp._expHandler
#write the actual code
- buff.writeIndented("# check responses\n" %self.params)
+ buff.writeIndented("# %(name)s stop & responses\n" %self.params)
+ buff.writeIndented("%s.stop() # sometimes helpful\n" % self.params['name'])
buff.writeIndented("if not %(name)s.savedFile:\n"%self.params)
buff.writeIndented(" %(name)s.savedFile = None\n" %(self.params))
buff.writeIndented("# store data for %s (%s)\n" %(currLoop.params['name'], currLoop.type))
|
{"golden_diff": "diff --git a/psychopy/app/builder/components/microphone.py b/psychopy/app/builder/components/microphone.py\n--- a/psychopy/app/builder/components/microphone.py\n+++ b/psychopy/app/builder/components/microphone.py\n@@ -70,7 +70,8 @@\n currLoop = self.exp._expHandler\n \n #write the actual code\n- buff.writeIndented(\"# check responses\\n\" %self.params)\n+ buff.writeIndented(\"# %(name)s stop & responses\\n\" %self.params)\n+ buff.writeIndented(\"%s.stop() # sometimes helpful\\n\" % self.params['name'])\n buff.writeIndented(\"if not %(name)s.savedFile:\\n\"%self.params)\n buff.writeIndented(\" %(name)s.savedFile = None\\n\" %(self.params))\n buff.writeIndented(\"# store data for %s (%s)\\n\" %(currLoop.params['name'], currLoop.type))\n", "issue": "Overlapping recordings problem\nI am having a problem with mic.record and mic.stop - I am currently on psychopy 1.81.00, but I have had the same problem in earlier versions. I have written some code which records until the participant hits a key, or until a time-limit is reached. I am getting occasional truncated recordings or zero-length recordings - these occur when I test the code myself, so it's not just the participants being trigger-happy. I think the problem occurs when the timer on some past recording runs out, it stops the current recording. So say you set a recording running with a limit of 10 seconds, send a mic.stop() after 5 seconds, then start a new recording, that new recording will be stopped after 5 seconds, when the timer on the original recording runs out - it doesn't seem to be quite as neat as that in practice, which is confusing, but you can see this in action with something like the following little program. How often to occurs depends on how unlucky you are, but if you run through the for loop 10-15 times you will get some truncated recordings. \n\nfrom psychopy import microphone,core,event, visual\n\ndef recording(window,trialNum,mic):\n print('recording ' + str(trialNum))\n mic.reset()\n instructionText = visual.TextStim(window, text='Count to five, then press space',color=\"black\",pos=(0,0.0),wrapWidth=2)\n instructionText.draw()\n window.flip()\n mic.record(7,block=False,filename=str(trialNum)+'.wav') #start recording\n event.waitKeys(maxWait='inf', keyList=['space']) #wait for a space from participant\n core.wait(0.1) #so you can hear the click of the spacebar\n window.flip()\n mic.stop() #stop the mic\n core.wait(0.1) #to get a flicker between screens\n# set up mic and window\n\nmicrophone.switchOn(sampleRate=44100)\nmic = microphone.AudioCapture()\nmyWin = visual.Window((800,600), allowGUI=True,color='white')\nfor t in range(100): #shouldn't need to do as many as 100 to get some truncated recordings!\n recording(myWin,t,mic)\nmicrophone.switchOff()\ncore.quit()\n\n", "before_files": [{"content": "# Part of the PsychoPy library\n# Copyright (C) 2014 Jonathan Peirce\n# Distributed under the terms of the GNU General Public License (GPL).\n\n# Author: Jeremy R. Gray, 2012\n\nfrom _base import *\nfrom os import path\nfrom psychopy.app.builder import components #for getInitVals()\n\nthisFolder = path.abspath(path.dirname(__file__))#the absolute path to the folder containing this path\niconFile = path.join(thisFolder,'microphone.png')\ntooltip = _translate('Microphone: basic sound capture (fixed onset & duration), okay for spoken words')\n\n_localized = {'stereo': _translate('Stereo')}\n\nclass MicrophoneComponent(BaseComponent):\n \"\"\"An event class for capturing short sound stimuli\"\"\"\n categories = ['Responses']\n def __init__(self, exp, parentName, name='mic_1',\n startType='time (s)', startVal=0.0,\n stopType='duration (s)', stopVal=2.0, startEstim='', durationEstim='',\n stereo=False\n ):\n super(MicrophoneComponent, self).__init__(exp, parentName, name=name,\n startType=startType, startVal=startVal,\n stopType=stopType, stopVal=stopVal,\n startEstim=startEstim, durationEstim=durationEstim)\n self.type='Microphone'\n self.url=\"http://www.psychopy.org/builder/components/microphone.html\"\n self.exp.requirePsychopyLibs(['microphone'])\n #params\n self.params['stereo']=Param(stereo, valType='bool',\n hint=_translate(\"Record two channels (stereo) or one (mono, smaller file)\"),\n label=_localized['stereo'])\n self.params['stopType'].allowedVals = ['duration (s)']\n self.params['stopType'].hint = _translate('The duration of the recording in seconds; blank = 0 sec')\n def writeStartCode(self,buff):\n # filename should have date_time, so filename_wav should be unique\n buff.writeIndented(\"wavDirName = filename + '_wav'\\n\")\n buff.writeIndented(\"if not os.path.isdir(wavDirName):\\n\" +\n \" os.makedirs(wavDirName) # to hold .wav files\\n\")\n def writeRoutineStartCode(self,buff):\n inits = components.getInitVals(self.params)\n buff.writeIndented(\"%s = microphone.AdvAudioCapture(name='%s', saveDir=wavDirName, stereo=%s)\\n\" %(\n inits['name'], inits['name'], inits['stereo']))\n def writeFrameCode(self,buff):\n \"\"\"Write the code that will be called every frame\"\"\"\n duration = \"%s\" % self.params['stopVal'] # type is code\n if not len(duration):\n duration = \"0\"\n # starting condition:\n buff.writeIndented(\"\\n\")\n buff.writeIndented(\"# *%s* updates\\n\" %(self.params['name']))\n self.writeStartTestCode(buff) # writes an if statement\n buff.writeIndented(\"%(name)s.status = STARTED\\n\" %(self.params))\n buff.writeIndented(\"%s.record(sec=%s, block=False) # start the recording thread\\n\" %\n (self.params['name'], duration))\n buff.setIndentLevel(-1, relative=True) # ends the if statement\n buff.writeIndented(\"\\n\")\n # these lines handle both normal end of rec thread, and user .stop():\n buff.writeIndented(\"if %(name)s.status == STARTED and not %(name)s.recorder.running:\\n\" % self.params)\n buff.writeIndented(\" %s.status = FINISHED\\n\" % self.params['name'])\n def writeRoutineEndCode(self,buff):\n #some shortcuts\n name = self.params['name']\n if len(self.exp.flow._loopList):\n currLoop = self.exp.flow._loopList[-1] #last (outer-most) loop\n else:\n currLoop = self.exp._expHandler\n\n #write the actual code\n buff.writeIndented(\"# check responses\\n\" %self.params)\n buff.writeIndented(\"if not %(name)s.savedFile:\\n\"%self.params)\n buff.writeIndented(\" %(name)s.savedFile = None\\n\" %(self.params))\n buff.writeIndented(\"# store data for %s (%s)\\n\" %(currLoop.params['name'], currLoop.type))\n\n #always add saved file name\n buff.writeIndented(\"%s.addData('%s.filename', %s.savedFile)\\n\" % (currLoop.params['name'],name,name))\n if currLoop.params['name'].val == self.exp._expHandler.name:\n buff.writeIndented(\"%s.nextEntry()\\n\" % self.exp._expHandler.name)\n # best not to do loudness / rms or other processing here\n", "path": "psychopy/app/builder/components/microphone.py"}], "after_files": [{"content": "# Part of the PsychoPy library\n# Copyright (C) 2014 Jonathan Peirce\n# Distributed under the terms of the GNU General Public License (GPL).\n\n# Author: Jeremy R. Gray, 2012\n\nfrom _base import *\nfrom os import path\nfrom psychopy.app.builder import components #for getInitVals()\n\nthisFolder = path.abspath(path.dirname(__file__))#the absolute path to the folder containing this path\niconFile = path.join(thisFolder,'microphone.png')\ntooltip = _translate('Microphone: basic sound capture (fixed onset & duration), okay for spoken words')\n\n_localized = {'stereo': _translate('Stereo')}\n\nclass MicrophoneComponent(BaseComponent):\n \"\"\"An event class for capturing short sound stimuli\"\"\"\n categories = ['Responses']\n def __init__(self, exp, parentName, name='mic_1',\n startType='time (s)', startVal=0.0,\n stopType='duration (s)', stopVal=2.0, startEstim='', durationEstim='',\n stereo=False\n ):\n super(MicrophoneComponent, self).__init__(exp, parentName, name=name,\n startType=startType, startVal=startVal,\n stopType=stopType, stopVal=stopVal,\n startEstim=startEstim, durationEstim=durationEstim)\n self.type='Microphone'\n self.url=\"http://www.psychopy.org/builder/components/microphone.html\"\n self.exp.requirePsychopyLibs(['microphone'])\n #params\n self.params['stereo']=Param(stereo, valType='bool',\n hint=_translate(\"Record two channels (stereo) or one (mono, smaller file)\"),\n label=_localized['stereo'])\n self.params['stopType'].allowedVals = ['duration (s)']\n self.params['stopType'].hint = _translate('The duration of the recording in seconds; blank = 0 sec')\n def writeStartCode(self,buff):\n # filename should have date_time, so filename_wav should be unique\n buff.writeIndented(\"wavDirName = filename + '_wav'\\n\")\n buff.writeIndented(\"if not os.path.isdir(wavDirName):\\n\" +\n \" os.makedirs(wavDirName) # to hold .wav files\\n\")\n def writeRoutineStartCode(self,buff):\n inits = components.getInitVals(self.params)\n buff.writeIndented(\"%s = microphone.AdvAudioCapture(name='%s', saveDir=wavDirName, stereo=%s)\\n\" %(\n inits['name'], inits['name'], inits['stereo']))\n def writeFrameCode(self,buff):\n \"\"\"Write the code that will be called every frame\"\"\"\n duration = \"%s\" % self.params['stopVal'] # type is code\n if not len(duration):\n duration = \"0\"\n # starting condition:\n buff.writeIndented(\"\\n\")\n buff.writeIndented(\"# *%s* updates\\n\" %(self.params['name']))\n self.writeStartTestCode(buff) # writes an if statement\n buff.writeIndented(\"%(name)s.status = STARTED\\n\" %(self.params))\n buff.writeIndented(\"%s.record(sec=%s, block=False) # start the recording thread\\n\" %\n (self.params['name'], duration))\n buff.setIndentLevel(-1, relative=True) # ends the if statement\n buff.writeIndented(\"\\n\")\n # these lines handle both normal end of rec thread, and user .stop():\n buff.writeIndented(\"if %(name)s.status == STARTED and not %(name)s.recorder.running:\\n\" % self.params)\n buff.writeIndented(\" %s.status = FINISHED\\n\" % self.params['name'])\n def writeRoutineEndCode(self,buff):\n #some shortcuts\n name = self.params['name']\n if len(self.exp.flow._loopList):\n currLoop = self.exp.flow._loopList[-1] #last (outer-most) loop\n else:\n currLoop = self.exp._expHandler\n\n #write the actual code\n buff.writeIndented(\"# %(name)s stop & responses\\n\" %self.params)\n buff.writeIndented(\"%s.stop() # sometimes helpful\\n\" % self.params['name'])\n buff.writeIndented(\"if not %(name)s.savedFile:\\n\"%self.params)\n buff.writeIndented(\" %(name)s.savedFile = None\\n\" %(self.params))\n buff.writeIndented(\"# store data for %s (%s)\\n\" %(currLoop.params['name'], currLoop.type))\n\n #always add saved file name\n buff.writeIndented(\"%s.addData('%s.filename', %s.savedFile)\\n\" % (currLoop.params['name'],name,name))\n if currLoop.params['name'].val == self.exp._expHandler.name:\n buff.writeIndented(\"%s.nextEntry()\\n\" % self.exp._expHandler.name)\n # best not to do loudness / rms or other processing here\n", "path": "psychopy/app/builder/components/microphone.py"}]}
| 1,971 | 201 |
gh_patches_debug_37142
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1872
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tests/test_passport.py::TestEnUS::testDates failure: ValueError: day is out of range for month
* Faker version: 18.10.0
* OS: Gentoo Linux amd64
It's possible that I've been incredibly lucky:
```
> expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
E ValueError: day is out of range for month
[…]
expiry_years = 10
issue_date = datetime.datetime(2020, 2, 29, 6, 57, 56)
```
Full traceback below.
### Steps to reproduce
1. `python -m pytest` ;-)
### Expected behavior
Tests passing ;-).
### Actual behavior
```pytb
_________________________________________________________ TestEnUS.testDates __________________________________________________________
self = <tests.test_passport.TestEnUS object at 0x7f6db2c3a920>, faker = <faker.proxy.Faker object at 0x7f6db21159f0>, num_samples = 20
def testDates(self, faker, num_samples=20):
age4 = date.today() - timedelta(days=4 * 365)
age12 = date.today() - timedelta(days=12 * 365)
age17 = date.today() - timedelta(days=17 * 365)
age23 = date.today() - timedelta(days=23 * 365)
age30 = date.today() - timedelta(days=30 * 365)
birthdays = [(age4, 4), (age12, 12), (age17, 17), (age23, 23), (age30, 30)]
for _ in range(num_samples):
for birthday in birthdays:
> birth_date_f, issue_date_f, expiry_date_f = faker.passport_dates(birthday[0])
_ = 4
age12 = datetime.date(2011, 6, 5)
age17 = datetime.date(2006, 6, 6)
age23 = datetime.date(2000, 6, 7)
age30 = datetime.date(1993, 6, 9)
age4 = datetime.date(2019, 6, 3)
birth_date = datetime.date(2006, 6, 6)
birth_date_f = '06 Jun 2006'
birthday = (datetime.date(2000, 6, 7), 23)
birthdays = [(datetime.date(2019, 6, 3), 4),
(datetime.date(2011, 6, 5), 12),
(datetime.date(2006, 6, 6), 17),
(datetime.date(2000, 6, 7), 23),
(datetime.date(1993, 6, 9), 30)]
expiry_date = datetime.date(2025, 4, 8)
expiry_date_f = '08 Apr 2025'
faker = <faker.proxy.Faker object at 0x7f6db21159f0>
issue_date = datetime.date(2020, 4, 8)
issue_date_f = '08 Apr 2020'
num_samples = 20
self = <tests.test_passport.TestEnUS object at 0x7f6db2c3a920>
tests/test_passport.py:55:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <faker.providers.passport.en_US.Provider object at 0x7f6db20938b0>, birthday = datetime.date(2000, 6, 7)
def passport_dates(self, birthday: date = date.today()) -> Tuple[str, str, str]:
"""Generates a formatted date of birth, issue, and expiration dates.
issue and expiration dates are conditioned to fall within U.S. standards of 5 and 10 year expirations
The ``birthday`` argument is a datetime.date object representing a date of birth.
Sources:
-https://travel.state.gov/content/travel/en/passports/passport-help/faqs.html
"""
birth_date = birthday.strftime("%d ") + birthday.strftime("%b ") + birthday.strftime("%Y")
today = date.today()
age = (today - birthday).days // 365
if age < 16:
expiry_years = 5
issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
# Checks if age is less than 5 so issue date is not before birthdate
if age < 5:
issue_date = self.generator.date_time_between(birthday, today)
expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
return birth_date, issue_date_fromat, expiry_date_format
elif age >= 26:
expiry_years = 10
issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
return birth_date, issue_date_fromat, expiry_date_format
else:
# In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years
expiry_years = 5
issue_date = self.generator.date_time_between(
today - timedelta(days=expiry_years * 365 - 1), birthday + timedelta(days=16 * 365 - 1)
)
# all people over 21 must have been over 16 when they recieved passport or it will be expired otherwise
if age >= 21:
issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
expiry_years = 10
> expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
E ValueError: day is out of range for month
age = 23
birth_date = '07 Jun 2000'
birthday = datetime.date(2000, 6, 7)
expiry_years = 10
issue_date = datetime.datetime(2020, 2, 29, 6, 57, 56)
self = <faker.providers.passport.en_US.Provider object at 0x7f6db20938b0>
today = datetime.date(2023, 6, 2)
faker/providers/passport/en_US/__init__.py:69: ValueError
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/passport/en_US/__init__.py`
Content:
```
1 import random
2
3 from datetime import date, timedelta
4 from typing import Tuple
5
6 from .. import Provider as PassportProvider
7
8
9 class Provider(PassportProvider):
10 """Implement passport provider for ``en_US`` locale.
11
12 Sources:
13
14 - https://travel.state.gov/content/travel/en/passports/passport-help/next-generation-passport.html
15 - https://www.vitalrecordsonline.com/glossary/passport-book-number
16 """
17
18 passport_number_formats = (
19 # NGP
20 "?########",
21 # Pre-NGP
22 "#########",
23 )
24
25 def passport_dates(self, birthday: date = date.today()) -> Tuple[str, str, str]:
26 """Generates a formatted date of birth, issue, and expiration dates.
27 issue and expiration dates are conditioned to fall within U.S. standards of 5 and 10 year expirations
28
29
30 The ``birthday`` argument is a datetime.date object representing a date of birth.
31
32 Sources:
33
34 -https://travel.state.gov/content/travel/en/passports/passport-help/faqs.html
35 """
36 birth_date = birthday.strftime("%d ") + birthday.strftime("%b ") + birthday.strftime("%Y")
37 today = date.today()
38 age = (today - birthday).days // 365
39 if age < 16:
40 expiry_years = 5
41 issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
42 # Checks if age is less than 5 so issue date is not before birthdate
43 if age < 5:
44 issue_date = self.generator.date_time_between(birthday, today)
45 expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
46
47 issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
48 expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
49 return birth_date, issue_date_fromat, expiry_date_format
50 elif age >= 26:
51 expiry_years = 10
52 issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
53 expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
54 issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
55 expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
56 return birth_date, issue_date_fromat, expiry_date_format
57
58 else:
59 # In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years
60 expiry_years = 5
61 issue_date = self.generator.date_time_between(
62 today - timedelta(days=expiry_years * 365 - 1), birthday + timedelta(days=16 * 365 - 1)
63 )
64 # all people over 21 must have been over 16 when they recieved passport or it will be expired otherwise
65 if age >= 21:
66 issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
67 expiry_years = 10
68
69 expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
70
71 issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
72 expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
73 return birth_date, issue_date_fromat, expiry_date_format
74
75 def passport_gender(self, seed: int = 0) -> str:
76 """Generates a string representing the gender displayed on a passport
77
78 Sources:
79
80 - https://williamsinstitute.law.ucla.edu/publications/x-gender-markers-passports/
81 """
82 if seed != 0:
83 random.seed(seed)
84
85 genders = ["M", "F", "X"]
86 gender = random.choices(genders, weights=[0.493, 0.493, 0.014], k=1)[0]
87 return gender
88
89 def passport_full(self) -> str:
90 """Generates a formatted sting with US Passport information"""
91 dob = self.passport_dob()
92 birth_date, issue_date, expiry_date = self.passport_dates(dob)
93 gender_g = self.passport_gender()
94 given_name, surname = self.passport_owner(gender=gender_g)
95 number = self.passport_number()
96
97 full_rep = """{first_name}\n{second_name}\n{gender}\n{dob}\n{issue}\n{expire}\n{num}\n"""
98 full_rep = full_rep.format(
99 first_name=given_name,
100 second_name=surname,
101 gender=gender_g,
102 dob=birth_date,
103 issue=issue_date,
104 expire=expiry_date,
105 num=number,
106 )
107 return full_rep
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/passport/en_US/__init__.py b/faker/providers/passport/en_US/__init__.py
--- a/faker/providers/passport/en_US/__init__.py
+++ b/faker/providers/passport/en_US/__init__.py
@@ -42,19 +42,9 @@
# Checks if age is less than 5 so issue date is not before birthdate
if age < 5:
issue_date = self.generator.date_time_between(birthday, today)
- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
-
- issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
- expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
- return birth_date, issue_date_fromat, expiry_date_format
elif age >= 26:
expiry_years = 10
issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
- issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
- expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
- return birth_date, issue_date_fromat, expiry_date_format
-
else:
# In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years
expiry_years = 5
@@ -66,11 +56,13 @@
issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)
expiry_years = 10
- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
+ if issue_date.day == 29 and issue_date.month == 2:
+ issue_date -= timedelta(days=1)
+ expiry_date = issue_date.replace(year=issue_date.year + expiry_years)
- issue_date_fromat = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
- expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
- return birth_date, issue_date_fromat, expiry_date_format
+ issue_date_format = issue_date.strftime("%d ") + issue_date.strftime("%b ") + issue_date.strftime("%Y")
+ expiry_date_format = expiry_date.strftime("%d ") + expiry_date.strftime("%b ") + expiry_date.strftime("%Y")
+ return birth_date, issue_date_format, expiry_date_format
def passport_gender(self, seed: int = 0) -> str:
"""Generates a string representing the gender displayed on a passport
|
{"golden_diff": "diff --git a/faker/providers/passport/en_US/__init__.py b/faker/providers/passport/en_US/__init__.py\n--- a/faker/providers/passport/en_US/__init__.py\n+++ b/faker/providers/passport/en_US/__init__.py\n@@ -42,19 +42,9 @@\n # Checks if age is less than 5 so issue date is not before birthdate\n if age < 5:\n issue_date = self.generator.date_time_between(birthday, today)\n- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n-\n- issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n- expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n- return birth_date, issue_date_fromat, expiry_date_format\n elif age >= 26:\n expiry_years = 10\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n- issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n- expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n- return birth_date, issue_date_fromat, expiry_date_format\n-\n else:\n # In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years\n expiry_years = 5\n@@ -66,11 +56,13 @@\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n expiry_years = 10\n \n- expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n+ if issue_date.day == 29 and issue_date.month == 2:\n+ issue_date -= timedelta(days=1)\n+ expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n \n- issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n- expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n- return birth_date, issue_date_fromat, expiry_date_format\n+ issue_date_format = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n+ expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n+ return birth_date, issue_date_format, expiry_date_format\n \n def passport_gender(self, seed: int = 0) -> str:\n \"\"\"Generates a string representing the gender displayed on a passport\n", "issue": "tests/test_passport.py::TestEnUS::testDates failure: ValueError: day is out of range for month\n* Faker version: 18.10.0\r\n* OS: Gentoo Linux amd64\r\n\r\nIt's possible that I've been incredibly lucky:\r\n\r\n```\r\n> expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\r\nE ValueError: day is out of range for month\r\n[\u2026]\r\nexpiry_years = 10\r\nissue_date = datetime.datetime(2020, 2, 29, 6, 57, 56)\r\n```\r\n\r\nFull traceback below.\r\n\r\n### Steps to reproduce\r\n\r\n1. `python -m pytest` ;-)\r\n\r\n### Expected behavior\r\n\r\nTests passing ;-).\r\n\r\n### Actual behavior\r\n\r\n```pytb\r\n_________________________________________________________ TestEnUS.testDates __________________________________________________________\r\n\r\nself = <tests.test_passport.TestEnUS object at 0x7f6db2c3a920>, faker = <faker.proxy.Faker object at 0x7f6db21159f0>, num_samples = 20\r\n\r\n def testDates(self, faker, num_samples=20):\r\n age4 = date.today() - timedelta(days=4 * 365)\r\n age12 = date.today() - timedelta(days=12 * 365)\r\n age17 = date.today() - timedelta(days=17 * 365)\r\n age23 = date.today() - timedelta(days=23 * 365)\r\n age30 = date.today() - timedelta(days=30 * 365)\r\n \r\n birthdays = [(age4, 4), (age12, 12), (age17, 17), (age23, 23), (age30, 30)]\r\n for _ in range(num_samples):\r\n for birthday in birthdays:\r\n> birth_date_f, issue_date_f, expiry_date_f = faker.passport_dates(birthday[0])\r\n\r\n_ = 4\r\nage12 = datetime.date(2011, 6, 5)\r\nage17 = datetime.date(2006, 6, 6)\r\nage23 = datetime.date(2000, 6, 7)\r\nage30 = datetime.date(1993, 6, 9)\r\nage4 = datetime.date(2019, 6, 3)\r\nbirth_date = datetime.date(2006, 6, 6)\r\nbirth_date_f = '06 Jun 2006'\r\nbirthday = (datetime.date(2000, 6, 7), 23)\r\nbirthdays = [(datetime.date(2019, 6, 3), 4),\r\n (datetime.date(2011, 6, 5), 12),\r\n (datetime.date(2006, 6, 6), 17),\r\n (datetime.date(2000, 6, 7), 23),\r\n (datetime.date(1993, 6, 9), 30)]\r\nexpiry_date = datetime.date(2025, 4, 8)\r\nexpiry_date_f = '08 Apr 2025'\r\nfaker = <faker.proxy.Faker object at 0x7f6db21159f0>\r\nissue_date = datetime.date(2020, 4, 8)\r\nissue_date_f = '08 Apr 2020'\r\nnum_samples = 20\r\nself = <tests.test_passport.TestEnUS object at 0x7f6db2c3a920>\r\n\r\ntests/test_passport.py:55: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nself = <faker.providers.passport.en_US.Provider object at 0x7f6db20938b0>, birthday = datetime.date(2000, 6, 7)\r\n\r\n def passport_dates(self, birthday: date = date.today()) -> Tuple[str, str, str]:\r\n \"\"\"Generates a formatted date of birth, issue, and expiration dates.\r\n issue and expiration dates are conditioned to fall within U.S. standards of 5 and 10 year expirations\r\n \r\n \r\n The ``birthday`` argument is a datetime.date object representing a date of birth.\r\n \r\n Sources:\r\n \r\n -https://travel.state.gov/content/travel/en/passports/passport-help/faqs.html\r\n \"\"\"\r\n birth_date = birthday.strftime(\"%d \") + birthday.strftime(\"%b \") + birthday.strftime(\"%Y\")\r\n today = date.today()\r\n age = (today - birthday).days // 365\r\n if age < 16:\r\n expiry_years = 5\r\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\r\n # Checks if age is less than 5 so issue date is not before birthdate\r\n if age < 5:\r\n issue_date = self.generator.date_time_between(birthday, today)\r\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\r\n \r\n issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\r\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\r\n return birth_date, issue_date_fromat, expiry_date_format\r\n elif age >= 26:\r\n expiry_years = 10\r\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\r\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\r\n issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\r\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\r\n return birth_date, issue_date_fromat, expiry_date_format\r\n \r\n else:\r\n # In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years\r\n expiry_years = 5\r\n issue_date = self.generator.date_time_between(\r\n today - timedelta(days=expiry_years * 365 - 1), birthday + timedelta(days=16 * 365 - 1)\r\n )\r\n # all people over 21 must have been over 16 when they recieved passport or it will be expired otherwise\r\n if age >= 21:\r\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\r\n expiry_years = 10\r\n \r\n> expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\r\nE ValueError: day is out of range for month\r\n\r\nage = 23\r\nbirth_date = '07 Jun 2000'\r\nbirthday = datetime.date(2000, 6, 7)\r\nexpiry_years = 10\r\nissue_date = datetime.datetime(2020, 2, 29, 6, 57, 56)\r\nself = <faker.providers.passport.en_US.Provider object at 0x7f6db20938b0>\r\ntoday = datetime.date(2023, 6, 2)\r\n\r\nfaker/providers/passport/en_US/__init__.py:69: ValueError\r\n```\r\n\n", "before_files": [{"content": "import random\n\nfrom datetime import date, timedelta\nfrom typing import Tuple\n\nfrom .. import Provider as PassportProvider\n\n\nclass Provider(PassportProvider):\n \"\"\"Implement passport provider for ``en_US`` locale.\n\n Sources:\n\n - https://travel.state.gov/content/travel/en/passports/passport-help/next-generation-passport.html\n - https://www.vitalrecordsonline.com/glossary/passport-book-number\n \"\"\"\n\n passport_number_formats = (\n # NGP\n \"?########\",\n # Pre-NGP\n \"#########\",\n )\n\n def passport_dates(self, birthday: date = date.today()) -> Tuple[str, str, str]:\n \"\"\"Generates a formatted date of birth, issue, and expiration dates.\n issue and expiration dates are conditioned to fall within U.S. standards of 5 and 10 year expirations\n\n\n The ``birthday`` argument is a datetime.date object representing a date of birth.\n\n Sources:\n\n -https://travel.state.gov/content/travel/en/passports/passport-help/faqs.html\n \"\"\"\n birth_date = birthday.strftime(\"%d \") + birthday.strftime(\"%b \") + birthday.strftime(\"%Y\")\n today = date.today()\n age = (today - birthday).days // 365\n if age < 16:\n expiry_years = 5\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n # Checks if age is less than 5 so issue date is not before birthdate\n if age < 5:\n issue_date = self.generator.date_time_between(birthday, today)\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n\n issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n return birth_date, issue_date_fromat, expiry_date_format\n elif age >= 26:\n expiry_years = 10\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n return birth_date, issue_date_fromat, expiry_date_format\n\n else:\n # In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years\n expiry_years = 5\n issue_date = self.generator.date_time_between(\n today - timedelta(days=expiry_years * 365 - 1), birthday + timedelta(days=16 * 365 - 1)\n )\n # all people over 21 must have been over 16 when they recieved passport or it will be expired otherwise\n if age >= 21:\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n expiry_years = 10\n\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n\n issue_date_fromat = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n return birth_date, issue_date_fromat, expiry_date_format\n\n def passport_gender(self, seed: int = 0) -> str:\n \"\"\"Generates a string representing the gender displayed on a passport\n\n Sources:\n\n - https://williamsinstitute.law.ucla.edu/publications/x-gender-markers-passports/\n \"\"\"\n if seed != 0:\n random.seed(seed)\n\n genders = [\"M\", \"F\", \"X\"]\n gender = random.choices(genders, weights=[0.493, 0.493, 0.014], k=1)[0]\n return gender\n\n def passport_full(self) -> str:\n \"\"\"Generates a formatted sting with US Passport information\"\"\"\n dob = self.passport_dob()\n birth_date, issue_date, expiry_date = self.passport_dates(dob)\n gender_g = self.passport_gender()\n given_name, surname = self.passport_owner(gender=gender_g)\n number = self.passport_number()\n\n full_rep = \"\"\"{first_name}\\n{second_name}\\n{gender}\\n{dob}\\n{issue}\\n{expire}\\n{num}\\n\"\"\"\n full_rep = full_rep.format(\n first_name=given_name,\n second_name=surname,\n gender=gender_g,\n dob=birth_date,\n issue=issue_date,\n expire=expiry_date,\n num=number,\n )\n return full_rep\n", "path": "faker/providers/passport/en_US/__init__.py"}], "after_files": [{"content": "import random\n\nfrom datetime import date, timedelta\nfrom typing import Tuple\n\nfrom .. import Provider as PassportProvider\n\n\nclass Provider(PassportProvider):\n \"\"\"Implement passport provider for ``en_US`` locale.\n\n Sources:\n\n - https://travel.state.gov/content/travel/en/passports/passport-help/next-generation-passport.html\n - https://www.vitalrecordsonline.com/glossary/passport-book-number\n \"\"\"\n\n passport_number_formats = (\n # NGP\n \"?########\",\n # Pre-NGP\n \"#########\",\n )\n\n def passport_dates(self, birthday: date = date.today()) -> Tuple[str, str, str]:\n \"\"\"Generates a formatted date of birth, issue, and expiration dates.\n issue and expiration dates are conditioned to fall within U.S. standards of 5 and 10 year expirations\n\n\n The ``birthday`` argument is a datetime.date object representing a date of birth.\n\n Sources:\n\n -https://travel.state.gov/content/travel/en/passports/passport-help/faqs.html\n \"\"\"\n birth_date = birthday.strftime(\"%d \") + birthday.strftime(\"%b \") + birthday.strftime(\"%Y\")\n today = date.today()\n age = (today - birthday).days // 365\n if age < 16:\n expiry_years = 5\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n # Checks if age is less than 5 so issue date is not before birthdate\n if age < 5:\n issue_date = self.generator.date_time_between(birthday, today)\n elif age >= 26:\n expiry_years = 10\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n else:\n # In cases between age 16 and 26, the issue date is 5 years ago, but expiry may be in 10 or 5 years\n expiry_years = 5\n issue_date = self.generator.date_time_between(\n today - timedelta(days=expiry_years * 365 - 1), birthday + timedelta(days=16 * 365 - 1)\n )\n # all people over 21 must have been over 16 when they recieved passport or it will be expired otherwise\n if age >= 21:\n issue_date = self.generator.date_time_between(today - timedelta(days=expiry_years * 365 - 1), today)\n expiry_years = 10\n\n if issue_date.day == 29 and issue_date.month == 2:\n issue_date -= timedelta(days=1)\n expiry_date = issue_date.replace(year=issue_date.year + expiry_years)\n\n issue_date_format = issue_date.strftime(\"%d \") + issue_date.strftime(\"%b \") + issue_date.strftime(\"%Y\")\n expiry_date_format = expiry_date.strftime(\"%d \") + expiry_date.strftime(\"%b \") + expiry_date.strftime(\"%Y\")\n return birth_date, issue_date_format, expiry_date_format\n\n def passport_gender(self, seed: int = 0) -> str:\n \"\"\"Generates a string representing the gender displayed on a passport\n\n Sources:\n\n - https://williamsinstitute.law.ucla.edu/publications/x-gender-markers-passports/\n \"\"\"\n if seed != 0:\n random.seed(seed)\n\n genders = [\"M\", \"F\", \"X\"]\n gender = random.choices(genders, weights=[0.493, 0.493, 0.014], k=1)[0]\n return gender\n\n def passport_full(self) -> str:\n \"\"\"Generates a formatted sting with US Passport information\"\"\"\n dob = self.passport_dob()\n birth_date, issue_date, expiry_date = self.passport_dates(dob)\n gender_g = self.passport_gender()\n given_name, surname = self.passport_owner(gender=gender_g)\n number = self.passport_number()\n\n full_rep = \"\"\"{first_name}\\n{second_name}\\n{gender}\\n{dob}\\n{issue}\\n{expire}\\n{num}\\n\"\"\"\n full_rep = full_rep.format(\n first_name=given_name,\n second_name=surname,\n gender=gender_g,\n dob=birth_date,\n issue=issue_date,\n expire=expiry_date,\n num=number,\n )\n return full_rep\n", "path": "faker/providers/passport/en_US/__init__.py"}]}
| 3,280 | 646 |
gh_patches_debug_15852
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4125
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cmake_find_package generator not forwarding all dependency properties
Some info first:
- conan v1.10.0
- cmake v3.13.1
- Linux GCC 8.1 x86_64 libstdc++11
If using CMake version >= 3.0 the `cmake_find_package` generator
generates CMake imported targets to easily import and track dependencies
of the required packages.
When using those imported targets in CMake, users get not only automatic
tracking of link dependencies **but also include directories and compile
options**. If we have three packages A, B, C, with C depending on B and
B depending on A (A <-- B <-- C) **C may require A include directories if A headers are
included in the public API of B**. In this scenario, if we are building
C with a cmake_find_package generator:
``` cmake
find_package(B REQUIRED)
add_library(C)
target_link_libraries(C PRIVATE B::B)
```
cmake correctly adds A's includes as part of C private include dirs
since the generated FindB.cmake generates not only B::B target but also
a target for A with all its properties, target that is linked against
B::B.
But if for some reason the A target (CONAN_PKG::A_A) had been defined previously,
the generator skips the generation of this target **and no longer links
A against B::B**, preventing A include dirs to be propagated to B and C.
I've found this issue when mixing bincrafters Qt package (which doesn't support the `cmake_find_package` generator) with a couple of more packages that I'm importing using the find package generator. I have to work this way since our guidelines encourage the usage of `find_package()` to require dependencies:
``` cmake
conan_basic_setup(TARGETS)
find_package(QtCore CONFIG REQUIRED)
find_package(foofromconan REQUIRED)
```
I know this use case is not common and shouldn't be encouraged, it's just an artifact of how the Qt package works right now (Our goal is to go full find_package() for transparent conan integration). But I think the "bug" in the generator could happen in different scenarios and the fix may be useful for others.
I've fixed this behavior by always adding the dependency targets to the list of targets to link (See #4125).
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/generators/cmake_find_package.py`
Content:
```
1 from conans.client.generators.cmake import DepsCppCmake
2 from conans.model import Generator
3
4
5 generic_find_package_template = """
6 message(STATUS "Conan: Using autogenerated Find{name}.cmake")
7 # Global approach
8 SET({name}_FOUND 1)
9 SET({name}_INCLUDE_DIRS {deps.include_paths})
10 SET({name}_INCLUDES {deps.include_paths})
11 SET({name}_DEFINITIONS {deps.defines})
12 SET({name}_LIBRARIES "") # Will be filled later
13 SET({name}_LIBRARIES_TARGETS "") # Will be filled later, if CMake 3
14 SET({name}_LIBS "") # Same as {name}_LIBRARIES
15
16 mark_as_advanced({name}_FOUND {name}_INCLUDE_DIRS {name}_INCLUDES
17 {name}_DEFINITIONS {name}_LIBRARIES {name}_LIBS)
18
19
20 # Find the real .lib/.a and add them to {name}_LIBS and {name}_LIBRARY_LIST
21 SET({name}_LIBRARY_LIST {deps.libs})
22 SET({name}_LIB_DIRS {deps.lib_paths})
23 foreach(_LIBRARY_NAME ${{{name}_LIBRARY_LIST}})
24 unset(CONAN_FOUND_LIBRARY CACHE)
25 find_library(CONAN_FOUND_LIBRARY NAME ${{_LIBRARY_NAME}} PATHS ${{{name}_LIB_DIRS}}
26 NO_DEFAULT_PATH NO_CMAKE_FIND_ROOT_PATH)
27 if(CONAN_FOUND_LIBRARY)
28 list(APPEND {name}_LIBRARIES ${{CONAN_FOUND_LIBRARY}})
29 if(NOT ${{CMAKE_VERSION}} VERSION_LESS "3.0")
30 # Create a micro-target for each lib/a found
31 set(_LIB_NAME CONAN_LIB::{name}_${{_LIBRARY_NAME}})
32 if(NOT TARGET ${{_LIB_NAME}})
33 # Create a micro-target for each lib/a found
34 add_library(${{_LIB_NAME}} UNKNOWN IMPORTED)
35 set_target_properties(${{_LIB_NAME}} PROPERTIES IMPORTED_LOCATION ${{CONAN_FOUND_LIBRARY}})
36 list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})
37 else()
38 message(STATUS "Skipping already existing target: ${{_LIB_NAME}}")
39 endif()
40 endif()
41 message(STATUS "Found: ${{CONAN_FOUND_LIBRARY}}")
42 else()
43 message(STATUS "Library ${{_LIBRARY_NAME}} not found in package, might be system one")
44 list(APPEND {name}_LIBRARIES_TARGETS ${{_LIBRARY_NAME}})
45 list(APPEND {name}_LIBRARIES ${{_LIBRARY_NAME}})
46 endif()
47 endforeach()
48 set({name}_LIBS ${{{name}_LIBRARIES}})
49
50 if(NOT ${{CMAKE_VERSION}} VERSION_LESS "3.0")
51 # Target approach
52 if(NOT TARGET {name}::{name})
53 add_library({name}::{name} INTERFACE IMPORTED)
54 if({name}_INCLUDE_DIRS)
55 set_target_properties({name}::{name} PROPERTIES
56 INTERFACE_INCLUDE_DIRECTORIES "${{{name}_INCLUDE_DIRS}}")
57 endif()
58 set_property(TARGET {name}::{name} PROPERTY INTERFACE_LINK_LIBRARIES ${{{name}_LIBRARIES_TARGETS}} "{deps.sharedlinkflags_list}" "{deps.exelinkflags_list}")
59 set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_DEFINITIONS {deps.compile_definitions})
60 set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_OPTIONS "{deps.cppflags_list}" "{deps.cflags_list}")
61 endif()
62 {find_dependencies}
63 endif()
64 """
65
66
67 class CMakeFindPackageGenerator(Generator):
68
69 @property
70 def filename(self):
71 pass
72
73 @property
74 def content(self):
75 ret = {}
76 for depname, cpp_info in self.deps_build_info.dependencies:
77 ret["Find%s.cmake" % depname] = self._single_find_package(depname, cpp_info)
78 return ret
79
80 @staticmethod
81 def _single_find_package(name, cpp_info):
82 deps = DepsCppCmake(cpp_info)
83 lines = []
84 if cpp_info.public_deps:
85 lines = CMakeFindPackageGenerator._transitive_lines(name, cpp_info)
86 tmp = generic_find_package_template.format(name=name, deps=deps,
87 find_dependencies="\n".join(lines))
88 return tmp
89
90 @staticmethod
91 def _transitive_lines(name, cpp_info):
92 lines = ["# Library dependencies", "include(CMakeFindDependencyMacro)"]
93 for dep in cpp_info.public_deps:
94 def property_lines(prop):
95 lib_t = "%s::%s" % (name, name)
96 dep_t = "%s::%s" % (dep, dep)
97 return ["get_target_property(tmp %s %s)" % (dep_t, prop),
98 "if(tmp)",
99 " set_property(TARGET %s APPEND PROPERTY %s ${tmp})" % (lib_t, prop),
100 'endif()']
101
102 lines.append("find_dependency(%s REQUIRED)" % dep)
103 lines.extend(property_lines("INTERFACE_LINK_LIBRARIES"))
104 lines.extend(property_lines("INTERFACE_COMPILE_DEFINITIONS"))
105 lines.extend(property_lines("INTERFACE_INCLUDE_DIRECTORIES"))
106 return lines
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/generators/cmake_find_package.py b/conans/client/generators/cmake_find_package.py
--- a/conans/client/generators/cmake_find_package.py
+++ b/conans/client/generators/cmake_find_package.py
@@ -33,10 +33,10 @@
# Create a micro-target for each lib/a found
add_library(${{_LIB_NAME}} UNKNOWN IMPORTED)
set_target_properties(${{_LIB_NAME}} PROPERTIES IMPORTED_LOCATION ${{CONAN_FOUND_LIBRARY}})
- list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})
else()
message(STATUS "Skipping already existing target: ${{_LIB_NAME}}")
endif()
+ list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})
endif()
message(STATUS "Found: ${{CONAN_FOUND_LIBRARY}}")
else()
|
{"golden_diff": "diff --git a/conans/client/generators/cmake_find_package.py b/conans/client/generators/cmake_find_package.py\n--- a/conans/client/generators/cmake_find_package.py\n+++ b/conans/client/generators/cmake_find_package.py\n@@ -33,10 +33,10 @@\n # Create a micro-target for each lib/a found\n add_library(${{_LIB_NAME}} UNKNOWN IMPORTED)\n set_target_properties(${{_LIB_NAME}} PROPERTIES IMPORTED_LOCATION ${{CONAN_FOUND_LIBRARY}})\n- list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})\n else()\n message(STATUS \"Skipping already existing target: ${{_LIB_NAME}}\")\n endif()\n+ list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})\n endif()\n message(STATUS \"Found: ${{CONAN_FOUND_LIBRARY}}\")\n else()\n", "issue": "cmake_find_package generator not forwarding all dependency properties\n Some info first:\r\n - conan v1.10.0\r\n - cmake v3.13.1\r\n - Linux GCC 8.1 x86_64 libstdc++11\r\n\r\nIf using CMake version >= 3.0 the `cmake_find_package` generator\r\ngenerates CMake imported targets to easily import and track dependencies\r\nof the required packages.\r\n\r\nWhen using those imported targets in CMake, users get not only automatic\r\ntracking of link dependencies **but also include directories and compile\r\noptions**. If we have three packages A, B, C, with C depending on B and\r\nB depending on A (A <-- B <-- C) **C may require A include directories if A headers are\r\nincluded in the public API of B**. In this scenario, if we are building\r\nC with a cmake_find_package generator:\r\n\r\n``` cmake\r\nfind_package(B REQUIRED)\r\nadd_library(C)\r\ntarget_link_libraries(C PRIVATE B::B)\r\n```\r\n\r\ncmake correctly adds A's includes as part of C private include dirs\r\nsince the generated FindB.cmake generates not only B::B target but also\r\na target for A with all its properties, target that is linked against\r\nB::B.\r\nBut if for some reason the A target (CONAN_PKG::A_A) had been defined previously,\r\nthe generator skips the generation of this target **and no longer links\r\nA against B::B**, preventing A include dirs to be propagated to B and C.\r\n\r\nI've found this issue when mixing bincrafters Qt package (which doesn't support the `cmake_find_package` generator) with a couple of more packages that I'm importing using the find package generator. I have to work this way since our guidelines encourage the usage of `find_package()` to require dependencies:\r\n\r\n``` cmake\r\nconan_basic_setup(TARGETS)\r\nfind_package(QtCore CONFIG REQUIRED)\r\nfind_package(foofromconan REQUIRED)\r\n```\r\nI know this use case is not common and shouldn't be encouraged, it's just an artifact of how the Qt package works right now (Our goal is to go full find_package() for transparent conan integration). But I think the \"bug\" in the generator could happen in different scenarios and the fix may be useful for others.\r\n\r\nI've fixed this behavior by always adding the dependency targets to the list of targets to link (See #4125).\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [x] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "from conans.client.generators.cmake import DepsCppCmake\nfrom conans.model import Generator\n\n\ngeneric_find_package_template = \"\"\"\nmessage(STATUS \"Conan: Using autogenerated Find{name}.cmake\")\n# Global approach\nSET({name}_FOUND 1)\nSET({name}_INCLUDE_DIRS {deps.include_paths})\nSET({name}_INCLUDES {deps.include_paths})\nSET({name}_DEFINITIONS {deps.defines})\nSET({name}_LIBRARIES \"\") # Will be filled later\nSET({name}_LIBRARIES_TARGETS \"\") # Will be filled later, if CMake 3\nSET({name}_LIBS \"\") # Same as {name}_LIBRARIES\n\nmark_as_advanced({name}_FOUND {name}_INCLUDE_DIRS {name}_INCLUDES\n {name}_DEFINITIONS {name}_LIBRARIES {name}_LIBS)\n\n\n# Find the real .lib/.a and add them to {name}_LIBS and {name}_LIBRARY_LIST\nSET({name}_LIBRARY_LIST {deps.libs})\nSET({name}_LIB_DIRS {deps.lib_paths})\nforeach(_LIBRARY_NAME ${{{name}_LIBRARY_LIST}})\n unset(CONAN_FOUND_LIBRARY CACHE)\n find_library(CONAN_FOUND_LIBRARY NAME ${{_LIBRARY_NAME}} PATHS ${{{name}_LIB_DIRS}}\n NO_DEFAULT_PATH NO_CMAKE_FIND_ROOT_PATH)\n if(CONAN_FOUND_LIBRARY)\n list(APPEND {name}_LIBRARIES ${{CONAN_FOUND_LIBRARY}})\n if(NOT ${{CMAKE_VERSION}} VERSION_LESS \"3.0\")\n # Create a micro-target for each lib/a found\n set(_LIB_NAME CONAN_LIB::{name}_${{_LIBRARY_NAME}})\n if(NOT TARGET ${{_LIB_NAME}})\n # Create a micro-target for each lib/a found\n add_library(${{_LIB_NAME}} UNKNOWN IMPORTED)\n set_target_properties(${{_LIB_NAME}} PROPERTIES IMPORTED_LOCATION ${{CONAN_FOUND_LIBRARY}})\n list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})\n else()\n message(STATUS \"Skipping already existing target: ${{_LIB_NAME}}\")\n endif()\n endif()\n message(STATUS \"Found: ${{CONAN_FOUND_LIBRARY}}\")\n else()\n message(STATUS \"Library ${{_LIBRARY_NAME}} not found in package, might be system one\")\n list(APPEND {name}_LIBRARIES_TARGETS ${{_LIBRARY_NAME}})\n list(APPEND {name}_LIBRARIES ${{_LIBRARY_NAME}})\n endif()\nendforeach()\nset({name}_LIBS ${{{name}_LIBRARIES}})\n\nif(NOT ${{CMAKE_VERSION}} VERSION_LESS \"3.0\")\n # Target approach\n if(NOT TARGET {name}::{name})\n add_library({name}::{name} INTERFACE IMPORTED)\n if({name}_INCLUDE_DIRS)\n set_target_properties({name}::{name} PROPERTIES\n INTERFACE_INCLUDE_DIRECTORIES \"${{{name}_INCLUDE_DIRS}}\")\n endif()\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_LINK_LIBRARIES ${{{name}_LIBRARIES_TARGETS}} \"{deps.sharedlinkflags_list}\" \"{deps.exelinkflags_list}\")\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_DEFINITIONS {deps.compile_definitions})\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_OPTIONS \"{deps.cppflags_list}\" \"{deps.cflags_list}\")\n endif()\n {find_dependencies}\nendif()\n\"\"\"\n\n\nclass CMakeFindPackageGenerator(Generator):\n\n @property\n def filename(self):\n pass\n\n @property\n def content(self):\n ret = {}\n for depname, cpp_info in self.deps_build_info.dependencies:\n ret[\"Find%s.cmake\" % depname] = self._single_find_package(depname, cpp_info)\n return ret\n\n @staticmethod\n def _single_find_package(name, cpp_info):\n deps = DepsCppCmake(cpp_info)\n lines = []\n if cpp_info.public_deps:\n lines = CMakeFindPackageGenerator._transitive_lines(name, cpp_info)\n tmp = generic_find_package_template.format(name=name, deps=deps,\n find_dependencies=\"\\n\".join(lines))\n return tmp\n\n @staticmethod\n def _transitive_lines(name, cpp_info):\n lines = [\"# Library dependencies\", \"include(CMakeFindDependencyMacro)\"]\n for dep in cpp_info.public_deps:\n def property_lines(prop):\n lib_t = \"%s::%s\" % (name, name)\n dep_t = \"%s::%s\" % (dep, dep)\n return [\"get_target_property(tmp %s %s)\" % (dep_t, prop),\n \"if(tmp)\",\n \" set_property(TARGET %s APPEND PROPERTY %s ${tmp})\" % (lib_t, prop),\n 'endif()']\n\n lines.append(\"find_dependency(%s REQUIRED)\" % dep)\n lines.extend(property_lines(\"INTERFACE_LINK_LIBRARIES\"))\n lines.extend(property_lines(\"INTERFACE_COMPILE_DEFINITIONS\"))\n lines.extend(property_lines(\"INTERFACE_INCLUDE_DIRECTORIES\"))\n return lines\n", "path": "conans/client/generators/cmake_find_package.py"}], "after_files": [{"content": "from conans.client.generators.cmake import DepsCppCmake\nfrom conans.model import Generator\n\n\ngeneric_find_package_template = \"\"\"\nmessage(STATUS \"Conan: Using autogenerated Find{name}.cmake\")\n# Global approach\nSET({name}_FOUND 1)\nSET({name}_INCLUDE_DIRS {deps.include_paths})\nSET({name}_INCLUDES {deps.include_paths})\nSET({name}_DEFINITIONS {deps.defines})\nSET({name}_LIBRARIES \"\") # Will be filled later\nSET({name}_LIBRARIES_TARGETS \"\") # Will be filled later, if CMake 3\nSET({name}_LIBS \"\") # Same as {name}_LIBRARIES\n\nmark_as_advanced({name}_FOUND {name}_INCLUDE_DIRS {name}_INCLUDES\n {name}_DEFINITIONS {name}_LIBRARIES {name}_LIBS)\n\n\n# Find the real .lib/.a and add them to {name}_LIBS and {name}_LIBRARY_LIST\nSET({name}_LIBRARY_LIST {deps.libs})\nSET({name}_LIB_DIRS {deps.lib_paths})\nforeach(_LIBRARY_NAME ${{{name}_LIBRARY_LIST}})\n unset(CONAN_FOUND_LIBRARY CACHE)\n find_library(CONAN_FOUND_LIBRARY NAME ${{_LIBRARY_NAME}} PATHS ${{{name}_LIB_DIRS}}\n NO_DEFAULT_PATH NO_CMAKE_FIND_ROOT_PATH)\n if(CONAN_FOUND_LIBRARY)\n list(APPEND {name}_LIBRARIES ${{CONAN_FOUND_LIBRARY}})\n if(NOT ${{CMAKE_VERSION}} VERSION_LESS \"3.0\")\n # Create a micro-target for each lib/a found\n set(_LIB_NAME CONAN_LIB::{name}_${{_LIBRARY_NAME}})\n if(NOT TARGET ${{_LIB_NAME}})\n # Create a micro-target for each lib/a found\n add_library(${{_LIB_NAME}} UNKNOWN IMPORTED)\n set_target_properties(${{_LIB_NAME}} PROPERTIES IMPORTED_LOCATION ${{CONAN_FOUND_LIBRARY}})\n else()\n message(STATUS \"Skipping already existing target: ${{_LIB_NAME}}\")\n endif()\n list(APPEND {name}_LIBRARIES_TARGETS ${{_LIB_NAME}})\n endif()\n message(STATUS \"Found: ${{CONAN_FOUND_LIBRARY}}\")\n else()\n message(STATUS \"Library ${{_LIBRARY_NAME}} not found in package, might be system one\")\n list(APPEND {name}_LIBRARIES_TARGETS ${{_LIBRARY_NAME}})\n list(APPEND {name}_LIBRARIES ${{_LIBRARY_NAME}})\n endif()\nendforeach()\nset({name}_LIBS ${{{name}_LIBRARIES}})\n\nif(NOT ${{CMAKE_VERSION}} VERSION_LESS \"3.0\")\n # Target approach\n if(NOT TARGET {name}::{name})\n add_library({name}::{name} INTERFACE IMPORTED)\n if({name}_INCLUDE_DIRS)\n set_target_properties({name}::{name} PROPERTIES\n INTERFACE_INCLUDE_DIRECTORIES \"${{{name}_INCLUDE_DIRS}}\")\n endif()\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_LINK_LIBRARIES ${{{name}_LIBRARIES_TARGETS}} \"{deps.sharedlinkflags_list}\" \"{deps.exelinkflags_list}\")\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_DEFINITIONS {deps.compile_definitions})\n set_property(TARGET {name}::{name} PROPERTY INTERFACE_COMPILE_OPTIONS \"{deps.cppflags_list}\" \"{deps.cflags_list}\")\n endif()\n {find_dependencies}\nendif()\n\"\"\"\n\n\nclass CMakeFindPackageGenerator(Generator):\n\n @property\n def filename(self):\n pass\n\n @property\n def content(self):\n ret = {}\n for depname, cpp_info in self.deps_build_info.dependencies:\n ret[\"Find%s.cmake\" % depname] = self._single_find_package(depname, cpp_info)\n return ret\n\n @staticmethod\n def _single_find_package(name, cpp_info):\n deps = DepsCppCmake(cpp_info)\n lines = []\n if cpp_info.public_deps:\n lines = CMakeFindPackageGenerator._transitive_lines(name, cpp_info)\n tmp = generic_find_package_template.format(name=name, deps=deps,\n find_dependencies=\"\\n\".join(lines))\n return tmp\n\n @staticmethod\n def _transitive_lines(name, cpp_info):\n lines = [\"# Library dependencies\", \"include(CMakeFindDependencyMacro)\"]\n for dep in cpp_info.public_deps:\n def property_lines(prop):\n lib_t = \"%s::%s\" % (name, name)\n dep_t = \"%s::%s\" % (dep, dep)\n return [\"get_target_property(tmp %s %s)\" % (dep_t, prop),\n \"if(tmp)\",\n \" set_property(TARGET %s APPEND PROPERTY %s ${tmp})\" % (lib_t, prop),\n 'endif()']\n\n lines.append(\"find_dependency(%s REQUIRED)\" % dep)\n lines.extend(property_lines(\"INTERFACE_LINK_LIBRARIES\"))\n lines.extend(property_lines(\"INTERFACE_COMPILE_DEFINITIONS\"))\n lines.extend(property_lines(\"INTERFACE_INCLUDE_DIRECTORIES\"))\n return lines\n", "path": "conans/client/generators/cmake_find_package.py"}]}
| 2,156 | 199 |
gh_patches_debug_22295
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-1439
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Subdomain request checking and error presentation
### Story
As a domain applicant, if I'm typing a subdomain on the domain page
I want to be presented with an error
so that I know that I can't submit a subdomain.
### Acceptance Criteria
- [ ] Leverage the existing in page error handling to present the user with content derived from #324
- [ ] Add a unit test to check validation
- [ ] Submissions should be denied if two dots are present. (Check for the edge case when two "." are not separated by characters: that state being "..")
- [ ] Submissions should be denied if two dots are present. (Check for the edge case when a "." is at the beginning if the domain without characters in front: that state being ".something."
- [ ] Confirm other edge cases
### Additional Context
_No response_
### Issue Links
Blocked by: #324
Related to: #720
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/api/views.py`
Content:
```
1 """Internal API views"""
2 from django.apps import apps
3 from django.views.decorators.http import require_http_methods
4 from django.http import HttpResponse, JsonResponse
5 from django.utils.safestring import mark_safe
6
7 from registrar.templatetags.url_helpers import public_site_url
8 from registrar.utility.errors import GenericError, GenericErrorCodes
9
10 import requests
11
12 from login_required import login_not_required
13
14 from cachetools.func import ttl_cache
15
16 from registrar.utility.s3_bucket import S3ClientError, S3ClientHelper
17
18
19 DOMAIN_FILE_URL = "https://raw.githubusercontent.com/cisagov/dotgov-data/main/current-full.csv"
20
21
22 DOMAIN_API_MESSAGES = {
23 "required": "Enter the .gov domain you want. Don’t include “www” or “.gov.”"
24 " For example, if you want www.city.gov, you would enter “city”"
25 " (without the quotes).",
26 "extra_dots": "Enter the .gov domain you want without any periods.",
27 # message below is considered safe; no user input can be inserted into the message
28 # body; public_site_url() function reads from local app settings and therefore safe
29 "unavailable": mark_safe( # nosec
30 "That domain isn’t available. "
31 "<a class='usa-link' href='{}' target='_blank'>"
32 "Read more about choosing your .gov domain.</a>".format(public_site_url("domains/choosing"))
33 ),
34 "invalid": "Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).",
35 "success": "That domain is available!",
36 "error": GenericError.get_error_message(GenericErrorCodes.CANNOT_CONTACT_REGISTRY),
37 }
38
39
40 # this file doesn't change that often, nor is it that big, so cache the result
41 # in memory for ten minutes
42 @ttl_cache(ttl=600)
43 def _domains():
44 """Return a list of the current .gov domains.
45
46 Fetch a file from DOMAIN_FILE_URL, parse the CSV for the domain,
47 lowercase everything and return the list.
48 """
49 DraftDomain = apps.get_model("registrar.DraftDomain")
50 # 5 second timeout
51 file_contents = requests.get(DOMAIN_FILE_URL, timeout=5).text
52 domains = set()
53 # skip the first line
54 for line in file_contents.splitlines()[1:]:
55 # get the domain before the first comma
56 domain = line.split(",", 1)[0]
57 # sanity-check the string we got from the file here
58 if DraftDomain.string_could_be_domain(domain):
59 # lowercase everything when we put it in domains
60 domains.add(domain.lower())
61 return domains
62
63
64 def check_domain_available(domain):
65 """Return true if the given domain is available.
66
67 The given domain is lowercased to match against the domains list. If the
68 given domain doesn't end with .gov, ".gov" is added when looking for
69 a match. If check fails, throws a RegistryError.
70 """
71 Domain = apps.get_model("registrar.Domain")
72 if domain.endswith(".gov"):
73 return Domain.available(domain)
74 else:
75 # domain search string doesn't end with .gov, add it on here
76 return Domain.available(domain + ".gov")
77
78
79 @require_http_methods(["GET"])
80 @login_not_required
81 def available(request, domain=""):
82 """Is a given domain available or not.
83
84 Response is a JSON dictionary with the key "available" and value true or
85 false.
86 """
87 DraftDomain = apps.get_model("registrar.DraftDomain")
88 # validate that the given domain could be a domain name and fail early if
89 # not.
90 if not (DraftDomain.string_could_be_domain(domain) or DraftDomain.string_could_be_domain(domain + ".gov")):
91 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["invalid"]})
92 # a domain is available if it is NOT in the list of current domains
93 try:
94 if check_domain_available(domain):
95 return JsonResponse({"available": True, "message": DOMAIN_API_MESSAGES["success"]})
96 else:
97 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["unavailable"]})
98 except Exception:
99 return JsonResponse({"available": False, "message": DOMAIN_API_MESSAGES["error"]})
100
101
102 @require_http_methods(["GET"])
103 @login_not_required
104 def get_current_full(request, file_name="current-full.csv"):
105 """This will return the file content of current-full.csv which is the command
106 output of generate_current_full_report.py. This command iterates through each Domain
107 and returns a CSV representation."""
108 return serve_file(file_name)
109
110
111 @require_http_methods(["GET"])
112 @login_not_required
113 def get_current_federal(request, file_name="current-federal.csv"):
114 """This will return the file content of current-federal.csv which is the command
115 output of generate_current_federal_report.py. This command iterates through each Domain
116 and returns a CSV representation."""
117 return serve_file(file_name)
118
119
120 def serve_file(file_name):
121 """Downloads a file based on a given filepath. Returns a 500 if not found."""
122 s3_client = S3ClientHelper()
123 # Serve the CSV file. If not found, an exception will be thrown.
124 # This will then be caught by flat, causing it to not read it - which is what we want.
125 try:
126 file = s3_client.get_file(file_name, decode_to_utf=True)
127 except S3ClientError as err:
128 # TODO - #1317: Notify operations when auto report generation fails
129 raise err
130
131 response = HttpResponse(file)
132 return response
133
```
Path: `src/registrar/config/urls.py`
Content:
```
1 """URL Configuration
2
3 For more information see:
4 https://docs.djangoproject.com/en/4.0/topics/http/urls/
5 """
6
7 from django.contrib import admin
8 from django.urls import include, path
9 from django.views.generic import RedirectView
10
11 from registrar import views
12 from registrar.views.application import Step
13 from registrar.views.utility import always_404
14 from api.views import available, get_current_federal, get_current_full
15
16
17 APPLICATION_NAMESPACE = views.ApplicationWizard.URL_NAMESPACE
18 application_urls = [
19 path("", views.ApplicationWizard.as_view(), name=""),
20 path("finished/", views.Finished.as_view(), name="finished"),
21 ]
22
23 # dynamically generate the other application_urls
24 for step, view in [
25 # add/remove steps here
26 (Step.ORGANIZATION_TYPE, views.OrganizationType),
27 (Step.TRIBAL_GOVERNMENT, views.TribalGovernment),
28 (Step.ORGANIZATION_FEDERAL, views.OrganizationFederal),
29 (Step.ORGANIZATION_ELECTION, views.OrganizationElection),
30 (Step.ORGANIZATION_CONTACT, views.OrganizationContact),
31 (Step.ABOUT_YOUR_ORGANIZATION, views.AboutYourOrganization),
32 (Step.AUTHORIZING_OFFICIAL, views.AuthorizingOfficial),
33 (Step.CURRENT_SITES, views.CurrentSites),
34 (Step.DOTGOV_DOMAIN, views.DotgovDomain),
35 (Step.PURPOSE, views.Purpose),
36 (Step.YOUR_CONTACT, views.YourContact),
37 (Step.OTHER_CONTACTS, views.OtherContacts),
38 (Step.NO_OTHER_CONTACTS, views.NoOtherContacts),
39 (Step.ANYTHING_ELSE, views.AnythingElse),
40 (Step.REQUIREMENTS, views.Requirements),
41 (Step.REVIEW, views.Review),
42 ]:
43 application_urls.append(path(f"{step}/", view.as_view(), name=step))
44
45
46 urlpatterns = [
47 path("", views.index, name="home"),
48 path(
49 "admin/logout/",
50 RedirectView.as_view(pattern_name="logout", permanent=False),
51 ),
52 path("admin/", admin.site.urls),
53 path(
54 "application/<id>/edit/",
55 views.ApplicationWizard.as_view(),
56 name=views.ApplicationWizard.EDIT_URL_NAME,
57 ),
58 path(
59 "application/<int:pk>",
60 views.ApplicationStatus.as_view(),
61 name="application-status",
62 ),
63 path(
64 "application/<int:pk>/withdraw",
65 views.ApplicationWithdrawConfirmation.as_view(),
66 name="application-withdraw-confirmation",
67 ),
68 path(
69 "application/<int:pk>/withdrawconfirmed",
70 views.ApplicationWithdrawn.as_view(),
71 name="application-withdrawn",
72 ),
73 path("health/", views.health),
74 path("openid/", include("djangooidc.urls")),
75 path("register/", include((application_urls, APPLICATION_NAMESPACE))),
76 path("api/v1/available/<domain>", available, name="available"),
77 path("api/v1/get-report/current-federal", get_current_federal, name="get-current-federal"),
78 path("api/v1/get-report/current-full", get_current_full, name="get-current-full"),
79 path(
80 "todo",
81 lambda r: always_404(r, "We forgot to include this link, sorry."),
82 name="todo",
83 ),
84 path("domain/<int:pk>", views.DomainView.as_view(), name="domain"),
85 path("domain/<int:pk>/users", views.DomainUsersView.as_view(), name="domain-users"),
86 path(
87 "domain/<int:pk>/dns",
88 views.DomainDNSView.as_view(),
89 name="domain-dns",
90 ),
91 path(
92 "domain/<int:pk>/dns/nameservers",
93 views.DomainNameserversView.as_view(),
94 name="domain-dns-nameservers",
95 ),
96 path(
97 "domain/<int:pk>/dns/dnssec",
98 views.DomainDNSSECView.as_view(),
99 name="domain-dns-dnssec",
100 ),
101 path(
102 "domain/<int:pk>/dns/dnssec/dsdata",
103 views.DomainDsDataView.as_view(),
104 name="domain-dns-dnssec-dsdata",
105 ),
106 path(
107 "domain/<int:pk>/your-contact-information",
108 views.DomainYourContactInformationView.as_view(),
109 name="domain-your-contact-information",
110 ),
111 path(
112 "domain/<int:pk>/org-name-address",
113 views.DomainOrgNameAddressView.as_view(),
114 name="domain-org-name-address",
115 ),
116 path(
117 "domain/<int:pk>/authorizing-official",
118 views.DomainAuthorizingOfficialView.as_view(),
119 name="domain-authorizing-official",
120 ),
121 path(
122 "domain/<int:pk>/security-email",
123 views.DomainSecurityEmailView.as_view(),
124 name="domain-security-email",
125 ),
126 path(
127 "domain/<int:pk>/users/add",
128 views.DomainAddUserView.as_view(),
129 name="domain-users-add",
130 ),
131 path(
132 "invitation/<int:pk>/delete",
133 views.DomainInvitationDeleteView.as_view(http_method_names=["post"]),
134 name="invitation-delete",
135 ),
136 ]
137
138 # we normally would guard these with `if settings.DEBUG` but tests run with
139 # DEBUG = False even when these apps have been loaded because settings.DEBUG
140 # was actually True. Instead, let's add these URLs any time we are able to
141 # import the debug toolbar package.
142 try:
143 import debug_toolbar # type: ignore
144
145 urlpatterns += [path("__debug__/", include(debug_toolbar.urls))]
146 except ImportError:
147 pass
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/api/views.py b/src/api/views.py
--- a/src/api/views.py
+++ b/src/api/views.py
@@ -84,6 +84,7 @@
Response is a JSON dictionary with the key "available" and value true or
false.
"""
+ domain = request.GET.get("domain", "")
DraftDomain = apps.get_model("registrar.DraftDomain")
# validate that the given domain could be a domain name and fail early if
# not.
diff --git a/src/registrar/config/urls.py b/src/registrar/config/urls.py
--- a/src/registrar/config/urls.py
+++ b/src/registrar/config/urls.py
@@ -73,7 +73,7 @@
path("health/", views.health),
path("openid/", include("djangooidc.urls")),
path("register/", include((application_urls, APPLICATION_NAMESPACE))),
- path("api/v1/available/<domain>", available, name="available"),
+ path("api/v1/available/", available, name="available"),
path("api/v1/get-report/current-federal", get_current_federal, name="get-current-federal"),
path("api/v1/get-report/current-full", get_current_full, name="get-current-full"),
path(
|
{"golden_diff": "diff --git a/src/api/views.py b/src/api/views.py\n--- a/src/api/views.py\n+++ b/src/api/views.py\n@@ -84,6 +84,7 @@\n Response is a JSON dictionary with the key \"available\" and value true or\n false.\n \"\"\"\n+ domain = request.GET.get(\"domain\", \"\")\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # validate that the given domain could be a domain name and fail early if\n # not.\ndiff --git a/src/registrar/config/urls.py b/src/registrar/config/urls.py\n--- a/src/registrar/config/urls.py\n+++ b/src/registrar/config/urls.py\n@@ -73,7 +73,7 @@\n path(\"health/\", views.health),\n path(\"openid/\", include(\"djangooidc.urls\")),\n path(\"register/\", include((application_urls, APPLICATION_NAMESPACE))),\n- path(\"api/v1/available/<domain>\", available, name=\"available\"),\n+ path(\"api/v1/available/\", available, name=\"available\"),\n path(\"api/v1/get-report/current-federal\", get_current_federal, name=\"get-current-federal\"),\n path(\"api/v1/get-report/current-full\", get_current_full, name=\"get-current-full\"),\n path(\n", "issue": "Subdomain request checking and error presentation\n### Story\n\nAs a domain applicant, if I'm typing a subdomain on the domain page\nI want to be presented with an error\nso that I know that I can't submit a subdomain.\n\n\n### Acceptance Criteria\n\n- [ ] Leverage the existing in page error handling to present the user with content derived from #324 \n- [ ] Add a unit test to check validation\n- [ ] Submissions should be denied if two dots are present. (Check for the edge case when two \".\" are not separated by characters: that state being \"..\")\n- [ ] Submissions should be denied if two dots are present. (Check for the edge case when a \".\" is at the beginning if the domain without characters in front: that state being \".something.\"\n- [ ] Confirm other edge cases\n\n### Additional Context\n\n_No response_\n\n### Issue Links\n\nBlocked by: #324\nRelated to: #720 \n", "before_files": [{"content": "\"\"\"Internal API views\"\"\"\nfrom django.apps import apps\nfrom django.views.decorators.http import require_http_methods\nfrom django.http import HttpResponse, JsonResponse\nfrom django.utils.safestring import mark_safe\n\nfrom registrar.templatetags.url_helpers import public_site_url\nfrom registrar.utility.errors import GenericError, GenericErrorCodes\n\nimport requests\n\nfrom login_required import login_not_required\n\nfrom cachetools.func import ttl_cache\n\nfrom registrar.utility.s3_bucket import S3ClientError, S3ClientHelper\n\n\nDOMAIN_FILE_URL = \"https://raw.githubusercontent.com/cisagov/dotgov-data/main/current-full.csv\"\n\n\nDOMAIN_API_MESSAGES = {\n \"required\": \"Enter the .gov domain you want. Don\u2019t include \u201cwww\u201d or \u201c.gov.\u201d\"\n \" For example, if you want www.city.gov, you would enter \u201ccity\u201d\"\n \" (without the quotes).\",\n \"extra_dots\": \"Enter the .gov domain you want without any periods.\",\n # message below is considered safe; no user input can be inserted into the message\n # body; public_site_url() function reads from local app settings and therefore safe\n \"unavailable\": mark_safe( # nosec\n \"That domain isn\u2019t available. \"\n \"<a class='usa-link' href='{}' target='_blank'>\"\n \"Read more about choosing your .gov domain.</a>\".format(public_site_url(\"domains/choosing\"))\n ),\n \"invalid\": \"Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).\",\n \"success\": \"That domain is available!\",\n \"error\": GenericError.get_error_message(GenericErrorCodes.CANNOT_CONTACT_REGISTRY),\n}\n\n\n# this file doesn't change that often, nor is it that big, so cache the result\n# in memory for ten minutes\n@ttl_cache(ttl=600)\ndef _domains():\n \"\"\"Return a list of the current .gov domains.\n\n Fetch a file from DOMAIN_FILE_URL, parse the CSV for the domain,\n lowercase everything and return the list.\n \"\"\"\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # 5 second timeout\n file_contents = requests.get(DOMAIN_FILE_URL, timeout=5).text\n domains = set()\n # skip the first line\n for line in file_contents.splitlines()[1:]:\n # get the domain before the first comma\n domain = line.split(\",\", 1)[0]\n # sanity-check the string we got from the file here\n if DraftDomain.string_could_be_domain(domain):\n # lowercase everything when we put it in domains\n domains.add(domain.lower())\n return domains\n\n\ndef check_domain_available(domain):\n \"\"\"Return true if the given domain is available.\n\n The given domain is lowercased to match against the domains list. If the\n given domain doesn't end with .gov, \".gov\" is added when looking for\n a match. If check fails, throws a RegistryError.\n \"\"\"\n Domain = apps.get_model(\"registrar.Domain\")\n if domain.endswith(\".gov\"):\n return Domain.available(domain)\n else:\n # domain search string doesn't end with .gov, add it on here\n return Domain.available(domain + \".gov\")\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef available(request, domain=\"\"):\n \"\"\"Is a given domain available or not.\n\n Response is a JSON dictionary with the key \"available\" and value true or\n false.\n \"\"\"\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # validate that the given domain could be a domain name and fail early if\n # not.\n if not (DraftDomain.string_could_be_domain(domain) or DraftDomain.string_could_be_domain(domain + \".gov\")):\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"invalid\"]})\n # a domain is available if it is NOT in the list of current domains\n try:\n if check_domain_available(domain):\n return JsonResponse({\"available\": True, \"message\": DOMAIN_API_MESSAGES[\"success\"]})\n else:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"unavailable\"]})\n except Exception:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"error\"]})\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef get_current_full(request, file_name=\"current-full.csv\"):\n \"\"\"This will return the file content of current-full.csv which is the command\n output of generate_current_full_report.py. This command iterates through each Domain\n and returns a CSV representation.\"\"\"\n return serve_file(file_name)\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef get_current_federal(request, file_name=\"current-federal.csv\"):\n \"\"\"This will return the file content of current-federal.csv which is the command\n output of generate_current_federal_report.py. This command iterates through each Domain\n and returns a CSV representation.\"\"\"\n return serve_file(file_name)\n\n\ndef serve_file(file_name):\n \"\"\"Downloads a file based on a given filepath. Returns a 500 if not found.\"\"\"\n s3_client = S3ClientHelper()\n # Serve the CSV file. If not found, an exception will be thrown.\n # This will then be caught by flat, causing it to not read it - which is what we want.\n try:\n file = s3_client.get_file(file_name, decode_to_utf=True)\n except S3ClientError as err:\n # TODO - #1317: Notify operations when auto report generation fails\n raise err\n\n response = HttpResponse(file)\n return response\n", "path": "src/api/views.py"}, {"content": "\"\"\"URL Configuration\n\nFor more information see:\n https://docs.djangoproject.com/en/4.0/topics/http/urls/\n\"\"\"\n\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom django.views.generic import RedirectView\n\nfrom registrar import views\nfrom registrar.views.application import Step\nfrom registrar.views.utility import always_404\nfrom api.views import available, get_current_federal, get_current_full\n\n\nAPPLICATION_NAMESPACE = views.ApplicationWizard.URL_NAMESPACE\napplication_urls = [\n path(\"\", views.ApplicationWizard.as_view(), name=\"\"),\n path(\"finished/\", views.Finished.as_view(), name=\"finished\"),\n]\n\n# dynamically generate the other application_urls\nfor step, view in [\n # add/remove steps here\n (Step.ORGANIZATION_TYPE, views.OrganizationType),\n (Step.TRIBAL_GOVERNMENT, views.TribalGovernment),\n (Step.ORGANIZATION_FEDERAL, views.OrganizationFederal),\n (Step.ORGANIZATION_ELECTION, views.OrganizationElection),\n (Step.ORGANIZATION_CONTACT, views.OrganizationContact),\n (Step.ABOUT_YOUR_ORGANIZATION, views.AboutYourOrganization),\n (Step.AUTHORIZING_OFFICIAL, views.AuthorizingOfficial),\n (Step.CURRENT_SITES, views.CurrentSites),\n (Step.DOTGOV_DOMAIN, views.DotgovDomain),\n (Step.PURPOSE, views.Purpose),\n (Step.YOUR_CONTACT, views.YourContact),\n (Step.OTHER_CONTACTS, views.OtherContacts),\n (Step.NO_OTHER_CONTACTS, views.NoOtherContacts),\n (Step.ANYTHING_ELSE, views.AnythingElse),\n (Step.REQUIREMENTS, views.Requirements),\n (Step.REVIEW, views.Review),\n]:\n application_urls.append(path(f\"{step}/\", view.as_view(), name=step))\n\n\nurlpatterns = [\n path(\"\", views.index, name=\"home\"),\n path(\n \"admin/logout/\",\n RedirectView.as_view(pattern_name=\"logout\", permanent=False),\n ),\n path(\"admin/\", admin.site.urls),\n path(\n \"application/<id>/edit/\",\n views.ApplicationWizard.as_view(),\n name=views.ApplicationWizard.EDIT_URL_NAME,\n ),\n path(\n \"application/<int:pk>\",\n views.ApplicationStatus.as_view(),\n name=\"application-status\",\n ),\n path(\n \"application/<int:pk>/withdraw\",\n views.ApplicationWithdrawConfirmation.as_view(),\n name=\"application-withdraw-confirmation\",\n ),\n path(\n \"application/<int:pk>/withdrawconfirmed\",\n views.ApplicationWithdrawn.as_view(),\n name=\"application-withdrawn\",\n ),\n path(\"health/\", views.health),\n path(\"openid/\", include(\"djangooidc.urls\")),\n path(\"register/\", include((application_urls, APPLICATION_NAMESPACE))),\n path(\"api/v1/available/<domain>\", available, name=\"available\"),\n path(\"api/v1/get-report/current-federal\", get_current_federal, name=\"get-current-federal\"),\n path(\"api/v1/get-report/current-full\", get_current_full, name=\"get-current-full\"),\n path(\n \"todo\",\n lambda r: always_404(r, \"We forgot to include this link, sorry.\"),\n name=\"todo\",\n ),\n path(\"domain/<int:pk>\", views.DomainView.as_view(), name=\"domain\"),\n path(\"domain/<int:pk>/users\", views.DomainUsersView.as_view(), name=\"domain-users\"),\n path(\n \"domain/<int:pk>/dns\",\n views.DomainDNSView.as_view(),\n name=\"domain-dns\",\n ),\n path(\n \"domain/<int:pk>/dns/nameservers\",\n views.DomainNameserversView.as_view(),\n name=\"domain-dns-nameservers\",\n ),\n path(\n \"domain/<int:pk>/dns/dnssec\",\n views.DomainDNSSECView.as_view(),\n name=\"domain-dns-dnssec\",\n ),\n path(\n \"domain/<int:pk>/dns/dnssec/dsdata\",\n views.DomainDsDataView.as_view(),\n name=\"domain-dns-dnssec-dsdata\",\n ),\n path(\n \"domain/<int:pk>/your-contact-information\",\n views.DomainYourContactInformationView.as_view(),\n name=\"domain-your-contact-information\",\n ),\n path(\n \"domain/<int:pk>/org-name-address\",\n views.DomainOrgNameAddressView.as_view(),\n name=\"domain-org-name-address\",\n ),\n path(\n \"domain/<int:pk>/authorizing-official\",\n views.DomainAuthorizingOfficialView.as_view(),\n name=\"domain-authorizing-official\",\n ),\n path(\n \"domain/<int:pk>/security-email\",\n views.DomainSecurityEmailView.as_view(),\n name=\"domain-security-email\",\n ),\n path(\n \"domain/<int:pk>/users/add\",\n views.DomainAddUserView.as_view(),\n name=\"domain-users-add\",\n ),\n path(\n \"invitation/<int:pk>/delete\",\n views.DomainInvitationDeleteView.as_view(http_method_names=[\"post\"]),\n name=\"invitation-delete\",\n ),\n]\n\n# we normally would guard these with `if settings.DEBUG` but tests run with\n# DEBUG = False even when these apps have been loaded because settings.DEBUG\n# was actually True. Instead, let's add these URLs any time we are able to\n# import the debug toolbar package.\ntry:\n import debug_toolbar # type: ignore\n\n urlpatterns += [path(\"__debug__/\", include(debug_toolbar.urls))]\nexcept ImportError:\n pass\n", "path": "src/registrar/config/urls.py"}], "after_files": [{"content": "\"\"\"Internal API views\"\"\"\nfrom django.apps import apps\nfrom django.views.decorators.http import require_http_methods\nfrom django.http import HttpResponse, JsonResponse\nfrom django.utils.safestring import mark_safe\n\nfrom registrar.templatetags.url_helpers import public_site_url\nfrom registrar.utility.errors import GenericError, GenericErrorCodes\n\nimport requests\n\nfrom login_required import login_not_required\n\nfrom cachetools.func import ttl_cache\n\nfrom registrar.utility.s3_bucket import S3ClientError, S3ClientHelper\n\n\nDOMAIN_FILE_URL = \"https://raw.githubusercontent.com/cisagov/dotgov-data/main/current-full.csv\"\n\n\nDOMAIN_API_MESSAGES = {\n \"required\": \"Enter the .gov domain you want. Don\u2019t include \u201cwww\u201d or \u201c.gov.\u201d\"\n \" For example, if you want www.city.gov, you would enter \u201ccity\u201d\"\n \" (without the quotes).\",\n \"extra_dots\": \"Enter the .gov domain you want without any periods.\",\n # message below is considered safe; no user input can be inserted into the message\n # body; public_site_url() function reads from local app settings and therefore safe\n \"unavailable\": mark_safe( # nosec\n \"That domain isn\u2019t available. \"\n \"<a class='usa-link' href='{}' target='_blank'>\"\n \"Read more about choosing your .gov domain.</a>\".format(public_site_url(\"domains/choosing\"))\n ),\n \"invalid\": \"Enter a domain using only letters, numbers, or hyphens (though we don't recommend using hyphens).\",\n \"success\": \"That domain is available!\",\n \"error\": GenericError.get_error_message(GenericErrorCodes.CANNOT_CONTACT_REGISTRY),\n}\n\n\n# this file doesn't change that often, nor is it that big, so cache the result\n# in memory for ten minutes\n@ttl_cache(ttl=600)\ndef _domains():\n \"\"\"Return a list of the current .gov domains.\n\n Fetch a file from DOMAIN_FILE_URL, parse the CSV for the domain,\n lowercase everything and return the list.\n \"\"\"\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # 5 second timeout\n file_contents = requests.get(DOMAIN_FILE_URL, timeout=5).text\n domains = set()\n # skip the first line\n for line in file_contents.splitlines()[1:]:\n # get the domain before the first comma\n domain = line.split(\",\", 1)[0]\n # sanity-check the string we got from the file here\n if DraftDomain.string_could_be_domain(domain):\n # lowercase everything when we put it in domains\n domains.add(domain.lower())\n return domains\n\n\ndef check_domain_available(domain):\n \"\"\"Return true if the given domain is available.\n\n The given domain is lowercased to match against the domains list. If the\n given domain doesn't end with .gov, \".gov\" is added when looking for\n a match. If check fails, throws a RegistryError.\n \"\"\"\n Domain = apps.get_model(\"registrar.Domain\")\n if domain.endswith(\".gov\"):\n return Domain.available(domain)\n else:\n # domain search string doesn't end with .gov, add it on here\n return Domain.available(domain + \".gov\")\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef available(request, domain=\"\"):\n \"\"\"Is a given domain available or not.\n\n Response is a JSON dictionary with the key \"available\" and value true or\n false.\n \"\"\"\n domain = request.GET.get(\"domain\", \"\")\n DraftDomain = apps.get_model(\"registrar.DraftDomain\")\n # validate that the given domain could be a domain name and fail early if\n # not.\n if not (DraftDomain.string_could_be_domain(domain) or DraftDomain.string_could_be_domain(domain + \".gov\")):\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"invalid\"]})\n # a domain is available if it is NOT in the list of current domains\n try:\n if check_domain_available(domain):\n return JsonResponse({\"available\": True, \"message\": DOMAIN_API_MESSAGES[\"success\"]})\n else:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"unavailable\"]})\n except Exception:\n return JsonResponse({\"available\": False, \"message\": DOMAIN_API_MESSAGES[\"error\"]})\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef get_current_full(request, file_name=\"current-full.csv\"):\n \"\"\"This will return the file content of current-full.csv which is the command\n output of generate_current_full_report.py. This command iterates through each Domain\n and returns a CSV representation.\"\"\"\n return serve_file(file_name)\n\n\n@require_http_methods([\"GET\"])\n@login_not_required\ndef get_current_federal(request, file_name=\"current-federal.csv\"):\n \"\"\"This will return the file content of current-federal.csv which is the command\n output of generate_current_federal_report.py. This command iterates through each Domain\n and returns a CSV representation.\"\"\"\n return serve_file(file_name)\n\n\ndef serve_file(file_name):\n \"\"\"Downloads a file based on a given filepath. Returns a 500 if not found.\"\"\"\n s3_client = S3ClientHelper()\n # Serve the CSV file. If not found, an exception will be thrown.\n # This will then be caught by flat, causing it to not read it - which is what we want.\n try:\n file = s3_client.get_file(file_name, decode_to_utf=True)\n except S3ClientError as err:\n # TODO - #1317: Notify operations when auto report generation fails\n raise err\n\n response = HttpResponse(file)\n return response\n", "path": "src/api/views.py"}, {"content": "\"\"\"URL Configuration\n\nFor more information see:\n https://docs.djangoproject.com/en/4.0/topics/http/urls/\n\"\"\"\n\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom django.views.generic import RedirectView\n\nfrom registrar import views\nfrom registrar.views.application import Step\nfrom registrar.views.utility import always_404\nfrom api.views import available, get_current_federal, get_current_full\n\n\nAPPLICATION_NAMESPACE = views.ApplicationWizard.URL_NAMESPACE\napplication_urls = [\n path(\"\", views.ApplicationWizard.as_view(), name=\"\"),\n path(\"finished/\", views.Finished.as_view(), name=\"finished\"),\n]\n\n# dynamically generate the other application_urls\nfor step, view in [\n # add/remove steps here\n (Step.ORGANIZATION_TYPE, views.OrganizationType),\n (Step.TRIBAL_GOVERNMENT, views.TribalGovernment),\n (Step.ORGANIZATION_FEDERAL, views.OrganizationFederal),\n (Step.ORGANIZATION_ELECTION, views.OrganizationElection),\n (Step.ORGANIZATION_CONTACT, views.OrganizationContact),\n (Step.ABOUT_YOUR_ORGANIZATION, views.AboutYourOrganization),\n (Step.AUTHORIZING_OFFICIAL, views.AuthorizingOfficial),\n (Step.CURRENT_SITES, views.CurrentSites),\n (Step.DOTGOV_DOMAIN, views.DotgovDomain),\n (Step.PURPOSE, views.Purpose),\n (Step.YOUR_CONTACT, views.YourContact),\n (Step.OTHER_CONTACTS, views.OtherContacts),\n (Step.NO_OTHER_CONTACTS, views.NoOtherContacts),\n (Step.ANYTHING_ELSE, views.AnythingElse),\n (Step.REQUIREMENTS, views.Requirements),\n (Step.REVIEW, views.Review),\n]:\n application_urls.append(path(f\"{step}/\", view.as_view(), name=step))\n\n\nurlpatterns = [\n path(\"\", views.index, name=\"home\"),\n path(\n \"admin/logout/\",\n RedirectView.as_view(pattern_name=\"logout\", permanent=False),\n ),\n path(\"admin/\", admin.site.urls),\n path(\n \"application/<id>/edit/\",\n views.ApplicationWizard.as_view(),\n name=views.ApplicationWizard.EDIT_URL_NAME,\n ),\n path(\n \"application/<int:pk>\",\n views.ApplicationStatus.as_view(),\n name=\"application-status\",\n ),\n path(\n \"application/<int:pk>/withdraw\",\n views.ApplicationWithdrawConfirmation.as_view(),\n name=\"application-withdraw-confirmation\",\n ),\n path(\n \"application/<int:pk>/withdrawconfirmed\",\n views.ApplicationWithdrawn.as_view(),\n name=\"application-withdrawn\",\n ),\n path(\"health/\", views.health),\n path(\"openid/\", include(\"djangooidc.urls\")),\n path(\"register/\", include((application_urls, APPLICATION_NAMESPACE))),\n path(\"api/v1/available/\", available, name=\"available\"),\n path(\"api/v1/get-report/current-federal\", get_current_federal, name=\"get-current-federal\"),\n path(\"api/v1/get-report/current-full\", get_current_full, name=\"get-current-full\"),\n path(\n \"todo\",\n lambda r: always_404(r, \"We forgot to include this link, sorry.\"),\n name=\"todo\",\n ),\n path(\"domain/<int:pk>\", views.DomainView.as_view(), name=\"domain\"),\n path(\"domain/<int:pk>/users\", views.DomainUsersView.as_view(), name=\"domain-users\"),\n path(\n \"domain/<int:pk>/dns\",\n views.DomainDNSView.as_view(),\n name=\"domain-dns\",\n ),\n path(\n \"domain/<int:pk>/dns/nameservers\",\n views.DomainNameserversView.as_view(),\n name=\"domain-dns-nameservers\",\n ),\n path(\n \"domain/<int:pk>/dns/dnssec\",\n views.DomainDNSSECView.as_view(),\n name=\"domain-dns-dnssec\",\n ),\n path(\n \"domain/<int:pk>/dns/dnssec/dsdata\",\n views.DomainDsDataView.as_view(),\n name=\"domain-dns-dnssec-dsdata\",\n ),\n path(\n \"domain/<int:pk>/your-contact-information\",\n views.DomainYourContactInformationView.as_view(),\n name=\"domain-your-contact-information\",\n ),\n path(\n \"domain/<int:pk>/org-name-address\",\n views.DomainOrgNameAddressView.as_view(),\n name=\"domain-org-name-address\",\n ),\n path(\n \"domain/<int:pk>/authorizing-official\",\n views.DomainAuthorizingOfficialView.as_view(),\n name=\"domain-authorizing-official\",\n ),\n path(\n \"domain/<int:pk>/security-email\",\n views.DomainSecurityEmailView.as_view(),\n name=\"domain-security-email\",\n ),\n path(\n \"domain/<int:pk>/users/add\",\n views.DomainAddUserView.as_view(),\n name=\"domain-users-add\",\n ),\n path(\n \"invitation/<int:pk>/delete\",\n views.DomainInvitationDeleteView.as_view(http_method_names=[\"post\"]),\n name=\"invitation-delete\",\n ),\n]\n\n# we normally would guard these with `if settings.DEBUG` but tests run with\n# DEBUG = False even when these apps have been loaded because settings.DEBUG\n# was actually True. Instead, let's add these URLs any time we are able to\n# import the debug toolbar package.\ntry:\n import debug_toolbar # type: ignore\n\n urlpatterns += [path(\"__debug__/\", include(debug_toolbar.urls))]\nexcept ImportError:\n pass\n", "path": "src/registrar/config/urls.py"}]}
| 3,482 | 275 |
gh_patches_debug_37009
|
rasdani/github-patches
|
git_diff
|
mozilla__pontoon-2846
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Refine pretranslation logic for strings with rejected suggestions
Currently, a string with suggestions is ignored by pretranslation.
We should:
* Pretranslate if all suggestions are submitted by users and rejected.
* Not pretranslate if a pretranslation was already rejected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pontoon/pretranslation/pretranslate.py`
Content:
```
1 import logging
2 import operator
3 import re
4
5 from django.db.models import CharField, Value as V
6 from django.db.models.functions import Concat
7
8 from fluent.syntax import FluentParser, FluentSerializer
9 from functools import reduce
10
11 from pontoon.base.models import User, TranslatedResource
12 from pontoon.base.fluent import FlatTransformer, create_locale_plural_variants
13 from pontoon.machinery.utils import (
14 get_google_translate_data,
15 get_translation_memory_data,
16 )
17
18
19 log = logging.getLogger(__name__)
20
21 parser = FluentParser()
22 serializer = FluentSerializer()
23
24
25 class PretranslationTransformer(FlatTransformer):
26 def __init__(self, locale):
27 self.services = []
28 self.locale = locale
29
30 def visit_SelectExpression(self, node):
31 create_locale_plural_variants(node, self.locale)
32 return self.generic_visit(node)
33
34 def visit_TextElement(self, node):
35 # Machine translation treats each line as separate sentence,
36 # hence we replace newline characters with spaces.
37 source = node.value.replace("\n", " ")
38
39 pretranslation, service = get_pretranslated_data(source, self.locale)
40
41 if pretranslation is None:
42 raise ValueError(
43 f"Pretranslation for `{source}` to {self.locale.code} not available."
44 )
45
46 node.value = pretranslation
47 self.services.append(service)
48 return node
49
50
51 def get_pretranslations(entity, locale):
52 """
53 Get pretranslations for the entity-locale pair using internal translation memory and
54 Google's machine translation.
55
56 For Fluent strings, uplift SelectExpressions, serialize Placeables as TextElements
57 and then only pretranslate TextElements. Set the most frequent TextElement
58 pretranslation author as the author of the entire pretranslation.
59
60 :arg Entity entity: the Entity object
61 :arg Locale locale: the Locale object
62
63 :returns: a list of tuples, consisting of:
64 - a pretranslation of the entity
65 - a plural form
66 - a user (representing TM or GT service)
67 """
68 source = entity.string
69 services = {
70 "tm": User.objects.get(email="[email protected]"),
71 "gt": User.objects.get(email="[email protected]"),
72 }
73
74 if entity.resource.format == "ftl":
75 source_ast = parser.parse_entry(source)
76 pt_transformer = PretranslationTransformer(locale)
77
78 try:
79 pretranslated_ast = pt_transformer.visit(source_ast)
80 except ValueError as e:
81 log.info(f"Fluent pretranslation error: {e}")
82 return []
83
84 pretranslation = serializer.serialize_entry(pretranslated_ast)
85
86 authors = [services[service] for service in pt_transformer.services]
87 author = max(set(authors), key=authors.count) if authors else services["tm"]
88
89 return [(pretranslation, None, author)]
90
91 else:
92 pretranslation, service = get_pretranslated_data(source, locale)
93
94 if pretranslation is None:
95 return []
96
97 author = services[service]
98 if entity.string_plural == "":
99 return [(pretranslation, None, author)]
100 else:
101 plural_forms = range(0, locale.nplurals or 1)
102 return [
103 (pretranslation, plural_form, author) for plural_form in plural_forms
104 ]
105
106
107 def get_pretranslated_data(source, locale):
108 # Empty strings do not need translation
109 if re.search("^\\s*$", source):
110 return source, "tm"
111
112 # Try to get matches from Translation Memory
113 tm_response = get_translation_memory_data(text=source, locale=locale)
114 tm_perfect = [t for t in tm_response if int(t["quality"]) == 100]
115 if tm_perfect:
116 return tm_perfect[0]["target"], "tm"
117
118 # Fetch from Google Translate
119 elif locale.google_translate_code:
120 gt_response = get_google_translate_data(text=source, locale=locale)
121 if gt_response["status"]:
122 return gt_response["translation"], "gt"
123
124 return None, None
125
126
127 def update_changed_instances(tr_filter, tr_dict, translations):
128 """
129 Update the latest activity and stats for changed Locales, ProjectLocales
130 & TranslatedResources
131 """
132 tr_filter = tuple(tr_filter)
133 # Combine all generated filters with an OK operator.
134 # `operator.ior` is the '|' Python operator, which turns into a logical OR
135 # when used between django ORM query objects.
136 tr_query = reduce(operator.ior, tr_filter)
137
138 translatedresources = TranslatedResource.objects.filter(tr_query).annotate(
139 locale_resource=Concat(
140 "locale_id", V("-"), "resource_id", output_field=CharField()
141 )
142 )
143
144 translatedresources.update_stats()
145
146 for tr in translatedresources:
147 index = tr_dict[tr.locale_resource]
148 translation = translations[index]
149 translation.update_latest_translation()
150
```
Path: `pontoon/pretranslation/__init__.py`
Content:
```
```
Path: `pontoon/pretranslation/tasks.py`
Content:
```
1 import logging
2
3 from django.db.models import Q, CharField, Value as V
4 from django.db.models.functions import Concat
5 from django.conf import settings
6 from pontoon.base.models import (
7 Project,
8 Entity,
9 TranslatedResource,
10 Translation,
11 )
12 from pontoon.actionlog.models import ActionLog
13 from pontoon.pretranslation.pretranslate import (
14 get_pretranslations,
15 update_changed_instances,
16 )
17 from pontoon.base.tasks import PontoonTask
18 from pontoon.sync.core import serial_task
19 from pontoon.checks.utils import bulk_run_checks
20
21
22 log = logging.getLogger(__name__)
23
24
25 @serial_task(settings.SYNC_TASK_TIMEOUT, base=PontoonTask, lock_key="project={0}")
26 def pretranslate(self, project_pk, locales=None, entities=None):
27 """
28 Identifies strings without any translations and any suggestions.
29 Engages TheAlgorithm (bug 1552796) to gather pretranslations.
30 Stores pretranslations as suggestions (approved=False) to DB.
31
32 :arg project_pk: the pk of the project to be pretranslated
33 :arg Queryset locales: the locales for the project to be pretranslated
34 :arg Queryset entites: the entities for the project to be pretranslated
35
36 :returns: None
37 """
38 project = Project.objects.get(pk=project_pk)
39
40 if not project.pretranslation_enabled:
41 log.info(f"Pretranslation not enabled for project {project.name}")
42 return
43
44 if locales:
45 locales = project.locales.filter(pk__in=locales)
46 else:
47 locales = project.locales
48
49 locales = locales.filter(
50 project_locale__project=project,
51 project_locale__pretranslation_enabled=True,
52 project_locale__readonly=False,
53 )
54
55 if not locales:
56 log.info(
57 f"Pretranslation not enabled for any locale within project {project.name}"
58 )
59 return
60
61 log.info(f"Fetching pretranslations for project {project.name} started")
62
63 if not entities:
64 entities = Entity.objects.filter(
65 resource__project=project,
66 obsolete=False,
67 )
68
69 entities = entities.prefetch_related("resource")
70
71 # get available TranslatedResource pairs
72 tr_pairs = (
73 TranslatedResource.objects.filter(
74 resource__project=project,
75 locale__in=locales,
76 )
77 .annotate(
78 locale_resource=Concat(
79 "locale_id", V("-"), "resource_id", output_field=CharField()
80 )
81 )
82 .values_list("locale_resource", flat=True)
83 .distinct()
84 )
85
86 # Fetch all distinct locale-entity pairs for which translation exists
87 translated_entities = (
88 Translation.objects.filter(
89 locale__in=locales,
90 entity__in=entities,
91 )
92 .annotate(
93 locale_entity=Concat(
94 "locale_id", V("-"), "entity_id", output_field=CharField()
95 )
96 )
97 .values_list("locale_entity", flat=True)
98 .distinct()
99 )
100
101 translated_entities = list(translated_entities)
102
103 translations = []
104
105 # To keep track of changed TranslatedResources and their latest_translation
106 tr_dict = {}
107
108 tr_filter = []
109 index = -1
110
111 for locale in locales:
112 log.info(f"Fetching pretranslations for locale {locale.code} started")
113 for entity in entities:
114 locale_entity = f"{locale.id}-{entity.id}"
115 locale_resource = f"{locale.id}-{entity.resource.id}"
116 if locale_entity in translated_entities or locale_resource not in tr_pairs:
117 continue
118
119 pretranslations = get_pretranslations(entity, locale)
120
121 if not pretranslations:
122 continue
123
124 for string, plural_form, user in pretranslations:
125 t = Translation(
126 entity=entity,
127 locale=locale,
128 string=string,
129 user=user,
130 approved=False,
131 pretranslated=True,
132 active=True,
133 plural_form=plural_form,
134 )
135
136 index += 1
137 translations.append(t)
138
139 if locale_resource not in tr_dict:
140 tr_dict[locale_resource] = index
141
142 # Add query for fetching respective TranslatedResource.
143 tr_filter.append(
144 Q(locale__id=locale.id) & Q(resource__id=entity.resource.id)
145 )
146
147 # Update the latest translation index
148 tr_dict[locale_resource] = index
149
150 log.info(f"Fetching pretranslations for locale {locale.code} done")
151
152 if len(translations) == 0:
153 return
154
155 translations = Translation.objects.bulk_create(translations)
156
157 # Log creating actions
158 actions_to_log = [
159 ActionLog(
160 action_type=ActionLog.ActionType.TRANSLATION_CREATED,
161 performed_by=t.user,
162 translation=t,
163 )
164 for t in translations
165 ]
166
167 ActionLog.objects.bulk_create(actions_to_log)
168
169 # Run checks on all translations
170 translation_pks = {translation.pk for translation in translations}
171 bulk_run_checks(Translation.objects.for_checks().filter(pk__in=translation_pks))
172
173 # Mark translations as changed
174 changed_translations = Translation.objects.filter(
175 pk__in=translation_pks,
176 # Do not sync translations with errors and warnings
177 errors__isnull=True,
178 warnings__isnull=True,
179 )
180 changed_translations.bulk_mark_changed()
181
182 # Update latest activity and stats for changed instances.
183 update_changed_instances(tr_filter, tr_dict, translations)
184
185 log.info(f"Fetching pretranslations for project {project.name} done")
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pontoon/pretranslation/__init__.py b/pontoon/pretranslation/__init__.py
--- a/pontoon/pretranslation/__init__.py
+++ b/pontoon/pretranslation/__init__.py
@@ -0,0 +1,4 @@
+AUTHORS = {
+ "tm": "[email protected]",
+ "gt": "[email protected]",
+}
diff --git a/pontoon/pretranslation/pretranslate.py b/pontoon/pretranslation/pretranslate.py
--- a/pontoon/pretranslation/pretranslate.py
+++ b/pontoon/pretranslation/pretranslate.py
@@ -14,6 +14,7 @@
get_google_translate_data,
get_translation_memory_data,
)
+from pontoon.pretranslation import AUTHORS
log = logging.getLogger(__name__)
@@ -66,10 +67,7 @@
- a user (representing TM or GT service)
"""
source = entity.string
- services = {
- "tm": User.objects.get(email="[email protected]"),
- "gt": User.objects.get(email="[email protected]"),
- }
+ services = {k: User.objects.get(email=email) for k, email in AUTHORS.items()}
if entity.resource.format == "ftl":
source_ast = parser.parse_entry(source)
diff --git a/pontoon/pretranslation/tasks.py b/pontoon/pretranslation/tasks.py
--- a/pontoon/pretranslation/tasks.py
+++ b/pontoon/pretranslation/tasks.py
@@ -8,8 +8,10 @@
Entity,
TranslatedResource,
Translation,
+ User,
)
from pontoon.actionlog.models import ActionLog
+from pontoon.pretranslation import AUTHORS
from pontoon.pretranslation.pretranslate import (
get_pretranslations,
update_changed_instances,
@@ -68,7 +70,7 @@
entities = entities.prefetch_related("resource")
- # get available TranslatedResource pairs
+ # Fetch all available locale-resource pairs (TranslatedResource objects)
tr_pairs = (
TranslatedResource.objects.filter(
resource__project=project,
@@ -83,12 +85,14 @@
.distinct()
)
- # Fetch all distinct locale-entity pairs for which translation exists
+ # Fetch all locale-entity pairs with non-rejected or pretranslated translations
+ pt_authors = [User.objects.get(email=email) for email in AUTHORS.values()]
translated_entities = (
Translation.objects.filter(
locale__in=locales,
entity__in=entities,
)
+ .filter(Q(rejected=False) | Q(user__in=pt_authors))
.annotate(
locale_entity=Concat(
"locale_id", V("-"), "entity_id", output_field=CharField()
|
{"golden_diff": "diff --git a/pontoon/pretranslation/__init__.py b/pontoon/pretranslation/__init__.py\n--- a/pontoon/pretranslation/__init__.py\n+++ b/pontoon/pretranslation/__init__.py\n@@ -0,0 +1,4 @@\n+AUTHORS = {\n+ \"tm\": \"[email protected]\",\n+ \"gt\": \"[email protected]\",\n+}\ndiff --git a/pontoon/pretranslation/pretranslate.py b/pontoon/pretranslation/pretranslate.py\n--- a/pontoon/pretranslation/pretranslate.py\n+++ b/pontoon/pretranslation/pretranslate.py\n@@ -14,6 +14,7 @@\n get_google_translate_data,\n get_translation_memory_data,\n )\n+from pontoon.pretranslation import AUTHORS\n \n \n log = logging.getLogger(__name__)\n@@ -66,10 +67,7 @@\n - a user (representing TM or GT service)\n \"\"\"\n source = entity.string\n- services = {\n- \"tm\": User.objects.get(email=\"[email protected]\"),\n- \"gt\": User.objects.get(email=\"[email protected]\"),\n- }\n+ services = {k: User.objects.get(email=email) for k, email in AUTHORS.items()}\n \n if entity.resource.format == \"ftl\":\n source_ast = parser.parse_entry(source)\ndiff --git a/pontoon/pretranslation/tasks.py b/pontoon/pretranslation/tasks.py\n--- a/pontoon/pretranslation/tasks.py\n+++ b/pontoon/pretranslation/tasks.py\n@@ -8,8 +8,10 @@\n Entity,\n TranslatedResource,\n Translation,\n+ User,\n )\n from pontoon.actionlog.models import ActionLog\n+from pontoon.pretranslation import AUTHORS\n from pontoon.pretranslation.pretranslate import (\n get_pretranslations,\n update_changed_instances,\n@@ -68,7 +70,7 @@\n \n entities = entities.prefetch_related(\"resource\")\n \n- # get available TranslatedResource pairs\n+ # Fetch all available locale-resource pairs (TranslatedResource objects)\n tr_pairs = (\n TranslatedResource.objects.filter(\n resource__project=project,\n@@ -83,12 +85,14 @@\n .distinct()\n )\n \n- # Fetch all distinct locale-entity pairs for which translation exists\n+ # Fetch all locale-entity pairs with non-rejected or pretranslated translations\n+ pt_authors = [User.objects.get(email=email) for email in AUTHORS.values()]\n translated_entities = (\n Translation.objects.filter(\n locale__in=locales,\n entity__in=entities,\n )\n+ .filter(Q(rejected=False) | Q(user__in=pt_authors))\n .annotate(\n locale_entity=Concat(\n \"locale_id\", V(\"-\"), \"entity_id\", output_field=CharField()\n", "issue": "Refine pretranslation logic for strings with rejected suggestions\nCurrently, a string with suggestions is ignored by pretranslation.\r\n\r\nWe should:\r\n* Pretranslate if all suggestions are submitted by users and rejected. \r\n* Not pretranslate if a pretranslation was already rejected.\n", "before_files": [{"content": "import logging\nimport operator\nimport re\n\nfrom django.db.models import CharField, Value as V\nfrom django.db.models.functions import Concat\n\nfrom fluent.syntax import FluentParser, FluentSerializer\nfrom functools import reduce\n\nfrom pontoon.base.models import User, TranslatedResource\nfrom pontoon.base.fluent import FlatTransformer, create_locale_plural_variants\nfrom pontoon.machinery.utils import (\n get_google_translate_data,\n get_translation_memory_data,\n)\n\n\nlog = logging.getLogger(__name__)\n\nparser = FluentParser()\nserializer = FluentSerializer()\n\n\nclass PretranslationTransformer(FlatTransformer):\n def __init__(self, locale):\n self.services = []\n self.locale = locale\n\n def visit_SelectExpression(self, node):\n create_locale_plural_variants(node, self.locale)\n return self.generic_visit(node)\n\n def visit_TextElement(self, node):\n # Machine translation treats each line as separate sentence,\n # hence we replace newline characters with spaces.\n source = node.value.replace(\"\\n\", \" \")\n\n pretranslation, service = get_pretranslated_data(source, self.locale)\n\n if pretranslation is None:\n raise ValueError(\n f\"Pretranslation for `{source}` to {self.locale.code} not available.\"\n )\n\n node.value = pretranslation\n self.services.append(service)\n return node\n\n\ndef get_pretranslations(entity, locale):\n \"\"\"\n Get pretranslations for the entity-locale pair using internal translation memory and\n Google's machine translation.\n\n For Fluent strings, uplift SelectExpressions, serialize Placeables as TextElements\n and then only pretranslate TextElements. Set the most frequent TextElement\n pretranslation author as the author of the entire pretranslation.\n\n :arg Entity entity: the Entity object\n :arg Locale locale: the Locale object\n\n :returns: a list of tuples, consisting of:\n - a pretranslation of the entity\n - a plural form\n - a user (representing TM or GT service)\n \"\"\"\n source = entity.string\n services = {\n \"tm\": User.objects.get(email=\"[email protected]\"),\n \"gt\": User.objects.get(email=\"[email protected]\"),\n }\n\n if entity.resource.format == \"ftl\":\n source_ast = parser.parse_entry(source)\n pt_transformer = PretranslationTransformer(locale)\n\n try:\n pretranslated_ast = pt_transformer.visit(source_ast)\n except ValueError as e:\n log.info(f\"Fluent pretranslation error: {e}\")\n return []\n\n pretranslation = serializer.serialize_entry(pretranslated_ast)\n\n authors = [services[service] for service in pt_transformer.services]\n author = max(set(authors), key=authors.count) if authors else services[\"tm\"]\n\n return [(pretranslation, None, author)]\n\n else:\n pretranslation, service = get_pretranslated_data(source, locale)\n\n if pretranslation is None:\n return []\n\n author = services[service]\n if entity.string_plural == \"\":\n return [(pretranslation, None, author)]\n else:\n plural_forms = range(0, locale.nplurals or 1)\n return [\n (pretranslation, plural_form, author) for plural_form in plural_forms\n ]\n\n\ndef get_pretranslated_data(source, locale):\n # Empty strings do not need translation\n if re.search(\"^\\\\s*$\", source):\n return source, \"tm\"\n\n # Try to get matches from Translation Memory\n tm_response = get_translation_memory_data(text=source, locale=locale)\n tm_perfect = [t for t in tm_response if int(t[\"quality\"]) == 100]\n if tm_perfect:\n return tm_perfect[0][\"target\"], \"tm\"\n\n # Fetch from Google Translate\n elif locale.google_translate_code:\n gt_response = get_google_translate_data(text=source, locale=locale)\n if gt_response[\"status\"]:\n return gt_response[\"translation\"], \"gt\"\n\n return None, None\n\n\ndef update_changed_instances(tr_filter, tr_dict, translations):\n \"\"\"\n Update the latest activity and stats for changed Locales, ProjectLocales\n & TranslatedResources\n \"\"\"\n tr_filter = tuple(tr_filter)\n # Combine all generated filters with an OK operator.\n # `operator.ior` is the '|' Python operator, which turns into a logical OR\n # when used between django ORM query objects.\n tr_query = reduce(operator.ior, tr_filter)\n\n translatedresources = TranslatedResource.objects.filter(tr_query).annotate(\n locale_resource=Concat(\n \"locale_id\", V(\"-\"), \"resource_id\", output_field=CharField()\n )\n )\n\n translatedresources.update_stats()\n\n for tr in translatedresources:\n index = tr_dict[tr.locale_resource]\n translation = translations[index]\n translation.update_latest_translation()\n", "path": "pontoon/pretranslation/pretranslate.py"}, {"content": "", "path": "pontoon/pretranslation/__init__.py"}, {"content": "import logging\n\nfrom django.db.models import Q, CharField, Value as V\nfrom django.db.models.functions import Concat\nfrom django.conf import settings\nfrom pontoon.base.models import (\n Project,\n Entity,\n TranslatedResource,\n Translation,\n)\nfrom pontoon.actionlog.models import ActionLog\nfrom pontoon.pretranslation.pretranslate import (\n get_pretranslations,\n update_changed_instances,\n)\nfrom pontoon.base.tasks import PontoonTask\nfrom pontoon.sync.core import serial_task\nfrom pontoon.checks.utils import bulk_run_checks\n\n\nlog = logging.getLogger(__name__)\n\n\n@serial_task(settings.SYNC_TASK_TIMEOUT, base=PontoonTask, lock_key=\"project={0}\")\ndef pretranslate(self, project_pk, locales=None, entities=None):\n \"\"\"\n Identifies strings without any translations and any suggestions.\n Engages TheAlgorithm (bug 1552796) to gather pretranslations.\n Stores pretranslations as suggestions (approved=False) to DB.\n\n :arg project_pk: the pk of the project to be pretranslated\n :arg Queryset locales: the locales for the project to be pretranslated\n :arg Queryset entites: the entities for the project to be pretranslated\n\n :returns: None\n \"\"\"\n project = Project.objects.get(pk=project_pk)\n\n if not project.pretranslation_enabled:\n log.info(f\"Pretranslation not enabled for project {project.name}\")\n return\n\n if locales:\n locales = project.locales.filter(pk__in=locales)\n else:\n locales = project.locales\n\n locales = locales.filter(\n project_locale__project=project,\n project_locale__pretranslation_enabled=True,\n project_locale__readonly=False,\n )\n\n if not locales:\n log.info(\n f\"Pretranslation not enabled for any locale within project {project.name}\"\n )\n return\n\n log.info(f\"Fetching pretranslations for project {project.name} started\")\n\n if not entities:\n entities = Entity.objects.filter(\n resource__project=project,\n obsolete=False,\n )\n\n entities = entities.prefetch_related(\"resource\")\n\n # get available TranslatedResource pairs\n tr_pairs = (\n TranslatedResource.objects.filter(\n resource__project=project,\n locale__in=locales,\n )\n .annotate(\n locale_resource=Concat(\n \"locale_id\", V(\"-\"), \"resource_id\", output_field=CharField()\n )\n )\n .values_list(\"locale_resource\", flat=True)\n .distinct()\n )\n\n # Fetch all distinct locale-entity pairs for which translation exists\n translated_entities = (\n Translation.objects.filter(\n locale__in=locales,\n entity__in=entities,\n )\n .annotate(\n locale_entity=Concat(\n \"locale_id\", V(\"-\"), \"entity_id\", output_field=CharField()\n )\n )\n .values_list(\"locale_entity\", flat=True)\n .distinct()\n )\n\n translated_entities = list(translated_entities)\n\n translations = []\n\n # To keep track of changed TranslatedResources and their latest_translation\n tr_dict = {}\n\n tr_filter = []\n index = -1\n\n for locale in locales:\n log.info(f\"Fetching pretranslations for locale {locale.code} started\")\n for entity in entities:\n locale_entity = f\"{locale.id}-{entity.id}\"\n locale_resource = f\"{locale.id}-{entity.resource.id}\"\n if locale_entity in translated_entities or locale_resource not in tr_pairs:\n continue\n\n pretranslations = get_pretranslations(entity, locale)\n\n if not pretranslations:\n continue\n\n for string, plural_form, user in pretranslations:\n t = Translation(\n entity=entity,\n locale=locale,\n string=string,\n user=user,\n approved=False,\n pretranslated=True,\n active=True,\n plural_form=plural_form,\n )\n\n index += 1\n translations.append(t)\n\n if locale_resource not in tr_dict:\n tr_dict[locale_resource] = index\n\n # Add query for fetching respective TranslatedResource.\n tr_filter.append(\n Q(locale__id=locale.id) & Q(resource__id=entity.resource.id)\n )\n\n # Update the latest translation index\n tr_dict[locale_resource] = index\n\n log.info(f\"Fetching pretranslations for locale {locale.code} done\")\n\n if len(translations) == 0:\n return\n\n translations = Translation.objects.bulk_create(translations)\n\n # Log creating actions\n actions_to_log = [\n ActionLog(\n action_type=ActionLog.ActionType.TRANSLATION_CREATED,\n performed_by=t.user,\n translation=t,\n )\n for t in translations\n ]\n\n ActionLog.objects.bulk_create(actions_to_log)\n\n # Run checks on all translations\n translation_pks = {translation.pk for translation in translations}\n bulk_run_checks(Translation.objects.for_checks().filter(pk__in=translation_pks))\n\n # Mark translations as changed\n changed_translations = Translation.objects.filter(\n pk__in=translation_pks,\n # Do not sync translations with errors and warnings\n errors__isnull=True,\n warnings__isnull=True,\n )\n changed_translations.bulk_mark_changed()\n\n # Update latest activity and stats for changed instances.\n update_changed_instances(tr_filter, tr_dict, translations)\n\n log.info(f\"Fetching pretranslations for project {project.name} done\")\n", "path": "pontoon/pretranslation/tasks.py"}], "after_files": [{"content": "import logging\nimport operator\nimport re\n\nfrom django.db.models import CharField, Value as V\nfrom django.db.models.functions import Concat\n\nfrom fluent.syntax import FluentParser, FluentSerializer\nfrom functools import reduce\n\nfrom pontoon.base.models import User, TranslatedResource\nfrom pontoon.base.fluent import FlatTransformer, create_locale_plural_variants\nfrom pontoon.machinery.utils import (\n get_google_translate_data,\n get_translation_memory_data,\n)\nfrom pontoon.pretranslation import AUTHORS\n\n\nlog = logging.getLogger(__name__)\n\nparser = FluentParser()\nserializer = FluentSerializer()\n\n\nclass PretranslationTransformer(FlatTransformer):\n def __init__(self, locale):\n self.services = []\n self.locale = locale\n\n def visit_SelectExpression(self, node):\n create_locale_plural_variants(node, self.locale)\n return self.generic_visit(node)\n\n def visit_TextElement(self, node):\n # Machine translation treats each line as separate sentence,\n # hence we replace newline characters with spaces.\n source = node.value.replace(\"\\n\", \" \")\n\n pretranslation, service = get_pretranslated_data(source, self.locale)\n\n if pretranslation is None:\n raise ValueError(\n f\"Pretranslation for `{source}` to {self.locale.code} not available.\"\n )\n\n node.value = pretranslation\n self.services.append(service)\n return node\n\n\ndef get_pretranslations(entity, locale):\n \"\"\"\n Get pretranslations for the entity-locale pair using internal translation memory and\n Google's machine translation.\n\n For Fluent strings, uplift SelectExpressions, serialize Placeables as TextElements\n and then only pretranslate TextElements. Set the most frequent TextElement\n pretranslation author as the author of the entire pretranslation.\n\n :arg Entity entity: the Entity object\n :arg Locale locale: the Locale object\n\n :returns: a list of tuples, consisting of:\n - a pretranslation of the entity\n - a plural form\n - a user (representing TM or GT service)\n \"\"\"\n source = entity.string\n services = {k: User.objects.get(email=email) for k, email in AUTHORS.items()}\n\n if entity.resource.format == \"ftl\":\n source_ast = parser.parse_entry(source)\n pt_transformer = PretranslationTransformer(locale)\n\n try:\n pretranslated_ast = pt_transformer.visit(source_ast)\n except ValueError as e:\n log.info(f\"Fluent pretranslation error: {e}\")\n return []\n\n pretranslation = serializer.serialize_entry(pretranslated_ast)\n\n authors = [services[service] for service in pt_transformer.services]\n author = max(set(authors), key=authors.count) if authors else services[\"tm\"]\n\n return [(pretranslation, None, author)]\n\n else:\n pretranslation, service = get_pretranslated_data(source, locale)\n\n if pretranslation is None:\n return []\n\n author = services[service]\n if entity.string_plural == \"\":\n return [(pretranslation, None, author)]\n else:\n plural_forms = range(0, locale.nplurals or 1)\n return [\n (pretranslation, plural_form, author) for plural_form in plural_forms\n ]\n\n\ndef get_pretranslated_data(source, locale):\n # Empty strings do not need translation\n if re.search(\"^\\\\s*$\", source):\n return source, \"tm\"\n\n # Try to get matches from Translation Memory\n tm_response = get_translation_memory_data(text=source, locale=locale)\n tm_perfect = [t for t in tm_response if int(t[\"quality\"]) == 100]\n if tm_perfect:\n return tm_perfect[0][\"target\"], \"tm\"\n\n # Fetch from Google Translate\n elif locale.google_translate_code:\n gt_response = get_google_translate_data(text=source, locale=locale)\n if gt_response[\"status\"]:\n return gt_response[\"translation\"], \"gt\"\n\n return None, None\n\n\ndef update_changed_instances(tr_filter, tr_dict, translations):\n \"\"\"\n Update the latest activity and stats for changed Locales, ProjectLocales\n & TranslatedResources\n \"\"\"\n tr_filter = tuple(tr_filter)\n # Combine all generated filters with an OK operator.\n # `operator.ior` is the '|' Python operator, which turns into a logical OR\n # when used between django ORM query objects.\n tr_query = reduce(operator.ior, tr_filter)\n\n translatedresources = TranslatedResource.objects.filter(tr_query).annotate(\n locale_resource=Concat(\n \"locale_id\", V(\"-\"), \"resource_id\", output_field=CharField()\n )\n )\n\n translatedresources.update_stats()\n\n for tr in translatedresources:\n index = tr_dict[tr.locale_resource]\n translation = translations[index]\n translation.update_latest_translation()\n", "path": "pontoon/pretranslation/pretranslate.py"}, {"content": "AUTHORS = {\n \"tm\": \"[email protected]\",\n \"gt\": \"[email protected]\",\n}\n", "path": "pontoon/pretranslation/__init__.py"}, {"content": "import logging\n\nfrom django.db.models import Q, CharField, Value as V\nfrom django.db.models.functions import Concat\nfrom django.conf import settings\nfrom pontoon.base.models import (\n Project,\n Entity,\n TranslatedResource,\n Translation,\n User,\n)\nfrom pontoon.actionlog.models import ActionLog\nfrom pontoon.pretranslation import AUTHORS\nfrom pontoon.pretranslation.pretranslate import (\n get_pretranslations,\n update_changed_instances,\n)\nfrom pontoon.base.tasks import PontoonTask\nfrom pontoon.sync.core import serial_task\nfrom pontoon.checks.utils import bulk_run_checks\n\n\nlog = logging.getLogger(__name__)\n\n\n@serial_task(settings.SYNC_TASK_TIMEOUT, base=PontoonTask, lock_key=\"project={0}\")\ndef pretranslate(self, project_pk, locales=None, entities=None):\n \"\"\"\n Identifies strings without any translations and any suggestions.\n Engages TheAlgorithm (bug 1552796) to gather pretranslations.\n Stores pretranslations as suggestions (approved=False) to DB.\n\n :arg project_pk: the pk of the project to be pretranslated\n :arg Queryset locales: the locales for the project to be pretranslated\n :arg Queryset entites: the entities for the project to be pretranslated\n\n :returns: None\n \"\"\"\n project = Project.objects.get(pk=project_pk)\n\n if not project.pretranslation_enabled:\n log.info(f\"Pretranslation not enabled for project {project.name}\")\n return\n\n if locales:\n locales = project.locales.filter(pk__in=locales)\n else:\n locales = project.locales\n\n locales = locales.filter(\n project_locale__project=project,\n project_locale__pretranslation_enabled=True,\n project_locale__readonly=False,\n )\n\n if not locales:\n log.info(\n f\"Pretranslation not enabled for any locale within project {project.name}\"\n )\n return\n\n log.info(f\"Fetching pretranslations for project {project.name} started\")\n\n if not entities:\n entities = Entity.objects.filter(\n resource__project=project,\n obsolete=False,\n )\n\n entities = entities.prefetch_related(\"resource\")\n\n # Fetch all available locale-resource pairs (TranslatedResource objects)\n tr_pairs = (\n TranslatedResource.objects.filter(\n resource__project=project,\n locale__in=locales,\n )\n .annotate(\n locale_resource=Concat(\n \"locale_id\", V(\"-\"), \"resource_id\", output_field=CharField()\n )\n )\n .values_list(\"locale_resource\", flat=True)\n .distinct()\n )\n\n # Fetch all locale-entity pairs with non-rejected or pretranslated translations\n pt_authors = [User.objects.get(email=email) for email in AUTHORS.values()]\n translated_entities = (\n Translation.objects.filter(\n locale__in=locales,\n entity__in=entities,\n )\n .filter(Q(rejected=False) | Q(user__in=pt_authors))\n .annotate(\n locale_entity=Concat(\n \"locale_id\", V(\"-\"), \"entity_id\", output_field=CharField()\n )\n )\n .values_list(\"locale_entity\", flat=True)\n .distinct()\n )\n\n translated_entities = list(translated_entities)\n\n translations = []\n\n # To keep track of changed TranslatedResources and their latest_translation\n tr_dict = {}\n\n tr_filter = []\n index = -1\n\n for locale in locales:\n log.info(f\"Fetching pretranslations for locale {locale.code} started\")\n for entity in entities:\n locale_entity = f\"{locale.id}-{entity.id}\"\n locale_resource = f\"{locale.id}-{entity.resource.id}\"\n if locale_entity in translated_entities or locale_resource not in tr_pairs:\n continue\n\n pretranslations = get_pretranslations(entity, locale)\n\n if not pretranslations:\n continue\n\n for string, plural_form, user in pretranslations:\n t = Translation(\n entity=entity,\n locale=locale,\n string=string,\n user=user,\n approved=False,\n pretranslated=True,\n active=True,\n plural_form=plural_form,\n )\n\n index += 1\n translations.append(t)\n\n if locale_resource not in tr_dict:\n tr_dict[locale_resource] = index\n\n # Add query for fetching respective TranslatedResource.\n tr_filter.append(\n Q(locale__id=locale.id) & Q(resource__id=entity.resource.id)\n )\n\n # Update the latest translation index\n tr_dict[locale_resource] = index\n\n log.info(f\"Fetching pretranslations for locale {locale.code} done\")\n\n if len(translations) == 0:\n return\n\n translations = Translation.objects.bulk_create(translations)\n\n # Log creating actions\n actions_to_log = [\n ActionLog(\n action_type=ActionLog.ActionType.TRANSLATION_CREATED,\n performed_by=t.user,\n translation=t,\n )\n for t in translations\n ]\n\n ActionLog.objects.bulk_create(actions_to_log)\n\n # Run checks on all translations\n translation_pks = {translation.pk for translation in translations}\n bulk_run_checks(Translation.objects.for_checks().filter(pk__in=translation_pks))\n\n # Mark translations as changed\n changed_translations = Translation.objects.filter(\n pk__in=translation_pks,\n # Do not sync translations with errors and warnings\n errors__isnull=True,\n warnings__isnull=True,\n )\n changed_translations.bulk_mark_changed()\n\n # Update latest activity and stats for changed instances.\n update_changed_instances(tr_filter, tr_dict, translations)\n\n log.info(f\"Fetching pretranslations for project {project.name} done\")\n", "path": "pontoon/pretranslation/tasks.py"}]}
| 3,347 | 611 |
gh_patches_debug_15719
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-20731
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
gfycat.com url changes
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2019.04.17**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/ytdl-org/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/ytdl-org/youtube-dl#faq) and [BUGS](https://github.com/ytdl-org/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/ytdl-org/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [x] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
gfycat.com has added dashes to some urls [https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball](https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball) causing a HTTP Error.
This could be fixed by excluding dashes in the url InfoExtractor.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/gfycat.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 from .common import InfoExtractor
5 from ..utils import (
6 int_or_none,
7 float_or_none,
8 qualities,
9 ExtractorError,
10 )
11
12
13 class GfycatIE(InfoExtractor):
14 _VALID_URL = r'https?://(?:www\.)?gfycat\.com/(?:ifr/|gifs/detail/)?(?P<id>[^/?#]+)'
15 _TESTS = [{
16 'url': 'http://gfycat.com/DeadlyDecisiveGermanpinscher',
17 'info_dict': {
18 'id': 'DeadlyDecisiveGermanpinscher',
19 'ext': 'mp4',
20 'title': 'Ghost in the Shell',
21 'timestamp': 1410656006,
22 'upload_date': '20140914',
23 'uploader': 'anonymous',
24 'duration': 10.4,
25 'view_count': int,
26 'like_count': int,
27 'dislike_count': int,
28 'categories': list,
29 'age_limit': 0,
30 }
31 }, {
32 'url': 'http://gfycat.com/ifr/JauntyTimelyAmazontreeboa',
33 'info_dict': {
34 'id': 'JauntyTimelyAmazontreeboa',
35 'ext': 'mp4',
36 'title': 'JauntyTimelyAmazontreeboa',
37 'timestamp': 1411720126,
38 'upload_date': '20140926',
39 'uploader': 'anonymous',
40 'duration': 3.52,
41 'view_count': int,
42 'like_count': int,
43 'dislike_count': int,
44 'categories': list,
45 'age_limit': 0,
46 }
47 }, {
48 'url': 'https://gfycat.com/gifs/detail/UnconsciousLankyIvorygull',
49 'only_matching': True
50 }]
51
52 def _real_extract(self, url):
53 video_id = self._match_id(url)
54
55 gfy = self._download_json(
56 'https://api.gfycat.com/v1/gfycats/%s' % video_id,
57 video_id, 'Downloading video info')
58 if 'error' in gfy:
59 raise ExtractorError('Gfycat said: ' + gfy['error'], expected=True)
60 gfy = gfy['gfyItem']
61
62 title = gfy.get('title') or gfy['gfyName']
63 description = gfy.get('description')
64 timestamp = int_or_none(gfy.get('createDate'))
65 uploader = gfy.get('userName')
66 view_count = int_or_none(gfy.get('views'))
67 like_count = int_or_none(gfy.get('likes'))
68 dislike_count = int_or_none(gfy.get('dislikes'))
69 age_limit = 18 if gfy.get('nsfw') == '1' else 0
70
71 width = int_or_none(gfy.get('width'))
72 height = int_or_none(gfy.get('height'))
73 fps = int_or_none(gfy.get('frameRate'))
74 num_frames = int_or_none(gfy.get('numFrames'))
75
76 duration = float_or_none(num_frames, fps) if num_frames and fps else None
77
78 categories = gfy.get('tags') or gfy.get('extraLemmas') or []
79
80 FORMATS = ('gif', 'webm', 'mp4')
81 quality = qualities(FORMATS)
82
83 formats = []
84 for format_id in FORMATS:
85 video_url = gfy.get('%sUrl' % format_id)
86 if not video_url:
87 continue
88 filesize = int_or_none(gfy.get('%sSize' % format_id))
89 formats.append({
90 'url': video_url,
91 'format_id': format_id,
92 'width': width,
93 'height': height,
94 'fps': fps,
95 'filesize': filesize,
96 'quality': quality(format_id),
97 })
98 self._sort_formats(formats)
99
100 return {
101 'id': video_id,
102 'title': title,
103 'description': description,
104 'timestamp': timestamp,
105 'uploader': uploader,
106 'duration': duration,
107 'view_count': view_count,
108 'like_count': like_count,
109 'dislike_count': dislike_count,
110 'categories': categories,
111 'age_limit': age_limit,
112 'formats': formats,
113 }
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/gfycat.py b/youtube_dl/extractor/gfycat.py
--- a/youtube_dl/extractor/gfycat.py
+++ b/youtube_dl/extractor/gfycat.py
@@ -11,7 +11,7 @@
class GfycatIE(InfoExtractor):
- _VALID_URL = r'https?://(?:www\.)?gfycat\.com/(?:ifr/|gifs/detail/)?(?P<id>[^/?#]+)'
+ _VALID_URL = r'https?://(?:www\.)?gfycat\.com/(?:ifr/|gifs/detail/)?(?P<id>[^-/?#]+)'
_TESTS = [{
'url': 'http://gfycat.com/DeadlyDecisiveGermanpinscher',
'info_dict': {
@@ -47,6 +47,9 @@
}, {
'url': 'https://gfycat.com/gifs/detail/UnconsciousLankyIvorygull',
'only_matching': True
+ }, {
+ 'url': 'https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball',
+ 'only_matching': True
}]
def _real_extract(self, url):
|
{"golden_diff": "diff --git a/youtube_dl/extractor/gfycat.py b/youtube_dl/extractor/gfycat.py\n--- a/youtube_dl/extractor/gfycat.py\n+++ b/youtube_dl/extractor/gfycat.py\n@@ -11,7 +11,7 @@\n \n \n class GfycatIE(InfoExtractor):\n- _VALID_URL = r'https?://(?:www\\.)?gfycat\\.com/(?:ifr/|gifs/detail/)?(?P<id>[^/?#]+)'\n+ _VALID_URL = r'https?://(?:www\\.)?gfycat\\.com/(?:ifr/|gifs/detail/)?(?P<id>[^-/?#]+)'\n _TESTS = [{\n 'url': 'http://gfycat.com/DeadlyDecisiveGermanpinscher',\n 'info_dict': {\n@@ -47,6 +47,9 @@\n }, {\n 'url': 'https://gfycat.com/gifs/detail/UnconsciousLankyIvorygull',\n 'only_matching': True\n+ }, {\n+ 'url': 'https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball',\n+ 'only_matching': True\n }]\n \n def _real_extract(self, url):\n", "issue": "gfycat.com url changes\n- [x] I've **verified** and **I assure** that I'm running youtube-dl **2019.04.17**\r\n\r\n### Before submitting an *issue* make sure you have:\r\n- [x] At least skimmed through the [README](https://github.com/ytdl-org/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/ytdl-org/youtube-dl#faq) and [BUGS](https://github.com/ytdl-org/youtube-dl#bugs) sections\r\n- [x] [Searched](https://github.com/ytdl-org/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones\r\n- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser\r\n\r\n### What is the purpose of your *issue*?\r\n- [x] Bug report (encountered problems with youtube-dl)\r\n- [x] Site support request (request for adding support for a new site)\r\n- [ ] Feature request (request for a new functionality)\r\n- [ ] Question\r\n- [ ] Other\r\n\r\ngfycat.com has added dashes to some urls [https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball](https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball) causing a HTTP Error. \r\nThis could be fixed by excluding dashes in the url InfoExtractor.\r\n\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n float_or_none,\n qualities,\n ExtractorError,\n)\n\n\nclass GfycatIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gfycat\\.com/(?:ifr/|gifs/detail/)?(?P<id>[^/?#]+)'\n _TESTS = [{\n 'url': 'http://gfycat.com/DeadlyDecisiveGermanpinscher',\n 'info_dict': {\n 'id': 'DeadlyDecisiveGermanpinscher',\n 'ext': 'mp4',\n 'title': 'Ghost in the Shell',\n 'timestamp': 1410656006,\n 'upload_date': '20140914',\n 'uploader': 'anonymous',\n 'duration': 10.4,\n 'view_count': int,\n 'like_count': int,\n 'dislike_count': int,\n 'categories': list,\n 'age_limit': 0,\n }\n }, {\n 'url': 'http://gfycat.com/ifr/JauntyTimelyAmazontreeboa',\n 'info_dict': {\n 'id': 'JauntyTimelyAmazontreeboa',\n 'ext': 'mp4',\n 'title': 'JauntyTimelyAmazontreeboa',\n 'timestamp': 1411720126,\n 'upload_date': '20140926',\n 'uploader': 'anonymous',\n 'duration': 3.52,\n 'view_count': int,\n 'like_count': int,\n 'dislike_count': int,\n 'categories': list,\n 'age_limit': 0,\n }\n }, {\n 'url': 'https://gfycat.com/gifs/detail/UnconsciousLankyIvorygull',\n 'only_matching': True\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n gfy = self._download_json(\n 'https://api.gfycat.com/v1/gfycats/%s' % video_id,\n video_id, 'Downloading video info')\n if 'error' in gfy:\n raise ExtractorError('Gfycat said: ' + gfy['error'], expected=True)\n gfy = gfy['gfyItem']\n\n title = gfy.get('title') or gfy['gfyName']\n description = gfy.get('description')\n timestamp = int_or_none(gfy.get('createDate'))\n uploader = gfy.get('userName')\n view_count = int_or_none(gfy.get('views'))\n like_count = int_or_none(gfy.get('likes'))\n dislike_count = int_or_none(gfy.get('dislikes'))\n age_limit = 18 if gfy.get('nsfw') == '1' else 0\n\n width = int_or_none(gfy.get('width'))\n height = int_or_none(gfy.get('height'))\n fps = int_or_none(gfy.get('frameRate'))\n num_frames = int_or_none(gfy.get('numFrames'))\n\n duration = float_or_none(num_frames, fps) if num_frames and fps else None\n\n categories = gfy.get('tags') or gfy.get('extraLemmas') or []\n\n FORMATS = ('gif', 'webm', 'mp4')\n quality = qualities(FORMATS)\n\n formats = []\n for format_id in FORMATS:\n video_url = gfy.get('%sUrl' % format_id)\n if not video_url:\n continue\n filesize = int_or_none(gfy.get('%sSize' % format_id))\n formats.append({\n 'url': video_url,\n 'format_id': format_id,\n 'width': width,\n 'height': height,\n 'fps': fps,\n 'filesize': filesize,\n 'quality': quality(format_id),\n })\n self._sort_formats(formats)\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': description,\n 'timestamp': timestamp,\n 'uploader': uploader,\n 'duration': duration,\n 'view_count': view_count,\n 'like_count': like_count,\n 'dislike_count': dislike_count,\n 'categories': categories,\n 'age_limit': age_limit,\n 'formats': formats,\n }\n", "path": "youtube_dl/extractor/gfycat.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n float_or_none,\n qualities,\n ExtractorError,\n)\n\n\nclass GfycatIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?gfycat\\.com/(?:ifr/|gifs/detail/)?(?P<id>[^-/?#]+)'\n _TESTS = [{\n 'url': 'http://gfycat.com/DeadlyDecisiveGermanpinscher',\n 'info_dict': {\n 'id': 'DeadlyDecisiveGermanpinscher',\n 'ext': 'mp4',\n 'title': 'Ghost in the Shell',\n 'timestamp': 1410656006,\n 'upload_date': '20140914',\n 'uploader': 'anonymous',\n 'duration': 10.4,\n 'view_count': int,\n 'like_count': int,\n 'dislike_count': int,\n 'categories': list,\n 'age_limit': 0,\n }\n }, {\n 'url': 'http://gfycat.com/ifr/JauntyTimelyAmazontreeboa',\n 'info_dict': {\n 'id': 'JauntyTimelyAmazontreeboa',\n 'ext': 'mp4',\n 'title': 'JauntyTimelyAmazontreeboa',\n 'timestamp': 1411720126,\n 'upload_date': '20140926',\n 'uploader': 'anonymous',\n 'duration': 3.52,\n 'view_count': int,\n 'like_count': int,\n 'dislike_count': int,\n 'categories': list,\n 'age_limit': 0,\n }\n }, {\n 'url': 'https://gfycat.com/gifs/detail/UnconsciousLankyIvorygull',\n 'only_matching': True\n }, {\n 'url': 'https://gfycat.com/acceptablehappygoluckyharborporpoise-baseball',\n 'only_matching': True\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n gfy = self._download_json(\n 'https://api.gfycat.com/v1/gfycats/%s' % video_id,\n video_id, 'Downloading video info')\n if 'error' in gfy:\n raise ExtractorError('Gfycat said: ' + gfy['error'], expected=True)\n gfy = gfy['gfyItem']\n\n title = gfy.get('title') or gfy['gfyName']\n description = gfy.get('description')\n timestamp = int_or_none(gfy.get('createDate'))\n uploader = gfy.get('userName')\n view_count = int_or_none(gfy.get('views'))\n like_count = int_or_none(gfy.get('likes'))\n dislike_count = int_or_none(gfy.get('dislikes'))\n age_limit = 18 if gfy.get('nsfw') == '1' else 0\n\n width = int_or_none(gfy.get('width'))\n height = int_or_none(gfy.get('height'))\n fps = int_or_none(gfy.get('frameRate'))\n num_frames = int_or_none(gfy.get('numFrames'))\n\n duration = float_or_none(num_frames, fps) if num_frames and fps else None\n\n categories = gfy.get('tags') or gfy.get('extraLemmas') or []\n\n FORMATS = ('gif', 'webm', 'mp4')\n quality = qualities(FORMATS)\n\n formats = []\n for format_id in FORMATS:\n video_url = gfy.get('%sUrl' % format_id)\n if not video_url:\n continue\n filesize = int_or_none(gfy.get('%sSize' % format_id))\n formats.append({\n 'url': video_url,\n 'format_id': format_id,\n 'width': width,\n 'height': height,\n 'fps': fps,\n 'filesize': filesize,\n 'quality': quality(format_id),\n })\n self._sort_formats(formats)\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': description,\n 'timestamp': timestamp,\n 'uploader': uploader,\n 'duration': duration,\n 'view_count': view_count,\n 'like_count': like_count,\n 'dislike_count': dislike_count,\n 'categories': categories,\n 'age_limit': age_limit,\n 'formats': formats,\n }\n", "path": "youtube_dl/extractor/gfycat.py"}]}
| 1,807 | 289 |
gh_patches_debug_8775
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-637
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PRAW does not work with custom SSL cert bundle
Because of the proxy I'm using, I need to use a custom SSL cert bundle. Normally using the requests library, this is achievable in one of 2 ways:
Explicitly setting `verify` to the path of the bundle:
```
requests.get('https://google.com', verify='/path/to/cacert.pem')
```
Or setting an environment variable so that all requests use it:
```
export REQUESTS_CA_BUNDLE='/path/to/cacert.pem'
requests.get('https://google.com')
```
The environment variable is preferred because this allows the requests library to work when called from other packages that I did not write.
However, this does not work with PRAW. The problem I see is severalfold:
Using `Session.request` from requests library gets the environment variable properly through the `merge_environment_settings` method:
https://github.com/kennethreitz/requests/blob/fb014560611f6ebb97e7deb03ad8336c3c8f2db1/requests/sessions.py#L461
https://github.com/kennethreitz/requests/blob/fb014560611f6ebb97e7deb03ad8336c3c8f2db1/requests/sessions.py#L617-L629
But this code is never reached since PRAW builds its own request and uses Session.send which does not pull the environment variable:
https://github.com/praw-dev/praw/blob/3902dc24b0f42e487e26481aae46352806e3e6a8/praw/handlers.py#L101-L102
PRAW does support a setting for `validate_certs` which gets passed along as the `verify` parameter to requests library. The issue here is that PRAW only allows a boolean. Setting this variable to the path of a `cacert.pem` file evaluates to False and turns off SSL verification:
https://github.com/praw-dev/praw/blob/3902dc24b0f42e487e26481aae46352806e3e6a8/praw/__init__.py#L222-L223
There are a couple ways to solve this that I can think of. I would be glad to help out with a fix if that is something that is desirable.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `praw/handlers.py`
Content:
```
1 """Provides classes that handle request dispatching."""
2
3 from __future__ import print_function, unicode_literals
4
5 import socket
6 import sys
7 import time
8 from functools import wraps
9 from praw.errors import ClientException
10 from praw.helpers import normalize_url
11 from requests import Session
12 from six import text_type
13 from six.moves import cPickle # pylint: disable=F0401
14 from threading import Lock
15 from timeit import default_timer as timer
16
17
18 class RateLimitHandler(object):
19 """The base handler that provides thread-safe rate limiting enforcement.
20
21 While this handler is threadsafe, PRAW is not thread safe when the same
22 `Reddit` instance is being utilized from multiple threads.
23
24 """
25
26 last_call = {} # Stores a two-item list: [lock, previous_call_time]
27 rl_lock = Lock() # lock used for adding items to last_call
28
29 @staticmethod
30 def rate_limit(function):
31 """Return a decorator that enforces API request limit guidelines.
32
33 We are allowed to make a API request every api_request_delay seconds as
34 specified in praw.ini. This value may differ from reddit to reddit. For
35 reddit.com it is 2. Any function decorated with this will be forced to
36 delay _rate_delay seconds from the calling of the last function
37 decorated with this before executing.
38
39 This decorator must be applied to a RateLimitHandler class method or
40 instance method as it assumes `rl_lock` and `last_call` are available.
41
42 """
43 @wraps(function)
44 def wrapped(cls, _rate_domain, _rate_delay, **kwargs):
45 cls.rl_lock.acquire()
46 lock_last = cls.last_call.setdefault(_rate_domain, [Lock(), 0])
47 with lock_last[0]: # Obtain the domain specific lock
48 cls.rl_lock.release()
49 # Sleep if necessary, then perform the request
50 now = timer()
51 delay = lock_last[1] + _rate_delay - now
52 if delay > 0:
53 now += delay
54 time.sleep(delay)
55 lock_last[1] = now
56 return function(cls, **kwargs)
57 return wrapped
58
59 @classmethod
60 def evict(cls, urls): # pylint: disable=W0613
61 """Method utilized to evict entries for the given urls.
62
63 :param urls: An iterable containing normalized urls.
64 :returns: The number of items removed from the cache.
65
66 By default this method returns False as a cache need not be present.
67
68 """
69 return 0
70
71 def __del__(self):
72 """Cleanup the HTTP session."""
73 if self.http:
74 try:
75 self.http.close()
76 except: # Never fail pylint: disable=W0702
77 pass
78
79 def __init__(self):
80 """Establish the HTTP session."""
81 self.http = Session() # Each instance should have its own session
82
83 def request(self, request, proxies, timeout, verify, **_):
84 """Responsible for dispatching the request and returning the result.
85
86 Network level exceptions should be raised and only
87 ``requests.Response`` should be returned.
88
89 :param request: A ``requests.PreparedRequest`` object containing all
90 the data necessary to perform the request.
91 :param proxies: A dictionary of proxy settings to be utilized for the
92 request.
93 :param timeout: Specifies the maximum time that the actual HTTP request
94 can take.
95 :param verify: Specifies if SSL certificates should be validated.
96
97 ``**_`` should be added to the method call to ignore the extra
98 arguments intended for the cache handler.
99
100 """
101 return self.http.send(request, proxies=proxies, timeout=timeout,
102 allow_redirects=False, verify=verify)
103 RateLimitHandler.request = RateLimitHandler.rate_limit(
104 RateLimitHandler.request)
105
106
107 class DefaultHandler(RateLimitHandler):
108 """Extends the RateLimitHandler to add thread-safe caching support."""
109
110 ca_lock = Lock()
111 cache = {}
112 cache_hit_callback = None
113 timeouts = {}
114
115 @staticmethod
116 def with_cache(function):
117 """Return a decorator that interacts with a handler's cache.
118
119 This decorator must be applied to a DefaultHandler class method or
120 instance method as it assumes `cache`, `ca_lock` and `timeouts` are
121 available.
122
123 """
124 @wraps(function)
125 def wrapped(cls, _cache_key, _cache_ignore, _cache_timeout, **kwargs):
126 def clear_timeouts():
127 """Clear the cache of timed out results."""
128 for key in list(cls.timeouts):
129 if timer() - cls.timeouts[key] > _cache_timeout:
130 del cls.timeouts[key]
131 del cls.cache[key]
132
133 if _cache_ignore:
134 return function(cls, **kwargs)
135 with cls.ca_lock:
136 clear_timeouts()
137 if _cache_key in cls.cache:
138 if cls.cache_hit_callback:
139 cls.cache_hit_callback(_cache_key)
140 return cls.cache[_cache_key]
141 # Releasing the lock before actually making the request allows for
142 # the possibility of more than one thread making the same request
143 # to get through. Without having domain-specific caching (under the
144 # assumption only one request to a domain can be made at a
145 # time), there isn't a better way to handle this.
146 result = function(cls, **kwargs)
147 # The handlers don't call `raise_for_status` so we need to ignore
148 # status codes that will result in an exception that should not be
149 # cached.
150 if result.status_code not in (200, 302):
151 return result
152 with cls.ca_lock:
153 cls.timeouts[_cache_key] = timer()
154 cls.cache[_cache_key] = result
155 return result
156 return wrapped
157
158 @classmethod
159 def clear_cache(cls):
160 """Remove all items from the cache."""
161 with cls.ca_lock:
162 cls.cache = {}
163 cls.timeouts = {}
164
165 @classmethod
166 def evict(cls, urls):
167 """Remove items from cache matching URLs.
168
169 Return the number of items removed.
170
171 """
172 if isinstance(urls, text_type):
173 urls = [urls]
174 urls = set(normalize_url(url) for url in urls)
175 retval = 0
176 with cls.ca_lock:
177 for key in list(cls.cache):
178 if key[0] in urls:
179 retval += 1
180 del cls.cache[key]
181 del cls.timeouts[key]
182 return retval
183 DefaultHandler.request = DefaultHandler.with_cache(RateLimitHandler.request)
184
185
186 class MultiprocessHandler(object):
187 """A PRAW handler to interact with the PRAW multi-process server."""
188
189 def __init__(self, host='localhost', port=10101):
190 """Construct an instance of the MultiprocessHandler."""
191 self.host = host
192 self.port = port
193
194 def _relay(self, **kwargs):
195 """Send the request through the server and return the HTTP response."""
196 retval = None
197 delay_time = 2 # For connection retries
198 read_attempts = 0 # For reading from socket
199 while retval is None: # Evict can return False
200 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
201 sock_fp = sock.makefile('rwb') # Used for pickle
202 try:
203 sock.connect((self.host, self.port))
204 cPickle.dump(kwargs, sock_fp, cPickle.HIGHEST_PROTOCOL)
205 sock_fp.flush()
206 retval = cPickle.load(sock_fp)
207 except: # pylint: disable=W0702
208 exc_type, exc, _ = sys.exc_info()
209 socket_error = exc_type is socket.error
210 if socket_error and exc.errno == 111: # Connection refused
211 sys.stderr.write('Cannot connect to multiprocess server. I'
212 's it running? Retrying in {0} seconds.\n'
213 .format(delay_time))
214 time.sleep(delay_time)
215 delay_time = min(64, delay_time * 2)
216 elif exc_type is EOFError or socket_error and exc.errno == 104:
217 # Failure during socket READ
218 if read_attempts >= 3:
219 raise ClientException('Successive failures reading '
220 'from the multiprocess server.')
221 sys.stderr.write('Lost connection with multiprocess server'
222 ' during read. Trying again.\n')
223 read_attempts += 1
224 else:
225 raise
226 finally:
227 sock_fp.close()
228 sock.close()
229 if isinstance(retval, Exception):
230 raise retval # pylint: disable=E0702
231 return retval
232
233 def evict(self, urls):
234 """Forward the eviction to the server and return its response."""
235 return self._relay(method='evict', urls=urls)
236
237 def request(self, **kwargs):
238 """Forward the request to the server and return its HTTP response."""
239 return self._relay(method='request', **kwargs)
240
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/praw/handlers.py b/praw/handlers.py
--- a/praw/handlers.py
+++ b/praw/handlers.py
@@ -98,8 +98,12 @@
arguments intended for the cache handler.
"""
- return self.http.send(request, proxies=proxies, timeout=timeout,
- allow_redirects=False, verify=verify)
+ settings = self.http.merge_environment_settings(
+ request.url, proxies, False, verify, None
+ )
+ return self.http.send(request, timeout=timeout, allow_redirects=False,
+ **settings)
+
RateLimitHandler.request = RateLimitHandler.rate_limit(
RateLimitHandler.request)
|
{"golden_diff": "diff --git a/praw/handlers.py b/praw/handlers.py\n--- a/praw/handlers.py\n+++ b/praw/handlers.py\n@@ -98,8 +98,12 @@\n arguments intended for the cache handler.\n \n \"\"\"\n- return self.http.send(request, proxies=proxies, timeout=timeout,\n- allow_redirects=False, verify=verify)\n+ settings = self.http.merge_environment_settings(\n+ request.url, proxies, False, verify, None\n+ )\n+ return self.http.send(request, timeout=timeout, allow_redirects=False,\n+ **settings)\n+\n RateLimitHandler.request = RateLimitHandler.rate_limit(\n RateLimitHandler.request)\n", "issue": "PRAW does not work with custom SSL cert bundle\nBecause of the proxy I'm using, I need to use a custom SSL cert bundle. Normally using the requests library, this is achievable in one of 2 ways:\n\nExplicitly setting `verify` to the path of the bundle:\n\n```\nrequests.get('https://google.com', verify='/path/to/cacert.pem')\n```\n\nOr setting an environment variable so that all requests use it:\n\n```\nexport REQUESTS_CA_BUNDLE='/path/to/cacert.pem'\n\nrequests.get('https://google.com')\n```\n\nThe environment variable is preferred because this allows the requests library to work when called from other packages that I did not write.\n\nHowever, this does not work with PRAW. The problem I see is severalfold:\n\nUsing `Session.request` from requests library gets the environment variable properly through the `merge_environment_settings` method:\n\nhttps://github.com/kennethreitz/requests/blob/fb014560611f6ebb97e7deb03ad8336c3c8f2db1/requests/sessions.py#L461\nhttps://github.com/kennethreitz/requests/blob/fb014560611f6ebb97e7deb03ad8336c3c8f2db1/requests/sessions.py#L617-L629\n\nBut this code is never reached since PRAW builds its own request and uses Session.send which does not pull the environment variable:\n\nhttps://github.com/praw-dev/praw/blob/3902dc24b0f42e487e26481aae46352806e3e6a8/praw/handlers.py#L101-L102\n\nPRAW does support a setting for `validate_certs` which gets passed along as the `verify` parameter to requests library. The issue here is that PRAW only allows a boolean. Setting this variable to the path of a `cacert.pem` file evaluates to False and turns off SSL verification:\n\nhttps://github.com/praw-dev/praw/blob/3902dc24b0f42e487e26481aae46352806e3e6a8/praw/__init__.py#L222-L223\n\nThere are a couple ways to solve this that I can think of. I would be glad to help out with a fix if that is something that is desirable.\n\n", "before_files": [{"content": "\"\"\"Provides classes that handle request dispatching.\"\"\"\n\nfrom __future__ import print_function, unicode_literals\n\nimport socket\nimport sys\nimport time\nfrom functools import wraps\nfrom praw.errors import ClientException\nfrom praw.helpers import normalize_url\nfrom requests import Session\nfrom six import text_type\nfrom six.moves import cPickle # pylint: disable=F0401\nfrom threading import Lock\nfrom timeit import default_timer as timer\n\n\nclass RateLimitHandler(object):\n \"\"\"The base handler that provides thread-safe rate limiting enforcement.\n\n While this handler is threadsafe, PRAW is not thread safe when the same\n `Reddit` instance is being utilized from multiple threads.\n\n \"\"\"\n\n last_call = {} # Stores a two-item list: [lock, previous_call_time]\n rl_lock = Lock() # lock used for adding items to last_call\n\n @staticmethod\n def rate_limit(function):\n \"\"\"Return a decorator that enforces API request limit guidelines.\n\n We are allowed to make a API request every api_request_delay seconds as\n specified in praw.ini. This value may differ from reddit to reddit. For\n reddit.com it is 2. Any function decorated with this will be forced to\n delay _rate_delay seconds from the calling of the last function\n decorated with this before executing.\n\n This decorator must be applied to a RateLimitHandler class method or\n instance method as it assumes `rl_lock` and `last_call` are available.\n\n \"\"\"\n @wraps(function)\n def wrapped(cls, _rate_domain, _rate_delay, **kwargs):\n cls.rl_lock.acquire()\n lock_last = cls.last_call.setdefault(_rate_domain, [Lock(), 0])\n with lock_last[0]: # Obtain the domain specific lock\n cls.rl_lock.release()\n # Sleep if necessary, then perform the request\n now = timer()\n delay = lock_last[1] + _rate_delay - now\n if delay > 0:\n now += delay\n time.sleep(delay)\n lock_last[1] = now\n return function(cls, **kwargs)\n return wrapped\n\n @classmethod\n def evict(cls, urls): # pylint: disable=W0613\n \"\"\"Method utilized to evict entries for the given urls.\n\n :param urls: An iterable containing normalized urls.\n :returns: The number of items removed from the cache.\n\n By default this method returns False as a cache need not be present.\n\n \"\"\"\n return 0\n\n def __del__(self):\n \"\"\"Cleanup the HTTP session.\"\"\"\n if self.http:\n try:\n self.http.close()\n except: # Never fail pylint: disable=W0702\n pass\n\n def __init__(self):\n \"\"\"Establish the HTTP session.\"\"\"\n self.http = Session() # Each instance should have its own session\n\n def request(self, request, proxies, timeout, verify, **_):\n \"\"\"Responsible for dispatching the request and returning the result.\n\n Network level exceptions should be raised and only\n ``requests.Response`` should be returned.\n\n :param request: A ``requests.PreparedRequest`` object containing all\n the data necessary to perform the request.\n :param proxies: A dictionary of proxy settings to be utilized for the\n request.\n :param timeout: Specifies the maximum time that the actual HTTP request\n can take.\n :param verify: Specifies if SSL certificates should be validated.\n\n ``**_`` should be added to the method call to ignore the extra\n arguments intended for the cache handler.\n\n \"\"\"\n return self.http.send(request, proxies=proxies, timeout=timeout,\n allow_redirects=False, verify=verify)\nRateLimitHandler.request = RateLimitHandler.rate_limit(\n RateLimitHandler.request)\n\n\nclass DefaultHandler(RateLimitHandler):\n \"\"\"Extends the RateLimitHandler to add thread-safe caching support.\"\"\"\n\n ca_lock = Lock()\n cache = {}\n cache_hit_callback = None\n timeouts = {}\n\n @staticmethod\n def with_cache(function):\n \"\"\"Return a decorator that interacts with a handler's cache.\n\n This decorator must be applied to a DefaultHandler class method or\n instance method as it assumes `cache`, `ca_lock` and `timeouts` are\n available.\n\n \"\"\"\n @wraps(function)\n def wrapped(cls, _cache_key, _cache_ignore, _cache_timeout, **kwargs):\n def clear_timeouts():\n \"\"\"Clear the cache of timed out results.\"\"\"\n for key in list(cls.timeouts):\n if timer() - cls.timeouts[key] > _cache_timeout:\n del cls.timeouts[key]\n del cls.cache[key]\n\n if _cache_ignore:\n return function(cls, **kwargs)\n with cls.ca_lock:\n clear_timeouts()\n if _cache_key in cls.cache:\n if cls.cache_hit_callback:\n cls.cache_hit_callback(_cache_key)\n return cls.cache[_cache_key]\n # Releasing the lock before actually making the request allows for\n # the possibility of more than one thread making the same request\n # to get through. Without having domain-specific caching (under the\n # assumption only one request to a domain can be made at a\n # time), there isn't a better way to handle this.\n result = function(cls, **kwargs)\n # The handlers don't call `raise_for_status` so we need to ignore\n # status codes that will result in an exception that should not be\n # cached.\n if result.status_code not in (200, 302):\n return result\n with cls.ca_lock:\n cls.timeouts[_cache_key] = timer()\n cls.cache[_cache_key] = result\n return result\n return wrapped\n\n @classmethod\n def clear_cache(cls):\n \"\"\"Remove all items from the cache.\"\"\"\n with cls.ca_lock:\n cls.cache = {}\n cls.timeouts = {}\n\n @classmethod\n def evict(cls, urls):\n \"\"\"Remove items from cache matching URLs.\n\n Return the number of items removed.\n\n \"\"\"\n if isinstance(urls, text_type):\n urls = [urls]\n urls = set(normalize_url(url) for url in urls)\n retval = 0\n with cls.ca_lock:\n for key in list(cls.cache):\n if key[0] in urls:\n retval += 1\n del cls.cache[key]\n del cls.timeouts[key]\n return retval\nDefaultHandler.request = DefaultHandler.with_cache(RateLimitHandler.request)\n\n\nclass MultiprocessHandler(object):\n \"\"\"A PRAW handler to interact with the PRAW multi-process server.\"\"\"\n\n def __init__(self, host='localhost', port=10101):\n \"\"\"Construct an instance of the MultiprocessHandler.\"\"\"\n self.host = host\n self.port = port\n\n def _relay(self, **kwargs):\n \"\"\"Send the request through the server and return the HTTP response.\"\"\"\n retval = None\n delay_time = 2 # For connection retries\n read_attempts = 0 # For reading from socket\n while retval is None: # Evict can return False\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock_fp = sock.makefile('rwb') # Used for pickle\n try:\n sock.connect((self.host, self.port))\n cPickle.dump(kwargs, sock_fp, cPickle.HIGHEST_PROTOCOL)\n sock_fp.flush()\n retval = cPickle.load(sock_fp)\n except: # pylint: disable=W0702\n exc_type, exc, _ = sys.exc_info()\n socket_error = exc_type is socket.error\n if socket_error and exc.errno == 111: # Connection refused\n sys.stderr.write('Cannot connect to multiprocess server. I'\n 's it running? Retrying in {0} seconds.\\n'\n .format(delay_time))\n time.sleep(delay_time)\n delay_time = min(64, delay_time * 2)\n elif exc_type is EOFError or socket_error and exc.errno == 104:\n # Failure during socket READ\n if read_attempts >= 3:\n raise ClientException('Successive failures reading '\n 'from the multiprocess server.')\n sys.stderr.write('Lost connection with multiprocess server'\n ' during read. Trying again.\\n')\n read_attempts += 1\n else:\n raise\n finally:\n sock_fp.close()\n sock.close()\n if isinstance(retval, Exception):\n raise retval # pylint: disable=E0702\n return retval\n\n def evict(self, urls):\n \"\"\"Forward the eviction to the server and return its response.\"\"\"\n return self._relay(method='evict', urls=urls)\n\n def request(self, **kwargs):\n \"\"\"Forward the request to the server and return its HTTP response.\"\"\"\n return self._relay(method='request', **kwargs)\n", "path": "praw/handlers.py"}], "after_files": [{"content": "\"\"\"Provides classes that handle request dispatching.\"\"\"\n\nfrom __future__ import print_function, unicode_literals\n\nimport socket\nimport sys\nimport time\nfrom functools import wraps\nfrom praw.errors import ClientException\nfrom praw.helpers import normalize_url\nfrom requests import Session\nfrom six import text_type\nfrom six.moves import cPickle # pylint: disable=F0401\nfrom threading import Lock\nfrom timeit import default_timer as timer\n\n\nclass RateLimitHandler(object):\n \"\"\"The base handler that provides thread-safe rate limiting enforcement.\n\n While this handler is threadsafe, PRAW is not thread safe when the same\n `Reddit` instance is being utilized from multiple threads.\n\n \"\"\"\n\n last_call = {} # Stores a two-item list: [lock, previous_call_time]\n rl_lock = Lock() # lock used for adding items to last_call\n\n @staticmethod\n def rate_limit(function):\n \"\"\"Return a decorator that enforces API request limit guidelines.\n\n We are allowed to make a API request every api_request_delay seconds as\n specified in praw.ini. This value may differ from reddit to reddit. For\n reddit.com it is 2. Any function decorated with this will be forced to\n delay _rate_delay seconds from the calling of the last function\n decorated with this before executing.\n\n This decorator must be applied to a RateLimitHandler class method or\n instance method as it assumes `rl_lock` and `last_call` are available.\n\n \"\"\"\n @wraps(function)\n def wrapped(cls, _rate_domain, _rate_delay, **kwargs):\n cls.rl_lock.acquire()\n lock_last = cls.last_call.setdefault(_rate_domain, [Lock(), 0])\n with lock_last[0]: # Obtain the domain specific lock\n cls.rl_lock.release()\n # Sleep if necessary, then perform the request\n now = timer()\n delay = lock_last[1] + _rate_delay - now\n if delay > 0:\n now += delay\n time.sleep(delay)\n lock_last[1] = now\n return function(cls, **kwargs)\n return wrapped\n\n @classmethod\n def evict(cls, urls): # pylint: disable=W0613\n \"\"\"Method utilized to evict entries for the given urls.\n\n :param urls: An iterable containing normalized urls.\n :returns: The number of items removed from the cache.\n\n By default this method returns False as a cache need not be present.\n\n \"\"\"\n return 0\n\n def __del__(self):\n \"\"\"Cleanup the HTTP session.\"\"\"\n if self.http:\n try:\n self.http.close()\n except: # Never fail pylint: disable=W0702\n pass\n\n def __init__(self):\n \"\"\"Establish the HTTP session.\"\"\"\n self.http = Session() # Each instance should have its own session\n\n def request(self, request, proxies, timeout, verify, **_):\n \"\"\"Responsible for dispatching the request and returning the result.\n\n Network level exceptions should be raised and only\n ``requests.Response`` should be returned.\n\n :param request: A ``requests.PreparedRequest`` object containing all\n the data necessary to perform the request.\n :param proxies: A dictionary of proxy settings to be utilized for the\n request.\n :param timeout: Specifies the maximum time that the actual HTTP request\n can take.\n :param verify: Specifies if SSL certificates should be validated.\n\n ``**_`` should be added to the method call to ignore the extra\n arguments intended for the cache handler.\n\n \"\"\"\n settings = self.http.merge_environment_settings(\n request.url, proxies, False, verify, None\n )\n return self.http.send(request, timeout=timeout, allow_redirects=False,\n **settings)\n\nRateLimitHandler.request = RateLimitHandler.rate_limit(\n RateLimitHandler.request)\n\n\nclass DefaultHandler(RateLimitHandler):\n \"\"\"Extends the RateLimitHandler to add thread-safe caching support.\"\"\"\n\n ca_lock = Lock()\n cache = {}\n cache_hit_callback = None\n timeouts = {}\n\n @staticmethod\n def with_cache(function):\n \"\"\"Return a decorator that interacts with a handler's cache.\n\n This decorator must be applied to a DefaultHandler class method or\n instance method as it assumes `cache`, `ca_lock` and `timeouts` are\n available.\n\n \"\"\"\n @wraps(function)\n def wrapped(cls, _cache_key, _cache_ignore, _cache_timeout, **kwargs):\n def clear_timeouts():\n \"\"\"Clear the cache of timed out results.\"\"\"\n for key in list(cls.timeouts):\n if timer() - cls.timeouts[key] > _cache_timeout:\n del cls.timeouts[key]\n del cls.cache[key]\n\n if _cache_ignore:\n return function(cls, **kwargs)\n with cls.ca_lock:\n clear_timeouts()\n if _cache_key in cls.cache:\n if cls.cache_hit_callback:\n cls.cache_hit_callback(_cache_key)\n return cls.cache[_cache_key]\n # Releasing the lock before actually making the request allows for\n # the possibility of more than one thread making the same request\n # to get through. Without having domain-specific caching (under the\n # assumption only one request to a domain can be made at a\n # time), there isn't a better way to handle this.\n result = function(cls, **kwargs)\n # The handlers don't call `raise_for_status` so we need to ignore\n # status codes that will result in an exception that should not be\n # cached.\n if result.status_code not in (200, 302):\n return result\n with cls.ca_lock:\n cls.timeouts[_cache_key] = timer()\n cls.cache[_cache_key] = result\n return result\n return wrapped\n\n @classmethod\n def clear_cache(cls):\n \"\"\"Remove all items from the cache.\"\"\"\n with cls.ca_lock:\n cls.cache = {}\n cls.timeouts = {}\n\n @classmethod\n def evict(cls, urls):\n \"\"\"Remove items from cache matching URLs.\n\n Return the number of items removed.\n\n \"\"\"\n if isinstance(urls, text_type):\n urls = [urls]\n urls = set(normalize_url(url) for url in urls)\n retval = 0\n with cls.ca_lock:\n for key in list(cls.cache):\n if key[0] in urls:\n retval += 1\n del cls.cache[key]\n del cls.timeouts[key]\n return retval\nDefaultHandler.request = DefaultHandler.with_cache(RateLimitHandler.request)\n\n\nclass MultiprocessHandler(object):\n \"\"\"A PRAW handler to interact with the PRAW multi-process server.\"\"\"\n\n def __init__(self, host='localhost', port=10101):\n \"\"\"Construct an instance of the MultiprocessHandler.\"\"\"\n self.host = host\n self.port = port\n\n def _relay(self, **kwargs):\n \"\"\"Send the request through the server and return the HTTP response.\"\"\"\n retval = None\n delay_time = 2 # For connection retries\n read_attempts = 0 # For reading from socket\n while retval is None: # Evict can return False\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock_fp = sock.makefile('rwb') # Used for pickle\n try:\n sock.connect((self.host, self.port))\n cPickle.dump(kwargs, sock_fp, cPickle.HIGHEST_PROTOCOL)\n sock_fp.flush()\n retval = cPickle.load(sock_fp)\n except: # pylint: disable=W0702\n exc_type, exc, _ = sys.exc_info()\n socket_error = exc_type is socket.error\n if socket_error and exc.errno == 111: # Connection refused\n sys.stderr.write('Cannot connect to multiprocess server. I'\n 's it running? Retrying in {0} seconds.\\n'\n .format(delay_time))\n time.sleep(delay_time)\n delay_time = min(64, delay_time * 2)\n elif exc_type is EOFError or socket_error and exc.errno == 104:\n # Failure during socket READ\n if read_attempts >= 3:\n raise ClientException('Successive failures reading '\n 'from the multiprocess server.')\n sys.stderr.write('Lost connection with multiprocess server'\n ' during read. Trying again.\\n')\n read_attempts += 1\n else:\n raise\n finally:\n sock_fp.close()\n sock.close()\n if isinstance(retval, Exception):\n raise retval # pylint: disable=E0702\n return retval\n\n def evict(self, urls):\n \"\"\"Forward the eviction to the server and return its response.\"\"\"\n return self._relay(method='evict', urls=urls)\n\n def request(self, **kwargs):\n \"\"\"Forward the request to the server and return its HTTP response.\"\"\"\n return self._relay(method='request', **kwargs)\n", "path": "praw/handlers.py"}]}
| 3,349 | 154 |
gh_patches_debug_21287
|
rasdani/github-patches
|
git_diff
|
kymatio__kymatio-384
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unexpected crush with J=1
Hi,
I faced the following problem: I get unexpected and unexplained crush when J=1 regardless of other parameters values. Please, find the code and the error message below.
Here's the code:
```
data = torch.Tensor(np.random.rand(128,3,32,32))
print("shape before scattering: {}".format(data.shape))
scatModel = Scattering2D(J=1,L=8, shape = (32,32), max_order=2)
a = scatModel(data)
print("shape after scattering: {}".format(a.shape))
```
And the error message:
> shape before scattering: torch.Size([128, 3, 32, 32])
> Traceback (most recent call last):
> File "/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/mixingMallatTest.py", line 24, in <module>
> a = scatModel(data)
> File "/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/lib/python3.5/site-packages/kymatio-0.2.0.dev0-py3.5.egg/kymatio/scattering2d/scattering2d.py", line 235, in __call__
> File "/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/lib/python3.5/site-packages/kymatio-0.2.0.dev0-py3.5.egg/kymatio/scattering2d/scattering2d.py", line 202, in forward
> KeyError: 0
Is it me or something is wrong?
Thank you,
Dmitry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kymatio/scattering2d/filter_bank.py`
Content:
```
1 """
2 Authors: Eugene Belilovsky, Edouard Oyallon and Sergey Zagoruyko
3 All rights reserved, 2017.
4 """
5
6 __all__ = ['filter_bank']
7
8 import numpy as np
9 from .utils import fft2
10
11
12 def filter_bank(M, N, J, L=8):
13 """
14 Builds in Fourier the Morlet filters used for the scattering transform.
15 Each single filter is provided as a dictionary with the following keys:
16 * 'j' : scale
17 * 'theta' : angle used
18 Parameters
19 ----------
20 M, N : int
21 spatial support of the input
22 J : int
23 logscale of the scattering
24 L : int, optional
25 number of angles used for the wavelet transform
26 Returns
27 -------
28 filters : list
29 A two list of dictionary containing respectively the low-pass and
30 wavelet filters.
31 Notes
32 -----
33 The design of the filters is optimized for the value L = 8.
34 """
35 filters = {}
36 filters['psi'] = []
37
38 for j in range(J):
39 for theta in range(L):
40 psi = {}
41 psi['j'] = j
42 psi['theta'] = theta
43 psi_signal = morlet_2d(M, N, 0.8 * 2**j,
44 (int(L-L/2-1)-theta) * np.pi / L,
45 3.0 / 4.0 * np.pi /2**j, 4.0/L)
46 psi_signal_fourier = fft2(psi_signal)
47 # drop the imaginary part, it is zero anyway
48 psi_signal_fourier = np.real(psi_signal_fourier)
49 for res in range(min(j + 1, J - 1)):
50 psi_signal_fourier_res = periodize_filter_fft(
51 psi_signal_fourier, res)
52 # add a trailing singleton dimension to mark it as non-complex
53 psi_signal_fourier_res = psi_signal_fourier_res[..., np.newaxis]
54 psi[res] = psi_signal_fourier_res
55 # Normalization to avoid doing it with the FFT.
56 psi[res] /= M*N// 2**(2*j)
57 filters['psi'].append(psi)
58
59 filters['phi'] = {}
60 phi_signal = gabor_2d(M, N, 0.8 * 2**(J-1), 0, 0)
61 phi_signal_fourier = fft2(phi_signal)
62 # drop the imaginary part, it is zero anyway
63 phi_signal_fourier = np.real(phi_signal_fourier)
64 filters['phi']['j'] = J
65 for res in range(J):
66 phi_signal_fourier_res = periodize_filter_fft(phi_signal_fourier, res)
67 # add a trailing singleton dimension to mark it as non-complex
68 phi_signal_fourier_res = phi_signal_fourier_res[..., np.newaxis]
69 filters['phi'][res] = phi_signal_fourier_res
70 # Normalization to avoid doing it with the FFT.
71 filters['phi'][res] /= M*N // 2 ** (2 * J)
72
73 return filters
74
75
76 def periodize_filter_fft(x, res):
77 """
78 Parameters
79 ----------
80 x : numpy array
81 signal to periodize in Fourier
82 res :
83 resolution to which the signal is cropped.
84
85 Returns
86 -------
87 crop : numpy array
88 It returns a crop version of the filter, assuming that
89 the convolutions will be done via compactly supported signals.
90 """
91 M = x.shape[0]
92 N = x.shape[1]
93
94 crop = np.zeros((M // 2 ** res, N // 2 ** res), x.dtype)
95
96 mask = np.ones(x.shape, np.float32)
97 len_x = int(M * (1 - 2 ** (-res)))
98 start_x = int(M * 2 ** (-res - 1))
99 len_y = int(N * (1 - 2 ** (-res)))
100 start_y = int(N * 2 ** (-res - 1))
101 mask[start_x:start_x + len_x,:] = 0
102 mask[:, start_y:start_y + len_y] = 0
103 x = np.multiply(x,mask)
104
105 for k in range(int(M / 2 ** res)):
106 for l in range(int(N / 2 ** res)):
107 for i in range(int(2 ** res)):
108 for j in range(int(2 ** res)):
109 crop[k, l] += x[k + i * int(M / 2 ** res), l + j * int(N / 2 ** res)]
110
111 return crop
112
113
114 def morlet_2d(M, N, sigma, theta, xi, slant=0.5, offset=0):
115 """
116 Computes a 2D Morlet filter.
117 A Morlet filter is the sum of a Gabor filter and a low-pass filter
118 to ensure that the sum has exactly zero mean in the temporal domain.
119 It is defined by the following formula in space:
120 psi(u) = g_{sigma}(u) (e^(i xi^T u) - beta)
121 where g_{sigma} is a Gaussian envelope, xi is a frequency and beta is
122 the cancelling parameter.
123
124 Parameters
125 ----------
126 M, N : int
127 spatial sizes
128 sigma : float
129 bandwidth parameter
130 xi : float
131 central frequency (in [0, 1])
132 theta : float
133 angle in [0, pi]
134 slant : float, optional
135 parameter which guides the elipsoidal shape of the morlet
136 offset : int, optional
137 offset by which the signal starts
138
139 Returns
140 -------
141 morlet_fft : ndarray
142 numpy array of size (M, N)
143 """
144 wv = gabor_2d(M, N, sigma, theta, xi, slant, offset)
145 wv_modulus = gabor_2d(M, N, sigma, theta, 0, slant, offset)
146 K = np.sum(wv) / np.sum(wv_modulus)
147
148 mor = wv - K * wv_modulus
149 return mor
150
151
152 def gabor_2d(M, N, sigma, theta, xi, slant=1.0, offset=0):
153 """
154 Computes a 2D Gabor filter.
155 A Gabor filter is defined by the following formula in space:
156 psi(u) = g_{sigma}(u) e^(i xi^T u)
157 where g_{sigma} is a Gaussian envelope and xi is a frequency.
158
159 Parameters
160 ----------
161 M, N : int
162 spatial sizes
163 sigma : float
164 bandwidth parameter
165 xi : float
166 central frequency (in [0, 1])
167 theta : float
168 angle in [0, pi]
169 slant : float, optional
170 parameter which guides the elipsoidal shape of the morlet
171 offset : int, optional
172 offset by which the signal starts
173
174 Returns
175 -------
176 morlet_fft : ndarray
177 numpy array of size (M, N)
178 """
179 gab = np.zeros((M, N), np.complex64)
180 R = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]], np.float32)
181 R_inv = np.array([[np.cos(theta), np.sin(theta)], [-np.sin(theta), np.cos(theta)]], np.float32)
182 D = np.array([[1, 0], [0, slant * slant]])
183 curv = np.dot(R, np.dot(D, R_inv)) / ( 2 * sigma * sigma)
184
185 for ex in [-2, -1, 0, 1, 2]:
186 for ey in [-2, -1, 0, 1, 2]:
187 [xx, yy] = np.mgrid[offset + ex * M:offset + M + ex * M, offset + ey * N:offset + N + ey * N]
188 arg = -(curv[0, 0] * np.multiply(xx, xx) + (curv[0, 1] + curv[1, 0]) * np.multiply(xx, yy) + curv[
189 1, 1] * np.multiply(yy, yy)) + 1.j * (xx * xi * np.cos(theta) + yy * xi * np.sin(theta))
190 gab += np.exp(arg)
191
192 norm_factor = (2 * 3.1415 * sigma * sigma / slant)
193 gab /= norm_factor
194
195 return gab
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kymatio/scattering2d/filter_bank.py b/kymatio/scattering2d/filter_bank.py
--- a/kymatio/scattering2d/filter_bank.py
+++ b/kymatio/scattering2d/filter_bank.py
@@ -46,7 +46,7 @@
psi_signal_fourier = fft2(psi_signal)
# drop the imaginary part, it is zero anyway
psi_signal_fourier = np.real(psi_signal_fourier)
- for res in range(min(j + 1, J - 1)):
+ for res in range(min(j + 1, max(J - 1, 1))):
psi_signal_fourier_res = periodize_filter_fft(
psi_signal_fourier, res)
# add a trailing singleton dimension to mark it as non-complex
@@ -54,6 +54,7 @@
psi[res] = psi_signal_fourier_res
# Normalization to avoid doing it with the FFT.
psi[res] /= M*N// 2**(2*j)
+
filters['psi'].append(psi)
filters['phi'] = {}
|
{"golden_diff": "diff --git a/kymatio/scattering2d/filter_bank.py b/kymatio/scattering2d/filter_bank.py\n--- a/kymatio/scattering2d/filter_bank.py\n+++ b/kymatio/scattering2d/filter_bank.py\n@@ -46,7 +46,7 @@\n psi_signal_fourier = fft2(psi_signal)\n # drop the imaginary part, it is zero anyway\n psi_signal_fourier = np.real(psi_signal_fourier)\n- for res in range(min(j + 1, J - 1)):\n+ for res in range(min(j + 1, max(J - 1, 1))):\n psi_signal_fourier_res = periodize_filter_fft(\n psi_signal_fourier, res)\n # add a trailing singleton dimension to mark it as non-complex\n@@ -54,6 +54,7 @@\n psi[res] = psi_signal_fourier_res\n # Normalization to avoid doing it with the FFT.\n psi[res] /= M*N// 2**(2*j)\n+\n filters['psi'].append(psi)\n \n filters['phi'] = {}\n", "issue": "Unexpected crush with J=1 \nHi, \r\n\r\nI faced the following problem: I get unexpected and unexplained crush when J=1 regardless of other parameters values. Please, find the code and the error message below. \r\n\r\nHere's the code:\r\n\r\n```\r\ndata = torch.Tensor(np.random.rand(128,3,32,32))\r\nprint(\"shape before scattering: {}\".format(data.shape))\r\n\r\nscatModel = Scattering2D(J=1,L=8, shape = (32,32), max_order=2)\r\na = scatModel(data)\r\n\r\nprint(\"shape after scattering: {}\".format(a.shape))\r\n```\r\n\r\nAnd the error message: \r\n\r\n> shape before scattering: torch.Size([128, 3, 32, 32])\r\n> Traceback (most recent call last):\r\n> File \"/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/mixingMallatTest.py\", line 24, in <module>\r\n> a = scatModel(data)\r\n> File \"/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/lib/python3.5/site-packages/kymatio-0.2.0.dev0-py3.5.egg/kymatio/scattering2d/scattering2d.py\", line 235, in __call__\r\n> File \"/user/HS221/dm00314/PycharmProjects/ScatterNetsTestFramework/venv/lib/python3.5/site-packages/kymatio-0.2.0.dev0-py3.5.egg/kymatio/scattering2d/scattering2d.py\", line 202, in forward\r\n> KeyError: 0\r\n\r\nIs it me or something is wrong?\r\n\r\nThank you, \r\nDmitry\n", "before_files": [{"content": "\"\"\"\nAuthors: Eugene Belilovsky, Edouard Oyallon and Sergey Zagoruyko\nAll rights reserved, 2017.\n\"\"\"\n\n__all__ = ['filter_bank']\n\nimport numpy as np\nfrom .utils import fft2\n\n\ndef filter_bank(M, N, J, L=8):\n \"\"\"\n Builds in Fourier the Morlet filters used for the scattering transform.\n Each single filter is provided as a dictionary with the following keys:\n * 'j' : scale\n * 'theta' : angle used\n Parameters\n ----------\n M, N : int\n spatial support of the input\n J : int\n logscale of the scattering\n L : int, optional\n number of angles used for the wavelet transform\n Returns\n -------\n filters : list\n A two list of dictionary containing respectively the low-pass and\n wavelet filters.\n Notes\n -----\n The design of the filters is optimized for the value L = 8.\n \"\"\"\n filters = {}\n filters['psi'] = []\n\n for j in range(J):\n for theta in range(L):\n psi = {}\n psi['j'] = j\n psi['theta'] = theta\n psi_signal = morlet_2d(M, N, 0.8 * 2**j,\n (int(L-L/2-1)-theta) * np.pi / L,\n 3.0 / 4.0 * np.pi /2**j, 4.0/L)\n psi_signal_fourier = fft2(psi_signal)\n # drop the imaginary part, it is zero anyway\n psi_signal_fourier = np.real(psi_signal_fourier)\n for res in range(min(j + 1, J - 1)):\n psi_signal_fourier_res = periodize_filter_fft(\n psi_signal_fourier, res)\n # add a trailing singleton dimension to mark it as non-complex\n psi_signal_fourier_res = psi_signal_fourier_res[..., np.newaxis]\n psi[res] = psi_signal_fourier_res\n # Normalization to avoid doing it with the FFT.\n psi[res] /= M*N// 2**(2*j)\n filters['psi'].append(psi)\n\n filters['phi'] = {}\n phi_signal = gabor_2d(M, N, 0.8 * 2**(J-1), 0, 0)\n phi_signal_fourier = fft2(phi_signal)\n # drop the imaginary part, it is zero anyway\n phi_signal_fourier = np.real(phi_signal_fourier)\n filters['phi']['j'] = J\n for res in range(J):\n phi_signal_fourier_res = periodize_filter_fft(phi_signal_fourier, res)\n # add a trailing singleton dimension to mark it as non-complex\n phi_signal_fourier_res = phi_signal_fourier_res[..., np.newaxis]\n filters['phi'][res] = phi_signal_fourier_res\n # Normalization to avoid doing it with the FFT.\n filters['phi'][res] /= M*N // 2 ** (2 * J)\n\n return filters\n\n\ndef periodize_filter_fft(x, res):\n \"\"\"\n Parameters\n ----------\n x : numpy array\n signal to periodize in Fourier\n res :\n resolution to which the signal is cropped.\n\n Returns\n -------\n crop : numpy array\n It returns a crop version of the filter, assuming that\n the convolutions will be done via compactly supported signals.\n \"\"\"\n M = x.shape[0]\n N = x.shape[1]\n\n crop = np.zeros((M // 2 ** res, N // 2 ** res), x.dtype)\n\n mask = np.ones(x.shape, np.float32)\n len_x = int(M * (1 - 2 ** (-res)))\n start_x = int(M * 2 ** (-res - 1))\n len_y = int(N * (1 - 2 ** (-res)))\n start_y = int(N * 2 ** (-res - 1))\n mask[start_x:start_x + len_x,:] = 0\n mask[:, start_y:start_y + len_y] = 0\n x = np.multiply(x,mask)\n\n for k in range(int(M / 2 ** res)):\n for l in range(int(N / 2 ** res)):\n for i in range(int(2 ** res)):\n for j in range(int(2 ** res)):\n crop[k, l] += x[k + i * int(M / 2 ** res), l + j * int(N / 2 ** res)]\n\n return crop\n\n\ndef morlet_2d(M, N, sigma, theta, xi, slant=0.5, offset=0):\n \"\"\"\n Computes a 2D Morlet filter.\n A Morlet filter is the sum of a Gabor filter and a low-pass filter\n to ensure that the sum has exactly zero mean in the temporal domain.\n It is defined by the following formula in space:\n psi(u) = g_{sigma}(u) (e^(i xi^T u) - beta)\n where g_{sigma} is a Gaussian envelope, xi is a frequency and beta is\n the cancelling parameter.\n\n Parameters\n ----------\n M, N : int\n spatial sizes\n sigma : float\n bandwidth parameter\n xi : float\n central frequency (in [0, 1])\n theta : float\n angle in [0, pi]\n slant : float, optional\n parameter which guides the elipsoidal shape of the morlet\n offset : int, optional\n offset by which the signal starts\n\n Returns\n -------\n morlet_fft : ndarray\n numpy array of size (M, N)\n \"\"\"\n wv = gabor_2d(M, N, sigma, theta, xi, slant, offset)\n wv_modulus = gabor_2d(M, N, sigma, theta, 0, slant, offset)\n K = np.sum(wv) / np.sum(wv_modulus)\n\n mor = wv - K * wv_modulus\n return mor\n\n\ndef gabor_2d(M, N, sigma, theta, xi, slant=1.0, offset=0):\n \"\"\"\n Computes a 2D Gabor filter.\n A Gabor filter is defined by the following formula in space:\n psi(u) = g_{sigma}(u) e^(i xi^T u)\n where g_{sigma} is a Gaussian envelope and xi is a frequency.\n\n Parameters\n ----------\n M, N : int\n spatial sizes\n sigma : float\n bandwidth parameter\n xi : float\n central frequency (in [0, 1])\n theta : float\n angle in [0, pi]\n slant : float, optional\n parameter which guides the elipsoidal shape of the morlet\n offset : int, optional\n offset by which the signal starts\n\n Returns\n -------\n morlet_fft : ndarray\n numpy array of size (M, N)\n \"\"\"\n gab = np.zeros((M, N), np.complex64)\n R = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]], np.float32)\n R_inv = np.array([[np.cos(theta), np.sin(theta)], [-np.sin(theta), np.cos(theta)]], np.float32)\n D = np.array([[1, 0], [0, slant * slant]])\n curv = np.dot(R, np.dot(D, R_inv)) / ( 2 * sigma * sigma)\n\n for ex in [-2, -1, 0, 1, 2]:\n for ey in [-2, -1, 0, 1, 2]:\n [xx, yy] = np.mgrid[offset + ex * M:offset + M + ex * M, offset + ey * N:offset + N + ey * N]\n arg = -(curv[0, 0] * np.multiply(xx, xx) + (curv[0, 1] + curv[1, 0]) * np.multiply(xx, yy) + curv[\n 1, 1] * np.multiply(yy, yy)) + 1.j * (xx * xi * np.cos(theta) + yy * xi * np.sin(theta))\n gab += np.exp(arg)\n\n norm_factor = (2 * 3.1415 * sigma * sigma / slant)\n gab /= norm_factor\n\n return gab\n", "path": "kymatio/scattering2d/filter_bank.py"}], "after_files": [{"content": "\"\"\"\nAuthors: Eugene Belilovsky, Edouard Oyallon and Sergey Zagoruyko\nAll rights reserved, 2017.\n\"\"\"\n\n__all__ = ['filter_bank']\n\nimport numpy as np\nfrom .utils import fft2\n\n\ndef filter_bank(M, N, J, L=8):\n \"\"\"\n Builds in Fourier the Morlet filters used for the scattering transform.\n Each single filter is provided as a dictionary with the following keys:\n * 'j' : scale\n * 'theta' : angle used\n Parameters\n ----------\n M, N : int\n spatial support of the input\n J : int\n logscale of the scattering\n L : int, optional\n number of angles used for the wavelet transform\n Returns\n -------\n filters : list\n A two list of dictionary containing respectively the low-pass and\n wavelet filters.\n Notes\n -----\n The design of the filters is optimized for the value L = 8.\n \"\"\"\n filters = {}\n filters['psi'] = []\n\n for j in range(J):\n for theta in range(L):\n psi = {}\n psi['j'] = j\n psi['theta'] = theta\n psi_signal = morlet_2d(M, N, 0.8 * 2**j,\n (int(L-L/2-1)-theta) * np.pi / L,\n 3.0 / 4.0 * np.pi /2**j, 4.0/L)\n psi_signal_fourier = fft2(psi_signal)\n # drop the imaginary part, it is zero anyway\n psi_signal_fourier = np.real(psi_signal_fourier)\n for res in range(min(j + 1, max(J - 1, 1))):\n psi_signal_fourier_res = periodize_filter_fft(\n psi_signal_fourier, res)\n # add a trailing singleton dimension to mark it as non-complex\n psi_signal_fourier_res = psi_signal_fourier_res[..., np.newaxis]\n psi[res] = psi_signal_fourier_res\n # Normalization to avoid doing it with the FFT.\n psi[res] /= M*N// 2**(2*j)\n\n filters['psi'].append(psi)\n\n filters['phi'] = {}\n phi_signal = gabor_2d(M, N, 0.8 * 2**(J-1), 0, 0)\n phi_signal_fourier = fft2(phi_signal)\n # drop the imaginary part, it is zero anyway\n phi_signal_fourier = np.real(phi_signal_fourier)\n filters['phi']['j'] = J\n for res in range(J):\n phi_signal_fourier_res = periodize_filter_fft(phi_signal_fourier, res)\n # add a trailing singleton dimension to mark it as non-complex\n phi_signal_fourier_res = phi_signal_fourier_res[..., np.newaxis]\n filters['phi'][res] = phi_signal_fourier_res\n # Normalization to avoid doing it with the FFT.\n filters['phi'][res] /= M*N // 2 ** (2 * J)\n\n return filters\n\n\ndef periodize_filter_fft(x, res):\n \"\"\"\n Parameters\n ----------\n x : numpy array\n signal to periodize in Fourier\n res :\n resolution to which the signal is cropped.\n\n Returns\n -------\n crop : numpy array\n It returns a crop version of the filter, assuming that\n the convolutions will be done via compactly supported signals.\n \"\"\"\n M = x.shape[0]\n N = x.shape[1]\n\n crop = np.zeros((M // 2 ** res, N // 2 ** res), x.dtype)\n\n mask = np.ones(x.shape, np.float32)\n len_x = int(M * (1 - 2 ** (-res)))\n start_x = int(M * 2 ** (-res - 1))\n len_y = int(N * (1 - 2 ** (-res)))\n start_y = int(N * 2 ** (-res - 1))\n mask[start_x:start_x + len_x,:] = 0\n mask[:, start_y:start_y + len_y] = 0\n x = np.multiply(x,mask)\n\n for k in range(int(M / 2 ** res)):\n for l in range(int(N / 2 ** res)):\n for i in range(int(2 ** res)):\n for j in range(int(2 ** res)):\n crop[k, l] += x[k + i * int(M / 2 ** res), l + j * int(N / 2 ** res)]\n\n return crop\n\n\ndef morlet_2d(M, N, sigma, theta, xi, slant=0.5, offset=0):\n \"\"\"\n Computes a 2D Morlet filter.\n A Morlet filter is the sum of a Gabor filter and a low-pass filter\n to ensure that the sum has exactly zero mean in the temporal domain.\n It is defined by the following formula in space:\n psi(u) = g_{sigma}(u) (e^(i xi^T u) - beta)\n where g_{sigma} is a Gaussian envelope, xi is a frequency and beta is\n the cancelling parameter.\n\n Parameters\n ----------\n M, N : int\n spatial sizes\n sigma : float\n bandwidth parameter\n xi : float\n central frequency (in [0, 1])\n theta : float\n angle in [0, pi]\n slant : float, optional\n parameter which guides the elipsoidal shape of the morlet\n offset : int, optional\n offset by which the signal starts\n\n Returns\n -------\n morlet_fft : ndarray\n numpy array of size (M, N)\n \"\"\"\n wv = gabor_2d(M, N, sigma, theta, xi, slant, offset)\n wv_modulus = gabor_2d(M, N, sigma, theta, 0, slant, offset)\n K = np.sum(wv) / np.sum(wv_modulus)\n\n mor = wv - K * wv_modulus\n return mor\n\n\ndef gabor_2d(M, N, sigma, theta, xi, slant=1.0, offset=0):\n \"\"\"\n Computes a 2D Gabor filter.\n A Gabor filter is defined by the following formula in space:\n psi(u) = g_{sigma}(u) e^(i xi^T u)\n where g_{sigma} is a Gaussian envelope and xi is a frequency.\n\n Parameters\n ----------\n M, N : int\n spatial sizes\n sigma : float\n bandwidth parameter\n xi : float\n central frequency (in [0, 1])\n theta : float\n angle in [0, pi]\n slant : float, optional\n parameter which guides the elipsoidal shape of the morlet\n offset : int, optional\n offset by which the signal starts\n\n Returns\n -------\n morlet_fft : ndarray\n numpy array of size (M, N)\n \"\"\"\n gab = np.zeros((M, N), np.complex64)\n R = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]], np.float32)\n R_inv = np.array([[np.cos(theta), np.sin(theta)], [-np.sin(theta), np.cos(theta)]], np.float32)\n D = np.array([[1, 0], [0, slant * slant]])\n curv = np.dot(R, np.dot(D, R_inv)) / ( 2 * sigma * sigma)\n\n for ex in [-2, -1, 0, 1, 2]:\n for ey in [-2, -1, 0, 1, 2]:\n [xx, yy] = np.mgrid[offset + ex * M:offset + M + ex * M, offset + ey * N:offset + N + ey * N]\n arg = -(curv[0, 0] * np.multiply(xx, xx) + (curv[0, 1] + curv[1, 0]) * np.multiply(xx, yy) + curv[\n 1, 1] * np.multiply(yy, yy)) + 1.j * (xx * xi * np.cos(theta) + yy * xi * np.sin(theta))\n gab += np.exp(arg)\n\n norm_factor = (2 * 3.1415 * sigma * sigma / slant)\n gab /= norm_factor\n\n return gab\n", "path": "kymatio/scattering2d/filter_bank.py"}]}
| 3,013 | 242 |
gh_patches_debug_22409
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-1551
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`xonsh.completers.pip` explodes if `pip` is not on PATH
On my Windows installation, Python is not on PATH (because multiple Python madness), and therefore neither is pip. However, the pip completer [expects pip to be on the path](https://github.com/xonsh/xonsh/blob/master/xonsh/completers/pip.py#L14).
This causes the completer to blow up with a `FileNotFoundError` when it tries to complete.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xonsh/completers/pip.py`
Content:
```
1 import re
2 import subprocess
3
4 import xonsh.lazyasd as xl
5
6 PIP_RE = xl.LazyObject(lambda: re.compile("pip(?:\d|\.)*"),
7 globals(), 'PIP_RE')
8 PIP_LIST_RE = xl.LazyObject(lambda: re.compile("pip(?:\d|\.)* (?:uninstall|show)"),
9 globals(), 'PIP_LIST_RE')
10
11
12 @xl.lazyobject
13 def ALL_COMMANDS():
14 help_text = str(subprocess.check_output(['pip', '--help'],
15 stderr=subprocess.DEVNULL))
16 commands = re.findall(" (\w+) ", help_text)
17 return [c for c in commands if c not in ['completion', 'help']]
18
19
20 def complete_pip(prefix, line, begidx, endidx, ctx):
21 """Completes python's package manager pip"""
22 line_len = len(line.split())
23 if (line_len > 3) or (line_len > 2 and line.endswith(' ')) or \
24 (not PIP_RE.search(line)):
25 return
26 if PIP_LIST_RE.search(line):
27 items = subprocess.check_output(['pip', 'list'], stderr=subprocess.DEVNULL)
28 items = items.decode('utf-8').splitlines()
29 return set(i.split()[0] for i in items)
30
31 if (line_len > 1 and line.endswith(' ')) or line_len > 2:
32 # "pip show " -> no complete (note space)
33 return
34 if prefix not in ALL_COMMANDS:
35 suggestions = [c for c in ALL_COMMANDS if c.startswith(prefix)]
36 if suggestions:
37 return suggestions, len(prefix)
38 return ALL_COMMANDS, len(prefix)
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xonsh/completers/pip.py b/xonsh/completers/pip.py
--- a/xonsh/completers/pip.py
+++ b/xonsh/completers/pip.py
@@ -11,8 +11,11 @@
@xl.lazyobject
def ALL_COMMANDS():
- help_text = str(subprocess.check_output(['pip', '--help'],
- stderr=subprocess.DEVNULL))
+ try:
+ help_text = str(subprocess.check_output(['pip', '--help'],
+ stderr=subprocess.DEVNULL))
+ except FileNotFoundError:
+ return []
commands = re.findall(" (\w+) ", help_text)
return [c for c in commands if c not in ['completion', 'help']]
@@ -24,7 +27,11 @@
(not PIP_RE.search(line)):
return
if PIP_LIST_RE.search(line):
- items = subprocess.check_output(['pip', 'list'], stderr=subprocess.DEVNULL)
+ try:
+ items = subprocess.check_output(['pip', 'list'],
+ stderr=subprocess.DEVNULL)
+ except FileNotFoundError:
+ return set()
items = items.decode('utf-8').splitlines()
return set(i.split()[0] for i in items)
|
{"golden_diff": "diff --git a/xonsh/completers/pip.py b/xonsh/completers/pip.py\n--- a/xonsh/completers/pip.py\n+++ b/xonsh/completers/pip.py\n@@ -11,8 +11,11 @@\n \n @xl.lazyobject\n def ALL_COMMANDS():\n- help_text = str(subprocess.check_output(['pip', '--help'],\n- stderr=subprocess.DEVNULL))\n+ try:\n+ help_text = str(subprocess.check_output(['pip', '--help'],\n+ stderr=subprocess.DEVNULL))\n+ except FileNotFoundError:\n+ return []\n commands = re.findall(\" (\\w+) \", help_text)\n return [c for c in commands if c not in ['completion', 'help']]\n \n@@ -24,7 +27,11 @@\n (not PIP_RE.search(line)):\n return\n if PIP_LIST_RE.search(line):\n- items = subprocess.check_output(['pip', 'list'], stderr=subprocess.DEVNULL)\n+ try:\n+ items = subprocess.check_output(['pip', 'list'],\n+ stderr=subprocess.DEVNULL)\n+ except FileNotFoundError:\n+ return set()\n items = items.decode('utf-8').splitlines()\n return set(i.split()[0] for i in items)\n", "issue": "`xonsh.completers.pip` explodes if `pip` is not on PATH\nOn my Windows installation, Python is not on PATH (because multiple Python madness), and therefore neither is pip. However, the pip completer [expects pip to be on the path](https://github.com/xonsh/xonsh/blob/master/xonsh/completers/pip.py#L14).\n\nThis causes the completer to blow up with a `FileNotFoundError` when it tries to complete.\n\n", "before_files": [{"content": "import re\nimport subprocess\n\nimport xonsh.lazyasd as xl\n\nPIP_RE = xl.LazyObject(lambda: re.compile(\"pip(?:\\d|\\.)*\"),\n globals(), 'PIP_RE')\nPIP_LIST_RE = xl.LazyObject(lambda: re.compile(\"pip(?:\\d|\\.)* (?:uninstall|show)\"),\n globals(), 'PIP_LIST_RE')\n\n\[email protected]\ndef ALL_COMMANDS():\n help_text = str(subprocess.check_output(['pip', '--help'],\n stderr=subprocess.DEVNULL))\n commands = re.findall(\" (\\w+) \", help_text)\n return [c for c in commands if c not in ['completion', 'help']]\n\n\ndef complete_pip(prefix, line, begidx, endidx, ctx):\n \"\"\"Completes python's package manager pip\"\"\"\n line_len = len(line.split())\n if (line_len > 3) or (line_len > 2 and line.endswith(' ')) or \\\n (not PIP_RE.search(line)):\n return\n if PIP_LIST_RE.search(line):\n items = subprocess.check_output(['pip', 'list'], stderr=subprocess.DEVNULL)\n items = items.decode('utf-8').splitlines()\n return set(i.split()[0] for i in items)\n\n if (line_len > 1 and line.endswith(' ')) or line_len > 2:\n # \"pip show \" -> no complete (note space)\n return\n if prefix not in ALL_COMMANDS:\n suggestions = [c for c in ALL_COMMANDS if c.startswith(prefix)]\n if suggestions:\n return suggestions, len(prefix)\n return ALL_COMMANDS, len(prefix)\n", "path": "xonsh/completers/pip.py"}], "after_files": [{"content": "import re\nimport subprocess\n\nimport xonsh.lazyasd as xl\n\nPIP_RE = xl.LazyObject(lambda: re.compile(\"pip(?:\\d|\\.)*\"),\n globals(), 'PIP_RE')\nPIP_LIST_RE = xl.LazyObject(lambda: re.compile(\"pip(?:\\d|\\.)* (?:uninstall|show)\"),\n globals(), 'PIP_LIST_RE')\n\n\[email protected]\ndef ALL_COMMANDS():\n try:\n help_text = str(subprocess.check_output(['pip', '--help'],\n stderr=subprocess.DEVNULL))\n except FileNotFoundError:\n return []\n commands = re.findall(\" (\\w+) \", help_text)\n return [c for c in commands if c not in ['completion', 'help']]\n\n\ndef complete_pip(prefix, line, begidx, endidx, ctx):\n \"\"\"Completes python's package manager pip\"\"\"\n line_len = len(line.split())\n if (line_len > 3) or (line_len > 2 and line.endswith(' ')) or \\\n (not PIP_RE.search(line)):\n return\n if PIP_LIST_RE.search(line):\n try:\n items = subprocess.check_output(['pip', 'list'],\n stderr=subprocess.DEVNULL)\n except FileNotFoundError:\n return set()\n items = items.decode('utf-8').splitlines()\n return set(i.split()[0] for i in items)\n\n if (line_len > 1 and line.endswith(' ')) or line_len > 2:\n # \"pip show \" -> no complete (note space)\n return\n if prefix not in ALL_COMMANDS:\n suggestions = [c for c in ALL_COMMANDS if c.startswith(prefix)]\n if suggestions:\n return suggestions, len(prefix)\n return ALL_COMMANDS, len(prefix)\n", "path": "xonsh/completers/pip.py"}]}
| 790 | 281 |
gh_patches_debug_11511
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Minor differences in what's displayed after user response 45.state-management bot
## Version
v4.50b4
## Describe the bug
There's a minor difference in what's displayed after the user responds to the bot. The javascript_nodejs bot exhibits the same behavior (see [issue 1718](https://github.com/microsoft/BotBuilder-Samples/issues/1718) for more information).
## To Reproduce
Run bot per README.md instructions
1. go to bot's folder
2. run `python install -r requirement.txt`, then run `python app.py`
3. open in Emulator
The csharp_dotnet and javascript_nodejs bots were also run via CLI.
## Expected behavior
Bot should look and function just like bots in other languages (specifically csharp_dotnet bot since there are currently issues with javascript_nodejs sample).
## Screenshots
**charp_dotnetcore bot**: Bot responds with, "Thanks <string_user_responded_with. To see conversation data, type anything." after user's second response. Also welcomes users. This is IMHO the best version/gold standard for the sample currently.

**Python bot**: Bot responds with, "Thanks <string_user_responded_with." after user's second response. Also welcomes user.

**javascript_nodejs bot**: Bot responds with, "Thanks <string_user_responded_with." after user's second response. Does not welcome user (addressed in [issue 1718](https://github.com/microsoft/BotBuilder-Samples/issues/1718)).

## Additional context
To fix: Add **"To see conversation data, type anything."** to the string in **line 62** in 45.state-management/bots/state_management_bot.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `samples/45.state-management/bots/state_management_bot.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 import time
5 import pytz
6 from datetime import datetime
7
8 from botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState
9 from botbuilder.schema import ChannelAccount
10
11 from data_models import ConversationData, UserProfile
12
13
14 class StateManagementBot(ActivityHandler):
15 def __init__(self, conversation_state: ConversationState, user_state: UserState):
16 if conversation_state is None:
17 raise TypeError(
18 "[StateManagementBot]: Missing parameter. conversation_state is required but None was given"
19 )
20 if user_state is None:
21 raise TypeError(
22 "[StateManagementBot]: Missing parameter. user_state is required but None was given"
23 )
24
25 self.conversation_state = conversation_state
26 self.user_state = user_state
27
28 self.conversation_data = self.conversation_state.create_property(
29 "ConversationData"
30 )
31 self.user_profile = self.conversation_state.create_property("UserProfile")
32
33 async def on_turn(self, turn_context: TurnContext):
34 await super().on_turn(turn_context)
35
36 await self.conversation_state.save_changes(turn_context)
37 await self.user_state.save_changes(turn_context)
38
39 async def on_members_added_activity(
40 self, members_added: [ChannelAccount], turn_context: TurnContext
41 ):
42 for member in members_added:
43 if member.id != turn_context.activity.recipient.id:
44 await turn_context.send_activity(
45 "Welcome to State Bot Sample. Type anything to get started."
46 )
47
48 async def on_message_activity(self, turn_context: TurnContext):
49 # Get the state properties from the turn context.
50 user_profile = await self.user_profile.get(turn_context, UserProfile)
51 conversation_data = await self.conversation_data.get(
52 turn_context, ConversationData
53 )
54
55 if user_profile.name is None:
56 # First time around this is undefined, so we will prompt user for name.
57 if conversation_data.prompted_for_user_name:
58 # Set the name to what the user provided.
59 user_profile.name = turn_context.activity.text
60
61 # Acknowledge that we got their name.
62 await turn_context.send_activity(f"Thanks { user_profile.name }.")
63
64 # Reset the flag to allow the bot to go though the cycle again.
65 conversation_data.prompted_for_user_name = False
66 else:
67 # Prompt the user for their name.
68 await turn_context.send_activity("What is your name?")
69
70 # Set the flag to true, so we don't prompt in the next turn.
71 conversation_data.prompted_for_user_name = True
72 else:
73 # Add message details to the conversation data.
74 conversation_data.timestamp = self.__datetime_from_utc_to_local(
75 turn_context.activity.timestamp
76 )
77 conversation_data.channel_id = turn_context.activity.channel_id
78
79 # Display state data.
80 await turn_context.send_activity(
81 f"{ user_profile.name } sent: { turn_context.activity.text }"
82 )
83 await turn_context.send_activity(
84 f"Message received at: { conversation_data.timestamp }"
85 )
86 await turn_context.send_activity(
87 f"Message received from: { conversation_data.channel_id }"
88 )
89
90 def __datetime_from_utc_to_local(self, utc_datetime):
91 now_timestamp = time.time()
92 offset = datetime.fromtimestamp(now_timestamp) - datetime.utcfromtimestamp(
93 now_timestamp
94 )
95 result = utc_datetime + offset
96 return result.strftime("%I:%M:%S %p, %A, %B %d of %Y")
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/samples/45.state-management/bots/state_management_bot.py b/samples/45.state-management/bots/state_management_bot.py
--- a/samples/45.state-management/bots/state_management_bot.py
+++ b/samples/45.state-management/bots/state_management_bot.py
@@ -59,7 +59,9 @@
user_profile.name = turn_context.activity.text
# Acknowledge that we got their name.
- await turn_context.send_activity(f"Thanks { user_profile.name }.")
+ await turn_context.send_activity(
+ f"Thanks { user_profile.name }. To see conversation data, type anything."
+ )
# Reset the flag to allow the bot to go though the cycle again.
conversation_data.prompted_for_user_name = False
|
{"golden_diff": "diff --git a/samples/45.state-management/bots/state_management_bot.py b/samples/45.state-management/bots/state_management_bot.py\n--- a/samples/45.state-management/bots/state_management_bot.py\n+++ b/samples/45.state-management/bots/state_management_bot.py\n@@ -59,7 +59,9 @@\n user_profile.name = turn_context.activity.text\n \n # Acknowledge that we got their name.\n- await turn_context.send_activity(f\"Thanks { user_profile.name }.\")\n+ await turn_context.send_activity(\n+ f\"Thanks { user_profile.name }. To see conversation data, type anything.\"\n+ )\n \n # Reset the flag to allow the bot to go though the cycle again.\n conversation_data.prompted_for_user_name = False\n", "issue": "Minor differences in what's displayed after user response 45.state-management bot\n## Version\r\nv4.50b4\r\n\r\n## Describe the bug\r\nThere's a minor difference in what's displayed after the user responds to the bot. The javascript_nodejs bot exhibits the same behavior (see [issue 1718](https://github.com/microsoft/BotBuilder-Samples/issues/1718) for more information).\r\n\r\n## To Reproduce\r\nRun bot per README.md instructions\r\n1. go to bot's folder\r\n2. run `python install -r requirement.txt`, then run `python app.py`\r\n3. open in Emulator\r\n\r\nThe csharp_dotnet and javascript_nodejs bots were also run via CLI. \r\n\r\n## Expected behavior\r\nBot should look and function just like bots in other languages (specifically csharp_dotnet bot since there are currently issues with javascript_nodejs sample). \r\n\r\n## Screenshots\r\n**charp_dotnetcore bot**: Bot responds with, \"Thanks <string_user_responded_with. To see conversation data, type anything.\" after user's second response. Also welcomes users. This is IMHO the best version/gold standard for the sample currently. \r\n\r\n\r\n**Python bot**: Bot responds with, \"Thanks <string_user_responded_with.\" after user's second response. Also welcomes user.\r\n\r\n\r\n**javascript_nodejs bot**: Bot responds with, \"Thanks <string_user_responded_with.\" after user's second response. Does not welcome user (addressed in [issue 1718](https://github.com/microsoft/BotBuilder-Samples/issues/1718)).\r\n\r\n\r\n\r\n## Additional context\r\nTo fix: Add **\"To see conversation data, type anything.\"** to the string in **line 62** in 45.state-management/bots/state_management_bot.py\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport time\nimport pytz\nfrom datetime import datetime\n\nfrom botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState\nfrom botbuilder.schema import ChannelAccount\n\nfrom data_models import ConversationData, UserProfile\n\n\nclass StateManagementBot(ActivityHandler):\n def __init__(self, conversation_state: ConversationState, user_state: UserState):\n if conversation_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. conversation_state is required but None was given\"\n )\n if user_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. user_state is required but None was given\"\n )\n\n self.conversation_state = conversation_state\n self.user_state = user_state\n\n self.conversation_data = self.conversation_state.create_property(\n \"ConversationData\"\n )\n self.user_profile = self.conversation_state.create_property(\"UserProfile\")\n\n async def on_turn(self, turn_context: TurnContext):\n await super().on_turn(turn_context)\n\n await self.conversation_state.save_changes(turn_context)\n await self.user_state.save_changes(turn_context)\n\n async def on_members_added_activity(\n self, members_added: [ChannelAccount], turn_context: TurnContext\n ):\n for member in members_added:\n if member.id != turn_context.activity.recipient.id:\n await turn_context.send_activity(\n \"Welcome to State Bot Sample. Type anything to get started.\"\n )\n\n async def on_message_activity(self, turn_context: TurnContext):\n # Get the state properties from the turn context.\n user_profile = await self.user_profile.get(turn_context, UserProfile)\n conversation_data = await self.conversation_data.get(\n turn_context, ConversationData\n )\n\n if user_profile.name is None:\n # First time around this is undefined, so we will prompt user for name.\n if conversation_data.prompted_for_user_name:\n # Set the name to what the user provided.\n user_profile.name = turn_context.activity.text\n\n # Acknowledge that we got their name.\n await turn_context.send_activity(f\"Thanks { user_profile.name }.\")\n\n # Reset the flag to allow the bot to go though the cycle again.\n conversation_data.prompted_for_user_name = False\n else:\n # Prompt the user for their name.\n await turn_context.send_activity(\"What is your name?\")\n\n # Set the flag to true, so we don't prompt in the next turn.\n conversation_data.prompted_for_user_name = True\n else:\n # Add message details to the conversation data.\n conversation_data.timestamp = self.__datetime_from_utc_to_local(\n turn_context.activity.timestamp\n )\n conversation_data.channel_id = turn_context.activity.channel_id\n\n # Display state data.\n await turn_context.send_activity(\n f\"{ user_profile.name } sent: { turn_context.activity.text }\"\n )\n await turn_context.send_activity(\n f\"Message received at: { conversation_data.timestamp }\"\n )\n await turn_context.send_activity(\n f\"Message received from: { conversation_data.channel_id }\"\n )\n\n def __datetime_from_utc_to_local(self, utc_datetime):\n now_timestamp = time.time()\n offset = datetime.fromtimestamp(now_timestamp) - datetime.utcfromtimestamp(\n now_timestamp\n )\n result = utc_datetime + offset\n return result.strftime(\"%I:%M:%S %p, %A, %B %d of %Y\")\n", "path": "samples/45.state-management/bots/state_management_bot.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nimport time\nimport pytz\nfrom datetime import datetime\n\nfrom botbuilder.core import ActivityHandler, ConversationState, TurnContext, UserState\nfrom botbuilder.schema import ChannelAccount\n\nfrom data_models import ConversationData, UserProfile\n\n\nclass StateManagementBot(ActivityHandler):\n def __init__(self, conversation_state: ConversationState, user_state: UserState):\n if conversation_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. conversation_state is required but None was given\"\n )\n if user_state is None:\n raise TypeError(\n \"[StateManagementBot]: Missing parameter. user_state is required but None was given\"\n )\n\n self.conversation_state = conversation_state\n self.user_state = user_state\n\n self.conversation_data = self.conversation_state.create_property(\n \"ConversationData\"\n )\n self.user_profile = self.conversation_state.create_property(\"UserProfile\")\n\n async def on_turn(self, turn_context: TurnContext):\n await super().on_turn(turn_context)\n\n await self.conversation_state.save_changes(turn_context)\n await self.user_state.save_changes(turn_context)\n\n async def on_members_added_activity(\n self, members_added: [ChannelAccount], turn_context: TurnContext\n ):\n for member in members_added:\n if member.id != turn_context.activity.recipient.id:\n await turn_context.send_activity(\n \"Welcome to State Bot Sample. Type anything to get started.\"\n )\n\n async def on_message_activity(self, turn_context: TurnContext):\n # Get the state properties from the turn context.\n user_profile = await self.user_profile.get(turn_context, UserProfile)\n conversation_data = await self.conversation_data.get(\n turn_context, ConversationData\n )\n\n if user_profile.name is None:\n # First time around this is undefined, so we will prompt user for name.\n if conversation_data.prompted_for_user_name:\n # Set the name to what the user provided.\n user_profile.name = turn_context.activity.text\n\n # Acknowledge that we got their name.\n await turn_context.send_activity(\n f\"Thanks { user_profile.name }. To see conversation data, type anything.\"\n )\n\n # Reset the flag to allow the bot to go though the cycle again.\n conversation_data.prompted_for_user_name = False\n else:\n # Prompt the user for their name.\n await turn_context.send_activity(\"What is your name?\")\n\n # Set the flag to true, so we don't prompt in the next turn.\n conversation_data.prompted_for_user_name = True\n else:\n # Add message details to the conversation data.\n conversation_data.timestamp = self.__datetime_from_utc_to_local(\n turn_context.activity.timestamp\n )\n conversation_data.channel_id = turn_context.activity.channel_id\n\n # Display state data.\n await turn_context.send_activity(\n f\"{ user_profile.name } sent: { turn_context.activity.text }\"\n )\n await turn_context.send_activity(\n f\"Message received at: { conversation_data.timestamp }\"\n )\n await turn_context.send_activity(\n f\"Message received from: { conversation_data.channel_id }\"\n )\n\n def __datetime_from_utc_to_local(self, utc_datetime):\n now_timestamp = time.time()\n offset = datetime.fromtimestamp(now_timestamp) - datetime.utcfromtimestamp(\n now_timestamp\n )\n result = utc_datetime + offset\n return result.strftime(\"%I:%M:%S %p, %A, %B %d of %Y\")\n", "path": "samples/45.state-management/bots/state_management_bot.py"}]}
| 1,773 | 169 |
gh_patches_debug_3102
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-4684
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update documentation for Embedding layer
The documentation corresponding [torch.nn.Embedding](http://pytorch.org/docs/master/nn.html) mentions that ```Keep in mind that only a limited number of optimizers support sparse gradients: currently it’s optim.SGD (cuda and cpu), and optim.Adagrad (cpu)```. This is outdated and now `SparseAdam` is also supported.
Update documentation for Embedding layer
The documentation corresponding [torch.nn.Embedding](http://pytorch.org/docs/master/nn.html) mentions that ```Keep in mind that only a limited number of optimizers support sparse gradients: currently it’s optim.SGD (cuda and cpu), and optim.Adagrad (cpu)```. This is outdated and now `SparseAdam` is also supported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/nn/modules/sparse.py`
Content:
```
1 import torch
2 from torch.autograd import Variable
3 from torch.nn.parameter import Parameter
4
5 from .module import Module
6 from .. import functional as F
7
8
9 class Embedding(Module):
10 r"""A simple lookup table that stores embeddings of a fixed dictionary and size.
11
12 This module is often used to store word embeddings and retrieve them using indices.
13 The input to the module is a list of indices, and the output is the corresponding
14 word embeddings.
15
16 Args:
17 num_embeddings (int): size of the dictionary of embeddings
18 embedding_dim (int): the size of each embedding vector
19 padding_idx (int, optional): If given, pads the output with zeros whenever it encounters the index.
20 max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this
21 norm_type (float, optional): The p of the p-norm to compute for the max_norm option
22 scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of
23 the words in the mini-batch.
24 sparse (boolean, optional): if ``True``, gradient w.r.t. weight matrix will be a sparse tensor. See Notes for
25 more details regarding sparse gradients.
26
27 Attributes:
28 weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)
29
30 Shape:
31 - Input: LongTensor `(N, W)`, N = mini-batch, W = number of indices to extract per mini-batch
32 - Output: `(N, W, embedding_dim)`
33
34 Notes:
35 Keep in mind that only a limited number of optimizers support
36 sparse gradients: currently it's `optim.SGD` (`cuda` and `cpu`),
37 and `optim.Adagrad` (`cpu`)
38
39 Examples::
40
41 >>> # an Embedding module containing 10 tensors of size 3
42 >>> embedding = nn.Embedding(10, 3)
43 >>> # a batch of 2 samples of 4 indices each
44 >>> input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]]))
45 >>> embedding(input)
46
47 Variable containing:
48 (0 ,.,.) =
49 -1.0822 1.2522 0.2434
50 0.8393 -0.6062 -0.3348
51 0.6597 0.0350 0.0837
52 0.5521 0.9447 0.0498
53
54 (1 ,.,.) =
55 0.6597 0.0350 0.0837
56 -0.1527 0.0877 0.4260
57 0.8393 -0.6062 -0.3348
58 -0.8738 -0.9054 0.4281
59 [torch.FloatTensor of size 2x4x3]
60
61 >>> # example with padding_idx
62 >>> embedding = nn.Embedding(10, 3, padding_idx=0)
63 >>> input = Variable(torch.LongTensor([[0,2,0,5]]))
64 >>> embedding(input)
65
66 Variable containing:
67 (0 ,.,.) =
68 0.0000 0.0000 0.0000
69 0.3452 0.4937 -0.9361
70 0.0000 0.0000 0.0000
71 0.0706 -2.1962 -0.6276
72 [torch.FloatTensor of size 1x4x3]
73
74 """
75
76 def __init__(self, num_embeddings, embedding_dim, padding_idx=None,
77 max_norm=None, norm_type=2, scale_grad_by_freq=False,
78 sparse=False):
79 super(Embedding, self).__init__()
80 self.num_embeddings = num_embeddings
81 self.embedding_dim = embedding_dim
82 if padding_idx is not None:
83 if padding_idx > 0:
84 assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'
85 elif padding_idx < 0:
86 assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'
87 padding_idx = self.num_embeddings + padding_idx
88 self.padding_idx = padding_idx
89 self.max_norm = max_norm
90 self.norm_type = norm_type
91 self.scale_grad_by_freq = scale_grad_by_freq
92 self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))
93 self.sparse = sparse
94
95 self.reset_parameters()
96
97 def reset_parameters(self):
98 self.weight.data.normal_(0, 1)
99 if self.padding_idx is not None:
100 self.weight.data[self.padding_idx].fill_(0)
101
102 def forward(self, input):
103 return F.embedding(
104 input, self.weight, self.padding_idx, self.max_norm,
105 self.norm_type, self.scale_grad_by_freq, self.sparse)
106
107 def __repr__(self):
108 s = '{name}({num_embeddings}, {embedding_dim}'
109 if self.padding_idx is not None:
110 s += ', padding_idx={padding_idx}'
111 if self.max_norm is not None:
112 s += ', max_norm={max_norm}'
113 if self.norm_type != 2:
114 s += ', norm_type={norm_type}'
115 if self.scale_grad_by_freq is not False:
116 s += ', scale_grad_by_freq={scale_grad_by_freq}'
117 if self.sparse is not False:
118 s += ', sparse=True'
119 s += ')'
120 return s.format(name=self.__class__.__name__, **self.__dict__)
121
122
123 class EmbeddingBag(Module):
124 r"""Computes sums or means of 'bags' of embeddings, without instantiating the
125 intermediate embeddings.
126
127 For bags of constant length,
128 * nn.EmbeddingBag with `mode=sum` is equivalent to nn.Embedding followed by `torch.sum(dim=1)`
129 * with `mode=mean` is equivalent to nn.Embedding followed by `torch.mean(dim=1)`
130
131 However, nn.EmbeddingBag is much more time and memory efficient than using a chain of these
132 operations.
133
134 Args:
135 num_embeddings (int): size of the dictionary of embeddings
136 embedding_dim (int): the size of each embedding vector
137 max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this
138 norm_type (float, optional): The p of the p-norm to compute for the max_norm option
139 scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of
140 the words in the dictionary.
141 mode (string, optional): 'sum' | 'mean'. Specifies the way to reduce the bag. Default: 'mean'
142
143 Attributes:
144 weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)
145
146 Inputs: input, offsets
147 - **input** (N or BxN): LongTensor containing the indices of the embeddings
148 to extract. When `input` is 1D Tensor of shape `N`,
149 an `offsets` Tensor is given, that contains the
150 starting position of each new sequence in the
151 mini-batch.
152 - **offsets** (B or None): LongTensor containing the starting positions of
153 each sample in a mini-batch of variable length
154 sequences. If `input` is 2D (BxN), then offsets
155 does not need to be given, as the `input` is
156 treated as a mini-batch of fixed length sequences
157 of length `N` each.
158
159
160 Shape:
161 - Input: LongTensor `N`, N = number of embeddings to extract
162 (or) LongTensor `BxN`, B = number of sequences in mini-batch,
163 N = number of embeddings per sequence
164 - Offsets: LongTensor `B`, B = number of bags. The values are the
165 offsets in `input` for each bag, i.e. the cumsum of lengths.
166 Offsets is not given if Input is 2D `BxN` Tensor,
167 the input is considered to be of fixed-length sequences
168 - Output: `(B, embedding_dim)`
169
170 Examples::
171
172 >>> # an Embedding module containing 10 tensors of size 3
173 >>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum')
174 >>> # a batch of 2 samples of 4 indices each
175 >>> input = Variable(torch.LongTensor([1,2,4,5,4,3,2,9]))
176 >>> offsets = Variable(torch.LongTensor([0,4]))
177 >>> embedding_sum(input, offsets)
178
179 Variable containing:
180 -0.7296 -4.6926 0.3295
181 -0.5186 -0.5631 -0.2792
182 [torch.FloatTensor of size 2x3]
183
184 """
185
186 def __init__(self, num_embeddings, embedding_dim,
187 max_norm=None, norm_type=2, scale_grad_by_freq=False,
188 mode='mean'):
189 super(EmbeddingBag, self).__init__()
190 self.num_embeddings = num_embeddings
191 self.embedding_dim = embedding_dim
192 self.max_norm = max_norm
193 self.norm_type = norm_type
194 self.scale_grad_by_freq = scale_grad_by_freq
195 self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))
196 self.mode = mode
197
198 self.reset_parameters()
199
200 def reset_parameters(self):
201 self.weight.data.normal_(0, 1)
202
203 def forward(self, input, offsets=None):
204 return F.embedding_bag(self.weight, input, offsets,
205 self.max_norm, self.norm_type,
206 self.scale_grad_by_freq, self.mode)
207
208 def __repr__(self):
209 s = '{name}({num_embeddings}, {embedding_dim}'
210 if self.max_norm is not None:
211 s += ', max_norm={max_norm}'
212 if self.norm_type != 2:
213 s += ', norm_type={norm_type}'
214 if self.scale_grad_by_freq is not False:
215 s += ', scale_grad_by_freq={scale_grad_by_freq}'
216 s += ', mode={mode}'
217 s += ')'
218 return s.format(name=self.__class__.__name__, **self.__dict__)
219
220 # TODO: SparseLinear
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/nn/modules/sparse.py b/torch/nn/modules/sparse.py
--- a/torch/nn/modules/sparse.py
+++ b/torch/nn/modules/sparse.py
@@ -34,7 +34,7 @@
Notes:
Keep in mind that only a limited number of optimizers support
sparse gradients: currently it's `optim.SGD` (`cuda` and `cpu`),
- and `optim.Adagrad` (`cpu`)
+ `optim.SparseAdam` (`cuda` and `cpu`) and `optim.Adagrad` (`cpu`)
Examples::
|
{"golden_diff": "diff --git a/torch/nn/modules/sparse.py b/torch/nn/modules/sparse.py\n--- a/torch/nn/modules/sparse.py\n+++ b/torch/nn/modules/sparse.py\n@@ -34,7 +34,7 @@\n Notes:\n Keep in mind that only a limited number of optimizers support\n sparse gradients: currently it's `optim.SGD` (`cuda` and `cpu`),\n- and `optim.Adagrad` (`cpu`)\n+ `optim.SparseAdam` (`cuda` and `cpu`) and `optim.Adagrad` (`cpu`)\n \n Examples::\n", "issue": "Update documentation for Embedding layer\nThe documentation corresponding [torch.nn.Embedding](http://pytorch.org/docs/master/nn.html) mentions that ```Keep in mind that only a limited number of optimizers support sparse gradients: currently it\u2019s optim.SGD (cuda and cpu), and optim.Adagrad (cpu)```. This is outdated and now `SparseAdam` is also supported.\nUpdate documentation for Embedding layer\nThe documentation corresponding [torch.nn.Embedding](http://pytorch.org/docs/master/nn.html) mentions that ```Keep in mind that only a limited number of optimizers support sparse gradients: currently it\u2019s optim.SGD (cuda and cpu), and optim.Adagrad (cpu)```. This is outdated and now `SparseAdam` is also supported.\n", "before_files": [{"content": "import torch\nfrom torch.autograd import Variable\nfrom torch.nn.parameter import Parameter\n\nfrom .module import Module\nfrom .. import functional as F\n\n\nclass Embedding(Module):\n r\"\"\"A simple lookup table that stores embeddings of a fixed dictionary and size.\n\n This module is often used to store word embeddings and retrieve them using indices.\n The input to the module is a list of indices, and the output is the corresponding\n word embeddings.\n\n Args:\n num_embeddings (int): size of the dictionary of embeddings\n embedding_dim (int): the size of each embedding vector\n padding_idx (int, optional): If given, pads the output with zeros whenever it encounters the index.\n max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this\n norm_type (float, optional): The p of the p-norm to compute for the max_norm option\n scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of\n the words in the mini-batch.\n sparse (boolean, optional): if ``True``, gradient w.r.t. weight matrix will be a sparse tensor. See Notes for\n more details regarding sparse gradients.\n\n Attributes:\n weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)\n\n Shape:\n - Input: LongTensor `(N, W)`, N = mini-batch, W = number of indices to extract per mini-batch\n - Output: `(N, W, embedding_dim)`\n\n Notes:\n Keep in mind that only a limited number of optimizers support\n sparse gradients: currently it's `optim.SGD` (`cuda` and `cpu`),\n and `optim.Adagrad` (`cpu`)\n\n Examples::\n\n >>> # an Embedding module containing 10 tensors of size 3\n >>> embedding = nn.Embedding(10, 3)\n >>> # a batch of 2 samples of 4 indices each\n >>> input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]]))\n >>> embedding(input)\n\n Variable containing:\n (0 ,.,.) =\n -1.0822 1.2522 0.2434\n 0.8393 -0.6062 -0.3348\n 0.6597 0.0350 0.0837\n 0.5521 0.9447 0.0498\n\n (1 ,.,.) =\n 0.6597 0.0350 0.0837\n -0.1527 0.0877 0.4260\n 0.8393 -0.6062 -0.3348\n -0.8738 -0.9054 0.4281\n [torch.FloatTensor of size 2x4x3]\n\n >>> # example with padding_idx\n >>> embedding = nn.Embedding(10, 3, padding_idx=0)\n >>> input = Variable(torch.LongTensor([[0,2,0,5]]))\n >>> embedding(input)\n\n Variable containing:\n (0 ,.,.) =\n 0.0000 0.0000 0.0000\n 0.3452 0.4937 -0.9361\n 0.0000 0.0000 0.0000\n 0.0706 -2.1962 -0.6276\n [torch.FloatTensor of size 1x4x3]\n\n \"\"\"\n\n def __init__(self, num_embeddings, embedding_dim, padding_idx=None,\n max_norm=None, norm_type=2, scale_grad_by_freq=False,\n sparse=False):\n super(Embedding, self).__init__()\n self.num_embeddings = num_embeddings\n self.embedding_dim = embedding_dim\n if padding_idx is not None:\n if padding_idx > 0:\n assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'\n elif padding_idx < 0:\n assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'\n padding_idx = self.num_embeddings + padding_idx\n self.padding_idx = padding_idx\n self.max_norm = max_norm\n self.norm_type = norm_type\n self.scale_grad_by_freq = scale_grad_by_freq\n self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))\n self.sparse = sparse\n\n self.reset_parameters()\n\n def reset_parameters(self):\n self.weight.data.normal_(0, 1)\n if self.padding_idx is not None:\n self.weight.data[self.padding_idx].fill_(0)\n\n def forward(self, input):\n return F.embedding(\n input, self.weight, self.padding_idx, self.max_norm,\n self.norm_type, self.scale_grad_by_freq, self.sparse)\n\n def __repr__(self):\n s = '{name}({num_embeddings}, {embedding_dim}'\n if self.padding_idx is not None:\n s += ', padding_idx={padding_idx}'\n if self.max_norm is not None:\n s += ', max_norm={max_norm}'\n if self.norm_type != 2:\n s += ', norm_type={norm_type}'\n if self.scale_grad_by_freq is not False:\n s += ', scale_grad_by_freq={scale_grad_by_freq}'\n if self.sparse is not False:\n s += ', sparse=True'\n s += ')'\n return s.format(name=self.__class__.__name__, **self.__dict__)\n\n\nclass EmbeddingBag(Module):\n r\"\"\"Computes sums or means of 'bags' of embeddings, without instantiating the\n intermediate embeddings.\n\n For bags of constant length,\n * nn.EmbeddingBag with `mode=sum` is equivalent to nn.Embedding followed by `torch.sum(dim=1)`\n * with `mode=mean` is equivalent to nn.Embedding followed by `torch.mean(dim=1)`\n\n However, nn.EmbeddingBag is much more time and memory efficient than using a chain of these\n operations.\n\n Args:\n num_embeddings (int): size of the dictionary of embeddings\n embedding_dim (int): the size of each embedding vector\n max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this\n norm_type (float, optional): The p of the p-norm to compute for the max_norm option\n scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of\n the words in the dictionary.\n mode (string, optional): 'sum' | 'mean'. Specifies the way to reduce the bag. Default: 'mean'\n\n Attributes:\n weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)\n\n Inputs: input, offsets\n - **input** (N or BxN): LongTensor containing the indices of the embeddings\n to extract. When `input` is 1D Tensor of shape `N`,\n an `offsets` Tensor is given, that contains the\n starting position of each new sequence in the\n mini-batch.\n - **offsets** (B or None): LongTensor containing the starting positions of\n each sample in a mini-batch of variable length\n sequences. If `input` is 2D (BxN), then offsets\n does not need to be given, as the `input` is\n treated as a mini-batch of fixed length sequences\n of length `N` each.\n\n\n Shape:\n - Input: LongTensor `N`, N = number of embeddings to extract\n (or) LongTensor `BxN`, B = number of sequences in mini-batch,\n N = number of embeddings per sequence\n - Offsets: LongTensor `B`, B = number of bags. The values are the\n offsets in `input` for each bag, i.e. the cumsum of lengths.\n Offsets is not given if Input is 2D `BxN` Tensor,\n the input is considered to be of fixed-length sequences\n - Output: `(B, embedding_dim)`\n\n Examples::\n\n >>> # an Embedding module containing 10 tensors of size 3\n >>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum')\n >>> # a batch of 2 samples of 4 indices each\n >>> input = Variable(torch.LongTensor([1,2,4,5,4,3,2,9]))\n >>> offsets = Variable(torch.LongTensor([0,4]))\n >>> embedding_sum(input, offsets)\n\n Variable containing:\n -0.7296 -4.6926 0.3295\n -0.5186 -0.5631 -0.2792\n [torch.FloatTensor of size 2x3]\n\n \"\"\"\n\n def __init__(self, num_embeddings, embedding_dim,\n max_norm=None, norm_type=2, scale_grad_by_freq=False,\n mode='mean'):\n super(EmbeddingBag, self).__init__()\n self.num_embeddings = num_embeddings\n self.embedding_dim = embedding_dim\n self.max_norm = max_norm\n self.norm_type = norm_type\n self.scale_grad_by_freq = scale_grad_by_freq\n self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))\n self.mode = mode\n\n self.reset_parameters()\n\n def reset_parameters(self):\n self.weight.data.normal_(0, 1)\n\n def forward(self, input, offsets=None):\n return F.embedding_bag(self.weight, input, offsets,\n self.max_norm, self.norm_type,\n self.scale_grad_by_freq, self.mode)\n\n def __repr__(self):\n s = '{name}({num_embeddings}, {embedding_dim}'\n if self.max_norm is not None:\n s += ', max_norm={max_norm}'\n if self.norm_type != 2:\n s += ', norm_type={norm_type}'\n if self.scale_grad_by_freq is not False:\n s += ', scale_grad_by_freq={scale_grad_by_freq}'\n s += ', mode={mode}'\n s += ')'\n return s.format(name=self.__class__.__name__, **self.__dict__)\n\n# TODO: SparseLinear\n", "path": "torch/nn/modules/sparse.py"}], "after_files": [{"content": "import torch\nfrom torch.autograd import Variable\nfrom torch.nn.parameter import Parameter\n\nfrom .module import Module\nfrom .. import functional as F\n\n\nclass Embedding(Module):\n r\"\"\"A simple lookup table that stores embeddings of a fixed dictionary and size.\n\n This module is often used to store word embeddings and retrieve them using indices.\n The input to the module is a list of indices, and the output is the corresponding\n word embeddings.\n\n Args:\n num_embeddings (int): size of the dictionary of embeddings\n embedding_dim (int): the size of each embedding vector\n padding_idx (int, optional): If given, pads the output with zeros whenever it encounters the index.\n max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this\n norm_type (float, optional): The p of the p-norm to compute for the max_norm option\n scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of\n the words in the mini-batch.\n sparse (boolean, optional): if ``True``, gradient w.r.t. weight matrix will be a sparse tensor. See Notes for\n more details regarding sparse gradients.\n\n Attributes:\n weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)\n\n Shape:\n - Input: LongTensor `(N, W)`, N = mini-batch, W = number of indices to extract per mini-batch\n - Output: `(N, W, embedding_dim)`\n\n Notes:\n Keep in mind that only a limited number of optimizers support\n sparse gradients: currently it's `optim.SGD` (`cuda` and `cpu`),\n `optim.SparseAdam` (`cuda` and `cpu`) and `optim.Adagrad` (`cpu`)\n\n Examples::\n\n >>> # an Embedding module containing 10 tensors of size 3\n >>> embedding = nn.Embedding(10, 3)\n >>> # a batch of 2 samples of 4 indices each\n >>> input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]]))\n >>> embedding(input)\n\n Variable containing:\n (0 ,.,.) =\n -1.0822 1.2522 0.2434\n 0.8393 -0.6062 -0.3348\n 0.6597 0.0350 0.0837\n 0.5521 0.9447 0.0498\n\n (1 ,.,.) =\n 0.6597 0.0350 0.0837\n -0.1527 0.0877 0.4260\n 0.8393 -0.6062 -0.3348\n -0.8738 -0.9054 0.4281\n [torch.FloatTensor of size 2x4x3]\n\n >>> # example with padding_idx\n >>> embedding = nn.Embedding(10, 3, padding_idx=0)\n >>> input = Variable(torch.LongTensor([[0,2,0,5]]))\n >>> embedding(input)\n\n Variable containing:\n (0 ,.,.) =\n 0.0000 0.0000 0.0000\n 0.3452 0.4937 -0.9361\n 0.0000 0.0000 0.0000\n 0.0706 -2.1962 -0.6276\n [torch.FloatTensor of size 1x4x3]\n\n \"\"\"\n\n def __init__(self, num_embeddings, embedding_dim, padding_idx=None,\n max_norm=None, norm_type=2, scale_grad_by_freq=False,\n sparse=False):\n super(Embedding, self).__init__()\n self.num_embeddings = num_embeddings\n self.embedding_dim = embedding_dim\n if padding_idx is not None:\n if padding_idx > 0:\n assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'\n elif padding_idx < 0:\n assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'\n padding_idx = self.num_embeddings + padding_idx\n self.padding_idx = padding_idx\n self.max_norm = max_norm\n self.norm_type = norm_type\n self.scale_grad_by_freq = scale_grad_by_freq\n self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))\n self.sparse = sparse\n\n self.reset_parameters()\n\n def reset_parameters(self):\n self.weight.data.normal_(0, 1)\n if self.padding_idx is not None:\n self.weight.data[self.padding_idx].fill_(0)\n\n def forward(self, input):\n return F.embedding(\n input, self.weight, self.padding_idx, self.max_norm,\n self.norm_type, self.scale_grad_by_freq, self.sparse)\n\n def __repr__(self):\n s = '{name}({num_embeddings}, {embedding_dim}'\n if self.padding_idx is not None:\n s += ', padding_idx={padding_idx}'\n if self.max_norm is not None:\n s += ', max_norm={max_norm}'\n if self.norm_type != 2:\n s += ', norm_type={norm_type}'\n if self.scale_grad_by_freq is not False:\n s += ', scale_grad_by_freq={scale_grad_by_freq}'\n if self.sparse is not False:\n s += ', sparse=True'\n s += ')'\n return s.format(name=self.__class__.__name__, **self.__dict__)\n\n\nclass EmbeddingBag(Module):\n r\"\"\"Computes sums or means of 'bags' of embeddings, without instantiating the\n intermediate embeddings.\n\n For bags of constant length,\n * nn.EmbeddingBag with `mode=sum` is equivalent to nn.Embedding followed by `torch.sum(dim=1)`\n * with `mode=mean` is equivalent to nn.Embedding followed by `torch.mean(dim=1)`\n\n However, nn.EmbeddingBag is much more time and memory efficient than using a chain of these\n operations.\n\n Args:\n num_embeddings (int): size of the dictionary of embeddings\n embedding_dim (int): the size of each embedding vector\n max_norm (float, optional): If given, will renormalize the embeddings to always have a norm lesser than this\n norm_type (float, optional): The p of the p-norm to compute for the max_norm option\n scale_grad_by_freq (boolean, optional): if given, this will scale gradients by the frequency of\n the words in the dictionary.\n mode (string, optional): 'sum' | 'mean'. Specifies the way to reduce the bag. Default: 'mean'\n\n Attributes:\n weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)\n\n Inputs: input, offsets\n - **input** (N or BxN): LongTensor containing the indices of the embeddings\n to extract. When `input` is 1D Tensor of shape `N`,\n an `offsets` Tensor is given, that contains the\n starting position of each new sequence in the\n mini-batch.\n - **offsets** (B or None): LongTensor containing the starting positions of\n each sample in a mini-batch of variable length\n sequences. If `input` is 2D (BxN), then offsets\n does not need to be given, as the `input` is\n treated as a mini-batch of fixed length sequences\n of length `N` each.\n\n\n Shape:\n - Input: LongTensor `N`, N = number of embeddings to extract\n (or) LongTensor `BxN`, B = number of sequences in mini-batch,\n N = number of embeddings per sequence\n - Offsets: LongTensor `B`, B = number of bags. The values are the\n offsets in `input` for each bag, i.e. the cumsum of lengths.\n Offsets is not given if Input is 2D `BxN` Tensor,\n the input is considered to be of fixed-length sequences\n - Output: `(B, embedding_dim)`\n\n Examples::\n\n >>> # an Embedding module containing 10 tensors of size 3\n >>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum')\n >>> # a batch of 2 samples of 4 indices each\n >>> input = Variable(torch.LongTensor([1,2,4,5,4,3,2,9]))\n >>> offsets = Variable(torch.LongTensor([0,4]))\n >>> embedding_sum(input, offsets)\n\n Variable containing:\n -0.7296 -4.6926 0.3295\n -0.5186 -0.5631 -0.2792\n [torch.FloatTensor of size 2x3]\n\n \"\"\"\n\n def __init__(self, num_embeddings, embedding_dim,\n max_norm=None, norm_type=2, scale_grad_by_freq=False,\n mode='mean'):\n super(EmbeddingBag, self).__init__()\n self.num_embeddings = num_embeddings\n self.embedding_dim = embedding_dim\n self.max_norm = max_norm\n self.norm_type = norm_type\n self.scale_grad_by_freq = scale_grad_by_freq\n self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))\n self.mode = mode\n\n self.reset_parameters()\n\n def reset_parameters(self):\n self.weight.data.normal_(0, 1)\n\n def forward(self, input, offsets=None):\n return F.embedding_bag(self.weight, input, offsets,\n self.max_norm, self.norm_type,\n self.scale_grad_by_freq, self.mode)\n\n def __repr__(self):\n s = '{name}({num_embeddings}, {embedding_dim}'\n if self.max_norm is not None:\n s += ', max_norm={max_norm}'\n if self.norm_type != 2:\n s += ', norm_type={norm_type}'\n if self.scale_grad_by_freq is not False:\n s += ', scale_grad_by_freq={scale_grad_by_freq}'\n s += ', mode={mode}'\n s += ')'\n return s.format(name=self.__class__.__name__, **self.__dict__)\n\n# TODO: SparseLinear\n", "path": "torch/nn/modules/sparse.py"}]}
| 3,291 | 133 |
gh_patches_debug_7489
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1020
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Search results seem to need some relevancy tweaking
Searches seem to have some relevancy issues. For example:

Or: https://warehouse.python.org/search/?q=django&page=1 - Django itself doesn't seem to appear in the first half-dozen or so pages (I gave up paging before I found it).
Jacob
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/views.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from pyramid.httpexceptions import (
14 HTTPException, HTTPSeeOther, HTTPMovedPermanently,
15 )
16 from pyramid.view import (
17 notfound_view_config, forbidden_view_config, view_config,
18 )
19 from sqlalchemy import func
20 from sqlalchemy.orm import aliased, joinedload
21
22 from warehouse.accounts import REDIRECT_FIELD_NAME
23 from warehouse.accounts.models import User
24 from warehouse.cache.origin import origin_cache
25 from warehouse.cache.http import cache_control
26 from warehouse.csrf import csrf_exempt
27 from warehouse.packaging.models import Project, Release, File
28 from warehouse.sessions import uses_session
29 from warehouse.utils.row_counter import RowCount
30 from warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory
31
32
33 @view_config(context=HTTPException, decorator=[csrf_exempt])
34 @notfound_view_config(
35 append_slash=HTTPMovedPermanently,
36 decorator=[csrf_exempt],
37 )
38 def httpexception_view(exc, request):
39 return exc
40
41
42 @forbidden_view_config()
43 def forbidden(exc, request):
44 # If the forbidden error is because the user isn't logged in, then we'll
45 # redirect them to the log in page.
46 if request.authenticated_userid is None:
47 url = request.route_url(
48 "accounts.login",
49 _query={REDIRECT_FIELD_NAME: request.path_qs},
50 )
51 return HTTPSeeOther(url)
52
53 # If we've reached here, then the user is logged in and they are genuinely
54 # not allowed to access this page.
55 # TODO: Style the forbidden page.
56 return exc
57
58
59 @view_config(
60 route_name="robots.txt",
61 renderer="robots.txt",
62 decorator=[
63 cache_control(1 * 24 * 60 * 60), # 1 day
64 origin_cache(
65 1 * 24 * 60 * 60, # 1 day
66 stale_while_revalidate=6 * 60 * 60, # 6 hours
67 stale_if_error=1 * 24 * 60 * 60, # 1 day
68 ),
69 ],
70 )
71 def robotstxt(request):
72 request.response.content_type = "text/plain"
73 return {}
74
75
76 @view_config(
77 route_name="index",
78 renderer="index.html",
79 decorator=[
80 origin_cache(
81 1 * 60 * 60, # 1 hour
82 stale_while_revalidate=10 * 60, # 10 minutes
83 stale_if_error=1 * 24 * 60 * 60, # 1 day
84 keys=["all-projects"],
85 ),
86 ]
87 )
88 def index(request):
89 project_names = [
90 r[0] for r in (
91 request.db.query(File.name)
92 .group_by(File.name)
93 .order_by(func.sum(File.downloads).desc())
94 .limit(5)
95 .all())
96 ]
97 release_a = aliased(
98 Release,
99 request.db.query(Release)
100 .distinct(Release.name)
101 .filter(Release.name.in_(project_names))
102 .order_by(Release.name, Release._pypi_ordering.desc())
103 .subquery(),
104 )
105 top_projects = (
106 request.db.query(release_a)
107 .options(joinedload(release_a.project),
108 joinedload(release_a.uploader))
109 .order_by(func.array_idx(project_names, release_a.name))
110 .all()
111 )
112
113 latest_releases = (
114 request.db.query(Release)
115 .options(joinedload(Release.project),
116 joinedload(Release.uploader))
117 .order_by(Release.created.desc())
118 .limit(5)
119 .all()
120 )
121
122 counts = dict(
123 request.db.query(RowCount.table_name, RowCount.count)
124 .filter(
125 RowCount.table_name.in_([
126 Project.__tablename__,
127 Release.__tablename__,
128 File.__tablename__,
129 User.__tablename__,
130 ]))
131 .all()
132 )
133
134 return {
135 "latest_releases": latest_releases,
136 "top_projects": top_projects,
137 "num_projects": counts.get(Project.__tablename__, 0),
138 "num_releases": counts.get(Release.__tablename__, 0),
139 "num_files": counts.get(File.__tablename__, 0),
140 "num_users": counts.get(User.__tablename__, 0),
141 }
142
143
144 @view_config(
145 route_name="search",
146 renderer="search/results.html",
147 decorator=[
148 origin_cache(
149 1 * 60 * 60, # 1 hour
150 stale_while_revalidate=10 * 60, # 10 minutes
151 stale_if_error=1 * 24 * 60 * 60, # 1 day
152 keys=["all-projects"],
153 )
154 ],
155 )
156 def search(request):
157 if request.params.get("q"):
158 query = request.es.query(
159 "multi_match",
160 query=request.params["q"],
161 fields=[
162 "name", "version", "author", "author_email", "maintainer",
163 "maintainer_email", "home_page", "license", "summary",
164 "description", "keywords", "platform", "download_url",
165 ],
166 ).suggest(
167 name="name_suggestion",
168 text=request.params["q"],
169 term={"field": "name"}
170 )
171 else:
172 query = request.es.query()
173
174 if request.params.get("o"):
175 query = query.sort(request.params["o"])
176
177 page = ElasticsearchPage(
178 query,
179 page=int(request.params.get("page", 1)),
180 url_maker=paginate_url_factory(request),
181 )
182
183 return {
184 "page": page,
185 "term": request.params.get("q"),
186 "order": request.params.get("o"),
187 }
188
189
190 @view_config(
191 route_name="includes.current-user-indicator",
192 renderer="includes/current-user-indicator.html",
193 decorator=[uses_session],
194 )
195 def current_user_indicator(request):
196 return {}
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/views.py b/warehouse/views.py
--- a/warehouse/views.py
+++ b/warehouse/views.py
@@ -159,7 +159,7 @@
"multi_match",
query=request.params["q"],
fields=[
- "name", "version", "author", "author_email", "maintainer",
+ "name^2", "version", "author", "author_email", "maintainer",
"maintainer_email", "home_page", "license", "summary",
"description", "keywords", "platform", "download_url",
],
|
{"golden_diff": "diff --git a/warehouse/views.py b/warehouse/views.py\n--- a/warehouse/views.py\n+++ b/warehouse/views.py\n@@ -159,7 +159,7 @@\n \"multi_match\",\n query=request.params[\"q\"],\n fields=[\n- \"name\", \"version\", \"author\", \"author_email\", \"maintainer\",\n+ \"name^2\", \"version\", \"author\", \"author_email\", \"maintainer\",\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n", "issue": "Search results seem to need some relevancy tweaking\nSearches seem to have some relevancy issues. For example:\n\n\n\nOr: https://warehouse.python.org/search/?q=django&page=1 - Django itself doesn't seem to appear in the first half-dozen or so pages (I gave up paging before I found it).\n\nJacob\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.csrf import csrf_exempt\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.sessions import uses_session\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\n@view_config(context=HTTPException, decorator=[csrf_exempt])\n@notfound_view_config(\n append_slash=HTTPMovedPermanently,\n decorator=[csrf_exempt],\n)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project),\n joinedload(release_a.uploader))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project),\n joinedload(Release.uploader))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n if request.params.get(\"q\"):\n query = request.es.query(\n \"multi_match\",\n query=request.params[\"q\"],\n fields=[\n \"name\", \"version\", \"author\", \"author_email\", \"maintainer\",\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n ).suggest(\n name=\"name_suggestion\",\n text=request.params[\"q\"],\n term={\"field\": \"name\"}\n )\n else:\n query = request.es.query()\n\n if request.params.get(\"o\"):\n query = query.sort(request.params[\"o\"])\n\n page = ElasticsearchPage(\n query,\n page=int(request.params.get(\"page\", 1)),\n url_maker=paginate_url_factory(request),\n )\n\n return {\n \"page\": page,\n \"term\": request.params.get(\"q\"),\n \"order\": request.params.get(\"o\"),\n }\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n decorator=[uses_session],\n)\ndef current_user_indicator(request):\n return {}\n", "path": "warehouse/views.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pyramid.httpexceptions import (\n HTTPException, HTTPSeeOther, HTTPMovedPermanently,\n)\nfrom pyramid.view import (\n notfound_view_config, forbidden_view_config, view_config,\n)\nfrom sqlalchemy import func\nfrom sqlalchemy.orm import aliased, joinedload\n\nfrom warehouse.accounts import REDIRECT_FIELD_NAME\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.cache.http import cache_control\nfrom warehouse.csrf import csrf_exempt\nfrom warehouse.packaging.models import Project, Release, File\nfrom warehouse.sessions import uses_session\nfrom warehouse.utils.row_counter import RowCount\nfrom warehouse.utils.paginate import ElasticsearchPage, paginate_url_factory\n\n\n@view_config(context=HTTPException, decorator=[csrf_exempt])\n@notfound_view_config(\n append_slash=HTTPMovedPermanently,\n decorator=[csrf_exempt],\n)\ndef httpexception_view(exc, request):\n return exc\n\n\n@forbidden_view_config()\ndef forbidden(exc, request):\n # If the forbidden error is because the user isn't logged in, then we'll\n # redirect them to the log in page.\n if request.authenticated_userid is None:\n url = request.route_url(\n \"accounts.login\",\n _query={REDIRECT_FIELD_NAME: request.path_qs},\n )\n return HTTPSeeOther(url)\n\n # If we've reached here, then the user is logged in and they are genuinely\n # not allowed to access this page.\n # TODO: Style the forbidden page.\n return exc\n\n\n@view_config(\n route_name=\"robots.txt\",\n renderer=\"robots.txt\",\n decorator=[\n cache_control(1 * 24 * 60 * 60), # 1 day\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=6 * 60 * 60, # 6 hours\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n ],\n)\ndef robotstxt(request):\n request.response.content_type = \"text/plain\"\n return {}\n\n\n@view_config(\n route_name=\"index\",\n renderer=\"index.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n ),\n ]\n)\ndef index(request):\n project_names = [\n r[0] for r in (\n request.db.query(File.name)\n .group_by(File.name)\n .order_by(func.sum(File.downloads).desc())\n .limit(5)\n .all())\n ]\n release_a = aliased(\n Release,\n request.db.query(Release)\n .distinct(Release.name)\n .filter(Release.name.in_(project_names))\n .order_by(Release.name, Release._pypi_ordering.desc())\n .subquery(),\n )\n top_projects = (\n request.db.query(release_a)\n .options(joinedload(release_a.project),\n joinedload(release_a.uploader))\n .order_by(func.array_idx(project_names, release_a.name))\n .all()\n )\n\n latest_releases = (\n request.db.query(Release)\n .options(joinedload(Release.project),\n joinedload(Release.uploader))\n .order_by(Release.created.desc())\n .limit(5)\n .all()\n )\n\n counts = dict(\n request.db.query(RowCount.table_name, RowCount.count)\n .filter(\n RowCount.table_name.in_([\n Project.__tablename__,\n Release.__tablename__,\n File.__tablename__,\n User.__tablename__,\n ]))\n .all()\n )\n\n return {\n \"latest_releases\": latest_releases,\n \"top_projects\": top_projects,\n \"num_projects\": counts.get(Project.__tablename__, 0),\n \"num_releases\": counts.get(Release.__tablename__, 0),\n \"num_files\": counts.get(File.__tablename__, 0),\n \"num_users\": counts.get(User.__tablename__, 0),\n }\n\n\n@view_config(\n route_name=\"search\",\n renderer=\"search/results.html\",\n decorator=[\n origin_cache(\n 1 * 60 * 60, # 1 hour\n stale_while_revalidate=10 * 60, # 10 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n keys=[\"all-projects\"],\n )\n ],\n)\ndef search(request):\n if request.params.get(\"q\"):\n query = request.es.query(\n \"multi_match\",\n query=request.params[\"q\"],\n fields=[\n \"name^2\", \"version\", \"author\", \"author_email\", \"maintainer\",\n \"maintainer_email\", \"home_page\", \"license\", \"summary\",\n \"description\", \"keywords\", \"platform\", \"download_url\",\n ],\n ).suggest(\n name=\"name_suggestion\",\n text=request.params[\"q\"],\n term={\"field\": \"name\"}\n )\n else:\n query = request.es.query()\n\n if request.params.get(\"o\"):\n query = query.sort(request.params[\"o\"])\n\n page = ElasticsearchPage(\n query,\n page=int(request.params.get(\"page\", 1)),\n url_maker=paginate_url_factory(request),\n )\n\n return {\n \"page\": page,\n \"term\": request.params.get(\"q\"),\n \"order\": request.params.get(\"o\"),\n }\n\n\n@view_config(\n route_name=\"includes.current-user-indicator\",\n renderer=\"includes/current-user-indicator.html\",\n decorator=[uses_session],\n)\ndef current_user_indicator(request):\n return {}\n", "path": "warehouse/views.py"}]}
| 2,273 | 129 |
gh_patches_debug_5513
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-2345
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pre-push hook failed with "ValueError: too many values to unpack (expected 4)"
### describe your issue
I ran
```
git push --dry-run origin HEAD^"{/^[a-zA-Z]+: }":refs/for/main%wip
```
and expected the hook to run properly, but it failed with a somewhat subtle error:
```
An unexpected error has occurred: ValueError: too many values to unpack (expected 4)
Check the log at $HOME/.cache/pre-commit/pre-commit.log
```
It was more clear from the `pre-commit.log` file, though (see below). I reproduced the issue using HEAD (f9473e756decd141a9834994840c1cb124564c2a) as well.
### pre-commit --version
2.12.1
### .pre-commit-config.yaml
```yaml
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: check-added-large-files
- id: check-json
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- repo: https://github.com/wwade/pre-commit-golang
rev: 503834f5c0933fbdf9a55e92329c1957e48f6d0a
hooks:
- id: go-fmt
- id: go-imports
- id: go-cyclo
args: [-over=15]
- id: validate-toml
- id: golangci-lint
- id: go-unit-tests
- id: go-mod-tidy
```
### ~/.cache/pre-commit/pre-commit.log (if present)
### version information
```
pre-commit version: 2.12.1
sys.version:
3.8.10 (default, Mar 15 2022, 12:22:08)
[GCC 9.4.0]
sys.executable: /usr/bin/python3
os.name: posix
sys.platform: linux
```
### error information
```
An unexpected error has occurred: ValueError: too many values to unpack (expected 4)
```
```
Traceback (most recent call last):
File "$HOME/.local/lib/python3.8/site-packages/pre_commit/error_handler.py", line 65, in error_handler
yield
File "$HOME/.local/lib/python3.8/site-packages/pre_commit/main.py", line 357, in main
return hook_impl(
File "$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py", line 223, in hook_impl
ns = _run_ns(hook_type, color, args, stdin)
File "$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py", line 195, in _run_ns
return _pre_push_ns(color, args, stdin)
File "$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py", line 113, in _pre_push_ns
_, local_sha, remote_branch, remote_sha = line.split()
ValueError: too many values to unpack (expected 4)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/commands/hook_impl.py`
Content:
```
1 from __future__ import annotations
2
3 import argparse
4 import os.path
5 import subprocess
6 import sys
7 from typing import Sequence
8
9 from pre_commit.commands.run import run
10 from pre_commit.envcontext import envcontext
11 from pre_commit.parse_shebang import normalize_cmd
12 from pre_commit.store import Store
13
14 Z40 = '0' * 40
15
16
17 def _run_legacy(
18 hook_type: str,
19 hook_dir: str,
20 args: Sequence[str],
21 ) -> tuple[int, bytes]:
22 if os.environ.get('PRE_COMMIT_RUNNING_LEGACY'):
23 raise SystemExit(
24 f"bug: pre-commit's script is installed in migration mode\n"
25 f'run `pre-commit install -f --hook-type {hook_type}` to fix '
26 f'this\n\n'
27 f'Please report this bug at '
28 f'https://github.com/pre-commit/pre-commit/issues',
29 )
30
31 if hook_type == 'pre-push':
32 stdin = sys.stdin.buffer.read()
33 else:
34 stdin = b''
35
36 # not running in legacy mode
37 legacy_hook = os.path.join(hook_dir, f'{hook_type}.legacy')
38 if not os.access(legacy_hook, os.X_OK):
39 return 0, stdin
40
41 with envcontext((('PRE_COMMIT_RUNNING_LEGACY', '1'),)):
42 cmd = normalize_cmd((legacy_hook, *args))
43 return subprocess.run(cmd, input=stdin).returncode, stdin
44
45
46 def _validate_config(
47 retv: int,
48 config: str,
49 skip_on_missing_config: bool,
50 ) -> None:
51 if not os.path.isfile(config):
52 if skip_on_missing_config or os.getenv('PRE_COMMIT_ALLOW_NO_CONFIG'):
53 print(f'`{config}` config file not found. Skipping `pre-commit`.')
54 raise SystemExit(retv)
55 else:
56 print(
57 f'No {config} file was found\n'
58 f'- To temporarily silence this, run '
59 f'`PRE_COMMIT_ALLOW_NO_CONFIG=1 git ...`\n'
60 f'- To permanently silence this, install pre-commit with the '
61 f'--allow-missing-config option\n'
62 f'- To uninstall pre-commit run `pre-commit uninstall`',
63 )
64 raise SystemExit(1)
65
66
67 def _ns(
68 hook_type: str,
69 color: bool,
70 *,
71 all_files: bool = False,
72 remote_branch: str | None = None,
73 local_branch: str | None = None,
74 from_ref: str | None = None,
75 to_ref: str | None = None,
76 remote_name: str | None = None,
77 remote_url: str | None = None,
78 commit_msg_filename: str | None = None,
79 checkout_type: str | None = None,
80 is_squash_merge: str | None = None,
81 rewrite_command: str | None = None,
82 ) -> argparse.Namespace:
83 return argparse.Namespace(
84 color=color,
85 hook_stage=hook_type.replace('pre-', ''),
86 remote_branch=remote_branch,
87 local_branch=local_branch,
88 from_ref=from_ref,
89 to_ref=to_ref,
90 remote_name=remote_name,
91 remote_url=remote_url,
92 commit_msg_filename=commit_msg_filename,
93 all_files=all_files,
94 checkout_type=checkout_type,
95 is_squash_merge=is_squash_merge,
96 rewrite_command=rewrite_command,
97 files=(),
98 hook=None,
99 verbose=False,
100 show_diff_on_failure=False,
101 )
102
103
104 def _rev_exists(rev: str) -> bool:
105 return not subprocess.call(('git', 'rev-list', '--quiet', rev))
106
107
108 def _pre_push_ns(
109 color: bool,
110 args: Sequence[str],
111 stdin: bytes,
112 ) -> argparse.Namespace | None:
113 remote_name = args[0]
114 remote_url = args[1]
115
116 for line in stdin.decode().splitlines():
117 local_branch, local_sha, remote_branch, remote_sha = line.split()
118 if local_sha == Z40:
119 continue
120 elif remote_sha != Z40 and _rev_exists(remote_sha):
121 return _ns(
122 'pre-push', color,
123 from_ref=remote_sha, to_ref=local_sha,
124 remote_branch=remote_branch,
125 local_branch=local_branch,
126 remote_name=remote_name, remote_url=remote_url,
127 )
128 else:
129 # ancestors not found in remote
130 ancestors = subprocess.check_output((
131 'git', 'rev-list', local_sha, '--topo-order', '--reverse',
132 '--not', f'--remotes={remote_name}',
133 )).decode().strip()
134 if not ancestors:
135 continue
136 else:
137 first_ancestor = ancestors.splitlines()[0]
138 cmd = ('git', 'rev-list', '--max-parents=0', local_sha)
139 roots = set(subprocess.check_output(cmd).decode().splitlines())
140 if first_ancestor in roots:
141 # pushing the whole tree including root commit
142 return _ns(
143 'pre-push', color,
144 all_files=True,
145 remote_name=remote_name, remote_url=remote_url,
146 remote_branch=remote_branch,
147 local_branch=local_branch,
148 )
149 else:
150 rev_cmd = ('git', 'rev-parse', f'{first_ancestor}^')
151 source = subprocess.check_output(rev_cmd).decode().strip()
152 return _ns(
153 'pre-push', color,
154 from_ref=source, to_ref=local_sha,
155 remote_name=remote_name, remote_url=remote_url,
156 remote_branch=remote_branch,
157 local_branch=local_branch,
158 )
159
160 # nothing to push
161 return None
162
163
164 _EXPECTED_ARG_LENGTH_BY_HOOK = {
165 'commit-msg': 1,
166 'post-checkout': 3,
167 'post-commit': 0,
168 'pre-commit': 0,
169 'pre-merge-commit': 0,
170 'post-merge': 1,
171 'post-rewrite': 1,
172 'pre-push': 2,
173 }
174
175
176 def _check_args_length(hook_type: str, args: Sequence[str]) -> None:
177 if hook_type == 'prepare-commit-msg':
178 if len(args) < 1 or len(args) > 3:
179 raise SystemExit(
180 f'hook-impl for {hook_type} expected 1, 2, or 3 arguments '
181 f'but got {len(args)}: {args}',
182 )
183 elif hook_type in _EXPECTED_ARG_LENGTH_BY_HOOK:
184 expected = _EXPECTED_ARG_LENGTH_BY_HOOK[hook_type]
185 if len(args) != expected:
186 arguments_s = 'argument' if expected == 1 else 'arguments'
187 raise SystemExit(
188 f'hook-impl for {hook_type} expected {expected} {arguments_s} '
189 f'but got {len(args)}: {args}',
190 )
191 else:
192 raise AssertionError(f'unexpected hook type: {hook_type}')
193
194
195 def _run_ns(
196 hook_type: str,
197 color: bool,
198 args: Sequence[str],
199 stdin: bytes,
200 ) -> argparse.Namespace | None:
201 _check_args_length(hook_type, args)
202 if hook_type == 'pre-push':
203 return _pre_push_ns(color, args, stdin)
204 elif hook_type in {'commit-msg', 'prepare-commit-msg'}:
205 return _ns(hook_type, color, commit_msg_filename=args[0])
206 elif hook_type in {'post-commit', 'pre-merge-commit', 'pre-commit'}:
207 return _ns(hook_type, color)
208 elif hook_type == 'post-checkout':
209 return _ns(
210 hook_type, color,
211 from_ref=args[0], to_ref=args[1], checkout_type=args[2],
212 )
213 elif hook_type == 'post-merge':
214 return _ns(hook_type, color, is_squash_merge=args[0])
215 elif hook_type == 'post-rewrite':
216 return _ns(hook_type, color, rewrite_command=args[0])
217 else:
218 raise AssertionError(f'unexpected hook type: {hook_type}')
219
220
221 def hook_impl(
222 store: Store,
223 *,
224 config: str,
225 color: bool,
226 hook_type: str,
227 hook_dir: str,
228 skip_on_missing_config: bool,
229 args: Sequence[str],
230 ) -> int:
231 retv, stdin = _run_legacy(hook_type, hook_dir, args)
232 _validate_config(retv, config, skip_on_missing_config)
233 ns = _run_ns(hook_type, color, args, stdin)
234 if ns is None:
235 return retv
236 else:
237 return retv | run(config, store, ns)
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/commands/hook_impl.py b/pre_commit/commands/hook_impl.py
--- a/pre_commit/commands/hook_impl.py
+++ b/pre_commit/commands/hook_impl.py
@@ -114,7 +114,8 @@
remote_url = args[1]
for line in stdin.decode().splitlines():
- local_branch, local_sha, remote_branch, remote_sha = line.split()
+ parts = line.rsplit(maxsplit=3)
+ local_branch, local_sha, remote_branch, remote_sha = parts
if local_sha == Z40:
continue
elif remote_sha != Z40 and _rev_exists(remote_sha):
|
{"golden_diff": "diff --git a/pre_commit/commands/hook_impl.py b/pre_commit/commands/hook_impl.py\n--- a/pre_commit/commands/hook_impl.py\n+++ b/pre_commit/commands/hook_impl.py\n@@ -114,7 +114,8 @@\n remote_url = args[1]\n \n for line in stdin.decode().splitlines():\n- local_branch, local_sha, remote_branch, remote_sha = line.split()\n+ parts = line.rsplit(maxsplit=3)\n+ local_branch, local_sha, remote_branch, remote_sha = parts\n if local_sha == Z40:\n continue\n elif remote_sha != Z40 and _rev_exists(remote_sha):\n", "issue": "pre-push hook failed with \"ValueError: too many values to unpack (expected 4)\"\n### describe your issue\n\nI ran\r\n\r\n```\r\ngit push --dry-run origin HEAD^\"{/^[a-zA-Z]+: }\":refs/for/main%wip\r\n```\r\n\r\nand expected the hook to run properly, but it failed with a somewhat subtle error:\r\n\r\n```\r\nAn unexpected error has occurred: ValueError: too many values to unpack (expected 4)\r\nCheck the log at $HOME/.cache/pre-commit/pre-commit.log\r\n```\r\n\r\nIt was more clear from the `pre-commit.log` file, though (see below). I reproduced the issue using HEAD (f9473e756decd141a9834994840c1cb124564c2a) as well.\n\n### pre-commit --version\n\n2.12.1\n\n### .pre-commit-config.yaml\n\n```yaml\nrepos:\r\n - repo: https://github.com/pre-commit/pre-commit-hooks\r\n rev: v3.2.0\r\n hooks:\r\n - id: check-added-large-files\r\n - id: check-json\r\n - id: check-yaml\r\n - id: end-of-file-fixer\r\n - id: trailing-whitespace\r\n\r\n - repo: https://github.com/wwade/pre-commit-golang\r\n rev: 503834f5c0933fbdf9a55e92329c1957e48f6d0a\r\n hooks:\r\n - id: go-fmt\r\n - id: go-imports\r\n - id: go-cyclo\r\n args: [-over=15]\r\n - id: validate-toml\r\n - id: golangci-lint\r\n - id: go-unit-tests\r\n - id: go-mod-tidy\n```\n\n\n### ~/.cache/pre-commit/pre-commit.log (if present)\n\n### version information\r\n\r\n```\r\npre-commit version: 2.12.1\r\nsys.version:\r\n 3.8.10 (default, Mar 15 2022, 12:22:08) \r\n [GCC 9.4.0]\r\nsys.executable: /usr/bin/python3\r\nos.name: posix\r\nsys.platform: linux\r\n```\r\n\r\n### error information\r\n\r\n```\r\nAn unexpected error has occurred: ValueError: too many values to unpack (expected 4)\r\n```\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"$HOME/.local/lib/python3.8/site-packages/pre_commit/error_handler.py\", line 65, in error_handler\r\n yield\r\n File \"$HOME/.local/lib/python3.8/site-packages/pre_commit/main.py\", line 357, in main\r\n return hook_impl(\r\n File \"$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py\", line 223, in hook_impl\r\n ns = _run_ns(hook_type, color, args, stdin)\r\n File \"$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py\", line 195, in _run_ns\r\n return _pre_push_ns(color, args, stdin)\r\n File \"$HOME/.local/lib/python3.8/site-packages/pre_commit/commands/hook_impl.py\", line 113, in _pre_push_ns\r\n _, local_sha, remote_branch, remote_sha = line.split()\r\nValueError: too many values to unpack (expected 4)\r\n```\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport argparse\nimport os.path\nimport subprocess\nimport sys\nfrom typing import Sequence\n\nfrom pre_commit.commands.run import run\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.parse_shebang import normalize_cmd\nfrom pre_commit.store import Store\n\nZ40 = '0' * 40\n\n\ndef _run_legacy(\n hook_type: str,\n hook_dir: str,\n args: Sequence[str],\n) -> tuple[int, bytes]:\n if os.environ.get('PRE_COMMIT_RUNNING_LEGACY'):\n raise SystemExit(\n f\"bug: pre-commit's script is installed in migration mode\\n\"\n f'run `pre-commit install -f --hook-type {hook_type}` to fix '\n f'this\\n\\n'\n f'Please report this bug at '\n f'https://github.com/pre-commit/pre-commit/issues',\n )\n\n if hook_type == 'pre-push':\n stdin = sys.stdin.buffer.read()\n else:\n stdin = b''\n\n # not running in legacy mode\n legacy_hook = os.path.join(hook_dir, f'{hook_type}.legacy')\n if not os.access(legacy_hook, os.X_OK):\n return 0, stdin\n\n with envcontext((('PRE_COMMIT_RUNNING_LEGACY', '1'),)):\n cmd = normalize_cmd((legacy_hook, *args))\n return subprocess.run(cmd, input=stdin).returncode, stdin\n\n\ndef _validate_config(\n retv: int,\n config: str,\n skip_on_missing_config: bool,\n) -> None:\n if not os.path.isfile(config):\n if skip_on_missing_config or os.getenv('PRE_COMMIT_ALLOW_NO_CONFIG'):\n print(f'`{config}` config file not found. Skipping `pre-commit`.')\n raise SystemExit(retv)\n else:\n print(\n f'No {config} file was found\\n'\n f'- To temporarily silence this, run '\n f'`PRE_COMMIT_ALLOW_NO_CONFIG=1 git ...`\\n'\n f'- To permanently silence this, install pre-commit with the '\n f'--allow-missing-config option\\n'\n f'- To uninstall pre-commit run `pre-commit uninstall`',\n )\n raise SystemExit(1)\n\n\ndef _ns(\n hook_type: str,\n color: bool,\n *,\n all_files: bool = False,\n remote_branch: str | None = None,\n local_branch: str | None = None,\n from_ref: str | None = None,\n to_ref: str | None = None,\n remote_name: str | None = None,\n remote_url: str | None = None,\n commit_msg_filename: str | None = None,\n checkout_type: str | None = None,\n is_squash_merge: str | None = None,\n rewrite_command: str | None = None,\n) -> argparse.Namespace:\n return argparse.Namespace(\n color=color,\n hook_stage=hook_type.replace('pre-', ''),\n remote_branch=remote_branch,\n local_branch=local_branch,\n from_ref=from_ref,\n to_ref=to_ref,\n remote_name=remote_name,\n remote_url=remote_url,\n commit_msg_filename=commit_msg_filename,\n all_files=all_files,\n checkout_type=checkout_type,\n is_squash_merge=is_squash_merge,\n rewrite_command=rewrite_command,\n files=(),\n hook=None,\n verbose=False,\n show_diff_on_failure=False,\n )\n\n\ndef _rev_exists(rev: str) -> bool:\n return not subprocess.call(('git', 'rev-list', '--quiet', rev))\n\n\ndef _pre_push_ns(\n color: bool,\n args: Sequence[str],\n stdin: bytes,\n) -> argparse.Namespace | None:\n remote_name = args[0]\n remote_url = args[1]\n\n for line in stdin.decode().splitlines():\n local_branch, local_sha, remote_branch, remote_sha = line.split()\n if local_sha == Z40:\n continue\n elif remote_sha != Z40 and _rev_exists(remote_sha):\n return _ns(\n 'pre-push', color,\n from_ref=remote_sha, to_ref=local_sha,\n remote_branch=remote_branch,\n local_branch=local_branch,\n remote_name=remote_name, remote_url=remote_url,\n )\n else:\n # ancestors not found in remote\n ancestors = subprocess.check_output((\n 'git', 'rev-list', local_sha, '--topo-order', '--reverse',\n '--not', f'--remotes={remote_name}',\n )).decode().strip()\n if not ancestors:\n continue\n else:\n first_ancestor = ancestors.splitlines()[0]\n cmd = ('git', 'rev-list', '--max-parents=0', local_sha)\n roots = set(subprocess.check_output(cmd).decode().splitlines())\n if first_ancestor in roots:\n # pushing the whole tree including root commit\n return _ns(\n 'pre-push', color,\n all_files=True,\n remote_name=remote_name, remote_url=remote_url,\n remote_branch=remote_branch,\n local_branch=local_branch,\n )\n else:\n rev_cmd = ('git', 'rev-parse', f'{first_ancestor}^')\n source = subprocess.check_output(rev_cmd).decode().strip()\n return _ns(\n 'pre-push', color,\n from_ref=source, to_ref=local_sha,\n remote_name=remote_name, remote_url=remote_url,\n remote_branch=remote_branch,\n local_branch=local_branch,\n )\n\n # nothing to push\n return None\n\n\n_EXPECTED_ARG_LENGTH_BY_HOOK = {\n 'commit-msg': 1,\n 'post-checkout': 3,\n 'post-commit': 0,\n 'pre-commit': 0,\n 'pre-merge-commit': 0,\n 'post-merge': 1,\n 'post-rewrite': 1,\n 'pre-push': 2,\n}\n\n\ndef _check_args_length(hook_type: str, args: Sequence[str]) -> None:\n if hook_type == 'prepare-commit-msg':\n if len(args) < 1 or len(args) > 3:\n raise SystemExit(\n f'hook-impl for {hook_type} expected 1, 2, or 3 arguments '\n f'but got {len(args)}: {args}',\n )\n elif hook_type in _EXPECTED_ARG_LENGTH_BY_HOOK:\n expected = _EXPECTED_ARG_LENGTH_BY_HOOK[hook_type]\n if len(args) != expected:\n arguments_s = 'argument' if expected == 1 else 'arguments'\n raise SystemExit(\n f'hook-impl for {hook_type} expected {expected} {arguments_s} '\n f'but got {len(args)}: {args}',\n )\n else:\n raise AssertionError(f'unexpected hook type: {hook_type}')\n\n\ndef _run_ns(\n hook_type: str,\n color: bool,\n args: Sequence[str],\n stdin: bytes,\n) -> argparse.Namespace | None:\n _check_args_length(hook_type, args)\n if hook_type == 'pre-push':\n return _pre_push_ns(color, args, stdin)\n elif hook_type in {'commit-msg', 'prepare-commit-msg'}:\n return _ns(hook_type, color, commit_msg_filename=args[0])\n elif hook_type in {'post-commit', 'pre-merge-commit', 'pre-commit'}:\n return _ns(hook_type, color)\n elif hook_type == 'post-checkout':\n return _ns(\n hook_type, color,\n from_ref=args[0], to_ref=args[1], checkout_type=args[2],\n )\n elif hook_type == 'post-merge':\n return _ns(hook_type, color, is_squash_merge=args[0])\n elif hook_type == 'post-rewrite':\n return _ns(hook_type, color, rewrite_command=args[0])\n else:\n raise AssertionError(f'unexpected hook type: {hook_type}')\n\n\ndef hook_impl(\n store: Store,\n *,\n config: str,\n color: bool,\n hook_type: str,\n hook_dir: str,\n skip_on_missing_config: bool,\n args: Sequence[str],\n) -> int:\n retv, stdin = _run_legacy(hook_type, hook_dir, args)\n _validate_config(retv, config, skip_on_missing_config)\n ns = _run_ns(hook_type, color, args, stdin)\n if ns is None:\n return retv\n else:\n return retv | run(config, store, ns)\n", "path": "pre_commit/commands/hook_impl.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport argparse\nimport os.path\nimport subprocess\nimport sys\nfrom typing import Sequence\n\nfrom pre_commit.commands.run import run\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.parse_shebang import normalize_cmd\nfrom pre_commit.store import Store\n\nZ40 = '0' * 40\n\n\ndef _run_legacy(\n hook_type: str,\n hook_dir: str,\n args: Sequence[str],\n) -> tuple[int, bytes]:\n if os.environ.get('PRE_COMMIT_RUNNING_LEGACY'):\n raise SystemExit(\n f\"bug: pre-commit's script is installed in migration mode\\n\"\n f'run `pre-commit install -f --hook-type {hook_type}` to fix '\n f'this\\n\\n'\n f'Please report this bug at '\n f'https://github.com/pre-commit/pre-commit/issues',\n )\n\n if hook_type == 'pre-push':\n stdin = sys.stdin.buffer.read()\n else:\n stdin = b''\n\n # not running in legacy mode\n legacy_hook = os.path.join(hook_dir, f'{hook_type}.legacy')\n if not os.access(legacy_hook, os.X_OK):\n return 0, stdin\n\n with envcontext((('PRE_COMMIT_RUNNING_LEGACY', '1'),)):\n cmd = normalize_cmd((legacy_hook, *args))\n return subprocess.run(cmd, input=stdin).returncode, stdin\n\n\ndef _validate_config(\n retv: int,\n config: str,\n skip_on_missing_config: bool,\n) -> None:\n if not os.path.isfile(config):\n if skip_on_missing_config or os.getenv('PRE_COMMIT_ALLOW_NO_CONFIG'):\n print(f'`{config}` config file not found. Skipping `pre-commit`.')\n raise SystemExit(retv)\n else:\n print(\n f'No {config} file was found\\n'\n f'- To temporarily silence this, run '\n f'`PRE_COMMIT_ALLOW_NO_CONFIG=1 git ...`\\n'\n f'- To permanently silence this, install pre-commit with the '\n f'--allow-missing-config option\\n'\n f'- To uninstall pre-commit run `pre-commit uninstall`',\n )\n raise SystemExit(1)\n\n\ndef _ns(\n hook_type: str,\n color: bool,\n *,\n all_files: bool = False,\n remote_branch: str | None = None,\n local_branch: str | None = None,\n from_ref: str | None = None,\n to_ref: str | None = None,\n remote_name: str | None = None,\n remote_url: str | None = None,\n commit_msg_filename: str | None = None,\n checkout_type: str | None = None,\n is_squash_merge: str | None = None,\n rewrite_command: str | None = None,\n) -> argparse.Namespace:\n return argparse.Namespace(\n color=color,\n hook_stage=hook_type.replace('pre-', ''),\n remote_branch=remote_branch,\n local_branch=local_branch,\n from_ref=from_ref,\n to_ref=to_ref,\n remote_name=remote_name,\n remote_url=remote_url,\n commit_msg_filename=commit_msg_filename,\n all_files=all_files,\n checkout_type=checkout_type,\n is_squash_merge=is_squash_merge,\n rewrite_command=rewrite_command,\n files=(),\n hook=None,\n verbose=False,\n show_diff_on_failure=False,\n )\n\n\ndef _rev_exists(rev: str) -> bool:\n return not subprocess.call(('git', 'rev-list', '--quiet', rev))\n\n\ndef _pre_push_ns(\n color: bool,\n args: Sequence[str],\n stdin: bytes,\n) -> argparse.Namespace | None:\n remote_name = args[0]\n remote_url = args[1]\n\n for line in stdin.decode().splitlines():\n parts = line.rsplit(maxsplit=3)\n local_branch, local_sha, remote_branch, remote_sha = parts\n if local_sha == Z40:\n continue\n elif remote_sha != Z40 and _rev_exists(remote_sha):\n return _ns(\n 'pre-push', color,\n from_ref=remote_sha, to_ref=local_sha,\n remote_branch=remote_branch,\n local_branch=local_branch,\n remote_name=remote_name, remote_url=remote_url,\n )\n else:\n # ancestors not found in remote\n ancestors = subprocess.check_output((\n 'git', 'rev-list', local_sha, '--topo-order', '--reverse',\n '--not', f'--remotes={remote_name}',\n )).decode().strip()\n if not ancestors:\n continue\n else:\n first_ancestor = ancestors.splitlines()[0]\n cmd = ('git', 'rev-list', '--max-parents=0', local_sha)\n roots = set(subprocess.check_output(cmd).decode().splitlines())\n if first_ancestor in roots:\n # pushing the whole tree including root commit\n return _ns(\n 'pre-push', color,\n all_files=True,\n remote_name=remote_name, remote_url=remote_url,\n remote_branch=remote_branch,\n local_branch=local_branch,\n )\n else:\n rev_cmd = ('git', 'rev-parse', f'{first_ancestor}^')\n source = subprocess.check_output(rev_cmd).decode().strip()\n return _ns(\n 'pre-push', color,\n from_ref=source, to_ref=local_sha,\n remote_name=remote_name, remote_url=remote_url,\n remote_branch=remote_branch,\n local_branch=local_branch,\n )\n\n # nothing to push\n return None\n\n\n_EXPECTED_ARG_LENGTH_BY_HOOK = {\n 'commit-msg': 1,\n 'post-checkout': 3,\n 'post-commit': 0,\n 'pre-commit': 0,\n 'pre-merge-commit': 0,\n 'post-merge': 1,\n 'post-rewrite': 1,\n 'pre-push': 2,\n}\n\n\ndef _check_args_length(hook_type: str, args: Sequence[str]) -> None:\n if hook_type == 'prepare-commit-msg':\n if len(args) < 1 or len(args) > 3:\n raise SystemExit(\n f'hook-impl for {hook_type} expected 1, 2, or 3 arguments '\n f'but got {len(args)}: {args}',\n )\n elif hook_type in _EXPECTED_ARG_LENGTH_BY_HOOK:\n expected = _EXPECTED_ARG_LENGTH_BY_HOOK[hook_type]\n if len(args) != expected:\n arguments_s = 'argument' if expected == 1 else 'arguments'\n raise SystemExit(\n f'hook-impl for {hook_type} expected {expected} {arguments_s} '\n f'but got {len(args)}: {args}',\n )\n else:\n raise AssertionError(f'unexpected hook type: {hook_type}')\n\n\ndef _run_ns(\n hook_type: str,\n color: bool,\n args: Sequence[str],\n stdin: bytes,\n) -> argparse.Namespace | None:\n _check_args_length(hook_type, args)\n if hook_type == 'pre-push':\n return _pre_push_ns(color, args, stdin)\n elif hook_type in {'commit-msg', 'prepare-commit-msg'}:\n return _ns(hook_type, color, commit_msg_filename=args[0])\n elif hook_type in {'post-commit', 'pre-merge-commit', 'pre-commit'}:\n return _ns(hook_type, color)\n elif hook_type == 'post-checkout':\n return _ns(\n hook_type, color,\n from_ref=args[0], to_ref=args[1], checkout_type=args[2],\n )\n elif hook_type == 'post-merge':\n return _ns(hook_type, color, is_squash_merge=args[0])\n elif hook_type == 'post-rewrite':\n return _ns(hook_type, color, rewrite_command=args[0])\n else:\n raise AssertionError(f'unexpected hook type: {hook_type}')\n\n\ndef hook_impl(\n store: Store,\n *,\n config: str,\n color: bool,\n hook_type: str,\n hook_dir: str,\n skip_on_missing_config: bool,\n args: Sequence[str],\n) -> int:\n retv, stdin = _run_legacy(hook_type, hook_dir, args)\n _validate_config(retv, config, skip_on_missing_config)\n ns = _run_ns(hook_type, color, args, stdin)\n if ns is None:\n return retv\n else:\n return retv | run(config, store, ns)\n", "path": "pre_commit/commands/hook_impl.py"}]}
| 3,473 | 149 |
gh_patches_debug_31529
|
rasdani/github-patches
|
git_diff
|
sagemath__sage-36565
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sage-download-file: Limit number of mirrors contacted
<div id="comment:0"></div>
In particular when `--enable-download-from-upstream-url` is in use.
CC: @jhpalmieri @dimpase @vbraun @williamstein
Component: **build**
_Issue created by migration from https://trac.sagemath.org/ticket/34411_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `build/sage_bootstrap/download/mirror_list.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Access the List of Sage Download Mirrors
4 """
5
6 #*****************************************************************************
7 # Copyright (C) 2015 Volker Braun <[email protected]>
8 #
9 # This program is free software: you can redistribute it and/or modify
10 # it under the terms of the GNU General Public License as published by
11 # the Free Software Foundation, either version 2 of the License, or
12 # (at your option) any later version.
13 # http://www.gnu.org/licenses/
14 #*****************************************************************************
15
16 import os
17 import contextlib
18 import logging
19 log = logging.getLogger()
20
21 from sage_bootstrap.compat import urllib, urlparse
22 from sage_bootstrap.env import SAGE_DISTFILES, SAGE_ROOT
23
24 from fcntl import flock, LOCK_SH, LOCK_EX
25 from errno import ENOLCK
26
27
28 def try_lock(fd, operation):
29 """
30 Try flock() but ignore ``ENOLCK`` errors, which could happen if the
31 file system does not support locking.
32 """
33 try:
34 flock(fd, operation)
35 except IOError as e:
36 if e.errno != ENOLCK:
37 raise
38
39
40 class MirrorListException(RuntimeError):
41 pass
42
43
44 class MirrorList(object):
45
46 def __init__(self):
47 self.sources = []
48 upstream_d = os.path.join(SAGE_ROOT, '.upstream.d')
49 for fname in sorted(os.listdir(upstream_d)):
50 if '~' in fname or '#' in fname:
51 # Ignore auto-save and backup files
52 continue
53 try:
54 with open(os.path.join(upstream_d, fname), 'r') as f:
55 for line in f:
56 line = line.strip()
57 if line.startswith('#'):
58 continue
59 if not line:
60 continue
61 line = line.replace('${SAGE_ROOT}', SAGE_ROOT)
62 line = line.replace('${SAGE_DISTFILES}', SAGE_DISTFILES)
63 if '${SAGE_SERVER}' in line:
64 SAGE_SERVER = os.environ.get("SAGE_SERVER", "")
65 if not SAGE_SERVER:
66 continue
67 line = line.replace('${SAGE_SERVER}', SAGE_SERVER)
68 if line.endswith('mirror_list'):
69 cache_filename = os.path.join(SAGE_DISTFILES, line.rpartition('/')[2])
70 self.sources.append(MirrorList_from_url(line, cache_filename))
71 else:
72 self.sources.append([line])
73 except IOError:
74 # Silently ignore files that do not exist
75 pass
76
77 def __iter__(self):
78 """
79 Iterate through the list of mirrors.
80
81 This is the main entry point into the mirror list. Every
82 script should just use this function to try mirrors in order
83 of preference. This will not just yield the official mirrors,
84 but also urls for packages that are currently being tested.
85 """
86 for source in self.sources:
87 for mirror in source:
88 yield mirror
89
90
91 class MirrorList_from_url(object):
92
93 MAXAGE = 24*60*60 # seconds
94
95 def __init__(self, url, filename):
96 self.url = url
97 self.filename = filename
98 self._mirrors = None
99
100 @property
101 def mirrors(self):
102 if self._mirrors is not None:
103 return self._mirrors
104
105 try:
106 self.mirrorfile = open(self.filename, 'r+t')
107 except IOError:
108 self.mirrorfile = open(self.filename, 'w+t')
109
110 with self.mirrorfile:
111 self.mirrorfd = self.mirrorfile.fileno()
112 try_lock(self.mirrorfd, LOCK_SH) # shared (read) lock
113 if self._must_refresh():
114 try_lock(self.mirrorfd, LOCK_EX) # exclusive (write) lock
115 # Maybe the mirror list file was updated by a different
116 # process while we waited for the lock? Check again.
117 if self._must_refresh():
118 self._refresh()
119 if self._mirrors is None:
120 self._mirrors = self._load()
121
122 return self._mirrors
123
124 def _load(self, mirror_list=None):
125 """
126 Load and return `mirror_list` (defaults to the one on disk) as
127 a list of strings
128 """
129 if mirror_list is None:
130 try:
131 self.mirrorfile.seek(0)
132 mirror_list = self.mirrorfile.read()
133 except IOError:
134 log.critical('Failed to load the cached mirror list')
135 return []
136 if mirror_list == '':
137 return []
138 import ast
139 try:
140 return ast.literal_eval(mirror_list)
141 except SyntaxError:
142 log.critical('Downloaded mirror list has syntax error: {0}'.format(mirror_list))
143 return []
144
145 def _save(self):
146 """
147 Save the mirror list for (short-term) future use.
148 """
149 self.mirrorfile.seek(0)
150 self.mirrorfile.write(repr(self.mirrors))
151 self.mirrorfile.truncate()
152 self.mirrorfile.flush()
153
154 def _port_of_mirror(self, mirror):
155 if mirror.startswith('http://'):
156 return 80
157 if mirror.startswith('https://'):
158 return 443
159 if mirror.startswith('ftp://'):
160 return 21
161 # Sensible default (invalid mirror?)
162 return 80
163
164 def _rank_mirrors(self):
165 """
166 Sort the mirrors by speed, fastest being first
167
168 This method is used by the YUM fastestmirror plugin
169 """
170 timed_mirrors = []
171 import time, socket
172 log.info('Searching fastest mirror')
173 timeout = socket.getdefaulttimeout()
174 if timeout is None:
175 timeout = 1
176 for mirror in self.mirrors:
177 if not mirror.startswith('http'):
178 log.debug('we currently can only handle http, got %s', mirror)
179 continue
180 port = self._port_of_mirror(mirror)
181 mirror_hostname = urlparse.urlsplit(mirror).netloc
182 time_before = time.time()
183 try:
184 sock = socket.create_connection((mirror_hostname, port), timeout)
185 sock.close()
186 except (IOError, socket.error, socket.timeout) as err:
187 log.warning(str(err).strip() + ': ' + mirror)
188 continue
189 result = time.time() - time_before
190 result_ms = int(1000 * result)
191 log.info(str(result_ms).rjust(5) + 'ms: ' + mirror)
192 timed_mirrors.append((result, mirror))
193 if len(timed_mirrors) == 0:
194 # We cannot reach any mirror directly, most likely firewall issue
195 if 'http_proxy' not in os.environ:
196 log.error('Could not reach any mirror directly and no proxy set')
197 raise MirrorListException('Failed to connect to any mirror, probably no internet connection')
198 log.info('Cannot time mirrors via proxy, using default order')
199 else:
200 timed_mirrors.sort()
201 self._mirrors = [m[1] for m in timed_mirrors]
202 log.info('Fastest mirror: ' + self.fastest)
203
204 def _age(self):
205 """
206 Return the age of the cached mirror list in seconds
207 """
208 import time
209 mtime = os.fstat(self.mirrorfd).st_mtime
210 now = time.mktime(time.localtime())
211 return now - mtime
212
213 def _must_refresh(self):
214 """
215 Return whether we must download the mirror list.
216
217 If and only if this method returns ``False`` is it admissible
218 to use the cached mirror list.
219 """
220 if os.fstat(self.mirrorfd).st_size == 0:
221 return True
222 return self._age() > self.MAXAGE
223
224 def _refresh(self):
225 """
226 Download and rank the mirror list.
227 """
228 log.info('Downloading the Sage mirror list')
229 try:
230 with contextlib.closing(urllib.urlopen(self.url)) as f:
231 mirror_list = f.read().decode("ascii")
232 except IOError:
233 log.critical('Downloading the mirror list failed, using cached version')
234 else:
235 self._mirrors = self._load(mirror_list)
236 self._rank_mirrors()
237 self._save()
238
239 def __iter__(self):
240 """
241 Iterate through the list of mirrors.
242
243 This is the main entry point into the mirror list. Every
244 script should just use this function to try mirrors in order
245 of preference. This will not just yield the official mirrors,
246 but also urls for packages that are currently being tested.
247 """
248 try:
249 yield os.environ['SAGE_SERVER']
250 except KeyError:
251 pass
252 for mirror in self.mirrors:
253 if not mirror.endswith('/'):
254 mirror += '/'
255 yield mirror + '/'.join(['spkg', 'upstream', '${SPKG}'])
256
257 @property
258 def fastest(self):
259 return next(iter(self))
260
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/build/sage_bootstrap/download/mirror_list.py b/build/sage_bootstrap/download/mirror_list.py
--- a/build/sage_bootstrap/download/mirror_list.py
+++ b/build/sage_bootstrap/download/mirror_list.py
@@ -170,9 +170,7 @@
timed_mirrors = []
import time, socket
log.info('Searching fastest mirror')
- timeout = socket.getdefaulttimeout()
- if timeout is None:
- timeout = 1
+ timeout = 1
for mirror in self.mirrors:
if not mirror.startswith('http'):
log.debug('we currently can only handle http, got %s', mirror)
@@ -190,6 +188,11 @@
result_ms = int(1000 * result)
log.info(str(result_ms).rjust(5) + 'ms: ' + mirror)
timed_mirrors.append((result, mirror))
+ timed_mirrors.sort()
+ if len(timed_mirrors) >= 5 and timed_mirrors[4][0] < 0.3:
+ # We don't need more than 5 decent mirrors
+ break
+
if len(timed_mirrors) == 0:
# We cannot reach any mirror directly, most likely firewall issue
if 'http_proxy' not in os.environ:
@@ -197,7 +200,6 @@
raise MirrorListException('Failed to connect to any mirror, probably no internet connection')
log.info('Cannot time mirrors via proxy, using default order')
else:
- timed_mirrors.sort()
self._mirrors = [m[1] for m in timed_mirrors]
log.info('Fastest mirror: ' + self.fastest)
|
{"golden_diff": "diff --git a/build/sage_bootstrap/download/mirror_list.py b/build/sage_bootstrap/download/mirror_list.py\n--- a/build/sage_bootstrap/download/mirror_list.py\n+++ b/build/sage_bootstrap/download/mirror_list.py\n@@ -170,9 +170,7 @@\n timed_mirrors = []\n import time, socket\n log.info('Searching fastest mirror')\n- timeout = socket.getdefaulttimeout()\n- if timeout is None:\n- timeout = 1\n+ timeout = 1\n for mirror in self.mirrors:\n if not mirror.startswith('http'):\n log.debug('we currently can only handle http, got %s', mirror)\n@@ -190,6 +188,11 @@\n result_ms = int(1000 * result)\n log.info(str(result_ms).rjust(5) + 'ms: ' + mirror)\n timed_mirrors.append((result, mirror))\n+ timed_mirrors.sort()\n+ if len(timed_mirrors) >= 5 and timed_mirrors[4][0] < 0.3:\n+ # We don't need more than 5 decent mirrors\n+ break\n+\n if len(timed_mirrors) == 0:\n # We cannot reach any mirror directly, most likely firewall issue\n if 'http_proxy' not in os.environ:\n@@ -197,7 +200,6 @@\n raise MirrorListException('Failed to connect to any mirror, probably no internet connection')\n log.info('Cannot time mirrors via proxy, using default order')\n else:\n- timed_mirrors.sort()\n self._mirrors = [m[1] for m in timed_mirrors]\n log.info('Fastest mirror: ' + self.fastest)\n", "issue": "sage-download-file: Limit number of mirrors contacted\n<div id=\"comment:0\"></div>\n\nIn particular when `--enable-download-from-upstream-url` is in use.\n\nCC: @jhpalmieri @dimpase @vbraun @williamstein\n\nComponent: **build**\n\n_Issue created by migration from https://trac.sagemath.org/ticket/34411_\n\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nAccess the List of Sage Download Mirrors\n\"\"\"\n\n#*****************************************************************************\n# Copyright (C) 2015 Volker Braun <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# (at your option) any later version.\n# http://www.gnu.org/licenses/\n#*****************************************************************************\n\nimport os\nimport contextlib\nimport logging\nlog = logging.getLogger()\n\nfrom sage_bootstrap.compat import urllib, urlparse\nfrom sage_bootstrap.env import SAGE_DISTFILES, SAGE_ROOT\n\nfrom fcntl import flock, LOCK_SH, LOCK_EX\nfrom errno import ENOLCK\n\n\ndef try_lock(fd, operation):\n \"\"\"\n Try flock() but ignore ``ENOLCK`` errors, which could happen if the\n file system does not support locking.\n \"\"\"\n try:\n flock(fd, operation)\n except IOError as e:\n if e.errno != ENOLCK:\n raise\n\n \nclass MirrorListException(RuntimeError):\n pass\n \n\nclass MirrorList(object):\n\n def __init__(self):\n self.sources = []\n upstream_d = os.path.join(SAGE_ROOT, '.upstream.d')\n for fname in sorted(os.listdir(upstream_d)):\n if '~' in fname or '#' in fname:\n # Ignore auto-save and backup files\n continue\n try:\n with open(os.path.join(upstream_d, fname), 'r') as f:\n for line in f:\n line = line.strip()\n if line.startswith('#'):\n continue\n if not line:\n continue\n line = line.replace('${SAGE_ROOT}', SAGE_ROOT)\n line = line.replace('${SAGE_DISTFILES}', SAGE_DISTFILES)\n if '${SAGE_SERVER}' in line:\n SAGE_SERVER = os.environ.get(\"SAGE_SERVER\", \"\")\n if not SAGE_SERVER:\n continue\n line = line.replace('${SAGE_SERVER}', SAGE_SERVER)\n if line.endswith('mirror_list'):\n cache_filename = os.path.join(SAGE_DISTFILES, line.rpartition('/')[2])\n self.sources.append(MirrorList_from_url(line, cache_filename))\n else:\n self.sources.append([line])\n except IOError:\n # Silently ignore files that do not exist\n pass\n\n def __iter__(self):\n \"\"\"\n Iterate through the list of mirrors.\n\n This is the main entry point into the mirror list. Every\n script should just use this function to try mirrors in order\n of preference. This will not just yield the official mirrors,\n but also urls for packages that are currently being tested.\n \"\"\"\n for source in self.sources:\n for mirror in source:\n yield mirror\n\n\nclass MirrorList_from_url(object):\n \n MAXAGE = 24*60*60 # seconds\n\n def __init__(self, url, filename):\n self.url = url\n self.filename = filename\n self._mirrors = None\n\n @property\n def mirrors(self):\n if self._mirrors is not None:\n return self._mirrors\n\n try:\n self.mirrorfile = open(self.filename, 'r+t')\n except IOError:\n self.mirrorfile = open(self.filename, 'w+t')\n\n with self.mirrorfile:\n self.mirrorfd = self.mirrorfile.fileno()\n try_lock(self.mirrorfd, LOCK_SH) # shared (read) lock\n if self._must_refresh():\n try_lock(self.mirrorfd, LOCK_EX) # exclusive (write) lock\n # Maybe the mirror list file was updated by a different\n # process while we waited for the lock? Check again.\n if self._must_refresh():\n self._refresh()\n if self._mirrors is None:\n self._mirrors = self._load()\n\n return self._mirrors\n\n def _load(self, mirror_list=None):\n \"\"\"\n Load and return `mirror_list` (defaults to the one on disk) as\n a list of strings\n \"\"\"\n if mirror_list is None:\n try:\n self.mirrorfile.seek(0)\n mirror_list = self.mirrorfile.read()\n except IOError:\n log.critical('Failed to load the cached mirror list')\n return []\n if mirror_list == '':\n return []\n import ast\n try:\n return ast.literal_eval(mirror_list)\n except SyntaxError:\n log.critical('Downloaded mirror list has syntax error: {0}'.format(mirror_list))\n return []\n\n def _save(self):\n \"\"\"\n Save the mirror list for (short-term) future use.\n \"\"\"\n self.mirrorfile.seek(0)\n self.mirrorfile.write(repr(self.mirrors))\n self.mirrorfile.truncate()\n self.mirrorfile.flush()\n\n def _port_of_mirror(self, mirror):\n if mirror.startswith('http://'):\n return 80\n if mirror.startswith('https://'):\n return 443\n if mirror.startswith('ftp://'):\n return 21\n # Sensible default (invalid mirror?)\n return 80\n\n def _rank_mirrors(self):\n \"\"\"\n Sort the mirrors by speed, fastest being first\n\n This method is used by the YUM fastestmirror plugin\n \"\"\"\n timed_mirrors = []\n import time, socket\n log.info('Searching fastest mirror')\n timeout = socket.getdefaulttimeout()\n if timeout is None:\n timeout = 1\n for mirror in self.mirrors:\n if not mirror.startswith('http'):\n log.debug('we currently can only handle http, got %s', mirror)\n continue\n port = self._port_of_mirror(mirror)\n mirror_hostname = urlparse.urlsplit(mirror).netloc\n time_before = time.time()\n try:\n sock = socket.create_connection((mirror_hostname, port), timeout)\n sock.close()\n except (IOError, socket.error, socket.timeout) as err:\n log.warning(str(err).strip() + ': ' + mirror)\n continue\n result = time.time() - time_before\n result_ms = int(1000 * result)\n log.info(str(result_ms).rjust(5) + 'ms: ' + mirror)\n timed_mirrors.append((result, mirror))\n if len(timed_mirrors) == 0:\n # We cannot reach any mirror directly, most likely firewall issue\n if 'http_proxy' not in os.environ:\n log.error('Could not reach any mirror directly and no proxy set')\n raise MirrorListException('Failed to connect to any mirror, probably no internet connection')\n log.info('Cannot time mirrors via proxy, using default order')\n else:\n timed_mirrors.sort()\n self._mirrors = [m[1] for m in timed_mirrors]\n log.info('Fastest mirror: ' + self.fastest)\n\n def _age(self):\n \"\"\"\n Return the age of the cached mirror list in seconds\n \"\"\"\n import time\n mtime = os.fstat(self.mirrorfd).st_mtime\n now = time.mktime(time.localtime())\n return now - mtime\n\n def _must_refresh(self):\n \"\"\"\n Return whether we must download the mirror list.\n\n If and only if this method returns ``False`` is it admissible\n to use the cached mirror list.\n \"\"\"\n if os.fstat(self.mirrorfd).st_size == 0:\n return True\n return self._age() > self.MAXAGE\n\n def _refresh(self):\n \"\"\"\n Download and rank the mirror list.\n \"\"\"\n log.info('Downloading the Sage mirror list')\n try:\n with contextlib.closing(urllib.urlopen(self.url)) as f:\n mirror_list = f.read().decode(\"ascii\")\n except IOError:\n log.critical('Downloading the mirror list failed, using cached version')\n else:\n self._mirrors = self._load(mirror_list)\n self._rank_mirrors()\n self._save()\n\n def __iter__(self):\n \"\"\"\n Iterate through the list of mirrors.\n\n This is the main entry point into the mirror list. Every\n script should just use this function to try mirrors in order\n of preference. This will not just yield the official mirrors,\n but also urls for packages that are currently being tested.\n \"\"\"\n try:\n yield os.environ['SAGE_SERVER']\n except KeyError:\n pass\n for mirror in self.mirrors:\n if not mirror.endswith('/'):\n mirror += '/'\n yield mirror + '/'.join(['spkg', 'upstream', '${SPKG}'])\n\n @property\n def fastest(self):\n return next(iter(self))\n", "path": "build/sage_bootstrap/download/mirror_list.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nAccess the List of Sage Download Mirrors\n\"\"\"\n\n#*****************************************************************************\n# Copyright (C) 2015 Volker Braun <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# (at your option) any later version.\n# http://www.gnu.org/licenses/\n#*****************************************************************************\n\nimport os\nimport contextlib\nimport logging\nlog = logging.getLogger()\n\nfrom sage_bootstrap.compat import urllib, urlparse\nfrom sage_bootstrap.env import SAGE_DISTFILES, SAGE_ROOT\n\nfrom fcntl import flock, LOCK_SH, LOCK_EX\nfrom errno import ENOLCK\n\n\ndef try_lock(fd, operation):\n \"\"\"\n Try flock() but ignore ``ENOLCK`` errors, which could happen if the\n file system does not support locking.\n \"\"\"\n try:\n flock(fd, operation)\n except IOError as e:\n if e.errno != ENOLCK:\n raise\n\n \nclass MirrorListException(RuntimeError):\n pass\n \n\nclass MirrorList(object):\n\n def __init__(self):\n self.sources = []\n upstream_d = os.path.join(SAGE_ROOT, '.upstream.d')\n for fname in sorted(os.listdir(upstream_d)):\n if '~' in fname or '#' in fname:\n # Ignore auto-save and backup files\n continue\n try:\n with open(os.path.join(upstream_d, fname), 'r') as f:\n for line in f:\n line = line.strip()\n if line.startswith('#'):\n continue\n if not line:\n continue\n line = line.replace('${SAGE_ROOT}', SAGE_ROOT)\n line = line.replace('${SAGE_DISTFILES}', SAGE_DISTFILES)\n if '${SAGE_SERVER}' in line:\n SAGE_SERVER = os.environ.get(\"SAGE_SERVER\", \"\")\n if not SAGE_SERVER:\n continue\n line = line.replace('${SAGE_SERVER}', SAGE_SERVER)\n if line.endswith('mirror_list'):\n cache_filename = os.path.join(SAGE_DISTFILES, line.rpartition('/')[2])\n self.sources.append(MirrorList_from_url(line, cache_filename))\n else:\n self.sources.append([line])\n except IOError:\n # Silently ignore files that do not exist\n pass\n\n def __iter__(self):\n \"\"\"\n Iterate through the list of mirrors.\n\n This is the main entry point into the mirror list. Every\n script should just use this function to try mirrors in order\n of preference. This will not just yield the official mirrors,\n but also urls for packages that are currently being tested.\n \"\"\"\n for source in self.sources:\n for mirror in source:\n yield mirror\n\n\nclass MirrorList_from_url(object):\n \n MAXAGE = 24*60*60 # seconds\n\n def __init__(self, url, filename):\n self.url = url\n self.filename = filename\n self._mirrors = None\n\n @property\n def mirrors(self):\n if self._mirrors is not None:\n return self._mirrors\n\n try:\n self.mirrorfile = open(self.filename, 'r+t')\n except IOError:\n self.mirrorfile = open(self.filename, 'w+t')\n\n with self.mirrorfile:\n self.mirrorfd = self.mirrorfile.fileno()\n try_lock(self.mirrorfd, LOCK_SH) # shared (read) lock\n if self._must_refresh():\n try_lock(self.mirrorfd, LOCK_EX) # exclusive (write) lock\n # Maybe the mirror list file was updated by a different\n # process while we waited for the lock? Check again.\n if self._must_refresh():\n self._refresh()\n if self._mirrors is None:\n self._mirrors = self._load()\n\n return self._mirrors\n\n def _load(self, mirror_list=None):\n \"\"\"\n Load and return `mirror_list` (defaults to the one on disk) as\n a list of strings\n \"\"\"\n if mirror_list is None:\n try:\n self.mirrorfile.seek(0)\n mirror_list = self.mirrorfile.read()\n except IOError:\n log.critical('Failed to load the cached mirror list')\n return []\n if mirror_list == '':\n return []\n import ast\n try:\n return ast.literal_eval(mirror_list)\n except SyntaxError:\n log.critical('Downloaded mirror list has syntax error: {0}'.format(mirror_list))\n return []\n\n def _save(self):\n \"\"\"\n Save the mirror list for (short-term) future use.\n \"\"\"\n self.mirrorfile.seek(0)\n self.mirrorfile.write(repr(self.mirrors))\n self.mirrorfile.truncate()\n self.mirrorfile.flush()\n\n def _port_of_mirror(self, mirror):\n if mirror.startswith('http://'):\n return 80\n if mirror.startswith('https://'):\n return 443\n if mirror.startswith('ftp://'):\n return 21\n # Sensible default (invalid mirror?)\n return 80\n\n def _rank_mirrors(self):\n \"\"\"\n Sort the mirrors by speed, fastest being first\n\n This method is used by the YUM fastestmirror plugin\n \"\"\"\n timed_mirrors = []\n import time, socket\n log.info('Searching fastest mirror')\n timeout = 1\n for mirror in self.mirrors:\n if not mirror.startswith('http'):\n log.debug('we currently can only handle http, got %s', mirror)\n continue\n port = self._port_of_mirror(mirror)\n mirror_hostname = urlparse.urlsplit(mirror).netloc\n time_before = time.time()\n try:\n sock = socket.create_connection((mirror_hostname, port), timeout)\n sock.close()\n except (IOError, socket.error, socket.timeout) as err:\n log.warning(str(err).strip() + ': ' + mirror)\n continue\n result = time.time() - time_before\n result_ms = int(1000 * result)\n log.info(str(result_ms).rjust(5) + 'ms: ' + mirror)\n timed_mirrors.append((result, mirror))\n timed_mirrors.sort()\n if len(timed_mirrors) >= 5 and timed_mirrors[4][0] < 0.3:\n # We don't need more than 5 decent mirrors\n break\n\n if len(timed_mirrors) == 0:\n # We cannot reach any mirror directly, most likely firewall issue\n if 'http_proxy' not in os.environ:\n log.error('Could not reach any mirror directly and no proxy set')\n raise MirrorListException('Failed to connect to any mirror, probably no internet connection')\n log.info('Cannot time mirrors via proxy, using default order')\n else:\n self._mirrors = [m[1] for m in timed_mirrors]\n log.info('Fastest mirror: ' + self.fastest)\n\n def _age(self):\n \"\"\"\n Return the age of the cached mirror list in seconds\n \"\"\"\n import time\n mtime = os.fstat(self.mirrorfd).st_mtime\n now = time.mktime(time.localtime())\n return now - mtime\n\n def _must_refresh(self):\n \"\"\"\n Return whether we must download the mirror list.\n\n If and only if this method returns ``False`` is it admissible\n to use the cached mirror list.\n \"\"\"\n if os.fstat(self.mirrorfd).st_size == 0:\n return True\n return self._age() > self.MAXAGE\n\n def _refresh(self):\n \"\"\"\n Download and rank the mirror list.\n \"\"\"\n log.info('Downloading the Sage mirror list')\n try:\n with contextlib.closing(urllib.urlopen(self.url)) as f:\n mirror_list = f.read().decode(\"ascii\")\n except IOError:\n log.critical('Downloading the mirror list failed, using cached version')\n else:\n self._mirrors = self._load(mirror_list)\n self._rank_mirrors()\n self._save()\n\n def __iter__(self):\n \"\"\"\n Iterate through the list of mirrors.\n\n This is the main entry point into the mirror list. Every\n script should just use this function to try mirrors in order\n of preference. This will not just yield the official mirrors,\n but also urls for packages that are currently being tested.\n \"\"\"\n try:\n yield os.environ['SAGE_SERVER']\n except KeyError:\n pass\n for mirror in self.mirrors:\n if not mirror.endswith('/'):\n mirror += '/'\n yield mirror + '/'.join(['spkg', 'upstream', '${SPKG}'])\n\n @property\n def fastest(self):\n return next(iter(self))\n", "path": "build/sage_bootstrap/download/mirror_list.py"}]}
| 2,931 | 390 |
gh_patches_debug_43180
|
rasdani/github-patches
|
git_diff
|
Project-MONAI__MONAI-7068
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Padding as an Argument to AutoEncoder
**Is your feature request related to a problem? Please describe.**
In the current implementation of the AutoEncoder class in the `monai.networks.nets` module, the padding parameter is not customizable. This limits the model's flexibility, as different padding strategies might suit different data-sizes.
https://github.com/Project-MONAI/MONAI/blob/18a671a7f12389dd8263a4c2232196dcca814bb9/monai/networks/nets/autoencoder.py#L90
**Describe the solution you'd like**
I would like to propose adding a padding argument to the AutoEncoder class constructor. This would allow users to specify the padding strategy when instantiating the model.
**Describe alternatives you've considered**
An alternative solution could be to create a subclass of AutoEncoder (like CustomAE) whenever a different padding strategy is needed. See below,
```{python}
class CustomAE(AutoEncoder):
def __init__(self, padding, **kwargs):
self.padding = padding
super().__init__(**kwargs)
def _get_encode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Module:
# ...
mod = Convolution(
spatial_dims=self.dimensions,
in_channels=in_channels,
out_channels=out_channels,
strides=strides,
kernel_size=self.kernel_size,
padding=self.padding,
# ...
)
return mod
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `monai/networks/nets/autoencoder.py`
Content:
```
1 # Copyright (c) MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11
12 from __future__ import annotations
13
14 from collections.abc import Sequence
15 from typing import Any
16
17 import torch
18 import torch.nn as nn
19
20 from monai.networks.blocks import Convolution, ResidualUnit
21 from monai.networks.layers.factories import Act, Norm
22
23 __all__ = ["AutoEncoder"]
24
25
26 class AutoEncoder(nn.Module):
27 """
28 Simple definition of an autoencoder and base class for the architecture implementing
29 :py:class:`monai.networks.nets.VarAutoEncoder`. The network is composed of an encode sequence of blocks, followed
30 by an intermediary sequence of blocks, and finally a decode sequence of blocks. The encode and decode blocks are
31 default :py:class:`monai.networks.blocks.Convolution` instances with the encode blocks having the given stride
32 and the decode blocks having transpose convolutions with the same stride. If `num_res_units` is given residual
33 blocks are used instead.
34
35 By default the intermediary sequence is empty but if `inter_channels` is given to specify the output channels of
36 blocks then this will be become a sequence of Convolution blocks or of residual blocks if `num_inter_units` is
37 given. The optional parameter `inter_dilations` can be used to specify the dilation values of the convolutions in
38 these blocks, this allows a network to use dilated kernels in this middle section. Since the intermediary section
39 isn't meant to change the size of the output the strides for all these kernels is 1.
40
41 Args:
42 spatial_dims: number of spatial dimensions.
43 in_channels: number of input channels.
44 out_channels: number of output channels.
45 channels: sequence of channels. Top block first. The length of `channels` should be no less than 2.
46 strides: sequence of convolution strides. The length of `stride` should equal to `len(channels) - 1`.
47 kernel_size: convolution kernel size, the value(s) should be odd. If sequence,
48 its length should equal to dimensions. Defaults to 3.
49 up_kernel_size: upsampling convolution kernel size, the value(s) should be odd. If sequence,
50 its length should equal to dimensions. Defaults to 3.
51 num_res_units: number of residual units. Defaults to 0.
52 inter_channels: sequence of channels defining the blocks in the intermediate layer between encode and decode.
53 inter_dilations: defines the dilation value for each block of the intermediate layer. Defaults to 1.
54 num_inter_units: number of residual units for each block of the intermediate layer. Defaults to 0.
55 act: activation type and arguments. Defaults to PReLU.
56 norm: feature normalization type and arguments. Defaults to instance norm.
57 dropout: dropout ratio. Defaults to no dropout.
58 bias: whether to have a bias term in convolution blocks. Defaults to True.
59 According to `Performance Tuning Guide <https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html>`_,
60 if a conv layer is directly followed by a batch norm layer, bias should be False.
61
62 Examples::
63
64 from monai.networks.nets import AutoEncoder
65
66 # 3 layers each down/up sampling their inputs by a factor 2 with no intermediate layer
67 net = AutoEncoder(
68 spatial_dims=2,
69 in_channels=1,
70 out_channels=1,
71 channels=(2, 4, 8),
72 strides=(2, 2, 2)
73 )
74
75 # 1 layer downsampling by 2, followed by a sequence of residual units with 2 convolutions defined by
76 # progressively increasing dilations, then final upsample layer
77 net = AutoEncoder(
78 spatial_dims=2,
79 in_channels=1,
80 out_channels=1,
81 channels=(4,),
82 strides=(2,),
83 inter_channels=(8, 8, 8),
84 inter_dilations=(1, 2, 4),
85 num_inter_units=2
86 )
87
88 """
89
90 def __init__(
91 self,
92 spatial_dims: int,
93 in_channels: int,
94 out_channels: int,
95 channels: Sequence[int],
96 strides: Sequence[int],
97 kernel_size: Sequence[int] | int = 3,
98 up_kernel_size: Sequence[int] | int = 3,
99 num_res_units: int = 0,
100 inter_channels: list | None = None,
101 inter_dilations: list | None = None,
102 num_inter_units: int = 2,
103 act: tuple | str | None = Act.PRELU,
104 norm: tuple | str = Norm.INSTANCE,
105 dropout: tuple | str | float | None = None,
106 bias: bool = True,
107 ) -> None:
108 super().__init__()
109 self.dimensions = spatial_dims
110 self.in_channels = in_channels
111 self.out_channels = out_channels
112 self.channels = list(channels)
113 self.strides = list(strides)
114 self.kernel_size = kernel_size
115 self.up_kernel_size = up_kernel_size
116 self.num_res_units = num_res_units
117 self.act = act
118 self.norm = norm
119 self.dropout = dropout
120 self.bias = bias
121 self.num_inter_units = num_inter_units
122 self.inter_channels = inter_channels if inter_channels is not None else []
123 self.inter_dilations = list(inter_dilations or [1] * len(self.inter_channels))
124
125 # The number of channels and strides should match
126 if len(channels) != len(strides):
127 raise ValueError("Autoencoder expects matching number of channels and strides")
128
129 self.encoded_channels = in_channels
130 decode_channel_list = list(channels[-2::-1]) + [out_channels]
131
132 self.encode, self.encoded_channels = self._get_encode_module(self.encoded_channels, channels, strides)
133 self.intermediate, self.encoded_channels = self._get_intermediate_module(self.encoded_channels, num_inter_units)
134 self.decode, _ = self._get_decode_module(self.encoded_channels, decode_channel_list, strides[::-1] or [1])
135
136 def _get_encode_module(
137 self, in_channels: int, channels: Sequence[int], strides: Sequence[int]
138 ) -> tuple[nn.Sequential, int]:
139 """
140 Returns the encode part of the network by building up a sequence of layers returned by `_get_encode_layer`.
141 """
142 encode = nn.Sequential()
143 layer_channels = in_channels
144
145 for i, (c, s) in enumerate(zip(channels, strides)):
146 layer = self._get_encode_layer(layer_channels, c, s, False)
147 encode.add_module("encode_%i" % i, layer)
148 layer_channels = c
149
150 return encode, layer_channels
151
152 def _get_intermediate_module(self, in_channels: int, num_inter_units: int) -> tuple[nn.Module, int]:
153 """
154 Returns the intermediate block of the network which accepts input from the encoder and whose output goes
155 to the decoder.
156 """
157 # Define some types
158 intermediate: nn.Module
159 unit: nn.Module
160
161 intermediate = nn.Identity()
162 layer_channels = in_channels
163
164 if self.inter_channels:
165 intermediate = nn.Sequential()
166
167 for i, (dc, di) in enumerate(zip(self.inter_channels, self.inter_dilations)):
168 if self.num_inter_units > 0:
169 unit = ResidualUnit(
170 spatial_dims=self.dimensions,
171 in_channels=layer_channels,
172 out_channels=dc,
173 strides=1,
174 kernel_size=self.kernel_size,
175 subunits=self.num_inter_units,
176 act=self.act,
177 norm=self.norm,
178 dropout=self.dropout,
179 dilation=di,
180 bias=self.bias,
181 )
182 else:
183 unit = Convolution(
184 spatial_dims=self.dimensions,
185 in_channels=layer_channels,
186 out_channels=dc,
187 strides=1,
188 kernel_size=self.kernel_size,
189 act=self.act,
190 norm=self.norm,
191 dropout=self.dropout,
192 dilation=di,
193 bias=self.bias,
194 )
195
196 intermediate.add_module("inter_%i" % i, unit)
197 layer_channels = dc
198
199 return intermediate, layer_channels
200
201 def _get_decode_module(
202 self, in_channels: int, channels: Sequence[int], strides: Sequence[int]
203 ) -> tuple[nn.Sequential, int]:
204 """
205 Returns the decode part of the network by building up a sequence of layers returned by `_get_decode_layer`.
206 """
207 decode = nn.Sequential()
208 layer_channels = in_channels
209
210 for i, (c, s) in enumerate(zip(channels, strides)):
211 layer = self._get_decode_layer(layer_channels, c, s, i == (len(strides) - 1))
212 decode.add_module("decode_%i" % i, layer)
213 layer_channels = c
214
215 return decode, layer_channels
216
217 def _get_encode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Module:
218 """
219 Returns a single layer of the encoder part of the network.
220 """
221 mod: nn.Module
222 if self.num_res_units > 0:
223 mod = ResidualUnit(
224 spatial_dims=self.dimensions,
225 in_channels=in_channels,
226 out_channels=out_channels,
227 strides=strides,
228 kernel_size=self.kernel_size,
229 subunits=self.num_res_units,
230 act=self.act,
231 norm=self.norm,
232 dropout=self.dropout,
233 bias=self.bias,
234 last_conv_only=is_last,
235 )
236 return mod
237 mod = Convolution(
238 spatial_dims=self.dimensions,
239 in_channels=in_channels,
240 out_channels=out_channels,
241 strides=strides,
242 kernel_size=self.kernel_size,
243 act=self.act,
244 norm=self.norm,
245 dropout=self.dropout,
246 bias=self.bias,
247 conv_only=is_last,
248 )
249 return mod
250
251 def _get_decode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Sequential:
252 """
253 Returns a single layer of the decoder part of the network.
254 """
255 decode = nn.Sequential()
256
257 conv = Convolution(
258 spatial_dims=self.dimensions,
259 in_channels=in_channels,
260 out_channels=out_channels,
261 strides=strides,
262 kernel_size=self.up_kernel_size,
263 act=self.act,
264 norm=self.norm,
265 dropout=self.dropout,
266 bias=self.bias,
267 conv_only=is_last and self.num_res_units == 0,
268 is_transposed=True,
269 )
270
271 decode.add_module("conv", conv)
272
273 if self.num_res_units > 0:
274 ru = ResidualUnit(
275 spatial_dims=self.dimensions,
276 in_channels=out_channels,
277 out_channels=out_channels,
278 strides=1,
279 kernel_size=self.kernel_size,
280 subunits=1,
281 act=self.act,
282 norm=self.norm,
283 dropout=self.dropout,
284 bias=self.bias,
285 last_conv_only=is_last,
286 )
287
288 decode.add_module("resunit", ru)
289
290 return decode
291
292 def forward(self, x: torch.Tensor) -> Any:
293 x = self.encode(x)
294 x = self.intermediate(x)
295 x = self.decode(x)
296 return x
297
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/monai/networks/nets/autoencoder.py b/monai/networks/nets/autoencoder.py
--- a/monai/networks/nets/autoencoder.py
+++ b/monai/networks/nets/autoencoder.py
@@ -58,6 +58,8 @@
bias: whether to have a bias term in convolution blocks. Defaults to True.
According to `Performance Tuning Guide <https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html>`_,
if a conv layer is directly followed by a batch norm layer, bias should be False.
+ padding: controls the amount of implicit zero-paddings on both sides for padding number of points
+ for each dimension in convolution blocks. Defaults to None.
Examples::
@@ -104,6 +106,7 @@
norm: tuple | str = Norm.INSTANCE,
dropout: tuple | str | float | None = None,
bias: bool = True,
+ padding: Sequence[int] | int | None = None,
) -> None:
super().__init__()
self.dimensions = spatial_dims
@@ -118,6 +121,7 @@
self.norm = norm
self.dropout = dropout
self.bias = bias
+ self.padding = padding
self.num_inter_units = num_inter_units
self.inter_channels = inter_channels if inter_channels is not None else []
self.inter_dilations = list(inter_dilations or [1] * len(self.inter_channels))
@@ -178,6 +182,7 @@
dropout=self.dropout,
dilation=di,
bias=self.bias,
+ padding=self.padding,
)
else:
unit = Convolution(
@@ -191,6 +196,7 @@
dropout=self.dropout,
dilation=di,
bias=self.bias,
+ padding=self.padding,
)
intermediate.add_module("inter_%i" % i, unit)
@@ -231,6 +237,7 @@
norm=self.norm,
dropout=self.dropout,
bias=self.bias,
+ padding=self.padding,
last_conv_only=is_last,
)
return mod
@@ -244,6 +251,7 @@
norm=self.norm,
dropout=self.dropout,
bias=self.bias,
+ padding=self.padding,
conv_only=is_last,
)
return mod
@@ -264,6 +272,7 @@
norm=self.norm,
dropout=self.dropout,
bias=self.bias,
+ padding=self.padding,
conv_only=is_last and self.num_res_units == 0,
is_transposed=True,
)
@@ -282,6 +291,7 @@
norm=self.norm,
dropout=self.dropout,
bias=self.bias,
+ padding=self.padding,
last_conv_only=is_last,
)
|
{"golden_diff": "diff --git a/monai/networks/nets/autoencoder.py b/monai/networks/nets/autoencoder.py\n--- a/monai/networks/nets/autoencoder.py\n+++ b/monai/networks/nets/autoencoder.py\n@@ -58,6 +58,8 @@\n bias: whether to have a bias term in convolution blocks. Defaults to True.\n According to `Performance Tuning Guide <https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html>`_,\n if a conv layer is directly followed by a batch norm layer, bias should be False.\n+ padding: controls the amount of implicit zero-paddings on both sides for padding number of points\n+ for each dimension in convolution blocks. Defaults to None.\n \n Examples::\n \n@@ -104,6 +106,7 @@\n norm: tuple | str = Norm.INSTANCE,\n dropout: tuple | str | float | None = None,\n bias: bool = True,\n+ padding: Sequence[int] | int | None = None,\n ) -> None:\n super().__init__()\n self.dimensions = spatial_dims\n@@ -118,6 +121,7 @@\n self.norm = norm\n self.dropout = dropout\n self.bias = bias\n+ self.padding = padding\n self.num_inter_units = num_inter_units\n self.inter_channels = inter_channels if inter_channels is not None else []\n self.inter_dilations = list(inter_dilations or [1] * len(self.inter_channels))\n@@ -178,6 +182,7 @@\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n+ padding=self.padding,\n )\n else:\n unit = Convolution(\n@@ -191,6 +196,7 @@\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n+ padding=self.padding,\n )\n \n intermediate.add_module(\"inter_%i\" % i, unit)\n@@ -231,6 +237,7 @@\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n+ padding=self.padding,\n last_conv_only=is_last,\n )\n return mod\n@@ -244,6 +251,7 @@\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n+ padding=self.padding,\n conv_only=is_last,\n )\n return mod\n@@ -264,6 +272,7 @@\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n+ padding=self.padding,\n conv_only=is_last and self.num_res_units == 0,\n is_transposed=True,\n )\n@@ -282,6 +291,7 @@\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n+ padding=self.padding,\n last_conv_only=is_last,\n )\n", "issue": "Add Padding as an Argument to AutoEncoder\n**Is your feature request related to a problem? Please describe.**\r\nIn the current implementation of the AutoEncoder class in the `monai.networks.nets` module, the padding parameter is not customizable. This limits the model's flexibility, as different padding strategies might suit different data-sizes. \r\nhttps://github.com/Project-MONAI/MONAI/blob/18a671a7f12389dd8263a4c2232196dcca814bb9/monai/networks/nets/autoencoder.py#L90\r\n\r\n**Describe the solution you'd like**\r\nI would like to propose adding a padding argument to the AutoEncoder class constructor. This would allow users to specify the padding strategy when instantiating the model. \r\n\r\n**Describe alternatives you've considered**\r\nAn alternative solution could be to create a subclass of AutoEncoder (like CustomAE) whenever a different padding strategy is needed. See below,\r\n```{python}\r\nclass CustomAE(AutoEncoder):\r\n def __init__(self, padding, **kwargs):\r\n self.padding = padding\r\n super().__init__(**kwargs)\r\n \r\n def _get_encode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Module:\r\n # ...\r\n mod = Convolution(\r\n spatial_dims=self.dimensions,\r\n in_channels=in_channels,\r\n out_channels=out_channels,\r\n strides=strides,\r\n kernel_size=self.kernel_size,\r\n padding=self.padding,\r\n # ...\r\n )\r\n return mod\r\n\r\n```\r\n\n", "before_files": [{"content": "# Copyright (c) MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import annotations\n\nfrom collections.abc import Sequence\nfrom typing import Any\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.networks.blocks import Convolution, ResidualUnit\nfrom monai.networks.layers.factories import Act, Norm\n\n__all__ = [\"AutoEncoder\"]\n\n\nclass AutoEncoder(nn.Module):\n \"\"\"\n Simple definition of an autoencoder and base class for the architecture implementing\n :py:class:`monai.networks.nets.VarAutoEncoder`. The network is composed of an encode sequence of blocks, followed\n by an intermediary sequence of blocks, and finally a decode sequence of blocks. The encode and decode blocks are\n default :py:class:`monai.networks.blocks.Convolution` instances with the encode blocks having the given stride\n and the decode blocks having transpose convolutions with the same stride. If `num_res_units` is given residual\n blocks are used instead.\n\n By default the intermediary sequence is empty but if `inter_channels` is given to specify the output channels of\n blocks then this will be become a sequence of Convolution blocks or of residual blocks if `num_inter_units` is\n given. The optional parameter `inter_dilations` can be used to specify the dilation values of the convolutions in\n these blocks, this allows a network to use dilated kernels in this middle section. Since the intermediary section\n isn't meant to change the size of the output the strides for all these kernels is 1.\n\n Args:\n spatial_dims: number of spatial dimensions.\n in_channels: number of input channels.\n out_channels: number of output channels.\n channels: sequence of channels. Top block first. The length of `channels` should be no less than 2.\n strides: sequence of convolution strides. The length of `stride` should equal to `len(channels) - 1`.\n kernel_size: convolution kernel size, the value(s) should be odd. If sequence,\n its length should equal to dimensions. Defaults to 3.\n up_kernel_size: upsampling convolution kernel size, the value(s) should be odd. If sequence,\n its length should equal to dimensions. Defaults to 3.\n num_res_units: number of residual units. Defaults to 0.\n inter_channels: sequence of channels defining the blocks in the intermediate layer between encode and decode.\n inter_dilations: defines the dilation value for each block of the intermediate layer. Defaults to 1.\n num_inter_units: number of residual units for each block of the intermediate layer. Defaults to 0.\n act: activation type and arguments. Defaults to PReLU.\n norm: feature normalization type and arguments. Defaults to instance norm.\n dropout: dropout ratio. Defaults to no dropout.\n bias: whether to have a bias term in convolution blocks. Defaults to True.\n According to `Performance Tuning Guide <https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html>`_,\n if a conv layer is directly followed by a batch norm layer, bias should be False.\n\n Examples::\n\n from monai.networks.nets import AutoEncoder\n\n # 3 layers each down/up sampling their inputs by a factor 2 with no intermediate layer\n net = AutoEncoder(\n spatial_dims=2,\n in_channels=1,\n out_channels=1,\n channels=(2, 4, 8),\n strides=(2, 2, 2)\n )\n\n # 1 layer downsampling by 2, followed by a sequence of residual units with 2 convolutions defined by\n # progressively increasing dilations, then final upsample layer\n net = AutoEncoder(\n spatial_dims=2,\n in_channels=1,\n out_channels=1,\n channels=(4,),\n strides=(2,),\n inter_channels=(8, 8, 8),\n inter_dilations=(1, 2, 4),\n num_inter_units=2\n )\n\n \"\"\"\n\n def __init__(\n self,\n spatial_dims: int,\n in_channels: int,\n out_channels: int,\n channels: Sequence[int],\n strides: Sequence[int],\n kernel_size: Sequence[int] | int = 3,\n up_kernel_size: Sequence[int] | int = 3,\n num_res_units: int = 0,\n inter_channels: list | None = None,\n inter_dilations: list | None = None,\n num_inter_units: int = 2,\n act: tuple | str | None = Act.PRELU,\n norm: tuple | str = Norm.INSTANCE,\n dropout: tuple | str | float | None = None,\n bias: bool = True,\n ) -> None:\n super().__init__()\n self.dimensions = spatial_dims\n self.in_channels = in_channels\n self.out_channels = out_channels\n self.channels = list(channels)\n self.strides = list(strides)\n self.kernel_size = kernel_size\n self.up_kernel_size = up_kernel_size\n self.num_res_units = num_res_units\n self.act = act\n self.norm = norm\n self.dropout = dropout\n self.bias = bias\n self.num_inter_units = num_inter_units\n self.inter_channels = inter_channels if inter_channels is not None else []\n self.inter_dilations = list(inter_dilations or [1] * len(self.inter_channels))\n\n # The number of channels and strides should match\n if len(channels) != len(strides):\n raise ValueError(\"Autoencoder expects matching number of channels and strides\")\n\n self.encoded_channels = in_channels\n decode_channel_list = list(channels[-2::-1]) + [out_channels]\n\n self.encode, self.encoded_channels = self._get_encode_module(self.encoded_channels, channels, strides)\n self.intermediate, self.encoded_channels = self._get_intermediate_module(self.encoded_channels, num_inter_units)\n self.decode, _ = self._get_decode_module(self.encoded_channels, decode_channel_list, strides[::-1] or [1])\n\n def _get_encode_module(\n self, in_channels: int, channels: Sequence[int], strides: Sequence[int]\n ) -> tuple[nn.Sequential, int]:\n \"\"\"\n Returns the encode part of the network by building up a sequence of layers returned by `_get_encode_layer`.\n \"\"\"\n encode = nn.Sequential()\n layer_channels = in_channels\n\n for i, (c, s) in enumerate(zip(channels, strides)):\n layer = self._get_encode_layer(layer_channels, c, s, False)\n encode.add_module(\"encode_%i\" % i, layer)\n layer_channels = c\n\n return encode, layer_channels\n\n def _get_intermediate_module(self, in_channels: int, num_inter_units: int) -> tuple[nn.Module, int]:\n \"\"\"\n Returns the intermediate block of the network which accepts input from the encoder and whose output goes\n to the decoder.\n \"\"\"\n # Define some types\n intermediate: nn.Module\n unit: nn.Module\n\n intermediate = nn.Identity()\n layer_channels = in_channels\n\n if self.inter_channels:\n intermediate = nn.Sequential()\n\n for i, (dc, di) in enumerate(zip(self.inter_channels, self.inter_dilations)):\n if self.num_inter_units > 0:\n unit = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=layer_channels,\n out_channels=dc,\n strides=1,\n kernel_size=self.kernel_size,\n subunits=self.num_inter_units,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n )\n else:\n unit = Convolution(\n spatial_dims=self.dimensions,\n in_channels=layer_channels,\n out_channels=dc,\n strides=1,\n kernel_size=self.kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n )\n\n intermediate.add_module(\"inter_%i\" % i, unit)\n layer_channels = dc\n\n return intermediate, layer_channels\n\n def _get_decode_module(\n self, in_channels: int, channels: Sequence[int], strides: Sequence[int]\n ) -> tuple[nn.Sequential, int]:\n \"\"\"\n Returns the decode part of the network by building up a sequence of layers returned by `_get_decode_layer`.\n \"\"\"\n decode = nn.Sequential()\n layer_channels = in_channels\n\n for i, (c, s) in enumerate(zip(channels, strides)):\n layer = self._get_decode_layer(layer_channels, c, s, i == (len(strides) - 1))\n decode.add_module(\"decode_%i\" % i, layer)\n layer_channels = c\n\n return decode, layer_channels\n\n def _get_encode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Module:\n \"\"\"\n Returns a single layer of the encoder part of the network.\n \"\"\"\n mod: nn.Module\n if self.num_res_units > 0:\n mod = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n subunits=self.num_res_units,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n last_conv_only=is_last,\n )\n return mod\n mod = Convolution(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n conv_only=is_last,\n )\n return mod\n\n def _get_decode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Sequential:\n \"\"\"\n Returns a single layer of the decoder part of the network.\n \"\"\"\n decode = nn.Sequential()\n\n conv = Convolution(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.up_kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n conv_only=is_last and self.num_res_units == 0,\n is_transposed=True,\n )\n\n decode.add_module(\"conv\", conv)\n\n if self.num_res_units > 0:\n ru = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=out_channels,\n out_channels=out_channels,\n strides=1,\n kernel_size=self.kernel_size,\n subunits=1,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n last_conv_only=is_last,\n )\n\n decode.add_module(\"resunit\", ru)\n\n return decode\n\n def forward(self, x: torch.Tensor) -> Any:\n x = self.encode(x)\n x = self.intermediate(x)\n x = self.decode(x)\n return x\n", "path": "monai/networks/nets/autoencoder.py"}], "after_files": [{"content": "# Copyright (c) MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import annotations\n\nfrom collections.abc import Sequence\nfrom typing import Any\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.networks.blocks import Convolution, ResidualUnit\nfrom monai.networks.layers.factories import Act, Norm\n\n__all__ = [\"AutoEncoder\"]\n\n\nclass AutoEncoder(nn.Module):\n \"\"\"\n Simple definition of an autoencoder and base class for the architecture implementing\n :py:class:`monai.networks.nets.VarAutoEncoder`. The network is composed of an encode sequence of blocks, followed\n by an intermediary sequence of blocks, and finally a decode sequence of blocks. The encode and decode blocks are\n default :py:class:`monai.networks.blocks.Convolution` instances with the encode blocks having the given stride\n and the decode blocks having transpose convolutions with the same stride. If `num_res_units` is given residual\n blocks are used instead.\n\n By default the intermediary sequence is empty but if `inter_channels` is given to specify the output channels of\n blocks then this will be become a sequence of Convolution blocks or of residual blocks if `num_inter_units` is\n given. The optional parameter `inter_dilations` can be used to specify the dilation values of the convolutions in\n these blocks, this allows a network to use dilated kernels in this middle section. Since the intermediary section\n isn't meant to change the size of the output the strides for all these kernels is 1.\n\n Args:\n spatial_dims: number of spatial dimensions.\n in_channels: number of input channels.\n out_channels: number of output channels.\n channels: sequence of channels. Top block first. The length of `channels` should be no less than 2.\n strides: sequence of convolution strides. The length of `stride` should equal to `len(channels) - 1`.\n kernel_size: convolution kernel size, the value(s) should be odd. If sequence,\n its length should equal to dimensions. Defaults to 3.\n up_kernel_size: upsampling convolution kernel size, the value(s) should be odd. If sequence,\n its length should equal to dimensions. Defaults to 3.\n num_res_units: number of residual units. Defaults to 0.\n inter_channels: sequence of channels defining the blocks in the intermediate layer between encode and decode.\n inter_dilations: defines the dilation value for each block of the intermediate layer. Defaults to 1.\n num_inter_units: number of residual units for each block of the intermediate layer. Defaults to 0.\n act: activation type and arguments. Defaults to PReLU.\n norm: feature normalization type and arguments. Defaults to instance norm.\n dropout: dropout ratio. Defaults to no dropout.\n bias: whether to have a bias term in convolution blocks. Defaults to True.\n According to `Performance Tuning Guide <https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html>`_,\n if a conv layer is directly followed by a batch norm layer, bias should be False.\n padding: controls the amount of implicit zero-paddings on both sides for padding number of points\n for each dimension in convolution blocks. Defaults to None.\n\n Examples::\n\n from monai.networks.nets import AutoEncoder\n\n # 3 layers each down/up sampling their inputs by a factor 2 with no intermediate layer\n net = AutoEncoder(\n spatial_dims=2,\n in_channels=1,\n out_channels=1,\n channels=(2, 4, 8),\n strides=(2, 2, 2)\n )\n\n # 1 layer downsampling by 2, followed by a sequence of residual units with 2 convolutions defined by\n # progressively increasing dilations, then final upsample layer\n net = AutoEncoder(\n spatial_dims=2,\n in_channels=1,\n out_channels=1,\n channels=(4,),\n strides=(2,),\n inter_channels=(8, 8, 8),\n inter_dilations=(1, 2, 4),\n num_inter_units=2\n )\n\n \"\"\"\n\n def __init__(\n self,\n spatial_dims: int,\n in_channels: int,\n out_channels: int,\n channels: Sequence[int],\n strides: Sequence[int],\n kernel_size: Sequence[int] | int = 3,\n up_kernel_size: Sequence[int] | int = 3,\n num_res_units: int = 0,\n inter_channels: list | None = None,\n inter_dilations: list | None = None,\n num_inter_units: int = 2,\n act: tuple | str | None = Act.PRELU,\n norm: tuple | str = Norm.INSTANCE,\n dropout: tuple | str | float | None = None,\n bias: bool = True,\n padding: Sequence[int] | int | None = None,\n ) -> None:\n super().__init__()\n self.dimensions = spatial_dims\n self.in_channels = in_channels\n self.out_channels = out_channels\n self.channels = list(channels)\n self.strides = list(strides)\n self.kernel_size = kernel_size\n self.up_kernel_size = up_kernel_size\n self.num_res_units = num_res_units\n self.act = act\n self.norm = norm\n self.dropout = dropout\n self.bias = bias\n self.padding = padding\n self.num_inter_units = num_inter_units\n self.inter_channels = inter_channels if inter_channels is not None else []\n self.inter_dilations = list(inter_dilations or [1] * len(self.inter_channels))\n\n # The number of channels and strides should match\n if len(channels) != len(strides):\n raise ValueError(\"Autoencoder expects matching number of channels and strides\")\n\n self.encoded_channels = in_channels\n decode_channel_list = list(channels[-2::-1]) + [out_channels]\n\n self.encode, self.encoded_channels = self._get_encode_module(self.encoded_channels, channels, strides)\n self.intermediate, self.encoded_channels = self._get_intermediate_module(self.encoded_channels, num_inter_units)\n self.decode, _ = self._get_decode_module(self.encoded_channels, decode_channel_list, strides[::-1] or [1])\n\n def _get_encode_module(\n self, in_channels: int, channels: Sequence[int], strides: Sequence[int]\n ) -> tuple[nn.Sequential, int]:\n \"\"\"\n Returns the encode part of the network by building up a sequence of layers returned by `_get_encode_layer`.\n \"\"\"\n encode = nn.Sequential()\n layer_channels = in_channels\n\n for i, (c, s) in enumerate(zip(channels, strides)):\n layer = self._get_encode_layer(layer_channels, c, s, False)\n encode.add_module(\"encode_%i\" % i, layer)\n layer_channels = c\n\n return encode, layer_channels\n\n def _get_intermediate_module(self, in_channels: int, num_inter_units: int) -> tuple[nn.Module, int]:\n \"\"\"\n Returns the intermediate block of the network which accepts input from the encoder and whose output goes\n to the decoder.\n \"\"\"\n # Define some types\n intermediate: nn.Module\n unit: nn.Module\n\n intermediate = nn.Identity()\n layer_channels = in_channels\n\n if self.inter_channels:\n intermediate = nn.Sequential()\n\n for i, (dc, di) in enumerate(zip(self.inter_channels, self.inter_dilations)):\n if self.num_inter_units > 0:\n unit = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=layer_channels,\n out_channels=dc,\n strides=1,\n kernel_size=self.kernel_size,\n subunits=self.num_inter_units,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n padding=self.padding,\n )\n else:\n unit = Convolution(\n spatial_dims=self.dimensions,\n in_channels=layer_channels,\n out_channels=dc,\n strides=1,\n kernel_size=self.kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n dilation=di,\n bias=self.bias,\n padding=self.padding,\n )\n\n intermediate.add_module(\"inter_%i\" % i, unit)\n layer_channels = dc\n\n return intermediate, layer_channels\n\n def _get_decode_module(\n self, in_channels: int, channels: Sequence[int], strides: Sequence[int]\n ) -> tuple[nn.Sequential, int]:\n \"\"\"\n Returns the decode part of the network by building up a sequence of layers returned by `_get_decode_layer`.\n \"\"\"\n decode = nn.Sequential()\n layer_channels = in_channels\n\n for i, (c, s) in enumerate(zip(channels, strides)):\n layer = self._get_decode_layer(layer_channels, c, s, i == (len(strides) - 1))\n decode.add_module(\"decode_%i\" % i, layer)\n layer_channels = c\n\n return decode, layer_channels\n\n def _get_encode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Module:\n \"\"\"\n Returns a single layer of the encoder part of the network.\n \"\"\"\n mod: nn.Module\n if self.num_res_units > 0:\n mod = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n subunits=self.num_res_units,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n padding=self.padding,\n last_conv_only=is_last,\n )\n return mod\n mod = Convolution(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n padding=self.padding,\n conv_only=is_last,\n )\n return mod\n\n def _get_decode_layer(self, in_channels: int, out_channels: int, strides: int, is_last: bool) -> nn.Sequential:\n \"\"\"\n Returns a single layer of the decoder part of the network.\n \"\"\"\n decode = nn.Sequential()\n\n conv = Convolution(\n spatial_dims=self.dimensions,\n in_channels=in_channels,\n out_channels=out_channels,\n strides=strides,\n kernel_size=self.up_kernel_size,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n padding=self.padding,\n conv_only=is_last and self.num_res_units == 0,\n is_transposed=True,\n )\n\n decode.add_module(\"conv\", conv)\n\n if self.num_res_units > 0:\n ru = ResidualUnit(\n spatial_dims=self.dimensions,\n in_channels=out_channels,\n out_channels=out_channels,\n strides=1,\n kernel_size=self.kernel_size,\n subunits=1,\n act=self.act,\n norm=self.norm,\n dropout=self.dropout,\n bias=self.bias,\n padding=self.padding,\n last_conv_only=is_last,\n )\n\n decode.add_module(\"resunit\", ru)\n\n return decode\n\n def forward(self, x: torch.Tensor) -> Any:\n x = self.encode(x)\n x = self.intermediate(x)\n x = self.decode(x)\n return x\n", "path": "monai/networks/nets/autoencoder.py"}]}
| 3,879 | 621 |
gh_patches_debug_21997
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2564
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MetricReaders must be registered in only one MeterProvider instance
From the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/sdk.md#metricreader):
> The SDK MUST NOT allow a MetricReader instance to be registered on more than one MeterProvider instance.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from atexit import register, unregister
16 from logging import getLogger
17 from threading import Lock
18 from typing import Optional, Sequence
19
20 from opentelemetry._metrics import Meter as APIMeter
21 from opentelemetry._metrics import MeterProvider as APIMeterProvider
22 from opentelemetry._metrics import NoOpMeter
23 from opentelemetry._metrics.instrument import Counter as APICounter
24 from opentelemetry._metrics.instrument import Histogram as APIHistogram
25 from opentelemetry._metrics.instrument import (
26 ObservableCounter as APIObservableCounter,
27 )
28 from opentelemetry._metrics.instrument import (
29 ObservableGauge as APIObservableGauge,
30 )
31 from opentelemetry._metrics.instrument import (
32 ObservableUpDownCounter as APIObservableUpDownCounter,
33 )
34 from opentelemetry._metrics.instrument import UpDownCounter as APIUpDownCounter
35 from opentelemetry.sdk._metrics.instrument import (
36 Counter,
37 Histogram,
38 ObservableCounter,
39 ObservableGauge,
40 ObservableUpDownCounter,
41 UpDownCounter,
42 )
43 from opentelemetry.sdk._metrics.measurement_consumer import (
44 MeasurementConsumer,
45 SynchronousMeasurementConsumer,
46 )
47 from opentelemetry.sdk._metrics.metric_reader import MetricReader
48 from opentelemetry.sdk._metrics.sdk_configuration import SdkConfiguration
49 from opentelemetry.sdk._metrics.view import View
50 from opentelemetry.sdk.resources import Resource
51 from opentelemetry.sdk.util.instrumentation import InstrumentationInfo
52 from opentelemetry.util._once import Once
53
54 _logger = getLogger(__name__)
55
56
57 class Meter(APIMeter):
58 def __init__(
59 self,
60 instrumentation_info: InstrumentationInfo,
61 measurement_consumer: MeasurementConsumer,
62 ):
63 super().__init__(instrumentation_info)
64 self._instrumentation_info = instrumentation_info
65 self._measurement_consumer = measurement_consumer
66
67 def create_counter(self, name, unit=None, description=None) -> APICounter:
68 return Counter(
69 name,
70 self._instrumentation_info,
71 self._measurement_consumer,
72 unit,
73 description,
74 )
75
76 def create_up_down_counter(
77 self, name, unit=None, description=None
78 ) -> APIUpDownCounter:
79 return UpDownCounter(
80 name,
81 self._instrumentation_info,
82 self._measurement_consumer,
83 unit,
84 description,
85 )
86
87 def create_observable_counter(
88 self, name, callback, unit=None, description=None
89 ) -> APIObservableCounter:
90
91 instrument = ObservableCounter(
92 name,
93 self._instrumentation_info,
94 self._measurement_consumer,
95 callback,
96 unit,
97 description,
98 )
99
100 self._measurement_consumer.register_asynchronous_instrument(instrument)
101
102 return instrument
103
104 def create_histogram(
105 self, name, unit=None, description=None
106 ) -> APIHistogram:
107 return Histogram(
108 name,
109 self._instrumentation_info,
110 self._measurement_consumer,
111 unit,
112 description,
113 )
114
115 def create_observable_gauge(
116 self, name, callback, unit=None, description=None
117 ) -> APIObservableGauge:
118
119 instrument = ObservableGauge(
120 name,
121 self._instrumentation_info,
122 self._measurement_consumer,
123 callback,
124 unit,
125 description,
126 )
127
128 self._measurement_consumer.register_asynchronous_instrument(instrument)
129
130 return instrument
131
132 def create_observable_up_down_counter(
133 self, name, callback, unit=None, description=None
134 ) -> APIObservableUpDownCounter:
135
136 instrument = ObservableUpDownCounter(
137 name,
138 self._instrumentation_info,
139 self._measurement_consumer,
140 callback,
141 unit,
142 description,
143 )
144
145 self._measurement_consumer.register_asynchronous_instrument(instrument)
146
147 return instrument
148
149
150 class MeterProvider(APIMeterProvider):
151 r"""See `opentelemetry._metrics.MeterProvider`.
152
153 Args:
154 metric_readers: Register metric readers to collect metrics from the SDK on demand. Each
155 `MetricReader` is completely independent and will collect separate streams of
156 metrics. TODO: reference ``PeriodicExportingMetricReader`` usage with push
157 exporters here.
158 resource: The resource representing what the metrics emitted from the SDK pertain to.
159 shutdown_on_exit: If true, registers an `atexit` handler to call
160 `MeterProvider.shutdown`
161 views: The views to configure the metric output the SDK
162
163 By default, instruments which do not match any `View` (or if no `View`\ s are provided)
164 will report metrics with the default aggregation for the instrument's kind. To disable
165 instruments by default, configure a match-all `View` with `DropAggregation` and then create
166 `View`\ s to re-enable individual instruments:
167
168 .. code-block:: python
169 :caption: Disable default views
170
171 MeterProvider(
172 views=[
173 View(instrument_name="*", aggregation=DropAggregation()),
174 View(instrument_name="mycounter"),
175 ],
176 # ...
177 )
178 """
179
180 def __init__(
181 self,
182 metric_readers: Sequence[MetricReader] = (),
183 resource: Resource = Resource.create({}),
184 shutdown_on_exit: bool = True,
185 views: Sequence[View] = (),
186 ):
187 self._lock = Lock()
188 self._meter_lock = Lock()
189 self._atexit_handler = None
190 self._sdk_config = SdkConfiguration(
191 resource=resource,
192 metric_readers=metric_readers,
193 views=views,
194 )
195 self._measurement_consumer = SynchronousMeasurementConsumer(
196 sdk_config=self._sdk_config
197 )
198
199 if shutdown_on_exit:
200 self._atexit_handler = register(self.shutdown)
201
202 self._meters = {}
203 self._metric_readers = metric_readers
204
205 for metric_reader in self._sdk_config.metric_readers:
206 metric_reader._set_collect_callback(
207 self._measurement_consumer.collect
208 )
209
210 self._shutdown_once = Once()
211 self._shutdown = False
212
213 def force_flush(self) -> bool:
214
215 # FIXME implement a timeout
216
217 for metric_reader in self._sdk_config.metric_readers:
218 metric_reader.collect()
219 return True
220
221 def shutdown(self):
222 # FIXME implement a timeout
223
224 def _shutdown():
225 self._shutdown = True
226
227 did_shutdown = self._shutdown_once.do_once(_shutdown)
228
229 if not did_shutdown:
230 _logger.warning("shutdown can only be called once")
231 return False
232
233 overall_result = True
234
235 for metric_reader in self._sdk_config.metric_readers:
236 metric_reader_result = metric_reader.shutdown()
237
238 if not metric_reader_result:
239 _logger.warning(
240 "MetricReader %s failed to shutdown", metric_reader
241 )
242
243 overall_result = overall_result and metric_reader_result
244
245 if self._atexit_handler is not None:
246 unregister(self._atexit_handler)
247 self._atexit_handler = None
248
249 return overall_result
250
251 def get_meter(
252 self,
253 name: str,
254 version: Optional[str] = None,
255 schema_url: Optional[str] = None,
256 ) -> Meter:
257
258 if self._shutdown:
259 _logger.warning(
260 "A shutdown `MeterProvider` can not provide a `Meter`"
261 )
262 return NoOpMeter(name, version=version, schema_url=schema_url)
263
264 if not name:
265 _logger.warning("Meter name cannot be None or empty.")
266 return NoOpMeter(name, version=version, schema_url=schema_url)
267
268 info = InstrumentationInfo(name, version, schema_url)
269 with self._meter_lock:
270 if not self._meters.get(info):
271 self._meters[info] = Meter(
272 info,
273 self._measurement_consumer,
274 )
275 return self._meters[info]
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py
@@ -177,6 +177,9 @@
)
"""
+ _all_metric_readers_lock = Lock()
+ _all_metric_readers = set()
+
def __init__(
self,
metric_readers: Sequence[MetricReader] = (),
@@ -200,9 +203,18 @@
self._atexit_handler = register(self.shutdown)
self._meters = {}
- self._metric_readers = metric_readers
for metric_reader in self._sdk_config.metric_readers:
+
+ with self._all_metric_readers_lock:
+ if metric_reader in self._all_metric_readers:
+ raise Exception(
+ f"MetricReader {metric_reader} has been registered "
+ "already in other MeterProvider instance"
+ )
+
+ self._all_metric_readers.add(metric_reader)
+
metric_reader._set_collect_callback(
self._measurement_consumer.collect
)
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py\n@@ -177,6 +177,9 @@\n )\n \"\"\"\n \n+ _all_metric_readers_lock = Lock()\n+ _all_metric_readers = set()\n+\n def __init__(\n self,\n metric_readers: Sequence[MetricReader] = (),\n@@ -200,9 +203,18 @@\n self._atexit_handler = register(self.shutdown)\n \n self._meters = {}\n- self._metric_readers = metric_readers\n \n for metric_reader in self._sdk_config.metric_readers:\n+\n+ with self._all_metric_readers_lock:\n+ if metric_reader in self._all_metric_readers:\n+ raise Exception(\n+ f\"MetricReader {metric_reader} has been registered \"\n+ \"already in other MeterProvider instance\"\n+ )\n+\n+ self._all_metric_readers.add(metric_reader)\n+\n metric_reader._set_collect_callback(\n self._measurement_consumer.collect\n )\n", "issue": "MetricReaders must be registered in only one MeterProvider instance\nFrom the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/sdk.md#metricreader):\r\n\r\n> The SDK MUST NOT allow a MetricReader instance to be registered on more than one MeterProvider instance.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom atexit import register, unregister\nfrom logging import getLogger\nfrom threading import Lock\nfrom typing import Optional, Sequence\n\nfrom opentelemetry._metrics import Meter as APIMeter\nfrom opentelemetry._metrics import MeterProvider as APIMeterProvider\nfrom opentelemetry._metrics import NoOpMeter\nfrom opentelemetry._metrics.instrument import Counter as APICounter\nfrom opentelemetry._metrics.instrument import Histogram as APIHistogram\nfrom opentelemetry._metrics.instrument import (\n ObservableCounter as APIObservableCounter,\n)\nfrom opentelemetry._metrics.instrument import (\n ObservableGauge as APIObservableGauge,\n)\nfrom opentelemetry._metrics.instrument import (\n ObservableUpDownCounter as APIObservableUpDownCounter,\n)\nfrom opentelemetry._metrics.instrument import UpDownCounter as APIUpDownCounter\nfrom opentelemetry.sdk._metrics.instrument import (\n Counter,\n Histogram,\n ObservableCounter,\n ObservableGauge,\n ObservableUpDownCounter,\n UpDownCounter,\n)\nfrom opentelemetry.sdk._metrics.measurement_consumer import (\n MeasurementConsumer,\n SynchronousMeasurementConsumer,\n)\nfrom opentelemetry.sdk._metrics.metric_reader import MetricReader\nfrom opentelemetry.sdk._metrics.sdk_configuration import SdkConfiguration\nfrom opentelemetry.sdk._metrics.view import View\nfrom opentelemetry.sdk.resources import Resource\nfrom opentelemetry.sdk.util.instrumentation import InstrumentationInfo\nfrom opentelemetry.util._once import Once\n\n_logger = getLogger(__name__)\n\n\nclass Meter(APIMeter):\n def __init__(\n self,\n instrumentation_info: InstrumentationInfo,\n measurement_consumer: MeasurementConsumer,\n ):\n super().__init__(instrumentation_info)\n self._instrumentation_info = instrumentation_info\n self._measurement_consumer = measurement_consumer\n\n def create_counter(self, name, unit=None, description=None) -> APICounter:\n return Counter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_up_down_counter(\n self, name, unit=None, description=None\n ) -> APIUpDownCounter:\n return UpDownCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_observable_counter(\n self, name, callback, unit=None, description=None\n ) -> APIObservableCounter:\n\n instrument = ObservableCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n def create_histogram(\n self, name, unit=None, description=None\n ) -> APIHistogram:\n return Histogram(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_observable_gauge(\n self, name, callback, unit=None, description=None\n ) -> APIObservableGauge:\n\n instrument = ObservableGauge(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n def create_observable_up_down_counter(\n self, name, callback, unit=None, description=None\n ) -> APIObservableUpDownCounter:\n\n instrument = ObservableUpDownCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n\nclass MeterProvider(APIMeterProvider):\n r\"\"\"See `opentelemetry._metrics.MeterProvider`.\n\n Args:\n metric_readers: Register metric readers to collect metrics from the SDK on demand. Each\n `MetricReader` is completely independent and will collect separate streams of\n metrics. TODO: reference ``PeriodicExportingMetricReader`` usage with push\n exporters here.\n resource: The resource representing what the metrics emitted from the SDK pertain to.\n shutdown_on_exit: If true, registers an `atexit` handler to call\n `MeterProvider.shutdown`\n views: The views to configure the metric output the SDK\n\n By default, instruments which do not match any `View` (or if no `View`\\ s are provided)\n will report metrics with the default aggregation for the instrument's kind. To disable\n instruments by default, configure a match-all `View` with `DropAggregation` and then create\n `View`\\ s to re-enable individual instruments:\n\n .. code-block:: python\n :caption: Disable default views\n\n MeterProvider(\n views=[\n View(instrument_name=\"*\", aggregation=DropAggregation()),\n View(instrument_name=\"mycounter\"),\n ],\n # ...\n )\n \"\"\"\n\n def __init__(\n self,\n metric_readers: Sequence[MetricReader] = (),\n resource: Resource = Resource.create({}),\n shutdown_on_exit: bool = True,\n views: Sequence[View] = (),\n ):\n self._lock = Lock()\n self._meter_lock = Lock()\n self._atexit_handler = None\n self._sdk_config = SdkConfiguration(\n resource=resource,\n metric_readers=metric_readers,\n views=views,\n )\n self._measurement_consumer = SynchronousMeasurementConsumer(\n sdk_config=self._sdk_config\n )\n\n if shutdown_on_exit:\n self._atexit_handler = register(self.shutdown)\n\n self._meters = {}\n self._metric_readers = metric_readers\n\n for metric_reader in self._sdk_config.metric_readers:\n metric_reader._set_collect_callback(\n self._measurement_consumer.collect\n )\n\n self._shutdown_once = Once()\n self._shutdown = False\n\n def force_flush(self) -> bool:\n\n # FIXME implement a timeout\n\n for metric_reader in self._sdk_config.metric_readers:\n metric_reader.collect()\n return True\n\n def shutdown(self):\n # FIXME implement a timeout\n\n def _shutdown():\n self._shutdown = True\n\n did_shutdown = self._shutdown_once.do_once(_shutdown)\n\n if not did_shutdown:\n _logger.warning(\"shutdown can only be called once\")\n return False\n\n overall_result = True\n\n for metric_reader in self._sdk_config.metric_readers:\n metric_reader_result = metric_reader.shutdown()\n\n if not metric_reader_result:\n _logger.warning(\n \"MetricReader %s failed to shutdown\", metric_reader\n )\n\n overall_result = overall_result and metric_reader_result\n\n if self._atexit_handler is not None:\n unregister(self._atexit_handler)\n self._atexit_handler = None\n\n return overall_result\n\n def get_meter(\n self,\n name: str,\n version: Optional[str] = None,\n schema_url: Optional[str] = None,\n ) -> Meter:\n\n if self._shutdown:\n _logger.warning(\n \"A shutdown `MeterProvider` can not provide a `Meter`\"\n )\n return NoOpMeter(name, version=version, schema_url=schema_url)\n\n if not name:\n _logger.warning(\"Meter name cannot be None or empty.\")\n return NoOpMeter(name, version=version, schema_url=schema_url)\n\n info = InstrumentationInfo(name, version, schema_url)\n with self._meter_lock:\n if not self._meters.get(info):\n self._meters[info] = Meter(\n info,\n self._measurement_consumer,\n )\n return self._meters[info]\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom atexit import register, unregister\nfrom logging import getLogger\nfrom threading import Lock\nfrom typing import Optional, Sequence\n\nfrom opentelemetry._metrics import Meter as APIMeter\nfrom opentelemetry._metrics import MeterProvider as APIMeterProvider\nfrom opentelemetry._metrics import NoOpMeter\nfrom opentelemetry._metrics.instrument import Counter as APICounter\nfrom opentelemetry._metrics.instrument import Histogram as APIHistogram\nfrom opentelemetry._metrics.instrument import (\n ObservableCounter as APIObservableCounter,\n)\nfrom opentelemetry._metrics.instrument import (\n ObservableGauge as APIObservableGauge,\n)\nfrom opentelemetry._metrics.instrument import (\n ObservableUpDownCounter as APIObservableUpDownCounter,\n)\nfrom opentelemetry._metrics.instrument import UpDownCounter as APIUpDownCounter\nfrom opentelemetry.sdk._metrics.instrument import (\n Counter,\n Histogram,\n ObservableCounter,\n ObservableGauge,\n ObservableUpDownCounter,\n UpDownCounter,\n)\nfrom opentelemetry.sdk._metrics.measurement_consumer import (\n MeasurementConsumer,\n SynchronousMeasurementConsumer,\n)\nfrom opentelemetry.sdk._metrics.metric_reader import MetricReader\nfrom opentelemetry.sdk._metrics.sdk_configuration import SdkConfiguration\nfrom opentelemetry.sdk._metrics.view import View\nfrom opentelemetry.sdk.resources import Resource\nfrom opentelemetry.sdk.util.instrumentation import InstrumentationInfo\nfrom opentelemetry.util._once import Once\n\n_logger = getLogger(__name__)\n\n\nclass Meter(APIMeter):\n def __init__(\n self,\n instrumentation_info: InstrumentationInfo,\n measurement_consumer: MeasurementConsumer,\n ):\n super().__init__(instrumentation_info)\n self._instrumentation_info = instrumentation_info\n self._measurement_consumer = measurement_consumer\n\n def create_counter(self, name, unit=None, description=None) -> APICounter:\n return Counter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_up_down_counter(\n self, name, unit=None, description=None\n ) -> APIUpDownCounter:\n return UpDownCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_observable_counter(\n self, name, callback, unit=None, description=None\n ) -> APIObservableCounter:\n\n instrument = ObservableCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n def create_histogram(\n self, name, unit=None, description=None\n ) -> APIHistogram:\n return Histogram(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n unit,\n description,\n )\n\n def create_observable_gauge(\n self, name, callback, unit=None, description=None\n ) -> APIObservableGauge:\n\n instrument = ObservableGauge(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n def create_observable_up_down_counter(\n self, name, callback, unit=None, description=None\n ) -> APIObservableUpDownCounter:\n\n instrument = ObservableUpDownCounter(\n name,\n self._instrumentation_info,\n self._measurement_consumer,\n callback,\n unit,\n description,\n )\n\n self._measurement_consumer.register_asynchronous_instrument(instrument)\n\n return instrument\n\n\nclass MeterProvider(APIMeterProvider):\n r\"\"\"See `opentelemetry._metrics.MeterProvider`.\n\n Args:\n metric_readers: Register metric readers to collect metrics from the SDK on demand. Each\n `MetricReader` is completely independent and will collect separate streams of\n metrics. TODO: reference ``PeriodicExportingMetricReader`` usage with push\n exporters here.\n resource: The resource representing what the metrics emitted from the SDK pertain to.\n shutdown_on_exit: If true, registers an `atexit` handler to call\n `MeterProvider.shutdown`\n views: The views to configure the metric output the SDK\n\n By default, instruments which do not match any `View` (or if no `View`\\ s are provided)\n will report metrics with the default aggregation for the instrument's kind. To disable\n instruments by default, configure a match-all `View` with `DropAggregation` and then create\n `View`\\ s to re-enable individual instruments:\n\n .. code-block:: python\n :caption: Disable default views\n\n MeterProvider(\n views=[\n View(instrument_name=\"*\", aggregation=DropAggregation()),\n View(instrument_name=\"mycounter\"),\n ],\n # ...\n )\n \"\"\"\n\n _all_metric_readers_lock = Lock()\n _all_metric_readers = set()\n\n def __init__(\n self,\n metric_readers: Sequence[MetricReader] = (),\n resource: Resource = Resource.create({}),\n shutdown_on_exit: bool = True,\n views: Sequence[View] = (),\n ):\n self._lock = Lock()\n self._meter_lock = Lock()\n self._atexit_handler = None\n self._sdk_config = SdkConfiguration(\n resource=resource,\n metric_readers=metric_readers,\n views=views,\n )\n self._measurement_consumer = SynchronousMeasurementConsumer(\n sdk_config=self._sdk_config\n )\n\n if shutdown_on_exit:\n self._atexit_handler = register(self.shutdown)\n\n self._meters = {}\n\n for metric_reader in self._sdk_config.metric_readers:\n\n with self._all_metric_readers_lock:\n if metric_reader in self._all_metric_readers:\n raise Exception(\n f\"MetricReader {metric_reader} has been registered \"\n \"already in other MeterProvider instance\"\n )\n\n self._all_metric_readers.add(metric_reader)\n\n metric_reader._set_collect_callback(\n self._measurement_consumer.collect\n )\n\n self._shutdown_once = Once()\n self._shutdown = False\n\n def force_flush(self) -> bool:\n\n # FIXME implement a timeout\n\n for metric_reader in self._sdk_config.metric_readers:\n metric_reader.collect()\n return True\n\n def shutdown(self):\n # FIXME implement a timeout\n\n def _shutdown():\n self._shutdown = True\n\n did_shutdown = self._shutdown_once.do_once(_shutdown)\n\n if not did_shutdown:\n _logger.warning(\"shutdown can only be called once\")\n return False\n\n overall_result = True\n\n for metric_reader in self._sdk_config.metric_readers:\n metric_reader_result = metric_reader.shutdown()\n\n if not metric_reader_result:\n _logger.warning(\n \"MetricReader %s failed to shutdown\", metric_reader\n )\n\n overall_result = overall_result and metric_reader_result\n\n if self._atexit_handler is not None:\n unregister(self._atexit_handler)\n self._atexit_handler = None\n\n return overall_result\n\n def get_meter(\n self,\n name: str,\n version: Optional[str] = None,\n schema_url: Optional[str] = None,\n ) -> Meter:\n\n if self._shutdown:\n _logger.warning(\n \"A shutdown `MeterProvider` can not provide a `Meter`\"\n )\n return NoOpMeter(name, version=version, schema_url=schema_url)\n\n if not name:\n _logger.warning(\"Meter name cannot be None or empty.\")\n return NoOpMeter(name, version=version, schema_url=schema_url)\n\n info = InstrumentationInfo(name, version, schema_url)\n with self._meter_lock:\n if not self._meters.get(info):\n self._meters[info] = Meter(\n info,\n self._measurement_consumer,\n )\n return self._meters[info]\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_metrics/__init__.py"}]}
| 2,820 | 280 |
gh_patches_debug_28331
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-4113
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
testing 5024: missing location label
**URL:** https://meinberlin-dev.liqd.net/projekte/burgerhaushalt-spandau/?mode=list
**user:** any
**expected behaviour:**
**behaviour:** location label (Bezeichnung des markierten Ortes) is missing
**important screensize:**
**device & browser:**
**Comment/Question:** maybe we need a smaller char restriction here? it's at 255 now, I wonder if something like 50 should be enough for something displayed as a tag? or continue with ... for longer words?
old list
<img width="446" alt="Bildschirmfoto 2021-12-21 um 16 35 27" src="https://user-images.githubusercontent.com/35491681/146956690-789f6d02-372c-4877-a4c9-c539b5fc90c3.png">
new list
<img width="446" alt="Bildschirmfoto 2021-12-21 um 16 34 09" src="https://user-images.githubusercontent.com/35491681/146956491-2472f9f2-e90d-4975-88a8-fbe1a7012657.png">
old list with long label
<img width="656" alt="Bildschirmfoto 2021-12-21 um 16 36 09" src="https://user-images.githubusercontent.com/35491681/146956804-ced5b4b8-0da8-42fc-a17c-901fc86efe9b.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/budgeting/serializers.py`
Content:
```
1 from django.contrib.contenttypes.models import ContentType
2 from rest_framework import serializers
3
4 from adhocracy4.categories.models import Category
5 from meinberlin.apps.votes.models import TokenVote
6
7 from .models import Proposal
8
9
10 class CategoryField(serializers.Field):
11
12 def to_internal_value(self, category):
13 if category:
14 return Category.objects.get(pk=category)
15 else:
16 return None
17
18 def to_representation(self, category):
19 return {'id': category.pk, 'name': category.name}
20
21
22 class ProposalSerializer(serializers.ModelSerializer):
23
24 creator = serializers.SerializerMethodField()
25 comment_count = serializers.SerializerMethodField()
26 positive_rating_count = serializers.SerializerMethodField()
27 negative_rating_count = serializers.SerializerMethodField()
28 category = CategoryField()
29 url = serializers.SerializerMethodField()
30 moderator_feedback = serializers.SerializerMethodField()
31 session_token_voted = serializers.SerializerMethodField()
32
33 class Meta:
34 model = Proposal
35 fields = ('budget', 'category', 'comment_count', 'created', 'modified',
36 'creator', 'is_archived', 'name', 'negative_rating_count',
37 'positive_rating_count', 'url', 'pk', 'moderator_feedback',
38 'session_token_voted')
39 read_only_fields = ('budget', 'category', 'comment_count', 'created',
40 'modified', 'creator', 'is_archived', 'name',
41 'negative_rating_count', 'positive_rating_count',
42 'url', 'pk', 'moderator_feedback',
43 'session_token_voted')
44
45 def get_creator(self, proposal):
46 return proposal.creator.username
47
48 def get_comment_count(self, proposal):
49 if hasattr(proposal, 'comment_count'):
50 return proposal.comment_count
51 else:
52 return 0
53
54 def get_positive_rating_count(self, proposal):
55 if hasattr(proposal, 'positive_rating_count'):
56 return proposal.positive_rating_count
57 else:
58 return 0
59
60 def get_negative_rating_count(self, proposal):
61 if hasattr(proposal, 'negative_rating_count'):
62 return proposal.negative_rating_count
63 else:
64 return 0
65
66 def get_url(self, proposal):
67 return proposal.get_absolute_url()
68
69 def get_moderator_feedback(self, proposal):
70 if hasattr(proposal, 'moderator_feedback'):
71 return (proposal.moderator_feedback,
72 proposal.get_moderator_feedback_display())
73 else:
74 return None
75
76 def get_session_token_voted(self, proposal):
77 """Serialize if proposal has been voted.
78
79 Returns bool that indicates whether the proposal has
80 been voted with the token in the current session
81 """
82 if 'request' in self.context:
83 if 'voting_token' in self.context['request'].session:
84 vote = TokenVote.objects.filter(
85 token__pk=self.context['request'].session['voting_token'],
86 content_type=ContentType.objects.get_for_model(
87 proposal.__class__),
88 object_pk=proposal.pk
89 )
90 if vote.exists():
91 return True
92
93 return False
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/budgeting/serializers.py b/meinberlin/apps/budgeting/serializers.py
--- a/meinberlin/apps/budgeting/serializers.py
+++ b/meinberlin/apps/budgeting/serializers.py
@@ -35,12 +35,12 @@
fields = ('budget', 'category', 'comment_count', 'created', 'modified',
'creator', 'is_archived', 'name', 'negative_rating_count',
'positive_rating_count', 'url', 'pk', 'moderator_feedback',
- 'session_token_voted')
+ 'point_label', 'session_token_voted')
read_only_fields = ('budget', 'category', 'comment_count', 'created',
'modified', 'creator', 'is_archived', 'name',
'negative_rating_count', 'positive_rating_count',
'url', 'pk', 'moderator_feedback',
- 'session_token_voted')
+ 'point_label', 'session_token_voted')
def get_creator(self, proposal):
return proposal.creator.username
@@ -73,6 +73,12 @@
else:
return None
+ def get_point_label(self, proposal):
+ if hasattr(proposal, 'point_label'):
+ return (proposal.point_label)
+ else:
+ return None
+
def get_session_token_voted(self, proposal):
"""Serialize if proposal has been voted.
|
{"golden_diff": "diff --git a/meinberlin/apps/budgeting/serializers.py b/meinberlin/apps/budgeting/serializers.py\n--- a/meinberlin/apps/budgeting/serializers.py\n+++ b/meinberlin/apps/budgeting/serializers.py\n@@ -35,12 +35,12 @@\n fields = ('budget', 'category', 'comment_count', 'created', 'modified',\n 'creator', 'is_archived', 'name', 'negative_rating_count',\n 'positive_rating_count', 'url', 'pk', 'moderator_feedback',\n- 'session_token_voted')\n+ 'point_label', 'session_token_voted')\n read_only_fields = ('budget', 'category', 'comment_count', 'created',\n 'modified', 'creator', 'is_archived', 'name',\n 'negative_rating_count', 'positive_rating_count',\n 'url', 'pk', 'moderator_feedback',\n- 'session_token_voted')\n+ 'point_label', 'session_token_voted')\n \n def get_creator(self, proposal):\n return proposal.creator.username\n@@ -73,6 +73,12 @@\n else:\n return None\n \n+ def get_point_label(self, proposal):\n+ if hasattr(proposal, 'point_label'):\n+ return (proposal.point_label)\n+ else:\n+ return None\n+\n def get_session_token_voted(self, proposal):\n \"\"\"Serialize if proposal has been voted.\n", "issue": "testing 5024: missing location label\n**URL:** https://meinberlin-dev.liqd.net/projekte/burgerhaushalt-spandau/?mode=list\r\n**user:** any\r\n**expected behaviour:** \r\n**behaviour:** location label (Bezeichnung des markierten Ortes) is missing\r\n**important screensize:**\r\n**device & browser:** \r\n**Comment/Question:** maybe we need a smaller char restriction here? it's at 255 now, I wonder if something like 50 should be enough for something displayed as a tag? or continue with ... for longer words?\r\n\r\nold list\r\n<img width=\"446\" alt=\"Bildschirmfoto 2021-12-21 um 16 35 27\" src=\"https://user-images.githubusercontent.com/35491681/146956690-789f6d02-372c-4877-a4c9-c539b5fc90c3.png\">\r\n\r\n\r\nnew list\r\n<img width=\"446\" alt=\"Bildschirmfoto 2021-12-21 um 16 34 09\" src=\"https://user-images.githubusercontent.com/35491681/146956491-2472f9f2-e90d-4975-88a8-fbe1a7012657.png\">\r\n\r\nold list with long label\r\n<img width=\"656\" alt=\"Bildschirmfoto 2021-12-21 um 16 36 09\" src=\"https://user-images.githubusercontent.com/35491681/146956804-ced5b4b8-0da8-42fc-a17c-901fc86efe9b.png\">\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from django.contrib.contenttypes.models import ContentType\nfrom rest_framework import serializers\n\nfrom adhocracy4.categories.models import Category\nfrom meinberlin.apps.votes.models import TokenVote\n\nfrom .models import Proposal\n\n\nclass CategoryField(serializers.Field):\n\n def to_internal_value(self, category):\n if category:\n return Category.objects.get(pk=category)\n else:\n return None\n\n def to_representation(self, category):\n return {'id': category.pk, 'name': category.name}\n\n\nclass ProposalSerializer(serializers.ModelSerializer):\n\n creator = serializers.SerializerMethodField()\n comment_count = serializers.SerializerMethodField()\n positive_rating_count = serializers.SerializerMethodField()\n negative_rating_count = serializers.SerializerMethodField()\n category = CategoryField()\n url = serializers.SerializerMethodField()\n moderator_feedback = serializers.SerializerMethodField()\n session_token_voted = serializers.SerializerMethodField()\n\n class Meta:\n model = Proposal\n fields = ('budget', 'category', 'comment_count', 'created', 'modified',\n 'creator', 'is_archived', 'name', 'negative_rating_count',\n 'positive_rating_count', 'url', 'pk', 'moderator_feedback',\n 'session_token_voted')\n read_only_fields = ('budget', 'category', 'comment_count', 'created',\n 'modified', 'creator', 'is_archived', 'name',\n 'negative_rating_count', 'positive_rating_count',\n 'url', 'pk', 'moderator_feedback',\n 'session_token_voted')\n\n def get_creator(self, proposal):\n return proposal.creator.username\n\n def get_comment_count(self, proposal):\n if hasattr(proposal, 'comment_count'):\n return proposal.comment_count\n else:\n return 0\n\n def get_positive_rating_count(self, proposal):\n if hasattr(proposal, 'positive_rating_count'):\n return proposal.positive_rating_count\n else:\n return 0\n\n def get_negative_rating_count(self, proposal):\n if hasattr(proposal, 'negative_rating_count'):\n return proposal.negative_rating_count\n else:\n return 0\n\n def get_url(self, proposal):\n return proposal.get_absolute_url()\n\n def get_moderator_feedback(self, proposal):\n if hasattr(proposal, 'moderator_feedback'):\n return (proposal.moderator_feedback,\n proposal.get_moderator_feedback_display())\n else:\n return None\n\n def get_session_token_voted(self, proposal):\n \"\"\"Serialize if proposal has been voted.\n\n Returns bool that indicates whether the proposal has\n been voted with the token in the current session\n \"\"\"\n if 'request' in self.context:\n if 'voting_token' in self.context['request'].session:\n vote = TokenVote.objects.filter(\n token__pk=self.context['request'].session['voting_token'],\n content_type=ContentType.objects.get_for_model(\n proposal.__class__),\n object_pk=proposal.pk\n )\n if vote.exists():\n return True\n\n return False\n", "path": "meinberlin/apps/budgeting/serializers.py"}], "after_files": [{"content": "from django.contrib.contenttypes.models import ContentType\nfrom rest_framework import serializers\n\nfrom adhocracy4.categories.models import Category\nfrom meinberlin.apps.votes.models import TokenVote\n\nfrom .models import Proposal\n\n\nclass CategoryField(serializers.Field):\n\n def to_internal_value(self, category):\n if category:\n return Category.objects.get(pk=category)\n else:\n return None\n\n def to_representation(self, category):\n return {'id': category.pk, 'name': category.name}\n\n\nclass ProposalSerializer(serializers.ModelSerializer):\n\n creator = serializers.SerializerMethodField()\n comment_count = serializers.SerializerMethodField()\n positive_rating_count = serializers.SerializerMethodField()\n negative_rating_count = serializers.SerializerMethodField()\n category = CategoryField()\n url = serializers.SerializerMethodField()\n moderator_feedback = serializers.SerializerMethodField()\n session_token_voted = serializers.SerializerMethodField()\n\n class Meta:\n model = Proposal\n fields = ('budget', 'category', 'comment_count', 'created', 'modified',\n 'creator', 'is_archived', 'name', 'negative_rating_count',\n 'positive_rating_count', 'url', 'pk', 'moderator_feedback',\n 'point_label', 'session_token_voted')\n read_only_fields = ('budget', 'category', 'comment_count', 'created',\n 'modified', 'creator', 'is_archived', 'name',\n 'negative_rating_count', 'positive_rating_count',\n 'url', 'pk', 'moderator_feedback',\n 'point_label', 'session_token_voted')\n\n def get_creator(self, proposal):\n return proposal.creator.username\n\n def get_comment_count(self, proposal):\n if hasattr(proposal, 'comment_count'):\n return proposal.comment_count\n else:\n return 0\n\n def get_positive_rating_count(self, proposal):\n if hasattr(proposal, 'positive_rating_count'):\n return proposal.positive_rating_count\n else:\n return 0\n\n def get_negative_rating_count(self, proposal):\n if hasattr(proposal, 'negative_rating_count'):\n return proposal.negative_rating_count\n else:\n return 0\n\n def get_url(self, proposal):\n return proposal.get_absolute_url()\n\n def get_moderator_feedback(self, proposal):\n if hasattr(proposal, 'moderator_feedback'):\n return (proposal.moderator_feedback,\n proposal.get_moderator_feedback_display())\n else:\n return None\n\n def get_point_label(self, proposal):\n if hasattr(proposal, 'point_label'):\n return (proposal.point_label)\n else:\n return None\n\n def get_session_token_voted(self, proposal):\n \"\"\"Serialize if proposal has been voted.\n\n Returns bool that indicates whether the proposal has\n been voted with the token in the current session\n \"\"\"\n if 'request' in self.context:\n if 'voting_token' in self.context['request'].session:\n vote = TokenVote.objects.filter(\n token__pk=self.context['request'].session['voting_token'],\n content_type=ContentType.objects.get_for_model(\n proposal.__class__),\n object_pk=proposal.pk\n )\n if vote.exists():\n return True\n\n return False\n", "path": "meinberlin/apps/budgeting/serializers.py"}]}
| 1,522 | 317 |
gh_patches_debug_56812
|
rasdani/github-patches
|
git_diff
|
microsoft__knossos-ksc-1027
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Segmentation fault in sqrl_pytorch-PyTorch CUDA
Just saw this while working on something else. I haven't done a lot to debug it, but note that it's in copydown, on a fairly innocuous operation (aten::sum(Tensor 2) -> Float), so might be something to do with KS_ALLOCATOR not being defined?
Or could just be out of memory not caught?

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/dl-capsule/sqrl.py`
Content:
```
1 import torch
2 import ksc.torch_frontend as knossos
3
4 # run-bench: Knossos source, and "nice" PyTorch implementation
5 # BEGINDOC
6 @knossos.register
7 def sqrl(x: torch.Tensor):
8 """
9 sqrl: Squared Leaky Relu
10 Like a capsule from /Stuck in a Rut/
11 Typically x is a 4x4 tensor, possibly
12 packed in a 4n x 4m array
13 """
14 y = torch.sum(x)
15 if y < 0.0:
16 t = -0.125 * x
17 else:
18 t = 1 / 2 * x ** 2
19 return torch.mean(torch.sin(t) * t)
20
21
22 # ENDDOC
23
24 # run-bench: PyTorch "fast" implementation
25 def sqrl_pytorch(x: torch.Tensor):
26 return sqrl(x)
27
28
29 # run-bench: PyTorch "nice" implementation
30 def sqrl_pytorch_nice(x: torch.Tensor):
31 return sqrl(x)
32
33
34 # run-bench: Define a range of values at which to call the methods
35 def sqrl_bench_configs():
36 yield torch.randn((4, 4))
37 yield torch.randn((16, 16))
38
39
40 #################################
41 #
42 # vsqrl - vectorized sqrl
43 #
44
45 vsqrl = knossos.vmap(sqrl)
46
47
48 # run-bench: Define a range of values at which to call the methods
49 def vsqrl_bench_configs():
50 yield torch.randn((10, 4, 4))
51 yield torch.randn((1000, 4, 4))
52 yield torch.randn((1000, 16, 16))
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/dl-capsule/sqrl.py b/examples/dl-capsule/sqrl.py
--- a/examples/dl-capsule/sqrl.py
+++ b/examples/dl-capsule/sqrl.py
@@ -23,12 +23,12 @@
# run-bench: PyTorch "fast" implementation
def sqrl_pytorch(x: torch.Tensor):
- return sqrl(x)
+ return sqrl.raw_f(x)
# run-bench: PyTorch "nice" implementation
def sqrl_pytorch_nice(x: torch.Tensor):
- return sqrl(x)
+ return sqrl.raw_f(x)
# run-bench: Define a range of values at which to call the methods
|
{"golden_diff": "diff --git a/examples/dl-capsule/sqrl.py b/examples/dl-capsule/sqrl.py\n--- a/examples/dl-capsule/sqrl.py\n+++ b/examples/dl-capsule/sqrl.py\n@@ -23,12 +23,12 @@\n \n # run-bench: PyTorch \"fast\" implementation\n def sqrl_pytorch(x: torch.Tensor):\n- return sqrl(x)\n+ return sqrl.raw_f(x)\n \n \n # run-bench: PyTorch \"nice\" implementation\n def sqrl_pytorch_nice(x: torch.Tensor):\n- return sqrl(x)\n+ return sqrl.raw_f(x)\n \n \n # run-bench: Define a range of values at which to call the methods\n", "issue": "Bug: Segmentation fault in sqrl_pytorch-PyTorch CUDA\nJust saw this while working on something else. I haven't done a lot to debug it, but note that it's in copydown, on a fairly innocuous operation (aten::sum(Tensor 2) -> Float), so might be something to do with KS_ALLOCATOR not being defined?\r\nOr could just be out of memory not caught?\r\n\r\n\n", "before_files": [{"content": "import torch\nimport ksc.torch_frontend as knossos\n\n# run-bench: Knossos source, and \"nice\" PyTorch implementation\n# BEGINDOC\[email protected]\ndef sqrl(x: torch.Tensor):\n \"\"\"\n sqrl: Squared Leaky Relu\n Like a capsule from /Stuck in a Rut/\n Typically x is a 4x4 tensor, possibly\n packed in a 4n x 4m array\n \"\"\"\n y = torch.sum(x)\n if y < 0.0:\n t = -0.125 * x\n else:\n t = 1 / 2 * x ** 2\n return torch.mean(torch.sin(t) * t)\n\n\n# ENDDOC\n\n# run-bench: PyTorch \"fast\" implementation\ndef sqrl_pytorch(x: torch.Tensor):\n return sqrl(x)\n\n\n# run-bench: PyTorch \"nice\" implementation\ndef sqrl_pytorch_nice(x: torch.Tensor):\n return sqrl(x)\n\n\n# run-bench: Define a range of values at which to call the methods\ndef sqrl_bench_configs():\n yield torch.randn((4, 4))\n yield torch.randn((16, 16))\n\n\n#################################\n#\n# vsqrl - vectorized sqrl\n#\n\nvsqrl = knossos.vmap(sqrl)\n\n\n# run-bench: Define a range of values at which to call the methods\ndef vsqrl_bench_configs():\n yield torch.randn((10, 4, 4))\n yield torch.randn((1000, 4, 4))\n yield torch.randn((1000, 16, 16))\n", "path": "examples/dl-capsule/sqrl.py"}], "after_files": [{"content": "import torch\nimport ksc.torch_frontend as knossos\n\n# run-bench: Knossos source, and \"nice\" PyTorch implementation\n# BEGINDOC\[email protected]\ndef sqrl(x: torch.Tensor):\n \"\"\"\n sqrl: Squared Leaky Relu\n Like a capsule from /Stuck in a Rut/\n Typically x is a 4x4 tensor, possibly\n packed in a 4n x 4m array\n \"\"\"\n y = torch.sum(x)\n if y < 0.0:\n t = -0.125 * x\n else:\n t = 1 / 2 * x ** 2\n return torch.mean(torch.sin(t) * t)\n\n\n# ENDDOC\n\n# run-bench: PyTorch \"fast\" implementation\ndef sqrl_pytorch(x: torch.Tensor):\n return sqrl.raw_f(x)\n\n\n# run-bench: PyTorch \"nice\" implementation\ndef sqrl_pytorch_nice(x: torch.Tensor):\n return sqrl.raw_f(x)\n\n\n# run-bench: Define a range of values at which to call the methods\ndef sqrl_bench_configs():\n yield torch.randn((4, 4))\n yield torch.randn((16, 16))\n\n\n#################################\n#\n# vsqrl - vectorized sqrl\n#\n\nvsqrl = knossos.vmap(sqrl)\n\n\n# run-bench: Define a range of values at which to call the methods\ndef vsqrl_bench_configs():\n yield torch.randn((10, 4, 4))\n yield torch.randn((1000, 4, 4))\n yield torch.randn((1000, 16, 16))\n", "path": "examples/dl-capsule/sqrl.py"}]}
| 896 | 166 |
gh_patches_debug_8708
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-6851
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add WantAuthnRequestsSigned Parameter to SAML Metadata Endpoint for Improved Integration with Spring Boot SAML Library
**Is your feature request related to a problem? Please describe.**
Yes, I consistently encounter an issue when integrating with the Spring Boot SAML Library. When the **WantAuthnRequestsSigned** parameter is missing in the SAML metadata endpoint within the XML file, the authentication page displays the message: "Verification Certificate configured, but request is not signed."
**Describe the solution you'd like**
I would like the **WantAuthnRequestsSigned="true"** parameter to be added to the XML file in the SAML metadata endpoint for the element **<md:IDPSSODescriptor protocolSupportEnumeration="urn:oasis:names:tc:SAML:2.0:protocol">**.
**Describe alternatives you've considered**
A potential alternative would be to modify the Spring Boot SAML Library to function even without the **WantAuthnRequestsSigned** parameter. However, this could lead to security concerns and is not the recommended approach.
**Additional context**
Adding this parameter is crucial for the correct functioning of authentication and the security of the system. It would be highly beneficial if this parameter were included in the XML file by default to prevent future integration issues.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/providers/saml/processors/metadata.py`
Content:
```
1 """SAML Identity Provider Metadata Processor"""
2 from hashlib import sha256
3 from typing import Iterator, Optional
4
5 import xmlsec # nosec
6 from django.http import HttpRequest
7 from django.urls import reverse
8 from lxml.etree import Element, SubElement, tostring # nosec
9
10 from authentik.providers.saml.models import SAMLProvider
11 from authentik.providers.saml.utils.encoding import strip_pem_header
12 from authentik.sources.saml.processors.constants import (
13 DIGEST_ALGORITHM_TRANSLATION_MAP,
14 NS_MAP,
15 NS_SAML_METADATA,
16 NS_SAML_PROTOCOL,
17 NS_SIGNATURE,
18 SAML_BINDING_POST,
19 SAML_BINDING_REDIRECT,
20 SAML_NAME_ID_FORMAT_EMAIL,
21 SAML_NAME_ID_FORMAT_PERSISTENT,
22 SAML_NAME_ID_FORMAT_TRANSIENT,
23 SAML_NAME_ID_FORMAT_X509,
24 SIGN_ALGORITHM_TRANSFORM_MAP,
25 )
26
27
28 class MetadataProcessor:
29 """SAML Identity Provider Metadata Processor"""
30
31 provider: SAMLProvider
32 http_request: HttpRequest
33 force_binding: Optional[str]
34
35 def __init__(self, provider: SAMLProvider, request: HttpRequest):
36 self.provider = provider
37 self.http_request = request
38 self.force_binding = None
39 self.xml_id = "_" + sha256(f"{provider.name}-{provider.pk}".encode("ascii")).hexdigest()
40
41 def get_signing_key_descriptor(self) -> Optional[Element]:
42 """Get Signing KeyDescriptor, if enabled for the provider"""
43 if not self.provider.signing_kp:
44 return None
45 key_descriptor = Element(f"{{{NS_SAML_METADATA}}}KeyDescriptor")
46 key_descriptor.attrib["use"] = "signing"
47 key_info = SubElement(key_descriptor, f"{{{NS_SIGNATURE}}}KeyInfo")
48 x509_data = SubElement(key_info, f"{{{NS_SIGNATURE}}}X509Data")
49 x509_certificate = SubElement(x509_data, f"{{{NS_SIGNATURE}}}X509Certificate")
50 x509_certificate.text = strip_pem_header(
51 self.provider.signing_kp.certificate_data.replace("\r", "")
52 )
53 return key_descriptor
54
55 def get_name_id_formats(self) -> Iterator[Element]:
56 """Get compatible NameID Formats"""
57 formats = [
58 SAML_NAME_ID_FORMAT_EMAIL,
59 SAML_NAME_ID_FORMAT_PERSISTENT,
60 SAML_NAME_ID_FORMAT_X509,
61 SAML_NAME_ID_FORMAT_TRANSIENT,
62 ]
63 for name_id_format in formats:
64 element = Element(f"{{{NS_SAML_METADATA}}}NameIDFormat")
65 element.text = name_id_format
66 yield element
67
68 def get_sso_bindings(self) -> Iterator[Element]:
69 """Get all Bindings supported"""
70 binding_url_map = {
71 (SAML_BINDING_REDIRECT, "SingleSignOnService"): self.http_request.build_absolute_uri(
72 reverse(
73 "authentik_providers_saml:sso-redirect",
74 kwargs={"application_slug": self.provider.application.slug},
75 )
76 ),
77 (SAML_BINDING_POST, "SingleSignOnService"): self.http_request.build_absolute_uri(
78 reverse(
79 "authentik_providers_saml:sso-post",
80 kwargs={"application_slug": self.provider.application.slug},
81 )
82 ),
83 }
84 for binding_svc, url in binding_url_map.items():
85 binding, svc = binding_svc
86 if self.force_binding and self.force_binding != binding:
87 continue
88 element = Element(f"{{{NS_SAML_METADATA}}}{svc}")
89 element.attrib["Binding"] = binding
90 element.attrib["Location"] = url
91 yield element
92
93 def get_slo_bindings(self) -> Iterator[Element]:
94 """Get all Bindings supported"""
95 binding_url_map = {
96 (SAML_BINDING_REDIRECT, "SingleLogoutService"): self.http_request.build_absolute_uri(
97 reverse(
98 "authentik_providers_saml:slo-redirect",
99 kwargs={"application_slug": self.provider.application.slug},
100 )
101 ),
102 (SAML_BINDING_POST, "SingleLogoutService"): self.http_request.build_absolute_uri(
103 reverse(
104 "authentik_providers_saml:slo-post",
105 kwargs={"application_slug": self.provider.application.slug},
106 )
107 ),
108 }
109 for binding_svc, url in binding_url_map.items():
110 binding, svc = binding_svc
111 if self.force_binding and self.force_binding != binding:
112 continue
113 element = Element(f"{{{NS_SAML_METADATA}}}{svc}")
114 element.attrib["Binding"] = binding
115 element.attrib["Location"] = url
116 yield element
117
118 def _prepare_signature(self, entity_descriptor: Element):
119 sign_algorithm_transform = SIGN_ALGORITHM_TRANSFORM_MAP.get(
120 self.provider.signature_algorithm, xmlsec.constants.TransformRsaSha1
121 )
122 signature = xmlsec.template.create(
123 entity_descriptor,
124 xmlsec.constants.TransformExclC14N,
125 sign_algorithm_transform,
126 ns="ds", # type: ignore
127 )
128 entity_descriptor.append(signature)
129
130 def _sign(self, entity_descriptor: Element):
131 digest_algorithm_transform = DIGEST_ALGORITHM_TRANSLATION_MAP.get(
132 self.provider.digest_algorithm, xmlsec.constants.TransformSha1
133 )
134 assertion = entity_descriptor.xpath("//md:EntityDescriptor", namespaces=NS_MAP)[0]
135 xmlsec.tree.add_ids(assertion, ["ID"])
136 signature_node = xmlsec.tree.find_node(assertion, xmlsec.constants.NodeSignature)
137 ref = xmlsec.template.add_reference(
138 signature_node,
139 digest_algorithm_transform,
140 uri="#" + self.xml_id,
141 )
142 xmlsec.template.add_transform(ref, xmlsec.constants.TransformEnveloped)
143 xmlsec.template.add_transform(ref, xmlsec.constants.TransformExclC14N)
144 key_info = xmlsec.template.ensure_key_info(signature_node)
145 xmlsec.template.add_x509_data(key_info)
146
147 ctx = xmlsec.SignatureContext()
148
149 key = xmlsec.Key.from_memory(
150 self.provider.signing_kp.key_data,
151 xmlsec.constants.KeyDataFormatPem,
152 None,
153 )
154 key.load_cert_from_memory(
155 self.provider.signing_kp.certificate_data,
156 xmlsec.constants.KeyDataFormatCertPem,
157 )
158 ctx.key = key
159 ctx.sign(signature_node)
160
161 def build_entity_descriptor(self) -> str:
162 """Build full EntityDescriptor"""
163 entity_descriptor = Element(f"{{{NS_SAML_METADATA}}}EntityDescriptor", nsmap=NS_MAP)
164 entity_descriptor.attrib["ID"] = self.xml_id
165 entity_descriptor.attrib["entityID"] = self.provider.issuer
166
167 if self.provider.signing_kp:
168 self._prepare_signature(entity_descriptor)
169
170 idp_sso_descriptor = SubElement(
171 entity_descriptor, f"{{{NS_SAML_METADATA}}}IDPSSODescriptor"
172 )
173 idp_sso_descriptor.attrib["protocolSupportEnumeration"] = NS_SAML_PROTOCOL
174
175 signing_descriptor = self.get_signing_key_descriptor()
176 if signing_descriptor is not None:
177 idp_sso_descriptor.append(signing_descriptor)
178
179 for binding in self.get_slo_bindings():
180 idp_sso_descriptor.append(binding)
181
182 for name_id_format in self.get_name_id_formats():
183 idp_sso_descriptor.append(name_id_format)
184
185 for binding in self.get_sso_bindings():
186 idp_sso_descriptor.append(binding)
187
188 if self.provider.signing_kp:
189 self._sign(entity_descriptor)
190
191 return tostring(entity_descriptor).decode()
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/authentik/providers/saml/processors/metadata.py b/authentik/providers/saml/processors/metadata.py
--- a/authentik/providers/saml/processors/metadata.py
+++ b/authentik/providers/saml/processors/metadata.py
@@ -171,6 +171,8 @@
entity_descriptor, f"{{{NS_SAML_METADATA}}}IDPSSODescriptor"
)
idp_sso_descriptor.attrib["protocolSupportEnumeration"] = NS_SAML_PROTOCOL
+ if self.provider.verification_kp:
+ idp_sso_descriptor.attrib["WantAuthnRequestsSigned"] = "true"
signing_descriptor = self.get_signing_key_descriptor()
if signing_descriptor is not None:
|
{"golden_diff": "diff --git a/authentik/providers/saml/processors/metadata.py b/authentik/providers/saml/processors/metadata.py\n--- a/authentik/providers/saml/processors/metadata.py\n+++ b/authentik/providers/saml/processors/metadata.py\n@@ -171,6 +171,8 @@\n entity_descriptor, f\"{{{NS_SAML_METADATA}}}IDPSSODescriptor\"\n )\n idp_sso_descriptor.attrib[\"protocolSupportEnumeration\"] = NS_SAML_PROTOCOL\n+ if self.provider.verification_kp:\n+ idp_sso_descriptor.attrib[\"WantAuthnRequestsSigned\"] = \"true\"\n \n signing_descriptor = self.get_signing_key_descriptor()\n if signing_descriptor is not None:\n", "issue": "Add WantAuthnRequestsSigned Parameter to SAML Metadata Endpoint for Improved Integration with Spring Boot SAML Library\n**Is your feature request related to a problem? Please describe.**\r\nYes, I consistently encounter an issue when integrating with the Spring Boot SAML Library. When the **WantAuthnRequestsSigned** parameter is missing in the SAML metadata endpoint within the XML file, the authentication page displays the message: \"Verification Certificate configured, but request is not signed.\"\r\n\r\n**Describe the solution you'd like**\r\nI would like the **WantAuthnRequestsSigned=\"true\"** parameter to be added to the XML file in the SAML metadata endpoint for the element **<md:IDPSSODescriptor protocolSupportEnumeration=\"urn:oasis:names:tc:SAML:2.0:protocol\">**.\r\n\r\n**Describe alternatives you've considered**\r\nA potential alternative would be to modify the Spring Boot SAML Library to function even without the **WantAuthnRequestsSigned** parameter. However, this could lead to security concerns and is not the recommended approach.\r\n\r\n**Additional context**\r\nAdding this parameter is crucial for the correct functioning of authentication and the security of the system. It would be highly beneficial if this parameter were included in the XML file by default to prevent future integration issues.\n", "before_files": [{"content": "\"\"\"SAML Identity Provider Metadata Processor\"\"\"\nfrom hashlib import sha256\nfrom typing import Iterator, Optional\n\nimport xmlsec # nosec\nfrom django.http import HttpRequest\nfrom django.urls import reverse\nfrom lxml.etree import Element, SubElement, tostring # nosec\n\nfrom authentik.providers.saml.models import SAMLProvider\nfrom authentik.providers.saml.utils.encoding import strip_pem_header\nfrom authentik.sources.saml.processors.constants import (\n DIGEST_ALGORITHM_TRANSLATION_MAP,\n NS_MAP,\n NS_SAML_METADATA,\n NS_SAML_PROTOCOL,\n NS_SIGNATURE,\n SAML_BINDING_POST,\n SAML_BINDING_REDIRECT,\n SAML_NAME_ID_FORMAT_EMAIL,\n SAML_NAME_ID_FORMAT_PERSISTENT,\n SAML_NAME_ID_FORMAT_TRANSIENT,\n SAML_NAME_ID_FORMAT_X509,\n SIGN_ALGORITHM_TRANSFORM_MAP,\n)\n\n\nclass MetadataProcessor:\n \"\"\"SAML Identity Provider Metadata Processor\"\"\"\n\n provider: SAMLProvider\n http_request: HttpRequest\n force_binding: Optional[str]\n\n def __init__(self, provider: SAMLProvider, request: HttpRequest):\n self.provider = provider\n self.http_request = request\n self.force_binding = None\n self.xml_id = \"_\" + sha256(f\"{provider.name}-{provider.pk}\".encode(\"ascii\")).hexdigest()\n\n def get_signing_key_descriptor(self) -> Optional[Element]:\n \"\"\"Get Signing KeyDescriptor, if enabled for the provider\"\"\"\n if not self.provider.signing_kp:\n return None\n key_descriptor = Element(f\"{{{NS_SAML_METADATA}}}KeyDescriptor\")\n key_descriptor.attrib[\"use\"] = \"signing\"\n key_info = SubElement(key_descriptor, f\"{{{NS_SIGNATURE}}}KeyInfo\")\n x509_data = SubElement(key_info, f\"{{{NS_SIGNATURE}}}X509Data\")\n x509_certificate = SubElement(x509_data, f\"{{{NS_SIGNATURE}}}X509Certificate\")\n x509_certificate.text = strip_pem_header(\n self.provider.signing_kp.certificate_data.replace(\"\\r\", \"\")\n )\n return key_descriptor\n\n def get_name_id_formats(self) -> Iterator[Element]:\n \"\"\"Get compatible NameID Formats\"\"\"\n formats = [\n SAML_NAME_ID_FORMAT_EMAIL,\n SAML_NAME_ID_FORMAT_PERSISTENT,\n SAML_NAME_ID_FORMAT_X509,\n SAML_NAME_ID_FORMAT_TRANSIENT,\n ]\n for name_id_format in formats:\n element = Element(f\"{{{NS_SAML_METADATA}}}NameIDFormat\")\n element.text = name_id_format\n yield element\n\n def get_sso_bindings(self) -> Iterator[Element]:\n \"\"\"Get all Bindings supported\"\"\"\n binding_url_map = {\n (SAML_BINDING_REDIRECT, \"SingleSignOnService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:sso-redirect\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n (SAML_BINDING_POST, \"SingleSignOnService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:sso-post\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n }\n for binding_svc, url in binding_url_map.items():\n binding, svc = binding_svc\n if self.force_binding and self.force_binding != binding:\n continue\n element = Element(f\"{{{NS_SAML_METADATA}}}{svc}\")\n element.attrib[\"Binding\"] = binding\n element.attrib[\"Location\"] = url\n yield element\n\n def get_slo_bindings(self) -> Iterator[Element]:\n \"\"\"Get all Bindings supported\"\"\"\n binding_url_map = {\n (SAML_BINDING_REDIRECT, \"SingleLogoutService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:slo-redirect\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n (SAML_BINDING_POST, \"SingleLogoutService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:slo-post\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n }\n for binding_svc, url in binding_url_map.items():\n binding, svc = binding_svc\n if self.force_binding and self.force_binding != binding:\n continue\n element = Element(f\"{{{NS_SAML_METADATA}}}{svc}\")\n element.attrib[\"Binding\"] = binding\n element.attrib[\"Location\"] = url\n yield element\n\n def _prepare_signature(self, entity_descriptor: Element):\n sign_algorithm_transform = SIGN_ALGORITHM_TRANSFORM_MAP.get(\n self.provider.signature_algorithm, xmlsec.constants.TransformRsaSha1\n )\n signature = xmlsec.template.create(\n entity_descriptor,\n xmlsec.constants.TransformExclC14N,\n sign_algorithm_transform,\n ns=\"ds\", # type: ignore\n )\n entity_descriptor.append(signature)\n\n def _sign(self, entity_descriptor: Element):\n digest_algorithm_transform = DIGEST_ALGORITHM_TRANSLATION_MAP.get(\n self.provider.digest_algorithm, xmlsec.constants.TransformSha1\n )\n assertion = entity_descriptor.xpath(\"//md:EntityDescriptor\", namespaces=NS_MAP)[0]\n xmlsec.tree.add_ids(assertion, [\"ID\"])\n signature_node = xmlsec.tree.find_node(assertion, xmlsec.constants.NodeSignature)\n ref = xmlsec.template.add_reference(\n signature_node,\n digest_algorithm_transform,\n uri=\"#\" + self.xml_id,\n )\n xmlsec.template.add_transform(ref, xmlsec.constants.TransformEnveloped)\n xmlsec.template.add_transform(ref, xmlsec.constants.TransformExclC14N)\n key_info = xmlsec.template.ensure_key_info(signature_node)\n xmlsec.template.add_x509_data(key_info)\n\n ctx = xmlsec.SignatureContext()\n\n key = xmlsec.Key.from_memory(\n self.provider.signing_kp.key_data,\n xmlsec.constants.KeyDataFormatPem,\n None,\n )\n key.load_cert_from_memory(\n self.provider.signing_kp.certificate_data,\n xmlsec.constants.KeyDataFormatCertPem,\n )\n ctx.key = key\n ctx.sign(signature_node)\n\n def build_entity_descriptor(self) -> str:\n \"\"\"Build full EntityDescriptor\"\"\"\n entity_descriptor = Element(f\"{{{NS_SAML_METADATA}}}EntityDescriptor\", nsmap=NS_MAP)\n entity_descriptor.attrib[\"ID\"] = self.xml_id\n entity_descriptor.attrib[\"entityID\"] = self.provider.issuer\n\n if self.provider.signing_kp:\n self._prepare_signature(entity_descriptor)\n\n idp_sso_descriptor = SubElement(\n entity_descriptor, f\"{{{NS_SAML_METADATA}}}IDPSSODescriptor\"\n )\n idp_sso_descriptor.attrib[\"protocolSupportEnumeration\"] = NS_SAML_PROTOCOL\n\n signing_descriptor = self.get_signing_key_descriptor()\n if signing_descriptor is not None:\n idp_sso_descriptor.append(signing_descriptor)\n\n for binding in self.get_slo_bindings():\n idp_sso_descriptor.append(binding)\n\n for name_id_format in self.get_name_id_formats():\n idp_sso_descriptor.append(name_id_format)\n\n for binding in self.get_sso_bindings():\n idp_sso_descriptor.append(binding)\n\n if self.provider.signing_kp:\n self._sign(entity_descriptor)\n\n return tostring(entity_descriptor).decode()\n", "path": "authentik/providers/saml/processors/metadata.py"}], "after_files": [{"content": "\"\"\"SAML Identity Provider Metadata Processor\"\"\"\nfrom hashlib import sha256\nfrom typing import Iterator, Optional\n\nimport xmlsec # nosec\nfrom django.http import HttpRequest\nfrom django.urls import reverse\nfrom lxml.etree import Element, SubElement, tostring # nosec\n\nfrom authentik.providers.saml.models import SAMLProvider\nfrom authentik.providers.saml.utils.encoding import strip_pem_header\nfrom authentik.sources.saml.processors.constants import (\n DIGEST_ALGORITHM_TRANSLATION_MAP,\n NS_MAP,\n NS_SAML_METADATA,\n NS_SAML_PROTOCOL,\n NS_SIGNATURE,\n SAML_BINDING_POST,\n SAML_BINDING_REDIRECT,\n SAML_NAME_ID_FORMAT_EMAIL,\n SAML_NAME_ID_FORMAT_PERSISTENT,\n SAML_NAME_ID_FORMAT_TRANSIENT,\n SAML_NAME_ID_FORMAT_X509,\n SIGN_ALGORITHM_TRANSFORM_MAP,\n)\n\n\nclass MetadataProcessor:\n \"\"\"SAML Identity Provider Metadata Processor\"\"\"\n\n provider: SAMLProvider\n http_request: HttpRequest\n force_binding: Optional[str]\n\n def __init__(self, provider: SAMLProvider, request: HttpRequest):\n self.provider = provider\n self.http_request = request\n self.force_binding = None\n self.xml_id = \"_\" + sha256(f\"{provider.name}-{provider.pk}\".encode(\"ascii\")).hexdigest()\n\n def get_signing_key_descriptor(self) -> Optional[Element]:\n \"\"\"Get Signing KeyDescriptor, if enabled for the provider\"\"\"\n if not self.provider.signing_kp:\n return None\n key_descriptor = Element(f\"{{{NS_SAML_METADATA}}}KeyDescriptor\")\n key_descriptor.attrib[\"use\"] = \"signing\"\n key_info = SubElement(key_descriptor, f\"{{{NS_SIGNATURE}}}KeyInfo\")\n x509_data = SubElement(key_info, f\"{{{NS_SIGNATURE}}}X509Data\")\n x509_certificate = SubElement(x509_data, f\"{{{NS_SIGNATURE}}}X509Certificate\")\n x509_certificate.text = strip_pem_header(\n self.provider.signing_kp.certificate_data.replace(\"\\r\", \"\")\n )\n return key_descriptor\n\n def get_name_id_formats(self) -> Iterator[Element]:\n \"\"\"Get compatible NameID Formats\"\"\"\n formats = [\n SAML_NAME_ID_FORMAT_EMAIL,\n SAML_NAME_ID_FORMAT_PERSISTENT,\n SAML_NAME_ID_FORMAT_X509,\n SAML_NAME_ID_FORMAT_TRANSIENT,\n ]\n for name_id_format in formats:\n element = Element(f\"{{{NS_SAML_METADATA}}}NameIDFormat\")\n element.text = name_id_format\n yield element\n\n def get_sso_bindings(self) -> Iterator[Element]:\n \"\"\"Get all Bindings supported\"\"\"\n binding_url_map = {\n (SAML_BINDING_REDIRECT, \"SingleSignOnService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:sso-redirect\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n (SAML_BINDING_POST, \"SingleSignOnService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:sso-post\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n }\n for binding_svc, url in binding_url_map.items():\n binding, svc = binding_svc\n if self.force_binding and self.force_binding != binding:\n continue\n element = Element(f\"{{{NS_SAML_METADATA}}}{svc}\")\n element.attrib[\"Binding\"] = binding\n element.attrib[\"Location\"] = url\n yield element\n\n def get_slo_bindings(self) -> Iterator[Element]:\n \"\"\"Get all Bindings supported\"\"\"\n binding_url_map = {\n (SAML_BINDING_REDIRECT, \"SingleLogoutService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:slo-redirect\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n (SAML_BINDING_POST, \"SingleLogoutService\"): self.http_request.build_absolute_uri(\n reverse(\n \"authentik_providers_saml:slo-post\",\n kwargs={\"application_slug\": self.provider.application.slug},\n )\n ),\n }\n for binding_svc, url in binding_url_map.items():\n binding, svc = binding_svc\n if self.force_binding and self.force_binding != binding:\n continue\n element = Element(f\"{{{NS_SAML_METADATA}}}{svc}\")\n element.attrib[\"Binding\"] = binding\n element.attrib[\"Location\"] = url\n yield element\n\n def _prepare_signature(self, entity_descriptor: Element):\n sign_algorithm_transform = SIGN_ALGORITHM_TRANSFORM_MAP.get(\n self.provider.signature_algorithm, xmlsec.constants.TransformRsaSha1\n )\n signature = xmlsec.template.create(\n entity_descriptor,\n xmlsec.constants.TransformExclC14N,\n sign_algorithm_transform,\n ns=\"ds\", # type: ignore\n )\n entity_descriptor.append(signature)\n\n def _sign(self, entity_descriptor: Element):\n digest_algorithm_transform = DIGEST_ALGORITHM_TRANSLATION_MAP.get(\n self.provider.digest_algorithm, xmlsec.constants.TransformSha1\n )\n assertion = entity_descriptor.xpath(\"//md:EntityDescriptor\", namespaces=NS_MAP)[0]\n xmlsec.tree.add_ids(assertion, [\"ID\"])\n signature_node = xmlsec.tree.find_node(assertion, xmlsec.constants.NodeSignature)\n ref = xmlsec.template.add_reference(\n signature_node,\n digest_algorithm_transform,\n uri=\"#\" + self.xml_id,\n )\n xmlsec.template.add_transform(ref, xmlsec.constants.TransformEnveloped)\n xmlsec.template.add_transform(ref, xmlsec.constants.TransformExclC14N)\n key_info = xmlsec.template.ensure_key_info(signature_node)\n xmlsec.template.add_x509_data(key_info)\n\n ctx = xmlsec.SignatureContext()\n\n key = xmlsec.Key.from_memory(\n self.provider.signing_kp.key_data,\n xmlsec.constants.KeyDataFormatPem,\n None,\n )\n key.load_cert_from_memory(\n self.provider.signing_kp.certificate_data,\n xmlsec.constants.KeyDataFormatCertPem,\n )\n ctx.key = key\n ctx.sign(signature_node)\n\n def build_entity_descriptor(self) -> str:\n \"\"\"Build full EntityDescriptor\"\"\"\n entity_descriptor = Element(f\"{{{NS_SAML_METADATA}}}EntityDescriptor\", nsmap=NS_MAP)\n entity_descriptor.attrib[\"ID\"] = self.xml_id\n entity_descriptor.attrib[\"entityID\"] = self.provider.issuer\n\n if self.provider.signing_kp:\n self._prepare_signature(entity_descriptor)\n\n idp_sso_descriptor = SubElement(\n entity_descriptor, f\"{{{NS_SAML_METADATA}}}IDPSSODescriptor\"\n )\n idp_sso_descriptor.attrib[\"protocolSupportEnumeration\"] = NS_SAML_PROTOCOL\n if self.provider.verification_kp:\n idp_sso_descriptor.attrib[\"WantAuthnRequestsSigned\"] = \"true\"\n\n signing_descriptor = self.get_signing_key_descriptor()\n if signing_descriptor is not None:\n idp_sso_descriptor.append(signing_descriptor)\n\n for binding in self.get_slo_bindings():\n idp_sso_descriptor.append(binding)\n\n for name_id_format in self.get_name_id_formats():\n idp_sso_descriptor.append(name_id_format)\n\n for binding in self.get_sso_bindings():\n idp_sso_descriptor.append(binding)\n\n if self.provider.signing_kp:\n self._sign(entity_descriptor)\n\n return tostring(entity_descriptor).decode()\n", "path": "authentik/providers/saml/processors/metadata.py"}]}
| 2,575 | 158 |
gh_patches_debug_31908
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-5322
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add add-exception command in the CLI
Motivation
----------
A CLI command to add a new exception is missing and need to be added
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/rucio/client/lifetimeclient.py`
Content:
```
1 # Copyright 2017-2018 CERN for the benefit of the ATLAS collaboration.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # Authors:
16 # - Cedric Serfon <[email protected]>, 2017
17 # - Vincent Garonne <[email protected]>, 2018
18 # - Martin Barisits <[email protected]>, 2018
19 # - Andrew Lister <[email protected]>, 2019
20
21 from __future__ import print_function
22
23 from json import loads
24 from requests.status_codes import codes
25
26 from rucio.client.baseclient import BaseClient
27 from rucio.client.baseclient import choice
28 from rucio.common.utils import build_url, render_json
29
30
31 class LifetimeClient(BaseClient):
32
33 """Lifetime client class for working with Lifetime Model exceptions"""
34
35 LIFETIME_BASEURL = 'lifetime_exceptions'
36
37 def list_exceptions(self, exception_id=None, states=None):
38 """
39 List exceptions to Lifetime Model.
40
41 :param id: The id of the exception
42 :param states: The states to filter
43 """
44
45 path = self.LIFETIME_BASEURL + '/'
46 params = {}
47 if exception_id:
48 params['exception_id'] = exception_id
49 if states:
50 params['states'] = exception_id
51 url = build_url(choice(self.list_hosts), path=path, params=params)
52
53 result = self._send_request(url)
54 if result.status_code == codes.ok:
55 lifetime_exceptions = self._load_json_data(result)
56 return lifetime_exceptions
57 else:
58 exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code)
59 raise exc_cls(exc_msg)
60
61 def add_exception(self, dids, account, pattern, comments, expires_at):
62 """
63 Add exceptions to Lifetime Model.
64
65 :param dids: The list of dids
66 :param account: The account of the requester.
67 :param pattern: The account.
68 :param comments: The comments associated to the exception.
69 :param expires_at: The expiration date of the exception.
70
71 returns: The id of the exception.
72 """
73 path = self.LIFETIME_BASEURL + '/'
74 url = build_url(choice(self.list_hosts), path=path)
75 data = {'dids': dids, 'account': account, 'pattern': pattern, 'comments': comments, 'expires_at': expires_at}
76 print(render_json(**data))
77 result = self._send_request(url, type_='POST', data=render_json(**data))
78 print(result.text)
79 if result.status_code == codes.created:
80 return loads(result.text)
81 exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code, data=result.content)
82 raise exc_cls(exc_msg)
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/rucio/client/lifetimeclient.py b/lib/rucio/client/lifetimeclient.py
--- a/lib/rucio/client/lifetimeclient.py
+++ b/lib/rucio/client/lifetimeclient.py
@@ -1,4 +1,5 @@
-# Copyright 2017-2018 CERN for the benefit of the ATLAS collaboration.
+# -*- coding: utf-8 -*-
+# Copyright 2017-2022 CERN
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -13,10 +14,13 @@
# limitations under the License.
#
# Authors:
-# - Cedric Serfon <[email protected]>, 2017
-# - Vincent Garonne <[email protected]>, 2018
+# - Cedric Serfon <[email protected]>, 2017-2022
+# - Vincent Garonne <[email protected]>, 2018
+# - Joaquín Bogado <[email protected]>, 2018
# - Martin Barisits <[email protected]>, 2018
# - Andrew Lister <[email protected]>, 2019
+# - David Población Criado <[email protected]>, 2021
+# - Igor Mandrichenko <[email protected]>, 2021
from __future__ import print_function
@@ -73,9 +77,7 @@
path = self.LIFETIME_BASEURL + '/'
url = build_url(choice(self.list_hosts), path=path)
data = {'dids': dids, 'account': account, 'pattern': pattern, 'comments': comments, 'expires_at': expires_at}
- print(render_json(**data))
result = self._send_request(url, type_='POST', data=render_json(**data))
- print(result.text)
if result.status_code == codes.created:
return loads(result.text)
exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code, data=result.content)
|
{"golden_diff": "diff --git a/lib/rucio/client/lifetimeclient.py b/lib/rucio/client/lifetimeclient.py\n--- a/lib/rucio/client/lifetimeclient.py\n+++ b/lib/rucio/client/lifetimeclient.py\n@@ -1,4 +1,5 @@\n-# Copyright 2017-2018 CERN for the benefit of the ATLAS collaboration.\n+# -*- coding: utf-8 -*-\n+# Copyright 2017-2022 CERN\n #\n # Licensed under the Apache License, Version 2.0 (the \"License\");\n # you may not use this file except in compliance with the License.\n@@ -13,10 +14,13 @@\n # limitations under the License.\n #\n # Authors:\n-# - Cedric Serfon <[email protected]>, 2017\n-# - Vincent Garonne <[email protected]>, 2018\n+# - Cedric Serfon <[email protected]>, 2017-2022\n+# - Vincent Garonne <[email protected]>, 2018\n+# - Joaqu\u00edn Bogado <[email protected]>, 2018\n # - Martin Barisits <[email protected]>, 2018\n # - Andrew Lister <[email protected]>, 2019\n+# - David Poblaci\u00f3n Criado <[email protected]>, 2021\n+# - Igor Mandrichenko <[email protected]>, 2021\n \n from __future__ import print_function\n \n@@ -73,9 +77,7 @@\n path = self.LIFETIME_BASEURL + '/'\n url = build_url(choice(self.list_hosts), path=path)\n data = {'dids': dids, 'account': account, 'pattern': pattern, 'comments': comments, 'expires_at': expires_at}\n- print(render_json(**data))\n result = self._send_request(url, type_='POST', data=render_json(**data))\n- print(result.text)\n if result.status_code == codes.created:\n return loads(result.text)\n exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code, data=result.content)\n", "issue": "Add add-exception command in the CLI\nMotivation\r\n----------\r\nA CLI command to add a new exception is missing and need to be added\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2017-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Cedric Serfon <[email protected]>, 2017\n# - Vincent Garonne <[email protected]>, 2018\n# - Martin Barisits <[email protected]>, 2018\n# - Andrew Lister <[email protected]>, 2019\n\nfrom __future__ import print_function\n\nfrom json import loads\nfrom requests.status_codes import codes\n\nfrom rucio.client.baseclient import BaseClient\nfrom rucio.client.baseclient import choice\nfrom rucio.common.utils import build_url, render_json\n\n\nclass LifetimeClient(BaseClient):\n\n \"\"\"Lifetime client class for working with Lifetime Model exceptions\"\"\"\n\n LIFETIME_BASEURL = 'lifetime_exceptions'\n\n def list_exceptions(self, exception_id=None, states=None):\n \"\"\"\n List exceptions to Lifetime Model.\n\n :param id: The id of the exception\n :param states: The states to filter\n \"\"\"\n\n path = self.LIFETIME_BASEURL + '/'\n params = {}\n if exception_id:\n params['exception_id'] = exception_id\n if states:\n params['states'] = exception_id\n url = build_url(choice(self.list_hosts), path=path, params=params)\n\n result = self._send_request(url)\n if result.status_code == codes.ok:\n lifetime_exceptions = self._load_json_data(result)\n return lifetime_exceptions\n else:\n exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code)\n raise exc_cls(exc_msg)\n\n def add_exception(self, dids, account, pattern, comments, expires_at):\n \"\"\"\n Add exceptions to Lifetime Model.\n\n :param dids: The list of dids\n :param account: The account of the requester.\n :param pattern: The account.\n :param comments: The comments associated to the exception.\n :param expires_at: The expiration date of the exception.\n\n returns: The id of the exception.\n \"\"\"\n path = self.LIFETIME_BASEURL + '/'\n url = build_url(choice(self.list_hosts), path=path)\n data = {'dids': dids, 'account': account, 'pattern': pattern, 'comments': comments, 'expires_at': expires_at}\n print(render_json(**data))\n result = self._send_request(url, type_='POST', data=render_json(**data))\n print(result.text)\n if result.status_code == codes.created:\n return loads(result.text)\n exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code, data=result.content)\n raise exc_cls(exc_msg)\n", "path": "lib/rucio/client/lifetimeclient.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2017-2022 CERN\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Cedric Serfon <[email protected]>, 2017-2022\n# - Vincent Garonne <[email protected]>, 2018\n# - Joaqu\u00edn Bogado <[email protected]>, 2018\n# - Martin Barisits <[email protected]>, 2018\n# - Andrew Lister <[email protected]>, 2019\n# - David Poblaci\u00f3n Criado <[email protected]>, 2021\n# - Igor Mandrichenko <[email protected]>, 2021\n\nfrom __future__ import print_function\n\nfrom json import loads\nfrom requests.status_codes import codes\n\nfrom rucio.client.baseclient import BaseClient\nfrom rucio.client.baseclient import choice\nfrom rucio.common.utils import build_url, render_json\n\n\nclass LifetimeClient(BaseClient):\n\n \"\"\"Lifetime client class for working with Lifetime Model exceptions\"\"\"\n\n LIFETIME_BASEURL = 'lifetime_exceptions'\n\n def list_exceptions(self, exception_id=None, states=None):\n \"\"\"\n List exceptions to Lifetime Model.\n\n :param id: The id of the exception\n :param states: The states to filter\n \"\"\"\n\n path = self.LIFETIME_BASEURL + '/'\n params = {}\n if exception_id:\n params['exception_id'] = exception_id\n if states:\n params['states'] = exception_id\n url = build_url(choice(self.list_hosts), path=path, params=params)\n\n result = self._send_request(url)\n if result.status_code == codes.ok:\n lifetime_exceptions = self._load_json_data(result)\n return lifetime_exceptions\n else:\n exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code)\n raise exc_cls(exc_msg)\n\n def add_exception(self, dids, account, pattern, comments, expires_at):\n \"\"\"\n Add exceptions to Lifetime Model.\n\n :param dids: The list of dids\n :param account: The account of the requester.\n :param pattern: The account.\n :param comments: The comments associated to the exception.\n :param expires_at: The expiration date of the exception.\n\n returns: The id of the exception.\n \"\"\"\n path = self.LIFETIME_BASEURL + '/'\n url = build_url(choice(self.list_hosts), path=path)\n data = {'dids': dids, 'account': account, 'pattern': pattern, 'comments': comments, 'expires_at': expires_at}\n result = self._send_request(url, type_='POST', data=render_json(**data))\n if result.status_code == codes.created:\n return loads(result.text)\n exc_cls, exc_msg = self._get_exception(headers=result.headers, status_code=result.status_code, data=result.content)\n raise exc_cls(exc_msg)\n", "path": "lib/rucio/client/lifetimeclient.py"}]}
| 1,184 | 513 |
gh_patches_debug_22903
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-9195
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SNAPDataset ram usage
### 🐛 Describe the bug
Ran the following code on python 3.10/3.11 and the process got killed by the os(tried on windows/wsl/mac)
for using too much RAM (tried to run both on a laptop with 16gb of memory and a desktop pc with 64gb of memory).
```python
from torch_geometric.datasets import SNAPDataset
dataset = SNAPDataset("./datasets/snap/twitter", "ego-twitter")
```
### Versions
PyTorch version: 2.0.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 14.0 (x86_64)
GCC version: Could not collect
Clang version: 15.0.0 (clang-1500.3.9.4)
CMake version: Could not collect
Libc version: N/A
Python version: 3.11.1 (main, Jan 26 2023, 14:19:45) [Clang 13.0.0 (clang-1300.0.29.30)] (64-bit runtime)
Python platform: macOS-14.0-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Intel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] torch==2.0.1
[pip3] torch_geometric==2.4.0
[pip3] torchaudio==2.0.2
[pip3] torchvision==0.15.2
[conda] Could not collect
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/datasets/snap_dataset.py`
Content:
```
1 import os
2 import os.path as osp
3 from typing import Any, Callable, Dict, List, Optional, Union
4
5 import fsspec
6 import numpy as np
7 import torch
8
9 from torch_geometric.data import Data, InMemoryDataset
10 from torch_geometric.io import fs
11 from torch_geometric.utils import coalesce
12
13
14 class EgoData(Data):
15 def __inc__(self, key: str, value: Any, *args: Any, **kwargs: Any) -> Any:
16 if key == 'circle':
17 return self.num_nodes
18 elif key == 'circle_batch':
19 return int(value.max()) + 1 if value.numel() > 0 else 0
20 return super().__inc__(key, value, *args, **kwargs)
21
22
23 def read_ego(files: List[str], name: str) -> List[EgoData]:
24 import pandas as pd
25
26 all_featnames = []
27 files = [
28 x for x in files if x.split('.')[-1] in
29 ['circles', 'edges', 'egofeat', 'feat', 'featnames']
30 ]
31 for i in range(4, len(files), 5):
32 featnames_file = files[i]
33 with fsspec.open(featnames_file, 'r') as f:
34 featnames = f.read().split('\n')[:-1]
35 featnames = [' '.join(x.split(' ')[1:]) for x in featnames]
36 all_featnames += featnames
37 all_featnames = sorted(list(set(all_featnames)))
38 all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}
39
40 data_list = []
41 for i in range(0, len(files), 5):
42 circles_file = files[i]
43 edges_file = files[i + 1]
44 egofeat_file = files[i + 2]
45 feat_file = files[i + 3]
46 featnames_file = files[i + 4]
47
48 x = None
49 if name != 'gplus': # Don't read node features on g-plus:
50 x_ego = pd.read_csv(egofeat_file, sep=' ', header=None,
51 dtype=np.float32)
52 x_ego = torch.from_numpy(x_ego.values)
53
54 x = pd.read_csv(feat_file, sep=' ', header=None, dtype=np.float32)
55 x = torch.from_numpy(x.values)[:, 1:]
56
57 x_all = torch.cat([x, x_ego], dim=0)
58
59 # Reorder `x` according to `featnames` ordering.
60 x_all = torch.zeros(x.size(0), len(all_featnames))
61 with fsspec.open(featnames_file, 'r') as f:
62 featnames = f.read().split('\n')[:-1]
63 featnames = [' '.join(x.split(' ')[1:]) for x in featnames]
64 indices = [all_featnames_dict[featname] for featname in featnames]
65 x_all[:, torch.tensor(indices)] = x
66 x = x_all
67
68 idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,
69 usecols=[0]).squeeze()
70
71 idx_assoc: Dict[str, int] = {}
72 for i, j in enumerate(idx):
73 idx_assoc[j] = i
74
75 circles: List[int] = []
76 circles_batch: List[int] = []
77 with fsspec.open(circles_file, 'r') as f:
78 for i, line in enumerate(f.read().split('\n')[:-1]):
79 circle_indices = [idx_assoc[c] for c in line.split()[1:]]
80 circles += circle_indices
81 circles_batch += [i] * len(circle_indices)
82 circle = torch.tensor(circles)
83 circle_batch = torch.tensor(circles_batch)
84
85 try:
86 row = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,
87 usecols=[0]).squeeze()
88 col = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,
89 usecols=[1]).squeeze()
90 except Exception:
91 continue
92
93 row = torch.tensor([idx_assoc[i] for i in row])
94 col = torch.tensor([idx_assoc[i] for i in col])
95
96 N = max(int(row.max()), int(col.max())) + 2
97 N = x.size(0) if x is not None else N
98
99 row_ego = torch.full((N - 1, ), N - 1, dtype=torch.long)
100 col_ego = torch.arange(N - 1)
101
102 # Ego node should be connected to every other node.
103 row = torch.cat([row, row_ego, col_ego], dim=0)
104 col = torch.cat([col, col_ego, row_ego], dim=0)
105 edge_index = torch.stack([row, col], dim=0)
106 edge_index = coalesce(edge_index, num_nodes=N)
107
108 data = EgoData(x=x, edge_index=edge_index, circle=circle,
109 circle_batch=circle_batch)
110
111 data_list.append(data)
112
113 return data_list
114
115
116 def read_soc(files: List[str], name: str) -> List[Data]:
117 import pandas as pd
118
119 skiprows = 4
120 if name == 'pokec':
121 skiprows = 0
122
123 edge_index = pd.read_csv(files[0], sep='\t', header=None,
124 skiprows=skiprows, dtype=np.int64)
125 edge_index = torch.from_numpy(edge_index.values).t()
126 num_nodes = edge_index.max().item() + 1
127 edge_index = coalesce(edge_index, num_nodes=num_nodes)
128
129 return [Data(edge_index=edge_index, num_nodes=num_nodes)]
130
131
132 def read_wiki(files: List[str], name: str) -> List[Data]:
133 import pandas as pd
134
135 edge_index = pd.read_csv(files[0], sep='\t', header=None, skiprows=4,
136 dtype=np.int64)
137 edge_index = torch.from_numpy(edge_index.values).t()
138
139 idx = torch.unique(edge_index.flatten())
140 idx_assoc = torch.full((edge_index.max() + 1, ), -1, dtype=torch.long)
141 idx_assoc[idx] = torch.arange(idx.size(0))
142
143 edge_index = idx_assoc[edge_index]
144 num_nodes = edge_index.max().item() + 1
145 edge_index = coalesce(edge_index, num_nodes=num_nodes)
146
147 return [Data(edge_index=edge_index, num_nodes=num_nodes)]
148
149
150 class SNAPDataset(InMemoryDataset):
151 r"""A variety of graph datasets collected from `SNAP at Stanford University
152 <https://snap.stanford.edu/data>`_.
153
154 Args:
155 root (str): Root directory where the dataset should be saved.
156 name (str): The name of the dataset.
157 transform (callable, optional): A function/transform that takes in an
158 :obj:`torch_geometric.data.Data` object and returns a transformed
159 version. The data object will be transformed before every access.
160 (default: :obj:`None`)
161 pre_transform (callable, optional): A function/transform that takes in
162 an :obj:`torch_geometric.data.Data` object and returns a
163 transformed version. The data object will be transformed before
164 being saved to disk. (default: :obj:`None`)
165 pre_filter (callable, optional): A function that takes in an
166 :obj:`torch_geometric.data.Data` object and returns a boolean
167 value, indicating whether the data object should be included in the
168 final dataset. (default: :obj:`None`)
169 force_reload (bool, optional): Whether to re-process the dataset.
170 (default: :obj:`False`)
171 """
172
173 url = 'https://snap.stanford.edu/data'
174
175 available_datasets = {
176 'ego-facebook': ['facebook.tar.gz'],
177 'ego-gplus': ['gplus.tar.gz'],
178 'ego-twitter': ['twitter.tar.gz'],
179 'soc-ca-astroph': ['ca-AstroPh.txt.gz'],
180 'soc-ca-grqc': ['ca-GrQc.txt.gz'],
181 'soc-epinions1': ['soc-Epinions1.txt.gz'],
182 'soc-livejournal1': ['soc-LiveJournal1.txt.gz'],
183 'soc-pokec': ['soc-pokec-relationships.txt.gz'],
184 'soc-slashdot0811': ['soc-Slashdot0811.txt.gz'],
185 'soc-slashdot0922': ['soc-Slashdot0902.txt.gz'],
186 'wiki-vote': ['wiki-Vote.txt.gz'],
187 }
188
189 def __init__(
190 self,
191 root: str,
192 name: str,
193 transform: Optional[Callable] = None,
194 pre_transform: Optional[Callable] = None,
195 pre_filter: Optional[Callable] = None,
196 force_reload: bool = False,
197 ) -> None:
198 self.name = name.lower()
199 assert self.name in self.available_datasets.keys()
200 super().__init__(root, transform, pre_transform, pre_filter,
201 force_reload=force_reload)
202 self.load(self.processed_paths[0])
203
204 @property
205 def raw_dir(self) -> str:
206 return osp.join(self.root, self.name, 'raw')
207
208 @property
209 def processed_dir(self) -> str:
210 return osp.join(self.root, self.name, 'processed')
211
212 @property
213 def processed_file_names(self) -> str:
214 return 'data.pt'
215
216 def _download(self) -> None:
217 if osp.isdir(self.raw_dir) and len(os.listdir(self.raw_dir)) > 0:
218 return
219
220 fs.makedirs(self.raw_dir, exist_ok=True)
221 self.download()
222
223 def download(self) -> None:
224 for name in self.available_datasets[self.name]:
225 fs.cp(f'{self.url}/{name}', self.raw_dir, extract=True)
226
227 def process(self) -> None:
228 raw_dir = self.raw_dir
229 filenames = fs.ls(self.raw_dir)
230 if len(filenames) == 1 and fs.isdir(filenames[0]):
231 raw_dir = filenames[0]
232
233 raw_files = fs.ls(raw_dir)
234
235 data_list: Union[List[Data], List[EgoData]]
236 if self.name[:4] == 'ego-':
237 data_list = read_ego(raw_files, self.name[4:])
238 elif self.name[:4] == 'soc-':
239 data_list = read_soc(raw_files, self.name[:4])
240 elif self.name[:5] == 'wiki-':
241 data_list = read_wiki(raw_files, self.name[5:])
242 else:
243 raise NotImplementedError
244
245 if len(data_list) > 1 and self.pre_filter is not None:
246 data_list = [data for data in data_list if self.pre_filter(data)]
247
248 if self.pre_transform is not None:
249 data_list = [self.pre_transform(data) for data in data_list]
250
251 self.save(data_list, self.processed_paths[0])
252
253 def __repr__(self) -> str:
254 return f'SNAP-{self.name}({len(self)})'
255
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/datasets/snap_dataset.py b/torch_geometric/datasets/snap_dataset.py
--- a/torch_geometric/datasets/snap_dataset.py
+++ b/torch_geometric/datasets/snap_dataset.py
@@ -22,6 +22,9 @@
def read_ego(files: List[str], name: str) -> List[EgoData]:
import pandas as pd
+ import tqdm
+
+ files = sorted(files)
all_featnames = []
files = [
@@ -38,7 +41,7 @@
all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}
data_list = []
- for i in range(0, len(files), 5):
+ for i in tqdm.tqdm(range(0, len(files), 5)):
circles_file = files[i]
edges_file = files[i + 1]
egofeat_file = files[i + 2]
@@ -65,6 +68,9 @@
x_all[:, torch.tensor(indices)] = x
x = x_all
+ if x.size(1) > 100_000:
+ x = x.to_sparse_csr()
+
idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,
usecols=[0]).squeeze()
|
{"golden_diff": "diff --git a/torch_geometric/datasets/snap_dataset.py b/torch_geometric/datasets/snap_dataset.py\n--- a/torch_geometric/datasets/snap_dataset.py\n+++ b/torch_geometric/datasets/snap_dataset.py\n@@ -22,6 +22,9 @@\n \n def read_ego(files: List[str], name: str) -> List[EgoData]:\n import pandas as pd\n+ import tqdm\n+\n+ files = sorted(files)\n \n all_featnames = []\n files = [\n@@ -38,7 +41,7 @@\n all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}\n \n data_list = []\n- for i in range(0, len(files), 5):\n+ for i in tqdm.tqdm(range(0, len(files), 5)):\n circles_file = files[i]\n edges_file = files[i + 1]\n egofeat_file = files[i + 2]\n@@ -65,6 +68,9 @@\n x_all[:, torch.tensor(indices)] = x\n x = x_all\n \n+ if x.size(1) > 100_000:\n+ x = x.to_sparse_csr()\n+\n idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,\n usecols=[0]).squeeze()\n", "issue": "SNAPDataset ram usage\n### \ud83d\udc1b Describe the bug\n\nRan the following code on python 3.10/3.11 and the process got killed by the os(tried on windows/wsl/mac)\r\nfor using too much RAM (tried to run both on a laptop with 16gb of memory and a desktop pc with 64gb of memory).\r\n\r\n```python\r\nfrom torch_geometric.datasets import SNAPDataset\r\ndataset = SNAPDataset(\"./datasets/snap/twitter\", \"ego-twitter\")\r\n```\r\n\n\n### Versions\n\nPyTorch version: 2.0.1\r\nIs debug build: False\r\nCUDA used to build PyTorch: None\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: macOS 14.0 (x86_64)\r\nGCC version: Could not collect\r\nClang version: 15.0.0 (clang-1500.3.9.4)\r\nCMake version: Could not collect\r\nLibc version: N/A\r\n\r\nPython version: 3.11.1 (main, Jan 26 2023, 14:19:45) [Clang 13.0.0 (clang-1300.0.29.30)] (64-bit runtime)\r\nPython platform: macOS-14.0-x86_64-i386-64bit\r\nIs CUDA available: False\r\nCUDA runtime version: No CUDA\r\nCUDA_MODULE_LOADING set to: N/A\r\nGPU models and configuration: No CUDA\r\nNvidia driver version: No CUDA\r\ncuDNN version: No CUDA\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\nIs XNNPACK available: True\r\n\r\nCPU:\r\nIntel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz\r\n\r\nVersions of relevant libraries:\r\n[pip3] mypy==0.991\r\n[pip3] mypy-extensions==0.4.3\r\n[pip3] numpy==1.24.1\r\n[pip3] torch==2.0.1\r\n[pip3] torch_geometric==2.4.0\r\n[pip3] torchaudio==2.0.2\r\n[pip3] torchvision==0.15.2\r\n[conda] Could not collect\n", "before_files": [{"content": "import os\nimport os.path as osp\nfrom typing import Any, Callable, Dict, List, Optional, Union\n\nimport fsspec\nimport numpy as np\nimport torch\n\nfrom torch_geometric.data import Data, InMemoryDataset\nfrom torch_geometric.io import fs\nfrom torch_geometric.utils import coalesce\n\n\nclass EgoData(Data):\n def __inc__(self, key: str, value: Any, *args: Any, **kwargs: Any) -> Any:\n if key == 'circle':\n return self.num_nodes\n elif key == 'circle_batch':\n return int(value.max()) + 1 if value.numel() > 0 else 0\n return super().__inc__(key, value, *args, **kwargs)\n\n\ndef read_ego(files: List[str], name: str) -> List[EgoData]:\n import pandas as pd\n\n all_featnames = []\n files = [\n x for x in files if x.split('.')[-1] in\n ['circles', 'edges', 'egofeat', 'feat', 'featnames']\n ]\n for i in range(4, len(files), 5):\n featnames_file = files[i]\n with fsspec.open(featnames_file, 'r') as f:\n featnames = f.read().split('\\n')[:-1]\n featnames = [' '.join(x.split(' ')[1:]) for x in featnames]\n all_featnames += featnames\n all_featnames = sorted(list(set(all_featnames)))\n all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}\n\n data_list = []\n for i in range(0, len(files), 5):\n circles_file = files[i]\n edges_file = files[i + 1]\n egofeat_file = files[i + 2]\n feat_file = files[i + 3]\n featnames_file = files[i + 4]\n\n x = None\n if name != 'gplus': # Don't read node features on g-plus:\n x_ego = pd.read_csv(egofeat_file, sep=' ', header=None,\n dtype=np.float32)\n x_ego = torch.from_numpy(x_ego.values)\n\n x = pd.read_csv(feat_file, sep=' ', header=None, dtype=np.float32)\n x = torch.from_numpy(x.values)[:, 1:]\n\n x_all = torch.cat([x, x_ego], dim=0)\n\n # Reorder `x` according to `featnames` ordering.\n x_all = torch.zeros(x.size(0), len(all_featnames))\n with fsspec.open(featnames_file, 'r') as f:\n featnames = f.read().split('\\n')[:-1]\n featnames = [' '.join(x.split(' ')[1:]) for x in featnames]\n indices = [all_featnames_dict[featname] for featname in featnames]\n x_all[:, torch.tensor(indices)] = x\n x = x_all\n\n idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,\n usecols=[0]).squeeze()\n\n idx_assoc: Dict[str, int] = {}\n for i, j in enumerate(idx):\n idx_assoc[j] = i\n\n circles: List[int] = []\n circles_batch: List[int] = []\n with fsspec.open(circles_file, 'r') as f:\n for i, line in enumerate(f.read().split('\\n')[:-1]):\n circle_indices = [idx_assoc[c] for c in line.split()[1:]]\n circles += circle_indices\n circles_batch += [i] * len(circle_indices)\n circle = torch.tensor(circles)\n circle_batch = torch.tensor(circles_batch)\n\n try:\n row = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,\n usecols=[0]).squeeze()\n col = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,\n usecols=[1]).squeeze()\n except Exception:\n continue\n\n row = torch.tensor([idx_assoc[i] for i in row])\n col = torch.tensor([idx_assoc[i] for i in col])\n\n N = max(int(row.max()), int(col.max())) + 2\n N = x.size(0) if x is not None else N\n\n row_ego = torch.full((N - 1, ), N - 1, dtype=torch.long)\n col_ego = torch.arange(N - 1)\n\n # Ego node should be connected to every other node.\n row = torch.cat([row, row_ego, col_ego], dim=0)\n col = torch.cat([col, col_ego, row_ego], dim=0)\n edge_index = torch.stack([row, col], dim=0)\n edge_index = coalesce(edge_index, num_nodes=N)\n\n data = EgoData(x=x, edge_index=edge_index, circle=circle,\n circle_batch=circle_batch)\n\n data_list.append(data)\n\n return data_list\n\n\ndef read_soc(files: List[str], name: str) -> List[Data]:\n import pandas as pd\n\n skiprows = 4\n if name == 'pokec':\n skiprows = 0\n\n edge_index = pd.read_csv(files[0], sep='\\t', header=None,\n skiprows=skiprows, dtype=np.int64)\n edge_index = torch.from_numpy(edge_index.values).t()\n num_nodes = edge_index.max().item() + 1\n edge_index = coalesce(edge_index, num_nodes=num_nodes)\n\n return [Data(edge_index=edge_index, num_nodes=num_nodes)]\n\n\ndef read_wiki(files: List[str], name: str) -> List[Data]:\n import pandas as pd\n\n edge_index = pd.read_csv(files[0], sep='\\t', header=None, skiprows=4,\n dtype=np.int64)\n edge_index = torch.from_numpy(edge_index.values).t()\n\n idx = torch.unique(edge_index.flatten())\n idx_assoc = torch.full((edge_index.max() + 1, ), -1, dtype=torch.long)\n idx_assoc[idx] = torch.arange(idx.size(0))\n\n edge_index = idx_assoc[edge_index]\n num_nodes = edge_index.max().item() + 1\n edge_index = coalesce(edge_index, num_nodes=num_nodes)\n\n return [Data(edge_index=edge_index, num_nodes=num_nodes)]\n\n\nclass SNAPDataset(InMemoryDataset):\n r\"\"\"A variety of graph datasets collected from `SNAP at Stanford University\n <https://snap.stanford.edu/data>`_.\n\n Args:\n root (str): Root directory where the dataset should be saved.\n name (str): The name of the dataset.\n transform (callable, optional): A function/transform that takes in an\n :obj:`torch_geometric.data.Data` object and returns a transformed\n version. The data object will be transformed before every access.\n (default: :obj:`None`)\n pre_transform (callable, optional): A function/transform that takes in\n an :obj:`torch_geometric.data.Data` object and returns a\n transformed version. The data object will be transformed before\n being saved to disk. (default: :obj:`None`)\n pre_filter (callable, optional): A function that takes in an\n :obj:`torch_geometric.data.Data` object and returns a boolean\n value, indicating whether the data object should be included in the\n final dataset. (default: :obj:`None`)\n force_reload (bool, optional): Whether to re-process the dataset.\n (default: :obj:`False`)\n \"\"\"\n\n url = 'https://snap.stanford.edu/data'\n\n available_datasets = {\n 'ego-facebook': ['facebook.tar.gz'],\n 'ego-gplus': ['gplus.tar.gz'],\n 'ego-twitter': ['twitter.tar.gz'],\n 'soc-ca-astroph': ['ca-AstroPh.txt.gz'],\n 'soc-ca-grqc': ['ca-GrQc.txt.gz'],\n 'soc-epinions1': ['soc-Epinions1.txt.gz'],\n 'soc-livejournal1': ['soc-LiveJournal1.txt.gz'],\n 'soc-pokec': ['soc-pokec-relationships.txt.gz'],\n 'soc-slashdot0811': ['soc-Slashdot0811.txt.gz'],\n 'soc-slashdot0922': ['soc-Slashdot0902.txt.gz'],\n 'wiki-vote': ['wiki-Vote.txt.gz'],\n }\n\n def __init__(\n self,\n root: str,\n name: str,\n transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None,\n pre_filter: Optional[Callable] = None,\n force_reload: bool = False,\n ) -> None:\n self.name = name.lower()\n assert self.name in self.available_datasets.keys()\n super().__init__(root, transform, pre_transform, pre_filter,\n force_reload=force_reload)\n self.load(self.processed_paths[0])\n\n @property\n def raw_dir(self) -> str:\n return osp.join(self.root, self.name, 'raw')\n\n @property\n def processed_dir(self) -> str:\n return osp.join(self.root, self.name, 'processed')\n\n @property\n def processed_file_names(self) -> str:\n return 'data.pt'\n\n def _download(self) -> None:\n if osp.isdir(self.raw_dir) and len(os.listdir(self.raw_dir)) > 0:\n return\n\n fs.makedirs(self.raw_dir, exist_ok=True)\n self.download()\n\n def download(self) -> None:\n for name in self.available_datasets[self.name]:\n fs.cp(f'{self.url}/{name}', self.raw_dir, extract=True)\n\n def process(self) -> None:\n raw_dir = self.raw_dir\n filenames = fs.ls(self.raw_dir)\n if len(filenames) == 1 and fs.isdir(filenames[0]):\n raw_dir = filenames[0]\n\n raw_files = fs.ls(raw_dir)\n\n data_list: Union[List[Data], List[EgoData]]\n if self.name[:4] == 'ego-':\n data_list = read_ego(raw_files, self.name[4:])\n elif self.name[:4] == 'soc-':\n data_list = read_soc(raw_files, self.name[:4])\n elif self.name[:5] == 'wiki-':\n data_list = read_wiki(raw_files, self.name[5:])\n else:\n raise NotImplementedError\n\n if len(data_list) > 1 and self.pre_filter is not None:\n data_list = [data for data in data_list if self.pre_filter(data)]\n\n if self.pre_transform is not None:\n data_list = [self.pre_transform(data) for data in data_list]\n\n self.save(data_list, self.processed_paths[0])\n\n def __repr__(self) -> str:\n return f'SNAP-{self.name}({len(self)})'\n", "path": "torch_geometric/datasets/snap_dataset.py"}], "after_files": [{"content": "import os\nimport os.path as osp\nfrom typing import Any, Callable, Dict, List, Optional, Union\n\nimport fsspec\nimport numpy as np\nimport torch\n\nfrom torch_geometric.data import Data, InMemoryDataset\nfrom torch_geometric.io import fs\nfrom torch_geometric.utils import coalesce\n\n\nclass EgoData(Data):\n def __inc__(self, key: str, value: Any, *args: Any, **kwargs: Any) -> Any:\n if key == 'circle':\n return self.num_nodes\n elif key == 'circle_batch':\n return int(value.max()) + 1 if value.numel() > 0 else 0\n return super().__inc__(key, value, *args, **kwargs)\n\n\ndef read_ego(files: List[str], name: str) -> List[EgoData]:\n import pandas as pd\n import tqdm\n\n files = sorted(files)\n\n all_featnames = []\n files = [\n x for x in files if x.split('.')[-1] in\n ['circles', 'edges', 'egofeat', 'feat', 'featnames']\n ]\n for i in range(4, len(files), 5):\n featnames_file = files[i]\n with fsspec.open(featnames_file, 'r') as f:\n featnames = f.read().split('\\n')[:-1]\n featnames = [' '.join(x.split(' ')[1:]) for x in featnames]\n all_featnames += featnames\n all_featnames = sorted(list(set(all_featnames)))\n all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}\n\n data_list = []\n for i in tqdm.tqdm(range(0, len(files), 5)):\n circles_file = files[i]\n edges_file = files[i + 1]\n egofeat_file = files[i + 2]\n feat_file = files[i + 3]\n featnames_file = files[i + 4]\n\n x = None\n if name != 'gplus': # Don't read node features on g-plus:\n x_ego = pd.read_csv(egofeat_file, sep=' ', header=None,\n dtype=np.float32)\n x_ego = torch.from_numpy(x_ego.values)\n\n x = pd.read_csv(feat_file, sep=' ', header=None, dtype=np.float32)\n x = torch.from_numpy(x.values)[:, 1:]\n\n x_all = torch.cat([x, x_ego], dim=0)\n\n # Reorder `x` according to `featnames` ordering.\n x_all = torch.zeros(x.size(0), len(all_featnames))\n with fsspec.open(featnames_file, 'r') as f:\n featnames = f.read().split('\\n')[:-1]\n featnames = [' '.join(x.split(' ')[1:]) for x in featnames]\n indices = [all_featnames_dict[featname] for featname in featnames]\n x_all[:, torch.tensor(indices)] = x\n x = x_all\n\n if x.size(1) > 100_000:\n x = x.to_sparse_csr()\n\n idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,\n usecols=[0]).squeeze()\n\n idx_assoc: Dict[str, int] = {}\n for i, j in enumerate(idx):\n idx_assoc[j] = i\n\n circles: List[int] = []\n circles_batch: List[int] = []\n with fsspec.open(circles_file, 'r') as f:\n for i, line in enumerate(f.read().split('\\n')[:-1]):\n circle_indices = [idx_assoc[c] for c in line.split()[1:]]\n circles += circle_indices\n circles_batch += [i] * len(circle_indices)\n circle = torch.tensor(circles)\n circle_batch = torch.tensor(circles_batch)\n\n try:\n row = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,\n usecols=[0]).squeeze()\n col = pd.read_csv(edges_file, sep=' ', header=None, dtype=str,\n usecols=[1]).squeeze()\n except Exception:\n continue\n\n row = torch.tensor([idx_assoc[i] for i in row])\n col = torch.tensor([idx_assoc[i] for i in col])\n\n N = max(int(row.max()), int(col.max())) + 2\n N = x.size(0) if x is not None else N\n\n row_ego = torch.full((N - 1, ), N - 1, dtype=torch.long)\n col_ego = torch.arange(N - 1)\n\n # Ego node should be connected to every other node.\n row = torch.cat([row, row_ego, col_ego], dim=0)\n col = torch.cat([col, col_ego, row_ego], dim=0)\n edge_index = torch.stack([row, col], dim=0)\n edge_index = coalesce(edge_index, num_nodes=N)\n\n data = EgoData(x=x, edge_index=edge_index, circle=circle,\n circle_batch=circle_batch)\n\n data_list.append(data)\n\n return data_list\n\n\ndef read_soc(files: List[str], name: str) -> List[Data]:\n import pandas as pd\n\n skiprows = 4\n if name == 'pokec':\n skiprows = 0\n\n edge_index = pd.read_csv(files[0], sep='\\t', header=None,\n skiprows=skiprows, dtype=np.int64)\n edge_index = torch.from_numpy(edge_index.values).t()\n num_nodes = edge_index.max().item() + 1\n edge_index = coalesce(edge_index, num_nodes=num_nodes)\n\n return [Data(edge_index=edge_index, num_nodes=num_nodes)]\n\n\ndef read_wiki(files: List[str], name: str) -> List[Data]:\n import pandas as pd\n\n edge_index = pd.read_csv(files[0], sep='\\t', header=None, skiprows=4,\n dtype=np.int64)\n edge_index = torch.from_numpy(edge_index.values).t()\n\n idx = torch.unique(edge_index.flatten())\n idx_assoc = torch.full((edge_index.max() + 1, ), -1, dtype=torch.long)\n idx_assoc[idx] = torch.arange(idx.size(0))\n\n edge_index = idx_assoc[edge_index]\n num_nodes = edge_index.max().item() + 1\n edge_index = coalesce(edge_index, num_nodes=num_nodes)\n\n return [Data(edge_index=edge_index, num_nodes=num_nodes)]\n\n\nclass SNAPDataset(InMemoryDataset):\n r\"\"\"A variety of graph datasets collected from `SNAP at Stanford University\n <https://snap.stanford.edu/data>`_.\n\n Args:\n root (str): Root directory where the dataset should be saved.\n name (str): The name of the dataset.\n transform (callable, optional): A function/transform that takes in an\n :obj:`torch_geometric.data.Data` object and returns a transformed\n version. The data object will be transformed before every access.\n (default: :obj:`None`)\n pre_transform (callable, optional): A function/transform that takes in\n an :obj:`torch_geometric.data.Data` object and returns a\n transformed version. The data object will be transformed before\n being saved to disk. (default: :obj:`None`)\n pre_filter (callable, optional): A function that takes in an\n :obj:`torch_geometric.data.Data` object and returns a boolean\n value, indicating whether the data object should be included in the\n final dataset. (default: :obj:`None`)\n force_reload (bool, optional): Whether to re-process the dataset.\n (default: :obj:`False`)\n \"\"\"\n\n url = 'https://snap.stanford.edu/data'\n\n available_datasets = {\n 'ego-facebook': ['facebook.tar.gz'],\n 'ego-gplus': ['gplus.tar.gz'],\n 'ego-twitter': ['twitter.tar.gz'],\n 'soc-ca-astroph': ['ca-AstroPh.txt.gz'],\n 'soc-ca-grqc': ['ca-GrQc.txt.gz'],\n 'soc-epinions1': ['soc-Epinions1.txt.gz'],\n 'soc-livejournal1': ['soc-LiveJournal1.txt.gz'],\n 'soc-pokec': ['soc-pokec-relationships.txt.gz'],\n 'soc-slashdot0811': ['soc-Slashdot0811.txt.gz'],\n 'soc-slashdot0922': ['soc-Slashdot0902.txt.gz'],\n 'wiki-vote': ['wiki-Vote.txt.gz'],\n }\n\n def __init__(\n self,\n root: str,\n name: str,\n transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None,\n pre_filter: Optional[Callable] = None,\n force_reload: bool = False,\n ) -> None:\n self.name = name.lower()\n assert self.name in self.available_datasets.keys()\n super().__init__(root, transform, pre_transform, pre_filter,\n force_reload=force_reload)\n self.load(self.processed_paths[0])\n\n @property\n def raw_dir(self) -> str:\n return osp.join(self.root, self.name, 'raw')\n\n @property\n def processed_dir(self) -> str:\n return osp.join(self.root, self.name, 'processed')\n\n @property\n def processed_file_names(self) -> str:\n return 'data.pt'\n\n def _download(self) -> None:\n if osp.isdir(self.raw_dir) and len(os.listdir(self.raw_dir)) > 0:\n return\n\n fs.makedirs(self.raw_dir, exist_ok=True)\n self.download()\n\n def download(self) -> None:\n for name in self.available_datasets[self.name]:\n fs.cp(f'{self.url}/{name}', self.raw_dir, extract=True)\n\n def process(self) -> None:\n raw_dir = self.raw_dir\n filenames = fs.ls(self.raw_dir)\n if len(filenames) == 1 and fs.isdir(filenames[0]):\n raw_dir = filenames[0]\n\n raw_files = fs.ls(raw_dir)\n\n data_list: Union[List[Data], List[EgoData]]\n if self.name[:4] == 'ego-':\n data_list = read_ego(raw_files, self.name[4:])\n elif self.name[:4] == 'soc-':\n data_list = read_soc(raw_files, self.name[:4])\n elif self.name[:5] == 'wiki-':\n data_list = read_wiki(raw_files, self.name[5:])\n else:\n raise NotImplementedError\n\n if len(data_list) > 1 and self.pre_filter is not None:\n data_list = [data for data in data_list if self.pre_filter(data)]\n\n if self.pre_transform is not None:\n data_list = [self.pre_transform(data) for data in data_list]\n\n self.save(data_list, self.processed_paths[0])\n\n def __repr__(self) -> str:\n return f'SNAP-{self.name}({len(self)})'\n", "path": "torch_geometric/datasets/snap_dataset.py"}]}
| 3,827 | 300 |
gh_patches_debug_40538
|
rasdani/github-patches
|
git_diff
|
borgbackup__borg-1403
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
borg mount crashes with empty archive
if one tries to mount a completely empty archive, borg mount crashes.
note: usually this never happens as one does not have empty archives.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `borg/fuse.py`
Content:
```
1 from collections import defaultdict
2 import errno
3 import io
4 import llfuse
5 import os
6 import stat
7 import tempfile
8 import time
9 from distutils.version import LooseVersion
10
11 import msgpack
12
13 from .archive import Archive
14 from .helpers import daemonize, bigint_to_int
15 from .logger import create_logger
16 from .lrucache import LRUCache
17 logger = create_logger()
18
19
20 # Does this version of llfuse support ns precision?
21 have_fuse_xtime_ns = hasattr(llfuse.EntryAttributes, 'st_mtime_ns')
22
23 fuse_version = LooseVersion(getattr(llfuse, '__version__', '0.1'))
24 if fuse_version >= '0.42':
25 def fuse_main():
26 return llfuse.main(workers=1)
27 else:
28 def fuse_main():
29 llfuse.main(single=True)
30 return None
31
32
33 class ItemCache:
34 def __init__(self):
35 self.fd = tempfile.TemporaryFile(prefix='borg-tmp')
36 self.offset = 1000000
37
38 def add(self, item):
39 pos = self.fd.seek(0, io.SEEK_END)
40 self.fd.write(msgpack.packb(item))
41 return pos + self.offset
42
43 def get(self, inode):
44 self.fd.seek(inode - self.offset, io.SEEK_SET)
45 return next(msgpack.Unpacker(self.fd, read_size=1024))
46
47
48 class FuseOperations(llfuse.Operations):
49 """Export archive as a fuse filesystem
50 """
51
52 allow_damaged_files = False
53
54 def __init__(self, key, repository, manifest, archive, cached_repo):
55 super().__init__()
56 self._inode_count = 0
57 self.key = key
58 self.repository = cached_repo
59 self.items = {}
60 self.parent = {}
61 self.contents = defaultdict(dict)
62 self.default_dir = {b'mode': 0o40755, b'mtime': int(time.time() * 1e9), b'uid': os.getuid(), b'gid': os.getgid()}
63 self.pending_archives = {}
64 self.accounted_chunks = {}
65 self.cache = ItemCache()
66 data_cache_capacity = int(os.environ.get('BORG_MOUNT_DATA_CACHE_ENTRIES', os.cpu_count() or 1))
67 logger.debug('mount data cache capacity: %d chunks', data_cache_capacity)
68 self.data_cache = LRUCache(capacity=data_cache_capacity, dispose=lambda _: None)
69 if archive:
70 self.process_archive(archive)
71 else:
72 # Create root inode
73 self.parent[1] = self.allocate_inode()
74 self.items[1] = self.default_dir
75 for archive_name in manifest.archives:
76 # Create archive placeholder inode
77 archive_inode = self.allocate_inode()
78 self.items[archive_inode] = self.default_dir
79 self.parent[archive_inode] = 1
80 self.contents[1][os.fsencode(archive_name)] = archive_inode
81 self.pending_archives[archive_inode] = Archive(repository, key, manifest, archive_name)
82
83 def mount(self, mountpoint, mount_options, foreground=False):
84 """Mount filesystem on *mountpoint* with *mount_options*."""
85 options = ['fsname=borgfs', 'ro']
86 if mount_options:
87 options.extend(mount_options.split(','))
88 try:
89 options.remove('allow_damaged_files')
90 self.allow_damaged_files = True
91 except ValueError:
92 pass
93 llfuse.init(self, mountpoint, options)
94 if not foreground:
95 daemonize()
96
97 # If the file system crashes, we do not want to umount because in that
98 # case the mountpoint suddenly appears to become empty. This can have
99 # nasty consequences, imagine the user has e.g. an active rsync mirror
100 # job - seeing the mountpoint empty, rsync would delete everything in the
101 # mirror.
102 umount = False
103 try:
104 signal = fuse_main()
105 umount = (signal is None) # no crash and no signal -> umount request
106 finally:
107 llfuse.close(umount)
108
109 def process_archive(self, archive, prefix=[]):
110 """Build fuse inode hierarchy from archive metadata
111 """
112 unpacker = msgpack.Unpacker()
113 for key, chunk in zip(archive.metadata[b'items'], self.repository.get_many(archive.metadata[b'items'])):
114 data = self.key.decrypt(key, chunk)
115 unpacker.feed(data)
116 for item in unpacker:
117 try:
118 # This can happen if an archive was created with a command line like
119 # $ borg create ... dir1/file dir1
120 # In this case the code below will have created a default_dir inode for dir1 already.
121 inode = self._find_inode(item[b'path'], prefix)
122 except KeyError:
123 pass
124 else:
125 self.items[inode] = item
126 continue
127 segments = prefix + os.fsencode(os.path.normpath(item[b'path'])).split(b'/')
128 del item[b'path']
129 num_segments = len(segments)
130 parent = 1
131 for i, segment in enumerate(segments, 1):
132 # Insert a default root inode if needed
133 if self._inode_count == 0 and segment:
134 archive_inode = self.allocate_inode()
135 self.items[archive_inode] = self.default_dir
136 self.parent[archive_inode] = parent
137 # Leaf segment?
138 if i == num_segments:
139 if b'source' in item and stat.S_ISREG(item[b'mode']):
140 inode = self._find_inode(item[b'source'], prefix)
141 item = self.cache.get(inode)
142 item[b'nlink'] = item.get(b'nlink', 1) + 1
143 self.items[inode] = item
144 else:
145 inode = self.cache.add(item)
146 self.parent[inode] = parent
147 if segment:
148 self.contents[parent][segment] = inode
149 elif segment in self.contents[parent]:
150 parent = self.contents[parent][segment]
151 else:
152 inode = self.allocate_inode()
153 self.items[inode] = self.default_dir
154 self.parent[inode] = parent
155 if segment:
156 self.contents[parent][segment] = inode
157 parent = inode
158
159 def allocate_inode(self):
160 self._inode_count += 1
161 return self._inode_count
162
163 def statfs(self, ctx=None):
164 stat_ = llfuse.StatvfsData()
165 stat_.f_bsize = 512
166 stat_.f_frsize = 512
167 stat_.f_blocks = 0
168 stat_.f_bfree = 0
169 stat_.f_bavail = 0
170 stat_.f_files = 0
171 stat_.f_ffree = 0
172 stat_.f_favail = 0
173 return stat_
174
175 def get_item(self, inode):
176 try:
177 return self.items[inode]
178 except KeyError:
179 return self.cache.get(inode)
180
181 def _find_inode(self, path, prefix=[]):
182 segments = prefix + os.fsencode(os.path.normpath(path)).split(b'/')
183 inode = 1
184 for segment in segments:
185 inode = self.contents[inode][segment]
186 return inode
187
188 def getattr(self, inode, ctx=None):
189 item = self.get_item(inode)
190 size = 0
191 dsize = 0
192 try:
193 for key, chunksize, _ in item[b'chunks']:
194 size += chunksize
195 if self.accounted_chunks.get(key, inode) == inode:
196 self.accounted_chunks[key] = inode
197 dsize += chunksize
198 except KeyError:
199 pass
200 entry = llfuse.EntryAttributes()
201 entry.st_ino = inode
202 entry.generation = 0
203 entry.entry_timeout = 300
204 entry.attr_timeout = 300
205 entry.st_mode = item[b'mode']
206 entry.st_nlink = item.get(b'nlink', 1)
207 entry.st_uid = item[b'uid']
208 entry.st_gid = item[b'gid']
209 entry.st_rdev = item.get(b'rdev', 0)
210 entry.st_size = size
211 entry.st_blksize = 512
212 entry.st_blocks = dsize / 512
213 # note: older archives only have mtime (not atime nor ctime)
214 if have_fuse_xtime_ns:
215 entry.st_mtime_ns = bigint_to_int(item[b'mtime'])
216 if b'atime' in item:
217 entry.st_atime_ns = bigint_to_int(item[b'atime'])
218 else:
219 entry.st_atime_ns = bigint_to_int(item[b'mtime'])
220 if b'ctime' in item:
221 entry.st_ctime_ns = bigint_to_int(item[b'ctime'])
222 else:
223 entry.st_ctime_ns = bigint_to_int(item[b'mtime'])
224 else:
225 entry.st_mtime = bigint_to_int(item[b'mtime']) / 1e9
226 if b'atime' in item:
227 entry.st_atime = bigint_to_int(item[b'atime']) / 1e9
228 else:
229 entry.st_atime = bigint_to_int(item[b'mtime']) / 1e9
230 if b'ctime' in item:
231 entry.st_ctime = bigint_to_int(item[b'ctime']) / 1e9
232 else:
233 entry.st_ctime = bigint_to_int(item[b'mtime']) / 1e9
234 return entry
235
236 def listxattr(self, inode, ctx=None):
237 item = self.get_item(inode)
238 return item.get(b'xattrs', {}).keys()
239
240 def getxattr(self, inode, name, ctx=None):
241 item = self.get_item(inode)
242 try:
243 return item.get(b'xattrs', {})[name]
244 except KeyError:
245 raise llfuse.FUSEError(llfuse.ENOATTR) from None
246
247 def _load_pending_archive(self, inode):
248 # Check if this is an archive we need to load
249 archive = self.pending_archives.pop(inode, None)
250 if archive:
251 self.process_archive(archive, [os.fsencode(archive.name)])
252
253 def lookup(self, parent_inode, name, ctx=None):
254 self._load_pending_archive(parent_inode)
255 if name == b'.':
256 inode = parent_inode
257 elif name == b'..':
258 inode = self.parent[parent_inode]
259 else:
260 inode = self.contents[parent_inode].get(name)
261 if not inode:
262 raise llfuse.FUSEError(errno.ENOENT)
263 return self.getattr(inode)
264
265 def open(self, inode, flags, ctx=None):
266 if not self.allow_damaged_files:
267 item = self.get_item(inode)
268 if b'chunks_healthy' in item:
269 # Processed archive items don't carry the path anymore; for converting the inode
270 # to the path we'd either have to store the inverse of the current structure,
271 # or search the entire archive. So we just don't print it. It's easy to correlate anyway.
272 logger.warning('File has damaged (all-zero) chunks. Try running borg check --repair. '
273 'Mount with allow_damaged_files to read damaged files.')
274 raise llfuse.FUSEError(errno.EIO)
275 return inode
276
277 def opendir(self, inode, ctx=None):
278 self._load_pending_archive(inode)
279 return inode
280
281 def read(self, fh, offset, size):
282 parts = []
283 item = self.get_item(fh)
284 for id, s, csize in item[b'chunks']:
285 if s < offset:
286 offset -= s
287 continue
288 n = min(size, s - offset)
289 if id in self.data_cache:
290 data = self.data_cache[id]
291 if offset + n == len(data):
292 # evict fully read chunk from cache
293 del self.data_cache[id]
294 else:
295 data = self.key.decrypt(id, self.repository.get(id))
296 if offset + n < len(data):
297 # chunk was only partially read, cache it
298 self.data_cache[id] = data
299 parts.append(data[offset:offset + n])
300 offset = 0
301 size -= n
302 if not size:
303 break
304 return b''.join(parts)
305
306 def readdir(self, fh, off):
307 entries = [(b'.', fh), (b'..', self.parent[fh])]
308 entries.extend(self.contents[fh].items())
309 for i, (name, inode) in enumerate(entries[off:], off):
310 yield name, self.getattr(inode), i + 1
311
312 def readlink(self, inode, ctx=None):
313 item = self.get_item(inode)
314 return os.fsencode(item[b'source'])
315
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/borg/fuse.py b/borg/fuse.py
--- a/borg/fuse.py
+++ b/borg/fuse.py
@@ -66,17 +66,13 @@
data_cache_capacity = int(os.environ.get('BORG_MOUNT_DATA_CACHE_ENTRIES', os.cpu_count() or 1))
logger.debug('mount data cache capacity: %d chunks', data_cache_capacity)
self.data_cache = LRUCache(capacity=data_cache_capacity, dispose=lambda _: None)
+ self._create_dir(parent=1) # first call, create root dir (inode == 1)
if archive:
self.process_archive(archive)
else:
- # Create root inode
- self.parent[1] = self.allocate_inode()
- self.items[1] = self.default_dir
for archive_name in manifest.archives:
# Create archive placeholder inode
- archive_inode = self.allocate_inode()
- self.items[archive_inode] = self.default_dir
- self.parent[archive_inode] = 1
+ archive_inode = self._create_dir(parent=1)
self.contents[1][os.fsencode(archive_name)] = archive_inode
self.pending_archives[archive_inode] = Archive(repository, key, manifest, archive_name)
@@ -106,6 +102,14 @@
finally:
llfuse.close(umount)
+ def _create_dir(self, parent):
+ """Create directory
+ """
+ ino = self.allocate_inode()
+ self.items[ino] = self.default_dir
+ self.parent[ino] = parent
+ return ino
+
def process_archive(self, archive, prefix=[]):
"""Build fuse inode hierarchy from archive metadata
"""
@@ -129,11 +133,6 @@
num_segments = len(segments)
parent = 1
for i, segment in enumerate(segments, 1):
- # Insert a default root inode if needed
- if self._inode_count == 0 and segment:
- archive_inode = self.allocate_inode()
- self.items[archive_inode] = self.default_dir
- self.parent[archive_inode] = parent
# Leaf segment?
if i == num_segments:
if b'source' in item and stat.S_ISREG(item[b'mode']):
@@ -149,9 +148,7 @@
elif segment in self.contents[parent]:
parent = self.contents[parent][segment]
else:
- inode = self.allocate_inode()
- self.items[inode] = self.default_dir
- self.parent[inode] = parent
+ inode = self._create_dir(parent)
if segment:
self.contents[parent][segment] = inode
parent = inode
|
{"golden_diff": "diff --git a/borg/fuse.py b/borg/fuse.py\n--- a/borg/fuse.py\n+++ b/borg/fuse.py\n@@ -66,17 +66,13 @@\n data_cache_capacity = int(os.environ.get('BORG_MOUNT_DATA_CACHE_ENTRIES', os.cpu_count() or 1))\n logger.debug('mount data cache capacity: %d chunks', data_cache_capacity)\n self.data_cache = LRUCache(capacity=data_cache_capacity, dispose=lambda _: None)\n+ self._create_dir(parent=1) # first call, create root dir (inode == 1)\n if archive:\n self.process_archive(archive)\n else:\n- # Create root inode\n- self.parent[1] = self.allocate_inode()\n- self.items[1] = self.default_dir\n for archive_name in manifest.archives:\n # Create archive placeholder inode\n- archive_inode = self.allocate_inode()\n- self.items[archive_inode] = self.default_dir\n- self.parent[archive_inode] = 1\n+ archive_inode = self._create_dir(parent=1)\n self.contents[1][os.fsencode(archive_name)] = archive_inode\n self.pending_archives[archive_inode] = Archive(repository, key, manifest, archive_name)\n \n@@ -106,6 +102,14 @@\n finally:\n llfuse.close(umount)\n \n+ def _create_dir(self, parent):\n+ \"\"\"Create directory\n+ \"\"\"\n+ ino = self.allocate_inode()\n+ self.items[ino] = self.default_dir\n+ self.parent[ino] = parent\n+ return ino\n+\n def process_archive(self, archive, prefix=[]):\n \"\"\"Build fuse inode hierarchy from archive metadata\n \"\"\"\n@@ -129,11 +133,6 @@\n num_segments = len(segments)\n parent = 1\n for i, segment in enumerate(segments, 1):\n- # Insert a default root inode if needed\n- if self._inode_count == 0 and segment:\n- archive_inode = self.allocate_inode()\n- self.items[archive_inode] = self.default_dir\n- self.parent[archive_inode] = parent\n # Leaf segment?\n if i == num_segments:\n if b'source' in item and stat.S_ISREG(item[b'mode']):\n@@ -149,9 +148,7 @@\n elif segment in self.contents[parent]:\n parent = self.contents[parent][segment]\n else:\n- inode = self.allocate_inode()\n- self.items[inode] = self.default_dir\n- self.parent[inode] = parent\n+ inode = self._create_dir(parent)\n if segment:\n self.contents[parent][segment] = inode\n parent = inode\n", "issue": "borg mount crashes with empty archive\nif one tries to mount a completely empty archive, borg mount crashes.\n\nnote: usually this never happens as one does not have empty archives.\n\n", "before_files": [{"content": "from collections import defaultdict\nimport errno\nimport io\nimport llfuse\nimport os\nimport stat\nimport tempfile\nimport time\nfrom distutils.version import LooseVersion\n\nimport msgpack\n\nfrom .archive import Archive\nfrom .helpers import daemonize, bigint_to_int\nfrom .logger import create_logger\nfrom .lrucache import LRUCache\nlogger = create_logger()\n\n\n# Does this version of llfuse support ns precision?\nhave_fuse_xtime_ns = hasattr(llfuse.EntryAttributes, 'st_mtime_ns')\n\nfuse_version = LooseVersion(getattr(llfuse, '__version__', '0.1'))\nif fuse_version >= '0.42':\n def fuse_main():\n return llfuse.main(workers=1)\nelse:\n def fuse_main():\n llfuse.main(single=True)\n return None\n\n\nclass ItemCache:\n def __init__(self):\n self.fd = tempfile.TemporaryFile(prefix='borg-tmp')\n self.offset = 1000000\n\n def add(self, item):\n pos = self.fd.seek(0, io.SEEK_END)\n self.fd.write(msgpack.packb(item))\n return pos + self.offset\n\n def get(self, inode):\n self.fd.seek(inode - self.offset, io.SEEK_SET)\n return next(msgpack.Unpacker(self.fd, read_size=1024))\n\n\nclass FuseOperations(llfuse.Operations):\n \"\"\"Export archive as a fuse filesystem\n \"\"\"\n\n allow_damaged_files = False\n\n def __init__(self, key, repository, manifest, archive, cached_repo):\n super().__init__()\n self._inode_count = 0\n self.key = key\n self.repository = cached_repo\n self.items = {}\n self.parent = {}\n self.contents = defaultdict(dict)\n self.default_dir = {b'mode': 0o40755, b'mtime': int(time.time() * 1e9), b'uid': os.getuid(), b'gid': os.getgid()}\n self.pending_archives = {}\n self.accounted_chunks = {}\n self.cache = ItemCache()\n data_cache_capacity = int(os.environ.get('BORG_MOUNT_DATA_CACHE_ENTRIES', os.cpu_count() or 1))\n logger.debug('mount data cache capacity: %d chunks', data_cache_capacity)\n self.data_cache = LRUCache(capacity=data_cache_capacity, dispose=lambda _: None)\n if archive:\n self.process_archive(archive)\n else:\n # Create root inode\n self.parent[1] = self.allocate_inode()\n self.items[1] = self.default_dir\n for archive_name in manifest.archives:\n # Create archive placeholder inode\n archive_inode = self.allocate_inode()\n self.items[archive_inode] = self.default_dir\n self.parent[archive_inode] = 1\n self.contents[1][os.fsencode(archive_name)] = archive_inode\n self.pending_archives[archive_inode] = Archive(repository, key, manifest, archive_name)\n\n def mount(self, mountpoint, mount_options, foreground=False):\n \"\"\"Mount filesystem on *mountpoint* with *mount_options*.\"\"\"\n options = ['fsname=borgfs', 'ro']\n if mount_options:\n options.extend(mount_options.split(','))\n try:\n options.remove('allow_damaged_files')\n self.allow_damaged_files = True\n except ValueError:\n pass\n llfuse.init(self, mountpoint, options)\n if not foreground:\n daemonize()\n\n # If the file system crashes, we do not want to umount because in that\n # case the mountpoint suddenly appears to become empty. This can have\n # nasty consequences, imagine the user has e.g. an active rsync mirror\n # job - seeing the mountpoint empty, rsync would delete everything in the\n # mirror.\n umount = False\n try:\n signal = fuse_main()\n umount = (signal is None) # no crash and no signal -> umount request\n finally:\n llfuse.close(umount)\n\n def process_archive(self, archive, prefix=[]):\n \"\"\"Build fuse inode hierarchy from archive metadata\n \"\"\"\n unpacker = msgpack.Unpacker()\n for key, chunk in zip(archive.metadata[b'items'], self.repository.get_many(archive.metadata[b'items'])):\n data = self.key.decrypt(key, chunk)\n unpacker.feed(data)\n for item in unpacker:\n try:\n # This can happen if an archive was created with a command line like\n # $ borg create ... dir1/file dir1\n # In this case the code below will have created a default_dir inode for dir1 already.\n inode = self._find_inode(item[b'path'], prefix)\n except KeyError:\n pass\n else:\n self.items[inode] = item\n continue\n segments = prefix + os.fsencode(os.path.normpath(item[b'path'])).split(b'/')\n del item[b'path']\n num_segments = len(segments)\n parent = 1\n for i, segment in enumerate(segments, 1):\n # Insert a default root inode if needed\n if self._inode_count == 0 and segment:\n archive_inode = self.allocate_inode()\n self.items[archive_inode] = self.default_dir\n self.parent[archive_inode] = parent\n # Leaf segment?\n if i == num_segments:\n if b'source' in item and stat.S_ISREG(item[b'mode']):\n inode = self._find_inode(item[b'source'], prefix)\n item = self.cache.get(inode)\n item[b'nlink'] = item.get(b'nlink', 1) + 1\n self.items[inode] = item\n else:\n inode = self.cache.add(item)\n self.parent[inode] = parent\n if segment:\n self.contents[parent][segment] = inode\n elif segment in self.contents[parent]:\n parent = self.contents[parent][segment]\n else:\n inode = self.allocate_inode()\n self.items[inode] = self.default_dir\n self.parent[inode] = parent\n if segment:\n self.contents[parent][segment] = inode\n parent = inode\n\n def allocate_inode(self):\n self._inode_count += 1\n return self._inode_count\n\n def statfs(self, ctx=None):\n stat_ = llfuse.StatvfsData()\n stat_.f_bsize = 512\n stat_.f_frsize = 512\n stat_.f_blocks = 0\n stat_.f_bfree = 0\n stat_.f_bavail = 0\n stat_.f_files = 0\n stat_.f_ffree = 0\n stat_.f_favail = 0\n return stat_\n\n def get_item(self, inode):\n try:\n return self.items[inode]\n except KeyError:\n return self.cache.get(inode)\n\n def _find_inode(self, path, prefix=[]):\n segments = prefix + os.fsencode(os.path.normpath(path)).split(b'/')\n inode = 1\n for segment in segments:\n inode = self.contents[inode][segment]\n return inode\n\n def getattr(self, inode, ctx=None):\n item = self.get_item(inode)\n size = 0\n dsize = 0\n try:\n for key, chunksize, _ in item[b'chunks']:\n size += chunksize\n if self.accounted_chunks.get(key, inode) == inode:\n self.accounted_chunks[key] = inode\n dsize += chunksize\n except KeyError:\n pass\n entry = llfuse.EntryAttributes()\n entry.st_ino = inode\n entry.generation = 0\n entry.entry_timeout = 300\n entry.attr_timeout = 300\n entry.st_mode = item[b'mode']\n entry.st_nlink = item.get(b'nlink', 1)\n entry.st_uid = item[b'uid']\n entry.st_gid = item[b'gid']\n entry.st_rdev = item.get(b'rdev', 0)\n entry.st_size = size\n entry.st_blksize = 512\n entry.st_blocks = dsize / 512\n # note: older archives only have mtime (not atime nor ctime)\n if have_fuse_xtime_ns:\n entry.st_mtime_ns = bigint_to_int(item[b'mtime'])\n if b'atime' in item:\n entry.st_atime_ns = bigint_to_int(item[b'atime'])\n else:\n entry.st_atime_ns = bigint_to_int(item[b'mtime'])\n if b'ctime' in item:\n entry.st_ctime_ns = bigint_to_int(item[b'ctime'])\n else:\n entry.st_ctime_ns = bigint_to_int(item[b'mtime'])\n else:\n entry.st_mtime = bigint_to_int(item[b'mtime']) / 1e9\n if b'atime' in item:\n entry.st_atime = bigint_to_int(item[b'atime']) / 1e9\n else:\n entry.st_atime = bigint_to_int(item[b'mtime']) / 1e9\n if b'ctime' in item:\n entry.st_ctime = bigint_to_int(item[b'ctime']) / 1e9\n else:\n entry.st_ctime = bigint_to_int(item[b'mtime']) / 1e9\n return entry\n\n def listxattr(self, inode, ctx=None):\n item = self.get_item(inode)\n return item.get(b'xattrs', {}).keys()\n\n def getxattr(self, inode, name, ctx=None):\n item = self.get_item(inode)\n try:\n return item.get(b'xattrs', {})[name]\n except KeyError:\n raise llfuse.FUSEError(llfuse.ENOATTR) from None\n\n def _load_pending_archive(self, inode):\n # Check if this is an archive we need to load\n archive = self.pending_archives.pop(inode, None)\n if archive:\n self.process_archive(archive, [os.fsencode(archive.name)])\n\n def lookup(self, parent_inode, name, ctx=None):\n self._load_pending_archive(parent_inode)\n if name == b'.':\n inode = parent_inode\n elif name == b'..':\n inode = self.parent[parent_inode]\n else:\n inode = self.contents[parent_inode].get(name)\n if not inode:\n raise llfuse.FUSEError(errno.ENOENT)\n return self.getattr(inode)\n\n def open(self, inode, flags, ctx=None):\n if not self.allow_damaged_files:\n item = self.get_item(inode)\n if b'chunks_healthy' in item:\n # Processed archive items don't carry the path anymore; for converting the inode\n # to the path we'd either have to store the inverse of the current structure,\n # or search the entire archive. So we just don't print it. It's easy to correlate anyway.\n logger.warning('File has damaged (all-zero) chunks. Try running borg check --repair. '\n 'Mount with allow_damaged_files to read damaged files.')\n raise llfuse.FUSEError(errno.EIO)\n return inode\n\n def opendir(self, inode, ctx=None):\n self._load_pending_archive(inode)\n return inode\n\n def read(self, fh, offset, size):\n parts = []\n item = self.get_item(fh)\n for id, s, csize in item[b'chunks']:\n if s < offset:\n offset -= s\n continue\n n = min(size, s - offset)\n if id in self.data_cache:\n data = self.data_cache[id]\n if offset + n == len(data):\n # evict fully read chunk from cache\n del self.data_cache[id]\n else:\n data = self.key.decrypt(id, self.repository.get(id))\n if offset + n < len(data):\n # chunk was only partially read, cache it\n self.data_cache[id] = data\n parts.append(data[offset:offset + n])\n offset = 0\n size -= n\n if not size:\n break\n return b''.join(parts)\n\n def readdir(self, fh, off):\n entries = [(b'.', fh), (b'..', self.parent[fh])]\n entries.extend(self.contents[fh].items())\n for i, (name, inode) in enumerate(entries[off:], off):\n yield name, self.getattr(inode), i + 1\n\n def readlink(self, inode, ctx=None):\n item = self.get_item(inode)\n return os.fsencode(item[b'source'])\n", "path": "borg/fuse.py"}], "after_files": [{"content": "from collections import defaultdict\nimport errno\nimport io\nimport llfuse\nimport os\nimport stat\nimport tempfile\nimport time\nfrom distutils.version import LooseVersion\n\nimport msgpack\n\nfrom .archive import Archive\nfrom .helpers import daemonize, bigint_to_int\nfrom .logger import create_logger\nfrom .lrucache import LRUCache\nlogger = create_logger()\n\n\n# Does this version of llfuse support ns precision?\nhave_fuse_xtime_ns = hasattr(llfuse.EntryAttributes, 'st_mtime_ns')\n\nfuse_version = LooseVersion(getattr(llfuse, '__version__', '0.1'))\nif fuse_version >= '0.42':\n def fuse_main():\n return llfuse.main(workers=1)\nelse:\n def fuse_main():\n llfuse.main(single=True)\n return None\n\n\nclass ItemCache:\n def __init__(self):\n self.fd = tempfile.TemporaryFile(prefix='borg-tmp')\n self.offset = 1000000\n\n def add(self, item):\n pos = self.fd.seek(0, io.SEEK_END)\n self.fd.write(msgpack.packb(item))\n return pos + self.offset\n\n def get(self, inode):\n self.fd.seek(inode - self.offset, io.SEEK_SET)\n return next(msgpack.Unpacker(self.fd, read_size=1024))\n\n\nclass FuseOperations(llfuse.Operations):\n \"\"\"Export archive as a fuse filesystem\n \"\"\"\n\n allow_damaged_files = False\n\n def __init__(self, key, repository, manifest, archive, cached_repo):\n super().__init__()\n self._inode_count = 0\n self.key = key\n self.repository = cached_repo\n self.items = {}\n self.parent = {}\n self.contents = defaultdict(dict)\n self.default_dir = {b'mode': 0o40755, b'mtime': int(time.time() * 1e9), b'uid': os.getuid(), b'gid': os.getgid()}\n self.pending_archives = {}\n self.accounted_chunks = {}\n self.cache = ItemCache()\n data_cache_capacity = int(os.environ.get('BORG_MOUNT_DATA_CACHE_ENTRIES', os.cpu_count() or 1))\n logger.debug('mount data cache capacity: %d chunks', data_cache_capacity)\n self.data_cache = LRUCache(capacity=data_cache_capacity, dispose=lambda _: None)\n self._create_dir(parent=1) # first call, create root dir (inode == 1)\n if archive:\n self.process_archive(archive)\n else:\n for archive_name in manifest.archives:\n # Create archive placeholder inode\n archive_inode = self._create_dir(parent=1)\n self.contents[1][os.fsencode(archive_name)] = archive_inode\n self.pending_archives[archive_inode] = Archive(repository, key, manifest, archive_name)\n\n def mount(self, mountpoint, mount_options, foreground=False):\n \"\"\"Mount filesystem on *mountpoint* with *mount_options*.\"\"\"\n options = ['fsname=borgfs', 'ro']\n if mount_options:\n options.extend(mount_options.split(','))\n try:\n options.remove('allow_damaged_files')\n self.allow_damaged_files = True\n except ValueError:\n pass\n llfuse.init(self, mountpoint, options)\n if not foreground:\n daemonize()\n\n # If the file system crashes, we do not want to umount because in that\n # case the mountpoint suddenly appears to become empty. This can have\n # nasty consequences, imagine the user has e.g. an active rsync mirror\n # job - seeing the mountpoint empty, rsync would delete everything in the\n # mirror.\n umount = False\n try:\n signal = fuse_main()\n umount = (signal is None) # no crash and no signal -> umount request\n finally:\n llfuse.close(umount)\n\n def _create_dir(self, parent):\n \"\"\"Create directory\n \"\"\"\n ino = self.allocate_inode()\n self.items[ino] = self.default_dir\n self.parent[ino] = parent\n return ino\n\n def process_archive(self, archive, prefix=[]):\n \"\"\"Build fuse inode hierarchy from archive metadata\n \"\"\"\n unpacker = msgpack.Unpacker()\n for key, chunk in zip(archive.metadata[b'items'], self.repository.get_many(archive.metadata[b'items'])):\n data = self.key.decrypt(key, chunk)\n unpacker.feed(data)\n for item in unpacker:\n try:\n # This can happen if an archive was created with a command line like\n # $ borg create ... dir1/file dir1\n # In this case the code below will have created a default_dir inode for dir1 already.\n inode = self._find_inode(item[b'path'], prefix)\n except KeyError:\n pass\n else:\n self.items[inode] = item\n continue\n segments = prefix + os.fsencode(os.path.normpath(item[b'path'])).split(b'/')\n del item[b'path']\n num_segments = len(segments)\n parent = 1\n for i, segment in enumerate(segments, 1):\n # Leaf segment?\n if i == num_segments:\n if b'source' in item and stat.S_ISREG(item[b'mode']):\n inode = self._find_inode(item[b'source'], prefix)\n item = self.cache.get(inode)\n item[b'nlink'] = item.get(b'nlink', 1) + 1\n self.items[inode] = item\n else:\n inode = self.cache.add(item)\n self.parent[inode] = parent\n if segment:\n self.contents[parent][segment] = inode\n elif segment in self.contents[parent]:\n parent = self.contents[parent][segment]\n else:\n inode = self._create_dir(parent)\n if segment:\n self.contents[parent][segment] = inode\n parent = inode\n\n def allocate_inode(self):\n self._inode_count += 1\n return self._inode_count\n\n def statfs(self, ctx=None):\n stat_ = llfuse.StatvfsData()\n stat_.f_bsize = 512\n stat_.f_frsize = 512\n stat_.f_blocks = 0\n stat_.f_bfree = 0\n stat_.f_bavail = 0\n stat_.f_files = 0\n stat_.f_ffree = 0\n stat_.f_favail = 0\n return stat_\n\n def get_item(self, inode):\n try:\n return self.items[inode]\n except KeyError:\n return self.cache.get(inode)\n\n def _find_inode(self, path, prefix=[]):\n segments = prefix + os.fsencode(os.path.normpath(path)).split(b'/')\n inode = 1\n for segment in segments:\n inode = self.contents[inode][segment]\n return inode\n\n def getattr(self, inode, ctx=None):\n item = self.get_item(inode)\n size = 0\n dsize = 0\n try:\n for key, chunksize, _ in item[b'chunks']:\n size += chunksize\n if self.accounted_chunks.get(key, inode) == inode:\n self.accounted_chunks[key] = inode\n dsize += chunksize\n except KeyError:\n pass\n entry = llfuse.EntryAttributes()\n entry.st_ino = inode\n entry.generation = 0\n entry.entry_timeout = 300\n entry.attr_timeout = 300\n entry.st_mode = item[b'mode']\n entry.st_nlink = item.get(b'nlink', 1)\n entry.st_uid = item[b'uid']\n entry.st_gid = item[b'gid']\n entry.st_rdev = item.get(b'rdev', 0)\n entry.st_size = size\n entry.st_blksize = 512\n entry.st_blocks = dsize / 512\n # note: older archives only have mtime (not atime nor ctime)\n if have_fuse_xtime_ns:\n entry.st_mtime_ns = bigint_to_int(item[b'mtime'])\n if b'atime' in item:\n entry.st_atime_ns = bigint_to_int(item[b'atime'])\n else:\n entry.st_atime_ns = bigint_to_int(item[b'mtime'])\n if b'ctime' in item:\n entry.st_ctime_ns = bigint_to_int(item[b'ctime'])\n else:\n entry.st_ctime_ns = bigint_to_int(item[b'mtime'])\n else:\n entry.st_mtime = bigint_to_int(item[b'mtime']) / 1e9\n if b'atime' in item:\n entry.st_atime = bigint_to_int(item[b'atime']) / 1e9\n else:\n entry.st_atime = bigint_to_int(item[b'mtime']) / 1e9\n if b'ctime' in item:\n entry.st_ctime = bigint_to_int(item[b'ctime']) / 1e9\n else:\n entry.st_ctime = bigint_to_int(item[b'mtime']) / 1e9\n return entry\n\n def listxattr(self, inode, ctx=None):\n item = self.get_item(inode)\n return item.get(b'xattrs', {}).keys()\n\n def getxattr(self, inode, name, ctx=None):\n item = self.get_item(inode)\n try:\n return item.get(b'xattrs', {})[name]\n except KeyError:\n raise llfuse.FUSEError(llfuse.ENOATTR) from None\n\n def _load_pending_archive(self, inode):\n # Check if this is an archive we need to load\n archive = self.pending_archives.pop(inode, None)\n if archive:\n self.process_archive(archive, [os.fsencode(archive.name)])\n\n def lookup(self, parent_inode, name, ctx=None):\n self._load_pending_archive(parent_inode)\n if name == b'.':\n inode = parent_inode\n elif name == b'..':\n inode = self.parent[parent_inode]\n else:\n inode = self.contents[parent_inode].get(name)\n if not inode:\n raise llfuse.FUSEError(errno.ENOENT)\n return self.getattr(inode)\n\n def open(self, inode, flags, ctx=None):\n if not self.allow_damaged_files:\n item = self.get_item(inode)\n if b'chunks_healthy' in item:\n # Processed archive items don't carry the path anymore; for converting the inode\n # to the path we'd either have to store the inverse of the current structure,\n # or search the entire archive. So we just don't print it. It's easy to correlate anyway.\n logger.warning('File has damaged (all-zero) chunks. Try running borg check --repair. '\n 'Mount with allow_damaged_files to read damaged files.')\n raise llfuse.FUSEError(errno.EIO)\n return inode\n\n def opendir(self, inode, ctx=None):\n self._load_pending_archive(inode)\n return inode\n\n def read(self, fh, offset, size):\n parts = []\n item = self.get_item(fh)\n for id, s, csize in item[b'chunks']:\n if s < offset:\n offset -= s\n continue\n n = min(size, s - offset)\n if id in self.data_cache:\n data = self.data_cache[id]\n if offset + n == len(data):\n # evict fully read chunk from cache\n del self.data_cache[id]\n else:\n data = self.key.decrypt(id, self.repository.get(id))\n if offset + n < len(data):\n # chunk was only partially read, cache it\n self.data_cache[id] = data\n parts.append(data[offset:offset + n])\n offset = 0\n size -= n\n if not size:\n break\n return b''.join(parts)\n\n def readdir(self, fh, off):\n entries = [(b'.', fh), (b'..', self.parent[fh])]\n entries.extend(self.contents[fh].items())\n for i, (name, inode) in enumerate(entries[off:], off):\n yield name, self.getattr(inode), i + 1\n\n def readlink(self, inode, ctx=None):\n item = self.get_item(inode)\n return os.fsencode(item[b'source'])\n", "path": "borg/fuse.py"}]}
| 3,861 | 606 |
gh_patches_debug_856
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1451
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dependecy conflict between botframework 4.11.0 and azure-identity 1.5.0
## Version
4.11 (also happening with 4.10)
## Describe the bug
`botframework-connector == 4.11.0` (current) requires `msal == 1.2.0`
`azure-identity == 1.5.0` (current) requires `msal >=1.6.0,<2.0.0`
This created a dependency conflict where bot libraries can't coexist in the same program. This used to work a couple of months ago (I bumped into this issue after revisiting some code I had worked on before).
## To Reproduce
This is my `requirements.txt` file, just add it and run `pipenv install -r requirements.txt` (versions pinned to :
```
botbuilder-core == 4.11
azure-keyvault-secrets
azure-identity == 1.5
botbuilder-ai == 4.11
```
## Expected behavior
Packages should install without conflict
## Screenshots
Extract from the error message `pipenv install` shows:
```
[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.
First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.
Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.
Hint: try $ pipenv lock --pre if it is a pre-release dependency.
ERROR: ERROR: Could not find a version that matches msal<2.0.0,==1.2.0,>=0.4.1,>=1.6.0
Tried: 0.1.0, 0.1.0, 0.2.0, 0.2.0, 0.3.0, 0.3.0, 0.3.1, 0.3.1, 0.4.0, 0.4.0, 0.4.1, 0.4.1, 0.5.0, 0.5.0, 0.5.1, 0.5.1, 0.6.0, 0.6.0, 0.6.1, 0.6.1, 0.7.0, 0.7.0, 0.8.0, 0.8.0, 0.8.0, 0.9.0, 0.9.0, 1.0.0, 1.0.0, 1.1.0, 1.1.0, 1.2.0, 1.2.0, 1.3.0, 1.3.0, 1.4.0, 1.4.0, 1.4.1, 1.4.1, 1.4.2, 1.4.2, 1.4.3, 1.4.3, 1.5.0, 1.5.0, 1.5.1, 1.5.1, 1.6.0, 1.6.0, 1.7.0, 1.7.0, 1.8.0, 1.8.0
There are incompatible versions in the resolved dependencies.
```
Relevant extract from the output of `pipenv graph` as per the suggestion above:
```
azure-identity==1.5.0
- msal [required: >=1.6.0,<2.0.0, installed: 1.2.0]
- msal-extensions [required: ~=0.3.0, installed: 0.3.0]
- msal [required: >=0.4.1,<2.0.0, installed: 1.2.0]
azure-keyvault-secrets==4.2.0
botbuilder-ai==4.11.0
- botbuilder-core [required: ==4.11.0, installed: 4.11.0]
- botframework-connector [required: ==4.11.0, installed: 4.11.0]
- msal [required: ==1.2.0, installed: 1.2.0]
```
## Additional context
This issue was also reported in [botbuilder-samples repo's issue 2978](https://github.com/microsoft/BotBuilder-Samples/issues/2978)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libraries/botframework-connector/setup.py`
Content:
```
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3 import os
4 from setuptools import setup
5
6 NAME = "botframework-connector"
7 VERSION = os.environ["packageVersion"] if "packageVersion" in os.environ else "4.12.0"
8 REQUIRES = [
9 "msrest==0.6.10",
10 "requests==2.23.0",
11 "cryptography==3.2",
12 "PyJWT==1.5.3",
13 "botbuilder-schema==4.12.0",
14 "adal==1.2.1",
15 "msal==1.2.0",
16 ]
17
18 root = os.path.abspath(os.path.dirname(__file__))
19
20 with open(os.path.join(root, "README.rst"), encoding="utf-8") as f:
21 long_description = f.read()
22
23 setup(
24 name=NAME,
25 version=VERSION,
26 description="Microsoft Bot Framework Bot Builder SDK for Python.",
27 author="Microsoft",
28 url="https://www.github.com/Microsoft/botbuilder-python",
29 keywords=["BotFrameworkConnector", "bots", "ai", "botframework", "botbuilder"],
30 install_requires=REQUIRES,
31 packages=[
32 "botframework.connector",
33 "botframework.connector.auth",
34 "botframework.connector.async_mixin",
35 "botframework.connector.operations",
36 "botframework.connector.models",
37 "botframework.connector.aio",
38 "botframework.connector.aio.operations_async",
39 "botframework.connector.teams",
40 "botframework.connector.teams.operations",
41 "botframework.connector.token_api",
42 "botframework.connector.token_api.aio",
43 "botframework.connector.token_api.models",
44 "botframework.connector.token_api.operations",
45 ],
46 include_package_data=True,
47 long_description=long_description,
48 long_description_content_type="text/x-rst",
49 license="MIT",
50 classifiers=[
51 "Programming Language :: Python :: 3.7",
52 "Intended Audience :: Developers",
53 "License :: OSI Approved :: MIT License",
54 "Operating System :: OS Independent",
55 "Development Status :: 5 - Production/Stable",
56 "Topic :: Scientific/Engineering :: Artificial Intelligence",
57 ],
58 )
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libraries/botframework-connector/setup.py b/libraries/botframework-connector/setup.py
--- a/libraries/botframework-connector/setup.py
+++ b/libraries/botframework-connector/setup.py
@@ -12,7 +12,7 @@
"PyJWT==1.5.3",
"botbuilder-schema==4.12.0",
"adal==1.2.1",
- "msal==1.2.0",
+ "msal==1.6.0",
]
root = os.path.abspath(os.path.dirname(__file__))
|
{"golden_diff": "diff --git a/libraries/botframework-connector/setup.py b/libraries/botframework-connector/setup.py\n--- a/libraries/botframework-connector/setup.py\n+++ b/libraries/botframework-connector/setup.py\n@@ -12,7 +12,7 @@\n \"PyJWT==1.5.3\",\n \"botbuilder-schema==4.12.0\",\n \"adal==1.2.1\",\n- \"msal==1.2.0\",\n+ \"msal==1.6.0\",\n ]\n \n root = os.path.abspath(os.path.dirname(__file__))\n", "issue": "dependecy conflict between botframework 4.11.0 and azure-identity 1.5.0\n## Version\r\n4.11 (also happening with 4.10)\r\n\r\n## Describe the bug\r\n`botframework-connector == 4.11.0` (current) requires `msal == 1.2.0`\r\n`azure-identity == 1.5.0` (current) requires `msal >=1.6.0,<2.0.0`\r\n\r\nThis created a dependency conflict where bot libraries can't coexist in the same program. This used to work a couple of months ago (I bumped into this issue after revisiting some code I had worked on before).\r\n\r\n## To Reproduce\r\nThis is my `requirements.txt` file, just add it and run `pipenv install -r requirements.txt` (versions pinned to :\r\n```\r\nbotbuilder-core == 4.11\r\nazure-keyvault-secrets\r\nazure-identity == 1.5\r\nbotbuilder-ai == 4.11\r\n```\r\n\r\n## Expected behavior\r\nPackages should install without conflict\r\n\r\n## Screenshots\r\nExtract from the error message `pipenv install` shows:\r\n```\r\n[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.\r\n First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.\r\n Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.\r\n Hint: try $ pipenv lock --pre if it is a pre-release dependency.\r\nERROR: ERROR: Could not find a version that matches msal<2.0.0,==1.2.0,>=0.4.1,>=1.6.0\r\nTried: 0.1.0, 0.1.0, 0.2.0, 0.2.0, 0.3.0, 0.3.0, 0.3.1, 0.3.1, 0.4.0, 0.4.0, 0.4.1, 0.4.1, 0.5.0, 0.5.0, 0.5.1, 0.5.1, 0.6.0, 0.6.0, 0.6.1, 0.6.1, 0.7.0, 0.7.0, 0.8.0, 0.8.0, 0.8.0, 0.9.0, 0.9.0, 1.0.0, 1.0.0, 1.1.0, 1.1.0, 1.2.0, 1.2.0, 1.3.0, 1.3.0, 1.4.0, 1.4.0, 1.4.1, 1.4.1, 1.4.2, 1.4.2, 1.4.3, 1.4.3, 1.5.0, 1.5.0, 1.5.1, 1.5.1, 1.6.0, 1.6.0, 1.7.0, 1.7.0, 1.8.0, 1.8.0\r\nThere are incompatible versions in the resolved dependencies.\r\n```\r\nRelevant extract from the output of `pipenv graph` as per the suggestion above:\r\n```\r\nazure-identity==1.5.0\r\n - msal [required: >=1.6.0,<2.0.0, installed: 1.2.0]\r\n - msal-extensions [required: ~=0.3.0, installed: 0.3.0]\r\n - msal [required: >=0.4.1,<2.0.0, installed: 1.2.0]\r\nazure-keyvault-secrets==4.2.0\r\nbotbuilder-ai==4.11.0\r\n - botbuilder-core [required: ==4.11.0, installed: 4.11.0]\r\n - botframework-connector [required: ==4.11.0, installed: 4.11.0]\r\n - msal [required: ==1.2.0, installed: 1.2.0]\r\n```\r\n\r\n## Additional context\r\nThis issue was also reported in [botbuilder-samples repo's issue 2978](https://github.com/microsoft/BotBuilder-Samples/issues/2978)\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.12.0\"\nREQUIRES = [\n \"msrest==0.6.10\",\n \"requests==2.23.0\",\n \"cryptography==3.2\",\n \"PyJWT==1.5.3\",\n \"botbuilder-schema==4.12.0\",\n \"adal==1.2.1\",\n \"msal==1.2.0\",\n]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=NAME,\n version=VERSION,\n description=\"Microsoft Bot Framework Bot Builder SDK for Python.\",\n author=\"Microsoft\",\n url=\"https://www.github.com/Microsoft/botbuilder-python\",\n keywords=[\"BotFrameworkConnector\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\n install_requires=REQUIRES,\n packages=[\n \"botframework.connector\",\n \"botframework.connector.auth\",\n \"botframework.connector.async_mixin\",\n \"botframework.connector.operations\",\n \"botframework.connector.models\",\n \"botframework.connector.aio\",\n \"botframework.connector.aio.operations_async\",\n \"botframework.connector.teams\",\n \"botframework.connector.teams.operations\",\n \"botframework.connector.token_api\",\n \"botframework.connector.token_api.aio\",\n \"botframework.connector.token_api.models\",\n \"botframework.connector.token_api.operations\",\n ],\n include_package_data=True,\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=\"MIT\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botframework-connector/setup.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\nimport os\nfrom setuptools import setup\n\nNAME = \"botframework-connector\"\nVERSION = os.environ[\"packageVersion\"] if \"packageVersion\" in os.environ else \"4.12.0\"\nREQUIRES = [\n \"msrest==0.6.10\",\n \"requests==2.23.0\",\n \"cryptography==3.2\",\n \"PyJWT==1.5.3\",\n \"botbuilder-schema==4.12.0\",\n \"adal==1.2.1\",\n \"msal==1.6.0\",\n]\n\nroot = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(root, \"README.rst\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=NAME,\n version=VERSION,\n description=\"Microsoft Bot Framework Bot Builder SDK for Python.\",\n author=\"Microsoft\",\n url=\"https://www.github.com/Microsoft/botbuilder-python\",\n keywords=[\"BotFrameworkConnector\", \"bots\", \"ai\", \"botframework\", \"botbuilder\"],\n install_requires=REQUIRES,\n packages=[\n \"botframework.connector\",\n \"botframework.connector.auth\",\n \"botframework.connector.async_mixin\",\n \"botframework.connector.operations\",\n \"botframework.connector.models\",\n \"botframework.connector.aio\",\n \"botframework.connector.aio.operations_async\",\n \"botframework.connector.teams\",\n \"botframework.connector.teams.operations\",\n \"botframework.connector.token_api\",\n \"botframework.connector.token_api.aio\",\n \"botframework.connector.token_api.models\",\n \"botframework.connector.token_api.operations\",\n ],\n include_package_data=True,\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=\"MIT\",\n classifiers=[\n \"Programming Language :: Python :: 3.7\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "libraries/botframework-connector/setup.py"}]}
| 1,871 | 131 |
gh_patches_debug_4120
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-2709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/cli/launcher/__init__.py`
Content:
```
1 import click
2 from .run import launch_multi_processes
3 from colossalai.context import Config
4
5
6 @click.command(help="Launch distributed training on a single node or multiple nodes",
7 context_settings=dict(ignore_unknown_options=True))
8 @click.option("-H",
9 "-host",
10 "--host",
11 type=str,
12 default=None,
13 help="the list of hostnames to launch in the format <host1>,<host2>")
14 @click.option(
15 "--hostfile",
16 type=str,
17 default=None,
18 help="Hostfile path that defines the device pool available to the job, each line in the file is a hostname")
19 @click.option("--include",
20 type=str,
21 default=None,
22 help="Specify computing devices to use during execution. String format is <host1>,<host2>,"
23 " only effective when used with --hostfile.")
24 @click.option(
25 "--exclude",
26 type=str,
27 default=None,
28 help=
29 "Specify computing devices to NOT use during execution. Mutually exclusive with --include. Formatting is the same as --includ,"
30 " only effective when used with --hostfile.")
31 @click.option("--num_nodes",
32 type=int,
33 default=-1,
34 help="Total number of worker nodes to use, only effective when used with --hostfile.")
35 @click.option("--nproc_per_node", type=int, default=None, help="Number of GPUs to use on each node.")
36 @click.option("--master_port",
37 type=int,
38 default=29500,
39 help="(optional) Port used by PyTorch distributed for communication during distributed training.")
40 @click.option("--master_addr",
41 type=str,
42 default="127.0.0.1",
43 help="(optional) IP address of node 0, will be inferred via 'hostname -I' if not specified.")
44 @click.option(
45 "--extra_launch_args",
46 type=str,
47 default=None,
48 help=
49 "Set additional torch distributed launcher arguments such as --standalone. The format is --extra_launch_args arg1=1,arg2=2. "
50 "This will be converted to --arg1=1 --arg2=2 during execution")
51 @click.option("--ssh-port", type=int, default=None, help="(optional) the port used for ssh connection")
52 @click.argument("user_script", type=str)
53 @click.argument('user_args', nargs=-1)
54 def run(host: str, hostfile: str, num_nodes: int, nproc_per_node: int, include: str, exclude: str, master_addr: str,
55 master_port: int, extra_launch_args: str, ssh_port: int, user_script: str, user_args: str) -> None:
56 """
57 To launch multiple processes on a single node or multiple nodes via command line.
58
59 Usage::
60 # run with 4 GPUs on the current node use default port 29500
61 colossalai run --nprocs_per_node 4 train.py
62
63 # run with 2 GPUs on the current node at port 29550
64 colossalai run --nprocs_per_node 4 --master_port 29550 train.py
65
66 # run on two nodes
67 colossalai run --host <host1>,<host2> --master_addr host1 --nprocs_per_node 4 train.py
68
69 # run with hostfile
70 colossalai run --hostfile <file_path> --master_addr <host> --nprocs_per_node 4 train.py
71
72 # run with hostfile with only included hosts
73 colossalai run --hostfile <file_path> --master_addr host1 --include host1,host2 --nprocs_per_node 4 train.py
74
75 # run with hostfile excluding the hosts selected
76 colossalai run --hostfile <file_path> --master_addr host1 --exclude host2 --nprocs_per_node 4 train.py
77 """
78 if not user_script.endswith('.py'):
79 click.echo(f'Error: invalid Python file {user_script}. Did you use a wrong option? Try colossalai run --help')
80 exit()
81
82 args_dict = locals()
83 args = Config(args_dict)
84 args.user_args = list(args.user_args)
85 launch_multi_processes(args)
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/cli/launcher/__init__.py b/colossalai/cli/launcher/__init__.py
--- a/colossalai/cli/launcher/__init__.py
+++ b/colossalai/cli/launcher/__init__.py
@@ -1,7 +1,9 @@
import click
-from .run import launch_multi_processes
+
from colossalai.context import Config
+from .run import launch_multi_processes
+
@click.command(help="Launch distributed training on a single node or multiple nodes",
context_settings=dict(ignore_unknown_options=True))
|
{"golden_diff": "diff --git a/colossalai/cli/launcher/__init__.py b/colossalai/cli/launcher/__init__.py\n--- a/colossalai/cli/launcher/__init__.py\n+++ b/colossalai/cli/launcher/__init__.py\n@@ -1,7 +1,9 @@\n import click\n-from .run import launch_multi_processes\n+\n from colossalai.context import Config\n \n+from .run import launch_multi_processes\n+\n \n @click.command(help=\"Launch distributed training on a single node or multiple nodes\",\n context_settings=dict(ignore_unknown_options=True))\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import click\nfrom .run import launch_multi_processes\nfrom colossalai.context import Config\n\n\[email protected](help=\"Launch distributed training on a single node or multiple nodes\",\n context_settings=dict(ignore_unknown_options=True))\[email protected](\"-H\",\n \"-host\",\n \"--host\",\n type=str,\n default=None,\n help=\"the list of hostnames to launch in the format <host1>,<host2>\")\[email protected](\n \"--hostfile\",\n type=str,\n default=None,\n help=\"Hostfile path that defines the device pool available to the job, each line in the file is a hostname\")\[email protected](\"--include\",\n type=str,\n default=None,\n help=\"Specify computing devices to use during execution. String format is <host1>,<host2>,\"\n \" only effective when used with --hostfile.\")\[email protected](\n \"--exclude\",\n type=str,\n default=None,\n help=\n \"Specify computing devices to NOT use during execution. Mutually exclusive with --include. Formatting is the same as --includ,\"\n \" only effective when used with --hostfile.\")\[email protected](\"--num_nodes\",\n type=int,\n default=-1,\n help=\"Total number of worker nodes to use, only effective when used with --hostfile.\")\[email protected](\"--nproc_per_node\", type=int, default=None, help=\"Number of GPUs to use on each node.\")\[email protected](\"--master_port\",\n type=int,\n default=29500,\n help=\"(optional) Port used by PyTorch distributed for communication during distributed training.\")\[email protected](\"--master_addr\",\n type=str,\n default=\"127.0.0.1\",\n help=\"(optional) IP address of node 0, will be inferred via 'hostname -I' if not specified.\")\[email protected](\n \"--extra_launch_args\",\n type=str,\n default=None,\n help=\n \"Set additional torch distributed launcher arguments such as --standalone. The format is --extra_launch_args arg1=1,arg2=2. \"\n \"This will be converted to --arg1=1 --arg2=2 during execution\")\[email protected](\"--ssh-port\", type=int, default=None, help=\"(optional) the port used for ssh connection\")\[email protected](\"user_script\", type=str)\[email protected]('user_args', nargs=-1)\ndef run(host: str, hostfile: str, num_nodes: int, nproc_per_node: int, include: str, exclude: str, master_addr: str,\n master_port: int, extra_launch_args: str, ssh_port: int, user_script: str, user_args: str) -> None:\n \"\"\"\n To launch multiple processes on a single node or multiple nodes via command line.\n\n Usage::\n # run with 4 GPUs on the current node use default port 29500\n colossalai run --nprocs_per_node 4 train.py\n\n # run with 2 GPUs on the current node at port 29550\n colossalai run --nprocs_per_node 4 --master_port 29550 train.py\n\n # run on two nodes\n colossalai run --host <host1>,<host2> --master_addr host1 --nprocs_per_node 4 train.py\n\n # run with hostfile\n colossalai run --hostfile <file_path> --master_addr <host> --nprocs_per_node 4 train.py\n\n # run with hostfile with only included hosts\n colossalai run --hostfile <file_path> --master_addr host1 --include host1,host2 --nprocs_per_node 4 train.py\n\n # run with hostfile excluding the hosts selected\n colossalai run --hostfile <file_path> --master_addr host1 --exclude host2 --nprocs_per_node 4 train.py\n \"\"\"\n if not user_script.endswith('.py'):\n click.echo(f'Error: invalid Python file {user_script}. Did you use a wrong option? Try colossalai run --help')\n exit()\n\n args_dict = locals()\n args = Config(args_dict)\n args.user_args = list(args.user_args)\n launch_multi_processes(args)\n", "path": "colossalai/cli/launcher/__init__.py"}], "after_files": [{"content": "import click\n\nfrom colossalai.context import Config\n\nfrom .run import launch_multi_processes\n\n\[email protected](help=\"Launch distributed training on a single node or multiple nodes\",\n context_settings=dict(ignore_unknown_options=True))\[email protected](\"-H\",\n \"-host\",\n \"--host\",\n type=str,\n default=None,\n help=\"the list of hostnames to launch in the format <host1>,<host2>\")\[email protected](\n \"--hostfile\",\n type=str,\n default=None,\n help=\"Hostfile path that defines the device pool available to the job, each line in the file is a hostname\")\[email protected](\"--include\",\n type=str,\n default=None,\n help=\"Specify computing devices to use during execution. String format is <host1>,<host2>,\"\n \" only effective when used with --hostfile.\")\[email protected](\n \"--exclude\",\n type=str,\n default=None,\n help=\n \"Specify computing devices to NOT use during execution. Mutually exclusive with --include. Formatting is the same as --includ,\"\n \" only effective when used with --hostfile.\")\[email protected](\"--num_nodes\",\n type=int,\n default=-1,\n help=\"Total number of worker nodes to use, only effective when used with --hostfile.\")\[email protected](\"--nproc_per_node\", type=int, default=None, help=\"Number of GPUs to use on each node.\")\[email protected](\"--master_port\",\n type=int,\n default=29500,\n help=\"(optional) Port used by PyTorch distributed for communication during distributed training.\")\[email protected](\"--master_addr\",\n type=str,\n default=\"127.0.0.1\",\n help=\"(optional) IP address of node 0, will be inferred via 'hostname -I' if not specified.\")\[email protected](\n \"--extra_launch_args\",\n type=str,\n default=None,\n help=\n \"Set additional torch distributed launcher arguments such as --standalone. The format is --extra_launch_args arg1=1,arg2=2. \"\n \"This will be converted to --arg1=1 --arg2=2 during execution\")\[email protected](\"--ssh-port\", type=int, default=None, help=\"(optional) the port used for ssh connection\")\[email protected](\"user_script\", type=str)\[email protected]('user_args', nargs=-1)\ndef run(host: str, hostfile: str, num_nodes: int, nproc_per_node: int, include: str, exclude: str, master_addr: str,\n master_port: int, extra_launch_args: str, ssh_port: int, user_script: str, user_args: str) -> None:\n \"\"\"\n To launch multiple processes on a single node or multiple nodes via command line.\n\n Usage::\n # run with 4 GPUs on the current node use default port 29500\n colossalai run --nprocs_per_node 4 train.py\n\n # run with 2 GPUs on the current node at port 29550\n colossalai run --nprocs_per_node 4 --master_port 29550 train.py\n\n # run on two nodes\n colossalai run --host <host1>,<host2> --master_addr host1 --nprocs_per_node 4 train.py\n\n # run with hostfile\n colossalai run --hostfile <file_path> --master_addr <host> --nprocs_per_node 4 train.py\n\n # run with hostfile with only included hosts\n colossalai run --hostfile <file_path> --master_addr host1 --include host1,host2 --nprocs_per_node 4 train.py\n\n # run with hostfile excluding the hosts selected\n colossalai run --hostfile <file_path> --master_addr host1 --exclude host2 --nprocs_per_node 4 train.py\n \"\"\"\n if not user_script.endswith('.py'):\n click.echo(f'Error: invalid Python file {user_script}. Did you use a wrong option? Try colossalai run --help')\n exit()\n\n args_dict = locals()\n args = Config(args_dict)\n args.user_args = list(args.user_args)\n launch_multi_processes(args)\n", "path": "colossalai/cli/launcher/__init__.py"}]}
| 1,354 | 121 |
gh_patches_debug_12616
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-python-9042
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
use bibtex in plot_evoked_whitening.py
convert references in `examples/visualization/plot_evoked_whitening.py` to use footcite / footbibliography
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/visualization/plot_evoked_whitening.py`
Content:
```
1 """
2 =============================================
3 Whitening evoked data with a noise covariance
4 =============================================
5
6 Evoked data are loaded and then whitened using a given noise covariance
7 matrix. It's an excellent quality check to see if baseline signals match
8 the assumption of Gaussian white noise during the baseline period.
9
10 Covariance estimation and diagnostic plots are based on [1]_.
11
12 References
13 ----------
14 .. [1] Engemann D. and Gramfort A. (2015) Automated model selection in
15 covariance estimation and spatial whitening of MEG and EEG signals, vol.
16 108, 328-342, NeuroImage.
17
18 """
19 # Authors: Alexandre Gramfort <[email protected]>
20 # Denis A. Engemann <[email protected]>
21 #
22 # License: BSD (3-clause)
23
24 import mne
25
26 from mne import io
27 from mne.datasets import sample
28 from mne.cov import compute_covariance
29
30 print(__doc__)
31
32 ###############################################################################
33 # Set parameters
34
35 data_path = sample.data_path()
36 raw_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw.fif'
37 event_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw-eve.fif'
38
39 raw = io.read_raw_fif(raw_fname, preload=True)
40 raw.filter(1, 40, n_jobs=1, fir_design='firwin')
41 raw.info['bads'] += ['MEG 2443'] # bads + 1 more
42 events = mne.read_events(event_fname)
43
44 # let's look at rare events, button presses
45 event_id, tmin, tmax = 2, -0.2, 0.5
46 reject = dict(mag=4e-12, grad=4000e-13, eeg=80e-6)
47
48 epochs = mne.Epochs(raw, events, event_id, tmin, tmax, picks=('meg', 'eeg'),
49 baseline=None, reject=reject, preload=True)
50
51 # Uncomment next line to use fewer samples and study regularization effects
52 # epochs = epochs[:20] # For your data, use as many samples as you can!
53
54 ###############################################################################
55 # Compute covariance using automated regularization
56 method_params = dict(diagonal_fixed=dict(mag=0.01, grad=0.01, eeg=0.01))
57 noise_covs = compute_covariance(epochs, tmin=None, tmax=0, method='auto',
58 return_estimators=True, verbose=True, n_jobs=1,
59 projs=None, rank=None,
60 method_params=method_params)
61
62 # With "return_estimator=True" all estimated covariances sorted
63 # by log-likelihood are returned.
64
65 print('Covariance estimates sorted from best to worst')
66 for c in noise_covs:
67 print("%s : %s" % (c['method'], c['loglik']))
68
69 ###############################################################################
70 # Show the evoked data:
71
72 evoked = epochs.average()
73
74 evoked.plot(time_unit='s') # plot evoked response
75
76 ###############################################################################
77 # We can then show whitening for our various noise covariance estimates.
78 #
79 # Here we should look to see if baseline signals match the
80 # assumption of Gaussian white noise. we expect values centered at
81 # 0 within 2 standard deviations for 95% of the time points.
82 #
83 # For the Global field power we expect a value of 1.
84
85 evoked.plot_white(noise_covs, time_unit='s')
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/visualization/plot_evoked_whitening.py b/examples/visualization/plot_evoked_whitening.py
--- a/examples/visualization/plot_evoked_whitening.py
+++ b/examples/visualization/plot_evoked_whitening.py
@@ -7,13 +7,12 @@
matrix. It's an excellent quality check to see if baseline signals match
the assumption of Gaussian white noise during the baseline period.
-Covariance estimation and diagnostic plots are based on [1]_.
+Covariance estimation and diagnostic plots are based on
+:footcite:`EngemannGramfort2015`.
References
----------
-.. [1] Engemann D. and Gramfort A. (2015) Automated model selection in
- covariance estimation and spatial whitening of MEG and EEG signals, vol.
- 108, 328-342, NeuroImage.
+.. footbibliography::
"""
# Authors: Alexandre Gramfort <[email protected]>
|
{"golden_diff": "diff --git a/examples/visualization/plot_evoked_whitening.py b/examples/visualization/plot_evoked_whitening.py\n--- a/examples/visualization/plot_evoked_whitening.py\n+++ b/examples/visualization/plot_evoked_whitening.py\n@@ -7,13 +7,12 @@\n matrix. It's an excellent quality check to see if baseline signals match\n the assumption of Gaussian white noise during the baseline period.\n \n-Covariance estimation and diagnostic plots are based on [1]_.\n+Covariance estimation and diagnostic plots are based on\n+:footcite:`EngemannGramfort2015`.\n \n References\n ----------\n-.. [1] Engemann D. and Gramfort A. (2015) Automated model selection in\n- covariance estimation and spatial whitening of MEG and EEG signals, vol.\n- 108, 328-342, NeuroImage.\n+.. footbibliography::\n \n \"\"\"\n # Authors: Alexandre Gramfort <[email protected]>\n", "issue": "use bibtex in plot_evoked_whitening.py\nconvert references in `examples/visualization/plot_evoked_whitening.py` to use footcite / footbibliography\r\n\n", "before_files": [{"content": "\"\"\"\n=============================================\nWhitening evoked data with a noise covariance\n=============================================\n\nEvoked data are loaded and then whitened using a given noise covariance\nmatrix. It's an excellent quality check to see if baseline signals match\nthe assumption of Gaussian white noise during the baseline period.\n\nCovariance estimation and diagnostic plots are based on [1]_.\n\nReferences\n----------\n.. [1] Engemann D. and Gramfort A. (2015) Automated model selection in\n covariance estimation and spatial whitening of MEG and EEG signals, vol.\n 108, 328-342, NeuroImage.\n\n\"\"\"\n# Authors: Alexandre Gramfort <[email protected]>\n# Denis A. Engemann <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport mne\n\nfrom mne import io\nfrom mne.datasets import sample\nfrom mne.cov import compute_covariance\n\nprint(__doc__)\n\n###############################################################################\n# Set parameters\n\ndata_path = sample.data_path()\nraw_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw.fif'\nevent_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw-eve.fif'\n\nraw = io.read_raw_fif(raw_fname, preload=True)\nraw.filter(1, 40, n_jobs=1, fir_design='firwin')\nraw.info['bads'] += ['MEG 2443'] # bads + 1 more\nevents = mne.read_events(event_fname)\n\n# let's look at rare events, button presses\nevent_id, tmin, tmax = 2, -0.2, 0.5\nreject = dict(mag=4e-12, grad=4000e-13, eeg=80e-6)\n\nepochs = mne.Epochs(raw, events, event_id, tmin, tmax, picks=('meg', 'eeg'),\n baseline=None, reject=reject, preload=True)\n\n# Uncomment next line to use fewer samples and study regularization effects\n# epochs = epochs[:20] # For your data, use as many samples as you can!\n\n###############################################################################\n# Compute covariance using automated regularization\nmethod_params = dict(diagonal_fixed=dict(mag=0.01, grad=0.01, eeg=0.01))\nnoise_covs = compute_covariance(epochs, tmin=None, tmax=0, method='auto',\n return_estimators=True, verbose=True, n_jobs=1,\n projs=None, rank=None,\n method_params=method_params)\n\n# With \"return_estimator=True\" all estimated covariances sorted\n# by log-likelihood are returned.\n\nprint('Covariance estimates sorted from best to worst')\nfor c in noise_covs:\n print(\"%s : %s\" % (c['method'], c['loglik']))\n\n###############################################################################\n# Show the evoked data:\n\nevoked = epochs.average()\n\nevoked.plot(time_unit='s') # plot evoked response\n\n###############################################################################\n# We can then show whitening for our various noise covariance estimates.\n#\n# Here we should look to see if baseline signals match the\n# assumption of Gaussian white noise. we expect values centered at\n# 0 within 2 standard deviations for 95% of the time points.\n#\n# For the Global field power we expect a value of 1.\n\nevoked.plot_white(noise_covs, time_unit='s')\n", "path": "examples/visualization/plot_evoked_whitening.py"}], "after_files": [{"content": "\"\"\"\n=============================================\nWhitening evoked data with a noise covariance\n=============================================\n\nEvoked data are loaded and then whitened using a given noise covariance\nmatrix. It's an excellent quality check to see if baseline signals match\nthe assumption of Gaussian white noise during the baseline period.\n\nCovariance estimation and diagnostic plots are based on\n:footcite:`EngemannGramfort2015`.\n\nReferences\n----------\n.. footbibliography::\n\n\"\"\"\n# Authors: Alexandre Gramfort <[email protected]>\n# Denis A. Engemann <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport mne\n\nfrom mne import io\nfrom mne.datasets import sample\nfrom mne.cov import compute_covariance\n\nprint(__doc__)\n\n###############################################################################\n# Set parameters\n\ndata_path = sample.data_path()\nraw_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw.fif'\nevent_fname = data_path + '/MEG/sample/sample_audvis_filt-0-40_raw-eve.fif'\n\nraw = io.read_raw_fif(raw_fname, preload=True)\nraw.filter(1, 40, n_jobs=1, fir_design='firwin')\nraw.info['bads'] += ['MEG 2443'] # bads + 1 more\nevents = mne.read_events(event_fname)\n\n# let's look at rare events, button presses\nevent_id, tmin, tmax = 2, -0.2, 0.5\nreject = dict(mag=4e-12, grad=4000e-13, eeg=80e-6)\n\nepochs = mne.Epochs(raw, events, event_id, tmin, tmax, picks=('meg', 'eeg'),\n baseline=None, reject=reject, preload=True)\n\n# Uncomment next line to use fewer samples and study regularization effects\n# epochs = epochs[:20] # For your data, use as many samples as you can!\n\n###############################################################################\n# Compute covariance using automated regularization\nmethod_params = dict(diagonal_fixed=dict(mag=0.01, grad=0.01, eeg=0.01))\nnoise_covs = compute_covariance(epochs, tmin=None, tmax=0, method='auto',\n return_estimators=True, verbose=True, n_jobs=1,\n projs=None, rank=None,\n method_params=method_params)\n\n# With \"return_estimator=True\" all estimated covariances sorted\n# by log-likelihood are returned.\n\nprint('Covariance estimates sorted from best to worst')\nfor c in noise_covs:\n print(\"%s : %s\" % (c['method'], c['loglik']))\n\n###############################################################################\n# Show the evoked data:\n\nevoked = epochs.average()\n\nevoked.plot(time_unit='s') # plot evoked response\n\n###############################################################################\n# We can then show whitening for our various noise covariance estimates.\n#\n# Here we should look to see if baseline signals match the\n# assumption of Gaussian white noise. we expect values centered at\n# 0 within 2 standard deviations for 95% of the time points.\n#\n# For the Global field power we expect a value of 1.\n\nevoked.plot_white(noise_covs, time_unit='s')\n", "path": "examples/visualization/plot_evoked_whitening.py"}]}
| 1,235 | 225 |
gh_patches_debug_25660
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-2713
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pending deprecation warning on fernet creation since 1.2.1
``` python
In [1]: from cryptography.fernet import Fernet
In [2]: key = Fernet.generate_key()
In [3]: fernet = Fernet(key)
/home/simon/.virtualenvs/project/local/lib/python2.7/site-packages/cryptography/x509/__init__.py:32: PendingDeprecationWarning: CRLExtensionOID has been renamed to CRLEntryExtensionOID
from cryptography.x509.oid import (
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/x509/__init__.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 from cryptography.x509.base import (
8 Certificate, CertificateBuilder, CertificateRevocationList,
9 CertificateRevocationListBuilder,
10 CertificateSigningRequest, CertificateSigningRequestBuilder,
11 InvalidVersion, RevokedCertificate, RevokedCertificateBuilder,
12 Version, load_der_x509_certificate, load_der_x509_crl, load_der_x509_csr,
13 load_pem_x509_certificate, load_pem_x509_crl, load_pem_x509_csr,
14 )
15 from cryptography.x509.extensions import (
16 AccessDescription, AuthorityInformationAccess,
17 AuthorityKeyIdentifier, BasicConstraints, CRLDistributionPoints,
18 CRLNumber, CRLReason, CertificateIssuer, CertificatePolicies,
19 DistributionPoint, DuplicateExtension, ExtendedKeyUsage, Extension,
20 ExtensionNotFound, ExtensionType, Extensions, GeneralNames,
21 InhibitAnyPolicy, InvalidityDate, IssuerAlternativeName, KeyUsage,
22 NameConstraints, NoticeReference, OCSPNoCheck, PolicyInformation,
23 ReasonFlags, SubjectAlternativeName, SubjectKeyIdentifier,
24 UnrecognizedExtension, UnsupportedExtension, UserNotice
25 )
26 from cryptography.x509.general_name import (
27 DNSName, DirectoryName, GeneralName, IPAddress, OtherName, RFC822Name,
28 RegisteredID, UniformResourceIdentifier, UnsupportedGeneralNameType,
29 _GENERAL_NAMES
30 )
31 from cryptography.x509.name import Name, NameAttribute
32 from cryptography.x509.oid import (
33 AuthorityInformationAccessOID, CRLEntryExtensionOID, CRLExtensionOID,
34 CertificatePoliciesOID, ExtendedKeyUsageOID, ExtensionOID, NameOID,
35 ObjectIdentifier, SignatureAlgorithmOID, _SIG_OIDS_TO_HASH
36 )
37
38
39 OID_AUTHORITY_INFORMATION_ACCESS = ExtensionOID.AUTHORITY_INFORMATION_ACCESS
40 OID_AUTHORITY_KEY_IDENTIFIER = ExtensionOID.AUTHORITY_KEY_IDENTIFIER
41 OID_BASIC_CONSTRAINTS = ExtensionOID.BASIC_CONSTRAINTS
42 OID_CERTIFICATE_POLICIES = ExtensionOID.CERTIFICATE_POLICIES
43 OID_CRL_DISTRIBUTION_POINTS = ExtensionOID.CRL_DISTRIBUTION_POINTS
44 OID_EXTENDED_KEY_USAGE = ExtensionOID.EXTENDED_KEY_USAGE
45 OID_FRESHEST_CRL = ExtensionOID.FRESHEST_CRL
46 OID_INHIBIT_ANY_POLICY = ExtensionOID.INHIBIT_ANY_POLICY
47 OID_ISSUER_ALTERNATIVE_NAME = ExtensionOID.ISSUER_ALTERNATIVE_NAME
48 OID_KEY_USAGE = ExtensionOID.KEY_USAGE
49 OID_NAME_CONSTRAINTS = ExtensionOID.NAME_CONSTRAINTS
50 OID_OCSP_NO_CHECK = ExtensionOID.OCSP_NO_CHECK
51 OID_POLICY_CONSTRAINTS = ExtensionOID.POLICY_CONSTRAINTS
52 OID_POLICY_MAPPINGS = ExtensionOID.POLICY_MAPPINGS
53 OID_SUBJECT_ALTERNATIVE_NAME = ExtensionOID.SUBJECT_ALTERNATIVE_NAME
54 OID_SUBJECT_DIRECTORY_ATTRIBUTES = ExtensionOID.SUBJECT_DIRECTORY_ATTRIBUTES
55 OID_SUBJECT_INFORMATION_ACCESS = ExtensionOID.SUBJECT_INFORMATION_ACCESS
56 OID_SUBJECT_KEY_IDENTIFIER = ExtensionOID.SUBJECT_KEY_IDENTIFIER
57
58 OID_DSA_WITH_SHA1 = SignatureAlgorithmOID.DSA_WITH_SHA1
59 OID_DSA_WITH_SHA224 = SignatureAlgorithmOID.DSA_WITH_SHA224
60 OID_DSA_WITH_SHA256 = SignatureAlgorithmOID.DSA_WITH_SHA256
61 OID_ECDSA_WITH_SHA1 = SignatureAlgorithmOID.ECDSA_WITH_SHA1
62 OID_ECDSA_WITH_SHA224 = SignatureAlgorithmOID.ECDSA_WITH_SHA224
63 OID_ECDSA_WITH_SHA256 = SignatureAlgorithmOID.ECDSA_WITH_SHA256
64 OID_ECDSA_WITH_SHA384 = SignatureAlgorithmOID.ECDSA_WITH_SHA384
65 OID_ECDSA_WITH_SHA512 = SignatureAlgorithmOID.ECDSA_WITH_SHA512
66 OID_RSA_WITH_MD5 = SignatureAlgorithmOID.RSA_WITH_MD5
67 OID_RSA_WITH_SHA1 = SignatureAlgorithmOID.RSA_WITH_SHA1
68 OID_RSA_WITH_SHA224 = SignatureAlgorithmOID.RSA_WITH_SHA224
69 OID_RSA_WITH_SHA256 = SignatureAlgorithmOID.RSA_WITH_SHA256
70 OID_RSA_WITH_SHA384 = SignatureAlgorithmOID.RSA_WITH_SHA384
71 OID_RSA_WITH_SHA512 = SignatureAlgorithmOID.RSA_WITH_SHA512
72
73 OID_COMMON_NAME = NameOID.COMMON_NAME
74 OID_COUNTRY_NAME = NameOID.COUNTRY_NAME
75 OID_DOMAIN_COMPONENT = NameOID.DOMAIN_COMPONENT
76 OID_DN_QUALIFIER = NameOID.DN_QUALIFIER
77 OID_EMAIL_ADDRESS = NameOID.EMAIL_ADDRESS
78 OID_GENERATION_QUALIFIER = NameOID.GENERATION_QUALIFIER
79 OID_GIVEN_NAME = NameOID.GIVEN_NAME
80 OID_LOCALITY_NAME = NameOID.LOCALITY_NAME
81 OID_ORGANIZATIONAL_UNIT_NAME = NameOID.ORGANIZATIONAL_UNIT_NAME
82 OID_ORGANIZATION_NAME = NameOID.ORGANIZATION_NAME
83 OID_PSEUDONYM = NameOID.PSEUDONYM
84 OID_SERIAL_NUMBER = NameOID.SERIAL_NUMBER
85 OID_STATE_OR_PROVINCE_NAME = NameOID.STATE_OR_PROVINCE_NAME
86 OID_SURNAME = NameOID.SURNAME
87 OID_TITLE = NameOID.TITLE
88
89 OID_CLIENT_AUTH = ExtendedKeyUsageOID.CLIENT_AUTH
90 OID_CODE_SIGNING = ExtendedKeyUsageOID.CODE_SIGNING
91 OID_EMAIL_PROTECTION = ExtendedKeyUsageOID.EMAIL_PROTECTION
92 OID_OCSP_SIGNING = ExtendedKeyUsageOID.OCSP_SIGNING
93 OID_SERVER_AUTH = ExtendedKeyUsageOID.SERVER_AUTH
94 OID_TIME_STAMPING = ExtendedKeyUsageOID.TIME_STAMPING
95
96 OID_ANY_POLICY = CertificatePoliciesOID.ANY_POLICY
97 OID_CPS_QUALIFIER = CertificatePoliciesOID.CPS_QUALIFIER
98 OID_CPS_USER_NOTICE = CertificatePoliciesOID.CPS_USER_NOTICE
99
100 OID_CERTIFICATE_ISSUER = CRLEntryExtensionOID.CERTIFICATE_ISSUER
101 OID_CRL_REASON = CRLEntryExtensionOID.CRL_REASON
102 OID_INVALIDITY_DATE = CRLEntryExtensionOID.INVALIDITY_DATE
103
104 OID_CA_ISSUERS = AuthorityInformationAccessOID.CA_ISSUERS
105 OID_OCSP = AuthorityInformationAccessOID.OCSP
106
107
108 __all__ = [
109 "load_pem_x509_certificate",
110 "load_der_x509_certificate",
111 "load_pem_x509_csr",
112 "load_der_x509_csr",
113 "load_pem_x509_crl",
114 "load_der_x509_crl",
115 "InvalidVersion",
116 "DuplicateExtension",
117 "UnsupportedExtension",
118 "ExtensionNotFound",
119 "UnsupportedGeneralNameType",
120 "NameAttribute",
121 "Name",
122 "ObjectIdentifier",
123 "ExtensionType",
124 "Extensions",
125 "Extension",
126 "ExtendedKeyUsage",
127 "OCSPNoCheck",
128 "BasicConstraints",
129 "CRLNumber",
130 "KeyUsage",
131 "AuthorityInformationAccess",
132 "AccessDescription",
133 "CertificatePolicies",
134 "PolicyInformation",
135 "UserNotice",
136 "NoticeReference",
137 "SubjectKeyIdentifier",
138 "NameConstraints",
139 "CRLDistributionPoints",
140 "DistributionPoint",
141 "ReasonFlags",
142 "InhibitAnyPolicy",
143 "SubjectAlternativeName",
144 "IssuerAlternativeName",
145 "AuthorityKeyIdentifier",
146 "GeneralNames",
147 "GeneralName",
148 "RFC822Name",
149 "DNSName",
150 "UniformResourceIdentifier",
151 "RegisteredID",
152 "DirectoryName",
153 "IPAddress",
154 "OtherName",
155 "Certificate",
156 "CertificateRevocationList",
157 "CertificateRevocationListBuilder",
158 "CertificateSigningRequest",
159 "RevokedCertificate",
160 "RevokedCertificateBuilder",
161 "CertificateSigningRequestBuilder",
162 "CertificateBuilder",
163 "Version",
164 "_SIG_OIDS_TO_HASH",
165 "OID_CA_ISSUERS",
166 "OID_OCSP",
167 "_GENERAL_NAMES",
168 "CRLExtensionOID",
169 "CertificateIssuer",
170 "CRLReason",
171 "InvalidityDate",
172 "UnrecognizedExtension",
173 ]
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/x509/__init__.py b/src/cryptography/x509/__init__.py
--- a/src/cryptography/x509/__init__.py
+++ b/src/cryptography/x509/__init__.py
@@ -4,6 +4,7 @@
from __future__ import absolute_import, division, print_function
+from cryptography import utils
from cryptography.x509.base import (
Certificate, CertificateBuilder, CertificateRevocationList,
CertificateRevocationListBuilder,
@@ -30,12 +31,19 @@
)
from cryptography.x509.name import Name, NameAttribute
from cryptography.x509.oid import (
- AuthorityInformationAccessOID, CRLEntryExtensionOID, CRLExtensionOID,
+ AuthorityInformationAccessOID, CRLEntryExtensionOID,
CertificatePoliciesOID, ExtendedKeyUsageOID, ExtensionOID, NameOID,
ObjectIdentifier, SignatureAlgorithmOID, _SIG_OIDS_TO_HASH
)
+CRLExtensionOID = utils.deprecated(
+ CRLEntryExtensionOID,
+ __name__,
+ "CRLExtensionOID has been renamed to CRLEntryExtensionOID",
+ utils.DeprecatedIn12
+)
+
OID_AUTHORITY_INFORMATION_ACCESS = ExtensionOID.AUTHORITY_INFORMATION_ACCESS
OID_AUTHORITY_KEY_IDENTIFIER = ExtensionOID.AUTHORITY_KEY_IDENTIFIER
OID_BASIC_CONSTRAINTS = ExtensionOID.BASIC_CONSTRAINTS
|
{"golden_diff": "diff --git a/src/cryptography/x509/__init__.py b/src/cryptography/x509/__init__.py\n--- a/src/cryptography/x509/__init__.py\n+++ b/src/cryptography/x509/__init__.py\n@@ -4,6 +4,7 @@\n \n from __future__ import absolute_import, division, print_function\n \n+from cryptography import utils\n from cryptography.x509.base import (\n Certificate, CertificateBuilder, CertificateRevocationList,\n CertificateRevocationListBuilder,\n@@ -30,12 +31,19 @@\n )\n from cryptography.x509.name import Name, NameAttribute\n from cryptography.x509.oid import (\n- AuthorityInformationAccessOID, CRLEntryExtensionOID, CRLExtensionOID,\n+ AuthorityInformationAccessOID, CRLEntryExtensionOID,\n CertificatePoliciesOID, ExtendedKeyUsageOID, ExtensionOID, NameOID,\n ObjectIdentifier, SignatureAlgorithmOID, _SIG_OIDS_TO_HASH\n )\n \n \n+CRLExtensionOID = utils.deprecated(\n+ CRLEntryExtensionOID,\n+ __name__,\n+ \"CRLExtensionOID has been renamed to CRLEntryExtensionOID\",\n+ utils.DeprecatedIn12\n+)\n+\n OID_AUTHORITY_INFORMATION_ACCESS = ExtensionOID.AUTHORITY_INFORMATION_ACCESS\n OID_AUTHORITY_KEY_IDENTIFIER = ExtensionOID.AUTHORITY_KEY_IDENTIFIER\n OID_BASIC_CONSTRAINTS = ExtensionOID.BASIC_CONSTRAINTS\n", "issue": "Pending deprecation warning on fernet creation since 1.2.1\n``` python\nIn [1]: from cryptography.fernet import Fernet\n\nIn [2]: key = Fernet.generate_key()\n\nIn [3]: fernet = Fernet(key)\n/home/simon/.virtualenvs/project/local/lib/python2.7/site-packages/cryptography/x509/__init__.py:32: PendingDeprecationWarning: CRLExtensionOID has been renamed to CRLEntryExtensionOID\n from cryptography.x509.oid import (\n```\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom cryptography.x509.base import (\n Certificate, CertificateBuilder, CertificateRevocationList,\n CertificateRevocationListBuilder,\n CertificateSigningRequest, CertificateSigningRequestBuilder,\n InvalidVersion, RevokedCertificate, RevokedCertificateBuilder,\n Version, load_der_x509_certificate, load_der_x509_crl, load_der_x509_csr,\n load_pem_x509_certificate, load_pem_x509_crl, load_pem_x509_csr,\n)\nfrom cryptography.x509.extensions import (\n AccessDescription, AuthorityInformationAccess,\n AuthorityKeyIdentifier, BasicConstraints, CRLDistributionPoints,\n CRLNumber, CRLReason, CertificateIssuer, CertificatePolicies,\n DistributionPoint, DuplicateExtension, ExtendedKeyUsage, Extension,\n ExtensionNotFound, ExtensionType, Extensions, GeneralNames,\n InhibitAnyPolicy, InvalidityDate, IssuerAlternativeName, KeyUsage,\n NameConstraints, NoticeReference, OCSPNoCheck, PolicyInformation,\n ReasonFlags, SubjectAlternativeName, SubjectKeyIdentifier,\n UnrecognizedExtension, UnsupportedExtension, UserNotice\n)\nfrom cryptography.x509.general_name import (\n DNSName, DirectoryName, GeneralName, IPAddress, OtherName, RFC822Name,\n RegisteredID, UniformResourceIdentifier, UnsupportedGeneralNameType,\n _GENERAL_NAMES\n)\nfrom cryptography.x509.name import Name, NameAttribute\nfrom cryptography.x509.oid import (\n AuthorityInformationAccessOID, CRLEntryExtensionOID, CRLExtensionOID,\n CertificatePoliciesOID, ExtendedKeyUsageOID, ExtensionOID, NameOID,\n ObjectIdentifier, SignatureAlgorithmOID, _SIG_OIDS_TO_HASH\n)\n\n\nOID_AUTHORITY_INFORMATION_ACCESS = ExtensionOID.AUTHORITY_INFORMATION_ACCESS\nOID_AUTHORITY_KEY_IDENTIFIER = ExtensionOID.AUTHORITY_KEY_IDENTIFIER\nOID_BASIC_CONSTRAINTS = ExtensionOID.BASIC_CONSTRAINTS\nOID_CERTIFICATE_POLICIES = ExtensionOID.CERTIFICATE_POLICIES\nOID_CRL_DISTRIBUTION_POINTS = ExtensionOID.CRL_DISTRIBUTION_POINTS\nOID_EXTENDED_KEY_USAGE = ExtensionOID.EXTENDED_KEY_USAGE\nOID_FRESHEST_CRL = ExtensionOID.FRESHEST_CRL\nOID_INHIBIT_ANY_POLICY = ExtensionOID.INHIBIT_ANY_POLICY\nOID_ISSUER_ALTERNATIVE_NAME = ExtensionOID.ISSUER_ALTERNATIVE_NAME\nOID_KEY_USAGE = ExtensionOID.KEY_USAGE\nOID_NAME_CONSTRAINTS = ExtensionOID.NAME_CONSTRAINTS\nOID_OCSP_NO_CHECK = ExtensionOID.OCSP_NO_CHECK\nOID_POLICY_CONSTRAINTS = ExtensionOID.POLICY_CONSTRAINTS\nOID_POLICY_MAPPINGS = ExtensionOID.POLICY_MAPPINGS\nOID_SUBJECT_ALTERNATIVE_NAME = ExtensionOID.SUBJECT_ALTERNATIVE_NAME\nOID_SUBJECT_DIRECTORY_ATTRIBUTES = ExtensionOID.SUBJECT_DIRECTORY_ATTRIBUTES\nOID_SUBJECT_INFORMATION_ACCESS = ExtensionOID.SUBJECT_INFORMATION_ACCESS\nOID_SUBJECT_KEY_IDENTIFIER = ExtensionOID.SUBJECT_KEY_IDENTIFIER\n\nOID_DSA_WITH_SHA1 = SignatureAlgorithmOID.DSA_WITH_SHA1\nOID_DSA_WITH_SHA224 = SignatureAlgorithmOID.DSA_WITH_SHA224\nOID_DSA_WITH_SHA256 = SignatureAlgorithmOID.DSA_WITH_SHA256\nOID_ECDSA_WITH_SHA1 = SignatureAlgorithmOID.ECDSA_WITH_SHA1\nOID_ECDSA_WITH_SHA224 = SignatureAlgorithmOID.ECDSA_WITH_SHA224\nOID_ECDSA_WITH_SHA256 = SignatureAlgorithmOID.ECDSA_WITH_SHA256\nOID_ECDSA_WITH_SHA384 = SignatureAlgorithmOID.ECDSA_WITH_SHA384\nOID_ECDSA_WITH_SHA512 = SignatureAlgorithmOID.ECDSA_WITH_SHA512\nOID_RSA_WITH_MD5 = SignatureAlgorithmOID.RSA_WITH_MD5\nOID_RSA_WITH_SHA1 = SignatureAlgorithmOID.RSA_WITH_SHA1\nOID_RSA_WITH_SHA224 = SignatureAlgorithmOID.RSA_WITH_SHA224\nOID_RSA_WITH_SHA256 = SignatureAlgorithmOID.RSA_WITH_SHA256\nOID_RSA_WITH_SHA384 = SignatureAlgorithmOID.RSA_WITH_SHA384\nOID_RSA_WITH_SHA512 = SignatureAlgorithmOID.RSA_WITH_SHA512\n\nOID_COMMON_NAME = NameOID.COMMON_NAME\nOID_COUNTRY_NAME = NameOID.COUNTRY_NAME\nOID_DOMAIN_COMPONENT = NameOID.DOMAIN_COMPONENT\nOID_DN_QUALIFIER = NameOID.DN_QUALIFIER\nOID_EMAIL_ADDRESS = NameOID.EMAIL_ADDRESS\nOID_GENERATION_QUALIFIER = NameOID.GENERATION_QUALIFIER\nOID_GIVEN_NAME = NameOID.GIVEN_NAME\nOID_LOCALITY_NAME = NameOID.LOCALITY_NAME\nOID_ORGANIZATIONAL_UNIT_NAME = NameOID.ORGANIZATIONAL_UNIT_NAME\nOID_ORGANIZATION_NAME = NameOID.ORGANIZATION_NAME\nOID_PSEUDONYM = NameOID.PSEUDONYM\nOID_SERIAL_NUMBER = NameOID.SERIAL_NUMBER\nOID_STATE_OR_PROVINCE_NAME = NameOID.STATE_OR_PROVINCE_NAME\nOID_SURNAME = NameOID.SURNAME\nOID_TITLE = NameOID.TITLE\n\nOID_CLIENT_AUTH = ExtendedKeyUsageOID.CLIENT_AUTH\nOID_CODE_SIGNING = ExtendedKeyUsageOID.CODE_SIGNING\nOID_EMAIL_PROTECTION = ExtendedKeyUsageOID.EMAIL_PROTECTION\nOID_OCSP_SIGNING = ExtendedKeyUsageOID.OCSP_SIGNING\nOID_SERVER_AUTH = ExtendedKeyUsageOID.SERVER_AUTH\nOID_TIME_STAMPING = ExtendedKeyUsageOID.TIME_STAMPING\n\nOID_ANY_POLICY = CertificatePoliciesOID.ANY_POLICY\nOID_CPS_QUALIFIER = CertificatePoliciesOID.CPS_QUALIFIER\nOID_CPS_USER_NOTICE = CertificatePoliciesOID.CPS_USER_NOTICE\n\nOID_CERTIFICATE_ISSUER = CRLEntryExtensionOID.CERTIFICATE_ISSUER\nOID_CRL_REASON = CRLEntryExtensionOID.CRL_REASON\nOID_INVALIDITY_DATE = CRLEntryExtensionOID.INVALIDITY_DATE\n\nOID_CA_ISSUERS = AuthorityInformationAccessOID.CA_ISSUERS\nOID_OCSP = AuthorityInformationAccessOID.OCSP\n\n\n__all__ = [\n \"load_pem_x509_certificate\",\n \"load_der_x509_certificate\",\n \"load_pem_x509_csr\",\n \"load_der_x509_csr\",\n \"load_pem_x509_crl\",\n \"load_der_x509_crl\",\n \"InvalidVersion\",\n \"DuplicateExtension\",\n \"UnsupportedExtension\",\n \"ExtensionNotFound\",\n \"UnsupportedGeneralNameType\",\n \"NameAttribute\",\n \"Name\",\n \"ObjectIdentifier\",\n \"ExtensionType\",\n \"Extensions\",\n \"Extension\",\n \"ExtendedKeyUsage\",\n \"OCSPNoCheck\",\n \"BasicConstraints\",\n \"CRLNumber\",\n \"KeyUsage\",\n \"AuthorityInformationAccess\",\n \"AccessDescription\",\n \"CertificatePolicies\",\n \"PolicyInformation\",\n \"UserNotice\",\n \"NoticeReference\",\n \"SubjectKeyIdentifier\",\n \"NameConstraints\",\n \"CRLDistributionPoints\",\n \"DistributionPoint\",\n \"ReasonFlags\",\n \"InhibitAnyPolicy\",\n \"SubjectAlternativeName\",\n \"IssuerAlternativeName\",\n \"AuthorityKeyIdentifier\",\n \"GeneralNames\",\n \"GeneralName\",\n \"RFC822Name\",\n \"DNSName\",\n \"UniformResourceIdentifier\",\n \"RegisteredID\",\n \"DirectoryName\",\n \"IPAddress\",\n \"OtherName\",\n \"Certificate\",\n \"CertificateRevocationList\",\n \"CertificateRevocationListBuilder\",\n \"CertificateSigningRequest\",\n \"RevokedCertificate\",\n \"RevokedCertificateBuilder\",\n \"CertificateSigningRequestBuilder\",\n \"CertificateBuilder\",\n \"Version\",\n \"_SIG_OIDS_TO_HASH\",\n \"OID_CA_ISSUERS\",\n \"OID_OCSP\",\n \"_GENERAL_NAMES\",\n \"CRLExtensionOID\",\n \"CertificateIssuer\",\n \"CRLReason\",\n \"InvalidityDate\",\n \"UnrecognizedExtension\",\n]\n", "path": "src/cryptography/x509/__init__.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom cryptography import utils\nfrom cryptography.x509.base import (\n Certificate, CertificateBuilder, CertificateRevocationList,\n CertificateRevocationListBuilder,\n CertificateSigningRequest, CertificateSigningRequestBuilder,\n InvalidVersion, RevokedCertificate, RevokedCertificateBuilder,\n Version, load_der_x509_certificate, load_der_x509_crl, load_der_x509_csr,\n load_pem_x509_certificate, load_pem_x509_crl, load_pem_x509_csr,\n)\nfrom cryptography.x509.extensions import (\n AccessDescription, AuthorityInformationAccess,\n AuthorityKeyIdentifier, BasicConstraints, CRLDistributionPoints,\n CRLNumber, CRLReason, CertificateIssuer, CertificatePolicies,\n DistributionPoint, DuplicateExtension, ExtendedKeyUsage, Extension,\n ExtensionNotFound, ExtensionType, Extensions, GeneralNames,\n InhibitAnyPolicy, InvalidityDate, IssuerAlternativeName, KeyUsage,\n NameConstraints, NoticeReference, OCSPNoCheck, PolicyInformation,\n ReasonFlags, SubjectAlternativeName, SubjectKeyIdentifier,\n UnrecognizedExtension, UnsupportedExtension, UserNotice\n)\nfrom cryptography.x509.general_name import (\n DNSName, DirectoryName, GeneralName, IPAddress, OtherName, RFC822Name,\n RegisteredID, UniformResourceIdentifier, UnsupportedGeneralNameType,\n _GENERAL_NAMES\n)\nfrom cryptography.x509.name import Name, NameAttribute\nfrom cryptography.x509.oid import (\n AuthorityInformationAccessOID, CRLEntryExtensionOID,\n CertificatePoliciesOID, ExtendedKeyUsageOID, ExtensionOID, NameOID,\n ObjectIdentifier, SignatureAlgorithmOID, _SIG_OIDS_TO_HASH\n)\n\n\nCRLExtensionOID = utils.deprecated(\n CRLEntryExtensionOID,\n __name__,\n \"CRLExtensionOID has been renamed to CRLEntryExtensionOID\",\n utils.DeprecatedIn12\n)\n\nOID_AUTHORITY_INFORMATION_ACCESS = ExtensionOID.AUTHORITY_INFORMATION_ACCESS\nOID_AUTHORITY_KEY_IDENTIFIER = ExtensionOID.AUTHORITY_KEY_IDENTIFIER\nOID_BASIC_CONSTRAINTS = ExtensionOID.BASIC_CONSTRAINTS\nOID_CERTIFICATE_POLICIES = ExtensionOID.CERTIFICATE_POLICIES\nOID_CRL_DISTRIBUTION_POINTS = ExtensionOID.CRL_DISTRIBUTION_POINTS\nOID_EXTENDED_KEY_USAGE = ExtensionOID.EXTENDED_KEY_USAGE\nOID_FRESHEST_CRL = ExtensionOID.FRESHEST_CRL\nOID_INHIBIT_ANY_POLICY = ExtensionOID.INHIBIT_ANY_POLICY\nOID_ISSUER_ALTERNATIVE_NAME = ExtensionOID.ISSUER_ALTERNATIVE_NAME\nOID_KEY_USAGE = ExtensionOID.KEY_USAGE\nOID_NAME_CONSTRAINTS = ExtensionOID.NAME_CONSTRAINTS\nOID_OCSP_NO_CHECK = ExtensionOID.OCSP_NO_CHECK\nOID_POLICY_CONSTRAINTS = ExtensionOID.POLICY_CONSTRAINTS\nOID_POLICY_MAPPINGS = ExtensionOID.POLICY_MAPPINGS\nOID_SUBJECT_ALTERNATIVE_NAME = ExtensionOID.SUBJECT_ALTERNATIVE_NAME\nOID_SUBJECT_DIRECTORY_ATTRIBUTES = ExtensionOID.SUBJECT_DIRECTORY_ATTRIBUTES\nOID_SUBJECT_INFORMATION_ACCESS = ExtensionOID.SUBJECT_INFORMATION_ACCESS\nOID_SUBJECT_KEY_IDENTIFIER = ExtensionOID.SUBJECT_KEY_IDENTIFIER\n\nOID_DSA_WITH_SHA1 = SignatureAlgorithmOID.DSA_WITH_SHA1\nOID_DSA_WITH_SHA224 = SignatureAlgorithmOID.DSA_WITH_SHA224\nOID_DSA_WITH_SHA256 = SignatureAlgorithmOID.DSA_WITH_SHA256\nOID_ECDSA_WITH_SHA1 = SignatureAlgorithmOID.ECDSA_WITH_SHA1\nOID_ECDSA_WITH_SHA224 = SignatureAlgorithmOID.ECDSA_WITH_SHA224\nOID_ECDSA_WITH_SHA256 = SignatureAlgorithmOID.ECDSA_WITH_SHA256\nOID_ECDSA_WITH_SHA384 = SignatureAlgorithmOID.ECDSA_WITH_SHA384\nOID_ECDSA_WITH_SHA512 = SignatureAlgorithmOID.ECDSA_WITH_SHA512\nOID_RSA_WITH_MD5 = SignatureAlgorithmOID.RSA_WITH_MD5\nOID_RSA_WITH_SHA1 = SignatureAlgorithmOID.RSA_WITH_SHA1\nOID_RSA_WITH_SHA224 = SignatureAlgorithmOID.RSA_WITH_SHA224\nOID_RSA_WITH_SHA256 = SignatureAlgorithmOID.RSA_WITH_SHA256\nOID_RSA_WITH_SHA384 = SignatureAlgorithmOID.RSA_WITH_SHA384\nOID_RSA_WITH_SHA512 = SignatureAlgorithmOID.RSA_WITH_SHA512\n\nOID_COMMON_NAME = NameOID.COMMON_NAME\nOID_COUNTRY_NAME = NameOID.COUNTRY_NAME\nOID_DOMAIN_COMPONENT = NameOID.DOMAIN_COMPONENT\nOID_DN_QUALIFIER = NameOID.DN_QUALIFIER\nOID_EMAIL_ADDRESS = NameOID.EMAIL_ADDRESS\nOID_GENERATION_QUALIFIER = NameOID.GENERATION_QUALIFIER\nOID_GIVEN_NAME = NameOID.GIVEN_NAME\nOID_LOCALITY_NAME = NameOID.LOCALITY_NAME\nOID_ORGANIZATIONAL_UNIT_NAME = NameOID.ORGANIZATIONAL_UNIT_NAME\nOID_ORGANIZATION_NAME = NameOID.ORGANIZATION_NAME\nOID_PSEUDONYM = NameOID.PSEUDONYM\nOID_SERIAL_NUMBER = NameOID.SERIAL_NUMBER\nOID_STATE_OR_PROVINCE_NAME = NameOID.STATE_OR_PROVINCE_NAME\nOID_SURNAME = NameOID.SURNAME\nOID_TITLE = NameOID.TITLE\n\nOID_CLIENT_AUTH = ExtendedKeyUsageOID.CLIENT_AUTH\nOID_CODE_SIGNING = ExtendedKeyUsageOID.CODE_SIGNING\nOID_EMAIL_PROTECTION = ExtendedKeyUsageOID.EMAIL_PROTECTION\nOID_OCSP_SIGNING = ExtendedKeyUsageOID.OCSP_SIGNING\nOID_SERVER_AUTH = ExtendedKeyUsageOID.SERVER_AUTH\nOID_TIME_STAMPING = ExtendedKeyUsageOID.TIME_STAMPING\n\nOID_ANY_POLICY = CertificatePoliciesOID.ANY_POLICY\nOID_CPS_QUALIFIER = CertificatePoliciesOID.CPS_QUALIFIER\nOID_CPS_USER_NOTICE = CertificatePoliciesOID.CPS_USER_NOTICE\n\nOID_CERTIFICATE_ISSUER = CRLEntryExtensionOID.CERTIFICATE_ISSUER\nOID_CRL_REASON = CRLEntryExtensionOID.CRL_REASON\nOID_INVALIDITY_DATE = CRLEntryExtensionOID.INVALIDITY_DATE\n\nOID_CA_ISSUERS = AuthorityInformationAccessOID.CA_ISSUERS\nOID_OCSP = AuthorityInformationAccessOID.OCSP\n\n\n__all__ = [\n \"load_pem_x509_certificate\",\n \"load_der_x509_certificate\",\n \"load_pem_x509_csr\",\n \"load_der_x509_csr\",\n \"load_pem_x509_crl\",\n \"load_der_x509_crl\",\n \"InvalidVersion\",\n \"DuplicateExtension\",\n \"UnsupportedExtension\",\n \"ExtensionNotFound\",\n \"UnsupportedGeneralNameType\",\n \"NameAttribute\",\n \"Name\",\n \"ObjectIdentifier\",\n \"ExtensionType\",\n \"Extensions\",\n \"Extension\",\n \"ExtendedKeyUsage\",\n \"OCSPNoCheck\",\n \"BasicConstraints\",\n \"CRLNumber\",\n \"KeyUsage\",\n \"AuthorityInformationAccess\",\n \"AccessDescription\",\n \"CertificatePolicies\",\n \"PolicyInformation\",\n \"UserNotice\",\n \"NoticeReference\",\n \"SubjectKeyIdentifier\",\n \"NameConstraints\",\n \"CRLDistributionPoints\",\n \"DistributionPoint\",\n \"ReasonFlags\",\n \"InhibitAnyPolicy\",\n \"SubjectAlternativeName\",\n \"IssuerAlternativeName\",\n \"AuthorityKeyIdentifier\",\n \"GeneralNames\",\n \"GeneralName\",\n \"RFC822Name\",\n \"DNSName\",\n \"UniformResourceIdentifier\",\n \"RegisteredID\",\n \"DirectoryName\",\n \"IPAddress\",\n \"OtherName\",\n \"Certificate\",\n \"CertificateRevocationList\",\n \"CertificateRevocationListBuilder\",\n \"CertificateSigningRequest\",\n \"RevokedCertificate\",\n \"RevokedCertificateBuilder\",\n \"CertificateSigningRequestBuilder\",\n \"CertificateBuilder\",\n \"Version\",\n \"_SIG_OIDS_TO_HASH\",\n \"OID_CA_ISSUERS\",\n \"OID_OCSP\",\n \"_GENERAL_NAMES\",\n \"CRLExtensionOID\",\n \"CertificateIssuer\",\n \"CRLReason\",\n \"InvalidityDate\",\n \"UnrecognizedExtension\",\n]\n", "path": "src/cryptography/x509/__init__.py"}]}
| 2,526 | 311 |
gh_patches_debug_7944
|
rasdani/github-patches
|
git_diff
|
hylang__hy-1710
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"\n" isn't mangled appropriately
=> (mangle "\n")
'hyx_XUnX'
=> (unmangle (mangle "\n"))
Traceback (most recent call last):
…
ValueError: invalid literal for int() with base 16: 'n'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/lex/__init__.py`
Content:
```
1 # Copyright 2018 the authors.
2 # This file is part of Hy, which is free software licensed under the Expat
3 # license. See the LICENSE.
4
5 from __future__ import unicode_literals
6
7 import re
8 import sys
9 import unicodedata
10
11 from hy._compat import str_type, isidentifier, UCS4
12 from hy.lex.exceptions import PrematureEndOfInput, LexException # NOQA
13 from hy.models import HyExpression, HySymbol
14
15 try:
16 from io import StringIO
17 except ImportError:
18 from StringIO import StringIO
19
20
21 def hy_parse(source):
22 """Parse a Hy source string.
23
24 Parameters
25 ----------
26 source: string
27 Source code to parse.
28
29 Returns
30 -------
31 out : instance of `types.CodeType`
32 """
33 source = re.sub(r'\A#!.*', '', source)
34 return HyExpression([HySymbol("do")] + tokenize(source + "\n"))
35
36
37 def tokenize(buf):
38 """
39 Tokenize a Lisp file or string buffer into internal Hy objects.
40 """
41 from hy.lex.lexer import lexer
42 from hy.lex.parser import parser
43 from rply.errors import LexingError
44 try:
45 return parser.parse(lexer.lex(buf))
46 except LexingError as e:
47 pos = e.getsourcepos()
48 raise LexException("Could not identify the next token.",
49 pos.lineno, pos.colno, buf)
50 except LexException as e:
51 if e.source is None:
52 e.source = buf
53 raise
54
55
56 mangle_delim = 'X'
57
58
59 def mangle(s):
60 """Stringify the argument and convert it to a valid Python identifier
61 according to Hy's mangling rules."""
62 def unicode_char_to_hex(uchr):
63 # Covert a unicode char to hex string, without prefix
64 return uchr.encode('unicode-escape').decode('utf-8').lstrip('\\U').lstrip('\\u').lstrip('0')
65
66 assert s
67
68 s = str_type(s)
69 s = s.replace("-", "_")
70 s2 = s.lstrip('_')
71 leading_underscores = '_' * (len(s) - len(s2))
72 s = s2
73
74 if s.endswith("?"):
75 s = 'is_' + s[:-1]
76 if not isidentifier(leading_underscores + s):
77 # Replace illegal characters with their Unicode character
78 # names, or hexadecimal if they don't have one.
79 s = 'hyx_' + ''.join(
80 c
81 if c != mangle_delim and isidentifier('S' + c)
82 # We prepend the "S" because some characters aren't
83 # allowed at the start of an identifier.
84 else '{0}{1}{0}'.format(mangle_delim,
85 unicodedata.name(c, '').lower().replace('-', 'H').replace(' ', '_')
86 or 'U{}'.format(unicode_char_to_hex(c)))
87 for c in unicode_to_ucs4iter(s))
88
89 s = leading_underscores + s
90 assert isidentifier(s)
91 return s
92
93
94 def unmangle(s):
95 """Stringify the argument and try to convert it to a pretty unmangled
96 form. This may not round-trip, because different Hy symbol names can
97 mangle to the same Python identifier."""
98
99 s = str_type(s)
100
101 s2 = s.lstrip('_')
102 leading_underscores = len(s) - len(s2)
103 s = s2
104
105 if s.startswith('hyx_'):
106 s = re.sub('{0}(U)?([_a-z0-9H]+?){0}'.format(mangle_delim),
107 lambda mo:
108 chr(int(mo.group(2), base=16))
109 if mo.group(1)
110 else unicodedata.lookup(
111 mo.group(2).replace('_', ' ').replace('H', '-').upper()),
112 s[len('hyx_'):])
113 if s.startswith('is_'):
114 s = s[len("is_"):] + "?"
115 s = s.replace('_', '-')
116
117 return '-' * leading_underscores + s
118
119
120 def unicode_to_ucs4iter(ustr):
121 # Covert a unicode string to an iterable object,
122 # elements in the object are single USC-4 unicode characters
123 if UCS4:
124 return ustr
125 ucs4_list = list(ustr)
126 for i, u in enumerate(ucs4_list):
127 if 0xD7FF < ord(u) < 0xDC00:
128 ucs4_list[i] += ucs4_list[i + 1]
129 del ucs4_list[i + 1]
130 return ucs4_list
131
132
133 def read(from_file=sys.stdin, eof=""):
134 """Read from input and returns a tokenized string.
135
136 Can take a given input buffer to read from, and a single byte as EOF
137 (defaults to an empty string).
138 """
139 buff = ""
140 while True:
141 inn = str(from_file.readline())
142 if inn == eof:
143 raise EOFError("Reached end of file")
144 buff += inn
145 try:
146 parsed = next(iter(tokenize(buff)), None)
147 except (PrematureEndOfInput, IndexError):
148 pass
149 else:
150 break
151 return parsed
152
153
154 def read_str(input):
155 return read(StringIO(str_type(input)))
156
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hy/lex/__init__.py b/hy/lex/__init__.py
--- a/hy/lex/__init__.py
+++ b/hy/lex/__init__.py
@@ -61,7 +61,10 @@
according to Hy's mangling rules."""
def unicode_char_to_hex(uchr):
# Covert a unicode char to hex string, without prefix
- return uchr.encode('unicode-escape').decode('utf-8').lstrip('\\U').lstrip('\\u').lstrip('0')
+ if len(uchr) == 1 and ord(uchr) < 128:
+ return format(ord(uchr), 'x')
+ return (uchr.encode('unicode-escape').decode('utf-8')
+ .lstrip('\\U').lstrip('\\u').lstrip('\\x').lstrip('0'))
assert s
|
{"golden_diff": "diff --git a/hy/lex/__init__.py b/hy/lex/__init__.py\n--- a/hy/lex/__init__.py\n+++ b/hy/lex/__init__.py\n@@ -61,7 +61,10 @@\n according to Hy's mangling rules.\"\"\"\n def unicode_char_to_hex(uchr):\n # Covert a unicode char to hex string, without prefix\n- return uchr.encode('unicode-escape').decode('utf-8').lstrip('\\\\U').lstrip('\\\\u').lstrip('0')\n+ if len(uchr) == 1 and ord(uchr) < 128:\n+ return format(ord(uchr), 'x')\n+ return (uchr.encode('unicode-escape').decode('utf-8')\n+ .lstrip('\\\\U').lstrip('\\\\u').lstrip('\\\\x').lstrip('0'))\n \n assert s\n", "issue": "\"\\n\" isn't mangled appropriately\n => (mangle \"\\n\")\r\n 'hyx_XUnX'\r\n => (unmangle (mangle \"\\n\"))\r\n Traceback (most recent call last):\r\n \u2026\r\n ValueError: invalid literal for int() with base 16: 'n'\r\n\n", "before_files": [{"content": "# Copyright 2018 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nfrom __future__ import unicode_literals\n\nimport re\nimport sys\nimport unicodedata\n\nfrom hy._compat import str_type, isidentifier, UCS4\nfrom hy.lex.exceptions import PrematureEndOfInput, LexException # NOQA\nfrom hy.models import HyExpression, HySymbol\n\ntry:\n from io import StringIO\nexcept ImportError:\n from StringIO import StringIO\n\n\ndef hy_parse(source):\n \"\"\"Parse a Hy source string.\n\n Parameters\n ----------\n source: string\n Source code to parse.\n\n Returns\n -------\n out : instance of `types.CodeType`\n \"\"\"\n source = re.sub(r'\\A#!.*', '', source)\n return HyExpression([HySymbol(\"do\")] + tokenize(source + \"\\n\"))\n\n\ndef tokenize(buf):\n \"\"\"\n Tokenize a Lisp file or string buffer into internal Hy objects.\n \"\"\"\n from hy.lex.lexer import lexer\n from hy.lex.parser import parser\n from rply.errors import LexingError\n try:\n return parser.parse(lexer.lex(buf))\n except LexingError as e:\n pos = e.getsourcepos()\n raise LexException(\"Could not identify the next token.\",\n pos.lineno, pos.colno, buf)\n except LexException as e:\n if e.source is None:\n e.source = buf\n raise\n\n\nmangle_delim = 'X'\n\n\ndef mangle(s):\n \"\"\"Stringify the argument and convert it to a valid Python identifier\n according to Hy's mangling rules.\"\"\"\n def unicode_char_to_hex(uchr):\n # Covert a unicode char to hex string, without prefix\n return uchr.encode('unicode-escape').decode('utf-8').lstrip('\\\\U').lstrip('\\\\u').lstrip('0')\n\n assert s\n\n s = str_type(s)\n s = s.replace(\"-\", \"_\")\n s2 = s.lstrip('_')\n leading_underscores = '_' * (len(s) - len(s2))\n s = s2\n\n if s.endswith(\"?\"):\n s = 'is_' + s[:-1]\n if not isidentifier(leading_underscores + s):\n # Replace illegal characters with their Unicode character\n # names, or hexadecimal if they don't have one.\n s = 'hyx_' + ''.join(\n c\n if c != mangle_delim and isidentifier('S' + c)\n # We prepend the \"S\" because some characters aren't\n # allowed at the start of an identifier.\n else '{0}{1}{0}'.format(mangle_delim,\n unicodedata.name(c, '').lower().replace('-', 'H').replace(' ', '_')\n or 'U{}'.format(unicode_char_to_hex(c)))\n for c in unicode_to_ucs4iter(s))\n\n s = leading_underscores + s\n assert isidentifier(s)\n return s\n\n\ndef unmangle(s):\n \"\"\"Stringify the argument and try to convert it to a pretty unmangled\n form. This may not round-trip, because different Hy symbol names can\n mangle to the same Python identifier.\"\"\"\n\n s = str_type(s)\n\n s2 = s.lstrip('_')\n leading_underscores = len(s) - len(s2)\n s = s2\n\n if s.startswith('hyx_'):\n s = re.sub('{0}(U)?([_a-z0-9H]+?){0}'.format(mangle_delim),\n lambda mo:\n chr(int(mo.group(2), base=16))\n if mo.group(1)\n else unicodedata.lookup(\n mo.group(2).replace('_', ' ').replace('H', '-').upper()),\n s[len('hyx_'):])\n if s.startswith('is_'):\n s = s[len(\"is_\"):] + \"?\"\n s = s.replace('_', '-')\n\n return '-' * leading_underscores + s\n\n\ndef unicode_to_ucs4iter(ustr):\n # Covert a unicode string to an iterable object,\n # elements in the object are single USC-4 unicode characters\n if UCS4:\n return ustr\n ucs4_list = list(ustr)\n for i, u in enumerate(ucs4_list):\n if 0xD7FF < ord(u) < 0xDC00:\n ucs4_list[i] += ucs4_list[i + 1]\n del ucs4_list[i + 1]\n return ucs4_list\n\n\ndef read(from_file=sys.stdin, eof=\"\"):\n \"\"\"Read from input and returns a tokenized string.\n\n Can take a given input buffer to read from, and a single byte as EOF\n (defaults to an empty string).\n \"\"\"\n buff = \"\"\n while True:\n inn = str(from_file.readline())\n if inn == eof:\n raise EOFError(\"Reached end of file\")\n buff += inn\n try:\n parsed = next(iter(tokenize(buff)), None)\n except (PrematureEndOfInput, IndexError):\n pass\n else:\n break\n return parsed\n\n\ndef read_str(input):\n return read(StringIO(str_type(input)))\n", "path": "hy/lex/__init__.py"}], "after_files": [{"content": "# Copyright 2018 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nfrom __future__ import unicode_literals\n\nimport re\nimport sys\nimport unicodedata\n\nfrom hy._compat import str_type, isidentifier, UCS4\nfrom hy.lex.exceptions import PrematureEndOfInput, LexException # NOQA\nfrom hy.models import HyExpression, HySymbol\n\ntry:\n from io import StringIO\nexcept ImportError:\n from StringIO import StringIO\n\n\ndef hy_parse(source):\n \"\"\"Parse a Hy source string.\n\n Parameters\n ----------\n source: string\n Source code to parse.\n\n Returns\n -------\n out : instance of `types.CodeType`\n \"\"\"\n source = re.sub(r'\\A#!.*', '', source)\n return HyExpression([HySymbol(\"do\")] + tokenize(source + \"\\n\"))\n\n\ndef tokenize(buf):\n \"\"\"\n Tokenize a Lisp file or string buffer into internal Hy objects.\n \"\"\"\n from hy.lex.lexer import lexer\n from hy.lex.parser import parser\n from rply.errors import LexingError\n try:\n return parser.parse(lexer.lex(buf))\n except LexingError as e:\n pos = e.getsourcepos()\n raise LexException(\"Could not identify the next token.\",\n pos.lineno, pos.colno, buf)\n except LexException as e:\n if e.source is None:\n e.source = buf\n raise\n\n\nmangle_delim = 'X'\n\n\ndef mangle(s):\n \"\"\"Stringify the argument and convert it to a valid Python identifier\n according to Hy's mangling rules.\"\"\"\n def unicode_char_to_hex(uchr):\n # Covert a unicode char to hex string, without prefix\n if len(uchr) == 1 and ord(uchr) < 128:\n return format(ord(uchr), 'x')\n return (uchr.encode('unicode-escape').decode('utf-8')\n .lstrip('\\\\U').lstrip('\\\\u').lstrip('\\\\x').lstrip('0'))\n\n assert s\n\n s = str_type(s)\n s = s.replace(\"-\", \"_\")\n s2 = s.lstrip('_')\n leading_underscores = '_' * (len(s) - len(s2))\n s = s2\n\n if s.endswith(\"?\"):\n s = 'is_' + s[:-1]\n if not isidentifier(leading_underscores + s):\n # Replace illegal characters with their Unicode character\n # names, or hexadecimal if they don't have one.\n s = 'hyx_' + ''.join(\n c\n if c != mangle_delim and isidentifier('S' + c)\n # We prepend the \"S\" because some characters aren't\n # allowed at the start of an identifier.\n else '{0}{1}{0}'.format(mangle_delim,\n unicodedata.name(c, '').lower().replace('-', 'H').replace(' ', '_')\n or 'U{}'.format(unicode_char_to_hex(c)))\n for c in unicode_to_ucs4iter(s))\n\n s = leading_underscores + s\n assert isidentifier(s)\n return s\n\n\ndef unmangle(s):\n \"\"\"Stringify the argument and try to convert it to a pretty unmangled\n form. This may not round-trip, because different Hy symbol names can\n mangle to the same Python identifier.\"\"\"\n\n s = str_type(s)\n\n s2 = s.lstrip('_')\n leading_underscores = len(s) - len(s2)\n s = s2\n\n if s.startswith('hyx_'):\n s = re.sub('{0}(U)?([_a-z0-9H]+?){0}'.format(mangle_delim),\n lambda mo:\n chr(int(mo.group(2), base=16))\n if mo.group(1)\n else unicodedata.lookup(\n mo.group(2).replace('_', ' ').replace('H', '-').upper()),\n s[len('hyx_'):])\n if s.startswith('is_'):\n s = s[len(\"is_\"):] + \"?\"\n s = s.replace('_', '-')\n\n return '-' * leading_underscores + s\n\n\ndef unicode_to_ucs4iter(ustr):\n # Covert a unicode string to an iterable object,\n # elements in the object are single USC-4 unicode characters\n if UCS4:\n return ustr\n ucs4_list = list(ustr)\n for i, u in enumerate(ucs4_list):\n if 0xD7FF < ord(u) < 0xDC00:\n ucs4_list[i] += ucs4_list[i + 1]\n del ucs4_list[i + 1]\n return ucs4_list\n\n\ndef read(from_file=sys.stdin, eof=\"\"):\n \"\"\"Read from input and returns a tokenized string.\n\n Can take a given input buffer to read from, and a single byte as EOF\n (defaults to an empty string).\n \"\"\"\n buff = \"\"\n while True:\n inn = str(from_file.readline())\n if inn == eof:\n raise EOFError(\"Reached end of file\")\n buff += inn\n try:\n parsed = next(iter(tokenize(buff)), None)\n except (PrematureEndOfInput, IndexError):\n pass\n else:\n break\n return parsed\n\n\ndef read_str(input):\n return read(StringIO(str_type(input)))\n", "path": "hy/lex/__init__.py"}]}
| 1,844 | 203 |
gh_patches_debug_18576
|
rasdani/github-patches
|
git_diff
|
openvinotoolkit__datumaro-800
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`loglevel` does not affect CLI output
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datumaro/cli/__main__.py`
Content:
```
1 # Copyright (C) 2019-2022 Intel Corporation
2 #
3 # SPDX-License-Identifier: MIT
4
5 import argparse
6 import logging as log
7 import os.path as osp
8 import sys
9 import warnings
10
11 from ..util.telemetry_utils import (
12 close_telemetry_session,
13 init_telemetry_session,
14 send_command_exception_info,
15 send_command_failure_info,
16 send_command_success_info,
17 )
18 from ..version import VERSION
19 from . import commands, contexts
20 from .util import add_subparser
21 from .util.errors import CliException
22
23 _log_levels = {
24 "debug": log.DEBUG,
25 "info": log.INFO,
26 "warning": log.WARNING,
27 "error": log.ERROR,
28 "critical": log.CRITICAL,
29 }
30
31
32 def loglevel(name):
33 return _log_levels[name]
34
35
36 class _LogManager:
37 @classmethod
38 def init_logger(cls, args=None):
39 # Define minimalistic parser only to obtain loglevel
40 parser = argparse.ArgumentParser(add_help=False)
41 cls._define_loglevel_option(parser)
42 args, _ = parser.parse_known_args(args)
43
44 log.basicConfig(format="%(asctime)s %(levelname)s: %(message)s", level=args.loglevel)
45
46 # Suppress own deprecation warnings
47 warnings.filterwarnings("ignore", category=DeprecationWarning, module=r"datumaro\..*")
48
49 @staticmethod
50 def _define_loglevel_option(parser):
51 parser.add_argument(
52 "--loglevel",
53 type=loglevel,
54 default="info",
55 help="Logging level (options: %s; default: %s)"
56 % (", ".join(_log_levels.keys()), "%(default)s"),
57 )
58 return parser
59
60
61 def _make_subcommands_help(commands, help_line_start=0):
62 desc = ""
63 for command_name, _, command_help in commands:
64 desc += (" %-" + str(max(0, help_line_start - 2 - 1)) + "s%s\n") % (
65 command_name,
66 command_help,
67 )
68 return desc
69
70
71 def _get_known_contexts():
72 return [
73 ("model", contexts.model, "Actions with models"),
74 ("project", contexts.project, "Actions with projects"),
75 ("source", contexts.source, "Actions with data sources"),
76 ("util", contexts.util, "Auxillary tools and utilities"),
77 ]
78
79
80 def _get_known_commands():
81 return [
82 ("Project modification:", None, ""),
83 ("add", commands.add, "Add dataset"),
84 ("create", commands.create, "Create empty project"),
85 ("import", commands.import_, "Import dataset"),
86 ("remove", commands.remove, "Remove dataset"),
87 ("", None, ""),
88 ("Project versioning:", None, ""),
89 ("checkout", commands.checkout, "Switch to another branch or revision"),
90 ("commit", commands.commit, "Commit changes in tracked files"),
91 ("log", commands.log, "List history"),
92 ("status", commands.status, "Display current status"),
93 ("", None, ""),
94 ("Dataset operations:", None, ""),
95 ("convert", commands.convert, "Convert dataset between formats"),
96 (
97 "describe-downloads",
98 commands.describe_downloads,
99 "Print information about downloadable datasets",
100 ),
101 ("detect-format", commands.detect_format, "Detect the format of a dataset"),
102 ("diff", commands.diff, "Compare datasets"),
103 ("download", commands.download, "Download a publicly available dataset"),
104 ("explain", commands.explain, "Run Explainable AI algorithm for model"),
105 ("export", commands.export, "Export dataset in some format"),
106 ("filter", commands.filter, "Filter dataset items"),
107 ("generate", commands.generate, "Generate synthetic dataset"),
108 ("info", commands.info, "Print dataset info"),
109 ("merge", commands.merge, "Merge datasets"),
110 ("patch", commands.patch, "Update dataset from another one"),
111 ("stats", commands.stats, "Compute dataset statistics"),
112 ("transform", commands.transform, "Modify dataset items"),
113 ("validate", commands.validate, "Validate dataset"),
114 ]
115
116
117 def _get_sensitive_args():
118 known_contexts = _get_known_contexts()
119 known_commands = _get_known_commands()
120
121 res = {}
122 for _, command, _ in known_contexts + known_commands:
123 if command is not None:
124 res.update(command.get_sensitive_args())
125
126 return res
127
128
129 def make_parser():
130 parser = argparse.ArgumentParser(
131 description="Dataset Framework", formatter_class=argparse.RawDescriptionHelpFormatter
132 )
133 if parser.prog == osp.basename(__file__): # python -m datumaro ...
134 parser.prog = "datumaro"
135
136 parser.add_argument("--version", action="version", version=VERSION)
137 _LogManager._define_loglevel_option(parser)
138
139 known_contexts = _get_known_contexts()
140 known_commands = _get_known_commands()
141
142 # Argparse doesn't support subparser groups:
143 # https://stackoverflow.com/questions/32017020/grouping-argparse-subparser-arguments
144 help_line_start = max((len(e[0]) for e in known_contexts + known_commands), default=0)
145 help_line_start = max((2 + help_line_start) // 4 + 1, 6) * 4 # align to tabs
146 subcommands_desc = ""
147 if known_contexts:
148 subcommands_desc += "Contexts:\n"
149 subcommands_desc += _make_subcommands_help(known_contexts, help_line_start)
150 if known_commands:
151 if subcommands_desc:
152 subcommands_desc += "\n"
153 subcommands_desc += "Commands:\n"
154 subcommands_desc += _make_subcommands_help(known_commands, help_line_start)
155 if subcommands_desc:
156 subcommands_desc += (
157 "\nRun '%s COMMAND --help' for more information on a command." % parser.prog
158 )
159
160 subcommands = parser.add_subparsers(
161 title=subcommands_desc, description="", help=argparse.SUPPRESS
162 )
163 for command_name, command, _ in known_contexts + known_commands:
164 if command is not None:
165 add_subparser(subcommands, command_name, command.build_parser)
166
167 return parser
168
169
170 def main(args=None):
171 _LogManager.init_logger(args)
172
173 parser = make_parser()
174 args = parser.parse_args(args)
175
176 if "command" not in args:
177 parser.print_help()
178 return 1
179
180 sensitive_args = _get_sensitive_args()
181 telemetry = init_telemetry_session(app_name="Datumaro", app_version=VERSION)
182
183 try:
184 retcode = args.command(args)
185 if retcode is None:
186 retcode = 0
187 except CliException as e:
188 log.error(e)
189 send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])
190 return 1
191 except Exception as e:
192 log.error(e)
193 send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])
194 raise
195 else:
196 if retcode:
197 send_command_failure_info(telemetry, args, sensitive_args=sensitive_args[args.command])
198 else:
199 send_command_success_info(telemetry, args, sensitive_args=sensitive_args[args.command])
200 return retcode
201 finally:
202 close_telemetry_session(telemetry)
203
204
205 if __name__ == "__main__":
206 sys.exit(main())
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/datumaro/cli/__main__.py b/datumaro/cli/__main__.py
--- a/datumaro/cli/__main__.py
+++ b/datumaro/cli/__main__.py
@@ -40,8 +40,17 @@
parser = argparse.ArgumentParser(add_help=False)
cls._define_loglevel_option(parser)
args, _ = parser.parse_known_args(args)
-
- log.basicConfig(format="%(asctime)s %(levelname)s: %(message)s", level=args.loglevel)
+ log_format = "%(asctime)s %(levelname)s: %(message)s"
+
+ # Try setting up logging with basicConfig.
+ # This does nothing, if other parts of the software
+ # already configured handlers, i.e. during imports and when
+ # main is called programmatically.
+ log.basicConfig(format=log_format, level=args.loglevel)
+ # Force-overwrite the log level and formatter
+ log.root.setLevel(args.loglevel)
+ for h in log.root.handlers:
+ h.setFormatter(log.Formatter(log_format))
# Suppress own deprecation warnings
warnings.filterwarnings("ignore", category=DeprecationWarning, module=r"datumaro\..*")
|
{"golden_diff": "diff --git a/datumaro/cli/__main__.py b/datumaro/cli/__main__.py\n--- a/datumaro/cli/__main__.py\n+++ b/datumaro/cli/__main__.py\n@@ -40,8 +40,17 @@\n parser = argparse.ArgumentParser(add_help=False)\n cls._define_loglevel_option(parser)\n args, _ = parser.parse_known_args(args)\n-\n- log.basicConfig(format=\"%(asctime)s %(levelname)s: %(message)s\", level=args.loglevel)\n+ log_format = \"%(asctime)s %(levelname)s: %(message)s\"\n+\n+ # Try setting up logging with basicConfig.\n+ # This does nothing, if other parts of the software\n+ # already configured handlers, i.e. during imports and when\n+ # main is called programmatically.\n+ log.basicConfig(format=log_format, level=args.loglevel)\n+ # Force-overwrite the log level and formatter\n+ log.root.setLevel(args.loglevel)\n+ for h in log.root.handlers:\n+ h.setFormatter(log.Formatter(log_format))\n \n # Suppress own deprecation warnings\n warnings.filterwarnings(\"ignore\", category=DeprecationWarning, module=r\"datumaro\\..*\")\n", "issue": "`loglevel` does not affect CLI output\n\n", "before_files": [{"content": "# Copyright (C) 2019-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nimport argparse\nimport logging as log\nimport os.path as osp\nimport sys\nimport warnings\n\nfrom ..util.telemetry_utils import (\n close_telemetry_session,\n init_telemetry_session,\n send_command_exception_info,\n send_command_failure_info,\n send_command_success_info,\n)\nfrom ..version import VERSION\nfrom . import commands, contexts\nfrom .util import add_subparser\nfrom .util.errors import CliException\n\n_log_levels = {\n \"debug\": log.DEBUG,\n \"info\": log.INFO,\n \"warning\": log.WARNING,\n \"error\": log.ERROR,\n \"critical\": log.CRITICAL,\n}\n\n\ndef loglevel(name):\n return _log_levels[name]\n\n\nclass _LogManager:\n @classmethod\n def init_logger(cls, args=None):\n # Define minimalistic parser only to obtain loglevel\n parser = argparse.ArgumentParser(add_help=False)\n cls._define_loglevel_option(parser)\n args, _ = parser.parse_known_args(args)\n\n log.basicConfig(format=\"%(asctime)s %(levelname)s: %(message)s\", level=args.loglevel)\n\n # Suppress own deprecation warnings\n warnings.filterwarnings(\"ignore\", category=DeprecationWarning, module=r\"datumaro\\..*\")\n\n @staticmethod\n def _define_loglevel_option(parser):\n parser.add_argument(\n \"--loglevel\",\n type=loglevel,\n default=\"info\",\n help=\"Logging level (options: %s; default: %s)\"\n % (\", \".join(_log_levels.keys()), \"%(default)s\"),\n )\n return parser\n\n\ndef _make_subcommands_help(commands, help_line_start=0):\n desc = \"\"\n for command_name, _, command_help in commands:\n desc += (\" %-\" + str(max(0, help_line_start - 2 - 1)) + \"s%s\\n\") % (\n command_name,\n command_help,\n )\n return desc\n\n\ndef _get_known_contexts():\n return [\n (\"model\", contexts.model, \"Actions with models\"),\n (\"project\", contexts.project, \"Actions with projects\"),\n (\"source\", contexts.source, \"Actions with data sources\"),\n (\"util\", contexts.util, \"Auxillary tools and utilities\"),\n ]\n\n\ndef _get_known_commands():\n return [\n (\"Project modification:\", None, \"\"),\n (\"add\", commands.add, \"Add dataset\"),\n (\"create\", commands.create, \"Create empty project\"),\n (\"import\", commands.import_, \"Import dataset\"),\n (\"remove\", commands.remove, \"Remove dataset\"),\n (\"\", None, \"\"),\n (\"Project versioning:\", None, \"\"),\n (\"checkout\", commands.checkout, \"Switch to another branch or revision\"),\n (\"commit\", commands.commit, \"Commit changes in tracked files\"),\n (\"log\", commands.log, \"List history\"),\n (\"status\", commands.status, \"Display current status\"),\n (\"\", None, \"\"),\n (\"Dataset operations:\", None, \"\"),\n (\"convert\", commands.convert, \"Convert dataset between formats\"),\n (\n \"describe-downloads\",\n commands.describe_downloads,\n \"Print information about downloadable datasets\",\n ),\n (\"detect-format\", commands.detect_format, \"Detect the format of a dataset\"),\n (\"diff\", commands.diff, \"Compare datasets\"),\n (\"download\", commands.download, \"Download a publicly available dataset\"),\n (\"explain\", commands.explain, \"Run Explainable AI algorithm for model\"),\n (\"export\", commands.export, \"Export dataset in some format\"),\n (\"filter\", commands.filter, \"Filter dataset items\"),\n (\"generate\", commands.generate, \"Generate synthetic dataset\"),\n (\"info\", commands.info, \"Print dataset info\"),\n (\"merge\", commands.merge, \"Merge datasets\"),\n (\"patch\", commands.patch, \"Update dataset from another one\"),\n (\"stats\", commands.stats, \"Compute dataset statistics\"),\n (\"transform\", commands.transform, \"Modify dataset items\"),\n (\"validate\", commands.validate, \"Validate dataset\"),\n ]\n\n\ndef _get_sensitive_args():\n known_contexts = _get_known_contexts()\n known_commands = _get_known_commands()\n\n res = {}\n for _, command, _ in known_contexts + known_commands:\n if command is not None:\n res.update(command.get_sensitive_args())\n\n return res\n\n\ndef make_parser():\n parser = argparse.ArgumentParser(\n description=\"Dataset Framework\", formatter_class=argparse.RawDescriptionHelpFormatter\n )\n if parser.prog == osp.basename(__file__): # python -m datumaro ...\n parser.prog = \"datumaro\"\n\n parser.add_argument(\"--version\", action=\"version\", version=VERSION)\n _LogManager._define_loglevel_option(parser)\n\n known_contexts = _get_known_contexts()\n known_commands = _get_known_commands()\n\n # Argparse doesn't support subparser groups:\n # https://stackoverflow.com/questions/32017020/grouping-argparse-subparser-arguments\n help_line_start = max((len(e[0]) for e in known_contexts + known_commands), default=0)\n help_line_start = max((2 + help_line_start) // 4 + 1, 6) * 4 # align to tabs\n subcommands_desc = \"\"\n if known_contexts:\n subcommands_desc += \"Contexts:\\n\"\n subcommands_desc += _make_subcommands_help(known_contexts, help_line_start)\n if known_commands:\n if subcommands_desc:\n subcommands_desc += \"\\n\"\n subcommands_desc += \"Commands:\\n\"\n subcommands_desc += _make_subcommands_help(known_commands, help_line_start)\n if subcommands_desc:\n subcommands_desc += (\n \"\\nRun '%s COMMAND --help' for more information on a command.\" % parser.prog\n )\n\n subcommands = parser.add_subparsers(\n title=subcommands_desc, description=\"\", help=argparse.SUPPRESS\n )\n for command_name, command, _ in known_contexts + known_commands:\n if command is not None:\n add_subparser(subcommands, command_name, command.build_parser)\n\n return parser\n\n\ndef main(args=None):\n _LogManager.init_logger(args)\n\n parser = make_parser()\n args = parser.parse_args(args)\n\n if \"command\" not in args:\n parser.print_help()\n return 1\n\n sensitive_args = _get_sensitive_args()\n telemetry = init_telemetry_session(app_name=\"Datumaro\", app_version=VERSION)\n\n try:\n retcode = args.command(args)\n if retcode is None:\n retcode = 0\n except CliException as e:\n log.error(e)\n send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n return 1\n except Exception as e:\n log.error(e)\n send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n raise\n else:\n if retcode:\n send_command_failure_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n else:\n send_command_success_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n return retcode\n finally:\n close_telemetry_session(telemetry)\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "datumaro/cli/__main__.py"}], "after_files": [{"content": "# Copyright (C) 2019-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nimport argparse\nimport logging as log\nimport os.path as osp\nimport sys\nimport warnings\n\nfrom ..util.telemetry_utils import (\n close_telemetry_session,\n init_telemetry_session,\n send_command_exception_info,\n send_command_failure_info,\n send_command_success_info,\n)\nfrom ..version import VERSION\nfrom . import commands, contexts\nfrom .util import add_subparser\nfrom .util.errors import CliException\n\n_log_levels = {\n \"debug\": log.DEBUG,\n \"info\": log.INFO,\n \"warning\": log.WARNING,\n \"error\": log.ERROR,\n \"critical\": log.CRITICAL,\n}\n\n\ndef loglevel(name):\n return _log_levels[name]\n\n\nclass _LogManager:\n @classmethod\n def init_logger(cls, args=None):\n # Define minimalistic parser only to obtain loglevel\n parser = argparse.ArgumentParser(add_help=False)\n cls._define_loglevel_option(parser)\n args, _ = parser.parse_known_args(args)\n log_format = \"%(asctime)s %(levelname)s: %(message)s\"\n\n # Try setting up logging with basicConfig.\n # This does nothing, if other parts of the software\n # already configured handlers, i.e. during imports and when\n # main is called programmatically.\n log.basicConfig(format=log_format, level=args.loglevel)\n # Force-overwrite the log level and formatter\n log.root.setLevel(args.loglevel)\n for h in log.root.handlers:\n h.setFormatter(log.Formatter(log_format))\n\n # Suppress own deprecation warnings\n warnings.filterwarnings(\"ignore\", category=DeprecationWarning, module=r\"datumaro\\..*\")\n\n @staticmethod\n def _define_loglevel_option(parser):\n parser.add_argument(\n \"--loglevel\",\n type=loglevel,\n default=\"info\",\n help=\"Logging level (options: %s; default: %s)\"\n % (\", \".join(_log_levels.keys()), \"%(default)s\"),\n )\n return parser\n\n\ndef _make_subcommands_help(commands, help_line_start=0):\n desc = \"\"\n for command_name, _, command_help in commands:\n desc += (\" %-\" + str(max(0, help_line_start - 2 - 1)) + \"s%s\\n\") % (\n command_name,\n command_help,\n )\n return desc\n\n\ndef _get_known_contexts():\n return [\n (\"model\", contexts.model, \"Actions with models\"),\n (\"project\", contexts.project, \"Actions with projects\"),\n (\"source\", contexts.source, \"Actions with data sources\"),\n (\"util\", contexts.util, \"Auxillary tools and utilities\"),\n ]\n\n\ndef _get_known_commands():\n return [\n (\"Project modification:\", None, \"\"),\n (\"add\", commands.add, \"Add dataset\"),\n (\"create\", commands.create, \"Create empty project\"),\n (\"import\", commands.import_, \"Import dataset\"),\n (\"remove\", commands.remove, \"Remove dataset\"),\n (\"\", None, \"\"),\n (\"Project versioning:\", None, \"\"),\n (\"checkout\", commands.checkout, \"Switch to another branch or revision\"),\n (\"commit\", commands.commit, \"Commit changes in tracked files\"),\n (\"log\", commands.log, \"List history\"),\n (\"status\", commands.status, \"Display current status\"),\n (\"\", None, \"\"),\n (\"Dataset operations:\", None, \"\"),\n (\"convert\", commands.convert, \"Convert dataset between formats\"),\n (\n \"describe-downloads\",\n commands.describe_downloads,\n \"Print information about downloadable datasets\",\n ),\n (\"detect-format\", commands.detect_format, \"Detect the format of a dataset\"),\n (\"diff\", commands.diff, \"Compare datasets\"),\n (\"download\", commands.download, \"Download a publicly available dataset\"),\n (\"explain\", commands.explain, \"Run Explainable AI algorithm for model\"),\n (\"export\", commands.export, \"Export dataset in some format\"),\n (\"filter\", commands.filter, \"Filter dataset items\"),\n (\"generate\", commands.generate, \"Generate synthetic dataset\"),\n (\"info\", commands.info, \"Print dataset info\"),\n (\"merge\", commands.merge, \"Merge datasets\"),\n (\"patch\", commands.patch, \"Update dataset from another one\"),\n (\"stats\", commands.stats, \"Compute dataset statistics\"),\n (\"transform\", commands.transform, \"Modify dataset items\"),\n (\"validate\", commands.validate, \"Validate dataset\"),\n ]\n\n\ndef _get_sensitive_args():\n known_contexts = _get_known_contexts()\n known_commands = _get_known_commands()\n\n res = {}\n for _, command, _ in known_contexts + known_commands:\n if command is not None:\n res.update(command.get_sensitive_args())\n\n return res\n\n\ndef make_parser():\n parser = argparse.ArgumentParser(\n description=\"Dataset Framework\", formatter_class=argparse.RawDescriptionHelpFormatter\n )\n if parser.prog == osp.basename(__file__): # python -m datumaro ...\n parser.prog = \"datumaro\"\n\n parser.add_argument(\"--version\", action=\"version\", version=VERSION)\n _LogManager._define_loglevel_option(parser)\n\n known_contexts = _get_known_contexts()\n known_commands = _get_known_commands()\n\n # Argparse doesn't support subparser groups:\n # https://stackoverflow.com/questions/32017020/grouping-argparse-subparser-arguments\n help_line_start = max((len(e[0]) for e in known_contexts + known_commands), default=0)\n help_line_start = max((2 + help_line_start) // 4 + 1, 6) * 4 # align to tabs\n subcommands_desc = \"\"\n if known_contexts:\n subcommands_desc += \"Contexts:\\n\"\n subcommands_desc += _make_subcommands_help(known_contexts, help_line_start)\n if known_commands:\n if subcommands_desc:\n subcommands_desc += \"\\n\"\n subcommands_desc += \"Commands:\\n\"\n subcommands_desc += _make_subcommands_help(known_commands, help_line_start)\n if subcommands_desc:\n subcommands_desc += (\n \"\\nRun '%s COMMAND --help' for more information on a command.\" % parser.prog\n )\n\n subcommands = parser.add_subparsers(\n title=subcommands_desc, description=\"\", help=argparse.SUPPRESS\n )\n for command_name, command, _ in known_contexts + known_commands:\n if command is not None:\n add_subparser(subcommands, command_name, command.build_parser)\n\n return parser\n\n\ndef main(args=None):\n _LogManager.init_logger(args)\n\n parser = make_parser()\n args = parser.parse_args(args)\n\n if \"command\" not in args:\n parser.print_help()\n return 1\n\n sensitive_args = _get_sensitive_args()\n telemetry = init_telemetry_session(app_name=\"Datumaro\", app_version=VERSION)\n\n try:\n retcode = args.command(args)\n if retcode is None:\n retcode = 0\n except CliException as e:\n log.error(e)\n send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n return 1\n except Exception as e:\n log.error(e)\n send_command_exception_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n raise\n else:\n if retcode:\n send_command_failure_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n else:\n send_command_success_info(telemetry, args, sensitive_args=sensitive_args[args.command])\n return retcode\n finally:\n close_telemetry_session(telemetry)\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "datumaro/cli/__main__.py"}]}
| 2,357 | 261 |
gh_patches_debug_15369
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-3044
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: isolated dask backend tests fail due to removed imports
For some reason lines 6 and 8 here: https://github.com/ibis-project/ibis/commit/a1262410310bb4d638a73e1cdfbe93c2b4089905#diff-96d84d9b6e9e84a2be7a046dc9853df1ca5fc6e894307339b02cd61e666c0149L6-L8
were removed.
This causes dasks tests to fail when they are run in isolation from other tests that (transitively) import from the pandas backend.
This is both a ci bug and a bug in the code, since we're not testing backends independently. Perhaps unsurprisingly I discovered the bug in #2937, which fixes the CI part of this problem.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ibis/backends/dask/__init__.py`
Content:
```
1 from typing import Mapping
2
3 import dask
4 import dask.dataframe as dd
5 import pandas as pd
6 import toolz
7 from dask.base import DaskMethodsMixin
8
9 import ibis.common.exceptions as com
10 import ibis.config
11 import ibis.expr.schema as sch
12 import ibis.expr.types as ir
13 from ibis.backends.pandas import BasePandasBackend
14
15 from .client import DaskDatabase, DaskTable, ibis_schema_to_dask
16 from .core import execute_and_reset
17
18 # Make sure that the pandas backend is loaded, dispatching has been
19 # executed, and options have been loaded
20 ibis.pandas
21
22
23 class Backend(BasePandasBackend):
24 name = 'dask'
25 database_class = DaskDatabase
26 table_class = DaskTable
27
28 def connect(self, dictionary):
29 # register dispatchers
30 from . import udf # noqa: F401
31
32 return super().connect(dictionary)
33
34 @property
35 def version(self):
36 return dask.__version__
37
38 def execute(
39 self,
40 query: ir.Expr,
41 params: Mapping[ir.Expr, object] = None,
42 limit: str = 'default',
43 **kwargs,
44 ):
45 if limit != 'default':
46 raise ValueError(
47 'limit parameter to execute is not yet implemented in the '
48 'dask backend'
49 )
50
51 if not isinstance(query, ir.Expr):
52 raise TypeError(
53 "`query` has type {!r}, expected ibis.expr.types.Expr".format(
54 type(query).__name__
55 )
56 )
57
58 result = self.compile(query, params, **kwargs)
59 if isinstance(result, DaskMethodsMixin):
60 return result.compute()
61 else:
62 return result
63
64 def compile(
65 self, query: ir.Expr, params: Mapping[ir.Expr, object] = None, **kwargs
66 ):
67 """Compile `expr`.
68
69 Notes
70 -----
71 For the dask backend returns a dask graph that you can run ``.compute``
72 on to get a pandas object.
73
74 """
75 return execute_and_reset(query, params=params, **kwargs)
76
77 def create_table(
78 self,
79 table_name: str,
80 obj: dd.DataFrame = None,
81 schema: sch.Schema = None,
82 ):
83 """Create a table."""
84 if obj is not None:
85 df = obj
86 elif schema is not None:
87 dtypes = ibis_schema_to_dask(schema)
88 df = schema.apply_to(
89 dd.from_pandas(
90 pd.DataFrame(columns=list(map(toolz.first, dtypes))),
91 npartitions=1,
92 )
93 )
94 else:
95 raise com.IbisError('Must pass expr or schema')
96
97 self.dictionary[table_name] = df
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ibis/backends/dask/__init__.py b/ibis/backends/dask/__init__.py
--- a/ibis/backends/dask/__init__.py
+++ b/ibis/backends/dask/__init__.py
@@ -6,6 +6,9 @@
import toolz
from dask.base import DaskMethodsMixin
+# import the pandas execution module to register dispatched implementations of
+# execute_node that the dask backend will later override
+import ibis.backends.pandas.execution # noqa: F401
import ibis.common.exceptions as com
import ibis.config
import ibis.expr.schema as sch
@@ -15,8 +18,7 @@
from .client import DaskDatabase, DaskTable, ibis_schema_to_dask
from .core import execute_and_reset
-# Make sure that the pandas backend is loaded, dispatching has been
-# executed, and options have been loaded
+# Make sure that the pandas backend options have been loaded
ibis.pandas
|
{"golden_diff": "diff --git a/ibis/backends/dask/__init__.py b/ibis/backends/dask/__init__.py\n--- a/ibis/backends/dask/__init__.py\n+++ b/ibis/backends/dask/__init__.py\n@@ -6,6 +6,9 @@\n import toolz\n from dask.base import DaskMethodsMixin\n \n+# import the pandas execution module to register dispatched implementations of\n+# execute_node that the dask backend will later override\n+import ibis.backends.pandas.execution # noqa: F401\n import ibis.common.exceptions as com\n import ibis.config\n import ibis.expr.schema as sch\n@@ -15,8 +18,7 @@\n from .client import DaskDatabase, DaskTable, ibis_schema_to_dask\n from .core import execute_and_reset\n \n-# Make sure that the pandas backend is loaded, dispatching has been\n-# executed, and options have been loaded\n+# Make sure that the pandas backend options have been loaded\n ibis.pandas\n", "issue": "bug: isolated dask backend tests fail due to removed imports\nFor some reason lines 6 and 8 here: https://github.com/ibis-project/ibis/commit/a1262410310bb4d638a73e1cdfbe93c2b4089905#diff-96d84d9b6e9e84a2be7a046dc9853df1ca5fc6e894307339b02cd61e666c0149L6-L8\r\n\r\nwere removed.\r\n\r\nThis causes dasks tests to fail when they are run in isolation from other tests that (transitively) import from the pandas backend.\r\n\r\nThis is both a ci bug and a bug in the code, since we're not testing backends independently. Perhaps unsurprisingly I discovered the bug in #2937, which fixes the CI part of this problem.\n", "before_files": [{"content": "from typing import Mapping\n\nimport dask\nimport dask.dataframe as dd\nimport pandas as pd\nimport toolz\nfrom dask.base import DaskMethodsMixin\n\nimport ibis.common.exceptions as com\nimport ibis.config\nimport ibis.expr.schema as sch\nimport ibis.expr.types as ir\nfrom ibis.backends.pandas import BasePandasBackend\n\nfrom .client import DaskDatabase, DaskTable, ibis_schema_to_dask\nfrom .core import execute_and_reset\n\n# Make sure that the pandas backend is loaded, dispatching has been\n# executed, and options have been loaded\nibis.pandas\n\n\nclass Backend(BasePandasBackend):\n name = 'dask'\n database_class = DaskDatabase\n table_class = DaskTable\n\n def connect(self, dictionary):\n # register dispatchers\n from . import udf # noqa: F401\n\n return super().connect(dictionary)\n\n @property\n def version(self):\n return dask.__version__\n\n def execute(\n self,\n query: ir.Expr,\n params: Mapping[ir.Expr, object] = None,\n limit: str = 'default',\n **kwargs,\n ):\n if limit != 'default':\n raise ValueError(\n 'limit parameter to execute is not yet implemented in the '\n 'dask backend'\n )\n\n if not isinstance(query, ir.Expr):\n raise TypeError(\n \"`query` has type {!r}, expected ibis.expr.types.Expr\".format(\n type(query).__name__\n )\n )\n\n result = self.compile(query, params, **kwargs)\n if isinstance(result, DaskMethodsMixin):\n return result.compute()\n else:\n return result\n\n def compile(\n self, query: ir.Expr, params: Mapping[ir.Expr, object] = None, **kwargs\n ):\n \"\"\"Compile `expr`.\n\n Notes\n -----\n For the dask backend returns a dask graph that you can run ``.compute``\n on to get a pandas object.\n\n \"\"\"\n return execute_and_reset(query, params=params, **kwargs)\n\n def create_table(\n self,\n table_name: str,\n obj: dd.DataFrame = None,\n schema: sch.Schema = None,\n ):\n \"\"\"Create a table.\"\"\"\n if obj is not None:\n df = obj\n elif schema is not None:\n dtypes = ibis_schema_to_dask(schema)\n df = schema.apply_to(\n dd.from_pandas(\n pd.DataFrame(columns=list(map(toolz.first, dtypes))),\n npartitions=1,\n )\n )\n else:\n raise com.IbisError('Must pass expr or schema')\n\n self.dictionary[table_name] = df\n", "path": "ibis/backends/dask/__init__.py"}], "after_files": [{"content": "from typing import Mapping\n\nimport dask\nimport dask.dataframe as dd\nimport pandas as pd\nimport toolz\nfrom dask.base import DaskMethodsMixin\n\n# import the pandas execution module to register dispatched implementations of\n# execute_node that the dask backend will later override\nimport ibis.backends.pandas.execution # noqa: F401\nimport ibis.common.exceptions as com\nimport ibis.config\nimport ibis.expr.schema as sch\nimport ibis.expr.types as ir\nfrom ibis.backends.pandas import BasePandasBackend\n\nfrom .client import DaskDatabase, DaskTable, ibis_schema_to_dask\nfrom .core import execute_and_reset\n\n# Make sure that the pandas backend options have been loaded\nibis.pandas\n\n\nclass Backend(BasePandasBackend):\n name = 'dask'\n database_class = DaskDatabase\n table_class = DaskTable\n\n def connect(self, dictionary):\n # register dispatchers\n from . import udf # noqa: F401\n\n return super().connect(dictionary)\n\n @property\n def version(self):\n return dask.__version__\n\n def execute(\n self,\n query: ir.Expr,\n params: Mapping[ir.Expr, object] = None,\n limit: str = 'default',\n **kwargs,\n ):\n if limit != 'default':\n raise ValueError(\n 'limit parameter to execute is not yet implemented in the '\n 'dask backend'\n )\n\n if not isinstance(query, ir.Expr):\n raise TypeError(\n \"`query` has type {!r}, expected ibis.expr.types.Expr\".format(\n type(query).__name__\n )\n )\n\n result = self.compile(query, params, **kwargs)\n if isinstance(result, DaskMethodsMixin):\n return result.compute()\n else:\n return result\n\n def compile(\n self, query: ir.Expr, params: Mapping[ir.Expr, object] = None, **kwargs\n ):\n \"\"\"Compile `expr`.\n\n Notes\n -----\n For the dask backend returns a dask graph that you can run ``.compute``\n on to get a pandas object.\n\n \"\"\"\n return execute_and_reset(query, params=params, **kwargs)\n\n def create_table(\n self,\n table_name: str,\n obj: dd.DataFrame = None,\n schema: sch.Schema = None,\n ):\n \"\"\"Create a table.\"\"\"\n if obj is not None:\n df = obj\n elif schema is not None:\n dtypes = ibis_schema_to_dask(schema)\n df = schema.apply_to(\n dd.from_pandas(\n pd.DataFrame(columns=list(map(toolz.first, dtypes))),\n npartitions=1,\n )\n )\n else:\n raise com.IbisError('Must pass expr or schema')\n\n self.dictionary[table_name] = df\n", "path": "ibis/backends/dask/__init__.py"}]}
| 1,257 | 224 |
gh_patches_debug_5574
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-2384
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Viewing of "file"-kind of CIV in archive items leads to 403
I created an archive item and added a file type CIV but when trying to view the file it leads to a permission denied error. It seems that the permission check when serving a CIV file is missing a check for archive item viewing. It only checks for algorithm jobs and evaluations:
https://github.com/comic/grand-challenge.org/blob/9322d09c0859998a77accb5c13d6db675504a9c1/app/grandchallenge/serving/views.py#L94-L117
Permissions for archives are only done on archive level (vs. archive item level) so we need to add a check here to see if the CIV belongs to an archive item and if the user has the `archives.view_archive` permission for that archive.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/serving/views.py`
Content:
```
1 import posixpath
2
3 from django.conf import settings
4 from django.core.exceptions import MultipleObjectsReturned, PermissionDenied
5 from django.db.models import F, Q
6 from django.http import Http404, HttpResponseRedirect
7 from django.utils._os import safe_join
8 from guardian.shortcuts import get_objects_for_user
9 from knox.auth import TokenAuthentication
10 from rest_framework.exceptions import AuthenticationFailed
11
12 from grandchallenge.cases.models import Image
13 from grandchallenge.challenges.models import ChallengeRequest
14 from grandchallenge.components.models import ComponentInterfaceValue
15 from grandchallenge.core.storage import internal_protected_s3_storage
16 from grandchallenge.evaluation.models import Submission
17 from grandchallenge.serving.models import Download
18
19
20 def protected_storage_redirect(*, name):
21 # Get the storage with the internal redirect and auth. This will prepend
22 # settings.AWS_S3_ENDPOINT_URL to the url
23 if not internal_protected_s3_storage.exists(name=name):
24 raise Http404("File not found.")
25
26 if settings.PROTECTED_S3_STORAGE_USE_CLOUDFRONT:
27 response = HttpResponseRedirect(
28 internal_protected_s3_storage.cloudfront_signed_url(name=name)
29 )
30 else:
31 url = internal_protected_s3_storage.url(name=name)
32 response = HttpResponseRedirect(url)
33
34 return response
35
36
37 def serve_images(request, *, pk, path, pa="", pb=""):
38 document_root = safe_join(
39 f"/{settings.IMAGE_FILES_SUBDIRECTORY}", pa, pb, str(pk)
40 )
41 path = posixpath.normpath(path).lstrip("/")
42 name = safe_join(document_root, path)
43
44 try:
45 image = Image.objects.get(pk=pk)
46 except Image.DoesNotExist:
47 raise Http404("Image not found.")
48
49 try:
50 user, _ = TokenAuthentication().authenticate(request)
51 except (AuthenticationFailed, TypeError):
52 user = request.user
53
54 if user.has_perm("view_image", image):
55 _create_download(creator_id=user.pk, image_id=image.pk)
56 return protected_storage_redirect(name=name)
57
58 raise PermissionDenied
59
60
61 def serve_submissions(request, *, submission_pk, **_):
62 try:
63 submission = Submission.objects.get(pk=submission_pk)
64 except Submission.DoesNotExist:
65 raise Http404("Submission not found.")
66
67 if request.user.has_perm("view_submission", submission):
68 _create_download(
69 creator_id=request.user.pk, submission_id=submission.pk
70 )
71 return protected_storage_redirect(
72 name=submission.predictions_file.name
73 )
74
75 raise PermissionDenied
76
77
78 def serve_component_interface_value(
79 request, *, component_interface_value_pk, **_
80 ):
81 try:
82 user, _ = TokenAuthentication().authenticate(request)
83 except (AuthenticationFailed, TypeError):
84 user = request.user
85
86 try:
87 # output should only be connected to a single job; throw error if not?
88 civ = ComponentInterfaceValue.objects.get(
89 pk=component_interface_value_pk
90 )
91 except (MultipleObjectsReturned, ComponentInterfaceValue.DoesNotExist):
92 raise Http404("No ComponentInterfaceValue found.")
93
94 if (
95 get_objects_for_user(
96 user=user, perms="algorithms.view_job", accept_global_perms=False
97 )
98 .filter(
99 Q(outputs__pk=component_interface_value_pk)
100 | Q(inputs__pk=component_interface_value_pk)
101 )
102 .exists()
103 ):
104 return protected_storage_redirect(name=civ.file.name)
105 elif (
106 get_objects_for_user(
107 user=user,
108 perms="evaluation.view_evaluation",
109 accept_global_perms=False,
110 )
111 .filter(
112 Q(outputs__pk=component_interface_value_pk)
113 | Q(inputs__pk=component_interface_value_pk)
114 )
115 .exists()
116 ):
117 return protected_storage_redirect(name=civ.file.name)
118
119 raise PermissionDenied
120
121
122 def _create_download(*, creator_id, image_id=None, submission_id=None):
123 kwargs = {"creator_id": creator_id}
124
125 if image_id is not None:
126 kwargs["image_id"] = image_id
127
128 if submission_id is not None:
129 kwargs["submission_id"] = submission_id
130
131 n_updated = Download.objects.filter(**kwargs).update(count=F("count") + 1)
132
133 if n_updated == 0:
134 Download.objects.create(**kwargs)
135
136
137 def serve_structured_challenge_submission_form(
138 request, *, challenge_request_pk, **_
139 ):
140 try:
141 challenge_request = ChallengeRequest.objects.get(
142 pk=challenge_request_pk
143 )
144 except ChallengeRequest.DoesNotExist:
145 raise Http404("Challenge request not found.")
146
147 if request.user.has_perm("challenges.view_challengerequest"):
148 return protected_storage_redirect(
149 name=challenge_request.structured_challenge_submission_form.name
150 )
151 else:
152 raise PermissionDenied
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/grandchallenge/serving/views.py b/app/grandchallenge/serving/views.py
--- a/app/grandchallenge/serving/views.py
+++ b/app/grandchallenge/serving/views.py
@@ -115,6 +115,16 @@
.exists()
):
return protected_storage_redirect(name=civ.file.name)
+ elif (
+ get_objects_for_user(
+ user=user,
+ perms="archives.view_archive",
+ accept_global_perms=False,
+ )
+ .filter(items__values__pk=component_interface_value_pk)
+ .exists()
+ ):
+ return protected_storage_redirect(name=civ.file.name)
raise PermissionDenied
|
{"golden_diff": "diff --git a/app/grandchallenge/serving/views.py b/app/grandchallenge/serving/views.py\n--- a/app/grandchallenge/serving/views.py\n+++ b/app/grandchallenge/serving/views.py\n@@ -115,6 +115,16 @@\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n+ elif (\n+ get_objects_for_user(\n+ user=user,\n+ perms=\"archives.view_archive\",\n+ accept_global_perms=False,\n+ )\n+ .filter(items__values__pk=component_interface_value_pk)\n+ .exists()\n+ ):\n+ return protected_storage_redirect(name=civ.file.name)\n \n raise PermissionDenied\n", "issue": "Viewing of \"file\"-kind of CIV in archive items leads to 403\nI created an archive item and added a file type CIV but when trying to view the file it leads to a permission denied error. It seems that the permission check when serving a CIV file is missing a check for archive item viewing. It only checks for algorithm jobs and evaluations:\r\n\r\nhttps://github.com/comic/grand-challenge.org/blob/9322d09c0859998a77accb5c13d6db675504a9c1/app/grandchallenge/serving/views.py#L94-L117\r\n\r\nPermissions for archives are only done on archive level (vs. archive item level) so we need to add a check here to see if the CIV belongs to an archive item and if the user has the `archives.view_archive` permission for that archive.\n", "before_files": [{"content": "import posixpath\n\nfrom django.conf import settings\nfrom django.core.exceptions import MultipleObjectsReturned, PermissionDenied\nfrom django.db.models import F, Q\nfrom django.http import Http404, HttpResponseRedirect\nfrom django.utils._os import safe_join\nfrom guardian.shortcuts import get_objects_for_user\nfrom knox.auth import TokenAuthentication\nfrom rest_framework.exceptions import AuthenticationFailed\n\nfrom grandchallenge.cases.models import Image\nfrom grandchallenge.challenges.models import ChallengeRequest\nfrom grandchallenge.components.models import ComponentInterfaceValue\nfrom grandchallenge.core.storage import internal_protected_s3_storage\nfrom grandchallenge.evaluation.models import Submission\nfrom grandchallenge.serving.models import Download\n\n\ndef protected_storage_redirect(*, name):\n # Get the storage with the internal redirect and auth. This will prepend\n # settings.AWS_S3_ENDPOINT_URL to the url\n if not internal_protected_s3_storage.exists(name=name):\n raise Http404(\"File not found.\")\n\n if settings.PROTECTED_S3_STORAGE_USE_CLOUDFRONT:\n response = HttpResponseRedirect(\n internal_protected_s3_storage.cloudfront_signed_url(name=name)\n )\n else:\n url = internal_protected_s3_storage.url(name=name)\n response = HttpResponseRedirect(url)\n\n return response\n\n\ndef serve_images(request, *, pk, path, pa=\"\", pb=\"\"):\n document_root = safe_join(\n f\"/{settings.IMAGE_FILES_SUBDIRECTORY}\", pa, pb, str(pk)\n )\n path = posixpath.normpath(path).lstrip(\"/\")\n name = safe_join(document_root, path)\n\n try:\n image = Image.objects.get(pk=pk)\n except Image.DoesNotExist:\n raise Http404(\"Image not found.\")\n\n try:\n user, _ = TokenAuthentication().authenticate(request)\n except (AuthenticationFailed, TypeError):\n user = request.user\n\n if user.has_perm(\"view_image\", image):\n _create_download(creator_id=user.pk, image_id=image.pk)\n return protected_storage_redirect(name=name)\n\n raise PermissionDenied\n\n\ndef serve_submissions(request, *, submission_pk, **_):\n try:\n submission = Submission.objects.get(pk=submission_pk)\n except Submission.DoesNotExist:\n raise Http404(\"Submission not found.\")\n\n if request.user.has_perm(\"view_submission\", submission):\n _create_download(\n creator_id=request.user.pk, submission_id=submission.pk\n )\n return protected_storage_redirect(\n name=submission.predictions_file.name\n )\n\n raise PermissionDenied\n\n\ndef serve_component_interface_value(\n request, *, component_interface_value_pk, **_\n):\n try:\n user, _ = TokenAuthentication().authenticate(request)\n except (AuthenticationFailed, TypeError):\n user = request.user\n\n try:\n # output should only be connected to a single job; throw error if not?\n civ = ComponentInterfaceValue.objects.get(\n pk=component_interface_value_pk\n )\n except (MultipleObjectsReturned, ComponentInterfaceValue.DoesNotExist):\n raise Http404(\"No ComponentInterfaceValue found.\")\n\n if (\n get_objects_for_user(\n user=user, perms=\"algorithms.view_job\", accept_global_perms=False\n )\n .filter(\n Q(outputs__pk=component_interface_value_pk)\n | Q(inputs__pk=component_interface_value_pk)\n )\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n elif (\n get_objects_for_user(\n user=user,\n perms=\"evaluation.view_evaluation\",\n accept_global_perms=False,\n )\n .filter(\n Q(outputs__pk=component_interface_value_pk)\n | Q(inputs__pk=component_interface_value_pk)\n )\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n\n raise PermissionDenied\n\n\ndef _create_download(*, creator_id, image_id=None, submission_id=None):\n kwargs = {\"creator_id\": creator_id}\n\n if image_id is not None:\n kwargs[\"image_id\"] = image_id\n\n if submission_id is not None:\n kwargs[\"submission_id\"] = submission_id\n\n n_updated = Download.objects.filter(**kwargs).update(count=F(\"count\") + 1)\n\n if n_updated == 0:\n Download.objects.create(**kwargs)\n\n\ndef serve_structured_challenge_submission_form(\n request, *, challenge_request_pk, **_\n):\n try:\n challenge_request = ChallengeRequest.objects.get(\n pk=challenge_request_pk\n )\n except ChallengeRequest.DoesNotExist:\n raise Http404(\"Challenge request not found.\")\n\n if request.user.has_perm(\"challenges.view_challengerequest\"):\n return protected_storage_redirect(\n name=challenge_request.structured_challenge_submission_form.name\n )\n else:\n raise PermissionDenied\n", "path": "app/grandchallenge/serving/views.py"}], "after_files": [{"content": "import posixpath\n\nfrom django.conf import settings\nfrom django.core.exceptions import MultipleObjectsReturned, PermissionDenied\nfrom django.db.models import F, Q\nfrom django.http import Http404, HttpResponseRedirect\nfrom django.utils._os import safe_join\nfrom guardian.shortcuts import get_objects_for_user\nfrom knox.auth import TokenAuthentication\nfrom rest_framework.exceptions import AuthenticationFailed\n\nfrom grandchallenge.cases.models import Image\nfrom grandchallenge.challenges.models import ChallengeRequest\nfrom grandchallenge.components.models import ComponentInterfaceValue\nfrom grandchallenge.core.storage import internal_protected_s3_storage\nfrom grandchallenge.evaluation.models import Submission\nfrom grandchallenge.serving.models import Download\n\n\ndef protected_storage_redirect(*, name):\n # Get the storage with the internal redirect and auth. This will prepend\n # settings.AWS_S3_ENDPOINT_URL to the url\n if not internal_protected_s3_storage.exists(name=name):\n raise Http404(\"File not found.\")\n\n if settings.PROTECTED_S3_STORAGE_USE_CLOUDFRONT:\n response = HttpResponseRedirect(\n internal_protected_s3_storage.cloudfront_signed_url(name=name)\n )\n else:\n url = internal_protected_s3_storage.url(name=name)\n response = HttpResponseRedirect(url)\n\n return response\n\n\ndef serve_images(request, *, pk, path, pa=\"\", pb=\"\"):\n document_root = safe_join(\n f\"/{settings.IMAGE_FILES_SUBDIRECTORY}\", pa, pb, str(pk)\n )\n path = posixpath.normpath(path).lstrip(\"/\")\n name = safe_join(document_root, path)\n\n try:\n image = Image.objects.get(pk=pk)\n except Image.DoesNotExist:\n raise Http404(\"Image not found.\")\n\n try:\n user, _ = TokenAuthentication().authenticate(request)\n except (AuthenticationFailed, TypeError):\n user = request.user\n\n if user.has_perm(\"view_image\", image):\n _create_download(creator_id=user.pk, image_id=image.pk)\n return protected_storage_redirect(name=name)\n\n raise PermissionDenied\n\n\ndef serve_submissions(request, *, submission_pk, **_):\n try:\n submission = Submission.objects.get(pk=submission_pk)\n except Submission.DoesNotExist:\n raise Http404(\"Submission not found.\")\n\n if request.user.has_perm(\"view_submission\", submission):\n _create_download(\n creator_id=request.user.pk, submission_id=submission.pk\n )\n return protected_storage_redirect(\n name=submission.predictions_file.name\n )\n\n raise PermissionDenied\n\n\ndef serve_component_interface_value(\n request, *, component_interface_value_pk, **_\n):\n try:\n user, _ = TokenAuthentication().authenticate(request)\n except (AuthenticationFailed, TypeError):\n user = request.user\n\n try:\n # output should only be connected to a single job; throw error if not?\n civ = ComponentInterfaceValue.objects.get(\n pk=component_interface_value_pk\n )\n except (MultipleObjectsReturned, ComponentInterfaceValue.DoesNotExist):\n raise Http404(\"No ComponentInterfaceValue found.\")\n\n if (\n get_objects_for_user(\n user=user, perms=\"algorithms.view_job\", accept_global_perms=False\n )\n .filter(\n Q(outputs__pk=component_interface_value_pk)\n | Q(inputs__pk=component_interface_value_pk)\n )\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n elif (\n get_objects_for_user(\n user=user,\n perms=\"evaluation.view_evaluation\",\n accept_global_perms=False,\n )\n .filter(\n Q(outputs__pk=component_interface_value_pk)\n | Q(inputs__pk=component_interface_value_pk)\n )\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n elif (\n get_objects_for_user(\n user=user,\n perms=\"archives.view_archive\",\n accept_global_perms=False,\n )\n .filter(items__values__pk=component_interface_value_pk)\n .exists()\n ):\n return protected_storage_redirect(name=civ.file.name)\n\n raise PermissionDenied\n\n\ndef _create_download(*, creator_id, image_id=None, submission_id=None):\n kwargs = {\"creator_id\": creator_id}\n\n if image_id is not None:\n kwargs[\"image_id\"] = image_id\n\n if submission_id is not None:\n kwargs[\"submission_id\"] = submission_id\n\n n_updated = Download.objects.filter(**kwargs).update(count=F(\"count\") + 1)\n\n if n_updated == 0:\n Download.objects.create(**kwargs)\n\n\ndef serve_structured_challenge_submission_form(\n request, *, challenge_request_pk, **_\n):\n try:\n challenge_request = ChallengeRequest.objects.get(\n pk=challenge_request_pk\n )\n except ChallengeRequest.DoesNotExist:\n raise Http404(\"Challenge request not found.\")\n\n if request.user.has_perm(\"challenges.view_challengerequest\"):\n return protected_storage_redirect(\n name=challenge_request.structured_challenge_submission_form.name\n )\n else:\n raise PermissionDenied\n", "path": "app/grandchallenge/serving/views.py"}]}
| 1,811 | 151 |
gh_patches_debug_17925
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-588
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix import error
```
>>> from parsl.dataflow.states import FINAL_FAILED_STATES
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/annawoodard/parsl/parsl/__init__.py", line 37, in <module>
from parsl.dataflow.dflow import DataFlowKernel, DataFlowKernelLoader
File "/home/annawoodard/parsl/parsl/dataflow/dflow.py", line 31, in <module>
from parsl.dataflow.usage_tracking.usage import UsageTracker
File "/home/annawoodard/parsl/parsl/dataflow/usage_tracking/usage.py", line 13, in <module>
from parsl.dataflow.states import FINAL_FAILED_STATES
ImportError: cannot import name 'FINAL_FAILED_STATES'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/dataflow/usage_tracking/usage.py`
Content:
```
1 import uuid
2 import time
3 import hashlib
4 import os
5 import getpass
6 import json
7 import logging
8 import socket
9 import sys
10 import platform
11 import multiprocessing as mp
12
13 from parsl.dataflow.states import FINAL_FAILED_STATES
14 from parsl.version import VERSION as PARSL_VERSION
15
16 logger = logging.getLogger(__name__)
17
18
19 def async_process(fn):
20 """ Decorator function to launch a function as a separate process """
21
22 def run(*args, **kwargs):
23 proc = mp.Process(target=fn, args=args, kwargs=kwargs)
24 proc.start()
25 return proc
26
27 return run
28
29
30 @async_process
31 def udp_messenger(domain_name, UDP_IP, UDP_PORT, sock_timeout, message):
32 """Send UDP messages to usage tracker asynchronously
33
34 This multiprocessing based messenger was written to overcome the limitations
35 of signalling/terminating a thread that is blocked on a system call. This
36 messenger is created as a separate process, and initialized with 2 queues,
37 to_send to receive messages to be sent to the internet.
38
39 Args:
40 - domain_name (str) : Domain name string
41 - UDP_IP (str) : IP address YYY.YYY.YYY.YYY
42 - UDP_PORT (int) : UDP port to send out on
43 - sock_timeout (int) : Socket timeout
44 - to_send (multiprocessing.Queue) : Queue of outgoing messages to internet
45 """
46 try:
47 if message is None:
48 raise ValueError("message was none")
49
50 encoded_message = bytes(message, "utf-8")
51
52 if encoded_message is None:
53 raise ValueError("utf-8 encoding of message failed")
54
55 if domain_name:
56 try:
57 UDP_IP = socket.gethostbyname(domain_name)
58 except Exception:
59 # (False, "Domain lookup failed, defaulting to {0}".format(UDP_IP))
60 pass
61
62 if UDP_IP is None:
63 raise Exception("UDP_IP is None")
64
65 if UDP_PORT is None:
66 raise Exception("UDP_PORT is None")
67
68 sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
69 sock.settimeout(sock_timeout)
70 sock.sendto(bytes(message, "utf-8"), (UDP_IP, UDP_PORT))
71 sock.close()
72
73 except socket.timeout:
74 logger.debug("Failed to send usage tracking data: socket timeout")
75 except OSError as e:
76 logger.debug("Failed to send usage tracking data: OSError: {}".format(e))
77 except Exception as e:
78 logger.debug("Failed to send usage tracking data: Exception: {}".format(e))
79
80
81 class UsageTracker (object):
82 """Anonymized Usage Tracking for Parsl.
83
84 Client for this is here : https://github.com/Parsl/parsl_tracking
85 This issue captures the discussion that went into functionality
86 implemented here : https://github.com/Parsl/parsl/issues/34
87
88 """
89
90 def __init__(self, dfk, ip='52.3.111.203', port=50077,
91 domain_name='tracking.parsl-project.org'):
92 """Initialize usage tracking unless the user has opted-out.
93
94 We will try to resolve the hostname specified in kwarg:domain_name
95 and if that fails attempt to use the kwarg:ip. Determining the
96 IP and sending message is threaded to avoid slowing down DFK
97 initialization.
98
99 Tracks usage stats by inspecting the internal state of the dfk.
100
101 Args:
102 - dfk (DFK object) : Data Flow Kernel object
103
104 KWargs:
105 - ip (string) : IP address
106 - port (int) : Port number, Default:50077
107 - domain_name (string) : Domain name, will override IP
108 Default: tracking.parsl-project.org
109 """
110
111 self.domain_name = domain_name
112 self.ip = ip
113 # The sock timeout will only apply to UDP send and not domain resolution
114 self.sock_timeout = 5
115 self.UDP_PORT = port
116 self.UDP_IP = None
117 self.procs = []
118 self.dfk = dfk
119 self.config = self.dfk.config
120 self.uuid = str(uuid.uuid4())
121 self.parsl_version = PARSL_VERSION
122 self.python_version = "{}.{}.{}".format(sys.version_info.major,
123 sys.version_info.minor,
124 sys.version_info.micro)
125 self.test_mode, self.tracking_enabled = self.check_tracking_enabled()
126 logger.debug("Tracking status: {}".format(self.tracking_enabled))
127 logger.debug("Testing mode : {}".format(self.test_mode))
128 self.initialized = False # Once first message is sent this will be True
129
130 def check_tracking_enabled(self):
131 """By default tracking is enabled.
132
133 If Test mode is set via env variable PARSL_TESTING, a test flag is set
134
135 Tracking is disabled if :
136 1. config["globals"]["usageTracking"] is set to False (Bool)
137 2. Environment variable PARSL_TRACKING is set to false (case insensitive)
138
139 """
140 track = True # By default we track usage
141 test = False # By default we are not in testing mode
142
143 testvar = str(os.environ.get("PARSL_TESTING", 'None')).lower()
144 if testvar == 'true':
145 test = True
146
147 if not self.config.usage_tracking:
148 track = False
149
150 envvar = str(os.environ.get("PARSL_TRACKING", True)).lower()
151 if envvar == "false":
152 track = False
153
154 return test, track
155
156 def construct_start_message(self):
157 """Collect preliminary run info at the start of the DFK.
158
159 Returns :
160 - Message dict dumped as json string, ready for UDP
161 """
162 uname = getpass.getuser().encode('latin1')
163 hashed_username = hashlib.sha256(uname).hexdigest()[0:10]
164 hname = socket.gethostname().encode('latin1')
165 hashed_hostname = hashlib.sha256(hname).hexdigest()[0:10]
166 message = {'uuid': self.uuid,
167 'uname': hashed_username,
168 'hname': hashed_hostname,
169 'test': self.test_mode,
170 'parsl_v': self.parsl_version,
171 'python_v': self.python_version,
172 'os': platform.system(),
173 'os_v': platform.release(),
174 'start': time.time()}
175
176 return json.dumps(message)
177
178 def construct_end_message(self):
179 """Collect the final run information at the time of DFK cleanup.
180
181 Returns:
182 - Message dict dumped as json string, ready for UDP
183 """
184 app_count = self.dfk.task_count
185
186 site_count = len([x for x in self.dfk.config.executors if x.managed])
187
188 failed_states = FINAL_FAILED_STATES
189 app_fails = len([t for t in self.dfk.tasks if
190 self.dfk.tasks[t]['status'] in failed_states])
191
192 message = {'uuid': self.uuid,
193 'end': time.time(),
194 't_apps': app_count,
195 'sites': site_count,
196 'c_time': None,
197 'failed': app_fails,
198 'test': self.test_mode,
199 }
200
201 return json.dumps(message)
202
203 def send_UDP_message(self, message):
204 """Send UDP message."""
205 x = 0
206 if self.tracking_enabled:
207 try:
208 proc = udp_messenger(self.domain_name, self.UDP_IP, self.UDP_PORT, self.sock_timeout, message)
209 self.procs.append(proc)
210 except Exception as e:
211 logger.debug("Usage tracking failed: {}".format(e))
212 else:
213 x = -1
214
215 return x
216
217 def send_message(self):
218 """Send message over UDP.
219
220 If tracking is disables, the bytes_sent will always be set to -1
221
222 Returns:
223 (bytes_sent, time_taken)
224 """
225 start = time.time()
226 message = None
227 if not self.initialized:
228 message = self.construct_start_message()
229 self.initialized = True
230 else:
231 message = self.construct_end_message()
232
233 self.send_UDP_message(message)
234 end = time.time()
235
236 return end - start
237
238 def __del__(self):
239 return self.close()
240
241 def close(self):
242 """We terminate (SIGTERM) the processes added to the self.procs list """
243 for proc in self.procs:
244 proc.terminate()
245
246
247 if __name__ == '__main__':
248
249 from parsl import *
250
251 set_stream_logger()
252 workers = ThreadPoolExecutor(max_workers=4)
253 dfk = DataFlowKernel(executors=[workers])
254
255 dfk.cleanup()
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/dataflow/usage_tracking/usage.py b/parsl/dataflow/usage_tracking/usage.py
--- a/parsl/dataflow/usage_tracking/usage.py
+++ b/parsl/dataflow/usage_tracking/usage.py
@@ -10,7 +10,7 @@
import platform
import multiprocessing as mp
-from parsl.dataflow.states import FINAL_FAILED_STATES
+from parsl.dataflow.states import FINAL_FAILURE_STATES
from parsl.version import VERSION as PARSL_VERSION
logger = logging.getLogger(__name__)
@@ -185,9 +185,8 @@
site_count = len([x for x in self.dfk.config.executors if x.managed])
- failed_states = FINAL_FAILED_STATES
app_fails = len([t for t in self.dfk.tasks if
- self.dfk.tasks[t]['status'] in failed_states])
+ self.dfk.tasks[t]['status'] in FINAL_FAILURE_STATES])
message = {'uuid': self.uuid,
'end': time.time(),
|
{"golden_diff": "diff --git a/parsl/dataflow/usage_tracking/usage.py b/parsl/dataflow/usage_tracking/usage.py\n--- a/parsl/dataflow/usage_tracking/usage.py\n+++ b/parsl/dataflow/usage_tracking/usage.py\n@@ -10,7 +10,7 @@\n import platform\n import multiprocessing as mp\n \n-from parsl.dataflow.states import FINAL_FAILED_STATES\n+from parsl.dataflow.states import FINAL_FAILURE_STATES\n from parsl.version import VERSION as PARSL_VERSION\n \n logger = logging.getLogger(__name__)\n@@ -185,9 +185,8 @@\n \n site_count = len([x for x in self.dfk.config.executors if x.managed])\n \n- failed_states = FINAL_FAILED_STATES\n app_fails = len([t for t in self.dfk.tasks if\n- self.dfk.tasks[t]['status'] in failed_states])\n+ self.dfk.tasks[t]['status'] in FINAL_FAILURE_STATES])\n \n message = {'uuid': self.uuid,\n 'end': time.time(),\n", "issue": "Fix import error\n```\r\n>>> from parsl.dataflow.states import FINAL_FAILED_STATES\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/annawoodard/parsl/parsl/__init__.py\", line 37, in <module>\r\n from parsl.dataflow.dflow import DataFlowKernel, DataFlowKernelLoader\r\n File \"/home/annawoodard/parsl/parsl/dataflow/dflow.py\", line 31, in <module>\r\n from parsl.dataflow.usage_tracking.usage import UsageTracker\r\n File \"/home/annawoodard/parsl/parsl/dataflow/usage_tracking/usage.py\", line 13, in <module>\r\n from parsl.dataflow.states import FINAL_FAILED_STATES\r\nImportError: cannot import name 'FINAL_FAILED_STATES'\r\n```\n", "before_files": [{"content": "import uuid\nimport time\nimport hashlib\nimport os\nimport getpass\nimport json\nimport logging\nimport socket\nimport sys\nimport platform\nimport multiprocessing as mp\n\nfrom parsl.dataflow.states import FINAL_FAILED_STATES\nfrom parsl.version import VERSION as PARSL_VERSION\n\nlogger = logging.getLogger(__name__)\n\n\ndef async_process(fn):\n \"\"\" Decorator function to launch a function as a separate process \"\"\"\n\n def run(*args, **kwargs):\n proc = mp.Process(target=fn, args=args, kwargs=kwargs)\n proc.start()\n return proc\n\n return run\n\n\n@async_process\ndef udp_messenger(domain_name, UDP_IP, UDP_PORT, sock_timeout, message):\n \"\"\"Send UDP messages to usage tracker asynchronously\n\n This multiprocessing based messenger was written to overcome the limitations\n of signalling/terminating a thread that is blocked on a system call. This\n messenger is created as a separate process, and initialized with 2 queues,\n to_send to receive messages to be sent to the internet.\n\n Args:\n - domain_name (str) : Domain name string\n - UDP_IP (str) : IP address YYY.YYY.YYY.YYY\n - UDP_PORT (int) : UDP port to send out on\n - sock_timeout (int) : Socket timeout\n - to_send (multiprocessing.Queue) : Queue of outgoing messages to internet\n \"\"\"\n try:\n if message is None:\n raise ValueError(\"message was none\")\n\n encoded_message = bytes(message, \"utf-8\")\n\n if encoded_message is None:\n raise ValueError(\"utf-8 encoding of message failed\")\n\n if domain_name:\n try:\n UDP_IP = socket.gethostbyname(domain_name)\n except Exception:\n # (False, \"Domain lookup failed, defaulting to {0}\".format(UDP_IP))\n pass\n\n if UDP_IP is None:\n raise Exception(\"UDP_IP is None\")\n\n if UDP_PORT is None:\n raise Exception(\"UDP_PORT is None\")\n\n sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP\n sock.settimeout(sock_timeout)\n sock.sendto(bytes(message, \"utf-8\"), (UDP_IP, UDP_PORT))\n sock.close()\n\n except socket.timeout:\n logger.debug(\"Failed to send usage tracking data: socket timeout\")\n except OSError as e:\n logger.debug(\"Failed to send usage tracking data: OSError: {}\".format(e))\n except Exception as e:\n logger.debug(\"Failed to send usage tracking data: Exception: {}\".format(e))\n\n\nclass UsageTracker (object):\n \"\"\"Anonymized Usage Tracking for Parsl.\n\n Client for this is here : https://github.com/Parsl/parsl_tracking\n This issue captures the discussion that went into functionality\n implemented here : https://github.com/Parsl/parsl/issues/34\n\n \"\"\"\n\n def __init__(self, dfk, ip='52.3.111.203', port=50077,\n domain_name='tracking.parsl-project.org'):\n \"\"\"Initialize usage tracking unless the user has opted-out.\n\n We will try to resolve the hostname specified in kwarg:domain_name\n and if that fails attempt to use the kwarg:ip. Determining the\n IP and sending message is threaded to avoid slowing down DFK\n initialization.\n\n Tracks usage stats by inspecting the internal state of the dfk.\n\n Args:\n - dfk (DFK object) : Data Flow Kernel object\n\n KWargs:\n - ip (string) : IP address\n - port (int) : Port number, Default:50077\n - domain_name (string) : Domain name, will override IP\n Default: tracking.parsl-project.org\n \"\"\"\n\n self.domain_name = domain_name\n self.ip = ip\n # The sock timeout will only apply to UDP send and not domain resolution\n self.sock_timeout = 5\n self.UDP_PORT = port\n self.UDP_IP = None\n self.procs = []\n self.dfk = dfk\n self.config = self.dfk.config\n self.uuid = str(uuid.uuid4())\n self.parsl_version = PARSL_VERSION\n self.python_version = \"{}.{}.{}\".format(sys.version_info.major,\n sys.version_info.minor,\n sys.version_info.micro)\n self.test_mode, self.tracking_enabled = self.check_tracking_enabled()\n logger.debug(\"Tracking status: {}\".format(self.tracking_enabled))\n logger.debug(\"Testing mode : {}\".format(self.test_mode))\n self.initialized = False # Once first message is sent this will be True\n\n def check_tracking_enabled(self):\n \"\"\"By default tracking is enabled.\n\n If Test mode is set via env variable PARSL_TESTING, a test flag is set\n\n Tracking is disabled if :\n 1. config[\"globals\"][\"usageTracking\"] is set to False (Bool)\n 2. Environment variable PARSL_TRACKING is set to false (case insensitive)\n\n \"\"\"\n track = True # By default we track usage\n test = False # By default we are not in testing mode\n\n testvar = str(os.environ.get(\"PARSL_TESTING\", 'None')).lower()\n if testvar == 'true':\n test = True\n\n if not self.config.usage_tracking:\n track = False\n\n envvar = str(os.environ.get(\"PARSL_TRACKING\", True)).lower()\n if envvar == \"false\":\n track = False\n\n return test, track\n\n def construct_start_message(self):\n \"\"\"Collect preliminary run info at the start of the DFK.\n\n Returns :\n - Message dict dumped as json string, ready for UDP\n \"\"\"\n uname = getpass.getuser().encode('latin1')\n hashed_username = hashlib.sha256(uname).hexdigest()[0:10]\n hname = socket.gethostname().encode('latin1')\n hashed_hostname = hashlib.sha256(hname).hexdigest()[0:10]\n message = {'uuid': self.uuid,\n 'uname': hashed_username,\n 'hname': hashed_hostname,\n 'test': self.test_mode,\n 'parsl_v': self.parsl_version,\n 'python_v': self.python_version,\n 'os': platform.system(),\n 'os_v': platform.release(),\n 'start': time.time()}\n\n return json.dumps(message)\n\n def construct_end_message(self):\n \"\"\"Collect the final run information at the time of DFK cleanup.\n\n Returns:\n - Message dict dumped as json string, ready for UDP\n \"\"\"\n app_count = self.dfk.task_count\n\n site_count = len([x for x in self.dfk.config.executors if x.managed])\n\n failed_states = FINAL_FAILED_STATES\n app_fails = len([t for t in self.dfk.tasks if\n self.dfk.tasks[t]['status'] in failed_states])\n\n message = {'uuid': self.uuid,\n 'end': time.time(),\n 't_apps': app_count,\n 'sites': site_count,\n 'c_time': None,\n 'failed': app_fails,\n 'test': self.test_mode,\n }\n\n return json.dumps(message)\n\n def send_UDP_message(self, message):\n \"\"\"Send UDP message.\"\"\"\n x = 0\n if self.tracking_enabled:\n try:\n proc = udp_messenger(self.domain_name, self.UDP_IP, self.UDP_PORT, self.sock_timeout, message)\n self.procs.append(proc)\n except Exception as e:\n logger.debug(\"Usage tracking failed: {}\".format(e))\n else:\n x = -1\n\n return x\n\n def send_message(self):\n \"\"\"Send message over UDP.\n\n If tracking is disables, the bytes_sent will always be set to -1\n\n Returns:\n (bytes_sent, time_taken)\n \"\"\"\n start = time.time()\n message = None\n if not self.initialized:\n message = self.construct_start_message()\n self.initialized = True\n else:\n message = self.construct_end_message()\n\n self.send_UDP_message(message)\n end = time.time()\n\n return end - start\n\n def __del__(self):\n return self.close()\n\n def close(self):\n \"\"\"We terminate (SIGTERM) the processes added to the self.procs list \"\"\"\n for proc in self.procs:\n proc.terminate()\n\n\nif __name__ == '__main__':\n\n from parsl import *\n\n set_stream_logger()\n workers = ThreadPoolExecutor(max_workers=4)\n dfk = DataFlowKernel(executors=[workers])\n\n dfk.cleanup()\n", "path": "parsl/dataflow/usage_tracking/usage.py"}], "after_files": [{"content": "import uuid\nimport time\nimport hashlib\nimport os\nimport getpass\nimport json\nimport logging\nimport socket\nimport sys\nimport platform\nimport multiprocessing as mp\n\nfrom parsl.dataflow.states import FINAL_FAILURE_STATES\nfrom parsl.version import VERSION as PARSL_VERSION\n\nlogger = logging.getLogger(__name__)\n\n\ndef async_process(fn):\n \"\"\" Decorator function to launch a function as a separate process \"\"\"\n\n def run(*args, **kwargs):\n proc = mp.Process(target=fn, args=args, kwargs=kwargs)\n proc.start()\n return proc\n\n return run\n\n\n@async_process\ndef udp_messenger(domain_name, UDP_IP, UDP_PORT, sock_timeout, message):\n \"\"\"Send UDP messages to usage tracker asynchronously\n\n This multiprocessing based messenger was written to overcome the limitations\n of signalling/terminating a thread that is blocked on a system call. This\n messenger is created as a separate process, and initialized with 2 queues,\n to_send to receive messages to be sent to the internet.\n\n Args:\n - domain_name (str) : Domain name string\n - UDP_IP (str) : IP address YYY.YYY.YYY.YYY\n - UDP_PORT (int) : UDP port to send out on\n - sock_timeout (int) : Socket timeout\n - to_send (multiprocessing.Queue) : Queue of outgoing messages to internet\n \"\"\"\n try:\n if message is None:\n raise ValueError(\"message was none\")\n\n encoded_message = bytes(message, \"utf-8\")\n\n if encoded_message is None:\n raise ValueError(\"utf-8 encoding of message failed\")\n\n if domain_name:\n try:\n UDP_IP = socket.gethostbyname(domain_name)\n except Exception:\n # (False, \"Domain lookup failed, defaulting to {0}\".format(UDP_IP))\n pass\n\n if UDP_IP is None:\n raise Exception(\"UDP_IP is None\")\n\n if UDP_PORT is None:\n raise Exception(\"UDP_PORT is None\")\n\n sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP\n sock.settimeout(sock_timeout)\n sock.sendto(bytes(message, \"utf-8\"), (UDP_IP, UDP_PORT))\n sock.close()\n\n except socket.timeout:\n logger.debug(\"Failed to send usage tracking data: socket timeout\")\n except OSError as e:\n logger.debug(\"Failed to send usage tracking data: OSError: {}\".format(e))\n except Exception as e:\n logger.debug(\"Failed to send usage tracking data: Exception: {}\".format(e))\n\n\nclass UsageTracker (object):\n \"\"\"Anonymized Usage Tracking for Parsl.\n\n Client for this is here : https://github.com/Parsl/parsl_tracking\n This issue captures the discussion that went into functionality\n implemented here : https://github.com/Parsl/parsl/issues/34\n\n \"\"\"\n\n def __init__(self, dfk, ip='52.3.111.203', port=50077,\n domain_name='tracking.parsl-project.org'):\n \"\"\"Initialize usage tracking unless the user has opted-out.\n\n We will try to resolve the hostname specified in kwarg:domain_name\n and if that fails attempt to use the kwarg:ip. Determining the\n IP and sending message is threaded to avoid slowing down DFK\n initialization.\n\n Tracks usage stats by inspecting the internal state of the dfk.\n\n Args:\n - dfk (DFK object) : Data Flow Kernel object\n\n KWargs:\n - ip (string) : IP address\n - port (int) : Port number, Default:50077\n - domain_name (string) : Domain name, will override IP\n Default: tracking.parsl-project.org\n \"\"\"\n\n self.domain_name = domain_name\n self.ip = ip\n # The sock timeout will only apply to UDP send and not domain resolution\n self.sock_timeout = 5\n self.UDP_PORT = port\n self.UDP_IP = None\n self.procs = []\n self.dfk = dfk\n self.config = self.dfk.config\n self.uuid = str(uuid.uuid4())\n self.parsl_version = PARSL_VERSION\n self.python_version = \"{}.{}.{}\".format(sys.version_info.major,\n sys.version_info.minor,\n sys.version_info.micro)\n self.test_mode, self.tracking_enabled = self.check_tracking_enabled()\n logger.debug(\"Tracking status: {}\".format(self.tracking_enabled))\n logger.debug(\"Testing mode : {}\".format(self.test_mode))\n self.initialized = False # Once first message is sent this will be True\n\n def check_tracking_enabled(self):\n \"\"\"By default tracking is enabled.\n\n If Test mode is set via env variable PARSL_TESTING, a test flag is set\n\n Tracking is disabled if :\n 1. config[\"globals\"][\"usageTracking\"] is set to False (Bool)\n 2. Environment variable PARSL_TRACKING is set to false (case insensitive)\n\n \"\"\"\n track = True # By default we track usage\n test = False # By default we are not in testing mode\n\n testvar = str(os.environ.get(\"PARSL_TESTING\", 'None')).lower()\n if testvar == 'true':\n test = True\n\n if not self.config.usage_tracking:\n track = False\n\n envvar = str(os.environ.get(\"PARSL_TRACKING\", True)).lower()\n if envvar == \"false\":\n track = False\n\n return test, track\n\n def construct_start_message(self):\n \"\"\"Collect preliminary run info at the start of the DFK.\n\n Returns :\n - Message dict dumped as json string, ready for UDP\n \"\"\"\n uname = getpass.getuser().encode('latin1')\n hashed_username = hashlib.sha256(uname).hexdigest()[0:10]\n hname = socket.gethostname().encode('latin1')\n hashed_hostname = hashlib.sha256(hname).hexdigest()[0:10]\n message = {'uuid': self.uuid,\n 'uname': hashed_username,\n 'hname': hashed_hostname,\n 'test': self.test_mode,\n 'parsl_v': self.parsl_version,\n 'python_v': self.python_version,\n 'os': platform.system(),\n 'os_v': platform.release(),\n 'start': time.time()}\n\n return json.dumps(message)\n\n def construct_end_message(self):\n \"\"\"Collect the final run information at the time of DFK cleanup.\n\n Returns:\n - Message dict dumped as json string, ready for UDP\n \"\"\"\n app_count = self.dfk.task_count\n\n site_count = len([x for x in self.dfk.config.executors if x.managed])\n\n app_fails = len([t for t in self.dfk.tasks if\n self.dfk.tasks[t]['status'] in FINAL_FAILURE_STATES])\n\n message = {'uuid': self.uuid,\n 'end': time.time(),\n 't_apps': app_count,\n 'sites': site_count,\n 'c_time': None,\n 'failed': app_fails,\n 'test': self.test_mode,\n }\n\n return json.dumps(message)\n\n def send_UDP_message(self, message):\n \"\"\"Send UDP message.\"\"\"\n x = 0\n if self.tracking_enabled:\n try:\n proc = udp_messenger(self.domain_name, self.UDP_IP, self.UDP_PORT, self.sock_timeout, message)\n self.procs.append(proc)\n except Exception as e:\n logger.debug(\"Usage tracking failed: {}\".format(e))\n else:\n x = -1\n\n return x\n\n def send_message(self):\n \"\"\"Send message over UDP.\n\n If tracking is disables, the bytes_sent will always be set to -1\n\n Returns:\n (bytes_sent, time_taken)\n \"\"\"\n start = time.time()\n message = None\n if not self.initialized:\n message = self.construct_start_message()\n self.initialized = True\n else:\n message = self.construct_end_message()\n\n self.send_UDP_message(message)\n end = time.time()\n\n return end - start\n\n def __del__(self):\n return self.close()\n\n def close(self):\n \"\"\"We terminate (SIGTERM) the processes added to the self.procs list \"\"\"\n for proc in self.procs:\n proc.terminate()\n\n\nif __name__ == '__main__':\n\n from parsl import *\n\n set_stream_logger()\n workers = ThreadPoolExecutor(max_workers=4)\n dfk = DataFlowKernel(executors=[workers])\n\n dfk.cleanup()\n", "path": "parsl/dataflow/usage_tracking/usage.py"}]}
| 2,988 | 225 |
gh_patches_debug_20633
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-460
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AWS::Serverless::Api Cors config transform error
#### cfn-lint version:
``` console
$ cfn-lint --version
cfn-lint 0.8.3
```
#### Description of issue:
When I have a `AWS::Serverless::Api` object with a [Cors Configuration](https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#cors-configuration) object in it I routinely get the following error when linting `template.yaml`
`E0001 Error transforming template: 'dict_node' object has no attribute 'start_mark'`
I also got the following stack trace when running
```
Traceback (most recent call last):
File "/usr/local/bin/cfn-lint", line 11, in <module>
sys.exit(main())
File "/usr/local/lib/python2.7/site-packages/cfnlint/__main__.py", line 36, in main
args.regions, args.override_spec))
File "/usr/local/lib/python2.7/site-packages/cfnlint/core.py", line 46, in run_cli
return run_checks(filename, template, rules, regions)
File "/usr/local/lib/python2.7/site-packages/cfnlint/core.py", line 316, in run_checks
matches.extend(runner.transform())
File "/usr/local/lib/python2.7/site-packages/cfnlint/__init__.py", line 894, in transform
matches = transform.transform_template()
File "/usr/local/lib/python2.7/site-packages/cfnlint/transform.py", line 115, in transform_template
sam_translator.translate(sam_template=self._template, parameter_values={}))
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/translator/translator.py", line 71, in translate
translated = macro.to_cloudformation(**kwargs)
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py", line 501, in to_cloudformation
rest_api, deployment, stage = api_generator.to_cloudformation()
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py", line 160, in to_cloudformation
rest_api = self._construct_rest_api()
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py", line 69, in _construct_rest_api
self._add_cors()
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py", line 212, in _add_cors
self.definition_body = editor.swagger
File "/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/swagger/swagger.py", line 298, in swagger
return copy.deepcopy(self._doc)
File "/usr/local/Cellar/python@2/2.7.15_1/Frameworks/Python.framework/Versions/2.7/lib/python2.7/copy.py", line 174, in deepcopy
y = copier(memo)
File "/usr/local/lib/python2.7/site-packages/cfnlint/decode/node.py", line 75, in __deepcopy__
result = cls.__new__(cls, self.start_mark, self.end_mark)
AttributeError: 'dict_node' object has no attribute 'start_mark'
```
Here is simple example I made to reproduce
```yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
Function:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/
Handler: app.lambda_handler
Runtime: nodejs8.10
Api:
Type: AWS::Serverless::Api
Properties:
Name: test
StageName: test
Cors:
AllowHeaders: "'my_custom_header,content-type'"
AllowOrigin: "'*'"
MaxAge: ""
DefinitionBody:
swagger: "2.0"
info:
version: "1.0"
title: "test"
basePath: "/"
schemes:
- "https"
paths:
/:
get:
x-amazon-apigateway-integration:
uri:
Fn::Sub: "arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${Function.Arn}/invocations"
passthroughBehavior: "when_no_match"
httpMethod: "POST"
type: "aws_proxy"
```
If you comment out the following lines then issue goes away:
```yaml
Cors:
AllowHeaders: "'my_custom_header,content-type'"
AllowOrigin: "'*'"
MaxAge: ""
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/decode/node.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import sys
18 import logging
19 from copy import deepcopy
20 import six
21
22 LOGGER = logging.getLogger(__name__)
23
24
25 class TemplateAttributeError(AttributeError):
26 """ Custom error to capture Attribute Errors in the Template """
27
28
29 def create_str_node_class(cls):
30 """
31 Create string node class
32 """
33 class node_class(cls):
34 """Node class created based on the input class"""
35 def __init__(self, x, start_mark, end_mark):
36 try:
37 cls.__init__(self, x)
38 except TypeError:
39 cls.__init__(self)
40 self.start_mark = start_mark
41 self.end_mark = end_mark
42
43 # pylint: disable=bad-classmethod-argument, unused-argument
44 def __new__(self, x, start_mark, end_mark):
45 if sys.version_info >= (3, 0):
46 return cls.__new__(self, x)
47
48 if isinstance(x, six.string_types):
49 return cls.__new__(self, x.encode('ascii', 'ignore'))
50
51 return cls.__new__(self, x)
52
53 def __getattr__(self, name):
54 raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))
55
56 def __deepcopy__(self, memo):
57 result = str_node(self, self.start_mark, self.end_mark)
58 memo[id(self)] = result
59 return result
60
61 def __copy__(self):
62 return self
63
64 node_class.__name__ = '%s_node' % cls.__name__
65 return node_class
66
67
68 def create_dict_node_class(cls):
69 """
70 Create dynamic node class
71 """
72 class node_class(cls):
73 """Node class created based on the input class"""
74 def __init__(self, x, start_mark, end_mark):
75 try:
76 cls.__init__(self, x)
77 except TypeError:
78 cls.__init__(self)
79 self.start_mark = start_mark
80 self.end_mark = end_mark
81 self.condition_functions = ['Fn::If']
82
83 def __deepcopy__(self, memo):
84 cls = self.__class__
85 result = cls.__new__(cls, self.start_mark, self.end_mark)
86 memo[id(self)] = result
87 for k, v in self.items():
88 result[deepcopy(k)] = deepcopy(v, memo)
89
90 return result
91
92 def __copy__(self):
93 return self
94
95 def get_safe(self, key, default=None, path=None, type_t=()):
96 """
97 Get values in format
98 """
99 path = path or []
100 value = self.get(key, default)
101 if not isinstance(value, (dict)):
102 if isinstance(value, type_t) or not type_t:
103 return [(value, (path[:] + [key]))]
104
105 results = []
106 for sub_v, sub_path in value.items_safe(path):
107 if isinstance(sub_v, type_t) or not type_t:
108 results.append((sub_v, sub_path))
109
110 return results
111
112 def items_safe(self, path=None, type_t=()):
113 """Get items while handling IFs"""
114 path = path or []
115 if len(self) == 1:
116 for k, v in self.items():
117 if k == 'Fn::If':
118 if isinstance(v, list):
119 if len(v) == 3:
120 for i, if_v in enumerate(v[1:]):
121 if isinstance(if_v, dict):
122 # yield from if_v.items_safe(path[:] + [k, i - 1])
123 # Python 2.7 support
124 for items, p in if_v.items_safe(path[:] + [k, i + 1]):
125 if isinstance(items, type_t) or not type_t:
126 yield items, p
127 elif isinstance(if_v, list):
128 if isinstance(if_v, type_t) or not type_t:
129 yield if_v, path[:] + [k, i + 1]
130 else:
131 if isinstance(if_v, type_t) or not type_t:
132 yield if_v, path[:] + [k, i + 1]
133 elif k != 'Ref' and v != 'AWS::NoValue':
134 if isinstance(self, type_t) or not type_t:
135 yield self, path[:]
136 else:
137 if isinstance(self, type_t) or not type_t:
138 yield self, path[:]
139
140 def __getattr__(self, name):
141 raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))
142
143 node_class.__name__ = '%s_node' % cls.__name__
144 return node_class
145
146
147 def create_dict_list_class(cls):
148 """
149 Create dynamic list class
150 """
151 class node_class(cls):
152 """Node class created based on the input class"""
153 def __init__(self, x, start_mark, end_mark):
154 try:
155 cls.__init__(self, x)
156 except TypeError:
157 cls.__init__(self)
158 self.start_mark = start_mark
159 self.end_mark = end_mark
160 self.condition_functions = ['Fn::If']
161
162 def __deepcopy__(self, memo):
163 cls = self.__class__
164 result = cls.__new__(cls, self.start_mark, self.end_mark)
165 memo[id(self)] = result
166 for _, v in enumerate(self):
167 result.append(deepcopy(v, memo))
168
169 return result
170
171 def __copy__(self):
172 return self
173
174 def items_safe(self, path=None, type_t=()):
175 """Get items while handling IFs"""
176 path = path or []
177 for i, v in enumerate(self):
178 if isinstance(v, dict):
179 for items, p in v.items_safe(path[:] + [i]):
180 if isinstance(items, type_t) or not type_t:
181 yield items, p
182 else:
183 if isinstance(v, type_t) or not type_t:
184 yield v, path[:] + [i]
185
186 def __getattr__(self, name):
187 raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))
188
189 node_class.__name__ = '%s_node' % cls.__name__
190 return node_class
191
192
193 str_node = create_str_node_class(str)
194 dict_node = create_dict_node_class(dict)
195 list_node = create_dict_list_class(list)
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/decode/node.py b/src/cfnlint/decode/node.py
--- a/src/cfnlint/decode/node.py
+++ b/src/cfnlint/decode/node.py
@@ -81,8 +81,7 @@
self.condition_functions = ['Fn::If']
def __deepcopy__(self, memo):
- cls = self.__class__
- result = cls.__new__(cls, self.start_mark, self.end_mark)
+ result = dict_node(self, self.start_mark, self.end_mark)
memo[id(self)] = result
for k, v in self.items():
result[deepcopy(k)] = deepcopy(v, memo)
@@ -160,8 +159,7 @@
self.condition_functions = ['Fn::If']
def __deepcopy__(self, memo):
- cls = self.__class__
- result = cls.__new__(cls, self.start_mark, self.end_mark)
+ result = list_node([], self.start_mark, self.end_mark)
memo[id(self)] = result
for _, v in enumerate(self):
result.append(deepcopy(v, memo))
|
{"golden_diff": "diff --git a/src/cfnlint/decode/node.py b/src/cfnlint/decode/node.py\n--- a/src/cfnlint/decode/node.py\n+++ b/src/cfnlint/decode/node.py\n@@ -81,8 +81,7 @@\n self.condition_functions = ['Fn::If']\n \n def __deepcopy__(self, memo):\n- cls = self.__class__\n- result = cls.__new__(cls, self.start_mark, self.end_mark)\n+ result = dict_node(self, self.start_mark, self.end_mark)\n memo[id(self)] = result\n for k, v in self.items():\n result[deepcopy(k)] = deepcopy(v, memo)\n@@ -160,8 +159,7 @@\n self.condition_functions = ['Fn::If']\n \n def __deepcopy__(self, memo):\n- cls = self.__class__\n- result = cls.__new__(cls, self.start_mark, self.end_mark)\n+ result = list_node([], self.start_mark, self.end_mark)\n memo[id(self)] = result\n for _, v in enumerate(self):\n result.append(deepcopy(v, memo))\n", "issue": "AWS::Serverless::Api Cors config transform error\n#### cfn-lint version:\r\n``` console\r\n$ cfn-lint --version\r\ncfn-lint 0.8.3\r\n```\r\n\r\n#### Description of issue:\r\nWhen I have a `AWS::Serverless::Api` object with a [Cors Configuration](https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#cors-configuration) object in it I routinely get the following error when linting `template.yaml` \r\n\r\n`E0001 Error transforming template: 'dict_node' object has no attribute 'start_mark'`\r\n\r\nI also got the following stack trace when running \r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/cfn-lint\", line 11, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/__main__.py\", line 36, in main\r\n args.regions, args.override_spec))\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/core.py\", line 46, in run_cli\r\n return run_checks(filename, template, rules, regions)\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/core.py\", line 316, in run_checks\r\n matches.extend(runner.transform())\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/__init__.py\", line 894, in transform\r\n matches = transform.transform_template()\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/transform.py\", line 115, in transform_template\r\n sam_translator.translate(sam_template=self._template, parameter_values={}))\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/translator/translator.py\", line 71, in translate\r\n translated = macro.to_cloudformation(**kwargs)\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/sam_resources.py\", line 501, in to_cloudformation\r\n rest_api, deployment, stage = api_generator.to_cloudformation()\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py\", line 160, in to_cloudformation\r\n rest_api = self._construct_rest_api()\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py\", line 69, in _construct_rest_api\r\n self._add_cors()\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/model/api/api_generator.py\", line 212, in _add_cors\r\n self.definition_body = editor.swagger\r\n File \"/Users/eaddingtonwhite/Library/Python/2.7/lib/python/site-packages/samtranslator/swagger/swagger.py\", line 298, in swagger\r\n return copy.deepcopy(self._doc)\r\n File \"/usr/local/Cellar/python@2/2.7.15_1/Frameworks/Python.framework/Versions/2.7/lib/python2.7/copy.py\", line 174, in deepcopy\r\n y = copier(memo)\r\n File \"/usr/local/lib/python2.7/site-packages/cfnlint/decode/node.py\", line 75, in __deepcopy__\r\n result = cls.__new__(cls, self.start_mark, self.end_mark)\r\nAttributeError: 'dict_node' object has no attribute 'start_mark'\r\n```\r\nHere is simple example I made to reproduce\r\n```yaml\r\nAWSTemplateFormatVersion: '2010-09-09'\r\nTransform: AWS::Serverless-2016-10-31\r\n\r\nResources:\r\n Function:\r\n Type: AWS::Serverless::Function\r\n Properties:\r\n CodeUri: hello_world/\r\n Handler: app.lambda_handler\r\n Runtime: nodejs8.10\r\n\r\n Api:\r\n Type: AWS::Serverless::Api\r\n Properties:\r\n Name: test\r\n StageName: test\r\n Cors:\r\n AllowHeaders: \"'my_custom_header,content-type'\"\r\n AllowOrigin: \"'*'\"\r\n MaxAge: \"\"\r\n DefinitionBody:\r\n swagger: \"2.0\"\r\n info:\r\n version: \"1.0\"\r\n title: \"test\"\r\n basePath: \"/\"\r\n schemes:\r\n - \"https\"\r\n paths:\r\n /:\r\n get:\r\n x-amazon-apigateway-integration:\r\n uri:\r\n Fn::Sub: \"arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${Function.Arn}/invocations\"\r\n passthroughBehavior: \"when_no_match\"\r\n httpMethod: \"POST\"\r\n type: \"aws_proxy\"\r\n```\r\n\r\nIf you comment out the following lines then issue goes away:\r\n```yaml\r\n Cors:\r\n AllowHeaders: \"'my_custom_header,content-type'\"\r\n AllowOrigin: \"'*'\"\r\n MaxAge: \"\"\r\n```\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport sys\nimport logging\nfrom copy import deepcopy\nimport six\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass TemplateAttributeError(AttributeError):\n \"\"\" Custom error to capture Attribute Errors in the Template \"\"\"\n\n\ndef create_str_node_class(cls):\n \"\"\"\n Create string node class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n\n # pylint: disable=bad-classmethod-argument, unused-argument\n def __new__(self, x, start_mark, end_mark):\n if sys.version_info >= (3, 0):\n return cls.__new__(self, x)\n\n if isinstance(x, six.string_types):\n return cls.__new__(self, x.encode('ascii', 'ignore'))\n\n return cls.__new__(self, x)\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n def __deepcopy__(self, memo):\n result = str_node(self, self.start_mark, self.end_mark)\n memo[id(self)] = result\n return result\n\n def __copy__(self):\n return self\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\ndef create_dict_node_class(cls):\n \"\"\"\n Create dynamic node class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n self.condition_functions = ['Fn::If']\n\n def __deepcopy__(self, memo):\n cls = self.__class__\n result = cls.__new__(cls, self.start_mark, self.end_mark)\n memo[id(self)] = result\n for k, v in self.items():\n result[deepcopy(k)] = deepcopy(v, memo)\n\n return result\n\n def __copy__(self):\n return self\n\n def get_safe(self, key, default=None, path=None, type_t=()):\n \"\"\"\n Get values in format\n \"\"\"\n path = path or []\n value = self.get(key, default)\n if not isinstance(value, (dict)):\n if isinstance(value, type_t) or not type_t:\n return [(value, (path[:] + [key]))]\n\n results = []\n for sub_v, sub_path in value.items_safe(path):\n if isinstance(sub_v, type_t) or not type_t:\n results.append((sub_v, sub_path))\n\n return results\n\n def items_safe(self, path=None, type_t=()):\n \"\"\"Get items while handling IFs\"\"\"\n path = path or []\n if len(self) == 1:\n for k, v in self.items():\n if k == 'Fn::If':\n if isinstance(v, list):\n if len(v) == 3:\n for i, if_v in enumerate(v[1:]):\n if isinstance(if_v, dict):\n # yield from if_v.items_safe(path[:] + [k, i - 1])\n # Python 2.7 support\n for items, p in if_v.items_safe(path[:] + [k, i + 1]):\n if isinstance(items, type_t) or not type_t:\n yield items, p\n elif isinstance(if_v, list):\n if isinstance(if_v, type_t) or not type_t:\n yield if_v, path[:] + [k, i + 1]\n else:\n if isinstance(if_v, type_t) or not type_t:\n yield if_v, path[:] + [k, i + 1]\n elif k != 'Ref' and v != 'AWS::NoValue':\n if isinstance(self, type_t) or not type_t:\n yield self, path[:]\n else:\n if isinstance(self, type_t) or not type_t:\n yield self, path[:]\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\ndef create_dict_list_class(cls):\n \"\"\"\n Create dynamic list class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n self.condition_functions = ['Fn::If']\n\n def __deepcopy__(self, memo):\n cls = self.__class__\n result = cls.__new__(cls, self.start_mark, self.end_mark)\n memo[id(self)] = result\n for _, v in enumerate(self):\n result.append(deepcopy(v, memo))\n\n return result\n\n def __copy__(self):\n return self\n\n def items_safe(self, path=None, type_t=()):\n \"\"\"Get items while handling IFs\"\"\"\n path = path or []\n for i, v in enumerate(self):\n if isinstance(v, dict):\n for items, p in v.items_safe(path[:] + [i]):\n if isinstance(items, type_t) or not type_t:\n yield items, p\n else:\n if isinstance(v, type_t) or not type_t:\n yield v, path[:] + [i]\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\nstr_node = create_str_node_class(str)\ndict_node = create_dict_node_class(dict)\nlist_node = create_dict_list_class(list)\n", "path": "src/cfnlint/decode/node.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport sys\nimport logging\nfrom copy import deepcopy\nimport six\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass TemplateAttributeError(AttributeError):\n \"\"\" Custom error to capture Attribute Errors in the Template \"\"\"\n\n\ndef create_str_node_class(cls):\n \"\"\"\n Create string node class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n\n # pylint: disable=bad-classmethod-argument, unused-argument\n def __new__(self, x, start_mark, end_mark):\n if sys.version_info >= (3, 0):\n return cls.__new__(self, x)\n\n if isinstance(x, six.string_types):\n return cls.__new__(self, x.encode('ascii', 'ignore'))\n\n return cls.__new__(self, x)\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n def __deepcopy__(self, memo):\n result = str_node(self, self.start_mark, self.end_mark)\n memo[id(self)] = result\n return result\n\n def __copy__(self):\n return self\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\ndef create_dict_node_class(cls):\n \"\"\"\n Create dynamic node class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n self.condition_functions = ['Fn::If']\n\n def __deepcopy__(self, memo):\n result = dict_node(self, self.start_mark, self.end_mark)\n memo[id(self)] = result\n for k, v in self.items():\n result[deepcopy(k)] = deepcopy(v, memo)\n\n return result\n\n def __copy__(self):\n return self\n\n def get_safe(self, key, default=None, path=None, type_t=()):\n \"\"\"\n Get values in format\n \"\"\"\n path = path or []\n value = self.get(key, default)\n if not isinstance(value, (dict)):\n if isinstance(value, type_t) or not type_t:\n return [(value, (path[:] + [key]))]\n\n results = []\n for sub_v, sub_path in value.items_safe(path):\n if isinstance(sub_v, type_t) or not type_t:\n results.append((sub_v, sub_path))\n\n return results\n\n def items_safe(self, path=None, type_t=()):\n \"\"\"Get items while handling IFs\"\"\"\n path = path or []\n if len(self) == 1:\n for k, v in self.items():\n if k == 'Fn::If':\n if isinstance(v, list):\n if len(v) == 3:\n for i, if_v in enumerate(v[1:]):\n if isinstance(if_v, dict):\n # yield from if_v.items_safe(path[:] + [k, i - 1])\n # Python 2.7 support\n for items, p in if_v.items_safe(path[:] + [k, i + 1]):\n if isinstance(items, type_t) or not type_t:\n yield items, p\n elif isinstance(if_v, list):\n if isinstance(if_v, type_t) or not type_t:\n yield if_v, path[:] + [k, i + 1]\n else:\n if isinstance(if_v, type_t) or not type_t:\n yield if_v, path[:] + [k, i + 1]\n elif k != 'Ref' and v != 'AWS::NoValue':\n if isinstance(self, type_t) or not type_t:\n yield self, path[:]\n else:\n if isinstance(self, type_t) or not type_t:\n yield self, path[:]\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\ndef create_dict_list_class(cls):\n \"\"\"\n Create dynamic list class\n \"\"\"\n class node_class(cls):\n \"\"\"Node class created based on the input class\"\"\"\n def __init__(self, x, start_mark, end_mark):\n try:\n cls.__init__(self, x)\n except TypeError:\n cls.__init__(self)\n self.start_mark = start_mark\n self.end_mark = end_mark\n self.condition_functions = ['Fn::If']\n\n def __deepcopy__(self, memo):\n result = list_node([], self.start_mark, self.end_mark)\n memo[id(self)] = result\n for _, v in enumerate(self):\n result.append(deepcopy(v, memo))\n\n return result\n\n def __copy__(self):\n return self\n\n def items_safe(self, path=None, type_t=()):\n \"\"\"Get items while handling IFs\"\"\"\n path = path or []\n for i, v in enumerate(self):\n if isinstance(v, dict):\n for items, p in v.items_safe(path[:] + [i]):\n if isinstance(items, type_t) or not type_t:\n yield items, p\n else:\n if isinstance(v, type_t) or not type_t:\n yield v, path[:] + [i]\n\n def __getattr__(self, name):\n raise TemplateAttributeError('%s.%s is invalid' % (self.__class__.__name__, name))\n\n node_class.__name__ = '%s_node' % cls.__name__\n return node_class\n\n\nstr_node = create_str_node_class(str)\ndict_node = create_dict_node_class(dict)\nlist_node = create_dict_list_class(list)\n", "path": "src/cfnlint/decode/node.py"}]}
| 3,395 | 251 |
gh_patches_debug_507
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1794
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: client doesn't retry "Job exceeded rate limits" for DDL query jobs that exceed quota for table update operations
In https://github.com/googleapis/python-bigquery-sqlalchemy/pull/1009#discussion_r1457644849 it seems that the query in https://btx-internal.corp.google.com/invocations/ffafb866-6bc0-423f-a86b-df69fb270d57/targets/cloud-devrel%2Fclient-libraries%2Fpython%2Fgoogleapis%2Fpython-bigquery-sqlalchemy%2Fpresubmit%2Fprerelease-deps;config=default/log with rate limits exceeded errors are not retried.
#### Environment details
- OS type and version:
- Python version: `python --version`
- pip version: `pip --version`
- `google-cloud-bigquery` version: `pip show google-cloud-bigquery`
#### Steps to reproduce
Run a DDL query more than 5 times in 10 seconds, violating the five table metadata update operations per 10 seconds per table limit (https://cloud.google.com/bigquery/quotas#standard_tables).
#### Code example
```python
import google.cloud.bigquery
bqclient = google.cloud.bigquery.Client()
sql = "ALTER TABLE `swast-scratch.my_dataset.my_table` ADD COLUMN IF NOT EXISTS my_string_col STRING"
for _ in range(100):
bqclient.query_and_wait(sql)
```
#### Stack trace
```
BadRequest Traceback (most recent call last)
Input In [4], in <cell line: 1>()
1 for _ in range(100):
----> 2 bqclient.query_and_wait(sql)
File ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/client.py:3503, in Client.query_and_wait(self, query, job_config, location, project, api_timeout, wait_timeout, retry, job_retry, page_size, max_results)
3497 _verify_job_config_type(job_config, QueryJobConfig)
3499 job_config = _job_helpers.job_config_with_defaults(
3500 job_config, self._default_query_job_config
3501 )
-> 3503 return _job_helpers.query_and_wait(
3504 self,
3505 query,
3506 job_config=job_config,
3507 location=location,
3508 project=project,
3509 api_timeout=api_timeout,
3510 wait_timeout=wait_timeout,
3511 retry=retry,
3512 job_retry=job_retry,
3513 page_size=page_size,
3514 max_results=max_results,
3515 )
File ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/_job_helpers.py:498, in query_and_wait(client, query, job_config, location, project, api_timeout, wait_timeout, retry, job_retry, page_size, max_results)
481 return table.RowIterator(
482 client=client,
483 api_request=functools.partial(client._call_api, retry, timeout=api_timeout),
(...)
494 num_dml_affected_rows=query_results.num_dml_affected_rows,
495 )
497 if job_retry is not None:
--> 498 return job_retry(do_query)()
499 else:
500 return do_query()
File /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)
345 target = functools.partial(func, *args, **kwargs)
346 sleep_generator = exponential_sleep_generator(
347 self._initial, self._maximum, multiplier=self._multiplier
348 )
--> 349 return retry_target(
350 target,
351 self._predicate,
352 sleep_generator,
353 self._timeout,
354 on_error=on_error,
355 )
File /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)
189 for sleep in sleep_generator:
190 try:
--> 191 return target()
193 # pylint: disable=broad-except
194 # This function explicitly must deal with broad exceptions.
195 except Exception as exc:
File ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/_job_helpers.py:439, in query_and_wait.<locals>.do_query()
437 # For easier testing, handle the retries ourselves.
438 if retry is not None:
--> 439 response = retry(client._call_api)(
440 retry=None, # We're calling the retry decorator ourselves.
441 span_name="BigQuery.query",
442 span_attributes=span_attributes,
443 method="POST",
444 path=path,
445 data=request_body,
446 timeout=api_timeout,
447 )
448 else:
449 response = client._call_api(
450 retry=None,
451 span_name="BigQuery.query",
(...)
456 timeout=api_timeout,
457 )
File /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)
345 target = functools.partial(func, *args, **kwargs)
346 sleep_generator = exponential_sleep_generator(
347 self._initial, self._maximum, multiplier=self._multiplier
348 )
--> 349 return retry_target(
350 target,
351 self._predicate,
352 sleep_generator,
353 self._timeout,
354 on_error=on_error,
355 )
File /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)
189 for sleep in sleep_generator:
190 try:
--> 191 return target()
193 # pylint: disable=broad-except
194 # This function explicitly must deal with broad exceptions.
195 except Exception as exc:
File ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/client.py:827, in Client._call_api(self, retry, span_name, span_attributes, job_ref, headers, **kwargs)
823 if span_name is not None:
824 with create_span(
825 name=span_name, attributes=span_attributes, client=self, job_ref=job_ref
826 ):
--> 827 return call()
829 return call()
File /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/cloud/_http/__init__.py:494, in JSONConnection.api_request(self, method, path, query_params, data, content_type, headers, api_base_url, api_version, expect_json, _target_object, timeout, extra_api_info)
482 response = self._make_request(
483 method=method,
484 url=url,
(...)
490 extra_api_info=extra_api_info,
491 )
493 if not 200 <= response.status_code < 300:
--> 494 raise exceptions.from_http_response(response)
496 if expect_json and response.content:
497 return response.json()
BadRequest: 400 POST https://bigquery.googleapis.com/bigquery/v2/projects/swast-scratch/queries?prettyPrint=false: Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas
In [5]: import sys
In [6]: exc = sys.last_value
In [7]: exc
Out[7]: google.api_core.exceptions.BadRequest('POST https://bigquery.googleapis.com/bigquery/v2/projects/swast-scratch/queries?prettyPrint=false: Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas')
In [8]: exc.reason
In [9]: exc.errors
Out[9]:
[{'message': 'Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas',
'domain': 'global',
'reason': 'jobRateLimitExceeded'}]
In [10]: exc.errors[0]["reason"]
Out[10]: 'jobRateLimitExceeded'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/retry.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from google.api_core import exceptions
16 from google.api_core import retry
17 from google.auth import exceptions as auth_exceptions # type: ignore
18 import requests.exceptions
19
20
21 _RETRYABLE_REASONS = frozenset(
22 ["rateLimitExceeded", "backendError", "internalError", "badGateway"]
23 )
24
25 _UNSTRUCTURED_RETRYABLE_TYPES = (
26 ConnectionError,
27 exceptions.TooManyRequests,
28 exceptions.InternalServerError,
29 exceptions.BadGateway,
30 exceptions.ServiceUnavailable,
31 requests.exceptions.ChunkedEncodingError,
32 requests.exceptions.ConnectionError,
33 requests.exceptions.Timeout,
34 auth_exceptions.TransportError,
35 )
36
37 _DEFAULT_RETRY_DEADLINE = 10.0 * 60.0 # 10 minutes
38
39 # Allow for a few retries after the API request times out. This relevant for
40 # rateLimitExceeded errors, which can be raised either by the Google load
41 # balancer or the BigQuery job server.
42 _DEFAULT_JOB_DEADLINE = 3.0 * _DEFAULT_RETRY_DEADLINE
43
44
45 def _should_retry(exc):
46 """Predicate for determining when to retry.
47
48 We retry if and only if the 'reason' is 'backendError'
49 or 'rateLimitExceeded'.
50 """
51 if not hasattr(exc, "errors") or len(exc.errors) == 0:
52 # Check for unstructured error returns, e.g. from GFE
53 return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)
54
55 reason = exc.errors[0]["reason"]
56 return reason in _RETRYABLE_REASONS
57
58
59 DEFAULT_RETRY = retry.Retry(predicate=_should_retry, deadline=_DEFAULT_RETRY_DEADLINE)
60 """The default retry object.
61
62 Any method with a ``retry`` parameter will be retried automatically,
63 with reasonable defaults. To disable retry, pass ``retry=None``.
64 To modify the default retry behavior, call a ``with_XXX`` method
65 on ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,
66 pass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.
67 """
68
69 DEFAULT_TIMEOUT = None
70 """The default API timeout.
71
72 This is the time to wait per request. To adjust the total wait time, set a
73 deadline on the retry object.
74 """
75
76 job_retry_reasons = "rateLimitExceeded", "backendError"
77
78
79 def _job_should_retry(exc):
80 if not hasattr(exc, "errors") or len(exc.errors) == 0:
81 return False
82
83 reason = exc.errors[0]["reason"]
84 return reason in job_retry_reasons
85
86
87 DEFAULT_JOB_RETRY = retry.Retry(
88 predicate=_job_should_retry, deadline=_DEFAULT_JOB_DEADLINE
89 )
90 """
91 The default job retry object.
92 """
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py
--- a/google/cloud/bigquery/retry.py
+++ b/google/cloud/bigquery/retry.py
@@ -73,7 +73,7 @@
deadline on the retry object.
"""
-job_retry_reasons = "rateLimitExceeded", "backendError"
+job_retry_reasons = "rateLimitExceeded", "backendError", "jobRateLimitExceeded"
def _job_should_retry(exc):
|
{"golden_diff": "diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py\n--- a/google/cloud/bigquery/retry.py\n+++ b/google/cloud/bigquery/retry.py\n@@ -73,7 +73,7 @@\n deadline on the retry object.\n \"\"\"\n \n-job_retry_reasons = \"rateLimitExceeded\", \"backendError\"\n+job_retry_reasons = \"rateLimitExceeded\", \"backendError\", \"jobRateLimitExceeded\"\n \n \n def _job_should_retry(exc):\n", "issue": "bug: client doesn't retry \"Job exceeded rate limits\" for DDL query jobs that exceed quota for table update operations \nIn https://github.com/googleapis/python-bigquery-sqlalchemy/pull/1009#discussion_r1457644849 it seems that the query in https://btx-internal.corp.google.com/invocations/ffafb866-6bc0-423f-a86b-df69fb270d57/targets/cloud-devrel%2Fclient-libraries%2Fpython%2Fgoogleapis%2Fpython-bigquery-sqlalchemy%2Fpresubmit%2Fprerelease-deps;config=default/log with rate limits exceeded errors are not retried.\r\n\r\n#### Environment details\r\n\r\n - OS type and version:\r\n - Python version: `python --version`\r\n - pip version: `pip --version`\r\n - `google-cloud-bigquery` version: `pip show google-cloud-bigquery`\r\n\r\n#### Steps to reproduce\r\n\r\nRun a DDL query more than 5 times in 10 seconds, violating the five table metadata update operations per 10 seconds per table limit (https://cloud.google.com/bigquery/quotas#standard_tables).\r\n\r\n#### Code example\r\n\r\n```python\r\nimport google.cloud.bigquery\r\nbqclient = google.cloud.bigquery.Client()\r\nsql = \"ALTER TABLE `swast-scratch.my_dataset.my_table` ADD COLUMN IF NOT EXISTS my_string_col STRING\"\r\nfor _ in range(100):\r\n bqclient.query_and_wait(sql)\r\n```\r\n\r\n#### Stack trace\r\n\r\n```\r\nBadRequest Traceback (most recent call last)\r\nInput In [4], in <cell line: 1>()\r\n 1 for _ in range(100):\r\n----> 2 bqclient.query_and_wait(sql)\r\n\r\nFile ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/client.py:3503, in Client.query_and_wait(self, query, job_config, location, project, api_timeout, wait_timeout, retry, job_retry, page_size, max_results)\r\n 3497 _verify_job_config_type(job_config, QueryJobConfig)\r\n 3499 job_config = _job_helpers.job_config_with_defaults(\r\n 3500 job_config, self._default_query_job_config\r\n 3501 )\r\n-> 3503 return _job_helpers.query_and_wait(\r\n 3504 self,\r\n 3505 query,\r\n 3506 job_config=job_config,\r\n 3507 location=location,\r\n 3508 project=project,\r\n 3509 api_timeout=api_timeout,\r\n 3510 wait_timeout=wait_timeout,\r\n 3511 retry=retry,\r\n 3512 job_retry=job_retry,\r\n 3513 page_size=page_size,\r\n 3514 max_results=max_results,\r\n 3515 )\r\n\r\nFile ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/_job_helpers.py:498, in query_and_wait(client, query, job_config, location, project, api_timeout, wait_timeout, retry, job_retry, page_size, max_results)\r\n 481 return table.RowIterator(\r\n 482 client=client,\r\n 483 api_request=functools.partial(client._call_api, retry, timeout=api_timeout),\r\n (...)\r\n 494 num_dml_affected_rows=query_results.num_dml_affected_rows,\r\n 495 )\r\n 497 if job_retry is not None:\r\n--> 498 return job_retry(do_query)()\r\n 499 else:\r\n 500 return do_query()\r\n\r\nFile /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)\r\n 345 target = functools.partial(func, *args, **kwargs)\r\n 346 sleep_generator = exponential_sleep_generator(\r\n 347 self._initial, self._maximum, multiplier=self._multiplier\r\n 348 )\r\n--> 349 return retry_target(\r\n 350 target,\r\n 351 self._predicate,\r\n 352 sleep_generator,\r\n 353 self._timeout,\r\n 354 on_error=on_error,\r\n 355 )\r\n\r\nFile /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)\r\n 189 for sleep in sleep_generator:\r\n 190 try:\r\n--> 191 return target()\r\n 193 # pylint: disable=broad-except\r\n 194 # This function explicitly must deal with broad exceptions.\r\n 195 except Exception as exc:\r\n\r\nFile ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/_job_helpers.py:439, in query_and_wait.<locals>.do_query()\r\n 437 # For easier testing, handle the retries ourselves.\r\n 438 if retry is not None:\r\n--> 439 response = retry(client._call_api)(\r\n 440 retry=None, # We're calling the retry decorator ourselves.\r\n 441 span_name=\"BigQuery.query\",\r\n 442 span_attributes=span_attributes,\r\n 443 method=\"POST\",\r\n 444 path=path,\r\n 445 data=request_body,\r\n 446 timeout=api_timeout,\r\n 447 )\r\n 448 else:\r\n 449 response = client._call_api(\r\n 450 retry=None,\r\n 451 span_name=\"BigQuery.query\",\r\n (...)\r\n 456 timeout=api_timeout,\r\n 457 )\r\n\r\nFile /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:349, in Retry.__call__.<locals>.retry_wrapped_func(*args, **kwargs)\r\n 345 target = functools.partial(func, *args, **kwargs)\r\n 346 sleep_generator = exponential_sleep_generator(\r\n 347 self._initial, self._maximum, multiplier=self._multiplier\r\n 348 )\r\n--> 349 return retry_target(\r\n 350 target,\r\n 351 self._predicate,\r\n 352 sleep_generator,\r\n 353 self._timeout,\r\n 354 on_error=on_error,\r\n 355 )\r\n\r\nFile /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/api_core/retry.py:191, in retry_target(target, predicate, sleep_generator, timeout, on_error, **kwargs)\r\n 189 for sleep in sleep_generator:\r\n 190 try:\r\n--> 191 return target()\r\n 193 # pylint: disable=broad-except\r\n 194 # This function explicitly must deal with broad exceptions.\r\n 195 except Exception as exc:\r\n\r\nFile ~/src/github.com/googleapis/python-bigquery/google/cloud/bigquery/client.py:827, in Client._call_api(self, retry, span_name, span_attributes, job_ref, headers, **kwargs)\r\n 823 if span_name is not None:\r\n 824 with create_span(\r\n 825 name=span_name, attributes=span_attributes, client=self, job_ref=job_ref\r\n 826 ):\r\n--> 827 return call()\r\n 829 return call()\r\n\r\nFile /opt/miniconda3/envs/dev-3.10/lib/python3.10/site-packages/google/cloud/_http/__init__.py:494, in JSONConnection.api_request(self, method, path, query_params, data, content_type, headers, api_base_url, api_version, expect_json, _target_object, timeout, extra_api_info)\r\n 482 response = self._make_request(\r\n 483 method=method,\r\n 484 url=url,\r\n (...)\r\n 490 extra_api_info=extra_api_info,\r\n 491 )\r\n 493 if not 200 <= response.status_code < 300:\r\n--> 494 raise exceptions.from_http_response(response)\r\n 496 if expect_json and response.content:\r\n 497 return response.json()\r\n\r\nBadRequest: 400 POST https://bigquery.googleapis.com/bigquery/v2/projects/swast-scratch/queries?prettyPrint=false: Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas\r\n\r\nIn [5]: import sys\r\n\r\nIn [6]: exc = sys.last_value\r\n\r\nIn [7]: exc\r\nOut[7]: google.api_core.exceptions.BadRequest('POST https://bigquery.googleapis.com/bigquery/v2/projects/swast-scratch/queries?prettyPrint=false: Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas')\r\n\r\nIn [8]: exc.reason\r\n\r\nIn [9]: exc.errors\r\nOut[9]: \r\n[{'message': 'Job exceeded rate limits: Your table exceeded quota for table update operations. For more information, see https://cloud.google.com/bigquery/docs/troubleshoot-quotas',\r\n 'domain': 'global',\r\n 'reason': 'jobRateLimitExceeded'}]\r\n\r\nIn [10]: exc.errors[0][\"reason\"]\r\nOut[10]: 'jobRateLimitExceeded'\r\n```\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions # type: ignore\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n exceptions.ServiceUnavailable,\n requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n requests.exceptions.Timeout,\n auth_exceptions.TransportError,\n)\n\n_DEFAULT_RETRY_DEADLINE = 10.0 * 60.0 # 10 minutes\n\n# Allow for a few retries after the API request times out. This relevant for\n# rateLimitExceeded errors, which can be raised either by the Google load\n# balancer or the BigQuery job server.\n_DEFAULT_JOB_DEADLINE = 3.0 * _DEFAULT_RETRY_DEADLINE\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry, deadline=_DEFAULT_RETRY_DEADLINE)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n\nDEFAULT_TIMEOUT = None\n\"\"\"The default API timeout.\n\nThis is the time to wait per request. To adjust the total wait time, set a\ndeadline on the retry object.\n\"\"\"\n\njob_retry_reasons = \"rateLimitExceeded\", \"backendError\"\n\n\ndef _job_should_retry(exc):\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n return False\n\n reason = exc.errors[0][\"reason\"]\n return reason in job_retry_reasons\n\n\nDEFAULT_JOB_RETRY = retry.Retry(\n predicate=_job_should_retry, deadline=_DEFAULT_JOB_DEADLINE\n)\n\"\"\"\nThe default job retry object.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions # type: ignore\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n exceptions.ServiceUnavailable,\n requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n requests.exceptions.Timeout,\n auth_exceptions.TransportError,\n)\n\n_DEFAULT_RETRY_DEADLINE = 10.0 * 60.0 # 10 minutes\n\n# Allow for a few retries after the API request times out. This relevant for\n# rateLimitExceeded errors, which can be raised either by the Google load\n# balancer or the BigQuery job server.\n_DEFAULT_JOB_DEADLINE = 3.0 * _DEFAULT_RETRY_DEADLINE\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry, deadline=_DEFAULT_RETRY_DEADLINE)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n\nDEFAULT_TIMEOUT = None\n\"\"\"The default API timeout.\n\nThis is the time to wait per request. To adjust the total wait time, set a\ndeadline on the retry object.\n\"\"\"\n\njob_retry_reasons = \"rateLimitExceeded\", \"backendError\", \"jobRateLimitExceeded\"\n\n\ndef _job_should_retry(exc):\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n return False\n\n reason = exc.errors[0][\"reason\"]\n return reason in job_retry_reasons\n\n\nDEFAULT_JOB_RETRY = retry.Retry(\n predicate=_job_should_retry, deadline=_DEFAULT_JOB_DEADLINE\n)\n\"\"\"\nThe default job retry object.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}]}
| 3,344 | 106 |
gh_patches_debug_23392
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2082
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
listing directive explodes badly if used wrong
Example:
```
.. listing:: hello.py
```
Which is a way too common first attempt to use it, crashes like this:
```
TaskError - taskid:render_posts:cache/posts/foo.html
PythonAction Error
Traceback (most recent call last):
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/doit/action.py", line 383, in execute
returned_value = self.py_callable(*self.args, **kwargs)
File "/home/ralsina/Desktop/proyectos/nikola/master/nikola/post.py", line 485, in compile
self.is_two_file),
File "/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py", line 100, in compile_html
output, error_level, deps = self.compile_html_string(data, source, is_two_file)
File "/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py", line 86, in compile_html_string
}, logger=self.logger, source_path=source_path, l_add_ln=add_ln, transforms=self.site.rst_transforms)
File "/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py", line 276, in rst2html
pub.publish(enable_exit_status=enable_exit_status)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/core.py", line 217, in publish
self.settings)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/readers/__init__.py", line 72, in read
self.parse()
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/readers/__init__.py", line 78, in parse
self.parser.parse(self.input, document)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/__init__.py", line 172, in parse
self.statemachine.run(inputlines, document, inliner=self.inliner)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py", line 170, in run
input_source=document['source'])
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/statemachine.py", line 239, in run
context, state, transitions)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/statemachine.py", line 460, in check_line
return method(match, context, next_state)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py", line 2299, in explicit_markup
nodelist, blank_finish = self.explicit_construct(match)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py", line 2311, in explicit_construct
return method(self, expmatch)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py", line 2054, in directive
directive_class, match, type_name, option_presets)
File "/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py", line 2103, in run_directive
result = directive_instance.run()
File "/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/listing.py", line 174, in run
lang = self.arguments.pop(0)
IndexError: pop from empty list
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/compile/rest/listing.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2015 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27
28 """Define and register a listing directive using the existing CodeBlock."""
29
30
31 from __future__ import unicode_literals
32 import io
33 import os
34 import uuid
35 try:
36 from urlparse import urlunsplit
37 except ImportError:
38 from urllib.parse import urlunsplit # NOQA
39
40 import docutils.parsers.rst.directives.body
41 import docutils.parsers.rst.directives.misc
42 from docutils import core
43 from docutils import nodes
44 from docutils.parsers.rst import Directive, directives
45 from docutils.parsers.rst.roles import set_classes
46 from docutils.parsers.rst.directives.misc import Include
47
48 from pygments.lexers import get_lexer_by_name
49 import pygments
50 import pygments.util
51
52 from nikola import utils
53 from nikola.plugin_categories import RestExtension
54
55
56 # A sanitized version of docutils.parsers.rst.directives.body.CodeBlock.
57 class CodeBlock(Directive):
58
59 """Parse and mark up content of a code block."""
60
61 optional_arguments = 1
62 option_spec = {'class': directives.class_option,
63 'name': directives.unchanged,
64 'number-lines': directives.unchanged, # integer or None
65 'linenos': directives.unchanged,
66 'tab-width': directives.nonnegative_int}
67 has_content = True
68
69 def run(self):
70 """Run code block directive."""
71 self.assert_has_content()
72
73 if 'linenos' in self.options:
74 self.options['number-lines'] = self.options['linenos']
75 if 'tab-width' in self.options:
76 self.content = [x.replace('\t', ' ' * self.options['tab-width']) for x in self.content]
77
78 if self.arguments:
79 language = self.arguments[0]
80 else:
81 language = 'text'
82 set_classes(self.options)
83 classes = ['code']
84 if language:
85 classes.append(language)
86 if 'classes' in self.options:
87 classes.extend(self.options['classes'])
88
89 code = '\n'.join(self.content)
90
91 try:
92 lexer = get_lexer_by_name(language)
93 except pygments.util.ClassNotFound:
94 raise self.error('Cannot find pygments lexer for language "{0}"'.format(language))
95
96 if 'number-lines' in self.options:
97 linenos = 'table'
98 # optional argument `startline`, defaults to 1
99 try:
100 linenostart = int(self.options['number-lines'] or 1)
101 except ValueError:
102 raise self.error(':number-lines: with non-integer start value')
103 else:
104 linenos = False
105 linenostart = 1 # actually unused
106
107 if self.site.invariant: # for testing purposes
108 anchor_ref = 'rest_code_' + 'fixedvaluethatisnotauuid'
109 else:
110 anchor_ref = 'rest_code_' + uuid.uuid4().hex
111
112 formatter = utils.NikolaPygmentsHTML(anchor_ref=anchor_ref, classes=classes, linenos=linenos, linenostart=linenostart)
113 out = pygments.highlight(code, lexer, formatter)
114 node = nodes.raw('', out, format='html')
115
116 self.add_name(node)
117 # if called from "include", set the source
118 if 'source' in self.options:
119 node.attributes['source'] = self.options['source']
120
121 return [node]
122
123 # Monkey-patch: replace insane docutils CodeBlock with our implementation.
124 docutils.parsers.rst.directives.body.CodeBlock = CodeBlock
125 docutils.parsers.rst.directives.misc.CodeBlock = CodeBlock
126
127
128 class Plugin(RestExtension):
129
130 """Plugin for listing directive."""
131
132 name = "rest_listing"
133
134 def set_site(self, site):
135 """Set Nikola site."""
136 self.site = site
137 # Even though listings don't use CodeBlock anymore, I am
138 # leaving these to make the code directive work with
139 # docutils < 0.9
140 CodeBlock.site = site
141 directives.register_directive('code', CodeBlock)
142 directives.register_directive('code-block', CodeBlock)
143 directives.register_directive('sourcecode', CodeBlock)
144 directives.register_directive('listing', Listing)
145 Listing.folders = site.config['LISTINGS_FOLDERS']
146 return super(Plugin, self).set_site(site)
147
148
149 # Add sphinx compatibility option
150 listing_spec = Include.option_spec
151 listing_spec['linenos'] = directives.unchanged
152
153
154 class Listing(Include):
155
156 """Create a highlighted block of code from a file in listings/.
157
158 Usage:
159
160 .. listing:: nikola.py python
161 :number-lines:
162
163 """
164
165 has_content = False
166 required_arguments = 1
167 optional_arguments = 1
168 option_spec = listing_spec
169
170 def run(self):
171 """Run listing directive."""
172 _fname = self.arguments.pop(0)
173 fname = _fname.replace('/', os.sep)
174 lang = self.arguments.pop(0)
175 if len(self.folders) == 1:
176 listings_folder = next(iter(self.folders.keys()))
177 if fname.startswith(listings_folder):
178 fpath = os.path.join(fname) # new syntax: specify folder name
179 else:
180 fpath = os.path.join(listings_folder, fname) # old syntax: don't specify folder name
181 else:
182 fpath = os.path.join(fname) # must be new syntax: specify folder name
183 self.arguments.insert(0, fpath)
184 self.options['code'] = lang
185 if 'linenos' in self.options:
186 self.options['number-lines'] = self.options['linenos']
187 with io.open(fpath, 'r+', encoding='utf8') as fileobject:
188 self.content = fileobject.read().splitlines()
189 self.state.document.settings.record_dependencies.add(fpath)
190 target = urlunsplit(("link", 'listing', fpath.replace('\\', '/'), '', ''))
191 generated_nodes = (
192 [core.publish_doctree('`{0} <{1}>`_'.format(_fname, target))[0]])
193 generated_nodes += self.get_code_from_file(fileobject)
194 return generated_nodes
195
196 def get_code_from_file(self, data):
197 """Create CodeBlock nodes from file object content."""
198 return super(Listing, self).run()
199
200 def assert_has_content(self):
201 """Listing has no content, override check from superclass."""
202 pass
203
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py
--- a/nikola/plugins/compile/rest/listing.py
+++ b/nikola/plugins/compile/rest/listing.py
@@ -171,7 +171,12 @@
"""Run listing directive."""
_fname = self.arguments.pop(0)
fname = _fname.replace('/', os.sep)
- lang = self.arguments.pop(0)
+ try:
+ lang = self.arguments.pop(0)
+ self.options['code'] = lang
+ except IndexError:
+ self.options['literal'] = True
+
if len(self.folders) == 1:
listings_folder = next(iter(self.folders.keys()))
if fname.startswith(listings_folder):
@@ -181,7 +186,6 @@
else:
fpath = os.path.join(fname) # must be new syntax: specify folder name
self.arguments.insert(0, fpath)
- self.options['code'] = lang
if 'linenos' in self.options:
self.options['number-lines'] = self.options['linenos']
with io.open(fpath, 'r+', encoding='utf8') as fileobject:
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py\n--- a/nikola/plugins/compile/rest/listing.py\n+++ b/nikola/plugins/compile/rest/listing.py\n@@ -171,7 +171,12 @@\n \"\"\"Run listing directive.\"\"\"\n _fname = self.arguments.pop(0)\n fname = _fname.replace('/', os.sep)\n- lang = self.arguments.pop(0)\n+ try:\n+ lang = self.arguments.pop(0)\n+ self.options['code'] = lang\n+ except IndexError:\n+ self.options['literal'] = True\n+\n if len(self.folders) == 1:\n listings_folder = next(iter(self.folders.keys()))\n if fname.startswith(listings_folder):\n@@ -181,7 +186,6 @@\n else:\n fpath = os.path.join(fname) # must be new syntax: specify folder name\n self.arguments.insert(0, fpath)\n- self.options['code'] = lang\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n with io.open(fpath, 'r+', encoding='utf8') as fileobject:\n", "issue": "listing directive explodes badly if used wrong\nExample: \n\n```\n.. listing:: hello.py\n```\n\nWhich is a way too common first attempt to use it, crashes like this:\n\n```\nTaskError - taskid:render_posts:cache/posts/foo.html\nPythonAction Error\nTraceback (most recent call last):\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/doit/action.py\", line 383, in execute\n returned_value = self.py_callable(*self.args, **kwargs)\n File \"/home/ralsina/Desktop/proyectos/nikola/master/nikola/post.py\", line 485, in compile\n self.is_two_file),\n File \"/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py\", line 100, in compile_html\n output, error_level, deps = self.compile_html_string(data, source, is_two_file)\n File \"/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py\", line 86, in compile_html_string\n }, logger=self.logger, source_path=source_path, l_add_ln=add_ln, transforms=self.site.rst_transforms)\n File \"/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/__init__.py\", line 276, in rst2html\n pub.publish(enable_exit_status=enable_exit_status)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/core.py\", line 217, in publish\n self.settings)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/readers/__init__.py\", line 72, in read\n self.parse()\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/readers/__init__.py\", line 78, in parse\n self.parser.parse(self.input, document)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/__init__.py\", line 172, in parse\n self.statemachine.run(inputlines, document, inliner=self.inliner)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py\", line 170, in run\n input_source=document['source'])\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/statemachine.py\", line 239, in run\n context, state, transitions)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/statemachine.py\", line 460, in check_line\n return method(match, context, next_state)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py\", line 2299, in explicit_markup\n nodelist, blank_finish = self.explicit_construct(match)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py\", line 2311, in explicit_construct\n return method(self, expmatch)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py\", line 2054, in directive\n directive_class, match, type_name, option_presets)\n File \"/home/ralsina/.virtualenvs/nikola/local/lib/python2.7/site-packages/docutils-0.12-py2.7.egg/docutils/parsers/rst/states.py\", line 2103, in run_directive\n result = directive_instance.run()\n File \"/home/ralsina/Desktop/proyectos/nikola/master/nikola/plugins/compile/rest/listing.py\", line 174, in run\n lang = self.arguments.pop(0)\nIndexError: pop from empty list\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\"Define and register a listing directive using the existing CodeBlock.\"\"\"\n\n\nfrom __future__ import unicode_literals\nimport io\nimport os\nimport uuid\ntry:\n from urlparse import urlunsplit\nexcept ImportError:\n from urllib.parse import urlunsplit # NOQA\n\nimport docutils.parsers.rst.directives.body\nimport docutils.parsers.rst.directives.misc\nfrom docutils import core\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.parsers.rst.roles import set_classes\nfrom docutils.parsers.rst.directives.misc import Include\n\nfrom pygments.lexers import get_lexer_by_name\nimport pygments\nimport pygments.util\n\nfrom nikola import utils\nfrom nikola.plugin_categories import RestExtension\n\n\n# A sanitized version of docutils.parsers.rst.directives.body.CodeBlock.\nclass CodeBlock(Directive):\n\n \"\"\"Parse and mark up content of a code block.\"\"\"\n\n optional_arguments = 1\n option_spec = {'class': directives.class_option,\n 'name': directives.unchanged,\n 'number-lines': directives.unchanged, # integer or None\n 'linenos': directives.unchanged,\n 'tab-width': directives.nonnegative_int}\n has_content = True\n\n def run(self):\n \"\"\"Run code block directive.\"\"\"\n self.assert_has_content()\n\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n if 'tab-width' in self.options:\n self.content = [x.replace('\\t', ' ' * self.options['tab-width']) for x in self.content]\n\n if self.arguments:\n language = self.arguments[0]\n else:\n language = 'text'\n set_classes(self.options)\n classes = ['code']\n if language:\n classes.append(language)\n if 'classes' in self.options:\n classes.extend(self.options['classes'])\n\n code = '\\n'.join(self.content)\n\n try:\n lexer = get_lexer_by_name(language)\n except pygments.util.ClassNotFound:\n raise self.error('Cannot find pygments lexer for language \"{0}\"'.format(language))\n\n if 'number-lines' in self.options:\n linenos = 'table'\n # optional argument `startline`, defaults to 1\n try:\n linenostart = int(self.options['number-lines'] or 1)\n except ValueError:\n raise self.error(':number-lines: with non-integer start value')\n else:\n linenos = False\n linenostart = 1 # actually unused\n\n if self.site.invariant: # for testing purposes\n anchor_ref = 'rest_code_' + 'fixedvaluethatisnotauuid'\n else:\n anchor_ref = 'rest_code_' + uuid.uuid4().hex\n\n formatter = utils.NikolaPygmentsHTML(anchor_ref=anchor_ref, classes=classes, linenos=linenos, linenostart=linenostart)\n out = pygments.highlight(code, lexer, formatter)\n node = nodes.raw('', out, format='html')\n\n self.add_name(node)\n # if called from \"include\", set the source\n if 'source' in self.options:\n node.attributes['source'] = self.options['source']\n\n return [node]\n\n# Monkey-patch: replace insane docutils CodeBlock with our implementation.\ndocutils.parsers.rst.directives.body.CodeBlock = CodeBlock\ndocutils.parsers.rst.directives.misc.CodeBlock = CodeBlock\n\n\nclass Plugin(RestExtension):\n\n \"\"\"Plugin for listing directive.\"\"\"\n\n name = \"rest_listing\"\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n self.site = site\n # Even though listings don't use CodeBlock anymore, I am\n # leaving these to make the code directive work with\n # docutils < 0.9\n CodeBlock.site = site\n directives.register_directive('code', CodeBlock)\n directives.register_directive('code-block', CodeBlock)\n directives.register_directive('sourcecode', CodeBlock)\n directives.register_directive('listing', Listing)\n Listing.folders = site.config['LISTINGS_FOLDERS']\n return super(Plugin, self).set_site(site)\n\n\n# Add sphinx compatibility option\nlisting_spec = Include.option_spec\nlisting_spec['linenos'] = directives.unchanged\n\n\nclass Listing(Include):\n\n \"\"\"Create a highlighted block of code from a file in listings/.\n\n Usage:\n\n .. listing:: nikola.py python\n :number-lines:\n\n \"\"\"\n\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n option_spec = listing_spec\n\n def run(self):\n \"\"\"Run listing directive.\"\"\"\n _fname = self.arguments.pop(0)\n fname = _fname.replace('/', os.sep)\n lang = self.arguments.pop(0)\n if len(self.folders) == 1:\n listings_folder = next(iter(self.folders.keys()))\n if fname.startswith(listings_folder):\n fpath = os.path.join(fname) # new syntax: specify folder name\n else:\n fpath = os.path.join(listings_folder, fname) # old syntax: don't specify folder name\n else:\n fpath = os.path.join(fname) # must be new syntax: specify folder name\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n with io.open(fpath, 'r+', encoding='utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n target = urlunsplit((\"link\", 'listing', fpath.replace('\\\\', '/'), '', ''))\n generated_nodes = (\n [core.publish_doctree('`{0} <{1}>`_'.format(_fname, target))[0]])\n generated_nodes += self.get_code_from_file(fileobject)\n return generated_nodes\n\n def get_code_from_file(self, data):\n \"\"\"Create CodeBlock nodes from file object content.\"\"\"\n return super(Listing, self).run()\n\n def assert_has_content(self):\n \"\"\"Listing has no content, override check from superclass.\"\"\"\n pass\n", "path": "nikola/plugins/compile/rest/listing.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2015 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\"Define and register a listing directive using the existing CodeBlock.\"\"\"\n\n\nfrom __future__ import unicode_literals\nimport io\nimport os\nimport uuid\ntry:\n from urlparse import urlunsplit\nexcept ImportError:\n from urllib.parse import urlunsplit # NOQA\n\nimport docutils.parsers.rst.directives.body\nimport docutils.parsers.rst.directives.misc\nfrom docutils import core\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.parsers.rst.roles import set_classes\nfrom docutils.parsers.rst.directives.misc import Include\n\nfrom pygments.lexers import get_lexer_by_name\nimport pygments\nimport pygments.util\n\nfrom nikola import utils\nfrom nikola.plugin_categories import RestExtension\n\n\n# A sanitized version of docutils.parsers.rst.directives.body.CodeBlock.\nclass CodeBlock(Directive):\n\n \"\"\"Parse and mark up content of a code block.\"\"\"\n\n optional_arguments = 1\n option_spec = {'class': directives.class_option,\n 'name': directives.unchanged,\n 'number-lines': directives.unchanged, # integer or None\n 'linenos': directives.unchanged,\n 'tab-width': directives.nonnegative_int}\n has_content = True\n\n def run(self):\n \"\"\"Run code block directive.\"\"\"\n self.assert_has_content()\n\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n if 'tab-width' in self.options:\n self.content = [x.replace('\\t', ' ' * self.options['tab-width']) for x in self.content]\n\n if self.arguments:\n language = self.arguments[0]\n else:\n language = 'text'\n set_classes(self.options)\n classes = ['code']\n if language:\n classes.append(language)\n if 'classes' in self.options:\n classes.extend(self.options['classes'])\n\n code = '\\n'.join(self.content)\n\n try:\n lexer = get_lexer_by_name(language)\n except pygments.util.ClassNotFound:\n raise self.error('Cannot find pygments lexer for language \"{0}\"'.format(language))\n\n if 'number-lines' in self.options:\n linenos = 'table'\n # optional argument `startline`, defaults to 1\n try:\n linenostart = int(self.options['number-lines'] or 1)\n except ValueError:\n raise self.error(':number-lines: with non-integer start value')\n else:\n linenos = False\n linenostart = 1 # actually unused\n\n if self.site.invariant: # for testing purposes\n anchor_ref = 'rest_code_' + 'fixedvaluethatisnotauuid'\n else:\n anchor_ref = 'rest_code_' + uuid.uuid4().hex\n\n formatter = utils.NikolaPygmentsHTML(anchor_ref=anchor_ref, classes=classes, linenos=linenos, linenostart=linenostart)\n out = pygments.highlight(code, lexer, formatter)\n node = nodes.raw('', out, format='html')\n\n self.add_name(node)\n # if called from \"include\", set the source\n if 'source' in self.options:\n node.attributes['source'] = self.options['source']\n\n return [node]\n\n# Monkey-patch: replace insane docutils CodeBlock with our implementation.\ndocutils.parsers.rst.directives.body.CodeBlock = CodeBlock\ndocutils.parsers.rst.directives.misc.CodeBlock = CodeBlock\n\n\nclass Plugin(RestExtension):\n\n \"\"\"Plugin for listing directive.\"\"\"\n\n name = \"rest_listing\"\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n self.site = site\n # Even though listings don't use CodeBlock anymore, I am\n # leaving these to make the code directive work with\n # docutils < 0.9\n CodeBlock.site = site\n directives.register_directive('code', CodeBlock)\n directives.register_directive('code-block', CodeBlock)\n directives.register_directive('sourcecode', CodeBlock)\n directives.register_directive('listing', Listing)\n Listing.folders = site.config['LISTINGS_FOLDERS']\n return super(Plugin, self).set_site(site)\n\n\n# Add sphinx compatibility option\nlisting_spec = Include.option_spec\nlisting_spec['linenos'] = directives.unchanged\n\n\nclass Listing(Include):\n\n \"\"\"Create a highlighted block of code from a file in listings/.\n\n Usage:\n\n .. listing:: nikola.py python\n :number-lines:\n\n \"\"\"\n\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n option_spec = listing_spec\n\n def run(self):\n \"\"\"Run listing directive.\"\"\"\n _fname = self.arguments.pop(0)\n fname = _fname.replace('/', os.sep)\n try:\n lang = self.arguments.pop(0)\n self.options['code'] = lang\n except IndexError:\n self.options['literal'] = True\n\n if len(self.folders) == 1:\n listings_folder = next(iter(self.folders.keys()))\n if fname.startswith(listings_folder):\n fpath = os.path.join(fname) # new syntax: specify folder name\n else:\n fpath = os.path.join(listings_folder, fname) # old syntax: don't specify folder name\n else:\n fpath = os.path.join(fname) # must be new syntax: specify folder name\n self.arguments.insert(0, fpath)\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n with io.open(fpath, 'r+', encoding='utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n target = urlunsplit((\"link\", 'listing', fpath.replace('\\\\', '/'), '', ''))\n generated_nodes = (\n [core.publish_doctree('`{0} <{1}>`_'.format(_fname, target))[0]])\n generated_nodes += self.get_code_from_file(fileobject)\n return generated_nodes\n\n def get_code_from_file(self, data):\n \"\"\"Create CodeBlock nodes from file object content.\"\"\"\n return super(Listing, self).run()\n\n def assert_has_content(self):\n \"\"\"Listing has no content, override check from superclass.\"\"\"\n pass\n", "path": "nikola/plugins/compile/rest/listing.py"}]}
| 3,451 | 273 |
gh_patches_debug_30324
|
rasdani/github-patches
|
git_diff
|
ros__ros_comm-269
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
roslaunch does not accept a package name if a file with the same name exists in the current directory
Reproduce with:
```
roscreate-pkg roslaunch_test
cd roslaunch_test
mkdir bin
mkdir launch
touch bin/roslaunch_test
echo "<launch/>" > launch/example.launch
cd bin
roslaunch roslaunch_test example.launch
```
Error output:
```
Usage: roslaunch [options] [package] <filename> [arg_name:=value...]
roslaunch: error: The following input files do not exist: example.launch
```
Without the file in `bin/` or with another working directory roslaunch executes without errors (and exits immediately as there are no nodes).
I am using roslaunch 1.9.47 installed from the binary package repository in ROS hydro.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/roslaunch/src/roslaunch/rlutil.py`
Content:
```
1 # Software License Agreement (BSD License)
2 #
3 # Copyright (c) 2009, Willow Garage, Inc.
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions
8 # are met:
9 #
10 # * Redistributions of source code must retain the above copyright
11 # notice, this list of conditions and the following disclaimer.
12 # * Redistributions in binary form must reproduce the above
13 # copyright notice, this list of conditions and the following
14 # disclaimer in the documentation and/or other materials provided
15 # with the distribution.
16 # * Neither the name of Willow Garage, Inc. nor the names of its
17 # contributors may be used to endorse or promote products derived
18 # from this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
21 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
22 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
23 # FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
24 # COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
25 # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
26 # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
27 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
29 # LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
30 # ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
31 # POSSIBILITY OF SUCH DAMAGE.
32
33 """
34 Uncategorized utility routines for roslaunch.
35
36 This API should not be considered stable.
37 """
38
39 from __future__ import print_function
40
41 import os
42 import sys
43 import time
44
45 import roslib.packages
46
47 import rosclean
48 import rospkg
49 import rosgraph
50
51 import roslaunch.core
52 import roslaunch.config
53 import roslaunch.depends
54 from rosmaster import DEFAULT_MASTER_PORT
55
56 def check_log_disk_usage():
57 """
58 Check size of log directory. If high, print warning to user
59 """
60 try:
61 d = rospkg.get_log_dir()
62 roslaunch.core.printlog("Checking log directory for disk usage. This may take awhile.\nPress Ctrl-C to interrupt")
63 disk_usage = rosclean.get_disk_usage(d)
64 # warn if over a gig
65 if disk_usage > 1073741824:
66 roslaunch.core.printerrlog("WARNING: disk usage in log directory [%s] is over 1GB.\nIt's recommended that you use the 'rosclean' command."%d)
67 else:
68 roslaunch.core.printlog("Done checking log file disk usage. Usage is <1GB.")
69 except:
70 pass
71
72 def resolve_launch_arguments(args):
73 """
74 Resolve command-line args to roslaunch filenames.
75
76 :returns: resolved filenames, ``[str]``
77 """
78
79 # strip remapping args for processing
80 args = rosgraph.myargv(args)
81
82 # user can either specify:
83 # - filename + launch args
84 # - package + relative-filename + launch args
85 if not args:
86 return args
87 resolved_args = None
88 top = args[0]
89 if os.path.isfile(top):
90 resolved_args = [top] + args[1:]
91 elif len(args) == 1:
92 raise roslaunch.core.RLException("[%s] does not exist. please specify a package and launch file"%(top))
93 else:
94 try:
95 resolved = roslib.packages.find_resource(top, args[1])
96 if len(resolved) == 1:
97 resolved = resolved[0]
98 elif len(resolved) > 1:
99 raise roslaunch.core.RLException("multiple files named [%s] in package [%s]:%s\nPlease specify full path instead" % (args[1], top, ''.join(['\n- %s' % r for r in resolved])))
100 except rospkg.ResourceNotFound as e:
101 raise roslaunch.core.RLException("[%s] is not a package or launch file name"%top)
102 if not resolved:
103 raise roslaunch.core.RLException("cannot locate [%s] in package [%s]"%(args[1], top))
104 else:
105 resolved_args = [resolved] + args[2:]
106 return resolved_args
107
108 def _wait_for_master():
109 """
110 Block until ROS Master is online
111
112 :raise: :exc:`RuntimeError` If unexpected error occurs
113 """
114 m = roslaunch.core.Master() # get a handle to the default master
115 is_running = m.is_running()
116 if not is_running:
117 roslaunch.core.printlog("roscore/master is not yet running, will wait for it to start")
118 while not is_running:
119 time.sleep(0.1)
120 is_running = m.is_running()
121 if is_running:
122 roslaunch.core.printlog("master has started, initiating launch")
123 else:
124 raise RuntimeError("unknown error waiting for master to start")
125
126 _terminal_name = None
127
128 def _set_terminal(s):
129 import platform
130 if platform.system() in ['FreeBSD', 'Linux', 'Darwin', 'Unix']:
131 try:
132 print('\033]2;%s\007'%(s))
133 except:
134 pass
135
136 def update_terminal_name(ros_master_uri):
137 """
138 append master URI to the terminal name
139 """
140 if _terminal_name:
141 _set_terminal(_terminal_name + ' ' + ros_master_uri)
142
143 def change_terminal_name(args, is_core):
144 """
145 use echo (where available) to change the name of the terminal window
146 """
147 global _terminal_name
148 _terminal_name = 'roscore' if is_core else ','.join(args)
149 _set_terminal(_terminal_name)
150
151 def get_or_generate_uuid(options_runid, options_wait_for_master):
152 """
153 :param options_runid: run_id value from command-line or ``None``, ``str``
154 :param options_wait_for_master: the wait_for_master command
155 option. If this is True, it means that we must retrieve the
156 value from the parameter server and need to avoid any race
157 conditions with the roscore being initialized. ``bool``
158 """
159
160 # Three possible sources of the run_id:
161 #
162 # - if we're a child process, we get it from options_runid
163 # - if there's already a roscore running, read from the param server
164 # - generate one if we're running the roscore
165 if options_runid:
166 return options_runid
167
168 # #773: Generate a run_id to use if we launch a master
169 # process. If a master is already running, we'll get the
170 # run_id from it instead
171 param_server = rosgraph.Master('/roslaunch')
172 val = None
173 while val is None:
174 try:
175 val = param_server.getParam('/run_id')
176 except:
177 if not options_wait_for_master:
178 val = roslaunch.core.generate_run_id()
179 return val
180
181 def check_roslaunch(f):
182 """
183 Check roslaunch file for errors, returning error message if check fails. This routine
184 is mainly to support rostest's roslaunch_check.
185
186 :param f: roslaunch file name, ``str``
187 :returns: error message or ``None``
188 """
189 try:
190 rl_config = roslaunch.config.load_config_default([f], DEFAULT_MASTER_PORT, verbose=False)
191 except roslaunch.core.RLException as e:
192 return str(e)
193
194 errors = []
195 # check for missing deps
196 base_pkg, file_deps, missing = roslaunch.depends.roslaunch_deps([f])
197 for pkg, miss in missing.iteritems():
198 if miss:
199 errors.append("Missing manifest dependencies: %s/manifest.xml: %s"%(pkg, ', '.join(miss)))
200
201 # load all node defs
202 nodes = []
203 for filename, rldeps in file_deps.iteritems():
204 nodes.extend(rldeps.nodes)
205
206 # check for missing packages
207 rospack = rospkg.RosPack()
208 for pkg, node_type in nodes:
209 try:
210 rospack.get_path(pkg)
211 except:
212 errors.append("cannot find package [%s] for node [%s]"%(pkg, node_type))
213
214 # check for missing nodes
215 for pkg, node_type in nodes:
216 try:
217 if not roslib.packages.find_node(pkg, node_type):
218 errors.append("cannot find node [%s] in package [%s]"%(node_type, pkg))
219 except Exception as e:
220 errors.append("unable to find node [%s/%s]: %s"%(pkg, node_type, str(e)))
221
222 # Check for configuration errors, #2889
223 for err in rl_config.config_errors:
224 errors.append('ROSLaunch config error: %s' % err)
225
226 if errors:
227 return '\n'.join(errors)
228
229 def print_file_list(roslaunch_files):
230 """
231 :param roslaunch_files: list of launch files to load, ``str``
232
233 :returns: list of files involved in processing roslaunch_files, including the files themselves.
234 """
235 from roslaunch.config import load_config_default, get_roscore_filename
236 import roslaunch.xmlloader
237 try:
238 loader = roslaunch.xmlloader.XmlLoader(resolve_anon=True)
239 config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)
240 files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]
241 print('\n'.join(files))
242 except roslaunch.core.RLException as e:
243 print(str(e), file=sys.stderr)
244 sys.exit(1)
245
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/roslaunch/src/roslaunch/rlutil.py b/tools/roslaunch/src/roslaunch/rlutil.py
--- a/tools/roslaunch/src/roslaunch/rlutil.py
+++ b/tools/roslaunch/src/roslaunch/rlutil.py
@@ -85,24 +85,26 @@
if not args:
return args
resolved_args = None
- top = args[0]
- if os.path.isfile(top):
- resolved_args = [top] + args[1:]
- elif len(args) == 1:
- raise roslaunch.core.RLException("[%s] does not exist. please specify a package and launch file"%(top))
- else:
+
+ # try to resolve launch file in package first
+ if len(args) >= 2:
try:
- resolved = roslib.packages.find_resource(top, args[1])
+ resolved = roslib.packages.find_resource(args[0], args[1])
+ if len(resolved) > 1:
+ raise roslaunch.core.RLException("multiple files named [%s] in package [%s]:%s\nPlease specify full path instead" % (args[1], args[0], ''.join(['\n- %s' % r for r in resolved])))
if len(resolved) == 1:
- resolved = resolved[0]
- elif len(resolved) > 1:
- raise roslaunch.core.RLException("multiple files named [%s] in package [%s]:%s\nPlease specify full path instead" % (args[1], top, ''.join(['\n- %s' % r for r in resolved])))
- except rospkg.ResourceNotFound as e:
- raise roslaunch.core.RLException("[%s] is not a package or launch file name"%top)
- if not resolved:
- raise roslaunch.core.RLException("cannot locate [%s] in package [%s]"%(args[1], top))
+ resolved_args = [resolved[0]] + args[2:]
+ except rospkg.ResourceNotFound:
+ pass
+ # try to resolve launch file
+ if resolved_args is None and os.path.isfile(args[0]):
+ resolved_args = [args[0]] + args[1:]
+ # raise if unable to resolve
+ if resolved_args is None:
+ if len(args) >= 2:
+ raise roslaunch.core.RLException("[%s] is neither a launch file in package [%s] nor is [%s] a launch file name" % (args[1], args[0], args[0]))
else:
- resolved_args = [resolved] + args[2:]
+ raise roslaunch.core.RLException("[%s] is not a launch file name" % args[0])
return resolved_args
def _wait_for_master():
|
{"golden_diff": "diff --git a/tools/roslaunch/src/roslaunch/rlutil.py b/tools/roslaunch/src/roslaunch/rlutil.py\n--- a/tools/roslaunch/src/roslaunch/rlutil.py\n+++ b/tools/roslaunch/src/roslaunch/rlutil.py\n@@ -85,24 +85,26 @@\n if not args:\n return args\n resolved_args = None\n- top = args[0]\n- if os.path.isfile(top):\n- resolved_args = [top] + args[1:]\n- elif len(args) == 1:\n- raise roslaunch.core.RLException(\"[%s] does not exist. please specify a package and launch file\"%(top))\n- else:\n+\n+ # try to resolve launch file in package first\n+ if len(args) >= 2:\n try:\n- resolved = roslib.packages.find_resource(top, args[1])\n+ resolved = roslib.packages.find_resource(args[0], args[1])\n+ if len(resolved) > 1:\n+ raise roslaunch.core.RLException(\"multiple files named [%s] in package [%s]:%s\\nPlease specify full path instead\" % (args[1], args[0], ''.join(['\\n- %s' % r for r in resolved])))\n if len(resolved) == 1:\n- resolved = resolved[0]\n- elif len(resolved) > 1:\n- raise roslaunch.core.RLException(\"multiple files named [%s] in package [%s]:%s\\nPlease specify full path instead\" % (args[1], top, ''.join(['\\n- %s' % r for r in resolved])))\n- except rospkg.ResourceNotFound as e:\n- raise roslaunch.core.RLException(\"[%s] is not a package or launch file name\"%top)\n- if not resolved:\n- raise roslaunch.core.RLException(\"cannot locate [%s] in package [%s]\"%(args[1], top))\n+ resolved_args = [resolved[0]] + args[2:]\n+ except rospkg.ResourceNotFound:\n+ pass\n+ # try to resolve launch file\n+ if resolved_args is None and os.path.isfile(args[0]):\n+ resolved_args = [args[0]] + args[1:]\n+ # raise if unable to resolve\n+ if resolved_args is None:\n+ if len(args) >= 2:\n+ raise roslaunch.core.RLException(\"[%s] is neither a launch file in package [%s] nor is [%s] a launch file name\" % (args[1], args[0], args[0]))\n else:\n- resolved_args = [resolved] + args[2:]\n+ raise roslaunch.core.RLException(\"[%s] is not a launch file name\" % args[0])\n return resolved_args\n \n def _wait_for_master():\n", "issue": "roslaunch does not accept a package name if a file with the same name exists in the current directory\nReproduce with:\n\n```\nroscreate-pkg roslaunch_test\ncd roslaunch_test\nmkdir bin\nmkdir launch\ntouch bin/roslaunch_test\necho \"<launch/>\" > launch/example.launch\ncd bin\nroslaunch roslaunch_test example.launch\n```\n\nError output:\n\n```\nUsage: roslaunch [options] [package] <filename> [arg_name:=value...]\n\nroslaunch: error: The following input files do not exist: example.launch\n```\n\nWithout the file in `bin/` or with another working directory roslaunch executes without errors (and exits immediately as there are no nodes).\n\nI am using roslaunch 1.9.47 installed from the binary package repository in ROS hydro.\n\n", "before_files": [{"content": "# Software License Agreement (BSD License)\n#\n# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above\n# copyright notice, this list of conditions and the following\n# disclaimer in the documentation and/or other materials provided\n# with the distribution.\n# * Neither the name of Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS\n# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE\n# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN\n# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nUncategorized utility routines for roslaunch.\n\nThis API should not be considered stable.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport sys\nimport time\n\nimport roslib.packages\n\nimport rosclean\nimport rospkg\nimport rosgraph\n\nimport roslaunch.core\nimport roslaunch.config\nimport roslaunch.depends\nfrom rosmaster import DEFAULT_MASTER_PORT\n\ndef check_log_disk_usage():\n \"\"\"\n Check size of log directory. If high, print warning to user\n \"\"\"\n try:\n d = rospkg.get_log_dir()\n roslaunch.core.printlog(\"Checking log directory for disk usage. This may take awhile.\\nPress Ctrl-C to interrupt\") \n disk_usage = rosclean.get_disk_usage(d)\n # warn if over a gig\n if disk_usage > 1073741824:\n roslaunch.core.printerrlog(\"WARNING: disk usage in log directory [%s] is over 1GB.\\nIt's recommended that you use the 'rosclean' command.\"%d)\n else:\n roslaunch.core.printlog(\"Done checking log file disk usage. Usage is <1GB.\") \n except:\n pass\n\ndef resolve_launch_arguments(args):\n \"\"\"\n Resolve command-line args to roslaunch filenames.\n\n :returns: resolved filenames, ``[str]``\n \"\"\"\n\n # strip remapping args for processing\n args = rosgraph.myargv(args)\n \n # user can either specify:\n # - filename + launch args\n # - package + relative-filename + launch args\n if not args:\n return args\n resolved_args = None\n top = args[0]\n if os.path.isfile(top):\n resolved_args = [top] + args[1:]\n elif len(args) == 1:\n raise roslaunch.core.RLException(\"[%s] does not exist. please specify a package and launch file\"%(top))\n else:\n try:\n resolved = roslib.packages.find_resource(top, args[1])\n if len(resolved) == 1:\n resolved = resolved[0]\n elif len(resolved) > 1:\n raise roslaunch.core.RLException(\"multiple files named [%s] in package [%s]:%s\\nPlease specify full path instead\" % (args[1], top, ''.join(['\\n- %s' % r for r in resolved])))\n except rospkg.ResourceNotFound as e:\n raise roslaunch.core.RLException(\"[%s] is not a package or launch file name\"%top)\n if not resolved:\n raise roslaunch.core.RLException(\"cannot locate [%s] in package [%s]\"%(args[1], top))\n else:\n resolved_args = [resolved] + args[2:]\n return resolved_args\n\ndef _wait_for_master():\n \"\"\"\n Block until ROS Master is online\n \n :raise: :exc:`RuntimeError` If unexpected error occurs\n \"\"\"\n m = roslaunch.core.Master() # get a handle to the default master\n is_running = m.is_running()\n if not is_running:\n roslaunch.core.printlog(\"roscore/master is not yet running, will wait for it to start\")\n while not is_running:\n time.sleep(0.1)\n is_running = m.is_running()\n if is_running:\n roslaunch.core.printlog(\"master has started, initiating launch\")\n else:\n raise RuntimeError(\"unknown error waiting for master to start\")\n\n_terminal_name = None\n\ndef _set_terminal(s):\n import platform\n if platform.system() in ['FreeBSD', 'Linux', 'Darwin', 'Unix']:\n try:\n print('\\033]2;%s\\007'%(s))\n except:\n pass\n \ndef update_terminal_name(ros_master_uri):\n \"\"\"\n append master URI to the terminal name\n \"\"\"\n if _terminal_name:\n _set_terminal(_terminal_name + ' ' + ros_master_uri)\n\ndef change_terminal_name(args, is_core):\n \"\"\"\n use echo (where available) to change the name of the terminal window\n \"\"\"\n global _terminal_name\n _terminal_name = 'roscore' if is_core else ','.join(args)\n _set_terminal(_terminal_name)\n\ndef get_or_generate_uuid(options_runid, options_wait_for_master):\n \"\"\"\n :param options_runid: run_id value from command-line or ``None``, ``str``\n :param options_wait_for_master: the wait_for_master command\n option. If this is True, it means that we must retrieve the\n value from the parameter server and need to avoid any race\n conditions with the roscore being initialized. ``bool``\n \"\"\"\n\n # Three possible sources of the run_id:\n #\n # - if we're a child process, we get it from options_runid\n # - if there's already a roscore running, read from the param server\n # - generate one if we're running the roscore\n if options_runid:\n return options_runid\n\n # #773: Generate a run_id to use if we launch a master\n # process. If a master is already running, we'll get the\n # run_id from it instead\n param_server = rosgraph.Master('/roslaunch')\n val = None\n while val is None:\n try:\n val = param_server.getParam('/run_id')\n except:\n if not options_wait_for_master:\n val = roslaunch.core.generate_run_id()\n return val\n \ndef check_roslaunch(f):\n \"\"\"\n Check roslaunch file for errors, returning error message if check fails. This routine\n is mainly to support rostest's roslaunch_check.\n\n :param f: roslaunch file name, ``str``\n :returns: error message or ``None``\n \"\"\"\n try:\n rl_config = roslaunch.config.load_config_default([f], DEFAULT_MASTER_PORT, verbose=False)\n except roslaunch.core.RLException as e:\n return str(e)\n \n errors = []\n # check for missing deps\n base_pkg, file_deps, missing = roslaunch.depends.roslaunch_deps([f])\n for pkg, miss in missing.iteritems():\n if miss:\n errors.append(\"Missing manifest dependencies: %s/manifest.xml: %s\"%(pkg, ', '.join(miss)))\n \n # load all node defs\n nodes = []\n for filename, rldeps in file_deps.iteritems():\n nodes.extend(rldeps.nodes)\n\n # check for missing packages\n rospack = rospkg.RosPack()\n for pkg, node_type in nodes:\n try:\n rospack.get_path(pkg)\n except:\n errors.append(\"cannot find package [%s] for node [%s]\"%(pkg, node_type))\n\n # check for missing nodes\n for pkg, node_type in nodes:\n try:\n if not roslib.packages.find_node(pkg, node_type):\n errors.append(\"cannot find node [%s] in package [%s]\"%(node_type, pkg))\n except Exception as e:\n errors.append(\"unable to find node [%s/%s]: %s\"%(pkg, node_type, str(e)))\n \n # Check for configuration errors, #2889\n for err in rl_config.config_errors:\n errors.append('ROSLaunch config error: %s' % err)\n\n if errors:\n return '\\n'.join(errors)\n \ndef print_file_list(roslaunch_files):\n \"\"\"\n :param roslaunch_files: list of launch files to load, ``str``\n\n :returns: list of files involved in processing roslaunch_files, including the files themselves.\n \"\"\"\n from roslaunch.config import load_config_default, get_roscore_filename\n import roslaunch.xmlloader\n try:\n loader = roslaunch.xmlloader.XmlLoader(resolve_anon=True)\n config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)\n files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]\n print('\\n'.join(files))\n except roslaunch.core.RLException as e:\n print(str(e), file=sys.stderr)\n sys.exit(1)\n\n", "path": "tools/roslaunch/src/roslaunch/rlutil.py"}], "after_files": [{"content": "# Software License Agreement (BSD License)\n#\n# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above\n# copyright notice, this list of conditions and the following\n# disclaimer in the documentation and/or other materials provided\n# with the distribution.\n# * Neither the name of Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS\n# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE\n# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN\n# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nUncategorized utility routines for roslaunch.\n\nThis API should not be considered stable.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport sys\nimport time\n\nimport roslib.packages\n\nimport rosclean\nimport rospkg\nimport rosgraph\n\nimport roslaunch.core\nimport roslaunch.config\nimport roslaunch.depends\nfrom rosmaster import DEFAULT_MASTER_PORT\n\ndef check_log_disk_usage():\n \"\"\"\n Check size of log directory. If high, print warning to user\n \"\"\"\n try:\n d = rospkg.get_log_dir()\n roslaunch.core.printlog(\"Checking log directory for disk usage. This may take awhile.\\nPress Ctrl-C to interrupt\") \n disk_usage = rosclean.get_disk_usage(d)\n # warn if over a gig\n if disk_usage > 1073741824:\n roslaunch.core.printerrlog(\"WARNING: disk usage in log directory [%s] is over 1GB.\\nIt's recommended that you use the 'rosclean' command.\"%d)\n else:\n roslaunch.core.printlog(\"Done checking log file disk usage. Usage is <1GB.\") \n except:\n pass\n\ndef resolve_launch_arguments(args):\n \"\"\"\n Resolve command-line args to roslaunch filenames.\n\n :returns: resolved filenames, ``[str]``\n \"\"\"\n\n # strip remapping args for processing\n args = rosgraph.myargv(args)\n \n # user can either specify:\n # - filename + launch args\n # - package + relative-filename + launch args\n if not args:\n return args\n resolved_args = None\n\n # try to resolve launch file in package first\n if len(args) >= 2:\n try:\n resolved = roslib.packages.find_resource(args[0], args[1])\n if len(resolved) > 1:\n raise roslaunch.core.RLException(\"multiple files named [%s] in package [%s]:%s\\nPlease specify full path instead\" % (args[1], args[0], ''.join(['\\n- %s' % r for r in resolved])))\n if len(resolved) == 1:\n resolved_args = [resolved[0]] + args[2:]\n except rospkg.ResourceNotFound:\n pass\n # try to resolve launch file\n if resolved_args is None and os.path.isfile(args[0]):\n resolved_args = [args[0]] + args[1:]\n # raise if unable to resolve\n if resolved_args is None:\n if len(args) >= 2:\n raise roslaunch.core.RLException(\"[%s] is neither a launch file in package [%s] nor is [%s] a launch file name\" % (args[1], args[0], args[0]))\n else:\n raise roslaunch.core.RLException(\"[%s] is not a launch file name\" % args[0])\n return resolved_args\n\ndef _wait_for_master():\n \"\"\"\n Block until ROS Master is online\n \n :raise: :exc:`RuntimeError` If unexpected error occurs\n \"\"\"\n m = roslaunch.core.Master() # get a handle to the default master\n is_running = m.is_running()\n if not is_running:\n roslaunch.core.printlog(\"roscore/master is not yet running, will wait for it to start\")\n while not is_running:\n time.sleep(0.1)\n is_running = m.is_running()\n if is_running:\n roslaunch.core.printlog(\"master has started, initiating launch\")\n else:\n raise RuntimeError(\"unknown error waiting for master to start\")\n\n_terminal_name = None\n\ndef _set_terminal(s):\n import platform\n if platform.system() in ['FreeBSD', 'Linux', 'Darwin', 'Unix']:\n try:\n print('\\033]2;%s\\007'%(s))\n except:\n pass\n \ndef update_terminal_name(ros_master_uri):\n \"\"\"\n append master URI to the terminal name\n \"\"\"\n if _terminal_name:\n _set_terminal(_terminal_name + ' ' + ros_master_uri)\n\ndef change_terminal_name(args, is_core):\n \"\"\"\n use echo (where available) to change the name of the terminal window\n \"\"\"\n global _terminal_name\n _terminal_name = 'roscore' if is_core else ','.join(args)\n _set_terminal(_terminal_name)\n\ndef get_or_generate_uuid(options_runid, options_wait_for_master):\n \"\"\"\n :param options_runid: run_id value from command-line or ``None``, ``str``\n :param options_wait_for_master: the wait_for_master command\n option. If this is True, it means that we must retrieve the\n value from the parameter server and need to avoid any race\n conditions with the roscore being initialized. ``bool``\n \"\"\"\n\n # Three possible sources of the run_id:\n #\n # - if we're a child process, we get it from options_runid\n # - if there's already a roscore running, read from the param server\n # - generate one if we're running the roscore\n if options_runid:\n return options_runid\n\n # #773: Generate a run_id to use if we launch a master\n # process. If a master is already running, we'll get the\n # run_id from it instead\n param_server = rosgraph.Master('/roslaunch')\n val = None\n while val is None:\n try:\n val = param_server.getParam('/run_id')\n except:\n if not options_wait_for_master:\n val = roslaunch.core.generate_run_id()\n return val\n \ndef check_roslaunch(f):\n \"\"\"\n Check roslaunch file for errors, returning error message if check fails. This routine\n is mainly to support rostest's roslaunch_check.\n\n :param f: roslaunch file name, ``str``\n :returns: error message or ``None``\n \"\"\"\n try:\n rl_config = roslaunch.config.load_config_default([f], DEFAULT_MASTER_PORT, verbose=False)\n except roslaunch.core.RLException as e:\n return str(e)\n \n errors = []\n # check for missing deps\n base_pkg, file_deps, missing = roslaunch.depends.roslaunch_deps([f])\n for pkg, miss in missing.iteritems():\n if miss:\n errors.append(\"Missing manifest dependencies: %s/manifest.xml: %s\"%(pkg, ', '.join(miss)))\n \n # load all node defs\n nodes = []\n for filename, rldeps in file_deps.iteritems():\n nodes.extend(rldeps.nodes)\n\n # check for missing packages\n rospack = rospkg.RosPack()\n for pkg, node_type in nodes:\n try:\n rospack.get_path(pkg)\n except:\n errors.append(\"cannot find package [%s] for node [%s]\"%(pkg, node_type))\n\n # check for missing nodes\n for pkg, node_type in nodes:\n try:\n if not roslib.packages.find_node(pkg, node_type):\n errors.append(\"cannot find node [%s] in package [%s]\"%(node_type, pkg))\n except Exception as e:\n errors.append(\"unable to find node [%s/%s]: %s\"%(pkg, node_type, str(e)))\n \n # Check for configuration errors, #2889\n for err in rl_config.config_errors:\n errors.append('ROSLaunch config error: %s' % err)\n\n if errors:\n return '\\n'.join(errors)\n \ndef print_file_list(roslaunch_files):\n \"\"\"\n :param roslaunch_files: list of launch files to load, ``str``\n\n :returns: list of files involved in processing roslaunch_files, including the files themselves.\n \"\"\"\n from roslaunch.config import load_config_default, get_roscore_filename\n import roslaunch.xmlloader\n try:\n loader = roslaunch.xmlloader.XmlLoader(resolve_anon=True)\n config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)\n files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]\n print('\\n'.join(files))\n except roslaunch.core.RLException as e:\n print(str(e), file=sys.stderr)\n sys.exit(1)\n\n", "path": "tools/roslaunch/src/roslaunch/rlutil.py"}]}
| 3,218 | 641 |
gh_patches_debug_41028
|
rasdani/github-patches
|
git_diff
|
plotly__dash-1932
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove `webdriver-manager` from `dash[testing]` requirements
This was added in #1801 but wasn't really clear why it was needed, and it reaches out to the internet during its installation (even if installed from a local PyPI mirror) which causes problems for some users.
[BUG] Dash DataTable style_header text_alignment breaks between Dash v2.0.0 and v2.1.0
Production environment is under a customer container hosting environment that hosts docker container in a large corporate environment. Docker container is setup with rhel 7 (Redhat) with an Apache 2.4 web server. Python 3.6 is the version of python using pip as the installation for packages.
- replace the result of `pip list | grep dash` below
```
dash 2.1.0
dash-bootstrap-components 1.0.2
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-renderer 1.9.1
dash-table 5.0.0
```
- if frontend related, tell us your Browser, Version and OS
- OS: MacOS Monterey version 12.2
- Browser Chrome
- Version 98.0.4758.80
**Describe the bug**
When using 'text-align': 'center' in the style_header directive within the dash_table.DataTable, under Dash 2.1.0, the headings for the table are not centered, rather they are right aligned, regardless of the setting of the 'text-align' value. In fact, directly editing the text-align within Chrome's developer tool will not change the alignment. Changing other attributes (font, color, etc... will work).
**Expected behavior**
I would expect that when 'text-align': 'center' is specified for the style_header directive within dash_table.DataTable that the headings for the columns specified would be centered above the column.
**Screenshots**

**Additional Information**
I've been able to workaround this issue by reverting to Dash 2.0.0 in my production build, but I have not been able to build a similar working environment, neither in pip nor conda. My production version is working. I only reverted to Dash 2.0.0 since it was a very recent release, and then the behavior of the dash_table.DataTable worked correctly. It was the only change I made to the Docker build. Now, regardless of whether I use Dash 2.0.0 or Dash 2.1.0, I'm seeing the persistent right alignment of headers in my DataTables.
I do not know if it will help, but here is an example of code that I saw work under Dash 2.0.0, and then fail once I upgraded to Dash 2.1.0:
```
import pandas as pd
from dash import dcc
# import dash_core_components as dcc
from dash import html
# import dash_html_components as html
import dash_bootstrap_components as dbc
from dash.dependencies import Input, Output
import plotly.express as px
import time
import random
app = dash.Dash(__name__)
def get_rand_data():
mylist=[random.randint(1,6) for _ in range(6)]
return mylist
def build_data(mylist):
df = pd.DataFrame({
"Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"],
"Amount": mylist,
"City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"]
})
dcc.Store(id='new_data', data=df.to_json())
return df
def draw_graph(df):
fig = px.bar(df, x="Fruit", y="Amount", color="City", barmode="group")
return fig
def get_table():
data_table = dash_table.DataTable(
columns=[
{"name": ["", "Year"], "id": "year"},
{"name": ["City", "Montreal"], "id": "montreal"},
{"name": ["City", "Toronto"], "id": "toronto"},
{"name": ["City", "Ottawa"], "id": "ottawa"},
{"name": ["City", "Vancouver"], "id": "vancouver"},
{"name": ["Climate", "Temperature"], "id": "temp"},
{"name": ["Climate", "Humidity"], "id": "humidity"},
],
data=[
{
"year": i,
"montreal": i * 10,
"toronto": i * 100,
"ottawa": i * -1,
"vancouver": i * -10,
"temp": i * -100,
"humidity": i * 5,
}
for i in range(10)
],
style_header={
'text-align': 'center',
},
merge_duplicate_headers=True,
)
return data_table
mylist=get_rand_data()
df = build_data(mylist)
fig = draw_graph(df)
data_table = get_table()
refresh_button = dbc.Button('Refresh Data', color="info", className="me-1", id='refresh_button_lmd')
app.layout = html.Div(children=[
html.H1(children='Hello Dash'),
refresh_button,
html.Div(children=[
data_table
]),
dcc.Store(id='new_data'),
dcc.Loading(
id='loading-data',
children=[
html.Div(children=[
dcc.Graph(
id='example-graph',
figure=fig
)
]
)
],
type='circle',
),
])
@app.callback(Output("example-graph", "figure"),
Input("new_data", "data"))
def on_data(data):
df = pd.read_json(data)
time.sleep(5)
fig = draw_graph(df)
return fig
@app.callback(Output('new_data', 'data'),
Input('refresh_button_lmd', 'n_clicks'))
def new_data(n_clicks):
if n_clicks is None:
print("Override Startup")
mylist = get_rand_data()
df = build_data(mylist)
data = df.to_json()
else:
print(f'Button was clicked, this is {n_clicks} times.')
mylist = get_rand_data()
df = build_data(mylist)
data=df.to_json()
return data
if __name__ == '__main__':
app.run_server(debug=True)
```
I suspect that perhaps an upgrade supporting the move to Dash 2.1.0 might be the issue, and that now that I've moved my base install, I do not know what library is causing this. Any help would be appreciated. I would like to remove the constraint of staying at Dash 2.0.0 as I saw faster response times with Dash 2.1.0. Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dash/development/update_components.py`
Content:
```
1 import sys
2 import subprocess
3 import shlex
4 import os
5 import argparse
6 import shutil
7 import logging
8 import coloredlogs
9
10
11 class _CombinedFormatter(
12 argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter
13 ):
14 pass
15
16
17 logger = logging.getLogger(__name__)
18 coloredlogs.install(
19 fmt="%(asctime)s,%(msecs)03d %(levelname)s - %(message)s", datefmt="%H:%M:%S"
20 )
21
22
23 def booststrap_components(components_source):
24
25 is_windows = sys.platform == "win32"
26
27 source_glob = (
28 components_source
29 if components_source != "all"
30 else "dash-core-components|dash-html-components|dash-table"
31 )
32
33 cmd = shlex.split(
34 "npx lerna exec --scope *@({})* -- npm i".format(source_glob),
35 posix=not is_windows,
36 )
37
38 with subprocess.Popen(
39 cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows
40 ) as proc:
41 out, err = proc.communicate()
42 status = proc.poll()
43
44 if err:
45 print(err.decode(), file=sys.stderr)
46
47 if status == 0:
48 print(
49 "🟢 Finished installing npm dependencies for the following component packages: {} (status={}) 🟢".format(
50 source_glob, status
51 ),
52 file=sys.stderr,
53 )
54 if not out:
55 print(
56 "Failed installing npm dependencies for the following component packages {} (status={})".format(
57 source_glob, status
58 ),
59 file=sys.stderr,
60 )
61
62
63 def build_components(components_source):
64
65 is_windows = sys.platform == "win32"
66
67 source_glob = (
68 components_source
69 if components_source != "all"
70 else "dash-core-components|dash-html-components|dash-table"
71 )
72
73 cmd = shlex.split(
74 "npx lerna exec --scope *@({})* -- npm run build".format(source_glob),
75 posix=not is_windows,
76 )
77
78 with subprocess.Popen(
79 cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows
80 ) as proc:
81 out, err = proc.communicate()
82 status = proc.poll()
83
84 if err:
85 print(err.decode(), file=sys.stderr)
86
87 if not out:
88 print(
89 "🟢 Finished updating the following component packages {} (status={}) 🟢".format(
90 source_glob, status
91 ),
92 file=sys.stderr,
93 )
94 sys.exit(1)
95
96 for package in source_glob.split("|"):
97 build_directory = os.path.join(
98 "components", package, package.replace("-", "_").rstrip("/\\")
99 )
100
101 dest_dir = (
102 "dcc"
103 if package == "dash-core-components"
104 else "html"
105 if package == "dash-html-components"
106 else "dash_table"
107 )
108
109 dest_path = os.path.join("dash", dest_dir)
110
111 if not os.path.exists(dest_path):
112 try:
113 os.makedirs(dest_path)
114 except OSError:
115 logger.exception("🚨 Having issues manipulating %s", dest_path)
116 sys.exit(1)
117
118 if not os.path.exists(build_directory):
119 print(
120 "Could not locate build artifacts. Check that the npm build process completed successfully for the given package: {}".format(
121 package
122 )
123 )
124 else:
125 print("🚚 Moving build artifacts from " + build_directory + " to Dash 🚚")
126 shutil.rmtree(dest_path)
127 shutil.copytree(build_directory, dest_path)
128 with open(os.path.join(dest_path, ".gitkeep"), "w"):
129 pass
130 print(
131 "🟢 Finished moving build artifacts from "
132 + build_directory
133 + " to Dash 🟢"
134 )
135
136
137 def cli():
138 parser = argparse.ArgumentParser(
139 prog="dash-update-components",
140 formatter_class=_CombinedFormatter,
141 description="Update the specified subcomponent libraries within Dash"
142 " by copying over build artifacts, dependencies, and dependency metadata.",
143 )
144 parser.add_argument(
145 "components_source",
146 help="A glob string that matches the Dash component libraries to be updated (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all'). The default argument is 'all'.",
147 default="all",
148 )
149
150 args = parser.parse_args()
151
152 booststrap_components(args.components_source)
153 build_components(args.components_source)
154
155
156 cli()
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dash/development/update_components.py b/dash/development/update_components.py
--- a/dash/development/update_components.py
+++ b/dash/development/update_components.py
@@ -42,20 +42,17 @@
status = proc.poll()
if err:
- print(err.decode(), file=sys.stderr)
+ print(("🛑 " if status else "") + err.decode(), file=sys.stderr)
- if status == 0:
+ if status or not out:
print(
- "🟢 Finished installing npm dependencies for the following component packages: {} (status={}) 🟢".format(
- source_glob, status
- ),
+ "🚨 Failed installing npm dependencies for component packages: {source_glob} (status={status}) 🚨",
file=sys.stderr,
)
- if not out:
+ sys.exit(1)
+ else:
print(
- "Failed installing npm dependencies for the following component packages {} (status={})".format(
- source_glob, status
- ),
+ f"🟢 Finished installing npm dependencies for component packages: {source_glob} 🟢",
file=sys.stderr,
)
@@ -82,13 +79,11 @@
status = proc.poll()
if err:
- print(err.decode(), file=sys.stderr)
+ print(("🛑 " if status else "") + err.decode(), file=sys.stderr)
- if not out:
+ if status or not out:
print(
- "🟢 Finished updating the following component packages {} (status={}) 🟢".format(
- source_glob, status
- ),
+ f"🚨 Finished updating component packages: {source_glob} (status={status}) 🚨",
file=sys.stderr,
)
sys.exit(1)
@@ -117,21 +112,18 @@
if not os.path.exists(build_directory):
print(
- "Could not locate build artifacts. Check that the npm build process completed successfully for the given package: {}".format(
- package
- )
+ "🚨 Could not locate build artifacts."
+ + " Check that the npm build process completed"
+ + f" successfully for package: {package} 🚨"
)
+ sys.exit(1)
else:
- print("🚚 Moving build artifacts from " + build_directory + " to Dash 🚚")
+ print(f"🚚 Moving build artifacts from {build_directory} to Dash 🚚")
shutil.rmtree(dest_path)
shutil.copytree(build_directory, dest_path)
with open(os.path.join(dest_path, ".gitkeep"), "w"):
pass
- print(
- "🟢 Finished moving build artifacts from "
- + build_directory
- + " to Dash 🟢"
- )
+ print(f"🟢 Finished moving build artifacts from {build_directory} to Dash 🟢")
def cli():
@@ -143,7 +135,9 @@
)
parser.add_argument(
"components_source",
- help="A glob string that matches the Dash component libraries to be updated (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all'). The default argument is 'all'.",
+ help="A glob string that matches the Dash component libraries to be updated"
+ " (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all')."
+ " The default argument is 'all'.",
default="all",
)
@@ -153,4 +147,5 @@
build_components(args.components_source)
-cli()
+if __name__ == "__main__":
+ cli()
|
{"golden_diff": "diff --git a/dash/development/update_components.py b/dash/development/update_components.py\n--- a/dash/development/update_components.py\n+++ b/dash/development/update_components.py\n@@ -42,20 +42,17 @@\n status = proc.poll()\n \n if err:\n- print(err.decode(), file=sys.stderr)\n+ print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n \n- if status == 0:\n+ if status or not out:\n print(\n- \"\ud83d\udfe2 Finished installing npm dependencies for the following component packages: {} (status={}) \ud83d\udfe2\".format(\n- source_glob, status\n- ),\n+ \"\ud83d\udea8 Failed installing npm dependencies for component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n- if not out:\n+ sys.exit(1)\n+ else:\n print(\n- \"Failed installing npm dependencies for the following component packages {} (status={})\".format(\n- source_glob, status\n- ),\n+ f\"\ud83d\udfe2 Finished installing npm dependencies for component packages: {source_glob} \ud83d\udfe2\",\n file=sys.stderr,\n )\n \n@@ -82,13 +79,11 @@\n status = proc.poll()\n \n if err:\n- print(err.decode(), file=sys.stderr)\n+ print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n \n- if not out:\n+ if status or not out:\n print(\n- \"\ud83d\udfe2 Finished updating the following component packages {} (status={}) \ud83d\udfe2\".format(\n- source_glob, status\n- ),\n+ f\"\ud83d\udea8 Finished updating component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n@@ -117,21 +112,18 @@\n \n if not os.path.exists(build_directory):\n print(\n- \"Could not locate build artifacts. Check that the npm build process completed successfully for the given package: {}\".format(\n- package\n- )\n+ \"\ud83d\udea8 Could not locate build artifacts.\"\n+ + \" Check that the npm build process completed\"\n+ + f\" successfully for package: {package} \ud83d\udea8\"\n )\n+ sys.exit(1)\n else:\n- print(\"\ud83d\ude9a Moving build artifacts from \" + build_directory + \" to Dash \ud83d\ude9a\")\n+ print(f\"\ud83d\ude9a Moving build artifacts from {build_directory} to Dash \ud83d\ude9a\")\n shutil.rmtree(dest_path)\n shutil.copytree(build_directory, dest_path)\n with open(os.path.join(dest_path, \".gitkeep\"), \"w\"):\n pass\n- print(\n- \"\ud83d\udfe2 Finished moving build artifacts from \"\n- + build_directory\n- + \" to Dash \ud83d\udfe2\"\n- )\n+ print(f\"\ud83d\udfe2 Finished moving build artifacts from {build_directory} to Dash \ud83d\udfe2\")\n \n \n def cli():\n@@ -143,7 +135,9 @@\n )\n parser.add_argument(\n \"components_source\",\n- help=\"A glob string that matches the Dash component libraries to be updated (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all'). The default argument is 'all'.\",\n+ help=\"A glob string that matches the Dash component libraries to be updated\"\n+ \" (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all').\"\n+ \" The default argument is 'all'.\",\n default=\"all\",\n )\n \n@@ -153,4 +147,5 @@\n build_components(args.components_source)\n \n \n-cli()\n+if __name__ == \"__main__\":\n+ cli()\n", "issue": "Remove `webdriver-manager` from `dash[testing]` requirements\nThis was added in #1801 but wasn't really clear why it was needed, and it reaches out to the internet during its installation (even if installed from a local PyPI mirror) which causes problems for some users.\n[BUG] Dash DataTable style_header text_alignment breaks between Dash v2.0.0 and v2.1.0\nProduction environment is under a customer container hosting environment that hosts docker container in a large corporate environment. Docker container is setup with rhel 7 (Redhat) with an Apache 2.4 web server. Python 3.6 is the version of python using pip as the installation for packages.\r\n\r\n- replace the result of `pip list | grep dash` below\r\n```\r\ndash 2.1.0 \r\ndash-bootstrap-components 1.0.2 \r\ndash-core-components 2.0.0 \r\ndash-html-components 2.0.0 \r\ndash-renderer 1.9.1 \r\ndash-table 5.0.0\r\n```\r\n\r\n- if frontend related, tell us your Browser, Version and OS\r\n\r\n - OS: MacOS Monterey version 12.2\r\n - Browser Chrome\r\n - Version 98.0.4758.80\r\n\r\n**Describe the bug**\r\n\r\nWhen using 'text-align': 'center' in the style_header directive within the dash_table.DataTable, under Dash 2.1.0, the headings for the table are not centered, rather they are right aligned, regardless of the setting of the 'text-align' value. In fact, directly editing the text-align within Chrome's developer tool will not change the alignment. Changing other attributes (font, color, etc... will work). \r\n\r\n**Expected behavior**\r\n\r\nI would expect that when 'text-align': 'center' is specified for the style_header directive within dash_table.DataTable that the headings for the columns specified would be centered above the column.\r\n\r\n**Screenshots**\r\n\r\n\r\n\r\n**Additional Information**\r\nI've been able to workaround this issue by reverting to Dash 2.0.0 in my production build, but I have not been able to build a similar working environment, neither in pip nor conda. My production version is working. I only reverted to Dash 2.0.0 since it was a very recent release, and then the behavior of the dash_table.DataTable worked correctly. It was the only change I made to the Docker build. Now, regardless of whether I use Dash 2.0.0 or Dash 2.1.0, I'm seeing the persistent right alignment of headers in my DataTables. \r\n\r\nI do not know if it will help, but here is an example of code that I saw work under Dash 2.0.0, and then fail once I upgraded to Dash 2.1.0:\r\n```\r\nimport pandas as pd\r\nfrom dash import dcc\r\n# import dash_core_components as dcc\r\nfrom dash import html\r\n# import dash_html_components as html\r\nimport dash_bootstrap_components as dbc\r\nfrom dash.dependencies import Input, Output\r\nimport plotly.express as px\r\nimport time\r\nimport random\r\n\r\napp = dash.Dash(__name__)\r\n\r\ndef get_rand_data():\r\n mylist=[random.randint(1,6) for _ in range(6)]\r\n return mylist\r\n\r\ndef build_data(mylist):\r\n df = pd.DataFrame({\r\n \"Fruit\": [\"Apples\", \"Oranges\", \"Bananas\", \"Apples\", \"Oranges\", \"Bananas\"],\r\n \"Amount\": mylist,\r\n \"City\": [\"SF\", \"SF\", \"SF\", \"Montreal\", \"Montreal\", \"Montreal\"]\r\n })\r\n dcc.Store(id='new_data', data=df.to_json())\r\n return df\r\n\r\ndef draw_graph(df):\r\n fig = px.bar(df, x=\"Fruit\", y=\"Amount\", color=\"City\", barmode=\"group\")\r\n return fig\r\n\r\ndef get_table():\r\n data_table = dash_table.DataTable(\r\n columns=[\r\n {\"name\": [\"\", \"Year\"], \"id\": \"year\"},\r\n {\"name\": [\"City\", \"Montreal\"], \"id\": \"montreal\"},\r\n {\"name\": [\"City\", \"Toronto\"], \"id\": \"toronto\"},\r\n {\"name\": [\"City\", \"Ottawa\"], \"id\": \"ottawa\"},\r\n {\"name\": [\"City\", \"Vancouver\"], \"id\": \"vancouver\"},\r\n {\"name\": [\"Climate\", \"Temperature\"], \"id\": \"temp\"},\r\n {\"name\": [\"Climate\", \"Humidity\"], \"id\": \"humidity\"},\r\n ],\r\n data=[\r\n {\r\n \"year\": i,\r\n \"montreal\": i * 10,\r\n \"toronto\": i * 100,\r\n \"ottawa\": i * -1,\r\n \"vancouver\": i * -10,\r\n \"temp\": i * -100,\r\n \"humidity\": i * 5,\r\n }\r\n for i in range(10)\r\n ],\r\n style_header={\r\n 'text-align': 'center',\r\n },\r\n merge_duplicate_headers=True,\r\n )\r\n return data_table\r\n\r\n\r\nmylist=get_rand_data()\r\ndf = build_data(mylist)\r\nfig = draw_graph(df)\r\ndata_table = get_table()\r\n\r\nrefresh_button = dbc.Button('Refresh Data', color=\"info\", className=\"me-1\", id='refresh_button_lmd')\r\n\r\napp.layout = html.Div(children=[\r\n html.H1(children='Hello Dash'),\r\n refresh_button,\r\n html.Div(children=[\r\n data_table\r\n ]),\r\n dcc.Store(id='new_data'),\r\n dcc.Loading(\r\n id='loading-data',\r\n children=[\r\n html.Div(children=[\r\n dcc.Graph(\r\n id='example-graph',\r\n figure=fig\r\n )\r\n ]\r\n )\r\n ],\r\n type='circle',\r\n ),\r\n])\r\n\r\n\r\[email protected](Output(\"example-graph\", \"figure\"),\r\n Input(\"new_data\", \"data\"))\r\ndef on_data(data):\r\n df = pd.read_json(data)\r\n time.sleep(5)\r\n fig = draw_graph(df)\r\n return fig\r\n\r\n\r\[email protected](Output('new_data', 'data'),\r\n Input('refresh_button_lmd', 'n_clicks'))\r\ndef new_data(n_clicks):\r\n if n_clicks is None:\r\n print(\"Override Startup\")\r\n mylist = get_rand_data()\r\n df = build_data(mylist)\r\n data = df.to_json()\r\n else:\r\n print(f'Button was clicked, this is {n_clicks} times.')\r\n mylist = get_rand_data()\r\n df = build_data(mylist)\r\n data=df.to_json()\r\n return data\r\n\r\nif __name__ == '__main__':\r\n app.run_server(debug=True)\r\n```\r\n\r\nI suspect that perhaps an upgrade supporting the move to Dash 2.1.0 might be the issue, and that now that I've moved my base install, I do not know what library is causing this. Any help would be appreciated. I would like to remove the constraint of staying at Dash 2.0.0 as I saw faster response times with Dash 2.1.0. Thanks!\n", "before_files": [{"content": "import sys\nimport subprocess\nimport shlex\nimport os\nimport argparse\nimport shutil\nimport logging\nimport coloredlogs\n\n\nclass _CombinedFormatter(\n argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter\n):\n pass\n\n\nlogger = logging.getLogger(__name__)\ncoloredlogs.install(\n fmt=\"%(asctime)s,%(msecs)03d %(levelname)s - %(message)s\", datefmt=\"%H:%M:%S\"\n)\n\n\ndef booststrap_components(components_source):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmd = shlex.split(\n \"npx lerna exec --scope *@({})* -- npm i\".format(source_glob),\n posix=not is_windows,\n )\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print(err.decode(), file=sys.stderr)\n\n if status == 0:\n print(\n \"\ud83d\udfe2 Finished installing npm dependencies for the following component packages: {} (status={}) \ud83d\udfe2\".format(\n source_glob, status\n ),\n file=sys.stderr,\n )\n if not out:\n print(\n \"Failed installing npm dependencies for the following component packages {} (status={})\".format(\n source_glob, status\n ),\n file=sys.stderr,\n )\n\n\ndef build_components(components_source):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmd = shlex.split(\n \"npx lerna exec --scope *@({})* -- npm run build\".format(source_glob),\n posix=not is_windows,\n )\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print(err.decode(), file=sys.stderr)\n\n if not out:\n print(\n \"\ud83d\udfe2 Finished updating the following component packages {} (status={}) \ud83d\udfe2\".format(\n source_glob, status\n ),\n file=sys.stderr,\n )\n sys.exit(1)\n\n for package in source_glob.split(\"|\"):\n build_directory = os.path.join(\n \"components\", package, package.replace(\"-\", \"_\").rstrip(\"/\\\\\")\n )\n\n dest_dir = (\n \"dcc\"\n if package == \"dash-core-components\"\n else \"html\"\n if package == \"dash-html-components\"\n else \"dash_table\"\n )\n\n dest_path = os.path.join(\"dash\", dest_dir)\n\n if not os.path.exists(dest_path):\n try:\n os.makedirs(dest_path)\n except OSError:\n logger.exception(\"\ud83d\udea8 Having issues manipulating %s\", dest_path)\n sys.exit(1)\n\n if not os.path.exists(build_directory):\n print(\n \"Could not locate build artifacts. Check that the npm build process completed successfully for the given package: {}\".format(\n package\n )\n )\n else:\n print(\"\ud83d\ude9a Moving build artifacts from \" + build_directory + \" to Dash \ud83d\ude9a\")\n shutil.rmtree(dest_path)\n shutil.copytree(build_directory, dest_path)\n with open(os.path.join(dest_path, \".gitkeep\"), \"w\"):\n pass\n print(\n \"\ud83d\udfe2 Finished moving build artifacts from \"\n + build_directory\n + \" to Dash \ud83d\udfe2\"\n )\n\n\ndef cli():\n parser = argparse.ArgumentParser(\n prog=\"dash-update-components\",\n formatter_class=_CombinedFormatter,\n description=\"Update the specified subcomponent libraries within Dash\"\n \" by copying over build artifacts, dependencies, and dependency metadata.\",\n )\n parser.add_argument(\n \"components_source\",\n help=\"A glob string that matches the Dash component libraries to be updated (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all'). The default argument is 'all'.\",\n default=\"all\",\n )\n\n args = parser.parse_args()\n\n booststrap_components(args.components_source)\n build_components(args.components_source)\n\n\ncli()\n", "path": "dash/development/update_components.py"}], "after_files": [{"content": "import sys\nimport subprocess\nimport shlex\nimport os\nimport argparse\nimport shutil\nimport logging\nimport coloredlogs\n\n\nclass _CombinedFormatter(\n argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter\n):\n pass\n\n\nlogger = logging.getLogger(__name__)\ncoloredlogs.install(\n fmt=\"%(asctime)s,%(msecs)03d %(levelname)s - %(message)s\", datefmt=\"%H:%M:%S\"\n)\n\n\ndef booststrap_components(components_source):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmd = shlex.split(\n \"npx lerna exec --scope *@({})* -- npm i\".format(source_glob),\n posix=not is_windows,\n )\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n\n if status or not out:\n print(\n \"\ud83d\udea8 Failed installing npm dependencies for component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n else:\n print(\n f\"\ud83d\udfe2 Finished installing npm dependencies for component packages: {source_glob} \ud83d\udfe2\",\n file=sys.stderr,\n )\n\n\ndef build_components(components_source):\n\n is_windows = sys.platform == \"win32\"\n\n source_glob = (\n components_source\n if components_source != \"all\"\n else \"dash-core-components|dash-html-components|dash-table\"\n )\n\n cmd = shlex.split(\n \"npx lerna exec --scope *@({})* -- npm run build\".format(source_glob),\n posix=not is_windows,\n )\n\n with subprocess.Popen(\n cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=is_windows\n ) as proc:\n out, err = proc.communicate()\n status = proc.poll()\n\n if err:\n print((\"\ud83d\uded1 \" if status else \"\") + err.decode(), file=sys.stderr)\n\n if status or not out:\n print(\n f\"\ud83d\udea8 Finished updating component packages: {source_glob} (status={status}) \ud83d\udea8\",\n file=sys.stderr,\n )\n sys.exit(1)\n\n for package in source_glob.split(\"|\"):\n build_directory = os.path.join(\n \"components\", package, package.replace(\"-\", \"_\").rstrip(\"/\\\\\")\n )\n\n dest_dir = (\n \"dcc\"\n if package == \"dash-core-components\"\n else \"html\"\n if package == \"dash-html-components\"\n else \"dash_table\"\n )\n\n dest_path = os.path.join(\"dash\", dest_dir)\n\n if not os.path.exists(dest_path):\n try:\n os.makedirs(dest_path)\n except OSError:\n logger.exception(\"\ud83d\udea8 Having issues manipulating %s\", dest_path)\n sys.exit(1)\n\n if not os.path.exists(build_directory):\n print(\n \"\ud83d\udea8 Could not locate build artifacts.\"\n + \" Check that the npm build process completed\"\n + f\" successfully for package: {package} \ud83d\udea8\"\n )\n sys.exit(1)\n else:\n print(f\"\ud83d\ude9a Moving build artifacts from {build_directory} to Dash \ud83d\ude9a\")\n shutil.rmtree(dest_path)\n shutil.copytree(build_directory, dest_path)\n with open(os.path.join(dest_path, \".gitkeep\"), \"w\"):\n pass\n print(f\"\ud83d\udfe2 Finished moving build artifacts from {build_directory} to Dash \ud83d\udfe2\")\n\n\ndef cli():\n parser = argparse.ArgumentParser(\n prog=\"dash-update-components\",\n formatter_class=_CombinedFormatter,\n description=\"Update the specified subcomponent libraries within Dash\"\n \" by copying over build artifacts, dependencies, and dependency metadata.\",\n )\n parser.add_argument(\n \"components_source\",\n help=\"A glob string that matches the Dash component libraries to be updated\"\n \" (eg.'dash-table' // 'dash-core-components|dash-html-components' // 'all').\"\n \" The default argument is 'all'.\",\n default=\"all\",\n )\n\n args = parser.parse_args()\n\n booststrap_components(args.components_source)\n build_components(args.components_source)\n\n\nif __name__ == \"__main__\":\n cli()\n", "path": "dash/development/update_components.py"}]}
| 3,124 | 809 |
gh_patches_debug_31015
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-1979
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Enhancement] OS/OSD runner is not separated in manifest_workflow and reduce runtime
We want OS and OSD runner to be separated when workflow create the new manifest file.
As of now both os and osd runner are pointing to the same one.
There are different configurations between the two runners.
The workflow also runs for way too long.
gradle properties does not require a gradle mavelocal to run beforehand.
Plus, gradle 7.x cannot build OS 1.0 anyway and will fail the workflow in the middle.
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/manifests_workflow/component_opensearch_min.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 from typing import Any, List
8
9 from git.git_repository import GitRepository
10 from manifests_workflow.component import Component
11 from manifests_workflow.component_opensearch import ComponentOpenSearch
12 from system.properties_file import PropertiesFile
13
14
15 class ComponentOpenSearchMin(Component):
16 def __init__(self, repo: GitRepository, snapshot: bool = False) -> None:
17 super().__init__(
18 "OpenSearch",
19 repo,
20 snapshot,
21 ["gradle:publish", "gradle:properties:version"],
22 )
23
24 @classmethod
25 def branches(self, url: str = "https://github.com/opensearch-project/OpenSearch.git") -> List[str]:
26 return Component.branches(url)
27
28 @classmethod
29 def checkout(self, path: str, branch: str = "main", snapshot: bool = False) -> 'ComponentOpenSearchMin':
30 return ComponentOpenSearchMin(
31 GitRepository("https://github.com/opensearch-project/OpenSearch.git", branch, path),
32 snapshot,
33 )
34
35 def publish_to_maven_local(self) -> None:
36 cmd = ComponentOpenSearch.gradle_cmd("publishToMavenLocal", {"build.snapshot": str(self.snapshot).lower()})
37 self.git_repo.execute_silent(cmd)
38
39 @property
40 def properties(self) -> PropertiesFile:
41 cmd = ComponentOpenSearch.gradle_cmd("properties", {"build.snapshot": str(self.snapshot).lower()})
42 return PropertiesFile(self.git_repo.output(cmd))
43
44 @property
45 def version(self) -> Any:
46 self.publish_to_maven_local()
47 return self.properties.get_value("version")
48
```
Path: `src/manifests_workflow/input_manifests.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import glob
8 import logging
9 import os
10 import re
11 from abc import abstractmethod
12 from typing import Dict, List, Type, Union
13
14 from manifests.input_manifest import InputManifest
15 from manifests.manifests import Manifests
16 from manifests_workflow.component_opensearch import ComponentOpenSearch
17 from manifests_workflow.component_opensearch_dashboards_min import ComponentOpenSearchDashboardsMin
18 from manifests_workflow.component_opensearch_min import ComponentOpenSearchMin
19 from system.temporary_directory import TemporaryDirectory
20
21
22 class InputManifests(Manifests):
23 def __init__(self, name: str) -> None:
24 self.name = name
25 self.prefix = name.lower().replace(" ", "-")
26 super().__init__(InputManifest, InputManifests.files(self.prefix))
27
28 @classmethod
29 def manifests_path(self) -> str:
30 return os.path.realpath(os.path.join(os.path.dirname(__file__), "..", "..", "manifests"))
31
32 @classmethod
33 def jenkins_path(self) -> str:
34 return os.path.realpath(os.path.join(os.path.dirname(__file__), "..", "..", "jenkins"))
35
36 @classmethod
37 def cron_jenkinsfile(self) -> str:
38 return os.path.join(self.jenkins_path(), "check-for-build.jenkinsfile")
39
40 @classmethod
41 def files(self, name: str) -> List:
42 results = []
43 for filename in glob.glob(os.path.join(self.manifests_path(), f"**/{name}-*.yml")):
44 # avoids the -maven manifest
45 match = re.search(rf"^{name}-([0-9.]*).yml$", os.path.basename(filename))
46 if match:
47 results.append(filename)
48 return results
49
50 @abstractmethod
51 def update(self, min_klass: Union[Type[ComponentOpenSearchMin], Type[ComponentOpenSearchDashboardsMin]], component_klass: Type[ComponentOpenSearch], keep: bool = False) -> None:
52 known_versions = self.versions
53 logging.info(f"Known versions: {known_versions}")
54 main_versions: Dict = {}
55 with TemporaryDirectory(keep=keep, chdir=True) as work_dir:
56 logging.info(f"Checking out components into {work_dir.name}")
57
58 # check out and build #main, 1.x, etc.
59 branches = min_klass.branches()
60
61 logging.info(f"Checking {self.name} {branches} branches")
62 for branch in branches:
63 c = min_klass.checkout(
64 path=os.path.join(work_dir.name, self.name.replace(" ", ""), branch),
65 branch=branch,
66 )
67
68 version = c.version
69 logging.info(f"{self.name}#{branch} is version {version}")
70 if version not in main_versions.keys():
71 main_versions[version] = [c]
72
73 if component_klass is not None:
74 # components can increment their own version first without incrementing min
75 manifest = self.latest
76 logging.info(f"Examining components in the latest manifest of {manifest.build.name} ({manifest.build.version})")
77 for component in manifest.components.values():
78 if component.name == self.name:
79 continue
80
81 logging.info(f"Checking out {component.name}#main")
82 component = component_klass.checkout(
83 name=component.name,
84 path=os.path.join(work_dir.name, component.name),
85 opensearch_version=manifest.build.version,
86 branch="main",
87 )
88
89 component_version = component.version
90 if component_version:
91 release_version = ".".join(component_version.split(".")[:3])
92 if release_version not in main_versions.keys():
93 main_versions[release_version] = []
94 main_versions[release_version].append(component)
95 logging.info(f"{component.name}#main is version {release_version} (from {component_version})")
96
97 # summarize
98 logging.info("Found versions on main:")
99 for main_version in main_versions.keys():
100 for component in main_versions[main_version]:
101 logging.info(f" {component.name}={main_version}")
102
103 # generate new manifests
104 for release_version in sorted(main_versions.keys() - known_versions):
105 self.write_manifest(release_version, main_versions[release_version])
106 self.add_to_cron(release_version)
107
108 def create_manifest(self, version: str, components: List = []) -> InputManifest:
109 data: Dict = {
110 "schema-version": "1.0",
111 "build": {
112 "name": self.name,
113 "version": version
114 },
115 "ci": {
116 "image": {
117 "name": "opensearchstaging/ci-runner:ci-runner-centos7-v1"
118 }
119 },
120 "components": [],
121 }
122
123 for component in components:
124 logging.info(f" Adding {component.name}")
125 data["components"].append(component.to_dict())
126
127 return InputManifest(data)
128
129 def write_manifest(self, version: str, components: List = []) -> None:
130 logging.info(f"Creating new version: {version}")
131 manifest = self.create_manifest(version, components)
132 manifest_dir = os.path.join(self.manifests_path(), version)
133 os.makedirs(manifest_dir, exist_ok=True)
134 manifest_path = os.path.join(manifest_dir, f"{self.prefix}-{version}.yml")
135 manifest.to_file(manifest_path)
136 logging.info(f"Wrote {manifest_path}")
137
138 def add_to_cron(self, version: str) -> None:
139 logging.info(f"Adding new version to cron: {version}")
140 jenkinsfile = self.cron_jenkinsfile()
141 with open(jenkinsfile, "r") as f:
142 data = f.read()
143
144 cron_entry = f"H/10 * * * * %INPUT_MANIFEST={version}/{self.prefix}-{version}.yml;TARGET_JOB_NAME=distribution-build-{self.prefix}\n"
145
146 if cron_entry in data:
147 raise ValueError(f"{jenkinsfile} already contains an entry for {self.prefix} {version}")
148
149 data = data.replace(
150 "parameterizedCron '''\n",
151 f"parameterizedCron '''\n{' ' * 12}{cron_entry}"
152 )
153
154 with open(jenkinsfile, "w") as f:
155 f.write(data)
156
157 logging.info(f"Wrote {jenkinsfile}")
158
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/manifests_workflow/component_opensearch_min.py b/src/manifests_workflow/component_opensearch_min.py
--- a/src/manifests_workflow/component_opensearch_min.py
+++ b/src/manifests_workflow/component_opensearch_min.py
@@ -32,10 +32,6 @@
snapshot,
)
- def publish_to_maven_local(self) -> None:
- cmd = ComponentOpenSearch.gradle_cmd("publishToMavenLocal", {"build.snapshot": str(self.snapshot).lower()})
- self.git_repo.execute_silent(cmd)
-
@property
def properties(self) -> PropertiesFile:
cmd = ComponentOpenSearch.gradle_cmd("properties", {"build.snapshot": str(self.snapshot).lower()})
@@ -43,5 +39,4 @@
@property
def version(self) -> Any:
- self.publish_to_maven_local()
return self.properties.get_value("version")
diff --git a/src/manifests_workflow/input_manifests.py b/src/manifests_workflow/input_manifests.py
--- a/src/manifests_workflow/input_manifests.py
+++ b/src/manifests_workflow/input_manifests.py
@@ -106,6 +106,11 @@
self.add_to_cron(release_version)
def create_manifest(self, version: str, components: List = []) -> InputManifest:
+ image_map = {
+ "opensearch": "opensearchstaging/ci-runner:ci-runner-centos7-opensearch-build-v1",
+ "opensearch-dashboards": "opensearchstaging/ci-runner:ci-runner-centos7-opensearch-dashboards-build-v1"
+ }
+
data: Dict = {
"schema-version": "1.0",
"build": {
@@ -114,7 +119,7 @@
},
"ci": {
"image": {
- "name": "opensearchstaging/ci-runner:ci-runner-centos7-v1"
+ "name": image_map[self.prefix]
}
},
"components": [],
|
{"golden_diff": "diff --git a/src/manifests_workflow/component_opensearch_min.py b/src/manifests_workflow/component_opensearch_min.py\n--- a/src/manifests_workflow/component_opensearch_min.py\n+++ b/src/manifests_workflow/component_opensearch_min.py\n@@ -32,10 +32,6 @@\n snapshot,\n )\n \n- def publish_to_maven_local(self) -> None:\n- cmd = ComponentOpenSearch.gradle_cmd(\"publishToMavenLocal\", {\"build.snapshot\": str(self.snapshot).lower()})\n- self.git_repo.execute_silent(cmd)\n-\n @property\n def properties(self) -> PropertiesFile:\n cmd = ComponentOpenSearch.gradle_cmd(\"properties\", {\"build.snapshot\": str(self.snapshot).lower()})\n@@ -43,5 +39,4 @@\n \n @property\n def version(self) -> Any:\n- self.publish_to_maven_local()\n return self.properties.get_value(\"version\")\ndiff --git a/src/manifests_workflow/input_manifests.py b/src/manifests_workflow/input_manifests.py\n--- a/src/manifests_workflow/input_manifests.py\n+++ b/src/manifests_workflow/input_manifests.py\n@@ -106,6 +106,11 @@\n self.add_to_cron(release_version)\n \n def create_manifest(self, version: str, components: List = []) -> InputManifest:\n+ image_map = {\n+ \"opensearch\": \"opensearchstaging/ci-runner:ci-runner-centos7-opensearch-build-v1\",\n+ \"opensearch-dashboards\": \"opensearchstaging/ci-runner:ci-runner-centos7-opensearch-dashboards-build-v1\"\n+ }\n+\n data: Dict = {\n \"schema-version\": \"1.0\",\n \"build\": {\n@@ -114,7 +119,7 @@\n },\n \"ci\": {\n \"image\": {\n- \"name\": \"opensearchstaging/ci-runner:ci-runner-centos7-v1\"\n+ \"name\": image_map[self.prefix]\n }\n },\n \"components\": [],\n", "issue": "[Enhancement] OS/OSD runner is not separated in manifest_workflow and reduce runtime\nWe want OS and OSD runner to be separated when workflow create the new manifest file.\r\nAs of now both os and osd runner are pointing to the same one.\r\nThere are different configurations between the two runners.\r\n\r\nThe workflow also runs for way too long.\r\ngradle properties does not require a gradle mavelocal to run beforehand.\r\n\r\nPlus, gradle 7.x cannot build OS 1.0 anyway and will fail the workflow in the middle.\r\n\r\nThanks.\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nfrom typing import Any, List\n\nfrom git.git_repository import GitRepository\nfrom manifests_workflow.component import Component\nfrom manifests_workflow.component_opensearch import ComponentOpenSearch\nfrom system.properties_file import PropertiesFile\n\n\nclass ComponentOpenSearchMin(Component):\n def __init__(self, repo: GitRepository, snapshot: bool = False) -> None:\n super().__init__(\n \"OpenSearch\",\n repo,\n snapshot,\n [\"gradle:publish\", \"gradle:properties:version\"],\n )\n\n @classmethod\n def branches(self, url: str = \"https://github.com/opensearch-project/OpenSearch.git\") -> List[str]:\n return Component.branches(url)\n\n @classmethod\n def checkout(self, path: str, branch: str = \"main\", snapshot: bool = False) -> 'ComponentOpenSearchMin':\n return ComponentOpenSearchMin(\n GitRepository(\"https://github.com/opensearch-project/OpenSearch.git\", branch, path),\n snapshot,\n )\n\n def publish_to_maven_local(self) -> None:\n cmd = ComponentOpenSearch.gradle_cmd(\"publishToMavenLocal\", {\"build.snapshot\": str(self.snapshot).lower()})\n self.git_repo.execute_silent(cmd)\n\n @property\n def properties(self) -> PropertiesFile:\n cmd = ComponentOpenSearch.gradle_cmd(\"properties\", {\"build.snapshot\": str(self.snapshot).lower()})\n return PropertiesFile(self.git_repo.output(cmd))\n\n @property\n def version(self) -> Any:\n self.publish_to_maven_local()\n return self.properties.get_value(\"version\")\n", "path": "src/manifests_workflow/component_opensearch_min.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport glob\nimport logging\nimport os\nimport re\nfrom abc import abstractmethod\nfrom typing import Dict, List, Type, Union\n\nfrom manifests.input_manifest import InputManifest\nfrom manifests.manifests import Manifests\nfrom manifests_workflow.component_opensearch import ComponentOpenSearch\nfrom manifests_workflow.component_opensearch_dashboards_min import ComponentOpenSearchDashboardsMin\nfrom manifests_workflow.component_opensearch_min import ComponentOpenSearchMin\nfrom system.temporary_directory import TemporaryDirectory\n\n\nclass InputManifests(Manifests):\n def __init__(self, name: str) -> None:\n self.name = name\n self.prefix = name.lower().replace(\" \", \"-\")\n super().__init__(InputManifest, InputManifests.files(self.prefix))\n\n @classmethod\n def manifests_path(self) -> str:\n return os.path.realpath(os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"manifests\"))\n\n @classmethod\n def jenkins_path(self) -> str:\n return os.path.realpath(os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"jenkins\"))\n\n @classmethod\n def cron_jenkinsfile(self) -> str:\n return os.path.join(self.jenkins_path(), \"check-for-build.jenkinsfile\")\n\n @classmethod\n def files(self, name: str) -> List:\n results = []\n for filename in glob.glob(os.path.join(self.manifests_path(), f\"**/{name}-*.yml\")):\n # avoids the -maven manifest\n match = re.search(rf\"^{name}-([0-9.]*).yml$\", os.path.basename(filename))\n if match:\n results.append(filename)\n return results\n\n @abstractmethod\n def update(self, min_klass: Union[Type[ComponentOpenSearchMin], Type[ComponentOpenSearchDashboardsMin]], component_klass: Type[ComponentOpenSearch], keep: bool = False) -> None:\n known_versions = self.versions\n logging.info(f\"Known versions: {known_versions}\")\n main_versions: Dict = {}\n with TemporaryDirectory(keep=keep, chdir=True) as work_dir:\n logging.info(f\"Checking out components into {work_dir.name}\")\n\n # check out and build #main, 1.x, etc.\n branches = min_klass.branches()\n\n logging.info(f\"Checking {self.name} {branches} branches\")\n for branch in branches:\n c = min_klass.checkout(\n path=os.path.join(work_dir.name, self.name.replace(\" \", \"\"), branch),\n branch=branch,\n )\n\n version = c.version\n logging.info(f\"{self.name}#{branch} is version {version}\")\n if version not in main_versions.keys():\n main_versions[version] = [c]\n\n if component_klass is not None:\n # components can increment their own version first without incrementing min\n manifest = self.latest\n logging.info(f\"Examining components in the latest manifest of {manifest.build.name} ({manifest.build.version})\")\n for component in manifest.components.values():\n if component.name == self.name:\n continue\n\n logging.info(f\"Checking out {component.name}#main\")\n component = component_klass.checkout(\n name=component.name,\n path=os.path.join(work_dir.name, component.name),\n opensearch_version=manifest.build.version,\n branch=\"main\",\n )\n\n component_version = component.version\n if component_version:\n release_version = \".\".join(component_version.split(\".\")[:3])\n if release_version not in main_versions.keys():\n main_versions[release_version] = []\n main_versions[release_version].append(component)\n logging.info(f\"{component.name}#main is version {release_version} (from {component_version})\")\n\n # summarize\n logging.info(\"Found versions on main:\")\n for main_version in main_versions.keys():\n for component in main_versions[main_version]:\n logging.info(f\" {component.name}={main_version}\")\n\n # generate new manifests\n for release_version in sorted(main_versions.keys() - known_versions):\n self.write_manifest(release_version, main_versions[release_version])\n self.add_to_cron(release_version)\n\n def create_manifest(self, version: str, components: List = []) -> InputManifest:\n data: Dict = {\n \"schema-version\": \"1.0\",\n \"build\": {\n \"name\": self.name,\n \"version\": version\n },\n \"ci\": {\n \"image\": {\n \"name\": \"opensearchstaging/ci-runner:ci-runner-centos7-v1\"\n }\n },\n \"components\": [],\n }\n\n for component in components:\n logging.info(f\" Adding {component.name}\")\n data[\"components\"].append(component.to_dict())\n\n return InputManifest(data)\n\n def write_manifest(self, version: str, components: List = []) -> None:\n logging.info(f\"Creating new version: {version}\")\n manifest = self.create_manifest(version, components)\n manifest_dir = os.path.join(self.manifests_path(), version)\n os.makedirs(manifest_dir, exist_ok=True)\n manifest_path = os.path.join(manifest_dir, f\"{self.prefix}-{version}.yml\")\n manifest.to_file(manifest_path)\n logging.info(f\"Wrote {manifest_path}\")\n\n def add_to_cron(self, version: str) -> None:\n logging.info(f\"Adding new version to cron: {version}\")\n jenkinsfile = self.cron_jenkinsfile()\n with open(jenkinsfile, \"r\") as f:\n data = f.read()\n\n cron_entry = f\"H/10 * * * * %INPUT_MANIFEST={version}/{self.prefix}-{version}.yml;TARGET_JOB_NAME=distribution-build-{self.prefix}\\n\"\n\n if cron_entry in data:\n raise ValueError(f\"{jenkinsfile} already contains an entry for {self.prefix} {version}\")\n\n data = data.replace(\n \"parameterizedCron '''\\n\",\n f\"parameterizedCron '''\\n{' ' * 12}{cron_entry}\"\n )\n\n with open(jenkinsfile, \"w\") as f:\n f.write(data)\n\n logging.info(f\"Wrote {jenkinsfile}\")\n", "path": "src/manifests_workflow/input_manifests.py"}], "after_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nfrom typing import Any, List\n\nfrom git.git_repository import GitRepository\nfrom manifests_workflow.component import Component\nfrom manifests_workflow.component_opensearch import ComponentOpenSearch\nfrom system.properties_file import PropertiesFile\n\n\nclass ComponentOpenSearchMin(Component):\n def __init__(self, repo: GitRepository, snapshot: bool = False) -> None:\n super().__init__(\n \"OpenSearch\",\n repo,\n snapshot,\n [\"gradle:publish\", \"gradle:properties:version\"],\n )\n\n @classmethod\n def branches(self, url: str = \"https://github.com/opensearch-project/OpenSearch.git\") -> List[str]:\n return Component.branches(url)\n\n @classmethod\n def checkout(self, path: str, branch: str = \"main\", snapshot: bool = False) -> 'ComponentOpenSearchMin':\n return ComponentOpenSearchMin(\n GitRepository(\"https://github.com/opensearch-project/OpenSearch.git\", branch, path),\n snapshot,\n )\n\n @property\n def properties(self) -> PropertiesFile:\n cmd = ComponentOpenSearch.gradle_cmd(\"properties\", {\"build.snapshot\": str(self.snapshot).lower()})\n return PropertiesFile(self.git_repo.output(cmd))\n\n @property\n def version(self) -> Any:\n return self.properties.get_value(\"version\")\n", "path": "src/manifests_workflow/component_opensearch_min.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport glob\nimport logging\nimport os\nimport re\nfrom abc import abstractmethod\nfrom typing import Dict, List, Type, Union\n\nfrom manifests.input_manifest import InputManifest\nfrom manifests.manifests import Manifests\nfrom manifests_workflow.component_opensearch import ComponentOpenSearch\nfrom manifests_workflow.component_opensearch_dashboards_min import ComponentOpenSearchDashboardsMin\nfrom manifests_workflow.component_opensearch_min import ComponentOpenSearchMin\nfrom system.temporary_directory import TemporaryDirectory\n\n\nclass InputManifests(Manifests):\n def __init__(self, name: str) -> None:\n self.name = name\n self.prefix = name.lower().replace(\" \", \"-\")\n super().__init__(InputManifest, InputManifests.files(self.prefix))\n\n @classmethod\n def manifests_path(self) -> str:\n return os.path.realpath(os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"manifests\"))\n\n @classmethod\n def jenkins_path(self) -> str:\n return os.path.realpath(os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"jenkins\"))\n\n @classmethod\n def cron_jenkinsfile(self) -> str:\n return os.path.join(self.jenkins_path(), \"check-for-build.jenkinsfile\")\n\n @classmethod\n def files(self, name: str) -> List:\n results = []\n for filename in glob.glob(os.path.join(self.manifests_path(), f\"**/{name}-*.yml\")):\n # avoids the -maven manifest\n match = re.search(rf\"^{name}-([0-9.]*).yml$\", os.path.basename(filename))\n if match:\n results.append(filename)\n return results\n\n @abstractmethod\n def update(self, min_klass: Union[Type[ComponentOpenSearchMin], Type[ComponentOpenSearchDashboardsMin]], component_klass: Type[ComponentOpenSearch], keep: bool = False) -> None:\n known_versions = self.versions\n logging.info(f\"Known versions: {known_versions}\")\n main_versions: Dict = {}\n with TemporaryDirectory(keep=keep, chdir=True) as work_dir:\n logging.info(f\"Checking out components into {work_dir.name}\")\n\n # check out and build #main, 1.x, etc.\n branches = min_klass.branches()\n\n logging.info(f\"Checking {self.name} {branches} branches\")\n for branch in branches:\n c = min_klass.checkout(\n path=os.path.join(work_dir.name, self.name.replace(\" \", \"\"), branch),\n branch=branch,\n )\n\n version = c.version\n logging.info(f\"{self.name}#{branch} is version {version}\")\n if version not in main_versions.keys():\n main_versions[version] = [c]\n\n if component_klass is not None:\n # components can increment their own version first without incrementing min\n manifest = self.latest\n logging.info(f\"Examining components in the latest manifest of {manifest.build.name} ({manifest.build.version})\")\n for component in manifest.components.values():\n if component.name == self.name:\n continue\n\n logging.info(f\"Checking out {component.name}#main\")\n component = component_klass.checkout(\n name=component.name,\n path=os.path.join(work_dir.name, component.name),\n opensearch_version=manifest.build.version,\n branch=\"main\",\n )\n\n component_version = component.version\n if component_version:\n release_version = \".\".join(component_version.split(\".\")[:3])\n if release_version not in main_versions.keys():\n main_versions[release_version] = []\n main_versions[release_version].append(component)\n logging.info(f\"{component.name}#main is version {release_version} (from {component_version})\")\n\n # summarize\n logging.info(\"Found versions on main:\")\n for main_version in main_versions.keys():\n for component in main_versions[main_version]:\n logging.info(f\" {component.name}={main_version}\")\n\n # generate new manifests\n for release_version in sorted(main_versions.keys() - known_versions):\n self.write_manifest(release_version, main_versions[release_version])\n self.add_to_cron(release_version)\n\n def create_manifest(self, version: str, components: List = []) -> InputManifest:\n image_map = {\n \"opensearch\": \"opensearchstaging/ci-runner:ci-runner-centos7-opensearch-build-v1\",\n \"opensearch-dashboards\": \"opensearchstaging/ci-runner:ci-runner-centos7-opensearch-dashboards-build-v1\"\n }\n\n data: Dict = {\n \"schema-version\": \"1.0\",\n \"build\": {\n \"name\": self.name,\n \"version\": version\n },\n \"ci\": {\n \"image\": {\n \"name\": image_map[self.prefix]\n }\n },\n \"components\": [],\n }\n\n for component in components:\n logging.info(f\" Adding {component.name}\")\n data[\"components\"].append(component.to_dict())\n\n return InputManifest(data)\n\n def write_manifest(self, version: str, components: List = []) -> None:\n logging.info(f\"Creating new version: {version}\")\n manifest = self.create_manifest(version, components)\n manifest_dir = os.path.join(self.manifests_path(), version)\n os.makedirs(manifest_dir, exist_ok=True)\n manifest_path = os.path.join(manifest_dir, f\"{self.prefix}-{version}.yml\")\n manifest.to_file(manifest_path)\n logging.info(f\"Wrote {manifest_path}\")\n\n def add_to_cron(self, version: str) -> None:\n logging.info(f\"Adding new version to cron: {version}\")\n jenkinsfile = self.cron_jenkinsfile()\n with open(jenkinsfile, \"r\") as f:\n data = f.read()\n\n cron_entry = f\"H/10 * * * * %INPUT_MANIFEST={version}/{self.prefix}-{version}.yml;TARGET_JOB_NAME=distribution-build-{self.prefix}\\n\"\n\n if cron_entry in data:\n raise ValueError(f\"{jenkinsfile} already contains an entry for {self.prefix} {version}\")\n\n data = data.replace(\n \"parameterizedCron '''\\n\",\n f\"parameterizedCron '''\\n{' ' * 12}{cron_entry}\"\n )\n\n with open(jenkinsfile, \"w\") as f:\n f.write(data)\n\n logging.info(f\"Wrote {jenkinsfile}\")\n", "path": "src/manifests_workflow/input_manifests.py"}]}
| 2,606 | 458 |
gh_patches_debug_15729
|
rasdani/github-patches
|
git_diff
|
Azure__azure-cli-extensions-601
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
min_pro is used in the example of help in express-route-cross-connection
- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)
### Extension name (the extension in question)
express-route-cross-connection
### Description of issue (in as much detail as possible)
https://github.com/Azure/azure-cli-extensions/blob/bbefbe73a620c6407b522484d6b2ba848cb4f9f5/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py#L131
We shouldn't use min_profile in the help example. It needs to be updated to supportedprofile instead.
-----
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py`
Content:
```
1 # --------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License. See License.txt in the project root for license information.
4 # --------------------------------------------------------------------------------------------
5
6 from knack.help_files import helps
7
8
9 helps['network cross-connection'] = """
10 type: group
11 short-summary: Manage customers' ExpressRoute circuits.
12 long-summary: >
13 To learn more about ExpressRoute circuits visit
14 https://docs.microsoft.com/en-us/azure/expressroute/howto-circuit-cli
15 """
16
17 helps['network cross-connection list'] = """
18 type: command
19 short-summary: List all ExpressRoute circuits for the current subscription.
20 examples:
21 - name: List all ExpressRoute circuits for the current subscription.
22 text: >
23 az network cross-connection list -g MyResourceGroup
24 """
25
26 helps['network cross-connection list-arp-tables'] = """
27 type: command
28 short-summary: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit peering.
29 examples:
30 - name: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit.
31 text: |
32 az network cross-connection list-arp-tables -g MyResourceGroup -n MyCircuit \\
33 --path primary --peering-name AzurePrivatePeering
34 """
35
36 helps['network cross-connection list-route-tables'] = """
37 type: command
38 short-summary: Show the current routing table of an ExpressRoute circuit peering.
39 examples:
40 - name: Show the current routing table of an ExpressRoute circuit peering.
41 text: |
42 az network cross-connection list-route-tables -g MyResourceGroup -n MyCircuit \\
43 --path primary --peering-name AzurePrivatePeering
44 """
45
46 helps['network cross-connection show'] = """
47 type: command
48 short-summary: Get the details of an ExpressRoute circuit.
49 examples:
50 - name: Get the details of an ExpressRoute circuit.
51 text: >
52 az network cross-connection show -n MyCircuit -g MyResourceGroup
53 """
54
55 helps['network cross-connection update'] = """
56 type: command
57 short-summary: Update settings of an ExpressRoute circuit.
58 examples:
59 - name: Change the SKU of an ExpressRoute circuit from Standard to Premium.
60 text: >
61 az network cross-connection update -n MyCircuit -g MyResourceGroup --sku-tier Premium
62 """
63
64 helps['network cross-connection wait'] = """
65 type: command
66 short-summary: Place the CLI in a waiting state until a condition of the ExpressRoute is met.
67 examples:
68 - name: Pause executing next line of CLI script until the ExpressRoute circuit is successfully provisioned.
69 text: az network cross-connection wait -n MyCircuit --g MyResourceGroup --created
70 """
71
72 helps['network cross-connection peering'] = """
73 type: group
74 short-summary: Manage ExpressRoute peering of an ExpressRoute circuit.
75 """
76
77 helps['network cross-connection peering create'] = """
78 type: command
79 short-summary: Create peering settings for an ExpressRoute circuit.
80 examples:
81 - name: Create Microsoft Peering settings with IPv4 configuration.
82 text: |
83 az network cross-connection peering create -g MyResourceGroup --circuit-name MyCircuit \\
84 --peering-type MicrosoftPeering --peer-asn 10002 --vlan-id 103 \\
85 --primary-peer-subnet 101.0.0.0/30 --secondary-peer-subnet 102.0.0.0/30 \\
86 --advertised-public-prefixes 101.0.0.0/30
87 - name: Add IPv6 settings to existing IPv4 config for Microsoft peering.
88 text: |
89 az network cross-connection peering update -g MyResourceGroup --circuit-name MyCircuit \\
90 --peering-type MicrosoftPeering --ip-version ipv6 --primary-peer-subnet 2002:db00::/126 \\
91 --secondary-peer-subnet 2003:db00::/126 --advertised-public-prefixes 2002:db00::/126
92 """
93
94 helps['network cross-connection peering delete'] = """
95 type: command
96 short-summary: Delete peering settings.
97 examples:
98 - name: Delete private peering.
99 text: >
100 az network cross-connection peering delete -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering
101 """
102
103 helps['network cross-connection peering list'] = """
104 type: command
105 short-summary: List peering settings of an ExpressRoute circuit.
106 examples:
107 - name: List peering settings of an ExpressRoute circuit.
108 text: >
109 az network cross-connection peering list -g MyResourceGroup --circuit-name MyCircuit
110 """
111
112 helps['network cross-connection peering show'] = """
113 type: command
114 short-summary: Get the details of an express route peering.
115 examples:
116 - name: Get private peering details of an ExpressRoute circuit.
117 text: >
118 az network cross-connection peering show -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering
119 """
120
121 helps['network cross-connection peering update'] = """
122 type: command
123 short-summary: Update peering settings of an ExpressRoute circuit.
124 examples:
125 - name: Add IPv6 Microsoft Peering settings to existing IPv4 config.
126 text: |
127 az network cross-connection peering update -g MyResourceGroup \\
128 --circuit-name MyCircuit --peering-type MicrosoftPeering --ip-version ipv6 \\
129 --primary-peer-subnet 2002:db00::/126 --secondary-peer-subnet 2003:db00::/126 \\
130 --advertised-public-prefixes 2002:db00::/126
131 min_profile: latest
132 """
133
```
Path: `src/express-route-cross-connection/setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # --------------------------------------------------------------------------------------------
4 # Copyright (c) Microsoft Corporation. All rights reserved.
5 # Licensed under the MIT License. See License.txt in the project root for license information.
6 # --------------------------------------------------------------------------------------------
7
8 from codecs import open
9 from setuptools import setup, find_packages
10
11 VERSION = "0.1.0"
12
13 CLASSIFIERS = [
14 'Development Status :: 4 - Beta',
15 'Intended Audience :: Developers',
16 'Intended Audience :: System Administrators',
17 'Programming Language :: Python',
18 'Programming Language :: Python :: 2',
19 'Programming Language :: Python :: 2.7',
20 'Programming Language :: Python :: 3',
21 'Programming Language :: Python :: 3.4',
22 'Programming Language :: Python :: 3.5',
23 'Programming Language :: Python :: 3.6',
24 'License :: OSI Approved :: MIT License',
25 ]
26
27 DEPENDENCIES = []
28
29 setup(
30 name='express-route-cross-connection',
31 version=VERSION,
32 description='Manage customer ExpressRoute circuits using an ExpressRoute cross-connection.',
33 long_description='These commands give ISPs limited ability to manage the ExpressRoute circuits of ' \
34 'their customers through an ExpressRoute cross-connection resource.',
35 license='MIT',
36 author='Microsoft Corporation',
37 author_email='[email protected]',
38 url='https://github.com/Azure/azure-cli-extensions/tree/master/src/express-route-cross-connection',
39 classifiers=CLASSIFIERS,
40 package_data={'azext_expressroutecrossconnection': ['azext_metadata.json']},
41 packages=find_packages(),
42 install_requires=DEPENDENCIES
43 )
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py b/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py
--- a/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py
+++ b/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py
@@ -128,5 +128,4 @@
--circuit-name MyCircuit --peering-type MicrosoftPeering --ip-version ipv6 \\
--primary-peer-subnet 2002:db00::/126 --secondary-peer-subnet 2003:db00::/126 \\
--advertised-public-prefixes 2002:db00::/126
- min_profile: latest
"""
diff --git a/src/express-route-cross-connection/setup.py b/src/express-route-cross-connection/setup.py
--- a/src/express-route-cross-connection/setup.py
+++ b/src/express-route-cross-connection/setup.py
@@ -8,7 +8,7 @@
from codecs import open
from setuptools import setup, find_packages
-VERSION = "0.1.0"
+VERSION = "0.1.1"
CLASSIFIERS = [
'Development Status :: 4 - Beta',
|
{"golden_diff": "diff --git a/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py b/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py\n--- a/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py\n+++ b/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py\n@@ -128,5 +128,4 @@\n --circuit-name MyCircuit --peering-type MicrosoftPeering --ip-version ipv6 \\\\\n --primary-peer-subnet 2002:db00::/126 --secondary-peer-subnet 2003:db00::/126 \\\\\n --advertised-public-prefixes 2002:db00::/126\n- min_profile: latest\n \"\"\"\ndiff --git a/src/express-route-cross-connection/setup.py b/src/express-route-cross-connection/setup.py\n--- a/src/express-route-cross-connection/setup.py\n+++ b/src/express-route-cross-connection/setup.py\n@@ -8,7 +8,7 @@\n from codecs import open\n from setuptools import setup, find_packages\n \n-VERSION = \"0.1.0\"\n+VERSION = \"0.1.1\"\n \n CLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n", "issue": "min_pro is used in the example of help in express-route-cross-connection\n- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)\r\n\r\n### Extension name (the extension in question)\r\nexpress-route-cross-connection\r\n\r\n### Description of issue (in as much detail as possible)\r\nhttps://github.com/Azure/azure-cli-extensions/blob/bbefbe73a620c6407b522484d6b2ba848cb4f9f5/src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py#L131\r\n\r\nWe shouldn't use min_profile in the help example. It needs to be updated to supportedprofile instead.\r\n-----\r\n\r\n\n", "before_files": [{"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom knack.help_files import helps\n\n\nhelps['network cross-connection'] = \"\"\"\n type: group\n short-summary: Manage customers' ExpressRoute circuits.\n long-summary: >\n To learn more about ExpressRoute circuits visit\n https://docs.microsoft.com/en-us/azure/expressroute/howto-circuit-cli\n\"\"\"\n\nhelps['network cross-connection list'] = \"\"\"\n type: command\n short-summary: List all ExpressRoute circuits for the current subscription.\n examples:\n - name: List all ExpressRoute circuits for the current subscription.\n text: >\n az network cross-connection list -g MyResourceGroup\n\"\"\"\n\nhelps['network cross-connection list-arp-tables'] = \"\"\"\n type: command\n short-summary: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit peering.\n examples:\n - name: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit.\n text: |\n az network cross-connection list-arp-tables -g MyResourceGroup -n MyCircuit \\\\\n --path primary --peering-name AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection list-route-tables'] = \"\"\"\n type: command\n short-summary: Show the current routing table of an ExpressRoute circuit peering.\n examples:\n - name: Show the current routing table of an ExpressRoute circuit peering.\n text: |\n az network cross-connection list-route-tables -g MyResourceGroup -n MyCircuit \\\\\n --path primary --peering-name AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection show'] = \"\"\"\n type: command\n short-summary: Get the details of an ExpressRoute circuit.\n examples:\n - name: Get the details of an ExpressRoute circuit.\n text: >\n az network cross-connection show -n MyCircuit -g MyResourceGroup\n\"\"\"\n\nhelps['network cross-connection update'] = \"\"\"\n type: command\n short-summary: Update settings of an ExpressRoute circuit.\n examples:\n - name: Change the SKU of an ExpressRoute circuit from Standard to Premium.\n text: >\n az network cross-connection update -n MyCircuit -g MyResourceGroup --sku-tier Premium\n\"\"\"\n\nhelps['network cross-connection wait'] = \"\"\"\n type: command\n short-summary: Place the CLI in a waiting state until a condition of the ExpressRoute is met.\n examples:\n - name: Pause executing next line of CLI script until the ExpressRoute circuit is successfully provisioned.\n text: az network cross-connection wait -n MyCircuit --g MyResourceGroup --created\n\"\"\"\n\nhelps['network cross-connection peering'] = \"\"\"\n type: group\n short-summary: Manage ExpressRoute peering of an ExpressRoute circuit.\n\"\"\"\n\nhelps['network cross-connection peering create'] = \"\"\"\n type: command\n short-summary: Create peering settings for an ExpressRoute circuit.\n examples:\n - name: Create Microsoft Peering settings with IPv4 configuration.\n text: |\n az network cross-connection peering create -g MyResourceGroup --circuit-name MyCircuit \\\\\n --peering-type MicrosoftPeering --peer-asn 10002 --vlan-id 103 \\\\\n --primary-peer-subnet 101.0.0.0/30 --secondary-peer-subnet 102.0.0.0/30 \\\\\n --advertised-public-prefixes 101.0.0.0/30\n - name: Add IPv6 settings to existing IPv4 config for Microsoft peering.\n text: |\n az network cross-connection peering update -g MyResourceGroup --circuit-name MyCircuit \\\\\n --peering-type MicrosoftPeering --ip-version ipv6 --primary-peer-subnet 2002:db00::/126 \\\\\n --secondary-peer-subnet 2003:db00::/126 --advertised-public-prefixes 2002:db00::/126\n\"\"\"\n\nhelps['network cross-connection peering delete'] = \"\"\"\n type: command\n short-summary: Delete peering settings.\n examples:\n - name: Delete private peering.\n text: >\n az network cross-connection peering delete -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection peering list'] = \"\"\"\n type: command\n short-summary: List peering settings of an ExpressRoute circuit.\n examples:\n - name: List peering settings of an ExpressRoute circuit.\n text: >\n az network cross-connection peering list -g MyResourceGroup --circuit-name MyCircuit\n\"\"\"\n\nhelps['network cross-connection peering show'] = \"\"\"\n type: command\n short-summary: Get the details of an express route peering.\n examples:\n - name: Get private peering details of an ExpressRoute circuit.\n text: >\n az network cross-connection peering show -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection peering update'] = \"\"\"\n type: command\n short-summary: Update peering settings of an ExpressRoute circuit.\n examples:\n - name: Add IPv6 Microsoft Peering settings to existing IPv4 config.\n text: |\n az network cross-connection peering update -g MyResourceGroup \\\\\n --circuit-name MyCircuit --peering-type MicrosoftPeering --ip-version ipv6 \\\\\n --primary-peer-subnet 2002:db00::/126 --secondary-peer-subnet 2003:db00::/126 \\\\\n --advertised-public-prefixes 2002:db00::/126\n min_profile: latest\n\"\"\"\n", "path": "src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py"}, {"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom codecs import open\nfrom setuptools import setup, find_packages\n\nVERSION = \"0.1.0\"\n\nCLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'License :: OSI Approved :: MIT License',\n]\n\nDEPENDENCIES = []\n\nsetup(\n name='express-route-cross-connection',\n version=VERSION,\n description='Manage customer ExpressRoute circuits using an ExpressRoute cross-connection.',\n long_description='These commands give ISPs limited ability to manage the ExpressRoute circuits of ' \\\n 'their customers through an ExpressRoute cross-connection resource.',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://github.com/Azure/azure-cli-extensions/tree/master/src/express-route-cross-connection',\n classifiers=CLASSIFIERS,\n package_data={'azext_expressroutecrossconnection': ['azext_metadata.json']},\n packages=find_packages(),\n install_requires=DEPENDENCIES\n)\n", "path": "src/express-route-cross-connection/setup.py"}], "after_files": [{"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom knack.help_files import helps\n\n\nhelps['network cross-connection'] = \"\"\"\n type: group\n short-summary: Manage customers' ExpressRoute circuits.\n long-summary: >\n To learn more about ExpressRoute circuits visit\n https://docs.microsoft.com/en-us/azure/expressroute/howto-circuit-cli\n\"\"\"\n\nhelps['network cross-connection list'] = \"\"\"\n type: command\n short-summary: List all ExpressRoute circuits for the current subscription.\n examples:\n - name: List all ExpressRoute circuits for the current subscription.\n text: >\n az network cross-connection list -g MyResourceGroup\n\"\"\"\n\nhelps['network cross-connection list-arp-tables'] = \"\"\"\n type: command\n short-summary: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit peering.\n examples:\n - name: Show the current Address Resolution Protocol (ARP) table of an ExpressRoute circuit.\n text: |\n az network cross-connection list-arp-tables -g MyResourceGroup -n MyCircuit \\\\\n --path primary --peering-name AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection list-route-tables'] = \"\"\"\n type: command\n short-summary: Show the current routing table of an ExpressRoute circuit peering.\n examples:\n - name: Show the current routing table of an ExpressRoute circuit peering.\n text: |\n az network cross-connection list-route-tables -g MyResourceGroup -n MyCircuit \\\\\n --path primary --peering-name AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection show'] = \"\"\"\n type: command\n short-summary: Get the details of an ExpressRoute circuit.\n examples:\n - name: Get the details of an ExpressRoute circuit.\n text: >\n az network cross-connection show -n MyCircuit -g MyResourceGroup\n\"\"\"\n\nhelps['network cross-connection update'] = \"\"\"\n type: command\n short-summary: Update settings of an ExpressRoute circuit.\n examples:\n - name: Change the SKU of an ExpressRoute circuit from Standard to Premium.\n text: >\n az network cross-connection update -n MyCircuit -g MyResourceGroup --sku-tier Premium\n\"\"\"\n\nhelps['network cross-connection wait'] = \"\"\"\n type: command\n short-summary: Place the CLI in a waiting state until a condition of the ExpressRoute is met.\n examples:\n - name: Pause executing next line of CLI script until the ExpressRoute circuit is successfully provisioned.\n text: az network cross-connection wait -n MyCircuit --g MyResourceGroup --created\n\"\"\"\n\nhelps['network cross-connection peering'] = \"\"\"\n type: group\n short-summary: Manage ExpressRoute peering of an ExpressRoute circuit.\n\"\"\"\n\nhelps['network cross-connection peering create'] = \"\"\"\n type: command\n short-summary: Create peering settings for an ExpressRoute circuit.\n examples:\n - name: Create Microsoft Peering settings with IPv4 configuration.\n text: |\n az network cross-connection peering create -g MyResourceGroup --circuit-name MyCircuit \\\\\n --peering-type MicrosoftPeering --peer-asn 10002 --vlan-id 103 \\\\\n --primary-peer-subnet 101.0.0.0/30 --secondary-peer-subnet 102.0.0.0/30 \\\\\n --advertised-public-prefixes 101.0.0.0/30\n - name: Add IPv6 settings to existing IPv4 config for Microsoft peering.\n text: |\n az network cross-connection peering update -g MyResourceGroup --circuit-name MyCircuit \\\\\n --peering-type MicrosoftPeering --ip-version ipv6 --primary-peer-subnet 2002:db00::/126 \\\\\n --secondary-peer-subnet 2003:db00::/126 --advertised-public-prefixes 2002:db00::/126\n\"\"\"\n\nhelps['network cross-connection peering delete'] = \"\"\"\n type: command\n short-summary: Delete peering settings.\n examples:\n - name: Delete private peering.\n text: >\n az network cross-connection peering delete -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection peering list'] = \"\"\"\n type: command\n short-summary: List peering settings of an ExpressRoute circuit.\n examples:\n - name: List peering settings of an ExpressRoute circuit.\n text: >\n az network cross-connection peering list -g MyResourceGroup --circuit-name MyCircuit\n\"\"\"\n\nhelps['network cross-connection peering show'] = \"\"\"\n type: command\n short-summary: Get the details of an express route peering.\n examples:\n - name: Get private peering details of an ExpressRoute circuit.\n text: >\n az network cross-connection peering show -g MyResourceGroup --circuit-name MyCircuit -n AzurePrivatePeering\n\"\"\"\n\nhelps['network cross-connection peering update'] = \"\"\"\n type: command\n short-summary: Update peering settings of an ExpressRoute circuit.\n examples:\n - name: Add IPv6 Microsoft Peering settings to existing IPv4 config.\n text: |\n az network cross-connection peering update -g MyResourceGroup \\\\\n --circuit-name MyCircuit --peering-type MicrosoftPeering --ip-version ipv6 \\\\\n --primary-peer-subnet 2002:db00::/126 --secondary-peer-subnet 2003:db00::/126 \\\\\n --advertised-public-prefixes 2002:db00::/126\n\"\"\"\n", "path": "src/express-route-cross-connection/azext_expressroutecrossconnection/_help.py"}, {"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom codecs import open\nfrom setuptools import setup, find_packages\n\nVERSION = \"0.1.1\"\n\nCLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'License :: OSI Approved :: MIT License',\n]\n\nDEPENDENCIES = []\n\nsetup(\n name='express-route-cross-connection',\n version=VERSION,\n description='Manage customer ExpressRoute circuits using an ExpressRoute cross-connection.',\n long_description='These commands give ISPs limited ability to manage the ExpressRoute circuits of ' \\\n 'their customers through an ExpressRoute cross-connection resource.',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://github.com/Azure/azure-cli-extensions/tree/master/src/express-route-cross-connection',\n classifiers=CLASSIFIERS,\n package_data={'azext_expressroutecrossconnection': ['azext_metadata.json']},\n packages=find_packages(),\n install_requires=DEPENDENCIES\n)\n", "path": "src/express-route-cross-connection/setup.py"}]}
| 2,496 | 304 |
gh_patches_debug_37896
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1337
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make StreamField lazily fetch related objects
I have a site that includes a list of pages in the footer (privacy policy, terms and conditions, etc). This is implemented using a `wagtailsettings` model with a join table/InlinePanel to `wagtailcore.Page`. Every page load thus fetches these pages to print their URL and title in the footer.
It appears that when a page is fetched, any related models referenced in that pages StreamField contents are also fetched. This means that loading the links for the footer of one page means fetching all of the images contained in the content of all of the footer pages. These extra database calls are clearly wasteful.
StreamField instances should lazily fetch related objects when the StreamField is first accessed, instead of as soon as it is loaded.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailcore/blocks/stream_block.py`
Content:
```
1 from __future__ import absolute_import, unicode_literals
2
3 import collections
4
5 from django import forms
6 from django.core.exceptions import ValidationError
7 from django.forms.utils import ErrorList
8 from django.template.loader import render_to_string
9 from django.utils.encoding import python_2_unicode_compatible, force_text
10 from django.utils.html import format_html_join
11 from django.utils.safestring import mark_safe
12
13 import six
14
15 from wagtail.wagtailcore.utils import escape_script
16
17 from .base import Block, DeclarativeSubBlocksMetaclass, BoundBlock
18 from .utils import indent, js_dict
19
20
21 __all__ = ['BaseStreamBlock', 'StreamBlock', 'StreamValue']
22
23
24 class BaseStreamBlock(Block):
25 # TODO: decide what it means to pass a 'default' arg to StreamBlock's constructor. Logically we want it to be
26 # of type StreamValue, but we can't construct one of those because it needs a reference back to the StreamBlock
27 # that we haven't constructed yet...
28 class Meta:
29 @property
30 def default(self):
31 return StreamValue(self, [])
32
33 def __init__(self, local_blocks=None, **kwargs):
34 self._constructor_kwargs = kwargs
35
36 super(BaseStreamBlock, self).__init__(**kwargs)
37
38 self.child_blocks = self.base_blocks.copy() # create a local (shallow) copy of base_blocks so that it can be supplemented by local_blocks
39 if local_blocks:
40 for name, block in local_blocks:
41 block.set_name(name)
42 self.child_blocks[name] = block
43
44 self.dependencies = self.child_blocks.values()
45
46 def render_list_member(self, block_type_name, value, prefix, index, errors=None):
47 """
48 Render the HTML for a single list item. This consists of an <li> wrapper, hidden fields
49 to manage ID/deleted state/type, delete/reorder buttons, and the child block's own HTML.
50 """
51 child_block = self.child_blocks[block_type_name]
52 child = child_block.bind(value, prefix="%s-value" % prefix, errors=errors)
53 return render_to_string('wagtailadmin/block_forms/stream_member.html', {
54 'child_blocks': self.child_blocks.values(),
55 'block_type_name': block_type_name,
56 'prefix': prefix,
57 'child': child,
58 'index': index,
59 })
60
61 def html_declarations(self):
62 return format_html_join(
63 '\n', '<script type="text/template" id="{0}-newmember-{1}">{2}</script>',
64 [
65 (
66 self.definition_prefix,
67 name,
68 mark_safe(escape_script(self.render_list_member(name, child_block.meta.default, '__PREFIX__', '')))
69 )
70 for name, child_block in self.child_blocks.items()
71 ]
72 )
73
74 @property
75 def media(self):
76 return forms.Media(js=['wagtailadmin/js/blocks/sequence.js', 'wagtailadmin/js/blocks/stream.js'])
77
78 def js_initializer(self):
79 # compile a list of info dictionaries, one for each available block type
80 child_blocks = []
81 for name, child_block in self.child_blocks.items():
82 # each info dictionary specifies at least a block name
83 child_block_info = {'name': "'%s'" % name}
84
85 # if the child defines a JS initializer function, include that in the info dict
86 # along with the param that needs to be passed to it for initializing an empty/default block
87 # of that type
88 child_js_initializer = child_block.js_initializer()
89 if child_js_initializer:
90 child_block_info['initializer'] = child_js_initializer
91
92 child_blocks.append(indent(js_dict(child_block_info)))
93
94 opts = {
95 'definitionPrefix': "'%s'" % self.definition_prefix,
96 'childBlocks': '[\n%s\n]' % ',\n'.join(child_blocks),
97 }
98
99 return "StreamBlock(%s)" % js_dict(opts)
100
101 def render_form(self, value, prefix='', errors=None):
102 if errors:
103 if len(errors) > 1:
104 # We rely on ListBlock.clean throwing a single ValidationError with a specially crafted
105 # 'params' attribute that we can pull apart and distribute to the child blocks
106 raise TypeError('ListBlock.render_form unexpectedly received multiple errors')
107 error_list = errors.as_data()[0].params
108 else:
109 error_list = None
110
111 # drop any child values that are an unrecognised block type
112 valid_children = [child for child in value if child.block_type in self.child_blocks]
113
114 list_members_html = [
115 self.render_list_member(child.block_type, child.value, "%s-%d" % (prefix, i), i,
116 errors=error_list[i] if error_list else None)
117 for (i, child) in enumerate(valid_children)
118 ]
119
120 return render_to_string('wagtailadmin/block_forms/stream.html', {
121 'label': self.label,
122 'prefix': prefix,
123 'list_members_html': list_members_html,
124 'child_blocks': self.child_blocks.values(),
125 'header_menu_prefix': '%s-before' % prefix,
126 })
127
128 def value_from_datadict(self, data, files, prefix):
129 count = int(data['%s-count' % prefix])
130 values_with_indexes = []
131 for i in range(0, count):
132 if data['%s-%d-deleted' % (prefix, i)]:
133 continue
134 block_type_name = data['%s-%d-type' % (prefix, i)]
135 try:
136 child_block = self.child_blocks[block_type_name]
137 except KeyError:
138 continue
139
140 values_with_indexes.append(
141 (
142 int(data['%s-%d-order' % (prefix, i)]),
143 block_type_name,
144 child_block.value_from_datadict(data, files, '%s-%d-value' % (prefix, i)),
145 )
146 )
147
148 values_with_indexes.sort()
149 return StreamValue(self, [
150 (child_block_type_name, value)
151 for (index, child_block_type_name, value) in values_with_indexes
152 ])
153
154 def clean(self, value):
155 cleaned_data = []
156 errors = []
157 for child in value: # child is a BoundBlock instance
158 try:
159 cleaned_data.append(
160 (child.block.name, child.block.clean(child.value))
161 )
162 except ValidationError as e:
163 errors.append(ErrorList([e]))
164 else:
165 errors.append(None)
166
167 if any(errors):
168 # The message here is arbitrary - outputting error messages is delegated to the child blocks,
169 # which only involves the 'params' list
170 raise ValidationError('Validation error in StreamBlock', params=errors)
171
172 return StreamValue(self, cleaned_data)
173
174 def to_python(self, value):
175 # the incoming JSONish representation is a list of dicts, each with a 'type' and 'value' field.
176 # Convert this to a StreamValue backed by a list of (type, value) tuples
177 return StreamValue(self, [
178 (child_data['type'], self.child_blocks[child_data['type']].to_python(child_data['value']))
179 for child_data in value
180 if child_data['type'] in self.child_blocks
181 ])
182
183 def get_prep_value(self, value):
184 if value is None:
185 # treat None as identical to an empty stream
186 return []
187
188 return [
189 {'type': child.block.name, 'value': child.block.get_prep_value(child.value)}
190 for child in value # child is a BoundBlock instance
191 ]
192
193 def render_basic(self, value):
194 return format_html_join('\n', '<div class="block-{1}">{0}</div>',
195 [(force_text(child), child.block_type) for child in value]
196 )
197
198 def get_searchable_content(self, value):
199 content = []
200
201 for child in value:
202 content.extend(child.block.get_searchable_content(child.value))
203
204 return content
205
206 def deconstruct(self):
207 """
208 Always deconstruct StreamBlock instances as if they were plain StreamBlocks with all of the
209 field definitions passed to the constructor - even if in reality this is a subclass of StreamBlock
210 with the fields defined declaratively, or some combination of the two.
211
212 This ensures that the field definitions get frozen into migrations, rather than leaving a reference
213 to a custom subclass in the user's models.py that may or may not stick around.
214 """
215 path = 'wagtail.wagtailcore.blocks.StreamBlock'
216 args = [self.child_blocks.items()]
217 kwargs = self._constructor_kwargs
218 return (path, args, kwargs)
219
220
221 class StreamBlock(six.with_metaclass(DeclarativeSubBlocksMetaclass, BaseStreamBlock)):
222 pass
223
224
225 @python_2_unicode_compatible # provide equivalent __unicode__ and __str__ methods on Py2
226 class StreamValue(collections.Sequence):
227 """
228 Custom type used to represent the value of a StreamBlock; behaves as a sequence of BoundBlocks
229 (which keep track of block types in a way that the values alone wouldn't).
230 """
231
232 @python_2_unicode_compatible
233 class StreamChild(BoundBlock):
234 """Provides some extensions to BoundBlock to make it more natural to work with on front-end templates"""
235 def __str__(self):
236 """Render the value according to the block's native rendering"""
237 return self.block.render(self.value)
238
239 @property
240 def block_type(self):
241 """
242 Syntactic sugar so that we can say child.block_type instead of child.block.name.
243 (This doesn't belong on BoundBlock itself because the idea of block.name denoting
244 the child's "type" ('heading', 'paragraph' etc) is unique to StreamBlock, and in the
245 wider context people are liable to confuse it with the block class (CharBlock etc).
246 """
247 return self.block.name
248
249 def __init__(self, stream_block, stream_data):
250 self.stream_block = stream_block # the StreamBlock object that handles this value
251 self.stream_data = stream_data # a list of (type_name, value) tuples
252 self._bound_blocks = {} # populated lazily from stream_data as we access items through __getitem__
253
254 def __getitem__(self, i):
255 if i not in self._bound_blocks:
256 type_name, value = self.stream_data[i]
257 child_block = self.stream_block.child_blocks[type_name]
258 self._bound_blocks[i] = StreamValue.StreamChild(child_block, value)
259
260 return self._bound_blocks[i]
261
262 def __len__(self):
263 return len(self.stream_data)
264
265 def __repr__(self):
266 return repr(list(self))
267
268 def __str__(self):
269 return self.stream_block.render(self)
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailcore/blocks/stream_block.py b/wagtail/wagtailcore/blocks/stream_block.py
--- a/wagtail/wagtailcore/blocks/stream_block.py
+++ b/wagtail/wagtailcore/blocks/stream_block.py
@@ -173,12 +173,12 @@
def to_python(self, value):
# the incoming JSONish representation is a list of dicts, each with a 'type' and 'value' field.
- # Convert this to a StreamValue backed by a list of (type, value) tuples
+ # This is passed to StreamValue to be expanded lazily - but first we reject any unrecognised
+ # block types from the list
return StreamValue(self, [
- (child_data['type'], self.child_blocks[child_data['type']].to_python(child_data['value']))
- for child_data in value
+ child_data for child_data in value
if child_data['type'] in self.child_blocks
- ])
+ ], is_lazy=True)
def get_prep_value(self, value):
if value is None:
@@ -246,15 +246,36 @@
"""
return self.block.name
- def __init__(self, stream_block, stream_data):
+ def __init__(self, stream_block, stream_data, is_lazy=False):
+ """
+ Construct a StreamValue linked to the given StreamBlock,
+ with child values given in stream_data.
+
+ Passing is_lazy=True means that stream_data is raw JSONish data as stored
+ in the database, and needs to be converted to native values
+ (using block.to_python()) when accessed. In this mode, stream_data is a
+ list of dicts, each containing 'type' and 'value' keys.
+
+ Passing is_lazy=False means that stream_data consists of immediately usable
+ native values. In this mode, stream_data is a list of (type_name, value)
+ tuples.
+ """
+ self.is_lazy = is_lazy
self.stream_block = stream_block # the StreamBlock object that handles this value
self.stream_data = stream_data # a list of (type_name, value) tuples
self._bound_blocks = {} # populated lazily from stream_data as we access items through __getitem__
def __getitem__(self, i):
if i not in self._bound_blocks:
- type_name, value = self.stream_data[i]
- child_block = self.stream_block.child_blocks[type_name]
+ if self.is_lazy:
+ raw_value = self.stream_data[i]
+ type_name = raw_value['type']
+ child_block = self.stream_block.child_blocks[type_name]
+ value = child_block.to_python(raw_value['value'])
+ else:
+ type_name, value = self.stream_data[i]
+ child_block = self.stream_block.child_blocks[type_name]
+
self._bound_blocks[i] = StreamValue.StreamChild(child_block, value)
return self._bound_blocks[i]
|
{"golden_diff": "diff --git a/wagtail/wagtailcore/blocks/stream_block.py b/wagtail/wagtailcore/blocks/stream_block.py\n--- a/wagtail/wagtailcore/blocks/stream_block.py\n+++ b/wagtail/wagtailcore/blocks/stream_block.py\n@@ -173,12 +173,12 @@\n \n def to_python(self, value):\n # the incoming JSONish representation is a list of dicts, each with a 'type' and 'value' field.\n- # Convert this to a StreamValue backed by a list of (type, value) tuples\n+ # This is passed to StreamValue to be expanded lazily - but first we reject any unrecognised\n+ # block types from the list\n return StreamValue(self, [\n- (child_data['type'], self.child_blocks[child_data['type']].to_python(child_data['value']))\n- for child_data in value\n+ child_data for child_data in value\n if child_data['type'] in self.child_blocks\n- ])\n+ ], is_lazy=True)\n \n def get_prep_value(self, value):\n if value is None:\n@@ -246,15 +246,36 @@\n \"\"\"\n return self.block.name\n \n- def __init__(self, stream_block, stream_data):\n+ def __init__(self, stream_block, stream_data, is_lazy=False):\n+ \"\"\"\n+ Construct a StreamValue linked to the given StreamBlock,\n+ with child values given in stream_data.\n+\n+ Passing is_lazy=True means that stream_data is raw JSONish data as stored\n+ in the database, and needs to be converted to native values\n+ (using block.to_python()) when accessed. In this mode, stream_data is a\n+ list of dicts, each containing 'type' and 'value' keys.\n+\n+ Passing is_lazy=False means that stream_data consists of immediately usable\n+ native values. In this mode, stream_data is a list of (type_name, value)\n+ tuples.\n+ \"\"\"\n+ self.is_lazy = is_lazy\n self.stream_block = stream_block # the StreamBlock object that handles this value\n self.stream_data = stream_data # a list of (type_name, value) tuples\n self._bound_blocks = {} # populated lazily from stream_data as we access items through __getitem__\n \n def __getitem__(self, i):\n if i not in self._bound_blocks:\n- type_name, value = self.stream_data[i]\n- child_block = self.stream_block.child_blocks[type_name]\n+ if self.is_lazy:\n+ raw_value = self.stream_data[i]\n+ type_name = raw_value['type']\n+ child_block = self.stream_block.child_blocks[type_name]\n+ value = child_block.to_python(raw_value['value'])\n+ else:\n+ type_name, value = self.stream_data[i]\n+ child_block = self.stream_block.child_blocks[type_name]\n+\n self._bound_blocks[i] = StreamValue.StreamChild(child_block, value)\n \n return self._bound_blocks[i]\n", "issue": "Make StreamField lazily fetch related objects\nI have a site that includes a list of pages in the footer (privacy policy, terms and conditions, etc). This is implemented using a `wagtailsettings` model with a join table/InlinePanel to `wagtailcore.Page`. Every page load thus fetches these pages to print their URL and title in the footer.\n\nIt appears that when a page is fetched, any related models referenced in that pages StreamField contents are also fetched. This means that loading the links for the footer of one page means fetching all of the images contained in the content of all of the footer pages. These extra database calls are clearly wasteful.\n\nStreamField instances should lazily fetch related objects when the StreamField is first accessed, instead of as soon as it is loaded.\n\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nimport collections\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.forms.utils import ErrorList\nfrom django.template.loader import render_to_string\nfrom django.utils.encoding import python_2_unicode_compatible, force_text\nfrom django.utils.html import format_html_join\nfrom django.utils.safestring import mark_safe\n\nimport six\n\nfrom wagtail.wagtailcore.utils import escape_script\n\nfrom .base import Block, DeclarativeSubBlocksMetaclass, BoundBlock\nfrom .utils import indent, js_dict\n\n\n__all__ = ['BaseStreamBlock', 'StreamBlock', 'StreamValue']\n\n\nclass BaseStreamBlock(Block):\n # TODO: decide what it means to pass a 'default' arg to StreamBlock's constructor. Logically we want it to be\n # of type StreamValue, but we can't construct one of those because it needs a reference back to the StreamBlock\n # that we haven't constructed yet...\n class Meta:\n @property\n def default(self):\n return StreamValue(self, [])\n\n def __init__(self, local_blocks=None, **kwargs):\n self._constructor_kwargs = kwargs\n\n super(BaseStreamBlock, self).__init__(**kwargs)\n\n self.child_blocks = self.base_blocks.copy() # create a local (shallow) copy of base_blocks so that it can be supplemented by local_blocks\n if local_blocks:\n for name, block in local_blocks:\n block.set_name(name)\n self.child_blocks[name] = block\n\n self.dependencies = self.child_blocks.values()\n\n def render_list_member(self, block_type_name, value, prefix, index, errors=None):\n \"\"\"\n Render the HTML for a single list item. This consists of an <li> wrapper, hidden fields\n to manage ID/deleted state/type, delete/reorder buttons, and the child block's own HTML.\n \"\"\"\n child_block = self.child_blocks[block_type_name]\n child = child_block.bind(value, prefix=\"%s-value\" % prefix, errors=errors)\n return render_to_string('wagtailadmin/block_forms/stream_member.html', {\n 'child_blocks': self.child_blocks.values(),\n 'block_type_name': block_type_name,\n 'prefix': prefix,\n 'child': child,\n 'index': index,\n })\n\n def html_declarations(self):\n return format_html_join(\n '\\n', '<script type=\"text/template\" id=\"{0}-newmember-{1}\">{2}</script>',\n [\n (\n self.definition_prefix,\n name,\n mark_safe(escape_script(self.render_list_member(name, child_block.meta.default, '__PREFIX__', '')))\n )\n for name, child_block in self.child_blocks.items()\n ]\n )\n\n @property\n def media(self):\n return forms.Media(js=['wagtailadmin/js/blocks/sequence.js', 'wagtailadmin/js/blocks/stream.js'])\n\n def js_initializer(self):\n # compile a list of info dictionaries, one for each available block type\n child_blocks = []\n for name, child_block in self.child_blocks.items():\n # each info dictionary specifies at least a block name\n child_block_info = {'name': \"'%s'\" % name}\n\n # if the child defines a JS initializer function, include that in the info dict\n # along with the param that needs to be passed to it for initializing an empty/default block\n # of that type\n child_js_initializer = child_block.js_initializer()\n if child_js_initializer:\n child_block_info['initializer'] = child_js_initializer\n\n child_blocks.append(indent(js_dict(child_block_info)))\n\n opts = {\n 'definitionPrefix': \"'%s'\" % self.definition_prefix,\n 'childBlocks': '[\\n%s\\n]' % ',\\n'.join(child_blocks),\n }\n\n return \"StreamBlock(%s)\" % js_dict(opts)\n\n def render_form(self, value, prefix='', errors=None):\n if errors:\n if len(errors) > 1:\n # We rely on ListBlock.clean throwing a single ValidationError with a specially crafted\n # 'params' attribute that we can pull apart and distribute to the child blocks\n raise TypeError('ListBlock.render_form unexpectedly received multiple errors')\n error_list = errors.as_data()[0].params\n else:\n error_list = None\n\n # drop any child values that are an unrecognised block type\n valid_children = [child for child in value if child.block_type in self.child_blocks]\n\n list_members_html = [\n self.render_list_member(child.block_type, child.value, \"%s-%d\" % (prefix, i), i,\n errors=error_list[i] if error_list else None)\n for (i, child) in enumerate(valid_children)\n ]\n\n return render_to_string('wagtailadmin/block_forms/stream.html', {\n 'label': self.label,\n 'prefix': prefix,\n 'list_members_html': list_members_html,\n 'child_blocks': self.child_blocks.values(),\n 'header_menu_prefix': '%s-before' % prefix,\n })\n\n def value_from_datadict(self, data, files, prefix):\n count = int(data['%s-count' % prefix])\n values_with_indexes = []\n for i in range(0, count):\n if data['%s-%d-deleted' % (prefix, i)]:\n continue\n block_type_name = data['%s-%d-type' % (prefix, i)]\n try:\n child_block = self.child_blocks[block_type_name]\n except KeyError:\n continue\n\n values_with_indexes.append(\n (\n int(data['%s-%d-order' % (prefix, i)]),\n block_type_name,\n child_block.value_from_datadict(data, files, '%s-%d-value' % (prefix, i)),\n )\n )\n\n values_with_indexes.sort()\n return StreamValue(self, [\n (child_block_type_name, value)\n for (index, child_block_type_name, value) in values_with_indexes\n ])\n\n def clean(self, value):\n cleaned_data = []\n errors = []\n for child in value: # child is a BoundBlock instance\n try:\n cleaned_data.append(\n (child.block.name, child.block.clean(child.value))\n )\n except ValidationError as e:\n errors.append(ErrorList([e]))\n else:\n errors.append(None)\n\n if any(errors):\n # The message here is arbitrary - outputting error messages is delegated to the child blocks,\n # which only involves the 'params' list\n raise ValidationError('Validation error in StreamBlock', params=errors)\n\n return StreamValue(self, cleaned_data)\n\n def to_python(self, value):\n # the incoming JSONish representation is a list of dicts, each with a 'type' and 'value' field.\n # Convert this to a StreamValue backed by a list of (type, value) tuples\n return StreamValue(self, [\n (child_data['type'], self.child_blocks[child_data['type']].to_python(child_data['value']))\n for child_data in value\n if child_data['type'] in self.child_blocks\n ])\n\n def get_prep_value(self, value):\n if value is None:\n # treat None as identical to an empty stream\n return []\n\n return [\n {'type': child.block.name, 'value': child.block.get_prep_value(child.value)}\n for child in value # child is a BoundBlock instance\n ]\n\n def render_basic(self, value):\n return format_html_join('\\n', '<div class=\"block-{1}\">{0}</div>',\n [(force_text(child), child.block_type) for child in value]\n )\n\n def get_searchable_content(self, value):\n content = []\n\n for child in value:\n content.extend(child.block.get_searchable_content(child.value))\n\n return content\n\n def deconstruct(self):\n \"\"\"\n Always deconstruct StreamBlock instances as if they were plain StreamBlocks with all of the\n field definitions passed to the constructor - even if in reality this is a subclass of StreamBlock\n with the fields defined declaratively, or some combination of the two.\n\n This ensures that the field definitions get frozen into migrations, rather than leaving a reference\n to a custom subclass in the user's models.py that may or may not stick around.\n \"\"\"\n path = 'wagtail.wagtailcore.blocks.StreamBlock'\n args = [self.child_blocks.items()]\n kwargs = self._constructor_kwargs\n return (path, args, kwargs)\n\n\nclass StreamBlock(six.with_metaclass(DeclarativeSubBlocksMetaclass, BaseStreamBlock)):\n pass\n\n\n@python_2_unicode_compatible # provide equivalent __unicode__ and __str__ methods on Py2\nclass StreamValue(collections.Sequence):\n \"\"\"\n Custom type used to represent the value of a StreamBlock; behaves as a sequence of BoundBlocks\n (which keep track of block types in a way that the values alone wouldn't).\n \"\"\"\n\n @python_2_unicode_compatible\n class StreamChild(BoundBlock):\n \"\"\"Provides some extensions to BoundBlock to make it more natural to work with on front-end templates\"\"\"\n def __str__(self):\n \"\"\"Render the value according to the block's native rendering\"\"\"\n return self.block.render(self.value)\n\n @property\n def block_type(self):\n \"\"\"\n Syntactic sugar so that we can say child.block_type instead of child.block.name.\n (This doesn't belong on BoundBlock itself because the idea of block.name denoting\n the child's \"type\" ('heading', 'paragraph' etc) is unique to StreamBlock, and in the\n wider context people are liable to confuse it with the block class (CharBlock etc).\n \"\"\"\n return self.block.name\n\n def __init__(self, stream_block, stream_data):\n self.stream_block = stream_block # the StreamBlock object that handles this value\n self.stream_data = stream_data # a list of (type_name, value) tuples\n self._bound_blocks = {} # populated lazily from stream_data as we access items through __getitem__\n\n def __getitem__(self, i):\n if i not in self._bound_blocks:\n type_name, value = self.stream_data[i]\n child_block = self.stream_block.child_blocks[type_name]\n self._bound_blocks[i] = StreamValue.StreamChild(child_block, value)\n\n return self._bound_blocks[i]\n\n def __len__(self):\n return len(self.stream_data)\n\n def __repr__(self):\n return repr(list(self))\n\n def __str__(self):\n return self.stream_block.render(self)\n", "path": "wagtail/wagtailcore/blocks/stream_block.py"}], "after_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nimport collections\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.forms.utils import ErrorList\nfrom django.template.loader import render_to_string\nfrom django.utils.encoding import python_2_unicode_compatible, force_text\nfrom django.utils.html import format_html_join\nfrom django.utils.safestring import mark_safe\n\nimport six\n\nfrom wagtail.wagtailcore.utils import escape_script\n\nfrom .base import Block, DeclarativeSubBlocksMetaclass, BoundBlock\nfrom .utils import indent, js_dict\n\n\n__all__ = ['BaseStreamBlock', 'StreamBlock', 'StreamValue']\n\n\nclass BaseStreamBlock(Block):\n # TODO: decide what it means to pass a 'default' arg to StreamBlock's constructor. Logically we want it to be\n # of type StreamValue, but we can't construct one of those because it needs a reference back to the StreamBlock\n # that we haven't constructed yet...\n class Meta:\n @property\n def default(self):\n return StreamValue(self, [])\n\n def __init__(self, local_blocks=None, **kwargs):\n self._constructor_kwargs = kwargs\n\n super(BaseStreamBlock, self).__init__(**kwargs)\n\n self.child_blocks = self.base_blocks.copy() # create a local (shallow) copy of base_blocks so that it can be supplemented by local_blocks\n if local_blocks:\n for name, block in local_blocks:\n block.set_name(name)\n self.child_blocks[name] = block\n\n self.dependencies = self.child_blocks.values()\n\n def render_list_member(self, block_type_name, value, prefix, index, errors=None):\n \"\"\"\n Render the HTML for a single list item. This consists of an <li> wrapper, hidden fields\n to manage ID/deleted state/type, delete/reorder buttons, and the child block's own HTML.\n \"\"\"\n child_block = self.child_blocks[block_type_name]\n child = child_block.bind(value, prefix=\"%s-value\" % prefix, errors=errors)\n return render_to_string('wagtailadmin/block_forms/stream_member.html', {\n 'child_blocks': self.child_blocks.values(),\n 'block_type_name': block_type_name,\n 'prefix': prefix,\n 'child': child,\n 'index': index,\n })\n\n def html_declarations(self):\n return format_html_join(\n '\\n', '<script type=\"text/template\" id=\"{0}-newmember-{1}\">{2}</script>',\n [\n (\n self.definition_prefix,\n name,\n mark_safe(escape_script(self.render_list_member(name, child_block.meta.default, '__PREFIX__', '')))\n )\n for name, child_block in self.child_blocks.items()\n ]\n )\n\n @property\n def media(self):\n return forms.Media(js=['wagtailadmin/js/blocks/sequence.js', 'wagtailadmin/js/blocks/stream.js'])\n\n def js_initializer(self):\n # compile a list of info dictionaries, one for each available block type\n child_blocks = []\n for name, child_block in self.child_blocks.items():\n # each info dictionary specifies at least a block name\n child_block_info = {'name': \"'%s'\" % name}\n\n # if the child defines a JS initializer function, include that in the info dict\n # along with the param that needs to be passed to it for initializing an empty/default block\n # of that type\n child_js_initializer = child_block.js_initializer()\n if child_js_initializer:\n child_block_info['initializer'] = child_js_initializer\n\n child_blocks.append(indent(js_dict(child_block_info)))\n\n opts = {\n 'definitionPrefix': \"'%s'\" % self.definition_prefix,\n 'childBlocks': '[\\n%s\\n]' % ',\\n'.join(child_blocks),\n }\n\n return \"StreamBlock(%s)\" % js_dict(opts)\n\n def render_form(self, value, prefix='', errors=None):\n if errors:\n if len(errors) > 1:\n # We rely on ListBlock.clean throwing a single ValidationError with a specially crafted\n # 'params' attribute that we can pull apart and distribute to the child blocks\n raise TypeError('ListBlock.render_form unexpectedly received multiple errors')\n error_list = errors.as_data()[0].params\n else:\n error_list = None\n\n # drop any child values that are an unrecognised block type\n valid_children = [child for child in value if child.block_type in self.child_blocks]\n\n list_members_html = [\n self.render_list_member(child.block_type, child.value, \"%s-%d\" % (prefix, i), i,\n errors=error_list[i] if error_list else None)\n for (i, child) in enumerate(valid_children)\n ]\n\n return render_to_string('wagtailadmin/block_forms/stream.html', {\n 'label': self.label,\n 'prefix': prefix,\n 'list_members_html': list_members_html,\n 'child_blocks': self.child_blocks.values(),\n 'header_menu_prefix': '%s-before' % prefix,\n })\n\n def value_from_datadict(self, data, files, prefix):\n count = int(data['%s-count' % prefix])\n values_with_indexes = []\n for i in range(0, count):\n if data['%s-%d-deleted' % (prefix, i)]:\n continue\n block_type_name = data['%s-%d-type' % (prefix, i)]\n try:\n child_block = self.child_blocks[block_type_name]\n except KeyError:\n continue\n\n values_with_indexes.append(\n (\n int(data['%s-%d-order' % (prefix, i)]),\n block_type_name,\n child_block.value_from_datadict(data, files, '%s-%d-value' % (prefix, i)),\n )\n )\n\n values_with_indexes.sort()\n return StreamValue(self, [\n (child_block_type_name, value)\n for (index, child_block_type_name, value) in values_with_indexes\n ])\n\n def clean(self, value):\n cleaned_data = []\n errors = []\n for child in value: # child is a BoundBlock instance\n try:\n cleaned_data.append(\n (child.block.name, child.block.clean(child.value))\n )\n except ValidationError as e:\n errors.append(ErrorList([e]))\n else:\n errors.append(None)\n\n if any(errors):\n # The message here is arbitrary - outputting error messages is delegated to the child blocks,\n # which only involves the 'params' list\n raise ValidationError('Validation error in StreamBlock', params=errors)\n\n return StreamValue(self, cleaned_data)\n\n def to_python(self, value):\n # the incoming JSONish representation is a list of dicts, each with a 'type' and 'value' field.\n # This is passed to StreamValue to be expanded lazily - but first we reject any unrecognised\n # block types from the list\n return StreamValue(self, [\n child_data for child_data in value\n if child_data['type'] in self.child_blocks\n ], is_lazy=True)\n\n def get_prep_value(self, value):\n if value is None:\n # treat None as identical to an empty stream\n return []\n\n return [\n {'type': child.block.name, 'value': child.block.get_prep_value(child.value)}\n for child in value # child is a BoundBlock instance\n ]\n\n def render_basic(self, value):\n return format_html_join('\\n', '<div class=\"block-{1}\">{0}</div>',\n [(force_text(child), child.block_type) for child in value]\n )\n\n def get_searchable_content(self, value):\n content = []\n\n for child in value:\n content.extend(child.block.get_searchable_content(child.value))\n\n return content\n\n def deconstruct(self):\n \"\"\"\n Always deconstruct StreamBlock instances as if they were plain StreamBlocks with all of the\n field definitions passed to the constructor - even if in reality this is a subclass of StreamBlock\n with the fields defined declaratively, or some combination of the two.\n\n This ensures that the field definitions get frozen into migrations, rather than leaving a reference\n to a custom subclass in the user's models.py that may or may not stick around.\n \"\"\"\n path = 'wagtail.wagtailcore.blocks.StreamBlock'\n args = [self.child_blocks.items()]\n kwargs = self._constructor_kwargs\n return (path, args, kwargs)\n\n\nclass StreamBlock(six.with_metaclass(DeclarativeSubBlocksMetaclass, BaseStreamBlock)):\n pass\n\n\n@python_2_unicode_compatible # provide equivalent __unicode__ and __str__ methods on Py2\nclass StreamValue(collections.Sequence):\n \"\"\"\n Custom type used to represent the value of a StreamBlock; behaves as a sequence of BoundBlocks\n (which keep track of block types in a way that the values alone wouldn't).\n \"\"\"\n\n @python_2_unicode_compatible\n class StreamChild(BoundBlock):\n \"\"\"Provides some extensions to BoundBlock to make it more natural to work with on front-end templates\"\"\"\n def __str__(self):\n \"\"\"Render the value according to the block's native rendering\"\"\"\n return self.block.render(self.value)\n\n @property\n def block_type(self):\n \"\"\"\n Syntactic sugar so that we can say child.block_type instead of child.block.name.\n (This doesn't belong on BoundBlock itself because the idea of block.name denoting\n the child's \"type\" ('heading', 'paragraph' etc) is unique to StreamBlock, and in the\n wider context people are liable to confuse it with the block class (CharBlock etc).\n \"\"\"\n return self.block.name\n\n def __init__(self, stream_block, stream_data, is_lazy=False):\n \"\"\"\n Construct a StreamValue linked to the given StreamBlock,\n with child values given in stream_data.\n\n Passing is_lazy=True means that stream_data is raw JSONish data as stored\n in the database, and needs to be converted to native values\n (using block.to_python()) when accessed. In this mode, stream_data is a\n list of dicts, each containing 'type' and 'value' keys.\n\n Passing is_lazy=False means that stream_data consists of immediately usable\n native values. In this mode, stream_data is a list of (type_name, value)\n tuples.\n \"\"\"\n self.is_lazy = is_lazy\n self.stream_block = stream_block # the StreamBlock object that handles this value\n self.stream_data = stream_data # a list of (type_name, value) tuples\n self._bound_blocks = {} # populated lazily from stream_data as we access items through __getitem__\n\n def __getitem__(self, i):\n if i not in self._bound_blocks:\n if self.is_lazy:\n raw_value = self.stream_data[i]\n type_name = raw_value['type']\n child_block = self.stream_block.child_blocks[type_name]\n value = child_block.to_python(raw_value['value'])\n else:\n type_name, value = self.stream_data[i]\n child_block = self.stream_block.child_blocks[type_name]\n\n self._bound_blocks[i] = StreamValue.StreamChild(child_block, value)\n\n return self._bound_blocks[i]\n\n def __len__(self):\n return len(self.stream_data)\n\n def __repr__(self):\n return repr(list(self))\n\n def __str__(self):\n return self.stream_block.render(self)\n", "path": "wagtail/wagtailcore/blocks/stream_block.py"}]}
| 3,429 | 671 |
gh_patches_debug_21386
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-9759
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Include the `task-run` as a related resources when emitting events.
### First check
- [X] I added a descriptive title to this issue.
- [X] I used the GitHub search to find a similar request and didn't find it.
- [X] I searched the Prefect documentation for this feature.
### Prefect Version
2.x
### Describe the current behavior
Currently task-runs aren't included as related resources when emitting events.
### Describe the proposed behavior
The current task run in the TaskRunContext should be included in any event fired while a task is running.
### Example Use
_No response_
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/events/related.py`
Content:
```
1 import asyncio
2 import pendulum
3 from typing import (
4 TYPE_CHECKING,
5 Any,
6 Awaitable,
7 Callable,
8 Dict,
9 Iterable,
10 List,
11 Optional,
12 Set,
13 Tuple,
14 Union,
15 )
16 from uuid import UUID
17 from pendulum.datetime import DateTime
18
19 from .schemas import RelatedResource
20
21 if TYPE_CHECKING:
22 from prefect._internal.schemas.bases import ObjectBaseModel
23
24 ResourceCacheEntry = Dict[str, Union[str, "ObjectBaseModel", None]]
25 RelatedResourceCache = Dict[str, Tuple[ResourceCacheEntry, DateTime]]
26
27 MAX_CACHE_SIZE = 100
28 RESOURCE_CACHE: RelatedResourceCache = {}
29
30
31 def tags_as_related_resources(tags: Iterable[str]) -> List[RelatedResource]:
32 return [
33 RelatedResource(
34 __root__={
35 "prefect.resource.id": f"prefect.tag.{tag}",
36 "prefect.resource.role": "tag",
37 }
38 )
39 for tag in sorted(tags)
40 ]
41
42
43 def object_as_related_resource(kind: str, role: str, object: Any) -> RelatedResource:
44 resource_id = f"prefect.{kind}.{object.id}"
45
46 return RelatedResource(
47 __root__={
48 "prefect.resource.id": resource_id,
49 "prefect.resource.role": role,
50 "prefect.resource.name": object.name,
51 }
52 )
53
54
55 async def related_resources_from_run_context(
56 exclude: Optional[Set[str]] = None,
57 ) -> List[RelatedResource]:
58 from prefect.client.orchestration import get_client
59 from prefect.context import FlowRunContext, TaskRunContext
60
61 if exclude is None:
62 exclude = set()
63
64 flow_run_context = FlowRunContext.get()
65 task_run_context = TaskRunContext.get()
66
67 if not flow_run_context and not task_run_context:
68 return []
69
70 flow_run_id: UUID = (
71 flow_run_context.flow_run.id
72 if flow_run_context
73 else task_run_context.task_run.flow_run_id
74 )
75
76 related_objects: list[ResourceCacheEntry] = []
77
78 async with get_client() as client:
79
80 async def dummy_read():
81 return {}
82
83 related_objects = [
84 await _get_and_cache_related_object(
85 kind="flow-run",
86 role="flow-run",
87 client_method=client.read_flow_run,
88 obj_id=flow_run_id,
89 cache=RESOURCE_CACHE,
90 )
91 ]
92
93 flow_run = related_objects[0]["object"]
94
95 if flow_run:
96 related_objects += list(
97 await asyncio.gather(
98 _get_and_cache_related_object(
99 kind="flow",
100 role="flow",
101 client_method=client.read_flow,
102 obj_id=flow_run.flow_id,
103 cache=RESOURCE_CACHE,
104 ),
105 (
106 _get_and_cache_related_object(
107 kind="deployment",
108 role="deployment",
109 client_method=client.read_deployment,
110 obj_id=flow_run.deployment_id,
111 cache=RESOURCE_CACHE,
112 )
113 if flow_run.deployment_id
114 else dummy_read()
115 ),
116 (
117 _get_and_cache_related_object(
118 kind="work-queue",
119 role="work-queue",
120 client_method=client.read_work_queue,
121 obj_id=flow_run.work_queue_id,
122 cache=RESOURCE_CACHE,
123 )
124 if flow_run.work_queue_id
125 else dummy_read()
126 ),
127 (
128 _get_and_cache_related_object(
129 kind="work-pool",
130 role="work-pool",
131 client_method=client.read_work_pool,
132 obj_id=flow_run.work_pool_name,
133 cache=RESOURCE_CACHE,
134 )
135 if flow_run.work_pool_name
136 else dummy_read()
137 ),
138 )
139 )
140
141 related = []
142 tags = set()
143
144 for entry in related_objects:
145 obj_ = entry.get("object")
146 if obj_ is None:
147 continue
148
149 assert isinstance(entry["kind"], str) and isinstance(entry["role"], str)
150
151 resource = object_as_related_resource(
152 kind=entry["kind"], role=entry["kind"], object=obj_
153 )
154
155 if resource.id in exclude:
156 continue
157
158 related.append(resource)
159 if hasattr(obj_, "tags"):
160 tags |= set(obj_.tags)
161
162 related += [
163 resource
164 for resource in tags_as_related_resources(tags)
165 if resource.id not in exclude
166 ]
167
168 return related
169
170
171 async def _get_and_cache_related_object(
172 kind: str,
173 role: str,
174 client_method: Callable[[Union[UUID, str]], Awaitable[Optional["ObjectBaseModel"]]],
175 obj_id: Union[UUID, str],
176 cache: RelatedResourceCache,
177 ) -> ResourceCacheEntry:
178 cache_key = f"{kind}.{obj_id}"
179 entry = None
180
181 if cache_key in cache:
182 entry, _ = cache[cache_key]
183 else:
184 obj_ = await client_method(obj_id)
185 entry = {
186 "kind": kind,
187 "object": obj_,
188 }
189
190 cache[cache_key] = (entry, pendulum.now("UTC"))
191
192 # In the case of a worker or agent this cache could be long-lived. To keep
193 # from running out of memory only keep `MAX_CACHE_SIZE` entries in the
194 # cache.
195 if len(cache) > MAX_CACHE_SIZE:
196 oldest_key = sorted(
197 [(key, timestamp) for key, (_, timestamp) in cache.items()],
198 key=lambda k: k[1],
199 )[0][0]
200
201 if oldest_key:
202 del cache[oldest_key]
203
204 # Because the role is event specific and can change depending on the
205 # type of event being emitted, this adds the role from the args to the
206 # entry before returning it rather than storing it in the cache.
207 entry["role"] = role
208 return entry
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/events/related.py b/src/prefect/events/related.py
--- a/src/prefect/events/related.py
+++ b/src/prefect/events/related.py
@@ -80,15 +80,33 @@
async def dummy_read():
return {}
- related_objects = [
- await _get_and_cache_related_object(
- kind="flow-run",
- role="flow-run",
- client_method=client.read_flow_run,
- obj_id=flow_run_id,
- cache=RESOURCE_CACHE,
+ if flow_run_context:
+ related_objects.append(
+ {
+ "kind": "flow-run",
+ "role": "flow-run",
+ "object": flow_run_context.flow_run,
+ },
+ )
+ else:
+ related_objects.append(
+ await _get_and_cache_related_object(
+ kind="flow-run",
+ role="flow-run",
+ client_method=client.read_flow_run,
+ obj_id=flow_run_id,
+ cache=RESOURCE_CACHE,
+ )
+ )
+
+ if task_run_context:
+ related_objects.append(
+ {
+ "kind": "task-run",
+ "role": "task-run",
+ "object": task_run_context.task_run,
+ },
)
- ]
flow_run = related_objects[0]["object"]
|
{"golden_diff": "diff --git a/src/prefect/events/related.py b/src/prefect/events/related.py\n--- a/src/prefect/events/related.py\n+++ b/src/prefect/events/related.py\n@@ -80,15 +80,33 @@\n async def dummy_read():\n return {}\n \n- related_objects = [\n- await _get_and_cache_related_object(\n- kind=\"flow-run\",\n- role=\"flow-run\",\n- client_method=client.read_flow_run,\n- obj_id=flow_run_id,\n- cache=RESOURCE_CACHE,\n+ if flow_run_context:\n+ related_objects.append(\n+ {\n+ \"kind\": \"flow-run\",\n+ \"role\": \"flow-run\",\n+ \"object\": flow_run_context.flow_run,\n+ },\n+ )\n+ else:\n+ related_objects.append(\n+ await _get_and_cache_related_object(\n+ kind=\"flow-run\",\n+ role=\"flow-run\",\n+ client_method=client.read_flow_run,\n+ obj_id=flow_run_id,\n+ cache=RESOURCE_CACHE,\n+ )\n+ )\n+\n+ if task_run_context:\n+ related_objects.append(\n+ {\n+ \"kind\": \"task-run\",\n+ \"role\": \"task-run\",\n+ \"object\": task_run_context.task_run,\n+ },\n )\n- ]\n \n flow_run = related_objects[0][\"object\"]\n", "issue": "Include the `task-run` as a related resources when emitting events.\n### First check\n\n- [X] I added a descriptive title to this issue.\n- [X] I used the GitHub search to find a similar request and didn't find it.\n- [X] I searched the Prefect documentation for this feature.\n\n### Prefect Version\n\n2.x\n\n### Describe the current behavior\n\nCurrently task-runs aren't included as related resources when emitting events.\n\n### Describe the proposed behavior\n\nThe current task run in the TaskRunContext should be included in any event fired while a task is running.\n\n### Example Use\n\n_No response_\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "import asyncio\nimport pendulum\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Awaitable,\n Callable,\n Dict,\n Iterable,\n List,\n Optional,\n Set,\n Tuple,\n Union,\n)\nfrom uuid import UUID\nfrom pendulum.datetime import DateTime\n\nfrom .schemas import RelatedResource\n\nif TYPE_CHECKING:\n from prefect._internal.schemas.bases import ObjectBaseModel\n\nResourceCacheEntry = Dict[str, Union[str, \"ObjectBaseModel\", None]]\nRelatedResourceCache = Dict[str, Tuple[ResourceCacheEntry, DateTime]]\n\nMAX_CACHE_SIZE = 100\nRESOURCE_CACHE: RelatedResourceCache = {}\n\n\ndef tags_as_related_resources(tags: Iterable[str]) -> List[RelatedResource]:\n return [\n RelatedResource(\n __root__={\n \"prefect.resource.id\": f\"prefect.tag.{tag}\",\n \"prefect.resource.role\": \"tag\",\n }\n )\n for tag in sorted(tags)\n ]\n\n\ndef object_as_related_resource(kind: str, role: str, object: Any) -> RelatedResource:\n resource_id = f\"prefect.{kind}.{object.id}\"\n\n return RelatedResource(\n __root__={\n \"prefect.resource.id\": resource_id,\n \"prefect.resource.role\": role,\n \"prefect.resource.name\": object.name,\n }\n )\n\n\nasync def related_resources_from_run_context(\n exclude: Optional[Set[str]] = None,\n) -> List[RelatedResource]:\n from prefect.client.orchestration import get_client\n from prefect.context import FlowRunContext, TaskRunContext\n\n if exclude is None:\n exclude = set()\n\n flow_run_context = FlowRunContext.get()\n task_run_context = TaskRunContext.get()\n\n if not flow_run_context and not task_run_context:\n return []\n\n flow_run_id: UUID = (\n flow_run_context.flow_run.id\n if flow_run_context\n else task_run_context.task_run.flow_run_id\n )\n\n related_objects: list[ResourceCacheEntry] = []\n\n async with get_client() as client:\n\n async def dummy_read():\n return {}\n\n related_objects = [\n await _get_and_cache_related_object(\n kind=\"flow-run\",\n role=\"flow-run\",\n client_method=client.read_flow_run,\n obj_id=flow_run_id,\n cache=RESOURCE_CACHE,\n )\n ]\n\n flow_run = related_objects[0][\"object\"]\n\n if flow_run:\n related_objects += list(\n await asyncio.gather(\n _get_and_cache_related_object(\n kind=\"flow\",\n role=\"flow\",\n client_method=client.read_flow,\n obj_id=flow_run.flow_id,\n cache=RESOURCE_CACHE,\n ),\n (\n _get_and_cache_related_object(\n kind=\"deployment\",\n role=\"deployment\",\n client_method=client.read_deployment,\n obj_id=flow_run.deployment_id,\n cache=RESOURCE_CACHE,\n )\n if flow_run.deployment_id\n else dummy_read()\n ),\n (\n _get_and_cache_related_object(\n kind=\"work-queue\",\n role=\"work-queue\",\n client_method=client.read_work_queue,\n obj_id=flow_run.work_queue_id,\n cache=RESOURCE_CACHE,\n )\n if flow_run.work_queue_id\n else dummy_read()\n ),\n (\n _get_and_cache_related_object(\n kind=\"work-pool\",\n role=\"work-pool\",\n client_method=client.read_work_pool,\n obj_id=flow_run.work_pool_name,\n cache=RESOURCE_CACHE,\n )\n if flow_run.work_pool_name\n else dummy_read()\n ),\n )\n )\n\n related = []\n tags = set()\n\n for entry in related_objects:\n obj_ = entry.get(\"object\")\n if obj_ is None:\n continue\n\n assert isinstance(entry[\"kind\"], str) and isinstance(entry[\"role\"], str)\n\n resource = object_as_related_resource(\n kind=entry[\"kind\"], role=entry[\"kind\"], object=obj_\n )\n\n if resource.id in exclude:\n continue\n\n related.append(resource)\n if hasattr(obj_, \"tags\"):\n tags |= set(obj_.tags)\n\n related += [\n resource\n for resource in tags_as_related_resources(tags)\n if resource.id not in exclude\n ]\n\n return related\n\n\nasync def _get_and_cache_related_object(\n kind: str,\n role: str,\n client_method: Callable[[Union[UUID, str]], Awaitable[Optional[\"ObjectBaseModel\"]]],\n obj_id: Union[UUID, str],\n cache: RelatedResourceCache,\n) -> ResourceCacheEntry:\n cache_key = f\"{kind}.{obj_id}\"\n entry = None\n\n if cache_key in cache:\n entry, _ = cache[cache_key]\n else:\n obj_ = await client_method(obj_id)\n entry = {\n \"kind\": kind,\n \"object\": obj_,\n }\n\n cache[cache_key] = (entry, pendulum.now(\"UTC\"))\n\n # In the case of a worker or agent this cache could be long-lived. To keep\n # from running out of memory only keep `MAX_CACHE_SIZE` entries in the\n # cache.\n if len(cache) > MAX_CACHE_SIZE:\n oldest_key = sorted(\n [(key, timestamp) for key, (_, timestamp) in cache.items()],\n key=lambda k: k[1],\n )[0][0]\n\n if oldest_key:\n del cache[oldest_key]\n\n # Because the role is event specific and can change depending on the\n # type of event being emitted, this adds the role from the args to the\n # entry before returning it rather than storing it in the cache.\n entry[\"role\"] = role\n return entry\n", "path": "src/prefect/events/related.py"}], "after_files": [{"content": "import asyncio\nimport pendulum\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Awaitable,\n Callable,\n Dict,\n Iterable,\n List,\n Optional,\n Set,\n Tuple,\n Union,\n)\nfrom uuid import UUID\nfrom pendulum.datetime import DateTime\n\nfrom .schemas import RelatedResource\n\nif TYPE_CHECKING:\n from prefect._internal.schemas.bases import ObjectBaseModel\n\nResourceCacheEntry = Dict[str, Union[str, \"ObjectBaseModel\", None]]\nRelatedResourceCache = Dict[str, Tuple[ResourceCacheEntry, DateTime]]\n\nMAX_CACHE_SIZE = 100\nRESOURCE_CACHE: RelatedResourceCache = {}\n\n\ndef tags_as_related_resources(tags: Iterable[str]) -> List[RelatedResource]:\n return [\n RelatedResource(\n __root__={\n \"prefect.resource.id\": f\"prefect.tag.{tag}\",\n \"prefect.resource.role\": \"tag\",\n }\n )\n for tag in sorted(tags)\n ]\n\n\ndef object_as_related_resource(kind: str, role: str, object: Any) -> RelatedResource:\n resource_id = f\"prefect.{kind}.{object.id}\"\n\n return RelatedResource(\n __root__={\n \"prefect.resource.id\": resource_id,\n \"prefect.resource.role\": role,\n \"prefect.resource.name\": object.name,\n }\n )\n\n\nasync def related_resources_from_run_context(\n exclude: Optional[Set[str]] = None,\n) -> List[RelatedResource]:\n from prefect.client.orchestration import get_client\n from prefect.context import FlowRunContext, TaskRunContext\n\n if exclude is None:\n exclude = set()\n\n flow_run_context = FlowRunContext.get()\n task_run_context = TaskRunContext.get()\n\n if not flow_run_context and not task_run_context:\n return []\n\n flow_run_id: UUID = (\n flow_run_context.flow_run.id\n if flow_run_context\n else task_run_context.task_run.flow_run_id\n )\n\n related_objects: list[ResourceCacheEntry] = []\n\n async with get_client() as client:\n\n async def dummy_read():\n return {}\n\n if flow_run_context:\n related_objects.append(\n {\n \"kind\": \"flow-run\",\n \"role\": \"flow-run\",\n \"object\": flow_run_context.flow_run,\n },\n )\n else:\n related_objects.append(\n await _get_and_cache_related_object(\n kind=\"flow-run\",\n role=\"flow-run\",\n client_method=client.read_flow_run,\n obj_id=flow_run_id,\n cache=RESOURCE_CACHE,\n )\n )\n\n if task_run_context:\n related_objects.append(\n {\n \"kind\": \"task-run\",\n \"role\": \"task-run\",\n \"object\": task_run_context.task_run,\n },\n )\n\n flow_run = related_objects[0][\"object\"]\n\n if flow_run:\n related_objects += list(\n await asyncio.gather(\n _get_and_cache_related_object(\n kind=\"flow\",\n role=\"flow\",\n client_method=client.read_flow,\n obj_id=flow_run.flow_id,\n cache=RESOURCE_CACHE,\n ),\n (\n _get_and_cache_related_object(\n kind=\"deployment\",\n role=\"deployment\",\n client_method=client.read_deployment,\n obj_id=flow_run.deployment_id,\n cache=RESOURCE_CACHE,\n )\n if flow_run.deployment_id\n else dummy_read()\n ),\n (\n _get_and_cache_related_object(\n kind=\"work-queue\",\n role=\"work-queue\",\n client_method=client.read_work_queue,\n obj_id=flow_run.work_queue_id,\n cache=RESOURCE_CACHE,\n )\n if flow_run.work_queue_id\n else dummy_read()\n ),\n (\n _get_and_cache_related_object(\n kind=\"work-pool\",\n role=\"work-pool\",\n client_method=client.read_work_pool,\n obj_id=flow_run.work_pool_name,\n cache=RESOURCE_CACHE,\n )\n if flow_run.work_pool_name\n else dummy_read()\n ),\n )\n )\n\n related = []\n tags = set()\n\n for entry in related_objects:\n obj_ = entry.get(\"object\")\n if obj_ is None:\n continue\n\n assert isinstance(entry[\"kind\"], str) and isinstance(entry[\"role\"], str)\n\n resource = object_as_related_resource(\n kind=entry[\"kind\"], role=entry[\"kind\"], object=obj_\n )\n\n if resource.id in exclude:\n continue\n\n related.append(resource)\n if hasattr(obj_, \"tags\"):\n tags |= set(obj_.tags)\n\n related += [\n resource\n for resource in tags_as_related_resources(tags)\n if resource.id not in exclude\n ]\n\n return related\n\n\nasync def _get_and_cache_related_object(\n kind: str,\n role: str,\n client_method: Callable[[Union[UUID, str]], Awaitable[Optional[\"ObjectBaseModel\"]]],\n obj_id: Union[UUID, str],\n cache: RelatedResourceCache,\n) -> ResourceCacheEntry:\n cache_key = f\"{kind}.{obj_id}\"\n entry = None\n\n if cache_key in cache:\n entry, _ = cache[cache_key]\n else:\n obj_ = await client_method(obj_id)\n entry = {\n \"kind\": kind,\n \"object\": obj_,\n }\n\n cache[cache_key] = (entry, pendulum.now(\"UTC\"))\n\n # In the case of a worker or agent this cache could be long-lived. To keep\n # from running out of memory only keep `MAX_CACHE_SIZE` entries in the\n # cache.\n if len(cache) > MAX_CACHE_SIZE:\n oldest_key = sorted(\n [(key, timestamp) for key, (_, timestamp) in cache.items()],\n key=lambda k: k[1],\n )[0][0]\n\n if oldest_key:\n del cache[oldest_key]\n\n # Because the role is event specific and can change depending on the\n # type of event being emitted, this adds the role from the args to the\n # entry before returning it rather than storing it in the cache.\n entry[\"role\"] = role\n return entry\n", "path": "src/prefect/events/related.py"}]}
| 2,160 | 307 |
gh_patches_debug_35609
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-3200
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DataStore Map and Explorer not displaying map tiles since 11 July 2016
Direct tile access to MapQuest maps has been discontinued as of 11 July 2016 and the DataStore Map and Explorer previews no longer display map tiles.
The issue actually lies with recline.js and it has been logged https://github.com/okfn/recline/issues/500 and there is a referenced patch to replace MapQuest with Open Street Map frodrigo/recline@3df0c2a2bb8897124bdbbca715b2be1fd99cb08f
Thought it would be useful to have a record here and request the packaged recline.js should be updated.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext/reclineview/plugin.py`
Content:
```
1 # encoding: utf-8
2
3 from logging import getLogger
4
5 from ckan.common import json
6 import ckan.plugins as p
7 import ckan.plugins.toolkit as toolkit
8
9 log = getLogger(__name__)
10 ignore_empty = p.toolkit.get_validator('ignore_empty')
11 natural_number_validator = p.toolkit.get_validator('natural_number_validator')
12 Invalid = p.toolkit.Invalid
13
14
15 def in_list(list_possible_values):
16 '''
17 Validator that checks that the input value is one of the given
18 possible values.
19
20 :param list_possible_values: function that returns list of possible values
21 for validated field
22 :type possible_values: function
23 '''
24 def validate(key, data, errors, context):
25 if not data[key] in list_possible_values():
26 raise Invalid('"{0}" is not a valid parameter'.format(data[key]))
27 return validate
28
29
30 def datastore_fields(resource, valid_field_types):
31 '''
32 Return a list of all datastore fields for a given resource, as long as
33 the datastore field type is in valid_field_types.
34
35 :param resource: resource dict
36 :type resource: dict
37 :param valid_field_types: field types to include in returned list
38 :type valid_field_types: list of strings
39 '''
40 data = {'resource_id': resource['id'], 'limit': 0}
41 fields = toolkit.get_action('datastore_search')({}, data)['fields']
42 return [{'value': f['id'], 'text': f['id']} for f in fields
43 if f['type'] in valid_field_types]
44
45
46 class ReclineViewBase(p.SingletonPlugin):
47 '''
48 This base class for the Recline view extensions.
49 '''
50 p.implements(p.IConfigurer, inherit=True)
51 p.implements(p.IResourceView, inherit=True)
52
53 def update_config(self, config):
54 '''
55 Set up the resource library, public directory and
56 template directory for the view
57 '''
58 toolkit.add_public_directory(config, 'theme/public')
59 toolkit.add_template_directory(config, 'theme/templates')
60 toolkit.add_resource('theme/public', 'ckanext-reclineview')
61
62 def can_view(self, data_dict):
63 resource = data_dict['resource']
64 return (resource.get('datastore_active') or
65 '_datastore_only_resource' in resource.get('url', ''))
66
67 def setup_template_variables(self, context, data_dict):
68 return {'resource_json': json.dumps(data_dict['resource']),
69 'resource_view_json': json.dumps(data_dict['resource_view'])}
70
71 def view_template(self, context, data_dict):
72 return 'recline_view.html'
73
74
75 class ReclineView(ReclineViewBase):
76 '''
77 This extension views resources using a Recline MultiView.
78 '''
79
80 def info(self):
81 return {'name': 'recline_view',
82 'title': 'Data Explorer',
83 'filterable': True,
84 'icon': 'table',
85 'requires_datastore': False,
86 'default_title': p.toolkit._('Data Explorer'),
87 }
88
89 def can_view(self, data_dict):
90 resource = data_dict['resource']
91
92 if (resource.get('datastore_active') or
93 '_datastore_only_resource' in resource.get('url', '')):
94 return True
95 resource_format = resource.get('format', None)
96 if resource_format:
97 return resource_format.lower() in ['csv', 'xls', 'xlsx', 'tsv']
98 else:
99 return False
100
101
102 class ReclineGridView(ReclineViewBase):
103 '''
104 This extension views resources using a Recline grid.
105 '''
106
107 def info(self):
108 return {'name': 'recline_grid_view',
109 'title': 'Grid',
110 'filterable': True,
111 'icon': 'table',
112 'requires_datastore': True,
113 'default_title': p.toolkit._('Table'),
114 }
115
116
117 class ReclineGraphView(ReclineViewBase):
118 '''
119 This extension views resources using a Recline graph.
120 '''
121
122 graph_types = [{'value': 'lines-and-points',
123 'text': 'Lines and points'},
124 {'value': 'lines', 'text': 'Lines'},
125 {'value': 'points', 'text': 'Points'},
126 {'value': 'bars', 'text': 'Bars'},
127 {'value': 'columns', 'text': 'Columns'}]
128
129 datastore_fields = []
130
131 datastore_field_types = ['numeric', 'int4', 'timestamp']
132
133 def list_graph_types(self):
134 return [t['value'] for t in self.graph_types]
135
136 def list_datastore_fields(self):
137 return [t['value'] for t in self.datastore_fields]
138
139 def info(self):
140 # in_list validator here is passed functions because this
141 # method does not know what the possible values of the
142 # datastore fields are (requires a datastore search)
143 schema = {
144 'offset': [ignore_empty, natural_number_validator],
145 'limit': [ignore_empty, natural_number_validator],
146 'graph_type': [ignore_empty, in_list(self.list_graph_types)],
147 'group': [ignore_empty, in_list(self.list_datastore_fields)],
148 'series': [ignore_empty, in_list(self.list_datastore_fields)]
149 }
150 return {'name': 'recline_graph_view',
151 'title': 'Graph',
152 'filterable': True,
153 'icon': 'bar-chart',
154 'requires_datastore': True,
155 'schema': schema,
156 'default_title': p.toolkit._('Graph'),
157 }
158
159 def setup_template_variables(self, context, data_dict):
160 self.datastore_fields = datastore_fields(data_dict['resource'],
161 self.datastore_field_types)
162 vars = ReclineViewBase.setup_template_variables(self, context,
163 data_dict)
164 vars.update({'graph_types': self.graph_types,
165 'graph_fields': self.datastore_fields})
166 return vars
167
168 def form_template(self, context, data_dict):
169 return 'recline_graph_form.html'
170
171
172 class ReclineMapView(ReclineViewBase):
173 '''
174 This extension views resources using a Recline map.
175 '''
176
177 map_field_types = [{'value': 'lat_long',
178 'text': 'Latitude / Longitude fields'},
179 {'value': 'geojson', 'text': 'GeoJSON'}]
180
181 datastore_fields = []
182
183 datastore_field_latlon_types = ['numeric']
184
185 datastore_field_geojson_types = ['text']
186
187 def list_map_field_types(self):
188 return [t['value'] for t in self.map_field_types]
189
190 def list_datastore_fields(self):
191 return [t['value'] for t in self.datastore_fields]
192
193 def info(self):
194 # in_list validator here is passed functions because this
195 # method does not know what the possible values of the
196 # datastore fields are (requires a datastore search)
197 schema = {
198 'offset': [ignore_empty, natural_number_validator],
199 'limit': [ignore_empty, natural_number_validator],
200 'map_field_type': [ignore_empty,
201 in_list(self.list_map_field_types)],
202 'latitude_field': [ignore_empty,
203 in_list(self.list_datastore_fields)],
204 'longitude_field': [ignore_empty,
205 in_list(self.list_datastore_fields)],
206 'geojson_field': [ignore_empty,
207 in_list(self.list_datastore_fields)],
208 'auto_zoom': [ignore_empty],
209 'cluster_markers': [ignore_empty]
210 }
211 return {'name': 'recline_map_view',
212 'title': 'Map',
213 'schema': schema,
214 'filterable': True,
215 'icon': 'map-marker',
216 'default_title': p.toolkit._('Map'),
217 }
218
219 def setup_template_variables(self, context, data_dict):
220 map_latlon_fields = datastore_fields(
221 data_dict['resource'], self.datastore_field_latlon_types)
222 map_geojson_fields = datastore_fields(
223 data_dict['resource'], self.datastore_field_geojson_types)
224
225 self.datastore_fields = map_latlon_fields + map_geojson_fields
226
227 vars = ReclineViewBase.setup_template_variables(self, context,
228 data_dict)
229 vars.update({'map_field_types': self.map_field_types,
230 'map_latlon_fields': map_latlon_fields,
231 'map_geojson_fields': map_geojson_fields
232 })
233 return vars
234
235 def form_template(self, context, data_dict):
236 return 'recline_map_form.html'
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckanext/reclineview/plugin.py b/ckanext/reclineview/plugin.py
--- a/ckanext/reclineview/plugin.py
+++ b/ckanext/reclineview/plugin.py
@@ -5,6 +5,7 @@
from ckan.common import json
import ckan.plugins as p
import ckan.plugins.toolkit as toolkit
+from pylons import config
log = getLogger(__name__)
ignore_empty = p.toolkit.get_validator('ignore_empty')
@@ -12,6 +13,15 @@
Invalid = p.toolkit.Invalid
+def get_mapview_config():
+ '''
+ Extracts and returns map view configuration of the reclineview extension.
+ '''
+ namespace = 'ckanext.spatial.common_map.'
+ return dict([(k.replace(namespace, ''), v) for k, v in config.iteritems()
+ if k.startswith(namespace)])
+
+
def in_list(list_possible_values):
'''
Validator that checks that the input value is one of the given
@@ -77,6 +87,8 @@
This extension views resources using a Recline MultiView.
'''
+ p.implements(p.ITemplateHelpers, inherit=True)
+
def info(self):
return {'name': 'recline_view',
'title': 'Data Explorer',
@@ -98,6 +110,11 @@
else:
return False
+ def get_helpers(self):
+ return {
+ 'get_map_config': get_mapview_config
+ }
+
class ReclineGridView(ReclineViewBase):
'''
@@ -174,6 +191,8 @@
This extension views resources using a Recline map.
'''
+ p.implements(p.ITemplateHelpers, inherit=True)
+
map_field_types = [{'value': 'lat_long',
'text': 'Latitude / Longitude fields'},
{'value': 'geojson', 'text': 'GeoJSON'}]
@@ -234,3 +253,8 @@
def form_template(self, context, data_dict):
return 'recline_map_form.html'
+
+ def get_helpers(self):
+ return {
+ 'get_mapview_config': get_mapview_config
+ }
|
{"golden_diff": "diff --git a/ckanext/reclineview/plugin.py b/ckanext/reclineview/plugin.py\n--- a/ckanext/reclineview/plugin.py\n+++ b/ckanext/reclineview/plugin.py\n@@ -5,6 +5,7 @@\n from ckan.common import json\n import ckan.plugins as p\n import ckan.plugins.toolkit as toolkit\n+from pylons import config\n \n log = getLogger(__name__)\n ignore_empty = p.toolkit.get_validator('ignore_empty')\n@@ -12,6 +13,15 @@\n Invalid = p.toolkit.Invalid\n \n \n+def get_mapview_config():\n+ '''\n+ Extracts and returns map view configuration of the reclineview extension.\n+ '''\n+ namespace = 'ckanext.spatial.common_map.'\n+ return dict([(k.replace(namespace, ''), v) for k, v in config.iteritems()\n+ if k.startswith(namespace)])\n+\n+\n def in_list(list_possible_values):\n '''\n Validator that checks that the input value is one of the given\n@@ -77,6 +87,8 @@\n This extension views resources using a Recline MultiView.\n '''\n \n+ p.implements(p.ITemplateHelpers, inherit=True)\n+\n def info(self):\n return {'name': 'recline_view',\n 'title': 'Data Explorer',\n@@ -98,6 +110,11 @@\n else:\n return False\n \n+ def get_helpers(self):\n+ return {\n+ 'get_map_config': get_mapview_config\n+ }\n+\n \n class ReclineGridView(ReclineViewBase):\n '''\n@@ -174,6 +191,8 @@\n This extension views resources using a Recline map.\n '''\n \n+ p.implements(p.ITemplateHelpers, inherit=True)\n+\n map_field_types = [{'value': 'lat_long',\n 'text': 'Latitude / Longitude fields'},\n {'value': 'geojson', 'text': 'GeoJSON'}]\n@@ -234,3 +253,8 @@\n \n def form_template(self, context, data_dict):\n return 'recline_map_form.html'\n+\n+ def get_helpers(self):\n+ return {\n+ 'get_mapview_config': get_mapview_config\n+ }\n", "issue": "DataStore Map and Explorer not displaying map tiles since 11 July 2016\nDirect tile access to MapQuest maps has been discontinued as of 11 July 2016 and the DataStore Map and Explorer previews no longer display map tiles. \n\nThe issue actually lies with recline.js and it has been logged https://github.com/okfn/recline/issues/500 and there is a referenced patch to replace MapQuest with Open Street Map frodrigo/recline@3df0c2a2bb8897124bdbbca715b2be1fd99cb08f\n\nThought it would be useful to have a record here and request the packaged recline.js should be updated.\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom logging import getLogger\n\nfrom ckan.common import json\nimport ckan.plugins as p\nimport ckan.plugins.toolkit as toolkit\n\nlog = getLogger(__name__)\nignore_empty = p.toolkit.get_validator('ignore_empty')\nnatural_number_validator = p.toolkit.get_validator('natural_number_validator')\nInvalid = p.toolkit.Invalid\n\n\ndef in_list(list_possible_values):\n '''\n Validator that checks that the input value is one of the given\n possible values.\n\n :param list_possible_values: function that returns list of possible values\n for validated field\n :type possible_values: function\n '''\n def validate(key, data, errors, context):\n if not data[key] in list_possible_values():\n raise Invalid('\"{0}\" is not a valid parameter'.format(data[key]))\n return validate\n\n\ndef datastore_fields(resource, valid_field_types):\n '''\n Return a list of all datastore fields for a given resource, as long as\n the datastore field type is in valid_field_types.\n\n :param resource: resource dict\n :type resource: dict\n :param valid_field_types: field types to include in returned list\n :type valid_field_types: list of strings\n '''\n data = {'resource_id': resource['id'], 'limit': 0}\n fields = toolkit.get_action('datastore_search')({}, data)['fields']\n return [{'value': f['id'], 'text': f['id']} for f in fields\n if f['type'] in valid_field_types]\n\n\nclass ReclineViewBase(p.SingletonPlugin):\n '''\n This base class for the Recline view extensions.\n '''\n p.implements(p.IConfigurer, inherit=True)\n p.implements(p.IResourceView, inherit=True)\n\n def update_config(self, config):\n '''\n Set up the resource library, public directory and\n template directory for the view\n '''\n toolkit.add_public_directory(config, 'theme/public')\n toolkit.add_template_directory(config, 'theme/templates')\n toolkit.add_resource('theme/public', 'ckanext-reclineview')\n\n def can_view(self, data_dict):\n resource = data_dict['resource']\n return (resource.get('datastore_active') or\n '_datastore_only_resource' in resource.get('url', ''))\n\n def setup_template_variables(self, context, data_dict):\n return {'resource_json': json.dumps(data_dict['resource']),\n 'resource_view_json': json.dumps(data_dict['resource_view'])}\n\n def view_template(self, context, data_dict):\n return 'recline_view.html'\n\n\nclass ReclineView(ReclineViewBase):\n '''\n This extension views resources using a Recline MultiView.\n '''\n\n def info(self):\n return {'name': 'recline_view',\n 'title': 'Data Explorer',\n 'filterable': True,\n 'icon': 'table',\n 'requires_datastore': False,\n 'default_title': p.toolkit._('Data Explorer'),\n }\n\n def can_view(self, data_dict):\n resource = data_dict['resource']\n\n if (resource.get('datastore_active') or\n '_datastore_only_resource' in resource.get('url', '')):\n return True\n resource_format = resource.get('format', None)\n if resource_format:\n return resource_format.lower() in ['csv', 'xls', 'xlsx', 'tsv']\n else:\n return False\n\n\nclass ReclineGridView(ReclineViewBase):\n '''\n This extension views resources using a Recline grid.\n '''\n\n def info(self):\n return {'name': 'recline_grid_view',\n 'title': 'Grid',\n 'filterable': True,\n 'icon': 'table',\n 'requires_datastore': True,\n 'default_title': p.toolkit._('Table'),\n }\n\n\nclass ReclineGraphView(ReclineViewBase):\n '''\n This extension views resources using a Recline graph.\n '''\n\n graph_types = [{'value': 'lines-and-points',\n 'text': 'Lines and points'},\n {'value': 'lines', 'text': 'Lines'},\n {'value': 'points', 'text': 'Points'},\n {'value': 'bars', 'text': 'Bars'},\n {'value': 'columns', 'text': 'Columns'}]\n\n datastore_fields = []\n\n datastore_field_types = ['numeric', 'int4', 'timestamp']\n\n def list_graph_types(self):\n return [t['value'] for t in self.graph_types]\n\n def list_datastore_fields(self):\n return [t['value'] for t in self.datastore_fields]\n\n def info(self):\n # in_list validator here is passed functions because this\n # method does not know what the possible values of the\n # datastore fields are (requires a datastore search)\n schema = {\n 'offset': [ignore_empty, natural_number_validator],\n 'limit': [ignore_empty, natural_number_validator],\n 'graph_type': [ignore_empty, in_list(self.list_graph_types)],\n 'group': [ignore_empty, in_list(self.list_datastore_fields)],\n 'series': [ignore_empty, in_list(self.list_datastore_fields)]\n }\n return {'name': 'recline_graph_view',\n 'title': 'Graph',\n 'filterable': True,\n 'icon': 'bar-chart',\n 'requires_datastore': True,\n 'schema': schema,\n 'default_title': p.toolkit._('Graph'),\n }\n\n def setup_template_variables(self, context, data_dict):\n self.datastore_fields = datastore_fields(data_dict['resource'],\n self.datastore_field_types)\n vars = ReclineViewBase.setup_template_variables(self, context,\n data_dict)\n vars.update({'graph_types': self.graph_types,\n 'graph_fields': self.datastore_fields})\n return vars\n\n def form_template(self, context, data_dict):\n return 'recline_graph_form.html'\n\n\nclass ReclineMapView(ReclineViewBase):\n '''\n This extension views resources using a Recline map.\n '''\n\n map_field_types = [{'value': 'lat_long',\n 'text': 'Latitude / Longitude fields'},\n {'value': 'geojson', 'text': 'GeoJSON'}]\n\n datastore_fields = []\n\n datastore_field_latlon_types = ['numeric']\n\n datastore_field_geojson_types = ['text']\n\n def list_map_field_types(self):\n return [t['value'] for t in self.map_field_types]\n\n def list_datastore_fields(self):\n return [t['value'] for t in self.datastore_fields]\n\n def info(self):\n # in_list validator here is passed functions because this\n # method does not know what the possible values of the\n # datastore fields are (requires a datastore search)\n schema = {\n 'offset': [ignore_empty, natural_number_validator],\n 'limit': [ignore_empty, natural_number_validator],\n 'map_field_type': [ignore_empty,\n in_list(self.list_map_field_types)],\n 'latitude_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'longitude_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'geojson_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'auto_zoom': [ignore_empty],\n 'cluster_markers': [ignore_empty]\n }\n return {'name': 'recline_map_view',\n 'title': 'Map',\n 'schema': schema,\n 'filterable': True,\n 'icon': 'map-marker',\n 'default_title': p.toolkit._('Map'),\n }\n\n def setup_template_variables(self, context, data_dict):\n map_latlon_fields = datastore_fields(\n data_dict['resource'], self.datastore_field_latlon_types)\n map_geojson_fields = datastore_fields(\n data_dict['resource'], self.datastore_field_geojson_types)\n\n self.datastore_fields = map_latlon_fields + map_geojson_fields\n\n vars = ReclineViewBase.setup_template_variables(self, context,\n data_dict)\n vars.update({'map_field_types': self.map_field_types,\n 'map_latlon_fields': map_latlon_fields,\n 'map_geojson_fields': map_geojson_fields\n })\n return vars\n\n def form_template(self, context, data_dict):\n return 'recline_map_form.html'\n", "path": "ckanext/reclineview/plugin.py"}], "after_files": [{"content": "# encoding: utf-8\n\nfrom logging import getLogger\n\nfrom ckan.common import json\nimport ckan.plugins as p\nimport ckan.plugins.toolkit as toolkit\nfrom pylons import config\n\nlog = getLogger(__name__)\nignore_empty = p.toolkit.get_validator('ignore_empty')\nnatural_number_validator = p.toolkit.get_validator('natural_number_validator')\nInvalid = p.toolkit.Invalid\n\n\ndef get_mapview_config():\n '''\n Extracts and returns map view configuration of the reclineview extension.\n '''\n namespace = 'ckanext.spatial.common_map.'\n return dict([(k.replace(namespace, ''), v) for k, v in config.iteritems()\n if k.startswith(namespace)])\n\n\ndef in_list(list_possible_values):\n '''\n Validator that checks that the input value is one of the given\n possible values.\n\n :param list_possible_values: function that returns list of possible values\n for validated field\n :type possible_values: function\n '''\n def validate(key, data, errors, context):\n if not data[key] in list_possible_values():\n raise Invalid('\"{0}\" is not a valid parameter'.format(data[key]))\n return validate\n\n\ndef datastore_fields(resource, valid_field_types):\n '''\n Return a list of all datastore fields for a given resource, as long as\n the datastore field type is in valid_field_types.\n\n :param resource: resource dict\n :type resource: dict\n :param valid_field_types: field types to include in returned list\n :type valid_field_types: list of strings\n '''\n data = {'resource_id': resource['id'], 'limit': 0}\n fields = toolkit.get_action('datastore_search')({}, data)['fields']\n return [{'value': f['id'], 'text': f['id']} for f in fields\n if f['type'] in valid_field_types]\n\n\nclass ReclineViewBase(p.SingletonPlugin):\n '''\n This base class for the Recline view extensions.\n '''\n p.implements(p.IConfigurer, inherit=True)\n p.implements(p.IResourceView, inherit=True)\n\n def update_config(self, config):\n '''\n Set up the resource library, public directory and\n template directory for the view\n '''\n toolkit.add_public_directory(config, 'theme/public')\n toolkit.add_template_directory(config, 'theme/templates')\n toolkit.add_resource('theme/public', 'ckanext-reclineview')\n\n def can_view(self, data_dict):\n resource = data_dict['resource']\n return (resource.get('datastore_active') or\n '_datastore_only_resource' in resource.get('url', ''))\n\n def setup_template_variables(self, context, data_dict):\n return {'resource_json': json.dumps(data_dict['resource']),\n 'resource_view_json': json.dumps(data_dict['resource_view'])}\n\n def view_template(self, context, data_dict):\n return 'recline_view.html'\n\n\nclass ReclineView(ReclineViewBase):\n '''\n This extension views resources using a Recline MultiView.\n '''\n\n p.implements(p.ITemplateHelpers, inherit=True)\n\n def info(self):\n return {'name': 'recline_view',\n 'title': 'Data Explorer',\n 'filterable': True,\n 'icon': 'table',\n 'requires_datastore': False,\n 'default_title': p.toolkit._('Data Explorer'),\n }\n\n def can_view(self, data_dict):\n resource = data_dict['resource']\n\n if (resource.get('datastore_active') or\n '_datastore_only_resource' in resource.get('url', '')):\n return True\n resource_format = resource.get('format', None)\n if resource_format:\n return resource_format.lower() in ['csv', 'xls', 'xlsx', 'tsv']\n else:\n return False\n\n def get_helpers(self):\n return {\n 'get_map_config': get_mapview_config\n }\n\n\nclass ReclineGridView(ReclineViewBase):\n '''\n This extension views resources using a Recline grid.\n '''\n\n def info(self):\n return {'name': 'recline_grid_view',\n 'title': 'Grid',\n 'filterable': True,\n 'icon': 'table',\n 'requires_datastore': True,\n 'default_title': p.toolkit._('Table'),\n }\n\n\nclass ReclineGraphView(ReclineViewBase):\n '''\n This extension views resources using a Recline graph.\n '''\n\n graph_types = [{'value': 'lines-and-points',\n 'text': 'Lines and points'},\n {'value': 'lines', 'text': 'Lines'},\n {'value': 'points', 'text': 'Points'},\n {'value': 'bars', 'text': 'Bars'},\n {'value': 'columns', 'text': 'Columns'}]\n\n datastore_fields = []\n\n datastore_field_types = ['numeric', 'int4', 'timestamp']\n\n def list_graph_types(self):\n return [t['value'] for t in self.graph_types]\n\n def list_datastore_fields(self):\n return [t['value'] for t in self.datastore_fields]\n\n def info(self):\n # in_list validator here is passed functions because this\n # method does not know what the possible values of the\n # datastore fields are (requires a datastore search)\n schema = {\n 'offset': [ignore_empty, natural_number_validator],\n 'limit': [ignore_empty, natural_number_validator],\n 'graph_type': [ignore_empty, in_list(self.list_graph_types)],\n 'group': [ignore_empty, in_list(self.list_datastore_fields)],\n 'series': [ignore_empty, in_list(self.list_datastore_fields)]\n }\n return {'name': 'recline_graph_view',\n 'title': 'Graph',\n 'filterable': True,\n 'icon': 'bar-chart',\n 'requires_datastore': True,\n 'schema': schema,\n 'default_title': p.toolkit._('Graph'),\n }\n\n def setup_template_variables(self, context, data_dict):\n self.datastore_fields = datastore_fields(data_dict['resource'],\n self.datastore_field_types)\n vars = ReclineViewBase.setup_template_variables(self, context,\n data_dict)\n vars.update({'graph_types': self.graph_types,\n 'graph_fields': self.datastore_fields})\n return vars\n\n def form_template(self, context, data_dict):\n return 'recline_graph_form.html'\n\n\nclass ReclineMapView(ReclineViewBase):\n '''\n This extension views resources using a Recline map.\n '''\n\n p.implements(p.ITemplateHelpers, inherit=True)\n\n map_field_types = [{'value': 'lat_long',\n 'text': 'Latitude / Longitude fields'},\n {'value': 'geojson', 'text': 'GeoJSON'}]\n\n datastore_fields = []\n\n datastore_field_latlon_types = ['numeric']\n\n datastore_field_geojson_types = ['text']\n\n def list_map_field_types(self):\n return [t['value'] for t in self.map_field_types]\n\n def list_datastore_fields(self):\n return [t['value'] for t in self.datastore_fields]\n\n def info(self):\n # in_list validator here is passed functions because this\n # method does not know what the possible values of the\n # datastore fields are (requires a datastore search)\n schema = {\n 'offset': [ignore_empty, natural_number_validator],\n 'limit': [ignore_empty, natural_number_validator],\n 'map_field_type': [ignore_empty,\n in_list(self.list_map_field_types)],\n 'latitude_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'longitude_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'geojson_field': [ignore_empty,\n in_list(self.list_datastore_fields)],\n 'auto_zoom': [ignore_empty],\n 'cluster_markers': [ignore_empty]\n }\n return {'name': 'recline_map_view',\n 'title': 'Map',\n 'schema': schema,\n 'filterable': True,\n 'icon': 'map-marker',\n 'default_title': p.toolkit._('Map'),\n }\n\n def setup_template_variables(self, context, data_dict):\n map_latlon_fields = datastore_fields(\n data_dict['resource'], self.datastore_field_latlon_types)\n map_geojson_fields = datastore_fields(\n data_dict['resource'], self.datastore_field_geojson_types)\n\n self.datastore_fields = map_latlon_fields + map_geojson_fields\n\n vars = ReclineViewBase.setup_template_variables(self, context,\n data_dict)\n vars.update({'map_field_types': self.map_field_types,\n 'map_latlon_fields': map_latlon_fields,\n 'map_geojson_fields': map_geojson_fields\n })\n return vars\n\n def form_template(self, context, data_dict):\n return 'recline_map_form.html'\n\n def get_helpers(self):\n return {\n 'get_mapview_config': get_mapview_config\n }\n", "path": "ckanext/reclineview/plugin.py"}]}
| 2,813 | 488 |
gh_patches_debug_37532
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-1633
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a CLI option for verbosity to the pytest plugin
The `HYPOTHESIS_VERBOSITY_LEVEL` environment variable is now deprecated (from #1211). An easy way to control verbosity is still useful though, so we would like to support this as a command-line flag.
This would be implemented in [`hypothesis.extra.pytestplugin`](https://github.com/HypothesisWorks/hypothesis/blob/master/hypothesis-python/src/hypothesis/extra/pytestplugin.py), similarly to [the deprecated version here](https://github.com/HypothesisWorks/hypothesis/blob/3c5f3906a7339af8bf2448281377abe903575245/hypothesis-python/src/hypothesis/_settings.py#L626-L629). The new ``--hypothesis-verbosity`` option should be applied *after* loading the profile specified by ``--hypothesis-profile`` (if given).
Finally, the new option should be listed in `docs/details.rst`, including that the verbosity option is applied after loading a profile.
*If you would like to work on this issue, feel free to comment and I will help you get started!*
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hypothesis-python/src/hypothesis/extra/pytestplugin.py`
Content:
```
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2018 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 import pytest
21
22 from hypothesis import core, settings
23 from hypothesis.reporting import default as default_reporter
24 from hypothesis.reporting import with_reporter
25 from hypothesis.statistics import collector
26 from hypothesis.internal.compat import OrderedDict, text_type
27 from hypothesis.internal.detection import is_hypothesis_test
28
29 LOAD_PROFILE_OPTION = '--hypothesis-profile'
30 PRINT_STATISTICS_OPTION = '--hypothesis-show-statistics'
31 SEED_OPTION = '--hypothesis-seed'
32
33
34 class StoringReporter(object):
35
36 def __init__(self, config):
37 self.config = config
38 self.results = []
39
40 def __call__(self, msg):
41 if self.config.getoption('capture', 'fd') == 'no':
42 default_reporter(msg)
43 if not isinstance(msg, text_type):
44 msg = repr(msg)
45 self.results.append(msg)
46
47
48 def pytest_addoption(parser):
49 group = parser.getgroup('hypothesis', 'Hypothesis')
50 group.addoption(
51 LOAD_PROFILE_OPTION,
52 action='store',
53 help='Load in a registered hypothesis.settings profile'
54 )
55 group.addoption(
56 PRINT_STATISTICS_OPTION,
57 action='store_true',
58 help='Configure when statistics are printed',
59 default=False
60 )
61 group.addoption(
62 SEED_OPTION,
63 action='store',
64 help='Set a seed to use for all Hypothesis tests'
65 )
66
67
68 def pytest_report_header(config):
69 profile = config.getoption(LOAD_PROFILE_OPTION)
70 if not profile:
71 profile = 'default'
72 settings_str = settings.get_profile(profile).show_changed()
73 if settings_str != '':
74 settings_str = ' -> %s' % (settings_str)
75 return 'hypothesis profile %r%s' % (profile, settings_str)
76
77
78 def pytest_configure(config):
79 core.running_under_pytest = True
80 profile = config.getoption(LOAD_PROFILE_OPTION)
81 if profile:
82 settings.load_profile(profile)
83 seed = config.getoption(SEED_OPTION)
84 if seed is not None:
85 try:
86 seed = int(seed)
87 except ValueError:
88 pass
89 core.global_force_seed = seed
90 config.addinivalue_line(
91 'markers',
92 'hypothesis: Tests which use hypothesis.')
93
94
95 gathered_statistics = OrderedDict() # type: dict
96
97
98 @pytest.mark.hookwrapper
99 def pytest_runtest_call(item):
100 if not (hasattr(item, 'obj') and is_hypothesis_test(item.obj)):
101 yield
102 else:
103 store = StoringReporter(item.config)
104
105 def note_statistics(stats):
106 gathered_statistics[item.nodeid] = stats
107
108 with collector.with_value(note_statistics):
109 with with_reporter(store):
110 yield
111 if store.results:
112 item.hypothesis_report_information = list(store.results)
113
114
115 @pytest.mark.hookwrapper
116 def pytest_runtest_makereport(item, call):
117 report = (yield).get_result()
118 if hasattr(item, 'hypothesis_report_information'):
119 report.sections.append((
120 'Hypothesis',
121 '\n'.join(item.hypothesis_report_information)
122 ))
123
124
125 def pytest_terminal_summary(terminalreporter):
126 if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):
127 return
128 terminalreporter.section('Hypothesis Statistics')
129 for name, statistics in gathered_statistics.items():
130 terminalreporter.write_line(name + ':')
131 terminalreporter.write_line('')
132
133 if not statistics.has_runs:
134 terminalreporter.write_line(' - Test was never run')
135 continue
136
137 terminalreporter.write_line((
138 ' - %d passing examples, %d failing examples,'
139 ' %d invalid examples') % (
140 statistics.passing_examples, statistics.failing_examples,
141 statistics.invalid_examples,
142 ))
143 terminalreporter.write_line(
144 ' - Typical runtimes: %s' % (statistics.runtimes,)
145 )
146 terminalreporter.write_line(
147 ' - Fraction of time spent in data generation: %s' % (
148 statistics.draw_time_percentage,))
149 terminalreporter.write_line(
150 ' - Stopped because %s' % (statistics.exit_reason,)
151 )
152 if statistics.events:
153 terminalreporter.write_line(' - Events:')
154 for event in statistics.events:
155 terminalreporter.write_line(
156 ' * %s' % (event,)
157 )
158 terminalreporter.write_line('')
159
160
161 def pytest_collection_modifyitems(items):
162 for item in items:
163 if not isinstance(item, pytest.Function):
164 continue
165 if getattr(item.function, 'is_hypothesis_test', False):
166 item.add_marker('hypothesis')
167
168
169 def load():
170 pass
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py
+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
@@ -19,7 +19,7 @@
import pytest
-from hypothesis import core, settings
+from hypothesis import Verbosity, core, settings
from hypothesis.reporting import default as default_reporter
from hypothesis.reporting import with_reporter
from hypothesis.statistics import collector
@@ -27,6 +27,7 @@
from hypothesis.internal.detection import is_hypothesis_test
LOAD_PROFILE_OPTION = '--hypothesis-profile'
+VERBOSITY_OPTION = '--hypothesis-verbosity'
PRINT_STATISTICS_OPTION = '--hypothesis-show-statistics'
SEED_OPTION = '--hypothesis-seed'
@@ -52,6 +53,12 @@
action='store',
help='Load in a registered hypothesis.settings profile'
)
+ group.addoption(
+ VERBOSITY_OPTION,
+ action='store',
+ choices=[opt.name for opt in Verbosity],
+ help='Override profile with verbosity setting specified'
+ )
group.addoption(
PRINT_STATISTICS_OPTION,
action='store_true',
@@ -68,7 +75,7 @@
def pytest_report_header(config):
profile = config.getoption(LOAD_PROFILE_OPTION)
if not profile:
- profile = 'default'
+ profile = settings._current_profile
settings_str = settings.get_profile(profile).show_changed()
if settings_str != '':
settings_str = ' -> %s' % (settings_str)
@@ -80,6 +87,16 @@
profile = config.getoption(LOAD_PROFILE_OPTION)
if profile:
settings.load_profile(profile)
+ verbosity_name = config.getoption(VERBOSITY_OPTION)
+ if verbosity_name:
+ verbosity_value = Verbosity[verbosity_name]
+ profile_name = '%s-with-%s-verbosity' % (
+ settings._current_profile, verbosity_name
+ )
+ # register_profile creates a new profile, exactly like the current one,
+ # with the extra values given (in this case 'verbosity')
+ settings.register_profile(profile_name, verbosity=verbosity_value)
+ settings.load_profile(profile_name)
seed = config.getoption(SEED_OPTION)
if seed is not None:
try:
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n@@ -19,7 +19,7 @@\n \n import pytest\n \n-from hypothesis import core, settings\n+from hypothesis import Verbosity, core, settings\n from hypothesis.reporting import default as default_reporter\n from hypothesis.reporting import with_reporter\n from hypothesis.statistics import collector\n@@ -27,6 +27,7 @@\n from hypothesis.internal.detection import is_hypothesis_test\n \n LOAD_PROFILE_OPTION = '--hypothesis-profile'\n+VERBOSITY_OPTION = '--hypothesis-verbosity'\n PRINT_STATISTICS_OPTION = '--hypothesis-show-statistics'\n SEED_OPTION = '--hypothesis-seed'\n \n@@ -52,6 +53,12 @@\n action='store',\n help='Load in a registered hypothesis.settings profile'\n )\n+ group.addoption(\n+ VERBOSITY_OPTION,\n+ action='store',\n+ choices=[opt.name for opt in Verbosity],\n+ help='Override profile with verbosity setting specified'\n+ )\n group.addoption(\n PRINT_STATISTICS_OPTION,\n action='store_true',\n@@ -68,7 +75,7 @@\n def pytest_report_header(config):\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if not profile:\n- profile = 'default'\n+ profile = settings._current_profile\n settings_str = settings.get_profile(profile).show_changed()\n if settings_str != '':\n settings_str = ' -> %s' % (settings_str)\n@@ -80,6 +87,16 @@\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if profile:\n settings.load_profile(profile)\n+ verbosity_name = config.getoption(VERBOSITY_OPTION)\n+ if verbosity_name:\n+ verbosity_value = Verbosity[verbosity_name]\n+ profile_name = '%s-with-%s-verbosity' % (\n+ settings._current_profile, verbosity_name\n+ )\n+ # register_profile creates a new profile, exactly like the current one,\n+ # with the extra values given (in this case 'verbosity')\n+ settings.register_profile(profile_name, verbosity=verbosity_value)\n+ settings.load_profile(profile_name)\n seed = config.getoption(SEED_OPTION)\n if seed is not None:\n try:\n", "issue": "Add a CLI option for verbosity to the pytest plugin\nThe `HYPOTHESIS_VERBOSITY_LEVEL` environment variable is now deprecated (from #1211). An easy way to control verbosity is still useful though, so we would like to support this as a command-line flag.\r\n\r\nThis would be implemented in [`hypothesis.extra.pytestplugin`](https://github.com/HypothesisWorks/hypothesis/blob/master/hypothesis-python/src/hypothesis/extra/pytestplugin.py), similarly to [the deprecated version here](https://github.com/HypothesisWorks/hypothesis/blob/3c5f3906a7339af8bf2448281377abe903575245/hypothesis-python/src/hypothesis/_settings.py#L626-L629). The new ``--hypothesis-verbosity`` option should be applied *after* loading the profile specified by ``--hypothesis-profile`` (if given).\r\n\r\nFinally, the new option should be listed in `docs/details.rst`, including that the verbosity option is applied after loading a profile.\r\n\r\n*If you would like to work on this issue, feel free to comment and I will help you get started!*\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2018 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport pytest\n\nfrom hypothesis import core, settings\nfrom hypothesis.reporting import default as default_reporter\nfrom hypothesis.reporting import with_reporter\nfrom hypothesis.statistics import collector\nfrom hypothesis.internal.compat import OrderedDict, text_type\nfrom hypothesis.internal.detection import is_hypothesis_test\n\nLOAD_PROFILE_OPTION = '--hypothesis-profile'\nPRINT_STATISTICS_OPTION = '--hypothesis-show-statistics'\nSEED_OPTION = '--hypothesis-seed'\n\n\nclass StoringReporter(object):\n\n def __init__(self, config):\n self.config = config\n self.results = []\n\n def __call__(self, msg):\n if self.config.getoption('capture', 'fd') == 'no':\n default_reporter(msg)\n if not isinstance(msg, text_type):\n msg = repr(msg)\n self.results.append(msg)\n\n\ndef pytest_addoption(parser):\n group = parser.getgroup('hypothesis', 'Hypothesis')\n group.addoption(\n LOAD_PROFILE_OPTION,\n action='store',\n help='Load in a registered hypothesis.settings profile'\n )\n group.addoption(\n PRINT_STATISTICS_OPTION,\n action='store_true',\n help='Configure when statistics are printed',\n default=False\n )\n group.addoption(\n SEED_OPTION,\n action='store',\n help='Set a seed to use for all Hypothesis tests'\n )\n\n\ndef pytest_report_header(config):\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if not profile:\n profile = 'default'\n settings_str = settings.get_profile(profile).show_changed()\n if settings_str != '':\n settings_str = ' -> %s' % (settings_str)\n return 'hypothesis profile %r%s' % (profile, settings_str)\n\n\ndef pytest_configure(config):\n core.running_under_pytest = True\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if profile:\n settings.load_profile(profile)\n seed = config.getoption(SEED_OPTION)\n if seed is not None:\n try:\n seed = int(seed)\n except ValueError:\n pass\n core.global_force_seed = seed\n config.addinivalue_line(\n 'markers',\n 'hypothesis: Tests which use hypothesis.')\n\n\ngathered_statistics = OrderedDict() # type: dict\n\n\[email protected]\ndef pytest_runtest_call(item):\n if not (hasattr(item, 'obj') and is_hypothesis_test(item.obj)):\n yield\n else:\n store = StoringReporter(item.config)\n\n def note_statistics(stats):\n gathered_statistics[item.nodeid] = stats\n\n with collector.with_value(note_statistics):\n with with_reporter(store):\n yield\n if store.results:\n item.hypothesis_report_information = list(store.results)\n\n\[email protected]\ndef pytest_runtest_makereport(item, call):\n report = (yield).get_result()\n if hasattr(item, 'hypothesis_report_information'):\n report.sections.append((\n 'Hypothesis',\n '\\n'.join(item.hypothesis_report_information)\n ))\n\n\ndef pytest_terminal_summary(terminalreporter):\n if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):\n return\n terminalreporter.section('Hypothesis Statistics')\n for name, statistics in gathered_statistics.items():\n terminalreporter.write_line(name + ':')\n terminalreporter.write_line('')\n\n if not statistics.has_runs:\n terminalreporter.write_line(' - Test was never run')\n continue\n\n terminalreporter.write_line((\n ' - %d passing examples, %d failing examples,'\n ' %d invalid examples') % (\n statistics.passing_examples, statistics.failing_examples,\n statistics.invalid_examples,\n ))\n terminalreporter.write_line(\n ' - Typical runtimes: %s' % (statistics.runtimes,)\n )\n terminalreporter.write_line(\n ' - Fraction of time spent in data generation: %s' % (\n statistics.draw_time_percentage,))\n terminalreporter.write_line(\n ' - Stopped because %s' % (statistics.exit_reason,)\n )\n if statistics.events:\n terminalreporter.write_line(' - Events:')\n for event in statistics.events:\n terminalreporter.write_line(\n ' * %s' % (event,)\n )\n terminalreporter.write_line('')\n\n\ndef pytest_collection_modifyitems(items):\n for item in items:\n if not isinstance(item, pytest.Function):\n continue\n if getattr(item.function, 'is_hypothesis_test', False):\n item.add_marker('hypothesis')\n\n\ndef load():\n pass\n", "path": "hypothesis-python/src/hypothesis/extra/pytestplugin.py"}], "after_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2018 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport pytest\n\nfrom hypothesis import Verbosity, core, settings\nfrom hypothesis.reporting import default as default_reporter\nfrom hypothesis.reporting import with_reporter\nfrom hypothesis.statistics import collector\nfrom hypothesis.internal.compat import OrderedDict, text_type\nfrom hypothesis.internal.detection import is_hypothesis_test\n\nLOAD_PROFILE_OPTION = '--hypothesis-profile'\nVERBOSITY_OPTION = '--hypothesis-verbosity'\nPRINT_STATISTICS_OPTION = '--hypothesis-show-statistics'\nSEED_OPTION = '--hypothesis-seed'\n\n\nclass StoringReporter(object):\n\n def __init__(self, config):\n self.config = config\n self.results = []\n\n def __call__(self, msg):\n if self.config.getoption('capture', 'fd') == 'no':\n default_reporter(msg)\n if not isinstance(msg, text_type):\n msg = repr(msg)\n self.results.append(msg)\n\n\ndef pytest_addoption(parser):\n group = parser.getgroup('hypothesis', 'Hypothesis')\n group.addoption(\n LOAD_PROFILE_OPTION,\n action='store',\n help='Load in a registered hypothesis.settings profile'\n )\n group.addoption(\n VERBOSITY_OPTION,\n action='store',\n choices=[opt.name for opt in Verbosity],\n help='Override profile with verbosity setting specified'\n )\n group.addoption(\n PRINT_STATISTICS_OPTION,\n action='store_true',\n help='Configure when statistics are printed',\n default=False\n )\n group.addoption(\n SEED_OPTION,\n action='store',\n help='Set a seed to use for all Hypothesis tests'\n )\n\n\ndef pytest_report_header(config):\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if not profile:\n profile = settings._current_profile\n settings_str = settings.get_profile(profile).show_changed()\n if settings_str != '':\n settings_str = ' -> %s' % (settings_str)\n return 'hypothesis profile %r%s' % (profile, settings_str)\n\n\ndef pytest_configure(config):\n core.running_under_pytest = True\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if profile:\n settings.load_profile(profile)\n verbosity_name = config.getoption(VERBOSITY_OPTION)\n if verbosity_name:\n verbosity_value = Verbosity[verbosity_name]\n profile_name = '%s-with-%s-verbosity' % (\n settings._current_profile, verbosity_name\n )\n # register_profile creates a new profile, exactly like the current one,\n # with the extra values given (in this case 'verbosity')\n settings.register_profile(profile_name, verbosity=verbosity_value)\n settings.load_profile(profile_name)\n seed = config.getoption(SEED_OPTION)\n if seed is not None:\n try:\n seed = int(seed)\n except ValueError:\n pass\n core.global_force_seed = seed\n config.addinivalue_line(\n 'markers',\n 'hypothesis: Tests which use hypothesis.')\n\n\ngathered_statistics = OrderedDict() # type: dict\n\n\[email protected]\ndef pytest_runtest_call(item):\n if not (hasattr(item, 'obj') and is_hypothesis_test(item.obj)):\n yield\n else:\n store = StoringReporter(item.config)\n\n def note_statistics(stats):\n gathered_statistics[item.nodeid] = stats\n\n with collector.with_value(note_statistics):\n with with_reporter(store):\n yield\n if store.results:\n item.hypothesis_report_information = list(store.results)\n\n\[email protected]\ndef pytest_runtest_makereport(item, call):\n report = (yield).get_result()\n if hasattr(item, 'hypothesis_report_information'):\n report.sections.append((\n 'Hypothesis',\n '\\n'.join(item.hypothesis_report_information)\n ))\n\n\ndef pytest_terminal_summary(terminalreporter):\n if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):\n return\n terminalreporter.section('Hypothesis Statistics')\n for name, statistics in gathered_statistics.items():\n terminalreporter.write_line(name + ':')\n terminalreporter.write_line('')\n\n if not statistics.has_runs:\n terminalreporter.write_line(' - Test was never run')\n continue\n\n terminalreporter.write_line((\n ' - %d passing examples, %d failing examples,'\n ' %d invalid examples') % (\n statistics.passing_examples, statistics.failing_examples,\n statistics.invalid_examples,\n ))\n terminalreporter.write_line(\n ' - Typical runtimes: %s' % (statistics.runtimes,)\n )\n terminalreporter.write_line(\n ' - Fraction of time spent in data generation: %s' % (\n statistics.draw_time_percentage,))\n terminalreporter.write_line(\n ' - Stopped because %s' % (statistics.exit_reason,)\n )\n if statistics.events:\n terminalreporter.write_line(' - Events:')\n for event in statistics.events:\n terminalreporter.write_line(\n ' * %s' % (event,)\n )\n terminalreporter.write_line('')\n\n\ndef pytest_collection_modifyitems(items):\n for item in items:\n if not isinstance(item, pytest.Function):\n continue\n if getattr(item.function, 'is_hypothesis_test', False):\n item.add_marker('hypothesis')\n\n\ndef load():\n pass\n", "path": "hypothesis-python/src/hypothesis/extra/pytestplugin.py"}]}
| 2,123 | 541 |
gh_patches_debug_26529
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-1172
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
s3: Support AWS credential settings from environment variables
dvc should also load credential information from system environment variables as awscli does.
Reference: https://docs.aws.amazon.com/cli/latest/userguide/cli-environment.html
For example: we should be able to run `dvc pull` despite absence of AWS profiles in _~/.aws_ if we had set the following environment variables:
```
$ export AWS_ACCESS_KEY_ID=somekey
$ export AWS_SECRET_ACCESS_KEY=somekey
$ export AWS_DEFAULT_REGION=someregion
```
The following command works:
```
aws s3 ls s3://bucketname
```
But this one does not:
```
dvc pull
```
A usecase for this is doing `dvc pull` in docker image building process, which would be much easier if if we can override configuration via environment variables.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/remote/s3.py`
Content:
```
1 import os
2 import threading
3 import posixpath
4
5 try:
6 import boto3
7 except ImportError:
8 boto3 = None
9
10 try:
11 from urlparse import urlparse
12 except ImportError:
13 from urllib.parse import urlparse
14
15 from dvc.logger import Logger
16 from dvc.progress import progress
17 from dvc.config import Config
18 from dvc.remote.base import RemoteBase
19 from dvc.remote.local import RemoteLOCAL
20 from dvc.exceptions import DvcException
21
22
23 class Callback(object):
24 def __init__(self, name, total):
25 self.name = name
26 self.total = total
27 self.current = 0
28 self.lock = threading.Lock()
29
30 def __call__(self, byts):
31 with self.lock:
32 self.current += byts
33 progress.update_target(self.name, self.current, self.total)
34
35
36 class RemoteS3(RemoteBase):
37 scheme = 's3'
38 REGEX = r'^s3://(?P<path>.*)$'
39 REQUIRES = {'boto3': boto3}
40 PARAM_ETAG = 'etag'
41
42 def __init__(self, project, config):
43 import configobj
44
45 self.project = project
46 storagepath = 's3://' + config.get(Config.SECTION_AWS_STORAGEPATH,
47 '').lstrip('/')
48 self.url = config.get(Config.SECTION_REMOTE_URL, storagepath)
49 self.region = config.get(Config.SECTION_AWS_REGION, None)
50 self.profile = config.get(Config.SECTION_AWS_PROFILE, 'default')
51 self.endpoint_url = config.get(Config.SECTION_AWS_ENDPOINT_URL, None)
52
53 credentialpath = config.get(Config.SECTION_AWS_CREDENTIALPATH, None)
54 if credentialpath:
55 creds_conf = configobj.ConfigObj(credentialpath)
56 creds = creds_conf.get(self.profile, {})
57 else:
58 creds = {}
59
60 self.creds = creds
61 self.region = creds.get('region', self.region)
62 self.aws_access_key_id = creds.get('aws_access_key_id', None)
63 self.aws_secret_access_key = creds.get('aws_secret_access_key', None)
64
65 @property
66 def bucket(self):
67 return urlparse(self.url).netloc
68
69 @property
70 def prefix(self):
71 return urlparse(self.url).path.lstrip('/')
72
73 @property
74 def s3(self):
75 if not self.creds:
76 session = boto3.session.Session(profile_name=self.profile)
77 else:
78 session = boto3.session.Session(
79 aws_access_key_id=self.aws_access_key_id,
80 aws_secret_access_key=self.aws_secret_access_key,
81 region_name=self.region)
82 return session.client('s3', endpoint_url=self.endpoint_url)
83
84 def get_etag(self, bucket, key):
85 try:
86 obj = self.s3.head_object(Bucket=bucket, Key=key)
87 except Exception:
88 raise DvcException('s3://{}/{} does not exist'.format(bucket, key))
89
90 return obj['ETag'].strip('"')
91
92 def save_info(self, path_info):
93 if path_info['scheme'] != 's3':
94 raise NotImplementedError
95
96 return {self.PARAM_ETAG: self.get_etag(path_info['bucket'],
97 path_info['key'])}
98
99 def changed(self, path_info, checksum_info):
100 if not self.exists([path_info])[0]:
101 return True
102
103 etag = checksum_info.get(self.PARAM_ETAG, None)
104 if etag is None:
105 return True
106
107 if self.changed_cache(etag):
108 return True
109
110 return checksum_info != self.save_info(path_info)
111
112 def _copy(self, from_info, to_info, s3=None):
113 s3 = s3 if s3 else self.s3
114
115 source = {'Bucket': from_info['bucket'],
116 'Key': from_info['key']}
117 self.s3.copy(source, to_info['bucket'], to_info['key'])
118
119 def save(self, path_info):
120 if path_info['scheme'] != 's3':
121 raise NotImplementedError
122
123 etag = self.get_etag(path_info['bucket'], path_info['key'])
124 key = posixpath.join(self.prefix, etag[0:2], etag[2:])
125 to_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}
126
127 self._copy(path_info, to_info)
128
129 return {self.PARAM_ETAG: etag}
130
131 @staticmethod
132 def to_string(path_info):
133 return "s3://{}/{}".format(path_info['bucket'], path_info['key'])
134
135 def changed_cache(self, etag):
136 key = posixpath.join(self.prefix, etag[0:2], etag[2:])
137 cache = {'scheme': 's3', 'bucket': self.bucket, 'key': key}
138
139 if {self.PARAM_ETAG: etag} != self.save_info(cache):
140 if self.exists([cache])[0]:
141 msg = 'Corrupted cache file {}'
142 Logger.warn(msg.format(self.to_string(cache)))
143 self.remove(cache)
144 return True
145
146 return False
147
148 def checkout(self, path_info, checksum_info):
149 if path_info['scheme'] != 's3':
150 raise NotImplementedError
151
152 etag = checksum_info.get(self.PARAM_ETAG, None)
153 if not etag:
154 return
155
156 if not self.changed(path_info, checksum_info):
157 msg = "Data '{}' didn't change."
158 Logger.info(msg.format(self.to_string(path_info)))
159 return
160
161 if self.changed_cache(etag):
162 msg = "Cache '{}' not found. File '{}' won't be created."
163 Logger.warn(msg.format(etag, self.to_string(path_info)))
164 return
165
166 if self.exists([path_info])[0]:
167 msg = "Data '{}' exists. Removing before checkout."
168 Logger.warn(msg.format(self.to_string(path_info)))
169 self.remove(path_info)
170 return
171
172 msg = "Checking out '{}' with cache '{}'."
173 Logger.info(msg.format(self.to_string(path_info), etag))
174
175 key = posixpath.join(self.prefix, etag[0:2], etag[2:])
176 from_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}
177
178 self._copy(from_info, path_info)
179
180 def remove(self, path_info):
181 if path_info['scheme'] != 's3':
182 raise NotImplementedError
183
184 Logger.debug('Removing s3://{}/{}'.format(path_info['bucket'],
185 path_info['key']))
186
187 self.s3.delete_object(Bucket=path_info['bucket'],
188 Key=path_info['key'])
189
190 def md5s_to_path_infos(self, md5s):
191 return [{'scheme': self.scheme,
192 'bucket': self.bucket,
193 'key': posixpath.join(self.prefix,
194 md5[0:2], md5[2:])} for md5 in md5s]
195
196 def _all_keys(self):
197 s3 = self.s3
198
199 keys = []
200 kwargs = {'Bucket': self.bucket,
201 'Prefix': self.prefix}
202 while True:
203 resp = s3.list_objects_v2(**kwargs)
204 contents = resp.get('Contents', None)
205 if not contents:
206 break
207
208 for obj in contents:
209 keys.append(obj['Key'])
210
211 token = resp.get('NextContinuationToken', None)
212 if not token:
213 break
214
215 kwargs['ContinuationToken'] = token
216
217 return keys
218
219 def exists(self, path_infos):
220 # NOTE: We mostly use exists() method when filtering a bulk of cache
221 # files to decide if we need to download/upload them and in s3
222 # list_objects_v2() is much-much faster than trying to check keys
223 # one-by-one.
224 ret = []
225
226 keys = self._all_keys()
227
228 for path_info in path_infos:
229 exists = False
230 if path_info['key'] in keys:
231 exists = True
232 ret.append(exists)
233
234 return ret
235
236 def upload(self, from_infos, to_infos, names=None):
237 names = self._verify_path_args(to_infos, from_infos, names)
238
239 s3 = self.s3
240
241 for from_info, to_info, name in zip(from_infos, to_infos, names):
242 if to_info['scheme'] != 's3':
243 raise NotImplementedError
244
245 if from_info['scheme'] != 'local':
246 raise NotImplementedError
247
248 Logger.debug("Uploading '{}' to '{}/{}'".format(from_info['path'],
249 to_info['bucket'],
250 to_info['key']))
251
252 if not name:
253 name = os.path.basename(from_info['path'])
254
255 total = os.path.getsize(from_info['path'])
256 cb = Callback(name, total)
257
258 try:
259 s3.upload_file(from_info['path'],
260 to_info['bucket'],
261 to_info['key'],
262 Callback=cb)
263 except Exception as exc:
264 msg = "Failed to upload '{}'".format(from_info['path'])
265 Logger.error(msg, exc)
266 continue
267
268 progress.finish_target(name)
269
270 def download(self,
271 from_infos,
272 to_infos,
273 no_progress_bar=False,
274 names=None):
275 names = self._verify_path_args(from_infos, to_infos, names)
276
277 s3 = self.s3
278
279 for to_info, from_info, name in zip(to_infos, from_infos, names):
280 if from_info['scheme'] != 's3':
281 raise NotImplementedError
282
283 if to_info['scheme'] == 's3':
284 self._copy(from_info, to_info, s3=s3)
285 continue
286
287 if to_info['scheme'] != 'local':
288 raise NotImplementedError
289
290 msg = "Downloading '{}/{}' to '{}'".format(from_info['bucket'],
291 from_info['key'],
292 to_info['path'])
293 Logger.debug(msg)
294
295 tmp_file = self.tmp_file(to_info['path'])
296 if not name:
297 name = os.path.basename(to_info['path'])
298
299 if no_progress_bar:
300 cb = None
301 else:
302 total = s3.head_object(Bucket=from_info['bucket'],
303 Key=from_info['key'])['ContentLength']
304 cb = Callback(name, total)
305
306 self._makedirs(to_info['path'])
307
308 try:
309 s3.download_file(from_info['bucket'],
310 from_info['key'],
311 tmp_file,
312 Callback=cb)
313 except Exception as exc:
314 msg = "Failed to download '{}/{}'".format(from_info['bucket'],
315 from_info['key'])
316 Logger.error(msg, exc)
317 return
318
319 os.rename(tmp_file, to_info['path'])
320
321 if not no_progress_bar:
322 progress.finish_target(name)
323
324 def _path_to_etag(self, path):
325 relpath = posixpath.relpath(path, self.prefix)
326 return posixpath.dirname(relpath) + posixpath.basename(relpath)
327
328 def _all(self):
329 keys = self._all_keys()
330 return [self._path_to_etag(key) for key in keys]
331
332 def gc(self, cinfos):
333 used_etags = [info[self.PARAM_ETAG] for info in cinfos['s3']]
334 used_etags += [info[RemoteLOCAL.PARAM_MD5] for info in cinfos['local']]
335
336 removed = False
337 for etag in self._all():
338 if etag in used_etags:
339 continue
340 path_info = {'scheme': 's3',
341 'key': posixpath.join(self.prefix,
342 etag[0:2], etag[2:]),
343 'bucket': self.bucket}
344 self.remove(path_info)
345 removed = True
346
347 return removed
348
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/remote/s3.py b/dvc/remote/s3.py
--- a/dvc/remote/s3.py
+++ b/dvc/remote/s3.py
@@ -47,7 +47,9 @@
'').lstrip('/')
self.url = config.get(Config.SECTION_REMOTE_URL, storagepath)
self.region = config.get(Config.SECTION_AWS_REGION, None)
- self.profile = config.get(Config.SECTION_AWS_PROFILE, 'default')
+ self.profile = os.getenv('AWS_PROFILE',
+ config.get(Config.SECTION_AWS_PROFILE,
+ 'default'))
self.endpoint_url = config.get(Config.SECTION_AWS_ENDPOINT_URL, None)
credentialpath = config.get(Config.SECTION_AWS_CREDENTIALPATH, None)
@@ -62,6 +64,12 @@
self.aws_access_key_id = creds.get('aws_access_key_id', None)
self.aws_secret_access_key = creds.get('aws_secret_access_key', None)
+ self.region = os.getenv('AWS_DEFAULT_REGION', self.region)
+ self.aws_access_key_id = os.getenv('AWS_ACCESS_KEY_ID',
+ self.aws_access_key_id)
+ self.aws_secret_access_key = os.getenv('AWS_SECRET_ACCESS_KEY',
+ self.aws_secret_access_key)
+
@property
def bucket(self):
return urlparse(self.url).netloc
|
{"golden_diff": "diff --git a/dvc/remote/s3.py b/dvc/remote/s3.py\n--- a/dvc/remote/s3.py\n+++ b/dvc/remote/s3.py\n@@ -47,7 +47,9 @@\n '').lstrip('/')\n self.url = config.get(Config.SECTION_REMOTE_URL, storagepath)\n self.region = config.get(Config.SECTION_AWS_REGION, None)\n- self.profile = config.get(Config.SECTION_AWS_PROFILE, 'default')\n+ self.profile = os.getenv('AWS_PROFILE',\n+ config.get(Config.SECTION_AWS_PROFILE,\n+ 'default'))\n self.endpoint_url = config.get(Config.SECTION_AWS_ENDPOINT_URL, None)\n \n credentialpath = config.get(Config.SECTION_AWS_CREDENTIALPATH, None)\n@@ -62,6 +64,12 @@\n self.aws_access_key_id = creds.get('aws_access_key_id', None)\n self.aws_secret_access_key = creds.get('aws_secret_access_key', None)\n \n+ self.region = os.getenv('AWS_DEFAULT_REGION', self.region)\n+ self.aws_access_key_id = os.getenv('AWS_ACCESS_KEY_ID',\n+ self.aws_access_key_id)\n+ self.aws_secret_access_key = os.getenv('AWS_SECRET_ACCESS_KEY',\n+ self.aws_secret_access_key)\n+\n @property\n def bucket(self):\n return urlparse(self.url).netloc\n", "issue": "s3: Support AWS credential settings from environment variables\ndvc should also load credential information from system environment variables as awscli does.\r\n\r\nReference: https://docs.aws.amazon.com/cli/latest/userguide/cli-environment.html\r\n\r\nFor example: we should be able to run `dvc pull` despite absence of AWS profiles in _~/.aws_ if we had set the following environment variables:\r\n\r\n```\r\n$ export AWS_ACCESS_KEY_ID=somekey\r\n$ export AWS_SECRET_ACCESS_KEY=somekey\r\n$ export AWS_DEFAULT_REGION=someregion\r\n```\r\n\r\nThe following command works:\r\n``` \r\naws s3 ls s3://bucketname\r\n```\r\n\r\nBut this one does not:\r\n```\r\ndvc pull\r\n```\r\n\r\nA usecase for this is doing `dvc pull` in docker image building process, which would be much easier if if we can override configuration via environment variables. \n", "before_files": [{"content": "import os\nimport threading\nimport posixpath\n\ntry:\n import boto3\nexcept ImportError:\n boto3 = None\n\ntry:\n from urlparse import urlparse\nexcept ImportError:\n from urllib.parse import urlparse\n\nfrom dvc.logger import Logger\nfrom dvc.progress import progress\nfrom dvc.config import Config\nfrom dvc.remote.base import RemoteBase\nfrom dvc.remote.local import RemoteLOCAL\nfrom dvc.exceptions import DvcException\n\n\nclass Callback(object):\n def __init__(self, name, total):\n self.name = name\n self.total = total\n self.current = 0\n self.lock = threading.Lock()\n\n def __call__(self, byts):\n with self.lock:\n self.current += byts\n progress.update_target(self.name, self.current, self.total)\n\n\nclass RemoteS3(RemoteBase):\n scheme = 's3'\n REGEX = r'^s3://(?P<path>.*)$'\n REQUIRES = {'boto3': boto3}\n PARAM_ETAG = 'etag'\n\n def __init__(self, project, config):\n import configobj\n\n self.project = project\n storagepath = 's3://' + config.get(Config.SECTION_AWS_STORAGEPATH,\n '').lstrip('/')\n self.url = config.get(Config.SECTION_REMOTE_URL, storagepath)\n self.region = config.get(Config.SECTION_AWS_REGION, None)\n self.profile = config.get(Config.SECTION_AWS_PROFILE, 'default')\n self.endpoint_url = config.get(Config.SECTION_AWS_ENDPOINT_URL, None)\n\n credentialpath = config.get(Config.SECTION_AWS_CREDENTIALPATH, None)\n if credentialpath:\n creds_conf = configobj.ConfigObj(credentialpath)\n creds = creds_conf.get(self.profile, {})\n else:\n creds = {}\n\n self.creds = creds\n self.region = creds.get('region', self.region)\n self.aws_access_key_id = creds.get('aws_access_key_id', None)\n self.aws_secret_access_key = creds.get('aws_secret_access_key', None)\n\n @property\n def bucket(self):\n return urlparse(self.url).netloc\n\n @property\n def prefix(self):\n return urlparse(self.url).path.lstrip('/')\n\n @property\n def s3(self):\n if not self.creds:\n session = boto3.session.Session(profile_name=self.profile)\n else:\n session = boto3.session.Session(\n aws_access_key_id=self.aws_access_key_id,\n aws_secret_access_key=self.aws_secret_access_key,\n region_name=self.region)\n return session.client('s3', endpoint_url=self.endpoint_url)\n\n def get_etag(self, bucket, key):\n try:\n obj = self.s3.head_object(Bucket=bucket, Key=key)\n except Exception:\n raise DvcException('s3://{}/{} does not exist'.format(bucket, key))\n\n return obj['ETag'].strip('\"')\n\n def save_info(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n return {self.PARAM_ETAG: self.get_etag(path_info['bucket'],\n path_info['key'])}\n\n def changed(self, path_info, checksum_info):\n if not self.exists([path_info])[0]:\n return True\n\n etag = checksum_info.get(self.PARAM_ETAG, None)\n if etag is None:\n return True\n\n if self.changed_cache(etag):\n return True\n\n return checksum_info != self.save_info(path_info)\n\n def _copy(self, from_info, to_info, s3=None):\n s3 = s3 if s3 else self.s3\n\n source = {'Bucket': from_info['bucket'],\n 'Key': from_info['key']}\n self.s3.copy(source, to_info['bucket'], to_info['key'])\n\n def save(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n etag = self.get_etag(path_info['bucket'], path_info['key'])\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n to_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n self._copy(path_info, to_info)\n\n return {self.PARAM_ETAG: etag}\n\n @staticmethod\n def to_string(path_info):\n return \"s3://{}/{}\".format(path_info['bucket'], path_info['key'])\n\n def changed_cache(self, etag):\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n cache = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n if {self.PARAM_ETAG: etag} != self.save_info(cache):\n if self.exists([cache])[0]:\n msg = 'Corrupted cache file {}'\n Logger.warn(msg.format(self.to_string(cache)))\n self.remove(cache)\n return True\n\n return False\n\n def checkout(self, path_info, checksum_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n etag = checksum_info.get(self.PARAM_ETAG, None)\n if not etag:\n return\n\n if not self.changed(path_info, checksum_info):\n msg = \"Data '{}' didn't change.\"\n Logger.info(msg.format(self.to_string(path_info)))\n return\n\n if self.changed_cache(etag):\n msg = \"Cache '{}' not found. File '{}' won't be created.\"\n Logger.warn(msg.format(etag, self.to_string(path_info)))\n return\n\n if self.exists([path_info])[0]:\n msg = \"Data '{}' exists. Removing before checkout.\"\n Logger.warn(msg.format(self.to_string(path_info)))\n self.remove(path_info)\n return\n\n msg = \"Checking out '{}' with cache '{}'.\"\n Logger.info(msg.format(self.to_string(path_info), etag))\n\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n from_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n self._copy(from_info, path_info)\n\n def remove(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n Logger.debug('Removing s3://{}/{}'.format(path_info['bucket'],\n path_info['key']))\n\n self.s3.delete_object(Bucket=path_info['bucket'],\n Key=path_info['key'])\n\n def md5s_to_path_infos(self, md5s):\n return [{'scheme': self.scheme,\n 'bucket': self.bucket,\n 'key': posixpath.join(self.prefix,\n md5[0:2], md5[2:])} for md5 in md5s]\n\n def _all_keys(self):\n s3 = self.s3\n\n keys = []\n kwargs = {'Bucket': self.bucket,\n 'Prefix': self.prefix}\n while True:\n resp = s3.list_objects_v2(**kwargs)\n contents = resp.get('Contents', None)\n if not contents:\n break\n\n for obj in contents:\n keys.append(obj['Key'])\n\n token = resp.get('NextContinuationToken', None)\n if not token:\n break\n\n kwargs['ContinuationToken'] = token\n\n return keys\n\n def exists(self, path_infos):\n # NOTE: We mostly use exists() method when filtering a bulk of cache\n # files to decide if we need to download/upload them and in s3\n # list_objects_v2() is much-much faster than trying to check keys\n # one-by-one.\n ret = []\n\n keys = self._all_keys()\n\n for path_info in path_infos:\n exists = False\n if path_info['key'] in keys:\n exists = True\n ret.append(exists)\n\n return ret\n\n def upload(self, from_infos, to_infos, names=None):\n names = self._verify_path_args(to_infos, from_infos, names)\n\n s3 = self.s3\n\n for from_info, to_info, name in zip(from_infos, to_infos, names):\n if to_info['scheme'] != 's3':\n raise NotImplementedError\n\n if from_info['scheme'] != 'local':\n raise NotImplementedError\n\n Logger.debug(\"Uploading '{}' to '{}/{}'\".format(from_info['path'],\n to_info['bucket'],\n to_info['key']))\n\n if not name:\n name = os.path.basename(from_info['path'])\n\n total = os.path.getsize(from_info['path'])\n cb = Callback(name, total)\n\n try:\n s3.upload_file(from_info['path'],\n to_info['bucket'],\n to_info['key'],\n Callback=cb)\n except Exception as exc:\n msg = \"Failed to upload '{}'\".format(from_info['path'])\n Logger.error(msg, exc)\n continue\n\n progress.finish_target(name)\n\n def download(self,\n from_infos,\n to_infos,\n no_progress_bar=False,\n names=None):\n names = self._verify_path_args(from_infos, to_infos, names)\n\n s3 = self.s3\n\n for to_info, from_info, name in zip(to_infos, from_infos, names):\n if from_info['scheme'] != 's3':\n raise NotImplementedError\n\n if to_info['scheme'] == 's3':\n self._copy(from_info, to_info, s3=s3)\n continue\n\n if to_info['scheme'] != 'local':\n raise NotImplementedError\n\n msg = \"Downloading '{}/{}' to '{}'\".format(from_info['bucket'],\n from_info['key'],\n to_info['path'])\n Logger.debug(msg)\n\n tmp_file = self.tmp_file(to_info['path'])\n if not name:\n name = os.path.basename(to_info['path'])\n\n if no_progress_bar:\n cb = None\n else:\n total = s3.head_object(Bucket=from_info['bucket'],\n Key=from_info['key'])['ContentLength']\n cb = Callback(name, total)\n\n self._makedirs(to_info['path'])\n\n try:\n s3.download_file(from_info['bucket'],\n from_info['key'],\n tmp_file,\n Callback=cb)\n except Exception as exc:\n msg = \"Failed to download '{}/{}'\".format(from_info['bucket'],\n from_info['key'])\n Logger.error(msg, exc)\n return\n\n os.rename(tmp_file, to_info['path'])\n\n if not no_progress_bar:\n progress.finish_target(name)\n\n def _path_to_etag(self, path):\n relpath = posixpath.relpath(path, self.prefix)\n return posixpath.dirname(relpath) + posixpath.basename(relpath)\n\n def _all(self):\n keys = self._all_keys()\n return [self._path_to_etag(key) for key in keys]\n\n def gc(self, cinfos):\n used_etags = [info[self.PARAM_ETAG] for info in cinfos['s3']]\n used_etags += [info[RemoteLOCAL.PARAM_MD5] for info in cinfos['local']]\n\n removed = False\n for etag in self._all():\n if etag in used_etags:\n continue\n path_info = {'scheme': 's3',\n 'key': posixpath.join(self.prefix,\n etag[0:2], etag[2:]),\n 'bucket': self.bucket}\n self.remove(path_info)\n removed = True\n\n return removed\n", "path": "dvc/remote/s3.py"}], "after_files": [{"content": "import os\nimport threading\nimport posixpath\n\ntry:\n import boto3\nexcept ImportError:\n boto3 = None\n\ntry:\n from urlparse import urlparse\nexcept ImportError:\n from urllib.parse import urlparse\n\nfrom dvc.logger import Logger\nfrom dvc.progress import progress\nfrom dvc.config import Config\nfrom dvc.remote.base import RemoteBase\nfrom dvc.remote.local import RemoteLOCAL\nfrom dvc.exceptions import DvcException\n\n\nclass Callback(object):\n def __init__(self, name, total):\n self.name = name\n self.total = total\n self.current = 0\n self.lock = threading.Lock()\n\n def __call__(self, byts):\n with self.lock:\n self.current += byts\n progress.update_target(self.name, self.current, self.total)\n\n\nclass RemoteS3(RemoteBase):\n scheme = 's3'\n REGEX = r'^s3://(?P<path>.*)$'\n REQUIRES = {'boto3': boto3}\n PARAM_ETAG = 'etag'\n\n def __init__(self, project, config):\n import configobj\n\n self.project = project\n storagepath = 's3://' + config.get(Config.SECTION_AWS_STORAGEPATH,\n '').lstrip('/')\n self.url = config.get(Config.SECTION_REMOTE_URL, storagepath)\n self.region = config.get(Config.SECTION_AWS_REGION, None)\n self.profile = os.getenv('AWS_PROFILE',\n config.get(Config.SECTION_AWS_PROFILE,\n 'default'))\n self.endpoint_url = config.get(Config.SECTION_AWS_ENDPOINT_URL, None)\n\n credentialpath = config.get(Config.SECTION_AWS_CREDENTIALPATH, None)\n if credentialpath:\n creds_conf = configobj.ConfigObj(credentialpath)\n creds = creds_conf.get(self.profile, {})\n else:\n creds = {}\n\n self.creds = creds\n self.region = creds.get('region', self.region)\n self.aws_access_key_id = creds.get('aws_access_key_id', None)\n self.aws_secret_access_key = creds.get('aws_secret_access_key', None)\n\n self.region = os.getenv('AWS_DEFAULT_REGION', self.region)\n self.aws_access_key_id = os.getenv('AWS_ACCESS_KEY_ID',\n self.aws_access_key_id)\n self.aws_secret_access_key = os.getenv('AWS_SECRET_ACCESS_KEY',\n self.aws_secret_access_key)\n\n @property\n def bucket(self):\n return urlparse(self.url).netloc\n\n @property\n def prefix(self):\n return urlparse(self.url).path.lstrip('/')\n\n @property\n def s3(self):\n if not self.creds:\n session = boto3.session.Session(profile_name=self.profile)\n else:\n session = boto3.session.Session(\n aws_access_key_id=self.aws_access_key_id,\n aws_secret_access_key=self.aws_secret_access_key,\n region_name=self.region)\n return session.client('s3', endpoint_url=self.endpoint_url)\n\n def get_etag(self, bucket, key):\n try:\n obj = self.s3.head_object(Bucket=bucket, Key=key)\n except Exception:\n raise DvcException('s3://{}/{} does not exist'.format(bucket, key))\n\n return obj['ETag'].strip('\"')\n\n def save_info(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n return {self.PARAM_ETAG: self.get_etag(path_info['bucket'],\n path_info['key'])}\n\n def changed(self, path_info, checksum_info):\n if not self.exists([path_info])[0]:\n return True\n\n etag = checksum_info.get(self.PARAM_ETAG, None)\n if etag is None:\n return True\n\n if self.changed_cache(etag):\n return True\n\n return checksum_info != self.save_info(path_info)\n\n def _copy(self, from_info, to_info, s3=None):\n s3 = s3 if s3 else self.s3\n\n source = {'Bucket': from_info['bucket'],\n 'Key': from_info['key']}\n self.s3.copy(source, to_info['bucket'], to_info['key'])\n\n def save(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n etag = self.get_etag(path_info['bucket'], path_info['key'])\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n to_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n self._copy(path_info, to_info)\n\n return {self.PARAM_ETAG: etag}\n\n @staticmethod\n def to_string(path_info):\n return \"s3://{}/{}\".format(path_info['bucket'], path_info['key'])\n\n def changed_cache(self, etag):\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n cache = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n if {self.PARAM_ETAG: etag} != self.save_info(cache):\n if self.exists([cache])[0]:\n msg = 'Corrupted cache file {}'\n Logger.warn(msg.format(self.to_string(cache)))\n self.remove(cache)\n return True\n\n return False\n\n def checkout(self, path_info, checksum_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n etag = checksum_info.get(self.PARAM_ETAG, None)\n if not etag:\n return\n\n if not self.changed(path_info, checksum_info):\n msg = \"Data '{}' didn't change.\"\n Logger.info(msg.format(self.to_string(path_info)))\n return\n\n if self.changed_cache(etag):\n msg = \"Cache '{}' not found. File '{}' won't be created.\"\n Logger.warn(msg.format(etag, self.to_string(path_info)))\n return\n\n if self.exists([path_info])[0]:\n msg = \"Data '{}' exists. Removing before checkout.\"\n Logger.warn(msg.format(self.to_string(path_info)))\n self.remove(path_info)\n return\n\n msg = \"Checking out '{}' with cache '{}'.\"\n Logger.info(msg.format(self.to_string(path_info), etag))\n\n key = posixpath.join(self.prefix, etag[0:2], etag[2:])\n from_info = {'scheme': 's3', 'bucket': self.bucket, 'key': key}\n\n self._copy(from_info, path_info)\n\n def remove(self, path_info):\n if path_info['scheme'] != 's3':\n raise NotImplementedError\n\n Logger.debug('Removing s3://{}/{}'.format(path_info['bucket'],\n path_info['key']))\n\n self.s3.delete_object(Bucket=path_info['bucket'],\n Key=path_info['key'])\n\n def md5s_to_path_infos(self, md5s):\n return [{'scheme': self.scheme,\n 'bucket': self.bucket,\n 'key': posixpath.join(self.prefix,\n md5[0:2], md5[2:])} for md5 in md5s]\n\n def _all_keys(self):\n s3 = self.s3\n\n keys = []\n kwargs = {'Bucket': self.bucket,\n 'Prefix': self.prefix}\n while True:\n resp = s3.list_objects_v2(**kwargs)\n contents = resp.get('Contents', None)\n if not contents:\n break\n\n for obj in contents:\n keys.append(obj['Key'])\n\n token = resp.get('NextContinuationToken', None)\n if not token:\n break\n\n kwargs['ContinuationToken'] = token\n\n return keys\n\n def exists(self, path_infos):\n # NOTE: We mostly use exists() method when filtering a bulk of cache\n # files to decide if we need to download/upload them and in s3\n # list_objects_v2() is much-much faster than trying to check keys\n # one-by-one.\n ret = []\n\n keys = self._all_keys()\n\n for path_info in path_infos:\n exists = False\n if path_info['key'] in keys:\n exists = True\n ret.append(exists)\n\n return ret\n\n def upload(self, from_infos, to_infos, names=None):\n names = self._verify_path_args(to_infos, from_infos, names)\n\n s3 = self.s3\n\n for from_info, to_info, name in zip(from_infos, to_infos, names):\n if to_info['scheme'] != 's3':\n raise NotImplementedError\n\n if from_info['scheme'] != 'local':\n raise NotImplementedError\n\n Logger.debug(\"Uploading '{}' to '{}/{}'\".format(from_info['path'],\n to_info['bucket'],\n to_info['key']))\n\n if not name:\n name = os.path.basename(from_info['path'])\n\n total = os.path.getsize(from_info['path'])\n cb = Callback(name, total)\n\n try:\n s3.upload_file(from_info['path'],\n to_info['bucket'],\n to_info['key'],\n Callback=cb)\n except Exception as exc:\n msg = \"Failed to upload '{}'\".format(from_info['path'])\n Logger.error(msg, exc)\n continue\n\n progress.finish_target(name)\n\n def download(self,\n from_infos,\n to_infos,\n no_progress_bar=False,\n names=None):\n names = self._verify_path_args(from_infos, to_infos, names)\n\n s3 = self.s3\n\n for to_info, from_info, name in zip(to_infos, from_infos, names):\n if from_info['scheme'] != 's3':\n raise NotImplementedError\n\n if to_info['scheme'] == 's3':\n self._copy(from_info, to_info, s3=s3)\n continue\n\n if to_info['scheme'] != 'local':\n raise NotImplementedError\n\n msg = \"Downloading '{}/{}' to '{}'\".format(from_info['bucket'],\n from_info['key'],\n to_info['path'])\n Logger.debug(msg)\n\n tmp_file = self.tmp_file(to_info['path'])\n if not name:\n name = os.path.basename(to_info['path'])\n\n if no_progress_bar:\n cb = None\n else:\n total = s3.head_object(Bucket=from_info['bucket'],\n Key=from_info['key'])['ContentLength']\n cb = Callback(name, total)\n\n self._makedirs(to_info['path'])\n\n try:\n s3.download_file(from_info['bucket'],\n from_info['key'],\n tmp_file,\n Callback=cb)\n except Exception as exc:\n msg = \"Failed to download '{}/{}'\".format(from_info['bucket'],\n from_info['key'])\n Logger.error(msg, exc)\n return\n\n os.rename(tmp_file, to_info['path'])\n\n if not no_progress_bar:\n progress.finish_target(name)\n\n def _path_to_etag(self, path):\n relpath = posixpath.relpath(path, self.prefix)\n return posixpath.dirname(relpath) + posixpath.basename(relpath)\n\n def _all(self):\n keys = self._all_keys()\n return [self._path_to_etag(key) for key in keys]\n\n def gc(self, cinfos):\n used_etags = [info[self.PARAM_ETAG] for info in cinfos['s3']]\n used_etags += [info[RemoteLOCAL.PARAM_MD5] for info in cinfos['local']]\n\n removed = False\n for etag in self._all():\n if etag in used_etags:\n continue\n path_info = {'scheme': 's3',\n 'key': posixpath.join(self.prefix,\n etag[0:2], etag[2:]),\n 'bucket': self.bucket}\n self.remove(path_info)\n removed = True\n\n return removed\n", "path": "dvc/remote/s3.py"}]}
| 3,882 | 296 |
gh_patches_debug_34216
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-3023
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Device Support Request] TS0601 by _TZE200_3ejwxpmu (QOXEZY Zigbee CO2 NDIR Sensor)
**Is your feature request related to a problem? Please describe.**
This is a NDIR CO2 sensor which measures carbon dioxide (additionally humidity and temperature). While I can connect it to ZHA, it generates no entities. Is it possible to integrate?
**Describe the solution you'd like**
I would like to be able to see all available entities.
<details>
<!-- Device signature can be acquired by clicking on the "Zigbee Device Signature" button in the device settings view -->
<summary>Device signature</summary>
{
"node_descriptor": "NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)",
"endpoints": {
"1": {
"profile_id": 260,
"device_type": "0x0051",
"in_clusters": [
"0x0000",
"0x0004",
"0x0005",
"0xef00"
],
"out_clusters": [
"0x000a",
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "_TZE200_3ejwxpmu",
"model": "TS0601",
"class": "zigpy.device.Device"
}
</details>
**Additional context**
Add any other context or screenshots about the feature request here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/tuya/air/ts0601_air_quality.py`
Content:
```
1 """Tuya Air Quality sensor."""
2
3 from zigpy.profiles import zgp, zha
4 from zigpy.quirks import CustomDevice
5 from zigpy.zcl.clusters.general import Basic, GreenPowerProxy, Groups, Ota, Scenes, Time
6
7 from zhaquirks.const import (
8 DEVICE_TYPE,
9 ENDPOINTS,
10 INPUT_CLUSTERS,
11 MODELS_INFO,
12 OUTPUT_CLUSTERS,
13 PROFILE_ID,
14 )
15 from zhaquirks.tuya.air import (
16 TuyaAirQualityCO2,
17 TuyaAirQualityFormaldehyde,
18 TuyaAirQualityHumidity,
19 TuyaAirQualityTemperature,
20 TuyaAirQualityVOC,
21 TuyaCO2ManufCluster,
22 )
23
24
25 class TuyaCO2Sensor(CustomDevice):
26 """Tuya Air quality device."""
27
28 signature = {
29 # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]
30 # device_version=1
31 # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,
32 # input_clusters=[0, 4, 5, 61184],
33 # output_clusters=[25, 10])
34 MODELS_INFO: [
35 ("_TZE200_8ygsuhe1", "TS0601"),
36 ("_TZE200_ryfmq5rl", "TS0601"),
37 ("_TZE200_yvx5lh6k", "TS0601"),
38 ("_TZE200_c2fmom5z", "TS0601"),
39 ],
40 ENDPOINTS: {
41 1: {
42 PROFILE_ID: zha.PROFILE_ID,
43 DEVICE_TYPE: zha.DeviceType.SMART_PLUG,
44 INPUT_CLUSTERS: [
45 Basic.cluster_id,
46 Groups.cluster_id,
47 Scenes.cluster_id,
48 TuyaCO2ManufCluster.cluster_id,
49 ],
50 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
51 }
52 },
53 }
54
55 replacement = {
56 ENDPOINTS: {
57 1: {
58 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
59 INPUT_CLUSTERS: [
60 Basic.cluster_id,
61 Groups.cluster_id,
62 Scenes.cluster_id,
63 TuyaCO2ManufCluster,
64 TuyaAirQualityCO2,
65 TuyaAirQualityFormaldehyde,
66 TuyaAirQualityHumidity,
67 TuyaAirQualityTemperature,
68 TuyaAirQualityVOC,
69 ],
70 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
71 }
72 }
73 }
74
75
76 class TuyaCO2SensorGPP(CustomDevice):
77 """Tuya Air quality device with GPP."""
78
79 signature = {
80 # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]
81 # device_version=1
82 # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,
83 # input_clusters=[0, 4, 5, 61184],
84 # output_clusters=[25, 10])
85 MODELS_INFO: [
86 ("_TZE200_8ygsuhe1", "TS0601"),
87 ("_TZE200_ryfmq5rl", "TS0601"),
88 ("_TZE200_yvx5lh6k", "TS0601"),
89 ("_TZE200_c2fmom5z", "TS0601"),
90 ],
91 ENDPOINTS: {
92 1: {
93 PROFILE_ID: zha.PROFILE_ID,
94 DEVICE_TYPE: zha.DeviceType.SMART_PLUG,
95 INPUT_CLUSTERS: [
96 Basic.cluster_id,
97 Groups.cluster_id,
98 Scenes.cluster_id,
99 TuyaCO2ManufCluster.cluster_id,
100 ],
101 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
102 },
103 242: {
104 # <SimpleDescriptor endpoint=242 profile=41440 device_type=97
105 # input_clusters=[]
106 # output_clusters=[33]
107 PROFILE_ID: zgp.PROFILE_ID,
108 DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
109 INPUT_CLUSTERS: [],
110 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
111 },
112 },
113 }
114
115 replacement = {
116 ENDPOINTS: {
117 1: {
118 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
119 INPUT_CLUSTERS: [
120 Basic.cluster_id,
121 Groups.cluster_id,
122 Scenes.cluster_id,
123 TuyaCO2ManufCluster,
124 TuyaAirQualityCO2,
125 TuyaAirQualityFormaldehyde,
126 TuyaAirQualityHumidity,
127 TuyaAirQualityTemperature,
128 TuyaAirQualityVOC,
129 ],
130 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
131 },
132 242: {
133 PROFILE_ID: zgp.PROFILE_ID,
134 DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
135 INPUT_CLUSTERS: [],
136 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
137 },
138 }
139 }
140
141
142 class TuyaNDIRCO2SensorGPP(CustomDevice):
143 """Tuya NIDR CO2 sensor with GPP."""
144
145 signature = {
146 # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)
147 # device_version=1
148 # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,
149 # input_clusters=[0, 4, 5, 61184],
150 # output_clusters=[25, 10])
151 MODELS_INFO: [
152 ("_TZE200_ogkdpgy2", "TS0601"),
153 ],
154 ENDPOINTS: {
155 1: {
156 PROFILE_ID: zha.PROFILE_ID,
157 DEVICE_TYPE: zha.DeviceType.SMART_PLUG,
158 INPUT_CLUSTERS: [
159 Basic.cluster_id,
160 Groups.cluster_id,
161 Scenes.cluster_id,
162 TuyaCO2ManufCluster.cluster_id,
163 ],
164 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
165 },
166 242: {
167 # <SimpleDescriptor endpoint=242 profile=41440 device_type=97
168 # input_clusters=[]
169 # output_clusters=[33]
170 PROFILE_ID: zgp.PROFILE_ID,
171 DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
172 INPUT_CLUSTERS: [],
173 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
174 },
175 },
176 }
177
178 replacement = {
179 ENDPOINTS: {
180 1: {
181 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
182 INPUT_CLUSTERS: [
183 Basic.cluster_id,
184 Groups.cluster_id,
185 Scenes.cluster_id,
186 TuyaCO2ManufCluster,
187 TuyaAirQualityCO2,
188 ],
189 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
190 },
191 242: {
192 PROFILE_ID: zgp.PROFILE_ID,
193 DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
194 INPUT_CLUSTERS: [],
195 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
196 },
197 }
198 }
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/tuya/air/ts0601_air_quality.py b/zhaquirks/tuya/air/ts0601_air_quality.py
--- a/zhaquirks/tuya/air/ts0601_air_quality.py
+++ b/zhaquirks/tuya/air/ts0601_air_quality.py
@@ -196,3 +196,64 @@
},
}
}
+
+
+class TuyaNDIRCO2SensorGPP2(CustomDevice):
+ """Tuya NIDR CO2 sensor."""
+
+ signature = {
+ # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.FullFunctionDevice|MainsPowered|RxOnWhenIdle|AllocateAddress: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)
+ # device_version=1
+ # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,
+ # input_clusters=[0, 4, 5, 61184],
+ # output_clusters=[10, 25])
+ MODELS_INFO: [
+ ("_TZE200_3ejwxpmu", "TS0601"),
+ ],
+ ENDPOINTS: {
+ 1: {
+ PROFILE_ID: zha.PROFILE_ID,
+ DEVICE_TYPE: zha.DeviceType.SMART_PLUG,
+ INPUT_CLUSTERS: [
+ Basic.cluster_id,
+ Groups.cluster_id,
+ Scenes.cluster_id,
+ TuyaCO2ManufCluster.cluster_id,
+ ],
+ OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
+ },
+ 242: {
+ # <SimpleDescriptor endpoint=242 profile=41440 device_type=97
+ # input_clusters=[]
+ # output_clusters=[33]
+ PROFILE_ID: zgp.PROFILE_ID,
+ DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
+ INPUT_CLUSTERS: [],
+ OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
+ },
+ },
+ }
+
+ replacement = {
+ ENDPOINTS: {
+ 1: {
+ DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
+ INPUT_CLUSTERS: [
+ Basic.cluster_id,
+ Groups.cluster_id,
+ Scenes.cluster_id,
+ TuyaCO2ManufCluster,
+ TuyaAirQualityCO2,
+ TuyaAirQualityHumidity,
+ TuyaAirQualityTemperature,
+ ],
+ OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
+ },
+ 242: {
+ PROFILE_ID: zgp.PROFILE_ID,
+ DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,
+ INPUT_CLUSTERS: [],
+ OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
+ },
+ }
+ }
|
{"golden_diff": "diff --git a/zhaquirks/tuya/air/ts0601_air_quality.py b/zhaquirks/tuya/air/ts0601_air_quality.py\n--- a/zhaquirks/tuya/air/ts0601_air_quality.py\n+++ b/zhaquirks/tuya/air/ts0601_air_quality.py\n@@ -196,3 +196,64 @@\n },\n }\n }\n+\n+\n+class TuyaNDIRCO2SensorGPP2(CustomDevice):\n+ \"\"\"Tuya NIDR CO2 sensor.\"\"\"\n+\n+ signature = {\n+ # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.FullFunctionDevice|MainsPowered|RxOnWhenIdle|AllocateAddress: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\n+ # device_version=1\n+ # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n+ # input_clusters=[0, 4, 5, 61184],\n+ # output_clusters=[10, 25])\n+ MODELS_INFO: [\n+ (\"_TZE200_3ejwxpmu\", \"TS0601\"),\n+ ],\n+ ENDPOINTS: {\n+ 1: {\n+ PROFILE_ID: zha.PROFILE_ID,\n+ DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n+ INPUT_CLUSTERS: [\n+ Basic.cluster_id,\n+ Groups.cluster_id,\n+ Scenes.cluster_id,\n+ TuyaCO2ManufCluster.cluster_id,\n+ ],\n+ OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n+ },\n+ 242: {\n+ # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n+ # input_clusters=[]\n+ # output_clusters=[33]\n+ PROFILE_ID: zgp.PROFILE_ID,\n+ DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n+ INPUT_CLUSTERS: [],\n+ OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n+ },\n+ },\n+ }\n+\n+ replacement = {\n+ ENDPOINTS: {\n+ 1: {\n+ DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n+ INPUT_CLUSTERS: [\n+ Basic.cluster_id,\n+ Groups.cluster_id,\n+ Scenes.cluster_id,\n+ TuyaCO2ManufCluster,\n+ TuyaAirQualityCO2,\n+ TuyaAirQualityHumidity,\n+ TuyaAirQualityTemperature,\n+ ],\n+ OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n+ },\n+ 242: {\n+ PROFILE_ID: zgp.PROFILE_ID,\n+ DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n+ INPUT_CLUSTERS: [],\n+ OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n+ },\n+ }\n+ }\n", "issue": "[Device Support Request] TS0601 by _TZE200_3ejwxpmu (QOXEZY Zigbee CO2 NDIR Sensor)\n**Is your feature request related to a problem? Please describe.**\r\nThis is a NDIR CO2 sensor which measures carbon dioxide (additionally humidity and temperature). While I can connect it to ZHA, it generates no entities. Is it possible to integrate?\r\n\r\n**Describe the solution you'd like**\r\nI would like to be able to see all available entities.\r\n\r\n<details>\r\n<!-- Device signature can be acquired by clicking on the \"Zigbee Device Signature\" button in the device settings view -->\r\n<summary>Device signature</summary>\r\n{\r\n \"node_descriptor\": \"NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\",\r\n \"endpoints\": {\r\n \"1\": {\r\n \"profile_id\": 260,\r\n \"device_type\": \"0x0051\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0xef00\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x000a\",\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"_TZE200_3ejwxpmu\",\r\n \"model\": \"TS0601\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n\r\n</details>\r\n\r\n**Additional context**\r\nAdd any other context or screenshots about the feature request here.\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Tuya Air Quality sensor.\"\"\"\n\nfrom zigpy.profiles import zgp, zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import Basic, GreenPowerProxy, Groups, Ota, Scenes, Time\n\nfrom zhaquirks.const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\nfrom zhaquirks.tuya.air import (\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n TuyaCO2ManufCluster,\n)\n\n\nclass TuyaCO2Sensor(CustomDevice):\n \"\"\"Tuya Air quality device.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_8ygsuhe1\", \"TS0601\"),\n (\"_TZE200_ryfmq5rl\", \"TS0601\"),\n (\"_TZE200_yvx5lh6k\", \"TS0601\"),\n (\"_TZE200_c2fmom5z\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n }\n }\n }\n\n\nclass TuyaCO2SensorGPP(CustomDevice):\n \"\"\"Tuya Air quality device with GPP.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_8ygsuhe1\", \"TS0601\"),\n (\"_TZE200_ryfmq5rl\", \"TS0601\"),\n (\"_TZE200_yvx5lh6k\", \"TS0601\"),\n (\"_TZE200_c2fmom5z\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n\n\nclass TuyaNDIRCO2SensorGPP(CustomDevice):\n \"\"\"Tuya NIDR CO2 sensor with GPP.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_ogkdpgy2\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n", "path": "zhaquirks/tuya/air/ts0601_air_quality.py"}], "after_files": [{"content": "\"\"\"Tuya Air Quality sensor.\"\"\"\n\nfrom zigpy.profiles import zgp, zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import Basic, GreenPowerProxy, Groups, Ota, Scenes, Time\n\nfrom zhaquirks.const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\nfrom zhaquirks.tuya.air import (\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n TuyaCO2ManufCluster,\n)\n\n\nclass TuyaCO2Sensor(CustomDevice):\n \"\"\"Tuya Air quality device.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_8ygsuhe1\", \"TS0601\"),\n (\"_TZE200_ryfmq5rl\", \"TS0601\"),\n (\"_TZE200_yvx5lh6k\", \"TS0601\"),\n (\"_TZE200_c2fmom5z\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n }\n }\n }\n\n\nclass TuyaCO2SensorGPP(CustomDevice):\n \"\"\"Tuya Air quality device with GPP.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=<DescriptorCapability.0: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)]\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_8ygsuhe1\", \"TS0601\"),\n (\"_TZE200_ryfmq5rl\", \"TS0601\"),\n (\"_TZE200_yvx5lh6k\", \"TS0601\"),\n (\"_TZE200_c2fmom5z\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n TuyaAirQualityFormaldehyde,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n TuyaAirQualityVOC,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n\n\nclass TuyaNDIRCO2SensorGPP(CustomDevice):\n \"\"\"Tuya NIDR CO2 sensor with GPP.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.AllocateAddress|RxOnWhenIdle|MainsPowered|FullFunctionDevice: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[25, 10])\n MODELS_INFO: [\n (\"_TZE200_ogkdpgy2\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n\n\nclass TuyaNDIRCO2SensorGPP2(CustomDevice):\n \"\"\"Tuya NIDR CO2 sensor.\"\"\"\n\n signature = {\n # NodeDescriptor(logical_type=<LogicalType.Router: 1>, complex_descriptor_available=0, user_descriptor_available=0, reserved=0, aps_flags=0, frequency_band=<FrequencyBand.Freq2400MHz: 8>, mac_capability_flags=<MACCapabilityFlags.FullFunctionDevice|MainsPowered|RxOnWhenIdle|AllocateAddress: 142>, manufacturer_code=4417, maximum_buffer_size=66, maximum_incoming_transfer_size=66, server_mask=10752, maximum_outgoing_transfer_size=66, descriptor_capability_field=<DescriptorCapability.NONE: 0>, *allocate_address=True, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False)\n # device_version=1\n # SizePrefixedSimpleDescriptor(endpoint=1, profile=260, device_type=81, device_version=1,\n # input_clusters=[0, 4, 5, 61184],\n # output_clusters=[10, 25])\n MODELS_INFO: [\n (\"_TZE200_3ejwxpmu\", \"TS0601\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SMART_PLUG,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n TuyaCO2ManufCluster,\n TuyaAirQualityCO2,\n TuyaAirQualityHumidity,\n TuyaAirQualityTemperature,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: zgp.PROFILE_ID,\n DEVICE_TYPE: zgp.DeviceType.PROXY_BASIC,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n", "path": "zhaquirks/tuya/air/ts0601_air_quality.py"}]}
| 3,522 | 811 |
gh_patches_debug_6667
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-633
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Version on GitHub different from version on PyPI
# Brief Description of Fix
<!-- Please describe the fix in terms of a "before" and "after". In other words, what's not so good about the current docs
page, and what you would like to see it become.
Example starter wording is provided. -->
Currently, the version in the repo is "0.19.0", whereas it's "0.20.0" on PyPI.
I would like to propose a change, such that the version is updated here.
# Relevant Context
<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available
to get you started. -->
- [Link to PyPI](https://pypi.org/project/pyjanitor/)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import re
2 from pathlib import Path
3
4 from setuptools import setup
5
6
7 def requirements():
8 with open("requirements.txt", "r+") as f:
9 return f.read()
10
11
12 def generate_long_description() -> str:
13 """
14 Extra chunks from README for PyPI description.
15
16 Target chunks must be contained within `.. pypi-doc` pair comments,
17 so there must be an even number of comments in README.
18
19 :returns: Extracted description from README
20
21 """
22 # Read the contents of README file
23 this_directory = Path(__file__).parent
24 with open(this_directory / "README.rst", encoding="utf-8") as f:
25 readme = f.read()
26
27 # Find pypi-doc comments in README
28 indices = [m.start() for m in re.finditer(".. pypi-doc", readme)]
29 if len(indices) % 2 != 0:
30 raise Exception("Odd number of `.. pypi-doc` comments in README")
31
32 # Loop through pairs of comments and save text between pairs
33 long_description = ""
34 for i in range(0, len(indices), 2):
35 start_index = indices[i] + 11
36 end_index = indices[i + 1]
37 long_description += readme[start_index:end_index]
38 return long_description
39
40
41 extra_spark = ["pyspark"]
42 extra_biology = ["biopython"]
43 extra_chemistry = ["rdkit"]
44 extra_engineering = ["unyt"]
45 extra_all = extra_biology + extra_engineering + extra_spark
46
47 setup(
48 name="pyjanitor",
49 version="0.19.0",
50 description="Tools for cleaning pandas DataFrames",
51 author="Eric J. Ma",
52 author_email="[email protected]",
53 url="https://github.com/ericmjl/pyjanitor",
54 packages=["janitor"],
55 install_requires=requirements(),
56 extras_require={
57 "all": extra_all,
58 "biology": extra_biology,
59 # "chemistry": extra_chemistry, should be inserted once rdkit
60 # fixes https://github.com/rdkit/rdkit/issues/1812
61 "engineering": extra_engineering,
62 "spark": extra_spark,
63 },
64 python_requires=">=3.6",
65 long_description=generate_long_description(),
66 long_description_content_type="text/x-rst",
67 )
68
```
Path: `janitor/__init__.py`
Content:
```
1 try:
2 import janitor.xarray
3 except ImportError:
4 pass
5
6 from .functions import * # noqa: F403, F401
7 from .math import *
8 from .ml import get_features_targets as _get_features_targets
9 from .utils import refactored_function
10
11 # from .dataframe import JanitorDataFrame as DataFrame # noqa: F401
12 # from .dataframe import JanitorSeries as Series # noqa: F401
13
14
15 @refactored_function(
16 "get_features_targets() has moved. Please use ml.get_features_targets()."
17 )
18 def get_features_targets(*args, **kwargs):
19 return _get_features_targets(*args, **kwargs)
20
21
22 __version__ = "0.19.0"
23
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/janitor/__init__.py b/janitor/__init__.py
--- a/janitor/__init__.py
+++ b/janitor/__init__.py
@@ -19,4 +19,4 @@
return _get_features_targets(*args, **kwargs)
-__version__ = "0.19.0"
+__version__ = "0.20.0"
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -46,7 +46,7 @@
setup(
name="pyjanitor",
- version="0.19.0",
+ version="0.20.0",
description="Tools for cleaning pandas DataFrames",
author="Eric J. Ma",
author_email="[email protected]",
|
{"golden_diff": "diff --git a/janitor/__init__.py b/janitor/__init__.py\n--- a/janitor/__init__.py\n+++ b/janitor/__init__.py\n@@ -19,4 +19,4 @@\n return _get_features_targets(*args, **kwargs)\n \n \n-__version__ = \"0.19.0\"\n+__version__ = \"0.20.0\"\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -46,7 +46,7 @@\n \n setup(\n name=\"pyjanitor\",\n- version=\"0.19.0\",\n+ version=\"0.20.0\",\n description=\"Tools for cleaning pandas DataFrames\",\n author=\"Eric J. Ma\",\n author_email=\"[email protected]\",\n", "issue": "Version on GitHub different from version on PyPI\n# Brief Description of Fix\r\n\r\n<!-- Please describe the fix in terms of a \"before\" and \"after\". In other words, what's not so good about the current docs\r\npage, and what you would like to see it become.\r\n\r\nExample starter wording is provided. -->\r\n\r\nCurrently, the version in the repo is \"0.19.0\", whereas it's \"0.20.0\" on PyPI.\r\n\r\nI would like to propose a change, such that the version is updated here.\r\n\r\n# Relevant Context\r\n\r\n<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available\r\nto get you started. -->\r\n\r\n- [Link to PyPI](https://pypi.org/project/pyjanitor/)\r\n\n", "before_files": [{"content": "import re\nfrom pathlib import Path\n\nfrom setuptools import setup\n\n\ndef requirements():\n with open(\"requirements.txt\", \"r+\") as f:\n return f.read()\n\n\ndef generate_long_description() -> str:\n \"\"\"\n Extra chunks from README for PyPI description.\n\n Target chunks must be contained within `.. pypi-doc` pair comments,\n so there must be an even number of comments in README.\n\n :returns: Extracted description from README\n\n \"\"\"\n # Read the contents of README file\n this_directory = Path(__file__).parent\n with open(this_directory / \"README.rst\", encoding=\"utf-8\") as f:\n readme = f.read()\n\n # Find pypi-doc comments in README\n indices = [m.start() for m in re.finditer(\".. pypi-doc\", readme)]\n if len(indices) % 2 != 0:\n raise Exception(\"Odd number of `.. pypi-doc` comments in README\")\n\n # Loop through pairs of comments and save text between pairs\n long_description = \"\"\n for i in range(0, len(indices), 2):\n start_index = indices[i] + 11\n end_index = indices[i + 1]\n long_description += readme[start_index:end_index]\n return long_description\n\n\nextra_spark = [\"pyspark\"]\nextra_biology = [\"biopython\"]\nextra_chemistry = [\"rdkit\"]\nextra_engineering = [\"unyt\"]\nextra_all = extra_biology + extra_engineering + extra_spark\n\nsetup(\n name=\"pyjanitor\",\n version=\"0.19.0\",\n description=\"Tools for cleaning pandas DataFrames\",\n author=\"Eric J. Ma\",\n author_email=\"[email protected]\",\n url=\"https://github.com/ericmjl/pyjanitor\",\n packages=[\"janitor\"],\n install_requires=requirements(),\n extras_require={\n \"all\": extra_all,\n \"biology\": extra_biology,\n # \"chemistry\": extra_chemistry, should be inserted once rdkit\n # fixes https://github.com/rdkit/rdkit/issues/1812\n \"engineering\": extra_engineering,\n \"spark\": extra_spark,\n },\n python_requires=\">=3.6\",\n long_description=generate_long_description(),\n long_description_content_type=\"text/x-rst\",\n)\n", "path": "setup.py"}, {"content": "try:\n import janitor.xarray\nexcept ImportError:\n pass\n\nfrom .functions import * # noqa: F403, F401\nfrom .math import *\nfrom .ml import get_features_targets as _get_features_targets\nfrom .utils import refactored_function\n\n# from .dataframe import JanitorDataFrame as DataFrame # noqa: F401\n# from .dataframe import JanitorSeries as Series # noqa: F401\n\n\n@refactored_function(\n \"get_features_targets() has moved. Please use ml.get_features_targets().\"\n)\ndef get_features_targets(*args, **kwargs):\n return _get_features_targets(*args, **kwargs)\n\n\n__version__ = \"0.19.0\"\n", "path": "janitor/__init__.py"}], "after_files": [{"content": "import re\nfrom pathlib import Path\n\nfrom setuptools import setup\n\n\ndef requirements():\n with open(\"requirements.txt\", \"r+\") as f:\n return f.read()\n\n\ndef generate_long_description() -> str:\n \"\"\"\n Extra chunks from README for PyPI description.\n\n Target chunks must be contained within `.. pypi-doc` pair comments,\n so there must be an even number of comments in README.\n\n :returns: Extracted description from README\n\n \"\"\"\n # Read the contents of README file\n this_directory = Path(__file__).parent\n with open(this_directory / \"README.rst\", encoding=\"utf-8\") as f:\n readme = f.read()\n\n # Find pypi-doc comments in README\n indices = [m.start() for m in re.finditer(\".. pypi-doc\", readme)]\n if len(indices) % 2 != 0:\n raise Exception(\"Odd number of `.. pypi-doc` comments in README\")\n\n # Loop through pairs of comments and save text between pairs\n long_description = \"\"\n for i in range(0, len(indices), 2):\n start_index = indices[i] + 11\n end_index = indices[i + 1]\n long_description += readme[start_index:end_index]\n return long_description\n\n\nextra_spark = [\"pyspark\"]\nextra_biology = [\"biopython\"]\nextra_chemistry = [\"rdkit\"]\nextra_engineering = [\"unyt\"]\nextra_all = extra_biology + extra_engineering + extra_spark\n\nsetup(\n name=\"pyjanitor\",\n version=\"0.20.0\",\n description=\"Tools for cleaning pandas DataFrames\",\n author=\"Eric J. Ma\",\n author_email=\"[email protected]\",\n url=\"https://github.com/ericmjl/pyjanitor\",\n packages=[\"janitor\"],\n install_requires=requirements(),\n extras_require={\n \"all\": extra_all,\n \"biology\": extra_biology,\n # \"chemistry\": extra_chemistry, should be inserted once rdkit\n # fixes https://github.com/rdkit/rdkit/issues/1812\n \"engineering\": extra_engineering,\n \"spark\": extra_spark,\n },\n python_requires=\">=3.6\",\n long_description=generate_long_description(),\n long_description_content_type=\"text/x-rst\",\n)\n", "path": "setup.py"}, {"content": "try:\n import janitor.xarray\nexcept ImportError:\n pass\n\nfrom .functions import * # noqa: F403, F401\nfrom .math import *\nfrom .ml import get_features_targets as _get_features_targets\nfrom .utils import refactored_function\n\n# from .dataframe import JanitorDataFrame as DataFrame # noqa: F401\n# from .dataframe import JanitorSeries as Series # noqa: F401\n\n\n@refactored_function(\n \"get_features_targets() has moved. Please use ml.get_features_targets().\"\n)\ndef get_features_targets(*args, **kwargs):\n return _get_features_targets(*args, **kwargs)\n\n\n__version__ = \"0.20.0\"\n", "path": "janitor/__init__.py"}]}
| 1,275 | 184 |
gh_patches_debug_18328
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-5219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: conan config install
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
Following situation:
Running conan 1.15.1 on Linux (Ubuntu 18.4 LTS)
When loading our configuration to a new `CONAN_USER_HOME` and start import our configuration:
`conan config install ~/work/scripts/conan/config/`
I get the following error:
`ERROR: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'`
When I just open in between `conan remote list` it works afterwards.
When running with Conan 1.14.1 it also works. So it must be a bug afterwards.
Here the recipe:
```
mkdir tempconan && cd tempconan
export CONAN_USER_HOME=/home/j/tempconan
conan config install ~/work/scripts/conan/config/
```
And the callstack:
```
j@ubuntu:~/tempconan$ conan config install ~/work/scripts/conan/config/Copying file version.txt to /home/j/tempconan/.conan/.
Copying file artifacts.properties to /home/j/tempconan/.conan/.
Processing conan.conf
Traceback (most recent call last):
File "/home/j/.local/lib/python3.6/site-packages/conans/client/command.py", line 1607, in run
method(args[0][1:])
File "/home/j/.local/lib/python3.6/site-packages/conans/client/command.py", line 478, in config
target_folder=args.target_folder)
File "/home/j/.local/lib/python3.6/site-packages/conans/client/conan_api.py", line 92, in wrapper
return f(*args, **kwargs)
File "/home/j/.local/lib/python3.6/site-packages/conans/client/conan_api.py", line 621, in config_install
source_folder=source_folder, target_folder=target_folder)
File "/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py", line 230, in configuration_install
_process_config(config, cache, output, requester)
File "/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py", line 182, in _process_config
_process_folder(config, config.uri, cache, output)
File "/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py", line 93, in _process_folder
os.remove(cache.registry_path)
FileNotFoundError: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'
ERROR: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/conf/config_installer.py`
Content:
```
1 import json
2 import os
3 import shutil
4
5 from contextlib import contextmanager
6 from six.moves.urllib.parse import urlparse
7
8 from conans import load
9 from conans.client import tools
10 from conans.client.cache.remote_registry import load_registry_txt,\
11 migrate_registry_file
12 from conans.client.tools import Git
13 from conans.client.tools.files import unzip
14 from conans.errors import ConanException
15 from conans.util.files import mkdir, rmdir, walk, save
16
17
18 def _hide_password(resource):
19 """
20 Hide password from url/file path
21
22 :param resource: string with url or file path
23 :return: resource with hidden password if present
24 """
25 password = urlparse(resource).password
26 return resource.replace(password, "<hidden>") if password else resource
27
28
29 def _handle_remotes(cache, remote_file):
30 # FIXME: Should we encourage to pass the remotes in json?
31 remotes, _ = load_registry_txt(load(remote_file))
32 cache.registry.define(remotes)
33
34
35 @contextmanager
36 def tmp_config_install_folder(cache):
37 tmp_folder = os.path.join(cache.cache_folder, "tmp_config_install")
38 # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/
39 tmp_folder = os.path.realpath(tmp_folder)
40 mkdir(tmp_folder)
41 try:
42 yield tmp_folder
43 finally:
44 rmdir(tmp_folder)
45
46
47 def _process_git_repo(config, cache, output):
48 output.info("Trying to clone repo: %s" % config.uri)
49 with tmp_config_install_folder(cache) as tmp_folder:
50 with tools.chdir(tmp_folder):
51 try:
52 args = config.args or ""
53 git = Git(verify_ssl=config.verify_ssl, output=output)
54 git.clone(config.uri, args=args)
55 output.info("Repo cloned!")
56 except Exception as e:
57 raise ConanException("Can't clone repo: %s" % str(e))
58 _process_folder(config, tmp_folder, cache, output)
59
60
61 def _process_zip_file(config, zippath, cache, output, tmp_folder, remove=False):
62 unzip(zippath, tmp_folder, output=output)
63 if remove:
64 os.unlink(zippath)
65 _process_folder(config, tmp_folder, cache, output)
66
67
68 def _handle_conan_conf(current_conan_conf, new_conan_conf_path):
69 current_conan_conf.read(new_conan_conf_path)
70 with open(current_conan_conf.filename, "w") as f:
71 current_conan_conf.write(f)
72
73
74 def _process_folder(config, folder, cache, output):
75 if config.source_folder:
76 folder = os.path.join(folder, config.source_folder)
77 for root, dirs, files in walk(folder):
78 dirs[:] = [d for d in dirs if d != ".git"]
79 if ".git" in root:
80 continue
81 for f in files:
82 if f == "settings.yml":
83 output.info("Installing settings.yml")
84 settings_path = cache.settings_path
85 shutil.copy(os.path.join(root, f), settings_path)
86 elif f == "conan.conf":
87 output.info("Processing conan.conf")
88 _handle_conan_conf(cache.config, os.path.join(root, f))
89 elif f == "remotes.txt":
90 output.info("Defining remotes from remotes.txt")
91 _handle_remotes(cache, os.path.join(root, f))
92 elif f in ("registry.txt", "registry.json"):
93 os.remove(cache.registry_path)
94 shutil.copy(os.path.join(root, f), cache.cache_folder)
95 migrate_registry_file(cache, output)
96 elif f == "remotes.json":
97 # Fix for Conan 2.0
98 raise ConanException("remotes.json install is not supported yet. Use 'remotes.txt'")
99 else:
100 # This is ugly, should be removed in Conan 2.0
101 if root == folder and f in ("README.md", "LICENSE.txt"):
102 output.info("Skip %s" % f)
103 continue
104 relpath = os.path.relpath(root, folder)
105 if config.target_folder:
106 target_folder = os.path.join(cache.cache_folder, config.target_folder,
107 relpath)
108 else:
109 target_folder = os.path.join(cache.cache_folder, relpath)
110 mkdir(target_folder)
111 output.info("Copying file %s to %s" % (f, target_folder))
112 shutil.copy(os.path.join(root, f), target_folder)
113
114
115 def _process_download(config, cache, output, requester):
116 with tmp_config_install_folder(cache) as tmp_folder:
117 output.info("Trying to download %s" % _hide_password(config.uri))
118 zippath = os.path.join(tmp_folder, "config.zip")
119 try:
120 tools.download(config.uri, zippath, out=output, verify=config.verify_ssl,
121 requester=requester)
122 _process_zip_file(config, zippath, cache, output, tmp_folder, remove=True)
123 except Exception as e:
124 raise ConanException("Error while installing config from %s\n%s" % (config.uri, str(e)))
125
126
127 class _ConfigOrigin(object):
128 def __init__(self, data):
129 self.type = data.get("type")
130 self.uri = data.get("uri")
131 self.verify_ssl = data.get("verify_ssl")
132 self.args = data.get("args")
133 self.source_folder = data.get("source_folder")
134 self.target_folder = data.get("target_folder")
135
136 def __eq__(self, other):
137 return (self.type == other.type and self.uri == other.uri and
138 self.args == other.args and self.source_folder == other.source_folder
139 and self.target_folder == other.target_folder)
140
141 def __ne__(self, other):
142 return not self.__eq__(other)
143
144 def json(self):
145 return {"type": self.type,
146 "uri": self.uri,
147 "verify_ssl": self.verify_ssl,
148 "args": self.args,
149 "source_folder": self.source_folder,
150 "target_folder": self.target_folder}
151
152 @staticmethod
153 def from_item(uri, config_type, verify_ssl, args, source_folder, target_folder):
154 config = _ConfigOrigin({})
155 if config_type:
156 config.type = config_type
157 else:
158 if uri.endswith(".git"):
159 config.type = "git"
160 elif os.path.isdir(uri):
161 config.type = "dir"
162 elif os.path.isfile(uri):
163 config.type = "file"
164 elif uri.startswith("http"):
165 config.type = "url"
166 else:
167 raise ConanException("Unable to deduce type config install: %s" % uri)
168 config.source_folder = source_folder
169 config.target_folder = target_folder
170 config.args = args
171 config.verify_ssl = verify_ssl
172 if os.path.exists(uri):
173 uri = os.path.abspath(uri)
174 config.uri = uri
175 return config
176
177
178 def _process_config(config, cache, output, requester):
179 if config.type == "git":
180 _process_git_repo(config, cache, output)
181 elif config.type == "dir":
182 _process_folder(config, config.uri, cache, output)
183 elif config.type == "file":
184 with tmp_config_install_folder(cache) as tmp_folder:
185 _process_zip_file(config, config.uri, cache, output, tmp_folder)
186 elif config.type == "url":
187 _process_download(config, cache, output, requester=requester)
188 else:
189 raise ConanException("Unable to process config install: %s" % config.uri)
190
191
192 def _save_configs(configs_file, configs):
193 save(configs_file, json.dumps([config.json() for config in configs],
194 indent=True))
195
196
197 def configuration_install(uri, cache, output, verify_ssl, requester, config_type=None,
198 args=None, source_folder=None, target_folder=None):
199 configs = []
200 configs_file = cache.config_install_file
201 if os.path.isfile(configs_file):
202 try:
203 configs = json.loads(load(configs_file))
204 except Exception as e:
205 raise ConanException("Error loading configs-install file: %s\n%"
206 % (configs_file, str(e)))
207 configs = [_ConfigOrigin(config) for config in configs]
208 if uri is None:
209 if config_type or args or not verify_ssl: # Not the defaults
210 if not configs:
211 raise ConanException("Called config install without arguments")
212 # Modify the last one
213 config = configs[-1]
214 config.config_type = config_type or config.type
215 config.args = args or config.args
216 config.verify_ssl = verify_ssl or config.verify_ssl
217 _process_config(config, cache, output, requester)
218 _save_configs(configs_file, configs)
219 else:
220 if not configs:
221 raise ConanException("Called config install without arguments")
222 # Execute the previously stored ones
223 for config in configs:
224 output.info("Config install: %s" % _hide_password(config.uri))
225 _process_config(config, cache, output, requester)
226 else:
227 # Execute and store the new one
228 config = _ConfigOrigin.from_item(uri, config_type, verify_ssl, args,
229 source_folder, target_folder)
230 _process_config(config, cache, output, requester)
231 if config not in configs:
232 configs.append(config)
233 else:
234 configs = [(c if c != config else config) for c in configs]
235 _save_configs(configs_file, configs)
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/conf/config_installer.py b/conans/client/conf/config_installer.py
--- a/conans/client/conf/config_installer.py
+++ b/conans/client/conf/config_installer.py
@@ -90,9 +90,13 @@
output.info("Defining remotes from remotes.txt")
_handle_remotes(cache, os.path.join(root, f))
elif f in ("registry.txt", "registry.json"):
- os.remove(cache.registry_path)
- shutil.copy(os.path.join(root, f), cache.cache_folder)
- migrate_registry_file(cache, output)
+ try:
+ os.remove(cache.registry_path)
+ except OSError:
+ pass
+ finally:
+ shutil.copy(os.path.join(root, f), cache.cache_folder)
+ migrate_registry_file(cache, output)
elif f == "remotes.json":
# Fix for Conan 2.0
raise ConanException("remotes.json install is not supported yet. Use 'remotes.txt'")
|
{"golden_diff": "diff --git a/conans/client/conf/config_installer.py b/conans/client/conf/config_installer.py\n--- a/conans/client/conf/config_installer.py\n+++ b/conans/client/conf/config_installer.py\n@@ -90,9 +90,13 @@\n output.info(\"Defining remotes from remotes.txt\")\n _handle_remotes(cache, os.path.join(root, f))\n elif f in (\"registry.txt\", \"registry.json\"):\n- os.remove(cache.registry_path)\n- shutil.copy(os.path.join(root, f), cache.cache_folder)\n- migrate_registry_file(cache, output)\n+ try:\n+ os.remove(cache.registry_path)\n+ except OSError:\n+ pass\n+ finally:\n+ shutil.copy(os.path.join(root, f), cache.cache_folder)\n+ migrate_registry_file(cache, output)\n elif f == \"remotes.json\":\n # Fix for Conan 2.0\n raise ConanException(\"remotes.json install is not supported yet. Use 'remotes.txt'\")\n", "issue": "Bug: conan config install\nTo help us debug your issue please explain:\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).\r\n- [x] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\nFollowing situation:\r\nRunning conan 1.15.1 on Linux (Ubuntu 18.4 LTS)\r\nWhen loading our configuration to a new `CONAN_USER_HOME` and start import our configuration:\r\n`conan config install ~/work/scripts/conan/config/`\r\nI get the following error:\r\n`ERROR: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'`\r\n\r\nWhen I just open in between `conan remote list` it works afterwards.\r\n\r\nWhen running with Conan 1.14.1 it also works. So it must be a bug afterwards.\r\n\r\nHere the recipe:\r\n```\r\nmkdir tempconan && cd tempconan\r\nexport CONAN_USER_HOME=/home/j/tempconan\r\nconan config install ~/work/scripts/conan/config/\r\n```\r\n\r\nAnd the callstack:\r\n```\r\nj@ubuntu:~/tempconan$ conan config install ~/work/scripts/conan/config/Copying file version.txt to /home/j/tempconan/.conan/.\r\nCopying file artifacts.properties to /home/j/tempconan/.conan/.\r\nProcessing conan.conf\r\nTraceback (most recent call last):\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/command.py\", line 1607, in run\r\n method(args[0][1:])\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/command.py\", line 478, in config\r\n target_folder=args.target_folder)\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/conan_api.py\", line 92, in wrapper\r\n return f(*args, **kwargs)\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/conan_api.py\", line 621, in config_install\r\n source_folder=source_folder, target_folder=target_folder)\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py\", line 230, in configuration_install\r\n _process_config(config, cache, output, requester)\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py\", line 182, in _process_config\r\n _process_folder(config, config.uri, cache, output)\r\n File \"/home/j/.local/lib/python3.6/site-packages/conans/client/conf/config_installer.py\", line 93, in _process_folder\r\n os.remove(cache.registry_path)\r\nFileNotFoundError: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'\r\n\r\nERROR: [Errno 2] No such file or directory: '/home/j/tempconan/.conan/remotes.json'\r\n\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "import json\nimport os\nimport shutil\n\nfrom contextlib import contextmanager\nfrom six.moves.urllib.parse import urlparse\n\nfrom conans import load\nfrom conans.client import tools\nfrom conans.client.cache.remote_registry import load_registry_txt,\\\n migrate_registry_file\nfrom conans.client.tools import Git\nfrom conans.client.tools.files import unzip\nfrom conans.errors import ConanException\nfrom conans.util.files import mkdir, rmdir, walk, save\n\n\ndef _hide_password(resource):\n \"\"\"\n Hide password from url/file path\n\n :param resource: string with url or file path\n :return: resource with hidden password if present\n \"\"\"\n password = urlparse(resource).password\n return resource.replace(password, \"<hidden>\") if password else resource\n\n\ndef _handle_remotes(cache, remote_file):\n # FIXME: Should we encourage to pass the remotes in json?\n remotes, _ = load_registry_txt(load(remote_file))\n cache.registry.define(remotes)\n\n\n@contextmanager\ndef tmp_config_install_folder(cache):\n tmp_folder = os.path.join(cache.cache_folder, \"tmp_config_install\")\n # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/\n tmp_folder = os.path.realpath(tmp_folder)\n mkdir(tmp_folder)\n try:\n yield tmp_folder\n finally:\n rmdir(tmp_folder)\n\n\ndef _process_git_repo(config, cache, output):\n output.info(\"Trying to clone repo: %s\" % config.uri)\n with tmp_config_install_folder(cache) as tmp_folder:\n with tools.chdir(tmp_folder):\n try:\n args = config.args or \"\"\n git = Git(verify_ssl=config.verify_ssl, output=output)\n git.clone(config.uri, args=args)\n output.info(\"Repo cloned!\")\n except Exception as e:\n raise ConanException(\"Can't clone repo: %s\" % str(e))\n _process_folder(config, tmp_folder, cache, output)\n\n\ndef _process_zip_file(config, zippath, cache, output, tmp_folder, remove=False):\n unzip(zippath, tmp_folder, output=output)\n if remove:\n os.unlink(zippath)\n _process_folder(config, tmp_folder, cache, output)\n\n\ndef _handle_conan_conf(current_conan_conf, new_conan_conf_path):\n current_conan_conf.read(new_conan_conf_path)\n with open(current_conan_conf.filename, \"w\") as f:\n current_conan_conf.write(f)\n\n\ndef _process_folder(config, folder, cache, output):\n if config.source_folder:\n folder = os.path.join(folder, config.source_folder)\n for root, dirs, files in walk(folder):\n dirs[:] = [d for d in dirs if d != \".git\"]\n if \".git\" in root:\n continue\n for f in files:\n if f == \"settings.yml\":\n output.info(\"Installing settings.yml\")\n settings_path = cache.settings_path\n shutil.copy(os.path.join(root, f), settings_path)\n elif f == \"conan.conf\":\n output.info(\"Processing conan.conf\")\n _handle_conan_conf(cache.config, os.path.join(root, f))\n elif f == \"remotes.txt\":\n output.info(\"Defining remotes from remotes.txt\")\n _handle_remotes(cache, os.path.join(root, f))\n elif f in (\"registry.txt\", \"registry.json\"):\n os.remove(cache.registry_path)\n shutil.copy(os.path.join(root, f), cache.cache_folder)\n migrate_registry_file(cache, output)\n elif f == \"remotes.json\":\n # Fix for Conan 2.0\n raise ConanException(\"remotes.json install is not supported yet. Use 'remotes.txt'\")\n else:\n # This is ugly, should be removed in Conan 2.0\n if root == folder and f in (\"README.md\", \"LICENSE.txt\"):\n output.info(\"Skip %s\" % f)\n continue\n relpath = os.path.relpath(root, folder)\n if config.target_folder:\n target_folder = os.path.join(cache.cache_folder, config.target_folder,\n relpath)\n else:\n target_folder = os.path.join(cache.cache_folder, relpath)\n mkdir(target_folder)\n output.info(\"Copying file %s to %s\" % (f, target_folder))\n shutil.copy(os.path.join(root, f), target_folder)\n\n\ndef _process_download(config, cache, output, requester):\n with tmp_config_install_folder(cache) as tmp_folder:\n output.info(\"Trying to download %s\" % _hide_password(config.uri))\n zippath = os.path.join(tmp_folder, \"config.zip\")\n try:\n tools.download(config.uri, zippath, out=output, verify=config.verify_ssl,\n requester=requester)\n _process_zip_file(config, zippath, cache, output, tmp_folder, remove=True)\n except Exception as e:\n raise ConanException(\"Error while installing config from %s\\n%s\" % (config.uri, str(e)))\n\n\nclass _ConfigOrigin(object):\n def __init__(self, data):\n self.type = data.get(\"type\")\n self.uri = data.get(\"uri\")\n self.verify_ssl = data.get(\"verify_ssl\")\n self.args = data.get(\"args\")\n self.source_folder = data.get(\"source_folder\")\n self.target_folder = data.get(\"target_folder\")\n\n def __eq__(self, other):\n return (self.type == other.type and self.uri == other.uri and\n self.args == other.args and self.source_folder == other.source_folder\n and self.target_folder == other.target_folder)\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n def json(self):\n return {\"type\": self.type,\n \"uri\": self.uri,\n \"verify_ssl\": self.verify_ssl,\n \"args\": self.args,\n \"source_folder\": self.source_folder,\n \"target_folder\": self.target_folder}\n\n @staticmethod\n def from_item(uri, config_type, verify_ssl, args, source_folder, target_folder):\n config = _ConfigOrigin({})\n if config_type:\n config.type = config_type\n else:\n if uri.endswith(\".git\"):\n config.type = \"git\"\n elif os.path.isdir(uri):\n config.type = \"dir\"\n elif os.path.isfile(uri):\n config.type = \"file\"\n elif uri.startswith(\"http\"):\n config.type = \"url\"\n else:\n raise ConanException(\"Unable to deduce type config install: %s\" % uri)\n config.source_folder = source_folder\n config.target_folder = target_folder\n config.args = args\n config.verify_ssl = verify_ssl\n if os.path.exists(uri):\n uri = os.path.abspath(uri)\n config.uri = uri\n return config\n\n\ndef _process_config(config, cache, output, requester):\n if config.type == \"git\":\n _process_git_repo(config, cache, output)\n elif config.type == \"dir\":\n _process_folder(config, config.uri, cache, output)\n elif config.type == \"file\":\n with tmp_config_install_folder(cache) as tmp_folder:\n _process_zip_file(config, config.uri, cache, output, tmp_folder)\n elif config.type == \"url\":\n _process_download(config, cache, output, requester=requester)\n else:\n raise ConanException(\"Unable to process config install: %s\" % config.uri)\n\n\ndef _save_configs(configs_file, configs):\n save(configs_file, json.dumps([config.json() for config in configs],\n indent=True))\n\n\ndef configuration_install(uri, cache, output, verify_ssl, requester, config_type=None,\n args=None, source_folder=None, target_folder=None):\n configs = []\n configs_file = cache.config_install_file\n if os.path.isfile(configs_file):\n try:\n configs = json.loads(load(configs_file))\n except Exception as e:\n raise ConanException(\"Error loading configs-install file: %s\\n%\"\n % (configs_file, str(e)))\n configs = [_ConfigOrigin(config) for config in configs]\n if uri is None:\n if config_type or args or not verify_ssl: # Not the defaults\n if not configs:\n raise ConanException(\"Called config install without arguments\")\n # Modify the last one\n config = configs[-1]\n config.config_type = config_type or config.type\n config.args = args or config.args\n config.verify_ssl = verify_ssl or config.verify_ssl\n _process_config(config, cache, output, requester)\n _save_configs(configs_file, configs)\n else:\n if not configs:\n raise ConanException(\"Called config install without arguments\")\n # Execute the previously stored ones\n for config in configs:\n output.info(\"Config install: %s\" % _hide_password(config.uri))\n _process_config(config, cache, output, requester)\n else:\n # Execute and store the new one\n config = _ConfigOrigin.from_item(uri, config_type, verify_ssl, args,\n source_folder, target_folder)\n _process_config(config, cache, output, requester)\n if config not in configs:\n configs.append(config)\n else:\n configs = [(c if c != config else config) for c in configs]\n _save_configs(configs_file, configs)\n", "path": "conans/client/conf/config_installer.py"}], "after_files": [{"content": "import json\nimport os\nimport shutil\n\nfrom contextlib import contextmanager\nfrom six.moves.urllib.parse import urlparse\n\nfrom conans import load\nfrom conans.client import tools\nfrom conans.client.cache.remote_registry import load_registry_txt,\\\n migrate_registry_file\nfrom conans.client.tools import Git\nfrom conans.client.tools.files import unzip\nfrom conans.errors import ConanException\nfrom conans.util.files import mkdir, rmdir, walk, save\n\n\ndef _hide_password(resource):\n \"\"\"\n Hide password from url/file path\n\n :param resource: string with url or file path\n :return: resource with hidden password if present\n \"\"\"\n password = urlparse(resource).password\n return resource.replace(password, \"<hidden>\") if password else resource\n\n\ndef _handle_remotes(cache, remote_file):\n # FIXME: Should we encourage to pass the remotes in json?\n remotes, _ = load_registry_txt(load(remote_file))\n cache.registry.define(remotes)\n\n\n@contextmanager\ndef tmp_config_install_folder(cache):\n tmp_folder = os.path.join(cache.cache_folder, \"tmp_config_install\")\n # necessary for Mac OSX, where the temp folders in /var/ are symlinks to /private/var/\n tmp_folder = os.path.realpath(tmp_folder)\n mkdir(tmp_folder)\n try:\n yield tmp_folder\n finally:\n rmdir(tmp_folder)\n\n\ndef _process_git_repo(config, cache, output):\n output.info(\"Trying to clone repo: %s\" % config.uri)\n with tmp_config_install_folder(cache) as tmp_folder:\n with tools.chdir(tmp_folder):\n try:\n args = config.args or \"\"\n git = Git(verify_ssl=config.verify_ssl, output=output)\n git.clone(config.uri, args=args)\n output.info(\"Repo cloned!\")\n except Exception as e:\n raise ConanException(\"Can't clone repo: %s\" % str(e))\n _process_folder(config, tmp_folder, cache, output)\n\n\ndef _process_zip_file(config, zippath, cache, output, tmp_folder, remove=False):\n unzip(zippath, tmp_folder, output=output)\n if remove:\n os.unlink(zippath)\n _process_folder(config, tmp_folder, cache, output)\n\n\ndef _handle_conan_conf(current_conan_conf, new_conan_conf_path):\n current_conan_conf.read(new_conan_conf_path)\n with open(current_conan_conf.filename, \"w\") as f:\n current_conan_conf.write(f)\n\n\ndef _process_folder(config, folder, cache, output):\n if config.source_folder:\n folder = os.path.join(folder, config.source_folder)\n for root, dirs, files in walk(folder):\n dirs[:] = [d for d in dirs if d != \".git\"]\n if \".git\" in root:\n continue\n for f in files:\n if f == \"settings.yml\":\n output.info(\"Installing settings.yml\")\n settings_path = cache.settings_path\n shutil.copy(os.path.join(root, f), settings_path)\n elif f == \"conan.conf\":\n output.info(\"Processing conan.conf\")\n _handle_conan_conf(cache.config, os.path.join(root, f))\n elif f == \"remotes.txt\":\n output.info(\"Defining remotes from remotes.txt\")\n _handle_remotes(cache, os.path.join(root, f))\n elif f in (\"registry.txt\", \"registry.json\"):\n try:\n os.remove(cache.registry_path)\n except OSError:\n pass\n finally:\n shutil.copy(os.path.join(root, f), cache.cache_folder)\n migrate_registry_file(cache, output)\n elif f == \"remotes.json\":\n # Fix for Conan 2.0\n raise ConanException(\"remotes.json install is not supported yet. Use 'remotes.txt'\")\n else:\n # This is ugly, should be removed in Conan 2.0\n if root == folder and f in (\"README.md\", \"LICENSE.txt\"):\n output.info(\"Skip %s\" % f)\n continue\n relpath = os.path.relpath(root, folder)\n if config.target_folder:\n target_folder = os.path.join(cache.cache_folder, config.target_folder,\n relpath)\n else:\n target_folder = os.path.join(cache.cache_folder, relpath)\n mkdir(target_folder)\n output.info(\"Copying file %s to %s\" % (f, target_folder))\n shutil.copy(os.path.join(root, f), target_folder)\n\n\ndef _process_download(config, cache, output, requester):\n with tmp_config_install_folder(cache) as tmp_folder:\n output.info(\"Trying to download %s\" % _hide_password(config.uri))\n zippath = os.path.join(tmp_folder, \"config.zip\")\n try:\n tools.download(config.uri, zippath, out=output, verify=config.verify_ssl,\n requester=requester)\n _process_zip_file(config, zippath, cache, output, tmp_folder, remove=True)\n except Exception as e:\n raise ConanException(\"Error while installing config from %s\\n%s\" % (config.uri, str(e)))\n\n\nclass _ConfigOrigin(object):\n def __init__(self, data):\n self.type = data.get(\"type\")\n self.uri = data.get(\"uri\")\n self.verify_ssl = data.get(\"verify_ssl\")\n self.args = data.get(\"args\")\n self.source_folder = data.get(\"source_folder\")\n self.target_folder = data.get(\"target_folder\")\n\n def __eq__(self, other):\n return (self.type == other.type and self.uri == other.uri and\n self.args == other.args and self.source_folder == other.source_folder\n and self.target_folder == other.target_folder)\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n def json(self):\n return {\"type\": self.type,\n \"uri\": self.uri,\n \"verify_ssl\": self.verify_ssl,\n \"args\": self.args,\n \"source_folder\": self.source_folder,\n \"target_folder\": self.target_folder}\n\n @staticmethod\n def from_item(uri, config_type, verify_ssl, args, source_folder, target_folder):\n config = _ConfigOrigin({})\n if config_type:\n config.type = config_type\n else:\n if uri.endswith(\".git\"):\n config.type = \"git\"\n elif os.path.isdir(uri):\n config.type = \"dir\"\n elif os.path.isfile(uri):\n config.type = \"file\"\n elif uri.startswith(\"http\"):\n config.type = \"url\"\n else:\n raise ConanException(\"Unable to deduce type config install: %s\" % uri)\n config.source_folder = source_folder\n config.target_folder = target_folder\n config.args = args\n config.verify_ssl = verify_ssl\n if os.path.exists(uri):\n uri = os.path.abspath(uri)\n config.uri = uri\n return config\n\n\ndef _process_config(config, cache, output, requester):\n if config.type == \"git\":\n _process_git_repo(config, cache, output)\n elif config.type == \"dir\":\n _process_folder(config, config.uri, cache, output)\n elif config.type == \"file\":\n with tmp_config_install_folder(cache) as tmp_folder:\n _process_zip_file(config, config.uri, cache, output, tmp_folder)\n elif config.type == \"url\":\n _process_download(config, cache, output, requester=requester)\n else:\n raise ConanException(\"Unable to process config install: %s\" % config.uri)\n\n\ndef _save_configs(configs_file, configs):\n save(configs_file, json.dumps([config.json() for config in configs],\n indent=True))\n\n\ndef configuration_install(uri, cache, output, verify_ssl, requester, config_type=None,\n args=None, source_folder=None, target_folder=None):\n configs = []\n configs_file = cache.config_install_file\n if os.path.isfile(configs_file):\n try:\n configs = json.loads(load(configs_file))\n except Exception as e:\n raise ConanException(\"Error loading configs-install file: %s\\n%\"\n % (configs_file, str(e)))\n configs = [_ConfigOrigin(config) for config in configs]\n if uri is None:\n if config_type or args or not verify_ssl: # Not the defaults\n if not configs:\n raise ConanException(\"Called config install without arguments\")\n # Modify the last one\n config = configs[-1]\n config.config_type = config_type or config.type\n config.args = args or config.args\n config.verify_ssl = verify_ssl or config.verify_ssl\n _process_config(config, cache, output, requester)\n _save_configs(configs_file, configs)\n else:\n if not configs:\n raise ConanException(\"Called config install without arguments\")\n # Execute the previously stored ones\n for config in configs:\n output.info(\"Config install: %s\" % _hide_password(config.uri))\n _process_config(config, cache, output, requester)\n else:\n # Execute and store the new one\n config = _ConfigOrigin.from_item(uri, config_type, verify_ssl, args,\n source_folder, target_folder)\n _process_config(config, cache, output, requester)\n if config not in configs:\n configs.append(config)\n else:\n configs = [(c if c != config else config) for c in configs]\n _save_configs(configs_file, configs)\n", "path": "conans/client/conf/config_installer.py"}]}
| 3,539 | 216 |
gh_patches_debug_33758
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-2587
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update default suggestions in `settings.py` to ones that work
## Description
Update docs and default suggestions in `settings.py`, because currently some of those suggestions don't actually work.
Currently, the `BaseSessionStore` is the default session store. The other possible stores a user can use are the `ShelveStore` and the `SQLiteStore` (currently part of viz).
The `ShelveStore` is the default suggestion to override the default in `settings.py`, but when users are using some sort of multiprocessing this store type will not work. See: https://github.com/kedro-org/kedro/issues/1442
Also look at the other default suggestions and verify that they make sense.
(Later consideration, but not part of this work)
If we move the `SQLiteStore` from viz to kedro core, we could add that as the default suggestion instead.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py`
Content:
```
1 """Project settings. There is no need to edit this file unless you want to change values
2 from the Kedro defaults. For further information, including these default values, see
3 https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html."""
4
5 # Instantiated project hooks.
6 # from {{cookiecutter.python_package}}.hooks import ProjectHooks
7 # HOOKS = (ProjectHooks(),)
8
9 # Installed plugins for which to disable hook auto-registration.
10 # DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
11
12 # Class that manages storing KedroSession data.
13 # from kedro.framework.session.shelvestore import ShelveStore
14 # SESSION_STORE_CLASS = ShelveStore
15 # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
16 # SESSION_STORE_ARGS = {
17 # "path": "./sessions"
18 # }
19
20 # Class that manages Kedro's library components.
21 # from kedro.framework.context import KedroContext
22 # CONTEXT_CLASS = KedroContext
23
24 # Directory that holds configuration.
25 # CONF_SOURCE = "conf"
26
27 # Class that manages how configuration is loaded.
28 # CONFIG_LOADER_CLASS = ConfigLoader
29 # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
30 # CONFIG_LOADER_ARGS = {
31 # "config_patterns": {
32 # "spark" : ["spark*/"],
33 # "parameters": ["parameters*", "parameters*/**", "**/parameters*"],
34 # }
35 # }
36
37 # Class that manages the Data Catalog.
38 # from kedro.io import DataCatalog
39 # DATA_CATALOG_CLASS = DataCatalog
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
--- a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
+++ b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py
@@ -3,6 +3,7 @@
https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html."""
# Instantiated project hooks.
+# For example, after creating a hooks.py and defining a ProjectHooks class there, do
# from {{cookiecutter.python_package}}.hooks import ProjectHooks
# HOOKS = (ProjectHooks(),)
@@ -10,22 +11,19 @@
# DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
# Class that manages storing KedroSession data.
-# from kedro.framework.session.shelvestore import ShelveStore
-# SESSION_STORE_CLASS = ShelveStore
+# from kedro.framework.session.store import BaseSessionStore
+# SESSION_STORE_CLASS = BaseSessionStore
# Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
# SESSION_STORE_ARGS = {
# "path": "./sessions"
# }
-# Class that manages Kedro's library components.
-# from kedro.framework.context import KedroContext
-# CONTEXT_CLASS = KedroContext
-
# Directory that holds configuration.
# CONF_SOURCE = "conf"
# Class that manages how configuration is loaded.
-# CONFIG_LOADER_CLASS = ConfigLoader
+# from kedro.config import OmegaConfigLoader
+# CONFIG_LOADER_CLASS = OmegaConfigLoader
# Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
# CONFIG_LOADER_ARGS = {
# "config_patterns": {
@@ -34,6 +32,10 @@
# }
# }
+# Class that manages Kedro's library components.
+# from kedro.framework.context import KedroContext
+# CONTEXT_CLASS = KedroContext
+
# Class that manages the Data Catalog.
# from kedro.io import DataCatalog
# DATA_CATALOG_CLASS = DataCatalog
|
{"golden_diff": "diff --git a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\n--- a/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\t\n+++ b/kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py\t\n@@ -3,6 +3,7 @@\n https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html.\"\"\"\n \n # Instantiated project hooks.\n+# For example, after creating a hooks.py and defining a ProjectHooks class there, do\n # from {{cookiecutter.python_package}}.hooks import ProjectHooks\n # HOOKS = (ProjectHooks(),)\n \n@@ -10,22 +11,19 @@\n # DISABLE_HOOKS_FOR_PLUGINS = (\"kedro-viz\",)\n \n # Class that manages storing KedroSession data.\n-# from kedro.framework.session.shelvestore import ShelveStore\n-# SESSION_STORE_CLASS = ShelveStore\n+# from kedro.framework.session.store import BaseSessionStore\n+# SESSION_STORE_CLASS = BaseSessionStore\n # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.\n # SESSION_STORE_ARGS = {\n # \"path\": \"./sessions\"\n # }\n \n-# Class that manages Kedro's library components.\n-# from kedro.framework.context import KedroContext\n-# CONTEXT_CLASS = KedroContext\n-\n # Directory that holds configuration.\n # CONF_SOURCE = \"conf\"\n \n # Class that manages how configuration is loaded.\n-# CONFIG_LOADER_CLASS = ConfigLoader\n+# from kedro.config import OmegaConfigLoader\n+# CONFIG_LOADER_CLASS = OmegaConfigLoader\n # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.\n # CONFIG_LOADER_ARGS = {\n # \"config_patterns\": {\n@@ -34,6 +32,10 @@\n # }\n # }\n \n+# Class that manages Kedro's library components.\n+# from kedro.framework.context import KedroContext\n+# CONTEXT_CLASS = KedroContext\n+\n # Class that manages the Data Catalog.\n # from kedro.io import DataCatalog\n # DATA_CATALOG_CLASS = DataCatalog\n", "issue": "Update default suggestions in `settings.py` to ones that work\n## Description\r\nUpdate docs and default suggestions in `settings.py`, because currently some of those suggestions don't actually work. \r\n\r\nCurrently, the `BaseSessionStore` is the default session store. The other possible stores a user can use are the `ShelveStore` and the `SQLiteStore` (currently part of viz).\r\n\r\nThe `ShelveStore` is the default suggestion to override the default in `settings.py`, but when users are using some sort of multiprocessing this store type will not work. See: https://github.com/kedro-org/kedro/issues/1442\r\n\r\nAlso look at the other default suggestions and verify that they make sense. \r\n\r\n(Later consideration, but not part of this work)\r\nIf we move the `SQLiteStore` from viz to kedro core, we could add that as the default suggestion instead. \r\n\n", "before_files": [{"content": "\"\"\"Project settings. There is no need to edit this file unless you want to change values\nfrom the Kedro defaults. For further information, including these default values, see\nhttps://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html.\"\"\"\n\n# Instantiated project hooks.\n# from {{cookiecutter.python_package}}.hooks import ProjectHooks\n# HOOKS = (ProjectHooks(),)\n\n# Installed plugins for which to disable hook auto-registration.\n# DISABLE_HOOKS_FOR_PLUGINS = (\"kedro-viz\",)\n\n# Class that manages storing KedroSession data.\n# from kedro.framework.session.shelvestore import ShelveStore\n# SESSION_STORE_CLASS = ShelveStore\n# Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.\n# SESSION_STORE_ARGS = {\n# \"path\": \"./sessions\"\n# }\n\n# Class that manages Kedro's library components.\n# from kedro.framework.context import KedroContext\n# CONTEXT_CLASS = KedroContext\n\n# Directory that holds configuration.\n# CONF_SOURCE = \"conf\"\n\n# Class that manages how configuration is loaded.\n# CONFIG_LOADER_CLASS = ConfigLoader\n# Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.\n# CONFIG_LOADER_ARGS = {\n# \"config_patterns\": {\n# \"spark\" : [\"spark*/\"],\n# \"parameters\": [\"parameters*\", \"parameters*/**\", \"**/parameters*\"],\n# }\n# }\n\n# Class that manages the Data Catalog.\n# from kedro.io import DataCatalog\n# DATA_CATALOG_CLASS = DataCatalog\n", "path": "kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py"}], "after_files": [{"content": "\"\"\"Project settings. There is no need to edit this file unless you want to change values\nfrom the Kedro defaults. For further information, including these default values, see\nhttps://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html.\"\"\"\n\n# Instantiated project hooks.\n# For example, after creating a hooks.py and defining a ProjectHooks class there, do\n# from {{cookiecutter.python_package}}.hooks import ProjectHooks\n# HOOKS = (ProjectHooks(),)\n\n# Installed plugins for which to disable hook auto-registration.\n# DISABLE_HOOKS_FOR_PLUGINS = (\"kedro-viz\",)\n\n# Class that manages storing KedroSession data.\n# from kedro.framework.session.store import BaseSessionStore\n# SESSION_STORE_CLASS = BaseSessionStore\n# Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.\n# SESSION_STORE_ARGS = {\n# \"path\": \"./sessions\"\n# }\n\n# Directory that holds configuration.\n# CONF_SOURCE = \"conf\"\n\n# Class that manages how configuration is loaded.\n# from kedro.config import OmegaConfigLoader\n# CONFIG_LOADER_CLASS = OmegaConfigLoader\n# Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.\n# CONFIG_LOADER_ARGS = {\n# \"config_patterns\": {\n# \"spark\" : [\"spark*/\"],\n# \"parameters\": [\"parameters*\", \"parameters*/**\", \"**/parameters*\"],\n# }\n# }\n\n# Class that manages Kedro's library components.\n# from kedro.framework.context import KedroContext\n# CONTEXT_CLASS = KedroContext\n\n# Class that manages the Data Catalog.\n# from kedro.io import DataCatalog\n# DATA_CATALOG_CLASS = DataCatalog\n", "path": "kedro/templates/project/{{ cookiecutter.repo_name }}/src/{{ cookiecutter.python_package }}/settings.py"}]}
| 871 | 496 |
gh_patches_debug_51452
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-389
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create desktop/application menu shortcut writes a bad .desktop file
File contents:
```
[Desktop Entry]
Type=Application
Name=%s
Icon=%s
Exec=lutris lutris:%s
Categories=Game
```
**How to reproduce**
Right click a game and select Create desktop shortcut.
Navigate to ~/Desktop
You see a file with name `gameslug-id.desktop` but it contains what's above. If you're in a file manager you see the game title instead of the filename, so it appears as `%s` there.
**Lutris debug output**
```
[system]:Executing which xdg-user-dir
```
Operating system: Arch Linux
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/shortcuts.py`
Content:
```
1 """Desktop file creator."""
2 import os
3 import stat
4 import shutil
5 import subprocess
6
7 from textwrap import dedent
8 from xdg import BaseDirectory
9 from gi.repository import GLib
10
11 from lutris.util import system
12 from lutris.util.log import logger
13 from lutris.settings import CACHE_DIR
14
15
16 def get_xdg_basename(game_slug, game_id, legacy=False):
17 if legacy:
18 filename = "{}.desktop".format(game_slug)
19 else:
20 filename = "{}-{}.desktop".format(game_slug, game_id)
21 return filename
22
23
24 def create_launcher(game_slug, game_id, game_name, desktop=False, menu=False):
25 """Create a .desktop file."""
26 desktop_dir = (
27 GLib.get_user_special_dir(GLib.UserDirectory.DIRECTORY_DESKTOP)
28 )
29 launcher_content = dedent(
30 """
31 [Desktop Entry]
32 Type=Application
33 Name=%s
34 Icon=%s
35 Exec=lutris lutris:%s
36 Categories=Game
37 """.format(game_name, 'lutris_{}'.format(game_slug), game_id)
38 )
39
40 launcher_filename = get_xdg_basename(game_slug, game_id, legacy=False)
41 tmp_launcher_path = os.path.join(CACHE_DIR, launcher_filename)
42 tmp_launcher = open(tmp_launcher_path, "w")
43 tmp_launcher.write(launcher_content)
44 tmp_launcher.close()
45 os.chmod(tmp_launcher_path, stat.S_IREAD | stat.S_IWRITE | stat.S_IEXEC |
46 stat.S_IRGRP | stat.S_IWGRP | stat.S_IXGRP)
47
48 if desktop:
49 shutil.copy(tmp_launcher_path,
50 os.path.join(desktop_dir, launcher_filename))
51 if menu:
52 menu_path = os.path.join(GLib.get_user_data_dir(), 'applications')
53 shutil.copy(tmp_launcher_path,
54 os.path.join(menu_path, launcher_filename))
55 os.remove(tmp_launcher_path)
56
57
58 def get_launcher_path(game_slug, game_id):
59 """Return the path of a XDG game launcher.
60 When legacy is set, it will return the old path with only the slug,
61 otherwise it will return the path with slug + id
62 """
63 xdg_executable = 'xdg-user-dir'
64 if not system.find_executable(xdg_executable):
65 logger.error("%s not found", xdg_executable)
66 return
67 desktop_dir = subprocess.Popen([xdg_executable, 'DESKTOP'],
68 stdout=subprocess.PIPE).communicate()[0]
69 desktop_dir = str(desktop_dir).strip()
70
71 legacy_launcher_path = os.path.join(
72 desktop_dir, get_xdg_basename(game_slug, game_id, legacy=True)
73 )
74 # First check if legacy path exists, for backward compatibility
75 if system.path_exists(legacy_launcher_path):
76 return legacy_launcher_path
77 # Otherwise return new path, whether it exists or not
78 return os.path.join(
79 desktop_dir, get_xdg_basename(game_slug, game_id, legacy=False)
80 )
81
82
83 def get_menu_launcher_path(game_slug, game_id):
84 """Return the path to a XDG menu launcher, prioritizing legacy paths if
85 they exist
86 """
87 menu_dir = os.path.join(BaseDirectory.xdg_data_home, 'applications')
88 menu_path = os.path.join(
89 menu_dir, get_xdg_basename(game_slug, game_id, legacy=True)
90 )
91 if system.path_exists(menu_path):
92 return menu_path
93 return os.path.join(
94 menu_dir, get_xdg_basename(game_slug, game_id, legacy=False)
95 )
96
97
98 def desktop_launcher_exists(game_slug, game_id):
99 return system.path_exists(get_launcher_path(game_slug, game_id))
100
101
102 def menu_launcher_exists(game_slug, game_id):
103 return system.path_exists(get_menu_launcher_path(game_slug, game_id))
104
105
106 def remove_launcher(game_slug, game_id, desktop=False, menu=False):
107 """Remove existing .desktop file."""
108 if desktop:
109 launcher_path = get_launcher_path(game_slug, game_id)
110 if system.path_exists(launcher_path):
111 os.remove(launcher_path)
112
113 if menu:
114 menu_path = get_menu_launcher_path(game_slug, game_id)
115 if system.path_exists(menu_path):
116 os.remove(menu_path)
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/shortcuts.py b/lutris/shortcuts.py
--- a/lutris/shortcuts.py
+++ b/lutris/shortcuts.py
@@ -30,9 +30,9 @@
"""
[Desktop Entry]
Type=Application
- Name=%s
- Icon=%s
- Exec=lutris lutris:%s
+ Name={}
+ Icon={}
+ Exec=lutris lutris:{}
Categories=Game
""".format(game_name, 'lutris_{}'.format(game_slug), game_id)
)
|
{"golden_diff": "diff --git a/lutris/shortcuts.py b/lutris/shortcuts.py\n--- a/lutris/shortcuts.py\n+++ b/lutris/shortcuts.py\n@@ -30,9 +30,9 @@\n \"\"\"\n [Desktop Entry]\n Type=Application\n- Name=%s\n- Icon=%s\n- Exec=lutris lutris:%s\n+ Name={}\n+ Icon={}\n+ Exec=lutris lutris:{}\n Categories=Game\n \"\"\".format(game_name, 'lutris_{}'.format(game_slug), game_id)\n )\n", "issue": "Create desktop/application menu shortcut writes a bad .desktop file\nFile contents:\n\n```\n[Desktop Entry]\nType=Application\nName=%s\nIcon=%s\nExec=lutris lutris:%s\nCategories=Game\n```\n\n**How to reproduce**\nRight click a game and select Create desktop shortcut.\nNavigate to ~/Desktop\nYou see a file with name `gameslug-id.desktop` but it contains what's above. If you're in a file manager you see the game title instead of the filename, so it appears as `%s` there.\n\n**Lutris debug output**\n\n```\n[system]:Executing which xdg-user-dir\n```\n\nOperating system: Arch Linux\n\n", "before_files": [{"content": "\"\"\"Desktop file creator.\"\"\"\nimport os\nimport stat\nimport shutil\nimport subprocess\n\nfrom textwrap import dedent\nfrom xdg import BaseDirectory\nfrom gi.repository import GLib\n\nfrom lutris.util import system\nfrom lutris.util.log import logger\nfrom lutris.settings import CACHE_DIR\n\n\ndef get_xdg_basename(game_slug, game_id, legacy=False):\n if legacy:\n filename = \"{}.desktop\".format(game_slug)\n else:\n filename = \"{}-{}.desktop\".format(game_slug, game_id)\n return filename\n\n\ndef create_launcher(game_slug, game_id, game_name, desktop=False, menu=False):\n \"\"\"Create a .desktop file.\"\"\"\n desktop_dir = (\n GLib.get_user_special_dir(GLib.UserDirectory.DIRECTORY_DESKTOP)\n )\n launcher_content = dedent(\n \"\"\"\n [Desktop Entry]\n Type=Application\n Name=%s\n Icon=%s\n Exec=lutris lutris:%s\n Categories=Game\n \"\"\".format(game_name, 'lutris_{}'.format(game_slug), game_id)\n )\n\n launcher_filename = get_xdg_basename(game_slug, game_id, legacy=False)\n tmp_launcher_path = os.path.join(CACHE_DIR, launcher_filename)\n tmp_launcher = open(tmp_launcher_path, \"w\")\n tmp_launcher.write(launcher_content)\n tmp_launcher.close()\n os.chmod(tmp_launcher_path, stat.S_IREAD | stat.S_IWRITE | stat.S_IEXEC |\n stat.S_IRGRP | stat.S_IWGRP | stat.S_IXGRP)\n\n if desktop:\n shutil.copy(tmp_launcher_path,\n os.path.join(desktop_dir, launcher_filename))\n if menu:\n menu_path = os.path.join(GLib.get_user_data_dir(), 'applications')\n shutil.copy(tmp_launcher_path,\n os.path.join(menu_path, launcher_filename))\n os.remove(tmp_launcher_path)\n\n\ndef get_launcher_path(game_slug, game_id):\n \"\"\"Return the path of a XDG game launcher.\n When legacy is set, it will return the old path with only the slug,\n otherwise it will return the path with slug + id\n \"\"\"\n xdg_executable = 'xdg-user-dir'\n if not system.find_executable(xdg_executable):\n logger.error(\"%s not found\", xdg_executable)\n return\n desktop_dir = subprocess.Popen([xdg_executable, 'DESKTOP'],\n stdout=subprocess.PIPE).communicate()[0]\n desktop_dir = str(desktop_dir).strip()\n\n legacy_launcher_path = os.path.join(\n desktop_dir, get_xdg_basename(game_slug, game_id, legacy=True)\n )\n # First check if legacy path exists, for backward compatibility\n if system.path_exists(legacy_launcher_path):\n return legacy_launcher_path\n # Otherwise return new path, whether it exists or not\n return os.path.join(\n desktop_dir, get_xdg_basename(game_slug, game_id, legacy=False)\n )\n\n\ndef get_menu_launcher_path(game_slug, game_id):\n \"\"\"Return the path to a XDG menu launcher, prioritizing legacy paths if\n they exist\n \"\"\"\n menu_dir = os.path.join(BaseDirectory.xdg_data_home, 'applications')\n menu_path = os.path.join(\n menu_dir, get_xdg_basename(game_slug, game_id, legacy=True)\n )\n if system.path_exists(menu_path):\n return menu_path\n return os.path.join(\n menu_dir, get_xdg_basename(game_slug, game_id, legacy=False)\n )\n\n\ndef desktop_launcher_exists(game_slug, game_id):\n return system.path_exists(get_launcher_path(game_slug, game_id))\n\n\ndef menu_launcher_exists(game_slug, game_id):\n return system.path_exists(get_menu_launcher_path(game_slug, game_id))\n\n\ndef remove_launcher(game_slug, game_id, desktop=False, menu=False):\n \"\"\"Remove existing .desktop file.\"\"\"\n if desktop:\n launcher_path = get_launcher_path(game_slug, game_id)\n if system.path_exists(launcher_path):\n os.remove(launcher_path)\n\n if menu:\n menu_path = get_menu_launcher_path(game_slug, game_id)\n if system.path_exists(menu_path):\n os.remove(menu_path)\n", "path": "lutris/shortcuts.py"}], "after_files": [{"content": "\"\"\"Desktop file creator.\"\"\"\nimport os\nimport stat\nimport shutil\nimport subprocess\n\nfrom textwrap import dedent\nfrom xdg import BaseDirectory\nfrom gi.repository import GLib\n\nfrom lutris.util import system\nfrom lutris.util.log import logger\nfrom lutris.settings import CACHE_DIR\n\n\ndef get_xdg_basename(game_slug, game_id, legacy=False):\n if legacy:\n filename = \"{}.desktop\".format(game_slug)\n else:\n filename = \"{}-{}.desktop\".format(game_slug, game_id)\n return filename\n\n\ndef create_launcher(game_slug, game_id, game_name, desktop=False, menu=False):\n \"\"\"Create a .desktop file.\"\"\"\n desktop_dir = (\n GLib.get_user_special_dir(GLib.UserDirectory.DIRECTORY_DESKTOP)\n )\n launcher_content = dedent(\n \"\"\"\n [Desktop Entry]\n Type=Application\n Name={}\n Icon={}\n Exec=lutris lutris:{}\n Categories=Game\n \"\"\".format(game_name, 'lutris_{}'.format(game_slug), game_id)\n )\n\n launcher_filename = get_xdg_basename(game_slug, game_id, legacy=False)\n tmp_launcher_path = os.path.join(CACHE_DIR, launcher_filename)\n tmp_launcher = open(tmp_launcher_path, \"w\")\n tmp_launcher.write(launcher_content)\n tmp_launcher.close()\n os.chmod(tmp_launcher_path, stat.S_IREAD | stat.S_IWRITE | stat.S_IEXEC |\n stat.S_IRGRP | stat.S_IWGRP | stat.S_IXGRP)\n\n if desktop:\n shutil.copy(tmp_launcher_path,\n os.path.join(desktop_dir, launcher_filename))\n if menu:\n menu_path = os.path.join(GLib.get_user_data_dir(), 'applications')\n shutil.copy(tmp_launcher_path,\n os.path.join(menu_path, launcher_filename))\n os.remove(tmp_launcher_path)\n\n\ndef get_launcher_path(game_slug, game_id):\n \"\"\"Return the path of a XDG game launcher.\n When legacy is set, it will return the old path with only the slug,\n otherwise it will return the path with slug + id\n \"\"\"\n xdg_executable = 'xdg-user-dir'\n if not system.find_executable(xdg_executable):\n logger.error(\"%s not found\", xdg_executable)\n return\n desktop_dir = subprocess.Popen([xdg_executable, 'DESKTOP'],\n stdout=subprocess.PIPE).communicate()[0]\n desktop_dir = str(desktop_dir).strip()\n\n legacy_launcher_path = os.path.join(\n desktop_dir, get_xdg_basename(game_slug, game_id, legacy=True)\n )\n # First check if legacy path exists, for backward compatibility\n if system.path_exists(legacy_launcher_path):\n return legacy_launcher_path\n # Otherwise return new path, whether it exists or not\n return os.path.join(\n desktop_dir, get_xdg_basename(game_slug, game_id, legacy=False)\n )\n\n\ndef get_menu_launcher_path(game_slug, game_id):\n \"\"\"Return the path to a XDG menu launcher, prioritizing legacy paths if\n they exist\n \"\"\"\n menu_dir = os.path.join(BaseDirectory.xdg_data_home, 'applications')\n menu_path = os.path.join(\n menu_dir, get_xdg_basename(game_slug, game_id, legacy=True)\n )\n if system.path_exists(menu_path):\n return menu_path\n return os.path.join(\n menu_dir, get_xdg_basename(game_slug, game_id, legacy=False)\n )\n\n\ndef desktop_launcher_exists(game_slug, game_id):\n return system.path_exists(get_launcher_path(game_slug, game_id))\n\n\ndef menu_launcher_exists(game_slug, game_id):\n return system.path_exists(get_menu_launcher_path(game_slug, game_id))\n\n\ndef remove_launcher(game_slug, game_id, desktop=False, menu=False):\n \"\"\"Remove existing .desktop file.\"\"\"\n if desktop:\n launcher_path = get_launcher_path(game_slug, game_id)\n if system.path_exists(launcher_path):\n os.remove(launcher_path)\n\n if menu:\n menu_path = get_menu_launcher_path(game_slug, game_id)\n if system.path_exists(menu_path):\n os.remove(menu_path)\n", "path": "lutris/shortcuts.py"}]}
| 1,537 | 130 |
gh_patches_debug_3113
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-42038
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"pause" module fails with NameError when "curses" is not installed
<!---
Verify first that your issue/request is not already reported on GitHub.
THIS FORM WILL BE READ BY A MACHINE, COMPLETE ALL SECTIONS AS DESCRIBED.
Also test if the latest release, and devel branch are affected too.
ALWAYS add information AFTER (OUTSIDE) these html comments.
Otherwise it may end up being automatically closed by our bot. -->
##### SUMMARY
The "pause" module fails with a NameError when the curses Python module is not available.
```
Traceback (most recent call last):
File "/usr/local/python/bin/ansible-playbook", line 118, in <module>
exit_code = cli.run()
File "/usr/local/python/lib/python2.7/site-packages/ansible/cli/playbook.py", line 122, in run
results = pbex.run()
File "/usr/local/python/lib/python2.7/site-packages/ansible/executor/playbook_executor.py", line 159, in run
result = self._tqm.run(play=play)
File "/usr/local/python/lib/python2.7/site-packages/ansible/executor/task_queue_manager.py", line 289, in run
play_return = strategy.run(iterator, play_context)
File "/usr/local/python/lib/python2.7/site-packages/ansible/plugins/strategy/linear.py", line 247, in run
action = action_loader.get(task.action, class_only=True)
File "/usr/local/python/lib/python2.7/site-packages/ansible/plugins/loader.py", line 366, in get
self._module_cache[path] = self._load_module_source(name, path)
File "/usr/local/python/lib/python2.7/site-packages/ansible/plugins/loader.py", line 345, in _load_module_source
module = imp.load_source(full_name, path, module_file)
File "/usr/local/python/lib/python2.7/site-packages/ansible/plugins/action/pause.py", line 44, in <module>
except (ImportError, curses.error):
NameError: name 'curses' is not defined
```
Caused by this code block introduced by https://github.com/ansible/ansible/pull/40134 to fix #35372:
```python
try:
import curses
curses.setupterm()
HAS_CURSES = True
except (ImportError, curses.error):
HAS_CURSES = False
```
A better fix would be to nest the curses.error try-catch within the block.
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
plugins/action/pause.py
##### ANSIBLE VERSION
ansible 2.5.4
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/etc/ansible/modules']
ansible python module location = /usr/local/python/lib/python2.7/site-packages/ansible
executable location = /usr/local/python/bin/ansible
python version = 2.7.10 (default, Oct 11 2015, 23:13:31) [GCC 4.8.3 20140911 (Red Hat 4.8.3-9)]
##### CONFIGURATION
N/A
##### OS / ENVIRONMENT
N/A
##### STEPS TO REPRODUCE
On a machine without "curses", run:
> $ ansible localhost -m pause -a 'seconds=1'
> ERROR! Unexpected Exception, this is probably a bug: name 'curses' is not defined
> to see the full traceback, use -vvv
##### EXPECTED RESULTS
N/A
##### ACTUAL RESULTS
See above.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/plugins/action/pause.py`
Content:
```
1 # Copyright 2012, Tim Bielawa <[email protected]>
2 #
3 # This file is part of Ansible
4 #
5 # Ansible is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Ansible is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
17 from __future__ import (absolute_import, division, print_function)
18 __metaclass__ = type
19
20 import datetime
21 import signal
22 import sys
23 import termios
24 import time
25 import tty
26
27 from os import isatty
28 from ansible.errors import AnsibleError
29 from ansible.module_utils._text import to_text, to_native
30 from ansible.module_utils.parsing.convert_bool import boolean
31 from ansible.module_utils.six import PY3
32 from ansible.plugins.action import ActionBase
33
34 try:
35 from __main__ import display
36 except ImportError:
37 from ansible.utils.display import Display
38 display = Display()
39
40 try:
41 import curses
42 curses.setupterm()
43 HAS_CURSES = True
44 except (ImportError, curses.error):
45 HAS_CURSES = False
46
47 if HAS_CURSES:
48 MOVE_TO_BOL = curses.tigetstr('cr')
49 CLEAR_TO_EOL = curses.tigetstr('el')
50 else:
51 MOVE_TO_BOL = b'\r'
52 CLEAR_TO_EOL = b'\x1b[K'
53
54
55 class AnsibleTimeoutExceeded(Exception):
56 pass
57
58
59 def timeout_handler(signum, frame):
60 raise AnsibleTimeoutExceeded
61
62
63 def clear_line(stdout):
64 stdout.write(b'\x1b[%s' % MOVE_TO_BOL)
65 stdout.write(b'\x1b[%s' % CLEAR_TO_EOL)
66
67
68 class ActionModule(ActionBase):
69 ''' pauses execution for a length or time, or until input is received '''
70
71 PAUSE_TYPES = ['seconds', 'minutes', 'prompt', 'echo', '']
72 BYPASS_HOST_LOOP = True
73
74 def run(self, tmp=None, task_vars=None):
75 ''' run the pause action module '''
76 if task_vars is None:
77 task_vars = dict()
78
79 result = super(ActionModule, self).run(tmp, task_vars)
80 del tmp # tmp no longer has any effect
81
82 duration_unit = 'minutes'
83 prompt = None
84 seconds = None
85 echo = True
86 echo_prompt = ''
87 result.update(dict(
88 changed=False,
89 rc=0,
90 stderr='',
91 stdout='',
92 start=None,
93 stop=None,
94 delta=None,
95 echo=echo
96 ))
97
98 if not set(self._task.args.keys()) <= set(self.PAUSE_TYPES):
99 result['failed'] = True
100 result['msg'] = "Invalid argument given. Must be one of: %s" % ", ".join(self.PAUSE_TYPES)
101 return result
102
103 # Should keystrokes be echoed to stdout?
104 if 'echo' in self._task.args:
105 try:
106 echo = boolean(self._task.args['echo'])
107 except TypeError as e:
108 result['failed'] = True
109 result['msg'] = to_native(e)
110 return result
111
112 # Add a note saying the output is hidden if echo is disabled
113 if not echo:
114 echo_prompt = ' (output is hidden)'
115
116 # Is 'prompt' a key in 'args'?
117 if 'prompt' in self._task.args:
118 prompt = "[%s]\n%s%s:" % (self._task.get_name().strip(), self._task.args['prompt'], echo_prompt)
119 else:
120 # If no custom prompt is specified, set a default prompt
121 prompt = "[%s]\n%s%s:" % (self._task.get_name().strip(), 'Press enter to continue, Ctrl+C to interrupt', echo_prompt)
122
123 # Are 'minutes' or 'seconds' keys that exist in 'args'?
124 if 'minutes' in self._task.args or 'seconds' in self._task.args:
125 try:
126 if 'minutes' in self._task.args:
127 # The time() command operates in seconds so we need to
128 # recalculate for minutes=X values.
129 seconds = int(self._task.args['minutes']) * 60
130 else:
131 seconds = int(self._task.args['seconds'])
132 duration_unit = 'seconds'
133
134 except ValueError as e:
135 result['failed'] = True
136 result['msg'] = u"non-integer value given for prompt duration:\n%s" % to_text(e)
137 return result
138
139 ########################################################################
140 # Begin the hard work!
141
142 start = time.time()
143 result['start'] = to_text(datetime.datetime.now())
144 result['user_input'] = b''
145
146 fd = None
147 old_settings = None
148 try:
149 if seconds is not None:
150 if seconds < 1:
151 seconds = 1
152
153 # setup the alarm handler
154 signal.signal(signal.SIGALRM, timeout_handler)
155 signal.alarm(seconds)
156
157 # show the timer and control prompts
158 display.display("Pausing for %d seconds%s" % (seconds, echo_prompt))
159 display.display("(ctrl+C then 'C' = continue early, ctrl+C then 'A' = abort)\r"),
160
161 # show the prompt specified in the task
162 if 'prompt' in self._task.args:
163 display.display(prompt)
164
165 else:
166 display.display(prompt)
167
168 # save the attributes on the existing (duped) stdin so
169 # that we can restore them later after we set raw mode
170 fd = None
171 try:
172 if PY3:
173 stdin = self._connection._new_stdin.buffer
174 stdout = sys.stdout.buffer
175 else:
176 stdin = self._connection._new_stdin
177 stdout = sys.stdout
178 fd = stdin.fileno()
179 except (ValueError, AttributeError):
180 # ValueError: someone is using a closed file descriptor as stdin
181 # AttributeError: someone is using a null file descriptor as stdin on windoez
182 stdin = None
183
184 if fd is not None:
185 if isatty(fd):
186
187 # grab actual Ctrl+C sequence
188 try:
189 intr = termios.tcgetattr(fd)[6][termios.VINTR]
190 except Exception:
191 # unsupported/not present, use default
192 intr = b'\x03' # value for Ctrl+C
193
194 # get backspace sequences
195 try:
196 backspace = termios.tcgetattr(fd)[6][termios.VERASE]
197 except Exception:
198 backspace = [b'\x7f', b'\x08']
199
200 old_settings = termios.tcgetattr(fd)
201 tty.setraw(fd)
202 tty.setraw(stdout.fileno())
203
204 # Only echo input if no timeout is specified
205 if not seconds and echo:
206 new_settings = termios.tcgetattr(fd)
207 new_settings[3] = new_settings[3] | termios.ECHO
208 termios.tcsetattr(fd, termios.TCSANOW, new_settings)
209
210 # flush the buffer to make sure no previous key presses
211 # are read in below
212 termios.tcflush(stdin, termios.TCIFLUSH)
213
214 while True:
215 try:
216 if fd is not None:
217 key_pressed = stdin.read(1)
218 if key_pressed == intr: # value for Ctrl+C
219 clear_line(stdout)
220 raise KeyboardInterrupt
221
222 if not seconds:
223 if fd is None or not isatty(fd):
224 display.warning("Not waiting for response to prompt as stdin is not interactive")
225 break
226
227 # read key presses and act accordingly
228 if key_pressed in (b'\r', b'\n'):
229 clear_line(stdout)
230 break
231 elif key_pressed in backspace:
232 # delete a character if backspace is pressed
233 result['user_input'] = result['user_input'][:-1]
234 clear_line(stdout)
235 if echo:
236 stdout.write(result['user_input'])
237 stdout.flush()
238 else:
239 result['user_input'] += key_pressed
240
241 except KeyboardInterrupt:
242 signal.alarm(0)
243 display.display("Press 'C' to continue the play or 'A' to abort \r"),
244 if self._c_or_a(stdin):
245 clear_line(stdout)
246 break
247
248 clear_line(stdout)
249
250 raise AnsibleError('user requested abort!')
251
252 except AnsibleTimeoutExceeded:
253 # this is the exception we expect when the alarm signal
254 # fires, so we simply ignore it to move into the cleanup
255 pass
256 finally:
257 # cleanup and save some information
258 # restore the old settings for the duped stdin fd
259 if not(None in (fd, old_settings)) and isatty(fd):
260 termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
261
262 duration = time.time() - start
263 result['stop'] = to_text(datetime.datetime.now())
264 result['delta'] = int(duration)
265
266 if duration_unit == 'minutes':
267 duration = round(duration / 60.0, 2)
268 else:
269 duration = round(duration, 2)
270 result['stdout'] = "Paused for %s %s" % (duration, duration_unit)
271
272 result['user_input'] = to_text(result['user_input'], errors='surrogate_or_strict')
273 return result
274
275 def _c_or_a(self, stdin):
276 while True:
277 key_pressed = stdin.read(1)
278 if key_pressed.lower() == b'a':
279 return False
280 elif key_pressed.lower() == b'c':
281 return True
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/ansible/plugins/action/pause.py b/lib/ansible/plugins/action/pause.py
--- a/lib/ansible/plugins/action/pause.py
+++ b/lib/ansible/plugins/action/pause.py
@@ -39,9 +39,14 @@
try:
import curses
- curses.setupterm()
- HAS_CURSES = True
-except (ImportError, curses.error):
+
+ # Nest the try except since curses.error is not available if curses did not import
+ try:
+ curses.setupterm()
+ HAS_CURSES = True
+ except curses.error:
+ HAS_CURSES = False
+except ImportError:
HAS_CURSES = False
if HAS_CURSES:
|
{"golden_diff": "diff --git a/lib/ansible/plugins/action/pause.py b/lib/ansible/plugins/action/pause.py\n--- a/lib/ansible/plugins/action/pause.py\n+++ b/lib/ansible/plugins/action/pause.py\n@@ -39,9 +39,14 @@\n \n try:\n import curses\n- curses.setupterm()\n- HAS_CURSES = True\n-except (ImportError, curses.error):\n+\n+ # Nest the try except since curses.error is not available if curses did not import\n+ try:\n+ curses.setupterm()\n+ HAS_CURSES = True\n+ except curses.error:\n+ HAS_CURSES = False\n+except ImportError:\n HAS_CURSES = False\n \n if HAS_CURSES:\n", "issue": "\"pause\" module fails with NameError when \"curses\" is not installed\n<!---\r\nVerify first that your issue/request is not already reported on GitHub.\r\nTHIS FORM WILL BE READ BY A MACHINE, COMPLETE ALL SECTIONS AS DESCRIBED.\r\nAlso test if the latest release, and devel branch are affected too.\r\nALWAYS add information AFTER (OUTSIDE) these html comments.\r\nOtherwise it may end up being automatically closed by our bot. -->\r\n\r\n##### SUMMARY\r\nThe \"pause\" module fails with a NameError when the curses Python module is not available.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/python/bin/ansible-playbook\", line 118, in <module>\r\n exit_code = cli.run()\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/cli/playbook.py\", line 122, in run\r\n results = pbex.run()\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/executor/playbook_executor.py\", line 159, in run\r\n result = self._tqm.run(play=play)\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/executor/task_queue_manager.py\", line 289, in run\r\n play_return = strategy.run(iterator, play_context)\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/plugins/strategy/linear.py\", line 247, in run\r\n action = action_loader.get(task.action, class_only=True)\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/plugins/loader.py\", line 366, in get\r\n self._module_cache[path] = self._load_module_source(name, path)\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/plugins/loader.py\", line 345, in _load_module_source\r\n module = imp.load_source(full_name, path, module_file)\r\n File \"/usr/local/python/lib/python2.7/site-packages/ansible/plugins/action/pause.py\", line 44, in <module>\r\n except (ImportError, curses.error):\r\nNameError: name 'curses' is not defined\r\n```\r\n\r\nCaused by this code block introduced by https://github.com/ansible/ansible/pull/40134 to fix #35372:\r\n\r\n```python\r\ntry:\r\n import curses\r\n curses.setupterm()\r\n HAS_CURSES = True\r\nexcept (ImportError, curses.error):\r\n HAS_CURSES = False\r\n```\r\n\r\nA better fix would be to nest the curses.error try-catch within the block.\r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\nplugins/action/pause.py\r\n\r\n##### ANSIBLE VERSION\r\nansible 2.5.4\r\n config file = /etc/ansible/ansible.cfg\r\n configured module search path = [u'/etc/ansible/modules']\r\n ansible python module location = /usr/local/python/lib/python2.7/site-packages/ansible\r\n executable location = /usr/local/python/bin/ansible\r\n python version = 2.7.10 (default, Oct 11 2015, 23:13:31) [GCC 4.8.3 20140911 (Red Hat 4.8.3-9)]\r\n\r\n##### CONFIGURATION\r\nN/A\r\n\r\n##### OS / ENVIRONMENT\r\nN/A\r\n\r\n##### STEPS TO REPRODUCE\r\nOn a machine without \"curses\", run:\r\n\r\n> $ ansible localhost -m pause -a 'seconds=1'\r\n> ERROR! Unexpected Exception, this is probably a bug: name 'curses' is not defined\r\n> to see the full traceback, use -vvv\r\n\r\n##### EXPECTED RESULTS\r\nN/A\r\n\r\n##### ACTUAL RESULTS\r\nSee above.\n", "before_files": [{"content": "# Copyright 2012, Tim Bielawa <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport datetime\nimport signal\nimport sys\nimport termios\nimport time\nimport tty\n\nfrom os import isatty\nfrom ansible.errors import AnsibleError\nfrom ansible.module_utils._text import to_text, to_native\nfrom ansible.module_utils.parsing.convert_bool import boolean\nfrom ansible.module_utils.six import PY3\nfrom ansible.plugins.action import ActionBase\n\ntry:\n from __main__ import display\nexcept ImportError:\n from ansible.utils.display import Display\n display = Display()\n\ntry:\n import curses\n curses.setupterm()\n HAS_CURSES = True\nexcept (ImportError, curses.error):\n HAS_CURSES = False\n\nif HAS_CURSES:\n MOVE_TO_BOL = curses.tigetstr('cr')\n CLEAR_TO_EOL = curses.tigetstr('el')\nelse:\n MOVE_TO_BOL = b'\\r'\n CLEAR_TO_EOL = b'\\x1b[K'\n\n\nclass AnsibleTimeoutExceeded(Exception):\n pass\n\n\ndef timeout_handler(signum, frame):\n raise AnsibleTimeoutExceeded\n\n\ndef clear_line(stdout):\n stdout.write(b'\\x1b[%s' % MOVE_TO_BOL)\n stdout.write(b'\\x1b[%s' % CLEAR_TO_EOL)\n\n\nclass ActionModule(ActionBase):\n ''' pauses execution for a length or time, or until input is received '''\n\n PAUSE_TYPES = ['seconds', 'minutes', 'prompt', 'echo', '']\n BYPASS_HOST_LOOP = True\n\n def run(self, tmp=None, task_vars=None):\n ''' run the pause action module '''\n if task_vars is None:\n task_vars = dict()\n\n result = super(ActionModule, self).run(tmp, task_vars)\n del tmp # tmp no longer has any effect\n\n duration_unit = 'minutes'\n prompt = None\n seconds = None\n echo = True\n echo_prompt = ''\n result.update(dict(\n changed=False,\n rc=0,\n stderr='',\n stdout='',\n start=None,\n stop=None,\n delta=None,\n echo=echo\n ))\n\n if not set(self._task.args.keys()) <= set(self.PAUSE_TYPES):\n result['failed'] = True\n result['msg'] = \"Invalid argument given. Must be one of: %s\" % \", \".join(self.PAUSE_TYPES)\n return result\n\n # Should keystrokes be echoed to stdout?\n if 'echo' in self._task.args:\n try:\n echo = boolean(self._task.args['echo'])\n except TypeError as e:\n result['failed'] = True\n result['msg'] = to_native(e)\n return result\n\n # Add a note saying the output is hidden if echo is disabled\n if not echo:\n echo_prompt = ' (output is hidden)'\n\n # Is 'prompt' a key in 'args'?\n if 'prompt' in self._task.args:\n prompt = \"[%s]\\n%s%s:\" % (self._task.get_name().strip(), self._task.args['prompt'], echo_prompt)\n else:\n # If no custom prompt is specified, set a default prompt\n prompt = \"[%s]\\n%s%s:\" % (self._task.get_name().strip(), 'Press enter to continue, Ctrl+C to interrupt', echo_prompt)\n\n # Are 'minutes' or 'seconds' keys that exist in 'args'?\n if 'minutes' in self._task.args or 'seconds' in self._task.args:\n try:\n if 'minutes' in self._task.args:\n # The time() command operates in seconds so we need to\n # recalculate for minutes=X values.\n seconds = int(self._task.args['minutes']) * 60\n else:\n seconds = int(self._task.args['seconds'])\n duration_unit = 'seconds'\n\n except ValueError as e:\n result['failed'] = True\n result['msg'] = u\"non-integer value given for prompt duration:\\n%s\" % to_text(e)\n return result\n\n ########################################################################\n # Begin the hard work!\n\n start = time.time()\n result['start'] = to_text(datetime.datetime.now())\n result['user_input'] = b''\n\n fd = None\n old_settings = None\n try:\n if seconds is not None:\n if seconds < 1:\n seconds = 1\n\n # setup the alarm handler\n signal.signal(signal.SIGALRM, timeout_handler)\n signal.alarm(seconds)\n\n # show the timer and control prompts\n display.display(\"Pausing for %d seconds%s\" % (seconds, echo_prompt))\n display.display(\"(ctrl+C then 'C' = continue early, ctrl+C then 'A' = abort)\\r\"),\n\n # show the prompt specified in the task\n if 'prompt' in self._task.args:\n display.display(prompt)\n\n else:\n display.display(prompt)\n\n # save the attributes on the existing (duped) stdin so\n # that we can restore them later after we set raw mode\n fd = None\n try:\n if PY3:\n stdin = self._connection._new_stdin.buffer\n stdout = sys.stdout.buffer\n else:\n stdin = self._connection._new_stdin\n stdout = sys.stdout\n fd = stdin.fileno()\n except (ValueError, AttributeError):\n # ValueError: someone is using a closed file descriptor as stdin\n # AttributeError: someone is using a null file descriptor as stdin on windoez\n stdin = None\n\n if fd is not None:\n if isatty(fd):\n\n # grab actual Ctrl+C sequence\n try:\n intr = termios.tcgetattr(fd)[6][termios.VINTR]\n except Exception:\n # unsupported/not present, use default\n intr = b'\\x03' # value for Ctrl+C\n\n # get backspace sequences\n try:\n backspace = termios.tcgetattr(fd)[6][termios.VERASE]\n except Exception:\n backspace = [b'\\x7f', b'\\x08']\n\n old_settings = termios.tcgetattr(fd)\n tty.setraw(fd)\n tty.setraw(stdout.fileno())\n\n # Only echo input if no timeout is specified\n if not seconds and echo:\n new_settings = termios.tcgetattr(fd)\n new_settings[3] = new_settings[3] | termios.ECHO\n termios.tcsetattr(fd, termios.TCSANOW, new_settings)\n\n # flush the buffer to make sure no previous key presses\n # are read in below\n termios.tcflush(stdin, termios.TCIFLUSH)\n\n while True:\n try:\n if fd is not None:\n key_pressed = stdin.read(1)\n if key_pressed == intr: # value for Ctrl+C\n clear_line(stdout)\n raise KeyboardInterrupt\n\n if not seconds:\n if fd is None or not isatty(fd):\n display.warning(\"Not waiting for response to prompt as stdin is not interactive\")\n break\n\n # read key presses and act accordingly\n if key_pressed in (b'\\r', b'\\n'):\n clear_line(stdout)\n break\n elif key_pressed in backspace:\n # delete a character if backspace is pressed\n result['user_input'] = result['user_input'][:-1]\n clear_line(stdout)\n if echo:\n stdout.write(result['user_input'])\n stdout.flush()\n else:\n result['user_input'] += key_pressed\n\n except KeyboardInterrupt:\n signal.alarm(0)\n display.display(\"Press 'C' to continue the play or 'A' to abort \\r\"),\n if self._c_or_a(stdin):\n clear_line(stdout)\n break\n\n clear_line(stdout)\n\n raise AnsibleError('user requested abort!')\n\n except AnsibleTimeoutExceeded:\n # this is the exception we expect when the alarm signal\n # fires, so we simply ignore it to move into the cleanup\n pass\n finally:\n # cleanup and save some information\n # restore the old settings for the duped stdin fd\n if not(None in (fd, old_settings)) and isatty(fd):\n termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)\n\n duration = time.time() - start\n result['stop'] = to_text(datetime.datetime.now())\n result['delta'] = int(duration)\n\n if duration_unit == 'minutes':\n duration = round(duration / 60.0, 2)\n else:\n duration = round(duration, 2)\n result['stdout'] = \"Paused for %s %s\" % (duration, duration_unit)\n\n result['user_input'] = to_text(result['user_input'], errors='surrogate_or_strict')\n return result\n\n def _c_or_a(self, stdin):\n while True:\n key_pressed = stdin.read(1)\n if key_pressed.lower() == b'a':\n return False\n elif key_pressed.lower() == b'c':\n return True\n", "path": "lib/ansible/plugins/action/pause.py"}], "after_files": [{"content": "# Copyright 2012, Tim Bielawa <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport datetime\nimport signal\nimport sys\nimport termios\nimport time\nimport tty\n\nfrom os import isatty\nfrom ansible.errors import AnsibleError\nfrom ansible.module_utils._text import to_text, to_native\nfrom ansible.module_utils.parsing.convert_bool import boolean\nfrom ansible.module_utils.six import PY3\nfrom ansible.plugins.action import ActionBase\n\ntry:\n from __main__ import display\nexcept ImportError:\n from ansible.utils.display import Display\n display = Display()\n\ntry:\n import curses\n\n # Nest the try except since curses.error is not available if curses did not import\n try:\n curses.setupterm()\n HAS_CURSES = True\n except curses.error:\n HAS_CURSES = False\nexcept ImportError:\n HAS_CURSES = False\n\nif HAS_CURSES:\n MOVE_TO_BOL = curses.tigetstr('cr')\n CLEAR_TO_EOL = curses.tigetstr('el')\nelse:\n MOVE_TO_BOL = b'\\r'\n CLEAR_TO_EOL = b'\\x1b[K'\n\n\nclass AnsibleTimeoutExceeded(Exception):\n pass\n\n\ndef timeout_handler(signum, frame):\n raise AnsibleTimeoutExceeded\n\n\ndef clear_line(stdout):\n stdout.write(b'\\x1b[%s' % MOVE_TO_BOL)\n stdout.write(b'\\x1b[%s' % CLEAR_TO_EOL)\n\n\nclass ActionModule(ActionBase):\n ''' pauses execution for a length or time, or until input is received '''\n\n PAUSE_TYPES = ['seconds', 'minutes', 'prompt', 'echo', '']\n BYPASS_HOST_LOOP = True\n\n def run(self, tmp=None, task_vars=None):\n ''' run the pause action module '''\n if task_vars is None:\n task_vars = dict()\n\n result = super(ActionModule, self).run(tmp, task_vars)\n del tmp # tmp no longer has any effect\n\n duration_unit = 'minutes'\n prompt = None\n seconds = None\n echo = True\n echo_prompt = ''\n result.update(dict(\n changed=False,\n rc=0,\n stderr='',\n stdout='',\n start=None,\n stop=None,\n delta=None,\n echo=echo\n ))\n\n if not set(self._task.args.keys()) <= set(self.PAUSE_TYPES):\n result['failed'] = True\n result['msg'] = \"Invalid argument given. Must be one of: %s\" % \", \".join(self.PAUSE_TYPES)\n return result\n\n # Should keystrokes be echoed to stdout?\n if 'echo' in self._task.args:\n try:\n echo = boolean(self._task.args['echo'])\n except TypeError as e:\n result['failed'] = True\n result['msg'] = to_native(e)\n return result\n\n # Add a note saying the output is hidden if echo is disabled\n if not echo:\n echo_prompt = ' (output is hidden)'\n\n # Is 'prompt' a key in 'args'?\n if 'prompt' in self._task.args:\n prompt = \"[%s]\\n%s%s:\" % (self._task.get_name().strip(), self._task.args['prompt'], echo_prompt)\n else:\n # If no custom prompt is specified, set a default prompt\n prompt = \"[%s]\\n%s%s:\" % (self._task.get_name().strip(), 'Press enter to continue, Ctrl+C to interrupt', echo_prompt)\n\n # Are 'minutes' or 'seconds' keys that exist in 'args'?\n if 'minutes' in self._task.args or 'seconds' in self._task.args:\n try:\n if 'minutes' in self._task.args:\n # The time() command operates in seconds so we need to\n # recalculate for minutes=X values.\n seconds = int(self._task.args['minutes']) * 60\n else:\n seconds = int(self._task.args['seconds'])\n duration_unit = 'seconds'\n\n except ValueError as e:\n result['failed'] = True\n result['msg'] = u\"non-integer value given for prompt duration:\\n%s\" % to_text(e)\n return result\n\n ########################################################################\n # Begin the hard work!\n\n start = time.time()\n result['start'] = to_text(datetime.datetime.now())\n result['user_input'] = b''\n\n fd = None\n old_settings = None\n try:\n if seconds is not None:\n if seconds < 1:\n seconds = 1\n\n # setup the alarm handler\n signal.signal(signal.SIGALRM, timeout_handler)\n signal.alarm(seconds)\n\n # show the timer and control prompts\n display.display(\"Pausing for %d seconds%s\" % (seconds, echo_prompt))\n display.display(\"(ctrl+C then 'C' = continue early, ctrl+C then 'A' = abort)\\r\"),\n\n # show the prompt specified in the task\n if 'prompt' in self._task.args:\n display.display(prompt)\n\n else:\n display.display(prompt)\n\n # save the attributes on the existing (duped) stdin so\n # that we can restore them later after we set raw mode\n fd = None\n try:\n if PY3:\n stdin = self._connection._new_stdin.buffer\n stdout = sys.stdout.buffer\n else:\n stdin = self._connection._new_stdin\n stdout = sys.stdout\n fd = stdin.fileno()\n except (ValueError, AttributeError):\n # ValueError: someone is using a closed file descriptor as stdin\n # AttributeError: someone is using a null file descriptor as stdin on windoez\n stdin = None\n\n if fd is not None:\n if isatty(fd):\n\n # grab actual Ctrl+C sequence\n try:\n intr = termios.tcgetattr(fd)[6][termios.VINTR]\n except Exception:\n # unsupported/not present, use default\n intr = b'\\x03' # value for Ctrl+C\n\n # get backspace sequences\n try:\n backspace = termios.tcgetattr(fd)[6][termios.VERASE]\n except Exception:\n backspace = [b'\\x7f', b'\\x08']\n\n old_settings = termios.tcgetattr(fd)\n tty.setraw(fd)\n tty.setraw(stdout.fileno())\n\n # Only echo input if no timeout is specified\n if not seconds and echo:\n new_settings = termios.tcgetattr(fd)\n new_settings[3] = new_settings[3] | termios.ECHO\n termios.tcsetattr(fd, termios.TCSANOW, new_settings)\n\n # flush the buffer to make sure no previous key presses\n # are read in below\n termios.tcflush(stdin, termios.TCIFLUSH)\n\n while True:\n try:\n if fd is not None:\n key_pressed = stdin.read(1)\n if key_pressed == intr: # value for Ctrl+C\n clear_line(stdout)\n raise KeyboardInterrupt\n\n if not seconds:\n if fd is None or not isatty(fd):\n display.warning(\"Not waiting for response to prompt as stdin is not interactive\")\n break\n\n # read key presses and act accordingly\n if key_pressed in (b'\\r', b'\\n'):\n clear_line(stdout)\n break\n elif key_pressed in backspace:\n # delete a character if backspace is pressed\n result['user_input'] = result['user_input'][:-1]\n clear_line(stdout)\n if echo:\n stdout.write(result['user_input'])\n stdout.flush()\n else:\n result['user_input'] += key_pressed\n\n except KeyboardInterrupt:\n signal.alarm(0)\n display.display(\"Press 'C' to continue the play or 'A' to abort \\r\"),\n if self._c_or_a(stdin):\n clear_line(stdout)\n break\n\n clear_line(stdout)\n\n raise AnsibleError('user requested abort!')\n\n except AnsibleTimeoutExceeded:\n # this is the exception we expect when the alarm signal\n # fires, so we simply ignore it to move into the cleanup\n pass\n finally:\n # cleanup and save some information\n # restore the old settings for the duped stdin fd\n if not(None in (fd, old_settings)) and isatty(fd):\n termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)\n\n duration = time.time() - start\n result['stop'] = to_text(datetime.datetime.now())\n result['delta'] = int(duration)\n\n if duration_unit == 'minutes':\n duration = round(duration / 60.0, 2)\n else:\n duration = round(duration, 2)\n result['stdout'] = \"Paused for %s %s\" % (duration, duration_unit)\n\n result['user_input'] = to_text(result['user_input'], errors='surrogate_or_strict')\n return result\n\n def _c_or_a(self, stdin):\n while True:\n key_pressed = stdin.read(1)\n if key_pressed.lower() == b'a':\n return False\n elif key_pressed.lower() == b'c':\n return True\n", "path": "lib/ansible/plugins/action/pause.py"}]}
| 3,943 | 157 |
gh_patches_debug_41709
|
rasdani/github-patches
|
git_diff
|
lisa-lab__pylearn2-1276
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove core files from whitelist
- [x] models/mlp.py
- [x] `costs/mlp/__init__.py`
- [x] costs/mlp/dropout.py
- [x] monitor.py
- [x] optimization/batch_gradient_descent.py
- [x] blocks.py
- [ ] expr/nnet.py
- [x] costs/cost.py
- [x] datasets/dense_design_matrix.py
- [x] datasets/dataset.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pylearn2/expr/nnet.py`
Content:
```
1 """
2 Useful expressions common to many neural network applications.
3 """
4 __authors__ = "Ian Goodfellow"
5 __copyright__ = "Copyright 2010-2013, Universite de Montreal"
6 __credits__ = ["Ian Goodfellow"]
7 __license__ = "3-clause BSD"
8 __maintainer__ = "LISA Lab"
9 __email__ = "pylearn-dev@googlegroups"
10
11 import numpy as np
12 import theano
13 from theano.printing import Print
14 from theano import tensor as T
15 from theano.gof.op import get_debug_values
16
17 def softmax_numpy(x):
18 """
19 .. todo::
20
21 WRITEME properly
22
23 Parameters
24 ----------
25 x : matrix
26
27 Returns
28 -------
29 rval : vector
30 rval[i] is the softmax of row i of x
31 """
32 stable_x = (x.T - x.max(axis=1)).T
33 numer = np.exp(stable_x)
34 return (numer.T / numer.sum(axis=1)).T
35
36 def pseudoinverse_softmax_numpy(x):
37 """
38 .. todo::
39
40 WRITEME properly
41
42 Parameters
43 ----------
44 x : vector
45
46 Returns
47 -------
48 y : vector
49 softmax(y) = x
50
51 Notes
52 -----
53 This problem is underdetermined, so we also impose y.mean() = 0
54 """
55 rval = np.log(x)
56 rval -= rval.mean()
57 return rval
58
59 def sigmoid_numpy(x):
60 """
61 .. todo::
62
63 WRITEME
64 """
65 assert not isinstance(x, theano.gof.Variable)
66 return 1. / (1. + np.exp(-x))
67
68 def inverse_sigmoid_numpy(x):
69 """
70 .. todo::
71
72 WRITEME
73 """
74 return np.log(x / (1. - x))
75
76 def arg_of_softmax(Y_hat):
77 """
78 Given the output of a call to theano.tensor.nnet.softmax,
79 returns the argument to the softmax (by tracing the Theano
80 graph).
81
82 Parameters
83 ----------
84 Y_hat : Variable
85 softmax(Z)
86
87 Returns
88 -------
89 Z : Variable
90 The variable that was passed to the Softmax op to create `Y_hat`.
91 Raises an error if `Y_hat` is not actually the output of a
92 Softmax.
93 """
94 assert hasattr(Y_hat, 'owner')
95 owner = Y_hat.owner
96 assert owner is not None
97 op = owner.op
98 if isinstance(op, Print):
99 assert len(owner.inputs) == 1
100 Y_hat, = owner.inputs
101 owner = Y_hat.owner
102 op = owner.op
103 if not isinstance(op, T.nnet.Softmax):
104 raise ValueError("Expected Y_hat to be the output of a softmax, "
105 "but it appears to be the output of " + str(op) + " of type "
106 + str(type(op)))
107 z ,= owner.inputs
108 assert z.ndim == 2
109 return z
110
111 def kl(Y, Y_hat, batch_axis):
112 """
113 Warning: This function expects a sigmoid nonlinearity in the
114 output layer. Returns a batch (vector) of mean across units of
115 KL divergence for each example,
116 KL(P || Q) where P is defined by Y and Q is defined by Y_hat:
117
118 p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)
119 For binary p, some terms drop out:
120 - p log q - (1-p) log (1-q)
121 - p log sigmoid(z) - (1-p) log sigmoid(-z)
122 p softplus(-z) + (1-p) softplus(z)
123
124 Parameters
125 ----------
126 Y : Variable
127 targets for the sigmoid outputs. Currently Y must be purely binary.
128 If it's not, you'll still get the right gradient, but the
129 value in the monitoring channel will be wrong.
130 Y_hat : Variable
131 predictions made by the sigmoid layer. Y_hat must be generated by
132 fprop, i.e., it must be a symbolic sigmoid.
133 batch_axis : list
134 list of axes to compute average kl divergence across.
135
136 Returns
137 -------
138 ave : Variable
139 average kl divergence between Y and Y_hat.
140 """
141
142 assert hasattr(Y_hat, 'owner')
143 assert batch_axis is not None
144
145 owner = Y_hat.owner
146 assert owner is not None
147 op = owner.op
148
149 if not hasattr(op, 'scalar_op'):
150 raise ValueError("Expected Y_hat to be generated by an Elemwise "
151 "op, got "+str(op)+" of type "+str(type(op)))
152 assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)
153
154 for Yv in get_debug_values(Y):
155 if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):
156 raise ValueError("Expected Y to be between 0 and 1. Either Y"
157 + "< 0 or Y > 1 was found in the input.")
158
159 z, = owner.inputs
160
161 term_1 = Y * T.nnet.softplus(-z)
162 term_2 = (1 - Y) * T.nnet.softplus(z)
163
164 total = term_1 + term_2
165 naxes = total.ndim
166 axes_to_reduce = list(range(naxes))
167 del axes_to_reduce[batch_axis]
168 ave = total.mean(axis=axes_to_reduce)
169
170 return ave
171
172 def elemwise_kl(Y, Y_hat):
173 """
174 Warning: This function expects a sigmoid nonlinearity in the
175 output layer. Returns a batch (vector) of mean across units of
176 KL divergence for each example,
177 KL(P || Q) where P is defined by Y and Q is defined by Y_hat:
178
179 p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)
180 For binary p, some terms drop out:
181 - p log q - (1-p) log (1-q)
182 - p log sigmoid(z) - (1-p) log sigmoid(-z)
183 p softplus(-z) + (1-p) softplus(z)
184
185 Parameters
186 ----------
187 Y : Variable
188 targets for the sigmoid outputs. Currently Y must be purely binary.
189 If it's not, you'll still get the right gradient, but the
190 value in the monitoring channel will be wrong.
191 Y_hat : Variable
192 predictions made by the sigmoid layer. Y_hat must be generated by
193 fprop, i.e., it must be a symbolic sigmoid.
194
195 Returns
196 -------
197 ave : Variable
198 kl divergence between Y and Y_hat.
199 """
200 assert hasattr(Y_hat, 'owner')
201
202 owner = Y_hat.owner
203 assert owner is not None
204 op = owner.op
205
206 if not hasattr(op, 'scalar_op'):
207 raise ValueError("Expected Y_hat to be generated by an Elemwise "
208 "op, got "+str(op)+" of type "+str(type(op)))
209 assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)
210
211 for Yv in get_debug_values(Y):
212 if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):
213 raise ValueError("Expected Y to be between 0 and 1. Either Y"
214 + "< 0 or Y > 1 was found in the input.")
215
216 z, = owner.inputs
217
218 term_1 = Y * T.nnet.softplus(-z)
219 term_2 = (1 - Y) * T.nnet.softplus(z)
220
221 total = term_1 + term_2
222
223 return total
224
225
226 def softmax_ratio(numer, denom):
227 """
228 .. todo::
229
230 WRITEME properly
231
232 Parameters
233 ----------
234 numer : Variable
235 Output of a softmax.
236 denom : Variable
237 Output of a softmax.
238
239 Returns
240 -------
241 ratio : Variable
242 numer / denom, computed in a numerically stable way
243 """
244
245 numer_Z = arg_of_softmax(numer)
246 denom_Z = arg_of_softmax(denom)
247 numer_Z -= numer_Z.max(axis=1).dimshuffle(0, 'x')
248 denom_Z -= denom_Z.min(axis=1).dimshuffle(0, 'x')
249
250 new_num = T.exp(numer_Z - denom_Z) * (T.exp(denom_Z).sum(
251 axis=1).dimshuffle(0, 'x'))
252 new_den = (T.exp(numer_Z).sum(axis=1).dimshuffle(0, 'x'))
253
254 return new_num / new_den
255
256 def compute_precision(tp, fp):
257 """
258 Computes the precision for the binary decisions.
259 Computed as tp/(tp + fp).
260
261 Parameters
262 ----------
263 tp : Variable
264 True positives.
265 fp : Variable
266 False positives.
267
268 Returns
269 -------
270 precision : Variable
271 Precision of the binary classifications.
272 """
273 precision = tp / T.maximum(1., tp + fp)
274 return precision
275
276 def compute_recall(y, tp):
277 """
278 Computes the recall for the binary classification.
279
280 Parameters
281 ----------
282 y : Variable
283 Targets for the binary classifications.
284 tp : Variable
285 True positives.
286
287 Returns
288 -------
289 recall : Variable
290 Recall for the binary classification.
291 """
292 recall = tp / T.maximum(1., y.sum())
293 return recall
294
295 def compute_f1(precision, recall):
296 """
297 Computes the f1 score for the binary classification.
298 Computed as,
299
300 f1 = 2 * precision * recall / (precision + recall)
301
302 Parameters
303 ----------
304 precision : Variable
305 Precision score of the binary decisions.
306 recall : Variable
307 Recall score of the binary decisions.
308
309 Returns
310 -------
311 f1 : Variable
312 f1 score for the binary decisions.
313 """
314 f1 = (2. * precision * recall /
315 T.maximum(1, precision + recall))
316 return f1
317
318
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pylearn2/expr/nnet.py b/pylearn2/expr/nnet.py
--- a/pylearn2/expr/nnet.py
+++ b/pylearn2/expr/nnet.py
@@ -14,6 +14,7 @@
from theano import tensor as T
from theano.gof.op import get_debug_values
+
def softmax_numpy(x):
"""
.. todo::
@@ -33,6 +34,7 @@
numer = np.exp(stable_x)
return (numer.T / numer.sum(axis=1)).T
+
def pseudoinverse_softmax_numpy(x):
"""
.. todo::
@@ -56,6 +58,7 @@
rval -= rval.mean()
return rval
+
def sigmoid_numpy(x):
"""
.. todo::
@@ -65,6 +68,7 @@
assert not isinstance(x, theano.gof.Variable)
return 1. / (1. + np.exp(-x))
+
def inverse_sigmoid_numpy(x):
"""
.. todo::
@@ -73,6 +77,7 @@
"""
return np.log(x / (1. - x))
+
def arg_of_softmax(Y_hat):
"""
Given the output of a call to theano.tensor.nnet.softmax,
@@ -102,12 +107,13 @@
op = owner.op
if not isinstance(op, T.nnet.Softmax):
raise ValueError("Expected Y_hat to be the output of a softmax, "
- "but it appears to be the output of " + str(op) + " of type "
- + str(type(op)))
- z ,= owner.inputs
+ "but it appears to be the output of " + str(op) +
+ " of type " + str(type(op)))
+ z, = owner.inputs
assert z.ndim == 2
return z
+
def kl(Y, Y_hat, batch_axis):
"""
Warning: This function expects a sigmoid nonlinearity in the
@@ -169,6 +175,7 @@
return ave
+
def elemwise_kl(Y, Y_hat):
"""
Warning: This function expects a sigmoid nonlinearity in the
@@ -253,6 +260,7 @@
return new_num / new_den
+
def compute_precision(tp, fp):
"""
Computes the precision for the binary decisions.
@@ -273,6 +281,7 @@
precision = tp / T.maximum(1., tp + fp)
return precision
+
def compute_recall(y, tp):
"""
Computes the recall for the binary classification.
@@ -292,6 +301,7 @@
recall = tp / T.maximum(1., y.sum())
return recall
+
def compute_f1(precision, recall):
"""
Computes the f1 score for the binary classification.
@@ -312,6 +322,5 @@
f1 score for the binary decisions.
"""
f1 = (2. * precision * recall /
- T.maximum(1, precision + recall))
- return f1
-
+ T.maximum(1, precision + recall))
+ return f1
\ No newline at end of file
|
{"golden_diff": "diff --git a/pylearn2/expr/nnet.py b/pylearn2/expr/nnet.py\n--- a/pylearn2/expr/nnet.py\n+++ b/pylearn2/expr/nnet.py\n@@ -14,6 +14,7 @@\n from theano import tensor as T\n from theano.gof.op import get_debug_values\n \n+\n def softmax_numpy(x):\n \"\"\"\n .. todo::\n@@ -33,6 +34,7 @@\n numer = np.exp(stable_x)\n return (numer.T / numer.sum(axis=1)).T\n \n+\n def pseudoinverse_softmax_numpy(x):\n \"\"\"\n .. todo::\n@@ -56,6 +58,7 @@\n rval -= rval.mean()\n return rval\n \n+\n def sigmoid_numpy(x):\n \"\"\"\n .. todo::\n@@ -65,6 +68,7 @@\n assert not isinstance(x, theano.gof.Variable)\n return 1. / (1. + np.exp(-x))\n \n+\n def inverse_sigmoid_numpy(x):\n \"\"\"\n .. todo::\n@@ -73,6 +77,7 @@\n \"\"\"\n return np.log(x / (1. - x))\n \n+\n def arg_of_softmax(Y_hat):\n \"\"\"\n Given the output of a call to theano.tensor.nnet.softmax,\n@@ -102,12 +107,13 @@\n op = owner.op\n if not isinstance(op, T.nnet.Softmax):\n raise ValueError(\"Expected Y_hat to be the output of a softmax, \"\n- \"but it appears to be the output of \" + str(op) + \" of type \"\n- + str(type(op)))\n- z ,= owner.inputs\n+ \"but it appears to be the output of \" + str(op) +\n+ \" of type \" + str(type(op)))\n+ z, = owner.inputs\n assert z.ndim == 2\n return z\n \n+\n def kl(Y, Y_hat, batch_axis):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n@@ -169,6 +175,7 @@\n \n return ave\n \n+\n def elemwise_kl(Y, Y_hat):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n@@ -253,6 +260,7 @@\n \n return new_num / new_den\n \n+\n def compute_precision(tp, fp):\n \"\"\"\n Computes the precision for the binary decisions.\n@@ -273,6 +281,7 @@\n precision = tp / T.maximum(1., tp + fp)\n return precision\n \n+\n def compute_recall(y, tp):\n \"\"\"\n Computes the recall for the binary classification.\n@@ -292,6 +301,7 @@\n recall = tp / T.maximum(1., y.sum())\n return recall\n \n+\n def compute_f1(precision, recall):\n \"\"\"\n Computes the f1 score for the binary classification.\n@@ -312,6 +322,5 @@\n f1 score for the binary decisions.\n \"\"\"\n f1 = (2. * precision * recall /\n- T.maximum(1, precision + recall))\n- return f1\n-\n+ T.maximum(1, precision + recall))\n+ return f1\n\\ No newline at end of file\n", "issue": "Remove core files from whitelist\n- [x] models/mlp.py\n- [x] `costs/mlp/__init__.py`\n- [x] costs/mlp/dropout.py\n- [x] monitor.py\n- [x] optimization/batch_gradient_descent.py\n- [x] blocks.py\n- [ ] expr/nnet.py\n- [x] costs/cost.py\n- [x] datasets/dense_design_matrix.py\n- [x] datasets/dataset.py\n\n", "before_files": [{"content": "\"\"\"\nUseful expressions common to many neural network applications.\n\"\"\"\n__authors__ = \"Ian Goodfellow\"\n__copyright__ = \"Copyright 2010-2013, Universite de Montreal\"\n__credits__ = [\"Ian Goodfellow\"]\n__license__ = \"3-clause BSD\"\n__maintainer__ = \"LISA Lab\"\n__email__ = \"pylearn-dev@googlegroups\"\n\nimport numpy as np\nimport theano\nfrom theano.printing import Print\nfrom theano import tensor as T\nfrom theano.gof.op import get_debug_values\n\ndef softmax_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n x : matrix\n\n Returns\n -------\n rval : vector\n rval[i] is the softmax of row i of x\n \"\"\"\n stable_x = (x.T - x.max(axis=1)).T\n numer = np.exp(stable_x)\n return (numer.T / numer.sum(axis=1)).T\n\ndef pseudoinverse_softmax_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n x : vector\n\n Returns\n -------\n y : vector\n softmax(y) = x\n\n Notes\n -----\n This problem is underdetermined, so we also impose y.mean() = 0\n \"\"\"\n rval = np.log(x)\n rval -= rval.mean()\n return rval\n\ndef sigmoid_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME\n \"\"\"\n assert not isinstance(x, theano.gof.Variable)\n return 1. / (1. + np.exp(-x))\n\ndef inverse_sigmoid_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME\n \"\"\"\n return np.log(x / (1. - x))\n\ndef arg_of_softmax(Y_hat):\n \"\"\"\n Given the output of a call to theano.tensor.nnet.softmax,\n returns the argument to the softmax (by tracing the Theano\n graph).\n\n Parameters\n ----------\n Y_hat : Variable\n softmax(Z)\n\n Returns\n -------\n Z : Variable\n The variable that was passed to the Softmax op to create `Y_hat`.\n Raises an error if `Y_hat` is not actually the output of a\n Softmax.\n \"\"\"\n assert hasattr(Y_hat, 'owner')\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n if isinstance(op, Print):\n assert len(owner.inputs) == 1\n Y_hat, = owner.inputs\n owner = Y_hat.owner\n op = owner.op\n if not isinstance(op, T.nnet.Softmax):\n raise ValueError(\"Expected Y_hat to be the output of a softmax, \"\n \"but it appears to be the output of \" + str(op) + \" of type \"\n + str(type(op)))\n z ,= owner.inputs\n assert z.ndim == 2\n return z\n\ndef kl(Y, Y_hat, batch_axis):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n output layer. Returns a batch (vector) of mean across units of\n KL divergence for each example,\n KL(P || Q) where P is defined by Y and Q is defined by Y_hat:\n\n p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)\n For binary p, some terms drop out:\n - p log q - (1-p) log (1-q)\n - p log sigmoid(z) - (1-p) log sigmoid(-z)\n p softplus(-z) + (1-p) softplus(z)\n\n Parameters\n ----------\n Y : Variable\n targets for the sigmoid outputs. Currently Y must be purely binary.\n If it's not, you'll still get the right gradient, but the\n value in the monitoring channel will be wrong.\n Y_hat : Variable\n predictions made by the sigmoid layer. Y_hat must be generated by\n fprop, i.e., it must be a symbolic sigmoid.\n batch_axis : list\n list of axes to compute average kl divergence across.\n\n Returns\n -------\n ave : Variable\n average kl divergence between Y and Y_hat.\n \"\"\"\n\n assert hasattr(Y_hat, 'owner')\n assert batch_axis is not None\n\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n\n if not hasattr(op, 'scalar_op'):\n raise ValueError(\"Expected Y_hat to be generated by an Elemwise \"\n \"op, got \"+str(op)+\" of type \"+str(type(op)))\n assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)\n\n for Yv in get_debug_values(Y):\n if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):\n raise ValueError(\"Expected Y to be between 0 and 1. Either Y\"\n + \"< 0 or Y > 1 was found in the input.\")\n\n z, = owner.inputs\n\n term_1 = Y * T.nnet.softplus(-z)\n term_2 = (1 - Y) * T.nnet.softplus(z)\n\n total = term_1 + term_2\n naxes = total.ndim\n axes_to_reduce = list(range(naxes))\n del axes_to_reduce[batch_axis]\n ave = total.mean(axis=axes_to_reduce)\n\n return ave\n\ndef elemwise_kl(Y, Y_hat):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n output layer. Returns a batch (vector) of mean across units of\n KL divergence for each example,\n KL(P || Q) where P is defined by Y and Q is defined by Y_hat:\n\n p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)\n For binary p, some terms drop out:\n - p log q - (1-p) log (1-q)\n - p log sigmoid(z) - (1-p) log sigmoid(-z)\n p softplus(-z) + (1-p) softplus(z)\n\n Parameters\n ----------\n Y : Variable\n targets for the sigmoid outputs. Currently Y must be purely binary.\n If it's not, you'll still get the right gradient, but the\n value in the monitoring channel will be wrong.\n Y_hat : Variable\n predictions made by the sigmoid layer. Y_hat must be generated by\n fprop, i.e., it must be a symbolic sigmoid.\n\n Returns\n -------\n ave : Variable\n kl divergence between Y and Y_hat.\n \"\"\"\n assert hasattr(Y_hat, 'owner')\n\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n\n if not hasattr(op, 'scalar_op'):\n raise ValueError(\"Expected Y_hat to be generated by an Elemwise \"\n \"op, got \"+str(op)+\" of type \"+str(type(op)))\n assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)\n\n for Yv in get_debug_values(Y):\n if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):\n raise ValueError(\"Expected Y to be between 0 and 1. Either Y\"\n + \"< 0 or Y > 1 was found in the input.\")\n\n z, = owner.inputs\n\n term_1 = Y * T.nnet.softplus(-z)\n term_2 = (1 - Y) * T.nnet.softplus(z)\n\n total = term_1 + term_2\n\n return total\n\n\ndef softmax_ratio(numer, denom):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n numer : Variable\n Output of a softmax.\n denom : Variable\n Output of a softmax.\n\n Returns\n -------\n ratio : Variable\n numer / denom, computed in a numerically stable way\n \"\"\"\n\n numer_Z = arg_of_softmax(numer)\n denom_Z = arg_of_softmax(denom)\n numer_Z -= numer_Z.max(axis=1).dimshuffle(0, 'x')\n denom_Z -= denom_Z.min(axis=1).dimshuffle(0, 'x')\n\n new_num = T.exp(numer_Z - denom_Z) * (T.exp(denom_Z).sum(\n axis=1).dimshuffle(0, 'x'))\n new_den = (T.exp(numer_Z).sum(axis=1).dimshuffle(0, 'x'))\n\n return new_num / new_den\n\ndef compute_precision(tp, fp):\n \"\"\"\n Computes the precision for the binary decisions.\n Computed as tp/(tp + fp).\n\n Parameters\n ----------\n tp : Variable\n True positives.\n fp : Variable\n False positives.\n\n Returns\n -------\n precision : Variable\n Precision of the binary classifications.\n \"\"\"\n precision = tp / T.maximum(1., tp + fp)\n return precision\n\ndef compute_recall(y, tp):\n \"\"\"\n Computes the recall for the binary classification.\n\n Parameters\n ----------\n y : Variable\n Targets for the binary classifications.\n tp : Variable\n True positives.\n\n Returns\n -------\n recall : Variable\n Recall for the binary classification.\n \"\"\"\n recall = tp / T.maximum(1., y.sum())\n return recall\n\ndef compute_f1(precision, recall):\n \"\"\"\n Computes the f1 score for the binary classification.\n Computed as,\n\n f1 = 2 * precision * recall / (precision + recall)\n\n Parameters\n ----------\n precision : Variable\n Precision score of the binary decisions.\n recall : Variable\n Recall score of the binary decisions.\n\n Returns\n -------\n f1 : Variable\n f1 score for the binary decisions.\n \"\"\"\n f1 = (2. * precision * recall /\n T.maximum(1, precision + recall))\n return f1\n\n", "path": "pylearn2/expr/nnet.py"}], "after_files": [{"content": "\"\"\"\nUseful expressions common to many neural network applications.\n\"\"\"\n__authors__ = \"Ian Goodfellow\"\n__copyright__ = \"Copyright 2010-2013, Universite de Montreal\"\n__credits__ = [\"Ian Goodfellow\"]\n__license__ = \"3-clause BSD\"\n__maintainer__ = \"LISA Lab\"\n__email__ = \"pylearn-dev@googlegroups\"\n\nimport numpy as np\nimport theano\nfrom theano.printing import Print\nfrom theano import tensor as T\nfrom theano.gof.op import get_debug_values\n\n\ndef softmax_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n x : matrix\n\n Returns\n -------\n rval : vector\n rval[i] is the softmax of row i of x\n \"\"\"\n stable_x = (x.T - x.max(axis=1)).T\n numer = np.exp(stable_x)\n return (numer.T / numer.sum(axis=1)).T\n\n\ndef pseudoinverse_softmax_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n x : vector\n\n Returns\n -------\n y : vector\n softmax(y) = x\n\n Notes\n -----\n This problem is underdetermined, so we also impose y.mean() = 0\n \"\"\"\n rval = np.log(x)\n rval -= rval.mean()\n return rval\n\n\ndef sigmoid_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME\n \"\"\"\n assert not isinstance(x, theano.gof.Variable)\n return 1. / (1. + np.exp(-x))\n\n\ndef inverse_sigmoid_numpy(x):\n \"\"\"\n .. todo::\n\n WRITEME\n \"\"\"\n return np.log(x / (1. - x))\n\n\ndef arg_of_softmax(Y_hat):\n \"\"\"\n Given the output of a call to theano.tensor.nnet.softmax,\n returns the argument to the softmax (by tracing the Theano\n graph).\n\n Parameters\n ----------\n Y_hat : Variable\n softmax(Z)\n\n Returns\n -------\n Z : Variable\n The variable that was passed to the Softmax op to create `Y_hat`.\n Raises an error if `Y_hat` is not actually the output of a\n Softmax.\n \"\"\"\n assert hasattr(Y_hat, 'owner')\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n if isinstance(op, Print):\n assert len(owner.inputs) == 1\n Y_hat, = owner.inputs\n owner = Y_hat.owner\n op = owner.op\n if not isinstance(op, T.nnet.Softmax):\n raise ValueError(\"Expected Y_hat to be the output of a softmax, \"\n \"but it appears to be the output of \" + str(op) +\n \" of type \" + str(type(op)))\n z, = owner.inputs\n assert z.ndim == 2\n return z\n\n\ndef kl(Y, Y_hat, batch_axis):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n output layer. Returns a batch (vector) of mean across units of\n KL divergence for each example,\n KL(P || Q) where P is defined by Y and Q is defined by Y_hat:\n\n p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)\n For binary p, some terms drop out:\n - p log q - (1-p) log (1-q)\n - p log sigmoid(z) - (1-p) log sigmoid(-z)\n p softplus(-z) + (1-p) softplus(z)\n\n Parameters\n ----------\n Y : Variable\n targets for the sigmoid outputs. Currently Y must be purely binary.\n If it's not, you'll still get the right gradient, but the\n value in the monitoring channel will be wrong.\n Y_hat : Variable\n predictions made by the sigmoid layer. Y_hat must be generated by\n fprop, i.e., it must be a symbolic sigmoid.\n batch_axis : list\n list of axes to compute average kl divergence across.\n\n Returns\n -------\n ave : Variable\n average kl divergence between Y and Y_hat.\n \"\"\"\n\n assert hasattr(Y_hat, 'owner')\n assert batch_axis is not None\n\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n\n if not hasattr(op, 'scalar_op'):\n raise ValueError(\"Expected Y_hat to be generated by an Elemwise \"\n \"op, got \"+str(op)+\" of type \"+str(type(op)))\n assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)\n\n for Yv in get_debug_values(Y):\n if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):\n raise ValueError(\"Expected Y to be between 0 and 1. Either Y\"\n + \"< 0 or Y > 1 was found in the input.\")\n\n z, = owner.inputs\n\n term_1 = Y * T.nnet.softplus(-z)\n term_2 = (1 - Y) * T.nnet.softplus(z)\n\n total = term_1 + term_2\n naxes = total.ndim\n axes_to_reduce = list(range(naxes))\n del axes_to_reduce[batch_axis]\n ave = total.mean(axis=axes_to_reduce)\n\n return ave\n\n\ndef elemwise_kl(Y, Y_hat):\n \"\"\"\n Warning: This function expects a sigmoid nonlinearity in the\n output layer. Returns a batch (vector) of mean across units of\n KL divergence for each example,\n KL(P || Q) where P is defined by Y and Q is defined by Y_hat:\n\n p log p - p log q + (1-p) log (1-p) - (1-p) log (1-q)\n For binary p, some terms drop out:\n - p log q - (1-p) log (1-q)\n - p log sigmoid(z) - (1-p) log sigmoid(-z)\n p softplus(-z) + (1-p) softplus(z)\n\n Parameters\n ----------\n Y : Variable\n targets for the sigmoid outputs. Currently Y must be purely binary.\n If it's not, you'll still get the right gradient, but the\n value in the monitoring channel will be wrong.\n Y_hat : Variable\n predictions made by the sigmoid layer. Y_hat must be generated by\n fprop, i.e., it must be a symbolic sigmoid.\n\n Returns\n -------\n ave : Variable\n kl divergence between Y and Y_hat.\n \"\"\"\n assert hasattr(Y_hat, 'owner')\n\n owner = Y_hat.owner\n assert owner is not None\n op = owner.op\n\n if not hasattr(op, 'scalar_op'):\n raise ValueError(\"Expected Y_hat to be generated by an Elemwise \"\n \"op, got \"+str(op)+\" of type \"+str(type(op)))\n assert isinstance(op.scalar_op, T.nnet.sigm.ScalarSigmoid)\n\n for Yv in get_debug_values(Y):\n if not (Yv.min() >= 0.0 and Yv.max() <= 1.0):\n raise ValueError(\"Expected Y to be between 0 and 1. Either Y\"\n + \"< 0 or Y > 1 was found in the input.\")\n\n z, = owner.inputs\n\n term_1 = Y * T.nnet.softplus(-z)\n term_2 = (1 - Y) * T.nnet.softplus(z)\n\n total = term_1 + term_2\n\n return total\n\n\ndef softmax_ratio(numer, denom):\n \"\"\"\n .. todo::\n\n WRITEME properly\n\n Parameters\n ----------\n numer : Variable\n Output of a softmax.\n denom : Variable\n Output of a softmax.\n\n Returns\n -------\n ratio : Variable\n numer / denom, computed in a numerically stable way\n \"\"\"\n\n numer_Z = arg_of_softmax(numer)\n denom_Z = arg_of_softmax(denom)\n numer_Z -= numer_Z.max(axis=1).dimshuffle(0, 'x')\n denom_Z -= denom_Z.min(axis=1).dimshuffle(0, 'x')\n\n new_num = T.exp(numer_Z - denom_Z) * (T.exp(denom_Z).sum(\n axis=1).dimshuffle(0, 'x'))\n new_den = (T.exp(numer_Z).sum(axis=1).dimshuffle(0, 'x'))\n\n return new_num / new_den\n\n\ndef compute_precision(tp, fp):\n \"\"\"\n Computes the precision for the binary decisions.\n Computed as tp/(tp + fp).\n\n Parameters\n ----------\n tp : Variable\n True positives.\n fp : Variable\n False positives.\n\n Returns\n -------\n precision : Variable\n Precision of the binary classifications.\n \"\"\"\n precision = tp / T.maximum(1., tp + fp)\n return precision\n\n\ndef compute_recall(y, tp):\n \"\"\"\n Computes the recall for the binary classification.\n\n Parameters\n ----------\n y : Variable\n Targets for the binary classifications.\n tp : Variable\n True positives.\n\n Returns\n -------\n recall : Variable\n Recall for the binary classification.\n \"\"\"\n recall = tp / T.maximum(1., y.sum())\n return recall\n\n\ndef compute_f1(precision, recall):\n \"\"\"\n Computes the f1 score for the binary classification.\n Computed as,\n\n f1 = 2 * precision * recall / (precision + recall)\n\n Parameters\n ----------\n precision : Variable\n Precision score of the binary decisions.\n recall : Variable\n Recall score of the binary decisions.\n\n Returns\n -------\n f1 : Variable\n f1 score for the binary decisions.\n \"\"\"\n f1 = (2. * precision * recall /\n T.maximum(1, precision + recall))\n return f1", "path": "pylearn2/expr/nnet.py"}]}
| 3,392 | 712 |
gh_patches_debug_4426
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-tf-569
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error while running the exported model
Hi,
I was trying to run the example given [https://github.com/OpenNMT/OpenNMT-tf/tree/master/examples/serving/python](url).
I am getting the following error.
> Source: I am going.
Traceback (most recent call last):
File "ende_client.py", line 66, in <module>
main()
File "ende_client.py", line 60, in main
output = translator.translate([text])
File "ende_client.py", line 22, in translate
return self._postprocess(outputs)
File "ende_client.py", line 47, in _postprocess
texts.append(self._tokenizer.detokenize(tokens))
TypeError: detokenize(): incompatible function arguments. The following argument types are supported:
1. (self: pyonmttok.Tokenizer, tokens: list, features: object = None) -> str
> Invoked with: <pyonmttok.Tokenizer object at 0x147d10d0d538>, array([b'\xe2\x96\x81Ich', b'\xe2\x96\x81gehe', b'.'], dtype=object)
> WARNING:tensorflow:Unresolved object in checkpoint: (root).examples_inputter.features_inputter.ids_to_tokens._initializer
> WARNING:tensorflow:Unresolved object in checkpoint: (root).examples_inputter.labels_inputter.ids_to_tokens._initializer
> WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/alpha/guide/checkpoints#loading_mechanics for details.
>
I have the updated version of pyonmttok.
Thanks,
Sriram
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/serving/python/ende_client.py`
Content:
```
1 import argparse
2 import os
3
4 import tensorflow as tf
5 import tensorflow_addons as tfa # Register TensorFlow Addons kernels.
6
7 import pyonmttok
8
9
10 class EnDeTranslator(object):
11
12 def __init__(self, export_dir):
13 imported = tf.saved_model.load(export_dir)
14 self._translate_fn = imported.signatures["serving_default"]
15 sp_model_path = os.path.join(export_dir, "assets.extra", "wmtende.model")
16 self._tokenizer = pyonmttok.Tokenizer("none", sp_model_path=sp_model_path)
17
18 def translate(self, texts):
19 """Translates a batch of texts."""
20 inputs = self._preprocess(texts)
21 outputs = self._translate_fn(**inputs)
22 return self._postprocess(outputs)
23
24 def _preprocess(self, texts):
25 all_tokens = []
26 lengths = []
27 max_length = 0
28 for text in texts:
29 tokens, _ = self._tokenizer.tokenize(text)
30 length = len(tokens)
31 all_tokens.append(tokens)
32 lengths.append(length)
33 max_length = max(max_length, length)
34 for tokens, length in zip(all_tokens, lengths):
35 if length < max_length:
36 tokens += [""] * (max_length - length)
37
38 inputs = {
39 "tokens": tf.constant(all_tokens, dtype=tf.string),
40 "length": tf.constant(lengths, dtype=tf.int32)}
41 return inputs
42
43 def _postprocess(self, outputs):
44 texts = []
45 for tokens, length in zip(outputs["tokens"].numpy(), outputs["length"].numpy()):
46 tokens = tokens[0][:length[0]]
47 texts.append(self._tokenizer.detokenize(tokens))
48 return texts
49
50
51 def main():
52 parser = argparse.ArgumentParser(description="Translation client example")
53 parser.add_argument("export_dir", help="Saved model directory")
54 args = parser.parse_args()
55
56 translator = EnDeTranslator(args.export_dir)
57
58 while True:
59 text = input("Source: ")
60 output = translator.translate([text])
61 print("Target: %s" % output[0])
62 print("")
63
64
65 if __name__ == "__main__":
66 main()
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/serving/python/ende_client.py b/examples/serving/python/ende_client.py
--- a/examples/serving/python/ende_client.py
+++ b/examples/serving/python/ende_client.py
@@ -43,7 +43,7 @@
def _postprocess(self, outputs):
texts = []
for tokens, length in zip(outputs["tokens"].numpy(), outputs["length"].numpy()):
- tokens = tokens[0][:length[0]]
+ tokens = tokens[0][:length[0]].tolist()
texts.append(self._tokenizer.detokenize(tokens))
return texts
|
{"golden_diff": "diff --git a/examples/serving/python/ende_client.py b/examples/serving/python/ende_client.py\n--- a/examples/serving/python/ende_client.py\n+++ b/examples/serving/python/ende_client.py\n@@ -43,7 +43,7 @@\n def _postprocess(self, outputs):\n texts = []\n for tokens, length in zip(outputs[\"tokens\"].numpy(), outputs[\"length\"].numpy()):\n- tokens = tokens[0][:length[0]]\n+ tokens = tokens[0][:length[0]].tolist()\n texts.append(self._tokenizer.detokenize(tokens))\n return texts\n", "issue": "Error while running the exported model \nHi,\r\n\r\nI was trying to run the example given [https://github.com/OpenNMT/OpenNMT-tf/tree/master/examples/serving/python](url).\r\n\r\nI am getting the following error.\r\n\r\n> Source: I am going.\r\nTraceback (most recent call last):\r\n File \"ende_client.py\", line 66, in <module>\r\n main()\r\n File \"ende_client.py\", line 60, in main\r\n output = translator.translate([text])\r\n File \"ende_client.py\", line 22, in translate\r\n return self._postprocess(outputs)\r\n File \"ende_client.py\", line 47, in _postprocess\r\n texts.append(self._tokenizer.detokenize(tokens))\r\nTypeError: detokenize(): incompatible function arguments. The following argument types are supported:\r\n 1. (self: pyonmttok.Tokenizer, tokens: list, features: object = None) -> str\r\n\r\n> Invoked with: <pyonmttok.Tokenizer object at 0x147d10d0d538>, array([b'\\xe2\\x96\\x81Ich', b'\\xe2\\x96\\x81gehe', b'.'], dtype=object)\r\n> WARNING:tensorflow:Unresolved object in checkpoint: (root).examples_inputter.features_inputter.ids_to_tokens._initializer\r\n> WARNING:tensorflow:Unresolved object in checkpoint: (root).examples_inputter.labels_inputter.ids_to_tokens._initializer\r\n> WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/alpha/guide/checkpoints#loading_mechanics for details.\r\n> \r\n\r\nI have the updated version of pyonmttok.\r\n\r\nThanks,\r\nSriram\n", "before_files": [{"content": "import argparse\nimport os\n\nimport tensorflow as tf\nimport tensorflow_addons as tfa # Register TensorFlow Addons kernels.\n\nimport pyonmttok\n\n\nclass EnDeTranslator(object):\n\n def __init__(self, export_dir):\n imported = tf.saved_model.load(export_dir)\n self._translate_fn = imported.signatures[\"serving_default\"]\n sp_model_path = os.path.join(export_dir, \"assets.extra\", \"wmtende.model\")\n self._tokenizer = pyonmttok.Tokenizer(\"none\", sp_model_path=sp_model_path)\n\n def translate(self, texts):\n \"\"\"Translates a batch of texts.\"\"\"\n inputs = self._preprocess(texts)\n outputs = self._translate_fn(**inputs)\n return self._postprocess(outputs)\n\n def _preprocess(self, texts):\n all_tokens = []\n lengths = []\n max_length = 0\n for text in texts:\n tokens, _ = self._tokenizer.tokenize(text)\n length = len(tokens)\n all_tokens.append(tokens)\n lengths.append(length)\n max_length = max(max_length, length)\n for tokens, length in zip(all_tokens, lengths):\n if length < max_length:\n tokens += [\"\"] * (max_length - length)\n\n inputs = {\n \"tokens\": tf.constant(all_tokens, dtype=tf.string),\n \"length\": tf.constant(lengths, dtype=tf.int32)}\n return inputs\n\n def _postprocess(self, outputs):\n texts = []\n for tokens, length in zip(outputs[\"tokens\"].numpy(), outputs[\"length\"].numpy()):\n tokens = tokens[0][:length[0]]\n texts.append(self._tokenizer.detokenize(tokens))\n return texts\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Translation client example\")\n parser.add_argument(\"export_dir\", help=\"Saved model directory\")\n args = parser.parse_args()\n\n translator = EnDeTranslator(args.export_dir)\n\n while True:\n text = input(\"Source: \")\n output = translator.translate([text])\n print(\"Target: %s\" % output[0])\n print(\"\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "examples/serving/python/ende_client.py"}], "after_files": [{"content": "import argparse\nimport os\n\nimport tensorflow as tf\nimport tensorflow_addons as tfa # Register TensorFlow Addons kernels.\n\nimport pyonmttok\n\n\nclass EnDeTranslator(object):\n\n def __init__(self, export_dir):\n imported = tf.saved_model.load(export_dir)\n self._translate_fn = imported.signatures[\"serving_default\"]\n sp_model_path = os.path.join(export_dir, \"assets.extra\", \"wmtende.model\")\n self._tokenizer = pyonmttok.Tokenizer(\"none\", sp_model_path=sp_model_path)\n\n def translate(self, texts):\n \"\"\"Translates a batch of texts.\"\"\"\n inputs = self._preprocess(texts)\n outputs = self._translate_fn(**inputs)\n return self._postprocess(outputs)\n\n def _preprocess(self, texts):\n all_tokens = []\n lengths = []\n max_length = 0\n for text in texts:\n tokens, _ = self._tokenizer.tokenize(text)\n length = len(tokens)\n all_tokens.append(tokens)\n lengths.append(length)\n max_length = max(max_length, length)\n for tokens, length in zip(all_tokens, lengths):\n if length < max_length:\n tokens += [\"\"] * (max_length - length)\n\n inputs = {\n \"tokens\": tf.constant(all_tokens, dtype=tf.string),\n \"length\": tf.constant(lengths, dtype=tf.int32)}\n return inputs\n\n def _postprocess(self, outputs):\n texts = []\n for tokens, length in zip(outputs[\"tokens\"].numpy(), outputs[\"length\"].numpy()):\n tokens = tokens[0][:length[0]].tolist()\n texts.append(self._tokenizer.detokenize(tokens))\n return texts\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Translation client example\")\n parser.add_argument(\"export_dir\", help=\"Saved model directory\")\n args = parser.parse_args()\n\n translator = EnDeTranslator(args.export_dir)\n\n while True:\n text = input(\"Source: \")\n output = translator.translate([text])\n print(\"Target: %s\" % output[0])\n print(\"\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "examples/serving/python/ende_client.py"}]}
| 1,284 | 129 |
gh_patches_debug_22338
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-554
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
id and last_modified should be stripped before validating the JSON schema
Otherwise it obliges everyone to add `id` and `last_modified` to their JSON schema or use `additionalProperties : true`.
- http://spacetelescope.github.io/understanding-json-schema/reference/object.html#properties
- See #256
- See #548
``` diff
try:
- jsonschema.validate(new, schema)
+ stripped = copy.deepcopy(new)
+ stripped.pop(self.model.id_field, None)
+ stripped.pop(self.model.modified_field, None)
+ jsonschema.validate(stripped, schema)
```
id and last_modified should be stripped before validating the JSON schema
Otherwise it obliges everyone to add `id` and `last_modified` to their JSON schema or use `additionalProperties : true`.
- http://spacetelescope.github.io/understanding-json-schema/reference/object.html#properties
- See #256
- See #548
``` diff
try:
- jsonschema.validate(new, schema)
+ stripped = copy.deepcopy(new)
+ stripped.pop(self.model.id_field, None)
+ stripped.pop(self.model.modified_field, None)
+ jsonschema.validate(stripped, schema)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/views/records.py`
Content:
```
1 import jsonschema
2 from cliquet import resource
3 from cliquet.errors import raise_invalid
4 from jsonschema import exceptions as jsonschema_exceptions
5 from pyramid.security import Authenticated
6 from pyramid.settings import asbool
7
8 from kinto.views import object_exists_or_404
9
10
11 class RecordSchema(resource.ResourceSchema):
12 class Options:
13 preserve_unknown = True
14
15
16 _parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'
17
18
19 @resource.register(name='record',
20 collection_path=_parent_path + '/records',
21 record_path=_parent_path + '/records/{{id}}')
22 class Record(resource.ShareableResource):
23
24 mapping = RecordSchema()
25 schema_field = 'schema'
26
27 def __init__(self, *args, **kwargs):
28 super(Record, self).__init__(*args, **kwargs)
29
30 # Check if already fetched before (in batch).
31 collections = self.request.bound_data.setdefault('collections', {})
32 collection_uri = self.get_parent_id(self.request)
33 if collection_uri not in collections:
34 # Unknown yet, fetch from storage.
35 collection_parent_id = '/buckets/%s' % self.bucket_id
36 collection = object_exists_or_404(self.request,
37 collection_id='collection',
38 parent_id=collection_parent_id,
39 object_id=self.collection_id)
40 collections[collection_uri] = collection
41
42 self._collection = collections[collection_uri]
43
44 def get_parent_id(self, request):
45 self.bucket_id = request.matchdict['bucket_id']
46 self.collection_id = request.matchdict['collection_id']
47 return '/buckets/%s/collections/%s' % (self.bucket_id,
48 self.collection_id)
49
50 def is_known_field(self, field_name):
51 """Without schema, any field is considered as known."""
52 return True
53
54 def process_record(self, new, old=None):
55 """Validate records against collection schema, if any."""
56 new = super(Record, self).process_record(new, old)
57
58 schema = self._collection.get('schema')
59 settings = self.request.registry.settings
60 schema_validation = 'experimental_collection_schema_validation'
61 if not schema or not asbool(settings.get(schema_validation)):
62 return new
63
64 collection_timestamp = self._collection[self.model.modified_field]
65
66 try:
67 jsonschema.validate(new, schema)
68 new[self.schema_field] = collection_timestamp
69 except jsonschema_exceptions.ValidationError as e:
70 field = e.path.pop() if e.path else e.validator_value.pop()
71 raise_invalid(self.request, name=field, description=e.message)
72
73 return new
74
75 def collection_get(self):
76 result = super(Record, self).collection_get()
77 self._handle_cache_expires(self.request.response)
78 return result
79
80 def get(self):
81 result = super(Record, self).get()
82 self._handle_cache_expires(self.request.response)
83 return result
84
85 def _handle_cache_expires(self, response):
86 """If the parent collection defines a ``cache_expires`` attribute,
87 then cache-control response headers are sent.
88
89 .. note::
90
91 Those headers are also sent if the
92 ``kinto.record_cache_expires_seconds`` setting is defined.
93 """
94 is_anonymous = Authenticated not in self.request.effective_principals
95 if not is_anonymous:
96 return
97
98 cache_expires = self._collection.get('cache_expires')
99 if cache_expires is None:
100 by_bucket = 'kinto.%s_record_cache_expires_seconds' % (
101 self.bucket_id)
102 by_collection = '%s_%s_record_cache_expires_seconds' % (
103 self.bucket_id, self.collection_id)
104 settings = self.request.registry.settings
105 cache_expires = settings.get(by_collection,
106 settings.get(by_bucket))
107
108 if cache_expires is not None:
109 response.cache_expires(seconds=cache_expires)
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/views/records.py b/kinto/views/records.py
--- a/kinto/views/records.py
+++ b/kinto/views/records.py
@@ -1,3 +1,5 @@
+import copy
+
import jsonschema
from cliquet import resource
from cliquet.errors import raise_invalid
@@ -64,12 +66,17 @@
collection_timestamp = self._collection[self.model.modified_field]
try:
- jsonschema.validate(new, schema)
- new[self.schema_field] = collection_timestamp
+ stripped = copy.deepcopy(new)
+ stripped.pop(self.model.id_field, None)
+ stripped.pop(self.model.modified_field, None)
+ stripped.pop(self.model.permissions_field, None)
+ stripped.pop(self.schema_field, None)
+ jsonschema.validate(stripped, schema)
except jsonschema_exceptions.ValidationError as e:
field = e.path.pop() if e.path else e.validator_value.pop()
raise_invalid(self.request, name=field, description=e.message)
+ new[self.schema_field] = collection_timestamp
return new
def collection_get(self):
|
{"golden_diff": "diff --git a/kinto/views/records.py b/kinto/views/records.py\n--- a/kinto/views/records.py\n+++ b/kinto/views/records.py\n@@ -1,3 +1,5 @@\n+import copy\n+\n import jsonschema\n from cliquet import resource\n from cliquet.errors import raise_invalid\n@@ -64,12 +66,17 @@\n collection_timestamp = self._collection[self.model.modified_field]\n \n try:\n- jsonschema.validate(new, schema)\n- new[self.schema_field] = collection_timestamp\n+ stripped = copy.deepcopy(new)\n+ stripped.pop(self.model.id_field, None)\n+ stripped.pop(self.model.modified_field, None)\n+ stripped.pop(self.model.permissions_field, None)\n+ stripped.pop(self.schema_field, None)\n+ jsonschema.validate(stripped, schema)\n except jsonschema_exceptions.ValidationError as e:\n field = e.path.pop() if e.path else e.validator_value.pop()\n raise_invalid(self.request, name=field, description=e.message)\n \n+ new[self.schema_field] = collection_timestamp\n return new\n \n def collection_get(self):\n", "issue": "id and last_modified should be stripped before validating the JSON schema\nOtherwise it obliges everyone to add `id` and `last_modified` to their JSON schema or use `additionalProperties : true`.\n- http://spacetelescope.github.io/understanding-json-schema/reference/object.html#properties\n- See #256 \n- See #548 \n\n``` diff\n try:\n- jsonschema.validate(new, schema)\n+ stripped = copy.deepcopy(new)\n+ stripped.pop(self.model.id_field, None)\n+ stripped.pop(self.model.modified_field, None)\n+ jsonschema.validate(stripped, schema)\n```\n\nid and last_modified should be stripped before validating the JSON schema\nOtherwise it obliges everyone to add `id` and `last_modified` to their JSON schema or use `additionalProperties : true`.\n- http://spacetelescope.github.io/understanding-json-schema/reference/object.html#properties\n- See #256 \n- See #548 \n\n``` diff\n try:\n- jsonschema.validate(new, schema)\n+ stripped = copy.deepcopy(new)\n+ stripped.pop(self.model.id_field, None)\n+ stripped.pop(self.model.modified_field, None)\n+ jsonschema.validate(stripped, schema)\n```\n\n", "before_files": [{"content": "import jsonschema\nfrom cliquet import resource\nfrom cliquet.errors import raise_invalid\nfrom jsonschema import exceptions as jsonschema_exceptions\nfrom pyramid.security import Authenticated\nfrom pyramid.settings import asbool\n\nfrom kinto.views import object_exists_or_404\n\n\nclass RecordSchema(resource.ResourceSchema):\n class Options:\n preserve_unknown = True\n\n\n_parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'\n\n\[email protected](name='record',\n collection_path=_parent_path + '/records',\n record_path=_parent_path + '/records/{{id}}')\nclass Record(resource.ShareableResource):\n\n mapping = RecordSchema()\n schema_field = 'schema'\n\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n if collection_uri not in collections:\n # Unknown yet, fetch from storage.\n collection_parent_id = '/buckets/%s' % self.bucket_id\n collection = object_exists_or_404(self.request,\n collection_id='collection',\n parent_id=collection_parent_id,\n object_id=self.collection_id)\n collections[collection_uri] = collection\n\n self._collection = collections[collection_uri]\n\n def get_parent_id(self, request):\n self.bucket_id = request.matchdict['bucket_id']\n self.collection_id = request.matchdict['collection_id']\n return '/buckets/%s/collections/%s' % (self.bucket_id,\n self.collection_id)\n\n def is_known_field(self, field_name):\n \"\"\"Without schema, any field is considered as known.\"\"\"\n return True\n\n def process_record(self, new, old=None):\n \"\"\"Validate records against collection schema, if any.\"\"\"\n new = super(Record, self).process_record(new, old)\n\n schema = self._collection.get('schema')\n settings = self.request.registry.settings\n schema_validation = 'experimental_collection_schema_validation'\n if not schema or not asbool(settings.get(schema_validation)):\n return new\n\n collection_timestamp = self._collection[self.model.modified_field]\n\n try:\n jsonschema.validate(new, schema)\n new[self.schema_field] = collection_timestamp\n except jsonschema_exceptions.ValidationError as e:\n field = e.path.pop() if e.path else e.validator_value.pop()\n raise_invalid(self.request, name=field, description=e.message)\n\n return new\n\n def collection_get(self):\n result = super(Record, self).collection_get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def get(self):\n result = super(Record, self).get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def _handle_cache_expires(self, response):\n \"\"\"If the parent collection defines a ``cache_expires`` attribute,\n then cache-control response headers are sent.\n\n .. note::\n\n Those headers are also sent if the\n ``kinto.record_cache_expires_seconds`` setting is defined.\n \"\"\"\n is_anonymous = Authenticated not in self.request.effective_principals\n if not is_anonymous:\n return\n\n cache_expires = self._collection.get('cache_expires')\n if cache_expires is None:\n by_bucket = 'kinto.%s_record_cache_expires_seconds' % (\n self.bucket_id)\n by_collection = '%s_%s_record_cache_expires_seconds' % (\n self.bucket_id, self.collection_id)\n settings = self.request.registry.settings\n cache_expires = settings.get(by_collection,\n settings.get(by_bucket))\n\n if cache_expires is not None:\n response.cache_expires(seconds=cache_expires)\n", "path": "kinto/views/records.py"}], "after_files": [{"content": "import copy\n\nimport jsonschema\nfrom cliquet import resource\nfrom cliquet.errors import raise_invalid\nfrom jsonschema import exceptions as jsonschema_exceptions\nfrom pyramid.security import Authenticated\nfrom pyramid.settings import asbool\n\nfrom kinto.views import object_exists_or_404\n\n\nclass RecordSchema(resource.ResourceSchema):\n class Options:\n preserve_unknown = True\n\n\n_parent_path = '/buckets/{{bucket_id}}/collections/{{collection_id}}'\n\n\[email protected](name='record',\n collection_path=_parent_path + '/records',\n record_path=_parent_path + '/records/{{id}}')\nclass Record(resource.ShareableResource):\n\n mapping = RecordSchema()\n schema_field = 'schema'\n\n def __init__(self, *args, **kwargs):\n super(Record, self).__init__(*args, **kwargs)\n\n # Check if already fetched before (in batch).\n collections = self.request.bound_data.setdefault('collections', {})\n collection_uri = self.get_parent_id(self.request)\n if collection_uri not in collections:\n # Unknown yet, fetch from storage.\n collection_parent_id = '/buckets/%s' % self.bucket_id\n collection = object_exists_or_404(self.request,\n collection_id='collection',\n parent_id=collection_parent_id,\n object_id=self.collection_id)\n collections[collection_uri] = collection\n\n self._collection = collections[collection_uri]\n\n def get_parent_id(self, request):\n self.bucket_id = request.matchdict['bucket_id']\n self.collection_id = request.matchdict['collection_id']\n return '/buckets/%s/collections/%s' % (self.bucket_id,\n self.collection_id)\n\n def is_known_field(self, field_name):\n \"\"\"Without schema, any field is considered as known.\"\"\"\n return True\n\n def process_record(self, new, old=None):\n \"\"\"Validate records against collection schema, if any.\"\"\"\n new = super(Record, self).process_record(new, old)\n\n schema = self._collection.get('schema')\n settings = self.request.registry.settings\n schema_validation = 'experimental_collection_schema_validation'\n if not schema or not asbool(settings.get(schema_validation)):\n return new\n\n collection_timestamp = self._collection[self.model.modified_field]\n\n try:\n stripped = copy.deepcopy(new)\n stripped.pop(self.model.id_field, None)\n stripped.pop(self.model.modified_field, None)\n stripped.pop(self.model.permissions_field, None)\n stripped.pop(self.schema_field, None)\n jsonschema.validate(stripped, schema)\n except jsonschema_exceptions.ValidationError as e:\n field = e.path.pop() if e.path else e.validator_value.pop()\n raise_invalid(self.request, name=field, description=e.message)\n\n new[self.schema_field] = collection_timestamp\n return new\n\n def collection_get(self):\n result = super(Record, self).collection_get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def get(self):\n result = super(Record, self).get()\n self._handle_cache_expires(self.request.response)\n return result\n\n def _handle_cache_expires(self, response):\n \"\"\"If the parent collection defines a ``cache_expires`` attribute,\n then cache-control response headers are sent.\n\n .. note::\n\n Those headers are also sent if the\n ``kinto.record_cache_expires_seconds`` setting is defined.\n \"\"\"\n is_anonymous = Authenticated not in self.request.effective_principals\n if not is_anonymous:\n return\n\n cache_expires = self._collection.get('cache_expires')\n if cache_expires is None:\n by_bucket = 'kinto.%s_record_cache_expires_seconds' % (\n self.bucket_id)\n by_collection = '%s_%s_record_cache_expires_seconds' % (\n self.bucket_id, self.collection_id)\n settings = self.request.registry.settings\n cache_expires = settings.get(by_collection,\n settings.get(by_bucket))\n\n if cache_expires is not None:\n response.cache_expires(seconds=cache_expires)\n", "path": "kinto/views/records.py"}]}
| 1,565 | 242 |
gh_patches_debug_24054
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1890
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Catch ValueError when updating orders if order is paid
This error should be caught.
Sentry Issue: [CONCREXIT-6V](https://sentry.io/organizations/thalia/issues/2472850301/?referrer=github_integration)
```
ValueError: This order has already been paid for.
(12 additional frame(s) were not displayed)
...
File "rest_framework/serializers.py", line 200, in save
self.instance = self.update(self.instance, validated_data)
File "sales/api/v2/admin/serializers/order.py", line 151, in update
OrderItemSerializer(item, context={"order": instance}).update(
File "sales/api/v2/admin/serializers/order.py", line 66, in update
super().update(instance, validated_data)
File "rest_framework/serializers.py", line 983, in update
instance.save()
File "sales/models/order.py", line 215, in save
raise ValueError("This order has already been paid for.")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/sales/api/v2/admin/serializers/order.py`
Content:
```
1 from django.core.exceptions import ObjectDoesNotExist
2 from django.utils.encoding import smart_str
3 from rest_framework import serializers
4
5 from members.api.v2.serializers.member import MemberSerializer
6 from payments.api.v2.serializers import PaymentSerializer
7 from sales.models.order import Order, OrderItem
8 from sales.models.product import ProductListItem
9
10
11 class ProductNameRelatedField(serializers.SlugRelatedField):
12 def get_queryset(self):
13 shift = self.root.context.get("shift", None)
14 if shift is None:
15 shift = self.root.instance.shift
16 return ProductListItem.objects.filter(product_list=shift.product_list)
17
18 def to_internal_value(self, data):
19 if type(data) is ProductListItem:
20 return data
21
22 queryset = self.get_queryset()
23 try:
24 return queryset.get(product__name=data)
25 except ObjectDoesNotExist:
26 self.fail(
27 "does_not_exist", slug_name=self.slug_field, value=smart_str(data)
28 )
29 except (TypeError, ValueError):
30 self.fail("invalid")
31
32 def to_representation(self, obj):
33 return obj.product.name
34
35
36 class OrderItemSerializer(serializers.ModelSerializer):
37 """Serializer for order items."""
38
39 class Meta:
40 model = OrderItem
41 fields = ("product", "amount", "total")
42 read_only_fields = ("total",)
43
44 product = ProductNameRelatedField("product")
45
46 total = serializers.DecimalField(
47 max_digits=6, decimal_places=2, min_value=0, read_only=True
48 )
49
50 def get_fields(self):
51 fields = super().get_fields()
52 request = self.context.get("request", None)
53 if request and request.user and request.user.has_perm("sales.custom_prices"):
54 fields["total"].read_only = False
55 return fields
56
57 def create(self, validated_data, **kwargs):
58 order = self.context["order"]
59 item = OrderItem.objects.create(order=order, **validated_data)
60 return item
61
62 def update(self, instance, validated_data, **kwargs):
63 order = self.context["order"]
64 instance.order = order
65 instance.total = None # Always recalculate the total amount if updating using API (note the difference from the model that only recalculates if the total is None, to deal with historic data and allow for special discounts)
66 super().update(instance, validated_data)
67 return instance
68
69
70 class OrderSerializer(serializers.ModelSerializer):
71 """Serializer for orders."""
72
73 class Meta:
74 model = Order
75 fields = (
76 "pk",
77 "shift",
78 "created_at",
79 "order_items",
80 "order_description",
81 "age_restricted",
82 "subtotal",
83 "discount",
84 "total_amount",
85 "num_items",
86 "payment",
87 "payer",
88 "payment_url",
89 )
90 read_only_fields = (
91 "pk",
92 "created_at",
93 "payment",
94 "num_items",
95 "order_description",
96 )
97
98 shift = serializers.PrimaryKeyRelatedField(read_only=True)
99
100 age_restricted = serializers.BooleanField(read_only=True)
101
102 order_items = OrderItemSerializer(many=True, required=False)
103
104 subtotal = serializers.DecimalField(
105 max_digits=6, decimal_places=2, min_value=0, read_only=True
106 )
107
108 discount = serializers.DecimalField(
109 max_digits=6, decimal_places=2, min_value=0, read_only=True
110 )
111
112 total_amount = serializers.DecimalField(
113 max_digits=6, decimal_places=2, min_value=0, read_only=True
114 )
115
116 payment = PaymentSerializer(read_only=True)
117
118 payer = MemberSerializer(read_only=True)
119
120 payment_url = serializers.URLField(read_only=True)
121
122 def get_fields(self):
123 fields = super().get_fields()
124 request = self.context.get("request", None)
125 if request and request.user and request.user.has_perm("sales.custom_prices"):
126 try:
127 fields["discount"].read_only = False
128 except KeyError:
129 pass
130 return fields
131
132 def create(self, validated_data):
133 shift = self.context["shift"]
134 order = Order.objects.create(shift=shift)
135 if "order_items" in validated_data:
136 items_data = validated_data.pop("order_items")
137 for item_data in items_data:
138 OrderItem.objects.create(order=order, **item_data)
139 return order
140
141 def update(self, instance, validated_data):
142 # Update the order items for an order
143 if "order_items" in validated_data:
144 items_data = validated_data.pop("order_items")
145 current_items = list(instance.order_items.all())
146
147 # Overwrite all existing order items by the newly provided ones
148 for item_data in items_data:
149 if len(current_items) > 0:
150 item = current_items.pop(0)
151 OrderItemSerializer(item, context={"order": instance}).update(
152 item, item_data
153 )
154 else:
155 # Create new order items if required
156 OrderItemSerializer(context={"order": instance}).create(
157 validated_data=item_data
158 )
159
160 # Delete all order items that we have not updated
161 for i in current_items:
162 i.delete()
163
164 # Update other fields of the order as default
165 instance = super().update(instance, validated_data)
166 instance = Order.objects.get(
167 pk=instance.pk
168 ) # refresh from database to update queryable properties
169 return instance
170
171
172 class OrderListSerializer(OrderSerializer):
173 class Meta:
174 model = Order
175 fields = (
176 "pk",
177 "created_at",
178 "total_amount",
179 "num_items",
180 )
181 read_only_fields = (
182 "pk",
183 "created_at",
184 "total_amount",
185 "num_items",
186 )
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/sales/api/v2/admin/serializers/order.py b/website/sales/api/v2/admin/serializers/order.py
--- a/website/sales/api/v2/admin/serializers/order.py
+++ b/website/sales/api/v2/admin/serializers/order.py
@@ -1,6 +1,7 @@
-from django.core.exceptions import ObjectDoesNotExist
+from django.core.exceptions import ObjectDoesNotExist, ValidationError
from django.utils.encoding import smart_str
from rest_framework import serializers
+from rest_framework.settings import api_settings
from members.api.v2.serializers.member import MemberSerializer
from payments.api.v2.serializers import PaymentSerializer
@@ -63,7 +64,10 @@
order = self.context["order"]
instance.order = order
instance.total = None # Always recalculate the total amount if updating using API (note the difference from the model that only recalculates if the total is None, to deal with historic data and allow for special discounts)
- super().update(instance, validated_data)
+ try:
+ super().update(instance, validated_data)
+ except ValueError as e:
+ raise ValidationError({api_settings.NON_FIELD_ERRORS_KEY: [e]})
return instance
|
{"golden_diff": "diff --git a/website/sales/api/v2/admin/serializers/order.py b/website/sales/api/v2/admin/serializers/order.py\n--- a/website/sales/api/v2/admin/serializers/order.py\n+++ b/website/sales/api/v2/admin/serializers/order.py\n@@ -1,6 +1,7 @@\n-from django.core.exceptions import ObjectDoesNotExist\n+from django.core.exceptions import ObjectDoesNotExist, ValidationError\n from django.utils.encoding import smart_str\n from rest_framework import serializers\n+from rest_framework.settings import api_settings\n \n from members.api.v2.serializers.member import MemberSerializer\n from payments.api.v2.serializers import PaymentSerializer\n@@ -63,7 +64,10 @@\n order = self.context[\"order\"]\n instance.order = order\n instance.total = None # Always recalculate the total amount if updating using API (note the difference from the model that only recalculates if the total is None, to deal with historic data and allow for special discounts)\n- super().update(instance, validated_data)\n+ try:\n+ super().update(instance, validated_data)\n+ except ValueError as e:\n+ raise ValidationError({api_settings.NON_FIELD_ERRORS_KEY: [e]})\n return instance\n", "issue": "Catch ValueError when updating orders if order is paid\nThis error should be caught.\n\nSentry Issue: [CONCREXIT-6V](https://sentry.io/organizations/thalia/issues/2472850301/?referrer=github_integration)\n\n```\nValueError: This order has already been paid for.\n(12 additional frame(s) were not displayed)\n...\n File \"rest_framework/serializers.py\", line 200, in save\n self.instance = self.update(self.instance, validated_data)\n File \"sales/api/v2/admin/serializers/order.py\", line 151, in update\n OrderItemSerializer(item, context={\"order\": instance}).update(\n File \"sales/api/v2/admin/serializers/order.py\", line 66, in update\n super().update(instance, validated_data)\n File \"rest_framework/serializers.py\", line 983, in update\n instance.save()\n File \"sales/models/order.py\", line 215, in save\n raise ValueError(\"This order has already been paid for.\")\n```\n", "before_files": [{"content": "from django.core.exceptions import ObjectDoesNotExist\nfrom django.utils.encoding import smart_str\nfrom rest_framework import serializers\n\nfrom members.api.v2.serializers.member import MemberSerializer\nfrom payments.api.v2.serializers import PaymentSerializer\nfrom sales.models.order import Order, OrderItem\nfrom sales.models.product import ProductListItem\n\n\nclass ProductNameRelatedField(serializers.SlugRelatedField):\n def get_queryset(self):\n shift = self.root.context.get(\"shift\", None)\n if shift is None:\n shift = self.root.instance.shift\n return ProductListItem.objects.filter(product_list=shift.product_list)\n\n def to_internal_value(self, data):\n if type(data) is ProductListItem:\n return data\n\n queryset = self.get_queryset()\n try:\n return queryset.get(product__name=data)\n except ObjectDoesNotExist:\n self.fail(\n \"does_not_exist\", slug_name=self.slug_field, value=smart_str(data)\n )\n except (TypeError, ValueError):\n self.fail(\"invalid\")\n\n def to_representation(self, obj):\n return obj.product.name\n\n\nclass OrderItemSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for order items.\"\"\"\n\n class Meta:\n model = OrderItem\n fields = (\"product\", \"amount\", \"total\")\n read_only_fields = (\"total\",)\n\n product = ProductNameRelatedField(\"product\")\n\n total = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n def get_fields(self):\n fields = super().get_fields()\n request = self.context.get(\"request\", None)\n if request and request.user and request.user.has_perm(\"sales.custom_prices\"):\n fields[\"total\"].read_only = False\n return fields\n\n def create(self, validated_data, **kwargs):\n order = self.context[\"order\"]\n item = OrderItem.objects.create(order=order, **validated_data)\n return item\n\n def update(self, instance, validated_data, **kwargs):\n order = self.context[\"order\"]\n instance.order = order\n instance.total = None # Always recalculate the total amount if updating using API (note the difference from the model that only recalculates if the total is None, to deal with historic data and allow for special discounts)\n super().update(instance, validated_data)\n return instance\n\n\nclass OrderSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for orders.\"\"\"\n\n class Meta:\n model = Order\n fields = (\n \"pk\",\n \"shift\",\n \"created_at\",\n \"order_items\",\n \"order_description\",\n \"age_restricted\",\n \"subtotal\",\n \"discount\",\n \"total_amount\",\n \"num_items\",\n \"payment\",\n \"payer\",\n \"payment_url\",\n )\n read_only_fields = (\n \"pk\",\n \"created_at\",\n \"payment\",\n \"num_items\",\n \"order_description\",\n )\n\n shift = serializers.PrimaryKeyRelatedField(read_only=True)\n\n age_restricted = serializers.BooleanField(read_only=True)\n\n order_items = OrderItemSerializer(many=True, required=False)\n\n subtotal = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n discount = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n total_amount = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n payment = PaymentSerializer(read_only=True)\n\n payer = MemberSerializer(read_only=True)\n\n payment_url = serializers.URLField(read_only=True)\n\n def get_fields(self):\n fields = super().get_fields()\n request = self.context.get(\"request\", None)\n if request and request.user and request.user.has_perm(\"sales.custom_prices\"):\n try:\n fields[\"discount\"].read_only = False\n except KeyError:\n pass\n return fields\n\n def create(self, validated_data):\n shift = self.context[\"shift\"]\n order = Order.objects.create(shift=shift)\n if \"order_items\" in validated_data:\n items_data = validated_data.pop(\"order_items\")\n for item_data in items_data:\n OrderItem.objects.create(order=order, **item_data)\n return order\n\n def update(self, instance, validated_data):\n # Update the order items for an order\n if \"order_items\" in validated_data:\n items_data = validated_data.pop(\"order_items\")\n current_items = list(instance.order_items.all())\n\n # Overwrite all existing order items by the newly provided ones\n for item_data in items_data:\n if len(current_items) > 0:\n item = current_items.pop(0)\n OrderItemSerializer(item, context={\"order\": instance}).update(\n item, item_data\n )\n else:\n # Create new order items if required\n OrderItemSerializer(context={\"order\": instance}).create(\n validated_data=item_data\n )\n\n # Delete all order items that we have not updated\n for i in current_items:\n i.delete()\n\n # Update other fields of the order as default\n instance = super().update(instance, validated_data)\n instance = Order.objects.get(\n pk=instance.pk\n ) # refresh from database to update queryable properties\n return instance\n\n\nclass OrderListSerializer(OrderSerializer):\n class Meta:\n model = Order\n fields = (\n \"pk\",\n \"created_at\",\n \"total_amount\",\n \"num_items\",\n )\n read_only_fields = (\n \"pk\",\n \"created_at\",\n \"total_amount\",\n \"num_items\",\n )\n", "path": "website/sales/api/v2/admin/serializers/order.py"}], "after_files": [{"content": "from django.core.exceptions import ObjectDoesNotExist, ValidationError\nfrom django.utils.encoding import smart_str\nfrom rest_framework import serializers\nfrom rest_framework.settings import api_settings\n\nfrom members.api.v2.serializers.member import MemberSerializer\nfrom payments.api.v2.serializers import PaymentSerializer\nfrom sales.models.order import Order, OrderItem\nfrom sales.models.product import ProductListItem\n\n\nclass ProductNameRelatedField(serializers.SlugRelatedField):\n def get_queryset(self):\n shift = self.root.context.get(\"shift\", None)\n if shift is None:\n shift = self.root.instance.shift\n return ProductListItem.objects.filter(product_list=shift.product_list)\n\n def to_internal_value(self, data):\n if type(data) is ProductListItem:\n return data\n\n queryset = self.get_queryset()\n try:\n return queryset.get(product__name=data)\n except ObjectDoesNotExist:\n self.fail(\n \"does_not_exist\", slug_name=self.slug_field, value=smart_str(data)\n )\n except (TypeError, ValueError):\n self.fail(\"invalid\")\n\n def to_representation(self, obj):\n return obj.product.name\n\n\nclass OrderItemSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for order items.\"\"\"\n\n class Meta:\n model = OrderItem\n fields = (\"product\", \"amount\", \"total\")\n read_only_fields = (\"total\",)\n\n product = ProductNameRelatedField(\"product\")\n\n total = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n def get_fields(self):\n fields = super().get_fields()\n request = self.context.get(\"request\", None)\n if request and request.user and request.user.has_perm(\"sales.custom_prices\"):\n fields[\"total\"].read_only = False\n return fields\n\n def create(self, validated_data, **kwargs):\n order = self.context[\"order\"]\n item = OrderItem.objects.create(order=order, **validated_data)\n return item\n\n def update(self, instance, validated_data, **kwargs):\n order = self.context[\"order\"]\n instance.order = order\n instance.total = None # Always recalculate the total amount if updating using API (note the difference from the model that only recalculates if the total is None, to deal with historic data and allow for special discounts)\n try:\n super().update(instance, validated_data)\n except ValueError as e:\n raise ValidationError({api_settings.NON_FIELD_ERRORS_KEY: [e]})\n return instance\n\n\nclass OrderSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for orders.\"\"\"\n\n class Meta:\n model = Order\n fields = (\n \"pk\",\n \"shift\",\n \"created_at\",\n \"order_items\",\n \"order_description\",\n \"age_restricted\",\n \"subtotal\",\n \"discount\",\n \"total_amount\",\n \"num_items\",\n \"payment\",\n \"payer\",\n \"payment_url\",\n )\n read_only_fields = (\n \"pk\",\n \"created_at\",\n \"payment\",\n \"num_items\",\n \"order_description\",\n )\n\n shift = serializers.PrimaryKeyRelatedField(read_only=True)\n\n age_restricted = serializers.BooleanField(read_only=True)\n\n order_items = OrderItemSerializer(many=True, required=False)\n\n subtotal = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n discount = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n total_amount = serializers.DecimalField(\n max_digits=6, decimal_places=2, min_value=0, read_only=True\n )\n\n payment = PaymentSerializer(read_only=True)\n\n payer = MemberSerializer(read_only=True)\n\n payment_url = serializers.URLField(read_only=True)\n\n def get_fields(self):\n fields = super().get_fields()\n request = self.context.get(\"request\", None)\n if request and request.user and request.user.has_perm(\"sales.custom_prices\"):\n try:\n fields[\"discount\"].read_only = False\n except KeyError:\n pass\n return fields\n\n def create(self, validated_data):\n shift = self.context[\"shift\"]\n order = Order.objects.create(shift=shift)\n if \"order_items\" in validated_data:\n items_data = validated_data.pop(\"order_items\")\n for item_data in items_data:\n OrderItem.objects.create(order=order, **item_data)\n return order\n\n def update(self, instance, validated_data):\n # Update the order items for an order\n if \"order_items\" in validated_data:\n items_data = validated_data.pop(\"order_items\")\n current_items = list(instance.order_items.all())\n\n # Overwrite all existing order items by the newly provided ones\n for item_data in items_data:\n if len(current_items) > 0:\n item = current_items.pop(0)\n OrderItemSerializer(item, context={\"order\": instance}).update(\n item, item_data\n )\n else:\n # Create new order items if required\n OrderItemSerializer(context={\"order\": instance}).create(\n validated_data=item_data\n )\n\n # Delete all order items that we have not updated\n for i in current_items:\n i.delete()\n\n # Update other fields of the order as default\n instance = super().update(instance, validated_data)\n instance = Order.objects.get(\n pk=instance.pk\n ) # refresh from database to update queryable properties\n return instance\n\n\nclass OrderListSerializer(OrderSerializer):\n class Meta:\n model = Order\n fields = (\n \"pk\",\n \"created_at\",\n \"total_amount\",\n \"num_items\",\n )\n read_only_fields = (\n \"pk\",\n \"created_at\",\n \"total_amount\",\n \"num_items\",\n )\n", "path": "website/sales/api/v2/admin/serializers/order.py"}]}
| 2,161 | 265 |
gh_patches_debug_40362
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1338
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update modifierclass.rst template to accept functions that aren't methods of a class
# Description
First noticed in PR #750, while trying to get the docs to show the full signatures and docstrings:
```rst
.. autosummary::
:toctree: _generated/
:nosignatures:
:template: modifierclass.rst
```
I'm getting the following warnings (which we treat as errors) when I try to build the docs:
```
WARNING: error while formatting arguments for pyhf.infer.calculators.generate_asimov_data: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.hypotest: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.fit: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.fixed_poi_fit: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.twice_nll: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.test_statistics.qmu: 'function' object has no attribute '__mro__'
```
which I believe is happening as `__mro__` only exists on the class, and these functions exist in the source code outside of a class definition.
This means that the [`modifierclass.rst` template](https://github.com/scikit-hep/pyhf/blob/1ee6e38d42d9551220f20de483e0049b28c848b0/docs/_templates/modifierclass.rst) will need to get updated to deal with functions that aren't methods of a class.
Fix up docstring for _minimize() functions in the optimizers
# Description
From https://github.com/scikit-hep/pyhf/pull/1338#pullrequestreview-596818258
> I'm not sure if it can be fixed here, but the "Minimizer Options" aren't being displayed correctly for the optimizer _minimize methods.

> we've never been able to see the `_minimize` methods before, so it isn't surprising they might not look perfect.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyhf/optimize/opt_minuit.py`
Content:
```
1 """Minuit Optimizer Class."""
2 from .. import exceptions
3 from .mixins import OptimizerMixin
4 import scipy
5 import iminuit
6
7
8 class minuit_optimizer(OptimizerMixin):
9 """
10 Optimizer that minimizes via :meth:`iminuit.Minuit.migrad`.
11 """
12
13 __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']
14
15 def __init__(self, *args, **kwargs):
16 """
17 Create :class:`iminuit.Minuit` optimizer.
18
19 .. note::
20
21 ``errordef`` should be 1.0 for a least-squares cost function and 0.5
22 for negative log-likelihood function. See page 37 of
23 http://hep.fi.infn.it/minuit.pdf. This parameter is sometimes
24 called ``UP`` in the ``MINUIT`` docs.
25
26
27 Args:
28 errordef (:obj:`float`): See minuit docs. Default is 1.0.
29 steps (:obj:`int`): Number of steps for the bounds. Default is 1000.
30 strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.
31 tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
32 """
33 self.name = 'minuit'
34 self.errordef = kwargs.pop('errordef', 1)
35 self.steps = kwargs.pop('steps', 1000)
36 self.strategy = kwargs.pop('strategy', None)
37 self.tolerance = kwargs.pop('tolerance', 0.1)
38 super().__init__(*args, **kwargs)
39
40 def _get_minimizer(
41 self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False
42 ):
43
44 step_sizes = [(b[1] - b[0]) / float(self.steps) for b in init_bounds]
45 fixed_vals = fixed_vals or []
46 # Minuit wants True/False for each parameter
47 fixed_bools = [False] * len(init_pars)
48 for index, val in fixed_vals:
49 fixed_bools[index] = True
50 init_pars[index] = val
51 step_sizes[index] = 0.0
52
53 # Minuit requires jac=callable
54 if do_grad:
55 wrapped_objective = lambda pars: objective_and_grad(pars)[0] # noqa: E731
56 jac = lambda pars: objective_and_grad(pars)[1] # noqa: E731
57 else:
58 wrapped_objective = objective_and_grad
59 jac = None
60
61 minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac)
62 minuit.errors = step_sizes
63 minuit.limits = init_bounds
64 minuit.fixed = fixed_bools
65 minuit.print_level = self.verbose
66 minuit.errordef = self.errordef
67 return minuit
68
69 def _minimize(
70 self,
71 minimizer,
72 func,
73 x0,
74 do_grad=False,
75 bounds=None,
76 fixed_vals=None,
77 options={},
78 ):
79
80 """
81 Same signature as :func:`scipy.optimize.minimize`.
82
83 Note: an additional `minuit` is injected into the fitresult to get the
84 underlying minimizer.
85
86 Minimizer Options:
87 maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
88 strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.
89 tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
90
91 Returns:
92 fitresult (scipy.optimize.OptimizeResult): the fit result
93 """
94 maxiter = options.pop('maxiter', self.maxiter)
95 # 0: Fast, user-provided gradient
96 # 1: Default, no user-provided gradient
97 strategy = options.pop(
98 'strategy', self.strategy if self.strategy else not do_grad
99 )
100 tolerance = options.pop('tolerance', self.tolerance)
101 if options:
102 raise exceptions.Unsupported(
103 f"Unsupported options were passed in: {list(options.keys())}."
104 )
105
106 minimizer.strategy = strategy
107 minimizer.tol = tolerance
108 minimizer.migrad(ncall=maxiter)
109 # Following lines below come from:
110 # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130
111 message = "Optimization terminated successfully."
112 if not minimizer.valid:
113 message = "Optimization failed."
114 fmin = minimizer.fmin
115 if fmin.has_reached_call_limit:
116 message += " Call limit was reached."
117 if fmin.is_above_max_edm:
118 message += " Estimated distance to minimum too large."
119
120 hess_inv = None
121 corr = None
122 unc = None
123 if minimizer.valid:
124 # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.
125 minimizer.hesse()
126 hess_inv = minimizer.covariance
127 corr = hess_inv.correlation()
128 unc = minimizer.errors
129
130 return scipy.optimize.OptimizeResult(
131 x=minimizer.values,
132 unc=unc,
133 corr=corr,
134 success=minimizer.valid,
135 fun=minimizer.fval,
136 hess_inv=hess_inv,
137 message=message,
138 nfev=minimizer.nfcn,
139 njev=minimizer.ngrad,
140 minuit=minimizer,
141 )
142
```
Path: `src/pyhf/optimize/opt_scipy.py`
Content:
```
1 """SciPy Optimizer Class."""
2 from .. import exceptions
3 from .mixins import OptimizerMixin
4 import scipy
5
6
7 class scipy_optimizer(OptimizerMixin):
8 """
9 Optimizer that uses :func:`scipy.optimize.minimize`.
10 """
11
12 __slots__ = ['name', 'tolerance']
13
14 def __init__(self, *args, **kwargs):
15 """
16 Initialize the scipy_optimizer.
17
18 See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.
19
20 Args:
21 tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
22 """
23 self.name = 'scipy'
24 self.tolerance = kwargs.pop('tolerance', None)
25 super().__init__(*args, **kwargs)
26
27 def _get_minimizer(
28 self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False
29 ):
30 return scipy.optimize.minimize
31
32 def _minimize(
33 self,
34 minimizer,
35 func,
36 x0,
37 do_grad=False,
38 bounds=None,
39 fixed_vals=None,
40 options={},
41 ):
42 """
43 Same signature as :func:`scipy.optimize.minimize`.
44
45 Minimizer Options:
46 maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
47 verbose (:obj:`bool`): print verbose output during minimization. Default is off.
48 method (:obj:`str`): minimization routine. Default is 'SLSQP'.
49 tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
50
51 Returns:
52 fitresult (scipy.optimize.OptimizeResult): the fit result
53 """
54 maxiter = options.pop('maxiter', self.maxiter)
55 verbose = options.pop('verbose', self.verbose)
56 method = options.pop('method', 'SLSQP')
57 tolerance = options.pop('tolerance', self.tolerance)
58 if options:
59 raise exceptions.Unsupported(
60 f"Unsupported options were passed in: {list(options.keys())}."
61 )
62
63 fixed_vals = fixed_vals or []
64 indices = [i for i, _ in fixed_vals]
65 values = [v for _, v in fixed_vals]
66 if fixed_vals:
67 constraints = [{'type': 'eq', 'fun': lambda v: v[indices] - values}]
68 # update the initial values to the fixed value for any fixed parameter
69 for idx, fixed_val in fixed_vals:
70 x0[idx] = fixed_val
71 else:
72 constraints = []
73
74 return minimizer(
75 func,
76 x0,
77 method=method,
78 jac=do_grad,
79 bounds=bounds,
80 constraints=constraints,
81 tol=tolerance,
82 options=dict(maxiter=maxiter, disp=bool(verbose)),
83 )
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -25,10 +25,12 @@
Args:
- errordef (:obj:`float`): See minuit docs. Default is 1.0.
- steps (:obj:`int`): Number of steps for the bounds. Default is 1000.
- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
+ errordef (:obj:`float`): See minuit docs. Default is ``1.0``.
+ steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.
+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.
+ tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``0.1``.
"""
self.name = 'minuit'
self.errordef = kwargs.pop('errordef', 1)
@@ -84,9 +86,12 @@
underlying minimizer.
Minimizer Options:
- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.
+ * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.
+ Default is to configure in response to ``do_grad``.
+ * tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``0.1``.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
diff --git a/src/pyhf/optimize/opt_scipy.py b/src/pyhf/optimize/opt_scipy.py
--- a/src/pyhf/optimize/opt_scipy.py
+++ b/src/pyhf/optimize/opt_scipy.py
@@ -18,7 +18,9 @@
See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.
Args:
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
+ tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``None``.
"""
self.name = 'scipy'
self.tolerance = kwargs.pop('tolerance', None)
@@ -43,10 +45,13 @@
Same signature as :func:`scipy.optimize.minimize`.
Minimizer Options:
- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
- verbose (:obj:`bool`): print verbose output during minimization. Default is off.
- method (:obj:`str`): minimization routine. Default is 'SLSQP'.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.
+ * verbose (:obj:`bool`): Print verbose output during minimization.
+ Default is ``False``.
+ * method (:obj:`str`): Minimization routine. Default is ``'SLSQP'``.
+ * tolerance (:obj:`float`): Tolerance for termination. See specific optimizer
+ for detailed meaning.
+ Default is ``None``.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
|
{"golden_diff": "diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py\n--- a/src/pyhf/optimize/opt_minuit.py\n+++ b/src/pyhf/optimize/opt_minuit.py\n@@ -25,10 +25,12 @@\n \n \n Args:\n- errordef (:obj:`float`): See minuit docs. Default is 1.0.\n- steps (:obj:`int`): Number of steps for the bounds. Default is 1000.\n- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.\n- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.\n+ errordef (:obj:`float`): See minuit docs. Default is ``1.0``.\n+ steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.\n+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.\n+ tolerance (:obj:`float`): Tolerance for termination.\n+ See specific optimizer for detailed meaning.\n+ Default is ``0.1``.\n \"\"\"\n self.name = 'minuit'\n self.errordef = kwargs.pop('errordef', 1)\n@@ -84,9 +86,12 @@\n underlying minimizer.\n \n Minimizer Options:\n- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.\n- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.\n- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.\n+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.\n+ * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.\n+ Default is to configure in response to ``do_grad``.\n+ * tolerance (:obj:`float`): Tolerance for termination.\n+ See specific optimizer for detailed meaning.\n+ Default is ``0.1``.\n \n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\ndiff --git a/src/pyhf/optimize/opt_scipy.py b/src/pyhf/optimize/opt_scipy.py\n--- a/src/pyhf/optimize/opt_scipy.py\n+++ b/src/pyhf/optimize/opt_scipy.py\n@@ -18,7 +18,9 @@\n See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.\n \n Args:\n- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.\n+ tolerance (:obj:`float`): Tolerance for termination.\n+ See specific optimizer for detailed meaning.\n+ Default is ``None``.\n \"\"\"\n self.name = 'scipy'\n self.tolerance = kwargs.pop('tolerance', None)\n@@ -43,10 +45,13 @@\n Same signature as :func:`scipy.optimize.minimize`.\n \n Minimizer Options:\n- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.\n- verbose (:obj:`bool`): print verbose output during minimization. Default is off.\n- method (:obj:`str`): minimization routine. Default is 'SLSQP'.\n- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.\n+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.\n+ * verbose (:obj:`bool`): Print verbose output during minimization.\n+ Default is ``False``.\n+ * method (:obj:`str`): Minimization routine. Default is ``'SLSQP'``.\n+ * tolerance (:obj:`float`): Tolerance for termination. See specific optimizer\n+ for detailed meaning.\n+ Default is ``None``.\n \n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n", "issue": "Update modifierclass.rst template to accept functions that aren't methods of a class\n# Description\r\n\r\nFirst noticed in PR #750, while trying to get the docs to show the full signatures and docstrings:\r\n\r\n```rst\r\n.. autosummary::\r\n :toctree: _generated/\r\n :nosignatures:\r\n :template: modifierclass.rst\r\n```\r\n\r\nI'm getting the following warnings (which we treat as errors) when I try to build the docs:\r\n```\r\nWARNING: error while formatting arguments for pyhf.infer.calculators.generate_asimov_data: 'function' object has no attribute '__mro__'\r\nWARNING: error while formatting arguments for pyhf.infer.hypotest: 'function' object has no attribute '__mro__'\r\nWARNING: error while formatting arguments for pyhf.infer.mle.fit: 'function' object has no attribute '__mro__'\r\nWARNING: error while formatting arguments for pyhf.infer.mle.fixed_poi_fit: 'function' object has no attribute '__mro__'\r\nWARNING: error while formatting arguments for pyhf.infer.mle.twice_nll: 'function' object has no attribute '__mro__'\r\nWARNING: error while formatting arguments for pyhf.infer.test_statistics.qmu: 'function' object has no attribute '__mro__'\r\n```\r\n\r\nwhich I believe is happening as `__mro__` only exists on the class, and these functions exist in the source code outside of a class definition.\r\n\r\nThis means that the [`modifierclass.rst` template](https://github.com/scikit-hep/pyhf/blob/1ee6e38d42d9551220f20de483e0049b28c848b0/docs/_templates/modifierclass.rst) will need to get updated to deal with functions that aren't methods of a class.\nFix up docstring for _minimize() functions in the optimizers\n# Description\r\n\r\nFrom https://github.com/scikit-hep/pyhf/pull/1338#pullrequestreview-596818258\r\n\r\n> I'm not sure if it can be fixed here, but the \"Minimizer Options\" aren't being displayed correctly for the optimizer _minimize methods.\r\n\r\n\r\n\r\n> we've never been able to see the `_minimize` methods before, so it isn't surprising they might not look perfect.\n", "before_files": [{"content": "\"\"\"Minuit Optimizer Class.\"\"\"\nfrom .. import exceptions\nfrom .mixins import OptimizerMixin\nimport scipy\nimport iminuit\n\n\nclass minuit_optimizer(OptimizerMixin):\n \"\"\"\n Optimizer that minimizes via :meth:`iminuit.Minuit.migrad`.\n \"\"\"\n\n __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Create :class:`iminuit.Minuit` optimizer.\n\n .. note::\n\n ``errordef`` should be 1.0 for a least-squares cost function and 0.5\n for negative log-likelihood function. See page 37 of\n http://hep.fi.infn.it/minuit.pdf. This parameter is sometimes\n called ``UP`` in the ``MINUIT`` docs.\n\n\n Args:\n errordef (:obj:`float`): See minuit docs. Default is 1.0.\n steps (:obj:`int`): Number of steps for the bounds. Default is 1000.\n strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.\n tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.\n \"\"\"\n self.name = 'minuit'\n self.errordef = kwargs.pop('errordef', 1)\n self.steps = kwargs.pop('steps', 1000)\n self.strategy = kwargs.pop('strategy', None)\n self.tolerance = kwargs.pop('tolerance', 0.1)\n super().__init__(*args, **kwargs)\n\n def _get_minimizer(\n self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False\n ):\n\n step_sizes = [(b[1] - b[0]) / float(self.steps) for b in init_bounds]\n fixed_vals = fixed_vals or []\n # Minuit wants True/False for each parameter\n fixed_bools = [False] * len(init_pars)\n for index, val in fixed_vals:\n fixed_bools[index] = True\n init_pars[index] = val\n step_sizes[index] = 0.0\n\n # Minuit requires jac=callable\n if do_grad:\n wrapped_objective = lambda pars: objective_and_grad(pars)[0] # noqa: E731\n jac = lambda pars: objective_and_grad(pars)[1] # noqa: E731\n else:\n wrapped_objective = objective_and_grad\n jac = None\n\n minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac)\n minuit.errors = step_sizes\n minuit.limits = init_bounds\n minuit.fixed = fixed_bools\n minuit.print_level = self.verbose\n minuit.errordef = self.errordef\n return minuit\n\n def _minimize(\n self,\n minimizer,\n func,\n x0,\n do_grad=False,\n bounds=None,\n fixed_vals=None,\n options={},\n ):\n\n \"\"\"\n Same signature as :func:`scipy.optimize.minimize`.\n\n Note: an additional `minuit` is injected into the fitresult to get the\n underlying minimizer.\n\n Minimizer Options:\n maxiter (:obj:`int`): maximum number of iterations. Default is 100000.\n strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.\n tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.\n\n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n # 0: Fast, user-provided gradient\n # 1: Default, no user-provided gradient\n strategy = options.pop(\n 'strategy', self.strategy if self.strategy else not do_grad\n )\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n f\"Unsupported options were passed in: {list(options.keys())}.\"\n )\n\n minimizer.strategy = strategy\n minimizer.tol = tolerance\n minimizer.migrad(ncall=maxiter)\n # Following lines below come from:\n # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130\n message = \"Optimization terminated successfully.\"\n if not minimizer.valid:\n message = \"Optimization failed.\"\n fmin = minimizer.fmin\n if fmin.has_reached_call_limit:\n message += \" Call limit was reached.\"\n if fmin.is_above_max_edm:\n message += \" Estimated distance to minimum too large.\"\n\n hess_inv = None\n corr = None\n unc = None\n if minimizer.valid:\n # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.\n minimizer.hesse()\n hess_inv = minimizer.covariance\n corr = hess_inv.correlation()\n unc = minimizer.errors\n\n return scipy.optimize.OptimizeResult(\n x=minimizer.values,\n unc=unc,\n corr=corr,\n success=minimizer.valid,\n fun=minimizer.fval,\n hess_inv=hess_inv,\n message=message,\n nfev=minimizer.nfcn,\n njev=minimizer.ngrad,\n minuit=minimizer,\n )\n", "path": "src/pyhf/optimize/opt_minuit.py"}, {"content": "\"\"\"SciPy Optimizer Class.\"\"\"\nfrom .. import exceptions\nfrom .mixins import OptimizerMixin\nimport scipy\n\n\nclass scipy_optimizer(OptimizerMixin):\n \"\"\"\n Optimizer that uses :func:`scipy.optimize.minimize`.\n \"\"\"\n\n __slots__ = ['name', 'tolerance']\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Initialize the scipy_optimizer.\n\n See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.\n\n Args:\n tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.\n \"\"\"\n self.name = 'scipy'\n self.tolerance = kwargs.pop('tolerance', None)\n super().__init__(*args, **kwargs)\n\n def _get_minimizer(\n self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False\n ):\n return scipy.optimize.minimize\n\n def _minimize(\n self,\n minimizer,\n func,\n x0,\n do_grad=False,\n bounds=None,\n fixed_vals=None,\n options={},\n ):\n \"\"\"\n Same signature as :func:`scipy.optimize.minimize`.\n\n Minimizer Options:\n maxiter (:obj:`int`): maximum number of iterations. Default is 100000.\n verbose (:obj:`bool`): print verbose output during minimization. Default is off.\n method (:obj:`str`): minimization routine. Default is 'SLSQP'.\n tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.\n\n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n verbose = options.pop('verbose', self.verbose)\n method = options.pop('method', 'SLSQP')\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n f\"Unsupported options were passed in: {list(options.keys())}.\"\n )\n\n fixed_vals = fixed_vals or []\n indices = [i for i, _ in fixed_vals]\n values = [v for _, v in fixed_vals]\n if fixed_vals:\n constraints = [{'type': 'eq', 'fun': lambda v: v[indices] - values}]\n # update the initial values to the fixed value for any fixed parameter\n for idx, fixed_val in fixed_vals:\n x0[idx] = fixed_val\n else:\n constraints = []\n\n return minimizer(\n func,\n x0,\n method=method,\n jac=do_grad,\n bounds=bounds,\n constraints=constraints,\n tol=tolerance,\n options=dict(maxiter=maxiter, disp=bool(verbose)),\n )\n", "path": "src/pyhf/optimize/opt_scipy.py"}], "after_files": [{"content": "\"\"\"Minuit Optimizer Class.\"\"\"\nfrom .. import exceptions\nfrom .mixins import OptimizerMixin\nimport scipy\nimport iminuit\n\n\nclass minuit_optimizer(OptimizerMixin):\n \"\"\"\n Optimizer that minimizes via :meth:`iminuit.Minuit.migrad`.\n \"\"\"\n\n __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Create :class:`iminuit.Minuit` optimizer.\n\n .. note::\n\n ``errordef`` should be 1.0 for a least-squares cost function and 0.5\n for negative log-likelihood function. See page 37 of\n http://hep.fi.infn.it/minuit.pdf. This parameter is sometimes\n called ``UP`` in the ``MINUIT`` docs.\n\n\n Args:\n errordef (:obj:`float`): See minuit docs. Default is ``1.0``.\n steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.\n strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.\n tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``0.1``.\n \"\"\"\n self.name = 'minuit'\n self.errordef = kwargs.pop('errordef', 1)\n self.steps = kwargs.pop('steps', 1000)\n self.strategy = kwargs.pop('strategy', None)\n self.tolerance = kwargs.pop('tolerance', 0.1)\n super().__init__(*args, **kwargs)\n\n def _get_minimizer(\n self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False\n ):\n\n step_sizes = [(b[1] - b[0]) / float(self.steps) for b in init_bounds]\n fixed_vals = fixed_vals or []\n # Minuit wants True/False for each parameter\n fixed_bools = [False] * len(init_pars)\n for index, val in fixed_vals:\n fixed_bools[index] = True\n init_pars[index] = val\n step_sizes[index] = 0.0\n\n # Minuit requires jac=callable\n if do_grad:\n wrapped_objective = lambda pars: objective_and_grad(pars)[0] # noqa: E731\n jac = lambda pars: objective_and_grad(pars)[1] # noqa: E731\n else:\n wrapped_objective = objective_and_grad\n jac = None\n\n minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac)\n minuit.errors = step_sizes\n minuit.limits = init_bounds\n minuit.fixed = fixed_bools\n minuit.print_level = self.verbose\n minuit.errordef = self.errordef\n return minuit\n\n def _minimize(\n self,\n minimizer,\n func,\n x0,\n do_grad=False,\n bounds=None,\n fixed_vals=None,\n options={},\n ):\n\n \"\"\"\n Same signature as :func:`scipy.optimize.minimize`.\n\n Note: an additional `minuit` is injected into the fitresult to get the\n underlying minimizer.\n\n Minimizer Options:\n * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.\n * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.\n Default is to configure in response to ``do_grad``.\n * tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``0.1``.\n\n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n # 0: Fast, user-provided gradient\n # 1: Default, no user-provided gradient\n strategy = options.pop(\n 'strategy', self.strategy if self.strategy else not do_grad\n )\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n f\"Unsupported options were passed in: {list(options.keys())}.\"\n )\n\n minimizer.strategy = strategy\n minimizer.tol = tolerance\n minimizer.migrad(ncall=maxiter)\n # Following lines below come from:\n # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130\n message = \"Optimization terminated successfully.\"\n if not minimizer.valid:\n message = \"Optimization failed.\"\n fmin = minimizer.fmin\n if fmin.has_reached_call_limit:\n message += \" Call limit was reached.\"\n if fmin.is_above_max_edm:\n message += \" Estimated distance to minimum too large.\"\n\n hess_inv = None\n corr = None\n unc = None\n if minimizer.valid:\n # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.\n minimizer.hesse()\n hess_inv = minimizer.covariance\n corr = hess_inv.correlation()\n unc = minimizer.errors\n\n return scipy.optimize.OptimizeResult(\n x=minimizer.values,\n unc=unc,\n corr=corr,\n success=minimizer.valid,\n fun=minimizer.fval,\n hess_inv=hess_inv,\n message=message,\n nfev=minimizer.nfcn,\n njev=minimizer.ngrad,\n minuit=minimizer,\n )\n", "path": "src/pyhf/optimize/opt_minuit.py"}, {"content": "\"\"\"SciPy Optimizer Class.\"\"\"\nfrom .. import exceptions\nfrom .mixins import OptimizerMixin\nimport scipy\n\n\nclass scipy_optimizer(OptimizerMixin):\n \"\"\"\n Optimizer that uses :func:`scipy.optimize.minimize`.\n \"\"\"\n\n __slots__ = ['name', 'tolerance']\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Initialize the scipy_optimizer.\n\n See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.\n\n Args:\n tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``None``.\n \"\"\"\n self.name = 'scipy'\n self.tolerance = kwargs.pop('tolerance', None)\n super().__init__(*args, **kwargs)\n\n def _get_minimizer(\n self, objective_and_grad, init_pars, init_bounds, fixed_vals=None, do_grad=False\n ):\n return scipy.optimize.minimize\n\n def _minimize(\n self,\n minimizer,\n func,\n x0,\n do_grad=False,\n bounds=None,\n fixed_vals=None,\n options={},\n ):\n \"\"\"\n Same signature as :func:`scipy.optimize.minimize`.\n\n Minimizer Options:\n * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.\n * verbose (:obj:`bool`): Print verbose output during minimization.\n Default is ``False``.\n * method (:obj:`str`): Minimization routine. Default is ``'SLSQP'``.\n * tolerance (:obj:`float`): Tolerance for termination. See specific optimizer\n for detailed meaning.\n Default is ``None``.\n\n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n verbose = options.pop('verbose', self.verbose)\n method = options.pop('method', 'SLSQP')\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n f\"Unsupported options were passed in: {list(options.keys())}.\"\n )\n\n fixed_vals = fixed_vals or []\n indices = [i for i, _ in fixed_vals]\n values = [v for _, v in fixed_vals]\n if fixed_vals:\n constraints = [{'type': 'eq', 'fun': lambda v: v[indices] - values}]\n # update the initial values to the fixed value for any fixed parameter\n for idx, fixed_val in fixed_vals:\n x0[idx] = fixed_val\n else:\n constraints = []\n\n return minimizer(\n func,\n x0,\n method=method,\n jac=do_grad,\n bounds=bounds,\n constraints=constraints,\n tol=tolerance,\n options=dict(maxiter=maxiter, disp=bool(verbose)),\n )\n", "path": "src/pyhf/optimize/opt_scipy.py"}]}
| 3,228 | 927 |
gh_patches_debug_31727
|
rasdani/github-patches
|
git_diff
|
onnx__onnx-5555
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use pillow to replace opencv in reference evaluator
Caveat: https://github.com/python-pillow/Pillow/issues/6047#issuecomment-1038150443
cc @jcwchen
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `onnx/reference/ops/op_image_decoder.py`
Content:
```
1 # Copyright (c) ONNX Project Contributors
2
3 # SPDX-License-Identifier: Apache-2.0
4 # pylint: disable=C0123,C3001,R0912,R0913,R0914,R1730,W0221,W0613
5
6 import numpy as np
7
8 from onnx.reference.op_run import OpRun
9
10
11 class ImageDecoder(OpRun):
12 def _run( # type: ignore
13 self,
14 encoded,
15 pixel_format="RGB",
16 ):
17 try:
18 # pylint: disable=import-outside-toplevel`
19 import cv2
20 except ImportError as e:
21 raise ImportError(
22 "opencv-python must be installed to use the reference implementation of the ImageDecoder operator"
23 ) from e
24 decoded = None
25 if pixel_format == "BGR":
26 decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)
27 elif pixel_format == "RGB":
28 decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)
29 decoded = cv2.cvtColor(decoded, cv2.COLOR_BGR2RGB)
30 elif pixel_format == "Grayscale":
31 decoded = cv2.imdecode(encoded, cv2.IMREAD_GRAYSCALE)
32 decoded = np.expand_dims(decoded, axis=2) # (H, W) to (H, W, 1)
33 else:
34 raise RuntimeError(f"pixel_format={pixel_format!r} is not supported.")
35 return (decoded,)
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/onnx/reference/ops/op_image_decoder.py b/onnx/reference/ops/op_image_decoder.py
--- a/onnx/reference/ops/op_image_decoder.py
+++ b/onnx/reference/ops/op_image_decoder.py
@@ -1,7 +1,10 @@
# Copyright (c) ONNX Project Contributors
# SPDX-License-Identifier: Apache-2.0
-# pylint: disable=C0123,C3001,R0912,R0913,R0914,R1730,W0221,W0613
+
+from __future__ import annotations
+
+import io
import numpy as np
@@ -9,27 +12,22 @@
class ImageDecoder(OpRun):
- def _run( # type: ignore
- self,
- encoded,
- pixel_format="RGB",
- ):
+ def _run(self, encoded: np.ndarray, pixel_format="RGB") -> tuple[np.ndarray]: # type: ignore
try:
- # pylint: disable=import-outside-toplevel`
- import cv2
+ import PIL.Image # pylint: disable=import-outside-toplevel
except ImportError as e:
raise ImportError(
- "opencv-python must be installed to use the reference implementation of the ImageDecoder operator"
+ "Pillow must be installed to use the reference implementation of the ImageDecoder operator"
) from e
- decoded = None
+ img = PIL.Image.open(io.BytesIO(encoded.tobytes()))
if pixel_format == "BGR":
- decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)
+ decoded = np.array(img)[:, :, ::-1]
elif pixel_format == "RGB":
- decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)
- decoded = cv2.cvtColor(decoded, cv2.COLOR_BGR2RGB)
+ decoded = np.array(img)
elif pixel_format == "Grayscale":
- decoded = cv2.imdecode(encoded, cv2.IMREAD_GRAYSCALE)
+ img = img.convert("L")
+ decoded = np.array(img)
decoded = np.expand_dims(decoded, axis=2) # (H, W) to (H, W, 1)
else:
- raise RuntimeError(f"pixel_format={pixel_format!r} is not supported.")
+ raise ValueError(f"pixel_format={pixel_format!r} is not supported.")
return (decoded,)
|
{"golden_diff": "diff --git a/onnx/reference/ops/op_image_decoder.py b/onnx/reference/ops/op_image_decoder.py\n--- a/onnx/reference/ops/op_image_decoder.py\n+++ b/onnx/reference/ops/op_image_decoder.py\n@@ -1,7 +1,10 @@\n # Copyright (c) ONNX Project Contributors\n \n # SPDX-License-Identifier: Apache-2.0\n-# pylint: disable=C0123,C3001,R0912,R0913,R0914,R1730,W0221,W0613\n+\n+from __future__ import annotations\n+\n+import io\n \n import numpy as np\n \n@@ -9,27 +12,22 @@\n \n \n class ImageDecoder(OpRun):\n- def _run( # type: ignore\n- self,\n- encoded,\n- pixel_format=\"RGB\",\n- ):\n+ def _run(self, encoded: np.ndarray, pixel_format=\"RGB\") -> tuple[np.ndarray]: # type: ignore\n try:\n- # pylint: disable=import-outside-toplevel`\n- import cv2\n+ import PIL.Image # pylint: disable=import-outside-toplevel\n except ImportError as e:\n raise ImportError(\n- \"opencv-python must be installed to use the reference implementation of the ImageDecoder operator\"\n+ \"Pillow must be installed to use the reference implementation of the ImageDecoder operator\"\n ) from e\n- decoded = None\n+ img = PIL.Image.open(io.BytesIO(encoded.tobytes()))\n if pixel_format == \"BGR\":\n- decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)\n+ decoded = np.array(img)[:, :, ::-1]\n elif pixel_format == \"RGB\":\n- decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)\n- decoded = cv2.cvtColor(decoded, cv2.COLOR_BGR2RGB)\n+ decoded = np.array(img)\n elif pixel_format == \"Grayscale\":\n- decoded = cv2.imdecode(encoded, cv2.IMREAD_GRAYSCALE)\n+ img = img.convert(\"L\")\n+ decoded = np.array(img)\n decoded = np.expand_dims(decoded, axis=2) # (H, W) to (H, W, 1)\n else:\n- raise RuntimeError(f\"pixel_format={pixel_format!r} is not supported.\")\n+ raise ValueError(f\"pixel_format={pixel_format!r} is not supported.\")\n return (decoded,)\n", "issue": "Use pillow to replace opencv in reference evaluator\nCaveat: https://github.com/python-pillow/Pillow/issues/6047#issuecomment-1038150443\r\n\r\ncc @jcwchen \n", "before_files": [{"content": "# Copyright (c) ONNX Project Contributors\n\n# SPDX-License-Identifier: Apache-2.0\n# pylint: disable=C0123,C3001,R0912,R0913,R0914,R1730,W0221,W0613\n\nimport numpy as np\n\nfrom onnx.reference.op_run import OpRun\n\n\nclass ImageDecoder(OpRun):\n def _run( # type: ignore\n self,\n encoded,\n pixel_format=\"RGB\",\n ):\n try:\n # pylint: disable=import-outside-toplevel`\n import cv2\n except ImportError as e:\n raise ImportError(\n \"opencv-python must be installed to use the reference implementation of the ImageDecoder operator\"\n ) from e\n decoded = None\n if pixel_format == \"BGR\":\n decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)\n elif pixel_format == \"RGB\":\n decoded = cv2.imdecode(encoded, cv2.IMREAD_COLOR)\n decoded = cv2.cvtColor(decoded, cv2.COLOR_BGR2RGB)\n elif pixel_format == \"Grayscale\":\n decoded = cv2.imdecode(encoded, cv2.IMREAD_GRAYSCALE)\n decoded = np.expand_dims(decoded, axis=2) # (H, W) to (H, W, 1)\n else:\n raise RuntimeError(f\"pixel_format={pixel_format!r} is not supported.\")\n return (decoded,)\n", "path": "onnx/reference/ops/op_image_decoder.py"}], "after_files": [{"content": "# Copyright (c) ONNX Project Contributors\n\n# SPDX-License-Identifier: Apache-2.0\n\nfrom __future__ import annotations\n\nimport io\n\nimport numpy as np\n\nfrom onnx.reference.op_run import OpRun\n\n\nclass ImageDecoder(OpRun):\n def _run(self, encoded: np.ndarray, pixel_format=\"RGB\") -> tuple[np.ndarray]: # type: ignore\n try:\n import PIL.Image # pylint: disable=import-outside-toplevel\n except ImportError as e:\n raise ImportError(\n \"Pillow must be installed to use the reference implementation of the ImageDecoder operator\"\n ) from e\n img = PIL.Image.open(io.BytesIO(encoded.tobytes()))\n if pixel_format == \"BGR\":\n decoded = np.array(img)[:, :, ::-1]\n elif pixel_format == \"RGB\":\n decoded = np.array(img)\n elif pixel_format == \"Grayscale\":\n img = img.convert(\"L\")\n decoded = np.array(img)\n decoded = np.expand_dims(decoded, axis=2) # (H, W) to (H, W, 1)\n else:\n raise ValueError(f\"pixel_format={pixel_format!r} is not supported.\")\n return (decoded,)\n", "path": "onnx/reference/ops/op_image_decoder.py"}]}
| 691 | 538 |
gh_patches_debug_7783
|
rasdani/github-patches
|
git_diff
|
conda__conda-build-249
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to build source.git_url based build recipes
See for an example: https://binstar.org/conda/conda-env/builds/2/3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_build/source.py`
Content:
```
1 from __future__ import absolute_import, division, print_function
2
3 import os
4 import sys
5 from os.path import join, isdir, isfile, abspath, expanduser
6 from shutil import copytree, ignore_patterns, copy2
7 from subprocess import check_call, Popen, PIPE
8
9 from conda.fetch import download
10 from conda.utils import hashsum_file
11
12 from conda_build import external
13 from conda_build.config import config
14 from conda_build.utils import rm_rf, tar_xf, unzip
15
16
17 SRC_CACHE = join(config.croot, 'src_cache')
18 GIT_CACHE = join(config.croot, 'git_cache')
19 HG_CACHE = join(config.croot, 'hg_cache')
20 SVN_CACHE = join(config.croot, 'svn_cache')
21 WORK_DIR = join(config.croot, 'work')
22
23
24 def get_dir():
25 if not isdir(WORK_DIR):
26 os.makedirs(WORK_DIR)
27 lst = [fn for fn in os.listdir(WORK_DIR) if not fn.startswith('.')]
28 if len(lst) == 1:
29 dir_path = join(WORK_DIR, lst[0])
30 if isdir(dir_path):
31 return dir_path
32 return WORK_DIR
33
34
35 def download_to_cache(meta):
36 ''' Download a source to the local cache. '''
37 print('Source cache directory is: %s' % SRC_CACHE)
38 if not isdir(SRC_CACHE):
39 os.makedirs(SRC_CACHE)
40
41 fn = meta['fn']
42 path = join(SRC_CACHE, fn)
43
44 if isfile(path):
45 print('Found source in cache: %s' % fn)
46 else:
47 print('Downloading source to cache: %s' % fn)
48 download(meta['url'], path)
49
50 for tp in 'md5', 'sha1', 'sha256':
51 if meta.get(tp) and hashsum_file(path, tp) != meta[tp]:
52 raise RuntimeError("%s mismatch: '%s' != '%s'" %
53 (tp.upper(), hashsum_file(path, tp), meta[tp]))
54
55 return path
56
57
58 def unpack(meta):
59 ''' Uncompress a downloaded source. '''
60 src_path = download_to_cache(meta)
61
62 os.makedirs(WORK_DIR)
63 print("Extracting download")
64 if src_path.lower().endswith(('.tar.gz', '.tar.bz2', '.tgz', '.tar.xz', '.tar')):
65 tar_xf(src_path, WORK_DIR)
66 elif src_path.lower().endswith('.zip'):
67 unzip(src_path, WORK_DIR)
68 else:
69 # In this case, the build script will need to deal with unpacking the source
70 print("Warning: Unrecognized source format. Source file will be copied to the SRC_DIR")
71 copy2(src_path, WORK_DIR)
72
73
74 def git_source(meta, recipe_dir):
75 ''' Download a source from Git repo. '''
76 if not isdir(GIT_CACHE):
77 os.makedirs(GIT_CACHE)
78
79 git = external.find_executable('git')
80 if not git:
81 sys.exit("Error: git is not installed")
82 git_url = meta['git_url']
83 if git_url.startswith('.'):
84 # It's a relative path from the conda recipe
85 os.chdir(recipe_dir)
86 git_dn = abspath(expanduser(git_url)).replace('/', '_')
87 else:
88 git_dn = git_url.split(':')[-1].replace('/', '_')
89 cache_repo = cache_repo_arg = join(GIT_CACHE, git_dn)
90 if sys.platform == 'win32':
91 cache_repo_arg = cache_repo_arg.replace('\\', '/')
92 if os.getenv('USERNAME') == 'builder':
93 cache_repo_arg = '/cygdrive/c/' + cache_repo_arg[3:]
94
95 # update (or create) the cache repo
96 if isdir(cache_repo):
97 check_call([git, 'fetch'], cwd=cache_repo)
98 else:
99 check_call([git, 'clone', '--mirror', git_url, cache_repo_arg], cwd=recipe_dir)
100 assert isdir(cache_repo)
101
102 # now clone into the work directory
103 checkout = meta.get('git_rev')
104 # if rev is not specified, and the git_url is local,
105 # assume the user wants the current HEAD
106 if not checkout and git_url.startswith('.'):
107 process = Popen(["git", "rev-parse", "HEAD"],
108 stdout=PIPE, stderr=PIPE,
109 cwd=git_url)
110 output = process.communicate()[0].strip()
111 checkout = output.decode('utf-8')
112 if checkout:
113 print('checkout: %r' % checkout)
114
115 check_call([git, 'clone', cache_repo_arg, WORK_DIR])
116 if checkout:
117 check_call([git, 'checkout', checkout], cwd=WORK_DIR)
118
119 git_info()
120 return WORK_DIR
121
122
123 def git_info(fo=None):
124 ''' Print info about a Git repo. '''
125 assert isdir(WORK_DIR)
126
127 # Ensure to explicitly set GIT_DIR as some Linux machines will not
128 # properly execute without it.
129 env = os.environ.copy()
130 env['GIT_DIR'] = join(WORK_DIR, '.git')
131 env = {str(key): str(value) for key, value in env.items()}
132 for cmd, check_error in [
133 ('git log -n1', True),
134 ('git describe --tags --dirty', False),
135 ('git status', True)]:
136 p = Popen(cmd.split(), stdout=PIPE, stderr=PIPE, cwd=WORK_DIR, env=env)
137 stdout, stderr = p.communicate()
138 stdout = stdout.decode('utf-8')
139 stderr = stderr.decode('utf-8')
140 if check_error and stderr and stderr.strip():
141 raise Exception("git error: %s" % stderr)
142 if fo:
143 fo.write(u'==> %s <==\n' % cmd)
144 fo.write(stdout + u'\n')
145 else:
146 print(u'==> %s <==\n' % cmd)
147 print(stdout + u'\n')
148
149
150 def hg_source(meta):
151 ''' Download a source from Mercurial repo. '''
152 hg = external.find_executable('hg')
153 if not hg:
154 sys.exit('Error: hg not installed')
155 hg_url = meta['hg_url']
156 if not isdir(HG_CACHE):
157 os.makedirs(HG_CACHE)
158 hg_dn = hg_url.split(':')[-1].replace('/', '_')
159 cache_repo = join(HG_CACHE, hg_dn)
160 if isdir(cache_repo):
161 check_call([hg, 'pull'], cwd=cache_repo)
162 else:
163 check_call([hg, 'clone', hg_url, cache_repo])
164 assert isdir(cache_repo)
165
166 # now clone in to work directory
167 update = meta.get('hg_tag') or 'tip'
168 print('checkout: %r' % update)
169
170 check_call([hg, 'clone', cache_repo, WORK_DIR])
171 check_call([hg, 'update', '-C', update], cwd=WORK_DIR)
172 return WORK_DIR
173
174
175
176 def svn_source(meta):
177 ''' Download a source from SVN repo. '''
178 def parse_bool(s):
179 return str(s).lower().strip() in ('yes', 'true', '1', 'on')
180
181 svn = external.find_executable('svn')
182 if not svn:
183 sys.exit("Error: svn is not installed")
184 svn_url = meta['svn_url']
185 svn_revision = meta.get('svn_rev') or 'head'
186 svn_ignore_externals = parse_bool(meta.get('svn_ignore_externals') or 'no')
187 if not isdir(SVN_CACHE):
188 os.makedirs(SVN_CACHE)
189 svn_dn = svn_url.split(':', 1)[-1].replace('/', '_').replace(':', '_')
190 cache_repo = join(SVN_CACHE, svn_dn)
191 if svn_ignore_externals:
192 extra_args = ['--ignore-externals']
193 else:
194 extra_args = []
195 if isdir(cache_repo):
196 check_call([svn, 'up', '-r', svn_revision] + extra_args, cwd=cache_repo)
197 else:
198 check_call([svn, 'co', '-r', svn_revision] + extra_args + [svn_url,
199 cache_repo])
200 assert isdir(cache_repo)
201
202 # now copy into work directory
203 copytree(cache_repo, WORK_DIR)
204 return WORK_DIR
205
206
207 def apply_patch(src_dir, path):
208 print('Applying patch: %r' % path)
209 if not isfile(path):
210 sys.exit('Error: no such patch: %s' % path)
211
212 patch = external.find_executable('patch')
213 if patch is None:
214 sys.exit("""\
215 Error:
216 Did not find 'patch' in: %s
217 You can install 'patch' using apt-get, yum (Linux), Xcode (MacOSX),
218 or conda, cygwin (Windows),
219 """ % (os.pathsep.join(external.dir_paths)))
220 check_call([patch, '-p0', '-i', path], cwd=src_dir)
221
222
223 def provide(recipe_dir, meta, patch=True):
224 """
225 given a recipe_dir:
226 - download (if necessary)
227 - unpack
228 - apply patches (if any)
229 """
230 print("Removing old work directory")
231 rm_rf(WORK_DIR)
232 if 'fn' in meta:
233 unpack(meta)
234 elif 'git_url' in meta:
235 git_source(meta, recipe_dir)
236 elif 'hg_url' in meta:
237 hg_source(meta)
238 elif 'svn_url' in meta:
239 svn_source(meta)
240 elif 'path' in meta:
241 print("Copying %s to %s" % (abspath(join(recipe_dir, meta.get('path'))), WORK_DIR))
242 copytree(abspath(join(recipe_dir, meta.get('path'))), WORK_DIR)
243 else: # no source
244 os.makedirs(WORK_DIR)
245
246 if patch:
247 src_dir = get_dir()
248 for patch in meta.get('patches', []):
249 apply_patch(src_dir, join(recipe_dir, patch))
250
251
252 if __name__ == '__main__':
253 print(provide('.',
254 {'url': 'http://pypi.python.org/packages/source/b/bitarray/bitarray-0.8.0.tar.gz',
255 'git_url': '[email protected]:ilanschnell/bitarray.git',
256 'git_tag': '0.5.2'}))
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_build/source.py b/conda_build/source.py
--- a/conda_build/source.py
+++ b/conda_build/source.py
@@ -83,7 +83,8 @@
if git_url.startswith('.'):
# It's a relative path from the conda recipe
os.chdir(recipe_dir)
- git_dn = abspath(expanduser(git_url)).replace('/', '_')
+ git_dn = abspath(expanduser(git_url))
+ git_dn = "_".join(git_dn.split(os.path.sep)[1:])
else:
git_dn = git_url.split(':')[-1].replace('/', '_')
cache_repo = cache_repo_arg = join(GIT_CACHE, git_dn)
|
{"golden_diff": "diff --git a/conda_build/source.py b/conda_build/source.py\n--- a/conda_build/source.py\n+++ b/conda_build/source.py\n@@ -83,7 +83,8 @@\n if git_url.startswith('.'):\n # It's a relative path from the conda recipe\n os.chdir(recipe_dir)\n- git_dn = abspath(expanduser(git_url)).replace('/', '_')\n+ git_dn = abspath(expanduser(git_url))\n+ git_dn = \"_\".join(git_dn.split(os.path.sep)[1:])\n else:\n git_dn = git_url.split(':')[-1].replace('/', '_')\n cache_repo = cache_repo_arg = join(GIT_CACHE, git_dn)\n", "issue": "Unable to build source.git_url based build recipes\nSee for an example: https://binstar.org/conda/conda-env/builds/2/3\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport os\nimport sys\nfrom os.path import join, isdir, isfile, abspath, expanduser\nfrom shutil import copytree, ignore_patterns, copy2\nfrom subprocess import check_call, Popen, PIPE\n\nfrom conda.fetch import download\nfrom conda.utils import hashsum_file\n\nfrom conda_build import external\nfrom conda_build.config import config\nfrom conda_build.utils import rm_rf, tar_xf, unzip\n\n\nSRC_CACHE = join(config.croot, 'src_cache')\nGIT_CACHE = join(config.croot, 'git_cache')\nHG_CACHE = join(config.croot, 'hg_cache')\nSVN_CACHE = join(config.croot, 'svn_cache')\nWORK_DIR = join(config.croot, 'work')\n\n\ndef get_dir():\n if not isdir(WORK_DIR):\n os.makedirs(WORK_DIR)\n lst = [fn for fn in os.listdir(WORK_DIR) if not fn.startswith('.')]\n if len(lst) == 1:\n dir_path = join(WORK_DIR, lst[0])\n if isdir(dir_path):\n return dir_path\n return WORK_DIR\n\n\ndef download_to_cache(meta):\n ''' Download a source to the local cache. '''\n print('Source cache directory is: %s' % SRC_CACHE)\n if not isdir(SRC_CACHE):\n os.makedirs(SRC_CACHE)\n\n fn = meta['fn']\n path = join(SRC_CACHE, fn)\n\n if isfile(path):\n print('Found source in cache: %s' % fn)\n else:\n print('Downloading source to cache: %s' % fn)\n download(meta['url'], path)\n\n for tp in 'md5', 'sha1', 'sha256':\n if meta.get(tp) and hashsum_file(path, tp) != meta[tp]:\n raise RuntimeError(\"%s mismatch: '%s' != '%s'\" %\n (tp.upper(), hashsum_file(path, tp), meta[tp]))\n\n return path\n\n\ndef unpack(meta):\n ''' Uncompress a downloaded source. '''\n src_path = download_to_cache(meta)\n\n os.makedirs(WORK_DIR)\n print(\"Extracting download\")\n if src_path.lower().endswith(('.tar.gz', '.tar.bz2', '.tgz', '.tar.xz', '.tar')):\n tar_xf(src_path, WORK_DIR)\n elif src_path.lower().endswith('.zip'):\n unzip(src_path, WORK_DIR)\n else:\n # In this case, the build script will need to deal with unpacking the source\n print(\"Warning: Unrecognized source format. Source file will be copied to the SRC_DIR\")\n copy2(src_path, WORK_DIR)\n\n\ndef git_source(meta, recipe_dir):\n ''' Download a source from Git repo. '''\n if not isdir(GIT_CACHE):\n os.makedirs(GIT_CACHE)\n\n git = external.find_executable('git')\n if not git:\n sys.exit(\"Error: git is not installed\")\n git_url = meta['git_url']\n if git_url.startswith('.'):\n # It's a relative path from the conda recipe\n os.chdir(recipe_dir)\n git_dn = abspath(expanduser(git_url)).replace('/', '_')\n else:\n git_dn = git_url.split(':')[-1].replace('/', '_')\n cache_repo = cache_repo_arg = join(GIT_CACHE, git_dn)\n if sys.platform == 'win32':\n cache_repo_arg = cache_repo_arg.replace('\\\\', '/')\n if os.getenv('USERNAME') == 'builder':\n cache_repo_arg = '/cygdrive/c/' + cache_repo_arg[3:]\n\n # update (or create) the cache repo\n if isdir(cache_repo):\n check_call([git, 'fetch'], cwd=cache_repo)\n else:\n check_call([git, 'clone', '--mirror', git_url, cache_repo_arg], cwd=recipe_dir)\n assert isdir(cache_repo)\n\n # now clone into the work directory\n checkout = meta.get('git_rev')\n # if rev is not specified, and the git_url is local,\n # assume the user wants the current HEAD\n if not checkout and git_url.startswith('.'):\n process = Popen([\"git\", \"rev-parse\", \"HEAD\"],\n stdout=PIPE, stderr=PIPE,\n cwd=git_url)\n output = process.communicate()[0].strip()\n checkout = output.decode('utf-8')\n if checkout:\n print('checkout: %r' % checkout)\n\n check_call([git, 'clone', cache_repo_arg, WORK_DIR])\n if checkout:\n check_call([git, 'checkout', checkout], cwd=WORK_DIR)\n\n git_info()\n return WORK_DIR\n\n\ndef git_info(fo=None):\n ''' Print info about a Git repo. '''\n assert isdir(WORK_DIR)\n\n # Ensure to explicitly set GIT_DIR as some Linux machines will not\n # properly execute without it.\n env = os.environ.copy()\n env['GIT_DIR'] = join(WORK_DIR, '.git')\n env = {str(key): str(value) for key, value in env.items()}\n for cmd, check_error in [\n ('git log -n1', True),\n ('git describe --tags --dirty', False),\n ('git status', True)]:\n p = Popen(cmd.split(), stdout=PIPE, stderr=PIPE, cwd=WORK_DIR, env=env)\n stdout, stderr = p.communicate()\n stdout = stdout.decode('utf-8')\n stderr = stderr.decode('utf-8')\n if check_error and stderr and stderr.strip():\n raise Exception(\"git error: %s\" % stderr)\n if fo:\n fo.write(u'==> %s <==\\n' % cmd)\n fo.write(stdout + u'\\n')\n else:\n print(u'==> %s <==\\n' % cmd)\n print(stdout + u'\\n')\n\n\ndef hg_source(meta):\n ''' Download a source from Mercurial repo. '''\n hg = external.find_executable('hg')\n if not hg:\n sys.exit('Error: hg not installed')\n hg_url = meta['hg_url']\n if not isdir(HG_CACHE):\n os.makedirs(HG_CACHE)\n hg_dn = hg_url.split(':')[-1].replace('/', '_')\n cache_repo = join(HG_CACHE, hg_dn)\n if isdir(cache_repo):\n check_call([hg, 'pull'], cwd=cache_repo)\n else:\n check_call([hg, 'clone', hg_url, cache_repo])\n assert isdir(cache_repo)\n\n # now clone in to work directory\n update = meta.get('hg_tag') or 'tip'\n print('checkout: %r' % update)\n\n check_call([hg, 'clone', cache_repo, WORK_DIR])\n check_call([hg, 'update', '-C', update], cwd=WORK_DIR)\n return WORK_DIR\n\n\n\ndef svn_source(meta):\n ''' Download a source from SVN repo. '''\n def parse_bool(s):\n return str(s).lower().strip() in ('yes', 'true', '1', 'on')\n\n svn = external.find_executable('svn')\n if not svn:\n sys.exit(\"Error: svn is not installed\")\n svn_url = meta['svn_url']\n svn_revision = meta.get('svn_rev') or 'head'\n svn_ignore_externals = parse_bool(meta.get('svn_ignore_externals') or 'no')\n if not isdir(SVN_CACHE):\n os.makedirs(SVN_CACHE)\n svn_dn = svn_url.split(':', 1)[-1].replace('/', '_').replace(':', '_')\n cache_repo = join(SVN_CACHE, svn_dn)\n if svn_ignore_externals:\n extra_args = ['--ignore-externals']\n else:\n extra_args = []\n if isdir(cache_repo):\n check_call([svn, 'up', '-r', svn_revision] + extra_args, cwd=cache_repo)\n else:\n check_call([svn, 'co', '-r', svn_revision] + extra_args + [svn_url,\n cache_repo])\n assert isdir(cache_repo)\n\n # now copy into work directory\n copytree(cache_repo, WORK_DIR)\n return WORK_DIR\n\n\ndef apply_patch(src_dir, path):\n print('Applying patch: %r' % path)\n if not isfile(path):\n sys.exit('Error: no such patch: %s' % path)\n\n patch = external.find_executable('patch')\n if patch is None:\n sys.exit(\"\"\"\\\nError:\n Did not find 'patch' in: %s\n You can install 'patch' using apt-get, yum (Linux), Xcode (MacOSX),\n or conda, cygwin (Windows),\n\"\"\" % (os.pathsep.join(external.dir_paths)))\n check_call([patch, '-p0', '-i', path], cwd=src_dir)\n\n\ndef provide(recipe_dir, meta, patch=True):\n \"\"\"\n given a recipe_dir:\n - download (if necessary)\n - unpack\n - apply patches (if any)\n \"\"\"\n print(\"Removing old work directory\")\n rm_rf(WORK_DIR)\n if 'fn' in meta:\n unpack(meta)\n elif 'git_url' in meta:\n git_source(meta, recipe_dir)\n elif 'hg_url' in meta:\n hg_source(meta)\n elif 'svn_url' in meta:\n svn_source(meta)\n elif 'path' in meta:\n print(\"Copying %s to %s\" % (abspath(join(recipe_dir, meta.get('path'))), WORK_DIR))\n copytree(abspath(join(recipe_dir, meta.get('path'))), WORK_DIR)\n else: # no source\n os.makedirs(WORK_DIR)\n\n if patch:\n src_dir = get_dir()\n for patch in meta.get('patches', []):\n apply_patch(src_dir, join(recipe_dir, patch))\n\n\nif __name__ == '__main__':\n print(provide('.',\n {'url': 'http://pypi.python.org/packages/source/b/bitarray/bitarray-0.8.0.tar.gz',\n 'git_url': '[email protected]:ilanschnell/bitarray.git',\n 'git_tag': '0.5.2'}))\n", "path": "conda_build/source.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport os\nimport sys\nfrom os.path import join, isdir, isfile, abspath, expanduser\nfrom shutil import copytree, ignore_patterns, copy2\nfrom subprocess import check_call, Popen, PIPE\n\nfrom conda.fetch import download\nfrom conda.utils import hashsum_file\n\nfrom conda_build import external\nfrom conda_build.config import config\nfrom conda_build.utils import rm_rf, tar_xf, unzip\n\n\nSRC_CACHE = join(config.croot, 'src_cache')\nGIT_CACHE = join(config.croot, 'git_cache')\nHG_CACHE = join(config.croot, 'hg_cache')\nSVN_CACHE = join(config.croot, 'svn_cache')\nWORK_DIR = join(config.croot, 'work')\n\n\ndef get_dir():\n if not isdir(WORK_DIR):\n os.makedirs(WORK_DIR)\n lst = [fn for fn in os.listdir(WORK_DIR) if not fn.startswith('.')]\n if len(lst) == 1:\n dir_path = join(WORK_DIR, lst[0])\n if isdir(dir_path):\n return dir_path\n return WORK_DIR\n\n\ndef download_to_cache(meta):\n ''' Download a source to the local cache. '''\n print('Source cache directory is: %s' % SRC_CACHE)\n if not isdir(SRC_CACHE):\n os.makedirs(SRC_CACHE)\n\n fn = meta['fn']\n path = join(SRC_CACHE, fn)\n\n if isfile(path):\n print('Found source in cache: %s' % fn)\n else:\n print('Downloading source to cache: %s' % fn)\n download(meta['url'], path)\n\n for tp in 'md5', 'sha1', 'sha256':\n if meta.get(tp) and hashsum_file(path, tp) != meta[tp]:\n raise RuntimeError(\"%s mismatch: '%s' != '%s'\" %\n (tp.upper(), hashsum_file(path, tp), meta[tp]))\n\n return path\n\n\ndef unpack(meta):\n ''' Uncompress a downloaded source. '''\n src_path = download_to_cache(meta)\n\n os.makedirs(WORK_DIR)\n print(\"Extracting download\")\n if src_path.lower().endswith(('.tar.gz', '.tar.bz2', '.tgz', '.tar.xz', '.tar')):\n tar_xf(src_path, WORK_DIR)\n elif src_path.lower().endswith('.zip'):\n unzip(src_path, WORK_DIR)\n else:\n # In this case, the build script will need to deal with unpacking the source\n print(\"Warning: Unrecognized source format. Source file will be copied to the SRC_DIR\")\n copy2(src_path, WORK_DIR)\n\n\ndef git_source(meta, recipe_dir):\n ''' Download a source from Git repo. '''\n if not isdir(GIT_CACHE):\n os.makedirs(GIT_CACHE)\n\n git = external.find_executable('git')\n if not git:\n sys.exit(\"Error: git is not installed\")\n git_url = meta['git_url']\n if git_url.startswith('.'):\n # It's a relative path from the conda recipe\n os.chdir(recipe_dir)\n git_dn = abspath(expanduser(git_url))\n git_dn = \"_\".join(git_dn.split(os.path.sep)[1:])\n else:\n git_dn = git_url.split(':')[-1].replace('/', '_')\n cache_repo = cache_repo_arg = join(GIT_CACHE, git_dn)\n if sys.platform == 'win32':\n cache_repo_arg = cache_repo_arg.replace('\\\\', '/')\n if os.getenv('USERNAME') == 'builder':\n cache_repo_arg = '/cygdrive/c/' + cache_repo_arg[3:]\n\n # update (or create) the cache repo\n if isdir(cache_repo):\n check_call([git, 'fetch'], cwd=cache_repo)\n else:\n check_call([git, 'clone', '--mirror', git_url, cache_repo_arg], cwd=recipe_dir)\n assert isdir(cache_repo)\n\n # now clone into the work directory\n checkout = meta.get('git_rev')\n # if rev is not specified, and the git_url is local,\n # assume the user wants the current HEAD\n if not checkout and git_url.startswith('.'):\n process = Popen([\"git\", \"rev-parse\", \"HEAD\"],\n stdout=PIPE, stderr=PIPE,\n cwd=git_url)\n output = process.communicate()[0].strip()\n checkout = output.decode('utf-8')\n if checkout:\n print('checkout: %r' % checkout)\n\n check_call([git, 'clone', cache_repo_arg, WORK_DIR])\n if checkout:\n check_call([git, 'checkout', checkout], cwd=WORK_DIR)\n\n git_info()\n return WORK_DIR\n\n\ndef git_info(fo=None):\n ''' Print info about a Git repo. '''\n assert isdir(WORK_DIR)\n\n # Ensure to explicitly set GIT_DIR as some Linux machines will not\n # properly execute without it.\n env = os.environ.copy()\n env['GIT_DIR'] = join(WORK_DIR, '.git')\n env = {str(key): str(value) for key, value in env.items()}\n for cmd, check_error in [\n ('git log -n1', True),\n ('git describe --tags --dirty', False),\n ('git status', True)]:\n p = Popen(cmd.split(), stdout=PIPE, stderr=PIPE, cwd=WORK_DIR, env=env)\n stdout, stderr = p.communicate()\n stdout = stdout.decode('utf-8')\n stderr = stderr.decode('utf-8')\n if check_error and stderr and stderr.strip():\n raise Exception(\"git error: %s\" % stderr)\n if fo:\n fo.write(u'==> %s <==\\n' % cmd)\n fo.write(stdout + u'\\n')\n else:\n print(u'==> %s <==\\n' % cmd)\n print(stdout + u'\\n')\n\n\ndef hg_source(meta):\n ''' Download a source from Mercurial repo. '''\n hg = external.find_executable('hg')\n if not hg:\n sys.exit('Error: hg not installed')\n hg_url = meta['hg_url']\n if not isdir(HG_CACHE):\n os.makedirs(HG_CACHE)\n hg_dn = hg_url.split(':')[-1].replace('/', '_')\n cache_repo = join(HG_CACHE, hg_dn)\n if isdir(cache_repo):\n check_call([hg, 'pull'], cwd=cache_repo)\n else:\n check_call([hg, 'clone', hg_url, cache_repo])\n assert isdir(cache_repo)\n\n # now clone in to work directory\n update = meta.get('hg_tag') or 'tip'\n print('checkout: %r' % update)\n\n check_call([hg, 'clone', cache_repo, WORK_DIR])\n check_call([hg, 'update', '-C', update], cwd=WORK_DIR)\n return WORK_DIR\n\n\n\ndef svn_source(meta):\n ''' Download a source from SVN repo. '''\n def parse_bool(s):\n return str(s).lower().strip() in ('yes', 'true', '1', 'on')\n\n svn = external.find_executable('svn')\n if not svn:\n sys.exit(\"Error: svn is not installed\")\n svn_url = meta['svn_url']\n svn_revision = meta.get('svn_rev') or 'head'\n svn_ignore_externals = parse_bool(meta.get('svn_ignore_externals') or 'no')\n if not isdir(SVN_CACHE):\n os.makedirs(SVN_CACHE)\n svn_dn = svn_url.split(':', 1)[-1].replace('/', '_').replace(':', '_')\n cache_repo = join(SVN_CACHE, svn_dn)\n if svn_ignore_externals:\n extra_args = ['--ignore-externals']\n else:\n extra_args = []\n if isdir(cache_repo):\n check_call([svn, 'up', '-r', svn_revision] + extra_args, cwd=cache_repo)\n else:\n check_call([svn, 'co', '-r', svn_revision] + extra_args + [svn_url,\n cache_repo])\n assert isdir(cache_repo)\n\n # now copy into work directory\n copytree(cache_repo, WORK_DIR)\n return WORK_DIR\n\n\ndef apply_patch(src_dir, path):\n print('Applying patch: %r' % path)\n if not isfile(path):\n sys.exit('Error: no such patch: %s' % path)\n\n patch = external.find_executable('patch')\n if patch is None:\n sys.exit(\"\"\"\\\nError:\n Did not find 'patch' in: %s\n You can install 'patch' using apt-get, yum (Linux), Xcode (MacOSX),\n or conda, cygwin (Windows),\n\"\"\" % (os.pathsep.join(external.dir_paths)))\n check_call([patch, '-p0', '-i', path], cwd=src_dir)\n\n\ndef provide(recipe_dir, meta, patch=True):\n \"\"\"\n given a recipe_dir:\n - download (if necessary)\n - unpack\n - apply patches (if any)\n \"\"\"\n print(\"Removing old work directory\")\n rm_rf(WORK_DIR)\n if 'fn' in meta:\n unpack(meta)\n elif 'git_url' in meta:\n git_source(meta, recipe_dir)\n elif 'hg_url' in meta:\n hg_source(meta)\n elif 'svn_url' in meta:\n svn_source(meta)\n elif 'path' in meta:\n print(\"Copying %s to %s\" % (abspath(join(recipe_dir, meta.get('path'))), WORK_DIR))\n copytree(abspath(join(recipe_dir, meta.get('path'))), WORK_DIR)\n else: # no source\n os.makedirs(WORK_DIR)\n\n if patch:\n src_dir = get_dir()\n for patch in meta.get('patches', []):\n apply_patch(src_dir, join(recipe_dir, patch))\n\n\nif __name__ == '__main__':\n print(provide('.',\n {'url': 'http://pypi.python.org/packages/source/b/bitarray/bitarray-0.8.0.tar.gz',\n 'git_url': '[email protected]:ilanschnell/bitarray.git',\n 'git_tag': '0.5.2'}))\n", "path": "conda_build/source.py"}]}
| 3,175 | 155 |
gh_patches_debug_3465
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-5208
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] ColumnSelect missing tag`"skip-inverse-transform"`
**Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
The ColumnSelect is missing the tag `"skip-inverse-transform"`. Thus, a TransformedTargetForecaster subsetting the `y` input will fail when calling predict.
**To Reproduce**
<!--
Add a Minimal, Complete, and Verifiable example (for more details, see e.g. https://stackoverflow.com/help/mcve
If the code is too long, feel free to put it in a public gist and link it in the issue: https://gist.github.com
-->
```python
from sktime.forecasting.naive import NaiveForecaster
from sktime.transformations.series.subset import ColumnSelect
from sktime.datasets import load_longley
y = load_longley()[1][["GNP", "UNEMP"]]
fc = ColumnSelect(["GNP"]) * NaiveForecaster()
fc.fit(y)
fc.predict(fh=[1])
```
**Expected behavior**
<!--
A clear and concise description of what you expected to happen.
-->
I would expect that the forecast is performed only on the selected time series without raising an error.
**Additional context**
<!--
Add any other context about the problem here.
-->
This would be fixed by just adding the tag `skip-inverse-transform` to ColumnSelect.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sktime/transformations/series/subset.py`
Content:
```
1 """Transformers for index and column subsetting."""
2 # copyright: sktime developers, BSD-3-Clause License (see LICENSE file).
3
4 __author__ = ["fkiraly"]
5
6 import pandas as pd
7
8 from sktime.transformations.base import BaseTransformer
9
10
11 class IndexSubset(BaseTransformer):
12 r"""Index subsetting transformer.
13
14 In transform, subsets `X` to the indices in `y.index`.
15 If `y` is None, returns `X` without subsetting.
16 numpy-based `X` are interpreted as having a RangeIndex starting at n,
17 where n is the number of numpy rows seen so far through `fit` and `update`.
18 Non-pandas types are interpreted as having index as after conversion to pandas,
19 via `datatypes.convert_to`, to the `"pd.DataFrame"` sktime type.
20
21 Parameters
22 ----------
23 index_treatment : str, optional, one of "keep" (default) or "remove"
24 determines which indices are kept in `Xt = transform(X, y)`
25 "keep" = all indices in y also appear in Xt. If not present in X, NA is filled.
26 "remove" = only indices that appear in both X and y are present in Xt.
27
28 Examples
29 --------
30 >>> from sktime.transformations.series.subset import IndexSubset
31 >>> from sktime.datasets import load_airline
32 >>> X = load_airline()[0:32]
33 >>> y = load_airline()[24:42]
34 >>> transformer = IndexSubset()
35 >>> X_subset = transformer.fit_transform(X=X, y=y)
36 """
37
38 _tags = {
39 "scitype:transform-input": "Series",
40 # what is the scitype of X: Series, or Panel
41 "scitype:transform-output": "Series",
42 # what scitype is returned: Primitives, Series, Panel
43 "scitype:instancewise": True, # is this an instance-wise transform?
44 "X_inner_mtype": ["pd.DataFrame", "pd.Series"],
45 "y_inner_mtype": ["pd.DataFrame", "pd.Series"],
46 "transform-returns-same-time-index": False,
47 "fit_is_empty": False,
48 "univariate-only": False,
49 "capability:inverse_transform": False,
50 "remember_data": True, # remember all data seen as _X
51 }
52
53 def __init__(self, index_treatment="keep"):
54 self.index_treatment = index_treatment
55 super().__init__()
56
57 def _transform(self, X, y=None):
58 """Transform X and return a transformed version.
59
60 private _transform containing the core logic, called from transform
61
62 Parameters
63 ----------
64 X : pd.DataFrame or pd.Series
65 Data to be transformed
66 y : pd.DataFrame or pd.Series
67 Additional data, e.g., labels for transformation
68
69 Returns
70 -------
71 Xt : pd.DataFrame or pd.Series, same type as X
72 transformed version of X
73 """
74 if y is None:
75 return X
76
77 X = self._X
78
79 index_treatment = self.index_treatment
80 ind_X_and_y = X.index.intersection(y.index)
81
82 if index_treatment == "remove":
83 Xt = X.loc[ind_X_and_y]
84 elif index_treatment == "keep":
85 Xt = X.loc[ind_X_and_y]
86 y_idx_frame = type(X)(index=y.index, dtype="float64")
87 Xt = Xt.combine_first(y_idx_frame)
88 else:
89 raise ValueError(
90 f'index_treatment must be one of "remove", "keep", but found'
91 f' "{index_treatment}"'
92 )
93 return Xt
94
95 @classmethod
96 def get_test_params(cls, parameter_set="default"):
97 """Return testing parameter settings for the estimator.
98
99 Parameters
100 ----------
101 parameter_set : str, default="default"
102 Name of the set of test parameters to return, for use in tests. If no
103 special parameters are defined for a value, will return `"default"` set.
104 There are currently no reserved values for transformers.
105
106 Returns
107 -------
108 params : dict or list of dict, default = {}
109 Parameters to create testing instances of the class
110 Each dict are parameters to construct an "interesting" test instance, i.e.,
111 `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.
112 `create_test_instance` uses the first (or only) dictionary in `params`
113 """
114 params1 = {"index_treatment": "remove"}
115 params2 = {"index_treatment": "keep"}
116
117 return [params1, params2]
118
119
120 class ColumnSelect(BaseTransformer):
121 r"""Column selection transformer.
122
123 In transform, subsets `X` to `columns` provided as hyper-parameters.
124
125 Sequence of columns in `Xt=transform(X)` is as in `columns` hyper-parameter.
126 Caveat: this means that `transform` may change sequence of columns,
127 even if no columns are removed from `X` in `transform(X)`.
128
129 Parameters
130 ----------
131 columns : pandas compatible index or index coercible, optional, default = None
132 columns to which X in transform is to be subset
133 integer_treatment : str, optional, one of "col" (default) and "coerce"
134 determines how integer index columns are treated
135 "col" = subsets by column iloc index, even if columns is not in X.columns
136 "coerce" = coerces to integer pandas.Index and attempts to subset
137 index_treatment : str, optional, one of "remove" (default) or "keep"
138 determines which column are kept in `Xt = transform(X, y)`
139 "remove" = only indices that appear in both X and columns are present in Xt.
140 "keep" = all indices in columns appear in Xt. If not present in X, NA is filled.
141
142 Examples
143 --------
144 >>> from sktime.transformations.series.subset import ColumnSelect
145 >>> from sktime.datasets import load_longley
146 >>> X = load_longley()[1]
147 >>> transformer = ColumnSelect(columns=["GNPDEFL", "POP", "FOO"])
148 >>> X_subset = transformer.fit_transform(X=X)
149 """
150
151 _tags = {
152 "scitype:transform-input": "Series",
153 # what is the scitype of X: Series, or Panel
154 "scitype:transform-output": "Series",
155 # what scitype is returned: Primitives, Series, Panel
156 "scitype:instancewise": True, # is this an instance-wise transform?
157 "X_inner_mtype": ["pd.DataFrame", "pd-multiindex", "pd_multiindex_hier"],
158 "y_inner_mtype": "None",
159 "transform-returns-same-time-index": True,
160 "fit_is_empty": True,
161 "univariate-only": False,
162 "capability:inverse_transform": False,
163 }
164
165 def __init__(self, columns=None, integer_treatment="col", index_treatment="remove"):
166 self.columns = columns
167 self.integer_treatment = integer_treatment
168 self.index_treatment = index_treatment
169 super().__init__()
170
171 def _transform(self, X, y=None):
172 """Transform X and return a transformed version.
173
174 private _transform containing the core logic, called from transform
175
176 Parameters
177 ----------
178 X : pd.DataFrame
179 Data to be transformed
180 y : Ignored argument for interface compatibility
181
182 Returns
183 -------
184 Xt : pd.DataFrame
185 transformed version of X
186 """
187 columns = self.columns
188 integer_treatment = self.integer_treatment
189 index_treatment = self.index_treatment
190
191 if columns is None:
192 return X
193 if pd.api.types.is_scalar(columns):
194 columns = [columns]
195
196 columns = pd.Index(columns)
197
198 if integer_treatment == "col" and pd.api.types.is_integer_dtype(columns):
199 columns = [x for x in columns if x < len(X.columns)]
200 col_idx = X.columns[columns]
201 return X[col_idx]
202
203 in_cols = columns.isin(X.columns)
204 col_X_and_cols = columns[in_cols]
205
206 if index_treatment == "remove":
207 Xt = X[col_X_and_cols]
208 elif index_treatment == "keep":
209 Xt = X.reindex(columns=columns)
210 else:
211 raise ValueError(
212 f'index_treatment must be one of "remove", "keep", but found'
213 f' "{index_treatment}"'
214 )
215 return Xt
216
217 @classmethod
218 def get_test_params(cls, parameter_set="default"):
219 """Return testing parameter settings for the estimator.
220
221 Parameters
222 ----------
223 parameter_set : str, default="default"
224 Name of the set of test parameters to return, for use in tests. If no
225 special parameters are defined for a value, will return `"default"` set.
226 There are currently no reserved values for transformers.
227
228 Returns
229 -------
230 params : dict or list of dict, default = {}
231 Parameters to create testing instances of the class
232 Each dict are parameters to construct an "interesting" test instance, i.e.,
233 `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.
234 `create_test_instance` uses the first (or only) dictionary in `params`
235 """
236 params1 = {"columns": None}
237 params2 = {"columns": [0, 2, 3]}
238 params3 = {"columns": ["a", "foo", "bar"], "index_treatment": "keep"}
239 params4 = {"columns": "a", "index_treatment": "keep"}
240
241 return [params1, params2, params3, params4]
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sktime/transformations/series/subset.py b/sktime/transformations/series/subset.py
--- a/sktime/transformations/series/subset.py
+++ b/sktime/transformations/series/subset.py
@@ -160,6 +160,7 @@
"fit_is_empty": True,
"univariate-only": False,
"capability:inverse_transform": False,
+ "skip-inverse-transform": True,
}
def __init__(self, columns=None, integer_treatment="col", index_treatment="remove"):
|
{"golden_diff": "diff --git a/sktime/transformations/series/subset.py b/sktime/transformations/series/subset.py\n--- a/sktime/transformations/series/subset.py\n+++ b/sktime/transformations/series/subset.py\n@@ -160,6 +160,7 @@\n \"fit_is_empty\": True,\n \"univariate-only\": False,\n \"capability:inverse_transform\": False,\n+ \"skip-inverse-transform\": True,\n }\n \n def __init__(self, columns=None, integer_treatment=\"col\", index_treatment=\"remove\"):\n", "issue": "[BUG] ColumnSelect missing tag`\"skip-inverse-transform\"`\n**Describe the bug**\r\n<!--\r\nA clear and concise description of what the bug is.\r\n-->\r\nThe ColumnSelect is missing the tag `\"skip-inverse-transform\"`. Thus, a TransformedTargetForecaster subsetting the `y` input will fail when calling predict.\r\n\r\n**To Reproduce**\r\n<!--\r\nAdd a Minimal, Complete, and Verifiable example (for more details, see e.g. https://stackoverflow.com/help/mcve\r\n\r\nIf the code is too long, feel free to put it in a public gist and link it in the issue: https://gist.github.com\r\n-->\r\n\r\n\r\n\r\n```python\r\nfrom sktime.forecasting.naive import NaiveForecaster\r\nfrom sktime.transformations.series.subset import ColumnSelect\r\nfrom sktime.datasets import load_longley\r\ny = load_longley()[1][[\"GNP\", \"UNEMP\"]]\r\nfc = ColumnSelect([\"GNP\"]) * NaiveForecaster()\r\nfc.fit(y)\r\nfc.predict(fh=[1])\r\n```\r\n\r\n**Expected behavior**\r\n<!--\r\nA clear and concise description of what you expected to happen.\r\n-->\r\nI would expect that the forecast is performed only on the selected time series without raising an error.\r\n\r\n**Additional context**\r\n<!--\r\nAdd any other context about the problem here.\r\n-->\r\nThis would be fixed by just adding the tag `skip-inverse-transform` to ColumnSelect.\r\n\n", "before_files": [{"content": "\"\"\"Transformers for index and column subsetting.\"\"\"\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file).\n\n__author__ = [\"fkiraly\"]\n\nimport pandas as pd\n\nfrom sktime.transformations.base import BaseTransformer\n\n\nclass IndexSubset(BaseTransformer):\n r\"\"\"Index subsetting transformer.\n\n In transform, subsets `X` to the indices in `y.index`.\n If `y` is None, returns `X` without subsetting.\n numpy-based `X` are interpreted as having a RangeIndex starting at n,\n where n is the number of numpy rows seen so far through `fit` and `update`.\n Non-pandas types are interpreted as having index as after conversion to pandas,\n via `datatypes.convert_to`, to the `\"pd.DataFrame\"` sktime type.\n\n Parameters\n ----------\n index_treatment : str, optional, one of \"keep\" (default) or \"remove\"\n determines which indices are kept in `Xt = transform(X, y)`\n \"keep\" = all indices in y also appear in Xt. If not present in X, NA is filled.\n \"remove\" = only indices that appear in both X and y are present in Xt.\n\n Examples\n --------\n >>> from sktime.transformations.series.subset import IndexSubset\n >>> from sktime.datasets import load_airline\n >>> X = load_airline()[0:32]\n >>> y = load_airline()[24:42]\n >>> transformer = IndexSubset()\n >>> X_subset = transformer.fit_transform(X=X, y=y)\n \"\"\"\n\n _tags = {\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n \"y_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n \"transform-returns-same-time-index\": False,\n \"fit_is_empty\": False,\n \"univariate-only\": False,\n \"capability:inverse_transform\": False,\n \"remember_data\": True, # remember all data seen as _X\n }\n\n def __init__(self, index_treatment=\"keep\"):\n self.index_treatment = index_treatment\n super().__init__()\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.DataFrame or pd.Series\n Data to be transformed\n y : pd.DataFrame or pd.Series\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n Xt : pd.DataFrame or pd.Series, same type as X\n transformed version of X\n \"\"\"\n if y is None:\n return X\n\n X = self._X\n\n index_treatment = self.index_treatment\n ind_X_and_y = X.index.intersection(y.index)\n\n if index_treatment == \"remove\":\n Xt = X.loc[ind_X_and_y]\n elif index_treatment == \"keep\":\n Xt = X.loc[ind_X_and_y]\n y_idx_frame = type(X)(index=y.index, dtype=\"float64\")\n Xt = Xt.combine_first(y_idx_frame)\n else:\n raise ValueError(\n f'index_treatment must be one of \"remove\", \"keep\", but found'\n f' \"{index_treatment}\"'\n )\n return Xt\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n There are currently no reserved values for transformers.\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n params1 = {\"index_treatment\": \"remove\"}\n params2 = {\"index_treatment\": \"keep\"}\n\n return [params1, params2]\n\n\nclass ColumnSelect(BaseTransformer):\n r\"\"\"Column selection transformer.\n\n In transform, subsets `X` to `columns` provided as hyper-parameters.\n\n Sequence of columns in `Xt=transform(X)` is as in `columns` hyper-parameter.\n Caveat: this means that `transform` may change sequence of columns,\n even if no columns are removed from `X` in `transform(X)`.\n\n Parameters\n ----------\n columns : pandas compatible index or index coercible, optional, default = None\n columns to which X in transform is to be subset\n integer_treatment : str, optional, one of \"col\" (default) and \"coerce\"\n determines how integer index columns are treated\n \"col\" = subsets by column iloc index, even if columns is not in X.columns\n \"coerce\" = coerces to integer pandas.Index and attempts to subset\n index_treatment : str, optional, one of \"remove\" (default) or \"keep\"\n determines which column are kept in `Xt = transform(X, y)`\n \"remove\" = only indices that appear in both X and columns are present in Xt.\n \"keep\" = all indices in columns appear in Xt. If not present in X, NA is filled.\n\n Examples\n --------\n >>> from sktime.transformations.series.subset import ColumnSelect\n >>> from sktime.datasets import load_longley\n >>> X = load_longley()[1]\n >>> transformer = ColumnSelect(columns=[\"GNPDEFL\", \"POP\", \"FOO\"])\n >>> X_subset = transformer.fit_transform(X=X)\n \"\"\"\n\n _tags = {\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd-multiindex\", \"pd_multiindex_hier\"],\n \"y_inner_mtype\": \"None\",\n \"transform-returns-same-time-index\": True,\n \"fit_is_empty\": True,\n \"univariate-only\": False,\n \"capability:inverse_transform\": False,\n }\n\n def __init__(self, columns=None, integer_treatment=\"col\", index_treatment=\"remove\"):\n self.columns = columns\n self.integer_treatment = integer_treatment\n self.index_treatment = index_treatment\n super().__init__()\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.DataFrame\n Data to be transformed\n y : Ignored argument for interface compatibility\n\n Returns\n -------\n Xt : pd.DataFrame\n transformed version of X\n \"\"\"\n columns = self.columns\n integer_treatment = self.integer_treatment\n index_treatment = self.index_treatment\n\n if columns is None:\n return X\n if pd.api.types.is_scalar(columns):\n columns = [columns]\n\n columns = pd.Index(columns)\n\n if integer_treatment == \"col\" and pd.api.types.is_integer_dtype(columns):\n columns = [x for x in columns if x < len(X.columns)]\n col_idx = X.columns[columns]\n return X[col_idx]\n\n in_cols = columns.isin(X.columns)\n col_X_and_cols = columns[in_cols]\n\n if index_treatment == \"remove\":\n Xt = X[col_X_and_cols]\n elif index_treatment == \"keep\":\n Xt = X.reindex(columns=columns)\n else:\n raise ValueError(\n f'index_treatment must be one of \"remove\", \"keep\", but found'\n f' \"{index_treatment}\"'\n )\n return Xt\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n There are currently no reserved values for transformers.\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n params1 = {\"columns\": None}\n params2 = {\"columns\": [0, 2, 3]}\n params3 = {\"columns\": [\"a\", \"foo\", \"bar\"], \"index_treatment\": \"keep\"}\n params4 = {\"columns\": \"a\", \"index_treatment\": \"keep\"}\n\n return [params1, params2, params3, params4]\n", "path": "sktime/transformations/series/subset.py"}], "after_files": [{"content": "\"\"\"Transformers for index and column subsetting.\"\"\"\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file).\n\n__author__ = [\"fkiraly\"]\n\nimport pandas as pd\n\nfrom sktime.transformations.base import BaseTransformer\n\n\nclass IndexSubset(BaseTransformer):\n r\"\"\"Index subsetting transformer.\n\n In transform, subsets `X` to the indices in `y.index`.\n If `y` is None, returns `X` without subsetting.\n numpy-based `X` are interpreted as having a RangeIndex starting at n,\n where n is the number of numpy rows seen so far through `fit` and `update`.\n Non-pandas types are interpreted as having index as after conversion to pandas,\n via `datatypes.convert_to`, to the `\"pd.DataFrame\"` sktime type.\n\n Parameters\n ----------\n index_treatment : str, optional, one of \"keep\" (default) or \"remove\"\n determines which indices are kept in `Xt = transform(X, y)`\n \"keep\" = all indices in y also appear in Xt. If not present in X, NA is filled.\n \"remove\" = only indices that appear in both X and y are present in Xt.\n\n Examples\n --------\n >>> from sktime.transformations.series.subset import IndexSubset\n >>> from sktime.datasets import load_airline\n >>> X = load_airline()[0:32]\n >>> y = load_airline()[24:42]\n >>> transformer = IndexSubset()\n >>> X_subset = transformer.fit_transform(X=X, y=y)\n \"\"\"\n\n _tags = {\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n \"y_inner_mtype\": [\"pd.DataFrame\", \"pd.Series\"],\n \"transform-returns-same-time-index\": False,\n \"fit_is_empty\": False,\n \"univariate-only\": False,\n \"capability:inverse_transform\": False,\n \"remember_data\": True, # remember all data seen as _X\n }\n\n def __init__(self, index_treatment=\"keep\"):\n self.index_treatment = index_treatment\n super().__init__()\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.DataFrame or pd.Series\n Data to be transformed\n y : pd.DataFrame or pd.Series\n Additional data, e.g., labels for transformation\n\n Returns\n -------\n Xt : pd.DataFrame or pd.Series, same type as X\n transformed version of X\n \"\"\"\n if y is None:\n return X\n\n X = self._X\n\n index_treatment = self.index_treatment\n ind_X_and_y = X.index.intersection(y.index)\n\n if index_treatment == \"remove\":\n Xt = X.loc[ind_X_and_y]\n elif index_treatment == \"keep\":\n Xt = X.loc[ind_X_and_y]\n y_idx_frame = type(X)(index=y.index, dtype=\"float64\")\n Xt = Xt.combine_first(y_idx_frame)\n else:\n raise ValueError(\n f'index_treatment must be one of \"remove\", \"keep\", but found'\n f' \"{index_treatment}\"'\n )\n return Xt\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n There are currently no reserved values for transformers.\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n params1 = {\"index_treatment\": \"remove\"}\n params2 = {\"index_treatment\": \"keep\"}\n\n return [params1, params2]\n\n\nclass ColumnSelect(BaseTransformer):\n r\"\"\"Column selection transformer.\n\n In transform, subsets `X` to `columns` provided as hyper-parameters.\n\n Sequence of columns in `Xt=transform(X)` is as in `columns` hyper-parameter.\n Caveat: this means that `transform` may change sequence of columns,\n even if no columns are removed from `X` in `transform(X)`.\n\n Parameters\n ----------\n columns : pandas compatible index or index coercible, optional, default = None\n columns to which X in transform is to be subset\n integer_treatment : str, optional, one of \"col\" (default) and \"coerce\"\n determines how integer index columns are treated\n \"col\" = subsets by column iloc index, even if columns is not in X.columns\n \"coerce\" = coerces to integer pandas.Index and attempts to subset\n index_treatment : str, optional, one of \"remove\" (default) or \"keep\"\n determines which column are kept in `Xt = transform(X, y)`\n \"remove\" = only indices that appear in both X and columns are present in Xt.\n \"keep\" = all indices in columns appear in Xt. If not present in X, NA is filled.\n\n Examples\n --------\n >>> from sktime.transformations.series.subset import ColumnSelect\n >>> from sktime.datasets import load_longley\n >>> X = load_longley()[1]\n >>> transformer = ColumnSelect(columns=[\"GNPDEFL\", \"POP\", \"FOO\"])\n >>> X_subset = transformer.fit_transform(X=X)\n \"\"\"\n\n _tags = {\n \"scitype:transform-input\": \"Series\",\n # what is the scitype of X: Series, or Panel\n \"scitype:transform-output\": \"Series\",\n # what scitype is returned: Primitives, Series, Panel\n \"scitype:instancewise\": True, # is this an instance-wise transform?\n \"X_inner_mtype\": [\"pd.DataFrame\", \"pd-multiindex\", \"pd_multiindex_hier\"],\n \"y_inner_mtype\": \"None\",\n \"transform-returns-same-time-index\": True,\n \"fit_is_empty\": True,\n \"univariate-only\": False,\n \"capability:inverse_transform\": False,\n \"skip-inverse-transform\": True,\n }\n\n def __init__(self, columns=None, integer_treatment=\"col\", index_treatment=\"remove\"):\n self.columns = columns\n self.integer_treatment = integer_treatment\n self.index_treatment = index_treatment\n super().__init__()\n\n def _transform(self, X, y=None):\n \"\"\"Transform X and return a transformed version.\n\n private _transform containing the core logic, called from transform\n\n Parameters\n ----------\n X : pd.DataFrame\n Data to be transformed\n y : Ignored argument for interface compatibility\n\n Returns\n -------\n Xt : pd.DataFrame\n transformed version of X\n \"\"\"\n columns = self.columns\n integer_treatment = self.integer_treatment\n index_treatment = self.index_treatment\n\n if columns is None:\n return X\n if pd.api.types.is_scalar(columns):\n columns = [columns]\n\n columns = pd.Index(columns)\n\n if integer_treatment == \"col\" and pd.api.types.is_integer_dtype(columns):\n columns = [x for x in columns if x < len(X.columns)]\n col_idx = X.columns[columns]\n return X[col_idx]\n\n in_cols = columns.isin(X.columns)\n col_X_and_cols = columns[in_cols]\n\n if index_treatment == \"remove\":\n Xt = X[col_X_and_cols]\n elif index_treatment == \"keep\":\n Xt = X.reindex(columns=columns)\n else:\n raise ValueError(\n f'index_treatment must be one of \"remove\", \"keep\", but found'\n f' \"{index_treatment}\"'\n )\n return Xt\n\n @classmethod\n def get_test_params(cls, parameter_set=\"default\"):\n \"\"\"Return testing parameter settings for the estimator.\n\n Parameters\n ----------\n parameter_set : str, default=\"default\"\n Name of the set of test parameters to return, for use in tests. If no\n special parameters are defined for a value, will return `\"default\"` set.\n There are currently no reserved values for transformers.\n\n Returns\n -------\n params : dict or list of dict, default = {}\n Parameters to create testing instances of the class\n Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n `create_test_instance` uses the first (or only) dictionary in `params`\n \"\"\"\n params1 = {\"columns\": None}\n params2 = {\"columns\": [0, 2, 3]}\n params3 = {\"columns\": [\"a\", \"foo\", \"bar\"], \"index_treatment\": \"keep\"}\n params4 = {\"columns\": \"a\", \"index_treatment\": \"keep\"}\n\n return [params1, params2, params3, params4]\n", "path": "sktime/transformations/series/subset.py"}]}
| 3,279 | 129 |
gh_patches_debug_30815
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-238
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement `map` for `LocalExecutor`
For some reason we avoided doing this, but it's actually entirely possible to do! Would be great for local debugging.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/engine/executors/local.py`
Content:
```
1 # Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula
2
3 from prefect.engine.executors.base import Executor
4
5
6 class LocalExecutor(Executor):
7 """
8 An executor that runs all functions synchronously and immediately in
9 the local thread. To be used mainly for debugging purposes.
10 """
11
12 def submit(self, fn, *args, **kwargs):
13 """
14 Submit a function to the executor for execution. Returns the result of the computation.
15
16 Args:
17 - fn (Callable): function which is being submitted for execution
18 - *args (Any): arguments to be passed to `fn`
19 - **kwargs (Any): keyword arguments to be passed to `fn`
20
21 Returns:
22 - Any: the result of `fn(*args, **kwargs)`
23 """
24 return fn(*args, **kwargs)
25
26 def wait(self, futures, timeout=None):
27 """
28 Returns:
29 - Any: whatever `futures` were provided
30 """
31 return futures
32
```
Path: `src/prefect/engine/executors/__init__.py`
Content:
```
1 # Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula
2
3 """
4 Prefect Executors implement the logic for how Tasks are run. The standard interface
5 for an Executor consists of the following methods:
6
7 - `submit(fn, *args, **kwargs)`: submit `fn(*args, **kwargs)` for execution;
8 note that this function is (in general) non-blocking, meaning that `executor.submit(...)`
9 will _immediately_ return a future-like object regardless of whether `fn(*args, **kwargs)`
10 has completed running
11 - `submit_with_context(fn, *args, context, **kwargs)`: submit `fn(*args,
12 **kwargs)` for execution with the provided `prefect.context`
13 - `wait(object)`: resolves any objects returned by `executor.submit` to
14 their values; this function _will_ block until execution of `object` is complete
15 - `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped
16 over based on the edge information contained in `upstream_states`. Any "mapped" Edge
17 will be converted into multiple function submissions, one for each value of the upstream mapped tasks.
18
19 Currently, the available executor options are:
20
21 - `LocalExecutor`: the no frills, straightforward executor - great for simple
22 debugging; tasks are executed immediately upon being called by `executor.submit()`.
23 Note that the `map` feature is currently _not_ supported with this executor.
24 - `SynchronousExecutor`: an executor that runs on `dask` primitives with the
25 synchronous dask scheduler; currently the default executor
26 - `DaskExecutor`: the most feature-rich of the executors, this executor runs
27 on `dask.distributed` and has support for multiprocessing, multithreading, and distributed execution.
28
29 Which executor you choose depends on whether you intend to use things like parallelism
30 of task execution.
31 """
32 import sys
33
34 from warnings import warn as _warn
35 from importlib import import_module as _import_module
36
37 import prefect as _prefect
38 from prefect.engine.executors.base import Executor
39 from prefect.engine.executors.local import LocalExecutor
40 from prefect.engine.executors.sync import SynchronousExecutor
41
42 if sys.version_info >= (3, 5):
43 from prefect.engine.executors.dask import DaskExecutor
44
45 try:
46 cfg_exec = _prefect.config.engine.executor
47 *module, cls_name = cfg_exec.split(".")
48 module = _import_module(".".join(module))
49 DEFAULT_EXECUTOR = getattr(module, cls_name)()
50 except:
51 _warn(
52 "Could not import {}, using prefect.engine.executors.LocalExecutor instead.".format(
53 _prefect.config.engine.executor
54 )
55 )
56 DEFAULT_EXECUTOR = LocalExecutor()
57
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/engine/executors/__init__.py b/src/prefect/engine/executors/__init__.py
--- a/src/prefect/engine/executors/__init__.py
+++ b/src/prefect/engine/executors/__init__.py
@@ -20,7 +20,6 @@
- `LocalExecutor`: the no frills, straightforward executor - great for simple
debugging; tasks are executed immediately upon being called by `executor.submit()`.
- Note that the `map` feature is currently _not_ supported with this executor.
- `SynchronousExecutor`: an executor that runs on `dask` primitives with the
synchronous dask scheduler; currently the default executor
- `DaskExecutor`: the most feature-rich of the executors, this executor runs
diff --git a/src/prefect/engine/executors/local.py b/src/prefect/engine/executors/local.py
--- a/src/prefect/engine/executors/local.py
+++ b/src/prefect/engine/executors/local.py
@@ -1,6 +1,9 @@
# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula
+from typing import Any, Callable, Iterable
+
from prefect.engine.executors.base import Executor
+from prefect.utilities.executors import dict_to_list
class LocalExecutor(Executor):
@@ -9,6 +12,17 @@
the local thread. To be used mainly for debugging purposes.
"""
+ def map(
+ self, fn: Callable, *args: Any, upstream_states=None, **kwargs: Any
+ ) -> Iterable[Any]:
+
+ states = dict_to_list(upstream_states)
+ results = []
+ for elem in states:
+ results.append(self.submit(fn, *args, upstream_states=elem, **kwargs))
+
+ return results
+
def submit(self, fn, *args, **kwargs):
"""
Submit a function to the executor for execution. Returns the result of the computation.
|
{"golden_diff": "diff --git a/src/prefect/engine/executors/__init__.py b/src/prefect/engine/executors/__init__.py\n--- a/src/prefect/engine/executors/__init__.py\n+++ b/src/prefect/engine/executors/__init__.py\n@@ -20,7 +20,6 @@\n \n - `LocalExecutor`: the no frills, straightforward executor - great for simple\n debugging; tasks are executed immediately upon being called by `executor.submit()`.\n- Note that the `map` feature is currently _not_ supported with this executor.\n - `SynchronousExecutor`: an executor that runs on `dask` primitives with the\n synchronous dask scheduler; currently the default executor\n - `DaskExecutor`: the most feature-rich of the executors, this executor runs\ndiff --git a/src/prefect/engine/executors/local.py b/src/prefect/engine/executors/local.py\n--- a/src/prefect/engine/executors/local.py\n+++ b/src/prefect/engine/executors/local.py\n@@ -1,6 +1,9 @@\n # Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\n \n+from typing import Any, Callable, Iterable\n+\n from prefect.engine.executors.base import Executor\n+from prefect.utilities.executors import dict_to_list\n \n \n class LocalExecutor(Executor):\n@@ -9,6 +12,17 @@\n the local thread. To be used mainly for debugging purposes.\n \"\"\"\n \n+ def map(\n+ self, fn: Callable, *args: Any, upstream_states=None, **kwargs: Any\n+ ) -> Iterable[Any]:\n+\n+ states = dict_to_list(upstream_states)\n+ results = []\n+ for elem in states:\n+ results.append(self.submit(fn, *args, upstream_states=elem, **kwargs))\n+\n+ return results\n+\n def submit(self, fn, *args, **kwargs):\n \"\"\"\n Submit a function to the executor for execution. Returns the result of the computation.\n", "issue": "Implement `map` for `LocalExecutor`\nFor some reason we avoided doing this, but it's actually entirely possible to do! Would be great for local debugging.\n", "before_files": [{"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\n\nfrom prefect.engine.executors.base import Executor\n\n\nclass LocalExecutor(Executor):\n \"\"\"\n An executor that runs all functions synchronously and immediately in\n the local thread. To be used mainly for debugging purposes.\n \"\"\"\n\n def submit(self, fn, *args, **kwargs):\n \"\"\"\n Submit a function to the executor for execution. Returns the result of the computation.\n\n Args:\n - fn (Callable): function which is being submitted for execution\n - *args (Any): arguments to be passed to `fn`\n - **kwargs (Any): keyword arguments to be passed to `fn`\n\n Returns:\n - Any: the result of `fn(*args, **kwargs)`\n \"\"\"\n return fn(*args, **kwargs)\n\n def wait(self, futures, timeout=None):\n \"\"\"\n Returns:\n - Any: whatever `futures` were provided\n \"\"\"\n return futures\n", "path": "src/prefect/engine/executors/local.py"}, {"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\n\n\"\"\"\nPrefect Executors implement the logic for how Tasks are run. The standard interface\nfor an Executor consists of the following methods:\n\n- `submit(fn, *args, **kwargs)`: submit `fn(*args, **kwargs)` for execution;\n note that this function is (in general) non-blocking, meaning that `executor.submit(...)`\n will _immediately_ return a future-like object regardless of whether `fn(*args, **kwargs)`\n has completed running\n- `submit_with_context(fn, *args, context, **kwargs)`: submit `fn(*args,\n **kwargs)` for execution with the provided `prefect.context`\n- `wait(object)`: resolves any objects returned by `executor.submit` to\n their values; this function _will_ block until execution of `object` is complete\n- `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped\n over based on the edge information contained in `upstream_states`. Any \"mapped\" Edge\n will be converted into multiple function submissions, one for each value of the upstream mapped tasks.\n\nCurrently, the available executor options are:\n\n- `LocalExecutor`: the no frills, straightforward executor - great for simple\n debugging; tasks are executed immediately upon being called by `executor.submit()`.\n Note that the `map` feature is currently _not_ supported with this executor.\n- `SynchronousExecutor`: an executor that runs on `dask` primitives with the\n synchronous dask scheduler; currently the default executor\n- `DaskExecutor`: the most feature-rich of the executors, this executor runs\n on `dask.distributed` and has support for multiprocessing, multithreading, and distributed execution.\n\nWhich executor you choose depends on whether you intend to use things like parallelism\nof task execution.\n\"\"\"\nimport sys\n\nfrom warnings import warn as _warn\nfrom importlib import import_module as _import_module\n\nimport prefect as _prefect\nfrom prefect.engine.executors.base import Executor\nfrom prefect.engine.executors.local import LocalExecutor\nfrom prefect.engine.executors.sync import SynchronousExecutor\n\nif sys.version_info >= (3, 5):\n from prefect.engine.executors.dask import DaskExecutor\n\ntry:\n cfg_exec = _prefect.config.engine.executor\n *module, cls_name = cfg_exec.split(\".\")\n module = _import_module(\".\".join(module))\n DEFAULT_EXECUTOR = getattr(module, cls_name)()\nexcept:\n _warn(\n \"Could not import {}, using prefect.engine.executors.LocalExecutor instead.\".format(\n _prefect.config.engine.executor\n )\n )\n DEFAULT_EXECUTOR = LocalExecutor()\n", "path": "src/prefect/engine/executors/__init__.py"}], "after_files": [{"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\n\nfrom typing import Any, Callable, Iterable\n\nfrom prefect.engine.executors.base import Executor\nfrom prefect.utilities.executors import dict_to_list\n\n\nclass LocalExecutor(Executor):\n \"\"\"\n An executor that runs all functions synchronously and immediately in\n the local thread. To be used mainly for debugging purposes.\n \"\"\"\n\n def map(\n self, fn: Callable, *args: Any, upstream_states=None, **kwargs: Any\n ) -> Iterable[Any]:\n\n states = dict_to_list(upstream_states)\n results = []\n for elem in states:\n results.append(self.submit(fn, *args, upstream_states=elem, **kwargs))\n\n return results\n\n def submit(self, fn, *args, **kwargs):\n \"\"\"\n Submit a function to the executor for execution. Returns the result of the computation.\n\n Args:\n - fn (Callable): function which is being submitted for execution\n - *args (Any): arguments to be passed to `fn`\n - **kwargs (Any): keyword arguments to be passed to `fn`\n\n Returns:\n - Any: the result of `fn(*args, **kwargs)`\n \"\"\"\n return fn(*args, **kwargs)\n\n def wait(self, futures, timeout=None):\n \"\"\"\n Returns:\n - Any: whatever `futures` were provided\n \"\"\"\n return futures\n", "path": "src/prefect/engine/executors/local.py"}, {"content": "# Licensed under LICENSE.md; also available at https://www.prefect.io/licenses/alpha-eula\n\n\"\"\"\nPrefect Executors implement the logic for how Tasks are run. The standard interface\nfor an Executor consists of the following methods:\n\n- `submit(fn, *args, **kwargs)`: submit `fn(*args, **kwargs)` for execution;\n note that this function is (in general) non-blocking, meaning that `executor.submit(...)`\n will _immediately_ return a future-like object regardless of whether `fn(*args, **kwargs)`\n has completed running\n- `submit_with_context(fn, *args, context, **kwargs)`: submit `fn(*args,\n **kwargs)` for execution with the provided `prefect.context`\n- `wait(object)`: resolves any objects returned by `executor.submit` to\n their values; this function _will_ block until execution of `object` is complete\n- `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped\n over based on the edge information contained in `upstream_states`. Any \"mapped\" Edge\n will be converted into multiple function submissions, one for each value of the upstream mapped tasks.\n\nCurrently, the available executor options are:\n\n- `LocalExecutor`: the no frills, straightforward executor - great for simple\n debugging; tasks are executed immediately upon being called by `executor.submit()`.\n- `SynchronousExecutor`: an executor that runs on `dask` primitives with the\n synchronous dask scheduler; currently the default executor\n- `DaskExecutor`: the most feature-rich of the executors, this executor runs\n on `dask.distributed` and has support for multiprocessing, multithreading, and distributed execution.\n\nWhich executor you choose depends on whether you intend to use things like parallelism\nof task execution.\n\"\"\"\nimport sys\n\nfrom warnings import warn as _warn\nfrom importlib import import_module as _import_module\n\nimport prefect as _prefect\nfrom prefect.engine.executors.base import Executor\nfrom prefect.engine.executors.local import LocalExecutor\nfrom prefect.engine.executors.sync import SynchronousExecutor\n\nif sys.version_info >= (3, 5):\n from prefect.engine.executors.dask import DaskExecutor\n\ntry:\n cfg_exec = _prefect.config.engine.executor\n *module, cls_name = cfg_exec.split(\".\")\n module = _import_module(\".\".join(module))\n DEFAULT_EXECUTOR = getattr(module, cls_name)()\nexcept:\n _warn(\n \"Could not import {}, using prefect.engine.executors.LocalExecutor instead.\".format(\n _prefect.config.engine.executor\n )\n )\n DEFAULT_EXECUTOR = LocalExecutor()\n", "path": "src/prefect/engine/executors/__init__.py"}]}
| 1,280 | 432 |
gh_patches_debug_24122
|
rasdani/github-patches
|
git_diff
|
microsoft__DeepSpeed-2567
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[REQUEST] Remove deprecated PyTorch code
**Is your feature request related to a problem? Please describe.**
DeepSpeed uses code that's deprecated. This causes problems for libraries built on deepspeed when testing.
**Describe the solution you'd like**
```
/usr/local/lib/python3.10/dist-packages/deepspeed/comm/torch.py:171: in get_global_rank
return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)
```
should instead use `get_global_rank` as recommended by the warning
```
E UserWarning: torch.distributed.distributed_c10d._get_global_rank is deprecated please use torch.distributed.distributed_c10d.get_global_rank instead
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepspeed/comm/__init__.py`
Content:
```
1 import torch
2 from .utils import *
3 from deepspeed import utils
4
5 supported_torch_version = False
6
7 # See more details at: https://github.com/pytorch/pytorch/pull/48767
8 # The PG API in torch versions lesser than 1.8 are different so it is
9 # non-trivial to support both in the same API. We will just use the
10 # DS comm. backend in deepspeed/comm/comm.py if torch version if 1.8+.
11
12 if older_torch():
13 # Add custom deepspeed torch comm functions here since we can't import deepspeed.comm
14 # NOTE: We can't call torch.distributed directly here. Current hack is to import functions before calling them.
15 supported_torch_version = False
16 from torch.distributed import *
17
18 def get_world_group():
19 return group.WORLD
20
21 def get_global_rank(group, group_rank):
22 from torch.distributed.distributed_c10d import _get_global_rank
23 return _get_global_rank(group, group_rank)
24
25 def allgather_fn(output_tensor, input_tensor, group=None, async_op=False):
26 from torch.distributed import all_gather, get_world_size
27 from torch import chunk
28 output_tensors = list(chunk(output_tensor, get_world_size(group)))
29 return all_gather(output_tensors, input_tensor, group=group, async_op=async_op)
30
31 def reduce_scatter_fn(output_tensor, input_tensor, group=None, async_op=False):
32 from torch.distributed import reduce_scatter, get_world_size
33 from torch import chunk
34 input_tensor_lst = list(chunk(input_tensor, get_world_size(group)))
35 return reduce_scatter(output_tensor, input_tensor_lst, group=group)
36
37 def configure(deepspeed_config=None,
38 enabled=None,
39 prof_all=None,
40 prof_ops=None,
41 verbose=None):
42 utils.logger.warn(
43 "Communication logging is not supported in torch versions older than 1.8")
44
45 else:
46 supported_torch_version = True
47 from .comm import *
48
```
Path: `deepspeed/comm/torch.py`
Content:
```
1 '''
2 Copyright 2021 The Microsoft DeepSpeed Team
3 '''
4 from deepspeed import utils
5
6 from .utils import *
7 from .backend import *
8 from .comm import *
9
10
11 class TorchBackend(Backend):
12 """
13 A light-weight wrapper class for torch.distributed API.
14 Only a subset of functions are wrapped. Once the init_process_group
15 is initialized, standard torch.distributed.* can be used directly
16 so no need to wrap all the functions. We can keep adding wrappers as
17 needed.
18 """
19 def __init__(self, backend, timeout, init_method, name='torch'):
20 super(TorchBackend, self).__init__()
21 self.torch_version_before_18 = older_torch()
22 self.has_allgather_base = has_allgather_base()
23 self.has_reduce_scatter_base = has_reduce_scatter_base()
24 self.initialized = True
25 self.name = name
26 # Future functionality to support ds.initialize() on a single GPU
27 # The idea is to fake that dist backend is initialized even when
28 # it is not so we can run on a single GPU without doing any init_process_group
29 self.single_gpu_mode = True
30 self.init_process_group(backend, timeout, init_method)
31
32 def init_process_group(self, backend, timeout, init_method):
33 if not torch.distributed.is_initialized():
34 torch.distributed.init_process_group(backend,
35 timeout=timeout,
36 init_method=init_method)
37 self.using_mpi = torch.distributed.get_backend() == 'mpi'
38
39 def all_reduce(self,
40 tensor,
41 op=torch.distributed.ReduceOp.SUM,
42 group=None,
43 async_op=False):
44 op = self._reduce_op(op)
45 return torch.distributed.all_reduce(tensor=tensor,
46 op=op,
47 group=group,
48 async_op=async_op)
49
50 def reduce(self, tensor, dst, op=ReduceOp.SUM, group=None, async_op=False):
51 return torch.distributed.reduce(tensor=tensor,
52 dst=dst,
53 op=self._reduce_op(op),
54 group=group,
55 async_op=async_op)
56
57 def reduce_scatter(self,
58 output,
59 input_list,
60 op=ReduceOp.SUM,
61 group=None,
62 async_op=False):
63 return torch.distributed.reduce_scatter(output=output,
64 input_list=input_list,
65 op=self._reduce_op(op),
66 group=group,
67 async_op=async_op)
68
69 def broadcast(self, tensor, src, group=None, async_op=False):
70 return torch.distributed.broadcast(tensor=tensor,
71 src=src,
72 group=group,
73 async_op=async_op)
74
75 def all_gather(self, tensor_list, tensor, group=None, async_op=False):
76 return torch.distributed.all_gather(tensor_list=tensor_list,
77 tensor=tensor,
78 group=group,
79 async_op=async_op)
80
81 def all_gather_base(self, output_tensor, input_tensor, group=None, async_op=False):
82 if self.has_allgather_base:
83 return torch.distributed.distributed_c10d._all_gather_base(
84 output_tensor=output_tensor,
85 input_tensor=input_tensor,
86 group=group,
87 async_op=async_op)
88 else:
89 utils.logger.warning(
90 "unable to find torch.distributed._all_gather_base. will fall back to "
91 "torch.distributed.reduce_scatter which will result in suboptimal performance. "
92 "please consider upgrading your pytorch installation.")
93 pass
94
95 def reduce_scatter_base(self,
96 output_tensor,
97 input_tensor,
98 group=None,
99 async_op=False):
100 if self.has_reduce_scatter_base:
101 return torch.distributed._reduce_scatter_base(output_tensor,
102 input_tensor,
103 group=group,
104 async_op=async_op)
105 else:
106 utils.logger.warning(
107 "unable to find torch.distributed._reduce_scatter_base. will fall back to "
108 "torch.distributed.reduce_scatter which will result in suboptimal performance. "
109 "please consider upgrading your pytorch installation.")
110 pass
111
112 def all_to_all_single(self,
113 output,
114 input,
115 output_split_sizes=None,
116 input_split_sizes=None,
117 group=None,
118 async_op=False):
119 return torch.distributed.all_to_all_single(output=output,
120 input=input,
121 output_split_sizes=output_split_sizes,
122 input_split_sizes=input_split_sizes,
123 group=group,
124 async_op=async_op)
125
126 def send(self, tensor, dst, group=None, tag=0):
127 return torch.distributed.send(tensor=tensor, dst=dst, group=group, tag=tag)
128
129 def recv(self, tensor, src=None, group=None, tag=0):
130 return torch.distributed.recv(tensor=tensor, src=src, group=group, tag=tag)
131
132 def isend(self, tensor, dst, group=None, tag=0):
133 return torch.distributed.isend(tensor=tensor, dst=dst, group=group, tag=tag)
134
135 def irecv(self, tensor, src=None, group=None, tag=0):
136 return torch.distributed.irecv(tensor=tensor, src=src, group=group, tag=tag)
137
138 def gather(self, tensor, gather_list=None, dst=0, group=None, async_op=False):
139 return torch.distributed.gather(tensor=tensor,
140 gather_list=gather_list,
141 dst=dst,
142 group=group,
143 async_op=async_op)
144
145 def scatter(self, tensor, scatter_list=None, src=0, group=None, async_op=False):
146 return torch.distributed.scatter(tensor=tensor,
147 scatter_list=scatter_list,
148 src=src,
149 group=group,
150 async_op=async_op)
151
152 def barrier(self):
153 return torch.distributed.barrier()
154
155 def get_rank(self, group=None):
156 return torch.distributed.get_rank(group=group)
157
158 def get_world_size(self, group=None):
159 return torch.distributed.get_world_size(group=group)
160
161 def is_initialized(self):
162 return torch.distributed.is_initialized()
163
164 def get_backend(self, group=None):
165 return torch.distributed.get_backend(group=group)
166
167 def new_group(self, ranks):
168 return torch.distributed.new_group(ranks)
169
170 def get_global_rank(self, group, group_rank):
171 return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)
172
173 def get_world_group(self):
174 return torch.distributed.group.WORLD
175
176 def destroy_process_group(self, group=None):
177 return torch.distributed.destroy_process_group(group=group)
178
179 def _reduce_op(self, op):
180 '''
181 Helper function. If the op provided is not a torch.dist.ReduceOp, convert it and return
182 '''
183 if not isinstance(op, torch.distributed.ReduceOp):
184 if op == ReduceOp.SUM:
185 op = torch.distributed.ReduceOp.SUM
186 elif op == ReduceOp.PRODUCT:
187 op = torch.distributed.ReduceOp.PRODUCT
188 elif op == ReduceOp.AVG:
189 op = torch.distributed.ReduceOp.AVG
190 elif op == ReduceOp.MIN:
191 op = torch.distributed.ReduceOp.MIN
192 elif op == ReduceOp.MAX:
193 op = torch.distributed.ReduceOp.MAX
194 elif op == ReduceOp.BAND:
195 op = torch.distributed.ReduceOp.BAND
196 elif op == ReduceOp.BOR:
197 op = torch.distributed.ReduceOp.BOR
198 elif op == ReduceOp.BXOR:
199 op = torch.distributed.ReduceOp.BXOR
200 return op
201
202
203 # This will become a light-weight wrapper around torch.distributed functions
204 # TODO: create some example to show how this wrapper can help profile communication
205 # TODO: make sure there is no performance regression with this approach
206 # TODO: explore monkey-patching if this does not work
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepspeed/comm/__init__.py b/deepspeed/comm/__init__.py
--- a/deepspeed/comm/__init__.py
+++ b/deepspeed/comm/__init__.py
@@ -19,7 +19,10 @@
return group.WORLD
def get_global_rank(group, group_rank):
- from torch.distributed.distributed_c10d import _get_global_rank
+ if hasattr(torch.distributed.distributed_c10d, "get_global_rank"):
+ from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank
+ else:
+ from torch.distributed.distributed_c10d import _get_global_rank
return _get_global_rank(group, group_rank)
def allgather_fn(output_tensor, input_tensor, group=None, async_op=False):
diff --git a/deepspeed/comm/torch.py b/deepspeed/comm/torch.py
--- a/deepspeed/comm/torch.py
+++ b/deepspeed/comm/torch.py
@@ -168,7 +168,11 @@
return torch.distributed.new_group(ranks)
def get_global_rank(self, group, group_rank):
- return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)
+ if hasattr(torch.distributed.distributed_c10d, "get_global_rank"):
+ from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank
+ else:
+ from torch.distributed.distributed_c10d import _get_global_rank
+ return _get_global_rank(group, group_rank)
def get_world_group(self):
return torch.distributed.group.WORLD
|
{"golden_diff": "diff --git a/deepspeed/comm/__init__.py b/deepspeed/comm/__init__.py\n--- a/deepspeed/comm/__init__.py\n+++ b/deepspeed/comm/__init__.py\n@@ -19,7 +19,10 @@\n return group.WORLD\n \n def get_global_rank(group, group_rank):\n- from torch.distributed.distributed_c10d import _get_global_rank\n+ if hasattr(torch.distributed.distributed_c10d, \"get_global_rank\"):\n+ from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank\n+ else:\n+ from torch.distributed.distributed_c10d import _get_global_rank\n return _get_global_rank(group, group_rank)\n \n def allgather_fn(output_tensor, input_tensor, group=None, async_op=False):\ndiff --git a/deepspeed/comm/torch.py b/deepspeed/comm/torch.py\n--- a/deepspeed/comm/torch.py\n+++ b/deepspeed/comm/torch.py\n@@ -168,7 +168,11 @@\n return torch.distributed.new_group(ranks)\n \n def get_global_rank(self, group, group_rank):\n- return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)\n+ if hasattr(torch.distributed.distributed_c10d, \"get_global_rank\"):\n+ from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank\n+ else:\n+ from torch.distributed.distributed_c10d import _get_global_rank\n+ return _get_global_rank(group, group_rank)\n \n def get_world_group(self):\n return torch.distributed.group.WORLD\n", "issue": "[REQUEST] Remove deprecated PyTorch code\n**Is your feature request related to a problem? Please describe.**\r\nDeepSpeed uses code that's deprecated. This causes problems for libraries built on deepspeed when testing.\r\n\r\n**Describe the solution you'd like**\r\n```\r\n/usr/local/lib/python3.10/dist-packages/deepspeed/comm/torch.py:171: in get_global_rank\r\n return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)\r\n```\r\nshould instead use `get_global_rank` as recommended by the warning\r\n```\r\nE UserWarning: torch.distributed.distributed_c10d._get_global_rank is deprecated please use torch.distributed.distributed_c10d.get_global_rank instead\r\n```\r\n\n", "before_files": [{"content": "import torch\nfrom .utils import *\nfrom deepspeed import utils\n\nsupported_torch_version = False\n\n# See more details at: https://github.com/pytorch/pytorch/pull/48767\n# The PG API in torch versions lesser than 1.8 are different so it is\n# non-trivial to support both in the same API. We will just use the\n# DS comm. backend in deepspeed/comm/comm.py if torch version if 1.8+.\n\nif older_torch():\n # Add custom deepspeed torch comm functions here since we can't import deepspeed.comm\n # NOTE: We can't call torch.distributed directly here. Current hack is to import functions before calling them.\n supported_torch_version = False\n from torch.distributed import *\n\n def get_world_group():\n return group.WORLD\n\n def get_global_rank(group, group_rank):\n from torch.distributed.distributed_c10d import _get_global_rank\n return _get_global_rank(group, group_rank)\n\n def allgather_fn(output_tensor, input_tensor, group=None, async_op=False):\n from torch.distributed import all_gather, get_world_size\n from torch import chunk\n output_tensors = list(chunk(output_tensor, get_world_size(group)))\n return all_gather(output_tensors, input_tensor, group=group, async_op=async_op)\n\n def reduce_scatter_fn(output_tensor, input_tensor, group=None, async_op=False):\n from torch.distributed import reduce_scatter, get_world_size\n from torch import chunk\n input_tensor_lst = list(chunk(input_tensor, get_world_size(group)))\n return reduce_scatter(output_tensor, input_tensor_lst, group=group)\n\n def configure(deepspeed_config=None,\n enabled=None,\n prof_all=None,\n prof_ops=None,\n verbose=None):\n utils.logger.warn(\n \"Communication logging is not supported in torch versions older than 1.8\")\n\nelse:\n supported_torch_version = True\n from .comm import *\n", "path": "deepspeed/comm/__init__.py"}, {"content": "'''\nCopyright 2021 The Microsoft DeepSpeed Team\n'''\nfrom deepspeed import utils\n\nfrom .utils import *\nfrom .backend import *\nfrom .comm import *\n\n\nclass TorchBackend(Backend):\n \"\"\"\n A light-weight wrapper class for torch.distributed API.\n Only a subset of functions are wrapped. Once the init_process_group\n is initialized, standard torch.distributed.* can be used directly\n so no need to wrap all the functions. We can keep adding wrappers as\n needed.\n \"\"\"\n def __init__(self, backend, timeout, init_method, name='torch'):\n super(TorchBackend, self).__init__()\n self.torch_version_before_18 = older_torch()\n self.has_allgather_base = has_allgather_base()\n self.has_reduce_scatter_base = has_reduce_scatter_base()\n self.initialized = True\n self.name = name\n # Future functionality to support ds.initialize() on a single GPU\n # The idea is to fake that dist backend is initialized even when\n # it is not so we can run on a single GPU without doing any init_process_group\n self.single_gpu_mode = True\n self.init_process_group(backend, timeout, init_method)\n\n def init_process_group(self, backend, timeout, init_method):\n if not torch.distributed.is_initialized():\n torch.distributed.init_process_group(backend,\n timeout=timeout,\n init_method=init_method)\n self.using_mpi = torch.distributed.get_backend() == 'mpi'\n\n def all_reduce(self,\n tensor,\n op=torch.distributed.ReduceOp.SUM,\n group=None,\n async_op=False):\n op = self._reduce_op(op)\n return torch.distributed.all_reduce(tensor=tensor,\n op=op,\n group=group,\n async_op=async_op)\n\n def reduce(self, tensor, dst, op=ReduceOp.SUM, group=None, async_op=False):\n return torch.distributed.reduce(tensor=tensor,\n dst=dst,\n op=self._reduce_op(op),\n group=group,\n async_op=async_op)\n\n def reduce_scatter(self,\n output,\n input_list,\n op=ReduceOp.SUM,\n group=None,\n async_op=False):\n return torch.distributed.reduce_scatter(output=output,\n input_list=input_list,\n op=self._reduce_op(op),\n group=group,\n async_op=async_op)\n\n def broadcast(self, tensor, src, group=None, async_op=False):\n return torch.distributed.broadcast(tensor=tensor,\n src=src,\n group=group,\n async_op=async_op)\n\n def all_gather(self, tensor_list, tensor, group=None, async_op=False):\n return torch.distributed.all_gather(tensor_list=tensor_list,\n tensor=tensor,\n group=group,\n async_op=async_op)\n\n def all_gather_base(self, output_tensor, input_tensor, group=None, async_op=False):\n if self.has_allgather_base:\n return torch.distributed.distributed_c10d._all_gather_base(\n output_tensor=output_tensor,\n input_tensor=input_tensor,\n group=group,\n async_op=async_op)\n else:\n utils.logger.warning(\n \"unable to find torch.distributed._all_gather_base. will fall back to \"\n \"torch.distributed.reduce_scatter which will result in suboptimal performance. \"\n \"please consider upgrading your pytorch installation.\")\n pass\n\n def reduce_scatter_base(self,\n output_tensor,\n input_tensor,\n group=None,\n async_op=False):\n if self.has_reduce_scatter_base:\n return torch.distributed._reduce_scatter_base(output_tensor,\n input_tensor,\n group=group,\n async_op=async_op)\n else:\n utils.logger.warning(\n \"unable to find torch.distributed._reduce_scatter_base. will fall back to \"\n \"torch.distributed.reduce_scatter which will result in suboptimal performance. \"\n \"please consider upgrading your pytorch installation.\")\n pass\n\n def all_to_all_single(self,\n output,\n input,\n output_split_sizes=None,\n input_split_sizes=None,\n group=None,\n async_op=False):\n return torch.distributed.all_to_all_single(output=output,\n input=input,\n output_split_sizes=output_split_sizes,\n input_split_sizes=input_split_sizes,\n group=group,\n async_op=async_op)\n\n def send(self, tensor, dst, group=None, tag=0):\n return torch.distributed.send(tensor=tensor, dst=dst, group=group, tag=tag)\n\n def recv(self, tensor, src=None, group=None, tag=0):\n return torch.distributed.recv(tensor=tensor, src=src, group=group, tag=tag)\n\n def isend(self, tensor, dst, group=None, tag=0):\n return torch.distributed.isend(tensor=tensor, dst=dst, group=group, tag=tag)\n\n def irecv(self, tensor, src=None, group=None, tag=0):\n return torch.distributed.irecv(tensor=tensor, src=src, group=group, tag=tag)\n\n def gather(self, tensor, gather_list=None, dst=0, group=None, async_op=False):\n return torch.distributed.gather(tensor=tensor,\n gather_list=gather_list,\n dst=dst,\n group=group,\n async_op=async_op)\n\n def scatter(self, tensor, scatter_list=None, src=0, group=None, async_op=False):\n return torch.distributed.scatter(tensor=tensor,\n scatter_list=scatter_list,\n src=src,\n group=group,\n async_op=async_op)\n\n def barrier(self):\n return torch.distributed.barrier()\n\n def get_rank(self, group=None):\n return torch.distributed.get_rank(group=group)\n\n def get_world_size(self, group=None):\n return torch.distributed.get_world_size(group=group)\n\n def is_initialized(self):\n return torch.distributed.is_initialized()\n\n def get_backend(self, group=None):\n return torch.distributed.get_backend(group=group)\n\n def new_group(self, ranks):\n return torch.distributed.new_group(ranks)\n\n def get_global_rank(self, group, group_rank):\n return torch.distributed.distributed_c10d._get_global_rank(group, group_rank)\n\n def get_world_group(self):\n return torch.distributed.group.WORLD\n\n def destroy_process_group(self, group=None):\n return torch.distributed.destroy_process_group(group=group)\n\n def _reduce_op(self, op):\n '''\n Helper function. If the op provided is not a torch.dist.ReduceOp, convert it and return\n '''\n if not isinstance(op, torch.distributed.ReduceOp):\n if op == ReduceOp.SUM:\n op = torch.distributed.ReduceOp.SUM\n elif op == ReduceOp.PRODUCT:\n op = torch.distributed.ReduceOp.PRODUCT\n elif op == ReduceOp.AVG:\n op = torch.distributed.ReduceOp.AVG\n elif op == ReduceOp.MIN:\n op = torch.distributed.ReduceOp.MIN\n elif op == ReduceOp.MAX:\n op = torch.distributed.ReduceOp.MAX\n elif op == ReduceOp.BAND:\n op = torch.distributed.ReduceOp.BAND\n elif op == ReduceOp.BOR:\n op = torch.distributed.ReduceOp.BOR\n elif op == ReduceOp.BXOR:\n op = torch.distributed.ReduceOp.BXOR\n return op\n\n\n# This will become a light-weight wrapper around torch.distributed functions\n# TODO: create some example to show how this wrapper can help profile communication\n# TODO: make sure there is no performance regression with this approach\n# TODO: explore monkey-patching if this does not work\n", "path": "deepspeed/comm/torch.py"}], "after_files": [{"content": "import torch\nfrom .utils import *\nfrom deepspeed import utils\n\nsupported_torch_version = False\n\n# See more details at: https://github.com/pytorch/pytorch/pull/48767\n# The PG API in torch versions lesser than 1.8 are different so it is\n# non-trivial to support both in the same API. We will just use the\n# DS comm. backend in deepspeed/comm/comm.py if torch version if 1.8+.\n\nif older_torch():\n # Add custom deepspeed torch comm functions here since we can't import deepspeed.comm\n # NOTE: We can't call torch.distributed directly here. Current hack is to import functions before calling them.\n supported_torch_version = False\n from torch.distributed import *\n\n def get_world_group():\n return group.WORLD\n\n def get_global_rank(group, group_rank):\n if hasattr(torch.distributed.distributed_c10d, \"get_global_rank\"):\n from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank\n else:\n from torch.distributed.distributed_c10d import _get_global_rank\n return _get_global_rank(group, group_rank)\n\n def allgather_fn(output_tensor, input_tensor, group=None, async_op=False):\n from torch.distributed import all_gather, get_world_size\n from torch import chunk\n output_tensors = list(chunk(output_tensor, get_world_size(group)))\n return all_gather(output_tensors, input_tensor, group=group, async_op=async_op)\n\n def reduce_scatter_fn(output_tensor, input_tensor, group=None, async_op=False):\n from torch.distributed import reduce_scatter, get_world_size\n from torch import chunk\n input_tensor_lst = list(chunk(input_tensor, get_world_size(group)))\n return reduce_scatter(output_tensor, input_tensor_lst, group=group)\n\n def configure(deepspeed_config=None,\n enabled=None,\n prof_all=None,\n prof_ops=None,\n verbose=None):\n utils.logger.warn(\n \"Communication logging is not supported in torch versions older than 1.8\")\n\nelse:\n supported_torch_version = True\n from .comm import *\n", "path": "deepspeed/comm/__init__.py"}, {"content": "'''\nCopyright 2021 The Microsoft DeepSpeed Team\n'''\nfrom deepspeed import utils\n\nfrom .utils import *\nfrom .backend import *\nfrom .comm import *\n\n\nclass TorchBackend(Backend):\n \"\"\"\n A light-weight wrapper class for torch.distributed API.\n Only a subset of functions are wrapped. Once the init_process_group\n is initialized, standard torch.distributed.* can be used directly\n so no need to wrap all the functions. We can keep adding wrappers as\n needed.\n \"\"\"\n def __init__(self, backend, timeout, init_method, name='torch'):\n super(TorchBackend, self).__init__()\n self.torch_version_before_18 = older_torch()\n self.has_allgather_base = has_allgather_base()\n self.has_reduce_scatter_base = has_reduce_scatter_base()\n self.initialized = True\n self.name = name\n # Future functionality to support ds.initialize() on a single GPU\n # The idea is to fake that dist backend is initialized even when\n # it is not so we can run on a single GPU without doing any init_process_group\n self.single_gpu_mode = True\n self.init_process_group(backend, timeout, init_method)\n\n def init_process_group(self, backend, timeout, init_method):\n if not torch.distributed.is_initialized():\n torch.distributed.init_process_group(backend,\n timeout=timeout,\n init_method=init_method)\n self.using_mpi = torch.distributed.get_backend() == 'mpi'\n\n def all_reduce(self,\n tensor,\n op=torch.distributed.ReduceOp.SUM,\n group=None,\n async_op=False):\n op = self._reduce_op(op)\n return torch.distributed.all_reduce(tensor=tensor,\n op=op,\n group=group,\n async_op=async_op)\n\n def reduce(self, tensor, dst, op=ReduceOp.SUM, group=None, async_op=False):\n return torch.distributed.reduce(tensor=tensor,\n dst=dst,\n op=self._reduce_op(op),\n group=group,\n async_op=async_op)\n\n def reduce_scatter(self,\n output,\n input_list,\n op=ReduceOp.SUM,\n group=None,\n async_op=False):\n return torch.distributed.reduce_scatter(output=output,\n input_list=input_list,\n op=self._reduce_op(op),\n group=group,\n async_op=async_op)\n\n def broadcast(self, tensor, src, group=None, async_op=False):\n return torch.distributed.broadcast(tensor=tensor,\n src=src,\n group=group,\n async_op=async_op)\n\n def all_gather(self, tensor_list, tensor, group=None, async_op=False):\n return torch.distributed.all_gather(tensor_list=tensor_list,\n tensor=tensor,\n group=group,\n async_op=async_op)\n\n def all_gather_base(self, output_tensor, input_tensor, group=None, async_op=False):\n if self.has_allgather_base:\n return torch.distributed.distributed_c10d._all_gather_base(\n output_tensor=output_tensor,\n input_tensor=input_tensor,\n group=group,\n async_op=async_op)\n else:\n utils.logger.warning(\n \"unable to find torch.distributed._all_gather_base. will fall back to \"\n \"torch.distributed.reduce_scatter which will result in suboptimal performance. \"\n \"please consider upgrading your pytorch installation.\")\n pass\n\n def reduce_scatter_base(self,\n output_tensor,\n input_tensor,\n group=None,\n async_op=False):\n if self.has_reduce_scatter_base:\n return torch.distributed._reduce_scatter_base(output_tensor,\n input_tensor,\n group=group,\n async_op=async_op)\n else:\n utils.logger.warning(\n \"unable to find torch.distributed._reduce_scatter_base. will fall back to \"\n \"torch.distributed.reduce_scatter which will result in suboptimal performance. \"\n \"please consider upgrading your pytorch installation.\")\n pass\n\n def all_to_all_single(self,\n output,\n input,\n output_split_sizes=None,\n input_split_sizes=None,\n group=None,\n async_op=False):\n return torch.distributed.all_to_all_single(output=output,\n input=input,\n output_split_sizes=output_split_sizes,\n input_split_sizes=input_split_sizes,\n group=group,\n async_op=async_op)\n\n def send(self, tensor, dst, group=None, tag=0):\n return torch.distributed.send(tensor=tensor, dst=dst, group=group, tag=tag)\n\n def recv(self, tensor, src=None, group=None, tag=0):\n return torch.distributed.recv(tensor=tensor, src=src, group=group, tag=tag)\n\n def isend(self, tensor, dst, group=None, tag=0):\n return torch.distributed.isend(tensor=tensor, dst=dst, group=group, tag=tag)\n\n def irecv(self, tensor, src=None, group=None, tag=0):\n return torch.distributed.irecv(tensor=tensor, src=src, group=group, tag=tag)\n\n def gather(self, tensor, gather_list=None, dst=0, group=None, async_op=False):\n return torch.distributed.gather(tensor=tensor,\n gather_list=gather_list,\n dst=dst,\n group=group,\n async_op=async_op)\n\n def scatter(self, tensor, scatter_list=None, src=0, group=None, async_op=False):\n return torch.distributed.scatter(tensor=tensor,\n scatter_list=scatter_list,\n src=src,\n group=group,\n async_op=async_op)\n\n def barrier(self):\n return torch.distributed.barrier()\n\n def get_rank(self, group=None):\n return torch.distributed.get_rank(group=group)\n\n def get_world_size(self, group=None):\n return torch.distributed.get_world_size(group=group)\n\n def is_initialized(self):\n return torch.distributed.is_initialized()\n\n def get_backend(self, group=None):\n return torch.distributed.get_backend(group=group)\n\n def new_group(self, ranks):\n return torch.distributed.new_group(ranks)\n\n def get_global_rank(self, group, group_rank):\n if hasattr(torch.distributed.distributed_c10d, \"get_global_rank\"):\n from torch.distributed.distributed_c10d import get_global_rank as _get_global_rank\n else:\n from torch.distributed.distributed_c10d import _get_global_rank\n return _get_global_rank(group, group_rank)\n\n def get_world_group(self):\n return torch.distributed.group.WORLD\n\n def destroy_process_group(self, group=None):\n return torch.distributed.destroy_process_group(group=group)\n\n def _reduce_op(self, op):\n '''\n Helper function. If the op provided is not a torch.dist.ReduceOp, convert it and return\n '''\n if not isinstance(op, torch.distributed.ReduceOp):\n if op == ReduceOp.SUM:\n op = torch.distributed.ReduceOp.SUM\n elif op == ReduceOp.PRODUCT:\n op = torch.distributed.ReduceOp.PRODUCT\n elif op == ReduceOp.AVG:\n op = torch.distributed.ReduceOp.AVG\n elif op == ReduceOp.MIN:\n op = torch.distributed.ReduceOp.MIN\n elif op == ReduceOp.MAX:\n op = torch.distributed.ReduceOp.MAX\n elif op == ReduceOp.BAND:\n op = torch.distributed.ReduceOp.BAND\n elif op == ReduceOp.BOR:\n op = torch.distributed.ReduceOp.BOR\n elif op == ReduceOp.BXOR:\n op = torch.distributed.ReduceOp.BXOR\n return op\n\n\n# This will become a light-weight wrapper around torch.distributed functions\n# TODO: create some example to show how this wrapper can help profile communication\n# TODO: make sure there is no performance regression with this approach\n# TODO: explore monkey-patching if this does not work\n", "path": "deepspeed/comm/torch.py"}]}
| 3,160 | 383 |
gh_patches_debug_38507
|
rasdani/github-patches
|
git_diff
|
pypa__pip-4293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pip freeze reports doubles in requirements files as "not installed"
* Pip version: 9.0.1
* Python version: all
* Operating system: all
### Description:
If a package is listed twice in a single requirements file, or once in two or more requirements files, then 'pip freeze -r requirements.txt' erroneously reports that the package isn't installed.
### What I've run:
```
pip install simplejson
cat <<EOF > requirements.txt
simplejson
simplejson
EOF
pip freeze -r requirements.txt
simplejson==3.10.0
Requirement file [requirements.txt] contains simplejson, but that package is not installed
## The following requirements were added by pip freeze:
```
Similarly, pip freeze now supports multiple '-r' options, and if the same package appears in more than one of the requirements files, then the same message about the package not being installed is displayed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pip/_internal/operations/freeze.py`
Content:
```
1 from __future__ import absolute_import
2
3 import logging
4 import os
5 import re
6 import warnings
7
8 from pip._vendor import pkg_resources
9 from pip._vendor.packaging.utils import canonicalize_name
10 from pip._vendor.pkg_resources import RequirementParseError
11
12 from pip._internal.exceptions import InstallationError
13 from pip._internal.req import InstallRequirement
14 from pip._internal.req.req_file import COMMENT_RE
15 from pip._internal.utils.deprecation import RemovedInPip11Warning
16 from pip._internal.utils.misc import (
17 dist_is_editable, get_installed_distributions
18 )
19
20 logger = logging.getLogger(__name__)
21
22
23 def freeze(
24 requirement=None,
25 find_links=None, local_only=None, user_only=None, skip_regex=None,
26 isolated=False,
27 wheel_cache=None,
28 exclude_editable=False,
29 skip=()):
30 find_links = find_links or []
31 skip_match = None
32
33 if skip_regex:
34 skip_match = re.compile(skip_regex).search
35
36 dependency_links = []
37
38 for dist in pkg_resources.working_set:
39 if dist.has_metadata('dependency_links.txt'):
40 dependency_links.extend(
41 dist.get_metadata_lines('dependency_links.txt')
42 )
43 for link in find_links:
44 if '#egg=' in link:
45 dependency_links.append(link)
46 for link in find_links:
47 yield '-f %s' % link
48 installations = {}
49 for dist in get_installed_distributions(local_only=local_only,
50 skip=(),
51 user_only=user_only):
52 try:
53 req = FrozenRequirement.from_dist(
54 dist,
55 dependency_links
56 )
57 except RequirementParseError:
58 logger.warning(
59 "Could not parse requirement: %s",
60 dist.project_name
61 )
62 continue
63 if exclude_editable and req.editable:
64 continue
65 installations[req.name] = req
66
67 if requirement:
68 # the options that don't get turned into an InstallRequirement
69 # should only be emitted once, even if the same option is in multiple
70 # requirements files, so we need to keep track of what has been emitted
71 # so that we don't emit it again if it's seen again
72 emitted_options = set()
73 for req_file_path in requirement:
74 with open(req_file_path) as req_file:
75 for line in req_file:
76 if (not line.strip() or
77 line.strip().startswith('#') or
78 (skip_match and skip_match(line)) or
79 line.startswith((
80 '-r', '--requirement',
81 '-Z', '--always-unzip',
82 '-f', '--find-links',
83 '-i', '--index-url',
84 '--pre',
85 '--trusted-host',
86 '--process-dependency-links',
87 '--extra-index-url'))):
88 line = line.rstrip()
89 if line not in emitted_options:
90 emitted_options.add(line)
91 yield line
92 continue
93
94 if line.startswith('-e') or line.startswith('--editable'):
95 if line.startswith('-e'):
96 line = line[2:].strip()
97 else:
98 line = line[len('--editable'):].strip().lstrip('=')
99 line_req = InstallRequirement.from_editable(
100 line,
101 isolated=isolated,
102 wheel_cache=wheel_cache,
103 )
104 else:
105 line_req = InstallRequirement.from_line(
106 COMMENT_RE.sub('', line).strip(),
107 isolated=isolated,
108 wheel_cache=wheel_cache,
109 )
110
111 if not line_req.name:
112 logger.info(
113 "Skipping line in requirement file [%s] because "
114 "it's not clear what it would install: %s",
115 req_file_path, line.strip(),
116 )
117 logger.info(
118 " (add #egg=PackageName to the URL to avoid"
119 " this warning)"
120 )
121 elif line_req.name not in installations:
122 logger.warning(
123 "Requirement file [%s] contains %s, but that "
124 "package is not installed",
125 req_file_path, COMMENT_RE.sub('', line).strip(),
126 )
127 else:
128 yield str(installations[line_req.name]).rstrip()
129 del installations[line_req.name]
130
131 yield(
132 '## The following requirements were added by '
133 'pip freeze:'
134 )
135 for installation in sorted(
136 installations.values(), key=lambda x: x.name.lower()):
137 if canonicalize_name(installation.name) not in skip:
138 yield str(installation).rstrip()
139
140
141 class FrozenRequirement(object):
142 def __init__(self, name, req, editable, comments=()):
143 self.name = name
144 self.req = req
145 self.editable = editable
146 self.comments = comments
147
148 _rev_re = re.compile(r'-r(\d+)$')
149 _date_re = re.compile(r'-(20\d\d\d\d\d\d)$')
150
151 @classmethod
152 def from_dist(cls, dist, dependency_links):
153 location = os.path.normcase(os.path.abspath(dist.location))
154 comments = []
155 from pip._internal.vcs import vcs, get_src_requirement
156 if dist_is_editable(dist) and vcs.get_backend_name(location):
157 editable = True
158 try:
159 req = get_src_requirement(dist, location)
160 except InstallationError as exc:
161 logger.warning(
162 "Error when trying to get requirement for VCS system %s, "
163 "falling back to uneditable format", exc
164 )
165 req = None
166 if req is None:
167 logger.warning(
168 'Could not determine repository location of %s', location
169 )
170 comments.append(
171 '## !! Could not determine repository location'
172 )
173 req = dist.as_requirement()
174 editable = False
175 else:
176 editable = False
177 req = dist.as_requirement()
178 specs = req.specs
179 assert len(specs) == 1 and specs[0][0] in ["==", "==="], \
180 'Expected 1 spec with == or ===; specs = %r; dist = %r' % \
181 (specs, dist)
182 version = specs[0][1]
183 ver_match = cls._rev_re.search(version)
184 date_match = cls._date_re.search(version)
185 if ver_match or date_match:
186 svn_backend = vcs.get_backend('svn')
187 if svn_backend:
188 svn_location = svn_backend().get_location(
189 dist,
190 dependency_links,
191 )
192 if not svn_location:
193 logger.warning(
194 'Warning: cannot find svn location for %s', req)
195 comments.append(
196 '## FIXME: could not find svn URL in dependency_links '
197 'for this package:'
198 )
199 else:
200 warnings.warn(
201 "SVN editable detection based on dependency links "
202 "will be dropped in the future.",
203 RemovedInPip11Warning,
204 )
205 comments.append(
206 '# Installing as editable to satisfy requirement %s:' %
207 req
208 )
209 if ver_match:
210 rev = ver_match.group(1)
211 else:
212 rev = '{%s}' % date_match.group(1)
213 editable = True
214 req = '%s@%s#egg=%s' % (
215 svn_location,
216 rev,
217 cls.egg_name(dist)
218 )
219 return cls(dist.project_name, req, editable, comments)
220
221 @staticmethod
222 def egg_name(dist):
223 name = dist.egg_name()
224 match = re.search(r'-py\d\.\d$', name)
225 if match:
226 name = name[:match.start()]
227 return name
228
229 def __str__(self):
230 req = self.req
231 if self.editable:
232 req = '-e %s' % req
233 return '\n'.join(list(self.comments) + [str(req)]) + '\n'
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pip/_internal/operations/freeze.py b/src/pip/_internal/operations/freeze.py
--- a/src/pip/_internal/operations/freeze.py
+++ b/src/pip/_internal/operations/freeze.py
@@ -1,11 +1,12 @@
from __future__ import absolute_import
+import collections
import logging
import os
import re
import warnings
-from pip._vendor import pkg_resources
+from pip._vendor import pkg_resources, six
from pip._vendor.packaging.utils import canonicalize_name
from pip._vendor.pkg_resources import RequirementParseError
@@ -70,6 +71,9 @@
# requirements files, so we need to keep track of what has been emitted
# so that we don't emit it again if it's seen again
emitted_options = set()
+ # keep track of which files a requirement is in so that we can
+ # give an accurate warning if a requirement appears multiple times.
+ req_files = collections.defaultdict(list)
for req_file_path in requirement:
with open(req_file_path) as req_file:
for line in req_file:
@@ -119,14 +123,28 @@
" this warning)"
)
elif line_req.name not in installations:
- logger.warning(
- "Requirement file [%s] contains %s, but that "
- "package is not installed",
- req_file_path, COMMENT_RE.sub('', line).strip(),
- )
+ # either it's not installed, or it is installed
+ # but has been processed already
+ if not req_files[line_req.name]:
+ logger.warning(
+ "Requirement file [%s] contains %s, but that "
+ "package is not installed",
+ req_file_path,
+ COMMENT_RE.sub('', line).strip(),
+ )
+ else:
+ req_files[line_req.name].append(req_file_path)
else:
yield str(installations[line_req.name]).rstrip()
del installations[line_req.name]
+ req_files[line_req.name].append(req_file_path)
+
+ # Warn about requirements that were included multiple times (in a
+ # single requirements file or in different requirements files).
+ for name, files in six.iteritems(req_files):
+ if len(files) > 1:
+ logger.warning("Requirement %s included multiple times [%s]",
+ name, ', '.join(sorted(set(files))))
yield(
'## The following requirements were added by '
|
{"golden_diff": "diff --git a/src/pip/_internal/operations/freeze.py b/src/pip/_internal/operations/freeze.py\n--- a/src/pip/_internal/operations/freeze.py\n+++ b/src/pip/_internal/operations/freeze.py\n@@ -1,11 +1,12 @@\n from __future__ import absolute_import\n \n+import collections\n import logging\n import os\n import re\n import warnings\n \n-from pip._vendor import pkg_resources\n+from pip._vendor import pkg_resources, six\n from pip._vendor.packaging.utils import canonicalize_name\n from pip._vendor.pkg_resources import RequirementParseError\n \n@@ -70,6 +71,9 @@\n # requirements files, so we need to keep track of what has been emitted\n # so that we don't emit it again if it's seen again\n emitted_options = set()\n+ # keep track of which files a requirement is in so that we can\n+ # give an accurate warning if a requirement appears multiple times.\n+ req_files = collections.defaultdict(list)\n for req_file_path in requirement:\n with open(req_file_path) as req_file:\n for line in req_file:\n@@ -119,14 +123,28 @@\n \" this warning)\"\n )\n elif line_req.name not in installations:\n- logger.warning(\n- \"Requirement file [%s] contains %s, but that \"\n- \"package is not installed\",\n- req_file_path, COMMENT_RE.sub('', line).strip(),\n- )\n+ # either it's not installed, or it is installed\n+ # but has been processed already\n+ if not req_files[line_req.name]:\n+ logger.warning(\n+ \"Requirement file [%s] contains %s, but that \"\n+ \"package is not installed\",\n+ req_file_path,\n+ COMMENT_RE.sub('', line).strip(),\n+ )\n+ else:\n+ req_files[line_req.name].append(req_file_path)\n else:\n yield str(installations[line_req.name]).rstrip()\n del installations[line_req.name]\n+ req_files[line_req.name].append(req_file_path)\n+\n+ # Warn about requirements that were included multiple times (in a\n+ # single requirements file or in different requirements files).\n+ for name, files in six.iteritems(req_files):\n+ if len(files) > 1:\n+ logger.warning(\"Requirement %s included multiple times [%s]\",\n+ name, ', '.join(sorted(set(files))))\n \n yield(\n '## The following requirements were added by '\n", "issue": "pip freeze reports doubles in requirements files as \"not installed\"\n* Pip version: 9.0.1\r\n* Python version: all\r\n* Operating system: all\r\n\r\n### Description:\r\nIf a package is listed twice in a single requirements file, or once in two or more requirements files, then 'pip freeze -r requirements.txt' erroneously reports that the package isn't installed.\r\n\r\n\r\n### What I've run:\r\n\r\n```\r\npip install simplejson\r\n\r\ncat <<EOF > requirements.txt\r\nsimplejson\r\nsimplejson\r\nEOF\r\n\r\npip freeze -r requirements.txt\r\nsimplejson==3.10.0\r\nRequirement file [requirements.txt] contains simplejson, but that package is not installed\r\n## The following requirements were added by pip freeze:\r\n```\r\n\r\nSimilarly, pip freeze now supports multiple '-r' options, and if the same package appears in more than one of the requirements files, then the same message about the package not being installed is displayed.\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport os\nimport re\nimport warnings\n\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.pkg_resources import RequirementParseError\n\nfrom pip._internal.exceptions import InstallationError\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.req.req_file import COMMENT_RE\nfrom pip._internal.utils.deprecation import RemovedInPip11Warning\nfrom pip._internal.utils.misc import (\n dist_is_editable, get_installed_distributions\n)\n\nlogger = logging.getLogger(__name__)\n\n\ndef freeze(\n requirement=None,\n find_links=None, local_only=None, user_only=None, skip_regex=None,\n isolated=False,\n wheel_cache=None,\n exclude_editable=False,\n skip=()):\n find_links = find_links or []\n skip_match = None\n\n if skip_regex:\n skip_match = re.compile(skip_regex).search\n\n dependency_links = []\n\n for dist in pkg_resources.working_set:\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt')\n )\n for link in find_links:\n if '#egg=' in link:\n dependency_links.append(link)\n for link in find_links:\n yield '-f %s' % link\n installations = {}\n for dist in get_installed_distributions(local_only=local_only,\n skip=(),\n user_only=user_only):\n try:\n req = FrozenRequirement.from_dist(\n dist,\n dependency_links\n )\n except RequirementParseError:\n logger.warning(\n \"Could not parse requirement: %s\",\n dist.project_name\n )\n continue\n if exclude_editable and req.editable:\n continue\n installations[req.name] = req\n\n if requirement:\n # the options that don't get turned into an InstallRequirement\n # should only be emitted once, even if the same option is in multiple\n # requirements files, so we need to keep track of what has been emitted\n # so that we don't emit it again if it's seen again\n emitted_options = set()\n for req_file_path in requirement:\n with open(req_file_path) as req_file:\n for line in req_file:\n if (not line.strip() or\n line.strip().startswith('#') or\n (skip_match and skip_match(line)) or\n line.startswith((\n '-r', '--requirement',\n '-Z', '--always-unzip',\n '-f', '--find-links',\n '-i', '--index-url',\n '--pre',\n '--trusted-host',\n '--process-dependency-links',\n '--extra-index-url'))):\n line = line.rstrip()\n if line not in emitted_options:\n emitted_options.add(line)\n yield line\n continue\n\n if line.startswith('-e') or line.startswith('--editable'):\n if line.startswith('-e'):\n line = line[2:].strip()\n else:\n line = line[len('--editable'):].strip().lstrip('=')\n line_req = InstallRequirement.from_editable(\n line,\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n else:\n line_req = InstallRequirement.from_line(\n COMMENT_RE.sub('', line).strip(),\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n\n if not line_req.name:\n logger.info(\n \"Skipping line in requirement file [%s] because \"\n \"it's not clear what it would install: %s\",\n req_file_path, line.strip(),\n )\n logger.info(\n \" (add #egg=PackageName to the URL to avoid\"\n \" this warning)\"\n )\n elif line_req.name not in installations:\n logger.warning(\n \"Requirement file [%s] contains %s, but that \"\n \"package is not installed\",\n req_file_path, COMMENT_RE.sub('', line).strip(),\n )\n else:\n yield str(installations[line_req.name]).rstrip()\n del installations[line_req.name]\n\n yield(\n '## The following requirements were added by '\n 'pip freeze:'\n )\n for installation in sorted(\n installations.values(), key=lambda x: x.name.lower()):\n if canonicalize_name(installation.name) not in skip:\n yield str(installation).rstrip()\n\n\nclass FrozenRequirement(object):\n def __init__(self, name, req, editable, comments=()):\n self.name = name\n self.req = req\n self.editable = editable\n self.comments = comments\n\n _rev_re = re.compile(r'-r(\\d+)$')\n _date_re = re.compile(r'-(20\\d\\d\\d\\d\\d\\d)$')\n\n @classmethod\n def from_dist(cls, dist, dependency_links):\n location = os.path.normcase(os.path.abspath(dist.location))\n comments = []\n from pip._internal.vcs import vcs, get_src_requirement\n if dist_is_editable(dist) and vcs.get_backend_name(location):\n editable = True\n try:\n req = get_src_requirement(dist, location)\n except InstallationError as exc:\n logger.warning(\n \"Error when trying to get requirement for VCS system %s, \"\n \"falling back to uneditable format\", exc\n )\n req = None\n if req is None:\n logger.warning(\n 'Could not determine repository location of %s', location\n )\n comments.append(\n '## !! Could not determine repository location'\n )\n req = dist.as_requirement()\n editable = False\n else:\n editable = False\n req = dist.as_requirement()\n specs = req.specs\n assert len(specs) == 1 and specs[0][0] in [\"==\", \"===\"], \\\n 'Expected 1 spec with == or ===; specs = %r; dist = %r' % \\\n (specs, dist)\n version = specs[0][1]\n ver_match = cls._rev_re.search(version)\n date_match = cls._date_re.search(version)\n if ver_match or date_match:\n svn_backend = vcs.get_backend('svn')\n if svn_backend:\n svn_location = svn_backend().get_location(\n dist,\n dependency_links,\n )\n if not svn_location:\n logger.warning(\n 'Warning: cannot find svn location for %s', req)\n comments.append(\n '## FIXME: could not find svn URL in dependency_links '\n 'for this package:'\n )\n else:\n warnings.warn(\n \"SVN editable detection based on dependency links \"\n \"will be dropped in the future.\",\n RemovedInPip11Warning,\n )\n comments.append(\n '# Installing as editable to satisfy requirement %s:' %\n req\n )\n if ver_match:\n rev = ver_match.group(1)\n else:\n rev = '{%s}' % date_match.group(1)\n editable = True\n req = '%s@%s#egg=%s' % (\n svn_location,\n rev,\n cls.egg_name(dist)\n )\n return cls(dist.project_name, req, editable, comments)\n\n @staticmethod\n def egg_name(dist):\n name = dist.egg_name()\n match = re.search(r'-py\\d\\.\\d$', name)\n if match:\n name = name[:match.start()]\n return name\n\n def __str__(self):\n req = self.req\n if self.editable:\n req = '-e %s' % req\n return '\\n'.join(list(self.comments) + [str(req)]) + '\\n'\n", "path": "src/pip/_internal/operations/freeze.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport collections\nimport logging\nimport os\nimport re\nimport warnings\n\nfrom pip._vendor import pkg_resources, six\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.pkg_resources import RequirementParseError\n\nfrom pip._internal.exceptions import InstallationError\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.req.req_file import COMMENT_RE\nfrom pip._internal.utils.deprecation import RemovedInPip11Warning\nfrom pip._internal.utils.misc import (\n dist_is_editable, get_installed_distributions\n)\n\nlogger = logging.getLogger(__name__)\n\n\ndef freeze(\n requirement=None,\n find_links=None, local_only=None, user_only=None, skip_regex=None,\n isolated=False,\n wheel_cache=None,\n exclude_editable=False,\n skip=()):\n find_links = find_links or []\n skip_match = None\n\n if skip_regex:\n skip_match = re.compile(skip_regex).search\n\n dependency_links = []\n\n for dist in pkg_resources.working_set:\n if dist.has_metadata('dependency_links.txt'):\n dependency_links.extend(\n dist.get_metadata_lines('dependency_links.txt')\n )\n for link in find_links:\n if '#egg=' in link:\n dependency_links.append(link)\n for link in find_links:\n yield '-f %s' % link\n installations = {}\n for dist in get_installed_distributions(local_only=local_only,\n skip=(),\n user_only=user_only):\n try:\n req = FrozenRequirement.from_dist(\n dist,\n dependency_links\n )\n except RequirementParseError:\n logger.warning(\n \"Could not parse requirement: %s\",\n dist.project_name\n )\n continue\n if exclude_editable and req.editable:\n continue\n installations[req.name] = req\n\n if requirement:\n # the options that don't get turned into an InstallRequirement\n # should only be emitted once, even if the same option is in multiple\n # requirements files, so we need to keep track of what has been emitted\n # so that we don't emit it again if it's seen again\n emitted_options = set()\n # keep track of which files a requirement is in so that we can\n # give an accurate warning if a requirement appears multiple times.\n req_files = collections.defaultdict(list)\n for req_file_path in requirement:\n with open(req_file_path) as req_file:\n for line in req_file:\n if (not line.strip() or\n line.strip().startswith('#') or\n (skip_match and skip_match(line)) or\n line.startswith((\n '-r', '--requirement',\n '-Z', '--always-unzip',\n '-f', '--find-links',\n '-i', '--index-url',\n '--pre',\n '--trusted-host',\n '--process-dependency-links',\n '--extra-index-url'))):\n line = line.rstrip()\n if line not in emitted_options:\n emitted_options.add(line)\n yield line\n continue\n\n if line.startswith('-e') or line.startswith('--editable'):\n if line.startswith('-e'):\n line = line[2:].strip()\n else:\n line = line[len('--editable'):].strip().lstrip('=')\n line_req = InstallRequirement.from_editable(\n line,\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n else:\n line_req = InstallRequirement.from_line(\n COMMENT_RE.sub('', line).strip(),\n isolated=isolated,\n wheel_cache=wheel_cache,\n )\n\n if not line_req.name:\n logger.info(\n \"Skipping line in requirement file [%s] because \"\n \"it's not clear what it would install: %s\",\n req_file_path, line.strip(),\n )\n logger.info(\n \" (add #egg=PackageName to the URL to avoid\"\n \" this warning)\"\n )\n elif line_req.name not in installations:\n # either it's not installed, or it is installed\n # but has been processed already\n if not req_files[line_req.name]:\n logger.warning(\n \"Requirement file [%s] contains %s, but that \"\n \"package is not installed\",\n req_file_path,\n COMMENT_RE.sub('', line).strip(),\n )\n else:\n req_files[line_req.name].append(req_file_path)\n else:\n yield str(installations[line_req.name]).rstrip()\n del installations[line_req.name]\n req_files[line_req.name].append(req_file_path)\n\n # Warn about requirements that were included multiple times (in a\n # single requirements file or in different requirements files).\n for name, files in six.iteritems(req_files):\n if len(files) > 1:\n logger.warning(\"Requirement %s included multiple times [%s]\",\n name, ', '.join(sorted(set(files))))\n\n yield(\n '## The following requirements were added by '\n 'pip freeze:'\n )\n for installation in sorted(\n installations.values(), key=lambda x: x.name.lower()):\n if canonicalize_name(installation.name) not in skip:\n yield str(installation).rstrip()\n\n\nclass FrozenRequirement(object):\n def __init__(self, name, req, editable, comments=()):\n self.name = name\n self.req = req\n self.editable = editable\n self.comments = comments\n\n _rev_re = re.compile(r'-r(\\d+)$')\n _date_re = re.compile(r'-(20\\d\\d\\d\\d\\d\\d)$')\n\n @classmethod\n def from_dist(cls, dist, dependency_links):\n location = os.path.normcase(os.path.abspath(dist.location))\n comments = []\n from pip._internal.vcs import vcs, get_src_requirement\n if dist_is_editable(dist) and vcs.get_backend_name(location):\n editable = True\n try:\n req = get_src_requirement(dist, location)\n except InstallationError as exc:\n logger.warning(\n \"Error when trying to get requirement for VCS system %s, \"\n \"falling back to uneditable format\", exc\n )\n req = None\n if req is None:\n logger.warning(\n 'Could not determine repository location of %s', location\n )\n comments.append(\n '## !! Could not determine repository location'\n )\n req = dist.as_requirement()\n editable = False\n else:\n editable = False\n req = dist.as_requirement()\n specs = req.specs\n assert len(specs) == 1 and specs[0][0] in [\"==\", \"===\"], \\\n 'Expected 1 spec with == or ===; specs = %r; dist = %r' % \\\n (specs, dist)\n version = specs[0][1]\n ver_match = cls._rev_re.search(version)\n date_match = cls._date_re.search(version)\n if ver_match or date_match:\n svn_backend = vcs.get_backend('svn')\n if svn_backend:\n svn_location = svn_backend().get_location(\n dist,\n dependency_links,\n )\n if not svn_location:\n logger.warning(\n 'Warning: cannot find svn location for %s', req)\n comments.append(\n '## FIXME: could not find svn URL in dependency_links '\n 'for this package:'\n )\n else:\n warnings.warn(\n \"SVN editable detection based on dependency links \"\n \"will be dropped in the future.\",\n RemovedInPip11Warning,\n )\n comments.append(\n '# Installing as editable to satisfy requirement %s:' %\n req\n )\n if ver_match:\n rev = ver_match.group(1)\n else:\n rev = '{%s}' % date_match.group(1)\n editable = True\n req = '%s@%s#egg=%s' % (\n svn_location,\n rev,\n cls.egg_name(dist)\n )\n return cls(dist.project_name, req, editable, comments)\n\n @staticmethod\n def egg_name(dist):\n name = dist.egg_name()\n match = re.search(r'-py\\d\\.\\d$', name)\n if match:\n name = name[:match.start()]\n return name\n\n def __str__(self):\n req = self.req\n if self.editable:\n req = '-e %s' % req\n return '\\n'.join(list(self.comments) + [str(req)]) + '\\n'\n", "path": "src/pip/_internal/operations/freeze.py"}]}
| 2,679 | 546 |
gh_patches_debug_9615
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-3264
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How to implement a "watcher" thread as suggested by the documentation?
The documentation of the [`timeout`](https://urllib3.readthedocs.io/en/latest/reference/urllib3.util.html#module-urllib3.util.timeout) module says:
> If your goal is to cut off any request after a set amount of wall clock time, consider having a second “watcher” thread to cut off a slow request.
How would that work?
It seems like it is [strongly discouraged or even impossible](https://stackoverflow.com/questions/323972/is-there-any-way-to-kill-a-thread) to kill a thread in Python, so what would that watcher thread do?
If it is not possible to write a watcher thread in Python, the documentation shouldn't suggest to do it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/urllib3/util/timeout.py`
Content:
```
1 from __future__ import annotations
2
3 import time
4 import typing
5 from enum import Enum
6 from socket import getdefaulttimeout
7
8 from ..exceptions import TimeoutStateError
9
10 if typing.TYPE_CHECKING:
11 from typing import Final
12
13
14 class _TYPE_DEFAULT(Enum):
15 # This value should never be passed to socket.settimeout() so for safety we use a -1.
16 # socket.settimout() raises a ValueError for negative values.
17 token = -1
18
19
20 _DEFAULT_TIMEOUT: Final[_TYPE_DEFAULT] = _TYPE_DEFAULT.token
21
22 _TYPE_TIMEOUT = typing.Optional[typing.Union[float, _TYPE_DEFAULT]]
23
24
25 class Timeout:
26 """Timeout configuration.
27
28 Timeouts can be defined as a default for a pool:
29
30 .. code-block:: python
31
32 import urllib3
33
34 timeout = urllib3.util.Timeout(connect=2.0, read=7.0)
35
36 http = urllib3.PoolManager(timeout=timeout)
37
38 resp = http.request("GET", "https://example.com/")
39
40 print(resp.status)
41
42 Or per-request (which overrides the default for the pool):
43
44 .. code-block:: python
45
46 response = http.request("GET", "https://example.com/", timeout=Timeout(10))
47
48 Timeouts can be disabled by setting all the parameters to ``None``:
49
50 .. code-block:: python
51
52 no_timeout = Timeout(connect=None, read=None)
53 response = http.request("GET", "https://example.com/", timeout=no_timeout)
54
55
56 :param total:
57 This combines the connect and read timeouts into one; the read timeout
58 will be set to the time leftover from the connect attempt. In the
59 event that both a connect timeout and a total are specified, or a read
60 timeout and a total are specified, the shorter timeout will be applied.
61
62 Defaults to None.
63
64 :type total: int, float, or None
65
66 :param connect:
67 The maximum amount of time (in seconds) to wait for a connection
68 attempt to a server to succeed. Omitting the parameter will default the
69 connect timeout to the system default, probably `the global default
70 timeout in socket.py
71 <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
72 None will set an infinite timeout for connection attempts.
73
74 :type connect: int, float, or None
75
76 :param read:
77 The maximum amount of time (in seconds) to wait between consecutive
78 read operations for a response from the server. Omitting the parameter
79 will default the read timeout to the system default, probably `the
80 global default timeout in socket.py
81 <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
82 None will set an infinite timeout.
83
84 :type read: int, float, or None
85
86 .. note::
87
88 Many factors can affect the total amount of time for urllib3 to return
89 an HTTP response.
90
91 For example, Python's DNS resolver does not obey the timeout specified
92 on the socket. Other factors that can affect total request time include
93 high CPU load, high swap, the program running at a low priority level,
94 or other behaviors.
95
96 In addition, the read and total timeouts only measure the time between
97 read operations on the socket connecting the client and the server,
98 not the total amount of time for the request to return a complete
99 response. For most requests, the timeout is raised because the server
100 has not sent the first byte in the specified time. This is not always
101 the case; if a server streams one byte every fifteen seconds, a timeout
102 of 20 seconds will not trigger, even though the request will take
103 several minutes to complete.
104
105 If your goal is to cut off any request after a set amount of wall clock
106 time, consider having a second "watcher" thread to cut off a slow
107 request.
108 """
109
110 #: A sentinel object representing the default timeout value
111 DEFAULT_TIMEOUT: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT
112
113 def __init__(
114 self,
115 total: _TYPE_TIMEOUT = None,
116 connect: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
117 read: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
118 ) -> None:
119 self._connect = self._validate_timeout(connect, "connect")
120 self._read = self._validate_timeout(read, "read")
121 self.total = self._validate_timeout(total, "total")
122 self._start_connect: float | None = None
123
124 def __repr__(self) -> str:
125 return f"{type(self).__name__}(connect={self._connect!r}, read={self._read!r}, total={self.total!r})"
126
127 # __str__ provided for backwards compatibility
128 __str__ = __repr__
129
130 @staticmethod
131 def resolve_default_timeout(timeout: _TYPE_TIMEOUT) -> float | None:
132 return getdefaulttimeout() if timeout is _DEFAULT_TIMEOUT else timeout
133
134 @classmethod
135 def _validate_timeout(cls, value: _TYPE_TIMEOUT, name: str) -> _TYPE_TIMEOUT:
136 """Check that a timeout attribute is valid.
137
138 :param value: The timeout value to validate
139 :param name: The name of the timeout attribute to validate. This is
140 used to specify in error messages.
141 :return: The validated and casted version of the given value.
142 :raises ValueError: If it is a numeric value less than or equal to
143 zero, or the type is not an integer, float, or None.
144 """
145 if value is None or value is _DEFAULT_TIMEOUT:
146 return value
147
148 if isinstance(value, bool):
149 raise ValueError(
150 "Timeout cannot be a boolean value. It must "
151 "be an int, float or None."
152 )
153 try:
154 float(value)
155 except (TypeError, ValueError):
156 raise ValueError(
157 "Timeout value %s was %s, but it must be an "
158 "int, float or None." % (name, value)
159 ) from None
160
161 try:
162 if value <= 0:
163 raise ValueError(
164 "Attempted to set %s timeout to %s, but the "
165 "timeout cannot be set to a value less "
166 "than or equal to 0." % (name, value)
167 )
168 except TypeError:
169 raise ValueError(
170 "Timeout value %s was %s, but it must be an "
171 "int, float or None." % (name, value)
172 ) from None
173
174 return value
175
176 @classmethod
177 def from_float(cls, timeout: _TYPE_TIMEOUT) -> Timeout:
178 """Create a new Timeout from a legacy timeout value.
179
180 The timeout value used by httplib.py sets the same timeout on the
181 connect(), and recv() socket requests. This creates a :class:`Timeout`
182 object that sets the individual timeouts to the ``timeout`` value
183 passed to this function.
184
185 :param timeout: The legacy timeout value.
186 :type timeout: integer, float, :attr:`urllib3.util.Timeout.DEFAULT_TIMEOUT`, or None
187 :return: Timeout object
188 :rtype: :class:`Timeout`
189 """
190 return Timeout(read=timeout, connect=timeout)
191
192 def clone(self) -> Timeout:
193 """Create a copy of the timeout object
194
195 Timeout properties are stored per-pool but each request needs a fresh
196 Timeout object to ensure each one has its own start/stop configured.
197
198 :return: a copy of the timeout object
199 :rtype: :class:`Timeout`
200 """
201 # We can't use copy.deepcopy because that will also create a new object
202 # for _GLOBAL_DEFAULT_TIMEOUT, which socket.py uses as a sentinel to
203 # detect the user default.
204 return Timeout(connect=self._connect, read=self._read, total=self.total)
205
206 def start_connect(self) -> float:
207 """Start the timeout clock, used during a connect() attempt
208
209 :raises urllib3.exceptions.TimeoutStateError: if you attempt
210 to start a timer that has been started already.
211 """
212 if self._start_connect is not None:
213 raise TimeoutStateError("Timeout timer has already been started.")
214 self._start_connect = time.monotonic()
215 return self._start_connect
216
217 def get_connect_duration(self) -> float:
218 """Gets the time elapsed since the call to :meth:`start_connect`.
219
220 :return: Elapsed time in seconds.
221 :rtype: float
222 :raises urllib3.exceptions.TimeoutStateError: if you attempt
223 to get duration for a timer that hasn't been started.
224 """
225 if self._start_connect is None:
226 raise TimeoutStateError(
227 "Can't get connect duration for timer that has not started."
228 )
229 return time.monotonic() - self._start_connect
230
231 @property
232 def connect_timeout(self) -> _TYPE_TIMEOUT:
233 """Get the value to use when setting a connection timeout.
234
235 This will be a positive float or integer, the value None
236 (never timeout), or the default system timeout.
237
238 :return: Connect timeout.
239 :rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None
240 """
241 if self.total is None:
242 return self._connect
243
244 if self._connect is None or self._connect is _DEFAULT_TIMEOUT:
245 return self.total
246
247 return min(self._connect, self.total) # type: ignore[type-var]
248
249 @property
250 def read_timeout(self) -> float | None:
251 """Get the value for the read timeout.
252
253 This assumes some time has elapsed in the connection timeout and
254 computes the read timeout appropriately.
255
256 If self.total is set, the read timeout is dependent on the amount of
257 time taken by the connect timeout. If the connection time has not been
258 established, a :exc:`~urllib3.exceptions.TimeoutStateError` will be
259 raised.
260
261 :return: Value to use for the read timeout.
262 :rtype: int, float or None
263 :raises urllib3.exceptions.TimeoutStateError: If :meth:`start_connect`
264 has not yet been called on this object.
265 """
266 if (
267 self.total is not None
268 and self.total is not _DEFAULT_TIMEOUT
269 and self._read is not None
270 and self._read is not _DEFAULT_TIMEOUT
271 ):
272 # In case the connect timeout has not yet been established.
273 if self._start_connect is None:
274 return self._read
275 return max(0, min(self.total - self.get_connect_duration(), self._read))
276 elif self.total is not None and self.total is not _DEFAULT_TIMEOUT:
277 return max(0, self.total - self.get_connect_duration())
278 else:
279 return self.resolve_default_timeout(self._read)
280
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/urllib3/util/timeout.py b/src/urllib3/util/timeout.py
--- a/src/urllib3/util/timeout.py
+++ b/src/urllib3/util/timeout.py
@@ -101,10 +101,6 @@
the case; if a server streams one byte every fifteen seconds, a timeout
of 20 seconds will not trigger, even though the request will take
several minutes to complete.
-
- If your goal is to cut off any request after a set amount of wall clock
- time, consider having a second "watcher" thread to cut off a slow
- request.
"""
#: A sentinel object representing the default timeout value
|
{"golden_diff": "diff --git a/src/urllib3/util/timeout.py b/src/urllib3/util/timeout.py\n--- a/src/urllib3/util/timeout.py\n+++ b/src/urllib3/util/timeout.py\n@@ -101,10 +101,6 @@\n the case; if a server streams one byte every fifteen seconds, a timeout\n of 20 seconds will not trigger, even though the request will take\n several minutes to complete.\n-\n- If your goal is to cut off any request after a set amount of wall clock\n- time, consider having a second \"watcher\" thread to cut off a slow\n- request.\n \"\"\"\n \n #: A sentinel object representing the default timeout value\n", "issue": "How to implement a \"watcher\" thread as suggested by the documentation?\nThe documentation of the [`timeout`](https://urllib3.readthedocs.io/en/latest/reference/urllib3.util.html#module-urllib3.util.timeout) module says:\r\n\r\n> If your goal is to cut off any request after a set amount of wall clock time, consider having a second \u201cwatcher\u201d thread to cut off a slow request.\r\n\r\nHow would that work?\r\n\r\nIt seems like it is [strongly discouraged or even impossible](https://stackoverflow.com/questions/323972/is-there-any-way-to-kill-a-thread) to kill a thread in Python, so what would that watcher thread do?\r\n\r\nIf it is not possible to write a watcher thread in Python, the documentation shouldn't suggest to do it.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport time\nimport typing\nfrom enum import Enum\nfrom socket import getdefaulttimeout\n\nfrom ..exceptions import TimeoutStateError\n\nif typing.TYPE_CHECKING:\n from typing import Final\n\n\nclass _TYPE_DEFAULT(Enum):\n # This value should never be passed to socket.settimeout() so for safety we use a -1.\n # socket.settimout() raises a ValueError for negative values.\n token = -1\n\n\n_DEFAULT_TIMEOUT: Final[_TYPE_DEFAULT] = _TYPE_DEFAULT.token\n\n_TYPE_TIMEOUT = typing.Optional[typing.Union[float, _TYPE_DEFAULT]]\n\n\nclass Timeout:\n \"\"\"Timeout configuration.\n\n Timeouts can be defined as a default for a pool:\n\n .. code-block:: python\n\n import urllib3\n\n timeout = urllib3.util.Timeout(connect=2.0, read=7.0)\n\n http = urllib3.PoolManager(timeout=timeout)\n\n resp = http.request(\"GET\", \"https://example.com/\")\n\n print(resp.status)\n\n Or per-request (which overrides the default for the pool):\n\n .. code-block:: python\n\n response = http.request(\"GET\", \"https://example.com/\", timeout=Timeout(10))\n\n Timeouts can be disabled by setting all the parameters to ``None``:\n\n .. code-block:: python\n\n no_timeout = Timeout(connect=None, read=None)\n response = http.request(\"GET\", \"https://example.com/\", timeout=no_timeout)\n\n\n :param total:\n This combines the connect and read timeouts into one; the read timeout\n will be set to the time leftover from the connect attempt. In the\n event that both a connect timeout and a total are specified, or a read\n timeout and a total are specified, the shorter timeout will be applied.\n\n Defaults to None.\n\n :type total: int, float, or None\n\n :param connect:\n The maximum amount of time (in seconds) to wait for a connection\n attempt to a server to succeed. Omitting the parameter will default the\n connect timeout to the system default, probably `the global default\n timeout in socket.py\n <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.\n None will set an infinite timeout for connection attempts.\n\n :type connect: int, float, or None\n\n :param read:\n The maximum amount of time (in seconds) to wait between consecutive\n read operations for a response from the server. Omitting the parameter\n will default the read timeout to the system default, probably `the\n global default timeout in socket.py\n <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.\n None will set an infinite timeout.\n\n :type read: int, float, or None\n\n .. note::\n\n Many factors can affect the total amount of time for urllib3 to return\n an HTTP response.\n\n For example, Python's DNS resolver does not obey the timeout specified\n on the socket. Other factors that can affect total request time include\n high CPU load, high swap, the program running at a low priority level,\n or other behaviors.\n\n In addition, the read and total timeouts only measure the time between\n read operations on the socket connecting the client and the server,\n not the total amount of time for the request to return a complete\n response. For most requests, the timeout is raised because the server\n has not sent the first byte in the specified time. This is not always\n the case; if a server streams one byte every fifteen seconds, a timeout\n of 20 seconds will not trigger, even though the request will take\n several minutes to complete.\n\n If your goal is to cut off any request after a set amount of wall clock\n time, consider having a second \"watcher\" thread to cut off a slow\n request.\n \"\"\"\n\n #: A sentinel object representing the default timeout value\n DEFAULT_TIMEOUT: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT\n\n def __init__(\n self,\n total: _TYPE_TIMEOUT = None,\n connect: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n read: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n ) -> None:\n self._connect = self._validate_timeout(connect, \"connect\")\n self._read = self._validate_timeout(read, \"read\")\n self.total = self._validate_timeout(total, \"total\")\n self._start_connect: float | None = None\n\n def __repr__(self) -> str:\n return f\"{type(self).__name__}(connect={self._connect!r}, read={self._read!r}, total={self.total!r})\"\n\n # __str__ provided for backwards compatibility\n __str__ = __repr__\n\n @staticmethod\n def resolve_default_timeout(timeout: _TYPE_TIMEOUT) -> float | None:\n return getdefaulttimeout() if timeout is _DEFAULT_TIMEOUT else timeout\n\n @classmethod\n def _validate_timeout(cls, value: _TYPE_TIMEOUT, name: str) -> _TYPE_TIMEOUT:\n \"\"\"Check that a timeout attribute is valid.\n\n :param value: The timeout value to validate\n :param name: The name of the timeout attribute to validate. This is\n used to specify in error messages.\n :return: The validated and casted version of the given value.\n :raises ValueError: If it is a numeric value less than or equal to\n zero, or the type is not an integer, float, or None.\n \"\"\"\n if value is None or value is _DEFAULT_TIMEOUT:\n return value\n\n if isinstance(value, bool):\n raise ValueError(\n \"Timeout cannot be a boolean value. It must \"\n \"be an int, float or None.\"\n )\n try:\n float(value)\n except (TypeError, ValueError):\n raise ValueError(\n \"Timeout value %s was %s, but it must be an \"\n \"int, float or None.\" % (name, value)\n ) from None\n\n try:\n if value <= 0:\n raise ValueError(\n \"Attempted to set %s timeout to %s, but the \"\n \"timeout cannot be set to a value less \"\n \"than or equal to 0.\" % (name, value)\n )\n except TypeError:\n raise ValueError(\n \"Timeout value %s was %s, but it must be an \"\n \"int, float or None.\" % (name, value)\n ) from None\n\n return value\n\n @classmethod\n def from_float(cls, timeout: _TYPE_TIMEOUT) -> Timeout:\n \"\"\"Create a new Timeout from a legacy timeout value.\n\n The timeout value used by httplib.py sets the same timeout on the\n connect(), and recv() socket requests. This creates a :class:`Timeout`\n object that sets the individual timeouts to the ``timeout`` value\n passed to this function.\n\n :param timeout: The legacy timeout value.\n :type timeout: integer, float, :attr:`urllib3.util.Timeout.DEFAULT_TIMEOUT`, or None\n :return: Timeout object\n :rtype: :class:`Timeout`\n \"\"\"\n return Timeout(read=timeout, connect=timeout)\n\n def clone(self) -> Timeout:\n \"\"\"Create a copy of the timeout object\n\n Timeout properties are stored per-pool but each request needs a fresh\n Timeout object to ensure each one has its own start/stop configured.\n\n :return: a copy of the timeout object\n :rtype: :class:`Timeout`\n \"\"\"\n # We can't use copy.deepcopy because that will also create a new object\n # for _GLOBAL_DEFAULT_TIMEOUT, which socket.py uses as a sentinel to\n # detect the user default.\n return Timeout(connect=self._connect, read=self._read, total=self.total)\n\n def start_connect(self) -> float:\n \"\"\"Start the timeout clock, used during a connect() attempt\n\n :raises urllib3.exceptions.TimeoutStateError: if you attempt\n to start a timer that has been started already.\n \"\"\"\n if self._start_connect is not None:\n raise TimeoutStateError(\"Timeout timer has already been started.\")\n self._start_connect = time.monotonic()\n return self._start_connect\n\n def get_connect_duration(self) -> float:\n \"\"\"Gets the time elapsed since the call to :meth:`start_connect`.\n\n :return: Elapsed time in seconds.\n :rtype: float\n :raises urllib3.exceptions.TimeoutStateError: if you attempt\n to get duration for a timer that hasn't been started.\n \"\"\"\n if self._start_connect is None:\n raise TimeoutStateError(\n \"Can't get connect duration for timer that has not started.\"\n )\n return time.monotonic() - self._start_connect\n\n @property\n def connect_timeout(self) -> _TYPE_TIMEOUT:\n \"\"\"Get the value to use when setting a connection timeout.\n\n This will be a positive float or integer, the value None\n (never timeout), or the default system timeout.\n\n :return: Connect timeout.\n :rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None\n \"\"\"\n if self.total is None:\n return self._connect\n\n if self._connect is None or self._connect is _DEFAULT_TIMEOUT:\n return self.total\n\n return min(self._connect, self.total) # type: ignore[type-var]\n\n @property\n def read_timeout(self) -> float | None:\n \"\"\"Get the value for the read timeout.\n\n This assumes some time has elapsed in the connection timeout and\n computes the read timeout appropriately.\n\n If self.total is set, the read timeout is dependent on the amount of\n time taken by the connect timeout. If the connection time has not been\n established, a :exc:`~urllib3.exceptions.TimeoutStateError` will be\n raised.\n\n :return: Value to use for the read timeout.\n :rtype: int, float or None\n :raises urllib3.exceptions.TimeoutStateError: If :meth:`start_connect`\n has not yet been called on this object.\n \"\"\"\n if (\n self.total is not None\n and self.total is not _DEFAULT_TIMEOUT\n and self._read is not None\n and self._read is not _DEFAULT_TIMEOUT\n ):\n # In case the connect timeout has not yet been established.\n if self._start_connect is None:\n return self._read\n return max(0, min(self.total - self.get_connect_duration(), self._read))\n elif self.total is not None and self.total is not _DEFAULT_TIMEOUT:\n return max(0, self.total - self.get_connect_duration())\n else:\n return self.resolve_default_timeout(self._read)\n", "path": "src/urllib3/util/timeout.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport time\nimport typing\nfrom enum import Enum\nfrom socket import getdefaulttimeout\n\nfrom ..exceptions import TimeoutStateError\n\nif typing.TYPE_CHECKING:\n from typing import Final\n\n\nclass _TYPE_DEFAULT(Enum):\n # This value should never be passed to socket.settimeout() so for safety we use a -1.\n # socket.settimout() raises a ValueError for negative values.\n token = -1\n\n\n_DEFAULT_TIMEOUT: Final[_TYPE_DEFAULT] = _TYPE_DEFAULT.token\n\n_TYPE_TIMEOUT = typing.Optional[typing.Union[float, _TYPE_DEFAULT]]\n\n\nclass Timeout:\n \"\"\"Timeout configuration.\n\n Timeouts can be defined as a default for a pool:\n\n .. code-block:: python\n\n import urllib3\n\n timeout = urllib3.util.Timeout(connect=2.0, read=7.0)\n\n http = urllib3.PoolManager(timeout=timeout)\n\n resp = http.request(\"GET\", \"https://example.com/\")\n\n print(resp.status)\n\n Or per-request (which overrides the default for the pool):\n\n .. code-block:: python\n\n response = http.request(\"GET\", \"https://example.com/\", timeout=Timeout(10))\n\n Timeouts can be disabled by setting all the parameters to ``None``:\n\n .. code-block:: python\n\n no_timeout = Timeout(connect=None, read=None)\n response = http.request(\"GET\", \"https://example.com/\", timeout=no_timeout)\n\n\n :param total:\n This combines the connect and read timeouts into one; the read timeout\n will be set to the time leftover from the connect attempt. In the\n event that both a connect timeout and a total are specified, or a read\n timeout and a total are specified, the shorter timeout will be applied.\n\n Defaults to None.\n\n :type total: int, float, or None\n\n :param connect:\n The maximum amount of time (in seconds) to wait for a connection\n attempt to a server to succeed. Omitting the parameter will default the\n connect timeout to the system default, probably `the global default\n timeout in socket.py\n <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.\n None will set an infinite timeout for connection attempts.\n\n :type connect: int, float, or None\n\n :param read:\n The maximum amount of time (in seconds) to wait between consecutive\n read operations for a response from the server. Omitting the parameter\n will default the read timeout to the system default, probably `the\n global default timeout in socket.py\n <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.\n None will set an infinite timeout.\n\n :type read: int, float, or None\n\n .. note::\n\n Many factors can affect the total amount of time for urllib3 to return\n an HTTP response.\n\n For example, Python's DNS resolver does not obey the timeout specified\n on the socket. Other factors that can affect total request time include\n high CPU load, high swap, the program running at a low priority level,\n or other behaviors.\n\n In addition, the read and total timeouts only measure the time between\n read operations on the socket connecting the client and the server,\n not the total amount of time for the request to return a complete\n response. For most requests, the timeout is raised because the server\n has not sent the first byte in the specified time. This is not always\n the case; if a server streams one byte every fifteen seconds, a timeout\n of 20 seconds will not trigger, even though the request will take\n several minutes to complete.\n \"\"\"\n\n #: A sentinel object representing the default timeout value\n DEFAULT_TIMEOUT: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT\n\n def __init__(\n self,\n total: _TYPE_TIMEOUT = None,\n connect: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n read: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,\n ) -> None:\n self._connect = self._validate_timeout(connect, \"connect\")\n self._read = self._validate_timeout(read, \"read\")\n self.total = self._validate_timeout(total, \"total\")\n self._start_connect: float | None = None\n\n def __repr__(self) -> str:\n return f\"{type(self).__name__}(connect={self._connect!r}, read={self._read!r}, total={self.total!r})\"\n\n # __str__ provided for backwards compatibility\n __str__ = __repr__\n\n @staticmethod\n def resolve_default_timeout(timeout: _TYPE_TIMEOUT) -> float | None:\n return getdefaulttimeout() if timeout is _DEFAULT_TIMEOUT else timeout\n\n @classmethod\n def _validate_timeout(cls, value: _TYPE_TIMEOUT, name: str) -> _TYPE_TIMEOUT:\n \"\"\"Check that a timeout attribute is valid.\n\n :param value: The timeout value to validate\n :param name: The name of the timeout attribute to validate. This is\n used to specify in error messages.\n :return: The validated and casted version of the given value.\n :raises ValueError: If it is a numeric value less than or equal to\n zero, or the type is not an integer, float, or None.\n \"\"\"\n if value is None or value is _DEFAULT_TIMEOUT:\n return value\n\n if isinstance(value, bool):\n raise ValueError(\n \"Timeout cannot be a boolean value. It must \"\n \"be an int, float or None.\"\n )\n try:\n float(value)\n except (TypeError, ValueError):\n raise ValueError(\n \"Timeout value %s was %s, but it must be an \"\n \"int, float or None.\" % (name, value)\n ) from None\n\n try:\n if value <= 0:\n raise ValueError(\n \"Attempted to set %s timeout to %s, but the \"\n \"timeout cannot be set to a value less \"\n \"than or equal to 0.\" % (name, value)\n )\n except TypeError:\n raise ValueError(\n \"Timeout value %s was %s, but it must be an \"\n \"int, float or None.\" % (name, value)\n ) from None\n\n return value\n\n @classmethod\n def from_float(cls, timeout: _TYPE_TIMEOUT) -> Timeout:\n \"\"\"Create a new Timeout from a legacy timeout value.\n\n The timeout value used by httplib.py sets the same timeout on the\n connect(), and recv() socket requests. This creates a :class:`Timeout`\n object that sets the individual timeouts to the ``timeout`` value\n passed to this function.\n\n :param timeout: The legacy timeout value.\n :type timeout: integer, float, :attr:`urllib3.util.Timeout.DEFAULT_TIMEOUT`, or None\n :return: Timeout object\n :rtype: :class:`Timeout`\n \"\"\"\n return Timeout(read=timeout, connect=timeout)\n\n def clone(self) -> Timeout:\n \"\"\"Create a copy of the timeout object\n\n Timeout properties are stored per-pool but each request needs a fresh\n Timeout object to ensure each one has its own start/stop configured.\n\n :return: a copy of the timeout object\n :rtype: :class:`Timeout`\n \"\"\"\n # We can't use copy.deepcopy because that will also create a new object\n # for _GLOBAL_DEFAULT_TIMEOUT, which socket.py uses as a sentinel to\n # detect the user default.\n return Timeout(connect=self._connect, read=self._read, total=self.total)\n\n def start_connect(self) -> float:\n \"\"\"Start the timeout clock, used during a connect() attempt\n\n :raises urllib3.exceptions.TimeoutStateError: if you attempt\n to start a timer that has been started already.\n \"\"\"\n if self._start_connect is not None:\n raise TimeoutStateError(\"Timeout timer has already been started.\")\n self._start_connect = time.monotonic()\n return self._start_connect\n\n def get_connect_duration(self) -> float:\n \"\"\"Gets the time elapsed since the call to :meth:`start_connect`.\n\n :return: Elapsed time in seconds.\n :rtype: float\n :raises urllib3.exceptions.TimeoutStateError: if you attempt\n to get duration for a timer that hasn't been started.\n \"\"\"\n if self._start_connect is None:\n raise TimeoutStateError(\n \"Can't get connect duration for timer that has not started.\"\n )\n return time.monotonic() - self._start_connect\n\n @property\n def connect_timeout(self) -> _TYPE_TIMEOUT:\n \"\"\"Get the value to use when setting a connection timeout.\n\n This will be a positive float or integer, the value None\n (never timeout), or the default system timeout.\n\n :return: Connect timeout.\n :rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None\n \"\"\"\n if self.total is None:\n return self._connect\n\n if self._connect is None or self._connect is _DEFAULT_TIMEOUT:\n return self.total\n\n return min(self._connect, self.total) # type: ignore[type-var]\n\n @property\n def read_timeout(self) -> float | None:\n \"\"\"Get the value for the read timeout.\n\n This assumes some time has elapsed in the connection timeout and\n computes the read timeout appropriately.\n\n If self.total is set, the read timeout is dependent on the amount of\n time taken by the connect timeout. If the connection time has not been\n established, a :exc:`~urllib3.exceptions.TimeoutStateError` will be\n raised.\n\n :return: Value to use for the read timeout.\n :rtype: int, float or None\n :raises urllib3.exceptions.TimeoutStateError: If :meth:`start_connect`\n has not yet been called on this object.\n \"\"\"\n if (\n self.total is not None\n and self.total is not _DEFAULT_TIMEOUT\n and self._read is not None\n and self._read is not _DEFAULT_TIMEOUT\n ):\n # In case the connect timeout has not yet been established.\n if self._start_connect is None:\n return self._read\n return max(0, min(self.total - self.get_connect_duration(), self._read))\n elif self.total is not None and self.total is not _DEFAULT_TIMEOUT:\n return max(0, self.total - self.get_connect_duration())\n else:\n return self.resolve_default_timeout(self._read)\n", "path": "src/urllib3/util/timeout.py"}]}
| 3,515 | 160 |
gh_patches_debug_55169
|
rasdani/github-patches
|
git_diff
|
spack__spack-19617
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Jupyter: No module named ipykernel_launcher
### Steps to reproduce the issue
```console
$ spack env create my-jupyter
$ spack env activate my-jupyter
$ spack add py-jupyter
$ spack add py-ipython
$ spack add py-ipykernel
$ spack add py-notebook
$ spack install
```
### Error Message
If I try to start `jupyter notebook` now and open a Python3 Notebook I get no working Python3 kernel
```
Kernel started: af71e14f-24f7-40a4-92a8-48e79f5d621c, name: python3
/home/axel/src/spack/opt/spack/linux-ubuntu18.04-skylake/gcc-8.4.0/python-3.8.6-wuh5zypqqvf3fba4ootslwky3plqqsqw/bin/python3.8: No module named ipykernel_launcher
[I 00:55:29.178 NotebookApp] KernelRestarter: restarting kernel (1/5), new random ports
/home/axel/src/spack/opt/spack/linux-ubuntu18.04-skylake/gcc-8.4.0/python-3.8.6-wuh5zypqqvf3fba4ootslwky3plqqsqw/bin/python3.8: No module named ipykernel_launcher
# ...
```
### Information on your system
```bash
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.5 LTS
Release: 18.04
Codename: bionic
```
`spack debug report`:
* **Spack:** 0.15.4-1470-99ef3d11c1
* **Python:** 3.8.6
* **Platform:** linux-ubuntu18.04-skylake
### Additional information
<!-- These boxes can be checked by replacing [ ] with [x] or by clicking them after submitting the issue. -->
- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform
- [x] I have searched the issues of this repo and believe this is not a duplicate
- [ ] I have run the failing commands in debug mode and reported the output
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/py-ipykernel/package.py`
Content:
```
1 # Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6
7 class PyIpykernel(PythonPackage):
8 """IPython Kernel for Jupyter"""
9
10 homepage = "https://pypi.python.org/pypi/ipykernel"
11 url = "https://pypi.io/packages/source/i/ipykernel/ipykernel-5.3.4.tar.gz"
12
13 version('5.3.4', sha256='9b2652af1607986a1b231c62302d070bc0534f564c393a5d9d130db9abbbe89d')
14 version('5.1.1', sha256='f0e962052718068ad3b1d8bcc703794660858f58803c3798628817f492a8769c')
15 version('5.1.0', sha256='0fc0bf97920d454102168ec2008620066878848fcfca06c22b669696212e292f')
16 version('4.10.0', sha256='699103c8e64886e3ec7053f2a6aa83bb90426063526f63a818732ff385202bad')
17 version('4.5.0', sha256='245a798edb8fd751b95750d8645d736dd739a020e7fc7d5627dac4d1c35d8295')
18 version('4.4.1', sha256='6d48398b3112efb733b254edede4b7f3262c28bd19f665b64ef1acf6ec5cd74f')
19 version('4.4.0', sha256='d516427c3bd689205e6693c9616302ef34017b91ada3c9ea3fca6e90702b7ffe')
20 version('4.3.1', sha256='8219d3eaa3e4d4efc5f349114e41a40f0986c91a960846bb81d5da817fb7cc3f')
21 version('4.3.0', sha256='f214c661328c836e02b6f185f98f3eccd7ce396791937493ffa1babf5e3267ab')
22 version('4.2.2', sha256='a876da43e01acec2c305abdd8e6aa55f052bab1196171ccf1cb9a6aa230298b0')
23 version('4.2.1', sha256='081a5d4db33db58697be2d682b92f79b2c239493445f13dd457c15bc3e52c874')
24 version('4.2.0', sha256='723b3d4baac20f0c9cd91fc75c3e813636ecb6c6e303fb34d628c3df078985a7')
25 version('4.1.1', sha256='d8c5555386d0f18f1336dea9800f9f0fe96dcecc9757c0f980e11fdfadb661ff')
26 version('4.1.0', sha256='e0e150ad55e487e49054efc9a4b0e2e17f27e1de77444b26760789077b146d86')
27
28 depends_on('[email protected]:2.8,3.3:', type=('build', 'run'))
29 depends_on('[email protected]:', when='@5.0:', type=('build', 'run'))
30 depends_on('[email protected]:', when='@5.2:', type=('build', 'run'))
31 depends_on('py-setuptools', type='build', when='@5:')
32 depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))
33 depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))
34 depends_on('[email protected]:', type=('build', 'run'))
35 depends_on('py-jupyter-client', type=('build', 'run'))
36 depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))
37 depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))
38 depends_on('py-appnope', when='platform=darwin', type=('build', 'run'))
39 depends_on('py-pytest@:5.3.3,5.3.5:', type='test')
40 depends_on('py-pytest-cov', type='test')
41 # depends_on('py-flaky', type='test')
42 depends_on('py-nose', type='test')
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/py-ipykernel/package.py b/var/spack/repos/builtin/packages/py-ipykernel/package.py
--- a/var/spack/repos/builtin/packages/py-ipykernel/package.py
+++ b/var/spack/repos/builtin/packages/py-ipykernel/package.py
@@ -40,3 +40,9 @@
depends_on('py-pytest-cov', type='test')
# depends_on('py-flaky', type='test')
depends_on('py-nose', type='test')
+
+ phases = ['build', 'install', 'install_data']
+
+ def install_data(self):
+ """ install the Jupyter kernel spec """
+ self.spec['python'].command('-m ipykernel', ['install'])
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/py-ipykernel/package.py b/var/spack/repos/builtin/packages/py-ipykernel/package.py\n--- a/var/spack/repos/builtin/packages/py-ipykernel/package.py\n+++ b/var/spack/repos/builtin/packages/py-ipykernel/package.py\n@@ -40,3 +40,9 @@\n depends_on('py-pytest-cov', type='test')\n # depends_on('py-flaky', type='test')\n depends_on('py-nose', type='test')\n+\n+ phases = ['build', 'install', 'install_data']\n+\n+ def install_data(self):\n+ \"\"\" install the Jupyter kernel spec \"\"\"\n+ self.spec['python'].command('-m ipykernel', ['install'])\n", "issue": "Jupyter: No module named ipykernel_launcher\n### Steps to reproduce the issue\r\n\r\n```console\r\n$ spack env create my-jupyter\r\n$ spack env activate my-jupyter\r\n$ spack add py-jupyter\r\n$ spack add py-ipython\r\n$ spack add py-ipykernel\r\n$ spack add py-notebook\r\n$ spack install\r\n```\r\n\r\n### Error Message\r\n\r\nIf I try to start `jupyter notebook` now and open a Python3 Notebook I get no working Python3 kernel\r\n```\r\nKernel started: af71e14f-24f7-40a4-92a8-48e79f5d621c, name: python3\r\n/home/axel/src/spack/opt/spack/linux-ubuntu18.04-skylake/gcc-8.4.0/python-3.8.6-wuh5zypqqvf3fba4ootslwky3plqqsqw/bin/python3.8: No module named ipykernel_launcher\r\n\r\n[I 00:55:29.178 NotebookApp] KernelRestarter: restarting kernel (1/5), new random ports\r\n/home/axel/src/spack/opt/spack/linux-ubuntu18.04-skylake/gcc-8.4.0/python-3.8.6-wuh5zypqqvf3fba4ootslwky3plqqsqw/bin/python3.8: No module named ipykernel_launcher\r\n\r\n# ...\r\n```\r\n\r\n### Information on your system\r\n\r\n```bash\r\n$ lsb_release -a\r\nNo LSB modules are available.\r\nDistributor ID:\tUbuntu\r\nDescription:\tUbuntu 18.04.5 LTS\r\nRelease:\t18.04\r\nCodename:\tbionic\r\n```\r\n\r\n`spack debug report`:\r\n* **Spack:** 0.15.4-1470-99ef3d11c1\r\n* **Python:** 3.8.6\r\n* **Platform:** linux-ubuntu18.04-skylake\r\n\r\n### Additional information\r\n\r\n<!-- These boxes can be checked by replacing [ ] with [x] or by clicking them after submitting the issue. -->\r\n- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform\r\n- [x] I have searched the issues of this repo and believe this is not a duplicate\r\n- [ ] I have run the failing commands in debug mode and reported the output\n", "before_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\n\nclass PyIpykernel(PythonPackage):\n \"\"\"IPython Kernel for Jupyter\"\"\"\n\n homepage = \"https://pypi.python.org/pypi/ipykernel\"\n url = \"https://pypi.io/packages/source/i/ipykernel/ipykernel-5.3.4.tar.gz\"\n\n version('5.3.4', sha256='9b2652af1607986a1b231c62302d070bc0534f564c393a5d9d130db9abbbe89d')\n version('5.1.1', sha256='f0e962052718068ad3b1d8bcc703794660858f58803c3798628817f492a8769c')\n version('5.1.0', sha256='0fc0bf97920d454102168ec2008620066878848fcfca06c22b669696212e292f')\n version('4.10.0', sha256='699103c8e64886e3ec7053f2a6aa83bb90426063526f63a818732ff385202bad')\n version('4.5.0', sha256='245a798edb8fd751b95750d8645d736dd739a020e7fc7d5627dac4d1c35d8295')\n version('4.4.1', sha256='6d48398b3112efb733b254edede4b7f3262c28bd19f665b64ef1acf6ec5cd74f')\n version('4.4.0', sha256='d516427c3bd689205e6693c9616302ef34017b91ada3c9ea3fca6e90702b7ffe')\n version('4.3.1', sha256='8219d3eaa3e4d4efc5f349114e41a40f0986c91a960846bb81d5da817fb7cc3f')\n version('4.3.0', sha256='f214c661328c836e02b6f185f98f3eccd7ce396791937493ffa1babf5e3267ab')\n version('4.2.2', sha256='a876da43e01acec2c305abdd8e6aa55f052bab1196171ccf1cb9a6aa230298b0')\n version('4.2.1', sha256='081a5d4db33db58697be2d682b92f79b2c239493445f13dd457c15bc3e52c874')\n version('4.2.0', sha256='723b3d4baac20f0c9cd91fc75c3e813636ecb6c6e303fb34d628c3df078985a7')\n version('4.1.1', sha256='d8c5555386d0f18f1336dea9800f9f0fe96dcecc9757c0f980e11fdfadb661ff')\n version('4.1.0', sha256='e0e150ad55e487e49054efc9a4b0e2e17f27e1de77444b26760789077b146d86')\n\n depends_on('[email protected]:2.8,3.3:', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0:', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.2:', type=('build', 'run'))\n depends_on('py-setuptools', type='build', when='@5:')\n depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))\n depends_on('[email protected]:', type=('build', 'run'))\n depends_on('py-jupyter-client', type=('build', 'run'))\n depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))\n depends_on('py-appnope', when='platform=darwin', type=('build', 'run'))\n depends_on('py-pytest@:5.3.3,5.3.5:', type='test')\n depends_on('py-pytest-cov', type='test')\n # depends_on('py-flaky', type='test')\n depends_on('py-nose', type='test')\n", "path": "var/spack/repos/builtin/packages/py-ipykernel/package.py"}], "after_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\n\nclass PyIpykernel(PythonPackage):\n \"\"\"IPython Kernel for Jupyter\"\"\"\n\n homepage = \"https://pypi.python.org/pypi/ipykernel\"\n url = \"https://pypi.io/packages/source/i/ipykernel/ipykernel-5.3.4.tar.gz\"\n\n version('5.3.4', sha256='9b2652af1607986a1b231c62302d070bc0534f564c393a5d9d130db9abbbe89d')\n version('5.1.1', sha256='f0e962052718068ad3b1d8bcc703794660858f58803c3798628817f492a8769c')\n version('5.1.0', sha256='0fc0bf97920d454102168ec2008620066878848fcfca06c22b669696212e292f')\n version('4.10.0', sha256='699103c8e64886e3ec7053f2a6aa83bb90426063526f63a818732ff385202bad')\n version('4.5.0', sha256='245a798edb8fd751b95750d8645d736dd739a020e7fc7d5627dac4d1c35d8295')\n version('4.4.1', sha256='6d48398b3112efb733b254edede4b7f3262c28bd19f665b64ef1acf6ec5cd74f')\n version('4.4.0', sha256='d516427c3bd689205e6693c9616302ef34017b91ada3c9ea3fca6e90702b7ffe')\n version('4.3.1', sha256='8219d3eaa3e4d4efc5f349114e41a40f0986c91a960846bb81d5da817fb7cc3f')\n version('4.3.0', sha256='f214c661328c836e02b6f185f98f3eccd7ce396791937493ffa1babf5e3267ab')\n version('4.2.2', sha256='a876da43e01acec2c305abdd8e6aa55f052bab1196171ccf1cb9a6aa230298b0')\n version('4.2.1', sha256='081a5d4db33db58697be2d682b92f79b2c239493445f13dd457c15bc3e52c874')\n version('4.2.0', sha256='723b3d4baac20f0c9cd91fc75c3e813636ecb6c6e303fb34d628c3df078985a7')\n version('4.1.1', sha256='d8c5555386d0f18f1336dea9800f9f0fe96dcecc9757c0f980e11fdfadb661ff')\n version('4.1.0', sha256='e0e150ad55e487e49054efc9a4b0e2e17f27e1de77444b26760789077b146d86')\n\n depends_on('[email protected]:2.8,3.3:', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0:', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.2:', type=('build', 'run'))\n depends_on('py-setuptools', type='build', when='@5:')\n depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))\n depends_on('[email protected]:', type=('build', 'run'))\n depends_on('py-jupyter-client', type=('build', 'run'))\n depends_on('[email protected]:', when='@:4.999', type=('build', 'run'))\n depends_on('[email protected]:', when='@5.0.0:', type=('build', 'run'))\n depends_on('py-appnope', when='platform=darwin', type=('build', 'run'))\n depends_on('py-pytest@:5.3.3,5.3.5:', type='test')\n depends_on('py-pytest-cov', type='test')\n # depends_on('py-flaky', type='test')\n depends_on('py-nose', type='test')\n\n phases = ['build', 'install', 'install_data']\n\n def install_data(self):\n \"\"\" install the Jupyter kernel spec \"\"\"\n self.spec['python'].command('-m ipykernel', ['install'])\n", "path": "var/spack/repos/builtin/packages/py-ipykernel/package.py"}]}
| 2,364 | 166 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.